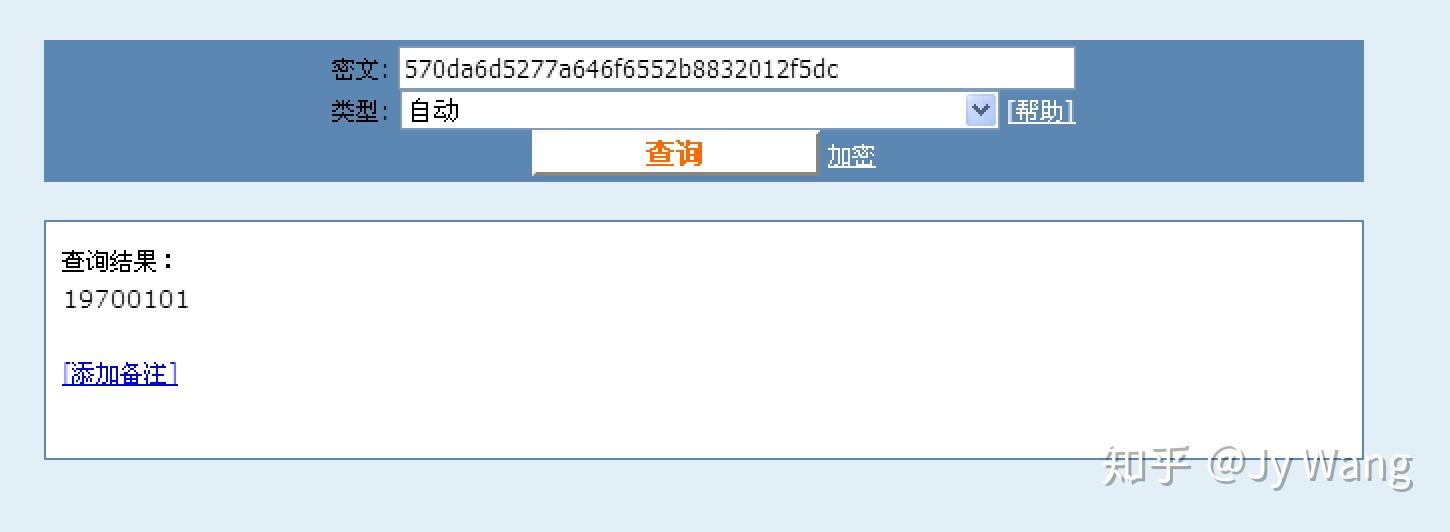
Как проверить MD5 хеш-сумму файла в Windows
Windows, Windows 10, Windows 7, Windows 8, Windows Server, Windows Vista, Windows XP- AJIekceu4
- 01.02.2018
- 81 381
- 12
- 28.05.2020
- 94
- 90
- 4
- Содержание статьи
- Вариант через расширение для проводника
- Вариант через командную строку (без установки программ)
- Вариант через командную строку (с установкой программы)
- Комментарии к статье ( 12 шт )
- Добавить комментарий
В некоторых ситуациях, может быть необходимо, посчитать MD5 хеш-сумму для файла, который вы скачали на свой компьютер.
Вариант через расширение для проводника
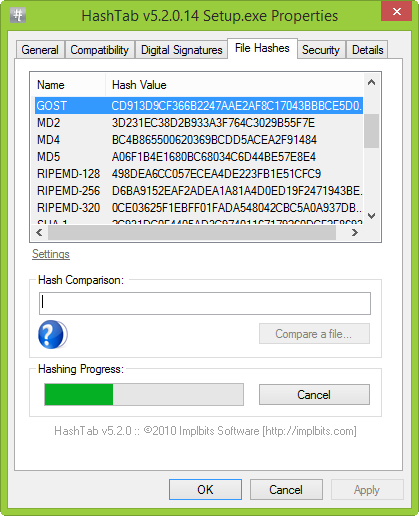
Для проводника Windows существует замечательная программа Hashtab, которая бесплатна для некоммерческого использования. Скачать ее можно с официального сайта. Выбираем бесплатную (Free) версию и жмем на кнопку «Download».
