Умные роботы поисковых систем | Продвижение бизнеса
- Определения и терминология
- Имена роботов
- Немного истории
- Что делают роботы поисковых систем
- Поведение роботов на сайте
- Управление роботами
- Выводы
Что такое роботы поисковых систем? Какую функцию они выполняют? Каковы особенности работы поисковых роботов? Здесь мы постараемся дать ответ на эти и некоторые другие вопросы, связанные с работой роботов.
Определения и терминология
В английском языке существует несколько вариантов названий поисковых роботов: robots, web bots, crawlers, spiders; в русском языке фактически прижился один термин — роботы, или сокращенно — боты.
На сайте www.robotstxt.org дается следующее определение роботам:
“Веб-робот — это программа, которая обходит гипертекстовую структуру WWW, рекурсивно запрашивая и извлекая документы”.
Ключевое слово в этом определении — рекурсивно, т.
Большинство поисковых роботов имеют свое уникальное имя (кроме тех роботов, которые по каким-то причинам маскируются под пользовательские браузерыБраузер — (программа просмотра, browser), программа, установленная на компьютере пользователя и позволяющая просматривать документы в определённых форматах (html, xml и др.). Программа позволяет ввести в поле адреса URL сайта и, при наличии соединения с Интернетом, получить указанную страницу с веб-сервера.
Имя робота можно увидеть в поле User-agentПаук (краулер, бот, робот поисковика) — система поисковой системы, осуществляющая индексацию веб-страниц интернета. Переходя по ссылкам, робот-паук копирует, обрабатывает и заносит в специальную базу данных все веб-страницы. Отследить заходы пауков на страницы вашего сайта можно по логам сервера или с помощью систем статистики. Полный список идентификаторов краулеров Яндекса можно найти здесь. User-agent робота Google — GoogleBot, Rambler — StackRambler…. серверных лог-файлов, отчетах систем серверных статистик, а также на страницах помощи поисковых систем.
Так, робота ЯндексаЯша (Яшка). Жаргон. Имеется в виду поисковая система Яндекс. собирательно называют Yandex, робота Рамблера — StackRamblerПаук (краулер, бот, робот поисковика) — система поисковой системы, осуществляющая индексацию веб-страниц интернета. Переходя по ссылкам, робот-паук копирует, обрабатывает и заносит в специальную базу данных все веб-страницы. Отследить заходы пауков на страницы вашего сайта можно по логам сервера или с помощью систем статистики.
Кроме имени робота, в поле User-agent может находиться больше информации: версия робота, предназначение и адрес страницы с дополнительной информацией.
Немного историиЕще в первой половине 1990-х годов, в период развития Интернета, существовала проблема веб-роботов, связанная с тем, что некоторые из первых роботов могли существенно загрузить веб-сервер, вплоть до его отказа, из-за того, что делали большое количество запросов к сайту за слишком короткое время.
В 1994 году был разработан протокол robots.txt, задающий исключения для роботов и позволяющий пользователям управлять поисковыми роботами в пределах своих сайтов. Об этих возможностях вы читали в главе 6 “Как сделать сайт доступным для поисковых систем”.
В дальнейшем, по мере роста Сети, количество поисковых роботов увеличивалось, а функциональность их постоянно расширялась. Некоторые поисковые роботы не дожили до наших дней, оставшись только в архивах серверных лог-файлов конца 1990-х. Кто сейчас вспоминает робота T-Rex, собирающего информацию для системы Lycos? Вымер, как динозавр, по имени которого назван. Или где можно найти Scooter — робот системы Altavista? Нигде! А ведь в 2002 году он еще активно индексировал документы.
Даже в имени основного робота Яндекса можно найти эхо минувших дней: фрагмент его полного имени “compatible; Win16;” был добавлен для совместимости с некоторыми старыми веб-серверами.
В поисковой машине функционирует несколько разных роботов, и у каждого свое предназначение. Перечислим некоторые из задач, выполняемых роботами:
- обработка запросов и извлечение документов;
- проверка ссылок;
- мониторинг обновлений;проверка доступности сайта или сервера;
- анализ контентаКонтент — содержание, наполнение сайта. Информация, представленная на веб-страницах. Хотя обычно под «контентом» подразумевают тексты, на самом деле это и изображения (фотографии и иллюстрации), и видеоролики, и интерактивные элементы. С точки зрения SEO самым важным является текстовый контент: его уникальность (отсутствие копий, в том числе и частичных, на других сайтах), насыщенность ключевыми словами, объем и HTML-верстка…. страниц для последующего размещения контекстной рекламыКонтекстная реклама — реклама, содержание которой зависит от запроса пользователя к поисковой системе.

- сбор контента в альтернативных форматах (графика, данные в форматахRSSnAtom).

- Yandex/1.01.001 (compatible; Win 16; I) —основной индексирующий робот.
- Yandex/1.01.001 (compatible; Win 16; P) —индексатор картинок.
- Yandex/1.01.001 (compatible; Win 16; H) —робот, определяющий зеркалаЗеркало — сайт, который по мнению поисковой системы является частичной или полной копией другого сайта. Самый частый случай возникновения зеркала — отсутствие серверного редиректа с кодом 301 URL с www и без www (то есть сайт просто выдает поисковику одинаковые страницы по адресам, например, www.
- Yandex/1.03.003 (compatible; Win 16; D) —робот, обращающийся к странице при добавлении ее через форму “Добавить URL”.
- Yandex/1.03.000 (compatible; Win 16; М) — робот, обращающийся при открытии страницы по ссылке “Найденные слова”.
- YandexBlog/0.99.101 (compatible; DOS3.30; Mozilla/5.0; В;robot) — робот, индексирующий xml-файлы для поиска по блогам.
- YandexSomething/1.0 — робот, индексирующий новостные потоки партнеров Яндекс.Новостей и файлы robots.txt для робота поиска по блогам.

Кроме того, в Яндексе работает несколько проверяющих роботов — “просту-кивалок”, которые только проверяют доступность документов, но не индексируют их.
- Yandex/2. 01.000 (compatible; Win 16; Dyatel; С) — “просту-кивалка” Яндекс.Каталога. Если сайт недоступен в течение нескольких дней, он снимается с публикации. Как только сайт начинает отвечать, он автоматически появляется в каталоге.
- Yandex/2.01.000 (compatible; Win 16; Dyatel; Z) — “просту-кивалка” Яндекс.Закладок. Ссылки на недоступные сайты выделяютсясерым цветом.
- Yandex/2.01.000 (compatible; Win 16; Dyatel; D) —”простуки-валка” Яндекс.ДиректаКонтекстная реклама — реклама, содержание которой зависит от запроса пользователя к поисковой системе. Так как подобная реклама показывается только тем, кто целенаправленно ищет информацию на тему запроса, её эффективность намного выше обычной. CTR контекстной рекламы составляет 3-4%, но нередко достигает и 30-40%. Подобная реклама обеспечивает лучшую конверсию посетителей в покупателей….. Она проверяет корректность ссылок из объявлений перед модерацией.
 01.000 (compatible; Win 16; Dyatel; С) — “просту-кивалка” Яндекс.Каталога. Если сайт недоступен в течение нескольких дней, он снимается с публикации. Как только сайт начинает отвечать, он автоматически появляется в каталоге.
01.000 (compatible; Win 16; Dyatel; С) — “просту-кивалка” Яндекс.Каталога. Если сайт недоступен в течение нескольких дней, он снимается с публикации. Как только сайт начинает отвечать, он автоматически появляется в каталоге.И все-таки наиболее распространенные роботы — это те, которые запрашивают, получают и архивируют документы для последующей обработки другими механизмами поисковой системы. Здесь уместно будет отделить робота от индексатора.
Здесь уместно будет отделить робота от индексатора.
Поисковый роботПоисковый робот — программа, являющаяся составной частью поисковой машины, и предназначенная для обхода страниц Интернета с целью занесения их в базу поисковика. Порядок обхода страниц, частота визитов регулируется алгоритмами поисковой машины. Запретить индексацию всего сайта или его части можно с помощью файла robots.txt, содержащего инструкции для поисковых роботов…. обходит сайты и получает документы в соответствии со своим внутренним списком адресов. В некоторых случаях робот может выполнять базовый анализ документов для пополнения списка адресов. Дальнейшей обработкой документов и построением индексаИндекс — база данных поисковой машины, так называемый инвертированный индекс, обычно напоминает индекс терминов, применяемый в учебниках и научных изданиях. Содержит словарь слов, встречающихся на интернет-страницах, с приписанными к ним списками адресов интернет-страниц, содержащих эти слова. Служит для поиска страниц с вхождениями заданных ключевых слов. Индекс пополняется поисковым роботом во время периодических обходов Интернета…. поисковой системы занимается уже индексатор поисковой машины. Робот в этой схеме является всего лишь “курьером” по сбору данных.
Индекс пополняется поисковым роботом во время периодических обходов Интернета…. поисковой системы занимается уже индексатор поисковой машины. Робот в этой схеме является всего лишь “курьером” по сбору данных.
Поведение роботов на сайте
Чем отличается поведение робота на сайте от поведения обычного пользователя?
- Управляемость. Прежде всего “интеллигентный” робот должен запросить с сервера файл robots.txt с инструкциями по индексации.
- Выборочное выкачивание. При запросе документа робот четко указывает типы запрашиваемых данных, в отличие от обычного браузераБраузер — (программа просмотра, browser), программа, установленная на компьютере пользователя и позволяющая просматривать документы в определённых форматах (html, xml и др.). Программа позволяет ввести в поле адреса URL сайта и, при наличии соединения с Интернетом, получить указанную страницу с веб-сервера…., готового принимать все подряд. Основные роботы популярных поисковиков в первую очередь будут запрашивать гипертекстовые и обычные текстовые документы, оставляя без внимания файлы стилен оформления CSSCSS (Cascading Style Sheets — каскадные таблицы стилей). Набор определенных свойств (стилей) для удобной настройки внешнего вида элементов веб-страницы., изображения, видео. Zip-архивы и т.п. В настоящее время также востребована информация в форматах PDF, Rich Text, MS Word, MS Excel и некоторых других.
- Непредсказуемость. Невозможно отследить или предсказать путь робота по сайту, поскольку он не оставляет информации в поле Referer — адрес страницы, откуда он пришел; робот просто запрашивает список документов, казалось бы, в случайном порядке, а на самом деле в соответствии со своим внутренним списком или очередью индексации.
