Блог Yoair — публикация в мировом блоге по антропологии.
Сообщение Просмотров: 111,113
Таблица ASCII (американский системный код для обмена информацией) — это стандарт кодирования символов, используемый в компьютерах и других устройствах для текстовых файлов. ASCII — это подмножество Unicode с набором символов из 128 символов. Символы включают заглавные и строчные буквы, цифры, знаки препинания, запоминающиеся символы и управляющие символы. Каждый символ в наборе символов имеет одинаковое шестнадцатеричное и восьмеричное значение, а также десятичное значение в диапазоне от 0 до 127.
ASCII — это стандарт кодировки символов для электронной связи. Текст представлен с помощью кода ASCII в компьютерах, телекоммуникационном оборудовании и других устройствах. Хотя они позволяют использовать гораздо больше символов, большинство современных методов кодирования символов основаны на ASCII.
Управление по присвоению номеров Интернета (IANA) поддерживает обозначение US-ASCII для этой кодировки символов.
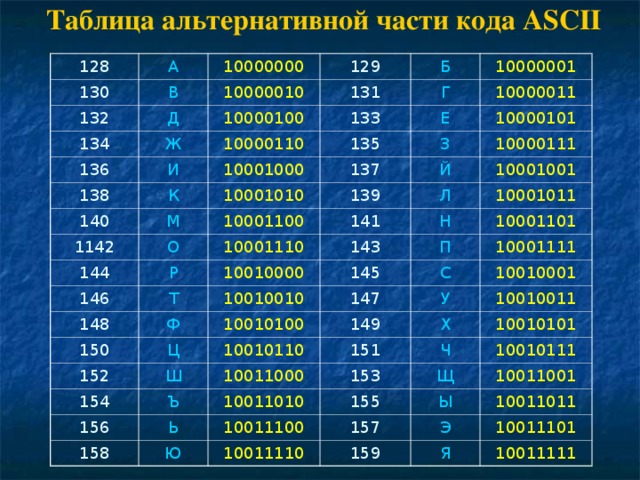
ASCII
Телеграфное кодирование вдохновило на разработку таблицы ASCII. Первоначально он использовался в коммерческих целях как семибитный код телетайпа, продвигаемый службами данных Bell. Учредительное собрание Американская Подкомитет X3.2 Ассоциации стандартов (ASA) (ныне Американский национальный институт стандартов или ANSI) в мае 1961 года ознаменовал начало работы над стандартом ASCII. Первоначальная версия стандарта была выпущена в 1963 г., в 1967 г. он претерпел существенные изменения, а последний раз обновлялся в 1986 г. По сравнению с предыдущими телеграфными кодами запланированный код Белла и код ASCII были организованы для более удобной сортировки списка (т. е. алфавитного ) и введена функциональность для устройств, отличных от телепринтеров].
Предоставлено: приятели науки.В 1969 году было определено использование формата таблицы ASCII для сетевого обмена. [9] В 2015 году этому документу был официально присвоен статус Интернет-стандарта.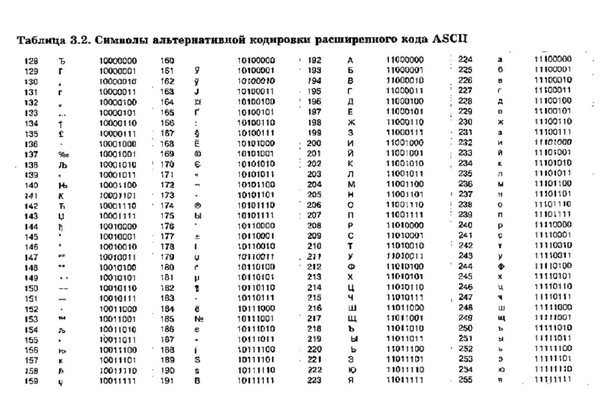
ASCII, изначально основанный на английском алфавите, кодирует 128 определенных символов в семибитные целые числа, как видно из диаграммы ASCII выше. Цифры от 0 до 9, строчные буквы от a до z, заглавные буквы от A до Z и знаки препинания входят в число 95 кодированных символов, которые можно распечатать. Более того, исходное определение ASCII включает 33 непечатаемых управляющих кода, созданных с помощью телетайпов; большинство из них уже устарели, а некоторые, такие как коды возврата каретки, перевода строки и табуляции, по-прежнему широко используются.
Строчная буква I, например, будет представлена двоичным числом 1101001 = шестнадцатеричное 69 I (девятая буква) = десятичное 105 в кодировке ASCII.
История ASCII
Таблица ASCII была создана под контролем Американской ассоциации стандартов (ASA). То Американская Ассоциация стандартов (ASA) превратилась в США Американского института стандартов (USASI) и, в конечном итоге, Американская Национальный институт стандартов (ANSI).
Для дополнительный После заполнения специальных символов и управляющих кодов ASCII был опубликован как ASA X3.4-1963, оставив 28 кодовых позиций без присвоенного значения и один неназначенный управляющий код. Был существенный спор о том, следует ли использовать дополнительные управляющие символы вместо строчного алфавита. Колебания длились недолго: в мае 1963 года рабочая группа CCITT по новому телеграфному алфавиту выступила за присвоение строчных букв стержням 6 и 7, а в октябре Международная организация по стандартизации TC 97 SC 2 решила включить корректировку в свои проект стандарта.
На собрании в мае 1963 года рабочая группа X3.2.4 одобрила переход на ASCII. Расположение строчных букв на палочках 6 и 7 привело к тому, что битовые шаблоны символов отклонились от верхнего регистра на один бит, что упростило сопоставление символов без учета регистра и дизайн клавиатур и принтеров.
Другие модификации, внесенные комитетом X3, включали добавление новых символов (скобки и вертикальные черты), переименование некоторых управляющих символов (SOM стало началом заголовка (SOH)), а также перемещение или удаление других (RU был удален).
Изменения стандарта таблиц ASCII:
- АСА Х3.4-1963
- ASA X3.4-1965 (утвержден, но не опубликован, тем не менее, используется станциями дисплея IBM 2260 и 2265 и системой управления дисплеем IBM 2848)
- США Х3.4-1967
- USAS X3.4-1968
- АНСИ Х3.4-1977
- АНСИ Х3.4-1986[
- ANSI X3.4-1986 (R1992)
- АНСИ Х3.4-1986 (Р1997)
- ANSI INCITS 4-1986 (R2002)
- ANSI INCITS 4-1986 (R2007)
- (ANSI) ПРЕИМУЩЕСТВА 4-1986 [R2012]
- (ANSI) INCITS 4-1986 [R2017]
Комитет X3 также рассмотрел методы передачи ASCII (сначала младший бит) и записи на перфорированной ленте в стандарте X3.15. Они предложили стандарт магнитной ленты с 9 дорожками и экспериментировали с различными форматами перфокарт.
Битовая ширина
На основе предшествующих методов кодирования телетайпа подкомитет X3.2 создал ASCII.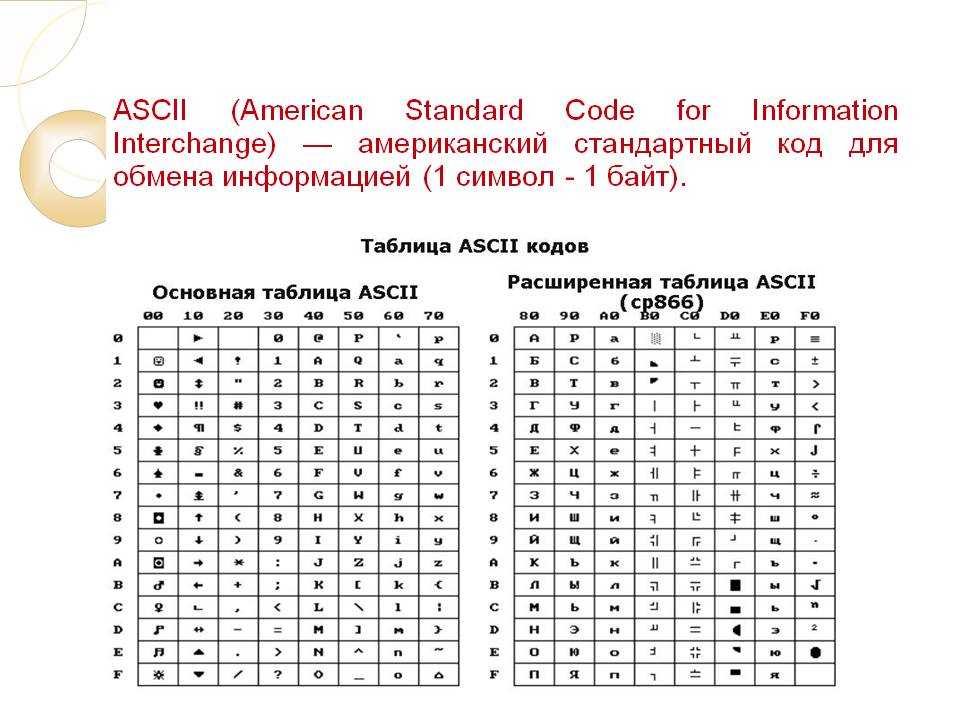 Как и другие кодировки символов, ASCII обеспечивает связь между цифровыми битовыми комбинациями и символьными символами (т. Е. Графемами и управляющими символами). Он позволяет цифровым устройствам обмениваться данными друг с другом и анализировать, хранить и передавать символьные данные, такие как письменный язык. До разработки ASCII кодировки содержали 26 букв алфавита, десять числовых цифр и от 11 до 25 уникальных визуальных символов. Чтобы включить все это в таблицу ASCII, требовалось более 64 кодов.
