[По полочкам] Кэширование / Хабр
Всем привет! Меня зовут Илья Денисов, я занимаюсь backend разработкой уже более пяти лет и сейчас пишу на языке go. Сегодня я предлагаю вам поговорить о кэшировании. Постараюсь рассказать о базовых концепциях, а также затронуть ряд особенностей, неочевидных на первый взгляд.
Что такое кэширование?
Кэширование – это способ хранения данных как можно ближе к месту их использования. Как правило, для этого используется быстродействующая память (RAM).
Для чего нужно кэширование?
Кэширование появилось давно и использовалось для ускорения работы процессора с оперативной памятью. Наверняка каждый из вас слышал об иерархии кэша L1, L2 и L3, применяемого в процессорах. Добавление кэша значительно ускорило работу с памятью, но и принесло дополнительные проблемы. Самая известная и сложная из них – это инвалидация данных. Мы уделим ей особое внимание чуть позже.
С этой проблемой (и рядом других, о которых мы тоже поговорим) связан главный принцип работы с кэшем. Он очень прост: если вы можете обойтись без кэширования, то именно так и сделайте.
Он очень прост: если вы можете обойтись без кэширования, то именно так и сделайте.
Например, если у вас простое приложение или небольшая нагрузка, то кэширование вам не нужно. Важно понимать, что кэширование само по себе “не бесплатное”, оно привносит в систему дополнительную сложность: появляются дополнительные компоненты, которые надо сопровождать, усложняется структура кода.
Но если у вас большая частота запросов (Requests per Second, RPS), если запросы эти “тяжелые ”, если вам слишком дорого масштабировать основное хранилище – любой из этих причин и, тем более, их сочетания достаточно, чтобы задуматься о кэшировании всерьез. При грамотном подходе оно поможет уменьшить в разы время ответа при обращении к данным.
Поэтому более продвинутый вариант принципа работы с кэшем можно сформулировать, перефразируя знаменитую цитату немецкого богослова XVIII века Карла Фридриха Этингера: “Дай мне удачу, чтобы без кэша можно было обойтись, дай мне сил, если обойтись без него нельзя – и дай мне мудрости отличить одну ситуацию от другой”.
Как работает кэширование?
Логически кэш представляет из себя базу типа ключ-значение. Каждая запись в кэше имеет “время жизни”, по истечении которого она удаляется. Это время называют термином Time To Live или TTL. Размер кэша гораздо меньше, чем у основного хранилища, но этот недостаток компенсируется высокой скоростью доступа к данным. Это достигается за счет размещения кэша в быстродействующей памяти ОЗУ (RAM). Поэтому обычно кэш содержит самые “горячие” данные.
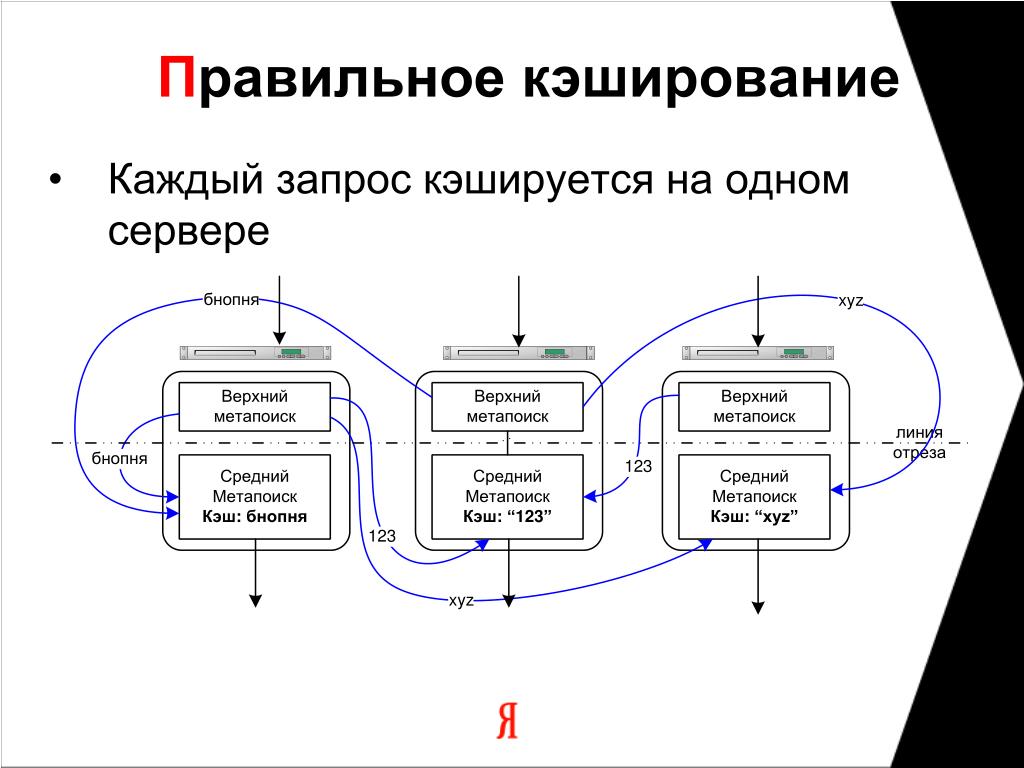
Вот самый базовый пример работы кэша:
Пример работы кэша
На первой схеме изображено первое обращение за данными:
Пользователь запрашивает некие данные
Кэш приложения ПУСТ, поэтому приложение обращается к базе данных (БД)
БД возвращает запрошенные данные приложению
Приложение сохраняет полученные данные в кэше
Пользователь получает данные
Вторая схема иллюстрирует последующие обращения за данными:
Пользователь запрашивает данные
Приложение уже имеет эти данные в кэше (ведь они были записаны туда при первом обращении) и поэтому НЕ ОБРАЩАЕТСЯ за ними к БД
Пользователь получает данные
Из этого простого примера видно, что только первый запрос данных приводит к обращению к БД. Все последующие запросы попадают в кэш до тех пор, пока не истечет TTL. Как только это произойдет, новый запрос снова обращается к БД и заново кэширует данные. Так будет продолжаться все время, пока приложение работает.
Все последующие запросы попадают в кэш до тех пор, пока не истечет TTL. Как только это произойдет, новый запрос снова обращается к БД и заново кэширует данные. Так будет продолжаться все время, пока приложение работает.
В результате мы экономим время не только на обработке запросов в БД, но и на сетевом обмене с БД. Все это значительно ускоряет время получения ответа пользователем.
Метрики кэша
Работу кэша можно оценивать при помощи множества метрик разной степени полезности. Я опишу те, которые считаю базовыми и наиболее полезными.
Объем памяти, выделенной под кэш. Это базовый показатель, по которому можно судить, сколько используется ресурсов
RPS чтения/записи – количество операций чтения/записи за единицу времени. В обычной ситуации количество операций чтения должно быть в разы больше количества операций записи. Обратное соотношение свидетельствует о проблемах в работе кэша
Количество элементов в кэше.
 Его полезно знать в дополнение к объему памяти, чтобы обнаруживать большие записи
Его полезно знать в дополнение к объему памяти, чтобы обнаруживать большие записиHit rate – процент извлечения данных из кэша. Чем он ближе к 100%, тем лучше. Этот параметр буквально определяет то, насколько наш кэш полезен и эффективен
Expired rate – процент удаления записей по истечении TTL. Этот показатель помогает обнаружить проблемы с производительностью, вызванные большим количеством записей с одновременно истекшим TTL
Eviction rate – процент вытеснения записей из кэша при достижении лимита используемой памяти. Важный показатель при выборе стратегий вытеснения, о которых мы поговорим чуть позже
 Его полезно знать в дополнение к объему памяти, чтобы обнаруживать большие записи
Его полезно знать в дополнение к объему памяти, чтобы обнаруживать большие записиЧто можно кэшировать?
Строго говоря, кэшировать можно что угодно, но не всегда это целесообразно. Все сильно зависит от данных и паттерна их использования.
Все данные можно условно разделить на 3 группы по частоте изменений:
Меняются часто. Такие данные изменяются в течение секунд или нескольких минут.
