Модель данных — это… Что такое Модель данных?
В классической теории баз данных, модель данных есть формальная теория представления и обработки данных в системе управления базами данных (СУБД), которая включает, по меньшей мере, три аспекта:
1) аспект структуры: методы описания типов и логических структур данных в базе данных;
2) аспект манипуляции: методы манипулирования данными;
3) аспект целостности: методы описания и поддержки целостности базы данных.
Аспект структуры определяет, что из себя логически представляет база данных, аспект манипуляции определяет способы перехода между состояниями базы данных (то есть способы модификации данных) и способы извлечения данных из базы данных, аспект целостности определяет средства описаний корректных состояний базы данных.
Модель данных — это абстрактное, самодостаточное, логическое определение объектов, операторов и прочих элементов, в совокупности составляющих абстрактную машину доступа к данным, с которой взаимодействует пользователь. Эти объекты позволяют моделировать структуру данных, а операторы — поведение данных
Каждая БД и СУБД строится на основе некоторой явной или неявной модели данных. Все СУБД, построенные на одной и той же модели данных, относят к одному типу. Например, основой реляционных СУБД является реляционная модель данных, сетевых СУБД — сетевая модель данных, иерархических СУБД — иерархическая модель данных и т.д.
В литературе, статьях и в обиходной речи иногда встречается использование термина «модель данных» в смысле «схема базы данных» («модель базы данных»). Такое использование является неверным, на что указывают многие авторитетные специалисты, в том числе К. Дж. Дейт, М. Р. Когаловский, С. Д. Кузнецов. Модель данных есть
М. Р. Когаловский поясняет эволюцию смысла термина следующим образом. Первоначально понятие модели данных употреблялось как синоним структуры данных в конкретной базе данных. В процессе развития теории систем баз данных термин «модель данных» приобрел новое содержание. Возникла потребность в термине, который обозначал бы инструмент, а не результат моделирования, и воплощал бы, таким образом, множество всевозможных баз данных некоторого класса. Во второй половине 1970-х годов во многих публикациях, посвященных указанным проблемам, для этих целей стал использоваться все тот же термин «модель данных». В настоящее время в научной литературе термин «модель данных» трактуется в подавляющем большинстве случаев в инструментальном смысле (как инструмент моделирования)
Тем не менее, длительное время термин «модель данных» использовался без формального определения. Одним из первых специалистов, который достаточно формально определил это понятие, был Э. Кодд. В статье «Модели данных в управлении базами данных»
- Коллекции типов объектов данных, образующих базовые строительные блоки для любой базы данных, соответствующей модели
- Коллекции общих правил целостности, ограничивающих набор экземпляров тех типов объектов, которые законным образом могут появиться в любой такой базе данных
- Коллекции операций, применимых к таким экземплярам объектов для выборки и других целей[4].
См. также
Примечания
Литература
- Дейт К. Дж. Введение в системы баз данных = Introduction to Database Systems. — 8-е изд. — М.: «Вильямс», 2006. — 1328 с. — ISBN 0-321-19784-4
- Когаловский М. Р. Перспективные технологии информационных систем. — М.: ДМК Пресс; Компания АйТи, 2003. — 288 с. — ISBN 5-279-02276-4
- Когаловский М. Р. Энциклопедия технологий баз данных. — М.: Финансы и статистика, 2002. — 800 с. — ISBN 5-279-02276-4
- Цикритзис Д., Лоховски Ф. Модели данных = D. Tsichritzis, F. Lochovsky. Data Models. Prentice Hall, 1982. — М.: Финансы и статистика, 1985. — 344 с.

В 1968 году была введена в эксплуатацию первая промышленная СУБД система IMS фирмы IBM. Это была первая иерархически база данных благодаря которой определили ряд фундаментальных понятий в теории систем баз данных, которые и до сих пор являются основополагающими для сетевой модели данных.
Такая форма используется:
a. Серверы каталогов, такие, как LDAP и Active Directory (допускают чёткое представление в виде дерева)
b. файловые, база настроек Windows WMI и Реестр Windows.
2) Сетевая

Такая модель данных используется:
1) в графических системах для формирования 3D изображений.
2) в системах пространственной координации объектов.
