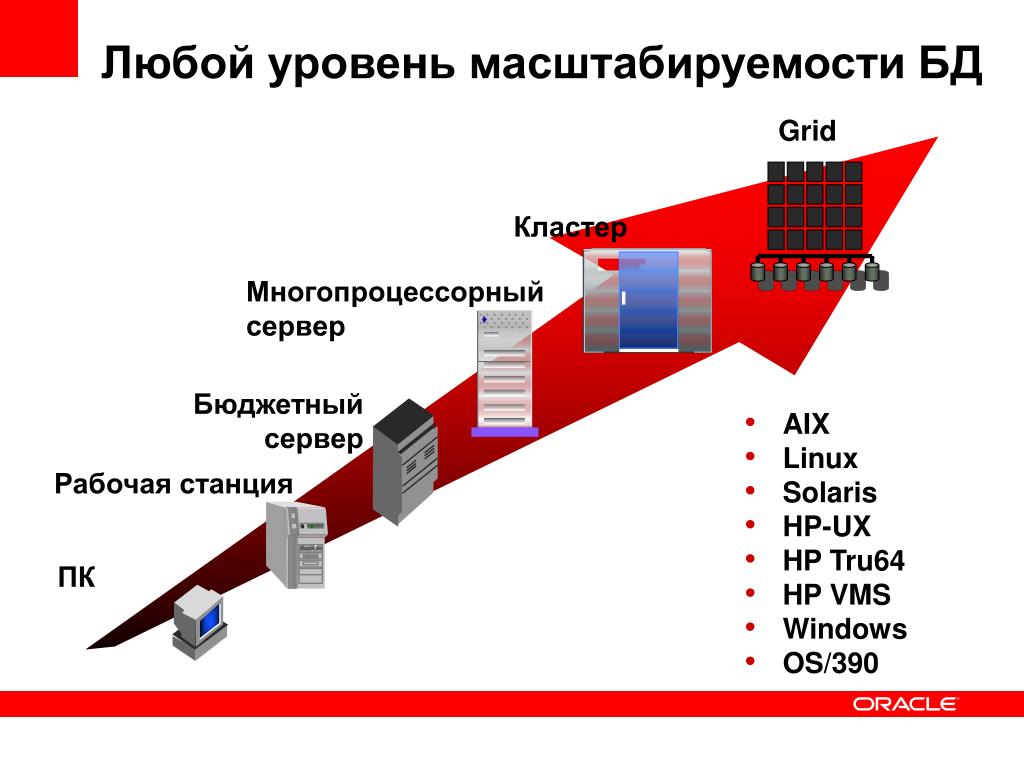
Масштабируемость системы
Масштабируемость — такое свойство вычислительной системы, которое обеспечивает предсказуемый рост системных характеристик, например, числа поддерживаемых пользователей, быстроты реакции, общей производительности и пр., при добавлении к ней вычислительных ресурсов. В случае сервера СУБД можно рассматривать два способа масштабирования — вертикальный и горизонтальный (рис. 2).
При горизонтальном масштабировании увеличивается число серверов СУБД, возможно, взаимодействующих друг с другом в прозрачном режиме, разделяя таким образом общую загрузку системы. Такое решение, видимо, будет все более популярным с ростом поддержки слабосвязанных архитектур и распределенных баз данных, однако обычно оно характеризуется сложным администрированием.
Вертикальное масштабирование подразумевает увеличение мощности отдельного сервера СУБД и достигается заменой аппаратного обеспечения (процессора, дисков) на более быстродействующее или добавлением дополнительных узлов.
Свойство масштабируемости актуально по двум основным причинам. Прежде всего, условия современного бизнеса меняются столь быстро, что делают невозможным долгосрочное планирование, требующее всестороннего и продолжительного анализа уже устаревших данных, даже для тех организаций, которые способны это себе позволить. Взамен приходит стратегия постепенного, шаг за шагом, наращивания мощности информационных систем. С другой стороны, изменения в технологии приводят к появлению все новых решений и снижению цен на аппаратное обеспечение, что потенциально делает архитектуру информационных систем более гибкой. Одновременно расширяется межоперабельность, открытость программных и аппаратных продуктов разных производителей, хотя пока их усилия, направленные на соответствие стандартам, согласованы лишь в узких секторах рынка. Без учета этих факторов потребитель не сможет воспользоваться преимуществами новых технологий, не замораживая средств, вложенных в недостаточно открытые или оказавшиеся бесперспективными технологии. В области хранения и обработки данных это требует, чтобы и СУБД, и сервер были масштабируемы. Сегодня ключевыми параметрами масштабируемости являются:
С другой стороны, изменения в технологии приводят к появлению все новых решений и снижению цен на аппаратное обеспечение, что потенциально делает архитектуру информационных систем более гибкой. Одновременно расширяется межоперабельность, открытость программных и аппаратных продуктов разных производителей, хотя пока их усилия, направленные на соответствие стандартам, согласованы лишь в узких секторах рынка. Без учета этих факторов потребитель не сможет воспользоваться преимуществами новых технологий, не замораживая средств, вложенных в недостаточно открытые или оказавшиеся бесперспективными технологии. В области хранения и обработки данных это требует, чтобы и СУБД, и сервер были масштабируемы. Сегодня ключевыми параметрами масштабируемости являются:
- поддержка многопроцессорной обработки;
- гибкость архитектуры.
Многопроцессорные системы
 е. операционной системы, аппаратного обеспечения, а также навыков администрирования. С этой целью возможно также применение систем с массовым параллелизмом (MPP), но пока их использование ограничивается специальными задачами, например, расчетными. При оценке сервера СУБД с параллельной архитектурой целесообразно обратить внимание на две основные характеристики расширяемости архитектуры: адекватности и прозрачности.
е. операционной системы, аппаратного обеспечения, а также навыков администрирования. С этой целью возможно также применение систем с массовым параллелизмом (MPP), но пока их использование ограничивается специальными задачами, например, расчетными. При оценке сервера СУБД с параллельной архитектурой целесообразно обратить внимание на две основные характеристики расширяемости архитектуры: адекватности и прозрачности.Свойство адекватности требует, чтобы архитектура сервера равно поддерживала один или десять процессоров без переустановки или существенных изменений в конфигурации, а также дополнительных программных модулей. Такая архитектура будет одинаково полезна и эффективна и в однопроцессорной системе, и, по мере роста сложности решаемых задач, на нескольких или даже на множестве (MPP) процессоров. В общем случае потребитель не должен дополнительно покупать и осваивать новые опции программного обеспечения.
Обеспечение прозрачности архитектуры сервера, в свою очередь, позволяет скрыть изменения конфигурации аппаратного обеспечения от приложений, т.
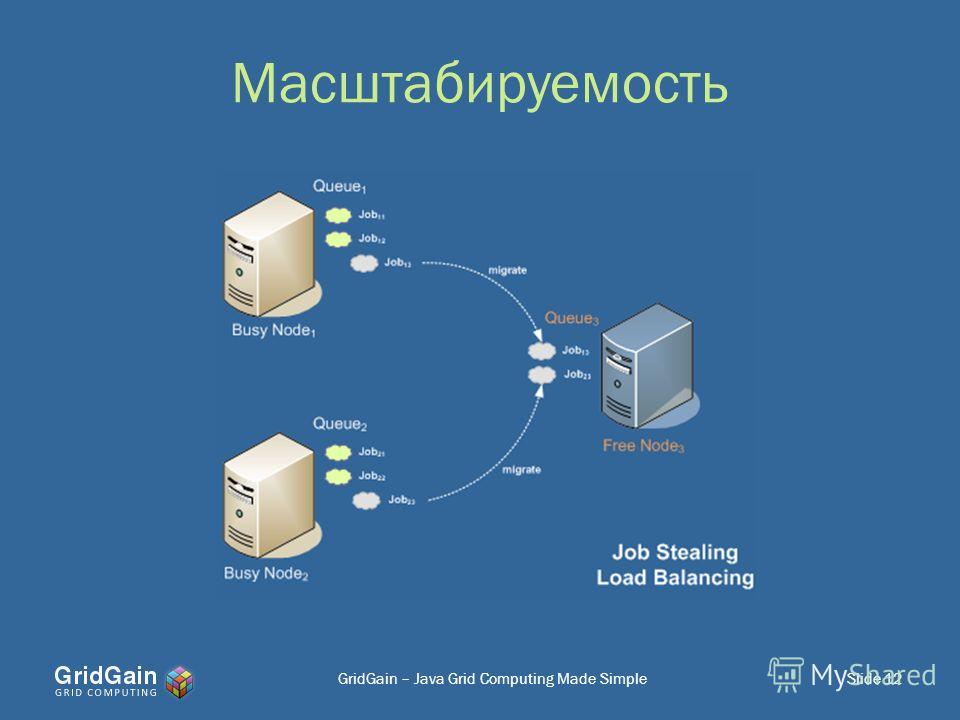
Качественная поддержка многопроцессорной обработки требует от сервера баз данных способности самостоятельно планировать выполнение множества обслуживаемых запросов, что обеспечило бы наиболее полное разделение доступных вычислительных ресурсов между задачами сервера. Запросы могут обрабатываться последовательно несколькими задачами или разделяться на подзадачи, которые, в свою очередь, могут быть выполнены параллельно (рис. 3). Последнее более оптимально, поскольку правильная реализация этого механизма обеспечивает выгоды, независимые от типов запросов и приложений.
Гибкость архитектуры
Независимо от степени мобильности, поддержки стандартов, параллелизма и других полезных качеств, производительность СУБД, имеющей ощутимые встроенные архитектурные ограничения, не может наращиваться свободно.
Обычно узким местом является невозможность динамической подстройки характеристик программ сервера баз данных. Способность на ходу определять такие параметры, как объем потребляемой памяти, число занятых процессоров, количество параллельных потоков выполнения заданий (будь то настоящие потоки (threads), процессы операционной системы или виртуальные процессоры) и количество фрагментов таблиц и индексов баз данных, а также их распределение по физическим дискам БЕЗ останова и перезапуска системы является требованием, вытекающим из сути современных приложений.
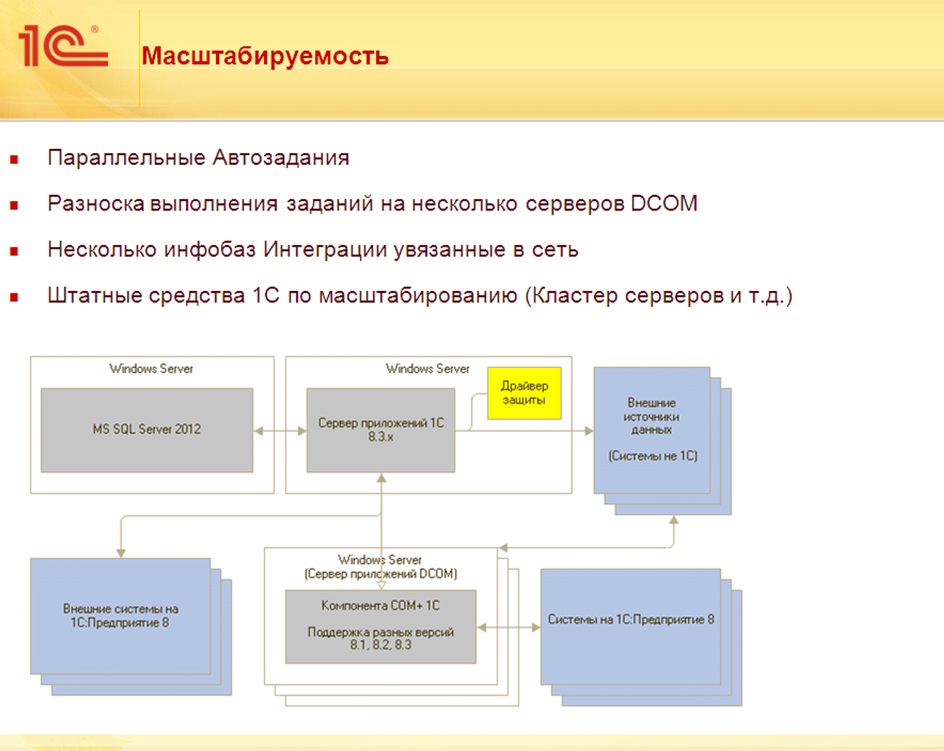
Масштабируемость
Масштабируемость — это способность системы адаптироваться к расширению предъявляемых требований и возрастанию объемов решаемых задач.
Работа одного прикладного решения в разных условиях
Система «1С:Предприятие 8» имеет хорошие возможности масштабирования. Она позволяет работать как в файловом варианте, так и с использованием технологии «клиент-сервер».
Персональное использование, файловый вариант работы
При работе в файловом варианте платформа может работать с локальной информационной базой, расположенной на том же компьютере, на котором работает пользователь. Такой вариант работы может использоваться в домашних условиях или при работе на ноутбуке.
Файловый вариант также обеспечивает возможность работы по локальной сети нескольких пользователей с одной информационной базой. Такой способ работы может использоваться в небольших рабочих группах, он прост в установке и эксплуатации.
Для больших рабочих групп и в масштабах предприятия может применяться клиент-серверный вариант работы, основанный на трехуровневой архитектуре с использованием кластера серверов «1С:Предприятия 8» и отдельной системы управления базами данных. Он обеспечивает надежное хранение данных и их эффективную обработку при одновременной работе большого количества пользователей.
Крупные холдинговые компании могут использовать работу в распределенной информационной базе, сочетающуюся с применением как файлового, так и клиент-серверного вариантов работы. Распределенная информационная база позволяет объединить удаленные друг от друга подразделения холдинга, а каждое из этих подразделений может использовать, в свою очередь, файловый или клиент-серверный варианты работы. Механизм распределенной информационной базы будет обеспечивать идентичность конфигураций, используемых в каждом из подразделений холдинга, и осуществлять обмен данными между отдельными информационными базами, входящими с состав распределенной системы.
Механизм распределенной информационной базы будет обеспечивать идентичность конфигураций, используемых в каждом из подразделений холдинга, и осуществлять обмен данными между отдельными информационными базами, входящими с состав распределенной системы.
Важно отметить, что одни и те же прикладные решения (конфигурации) могут использоваться как в файловом, так и в клиент-серверном варианте работы. При переходе от файлового варианта к технологии «клиент-сервер» не требуется вносить изменения в прикладное решение. Поэтому выбор варианта работы целиком зависит от потребностей заказчика и его финансовых возможностей. На начальной стадии можно работать в файловом варианте, а затем с увеличением количества пользователей и объема базы данных можно легко перейти на клиент-серверный вариант работы со своей информационной базы.
Многопользовательская работа
Одним из основных показателей масштабируемости системы является возможность эффективной работы при увеличении количества решаемых задач, объема обрабатываемых данных и количества интенсивно работающих пользователей.
В варианте клиент-сервер обеспечивается возможность параллельной работы большого количества пользователей. Как показывают тесты, с ростом числа пользователей скорость ввода документов уменьшается очень медленно. Это означает, что при увеличении количества интенсивно работающих пользователей скорость реакции автоматизированной системы остается на приемлемом уровне.
В модели данных, поддерживаемой системой «1С:Предприятие 8», не существует таблиц базы данных, однозначно приводящих к конкурентному доступу со стороны нескольких пользователей. Конкурентный доступ возникает только при обращении к логически связанным данным и не затрагивает данные, не связанные между собой с точки зрения предметной области.
При выполнении регламентных операций исключены ситуации, когда для начала работы в некотором отчетном периоде требуется установка монопольного режима. Регламентные операции могут выполняться в удобные для пользователей и организации моменты времени. Монопольный режим устанавливается не при запуске системы, а в тот момент, когда необходимо выполнение операции, требующей его включения. После выполнения таких операций монопольный режим может быть отключен.
Монопольный режим устанавливается не при запуске системы, а в тот момент, когда необходимо выполнение операции, требующей его включения. После выполнения таких операций монопольный режим может быть отключен.
Механизмы оптимизации
Технологическая платформа «1С:Предприятия 8» содержит ряд механизмов, оптимизирующих скорость работы прикладных решений.
Управление блокировками в транзакции
Режим управляемых блокировок в транзакции позволяет управлять блокировками данных в терминах предметной области и повышает параллельность работы пользователей. Подробнее…
Выполнение на сервере
В варианте клиент-сервер использование сервера «1С:Предприятия 8» позволяет сосредоточить на нем выполнение наиболее объемных операций по обработке данных. Например, при выполнении даже весьма сложных запросов программа, работающая у пользователя, будет получать только необходимую ей выборку, а вся промежуточная обработка будет выполняться на сервере. Обычно увеличить мощность сервера гораздо проще, чем обновить весь парк клиентских машин.
Обычно увеличить мощность сервера гораздо проще, чем обновить весь парк клиентских машин.
Кэширование данных
Система «1С:Предприятие 8» использует механизм кэширования данных, считанных из базы данных при использовании объектной техники. При обращении к реквизиту объекта выполняется чтение всех данных объекта в кэш, расположенный в оперативной памяти. Последующие обращения к реквизитам того же объекта будут направляться уже в кэш, а не в базу данных, что значительно сокращает время, затрачиваемое на получение нужных данных.
Работа встроенного языка на сервере
При работе в клиент-серверном варианте вся работа прикладных объектов выполняется только на сервере. Функциональность форм и командного интерфейса также реализована на сервере.
На сервере выполняется подготовка данных формы, расположение элементов, запись данных формы после изменения. На клиенте отображается уже подготовленная на сервере форма, выполняется ввод данных и вызовы сервера для записи введенных данных и других необходимых действий.
На клиенте отображается уже подготовленная на сервере форма, выполняется ввод данных и вызовы сервера для записи введенных данных и других необходимых действий.
Аналогично командный интерфейс формируется на сервере и отображается на клиенте. Также и отчеты формируются полностью на сервере и отображаются на клиенте.
Примеры технологических параметров внедрений решения «Управление производственным предприятием»
В этом разделе публикуется развернутая информация о технологических параметрах внедрений «1C:Предприятие 8. Управление производственным предприятием» на предприятиях различного масштаба и профиля деятельности.
Цель раздела — ознакомить ИТ- специалистов с данными о реально используемом оборудовании и с примерами нагрузки реальных внедрений «1С:Предприятия 8».
Также эта информация может быть полезна и для пользователей всех программ системы «1С:Предприятие 8».
1С:Центр управления производительностью — инструмент мониторинга и анализа производительности
1С:Центр управления производительностью (1С:ЦУП) — инструмент мониторинга и анализа производительности информационных систем на платформе «1С:Предприятие 8». 1С:ЦУП предназначен для оценки производительности системы, сбора подробной технической информации об имеющихся проблемах производительности и анализа этой информации с целью дальнейшей оптимизации. Подробнее…
1С:ТестЦентр — инструмент автоматизации нагрузочных испытаний
1С:ТестЦентр — инструмент автоматизации многопользовательских нагрузочных испытаний информационных систем на платформе «1С:Предприятие 8». С его помощью можно моделировать работу предприятия без участия реальных пользователей, что позволяет оценивать применимость, производительность и масштабируемость информационной системы в реальных условиях. Подробнее…
Подробнее…
Внедрение корпоративных информационных систем на платформе «1С:Предприятие 8»
Опыт внедрения прикладных решений на платформе «1С:Предприятие 8» показывает, что система позволяет решать задачи различной степени сложности — от автоматизации одного рабочего места до создания информационных систем масштаба предприятия.
В то же время, внедрение большой информационной системы предъявляет повышенные требования по сравнению с небольшим или средним внедрением. Информационная система масштаба предприятия должна обеспечивать приемлемую производительность в условиях одновременной и интенсивной работы большого количества пользователей, которые используют одни и те же информационные и аппаратные ресурсы в конкурентном режиме. Подробнее…
База знаний по технологическим вопросам крупных внедрений
Фирма «1С», совместно с сертифицированными «1С:Экспертами по технологическим вопросам» и другими техническими специалистами, ведет и регулярно обновляет базу знаний по технологическим вопросам крупных внедрений.
База знаний — это постоянно пополняемый информационный ресурс, который является основным источником информации по технологическим вопросам крупных внедрений:
- Методики и технологии, ориентированные на повышение качества крупных внедрений
- Технологические проблемы крупных внедрений и способы их решения
Подробнее…
Масштабируемость: рост системы в разных направлениях
Перевод статьи «Scalability: Growing a System in Different Directions».
Вокруг распределенных систем ходит много разговоров, но все они крутятся, собственно, вокруг размеров. Причем, говоря о размере, люди обычно подразумевают размер самой системы. И когда дело касается распределенных систем, оказывается, размер действительно имеет значение.
Сфера компьютерных вычислений имеет
удивительно длинную историю. Но если
мы говорим о распределенных системах,
то история немного отличается. Распределенные вычисления в нашем
современном понимании начали появляться
в поздние 1960-е и ранние 1970-е, когда
компьютеры начали взаимодействовать
в сетях (Ethernet).
Распределенные вычисления в нашем
современном понимании начали появляться
в поздние 1960-е и ранние 1970-е, когда
компьютеры начали взаимодействовать
в сетях (Ethernet).
В течение следующего десятилетия распределенные вычисления становились все более распространенными. Любопытно, что системы начали становиться «распределенными», когда появилась одна массивная распределенная система – интернет.
К 1980-м компьютеры уже использовались повсеместно, а доступ к интернету (и другим сетям) стал более обыденным. Не углубляясь в детали, можно заключить, что машин стало больше, а кроме того, они стали гораздо больше взаимодействовать друг с другом.
Такой тип «роста» имеет собственное
название в царстве распределенных
систем. Фактически, сегодня многие
инженеры (и не только занимающиеся
распределенными системами) довольно
широко используют этот термин. Я говорю,
конечно же, о масштабируемости. Итак,
давайте рассмотрим, что такое масштабируемая
распределенная система, а также – каким
образом система может расти.
Как происходит масштабирование?
Масштабируемость системы может означать много различных вещей в зависимости от того, с чем имеет дело эта система, а также от того, какая часть системы растет. Но в общих чертах можно сказать, что если система обладает масштабируемостью, значит, она может продолжать справляться со своей работой и действовать эффективно в условиях своего роста.
Но что такое «рост»? Какая часть системы увеличивается?
Говоря о том, что система растет, в разных случаях мы, скорее всего, будем иметь в виду разные вещи. Другими словами, система запросто может расти в разных направлениях.
Определение: масштабируемой распределенной системой называется такая система, которая продолжает эффективно работать по мере возрастания количества пользователей и ресурсов.Например, мы можем утверждать, что система растет, если растет число пользователей, взаимодействующих с ней. Если с системой работало 5 тысяч пользователей и вдруг их число возросло до 50 тысяч, это определенно своего рода рост системы!
Как система может расти? Больше данных, больше процессов, больше машин, больше пользователей. Обычно система растет не в одном направлении!
Обычно система растет не в одном направлении!Но система также может расти и в плане ее собственных ресурсов. Например, однажды она может получить особенно высокий трафик, а следовательно, очень большое количество данных, которые нужно обрабатывать. Или система может особенно интенсивно использоваться в определенный период времени, что приведет к значительному росту количества одновременно запущенных процессов. Или вот еще пример: единая система может расти за счет числа физических машин (серверов) внутри нее.
Все эти вещи – данные, процессы, машины – представляют собой различные направления, по которым может происходить рост системы. И, как мы выяснили ранее, наплыв пользователей это тоже один из видов роста системы.
На самом деле в реальном мире
распределенные системы растут не в
одном направлении, а в нескольких
одновременно. Например, мы можем заметить,
что в результате наплыва пользователей
возросло и количество данных. А для
обработки большего количества данных
мы добавляем новые серверы или базы
данных.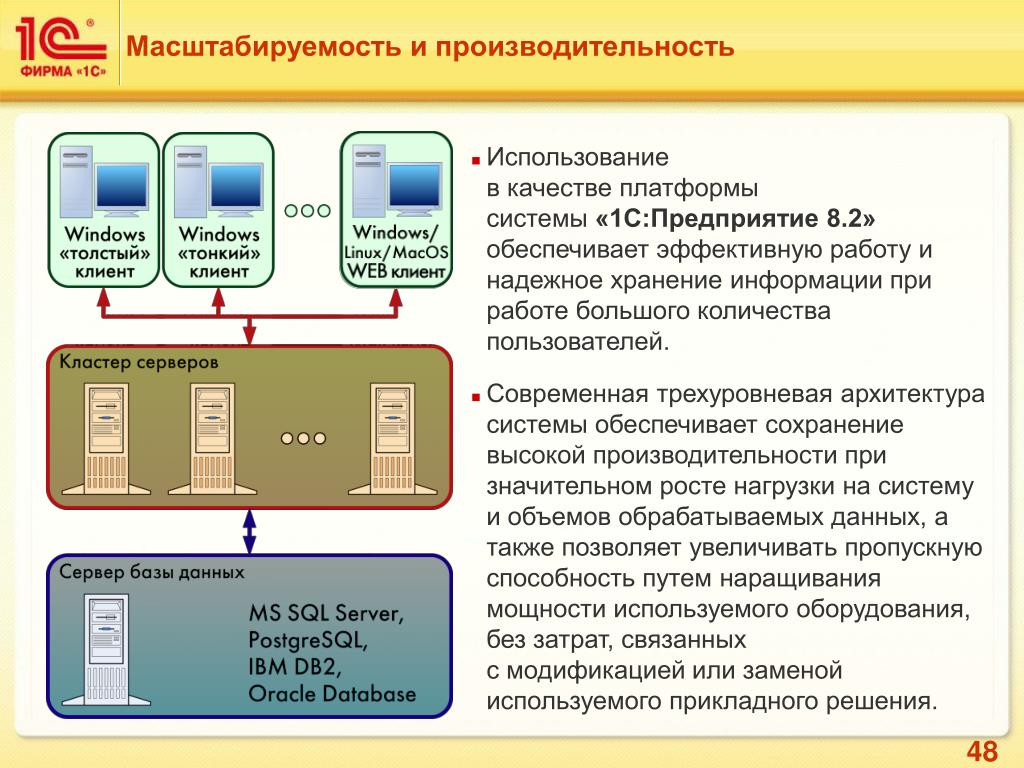
В реальном мире распределенная система имеет тенденцию расти в больше, чем в одном направлении.
