Что такое кэширование? Глоссарий веб-хостинга
Кэширование — это процесс хранения часто используемых данных во временном хранилище (кеше) для сокращения времени, необходимого для извлечения данных из исходного источника.
Кэширование — это способ хранения информации для более быстрого доступа к ней в будущем. Это все равно, что держать копию книги, которую вы часто читаете, на прикроватной тумбочке вместо того, чтобы идти в библиотеку каждый раз, когда вы хотите ее прочитать. Точно так же, когда вы посещаете веб-сайт, ваш компьютер будет хранить часть информации о веб-сайте, чтобы при следующем посещении он загружался быстрее.
Кэширование — это процесс, который стал неотъемлемой частью нашей повседневной работы в Интернете. Это метод хранения часто используемых данных в кэше, который представляет собой область временного хранения. Это облегчает более быстрый доступ к данным, повышая производительность приложений и системы. Кэширование широко используется в веб-браузерах, серверах и сетях доставки контента.
Кэширование позволяет эффективно повторно использовать ранее извлеченные или вычисленные данные, тем самым сокращая время, необходимое для доступа к данным. Когда делается запрос данных, к которым ранее обращались, кэш может ответить на запрос напрямую, без необходимости извлекать данные из основного хранилища. Это приводит к более быстрому времени отклика и уменьшению задержки. Кэширование обычно используется на серверах для повышения производительности веб-сайта и может быть реализовано в оперативной памяти или на диске.
В целом, кэширование — это важный процесс, который произвел революцию в способах доступа к данным в Интернете. Он стал фундаментальной частью современных вычислений, позволяя нам получать доступ к данным быстрее и эффективнее. Благодаря уменьшению задержки и повышению производительности системы кэширование стало важным инструментом как для бизнеса, так и для частных лиц.
Что такое кеширование?
Определение
Кэширование — это процесс хранения часто используемых данных во временном хранилище, называемом кешем. Цель кэширования — повысить производительность приложений и системы за счет сокращения времени, необходимого для доступа к данным. При запросе данных, хранящихся в кеше, система может извлечь данные из кеша вместо того, чтобы извлекать их из исходного источника, что может быть медленнее.
Цель кэширования — повысить производительность приложений и системы за счет сокращения времени, необходимого для доступа к данным. При запросе данных, хранящихся в кеше, система может извлечь данные из кеша вместо того, чтобы извлекать их из исходного источника, что может быть медленнее.
Как работает кэширование?
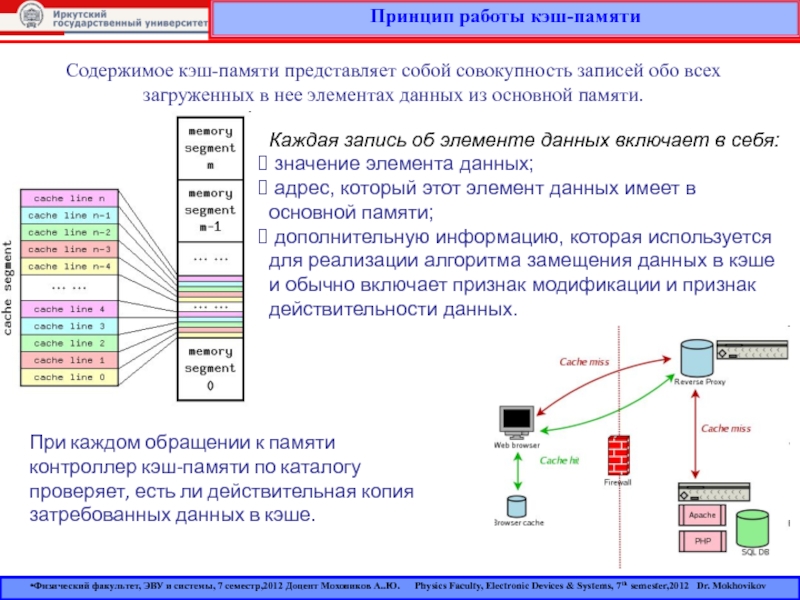
Когда делается запрос данных, система проверяет кэш, чтобы убедиться, что данные уже там сохранены. Если это так, система извлекает данные из кеша и передает их пользователю. Если данных нет в кеше, система извлекает их из исходного источника и сохраняет в кеше для будущего использования. В следующий раз, когда данные будут запрошены, они будут предоставлены из кеша, что быстрее, чем получение их из исходного источника.
Типы кеширования
Существует несколько типов кэширования, включая кэширование в памяти, кэширование в памяти и кэширование на диске. Кэширование памяти сохраняет данные в кэш-памяти системы, что быстрее, чем их хранение на диске. Кэширование в памяти сохраняет данные в оперативной памяти системы, что даже быстрее, чем кэширование в памяти. Кэширование диска сохраняет данные на диске, что медленнее, чем кэширование в памяти, но может хранить больше данных.
Кэширование диска сохраняет данные на диске, что медленнее, чем кэширование в памяти, но может хранить больше данных.
Кэширование также может выполняться на разных уровнях, включая веб-браузер, веб-сервер, CDN (сеть доставки контента) и исходный сервер. Веб-браузеры кэшируют HTML, изображения и код, чтобы уменьшить количество запросов к веб-серверу. Веб-серверы кэшируют данные ответов, чтобы снизить нагрузку на ЦП и повысить производительность приложений. CDN кэшируют контент, чтобы уменьшить задержку и улучшить взаимодействие с пользователем. Исходные серверы кэшируют данные, чтобы снизить нагрузку на внутренние серверы и повысить производительность приложений.
API также могут использовать кэширование для повышения производительности. Когда делается запрос API, система может проверить кеш, чтобы увидеть, сохранен ли там ответ. Если это так, система может обслужить ответ из кеша вместо повторной обработки запроса.
В заключение следует отметить, что кэширование является ценным методом повышения производительности приложений и систем за счет сокращения времени, необходимого для доступа к часто используемым данным. Сохраняя данные в кэше, системы могут быстрее извлекать данные и снижать нагрузку на внутренние серверы.
Сохраняя данные в кэше, системы могут быстрее извлекать данные и снижать нагрузку на внутренние серверы.
Преимущества кэширования
Кэширование — это метод, который может принести приложениям многочисленные преимущества за счет повышения их производительности, снижения затрат и увеличения пропускной способности. Вот некоторые из наиболее важных преимуществ кэширования:
Улучшенная производительность
Одним из основных преимуществ кэширования является то, что оно может значительно повысить производительность приложений. Это связано с тем, что чтение данных из кэша в памяти выполняется намного быстрее, чем доступ к данным из хранилища данных на диске. Сохраняя часто используемые данные в ОЗУ, кэширование уменьшает задержку, связанную с доступом к данным с более медленных устройств хранения с более длительным сроком службы. Это может улучшить взаимодействие с пользователем и повысить эффективность критически важных бизнес-процессов.
Экономически эффективным
Кэширование также может помочь снизить затраты, связанные с использованием базы данных. Сохраняя часто используемые данные в памяти, кэширование сокращает количество раз, которое необходимо извлечь данные из базы данных. Это может помочь снизить нагрузку на сервер базы данных, что, в свою очередь, может помочь сократить использование базы данных и затраты.
Сохраняя часто используемые данные в памяти, кэширование сокращает количество раз, которое необходимо извлечь данные из базы данных. Это может помочь снизить нагрузку на сервер базы данных, что, в свою очередь, может помочь сократить использование базы данных и затраты.
Более высокая пропускная способность
Кэширование также может помочь увеличить пропускную способность, то есть количество данных, которое может быть обработано системой за заданный промежуток времени. Сохраняя часто используемые данные в памяти, кэширование может помочь сократить время, необходимое для извлечения данных из базы данных или другого устройства хранения. Это может помочь увеличить общую пропускную способность приложения.
Кэширование может принимать разные формы, включая веб-кэш, распределенный кеш и кеш в памяти. Некоторые популярные решения для кэширования включают Redis, Memcached и Hazelcast. Сети доставки контента (CDN) также используют кэширование для хранения часто используемого контента в географически распределенных местах, сокращая время загрузки и защищая от кибератак.
В целом, кэширование — это мощный метод, который может принести приложениям множество преимуществ. Повышая производительность, снижая затраты и увеличивая пропускную способность, кэширование может помочь обеспечить скорость, эффективность и надежность приложений.
Лучшие практики кэширования
Кэширование — это мощный инструмент для повышения производительности и масштабируемости веб-приложений. Однако, чтобы полностью использовать кэширование, важно следовать некоторым рекомендациям. В этом разделе мы обсудим некоторые из лучших практик кэширования.
Инвалидация кеша
Инвалидация кеша — это процесс удаления устаревших или устаревших данных из кеша. Важно аннулировать кэш при изменении данных, чтобы обеспечить актуальность кэшированных данных. Есть несколько способов аннулировать кеш:
- Время жизни (TTL): установите ограничение по времени, в течение которого кэш может хранить данные. По истечении TTL кэш будет аннулирован.
- Заголовок управления кэшем: используйте заголовок Cache-Control, чтобы указать, как долго кэш может хранить данные.
 Этот заголовок также может использоваться для указания других параметров, связанных с кешем, например, может ли кеш совместно использоваться несколькими пользователями или следует ли повторно проверять кеш перед обслуживанием данных.
