Кодирование и декодирование / Хабр
Причиной разобраться в том, как же работает UTF-8 и что такое Юникод заставил тот факт, что VBScript не имеет встроенных функций работы с UTF-8. А так как ничего рабочего не нашел, то пришлось писть/дописывать самому. Опыт на мой взгляд полезный в любом случае. Для лучшего понимания начну с теории.
О Юникоде
До появления Юникода широко использовались 8-битные кодировки, главные минусы которых очевидны:
- Всего 255 символов, да и то часть из них не графические;
- Возможность открыть документ не с той кодировкой, в которой он был создан;
- Шрифты необходимо создавать для каждой кодировки.
Так и было решено создать единый стандарт «широкой» кодировки, которая включала бы все символы (при чем сначала хотели в нее включить только обычные символы, но потом передумали и начали добавлять и экзотические). Юникод использует 1 112 064 кодовых позиций (больше чем 16 бит). Начало дублирует ASCII, а дальше остаток латиницы, кирилица, другие европейские и азиатские символы. Для обозначений символов используют шестнадцатеричную запись вида «U+xxxx» для первых 65k и с большим количеством цифр для остальных.
Юникод использует 1 112 064 кодовых позиций (больше чем 16 бит). Начало дублирует ASCII, а дальше остаток латиницы, кирилица, другие европейские и азиатские символы. Для обозначений символов используют шестнадцатеричную запись вида «U+xxxx» для первых 65k и с большим количеством цифр для остальных.
О UTF-8
UTF-8 является лишь представлением Юникода в 8-битном виде. Символы с кодами меньше 128 представляются одним байтом, а так как в Юникоде они повторяют ASCII, то текст написанный только этими символами будет являться текстом в ASCII. Символы же с кодами от 128 кодируются 2-мя байтами, с кодами от 2048 — 3-мя, от 65536 — 4-мя. Так можно было бы и до 6-ти байт дойти, но кодировать ими уже ничего.
0x00000000 — 0x0000007F: 0xxxxxxx 0x00000080 — 0x000007FF: 110xxxxx 10xxxxxx 0x00000800 — 0x0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx 0x00010000 — 0x001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
Кодируем в UTF-8
- Каждый символ превращаем в Юникод.

- Проверяем из какого символ диапазона.
- Если код символа меньше 128, то к результату добавляем его в неизменном виде.
- Если код символа меньше 2048, то берем последние 6 бит и первые 5 бит кода символа. К первым 5 битам добавляем 0xC0 и получаем первый байт последовательности, а к последним 6 битам добавляем 0x80 и получаем второй байт. Конкатенируем и добавляем к результату.
- Похожим образом можем продолжить и для больших кодов, но если символ за пределами U+FFFF придется иметь дело с UTF-16 суррогатами.
Function EncodeUTF8(s)
Dim i, c, utfc, b1, b2, b3
For i=1 to Len(s)
c = ToLong(AscW(Mid(s,i,1)))
If c < 128 Then
utfc = chr( c)
ElseIf c < 2048 Then
b1 = c Mod &h50
b2 = (c - b1) / &h50
utfc = chr(&hC0 + b2) & chr(&h80 + b1)
ElseIf c < 65536 And (c < 55296 Or c > 57343) Then
b1 = c Mod &h50
b2 = ((c - b1) / &h50) Mod &h50
b3 = (c - b1 - (&h50 * b2)) / &h2000
utfc = chr(&hE0 + b3) & chr(&h80 + b2) & chr(&h80 + b1)
Else
' Младший или старший суррогат UTF-16
utfc = Chr(&hEF) & Chr(&hBF) & Chr(&hBD)
End If
EncodeUTF8 = EncodeUTF8 + utfc
Next
End Function
Function ToLong(intVal)
If intVal < 0 Then
ToLong = CLng(intVal) + &h20000
Else
ToLong = CLng(intVal)
End If
End Function
Декодируем UTF-8
- Ищем первый символ вида 11xxxxxx
- Считаем все последующие байты вида 10xxxxxx
- Если последовательность из двух байт и первый байт вида 110xxxxx, то отсекаем приставки и складываем, умножив первый байт на 0x40.
