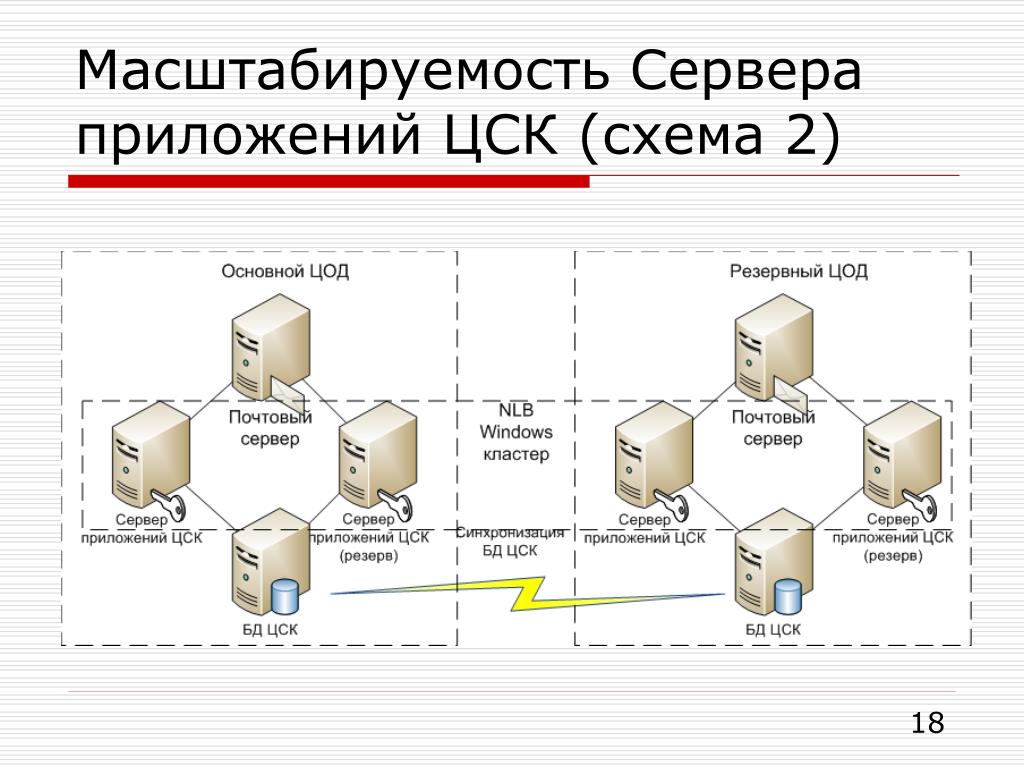
Масштабируемость системы
Масштабируемость — такое свойство вычислительной системы, которое обеспечивает предсказуемый рост системных характеристик, например, числа поддерживаемых пользователей, быстроты реакции, общей производительности и пр., при добавлении к ней вычислительных ресурсов. В случае сервера СУБД можно рассматривать два способа масштабирования — вертикальный и горизонтальный (рис. 2).
При горизонтальном масштабировании увеличивается число серверов СУБД, возможно, взаимодействующих друг с другом в прозрачном режиме, разделяя таким образом общую загрузку системы. Такое решение, видимо, будет все более популярным с ростом поддержки слабосвязанных архитектур и распределенных баз данных, однако обычно оно характеризуется сложным администрированием.
Вертикальное масштабирование подразумевает увеличение мощности отдельного сервера СУБД и достигается заменой аппаратного обеспечения (процессора, дисков) на более быстродействующее или добавлением дополнительных узлов.
Свойство масштабируемости актуально по двум основным причинам. Прежде всего, условия современного бизнеса меняются столь быстро, что делают невозможным долгосрочное планирование, требующее всестороннего и продолжительного анализа уже устаревших данных, даже для тех организаций, которые способны это себе позволить. Взамен приходит стратегия постепенного, шаг за шагом, наращивания мощности информационных систем.
- поддержка многопроцессорной обработки;
- гибкость архитектуры.
Многопроцессорные системы
Для вертикального масштабирования все чаще используются симметричные многопроцессорные системы (SMP), поскольку в этом случае не требуется смены платформы, т. е. операционной системы, аппаратного обеспечения, а также навыков администрирования. С этой целью возможно также применение систем с массовым параллелизмом (MPP), но пока их использование ограничивается специальными задачами, например, расчетными. При оценке сервера СУБД с параллельной архитектурой целесообразно обратить внимание на две основные характеристики расширяемости архитектуры: адекватности и прозрачности.
е. операционной системы, аппаратного обеспечения, а также навыков администрирования. С этой целью возможно также применение систем с массовым параллелизмом (MPP), но пока их использование ограничивается специальными задачами, например, расчетными. При оценке сервера СУБД с параллельной архитектурой целесообразно обратить внимание на две основные характеристики расширяемости архитектуры: адекватности и прозрачности.
Свойство адекватности требует, чтобы архитектура сервера равно поддерживала один или десять процессоров без переустановки или существенных изменений в конфигурации, а также дополнительных программных модулей. Такая архитектура будет одинаково полезна и эффективна и в однопроцессорной системе, и, по мере роста сложности решаемых задач, на нескольких или даже на множестве (MPP) процессоров. В общем случае потребитель не должен дополнительно покупать и осваивать новые опции программного обеспечения.