Этот заголовок также может использоваться для указания других параметров, связанных с кешем, например, может ли кеш совместно использоваться несколькими пользователями или следует ли повторно проверять кеш перед обслуживанием данных. - Ручная недействительность: аннулировать кеш вручную при изменении данных. Это можно сделать, отправив запрос на сервер с определенным заголовком, который сообщает серверу о недействительности кеша.
 Этот заголовок также может использоваться для указания других параметров, связанных с кешем, например, может ли кеш совместно использоваться несколькими пользователями или следует ли повторно проверять кеш перед обслуживанием данных.
Этот заголовок также может использоваться для указания других параметров, связанных с кешем, например, может ли кеш совместно использоваться несколькими пользователями или следует ли повторно проверять кеш перед обслуживанием данных.Политики замены кэша
Политики замены кэша определяют, какие элементы должны быть удалены из кэша, когда кэш заполнен. Существует несколько политик замены кэша, каждая из которых имеет свои преимущества и недостатки. Некоторые из наиболее распространенных политик:
- Наименее недавно использованные (LRU): удалить из кэша наименее использовавшийся элемент.
- Первый пришел — первый ушел (FIFO): удалить самый старый элемент из кэша.
- Наименее часто используемые (LFU): удалить наименее часто используемый элемент из кэша.

Заголовок управления кэшем
Заголовок Cache-Control — это HTTP-заголовок, управляющий кэшированием. Его можно использовать, чтобы указать, как долго кеш может хранить данные, может ли кеш совместно использоваться несколькими пользователями и должен ли кеш повторно проверяться перед обслуживанием данных. Заголовок Cache-Control также можно использовать для указания других параметров, связанных с кэшем, например, должен ли кэш хранить данные на диске или в памяти.
Другие соображения
При внедрении кэширования необходимо учитывать несколько других соображений:
- Расположение кэша: Подумайте, где хранить кеш. Кэширование может выполняться в основной памяти, на жестком диске или в сети доставки контента (CDN).
- Блок управления памятью (MMU): учитывать MMU при кэшировании в основной памяти. MMU отвечает за управление распределением памяти и может влиять на производительность кэша.
- Серверная база данных: при кэшировании учитывайте внутреннюю базу данных. Если данные в кэше не syncв сочетании с серверной базой данных это может привести к несоответствиям.
- Кэширование CDN: учитывайте кэширование CDN при использовании CDN. Кэширование CDN может повысить производительность кэша за счет хранения данных ближе к пользователю.
- Кэширование DNS: учитывайте кэширование DNS при использовании CDN. Кэширование DNS может уменьшить задержку поиска DNS и повысить производительность кэша.
 Если данные в кэше не syncв сочетании с серверной базой данных это может привести к несоответствиям.
Если данные в кэше не syncв сочетании с серверной базой данных это может привести к несоответствиям.В заключение, кэширование — это мощный инструмент для повышения производительности и масштабируемости веб-приложений. Следуя рекомендациям по кэшированию, таким как аннулирование кеша, политики замены кеша и использование заголовка Cache-Control, вы можете обеспечить эффективность и действенность своего кеша.
Технологии кэширования
Кэширование — это важнейшая технология, которая повышает производительность приложений за счет сокращения времени отклика часто используемых данных. Технологии кэширования можно разделить на четыре категории: кэширование в памяти, прокси-кэширование, кэширование CDN и кэширование браузера.
Кэширование в памяти
Кэширование в памяти сохраняет часто используемые данные во временной памяти, такой как DRAM, чтобы сократить время, необходимое для извлечения данных из более медленных устройств хранения. Эта технология используется в различных приложениях, таких как управление сеансами, хранилища данных типа «ключ-значение» и базы данных NoSQL. Кэширование в памяти может значительно сократить время отклика приложения и улучшить взаимодействие с пользователем.
Кэширование прокси
Кэширование прокси хранит часто используемые данные на прокси-сервере между клиентом и сервером. Когда клиент запрашивает данные, прокси-сервер проверяет свой кэш, чтобы узнать, доступны ли запрошенные данные. Если данные доступны, прокси-сервер возвращает их клиенту, не перенаправляя запрос на сервер. Прокси-кэширование может повысить производительность приложений за счет сокращения использования полосы пропускания и времени отклика сервера.
Кэширование CDN
Кэширование CDN хранит часто используемые данные на нескольких серверах, распределенных по всему миру. Когда клиент запрашивает данные, сервер CDN, ближайший к клиенту, возвращает данные. Кэширование CDN может повысить производительность приложений за счет сокращения времени отклика и использования пропускной способности сервера. Кэширование CDN обычно используется для мультимедийного контента, такого как изображения и видео.
Когда клиент запрашивает данные, сервер CDN, ближайший к клиенту, возвращает данные. Кэширование CDN может повысить производительность приложений за счет сокращения времени отклика и использования пропускной способности сервера. Кэширование CDN обычно используется для мультимедийного контента, такого как изображения и видео.
Кэширование браузера
Кэширование браузера сохраняет часто используемые данные в браузере клиента. Когда клиент запрашивает данные, браузер проверяет свой кэш, чтобы узнать, доступны ли запрошенные данные. Если данные доступны, браузер возвращает их клиенту, не запрашивая их у сервера. Кэширование браузера может улучшить взаимодействие с пользователем за счет сокращения времени отклика приложения и использования полосы пропускания.
Технологии кэширования необходимы для повышения производительности приложений и сокращения времени отклика часто используемых данных. Используя технологии кэширования, разработчики могут значительно улучшить взаимодействие с пользователем и сократить использование пропускной способности сервера.
Более Чтение
Кэширование — это процесс хранения подмножества данных на уровне высокоскоростного хранилища данных, обычно временного по своей природе, чтобы будущие запросы на эти данные обслуживались быстрее, чем это возможно при доступе к основному месту хранения данных. Это позволяет эффективно повторно использовать ранее извлеченные или вычисленные данные (источник: AWS). В вычислениях кеш — это аппаратный или программный компонент, который хранит данные, чтобы будущие запросы на эти данные могли обслуживаться быстрее. Данные, хранящиеся в кэше, могут быть результатом более ранних вычислений или копией данных, хранящихся в другом месте (источник: Википедия)).
Связанные термины производительности веб-сайта
- Что такое КДН
Кэширование
Кеширование — механизм, с помощью которого можно повысить скорость работы приложения за счёт переноса часто используемых данных в очень быстрое хранилище.
Кэширование очень активно используют во множестве систем.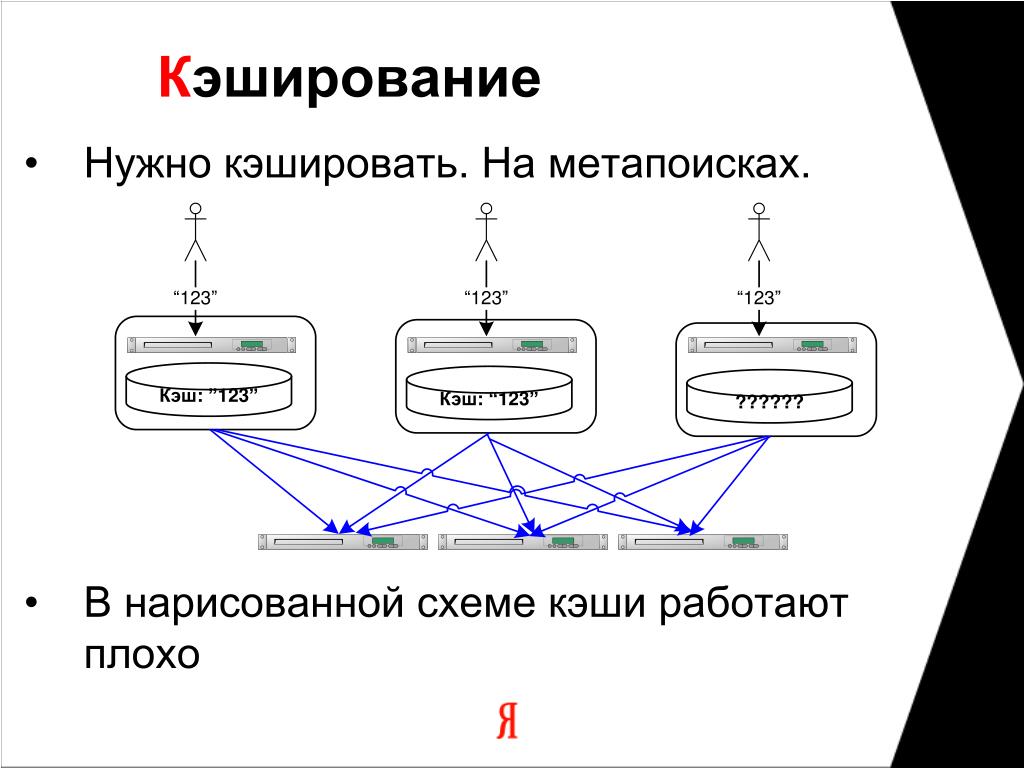 Например:
Например:
- Внутренний кэш баз данных.
- DNS кэш внутри нашего компьютера или браузера.
- Кэш статического контента в браузере.
- CDN также является своего рода кэшем.
В любом приложении есть операции, которые долго выполнялись, но результат которых можно сохранить на какое-то время. Это позволит меньше выполнять таких операций и отдавать заранее сохранённые данные.
Что можно кэшировать?
- Запросы в базу данных.
- Пользовательские сессии.
- Медленные операции внутри приложения (расчеты, какие-то итоговые данные и т. д.)
- Запросы к внешним системам.
