Инструкция по переходу на UTF-8
Вычислительная система кафедры перешла на использование многобайтовой кодировки UTF-8 для файловых систем и пользовательского окружения вместо однобайтовой кодировки KOI8-R. В данной инструкции рассматриваются типичные проблемы, которые могли возникнуть у пользователей в связи с данным переходом и предлагаются способы их решения (изменения настроек, команды и т.п.).
Основные понятия
Юнико́д, или Унико́д (англ. Unicode™) — стандарт кодирования символов, позволяющий представить знаки практически всех письменных языков.
UTF-8 (от англ. Unicode Transformation Format — формат преобразования Юникода) — кодировка, реализующая представление Юникода, совместимое с 8-битным кодированием текста.
Важно понимать, что один символ в кодировке UTF-8 может быть
представлен более чем одним байтом. С этим связано, например, то, что
файл, содержащий текст в кодировке UTF-8 будет иметь больший размер по
сравнению с файлом, содержащим тот-же текст в кодировке KOI8-R.
Пример: команда wc имеет ключ -c для подсчета байтов и ключ -m для подсчета символов.
$ echo -n "Слово." | wc -c 11 $ echo -n "Слово." | wc -m 6
Имена файлов
Имена файлов были перекодированы автоматически с помощью утилиты convmv:
convmv -r -f koi8-r -t utf-8 --notest <каталог>
Каждому пользователю, в домашнем каталоге которого утилита convmv переименовала хотя бы один файл, был автоматически выслан журнал переименований.
При необходимости можно выполнить обратное преобразование:
convmv -r -f utf-8 -t koi8-r <файлы и каталоги>
После проверки вывода команды повторить с ключем —notest. Ключ -r включает рекурсивный обход каталогов.
Содержимое файлов
Для того, чтобы преобразовать содержимое файлов из кодировки KOI8-R в кодировку UTF-8 можно воспользоваться командой:
recode koi8-r..utf-8 <filename>
Для потокового перекодирования используется команда:
iconv -f koi8-r <filename>
Редактор Emacs может автоматически распознать кодировку текста при
открытии файла. Принудительно задать кодировку открытия или сохранения
файла в редакторе Emacs можно следующим образом:
Принудительно задать кодировку открытия или сохранения
файла в редакторе Emacs можно следующим образом:
- Ввести комбинацию клавиш
C-x RET c. - Внизу экрана будет запрошена кодировка, которую вы хотите применить для следующей команды.
- Введите команду, которая будет выполнена с применением введенной на предыдущем шаге кодировки, например:
- комбинацию клавиш для открытия файла:
C-x C-f; - комбинацию клавиш для сохранения файла:
C-x C-s.
- комбинацию клавиш для открытия файла:
Приложения
Текстовый терминал из Windows
Для корректного отображения русского текста при входе на серверы кафедры с помощью терминального клиента PuTTY нужно указать в настройках:
- Раздел Window/Translation
- Character set translation on recieved data: UTF-8
Текстовый терминал из Linux
Если системная локаль не UTF-8, то необходимо запустить X-терминал с поддержкой UTF-8 и выполнить вход по ssh из него.
Если системная локаль UTF-8, то никаких дополнительных действий предпринимать не надо.
Если по какой-то причине при входе по ssh не установились правильно переменные окружения локали (вывод команды locale не содержит строки LANG=ru_RU.UTF-8), то необходимо выполнить команду:
export LANG=ru_RU.UTF-8
WinSCP
Для корректного отображения русских имен файлов:
- Раздел Environment
- UTF-8 encoding for filenames: On
TEX
- После выполнения перекодировки содержимого tex-файла (см. Содержимое файлов) необходимо сменить кодировку в преамбуле:
Было:
\usepackage[koi8-r]{inputenc}
Стало:
\usepackage[utf8x]{inputenc}
- Также необходимо подключить пакет ucs:
\usepackage{ucs}
- Для установки диакритических знаков (ударений) нужно использовать полную форму стандартной записи \’, т.е.:
Б\'{о}льшую
Bibtex
Bib-файлы, содержащие описание литературы, хранятся в кодировке KOI8-R. После выполнения команды bibtex
необходимо сначала перекодировать получившийся bbl-файл в кодировку
UTF-8 (см. Содержимое файлов), а затем выполнять трансляцию
tex-файлов, подключающих этот список литературы.