Как и другие кодировки символов, ASCII обеспечивает связь между цифровыми битовыми комбинациями и символьными символами (т. Е. Графемами и управляющими символами). Он позволяет цифровым устройствам обмениваться данными друг с другом и анализировать, хранить и передавать символьные данные, такие как письменный язык. До разработки ASCII кодировки содержали 26 букв алфавита, десять числовых цифр и от 11 до 25 уникальных визуальных символов. Чтобы включить все это в таблицу ASCII, требовалось более 64 кодов.
ITA2 был основан на 5-битном телеграфном коде Эмиля Бодо, который он разработал в 1870 году и запатентовал в 1874 году.
Комитет обсудил идею функции сдвига (аналогичной той, что есть в ITA2). Это позволило бы представить более 64 кодов шестибитным кодом. Некоторые коды символов в сдвинутом коде определяют альтернативы для следующих кодов символов. Он обеспечивает краткое кодирование, но менее надежен для передачи данных, поскольку ошибка кода сдвига часто делает большую часть передачи неразборчивой. Поскольку группа стандартов отказалась от перемещения, ASCII требовал как минимум семибитного кода.
Поскольку группа стандартов отказалась от перемещения, ASCII требовал как минимум семибитного кода.
Комитет исследовал восьмибитное кодирование, потому что восемь битов (октетов) позволили бы двум четырехбитным шаблонам эффективно кодировать две цифры с помощью двоичного десятичного числа. Однако при любой передаче данных необходимо отправить восемь битов, когда будет достаточно семи. Чтобы снизить затраты на передачу данных, группа решила использовать семибитное кодирование. Поскольку перфорированная лента могла записывать восемь бит в одном месте за раз, в ней также предусматривался небольшой бит для проверки ошибок, если это необходимо. Восьмиразрядные устройства (с октетами в качестве собственного типа данных), которые не выполняли проверку четности, обычно устанавливали восьмой бит в 0.
Кредит: ВикимедиаВнутренняя организация
Сам код в таблице ASCII был разработан таким образом, что большинство управляющих кодов и все визуальные коды были сгруппированы для облегчения распознавания. Первые две «палочки ASCII» (32 места) были отведены под управляющие символы. Перед изображениями должен был стоять символ «пробел», чтобы упростить сортировку. Поэтому она стала позицией 20. По той же причине перед числами ставились многочисленные уникальные знаки, обычно используемые в качестве разделителей. Комитет решил, что критически важно разрешить использование 64-значных алфавитов в верхнем регистре, и решил разработать ASCII, который можно было бы легко сократить до пригодного для использования 64-значного набора графических кодов, как это было сделано в коде DEC SIXBIT (1963).
Первые две «палочки ASCII» (32 места) были отведены под управляющие символы. Перед изображениями должен был стоять символ «пробел», чтобы упростить сортировку. Поэтому она стала позицией 20. По той же причине перед числами ставились многочисленные уникальные знаки, обычно используемые в качестве разделителей. Комитет решил, что критически важно разрешить использование 64-значных алфавитов в верхнем регистре, и решил разработать ASCII, который можно было бы легко сократить до пригодного для использования 64-значного набора графических кодов, как это было сделано в коде DEC SIXBIT (1963).
В результате строчные буквы не чередовались с прописными. Вместо этого перед буквами помещались уникальные и числовые коды, чтобы строчные буквы и другие визуальные параметры были доступны. Например, буква А была помещена в позицию 41, чтобы соответствовать проекту соответствующего британского стандарта. Цифры 0–9 имеют префикс 011, в то время как оставшиеся 4 бита соответствуют своим двоичным значениям, что упрощает преобразование в десятичные числа с двоичным кодом.
Многие не буквенно-цифровые символы были перемещены в соответствии с их перемещением на пишущих машинках; Существенное отличие состоит в том, что они были основаны на механических пишущих машинках, а не на электрических. Например, Remington № 2 (1878 г.), первая пишущая машинка с клавишей Shift, установила стандарт для механических пишущих машинок. Сдвинутые значения 23456789- были использованы «# $ процентов _ & ‘() — ранние пишущие машинки опускали 0 и 1, заменяя их на O (заглавная буква o) и l (строчная буква L), но 1! и 0) пары стали общими, как только 0 и 1 стали общими. В итоге в ASCII! «# $ Процентов были помещены на места 1–5 второй ручки, соответствующие цифрам 1–5 соседней ручки. Однако скобка не могла равняться 9 и 0, потому что пробел занял место, соответствующее 0.
Это было решено путем удаления (подчеркивания) из 6 и перестановки оставшихся букв. Он соответствовал скобкам с 8 и 9 на многих европейских пишущих машинках. Эта разница между пишущими машинками и клавиатурами с битовой парой привела к созданию клавиатур с битовой парой, в первую очередь Teletype Model 33, в которой использовалась раскладка со смещением влево, соответствующая ASCII, а не стандартным механическим пишущим машинкам.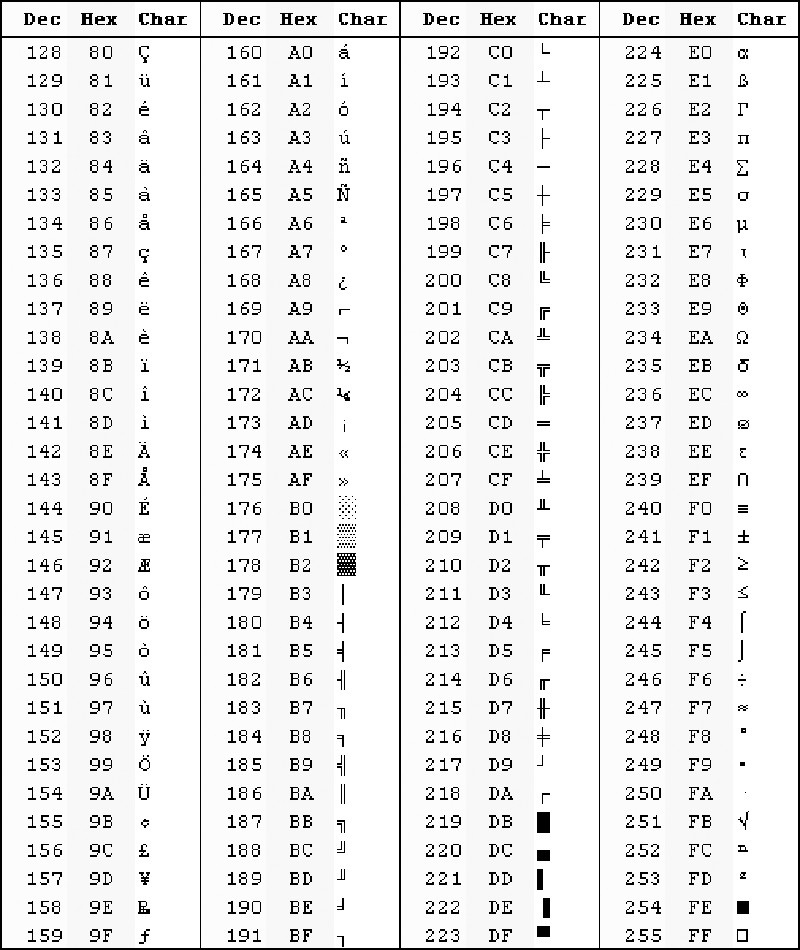 Электрические пишущие машинки, в основном IBM Selectric (1961), использовали несколько иную компоновку, которая с тех пор стала стандартной для компьютеров. Он последовал за IBM PC (1981), особенно Model M (1984). Таким образом, значения сдвига для символов, существующих на современных клавиатурах, не так близки к таблице ASCII.
Электрические пишущие машинки, в основном IBM Selectric (1961), использовали несколько иную компоновку, которая с тех пор стала стандартной для компьютеров. Он последовал за IBM PC (1981), особенно Model M (1984). Таким образом, значения сдвига для символов, существующих на современных клавиатурах, не так близки к таблице ASCII.
Символ /? пара также использовалась на № 2, как и пары,.> (другие клавиатуры, включая № 2, не сдвигались, (запятая) или. (точка), что позволяло использовать их в верхнем регистре без отмены сдвига ). С другой стороны, ASCII разделил пару;: (начиная с № 2) и переставил математические символы (различные нормы, часто — * = +) на: *; + — =.
Некоторые часто встречающиеся буквы, в частности 1214, были опущены, в то время как ‘было добавлено как диакритический знак для международного использования, а> для математического использования. Это наряду с простыми линейными символами | (в дополнение к обычному /). Знак @ не использовался в континентальной Европе, и комитет ожидал, что его заменит вариант с акцентом на французском.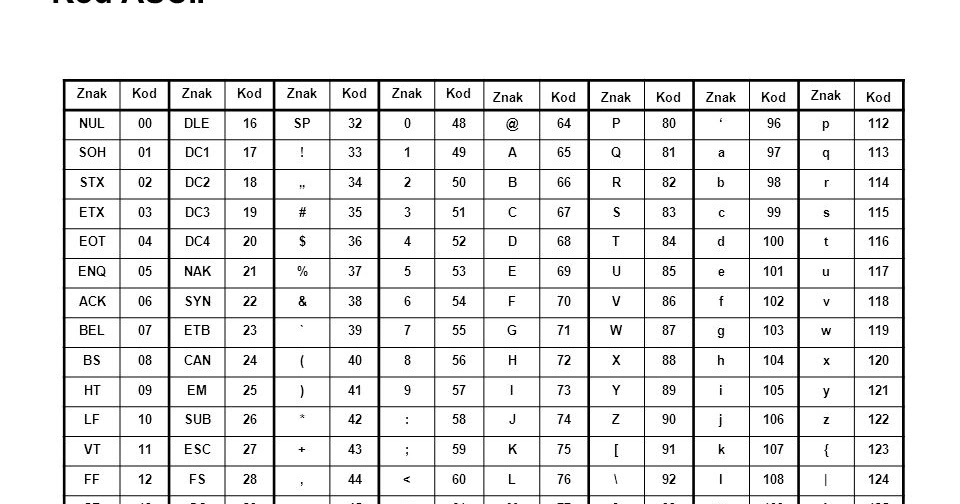 Таким образом, он был помещен на позицию 40, непосредственно перед буквой A.