Алгоритм работы
Приложение в первую очередь идёт за данными в кэш, если они там есть, то запроса в базу данных не происходит, что позволяет сэкономить время и ресурсы, такой случай называется попаданием кэша. Если данных нету, то приложение читает данные из базы данных после чего кладёт их в кэш для дальнейшего использования, такая ситуация называется промахом кэша. На основании этих двух показателей можно вычислить эффективность системы кэширования.
На основании этих двух показателей можно вычислить эффективность системы кэширования.
Стратегии кэширования
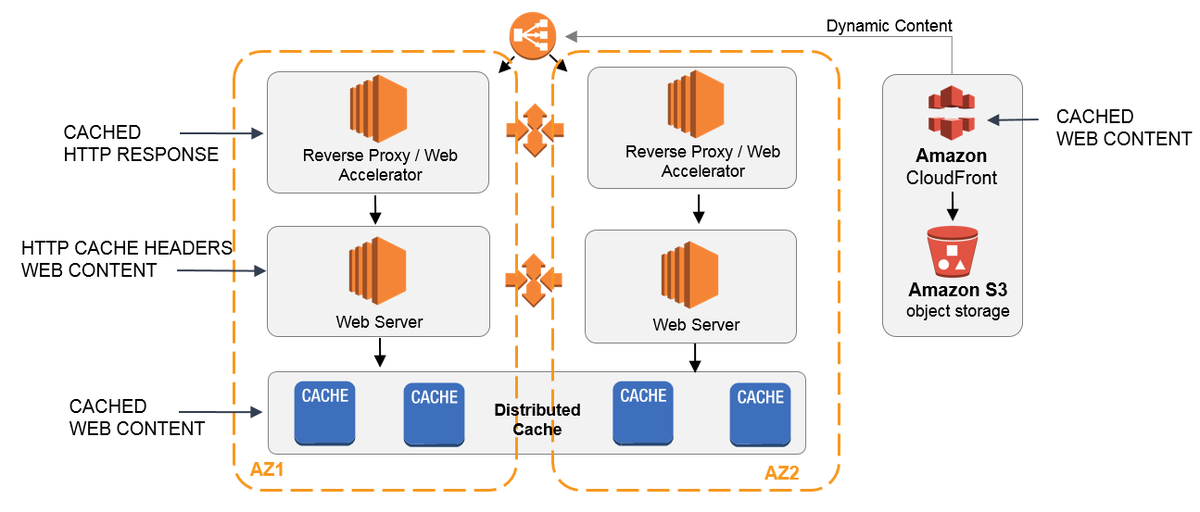
Cache Aside
Самый простой способ кэширования, зачастую множество фреймворков уже имеют встроенную реализацию.
В такой системе данные лениво загружаются в кэш. Пользователь делает запрос к нашей системе, после этого приложение сначала идет в кэш, если данные в нем есть, то возвращает их клиенту иначе идет в базу данных, обновляет кэш и отдает пользователю.
Плюсы:
- Отлично подходит для тяжелых операций чтения.
- Обычно система устойчива к отказу кэша. Если он упадет всегда можно пойти напрямую в базу данных.
- Возможно использовать разные структуры данных для кэша и базы данных. Особенно полезно когда нам нужно закешировать результат какой-то сложной выборки
Минусы:
- Из-за того что запись идет напрямую в базу данных, данные в кэше могут стать не консистентными. Для этого нужно использовать TTL (время жизни данных в кэше) или инвалидировать кэш, когда нужно гарантированно отдавать актуальные данные.
Read Through
Очень похожий на ленивый кэш, но в таком случае данные всегда остаются консистентными. Это достигается за счет того что приложение читает данные только из кэша, а уже он сам идет в базу данных в случае промаха.
Плюсы:
- Отлично работает с тяжелыми операциями чтения.
- Данные всегда в консистентном виде.
Минусы:
- Модель данных в кэше и в базе данных не могут отличатся.
- Первый запрос в кэш всегда будет приводить к промаху и последующему запросу в БД. Эту проблему можно — решить с помощью “прогревания” кэша.
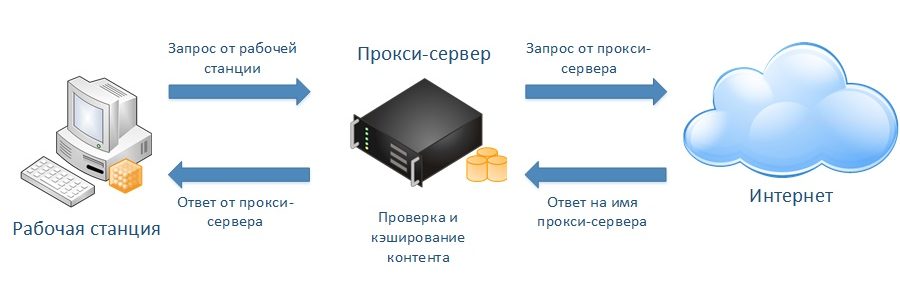
Write Through
Эта стратегия подразумевает приложение сначала запишет данные в кэш, после чего сохранит их в базу данных.
Лучше всего использовать эту стратегию вместе с read-through подходом. В таком случае мы получаем плюсы двух стратегий.
Плюсы:
- Гарантирует полною консистентность данных.
- Отлично работает с тяжелыми операциями записи.
Минусы:
- Добавляет дополнительную задержку для операций записи.
Write Back
Самый сложный способ кэширования, в нем все операции записи происходят только в кэше, откуда они с некоторой задержкой попадают в основное хранилище.
Плюсы:
- Позволяет сильно оптимизировать сложные операции записи.
- Данные всегда в консистентном виде.
Минусы:
- Сложность реализации.
- Есть шанс потерять данные если произойдет сбой кэша до того как данные запишутся в основное хранилище.
Алгоритмы вытеснения
Если в кэше нет свободного места для новых данных, то в работу вступают разнообразные механизмы вытеснения (очистки) кэша.
- LRU (Least recently used) — алгоритм, который находит и вытесняет данные, которые не использовались дольше всех.
- MRU (Most Recently Used) — вытесняются последние используемые данные.
- LFU (Least Frequently Used) — вытесняются редко запрашиваемые данные.
Выбор правильного алгоритма зависит от того как данные используются в системе. LRU подходит в тех случая когда данные гарантированно будут повторно используемые. MRU подходит для данных, которые запрашивались совсем недавно, но данные не будут повторно использованы в ближайшее время.
LRU подходит в тех случая когда данные гарантированно будут повторно используемые. MRU подходит для данных, которые запрашивались совсем недавно, но данные не будут повторно использованы в ближайшее время.
Проблемы с кэшированием
В процессе создания и работы кэширующей системы может возникнуть набор разные проблем и вопросы, такие как:
- Деление данных между кэширующими серверами.
- Параллельные запросы на обновление данных.
- “Холодный” старт приложения.
Деление данных между кэширующими серверами
Для повышения надежности и производительности системы кеширования приходится разделять ее на несколько серверов. Поэтому возникает вопрос как делить данные между серверами.
Вариант 1. Использовать хеширование ключей. В таком случае данные разделяются по серверам в зависимости от ключа кэширования. Для этого используется хеш функция, которая на вход принимает ключ и возвращает номер сервера.
Проблема такого подхода заключается в том, что в случае падения сервера мы теряем почти 80% данных из-за изменения месторасположения ключей.
Вариант 2. Логическое разделение данных на основе какого-то признака. Например мы можем разделять данные на основании пользователя. Так данные одного пользователя будут лежать рядом на одном сервере.
Примеры проблем и их решения отлично описаны в статье “Проблемы при работе с кэшем и способы их решения”
Параллельные запросы на обновление данных
Время от времени данные в кеше протухают и удаляются. В таком случае их необходимо обновить. Обычно это происходит, когда запрос обращается в кэш, видит, что данных нет, идет за ними в БД после чего обновляет кэш. Может возникнуть ситуация, когда таких запросов нескольколько, тогда все они пойдут в базу данных и нагрузят систему.
Решение 1. Блокировка перед обновлением кеша. Первый запрос получает уникальную блокировку на загрузку данных в кэш, все остальные ожидают блокировку. Это решает проблему с обновлением, но порождает новые: как обрабатывать таймауты, как правильно подобрать время блокировки и т.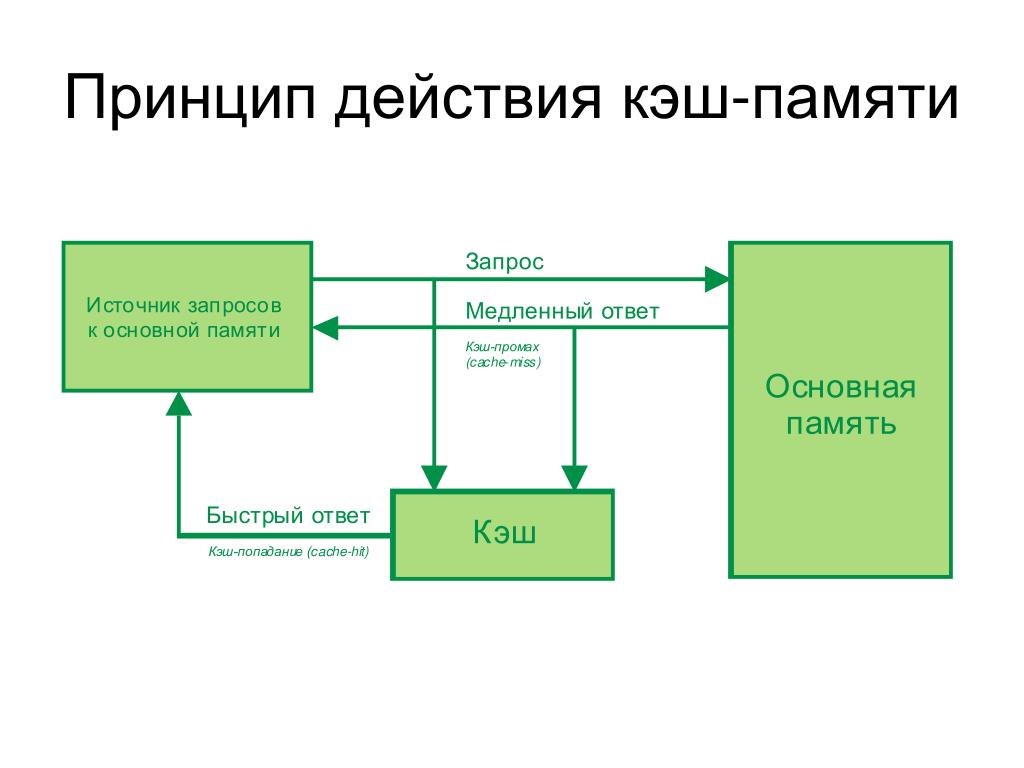 д.