Обеспечение прозрачности архитектуры сервера, в свою очередь, позволяет скрыть изменения конфигурации аппаратного обеспечения от приложений, т. е. гарантирует переносимость прикладных программных систем. В частности, в сильно связанных многопроцессорных архитектурах приложение может взаимодействовать с сервером через сегмент разделяемой памяти, тогда как при использовании слабосвязанных многосерверных систем (кластеров) для этой цели может быть применен механизм сообщений. Приложение не должно учитывать возможности реализации аппаратной архитектуры — способы манипулирования данными и программный интерфейс доступа к базе данных обязаны оставаться одинаковыми и в равной степени эффективными.
е. гарантирует переносимость прикладных программных систем. В частности, в сильно связанных многопроцессорных архитектурах приложение может взаимодействовать с сервером через сегмент разделяемой памяти, тогда как при использовании слабосвязанных многосерверных систем (кластеров) для этой цели может быть применен механизм сообщений. Приложение не должно учитывать возможности реализации аппаратной архитектуры — способы манипулирования данными и программный интерфейс доступа к базе данных обязаны оставаться одинаковыми и в равной степени эффективными.
Качественная поддержка многопроцессорной обработки требует от сервера баз данных способности самостоятельно планировать выполнение множества обслуживаемых запросов, что обеспечило бы наиболее полное разделение доступных вычислительных ресурсов между задачами сервера. Запросы могут обрабатываться последовательно несколькими задачами или разделяться на подзадачи, которые, в свою очередь, могут быть выполнены параллельно (рис. 3). Последнее более оптимально, поскольку правильная реализация этого механизма обеспечивает выгоды, независимые от типов запросов и приложений. На эффективность обработки огромное воздействие оказывает уровень гранулярности рассматриваемых задачей-планировщиком операций. При грубой гранулярности, например, на уровне отдельных SQL-запросов, разделение ресурсов вычислительной системы (процессоров, памяти, дисков) не будет оптимальным — задача будет простаивать, ожидая окончания необходимых для завершения SQL-запроса операций ввода/вывода, хотя бы в очереди к ней стояли другие запросы, требующие значительной вычислительной работы. При более тонкой гранулярности разделение ресурсов происходит даже внутри одного SQL-запроса, что еще нагляднее проявляется при параллельной обработке нескольких запросов. Применение планировщика обеспечивает привлечение больших ресурсов системы к решению собственно задач обслуживания базы данных и минимизирует простои.
На эффективность обработки огромное воздействие оказывает уровень гранулярности рассматриваемых задачей-планировщиком операций. При грубой гранулярности, например, на уровне отдельных SQL-запросов, разделение ресурсов вычислительной системы (процессоров, памяти, дисков) не будет оптимальным — задача будет простаивать, ожидая окончания необходимых для завершения SQL-запроса операций ввода/вывода, хотя бы в очереди к ней стояли другие запросы, требующие значительной вычислительной работы. При более тонкой гранулярности разделение ресурсов происходит даже внутри одного SQL-запроса, что еще нагляднее проявляется при параллельной обработке нескольких запросов. Применение планировщика обеспечивает привлечение больших ресурсов системы к решению собственно задач обслуживания базы данных и минимизирует простои.
Гибкость архитектуры
Независимо от степени мобильности, поддержки стандартов, параллелизма и других полезных качеств, производительность СУБД, имеющей ощутимые встроенные архитектурные ограничения, не может наращиваться свободно. Наличие документированных или практических ограничений на число и размеры объектов базы данных и буферов памяти, количество одновременных подключений, на глубину рекурсии вызова процедур и подчиненных запросов (subqueries) или срабатывания триггеров базы данных является таким же ограничением применимости СУБД как, например, невозможность переноса на несколько вычислительных платформ. Параметры, ограничивающие сложность запросов к базе данных, в особенности размеры динамических буферов и стека для рекурсивных вызовов, должны настраиваться в динамике и не требовать остановки системы для реконфигурации. Нет смысла покупать новый мощный сервер, если ожидания не могут быть удовлетворены из-за внутренних ограничений СУБД.
Наличие документированных или практических ограничений на число и размеры объектов базы данных и буферов памяти, количество одновременных подключений, на глубину рекурсии вызова процедур и подчиненных запросов (subqueries) или срабатывания триггеров базы данных является таким же ограничением применимости СУБД как, например, невозможность переноса на несколько вычислительных платформ. Параметры, ограничивающие сложность запросов к базе данных, в особенности размеры динамических буферов и стека для рекурсивных вызовов, должны настраиваться в динамике и не требовать остановки системы для реконфигурации. Нет смысла покупать новый мощный сервер, если ожидания не могут быть удовлетворены из-за внутренних ограничений СУБД.
Обычно узким местом является невозможность динамической подстройки характеристик программ сервера баз данных. Способность на ходу определять такие параметры, как объем потребляемой памяти, число занятых процессоров, количество параллельных потоков выполнения заданий (будь то настоящие потоки (threads), процессы операционной системы или виртуальные процессоры) и количество фрагментов таблиц и индексов баз данных, а также их распределение по физическим дискам БЕЗ останова и перезапуска системы является требованием, вытекающим из сути современных приложений. В идеальном варианте каждый из этих параметров можно было бы изменить динамически в заданных для конкретного пользователя пределах.
В идеальном варианте каждый из этих параметров можно было бы изменить динамически в заданных для конкретного пользователя пределах.
Основы масштабирования / Хабр
Прочитав в этом блоге о балансировке на стороне клиента, решил опубликовать свою статью, в которой описаны основные принципы масштабирования для web-проектов. Надеюсь, хабралюдям будет интересно почитать.
