Запросы в Access — Базы данных Access
Запросы в Access являются основным инструментом выборки, обновления и обработки данных в таблицах базы данных. Access в соответствии с концепцией реляционных баз данных для выполнения запросов использует язык структурированных запросов SQL (Structured Query Language). С помощью инструкций языка SQL реализуется любой запрос в Access.
Основным видом запроса является запрос на выборку. Результатом выполнения этого запроса является новая таблица, которая существует до закрытия запроса. Записи формируются путем объединения записей таблиц, на которых построен запрос. Способ объединения записей таблиц указывается при определении их связи в схеме данных или при создании запроса. Условия отбора, сформулированные в запросе, позволяют фильтровать записи, составляющие результат объединения таблиц.
В Access может быть создано несколько видов запроса:
- запрос на выборку — выбирает данные из одной таблицы или запроса или нескольких взаимосвязанных таблиц и других запросов. Результатом является таблица, которая существует до закрытия запроса. Формирование записей таблицы результата производится в соответствии с заданными условиями отбора и при использовании нескольких таблиц путем объединения их записей;
- запрос на создание таблицы — выбирает данные из взаимосвязанных таблиц и других запросов, но, в отличие от запроса на выборку, результат сохраняет в новой постоянной таблице;
- запросы на обновление, добавление, удаление — являются запросами действия, в результате выполнения которых изменяются данные в таблицах.
Запросы в Access в режиме конструктора содержат схему данных, отображающую используемые таблицы, и бланк запроса, в котором конструируется структура таблицы запроса и условия выборки записей (рис. 4.1).
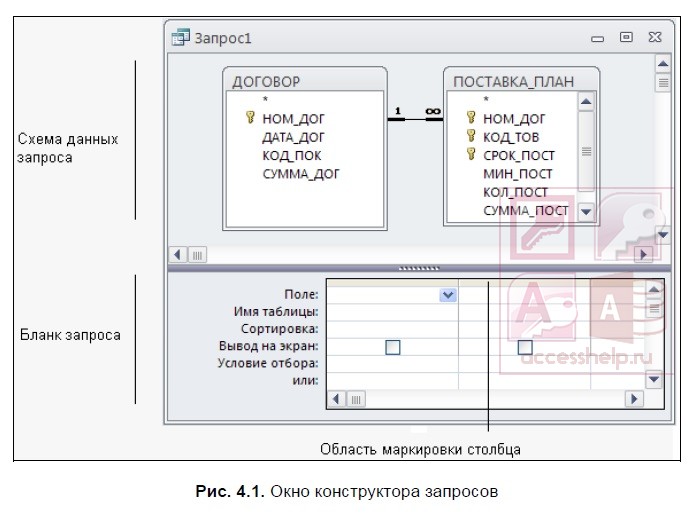
С помощью запроса можно выполнить следующие виды обработки данных:
- включить в таблицу запроса выбранные пользователем поля таблицы;
- произвести вычисления в каждой из полученных записей;
- выбрать записи, удовлетворяющие условиям отбора;
- сформировать на основе объединения записей взаимосвязанных таблиц новую виртуальную таблицу;
- сгруппировать записи, которые имеют одинаковые значения в одном или нескольких полях, одновременно выполнить над другими полями группы статистические функции и в результат включить одну запись для каждой группы;
- создать новую таблицу базы данных, используя данные из существующих таблиц;
- произвести обновление полей в выбранном подмножестве записей;
- удалить выбранное подмножество записей из таблицы базы данных;
- добавить выбранное подмножество записей в другую таблицу.
Запросы в Access служат источниками записей для других запросов, форм, отчетов. С помощью запроса можно собрать полные сведения для формирования некоторого документа предметной области из нескольких таблиц, далее использовать его для создания формы — электронного представления этого документа. Если форма или отчет создаются мастером на основе нескольких взаимосвязанных таблиц, то для них в качестве источника записей автоматически формируется запрос.
SQL запросы быстро. Часть 1 / Хабр
Введение
Язык SQL очень прочно влился в жизнь бизнес-аналитиков и требования к кандидатам благодаря простоте, удобству и распространенности. Из собственного опыта могу сказать, что наиболее часто SQL используется для формирования выгрузок, витрин (с последующим построением отчетов на основе этих витрин) и администрирования баз данных. И поскольку повседневная работа аналитика неизбежно связана с выгрузками данных и витринами, навык написания SQL запросов может стать фактором, из-за которого кандидат или получит преимущество, или будет отсеян. Печальная новость в том, что не каждый может рассчитывать получить его на студенческой скамье. Хорошая новость в том, что в изучении SQL нет ничего сложного, это быстро, а синтаксис запросов прост и понятен. Особенно это касается тех, кому уже доводилось сталкиваться с более сложными языками.
Практика
Введение в синтаксис будет рассмотрено на примере открытой базы данных, предназначенной специально для практики SQL. Чтобы твое обучение прошло максимально эффективно, открой ссылку ниже в новой вкладке и сразу запускай приведенные примеры, это позволит тебе лучше закрепить материал и самостоятельно поработать с синтаксисом.
Кликнуть здесь
После перехода по ссылке можно будет увидеть сам редактор запросов и вывод данных в центральной части экрана, список таблиц базы данных находится в правой части.
Структура sql-запросов
Общая структура запроса выглядит следующим образом:
SELECT ('столбцы или * для выбора всех столбцов; обязательно') FROM ('таблица; обязательно') WHERE ('условие/фильтрация, например, city = 'Moscow'; необязательно') GROUP BY ('столбец, по которому хотим сгруппировать данные; необязательно') HAVING ('условие/фильтрация на уровне сгруппированных данных; необязательно') ORDER BY ('столбец, по которому хотим отсортировать вывод; необязательно')
Разберем структуру. Для удобства текущий изучаемый элемент в запроса выделяется CAPS’ом.
SELECT, FROM
SELECT, FROM — обязательные элементы запроса, которые определяют выбранные столбцы, их порядок и источник данных.
Выбрать все (обозначается как *) из таблицы Customers:
SELECT * FROM CustomersВыбрать столбцы CustomerID, CustomerName из таблицы Customers:
SELECT CustomerID, CustomerName FROM Customers
WHERE
WHERE — необязательный элемент запроса, который используется, когда нужно отфильтровать данные по нужному условию. Очень часто внутри элемента where используются IN / NOT IN для фильтрации столбца по нескольким значениям, AND / OR для фильтрации таблицы по нескольким столбцам.
Фильтрация по одному условию и одному значению:
select * from Customers
WHERE City = 'London'Фильтрация по одному условию и нескольким значениям с применением IN (включение) или NOT IN (исключение):
select * from Customers where City IN ('London', 'Berlin')
select * from Customers
where City NOT IN ('Madrid', 'Berlin','Bern')Фильтрация по нескольким условиям с применением AND (выполняются все условия) или OR (выполняется хотя бы одно условие) и нескольким значениям:
select * from Customers
where Country = 'Germany' AND City not in ('Berlin', 'Aachen') AND CustomerID > 15select * from Customers
where City in ('London', 'Berlin') OR CustomerID > 4GROUP BY
GROUP BY — необязательный элемент запроса, с помощью которого можно задать агрегацию по нужному столбцу (например, если нужно узнать какое количество клиентов живет в каждом из городов).
При использовании GROUP BY обязательно:
- перечень столбцов, по которым делается разрез, был одинаковым внутри SELECT и внутри GROUP BY,
- агрегатные функции (SUM, AVG, COUNT, MAX, MIN) должны быть также указаны внутри SELECT с указанием столбца, к которому такая функция применяется.
Группировка количества клиентов по городу:
select City, count(CustomerID) from Customers
GROUP BY CityГруппировка количества клиентов по стране и городу:
select Country, City, count(CustomerID) from Customers
GROUP BY Country, CityГруппировка продаж по ID товара с разными агрегатными функциями: количество заказов с данным товаром и количество проданных штук товара:
select ProductID, COUNT(OrderID), SUM(Quantity) from OrderDetails GROUP BY ProductID
Группировка продаж с фильтрацией исходной таблицы. В данном случае на выходе будет таблица с количеством клиентов по городам Германии:
select City, count(CustomerID) from Customers
WHERE Country = 'Germany'
GROUP BY CityПереименование столбца с агрегацией с помощью оператора AS. По умолчанию название столбца с агрегацией равно примененной агрегатной функции, что далее может быть не очень удобно для восприятия.
select City, count(CustomerID) AS Number_of_clients from Customers
group by CityHAVING
HAVING — необязательный элемент запроса, который отвечает за фильтрацию на уровне сгруппированных данных (по сути, WHERE, но только на уровень выше).
select City, count(CustomerID) from Customers
group by City
HAVING count(CustomerID) >= 5 В случае с переименованным столбцом внутри HAVING можно указать как и саму агрегирующую конструкцию count(CustomerID), так и новое название столбца number_of_clients:
select City, count(CustomerID) as number_of_clients from Customers
group by City
HAVING number_of_clients >= 5Пример запроса, содержащего WHERE и HAVING. В данном запросе сначала фильтруется исходная таблица по пользователям, рассчитывается количество клиентов по городам и остаются только те города, где количество клиентов не менее 5:
select City, count(CustomerID) as number_of_clients from Customers WHERE CustomerName not in ('Around the Horn','Drachenblut Delikatessend') group by City HAVING number_of_clients >= 5
ORDER BY
ORDER BY — необязательный элемент запроса, который отвечает за сортировку таблицы.
Простой пример сортировки по одному столбцу. В данном запросе осуществляется сортировка по городу, который указал клиент:
select * from Customers
ORDER BY CityОсуществлять сортировку можно и по нескольким столбцам, в этом случае сортировка происходит по порядку указанных столбцов:
select * from Customers
ORDER BY Country, CityПо умолчанию сортировка происходит по возрастанию для чисел и в алфавитном порядке для текстовых значений. Если нужна обратная сортировка, то в конструкции ORDER BY после названия столбца надо добавить DESC:
select * from Customers
order by CustomerID DESCОбратная сортировка по одному столбцу и сортировка по умолчанию по второму:
select * from Customers
order by Country DESC, CityJOIN
JOIN — необязательный элемент, используется для объединения таблиц по ключу, который присутствует в обоих таблицах. Перед ключом ставится оператор ON.
Запрос, в котором соединяем таблицы Order и Customer по ключу CustomerID, при этом перед названиям столбца ключа добавляется название таблицы через точку:
select * from Orders
JOIN Customers ON Orders.CustomerID = Customers.CustomerIDНередко может возникать ситуация, когда надо промэппить одну таблицу значениями из другой. В зависимости от задачи, могут использоваться разные типы присоединений. INNER JOIN — пересечение, RIGHT/LEFT JOIN для мэппинга одной таблицы знаениями из другой,
select * from Orders
join Customers on Orders.CustomerID = Customers.CustomerID
where Customers.CustomerID >10Внутри всего запроса JOIN встраивается после элемента from до элемента where, пример запроса:
Другие типы JOIN’ов можно увидеть на замечательной картинке ниже:
В следующей части подробнее поговорим о типах JOIN’ов и вложенных запросах.