Их кэширование чаще всего бессмысленно, хотя иногда может и пригодится.
 Их кэширование чаще всего бессмысленно, хотя иногда может и пригодится.
Их кэширование чаще всего бессмысленно, хотя иногда может и пригодится.Пример: ошибки (кэширование ошибок может быть настолько важным, что мы посвятили ему целую главу ближе к концу статьи)
Меняются нечасто. Такие данные изменяются в течение минут, часов, дней. Именно в этом случае вы чаще всего задаетесь вопросом “Стоит ли мне кэшировать это?”
Примеры: списки товаров на сайте, описания товаров
Меняются крайне редко или не меняются никогда. Такие данные меняются в течение недель, месяцев и лет. В этом случае данные можно спокойно кэшировать. НО! Ни в коем случае нельзя усыплять бдительность верой в то, что какие-либо данные никогда не изменятся. Рано или поздно они изменятся, поэтому всегда выставляйте всем данным разумный TTL. ВСЕГДА!
Пример: картинки, DNS
Типы кэшей
С точки зрения архитектуры, можно выделить два типа кэшей: встроенный кэш (inline) и отдельный кэш (sidecar).
Встроенный кэш – это кэш, который “живет” в том же процессе, что и основное приложение. Они делят один сегмент памяти, поэтому за данными можно обращаться напрямую. В качестве такого кэша может выступать map – обычный инструмент из арсенала go – или другие структуры данных (подробнее об этом можно почитать здесь: https://github.com/hashicorp/golang-lru). Вот принципиальная схема работы inline cache:
Встроенный кэш (inline)
Отдельные кэши (sidecar) – это обособленный процесс со своей выделенной памятью. Как правило, это хранилище типа ключ-значение, которое используется как кэш для основного. Примеры такого типа кэша – Redis, Memcached и другие хранилища типа ключ-значение. Вот принципиальная схема их работы:
Отдельные кэши (sidecar)
Сравнение двух типов кэшей:
Характеристика | Встроенный кэш (inline) | Отдельные кэши (sidecar) |
Скорость ответа | Выше: обращаемся напрямую к памяти | Ниже: есть сетевые вызовы, а также оверхед на работу самого хранилища |
Память | Кэш и приложение делят одну область памяти, поэтому ее тратится меньше | Под кэш выделена отдельная память, поэтому ее тратится больше |
Согласованность данных | Плохая: каждая копия приложения содержит только свои данные | Хорошая: все копии приложения обращаются к единому хранилищу |
Масштабирование | Кэш нельзя масштабировать отдельно от приложения | Кэш и приложение можно масштабировать независимо друг от друга |
Ресурсы (память, ЦПУ и т. | Общие, поскольку “живут” в одном процессе | Выделенные, поскольку “живут” в разных процессах |
Простота сопровождения | Проще: кэш – просто структура данных, предоставляемая библиотекой | Сложнее: кэш – отдельно разворачиваемый компонент, требующий отдельного мониторинга и экспертизы |
Изолированность | Низкая: проводить отдельно работы над кэшем крайне сложно | Высокая: мы можем проводить любые работы над кэшем независимо от приложения |
Горячий старт | Сложнее: приложение обычно не общается с диском напрямую | Проще: например, redis может периодически сбрасывать данные на диск и восстанавливать состояние после рестарта |
 д.)
д.)Не стоит думать, что один тип кэша хуже другого. У каждого из них свои достоинства и недостатки и каждый из них нужно применять с умом. Более того, их можно комбинировать. Например, вы можете использовать встроенный кэш как L1, а отдельный кэш как L2 перед основным хранилищем. В результате, такая схема может в разы сократить время ответа и снизить нагрузку на основное хранилище.
У каждого из них свои достоинства и недостатки и каждый из них нужно применять с умом. Более того, их можно комбинировать. Например, вы можете использовать встроенный кэш как L1, а отдельный кэш как L2 перед основным хранилищем. В результате, такая схема может в разы сократить время ответа и снизить нагрузку на основное хранилище.
Стратегии работы с кэшем
Рассмотрим стратегии чтения и записи при работе с кэшем. В приведенных далее примерах кэш может быть как встроенным, так отдельным. Под “приложением” подразумевается некая бизнес-логика. Упор делается на описание взаимодействия компонентов друг с другом.
Cache through (Сквозное кэширование)
В рамках этой этой стратегии все запросы от приложения проходят через кэш. В коде это может выглядеть как связующее звено или “декоратор” над основным хранилищем. Таким образом, для приложения кэш и основная БД выглядят как один компонент хранилища.
Read through (Сквозное чтение)
Read through (Сквозное чтение)
Приходит запрос на получение данных
Пытаемся прочитать данные из кэша
В кэше нужных данных нет, происходит промах (miss)
Кэш перенаправляет запрос в БД.
Это важный нюанс стратегии: к БД обращается именно кэш, а не приложениеХранилище отдает данные
Сохраняем данные в кэш
Отдаем запрошенные данные приложению. Для приложения это выглядит так, как если бы хранилище просто вернуло ему данные, то есть шаги 3-6 скрыты от основной бизнес-логики
Возвращаем результат запроса
 Это важный нюанс стратегии: к БД обращается именно кэш, а не приложение
Это важный нюанс стратегии: к БД обращается именно кэш, а не приложениеWrite through (Сквозная запись)
Write through (Сквозная запись)
Приходит запрос на вставку каких-либо данных
Отправляем запрос на запись через кэш. В этот момент кэш выступает только как прокси и сам по себе ничего не делает
Сохраняем данные в БД
БД возвращает результат запроса
Сохраняем данные в кэш. Делаем мы это специально после вставки, чтобы кэш и БД были консистентны. Если бы мы писали данные в кэш на шаге 2, а при этом на шаге 3 произошла бы ошибка, то кэш содержал бы данные, которых нет в БД, что может привести к печальным последствиям
Отдаем запрошенные данные приложению
Возвращаем результат запроса
Преимущества:
Недостатки:
Cache aside (Кэширование на стороне)
В этой стратегии, приложение координирует запросы в кэш и БД и само решает, куда и в какой момент нужно обращаться. В коде это выглядит как два хранилища: одно постоянное, второе – временное.
В коде это выглядит как два хранилища: одно постоянное, второе – временное.
Read aside (Чтение на стороне)
Read aside (Чтение на стороне)
Приходит запрос на получение данных
Пытаемся читать из кэша
В кэше нужных данных нет, происходит промах (miss)
Приложение само обращается к хранилищу. В этом главное отличие от сквозного подхода: бизнес-логика в любой момент времени сама решает, куда обращаться – к кэшу или к БД
БД отдает данные
Сохраняем данные в кэш
Возвращаем результат запроса
Write aside (Запись на стороне)
Write aside (Запись на стороне)
Приходит запрос на вставку каких-либо данных
Сохраняем данные в БД
БД возвращает результат запроса
Сохраняем данные в кэш. Опять-таки, мы намеренно делаем это после вставки, чтобы кэш и БД были консистентны. Сохранение данных в кэше перед шагом 2 и ошибка на шаге 2 привели бы к появлению в кэше данных, которых нет в БД.
Результат был бы все тот же – печальные последствияВозвращаем результат запроса
 Результат был бы все тот же – печальные последствия
Результат был бы все тот же – печальные последствияПреимущества:
Недостатки:
Схема работы немного сложнее с точки зрения организации кода
В коде сложнее добавить/убрать кэш, поскольку это отдельный компонент, с которым взаимодействует бизнес-логика. Изменить этого взаимодействие может быть сложно
Cache ahead (Опережающие кэширование)
Эта стратегия предназначена только для запросов на чтение. Они всегда идут только в кэш, никогда не попадая в БД напрямую. По факту мы работаем со снимком состояния БД и обновляем его с некоторой периодичностью. Для приложения это выглядит просто как хранилище, как и в случае со сквозным кэшированием.