- Аналогично для более длинных последовательностей.
- Заменяем всю последовательность на нужный символ Юникода.

Function DecodeUTF8(s)
Dim i, c, n, b1, b2, b3
i = 1
Do While i <= len(s)
c = asc(mid(s,i,1))
If (c and &hC0) = &hC0 Then
n = 1
Do While i + n <= len(s)
If (asc(mid(s,i+n,1)) and &hC0) <> &h80 Then
Exit Do
End If
n = n + 1
Loop
If n = 2 and ((c and &hE0) = &hC0) Then
b1 = asc(mid(s,i+1,1)) and &h4F
b2 = c and &h2F
c = b1 + b2 * &h50
Elseif n = 3 and ((c and &hF0) = &hE0) Then
b1 = asc(mid(s,i+2,1)) and &h4F
b2 = asc(mid(s,i+1,1)) and &h4F
b3 = c and &h0F
c = b3 * &h2000 + b2 * &h50 + b1
Else
' Символ больше U+FFFF или неправильная последовательность
c = &hFFFD
End if
s = left(s,i-1) + chrw( c) + mid(s,i+n)
Elseif (c and &hC0) = &h80 then
' Неожидаемый продолжающий байт
s = left(s,i-1) + chrw(&hFFFD) + mid(s,i+1)
End If
i = i + 1
Loop
DecodeUTF8 = s
End Function
Ссылки
Юникод на Википедии
Исходник для ASP+VBScript
UPD: Обработка ошибочных последовательностей и ошибка с типом Integer, который возвращает AscW.
/utf-8 (задайте для исходного кода и кодировки выполнения значение UTF-8)
Twitter LinkedIn Facebook Адрес электронной почты
- Статья
Задает как исходный набор символов, так и набор символов выполнения как UTF-8.
Синтаксис
/utf-8
С помощью /utf-8 параметра можно указать исходный набор символов и набор символов выполнения в кодировке с помощью UTF-8. Это эквивалентно указанию /source-charset:utf-8 /execution-charset:utf-8 в командной строке. Любой из этих параметров также включает параметр /validate-charset по умолчанию. Список поддерживаемых идентификаторов кодовых страниц и имен наборов символов см. в разделе Идентификаторы кодовых страниц.
По умолчанию Visual Studio обнаруживает метку порядка байтов, чтобы определить, находится ли исходный файл в закодированном формате Юникода, например или UTF-16UTF-8. Если метка порядка байтов не найдена, предполагается, что исходный файл закодирован в текущей пользовательской кодовой странице, если вы не указали кодовую страницу с помощью /utf-8 параметра или /source-charset . Visual Studio позволяет сохранять исходный код C++ в любой из нескольких кодировк. Сведения об исходных кодировках и наборах символов выполнения см. в разделе Наборы символов в языковой документации.
Visual Studio позволяет сохранять исходный код C++ в любой из нескольких кодировк. Сведения об исходных кодировках и наборах символов выполнения см. в разделе Наборы символов в языковой документации.
Установка параметра в Visual Studio или программным способом
Установка данного параметра компилятора в среде разработки Visual Studio
Откройте диалоговое окно Окна свойств проекта. Подробнее см. в статье Настройка компилятора C++ и свойств сборки в Visual Studio.
Выберите страницу свойствC/C++>Command Line
В разделе Дополнительные параметры добавьте
/utf-8параметр , чтобы указать предпочитаемую кодировку.Выберите ОК для сохранения внесенных изменений.
Установка данного параметра компилятора программным способом
- См. раздел AdditionalOptions.
