Отлично, для 128 символов достаточно 7 бит. С другой стороны, в байте 8 бит и каналы связи 8-битные (забудем про «доисторические» времена, когда в байте и каналах бит было меньше). По 8-ми битному каналу будем передавать 7 бит кода символа и 1 бит контрольный (для повышения надежности и распознавания ошибок). И все было замечательно, пока компьютеры не стали использоваться в других странах (где латиница содержит больше 26 символов или вообще используется не латинский алфавит). Вместо того, чтобы всем поголовно освоить английский, жители СССР, Франции, Германии, Грузии и десятков других стран захотели, чтобы компьютер общался с ними на их родном языке. Пути были разные (в зависимости от остроты проблемы): одно дело, если к 26 символам латиницы надо добавить 2-3 национальных символа (можно пожертвовать какими-то специальными) и другое дело, когда надо «вклинить» кириллицу.

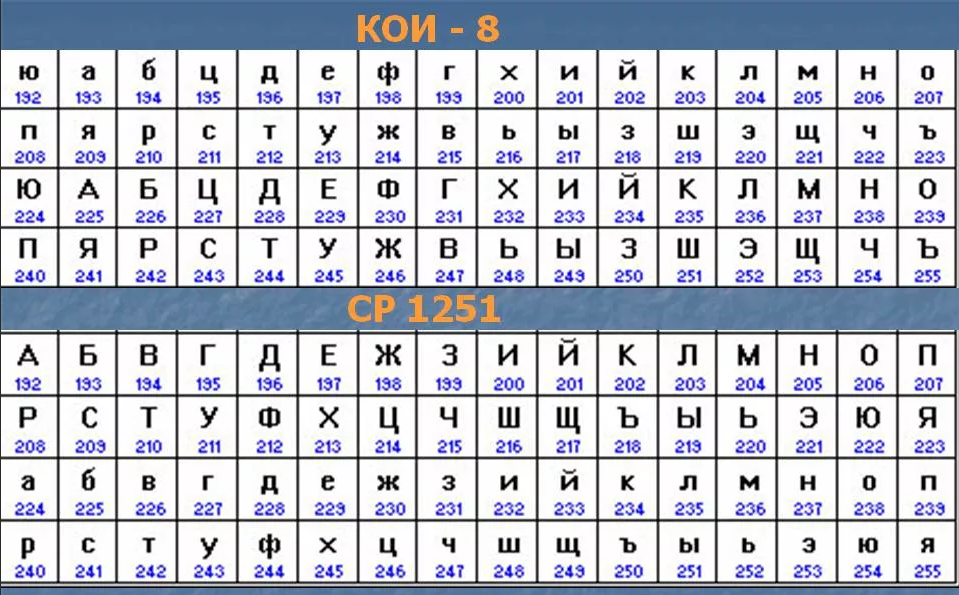
Решением стала разработанная фирмой IBM технология кодовых страниц. К этому времени «контрольный символ» при передаче потерял свою актуальность и все 8-бит можно было использовать для кода символа. Вместо диапазона кодов 0-127 стал доступен диапазон 0-255. Кодовая страница (или кодировка)– это сопоставление кода из диапазона 0-255 некоему графическому образу (например, букве «Я» кириллицы или букве «омега» греческого). Нельзя сказать «символ с кодом 211 выглядит так», но можно сказать «символ с кодом 211 в кодовой странице CP1251 выглядит так: У, а в CP1253(греческая) выглядит так: Σ ». Во всех (или почти всех) кодовых таблица первые 128 кодов соответствуют таблице ASCII, только для первых 32 непечатных кодов IBM «назначила» свои картинки (которые показывается при выводе на экран монитора).


Тем не менее в целом кодовые страницы позволили решить проблему вывода национальных символов (устройство просто должно уметь работать с соответствующей кодовой страницей), но породили проблему множественности кодировок, когда почтовая программа отправляет данные в одной кодировке, а принимающая программа показывает их в другой. В результате пользователь видит так называемые «кракозябры» (вместо «привет» написано «ЏаЁўҐв» или «оПХБЕР»). Потребовались программы-перекодировщики, переводящие данные из одной кодировки в другую. Увы, порой письма при прохождении через почтовые серверы неоднократно автоматически перекодировались (или даже «обрезался» 8-й бит) и нужно было найти и выполнить всю цепочку обратных преобразований.
После массового перехода на Windows к трем кодовым страницам добавилась четвертая (Windows-1251 она же CP1251 она же ANSI ) и пятая (CP866 она же OEM или DOS). Не удивляйтесь — Windows для работы с кириллицей в консоли по-умолчанию использует кодировку CP866 (русские символы такие же как в «альтернативной кодировке», только некоторые спецсимволы отличаются), для других целей — кодировку CP1251. Почему Windows понадобилось две кодировки, неужели нельзя было обойтись одной? Увы, не получается: DOS-кодировка используется в именах файлов (тяжелое наследие DOS) и консольные команды типа dir, copy должны правильно показывать и правильно обрабатывать досовские имена файлов. С другой стороны, в этой кодировке много кодов отведено символам псевдографики (различным рамкам и т.п.), а Windows работает в графическом режиме и ей (а точнее, windows-приложениям) не нужны символы псевдографики (но нужны занятые ими коды, которые в CP1251 использованы для других полезных символов). Пять кириллических кодировок поначалу еще больше усугубили ситуацию, но со временем наиболее популярными стали Windows-1251 и KOI8, а досовскими просто стали меньше пользоваться.