Масштабируемость — способность устройства увеличивать свои
возможности
путем наращивания числа функциональных блоков,
выполняющих одни и
те же задачи.
Глоссарий.ru
Обычно о масштабировании начинают думать тогда, когда один
сервер не справляется с возложенной на него работой. С чем именно он не
справляется? Работа любого web-сервера по большому счету сводится к основному
занятию компьютеров — обработке данных. Ответ на HTTP (или любой другой) запрос
 Соответственно,
Соответственно,у нас есть две основные сущности — это данные (характеризуемые своим объемом) и
вычисления (характеризуемые сложностью). Сервер может не справляться со своей
работой по причине большого объема данных (они могут физически не помещаться на
сервере), либо по причине большой вычислительной нагрузки. Речь здесь идет,
конечно, о суммарной нагрузке — сложность обработки одного запроса может быть
невелика, но большое их количество может «завалить» сервер.
В основном мы будем говорить о масштабировании на примере
других областей применения. Сначала мы рассмотрим архитектуру проекта и простое
распределение ее составных частей на несколько серверов, а затем поговорим о
масштабировании вычислений и данных.
Типичная архитектура сайта
Жизнь типичного сайта начинается с очень простой архитектуры
— это один web-сервер (обычно в его роли выступает Apache),
который занимается всей работой по обслуживанию HTTP-запросов,
поступающих от посетителей. Он отдает клиентам так называемую «статику», то
Он отдает клиентам так называемую «статику», то
jpg, png), листы стилей (css), клиентские скрипты (js, swf). Тот же сервер
отвечает на запросы, требующие вычислений — обычно это формирование
html-страниц, хотя иногда «на лету» создаются и изображения и другие документы.
Чаще всего ответы на такие запросы формируются скриптами, написанными на php,
perl или других языках.
Минус такой простой схемы работы в том, что разные по
характеру запросы (отдача файлов с диска и вычислительная работа скриптов)
обрабатываются одним и тем же web-сервером. Вычислительные запросы требуют
держать в памяти сервера много информации (интерпретатор скриптового языка,
вычислительных ресурсов. Выдача статики, наоборот, требует мало ресурсов
процессора, но может занимать продолжительное время, если у клиента низкая
скорость связи.
 Внутреннее устройство сервера Apache предполагает, что каждое
Внутреннее устройство сервера Apache предполагает, что каждоесоединение обрабатывается отдельным процессом. Это удобно для работы скриптов,
однако неоптимально для обработки простых запросов. Получается, что тяжелые (от
запроса, затем при отправке ответа), впустую занимая память сервера.
Решение этой проблемы — распределение работы по обработке
запросов между двумя разными программами — т.е. разделение на frontend и
backend. Легкий frontend-сервер выполняет задачи по отдаче статики, а остальные
запросы перенаправляет (проксирует) на backend, где выполняется формирование
страниц. Ожидание медленных клиентов также берет на себя frontend, и если он использует
мультиплексирование (когда один процесс обслуживает нескольких клиентов — так
стоит.

Из других компонент сайта следует отметить базу данных, в
которой обычно хранятся основные данные системы — тут наиболее популярны
бесплатные СУБД MySQL и PostgreSQL. Часто отдельно выделяется хранилище
бинарных файлов, где содержатся картинки (например, иллюстрации к статьям
сайта, аватары и фотографии пользователей) или другие файлы.
Таким образом, мы получили схему архитектуры, состоящую из
нескольких компонент.
Обычно в начале жизни сайта все компоненты архитектуры
есть простое решение — вынести наиболее легко отделяемые части на другой
сервер. Проще всего начать с базы данных — перенести ее на отдельный сервер и
изменить реквизиты доступа в скриптах. Кстати, в этот момент мы сталкиваемся с
важностью правильной архитектуры программного кода. Если работа с базой данных
вынесена в отдельный модуль, общий для всего сайта — то исправить параметры
соединения будет просто.

Пути дальнейшего разделения компонент тоже понятны — например, можно вынести frontend на отдельный сервер. Но обычно frontend
прироста производительности. Чаще всего сайт упирается в производительность
скриптов — формирование ответа (html-страницы) занимает слишком долгое время.
Поэтому следующим шагом обычно является масштабирование backend-сервера.
Распределение вычислений
Типичная ситуация для растущего сайта — база данных уже
вынесена на отдельную машину, разделение на frontend и backend выполнено,
однако посещаемость продолжает увеличиваться и backend не успевает обрабатывать
запросы. Это значит, что нам необходимо распределить вычисления на несколько
него программы и скрипты, необходимые для работы backend.
После этого надо сделать так, чтобы запросы пользователей распределялись
(балансировались) между полученными серверами.
 О разных способах балансировки
О разных способах балансировкибудет сказано ниже, пока же отметим, что обычно этим занимается frontend,
который настраивают так, чтобы он равномерно распределял запросы между
серверами.
Важно, чтобы все backend-серверы были способны правильно
отвечать на запросы. Обычно для этого необходимо, чтобы каждый из них работал с
одним и тем же актуальным набором данных. Если мы храним всю информацию в единой
базе данных, то СУБД сама обеспечит совместный доступ и согласованность данных.
Если же некоторые данные хранятся локально на сервере (например, php-сессии
клиента), то стоит подумать о переносе их в общее хранилище, либо о более
сложном алгоритме распределения запросов.