Измеряем масштабируемость: масштабируемость по размеру, географическая и административная масштабируемостьС учетом того, что система может расти по-разному, имеет смысл говорить о масштабируемости системы в привязке к тому, как именно она растет. Чтобы конкретизировать форму масштабируемости, придумано несколько терминов. Основные из них – масштабируемость по размеру, географическая масштабируемость и административная масштабируемость. Это три формы часто называют измерениями масштабируемости. Давайте рассмотрим каждую из них подробнее.
Рост, измеряемый количественно
Первое измерение масштабируемости
лежит на пересечении двух вещей, которые
мы уже обсуждали: количества пользователей
и количества ресурсов (какими бы эти
ресурсы ни были). Мы знаем, что и то, и
другое может возрастать количественно.
Когда такое происходит, мы говорим, что
система увеличилась в размерах.
Если система обладает масштабируемостью по размеру, это означает, что она сохраняет свою производительность и остается пригодной к использованию независимо от того, как много ресурсов она может получить.
Возьмем пример. Скажем, наша распределенная система в какой-то день получает высокий трафик. На основе этого мы можем понять, что объем нашей базы данных или существующее количество серверов нашей системы просто не могут справиться с многочисленными запросами в день с особенно высоким трафиком.
Мы можем решить увеличить объем базы
данных или на несколько часов добавить
серверы для обработки большего потока
данных. Но если наша система масштабируется
по размеру, добавление новых узлов не
должно отрицательно сказаться на
производительности. То есть, если мы
решили добавить больше узлов для
обработки ресурсов или обслуживания
пользователей, в результате не должны
упасть производительность и эффективность
работы всей системы. Наша система должна
иметь возможность продолжать работу
на уровне, который ожидают от нее
пользователи, и, разумеется, для
пользователей работа с этой системой
не должна замедлиться.
Рост с увеличением сложности
До сих пор мы говорили о добавлении ресурсов или пользователей в функционирующую систему. Но по мере роста системы мы можем обнаружить, что добавление узлов не решает проблему. Фактически, порой само это добавление может приводить к непредсказуемым последствиям.
На первый взгляд может показаться, что добавить узлы или ресурсы в систему довольно легко. Однако это очень наивный подход к сложной проблеме. Если речь идет о распределенной системе, географическая и административная масштабируемость имеют много нюансов, которые могут быть не слишком очевидными.
Увеличение расстояний
Когда система начинает существенно увеличиваться в размерах, мы должны обдумать еще один вопрос: где конкретно расположены наши ресурсы? Здесь и выходит на сцену географическая масштабируемость.
Если система обладает географической
масштабируемостью, она может продолжать
эффективно функционировать и использоваться
вне зависимости от расстояния между
пользователями и ресурсами системы.
Вначале это может показаться странным или смешным, но погодите. Скажем, чтобы сделать нашу систему масштабируемой по размеру, мы добавляем больше узлов, которые помогут справиться с возросшей нагрузкой. Если эти узлы – серверы, они могут располагаться в одном месте или в разных местах. И если мы добавляем в нашу систему что-то значительное, такое как целый дата-центр, этот наш новый дата-центр может располагаться достаточно далеко от того дата-центра, который у нас был изначально.
Добавление еще одного узла в нашу систему может казаться простым делом. Но мы помним, что наша цель – создание системы, которая продолжит эффективно функционировать, и к которой по-прежнему смогут легко получать доступ пользователи. В этих условиях добавление нового узла осложняет достижение нашей цели.
Мы, конечно, можем добавлять новые
узлы в нашу систему и без учета дистанций
между ними. Но это зависит от расположения
узлов и расстояния между ними и
пользователями. Под расстоянием следует
понимать буквальное физическое
пространство между ними, т. е.,
расстояние в географическом смысле.
е.,
расстояние в географическом смысле.
Но почему вообще расстояние имеет значение? Потому что пересылка данных и взаимодействие разных частей системы занимают определенное время. Два узла, находящиеся в одной комнате, обмениваются информацией гораздо быстрее, чем два узла, находящиеся в два раза дальше друг от друга. К сожалению, существуют физические (географические?) ограничения, справиться с которыми не поможет даже очень хороший wifi.
Если система обладает географической масштабируемостью, добавление новых узлов не увеличивает количество времени, необходимого для коммуникации между ними.
Таким образом, добавляя каждый новый узел, нужно учитывать его физическое расположение по отношению к остальным частям системы.
Рост затрачиваемых усилий
Наконец, если система растет по размеру
и в географическом плане, возникает
последний вопрос: кто будет наблюдать
за новыми частями расширяющейся системы?
Мы подобрались к административной
масштабируемости.
Если система обладает административной масштабируемостью, добавление новых узлов не должно вызывать существенного роста количества усилий, необходимых для управления этими новыми узлами.
Это особенно важно, если система используется многими администраторами (людьми или организациями, запускающими эту систему наравне с другими людьми и организациями). Каждый из них должен иметь возможность использовать систему, даже когда ею уже пользуются другие.
Административная масштабируемость это еще одно измерение масштабируемости, о котором часто забывают. И если нам легко счесть добавление еще одного узла простым решением проблемы роста системы, нам так же легко забыть, что добавление ресурсов в систему означает, что в будущем понадобятся дополнительные усилия для их поддержки.
В системе, обладающей административной масштабируемостью, добавление ресурсов по мере роста системы не должно вызывать сильного увеличения управленческих усилий.
Если для масштабирования нашей системы
нам потребовалось добавить целый
дата-центр узлов, мы должны суметь
прикинуть количество человеко-часов,
которое потребуется на поддержку этих
узлов и их работоспособности.
Очень часто, говоря о том, что нужно сделать систему масштабируемой, разработчики на самом деле думают только об увеличении размеров системы. Однако, как и многие другие вещи, распределенные системы развиваются больше, чем в одном направлении. Масштабируемость по размеру это лишь один из аспектов проблемы. Очень важно учитывать также географическую и административную масштабируемость. А обратив внимание на каждый из этих аспектов, мы обнаружим множество нюансов и своих сложностей.
Расширяемость и масштабируемость | Компьютерные сети
Термины «расширяемость» и «масштабируемость» иногда неверно используют как синонимы.
Расширяемость означает возможность сравнительно простого добавления отдельных компонентов сети (пользователей, компьютеров, приложений, служб), наращивания длины сегментов кабелей и замены существующей аппаратуры более мощной.
При этом принципиально важно, что простота расширения системы иногда может обеспечиваться в определенных пределах. Например, локальная сеть Ethernet, построенная на основе одного разделяемого сегмента коаксиального кабеля, обладает хорошей расширяемостью в том смысле, что позволяет легко подключать новые станции. Однако такая сеть имеет ограничение на число станций — оно не должно превышать 30-40. Хотя сеть допускает физическое подключение к сегменту и большего числа станций (до 100), при этом резко снижается производительность сети. Наличие такого ограничения и является признаком плохой масштабируемости системы при ее хорошей расширяемости.
Например, локальная сеть Ethernet, построенная на основе одного разделяемого сегмента коаксиального кабеля, обладает хорошей расширяемостью в том смысле, что позволяет легко подключать новые станции. Однако такая сеть имеет ограничение на число станций — оно не должно превышать 30-40. Хотя сеть допускает физическое подключение к сегменту и большего числа станций (до 100), при этом резко снижается производительность сети. Наличие такого ограничения и является признаком плохой масштабируемости системы при ее хорошей расширяемости.
Масштабируемость означает, что сеть позволяет наращивать количество узлов и протяженность связей в очень широких пределах, при этом производительность сети не снижается.
Для обеспечения масштабируемости сети приходится применять дополнительное коммуникационное оборудование и специальным образом структурировать сеть. Обычно масштабируемое решение обладает многоуровневой иерархической структурой, которая позволяетдобавлять элементы на каждом уровне иерархии без изменения главной идеи проекта.
Примером хорошо масштабируемой сети является Интернет, технология которого (TCP/IP) оказалась способной поддерживать сеть в масштабах земного шара. Организационная структура Интернета, которую мы рассмотрели в главе 5, образует несколько иерархических уровней: сети пользователей, сетей локальных поставщиков услуг и т. д. вверх по иерархии вплоть до сетей межнациональных поставщиков услуг. Технология TCP/IP, на которой построен Интернет, также позволяет строить иерархические сети. Основной протокол Интернета (IP) основан на двухуровневой модели: нижний уровень составляют отдельные сети (чаще всего сети корпоративных пользователей), а верхний уровень — это составная сеть, объединяющая эти сети. Стек TCP/IP поддерживает также концепцию автономной системы. В автономную систему входят все составные сети одного поставщика услуг, так что автономная система представляет собой более высокий уровень иерархии.
Наличие автономных систем в Интернете позволяет упростить решение задачи нахождение оптимального маршрута — сначала ищется оптимальный маршрут между автономными системами, а затем каждая автономная система находит оптимальный маршрут внутри себя.
Не только сама сеть должна быть масштабируемой, но и устройства, работающие на магистрали сети, также должны обладать этим свойством, так как рост сети не должен приводить к необходимости постоянной смены оборудования. Поэтому магистральные коммутаторы и маршрутизаторы строятся обычно по модульному принципу, позволяя наращивать количество интерфейсов и производительность обработки пакетов в широких пределах.
Как обеспечить масштабируемость облака | Dinarys
Главная / Блог / Как обеспечить масштабируемость облака
Поскольку общие объемы нагрузки на вычислительные системы все больше растут, они адаптируются и становятся более сложными с точки зрения базовой архитектуры. Создаются новые программные инструменты и интегрируются для оптимизации производительности, расширяются возможности сервера и т. д. Все эти процессы оптимизации системы определяются одним понятием — масштабирование — одна из ключевых специализаций экспертов DevOps.
Есть идеи по поводу вашего проекта?
Свяжитесь с нами!
Сделать запросЧто такое масштабируемость и как обеспечить ее для вашего бизнеса, когда большинство операционных мощностей сосредоточено в облаке? Давайте углубимся в тему.
Источник изображения: Static.bluepiit
Что такое масштабируемость?
Каково окончательное определение масштабируемости?
В основном, это способность повышать производительность системы наиболее рациональным способом. На практике это обычно достигается путем добавления вычислительных ресурсов, как аппаратных, так и / или программных. Однако, переписать существующий код в большинстве случаев является довольно радикальным решением, поэтому в 9 из 10 случаев компании останавливают увеличение количества серверов или расширение возможностей существующей серверной системы.
Обратите внимание, что необходимость в масштабировании возникает не только тогда, когда общая производительность системы становится низкой и недостаточной. Существующая и работающая архитектура может работать очень хорошо, но лаги могут препятствовать процессам из-за быстрого роста пользовательского трафика.
Существующая и работающая архитектура может работать очень хорошо, но лаги могут препятствовать процессам из-за быстрого роста пользовательского трафика.
Если вы хотите проверить, насколько эффективно работают ваши сетевые протоколы и ресурсы веб-сервера, вы можете использовать любую доступную утилиту тестера нагрузки (например, siege), которая будет эмулировать искусственный приток пользователей на ваш сервер с тоннами запросов. Вам просто нужно отследить два ключевых параметра: n — определяет общее количество запросов и c — указывает количество одновременных запросов.
В результате вы получаете RPS (количество запросов в секунду), которое показывает, сколько запросов ваша серверная система способна обработать в данный момент. Это отражает максимальное количество пользователей, которое, если они попытаются одновременно взаимодействовать с вашим сервером, может привести к сбою системы. Эта процедура тестирования в конечном итоге показывает, чего ожидать, и насколько важно создать архитектуру, подверженную масштабируемости.
С другой стороны, подумайте хотя бы на секунду, возможно, вам будет удобнее настроить некоторые конфигурации серверов и оптимизировать процедуры обналичивания в вашем конкретном случае.
Таким образом, вы можете безопасно отложить масштабирование до лучших времен.
Есть идеи по поводу вашего проекта?
Свяжитесь с нами!
Сделать запросТипы масштабирования
Основные и наиболее распространенные типы процедур масштабирования включают в себя:
Вертикальное масштабирование — увеличение
Источник изображения: Dzone
Вертикальное масштабирование — это когда общая мощь бизнеса увеличивается за счет повышения производительности внутренних ресурсов сервера — процессоров, памяти, дисков и емкости сети. Сервер в своей базовой форме остается неизменным.
Горизонтальное масштабирование — масштабирование
Источник изображения: Dzone
В поле зрения есть реальная позиция — увеличение против масштабирования. Что лучше?
Что лучше?
В частности, поскольку цифровая нагрузка и трафик постоянно растут, вертикальное масштабирование рано или поздно сталкивается с ограничениями в виде технических спецификаций серверов. Вот где в игру вступает горизонтальное масштабирование. Основное значение этого термина определяет, что вычислительные мощности увеличиваются путем добавления идентичных узлов поверх существующих. Горизонтальное масштабирование чаще всего достигается при наличии настроенной серверной инфраструктуры (в частности, центров обработки данных), а также согласованной схемы взаимодействия между серверами.
Диагональное масштабирование
Это относительно новый термин, который придумал Джон Аллспо — автор и соучредитель Adaptive Capacity Labs. Таким образом, диагональное масштабирование объединяет лучшее из двух миров и определяет вертикальное масштабирование горизонтально масштабированных узлов, которые уже реализованы в существующей серверной инфраструктуре.
Как обеспечить максимальную масштабируемость
Теперь несколько практических советов, которые помогут вам провести процедуру масштабируемости облачных вычислений наиболее правильно, с минимальными затратами.
Проводить балансировку нагрузки
Распределение нагрузки подразумевает комплекс усилий по распределению процессов вычислительной сети между несколькими аппаратно-программными ресурсами (дисками, процессорами или отдельными серверами), которые сосредоточены в одном сокете или кластере. Основная цель здесь — оптимизировать расходы вычислительных мощностей, повысить производительность сети, сократить временные затраты при обработке сетевых запросов, а также снизить шансы того, что определенный сервер ответит на DDoS в какой-то замечательный момент.
Кроме того, распределение нагрузки между несколькими узлами (вместо полной эксплуатации одного узла) повышает доступность услуг, предоставляемых вашей компанией. В частности, если у вас под рукой есть несколько дополнительных серверов, то даже если какой-то рабочий блок выходит из строя, у вас есть готовая автоматическая замена.
В частности, если у вас под рукой есть несколько дополнительных серверов, то даже если какой-то рабочий блок выходит из строя, у вас есть готовая автоматическая замена.
Процедура балансировки реализуется с помощью целого набора алгоритмов и методов, каждый из которых соответствует следующим уровням модели OSI: Сеть, Транспорт и Приложение. В практической реализации это требует использования нескольких физических серверов вместе со специализированным программным обеспечением, аналогичным веб-серверу Nginx.
Обратитесь к услугам автоматического масштабирования
Автоматическое масштабирование является особым подходом к динамическому масштабированию в контексте облачных сервисов (т.е. масштабирование, которое подразумевает настройку вычислительных мощностей в соответствии с объемом сетевой нагрузки). В частности, пользователям служб, которые включают процедуры автоматического масштабирования (наиболее известными из которых являются Amazon Web Service, Google Cloud Platform и Microsoft Azure), предоставляются дополнительные виртуальные машины, если это необходимо (которые могут быть автоматически исключены из кластера или контейнера). по мере успокоения трафика и интенсивности запросов).
по мере успокоения трафика и интенсивности запросов).
Благодаря такому подходу компании получают улучшенную доступность, отказоустойчивость, а также максимальные возможности экономии бюджета. С такими услугами вы используете столько серверной мощности, сколько вам нужно в данный момент. Это довольно выигрышный вариант, в отличие от физического масштабирования, когда вам необходимо приобрести и дополнительно поддерживать дорогостоящее оборудование.
Обратите внимание, что автоматическая облачная масштабируемость всегда идет рука об руку с решениями для балансировки нагрузки.
Контейнеры микросервисов, кластеризация
Вы можете использовать ресурсоэффективные процедуры повышения производительности, которые объединяют сервисы в контейнеры, а затем собирают эти контейнеры в кластеры. За кластеризацией следуют определения сценариев, которые либо добавляют недостающие ресурсы (экземпляры), если это необходимо, либо минимизируют выделение ресурсов, чтобы избежать их избытка.
Реализовать кеширование
Во время горизонтального масштабирования простое кэширование памяти не может быть реализовано сразу для нескольких узлов, поэтому его необходимо оптимизировать. В частности, такие хранилища, как Memcached или Redis, можно использовать для комбинированного распределения данных кэша между итерациями приложения. Эти инструменты работают в соответствии с различными алгоритмами, так что объем данных кэширования уменьшается. Кэш-хранилища также хорошо защищены от ошибок репликации и хранения данных.
При использовании кеш-хранилищ важно предотвратить ситуацию, когда разные итерации приложения одновременно запрашивают некэшированные данные. Для этого необходимо обновить данные кэширования вне потока производительности вашего приложения и использовать их непосредственно в приложении.
Таким образом, при правильном подходе кэширование может помочь вашим системам получить возможность масштабирования в облаке для обработки интенсивных нагрузок и достижения оптимальной производительности.
Использовать услуги CDN
CDN — это сеть физически удаленных компьютеров, которые передают контент пользователям услуг. Другими словами, это распределенное хранилище и использование кэша. Обычно обращение к CDN является наиболее актуальным, когда веб-служба, веб-сайт или полнофункциональное приложение ориентированы на пользовательскую аудиторию, которая распределена по территории нескольких стран. Ценообразование CDN напрямую зависит от объемов трафика, проходящего через сервис.
В качестве альтернативы CDN может быть убыточным решением, если ваша TA, несмотря на широкое территориальное распределение, имеет локализации с концентрацией определенных пользователей. То есть, предположим, что около 60% вашей TA основано в США, 30% в Лондоне, а остальные 10% разбросаны по всей планете. В таком случае использование CDN будет рациональным решением только для последних 10% (тогда как в других местах потребуется установка новых серверов).
Как мы решаем проблемы масштабирования?
В настоящее время среди наших ярких примеров масштабирования, проведенного собственными специалистами, можно назвать создание архитектуры высокой масштабируемости для таких общедоступных облачных хранилищ, как AWS, Microsoft Azure, Google Cloud и Digital Ocean. Мы используем сценарии автоматического развертывания среды с помощью Terraform — системы следующего поколения для создания, управления и настройки облачной инфраструктуры. Наши серверные кластеры основаны на программном обеспечении для автоматического масштабирования Kubernetes и вспомогательной технологии контейнеризации Docker.
Заключение
Источник изображения: CDN.Lynda
Используя масштабируемость в среде облачных вычислений с помощью вышеупомянутых и других методов, вы можете расти быстрее и проще, а также оставаться гибкими на протяжении всего пути. Если вы стремитесь выбрать правильный подход к масштабированию, вам обязательно следует обратиться к экспертам. Позвольте нам найти вам специалистов DevOps, которые предоставят наиболее оптимальную серверную инфраструктуру для вашего конкретного бизнеса, которая будет адаптирована к нагрузкам любой интенсивности.
Позвольте нам найти вам специалистов DevOps, которые предоставят наиболее оптимальную серверную инфраструктуру для вашего конкретного бизнеса, которая будет адаптирована к нагрузкам любой интенсивности.
Тестируем масштабируемость – пошаговая инструкция
Ваше приложение может быть практически идеальным, но если оно не имеет возможности масштабирования, то внезапный пик трафика может подвесить всю систему. Поэтому обеспечить возможность быстрого расширения доступной базы ресурсов и протестировать возможности масштабирования в стресс-тестах на нагрузку – важно для обеспечения стабильности работы.
Важность масштабирования
Масштабируемость это, в первую очередь, способность сети, системы или процесса адаптироваться к внезапным изменениям. Это может быть резко возросший поток посетителей или объем передачи данных или какие-то другие нагрузки. Тесты масштабируемости симулируют различные сценарии возникновения подобных пиковых нагрузок, чтобы проверить готовность вашего приложения к критическим ситуациям.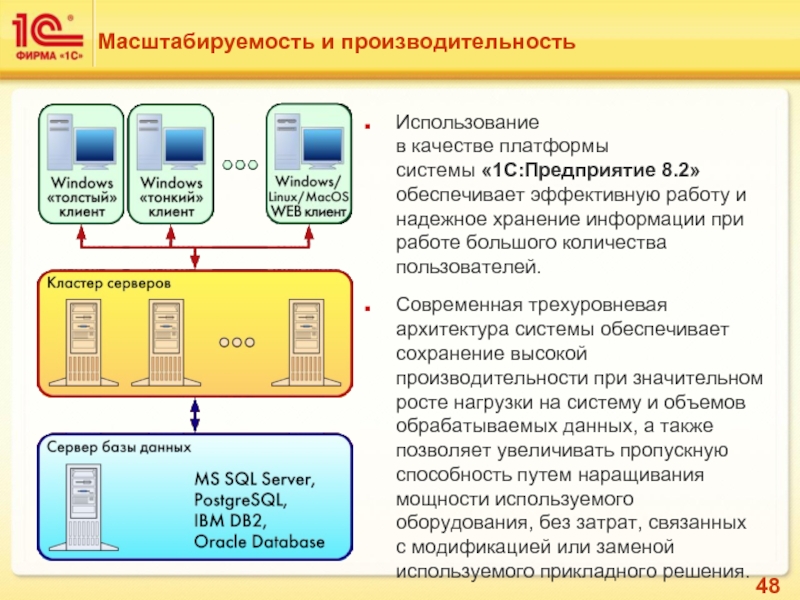
Стресс-тесты очень важны, потому что неспособность вашего приложения справляться с нагрузками может похоронить все ваши усилия по развитию бизнеса. К примеру, если вы планируете большие продажи в рамках какой-то акции, то должны подготовиться к резкому увеличению привлеченных вами покупателей. Иначе сайт не выдержит нагрузки, и те покупатели, на привлечение которых вы тратили средства и силы, попросту уйдут, хотя были уже готовы что-то у вас купить. Например, так случилось с канадской железнодорожной компанией VIA Rail, которая объявила о скидках в честь 150-летия Канады. Акция оказалась настолько популярной, что приток покупателей практически остановил все онлайн продажи этой компании.
Масштабируемость, надежность и производительность – практически синонимы. Они характеризуют то, насколько ваша система готова к рабочим нагрузкам.
Для улучшения масштабируемости нет единого подхода. То, что годится для небольшого сайта, не подойдет для серверов MMORPG. Разработчик должен понимать особенности своего приложения. Например, если ваш сайт сильно зависит от производительности базы данных, вы должны обратить внимание на ее функционирование при резко возрастающем потоке посетителей.
Например, если ваш сайт сильно зависит от производительности базы данных, вы должны обратить внимание на ее функционирование при резко возрастающем потоке посетителей.
Тестирование масштабирования
Основная задача нагрузочного теста проста – определить, в какой момент и почему система перестает справляться с нагрузкой и как это можно исправить. Но этот процесс не так прост, как кажется. И часто требуются определенные компромиссы и сложные решения. Например, при написании PHP-приложения придется пожертвовать скоростью, но организовать загрузку данных не одним файлом, а по частям.
Тестирование поможет вам определить как снижение производительности приложения на стороне клиента и ухудшение его клиентских качеств для пользователя, так и устойчивость ваших серверов к нагрузкам.
При тестировании масштабируемости нужно учитывать ряд факторов:
- Время отклика
- Время отрисовки на экране
- Пропускную способность
- Количество запросов в секунду
- Использование сети
- Использование памяти
- Время, требуемое для выполнения задач
Цели тестирования масштабирования
В идеале, конечно, хотелось бы, чтобы приложение работало одинаково хорошо во всех ситуациях. Но это, увы, недостижимые мечты. Надо ставить реалистичные цели. И более конкретные.
Но это, увы, недостижимые мечты. Надо ставить реалистичные цели. И более конкретные.
Например, «приложение должно при определенной нагрузке иметь определенное время отклика». И уточнить – какое. Другая цель – «сервер должен оставаться работоспособным при большой нагрузке». И уточнить, что имеется в виду под «большой нагрузкой». Или – «время проведения транзакции при 100 одновременных посетителях не должно быть больше 4 секунд» — тоже конкретная цель.
Приложения нужно протестировать на различные параметры, и конечным итогом ваших тестов должно явиться понимание, что именно ограничивает производительность при пиковых нагрузках – сеть, базы данных, оборудование или программное обеспечение.
Подготовка к тестированию
Когда вы разрабатываете новое приложение, вы не знаете, сколько у него будет пользователей через несколько лет. И по мере того, как к вам будет приходить успех, у вас будут множиться проблемы. Например, если вы храните данные о новых посетителях в базе данных, внезапный рост посещаемости может замедлить работу всего, что завязано на базы данных.