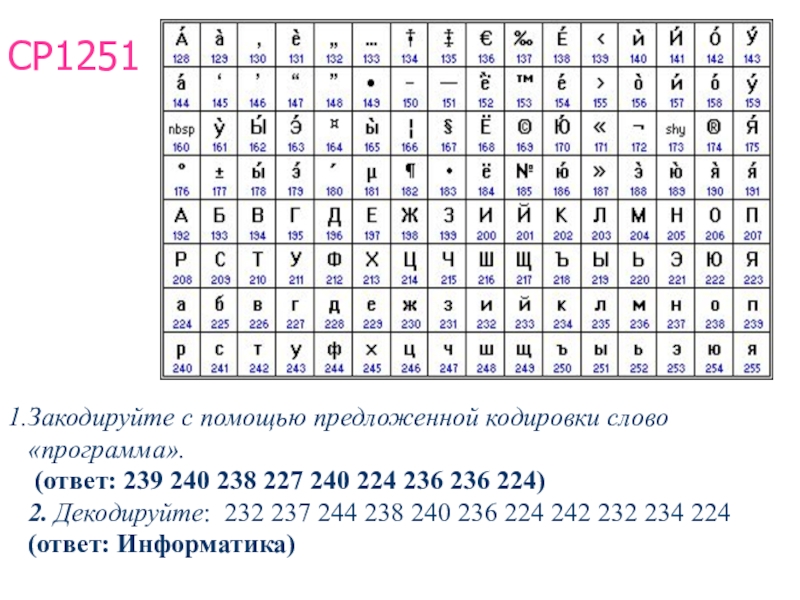
Решение проблемы кодировок пришло, когда повсеместно стала внедряться система Unicode (и для персональных ОС и для серверов). Unicode каждому национальному символу ставит в соответствие раз и навсегда закрепленное за ним 20-ти битовое число («точку» в кодовом пространстве Unicode, причем чаще всего хватает 16 бит, поскольку 20-битные коды используются для редких символов и иероглифов), поэтому нет необходимости перекодировать (подробнее об Unicode см следующую запись в журнале). Теперь для любой пары <код байта>+<кодовая страница> можно определить соответствующий ей код в Unicode (сейчас в кодовых страницах для каждого 8-битного кода показывается 16-битный код Unicode) и потом при необходимости вывести этот символ для любой кодовой страницы, где он присутствует. В настоящее время проблема кодировок и перекодировок для пользователей практически исчезла, но все же изредка приходят письма, где либо тема письма либо содержание «не в той» кодировке.
Интересно, что примерно год назад проблема кодировок ненадолго всплыла при «наезде» ФАС на сотовых операторов, мол те дискриминируют русскоязычных пользователей, поскольку за передачу кириллицы берут больше. Это объясняется техническим решением, выбранным разработчиком протокола SMS связи. Если бы его россияне разработали, они бы, возможно, отдали приоритет кириллице. В указанной статье «начальник управления контроля транспорта и связи Дмитрий Рутенберг отметил, что существуют и восьмибитные кодировки для кириллицы, которые могли бы использовать операторы.» Во как — на улице 21-й век, Unicode шагает по миру, а господин Рутенберг тянет нас в начало 90-х, когда шла «война кодировок» и проблема перекодировок стояла во весь рост. Интересно, в какой кодировке должен получить СМС Вася Пупкин, пользующийся финским телефоном, находящийся в Турции на отдыхе, от жены с корейским телефоном, отправляющей СМС из Казахстана? А от своего французского компаньона (с японским телефоном), находящегося в Испании? Думаю, никакой начальник ответа на этот вопрос дать не сможет. К счастью, это «экономное» предложение не воплотилось в жизнь.
К счастью, это «экономное» предложение не воплотилось в жизнь.
Юный читатель может спросить — а что помешало сразу использовать Unicode, зачем были придуманы эти заморочки с кодовыми страницами? Думаю, дело в финансовой стороне проблемы. Unicode требует в 2 раза больше памяти, а память стоит денег (и дисковая и ОЗУ). Стал бы американец покупать компьютер на 1-2 тыс дороже из-за того, что «теперь новая ОС требует больше памяти, но позволяет без проблем работать с русским, европейскими, арабскими языками»? Боюсь, простой англоязычный покупатель воспринял бы такой аргумент «неадекватно» (и обратился бы к другим производителям).
Какие существуют кодировки русских букв в компьютере
Статьи › Код › Какие коды соответствуют таким операциям как перевод строки ввод пробела и др
К сожалению, в настоящее время существуют пять различных кодировок кириллицы (КОИ8-Р, Windows. MS-DOS, Macintosh и ISO). Из-за этого часто возникают проблемы с переносом русского текста с одного компьютера на другой, из одной программной системы в другую.
- В компьютере существуют пять кодировок кириллицы
- Наиболее распространённые кодировки с русским языком — UTF-8, Windows-1251, CP-866, KOI-8R, ISO-8859-5
- Распространённые кодировки символов — ISO 646. ASCII, BCDIC, EBCDIC, ISO 8859 и другие
- Кодовые таблицы для русских букв — Windows (CP1251), MS-DOS (CP866), KOI-8, Mac (Macintosh), ISO (OS UNIX)
- Windows-1251 — стандартная 8-битная кодировка для русских версий Microsoft Windows до 10-й версии
- Медикаментозное кодирование — самый распространенный и эффективный метод воздержания от алкоголя
- Чтобы узнать, какая кодировка стоит на компьютере, нужно открыть текстовый файл в блокноте и выбрать пункт «Сохранить как»
- Существуют числовые, символьные и графические способы кодирования информации
- Наиболее универсальной таблицей кодировок считается UTF-8, также распространены ASCII, UNICODE и другие.
