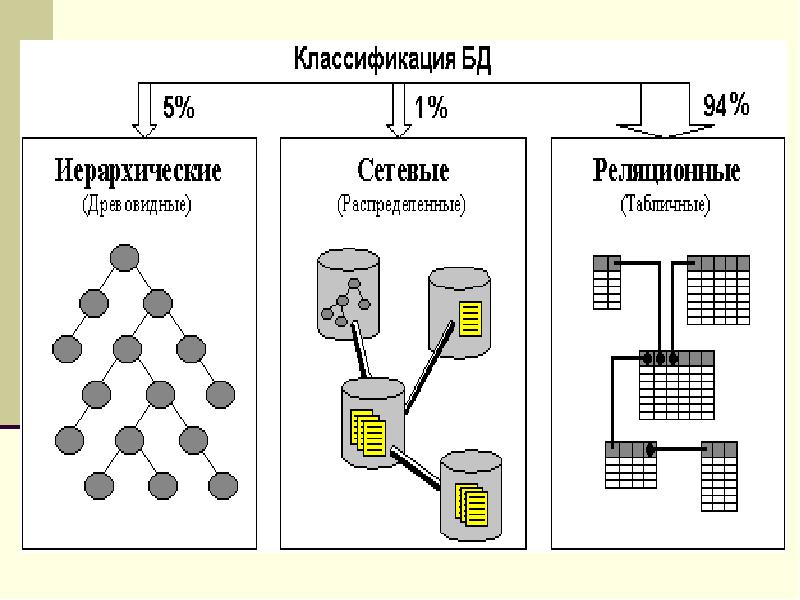
3.Классические модели систем бд – организация и обработка данных.
Хранимые в базе данные имеют определенную логическую структуру — иными словами, описываются некоторой моделью представления данных (моделью данных), поддерживаемой СУБД. К числу классических относятся следующие модели данных:
• иерархическая, • сетевая, • реляционная. • постреляционная,
• многомерная, • объектно-ориентированная.
Иерархическая модель
В иерархической модели связи между данными можно описать с помощью упорядоченного графа (или дерева). Для описания структуры (схемы) иерархической БД на некотором языке программирования используется тип данных «дерево». Тип «дерево» схож с типами данных «структура» языков программирования ПЛ/1 и С и «запись» языка Паскаль. В них допускается вложенность типов, каждый из которых находится на некотором уровне.
Тип
«дерево» является составным.
В соответствии с определением типа «дерево», можно заключить, что между предками и потомками автоматически поддерживается контроль целостности связей. Основное правило контроля целостности формулируется следующим образом: потомок не может существовать без родителя, а у некоторых родителей может не быть потомков. Механизмы поддержания целостности связей между записями различных деревьев отсутствуют.
К достоинствам иерархической
модели данных относятся эффективное
использование памяти ЭВМ и неплохие
показатели времени выполнения основных
операций над данными.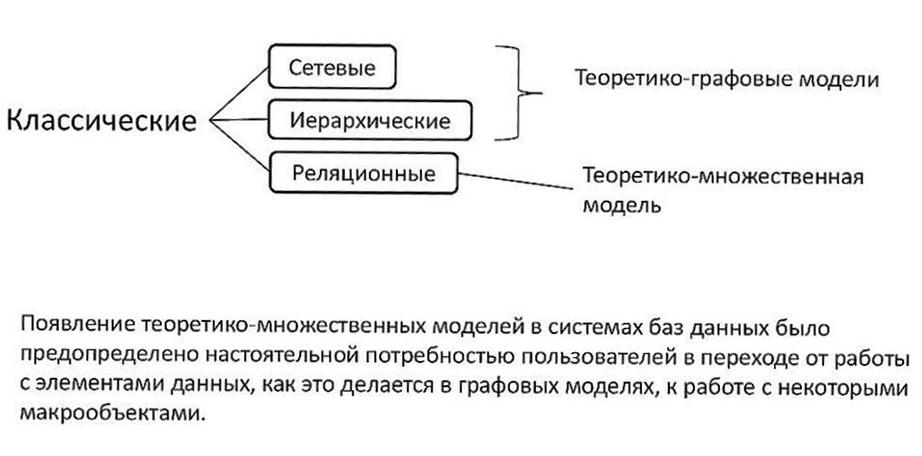 Иерархическая
модель данных удобна для работы с
иерархически упорядоченной информацией.
Иерархическая
модель данных удобна для работы с
иерархически упорядоченной информацией.
Недостатком
Сетевая модель
Сетевая модель данных позволяет отображать разнообразные взаимосвязи элементов данных в виде произвольного графа, обобщая тем самым иерархическую модель
Для описания схемы сетевой БД используется две группы типов: «запись» и «связь». Тип «связь» определяется для двух типов «запись»: предка и потомка. Переменные типа «связь» являются экземплярами связей.
Достоинством сетевой модели данных является возможность эффективной реализации по показателям затрат памяти и оперативности. В сравнении с иерархической моделью сетевая модель предоставляет
большие возможности в смысле допустимости образования произвольных связей.
Недостатком сетевой
модели данных является высокая сложность
и жесткость схемы БД, построенной на
ее основе, а также сложность для понимания
и выполнения обработки информации в БД
обычным пользователем.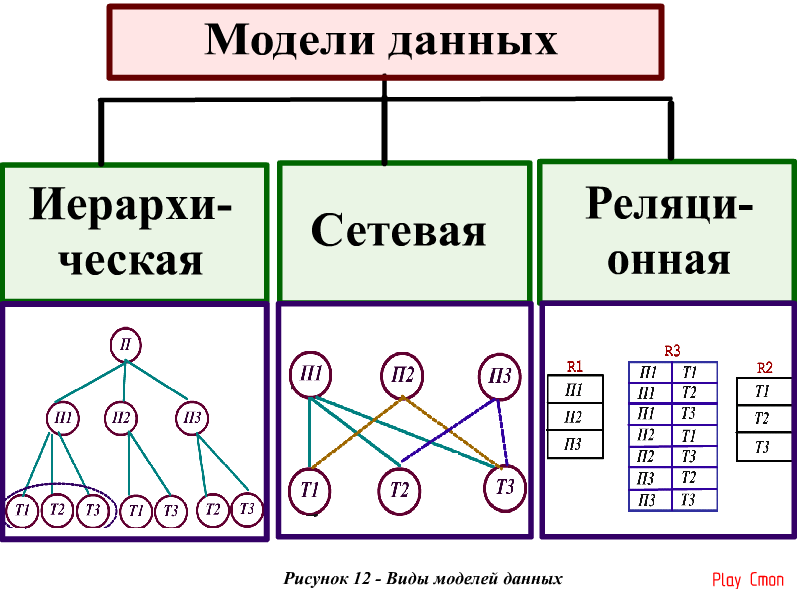 Кроме того,
в сетевой модели данных ослаблен контроль
целостности связей вследствие допустимости
установления произвольных связей между
записями.
Кроме того,
в сетевой модели данных ослаблен контроль
целостности связей вследствие допустимости
установления произвольных связей между
записями.
Реляционная модель
Реляционная модель данных предложена сотрудником фирмы IBM Эдгаром Коддом и основывается на понятии отношение (relation).
Отношение представляет собой множество элементов, называемых кортежами. Наглядной формой представления отношения является привычная для человеческого восприятия двумерная таблица.
Таблица имеет строки (записи) и столбцы (колонки). Каждая строка таблицы имеет одинаковую структуру и состоит из полей. Строкам таблицы соответствуют кортежи, а столбцам — атрибуты отношения.
С помощью одной таблицы удобно описывать простейший вид связей между данными, а именно деление одного объекта (явления, сущности, системы и проч.), информация о котором хранится в таблице, на множество подобъектов, каждому из которых соответствует строка или запись таблицы. Поскольку в рамках одной таблицы не удается описать более сложные логические структуры данных из предметной области, применяют

Физическое размещение данных в реляционных базах на внешних носителях легко осуществляется с помощью обычных файлов.
Достоинство реляционной модели данных заключается в простоте, понятности и удобстве физической реализации на ЭВМ. Именно простота и понятность для пользователя явились основной причиной их широкого использования.
Основными недостатками реляционной модели являются следующие: отсутствие стандартных средств идентификации отдельных записей и сложность описания иерархических и сетевых связей.
ИЕРАРХИЧЕСКАЯ, СЕТЕВАЯ И РЕЛЯЦИОННАЯ МОДЕЛИ ПРЕДСТАВЛЕНИЯ ДАННЫХ
Информация в базе данных определенным образом
структурирована, т.е. ее можно описать моделью представления данных
(моделью данных), поддерживаемой СУБД. Классические модели
представления данных: иерархическая, сетевая, реляционная. При использовании иерархической модели представления данных
связи между данными можно описать с помощью упорядоченного графа
(или дерева). При программировании для описания структуры
иерархической базы данных используется тип данных «дерево».
Основные достоинства иерархической модели данных:
1) эффективное использование памяти ЭВМ;
2) скорость выполнения основных операций над данными;
3) удобство работы с иерархически упорядоченной информацией.
Недостатки иерархической модели представления данных:
1) громоздкость данной модели для обработки информации с
достаточно сложными логическими связями;
2) трудность в понимании ее функционирования обычным
пользователем.
Достаточно небольшое количество СУБД построено на
иерархической модели данных.
Сетевую модель представления данных можно рассматривать как
развитие и обобщение иерархической модели данных, позволяющее
отображать разнообразные взаимосвязи данных в виде произвольного
графа.
При использовании иерархической модели представления данных
связи между данными можно описать с помощью упорядоченного графа
(или дерева). При программировании для описания структуры
иерархической базы данных используется тип данных «дерево».
Основные достоинства иерархической модели данных:
1) эффективное использование памяти ЭВМ;
2) скорость выполнения основных операций над данными;
3) удобство работы с иерархически упорядоченной информацией.
Недостатки иерархической модели представления данных:
1) громоздкость данной модели для обработки информации с
достаточно сложными логическими связями;
2) трудность в понимании ее функционирования обычным
пользователем.
Достаточно небольшое количество СУБД построено на
иерархической модели данных.
Сетевую модель представления данных можно рассматривать как
развитие и обобщение иерархической модели данных, позволяющее
отображать разнообразные взаимосвязи данных в виде произвольного
графа.

Работа с базой данных
Модель работы с базой данных
Модель базы данных «1С:Предприятия 8» имеет ряд особенностей, отличающих ее от классических моделей систем управления базами данных (например, основанных на реляционных таблицах), с которыми имеют дело разработчики в универсальных системах.
Основное отличие заключается в том, что разработчик «1С:Предприятия 8» не обращается к базе данных напрямую. Непосредственно он работает с платформой «1С:Предприятия 8». При этом он может:
При этом он может:
- описывать структуры данных в конфигураторе,
- манипулировать данными с помощью объектов встроенного языка,
- составлять запросы к данным, используя язык запросов.
Платформа «1С:Предприятия 8» обеспечивает операции исполнения запросов, описания структур данных и манипулирования данными, транслируя их в соответствующие команды. Это могут быть команды системы управления базами данных, в случае клиент-серверного варианта работы, или команды собственного движка базы данных для файлового варианта.
Общая система типов
Важной особенностью работы с базой данных является то, что в «1С:Предприятии 8» реализована общая система типов языка и полей баз данных. Иными словами, разработчик одинаковым образом определяет поля базы данных и переменные встроенного языка и одинаковым образом работает с ними.
Этим система «1С:Предприятие 8» выгодно отличается от универсальных инструментальных средств. Обычно, при создании бизнес-приложений с использованием универсальных сред разработки, используются отдельно поставляемые системы управления базами данных. А это значит, что разработчику приходится постоянно заботиться о преобразованиях между типами данных, поддерживаемыми той или иной системы управления базами данных, и типами, поддерживаемыми языком программирования.
Обычно, при создании бизнес-приложений с использованием универсальных сред разработки, используются отдельно поставляемые системы управления базами данных. А это значит, что разработчику приходится постоянно заботиться о преобразованиях между типами данных, поддерживаемыми той или иной системы управления базами данных, и типами, поддерживаемыми языком программирования.
Хранение ссылок на объекты
При манипулировании данными, хранящимися в базе данных «1С:Предприятия 8», зачастую используется объектный подход. Это значит, что обращение (чтение и запись) к некоторой совокупности данных, хранящихся в базе, происходит как к единому целому. Например, используя объектную технику, можно манипулировать данными справочников, документов, планов видов характеристик, планов счетов и т.д.
Характерной особенностью объектного манипулирования данными является то, что на каждый объект, как совокупность данных, существует уникальная ссылка, позволяющая однозначно идентифицировать этот объект в базе данных.
Эта ссылка также хранится в поле базы данных, вместе с остальными данными объекта. Кроме того, ссылка может быть использована как значение какого-либо поля другого объекта. Например, ссылка на объект справочника Контрагенты может быть использована как значение соответствующего реквизита документа Приходная накладная.
Составные типы
Существенной возможностью модели данных, которая поддерживается «1С:Предприятием 8», является то, что для поля базы данных можно определить сразу несколько типов данных, значения которых могут храниться в этом поле. При этом значение в каждый момент времени будет храниться одно, но оно может быть разных типов — как ссылочных, так и примитивных — число, строка, дата и т.п.:
Такая возможность очень важна для экономических задач — например, в расходной накладной в качестве покупателя может быть указано либо юридическое лицо из справочника организаций, либо физическое лицо из справочника частных лиц.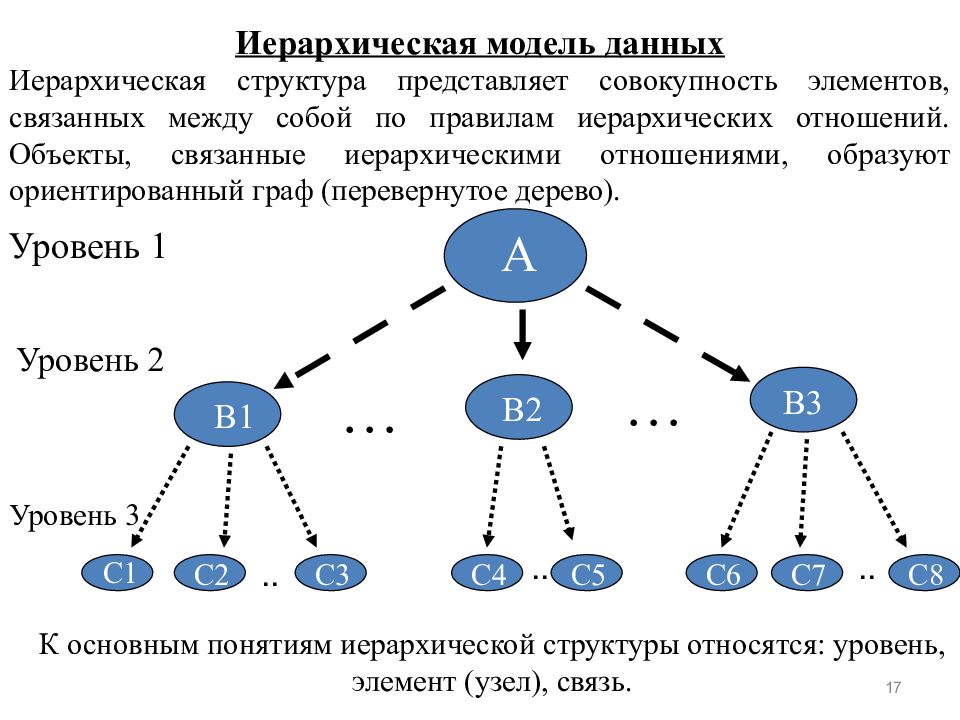 Соответственно, при проектировании базы данных разработчик может определить поле, которое будет хранить значение любого из этих типов.
Соответственно, при проектировании базы данных разработчик может определить поле, которое будет хранить значение любого из этих типов.
Хранение любых данных как Хранилище значения
Идеология создания прикладных решений в «1С:Предприятии 8» предполагает, что все файлы, имеющие отношение к данному прикладному решению, нужно хранить в самой базе данных.
Для этого введен специальный тип данных — ХранилищеЗначения. Поля базы данных могут хранить значения такого типа, а встроенный язык содержит специальный одноименный объект, позволяющий преобразовывать значения других типов к специальному формату Хранилища значений.
Благодаря этому разработчик имеет возможность сохранять в базе данных значения, тип которых не может быть выбран в качестве типа поля базы данных, например, графические изображения.
Создание и обновление структур данных на основе метаданных
В процессе создания или модификации прикладного решения разработчик избавлен от необходимости каких-либо действий по непосредственному изменению структуры полей базы данных прикладного решения.
Разработчику достаточно путем визуального конструирования описать структуру используемых объектов прикладного решения, состав их реквизитов, табличных частей, форм и пр.
Все действия по созданию или изменению структуры таблиц базы данных платформа выполнит самостоятельно, на основании состава объектов прикладного решения и их характеристик.
Например, для того, чтобы в справочнике сотрудников появилась возможность хранить сведения о составе семьи сотрудника, разработчику «1С:Предприятия 8» не нужно создавать в базе данных специальную новую таблицу, задавать правила, по которым данные, хранящиеся в этой таблице, будут связаны с данными из основной таблицы, программировать алгоритмы совместного доступа к данным этих таблиц, создавать алгоритмы проверки прав доступа к данным, находящимся в подчиненной таблице и пр.
Все, что требуется сделать разработчику — щелчком мыши добавить к справочнику табличную часть и задать два ее строковых реквизита: Имя и Родство. При сохранении или обновлении конфигурации платформа самостоятельно выполнит реорганизацию структуры базы данных, создаст необходимые таблицы и т.д.
