Как работают кодировки текста. Откуда появляются «кракозябры». Принципы кодирования. Обобщение и детальный разбор / Хабр
Данная статья имеет цель собрать воедино и разобрать принципы и механизм работы кодировок текста, подробно этот механизм разобрать и объяснить. Полезна она будет тем, кто только примерно представляет, что такое кодировки текста и как они работают, чем отличаются друг от друга, почему иногда появляются не читаемые символы, какой принцип кодирования имеют разные кодировки.
Чтобы получить детальное понимание этого вопроса придется прочитать и свести воедино не одну статью и потратить довольно значительное время на это. В данном материале же это все собрано воедино и по идее должно сэкономить время и разбор на мой взгляд получился довольно подробный.
О чем будет под катом: принцип работы одно байтовых кодировок (ASCII, Windows-1251 и т.д.), предпосылки появления Unicode, что такое Unicode, Unicode-кодировки UTF-8, UTF-16, их отличия, принципиальные особенности, совместимость и несовместимость разных кодировок, принципы кодирования символов, практический разбор кодирования и декодирования.
Вопрос с кодировками сейчас конечно уже потерял актуальность, но все же знать как они работают сейчас и как работали раньше и при этом не потратить много времени на это думаю лишним не будет.
Предпосылки Unicode
Начать думаю стоит с того времени когда компьютеризация еще не была так сильно развита и только набирала обороты. Тогда разработчики и стандартизаторы еще не думали, что компьютеры и интернет наберут такую огромную популярность и распространенность. Собственно тогда то и возникла потребность в кодировке текста. В каком то же виде нужно было хранить буквы в компьютере, а он (компьютер) только единицы и нули понимает. Так была разработана одно-байтовая кодировка ASCII (скорее всего она не первая кодировка, но она наиболее распространенная и показательная, по этому ее будем считать за эталонную). Что она из себя представляет? Каждый символ в этой кодировке закодирован 8-ю битами. Несложно посчитать что исходя из этого кодировка может содержать 256 символов (восемь бит, нулей или единиц 28=256).
Первые 7 бит (128 символов 2
Думаю проблема с национальными кодировками понятна. Собственно этих национальных кодировок стало очень много, а интернет стал очень широким, и в нем каждый хотел писать на своем языке и не хотел чтобы его язык выглядел как кракозябры. Было два выхода, указывать для каждой страницы кодировки, либо создать одну общую для всех символов в мире таблицу символов. Победил второй вариант, так создали Unicode таблицу символов.
Небольшой практикум ASCII
Возможно покажется элементарщиной, но раз уж решил объяснять все и подробно, то это надо.
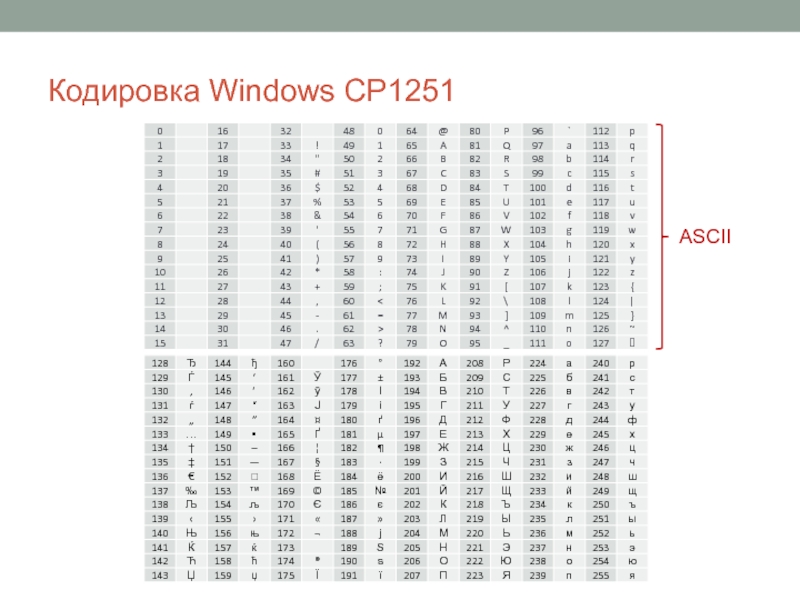
Вот таблица символов ASCII:
Тут имеем 3 колонки:
- номер символа в десятичном формате
- номер символа в шестнадцатиричном формате
- представление самого символа.