- Скорость. Небольшое время между запросами разных документов. Здесь речь идет о секундах или долях секунды между запросами двух разных документов. Для некоторых роботов есть даже специальные инструкции,которые указываются в файле robots.txt, по ограничению скорости запроса документов, чтобы не перегрузить сайт.
 Набор определенных свойств (стилей) для удобной настройки внешнего вида элементов веб-страницы., изображения, видео. Zip-архивы и т.п. В настоящее время также востребована информация в форматах PDF, Rich Text, MS Word, MS Excel и некоторых других.
Набор определенных свойств (стилей) для удобной настройки внешнего вида элементов веб-страницы., изображения, видео. Zip-архивы и т.п. В настоящее время также востребована информация в форматах PDF, Rich Text, MS Word, MS Excel и некоторых других.Как может выглядеть HTML-страница в глазах робота, мы не знаем, но можем попытаться себе это представить, отключая в браузере отображение графики и стилевого оформления.
Таким образом, можно сделать вывод, что поисковые роботы закачивают в свой индексИндекс — база данных поисковой машины, так называемый инвертированный индекс, обычно напоминает индекс терминов, применяемый в учебниках и научных изданиях. Содержит словарь слов, встречающихся на интернет-страницах, с приписанными к ним списками адресов интернет-страниц, содержащих эти слова. Служит для поиска страниц с вхождениями заданных ключевых слов. Индекс пополняется поисковым роботом во время периодических обходов Интернета…. HTML-структуру страницы, но без элементов оформления и без картинок.
Управление роботами.
Как же вебмастер может управлять поведением поисковых роботов на своем сайте?
Как уже было сказано выше, в 1994 году в результате открытых дебатов вебмастеров был разработан специальный протокол исключений для роботов. До настоящего времени этот протокол так и не стал стандартом, который обязаны соблюдать все без исключения роботы, оставшись лишь в статусе строгих рекомендаций. Не существует инстанции, куда можно пожаловаться на робота, не соблюдающего правила исключений, можно лишь запретить доступ к сайту уже с помощью настроек веб-сервера или сетевых интерфейсов для IP-адресов, с которых “неинтеллигентный” робот отсылал свои запросы.
Не существует инстанции, куда можно пожаловаться на робота, не соблюдающего правила исключений, можно лишь запретить доступ к сайту уже с помощью настроек веб-сервера или сетевых интерфейсов для IP-адресов, с которых “неинтеллигентный” робот отсылал свои запросы.
Однако роботы крупных поисковых систем соблюдают правила исключений, более того, вносят в них свои расширения.
Об инструкциях специального файла robots.txt. и о специальном мета-теге robots подробно рассказывалось в главе 6 “Как сделать сайт доступным для поисковых систем”.
С помощью дополнительных инструкций в robots.txt, которых нет в стандарте, некоторые поисковые системы позволяют более гибко управлять поведением своих роботов. Так, с помощью инструкции Crawl-delaу вебмастер может устанавливать временной промежуток между последовательными запросами двух документов для роботов Yahoo! и MSN, а с помощью инструкции Но-; t указать адрес основного зеркала сайта для Яндекса. Однако работать с нестандартными инструкциями в robots.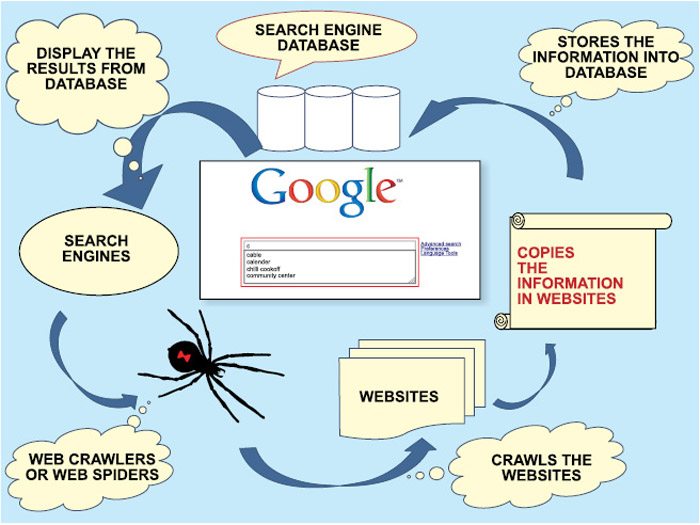 txi следует очень осторожно, поскольку робот другой поисковой системы может проигнорировать не только непонятную ему инструкцию, но и весь набор правил, связанных с ней.
txi следует очень осторожно, поскольку робот другой поисковой системы может проигнорировать не только непонятную ему инструкцию, но и весь набор правил, связанных с ней.
Управлять посещениями поисковых роботов можно и косвенно, например, робот поисковой системы GoogleАмериканская транснациональная корпорация, реорганизованная 15 октября 2015 года в международный конгломерат Alphabet Inc., компания в составе холдинга инвестируюет в интернет-поиск, облачные вычисления и рекламные технологии. чаще будет повторно забирать те документы, на которые много ссылаются с других сайтов.
Выводы.
Роботы — необходимая и очень важная составная часть поисковых систем. Если представить поисковую систему как “черный ящик”, где выдачаВыдача (SERP, Search Engine Results Page) — страница выдачи поисковых результатов. Показывается пользователю поисковика в ответ на запрос. Все популярные ПС демонстрируют первые десять наиболее релевантных (соответствующих запросу) результатов — это и есть ТОП10. Попасть в первую десятку по нужным ключевым словам очень важно, так как следующие 10 результатов смотрят менее 20% пользователей (по коммерческим запросам — еще меньше). ТОП 10 «снимает все сливки», борьба за места в нем — основная задача SEO…. результатов поиска — это “выход” системы, то поисковые роботы — это “вход”, на который поступают документы.
Попасть в первую десятку по нужным ключевым словам очень важно, так как следующие 10 результатов смотрят менее 20% пользователей (по коммерческим запросам — еще меньше). ТОП 10 «снимает все сливки», борьба за места в нем — основная задача SEO…. результатов поиска — это “выход” системы, то поисковые роботы — это “вход”, на который поступают документы.
Если грамотно подавать свои страницы на этот “вход”, управляя поведением поискового роботаПоисковый робот — программа, являющаяся составной частью поисковой машины, и предназначенная для обхода страниц Интернета с целью занесения их в базу поисковика. Порядок обхода страниц, частота визитов регулируется алгоритмами поисковой машины. Запретить индексацию всего сайта или его части можно с помощью файла robots.txt, содержащего инструкции для поисковых роботов…., можно добиться лучших результатов индексации — периодичности, полноты и лучшего ранжированияРанжирование — процесс выбора страниц из базы поисковой машины, соответствующих запросу пользователя, и упорядочение их по степени убывания соответствия (релевантности) запросу. .
.
Поисковый робот Яндекса, Google и других поисковиков
Поисковый робот – это программа, использующая специальные алгоритмы для поиска в сети Интернет различной информации на страницах сайтов и формирования собственной базы данных из них. Также этот механизм может носить и другие названия, например паук, краулер, бот или webrobot и т. п. Все они решают одни и те же задачи – проводят индексацию сайтов в соответствии с поисковыми запросами пользователей.
Как это работает
Робот является программой браузерного типа, и он постоянно пребывает в состоянии непрерывного сканирования Сети. Изначально для индексации предусмотрены специальные каталоги, в которые веб-мастера вносят новые сайты вручную. Также робот самостоятельно переходит с других ресурсов по ссылкам, ведущим на продвигаемые страницы.
Поисковый робот регулярно обращается к уже известным ему ресурсам и индексирует любые изменения, которые на них происходят. Периодичность зависит от того, с какой частотой и динамикой обновляется сам сайт. Например, новостные порталы могут индексироваться каждые несколько минут. Если же информация на самом сайте обновляется раз в неделю, то и поисковый робот будет индексировать его с той же частотой.
Например, новостные порталы могут индексироваться каждые несколько минут. Если же информация на самом сайте обновляется раз в неделю, то и поисковый робот будет индексировать его с той же частотой.
Разновидности поисковых роботов
Как у «Яндекса», так и у Google существует большое число различных роботов, каждый из которых решает свои конкретные задачи, а именно:
- ведет основную индексацию сайтов и страниц;
- индексирует графический контент – картинки, видео;
- ищет зеркала ресурсов, фавиконы;
- сканирует новости;
- индексирует сайты рекламной сети;
- проверяет общее качество страницы и ее соответствие параметрам индексации.
Такое разделение делает работу роботов более эффективной и быстрой. По аналогичному принципу работают и пауки других поисковых машин, таких как Rambler, Yahoo и т. п.
Cloaking — Словарь— PromoPult.
 ru
ruКлоакинг (от англ. to cloak — «маскировать, скрывать») — это отображение на странице сайта разного контента пользователям и поисковым роботам. Приравнивается к методам черного SEO, так как используется в целях манипуляции выдачей.
Идентификация посетителя страницы (поисковик или человек) и определение, какую именно информацию показать в данный момент, происходит по IP-адресу или User-Agent.
Цели использования клоакинга
Клоакинг применяется в корыстных целях подмены контента для обмана поисковиков. Владелец стремится продвинуть сайт по одним ключевым словам, а пользователям показывает совершенно другой контент.
Например, человек хочет скачать фильм и ищет нужный сайт в поиске. Попадая на страницу из топ-10, он обнаруживает, что данного фильма на ней нет. Вместо описания фильма и ссылки на скачивание размещена реклама.
Реализация метода клоакинга
Реализация клоакинга требует от веб-мастера не только навыков программирования и знания методов поисковой оптимизации, но и наличия базы данных IP поисковых роботов.
Метод клоакинга осуществляется при помощи скриптов, которые выполняются на веб-сервере: сервер получает запрос, запускает скрипт, который по ряду параметров (IP или User-Agent) определяет источник запроса (пользователь или робот) и выдает соответствующую версию страницы.
Разоблачение клоакинга
В прошлом клоакинг успешно применялся веб-мастерами, однако с развитием поисковых технологий и совершенствованием поисковых алгоритмов этот метод утратил свою значимость.