После выполнения команды bibtex
необходимо сначала перекодировать получившийся bbl-файл в кодировку
UTF-8 (см. Содержимое файлов), а затем выполнять трансляцию
tex-файлов, подключающих этот список литературы.
О кодировках и кодовых страницах / Хабр
Вряд ли это сейчас сильно актуально, но может кому-то покажется интересным (или просто вспомнит былые годы).
Начну с небольшого экскурса в историю компьютера. Поскольку компьютер использовался для обработки информации, то он просто обязан представлять эту информацию в «человеческом» виде. Компьютер хранит информацию в виде чисел (байтов), а человек воспринимает символы (буквы, цифры, различные знаки). Значит, надо сделать сопоставление число <-> символ и задача будет решена. Сначала посчитаем, сколько символов нам надо (не забудем, что «мы» — американцы, использующие латинский алфавит). Нам надо 10 цифр + 26 заглавных букв английского алфавита + 26 строчных букв + математические знаки (хотя бы +-/*=><%) + знаки препинания (.
Отлично, для 128 символов достаточно 7 бит. С другой стороны, в байте 8 бит и каналы связи 8-битные (забудем про «доисторические» времена, когда в байте и каналах бит было меньше). По 8-ми битному каналу будем передавать 7 бит кода символа и 1 бит контрольный (для повышения надежности и распознавания ошибок). И все было замечательно, пока компьютеры не стали использоваться в других странах (где латиница содержит больше 26 символов или вообще используется не латинский алфавит). Вместо того, чтобы всем поголовно освоить английский, жители СССР, Франции, Германии, Грузии и десятков других стран захотели, чтобы компьютер общался с ними на их родном языке. Пути были разные (в зависимости от остроты проблемы): одно дело, если к 26 символам латиницы надо добавить 2-3 национальных символа (можно пожертвовать какими-то специальными) и другое дело, когда надо «вклинить» кириллицу.

Решением стала разработанная фирмой IBM технология кодовых страниц. К этому времени «контрольный символ» при передаче потерял свою актуальность и все 8-бит можно было использовать для кода символа. Вместо диапазона кодов 0-127 стал доступен диапазон 0-255. Кодовая страница (или кодировка)– это сопоставление кода из диапазона 0-255 некоему графическому образу (например, букве «Я» кириллицы или букве «омега» греческого). Нельзя сказать «символ с кодом 211 выглядит так», но можно сказать «символ с кодом 211 в кодовой странице CP1251 выглядит так: У, а в CP1253(греческая) выглядит так: Σ ». Во всех (или почти всех) кодовых таблица первые 128 кодов соответствуют таблице ASCII, только для первых 32 непечатных кодов IBM «назначила» свои картинки (которые показывается при выводе на экран монитора).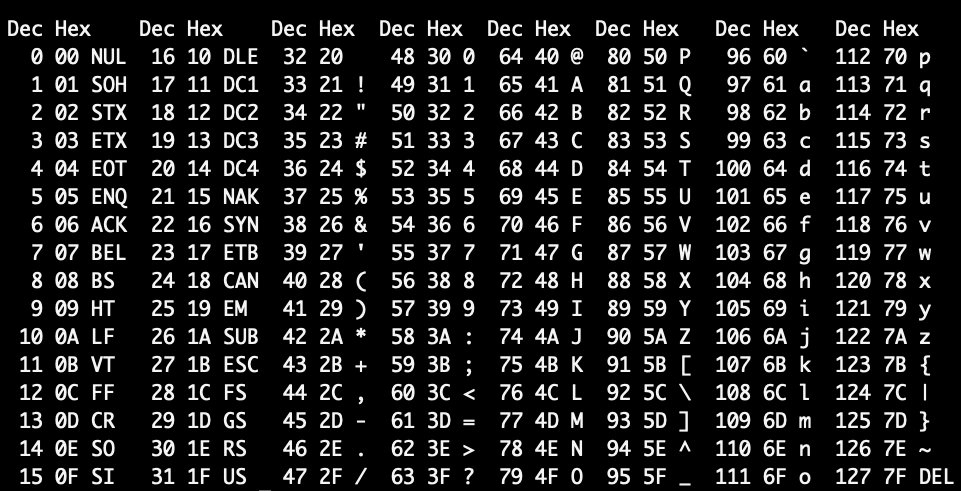
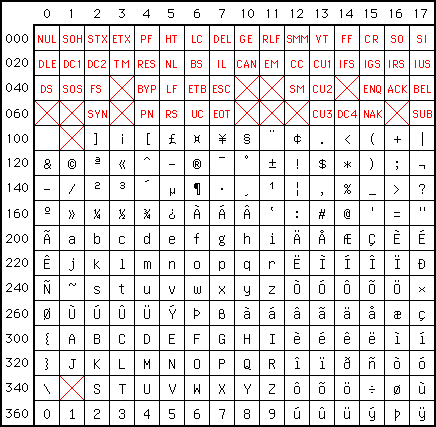
 От KOI8 тоже «отпочковывались» варианты — украинский, белорусский, таджикский, кавказский и др. Оборудование (принтеры, видеодаптеры) тоже надо было настраивать (или «прошивать») для работы со своими кодировками. Коммерсанты могли привезти дешевую партию принтеров (из эмиратов, например, по бартеру) а они не работали с русскими кодировками.