После установки программы, в контекстном меню проводника появится новая вкладка «Хеш-суммы файлов», выбрав которую, программа автоматически посчитает хеш-суммы для выбранного файла в зависимости от того, какие алгоритмы выбраны в ее настройках.
Вариант через командную строку (без установки программ)
В том случае, если вам не хочется устанавливать какие-либо программы, то можно обойтись встроенными средствами Windows, для этого можно воспользоваться утилитой CertUtil.
Для проверки MD5 хеша, достаточно ввести следующую команду:
certutil -hashfile C:\Users\Admin\Downloads\HashTab_v6.0.0.34_Setup.exe MD5
C:\Users\Admin\Downloads\HashTab_v6.0.0.34_Setup.exe — это путь к тому файлу, хеш-сумму которого мы хотим посчитать.
Как видно на скриншоте, хеш-сумма нашего файла 62130c3964… полностью идентична той, которую мы получили с помощью первого способа.
Вариант через командную строку (с установкой программы)
В случае, если необходимо посчитать хеш-сумму файла через командную строку, мы можем воспользоваться утилитой от Microsoft, которая годится как раз для таких случаев. Скачиваем ее с официального сайта Microsoft и устанавливаем. Для этого надо будет создать какую-либо папку на жестком диске и указать ее в процессе установки. В нашем примере, программа была установлена в папку C:\Program Files (x86)\FCIV. Для того, чтобы посчитать MD5 хеш-сумму файла, нам необходимо запусить командную строку и в ней набрать следующую команду:
"C:\Program Files (x86)\FCIV\fciv.exe" -md5 C:\Users\Admin\Downloads\HashTab_v6.0.0.34_Setup.exe
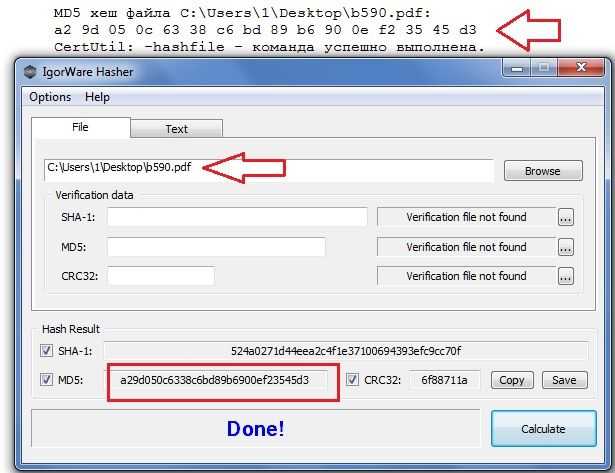
Как видите, MD5 хеш-сумма одинакова как для всех трех способов, которые рассмотрены в данной статье.
"C:\Program Files (x86)\FCIV\fciv.exe" — это путь к файлу fciv.exe-md5 — указание алгоритма по которому fciv.exe будет считать хеш-суммуC:\Users\Admin\Downloads\HashTab_v6.0.0.34_Setup.exe — путь к файлу, для которого мы считаем хеш-сумму.
Сгенерируйте контрольную сумму md5 для всех файлов в каталоге — Yodo.im
yodo.im
#1
Я хотел бы создать список контрольных сумм md5 для всех файлов в каталоге.
Я хочу cat filename | md5sum > ouptput.txt. Я хочу сделать это за 1 шаг для всех файлов в моем каталоге.
Любая помощь была бы очень кстати.
Maxx
Вы можете пройти md5sum несколько имен файлов или расширений bash:
$ md5sum * > checklist.chk # generates a list of checksums for any file that matches *$ md5sum -c checklist.chk # runs through the list to check themcron: OKdatabase.sqlite3: OKfabfile.py: OKfabfile.pyc: OKmanage.py: OKnginx.conf: OKuwsgi.ini: OK
Если вы хотите пофантазировать, вы можете использовать такие вещи, как find для детализации и фильтрации файлов, а также для рекурсивной работы:
find -type f -exec md5sum "{}" + > checklist.chkAlino4ka
#3
Отличная программа для создания / проверки контрольной суммы — это rhash.