Итак, закодируем строку «ok» (англ.) в кодировке ASCII. Символ «o» (англ.) имеет позицию 111 в десятичном виде и 6F в шестнадцатиричном. Переведем это в двоичную систему —
Переведем это в двоичную систему — 01101111. Символ «k» (англ.) — позиция 107 в десятеричной и 6B в шестнадцатиричной, переводим в двоичную — 01101011. Итого строка «ok» закодированная в ASCII будет выглядеть так — 01101111 01101011. Процесс декодирования будет обратный. Берем по 8 бит, переводим их в 10-ичную кодировку, получаем номер символа, смотрим по таблице что это за символ.
Unicode
С предпосылками создания общей таблицы для всех в мире символов, разобрались. Теперь собственно, к самой таблице. Unicode — именно эта таблица и есть (это не кодировка, а именно таблица символов). Она состоит из 1 114 112 позиций. Большинство этих позиций пока не заполнены символами, так что вряд ли понадобится это пространство расширять.
Разделено это общее пространство на 17 блоков, по 65 536 символов в каждом. Каждый блок содержит свою группу символов. Нулевой блок — базовый, там собраны наиболее употребляемые символы всех современных алфавитов.
Итого емкость символов юникода составляет от 0 до 10FFFF (в шестнадцатиричном виде).
Записываются символы в шестнадцатиричном виде с приставкой «U+». Например первый базовый блок включает в себя символы от U+0000 до U+FFFF (от 0 до 65 535), а последний семнадцатый блок от U+100000 до U+10FFFF (от 1 048 576 до 1 114 111).
Отлично теперь вместо зоопарка национальных кодировок, у нас есть всеобъемлющая таблица, в которой зашифрованы все символы которые нам могут пригодиться. Но тут тоже есть свои недостатки. Если раньше каждый символ был закодирован одним байтом, то теперь он может быть закодирован разным количеством байтов. Например для кодирования всех символов английского алфавита по прежнему достаточно одного байта например тот же символ «o» (англ.) имеет в юникоде номер U+006F, то есть тот же самый номер как и в ASCII —
 А вот для кодирования символа «U+103D5» (это древнеперсидская цифра сто) — 103D5 в шестнадцатиричной и 66 517 в десятеричной, тут нам потребуется уже три байта.
А вот для кодирования символа «U+103D5» (это древнеперсидская цифра сто) — 103D5 в шестнадцатиричной и 66 517 в десятеричной, тут нам потребуется уже три байта.Решить эту проблему уже должны юникод-кодировки, такие как UTF-8 и UTF-16. Далее речь пойдет про них.
UTF-8
UTF-8 является юникод-кодировкой переменной длинны, с помощью которой можно представить любой символ юникода.
Давайте поподробнее про переменную длину, что это значит? Первым делом надо сказать, что структурной (атомарной) единицей этой кодировки является байт. То что кодировка переменной длинны, значит, что один символ может быть закодирован разным количеством структурных единиц кодировки, то есть разным количеством байтов. Так например латиница кодируется одним байтом, а кириллица двумя байтами.
Немного отступлю от темы, надо написать про совместимость ASCII и UTF
То что латинские символы и основные управляющие конструкции, такие как переносы строк, табуляции и т.