- Какие кодировки с русскими буквами
- Какие бывают кодировки символов
- Какие кодовые таблицы используют для кодировки русских букв
- Какая кодировка в Windows
- Какая кодировка лучшая
- Как узнать какая кодировка стоит на компьютере
- Какие бывают кодировки в информатике
- Какие таблицы кодировок вы знаете
- Что такое UTF-16 и UTF-8 чем различаются эти кодировки
- Как кодируются буквы
- В чем различие между ASCII и Unicode
- Где используется UTF-8
- Что такое кодировка it
- Какая кодировка в Chrome
- Что за кодировка ANSI
- Как кодировать текст в UTF-8
- Как работает юникод
- Какая кодировка в Python
- Для чего нужно кодирование Юникод
- Сколько символов в кодировке
- Что означает знак х
- Какие стандарты кодирования символов в Интернете были зарегистрированы для представления на компьютере русских букв
- Что такое алфавит в кодировании
- Как указать кодировку UTF-8
- Как расшифровать кодировку UTF-8
- Как поставить кодировку UTF-8 в С ++
- Какие кодировки с русскими буквами используются в сети Интернет кодировка MS-DOS
Какие кодировки с русскими буквами
Наиболее распространёнными кодировками с поддержкой Русского языка (с использованием символов Кириллицы) являются: UTF-8, Windows-1251, CP-866, KOI-8R, ISO-8859-5.
Какие бывают кодировки символов
Распространённые кодировки:
- ISO 646. ASCII.
- BCDIC.
- EBCDIC.
- ISO 8859:
- Кодировки Microsoft Windows:
- MacRoman, MacCyrillic.
- КОИ8 (KOI8-R, KOI8-U…),
- Болгарская кодировка
Какие кодовые таблицы используют для кодировки русских букв
В настоящее время существует 5 кодовых таблиц для русских букв: Windows (СР(кодовая страница)1251), MS — DOS (СР(кодовая страница)866), KOИ — 8 (Код обмена информацией, 8-битный) (используется в OS UNIX), Mac (Macintosh), ISO (OS UNIX).
Какая кодировка в Windows
Windows-1251 — набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для русских версий Microsoft Windows до 10-й версии. В прошлом пользовалась довольно большой популярностью. Была создана на базе кодировок, использовавшихся в ранних «самопальных» русификаторах Windows в 1990—1991 гг.
Какая кодировка лучшая
Медикаментозное кодирование: на сегодняшний день остается самым распространенным и эффективным методом, который гарантирует надёжное воздержание от алкоголя. А самыми используемыми препаратами остается Эспераль и Дисульфирам.
А самыми используемыми препаратами остается Эспераль и Дисульфирам.
Как узнать какая кодировка стоит на компьютере
Открыть искомый текстовый файл в Блокноте Windows и выбрать пункт меню «Файл» -> «Сохранить как». Пример текстового файла, в котором русский текст задан в формате UTF, но это не очевидно при открытии. 2. В открывшемся диалоговом окне вы сразу видите, в какой кодировке был сохранён текст в текстовом файле.
Способы кодирования информации: при помощи чисел — числовой. Кодирование при помощи знаков того же алфавита, что и исходный текст — символьный. Кодирование при помощи рисунков и значков — графический.
Какие таблицы кодировок вы знаете
Существует множество разнообразных кодировок, наиболее распространённой и универсальной на данный момент является кодировка UTF-8. Также существуют такие таблицы, как ASCII, UNICODE и многие другие.
Что такое UTF-16 и UTF-8 чем различаются эти кодировки
UTF-8 — стандарт кодирования, преобразующий номера ячеек таблицы Юникод в бинарные коды с использованием переменного количества бит: 8, 16, 24 или 32. UTF-16 — стандарт кодирования, преобразующий номера ячеек таблицы Юникод в бинарные коды с использованием переменного количества бит:16 или 32.
UTF-16 — стандарт кодирования, преобразующий номера ячеек таблицы Юникод в бинарные коды с использованием переменного количества бит:16 или 32.
Как кодируются буквы
Каждая буква также кодируется своим номером в алфавите, НО номер всегда записывается двумя цифрами: к записи однозначных чисел слева добавляется 0. Например, код А — 01, код Б — 02 и т. д. В этом случае кодом текста АББА будет 01020201.
В чем различие между ASCII и Unicode
Важно не путать ее с ASCII — эти понятия не идентичны. ASCII появилась раньше и включает в себя меньше символов. В стандартной таблице их всего 128, если не считать расширений для других языков. А в «Юникоде», который реализуют кодировки UTF-8 и UTF-32, сейчас 2²¹ символов — это больше чем два миллиона.
Где используется UTF-8
Кодировка UTF-8 сейчас является доминирующей в веб-пространстве. Она также нашла широкое применение в UNIX-подобных операционных системах. Формат UTF-8 был разработан 2 сентября 1992 года Кеном Томпсоном и Робом Пайком, и реализован в Plan 9. Идентификатор кодировки в Windows — 65001.
Идентификатор кодировки в Windows — 65001.
Что такое кодировка it
Кодировка — это набор правил, описывающий способ перевода одного представления в другое. Прочие термины, заслуживающие прояснения: Набор символов, чарсет, charset — Набор символов, который может быть закодирован. «Кодировка ASCII включает набор из 128 символов».
Какая кодировка в Chrome
Откройте меню «Вид» в верхней части браузера. Нажмите «Кодировка текста». Выберите Unicode (UTF-8) в раскрывающемся меню.