Поскольку разные ситуации порождают разные проблемы, нужно тестировать приложения с малым, средним и большим приростом нагрузки. При небольших нагрузках все должно работать безупречно, и этот тест поможет вам определить базовую производительность вашей системы. Средние нагрузки помогут понять, как будет себя вести приложение в обычном режиме, под нагрузкой, а большие – как оно справляется с пиковым приростом посетителей. И на каждом этапе, наверняка, вскроются свои проблемы.
Нужно быть уверенным, что конфигурация оборудования и среды остается во всех режимах тестирования одной и той же.
Рисунок ниже показывает почти идеальную зависимость использования памяти от времени. В данном тесте нагрузка постепенно возрастает, и время показывает фактически величину нагрузки. Идеально масштабируемая система сначала демонстрирует рост потребляемых ресурсов, а затем – стабильные показатели. График говорит о том, что памяти хватает на все три режима нагрузки.
Другой график, ниже, иллюстрирует пропорциональный нагрузке рост использования ресурсов. В данном случае растет время исполнения запроса с ростом числа посетителей.
В данном случае растет время исполнения запроса с ростом числа посетителей.
Пропорциональный рост говорит о том, что в принципе, ваше оборудование работает как положено и тут не возникнет внезапного ухудшения производительности при росте числа посетителей. Если же он не пропорционален нагрузке, надо обратить внимание на ресурсы оборудования, изменить их конфигурацию для достижения желаемого результата и снова – тестировать.
Масштабирование – вертикальное или горизонтальное
После первого цикла тестов вы будете менять конфигурацию оборудования. Расширять или же увеличивать производительность – масштабировать горизонтально или вертикально. Это не одно и то же.
- Вертикальное масштабирование – замена оборудования на более производительное. Например, замена процессора на более мощный
- Горизонтальное масштабирование – увеличение количества доступных ресурсов. Например, подключить для обслуживания вашего приложения еще один сервер
Оба этих подхода имеют как плюсы, так и минусы. Вертикальное масштабирование выглядит проще, но у процессоров есть предел производительности, и тут не получится повышать мощность сколько угодно. Горизонтальное масштабирование дает стабильный результат прироста мощности, но это может оказаться затратным.
Вертикальное масштабирование выглядит проще, но у процессоров есть предел производительности, и тут не получится повышать мощность сколько угодно. Горизонтальное масштабирование дает стабильный результат прироста мощности, но это может оказаться затратным.
Тестирование масштабирования – чек-лист
Вот типичная последовательность действий при тестировании масштабирования:
- Выберите какой-нибудь повторяющийся во время выполнения вашего приложения процесс
- Определите ваши критерии, по которым будете оценивать масштабируемость и производительность
- Составьте список инструментов для тестирования
- Зафиксируйте окружение и конфигурацию оборудования
- Составьте план, продумайте сценарии нагрузочного теста
- Напишите визуальный скрипт и загрузите тестовые сценарии
- Выполните тесты
- Проанализируйте результаты
Информация, полученная вами, послужит руководством для проведения апгрейдов. Например, если ваша компания ожидает рост посещаемости на 400 процентов в ближайшие месяцы, надо повышать производительность серверов. Или добавлять память. Возможно – надо менять серверное ПО. Все это вы должны выяснить в процессе тестирования. Тесты должны помочь вам выработать грамотную стратегию повышения производительности.
Или добавлять память. Возможно – надо менять серверное ПО. Все это вы должны выяснить в процессе тестирования. Тесты должны помочь вам выработать грамотную стратегию повышения производительности.
Разработка стресс-тестов
Нагрузочное тестирование имеет смысл и пользу только тогда, когда сценарии стресс-тестов хорошо проработаны. Параметры нагрузки продуманы в соответствии с реально ожидаемыми нагрузками и возможностями оборудования, а конфигурация аппаратной среды и окружения зафиксирована и одинакова для всех серий тестов. При этом должны контролироваться различные параметры, характеризующие загрузку – использование памяти, нагрузка на процессор и т.п.
Вот типичные шаги при разработке грамотного теста.
- Начните с разработки различных сценариев поведения пользователей. Проверьте их и задокументируйте – какие именно запросы поступают приложению в процессе их исполнения.
- Спроектируйте тест, моделирующий различное количество одновременных посетителей, с различной скоростью сети и различными версиями браузеров.

- Запустите тест, моделируя поступающие от пользователей запросы.
- Масштабируйте оборудование или программное обеспечение.
- Повторите тесты – и так до тех пор, пока производительность не будет соответствовать вашим требованиям.
Обеспечьте одинаковую конфигурацию и одинаковый сценарий роста нагрузки в различных тестах. IBM, кстати, разработало огромную инструкцию по проведению стресс-тестов.
Советы по улучшению масштабируемости и проведению тестов
- Разгрузите свою базу данных, ограничив количество открытых соединений и транзакций. Но не перекладывайте все на приложение – непропорциональное распределение нагрузки приведет к другим проблемам.
- Кэш может сильно помочь с выгрузкой ресурсов. Используйте CDN для разгрузки ваших серверов и даже более того – мощные сервера CDN ускорят работу вашего приложения.
- Не нужно хранить все подряд в базе данных. Используйте базы данных для хранения действительно важной для вашего бизнеса или для вашего приложения информации.
- Ограничьте доступ к тем ресурсам, которых не хватает. Если несколько процессов требуют выполнения одного и того же процесса, поставьте их в очередь – пусть ожидают завершения выполнения предыдущего запроса. Иначе зависнут все.
- Разбиение процессов на асинхронные потоки и параллельное их выполнение небольшим, ограниченным количеством обработчиков существенно повышает производительность.
- Обмен данными по сети гораздо более медленный, чем операции в памяти – уменьшите количество запросов-ответов от вашего приложения клиенту.
- Меняйте только одну переменную за один раз. Да, это потребует больше времени на отладку, но зато вы поймете, что конкретно привело к тем или иным изменениям.
- Обнулите всё, что возможно, до проведения теста, чтобы результаты работы предыдущего теста не влияли на последующий. Рекомендуется перезагрузка серверного ПО и пр., но само оборудование можно все-таки не перегружать.
- Каждый раз, когда вы проводите повторные тесты, выполняйте их все. Не стоит надеяться на результаты, полученные полгода назад – все могло существенно измениться.
- По максимуму автоматизируйте процесс тестирования. Тогда тесты можно будет запускать и в нерабочее время. Кроме того, автоматизация стандартизует условия проведения тестов.
 Не стоит надеяться на результаты, полученные полгода назад – все могло существенно измениться.
Не стоит надеяться на результаты, полученные полгода назад – все могло существенно измениться.Средства тестирования масштабирования
Выбор средств зависит от масштабов вашего проекта, его особенностей и т. п. К счастью, сейчас нет недостатка в бесплатных средствах для нагрузочного тестирования.
Вот некоторые из них:
TechBeacon приводит список из 12 бесплатных средств для нагрузочного тестирования.
Заключение
Масштабируемость, устойчивость к пиковым нагрузкам вещь далеко не второстепенная. От нее зависит успех любого приложения или интернет-магазина. Мудрый совет опытного бизнесмена – «Если вы не растете, вы умираете» в данном случае относится к ресурсам, которые обеспечат работоспособность и выживаемость вашей системы при внезапном наплыве посетителей. О котором, вы, как и все, мечтаете и к которому стремитесь.
Масштабируемость | Computerworld Россия | Издательство «Открытые системы»
Определение
Масштабируемость — это возможность увеличить вычислительную мощность Web-сайта или компьютерной системы (в частности, их способности выполнять больше операций или транзакций за определенный период времени) за счет установки большего числа процессоров или их замены на более мощные.
Бизнес начинается с конкретного набора требований к информационной системе. Однако с ростом компании растет важность вопроса о масштабируемости ее компьютерных систем.
Масштабируемость — вещь хорошая, поскольку означает, что вам не придется начинать с нуля и создавать абсолютно новую информационную систему с новым программным и аппаратным обеспечением. Если у вас есть масштабируемая система, то, скорее всего, вам удастся сохранить то же самое программное обеспечение, попросту нарастив аппаратную часть системы. В самой этой идее нет ничего нового, однако современные реалии, в частност, распространение электронной коммерции, изменили практику реализации — и отношение к ней — масштабируемых компьютерных систем.
Если у вас есть масштабируемая система, то, скорее всего, вам удастся сохранить то же самое программное обеспечение, попросту нарастив аппаратную часть системы. В самой этой идее нет ничего нового, однако современные реалии, в частност, распространение электронной коммерции, изменили практику реализации — и отношение к ней — масштабируемых компьютерных систем.
Вглубь или вширь?
Два термина характеризуют две стратегии масштабирования: масштабирование вглубь или масштабирование вширь.
Масштабирование вглубь — это традиционный подход. Вместо небольшого сервера приобретается более крупный многопроцессорный сервер (или кластер серверов). Если этого недостаточно, возможно, понадобится мэйнфрейм или даже суперкомпьютер.
У этого подхода есть существенный недостаток — он требует неоправданно больших затрат времени и финансовых средств. В современной бизнес-среде, особенно в области электронной коммерции, долгосрочное планирование и итоговая эффективность могут оказаться менее приоритетными, нежели возможность быстро и с разумными затратами приступить к использованию нового приложения. Вследствие этого оказывается более предпочтительным иной подход, который относительно быстр и прост и предусматривает покупку набора недорогих стандартных серверных модулей.
Вследствие этого оказывается более предпочтительным иной подход, который относительно быстр и прост и предусматривает покупку набора недорогих стандартных серверных модулей.
Нельзя утверждать, что какой-либо из этих подходов изначально лучше другого: каждый имеет свои преимущества. И сегодня компании, занимающиеся электронной коммерцией, выбирают прагматические стратегии роста, которые предусматривают масштабирование как вглубь, так и вширь. По мере роста числа транзакций и количества посетителей узлов Web-серверы и серверы приложений масштабируются за счет добавления других небольших серверов, на которых работают многочисленные копии программного обеспечения.
В то же время крупные серверы баз данных масштабируются более медленно и обдуманно путем установки мощных многопроцессорных компьютеров, на которых работает одна копия программного обеспечения сервера баз данных.
Брайан Ричардсон, аналитик компании Meta Group, считает, что масштабирование вширь — наиболее приемлемый способ для Web-серверов и серверов приложений, поскольку нет необходимости, чтобы каждая транзакция обрабатывалась одной и той же копией приложения. Серверы баз данных, однако, лучше работают в том случае, когда используется один экземпляр приложения. Это предотвращает возникновение конфликтов при выполнении транзакций — к примеру, торговая компания не может обещать доставить товар, которого еще нет на складе.
Серверы баз данных, однако, лучше работают в том случае, когда используется один экземпляр приложения. Это предотвращает возникновение конфликтов при выполнении транзакций — к примеру, торговая компания не может обещать доставить товар, которого еще нет на складе.
Ричардсон считает, что «накопительный» подход к масштабированию Web-серверов и приложений с одно- или двухпроцессорными платформами не только прост, но и дешев.
«В данном случае важны не общая стоимость владения и вычислительная эффективность с точки зрения перспектив последующей обработки, — сказал он. — Здесь важнее скорость развертывания системы. Насколько быстро вы сможете приступить к использованию нового приложения? Насколько быстро вы сможете начать обрабатывать транзакции электронной коммерции со своими бизнес-партнерами? Как правило, общая стоимость владения играет второстепенную роль по сравнению с гибкостью и адаптируемостью решения. Нередко куда важнее легко и быстро установить небольшие серверы и сократить срок реализации проекта на полгода».
Время покупать
Уэйн Керночан, аналитик компании Aberdeen Group, согласен с этим мнением.
«Честно говоря, использование множества небольших серверов — это быстрый, но грубый подход, — отметил он. — Он применим с такими Web-приложениями, как электронная почта или служба каталогов, которые просто ?перебрасываются? на другой сервер… Такой подход имеет смысл, когда вы изо всех сил торопитесь начать работу, и отдаленное будущее вас не очень интересует».
Однако Дэвид Фридландер, аналитик компании Giga Information Group, уверен, что «именно за счет масштабирования вглубь, а не вширь вы сможете добиться, чтобы одному экземпляру приложения доставалось больше процессорных ресурсов. Если вы работаете с биржей ценных бумаг или обрабатываете тысячи финансовых транзакций в секунду, вам потребуется такое более мощное процессорное ядро».
«В случае с одним крупным сервером вам не нужно столько внимания уделять сети, так как она находится внутри системы и это намного упрощает администрирование, — добавил Керночан. — Это важно, поскольку наши исследования показывают, что административные затраты с течением времени перекрывают все остальные расходы».
— Это важно, поскольку наши исследования показывают, что административные затраты с течением времени перекрывают все остальные расходы».
Но с точки зрения краткосрочной перспективы расходы на приобретение, а не на поддержку сервера немаловажны для большинства компаний, работающих в области электронной коммерции. Цены на серверы варьируются в весьма широком диапазоне, но восьмипроцессорный компьютер может обойтись компании в два раза дороже, чем двухпроцессорный. Так или иначе, соотношение цен не в пользу более крупного компьютера до тех пор, пока дело ограничивается четырьмя процессорами или пока база данных не станет очень большой.
Стоит помнить о том, что операционные системы могут по-разному поддерживать различные подходы к масштабированию. Так, теоретически операционная система Windows 2000 Datacenter Server, которую готовит к выпуску корпорация Microsoft, в состоянии сделать масштабирование вглубь более приемлемым и более эффективным, нежели масштабирование вширь. Datacenter дает возможность пользователям начать с небольшого сервера и добавлять в систему вплоть до 32 процессоров. Но, по мнению Ричардсона, масштабирование в таком стиле, скорее всего, в конечном итоге обойдется компании дороже, чем масштабирование за счет приобретения небольших серверов.
Но, по мнению Ричардсона, масштабирование в таком стиле, скорее всего, в конечном итоге обойдется компании дороже, чем масштабирование за счет приобретения небольших серверов.
В свете продолжающегося быстрого роста оборотов электронной коммерции весьма вероятно, что каждая стратегия, будь то масштабирование вглубь или вширь, по-прежнему будет находить своих сторонников.
Поделитесь материалом с коллегами и друзьями
Определение масштабируемости
Что такое масштабируемость?
Масштабируемость — это характеристика организации, системы, модели или функции, которая описывает ее способность справляться и хорошо работать в условиях возрастающей или расширяющейся рабочей нагрузки или объема. Хорошо масштабируемая система сможет поддерживать или даже повышать уровень производительности или эффективности, даже если она проверяется все более и более высокими эксплуатационными требованиями.
На финансовых рынках под масштабируемостью понимается способность финансовых институтов справляться с возросшими требованиями рынка; В корпоративной среде масштабируемая компания — это компания, которая может поддерживать или улучшать размер прибыли при увеличении объема продаж.
Ключевые выводы
- Масштабируемость описывает способность системы легко адаптироваться к возросшей рабочей нагрузке или требованиям рынка.
- Масштабируемая компания может получить выгоду от эффекта масштаба и быстро наращивать производство.
- Масштабируемость становится все более актуальной в последние годы, поскольку технологии облегчили привлечение большего числа клиентов и расширение рынков по всему миру.
Понимание масштабируемости
Масштабируемость, будь то в финансовом контексте или в контексте бизнес-стратегии, описывает способность компании расти, не ограничиваясь ее структурой или доступными ресурсами, когда она сталкивается с увеличением производства.Идея масштабируемости становится все более актуальной в последние годы, поскольку технологии облегчили привлечение клиентов, расширение рынков и масштабирование.
Эта концепция тесно связана с термином «эффект масштаба», когда определенные компании могут снизить свои производственные затраты и повысить прибыльность по мере роста и увеличения производства. В ситуациях, когда увеличение производства увеличивает затраты и снижает прибыль, это называется эффектом масштаба.
В ситуациях, когда увеличение производства увеличивает затраты и снижает прибыль, это называется эффектом масштаба.
Пример масштабируемости в техническом секторе
Некоторые технологические компании, например, обладают удивительной способностью быстро масштабироваться, что дает им большие возможности для роста.Причина этого заключается в отсутствии материальных запасов и модели «программное обеспечение как услуга» (SaaS) для производства товаров и услуг. Компаниям с низкими операционными накладными расходами и минимальной нагрузкой на складские помещения и инвентаризацию или вообще без нее не требуется много ресурсов или инфраструктуры для быстрого роста.
Даже компании, не связанные напрямую с технологической отраслью, имеют большую возможность масштабирования за счет использования определенных технологий. Привлечение клиентов, например, с помощью таких инструментов, как цифровая реклама, стало намного проще.
Даже банковские учреждения могут внедрять стратегии цифровой рекламы для увеличения числа подписчиков на услуги онлайн-банкинга, увеличения своей клиентской базы и потенциального дохода. К другим технологиям, которые помогают в масштабировании, относятся трудосберегающие, такие как автоматизированные системы управления складом, используемые крупными розничными торговцами, включая Amazon и Wal-Mart.
К другим технологиям, которые помогают в масштабировании, относятся трудосберегающие, такие как автоматизированные системы управления складом, используемые крупными розничными торговцами, включая Amazon и Wal-Mart.
Особые соображения
По своей сути масштабируемый бизнес — это бизнес, ориентированный на реализацию процессов, ведущих к эффективной работе.Рабочий процесс и структура бизнеса допускают масштабируемость.
У всех масштабируемых компаний есть устоявшаяся группа лидеров, включая руководителей высшего звена, инвесторов и советников, которые обеспечивают стратегию и направление. Масштабируемые компании также имеют единообразную рекламу бренда в своих подразделениях и регионах. Отсутствие контроля над брендом иногда приводит к тому, что компании теряют из виду свою основную ценность, что снижает масштабируемость. Yahoo — тому пример. После того, как компания быстро расширилась, она потеряла из виду свой основной бизнес и потерпела неудачу.
Масштабируемая компания имеет эффективные инструменты для измерения, поэтому весь бизнес можно оценивать и управлять им на каждом уровне. Такое управление приводит к эффективным операциям, описанным выше, и помогает при составлении бюджета капиталовложений.
Такое управление приводит к эффективным операциям, описанным выше, и помогает при составлении бюджета капиталовложений.
Высокая масштабируемость —
Это гостевой пост Пэдди Байерса, соучредителя и технического директора Ably, платформы доставки данных в реальном времени. Вы можете просмотреть исходную статью в блоге Ably.
Пользователи должны знать, что они могут полагаться на предоставляемую им услугу. На практике, поскольку время от времени отдельные элементы неизбежно выходят из строя, это означает, что вы должны иметь возможность продолжать работу, несмотря на эти отказы.
В этой статье мы подробно обсуждаем концепции надежности и отказоустойчивости и объясняем, как платформа Ably спроектирована с использованием отказоустойчивых подходов для обеспечения гарантий надежности.
В качестве основы для этого обсуждения сначала несколько определений:
Надежность
Степень, на которую можно положиться на продукт или услугу.Доступность
Степень доступности продукта или услуги для использования при необходимости. Это часто сводится к обеспечению достаточного резервирования ресурсов со статистически независимыми отказами.Надежность
Степень, в которой продукт или услуга соответствуют своей спецификации при использовании. Это означает, что система, которая не только доступна, но и спроектирована с обширными избыточными мерами, чтобы продолжала работать так, как ожидают ее пользователи .Отказоустойчивость
Способность системы оставаться надежной (как доступной, так и надежной) при наличии сбоев определенных компонентов или подсистем.
 Доступность и Надежность — это формы надежности.
Доступность и Надежность — это формы надежности. Отказоустойчивые системы допускают отказы: они разработаны для смягчения воздействия неблагоприятных обстоятельств и обеспечения надежности системы для конечного пользователя. Методы отказоустойчивости могут использоваться для повышения доступности и надежности.
Методы отказоустойчивости могут использоваться для повышения доступности и надежности.
Доступность можно условно рассматривать как гарантию безотказной работы; Надежность можно рассматривать как качество этого времени безотказной работы, то есть гарантию того, что функциональность и удобство работы пользователей сохранятся максимально эффективно, несмотря на неблагоприятные условия.
Если услуга недоступна для использования в то время, когда она необходима, значит, доступность недостаточна. Если служба доступна, но при ее использовании отличается от ожидаемого поведения, это означает недостаток надежности. Отказоустойчивые подходы к проектированию устраняют эти недостатки, чтобы обеспечить непрерывность как для бизнеса, так и для удобства пользователей.
Доступность, надежность и состояние
В большинстве случаев первичной основой отказоустойчивого проектирования является избыточность : наличие большего количества компонентов или мощности, чем минимальное, необходимое для предоставления услуги. Ключевые вопросы касаются того, какую форму принимает эта избыточность и как ею управлять.
Ключевые вопросы касаются того, какую форму принимает эта избыточность и как ею управлять.
В физическом мире классически существует различие между
- доступность ситуаций, когда допустимо остановить услугу, а затем возобновить ее, например, остановка для замены автомобильной шины; и
- надежность ситуации, когда непрерывность обслуживания имеет важное значение, с постоянно работающими резервными элементами, такими как двигатели самолетов.
Характер требования к непрерывности влияет на способ обеспечения резервной пропускной способности.
В контексте распределенных систем в Ably мы думаем об аналогичном различии между компонентами, которые не имеют состояния , и теми, которые имеют состояние , , соответственно.
Компоненты без сохранения состояния выполняют свои функции без какой-либо зависимости от долгоживущего состояния. Каждый вызов службы может выполняться независимо от любого предыдущего вызова. Отказоустойчивая конструкция этих компонентов сравнительно проста: достаточно ресурсов доступно , чтобы можно было обработать любой отдельный вызов, даже если некоторые ресурсы вышли из строя.
Отказоустойчивая конструкция этих компонентов сравнительно проста: достаточно ресурсов доступно , чтобы можно было обработать любой отдельный вызов, даже если некоторые ресурсы вышли из строя.
Компоненты с отслеживанием состояния имеют внутреннюю зависимость от состояния для предоставления услуг. Наличие состояния неявно связывает вызов службы с прошлыми и будущими вызовами. Суть отказоустойчивости для этих компонентов, как и в случае с двигателями самолета, заключается в возможности обеспечить непрерывность работы, в частности, непрерывность состояния, от которого зависит обслуживание.Это обеспечивает надежность .
В оставшейся части этой статьи мы приведем примеры каждой из этих ситуаций и объясним инженерные проблемы, возникающие при достижении отказоустойчивости на практике.
Само собой разумеющееся отношение к отказу
В отказоустойчивых конструкциях отказы рассматриваются как обычное дело. В крупномасштабных системах предполагается, что отказы компонентов рано или поздно произойдут. Любой отдельный отказ должен рассматриваться как неизбежный, а отказы компонентов в совокупности должны происходить постоянно.
В крупномасштабных системах предполагается, что отказы компонентов рано или поздно произойдут. Любой отдельный отказ должен рассматриваться как неизбежный, а отказы компонентов в совокупности должны происходить постоянно.
В отличие от физического мира, отказы в цифровых системах обычно не двоичны. Классические меры надежности компонентов (например, среднее время наработки на отказ или MTBF) не применяются; услуги ухудшаются по мере отказа. Византийские разломы — классический пример.
Например, системный компонент может работать с перебоями или выдавать вводящие в заблуждение выходные данные. Или вы можете зависеть от внешних партнеров, которые не уведомляют вас о неудаче, пока она не станет серьезной с их стороны, что затруднит вашу работу.
Чтобы быть терпимым к небинарным сбоям, требуется много размышлений, инженерии, а иногда и вмешательства человека. Каждый потенциальный отказ должен быть идентифицирован и классифицирован, а затем должен быть в состоянии быстро устранить или избежать с помощью обширных испытаний и надежных проектных решений. Основная задача при разработке отказоустойчивых систем — это понимание природы отказов и способов их обнаружения и устранения, особенно когда они частичные или периодические, чтобы продолжать предоставлять услуги пользователям максимально эффективно.
Основная задача при разработке отказоустойчивых систем — это понимание природы отказов и способов их обнаружения и устранения, особенно когда они частичные или периодические, чтобы продолжать предоставлять услуги пользователям максимально эффективно.
Услуги без гражданства
Уровни обслуживания, которые не имеют состояния не имеют основного требования для непрерывности обслуживания для любого отдельного компонента. Доступность ресурсов напрямую влияет на доступность уровня в целом. Доступ к дополнительным ресурсам, отказы которых статистически независимы, является ключом к поддержанию работоспособности системы. Везде, где это возможно, уровни не имеют состояния, что является ключевым фактором не только доступности, но и масштабируемости.
Для объектов без состояния достаточно иметь несколько независимо доступных компонентов, чтобы продолжать предоставлять услуги. Без состояния долговечность любого отдельного компонента не является проблемой.
Однако просто иметь дополнительные ресурсы недостаточно: вы также должны эффективно их использовать. У вас должен быть способ определения доступности ресурсов и балансировки нагрузки между избыточными ресурсами.
Таким образом, вам нужно ответить на следующие вопросы:
- Как выжить в разного рода неудачах?
- Какой уровень резервирования возможен?
- Каковы затраты ресурсов и производительности на поддержание этих уровней избыточности?
- Каковы эксплуатационные расходы на управление этими уровнями резервирования?