3) Реляционная — данные в базе данных представляют собой набор отношений. Отношения (таблицы) отвечают определенным условиям целостности. Реляционная модель данных поддерживает декларативные ограничения целостности уровня домена (типа данных), уровня отношения
и уровня базы данных.

Такая форма используется:
a. Oracle
b. MS SQL, MY SQL
c. Potgresql
d. MS Access
4) Объектная и объектно-ориентированная – Данные в таких базах представляют из себя объекты с определенными наборами свойств и методов и поведения. Отношения данных объектов строятся на основе обобщения свойств и методов и поведения различных объектов по отношению друг к друг
Модели данных
Определение 1
Модель данных является некоторой абстракцией, которая прикладывается к конкретным данным и позволяет трактовать их, как информацию, т.е. сведения содержат не только набор определенных данных, но и связи между ними.
Иначе говоря, моделью данных (МД) описывается определенный набор родовых понятий и признаков, которыми обладают все конкретные системы управления базами данных (СУБД) и управляемые ими базы данных (БД), если они используют эту модель. Наличие модели данных дает возможность сравнить конкретные реализации с помощью одного общего языка.
Классификация моделей данных
Физическая модель данных работает с категориями, которые касаются организации внешней памяти и структур хранения, которые используются в данной операционной среде. В настоящее время в качестве физических моделей применяют разные методы размещения данных, которые основаны на файловых структурах: организации файлов прямого и последовательного доступов, индексных и инвертированных файлов, файлов, использующих разные способы кэширования, взаимосвязанных файлов.
Готовые работы на аналогичную тему
Помимо этого, современными БД широко используются страничные организации данных. Физические модели данных, которые основаны на страничной организации, наиболее перспективны в наши дни.
На рисунке 1 представлена схема классификации моделей данных.
Максимальный интерес вызван моделями данных, которые используются на концептуальном уровне. По отношению к ним внешние модели называют подсхемами и используют те же абстрактные категории, что и концептуальные модели данных.
Инфологические модели данных используют на ранних стадиях проектирования в целях описания структуры данных в процессе разработки приложения, а даталогические модели уже поддерживаются конкретной СУБД. Физическими моделями описываются структуры и принципы их хранения во внешней памяти, а также доступ к ним, зависящий от используемых аппаратных средств и программного обеспечения низкого уровня. Среди разновидностей инфологических моделей наиболее распространена модель Сущность-связь.
Различают даталогические модели двух основных категорий:
- Документальные модели данных. Эти модели относятся к слабоструктурированной информации, которая ориентирована, как правило, на свободные форматы документов и текстов на естественном языке.
- Модели, которые ориентированы на формат документа. Данные модели основаны на разных языках разметки документов, но связаны со стандартным общим языком разметки – SGML (Standart Generalised Markup Language), утвержденном ISO в качестве стандарта в 80-е годы прошлого столетия. Данный язык используется при создании других языков разметки, им определяются допустимые наборы тегов (ссылок), их атрибуты и внутренняя структура документа. Контроль за правильностью применения тегов возлагается на специальный набор правил, которые называют DTD-описаниями, используемыми программой клиента при разборе документа. Каждому классу документов соответствует свой набор правил грамматики используемого языка разметки. Язык SGML применяется для описания структурированных данных, организации информации, содержащейся в документах, представления этой информации в стандартизованном формате. В связи со сложностью самого SGML его использовали, как правило, при описании синтаксисов других языков (например, HTML), и малое количество приложений работало непосредственно с SGML-документами.
Гораздо более простым и удобным, чем SGML, является язык HTML, позволяющий оформлять элементы документа с помощью некоторого ограниченного набора инструкций (тегов) для осуществления процесса разметки. Инструкции HTML в основном используются в управлении процессом вывода содержимого документа на экран программы-клиента и определяют таким образом способ представления документа, а не его структуру. Как элемент гипертекстовой БД, описываемой HTML, представлен текстовый файл, легко передаваемый по сети с использованием протокола HTTP. Данная особенность, а также тот факт, что HTML представляет собой открытый стандарт и большая масса пользователей может применять возможности данного языка при оформлении своих документов повлияли на рост популярности HTML, ставшим на сегодняшний день главным механизмом представления информации в Интернете. Однако и HTML уже перестает удовлетворять в полном объеме требованиям, которые предъявляются современными разработчиками к языкам такого типа. Поэтому ему на смену пришел новый язык гипертекстовой разметки, более мощный, гибкий и удобный язык XML.