Сегодня любой клоакинг легко поддается распознаванию. Пользователь при помощи специальной программы (например, инструмента в Google Search Console «Посмотреть как Googlebot») может представиться пауком и увидеть оптимизированную страницу. Или, наоборот, поисковик может изменить имя робота, которое не содержится в скрипте веб-сервера, и увидеть страницу сайта, созданную для пользователей.
Аналогично и с клоакингом, реализуемым с помощью IP. Несмотря на то, что подделать IP-адрес невозможно, обнаружить данный метод все же реально. Например, ручной проверкой через прокси-сервер. Кроме того, располагать базой данных диапазона IP-адресов поисковых машин — удовольствие дорогое. Они постоянно обновляются, что усложняет работу и увеличивает стоимость их приобретения.
Например, ручной проверкой через прокси-сервер. Кроме того, располагать базой данных диапазона IP-адресов поисковых машин — удовольствие дорогое. Они постоянно обновляются, что усложняет работу и увеличивает стоимость их приобретения.
Также поддельный контент, не отвечающий ожиданиям пользователей, провоцирует массу отказов и большой отток трафика со страницы. Плохие поведенческие факторы тоже дают сигнал поисковым машинам, что с сайтом что-то не так.
Клоакинг и поисковые машины
Клоакинг — это мошенничество, а поисковые системы стремятся ранжировать только качественный полезный контент. Поэтому сайты с подменным контентом приравниваются к спаму и в случае обнаружения удаляются из индекса. Вкладывать в этот метод время и деньги не имеет смысла — гораздо эффективнее заниматься белым SEO и делать хорошие качественные сайты.
См. также:
поисковых систем — как работают веб-пауки и почему это важно знать?
Понимание основ работы поисковых систем поможет вам проиндексировать больше страниц вашего веб-сайта поисковыми системами. Пауки — это инструменты или программы, которые поисковые системы используют для поиска в сети и сбора информации по мере того, как страницы создаются каждый день.
Пауки — это инструменты или программы, которые поисковые системы используют для поиска в сети и сбора информации по мере того, как страницы создаются каждый день.
Пауки! Да, верно — пауки!
Задумайтесь на мгновение — Интернет — это взаимосвязанная «паутина» страниц, связанных друг с другом веб-ссылками.Google выпускает миллионы пауков каждый день, чтобы сканировать миллиарды и миллиарды веб-страниц. Теперь представьте себе паутину и изучите, как каждая нить сети связана друг с другом. Паук будет ползать по каждой паутине (или веб-странице), чтобы добраться от А до Б.
Что такое паук поисковой машины?
Интернет-паук — это программа, которая автоматически загружает страницы с вашего сайта. Кроме того, он также известен как бот, робот или краулер. Нам нравится называть это действие «сканированием» или «сканированием» веб-страницы.В результате паук будет собирать информацию о каждой из ваших веб-страниц.
Как заставить пауков посещать мои веб-страницы?
Раньше заставить паука посетить вашу веб-страницу было так же просто, как зайти в Google и отправить свой сайт. Следовательно, для того, чтобы заставить паука сканировать вашу веб-страницу сегодня, вам необходимо иметь ссылки с других веб-сайтов. Задумайтесь на минутку о логике этого. Хотя Интернет растет с каждым днем, пауки должны иметь возможность эффективно переходить с одной страницы на другую.Итак, вам нужно получить ссылки на других сайтах, указывающие на ваш собственный — итоговый результат.
Следовательно, для того, чтобы заставить паука сканировать вашу веб-страницу сегодня, вам необходимо иметь ссылки с других веб-сайтов. Задумайтесь на минутку о логике этого. Хотя Интернет растет с каждым днем, пауки должны иметь возможность эффективно переходить с одной страницы на другую.Итак, вам нужно получить ссылки на других сайтах, указывающие на ваш собственный — итоговый результат.
Что делает паук, когда попадает на вашу веб-страницу?
Первое, что сделает паук, это сделает пару быстрых проверок, чтобы увидеть, действительно ли им разрешено даже искать на данной странице. Следовательно, есть два способа узнать, разрешено ли ему индексировать или сканировать веб-страницу.
- , проверив файл robots.txt или
- любые заголовки http.
Как только разрешение будет предоставлено, паук будет собирать любые метаданные HTML, предоставленные страницей. Мета-данные — это информация, которая помогает категоризировать и систематизировать контент веб-страницы для поисковых систем. Скоро напишу еще одну статью о метаданных!
Скоро напишу еще одну статью о метаданных!
Что проверяют веб-пауки?
После того, как паук прошел предварительную проверку разрешений и метаданных, он начнет собирать контент.
- Заголовки страниц
- Подпозиции
- Изображения
- Все абзацы считаются частью вашего содержания.
Прежде всего, наиболее важным элементом, который вы можете добавить в свой контент, будут ссылки на другие страницы вашего сайта или сайты других людей.Следовательно, ссылки на другие веб-сайты, которые полезны по отношению к вашему собственному контенту, увеличит пользовательский опыт на . Но зачем вам давать ссылку на чужой веб-сайт и перемещать людей с вашего сайта на их? В результате Google уделяет еще больше внимания , создавая отличный пользовательский опыт. , следовательно, заявляет об этом в своей миссии. «Организовать мировую информацию и сделать ее общедоступной и полезной» .
Реальные люди, нанятые Google для просмотра вашего сайта
Google выводит «пользовательский опыт» на новый уровень, нанимая людей для посещения проиндексированных веб-сайтов и прохождения контрольного списка элементов, чтобы помочь оценить уровень пользовательского опыта. Это очень важно понимать, потому что Google понимает, что «пауки» могут делать только в отношении оценки и сбора информации. Лучший совет, который я могу дать вашей основной стратегии поисковой оптимизации, — это создать наилучший пользовательский опыт, который вы знаете.
Это очень важно понимать, потому что Google понимает, что «пауки» могут делать только в отношении оценки и сбора информации. Лучший совет, который я могу дать вашей основной стратегии поисковой оптимизации, — это создать наилучший пользовательский опыт, который вы знаете.
В заключение…
Соревноваться за ключевые слова, по которым ваши конкуренты уже занимают место в рейтинге, непросто, и в большинстве случаев это трудный подъем. Более того, сегодня Google уделяет больше внимания тому, чтобы пользователи смотрели ваш сайт на мобильных устройствах.При рассмотрении вопроса о поисковой оптимизации учитывается так много факторов, и мы только начали касаться поверхности! Вам нужны услуги по поисковой оптимизации? Если да, свяжитесь с нами и заполните форму предложения на нашем веб-сайте. Вы можете поблагодарить нас позже!
Как поисковые роботы Google индексируют ваш сайт
Перед тем, как начать поиск, поисковые роботы собирают информацию с сотен миллиардов веб-страниц и систематизируют ее в поисковом индексе.
Процесс сканирования начинается со списка веб-адресов из прошлых сканирований и карт сайта, предоставленных владельцами веб-сайтов.Когда наши сканеры посещают эти сайты, они используют ссылки на этих сайтах для обнаружения других страниц. Программа уделяет особое внимание новым сайтам, изменениям существующих сайтов и мертвым ссылкам. Компьютерные программы определяют, какие сайты сканировать, как часто и сколько страниц загружать с каждого сайта.
Мы предлагаем Search Console, чтобы дать владельцам сайтов детальный выбор способов сканирования их сайта Google: они могут предоставить подробные инструкции о том, как обрабатывать страницы на своих сайтах, могут запросить повторное сканирование или могут полностью отказаться от сканирования с помощью файла под названием robots.текст». Google никогда не принимает оплату за более частое сканирование сайта — мы предоставляем одни и те же инструменты для всех веб-сайтов, чтобы обеспечить наилучшие результаты для наших пользователей.
Поиск информации путем сканирования
Интернет похож на постоянно растущую библиотеку с миллиардами книг и без центральной файловой системы. Мы используем программное обеспечение, известное как веб-сканеры, для обнаружения общедоступных веб-страниц. Поисковые роботы просматривают веб-страницы и переходят по ссылкам на этих страницах, как если бы вы просматривали контент в Интернете.Они переходят от ссылки к ссылке и возвращают данные об этих веб-страницах на серверы Google.
Организация информации путем индексации
Когда сканеры находят веб-страницу, наши системы обрабатывают ее содержимое, как и браузер. Мы принимаем во внимание ключевые сигналы — от ключевых слов до актуальности веб-сайта — и отслеживаем все это в поисковом индексе.
Индекс поиска Google содержит сотни миллиардов веб-страниц и имеет размер более 100 000 000 гигабайт. Это похоже на указатель в конце книги — с записью для каждого слова, встречающегося на каждой веб-странице, которую мы индексируем. Когда мы индексируем веб-страницу, мы добавляем ее в записи для всех содержащихся на ней слов.
Это похоже на указатель в конце книги — с записью для каждого слова, встречающегося на каждой веб-странице, которую мы индексируем. Когда мы индексируем веб-страницу, мы добавляем ее в записи для всех содержащихся на ней слов.
С помощью сети знаний мы продолжаем расширять возможности сопоставления ключевых слов, чтобы лучше понимать людей, места и вещи, которые вам небезразличны. Для этого мы организуем не только информацию о веб-страницах, но и другие типы информации.Сегодня Google Search может помочь вам найти текст в миллионах книг из крупных библиотек, узнать время в пути из местного агентства общественного транспорта или помочь вам ориентироваться в данных из общедоступных источников, таких как Всемирный банк.
Урок 2: Поисковый паук
Search Spider — важная часть процесса индексации поисковой системы. Эти пауки отвечают за чтение кодов вашего сайта. Помните, что все веб-сайты представляют собой коды, и эти коды считываются пауками, когда поисковые системы сохраняют их в своей базе данных.
Помните, что все веб-сайты представляют собой коды, и эти коды считываются пауками, когда поисковые системы сохраняют их в своей базе данных.
Нет, это не другой вид паукообразных…
Если вы хотите узнать, как работает поиск, вы должны знать, что делает поиск тика. В этом уроке я буду обсуждать поисковые пауки и три типа поисковых пауков Google.
Для чего нужен поисковый паук?
Когда у вас есть веб-сайт, вы знаете, что это все коды. Это функция веб-браузера для отображения этих кодов в формате, понятном человеческому глазу. .Картинки вы видите? Это все коды. Флеш-ролик, который вы смотрите? Да, это все коды. Видео с Youtube? Все коды.