Он может создавать файлы, совместимые с SFV, и проверять их тоже.
Он поддерживает md4, md5, sha1, sha512, crc32 и многие другие.
Он может выполнять рекурсивное создание (
-rвариант), какmd5deepилиsha1deep.И последнее, но не менее важное: вы можете отформатировать выходные данные файла контрольной суммы. Например:
rhash --md5 -p '%h,%p\n' -r /home/ > checklist.csv
выводит CSV-файл, включающий полный путь к файлам, рекурсивно начинающийся с
/homeкаталог.
Я также нахожу, что -e возможность переименовывать файлы, вставляя сумму crc32 в имя, чрезвычайно полезна.
Обратите внимание, что вы также можете изменить md5sum с rhash в Примеры PhoenixNL72.
Katya
#4
Вот два более обширных примера:
Создайте файл md5 в каждом каталоге, в котором его еще нет, с абсолютными путями:
find "$PWD" -type d | sort | while read dir; do [ ! -f "${dir}"/@md5Sum. md5 ] && echo "Processing " "${dir}" || echo "Skipped " "${dir}" " @md5Sum.md5 already present" ; [ ! -f "${dir}"/@md5Sum.md5 ] && md5sum "${dir}"/* > "${dir}"/@md5Sum.md5 ; chmod a=r "${dir}"/@md5Sum.md5;done
md5 ] && echo "Processing " "${dir}" || echo "Skipped " "${dir}" " @md5Sum.md5 already present" ; [ ! -f "${dir}"/@md5Sum.md5 ] && md5sum "${dir}"/* > "${dir}"/@md5Sum.md5 ; chmod a=r "${dir}"/@md5Sum.md5;done Создайте файл md5 в каждой папке, в которой его еще нет: никаких путей, только имена файлов:
find "$PWD" -type d | sort | while read dir; do cd "${dir}"; [ ! -f @md5Sum.md5 ] && echo "Processing " "${dir}" || echo "Skipped " "${dir}" " @md5Sum.md5 allready present" ; [ ! -f @md5Sum.md5 ] && md5sum * > @md5Sum.md5 ; chmod a=r "${dir}"/@md5Sum.md5 ;done
 md5 ] && echo "Processing " "${dir}" || echo "Skipped " "${dir}" " @md5Sum.md5 already present" ; [ ! -f "${dir}"/@md5Sum.md5 ] && md5sum "${dir}"/* > "${dir}"/@md5Sum.md5 ; chmod a=r "${dir}"/@md5Sum.md5;done
md5 ] && echo "Processing " "${dir}" || echo "Skipped " "${dir}" " @md5Sum.md5 already present" ; [ ! -f "${dir}"/@md5Sum.md5 ] && md5sum "${dir}"/* > "${dir}"/@md5Sum.md5 ; chmod a=r "${dir}"/@md5Sum.md5;done Разница между 1 и 2 заключается в том, как файлы представлены в результирующем файле md5.
Команды выполняют следующее:
- Создайте список имен каталогов для текущей папки. (Дерево)
- Отсортируйте список папок.
- Проверьте в каждом каталоге, существует ли файл @md5sum.md5. Вывод пропущен, если он существует, обработка вывода, если он не существует.
- Если файл @md5Sum.md5 не существует, md5Sum сгенерирует файл с контрольными суммами всех файлов в папке.5) Установите для сгенерированного файла @md5Sum.md5 значение только для чтения.

>Выходные данные всего этого скрипта могут быть перенаправлены в файл (…..;done test.log) или переданы в другую программу (например, grep).Выходные данные будут сообщать вам только о том, какие каталоги были пропущены, а какие были обработаны.
После успешного запуска вы получите файл @md5Sum.md5 в каждом подкаталоге вашего текущего каталога
Я назвал файл @md5Sum.md5, чтобы он был указан в верхней части каталога в общей папке samba.