При сохранении или обновлении конфигурации платформа самостоятельно выполнит реорганизацию структуры базы данных, создаст необходимые таблицы и т.д.
Объектный / табличный доступ к данным
Штатной возможностью «1С:Предприятия 8» является поддержка двух способов доступа к данным — объектного (для чтения и записи) и табличного (для чтения).
В объектной модели разработчик оперирует объектами встроенного языка. В этой модели обращения к объекту, например документу, происходят как к единому целому — он полностью загружается в память, вместе с вложенными таблицами, к которым можно обращаться средствами встроенного языка как к коллекциям записей и т.д.
При манипулировании данными в объектной модели обеспечивается сохранение целостности объектов, кэширование объектов, вызов соответствующих обработчиков событий и т.д.
В табличной модели все множество объектов того или иного класса представляется как совокупность связанных между собой таблиц, к которым можно обращаться при помощи запросов — как к отдельной таблице, так и к нескольким таблицам во взаимосвязи:
В этом случае разработчик получает доступ к данным сразу нескольких объектов, что очень удобно для анализа больших объемов данных, например, при создании отчетов.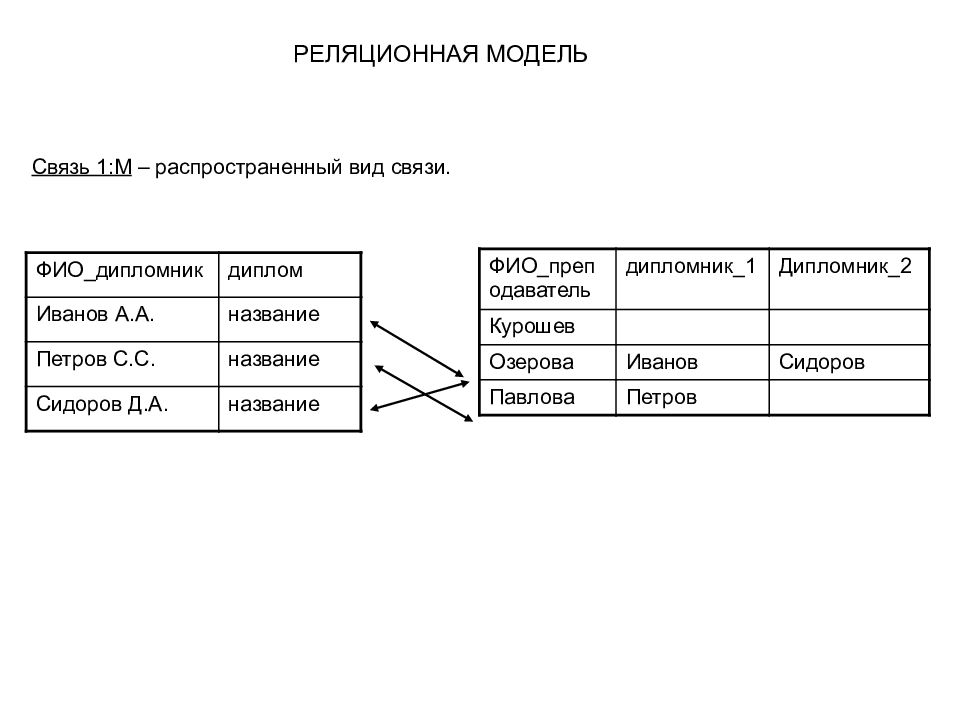 Однако в силу того, что данные, выбираемые таким способом, содержат не все, а лишь некоторые реквизиты анализируемых объектов, табличный способ доступа не позволяет изменять эти данные.
Однако в силу того, что данные, выбираемые таким способом, содержат не все, а лишь некоторые реквизиты анализируемых объектов, табличный способ доступа не позволяет изменять эти данные.
Обобщение моделей данных в создании ИС (Научная работа)
АВТОНОМНАЯ НЕКОМЕРЧЕСКАЯ ОРГАНИЗАЦИЯ
ЕВРАЗИЙСКИЙ ОТКРЫТЫЙ ИНСТИТУТ
Коломенский филиал
НАУЧНО-ИССЛЕДОВАТЕЛЬСКАЯ РАБОТА
Обобщение моделей данных в создании ИС
Выполнили:
Студентки 4 курса группы 41-П
Хромова Валентина Сергеевна
ИНС № 0021-02014
Литвиненко Мария Николаевна
ИНС № 0021-01931
г. Коломна, 2009 год
ОГЛАВЛЕНИЕ
Введение
Глава I. Классические модели данных
Классические модели данных
1.1 Иерархическая модель данных
1.2 Сетевая модель данных
1.3 Реляционная модель данных
Глава II. Неклассические модели данных
Постреляционная модель данных
Многомерная модель данных
Объектно-ориентированная модель данных
Глава III. Сравнение классических моделей данных
3.1 Достоинства и недостатки реляционной модели
3.3 Достоинства и недостатки сетевой модели
3.2 Достоинства и недостатки иерархической модели
ЗаключениеСписок использованной литературы
Приложение
Введение
Современная жизнь немыслима
без эффективного управления. Важной
категорией являются системы обработки
информации, от которых во многом зависит
эффективность работы любого предприятия
или учреждения. Такая система должна:
Важной
категорией являются системы обработки
информации, от которых во многом зависит
эффективность работы любого предприятия
или учреждения. Такая система должна:
— обеспечивать получение общих и/или детализированных отчетов по
итогам работы;
— позволять легко определять тенденции изменения важнейших
показателей;
— обеспечивать получение информации, критической по времени, без
существенных задержек;
— выполнять точный и полный анализ данных.
Современные системы
управления базами данных (СУБД) в основном
являются приложениями Windows, так как
данная среда позволяет более полно
использовать возможности персональной
ЭВМ, нежели среда DOS. Снижение стоимости
высокопроизводительных ПК обусловил
не только широкий переход к среде
Windows, где разработчик программного
обеспечения может в меньшей степени
заботиться о распределении ресурсов,
но также сделал программное обеспечение
ПК в целом и СУБД в частности менее
критичными к аппаратным ресурсам ЭВМ. Среди наиболее ярких представителей
систем управления базами данных можно
отметить: Lotus
Approach,
Microsoft
Access,
Borland
dBase,
Borland
Paradox,
Microsoft
Visual
FoxPro,
Microsoft
Visual
Basic,
а также баз данных Microsoft SQL Server и Oracle,
используемые в приложениях, построенных
по технологии «клиент-сервер». Фактически,
у любой современной СУБД существует
аналог, выпускаемый другой компанией,
имеющий аналогичную область применения
и возможности, любое приложение способно
работать со многими форматами представления
данных, осуществлять экспорт и импорт
данных благодаря наличию большого числа
конвертеров. Общепринятыми, также,
являются технологии, позволяющие
использовать возможности других
приложений, например, текстовых
процессоров, пакетов построения графиков
и т.п., и встроенные версии языков высокого
уровня (чаще – диалекты SQL и/или VBA) и
средства визуального программирования
интерфейсов разрабатываемых приложений.
Поэтому уже не имеет существенного
значения на каком языке и на основе
какого пакета написано конкретное
приложение, и какой формат данных в нем
используется.
Среди наиболее ярких представителей
систем управления базами данных можно
отметить: Lotus
Approach,
Microsoft
Access,
Borland
dBase,
Borland
Paradox,
Microsoft
Visual
FoxPro,
Microsoft
Visual
Basic,
а также баз данных Microsoft SQL Server и Oracle,
используемые в приложениях, построенных
по технологии «клиент-сервер». Фактически,
у любой современной СУБД существует
аналог, выпускаемый другой компанией,
имеющий аналогичную область применения
и возможности, любое приложение способно
работать со многими форматами представления
данных, осуществлять экспорт и импорт
данных благодаря наличию большого числа
конвертеров. Общепринятыми, также,
являются технологии, позволяющие
использовать возможности других
приложений, например, текстовых
процессоров, пакетов построения графиков
и т.п., и встроенные версии языков высокого
уровня (чаще – диалекты SQL и/или VBA) и
средства визуального программирования
интерфейсов разрабатываемых приложений.
Поэтому уже не имеет существенного
значения на каком языке и на основе
какого пакета написано конкретное
приложение, и какой формат данных в нем
используется.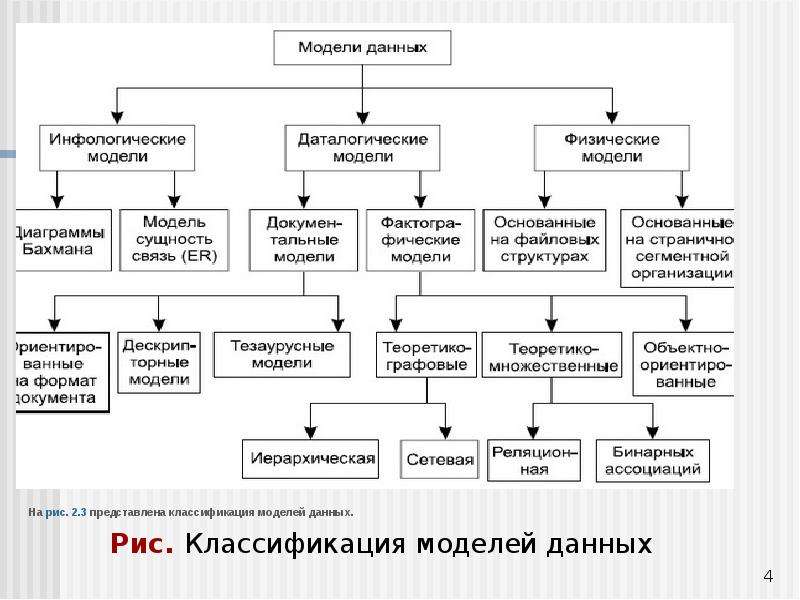 Более того, стандартом
«де-факто» стала «быстрая разработка
приложений» или RAD (от английского Rapid
Application Development), основанная на широко
декларируемом в литературе «открытом
подходе», то есть необходимость и
возможность использования различных
прикладных программ и технологий для
разработки более гибких и мощных систем
обработки данных. Поэтому в одном ряду
с «классическими» СУБД все чаще
упоминаются языки программирования
Visual Basic 4.0 и Visual C++, которые позволяют
быстро создавать необходимые компоненты
приложений, критичные по скорости
работы, которые трудно, а иногда невозможно
разработать средствами «классических»
СУБД. Современный подход к управлению
базами данных подразумевает также
широкое использование технологии
«клиент-сервер».
Более того, стандартом
«де-факто» стала «быстрая разработка
приложений» или RAD (от английского Rapid
Application Development), основанная на широко
декларируемом в литературе «открытом
подходе», то есть необходимость и
возможность использования различных
прикладных программ и технологий для
разработки более гибких и мощных систем
обработки данных. Поэтому в одном ряду
с «классическими» СУБД все чаще
упоминаются языки программирования
Visual Basic 4.0 и Visual C++, которые позволяют
быстро создавать необходимые компоненты
приложений, критичные по скорости
работы, которые трудно, а иногда невозможно
разработать средствами «классических»
СУБД. Современный подход к управлению
базами данных подразумевает также
широкое использование технологии
«клиент-сервер».
Таким образом, на сегодняшний
день разработчик не связан рамками
какого-либо конкретного пакета, а в
зависимости от поставленной задачи
может использовать самые разные
приложения. Поэтому, более важным
представляется общее направление
развития СУБД и других средств разработки
приложений в настоящее время.
Актуальность темы определяется тем, что цель любой информационной системы – обработка данных об объектах реального мира. Основные идеи современной информационной технологии базируются на концепции баз данных.
Хранимые в базе данные имеют определенную логическую структуру — иными словами, описываются некоторой моделью представления данных (моделью данных), поддерживаемой СУБД.
Объектом исследования являются следующие классических модели данных.
Иерархическая;
Сетевая;
Реляционная;
Кроме того, в последние годы появились и стали более активно внедряться на практике следующие модели данных:
постреляционная;
многомерная;
объектно-ориентированная.
Разрабатываются также всевозможные
системы, основанные на других моделях
данных, расширяющих известные модели.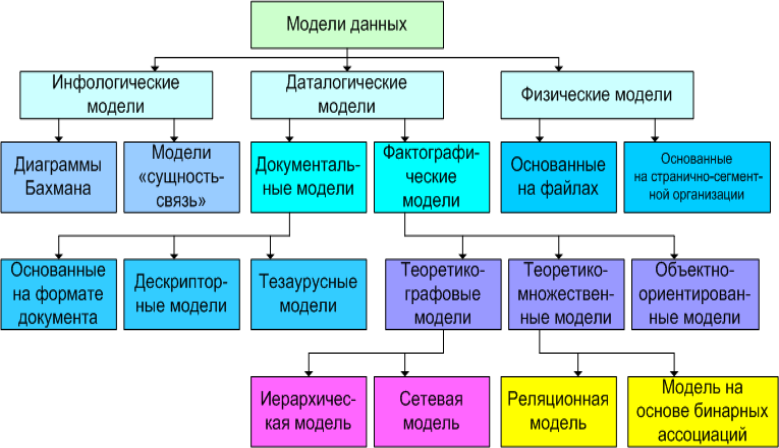 B их числе можно назвать объектно-реляционные,
дедуктивно-объектно-ориентированные,
семантические, концептуальные и
ориентированные модели. Некоторые из
этих моделей служат для интеграции баз
данных, баз знаний и языков программирования.
B их числе можно назвать объектно-реляционные,
дедуктивно-объектно-ориентированные,
семантические, концептуальные и
ориентированные модели. Некоторые из
этих моделей служат для интеграции баз
данных, баз знаний и языков программирования.
B некоторых СУБД поддерживаются одновременно несколько моделей данных. Например, в системе ИНТЕРБАЗА для приложений применяется сетевой язык манипулирования данными, а в пользовательском интерфейсе реализованы языки SQL и QBE.
Цель работы — описать структуру каждой модели данных, недостатки и достоинства, привести примеры использования в практике каждой модели.
Задачи исследования:
Изучить иерархическую модель данных;
Изучить сетевую модель данных;
Изучить реляционную модель данных;
Изучить постреляционную модель данных;
Изучить многомерную модель данных;
Изучить объектно-ориентированную модель данных;
Сравнить классические модели данных.

Теоретическая основа исследования – структуры моделей, представление связей, недостатки и достоинства, каждой модели. Использованы работы авторов: А.И. Мишенин, И.Г. Семакин, Е.К. Хеннер, Г.Н. Смирнова, А.А. Сорокин, Ю.Ф. Тельнов, А.Д. Хомоненко, В.М. Цыганков, М.Г. Мальцев
Глава I. Классические модели данных
Классическая модель — Энциклопедия по машиностроению XXL
Перечисленные выше причины изменения показателя преломления связаны с воздействием поля световой волны на концентрацию и ориентацию молекул, т. е. на ее внешние степени свободы. Рассмотрим теперь влияние поля на поляризуемость молекулы. При выяснении этого вопроса будем исходить из простой классической модели, подробно обсужденной в 156. Согласно этой модели, поляризация среды определяется смещением х электронов из их положений равновесия, причем [c.835]Пространство и время.
 Механическое движение происходит в пространстве и времени. В теоретической механике в качестве моделей реальных пространства и времени принимаются их простейшие модели — абсолютное пространство и абсолютное время, существование которых постулируется. Абсолютные пространство и время считаются независимыми одно от другого в этом состоит основное отличие классической модели пространства и времени от их модели в теории относительности, где пространство и время взаимосвязаны.
[c.13]
Механическое движение происходит в пространстве и времени. В теоретической механике в качестве моделей реальных пространства и времени принимаются их простейшие модели — абсолютное пространство и абсолютное время, существование которых постулируется. Абсолютные пространство и время считаются независимыми одно от другого в этом состоит основное отличие классической модели пространства и времени от их модели в теории относительности, где пространство и время взаимосвязаны.
[c.13]Физическая природа диамагнетизма может быть понята на основе классической модели атома, в которой считается, что электроны движутся вокруг ядра по замкнутым орбитам. Каждая электронная орбита аналогична витку с током. Поведение витка с током в магнитном поле хорошо известно из теории электромагнетизма. Согласно закону Ленца, при изменении магнитного потока, пронизывающего контур с током, в контуре возникает э. д. с. индукции, в результате чего изменяется ток. Это приводит к появлению дополнительного магнитного момента, направленного так, чтобы противодействовать внешнему магнитному полю. Другими словами, индуцированный магнитный момент направлен против поля. В контуре, образуемом. движущимся по орбите электроном, в отличие от обычного витка с током сопротивление равно нулю. Вследствие этого, индуцированный магнитным полем ток сохраняется до тех пор, пока существует поле. Магнитный момент, связанный с этим током, и есть диамагнитный момент.
[c.322]
Другими словами, индуцированный магнитный момент направлен против поля. В контуре, образуемом. движущимся по орбите электроном, в отличие от обычного витка с током сопротивление равно нулю. Вследствие этого, индуцированный магнитным полем ток сохраняется до тех пор, пока существует поле. Магнитный момент, связанный с этим током, и есть диамагнитный момент.