При возникновении вопросов/пожеланий, всегда прошу обращаться!
|
Точно соответствуют значению, например 02.02.2006 |
#02.02.2006# |
Возвращает записи транзакций, выполненных 2 февраля 2006 г. Обязательно ставьте знаки # до и после значений даты, чтобы Access мог отличить значения даты от текстовых строк. |
|
Не соответствуют значению, такому как 02.02.2006 |
Not #02.02.2006# |
Возвращает записи транзакций, выполненных в любой день, кроме 2 февраля 2006 г. |
|
Содержат значения, которые предшествуют определенной дате, например 02.02.2006 |
< #02.02.2006# |
Возвращает записи транзакций, выполненных до 2 февраля 2006 г. Чтобы просмотреть транзакции, выполненные в определенную дату или до нее, воспользуйтесь оператором <= вместо оператора <. |
|
Содержат значения, которые следуют за определенной датой, например 02.02.2006 |
> #02.02.2006# |
Возвращает записи транзакций, выполненных после 2 февраля 2006 г. Чтобы просмотреть транзакции, выполненные в определенную дату или после нее, воспользуйтесь оператором >= вместо оператора >. |
|
Содержат значения, которые входят в определенный диапазон дат |
>#02.02.2006# and <#04.02.2006# |
Возвращает записи транзакций, выполненных в период между 2 и 4 февраля 2006 г. Кроме того, для фильтрации по диапазону значений, включая конечные значения, вы можете использовать оператор Between. Например, выражение Between #02.02.2006# and #04.02.2006# идентично выражению >=#02.02.2006# and <=#04.02.2006#. |
|
Содержат значения, которые не входят в определенный диапазон |
<#02.02.2006# or >#04.02.2006# |
Возвращает записи транзакций, выполненных до 2 февраля 2006 г. или после 4 февраля 2006 г. |
|
Содержат одно из двух заданных значений, например 02.02.2006 или 03.02.2006 |
#02.02.2006# or #03.02.2006# |
Возвращает записи транзакций, выполненных 2 или 3 февраля 2006 г. |
|
Содержит одно из нескольких значений |
In (#01.02.2006#, #01.03.2006#, #01.04.2006#) |
Возвращает записи транзакций, выполненных 1 февраля 2006 г., 1 марта 2006 г. или 1 апреля 2006 г. |
|
Содержат дату, которая выпадает на определенный месяц (вне зависимости от года), например декабрь |
DatePart(«m»; [ДатаПродажи]) = 12 |
Возвращает записи транзакций, выполненных в декабре любого года. |
|
Содержат дату, которая выпадает на определенный квартал (вне зависимости от года), например первый |
DatePart(«q»; [ДатаПродажи]) = 1 |
Возвращает записи транзакций, выполненных в первом квартале любого года. |
|
Содержат текущую дату |
Date() |
Возвращает записи транзакций, выполненных сегодня. Если сегодняшняя дата — 02.02.2006 г., вы увидите записи, в поле «ДатаЗаказа» которых указано 2 февраля 2006 г. |
|
Содержат вчерашнюю дату |
Date()-1 |
Возвращает записи транзакций, выполненных вчера. Если сегодняшняя дата — 02.02.2006 г., вы увидите записи за 1 февраля 2006 г. |
|
Содержат завтрашнюю дату |
Date() + 1 |
Возвращает записи транзакций, которые будут выполнены завтра. Если сегодняшняя дата — 02.02.2006 г., вы увидите записи за 3 февраля 2006 г. |
|
Содержат даты, которые выпадают на текущую неделю |
DatePart(«ww»; [ДатаПродажи]) = DatePart(«ww»; Date()) and Year([ДатаПродажи]) = Year(Date()) |
Возвращает записи транзакций, выполненных за текущую неделю. Неделя начинается в воскресенье и заканчивается в субботу. |
|
Содержат даты, которые выпадают на прошлую неделю |
Year([ДатаПродажи])* 53 + DatePart(«ww»; [ДатаПродажи]) = Year(Date())* 53 + DatePart(«ww»; Date()) — 1 |
Возвращает записи транзакций, выполненных за прошлую неделю. Неделя начинается в воскресенье и заканчивается в субботу. |
|
Содержат даты, которые выпадают на следующую неделю |
Year([ДатаПродажи])* 53+DatePart(«ww»; [ДатаПродажи]) = Year(Date())* 53+DatePart(«ww»; Date()) + 1 |
Возвращает записи транзакций, которые будут выполнены на следующей неделе. Неделя начинается в воскресенье и заканчивается в субботу. |
|
Содержат дату, которая выпадает на последние 7 дней |
Between Date() and Date()-6 |
Возвращает записи транзакций, выполненных за последние 7 дней. Если сегодняшняя дата — 02.02.2006 г., вы увидите записи за период с 24 января 2006 г. по 2 февраля 2006 г. |
|
Содержат дату, которая выпадает на текущий месяц |
Year([ДатаПродажи]) = Year(Now()) And Month([ДатаПродажи]) = Month(Now()) |
Возвращает записи за текущий месяц. Если сегодняшняя дата — 02.02.2006 г., вы увидите записи за февраль 2006 г. |
|
Содержат дату, которая выпадает на прошлый месяц |
Year([ДатаПродажи])* 12 + DatePart(«m»; [ДатаПродажи]) = Year(Date())* 12 + DatePart(«m»; Date()) — 1 |
Возвращает записи за прошлый месяц. Если сегодняшняя дата — 02.02.2006 г., вы увидите записи за январь 2006 г. |
|
Содержат дату, которая выпадает на следующий месяц |
Year([ДатаПродажи])* 12 + DatePart(«m»; [ДатаПродажи]) = Year(Date())* 12 + DatePart(«m»; Date()) + 1 |
Возвращает записи за следующий месяц. Если сегодняшняя дата — 02.02.2006 г., вы увидите записи за март 2006 г. |
|
Содержат дату, которая выпадает на последние 30 дней или 31 день |
Between Date( ) And DateAdd(«M», -1, Date( )) |
Записи о продажах за месяц. Если сегодняшняя дата — 02.02.2006 г., вы увидите записи за период со 2 января 2006 г. по 2 февраля 2006 г. |
|
Содержат дату, которая выпадает на текущий квартал |
Year([ДатаПродажи]) = Year(Now()) And DatePart(«q»; Date()) = DatePart(«q»; Now()) |
Возвращает записи за текущий квартал. Если сегодняшняя дата — 02.02.2006 г., вы увидите записи за первый квартал 2006 г. |
|
Содержат дату, которая выпадает на прошлый квартал |
Year([ДатаПродажи])*4+DatePart(«q»;[ДатаПродажи]) = Year(Date())*4+DatePart(«q»;Date())- 1 |
Возвращает записи за прошлый квартал. Если сегодняшняя дата — 02.02.2006 г., вы увидите записи за последний квартал 2005 г. |
|
Содержат дату, которая выпадает на следующий квартал |
Year([ДатаПродажи])*4+DatePart(«q»;[ДатаПродажи]) = Year(Date())*4+DatePart(«q»;Date())+1 |
Возвращает записи за следующий квартал. Если сегодняшняя дата — 02.02.2006 г., вы увидите записи за второй квартал 2006 г. |
|
Содержат дату, которая выпадает на текущий год |
Year([ДатаПродажи]) = Year(Date()) |
Возвращает записи за текущий год. Если сегодняшняя дата — 02.02.2006 г., вы увидите записи за 2006 г. |
|
Содержат дату, которая выпадает на прошлый год |
Year([ДатаПродажи]) = Year(Date()) — 1 |
Возвращает записи транзакций, выполненных в прошлом году. Если сегодняшняя дата — 02.02.2006 г., вы увидите записи за 2005 г. |
|
Содержат дату, которая выпадает на следующий год |
Year([ДатаПродажи]) = Year(Date()) + 1 |
Возвращает записи транзакций, которые будут выполнены в следующем году. Если сегодняшняя дата — 02.02.2006 г., вы увидите записи за 2007 г. |
|
Содержат дату, которая приходится на период с 1 января до текущей даты (записи с начала года до настоящего момента) |
Year([ДатаПродажи]) = Year(Date()) and Month([ДатаПродажи]) <= Month(Date()) and Day([ДатаПродажи]) <= Day (Date()) |
Возвращает записи транзакций, которые приходятся на период с 1 января текущего года до сегодняшней даты. Если сегодняшняя дата — 02.02.2006 г., вы увидите записи за период с 1 января 2006 г. по 2 февраля 2006 г. |
|
Содержат прошедшую дату |
< Date() |
Возвращает записи транзакций, выполненных до сегодняшнего дня. |
|
Содержат будущую дату |
> Date() |
Возвращает записи транзакций, которые будут выполнены после сегодняшнего дня. |
|
Фильтр пустых (или отсутствующих) значений |
Is Null |
Возвращает записи, в которых не указана дата транзакции. |
|
Фильтр непустых значений |
Is Not Null |
Возвращает записи, в которых указана дата транзакции. |
Создание простого запроса на выборку
Примечание: Мы стараемся как можно оперативнее обеспечивать вас актуальными справочными материалами на вашем языке. Эта страница переведена автоматически, поэтому ее текст может содержать неточности и грамматические ошибки. Для нас важно, чтобы эта статья была вам полезна. Просим вас уделить пару секунд и сообщить, помогла ли она вам, с помощью кнопок внизу страницы. Для удобства также приводим ссылку на оригинал (на английском языке).
Если вам нужно выбрать определенные данные из одного или нескольких источников, можно воспользоваться запросом на выборку. Запрос на выборку позволяет получить только необходимые сведения, а также помогает объединять информацию из нескольких источников. В качестве источников данных для запросов на выборку можно использовать таблицы и другие такие же запросы. В этом разделе вкратце рассматриваются запросы на выборку и предлагаются пошаговые инструкции по их созданию с помощью Мастера запросов либо в Конструктор.
Если вы хотите узнать больше о принципах работы запросов на примере базы данных Northwind, ознакомьтесь со статьей Общие сведения о запросах.
В этой статье
-
Overview
-
Создание запроса SELECT с помощью мастера запросов
-
Создание запроса в режиме конструктора
-
Создание запроса на выборку в веб-приложении Access
Общие сведения
Когда возникает потребность в каких-то данных, редко бывает необходимо все содержимое одной таблицы. Например, если вам нужна информация из таблицы контактов, как правило, речь идет о конкретной записи или только о номере телефона. Иногда бывает необходимо объединить данные сразу из нескольких таблиц, например совместить информацию о клиентах со сведениями о заказчиках. Для выбора необходимых данных используются запросы на выборку.
Запрос на выборку — это объект базы данных, который показывает информацию в Режим таблицы. Запрос не хранит данные, но содержит данные, которые хранятся в таблицах. В запросе можно отобразить данные из одной или нескольких таблиц, из других запросов или из двух сочетаний.
Преимущества запросов
Запрос позволяет выполнять перечисленные ниже задачи.
-
Просматривать значения только из полей, которые вас интересуют. При открытии таблицы отображаются все поля. Вы можете сохранить запрос, который выдает лишь некоторые из них.
Примечание: Запрос только возвращает данные, но не сохраняет их. При сохранении запроса вы не сохраняете копию соответствующих данных.
-
Объединять данные из нескольких источников. В таблице обычно можно увидеть только те сведения, которые в ней хранятся. Запрос позволяет выбрать поля из разных источников и указать, как именно нужно объединить информацию.