Проверка всех файлов @md5Sum.md5 может быть выполнена с помощью следующих команд:
find "$PWD" -name @md5Sum.md5 | sort | while read file; do cd "${file%/*}"; md5sum -c @md5Sum.md5; done > checklog.txtПосле этого вы можете использовать grep для checklog.txt используя grep -v OK, чтобы получить список всех файлов, которые отличаются.
Чтобы повторно создать файл @md5Sum.md5 в определенном каталоге, например, при изменении или добавлении файлов, либо удалите файл @md5Sum.md5, либо переименуйте его и снова запустите команду generate.
Alexandra_S
#5
Я столкнулся с этой проблемой, и хотя вышеприведенные решения элегантны, мне нужен был быстрый и грязный взлом для этой ситуации: 1 каталог с подкаталогами на один уровень глубже внутри него.
Итак, введите каталог в оболочке и запустите:
md5sum * */* 2>/dev/null > md5sum.md5
>Это позволяет получить все файлы в каталоге верхнего уровня, удалить предупреждение об ошибке о том, что подкаталоги являются каталогами, а затем запустить md5sums для содержимого подкаталога. Преимущество: легко запоминается, делает именно то, что должен делать. Я всегда путаюсь в синтаксисе поиска и никогда не могу запомнить его сразу, так что не нужно зацикливаться и т.д., Имея дело с пробелами в именах каталогов, этот лайнер работал нормально. Не надежное мощное решение, не подходит для подкаталогов 1 уровня, но быстрое и простое решение проблемы.
Я всегда путаюсь в синтаксисе поиска и никогда не могу запомнить его сразу, так что не нужно зацикливаться и т.д., Имея дело с пробелами в именах каталогов, этот лайнер работал нормально. Не надежное мощное решение, не подходит для подкаталогов 1 уровня, но быстрое и простое решение проблемы.
Anna4ka
#6
Вот мой:
time find dirname/|xargs md5sum |tee dirname.md5
Он выдает ошибки, когда пытается вычислить его для каталога, но для меня этого достаточно.
Alina_kudry
#7
найди . -введите f -exec md5sum {} > md5sums. txt \;
txt \;
это все, что вам нужно!
Savva_P
#8
Or rather: find . -type f -exec md5sum {} > {}.md5sum \;
Освоение хеш-функций в C: раскрытие тайны SHA-256 и MD5
Фото Pixabay на PexelsПошаговое руководство по внедрению SHA-256 и MD5 в C безопасные транзакции и коммуникации?
Хотите научиться программировать криптографические хеш-функции на C? Не смотрите дальше! В этом руководстве мы рассмотрим внутреннюю работу двух наиболее широко используемых алгоритмов: MD5 и SHA-256. Вы не только узнаете, как работают эти алгоритмы, но и сможете реализовать их самостоятельно. Кроме того, завершенная реализация этих концепций доступна в прилагаемом репозитории GitHub, поэтому вы можете увидеть, как это делается, и начать экспериментировать самостоятельно. Так что присоединяйтесь к нам и расскажите о мире шифрования!
Так что присоединяйтесь к нам и расскажите о мире шифрования!
GitHub — jterrazz/42-ssl-md5: 🔒 Реализация OpenSSL на C. Поддерживает md5, sha1, sha256, sha224…
🔒 Реализация OpenSSL на C. Поддерживает алгоритмы md5, sha1, sha256, sha224 и sha5124 и sha5124 . Средняя статья – это… 9
- Обеспечение целостности сообщений или файлов работа» для использования в криптовалютах, таких как Биткойн и Эфириум
- Генерация и проверка цифровых подписей
Типичная криптографическая функция занимает произвольного размера для ввода и создает хеш фиксированной длины . Например, MD5 создает 128-битные хэши, а SHA-256 — 256-битные хэши. При представлении в шестнадцатеричном виде хэши MD5 имеют длину 16 символов, а хэши SHA-256 имеют длину 32 символа (поскольку две буквы представляют один байт, а один байт равен 8 битам).
Преобразование хэша md5Криптографические хэш-функции обладают несколькими фундаментальными свойствами:
- Детерминизм : Один и тот же ввод всегда дает один и тот же вывод.