См. также
Параметры компилятора MSVC
Синтаксис командной строки компилятора MSVC/execution-charset (Задать кодировку выполнения)/source-charset (Задать исходную кодировку)
/validate-charset (Проверка на наличие совместимых символов)
21), более чем достаточно для охвата текущих 1 112 064 кодовых точек Unicode.Вместо символов на самом деле правильнее ссылаться на кодовых точек при обсуждении систем кодирования. Кодовые точки позволяют абстрагироваться от термина символов и являются элементарной единицей хранения информации в кодировке. Большинство кодовых точек представляют один символ, но некоторые представляют такую информацию, как форматирование.
UTF-8 — это стандарт кодирования «переменной ширины». Это означает, что он кодирует каждую кодовую точку разным количеством байтов, от одного до четырех.
Обратная совместимость с ASCII
UTF-8 использует один байт для представления кодовых точек от 0 до 127. Эти первые 128 кодовых точек Unicode полностью соответствуют сопоставлению символов ASCII, поэтому символы ASCII также являются допустимыми символами UTF-8.
Как работает UTF-8: пример
Первый байт UTF-8 указывает, сколько байтов последует за ним. Затем биты кодовой точки «распределяются» по следующим байтам. Лучше всего это пояснить на примере:
Unicode присваивает французской букве é кодовую точку U+00E9.. Это 11101001 в двоичном формате; он не является частью набора символов ASCII. UTF-8 представляет это восьмибитное число двумя байтами.
Старшие биты обоих байтов содержат метаданные. Первый байт начинается с 110 . Единицы указывают, что это двухбайтовая последовательность, а 0 указывает, что биты кодовой точки будут следовать. Второй байт начинается с 10, чтобы сигнализировать о том, что он является продолжением последовательности UTF-8.
Второй байт начинается с 10, чтобы сигнализировать о том, что он является продолжением последовательности UTF-8.
Остается 11 «слотов» для битов кодовой точки. Помните, что U+00E9кодовая точка требует только восемь бит. UTF-8 дополняет начальные биты тремя 0 , чтобы полностью «заполнить» оставшиеся пробелы.
Результирующее представление UTF-8 для é (U+00E9): 1100001110101001 .
Как Twilio обрабатывает символы UTF-8?
UTF-8 является доминирующей кодировкой World Wide Web, поэтому ваш код, скорее всего, закодирован в соответствии с этим стандартом.
Для SMS-сообщений Twilio использует самый компактный доступный метод кодирования. Twilio по умолчанию использует GSM-7 и возвращается к UCS-2, если ваше сообщение содержит какие-либо символы, отличные от GSM-7. Использование стандартов кодирования GSM-7 по сравнению со стандартами кодирования UCS-2 может повлиять на количество сегментов, необходимых для отправки вашего сообщения.
Twilio Copilot автоматически распознает символы Unicode, которые легко пропустить, например умные кавычки (〞) или длинное тире (—), и заменяет их аналогичным символом. Это позволяет максимально снизить количество сегментов сообщений и цены.
Не беспокойтесь, если ваша строка «Ooh làlà» в кодировке UTF-8 придет по SMS — программируемое SMS Twilio поможет вам.
Готовы начать строительство? Войти Сейчас.