-
Использовать выражения в качестве полей. Например, в роли поля может выступить функция, возвращающая дату, а с помощью функции форматирования можно управлять форматом значений из полей в результатах запроса.
-
Просматривать записи, которые отвечают указанным вами условиям. При открытии таблицы отображаются все записи. Вы можете сохранить запрос, который выдает лишь некоторые из них.
Основные этапы создания запроса на выборку
Вы можете создать запрос на выборку с помощью мастера или конструктора запросов. Некоторые элементы недоступны в мастере, однако их можно добавить позже из конструктора. Хотя это разные способы, основные этапы аналогичны.
-
Выберите таблицы или запросы, которые хотите использовать в качестве источников данных.
-
Укажите поля из источников данных, которые хотите включить в результаты.
-
Также можно задать условия, которые ограничивают набор возвращаемых запросов записей.
Создав запрос на выборку, запустите его, чтобы посмотреть результаты. Чтобы выполнить запрос на выборку, откройте его в режиме таблицы. Сохранив запрос, вы сможете использовать его позже (например, в качестве источника данных для формы, отчета или другого запроса).
Создание запроса на выборку с помощью мастера запросов
Мастер позволяет автоматически создать запрос на выборку. При использовании мастера вы не полностью контролируете все детали процесса, однако таким способом запрос обычно создается быстрее. Кроме того, мастер иногда обнаруживает в запросе простые ошибки и предлагает выбрать другое действие.
Подготовка
Если вы используете поля из источников данных, которые не связаны между собой, мастер запросов предлагает создать между ними отношения. Он откроет окно отношений, однако если вы внесете какие-то изменения, то вам потребуется перезапустить мастер. Таким образом, перед запуском мастера имеет смысл сразу создать все отношения, которые потребуются вашему запросу.
Дополнительную информацию о создании отношений между таблицами можно найти в статье Руководство по связям между таблицами.
Использование мастера запросов
-
На вкладке Создание в группе Запросы нажмите кнопку Мастер запросов.

-
В диалоговом окне Новый запрос выберите пункт Простой запрос и нажмите кнопку ОК.
-
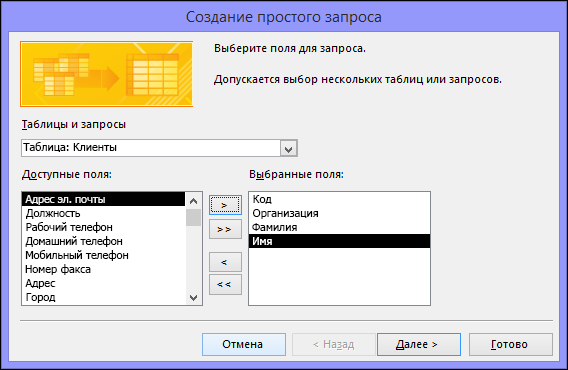
Теперь добавьте поля. Вы можете добавить до 255 полей из 32 таблиц или запросов.
Для каждого поля выполните два указанных ниже действия.
-
В разделе Таблицы и запросы щелкните таблицу или запрос, содержащие поле.
-
В разделе Доступные поля дважды щелкните поле, чтобы добавить его в список Выбранные поля. Если вы хотите добавить в запрос все поля, нажмите кнопку с двумя стрелками вправо (>>).
-
Добавив в запрос все необходимые поля, нажмите кнопку Далее.
-
-
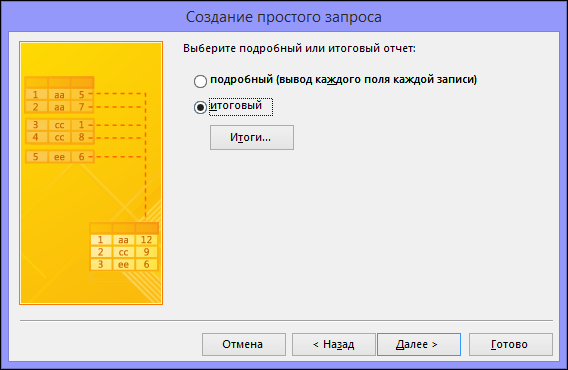
Если вы не добавили ни одного числового поля (поля, содержащего числовые данные), перейдите к действию 9. При добавлении числового поля вам потребуется выбрать, что именно вернет запрос: подробности или итоговые данные.
Выполните одно из указанных ниже действий.
-
Если вы хотите просмотреть отдельные записи, выберите пункт подробный и нажмите кнопку Далее. Перейдите к действию 9.
-
Если вам нужны итоговые числовые данные, например средние значения, выберите пункт итоговый и нажмите кнопку Итоги.
-
-
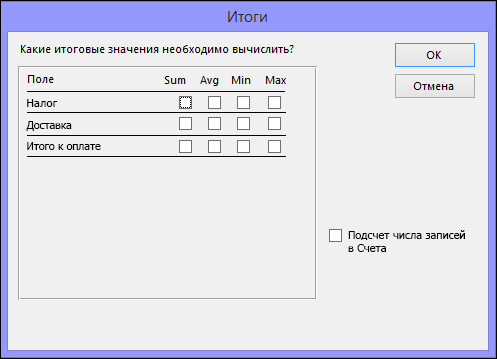
В диалоговом окне Итоги укажите необходимые поля и типы итоговых данных. В списке будут доступны только числовые поля.
Для каждого числового поля выберите одну из перечисленных ниже функций.
-
Sum — запрос вернет сумму всех значений, указанных в поле.
-
Avg — запрос вернет среднее значение поля.
-
Min — запрос вернет минимальное значение, указанное в поле.
-
Max — запрос вернет максимальное значение, указанное в поле.
-
-
Если вы хотите, чтобы в результатах запроса отобразилось число записей в источнике данных, установите соответствующий флажок Подсчет числа записей в (название источника данных).
-
Нажмите ОК, чтобы закрыть диалоговое окно Итоги.
-
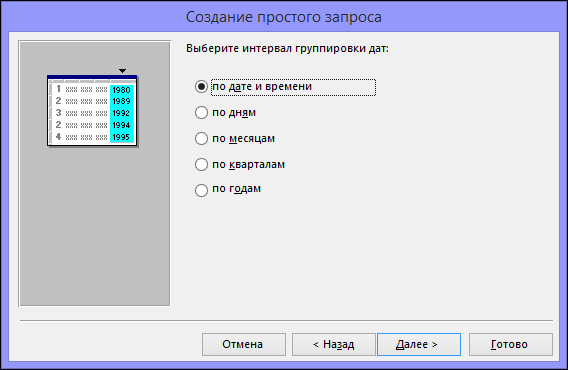
Если вы не добавили в запрос ни одного поля даты и времени, перейдите к действию 9. Если вы добавили в запрос поля даты и времени, мастер запросов предложит вам выбрать способ группировки значений даты. Предположим, вы добавили в запрос числовое поле («Цена») и поле даты и времени («Время_транзакции»), а затем в диалоговом окне Итоги указали, что хотите отобразить среднее значение по числовому полю «Цена». Поскольку вы добавили поле даты и времени, вы можете подсчитать итоговые величины для каждого уникального значения даты и времени, например для каждого месяца, квартала или года.
Выберите период, который хотите использовать для группировки значений даты и времени, а затем нажмите кнопку Далее.
Примечание: В режиме конструктора для группировки значений по периодам можно использовать выражения, однако в мастере доступны только указанные здесь варианты.
-
На последней странице мастера задайте название запроса, укажите, хотите ли вы открыть или изменить его, и нажмите кнопку Готово.
Если вы решили открыть запрос, он отобразит выбранные данные в режиме таблицы. Если вы решили изменить запрос, он откроется в режиме конструктора.

К началу страницы
Создание запроса в режиме конструктора
В режиме конструктора можно вручную создать запрос на выборку. В этом режиме вы полнее контролируете процесс создания запроса, однако здесь легче допустить ошибку и необходимо больше времени, чем в мастере.
Создание запроса
-
Действие 1. Добавьте источники данных
-
Действие 2. Соедините связанные источники данных
-
Действие 3. Добавьте выводимые поля
-
Действие 4. Укажите условия
-
Действие 5. Рассчитайте итоговые значения
-
Действие 6. Просмотрите результаты
Действие 1. Добавьте источники данных
В режиме конструктора источники данных и поля добавляются на разных этапах, так как для добавления источников используется диалоговое окно Добавление таблицы. Однако вы всегда можете добавить дополнительные источники позже.
-
На вкладке Создание в группе Другое нажмите кнопку Конструктор запросов.
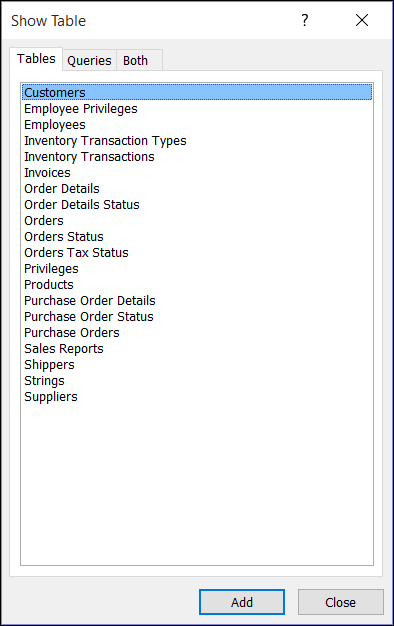
-
В диалоговом окне Добавление таблицы на вкладке Таблицы, Запросы или Таблицы и запросы дважды щелкните каждый источник данных, который хотите использовать, или выберите их и нажмите кнопку Добавить.
-
Закройте диалоговое окно Добавление таблицы.
Автоматическое соединение
Если между добавляемыми источниками данных уже заданы отношения, они автоматически добавляются в запрос в качестве соединений. Соединения определяют, как именно следует объединять данные из связанных источников. Access также автоматически создает соединение между двумя таблицами, если они содержат поля с совместимыми типами данных и одно из них — первичный ключ.
Вы можете настроить соединения, добавленные приложением Access. Access выбирает тип создаваемого соединения на основе отношения, которое ему соответствует. Если Access создает соединение, но для него не определено отношение, Access добавляет внутреннее соединение.
Если приложение Access при добавлении источников данных автоматически создало соединения правильных типов, вы можете перейти к действию 3 (добавление выводимых полей).
Повторное использование одного источника данных
В некоторых случаях вы можете присоединиться к двум копиям одной и той же таблицы или запроса, которые называются самосоединение, и будут объединять записи из той же таблицы, если в Объединенных полях есть совпадающие значения. Например, предположим, что у вас есть таблица Employees, в которой поле «подчиняется» для записи каждого сотрудника отображает его идентификатор своего руководителя вместо имени. Вы можете использовать самосоединение для отображения имени руководителя в записи каждого сотрудника.
При добавлении источника данных во второй раз Access присвоит имени второго экземпляра окончание «_1». Например, при повторном добавлении таблицы «Сотрудники» ее второй экземпляр будет называться «Сотрудники_1».
Действие 2. Соедините связанные источники данных
Если источники данных, добавленные в запрос, уже имеют отношения, Access автоматически создает внутреннее соединение для каждой связи. Если используется целостность данных, Access также отображает «1» над линией соединения, чтобы показать, какая таблица находится на стороне «один» элемента отношение «один-ко-многим» и символ бесконечности (∞), чтобы показать, какая таблица находится на стороне «многие».