Распределить по нескольким серверам можно не только работу
скриптов, но и вычисления, производимые базой данных. Если СУБД выполняет много
сложных запросов, занимая процессорное время сервера, можно создать несколько
копий базы данных на разных серверах. При этом возникает вопрос синхронизации
При этом возникает вопрос синхронизации
данных при изменениях, и здесь применимы несколько подходов.
- Синхронизация на уровне приложения. В этом случае наши
скрипты самостоятельно записывают изменения на все копии базы данных (и сами несут
ответственность за правильность данных). Это не лучший вариант, поскольку он
требует осторожности при реализации и весьма неустойчив к ошибкам. - Репликация — то есть автоматическое тиражирование
изменений, сделанных на одном сервере, на все остальные сервера. Обычно при
использовании репликации изменения записываются всегда на один и тот же сервер — его называют master, а остальные копии — slave. В большинстве СУБД есть
встроенные или внешние средства для организации репликации. Различают
синхронную репликацию — в этом случае запрос на изменение данных будет ожидать,
пока данные будут скопированы на все сервера, и лишь потом завершится успешно — и асинхронную — в этом случае изменения копируются на slave-сервера с
задержкой, зато запрос на запись завершается быстрее.
- Multi-master репликация. Этот подход аналогичен
предыдущему, однако тут мы можем производить изменение данных, обращаясь не к
одному определенному серверу, а к любой копии базы. При этом изменения
синхронно или асинхронно попадут на другие копии. Иногда такую схему называют
термином «кластер базы данных».

Возможны разные варианты распределения системы по серверам.
Например, у нас может быть один сервер базы данных и несколько backend (весьма
типичная схема), или наоборот — один backend и несколько БД. А если мы масштабируем
и backend-сервера, и базу данных, то можно объединить backend и копию базы на
одной машине. В любом случае, как только у нас появляется несколько экземпляров
какого-либо сервера, возникает вопрос, как правильно распределить между ними
нагрузку.
Методы балансировки
Пусть мы создали несколько серверов (любого назначения — http, база данных и т. п.), каждый из которых может обрабатывать запросы. Перед
п.), каждый из которых может обрабатывать запросы. Перед
нами встает задача — как распределить между ними работу, как узнать, на какой
сервер отправлять запрос? Возможны два основных способа распределения запросов.
- Балансирующий узел. В этом случае клиент шлет запрос на один
фиксированный, известный ему сервер, а тот уже перенаправляет запрос на один из
рабочих серверов. Типичный пример — сайт с одним frontend и несколькими
backend-серверами, на которые проксируются запросы. Однако «клиент» может
находиться и внутри нашей системы — например, скрипт может слать запрос к
прокси-серверу базы данных, который передаст запрос одному из серверов СУБД.
Сам балансирующий узел может работать как на отдельном сервере, так и на одном
из рабочих серверов.Преимущества этого подхода в том,
что клиенту ничего не надо знать о внутреннем устройстве системы — о количестве
серверов, об их адресах и особенностях — всю эту информацию знает только
балансировщик. Однако недостаток в том, что балансирующий узел является единой
точкой отказа системы — если он выйдет из строя, вся система окажется
неработоспособна. Кроме того, при большой нагрузке балансировщик может просто перестать
справляться со своей работой, поэтому такой подход применим не всегда. - Балансировка на стороне клиента. Если мы хотим избежать
единой точки отказа, существует альтернативный вариант — поручить выбор сервера
самому клиенту. В этом случае клиент должен знать о внутреннем устройстве нашей
системы, чтобы уметь правильно выбирать, к какому серверу обращаться.
Несомненным плюсом является отсутствие точки отказа — при отказе одного из
серверов клиент сможет обратиться к другим. Однако платой за это является
усложнение логики клиента и меньшая гибкость балансировки.
 Однако недостаток в том, что балансирующий узел является единой
Однако недостаток в том, что балансирующий узел является единойРазумеется, существуют и комбинации этих подходов. Например,
такой известный способ распределения нагрузки, как DNS-балансировка, основан на
том, что при определении IP-адреса сайта клиенту выдается
адрес одного из нескольких одинаковых серверов. Таким образом, DNS выступает в
Таким образом, DNS выступает в
роли балансирующего узла, от которого клиент получает «распределение». Однако
сама структура DNS-серверов предполагает отсутствие точки отказа за счет
дублирования — то есть сочетаются достоинства двух подходов. Конечно, у такого
способа балансировки есть и минусы — например, такую систему сложно динамически
перестраивать.
Работа с сайтом обычно не ограничивается одним запросом.
Поэтому при проектировании важно понять, могут ли последовательные запросы
клиента быть корректно обработаны разными серверами, или клиент должен быть
привязан к одному серверу на время работы с сайтом. Это особенно важно, если на
сайте сохраняется временная информация о сессии работы пользователя (в этом
случае тоже возможно свободное распределение — однако тогда необходимо хранить
сессии в общем для всех серверов хранилище). «Привязать» посетителя к
конкретному серверу можно по его IP-адресу (который, однако, может меняться),
или по cookie (в которую заранее записан идентификатор сервера), или даже
просто перенаправив его на нужный домен.
С другой стороны, вычислительные сервера могут быть и не равноправными.
В некоторых случаях выгодно поступить наоборот, выделить отдельный сервер для
обработки запросов какого-то одного типа — и получить вертикальное разделение
функций. Тогда клиент или балансирующий узел будут выбирать сервер в
зависимости от типа поступившего запроса. Такой подход позволяет отделить
важные (или наоборот, не критичные, но тяжелые) запросы от остальных.