д.
Решение 2. Фоновое обновление кэша. Приложение всегда читает данные из кеша и никогда не ходит в базу данных. Данные в кеше обновляет специальный скрипт или программа, которая работает в фоне. В таком случае никогда не наступит параллельного обновления кеша. Но возникает проблема с временем реакции на изменение данных в БД.
Решение 3. Вероятностное обновление данных. Обновляем не только данные, которых нет в кэше, но и с какой-то вероятностью те что уже есть. Это позволит обновить данные, до того как они протухнут и будут удалены.
Решение 4. Дублирование ключей. В системе есть два ключа, где второй имеет время жизни немного больше чем первый. В таком случае после того как исчезнет первый ключ мы обновляем его данные, но остальные запросы на чтение могут взять данные из второго ключа.
«Холодный» старт приложения
В момент запуска приложения данных в кэше может не быть. Как только пойдут запросы от пользователей все они пойдут массово в базу данных и начнуть одновременно обновлять кэш. Такая ситуация может привести к резкому падению производительности всей системы.
Такая ситуация может привести к резкому падению производительности всей системы.
Решение. Можно прибегнуть к технике «прогревания» кеша. В таком случае при старте приложения мы также наполняем кэш данными, которые активно используются.
Итого
Кэширование это очень мощный и простой в использовании механизм, который позволяет значительно увеличить производительность системы. Если вы планируете использовать кэш, то стоит внимательно посмотреть на то какие данные вы хотите кэшировать и как они используются. От этого зависит эффективность решения и какую стратегию выбрать.
Ссылки
- Кэширование данных
- Обзор кэширования от amazon
- Кэширование и производительность веб-приложений
- 11 видов кэширования для современного сайта
- Тяжелое кэширование
- Проблемы при работе с кэшем и способы их решения
- Проблема одновременного перестроения кэшей
Как работает кэширование | Как работает
«» Кэширование значительно увеличивает скорость, с которой ваш компьютер извлекает биты и байты из памяти. Андрей Онуфриенко / Getty Images
Андрей Онуфриенко / Getty ImagesЕсли вы покупали компьютер, то слышали слово «кэш». Современные компьютеры имеют кэши L1 и L2, а многие теперь также имеют кэш L3. Возможно, вы также получили совет по этой теме от благонамеренных друзей, возможно, что-то вроде «Не покупайте этот чип Celeron, в нем нет кэша!»
Advertisement
Оказывается, кэширование — это важный информационный процесс, который присутствует на каждом компьютере в различных формах. Существуют кэши памяти, аппаратные и программные дисковые кэши, кэши страниц и многое другое. Виртуальная память — это даже форма кэширования. В этой статье мы рассмотрим кэширование, чтобы вы поняли, почему оно так важно.
Содержимое- Простой пример: до кэширования
- Простой пример: после кеша
- Компьютерные кэши
- Подсистемы кэширования
- Технология кэширования
- Место ссылки
htm»> Простой пример: до кэширования
 htm»> Простой пример: до кэширования
htm»> Простой пример: до кэшированияКэширование — это технология, основанная на подсистеме памяти вашего компьютера. Основная цель кэш-памяти — ускорить работу вашего компьютера, сохраняя при этом низкую цену компьютера. Кэширование позволяет быстрее выполнять задачи на компьютере.
Чтобы понять основную идею системы кэширования, давайте начнем с очень простого примера, в котором используется библиотекарь для демонстрации концепции кэширования. Давайте представим библиотекаря за своим столом. Он здесь, чтобы дать вам книги, которые вы просите. Для простоты предположим, что вы не можете получить книги самостоятельно — вам нужно попросить у библиотекаря любую книгу, которую вы хотите прочитать, и он принесет ее для вас из набора стопок в кладовой (таким образом устроена библиотека конгресса в Вашингтоне, округ Колумбия). Во-первых, начнем с библиотекаря без кеша.
Реклама
Приходит первый покупатель. Он просит книгу Моби Дик . Библиотекарь идет в кладовую, берет книгу, возвращается к прилавку и отдает книгу покупателю.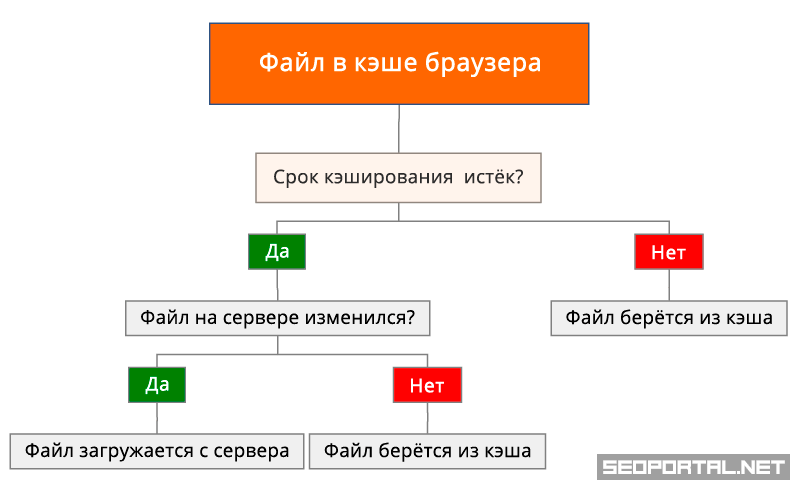 Позже клиент возвращается, чтобы вернуть книгу. Библиотекарь берет книгу и возвращает ее в кладовую. Затем он возвращается к своему прилавку, ожидая другого покупателя. Скажем, следующий клиент просит Моби Дик (вы видели, что это приближается…). Затем библиотекарь должен вернуться в кладовую, чтобы взять книгу, с которой он недавно работал, и отдать ее клиенту. В соответствии с этой моделью библиотекарь должен совершить полный обход, чтобы получить каждую книгу, даже очень популярную, которую часто запрашивают. Есть ли способ улучшить работу библиотекаря?
Позже клиент возвращается, чтобы вернуть книгу. Библиотекарь берет книгу и возвращает ее в кладовую. Затем он возвращается к своему прилавку, ожидая другого покупателя. Скажем, следующий клиент просит Моби Дик (вы видели, что это приближается…). Затем библиотекарь должен вернуться в кладовую, чтобы взять книгу, с которой он недавно работал, и отдать ее клиенту. В соответствии с этой моделью библиотекарь должен совершить полный обход, чтобы получить каждую книгу, даже очень популярную, которую часто запрашивают. Есть ли способ улучшить работу библиотекаря?
Да, есть способ — мы можем поставить кэш на библиотекарь. В следующем разделе мы рассмотрим тот же пример, но на этот раз библиотекарь будет использовать систему кэширования.
Реклама
Простой пример: после кеша
Дадим библиотекарю рюкзак, в котором он сможет хранить 10 книг (в компьютерных терминах библиотекарь теперь имеет тайник на 10 книг). В этот рюкзак он будет складывать книги, которые возвращают ему клиенты, максимум до 10. Давайте воспользуемся предыдущим примером, но теперь с нашим новым и улучшенным кэширующим библиотекарем.
В этот рюкзак он будет складывать книги, которые возвращают ему клиенты, максимум до 10. Давайте воспользуемся предыдущим примером, но теперь с нашим новым и улучшенным кэширующим библиотекарем.
День начинается. Рюкзак библиотекаря пуст. Приходит наш первый клиент и просит Моби Дик . Никакого волшебства здесь нет — библиотекарь должен пойти в кладовую, чтобы взять книгу. Он отдает клиенту. Позже клиент возвращается и возвращает книгу библиотекарю. Вместо того, чтобы вернуться в кладовую, чтобы вернуть книгу, библиотекарь кладет книгу в свой рюкзак и стоит там (сначала он проверяет, не полон ли мешок — об этом позже). Приходит другой клиент и просит Моби Дик . Прежде чем отправиться в кладовую, библиотекарь проверяет, нет ли этого названия в его рюкзаке. Он находит! Все, что ему нужно сделать, это взять книгу из рюкзака и отдать клиенту. Нет необходимости заходить на склад, поэтому клиент обслуживается более эффективно.