Если вы добавили в запрос другие запросы и не создали между ними отношения, Access не создает автоматических соединений ни между ними, ни между запросами и таблицами, которые не связаны между собой. Если Access не создает соединения при добавлении источников данных, как правило, их следует создать вручную. Источники данных, которые не соединены с другими источниками, могут привести к проблемам в результатах запроса.
Кроме того, можно сменить тип соединения с внутреннего на внешнее соединение, чтобы запрос включал больше записей.
Добавление соединения
-
Чтобы создать соединение, перетащите поле из одного источника данных в соответствующее поле в другом источнике.
Access добавит линию между двумя полями, чтобы показать, что они соединены.

Изменение соединения
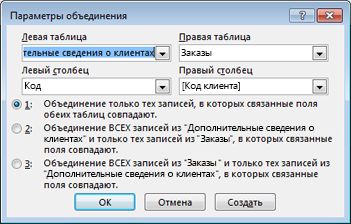
-
Дважды щелкните соединение, которое требуется изменить.
Откроется диалоговое окно Параметры соединения.
-
Ознакомьтесь с тремя вариантами в диалоговом окне Параметры соединения.
-
Выберите нужный вариант и нажмите кнопку ОК.
После создания соединений можно добавить выводимые поля: они будут содержать данные, которые должны отображаться в результатах.
Действие 3. Добавьте выводимые поля
Вы можете легко добавить поле из любого источника данных, добавленного в действии 1.
-
Для этого перетащите поле из источника в верхней области окна конструктора запросов вниз в строку Поле бланка запроса (в нижней части окна конструктора).
При добавлении поля таким образом Access автоматически заполняет строку Таблица в таблице конструктора в соответствии с источником данных поля.
Совет: Чтобы быстро добавить все поля в строку «Поле» бланка запроса, дважды щелкните имя таблицы или запроса в верхней области, чтобы выделить все поля в нем, а затем перетащите их все сразу вниз на бланк.
Использование выражения в качестве выводимого поля
Вы можете использовать выражение в качестве выводимого поля для вычислений или создания результатов запроса с помощью функции. В выражениях могут использоваться данные из любых источников запроса, а также функции, например Format или InStr, константы и арифметические операторы.
-
В пустом столбце таблицы запроса щелкните строку Поле правой кнопкой мыши и выберите в контекстном меню пункт Масштаб.
-
В поле Масштаб введите или вставьте необходимое выражение. Перед выражением введите имя, которое хотите использовать для результата выражения, а после него — двоеточие. Например, чтобы обозначить результат выражения как «Последнее обновление», введите перед ним фразу Последнее обновление:.
Примечание: С помощью выражений можно выполнять самые разные задачи. Их подробное рассмотрение выходит за рамки этой статьи. Дополнительные сведения о создании выражений см. в статье Создание выражений.
Действие 4. Укажите условия
Это необязательно.
С помощью условий можно ограничить количество записей, которые возвращает запрос, выбирая только те из них, значения полей в которых отвечают заданным критериям.
Определение условий для выводимого поля
-
В таблице конструктора запросов в строке Условие отбора поля, значения в котором вы хотите отфильтровать, введите выражение, которому должны удовлетворять значения в поле для включения в результат. Например, чтобы включить в запрос только записи, в которых в поле «Город» указано «Рязань», введите Рязань в строке Условие отбора под этим полем.
Различные примеры выражений условий для запросов можно найти в статье Примеры условий запроса.
-
Укажите альтернативные условия в строке или под строкой Условие отбора.
Когда указаны альтернативные условия, запись включается в результаты запроса, если значение соответствующего поля удовлетворяет любому из указанных условий.
Условия для нескольких полей
Условия можно задать для нескольких полей. В этом случае для включения записи в результаты должны выполняться все условия в соответствующей строке Условия отбора либо Или.
Настройка условий на основе поля, которое не включается в вывод
Вы можете добавить в запрос поле, но не включать его значения в выводимые результаты. Это позволяет использовать содержимое поля для ограничения результатов, но при этом не отображать его.
-
Добавьте поле в таблицу запроса.
-
Снимите для него флажок в строке Показывать.
-
Задайте условия, как для выводимого поля.
Действие 5. Рассчитайте итоговые значения
Этот этап является необязательным.
Вы также можете вычислить итоговые значения для числовых данных. Например, может потребоваться просмотреть среднюю цену или общие продажи.
Для расчета итоговых значений в запросе используется строка Итого. По умолчанию строка Итого не отображается в режиме конструктора.
-
Когда запрос открыт в конструкторе, на вкладке «Конструктор» в группе «Показать или скрыть» нажмите кнопку Итоги.
Access отобразит строку Итого на бланке запроса.
-
Для каждого необходимого поля в строке Итого выберите нужную функцию. Набор доступных функций зависит от типа данных в поле.
Дополнительные сведения о функциях строки «Итого» в запросах см. в статье Суммирование или подсчет значений в таблице с помощью строки «Итого».
Действие 6. Просмотрите результаты
Чтобы увидеть результаты запроса, на вкладке «Конструктор» нажмите кнопку Выполнить. Access отобразит результаты запроса в режиме таблицы.
Чтобы вернуться в режим конструктора и внести в запрос изменения, щелкните Главная > Вид > Конструктор.
Настраивайте поля, выражения или условия и повторно выполняйте запрос, пока он не будет возвращать нужные данные.
К началу страницы
Создание запроса на выборку в веб-приложении Access
В веб-приложении Access создать такой же запрос на выборку можно почти так же, как и в приложении для классических баз данных. Нужно только выполнить несколько дополнительных действий, чтобы отобразить результаты запроса в браузере.
|
Важно Корпорация Майкрософт больше не рекомендует создавать и использовать веб-приложения Access в SharePoint. В качестве альтернативного средства для бизнес-решений, не требующих дополнительного программирования и работающих в браузере и на мобильных устройствах, рекомендуется использовать Microsoft Power Apps. |
-
Откройте веб-приложение в Access.
-
Выберите Главная > Дополнительно > Запрос.
-
В диалоговом окне Добавление таблицы на вкладке Таблицы, Запросы или Таблицы и запросы дважды щелкните каждый источник данных, который хотите использовать, или выберите их и нажмите кнопку Добавить. По завершении нажмите кнопку Закрыть.
-
Перетащите поля из источника в верхней области окна бланка запроса вниз в строку Поле таблицы конструктора (в нижней части окна конструктора).
-
Добавьте для полей необходимые условия.
-
Щелкните вкладку запроса правой кнопкой мыши, выберите команду Сохранить и присвойте запросу имя.
-
Чтобы увидеть результаты запроса, щелкните правой кнопкой мыши вкладку запроса и выберите пункт Режим таблицы.
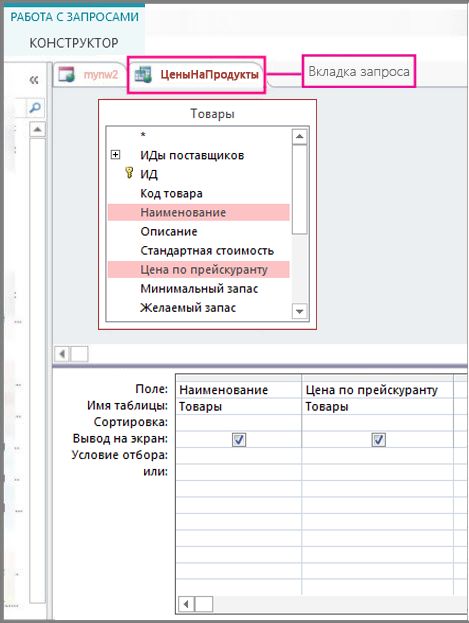
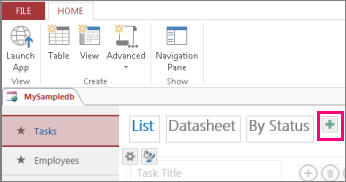
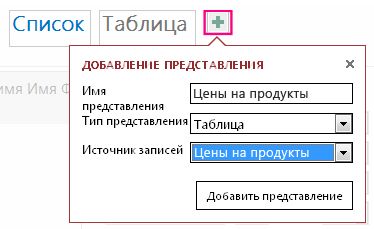
Чтобы сделать результаты запроса доступными в браузере, нужно добавить представление запроса на экране выбора таблиц. Чтобы добавить новое представление в заголовок на экране выбора таблиц, выполните указанные ниже действия.
-
Щелкните заголовок таблицы в области выбора таблиц слева и нажмите кнопку Добавить представление (знак «плюс»).
-
В диалоговом окне Добавление нового представления введите имя представления в поле имя представления , выберите тип представленияи укажите имя запроса в поле Источник записей .
Совет: Если в запросе было использовано несколько таблиц, можно добавить представление для любых из них или для всех.
-
Выберите Главная > Запустить приложение чтобы открыть новое представление в браузере.
-
Если запрос поддерживает возможность обновления, щелкните имя таблицы, а затем — имя представления, чтобы добавить, изменить или удалить данные в нем.
К началу страницы
О, эти планы запросов / Хабр
История стара как мир. Две таблицы:
- Cities – 100 уникальных городов.
- People – 10 млн. людей. У некоторых людей город может быть не указан.
Распределение людей по городам – равномерное.
Индексы на поля Cites.Id, Cites.Name, People .CityId – в наличии.
Нужно выбрать первых 100 записей People, отсортированных по Cites.
Засучив рукава, бодро пишем:
select top 100 p.Name, c.Name as City from People p
left join Cities c on c.Id=p.CityId
order by c.Name
При этом мы получим что-то вроде:
За… 6 секунд. (MS SQL 2008 R2, i5 / 4Gb)
Но как же так! Откуда 6 секунд?! Мы ведь знаем, что в первых 100 записях будет исключительно Алматы! Ведь записей – 10 миллионов, и значит на город приходится по 100 тыс. Даже если это и не так, мы ведь можем выбрать первый город в списке, и проверить, наберется ли у него хотя бы 100 жителей.
Почему SQL сервер, обладая статистикой, не делает так:
select * from People p
left join Cities c on c.Id=p.CityId
where p.CityId
in (select top 1 id from Cities order by Name)
order by c.[Name]
Данный запрос возвращает примерно 100 тыс. записей менее чем за секунду! Убедились, что есть искомые 100 записей и отдали их очень-очень быстро.
Однако MSSQL делает все по плану. А план у него, «чистый термояд» (с).
Вопрос к знатокам:
каким образом необходимо исправить SQL запрос или сделать какие-то действия над сервером, чтобы получить по первому запросу результат в 10 раз быстрее?
P.S.
CREATE TABLE [dbo].[People] (
[Id] uniqueidentifier NOT NULL,
[Name] nvarchar(50) NOT NULL,
[CityId] uniqueidentifier
)
ON [PRIMARY]
GO
CREATE TABLE [dbo].[Cities] (
[Id] uniqueidentifier NOT NULL,
[Name] nvarchar(50) NOT NULL,
)
ON [PRIMARY]
GO
P.P.S
Откуда растут ноги:
Задача вполне реальная. Есть таблица с основной сущностью, от нее по принципу «звезда» отходит множество измерений. Пользователю нужно ее отобразить в гриде, предоставив сортировку по полям.
Начиная с некоторого размера основной таблицы сортировка сводится к тому, что выбирается окно с одинаковыми (крайними) значениями, (вроде «Алматы») но при этом система начинает жутко тормозить.