Давайте возьмем символ «o»(англ.) из примера про ASCII выше. Помним что в таблице ASCII символов он находится на 111 позиции, в битовом виде это будет 01101111. В таблице юникода этот символ — U+006F что в битовом виде тоже будет
01101111. И теперь так, как UTF — это кодировка переменной длины, то в ней этот символ будет закодирован одним байтом. То есть представление данного символа в обеих кодировках будет одинаково. И так для всего диапазона символов от 0 до 128. То есть если ваш документ состоит из английского текста то вы не заметите разницы если откроете его и в кодировке UTF-8 и UTF-16 и ASCII (прим. в UTF-16 такие символы все равно будут закодированы двумя байтами, по этому вы не увидите разницы, если ваш редактор будет игнорировать нулевые байты), и так до момента пока вы не начнете работать с национальным алфавитом.
Сравним на практике как будет выглядеть фраза «Hello мир» в трех разных кодировках: Windows-1251 (русская кодировка), ISO-8859-1 (кодировка западно-европейских языков), UTF-8 (юникод-кодировка). Суть данного примера состоит в том что фраза написана на двух языках. Посмотрим как она будет выглядеть в разных кодировках.
В кодировке ISO-8859-1 нет таких символов «м», «и» и «р».
Теперь давайте поработаем с кодировками и разберемся как преобразовать строку из одной кодировки в другую и что будет если преобразование неправильное, или его нельзя осуществить из за разницы в кодировках.
Будем считать что изначально фраза была записана в кодировке Windows-1251. Исходя из таблицы выше запишем эту фразу в двоичном виде, в кодировке Windows-1251. Для этого нам потребуется всего только перевести из десятеричной или шестнадцатиричной системы (из таблицы выше) символы в двоичную.
01001000 01100101 01101100 01101100 01101111 00100000 11101100 11101000 11110000
Отлично, вот это и есть фраза «Hello мир» в кодировке Windows-1251.
Теперь представим что вы имеете файл с текстом, но не знаете в какой кодировке этот текст. Вы предполагаете что он в кодировке ISO-8859-1 и открываете его в своем редакторе в этой кодировке. Как сказано выше с частью символов все в порядке, они есть в этой кодировке, и даже находятся на тех же местах, но вот с символами из слова «мир» все сложнее. Этих символов в этой кодировке нет, а на их местах в кодировке ISO-8859-1 находятся совершенно другие символы. А конкретно «м» — позиция 236, «и» — 232. «р» — 240. И на этих позициях в кодировке ISO-8859-1 находятся следующие символы позиция 236 — символ «ì», 232 — «è», 240 — «ð»
Значит фраза «Hello мир» закодированная в Windows-1251 и открытая в кодировке ISO-8859-1 будет выглядеть так: «Hello ìèð». Вот и получается что эти две кодировки совместимы лишь частично, и корректно перекодировать строку из одной кодировке в другую не получится, потому что там просто напросто нет таких символов.
Тут и будут необходимы юникод-кодировки, а конкретно в данном случае рассмотрим UTF-8. То что символы в ней могут быть закодированы разным количеством байтов от 1 до 4 мы уже выяснили. Теперь стоит сказать что с помощью UTF могут быть закодированы не только 256 символов, как в двух предыдущих, а вобще все символы юникода
То что символы в ней могут быть закодированы разным количеством байтов от 1 до 4 мы уже выяснили. Теперь стоит сказать что с помощью UTF могут быть закодированы не только 256 символов, как в двух предыдущих, а вобще все символы юникода
Работает она следующим образом. Первый бит каждого байта кодирующего символ отвечает не за сам символ, а за определение байта. То есть например если ведущий (первый) бит нулевой, то это значит что для кодирования символа используется всего один байт. Что и обеспечивает совместимость с ASCII. Если внимательно посмотрите на таблицу символов ASCII то увидите что первые 128 символов (английский алфавит, управляющие символы и знаки препинания) если их привести к двоичному виду, все начинаются с нулевого бита (будьте внимательны, если будете переводить символы в двоичную систему с помощью например онлайн конвертера, то первый нулевой ведущий бит может быть отброшен, что может сбить с толку).
01001000 — первый бит ноль, значит 1 байт кодирует 1 символ -> «H»
01100101 — первый бит ноль, значит 1 байт кодирует 1 символ -> «e»
Если первый бит не нулевой то символ кодируется несколькими байтами.
