Почему позиции сайта постоянно меняются? – Вопросы о SEO – АлаичЪ и Ко
Позиции сайта по какому-то конкретному запросу или вообще абстрактному множеству запросов изменяются с течением времени – это надо принять как данность и смириться.
И все же, какие причины постоянного изменения позиций?
- Примерно до 2011 года позиции сайтов в выдаче Яндекса изменялись только в определенные даты – так называемые, апдейты поисковой выдачи или просто «апы» – когда поисковик обновлял состав базы данных документов, обновлял характеристики сайтов и т.д. Происходило это с различной частотой – от 2 раз в неделю, до нескольких раз в месяц.
На сегодняшний день апдейты никуда не делись и случаются со стабильной частотой 2 раза в неделю, именно в эти даты новые документы или изменения уже существующих документов попадают в поисковый индекс и их можно найти в поиске. Но серьезного влияния на позиции сайтов они не оказывают. По сравнению с другими обстоятельствами… - Надо иметь ввиду, что на каждом компьютере и независимо от того, авторизованы вы в Яндексе или Google, имеет место быть персонализированная выдача – явление, когда результаты поиска подстраиваются под интересы пользователя, основываясь на его предыдущих сессиях, поведении и посещении различных сайтов.

- В 2015 году Яндекс анонсировал новый подход к определению релевантности документов – «Многорукий бандит». Данный алгоритм занимается ротацией сайтов (документов) в поисковой выдаче с целью сбора определенной информации для сайтов, находящихся за пределами топа. Таким образом в течение дня, даже в течение часа сайты в поиске постоянно меняются местами. В зависимости от типа запроса, региона и других факторов сила и вероятность такого «шторма» меняется.
Именно поэтому анализировать и смотреть позиции сайта необходимо не сиюминутно, а в динамике, наблюдать за тенденцией и средней позицией по запросу. - Все описанное выше применимо в первую очередь для Яндекса. В Google все проще и понятнее. Там нет апдейтов поисковой базы – этот процесс происходит постоянно в реальном времени, поэтому если позиции и будут меняться, то плавно. А персонализация в Google работает по аналогии с Яндексом и при условии авторизации в своем аккаунте.

Вполне резонно вы можете спросить, а почему же определенные сайты по определенному запросу стабильно на первом, втором или третьем месте? В таких случаях это значит, что определенный сайт превосходит своих конкурентов по определенному запросу настолько, что его важность не подвергается сомнению. Это достигается долгой и упорной работой и результат невозможно спрогнозировать.
В связи с множеством неопределенностей, сложностей и ненужных телодвижений мы стараемся убедить всех наших клиентов измерять результат нашей работы не достигнутыми позициями по определенным запросам, а ростом трафика на сайт с поисковых систем. Правда такой подход применим для больших сайтов, например, интернет-магазинов или каталогов, а для небольших сайтов услуг приходится снимать позиции и следить за динамикой.
Правда такой подход применим для больших сайтов, например, интернет-магазинов или каталогов, а для небольших сайтов услуг приходится снимать позиции и следить за динамикой.
Надеемся, это внесло хотя бы немного ясности в нашу мутную деятельность 🙂
Другие вопросы, которые вы часто нам задаете:
- А если мой сайт уже оптимизирован и проведено много работ по seo?
- Почему мой сайт невозможно продвинуть по определенному запросу?
- Какие гарантии при продвижении сайта мы даем?
- Почему позиции сайта постоянно меняются?
- Сколько поисковых запросов мы продвигаем?
- От чего зависит срок продвижения сайта? Когда ждать результат?
- Примерный план продвижения сайта
- Какой бюджет необходим в месяц на контекстную рекламу?
- Из чего складывается стоимость услуг?
- Есть ли отчеты и в какой форме? Как можно контролировать процесс?
Отслеживание SEO поисковых запросов в коллтрекинге
SEO отслеживание поисковых запросов
Яндекс занимает лидирующее место по органическим запросам на сайтах РФ. Последнее время условия, которые диктует Яндекс по отношению к внутренней оптимизации положительно влияют на SEO рынок и качество сайтов. Сайты становятся значительно релевантнее, вступает в дело внутренняя оптимизация — происходит дробление страниц под определенные группы ключевых запросов. Более того, в контекстную рекламу приходит чисто «сеошный» показатель качества. Это не только релевантность посадочной страницы поисковому запросу, но и такой нашумевший показатель как ПФ фактор (пользовательский фактор). Но это отступление. Проблема в том, что с каждым днем становится все сложнее «получать» ключевые слова из поиска Яндекса и Google, и ниже мы расскажем почему.
Последнее время условия, которые диктует Яндекс по отношению к внутренней оптимизации положительно влияют на SEO рынок и качество сайтов. Сайты становятся значительно релевантнее, вступает в дело внутренняя оптимизация — происходит дробление страниц под определенные группы ключевых запросов. Более того, в контекстную рекламу приходит чисто «сеошный» показатель качества. Это не только релевантность посадочной страницы поисковому запросу, но и такой нашумевший показатель как ПФ фактор (пользовательский фактор). Но это отступление. Проблема в том, что с каждым днем становится все сложнее «получать» ключевые слова из поиска Яндекса и Google, и ниже мы расскажем почему.
Бесплатный статический коллтрекинг и виртуальная АТС.
ПодробнееКоллтрекинг по низкочастотным запросам
Недавно в официальном блоге Яндекс Метрики сообщили, что если поисковый запрос насчитывает менее 10 переходов на сайт за 30 дней, то он не будет отображаться в «отчете по ключевым словам». Тоесть, теперь, если пользователь перешел по ультра низкочастотному запросу и совершил звонок, то, к сожалению, кроме «Yandex.Organic» в отчете по коллтрекингу вы не увидите. Теоретически запрос можно получить, но только если увеличить период выборки, что не дает полноценного инструмента отслеживания. Увы, это новая особенность Метрики.
Тоесть, теперь, если пользователь перешел по ультра низкочастотному запросу и совершил звонок, то, к сожалению, кроме «Yandex.Organic» в отчете по коллтрекингу вы не увидите. Теоретически запрос можно получить, но только если увеличить период выборки, что не дает полноценного инструмента отслеживания. Увы, это новая особенность Метрики.
Хотя, если посмотреть на скриншот ниже, то в нем можно понять, что там указаны ультра НЧ запросы. Они насчитывают менее 10 переходов на сайт. Это означает что мы зачастую можем расшифровать запрос.
В Google ситуация еще более запутанная, там с трудом возможно учитывать и обычные ключевые запросы. Их приходится «выдергивать» через Google Analytics, который в свою очередь их берет из Adwords, но большая часть запросов остается зашифрованной.
Если мы не можем определить ультра НЧ запрос?
Если получить НЧ запрос не представляется возможным, то нами был придуман более удобный подход (одновременно для Яндекса и Google).
Поскольку последнее время все запросы обычно ведут на соответствующие релевантные страницы, то понять ключевой запрос не составляет труда, если знать с какой страницы произошел звонок (учитывая что при кластеризации семантика закладывается в текст страницы).
При звонках с органики, помимо попытки отобразить ключевой запрос мы подтягиваем в отчет название (title) страницы. У вас появляется возможность отслеживать поисковые запросы через группу НЧ запросов по странице. Как правильно, НЧ запросы уже не используются в одноцентовых рекламных кампаниях и их собирать уже не имеет смысла, а с точки зрения оптимизации самой РК в поиске, то отдельный ультра НЧ ключевой запрос не представляет ценности. Такой запрос может повториться раз в несколько месяцев, поэтому достаточную информативность представляет понимание именно точки входа и как следствие группы НЧ запросов. Но повторимся, что очень часто мы даже ультра НЧ запросы можем расшифровать.
Как можно экономить пулл номеров на органике?
Мы не рекомендуем использовать данный подход, поскольку пропадает возможность проводить мультиканальную аналитику. Очень часто пользователи сначала приходят на сайт с платных каналов, но возвращаются через поисковую выдачу.
Очень часто пользователи сначала приходят на сайт с платных каналов, но возвращаются через поисковую выдачу.
Если у вас не стоит задачи отслеживать поисковую выдачу и ключевые запросы из органики, а трафика на сайте с Яндекса и Гугла достаточно много, то можно значительно снизить необходимо количество телефонных номеров. В системе можно за каждой поисковой системой закрепить свой «оффлайновый» телефонный номер. Это означает, что к поисковой системе (или обоим поисковым системам) будет привязан только 1 телефонный номер. Когда будет поступать телефонный звонок, то в коллтрекинг отчете будет отображаться также как при треккинге оффлайн рекламы, то есть будет показано «Яндекс Органика», но без ключевого запроса. Вы можете использовать такой подход по отношению к любому виду трафика, если он имеет большую долю в общем трафике вашего сайта и не требует оценки вплоть до ключевого запроса.
Раздел:
Система сквозной аналитики
«Яндекс» описал 2020 год в запросах пользователей :: Общество :: РБК
В марте люди искали также информацию о падении курса рубля и цен на нефть.
В апреле пользователи «Яндекса» интересовались новостями про дело против Олега Тинькова, слухами о смерти Ким Чен Ына и скандалом, разгоревшимся из-за высказывания телеведущей Регины Тодоренко о домашнем насилии.
Читайте на РБК Pro
К началу мая актуальными стали данные о готовящихся выборах в Белоруссии и по-прежнему чаще всего искали информацию о пандемии коронавирусной инфекции. На некоторое время заинтересовал аудиторию поисковика и скандал из-за недвижимости Елены Малышевой. К концу месяца чаще стали искать информацию о движении Black Lives Matters в США, данные о готовящихся изменениях Конституции России, а также информацию о введении электронных медицинских карт в столице.
В июне на второе место по популярности после COVID-19 ненадолго вышло резонансное ДТП с участием Михаила Ефремова, затем этот инфоповод уступил место приближающемуся голосованию о поправках в Конституцию.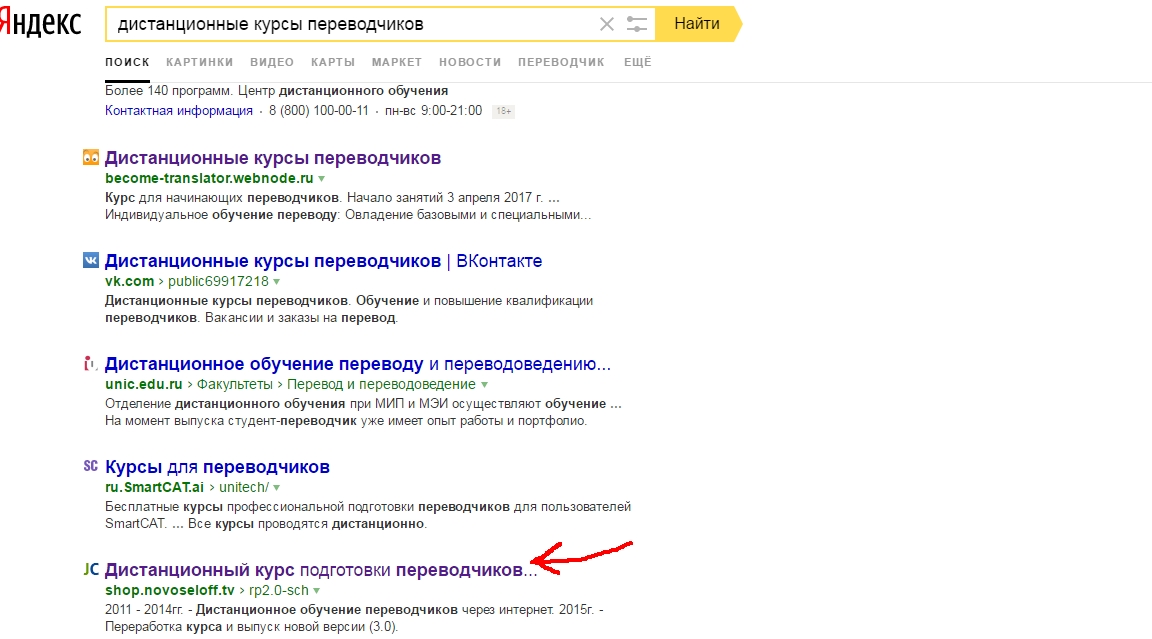 Среди светских новостей россиян больше всего интересовал развод Кристины Асмус и Гарика Харламова, этот запрос на некоторое время вышел в топ-3 тем по популярности. Искали обитатели Рунета также сообщения о вспышке бубонной чумы в Монголии и параде планет, который прошел 4 июля.