Сохранение файла CSV/Excel в кодировке UTF-8 – Импорт и экспорт товаров WooCommerce
При использовании плагина Import Export Suite for WooCommerce входной CSV-файл должен быть закодирован в формате UTF-8. Это гарантирует, что все ваши типы сообщений, такие как продукты, заказы, пользователи и т. д., импортируются точно. Во время импорта вы можете избежать ненужных символов, таких как ž, ? и т. д. Если файл CSV не имеет кодировки UTF-8, такие символы, как ™, ®, © и т. д., будут преобразованы в нежелательные символы.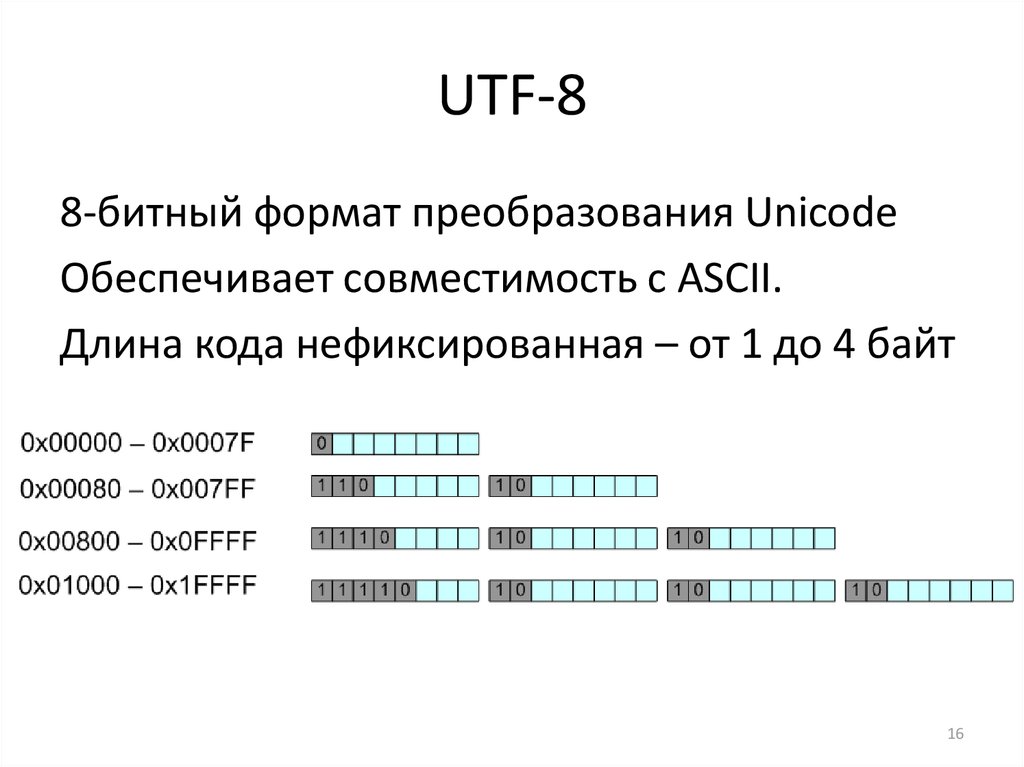
В этой статье объясняется, как применять кодировку UTF-8 с основными приложениями для работы с электронными таблицами, такими как Microsoft Excel и Блокнот для Windows и Apple Numbers и TextEdit для Mac. Поскольку Google Sheets — это широко используемое приложение для работы с электронными таблицами, в этой статье также объясняется кодировка UTF-8 с Google Sheets .
Что такое кодировка UTF-8?
Символ в UTF-8 может иметь длину от 1 до 4 байт. UTF-8 может представлять любой символ стандарта Unicode, а также обратно совместим с ASCII. Это наиболее предпочтительная кодировка для электронной почты и веб-страниц. Это доминирующая кодировка символов для всемирной паутины.
Вот два примера:
Образец 1: Электронная таблица без кодировки UTF-8 Образец 2: Электронная таблица без кодировки UTF-8Как сохранить CSV-файл как UTF-8 с помощью Libre Office?
Шаг 1 — Чтобы сохранить файл CSV в кодировке UTF-8, выполните следующие действия: Откройте LibreOffice и перейдите к Файлы в строке меню. Нажмите «Открыть» и выберите файл на компьютере, который вы хотите сохранить как файл в кодировке UTF-8.
Нажмите «Открыть» и выберите файл на компьютере, который вы хотите сохранить как файл в кодировке UTF-8.
Шаг 2 – После открытия файла перейдите к Файл > Сохранить как . В открывшемся диалоговом окне введите имя файла и выберите Text CSV (.csv) в раскрывающемся списке Сохранить как тип .
Проверьте параметры Изменить настройки фильтра .
Сохранить файл как CSVНажмите Сохранить .
Шаг 3 — В появившемся диалоговом окне Экспорт текстового файла выберите параметр Unicode (UTF-8) в раскрывающемся списке Набор символов .