[c.322]
В то же время формула (10.18), из которой получено выражение для парамагнитной восприимчивости, противоречит третьему началу термодинамики. При 7-vO К энтропия системы должна стремиться к нулю. Вычисление энтропии в рамках классической модели парамагнетизма Ланжевена приводит к тому, что 5- — оо при К. Причина этого противоречия заключается в том, что [c.326]
Если два состояния системы обладают одинаковой энергией, то их часто называют вырожденными. К сожалению, термин вырожденные может иметь два совершенно разных значения. Здесь оно использовано в том смысле, что электронная теплоемкость вырождается (деградирует) по сравнению с ее большим значением, вытекаемым из классических моделей.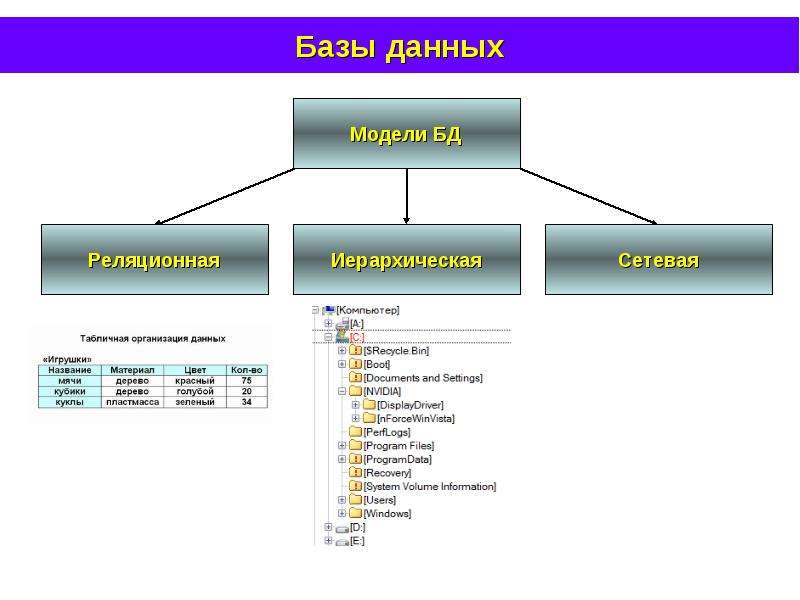 Ряд других свойств также вырождается в результате квантовых ограничений, поэтому говорят, что в металле имеется сильно вырожденный электронный газ . И в полупроводниках электронный газ может быть как вырожденным, так и невырожденным в зависимости от того, имеется ли достаточное число свободных электронов, чтобы стали существенными квантовые ограничения движения электронов.
[c.126]
Ряд других свойств также вырождается в результате квантовых ограничений, поэтому говорят, что в металле имеется сильно вырожденный электронный газ . И в полупроводниках электронный газ может быть как вырожденным, так и невырожденным в зависимости от того, имеется ли достаточное число свободных электронов, чтобы стали существенными квантовые ограничения движения электронов.
[c.126]
Наглядное представление о происхождении колебательных спектров можно получить на основе классической модели колебания двухатомной молекулы. Согласно электромагнитной теории света, излучение и поглощение электромагнитной энергии связано с движущимися зарядами. Величина излучаемой и поглощаемой энергии зависит от изменения дипольного момента молекулы при ее колебании. Если дипольный момент при колебании не меняется, то излучения или поглощения энергии не происходит. [c.97]
Весьма интересно еще одно следствие из выражения (5.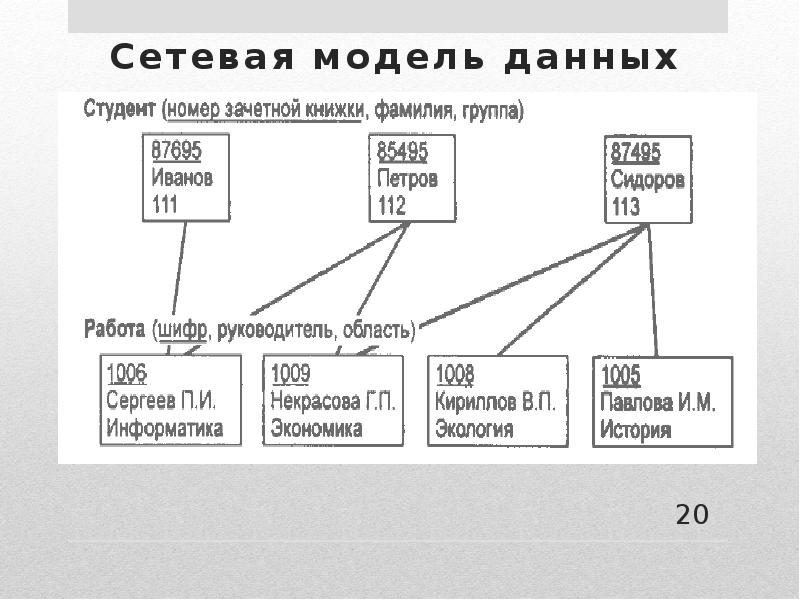 1). Оно означает, что электрон в периодическом поле кристаллической решетки, состоящей из неподвижных атомов, имеет стационарные, не зависящие от времени энергетические уровни и может бесконечно долго двигаться, не теряя средней скорости и не испытывая сопротивления. Этот результат явно противоречит более ранним представлениям об электропроводности кристаллов, указывая на ограниченность классической модели.
[c.88]
1). Оно означает, что электрон в периодическом поле кристаллической решетки, состоящей из неподвижных атомов, имеет стационарные, не зависящие от времени энергетические уровни и может бесконечно долго двигаться, не теряя средней скорости и не испытывая сопротивления. Этот результат явно противоречит более ранним представлениям об электропроводности кристаллов, указывая на ограниченность классической модели.
[c.88]
Спин. Из экспериментальных данных по дублетной структуре спектров щелочных металлов (см. 33) следует, что электрон обладает собственным моментом импульса, получившим название спина. Объяснить возникновение спина какой-то классической моделью оказалось невозможным. Спин является первоначальным свойством электрона, и задача заключается не в том, чтобы объяснить, а в том, чтобы описать его. [c.211]
Скорость деформации ед.п, основанная на классической модели диффузионной ползучести с учетом данных Набарро —Херринга, выражается так
[c. 564]
564]
Классические модели линейной теории упругости изотропных или анизотропных кристаллических или других сред описывают далеко не все явления, происходящие при деформировании твердых тел. [c.410]
Так как в задачах о распространении волн характерный размер неоднородности деформации имеет первостепенную важность, первой тестовой задачей, из которой можно извлечь информацию о пригодности той или иной теории к исследованию динамического поведения, является задача распространения гармонических волн в бесконечной композиционной среде. Характерным размером здесь является длина волны Л, которая обычно вводится при помощи волнового числа k = 2я/Л. При наличии дисперсии гармонические волны различной длины распространяются с разными скоростями. Теория эффективных модулей непригодна для описания этого факта, так как классическая модель анизотропного континуума не может объяснить явление дисперсии свободных гармонических волн, которое имеет место в композиционной среде достаточной протяженности в том случае, когда длина волны имеет тот же порядок, что и характерный размер структуры. Для слоистой среды,
[c.357]
Для слоистой среды,
[c.357]
Общие особенности задачи определения главных колебаний хорошо объясняются на простой классической модели, которая дает полное представление о поведении линейной трехатомной молекулы. В этой модели материальная точка массы М упруго связана с двумя другими материальными точками, каждая из которых имеет массу т. В каждом случае упругая постоянная равна р, и в положении равновесия точки находятся на одной прямой на одинаковых расстояниях одна от другой при этом рассматривается движение только по прямой (см. рис. 2). [c.52]
Абсолютно черных тел в том понимании, как они были определены в 1-1 и 1-2, в природе не существует. Классической моделью абсолютно черного тела является [c.283]
Надежность является одной из основных проблем современной техники. Благодаря совместным усилиям специалистов различного профиля, в том числе инженеров, математиков, экономистов, в настоящее время в этой области достигнуты значительные успехи. Для повышения надежности используются разнообразные методы, затрагивающие вопросы технологии, конструкции, структуры и правил эксплуатации технических систем. Одним из основных методов повышения надежности является введение избыточности, в частности, структурное (аппаратурное) резервирование. Структурное резервирование в течение длительного времени считалось универсальным методом, позволяющим создавать из ненадежных элементов сколь угодно надежные системы [89]. Однако при схемной реализации этот метод не является столь безукоризненным, как это следует из классических моделей надежности, прежде всего из-за наличия в элементах двух типов отказов, неидеальности переключателя резерва, перераспределения нагрузки при отказах отдельных элементов. Поэтому внимание разработчиков сложных систем в последние годы все чаще обращается к другим видам избыточности, в частности к временной.
[c.3]
Для повышения надежности используются разнообразные методы, затрагивающие вопросы технологии, конструкции, структуры и правил эксплуатации технических систем. Одним из основных методов повышения надежности является введение избыточности, в частности, структурное (аппаратурное) резервирование. Структурное резервирование в течение длительного времени считалось универсальным методом, позволяющим создавать из ненадежных элементов сколь угодно надежные системы [89]. Однако при схемной реализации этот метод не является столь безукоризненным, как это следует из классических моделей надежности, прежде всего из-за наличия в элементах двух типов отказов, неидеальности переключателя резерва, перераспределения нагрузки при отказах отдельных элементов. Поэтому внимание разработчиков сложных систем в последние годы все чаще обращается к другим видам избыточности, в частности к временной.
[c.3]
Возможности классической модели.
 В основу теории оболочек положена модель, представленная на рис. 1.1. Как отмечено выше, эта модель ТТО привела к появлению ряда неустранимых противоречий в рамках теории. В настоящее время появились работы, относящиеся к общим вопросам теории оболочек [6, 8, 11, 18, 21,
[c.6]
В основу теории оболочек положена модель, представленная на рис. 1.1. Как отмечено выше, эта модель ТТО привела к появлению ряда неустранимых противоречий в рамках теории. В настоящее время появились работы, относящиеся к общим вопросам теории оболочек [6, 8, 11, 18, 21,
[c.6]В то же время анализ классической модели ТТО [18] свидетельствует о возможностях, заложенных в ее метод, уже позволяющих перейти к инвариантным разрешающим уравнениям. [c.6]
| Рис. 1.1. Классическая модель оболочки |
 15]
15]В соответствии с классической моделью (рис. 1.1) необходимо решать систему конечно-разностных (2.17), а не дифференциальных уравнений. Отождествление же системы (2.17) с аналогично выглядящей системой дифференциальных уравнений требует математического обоснования и разрешения противоречий в соотношениях (2.10) и (2.12). В классической ТТО и пластин этот анализ отсутствует. [c.22]
Из этого вывода и вывода (2.18) следует, что классическая модель ТТО приводит к необходимости использования асимптотического представления функций, описывающих НДС элемента. Из [c.23]
Классическая модель ТТО приводит к возможности использования асимптотических преобразований. [c.25]
Как видим, система уравнений неразрывности не обеспечивает сплошности континуума. Для того чтобы уравнения сплошности выполнялись, необходимо уменьшить размеры элемента оболочки до dsi системе уравнений равновесия, внешне похожей на классическую форму записи, не соответствует условие сплошности, и система приводит к разрывам в оболочке. [c.26]
[c.26]
Итак, классическая модель включает в себя неустранимое противоречие между системой уравнений равновесия и неразрывности. Это означает, что она может привести к внутренней неустойчивости всей системы взглядов в некоторых случаях, о которых говорилось, к примеру, выше. Для преодоления этого противоречия и придания всей системе ТТО внутренней устойчивости необходимо построение модели, которая позволит обоснованно использовать аппарат дифференциального исчисления. [c.26]
Модель теории тонких оболочек, предложенная в настоящей работе, позволяет представлять НДС оболочки в виде двумерного потока в слое, ограниченном поверхностями (+Л —Л), а также вводить меньшую по сравнению с классической моделью ТТО степень усреднения компонент НДС. При этом становится возможным использовать действительно локальные свойства математической модели (ASi- 0), перейти к теории, рассматривающей третью квадратичную форму поверхности и упростить разрешающие уравнения, снизить их порядок, привести к инвариантному относительно преобразования координат виду. [c.42]
[c.42]
Ввиду кратковременности действия силы классическая модель Бер- . 1. 1и — Эйлера недостаточно точна, приходится пользоваться моделью I Н. Тимошенко. Численная реализация таких решений требует большого расхода машинного времени, поэтому представляет интерес построение приближенных моделей. [c.71]
В некоторых случаях многофазная смесь может быть описана в рамках одной из известных классических моделей, в которых неоднородность отражается в значениях модулей, коэффициентов сжимаемости, теплоемкостей и т. д. (заранее определяемых через физические свойства фаз), т. е. только в уравнениях состояния смеси (см. 5 гл. 1). Например, жидкость с пузырями может иногда описываться в рамках идеальной сжимаемой жидкости, а грунт — в рамках упругой или упруго-пластической модели. Но при более интенсивных нагрузках, скоростях движения или в ударных процессах эти классические модели обычно перестают работать и требуется введение новых моделей и новых параметров, в частности, последовательно учитывающих неоднофазность, а именно существенно различное поведение фаз (различие плотностей, скоростей, давлений, температур, деформаций и т.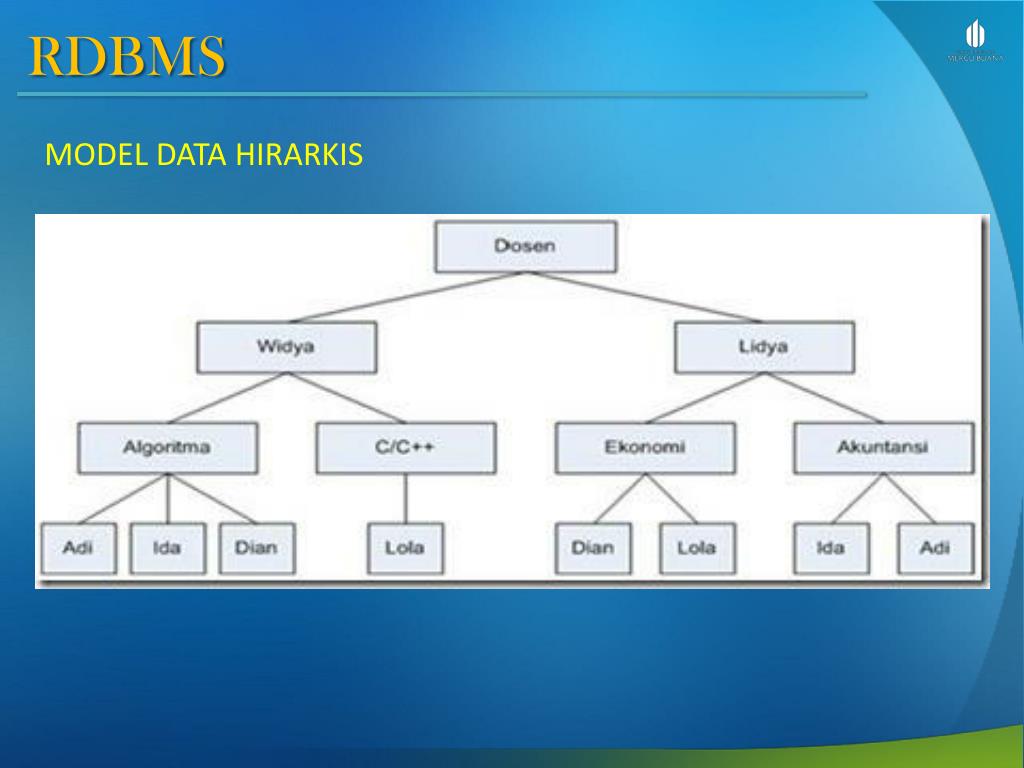 д.) и взаимодействие фаз между собой. При этом проблема математического моделирования без привлечения дополнительных эмпирических или феноменологических соотношений и коэффициентов достаточно строго и обоснованно (например, методом осреднения более элементарных уравнений) может быть решена только для очень частных классов гетерогенных смесей и процессов. Эти случаи тем не менее представляют большое методическое значение, так как соответствующие им уравнения могут рассматриваться в качестве предельных или эталонов, дающих опорные пункты при менее строгом моделировании сложных реальных смесей, с привлечением дополнительных гипотез и феноменологических соотношений. Два таких предельных случая подробно рассмотрены в 5, 6 гл. 3.
[c.6]
д.) и взаимодействие фаз между собой. При этом проблема математического моделирования без привлечения дополнительных эмпирических или феноменологических соотношений и коэффициентов достаточно строго и обоснованно (например, методом осреднения более элементарных уравнений) может быть решена только для очень частных классов гетерогенных смесей и процессов. Эти случаи тем не менее представляют большое методическое значение, так как соответствующие им уравнения могут рассматриваться в качестве предельных или эталонов, дающих опорные пункты при менее строгом моделировании сложных реальных смесей, с привлечением дополнительных гипотез и феноменологических соотношений. Два таких предельных случая подробно рассмотрены в 5, 6 гл. 3.