Хочется иметь ОДИН параметризированный запрос, который будет эффективно работать как с малым размером таблицы People так и с большим.
P.P.P.S
Интересно, что если бы City были бы NotNull и использовался InnerJoin то запрос выполняется мгновенно.
Интересно, что ДАЖЕ ЕСЛИ поле City было бы NotNull но использовался LeftJoin – то запрос тормозит.
В комментах идея: Сперва выбрать все InnerJoin а потом Union по Null значениям. Завтра проверю эту и остальные безумные идеи )
P.P.P.P.S Попробовал. Сработало!
WITH Help AS
(
select top 100 p.Name, c.Name as City from People p
INNER join Cities c on c.Id=p.CityId
order by c.Name ASC
UNION
select top 100 p.Name, NULL as City from People p
WHERE p.CityId IS NULL
)
SELECT TOP 100 * FROM help
Дает 150 миллисекунд при тех же условиях! Спасибо holem.
Эти базы данных бесплатны, благодаря SQL удобно интегрируются с остальными компонентами в системе, они популярны и с ними умеют работать большинство разработчиков и аналитиков. Нагрузку (трафик и объемы) они могут переварить достаточно объемную, чтобы спокойно продержаться до того момента, когда компания сможет позволить себе более сложные (и дорогие) решения для аналитики и отчетов.
Исходная позиция
Однако даже в многократно изученной технологии всегда существуют разные нюансы, способные внезапно прибавить забот инженерам. Помимо надежности, наиболее часто упоминаемая проблема с базами данных – это их производительность. Очевидно, что с ростом количества данных скорость ответа БД падает, но если это происходит предсказуемо и согласуется с ростом нагрузки, то это не так и плохо. Всегда можно заранее увидеть, когда БД начинает требовать внимания и запланировать апгрейд или переход на принципиально другую БД. Гораздо хуже, если производительность БД деградирует непредсказуемо.
Тема улучшения производительности БД стара как мир и очень обширна, и в этой статье хотелось бы сфокусироваться только на одном направлении. А именно, на оценке эффективности планов запросов в БД PostgreSQL, а также изменению этой эффективности во времени, чтобы сделать поведение планировщика БД более предсказуемым.
Несмотря на то, что многие вещи о которых пойдет речь применимы ко всем недавним версиям этой БД, в примерах ниже подразумевается версия 11.2, последняя на текущий момент.
Перед тем, как мы погрузимся в подробности, имеет смысл сделать лирическое отступление и сказать пару слов о том, откуда вообще могут браться проблемы с производительностью в реляционных БД. Чем же именно занята БД, когда она «тормозит»? Нехватка памяти (большое количество обращений к диску или сети), слабый процессор, это все очевидные проблемы с понятными решениями, но что еще может влиять на скорость выполнения запроса?
Освежим воспоминания
Для того, чтобы БД ответила на SQL-запрос, ей необходимо построить план запроса (в какие таблицы и колонки посмотреть, какие индексы понадобятся, что оттуда забрать, что с чем сравнить, сколько потребуется памяти и так далее). План этот формируется в виде дерева, узлами в котором являются всего несколько типовых операций, с разной вычислительной сложностью. Вот несколько из них, для примера (N – число строк с которыми нужно провести операцию):
| Операция | Что выполняется | Затратность |
|---|---|---|
| Операции выборки данных SELECT … WHERE … | ||
| Seq Scan | Загружаем каждую строку из таблицы и проверяем условие. | O(N) |
| Index Scan (b-tree index) |
Данные есть прямо в индексе, поэтому ищем по условию нужные элементы индекса и берем данные оттуда. | O(log(N)), поиск элемента в отсортированном дереве. |
| Index Scan (hash index) |
Данные есть прямо в индексе, поэтому ищем по условию нужные элементы индекса и берем данные оттуда. | O(1), поиск элемента в хэш-таблице, без учета затратности создания хэшей |
| Bitmap Heap Scan | Выбираем номера нужных строк по индексу, затем загружаем только нужные строки и проводим с ними дополнительные проверки. | Index Scan + Seq Scan (M), Где M – число найденных строк после Index Scan. Предполагается что M << N, т.е. индекс полезнее чем Seq Scan. |
| Операции соединения (JOIN, SELECT из нескольких таблиц) | ||
| Nested Loop | Для каждой строки из левой таблицы ищем подходящую строку в правой таблице. | O(N2). Но если одна из таблиц значительно меньше другой (словарь) и практически не растет со временем, то фактическая затратность может снизиться до O(N). |
| Hash Join | Для каждой строки из левой и правой таблицы считаем хэш, за счет чего уменьшается число переборов возможных вариантов соединения. | O(N), но в случае очень неэффективной функции хэша или большого количества одинаковых полей для соединения может быть и O(N2) |
| Merge Join | Сортируем по условию левую и правую таблицы, после чего объединяем два отсортированных списка | O(N*log(N)) Затраты на сортировку + проход по списку. |
| Операции агрегации (GROUP BY, DISTINCT) | ||
| Group Aggregate | Сортируем таблицу по условию агрегации и потом в отсортированном списке группируем соседние строки. | O(N*log(N)) |
| Hash Aggregate | Считаем хэш для условия агрегации, для каждой строки. Для строк с одинаковым hash проводим агрегацию. | O(N) |
Как можно понять, затратность запроса очень сильно зависит от того, как расположены данные в таблицах и как этот порядок соответствует используемым операциям хэширования. Nested Loop, несмотря на его затратность в O(N2) может быть выгоднее Hash Join или Merge Join когда одна из соединяемых таблиц вырождается до одной-нескольких строк.
Кроме ресурсов CPU, затратность включает в себя и использование памяти. И то, и другое – ограниченный ресурс, поэтому планировщику запросов приходится искать компромисс. Если две таблицы математически выгоднее соединить через Hash Join, но в памяти просто нет места под такую большую хэш-таблицу, БД может быть вынуждена использовать Merge Join, например. А «медленный» Nested Loop вообще не требует дополнительной памяти и готов выдавать результаты прямо сразу после запуска.
Относительную затратность этих операций нагляднее показать на графике. Здесь не абсолютные цифры, просто примерное отношение разных операций.
График Nested Loop «стартует» ниже, т.к. для него не требуется ни дополнительных вычислений, ни выделения памяти или копирования промежуточных данных, но у него затратность O(N2). У Merge Join и Hash Join начальная затратность выше, однако после некоторых величин N они начинают выигрывать во времени у Nested Loop. Планировщик старается выбрать план с наименьшими затратами и на графике выше придерживается разных операций при разном N (зеленая пунктирная стрелка). При числе строк до N1 выгоднее использовать Nested Loop, от N1 до N2 выгоднее Merge Join, далее после N2 выгоднее становится Hash Join, однако Hash Join требует памяти для создания хэш-таблиц. И при достижении N3 этой памяти становится недостаточно, что приводит к вынужденному использованию Merge Join.
При выборе плана планировщик оценивает затратность каждой операции в плане с помощью набора относительной затратности некоторых «атомарных» операций в БД. Как, например, вычисления, сравнения, загрузка страницы в память, и т.п. Вот список некоторых таких параметров из конфигурации по умолчанию, их не так много:
| Константа относительной затратности | Значение по умолчанию |
|---|---|
| seq_page_cost | 1.0 |
| random_page_cost | 4.0 |
| cpu_tuple_cost | 0.01 |
| cpu_index_tuple_cost | 0.005 |
| cpu_operator_cost | 0.0025 |
| parallel_tuple_cost | 0.1 |
| parallel_setup_cost | 1000.0 |
Правда, одних только этих констант мало, нужно еще знать то самое «N», то есть, сколько же именно строк из предыдущих результатов придется обработать в каждой такой операции. Верхняя граница тут очевидна – БД «знает» сколько данных в любой таблице и всегда может посчитать «по-максимуму». К примеру, если у вас две таблицы по 100 строк, то их соединение может дать от 0 до 10000 строк на выходе. Соответственно, у следующей операции на входе может быть до 10000 строк.
Но если знать хоть немного о природе данных в таблицах, это число строк можно предсказать более точно. Например, для двух таблиц по 100 строк из примера выше, если вы заранее знаете, что объединение даст не 10 тысяч строк, а те же 100, предполагаемая затратность следующей операции сильно сокращается. В этом случае данный план мог бы стать эффективнее других.
Оптимизация плана «из коробки»
Для того чтобы у планировщика была возможность более точно предсказывать размер промежуточных результатов, в PostgreSQL используется сбор статистики по таблицам, которая копится в pg_statistic, или в ее более удобочитаемом варианте – в pg_stats. Обновляется она автоматически при запуске vacuum, либо явно при команде ANALYZE. В этой таблице хранится разнообразная информация о том, какие данные и какой природы имеются в таблицах. В частности, гистограммы значений, процент пустых полей и другая информация. Все это планировщик использует, чтобы более точно спрогнозировать объемы данных для каждой операции в дереве плана, и, таким образом, более точно посчитать затратность операций и плана в целом.
Возьмем, например, запрос:
SELECT t1.important_value FROM t1 WHERE t1.a > 100Предположим, что гистограмма значений в колонке «t1.a» выявила, что значения, большие 100 встречаются в примерно 1% строк таблицы. Тогда можно предсказать, что такая выборка вернет около сотой доли всех строк из таблицы «t1».
БД дает возможность посмотреть на прогнозируемую затратность плана через команду EXPLAIN, а фактическое время его работы — с помощью EXPLAIN ANALYZE.
Вроде бы с автоматической статистикой теперь все должно быть хорошо, но и тут могут быть сложности. Об этом есть хорошая статья от компании Citus Data, с примером неэффективности автоматической статистики и о сборе дополнительной статистики с помощью CREATE STATISTICS (доступна с PG 10.0).
Итак, для планировщика существуют два источника ошибок в вычислении затратности:
- Относительная затратность примитивных операций (seq_page_cost, cpu_operator_cost, и так далее) по умолчанию могут сильно отличаться от реальности (cpu cost 0.01, srq page load cost – 1 или 4 для random page load). Далеко не факт, что 100 сравнений будут равны 1 загрузке страницы.
- Ошибка с прогнозом числа строк в промежуточных операциях. Фактическая затратность операции в таком случае может сильно отличаться от прогноза.
В сложных запросах составление и прогнозирование всех возможных планов может само по себе занять массу времени. Что толку вернуть данные за 1 секунду, если БД только планировала запрос минуту? В PostgreSQL есть для такой ситуации Geqo optimizer, это планировщик, который строит не все возможные варианты планов, а начинает с нескольких случайных и достраивает наилучшие, прогнозируя пути снижения затратности. Все это тоже не улучшает точность прогноза, хотя и ускоряет нахождение хоть какого-нибудь более-менее оптимального плана.
Внезапные планы — конкуренты
Если все складывается удачно, ваш запрос отрабатывает максимально быстро. С ростом количества данных скорость выполнения запросов в БД постепенно увеличивается, и через некоторое время, наблюдая за ней, можно примерно предсказать, когда потребуется увеличить память или число ядер CPU или расширить кластер и т.п.