Для двухбайтовых символов первые три бита должны быть такие — 110
11010000 10111100 — в начале 110, значит 2 байта кодируют 1 символ. Второй байт в таком случае всегда начинается с 10. Итого отбрасываем управляющие биты (начальные, которые выделены красным и зеленым) и берем все оставшиеся (10000111100), переводим их в шестнадцатиричный вид (043С) -> U+043C в юникоде равно символ «м».
для трех-байтовых символов в первом байте ведущие биты — 1110
11101000 10000111 101010101 — суммируем все кроме управляющих битов и получаем что в 16-ричной равно 103В5, U+103D5 — древнеперситдская цифра сто (10000001111010101)
для четырех-байтовых символов в первом байте ведущие биты — 11110
11110100 10001111 10111111 10111111 — U+10FFFF это последний допустимый символ в таблице юникода (100001111111111111111)
Теперь, при желании, можем записать нашу фразу в кодировке UTF-8.
UTF-16
UTF-16 также является кодировкой переменной длинны. Главное ее отличие от UTF-8 состоит в том что структурной единицей в ней является не один а два байта. То есть в кодировке UTF-16 любой символ юникода может быть закодирован либо двумя, либо четырьмя байтами. Давайте для понятности в дальнейшем пару таких байтов я буду называть кодовой парой. Исходя из этого любой символ юникода в кодировке UTF-16 может быть закодирован либо одной кодовой парой, либо двумя.
Начнем с символов которые кодируются одной кодовой парой. Легко посчитать что таких символов может быть 65 535 (2в16), что полностью совпадает с базовым блоком юникода. Все символы находящиеся в этом блоке юникода в кодировке UTF-16 будут закодированы одной кодовой парой (двумя байтами), тут все просто.
символ «o» (латиница) — 00000000 01101111
символ «M» (кириллица) — 00000100 00011100
Теперь рассмотрим символы за пределами базового юникод диапазона. Для их кодирования потребуется уже две кодовые пары (4 байта). И механизм их кодирования немного сложнее, давайте по порядку.
Для их кодирования потребуется уже две кодовые пары (4 байта). И механизм их кодирования немного сложнее, давайте по порядку.
Для начала введем понятия суррогатной пары. Суррогатная пара — это две кодовые пары используемые для кодирования одного символа (итого 4 байта). Для таких суррогатных пар в таблице юникода отведен специальный диапазон от D800 до DFFF. Это значит, что при преобразовании кодовой пары из байтового вида в шестнадцатиричный вы получаете число из этого диапазона, то перед вами не самостоятельный символ, а суррогатная пара.
Чтобы закодировать символ из диапазона 10000 — 10FFFF (то есть символ для которого нужно использовать более одной кодовой пары) нужно:
- из кода символа вычесть 10000(шестнадцатиричное) (это наименьшее число из диапазона 10000 — 10FFFF)
- в результате первого пункта будет получено число не больше FFFFF, занимающее до 20 бит
- ведущие 10 бит из полученного числа суммируются с D800 (начало диапазона суррогатных пар в юникоде)
- следующие 10 бит суммируются с DC00 (тоже число из диапазона суррогатных пар)
- после этого получатся 2 суррогатные пары по 16 бит, первые 6 бит в каждой такой паре отвечают за определение того что это суррогат,
- десятый бит в каждом суррогате отвечает за его порядок если это 1 то это первый суррогат, если 0, то второй
Разберем это на практике, думаю станет понятнее.