Вот почему метатеги фактически читаются поисковыми системами, даже если они не отображаются в браузере HTML. Потому что это часть кода. И поисковые пауки сканируют код, а не отображение браузера.
Как я уже говорил в прошлом уроке, поисковая система выполняет три основные задачи: индексирование, получение и ранжирование. Search Spiders выполняют большую часть работы, когда дело доходит до первой части работы поисковых систем, которая заключается в индексировании.
Search Spiders выполняют большую часть работы, когда дело доходит до первой части работы поисковых систем, которая заключается в индексировании.
Все коды на вашем веб-сайте должны быть прочитаны, чтобы он был успешно проиндексирован . Если он плохо читается, он будет отображаться в базе данных Google в искаженном виде, который мы сможем увидеть через его кеш в результатах поиска. Есть разные типы кодов, с которыми должен иметь дело поисковый паук. Есть PHP, JAVA, HTML, C # и так далее…
Что удивительно в поисковом пауке, так это то, что он не плетет собственную сеть. Он использует ссылки, которые входят и уходят с вашего веб-сайта для его перемещения.Он сканирует исходящие ссылки с вашего веб-сайта на другой веб-сайт, на который вы указываете. И то, как он будет сканировать ваш веб-сайт, вероятно, произойдет таким же образом — по исходящей ссылке другого веб-сайта, указывающей на вашу.
Существует три вида пауков поисковых систем Google, более известные как роботы Google.
Первый из них — это бот AdSense . Этот бот предназначен для страниц с Google AdSense. Когда создается новая страница с рекламой Google AdSense, активируется JavaScript в коде AdSense, чтобы отправить сообщение боту AdSense.Бот AdSense, в свою очередь, просканирует страницу в течение 15 минут, чтобы определить, какое объявление лучше всего разместить и запустить на веб-странице. Но это для людей, которые используют AdSense.
Во-вторых, у нас есть Freshbot . Freshbot сканирует наиболее посещаемые страницы вашего сайта. На самом деле не имеет значения, одна ли у вас популярная страница или много. Есть веб-сайты, которые сканируются каждые десять минут из-за быстрого оборота контента и популярности таких страниц, как CNN.com или Amazon.com и т. д. Типичный веб-сайт, скорее всего, сканируется Freshbot от 1 до 14 дней, в зависимости от того, насколько популярны эти страницы.
Freshbot также открывает путь к третьему боту — DeepCrawl .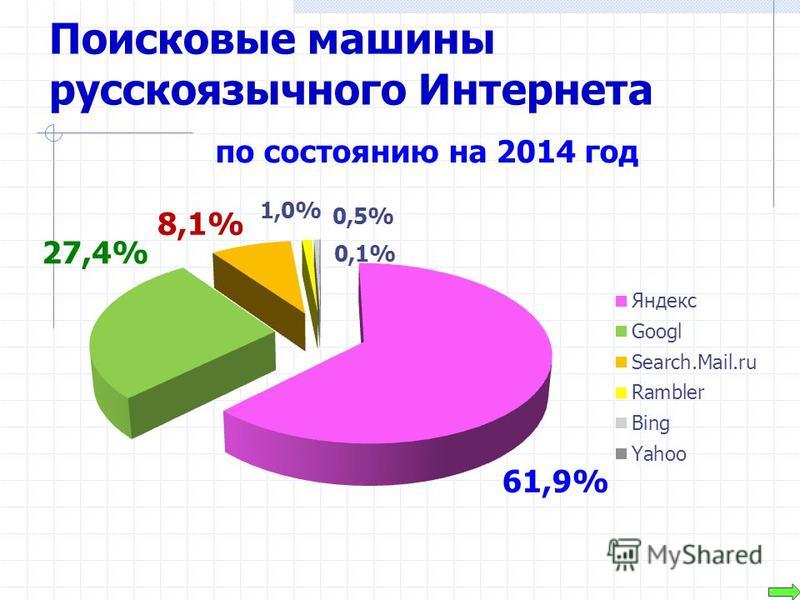 Freshbot ищет все более глубокие ссылки на вашем сайте и сохраняет их для использования DeepCrawl. DeepCrawl индексирует ваш сайт примерно раз в месяц. По этой причине Google может занять до месяца или больше, чтобы проиндексировать весь ваш веб-сайт даже при наличии карты сайта Google.
Freshbot ищет все более глубокие ссылки на вашем сайте и сохраняет их для использования DeepCrawl. DeepCrawl индексирует ваш сайт примерно раз в месяц. По этой причине Google может занять до месяца или больше, чтобы проиндексировать весь ваш веб-сайт даже при наличии карты сайта Google.
Вы можете прочитать о новой системе индексирования Google — Google Caffeine, чтобы узнать больше о том, как Google индексирует веб-сайты.
С уважением,
Шон Патрик Си
Основатель и специалист по SEO-хакерству
Search Engine Spider — Brightery
Что такое паук поисковой системы и паук поисковой системы, что означает сканирование? и что делает Google Spider и как он работает и индексирует страницы. SEO Spider Определение, объяснение и использование.
Search Engine Spider
Определение SEO Spider
Он известен как Spider, Web Spider, SEO Spider, Search Engine Spider, а также Crawler , Web Crawler , Crawling . . .так далее.
. .так далее.
SEO Spider Explaination
Паук поисковой машины — это программа / автоматизированный скрипт, который просматривает всемирную паутину методично и автоматически. И этот процесс обычно называется сканированием в Интернете, сканированием, сканированием в Интернете или поиском пауков.
Использование пауков в поисковых системах
Многие веб-сайты используют Web Crawling как средство предоставления актуальных данных. Spider в основном используется для создания копий всех страниц веб-сайта для процесса архивирования и индексации поисковой системы. Процесс индексации — это процесс загрузки страниц для обеспечения быстрого поиска.
Паук поисковой системы также может использоваться для автоматизации и обслуживания задач на веб-сайте, таких как проверка ссылок или проверка кода. Кроме того, паук поисковой машины может использоваться для сбора нескольких типов информации с веб-страниц, например для сбора адресов электронной почты (иногда для рассылки спама).
Значение обхода
Значение обхода — это определение программы, которая посещает веб-сайты, читает страницы и сохраняет информацию, чтобы создавать записи и запросы для процесса индексирования веб-сайта поисковыми системами.
Обычные поисковые машины (, такие как Google, Bing, Яндекс и т. Д. ) в Интернете имеют эту программу, которая также известна как «паук» или «краулер».
Они обычно запрограммированы для посещения сайтов, загрузки контента, архивирования запросов, которые были отправлены их владельцами как новые или обновленные.Когда пользователь ищет ключевое слово, поисковые системы предоставляют релевантный контент, связанный с запрошенным ключевым словом.
Связанное содержимое: Что сканирует?
Google Spider
Google Spider — это бот от Google. Как работает Google Spider? Google получает информацию из множества различных источников, таких как:
- Веб-страницы.
- контент, добавленный пользователем, например, пользовательские материалы в Google Мой бизнес и Карты.
- Со сканированием книг.
- Открытые и общедоступные базы данных в Интернете.
- Любой открытый ресурс.

Google выполняет основные шаги для создания результатов с веб-страниц:
- Индексирование
- Обслуживание (и ранжирование)
Примечание. Робот Spiderbot аналогичен роботу-роботу.
Как поисковые роботы индексируют ваш веб-сайт
Если вы когда-нибудь задумывались, как поисковые системы находят ваш сайт, ответ прост: они рассылают сканеры.Сканеры поисковых систем, созданные для имитации взаимодействия пользователей с вашим сайтом, просматривают структуру вашего контента и возвращают его для индексирования.
Когда вы создаете свой веб-сайт, чтобы ботам было проще находить и анализировать важную информацию, вы не просто настраиваете свой веб-сайт на более высокий рейтинг; вы также создаете удобную среду для пользователей.
Мы кратко рассмотрели процесс сканирования в статье Как работают поисковые системы? Руководство по пониманию алгоритмов поисковых систем, но здесь мы делаем еще один шаг вперед. В этой статье подробно рассказывается о функциональных возможностях поисковых роботов, а также рассматриваются различные типы поисковых роботов, с которыми вы столкнетесь, как они работают и что вы можете сделать для оптимизации своего сайта.
В этой статье подробно рассказывается о функциональных возможностях поисковых роботов, а также рассматриваются различные типы поисковых роботов, с которыми вы столкнетесь, как они работают и что вы можете сделать для оптимизации своего сайта.
В конце концов, задача каждого поискового робота — узнать как можно больше о том, что предлагает ваш веб-сайт. Повышение эффективности этого процесса гарантирует, что вы всегда будете отображать в поисковой выдаче самый актуальный контент.
Что такое поисковый робот?
Сканеры поисковых систем, также называемые ботами или пауками, — это автоматизированные программы, которые поисковые системы используют для просмотра содержания вашего веб-сайта.Руководствуясь сложными алгоритмами, они систематически просматривают Интернет, чтобы получить доступ к существующим веб-страницам и обнаружить новый контент. После сбора данных с вашего веб-сайта поисковые роботы возвращают их в соответствующие поисковые системы для индексации.
Пример поискового робота На протяжении этого процесса сканеры просматривают HTML, внутренние ссылки и структурные элементы каждой страницы вашего веб-сайта. Затем эта информация объединяется и формулируется в исчерпывающую картину того, что может предложить ваш веб-сайт.
Затем эта информация объединяется и формулируется в исчерпывающую картину того, что может предложить ваш веб-сайт.
Как работают поисковые роботы?
Поисковые системы периодически рассылают этих ботов для сканирования и повторного сканирования вашего сайта. Когда сканер просматривает ваш сайт, он делает это методично, следуя правилам и структурам, определенным вашим файлом robots.txt и картой сайта. Эти элементы дают роботу инструкции о том, какие страницы следует просматривать, а какие игнорировать, и предоставляют актуальную информацию о составе вашего сайта.
Когда сканер заходит на ваш сайт, первое, на что он смотрит, — это ваши роботы.txt файл. В этом файле описаны конкретные правила, по которым части вашего веб-сайта должны и не должны сканироваться. Если вы не настроите это правильно, возникнут проблемы со сканированием вашего сайта, и его будет невозможно проиндексировать.