Cache ahead (Опережающие кэширование)
Входящие запросы на чтение:
Приходит запрос на получение данных
Читаем из кэша. Если в кэше нет нужных данных, то возвращаем ошибку. К БД в случае промаха не обращаемся
Если данные есть, то отдаем их приложению
Возвращаем результат запроса
Обновление кэша:
Периодически запускается фоновый процесс, который читает данные из БД.
Читаем актуальные данные из БД
БД отдает данные
Сохраняем данные в кэш

Преимущества:
Минимальная и полностью контролируемая нагрузка на БД. Клиентские запросы не могут повлиять на БД
В коде легко добавить/убрать кэш, поскольку можно просто заменить кэш на основное хранилище и обращаться уже к нему
Простота, так как не приходится иметь дело с двумя хранилищами
Недостатки:
Кэш отстает от основного хранилища на период между запусками обновления кэша. Нужно помнить, что на момент обращения свежие данные могут еще “не доехать” до кэша. Эта проблема может быть решена использованием сквозной записи или записи на стороне. Тогда, при обновлении данных в БД, данные будут обновляться и в кэше
Вы можете использовать описанные стратегии в любых комбинациях. Например, вы можете взять опережающие кэширование, добавить туда сквозную запись и чтение на стороне, чтобы добиться максимальный актуальности данных и избежать промахов по максимуму!
Стратегии инвалидации
Инвалидация – это процесс удаления данных из кэша или пометка их как недействительных. Делается это для того, чтобы гарантировать актуальность данных, с которыми работает приложение.
Делается это для того, чтобы гарантировать актуальность данных, с которыми работает приложение.
Инвалидация по TTL
TTL (Time To Live) – время жизни данных в кэше. При сохранении данных в кэш для них устанавливается TTL и данные будут обновляться с периодичностью не менее TTL.
Это самый простой способ инвалидации данных. Тем не менее, у этой стратегии есть свои подводные камни.
Самый главный из них – вопрос длительности TTL. Если TTL слишком короткий, то запись может “протухнуть” и стать недействительной раньше, чем обновление было бы необходимо, что приведет к отправке повторного запроса в источник данных. Если TTL слишком длинный, то запись может содержать устаревшие данные, что может привести к ошибкам или неправильной работе приложения. Обычно ответ на этот вопрос подбирается эмпирическим путем.
Есть, впрочем, и другой вариант. Источник данных может присылать TTL сам, тогда клиенту не придется выбирать TTL, а просто брать предлагаемый. Такой подход, например, можно использовать в HTTP.
Такой подход, например, можно использовать в HTTP.
Сложность иного рода возникает, если записи становятся недействительными одновременно в большом количестве. В таком случае возникает множество запросов в источник данных, что может привести к проблемам с производительностью, а то и вовсе “положить” его. Для избежания подобной ситуации, можно использовать jitter.
Jitter – это случайное значение, добавляемое к TTL. Если в обычном случае все записи имеют, например, TTL = 60 сек., то при использовании jitter с диапазоном от 0 до 10 сек. TTL будет принимать значение от 60 до 70 сек. Это позволит сгладить количество записей, переходящих в состояние недействительных одновременно.
Jitter позволил нам сгладить нагрузку на источник данных, когда “протухает” много записей сразу. Но что делать, если есть одна запись, которую интенсивно используют? Ее инвалидация приведет к тому, что все запросы, которые не нашли данных в кэше, одновременно обратятся к источнику. Тогда нам нужно схлопнуть все эти запросы в один. В go есть для этого отличная библиотека singleflight. Она определяет одинаковые запросы, возникающие одномоментно, выполняет лишь один запрос в источник, а затем отдает результат всем изначальным запросам. Таким образом, если у нас возникли десять запросов, библиотека выполнит только один из них, а результат вернет всем десяти. Стоит отметить, что эта библиотека работает только в рамках одного экземпляра приложения. Если у вас их несколько, то даже с использованием этой библиотеки в источник может уйти больше одного запроса.
В go есть для этого отличная библиотека singleflight. Она определяет одинаковые запросы, возникающие одномоментно, выполняет лишь один запрос в источник, а затем отдает результат всем изначальным запросам. Таким образом, если у нас возникли десять запросов, библиотека выполнит только один из них, а результат вернет всем десяти. Стоит отметить, что эта библиотека работает только в рамках одного экземпляра приложения. Если у вас их несколько, то даже с использованием этой библиотеки в источник может уйти больше одного запроса.
Инвалидация по событию
При таком подходе данные инвалидируют при наступлении некоего события – обычно это обновление данных в источнике. На самом деле, мы уже рассмотрели этот способ, когда говорили про стратегии использования кэширования, а именно write through и write aside.
Также в качестве события для инвалидации данных может выступать время последней модификации данных. Такой способ используется в HTTP.
Стратегии вытеснения
Размер кэша ограничен, он гораздо меньше основного хранилища, а значит, мы не может разместить в нем все данные. Что делать, когда память, выделенная под кэш, полностью заполнена, а новые записи продолжают поступать?
Что делать, когда память, выделенная под кэш, полностью заполнена, а новые записи продолжают поступать?
Ничего не делать
Конечно, можно игнорировать все новые записи и ждать, пока существующие истекут по TTL. Однако в общем случае это крайне неэффективно, поскольку все запросы идут в источник данных и все преимущества кэша нивелируются. Поэтому обычно используются более эффективные стратегии вытеснения.
Random
Random – стратегия вытеснения, при которой удаляются случайные записи. Это самая простая стратегия: просто удаляем то, что первым попалось под руку. Но этот способ недалеко ушел от стратегии “ничего не делать”.
TTL
TTL – стратегия вытеснения, предусматривающая удаление той записи, которой осталось меньше всего “жить”, то есть у которой TTL истечет раньше всех. Как и random, эта стратегия немного лучше, чем “ничего не делать”, но все еще недостаточно эффективна.
LRU
LRU (Least Recently Used) – стратегия вытеснения, которая опирается на время последнего использования записи. Она удаляет записи, у которых время последнего использования старше остальных. Таким образом, в кэше остаются записи, которые использовались недавно. Эта стратегия опирается уже не на случай, а на паттерн использования данных, поэтому она гораздо эффективнее предыдущих.
Она удаляет записи, у которых время последнего использования старше остальных. Таким образом, в кэше остаются записи, которые использовались недавно. Эта стратегия опирается уже не на случай, а на паттерн использования данных, поэтому она гораздо эффективнее предыдущих.
Эта стратегия хорошо подходит, когда:
недавно использованные данные, скорее всего, будут использованы снова в ближайшем будущем
нет данных, которые используются чаще остальных
вы не знаете, что именно вам нужно
LFU
LFU (Least Frequently Used) – стратегия вытеснения, опирающаяся на частоту использования записи. Она удаляет записи, которые использовались реже всего. Так в кэше остаются данные, которые использовались чаще других. Эта стратегия тоже опирается не на случай, а на паттерн использования данных, поэтому она тоже эффективнее остальных и является альтернативой LRU.
Эта стратегия хорошо подходит, когда есть данные, которые используются значительно чаще остальных. Такие данные разумно не вытеснять из кэша, чтобы избежать лишних “походов” в источник.
Такие данные разумно не вытеснять из кэша, чтобы избежать лишних “походов” в источник.
Кэширование ошибок
Ранее я упомянул, что мы можем кэшировать ошибки. На первый взгляд это может показаться странным: зачем нам вообще кэшировать ошибки? На самом деле, это крайне полезная штука.
Представим себе, что клиент запрашивает данные, которых нет в источнике. Пусть это будем информация о товаре по id. Казалось бы, нет данных и ладно: просто сходим в источник, ничего не получим и сообщим клиенту. Но что, если таких запросов много? А что, если кто-то делает это специально?
Это типичная схема так называемой атаки через промахи кэша (cache miss attack). Ее суть в запрашивании данных, которых заведомо не может быть в кэше, поскольку их нет в источнике. Вал таких запросов может привести к проблемам с производительностью источника и даже к его “падению”. Этого можно избежать, если кэшировать ошибку, тогда последующие запросы того же рода будут попадать в кэш и источник не пострадает.