Таким образом, он был помещен на позицию 40, непосредственно перед буквой A.
Коды управления считаются необходимыми для дата передача была началом сообщения (SOM), концом адреса (EOA), концом сообщения (EOM), концом передачи (EOT), «кто вы?» (WRU), «ты?» (RU), управление зарезервированным устройством (DC0), синхронный режим ожидания (SYNC) и подтверждение (ACK). Они были размещены так, чтобы расстояние Хэмминга между их битовыми последовательностями было как можно меньше.
Порядок персонажей
Порядок ASCII-кодов часто называют ASCII-кодовым порядком. Сбор данных иногда выполняется в этом порядке, а не в «обычном» алфавитном порядке (последовательность сортировки). Ниже приведены наиболее значительные отклонения от порядка ASCII:
Прописные буквы всегда идут перед строчными; например, «Z» стоит перед «a». Точно так же цифры и различные знаки препинания всегда появляются перед буквами. Перед сравнением данных ASCII промежуточный порядок заменяет символы верхнего регистра на нижний регистр.
Управляющие персонажи
Таблица ASCII сохраняет исходные 32 кода (десятичные числа 0–31) для управляющих символов: коды, которые изначально предназначались для управления устройствами (например, принтерами), которые используют ASCII или предоставляют метаинформацию о потоках данных, например, о тех, которые хранятся на магнитной ленте, а не для представления информации для печати.
Например, буква 10 символизирует функцию «перевода строки» (которая вызывает продвижение бумаги в принтере), а буква 8 означает «возврат». Контрольные символы без пробелов определяются RFC 2822 как контрольные символы, не содержащие возврата каретки, перевода строки или пробелов. ASCII не предоставляет никакой системы для выражения структуры или внешнего вида текста внутри документа, кроме управляющих символов, которые определяют базовое строчно-ориентированное форматирование. Другие методы включают языки разметки, макет и форматирование страницы, а также макет и форматирование документа.
В исходном стандарте ASCII для каждого управляющего символа использовались только краткие описательные предложения. Создаваемая этим неоднозначность иногда была преднамеренной, например, когда символ использовалась в терминальной ссылке несколько иначе, чем в потоке данных, а иногда и непреднамеренной, например, когда значение слова «удалить» было неясным.
Создаваемая этим неоднозначность иногда была преднамеренной, например, когда символ использовалась в терминальной ссылке несколько иначе, чем в потоке данных, а иногда и непреднамеренной, например, когда значение слова «удалить» было неясным.
Teletype Model 33 ASR, печатный терминал с опцией считывания / перфорации бумажной ленты, был, вероятно, наиболее значимым инструментом для интерпретации этих символов. До 1980-х годов бумажная лента была распространенным носителем для долгосрочного хранения программ, потому что она была менее дорогой и в некоторых отношениях менее хрупкой, чем магнитная лента. В результате машинные присвоения кодов 17, 19 и 127 на Teletype Model 33 стали де-факто стандартами.
Модель 33 также была необычной для буквальной интерпретации определения Control-G (код 7, BEL, что означает предупреждение оператора), поскольку устройство имело настоящий звонок, который звучал при получении символа BEL. Поскольку верхняя часть клавиши O также отображает символ стрелки влево, несоответствующее использование кода 15 (Control-O, Shift In) интерпретируется как «удаление предыдущего символа» также было принято многими ранними системами разделения времени, но в конечном итоге от него отказались.
Когда ASR Teletype 33, оборудованный автоматическим устройством считывания бумажной ленты, получил Control-S (XOFF, аббревиатура от «передача выключена»), устройство чтения ленты остановилось, получив Control-Q (XON, «передача включена») перезапустило ленту. читатель. Этот подход использовался различными ранними компьютерными операционными системами в качестве сигнала «рукопожатия», советующего отправителю прекратить передачу из-за надвигающегося переполнения; он до сих пор используется в качестве метода ручного управления выводом во многих системах. Control-S сохраняет свое значение в определенных системах, хотя Control-Q заменяется вторым Control-S для продолжения вывода. 33 ASR можно также настроить на использование Control-R (DC2) и Control-T (DC4) для запуска и остановки перфорации ленты; в определенных системах соответствующий контрольный символ, записанный на крышке клавиатуры над определенной буквой, был TAPE и TAPE, соответственно.
Удалить и клавишу Backspace
Поскольку телетайп не мог переместить голову назад, он не мог нажать клавишу на клавиатуре для передачи BS (backspace). Вместо этого был ключ RUBOUT, который отправлял код 127. (DEL). Функция этой клавиши заключалась в стирании ошибок на бумажной ленте, набранной вручную: оператору приходилось делать резервную копию, нажимая кнопку на перфораторе ленты, затем вводить стирание, которое заполняло все отверстия и заменяло ошибку предполагаемой. игнорируемый персонаж. Телетайпы часто использовались для менее дорогих компьютеров Digital Equipment Corporation. Поэтому эти системы должны были использовать доступную клавишу и код DEL для удаления предыдущего символа.
Вместо этого был ключ RUBOUT, который отправлял код 127. (DEL). Функция этой клавиши заключалась в стирании ошибок на бумажной ленте, набранной вручную: оператору приходилось делать резервную копию, нажимая кнопку на перфораторе ленты, затем вводить стирание, которое заполняло все отверстия и заменяло ошибку предполагаемой. игнорируемый персонаж. Телетайпы часто использовались для менее дорогих компьютеров Digital Equipment Corporation. Поэтому эти системы должны были использовать доступную клавишу и код DEL для удаления предыдущего символа.
В результате видеотерминалы DEC (по умолчанию) передавали код DEL для клавиши «Backspace», а клавиша «Delete» отправляла escape-последовательность и многие другие терминалы отправил BS для клавиши Backspace. В результате драйвер терминала Unix мог использовать только один код для удаления предыдущего символа. Его можно было изменить либо на BS, либо на DEL, но не на оба, что привело к длительному периоду ухудшения, когда пользователям приходилось настраивать его в зависимости от терминала, который они использовали. Поскольку предполагалось, что никакой ключ не доставил BS, Control + H использовался по разным причинам, например, для команды префикса «help» в GNU Emacs.
Поскольку предполагалось, что никакой ключ не доставил BS, Control + H использовался по разным причинам, например, для команды префикса «help» в GNU Emacs.
Ключ побега
Многим дополнительным контрольным кодам присвоены значения, существенно отличающиеся от их оригинальных. Например, «escape-символ» (ESC, код 27) был разработан для передачи других управляющих символов в виде литералов, а не для указания их значения. Однако это точное значение «escape», как видно в кодировках URL, строках языка C и других системах, где некоторые символы зарезервированы.
Это значение было заимствовано и со временем изменилось. В настоящее время ESC, передаваемый на терминал, обычно отмечает начало последовательности команд. Он имеет форму «escape-кода ANSI» из ECMA-48 (1972) и его последователей, начиная с ESC, за которым следует символ «[». ESC, передаваемый с терминала, обычно используется как внеполосный символ для завершения операции, например, в текстовых редакторах TECO и vi. Кроме того, ESC часто предлагает программе в графическом интерфейсе пользователя (GUI) и оконных системах прервать текущую операцию или полностью выйти (завершить).
Заключение
Таблица ASCII была впервые коммерчески использована в 1963 году в качестве 7-битного телетайпного кода для сети TWX (TeletypeWriter eXchange) компании American Telephone & Telegraph. TWX изначально использовал предыдущую 5-битную ITA2, которая также использовалась в конкурирующих телексных системах Telex. Боб Бемер представил такие функции, как бежать последовательности. Его английский коллега Хью МакГрегор Росс внес свой вклад в распространение этой работы. Благодаря его обширным исследованиям ASCII, Беммера назвали «отцом ASCII». ASCII была самой популярной кодировкой символов во всемирной паутине до декабря 2007 года, когда ее превзошла кодировка UTF8. UTF8 обратно совместим с ASCII
НРАВИТСЯ:
подобно Загрузка…
ASCII — стандарт для стандартов | Computerworld Россия
«Открытые системы»
Необходимость установить соответствие между графическим представлением символов и их двоичными кодами возникла уже при первых попытках применить компьютеры для работы с текстами
Называя компьютер компьютером, его создатели не предполагали в своем детище открывшихся позже коммуникационных способностей.
Задача установления соответствия между графическим представлением символов и их двоичными кодами возникла при первых же попытках применить компьютеры для работы с текстами. Из-за отсутствия стандартов ее всякий раз решали по-разному; в иных случаях кодировку привязывали и к формату перфокарты, и к машинному слову. Первой не вполне удавшейся попыткой стандартизации (1956 год) оказалось создание шестибитного кода Fieldata. В экспериментальном порядке он был реализован на компьютерах UNIVAC 1100, но к 1962 году эти работы прекратились.
| ASCII оказался долгожителем, став одним из самых успешных примеров стандартизации за всю компьютерную историю |
Преемником Fieldata стал семибитный код ASCII (American Standard Code for Information Interchange). За долгие годы появилось множество надстроек для создания национальных и международных версий кода ASCII. В частности, ASCII вошел в бесконечный ряд кодировок по ГОСТу, к счастью сегодня забытых, в Windows 1251 и 1242, в KOI-8R, в Unicode и многие другие коды.