[c.6]
Существует много способов определения среднего времени жизни возбужденного атома. Остановимся на очень интересном и получившем в последнее время широкое распростра.чение оп-тико-магнитном методе. Поясним его на классической модели, полностью описывающей явление лишь в некоторых частных случаях, но качественно отражающей и общее решение задачи. [c.229]
[c.229]
Заключгпельная часть/»лови 3 (раздеты 3.S — 3.7) посвящена описанию фрактальной модели образования критических зародышей, которая является альтернативной по отношению к классической модели зародышеобразования Опираясь на эту модель, производится описание механизмов дальнейшего роста критических зародышей в процессе кристаллизации [c.3]
Глава 3 посвящена вопросам формирования конструкционных материалов В ее первой части (раздел 3.1) рассматриваются различные аспекты процесса кристаллизации металлических материалов. Приводятся классические сведения об атомно-кристаллическом строении твердых тел. Оригинальным является изложение фрактальной модели формирования зародыша кристаллизации, при по-мощи которой объясняется энергетическое несоответствие, имеющее место в классической модели. Интересна также ориганальная иерархическая модель роста зародыша и описание эффектов посткрисгаллизации. Посткристаллизация является чрезвычайно важным этапом формирования материала, но даже в специальной литературе, на наш взгляд, этому явлению уделяется недостаточное внимание. [c.8]
[c.8]
В чем отличие классической модели образования зародышей новой фазы но флуктуа-ционному механизму и фуллереиной модели [c.377]
Соотпсшения, выражают,по влияние взаимодействия магнитных ионов на восприимчивость, былз впервые получены Лоренцем и Онзагером. Расчеты последних основывались на классических моделях соответствующие формулы ужо обсуждались в и. 7. Можно использовать разложение в ряд Ван-Флека с прибавлением к энергии ионов члена — E jui [c.467]
В определенных физических ситуациях модель квантового объекта сводится в своей существенной части либо к классической модели волны, либо к классической модели маге-риальной точки. В этих случаях квантовый объект приобретает наглядный классический образ и хорошо описы-ваел ся соогвегствующей классической моделью. [c.37]
При увеличении интенсивности возбуждающего света возникает вынужденное комбинационное рассеяние света. Оно обусловлено тем, что возникшее в результате рассеяния излучение на комбинационных частотах в свою очередь становится возбуждающим излучением, которое действует на молекулы рассеивателя. Благодаря этому в молекулах происходит раскачка колебаний, приводящая к усилению пербизлучения на комбинационных частотах. Если рассмотреть этот процесс в классической модели излучения по этапам, то он развивается следующим образом. Суммарное электрическое поле падающей и рассеянной волн вызывает поляризацию молекулы, а возникающий при этом дипольный момент молекулы пропорционален суммарной напряженности электрического поля падающей и рассеянной волн, т. е. колеблется с соответствующей комбинационной частотой. Благодаря этому потенциальная энергия взаимодействия ядер в молекуле изменяется на величину, пропорциональную произведению дипольного момента на квадрат суммарного электрического поля.
[c.267]
Оно обусловлено тем, что возникшее в результате рассеяния излучение на комбинационных частотах в свою очередь становится возбуждающим излучением, которое действует на молекулы рассеивателя. Благодаря этому в молекулах происходит раскачка колебаний, приводящая к усилению пербизлучения на комбинационных частотах. Если рассмотреть этот процесс в классической модели излучения по этапам, то он развивается следующим образом. Суммарное электрическое поле падающей и рассеянной волн вызывает поляризацию молекулы, а возникающий при этом дипольный момент молекулы пропорционален суммарной напряженности электрического поля падающей и рассеянной волн, т. е. колеблется с соответствующей комбинационной частотой. Благодаря этому потенциальная энергия взаимодействия ядер в молекуле изменяется на величину, пропорциональную произведению дипольного момента на квадрат суммарного электрического поля.
[c.267]
Понятие сплошной среды не так просто, как может показаться на первый взгляд и как это казалось подавляющему большинству ученых в XIX и первой половине XX столетий. Оказывается, что можно строить разные модели сплошной среды, наделяя их разными свойствами. Простейшая модель, которую мы будем называть классической моделью, вводится следующим образом. Примем за основное первичное понятие материальную точку. В кинематике это понятие тождественно с понятием геометрической точкп. Можно представить себе точку как сферу бесконечно малого радиуса. При стремлении радиуса к нулю единственной величиной, индивидуализирующей точку, остается радиус-вектор центра сферы или три числа — координаты точки. Представляя себе некоторую замкнутую область пространства непрерывно заполненной точками, мы получим модель сплошной среды. Пусть Xio — координаты некоторой точки в момент времени to. При движении среды координаты данной точки меняются, в момент t они принимают значения Xi t). Движение среды полностью задано, если функции Xi(t) для каждой индивидуальной точки известны. Именно так определяется кинематика классической модели сплошной среды. До недавнего времени эта модель была единственной, на основе ее строились все механические теории.
Оказывается, что можно строить разные модели сплошной среды, наделяя их разными свойствами. Простейшая модель, которую мы будем называть классической моделью, вводится следующим образом. Примем за основное первичное понятие материальную точку. В кинематике это понятие тождественно с понятием геометрической точкп. Можно представить себе точку как сферу бесконечно малого радиуса. При стремлении радиуса к нулю единственной величиной, индивидуализирующей точку, остается радиус-вектор центра сферы или три числа — координаты точки. Представляя себе некоторую замкнутую область пространства непрерывно заполненной точками, мы получим модель сплошной среды. Пусть Xio — координаты некоторой точки в момент времени to. При движении среды координаты данной точки меняются, в момент t они принимают значения Xi t). Движение среды полностью задано, если функции Xi(t) для каждой индивидуальной точки известны. Именно так определяется кинематика классической модели сплошной среды. До недавнего времени эта модель была единственной, на основе ее строились все механические теории.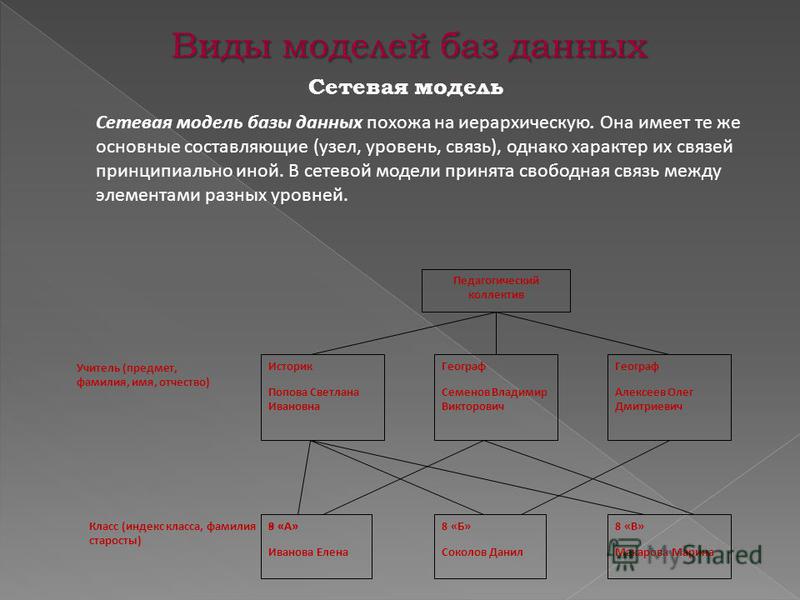 Но можно представить себе и иные сплошные среды, наделенные некоторой внутренней структурой. Будем рассматривать, например, материальную точку как бесконечно малый эллипсоид. Устремляя его размеры к нулю и сохраняя при этом нанравления главных осей, мы получим среду, с каж-
[c.22]
Но можно представить себе и иные сплошные среды, наделенные некоторой внутренней структурой. Будем рассматривать, например, материальную точку как бесконечно малый эллипсоид. Устремляя его размеры к нулю и сохраняя при этом нанравления главных осей, мы получим среду, с каж-
[c.22]
Можно пойти дальше по этому пути и предположить, что взаимодействие осуществляется также посредством некоторых образований типа рассмотренных в конце предыдущего параграфа двойных сил, которые распределены по поверхности непрерывно. В современных теориях сплошных сред подобные предположения делаются, однако значение их состоит скорее в иллюстрации весьма большой степени общности, которая может быть достигнута в рамках представления о сплошной среде и о потенциальной возможности значительного расширения этих рамок с тем, чтобы описать эффекты, относимые обычно за счет дискретности строения реальных тел. Но существующие теории, уже нашедшие применения к реальным объектам, строятся почти искючительно на основе классической модели, которая до недавнего времени представлялась совершенно очевидной и единственно возможной. [c.31]
[c.31]
В подавляющем большинстве кристаллов атомы настолько массивны и взаимодействуют настолько сильно, что амплитуда их нулевых колебаний оказывается значительно меньше межатомного расстояния. В таких кристаллах весьма хорошим приближением является обычная классическая модель, согласно которой атомы лока-лизованы в узлах или междоузлиях кристаллической решетки. В идеальном случае такая решетка может рассматриваться как периодическая в трех направлениях структура локализованных в определенных точках атомов, а отклонения от идеальности — как дефекты кристаллической решетки. [c.32]
В классической модели магнитный момент атома водорода в нормальном (невозбужденном) состоянии легко рассчитывается следующим образом. Отношение заряда злектрона к периоду его обращения в атоме предетавляет собой силу тока [c.310]
Если рассматривать классические модели, для которых (L/dг)м= (L/dг)н и Ре1 =Ке1н, то соотношение упрощается. [c.238]
[c.238]
В заключение необходимо отметить, что принцип многокамер-ности позволяет получить любые заданные размеры площади излучающей поверхности, что обуславливается лишь количеством ячеек и возможностью обеспечения одинаковой температуры по поверхности ячеек. С увеличением диаметра излучающей площади осевой размер модели будет оставаться таким же небольшим (например, 70 мм), как в данных конетрукциях. В этом существенное преимущество многокамерного черного тела перед классической моделью, выполняемой в виде одной полости. [c.70]
При fj = onst это классическая модель (1.9) вязкой ньютоновской жидкости. Коэффициент знакопеременной вязкости согласно модели Новикова-Яненко [99, 100] имеет вид [c.85]
В данном томе обобщены последние мировые достижения в современной теории и методах расчета деталей и узлов машин. В рамках принятых гипотез и моделей — это точные методы расчета динамических и тепловых нагрузок, напряженно-деформированного состояния, статической и динамической устойчивости. В качестве расчетных классических моделей рассмотрены систехш с распределенными параметрами применительно к моделям стержней, пластин, оболочек и др. [c.15]
Восьмой, девятый и десятый разделы тома (хн. 2) ПОСВ.ЯЩ6НЫ изложению теории и методам расчета напряженно-деформированного состояния классических моделей прикладной механики — стержней и стержневых систем, пластин и оболочек, дисков и. толстостенных труб с учето.м свойств пластичности и ползучести материала, в линейной и нелинейной постановках. Рассмотрены задачи устойчивосги и кoJseбaний, даны методы численного расчета. [c.16]
Средство миграции, поддерживаемое платформой. — Azure Virtual Machines
- Чтение занимает 12 мин
В этой статье
Важно!
Сегодня примерно на 90 % виртуальных машин IaaS используется служба Azure Resource Manager. По состоянию на 28 февраля 2020 г. классические виртуальные машины являются устаревшими и будут полностью выведены из эксплуатации до 1 марта 2023 г. Узнайте больше об этом устаревании и о том, как оно влияет на вас.
Давайте подробно рассмотрим миграцию из классической модели развертывания Azure в модель развертывания с помощью Azure Resource Manager. Мы рассмотрим ресурсы на уровне ресурсов и функций. Это поможет вам понять, как платформа Azure переносит ресурсы между двумя моделями развертывания. Чтобы получить дополнительную информацию, прочтите статью с объявлением о выпуске службы Поддерживаемый платформой перенос ресурсов IaaS из классической модели в модель Azure Resource Manager.
Перенос ресурсов IaaS из классической модели развертывания в модель развертывания с помощью Azure Resource Manager
Во-первых, важно понимать разницу между операциями плоскости данных и плоскости управления в инфраструктуре как услуге (IaaS).
- Плоскость управления описывает вызовы, поступающие в плоскость управления или API для изменения ресурсов. Например, такие операции, как создание виртуальной машины, перезапуск виртуальной машины и добавление в виртуальную сеть новой подсети, оперируют работающими ресурсами. Они не оказывают непосредственного влияния на подключение к виртуальным машинам.
- Плоскость данных (приложение) описывает среду выполнения приложения, включая взаимодействие с экземплярами, которое не осуществляется через API Azure. Например, доступ к веб-сайту или извлечение данных из работающего экземпляра SQL Server или сервера MongoDB считаются операциями в плоскости данных или взаимодействием с приложением. К другим примерам относятся копирование большого двоичного объекта из учетной записи хранения и доступ к общедоступному IP-адресу для подключения к виртуальной машине с помощью протокола удаленного рабочего стола (RDP) или Secure Shell (SSH). Эти операции обеспечивают рабочее состояние приложения для вычислительных и сетевых ресурсов, а также ресурсов хранения.
В классической модели развертывания и стеках Resource Manager используется одна и та же плоскость данных. Разница в том, что в процессе переноса Майкрософт преобразует представление ресурсов из классической модели развертывания в представление в стеке Resource Manager. Поэтому для управлениями ресурсами в стеке Resource Manager необходимо использовать новые средства, API-интерфейсы и пакеты SDK.
Примечание
В некоторых сценариях миграции платформа Azure останавливает, освобождает и перезапускает виртуальные машины. Этот приводит к кратковременному отключению плоскости данных.
Процесс миграции
Перед началом миграции сделайте следующее:
- Убедитесь, что ресурсы, которые вы хотите перенести, не используют какие-либо неподдерживаемые компоненты или конфигурации. Обычно платформа обнаруживает такие проблемы и выдает ошибку.
- В ходе подготовки виртуальные машины, которые не находятся в виртуальной сети, останавливаются, а их распределение отменяется. Если вы не хотите потерять общедоступный IP-адрес, зарезервируйте его, прежде чем начать подготовку. Если виртуальные машины расположены в виртуальной сети, они не будут остановлены и их распределение не будет отменено.
- Планируйте провести миграцию в нерабочее время, чтобы справиться с любыми непредвиденными сбоями, которые могут возникнуть.
- Скачайте текущую конфигурацию виртуальных машин с помощью PowerShell, команд интерфейса командной строки или интерфейсов REST API, чтобы упростить проверку после завершения подготовки.
- Обновите скрипты автоматизации и ввода в эксплуатацию для работы с моделью развертывания с помощью Resource Manager, прежде чем начать миграцию. При необходимости можно выполнять операции GET, пока ресурсы находятся в состоянии подготовки.
- Оцените политики управления доступом на основе ролей Azure (Azure RBAC), настроенные для ресурсов IaaS, развернутых с помощью классической модели, и составьте план на период после завершения миграции.
Ниже представлен рабочий процесс переноса:
Примечание
Все операции, описанные в следующих разделах, являются идемпотентными. Если вы столкнетесь с какой-либо проблемой, не связанной с неподдерживаемой функцией или ошибкой конфигурации, повторите подготовку, прервите или зафиксируйте текущую операцию. Платформа Azure попытается повторить действие.
Проверить
Операция проверки — это первый шаг в процессе переноса. На этом шаге анализируется состояние ресурсов, которые требуется перенести в классической модели развертывания. Эта операция проверяет, можно ли переносить ресурсы (результат проверки — успех или сбой).
Выберите виртуальную сеть или облачную службу (если она не является виртуальной сетью), которую нужно проверить перед переносом. Если ресурс нельзя перенести, Azure указывает причину.
Операция проверки ничего не проверяет
Эта операция только анализирует состояние ресурсов в классической модели развертывания. На этом этапе можно выполнить проверку на наличие всевозможных ошибок и неподдерживаемых сценариев в зависимости от различных конфигураций в классической модели развертывания. Однако невозможно проверить все ошибки, которые могут произойти при переносе ресурсов в стек Azure Resource Manager. Эти ошибки можно проверить только при преобразовании ресурсов на следующем этапе переноса, то есть на этапе подготовки. В следующей таблице перечислены все проблемы, которые не проверяет операция проверки.
| Операция проверки не проверяет работу сети. |
|---|
| Наличие шлюза ER и VPN-шлюза в виртуальной сети. |
| Отсутствие подключения к шлюзу виртуальной сети. |
| Все каналы ER, которые предварительно перенесены в стек Azure Resource Manager. |
| Проверки квот Azure Resource Manager на наличие сетевых ресурсов. Например: статический общедоступный IP-адрес, динамические общедоступные IP-адреса, подсистема балансировки нагрузки, группы безопасности сети, таблицы маршрутов и сетевые интерфейсы. |
| Проверка на допустимость всех правил подсистемы балансировки нагрузки в развернутой службе и в виртуальной сети. |
| Проверка на наличие конфликтующих частных IP-адресов на остановленных (освобожденных) виртуальных машинах в одной виртуальной сети. |
Подготовка.
Операция подготовки — это второй шаг в процессе переноса. На этом этапе моделируется преобразование ресурсов IaaS из классической модели развертывания в ресурсы Azure Resource Manager. Затем ресурсы отображаются на экране рядом для наглядности.
Примечание
Ресурсы в классической модели развертывания на этом этапе не изменяются. Поэтому вы можете уверенно выполнять этот шаг при пробном переносе.
Выберите виртуальную сеть или облачную службу (если она не является виртуальной сетью), которую нужно подготовить к переносу.
- Если ресурс не может быть перенесен, Azure остановит процесс переноса и укажет причину, по которой не удалось выполнить операцию подготовки.
- Если ресурс можно перенести, Azure заблокирует операции в плоскости управления для переносимых ресурсов. Например, вы не сможете добавить диск данных в виртуальную машину, которая переносится.
Затем Azure начнет перенос метаданных переносимых ресурсов из классической модели развертывания в модель развертывания с помощью Resource Manager.
После завершения подготовки можно будет визуализировать ресурсы в классической модели развертывания и в модели развертывания с помощью Resource Manager. Для каждой облачной службы в классической модели развертывания платформа Azure создает имя группы ресурсов по шаблону cloud-service-name>-Migrated.