Реклама
Что делать, если клиент попросил название не в кеше (рюкзаке)? В этом случае библиотекарь менее эффективен с тайником, чем без него, потому что сначала библиотекарь тратит время на поиск книги в своем рюкзаке. Одной из задач проектирования кэша является минимизация влияния поиска в кэше, и современное оборудование свело эту задержку практически к нулю. Даже в нашем простом примере с библиотекарем время задержки (время ожидания) поиска в кэше настолько мало по сравнению со временем, которое требуется для возвращения в хранилище, что оно не имеет значения. Тайник небольшой (10 книг), и время, необходимое для того, чтобы заметить промах, составляет лишь ничтожную долю времени, которое занимает путешествие в кладовую.
Одной из задач проектирования кэша является минимизация влияния поиска в кэше, и современное оборудование свело эту задержку практически к нулю. Даже в нашем простом примере с библиотекарем время задержки (время ожидания) поиска в кэше настолько мало по сравнению со временем, которое требуется для возвращения в хранилище, что оно не имеет значения. Тайник небольшой (10 книг), и время, необходимое для того, чтобы заметить промах, составляет лишь ничтожную долю времени, которое занимает путешествие в кладовую.
Из этого примера вы можете увидеть несколько важных фактов о кэшировании:
- Технология кэширования — это использование более быстрого, но меньшего типа памяти для ускорения более медленного, но большего типа памяти.
- При использовании кэша вы должны проверить кэш, чтобы увидеть, есть ли там элемент. Если он есть, это называется попаданием в кэш . В противном случае это называется промахом кэша , и компьютер должен ждать прохождения туда и обратно из большей и более медленной области памяти.
- Кэш имеет некоторый максимальный размер, который намного меньше большей области хранения.
- Можно иметь несколько уровней кэша. В нашем примере с библиотекарем меньший, но более быстрый тип памяти — это рюкзак, а кладовая представляет собой более крупный и медленный тип памяти. Это одноуровневый кеш. Там может быть еще один уровень тайника, состоящий из полки, которая может вместить 100 книг за прилавком. Библиотекарь может проверить рюкзак, затем полку и затем кладовую. Это будет двухуровневый кеш.
Реклама
Компьютерные кэши
Компьютер — это машина, в которой мы измеряем время очень маленькими шагами. Когда микропроцессор обращается к основной памяти (ОЗУ), он делает это примерно за 60 наносекунд (60 миллиардных долей секунды). Это довольно быстро, но намного медленнее, чем обычный микропроцессор. Микропроцессоры могут иметь время цикла всего 2 наносекунды, поэтому для микропроцессора 60 наносекунд кажутся вечностью.
Что, если мы встроим в материнскую плату специальный банк памяти, небольшой, но очень быстрый (около 30 наносекунд)? Это уже в два раза быстрее, чем доступ к основной памяти. Это называется кэшем 2-го уровня или 9-го уровня.0031 Кэш второго уровня . Что, если мы встроим еще меньшую, но более быструю систему памяти прямо в микросхему микропроцессора? Таким образом, доступ к этой памяти будет осуществляться со скоростью микропроцессора, а не со скоростью шины памяти. Это кэш L1 , который на 233-мегагерцовом (МГц) Pentium в 3,5 раза быстрее, чем кэш L2, который в два раза быстрее, чем доступ к основной памяти.
Реклама
Некоторые микропроцессоры имеют два уровня кэша, встроенные прямо в чип. В этом случае кэш материнской платы — кэш, который существует между микропроцессором и основной системной памятью — становится уровнем 3 или 9.0031 Кэш L3 .
В компьютере много подсистем; вы можете поместить кеш между многими из них, чтобы улучшить производительность. Вот пример. У нас есть микропроцессор (самая быстрая вещь в компьютере). Кроме того, есть кэш L1, который кэширует кэш L2, который кэширует основную память, которая может использоваться (и часто используется) в качестве кэша для еще более медленных периферийных устройств, таких как жесткие диски и компакт-диски. Жесткие диски также используются для кэширования еще более медленного носителя — вашего интернет-соединения.
Вот пример. У нас есть микропроцессор (самая быстрая вещь в компьютере). Кроме того, есть кэш L1, который кэширует кэш L2, который кэширует основную память, которая может использоваться (и часто используется) в качестве кэша для еще более медленных периферийных устройств, таких как жесткие диски и компакт-диски. Жесткие диски также используются для кэширования еще более медленного носителя — вашего интернет-соединения.
Реклама
Подсистемы кэширования
Ваше подключение к Интернету является самым медленным каналом на вашем компьютере. Итак, ваш браузер (Internet Explorer, Netscape, Opera и т. д.) использует жесткий диск для хранения HTML-страниц, помещая их в специальную папку на вашем диске. Когда вы впервые запрашиваете HTML-страницу, ваш браузер отображает ее, и ее копия также сохраняется на вашем диске. В следующий раз, когда вы запросите доступ к этой странице, ваш браузер проверит, является ли дата файла в Интернете более новой, чем дата, сохраненная в кэше. Если дата совпадает, ваш браузер использует дату на жестком диске, а не загружает ее из Интернета. В этом случае меньшая, но более быстрая система памяти — это ваш жесткий диск, а большая и медленная — это Интернет.
Если дата совпадает, ваш браузер использует дату на жестком диске, а не загружает ее из Интернета. В этом случае меньшая, но более быстрая система памяти — это ваш жесткий диск, а большая и медленная — это Интернет.
Кэш также может быть построен непосредственно на периферийных устройствах . Современные жесткие диски поставляются с быстрой памятью, около 512 килобайт, жестко подключенной к жесткому диску. Компьютер не использует эту память напрямую — ее использует контроллер жесткого диска. Для компьютера эти микросхемы памяти являются самим диском. Когда компьютер запрашивает данные с жесткого диска, контроллер жесткого диска проверяет эту память, прежде чем перемещать механические части жесткого диска (что очень медленно по сравнению с памятью). Если он находит данные, запрошенные компьютером в кеше, он возвращает данные, хранящиеся в кеше, без фактического доступа к данным на самом диске, что экономит много времени.
Реклама
Вот эксперимент, который вы можете провести.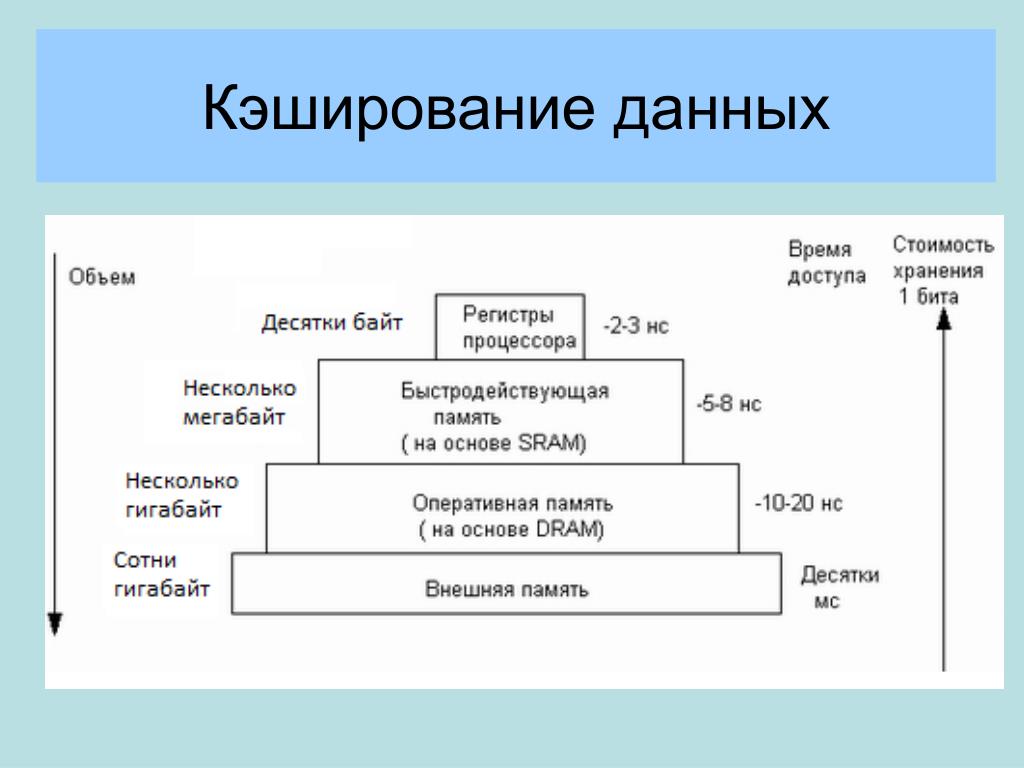 Ваш компьютер кэширует дисковод гибких дисков вместе с основной памятью, и вы действительно можете видеть, как это происходит. Получите доступ к большому файлу с дискеты — например, откройте 300-килобайтный текстовый файл в текстовом редакторе. В первый раз вы увидите, как загорается свет на вашей дискете, и вы будете ждать. Дискета работает очень медленно, поэтому загрузка файла займет 20 секунд. Теперь закройте редактор и снова откройте тот же файл. Во второй раз (не ждите 30 минут и не выполняйте большой доступ к диску между двумя попытками) вы не увидите, как загорается индикатор, и вы не будете ждать. Операционная система проверила в кэше своей памяти дискету и нашла то, что искала. Таким образом, вместо ожидания 20 секунд данные были найдены в подсистеме памяти намного быстрее, чем когда вы впервые попытались это сделать (один доступ к гибкому диску занимает 120 миллисекунд, а один доступ к основной памяти занимает около 60 наносекунд — это намного быстрее). Вы могли бы запустить тот же тест на жестком диске, но он более заметен на дисководе, потому что он очень медленный.