За долгие годы появилось множество надстроек для создания национальных и международных версий кода ASCII. В частности, ASCII вошел в бесконечный ряд кодировок по ГОСТу, к счастью сегодня забытых, в Windows 1251 и 1242, в KOI-8R, в Unicode и многие другие коды.
ASCII оказался долгожителем, став одним из самых успешных примеров стандартизации за всю компьютерную историю. Однако сегодня многие его элементы стали очевидной архаикой. Практически не используется большая часть из множества непечатаемых символов, которые когда-то требовались для управления процессом передачи данных, работой телетайпов и других периферийных устройств. Среди них ACK и NAK, подтверждающие или отвергающие получение, звонок колокольчика BELL, символы от 1С до 1F для управления файлами и т. д. В ASCII реализована и изящная, но сегодня практически бесполезная возможность управления с использованием так называемых «Escape-последовательностей». Этот вид особых цепочек символов, начинающихся с символа Escape, позволяет создавать собственный набор команд для управления тем или иным подключенным по последовательному интерфейсу устройством, например алфавитно-цифровым терминалом.
У ASCII есть законный отец — Боб Бемер, чей приоритет очевиден. Но и у него были предшественники; среди них особая роль принадлежит французскому изобретателю Жан-Морису Эмилю Бодо, который в 1874 году предложил пятибитный код для телеграфии, по-настоящему цифровой в отличие от эмпирического кода Морзе. Изобретение Бодо позволило отказаться от телеграфного ключа и использовать для ввода специальную клавиатуру с пятью клавишами.
В 1901 году американец Дональд Мюррей адаптировал код Бодо к обычной клавиатуре QWERTY; в этом виде он и существует как International Telegraph Alphabet No 2 (ITA2). Русская версия кода Бодо известна под именем MTK-2. Имя изобретателя увековечено в названии единицы измерения скорости передачи данных «бод».
Бемер был выдающимся программистом первого поколения. Начав работать в 1949 году, за долгую профессиональную жизнь он внес в программирование немало нового. Ему принадлежит авторство терминов Кобол, CODASYL, Software Factory. Именно Бемер первым заговорил о проблеме Y2K — задолго до того, как она обеспокоила человечество.
В 1959 году, в его бытность сотрудником IBM, Бемер начал работать над задачами, связанными с упаковкой текстов. Заслуга Бемера в том, что в своем подходе к проблеме кодировки символов он смог уловить будущую связь между коммуникациями и компьютерами. В первой версии разработанный им код ASCII не стал универсальным: поначалу он задумывался как средство для обмена данными с электромеханическими терминалами. В этом качестве ASCII был опубликован в 1963 году ассоциацией ASA (American Standards Association), позже ставшей институтом ANSI (American National Standards Institute). В своем исходном виде ASCII был семибитным (максимальное число кодируемых символов равнялось 128), а восьмой бит являлся контрольным. В нем не было даже заглавных букв.
Первоначальная версия кодировки была доведена до рабочего состояния в 1968 году как стандарт ANSI X3. 4 под именем US-ASCII. Ограниченность всего 96 печатными символами оказалась серьезным барьером на пути распространения стандарта: даже британский английский требует еще одного символа для обозначения фунта стерлингов, да и во всех остальных языках, письменность которых построена на латинице, есть специфические символы. Еще большие сложности возникают при необходимости работы с кириллицей.
4 под именем US-ASCII. Ограниченность всего 96 печатными символами оказалась серьезным барьером на пути распространения стандарта: даже британский английский требует еще одного символа для обозначения фунта стерлингов, да и во всех остальных языках, письменность которых построена на латинице, есть специфические символы. Еще большие сложности возникают при необходимости работы с кириллицей.
Из-за привязанности к местной специфике на протяжении почти двух десятилетий стандарт не был широко востребован за пределами Соединенных Штатов. В эпоху мэйнфреймов и мини-ЭВМ не было проблемы массовости и интернационализации. Даже в IBM, где в 60-е годы работал Бемер, использовалась альтернативная кодировка EBCDIC. Кстати, были попытки сделать национальные версии и этой кодировки, но результаты широкого распространения не получили. Единственным компьютером, на котором ASCII применялся для представления текстовых данных, был UNIVAC 1050; чаще же этот код использовался для обмена с печатающими, а в последующем — и с алфавитно-цифровыми терминалами.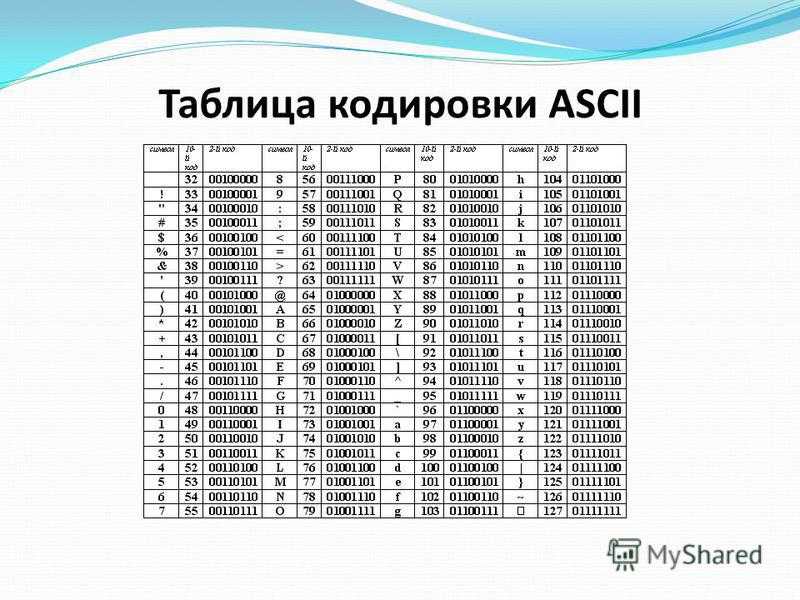
Однако по мере распространения американских компьютерных технологий по всему миру, особенно с появлением ОС Unix и ПК, возникла острая необходимость в принятии единой системы кодировки, и лучшим претендентом на роль прототипа стандарта оказался ASCII. Попытки создания международных стандартов предпринимались и ранее; так, для телеграфии в 1972 году на основе ASCII был разработан стандарт ISO 646, но его с трудом можно было признать международным, ведь в те же самые 128 символов упаковывались самые разнообразные алфавиты, а потому существовало столько же версий, сколько языков. Для кириллицы был разработан код КОИ-7. Выход из положения стал возможен за счет отказа от контрольного бита и перехода к восьмибитной упаковке. Новый набор символов стали называть «расширенным»; именно в этом виде он хорошо известен сегодня.
В СССР вопрос «кириллизации» решался мучительно, но в конечном итоге эволюционный процесс естественным образом завершился. На сегодняшний день существует несколько вариантов кодировки КОИ-8; помимо русской KOI8-R, есть еще украинская KOI8-U.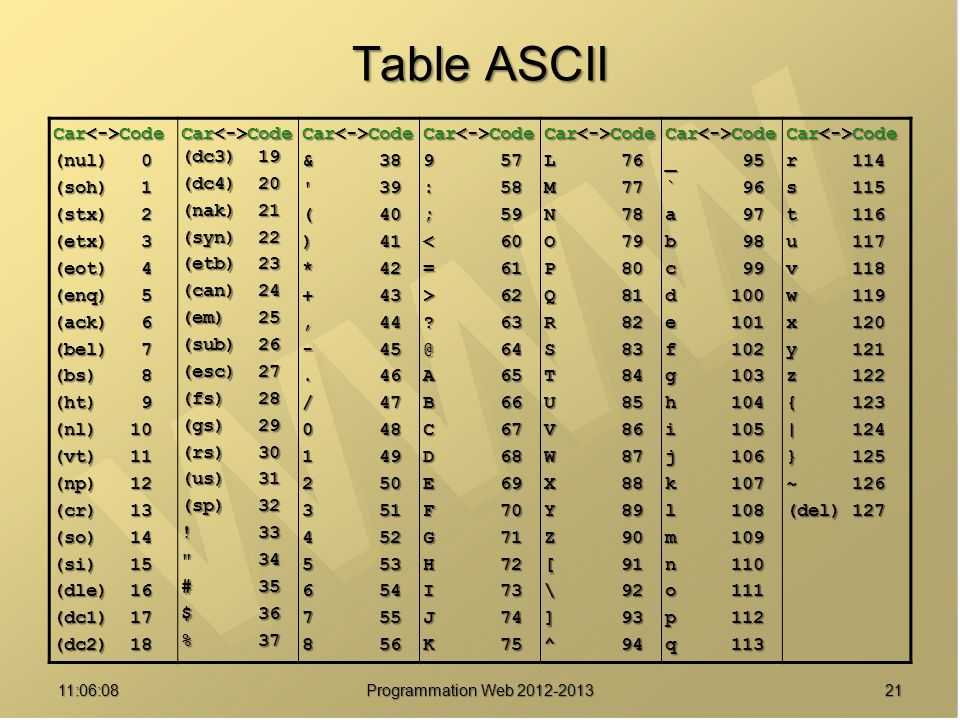 Основной объем работы по созданию KOI8-R выполнил Андрей Чернов. С его подачи KOI8-R стал фактическим стандартом для обмена русскоязычными сообщениями в Internet, это сетевая и транспортная кодировка. Во внутреннем представлении в компьютерах может использоваться и локальная кодировка, например Windows-1251.
Основной объем работы по созданию KOI8-R выполнил Андрей Чернов. С его подачи KOI8-R стал фактическим стандартом для обмена русскоязычными сообщениями в Internet, это сетевая и транспортная кодировка. Во внутреннем представлении в компьютерах может использоваться и локальная кодировка, например Windows-1251.