Для примера зашифруем символ, а потом расшифруем. Возьмем древнеперсидскую цифру сто (U+103D5):
- 103D5 — 10000 = 3D5
- 3D5 =
0000000000 1111010101(ведущие 10 бит получились нулевые приведем это к шестнадцатиричному числу, получим 0 (первые десять), 3D5 (вторые десять)) - 0 + D800 = D800 (
1101100000000000) первые 6 бит определяют что число из диапазона суррогатных пар десятый бит (справа) нулевой, значит это первый суррогат - 3D5 + DC00 = DFD5 (
1101111111010101) первые 6 бит определяют что число из диапазона суррогатных пар десятый бит (справа) единица, значит это второй суррогат - итого данный символ в UTF-16 —
1101100000000000 1101111111010101
Теперь наоборот раскодируем. Допустим что у нас есть вот такой код — 1101100000100010 1101111010001000:
- переведем в шестнадцатиричный вид = D822 DE88 (оба значения из диапазона суррогатных пар, значит перед нами суррогатная пара)
1101100000100010— десятый бит (справа) нулевой, значит первый суррогат1101111010001000— десятый бит (справа) единица, значит второй суррогат- отбрасываем по 6 бит отвечающих за определение суррогата, получим
0000100010 1010001000(8A88) - прибавляем 10000 (меньшее число суррогатного диапазона) 8A88 + 10000 = 18A88
- смотрим в таблице юникода символ U+18A88 = Tangut Component-649.
 Компоненты тангутского письма.
Компоненты тангутского письма.
 Компоненты тангутского письма.
Компоненты тангутского письма.Спасибо тем кто смог дочитать до конца, надеюсь было полезно и не очень занудно.
Вот некоторые интересные ссылки по данной теме:
habr.com/ru/post/158895 — полезные общие сведения по кодировкам
habr.com/ru/post/312642 — про юникод
unicode-table.com/ru — сама таблица юникод символов
Ну и собственно куда же без нее
ru.wikipedia.org/wiki/%D0%AE%D0%BD%D0%B8%D0%BA%D0%BE%D0%B4 — юникод
ru.wikipedia.org/wiki/ASCII — ASCII
ru.wikipedia.org/wiki/UTF-8 — UTF-8
ru.wikipedia.org/wiki/UTF-16 — UTF-16
Кодировки
Главный модуль
Основные сведения
При задании кодировки языка и выбора его идентификатора используются следующие аббревиатуры и константы.
| Язык | Идентификатор | Кодировка |
|---|---|---|
| Russian | ru | iso-8859-5, windows-1251, koi8-r |
| English | en | iso-8859-1, windows-1252 |
| Afrikaans | af | iso-8859-1, windows-1252 |
| Albanian | sq | iso-8859-1, windows-1250 |
| Arabic | ar | iso-8859-6, windows-1256 |
| Basque | eu | iso-8859-1, windows-1252 |
| Bulgarian | bg | iso-8859-5, windows-1251 |
| Belorussian | be | iso-8859-5, windows-1251 |
| Catalan | ca | iso-8859-15, windows-1252 |
| Croatian | hr | iso-8859-2, windows-1250 |
| Czech | cs | iso-8859-2, windows-1250 |
| Danish | da | iso-8859-1, windows-1252 |
| Dutch | nl | iso-8859-1, windows-1252 |
| Esperanto | eo | iso-8859-3 |
| Estonian | et | iso-8859-15, windows-1257 |
| Faroese | fo | iso-8859-1, windows-1252 |
| Finnish | fi | iso-8859-1, windows-1252 |
| French | fr | iso-8859-1, windows-1252 |
| Galician | gl | iso-8859-1, windows-1252 |
| German | de | iso-8859-1, windows-1252 |
| Greek | el | iso-8859-7 |
| Hebrew | iw | iso-8859-8 |
| Hungarian | hu | iso-8859-2, windows-1250 |
| Icelandic | is | iso-8859-1, windows-1252 |
| Irish | ga | iso-8859-1, windows-1252 |
| Italian | it | iso-8859-1, windows-1252 |
| Japanese | ja | shift_jis, iso-2022-jp, euc-jp |
| Korean | ko | euc-kr |
| Latvian | lv | iso-8859-13, windows-1257 |
| Lithuanian | lt | iso-8859-13, windows-1257 |
| Macedonian | mk | iso-8859-5, windows-1251 |
| Maltese | mt | iso-8859-3 |
| Norwegian | no | iso-8859-1, windows-1252 |
| Polish | pl | iso-8859-2, windows-1250 |
| Portuguese | pt | iso-8859-1, windows-1252 |
| Portuguese (бразильский) | br | iso-8859-1, windows-1252 |
| Romanian | ro | iso-8859-2, windows-1250 |
| Scottish | gd | iso-8859-1, windows-1252 |
| Serbian cyrillic | sr | iso-8859-5, windows-1251 |