Среди светских новостей россиян больше всего интересовал развод Кристины Асмус и Гарика Харламова, этот запрос на некоторое время вышел в топ-3 тем по популярности. Искали обитатели Рунета также сообщения о вспышке бубонной чумы в Монголии и параде планет, который прошел 4 июля.
Начало августа в информационной картине «Яндекса» определили запросы о взрыве в Бейруте, который унес жизни почти 200 человек, затем почти сразу на первое место по числу запросов вышли выборы и последовавшие за эти масштабные протесты в Белоруссии. Интерес к эпидемии коронавирусной инфекции в этот же месяц несколько снизился. Новой темой, интересовавшей россиян, стали экологические протесты в Башкирии, где прошли демонстрации против уничтожения горы Куштау. Конец августа отмечен всплеском интереса к отравлению оппозиционного политика Алексея Навального, которому стало плохо в самолете по пути из Томска в Москву.
Интерес к эпидемии коронавирусной инфекции в этот же месяц несколько снизился. Новой темой, интересовавшей россиян, стали экологические протесты в Башкирии, где прошли демонстрации против уничтожения горы Куштау. Конец августа отмечен всплеском интереса к отравлению оппозиционного политика Алексея Навального, которому стало плохо в самолете по пути из Томска в Москву.
К концу месяца пандемия вновь вышла на первое место в списке интересовавших россиян тем.
В сентябре в «Яндексе» также искали информацию о едином дне голосования и вновь — о ДТП с участием Ефремова, которому вынесли приговор. Из светских новостей россияне заинтересовались отношениями Тарзана и Анастасии Шульженко. В конце сентября вновь разгорелся конфликт в Нагорном Карабахе и число запросов о нем резко возросло. Искали люди также данные о самосожжении журналистки Ирины Славиной и новости о пропавшем во Владимирской области семилетнем мальчике. Мальчика нашли в ноябре, и это также отразилось в «Яндексе».
В октябре больше всего аудиторию интересовали коронавирус и конфликт в Нагорном Карабахе, возрос интерес к приближающимся выборам в США. Кроме того, суд в Москве вынес приговор по делу 72-летней актрисы Натальи Дрожжиной и ее супруга Михаила Цивина, обвиняемых по делу о мошенничестве с недвижимостью и банковскими счетами покойного народного артиста Алексея Баталова, и это отразилось на поисковых запросах.
Темами ноября
В декабре информационная картина изменилась мало: пандемия по-прежнему интересует россиян больше всего, люди все еще ищут информацию о конфликте в Нагорном Карабахе и выборах президента США, а также о деле Михаила Ефремова и протестах в Белоруссии и Хабаровске.
Автор
Наталья Демченкорассказываем, что такое YATI и почему это круто
 В компании называют это самым важным событием в Поиске за последние 10 лет, поэтому мы решили в партнерстве с Яндексом подробнее рассказать, как работает эта технология и зачем она нужна.
В компании называют это самым важным событием в Поиске за последние 10 лет, поэтому мы решили в партнерстве с Яндексом подробнее рассказать, как работает эта технология и зачем она нужна.Что такое YATI
Как говорят о YATI в самом Яндексе — это передовая технология анализа текстов, и на ней уже работает поисковая машина компании. Ключевой элемент YATI — это собственная реализация трансформеров, под которыми имеется в виду общее название популярной нейросетевой архитектуры, лежащей в основе современных подходов к анализу текста. А сама аббревиатура YATI расшифровывается как Yet Another Transformer with Improvements, то есть «Ещё один трансформер с улучшениями».
Что такое трансформеры
Если говорить совсем уж простыми словами, то трансформеры — это сверхбольшие и сверхсложные нейронные сети, которые с легкостью могут справляться с самыми разными задачами в сфере обработки естественного языка — от машинного перевода до генерации текстов. Однако «под капотом» этой «лёгкости» скрываются значительные вычислительные мощности, во много раз превосходящие все то, что было раньше.
Как нам рассказали в Яндексе, нейросеть, которая использовалась в Поиске до обновления, обучалась всего на одном графическом ускорителе Tesla v100 буквально за час. Но если на том же самом ускорителе начать обучать нейросеть-трансформер, то придется ждать целых 10 лет.
Внедрение трансформеров потребовало от Яндекса использования сотен аналогичных ускорителей с реализацией быстрой передачи данных между ними — для этого компания построила специализированный вычислительный кластер с распределенным обучением на нем.
То есть переход на YATI стал для компании еще и сложной инженерной задачей: потребовалось объединить много ускорителей в кластеры, связать их в сеть и разработать для получившихся серверов мощную систему охлаждения.
Нам потребовалось немного времени, пара сотен GPU-карт, место в одном из дата-центров Яндекса и классные инженеры. К счастью, всё это у нас было. Мы собрали несколько версий кластера и успешно запустили на нём обучение. Теперь модель одновременно обучается примерно на 100 ускорителях, которые физически расположены в разных серверах и общаются друг с другом через сеть.
 И даже с такими ресурсами на обучение уходит около месяца, — отметил Александр Готманов, руководитель группы нейросетевых технологий Поиска.
И даже с такими ресурсами на обучение уходит около месяца, — отметил Александр Готманов, руководитель группы нейросетевых технологий Поиска.Преимущества YATI и трансформеров
Как и прежде, Поиск Яндекса, работающий на YATI, сопоставляет семантическую близость запроса и документа. Однако в отличие от предыдущих нейросетевых моделей Яндекса «Палех» и «Королёв», YATI учится предсказывать не клик пользователя, а оценку эксперта, и в этом между ними фундаментальная разница.
Однако YATI на порядок эффективнее предшественников за счет преимуществ трансформеров, и благодаря им Поиск:
- научился работать не только с короткими, такими как запросы или заголовки статей, но и с длинными текстами;
- получил «механизм внимания», который позволяет выделять в тексте самые значимые фрагменты;
- начал обращать внимание на порядок слов и учитывать контекст, то есть то, как слова влияют друг на друга.
Теперь, например, Яндекс поймет, когда вы будете искать билеты на поезд из Курска в Санкт-Петербург, что вам нужно попасть именно из Курска в Санкт-Петербург, а не наоборот.
Также Поиск стал грамотнее распознавать запросы с опечатками, поэтому выдача стала релевантнее:
Что в итоге?
Несмотря на то, что YATI решает похожую задачу, он намного лучше работает со смыслом запроса, а значит значительно точнее понимает, какая конкретно информация будет наиболее релевантной запросу пользователя. Именно поэтому в Яндексе считают внедрение этой технологии самым важным событием в Поиске за последние десять лет.
Это внедрение принесло нам рекордные улучшения в ранжировании за последние 10 лет (со времён внедрения Матрикснета). Просто для сравнения: «Палех» и «Королёв» вместе повлияли на поиск меньше, чем новая модель на трансформерах. Более того, в поиске рассчитываются тысячи факторов, но если выключить их все и оставить только новую модель, то качество ранжирования по основной офлайн-метрике упадёт лишь на 4-5%! — объяснил Александр Готманов.В таблице сравнивается качество нескольких нейросетевых алгоритмов в задаче ранжирования.
 Подробнее здесь
Подробнее здесьАлександр добавил, что применение тяжелых нейросетевых моделей, которые точнее приближают структуру естественного языка и лучше учитывают семантические связи между словами в тексте, поможет пользователям встречаться с эффектом «поиска по смыслу» ещё чаще, чем раньше.
Узнать о YATI во всех технических подробностях, а также о том, какие новшества Яндекс привнес в нейросети-трансформеры, можно по ссылке:
Трансформеры в Поиске: как Яндекс применил тяжёлые нейросети для поиска по смыслу
Привет, Хабр. Меня зовут Саша Готманов, я руковожу группой нейросетевых технологий в поиске Яндекса. На YaC 2020 мы впервые рассказали о внедрении трансформера —…
Яндекс существенно изменяет систему ранжирования. Как подготовить сайт к Яндекс YATI?
Яндекс заявил о внедрении нейросетевой архитектуры для ранжирования страниц. В компании называют изменение наиболее значимым событием в поиске за последние 10 лет.Что меняется? Как работает алгоритм? Как подготовить сайт к изменениям?
Стараемся разъяснить понятным языком.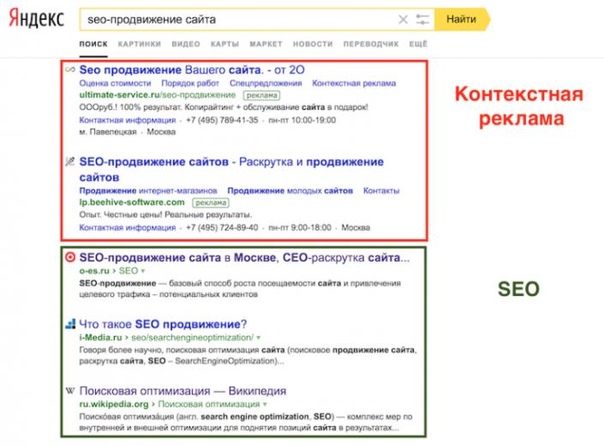
Yet Another Transformer with Improvements — Новая технология анализа текста
Что произошло? Яндекс официально заявил о внедрении нейросетевой архитектуры Yet Another Transformer with Improvements для ранжирования результатов поисковой выдачи.
Благодаря технологии поиск Яндекса научился лучше оценивать смысловую связь между запросами пользователей и содержанием документов.
Изменения настолько существенные, что по мнению специалистов Яндекса, это наиболее значимое событие для поисковой системы за последние 10 лет, то бишь со времен запуска Матрикснета.
Анонс алгоритма на видео. Про обновление в поисковой системе с 56:41.
Технология дорогая. Реализация на практике требует множество GPU карточек, которые физически связаны через шину в одну плату. Сервера размещаются очень близко в стойках. Между собой сервера связаны сетью.
YATI выглядит так:
Как работает? Сначала опишем кратко, а далее разъясним в подробностях.
Для обучения на вход в трансформеры подаются поисковые запросы и тексты документов, которые открывали пользователи поиска.
В Яндексе есть понятие эталон документа. Как появились эталоны? Асессоры используя сложную шкалу оценки проводили анализ текстов на предмет релевантности запросам.
В результате эталоном выступает документ, который прошел экспертную разметку.
Эталоны подаются на вход в систему трансформеров.
Далее инженеры обучили трансформер угадывать экспертную оценку.
Так трансформеры учатся ранжировать страницы по всем ключевым фразам.
По завершению обучения провели анализ на предмет качества поиска.
Например, отключения учета внешних ссылок приводило к значимому снижению качества поиска.
Результаты показали, что технология дала рекордный уровень в качестве поиска.