От KOI8 тоже «отпочковывались» варианты — украинский, белорусский, таджикский, кавказский и др. Оборудование (принтеры, видеодаптеры) тоже надо было настраивать (или «прошивать») для работы со своими кодировками. Коммерсанты могли привезти дешевую партию принтеров (из эмиратов, например, по бартеру) а они не работали с русскими кодировками.Тем не менее в целом кодовые страницы позволили решить проблему вывода национальных символов (устройство просто должно уметь работать с соответствующей кодовой страницей), но породили проблему множественности кодировок, когда почтовая программа отправляет данные в одной кодировке, а принимающая программа показывает их в другой. В результате пользователь видит так называемые «кракозябры» (вместо «привет» написано «ЏаЁўҐв» или «оПХБЕР»). Потребовались программы-перекодировщики, переводящие данные из одной кодировки в другую. Увы, порой письма при прохождении через почтовые серверы неоднократно автоматически перекодировались (или даже «обрезался» 8-й бит) и нужно было найти и выполнить всю цепочку обратных преобразований.
После массового перехода на Windows к трем кодовым страницам добавилась четвертая (Windows-1251 она же CP1251 она же ANSI ) и пятая (CP866 она же OEM или DOS). Не удивляйтесь — Windows для работы с кириллицей в консоли по-умолчанию использует кодировку CP866 (русские символы такие же как в «альтернативной кодировке», только некоторые спецсимволы отличаются), для других целей — кодировку CP1251. Почему Windows понадобилось две кодировки, неужели нельзя было обойтись одной? Увы, не получается: DOS-кодировка используется в именах файлов (тяжелое наследие DOS) и консольные команды типа dir, copy должны правильно показывать и правильно обрабатывать досовские имена файлов. С другой стороны, в этой кодировке много кодов отведено символам псевдографики (различным рамкам и т.п.), а Windows работает в графическом режиме и ей (а точнее, windows-приложениям) не нужны символы псевдографики (но нужны занятые ими коды, которые в CP1251 использованы для других полезных символов). Пять кириллических кодировок поначалу еще больше усугубили ситуацию, но со временем наиболее популярными стали Windows-1251 и KOI8, а досовскими просто стали меньше пользоваться. Еще при использовании Windows стало неважно, какая кодировка в видеоадаптере (только изредка, до загрузки Windows в диагностических сообщениях можно видеть «кракозябры»).
Еще при использовании Windows стало неважно, какая кодировка в видеоадаптере (только изредка, до загрузки Windows в диагностических сообщениях можно видеть «кракозябры»).
Решение проблемы кодировок пришло, когда повсеместно стала внедряться система Unicode (и для персональных ОС и для серверов). Unicode каждому национальному символу ставит в соответствие раз и навсегда закрепленное за ним 20-ти битовое число («точку» в кодовом пространстве Unicode, причем чаще всего хватает 16 бит, поскольку 20-битные коды используются для редких символов и иероглифов), поэтому нет необходимости перекодировать (подробнее об Unicode см следующую запись в журнале). Теперь для любой пары <код байта>+<кодовая страница> можно определить соответствующий ей код в Unicode (сейчас в кодовых страницах для каждого 8-битного кода показывается 16-битный код Unicode) и потом при необходимости вывести этот символ для любой кодовой страницы, где он присутствует. В настоящее время проблема кодировок и перекодировок для пользователей практически исчезла, но все же изредка приходят письма, где либо тема письма либо содержание «не в той» кодировке.