Роберт Бемер
(1920-2004) начал свою карьеру программиста в 1949 году и с тех пор не прекращал работать до последних дней жизни. В его послужном списке такие компании, как RAND Corporation, Marquardt, Lockheed, IBM, где он занимал пост директора по вопросам стандартов программирования, Univac, Bull GE, General Electric и Honeywell. Он участвовал в создании кода ASCII, без которого невозможна сегодняшняя электронная почта, Web, лазерные принтеры и видеоигры. Бемер обладал счастливым даром оказываться в нужное время в нужном месте. Наряду с работами над ASCII, он принимал участие в разработке языка программирования Кобол. В 1971 году он первый выступил с предостережением, что представление года двумя цифрами чревато серьезной проблемой при наступлении третьего тысячелетия — так называемая проблема 2000 года. В то время для решение этой проблемы нужно было применять только четырехзначное обозначение даты. К нему, как это обычно и бывает, не прислушались, в результате только в США на решение этой проблемы было затрачено 122 млрд. долл. Личная жизнь Бемера была столь же яркой, как и его карьера: он был женат шесть раз на пяти женщинах, у него было пять детей от первого брака и шесть — от другого. Кроме того, Бемер усыновил еще двоих детей.
В то время для решение этой проблемы нужно было применять только четырехзначное обозначение даты. К нему, как это обычно и бывает, не прислушались, в результате только в США на решение этой проблемы было затрачено 122 млрд. долл. Личная жизнь Бемера была столь же яркой, как и его карьера: он был женат шесть раз на пяти женщинах, у него было пять детей от первого брака и шесть — от другого. Кроме того, Бемер усыновил еще двоих детей.
Эмиль Бодо
родился в 1845 году в семье фермера. В детстве и в юности никто не смог бы даже предположить, что этот человек — типичный сельский житель, получивший только начальное образование и, казалось бы, посвятивший себя сельскохозяйственному труду, станет гениальным изобретателем. В 1870 году он поступил на работу в Управление телеграфных линий. Его заинтересовала научная сторона дела и он начал активно заниматься самообразованием в свободное время. Его рвение было отмечено, и Бодо перевели в Париж, работать на центральной телеграфной станции. Он продолжал обучение, параллельно занимаясь изобретательством, — начал работать над созданием телеграфного аппарата. В 1880 году он получил должность контролера, а затем, после успешного ввода в действие своей системы, стал инженером. В 1882 году Бодо был уже инспектором-инженером. Он поставил своей задачей повышение эффективности чрезвычайно медленной телеграфной передачи. Он предложил идею, названную «печатным телеграфом Бодо». Сейчас такой принцип можно было бы назвать синхронным мультиплексированием по времени. В 1870 году Бодо разработал первый действительно цифровой телеграфный код, который известен как International Telegraph Code № 1.
Он продолжал обучение, параллельно занимаясь изобретательством, — начал работать над созданием телеграфного аппарата. В 1880 году он получил должность контролера, а затем, после успешного ввода в действие своей системы, стал инженером. В 1882 году Бодо был уже инспектором-инженером. Он поставил своей задачей повышение эффективности чрезвычайно медленной телеграфной передачи. Он предложил идею, названную «печатным телеграфом Бодо». Сейчас такой принцип можно было бы назвать синхронным мультиплексированием по времени. В 1870 году Бодо разработал первый действительно цифровой телеграфный код, который известен как International Telegraph Code № 1.
Андрей Чернов
родился в 1966 году, высшее образование получил на факультете ВМиК МГУ. После окончания университета Чернов ушел в ИПК Минавтопрома разрабатывать систему Unix, откуда перешел в кооператив «Демос», в дальнейшем — в АО «Релком». Всенародную известность Чернову принесла разработка почтовой программы UUPC/@ (русифицированная версия оригинального UUPC, а всемирную — разработка стандарта KOI-8 для электронной почты.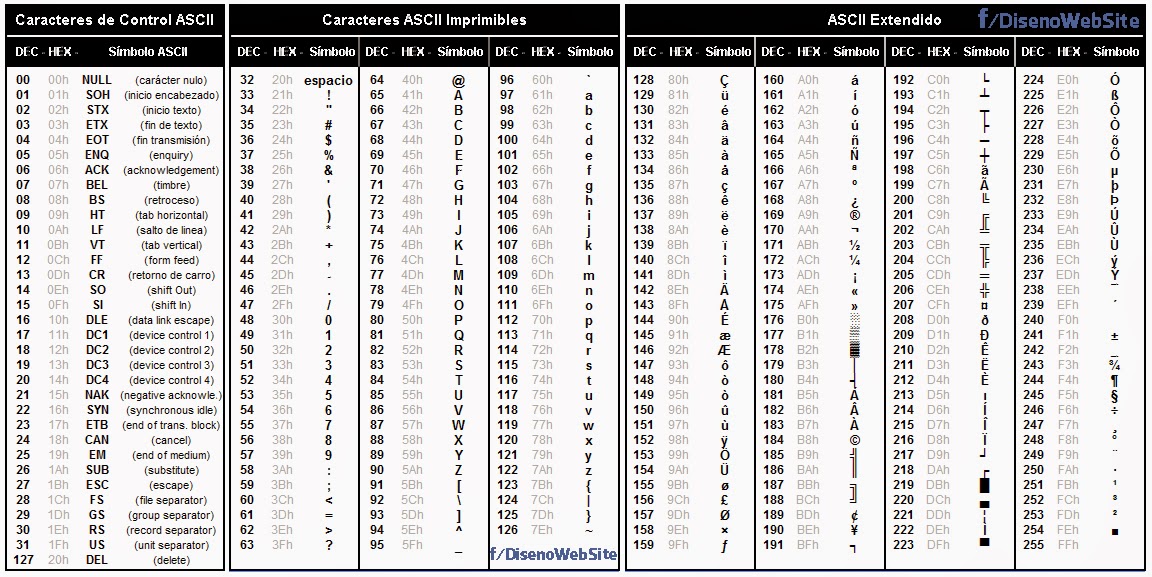
Список проектов, в которых Чернов участвовал как программист или консультант, имеет широкую географию. Во многих случаях он выполнял роль связующего звена между двумя мирами — миром англоязычных программистов и миром отечественных пользователей. В течение долгого времени Чернов является активным членом международной команды разработчиков FreeBSD. Хотя он не отказывается от коммерческих проектов (и охотно в них участвует), он — один из немногих сохранившихся аборигенов киберпространства, по духу близкий к программистам начала 70-х, поднимавших Unix и первые компьютерные сети в эпоху, когда еще большинство программных кодов были в общественном доступе. Чернов, по его собственному определению, биомеханоид, хотя его в равной степени можно назвать магом, конструктивным хакером и юниксоидом.
Набор символов US ASCII
Набор символов US ASCII US ASCII, ANSI X3.4-1986 (Международная справочная версия ISO 646) Коды от 0 до 31 и 127 (десятичные) являются непечатаемыми управляющими символами.
Код 32 (десятичный) является непечатаемым символом пробела.
Коды от 33 до 126 (десятичные) являются печатаемыми графическими символами.
Легенда:
Char Печатное представление символа, если таковой имеется
Декабрь Десятичный код символа
Row/Col Десятичное представление строки/столбца для символа
Oct Восьмеричный (с основанием 8) код символа
Hex Шестнадцатеричный (с основанием 16) код символа
Проект Кермит / Колумбийский университет / kermit@columbia.