Распределение данных
Мы научились распределять вычисления, поэтому большая
посещаемость для нас не проблема. Однако объемы данных продолжают расти,
хранить и обрабатывать их становится все сложнее — а значит, пора строить
распределенное хранилище данных. В этом случае у нас уже не будет одного или
нескольких серверов, содержащих полную копию базы данных. Вместо этого, данные
будут распределены по разным серверам. Какие возможны схемы распределения?
- Вертикальное распределение (vertical partitioning) — в простейшем случае
представляет собой вынесение отдельных таблиц базы данных на другой сервер. При
этом нам потребуется изменить скрипты, чтобы обращаться к разным серверам за
разными данными. В пределе мы можем хранить каждую таблицу на отдельном сервере
(хотя на практике это вряд ли будет выгодно). Очевидно, что при таком
распределении мы теряем возможность делать SQL-запросы, объединяющие данные из
двух таблиц, находящихся на разных серверах. При необходимости можно реализовать
логику объединения в приложении, но это будет не столь эффективно, как в СУБД.
Поэтому при разбиении базы данных нужно проанализировать связи между таблицами,
чтобы разносить максимально независимые таблицы.Более сложный случай
вертикального распределения базы — это декомпозиция одной таблицы, когда часть
ее столбцов оказывается на одном сервере, а часть — на другом. Такой прием
встречается реже, но он может использоваться, например, для отделения маленьких
и часто обновляемых данных от большого объема редко используемых. - Горизонтальное распределение (horizontal partitioning) — заключается в
распределении данных одной таблицы по нескольким серверам. Фактически, на
каждом сервере создается таблица такой же структуры, и в ней хранится
определенная порция данных. Распределять данные по серверам можно по разным
критериям: по диапазону (записи с id < 100000 идут на сервер А, остальные — на сервер Б), по списку значений (записи типа «ЗАО» и «ОАО» сохраняем на сервер
А, остальные — на сервер Б) или по значению хэш-функции от некоторого поля
записи. Горизонтальное разбиение данных позволяет хранить неограниченное
количество записей, однако усложняет выборку. Наиболее эффективно можно выбирать
записи только когда известно, на каком сервере они хранятся.
 При
При
Для выбора правильной схемы распределения данных необходимо
внимательно проанализировать структуру базы. Существующие таблицы (и, возможно,
отдельные поля) можно классифицировать по частоте доступа к записям, по частоте
обновления и по взаимосвязям (необходимости делать выборки из нескольких
таблиц).
Как упоминалось выше, кроме базы данных сайту часто требуется
хранилище для бинарных файлов. Распределенные системы хранения файлов
(фактически, файловые системы) можно разделить на два класса.
- Работающие на уровне операционной системы. При этом для
приложения работа с файлами в такой системе не отличается от обычной работы с
файлами. Обмен информацией между серверами берет на себя операционная система.
В качестве примеров таких файловых систем можно привести давно известное
семейство NFS или менее известную, но более современную систему Lustre. - Реализованные на уровне приложения распределенные
хранилища подразумевают, что работу по обмену информацией производит само
приложение. Обычно функции работы с хранилищем для удобства вынесены в
отдельную библиотеку. Один из ярких примеров такого хранилища — MogileFS, разработанная
создателями LiveJournal. Другой распространенный пример — использование
протокола WebDAV и поддерживающего его хранилища.
 Другой распространенный пример — использование
Другой распространенный пример — использованиеНадо отметить, что распределение данных решает не только
вопрос хранения, но и частично вопрос распределения нагрузки — на каждом
сервере становится меньше записей, и потому обрабатываются они быстрее.
Сочетание методов распределения вычислений и данных позволяет построить
потенциально неограниченно-масштабируемую архитектуру, способную работать с
любым количеством данных и любыми нагрузками.
Выводы
Подводя итог сказанному, сформулируем выводы в виде кратких тезисов.
- Две основные (и связанные между собой) задачи масштабирования — это распределение вычислений и распределение данных
- Типичная архитектура сайта подразумевает разделение ролей и
включает frontend, backend, базу данных и иногда хранилище файлов - При небольших объемах данных и больших нагрузках применяют
зеркалирование базы данных — синхронную или асинхронную репликацию - При больших объемах данных необходимо распределить базу данных — разделить
ее вертикально или горизонтально - Бинарные файлы хранятся в распределенных файловых системах
(реализованных на уровне ОС или в приложении) - Балансировка (распределение запросов) может быть равномерная или
с разделением по функционалу; с балансирующим узлом, либо на стороне клиента - Правильное сочетание методов позволит держать любые нагрузки 😉
Ссылки
Продолжить изучение этой темы можно на интересных англоязычных сайтах и блогах:
- http://www. highscalability.com/
- http://www.royans.net/arch/
- http://poorbuthappy.com/ease/… -bloglines-vox-and-more
- http://www.possibility.com/epowiki/Wiki.jsp?page=Scalability
 highscalability.com/
highscalability.com/P.S. Комментарии, конечно, приветствуются 😉
Что означает масштабируемость для систем и служб?
Масштабируемая система — это система, способная справляться с быстрыми изменениями рабочих нагрузок и требований пользователей. Масштабируемость — это мера того, насколько хорошо система реагирует на изменения, добавляя или удаляя ресурсы для удовлетворения потребностей. Архитектура — это оборудование, программное обеспечение, технологии и передовой опыт, используемые для построения сетей, приложений, процессов и служб, из которых состоит вся ваша система.