Две основные функции, на которые следует обратить внимание в файле robots. txt: разрешить и запретить :
txt: разрешить и запретить :
- Установка для URL-адреса разрешить означает, что поисковые роботы будут возвращать их для индексирования.
- Установка для URL запретить означает, что поисковый робот будет их игнорировать.
Для большей части создаваемого содержимого необходимо установить значение разрешить — следует игнорировать только частные страницы, такие как учетные записи пользователей или страницы групп, содержащие личную информацию.
Вот шаблон того, как записать этот файл:
User-agent: [имя поискового робота]
Разрешить: [строки URL, которые нужно сканировать]
Disallow: [Строки URL, которые вы не хотите сканироваться]
После того, как вы определили части вашего веб-сайта, к которым могут обращаться поисковые роботы, они будут перемещаться по вашему содержанию и структуре ссылок, чтобы проанализировать базовую структуру вашего веб-сайта.Чтобы сделать этот процесс более эффективным, сканеры просматривают вашу карту сайта.
Карта сайта — это файл XML, в котором перечислены все URL-адреса вашего веб-сайта. Он обеспечивает структурный обзор каждой страницы и направляет поискового робота по вашему сайту как можно быстрее и эффективнее. Карта сайта также может использоваться для присвоения приоритета определенным страницам вашего веб-сайта, сообщая сканеру, какой контент вы считаете наиболее важным. Поступая так, вы даете поисковым системам команду повысить воспринимаемую важность рейтинга.
Думайте о веб-сканерах как о картографах или исследователях, стремящихся нанести на карту каждый уголок недавно открытого суши. Их экспедиция может выглядеть примерно так:
- Ползунки начинают работу с поисковой системы, чтобы подготовиться к своему путешествию.
- Они отправляются в каждый уголок Интернета в поисках данных (веб-сайтов), чтобы заполнить свою карту.
- Используя файлы robots.txt и карты сайта, поисковый робот просматривает содержимое вашего сайта, чтобы составить полную картину того, что он содержит.
- Сканеры берут то, что они узнали в своем путешествии, и возвращают это домой поисковой системе.
- Затем они добавляют любую новую информацию о вашем сайте в основную карту поисковой системы, которая затем будет использоваться для индексации и ранжирования вашего контента в соответствии с рядом различных факторов.
- Оттуда сканеры делают все это снова и снова, снова и снова.

В условиях постоянно меняющегося ландшафта веб-сайтов в Интернете поисковые роботы должны регулярно выполнять каждый из этих шагов, чтобы иметь самую свежую информацию.Для этого большинство поисковых роботов будут проверять ваш сайт каждые несколько секунд, гарантируя, что любые сделанные вами обновления будут быстро проиндексированы, ранжированы и представлены поисковикам в поисковой выдаче.
При создании или обновлении своего веб-сайта подумайте о том, что вы можете сделать, чтобы поисковым роботам было как можно проще заполнять свою карту.
Топ-5 поисковых роботов
Каждая основная поисковая система на планете имеет собственный веб-сканер. Хотя каждый из них выполняет одни и те же задачи, существуют небольшие различия в том, как каждый из них сканирует ваш сайт.Понимание этих различий поможет вам создать веб-сайт, адаптированный для каждой поисковой системы.
Хотя каждый из них выполняет одни и те же задачи, существуют небольшие различия в том, как каждый из них сканирует ваш сайт.Понимание этих различий поможет вам создать веб-сайт, адаптированный для каждой поисковой системы.
Googlebot
Как самая популярная поисковая система в мире, протоколы Google являются стандартом для большинства программ-роботов. Их сканер, одноименный робот Googlebot, на самом деле состоит из двух отдельных программ-роботов, одна из которых имитирует пользователя настольного компьютера, а другая — мобильного пользователя, названных Googlebot Desktop и Googlebot Smartphone соответственно. Оба бота будут сканировать ваш сайт примерно каждые несколько секунд.
По словам Нила Пателя, одна из лучших вещей, которые вы можете сделать для оптимизации своего сайта для робота Googlebot, — это упростить задачу: «Робот Googlebot не сканирует JavaScript, фреймы, DHTML, Flash и Ajax-контент так же хорошо, как HTML. » Создание вашего сайта таким образом может иметь большое значение для упрощения работы и для ваших читателей — правильно отформатированный HTML-код обрабатывается намного быстрее и надежнее, чем другие протоколы.
Это означает, что ваш сайт будет работать быстрее, что является положительным сигналом, на который Google обращает внимание при ранжировании вашего сайта.В результате оптимизации вашего сайта для сканирования вы также увеличиваете его рейтинг. Помните об этом, когда читаете, как роботы других поисковых систем просматривают ваш сайт. Можно настроить структуру вашего веб-сайта, чтобы напрямую обращаться к каждому из них. Далее, Bingbot.
Bingbot
Первичный поисковый робот Bing называется Bingbot (, здесь вы увидите тему с именами) . У них также есть сканеры AdIdxBot и BingPreview для рекламы и страниц предварительного просмотра соответственно.Однако, в отличие от Google, Bing не имеет отдельного сканера для мобильных сайтов.
Хотя Bingbot следует многим из тех же стандартов, что и Google, у вас есть дополнительный контроль, когда дело доходит до того, как и когда Bing сканирует ваш сайт. Bing оптимизирует время сканирования на основе собственных алгоритмов, но позволит вам настроить это время с помощью инструмента управления сканированием.
Этот контроль гарантирует, что вы не столкнетесь с какими-либо проблемами со скоростью сайта во время высокого входящего трафика.Bing также включает много информации о том, как они проводят этот процесс, в свои рекомендации для веб-мастеров.
Изучение этих рекомендаций поможет вам адаптировать свой сайт к их поисковому роботу, что поможет вам увеличить трафик и улучшить взаимодействие с посетителями. Когда вы понимаете, как Bing использует свой веб-сканер, это также помогает вам понять нашу следующую поисковую систему.
DuckDuckBot
DuckDuckBot — программа-обходчик для поисковой системы DuckDuckGo, ориентированной на конфиденциальность.Хотя DuckDuckGo использует API Bing для отображения релевантных результатов поиска, а также примерно 400 дополнительных источников, их собственный сканер по-прежнему выполняет часть работы по проверке вашего веб-сайта.
Основное отличие их сканера заключается в том, что он отдает приоритет наиболее безопасным веб-сайтам. Хотя нетрудно понять, что вы должны использовать безопасный протокол SSL для своего веб-сайта, как для безопасности, так и для преимуществ SEO, DuckDuckBot уделяет внимание безопасности как наиболее важному фактору ранжирования.
Хотя нетрудно понять, что вы должны использовать безопасный протокол SSL для своего веб-сайта, как для безопасности, так и для преимуществ SEO, DuckDuckBot уделяет внимание безопасности как наиболее важному фактору ранжирования.
Если вы ориентируетесь на рейтинги в DuckDuckGo, вам нужно понять, как сделать ваш сайт максимально безопасным. Это означает отказ от инвазивного отслеживания JavaScript или рекламных платформ для интеллектуального анализа данных. Но это может быть выгодно, если ваша целевая аудитория заботится о безопасности / конфиденциальности.
Просто имейте в виду, что отслеживание результатов поиска на определенной платформе может быть проблематичным, если вы не будете осторожны. Не стоит навешивать на свой сайт слишком узкий таргетинг.
Baiduspider
Baiduspider — это веб-сканер китайской поисковой системы Baidu.Baiduspider — один из самых частых поисковых роботов в Интернете, который следует учитывать прежде всего, когда вы ориентируетесь на определенную международную аудиторию. У них также есть особые правила чтения файла robots.txt.
У них также есть особые правила чтения файла robots.txt.
Когда вы создаете файл robots.txt для Baiduspider, у вас есть возможность проиндексировать свой сайт и, в то же время, заблокировать следующие функции:
- Переход по ссылкам на странице
- Кэширование страницы результатов
- Просмотр изображений
Такая специфичность дает вам больше контроля, чем многие другие поисковые роботы, о которых мы говорим сегодня.Baidu также сообщает нам, что они используют несколько различных агентов для сканирования определенных типов контента. Это дает вам возможность создавать еще более точные правила на основе бота, который, по вашему мнению, активно сканирует ваш сайт.
Яндекс-бот
Яндекс-бот — это краулер для российской поисковой системы Яндекс. Подобно Baidubot, они используют один и тот же сканер для всего Интернета с разными агентами для определенных типов контента. Кроме того, есть специальные теги, которые вы можете добавить на свой сайт, чтобы упростить индексацию Яндексом.
Самым заметным из этих тегов отслеживания является Яндекс.Метрика . Используя этот тег, вы можете напрямую увеличить скорость сканирования Яндекс. Привязка его к вашей учетной записи Яндекс веб-мастера делает еще один шаг вперед, еще больше увеличивая скорость.
Когда вы думаете о том, как настроить таргетинг на конкретных поисковых роботов с помощью инфраструктуры вашего веб-сайта, примите во внимание, что каждый из них ищет более или менее одно и то же, с небольшими изменениями в способах их достижения.Создание логичного сайта, структурированного в соответствии с правилами, о которых мы говорили в статье «Как работают поисковые роботы?» раздел и с которым легко взаимодействовать, гарантируют, что у вас будет максимальный рейтинг с этой точки зрения.
Оптимизация вашего сайта для поисковых роботов
Поисковые роботы применяют очень систематический подход к проверке вашего сайта. Понимание того, как они собирают информацию и возвращают ее для индексации, помогает повысить ваш рейтинг. Любые оплошности в процессе могут не только повредить вашему рейтингу, но и сделать ваш сайт невидимым для поисковых систем.
Любые оплошности в процессе могут не только повредить вашему рейтингу, но и сделать ваш сайт невидимым для поисковых систем.
Самое важное, что вам нужно сделать, — это создать стандартизированный файл robots.txt и актуальную карту сайта. Это гарантирует, что в соответствии с плиткой robots.txt будут сканироваться только соответствующие страницы вашего веб-сайта. И вы всегда сможете продемонстрировать правильную структуру ссылок и приоритет в своей карте сайта. Чтобы упростить эту задачу, вы можете определить карту сайта прямо в файле robots.txt:
User-agent: [имя поискового робота]
Разрешить: [строки URL, которые нужно сканировать]
Запретить: [строки URL, которые не нужно сканировать]
Карта сайта: https://www.yourdomain.com/sitemap.xml
Просто убедитесь, что вы используете правильную структуру URL, основанную на провайдере вашего веб-сайта.