- Скорость : Процесс должен иметь возможность быстро вычислять хэши для любого входного размера.
- Односторонность : Должно быть невозможно определить входные данные по хэшу.
- Устойчивость к коллизиям : Криптографическая хеш-функция считается устойчивой к коллизиям, если с вычислительной точки зрения невозможно найти два различных входа, которые производят один и тот же хеш-выход.
- Лавинный эффект : Даже незначительное изменение входных данных должно привести к значительному изменению хэша.

Эти свойства обеспечивают эффективное использование хеш-функций в криптографических целях.
md5
Хотя алгоритм MD5 имеет исторический интерес , он больше не считается безопасным для криптографических целей из-за известных уязвимостей, которые позволяют множеству входных данных производить один и тот же хеш-выход. Тем не менее, его все еще можно использовать для целей, не связанных с криптографией, таких как проверка целостности загруженного файла на предмет непреднамеренного повреждения . Важно отметить, что MD5 не следует использовать для критически важных с точки зрения безопасности приложений.
Важно отметить, что MD5 не следует использовать для критически важных с точки зрения безопасности приложений.
sha256
Семейство криптографических хэш-функций SHA-2, которое включает SHA-256, было разработано как усовершенствование функций SHA-1 и SHA-0. Оба имеют корней в алгоритме MD5 . Таким образом, между различными функциями SHA есть много общего.
Алгоритм SHA-256 считается безопасным, потому что с вычислительной точки зрения невозможно определить входные данные по выходным хэшам. Однако он не рекомендуется для хранения паролей в базах данных из-за его относительно низкой стоимости вычислений, что делает его уязвимым для атак методом перебора и радужных таблиц.
Шаг 1 — Форматирование ввода
Функции перетасовки, используемые в алгоритмах криптографического хеширования, предъявляют особые требования к входному сообщению. В частности, сообщение должно быть разделено на фрагментов по 512 бит , а результирующее отформатированное сообщение должно соответствовать определенным критериям.
Чтобы убедиться, что отформатированное сообщение имеет правильный размер, предпринимаются следующие шаги:
- В конец сообщения добавляется бит «1», и достаточно « Нулевые биты добавляются, чтобы сделать длину отформатированного сообщения кратной (512–64) битам.
- Размер исходного сообщения сохраняется в 64-битном формате в оставшемся пространстве в конце отформатированного сообщения.
Затем длину отформатированного сообщения можно рассчитать по следующей формуле: выровнено = (nb + (X-1)) & ~(X-1) байтов ‘X’.
Функция build_msg также может иметь параметр is_little_endian, указывающий порядок байтов входного сообщения. Endianness относится к порядку, в котором биты хранятся в памяти, и может быть либо с прямым порядком байтов или с прямым порядком байтов . Вы можете узнать больше о порядке байтов в этой статье:
Little & Big Endian
Little и Big Endian — это два способа хранения многобайтовых типов данных (int, float и т.
 д.). В машинах с прямым порядком следования порядков байтов, последний…
д.). В машинах с прямым порядком следования порядков байтов, последний…medium.com
Чтобы преобразовать 64-битное число из одного порядка байтов в другой , вы можете использовать следующую функцию:
Алгоритм перетасовки работает путем итеративного инвертирования маленьких группы двухбайтовых соседей , начиная с самой маленькой группы и постепенно расширяясь до более крупных групп.
bswap(uint64_t)Шаг 2 — Перетасовка данных
Этапы перетасовки для алгоритмов криптографического хеширования немного различаются в зависимости от того, используете ли вы MD5 или SHA-256 . Однако в обоих случаях сообщение делится на 512-битные куски.
Алгоритм использует 32-битных буферов для хранения данных (4 для MD5 и 8 для SHA-256). Для каждого фрагмента алгоритм выполняет математические операции с этими буферами, которые изменяют их состояние. Хотя детали этих операций могут быть сложными, вы можете узнать о них больше в следующих статьях или изучив реализацию в моем проекте: SHA-256 и MD5.