Примечание
Нельзя выбрать имя группы ресурсов, созданной для перенесенных ресурсов (то есть -Migrated). Но после завершения переноса можно использовать функцию Azure Resource Manager для перемещения ресурсов в нужную группу ресурсов. Дополнительные сведения см. в статье Перемещение ресурсов в новую группу ресурсов или подписку.
Ниже приведены два снимка экрана, на которых показан результат успешной операции подготовки. На первом показана группа ресурсов, содержащая исходную облачную службу. На втором — группа ресурсов -Migrated, содержащая эквивалентные ресурсы Azure Resource Manager.
Ниже представлена фактическая схема ресурсов после завершения этапа подготовки. Обратите внимание, что в плоскости данных используется один и тот же ресурс. Он представлен в плоскости управления в классической модели развертывания и в плоскости управления в модели развертывания с помощью Resource Manager.
Примечание
Виртуальные машины, не входящие в виртуальную сеть в классической модели развертывания, на этом этапе переноса останавливаются, и их распределение отменяется.
Проверка (вручную или с помощью сценария)
На этапе проверки можно дополнительно использовать конфигурацию, скачанную ранее, чтобы проверить, правильно ли выполнен перенос. Можно также войти на портал и выборочно просмотреть свойства и ресурсы, чтобы проверить, правильно ли выполнен перенос метаданных.
В случае переноса виртуальной сети большинство конфигураций виртуальных машин не будут перезапущены. Но можно проверить, работают ли приложения на виртуальных машинах.
Можно проверить функцию мониторинга и рабочие скрипты, чтобы убедиться, что виртуальные машины и обновленные скрипты работают правильно. Если ресурсы находятся в состоянии подготовки, то для них доступны только операции GET.
Длительность переноса не фиксирована. В этом состоянии время не ограничено. Тем не менее плоскость управления для этих ресурсов будет заблокирована, пока не будет выполнено прерывание или фиксация.
Если возникнут какие-либо неполадки, всегда можно прервать миграцию и вернуться к классической модели развертывания. После этого Azure разблокирует операции с ресурсами в плоскости управления, чтобы вы могли возобновить обычную работу этих виртуальных машин в классической модели развертывания.
Прерывание
Это необязательный шаг, который позволяет отменить изменения в классической модели развертывания и прервать миграцию. Эта операция удаляет метаданные Resource Manager для ресурсов, созданные на этапе подготовки.
Примечание
Эту операцию нельзя выполнить, если вы начали фиксацию.
Commit
После завершения проверки миграцию можно зафиксировать. Ресурсы больше не будут отображаться в классической модели развертывания. Они будут доступны только в модели развертывания с помощью Resource Manager. Перенесенными ресурсами можно управлять только на новом портале.
Примечание
Эта идемпотентная операция. Если не удалось выполнить операцию, повторите ее. Если проблема не будет устранена, создайте запрос в службу поддержки или опубликуйте вопрос на странице Microsoft Q&A.
Блок-схема миграции
Ниже представлена блок-схема, на которой показано, как выполнить перенос:
Преобразование ресурсов классической модели развертывания в ресурсы модели развертывания с помощью Resource Manager
В таблице ниже представлены ресурсы в классической модели развертывания и в модели развертывания с помощью Resource Manager. Остальные функции и ресурсы в настоящий момент не поддерживаются.
| Представление классической модели | Представление Resource Manager | Примечания |
|---|---|---|
| Имя облачной службы (имя размещенной службы) | DNS-имя | Во время миграции для каждой облачной службы создается новая группа ресурсов, которая именуется по шаблону <cloudservicename>-migrated. Эта группа ресурсов содержит все ваши ресурсы. Имя облачной службы становится DNS-именем, связанным с общедоступным IP-адресом. |
| Виртуальная машина | Виртуальная машина | Свойства, относящиеся к виртуальной машине, переносятся без изменений. Определенные данные osProfile, например имя компьютера, не хранятся в классической модели развертывания. После миграции они остаются пустыми. |
| Ресурсы дисков, подключенные к виртуальной машине | Скрытые диски, подключенные к виртуальной машине | Диски не моделируются в виде ресурсов верхнего уровня в модели развертывания с помощью Resource Manager. Они переносятся в качестве скрытых дисков в виртуальной машине. В настоящее время поддерживаются только диски, подключенные к виртуальной машине. Теперь виртуальные машины Resource Manager могут использовать учетные записи хранения в классической модели развертывания, что позволяет легко перенести диски без изменений. |
| Расширения виртуальных машин | Расширения виртуальных машин | Все расширения ресурсов (кроме расширений XML) переносятся из классической модели развертывания. |
| Сертификаты виртуальных машин | Сертификаты в хранилище ключей Azure | Если облачная служба содержит сертификаты службы, процесс миграции создаст новое хранилище ключей Azure для каждой облачной службы и переместит сертификаты в это хранилище ключей. В виртуальных машинах будут обновлены ссылки на сертификаты из хранилища ключей. Не удаляйте хранилище ключей. Если это сделать, виртуальная машина может перестать работать. |
| Конфигурация WinRM | Конфигурация WinRM в osProfile | Конфигурация службы удаленного управления Windows в ходе миграции перемещается без изменений. |
| Свойство группы доступности | Ресурс группы доступности | Спецификация группы доступности является свойством виртуальной машины в классической модели развертывания. Группы доступности становятся ресурсами верхнего уровня в ходе миграции. Не поддерживаются следующие конфигурации: несколько групп доступности на одну облачную службу либо одна или несколько групп доступности с виртуальными машинами, которые не находятся в какой-либо группе доступности в облачной службе. |
| Конфигурация сети в виртуальной машине | Основной сетевой интерфейс | Конфигурация сети в виртуальной машине после миграции представлена ресурсом основного сетевого интерфейса. У виртуальных машин, которые не находятся в виртуальной сети, при миграции изменится внутренний IP-адрес. |
| Несколько сетевых интерфейсов в виртуальной машине | Сетевые интерфейсы | Если с виртуальной машиной связано несколько сетевых интерфейсов, в ходе миграции каждый из них (и все соответствующие свойства) становится ресурсом верхнего уровня. |
| Набор конечных точек с балансировкой нагрузки | Подсистема балансировки нагрузки | В классической модели развертывания платформа назначает скрытый балансировщик нагрузки для каждой облачной службы. Во время миграции создается новый ресурс балансировщика нагрузки, а набор конечных точек с балансировкой нагрузки преобразовывается в правила балансировщика нагрузки. |
| Правила преобразования сетевых адресов для входящих подключений | Правила преобразования сетевых адресов для входящих подключений | При миграции входные конечные точки, определенные на виртуальной машине, преобразовываются в правила преобразования сетевых адресов для входящих подключений в балансировщике нагрузки. |
| Виртуальный IP-адрес | Общедоступный IP-адрес с DNS-именем | Виртуальный IP-адрес становится общедоступным IP-адресом, связанным с подсистемой балансировки нагрузки. Виртуальный IP-адрес можно перенести только в том случае, если ему назначена входная конечная точка. |
| Виртуальная сеть | Виртуальная сеть | Виртуальная сеть и все ее свойства переносятся в модель развертывания с помощью Resource Manager. Создается новая группа ресурсов с именем -migrated. |
| Зарезервированные IP-адреса | Общедоступный IP-адрес с методом статического выделения | Зарезервированные IP-адреса, связанные с балансировщиком нагрузки, переносятся вместе с облачной службой или виртуальной машиной. Несвязанные зарезервированные IP-адреса можно перенести с помощью командлета Move-AzureReservedIP. |
| Общедоступный IP-адрес для каждой виртуальной машины | Общедоступный IP-адрес с методом динамического выделения | Общедоступный IP-адрес, связанный с виртуальной машиной, преобразуется в ресурс общедоступного IP-адреса со статическим методом выделения. |
| Группы NSG | Группы NSG | Группы безопасности сети, связанные с подсетью, в ходе миграции клонируются в модель развертывания с помощью Resource Manager. Группа безопасности сети в классической модели развертывания не удаляется в ходе миграции. Однако на период миграции для группы безопасности сети блокируются операции в плоскости управления. Несвязанные группы безопасности сети можно перенести с помощью командлета Move-AzureNetworkSecurityGroup. |
| «Серверы DNS» | «Серверы DNS» | DNS-серверы, связанные с виртуальной сетью или виртуальной машиной, переносятся в ходе миграции соответствующего ресурса вместе со всеми свойствами. |
| Определяемые пользователем маршруты | Определяемые пользователем маршруты | Определяемые пользователем маршруты, связанные с подсетью, в ходе миграции клонируются в модель развертывания с помощью Resource Manager. Определяемый пользователем маршрут (UDR) в классической модели развертывания не удаляется в ходе миграции. На период миграции для определяемого пользователем маршрута блокируются операции в плоскости управления. Несвязанные определяемые пользователем маршруты можно перенести с помощью командлета Move-AzureRouteTable. |
| Свойство IP-пересылки в конфигурации сети виртуальной машины | Свойство IP-пересылки в сетевой карте | Свойство IP-пересылки в виртуальной машине во время миграции преобразуется в свойство в сетевом интерфейсе. |
| Балансировщик нагрузки с несколькими IP-адресами | Балансировщик нагрузки с несколькими ресурсами IP-адресов | Каждый общедоступный IP-адрес, связанный с подсистемой балансировки нагрузки, после миграции преобразуется в ресурс общедоступного IP-адреса и связывается с подсистемой балансировки нагрузки. |
| Внутренние DNS-имена в виртуальной машине | Внутренние DNS-имена в сетевой карте | Во время миграции внутренние DNS-суффиксы виртуальных машин переносятся в свойство только для чтения InternalDomainNameSuffix в сетевой карте. После миграции суффикс не изменяется. Разрешение виртуальной машины также не должно измениться. |
| Шлюз виртуальной сети | Шлюз виртуальной сети | Свойства шлюза виртуальной сети переносятся без изменений. Виртуальный IP-адрес, связанной со шлюзом, также не меняется. |
| Сайт локальной сети | Шлюз локальной сети | Свойства сайта локальной сети переносятся без изменений в новый ресурс — шлюз локальной сети. Это касается префиксов локальных адресов и IP-адреса удаленного шлюза. |
| Ссылки на подключения | Соединение | Ссылки на подключения между шлюзом и сайтом локальной сети в конфигурации сети представлены новым ресурсом, который называется «Подключение». Все свойства ссылки на подключение в файлах конфигурации сети копируются без изменений в ресурс «Подключение». Возможность подключения между виртуальными сетями в классической модели развертывания обеспечивается благодаря созданию двух туннелей IPsec к сайтам локальной сети, представляющим виртуальные сети. Это преобразуется в подключение типа «виртуальная сеть — виртуальная сеть» в модели Resource Manager, для которого не нужны шлюзы локальной сети. |
При переносе ресурсов из классической модели в модель развертывания с помощью Resource Manager необходимо обновить существующую службу автоматизации или набор инструментов, чтобы обеспечить их работу после миграции.
Дальнейшие действия
Классическая модель — Энциклопедия по экономике
Первое из указанных требований означает, что предназначенная к использованию в практике планирования модель (далее для краткости эти модели называются плановыми) должна быть ориентирована на решение конкретной планово-экономической задачи, предусмотренной существующей или проектируемой методологией планирования. Это диктует необходимость трансформации многих известных экономико-математических моделей. Так, например, классическая модель межотраслевого баланса позволяет рассчитывать сбалансированные объемы выпусков продукции при заданной матрице коэффициентов прямых затрат и известном конечном продукте. Однако на практике такая задача может возникнуть лишь на завершающем этапе работы над планом, когда уже -рассмотрены вопросы технической политики в отраслях и приняты соответствующие решения (а значит, известна матрица плановых коэффициентов прямых затрат), изучены и обоснованы объем и структура капитальных вложений, товарооборота, экспорта и импорта (а значит, известен конечный продукт). Между тем очевидно, что межотраслевые модели наибольшую пользу могут принести как раз на начальных стадиях работы над планом при проработке вариантов структурной политики. Поэтому на основе стандартного межотраслевого баланса необходимо разрабатывать различные постановки межотраслевых моделей, нацеленные на решение конкретных практических задач в данном режиме функционирования АСПР и на данной стадии разработки плана. Примерами таких постановок являются, в частности, оптимизационная межотраслевая модель корректировки заданий пятилетнего плана на очередной год для стадии формирования проекта [c.118]В главах 3,4 рассмотрены классические линейные регрессионные модели в главе 3 — парные регрессионные модели, на примере которых наиболее доступно и наглядно удается проследить базовые понятия регрессионного анализа, выяснить основные предпосылки классической модели, дать оценку ее параметров и геометрическую интерпретацию в главе 4 — обобщение [c.3]
Наиболее хорошо изучены линейные регрессионные модели, удовлетворяющие условиям (1.6), (1.7) и свойству постоянства дисперсии ошибок регрессии, — они называются классическими моделями. [c.19]
При рассмотрении классической модели регрессии характер экспериментальных данных, как правило, не имеет принципиального значения. Однако это оказывается не так, если условия классической модели нарушены. [c.133]
В этой главе мы остановимся на некоторых общих понятиях и вопросах, связанных с временными рядами, использованием регрессионных моделей временных рядов для прогнозирования. При анализе точности этих моделей и определении интервальных ошибок прогноза на их основе, будем полагать, что рассматриваемые в главе регрессионные модели временных рядов удовлетворяют условиям классической модели. Модели временных рядов, в которых нарушены эти условия, будут рассмотрены в гл. 7, 8. [c.133]
Пример 6.4. По данным табл. 6.1 дать точечную и с надежностью 0,95 интервальную оценки прогноза среднего и индивидуального значений спроса на некоторый товар на момент t= 9 (девятый год). (Полагаем, что тренд линейный, а возмущения удовлетворяют требованиям классической модели (см. дальше, пример 7.8.) [c.145]
Полагая, что тренд линейный и условия классической модели выполнены [c.149]
Для доказательства оптимальных свойств оценки Ь преобразуем исходные данные — матрицу X, вектор Y и возмущение Е к виду, при котором выполнены требования классической модели регрессии. [c.153]
Нетрудно проверить, что в случае классической модели, т. е. при выполнении предпосылки = Q = [c.154]
Предположим, что средние квадратические (стандартные) отклонения возмущений о, пропорциональны значениям объясняющей переменной X (это означает постоянство часто встречающегося на практике относительного (а не абсолютного, как в классической модели) разброса возмущений е, регрессионной модели. [c.159]
Вначале по исходным наблюдениям находят состоятельные оценки параметров 0=(0ь 02,-ч 6Л) — Затем получают оценку параметра ст2. В соответствии с (4.21) такая оценка для классической модели находится делением минимальной остаточной сум- [c.186]
Если уравнения (9.18), (9.19) по отдельности удовлетворяют условиям классической модели, матрицы Z// — скалярные. Тогда [c.237]
Выбор одной из двух классических моделей. Теоретические аспекты [c.243]
В этом параграфе мы рассмотрим проблемы спецификации классической модели, удовлетворяющей предпосылкам 1—6 (см. 4.2). Соответствующая задача может быть сформулирована следующим образом. Пусть регрессоры разделены на две группы — Хи Z, причем регрессоры X являются важными, и параметры при них требуется оценить с максимально возможной точностью, между тем, как регрессоры Z представляют значительно меньший интерес, и оценки соответствующих им параметров сами по себе для нас не важны. Следует выбрать одну из моделей [c.243]
Рассматриваются две альтернативные модели, удовлетворяющие условиям классической модели [c.257]
Пусть справедлива следующая модель, удовлетворяющая условиям классической модели [c.257]
Классическая модель регрессии 19, 61 [c.300]
Как в классической модели устанавливается уровень цен [c.455]
Как в классической модели определяются процентные ставки [c.455]
Классическая модель была первой систематической попыткой объяснить детерминанты таких важных макроэкономических, или агрегатных, переменных, как уровень цен, валовой национальный продукт, уровень занятости и расходов. С помощью классической модели также пытались дать объяснение взаимосвязи этих переменных и роли денег. [c.456]
В 1970—80-е годы развернулись острые дискуссии среди экономистов по поводу оптимальной модели экономики (оптимальной в смысле наиболее точно предсказуемой) и теории, в которой денежно-кредитная политика занимала бы достойное место. Хотя было создано несколько специфических теорий, большинство экономистов в 1990-е годы делится на две основные группы. Первая пытается восстановить существенные элементы исходной классической модели, дополнив их некоторыми положениями кейнсианства, которые они считали полезными. Ядро этой группы называют сторонниками новой классической макроэкономики. Они продолжают традиции экономистов-классиков, утверждая, что предпосылка об эластичности цен, заработной платы и процентных ставок является основой для оптимальной модели экономики и анализа роли денег в ней. [c.458]
Главным выводом классической модели и, естественно, основой основ теории денег является постулат предложение товаров порождает спрос . Эта фраза, принадлежащая Жану Батисту Сею (Say, 1767—1832), известна как закон Сея (Say s law). Действительно ли эта фраза является описанием закона — это дискуссионный вопрос среди экономистов, исследующих механизм функционирования экономики и определение оптимальной денежной массы. [c.460]
Пре,ц -. инки классической модели [c.460]
В основе классической модели лежат три ключевые предпосылки [c.460]
Работнику важна реальная (скорректированная с учетом уровня цен) заработная плата, так как именно она является мерой покупательной способности дохода работника. Предположим, что работник получает повышение зарплаты на 50%. Если цены товаров и услуг, которые он мог купить, также возрастут на 50%, тогда работник не станет богаче, работая большее или меньшее время, чем в данный момент. Если поведение будет несколько другим, то это значит, что работник страдает от денежной иллюзии. В классической модели вероятность денежной иллюзии очевидно отвергается. [c.469]