Ваша система, включающая архитектуру, услуги, продукты и все, что определяет ваш бренд, считается масштабируемой, когда:
- Он может добавлять ресурсы и масштабироваться, чтобы беспрепятственно справляться с растущим спросом клиентов и большими рабочими нагрузками.
- Он может легко и беспрепятственно удалять ресурсы при снижении спроса и рабочих нагрузок.

Идея состоит в том, чтобы построить систему, которая может регулировать производительность в соответствии с постоянно меняющимся спросом. Система должна быть высокодоступной, и она должна быть доступна для всех ваших клиентов в любое время и в любом месте.
Например, хорошо спроектированный, масштабируемый веб-сайт будет одинаково хорошо работать независимо от того, одновременно к нему обращаются один или несколько тысяч пользователей. Не должно быть никакого заметного снижения функциональности по мере входа в систему большего количества пользователей.
Что такое шаблон масштабируемости?
Вы когда-нибудь играли с кубиками LEGO®? Может быть, вы пытались построить конструкцию, не следуя инструкциям, только для того, чтобы она рухнула? Но когда вы следовали тщательно проиллюстрированным инструкциям, у вас получалась прочная конструкция, которая разрушилась бы, только если бы вы намеренно раздвинули кирпичи. Методы строительства, показанные в инструкциях, были протестированы и доказали свою эффективность в решении общих структурных проблем, с которыми сталкиваются многие строители.
Методы строительства, показанные в инструкциях, были протестированы и доказали свою эффективность в решении общих структурных проблем, с которыми сталкиваются многие строители.
Архитектурные шаблоны при разработке компьютеров аналогичны методам сборки LEGO®, описанным в инструкциях. Они представляют собой набор методов разработки и программирования, которые доказали свою эффективность в решении общих проблем при разработке компьютерных систем. Эти шаблоны имеют хорошую структуру проектирования, имеют четко определенные свойства и успешно решали проблемы в прошлом.
Но это не значит, что вам подойдет любой шаблон масштабируемости. Ваша задача состоит в том, чтобы выбрать подходящие шаблоны и адаптировать их для решения проблем, уникальных для вашей системы. Шаблоны масштабируемости экономят ваше время, потому что большая часть работы уже сделана за вас.
Какие существуют общие шаблоны масштабируемости?
На выбор предлагается несколько шаблонов масштабируемой архитектуры. Здесь мы обсудим некоторые из наиболее распространенных шаблонов, используемых для решения проблем архитектурного масштабирования.
Здесь мы обсудим некоторые из наиболее распространенных шаблонов, используемых для решения проблем архитектурного масштабирования.
Масштабный куб AKF
Это трехмерная модель, определяющая три подхода к масштабированию по осям X, Y и Z.
Масштабирование по оси X
Ось X описывает масштабирование через несколько экземпляров одного и того же компонента. Вы делаете это путем клонирования или репликации службы, приложения или набора данных за балансировщиком нагрузки. Итак, если у вас N клонов запущенного приложения, каждый экземпляр обрабатывает 1/ N нагрузки.
Шаблоны масштабирования по оси X просты в реализации и повышают масштабируемость транзакций. Но их обслуживание может быть дорогостоящим, поскольку целые наборы данных реплицируются на несколько серверов, а кэши данных растут в геометрической прогрессии.
Масштабирование по оси Y
Масштабирование по оси Y определяется разделением или сегментацией разнородных компонентов на несколько макро- или микросервисов по границам глаголов или существительных. Например, сегмент на основе глагола может определять такую услугу, как проверка. Сегмент, основанный на существительном, может описывать корзину.
Например, сегмент на основе глагола может определять такую услугу, как проверка. Сегмент, основанный на существительном, может описывать корзину.
Каждая служба может масштабироваться независимо, что позволяет применять больше ресурсов только к тем службам, которые в данный момент в них нуждаются. Чтобы обеспечить высокую доступность, каждая служба должна иметь собственный набор данных без общего доступа.
Индивидуальные наборы данных помогают локализовать сбои, чтобы можно было быстро и легко диагностировать и устранять проблемы без сканирования всей системы. Но ось Y требует много времени для настройки и не очень проста в реализации.
Масштаб по оси Z
В то время как ось Y разделяет непохожие компоненты, ось Z используется для сегментации похожих компонентов в вашей системе. На каждом сервере выполняется идентичная копия кода, но только для подмножества (или сегмента) этих данных.
Обычно разделение по оси Z используется для клиентов по географическому местоположению или клиентов по типу. Например, платные клиенты новостного сайта с подпиской могут иметь неограниченный круглосуточный доступ ко всему контенту сайта. Платные клиенты того же сайта имеют доступ к тем же данным, но они могут быть ограничены открытием и чтением только трех или четырех статей в месяц.
Например, платные клиенты новостного сайта с подпиской могут иметь неограниченный круглосуточный доступ ко всему контенту сайта. Платные клиенты того же сайта имеют доступ к тем же данным, но они могут быть ограничены открытием и чтением только трех или четырех статей в месяц.
Эта настройка может снизить эксплуатационные расходы, поскольку сегменты данных меньше и требуют меньше ресурсов хранения. Но ось Z требует много времени для проектирования и реализации и требует большой автоматизации для снижения накладных расходов системы.
Горизонтальные и вертикальные шаблоны масштабируемости
Масштабирование можно увеличивать (по вертикали) или уменьшать (по горизонтали).