Но тут тоже нужно быть осторожным. Если хранить в одном кэше и полезные данные, и ошибки, то в случае атаки полезные данные могут вытеснены из кэша. Поэтому я бы рекомендовал иметь выделенный кэш под ошибки. Он может быть меньшего объема, чем основной кэш.
Также кэширование ошибок полезно, если сервис, к которому вы обращаетесь, “почувствовал себя плохо”. Чтобы не забивать его запросами, которые, скорее всего, не будут выполнены, а лишь усугубят проблему, лучше кэшировать ошибки на несколько секунд. Таким образом, мы перестанем оказывать негативное воздействие на сервис и дадим ему возможность нормализоваться. Но с этой задачей лучше справляется паттерн Circuit Breaker, который мы не будем рассматривать в рамках этой статьи.
Заключение
На этом пока все. Я не ставил перед собой целью раскрыть тему кэширования исчерпывающе: наверняка многие вещи остались не рассмотренными в рамках этой статьи. Я хотел лишь предоставить структурированную основу и хочу верить, что у меня это получилось.
Надеюсь, данный материал оказался вам полезен, вы открыли для себя что-то новое или структурировали уже известное.
Полезные ссылки
О стратегиях вытеснения на примере инструментов redis
Трудности и стратегии кэширования на сайте Amazon
Основы кэширования от Amazon
Базовый “ликбез” и ссылки на первоисточники от Wikipedia
Что такое кэширование карт?—Документация (10.3 и 10.3.1)
В этом разделе
- Что происходит во время процесса кэширования?
- Можно ли кэшировать все карты?
- Есть ли при этом возможность получить базовые данные?
- Как начать кэширование?
Кэширование карт — очень эффективный способ заставить ваши карты и сервисы изображений работать быстрее. При создании кэша карты сервер отрисовывает всю карту на нескольких уровнях масштабирования и сохраняет копии этих изображений. После этого, когда кто-нибудь запрашивает карту, сервер может предоставить эти изображения. Всякий раз, когда сервер получает запрос на карту, он гораздо быстрее возвратит кэшированное изображение, чем заново нарисует карту. Другое преимущество кэширования состоит в том, что высокая детализация изображения не сказывается на времени предоставления информации.
Всякий раз, когда сервер получает запрос на карту, он гораздо быстрее возвратит кэшированное изображение, чем заново нарисует карту. Другое преимущество кэширования состоит в том, что высокая детализация изображения не сказывается на времени предоставления информации.
Что происходит во время процесса кэширования?
Кэширование не происходит автоматически. Чтобы создать кэш, сначала нужно разработать карту, а затем предоставить ее для совместного использования. После этого нужно задать некоторые параметры кэша и начать создание листов. Можно создать все листы сразу или разрешить формирование некоторых листов по необходимости, т.е. при первом обращении к ним.
При кэшировании карты вы отрисовываете ее на нескольких заданных уровнях масштабирования, чтобы затем пользователи смогли приближать и отдалять карту. При выборе параметров кэша нужно определить, какие масштабы требуется кэшировать. Если это просто первая проба инструментов кэширования, можно разрешить компьютеру выбрать какие-то масштабы. Однако обычно масштабы заранее подбирают так, чтобы обеспечить качественное отображение карты в каждом из этих масштабов. Следует записать масштабы и использовать их при разработке карт в ArcMap. Когда придет время создавать кэш, нужно указать эти масштабы в настройках инструмента создания кэша.
Однако обычно масштабы заранее подбирают так, чтобы обеспечить качественное отображение карты в каждом из этих масштабов. Следует записать масштабы и использовать их при разработке карт в ArcMap. Когда придет время создавать кэш, нужно указать эти масштабы в настройках инструмента создания кэша.
Есть и другие параметры, которые важно понимать при создании кэша. Дополнительные сведения можно найти в разделе Доступные свойства кэша карты.
Кэш хранится в директории кэша вашего сервера. При установке ArcGIS for Server директория кэша сервера создается в локальной папке. При добавлении дополнительных ГИС-серверов для поддержки сайта следует настроить общий доступ к директории кэша сервера, для того чтобы она была доступна с других задействованных компьютеров.
Выбираемые масштабы и устанавливаемые значения параметров кэша составляют схему листов. В каждом кэше есть файл схемы листов, который можно импортировать при создании новых кэшей, чтобы все кэши использовали одни и те же размеры листов и масштабы. Это как правило помогает поднять производительность веб-приложений, содержащих более одного кэшированного сервиса. Дополнительно можно выбрать именно ту схему листов, которая используется в ArcGIS Online, Bing Maps и Google Maps. Это позволит накладывать ваши листы кэша на листы этих картографических онлайн-сервисов.
Это как правило помогает поднять производительность веб-приложений, содержащих более одного кэшированного сервиса. Дополнительно можно выбрать именно ту схему листов, которая используется в ArcGIS Online, Bing Maps и Google Maps. Это позволит накладывать ваши листы кэша на листы этих картографических онлайн-сервисов.
Можно ли кэшировать все карты?
Кэш карты представляет собой снимок карты в какой-то момент времени. Поэтому кэш прекрасно работает для таких карт, которые нечасто меняются. К ним относятся: карты улиц, изображения и карты рельефа.
Если даже данные изменяются, все равно можно использовать кэширование, периодически обновляя кэш с помощью соответствующих инструментов. Также настраивается и график автоматического запуска таких обновлений. Чтобы понять, можно ли кэшировать карту, которая часто меняется, полезно ответить на вопросы:
Насколько актуальной должна быть моя карта?
Если необходимо, чтобы данные на карте были «живыми», если недопустима временная задержка, кэширование неприемлемо. Однако если короткая задержка допустима, и за это временное окно кэш можно обновить, кэширование можно применять.
Однако если короткая задержка допустима, и за это временное окно кэш можно обновить, кэширование можно применять.
Насколько велик кэш и насколько широко распространены изменения данных?
Эти два вопроса дополняют друг друга. Большой кэш требует больше времени на создание. Практичней обновлять большой кэш только в случае, если есть возможность изолировать область изменений и обновлений. Если кэш невелик, можно позволить себе быструю перестройку всего кэша.
Если обновления нельзя выполнить за приемлемое время, кэширование для такой карты неудобно.
После решения перечисленных вопросов используйте кэширование в тех случаях, где оно подходит. Повышение производительности, пожалуй, наиболее ценное преимущество, получаемое при создании и обновлении кэша.
Дополнительная информация об обновлении кэша сервера находится в разделе Обновления кэша карты.
Есть ли при этом возможность получить базовые данные?
Хотя кэши карты представляют собой изображения данных, вы все же можете разрешить пользователям выполнять задачи поиска, идентификации и запросы в картографическом сервисе. Эти инструменты получают с сервера географические положения объектов и возвращают результаты. Приложение выводит поверх кэшированного изображения результаты в формате исходного графического слоя.
Эти инструменты получают с сервера географические положения объектов и возвращают результаты. Приложение выводит поверх кэшированного изображения результаты в формате исходного графического слоя.
Как начать кэширование?
Для начала кэширования необходимо опубликовать картографический сервис или сервис изображений. В процессе публикации выполняется настройка свойств в диалоговом окне Редактор сервисов (Service Editor). Здесь можно определить масштабы и экстент кэша. Выполните действия, описанные в разделе Как опубликовать сервис, чтобы узнать, как открыть Редактор сервисов (Service Editor).
Вы можете создать листы при публикации сервиса (что подходит для небольшого кэша) или сформировать кэш самостоятельно после публикации (подходит для большого кэша, когда вы хотите географически ограничить кэш, формируемый для больших масштабов). Если вы создаете кэш самостоятельно, используйте инструмент геообработки Управление листами кэша картографического сервиса (Manage Map Server Cache Tiles) из набора инструментов Серверные инструменты (Server Tools).
Отзыв по этому разделу?