Определение 2
XML (Extensible Markup Language) является языком разметки, описывающим целый класс объектов данных, которые называются XML-документами.
Замечание 1
Кроме того, его используют как средство описания грамматики других языков и как средство контроля за правильностью составления документов. Сам XML не содержит никаких тегов разметки, он лишь определяет порядок их создания.
Тезаурусные модели построены по принципу организации словарей, они включают в себя определенные языковые конструкции и принципы их взаимодействия в заданной грамматике. Данные модели эффективно применяются в системах перевода, особенно многоязыковых. Принцип хранения информации в данных системах именно и подчиняется тезаурусным моделям. Дескрипторные модели являются самыми простыми из документальных моделей, их широко применяли на ранних стадиях использования документальных БД. В данных моделях каждому документу соответствовал дескриптор — описатель, который имел жесткую структуру и описывал документ в соответствии с характеристиками, требующимися для работы с документами в разрабатываемой документальной БД.
Хранимые в базе данные представлены определенной логической структурой, т.е. описаны определенной моделью представления данных (моделью данных), которая поддерживается СУБД.
К классическим моделям данных относятся:
- иерархическая;
- сетевая;
- реляционная.
Помимо этого, в последние годы стали появляться и активно внедряться на практике следующие модели данных:
- постреляционная;
- многомерная;
- объектно-ориентированная.
Разрабатывают также всевозможные системы, которые основаны на других моделях данных, расширяющих известные модели. К ним относят; объектно-реляционные, дедуктивно-объектно-ориентированные, семантические, концептуальные и ориентированные модели.
Иерархическая модель
Первая версия СУБД появилась в 1968г. Она содержала модель, представляющую собой упорядоченные наборы деревьев. Данная модель данных построена по принципу иерархии типов объектов (один тип объекта — главный, другие – подчиненные).
Определение 3
Узел дерева — это совокупность атрибутов описания объекта.
Главный и подчиненные объекты связаны по типу «один ко многим». Для каждого подчиненного типа объекта имеется лишь один исходный тип объекта.
Основной недостаток данной модели – достаточно длительный поиск необходимой информации.
Сетевая модель
В данной модели любой объект может быть как главным, так и подчиненным. Каждый объект имеет возможность участвовать в любом числе взаимодействий. Другими словами, любая информационная единица может иметь множество предков и множество потомков.
В моделях подобного рода связи заложены внутри описаний объектов.
Достоинством является гибкость модели, т.е. имеется возможность повышения быстродействия системы.
Недостатком является нагрузка на информационные ресурсы.
Реляционная модель данных (РМД) свое название получила от английского термина relation, что означает «отношение». При соблюдении определенных условий отношение можно представить в виде двумерной привычной для человека таблицы. Основная масса современных БД для компьютеров являются реляционными.
Определение 4
Достоинства реляционной модели данных – это простота, удобство реализации на ЭВМ, наличие теоретического обоснования и возможность формирования гибкой схемы БД, которая допускает настройку при формировании запросов.
Замечание 2
Подобная модель используется, как правило, в базах данных среднего размера. При увеличении количества таблиц в базе данных снижается скорость работы с ней. Возникают также проблемы при создании систем со сложными структурами данных (например, систем автоматизации проектирования).
Объектно-ориентированные БД включают в свой состав 2 модели данных: реляционную и сетевую, и применяются при создании крупных баз данных со сложными структурами.
По характеру использования СУБД бывают:
- персональными (СУБДП):
- многопользова¬тельскими (СУБДМ).
К персональным СУБД относят Visual FoxPro, Paradox, Clipper, dBase, Access и др. К многопользовательским СУБД относят Oracle и Informix. Многопользовательские СУБД состоят из сервера БД и клиентской части, работают в неоднородной вычислительной среде (разные типы ЭВМ и различные операционные системы). Поэтому СУБДМ можно использовать для создания информационной системы, функционирующей по технологии «клиент-сервер». Универсальность многопользовательских СУБД отражается на их высокой цене и компьютерных ресурсах, необходимых для их поддержки.