| Serbian latin | sr | iso-8859-2, windows-1250 |
| Slovak | sk | iso-8859-2, windows-1250 |
| Slovenian | sl | iso-8859-2, windows-1250 |
| Spanish | la | iso-8859-1, windows-1252 |
| Swedish | sv | iso-8859-1, windows-1252 |
| Turkish | tr | iso-8859-9, windows-1254 |
| Ukrainian | ua |
windows-1251, koi8-u |
© «Битрикс», 2001-2023, «1С-Битрикс», 2023
Наверх
кодовых страниц — приложения Win32
- Статья
Большинство приложений, написанных сегодня, обрабатывают символьные данные в основном как Unicode, используя кодировку UTF-16. Однако многие устаревшие приложения продолжают использовать наборы символов на основе кодовых страниц. Даже новым приложениям иногда приходится работать с кодовыми страницами, часто по одной из следующих причин:
- Для связи с устаревшими приложениями.
- Для связи со старыми почтовыми серверами и серверами новостей, которые могут не всегда поддерживать Unicode.
- Для связи с консолью Windows в устаревших целях. (Консоль поддерживает Unicode, но некоторые устаревшие инструменты командной строки могут не поддерживаться.)
Примечание
Новые приложения Windows должны использовать Unicode, чтобы избежать несоответствий различных кодовых страниц и упростить локализацию.
Каждая кодовая страница представлена идентификатором кодовой страницы, например 1252, и обрабатывается функциями Unicode и API набора символов. Список поддерживаемых идентификаторов кодовых страниц см. в разделе Идентификаторы кодовых страниц. Справочник «Кодовые страницы» в Глобальном центре разработчиков Microsoft Go дает полное описание многих кодовых страниц.
Список поддерживаемых идентификаторов кодовых страниц см. в разделе Идентификаторы кодовых страниц. Справочник «Кодовые страницы» в Глобальном центре разработчиков Microsoft Go дает полное описание многих кодовых страниц.
Кодовые страницы Windows, обычно называемые «кодовыми страницами ANSI», представляют собой кодовые страницы, для которых значения, отличные от ASCII (значения больше 127), представляют международные символы. Эти кодовые страницы изначально используются в Windows Me, а также доступны в Windows NT и более поздних версиях.
Примечание
Первоначально кодовая страница Windows 1252, кодовая страница, обычно используемая для английского и других западноевропейских языков, была основана на проекте Американского национального института стандартов (ANSI). Этот проект в конечном итоге стал ISO 8859-1, но кодовая страница Windows 1252 была реализована до того, как стандарт стал окончательным, и это не совсем то же самое, что ISO 8859-1.
Многие функции Windows API имеют версии «A» (ANSI) и «W» (широкий, Unicode). Версия «A» обрабатывает текст на основе кодовых страниц Windows, а версия «W» обрабатывает текст в формате Unicode. См. Типы данных Windows для строк и Соглашения для прототипов функций.
Версия «A» обрабатывает текст на основе кодовых страниц Windows, а версия «W» обрабатывает текст в формате Unicode. См. Типы данных Windows для строк и Соглашения для прототипов функций.
Кодовые страницы Windows также иногда называют «активными кодовыми страницами» или «системными активными кодовыми страницами». В операционной системе Windows всегда есть одна активная в данный момент кодовая страница Windows. Все версии функций API ANSI используют текущую активную кодовую страницу.
Кодовые страницы производителя оригинального оборудования (OEM) — это кодовые страницы, для которых значения, отличные от ASCII, представляют символы рисования линий и пунктуации. Эти кодовые страницы изначально использовались для MS-DOS и до сих пор используются для консольных приложений. Они также используются для нерасширенных имен файлов в файловых системах FAT12, FAT16 и FAT32, как описано в разделе Наборы символов, используемые в именах файлов. Обычная кодовая страница OEM для английского языка — кодовая страница 437.