Последующие компромиссы заключаются в следующем:
- Требования клиентов для достижения высокой доступности
- Операционные расходы бизнеса
- Реальная инженерная практичность, позволяющая сделать это возможным
Избыточные компоненты и, в свою очередь, их зависимости должны быть спроектированы, сконфигурированы и эксплуатироваться таким образом, чтобы гарантировать статистическую независимость любых отказов. Простая математика такова: статистически независимые отказы экспоненциально снижают ваши шансы на катастрофический отказ по мере увеличения уровня избыточности. Если отказы настроены так, чтобы происходить в статистических разрозненных хранилищах, то кумулятивный эффект отсутствует, и вы уменьшаете вероятность полного отказа на целый порядок с каждым дополнительным избыточным ресурсом.
Простая математика такова: статистически независимые отказы экспоненциально снижают ваши шансы на катастрофический отказ по мере увеличения уровня избыточности. Если отказы настроены так, чтобы происходить в статистических разрозненных хранилищах, то кумулятивный эффект отсутствует, и вы уменьшаете вероятность полного отказа на целый порядок с каждым дополнительным избыточным ресурсом.
В Ably, чтобы повысить статистическую независимость отказов, мы размещаем / распределяем емкость в нескольких зонах доступности и в нескольких регионах.Предлагать услуги из нескольких зон доступности в одном регионе относительно просто: AWS позволяет это с минимальными усилиями. Зоны доступности обычно имеют хорошую репутацию независимых отказов, поэтому этот шаг сам по себе обеспечивает наличие достаточной избыточности для поддержки очень высоких уровней доступности.
Однако это еще не все. Недостаточно полагаться на какой-либо конкретный регион по нескольким причинам — иногда несколько зон доступности (AZ) действительно выходят из строя одновременно; иногда могут возникать проблемы с локальным подключением, делающие регион недоступным; а иногда в регионе могут быть просто ограничения емкости, которые не позволяют поддерживать там все службы. В результате мы также способствуем доступности услуг, предоставляя услуги в нескольких регионах. Это лучший способ обеспечить статистическую независимость отказов.
В результате мы также способствуем доступности услуг, предоставляя услуги в нескольких регионах. Это лучший способ обеспечить статистическую независимость отказов.
Установить избыточность, охватывающую несколько регионов, не так просто, как поддерживать несколько зон доступности. Например, не имеет смысла просто иметь балансировщик нагрузки, распределяющий запросы между регионами; сам балансировщик нагрузки существует в каком-то регионе и может стать недоступным.
Вместо этого мы используем комбинацию мер для обеспечения того, чтобы клиентские запросы в любое время могли быть перенаправлены в регион, который считается работоспособным и имеет доступные услуги.Эта маршрутизация предпочтительно должна быть в ближайший регион, но маршрутизация в нелокальные регионы должна быть возможна, когда ближайший регион не может предоставлять услуги.
Сервисы с отслеживанием состояния
В Ably надежность означает непрерывность бизнеса сервисов с отслеживанием состояния, и решить эту проблему значительно сложнее, чем просто доступность.
Службы с отслеживанием состояния имеют внутреннюю зависимость от состояния, которая сохраняется при каждом отдельном вызове службы. Непрерывность этого состояния означает правильность обслуживания, предоставляемого слоем в целом.Это требование непрерывности означает, что отказоустойчивость этих сервисов достигается за счет классического понимания их надежности. Резервирование должно использоваться постоянно, чтобы состояние не потерялось в случае сбоя. При обнаружении и устранении неисправностей необходимо учитывать возможные византийские режимы отказа с помощью механизмов формирования консенсуса.
Самая упрощенная аналогия — с безопасностью самолета. Авиакатастрофа является катастрофой, потому что вы — и ваше государство — находитесь на конкретном самолете ; это тот самолет , который должен обеспечивать бесперебойную работу.Если этого не произойдет, состояние будет потеряно, и вам не будет предоставлена возможность продолжить переход на другой самолет.
Для всего, что зависит от состояния, при выборе альтернативного ресурса требуется возможность продолжить работу с новым ресурсом там, где предыдущий ресурс остановился. Таким образом, состояние является требованием, и в этих случаях одной доступности недостаточно.
В Ably мы предоставляем достаточно резервной мощности для ресурсов без сохранения состояния, чтобы удовлетворить все требования наших клиентов к доступности.Однако для ресурсов с отслеживанием состояния нам нужны не только избыточные ресурсы, но и явные механизмы для использования этой избыточности, чтобы поддерживать наши гарантии обслуживания функциональной непрерывности .
Например, если обработка для определенного канала происходит в конкретном экземпляре в кластере, и этот экземпляр выходит из строя (вынуждая эту роль канала перемещаться), должны быть на месте механизмы, гарантирующие, что все может продолжаться.
Это работает на нескольких уровнях.На одном уровне должен существовать механизм, гарантирующий, что обработка этого канала будет переназначена другому, исправному ресурсу. На другом уровне должна быть уверенность в том, что переназначенный ресурс продолжает работу точно в том месте, где обработка была остановлена в предыдущем месте. Кроме того, каждый из этих механизмов реализован и эксплуатируется с определенным уровнем избыточности, чтобы удовлетворить общие требования к гарантии для услуги.
На другом уровне должна быть уверенность в том, что переназначенный ресурс продолжает работу точно в том месте, где обработка была остановлена в предыдущем месте. Кроме того, каждый из этих механизмов реализован и эксплуатируется с определенным уровнем избыточности, чтобы удовлетворить общие требования к гарантии для услуги.
Эффективность этих механизмов обеспечения непрерывности напрямую влияет на поведение и гарантии этого поведения на границе предоставления услуг.Возьмем одну конкретную проблему в приведенном выше сценарии: для любого данного сообщения вам необходимо с уверенностью знать, завершена ли обработка этого сообщения.
Когда клиент отправляет сообщение в Ably для публикации, а служба принимает сообщение для публикации, она признает эту попытку успешной или неудачной. На данный момент основной вопрос о доступности :
Какую часть времени служба принимает (и затем обрабатывает) сообщение, а не отклоняет его?
Минимальная цель в этом случае — четыре, пять или даже шесть девяток.
Если вы попытаетесь опубликовать, и мы сообщим вам, что мы не смогли этого сделать, то это всего лишь недостаток доступности . Это не очень хорошо, но в итоге вы осознаете ситуацию.
Однако, если мы ответим успешно — «да, мы получили ваше сообщение» — но тогда мы не сможем выполнить всю его последующую обработку, тогда это будет другой вид сбоя. Это нарушение нашей гарантии функционального обслуживания. Это недостаток надежности , и это гораздо более сложная проблема для решения в распределенной системе — для удовлетворения этого требования требуются значительные инженерные усилия и сложность.
Архитектурные подходы для достижения надежности
Ниже приведены две иллюстрации архитектурных подходов, которые мы применяем в Ably для оптимального использования избыточности в нашем ядре обработки сообщений.
Размещение роли с отслеживанием состояния
В общем, горизонтальная масштабируемость достигается за счет распределения работы по масштабируемому кластеру ресурсов обработки. Что касается сущностей, которые выполняют обработку без сохранения состояния, они могут быть распределены по доступным ресурсам с несколькими ограничениями на их размещение: местоположение любой данной операции может быть определено на основе балансировки нагрузки, близости или других соображений оптимизации.
Что касается сущностей, которые выполняют обработку без сохранения состояния, они могут быть распределены по доступным ресурсам с несколькими ограничениями на их размещение: местоположение любой данной операции может быть определено на основе балансировки нагрузки, близости или других соображений оптимизации.
Между тем, в случае операций с отслеживанием состояния и при размещении ролей обработки необходимо учитывать их природу с отслеживанием состояния, чтобы, например, все заинтересованные объекты могли согласовать конкретное расположение любой данной роли.
Конкретным примером является обработка сообщений канала: всякий раз, когда канал активен, ему назначается ресурс, который его обрабатывает. Процесс с отслеживанием состояния позволяет достичь большей производительности: мы знаем больше о сообщении во время обработки, поэтому нам не нужно искать его — мы можем просто обработать его и отправить.
Чтобы распределить все каналы по всем доступным ресурсам как можно более равномерно, мы используем согласованное хеширование, при этом базовая служба обнаружения кластера обеспечивает консенсус как по работоспособности узла, так и по членству в хэшировании.
Достижение консенсуса с помощью последовательного алгоритма размещения в хэш-кольце
Механизм размещения требуется не только для определения начального размещения роли, но также для перемещения роли при возникновении события, такого как отказ узла, которое вызывает перемещение роли.Таким образом, этот механизм динамического размещения является основной функцией, обеспечивающей непрерывность и надежность услуг.
Обнаружить, хэшировать, возобновить
Первым шагом в устранении неисправности является ее обнаружение. Как обсуждалось выше, это классически сложно из-за необходимости достижения почти одновременного консенсуса между распределенными объектами. После обнаружения обновленное состояние хеширования подразумевает новое местоположение этого ресурса, и с этого момента канал и состояние отказавшего ресурса должны возобновиться в новом местоположении с непрерывностью.
Даже если роль завершилась неудачно и в результате произошла потеря состояния, необходимо, чтобы состояние сохранялось в достаточном количестве (и с достаточной избыточностью), чтобы возобновление роли было возможным с непрерывностью. Возобновление с непрерывностью — вот что позволяет сервису быть надежным при наличии такого рода сбоев; состояние каждого сообщения в полете сохраняется при перемещении роли. Если бы мы не смогли этого сделать и просто восстановили бы роль без непрерывности состояния, мы могли бы гарантировать доступность сервиса, но не надежность .
Возобновление с непрерывностью — вот что позволяет сервису быть надежным при наличии такого рода сбоев; состояние каждого сообщения в полете сохраняется при перемещении роли. Если бы мы не смогли этого сделать и просто восстановили бы роль без непрерывности состояния, мы могли бы гарантировать доступность сервиса, но не надежность .
Уровень сохраняемости канала
Когда сообщение публикуется, мы выполняем некоторую обработку, принимаем решение об успехе или неудаче, а затем отвечаем на звонок. Гарантия надежности означает уверенность в том, что после подтверждения сообщения вся последующая передача, подразумеваемая этим, действительно будет иметь место. Это, в свою очередь, означает, что мы можем подтвердить сообщение только тогда, когда мы точно знаем, что оно постоянно сохраняется, с достаточной избыточностью, чтобы впоследствии его нельзя было потерять.
Сначала мы записываем получение сообщения в как минимум в двух разных зонах доступности (AZ). Тогда у нас есть то же требование избыточности нескольких зон доступности для самой последующей обработки. Это ядро уровня сохраняемости в Ably: мы пишем сообщение в несколько мест, а также следим за тем, чтобы процесс его написания был транзакционным. Вы уходите, зная, что сообщение было написано либо неудачно, , либо однозначно удачно . Имея уверенность в этом, можно гарантировать, что в конечном итоге последующая обработка произойдет, даже если будут сбои в ролях, ответственных за эту обработку.
Тогда у нас есть то же требование избыточности нескольких зон доступности для самой последующей обработки. Это ядро уровня сохраняемости в Ably: мы пишем сообщение в несколько мест, а также следим за тем, чтобы процесс его написания был транзакционным. Вы уходите, зная, что сообщение было написано либо неудачно, , либо однозначно удачно . Имея уверенность в этом, можно гарантировать, что в конечном итоге последующая обработка произойдет, даже если будут сбои в ролях, ответственных за эту обработку.
Обеспечение того, чтобы сообщения сохранялись в нескольких зонах доступности, позволяет предположить, что сбои в этих зонах независимы, поэтому одно событие или причина не могут привести к потере данных. Для организации такого размещения требуется оркестровка с учетом зоны доступности, а для обеспечения того, чтобы запись в несколько мест на самом деле была транзакционной, требуется распределенный консенсус на уровне сохраняемости сообщений.
Такое структурирование позволяет нам начать вероятностную количественную оценку уровня уверенности. Сбой службы может возникнуть только в том случае, если имеется сложный сбой, то есть сбой в одной зоне доступности и, прежде чем этот сбой будет исправлен, сбой во второй зоне доступности.
Сбой службы может возникнуть только в том случае, если имеется сложный сбой, то есть сбой в одной зоне доступности и, прежде чем этот сбой будет исправлен, сбой во второй зоне доступности.
В нашей математической модели, когда один узел выходит из строя, мы знаем, сколько времени требуется, чтобы обнаружить и достичь консенсуса в отношении сбоя, и сколько времени потребуется, чтобы впоследствии переместить роль. Зная это вместе с частотой отказов каждой зоны доступности, можно смоделировать вероятность возникновения сложного отказа, который приводит к потере непрерывности состояния.Это основа, на которой мы можем предоставить нашу гарантию надежности в восемь девяток.
Рекомендации по внедрению
Даже если у вас есть теоретический подход к достижению определенного аспекта отказоустойчивости, существует множество практических аспектов и аспектов системной инженерии, которые следует учитывать в более широком контексте системы в целом. Ниже мы приводим несколько примеров. Чтобы продолжить изучение этой темы, прочтите и / или просмотрите наше подробное описание темы «Скрытые проблемы масштабирования распределенных систем — проектирование систем в реальном мире».
Чтобы продолжить изучение этой темы, прочтите и / или просмотрите наше подробное описание темы «Скрытые проблемы масштабирования распределенных систем — проектирование систем в реальном мире».
Формирование консенсуса в глобально распределенных системах
Механизмы, описанные выше, такие как алгоритм размещения ролей, могут быть эффективны только в том случае, если все участвующие объекты согласны с топологией кластера вместе с состоянием и работоспособностью каждого узла.
Это классическая проблема формирования консенсуса, когда члены кластера, которые сами могут потерпеть неудачу, должны согласовать статус одного из своих членов. Протоколы формирования консенсуса, такие как Raft / Paxos, широко известны и имеют серьезные теоретические гарантии, но также имеют практические ограничения с точки зрения масштабируемости и пропускной способности.В частности, они неэффективны в сетях, охватывающих несколько регионов, поскольку их эффективность снижается, если задержка становится слишком высокой при обмене данными между одноранговыми узлами.
Вместо этого наши партнеры используют протокол Gossip, который в конечном итоге является согласованным, отказоустойчивым и может работать в разных регионах. Сплетни используются среди регионов для обмена информацией о топологии, а также для построения карты сети, и этот широкий консенсус по состоянию кластера затем используется в качестве основы для обмена различными деталями в масштабах всего кластера.
Здоровье не двоичное
Классическая теория, которая привела к развитию Paxos и Raft, возникла из признания того, что отказавшие или нездоровые сущности часто не просто падают или перестают реагировать. Вместо этого отказавшие элементы могут демонстрировать частично работающее поведение, такое как отложенные ответы, более высокая частота ошибок или, в принципе, произвольное сбивающее с толку или вводящее в заблуждение поведение (см. Византийский отказ). Эта проблема является повсеместной и распространяется даже на способ взаимодействия клиента со службой.
Когда клиент пытается подключиться к конечной точке в данном регионе, возможно, что этот регион недоступен. Если он полностью недоступен, то это простой сбой, и мы сможем обнаружить это и перенаправить клиента на более зеленые пастбища в рамках инфраструктуры. Но на практике происходит то, что регионы часто могут находиться в частично деградированном состоянии, когда они работают в 900–45 или 900–46 случаях. Это означает, что у самого клиента есть проблема с обработкой сбоя — зная, куда перенаправить для получения обслуживания, и зная, когда повторить попытку получения обслуживания из конечной точки по умолчанию.
Если он полностью недоступен, то это простой сбой, и мы сможем обнаружить это и перенаправить клиента на более зеленые пастбища в рамках инфраструктуры. Но на практике происходит то, что регионы часто могут находиться в частично деградированном состоянии, когда они работают в 900–45 или 900–46 случаях. Это означает, что у самого клиента есть проблема с обработкой сбоя — зная, куда перенаправить для получения обслуживания, и зная, когда повторить попытку получения обслуживания из конечной точки по умолчанию.
Это еще один пример общей проблемы отказоустойчивости: при большом количестве движущихся частей каждая вещь вносит дополнительную сложность. Если эта часть сломается или что-то изменится, как вы достигнете консенсуса относительно существования изменения, природы изменения и последующего плана действий ?
Проблемы с доступностью ресурсов
На очень простом уровне можно обеспечить избыточную емкость, только если требуемые ресурсы доступны.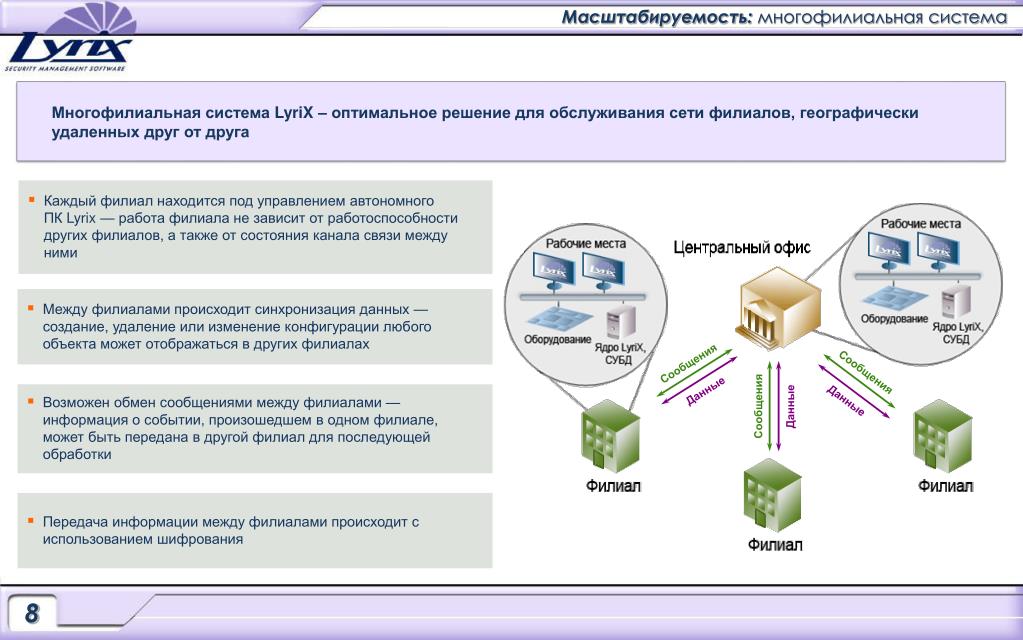 Иногда возникают ситуации, когда ресурсы просто недоступны в тот момент, когда они востребованы в одном регионе, и возникает необходимость переложить спрос в другой регион.
Иногда возникают ситуации, когда ресурсы просто недоступны в тот момент, когда они востребованы в одном регионе, и возникает необходимость переложить спрос в другой регион.
Однако проблема доступности ресурсов также проявляется более сложным образом, когда вы понимаете, что сами механизмы отказоустойчивости требуют ресурсов для работы.
Например, есть механизм для управления перемещением ролей при изменении топологии. Сама эта функция требует ресурсов для работы, таких как ЦП и память затронутых экземпляров.
Но что, если ваш сбой произошел именно из-за того, что у вас закончился процессор или память? Теперь вы пытаетесь справиться с этими сбоями, но для этого вам понадобятся… ЦП и памяти. Это означает, что существует несколько измерений, в которых вам необходимо обеспечить наличие запаса емкости ресурсов, чтобы меры по обеспечению отказоустойчивости могли быть приняты в то время, когда они необходимы.
Проблемы масштабируемости ресурсов
В дополнение к вышеизложенному, речь идет не только о доступности ресурсов, но и о скорости роста спроса на них.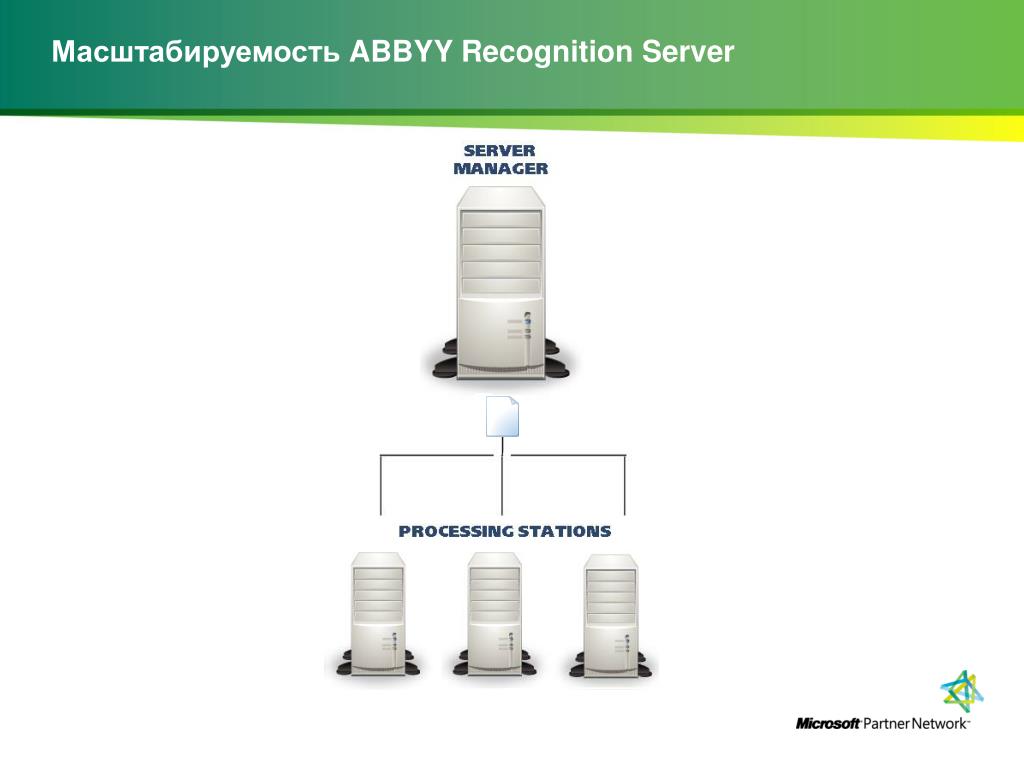 В устойчивом, работоспособном состоянии у вас может быть N, каналов, N, соединений и N сообщений с емкостью N , чтобы справиться со всем этим. Теперь представьте, что для этого кластера из N произошел сбой и последовал сбой. Если объем работы, необходимый для компенсации сбоя, составляет N², то поддержание запаса мощности становится неустойчивым, и единственное доступное средство восстановления — переключение на неповрежденный регион или кластер.
В устойчивом, работоспособном состоянии у вас может быть N, каналов, N, соединений и N сообщений с емкостью N , чтобы справиться со всем этим. Теперь представьте, что для этого кластера из N произошел сбой и последовал сбой. Если объем работы, необходимый для компенсации сбоя, составляет N², то поддержание запаса мощности становится неустойчивым, и единственное доступное средство восстановления — переключение на неповрежденный регион или кластер.
Упрощенные механизмы отказоустойчивости могут демонстрировать такое поведение O ( N² ) или хуже, поэтому подходы необходимо анализировать с учетом этого. Это еще одно напоминание о том, что, хотя что-то может потерпеть неудачу только потому, что оно каким-то образом сломалось, также возможно, что оно может пойти не так, потому что оно имеет непредвиденный масштаб, сложность или другие неустойчивые последствия для ресурсов.
Заключение
Отказоустойчивость — это подход к построению систем, способных противостоять и уменьшать неблагоприятные события и условия эксплуатации, чтобы надежно продолжать предоставлять уровень обслуживания, ожидаемый пользователями системы.
Инжиниринг надежности в физическом мире классически проводит различие между доступностью , и надежностью , , и существуют хорошо понятные формулы для достижения каждой из них за счет отказоустойчивости и избыточности. В Ably мы проводим аналогичное различие в мире систем между компонентами, которые не имеют состояния , и теми, которые имеют состояние , .
Отказоустойчивость для компонентов без сохранения состояния достигается так же, как и для доступности в физическом мире: за счет предоставления избыточных элементов, отказ которых статистически независим.Отказоустойчивость компонентов с отслеживанием состояния можно сравнить с проблемой физической надежности: это гарантия бесперебойного обслуживания. Непрерывность состояния необходима для того, чтобы можно было допустить отказы, сохраняя при этом правильность и непрерывность предоставляемой услуги .