Определение 5
СУБДП — это совокупность языковых и программных средств создания, ведения и использования БД. С их помощью можно создавать персональные БД и недорогие приложения, работающие с ними, и при необходимости приложения, работающие с сервером БД.
Виды моделей данных
Изучив эту тему, вы узнаете и повторите::
— что представляет собой модель данных;
— в чем особенность иерархической модели данных;
— в чем особенность сетевой модели данных;
— в чем особенность реляционной модели данных;
— как устанавливаются связи в реляционной модели.
Представление о модели данных
Прежде чем переходить к работе по созданию базы данных на компьютере, необходимо разработать модель данных.
Начнем рассмотрение этого понятия на примере предметной области Школьная библиотека. В любой библиотеке для поиска нужной литературы используются каталоги, в которых хранятся сведения обо всех имеющихся в ней книгах. Каталоги бывают алфавитные (рис. 4.2) и предметные (рис. 4.3). Каталог состоит из карточек. В карточке содержатся сведения об одной книге. Карточки создаются в двух экземплярах, один из которых хранится в алфавитном каталоге, а другой — в предметном. Оба каталога содержат одни и те же карточки, но расставлены они в разном порядке.
Рис. 4.2. Алфавитный каталог
Рис. 4.3. Предметный каталог
Рассмотрим, как организована структура библиотечного каталога. Каталог, как объект, можно описать информационной моделью, для представления которой используются разнообразные формы. Так, например, информационная модель предметного каталога школьной библиотеки может быть отображена в наглядной графической форме в виде иерархической структуры (рис. 4.4).
Рис. 4.4. Информационная модель предметного каталога
школьной библиотеки в виде иерархической структуры
Другой формой представления информационной модели могут быть таблицы, где в отличие от предыдущей формы можно кроме указания объектов отобразить и их свойства. Например, для отображения свойств объектов предметной области Школьная библиотека можно создать две таблицы — художественной и учебной литературы. Эта же информация может быть представлена в виде совокупности более детализированных таблиц.
Например, информация о художественной литературе может быть представлена в виде двух таблиц — для иностранной и русской литературы, а учебная — в виде нескольких таблиц для физики, биологии, химии и т. д. Каждая запись в такой таблице является аналогом карточки каталога и отражает сведения только об одной книге. Таким образом, одна база данных может состоять из нескольких таблиц, связь между которыми необходимо организовать по определенным правилам.
Важно не только собрать вместе нужную информацию, но и удачно ее структурировать, то есть создать информационную модель данных и представить в определенной форме. Это позволит понять информационную структуру объекта и создать необходимые процедуры для извлечения из базы данных нужной информации.
Применительно к базам данных такая информационная модель получила более короткое название — модель данных.
 Модель данных — это совокупность взаимосвязанных по определенному правилу данных.
Модель данных — это совокупность взаимосвязанных по определенному правилу данных.
Информация, отражающая существенные признаки объекта, процесса, явления и хранящаяся в памяти компьютера, представляет собой компьютерную информационную модель. Выделяют три основные модели данных: иерархическую, сетевую и реляционную. Рассмотрим каждую из них.
Иерархическая модель данных
Иерархическая модель данных отображает взаимосвязь информационных объектов по уровням подчиненности. На верхнем (корневом) уровне расположен единственный информационный объект. Ему подчиняется несколько информационных объектов второго уровня. Каждому информационному объекту второго уровня подчиняется несколько информационных объектов третьего уровня и т. д.
Рассмотрим примеры иерархических моделей.
На верхнем уровне информационной модели Школы Санкт- Петербурга (рис. 4.5) расположен корневой объект — информация о городе Санкт-Петербурге. Город состоит их нескольких районов, информация о которых отражена на втором уровне. В каждом районе имеется несколько школ — это объекты третьего уровня. Можно продолжить дальнейшее разделение по уровням иерархии: на четвертом уровне находятся классы, на пятом — ученики. Каждый уровень (кроме первого) отображает информацию о классе объектов. В данной модели можно выделить следующие классы: районы, школы, классы, ученики.
Рис. 4.5. Пример иерархической модели данных Школы Санкт-Петербурга
В обобщенном виде модель изображается в виде дерева, элементами которого являются узлы, распределенные по уровням, и дуги (рис. 4.6).