Далее система начинает работать с поисковой выдачей.
Далее разберемся с вопросами в деталях.
Как работал поиск раньше?
Задача поиска заключается в оценке смысловой связи между поисковым запросом и документом из интернета.
Для решения задачи требуется алгоритм предсказания, содержит ли документ ответ на запрос пользователя. Иначе говоря, есть ли на странице релевантная запросу информация.
Поисковый алгоритм оперирует ключевыми словами из запроса и текста документа чисто математически. Например, алгоритмически легко посчитать число совпадающих слов в запросе и документе или длину самой длинной подстроки из запроса, которая присутствует и в документе.
Также легко воспользоваться накопленными данными поиска о поведенческих факторах на выдаче и достать из заранее подготовленной таблицы сведения о количестве кликов. Если значение кликов высокое, то значит документ релевантен ключевой фразе.
Каждый такой расчёт приносит полезную информацию о наличии семантической связи и эффективен на практике.
Поэтому следует оптимизировать сниппеты. Как улучшить привлекательность заголовка? Провести анализ конкурентной среды, чтобы найти наиболее удачные идеи для последующей реализации. К примеру, используя сервис MegaIndex.
Ссылка на сервис — Анализ сниппетов.
В поисковой системы реализованы различные эвристические алгоритмы. Например, только способов посчитать общие слова запроса и документа было предложено и внедрено несколько десятков.
Пример алгоритма:
t — вхождение ключевого слова из запроса в документ.
Каждому t присваивается вес с учетом частотности слова в корпусе и расстояний до ближайших вхождений других слов запроса в документ слева LeftDist и справа RightDist по тексту.
Затем полученные значения суммируются по всем найденным на странице ключевым словам.
Каждый такой алгоритм позволял получить минимальный, но статистически значимый прирост качества модели, то есть чуть приблизить самую смысловую связь запроса и страницы.
Следующим шагом было расширение исходного поискового запроса. Подход такой:
- Слова из запроса можно расширить близкими им по смыслу словами или фразами;
- Вместо исходного запроса пользователя можно взять другой, который сформулирован иначе, но выражает схожую информационную потребность.
Например:
отдых на северном ледовитом океане
Близкие по смыслу фразы:
путешествие по северному ледовитому океану можно ли купаться в баренцевом море летом
Как поисковая система находит такие запросы? Способы разные. Например, использование логов запросов.
Похожий ключевые фразы можно использовать во всех эвристических расчётах сразу. Достаточно взять уже готовый алгоритм и заменить в нем один текст запроса на другой.
Аналогично запросам можно расширять и семантику документа, собирая для него альтернативные тексты, которые в Яндексе называют словом стримы.
Например, в стрим страницы входят все тексты входящих ссылок или тексты запросов в поиск, по которым пользователи часто выбирают конкретную страницу на выдаче.
Стримы можно использовать в любом готовом эвристическом алгоритме, используя вместо исходного текста документа.
Расширения и стримы являются примером дополнительных контентных признаков, которые поиск умеет ассоциировать с запросом и документом.
Большая часть таких алгоритмов утратили актуальность из-за спама, но сами расширения и стримы продолжают использоваться, только теперь уже в качестве входов для нейронных сетей.
Как работает Яндекс YATI?
Факторы подаются на вход одной итоговой модели. Для обучения модели используется открытая реализация алгоритма GBDT (Gradient Boosting Decision Trees) — CatBoost.
Схема вычисления релевантности выглядит так:
Описанные выше способы расчета приносят полезную информацию о наличии семантической связи, но не опираются на смысловое понимание текста.
Нейросети в ранжировании
Развитие алгоритмов ранжирования заключается в решении задачи по приближению семантической связи запроса и страницы сайта.
Схема с нейросетями изначально работала так:
- Каждое слово превращалось в вектор;
- Вектора суммируются в один, который и используется как представление всего текста. Взаимный порядок слов при этом теряется или учитывается лишь частично с помощью специальных технических трюков. Кроме того, размер «словаря» у такой сети ограничен; неизвестное слово в лучшем случае удаётся разбить на частотные сочетания букв (например, на триграммы) в надежде сохранить хотя бы часть смысла;
- Вектор мешка слов затем пропускается через несколько плотных слоёв нейронов, на выходе которых образуется семантический вектор (иначе эмбеддинг, от англ. embedding, вложение; имеется в виду, что исходный объект-текст вкладывается в n-мерное пространство семантических векторов).
Замечательная особенность такого вектора в том, что он позволяет приближать сложные смысловые свойства текста с помощью сравнительно простых математических операций.
 Например, чтобы оценить смысловую связь запроса и документа, можно каждый из них сначала превратить в отдельный вектор, а затем вектора скалярно перемножить друг на друга или посчитать косинусное расстояние.
Например, чтобы оценить смысловую связь запроса и документа, можно каждый из них сначала превратить в отдельный вектор, а затем вектора скалярно перемножить друг на друга или посчитать косинусное расстояние.Нейронная сеть обучается приближать смысловую связь между запросом и документом на миллиардах обучающих примеров.
В качестве таргета (то есть целевого, истинного значения релевантности) используются предпочтения пользователей, которые можно определить по логам поиска. Точнее, можно предположить, что определённый шаблон поведения пользователя хорошо коррелирует с наличием (или, что не менее важно, с отсутствием) смысловой связи между запросом и показанным по нему документом, и собрать на его основе вариант таргета для обучения.
Если в качестве положительного примера обычно подходит документ с кликом по запросу, то найти хороший отрицательный пример гораздо труднее.
Например, оказывается, что почти бесполезно брать в качестве отрицательных документы, для которых был показ, но не было клика по запросу.
Ограничивающее свойство такой сети: весь входной текст с самого начала представляется одним вектором ограниченного размера, который должен полностью описывать смысл.
Однако реальный текст обладает сложной структурой. Размер может сильно меняться, а смысловое содержание может быть очень разнородным. Каждое слово и предложение обладают своим особым контекстом и добавляют свою часть содержания, при этом разные части текста документа могут быть в разной степени связаны с запросом пользователя. Поэтому простая нейронная сеть может дать лишь очень грубое приближение реальной семантики, которое в основном работает для коротких текстов.
Тем не менее тестирование показало, что качество поиска все же улучшается. Плотные feed-forward-сети легли в основу двух крупных алгоритмов Палех и Королев. Ключевыми вопросами при решении задачи были:
- На какой кликовый таргет учить?
- Какие данные и в каком виде подавать на вход?
Нейронная сеть, сначала обученная на миллиардах переформулировок, а затем дообученная на сильно меньшем количестве экспертных оценок, заметно улучшает качество ранжирования.
Характерный пример применения подхода transfer learning:
Модель сначала обучается решать более простую или более общую задачу на большой выборке (этот этап также называют предварительным обучением или предобучением, англ. pre-tain), а затем быстро адаптируется под конкретную задачу уже на сильно меньшем числе примеров (этот этап называют дообучением или настройкой, англ. fine-tune).
В случае простых feed-forward-сетей transfer learning уже приносит пользу, но наибольшего эффекта метод достигает с появлением архитектур следующего поколения.
Нейросети-трансформеры
Следующий уровень развития заключается в применении трансформеров. В сетях с архитектурой трансформеров каждый элемент текста:
- Представляется отдельным вектором;
- Обрабатывается по отдельности;
- Сохраняет при этом своё положение.
Элементом может быть отдельное слово, знак пунктуации или частотная последовательность символов, например byte pair encoding.
Важно, что сеть также включает механизм внимания, который позволяет при вычислениях концентрироваться на разных фрагментах входного текста.
Значит, сеть может выделить часть страницы интернет-магазина, в которой речь идёт именно о нужном пользователю товаре. Остальные части тоже могут быть учтены, но влияние на результат будет меньше.
Иными словами, механизм внимания позволяет оценивать в формате запрос — часть страницы.
Сеть YATI обучается по такому алгоритму:
- Сначала учится свойствам языка, решая задачу Masked Language Model, но обучается сразу на текстах, характерных для задачи ранжирования. Уже на этом этапе вход модели состоит из запроса и документа, и Яндекс с самого начала обучает модель предсказывать еще и вероятность клика на документ по запросу;
- Далее происходит дополнительное обучение модели на более простых и дешёвых толокерских оценках релевантности количестве;
- Затем на более сложных и дорогих оценках асессоров;
- И наконец, обучается на итоговую метрику, которая объединяет в себе сразу несколько аспектов. По итоговой метрике Яндекс оценивает качество ранжирования.
На вход модели подаются те же контентные признаки, о которых шла речь в самом начале. Конкретно:
- Текст запроса, а также расширения;
- Фрагменты содержимого документа;
- Стримы.
Документ целиком пока не анализируется. Поисковая система разбивает страницы на зоны: основное содержание, заголовки и так далее.
Тяжелые модели слишком дороги в реализации. Поэтому в Яндексе создали легкие модели, которые пародируют тяжелые. Простой модель копирует поведение более сложной, обучаясь на предсказания в офлайне. В результате качество поиска падает, но не критично. Скорость расчета растет критично.
В Яндекс разделили модели на онлайн и оффлайн, чтобы нагрузка была низкой и качество поиска было высоким.
Схема:
- Часть модели применяется только к запросу.
- Часть — только к документу;
- Что получилось, затем обрабатывается финальной связывающей модель.
YATI и SEO
По мере внедрения YATI трафик из поисковой выдачи будет перетекать от мелких сайтов, заточенных по низкочастотные ключевые фразы, к крупным авторитетным сайтам.
Важные нюансы
Большое количество неинтересных для поиска страниц на сайте способно снизить релевантность действительно важных страниц.
Яндекс:
Модель вполне может выучивать свойства хоста как целого и использовать это как первое приближение к ответу. Тогда ей потребуется больше «сигнала», чтобы преодолеть такое выученное смещение.
Текст следует делить на информативные заголовки.
Яндекс:
Текущий алгоритм в первую очередь выделяет области с основным текстовым содержанием (содержание статьи, описание товара в магазине, etc) и дополнительно смотрит на общую структуру, включая заголовки разделов. При этом может использоваться как вся доступная нам разметка и структура на веб-странице, так и структура самого текста (т.е. не размеченная явно, но понятная из синтаксиса и содержания). Поэтому у страницы должно быть хорошее текстовое содержание, которое (при большом объеме текста) логично поделено на разделы с информативными заголовками. Явная разметка упростит задачу для наших алгоритмов. Если текста немного (условно 10 предложений или меньше), то мы скорее всего просто «прочитаем» его целиком и никакого дополнительного деления не требуется.
Сегментация текста нужна для правильного выбор информации, которая затем подается в модель.
Яндекс:
Подчеркну, что сегментация используется только для выделения фрагментов, которые мы покажем модели, но не для оценки их относительной значимости. Это «решает» уже модель. Например, в конкретном случае модель вполне может решить что текст размеченный как заголовок на самом деле не информативен, и тогда он не повлияет на предсказание.
Пересчет релевантности страницы происходит после переиндексации страницы сайта.
Расчет модели происходит при каждом переобходе страницы, частота которого зависит от разных факторов. Если содержимое страницы не поменялось, то переобход для модели YATI ничего не изменит — произойдет повторное применение к тем же фрагментам текста, что и раньше.
Как подготовить сайт к системе ранжирования YATI?
При ранжировании трансформеры позволяют добиться нового уровня качества при моделировании семантической связи запроса и документа, а также дают возможность извлекать полезную для поиска информацию из более длинных текстов.
Из логики алгоритма следует, что надо создавать страницы с расширенным семантическим ядром. Вместо количества делать акцент на качество.