Как для кодовых страниц Windows, так и для кодовых страниц OEM значения кода от 0x00 до 0x7F соответствуют 7-битному набору символов ASCII. Кодовые значения от 0x00 до 0x19 и 0x7F всегда представляют собой стандартные управляющие символы, а от 0x20 до 0x7E — стандартизированные отображаемые символы. Символы, представленные остальными кодами, от 0x80 до 0xff, различаются в зависимости от набора символов. Каждый набор символов включает различные специальные символы, обычно настроенные для языка или группы языков. Кодовая страница Windows 1252 и кодовая страница OEM 437 обычно используются в США.
Помимо кодовых страниц Windows и OEM, ваши приложения могут использовать неродные кодовые страницы. Примерами являются кодовые страницы EBCDIC и Macintosh.
Две кодировки Unicode (UTF-7 и UTF-8) реализованы как кодовые страницы. Как и другие кодовые страницы, каждая страница известна по числовому идентификатору и может обрабатываться многими из тех же функций API Unicode и набора символов.
Кодовые страницы могут быть либо страницами с однобайтовым набором символов (SBCS), либо страницами с двухбайтовым набором символов (DBCS). На страницах SBCS каждый байт напрямую кодирует один символ, так что можно представить ровно 256 различных символов (включая управляющие символы, буквы, цифры, знаки препинания, символы и т.п.). Кодовые страницы DBCS используются для таких языков, как японский и китайский. В такой кодовой странице некоторые символы имеют двухбайтовую кодировку с определенными значениями байтов (всегда значения больше 127), выступающими в качестве «начальных байтов». Вместо того, чтобы кодировать символы сами по себе, начальные байты могут быть сопоставлены с символом только в сочетании с «конечным байтом».
Некоторые устаревшие протоколы требуют использования кодовых страниц SBCS и DBCS. Каждая кодовая страница SBCS/DBCS поддерживает разные символы, но ни одна кодовая страница не поддерживает весь набор символов, предоставляемых Unicode. Каждая кодовая страница SBCS/DBCS поддерживает разные подмножества, закодированные по-разному.
Примечание
Данные, преобразованные из одной кодовой страницы SBCS или DBCS в другую, могут быть повреждены, поскольку одно и то же значение данных на разных кодовых страницах может кодировать разные символы. Данные, преобразованные из Unicode в SBCS или DBCS, могут быть потеряны, так как данная кодовая страница может не соответствовать каждому символу, используемому в этих конкретных данных Unicode.
Помимо кодовых страниц SBCS и DBCS, в ваших приложениях доступны кодовые страницы многобайтовых наборов символов 52936, 54936, 51949 и 5022x, которые используют подход, аналогичный подходу для DBCS. Однако кодовая страница многобайтового набора символов выходит за рамки двухбайтовых кодировок некоторых символов. UTF-7 и UTF-8 используют аналогичный подход для кодирования Unicode на основе 7-битных и 8-битных байтов соответственно. Дополнительные сведения см. в разделе Юникод.
Несколько функций Unicode и наборов символов позволяют вашим приложениям обрабатывать кодовые страницы. Приложение может использовать GetCPInfo и GetCPInfoEx функции для получения информации о кодовой странице. Эта информация включает символ по умолчанию, используемый, когда символ в преобразованной строке не имеет соответствующей записи на кодовой странице.
Приложение может использовать GetCPInfo и GetCPInfoEx функции для получения информации о кодовой странице. Эта информация включает символ по умолчанию, используемый, когда символ в преобразованной строке не имеет соответствующей записи на кодовой странице.
Приложение может использовать функции MultiByteToWideChar и WideCharToMultiByte для преобразования между строками на основе кодовых страниц Windows и строк Unicode. Хотя их имена относятся к «MultiByte», эти функции одинаково хорошо работают с кодовыми страницами SBCS, DBCS и многобайтовыми наборами символов.