Узел представляет информационную модель объекта, находящегося на данном уровне иерархии. Дуги показывают связи между объектами разных уровней.
Сформулируем основные свойства иерархической модели.
♦ Модель имеет только одну вершину первого уровня, называемую корнем.
Рис. 4.6. Графическое изображение иерархической модели в обобщенном виде
♦ Между узлами двух соседних уровней установлены следующие отношения. Каждый узел нижнего уровня должен быть связан только с одним узлом верхнего уровня. Каждый узел верхнего уровня может быть связан с несколькими узлами нижнего уровня. Такая связь называется «один-ко-многим», условно записывается как соотношение 1:М.
♦ Узлы последнего нижнего уровня не имеют подчиненных узлов.
♦ Каждый узел имеет имя (идентификатор).
♦ Узлы одного уровня образуют один класс объектов.
Примером иерархической модели данных является структура каталога (рис. 4.7), отражающая информацию о хранящихся на компьютере файлах.
Эта структура представляет совокупность папок и файлов, распределенных по уровням вложенности. Корневой папкой является жесткий диск.
Каждая папка или файл является узлом иерархической модели и характеризуется конкретными значениями параметров, посредством которых описывается соответствующий класс объектов.
Иерархической моделью данных является также генеалогическое дерево, показывающее наследственные связи между родственниками.
Рис. 4.7. Иерархическая структура каталога
Контрольные вопросы и задания
1. Что такое модель данных и для чего она нужна?
2. Приведите определение информационной модели и сопоставьте его с определением модели данных. Найдите у них общие и различающиеся характеристики.
3. Какие вы знаете формы представления информационной модели? Сравните их и сделайте вывод о том, когда лучше использовать ту или иную форму представления.
4. Приведите примеры моделей данных для разных предметных областей.
5. Что представляет собой иерархическая модель данных в общем виде?
6. Что такое узел иерархической модели данных?
7. В чем состоят свойства иерархической модели данных?
8. Приведите примеры иерархических моделей данных.
9. Что представляет собой сетевая модель данных в общем виде?
10. В чем состоят свойства сетевой модели данных?
11. Приведите примеры сетевых моделей данных.
12. Что представляет собой реляционная модель данных в общем виде?
13. Как вы понимаете связь между информационными объектами 1:1? Приведите примеры такого типа связей.
14. Как вы понимаете связь между информационными объектами 1:М? Приведите примеры этого типа связей.
15. Как вы понимаете связь между информационными объектами М:М? Приведите примеры данного типа связей.
16. В чем состоят свойства реляционной модели данных?
17. Приведите примеры реляционных моделей данных.
18. Как графически отображается реляционная модель данных?
19. Приведите примеры преобразования иерархической модели в реляционную.
20. Приведите примеры преобразования сетевой модели в реляционную.
Аннотация: Лекция посвящена первым теоретико-графовым моделям, использовавшимся в ранних системах управления БД
Как уже упоминалось ранее, эти модели отражают совокупность объектов реального мира в виде графа взаимосвязанных информационных объектов. В зависимости от типа графа выделяют иерархическую или сетевую модели. Исторически эти модели появились раньше, и в настоящий момент они используются реже, чем более современная реляционная модель данных. Однако до сих пор существуют системы, работающие на основе этих моделей, а одна из концепций развития объектно-ориентированных баз данных предполагает объединение принципов сетевой модели с концепцией реляционной.
Иерархическая модель данных
Иерархическая модель данных является наиболее простой среди всех даталогических моделей. Исторически она появилась первой среди всех даталогических моделей: именно эту модель поддерживает первая из зарегистрированных промышленных СУБД IMS фирмы IBM.
Появление иерархической модели связано с тем, что в реальном мире очень многие связи соответствуют иерархии, когда один объект выступает как родительский, а с ним может быть связано множество подчиненных объектов. Иерархия проста и естественна в отображении взаимосвязи между классами объектов.