Но нужно учитывать то, что у оптимального плана существую конкуренты с близкой затратностью на выполнение, которых мы не видим. И если БД внезапно меняет план запроса на другой, это становится сюрпризом. Хорошо, если БД «перескочит» на более эффективный план. А если нет? Посмотрим, например, на картинку. Это прогнозируемая затратность и реальное время выполнения двух планов (красного и зеленого):
Здесь зеленым изображен один план и красным – его ближайший «конкурент». Пунктиром изображен график прогнозируемой затратности, сплошной линией – реальное время. Серой пунктирной стрелкой изображен выбор планировщика.
Предположим, что в один прекрасный вечер пятницы прогнозируемое число строк в некоторой промежуточной операции достигает N1 и «красный» прогноз начинает выигрывать у «зеленого». Планировщик начинает использовать его. Фактическое же время выполнения запросов сразу подскакивает (переход с зеленой сплошной линии на красную), то есть график деградации БД принимает вид ступеньки (а может и «стены»). На практике такая «стена» может увеличить время выполнения запроса на порядок и больше.
Стоит отметить, что такая ситуация, вероятно, более типична для бэкофиса и аналитики, чем для фронтенда, поскольку последний обычно приспособлен к большему количеству одновременных запросов и, следовательно, использует более простые запросы в БД, где и ошибка в прогнозах плана меньше. Если же это БД для построения отчетности или аналитики, запросы могут быть произвольно сложными.
Как же с этим жить?
Возникает вопрос, а можно ли как-нибудь было предвидеть такие вот «подводные» невидимые планы? Ведь проблема даже не в том, что они не оптимальны, а в том, что переключение на другой план может произойти непредсказуемо, и, по закону подлости, в самый неудачный для этого момент.
Напрямую, к сожалению, их не увидеть, но можно поискать альтернативные планы путем изменения собственно весов, по которым они выбираются. Смысл такого подхода в том, чтобы убрать из поля зрения текущий план, который планировщик считает оптимальным, чтобы оптимальным стал какой-нибудь из ближайших его конкурентов, и, таким образом, его можно было бы увидеть через команду EXPLAIN. Периодически проверяя изменения затратности в таких «конкурентах» и в основном плане можно оценить вероятность того, что БД скоро «перескочит» на другой план.
Кроме сбора данных о прогнозах альтернативных планов можно их запускать и измерять их производительность, что также дает представление о внутреннем «самочувствии» БД.
Давайте посмотрим, какие средства у нас есть для таких экспериментов.
Во-первых, можно прямо «запрещать» конкретные операции с помощью переменных сессии. Удобно то, что их не надо менять в конфиге и перезагружать БД, их значение меняется только в текущей открытой сессии и не влияет на остальные сессии, так что можно экспериментировать прямо на реальных данных. Вот их список со значениями по умолчанию. Почти все операции включены:
| Используемые операции | Значение по умолчанию |
|---|---|
| enable_bitmapscan enable_hashagg enable_hashjoin enable_indexscan enable_indexonlyscan enable_material enable_mergejoin enable_nestloop enable_parallel_append enable_seqscan enable_sort enable_tidscan enable_parallel_hash enable_partition_pruning |
on |
| enable_partitionwise_join enable_partitionwise_aggregate |
off |
Запрещая или разрешая отдельные операции, мы заставляем планировщик выбирать другие планы, которые мы можем увидеть все той же командой EXPLAIN. На самом деле, «запрет» операций не запрещает их использование, а просто сильно увеличивает их затратность. В PostgreSQL каждой «запрещенной» операции автоматически «накидывается» затратность равная 10 миллиардам условных единиц. При этом в EXPLAIN суммарные веса плана могут получиться запредельно высокими, но на фоне этих десятков миллиардов вес остальных операций хорошо просматривается, так как он обычно укладывается в меньшие порядки.
Особого интереса заслуживают две операции из перечисленных:
- Hash Join. Ее сложность — O(N), но при ошибке с прогнозом в размере результата можно не поместиться в память и придется делать Merge Join, с затратностью O(N*log(N)).
- Nested Loop. Ее сложность O(N2), поэтому ошибка в прогнозе размеров квадратично влияет на скорость выполнения такого соединения.
Например, возьмем некоторые реальные цифры из запросов, оптимизацией которых мы занимались в нашей компании.
План 1. Со всеми разрешенными операциями суммарная затратность наиболее оптимального плана составляла 274962.09 единиц.
План 2. С «запрещенным» nested loop затратность выросла до 40000534153.85. Вот эти 40 миллиардов, составляющие основную часть затратности – это 4 раза использованный Nested Loop, несмотря на запрет. А оставшиеся 534153.85 – это как раз и есть прогноз затратности всех остальных операций в плане. Он, как мы видим, примерно в 2 раза превышает затратность оптимального плана, то есть достаточно близок к нему.
План 3. С «запрещенным» Hash Join затратность составила 383253.77. План был действительно составлен без использования операции Hash Join, так как мы не видим никаких миллиардов. Затратность его, тем не менее, на 30% выше, чем у оптимального, что тоже очень близко.
В реальности же времена выполнения запросов были такие:
План 1 (все операции разрешены) выполнился за ~ 9 минут.
План 2 (с «запрещенным» nested loop) выполнился за 1.5 секунды.
План 3 (с «запрещенным» hash join) выполнился за ~ 5 минут.
Причина, как можно заметить, в ошибочном прогнозе затратности Nested Loop. И действительно, при сравнении EXPLAIN c EXPLAIN ANALYZE в нем обнаруживается ошибка с определением того самого злосчастного N на промежуточной операции. Вместо прогнозируемой одной строки Nested Loop встретился с несколькими тысячами строк, из-за чего время выполнения запроса выросло на пару порядков.
Экономия с «запрещенным» Hash Join связана с заменой хэширования на сортировку и Merge Join, который отработал в данном случае быстрее чем Hash Join. Заметим, что этот план 2 в реальности почти в два раза быстрее «оптимального» плана 1. Хотя прогнозировалось, что он будет медленнее.
На практике, если ваш запрос внезапно (после апгдейда БД или просто сам собой) стал выполняться значительно дольше чем до этого, попробуйте для начала запретить либо Hash Join либо Nested Loop и посмотреть, как это влияет на скорость выполнения запроса. В удачном случае вам удастся хотя бы запретить новый неоптимальный план, и, вернуться к предыдущему, быстрому.
Для того чтобы это сделать не нужно изменять конфигурационные файлы PostgreSQL с рестартом базы, достаточно просто в любой консоли изменить значение нужной переменной на время открытой сессии с БД. Остальные сессии не будут затронуты, конфигурация изменится только для вашей текущей сессии. Например, так:
SET enable_hashjoin=’on’;
SET enable_nestloop=’off’;
SELECT …
FROM …
(и остальная часть анализируемого запроса)
Второе средство повлиять на выбор плана – это изменение собственно весов низкоуровневых операций. Здесь универсального рецепта нет, но, к примеру, если у вас БД с «разогретым» кэшем и данные целиком помещаются в памяти, вполне вероятно, что затратность последовательной подгрузки страницы не отличается от затратности подгрузки случайной страницы. Тогда как в конфиге по умолчанию случайная в 4 раза более затратна чем последовательная.
Или, другой пример, условная затратность запуска параллельной обработки равна по умолчанию 1000, тогда как затратность подгрузки страницы 1.0. Начинать имеет смысл с изменения только одного из параметров за раз, чтобы определить влияет ли именно он на выбор плана. Самые простые способы – это для начала выставить параметр в 0 или в какое-нибудь высокое значение (1 миллион).
Однако нужно помнить, что, улучшив производительность в одном запросе вы можете ухудшить ее в другом. В общем, тут широкое поле для экспериментов. Лучше пробовать менять их по одному, по очереди.
Альтернативные варианты лечения
Рассказ про планировщик был бы неполным без упоминания, как минимум, двух расширений PostgreSQL.
Первое – это SR_PLAN, для сохранения рассчитанного плана и принудительного использования его в дальнейшем. Это помогает сделать поведение БД более предсказуемым в смысле выбора плана.
Второе – Adaptive Query Optimizer, которое реализует обратную связь планировщику от реального времени выполнения запроса, то есть планировщик измеряет фактические результаты выполненного запроса и корректирует свои планы в будущем с учетом этого. БД таким образом, «самонастраивается» для конкретных данных и запросов.
Чем еще занимается БД, когда она «тормозит»?
Теперь, когда с планированием запросов мы более или менее разобрались, посмотрим, что еще можно улучшить как в самой БД, так и в приложениях, которые ее используют, чтобы получить максимум производительности от нее.
Предположим, что план запроса уже оптимален. Если исключить самые очевидные проблемы (мало памяти или медленный диск/сеть), то остаются еще затраты на расчет хэшей. Здесь, вероятно, кроются великие возможности для будущего улучшения PostgreSQL (с помощью GPU или даже SSE2/SSE3/AVX инструкций CPU), однако пока этого нет и вычисления хэшей почти не используют аппаратные возможности «железа». В этом базе данных можно немного помочь.
Если вы обратили внимание, по умолчанию индексы в PostgreSQL создаются как b-tree. Их полезность в том, что они достаточно универсальны. Такой индекс можно использовать и с условиями равенства, и с условиями сравнения (больше или меньше). Поиск элемента в таком индексе – это логарифмическая затратность. Но если ваш запрос содержит только условие равенства, индексы можно создавать еще и как hash index, затратность поиска в котором — константа.
Далее, еще можно попытаться изменить запрос так чтобы использовать параллельное его выполнение. Чтобы понять, как именно его переписать, лучше всего ознакомиться со списком случаев, когда параллелизм автоматически запрещается планировщиком и избегать таких ситуаций. Руководство на эту тему достаточно кратко описывает все ситуации, поэтому нет смысла повторять их здесь.
Что же делать, если запрос все же плохо получается сделать параллельным? Весьма грустно наблюдать, как в вашей мощной многоядерной БД, где вы единственный клиент, одно ядро занято на 100%, а все остальные ядра просто на это смотрят. В этом случае приходится помогать базе со стороны приложения. Поскольку каждой сессии назначается свое ядро, можно открыть их несколько и поделить общий запрос на части, делая более короткие и более быстрые выборки, объединяя их в общий результат уже в приложении. Это позволит занять максимум доступных ресурсов CPU в БД PostgreSQL.
В заключение хотелось бы отметить, что перечисленные возможности диагностики и оптимизации – это всего лишь верхушка айсберга, однако они достаточно просты в использовании и могут помочь быстро идентифицировать проблему прямо на рабочих данных без риска испортить конфиг или нарушить работу других приложений.
Удачных вам запросов, с точными и короткими планами.
Выполнение запроса — Access
Примечание: Мы стараемся как можно оперативнее обеспечивать вас актуальными справочными материалами на вашем языке. Эта страница переведена автоматически, поэтому ее текст может содержать неточности и грамматические ошибки. Для нас важно, чтобы эта статья была вам полезна. Просим вас уделить пару секунд и сообщить, помогла ли она вам, с помощью кнопок внизу страницы. Для удобства также приводим ссылку на оригинал (на английском языке).
Запрос — это набор инструкций, которые можно использовать для работы с данными. Для выполнения этих инструкций нужно выполнить запрос. В дополнение к возврату результатов, которые могут быть отсортированы, сгруппированы или отфильтрованы, запрос также может создавать, копировать, удалять и изменять данные.