Требуется адаптировать формат текстов под текст для людей и расширить семантические ядра страниц. Как? Например, так:
- Расширить семантическое ядро вхождениями релевантных ключевых фраз из поисковой видимости;
- Найти поисковые запросы из систем аналитики, по которым был привлечен трафик на сайт, добавить релевантные фразы в контент;
- Добавить в текст релевантные фразы из поисковых подсказок. В подсказках появляются низкочастотные фразы, которых нет в других системах;
- Проверить логи внутреннего поиска и добавлять в контент найденные релевантные ключевые фразы.
Как выгрузить ключевые фразы из поисковой видимости? Самый простой способ заключается в выгрузке данных из базы MegaIndex.
Как этот способ работает? Робот MegaIndex регулярно сканирует поисковую выдачу, чтобы собирать и обновлять списки ключевых фраз, по которым ранжируются страницы. Результат сохраняется в базу. В результате сервис позволяет находить релевантными ключевые фразы, которые следует добавить на страницу.
Ссылка на сервис — Поиск похожих фраз.
Сервис бесплатный.
Пример:
Рекомендованный материал в блоге MegaIndex по теме расширения списка ключевых фраз похожими по ссылке далее — Как находить дополнительные ключевые фразы, чтобы привлечь больше трафика?
Выводы
В поисковой системе Яндекс разработана нейросетевая архитектура для ранжирования. Название — Yet Another Transformer with Improvements.
Система анализирует разные блоки текста на странице сайта.
Задача система заключается в анализе соответствия смысла запроса и смысла текста на странице.
Алгоритм способен:
- Анализировать как короткое содержание, так очень длинные тексты;
- Определять самые значимые фрагменты текста на странице сайта;
- Учитывать порядок слов, и учитывать контекст. Важно, например, при поиске билетов.
Благодаря трансформерам алгоритмы стали лучше оценивать смысловую связь между запросами пользователей и содержанием документов.
Яндекс:
Внедрение принесло рекордные улучшения в ранжировании за последние 10 лет (со времён внедрения Матрикснета). Просто для сравнения: Палех и Королёв вместе повлияли на поиск меньше, чем новая модель на трансформерах. Более того, в поиске рассчитываются тысячи факторов, но если выключить их все и оставить только новую модель, то качество ранжирования по основной офлайн-метрике упадёт лишь на 4-5%!
Похожая идея чуть легла в основу проекта BERT (Bidirectional Encoder Representations from Transformers) от Google. Рекомендованные материалы в блоге MegaIndex на тему алгоритма от Google по ссылкам далее:
Крайне интересное обновление. Что делать? Если просто, то владельцам сайтов следует:
- Заняться повышением качества текстов. Учитывать похожие поисковые запросы и стримы;
- Поделить страницу на секции, так чтобы у модели или у сегментатора было больше очевидных структурных признаков, которые можно использовать при анализе.
Найти похожие запросы помогает сервис MegaIndex. Ссылка на сервис — Поиск похожих фраз. Сервис бесплатный.
Раньше мы сообщали, что Yandex планирует внедрять аналог BERT. Технология начала работать в Яндекс поиске с осени 2020-года для всех запросов. Следующий этап в расширении зоны анализа до всего документа.
Остались ли у вас вопросы, замечания или комментарии? Что вы думаете о Yandex YATI? Напишите в комментариях.
Кейс: как попасть в топ поиска и увеличить трафик за три месяца
Анастасия Курдюкова, специалист по поисковому продвижению интернет-агентства Sabit, специально для блога Нетологии поделилась кейсом о том, как вывести сайта в топ и десятикратно увеличить трафик за три месяца. Статья участвует в конкурсе блога.
К нам обратилась компания по продаже техники Apple за региональным продвижением, а именно по Самаре. Нам дали всего полгода, чтобы вывести сайт в топ поиска.
Но нас ждали свои трудности. Началось все с того, что это высококонкурентная ниша. В этом можно убедиться, посмотрев выдачу по запросу «купить айфон» или поискав магазины с техникой Apple на картах. Кроме того, новый сайт на старте продвижения был закрыт от индексации поисковыми роботами, и «Яндекс» даже не знал о его существовании. При этом домен был не новым. Раньше на нём располагались сайты из других регионов, поэтому привязка была к другим городам. Это могло негативно сказаться на продвижении по Самаре.
Программа обучения: «SEO-оптимизатор: как поднять продажи с помощью интернет-маркетинга»
Главное — начать
Перед тем как открыть сайт для поисковых роботов, надо было настроить техническую часть. Что мы сделали?
Для начала мы выбрали основное зеркало сайта и настроили редиректы с неглавных зеркал. Поисковые роботы должны были индексировать только основной сайт и не тратить время на смысловые дубли.
Помните, что дублями могут быть сайты с разными протоколами (http/https) или с наличием или отсутствием префикса www в начале url.
Затем мы оптимизировали мета-теги title и description, а также заголовки h2 на страницах, чтобы донести до пользователя и поисковых систем информацию о данных на сайте. Исправили технические ошибки: удалили ссылки на несуществующие страницы, скорректировали файл robots.txt, отвечающий за правильную индексацию сайта и многое другое.
На этапе разработки сайта уже была добавлена микроразметка Schema.org. Её основной целью было структурировать и облегчить поисковым системам извлечение и обработку информации, а затем качественно представить её в поиске. На страницах была размечена основная информация о товарах: наименование, цвет, характеристики. Нам было важно, чтобы пользователи видели стоимость продукции уже в поисковой выдаче. Нужно было сделать акцент на главном преимуществе компании — самых низких ценах в городе. Ну, и присвоили сайту регион «Самара».
Ссылка на сайт в «Яндексе» по запросу «купить айфон 7 в самаре»
Сайт был открыт к индексации 13 апреля. В это же время начался сбор позиций. Для удобства сбора позиций и получения ясной картины видимости сайта мы взяли наиболее высокочастотные фразы.
В первую неделю сайт вошел в топ-100 и начал в нём подниматься, несмотря на возраст и отсутствие авторитета. Вот некоторые из высокочастотных запросов, по которым продвигается сайт:
Открыть в полном размере →
В мае сайт почти по всем запросам закрепился в топ-10 поисковой выдачи «Яндекса».
Открыть в полном размере →
Что было дальше
Следующим этапом было укрепление достигнутых позиций. Клиент присоединился к Яндекс.Маркету. Дополнительно был подключен сервис «Товары и цены» от Яндекса. Таким образом ресурс увеличил авторитет: повысились лояльность и узнаваемость. А сервисам Яндекса обычно доверяют. С помощью этих каналов мы нашли дополнительный источник целевых клиентов на сайт.
Параллельно добавили карточки в Яндекс.Справочник и Google Мой бизнес, позволившие нам размещаться на Яндекс.Картах и Google Maps. Заполнили их подробной информацией о компании и фотографиями. Карты — это еще один дополнительный источник привлечения клиентов на сайт и повышения доверия со стороны поисковиков.
По опыту прошлых проектов мы знали, что привлечение на сайт релевантного трафика, пусть и по низкочастотным запросам, влияет на позиции высокочастотных запросов. Такие посетители совершают покупки на сайте, улучшая поведенческие факторы. Это приводит к лучшей видимости сайта в поисковых системах.
Мы проработали большой пул запросов, по которым ищут технику Apple, с помощью специальных сервисов. Из него следовало, что посетители чаще ищут определенные модели смартфонов и при выборе ориентируются на цвет и объём памяти. Остальные характеристики не так важны.
Для проработки подобной группы запросов мы добавили 145 статичных страниц фильтрации под все цвета и объемы памяти смартфонов и проработали все комбинации «объём+цвет».
При этом мы проводили мониторинг конкурентов и перенимали различные полезные для посетителей элементы на сайте. Так, мы добавили на сайт блок товаров «хиты продаж», кнопку «купить в 1 клик» и выпадающее меню. Эти доработки были необходимы, так как посетители уже привыкли к определенным стандартам внешнего вида сайта в сети.
Мы отказались от приемов нечистого SEO — это могло дать краткосрочный результат, но позже привести к санкциям от поисковых систем. Мы не занимались закупкой ссылок, добавлением скрытого текста на сайт и не использовали избыточное вхождение «ключевиков». Санкциями за подобные действия могут быть искусственное занижение страниц сайта по запросу или группе запросов, а также выпадение сайта за топ-100.
В некоторых случаях выйти из-под санкций можно с помощью небольших доработок, а иногда для этого приходится заново создавать сайт.
Результаты
Через 3 месяца после открытия сайта и начала сбора позиций мы пришли к следующему:
- сайт находится в топ-10 по всем высокочастотным запросам. Например, «купить айфон» или «магазин apple», так и по низкочастотным;
- в топ вышли запросы по остальной технике Apple на сайте, хотя мы не делали на ней акцент при продвижении;
- трафик на сайт вырос в 10 раз за этот период: с 136 переходов в апреле до 1463 в июле.
Динамика изменения трафика
Выводы
- Поисковые системы положительно воспринимают молодые сайты, если те предлагают посетителям качественный контент, совмещенный с понятной и привычной посетителю структурой сайта.
- Даже в самой высококонкурентной тематике можно быстро выйти в топ, используя приёмы «белого seo», если цель — дать посетителю полный ответ на запрос и сделать его пребывание на сайте комфортным.
- Важно постоянно отслеживать конкурентов и перенимать у них лучшие техники продвижения, и предложить нечто новое, отличающее вас от остальных.
Читать еще: «Как узнать затраты конкурента на контекст»
Сейчас сайт закрепился в топе, и теперь мы работаем над увеличением трафика и над улучшением его показателей качества.
Открыть в полном размере →
Мнение автора и редакции может не совпадать. Хотите написать колонку для «Нетологии»? Читайте наши условия публикации.
Как правильно искать в Яндексе — расширенный и семейный поиск, язык запросов и настройки
Главная / Как самому раскрутить сайт / SEO21 января 2021
- Удобно ли искать в Яндексе?
- Настройки и возможности поисковой системы
- Поисковые подсказки и секреты выдачи
- Семейный поиск, а также связанные запросы
- Расширенный поиск или язык запросов Яндекса
Здравствуйте, уважаемые читатели блога KtoNaNovenkogo.ru. Сегодня я хочу продолжить тему поиска информации в интернете и перейти к описанию своего основного инструмента, которым пользуюсь уже второе тысячелетие.
Так исторически сложилось, что обычно я сначала веду поиск в Яндексе, а уже потом, если ничего достойного найдено не будет, переключаюсь на Гугл (недавно, кстати, я писал про то, какие инструменты могут помочь при поиске в Гугле и как их можно использовать).
В Яндексе, так же как и в Гугле, имеет место быть свой (но очень похожий) языка запросов, расширенный фильтр, а так же семейный поиск. Правда, нет такого богатого набора фильтров в самой поисковой выдаче (странице с результатами поиска), но зато имеет место быть отображение фавиконов сайтов, которые в этой выдаче присутствуют. Не знаю как вам, но мне это дело очень помогает быстро найти достойные моего внимания сайты, которым я доверяю и ответы которых меня до этого вполне устраивали.
Удобно ли искать в Яндексе?
Вообще, конечно же, немного странным выглядит то, что про основной инструмент корпорации Yandex (читайте, почему Яндекс называется именно Яндексом) я пишу уже после того, как обозрел другие (второстепенные по отношении к поиску) сервисы:
- Главная страница и паспорт Яндекса — в отличии от Гугла, зеркало рунета изначально приняло решение об использовании своей главной (стартовой) страницы для удобства пользователей и для своей выгоды (показывает там баннеры буквально за копейки). В связи с чем, эту страницу сейчас можно настраивать, менять темы, отключать рекламу т.п. Ну, и по аналогии с Гугл аккаунтом был введен Паспорт, который действителен на всей территории всех владений зеркала рунета.