Ваш компьютер кэширует дисковод гибких дисков вместе с основной памятью, и вы действительно можете видеть, как это происходит. Получите доступ к большому файлу с дискеты — например, откройте 300-килобайтный текстовый файл в текстовом редакторе. В первый раз вы увидите, как загорается свет на вашей дискете, и вы будете ждать. Дискета работает очень медленно, поэтому загрузка файла займет 20 секунд. Теперь закройте редактор и снова откройте тот же файл. Во второй раз (не ждите 30 минут и не выполняйте большой доступ к диску между двумя попытками) вы не увидите, как загорается индикатор, и вы не будете ждать. Операционная система проверила в кэше своей памяти дискету и нашла то, что искала. Таким образом, вместо ожидания 20 секунд данные были найдены в подсистеме памяти намного быстрее, чем когда вы впервые попытались это сделать (один доступ к гибкому диску занимает 120 миллисекунд, а один доступ к основной памяти занимает около 60 наносекунд — это намного быстрее). Вы могли бы запустить тот же тест на жестком диске, но он более заметен на дисководе, потому что он очень медленный.
Чтобы дать вам общую картину, вот список обычных систем кэширования:
- Кэш первого уровня — Доступ к памяти на полной скорости микропроцессора (10 наносекунд, размер от 4 до 16 килобайт)
- L 2 кэш — доступ к памяти типа SRAM (около 20–30 нс, размер от 128 до 512 килобайт)
- Основная память — доступ к памяти типа RAM (около 60 наносекунд, размер от 32 до 128 мегабайт)
- Жесткий диск — Механический, медленный (около 12 миллисекунд, размер от 1 до 10 гигабайт)
- Интернет — Невероятно медленный (от 1 секунды до 3 дней, неограниченный размер)
Как видите, кэш L1 кэширует кэш L2, в котором кэшируется основная память, которую можно использовать для кэширования дисковых подсистем и так далее.
Реклама
Технология кэширования
На этом этапе часто задают вопрос: «Почему бы не сделать так, чтобы вся память компьютера работала с той же скоростью, что и кэш L1, чтобы кэширование не требовалось?» Это сработает, но будет невероятно дорого. Идея кэширования состоит в том, чтобы использовать небольшой объем дорогой памяти для ускорения большого объема более медленной и менее дорогой памяти.
Идея кэширования состоит в том, чтобы использовать небольшой объем дорогой памяти для ускорения большого объема более медленной и менее дорогой памяти.
При проектировании компьютера цель состоит в том, чтобы позволить микропроцессору работать на полной скорости с минимальными затратами. Чип с частотой 500 МГц выполняет 500 миллионов циклов за одну секунду (один цикл каждые две наносекунды). Без кэшей L1 и L2 доступ к основной памяти занимает 60 наносекунд, или около 30 потерянных циклов доступа к памяти.
Реклама
Когда вы думаете об этом, кажется невероятным, что такие относительно небольшие объемы памяти могут максимально эффективно использовать гораздо большие объемы памяти. Подумайте о 256-килобайтном кэше L2, который кэширует 64 мегабайта оперативной памяти. В этом случае 256 000 байт эффективно кэшируют 64 000 000 байт. Почему это работает?
В компьютерных науках у нас есть теоретическое понятие, называемое местоположением ссылки . Это означает, что в довольно большой программе одновременно используются только небольшие части. Как ни странно, локальность ссылок работает для подавляющего большинства программ. Даже если размер исполняемого файла составляет 10 мегабайт, в любой момент времени используется только несколько байтов этой программы, и скорость их повторения очень высока. На следующей странице вы узнаете больше о локальности ссылок.
Как ни странно, локальность ссылок работает для подавляющего большинства программ. Даже если размер исполняемого файла составляет 10 мегабайт, в любой момент времени используется только несколько байтов этой программы, и скорость их повторения очень высока. На следующей странице вы узнаете больше о локальности ссылок.
Реклама
Место ссылки
Давайте посмотрим на следующий псевдокод, чтобы понять, почему локальность ссылок работает (см. Как работает программирование на C, чтобы разобраться в этом):
Вывод на экран «Введите число от 1 до 100»
Чтение ввода от пользователя
Поместить значение от пользователя в переменную X
Поместите значение 100 в переменную Y
Поместите значение 1 в переменную Z
Цикл Y количество раз
Разделить Z на X
Если остаток от деления = 0
затем выведите « Z кратно X »
Добавить 1 к Z
Вернуться к циклу
Конец Эта небольшая программа просит пользователя ввести число от 1 до 100. Она считывает значение, введенное пользователем. Затем программа делит каждое число от 1 до 100 на число, введенное пользователем. Он проверяет, равен ли остаток 0 (деление по модулю). Если это так, программа выводит «Z кратно X» (например, 12 кратно 6) для каждого числа от 1 до 100. Затем программа завершается.
Она считывает значение, введенное пользователем. Затем программа делит каждое число от 1 до 100 на число, введенное пользователем. Он проверяет, равен ли остаток 0 (деление по модулю). Если это так, программа выводит «Z кратно X» (например, 12 кратно 6) для каждого числа от 1 до 100. Затем программа завершается.
Реклама
Даже если вы немного разбираетесь в компьютерном программировании, легко понять, что в 11 строках этой программы 9Часть 0031 цикла (строки с 7 по 9) выполняется 100 раз. Все остальные строки выполняются только один раз. Строки с 7 по 9 будут выполняться значительно быстрее из-за кэширования.
Эта программа очень маленькая и может легко уместиться в самом маленьком кэше L1, но допустим, что эта программа огромна. Результат остается прежним. Когда вы программируете, многие действия происходят внутри циклов. Текстовый процессор тратит 95 процентов времени на ожидание вашего ввода и отображение его на экране. Эта часть программы текстового процессора находится в кэше.
Это соотношение 95% к 5% (приблизительно) и есть то, что мы называем локальностью ссылки, и именно поэтому кэш работает так эффективно. По этой же причине такой маленький кэш может эффективно кэшировать такую большую систему памяти. Вы можете понять, почему не стоит создавать компьютер с самой быстрой памятью во всем мире. Мы можем обеспечить 95 процентов этой эффективности за небольшую часть стоимости.
Для получения дополнительной информации о кэшировании и смежных темах перейдите по ссылкам на следующей странице.
Реклама
Часто задаваемые вопросы
Для чего используется кэширование?
Кэширование используется для повышения производительности системы за счет хранения данных во временном расположении, чтобы их можно было быстрее извлечь.
Что такое кэширование в памяти?
Кэширование памяти — это процесс, при котором данные сохраняются в памяти компьютера, чтобы к ним можно было получить более быстрый доступ. Когда данные кэшируются в памяти, они сохраняются в резервном месте, чтобы к ним можно было получить доступ быстрее, чем если бы они хранились на диске или другом более медленном устройстве хранения.
Когда данные кэшируются в памяти, они сохраняются в резервном месте, чтобы к ним можно было получить доступ быстрее, чем если бы они хранились на диске или другом более медленном устройстве хранения.
Что такое кэширование и как оно работает?
Кэширование — это метод, используемый для хранения данных во временном месте, чтобы к ним можно было получить быстрый и эффективный доступ. Когда данные кэшируются, они хранятся в легкодоступном месте, и их извлечение не требует много времени или усилий.
Много дополнительной информации
Статьи по теме
Другие полезные ссылки
- Руководство для ПК: «Слои» кэша
- Webopedia: Cache
- Основы кэширования
- Создание собственного кэша данных в памяти — PDF
- Модель кэширования функций ядра операционной системы
Процитируйте это!
Пожалуйста, скопируйте/вставьте следующий текст, чтобы правильно цитировать эту статью HowStuffWorks. com:
com:
Guy Provost
«Как работает кэширование»
1 апреля 2000 г.
HowStuffWorks.com.
Citation
Как работает кэширование | Как работает
«» Кэширование значительно увеличивает скорость, с которой ваш компьютер извлекает биты и байты из памяти. Андрей Онуфриенко / Getty ImagesЕсли вы покупали компьютер, то слышали слово «кэш». Современные компьютеры имеют кэши L1 и L2, а многие теперь также имеют кэш L3. Возможно, вы также получили совет по этой теме от благонамеренных друзей, возможно, что-то вроде «Не покупайте этот чип Celeron, в нем нет кэша!»
Advertisement
Оказывается, кэширование — это важный информационный процесс, который присутствует на каждом компьютере в различных формах. Существуют кэши памяти, аппаратные и программные дисковые кэши, кэши страниц и многое другое. Виртуальная память — это даже форма кэширования. В этой статье мы рассмотрим кэширование, чтобы вы поняли, почему оно так важно.
- Простой пример: до кэширования
- Простой пример: после кеша
- Компьютерные кэши
- Подсистемы кэширования
- Технология кэширования
- Место ссылки
Простой пример: до кэширования
Кэширование — это технология, основанная на подсистеме памяти вашего компьютера. Основная цель кэш-памяти — ускорить работу вашего компьютера, сохраняя при этом низкую цену компьютера. Кэширование позволяет быстрее выполнять задачи на компьютере.