В этой статье объясняется, как выполнять запросы и обеспечивается краткий обзор различных типов запросов. В этой статье также рассматриваются сообщения об ошибках, которые могут возникнуть при выполнении различных типов запросов, и инструкции по ее устранению или исправлению.
В этой статье не представлены пошаговые инструкции по созданию запросов.
Важно: Нельзя выполнять запросы на изменение, если база данных работает в отключенном режиме — в режиме ограниченной функциональности, который Access использует для защиты данных в определенных обстоятельствах. Вы можете увидеть предупреждение в диалоговом окне или предупреждение на панели сообщений.
Дополнительные сведения об отключенном режиме и о том, как включить запросы на изменение, можно найти в разделе выполнение запроса на изменение.
В этой статье
-
Выполнение запроса на выборку или перекрестный запрос
-
Выполнение запроса на изменение
-
Выполнение запроса с параметрами
-
Выполнение запроса, зависящего от SQL
-
Устранение неполадок с сообщением об ошибке
Выполнение запроса на выборку или перекрестный запрос
Запросы на выборку и перекрестный запрос используются для получения и представления данных, а для предоставления форм и отчетов с данными. При выполнении запроса на выборку или перекрестный запрос Access отображает результаты в Режим таблицы.
Выполнение запроса
-
Найдите запрос в области навигации.
-
Выполните одно из следующих действий.
-
Дважды щелкните запрос, который вы хотите выполнить.
-
Выберите запрос, который требуется выполнить, а затем нажмите клавишу ВВОД.
-
Если запрос, который вы хотите выполнить, открыт в Конструктор, вы также можете запустить его, нажав кнопку выполнить в группе результаты на вкладке конструктор ленты, части Пользовательский интерфейс Microsoft Office Fluent.
К началу страницы
Выполнение запроса на изменение
Существует четыре типа запросов на изменение: запросы на добавление, удаление, запросы на обновление и запросы на создание таблицы. За исключением запросов на создание таблиц (которые создают новые таблицы), запросы на изменение изменяют данные в таблицах, на которых они основаны. Эти изменения нельзя легко отменить, например, нажав клавиши CTRL + Z. Если вы вносите изменения с помощью запроса на изменение, который позже решит, что вы не хотите делать, обычно потребуется восстановить данные из резервной копии. По этой причине перед выполнением запроса на изменение вы должны убедиться, что у вас есть свежая резервная копия базовых данных.
Вы можете уменьшить риск выполнения запроса на изменение, предварительно просмотрев данные, для которых будет выполняться операция. Это можно сделать двумя способами.
-
Просмотрите запрос на изменение в режиме таблицы, прежде чем запускать его. Для этого откройте запрос в конструкторе, нажмите кнопку Просмотр на Строка состояния Access, а затем в контекстном меню выберите пункт режим таблицы . Чтобы вернуться в режим конструктора, снова нажмите кнопку Просмотреть , а затем в контекстном меню выберите пункт режим конструктора .
-
Измените запрос на запрос на выборку и запустите его.
Примечание: Обратите внимание на то, что вы запускаете запрос на изменение (Добавление, обновление, создание таблицы или удаление), поэтому вы можете изменить запрос обратно на этот тип после предварительного просмотра данных с помощью этого метода.
Выполнение запроса на изменение в качестве запроса на выборку
-
Откройте запрос на изменение в режиме конструктора.
-
На вкладке конструктор в группе тип запроса нажмите кнопку выбрать.
-
На вкладке Конструктор в группе Результаты нажмите кнопку Выполнить.
-
Выполнение запроса
Когда вы будете готовы выполнить запрос на изменение, дважды щелкните его в области навигации или щелкните его, а затем нажмите клавишу ВВОД.
Важно: По умолчанию Access отключает все запросы на изменение в базе данных, если не указано, что вы доверяете базе данных. Вы можете указать, что вы доверяете базе данных с помощью панели сообщений, под лентой.

Доверие базе данных
-
На панели сообщений нажмите Параметры.
Откроется диалоговое окно Параметры безопасности Microsoft Office.
-
Выберите Включить это содержимое, а затем кнопку ОК.
Выполнение запроса с параметрами
запрос с параметрами предложит вам ввести значение при запуске. При указании значения запрос с параметрами применяет его в качестве критерия поля. Поле, к которому применяется критерий, заданный в конструкторе запросов. Если при появлении запроса не указывается значение, запрос с параметрами интерпретирует введенные данные как пустую строку.
Запрос С параметрами всегда также является другим типом запроса. Большинство запросов с параметрами — запросы на выборку или перекрестный запрос, но запросы на добавление, создание таблицы и обновление также могут быть запросами с параметрами.
Вы запускаете запрос с параметрами в соответствии с другим типом запроса, но в общем случае используйте описанную ниже процедуру.
Выполнение запроса
-
Найдите запрос в области навигации.
-
Выполните одно из следующих действий.
-
Дважды щелкните запрос, который вы хотите выполнить.
-
Выберите запрос, который нужно выполнить, и нажмите клавишу ВВОД.
-
-
Когда появится запрос с параметрами, введите значение, которое будет использоваться в качестве условия.
К началу страницы
Выполнение запроса, зависящего от SQL
Существует три основных типа SQL-запрос: запросы на объединение, передаваемые запросы и управляющие запросы данных.
Запросы на объединение объединяют данные из двух или нескольких таблиц, но не так же, как и другие запросы. В то время как большинство запросов объединяют данные, объединяя строки, запросы на объединение объединяют данные путем добавления строк. Запросы на объединение отличаются от запросов на добавление в запросах на объединение, но не изменяют базовые таблицы. Запросы на объединение добавляют в набор записей строки, которые не сохраняются после закрытия запроса.
ПереДаваемые запросы не обрабатываются ядром СУБД, которая поставляется вместе с Access; Вместо этого они передаются непосредственно на удаленный сервер базы данных, который производит обработку, а затем передает результаты обратно в Access.
Запросы определения данных — это особый тип запроса, который не обрабатывает данные; Вместо этого запросы определения данных создают, удаляют или изменяют другие объекты базы данных.
Запросы SQL нельзя открывать в режиме конструктора. Они могут быть открыты только в режиме SQL или запущены. За исключением запросов определения данных, выполнение запроса SQL откроет ее в режиме таблицы.
Выполнение запроса
-
Найдите запрос в области навигации.
-
Выполните одно из следующих действий.
-
Дважды щелкните запрос, который вы хотите выполнить.
-
Выберите запрос, который требуется выполнить, а затем нажмите клавишу ВВОД.
-
К началу страницы
Устранение неполадок с сообщением об ошибке
В приведенной ниже таблице показаны некоторые распространенные сообщения об ошибках, которые могут возникнуть. Эти ошибки могут выводиться как сообщение в ячейке (вместо ожидаемого значения) или как сообщение об ошибке. Разделы, которые следуют за списком, включают процедуры, которые можно использовать для устранения этих ошибок.
Примечание: Это содержимое этой таблицы не является исчерпывающим. Если сообщение об ошибке не отображается, вы можете отправить отзыв, воспользовавшись формой в конце этой статьи и указанными сведениями о сообщении об ошибке в появившемся поле примечания.
Сообщение об ошибке | Проблема | Решение |
|---|---|---|
|
Несоответствие типов в выражении |
Запрос может объединять поля с разными типами данных. |
Проверьте структуру запроса и убедитесь, что объединенные поля имеют один и тот же тип данных. Инструкции можно найти в разделе Проверка Объединенных полей запроса. |
|
Удалена запись |
Это может произойти, если либо объект, либо база данных повреждены. |
Сжатие и восстановление базы данных. Инструкции можно найти в разделе Сжатие и восстановление базы данных. |
|
Циклическая ссылка, связанная с псевдонимом |
Псевдоним, присвоенный полю, совпадает с компонентом выражения для этого поля. Псевдоним — это имя, которое задается для любого выражения в строке поля бланка запроса, которое не является фактическим полем. Если вы не хотите, чтобы вы ни навводили себя, Access выдает ему псевдоним. Например, Выражение1. За псевдонимом следует сразу двоеточие (:), а затем выражение. При выполнении запроса псевдоним становится именем столбца в таблице. |
Измените псевдоним. Инструкции можно найти в разделе Изменение псевдонима поля. |
|
#Error |
Эта ошибка может возникать, если значение вычисляемого поля больше значения, разрешенного значением свойства FieldSize поля. Это также происходит, если знаменатель вычисляемого поля равен нулю (0). |
Убедитесь, что знаменатель вычисляемого поля не равен нулю (0). При необходимости измените свойство FieldSize . |
|
#Deleted |
Запись, на которую вы ссылались, была удалена. |
Если запись была удалена случайно, ее необходимо восстановить из резервной копии. Если удаление было сделано умышленно, вы можете закрыть это сообщение об ошибке, нажав клавиши SHIFT + F9, чтобы обновить запрос. |
Проверка Объединенных полей запроса
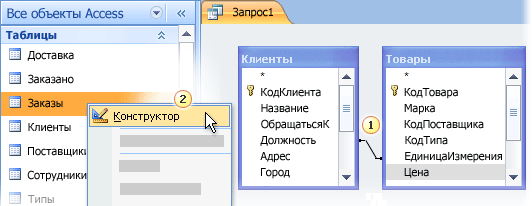
Для проверки типов данных полей в запросе вы можете просмотреть исходные таблицы в режиме конструктора и проверить свойства проверяемых полей.
-
Откройте запрос в режиме конструктора. Соединения выводятся в виде линий, соединяющих поля в исходных таблицах. Обратите внимание на имена таблиц и полей для каждого соединения.
-
В области навигации щелкните правой кнопкой мыши все таблицы, которые содержат одно или несколько полей, Объединенных в запрос, и выберите пункт конструктор.
1. Объединенные поля с разными типами данных.
2. Щелкните таблицу правой кнопкой мыши и выберите команду Конструктор.
-
Для каждого соединения Сравните значения в столбце тип данных в сетке конструктора таблиц для полей, участвующих в этом соединении.
1. Проверьте тип данных Объединенных полей в режиме конструктора таблицы.
-
Чтобы перейти к таблице и просмотреть ее поля, щелкните вкладку с именем этой таблицы.

К началу страницы
Сжатие и восстановление базы данных
Выполнение служебной программы сжатия и восстановления базы данных в Access может повысить производительность базы данных. Эта служебная программа создает копию файла базы данных и, если она фрагментирована, перемещает файл базы данных на диск. После завершения процесса сжатия и восстановления сжатая база данных освобождает неиспользуемое пространство и обычно меньше исходного. Регулярное сжатие базы данных позволяет обеспечить оптимальную производительность приложения базы данных, а также устранять ошибки, возникающие в результате проблем с оборудованием, сбоев питания или скачков и других причин.
После завершения операции сжатия скорость запроса улучшена, так как базовые данные переписаны в таблицы на смежных страницах. Поиск непрерывных страниц выполняется намного быстрее, чем сканирование фрагментированных страниц. Кроме того, запросы оптимизируются после каждого сжатия базы данных.
При выполнении операции сжатия вы можете использовать исходное имя сжатого файла базы данных или использовать другое имя для создания отдельного файла. Если вы используете одно и то же имя и база данных сжимается успешно, Access автоматически заменяет исходный файл компактной версией.
Установка параметра, который автоматизирует этот процесс
-
На вкладке Файл выберите пункт Параметры, чтобы открыть диалоговое окно Параметры Access.