Вертикальное масштабирование
Вертикальное масштабирование — это увеличение возможностей компонента, например сервера, для повышения его производительности. Например, чем больше трафика попадает на ваш сервер, тем ниже его производительность. Добавление большего количества ОЗУ и накопителей повышает производительность сервера, поэтому он может легче справляться с возросшим трафиком.
Вертикальное масштабирование легко внедрить, сэкономить деньги, поскольку не нужно покупать новые ресурсы, и его легко поддерживать. Но они могут быть единой точкой отказа, что может привести к значительному простою.
Компания, только начинающая свою деятельность, может использовать вертикальное масштабирование для снижения затрат. Но вертикальный подход в конечном итоге приведет к ограничению ОЗУ и хранилища, и вам потребуется добавить больше ресурсов, чтобы не отставать от спроса.
Горизонтальное масштабирование
Горизонтальное масштабирование — это увеличение производительности за счет добавления ресурсов того же типа в систему. Например, вместо увеличения мощности одного сервера для повышения его производительности вы добавляете в систему дополнительные серверы. Балансировщик нагрузки помогает распределять нагрузку на разные серверы в зависимости от их доступности. Это повышает общую производительность системы.
Больше вычислительных ресурсов означает большую отказоустойчивость и меньший риск простоя. Но добавление серверов и балансировщиков нагрузки может быть дорогостоящим. Вам следует рассмотреть возможность использования комбинации локальных и облачных ресурсов для обработки возросшего трафика.
Но добавление серверов и балансировщиков нагрузки может быть дорогостоящим. Вам следует рассмотреть возможность использования комбинации локальных и облачных ресурсов для обработки возросшего трафика.
Балансировка нагрузки
Балансировщики нагрузки эффективно распределяют пользовательские запросы и рабочие нагрузки по группе внутренних серверов. Идея состоит в том, чтобы сбалансировать работу между различными ресурсами, чтобы ни один ресурс не был перегружен. Балансировка нагрузки помогает вашему ИТ-отделу обеспечить доступность и масштабируемость ваших сервисов.
В задачи балансировщика нагрузки входят:
- Определение доступных ресурсов в системе.
- Проверьте работоспособность ресурсов, чтобы определить, какие ресурсы не только доступны, но и правильно ли они работают для обработки рабочей нагрузки. Если доступный сервер поврежден, балансировщик нагрузки должен перекрыть путь к нему и переключиться на другой сервер так, чтобы пользователь не заметил каких-либо задержек или простоев.
- Определите, какой алгоритм следует использовать для балансировки работы между несколькими работоспособными внутренними серверами.

Общие методы (алгоритмы) балансировки нагрузки включают:
- Метод наименьшего количества соединений : Трафик направляется на сервер с наименьшим количеством активных соединений.
- Метод наименьшего времени отклика : Балансировщик нагрузки измеряет количество времени, которое требуется серверу для ответа на запрос мониторинга работоспособности. Трафик отправляется на самый работоспособный сервер с наименьшим временем отклика. Некоторые балансировщики нагрузки будут учитывать активные соединения с этим алгоритмом.
- Метод циклического перебора : Трафик отправляется на первый доступный сервер независимо от его текущей рабочей нагрузки и активных подключений. После того, как этот сервер получает и обрабатывает запрос, балансировщик нагрузки перемещает его в конец очереди. Риск заключается в том, что сервер, который получает запросы с интенсивным использованием процессора, может все еще усердно работать над предыдущими запросами, когда он снова достигает вершины очереди.
- Методы хеширования : Решение о том, какой сервер получит запрос, зависит от хэша данных из входящего пакета. Эти данные могут включать такую информацию, как IP-адрес, номер порта или доменное имя.
 Риск заключается в том, что сервер, который получает запросы с интенсивным использованием процессора, может все еще усердно работать над предыдущими запросами, когда он снова достигает вершины очереди.
Риск заключается в том, что сервер, который получает запросы с интенсивным использованием процессора, может все еще усердно работать над предыдущими запросами, когда он снова достигает вершины очереди.Кэширование — Сети доставки контента (CDN)
CDN — это глобальная сеть серверов, которые используются для оптимизации и ускорения доступа к статическим веб-ресурсам и их распространения. Статические свойства — это такие вещи, как Javascript, CSS, изображения и другие медиафайлы, которые меняются не очень часто.
До 80% веб-сайта может состоять из статического контента. Например, видео, доступные в потоковом сервисе, меняются не очень часто. Некоторые из их видео становятся очень популярными и могут набирать миллионы просмотров каждый день. Разгрузка этого статического контента в CDN снижает нагрузку на исходный сервер, улучшает контент в глобальном масштабе и перемещает данные ближе к клиентам, делая их легкодоступными и высокодоступными.
Разгрузка этого статического контента в CDN снижает нагрузку на исходный сервер, улучшает контент в глобальном масштабе и перемещает данные ближе к клиентам, делая их легкодоступными и высокодоступными.
Микросервисы
Микросервисы — это, по сути, набор различных небольших приложений, которые могут работать вместе. Каждый микросервис имеет свою цель и ответственность. И несколько разных команд могут разрабатывать их независимо от других микросервисов. Функционирование микросервисов не зависит друг от друга, но они должны иметь возможность взаимодействовать друг с другом.
Микросервисы легко масштабировать, потому что вам нужно масштабировать только те из них, которые в данный момент в этом нуждаются. Их можно развертывать самостоятельно, без согласования с различными командами разработчиков. Микросервисы хорошо подходят для веб-приложений, быстрой разработки и развертывания, а также для команд, разбросанных по всему миру.