Что за кодировка ANSI
ANSI-графика — расширение ASCII-графики. Этот вид цифровой графики создаёт картинку из символов, но использует не только символы, предлагаемые кодировкой ASCII, а все 224 печатных символа, 16 цветов шрифта и 8 фоновых цветов, поддерживаемых драйвером ANSI. SYS, который использовался в системе MS-DOS.
Как кодировать текст в UTF-8
Кодируем в UTF-8:
- Каждый символ превращаем в Юникод.
- Проверяем из какого символ диапазона.

- Если код символа меньше 128, то к результату добавляем его в неизменном виде.
- Если код символа меньше 2048, то берем последние 6 бит и первые 5 бит кода символа.

Как работает юникод
Юникод постулирует чёткое разграничение между символами, их представлением в компьютере и их отображением на устройстве вывода. Юникод-символы не всегда соответствуют символу в традиционно-наивном понимании, например букве, цифре, пунктуационному знаку или иероглифу.
Какая кодировка в Python
По умолчанию Python использует кодировку utf-8, но видимо запись в файл происходила не с её помощью. Здесь нам придёт на помощь дополнительный параметр функции open — параметр encoding, который позволяет указать конкретную кодировку, в которой следует прочитать файл (или записывать в него).
Для чего нужно кодирование Юникод
Применение этого стандарта позволяет закодировать очень большое число символов из разных систем письменности: в документах, закодированных по стандарту Юникод, могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, символы музыкальной нотной нотации, при этом
Сколько символов в кодировке
Unicode содержит 1,114,112 кодовых значений; на настоящий момент времени, для них назначено более 96,000 символов.
Что означает знак х
Буквой X часто обозначают неизвестное значение или неизвестный объект (в математике, литературе, разговорной речи). В польском, финском, румынском и ряде других языков эта буква используется только в заимствованных словах.
Какие стандарты кодирования символов в Интернете были зарегистрированы для представления на компьютере русских букв
Первые русские ЭВМ использовали 7-битную кодировку символов КОИ-7 (Код Обмена Информацией семибитный — рисунок 1.3), в которой присутствовали прописные латинские буквы, а на месте строчных латинских были русские прописные буквы (кириллица).
Что такое алфавит в кодировании
Алфавитное кодирование — вид кодирования, построенный на взаимной однозначности кодирования слов некоторого алфавита при помощи замены каждой буквы некоторым словом того же или какого-либо другого алфавита.
Как указать кодировку UTF-8
Откройте меню «Вид» в верхней части браузера. Нажмите «Кодировка текста». Выберите Unicode (UTF-8) в раскрывающемся меню.
Как расшифровать кодировку UTF-8
Unicode Transformation Format, 8-bit — «формат преобразования Юникода, 8-бит») — распространённый стандарт кодирования символов, позволяющий более компактно хранить и передавать символы Юникода, используя переменное количество байт (от 1 до 4), и обеспечивающий полную обратную совместимость с 7-битной кодировкой ASCII.
Как поставить кодировку UTF-8 в С ++
Выберите страницу свойствC/C++>Command Lineсвойства> конфигурации. В разделе Дополнительные параметры добавьте /utf-8 параметр, чтобы указать предпочитаемую кодировку. Выберите ОК для сохранения внесенных изменений.
Какие кодировки с русскими буквами используются в сети Интернет кодировка MS-DOS
Кодировки русских букв:
- CP-866. Кодировка 866 (альтернативная). Используется в системе MS-DOS, а также в текстовой консоли Windows.
- KOI-8. Кодировка KOI-8 используется в операционных системах семейства UNIX. Русские буквы одним старшим битом отличаются от созвучных им латинских букв.
- CP-1251. Кодировка 1251 (Windows).

Windows-1251
Windows-1251Кодировка ( CCS ) Windows-1251 (CP1251.TXT).
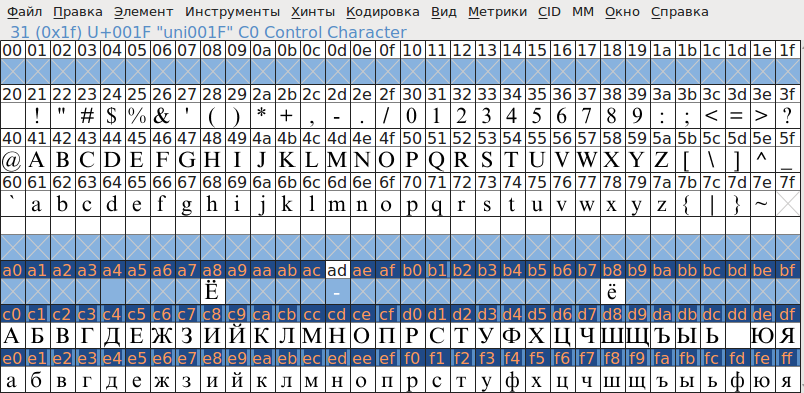
# # Имя: cp1251 в таблицу Unicode # Версия Юникода: 2.0 # Версия таблицы: 2.01 # Формат таблицы: Формат A # Дата: 15.04.98 # # Контакт: [email protected] # # Общие примечания: нет # # Формат: три столбца, разделенных табуляцией. # Столбец №1 — это код cp1251 (в шестнадцатеричном формате) # Столбец № 2 — это Unicode (в шестнадцатеричном формате 0xXXXX) # Столбец №3 — это имя Unicode (после знака комментария '#') # # Записи идут в порядке cp1251 # 0x00 0x0000 #НОЛЬ 0x01 0x0001 # НАЧАЛО ЗАГОЛОВКА 0x02 0x0002 # НАЧАЛО ТЕКСТА 0x03 0x0003 #КОНЕЦ ТЕКСТА 0x04 0x0004 # КОНЕЦ ПЕРЕДАЧИ 0x05 0x0005 # ЗАПРОС 0x06 0x0006 # ПОДТВЕРЖДЕНИЕ 0x07 0x0007 # ЗВОНОК 0x08 0x0008 # НАЗАД 0x090x0009 # ГОРИЗОНТАЛЬНАЯ ТАБЛИЦА 0x0A 0x000A # ПЕРЕВОД СТРОКИ 0x0B 0x000B #ВЕРТИКАЛЬНАЯ ТАБУЛЯЦИЯ 0x0C 0x000C #ПОДАЧА ФОРМЫ 0x0D 0x000D #ВОЗВРАТ КАРЕТКИ 0x0E 0x000E #СМЕЩЕНИЕ ВНЕ 0x0F 0x000F #СМЕЩЕНИЕ В 0x10 0x0010 # ESCAPE КАНАЛА ДАННЫХ 0x11 0x0011 #УПРАВЛЕНИЕ УСТРОЙСТВОМ ОДИН 0x12 0x0012 #УПРАВЛЕНИЕ УСТРОЙСТВОМ ДВА 0x13 0x0013 #УПРАВЛЕНИЕ УСТРОЙСТВОМ ТРИ 0x14 0x0014 #УПРАВЛЕНИЕ УСТРОЙСТВОМ ЧЕТЫРЕ 0x15 0x0015 #ОТРИЦАТЕЛЬНОЕ ПОДТВЕРЖДЕНИЕ 0x16 0x0016 #СИНХРОННЫЙ ПРОСТОЙ 0x17 0x0017 # КОНЕЦ БЛОКА ПЕРЕДАЧИ 0x18 0x0018 #ОТМЕНА 0x190x0019 #КОНЕЦ СРЕДСТВА 0x1A 0x001A #ЗАМЕНИТЬ 0x1B 0x001B #ESCAPE 0x1C 0x001C # РАЗДЕЛИТЕЛЬ ФАЙЛОВ 0x1D 0x001D # РАЗДЕЛИТЕЛЬ ГРУПП 0x1E 0x001E #РАЗДЕЛИТЕЛЬ ЗАПИСИ 0x1F 0x001F #РАЗДЕЛИТЕЛЬ БЛОК 0x20 0x0020 #ПРОБЕЛ 0x21 0x0021 #ВОСКЛИЦАТЕЛЬНЫЙ ЗНАК 0x22 0x0022 #КАТЫЧКА 0x23 0x0023 # ЗНАК НОМЕРА 0x24 0x0024 #ЗНАК ДОЛЛАРА 0x25 0x0025 # ЗНАК ПРОЦЕНТА 0x26 0x0026 #АМПЕРСАНД 0x27 0x0027 #АПОСТРФ 0x28 0x0028 # ЛЕВАЯ СКОБКА 0x290x0029 #ПРАВАЯ СКОБКА 0x2A 0x002A #ЗВЕЗДОЧКА 0x2B 0x002B # ЗНАК ПЛЮС 0x2C 0x002C # ЗАПЯТАЯ 0x2D 0x002D #ДЕФИС-МИНУС 0x2E 0x002E #ПОЛНАЯ СТОП 0x2F 0x002F #СОЛИДУС 0x30 0x0030 #ЦИФРА НОЛЬ 0x31 0x0031 # ЦИФРА ОДИН 0x32 0x0032 # ВТОРАЯ ЦИФРА 0x33 0x0033 # ЦИФРА ТРИ 0x34 0x0034 #ЧЕТВЕРТАЯ ЦИФРА 0x35 0x0035 #ЦИФРА ПЯТАЯ 0x36 0x0036 #ЦИФРА ШЕСТЬ 0x37 0x0037 # ЦИФРА СЕДЬМАЯ 0x38 0x0038 #ЦИФРА ВОСЕМЬ 0x39 0x0039 #ЦИФРА ДЕВЯТЬ 0x3A 0x003A #COLON 0x3B 0x003B # ТОЧКА С ЗАПЯТОЙ 0x3C 0x003C # ЗНАК МЕНЬШЕ 0x3D 0x003D #ЗНАК РАВНО 0x3E 0x003E # ЗНАК БОЛЬШЕ 0x3F 0x003F #ВОПРОСИТЕЛЬНЫЙ ЗНАК 0x40 0x0040 #КОММЕРЧЕСКИЙ В 0x41 0x0041 #ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА A 0x42 0x0042 #ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА B 0x43 0x0043 #ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА C 0x44 0x0044 #ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА D 0x45 0x0045 #ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА E 0x46 0x0046 #ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА F 0x47 0x0047 #ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА G 0x48 0x0048 #ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА H 0x490x0049 #ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА I 0x4A 0x004A #ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА J 0x4B 0x004B #ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА K 0x4C 0x004C #ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА L 0x4D 0x004D #ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА M 0x4E 0x004E #ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА N 0x4F 0x004F #ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА O 0x50 0x0050 #ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА P 0x51 0x0051 #ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА Q 0x52 0x0052 #ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА R 0x53 0x0053 #ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА S 0x54 0x0054 #ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА T 0x55 0x0055 #ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА U 0x56 0x0056 #ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА V 0x57 0x0057 #ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА W 0x58 0x0058 #ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА X 0x590x0059 # ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА Y 0x5A 0x005A #ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА Z 0x5B 0x005B # ЛЕВАЯ КВАДРАТНАЯ СКОБКА 0x5C 0x005C #ОБРАТНОЕ СОЛИДУС 0x5D 0x005D #ПРАВАЯ КВАДРАТНАЯ СКОБКА 0x5E 0x005E #ЦИРКУМФЛЕКС АКЦЕНТ 0x5F 0x005F #НИЗКАЯ ЛИНИЯ 0x60 0x0060 #МОГИЛЬНЫЙ АКЦЕНТ 0x61 0x0061 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A 0x62 0x0062 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА B 0x63 0x0063 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА C 0x64 0x0064 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА D 0x65 0x0065 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА E 0x66 0x0066 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА F 0x67 0x0067 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА G 0x68 0x0068 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА H 0x690x0069 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА I 0x6A 0x006A # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА J 0x6B 0x006B # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА K 0x6C 0x006C # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА L 0x6D 0x006D # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА M 0x6E 0x006E # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА N 0x6F 0x006F # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O 0x70 0x0070 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА P 0x71 0x0071 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Q 0x72 0x0072 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА R 0x73 0x0073 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА S 0x74 0x0074 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Т 0x75 0x0075 