Чтобы быть отказоустойчивой, система должна рассматривать отказы не как исключительные события, а как нечто ожидаемое рутинное.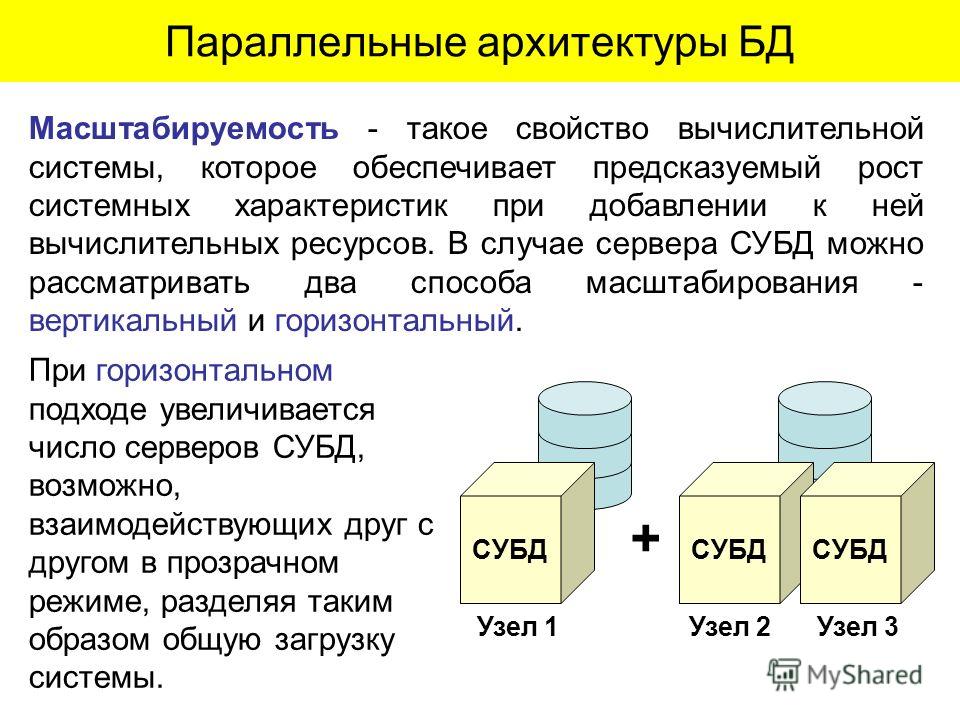 В отличие от теоретических моделей успеха и неудачи, угрозы здоровью системы в реальном мире не являются бинарными и требуют сложных теоретических и практических подходов для смягчения.
В отличие от теоретических моделей успеха и неудачи, угрозы здоровью системы в реальном мире не являются бинарными и требуют сложных теоретических и практических подходов для смягчения.
Служба Ably состоит из нескольких уровней, каждый из которых использует широкий спектр механизмов отказоустойчивости. В частности, мы столкнулись с трудными инженерными проблемами, которые включают, среди прочего, размещение ролей с отслеживанием состояния, обнаружение, хеширование и постепенное возобновление обслуживания. Мы также сформулировали и обеспечиваем гарантию обслуживания на уровне постоянства канала, такую как гарантированная дальнейшая обработка после того, как мы подтверждаем, что мы получили сообщение.
Помимо теоретических подходов, проектирование отказоустойчивых систем связано с множеством реальных проблем системного проектирования. Это включает в себя проблемы доступности и масштабируемости инфраструктуры, а также решение проблем формирования консенсуса и согласования постоянно меняющихся топологий всех кластеров и узлов в глобально распределенной системе с непредсказуемым / трудно обнаруживаемым состоянием работоспособности любого данного объекта на сеть.
Платформа Ably была разработана с самого начала с учетом этих принципов с целью предоставления лучшего в своем классе корпоративного решения.Вот почему мы можем с уверенностью предоставить наши гарантии уровня обслуживания, как доступности, так и надежности — и, следовательно, надежности и отказоустойчивости.
Свяжитесь с нами, чтобы узнать больше об Ably и о том, как мы можем помочь вам обеспечить бесперебойную работу в реальном времени для ваших клиентов.
Избранное за все время —
Вот некоторые из любимых сообщений о HighScalability …
- Все, что в Интернете говорится о масштабируемости статей.
- Объясни облако, как будто я 10
- Архитектура YouTube
- Веселое видео: реляционная база данных против NoSQL Fanbois
- Изобилие рыбной архитектуры
- Программирование, управляемое машинным обучением: новое программирование для нового мира
- Джефф Дин о широкомасштабном глубоком обучении в Google
- Масштабирование Pinterest — от 0 до 10 миллиардов просмотров страниц в месяц за два года
- Архитектура Google
- Давайте построим города-производители для людей-производителей на основе новых ресурсов, таких как пропускная способность, вычислительные ресурсы и производство с атомарной точностью
- Секрет масштабирования: вы не можете линейно масштабировать усилия с помощью емкости
- Netflix: что происходит, когда вы нажимаете Play?
- Построение супер масштабируемых систем: Blade Runner встречает автономные вычисления в окружающем облаке
- : аргументы в пользу создания масштабируемых сервисов с отслеживанием состояния в современную эпоху
- Как Twitter хранит 250 миллионов твитов в день с использованием MySQL
- Масштабирование Twitter: повышение скорости Twitter на 10000 процентов
- Архитектура WhatsApp Facebook купили за 19 миллиардов долларов
- Netflix: что происходит, когда вы нажимаете Play?
- Как в Amazon разрабатывается программное обеспечение?
- Как WhatsApp вырос до почти 500 миллионов пользователей, 11 000 ядер и 70 миллионов сообщений в секунду
- Архитектура Flickr
- Руководство для начинающих по масштабированию до более 11 миллионов пользователей на Amazon AWS
- Как объяснить необоснованную эффективность ИТ?
- Мэтт Каттс: 10 уроков, извлеченных с первых дней существования Google
- Архитектура Amazon
- Джефф Дин о широкомасштабном глубоком обучении в Google
- Руководство для начинающих по масштабированию до более 11 миллионов пользователей на Amazon AWS
- Обновление StackOverflow: 560 млн просмотров страниц в месяц, 25 серверов, и все дело в производительности
- Oculus вызывает разлом, но сделка с Facebook позволит избежать кризиса масштабирования виртуальной реальности
- Как я научился перестать беспокоиться и полюбить Использование большого дискового пространства для масштабирования
- Архитектура переполнения стека
- Как PayPal увеличивал объемы ежедневных операций до миллиардов транзакций, используя всего 8 виртуальных машин
- Как Google выполняет проектирование планетарного масштаба для инфраструктуры планетарного масштаба?
- 7 лет уроков по масштабированию YouTube за 30 минут
- Как работает проверка безопасности Facebook
- Архитектура, которую Twitter использует для работы со 150 миллионами активных пользователей, 300 000 запросов в секунду, пожарным шлангом 22 МБ / с и отправкой твитов менее чем за 5 секунд
- Google о системах, устойчивых к задержкам: создание предсказуемого целого из непредсказуемых частей
- Необычный подход к проектированию баз данных: появление осколка
- Построение супер масштабируемых систем: Blade Runner встречает автономные вычисления в окружающем облаке
- Стартапы создают новую систему мира для ИТ
- Являются ли облачные архитектуры памяти следующим большим шагом?
- Задержка повсюду, и она стоит ваших продаж — как ее сократить
- Как мемристоры все изменят?
- 360-градусный вид всего стека Netflix Архитектура
- DataSift: анализ данных в реальном времени со скоростью 120000 твитов в секунду
- Полезные блоги о масштабируемости
- Обновление архитектуры Pinterest — 18 миллионов посетителей, 10-кратный рост, 12 сотрудников, 410 ТБ данных
- Масштабирование трафика: группа людей по запросу самоуправляемых роботизированных машин, которые автоматически заправляются от дешевых солнечных батарей
- Создание серверной части для социального продукта
- Почему моя слизистая плесень лучше, чем ваш кластер Hadoop
- VoltDB развенчивает шесть городских мифов о SQL и в процессе предоставляет OLTP масштабируемого Интернета
- Каноническая облачная архитектура
- Как запрограммировать компьютер с 10 терабайтами ОЗУ?
- Джастин. Архитектура телевещания в прямом эфире
- Почему Facebook, Digg и Twitter так сложно масштабировать?
- Для чего, черт возьми, вы на самом деле используете NoSQL?
- Как Google изобрел удивительную сеть центров обработки данных, только они могли создать
- Архитектура социальных игр Playfish — 50 миллионов пользователей в месяц и рост
- Обновленный большой список статей об отключении Amazon
- Использование протоколов сплетен для обнаружения сбоев, мониторинга, обмена сообщениями и других полезных вещей
- Сага Etsy: от разрозненности до счастья — миллиарды просмотров страниц в месяц
- Как Twitter хранит 250 миллионов твитов в день с использованием MySQL
- Архитектура Tumblr — 15 миллиардов просмотров страниц в месяц и масштабировать сложнее, чем Twitter
- Пришло время избавиться от модели ОС Linux в облаке?
- Состояние NoSQL в 2012 г.
- Ask HighScalability: решение проблем масштабирования с помощью новостных лент в Redis. Любой совет?
- Хронология Facebook: принесла вам сила денормализации
- Идеальная пятая часть замечаний по масштабируемости
- Архитектура ячеек
- Elements Of Scale: создание и масштабирование платформ данных
- Instagram улучшил производительность своего приложения. Вот как.
- Netflix: разработка, развертывание и поддержка программного обеспечения в соответствии с принципами облака
- Архитектура Instagram: 14 миллионов пользователей, терабайты фотографий, сотни экземпляров, десятки технологий
- Как мы можем построить более сложные сложные системы? Контейнеры, микросервисы и непрерывная доставка.
- Потрясающий масштаб AWS и его значение для будущего облака
- Архитектура Instagram Facebook купили за крутой миллиард долларов
- 10 вариаций шаблонов архитектуры ядра для достижения масштабируемости Обновления архитектуры
- StackExchange — бесперебойная работа, Amazon в 4 раза дороже
- Обеспечьте надежную неограниченную масштабируемость с помощью подвижной машины для пиршества
- Архитектура с тегами — масштабирование до 100 миллионов пользователей, 1000 серверов и 5 миллиардов просмотров страниц
- 17 методов масштабирования поворотного стола. FM и Labmeeting миллионам пользователей
- 5 ядов масштабируемости и 3 противоядия масштабируемости облаков
- Секрет масштабирования: вы не можете линейно масштабировать усилия с помощью емкости
- Обязательно посмотрите: 5 шагов к масштабированию MongoDB (или любой БД) за 8 минут
- Что изменения цен на Google App Engine говорят о будущем веб-архитектуры
- Три возраста Google — пакетная обработка, склад, мгновенная обработка
- Большой список 20 распространенных узких мест
- 10 секретов EBay для масштабирования всей планеты
- Обновление архитектуры Instagram: что нового в Instagram? Стратегия
- : запуск масштабируемого, доступного и дешевого статического сайта на S3 или GitHub Документ
- : Сеть Akamai — 61 000 серверов, 1000 сетей, 70 стран
- LevelDB — быстрая и легкая база данных ключей / значений от авторов MapReduce и BigTable
- Джим Старки создает дивный новый мир, переосмысливая базы данных для облака
- Архитектура Peecho — масштабируемость без лишних затрат
- Google+ построен с использованием инструментов, которые вы тоже можете использовать: Closure, Java Servlets, JavaScript, BigTable, Colossus, Quick Turnaround
- Революция облачной архитектуры
- Секрет 10 миллионов одновременных подключений — проблема в ядре, а не решение
- 11 распространенных случаев использования Интернета, решенных в Redis
- Архитектура TripAdvisor — 40 млн посетителей, 200 млн динамических просмотров страниц, 30 ТБ данных
- 35+ вариантов использования для выбора следующей базы данных NoSQL
- 101 вопрос, который следует задать при рассмотрении базы данных NoSQL
- Удивительный список статей о продвинутых распределенных системах
- Переполнение стека делает медленные страницы в 100 раз быстрее за счет простой настройки SQL
- Heroku Emergency Strategy: система управления инцидентами и 8-часовая ротация операций для свежих мыслей
- 6 способов не масштабировать, которые сделают вас модными, популярными и любимыми венчурными инвесторами
- Стратегия Империи Ацтеков: используйте двойные трубы в акведуке для обеспечения высокой доступности
- Убил ли стек Microsoft MySpace?
- Новая система аналитики Facebook в реальном времени: HBase обрабатывает 20 миллиардов событий в день
- 6 уроков из Dropbox — миллион файлов сохраняется каждые 15 минут
- Этому материалу не учат, вы узнаете его по крупицам, решая каждую проблему.
- Станет ли Node.Js частью стека? SimpleGeo говорит, что да.
- Совет от Google Pro: используйте предварительные вычисления, чтобы выбрать лучший дизайн
- Netflix: постоянное тестирование отказавшими серверами с помощью Chaos Monkey
- 7 шаблонов проектирования для почти бесконечной масштабируемости
- Для чего, черт возьми, вы на самом деле используете NoSQL?
- Потрясающий масштаб AWS и его значение для будущего облака
- GPU против CPU Smackdown: рост архитектур, ориентированных на пропускную способность
- 8 широко используемых шаблонов проектирования масштабируемых систем
- Отличное вводное видео о масштабируемости от Harvard Computer Science
- Новая система обмена сообщениями Facebook в реальном времени: HBase будет хранить более 135 миллиардов сообщений в месяц
- Facebook со скоростью 13 миллионов запросов в секунду рекомендует: минимизировать дисперсию запросов
- Machine VM + Cloud API — переписывание облака с нуля
- 10 золотых принципов создания успешных мобильных / веб-приложений
- Проблемы с Sharding — чему мы можем научиться из инцидента с Foursquare?
- Google Colossus выполняет поиск в реальном времени, выгружая MapReduce
- 6 способов убить ваши серверы — научимся масштабировать на сложном уровне
- Misco: платформа MapReduce для мобильных систем — начало окружающего облака?
- Масштабирование инфраструктуры AWS — инструменты и шаблоны
- Vertical Scaling Ascendant — Как твердотельные накопители меняют архитектуру?
- Подумайте о задержке как о псевдопостоянном разделе сети
- 7 стратегий масштабирования, которые используют Facebook для роста до 500 миллионов пользователей
- Как мы можем стимулировать движение исследований из башни из слоновой кости в производство?
- Подсчет больших данных: как подсчитать миллиард различных объектов, используя только 1. 5 КБ памяти
- Google: укрощение длинного хвоста задержки — когда больше машин дает худшие результаты
- Программирование «Просить прощения» — или как мы запрограммируем 1000 ядер
- Грейс Хоппер Программистам: помните о наносекундах!
- Анатомия технологии поиска: база данных NoSQL Blekko
- Анатомия поисковых технологий: сканирование с использованием комбинаторов
- C для вычислений — Google Compute Engine (GCE)
- Неортодоксальный подход к проектированию баз данных: появление осколка
- 10 золотых принципов создания успешных мобильных / веб-приложений
- Производительность распределенных структур данных, работающих в «согласованной с кешем» сетке данных в памяти
- Архитектура MemSQL — Быстрая (MVCC, InMem, LockFree, CodeGen) и знакомая (SQL)
- Призматическая архитектура — использование машинного обучения в социальных сетях для определения того, что следует читать в Интернете
- Изменение архитектуры: новые сети центров обработки данных сделают ваш код и данные бесплатными
- Архитектура MemSQL — Быстрая (MVCC, InMem, LockFree, CodeGen) и знакомая (SQL)
- Призматическая архитектура — использование машинного обучения в социальных сетях для определения того, что следует читать в Интернете
- Скрытая история: последний пик трансконтинентальной железной дороги был ранней версией Интернета вещей
- Ваш генератор нагрузки, вероятно, лжет вам — примите красную таблетку и узнайте, почему
- Чему нас научит удивительная гонка на Южный полюс о стартапах?
- Если вы программируете сотовый телефон как сервер, вы делаете это неправильно
- Vertical Scaling Ascendant — Как твердотельные накопители меняют архитектуру?
- 10 золотых принципов создания успешных мобильных / веб-приложений
- Умные способы, которыми Chrome скрывает задержку, предугадывая все ваши потребности
- Эпическое обновление TripAdvisor: почему бы не работать в облаке? Великий эксперимент.
- Самое удивительное открытие Google Spanner: NoSQL отсутствует, а NewSQL находится в
- Рецепт 10 ингредиентов Русса для производства 1 миллиона транзакций в секунду на оборудовании стоимостью 5 тысяч долларов
- Sharding The Hibernate Way
- Мать всех дебатов о нормализации базы данных о кодировании ужасов
- Постоянно записывать все
- Секрет масштабирования № 2: денормализация вашего пути к скорости и прибыли Стратегия
- : масштабирование по диагонали — не забудьте масштабировать и увеличивать Документ
- : О разработке и развертывании служб Интернет-масштаба Стратегия
- : три метода преодоления скачков трафика за счет быстрого масштабирования вашего сайта
- ZooKeeper — надежная масштабируемая распределенная система координации
- GridGain: одна вычислительная сеть, множество сетей данных
- Масштабирование искоренения спама с помощью целенаправленных игр: Die Spammer Die!
- Google AppEngine — второй взгляд
- Облачное программирование напрямую направляет распределение затрат на разработку программного обеспечения
- Бумага: конец архитектурной эры (время для полного переписывания)
- В какой-то момент стоимость серверов превышает затраты на программистов
- Бросьте КИСЛОТУ и подумайте о данных
- Как добиться успеха в планировании мощностей, не прилагая особых усилий: интервью с Джоном Олспоу из Flickr о его новой книге
- Десять уроков первого года работы GitHub в 2008 году
- Как Google обслуживает данные из нескольких центров обработки данных
- Стратегия: разбить кучу собак Memcache
- Создание масштабируемых систем с использованием данных в качестве составного материала
- MySQL и Memcached: конец эпохи?
- Семь признаков, что вам может понадобиться база данных NoSQL
- 7 уроков, извлеченных при создании Reddit до 270 миллионов просмотров страниц в месяц
- Как мы можем стимулировать движение исследований из башни из слоновой кости в производство?
- 6 способов убить ваши серверы — научимся масштабировать на сложном уровне
- Machine VM + Cloud API — переписывание облака с нуля
- Heroku Emergency Strategy: система управления инцидентами и 8-часовая ротация операций для свежих мыслей
- 6 способов не масштабировать, которые сделают вас модными, популярными и любимыми венчурными инвесторами
- Google+ построен с использованием инструментов, которые вы тоже можете использовать: Closure, Java Servlets, JavaScript, BigTable, Colossus, Quick Turnaround
- Шесть горьких уроков о масштабировании системы на миллион пользователей
- 20 крупнейших узких мест Шона Халла, которые снижают и замедляют масштабируемость
- Как Twitter хранит 250 миллионов твитов в день с использованием MySQL
- Устойчивость — это новая норма — подробный взгляд на то, что это значит, и как ее реализовать
- Переключите базы данных на флэш-память. Сейчас же. Или вы делаете это неправильно.
- Ask HS: как будут выглядеть программирование и архитектура в 2020 году?
- Обеспечение отказоустойчивости будет таким же 2013
- Pinterest снижает затраты с 54 до 20 долларов в час за счет автоматического отключения систем
- Правила Роберта Скобла для успешного масштабирования стартапов
- Что, если бы машины арендовали, как мы нанимаем программистов?
- Как Facebook делает мобильную работу в масштабе для всех телефонов, на всех экранах и во всех сетях
- Четыре мета-секрета масштабирования в Facebook
- Facebook со скоростью 13 миллионов запросов в секунду рекомендует: минимизировать дисперсию запросов
- Google: укрощение длинного хвоста задержки — когда больше машин дает худшие результаты
- Стратегия Google: древовидное распределение запросов и ответов
- AppBackplane — платформа для поддержки нескольких архитектур приложений
- Меняющееся лицо масштаба — обратная сторона масштабирования в эпоху контекста
- Помимо потоков и обратных вызовов — плюсы и минусы архитектуры приложения
- 42 проблемы с монстрами, которые атакуют по мере увеличения нагрузки
- Когда вся программа представляет собой график — Библиотека сантехники Prismatic
- Лучшее кеширование браузера важнее, чем отсутствие JavaScript или быстрые сети для производительности HTTP
- Архитектура DuckDuckGo — 1 миллион глубоких поисков в день и растет
- Еще числа, которые должен знать каждый выдающийся программист
- Чему нас научит удивительная гонка на Южный полюс о стартапах?
- 100 уроков без проклятия от Гордона Рамзи по созданию отличного программного обеспечения
- Как создать сотую культуру разработки программного обеспечения обезьяны?
- Использование облачных вычислений в Yelp — 102 миллиона посетителей в месяц и 39 миллионов отзывов
- Разрушая 4 современных мифа об оборудовании: действительно ли память, жесткие и твердотельные диски — произвольный доступ?
- 10 смертных грехов против масштабируемости
- Это не моя проблема — я их сдам
- 100 уроков без проклятия от Гордона Рамзи по созданию отличного программного обеспечения
- Архитектура Salesforce — как они справляются 1. 3 миллиарда транзакций в день
- Масштабирование почтового ящика — от 0 до одного миллиона пользователей за 6 недель и 100 миллионов сообщений в день
- Архитектура Cinchcast — производство 1500 часов аудио каждый день
- Архитектура StubHub: удивительная сложность крупнейшего в мире рынка билетов
- IDoneThis — масштабирование почтового приложения с нуля
- Архитектура ESPN в масштабе — скорость 100 000 духовых-ядер в секунду
- Одна история жизни, рассказанная в очередях
- Как на самом деле пакетные запросы могут сократить задержку?
- Как Google поддерживает Интернет вместе с эксабайтами других данных
- 10 вещей, за которыми Bitly следовало следить
- Как Next Big Sound отслеживает более триллиона воспроизведений, лайков и многого другого с помощью системы контроля версий для данных Hadoop
- Как бы вы построили следующий Интернет? Гагары, дроны, вертолеты, спутники или что-то еще?
- 8 способов, которыми Stardog сделал свою базу данных безумно масштабируемой
- Архитектура NYTimes: нет головы, нет мастера, нет единой точки отказа
- Под Сноуденом Light Выбор архитектуры программного обеспечения становится мрачным
- Как HipChat сохраняет и индексирует миллиарды сообщений с помощью ElasticSearch и Redis
- То, что происходит, пока ваш мозг спит, удивительно похоже на то, как компьютеры остаются в здравом уме
- 22 рекомендации по созданию эффективного веб-программного обеспечения с высоким трафиком
- Как на самом деле пакетные запросы могут сократить задержку?
- Развитие архитектуры Bazaarvoice до 500 миллионов уникальных пользователей в месяц
- Одна история жизни, рассказанная в очередях
- Скрытая история: последний пик трансконтинентальной железной дороги был ранней версией Интернета вещей
- Мы наконец-то решили проблему 10K — на этот раз для управления серверами с серверами 2000x, управляемыми с помощью системного администратора
- Google утверждает, что цены на облачные услуги будут соответствовать закону Мура: все ли мы сейчас арендаторы?
- 10 вещей, которые следует знать об AWS
- Масштабируемый компьютер FireBox Warehouse в 2020 году будет иметь 1K сокетов, 100K ядер, 100PB NV RAM и сеть 4Pb / S
- Архитектура ESPN в масштабе — скорость 100000 духовых-ядер в секунду
- Санджай Гемават из Google О том, что сделало Google Google и большой карьерный совет в области больших данных
- Закон Литтла, масштабируемость и отказоустойчивость: ОС — ваше узкое место. Что ты можешь сделать?
- Как Google поддерживает Интернет вместе с эксабайтами других данных
- Вычислительные архитектуры планетарного масштаба для электронной торговли и как алгоритмы формируют наш мир Документ
- : Специализация сетевого стека для повышения производительности
- Как архитектура AOL.Com выросла до уровня доступности 99,999%, 8 миллионов посетителей в день и 200 000 запросов в секунду
- 5 советов по масштабированию баз данных NoSQL: не доверяйте предположениям
- Закон Литтла, масштабируемость и отказоустойчивость: ОС — ваше узкое место.Что ты можешь сделать?
- Вот 1300-летнее решение повышения устойчивости — восстановление, восстановление, восстановление
- Вот почему Microsoft выиграла. И почему они проиграли. Микросервисы
- — не бесплатный обед! Обновление
- на Disqus: все еще о реальном времени, но Go уничтожает Python
- 10 ошибок кэширования при блокировке программ
- Bitly: извлеченные уроки по созданию распределенной системы, обрабатывающей 6 миллиардов кликов в месяц
- 9 принципов высокоэффективных программ
- Как Twitter использует Redis для масштабирования — 105 ТБ ОЗУ, 39 млн запросов в секунду, более 10 000 экземпляров
- Все правильно: взгляд на централизованные и децентрализованные системы глазами мгновенного воспроизведения
- 10 стандартных настроек сервера для вашего веб-приложения
- Стратегия: измените проблему
- Давайте построим города-производители для людей-производителей на основе новых ресурсов, таких как пропускная способность, вычислительные ресурсы и производство с атомарной точностью
- Простой способ создания растущей архитектуры стартапа с использованием HAProxy, PHP, Redis и MySQL для обработки 1 миллиарда запросов в неделю
- Великие микросервисы против монолитных приложений Twitter Melee
- Обновление StackOverflow: 560 млн просмотров страниц в месяц, 25 серверов, и все дело в производительности
- Секрет масштабирования: вы не можете линейно масштабировать усилия с помощью емкости
- 10 стандартных настроек сервера для вашего веб-приложения
- Все сотрудники должны быть ограничены только своими способностями, а не отсутствием ресурсов
- Большая проблема — средние данные
- The Machine: новый масштабируемый компьютер HP на базе мемристоров для центров обработки данных — все еще меняет
- Сделайте любую платформу менее отстойной с помощью этих 10 проницательных уроков
- Мы оставляем на столе 3–4-кратную производительность только из-за конфигурации
- Aeron: действительно ли нам нужна еще одна система обмена сообщениями?
- Facebook Mobile Drops Pull for Push-Based Snapshot + Delta Model
- Как League Of Legends увеличила чат до 70 миллионов игроков — для этого нужно много миньонов
- Это не моя проблема — я их сдам
- Instagram улучшил производительность своего приложения. Вот как
- Спасение аутсорсингового проекта от краха: 8 обнаруженных проблем и 8 извлеченных уроков Архитектура
- Vinted: поддержание стабильности загруженного портала за счет развертывания нескольких сотен раз в день
- Мэтт Каттс: 10 уроков, извлеченных с первых дней существования Google Бумага
- : неизменность меняет все Пэт Хелланд
- Учитесь на моей боли — 5 уроков по быстрому масштабированию из приключений Элло
- Полное руководство: 5 методов отладки производственных серверов в масштабе
- Фон Нейман дал нам один совет: ничего не создавать.