Символ Dec Col/Row Oct Hex Название и описание
0 00/00 00 00 НОЛЬ (Ctrl-@) НОЛЬ 1 00/01 01 01 SOH (Ctrl-A) НАЧАЛО ЗАГОЛОВКА 2 00/02 02 02 STX (Ctrl-B) НАЧАЛО ТЕКСТА 3 00/03 03 03 ETX (Ctrl-C) КОНЕЦ ТЕКСТА 4 00/04 04 04 EOT (Ctrl-D) КОНЕЦ ПЕРЕДАЧИ 5 00/05 05 05 ENQ (Ctrl-E) ЗАПРОС 6 00/06 06 06 ПОДТВЕРЖДЕНИЕ (Ctrl-F) ПОДТВЕРЖДЕНИЕ 7 00/07 07 07 БЕЛ (Ctrl-G) БЕЛЛ (звуковой сигнал) 8 00/08 10 08 БС (Ctrl-H) BACKSPACE 900/09 11 09 HT (Ctrl-I) ГОРИЗОНТАЛЬНАЯ ВКЛАДКА 10 00/10 12 0A LF (Ctrl-J) ПЕРЕВОД СТРОКИ 11 00/11 13 0B VT (Ctrl-K) ВЕРТИКАЛЬНАЯ ЗАКЛАДКА 12 00/12 14 0C FF (Ctrl-L) ПОДАЧА ФОРМЫ 13 00/13 15 0D CR (Ctrl-M) ВОЗВРАТ КАРЕТКИ 14 00/14 16 0E SO (Ctrl-N) SHIFT OUT 15 00/15 17 0F SI (Ctrl-O) SHIFT IN 16 01/00 20 10 DLE (Ctrl-P) ESCAPE КАНАЛА ДАННЫХ 17 01/01 21 11 DC1 (Ctrl-Q) УПРАВЛЕНИЕ УСТРОЙСТВОМ 1 (XON) 18 01/02 22 12 DC2 (Ctrl-R) УПРАВЛЕНИЕ УСТРОЙСТВОМ 2 1901/03 23 13 DC3 (Ctrl-S) УПРАВЛЕНИЕ УСТРОЙСТВОМ 3 (XOFF) 20 01/04 24 14 DC4 (Ctrl-T) УПРАВЛЕНИЕ УСТРОЙСТВОМ 4 21 01/05 25 15 НЕТ (Ctrl-U) ОТРИЦАТЕЛЬНОЕ ПОДТВЕРЖДЕНИЕ 22 01/06 26 16 SYN (Ctrl-V) СИНХРОННЫЙ ХОЛОСТОЙ ХОД 23 01/07 27 17 ETB (Ctrl-W) КОНЕЦ БЛОКА ПЕРЕДАЧИ 24 01/08 30 18 МОЖЕТ (Ctrl-X) ОТМЕНА 25 01/09 31 19 EM (Ctrl-Y) КОНЕЦ СРЕДСТВА 26 01/10 32 1A ЗАМЕНА (Ctrl-Z) ЗАМЕНА 27 01/11 33 1B ESC (Ctrl-[) ESCAPE 28 01/12 34 1С ФС (Ctrl-\) РАЗДЕЛИТЕЛЬ ФАЙЛОВ 29) РАЗДЕЛИТЕЛЬ ЗАПИСИ 31 01/15 37 1F US (Ctrl-_) РАЗДЕЛИТЕЛЬ БЛОКОВ
( ) 32 02/00 40 20 ПРОБЕЛ (!) 33 01.02.41 21 ВОСКЛИЦАТЕЛЬНЫЙ ЗНАК ("") 34 02/02 42 22 КАвычки (#) 35 02/03 43 23 ЗНАК ЦИФРЫ ($) 36 02/04 44 24 ЗНАК ДОЛЛАРА (%) 37 02/05 45 25 ЗНАК ПРОЦЕНТА (&) 38 02/06 46 26 АМПЕРСАНД (') 39 02/07 47 27 АПОСТРОФ (() 40 02/08 50 28 ЛЕВАЯ СКОБКА ()) 41 02/0951 29 ПРАВАЯ СКОБКА (*) 42 02/10 52 2A ЗВЕЗДОЧКА (+) 43 02/11 53 2B ЗНАК ПЛЮС (,) 44 02/12 54 2С ЗАПЯТАЯ (-) 45 02/13 55 2D ДЕФИС, МИНУС (.) 46 02/14 56 2E ПЕРИОД, ПОЛНАЯ ОСТАНОВКА (/) 47 15.02 57 2Э СОЛИДУС, СЛЕШ (0) 48 03/00 60 30 ЗНАЧНЫЙ НОЛЬ (1) 49 03/01 61 31 ЦИФРА ЕДИНИЦА (2) 50 03/02 62 32 ЦИФРА ДВА (3) 51 03/03 63 33 ЦИФРА ТРИ (4) 52 03/04 64 34 ЦИФРА ЧЕТЫРЕ (5) 53 03/05 65 35 ЦИФРА ПЯТЬ (6) 54 03/06 66 36 ЦИФРА ШЕСТЬ (7) 55 03/07 67 37 ЦИФРА СЕМЬ (8) 56 03/08 70 38 ЦИФРА ВОСЕМЬ (9) 57 03/09 71 39 ЦИФРА ДЕВЯТЬ (:) 58 03/10 72 3A ТОЛСТАЯ (;) 59 03/11 73 3B ТОЧКА С ЗАПЯТОЙ (<) 60 03/12 74 3C ЗНАК "МЕНЬШЕ", ЛЕВАЯ УГЛОВАЯ СКОБКА (=) 61 03/13 75 3D ЗНАК РАВНО (>) 62 03/14 76 3E ЗНАК БОЛЬШЕ, ПРЯМАЯ СКОБКА (?) 63 03/15 77 3F ВОПРОСИТЕЛЬНЫЙ ЗНАК (@) 64 04/00 100 40 КОММЕРЧЕСКОЕ ОБЪЯВЛЕНИЕ НА ЗНАКЕ (А) 65 04/01 101 41 ЗАГЛАВНАЯ БУКВА А (B) 66 04/02 102 42 ЗАГЛАВНАЯ БУКВА B (С) 67 04/03 103 43 ЗАГЛАВНАЯ БУКВА С (D) 68 04/04 104 44 ЗАГЛАВНАЯ БУКВА D (Э) 6905/04 105 45 ЗАГЛАВНАЯ БУКВА Е (F) 70 04/06 106 46 ЗАГЛАВНАЯ БУКВА F (G) 71 04/07 107 47 ЗАГЛАВНАЯ БУКВА G (H) 72 04/08 110 48 ЗАГЛАВНАЯ БУКВА H (I) 73 04/09 111 49 ЗАГЛАВНАЯ БУКВА I (J) 74 04/10 112 4A ЗАГЛАВНАЯ БУКВА J (К) 75 04/11 113 4B ЗАГЛАВНАЯ БУКВА K (L) 76 04/12 114 4C ЗАГЛАВНАЯ БУКВА L (М) 77 04/13 115 4D ЗАГЛАВНАЯ БУКВА М (N) 78 04/14 116 4E ЗАГЛАВНАЯ БУКВА N (О) 7915/04 117 4F ЗАГЛАВНАЯ БУКВА O (P) 80 05/00 120 50 ЗАГЛАВНАЯ БУКВА P (Q) 81 05/01 121 51 ЗАГЛАВНАЯ БУКВА Q (R) 82 05/02 122 52 ЗАГЛАВНАЯ БУКВА R (S) 83 05/03 123 53 ЗАГЛАВНАЯ БУКВА S (Т) 84 05/04 124 54 ЗАГЛАВНАЯ БУКВА Т (U) 85 05/05 125 55 ЗАГЛАВНАЯ БУКВА U (V) 86 05/06 126 56 ЗАГЛАВНАЯ БУКВА V (W) 87 05/07 127 57 ЗАГЛАВНАЯ БУКВА W (X) 88 05/08 130 58 ЗАГЛАВНАЯ БУКВА X (Д) 89) 94 05/14 136 5E CIRCUMFLEX АКЦЕНТ (_) 95 05/15 137 5F НИЖНЯЯ ЛИНИЯ, ПОДЧИНКА (`) 96 06/00 140 60 ГРАВИЙ АКЦЕНТ (а) 97 06/01 141 61 СТРОЧНАЯ БУКВА а (b) 98 06/02 142 62 СТРОЧНАЯ БУКВА b (c) 99 03/06 143 63 СТРОЧНАЯ БУКВА c (d) 100 06/04 144 64 СТРОЧНАЯ БУКВА d (e) 101 06/05 145 65 СТРОЧНАЯ БУКВА e (f) 102 06/06 146 66 СТРОЧНАЯ БУКВА f (g) 103 07/06 147 67 СТРОЧНАЯ БУКВА g (h) 104 06/08 150 68 СТРОЧНАЯ БУКВА h (и) 105 06/09151 69 СТРОЧНАЯ БУКВА i (j) 106 06/10 152 6A СТРОЧНАЯ БУКВА j (k) 107 06/11 153 6B СТРОЧНАЯ БУКВА k (л) 108 06/12 154 6C СТРОЧНАЯ БУКВА l (m) 109 06/13 155 6D СТРОЧНАЯ БУКВА m (n) 110 06/14 156 6E СТРОЧНАЯ БУКВА n (o) 111 06/15 157 6F СТРОЧНАЯ БУКВА o (p) 112 07/00 160 70 СТРОЧНАЯ БУКВА p (q) 113 07/01 161 71 СТРОЧНАЯ БУКВА q (r) 114 07/02 162 72 СТРОЧНАЯ БУКВА r (s) 115 03/07 163 73 СТРОЧНАЯ БУКВА s (t) 116 07/04 164 74 СТРОЧНАЯ БУКВА t (u) 117 07/05 165 75 СТРОЧНАЯ БУКВА u (v) 118 07/06 166 76 СТРОЧНАЯ БУКВА v (ж) 11907/07 167 77 СТРОЧНАЯ БУКВА w (x) 120 07/08 170 78 СТРОЧНАЯ БУКВА x (y) 121 07/09 171 79 СТРОЧНАЯ БУКВА y (z) 122 07/10 172 7A СТРОЧНАЯ БУКВА z ({) 123 07/11 173 7B ЛЕВАЯ ФИГУРНАЯ СКОБКА, ЛЕВАЯ СКОБКА (|) 124 07/12 174 7C ВЕРТИКАЛЬНАЯ ЛИНИЯ, ВЕРТИКАЛЬНАЯ СТРУНА (}) 125 13/07 175 7D ПРАВАЯ ФИГУРНАЯ СКОБКА, ПРАВАЯ СКОБКА (~) 126 14/07 176 7E ТИЛЬДА
127 15/07 177 7F РУБ (Ctrl-?) РУБАУТ (УДАЛИТЬ)
 02.41 21 ВОСКЛИЦАТЕЛЬНЫЙ ЗНАК
("") 34 02/02 42 22 КАвычки
(#) 35 02/03 43 23 ЗНАК ЦИФРЫ
($) 36 02/04 44 24 ЗНАК ДОЛЛАРА
(%) 37 02/05 45 25 ЗНАК ПРОЦЕНТА
(&) 38 02/06 46 26 АМПЕРСАНД
(') 39 02/07 47 27 АПОСТРОФ
(() 40 02/08 50 28 ЛЕВАЯ СКОБКА
()) 41 02/0951 29 ПРАВАЯ СКОБКА
(*) 42 02/10 52 2A ЗВЕЗДОЧКА
(+) 43 02/11 53 2B ЗНАК ПЛЮС
(,) 44 02/12 54 2С ЗАПЯТАЯ
(-) 45 02/13 55 2D ДЕФИС, МИНУС
(.) 46 02/14 56 2E ПЕРИОД, ПОЛНАЯ ОСТАНОВКА
(/) 47 15.02 57 2Э СОЛИДУС, СЛЕШ
(0) 48 03/00 60 30 ЗНАЧНЫЙ НОЛЬ
(1) 49 03/01 61 31 ЦИФРА ЕДИНИЦА
(2) 50 03/02 62 32 ЦИФРА ДВА
(3) 51 03/03 63 33 ЦИФРА ТРИ
(4) 52 03/04 64 34 ЦИФРА ЧЕТЫРЕ
(5) 53 03/05 65 35 ЦИФРА ПЯТЬ
(6) 54 03/06 66 36 ЦИФРА ШЕСТЬ
(7) 55 03/07 67 37 ЦИФРА СЕМЬ
(8) 56 03/08 70 38 ЦИФРА ВОСЕМЬ
(9) 57 03/09 71 39 ЦИФРА ДЕВЯТЬ
(:) 58 03/10 72 3A ТОЛСТАЯ
(;) 59 03/11 73 3B ТОЧКА С ЗАПЯТОЙ