Что такое кэширование? | Microsoft Azure
Разработчики и ИТ-специалисты используют кэширование для сохранения и доступа к данным типа «ключ-значение» во временной памяти быстрее и с меньшими усилиями, чем данные, хранящиеся в обычном хранилище данных. Кэши полезны в нескольких сценариях с несколькими технологиями, такими как кэширование компьютера с оперативной памятью (ОЗУ), сетевое кэширование в сети доставки контента, веб-кэш для веб-мультимедийных данных или облачный кеш, чтобы помочь сделать облачные приложения более отказоустойчивыми. . Разработчики часто разрабатывают приложения для кэширования обработанных данных, а затем переназначают их для обслуживания запросов быстрее, чем при стандартных запросах к базе данных.
Вы можете использовать кэширование для снижения затрат на базу данных, обеспечения более высокой пропускной способности и меньшей задержки, чем может предложить большинство баз данных, а также для повышения производительности облачных и веб-приложений.
Как кэширование работает для баз данных?
Разработчики могут дополнить первичную базу данных кэшем базы данных, который они могут поместить в базу данных или приложение или настроить как отдельный уровень. Хотя они обычно полагаются на обычную базу данных для хранения больших, надежных и полных наборов данных, они используют кэш для хранения временных подмножеств данных для быстрого поиска.
Вы можете использовать кэширование со всеми типами хранилищ данных, включая базы данных NoSQL, а также реляционные базы данных, такие как SQL Server, MySQL или MariaDB. Кэширование также хорошо работает со многими конкретными платформами данных, такими как База данных Azure для PostgreSQL, База данных SQL Azure или Управляемый экземпляр Azure SQL. Мы рекомендуем изучить, какой тип хранилища данных лучше всего соответствует вашим требованиям, прежде чем вы начнете настраивать архитектуру данных. Например, вы хотели бы понять, что такое PostgreSQL, прежде чем использовать его для объединения реляционных и неструктурированных хранилищ данных.
Преимущества слоев кэша и что такое Redis?
Разработчики используют многоуровневые кэши, называемые уровнями кэша, для хранения различных типов данных в отдельных кэшах в соответствии с требованиями. Добавляя слой кэша или несколько, вы можете значительно улучшить пропускную способность и показатели задержки уровня данных.
Redis — это популярная структура данных в памяти с открытым исходным кодом, используемая для создания высокопроизводительных слоев кэша и других хранилищ данных. Недавнее исследование показало, что добавление кэша Azure для Redis к образцу приложения увеличило пропускную способность данных более чем на 800 % и уменьшило задержку более чем на 1000 %9.0019 1
Кэши также могут снизить совокупную стоимость владения (TCO) для уровня данных. Используя кэши для обслуживания наиболее распространенных запросов и снижения нагрузки на базу данных, вы можете снизить потребность в избыточном выделении экземпляров базы данных, что приведет к значительной экономии средств и снижению совокупной стоимости владения.
Типы кэширования
Ваша стратегия кэширования зависит от того, как ваше приложение читает и записывает данные. Ваше приложение требует интенсивной записи или данные записываются один раз и часто считываются? Всегда ли возвращаемые данные уникальны? Различные шаблоны доступа к данным будут влиять на то, как вы настраиваете кэш. К распространенным типам кэширования относятся резервное кэширование, сквозное чтение/сквозная запись и отложенная/обратная запись.
Cache-aside
Для приложений с большими рабочими нагрузками по чтению разработчики часто используют шаблон программирования без кэширования, или «побочный кэш». Они размещают дополнительный кэш за пределами приложения, которое затем может подключаться к кешу для запроса и извлечения данных или напрямую к базе данных, если данных нет в кеше. Когда приложение извлекает данные, оно копирует их в кеш для будущих запросов.
Дополнительный кэш можно использовать для повышения производительности приложений, обеспечения согласованности между кэшем и хранилищем данных и предотвращения устаревания данных в кэше.
Кэш со сквозной записью/чтением
Кэш со сквозной записью постоянно обновляется, а при кэшировании со сквозной записью приложение записывает данные в кеш, а затем в базу данных. Оба кеша находятся на одной линии с базой данных, и приложение рассматривает их как основное хранилище данных.
Кэш сквозного чтения помогает упростить приложения, в которых одни и те же данные запрашиваются снова и снова, но сам кэш сложнее, а двухэтапный процесс сквозной записи может создавать задержки. Разработчики объединяют их, чтобы обеспечить согласованность данных между кешем и базой данных, уменьшить задержку кеша сквозной записи и упростить обновление кеша сквозного чтения.
С помощью кэширования со сквозной записью и чтением разработчики могут упростить код приложения, повысить масштабируемость кэша и минимизировать нагрузку на базу данных.
Кэш отложенной/обратной записи
В этом сценарии приложение записывает данные в кеш, что немедленно подтверждается, а затем сам кеш записывает данные обратно в базу данных в фоновом режиме.
Распределенный кэш и хранилище сеансов
Люди часто путают распределенные кэши с хранилищами сеансов, которые похожи, но имеют разные требования и цели. Вместо использования распределенного кеша для дополнения базы данных разработчики реализуют хранилища сеансов, которые являются временными хранилищами данных на пользовательском уровне для профилей, сообщений и других пользовательских данных в приложениях, ориентированных на сеансы, таких как веб-приложения.
Что такое хранилище сеансов?
Приложения, ориентированные на сеанс, отслеживают действия пользователей, когда они вошли в приложения. Чтобы сохранить эти данные при выходе пользователя из системы, вы можете хранить их в хранилище сеансов, что улучшает управление сеансами, снижает затраты и повышает производительность приложений.
Чем использование хранилища сеансов отличается от кэширования базы данных?
В хранилище сеансов данные не распределяются между разными пользователями, а при кэшировании разные пользователи могут получить доступ к одному и тому же кэшу. Разработчики используют кэширование для повышения производительности базы данных или экземпляра хранилища, а хранилища сеансов — для повышения производительности приложений за счет записи данных в хранилище в памяти, что устраняет необходимость доступа к базе данных вообще.
Данные, записанные в хранилище сеансов, обычно недолговечны, в то время как данные, кэшированные в первичной базе данных, обычно предназначены для гораздо более длительного хранения. Хранилище сеансов требует репликации, высокой доступности и надежности данных, чтобы гарантировать, что транзакционные данные не будут потеряны, а пользователи останутся вовлеченными. С другой стороны, если данные в стороннем кеше теряются, их копия всегда есть в постоянной базе данных.
Преимущества кэширования
Улучшена производительность приложений
Чтение данных из кэша в памяти выполняется намного быстрее, чем доступ к данным из дискового хранилища данных. А благодаря более быстрому доступу к данным общая работа с приложением значительно улучшается.
Сокращение использования базы данных и затрат
Кэширование приводит к меньшему количеству запросов к базе данных, повышению производительности и снижению затрат за счет ограничения необходимости масштабирования инфраструктуры базы данных и снижения платы за пропускную способность.
Масштабируемая и предсказуемая производительность
Один экземпляр кэша может обрабатывать миллионы запросов в секунду, предлагая уровень пропускной способности и масштабируемости, с которым не могут сравниться базы данных. Кэширование также обеспечивает гибкость, которая вам нужна, независимо от того, масштабируете ли вы свои приложения и хранилища данных.
Для чего используется кэширование?
Кэширование вывода
Кэширование вывода помогает повысить производительность веб-страницы за счет сохранения полного исходного кода страниц, такого как HTML и клиентские сценарии, которые сервер отправляет в браузеры для отображения. Каждый раз, когда пользователь просматривает страницу, сервер кэширует выходной код в памяти приложения. Это позволяет приложению обслуживать запросы без запуска кода страницы или взаимодействия с другими серверами.
Кэширование данных и кэширование базы данных
Скорость и пропускная способность базы данных могут быть ключевыми факторами общей производительности приложения. Кэширование базы данных используется для частых обращений к данным, которые редко меняются, например к данным о ценах или запасах. Это помогает веб-сайтам и приложениям загружаться быстрее, увеличивая пропускную способность и снижая задержку при извлечении данных из серверных баз данных.
Кэширование базы данных используется для частых обращений к данным, которые редко меняются, например к данным о ценах или запасах. Это помогает веб-сайтам и приложениям загружаться быстрее, увеличивая пропускную способность и снижая задержку при извлечении данных из серверных баз данных.