Шаг 4 – Установите поле и разделитель текста по своему усмотрению или оставьте как есть.
Шаг 5 — Нажмите OK .
Это сохранит файл в кодировке UTF-8 в Libre Office.
Как сохранить файл CSV в кодировке UTF-8 с помощью электронной таблицы Google?
Чтобы сохранить файл CSV в кодировке UTF-8, вы можете загрузить файл на Google Диск и легко сохранить его в кодировке UTF-8. Шаги указаны ниже:
Шаги указаны ниже:
Шаги 1 – Сначала откройте свою учетную запись Google Drive . Нажмите кнопку NEW в верхнем левом углу и выберите параметр Загрузить файлы .
Вариант загрузки файла на Google ДискШаг 2 — Найдите нужный CSV-файл и начните его загрузку.
Шаг 3 — Откройте загруженный файл с помощью Таблицы Google .
Шаг 4 — Перейдите к Файл > Загрузить как, и выберите Значения, разделенные запятыми (.csv, текущий лист) опция .
Загрузка в формате CSV в Google SheetsЗагруженный файл по умолчанию сохраняется в кодировке UTF-8 и может быть правильно импортирован при загрузке в наш подключаемый модуль Import Export Suite for WooCommerce .
Как сохранить файл CSV как UTF-8 в Microsoft Excel?
Шаги указаны ниже:
Шаг 1 — Откройте файл CSV с помощью Лист Microsoft Excel .
Шаг 2 – Перейдите к пункту меню Файл и нажмите Сохранить как .
Появится окно, показанное ниже:
Параметр «Сохранить как» в Microsoft ExcelШаг 3 — Нажмите Обзор , чтобы выбрать место для сохранения файла.
Появится окно Сохранить как , как показано ниже:
Опция Сохранить как в Microsoft ExcelШаг 4 – Введите имя файла.
Шаг 5 – Выберите параметр Сохранить как тип как CSV (с разделителями-запятыми) (*.csv) .
Шаг 6 – . Щелкните раскрывающийся список Инструменты и выберите Веб-параметры . Появится новое окно веб-параметров, как показано ниже:
Веб-параметры Шаг 7 — На вкладке Кодировка выберите параметр Unicode (UTF-8) из раскрывающегося списка Сохранить этот документ как .
Наконец, нажмите Ok, и сохраните файл.
Как сохранить файл CSV в формате UTF-8 с помощью Блокнота?
Шаги описаны ниже: Откройте файл CSV с помощью Notepad .
Шаг 1 — Откройте файл CSV с помощью Блокнота .
Шаг 2 — Перейдите к File > Сохранить как . Скриншот меню показан ниже:
Меню «Файл Блокнота»Шаг 3 — Выберите место для файла.
Появится окно Сохранить как , как показано ниже:
Параметр «Сохранить как» в БлокнотеШаг 4 – Выберите параметр Сохранить как тип как Все файлы (*.*) .
Шаг 5 — Укажите имя файла с расширением .csv .
Шаг 6 – В раскрывающемся списке Encoding выберите вариант UTF-8 .
Шаг 7 – Нажмите Сохранить , чтобы сохранить файл.
Таким образом, вы можете сохранить файл в кодировке UTF-8 с помощью Блокнота.
Как сохранить CSV-файл как UTF-8 в Apple Numbers?
Шаги указаны ниже:
Шаг 1 — Откройте файл с Apple Numbers .
Шаг 2 — Перейдите к File > Экспорт в > CSV . Скриншот настроек показан ниже:
Экспорт в CSV с помощью Apple NumbersШаг 3 – В разделе «Дополнительные параметры» выберите параметр Unicode (UTF-8) для кодировки текста. Скриншот настроек показан ниже:
Дополнительные параметры в Apple NumbersШаг 4 — Нажмите Далее .
Дальнейшие настройки отображаются, как показано на снимке экрана ниже:
Параметр экспорта в Apple Numbers Шаг 5 — Введите имя файла и нажмите Экспорт , чтобы сохранить файл в кодировке UTF-8.