- Линус: «Будущее за параллельными вычислениями» — пустяк.
- Масштабируемость как услуга Документ
- : управление крупномасштабным кластером в Google с помощью Borg
- Большая проблема — средние данные
- Многопоточное программирование действительно стало для собак
- The Machine: новый масштабируемый компьютер HP на базе мемристоров для центров обработки данных — все еще меняет
- Все сотрудники должны быть ограничены только их способностями, а не отсутствием ресурсов.
- Архитектура Auth0 — работа в нескольких облачных провайдерах и регионах
- Сделайте любую платформу менее отстойной с помощью этих 10 проницательных уроков
- Черная магия систематического уменьшения джиттера ОС Linux
- 6 способов победить приближающуюся армию роботов
- Как мы масштабируем серверные системы VividCortex
- Семь самых отвратительных антипаттернов в микросервисах
- HappyPancake: ретроспектива построения простой и масштабируемой основы
- Конвергенция, которая меняет все: гравитация данных + контейнеры + микросервисы
- AppLovin: маркетинг для мобильных потребителей во всем мире путем обработки 30 миллиардов запросов в день
- Увеличение размера Ким Кардашьян до 100 миллионов просмотров страниц
- Спасение аутсорсингового проекта от краха: 8 обнаруженных проблем и 8 извлеченных уроков Архитектура
- Vinted: поддержание стабильности загруженного портала за счет развертывания нескольких сотен раз в день
- Как отладка похожа на поиск серийных убийц
- Дорога ярости Algolia к всемирному API, часть 3
- Создание серверной части для социального продукта
- Это. Только. Этот.
- 64 Сеть, что можно и нельзя делать для игровых движков. Часть IIIa: на стороне сервера
- Почему моя капля воды лучше, чем ваш кластер Hadoop
- Как Autodesk реализовал масштабируемую обработку событий на Mesos
- Хотите IoT? Вот как крупная коммунальная компания США собирает данные о мощности с более чем 5,5 миллионов счетчиков
- Как Uber масштабирует свою рыночную платформу реального времени
- Стимуляторы торговли и очень старая идея повышения вовлеченности пользователей
- Создание глобально распределенных критически важных приложений: уроки из окопов, часть 2
- 7 стратегий для 10-кратных преобразований
- Спросите HighScalability: выберите асинхронный сервер приложений или несколько серверов блокировки?
- Как Facebook сообщает вашим друзьям, что вы в безопасности в случае бедствия менее чем за пять минут
- Как новые технологии памяти повлияют на базы данных в памяти?
- Uber идет нестандартно: использование телефонов с драйверами в качестве резервного центра обработки данных
- 5 уроков и 8 изменений в отрасли за 5 лет, как технический директор Etsy
- Как Uber масштабирует свою рыночную платформу реального времени
- Как Shopify весы для обработки флэш-продаж от Канье Уэста и Суперкубка
- Какие идеи в IT должны умереть?
- 5 уроков за 5 лет построения Instagram Сегмент
- : восстановление инфраструктуры с помощью Docker, ECS и Terraform
- Глубокие уроки от Google и EBay по построению экосистем микросервисов
- Как влияет использование задержки Docker?
- Бессерверный запуск — долой серверы!
- Злоба, глупость или невнимание? Использование обзоров кода для поиска бэкдоров
- Переход Google от единого центра обработки данных к отказоустойчивому к собственной многосетевой архитектуре
- Как создать интеграцию вашей системы управления недвижимостью с использованием микросервисов
- Давайте пожертвуем наши органы и неиспользуемые облачные циклы науке
- Уроки, извлеченные из масштабирования Uber до 2000 инженеров, 1000 сервисов и 8000 репозиториев Git
- Как Uber управляет миллионом операций записи в секунду, используя Mesos и Cassandra в нескольких центрах обработки данных
- Архитектура клуба для бритья за доллар Unilever купила за 1 миллиард долларов Создание кода
- : внутреннее святилище производительности базы данных
- «Кошки-мышки» о внедрении защиты от спама для почты. Электронная почта Ru Group и что с этим делать Tarantool
- Архитектура Always On — Выход за рамки устаревшего аварийного восстановления
- Как Facebook транслирует прямые трансляции для 800 000 одновременных зрителей
- Как Twitter обрабатывает 3000 изображений в секунду
- Гигантская экономика нарушает социальное обеспечение
- Путешествие по тому, как Zapier автоматизирует миллиарды задач автоматизации рабочих процессов
- Облачное программирование напрямую направляет распределение затрат на разработку программного обеспечения
- Что изменения цен на Google App Engine говорят о будущем веб-архитектуры
- Совет от Google Pro: используйте предварительные вычисления, чтобы выбрать лучший дизайн
- Стратегия Google: древовидное распределение запросов и ответов
- Этому материалу не учат, вы узнаете его по крупицам, решая каждую проблему. Стратегия
- : резервное копирование на диск для скорости, резервное копирование на ленту для сохранения бекона, просто спросите Google
- Три возраста Google — пакетная обработка, склад, мгновенная обработка
- Подсчет больших данных: как подсчитать миллиард различных объектов, используя всего 1,5 КБ памяти
- Результаты поиска Google: централизованное управление, распределенные архитектуры данных работают лучше, чем полностью децентрализованные архитектуры
- Facebook: пример канонической архитектуры для масштабирования миллиардов сообщений
- Каноническая облачная архитектура
- Как я научился перестать беспокоиться и полюбить, используя много места на диске для масштабирования
- Руководство для начинающих по масштабированию до более 11 миллионов пользователей на Amazon AWS
- Уроки, извлеченные из масштабирования Uber до 2000 инженеров, 1000 сервисов и 8000 репозиториев Git
- Великие микросервисы против монолитных приложений Twitter Melee
- Джастин. Архитектура телевещания в прямом эфире
- Вечная экономия на внутреннем спотовом рынке Netflix
- Во что вы верите сейчас, когда не делали этого пять лет назад? Централизованные победы. Децентрализованные убытки.
- Как бы вы построили следующий Интернет? Гагары, дроны, вертолеты, спутники или что-то еще?
- Программирование, управляемое машинным обучением: новое программирование для нового мира
- Архитектура Always On — Выход за рамки устаревшего аварийного восстановления
- Как вы объясните необоснованную эффективность облачной безопасности?
- Как Google выполняет проектирование планетарного масштаба для инфраструктуры планетарного масштаба?
- Стратегия: разбить кучу собак Memcache
- Стратегия Google и Netflix: используйте частичные ответы для уменьшения размера запросов
- Вот 1300-летнее решение повышения устойчивости — восстановление, восстановление, восстановление
- Архитектура Tumblr, которую Yahoo купила за крутой миллиард долларов
 Архитектура телевещания в прямом эфире
Архитектура телевещания в прямом эфире Любой совет?
Любой совет? FM и Labmeeting миллионам пользователей
FM и Labmeeting миллионам пользователей
 5 КБ памяти
5 КБ памяти
 Сейчас же. Или вы делаете это неправильно.
Сейчас же. Или вы делаете это неправильно.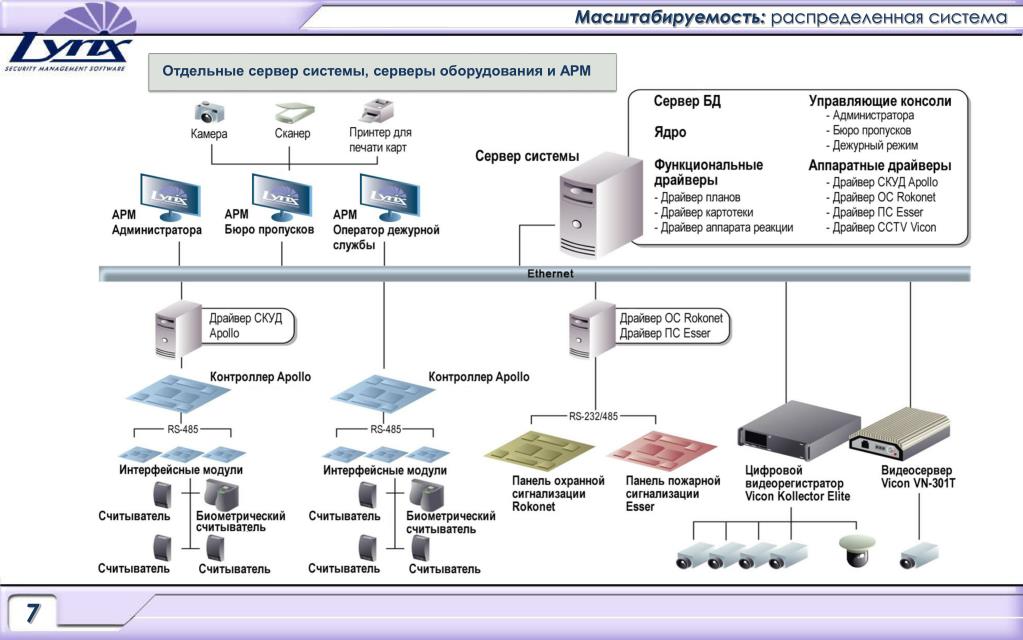 3 миллиарда транзакций в день
3 миллиарда транзакций в день Что ты можешь сделать?
Что ты можешь сделать? Вот как
Вот как
.png) Только. Этот.
Только. Этот. Электронная почта Ru Group и что с этим делать Tarantool
Электронная почта Ru Group и что с этим делать Tarantool Архитектура телевещания в прямом эфире
Архитектура телевещания в прямом эфиреСообщения, обучающие основам
Всего сообщений —
заявок по категориям
Щелкните категорию ниже, чтобы просмотреть список всех записей в этой категории.
записей по неделям
Щелкните неделю ниже, чтобы просмотреть список статей, опубликованных за эту неделю.
- 14 февраля 2021 — 20 февраля 2021 (3)
- 31 января 2021 — 6 февраля 2021 (2)
- 24 января 2021 — 30 января 2021 (1)
- 3 января 2021 — январь 9, 2021 (1)
- 20 декабря 2020 г. — 26 декабря 2020 г. (2)
- 13 декабря 2020 г. — 19 декабря 2020 г. (1)
- 6 декабря 2020 г. — 12 декабря 2020 г. (1)
- 22 ноября 2020 г. — 28 ноября 2020 г. (1)
- 8 ноября 2020 г. — 14 ноября 2020 г. (1)
- 1 ноября 2020 г. — 7 ноября 2020 г. (2)
- 11 октября 2020 г. — 17 октября 2020 (1)
- 27 сентября 2020 г. — 3 октября 2020 г. (1)
- 20 сентября 2020 г. — 26 сентября 2020 г. (2)
- 13 сентября 2020 г. — 19 сентября 2020 г. (3)
- 30 августа , 2020 — 5 сентября 2020 г. (2)
- 2 августа 2020 г. — 8 августа 2020 г. (1)
- 26 июля 2020 г. — 1 августа 2020 г. (1)
- 5 июля 2020 г. — 11 июля 2020 г. ( 1) 90 011 21 июня 2020 г. — 27 июня 2020 г. (1)
- 14 июня 2020 г. — 20 июня 2020 г. (1)
- 7 июня 2020 г. — 13 июня 2020 г. (1)
- 24 мая 2020 г. — 30 мая , 2020 (1)
- 10 мая 2020 г. — 16 мая 2020 г. (4)
- 3 мая 2020 г. — 9 мая 2020 г. (1)
- 26 апреля 2020 г. — 2 мая 2020 г. (2)
- апрель 12, 2020 — 18 апреля, 2020 (2)
- 5 апреля 2020 — 11 апреля 2020 (2)
- 29 марта 2020 — 4 апреля 2020 (1)
- 22 марта 2020 — 28 марта 2020 (2)
- 15 марта 2020 г. — 21 марта 2020 г. (1)
- 8 марта 2020 г. — 14 марта 2020 г. (1)
- 1 марта 2020 г. — 7 марта 2020 г. (1)
- 23 февраля, 2020 — 29 февраля 2020 г. (2)
- 16 февраля 2020 г. — 22 февраля 2020 г. (3)
- 9 февраля 2020 г. — 15 февраля 2020 г. (2)
- 2 февраля 2020 г. — 8 февраля 2020 г. (2 )
- 19 января 2020 г. — 25 января 2020 г. (3)
- 5 января 2020 г. — 11, 2 января 020 (3)
- 8 декабря 2019 — 14 декабря 2019 (1)
- 1 декабря 2019 — 7 декабря 2019 (1)
- 24 ноября 2019 — 30 ноября 2019 (1)
- 10 ноября , 2019 — 16 ноября 2019 г. (2)
- 27 октября 2019 г. — 2 ноября 2019 г. (3)
- 20 октября 2019 г. — 26 октября 2019 г. (1)
- 13 октября 2019 г. — 19 октября 2019 г. ( 2)
- 6 октября 2019 г. — 12 октября 2019 г. (1)
- 29 сентября 2019 г. — 5 октября 2019 г. (3)
- 22 сентября 2019 г. — 28 сентября 2019 г. (1)
- 15 сентября 2019 г. — 21 сентября 2019 г. (3)
- 1 сентября 2019 г. — 7 сентября 2019 г. (3)
- 18 августа 2019 г. — 24 августа 2019 г. (2)
- 11 августа 2019 г. — 17 августа 2019 г. (1)
- 4 августа 2019 — 10 августа 2019 (1)
- 28 июля 2019 — 3 августа 2019 (1)
- 21 июля 2019 — 27 июля 2019 (1)
- 14 июля 2019 — июль 20, 2019 (2) 90 011 7 июля 2019 г.
- 23 июня 2019 г. — 29 июня 2019 г. (2)
- 2 июня 2019 г. — 8 июня 2019 г. (1)
- 12 мая 2019 г. — 18 мая , 2019 (2)
- 5 мая 2019 г. — 11 мая 2019 г. (1)
- 28 апреля 2019 г. — 4 мая 2019 г. (1)
- 21 апреля 2019 г. — 27 апреля 2019 г. (1)
- апрель 14, 2019 — 20 апреля 2019 (3)
- 7 апреля 2019 — 13 апреля 2019 (3)
- 31 марта 2019 — 6 апреля 2019 (2)
- 24 марта 2019 — 30 марта 2019 (1)
- 17 марта 2019 г. — 23 марта 2019 г. (2)
- 10 марта 2019 г. — 16 марта 2019 г. (1)
- 3 марта 2019 г. — 9 марта 2019 г. (4)
- 24 февраля, 2019 — 2 марта 2019 г. (3)
- 17 февраля 2019 г. — 23 февраля 2019 г. (3)
- 10 февраля 2019 г. — 16 февраля 2019 г. (1)
- 3 февраля 2019 г. — 9 февраля 2019 г. (3 )
- 27 января 2019 г. — 2 февраля 2019 г. (2)
- 20 января 2019 г. — 26 января, г. 2019 (1)
- 13 января 2019 — 19 января 2019 (2)
- 6 января 2019 — 12 января 2019 (3)
- 30 декабря 2018 — 5 января 2019 (2)
- 16 декабря , 2018 — 22 декабря 2018 (2)
- 9 декабря 2018 — 15 декабря 2018 (2)
- 2 декабря 2018 — 8 декабря 2018 (3)
- 25 ноября 2018 — 1 декабря 2018 ( 1)
- 18 ноября 2018 — 24 ноября 2018 (1)
- 11 ноября 2018 — 17 ноября 2018 (3)
- 4 ноября 2018 — 10 ноября 2018 (2)
- 28 октября 2018 — 3 ноября 2018 г. (2)
- 21 октября 2018 г. — 27 октября 2018 г. (1)
- 14 октября 2018 г. — 20 октября 2018 г. (1)
- 7 октября 2018 г. — 13 октября 2018 г. (1)
- 30 сентября 2018 г. — 6 октября 2018 г. (2)
- 23 сентября 2018 г. — 29 сентября 2018 г. (1)
- 16 сентября 2018 г. — 22 сентября 2018 г. (3)
- 9 сентября 2018 г. — сентябрь 15 января 2018 г. (2)
- 2 сентября 2018 г. — 8 сентября 2018 г. (3)
- 26 августа 2018 г. — 1 сентября 2018 г. (2)
- 19 августа 2018 г. — 25 августа 2018 г. (3)
- 12 августа 2018 — 18 августа 2018 (2)
- 5 августа 2018 — 11 августа 2018 (3)
- 29 июля 2018 — 4 августа 2018 (1)
- 22 июля 2018 — 28 июля , 2018 (2)
- 15 июля 2018 — 21 июля 2018 (1)
- 8 июля 2018 — 14 июля 2018 (2)
- 1 июля 2018 — 7 июля 2018 (2)
- июнь 24, 2018 — 30 июня 2018 г. (1)
- 17 июня 2018 г. — 23 июня 2018 г. (3)
- 10 июня 2018 г. — 16 июня 2018 г. (1)
- 3 июня 2018 г. — 9 июня 2018 г. (2)
- 29 апреля 2018 г. — 5 мая 2018 г. (1)
- 22 апреля 2018 г. — 28 апреля 2018 г. (5)
- 15 апреля 2018 г. — 21 апреля 2018 г. (2)
- 8 апреля, 2018 — 14 апреля 2018 г. (3)
- 1 апреля 2018 г. — 7 апреля 2018 г. (3)
- 25 марта, 2018 — 31 марта 2018 (2)
- 11 марта 2018 — 17 марта 2018 (2)
- 4 марта 2018 — 10 марта 2018 (1)
- 25 февраля 2018 — 3 марта 2018 (2 )
- 18 февраля 2018 г. — 24 февраля 2018 г. (2)
- 11 февраля 2018 г. — 17 февраля 2018 г. (2)
- 4 февраля 2018 г. — 10 февраля 2018 г. (1)
- 28 января 2018 г. — 3 февраля 2018 г. (4)
- 14 января 2018 г. — 20 января 2018 г. (3)
- 7 января 2018 г. — 13 января 2018 г. (2)
- 31 декабря 2017 г. — 6 января 2018 г. (1)
- 17 декабря 2017 — 23 декабря 2017 (1)
- 10 декабря 2017 — 16 декабря 2017 (2)
- 3 декабря 2017 — 9 декабря 2017 (3)
- 26 ноября 2017 — 2 декабря , 2017 (1)
- 19 ноября 2017 — 25 ноября 2017 (1)
- 12 ноября 2017 — 18 ноября 2017 (2)
- 5 ноября 2017 — 11 ноября 2017 (3)
- Октябрь 29, 2017 — Нет 4 ноября 2017 г. (1)
- 22 октября 2017 г. — 28 октября 2017 г. (4)
- 15 октября 2017 г. — 21 октября 2017 г. (2)
- 8 октября 2017 г. — 14 октября 2017 г. (3)
- 1 октября 2017 — 7 октября 2017 (2)
- 24 сентября 2017 — 30 сентября 2017 (4)
- 17 сентября 2017 — 23 сентября 2017 (2)
- 10 сентября 2017 — 16 сентября , 2017 (3)
- 3 сентября 2017 г. — 9 сентября 2017 г. (1)
- 27 августа 2017 г. — 2 сентября 2017 г. (2)
- 20 августа 2017 г. — 26 августа 2017 г. (1)
- август 13 — 19 августа 2017 г. (3)
- 30 июля 2017 г. — 5 августа 2017 г. (3)
- 23 июля 2017 г. — 29 июля 2017 г. (2)
- 16 июля 2017 г. — 22 июля 2017 г. (2)
- 9 июля 2017 г. — 15 июля 2017 г. (2)
- 2 июля 2017 г. — 8 июля 2017 г. (2)
- 28 мая 2017 г. — 3 июня 2017 г. (1)
- 21 мая, 2017 — 27 мая, 2017 (2)
- 14 мая 2017 — Ма 20 лет 2017 г. (2)
- 7 мая 2017 г. — 13 мая 2017 г. (3)
- 30 апреля 2017 г. — 6 мая 2017 г. (3)
- 23 апреля 2017 г. — 29 апреля 2017 г. (2)
- 16 апреля 2017 г. — 22 апреля 2017 г. (1)
- 9 апреля 2017 г. — 15 апреля 2017 г. (3)
- 2 апреля 2017 г. — 8 апреля 2017 г. (1)
- 26 марта 2017 г. — 1 апреля , 2017 (4)
- 19 марта 2017 г. — 25 марта 2017 г. (1)
- 12 марта 2017 г. — 18 марта 2017 г. (3)
- 5 марта 2017 г. — 11 марта 2017 г. (2)
- февраль 26, 2017 — 4 марта 2017 г. (4)
- 19 февраля 2017 г. — 25 февраля 2017 г. (3)
- 12 февраля 2017 г. — 18 февраля 2017 г. (2)
- 5 февраля 2017 г. — 11 февраля 2017 г. (3)
- 29 января 2017 г. — 4 февраля 2017 г. (4)
- 22 января 2017 г. — 28 января 2017 г. (2)
- 15 января 2017 г. — 21 января 2017 г. (3)
- 8 января, 2017 — 14 января 2017 (1)
- 1 января 2017 — 7, 20 января 17 (4)
- 18 декабря 2016 — 24 декабря 2016 (3)
- 11 декабря 2016 — 17 декабря 2016 (3)
- 4 декабря 2016 — 10 декабря 2016 (3)
- 27 ноября , 2016 — 3 декабря 2016 (2)
- 20 ноября 2016 — 26 ноября 2016 (3)
- 13 ноября 2016 — 19 ноября 2016 (3)
- 6 ноября 2016 — 12 ноября 2016 ( 3)
- 16 октября 2016 г. — 22 октября 2016 г. (3)
- 9 октября 2016 г. — 15 октября 2016 г. (3)
- 2 октября 2016 г. — 8 октября 2016 г. (1)
- 25 сентября 2016 г. — 1 октября 2016 г. (3)
- 18 сентября 2016 г. — 24 сентября 2016 г. (1)
- 11 сентября 2016 г. — 17 сентября 2016 г. (4)
- 4 сентября 2016 г. — 10 сентября 2016 г. (2)
- 28 августа 2016 г. — 3 сентября 2016 г. (4)
- 21 августа 2016 г. — 27 августа 2016 г. (2)
- 14 августа 2016 г. — 20 августа 2016 г. (3)
- 7 августа 2016 г. — август 13, 2016 (2)
- 31 июля 2016 г. — 6 августа 2016 г. (4)
- 24 июля 2016 г. — 30 июля 2016 г. (2)
- 17 июля 2016 г. — 23 июля 2016 г. (4)
- 10 июля , 2016 — 16 июля 2016 (3)
- 3 июля 2016 — 9 июля 2016 (3)
- 26 июня 2016 — 2 июля 2016 (3)
- 19 июня 2016 — 25 июня 2016 ( 2)
- 12 июня 2016 — 18 июня 2016 (3)
- 8 мая 2016 — 14 мая 2016 (2)
- 1 мая 2016 — 7 мая 2016 (2)
- 24 апреля 2016 — 30 апреля 2016 г. (5)
- 17 апреля 2016 г. — 23 апреля 2016 г. (3)
- 10 апреля 2016 г. — 16 апреля 2016 г. (4)
- 3 апреля 2016 г. — 9 апреля 2016 г. (2)
- 27 марта 2016 г. — 2 апреля 2016 г. (4)
- 20 марта 2016 г. — 26 марта 2016 г. (3)
- 13 марта 2016 г. — 19 марта 2016 г. (4)
- 6 марта 2016 г. — март 12, 2016 (3)
- 28 февраля 2016 — 5 марта 2016 (6)
- 21 февраля 2016 — 27 февраля 2016 (3)
- 14 февраля 2016 — 20 февраля 2016 (3)
- 7 февраля 2016 — 13 февраля 2016 (4)
- 31 января 2016 — 6 февраля 2016 (5)
- 24 января, 2016 — 30 января 2016 (3)
- 17 января 2016 — 23 января 2016 (5)
- 10 января 2016 — 16 января 2016 (4)
- 3 января 2016 — 9 января 2016 (4 )
- 27 декабря 2015 г. — 2 января 2016 г. (3)
- 13 декабря 2015 г. — 19 декабря 2015 г. (3)
- 6 декабря 2015 г. — 12 декабря 2015 г. (4)
- 29 ноября 2015 г. — 5 декабря 2015 г. (2)
- 22 ноября 2015 г. — 28 ноября 2015 г. (3)
- 15 ноября 2015 г. — 21 ноября 2015 г. (3)
- 8 ноября 2015 г. — 14 ноября 2015 г. (4)
- 1 ноября 2015 г. — 7 ноября 2015 г. (4)
- 25 октября 2015 г. — 31 октября 2015 г. (4)
- 18 октября 2015 г. — 24 октября 2015 г. (3)