Хранение данных сеанса пользователя
Пользователи приложений часто создают данные, которые необходимо хранить в течение коротких периодов времени. Хранилище данных в памяти, такое как Redis, идеально подходит для эффективного и надежного хранения больших объемов данных сеанса, таких как пользовательский ввод, записи в корзине покупок или настройки персонализации, при меньших затратах, чем хранение или базы данных.
Брокеры сообщений и архитектуры публикации/подписки
Облачным приложениям часто необходимо обмениваться данными между службами, и они могут использовать кэширование для реализации архитектур публикации/подписки или брокера сообщений, которые уменьшают задержку и ускоряют управление данными.
Приложения и API
Подобно браузерам, приложения сохраняют важные файлы и данные, чтобы быстро перезагружать эту информацию при необходимости. Кэшированные ответы API устраняют потребность или нагрузку на серверы приложений и базы данных, обеспечивая более быстрое время отклика и лучшую производительность.
1 Заявления о производительности основаны на данных исследования, которое было заказано Microsoft и проведено GigaOm в октябре 2020 года. В исследовании сравнивалась производительность тестового приложения с использованием базы данных Azure с использованием и без использования кэширования Azure Cache для Redis. решение. В качестве элемента базы данных в исследовании использовались База данных SQL Azure и База данных Azure для PostgreSQL. Экземпляр базы данных SQL Azure общего назначения с 2 виртуальными ядрами Gen5 и экземпляр базы данных Azure общего назначения с 2 виртуальными ядрами для PostgreSQL использовались с 6-гигабайтным экземпляром P1 Premium Azure для Redis.
Бесплатная учетная запись
Попробуйте службы облачных вычислений Azure бесплатно в течение 30 дней.
Попробуйте Azure бесплатно
Оплата по мере использования
Начните работу с оплатой по мере использования. Никаких предварительных обязательств — отмените в любое время.
Узнайте больше о оплате по мере использования
Добавьте в свое приложение гибкий уровень кэширования с полностью управляемой службой Redis. Узнайте, как начать работу с кэшем Azure для Redis.
Узнайте, как начать работу с кэшем Azure для Redis.
Начать
Если вы хотите использовать гибкое файловое кэширование для высокопроизводительных приложений, прочтите о кэше Azure HPC.
Кэш Azure HPC
Мы можем вам помочь?
Кэширование — концепция проектирования системы для начинающих
Введение:
Кэширование — это концепция проектирования системы, которая предусматривает хранение часто используемых данных в легко и быстро доступном месте. Цель кэширования — повысить производительность и эффективность системы за счет сокращения времени, необходимого для доступа к часто используемым данным.
Кэширование можно использовать в различных системах, включая веб-приложения, базы данных и операционные системы. В каждом случае кэширование работает путем хранения данных, к которым часто обращаются, в местоположении, которое находится ближе к пользователю или приложению. Это может включать хранение данных в памяти или на локальном жестком диске.
Это может включать хранение данных в памяти или на локальном жестком диске.
Вот несколько ключевых моментов, которые нужно понять о кэшировании:
- Как это работает: При запросе данных система сначала проверяет, сохранены ли данные в кэше. Если это так, система извлекает данные из кэша, а не из исходного источника. Это может значительно сократить время, необходимое для доступа к данным.
- Типы кэширования. Существует несколько типов кэширования, включая кэширование в памяти, дисковое кэширование и распределенное кэширование. При кэшировании в памяти данные хранятся в памяти, а при кэшировании на диске данные сохраняются на локальном жестком диске. Распределенное кэширование предполагает хранение данных в нескольких системах для повышения доступности и производительности.
- Освобождение кэша: кэши могут со временем переполняться, что может вызвать проблемы с производительностью. Чтобы предотвратить это, кэши обычно предназначены для автоматического исключения старых или менее часто используемых данных, чтобы освободить место для новых данных.
- Согласованность кэша. Кэширование может вызвать проблемы с согласованностью данных, особенно в системах, где несколько пользователей или приложений имеют доступ к одним и тем же данным. Чтобы предотвратить это, системы могут использовать методы аннулирования кеша или реализовывать протокол согласованности кеша, чтобы гарантировать, что данные остаются согласованными для всех пользователей и приложений.

К преимуществам кэширования относятся:
- Повышенная производительность: Кэширование может значительно сократить время, необходимое для доступа к часто используемым данным, что может повысить производительность и скорость отклика системы.
- Снижение нагрузки на исходный источник. За счет уменьшения объема данных, к которым необходимо получить доступ из исходного источника, кэширование может снизить нагрузку на источник и повысить его масштабируемость и надежность.
- Экономия средств. Кэширование может снизить потребность в дорогостоящем оборудовании или обновлении инфраструктуры за счет повышения эффективности существующих ресурсов.
Однако есть и некоторые потенциальные недостатки кэширования, в том числе:
- Несогласованность данных. Если согласованность кэша не поддерживается должным образом, кэширование может вызвать проблемы с согласованностью данных.
- Проблемы с вытеснением кэша: Если политики вытеснения кэша разработаны неправильно, кэширование может привести к проблемам с производительностью или потере данных.
- Дополнительная сложность. Кэширование может усложнить систему, что усложнит ее проектирование, внедрение и обслуживание.
- В целом, кэширование — это мощная концепция проектирования системы, которая может значительно повысить производительность и эффективность системы. Понимая ключевые принципы кэширования и потенциальные преимущества и недостатки, разработчики могут принимать обоснованные решения о том, когда и как использовать кэширование в своих системах.
Facebook, Instagram, Amazon, Flipkart … эти приложения являются любимыми для многих людей и, скорее всего, это самые посещаемые веб-сайты в вашем списке.
Вы когда-нибудь замечали, что эти веб-сайты загружаются быстрее, чем совершенно новый веб-сайт? А вы когда-нибудь замечали, что при медленном интернет-соединении при просмотре веб-сайта тексты загружаются перед любыми изображениями высокого качества?
Почему это происходит? Ответ Кэширование.
Если вы проверите свою страницу Instagram при медленном интернет-соединении, вы заметите, что изображения продолжают загружаться, но текст отображается. Для любого бизнеса эти вещи имеют большое значение. Лучшее качество обслуживания клиентов/пользователей — это самое важное, и вы можете потерять много клиентов из-за плохого взаимодействия с вашим сайтом. Пользователь немедленно переключается на другой веб-сайт, если обнаруживает, что текущему веб-сайту требуется больше времени для загрузки или отображения результатов. Вы можете взять пример с просмотра любимого сериала в любом приложении для потокового видео. Как бы вы себя чувствовали, если бы видео все время буферизировалось? Скорее всего, вы не будете пользоваться этой услугой и прекратите подписку. Или вы также можете записаться на самый оптимизированный живой курс, который составляет System Design — онлайн-курс , специально созданный для тех, кто хочет успешно пройти собеседование.
Или вы также можете записаться на самый оптимизированный живой курс, который составляет System Design — онлайн-курс , специально созданный для тех, кто хочет успешно пройти собеседование.
Все вышеперечисленные проблемы можно решить, улучшив удержание и вовлеченность на вашем веб-сайте, а также обеспечив наилучшее взаимодействие с пользователем. И одно из лучших решений — Кэширование .