Основными информационными единицами в иерархической модели являются: база данных (БД), сегмент и поле. Поле данных определяется как минимальная, неделимая единица данных, доступная пользователю с помощью СУБД. Например, если в задачах требуется печатать в документах адрес клиента, но не требуется дополнительного анализа полного адреса, то есть города, улицы, дома, квартиры, то мы можем принять весь адрес за элемент данных, и он будет храниться полностью, а пользователь сможет получить его только как полную строку символов из БД. Если же в наших задачах существует анализ частей, составляющих адрес, например города, где расположен клиент, то нам необходимо выделить город как отдельный элемент данных, только в этом случае пользователь может получить к нему доступ и выполнить, например, запрос на поиск всех клиентов, которые проживают в конкретном городе, например в Париже. Однако если пользователю понадобится и полный адрес клиента, то остальную информацию по адресу также необходимо хранить в отдельном поле, которое может быть названо, например, Сокращенный адрес. В этом случае для каждого клиента в БД хранится как Город, так и Сокращенный адрес.
Сегмент в терминологии Американской Ассоциации по базам данных DBTG (Data Base Task Group) называется записью, при этом в рамках иерархической модели определяются два понятия: тип сегмента или тип записи и экземпляр сегмента или экземпляр записи.
Тип сегмента — это поименованная совокупность типов элементов данных, в него входящих. Экземпляр сегмента образуется из конкретных значений полей или элементов данных, в него входящих. Каждый тип сегмента в рамках иерархической модели образует некоторый набор однородных записей. Для возможности различия отдельных записей в данном наборе каждый тип сегмента должен иметь ключ или набор ключевых атрибутов (полей, элементов данных). Ключом называется набор элементов данных, однозначно идентифицирующих экземпляр сегмента. Например, рассматривая тип сегмента, описывающий сотрудника организации, мы должны выделить те характеристики сотрудника, которые могут его однозначно идентифицировать в рамках БД предприятия. Если предположить, что на предприятии могут работать однофамильцы, то, вероятно, наиболее надежным будет идентифицировать сотрудника по его табельному номеру. Однако если мы будем строить БД, содержащую описание множества граждан, например нашей страны, то, скорее всего, нам придется в качестве ключа выбрать совокупность полей, отражающих его паспортные данные.
В иерархической модели сегменты объединяются в ориентированный древовидный граф. При этом полагают, что направленные ребра графа отражают иерархические связи между сегментами: каждому экземпляру сегмента, стоящему выше по иерархии и соединенному с данным типом сегмента, соответствует несколько (множество) экземпляров данного (подчиненного) типа сегмента. Тип сегмента, находящийся на более высоком уровне иерархии, называется логически исходным по отношению к типам сегментов, соединенным с данным направленными иерархическими ребрами, которые в свою очередь называются логически подчиненными по отношению к этому типу сегмента. Иногда исходные сегменты называют сегментами-предками, а подчиненные сегменты называют сегментами-потомками.

Рис. 3.1. Пример иерархических связей между сегментами
На концептуальном уровне определяется понятие схемы БД в терминологии иерархической модели.
Схема иерархической БД представляет собой совокупность отдельных деревьев, каждое дерево в рамках модели называется физической базой данных.Каждая физическая БД удовлетворяет следующим иерархическим ограничениям:
- в каждой физической БД существует один корневой сегмент, то есть сегмент, у которого нет логически исходного (родительского) типа сегмента;
- каждый логически исходный сегмент может быть связан с произвольным числом логически подчиненных сегментов;
- каждый логически подчиненный сегмент может быть связан только с одним логически исходным (родительским ) сегментом.
Очень важно понимать различие между сегментом и типом сегмента — оно такое же, как между типом переменной и самой переменной: сегмент является экземпляром типа сегмента. Например, у нас может быть тип сегмента Группа (Номер, Староста) и сегменты этого типа, такие как (4305, Петров Ф. И.) или (383, Кустова Т. С).
Между экземплярами сегментов также существуют иерархические связи. Рассмотрим, например, иерархический граф, представленный на рис. 3.2.
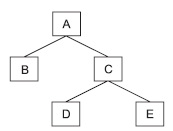
Рис. 3.2. Пример структуры иерархического дерева
Каждый тип сегмента может иметь множество соответствующих ему экземпляров. Между экземплярами сегментов также существуют иерархические связи.
На рис. 3.3 представлены 2 экземпляра иерархического дерева соответствующей структуры.