(<) 60 03/12 74 3C ЗНАК "МЕНЬШЕ", ЛЕВАЯ УГЛОВАЯ СКОБКА
(=) 61 03/13 75 3D ЗНАК РАВНО
(>) 62 03/14 76 3E ЗНАК БОЛЬШЕ, ПРЯМАЯ СКОБКА
(?) 63 03/15 77 3F ВОПРОСИТЕЛЬНЫЙ ЗНАК
(@) 64 04/00 100 40 КОММЕРЧЕСКОЕ ОБЪЯВЛЕНИЕ НА ЗНАКЕ
(А) 65 04/01 101 41 ЗАГЛАВНАЯ БУКВА А
(B) 66 04/02 102 42 ЗАГЛАВНАЯ БУКВА B
(С) 67 04/03 103 43 ЗАГЛАВНАЯ БУКВА С
(D) 68 04/04 104 44 ЗАГЛАВНАЯ БУКВА D
(Э) 6905/04 105 45 ЗАГЛАВНАЯ БУКВА Е
(F) 70 04/06 106 46 ЗАГЛАВНАЯ БУКВА F
(G) 71 04/07 107 47 ЗАГЛАВНАЯ БУКВА G
(H) 72 04/08 110 48 ЗАГЛАВНАЯ БУКВА H
(I) 73 04/09 111 49 ЗАГЛАВНАЯ БУКВА I
(J) 74 04/10 112 4A ЗАГЛАВНАЯ БУКВА J
(К) 75 04/11 113 4B ЗАГЛАВНАЯ БУКВА K
(L) 76 04/12 114 4C ЗАГЛАВНАЯ БУКВА L
(М) 77 04/13 115 4D ЗАГЛАВНАЯ БУКВА М
(N) 78 04/14 116 4E ЗАГЛАВНАЯ БУКВА N
(О) 7915/04 117 4F ЗАГЛАВНАЯ БУКВА O
(P) 80 05/00 120 50 ЗАГЛАВНАЯ БУКВА P
(Q) 81 05/01 121 51 ЗАГЛАВНАЯ БУКВА Q
(R) 82 05/02 122 52 ЗАГЛАВНАЯ БУКВА R
(S) 83 05/03 123 53 ЗАГЛАВНАЯ БУКВА S
(Т) 84 05/04 124 54 ЗАГЛАВНАЯ БУКВА Т
(U) 85 05/05 125 55 ЗАГЛАВНАЯ БУКВА U
(V) 86 05/06 126 56 ЗАГЛАВНАЯ БУКВА V
(W) 87 05/07 127 57 ЗАГЛАВНАЯ БУКВА W
(X) 88 05/08 130 58 ЗАГЛАВНАЯ БУКВА X
(Д) 89) 94 05/14 136 5E CIRCUMFLEX АКЦЕНТ
(_) 95 05/15 137 5F НИЖНЯЯ ЛИНИЯ, ПОДЧИНКА
(`) 96 06/00 140 60 ГРАВИЙ АКЦЕНТ
(а) 97 06/01 141 61 СТРОЧНАЯ БУКВА а
(b) 98 06/02 142 62 СТРОЧНАЯ БУКВА b
(c) 99 03/06 143 63 СТРОЧНАЯ БУКВА c
(d) 100 06/04 144 64 СТРОЧНАЯ БУКВА d
(e) 101 06/05 145 65 СТРОЧНАЯ БУКВА e
(f) 102 06/06 146 66 СТРОЧНАЯ БУКВА f
(g) 103 07/06 147 67 СТРОЧНАЯ БУКВА g
(h) 104 06/08 150 68 СТРОЧНАЯ БУКВА h
(и) 105 06/09151 69 СТРОЧНАЯ БУКВА i
(j) 106 06/10 152 6A СТРОЧНАЯ БУКВА j
(k) 107 06/11 153 6B СТРОЧНАЯ БУКВА k
(л) 108 06/12 154 6C СТРОЧНАЯ БУКВА l
(m) 109 06/13 155 6D СТРОЧНАЯ БУКВА m
(n) 110 06/14 156 6E СТРОЧНАЯ БУКВА n
(o) 111 06/15 157 6F СТРОЧНАЯ БУКВА o
(p) 112 07/00 160 70 СТРОЧНАЯ БУКВА p
(q) 113 07/01 161 71 СТРОЧНАЯ БУКВА q
(r) 114 07/02 162 72 СТРОЧНАЯ БУКВА r
(s) 115 03/07 163 73 СТРОЧНАЯ БУКВА s
(t) 116 07/04 164 74 СТРОЧНАЯ БУКВА t
(u) 117 07/05 165 75 СТРОЧНАЯ БУКВА u
(v) 118 07/06 166 76 СТРОЧНАЯ БУКВА v
(ж) 11907/07 167 77 СТРОЧНАЯ БУКВА w
(x) 120 07/08 170 78 СТРОЧНАЯ БУКВА x
(y) 121 07/09 171 79 СТРОЧНАЯ БУКВА y
(z) 122 07/10 172 7A СТРОЧНАЯ БУКВА z
({) 123 07/11 173 7B ЛЕВАЯ ФИГУРНАЯ СКОБКА, ЛЕВАЯ СКОБКА
(|) 124 07/12 174 7C ВЕРТИКАЛЬНАЯ ЛИНИЯ, ВЕРТИКАЛЬНАЯ СТРУНА
(}) 125 13/07 175 7D ПРАВАЯ ФИГУРНАЯ СКОБКА, ПРАВАЯ СКОБКА
(~) 126 14/07 176 7E ТИЛЬДА
02.41 21 ВОСКЛИЦАТЕЛЬНЫЙ ЗНАК
("") 34 02/02 42 22 КАвычки
(#) 35 02/03 43 23 ЗНАК ЦИФРЫ
($) 36 02/04 44 24 ЗНАК ДОЛЛАРА
(%) 37 02/05 45 25 ЗНАК ПРОЦЕНТА
(&) 38 02/06 46 26 АМПЕРСАНД
(') 39 02/07 47 27 АПОСТРОФ
(() 40 02/08 50 28 ЛЕВАЯ СКОБКА
()) 41 02/0951 29 ПРАВАЯ СКОБКА
(*) 42 02/10 52 2A ЗВЕЗДОЧКА
(+) 43 02/11 53 2B ЗНАК ПЛЮС
(,) 44 02/12 54 2С ЗАПЯТАЯ
(-) 45 02/13 55 2D ДЕФИС, МИНУС
(.) 46 02/14 56 2E ПЕРИОД, ПОЛНАЯ ОСТАНОВКА
(/) 47 15.02 57 2Э СОЛИДУС, СЛЕШ
(0) 48 03/00 60 30 ЗНАЧНЫЙ НОЛЬ
(1) 49 03/01 61 31 ЦИФРА ЕДИНИЦА
(2) 50 03/02 62 32 ЦИФРА ДВА
(3) 51 03/03 63 33 ЦИФРА ТРИ
(4) 52 03/04 64 34 ЦИФРА ЧЕТЫРЕ
(5) 53 03/05 65 35 ЦИФРА ПЯТЬ
(6) 54 03/06 66 36 ЦИФРА ШЕСТЬ
(7) 55 03/07 67 37 ЦИФРА СЕМЬ
(8) 56 03/08 70 38 ЦИФРА ВОСЕМЬ
(9) 57 03/09 71 39 ЦИФРА ДЕВЯТЬ
(:) 58 03/10 72 3A ТОЛСТАЯ
(;) 59 03/11 73 3B ТОЧКА С ЗАПЯТОЙ
(<) 60 03/12 74 3C ЗНАК "МЕНЬШЕ", ЛЕВАЯ УГЛОВАЯ СКОБКА
(=) 61 03/13 75 3D ЗНАК РАВНО
(>) 62 03/14 76 3E ЗНАК БОЛЬШЕ, ПРЯМАЯ СКОБКА
(?) 63 03/15 77 3F ВОПРОСИТЕЛЬНЫЙ ЗНАК
(@) 64 04/00 100 40 КОММЕРЧЕСКОЕ ОБЪЯВЛЕНИЕ НА ЗНАКЕ
(А) 65 04/01 101 41 ЗАГЛАВНАЯ БУКВА А
(B) 66 04/02 102 42 ЗАГЛАВНАЯ БУКВА B
(С) 67 04/03 103 43 ЗАГЛАВНАЯ БУКВА С
(D) 68 04/04 104 44 ЗАГЛАВНАЯ БУКВА D
(Э) 6905/04 105 45 ЗАГЛАВНАЯ БУКВА Е
(F) 70 04/06 106 46 ЗАГЛАВНАЯ БУКВА F
(G) 71 04/07 107 47 ЗАГЛАВНАЯ БУКВА G
(H) 72 04/08 110 48 ЗАГЛАВНАЯ БУКВА H
(I) 73 04/09 111 49 ЗАГЛАВНАЯ БУКВА I
(J) 74 04/10 112 4A ЗАГЛАВНАЯ БУКВА J
(К) 75 04/11 113 4B ЗАГЛАВНАЯ БУКВА K
(L) 76 04/12 114 4C ЗАГЛАВНАЯ БУКВА L
(М) 77 04/13 115 4D ЗАГЛАВНАЯ БУКВА М
(N) 78 04/14 116 4E ЗАГЛАВНАЯ БУКВА N
(О) 7915/04 117 4F ЗАГЛАВНАЯ БУКВА O
(P) 80 05/00 120 50 ЗАГЛАВНАЯ БУКВА P
(Q) 81 05/01 121 51 ЗАГЛАВНАЯ БУКВА Q
(R) 82 05/02 122 52 ЗАГЛАВНАЯ БУКВА R
(S) 83 05/03 123 53 ЗАГЛАВНАЯ БУКВА S
(Т) 84 05/04 124 54 ЗАГЛАВНАЯ БУКВА Т
(U) 85 05/05 125 55 ЗАГЛАВНАЯ БУКВА U
(V) 86 05/06 126 56 ЗАГЛАВНАЯ БУКВА V
(W) 87 05/07 127 57 ЗАГЛАВНАЯ БУКВА W
(X) 88 05/08 130 58 ЗАГЛАВНАЯ БУКВА X
(Д) 89) 94 05/14 136 5E CIRCUMFLEX АКЦЕНТ
(_) 95 05/15 137 5F НИЖНЯЯ ЛИНИЯ, ПОДЧИНКА
(`) 96 06/00 140 60 ГРАВИЙ АКЦЕНТ
(а) 97 06/01 141 61 СТРОЧНАЯ БУКВА а
(b) 98 06/02 142 62 СТРОЧНАЯ БУКВА b
(c) 99 03/06 143 63 СТРОЧНАЯ БУКВА c
(d) 100 06/04 144 64 СТРОЧНАЯ БУКВА d
(e) 101 06/05 145 65 СТРОЧНАЯ БУКВА e
(f) 102 06/06 146 66 СТРОЧНАЯ БУКВА f
(g) 103 07/06 147 67 СТРОЧНАЯ БУКВА g
(h) 104 06/08 150 68 СТРОЧНАЯ БУКВА h
(и) 105 06/09151 69 СТРОЧНАЯ БУКВА i
(j) 106 06/10 152 6A СТРОЧНАЯ БУКВА j
(k) 107 06/11 153 6B СТРОЧНАЯ БУКВА k
(л) 108 06/12 154 6C СТРОЧНАЯ БУКВА l
(m) 109 06/13 155 6D СТРОЧНАЯ БУКВА m
(n) 110 06/14 156 6E СТРОЧНАЯ БУКВА n
(o) 111 06/15 157 6F СТРОЧНАЯ БУКВА o
(p) 112 07/00 160 70 СТРОЧНАЯ БУКВА p
(q) 113 07/01 161 71 СТРОЧНАЯ БУКВА q
(r) 114 07/02 162 72 СТРОЧНАЯ БУКВА r
(s) 115 03/07 163 73 СТРОЧНАЯ БУКВА s
(t) 116 07/04 164 74 СТРОЧНАЯ БУКВА t
(u) 117 07/05 165 75 СТРОЧНАЯ БУКВА u
(v) 118 07/06 166 76 СТРОЧНАЯ БУКВА v
(ж) 11907/07 167 77 СТРОЧНАЯ БУКВА w
(x) 120 07/08 170 78 СТРОЧНАЯ БУКВА x
(y) 121 07/09 171 79 СТРОЧНАЯ БУКВА y
(z) 122 07/10 172 7A СТРОЧНАЯ БУКВА z
({) 123 07/11 173 7B ЛЕВАЯ ФИГУРНАЯ СКОБКА, ЛЕВАЯ СКОБКА
(|) 124 07/12 174 7C ВЕРТИКАЛЬНАЯ ЛИНИЯ, ВЕРТИКАЛЬНАЯ СТРУНА