- Яндекс Вебмастер — то место, куда все владельцы сайтов добавляют свои детища, а потом с трепетом следят за их индексацией и видимостью в этой поисковой системе, а затем рвут волосы и пишут жалостливые или же гневные письма в службу поддержки, если что-то пойдет не так.
- Яндекс Деньги — наверное, вторая по популярности после Вебмани платежная система в рунете. Хотя, если брать в расчет Киви кошельки, то получается, что третья. Но не суть важно, ибо само название придает ей определенную статусность и повышает доверие пользователей к ней.
- Яндекс Директ — основной источник получения баснословных доходов для этой корпорации, который заключается в размещении текстовых объявлений сверху, справа или снизу органической поисковой выдачи. Хотите получать посетителей и покупателей для своих интернет магазинов, сайтов услуг и т.д? Тогда регистрируйтесь в Директе, читайте мою статью про принципы работы этой аукционной системы (по приведенной ссылке) и получайте желаемое.
- Рекламная сеть Яндекса — это оборотная сторона Директа. Дело в том, что Yandex обладает отлаженной системой работы с контекстной рекламой, так почему же ему ограничиваться лишь своей собственной поисковой выдачей (страницей с результатами поиска)? Ведь кругом куча информационных и коммерческих сайтов, которые с удовольствием будут размещать эти же контекстные объявления у себя и с удовольствием будут отдавать пятьдесят процентов (пятидесятину) за это дело зеркалу рунета.
- Яндекс Метрика — система статистики посещаемости сайтов для не очень продвинутых (не помешанных на аналитике) вебмастеров. Она выгодно отличается от аналогичного инструмента Гугла (Аналистикса) тем, что имеет интуитивно понятный и нарядный интерфейс, а так же совсем не перегружена функционалом. Для продвинутых же в Метрике есть Вебвизор. Так то вот, знай наших.
- Яндекс почта — реальная альтернатива засилью почты от Майла в рунете и популярному среди продвинутых пользователей гугловскому детищу Джимейл. По функционалу новая инкарнация Yandex Mail не сильно уступает последнему, а в некоторых аспектах даже превосходит. Например, имеется бесплатная возможность получения почты для домена в Яндексе, что в Гугле сейчас стало стоить малую копеечку (почта для домена в Гугл Аппс).
- Облачное хранилище Яндекс Диск — довесок к почте, который призван стать реальной альтернативой Дропбоксу (читайте про то, как пользоваться Dropbox) и подобных ему сервисов облачных хранилищ, что детищу зеркала рунета, в общем-то, неплохо удается.
- Поиск по вашему сайту от Яндекса — корпорация не жадная (в известной степени) и готова поделиться с вами своим движком, который будет осуществлять поиск среди материалов только вашего сайта. Останется лишь настроить внешний вид формы поиска и установить ее у себя в удобном месте.
- Тиц и Виц Яндекса — это не сервисы, но важные инструменты, с помощью которых компания оценивает статический вес всех проиндексированных документов (читайте про то, как тяжко и натужно работают поисковые системы), а обычные пользователи могут оценить, за какую цену стоит продавать или покупать ссылки с определенных сайтов (читайте про биржи статей Миралинкс, вечных ссылок ГГЛ или Ротапост)
- Яндекс Народ — почивший в бозе (а точнее в Юкозе) бесплатный конструктор народных сайтов. Как и Гугл (называемый еще корпорацией добра), зеркало рунета освобождается от сервисов не приносящих свою долю прибыли в общий котел. Места альтруизму, увы, уже не осталось даже у тех, кто может себе это позволить. Всем и вся правят деньги.
- Яндекс бар (Элементы) — довольно популярная надстройка над браузерами, которая, правда, самой поисковой системе гораздо нужнее, чем пользователям (установка поиска по умолчанию, домашней страницы, сбор пользовательских предпочтений и т.п.). Да, все это не так агрессивно реализовано, как у Вебальты, но что-то общее имеется.
- Визуальные закладки Яндекса — Сейчас по каким-то загадочным причинам (может быть из-за сложившегося негативного мнения о нем) Бар был переименован в Элементы, а так же отдельным приложение выпускаются очень удобные визуальные закладки (тут придраться даже не к чему, если, правда, не будете обновлять их до последней версии).
- Яндекс Браузер — еще одна попытка влияния на умы пользователей в плане выбора поиска по умолчанию и домашней страницы, а так же очень хороший способ сбора пользовательских предпочтений.
- Блок Яндекса Поделиться — набор кнопок для добавления анонсов статей на сайте в популярные социальные сети. Статистику этого блока можно отслеживать в Метрике, ну, а так же она будет непосредственно интересна и полезна самому зеркалу рунета.
- Апдейты Яндекса — это не сервис и не инструмент, а просто констатация того, что эта поисковая система пока еще не способна осуществлять ранжирование в реальном времени и обновляет поисковую выдачу дискретно через определенные неравнозначные временные интервалы, как правило, измеряемые единицами или даже десятком дней. Момент, когда процент поисковых запросов, выдача по которым обновилась, становится ощутимым и принято называть апом. Апнуться может еще и Тиц, и фавиконки, и поиск по картинкам и…
- Яндекс картинки — вариация поиска, о которой мы еще поговорим в этой статье. Правда, зеркало рунета так еще и не научилось искать по образцу изображения, как это умеет делать Гугл или Тинай.
- Онлайн переводчик от Яндекса — ну, конечно же, это далеко еще не Google translate, но иметь такой инструмент любая уважающая себя мегакорпация интернета просто обязана
- Проверка правописания в Яндексе — тут и сказать особо нечего, ибо сервис очень удобный и вполне претендует на звание лучшего в рунете
- Каталог Яндекса — это такое место, куда хотят пропихнуть свои сайты все вебмастера, но, к сожалению, попасть туда даже на платной основе удается далеко не всем. Принято считать, что наличие сайта в Каталоге положительно влияет на его посещаемость и Тиц, но верно, скорее всего, лишь последнее утверждение.
- Яндекс Вордстат — пожалуй, чтоSeo продвижение в рунете было бы крайне затруднительным без этого сервиса. Но зеркало рунета вынуждено было пойти на его создание, чтобы их кормильцы из числа рекламодателей Директа имели бы возможность подбирать наиболее подходящие ключевые слова для показа своих объявлений. Естественно, что этой статистикой поисковых запросов пользуются и Сеошники, при составлении семантического ядра и подбора анкоров для обратных ссылок.
Наверное, это произошло потому, что сам процесс поиска информации в интернете стал для нас такой же само собой разумеющейся вещью, как дышать, ходить, говорить и т.п. Мы на этом не заостряем внимание, хотя, если подходить к этому процессу с толком и расстановкой, то можно будет существенно сэкономить свое время, нервы и найти то, что в обычных условиях ускользнуло бы от нашего внимания.
Итак, давайте пробежимся по внешнему виду страницы с результатами поиска и тем инструментам, что там присутствуют.
В самом верху расположен список других сервисов и тематических поисков Яндекса, которые вас могут заинтересовать. Однако, и в результаты общей поисковой выдачи подмешиваются результаты из поиска по новостям, товарам, картинкам и т.п. Например, справа отображаются изображения как раз из поиска по картинкам.
По некоторым типам запросов Яндекс (равно как и Гугл) умеет давать довольно-таки специфические ответы. У зеркала рунета это фича обзывается колдунщиком. Колдунщиков достаточно много (про них можно почитать и посмотреть на этой странице). Иногда колдунщик выводит свой блок, на подобии того, что я описывал в статье про Яндекс цвета, а иногда дает только ссылку, например, на Маркет.
При запросе погоды, сразу после формы ввода запроса, вы увидите погодный колдунщик:
Настройки и возможности поиска
Если у вас медленный интернет канал (например, через мобильник), то можете отключить показ графического баннера и картинки, расположенных справа (кнопка «Настройка» в правом верхнем углу окна выдачи).
По умолчанию в настройках окна поиска так же включено отображение пиктограмм сайтов (фавиконов), которые позволяют на визуальном уровне очень быстро отыскать среди результатов те сайты, которым вы привыкли доверять. Так же там можно будет увеличить число ответов на странице с результатами до 50 штук, что, лично я, и делаю, ибо в первой десятке очень много шума присутствует, как правило.
Можно включить отображение отдельной статистики по каждому из слов, содержащихся в вашем запросе (отображается под формой ввода запроса), но это для подавляющего большинства пользователей будет ненужным излишеством. Да, еще в поисковой выдаче Яндекса иногда можно увидеть диалоговые подсказки (см. серые кнопочки на предыдущем скриншоте под формой ввода запроса), которые позволяют быстро просмотреть результаты по уточненному запросу.
Поисковые подсказки и что важного можно увидеть в выдаче (результатах)
Да, я же ведь еще про поисковые подсказки Яндекса не сказал. Они теперь по умолчанию становятся персонализированными и учитывают все набранные вами ранее запросы и все остальные нюансы вашей личной жизни.
Отключить их персонализацию можно либо на этой странице, либо перейдя по соответствующей ссылке (Мои запросы) прямо из выпадающего окна с этими самыми поисковыми подсказками.
Видите, эта страница с настройками отличается от общей страницы настроек поиска. Почему то у Яндекса таких страниц несколько и функционал некоторых из них пересекается. Узреть все возможные настройки поиска зеркала рунета можно будет на странице Tune.yandex.ru.
Но вернемся к нашим баранам, а именно к странице настроек поиска, которая живет по этому адресу. Что там еще можно настроить, чтобы искать в Яндексе не было бы мучительно больно? Ну, для меня однозначно удобнее открывать страницы сайтов из результатов поиска в новом окне (то же самое, кстати, я стараюсь реализовать и на этом блоге). Так же, я активировал в пункте «Мои находки» запись истории своих поисков, ибо бывает необходимо найти сайт, который забыл добавить в закладки, но ранее искал через поисковик. В случае чего эту историю можно будет очистить (читайте об это в статье про то, как удалить историю в Яндексе).
Раньше я так же выбирал отображение более подробного сниппета, взятого из текста сайта (в области «Описание документа» вариант «Расширенное») или же его описания, чтобы лишний раз не переходить на те ресурсы, где ответа на мой вопрос, скорее всего, не найдется. Сейчас же, при достаточно быстром интернете, проще перейти на сайт, чем вчитываться в сниппет, который формируется зеркалом рунета не всегда удачно и информативно.
Под сниппетом расположена цепочка ссылок, ведущая к найденному документу на данном сайте (похоже на хлебные крошки), которая в некоторых случаях может стимулировать дополнительные клики, если их привлечет название рубрики или раздела, где эта самая страница живет. Обычно, эти цепочки и берутся их хлебных крошек, имеющихся на сайте.
Заголовок документа берется из мета тега Тайтл, хотя иногда могут делаться и исключения. Но это скорее важно не тем кто ищет в Яндексе, а тем, кто хочет чтобы их нашли (вебмастерам).
Пользователю же интереснее, например, ссылка «Копия», которая позволяет посмотреть сохраненную в кэше поисковой машины копию данного документа. Это может понадобиться в случае временной недоступности данного сайта или же в случае заражения сайта вирусом, что приведет к невозможности перехода на него с выдачи Яндекса.
К тому же, на странице с копией набранные вами ключевые слова будут выделены ярким желтым фоном, хотя, это дело можно отключить простым снятием галочки в поле «выделять слова запроса». Стрелочками справа и слева от текста запроса можно будет перемещаться между найденными ключевыми словам и в тексте.