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА U 0x76 0x0076 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА V 0x77 0x0077 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА W 0x78 0x0078 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА X 0x790x0079 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Y 0x7A 0x007A # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Z 0x7B 0x007B # ЛЕВАЯ ФИГУРНАЯ СКОБКА 0x7C 0x007C #ВЕРТИКАЛЬНАЯ ЛИНИЯ 0x7D 0x007D #ПРАВАЯ ФИГУРНАЯ СКОБКА 0x7E 0x007E #ТИЛЬДА 0x7F 0x007F #УДАЛИТЬ 0x80 0x0402 #КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА DJE 0x81 0x0403 #КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА GJE 0x82 0x201A # ОДИНОЧНАЯ МЛАДШАЯ-9 КАВАТЫ 0x83 0x0453 #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА GJE 0x84 0x201E #ДВОЙНАЯ МЛАДШАЯ-9 КАВАТЫ 0x85 0x2026 #ГОРИЗОНТАЛЬНЫЙ ЭЛЛИПСИС 0x86 0x2020 # КИНЖАЛ 0x87 0x2021 # ДВОЙНОЙ КИНЖАЛ 0x88 0x20AC #ЗНАК ЕВРО 0x890x2030 #ПРОМЫШЛЕННЫЙ ЗНАК 0x8A 0x0409 #КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА LJE 0x8B 0x2039 #ОДИНАРНЫЙ УГОЛ, НАПРАВЛЕННЫЙ ВЛЕВО КАВАТЫ 0x8C 0x040A #КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА NJE 0x8D 0x040C #КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА KJE 0x8E 0x040B #КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА ЦШЕ 0x8F 0x040F #КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА ДЖЕ 0x90 0x0452 #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА DJE 0x91 0x2018 # ЛЕВАЯ ОДИНАРНАЯ КАВАТЫ 0x92 0x2019 #ПРАВАЯ ОДИНАРНАЯ КАВАТЫ 0x93 0x201C #ЛЕВАЯ ДВОЙНАЯ КАВАТЫ 0x94 0x201D #ПРАВАЯ ДВОЙНАЯ КАПОТА 0x95 0x2022 #ПУЛЯ 0x96 0x2013 #EN ТИРЕ 0x97 0x2014 #ЭМ ТИРЕ 0x98 # НЕОПРЕДЕЛЕНО 0x99 0x2122 # ЗНАК ТОРГОВОЙ МАРКИ 0x9A 0x0459 #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА LJE 0x9B 0x203A #ОДИНОЧНЫЙ УГОЛ, УКАЗЫВАЮЩИЙ ВПРАВО КАВАТЫ 0x9C 0x045A #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА NJE 0x9D 0x045C #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА KJE 0x9E 0x045B #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА ЦШЕ 0x9F 0x045F #СТРОЧНАЯ БУКВА ДЖЕ 0xA0 0x00A0 #БЕЗ РАЗРЫВА ПРОБЕЛ 0xA1 0x040E #КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА КОРОТКАЯ U 0xA2 0x045E #КИРИЛЛИЧЕСКАЯ СТРОЧНАЯ БУКВА КОРОТКАЯ U 0xA3 0x0408 # ЗАГЛАВНАЯ БУКВА JE 0xA4 0x00A4 #ЗНАК ВАЛЮТЫ 0xA5 0x0490 #КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА GHE С ВВЕРХОМ 0xA6 0x00A6 # Сломанная полоса 0xA7 0x00A7 # ЗНАК СЕКЦИИ 0xA8 0x0401 # ЗАГЛАВНАЯ БУКВА IO 0xA9 0x00A9 # ЗНАК АВТОРСКОГО ПРАВА 0xAA 0x0404 #КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА УКРАИНСКИЙ IE 0xAB 0x00AB #НАПРАВЛЯЮЩАЯ ВЛЕВО ДВУХУГОЛЬНАЯ КАВАЧКА 0xAC 0x00AC # НЕ ЗНАК 0xAD 0x00AD #МЯГКИЙ ДЕФЕС 0xAE 0x00AE ЗНАК ЗАРЕГИСТРИРОВАННЫЙ # 0xAF 0x0407 #КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА ЙИ 0xB0 0x00B0 #ЗНАК СТЕПЕНИ 0xB1 0x00B1 # ЗНАК ПЛЮС-МИНУС 0xB2 0x0406 #КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА БЕЛОРУССКО-УКРАИНСКАЯ I 0xB3 0x0456 #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА БЕЛОРУССКО-УКРАИНСКАЯ I 0xB4 0x0491 #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА GHE С ПЕРЕВЕРТОМ ВВЕРХ 0xB5 0x00B5 #МИКРОЗНАК 0xB6 0x00B6 ЗНАК #ПИЛКРОУ 0xB7 0x00B7 #СРЕДНЯЯ ТОЧКА 0xB8 0x0451 #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА IO 0xB9 0x2116 # ЗНАК ЦИФРЫ 0xBA 0x0454 #СТРОЧНАЯ КИРИЛЛИЧНАЯ УКРАИНСКАЯ БУКВА IE 0xBB 0x00BB # ДВУХУГОЛЬНАЯ КАВАЧКА, УКАЗЫВАЮЩАЯ ВПРАВО 0xBC 0x0458 #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА JE 0xBD 0x0405 # ЗАГЛАВНАЯ БУКВА ДЗЕ 0xBE 0x0455 #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА ДЗЕ 0xBF 0x0457 #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА ЙИ 0xC0 0x0410 # ЗАГЛАВНАЯ БУКВА A 0xC1 0x0411 #КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА BE 0xC2 0x0412 # ЗАГЛАВНАЯ БУКВА VE 0xC3 0x0413 #КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА GHE 0xC4 0x0414 # ЗАГЛАВНАЯ БУКВА DE 0xC5 0x0415 #КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА IE 0xC6 0x0416 # ЗАГЛАВНАЯ БУКВА ЖЕ 0xC7 0x0417 # ЗАГЛАВНАЯ БУКВА ZE 0xC8 0x0418 # ЗАГЛАВНАЯ БУКВА I 0xC90x0419 #КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА КОРОТКАЯ I 0xCA 0x041A #КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА КА 0xCB 0x041B #КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА EL 0xCC 0x041C #КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА EM 0xCD 0x041D #КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА EN 0xCE 0x041E #КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА O 0xCF 0x041F #КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА PE 0xD0 0x0420 #КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА ER 0xD1 0x0421 #КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА ES 0xD2 0x0422 # ЗАГЛАВНАЯ БУКВА TE 0xD3 0x0423 # ЗАГЛАВНАЯ БУКВА U 0xD4 0x0424 #КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА EF 0xD5 0x0425 # ЗАГЛАВНАЯ БУКВА HA 0xD6 0x0426 #КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА TSE 0xD7 0x0427 #КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА ЧЕ 0xD8 0x0428 #КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА ША 0xD90x0429 # ЗАГЛАВНАЯ БУКВА ЩА 0xDA 0x042A #ПРОГЛАВНАЯ БУКВА КИРИЛЛИЧЕСКИЙ ЖЕСТКИЙ ЗНАК 0xDB 0x042B #КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА ЕРУ 0xDC 0x042C #КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА МЯГКИЙ ЗНАК 0xDD 0x042D #КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА E 0xDE 0x042E # ЗАГЛАВНАЯ БУКВА Ю 0xDF 0x042F # ЗАГЛАВНАЯ БУКВА YA 0xE0 0x0430 #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА A 0xE1 0x0431 #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА BE 0xE2 0x0432 #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА VE 0xE3 0x0433 #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА GHE 0xE4 0x0434 #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА DE 0xE5 0x0435 #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА IE 0xE6 0x0436 #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА ЖЕ 0xE7 0x0437 #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА ZE 0xE8 0x0438 #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА I 0xE90x0439 #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА КОРОТКАЯ I 0xEA 0x043A #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА КА 0xEB 0x043B #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА EL 0xEC 0x043C #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА EM 0xED 0x043D #СТРОЧНАЯ БУКВА EN 0xEE 0x043E #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА O 0xEF 0x043F #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА PE 0xF0 0x0440 #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА ER 0xF1 0x0441 #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА ES 0xF2 0x0442 #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА TE 0xF3 0x0443 #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА U 0xF4 0x0444 #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА EF 0xF5 0x0445 # СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА HA 0xF6 0x0446 #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА ТСЭ 0xF7 0x0447 #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА ЧЕ 0xF8 0x0448 #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА ША 0xF90x0449 #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА ЩА 0xFA 0x044A #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА ЖЕСТКИЙ ЗНАК 0xFB 0x044B #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА ЕРУ 0xFC 0x044C #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА МЯГКИЙ ЗНАК 0xFD 0x044D #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА E 0xFE 0x044E #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА Ю 0xFF 0x044F #СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА Я
Codepage & Co.
 Codepage & Co.
В начале 1980-х годов еще не существовало согласованных международных стандартов.
например, ISO-8859 или Unicode о том, как расширить US-ASCII для международных пользователей, и многие
производители придумали собственные кодировки, используя трудно запоминаемые
номера:
Codepage & Co.
В начале 1980-х годов еще не существовало согласованных международных стандартов.
например, ISO-8859 или Unicode о том, как расширить US-ASCII для международных пользователей, и многие
производители придумали собственные кодировки, используя трудно запоминаемые
номера:Кодовые страницы MS-DOS
CP437 (DOSLatinUS)
Промышленный стандарт IBM Персональный компьютер начинался со знаменитой кодовой страницы CP437 с много рисованных символов и несколько избранных иностранных букв:
кодировка=cp437
[ТЕКСТ]
[БДФ]
CP850 (DOSLatin1)
Некоторые более поздние версии MS-DOS позволяли изменять кодовые страницы на Видеокарты VGA до чего-то вроде CP850, которые представляли репертуар Latin1 на позициях совместим с CP437, так что рисование линий по-прежнему работал:
кодировка=cp850
[ТЕКСТ]
[БДФ]
CP852 (DOSLatin2)
CP852 сделал то же самое для Latin2 (Восточная Европа):
кодировка=cp852
[ТЕКСТ]
[БДФ]
CP855 (ДОСКириллица)
CP855 был введен как соответствующая кодовая страница кириллицы:
кодировка=cp855
[ТЕКСТ]
[БДФ]
CP866 (DOSCyrillicRussian)
За CP855 вскоре последовал CP866, который следовал более логичному порядку русского алфавита альтернативный вариант, который предпочли многие российские пользователи:
кодировка=cp866
[ТЕКСТ]
[БДФ]
Еще более широко используемая кириллическая кодировка (KOI8-R) позже получила номер CP878.