Рациональный работник в классической модели согласится работать дополнительное время только при условии, что реальная заработная плата действительно повысится. Ставка реальной заработной платы может возрасти при двух обстоятельствах 1) если ставка номинальной заработной платы увеличивается при неизменности уровня цен 2) если уровень цен падает при неизменности номинальной заработной платы. Рисунок 18-6 иллюстрирует влияние роста номинальной заработной платы с WQ до W. при фиксированном уровне цен PQ. Как показано на рис. 18-6/1, это влечет за собой рост реальной заработной платы, что побуждает работника предоставлять больше трудовых услуг. Поэтому график предложения труда Ns имеет положительный наклон. На рис. 18-6Б показан тот же результат, но только по оси ординат откладываются значения номинальной заработной платы. Предложение труда возрастет на то же значение, но предложение труда зависит от цен на продукцию. Поэтому мы обозначим NS(P0) этот вариант графика предложения труда, который связан особым образом с уровнем цен PQ. Графическое представление предложения труда отдельно взятого работника предполагает движение вдоль кривой при увеличении номинальной заработной платы. [c.469]
Что произойдет затем Ответ классической модели состоит в том, что номинальная заработная плата будет уменьшаться по мере того, как незанятые работники будут конкурировать с имеющими работу. Они будут согласны на меньшую заработную [c.471]
Построение графика совокупного предложения в классической модели. Если уровень цен упадет вдвое, реальная заработная плата станет в два раза больше при неизменности ее номинальной ставки И/, (рис. А). При более высокой реальной заработной плате, W0/(P0/2) = 2W0/P0, существует избыток рабочей силы. Номинальная заработная плата уменьшается, пока на рынке труда не установится равновесие при полной занятости, которому соответствует определенное количество рабочей силы /V0. Соответственно, когда уровень цен уменьшится вдвое, предельный продукт труда уменьшается и спрос на труд падает (рис. Б). Работники понимают, что их реальная заработная плата стала больше, так что растет предложение их услуг. В общем занятость остается на уровне Л/0. Объем производства (рис. В) не изменяется при равновесии. Поэтому уменьшение уровня цен не влияет на реальный объем производства прямая совокупного предложения расположена вертикально (рис. Г). [c.472]
График совокупного предложения в классической модели при полной занятости представляет собой вертикальную прямую. В результате объем продукции определяется ее предложением. В классической модели когда задано расположение графика совокупного предложения в экономике, то известен и краткосрочный объем производства, независимо от любых других факторов. [c.474]
Важной чертой построения графика совокупного предложения является то, что мы определяли равновесный уровень заработной платы и занятости при данном уровне цен мы не рассматривали сам процесс установления уровня цен. Это не означает, что мы не заинтересованы в этом. Естественно, процесс установления цен в классической модели важен лишь для понимания весьма ограниченной роли, которую экономисты-классики предназначали денежно-кредитной политике. [c.474]
Экономисты-классики считали, что решающим детерминантом уровня цен в экономике является количество денег в обращении. Это означало, что для определения уровня цен нужно было знать, сколько денег все домашние хозяйства склонны хранить. Следовательно, анализ установления уровня цен в классической модели начинается в теории спроса на деньги. [c.474]
Колич и чая теория денег Краеугольным камнем классической модели опреде- [c.474]
График совокупного спроса в классической модели. График совокупного спроса на произведенные товары и услуги строится на основе кембриджского уравнения. У него отрицательный наклон, т. е. значения функции убывают. Это означает, что при более низком уровне цен, при неизменных номинальной денежной массе и коэффициенте k кембриджского уравнения спрос на товары и услуги возрастет. [c.476]
Американская модель строится на относительно большой самостоятельности отдельных штатов. Зачастую она рассматривается как классическая модель бюджетного федерализма2. В США отсутствует система горизонтального долевого распределения доходов. Большинство федеральных субсидий штатам зависит от объемов долевого финансирования штатными и местными органами власти. Такая политика не направлена на выравнивание социально-экономических условий жизнедеятельности регионов. Более того, она содействует прежде всего развитию богатых штатов. [c.235]
В главе 7 представлены обобщенная линейная модель множественной регрессии и обобщенный метод наименьших квадратов. Исследуется комплекс вопросов, связанных с нарушением предпосылок классической модели регрессии — гетероскедастично-стью и автокоррелированностью остатков временного ряда, их тестированием и устранением, идентификацией временного ряда. [c.4]
Найденное уравнение регрессии значимо на 5%-ном уровне по /-критерию, так как фактически наблюдаемое значение статистики F= 24,32 > /o,05 i i9 = 4,35. Можно показать (например, с помощью критерия Дарбина—Уотсона) (см. далее, 7.7)), что возмущения (ошибки) е/ в данной модели удовлетворяют условиям классической модели и для проведения прогноза могут быть использованы уже изученные нами методы. [c.148]
Модели AR H и GAR H удовлетворяют всем условиям классической модели, и метод наименьших квадратов позволяет получить оптимальные линейные оценки. В то же время можно получить более эффективные нелинейные оценки методом максимального правдоподобия. В отличие от модели с независимыми нормально распределенными ошибками регрессии в AR H-модели оценки максимального правдоподобия отличаются от оценок, полученных методом наименьших квадратов. [c.217]
Классическая экономическая теория была основной теоретической школой начиная с 1770-х II до 1930-х годов. В круг приверженцев этой школы входят такие умы, как Адам Смит (1723—1790), Дэвид Юм (1711—1776), Давид Рикардо (1772—1823), Джеймс Милль (1773—1836) и его сын Джон Стюарт Милль (1806—1873), Томас Мальтус (1766—1834), Карл Маркс (1818—1883), а также А. С. Пигу (1877— 1959) и другие экономисты-неоклассики более позднего периода — Л. Вальрас (1834—1910), А. Маршалл (1842—1924) и К. Виксель (1851—1926). Даже Н. Коперник (1473—1543), будучи астрономом, внес вклад в классическую модель, и есть все основания полагать, что Т. Мальтус повлиял на учение об эволюции Чарльза Дарвина. Классическая модель, как показано в данной главе, является комбинацией макроэкономической теории кембриджской школы и пересмотренной Джоном Мей-нардом Кейнсом теории, которую мы в дальнейшем рассмотрим. [c.456]
Экономические агенты не страдают от денежной иллюзии (money illusion). Это означает, что в общем покупатели и продавцы правильно понимают и реагируют только на изменения реальных величин (т. е. относительных или скорректированных с учетом уровня цен) цен, заработной платы и процентных ставок. Они не изменяют объема купли-продажи конечной продукции и факторов производства вследствие простых изменений номинальных цен. Например, предположим, что данное домашнее хозяйство приобрело определенный набор товаров и услуг и предоставило определенное количество труда и других факторных услуг (услуги таких факторов производства, как земля и капитал) в течение года. Отсутствие денежной иллюзии означает, что домашнее хозяйство купит или продаст то же количество товаров (услуг) или факторных услуг, если за этот год доход увеличился в три раза при трехкратном увеличении цен. Поскольку реальные, или относительные, цены не изменились, классическая модель предполагает, что объем сделок домашнего хозяйства на рынке сохранится на том же уровне при прочих равных условиях. Иными словами, домашнее хозяйство не пострадает от денежной иллюзии. [c.461]
Безраьи ], н классической модели В классической модели безработица — явление временное. Если на рынке труда существует избыток рабочей силы, то ставки номинальной заработной платы будут скорректированы, чтобы избавиться от него. Однако экономисты-классики признавали, что иногда на практике имеет место безработица в течение длительного периода. Означает ли это, что в классической модели что-то неправильно Экономисты-классики так не считали. Длительная безработица, по их мнению, может возникать по причине воздействия каких-либо внешних факторов, как-то принятие законов о минимальной заработной плате или введение других ограничений (например, установление профсоюзами ставок заработной платы уменьшает эластичность заработной платы перед изменением цен). Они не принимали эти факторы всерьез настолько, чтобы включать их в модель экономики. Более того, они считали, что такие институциональные ограничения гибкости номинальной заработной платы были не нужны и что даже при их введении долго действовать они не будут. Как мы увидим в следующих главах, современные экономисты продолжают дискутировать по этим вопросам. [c.474]
Глава 4 Типы моделей данных — Проектирование базы данных — 2-е издание
Эдриен Ватт и Нельсон Энг
Концептуальные модели данных высокого уровня
Концептуальные модели данных высокого уровня предоставляют концепции для представления данных способами, близкими к тому, как люди воспринимают данные. Типичным примером является модель отношений сущностей, в которой используются такие основные концепции, как сущности, атрибуты и отношения. Сущность представляет собой объект реального мира, такой как сотрудник или проект.У объекта есть атрибуты, которые представляют такие свойства, как имя, адрес и дата рождения сотрудника. Отношение представляет собой ассоциацию между объектами; например, сотрудник работает над многими проектами. Между сотрудником и каждым проектом существуют отношения.
Логические модели данных на основе записей
Основанные на записях логические модели данных предоставляют концепции, понятные пользователям, но не слишком далеки от способа хранения данных в компьютере. Три хорошо известных модели данных этого типа — это реляционные модели данных, сетевые модели данных и иерархические модели данных.
- Реляционная модель представляет данные как отношения , или таблицы. Например, в системе членства в Science World каждое членство состоит из множества членов (см. Рис. 2.2 в главе 2). Идентификатор членства, дата истечения срока действия и адресная информация — это поля в членстве. Среди участников — Микки, Минни, Майти, Дор, Том, Кинг, Человек и Лось. Каждая запись называется экземпляром таблицы членства.
- Сетевая модель представляет данные как типы записей.Эта модель также представляет ограниченный тип отношения «один ко многим», называемый набором типа , как показано на рисунке 4.1.
- Иерархическая модель представляет данные в виде иерархической древовидной структуры. Каждая ветвь иерархии представляет собой ряд связанных записей. Рисунок 4.2 показывает эту схему в нотации иерархической модели.
экземпляр : запись в таблице
сетевая модель : представляет данные как типы записей
отношение : еще один термин для таблицы
реляционная модель : представляет данные в виде отношений или таблиц
установить тип : ограниченный тип отношения «один ко многим»
- Что такое модель данных?
- Что такое концептуальная модель данных высокого уровня?
- Что такое организация? Атрибут? Отношения?
- Перечислите и кратко опишите общие модели логических данных на основе записей.
Атрибуция
Эта глава Database Design является производной копией Database System Concepts от Нгуен Ким Ань под лицензией Creative Commons Attribution License 3.0 лицензия
Адриенн Ватт написала следующий материал:
- Ключевые термины
- Упражнения
Начать работу с классической моделью данных Campaign
Концептуальная модель данных базы данных Adobe Campaign состоит из набора встроенных таблиц и их взаимодействия.На этой странице перечислены основные таблицы и концепции.
Обзор
Adobe Campaign использует реляционную базу данных, содержащую таблицы, которые связаны между собой. Базовую структуру модели данных Adobe Campaign можно описать следующим образом.
Таблица получателей
Модель данных опирается на основную таблицу, которая по умолчанию является таблицей получателей ( NmsRecipient ). Эта таблица позволяет хранить все маркетинговые профили.
Подробнее о таблице получателей см. В этом разделе.
Стол доставки
Модель данных также включает часть, предназначенную для хранения всех маркетинговых действий. Обычно это таблица доставки ( NmsDelivery ). Каждая запись в этой таблице представляет действие доставки или шаблон доставки. Он содержит все необходимые параметры для выполнения доставки, такие как цель, контент и т. Д.
Бревенчатые столы
Другая часть модели данных позволяет временно хранить все журналы, связанные с выполнением кампаний.
Журналы доставки — это все сообщения, отправленные получателям или устройствам по всем каналам. Основная таблица журналов доставки ( NmsBroadLog ) содержит журналы доставки для всех получателей.
В основной таблице журналов отслеживания ( NmsTrackingLog ) хранятся журналы отслеживания для всех получателей. Журналы отслеживания относятся к реакции получателей, например к открытиям электронной почты и кликам. Каждой реакции соответствует журнал отслеживания.
Журналы доставки и журналы отслеживания удаляются по истечении определенного периода, который указан в Adobe Campaign и может быть изменен.Поэтому настоятельно рекомендуется регулярно экспортировать журналы.
Технические столы
Наконец, часть модели данных состоит из технических данных, используемых для прикладного процесса, включая операторов и права пользователей ( NmsGroup ), папки ( XtkFolder ).
Использование таблицы получателей по умолчанию
Стандартная таблица получателей в Adobe Campaign является хорошей отправной точкой для построения вашей модели данных. Он имеет ряд предопределенных полей и ссылок на таблицы, которые можно легко расширить.Это особенно полезно, когда вы в основном ориентируетесь на получателей, потому что это соответствует простой модели данных, ориентированной на получателя.
Преимущества использования стандартной таблицы получателей следующие:
- Готовая работа с такими функциями, как подписки, начальные списки, опросы, социальные сети и т. Д.
- Обеспечение маркетинговой базы данных с моделью данных, ориентированной на получателя.
- Более быстрое внедрение.
- Простота обслуживания службой поддержки и партнерами.
Однако можно расширить таблицу получателей, но не уменьшить количество полей или ссылок в таблице.
ВАЖНО
Рекомендуется не удалять поля (даже если они бесполезны) в таблице получателей, так как это может привести к ошибкам во встроенных модулях.
Кроме того, поскольку таблица получателей является частью продукта, как таблица, так и связанная с ней форма развиваются по мере изменения продукта. Поэтому требуется дополнительное обслуживание, чтобы убедиться, что все расширения по-прежнему действительны после обновления.
Расширение модели данных
При запуске Adobe Campaign вам необходимо оценить модель данных по умолчанию, чтобы проверить, какая таблица лучше всего подходит для хранения ваших маркетинговых данных.
При необходимости вы можете использовать таблицу получателей по умолчанию с нестандартными полями, как описано в этом разделе.
При необходимости можно расширить двумя механизмами:
- Расширить существующую таблицу новыми полями. Например, вы можете добавить новое поле «Лояльность» в таблицу «Получатель».
- Создайте новую таблицу, например таблицу «Покупки», в которой перечислены все покупки, сделанные каждым профилем базы данных, и свяжите ее с таблицей «Получатель».
Дополнительные сведения о настройке схем расширений для расширения концептуальной модели данных см. В разделе «О редакции схемы».
ВАЖНО
Расширение модели данных зарезервировано для опытных пользователей.
Использование настраиваемой таблицы получателей
При разработке модели данных Adobe Campaign вы можете использовать готовую таблицу получателей или решить создать настраиваемую таблицу таблицы получателей для хранения ваших маркетинговых профилей.
Действительно, если ваша модель данных не соответствует структуре, ориентированной на получателя, вы можете настроить другие таблицы в качестве измерения таргетинга в Adobe Campaign. Например, это может быть актуально, когда вам нужно настроить таргетинг на домохозяйства, учетные записи (например, мобильные телефоны) и компании / сайты, а не просто на получателей.
В этом разделе подробно описаны все принципы и действия, необходимые для использования настраиваемой таблицы получателей.
Преимущества использования настраиваемой таблицы получателей:
Гибкая модель данных — Стандартная таблица получателей бесполезна, если вам не нужно большинство полей таблицы получателей или если модель данных не ориентирована на получателей.
Масштабируемость — Для больших объемов требуется оптимизированная таблица с несколькими полями для эффективного проектирования. В стандартной таблице получателей будет слишком много бесполезных полей, что может повлиять на производительность и снизить эффективность.
Расположение данных — Если данные находятся во внешней существующей маркетинговой базе данных, может потребоваться слишком много усилий для использования готовой таблицы получателей. Создать новую на основе существующей конструкции проще.
Простая миграция — Не требуется никакого обслуживания для проверки того, что все расширения по-прежнему действительны после обновления.
ВАЖНО
Использование настраиваемой таблицы получателей зарезервировано для опытных пользователей и имеет некоторые ограничения. Подробнее об этом см. В этом разделе.
Узнайте больше о модели данных Campaign в этих разделах:
Описание основных таблиц — Подробнее об описании модели данных Campaign Classic по умолчанию см. В этом разделе.
Полное описание каждой таблицы — Чтобы получить доступ к полному описанию каждой таблицы, перейдите в Админ> Конфигурация> Схемы данных , выберите ресурс из списка и щелкните вкладку Документация .
Схемы кампании — Физическая и логическая структура данных, переносимых в приложении, описана в XML. Он подчиняется специальной грамматике Adobe Campaign, называемой схемой.Чтобы узнать больше о схемах Adobe Campaign, прочтите этот раздел.
Лучшие практики модели данных — Изучите архитектуру модели данных Campaign и соответствующие передовые методы в этом разделе.
— обзор
10.4 Типы коллекций
Подходы к моделированию данных значительно различаются по поддержке типов коллекций . Хотя цели реализации часто поддерживают такие типы (например, SQL: 2003 поддерживает массивы, типы строк и пакеты), подходы к высокоуровневому моделированию данных обычно не обеспечивают прямой поддержки или только очень ограниченную прямую поддержку.Даже когда не предоставляется прямая поддержка коллекций фактов, можно смоделировать ту же информацию в терминах элементарных фактов, поэтому проблема поддержки типов коллекции — это вопрос удобства, а не выразимости. При концептуальном моделировании чаще всего встречаются следующие типы коллекций:
- •
Набор (неупорядоченный, без дубликатов)
- •
Пакет или мультимножество (неупорядоченный, дубликаты разрешены)
- •
Упорядоченный набор или уникальная последовательность (заказанные, без дубликатов)
- •
Последовательность (заказанный пакет)
- •
Массив (индексированная последовательность)
- •
Схема ER
Хотя использование типов коллекций в логических и физических структурах данных имеет смысл, вопрос о том, следует ли вообще использовать типы коллекций в концептуальном анализе, все еще остается спорным.Добавление конструкторов для создания различных типов коллекций требует дополнительных языковых функций, чтобы не только объявлять такие структуры, но и управлять ими. Благодаря параметрам сбора у разработчика моделей теперь есть гораздо больше вариантов того, как сформулировать модель, обновить или запросить.