Но есть еще лучший способ увидеть то, чего уже нет — это Webarchive почти всех сайтов интернета. Очень интересная штука и даже про тонкий или не очень юмор самого Яндекса может нам поведать (источник находится тут, а выделенный фрагмент виден только при выделении, ибо написан белым шрифтом на белом фоне, что строжайше запрещено делать правилами самих же поисковиков).
Так же вы, наверное, заметили, что, как правило, в результатах поиска Яндекса, да и Гугла тоже, чаще всего присутствует лишь одна страница с сайта. Вот. А если вам интересен именно этот ресурс и вся информация по интересующей вас проблеме найденная только на нем, то тут вам на помощь придет кнопка «Еще».
Значительно реже вы можете встретить надпись «Найдено по ссылке», что будет говорить вам о том, что слов из вашего запроса на этом сайте найдено не было, но зато имеют место быть ссылки ведущие на этот документ, в анкоре которых такие слова присутствовали. Похожим образом сайт Буша младшего с успехом искался по совсем нелицеприятной фразе, которой в тексте его страниц быть не могло. Угадайте, каким образом так получилось?
Следующая область настроек поиска Яндекса позволяет выбрать язык, на котором вы предпочли бы видеть ответы, а так же имеется возможность запретить автоматическое исправление сделанных вами в запросе опечаток или же ошибок. На самом деле, раньше даже была такая тенденция, как продвижение по запросам с ошибками, которые часто повторяются. Но сейчас Яндекс сам их исправляет и фишка уже не работает.
Семейный поиск, прямой эфир и связанные запросы
Здесь же вы можете включить или, наоборот, отключить фильтрацию взрослого контента (кому что надо). По умолчанию используется умеренный фильтр, когда взрослый контент будет показываться только в случае вашего явно выраженного в запросе желания его увидеть. Если же компьютером пользуются дети, то лучше всего будет переключиться на Семейный поиск, во избежании всяческих неприятных эксцессов.
Ну, а если вы уж наверняка хотите предотвратить возможность включения взрослого контента в результаты поиска, то можно будет пользоваться специальным сайтом Яндекса для семейного поиска Family.yandex.ru, который выглядит точно так же, как и главная страница зеркала рунета, и который можно будет добавить в качестве поиска по умолчанию и домашней страницы в используемые вами браузеры.
Есть у них и специальный поиск людей Yandex People, где можно искать человека как по всем популярным сетям, так и по какой-то отдельной из них.
Раз уж мы заговорили от специальных сайтах Яндекса со специфическим поиском, то как вам такой вариант Днез-поиска, когда по нажатию кнопки «Найти» будет показываться выдача по одному из набираемому сейчас запросу:
Так же очень занимательно будет перейти по ссылке «Прямой эфир» и увидеть на фоне карты мира, какие именно запросы и в какой точке планеты набирают те, кто пытается что-то искать в Яндексе.
В последней части настроек поисковой выдачи вы сможете включить или отключить слежение Яндекса за вами и учета полученных данных при формировании подсказок и выдачи.
Так же как и в Гугле, на тех, кто решится что-то искать в Яндексе, будет заведено досье, которое можно будет посмотреть перейдя по ссылке «Мои находки». Все, с настройками покончено.
Кстати, внизу окна с результатами поиска довольно часто встречаются связанные запросы, которые вводили те же самые пользователи, пытаясь найти ответ на мучающий их вопрос. Во-первых, вы можете, щелкнув по ним, увидеть страницу с этими результатами поиска, ну, а во-вторых, вебмастера могут тут подобрать новые ключевые слова для их будущих статей.
В отличии от богатых наборов фильтров Гугла, у зеркала рунета мы наблюдаем лишь переключатели сортировки по релевантности (соответствию тексту запроса) или по дате. Причем последний способ выдает сайты крайне далекие от того, что вы хотели увидеть вводя свой запрос.
Расширенный поиск и язык запросов Яндекса
Все возможности по фильтрации сосредоточены исключительно в расширенном поиске Яндекс (справа от поисковой строки значок с двумя горизонтальными линиями), который мы сейчас по быстрому и рассмотрим.
Таким образом, профессионально искать в Яндексе могут не только знатоки языка запросов этой поисковой системы (он, кстати, очень похож на язык запросов Гугла), но и обычные неподготовленные пользователи. Сначала вы вводите запрос в поле «Я ищу», где можно будет применить один или несколько операторов, чтобы сузить область поиска. В Гугле, в этом плане, расширенный поиск более функционален.
Давайте сейчас пробежимся по тем операторам языка поисковых запросов, которые реально могут понадобиться:
По умолчанию между всеми словами запроса Яндекс расставляет логический оператор ИЛИ. Однако, если вам нужно, чтобы в результатах выдачи одно из слов присутствовало бы обязательно, то поставьте перед ним знак + без пробела справа, но с обязательным пробелом слева:
продвижение сайтов +москва
Так же, как и любой другой поисковик, зеркало рунета игнорирует слова, которые слишком часто встречаются в запросах. Это так называемые стоп-слова и чаще всего это предлоги, частицы или местоимения. Для того, чтобы эти стоп-слова учитывались вами, опять же достаточно будет поставить перед ними без пробела знак +:
движок +для сайта
Искать можно и с помощью оператора отрицания. Например, вам нужно найти обзор какой-нибудь вещи, но вам в результатах попадаются одни интернет магазины с этим товаром. Как быть? Довольно просто. Достаточно поставить перед словами, которые вы не хотите видеть в выдаче, двойную тильду ~~ (с пробелом между ними и словом), ну, или на худой конец знак минуса (без пробела справа, но с пробелом слева):
Ipad 4 ~~ цены ~~ купить
Ipad 4 -цены -купить
- Часто люди ищут цитаты и для этого имеется возможность заключить эту фразу в двойные кавычки, чтобы Яндекс искал эти слова в этой же последовательности.
- Если вы в какой-либо цитате, пословице или поговорке забыли одно или несколько слов, то можете вместо них поставить знак или знаки звездочки * отделенные от других слов пробелами:
"почил в *"
По умолчанию Яндекс понимает морфологию русского языка и осуществляет поиск не только по тем словоформам (падежам и числам), которые вы употребили в запросе, но и по всем остальным (умный типа). Правда, частей речи это не касается (если указали в запросе существительное, то прилагательные, образованные от этого слова, искаться не будут). Но это уже не суть важно.
Другое дело, что в редких случаях вам может понадобиться запретить Яндексу искать с учетом морфологии. Это можно сделать с помощью восклицательного знака поставленного без пробела перед тем словом, которое надо будет искать только в той форме, в которой вы его употребили (падеже, числе).
"!продвижение !сайта"
Причем, если искомое слово обычно пишется с большой буквы (например, фамилия), то восклицательный знак перед таким словом заставит поисковик искать только слова с большой буквы:
!Лев !Николаевич
Еще есть вариант использования двойного восклицательного знака, который заставляет зеркало рунета искать по словарной форме этого слова, но я далек от лингвистики и не понял, в каких случаях это может быть полезным.
Часто может возникнуть ситуация, что поиск на сайте, который вам интересен, настолько туп и глуп, что лучше им не пользоваться. В этом случае вы, конечно же, можете обратиться к расширенному поиску Яндекса (см. скриншот чуть выше) и указать адрес нужного сайта (или нескольких сайтов через запятую), чтобы ограничить область поиска.
Но так сделать может каждый. Гораздо эффектнее будет выглядеть использование оператора языка запросов Site, который будет выглядеть примерно так:
продвижение сайтов site:https://ktonanovenkogo.ru
- Так же расширенный поиск позволяет выбрать тип документов, в которых будет искаться нужная вам фраза (обычные интернет странички, пдф документы, вордовские файлы и еще что-то там такое). Удобно же, когда реферат или диплом будет найден именно в том формате, который требуется для его сдачи — не нужно лишних телодвижений совершать. Однако, оператором Mime воспользоваться будет значительно более круто:
продвижение сайтов mime:doc
- Не совсем понятно, для чего это может понадобиться, но у зеркала рунета издревле существуют операторы & и &&, которые позволяют искать разделенные им слова в одном предложении или в одном документе (фактически && заменяет умолчательный логический оператор ИЛИ на оператор И)
Еще более загадочным для меня является оператор языка запросов Яндекса в виде слеша «/», который позволяет задавать интервал (измеряемый в количестве слов), который будет выдерживаться при поиске по вашему запросу. Расстояние между соседними словами принимается равным единице.
продвижение /2 сайтов
Это означает, что между словами «продвижение» и «сайт» в найденных документах не может стоять более одного слова. А есть еще варианты использования знака плюс или минус перед цифрой для определения порядка следования слов. Да, а еще туда же можно и & (&&) впихнуть, чтобы уж совсем у бедного пользователя башню снесло:
продвижение &&/(-1 +2) сайтов
- И как вы могли видеть из последнего примера, для составления сверхсложных запросов можем использовать круглые скобки.
- В расширенном поиске можно довольно тонко ограничивать область, задавая определенный временной интервал, когда эти документы были созданы или обновлены. Существуют так же и операторы языка запросов, которые позволяют делать тоже самое — Date. Он позволяет задавать как конкретную дату, так и интервалы.
Примеры использования всех упомянутых и позабытых операторов вы найдете здесь, возможно, что это поможет вам искать в Яндексе более продуктивно, быстро и с меньшей затратой нервных клеток.
Удачи вам! До скорых встреч на страницах блога KtoNaNovenkogo.ru
Использую для заработка
Формат запроса. Places API
Доступ к сервису осуществляется с помощью GET-запроса по адресу https://search-maps.yandex.ru/v1/. Обязательными параметрами запроса являются текст, язык и apikey.
В ответ сервер возвращает найденные объекты, отсортированные по релевантности запросу. За один поисковый запрос можно получить до 500 объектов.
https://search-maps.yandex.ru/v1/
? [= <ключ>]
& [= <поисковый запрос>]
& [= <типы объектов>]
& [= <язык ответа>]
& [= <центр области поиска>]
& [= <размер области поиска>]
& [= <координаты области поиска>]
& [= <не искать за пределами области поиска>]
& [= <количество результатов в ответе>]
& [= <количество результатов, которые нужно пропустить>]
& [= <название функции>] | Параметры запроса | |
apikey | Ключ для доступа к сервису.Вы можете получать ключи и управлять ими в Личном кабинете разработчика. |
текст | Текст поискового запроса. Например, название географического объекта, адрес, координаты, название компании или номер телефона. Примеры (без кодировки URL): |
тип | Типы возвращаемых результатов. Возможные значения: Пример: |
lang | Предпочтительный язык ответа. Установите в качестве идентификатора локали в формате lang = language_region , где
Поддерживаемые значения: Если параметр имеет значение локали, которого нет в этом списке, служба выбирает язык, наиболее близкий к заданному. Пример: |
ll | Центр области поиска. Определяется долготой и широтой, разделенными запятой. Долгота и широта указываются в градусах, представленных десятичными знаками. Используется вместе с параметром spn, который определяет размер области поиска. Игнорируется при обратном геокодировании. Пример: |
spn | Размер области поиска. Определяется с помощью диапазона долготы и широты, разделенных запятой. Пролеты указываются в градусах, представленных десятичными знаками. Используется вместе с параметром ll, который определяет центр области поиска. Игнорируется при обратном геокодировании. Пример: |
bbox | Альтернативный метод настройки области поиска (см. Границы области поиска определяются как географические координаты левого нижнего и правого верхнего углов области (в порядке «долгота, широта»). Примечание. Если одновременно установлены Пример: |
rspn | Указывает на «строгое» ограничение области поиска. Если ничего не найдено в области поиска (заданной с помощью параметров ll + spn или bbox), служба пытается найти результаты за ее пределами. Вы можете использовать параметр Возможные значения: |
результаты | Количество возвращаемых объектов. По умолчанию 10. Максимальное значение — 500. Пример: |
skip | Количество объектов, которые нужно пропустить в ответе (начиная с первого). Пример: |
обратный вызов | Имя функции JavaScript для передачи ответа (по соглашению JSONP). Пример: |
Примеры. Places API
Поиск объекта по имени:
https://search-maps.yandex.ru/v1/?text=village of Tolstik & type = geo & lang = en_US & apikey = < Ключ API > Поиск объекта по адресу:
https: // search-maps.yandex.ru/v1/?text=18 Амурская улица, Свободный & type = geo & lang = en_us & apikey = < API-ключ > Запрос с опечаткой "Mascow". Ответ будет содержать исправленную версию.