Кэширование – Введение
Допустим, вы каждый день готовите ужин и вам нужны ингредиенты для приготовления пищи. Всякий раз, когда вы готовите еду, вы пойдете в ближайший магазин, чтобы купить эти ингредиенты? Абсолютно нет. Это трудоемкий процесс, и каждый раз вместо похода в ближайший магазин хочется один раз купить ингредиенты и хранить их в холодильнике. Это сэкономит много времени. Это кеширование и ваш 9Холодильник 0169 работает как тайник/местный магазин/временный склад . Время приготовления сокращается, если продукты уже есть в вашем холодильнике.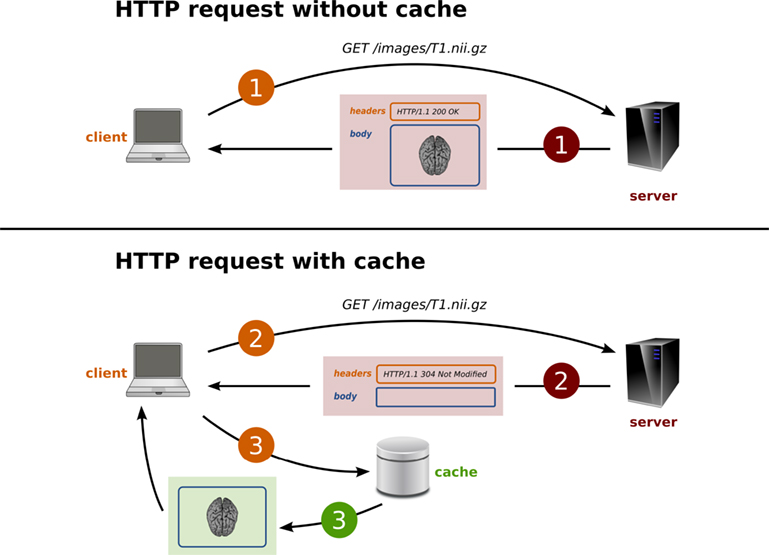
То же самое происходит и в системе. В системе доступ к данным из основной памяти (ОЗУ) выполняется быстрее, чем доступ к данным из вторичной памяти (диска). Кэширование действует как локальное хранилище для данных, и извлекать данные из этого локального или временного хранилища проще и быстрее, чем из базы данных. Считай это кратковременная память с ограниченным пространством, но более быстрая и содержит элементы, к которым последний раз обращались . Поэтому, если вам нужно часто полагаться на определенный фрагмент данных, кэшируйте данные и быстрее извлекайте их из памяти, а не с диска.
Примечание: Вы знаете о преимуществах кэш-памяти, но это не означает, что вы храните всю информацию в кэш-памяти для более быстрого доступа. Вы не можете этого сделать по нескольким причинам. Одной из причин является аппаратное обеспечение кэша, которое намного дороже, чем обычная база данных. Кроме того, время поиска увеличится, если вы храните тонны данных в своем кеше. Короче говоря, кеш должен иметь наиболее актуальную информацию в соответствии с запросом, который будет поступать в будущем.
Короче говоря, кеш должен иметь наиболее актуальную информацию в соответствии с запросом, который будет поступать в будущем.
Куда можно добавить кэш?
Кэширование используется почти на каждом уровне вычислений. Например, в аппаратном обеспечении у вас есть различные уровни кэш-памяти. У вас есть кеш-память уровня 1, которая является кэш-памятью ЦП, затем у вас есть кеш-память уровня 2, и, наконец, у вас будет обычная ОЗУ (оперативная память). Вы также должны кэшировать в операционных системах, таких как кэширование различных расширений ядра или файлов приложений. У вас также есть кэширование в веб-браузере, чтобы уменьшить время загрузки веб-сайта. Таким образом, кэширование можно использовать практически на всех уровнях: аппаратном обеспечении, ОС, веб-браузерах и веб-приложениях, но чаще всего оно находится ближе всего к внешнему интерфейсу.
Как работает кэш?
Обычно веб-приложение хранит данные в базе данных. Когда клиент запрашивает некоторые данные, они извлекаются из базы данных, а затем возвращаются пользователю. Чтение данных из базы данных требует 90 169 сетевых вызовов и операции ввода-вывода 90 170, что требует много времени. Кэш уменьшает количество сетевых обращений к базе данных и повышает производительность системы. Возьмем пример Twitter: когда твит становится вирусным, огромное количество клиентов запрашивают такой же твит. Twitter — это гигантский веб-сайт с миллионами пользователей. Читать данные с дисков для такого большого объема пользовательских запросов неэффективно. до уменьшить количество обращений к базе данных, мы можем использовать кеш и твиты могут предоставляться намного быстрее.
Чтение данных из базы данных требует 90 169 сетевых вызовов и операции ввода-вывода 90 170, что требует много времени. Кэш уменьшает количество сетевых обращений к базе данных и повышает производительность системы. Возьмем пример Twitter: когда твит становится вирусным, огромное количество клиентов запрашивают такой же твит. Twitter — это гигантский веб-сайт с миллионами пользователей. Читать данные с дисков для такого большого объема пользовательских запросов неэффективно. до уменьшить количество обращений к базе данных, мы можем использовать кеш и твиты могут предоставляться намного быстрее.
В обычное веб-приложение мы можем добавить кэш сервера приложений, хранилище в памяти , такое как Redis, вместе с нашим сервером приложений. При первом запросе необходимо будет сделать вызов к базе данных для обработки запроса. Это известно как промах кэша . Прежде чем вернуть результат пользователю, он будет сохранен в кэше. Когда пользователь во второй раз делает тот же запрос, приложение сначала проверит ваш кеш, чтобы увидеть, кешируется ли результат для этого запроса или нет. Если да, то результат будет возвращен из хранилища в памяти. Это известно как 9Кэш 0169 попал в . Время ответа на запрос во второй раз будет намного меньше, чем в первый раз.
Если да, то результат будет возвращен из хранилища в памяти. Это известно как 9Кэш 0169 попал в . Время ответа на запрос во второй раз будет намного меньше, чем в первый раз.
Типы кэша
Обычно существует четыре типа кэша…
1. Кэш сервера приложений
В « Как работает кэш? » мы обсуждали, как кеш сервера приложений можно добавить в веб-приложение. Допустим, в веб-приложении веб-сервер имеет один узел. Кэш можно добавить в память вместе с сервером приложений. Запрос пользователя будет храниться в этом кеше, и всякий раз, когда тот же запрос будет поступать снова, он будет возвращен из кеша. Для новый запрос , данные будут извлечены с диска, а затем возвращены. Как только новый запрос будет возвращен с диска, он будет сохранен в том же кэше для следующего запроса от пользователя. Размещение кеша на узле уровня запроса позволяет использовать локальное хранилище.
Примечание: Когда вы помещаете кеш в память, объем памяти на сервере будет использоваться кешем. Если количество результатов, с которыми вы работаете, очень мало, вы можете хранить кеш в памяти.
Если количество результатов, с которыми вы работаете, очень мало, вы можете хранить кеш в памяти.
Проблема возникает, когда вам нужно масштабировать вашу систему . Вы добавляете несколько серверов в свое веб-приложение (поскольку один узел не может обрабатывать большой объем запросов) и у вас есть балансировщик нагрузки , который отправляет запросы на любой узел. В этом сценарии вы получите много 90 169 промахов кэша 90 170, потому что каждый узел не будет знать об уже кэшированном запросе. Это не очень хорошо, и для решения этой проблемы у нас есть два варианта: Распределить кэш и Глобальный кэш. Давайте обсудим это…
2. Распределенный кэш
В распределенном кэше каждый узел будет иметь часть всего пространства кэша, а затем, используя функцию последовательного хэширования, каждый запрос может быть направлен туда, где можно найти запрос кэша. Предположим, у нас есть 10 узлов в распределенной системе, и мы используем балансировщик нагрузки для маршрутизации запроса, тогда…
- Каждый из его узлов будет иметь небольшую часть кэшированных данных.
- Чтобы определить, какой узел имеет какой запрос, кэш делится на части с использованием согласованной функции хэширования, каждый запрос может быть направлен туда, где можно найти кэшированный запрос. Если запрашивающий узел ищет определенный фрагмент данных, он может быстро узнать, где искать в распределенном кеше, чтобы проверить, доступны ли данные.
- Мы можем легко увеличить кэш-память, просто добавив новый узел в пул запросов.
3. Глобальный кэш
Как следует из названия, у вас будет единое кэш-пространство, и все узлы будут использовать это единое пространство. Каждый запрос будет направляться в это единственное пространство кеша. Существует два типа глобального кеша
- Во-первых, когда запрос кеша не найден в глобальном кеше, кеш должен найти недостающую часть данных из любого места, лежащего в основе хранилища (база данных, диск и т. д.). ).