Для большинства ботов, с которыми вы столкнетесь, скорость сканирования будет оптимизирована на основе определенных правил в алгоритмах поисковых систем. Но всегда полезно перепроверить скорость сканирования, когда у вас есть такая возможность.Bing, DuckDuckGo и Baidu предоставляют инструменты для проверки и обновления скорости сканирования в зависимости от того, что лучше всего подходит для вашего сайта. Если ваш сайт получает приток трафика утром в будние дни, настройка скорости сканирования позволяет вам указать роботу замедлить работу в это время и сканировать больше поздно вечером.
Но всегда полезно перепроверить скорость сканирования, когда у вас есть такая возможность.Bing, DuckDuckGo и Baidu предоставляют инструменты для проверки и обновления скорости сканирования в зависимости от того, что лучше всего подходит для вашего сайта. Если ваш сайт получает приток трафика утром в будние дни, настройка скорости сканирования позволяет вам указать роботу замедлить работу в это время и сканировать больше поздно вечером.
Используя эту логику, вы можете спланировать график публикации для создания общедоступного контента непосредственно перед тем, как поисковые роботы сделают свою работу. Таким образом вы обеспечите максимально быстрое сканирование, индексирование и ранжирование каждой новой страницы, которую вы создаете.
Еще один способ обеспечить такой уровень эффективности сканирования — использовать внутренние ссылки. Когда вы соединяете похожие страницы вместе логичным и простым способом, это дает поисковым роботам простой способ быстрее просматривать контент. Это позволяет им составить более полную картину общей ценности вашего сайта.
Это позволяет им составить более полную картину общей ценности вашего сайта.
Не забывайте и о возможностях внешнего связывания. Когда на вас ссылаются из доменов с более широкими полномочиями или с более длительным сроком владения в Интернете, это дает сканерам повод убедиться, что ваша страница актуальна насколько это возможно.Многие из этих программ будут отдавать приоритет веб-сайтам с более высоким рейтингом и надежностью домена, поэтому чем больше ссылок вы сможете получить, тем более привлекательным будет ваш сайт.
Сканирование — это первый шаг к повышению рейтинга вашего контента в поисковых системах. Важно упростить этот процесс, чтобы любой сканер поисковой системы, попавший на ваш сайт, мог быстро проанализировать структуру и вернуться домой, чтобы добавить ее в индекс. После этого вы на один шаг приблизитесь к тому, чтобы ваш сайт попал в поисковую выдачу.
Упростите сканирование вашего сайта
Когда сканер поисковой системы просматривает ваш сайт, он делает это почти так же, как и пользователь. Если правильно проанализировать данные сложно, значит, вы настраиваете себя на более низкий рейтинг. Зная основную технологию и протоколы, которым следуют эти сканеры, вы с самого начала сможете оптимизировать свой сайт для повышения его рейтинга.
Если правильно проанализировать данные сложно, значит, вы настраиваете себя на более низкий рейтинг. Зная основную технологию и протоколы, которым следуют эти сканеры, вы с самого начала сможете оптимизировать свой сайт для повышения его рейтинга.
Оптимизация возможности сканирования вашей страницы, вероятно, является одним из самых простых технических изменений, которые вы можете внести на свой веб-сайт с точки зрения SEO.Если ваша карта сайта и файл robots.txt в порядке, любые внесенные вами изменения будут отображаться в поисковой выдаче как можно скорее.
Поисковые роботы и сканирование
- WooRank
- Руководства по SEO
- Поисковые роботы
Что такое поисковый робот?
Поисковые роботы, также называемые пауками, роботами или просто ботами, представляют собой программы или сценарии, которые систематически и автоматически просматривают страницы в Интернете. Целью этого автоматического просмотра обычно является чтение страниц, посещаемых поисковым роботом, с целью добавления их в индекс поисковой системы.
Целью этого автоматического просмотра обычно является чтение страниц, посещаемых поисковым роботом, с целью добавления их в индекс поисковой системы.
Поисковые системы, такие как Google, используют поисковые роботы для чтения веб-страниц и хранят список слов, найденных на странице, и их местонахождение. Они также собирают данные об удобстве использования, такие как скорость и статусы ошибок HTTP.
Эти данные хранятся в индексе поисковых систем — огромных базах данных веб-страниц.
Когда вы выполняете поиск в Google, вы на самом деле ищете в индексе Google, а не в реальной сети.Затем Google отображает проиндексированные страницы, соответствующие запросу, и предоставляет ссылки на реальные страницы.
Поскольку современная сеть содержит несколько различных типов контента, а у поисковых систем есть способы поиска именно для этого типа контента, у крупнейших поисковых систем есть сканеры, предназначенные для сканирования определенных типов страниц или файлов. Эти поля включают:
Эти поля включают:
- Общее веб-содержимое
- Изображения
- Видео
- Новости
- Объявления
- мобильный
У каждого типа искателя есть свой агент пользователя.Посмотрите, что сканирует каждый пользовательский агент, в нашем руководстве robots.txt.
Как работают поисковые роботы?
На практическом уровне «сканирование» происходит, когда поисковый робот получает URL-адрес для проверки, выбирает страницу и затем сохраняет ее на локальном компьютере. Вы можете сделать это самостоятельно, перейдя на страницу, щелкнув правой кнопкой мыши и выбрав «Сохранить как…»
Сканерыполучают свои URL-адреса, проверяя карту сайта домена или переходя по ссылкам, которые они находят на другой странице.
Карты сайта играют важную роль на этом этапе, поскольку они предоставляют поисковым роботам удобный организованный список URL-адресов для доступа.Они также предоставляют детали, которые влияют на , как Google решает сканировать каждую страницу.
Что такое краулинговый бюджет?
Конечно, даже у Google есть ограниченные ресурсы (не важно, насколько велик этот лимит). Таким образом, робот Googlebot работает с так называемым «бюджетом сканирования». Бюджет сканирования — это просто количество URL-адресов на веб-сайте, которые Google хочет и может сканировать.
В бюджет сканирования Google для веб-сайта входят два компонента:
Ограничение скорости сканирования: Google не хочет влиять на пользовательский интерфейс веб-сайта при его сканировании, поэтому ограничивает количество страниц, которые сканер может получить за один раз.
Требование сканирования: Проще говоря, это желание Google сканировать ваш сайт. Google не заинтересован в сканировании URL-адресов, которые не выглядят так, как будто они приносят пользу пользователям (параметры URL, фасетная навигация, идентификаторы сеансов и т. Д.). Таким образом, даже если робот Googlebot не достигнет предела скорости сканирования, он не будет тратить свои ресурсы на сканирование этих страниц.

Хорошая новость заключается в том, что ограничение скорости сканирования и потребность в сканировании могут меняться в зависимости от того, что Google находит на вашем сайте.Эти факторы влияют на краулинговый бюджет вашего сайта:
Скорость сайта: Google не любит ждать, поэтому быстрые страницы побудят его сканировать больше страниц. Кроме того, скорость — признак здорового веб-сайта, поэтому Google сможет вложить больше ресурсов в сканирование.
Страницы с ошибками: Если сервер отвечает на множество запросов от Google кодами ошибок, это помешает Google пытаться сканировать страницы, потому что это будет выглядеть как веб-сайт с множеством проблем.
Популярность: Чем более популярной, по мнению Google, является ваша страница, тем чаще он будет сканировать ее, чтобы поддерживать актуальность в своем индексе.
Свежесть: Не секрет, что Google любит свежий (новый, актуальный) контент.
Публикация нового содержания сообщит Google, что на вашем веб-сайте есть новые страницы, которые нужно сканировать на регулярной основе. Более свежий контент означает больше обходов.
 Публикация нового содержания сообщит Google, что на вашем веб-сайте есть новые страницы, которые нужно сканировать на регулярной основе. Более свежий контент означает больше обходов.
Публикация нового содержания сообщит Google, что на вашем веб-сайте есть новые страницы, которые нужно сканировать на регулярной основе. Более свежий контент означает больше обходов.Альтернативные URL-адреса, такие как AMP или hreflang, могут сканироваться Google — то же самое для JavaScript и CSS.
Что такое индексирование поиска?
После того, как страница просканирована, Google необходимо извлечь информацию о странице, чтобы сохранить ее в своем индексе. Поисковые системы используют различные алгоритмы и эвристики, чтобы определить, какие слова в содержимом страницы являются важными и релевантными. Добавление семантической разметки, такой как Schema.org, поможет поисковым системам лучше понять вашу страницу.
После получения, сохранения и анализа страницы извлеченная из нее информация сохраняется в индексе поисковой системы.Когда кто-то использует запрос в поиске, информация в индексе используется для определения страниц, относящихся к этому запросу.
Как оптимизировать сканирование Google
Для ранжирования в результатах поиска необходимо сначала проиндексировать страницу. Чтобы проиндексировать страницу, сначала необходимо просканировать ее. Следовательно, возможность сканирования (или ее отсутствие) оказывает огромное влияние на SEO.
Вы не можете напрямую контролировать, какие страницы сканеры Google решат сканировать, но вы можете дать им подсказки о том, какие страницы лучше всего сканировать, а какие им следует игнорировать.
Есть три основных способа помочь контролировать, когда, где и как Google сканирует ваши страницы. Они не являются абсолютными (у Google есть собственное мнение), но они помогут гарантировать, что ваши самые важные страницы будут найдены поисковыми роботами.
Роль Robots.txt
Первое, что делает поисковый робот, попадая на страницу, — это открывает файл robots.txt сайта. Это делает файл robots.txt первой возможностью направить поисковые роботы на расстояние от того, что они сочли бы малоценными URL-адресами.
Вы можете использовать директиву disallow в robots.txt, чтобы роботы не заходили на страницы, которые вам не нужны в результатах поиска:
- Спасибо или страница подтверждения заказа
- Дублированный контент
- Страница результатов поиска по сайту
- Отсутствует на складе или другие страницы с ошибками
Не используйте файл robots.txt для запрета встроенных URL-адресов, таких как JavaScript или CSS. Сканеры должны использовать бюджет сканирования для этих URL-адресов, но Google необходимо , чтобы иметь возможность полностью отобразить страницу и правильно ее понять.