Наш опыт показывает, что типы коллекций следует использовать с особой осторожностью при разработке концептуальной модели. Недисциплинированное использование конструкторов часто приводит к неправильным или неполным решениям или игнорированию более простого решения, не использующего коллекции.Вспомните наш предыдущий совет в Разделе 9.3 против использования многозначных атрибутов в концептуальных моделях.
Следующие пункты были предложены в пользу использования концептуального конструктора: коллекции приводят к более компактным моделям; они лучше раскрывают связь между концептуальными моделями и физическими моделями, использующими коллекции; и они позволяют непосредственно моделировать безымянные структуры.
Следующие пункты были предложены против использования типов коллекций в качестве типов первого класса в концептуальных моделях: коллекции усложняют вербализацию и пополнение; коллекции часто усложняют ограничения и скрывают другие детали; выбрать лучший конструктор часто бывает непросто; следует избегать безымянных структур, потому что на них неудобно ссылаться; и можно по-прежнему преобразовывать в коллекции в физической модели, просто аннотируя процесс сопоставления.
Главный вопрос спора заключается в том, стоит ли включать безымянных коллекций в концептуальные модели. В качестве классического примера (Хаммер и МакЛеод, 1981) рассмотрим конвой как безымянных кораблей. Это можно смоделировать в PSM, используя тип набора наборов, как показано на рисунке 10.36 (a). Хотя для типов коллекций существуют различные обозначения, здесь мы изображаем их в виде мягких прямоугольников, причем тип коллекции (набор, сумка и т. Д.) Выделен жирным шрифтом.
Рисунок 10.36. Конвой смоделирован как (а) безымянный набор и (б) именованный простой объект.
На рис. 10.36 (b) показана альтернативная плоская схема как в ORM, так и в UML с использованием ассоциации и имени для идентификации каждого конвоя. На практике названия конвоев очень полезны, так как они упрощают вербализацию фактов о конвоях и проверку ограничений. Ограничение уникальности в модели ORM утверждает, что каждый Корабль находится не более чем в одном Конвое. Это ограничение также отражено на диаграмме UML, поскольку закрашенный ромб указывает на состав (сильная агрегация).Это ограничение отсутствует на рис. 10.36 (а). В большинстве случаев использование типов коллекций затрудняет выражение ограничений для членов коллекции. Связь в плоской модели также может быть удобно заполнена экземплярами фактов, чтобы помочь проверить ограничение.
В целях создания моментальных снимков колонну удобно идентифицировать по ее названию (или по ее флагману). Тип факта о членстве в конвое может быть временно преобразован для сохранения исторической записи членства либо с помощью троичных единиц: «Корабль присоединился к конвою в дату» и «Корабль покинул конвой в день», либо путем вложения исторической ассоциации m: n «Корабль находился в конвое в качестве членства в конвое», и добавление ConvoyMembership началось Дата; Членство в конвое закончилось Дата.В UML эта история может быть смоделирована с использованием ConvoyMembership в качестве класса ассоциации с соответствующими атрибутами даты (возможно, многозначными) или ассоциациями. Правильно ли с философской точки зрения использовать слово «конвой», чтобы позволить конвою быть таким же конвоем после того, как корабль уходит, не представляет особого практического интереса.
В качестве связанного примера рассмотрим понятие членства в команде, когда человек может быть членом многих команд и наоборот. На рис. 10.37 показано, как смоделировать это в ORM с конструктором множества и без него.На рис. 10.37 (b) обведенный «{_}» изображает ограничение экстенсиональной уникальности (ter Hofstede and van der Weide, 1994), чтобы объявить, что команды могут определяться их членством (т. набор членов). Включена выборка для двух команд. Подчеркивание (как полоса уникальности) внутри фигурных скобок интуитивно подсказывает, что набор уникален. Альтернативное обозначение этого ограничения — «eu» в кружке. Это ограничение неявно показано на рисунке 10.37 (а). Его использование на рис. 10.37 (b) позволяет использовать безымянные структуры без введения типов коллекций.
Рисунок 10.37. Три способа членства в модельной команде.
Бакема, Цварт и ван дер Лек (1994) предоставляют еще одну нотацию для этого ограничения и утверждают, что, если команды не имеют названия в реальном мире, это должно быть отражено в концептуальной модели, чтобы подчиняться принципу концептуализации только путем моделирования. концептуально релевантные функции. Мы принимаем расслабленное прочтение этого принципа, поощряя введение идентификаторов, которые улучшают удобство использования модели.На рис. 10.37 (c) мы добавляем код команды в качестве простого идентификатора команд, чтобы облегчить обсуждение команд. Ограничение экстенсиональной уникальности по-прежнему требуется, если мы определенно не хотим, чтобы две разные команды имели одинаковое членство, как показано в приведенном контрпримере. Это ограничение обходится очень дорого, поэтому его следует использовать только при необходимости.
Сложный пример, цитируемый в литературе по ORM для оправдания использования конструкторов, касается химических реакций (Falkenberg, 1993).Это моделирует такие реакции, как 2H 2 + O 2 ⇆ 2H 2 O Один из способов смоделировать это с заданным типом сбора показан на рисунке 10.38 (a). Эта схема, основанная на решении Тер Хофстеде, Пропер и ван дер Вейде (1992), рассматривает каждую сторону уравнения реакции как набор химических величин, например {(H 2 , 2), (O 2) , 1)}. Затем сама реакция фиксируется в ассоциации двоичных входов / выходов. Альтернативная плоская модель показана на рисунке 10.38 (б). Здесь число реакции вводится как удобный способ обозначения реакций. Эта модель также показывает сложный пример ограничения экстенсиональной уникальности.
Рисунок 10.38. Химические реакции смоделированы (а) с и (б) без безымянных наборов.
Хотя рисунок 10.38 (a) более компактен, использование конструктора множества затрудняет его размышление. Например, в нем отсутствует простое ограничение, показанное на рис. 10.38 (b). Вы можете это заметить? Ограничения уникальности на рисунке 10.38 (b) гарантировать, что каждое химическое вещество встречается не более одного раза на каждой стороне реакции (например, чтобы исключить такие уравнения, как 5H ⇆ 3H + 2H). На рис. 10.38 (а) это не выполняется. Например, мы можем заполнить ассоциацию ввода / вывода кортежем <{(H, 5)}, {(H, 3), (H, 2)}>. Модель, основанная на множестве, усложняет понимание и выражение этого ограничения.
На рис. 10.38 (a) реакционная ассоциация составляет m: n (предположительно, другие условия, такие как катализаторы и температура, могут быть изменены, чтобы одни и те же исходные реагенты давали разные результаты).Если вместо этого мы потребуем, чтобы один и тот же вход всегда давал один и тот же результат, эта связь становится 1: 1. Это легко смоделировать на рис. 10.38 (a), но сложнее смоделировать на рис. 10.38 (b). Это один из тех редких случаев, когда мы сталкиваемся с ограничением для коллекции, которое нельзя легко смоделировать как ограничение для членов. Противоположная ситуация (ограничение на члены, которое трудно смоделировать на коллекциях) встречается гораздо чаще.
Фалькенберг (1993) моделирует химическую реакцию как набор пар объект-роль.Хотя структуру этой модели сложно понять даже разработчикам моделей, а тем более экспертам в предметной области, Фалькенберг утверждает, что это единственный правильный способ смоделировать ситуацию, основанный на детерминированном принципе, согласно которому один экземпляр перехода при рождении должен соответствовать ровно одному объекту. пример. Наша точка зрения состоит в том, что коммуникация важнее детерминизма, и часто существует множество правильных способов моделирования одной и той же области бизнеса.
Хотя кажется, что нет убедительных доводов для введения типов коллекций в качестве первоклассных граждан в концептуальную модель, нам все же нужен какой-то способ указать коллекции для реализации в целевых объектах, которые поддерживают такие структуры.Хотя это может быть сделано непосредственно в логической схеме, желательно, чтобы было двустороннее преобразование между концептуальным и логическим уровнями, чтобы изменения на одном можно было передавать другому, чтобы поддерживать синхронизацию моделей. Один простой способ сделать это — указать сопоставления типов коллекций как аннотаций к чистой концептуальной схеме, в результате чего аннотированная концептуальная схема будет использоваться только разработчиком, а не экспертом в предметной области, с единственной целью управления сопоставлением между концептуальным и нижние уровни.Для разных целей реализации можно выбрать разные аннотации. На момент написания стандартных аннотаций для этой цели еще не было доработано. Для дальнейшего обсуждения этого понятия см. Halpin (2000b).
Мы завершаем этот раздел показом, как смоделировать различные типы коллекций косвенно, используя плоский подход. На рис. 10.39 (а) используется конструктор уникальной последовательности для моделирования упорядоченного набора авторов. Рисунок 10.39 (b) моделирует это в UML, применяя свойство {order} к концу ассоциации ({unique} предполагается по умолчанию для этой коллекции).Это можно смоделировать в плоской ORM, введя тип объекта Position для хранения последовательной позиции любого автора в списке, как показано на рис. 10.39 (c). Ограничение уникальности для первых двух ролей объявляет, что автор занимает не более одной позиции для каждой статьи; ограничение на первую и третью роли указывает, что в любой статье каждая позиция занята не более чем одним автором. Текстовое ограничение указывает, что позиции в списке нумеруются последовательно, начиная с 1.
Рисунок 10.39. Различные способы моделирования упорядоченных множеств.
Хотя это троичное представление может показаться неудобным, его легко заполнить и оно облегчает любое обсуждение, связанное с положением (например, кто второй автор статьи 21?). С точки зрения реализации все же можно выбрать структуру последовательности: это может упростить обновления, локализуя их влияние. Тем не менее, накладные расходы на обновление позиционной структуры не являются обременительными при постоянной обработке (например, чтобы удалить автора n , просто установите позицию в позицию -1 для позиции> n ).
При моделировании типов коллекций требуется осторожность. Рисунок 10.40 (a) связывает каждый тип факта с упорядоченным набором ролей, а рисунок 10.40 (b) сглаживает его до тернарности. Прежде чем читать дальше, посмотрите, сможете ли вы обнаружить что-то не так с этими схемами.
Рисунок 10.40. Можете ли вы заметить, что не так со схемами (а) и (б)?
Обе схемы опускают ограничение, согласно которому каждая роль принадлежит только одному типу фактов. Рисунок 10.40 (a) требует, чтобы каждый список ролей принадлежал не более чем к одному типу фактов, но этого недостаточно; использование здесь типа коллекции не позволяет нам графически зафиксировать требуемое ограничение уникальности.Тернар на рис. 10.40 (b) не является элементарным (ограничение уникальности применяется к его второй роли). Рисунок 10.40 (c) дает правильное решение.
Напомним, что пакетов (мультимножества) — это неупорядоченные коллекции с разрешенными дубликатами. Они могут быть реализованы троичными ассоциациями с использованием типа объекта частоты для подсчета количества появлений для каждой записи. Например, предположим, что учащийся 1001 получает пакет оценок [A, A, B, B, B] в пяти тестах, а учащийся 1002 получает пакет оценок [B, B, B] в трех тестах.Это можно смоделировать в плоской ORM, как показано на рисунке 10.41 (a). По умолчанию многозначная ассоциация заканчивается на UML-обозначениях наборов (уникальных и неупорядоченных). Предполагая, что здесь разрешен неуникальный параметр (спецификация UML не ясна по этому вопросу), параметр пакета может быть задан свойством {nonunique}, как показано на рисунке 10.41 (b).
Рисунок 10.41. Моделирование набора оценок для каждого студента в (а) ORM и (б) UML.
Напомним, что последовательность — это заказанный пакет (упорядоченный набор с допустимыми дубликатами).Например, абзац — это последовательность предложений. Последовательности могут быть смоделированы в плоской ORM с использованием троичной ассоциации с типом объекта «Позиция» в ключе. Предположим, что в лотерее призы разыгрываются последовательности людей в порядке убывания суммы призов, не имеющих связи. Например, призы в лотерее L1 могут быть присуждены последовательности (Энн Смит, Том Джонс, Энн Смит). Это можно смоделировать в плоской ORM, используя Rank в качестве типа позиции, как показано на рис. 10.42 (a), вместе с выборочной совокупностью. Рисунок 10.42 (b) моделирует это в UML, используя параметр {упорядоченный, неуникальный}, предполагая, что это разрешено.
Рисунок 10.42. Моделирование последовательности в (а) плоской ORM и (б) UML.
Массивы — это индексированные последовательности. Они могут быть смоделированы в плоской ORM с использованием троичной системы с типом «Position» для индекса как части ключа. Например, модель ORM на рис. 10.43 (a) использует Place в качестве типа позиции для записи первых трех мест в спортивных соревнованиях, предполагая, что ничьи не разрешены.
Рисунок 10.43. Моделирование массивов без увязок мест проведения спортивных мероприятий в плоской ОРМ.
Используя подходящую аннотацию сопоставления, это можно сопоставить с индексированным массивом стран внутри спортивных событий, что приведет к модели объектно-реляционной базы данных, такой как
| SportEvent | ( eventName , массив результатов; массив; [1..3] страны) | |
| «Мужские 100 м вольным стилем» | [1: «США» 2: «Австралия» 3: «США»] | |
Рис.43 (b) показан аналогичный пример с дополнительным ограничением уникальности (каждая страна имеет не более одного ранга в любом данном виде спорта). Опять же, никаких галстуков не допускается. Это может быть сопоставлено с уникальной структурой массива (уникальность которой указывается подчеркиванием) следующим образом:
| Sport | ( sportName , results; массив [1..3] of Country) | |
| «Плавание» | 1: «США» 2: «AU» 3: «CN»] | |
Хотя прямое использование типов коллекций в концептуальной модели может привести к компактности, альтернативная плоская модель (без конструкторы) сравнимого удобства общедоступны.Использование конструкторов часто затрудняет выражение ограничений (которые обычно возникают на членах, а не на коллекциях).
Поскольку конструкторы включают составные факты, их неудобно заполнять или проверять на предмет проверки, и они требуют более сложных навыков моделирования. Конструкторы иногда используются, даже если есть более простое решение для моделирования без них. Кажется, лучше переложить использование конструктора на аннотации, которые определяют более позднюю фазу сопоставления.
Упражнение 10.4
- 1.
В Terry’s Railway каждый поезд состоит из одного локомотива и одного вагона (последовательность железнодорожных вагонов). Каждый вагон классифицируется как первый, второй или третий класс. Возможно, вагон в настоящее время не входит в состав поезда. Поезда, вагоны и локомотивы обозначаются номерами. Один и тот же локомотив может приводить в движение многие поезда.
- (a)
Один и тот же вагон может принадлежать более чем одному поезду (например,(например, вагон утреннего поезда во второй половине дня можно использовать в другом поезде). Однако один и тот же состав вагона может использоваться только в одном составе. Смоделируйте это в ORM, используя конструктор типа коллекции.
- (b)
Смоделируйте домен, описанный в (a), без использования конструктора типа коллекции.
- (c)
Предположим теперь, что каждый поезд однозначно определяется своим составом (то есть его локомотивом и составом вагона). Требуются ли какие-либо изменения в вашей модели, чтобы (а) это уловить? Объяснять.
- (d)
Можно ли графически зафиксировать это дополнительное ограничение в вашем решении для (b)? Ответьте да или нет.
- (e)
Домен изменен таким образом, что каждый вагон принадлежит не более чем одному поезду. Можно ли добавить это правило в качестве графического ограничения (без добавления типа факта) к вашему решению для пункта (а)? Ответьте да или нет.
- (f)
Измените решение согласно пункту (b), чтобы правило в пункте (e) отображалось графически.
- (g)
Если ограничение состава в (c) также применяется к вашему решению в (f), нужно ли добавлять какие-либо дополнительные ограничения к этому решению? Ответьте да или нет.
- 2.
В крикете игрок может забивать пробежки в одиночном, четверном или шестом разряде. Некоторые игроки могут забить утку (без пробежек). Следующий отрывок из отчета перечисляет набор пробежек (без учета порядка) для каждого игрока в крикет. Каждый игрок в крикет принадлежит ровно одной команде. Смоделируйте это в плоской ORM.
| Игрок в крикет | Команда | Беги |
|---|---|---|
| Дон Супермен | A | 6, 6, 6, 4, 6, 4, 6 , 1, 6 |
| Fred Bloggs | A | |
| Mark Hitter | B | 1, 1, 1, 1, 4, 1, 1 |
Концептуальное моделирование данных — обзор 9000
3.1.2.8.2 Жизненный цикл Data Centric
Следующая проблема, которая возникает тогда, — это то, что происходит, если вы используете SDLC для чего-то другого, кроме разработки программного приложения.Ответ заключается в том, что даже несмотря на то, что SDLC хорошо подходит для поддержки этапов разработки прикладной системы, он, в отличие от этого, плохо подходит в качестве жизненного цикла для других основных категорий действий, требующих проектных групп. Первое, что мы обсудим, — это жизненный цикл хранилищ данных со связанными с ними артефактами, такими как ODS и витрины данных.