- 11 октября 2015 г. — 17 октября , 2015 г. (5)
- 4 октября 2015 г. — 10 октября 2015 г. (3)
- 27 сентября 2015 г. — 3 октября 2015 г. (4)
- 20 сентября 2015 г. — 26 сентября 2015 г. (3)
- 13 сентября, 2015 — 19 сентября 2015 г. (4)
- 6 сентября 2015 — 12 сентября 2015 г. (3)
- 30 августа 2015 г. — 5 сентября 2015 г. (5)
- 23 августа 2015 г. — 29 августа 2015 г. (3) )
- 16 августа 2015 — 22 августа 2015 (4)
- 9 августа 2015 — 15 августа 2015 (3)
- 2 августа 2015 — 8 августа 2015 (4)
- 26 июля 2015 — 1 августа 2015 г. (4)
- 19 июля 2015 г. — 25 июля 2015 г. (4)
- 12 июля 2015 г. — 18 июля 2015 г. (5)
- 5 июля 2015 г. — 11 июля 2015 г. (4)
- 14 июня 2015 г. — 20 июня 2015 г. (1)
- 7 июня 2015 г. — 13 июня 2015 г. (3)
- 31 мая 2015 г. — 6 июня 2015 г. (5)
- 24 мая 2015 г. — 30 мая , 2015 (4)
- 17 мая 2015 — 23 мая 2015 (4) 90 011 10 мая 2015 г. — 16 мая 2015 г. (4)
- 3 мая 2015 г. — 9 мая 2015 г. (3)
- 26 апреля 2015 г. — 2 мая 2015 г. (4)
- 12 апреля 2015 г. — 18 апреля , 2015 (5)
- 5 апреля 2015 — 11 апреля 2015 (3)
- 29 марта 2015 — 4 апреля 2015 (4)
- 22 марта 2015 — 28 марта 2015 (3)
- марта 15, 2015 — 21 марта 2015 г. (4)
- 8 марта 2015 г. — 14 марта 2015 г. (5)
- 1 марта 2015 г. — 7 марта 2015 г. (3)
- 22 февраля 2015 г. — 28 февраля 2015 г. (3)
- 15 февраля 2015 — 21 февраля 2015 (4)
- 8 февраля 2015 — 14 февраля 2015 (3)
- 1 февраля 2015 — 7 февраля 2015 (4)
- 25 января, 2015 — 31 января 2015 (3)
- 18 января 2015 — 24 января 2015 (4)
- 11 января 2015 — 17 января 2015 (3)
- 4 января 2015 — 10 января 2015 (4) )
- 28 декабря 2014 г. — 3 января 2015 г. (2)
- декабрь 21 декабря 2014 г. — 27 декабря 2014 г. (2)
- 14 декабря 2014 г. — 20 декабря 2014 г. (5)
- 7 декабря 2014 г. — 13 декабря 2014 г. (4)
- 30 ноября 2014 г. — 6 декабря, 2014 (3)
- 23 ноября 2014 г. — 29 ноября 2014 г. (3)
- 16 ноября 2014 г. — 22 ноября 2014 г. (3)
- 9 ноября 2014 г. — 15 ноября 2014 г. (4)
- 2 ноября , 2014 — 8 ноября 2014 г. (3)
- 26 октября 2014 г. — 1 ноября 2014 г. (3)
- 19 октября 2014 г. — 25 октября 2014 г. (3)
- 12 октября 2014 г. — 18 октября 2014 г. ( 4)
- 5 октября 2014 г. — 11 октября 2014 г. (3)
- 28 сентября 2014 г. — 4 октября 2014 г. (3)
- 21 сентября 2014 г. — 27 сентября 2014 г. (3)
- 14 сентября 2014 г. — 20 сентября 2014 г. (4)
- 7 сентября 2014 г. — 13 сентября 2014 г. (3)
- 31 августа 2014 г. — 6 сентября 2014 г. (4)
- 24 августа 2014 г. — 30 августа 2014 г. (3) 9 0011 17 августа 2014 г. — 23 августа 2014 г. (4)
- 10 августа 2014 г. — 16 августа 2014 г. (3)
- 3 августа 2014 г. — 9 августа 2014 г. (4)
- 27 июля 2014 г. — 2 августа , 2014 (4)
- 20 июля 2014 г. — 26 июля 2014 г. (3)
- 13 июля 2014 г. — 19 июля 2014 г. (3)
- 6 июля 2014 г. — 12 июля 2014 г. (4)
- июнь 29, 2014 — 5 июля 2014 г. (3)
- 22 июня 2014 г. — 28 июня 2014 г. (3)
- 15 июня 2014 г. — 21 июня 2014 г. (1)
- 8 июня 2014 г. — 14 июня 2014 г. (1)
- 1 июня 2014 г. — 7 июня 2014 г. (1)
- 25 мая 2014 г. — 31 мая 2014 г. (1)
- 18 мая 2014 г. — 24 мая 2014 г. (4)
- 11 мая, 2014 — 17 мая 2014 г. (5)
- 4 мая 2014 г. — 10 мая 2014 г. (3)
- 27 апреля 2014 г. — 3 мая 2014 г. (5)
- 20 апреля 2014 г. — 26 апреля 2014 г. (3 )
- 13 апреля 2014 г. — 19 апреля 2014 г. (4)
- 6 апреля 2014 г. — 12 апреля 2014 г. (4)
- 30 марта 2014 г. — 5 апреля 2014 г. (5)
- 23 марта 2014 г. — 29 марта 2014 г. (4)
- 16 марта 2014 г. — 22 марта 2014 г. (5)
- 9 марта 2014 г. — 15 марта 2014 г. (5)
- 2 марта 2014 г. — 8 марта 2014 г. (4)
- 23 февраля 2014 г. — 1 марта 2014 г. (3)
- 16 февраля 2014 г. — 22 февраля 2014 г. (4)
- 9 февраля 2014 г. — февраль 15, 2014 (4)
- 2 февраля 2014 — 8 февраля 2014 (4)
- 26 января 2014 — 1 февраля 2014 (3)
- 19 января 2014 — 25 января 2014 (4)
- 12 января 2014 г. — 18 января 2014 г. (5)
- 5 января 2014 г. — 11 января 2014 г. (4)
- 29 декабря 2013 г. — 4 января 2014 г. (3)
- 22 декабря 2013 г. — 28 декабря 2013 (2)
- 15 декабря 2013 — 21 декабря 2013 (3)
- 8 декабря 2013 — 14 декабря 2013 (5)
- 1 декабря 2013 — 7 декабря 2013 (3)
- 24 ноября , 2013 — 30 ноября 2013 (4) 9 0012
- 17 ноября 2013 г. — 23 ноября 2013 г. (3)
- 10 ноября 2013 г. — 16 ноября 2013 г. (4)
- 3 ноября 2013 г. — 9 ноября 2013 г. (4)
- 27 октября 2013 г. — ноябрь 2, 2013 (4)
- 20 октября 2013 г. — 26 октября 2013 г. (3)
- 13 октября 2013 г. — 19 октября 2013 г. (4)
- 6 октября 2013 г. — 12 октября 2013 г. (3)
- 29 сентября 2013 г. — 5 октября 2013 г. (4)
- 22 сентября 2013 г. — 28 сентября 2013 г. (3)
- 15 сентября 2013 г. — 21 сентября 2013 г. (4)
- 8 сентября 2013 г. — 14 сентября, 2013 (3)
- 1 сентября 2013 г. — 7 сентября 2013 г. (4)
- 25 августа 2013 г. — 31 августа 2013 г. (3)
- 18 августа 2013 г. — 24 августа 2013 г. (4)
- 11 августа , 2013 — 17 августа 2013 г. (3)
- 4 августа 2013 г. — 10 августа 2013 г. (3)
- 21 июля 2013 г. — 27 июля 2013 г. (2)
- 14 июля 2013 г. — 20 июля 2013 г. ( 4)
- 7 июля 2013 г. — 13 июля 2013 г. (3)
- 30 июня 2013 г. — 6 июля 2013 г. (3)
- 23 июня 2013 г. — 29 июня 2013 г. (5)
- 16 июня 2013 г. — 22 июня, 2013 (3)
- 9 июня 2013 г. — 15 июня 2013 г. (4)
- 2 июня 2013 г. — 8 июня 2013 г. (4)
- 26 мая 2013 г. — 1 июня 2013 г. (4)
- 19 мая , 2013 — 25 мая 2013 г. (4)
- 12 мая 2013 г. — 18 мая 2013 г. (5)
- 5 мая 2013 г. — 11 мая 2013 г. (4)
- 28 апреля 2013 г. — 4 мая 2013 г. ( 4)
- 21 апреля 2013 г. — 27 апреля 2013 г. (4)
- 14 апреля 2013 г. — 20 апреля 2013 г. (4)
- 7 апреля 2013 г. — 13 апреля 2013 г. (3)
- 31 марта 2013 г. — 6 апреля 2013 г. (5)
- 24 марта 2013 г. — 30 марта 2013 г. (3)
- 17 марта 2013 г. — 23 марта 2013 г. (4)
- 10 марта 2013 г. — 16 марта 2013 г. (4)
- 3 марта 2013 г. — 9 марта 2013 г. (6)
- 24 февраля 2013 г. — 2 марта 2013 г. (3)
- 17 февраля 2013 г. — 23 февраля 2013 г. (4)
- 10 февраля 2013 г. — 16 февраля 2013 г. (4)
- 3 февраля 2013 г. — 9 февраля 2013 г. (6)
- 27 января 2013 г. — 2 февраля 2013 г. (3)
- 20 января 2013 г. — 26 января 2013 г. (5)
- 13 января 2013 г. — 19 января 2013 г. (4)
- 6 января 2013 г. — 12 января 2013 г. (4)
- 30 декабря 2012 г. — 5 января , 2013 (3)
- 23 декабря 2012 г. — 29 декабря 2012 г. (3)
- 16 декабря 2012 г. — 22 декабря 2012 г. (3)
- 9 декабря 2012 г. — 15 декабря 2012 г. (4)
- декабрь 2, 2012 — 8 декабря 2012 г. (3)
- 25 ноября 2012 г. — 1 декабря 2012 г. (4)
- 18 ноября 2012 г. — 24 ноября 2012 г. (2)
- 11 ноября 2012 г. — 17 ноября 2012 г. (3)
- 4 ноября 2012 г. — 10 ноября 2012 г. (3)
- 28 октября 2012 г. — 3 ноября 2012 г. (5)
- 21 октября 2012 г. — 27 октября 2012 г. (4)
- 14 октября, 201 2 — 20 октября 2012 г. (5)
- 7 октября 2012 г. — 13 октября 2012 г. (5)
- 30 сентября 2012 г. — 6 октября 2012 г. (4)
- 23 сентября 2012 г. — 29 сентября 2012 г. (3 )
- 16 сентября 2012 г. — 22 сентября 2012 г. (4)
- 9 сентября 2012 г. — 15 сентября 2012 г. (5)
- 2 сентября 2012 г. — 8 сентября 2012 г. (3)
- 26 августа 2012 г. — 1 сентября 2012 г. (4)
- 19 августа 2012 г. — 25 августа 2012 г. (5)
- 12 августа 2012 г. — 18 августа 2012 г. (4)
- 5 августа 2012 г. — 11 августа 2012 г. (5)
- 29 июля 2012 г. — 4 августа 2012 г. (5)
- 22 июля 2012 г. — 28 июля 2012 г. (5)
- 15 июля 2012 г. — 21 июля 2012 г. (4)
- 8 июля 2012 г. — 14 июля , 2012 (5)
- 1 июля 2012 г. — 7 июля 2012 г. (4)
- 24 июня 2012 г. — 30 июня 2012 г. (4)
- 17 июня 2012 г. — 23 июня 2012 г. (5)
- июнь 10, 2012 — 16 июня 2012 г. (4)
- 3 июня 2012 г. — 9 июня 2012 г. (6)
- 27 мая 2012 г. — 2 июня 2012 г. (3)
- 20 мая 2012 г. — 26 мая 2012 г. (5)
- 13 мая 2012 г. — 19 мая 2012 г. (3)
- 6 мая 2012 г. — 12 мая 2012 г. (5)
- 29 апреля 2012 г. — 5 мая 2012 г. (4)
- 22 апреля 2012 г. — 28 апреля 2012 г. (4)
- 15 апреля 2012 г. — 21 апреля , 2012 (4)
- 8 апреля 2012 г. — 14 апреля 2012 г. (4)
- 1 апреля 2012 г. — 7 апреля 2012 г. (4)
- 25 марта 2012 г. — 31 марта 2012 г. (5)
- март 18, 2012 — 24 марта 2012 г. (4)
- 11 марта 2012 г. — 17 марта 2012 г. (4)
- 4 марта 2012 г. — 10 марта 2012 г. (3)
- 26 февраля 2012 г. — 3 марта 2012 г. (5)
- 19 февраля 2012 г. — 25 февраля 2012 г. (3)
- 12 февраля 2012 г. — 18 февраля 2012 г. (5)
- 5 февраля 2012 г. — 11 февраля 2012 г. (3)
- 29 января, г. 2012 — 4 февраля 2012 г. (5)
- 22 января 2012 г. — 28 января 2012 г. (4) 9 0011 15 января 2012 г. — 21 января 2012 г. (4)
- 8 января 2012 г. — 14 января 2012 г. (4)
- 1 января 2012 г. — 7 января 2012 г. (4)
- 25 декабря 2011 г. — 31 декабря , 2011 (3)
- 18 декабря 2011 г. — 24 декабря 2011 г. (5)
- 11 декабря 2011 г. — 17 декабря 2011 г. (4)
- 4 декабря 2011 г. — 10 декабря 2011 г. (4)
- ноябрь 27 ноября 2011 г. — 3 декабря 2011 г. (3)
- 20 ноября 2011 г. — 26 ноября 2011 г. (2)
- 13 ноября 2011 г. — 19 ноября 2011 г. (4)
- 6 ноября 2011 г. — 12 ноября 2011 г. (4)
- 30 октября 2011 г. — 5 ноября 2011 г. (4)
- 23 октября 2011 г. — 29 октября 2011 г. (4)
- 9 октября 2011 г. — 15 октября 2011 г. (1)
- 25 сентября, 2011 — 1 октября 2011 (6)
- 18 сентября 2011 — 24 сентября 2011 (6)
- 11 сентября 2011 — 17 сентября 2011 (4)
- 4 сентября 2011 — 10 сентября 2011 (4 )
- 28 августа 2011 г. — 3 сентября 2011 г. (3)
- 21 августа 2011 г. — 27 августа 2011 г. (5)
- 14 августа 2011 г. — 20 августа 2011 г. (4)
- 7 августа 2011 г. — август 13, 2011 (4)
- 31 июля 2011 г. — 6 августа 2011 г. (4)
- 24 июля 2011 г. — 30 июля 2011 г. (5)
- 17 июля 2011 г. — 23 июля 2011 г. (4)
- 10 июля 2011 г. — 16 июля 2011 г. (4)
- 3 июля 2011 г. — 9 июля 2011 г. (4)
- 26 июня 2011 г. — 2 июля 2011 г. (5)
- 19 июня 2011 г. — 25 июня 2011 (4)
- 12 июня 2011 г. — 18 июня 2011 г. (6)
- 5 июня 2011 г. — 11 июня 2011 г. (5)
- 29 мая 2011 г. — 4 июня 2011 г. (4)
- 22 мая , 2011 — 28 мая 2011 г. (3)
- 15 мая 2011 г. — 21 мая 2011 г. (5)
- 8 мая 2011 г. — 14 мая 2011 г. (4)
- 1 мая 2011 г. — 7 мая 2011 г. ( 5)
- 24 апреля 2011 г. — 30 апреля 2011 г. (3)
- 17 апреля 2011 г. — 23 апреля 2011 г. (3)
- 10 апреля 2011 г. — 16 апреля 2011 г. (6)
- 3 апреля 2011 г. — 9 апреля 2011 г. (4)
- 27 марта 2011 г. — 2 апреля 2011 г. (4)
- 20 марта 2011 г. — 26 марта, 2011 (4)
- 13 марта 2011 г. — 19 марта 2011 г. (5)
- 6 марта 2011 г. — 12 марта 2011 г. (3)
- 27 февраля 2011 г. — 5 марта 2011 г. (4)
- 20 февраля , 2011 — 26 февраля 2011 г. (3)
- 13 февраля 2011 г. — 19 февраля 2011 г. (4)
- 6 февраля 2011 г. — 12 февраля 2011 г. (4)
- 30 января 2011 г. — 5 февраля 2011 г. ( 4)
- 23 января 2011 г. — 29 января 2011 г. (3)
- 16 января 2011 г. — 22 января 2011 г. (4)
- 9 января 2011 г. — 15 января 2011 г. (3)
- 2 января 2011 г. — 8 января 2011 г. (4)
- 26 декабря 2010 г. — 1 января 2011 г. (3)
- 19 декабря 2010 г. — 25 декабря 2010 г. (4)
- 12 декабря 2010 г. — 18 декабря 2010 г. (3)
- 5 декабря 2010 г. — 11, 2 декабря 010 (3)
- 28 ноября 2010 г. — 4 декабря 2010 г. (5)
- 21 ноября 2010 г. — 27 ноября 2010 г. (3)
- 14 ноября 2010 г. — 20 ноября 2010 г. (5)
- 7 ноября , 2010 — 13 ноября 2010 г. (5)
- 31 октября 2010 г. — 6 ноября 2010 г. (3)
- 24 октября 2010 г. — 30 октября 2010 г. (7)
- 17 октября 2010 г. — 23 октября 2010 г. ( 5)
- 10 октября 2010 г. — 16 октября 2010 г. (3)
- 3 октября 2010 г. — 9 октября 2010 г. (4)
- 26 сентября 2010 г. — 2 октября 2010 г. (6)
- 19 сентября 2010 г. — 25 сентября 2010 г. (4)
- 12 сентября 2010 г. — 18 сентября 2010 г. (3)
- 5 сентября 2010 г. — 11 сентября 2010 г. (6)
- 29 августа 2010 г. — 4 сентября 2010 г. (6)
- 22 августа 2010 г. — 28 августа 2010 г. (5)
- 15 августа 2010 г. — 21 августа 2010 г. (3)
- 8 августа 2010 г. — 14 августа 2010 г. (6)
- 1 августа 2010 г. — август 7, 2010 ( 5)
- 25 июля 2010 г. — 31 июля 2010 г. (5)
- 18 июля 2010 г. — 24 июля 2010 г. (4)
- 11 июля 2010 г. — 17 июля 2010 г. (6)
- 4 июля 2010 г. — 10 июля 2010 г. (3)
- 27 июня 2010 г. — 3 июля 2010 г. (3)
- 20 июня 2010 г. — 26 июня 2010 г. (4)
- 13 июня 2010 г. — 19 июня 2010 г. (4)
- 6 июня 2010 г. — 12 июня 2010 г. (4)
- 30 мая 2010 г. — 5 июня 2010 г. (5)
- 23 мая 2010 г. — 29 мая 2010 г. (2)
- 16 мая 2010 г. — май 22, 2010 (2)
- 9 мая 2010 г. — 15 мая 2010 г. (3)
- 2 мая 2010 г. — 8 мая 2010 г. (5)
- 25 апреля 2010 г. — 1 мая 2010 г. (5)
- 18 апреля 2010 г. — 24 апреля 2010 г. (3)
- 11 апреля 2010 г. — 17 апреля 2010 г. (4)
- 4 апреля 2010 г. — 10 апреля 2010 г. (5)
- 28 марта 2010 г. — 3 апреля, 2010 (2)
- 21 марта 2010 г. — 27 марта 2010 г. (3)
- 14 марта 2010 г. — 20 марта 2010 г. (3)
- 7 марта, г. 2010 — 13 марта 2010 г. (5)
- 28 февраля 2010 г. — 6 марта 2010 г. (4)
- 21 февраля 2010 г. — 27 февраля 2010 г. (5)
- 14 февраля 2010 г. — 20 февраля 2010 г. (4 )
- 7 февраля 2010 г. — 13 февраля 2010 г. (3)
- 31 января 2010 г. — 6 февраля 2010 г. (6)
- 24 января 2010 г. — 30 января 2010 г. (4)
- 17 января 2010 г. — 23 января 2010 г. (3)
- 10 января 2010 г. — 16 января 2010 г. (3)
- 3 января 2010 г. — 9 января 2010 г. (1)
- 27 декабря 2009 г. — 2 января 2010 г. (2)
- 20 декабря 2009 г. — 26 декабря 2009 г. (2)
- 13 декабря 2009 г. — 19 декабря 2009 г. (4)
- 29 ноября 2009 г. — 5 декабря 2009 г. (1)
- 22 ноября 2009 г. — 28 ноября , 2009 (5)
- 15 ноября 2009 г. — 21 ноября 2009 г. (2)
- 8 ноября 2009 г. — 14 ноября 2009 г. (2)
- 1 ноября 2009 г. — 7 ноября 2009 г. (4)
- октябрь 25, 2 009 — 31 октября 2009 г. (8)
- 18 октября 2009 г. — 24 октября 2009 г. (3)
- 11 октября 2009 г. — 17 октября 2009 г. (4)
- 4 октября 2009 г. — 10 октября 2009 г. (5 )
- 27 сентября 2009 г. — 3 октября 2009 г. (3)
- 20 сентября 2009 г. — 26 сентября 2009 г. (2)
- 13 сентября 2009 г. — 19 сентября 2009 г. (6)
- 6 сентября 2009 г. — 12 сентября 2009 г. (9)
- 30 августа 2009 г. — 5 сентября 2009 г. (5)
- 23 августа 2009 г. — 29 августа 2009 г. (3)
- 16 августа 2009 г. — 22 августа 2009 г. (6)
- 9 августа 2009 г. — 15 августа 2009 г. (4)
- 2 августа 2009 г. — 8 августа 2009 г. (8)
- 26 июля 2009 г. — 1 августа 2009 г. (7)
- 19 июля 2009 г. — 25 июля , 2009 (3)
- 12 июля 2009 г. — 18 июля 2009 г. (4)
- 5 июля 2009 г. — 11 июля 2009 г. (3)
- 28 июня 2009 г. — 4 июля 2009 г. (12)
- июнь 21 июня 2009 г. — 27 июня 2009 г. (5) 900 11 июня 14, 2009 — 20 июня 2009 г. (6)
- 7 июня 2009 г. — 13 июня 2009 г. (7)
- 31 мая 2009 г. — 6 июня 2009 г. (11)
- 24 мая 2009 г. — 30 мая 2009 г. (5)
- 17 мая 2009 г. — 23 мая 2009 г. (5)
- 10 мая 2009 г. — 16 мая 2009 г. (5)
- 3 мая 2009 г. — 9 мая 2009 г. (8)
- 26 апреля, г. 2009 — 2 мая 2009 г. (7)
- 19 апреля 2009 г. — 25 апреля 2009 г. (7)
- 12 апреля 2009 г. — 18 апреля 2009 г. (9)
- 5 апреля 2009 г. — 11 апреля 2009 г. (9 )
- 29 марта 2009 г. — 4 апреля 2009 г. (6)
- 22 марта 2009 г. — 28 марта 2009 г. (3)
- 15 марта 2009 г. — 21 марта 2009 г. (9)
- 8 марта 2009 г. — 14 марта 2009 г. (9)
- 1 марта 2009 г. — 7 марта 2009 г. (5)
- 22 февраля 2009 г. — 28 февраля 2009 г. (6)
- 15 февраля 2009 г. — 21 февраля 2009 г. (5)
- 8 февраля 2009 г. — 14 февраля 2009 г. (3)
- 1 февраля 2009 г. — 7 февраля 2009 г. (5) 900 11 25 января 2009 г. — 31 января 2009 г. (4)
- 18 января 2009 г. — 24 января 2009 г. (4)
- 11 января 2009 г. — 17 января 2009 г. (8)
- 4 января 2009 г. — 10 января , 2009 (7)
- 28 декабря 2008 г. — 3 января 2009 г. (6)
- 21 декабря 2008 г. — 27 декабря 2008 г. (2)
- 14 декабря 2008 г. — 20 декабря 2008 г. (9)
- декабрь 7, 2008 — 13 декабря 2008 г. (2)
- 30 ноября 2008 г. — 6 декабря 2008 г. (12)
- 23 ноября 2008 г. — 29 ноября 2008 г. (2)
- 16 ноября 2008 г. — 22 ноября 2008 г. (3)
- November 9, 2008 — November 15, 2008 (7)
- November 2, 2008 — November 8, 2008 (3)
- October 26, 2008 — November 1, 2008 (6)
- October 19, 2008 — October 25, 2008 (7)
- October 12, 2008 — October 18, 2008 (15)
- October 5, 2008 — October 11, 2008 (7)
- September 28, 2008 — October 4, 2008 (5 ) 9 0011 September 21, 2008 — September 27, 2008 (11)
- September 14, 2008 — September 20, 2008 (2)
- September 7, 2008 — September 13, 2008 (3)
- August 31, 2008 — September 6, 2008 (6)
- August 24, 2008 — August 30, 2008 (4)
- August 17, 2008 — August 23, 2008 (5)
- August 10, 2008 — August 16, 2008 (4)
- August 3, 2008 — August 9, 2008 (2)
- July 27, 2008 — August 2, 2008 (1)
- July 20, 2008 — July 26, 2008 (6)
- July 13, 2008 — July 19, 2008 (3)
- July 6, 2008 — July 12, 2008 (3)
- June 22, 2008 — June 28, 2008 (1)
- June 8, 2008 — June 14, 2008 (4)
- June 1, 2008 — June 7, 2008 (4)
- May 25, 2008 — May 31, 2008 (13)
- May 18, 2008 — May 24, 2008 (3)
- May 11, 2008 — May 17, 2008 (4)
- May 4, 2008 — May 10, 2008 (3)
- April 27, 2008 — May 3, 2 008 (5)
- April 20, 2008 — April 26, 2008 (5)
- April 13, 2008 — April 19, 2008 (2)
- April 6, 2008 — April 12, 2008 (5)
- March 30, 2008 — April 5, 2008 (6)
- March 23, 2008 — March 29, 2008 (5)
- March 16, 2008 — March 22, 2008 (10)
- March 9, 2008 — March 15, 2008 (4)
- March 2, 2008 — March 8, 2008 (9)
- February 24, 2008 — March 1, 2008 (6)
- February 17, 2008 — February 23, 2008 (8)
- February 10, 2008 — February 16, 2008 (6)
- February 3, 2008 — February 9, 2008 (8)
- January 27, 2008 — February 2, 2008 (12)
- January 20, 2008 — January 26, 2008 (5)
- January 13, 2008 — January 19, 2008 (9)
- January 6, 2008 — January 12, 2008 (8)