Чтобы понять основную идею системы кэширования, давайте начнем с очень простого примера, в котором используется библиотекарь для демонстрации концепции кэширования. Давайте представим библиотекаря за своим столом. Он здесь, чтобы дать вам книги, которые вы просите. Для простоты предположим, что вы не можете получить книги самостоятельно — вам нужно попросить у библиотекаря любую книгу, которую вы хотите прочитать, и он принесет ее для вас из набора стопок в кладовой (таким образом устроена библиотека конгресса в Вашингтоне, округ Колумбия). Во-первых, начнем с библиотекаря без кеша.
Во-первых, начнем с библиотекаря без кеша.
Реклама
Приходит первый покупатель. Он просит книгу Моби Дик . Библиотекарь идет в кладовую, берет книгу, возвращается к прилавку и отдает книгу покупателю. Позже клиент возвращается, чтобы вернуть книгу. Библиотекарь берет книгу и возвращает ее в кладовую. Затем он возвращается к своему прилавку, ожидая другого покупателя. Скажем, следующий клиент просит Моби Дик (вы видели, что это приближается…). Затем библиотекарь должен вернуться в кладовую, чтобы взять книгу, с которой он недавно работал, и отдать ее клиенту. В соответствии с этой моделью библиотекарь должен совершить полный обход, чтобы получить каждую книгу, даже очень популярную, которую часто запрашивают. Есть ли способ улучшить работу библиотекаря?
Да, есть способ — мы можем поставить кэш на библиотекарь. В следующем разделе мы рассмотрим тот же пример, но на этот раз библиотекарь будет использовать систему кэширования.
Реклама
 htm»> Простой пример: после кеша
htm»> Простой пример: после кешаДадим библиотекарю рюкзак, в котором он сможет хранить 10 книг (в компьютерных терминах библиотекарь теперь имеет тайник на 10 книг). В этот рюкзак он будет складывать книги, которые возвращают ему клиенты, максимум до 10. Давайте воспользуемся предыдущим примером, но теперь с нашим новым и улучшенным кэширующим библиотекарем.
День начинается. Рюкзак библиотекаря пуст. Приходит наш первый клиент и просит Моби Дик . Никакого волшебства здесь нет — библиотекарь должен пойти в кладовую, чтобы взять книгу. Он отдает клиенту. Позже клиент возвращается и возвращает книгу библиотекарю. Вместо того, чтобы вернуться в кладовую, чтобы вернуть книгу, библиотекарь кладет книгу в свой рюкзак и стоит там (сначала он проверяет, не полон ли мешок — об этом позже). Приходит другой клиент и просит Моби Дик . Прежде чем отправиться в кладовую, библиотекарь проверяет, нет ли этого названия в его рюкзаке. Он находит! Все, что ему нужно сделать, это взять книгу из рюкзака и отдать клиенту. Нет необходимости заходить на склад, поэтому клиент обслуживается более эффективно.
Нет необходимости заходить на склад, поэтому клиент обслуживается более эффективно.
Реклама
Что делать, если клиент попросил название не в кеше (рюкзаке)? В этом случае библиотекарь менее эффективен с тайником, чем без него, потому что сначала библиотекарь тратит время на поиск книги в своем рюкзаке. Одной из задач проектирования кэша является минимизация влияния поиска в кэше, и современное оборудование свело эту задержку практически к нулю. Даже в нашем простом примере с библиотекарем время задержки (время ожидания) поиска в кэше настолько мало по сравнению со временем, которое требуется для возвращения в хранилище, что оно не имеет значения. Тайник небольшой (10 книг), и время, необходимое для того, чтобы заметить промах, составляет лишь ничтожную долю времени, которое занимает путешествие в кладовую.
Из этого примера вы можете увидеть несколько важных фактов о кэшировании:
- Технология кэширования — это использование более быстрого, но меньшего типа памяти для ускорения более медленного, но большего типа памяти.
- При использовании кэша вы должны проверить кэш, чтобы увидеть, есть ли там элемент. Если он есть, это называется попаданием в кэш . В противном случае это называется промахом кэша , и компьютер должен ждать прохождения туда и обратно из большей и более медленной области памяти.
- Кэш имеет некоторый максимальный размер, который намного меньше большей области хранения.
- Можно иметь несколько уровней кэша. В нашем примере с библиотекарем меньший, но более быстрый тип памяти — это рюкзак, а кладовая представляет собой более крупный и медленный тип памяти. Это одноуровневый кеш. Там может быть еще один уровень тайника, состоящий из полки, которая может вместить 100 книг за прилавком. Библиотекарь может проверить рюкзак, затем полку и затем кладовую. Это будет двухуровневый кеш.

Реклама
Компьютерные кэши
Компьютер — это машина, в которой мы измеряем время очень маленькими шагами. Когда микропроцессор обращается к основной памяти (ОЗУ), он делает это примерно за 60 наносекунд (60 миллиардных долей секунды). Это довольно быстро, но намного медленнее, чем обычный микропроцессор. Микропроцессоры могут иметь время цикла всего 2 наносекунды, поэтому для микропроцессора 60 наносекунд кажутся вечностью.
Когда микропроцессор обращается к основной памяти (ОЗУ), он делает это примерно за 60 наносекунд (60 миллиардных долей секунды). Это довольно быстро, но намного медленнее, чем обычный микропроцессор. Микропроцессоры могут иметь время цикла всего 2 наносекунды, поэтому для микропроцессора 60 наносекунд кажутся вечностью.
Что, если мы встроим в материнскую плату специальный банк памяти, небольшой, но очень быстрый (около 30 наносекунд)? Это уже в два раза быстрее, чем доступ к основной памяти. Это называется кэшем 2-го уровня или 9-го уровня.0031 Кэш второго уровня . Что, если мы встроим еще меньшую, но более быструю систему памяти прямо в микросхему микропроцессора? Таким образом, доступ к этой памяти будет осуществляться со скоростью микропроцессора, а не со скоростью шины памяти. Это кэш L1 , который на 233-мегагерцовом (МГц) Pentium в 3,5 раза быстрее, чем кэш L2, который в два раза быстрее, чем доступ к основной памяти.
Реклама
Некоторые микропроцессоры имеют два уровня кэша, встроенные прямо в чип. В этом случае кэш материнской платы — кэш, который существует между микропроцессором и основной системной памятью — становится уровнем 3 или 9.0031 Кэш L3 .
В этом случае кэш материнской платы — кэш, который существует между микропроцессором и основной системной памятью — становится уровнем 3 или 9.0031 Кэш L3 .
В компьютере много подсистем; вы можете поместить кеш между многими из них, чтобы улучшить производительность. Вот пример. У нас есть микропроцессор (самая быстрая вещь в компьютере). Кроме того, есть кэш L1, который кэширует кэш L2, который кэширует основную память, которая может использоваться (и часто используется) в качестве кэша для еще более медленных периферийных устройств, таких как жесткие диски и компакт-диски. Жесткие диски также используются для кэширования еще более медленного носителя — вашего интернет-соединения.
Реклама
Подсистемы кэширования
Ваше подключение к Интернету является самым медленным каналом на вашем компьютере. Итак, ваш браузер (Internet Explorer, Netscape, Opera и т. д.) использует жесткий диск для хранения HTML-страниц, помещая их в специальную папку на вашем диске. Когда вы впервые запрашиваете HTML-страницу, ваш браузер отображает ее, и ее копия также сохраняется на вашем диске. В следующий раз, когда вы запросите доступ к этой странице, ваш браузер проверит, является ли дата файла в Интернете более новой, чем дата, сохраненная в кэше. Если дата совпадает, ваш браузер использует дату на жестком диске, а не загружает ее из Интернета. В этом случае меньшая, но более быстрая система памяти — это ваш жесткий диск, а большая и медленная — это Интернет.
Когда вы впервые запрашиваете HTML-страницу, ваш браузер отображает ее, и ее копия также сохраняется на вашем диске. В следующий раз, когда вы запросите доступ к этой странице, ваш браузер проверит, является ли дата файла в Интернете более новой, чем дата, сохраненная в кэше. Если дата совпадает, ваш браузер использует дату на жестком диске, а не загружает ее из Интернета. В этом случае меньшая, но более быстрая система памяти — это ваш жесткий диск, а большая и медленная — это Интернет.
Кэш также может быть построен непосредственно на периферийных устройствах . Современные жесткие диски поставляются с быстрой памятью, около 512 килобайт, жестко подключенной к жесткому диску. Компьютер не использует эту память напрямую — ее использует контроллер жесткого диска. Для компьютера эти микросхемы памяти являются самим диском. Когда компьютер запрашивает данные с жесткого диска, контроллер жесткого диска проверяет эту память, прежде чем перемещать механические части жесткого диска (что очень медленно по сравнению с памятью). Если он находит данные, запрошенные компьютером в кеше, он возвращает данные, хранящиеся в кеше, без фактического доступа к данным на самом диске, что экономит много времени.
Если он находит данные, запрошенные компьютером в кеше, он возвращает данные, хранящиеся в кеше, без фактического доступа к данным на самом диске, что экономит много времени.