Блокирование файлов CSS и JS приведет к неточному или неполному сканированию и индексированию, в результате чего Google будет видеть страницу иначе, чем люди, может даже привести к снижению рейтинга.
Роль XML-карт сайта
Прочтите руководство по XML-файлам Sitemap, чтобы узнать больше о том, как они влияют на сканирование.
XML похожи на противоположность файла robots.txt. Они сообщают поисковым системам, какие страницы они должны сканировать . И хотя Google не обязан сканировать все URL-адреса в карте сайта (в отличие от robots.txt, что является обязательным), вы можете использовать информацию о страницах, чтобы помочь Google сканировать страницы более разумно.
Ваша карта сайта также очень важна для обеспечения того, чтобы Google мог найти страницы на вашем сайте, это жизненно важный инструмент, если ваша внутренняя структура ссылок не очень сильна.
Использование тегов nofollow
Помните, что поисковые роботы переходят со страницы на страницу по ссылкам. Однако вы можете добавить атрибут rel = «nofollow», чтобы роботы , а не переходили по ссылкам.Когда поисковая система встречает ссылку nofollow, она игнорирует ее.
Вы можете nofollow по ссылке двумя способами:
Мета-тег. Если вы не хотите, чтобы поисковые системы сканировали какие-либо ссылки на странице, добавьте атрибут content = «nofollow» в метатег robots.
Тег выглядит следующим образом:Якорные теги: если вам нужен детальный подход к ссылкам nofollow, добавьте атрибут rel = «nofollow» к фактическому тегу ссылки, например:
Вам может быть интересно, как использование атрибута noindex в метатеге robots влияет на сканирование. Короче говоря, это не так. Google по-прежнему будет сканировать страницу с атрибутом noindex и переходить по всем ссылкам dofollow на странице. Он просто не будет хранить страницу и ее данные в индексе.
Поиск ошибок сканирования
Ошибки сканирования возникают, когда Google пытается получить страницу, но по какой-то причине не может получить доступ к URL.Ошибки сканирования могут возникать на уровне всего сайта (проблемы с DNS, простоем сервера или robots.txt) или на уровне страницы (тайм-аут, программный 404, не найдено и т. Д.).
Сканирование сайтаWooRank проверяет ваш сайт на наличие проблем, которые могут вызывать проблемы, мешающие вашему сайту хорошо работать в поисковых системах.
В отчете об индексировании в консоли поиска Google будут перечислены страницы, с которыми Google сталкивается, при сканировании которых возникают проблемы, а также проблема, которая не позволяет Google правильно их проиндексировать.
Ознакомьтесь с новой Search Console.
Как работает поисковая система? + Повысьте эффективность SEO |…
Хотя вы всегда должны создавать контент веб-сайта, ориентированный на ваших клиентов, а не на поисковые системы, важно понимать, как работает поисковая система. Как только вы это узнаете, вы можете переходить к следующему шагу, который включает элементы, которые ищет поисковая система.
Как работают поисковые системы?
Большинство поисковых систем создают индекс на основе сканирования, то есть процесса, посредством которого такие системы, как Google, Yahoo и другие, находят новые страницы для индексации.Механизмы, известные как боты или пауки, сканируют Интернет в поисках новых страниц (1). Боты обычно начинают со списка URL-адресов веб-сайтов, определенных в ходе предыдущих сканирований. Когда они обнаруживают новые ссылки на этих страницах с помощью таких тегов, как HREF и SRC, они добавляют их в список сайтов для индексации.
Затем поисковые системы используют свои алгоритмы, чтобы предоставить вам ранжированный список из своего индекса того, какие страницы вам должны быть наиболее интересны на основе используемых вами поисковых запросов.Затем механизм вернет список результатов в Интернете, ранжированных с использованием его определенного алгоритма.В Google другие элементы, такие как персонализированные и универсальные результаты, также могут изменить рейтинг вашей страницы. В персонализированных результатах поисковая система использует дополнительную информацию о пользователе, чтобы возвращать результаты, которые непосредственно отвечают их интересам. Универсальные результаты поиска объединяют видео, изображения и новости Google для создания более крупной картинки, что может означать усиление конкуренции со стороны других веб-сайтов по тем же ключевым словам.
Вот основные элементы, которые нужно изменить при разработке вашего магазина для SEO:
Архитектура — Сделайте веб-сайты, которые поисковые системы могут легко сканировать.
Это включает в себя несколько элементов, например, как контент организован и категоризирован, и как отдельные веб-сайты связаны друг с другом. Карта сайта XML может позволить вам предоставить список URL-адресов поисковым системам для сканирования и индексации. (2)Контент — Хороший контент — один из самых важных элементов для SEO, потому что он сообщает поисковым системам, что ваш сайт актуален. Речь идет не только о ключевых словах, но и о написании привлекательного контента, который будет часто интересовать ваших клиентов.
Ссылки — Когда много людей ссылаются на определенный сайт, это предупреждает поисковые системы о том, что этот конкретный сайт является авторитетным, что повышает его рейтинг. Сюда входят ссылки из источников в социальных сетях. Когда ваш сайт ссылается на другие авторитетные платформы, поисковые системы также с большей вероятностью оценит ваш контент как качественный.
Ключевые слова — Ключевые слова, которые вы используете, являются одним из основных методов, используемых поисковыми системами для ранжирования вас.
Использование тщательно подобранных ключевых слов может помочь нужным клиентам найти вас.Если вы управляете ювелирным магазином, но никогда не упоминаете слова «ювелирные изделия», «ожерелье» или «браслет», алгоритм Google может не считать вас экспертом в этой области.Описание заголовков — Хотя он может не отображаться на веб-сайте, поисковые системы обращают внимание на тег заголовка в html-коде вашего сайта, слова между
</ title>, потому что он, вероятно, описывает то, что веб-сайт это примерно, как название книги или заголовок газеты.</p><p> <strong> Содержание страницы </strong> — Не прячьте важную информацию во Flash и мультимедийные элементы, такие как видео.Поисковые системы не могут видеть изображения и видео или сканировать контент в плагинах Flash и Java.</p><p> <strong> Внутренние ссылки </strong> — Включение внутренних ссылок помогает поисковым системам более эффективно сканировать ваш сайт, но также способствует тому, что многие специалисты по SEO называют «ссылочным весом».<img class="lazy lazy-hidden" src="//ylianova.ru/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='/800/600/https/i.pinimg.com/736x/31/39/e4/3139e4c2f3f976fd46ada0761264e0ee.jpg' style='float: right;' /><noscript><img src='/800/600/https/i.pinimg.com/736x/31/39/e4/3139e4c2f3f976fd46ada0761264e0ee.jpg' style='float: right;' /></noscript><div class='yarpp-related yarpp-related-none'><p>No related posts.</p></div></div></div><div class="post-sharrre group"><div id="twitter" data-url="https://ylianova.ru/raznoe-2/kakuyu-rabotu-vypolnyayut-pauki-poiskovyh-mashin-kakuyu-rabotu-vypolnyayut-raboty-poiskovyh-mashin-poiskovye-mashiny-poiskoviki-i-roboty-pauki-budushhee-poiskovikov-kak-vedut-sebya-roboty-i-kak-i.html" data-text="Какую работу выполняют пауки поисковых машин: Какую работу выполняют работы поисковых машин. Поисковые машины, поисковики и роботы-пауки. Будущее поисковиков. Как ведут себя роботы и как ими управлять" data-title="Tweet"></div><div id="facebook" data-url="https://ylianova.ru/raznoe-2/kakuyu-rabotu-vypolnyayut-pauki-poiskovyh-mashin-kakuyu-rabotu-vypolnyayut-raboty-poiskovyh-mashin-poiskovye-mashiny-poiskoviki-i-roboty-pauki-budushhee-poiskovikov-kak-vedut-sebya-roboty-i-kak-i.html" data-text="Какую работу выполняют пауки поисковых машин: Какую работу выполняют работы поисковых машин. Поисковые машины, поисковики и роботы-пауки. Будущее поисковиков. Как ведут себя роботы и как ими управлять" data-title="Like"></div><div id="googleplus" data-url="https://ylianova.ru/raznoe-2/kakuyu-rabotu-vypolnyayut-pauki-poiskovyh-mashin-kakuyu-rabotu-vypolnyayut-raboty-poiskovyh-mashin-poiskovye-mashiny-poiskoviki-i-roboty-pauki-budushhee-poiskovikov-kak-vedut-sebya-roboty-i-kak-i.html" data-text="Какую работу выполняют пауки поисковых машин: Какую работу выполняют работы поисковых машин. Поисковые машины, поисковики и роботы-пауки. Будущее поисковиков. Как ведут себя роботы и как ими управлять" data-title="+1"></div><div id="pinterest" data-url="https://ylianova.ru/raznoe-2/kakuyu-rabotu-vypolnyayut-pauki-poiskovyh-mashin-kakuyu-rabotu-vypolnyayut-raboty-poiskovyh-mashin-poiskovye-mashiny-poiskoviki-i-roboty-pauki-budushhee-poiskovikov-kak-vedut-sebya-roboty-i-kak-i.html" data-text="Какую работу выполняют пауки поисковых машин: Какую работу выполняют работы поисковых машин. Поисковые машины, поисковики и роботы-пауки. Будущее поисковиков. Как ведут себя роботы и как ими управлять" data-title="Pin It"></div></div></div></article><ul class="post-nav group"><li class="next"><a href="https://ylianova.ru/raznoe-2/gugl-golosovoj-poisk-dlya-kompyutera-ustanovka-golosovogo-poiska-okej-gugl-na-kompyuter-ili-noutbuk.html" rel="next"><i class="fa fa-chevron-right"></i><strong>Вперед</strong> <span>Гугл голосовой поиск для компьютера: Установка голосового поиска «Окей Гугл» на компьютер или ноутбук</span></a></li><li class="previous"><a href="https://ylianova.ru/verstka/adaptivnaya-verstka-css-media-screen-adaptivnyj-i-mobilnyj-dizajn-s-css3-media-queries-xabr.html" rel="prev"><i class="fa fa-chevron-left"></i><strong>Назад</strong> <span>Адаптивная верстка css media screen: Адаптивный и мобильный дизайн с CSS3 Media Queries / Хабр</span></a></li></ul><section id="comments" class="themeform"><div id="respond" class="comment-respond"><h3 id="reply-title" class="comment-reply-title">Добавить комментарий <small><a rel="nofollow" id="cancel-comment-reply-link" href="/raznoe-2/kakuyu-rabotu-vypolnyayut-pauki-poiskovyh-mashin-kakuyu-rabotu-vypolnyayut-raboty-poiskovyh-mashin-poiskovye-mashiny-poiskoviki-i-roboty-pauki-budushhee-poiskovikov-kak-vedut-sebya-roboty-i-kak-i.html#respond" style="display:none;">Отменить ответ</a></small></h3><form action="https://ylianova.ru/wp-comments-post.php" method="post" id="commentform" class="comment-form"><p class="comment-notes"><span id="email-notes">Ваш адрес email не будет опубликован.