-
Выберите пункт Текущая база данных , а затем в разделе Параметры приложенийустановите флажок Сжимать при закрытии .
Это приведет к тому, что Access автоматически сжимает и восстанавливает базу данных при каждом ее закрытии.
Сжатие и восстановление базы данных вручную
-
Выберите Работа с базами данных _гт_ Сжать и восстановить базу данных.
К началу страницы
Изменение псевдонима поля
-
Откройте запрос в режиме конструктора.
-
В бланке запроса найдите поля с псевдонимами. В конце имени поля появятся двоеточие, например Имя:.
-
Убедитесь, что псевдоним не совпадает с именем поля, которое является частью выражения Alias. Если это так, измените псевдоним.
К началу страницы
- Товары
- Клиенты
- Случаи использования
- Переполнение стека Публичные вопросы и ответы
- Команды Частные вопросы и ответы для вашей команды
- предприятие Частные вопросы и ответы для вашего предприятия
- работы Программирование и связанные с ним технические возможности карьерного роста
- Талант Нанимать технический талант
- реклама Связаться с разработчиками по всему миру
- Товары
- Клиенты
- Случаи использования
- Переполнение стека Публичные вопросы и ответы
- Команды Частные вопросы и ответы для вашей команды
- предприятие Частные вопросы и ответы для вашего предприятия
- работы Программирование и связанные с ним технические возможности карьерного роста
- Талант Нанимать технический талант
- Товары
- Клиенты
- Случаи использования
- Переполнение стека Публичные вопросы и ответы
- Команды Частные вопросы и ответы для вашей команды
- предприятие Частные вопросы и ответы для вашего предприятия
- работы Программирование и связанные с ним технические возможности карьерного роста
- Талант Нанимать технический талант
Запрос к базе данных включает извлечение некоторых конкретных или всех данных из одной или нескольких таблиц или представлений. Microsoft Access предлагает мощную управляемую функцию запросов, которая помогает вам легко создавать запросы, даже если вы не знаете, как написать Script Language .
Но иногда эти запросы доступа проходят через различные ошибки и проблемы. Итак, что касается этого здесь, в этом посте мы настроили некоторые наиболее часто встречающиеся ошибки запроса Access.Взгляните на них и узнайте лучшие исправления, чтобы исправить их без проблем.
типичных ошибок MS Access Query:
- Операция должна использовать обновляемый запрос (Ошибка 3073)
- Сообщение об ошибке при запуске запроса в Access: «Не удается сгруппировать поля, выбранные с помощью‘ * ‘»
- Сообщение об ошибке «Превышен системный ресурс» при выполнении запроса в Access 2010
- «ORA-01013 Пользователь запросил отмену текущей операции.”
- «Запрос не может быть выполнен»
Ошибка № 1 Операция должна использовать обновляемый запрос (Ошибка 3073)
Запрос на обновление — это запрос действия (оператор SQL), который изменяет набор записей в соответствии с указанными критериями (условиями поиска). Это мощная функция и очень важная фундаментальная часть реляционной базы данных, поскольку она позволяет изменять огромное количество записей за один раз.
Пример:
ОБНОВЛЕНИЕ Синтаксис запроса SQL
ОБНОВЛЕНИЕ таблицы
[присоединиться]
SET новое значение
ГДЕ критерии
Описание ошибки:
Что ж, эта конкретная операция «должна использовать обновляемый запрос». Сообщение об ошибке в основном возникает при попытке обновить данные в запросе или в форме.Вы можете получить одну из следующих ошибок:
Операция должна использовать обновляемый запрос.
или
Этот набор записей не подлежит обновлению.
Номер ошибки: Ошибка 3073
Вот скриншот следующей ошибки:
Устранение неполадок«Операция должна использовать обновляемый запрос» Ошибка
Для устранения этой ошибки доступа 3073 самое первое, что вам нужно сделать, это просто проверить, является ли базовая таблица обновляемой или нет.для этого вам просто нужно открыть таблицу и вручную попытаться отредактировать поле. Если вы не можете сделать это вручную, то запрос также не может внести изменения. Вот причины возникновения этой проблемы, поэтому попробуйте исправить их:
- Может быть файл базы данных установлен на ReadOnly . Таким образом, ни один из данных не может быть изменен. Измените это на уровне Windows, если база данных находится на CD, и скопируйте ее на жесткий диск.
- Если вы используете систему безопасности Access , то у вас нет прав для редактирования данных.В этом случае войдите в систему как администратор или введите имя пользователя и пароль, которые позволяют вам вносить изменения.
- Вы не можете изменять данные с внутренним источником данных, если таблица связана.
Также читайте
Access Query Designing: Как запустить мастер запросов в Access
- Если вы связаны с серверной таблицей sql или имеете Project Data Project (ADP) , и у этой таблицы нет первичного ключа, то вы не можете редактировать любое поле таблицы из доступа.
- Добавьте поле соединения со стороны «много» к своему запросу, чтобы вы могли добавлять в него новые записи.
- Необходимо также включить каскадные обновления между двумя таблицами.
Ошибка № 2 «Превышен системный ресурс» Ошибка
Симптомы:
Ошибка запроса доступа «Системный ресурс превышен» возникает при выполнении сложного запроса, который применяется ко многим записям.
Разрешениедля исправления ошибки «Превышен системный ресурс»
Чтобы устранить эту ошибку «Превышен системный ресурс», примените следующее обновление:
2760394 Описание пакета исправлений Access 2010 (ace-x-none.MSP.
Ошибка № 3 «ORA-01013 Пользователь запросил отмену текущей операции»
Описание ошибки:
Эта конкретная ошибка доступа «ORA-01013, запрошенная пользователем, отмена текущей операции» встречается при выполнении запроса к таблице при доступе с использованием источника данных ODBC. Пользователи также поймали эту ошибку, когда они не отменили запрос.
Разрешение, чтобы исправить «ORA-01013 Пользователь запросил отмену текущей операции».
Чтобы устранить эту ошибку, необходимо настроить параметры драйвера ODBC.Вот шаги, чтобы сделать это, так что просто следуйте этому правильно:
1. Нажмите на Пуск> Настройки> Панель управления> Администрирование> Источники данных (ODBC) .
2. Откройте вкладку «Системный DSN» в окне администратора источника данных ODBC.
3. Назначьте имя источника данных Banner / Oracle из списка .
4.Нажмите кнопку Настроить.
5. На вкладке Приложение окна Конфигурация драйвера Oracle ODBC.
ТАКЖЕ ЧИТАЙТЕ
Как исправить ошибку MS Access во время выполнения 3146 Ошибка вызова ODBC?
6. Снимите все флажки, за исключением подключения только для чтения, снимите флажок для всех Включить аварийное переключение.
8. Коснитесь опции ОК, чтобы сохранить все изменения.
9. Перезагрузите компьютер.
Ошибка № 4: «Невозможно сгруппировать поля, выбранные с помощью‘ * ‘»
Симптомы
Вы можете получить эту ошибку Access «Невозможно сгруппировать по полям, выбранным с помощью‘ * », при выполнении запроса в базе данных Microsoft Access.Это использует одну из следующих агрегатных функций:
Полученное сообщение об ошибке выглядит следующим образом:
Невозможно сгруппировать поля, выбранные с помощью *.
Причина
Эта конкретная ошибка запроса доступа возникает, когда вы используете агрегатные функции в запросе и не устанавливаете свойство Выводить все поля запроса в , а не в .
Если для свойства «Вывести все поля» запроса задано значение Да, , в предложение select запроса доступа добавляется символ подстановки (*).Это * представляет все столбцы таблиц базы данных. Однако вы не можете использовать дикий символ вместе с агрегатной функцией в предложении select запроса доступа.
По этой причине при запуске запроса доступа может появиться сообщение об ошибке «Невозможно сгруппировать поля, выбранные с помощью‘ * ‘».
Разрешениедля «Невозможно сгруппировать поля, выбранные с помощью‘ * ‘»
Чтобы исправить эту ошибку, задайте для свойства «Вывести все поля» запроса значение № и выполните запрос, использующий статистическую функцию.Для этого просто выполните следующие действия:
- Откройте базу данных Access, у которой возникла проблема с запросом.
- В окне базы данных нажмите Запросы под Объекты
- Щелкните группу Запросы в левой области навигации. Щелкните правой кнопкой мыши запрос, который необходимо изменить, и нажмите Представление дизайна .
- В меню Вид выберите пункт Свойства .
- Нажмите на вкладку Design и перейдите на страницу свойств в Инструменты .
- В диалоговом окне Свойства запроса задайте для свойства запроса Выводить все поля значение
Нет . - Перейдите на вкладку Хранимая процедура в диалоговом окне Свойство . Убедитесь, что опция Вывести все столбцы не выбрана.
- В меню Query выберите Выполнить .
- Перейдите на вкладку Design и нажмите Запустить в Инструменты
Ошибка № 5 Доступ «Запрос не может быть завершен» Ошибка
Для удаленного извлечения данных из базы данных SQL-сервера в сети база данных Access использует связанные таблицы.Ошибка вызвана из-за сложного запроса Make Table Query, который объединяет две локальные таблицы Access с связанной таблицей SQL Server .
Таблица SQL-сервера значительно увеличила свой размер, поэтому запрос использует больше временных ресурсов на локальном ПК. Как, чтобы обрабатывать запрос, пока он не может больше нести с Максимальный лимит 2 ГБ достиг .
Вот скриншот ошибки:
Разрешениедля ошибки «Невозможно выполнить запрос»
Для решения этой конкретной проблемы целесообразно преобразовать запрос в Pass-Through .Но это также имеет отрицательный момент, так как невозможно передать локальные таблицы доступа на удаленный SQL Server для обработки данных, как это используется в соединении SQL. Access может легко получить удаленные данные, но не может получить локальные данные.
Решениедля восстановления потерянного / удаленного запроса доступа
Если в случае исправления ошибки запроса Access вы потеряли свои запросы доступа, вам также не нужно беспокоиться. Просто попробуйте Access Repair and Recovery Tool , который предназначен для устранения любых проблем с повреждениями, с которыми вы столкнулись.Файл базы данных mdb или .accdb.
Этот инструмент способен исправлять почти все незначительные и серьезные повреждения, инструмент восстанавливает поврежденные объекты базы данных, такие как таблицы, связанные таблицы, индексы, модули и макросы и т. Д.
Вывод:
Теперь вы можете легко обрабатывать любые из этих ошибок запроса доступа. Теперь вы вооружены совершенными исправлениями для устранения ошибок, связанных с запросами, и проблемы с вашей базой данных Access.
Все еще есть проблемы? Исправьте их с помощью Stellar Repair for Access:Это программное обеспечение обеспечивает плавное восстановление и восстановление базы данных ACCDB и MDB и восстанавливает все объекты, включая таблицы, отчеты, запросы, записи, формы и индексы, а также модули, макросы и т. Д.Исправьте проблемы Microsoft Access сейчас в 3 простых шага:
Pearson Willey
Pearson Willey — разработчик контента для веб-сайтов и планировщик контента. Помимо этого, он также заядлый читатель. Таким образом, он очень хорошо знает, как написать привлекательный контент для читателей. Писать как растущий край для него. Он любит изучать свои знания в MS Access и делиться техническими блогами.