Интересно, что примерно год назад проблема кодировок ненадолго всплыла при «наезде» ФАС на сотовых операторов, мол те дискриминируют русскоязычных пользователей, поскольку за передачу кириллицы берут больше. Это объясняется техническим решением, выбранным разработчиком протокола SMS связи. Если бы его россияне разработали, они бы, возможно, отдали приоритет кириллице. В указанной статье «начальник управления контроля транспорта и связи Дмитрий Рутенберг отметил, что существуют и восьмибитные кодировки для кириллицы, которые могли бы использовать операторы.» Во как — на улице 21-й век, Unicode шагает по миру, а господин Рутенберг тянет нас в начало 90-х, когда шла «война кодировок» и проблема перекодировок стояла во весь рост. Интересно, в какой кодировке должен получить СМС Вася Пупкин, пользующийся финским телефоном, находящийся в Турции на отдыхе, от жены с корейским телефоном, отправляющей СМС из Казахстана? А от своего французского компаньона (с японским телефоном), находящегося в Испании? Думаю, никакой начальник ответа на этот вопрос дать не сможет. К счастью, это «экономное» предложение не воплотилось в жизнь.
К счастью, это «экономное» предложение не воплотилось в жизнь.
Юный читатель может спросить — а что помешало сразу использовать Unicode, зачем были придуманы эти заморочки с кодовыми страницами? Думаю, дело в финансовой стороне проблемы. Unicode требует в 2 раза больше памяти, а память стоит денег (и дисковая и ОЗУ). Стал бы американец покупать компьютер на 1-2 тыс дороже из-за того, что «теперь новая ОС требует больше памяти, но позволяет без проблем работать с русским, европейскими, арабскими языками»? Боюсь, простой англоязычный покупатель воспринял бы такой аргумент «неадекватно» (и обратился бы к другим производителям).
Использовать кодовые страницы UTF-8 в приложениях для Windows — Приложения для Windows
Обратная связь Редактировать
Твиттер LinkedIn Фейсбук Эл. адрес
- Статья
- 2 минуты на чтение
Используйте кодировку символов UTF-8 для оптимальной совместимости между веб-приложениями и другими платформами на базе *nix (Unix, Linux и варианты), минимизируйте ошибки локализации и уменьшите затраты на тестирование.
UTF-8 — это универсальная кодовая страница для интернационализации, которая может кодировать весь набор символов Unicode. Он широко используется в Интернете и используется по умолчанию для платформ на основе * nix.
Установите кодовую страницу процесса в UTF-8
Начиная с версии Windows 1903 (обновление за май 2019 г.) вы можете использовать свойство ActiveCodePage в appxmanifest для упакованных приложений или манифест fusion для неупакованных приложений, чтобы заставить процесс используйте UTF-8 в качестве кодовой страницы процесса.
Вы можете объявить это свойство и использовать его в более ранних сборках Windows, но вы должны выполнять обнаружение и преобразование устаревших кодовых страниц как обычно.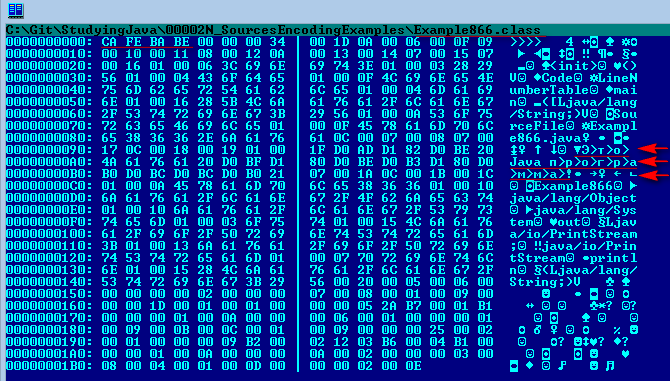 С минимальной целевой версией Windows версии 1903, кодовая страница процесса всегда будет UTF-8, поэтому можно избежать обнаружения и преобразования устаревшей кодовой страницы.
С минимальной целевой версией Windows версии 1903, кодовая страница процесса всегда будет UTF-8, поэтому можно избежать обнаружения и преобразования устаревшей кодовой страницы.