CP874 (DOSThai)
Тайский процессор Microsoft CP874 также соответствует установленным стандартам. а именно ТИС-620, но добавляет нестандартные символы в неиспользуемых позициях:
кодировка=cp874
[ТЕКСТ]
[БДФ]
CP737..CP862
Теперь я избавил вас от кровавых подробностей из
- CP737
- DOSГреческий
- CP775
- DOSBaltRim
- CP857
- DOSТурецкий
- CP860
- DOSПортугальский
- CP861
- DOSисландский
- CP862
- DOSИврит
- CP863
- DOSCanadaF
- CP864
- DOSAрабский
- CP865
- DOSNordic
- CP869
- DOSGreek2
Кодовые страницы MS-Windows
CP1252 (WinLatin1)
С появлением Windows Microsoft осмелилась попрощаться с
символы рисования линий и совместимость с CP437, а также принят модифицированный расширенный набор ISO-8859. -1 как CP1252:
-1 как CP1252:
кодировка = Windows-1252
[ТЕКСТ]
[БДФ]
CP1250 (WinLatin2)
Как ни странно, WinLatin2 получил номер CP1250 и отличается от ISO-8859-2 в некоторых позициях, но принесли Microsoft большой доход на развивающихся рынках Восточная Европа в 1990-е годы:
кодировка = Windows-1250
[ТЕКСТ]
[БДФ]
CP1251 (WinCyrillic)
Другим таким примером является кириллица. кодовая страница CP1251, для которой Microsoft зарегистрировала метку «Windows-1251». По состоянию на декабрь 1997, даже новый веб-сервер ГОСТа (Lotus Notes) приветствует вас с кодировкой=WINDOWS-1251. ГОСТ (российская стандартизация органа и организации-члена ISO) не даже после своего стандартов больше нет!
CP1251 имеет богатый репертуар в порядке, несовместимом с обоими ISO-IR-111 (KOI8) и ISO-8859-5:
кодировка = Windows-1251
[ТЕКСТ]
[БДФ]
CP1257 (WinBaltic)
Это WinBaltic, который мог послужить моделью для ISOLatin7:
кодировка = Windows-1257
[ТЕКСТ]
[БДФ]
CP1253.
 ..CP1258 Вы понимаете, другие кодовые страницы Windows:
..CP1258 Вы понимаете, другие кодовые страницы Windows:- 1253
- WinGreek отличается от ISO-8859-7 расположением заглавной буквы с тонами и только несколько символов.
- 1254
- WinTurkish делает с WinLatin1 что ISO-8859-9 соответствует ISO-8859-1.
- 1255
- WinHebrew совместим по буквам с ISO-8859-8.
- 1256
- WinArabic сохраняет символы и маленькие французские буквы из WinLatin1 и вставляет арабские буквы в свободные слоты так, чтобы только позиции =C1..=D6 (первая половина арабский алфавит) совместимы с ISO-8859-6.
- 1257
- WinBaltic совместим по буквам с ISOLatin7.
- 1258
- WinVietnamese похож на WinLatin1 и сильно отличается от VISCII.
Кодовые страницы CJK
В отличие от кодировок расширенного кодирования Unix EUC, все
следующие восточноазиатских кодовых страниц незаконно повторно используют C1
управляющие коды {=80. .=9F} для их ведущих байтов и значений ASCII
{=40..=7E} для их вторых байтов, чтобы закодировать более десяти
тысяча символов с двумя байтами. Это означает, что значения ASCII
за пределами =3F в своих потоках байтов не всегда означают символы ASCII.
.=9F} для их ведущих байтов и значений ASCII
{=40..=7E} для их вторых байтов, чтобы закодировать более десяти
тысяча символов с двумя байтами. Это означает, что значения ASCII
за пределами =3F в своих потоках байтов не всегда означают символы ASCII.
- CP932
- Shift-JIS объединяет Японские кодировки JIS X 0201 (один байт на символ) и JIS X 0208 (два байта на символ), чтобы JIS X 0201 Hiragana оставался однобайтовые символы половинной ширины и 60 свободных 8-битных кодовых позиций которые не содержат хираганы, используются в качестве ведущих байтов для 7076 кандзи и 648 других символов полной ширины. В отличие от EUC-JP, Shift-JIS не имеет осталось место для дополнительных 5802 кандзи из JIS X 0212.
- CP936
- GBK расширяет EUC-CN (8-битный кодировка GB 2312-80 с 6763 hanzi) для упрощенного zh_CN Материк китайский , чтобы покрыть все 20902 иероглифов хань, найденных в Юникод (GB 13000.1-93).
- CP949
- UnifiedHangul (UHC) — это расширенный набор Корейский EUC-KR (8-битная кодировка KS C 5601-1992 с
его 2350 слогов хангыль и 4888 ханджа) с 8822 дополнительными
предварительно составленные слоги хангыль в диапазоне C1.