MD5 — Википедия
Алгоритм дайджеста сообщения MD5 — это широко используемая хеш-функция, производящая 128-битное хэш-значение. Хотя MD5 был…
en.wikipedia.org
SHA-2 — Википедия
SHA-256 участвует в процессе аутентификации программных пакетов Debian и в стандарте подписи сообщений DKIM…
en.wikipedia.org
Последний шаг — построить хэш из буферов
После шага перетасовки алгоритм возвращает 4 (или 8 для SHA-256) буферов, которых может быть используется для создания читаемого хэша . Для получения хэша эти буферы объединяются, используя их шестнадцатеричное представление .
Еще одна проблема, которую следует учитывать при использовании алгоритма MD5: буферы имеют формат с прямым порядком байтов , что означает, что биты должны быть инвертированы для 32-битных чисел, чтобы печатать их в правильном порядке.
Вам нужна помощь в реализации SHA-256? Ознакомьтесь с этим пошаговым руководством, чтобы получить полезную информацию о процессе.
SHA-256
Не полагайтесь на результаты этого инструмента. Гарантия не подразумевается. Инструкции: Начните здесь, в «пользовательском интерфейсе»…
docs.google.com
Я надеюсь, что это руководство дало вам четкое представление о криптографических функциях. Если вы хотите увидеть полную реализацию этих концепций, обязательно ознакомьтесь с моим кодом на GitHub. И не стесняйтесь обращаться, если у вас есть какие-либо вопросы или вам нужны дополнительные рекомендации. Удачного кодирования!
Устали поддерживать крупные корпорации каждый раз, когда делаете покупки в Интернете? Перейти на open.mt, децентрализованная торговая площадка, использующая технологию блокчейн для обеспечения одноранговой торговли без посредников . Вы можете не только получать более выгодные цены и более быстрые транзакции, но и поддерживать своих местных продавцов и поддерживать процветание своего сообщества.
Следите за новостями о нашем прогрессе, и станьте первым, кто присоединится к open. mt сообществу , когда мы запустим. Я ценю вашу поддержку, и мы не можем дождаться, чтобы приветствовать вас на нашем открытом рынке!
mt сообществу , когда мы запустим. Я ценю вашу поддержку, и мы не можем дождаться, чтобы приветствовать вас на нашем открытом рынке!
Технологии открытого рынка
Поддержите свое сообщество и совершайте покупки на месте с open.mt! Наш децентрализованный рынок использует технологию блокчейна для P2P…
blog.open.mt
Реализация быстрого хэша MD5 в сборке x86
Ради эксперимента я хотел посмотреть, насколько я могу оптимизировать свою реализацию хеш-функции x86 MD5 для увеличения скорости. Я начал с довольно простой наивной реализации, затем переупорядочил инструкции и сделал эквивалентные логические преобразования. Каждый успешный трюк с оптимизацией добавлял несколько МБ/с скорости, но после почти сотни попыток (из которых около 20 были успешными) общий результат был ошеломляющим 59.% увеличения скорости.
Исходный код
Код состоит из нескольких частей:
Три взаимозаменяемые версии функции сжатия MD5:
- В сборке x86, наивно (md5-naive-x86. S).
- В сборке x86, после обширной оптимизации (md5-fast-x86.S).
- В C, для сравнения с x86-версией (md5.c).
- В сборке x86, наивно (md5-naive-x86.
Полная хеш-функция MD5 (на C), которая обрабатывает разбиение блока и заполнение хвоста. Это не нагружает ЦП, потому что его работа заключается только в настройке соответствующих данных для обработки функцией сжатия.
Запускаемая основная программа, которая проверяет правильность и выполняет тест скорости.
Файлы:
- md5-test.c
- md5.c
- md5-наивный-x86.S
- md5-быстро-x86.S
- md5-быстро-x8664.S
Чтобы использовать этот код, скомпилируйте его в Linux с помощью одной из следующих команд:
-
куб.см md5-test.c md5.c -o md5-test(х86, х86-64) -
cc md5-test.c md5-naive-x86.S -o md5-test(только x86) -
cc md5-test.c md5-fast-x86.S -o md5-test(только x86) -
cc md5-test.(только x86-64) c md5-fast-x8664.S -o md5-test
 c md5-fast-x8664.S -o md5-test
c md5-fast-x8664.S -o md5-test Затем запустите исполняемый файл с помощью ./md5-test .