Примечание
Закодированный символ занимает от 1 до 4 байтов. Кодировка UTF-8 поддерживает более длинные последовательности байтов, до 6 байтов, но самая большая кодовая точка Unicode 6.0 (U+10FFFF) занимает всего 4 байта.
Примеры
Манифест Appx для упакованного приложения:
<Пакет xmlns="http://schemas.microsoft.com/appx/manifest/foundation/windows10"
...
xmlns:uap7="http://schemas.microsoft.com/appx/manifest/uap/windows10/7"
xmlns:uap8="http://schemas.microsoft.com/appx/manifest/uap/windows10/8"
...
IgnorableNamespaces="... uap7 uap8 ...">
<Приложения>
<Приложение...>
UTF-8
Манифест Fusion для неупакованного приложения Win32:
0" encoding="UTF-8" standalone="yes"?>
<приложение> <настройки окна> UTF-8
Примечание
Добавьте манифест к существующему исполняемому файлу из командной строки с помощью mt.exe -manifest
-A vs. -W APIs
API Win32 часто поддерживают варианты -A и -W.
Варианты -A распознают кодовую страницу ANSI, настроенную в системе, и поддерживают char* , а варианты -W работают в UTF-16 и поддерживают WCHAR .
До недавнего времени Windows делала упор на варианты «Unicode» -W, а не на -A API. Однако в недавних выпусках использовалась кодовая страница ANSI и API-интерфейсы -A в качестве средства внедрения поддержки UTF-8 в приложения. Если кодовая страница ANSI настроена для UTF-8, API-интерфейсы -A обычно работают в UTF-8. Преимущество этой модели заключается в поддержке существующего кода, созданного с помощью API-интерфейсов -A, без каких-либо изменений кода.
Если кодовая страница ANSI настроена для UTF-8, API-интерфейсы -A обычно работают в UTF-8. Преимущество этой модели заключается в поддержке существующего кода, созданного с помощью API-интерфейсов -A, без каких-либо изменений кода.
Преобразование кодовой страницы
Поскольку Windows изначально работает в UTF-16 ( WCHAR ), вам может потребоваться преобразовать данные UTF-8 в UTF-16 (или наоборот) для взаимодействия с Windows API.
MultiByteToWideChar и WideCharToMultiByte позволяют выполнять преобразование между UTF-8 и UTF-16 ( WCHAR ) (и другими кодовыми страницами). Это особенно полезно, когда устаревший API Win32 может понимать только WCHAR . Эти функции позволяют преобразовать ввод UTF-8 в .WCHAR для передачи в -W API, а затем, при необходимости, обратного преобразования любых результатов.
При использовании этих функций с CodePage , установленным на CP_UTF8 , используйте dwFlags из 0 или MB_ERR_INVALID_CHARS , в противном случае возникает ERROR_INVALID0500 .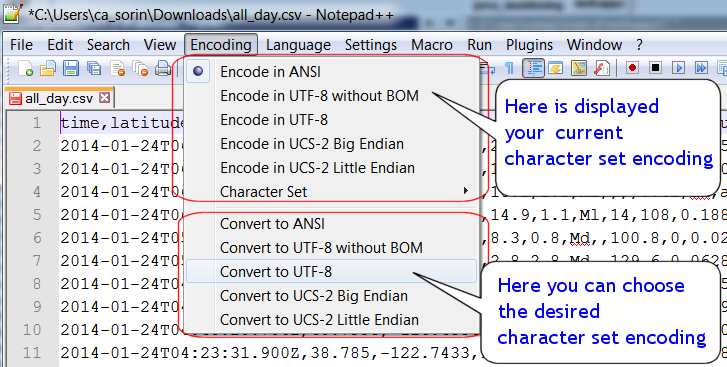
Примечание
CP_ACP соответствует CP_UTF8 только при работе в Windows версии 1903 (обновление за май 2019 г.) или более поздней версии, а для описанного выше свойства ActiveCodePage установлено значение UTF-8. В противном случае он учитывает кодовую страницу устаревшей системы. Мы рекомендуем использовать CP_UTF8 явно.
- Кодовые страницы
- Идентификаторы кодовых страниц
Обратная связь
Отправить и просмотреть отзыв для
Этот продукт Эта страница
Просмотреть все отзывы о странице
asp classic — кодовая страница 65001 и utf-8 — это одно и то же?
<%@LANGUAGE="VBSCRIPT" CODEPAGE="65001"%>dtd"> <голова>
Верен ли приведенный выше код?