(}) 125 13/07 175 7D ПРАВАЯ ФИГУРНАЯ СКОБКА, ПРАВАЯ СКОБКА
(~) 126 14/07 176 7E ТИЛЬДА
 edu
edu 3.3.5 Кодировка символов
Содержание
- 1. ASCII и Unicode
- Учись
- 2. Использование таблицы ASCII в программировании
- Учись
- 3. Наборы символов
- Учись
- Значок
- Значок
- Значок
Разветвите меня на GitHub
1 ASCII и Unicode
Learn It
- Каждый раз, когда на клавиатуре набирается символ, выводится кодовое число. переданы на компьютер.
- Кодовые числа хранятся в двоичном формате на компьютерах как
Наборы символов, называемыеASCII. - В таблице ниже показана версия ASCII, в которой для кодирования используется 7 бит.
каждый персонаж. Самое большое число, которое может храниться в 7 битах, равно
1111111в двоичном формате (127 в десятичном) . Поэтому 128 различных символы могут быть представлены в наборе символов ASCII (Использование коды от 0 до 127) . Более чем достаточно, чтобы охватить всех персонажей на
стандартная англоязычная клавиатура. - Щелкните здесь, чтобы просмотреть полную таблицу ASCII.
 Более чем достаточно, чтобы охватить всех персонажей на
стандартная англоязычная клавиатура.
Более чем достаточно, чтобы охватить всех персонажей на
стандартная англоязычная клавиатура."Первоначально основанный на английском алфавите, ASCII кодирует 128 указанных символов в 7-битные двоичные целые числа, как показано на приведенной выше диаграмме ASCII. Закодированные символы — это числа от 0 до 9, строчные буквы от a до z, прописные буквы от A до Z, основные знаки препинания, контрольные коды это произошло с машинами телетайпа и пробелом. Например, строчная буква j станет двоичное 1101010 и десятичное 106. ASCII включает определения для 128 символов: 33 непечатаемые управляющие символы (многие из них уже устарели), влияющие на отображение текста и пробелов. обработано и 95 печатных символов, включая пробел." - из Википедии
- ASCII используется уже давно. Но у него есть серьезные недостатки:
- Он использует только английский алфавит.
- Он ограничен 7 битами, поэтому может представлять только 128 различных символов.
- Его нельзя использовать для нелатинских языков, таких как китайский.
- Символьная форма десятичной цифры В ASCII числовой символ не совпадает с фактическим числовым значением. Например, значение ASCII 011 0100 напечатает символ «4», двоичное значение фактически равно десятичному числу 52. Поэтому ASCII нельзя использовать для арифметики.

2 Использование таблицы ASCII в программировании
Learn It
- Коды символов сгруппированы и выполняются последовательно; т. е. если
A65тогдаCдолжно быть67. - Шаблон применяется к другим группам, таким как цифры и строчные буквы.
буквы, поэтому можно сказать, что, поскольку
7равно55,9должно быть57. Кроме того,7<9иa>А. - Обратите внимание, что значение кода ASCII для
5(0011 0101) отличается из чистого двоичного значения для 5 (0000 0101) . Вот почему ты
не может выполнять вычисления с числами, которые вводятся в виде строк. - Другой пример, значение ASCII
011 0100напечатает символ4, двоичное значение фактически равно десятичному числу52.
 Вот почему ты
не может выполнять вычисления с числами, которые вводятся в виде строк.
Вот почему ты
не может выполнять вычисления с числами, которые вводятся в виде строк.3 набора символов
Learn It
Расширенный код ASCII
- В основных кодах ASCII для каждого символа используется 7 бит (как показано на таблицу выше). Это дает в общей сложности 128 (2 7 ) возможных уникальных символов.
- Набор символов
Extended ASCIIиспользует 8 бит, что дает дополнительные 128 символов (т. е. всего 256). - Дополнительные символы представляют символы иностранных языков и специальные символы, такие как Ö € или →.
Юникод
-
Unicode(уникальная, универсальная и унифицированная кодировка символов) новый стандарт представления символовна всех языках мира. Это было введено для устранения недостатков ASCII. - Последняя версия Unicode содержит более 120 000 символов, охватывающих 129 современных и исторических шрифтов, а также как несколько наборов символов.
- Кодировка символов ASCII является подмножеством Unicode.
- Unicode может быть реализован с помощью различных кодировок символов.
Стандарт Unicode определяет
UTF-8,UTF-16иUTF-32. - Таким образом, они используют от
8 до 32 битна символ и имеют Преимущество в том, что он представляет гораздо больше уникальных символов, чем ASCII. из-за большего количества битов, доступных для хранения кода символа. - Он использует те же коды, что и ASCII, до 127.
-
UTF-8, доминирующая кодировка во всемирной паутине ( используется в более чем 92% веб-сайтов ), использует один байт для первых 128 кодовых точек и до 4 байтов для других символов. Первый 128 код Unicode точки — это символы ASCII, что означает, что любой текст ASCII также текст UTF-8. -
UTF-16, использует16 битдля представления каждого символа. Это означает, что он может представлять65 536 различных символов. -
UTF-32, использует32 битадля представления каждого символа, что означает, что он может представлять набор символов из4 294 967 296 возможных символов, достаточно для всех известных языков. - Его основное преимущество заключается в том, что он обеспечивает уникальный стандарт для всех системы письменности мира. Это позволяет использовать многоязычный текст в любом язык.
 Это было введено для устранения недостатков ASCII.
Это было введено для устранения недостатков ASCII.
- Преимущества Unicode перед ASCII
- Может иметь представление большего диапазона символов.
- Может быть представлено больше языков или все ( современные ) языки (в одном наборе символов).
- Улучшена переносимость документов в Unicode, поскольку каждый символ имеет уникальное представление в Unicode.