В отличие от разработки прикладных систем, которые определяются бизнес-требованиями, которые превращаются в бизнес-правила, автоматизирующие бизнес-процессы, разработка хранилищ данных — это усилия, ориентированные на данные, которые идентифицируют и собирают информацию для поддержки оперативной отчетности, специальной отчетности и BI.
Этапы разработки хранилищ данных называются DCLC. В отличие от набора бизнес-правил в SDLC, DCLC определяет категории вариантов использования и категории данных, которые необходимы для поддержки этих вариантов использования.
Таким образом, категории вариантов использования могут относиться к различным формам отчетности о рисках, деятельности главной книги, соблюдению нормативных требований или маркетингу. В ответ на эти категории вариантов использования категории данных и связанные с ними точки данных необходимы для определения объема требований к данным.Основными архитектурными артефактами, необходимыми для поддержки этого шага, являются LDA и связанные с ним концептуальные модели данных.
Чтобы кратко описать это сейчас, LDA — это бизнес-артефакт, который представляет собой реестр каждого бизнес-контекста данных на предприятии, называемых предметными областями бизнес-данных (BDSA). У каждого BDSA есть соответствующая концептуальная модель данных, которая создается только для этих областей бизнеса, когда возникает необходимость.
LDA обсуждается далее в разделе 4.1.2. Однако суть в том, что существует по крайней мере еще один жизненный цикл, который необходим для разработки систем, ориентированных на данные, таких как хранилища данных и ODS.
Подводя итог в соответствии с ранее описанным SDLC, 11 этапов DCLC включают:
- ▪
требования к данным —определение вариантов использования и категорий данных,
- ▪
определить участников бизнеса
- ▪
оценить объем
- ▪
определить факторы бизнеса
- ▪
определить типы сценариев использования
анализ данных —оценка источников данных,
- ▪
оценка существующих и перспективных внутренних источников данных
- ▪
исследование бесплатных и платных каналов внешних данных
- ▪
- распределить источники и каналы по типам сценариев использования 9000 3
- ▪
Подтвердить распределение с заинтересованными сторонами
- ▪
профилирование данных — анализ качества данных требуемых точек данных,
- ▪
профиль каждого источника
- ▪
сравнить профиль с логической моделью данных, чтобы подтвердить его надлежащее использование
- ▪
применить онтологию для предполагаемого использования
- ▪
определить глобальные справочные данные и связанные коды данных
- ▪
архитектура логических данных — классификация каждой точки данных в соответствии с бизнес-контекстом LDA и сбор бизнес-метаданных каждой точки данных,
- ▪
определение бизнес-контекста в рамках LDA
- ▪
90 014 определить связанные точки данных
- ▪
определить бизнес-метаданные
- ▪
опубликовать обновленный LDA
- ▪
глоссарий концептуальное моделирование данных концептуальное моделирование данных элемент в связанную с ним концептуальную модель данных,
- ▪
включить элементы глоссария в модели концептуальных данных
- ▪
установить любые дополнительные элементы глоссария схожих или связанных данных
- ▪
проверить данные глоссарий элемент бизнес-контекст
- ▪
опубликовать обновленные модели концептуальных данных
- ▪
моделирование логических данных —включение обновлений концептуальных моделей данных в модели логических данных,
- ▪ 9 0254
включает обновления концептуальной модели данных
- ▪
поддерживает ранее существовавшие представления приложений
- ▪
проводит обзор коллегиальных моделей
- обновленные модели данных 5 9000 публикуют логические данные
моделирование физических данных —внедрение обновлений логической модели данных в физические конструкции,
- ▪
внедрение обновлений логической модели данных
- ▪
сбор анализа пути транзакции
- ▪
включить требования к физическому дизайну
- ▪
провести экспертную оценку модели
- ▪
опубликовать обновленные модели физических данных
- 5
обнаружение данных —обнаружение источников данных
- ▪
определение источников данных
- ▪
оценка источника данных
- ▪
выбор лучших данных источник (и)
сбор данных —Извлечение данных в зону посадки
- ▪
извлечь выбранные данные в зону посадки
очистка данных — (также известная как очистка данных) очистка данных на основе спецификаций профилирования данных,
- ▪
профилирование извлеченных данных
- ▪
разработка спецификаций очистки данных
очистить данные и сохранить историю
- ▪
запись показателей качества данных
стандартизация данных — стандартизация кодов для всех данных в зоне посадки,
- ▪
разработка спецификаций стандартизации данных
применить значения кодовой таблицы из глобального справочника данных
- ▪
метрики стандартизации записи
интеграция данных — стандартизация и интеграция очищенных данных в ODS-слой ,
- ▪
разработка спецификаций интеграции данных
- ▪
создание баз данных уровня ODS в разработке
- ▪
интеграция данных в разработку с маскированием конфиденциальных данных
запись показателей интеграции данных
принятие пользователем — тестирование бизнес-пользователей,
- ▪
миграция в QA пользователей
- ▪
- бизнес-тестирования маскирование
производство — переход к производству и мониторинг показателей хранилища данных
- ▪
повторно протестировать и выполнить оценку «годен / нет»
Данные Архивы — DATAVERSITY
Чтобы просмотреть только слайды из этой презентации, щелкните ЗДЕСЬ >> О вебинаре Очевидно, что существуют передовые методы управления данными, а также полезный процесс для улучшения существующих методов управления данными.Возникает вопрос: если мы понимаем цель, как разработать процесс достижения цели управления данными? Эта программа […]
По мере роста популярности облачных сервисов Snowflake превратилась в одну из ведущих платформ для хранилищ данных в облаке. Специалисты по обработке данных, которые проектируют хранилища данных Snowflake и управляют ими, могут использовать ER / Studio для регистрации требований организации, преобразования требований в дизайн и развертывания дизайна в Snowflake. Присоединяйтесь к IDERA для демонстрации того, как ER / Studio […]
Чтобы просмотреть только слайды из этой презентации, щелкните ЗДЕСЬ >> Этот веб-семинар спонсируется: О веб-семинаре Предприятия быстро переходят на базы данных NoSQL для поддержки своих современных приложений.Однако миграция технологий сопряжена с риском, особенно если вам нужно изменить модель данных. Что, если бы вы могли разместить относительно неизмененную схему СУБД […]
Чтобы просмотреть только слайды из этой презентации, щелкните ЗДЕСЬ >> О вебинаре Моделирование графических данных, разумеется, хорошо для графических баз данных. Но он также может служить общей концептуальной / логической моделью. Этот веб-семинар объясняет все аспекты, начиная с обзора, а затем переходя к различиям между моделированием графических данных и «классическим» моделированием данных, […]
Чтобы просмотреть только слайды из этой презентации, щелкните ЗДЕСЬ >> Этот веб-семинар спонсируется: О веб-семинаре Можно ли добиться гибкости схемы без ущерба для транзакций или целостности данных? Да — путем расширения реляционных данных с помощью документов JSON! Вы можете индексировать и запрашивать данные независимо от того, являются ли они структурированными, полуструктурированными или и тем, и другим.Присоединяйтесь к […]
Чтобы просмотреть только слайды из этой презентации, щелкните ЗДЕСЬ >> О веб-семинаре Поскольку каждая организация производит и распространяет данные в рамках своей повседневной деятельности, тенденции данных становятся все более и более важными в сознании основного делового мира. Однако для многих организаций в различных отраслях понимание этого развития начинается и заканчивается […]
Чтобы просмотреть только слайды из этой презентации, щелкните ЗДЕСЬ >> Дата выхода в эфир: 18 июня 2019 г. Этот веб-семинар спонсируется: О веб-семинаре С изменениями в методологиях разработки программного обеспечения роль разработчика моделей данных значительно изменилась.Во многих организациях разработчики моделей данных теперь оказываются сторонними наблюдателями, отнесенными к документации «после […]
Дата выхода в эфир: 16 апреля 2019 г. Этот веб-семинар Спонсор: Чтобы просмотреть слайды для этой презентации, щелкните ЗДЕСЬ >> О веб-семинаре В условиях постоянно усложняющейся экосистемы данных модель корпоративных данных (EDM) является стратегическим императивом, чтобы каждый организация должна принять. Модель данных предприятия обеспечивает контекст и согласованность для всех организационных […]
Дата выхода в эфир: 21 августа 2010 г. Чтобы просмотреть только слайды из этой презентации, щелкните здесь >> Этот веб-семинар спонсируется: О веб-семинаре С изменениями в методологиях разработки программного обеспечения роль разработчика моделей данных значительно изменилась.Во многих организациях разработчики моделей данных теперь оказываются сторонними наблюдателями, отнесенными к документации «после […]
Чтобы просмотреть только слайды из этой презентации, щелкните ЗДЕСЬ >> Этот веб-семинар спонсируется: О веб-семинаре При запуске инициативы по управлению данными заинтересованные стороны могут не полностью осознавать сложность архитектуры данных или не знать, как определить необходимые процессы для реализации программы управления. Фактически, управление данными может означать […]
Практическое руководство. Определение модели с помощью вертикального сопоставления
При вертикальном отображении каждый класс имеет свою собственную таблицу, содержащую только свои поля.
Преимущества вертикального картирования:
- Таблицы нормализованы, поскольку они содержат только столбцы для полей того класса, для которого они предназначены, а строки присутствуют только для экземпляров этого класса
- Новые подклассы могут быть добавлены без изменения существующих таблиц
- Столбец дискриминатора не требуется. Это может помочь при отображении иерархии наследования на существующие таблицы.
Недостатки вертикального картографирования:
- Объединения используются для выборки полей из возможных подклассов в одном запросе.Если тип извлекаемого экземпляра известен, то объединяются только его таблицы, в противном случае должны быть включены все возможные таблицы подклассов.
- Для создания, обновления или удаления экземпляра требуется несколько операторов INSERT, UPDATE или DELETE (по одному для каждой задействованной таблицы)
Чтобы включить вертикальное сопоставление для подкласса, измените его стратегию сопоставления в мастере прямого сопоставления на вертикальное . Это изменение необходимо сделать для каждого дочернего класса, чтобы он отображался вертикально.Настройка для класса «Собака» выглядит так:
Соответствующие таблицы для примерной иерархии классов с вертикальным отображением показаны ниже:
Обратите внимание, что в таблице «домашнее животное» есть столбец дискриминатора. Его можно отключить так же, как и для «плоского сопоставления» — выбрав параметр {no} в поле со списком Значение дискриминатора для базового класса.
SQL для выборки всех домашних животных для отображения вертикального наследования без столбца дискриминатора показан ниже.Все таблицы втягиваются с помощью ВНЕШНИХ объединений, и для определения типа строки используется нулевой / ненулевой статус каждого из их первичных ключей. С помощью одного запроса можно получить любое количество экземпляров разных типов. Некоторые инструменты сопоставления O / R даже запускают дополнительный запрос для каждой возвращаемой строки, чтобы определить ее истинный тип (N + 1 запросов) или запускают отдельный запрос для каждой возможной таблицы и объединяют результаты в памяти:
| SQL | Копировать код |
|---|---|
ВЫБРАТЬ a.pet_id, b.pet_id, c.pet_id, d.pet_id, e.pet_id, | |
Если используется столбец дискриминатора, SQL имеет следующий вид:
| SQL | Копировать код |
|---|---|
ВЫБРАТЬ a.pet_id, a.voa_class, a.nme, a.voa_version, | |
Если известно, что все возвращенные экземпляры относятся к данному подклассу, OpenAccess ORM оптимизирует объединения, как показано в этом примере:
OQL | Копировать код |
|---|---|
ВЫБРАТЬ * ИЗ DogExtent | |
Обратите внимание, что соединение INNER используется для получения полей базового класса:
| SQL | Копировать код |
|---|---|
ВЫБРАТЬ a.pet_id, a.pet_id, c.pet_id, d.pet_id, | |
Если подкласс — листовой класс, тогда все соединения будут ВНУТРЕННИМИ соединениями:
| OQL | Копировать код |
|---|---|
ВЫБРАТЬ * ОТ RottweilerExtent | |
SQL | Копировать код |
|---|---|
ВЫБРАТЬ a.pet_id, a.cats_eaten, b.best_friend, c.nme, c.voa_version | |
MySQL :: MySQL Workbench Manual :: 9.3.1 Создание модели
В этом руководстве описывается, как создать новую модель базы данных и как для перенаправления модели на действующий сервер MySQL.
Запустите MySQL Workbench.На главном экране щелкните вид моделей на боковой панели, а затем щелкните (+) рядом с Модели. Или вы можете нажать а затем из меню (показано на рисунке, что следует).
Рисунок 9.22 Учебное пособие по началу работы — главный экран
Модель может содержать несколько схем. Обратите внимание, что когда вы создаете новая модель, она содержит схему
mydbот По умолчанию. Вы можете изменить имя этой схемы по умолчанию как необходимо или вы можете удалить его.Нажмите кнопку + справа от панель инструментов «Физические схемы» для добавления нового схема. Имя схемы по умолчанию —
new_schema1, который теперь можно изменить наdvd_collection, изменив его Поле имени. Подтвердите это изменение в Панель физических схем, показанная на следующем фигура. Теперь вы готовы добавить таблицу.Рисунок 9.23 Учебное пособие по началу работы — новая схема
Дважды щелкните Добавить таблицу в Раздел «Физические схемы».
Это автоматически загружает редактор таблиц с таблицей по умолчанию. имя
таблица1. Редактировать таблицу Поле имени для изменения имени таблицы стаблица1дофильмы.Затем добавьте столбцы в свою таблицу. Дважды щелкните столбец Имя ячейки и первое поле по умолчанию
moviesid, потому что (по умолчанию) MySQL Workbench добавляетidк имени таблицы для начального поле.Изменитеmoviesidнаmovie_idи оставьте Тип данных какINT, и также выберите PK (ПЕРВИЧНЫЙ КЛЮЧ), NN (НЕ NULL) и AI (AUTO_INCREMENT) флажки.Добавьте два дополнительных столбца, описанных в следующей таблице. На рисунке после таблицы показаны все три столбца. в фильмах
Имя столбца Тип данных Свойства столбца movie_titleVARCHAR (45) NN release_dateДАТА (ГГГГ-ММ-ДД) Нет Рисунок 9.24 Учебное пособие по началу работы — Редактирование столбцов таблицы
Для визуального представления (диаграммы EER) этой схемы выберите а затем создать диаграмму EER для модель. На следующем рисунке показана новая вкладка с названием Диаграмма EER, которая отображает диаграмму представление таблицы фильмов и столбцов.
Рисунок 9.25 Учебное пособие по началу работы — Схема EER
В редакторе таблиц измените имя столбца
movie_titleдоtitle.Обратите внимание, что диаграмма EER автоматически обновляется, чтобы отразить это изменение.Примечание
Чтобы открыть редактор таблиц, либо вернитесь к Вкладка MySQL Model и щелкните правой кнопкой мыши на
фильмытаблица или щелкните правой кнопкой мыши нафильмына диаграмме EER и выберите вариант.Сохраните модель, выбрав, а затем из меню или щелкните значок Сохранить модель в текущий файл на панель инструментов меню.Для этого урока введите
Home_Mediaи затем щелкните Сохранить.
Перед синхронизацией вашей новой модели с действующим сервером MySQL, подтвердите, что вы уже создали соединение MySQL. Этот учебник предполагает, что вы уже создали соединение. Если нет, см. Раздел 5.2, «Создание нового соединения с MySQL (Учебное пособие)» и используйте этот учебник для создания MySQL-соединения с именем MyFirstConnection, хотя альтернатива подключение тоже может работать.
Теперь перенесите вашу модель на действующий сервер MySQL следующим образом:
Выберите, а затем в меню, чтобы открыть Переслать Мастер создания базы данных.
Шаг Параметры подключения выбирает подключение MySQL и опционально устанавливает дополнительные параметры для выбранного MySQL связь. Внесите необходимые изменения в подключение и нажмите Следующий.
Примечание
Здесь вы можете выбрать другое соединение MySQL, но в этом руководстве используется MyFirstConnection.
На шаге Options перечислены необязательные расширенные параметры (как показано на рисунок ниже). В этом руководстве вы можете игнорировать эти параметры и нажмите Далее.
Рисунок 9.26 Учебное пособие по началу работы — параметры
Выберите объект для экспорта на действующий сервер MySQL. В этом случай, есть только одна таблица (
dvd_collection.movie). ВыберитеЭкспорт объектов таблицы MySQL(как рисунок, который показывает), а затем нажмите кнопку Далее.Рисунок 9.27 Учебное пособие по началу работы — выбор объектов
Шаг Просмотр сценария SQL отображает сценарий SQL, который будет выполняется на живом сервере для создания вашей схемы. Обзор сценарий, чтобы убедиться, что вы понимаете операции, которые осуществляться.
Нажмите Далее, чтобы выполнить форвард-инжиниринговый процесс.
Рисунок 9.28 Учебное пособие по началу работы — просмотр сценария SQL
Шаг «Прогресс фиксации» подтверждает, что каждая задача была выполнена. Щелкните Показать журналы, чтобы просмотреть журналы. Если нет присутствуют ошибки, нажмите Close, чтобы закрыть Мастер.
Новая база данных
dvd_collectionтеперь доступна присутствует на сервере MySQL. Подтвердите это, открыв MySQL подключения и просмотра списка схем, или выполнивПОКАЗАТЬ БАЗЫ ДАННЫХиз командной строки MySQL Клиент ( mysql ).Щелкните значок Сохранить модель в текущий файл. на панели инструментов меню, чтобы сохранить модель.