- asp-классический
- кодовые страницы
Да.
UTF-8 — это CP65001 в Windows (это просто способ указать UTF-8 в устаревшей кодовой странице). Насколько я читал, ASP может обрабатывать UTF-8, если указано таким образом.
9
Ваш код правильный, хотя я предпочитаю устанавливать CharSet в коде, а не использовать метатег: —
<% Response.CharSet = "UTF-8" %>
Кодовая страница 65001 относится к набору символов UTF-8. Вам нужно будет убедиться, что ваша страница asp (и любые включения) сохранены как UTF-8, если они содержат какие-либо символы за пределами стандартного набора символов ASCII.
Указав атрибут CODEPAGE в блоке <%@, вы указываете, что все, что пишется с использованием Response.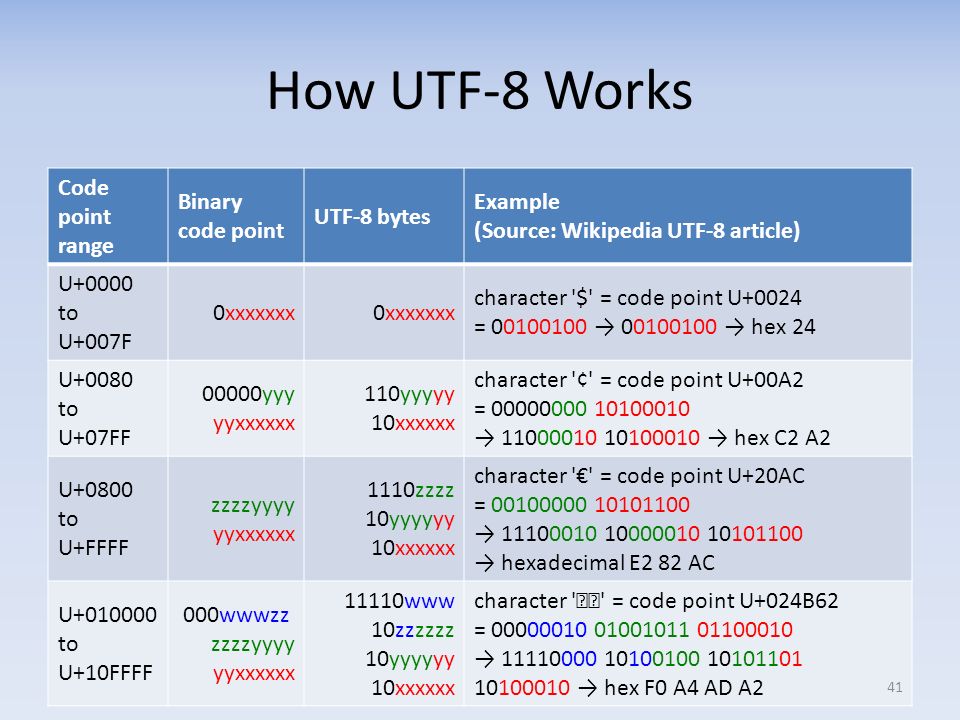 Write, должно быть закодировано с указанной кодовой страницей, в данном случае 65001 (utf-8). Стоит иметь в виду, что это не влияет на статический контент, который дословно отправляется байт за байтом в ответ. Следовательно, причина, по которой файл должен быть фактически сохранен с использованием указанной кодовой страницы.
Write, должно быть закодировано с указанной кодовой страницей, в данном случае 65001 (utf-8). Стоит иметь в виду, что это не влияет на статический контент, который дословно отправляется байт за байтом в ответ. Следовательно, причина, по которой файл должен быть фактически сохранен с использованием указанной кодовой страницы.
Свойство CharSet ответа задает значение CharSet заголовка Content-Type. Это не влияет на то, как контент может быть закодирован, он просто сообщает клиенту, какая кодировка принимается. Опять же важно, чтобы его значение соответствовало фактической отправленной кодировке.
3
Да, 65001 — это идентификатор кодовой страницы Windows для UTF-8, как указано на веб-сайте Microsoft. Википедия предполагает, что кодовая страница IBM 128 и кодовая страница SAP 4110 также являются индикаторами для UTF-8.
1
ответ.кодовая страница = 65001
, похоже, дают плохой результат, когда физический файл сохраняется как utf-8
В противном случае он работает так, как должен.