https://search-maps.yandex.ru/v1/?text=Mascow&type=geo&lang=en_US&apikey= < API-ключ > Поиск компании по названию:
https: / /search-maps.yandex.ru/v1/?text=Shear Pleasure & type = biz & lang = ru_RU & apikey = < API-ключ > Поиск компании по номеру телефона:
https: // search-maps .yandex.ru/v1/?text=+7(495)739-70-00&type=biz&lang=ru_RU&apikey= < API-ключ > Поиск компании по предоставленной услуге:
https: // search-maps.yandex.ru/v1/?text=cut,style&type=biz&lang=en_us&apikey= < API-ключ > Найдите компанию по указанному адресу:
https: // search- maps.yandex.ru/v1/?text=Авторемонт, Москва, Смоленская улица & type = biz & lang = ru_RU & apikey = < API key > Поиск компании по нескольким параметрам:
https: // search -карты.yandex.ru/v1/?text=аптека день, оплата картой & type = biz & lang = en_us & apikey = < API-ключ > Если в запросе указана область поиска, в результатах сначала будут показаны объекты, наиболее близкие к этой области . Например:
https://search-maps.yandex.ru/v1/?text=деревня Пожарище & ll = 40.17248,60.594641 & spn = 3.552069,2.400552 & lang = ru_RU & apikey = < API-ключ > Некоторые запросы могут соответствовать нескольким объектам.В запросе, отправленном в геокодер, можно указать желаемое количество объектов для получения в ответе и количество первого.
Выведите первые 5 результатов:
https://search-maps.yandex.ru/v1/?text=ul. Грибоедова & results = 5 & lang = ru_RU & apikey = < API key > Вывести один результат, начиная с третьего:
https://search-maps.yandex.ru/v1/?text=Red Square & results = 1 & skip = 2 & lang = en_us & apikey = < Ключ API > Политики безопасности современных браузеров не позволяют веб-страницам загружать данные со сторонних серверов.Сторонний - это сервер, доменное имя которого отличается от доменного имени сервера, на котором находится страница. При создании страницы, запрашивающей результаты геокодирования, используйте технологию JSONP.
При использовании JSONP имя функции передается на сервер, возвращающий данные. Результаты возвращаются в формате JSON, но как параметр функции с указанным именем.
Чтобы получить результаты поиска в формате JSONP, вы должны присвоить параметру обратного вызова имя функции, которая будет обрабатывать результаты, возвращенные в формате JSON.Например:
https://search-maps.yandex.ru/v1/?text=Moscow, ul. Крылатский Холми & lang = en_us & apikey = < API-ключ > & callback = my_callback Сервер возвращает объект JSON, заключенный в указанную функцию:
my_callback ({
"status": "успех",
"данные": {
"type": "FeatureCollection",
"характеристики": {
"ResponseMetaData": {
"SearchRequest": {
«запрос»: «Москва, ул.Крылатские холмы »,
...
}
}
}
}
}) Поиск географических объектов. Places API
В этом разделе представлен пример запроса и ответа службы при поиске географических объектов.
https://search-maps.yandex.ru/v1/?text=Rai,Russia&type=geo&lang=en_US&apikey= < API-ключ > Ответ службы показан ниже (для обратного геокодирование, формат ответа тот же).
Внимание. Мы гарантируем поддержку только тех полей, которые описаны в примере ниже. Мы не рекомендуем использовать другие поля, которые есть в ответе, но не описаны в документации. Такие поля могут не поддерживаться в будущем.
{
"type": "FeatureCollection",
"характеристики": {
"ResponseMetaData": {
"SearchRequest": {
"запрос": "Рай, Россия",
«результатов»: 10,
«пропустить»: 0,
"boundedBy": [
[
37.04842675, г.
55,43644829
],
[
38.175, г.
56.046
]
]
},
"SearchResponse": {
«найдено»: 24,
"Точка": {
"type": "Point",
"координаты": [
32.01884032,
54,70408144
]
},
"boundedBy": [
[
32.00759341, г.
54,70136583
],
[
32.03008723, г.
54,70679686
]
],
"дисплей": "одиночный"
}
}
},
"Особенности": [
{
"type": "Feature",
"характеристики": {
"GeocoderMetaData": {
"добрый": "местность",
«текст»: «Россия, Смоленская область, Смоленская область, село Рай»,
"точность": "другое"
},
"описание": "Смоленская область, Смоленская область, Россия",
"name": "деревня Рай",
"boundedBy": [
[
32.007593, г.
54,701366
],
[
32.030087, г.
54,706797
]
]
},
"geometry": {
"type": "Point",
"координаты": [
32.024464, г.
54,704602
]
}
}
]
}
Контейнер для метаданных, описывающих запрос и ответ. Обязательное поле.
Метаданные, описывающие запрос и ответ. Обязательное поле.
Метаданные, описывающие запрос.Обязательное поле.
Строка запроса. Обязательное поле.
результатов
Максимальное количество возвращаемых результатов.
пропустить
Количество результатов, которые нужно пропустить.
boundedBy
Границы области, в которой предположительно находятся объекты поиска.
Устанавливаются как координаты левого верхнего и правого нижнего углов области. Координаты задаются в порядке «широта, долгота».
Границы области автоматически определяются сервисом.
Метаданные, описывающие ответ. Обязательное поле.
Количество найденных объектов. Обязательное поле.
Этот элемент используется для совместимости с форматом GeoJSON. Обязательное поле.
Тип геометрии. Обязательное поле.
Координаты объекта. Обязательное поле.
boundedBy
Границы области просмотра для найденных объектов.Содержит координаты левого нижнего и правого верхнего углов области. Координаты задаются в порядке «долгота, широта».
дисплей
Рекомендации по отображению результатов поиска. Возможные значения:
Контейнер для результатов поиска. Обязательное поле.
Метаданные, описывающие найденный объект. Обязательное поле.
Подробная информация о найденном объекте. Обязательное поле.
Вид топонима.Возможные значения:
«дом» - дом
«улица» - улица
«метро» - станция метро (метро)
«район» - городской район
«местность» "- населенный пункт (город / село / поселок / ...).
Обязательное поле.
Полный адрес объекта. Обязательное поле.
Точность сопоставления найденного номера дома с номером дома в запросе (дополнительная информация).Обязательное поле. описание
Текст, который рекомендуется установить в качестве подзаголовка при отображении найденного объекта.
имя
Текст, который рекомендуется задавать в качестве заголовка при отображении найденного объекта.
boundedBy
Границы области, в которой расположена компания. Содержит координаты левого нижнего и правого верхнего углов области. Координаты задаются в порядке «долгота, широта».
Описание геометрии найденного объекта. Обязательное поле.
Тип геометрии. Обязательное поле.
Координаты объекта. Обязательное поле.
* Обязательно
Яндекс - Технологии - Поиск на основе местоположения
В зависимости от региона от 15 до 30% всех поисковых запросов на Яндексе требуют информации о продуктах, услугах, личностях или событиях, связанных с текущим местоположением пользователя. Соответственно, Яндекс отвечает на такие запросы результатами поиска, которые различаются от региона к региону.Кто-то в Москве, ищущий юриста, увидит ссылки на сайты поставщиков юридических услуг в Москве, а человек, выполняющий такой же поисковый запрос в Киеве, найдет ссылки на сайты местных юридических фирм.
Поиск на основе местоположения доступен в тех городах России, Украины и Беларуси, где количество местных веб-сайтов позволяет использовать эту функцию. Результаты на основе местоположения также доступны для пользователей Интернета в Казахстане и Турции.
Не все поисковые запросы требуют ответов на основе местоположения.Не имеет большого значения, где находится искатель, когда он ищет книгу, рецепт или закон физики. С другой стороны, те, кто просит тренажерный зал или такси, скорее всего, будут искать тренажерный зал, ближайший к месту их проживания, или компанию такси в своем городе.
Люди в разных местах, ищущие одно и то же, могут ожидать, что найдут что-то совершенно другое. Очень часто это поисковые запросы по именам местных знаменитостей или компаний. Интернет-пользователь в Москве, вводящий запрос «орбита», на самом деле ищет кинотеатр, в то время как кто-то в Ростове-на-Дону, выполняющий тот же запрос, ожидает увидеть сайт автосалона, и если этот поиск поступает из Израиля, Автор, скорее всего, будет искать популярный местный веб-портал.
Способность поисковой системы определять разницу между теми пользовательскими запросами, которые требуют результатов на основе местоположения, и теми, которые не требуют результатов, имеет решающее значение для ее способности понимать намерения искателя и предоставлять наилучшие результаты поиска для ответа на них.
Механизм, который позволяет поисковой системе определять, соответствует ли текущее местоположение поисковика запросу, основан на статистике поиска. Запрос, зависящий от местоположения, может не содержать терминов, указывающих на его географическое положение, но в нем должны быть слова, которые часто встречаются вместе с такими терминами.Например, поисковый запрос «транспорт» будет классифицирован как зависящий от местоположения, потому что те, кто использует это слово в своих поисках, также часто добавляют местоположение.
Местоположение поиска определяется, в первую очередь, IP-адресом искателя. Однако эта информация не является универсальной - IP-адрес может быть присвоен интернет-провайдером, зарегистрированным в другом регионе. Яндекс постоянно обновляет свой классификатор для идентификации регионов, используя информацию, которую он получает от клиентов, партнеров и конечных пользователей.Он всегда информирует пользователей об их текущем местонахождении. Он отображается в правом верхнем углу страницы результатов поиска и может быть изменен вручную в настройках.
Поиск Яндекса отвечает на запросы, зависящие от местоположения, релевантными для региона поискового запроса. Наиболее релевантные результаты по поисковому запросу, зависящему от местоположения, как правило, поступают с локальных веб-ресурсов. Это, однако, не означает, что хороший ответ не может быть получен с веб-сайта, не зависящего от местоположения, или с веб-сайта в другом регионе.При доставке результатов поиска по запросу, зависящему от местоположения, локальные ресурсы имеют приоритет над другими, только если все остальные факторы равны. Пользователи Яндекса могут ограничить свой поиск исключительно локальными ресурсами в настройках поисковой системы. Если в поисковом запросе упоминается географическое название, Яндекс показывает результаты, релевантные этому месту, независимо от текущего местоположения пользователя. Таким образом, кто-то, ищущий отель в Санкт-Петербурге, увидит ссылки на сайты отелей в этом городе, даже если они ищут из Москвы.Когда пользователь получает ссылку на результаты поиска Яндекса от кого-то из другого региона, он видит именно ту страницу, которая была отправлена, а не результаты поиска, соответствующие их местоположению. Это возможно, потому что информация о текущем местоположении пользователя встроена в веб-адрес страницы.