Примечание
WideCharToMultiByte могут быть потеряны некоторые данные, если предоставленная кодовая страница не может представить все символы в строке Unicode.
Ваше приложение может выполнять преобразование между кодовыми страницами Windows и кодовыми страницами OEM с помощью стандартных функций библиотеки времени выполнения C. Однако использование этих функций сопряжено с риском потери данных, поскольку символы, которые могут быть представлены каждой кодовой страницей, не совпадают точно.
Однако использование этих функций сопряжено с риском потери данных, поскольку символы, которые могут быть представлены каждой кодовой страницей, не совпадают точно.
Ваши приложения также могут вызывать Функция GetACP . Эта функция извлекает идентификатор текущей кодовой страницы Windows (ANSI).
Наборы символов
В чем разница между кодировкой Windows-1252 и ANSI?
спросил
Изменено 1 месяц назад
Просмотрено 15 тысяч раз
Я пытаюсь преобразовать кодировку UTF-8 в кодировку ANSI с помощью инструмента.
Но показывает Western European (Windows)-1252 вместо ANSI .
Это одно и то же? Должен ли я продолжать это?
- кодировка
- кодировка символов
- ansi
В чем разница между кодировкой Windows-1252 и ANSI?
См. ниже. На практике это, вероятно, не будет иметь большого значения для вашей конверсии.
Если у вас есть копия исходного файла, вы всегда можете применить другое преобразование, если это необходимо.
Сказав, что существуют способы преобразования UTF-8 в ANSI.
Windows-1252
Эта кодировка символов является надмножеством ISO 8859-1 с точки зрения печатных символов, но отличается от ISO-8859-1 IANA использованием отображаемых символов, а не управляющих символов в диапазоне от 80 до 9F (шестнадцатеричный). Заметные дополнительные символы включают фигурные кавычки и все печатные символы, которые есть в ISO 8859.-15. Windows известен под номером кодовой страницы 1252 и одобренным IANA именем «windows-1252».
. ..
..
Исторически сложилось так, что фраза «Кодовая страница ANSI» (ACP) используется в Windows для обозначения различных кодовых страниц, считающихся собственными. Предполагалось, что большинство из них будут стандартами ANSI, такими как ISO-8859-1. Несмотря на то, что Windows-1252 была первой и, безусловно, самой популярной кодовой страницей, названной так на языке Microsoft Windows, кодовая страница никогда не была стандартом ANSI. Microsoft объясняет: «Термин ANSI, используемый для обозначения кодовых страниц Windows, является исторической ссылкой, но в настоящее время это неправильное название, которое продолжает сохраняться в сообществе Windows».0013
Источник Windows-1252
Обратите внимание, что, несмотря на приведенное выше заявление Microsoft, они по-прежнему называют Windows 1252 «ANSI»:
Страница исходного кода 1252 Windows Latin 1 (ANSI)
4
Являются ли Windows-1252 и ANSI одним и тем же? — Да, для западноевропейских языков они идентичны
кодировки. 1
1
Другие естественные языки смотрите в моей таблице в конце этот ответ.
К сожалению, страницы Википедии по теме, это и
this,
изобилуют запутанными заявлениями и утверждениями без ссылок.
Лучше обратиться сразу к
один из источников, на который Википедия ссылается на .
Он был написан в мае 2002 года и гласит:
.Термин «ANSI», используемый для обозначения кодовых страниц Windows, является исторической справкой, но в настоящее время это неправильное название, которое продолжает сохраняться в сообществе Windows. Источником этого является тот факт, что кодовая страница Windows 1252 изначально был основан на проекте ANSI, который стал стандартом ISO. 8859-1. Однако при добавлении кодовых точек в диапазон, зарезервированный для управляющих кодов, в стандарте ISO кодовая страница Windows 1252 и последующие Кодовые страницы Windows, первоначально основанные на серии ISO 8859-x, отклонились из ИСО. По сей день [май 2002 г.