Результаты тестов
| Код | Сборник | Скорость на x86 | Скорость на x86-64 |
|---|---|---|---|
| C | GCC -O0 | 122 MiB/s | 123 MiB/s |
| C | GCC -O1 | 379 MiB/s | 390 MiB/s |
| C | GCC -O2 | 387 MiB/s | 389 MiB/s |
| C | GCC -O3 | 387 MiB/s | 389 MiB/s |
| C | GCC -O1 -fomit-frame-pointer | 382 MiB/s | |
| C | GCC -O2 -fomit-frame-pointer | 389 MiB/s | |
| C | GCC -O3 -fomit-frame-pointer | 390 MiB/s | |
| Assembly (naive) | GCC -O0 | 270 MiB/s | |
| Assembly (fast) | GCC -O1 | 430 МБ/с | |
| Assembly (fast) | GCC -O2 | 427 MiB/s | |
| Assembly (OpenSSL [0] ) | GCC -O0 | 410 MiB/s |
На обеих архитектурах ЦП мой ассемблерный код примерно в 1,10 раза быстрее, чем мой код C, лучше всего скомпилированный GCC.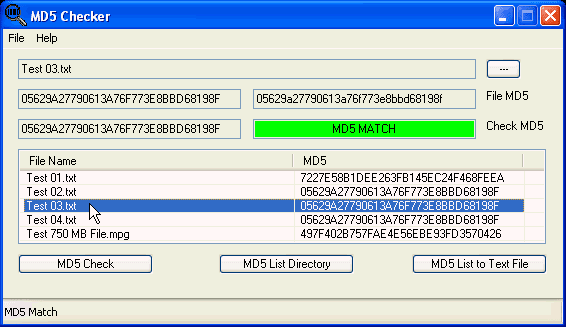 Более того, код C и ассемблерный код, скомпилированные с различными опциями, имеют одинаковую скорость на обеих архитектурах.
Более того, код C и ассемблерный код, скомпилированные с различными опциями, имеют одинаковую скорость на обеих архитектурах.
Все приведенные выше результаты тестов основаны на следующем: ЦП = Intel Core 2 Quad Q6600 2,40 ГГц (однопоточный), ОС = Ubuntu 10.04 (32-разрядная и 64-разрядная), компилятор = GCC 4.4.3.
Примечания
Мой первоначальный наивный код уже был развернут циклически. Поскольку моей целью была оптимизация по скорости, было бы бессмысленно начинать с реализации, которая по-прежнему связана с накладными расходами на управление циклами.
Я был удивлен, увидев, что мой наивный код x86 работал намного медленнее, чем сгенерированный код GCC, и что мой окончательный оптимизированный вручную код был не намного быстрее, чем лучший код GCC.
Иногда добавление дополнительных инструкций и выполнение больше арифметических вычислений приводит к более быстрому коду. Я думаю, это сработало, потому что я сделал график зависимости данных более мелким и воспользовался преимуществами суперскалярного процессора.
При наличии нескольких потоков инструкций, выполняющих независимые вычисления, использование различных способов их чередования очень важно для повышения производительности суперскалярного процессора.
Злоупотребление инструкцией LEA для добавления двух регистров и константы — классический прием оптимизации с предсказуемым улучшением.
У меня было достаточно регистров для хранения всех соответствующих значений (4 для состояния MD5, 2 для промежуточных вычислений за раунд, 1 для основания массива блоков и 1 для стека), что определенно сделало код короче и Быстрее. Однако я не использовал регистр EBP обычным способом.
Обе мои реализации MD5 для x86 и C используют макросы препроцессора C для генерации повторяющегося кода.
Код x86-64: Все файлы C работают правильно без изменений на x86-64. Я внес минимальные изменения в ассемблерный код только для того, чтобы адаптироваться к соглашению о вызовах и заменить 32-битные константы числами со знаком.