Яндекс также использует текущее местоположение искателя, чтобы предоставить ему релевантную информацию в результатах поиска и в результатах поиска с указанием погоды, событий, вакансий, рабочих адресов и т. Д.Таким образом, улица Ленина, которую пользователи увидят в Яндексе, будет относиться именно к улице Ленина в их собственном городе, а не в каком-либо другом.Поисковая система определяет регион веб-сайта с помощью ряда атрибутов, включая контактную информацию на его страницах, его IP-адрес, регион, который он часто упоминает, и т. Д.
Региональные веб-сайты компании обычно идентифицируются как локальные в соответствующих регионы. Веб-сайт компании может быть классифицирован как национальный независимо от того, где находится головной офис компании, если эта компания имеет национальное, а не региональное присутствие, например, почтовая служба.Та же логика применима к веб-сайтам, доступность которых в Интернете намного важнее, чем их физическое местонахождение - электронные библиотеки или службы электронной почты являются хорошим примером.
Яндекс.Карт в App Store
Найдите адрес или лучшие места поблизости как в Интернете, так и в автономном режиме. Яндекс.Карты предоставляют информацию об организациях и помогают добраться до места назначения на машине, общественном транспорте, велосипеде или пешком в зависимости от текущей дорожной обстановки.
Найдите и выберите местоположения:
• Самая большая база данных организации и фильтры для уточнения поиска.
• Подробная информация: контакты, режим работы, предоставляемые услуги, фотографии, отзывы.
• Планы этажей, позволяющие ориентироваться в крупных торговых центрах Москвы.
• Поиск мест и адресов без подключения к Интернету (автономные карты).
• Просматривайте места, сохраненные на вашем смартфоне, планшете и ПК.
Пользовательские настройки карты:
• Местоположение автобусов, трамваев, троллейбусов и маршруток в реальном времени.
• Дорожные карты, показывающие текущую дорожную обстановку в городе.
• Парковочный слой с указанием места и стоимости служебной парковки.
• Панорамы улиц для любого адреса со стороны дороги.
• Выберите один из трех типов карты: дорожная карта, спутниковая и гибридная.
Общественный транспорт, автомобильные, велосипедные и пешеходные маршруты:
• Пешеходная навигация: пути между зданиями, через парки, площади и другие пешеходные зоны.
• Велосипедная навигация: типы дорог, предпочтения подземных и эстакад, а также предупреждения о шоссе.
• Маршруты общественного транспорта с расписанием и примерным временем прибытия.
• Оптимальные маршруты движения, основанные на реальных условиях движения и вариантах вождения.
• Пошаговые инструкции с голосовой навигацией.
• Уведомления о камерах контроля скорости, ограничении скорости и превышении скорости.
• Обновления в режиме реального времени о дорожном движении, дорожно-транспортных происшествиях, радаре скорости и многом другом.
Офлайн-карты:
• Автомобильные маршруты и голосовая навигация.
• Загружаемые облегченные карты (минимальный объем памяти, например, карта Москвы составляет всего 187 МБ).
• База данных организаций с графиком работы, предоставляемыми услугами и др.
• Более 2000 городов в России, Армении, Беларуси, Грузии, Казахстане, Латвии, Турции, Украине и Эстонии.
Информация от пользователей:
• Отметьте дорожные события на карте и комментируйте сообщения пользователей.
• Регулярные обновления общедоступной карты информируют вас о вашем городе.
• Пишите обзоры, загружайте фотографии и обновляйте информацию об организациях.
На Яндекс.Картах есть приложение Apple Watch.Используйте его, чтобы:
• Перемещаться по карте.
• Просмотр ближайшей станции метро и остановок общественного транспорта.
• Узнайте, когда общественный транспорт прибудет на ближайшую остановку.
• Отслеживайте структуру трафика на несколько часов раньше времени.
• Просмотр прогнозов погоды.
EdmundMartin / yansearch: Оболочка Python над API поиска Яндекса упрощает задачу выполнения запроса API поиска Яндекса. Дополнительные функции будут добавлены.
GitHub - EdmundMartin / yansearch: Оболочка Python над API поиска Яндекса упрощает задачу выполнения запроса API поиска Яндекса.Дополнительные функции будут добавлены.Оболочка Python над API поиска Яндекса упрощает задачу выполнения запроса API поиска Яндекса. Дополнительные функции будут добавлены.
Файлы
Постоянная ссылка Не удалось загрузить последнюю информацию о фиксации.Тип
Имя
Последнее сообщение фиксации
Время фиксации
Python-оболочка над API поиска Яндекса упрощает задачу выполнения запроса API поиска Яндекса.Дополнительные функции будут добавлены.
Примеры использования
из yansearch import search_api
search_scraper = search_api ('yandex_user_name', 'yandex_api_key')
xml_file = search_scraper.get_results ('Ваше ключевое слово') Оболочка находится над API поиска Яндекса и требует для работы только одного аргумента - ключевого слова, по которому нужно собирать результаты. На данный момент существует единственный способ сгруппировать возвращенные результаты: результаты сгруппированы в список, как если бы вы выполняли поиск на Яндексе.
В настоящее время обработка ошибок требует улучшения, поскольку по умолчанию API поиска Яндекса возвращает код ошибки в возвращенном XML.
Необязательные аргументы
из yansearch import search_api
search_scraper = search_api ('yandex_user_name', 'yandex_api_key')
xml_file = search_scraper.get_results ('Ваше ключевое слово', 'ru', 213, rlv, 'none', 50) Функция также принимает ряд необязательных аргументов.
- Язык - поиск Яндекса поддерживает несколько языков, однако допустимые языки зависят от того, какую версию API вы используете.Worldwide поддерживает только en (английский), тогда как стандартный локальный вариант API поддерживает русский, украинский и казахский языки.
- Число «213» относится к месту, в котором выполняется поиск. Полный список различных локаций можно найти на сайте Yandex XML. Переменная местоположения не используется во всемирной версии API, и по умолчанию для местоположения установлено значение Москва, Российская Федерация.
- Следующая переменная указывает порядок, в котором должны быть возвращены результаты.Стандартный вариант возвращает результаты, которые могут быть либо отображением самых последних в первую очередь, либо порядком релевантности. По умолчанию отображает их в порядке относительности.
Около
Оболочка Python над API поиска Яндекса упрощает задачу выполнения запроса API поиска Яндекса. Дополнительные функции будут добавлены.
ресурсов
Вы не можете выполнить это действие в настоящее время.Вы вошли в систему с другой вкладкой или окном. Перезагрузите, чтобы обновить сеанс. Вы вышли из системы на другой вкладке или в другом окне. Перезагрузите, чтобы обновить сеанс.Эксклюзив: западная разведка взломала «российский Google» Яндекс, чтобы шпионить за аккаунтами - источники
ВАШИНГТОН / ЛОНДОН / САН-ФРАНЦИСКО (Рейтер) - Хакеры, работающие на западные спецслужбы, ворвались в российскую поисковую компанию Яндекс в конце 2018 года, применив редкий тип о вредоносном ПО в попытке шпионить за учетными записями пользователей, сообщили Reuters четыре человека, осведомленных в этом вопросе.
ФОТО ФАЙЛА: Логотип российской интернет-группы «Яндекс» изображен в штаб-квартире компании в Москве, Россия, 4 октября 2018 г. REUTERS / Шамиль Жуматов / Фото из файла
Известно, что вредоносное ПО под названием Regin используется « Источники сообщили, что "Five Eyes" объединяет США, Великобританию, Австралию, Новую Зеландию и Канаду по обмену разведданными. Спецслужбы этих стран от комментариев отказались.
Западные кибератаки против России редко признаются и редко обсуждаются публично.Невозможно определить, какая из пяти стран стояла за атакой на Яндекс, сообщили источники в России и других странах, трое из которых непосредственно знали о взломе. Нарушение произошло в период с октября по ноябрь 2018 года.
Представитель «Яндекса» Илья Грабовский признал факт инцидента в заявлении Рейтер, но отказался предоставить дополнительные подробности.
«Эта конкретная атака была обнаружена на очень ранней стадии командой безопасности Яндекса. Он был полностью нейтрализован до того, как был нанесен какой-либо ущерб », - сказал он.«Благодаря ответным действиям службы безопасности Яндекса данные пользователей не были скомпрометированы атакой».
Компания, широко известная как «российский Google» за широкий спектр онлайн-услуг, от поиска в Интернете до электронной почты и заказа такси, сообщает, что у нее более 108 миллионов пользователей в месяц в России. Он также работает в Беларуси, Казахстане и Турции.
Источники, описавшие атаку агентству Reuters, заявили, что хакеры, похоже, искали техническую информацию, которая могла бы объяснить, как Яндекс аутентифицирует учетные записи пользователей.Такая информация может помочь шпионскому агентству выдать себя за пользователя Яндекса и получить доступ к его личным сообщениям.
Взлом отдела исследований и разработок Яндекса был предназначен для шпионажа, а не для нарушения или кражи интеллектуальной собственности, сообщили источники. По их словам, хакеры тайно сохраняли доступ к Яндексу в течение как минимум нескольких недель, оставаясь незамеченными.
Вредоносная программа Regin была идентифицирована как инструмент Five Eyes в 2014 году после разоблачений бывшего подрядчика Агентства национальной безопасности США (АНБ) Эдварда Сноудена.
Репортажи The Intercept в сотрудничестве с голландско-бельгийской газетой связали более раннюю версию Regin со взломом бельгийской телекоммуникационной компании Belgacom в 2013 году и указали, что ответственность за это несут британское шпионское агентство Government Communications Headquarter (GCHQ) и АНБ. В то время GCHQ отказался от комментариев, а АНБ отрицало свою причастность.
‘CROWN JEWEL’
Эксперты по безопасности говорят, что приписывание кибератак может быть затруднено из-за методов обфускации, используемых хакерами.
Однако, по словам источников, часть кода Regin, обнаруженного в системах Яндекса, не использовалась в ходе каких-либо известных предыдущих кибератак, что снижает риск того, что злоумышленники намеренно использовали известные западные хакерские инструменты, чтобы замести следы.
Яндекс позвонил в российскую компанию по кибербезопасности Kaspersky, которая установила, что злоумышленники нацелены на группу разработчиков внутри Яндекса, сообщили три источника. В частной оценке Kaspersky, описанной Reuters, сделан вывод, что хакеры, вероятно, связанные с западной разведкой, взломали Яндекс с помощью Regin.
Представитель «Лаборатории Касперского» от комментариев отказалась.
В Управлении национальной разведки США от комментариев отказались. Совет национальной безопасности Белого дома не ответил на запрос о комментарии.
Официальный представитель Кремля Дмитрий Песков заявил, что российское правительство не знало об этой конкретной атаке на Яндекс. «Яндекс и другие российские компании подвергаются атакам каждый день. Многие нападения происходят из западных стран », - сказал он.
Московский Яндекс, котирующийся на NASDAQ в США и Московской бирже, попал под более жесткий регулирующий контроль со стороны правительства России после принятия новых законов об Интернете.
Американская компания Symantec, занимающаяся кибербезопасностью, заявила, что недавно обнаружила новую версию Regin.Symantec отказалась обсуждать, где был обнаружен этот образец, сославшись на конфиденциальность клиента.
«Регин - жемчужина атакующих структур, используемых для шпионажа. «Его архитектура, сложность и возможности находятся на одном уровне», - сказал Рейтер Викрам Такур, технический директор Symantec Security Response.