Реклама
Вот эксперимент, который вы можете провести. Ваш компьютер кэширует дисковод гибких дисков вместе с основной памятью, и вы действительно можете видеть, как это происходит. Получите доступ к большому файлу с дискеты — например, откройте 300-килобайтный текстовый файл в текстовом редакторе. В первый раз вы увидите, как загорается свет на вашей дискете, и вы будете ждать. Дискета работает очень медленно, поэтому загрузка файла займет 20 секунд. Теперь закройте редактор и снова откройте тот же файл. Во второй раз (не ждите 30 минут и не выполняйте большой доступ к диску между двумя попытками) вы не увидите, как загорается индикатор, и вы не будете ждать. Операционная система проверила в кэше своей памяти дискету и нашла то, что искала. Таким образом, вместо ожидания 20 секунд данные были найдены в подсистеме памяти намного быстрее, чем когда вы впервые попытались это сделать (один доступ к гибкому диску занимает 120 миллисекунд, а один доступ к основной памяти занимает около 60 наносекунд — это намного быстрее). Вы могли бы запустить тот же тест на жестком диске, но он более заметен на дисководе, потому что он очень медленный.
Вы могли бы запустить тот же тест на жестком диске, но он более заметен на дисководе, потому что он очень медленный.
Чтобы дать вам общую картину, вот список обычных систем кэширования:
- Кэш первого уровня — Доступ к памяти на полной скорости микропроцессора (10 наносекунд, размер от 4 до 16 килобайт)
- L 2 кэш — доступ к памяти типа SRAM (около 20–30 нс, размер от 128 до 512 килобайт)
- Основная память — доступ к памяти типа RAM (около 60 наносекунд, размер от 32 до 128 мегабайт)
- Жесткий диск — Механический, медленный (около 12 миллисекунд, размер от 1 до 10 гигабайт)
- Интернет — Невероятно медленный (от 1 секунды до 3 дней, неограниченный размер)
Как видите, кэш L1 кэширует кэш L2, в котором кэшируется основная память, которую можно использовать для кэширования дисковых подсистем и так далее.
Реклама
 htm»> Технология кэширования
htm»> Технология кэшированияНа этом этапе часто задают вопрос: «Почему бы не сделать так, чтобы вся память компьютера работала с той же скоростью, что и кэш L1, чтобы кэширование не требовалось?» Это сработает, но будет невероятно дорого. Идея кэширования состоит в том, чтобы использовать небольшой объем дорогой памяти для ускорения большого объема более медленной и менее дорогой памяти.
При проектировании компьютера цель состоит в том, чтобы позволить микропроцессору работать на полной скорости с минимальными затратами. Чип с частотой 500 МГц выполняет 500 миллионов циклов за одну секунду (один цикл каждые две наносекунды). Без кэшей L1 и L2 доступ к основной памяти занимает 60 наносекунд, или около 30 потерянных циклов доступа к памяти.
Реклама
Когда вы думаете об этом, кажется невероятным, что такие относительно небольшие объемы памяти могут максимально эффективно использовать гораздо большие объемы памяти. Подумайте о 256-килобайтном кэше L2, который кэширует 64 мегабайта оперативной памяти. В этом случае 256 000 байт эффективно кэшируют 64 000 000 байт. Почему это работает?
В этом случае 256 000 байт эффективно кэшируют 64 000 000 байт. Почему это работает?
В компьютерных науках у нас есть теоретическое понятие, называемое местоположением ссылки . Это означает, что в довольно большой программе одновременно используются только небольшие части. Как ни странно, локальность ссылок работает для подавляющего большинства программ. Даже если размер исполняемого файла составляет 10 мегабайт, в любой момент времени используется только несколько байтов этой программы, и скорость их повторения очень высока. На следующей странице вы узнаете больше о локальности ссылок.
Реклама
Место ссылки
Давайте посмотрим на следующий псевдокод, чтобы понять, почему локальность ссылок работает (см. Как работает программирование на C, чтобы разобраться в этом):
Вывод на экран «Введите число от 1 до 100»
Чтение ввода от пользователя
Поместить значение от пользователя в переменную X
Поместите значение 100 в переменную Y
Поместите значение 1 в переменную Z
Цикл Y количество раз
Разделить Z на X
Если остаток от деления = 0
затем выведите « Z кратно X »
Добавить 1 к Z
Вернуться к циклу
Конец Эта небольшая программа просит пользователя ввести число от 1 до 100. Она считывает значение, введенное пользователем. Затем программа делит каждое число от 1 до 100 на число, введенное пользователем. Он проверяет, равен ли остаток 0 (деление по модулю). Если это так, программа выводит «Z кратно X» (например, 12 кратно 6) для каждого числа от 1 до 100. Затем программа завершается.
Она считывает значение, введенное пользователем. Затем программа делит каждое число от 1 до 100 на число, введенное пользователем. Он проверяет, равен ли остаток 0 (деление по модулю). Если это так, программа выводит «Z кратно X» (например, 12 кратно 6) для каждого числа от 1 до 100. Затем программа завершается.
Реклама
Даже если вы немного разбираетесь в компьютерном программировании, легко понять, что в 11 строках этой программы 9Часть 0031 цикла (строки с 7 по 9) выполняется 100 раз. Все остальные строки выполняются только один раз. Строки с 7 по 9 будут выполняться значительно быстрее из-за кэширования.
Эта программа очень маленькая и может легко уместиться в самом маленьком кэше L1, но допустим, что эта программа огромна. Результат остается прежним. Когда вы программируете, многие действия происходят внутри циклов. Текстовый процессор тратит 95 процентов времени на ожидание вашего ввода и отображение его на экране. Эта часть программы текстового процессора находится в кэше.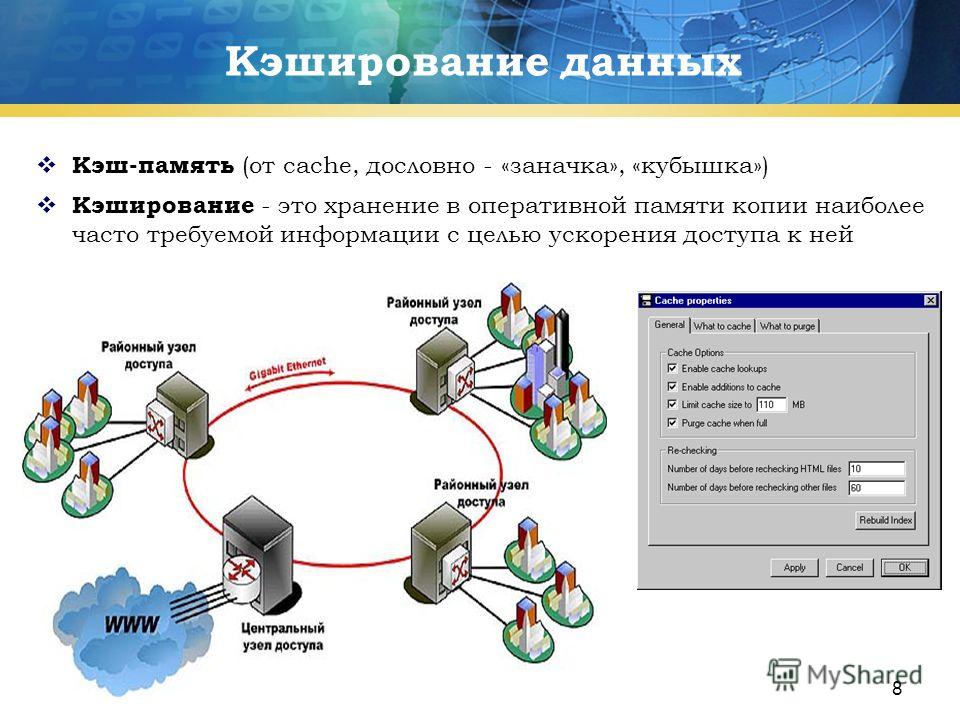
Это соотношение 95% к 5% (приблизительно) и есть то, что мы называем локальностью ссылки, и именно поэтому кэш работает так эффективно. По этой же причине такой маленький кэш может эффективно кэшировать такую большую систему памяти. Вы можете понять, почему не стоит создавать компьютер с самой быстрой памятью во всем мире. Мы можем обеспечить 95 процентов этой эффективности за небольшую часть стоимости.
Для получения дополнительной информации о кэшировании и смежных темах перейдите по ссылкам на следующей странице.
Реклама
Часто задаваемые вопросы
Для чего используется кэширование?
Кэширование используется для повышения производительности системы за счет хранения данных во временном расположении, чтобы их можно было быстрее извлечь.
Что такое кэширование в памяти?
Кэширование памяти — это процесс, при котором данные сохраняются в памяти компьютера, чтобы к ним можно было получить более быстрый доступ. Когда данные кэшируются в памяти, они сохраняются в резервном месте, чтобы к ним можно было получить доступ быстрее, чем если бы они хранились на диске или другом более медленном устройстве хранения.
Когда данные кэшируются в памяти, они сохраняются в резервном месте, чтобы к ним можно было получить доступ быстрее, чем если бы они хранились на диске или другом более медленном устройстве хранения.
Что такое кэширование и как оно работает?
Кэширование — это метод, используемый для хранения данных во временном месте, чтобы к ним можно было получить быстрый и эффективный доступ. Когда данные кэшируются, они хранятся в легкодоступном месте, и их извлечение не требует много времени или усилий.
Много дополнительной информации
Статьи по теме
Другие полезные ссылки
- Руководство для ПК: «Слои» кэша
- Webopedia: Cache
- Основы кэширования
- Создание собственного кэша данных в памяти — PDF
- Модель кэширования функций ядра операционной системы
Процитируйте это!
Пожалуйста, скопируйте/вставьте следующий текст, чтобы правильно цитировать эту статью HowStuffWorks.