- December 30, 2007 — January 5, 2008 (6)
- December 23, 2007 — December 29, 2007 (5)
- December 16, 2007 — December 22, 2007 (3)
- December 9, 2007 — December 15, 2007 (10)
- December 2, 2007 — December 8, 2007 (8)
- November 25, 2007 — December 1, 2007 (5)
- November 18, 2007 — November 24, 2007 (6)
- November 11, 2007 — November 17, 2007 (12)
- November 4, 2007 — November 10, 2007 (7)
- October 28, 2007 — November 3, 2007 (5)
- October 21, 2007 — October 27, 2007 (8)
- October 14, 2007 — October 20, 2007 (7)
- October 7, 2007 — October 13, 2007 (8)
- September 30, 2007 — October 6, 2007 (9)
- September 23, 2007 — September 29, 2007 (5)
- September 16, 2007 — September 22, 2007 (6)
- September 9, 2007 — September 15, 2007 (8)
- September 2, 2007 — September 8, 2007 (6)
- August 26, 2007 — September 1, 2007 (5)
- August 19, 2007 — August 25, 2007 (7)
- August 12, 2007 — August 18, 2007 (3)
- August 5, 2007 — August 11, 2007 (5)
- July 29, 2007 — August 4, 2007 (22)
- July 22, 2007 — July 28, 2007 (18)
- July 15, 2007 — July 21, 2007 (12)
- July 8, 2007 — July 14, 2007 (7)
- July 1, 2007 — July 7, 2007 (1)
 — 8 августа 2020 г. (1)
— 8 августа 2020 г. (1) (2 )
(2 )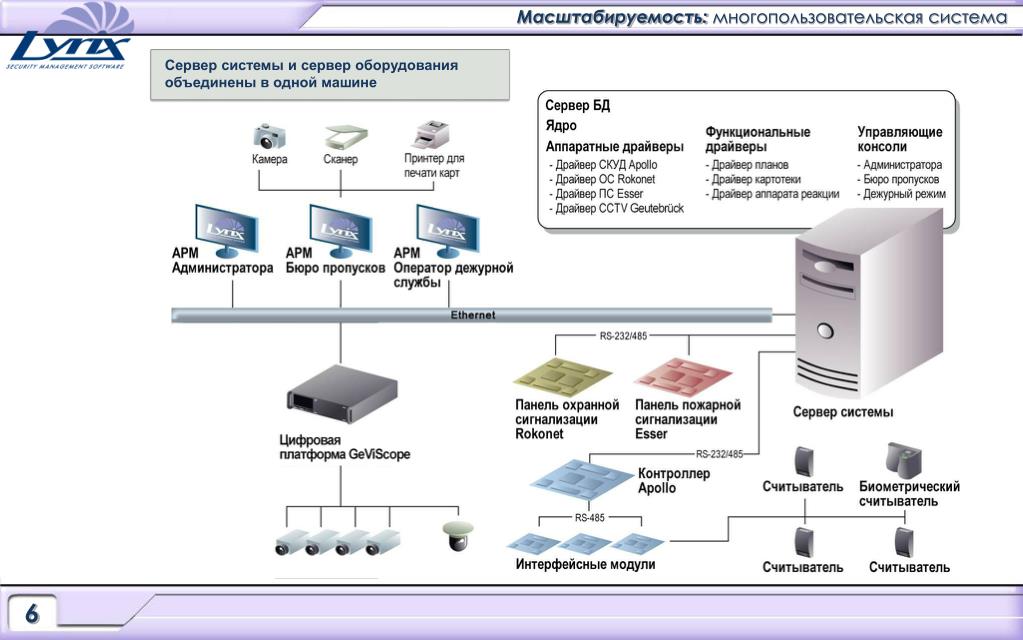 — 13 июля 2019 г. (1)
— 13 июля 2019 г. (1) (2)
(2) — 16 июня 2018 г. (1)
— 16 июня 2018 г. (1)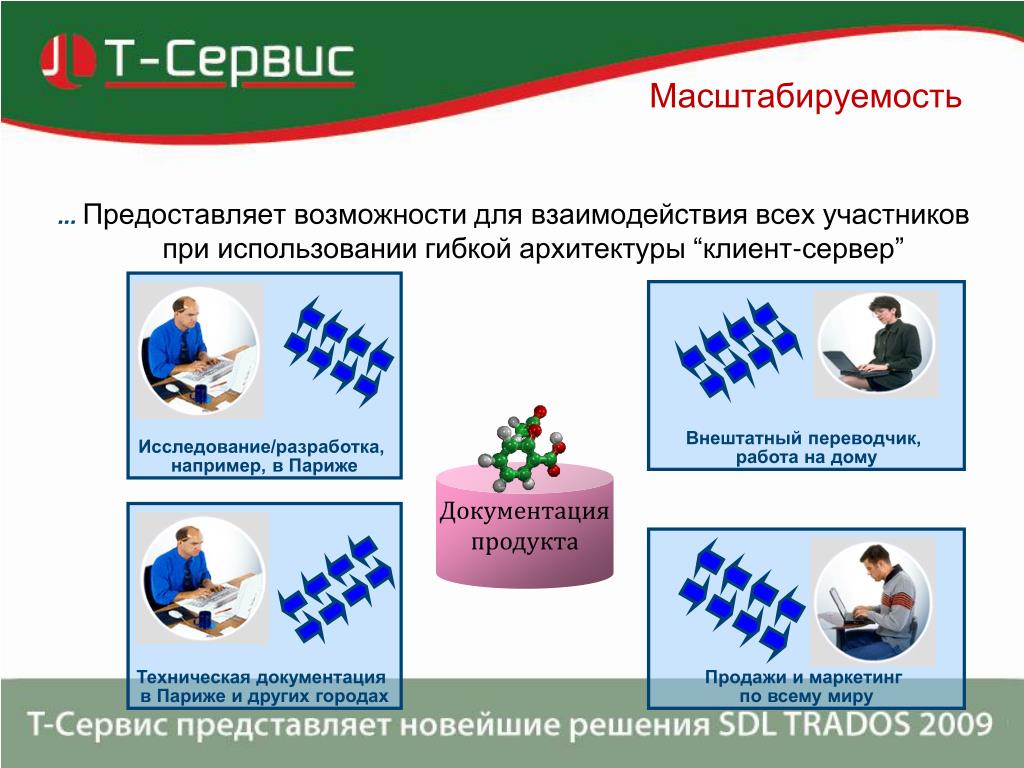 (1)
(1) (3)
(3) — 22 октября 2016 г. (3)
— 22 октября 2016 г. (3) (5)
(5) — 28 ноября 2015 г. (3)
— 28 ноября 2015 г. (3) — 18 июля 2015 г. (5)
— 18 июля 2015 г. (5) — 3 января 2015 г. (2)
— 3 января 2015 г. (2) (3)
(3) — 5 апреля 2014 г. (5)
— 5 апреля 2014 г. (5) — 16 ноября 2013 г. (4)
— 16 ноября 2013 г. (4) — 29 июня 2013 г. (5)
— 29 июня 2013 г. (5) — 9 февраля 2013 г. (6)
— 9 февраля 2013 г. (6) — 29 сентября 2012 г. (3 )
— 29 сентября 2012 г. (3 ) — 12 мая 2012 г. (5)
— 12 мая 2012 г. (5)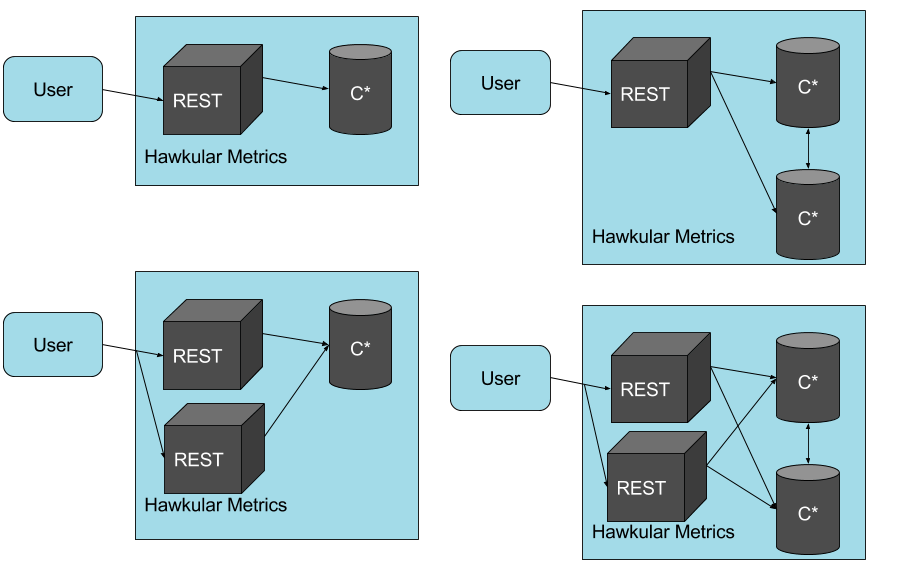 — 24 декабря 2011 г. (5)
— 24 декабря 2011 г. (5) — 30 июля 2011 г. (5)
— 30 июля 2011 г. (5) — 5 марта 2011 г. (4)
— 5 марта 2011 г. (4) — 23 октября 2010 г. ( 5)
— 23 октября 2010 г. ( 5) (4)
(4) (3)
(3) — 5 сентября 2009 г. (5)
— 5 сентября 2009 г. (5) — 18 апреля 2009 г. (9)
— 18 апреля 2009 г. (9) — 6 декабря 2008 г. (12)
— 6 декабря 2008 г. (12)Entries by Month
Click on a month below to view a list of articles published during that month.
Начните здесь — Высокая масштабируемость —
Эта страница поможет вам начать работу с высокой масштабируемостью. Вот несколько полезных тем, которые помогут вам начать …
- Почему существует сайт с высокой масштабируемостью?
- Хорошие вещи для чтения.
- Участвуйте, добавляя свои ссылки на интересные сайты и статьи.
- Участвуйте, подписавшись на RSS-канал.
- Рассмотрите множество преимуществ регистрации в качестве пользователя.
- Как мне получить уведомление об изменениях содержания и комментариев?
- Contact Высокая масштабируемость.
- Об.
Почему существует сайт с высокой масштабируемостью?
Чтобы помочь вам создавать успешные масштабируемые веб-сайты.
Этот сайт пытается объединить все знания, искусство, науку, практику и опыт создания масштабируемых веб-сайтов в одном месте, чтобы вы могли научиться уверенно создавать свой веб-сайт.
Когда становится ясно, что вы должны развивать свой сайт или умереть, большинство людей понятия не имеют, с чего начать.Это не тот навык, которому вы научитесь в школе или почерпнете из журнальной статьи, когда летите домой. Нет, создание масштабируемых систем — это совокупность знаний, медленно накапливаемых с течением времени из с трудом добытого опыта и множества неудачных сражений. Надеюсь, этот сайт продвинет вас дальше и быстрее по кривой обучения успеха.
Создатели популярных веб-сайтов в конечном итоге сталкиваются с важным вопросом: как мне масштабировать? Каждый создатель успешных веб-сайтов должен ответить на этот вопрос и применить свои ответы на практике.
Вы можете спросить:
- Как мне справиться с тем, что меня раскопали или коснулись?
- На что я могу потратить свой бюджет?
- Как мне добавлять новых и новых пользователей?
- Какое программное обеспечение мне следует использовать? LAMP, WAMP или .Net?
- Что мне следует использовать: управляемые или неуправляемые системы? Выделенный, совмещенный, VPS, хостинг или что-то еще?
- Какую машину и операционную систему мне следует использовать?
- Как мне восстановиться после аварии?
- Как мне измерить и улучшить производительность?
- Где мне найти людей, чтобы мне помочь?
- Какой центр обработки данных мне использовать?
- Какого провайдера мне следует использовать?
- Как я могу структурировать свое программное обеспечение для масштабирования?
- Как настроить кеширование?
- Как должна выглядеть моя схема базы данных?
- Какую базу данных мне использовать?
- Какой язык и фреймворк мне следует использовать?
- Как я могу гарантировать, что мои данные всегда доступны и никогда не потеряны?
- Как мне контролировать все мое программное обеспечение и машины?
- Как мне обучить моих программистов создавать этот тип программного обеспечения?
- Как выполнить аварийное переключение моих веб-серверов, баз данных и т. Д.?
- Как мне перейти в несколько географических регионов?
- Как мне обрабатывать данные сеанса?
- Как мне обеспечить поддержку, обновления и развертывание функций?
 Д.?
Д.?У вас наверняка тысячи таких вопросов.Где найти ответы? Ответы есть. Как создать масштабируемый сайт — не секрет, информация просто разложена. И все же это больше искусство, чем наука. Все проблемы разные. У вашего сайта могут быть особые требования, которые делают его достаточно разным, чтобы вы могли воспользоваться советом.
И вот о чем весь этот сайт. Объединение единомышленников, чтобы помочь каждому узнать все, что можно, о создании лучших веб-сайтов.
Полезные вещи для чтения.
Если вам интересен этот сайт, вы, вероятно, захотите создать свой собственный сайт-монстр. Нет лучшего способа учиться, чем учиться у лучших реальных архитектур. Real Life Architectures — это продолжающаяся серия сообщений о том, как действительно успешные веб-сайты, такие как eBay, Flickr, MySpace, LiveJournal и Amazon, создают свои веб-сайты.
Учитесь у тех, кто уже сделал это, и добавьте свой личный поворот, чтобы сделать его своим.
Участвуйте, добавляя свои ссылки на интересные сайты и статьи.
Одно из невероятных бесплатных вознаграждений для пользователей за регистрацию в качестве пользователя High Scalability — это возможность публиковать статьи на главной странице. Количество материалов по темам, связанным с высокой масштабируемостью, огромно и постоянно развивается, поэтому, если люди поделятся своими находками, это поможет всем не отставать от новинок.
Все, что вам нужно сделать, чтобы публиковать свои статьи, это:
- Зарегистрируйтесь как пользователь.
- Войти.
- Выберите ссылку разместить новую запись вверху страницы.
- Заполните форму и нажмите «Отправить». И вы сделали!
Примите участие, подписавшись на RSS-канал.
Если вы хотите участвовать в работе этого веб-сайта, читая сообщения RSS, просто вставьте следующий URL-адрес в свою любимую программу чтения RSS: http://feeds.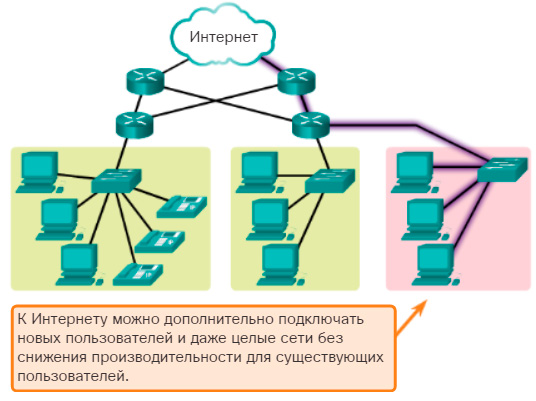 feedburner.com/HighScalability. Для ленты комментариев подпишитесь на http://highscalability.squarespace.com/blog/rss-comments.xml.
feedburner.com/HighScalability. Для ленты комментариев подпишитесь на http://highscalability.squarespace.com/blog/rss-comments.xml.
Рассмотрите множество преимуществ регистрации в качестве пользователя.
Хорошо, если честно, от регистрации в качестве пользователя не так много преимуществ.Мы ненавидим сайты, которые заставляют вас зарегистрироваться, прежде чем вы сможете сделать что-нибудь полезное. Мы сделали так, чтобы вы могли делать все самое интересное без регистрации. Но если вы все же зарегистрируетесь, вы можете опубликовать статью и подписаться на изменения статьи по электронной почте. Вот и все. Надеюсь, позже у нас будут хорошие дверные призы.
Как я могу получать уведомления об изменениях содержания и комментариев?
- RSS, наверное, самый простой способ. Пожалуйста, посмотрите раздел RSS немного раньше на странице.
- Зарегистрированные пользователи могут войти в систему и выбрать Подписаться на обновления страницы в правом верхнем углу страницы.

Правила проводки
Я действительно хочу, чтобы люди публиковали все, что им интересно, но это Интернет. Итак, пожалуйста:
- Не размещайте анонсы о новых версиях продукта, классах и т. Д. Скоро сайт превратится в анонсы, люди перестанут читать, и это будет плохо. Пожалуйста, пришлите мне свое объявление, и я смогу поместить его в свой еженедельный пост с горячими ссылками.
Около
Некоторые люди спрашивали, кто я.Хороший вопрос. Я все еще работаю над этим 🙂 Меня, однако, зовут Тодд Хофф, и мой личный веб-сайт находится по адресу http://toddhoff.com. У меня большой опыт работы с крупномасштабными распределенными системами и давний интерес к этой теме. В конце концов я решил, что, поскольку я все время читаю эти материалы, я могу создать сайт об этом!
Я надеюсь, что вы найдете этот сайт полезным в повседневной работе в окопах.
Мини FAQ
- Почему некоторые из ваших страниц выглядят ужасно? Во время перехода от Drupal к Squarespace мне пришлось экспортировать контент и попытаться автоматически переформатировать его, чтобы он выглядел презентабельно в Squarespace. К сожалению, этот процесс не всегда срабатывал. Я сделал много ручных правок, чтобы исправить все, что мог, но на этом сайте много контента, и я многое пропустил. Поэтому я пытаюсь постепенно улучшать его. Если есть страница, которая, по вашему мнению, требует внимания, дайте мне знать.
 К сожалению, этот процесс не всегда срабатывал. Я сделал много ручных правок, чтобы исправить все, что мог, но на этом сайте много контента, и я многое пропустил. Поэтому я пытаюсь постепенно улучшать его. Если есть страница, которая, по вашему мнению, требует внимания, дайте мне знать.
К сожалению, этот процесс не всегда срабатывал. Я сделал много ручных правок, чтобы исправить все, что мог, но на этом сайте много контента, и я многое пропустил. Поэтому я пытаюсь постепенно улучшать его. Если есть страница, которая, по вашему мнению, требует внимания, дайте мне знать.Высокая масштабируемость —
Эта статья — глава из моей новой книги «Объясни облако, как будто мне 10».Первый выпуск был написан специально для новичков в облачной среде. Я сделал несколько обновлений и добавил несколько глав — Netflix: Что происходит, когда вы нажимаете Play? и Что такое облачные вычисления? — , которые на пару шагов отстают от новичка. Думаю, даже достаточно опытные люди могут что-то получить от этого.
Так что, если вы ищете хорошее представление об облаке или знаете кого-нибудь, пожалуйста, взгляните. Думаю, тебе понравится. Я очень горжусь тем, что получилось.
Я очень горжусь тем, что получилось.
Я собрал эту главу из десятков источников, которые временами были несколько противоречивыми. Факты на местах со временем меняются и зависят от того, кто рассказывает историю и к какой аудитории они обращаются. Я попытался создать как можно более связное повествование. Если есть какие-то ошибки, я буду более чем счастлив их исправить. Имейте в виду, что эта статья не является подробным техническим описанием. Это статья с большой картинкой. Я, например, ни разу не упоминаю слово микросервис 🙂
Netflix кажется таким простым.Нажмите кнопку воспроизведения, и видео волшебным образом появится. Легко, правда? Не так много.
Учитывая наше обсуждение в Что такое облачные вычисления? В главе можно ожидать, что Netflix будет обслуживать видео с помощью AWS. Нажмите кнопку воспроизведения в приложении Netflix, и видео, хранящееся в S3, будет транслироваться с S3 через Интернет прямо на ваше устройство.
Совершенно разумный подход… для гораздо меньшего объема услуг.
Но Netflix работает совсем не так. Это намного сложнее и интереснее, чем вы можете себе представить.
Чтобы понять, почему, давайте посмотрим на впечатляющую статистику Netflix за 2017 год.
- Netflix имеет более 110 миллионов подписчиков.
- Netflix работает более чем в 200 странах.
- Netflix приносит около 3 миллиардов долларов дохода в квартал.
- Netflix добавляет более 5 миллионов новых подписчиков в квартал.
- Netflix воспроизводит более 1 миллиарда часов видео каждую неделю. Для сравнения: YouTube транслирует 1 миллиард часов видео каждый день , а Facebook транслирует 110 миллионов часов видео каждый день.
- Netflix проиграл 250 миллионов часов видео за один день в 2017 году. На
- Netflix приходится более 37% пикового интернет-трафика в США.
- Netflix планирует потратить 7 миллиардов долларов на новый контент в 2018 году.

Что мы узнали?
Netflix огромен. Они глобальны, у них много участников, они смотрят много видео и у них много денег.
Другой важный факт — Netflix основан на подписке.Участники платят Netflix ежемесячно и могут отменить подписку в любое время. Когда вы нажимаете кнопку воспроизведения, чтобы расслабиться на Netflix, это должно работать лучше. Недовольные участники отписываются.
Netflix работает в двух облаках: AWS и Open Connect.
Как Netflix делает своих участников счастливыми? Конечно с облаком. На самом деле Netflix использует два разных облака: AWS и Open Connect.
Оба облака должны работать вместе, чтобы предоставлять бесконечные часы приятного для клиентов видео.
Три части Netflix: клиент, серверная часть, CDN.
Netflix можно разделить на три части: клиент, серверная часть и CDN.
Клиент — это пользовательский интерфейс на любом устройстве, используемом для просмотра и воспроизведения видео Netflix. Это может быть приложение на вашем iPhone, веб-сайт на вашем настольном компьютере или даже приложение на вашем Smart TV. Netflix контролирует каждого клиента для каждого устройства.
Это может быть приложение на вашем iPhone, веб-сайт на вашем настольном компьютере или даже приложение на вашем Smart TV. Netflix контролирует каждого клиента для каждого устройства.
Все, что происходит до того, как вы нажмете play , происходит в бэкэнде , который работает в AWS.Это включает в себя такие вещи, как подготовка всего нового входящего видео и обработка запросов от всех приложений, веб-сайтов, телевизоров и других устройств.
Все, что происходит после того, как вы нажмете play , обрабатывается Open Connect. Open Connect — это настраиваемая глобальная сеть доставки контента (CDN) Netflix. Когда вы нажимаете кнопку воспроизведения, видео подается из Open Connect. Не волнуйтесь; мы поговорим о том, что это значит позже.
Интересно, что в Netflix на самом деле не говорят, что нажимает воспроизведение на видео , они говорят, что нажимают на начало заголовка .В каждой отрасли есть свой жаргон.
Контролируя все три области — клиент, серверную часть и CDN — Netflix добился полной вертикальной интеграции.
Netflix контролирует просмотр видео от начала до конца. Вот почему он просто работает, когда вы нажимаете кнопку воспроизведения из любой точки мира. Вы надежно получаете контент, который хотите смотреть, тогда, когда вы хотите его посмотреть.
Давайте посмотрим, как Netflix добивается этого.
В 2008 году Netflix начала переходить на AWSНажмите, чтобы узнать больше…
Что такое масштабируемость? — Определение с сайта WhatIs.com
КВ информационных технологиях масштабируемость (часто обозначаемая как масштабируемость ), по-видимому, имеет два применения:
1) Это способность компьютерного приложения или продукта (аппаратного или программного обеспечения) продолжать нормально функционировать, когда оно (или его контекст) изменяется в размере или объеме для удовлетворения потребностей пользователя. Как правило, масштабирование выполняется до большего размера или объема. Изменение масштаба может касаться самого продукта (например, линейки компьютерных систем разного размера с точки зрения хранилища, ОЗУ и т. Д.) Или перемещения масштабируемого объекта в новый контекст (например, новую операционную систему) .
Изменение масштаба может касаться самого продукта (например, линейки компьютерных систем разного размера с точки зрения хранилища, ОЗУ и т. Д.) Или перемещения масштабируемого объекта в новый контекст (например, новую операционную систему) .
Пример: Джон Янг в своей книге Exploring IBM New-Age Mainframes описывает операционную систему RS / 6000 SP как систему, обеспечивающую масштабируемость («способность сохранять уровни производительности при добавлении дополнительных процессоров»). Другой пример: масштабируемые шрифты при печати — это шрифты, размер которых можно уменьшать или увеличивать с помощью программного обеспечения без потери качества.
2) Это способность не только хорошо работать в масштабированной ситуации, но и в полной мере использовать ее.Например, прикладная программа была бы масштабируемой, если бы ее можно было перенести с меньшей операционной системы на более крупную и в полной мере использовать преимущества более крупной операционной системы с точки зрения производительности (время отклика пользователя и т.