- Во-вторых, если запрос приходит, а кеш не находит данные, запрашивающий узел напрямую связывается с БД или сервером для получения запрошенных данных.

4. CDN (сеть распространения контента)
CDN используется там, где веб-сайт обслуживает большое количество статического контента. Это может быть файл HTML, файл CSS, файл JavaScript, изображения, видео и т. д. Сначала запросите у CDN данные, если они существуют, данные будут возвращены. Если нет, CDN будет запрашивать внутренние серверы, а затем кэшировать их локально.
Cache Invalidation
Кэширование — это хорошо, но как насчет данных, которые постоянно обновляются в базе данных? Если данные изменены в БД, они должны быть признаны недействительными, чтобы избежать непоследовательного поведения приложения. Итак, как бы вы обеспечили согласованность данных в своем кэше с данными из вашего источника правды в базе данных? Для этого нам нужно использовать некоторый подход к аннулированию кеша. Существует три различных схемы аннулирования кеша. Давайте обсудим это один за другим…
1. Запись через кэш
Как следует из названия, данные сначала записываются в кэш, а затем в базу данных. Таким образом, вы можете сохранить согласованность ваших данных между вашей базой данных и вашим кешем. Каждое чтение из кэша следует за самой последней записью.
Таким образом, вы можете сохранить согласованность ваших данных между вашей базой данных и вашим кешем. Каждое чтение из кэша следует за самой последней записью.
Преимущество этого подхода заключается в том, что вы минимизируете риск потери данных, поскольку они записываются как в кэш, так и в базу данных. Но недостатком этого подхода является более высокая задержка для операции записи, поскольку вам нужно записывать данные в двух местах для одного запроса на обновление. Если у вас нет большого объема данных, это нормально, но если у вас интенсивная операция записи, то этот подход не подходит в этих случаях.
Мы можем использовать этот подход для приложений, которые часто повторно считывают данные после их сохранения в базе данных. В этих приложениях задержка записи может быть компенсирована более низкой задержкой чтения и согласованностью.
2. Запись в кэш Подобно сквозной записи, вы записываете в базу данных, но в этом случае вы не обновляете кеш. Таким образом, данные записываются напрямую в хранилище, минуя кеш. Вам не нужно загружать кеш данными, которые не будут перечитываться. Этот подход уменьшает количество операций лавинной записи по сравнению с кешем со сквозной записью. Недостатком этого подхода является то, что запрос на чтение недавно записанных данных приводит к промаху кеша и должен быть прочитан из более медленного бэкенда. Таким образом, этот подход подходит для приложений, которые не часто перечитывают самые последние данные.
Таким образом, данные записываются напрямую в хранилище, минуя кеш. Вам не нужно загружать кеш данными, которые не будут перечитываться. Этот подход уменьшает количество операций лавинной записи по сравнению с кешем со сквозной записью. Недостатком этого подхода является то, что запрос на чтение недавно записанных данных приводит к промаху кеша и должен быть прочитан из более медленного бэкенда. Таким образом, этот подход подходит для приложений, которые не часто перечитывают самые последние данные.
3. Кэш обратной записи
Мы обсуждали, что кэш со сквозной записью не подходит для систем с интенсивной записью из-за более высокой задержки. Для таких систем мы можем использовать подход кэширования с обратной записью. Сначала сбросьте данные из кеша, а затем запишите данные только в кеш. Как только данные будут обновлены в кеше, пометьте данные как измененные, что означает, что данные необходимо обновить в БД позже. Позже будет выполнено асинхронное задание, и через равные промежутки времени будут считаны измененные данные из кеша для обновления базы данных соответствующими значениями.
Проблема с этим подходом заключается в том, что пока вы не запланируете обновление базы данных, система рискует потерять данные. Допустим, вы обновили данные в кеше, но произошел сбой диска, и измененные данные не были обновлены в БД. Поскольку база данных является источником истины, если вы читаете данные из базы данных, вы не получите точного результата.
Политика выселения
Мы обсудили так много концепций кэширования… теперь у вас может возникнуть один вопрос. Когда нам нужно сделать/загрузить запись в кеш и какие данные нам нужно до удалить из кеша ?
Кэш в вашей системе может быть заполнен в любой момент времени. Итак, нам нужно использовать какой-то алгоритм или стратегию для удаления данных из кеша, и нам нужно загрузить другие данные, которые с большей вероятностью будут доступны в будущем. Чтобы принять это решение, мы можем использовать некоторую политику вытеснения кеша. Давайте обсудим некоторые политики вытеснения кеша один за другим…
Давайте обсудим некоторые политики вытеснения кеша один за другим…
LRU является наиболее популярным полисом по нескольким причинам. Он прост, имеет хорошую производительность во время выполнения и имеет достойную частоту срабатываний при обычных рабочих нагрузках. Как следует из названия, эта политика сначала удаляет из кеша наименее использовавшийся элемент. Когда кеш заполняется, он удаляет последние использованные данные, и в кеш добавляется самая последняя запись.
Всякий раз, когда вам нужно добавить запись в кеш, держите ее наверху и удаляйте самые нижние записи из кеша, которые использовались реже всего. Первые записи будут, может быть, несколько секунд назад, а затем вы продолжите движение вниз по списку минут назад, часов назад, лет назад, а затем удалите последнюю запись (которая реже всего использовалась).
Рассмотрим в качестве примера любую социальную сеть: есть знаменитость, которая опубликовала сообщение или комментарий, и все хотят получить этот комментарий. Таким образом, вы держите это сообщение в верхней части кеша, и оно остается в верхней части кеша в зависимости от того, насколько последним является сообщение. Когда пост становится круче или люди перестают смотреть или просматривать этот пост, он продолжает помещаться в конец кеша, а затем полностью удаляется из кеша. Мы можем реализовать LRU, используя двусвязный список и хеш-функцию, содержащую ссылку на узел в списке.
Таким образом, вы держите это сообщение в верхней части кеша, и оно остается в верхней части кеша в зависимости от того, насколько последним является сообщение. Когда пост становится круче или люди перестают смотреть или просматривать этот пост, он продолжает помещаться в конец кеша, а затем полностью удаляется из кеша. Мы можем реализовать LRU, используя двусвязный список и хеш-функцию, содержащую ссылку на узел в списке.
Эта политика подсчитывает частоту каждого запрошенного элемента и удаляет из кэша наименее часто используемый элемент. Итак, здесь мы подсчитываем количество обращений к элементу данных и отслеживаем частоту для каждого элемента. Когда размер кеша достигает заданного порога, мы удаляем запись с наименьшей частотой.
В реальной жизни мы можем взять пример набора текста на телефоне. Ваш телефон предлагает несколько слов, когда вы вводите что-то в текстовое поле. Вместо того, чтобы вводить слово целиком, у вас есть возможность выбрать одно из этих нескольких слов. В этом случае ваш телефон отслеживает частоту каждого слова, которое вы набираете, и сохраняет для него кеш. В дальнейшем слово с наименьшей частотой выбрасывается из кеша по мере необходимости. Если мы находим связь между несколькими словами, то наименее последнее использованное слово удаляется.
В этом случае ваш телефон отслеживает частоту каждого слова, которое вы набираете, и сохраняет для него кеш. В дальнейшем слово с наименьшей частотой выбрасывается из кеша по мере необходимости. Если мы находим связь между несколькими словами, то наименее последнее использованное слово удаляется.
Этот подход удаляет из кэша последний использованный элемент. Мы отдаем предпочтение тому, чтобы более старый элемент оставался в кэше. Этот подход подходит в тех случаях, когда пользователь менее заинтересован в проверке последних данных или элементов. Теперь вы можете подумать, что чаще всего пользователи интересуются последними данными или записями, так где же их можно использовать? Что ж, вы можете взять пример с приложения для знакомств Tinder, где можно использовать MRU.
Tinder хранит в кэше все возможные совпадения пользователя. Он не рекомендует пользователю тот же профиль, когда он проводит пальцем по профилю влево/вправо в приложении.