</span> <span class="required-field-message">Обязательные поля помечены <span class="required">*</span></span></p><p class="comment-form-comment"><label for="comment">Комментарий <span class="required">*</span></label><textarea id="comment" name="comment" cols="45" rows="8" maxlength="65525" required="required"></textarea></p><p class="comment-form-author"><label for="author">Имя <span class="required">*</span></label> <input id="author" name="author" type="text" value="" size="30" maxlength="245" autocomplete="name" required="required" /></p><p class="comment-form-email"><label for="email">Email <span class="required">*</span></label> <input id="email" name="email" type="text" value="" size="30" maxlength="100" aria-describedby="email-notes" autocomplete="email" required="required" /></p><p class="comment-form-url"><label for="url">Сайт</label> <input id="url" name="url" type="text" value="" size="30" maxlength="200" autocomplete="url" /></p><p class="form-submit"><input name="submit" type="submit" id="submit" class="submit" value="Отправить комментарий" /> <input type='hidden' name='comment_post_ID' value='8110' id='comment_post_ID' /> <input type='hidden' name='comment_parent' id='comment_parent' value='0' /></p></form></div></section></div></section><div class="sidebar s1"> <a class="sidebar-toggle" title="Развернуть боковую панель"><i class="fa icon-sidebar-toggle"></i></a><div class="sidebar-content"><div id="search-2" class="widget widget_search"><form method="get" class="searchform themeform" action="https://ylianova.ru/"><div> <input type="text" class="search" name="s" onblur="if(this.value=='')this.value='Введите поисковую фразу';" onfocus="if(this.value=='Введите поисковую фразу')this.value='';" value="Введите поисковую фразу" /></div></form></div><div id="nav_menu-2" class="widget widget_nav_menu"><h3>Рубрики</h3><div class="menu-2-container"><ul id="menu-2" class="menu"><li id="menu-item-5370" class="menu-item menu-item-type-taxonomy menu-item-object-category menu-item-5370"><a href="https://ylianova.ru/category/css">Css</a></li><li id="menu-item-5371" class="menu-item menu-item-type-taxonomy menu-item-object-category menu-item-5371"><a href="https://ylianova.ru/category/html">Html</a></li><li id="menu-item-5372" class="menu-item menu-item-type-taxonomy menu-item-object-category menu-item-5372"><a href="https://ylianova.ru/category/http">Http</a></li><li id="menu-item-5373" class="menu-item menu-item-type-taxonomy menu-item-object-category menu-item-5373"><a href="https://ylianova.ru/category/javascript">Javascript</a></li><li id="menu-item-5374" class="menu-item menu-item-type-taxonomy menu-item-object-category menu-item-5374"><a href="https://ylianova.ru/category/photoshop">Photoshop</a></li><li id="menu-item-5375" class="menu-item menu-item-type-taxonomy menu-item-object-category menu-item-5375"><a href="https://ylianova.ru/category/verstka">Верстка</a></li><li id="menu-item-5376" class="menu-item menu-item-type-taxonomy menu-item-object-category menu-item-5376"><a href="https://ylianova.ru/category/raznoe">Вопросы и ответы</a></li><li id="menu-item-5377" class="menu-item menu-item-type-taxonomy menu-item-object-category menu-item-5377"><a href="https://ylianova.ru/category/maket">Макет</a></li><li id="menu-item-5378" class="menu-item menu-item-type-taxonomy menu-item-object-category menu-item-5378"><a href="https://ylianova.ru/category/sajt">Развитие сайтов</a></li><li id="menu-item-5380" class="menu-item menu-item-type-taxonomy menu-item-object-category menu-item-5380"><a href="https://ylianova.ru/category/sajt-2">Сайт</a></li><li id="menu-item-5381" class="menu-item menu-item-type-taxonomy menu-item-object-category menu-item-5381"><a href="https://ylianova.ru/category/shablon-2">Шаблон</a></li><li id="menu-item-5382" class="menu-item menu-item-type-taxonomy menu-item-object-category menu-item-5382"><a href="https://ylianova.ru/category/shrift-2">Шрифт</a></li><li id="menu-item-5379" class="menu-item menu-item-type-taxonomy menu-item-object-category current-post-ancestor current-menu-parent current-post-parent menu-item-5379"><a href="https://ylianova.ru/category/raznoe-2">Разное</a></li></ul></div></div><div id="categories-3" class="widget widget_categories"><h3>Рубрики</h3><ul><li class="cat-item cat-item-5"><a href="https://ylianova.ru/category/css">Css</a></li><li class="cat-item cat-item-4"><a href="https://ylianova.ru/category/html">Html</a></li><li class="cat-item cat-item-9"><a href="https://ylianova.ru/category/http">Http</a></li><li class="cat-item cat-item-10"><a href="https://ylianova.ru/category/javascript">Javascript</a></li><li class="cat-item cat-item-20"><a href="https://ylianova.ru/category/linux">Linux</a></li><li class="cat-item cat-item-11"><a href="https://ylianova.ru/category/photoshop">Photoshop</a></li><li class="cat-item cat-item-19"><a href="https://ylianova.ru/category/adaptiv">Адаптив</a></li><li class="cat-item cat-item-17"><a href="https://ylianova.ru/category/verstka">Верстка</a></li><li class="cat-item cat-item-3"><a href="https://ylianova.ru/category/raznoe">Вопросы и ответы</a></li><li class="cat-item cat-item-16"><a href="https://ylianova.ru/category/maket">Макет</a></li><li class="cat-item cat-item-6"><a href="https://ylianova.ru/category/sajt">Развитие сайтов</a></li><li class="cat-item cat-item-13"><a href="https://ylianova.ru/category/raznoe-2">Разное</a></li><li class="cat-item cat-item-12"><a href="https://ylianova.ru/category/sajt-2">Сайт</a></li><li class="cat-item cat-item-1"><a href="https://ylianova.ru/category/sovety">Советы</a></li><li class="cat-item cat-item-15"><a href="https://ylianova.ru/category/shablon-2">Шаблон</a></li><li class="cat-item cat-item-7"><a href="https://ylianova.ru/category/shablon">Шаблоны</a></li><li class="cat-item cat-item-14"><a href="https://ylianova.ru/category/shrift-2">Шрифт</a></li><li class="cat-item cat-item-8"><a href="https://ylianova.ru/category/shrift">Шрифты</a></li></ul></div></div></div></div></div><footer id="footer"><section id="footer-bottom"><div class="container"> <a id="back-to-top" href="#"><i class="fa fa-angle-up"></i></a><div class="pad group"><div class="grid one-half"><div id="copyright"><p>Блог сумасшедшего сисадмина © 2025. Все права защищены.</p></div><div id="credit"><p><a href="/sitemap.xml" class="c_sitemap">Карта сайта</a></p></div></div><div class="grid one-half last"></div></div></div></section></footer></div> <noscript><style>.lazyload{display:none}</style></noscript><script data-noptimize="1">window.lazySizesConfig=window.lazySizesConfig||{};window.lazySizesConfig.loadMode=1;</script><script async data-noptimize="1" src='https://ylianova.ru/wp-content/plugins/autoptimize/classes/external/js/lazysizes.min.js'></script> <!--[if lt IE 9]> <script src="https://ylianova.ru/wp-content/themes/anew/js/ie/respond.js"></script> <![endif]--> <!-- noptimize --> <style>iframe,object{width:100%;height:480px}img{max-width:100%}</style><script>new Image().src="//counter.yadro.ru/hit?r"+escape(document.referrer)+((typeof(screen)=="undefined")?"":";s"+screen.width+"*"+screen.height+"*"+(screen.colorDepth?screen.colorDepth:screen.pixelDepth))+";u"+escape(document.URL)+";h"+escape(document.title.substring(0,150))+";"+Math.random();</script> <!-- /noptimize --> <script defer src="https://ylianova.ru/wp-content/cache/autoptimize/js/autoptimize_e53cd8e8c9ad800cb6c734eb3954364d.js"></script></body></html><script src="/cdn-cgi/scripts/7d0fa10a/cloudflare-static/rocket-loader.min.js" data-cf-settings="006e57b0c82e1a6b19e772a7-|49" defer></script>
 Тег выглядит следующим образом:
Тег выглядит следующим образом:

 Затем поисковые системы используют свои алгоритмы, чтобы предоставить вам ранжированный список из своего индекса того, какие страницы вам должны быть наиболее интересны на основе используемых вами поисковых запросов.
Затем поисковые системы используют свои алгоритмы, чтобы предоставить вам ранжированный список из своего индекса того, какие страницы вам должны быть наиболее интересны на основе используемых вами поисковых запросов. Это включает в себя несколько элементов, например, как контент организован и категоризирован, и как отдельные веб-сайты связаны друг с другом. Карта сайта XML может позволить вам предоставить список URL-адресов поисковым системам для сканирования и индексации. (2)
Это включает в себя несколько элементов, например, как контент организован и категоризирован, и как отдельные веб-сайты связаны друг с другом. Карта сайта XML может позволить вам предоставить список URL-адресов поисковым системам для сканирования и индексации. (2) Использование тщательно подобранных ключевых слов может помочь нужным клиентам найти вас.Если вы управляете ювелирным магазином, но никогда не упоминаете слова «ювелирные изделия», «ожерелье» или «браслет», алгоритм Google может не считать вас экспертом в этой области.
Использование тщательно подобранных ключевых слов может помочь нужным клиентам найти вас.Если вы управляете ювелирным магазином, но никогда не упоминаете слова «ювелирные изделия», «ожерелье» или «браслет», алгоритм Google может не считать вас экспертом в этой области.