Микросервисы эффективно масштабируют транзакции, большие наборы данных и помогают вам создавать изоляцию сбоев, что обеспечивает высокую доступность ваших систем. Кроме того, поскольку большие разрозненные функции могут быть разбиты на более мелкие сервисы, сложность вашей кодовой базы снижается.
Кроме того, поскольку большие разрозненные функции могут быть разбиты на более мелкие сервисы, сложность вашей кодовой базы снижается.
Разделение
По сути, это разделение большой базы данных на более мелкие, более управляемые и масштабируемые компоненты. Когда база данных становится больше, в ней выполняется больше запросов и транзакций. Это замедляет время ответа на запросы к базе данных. А поддерживать огромную базу данных может быть очень дорого.
Осколок — это отдельный раздел базы данных. Чтобы распределить рабочую нагрузку, эти разделы могут существовать на нескольких распределенных серверах баз данных и распределяться между ними.
Вы можете захотеть использовать сегментирование, когда ваши базы данных становятся слишком большими, потому что:
- Небольшими базами данных легче управлять.
- Небольшие базы данных работают быстрее, и каждый отдельный фрагмент может превзойти по производительности одну большую базу данных.
- Базы данных меньшего размера легче масштабировать, так как новые сегменты данных можно создавать и распределять между несколькими серверами.
- Шардинг может снизить затраты, потому что вам не нужны огромные и дорогие серверы для их размещения.

Реализация шаблонов масштабируемой архитектуры в вашей системе должна помочь вашей системе поддерживать свою производительность при увеличении входной нагрузки.
Что такое масштабируемость? — Определение из SearchDataCenter.com
По
- Участник TechTarget
В информационных технологиях масштабируемость (часто пишется как масштабируемость ) имеет два значения:
1) Способность компьютерного приложения или продукта (аппаратного или программного обеспечения) продолжать нормально функционировать, когда оно (или его контекст) изменяется в размере или объеме для удовлетворения потребности пользователя. Как правило, масштабирование выполняется до большего размера или объема. Масштабирование может быть самого продукта (например, линейка компьютерных систем разного размера с точки зрения хранилища, оперативной памяти и т. д.) или перемещения масштабируемого объекта в новый контекст (например, новую операционную систему). .
Как правило, масштабирование выполняется до большего размера или объема. Масштабирование может быть самого продукта (например, линейка компьютерных систем разного размера с точки зрения хранилища, оперативной памяти и т. д.) или перемещения масштабируемого объекта в новый контекст (например, новую операционную систему). .
Пример: Джон Янг в своей книге Изучение мэйнфреймов IBM New-Age описывает операционную систему RS/6000 SP как систему, обеспечивающую масштабируемость («способность сохранять уровни производительности при добавлении дополнительных процессоров»). Другой пример: в печати масштабируемые шрифты — это шрифты, размер которых можно уменьшить или увеличить с помощью программного обеспечения без потери качества.
2) Это способность не только хорошо функционировать в масштабируемой ситуации, но и в полной мере использовать ее преимущества. Например, прикладная программа была бы масштабируемой, если бы ее можно было перенести из операционной системы меньшего размера в операционную систему большего размера и в полной мере воспользоваться преимуществами большей операционной системы с точки зрения производительности (время отклика пользователя и т. д.) и большего числа пользователей, которые можно было справиться.
д.) и большего числа пользователей, которые можно было справиться.
Обычно легче обеспечить масштабируемость вверх, чем вниз, поскольку разработчики часто должны полностью использовать ресурсы системы (например, объем доступного дискового пространства) при первоначальном написании кода приложения. Снижение масштаба продукта может означать попытку достичь тех же результатов в более ограниченной среде.
Последнее обновление: июнь 2021 г.
Продолжить чтение О масштабируемости- Как повысить масштабируемость хранилища?
- Мастер масштабируемости приложений в облачных вычислениях вместе с разработчиками
- Коронавирус тестирует масштабируемость облачных сервисов совместной работы
- Как сегментация блокчейна решает проблему масштабируемости блокчейна
- Что поставщики подразумевают под «масштабируемостью»?
масштабируемое хранилище
Автор: Пол Кирван
Уроки Readability Consortium для маркетингового контента
Автор: Дон Флакингер
шрифт
Автор: Кэти Террелл Ханна
принтер
Автор: Кэти Террелл Ханна
SearchWindowsServer
- Как выполнить резервное копирование и восстановление членства в группе AD
Вы можете решить некоторые проблемы с Active Directory несколькими щелчками мыши, но все становится сложнее, когда они включают много уровней .
.. - Как избежать распространенных проблем с резервным копированием и восстановлением GPO
Объекты групповой политики помогают администраторам контролировать корпоративную среду, но требуется некоторое планирование, чтобы понять, как …
- Освещение конференции Microsoft Ignite 2022
Новости, связанные с постоянно расширяющимся портфелем облачных предложений технологической компании, как ожидается, займут центральное место на …
 ..
..SearchCloudComputing
- С помощью этого руководства настройте базовый рабочий процесс AWS Batch
AWS Batch позволяет разработчикам запускать тысячи пакетов в AWS. Следуйте этому руководству, чтобы настроить этот сервис, создать свой собственный…
- Партнеры Oracle теперь могут продавать Oracle Cloud как свои собственные
Alloy, новая инфраструктурная платформа, позволяет партнерам и аффилированным с Oracle предприятиям перепродавать OCI клиентам в регулируемых .