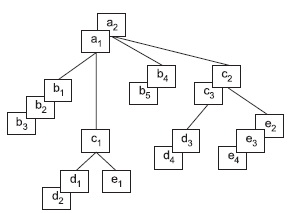
Рис. 3.3. Пример двух экземпляров данного дерева
Экземпляры-потомки одного типа, связанные с одним экземпляром сегмента-предка, называют «близнецами». Так, для нашего примера экземпляры b1, b2 и b3 являются «близнецами», но экземпляр b4 подчинен другому экземпляру родительского сегмента, и он не является «близнецом» по отношению к экземплярам b1, b2 и b3. Набор всех экземпляров сегментов, подчиненных одному экземпляру корневого сегмента, называется физической записью. Количество экземпляров-потомков может быть разным для разных экземпляров родительских сегментов, поэтому в общем случае физические записи имеют разную длину. Так, используя принцип линейной записи иерархических графов, пример на рис. 3.3 можно представить в виде двух записей:
| а1 b1 b2 b3 c1 d1 d2 e1 | a2 b4 b5 c2 c3 d3 d4 e2 e3 e4 |
|---|---|
| Запись 1 | Запись 2 |
Как видно из нашего примера, физические записи в иерархической модели различаются по длине и структуре.
Язык описания данных иерархической модели
В рамках иерархической модели выделяют языковые средства описания данных (DDL, Data Definition Language) и средства манипулирования данными (DML, Data Manipulation Language).
Каждая физическая база описывается набором операторов, определяющих как ее логическую структуру, так и структуру хранения БД. Описание начинается с оператора DBD (Data Base Definition):
DBD Name = < имя БД>, ACCESS = < способ доступа>
Способ доступа определяет способ организации взаимосвязи физических записей. Определено 5 способов доступа: HSAM — hierarchical sequential access method (иерархически последовательный метод), HISAM — hierarchical index sequential access method (иерархически индексно-последовательный метод), HDAM — hierarchical direct access method (иерархически прямой метод), HIDAM — hierarchical index direct access method (иерархически индексно-прямой метод), INDEX — индексный метод.
Далее идет описание наборов данных, предназначенных для хранения БД:
DATA SET DD1 = < имя оператора, определяющего хранимый набор данных>, DEVICE =< устройство хранения БД>, [OVFLW = < имя области переполнения>]
Так как физические записи имеют разную длину, то при модификации данных запись может увеличиться и превысит исходную длину записи до модификации. В этом случае при определенных методах хранения может понадобиться дополнительное пространство хранения, где и будут размещены дополнительные данные. Это пространство и называется областью переполнения.
После описания всей физической БД идет описание типов сегментов, ее составляющих, в соответствии с иерархией. Описание сегментов всегда начинается с описания корневого сегмента. Общая схема описания типа сегмента такова:
SEGM NAME = < имя сегмента>, BYTES =< размер в байтах>, FREQ = <средняя частота реализаций сегмента под одним исходным> PARENT = <имя родительского сегмента>
Параметр FREQ определяет среднее количество экземпляров данного сегмента, связанных с одним экземпляром родительского сегмента. Для корневого сегмента это число возможных экземпляров корневого сегмента.
Для корневого сегмента параметр PARENT равен 0 (нулю).
Далее для каждого сегмента дается описание полей :
FIELD NAME = {(<имя поля> [, SEQ],{U | M}) | <имя поля> },
START = < номер байта, с которого начинается значения поля >,
BYTES = <размер поля в байтах>,
TYPE = {X | P | C}Признак SEQ — задается для ключевого поля, если экземпляры данного сегмента физически упорядочены в соответствии со значениями данного поля.
Параметр U задается, если значения ключевого поля уникальны для всех экземпляров данного сегмента, M — в противном случае. Если поле является ключевым, то его описание задается в круглых скобках, в противном случае имя поля задается без скобок. Параметр TYPE определяет тип данных. Для ранних иерархических моделей были определены только три типа данных: X — шестнадцатеричный, P —упакованный десятичный, C — символьный.
Заканчивается описание схемы вызовом процедуры генерации:
- DBDGEN — указывает на конец последовательности управляющих операторов описания БД;
- FINISH — устанавливает ненулевой код завершения при обнаружении ошибки;
- END — конец.
В системе может быть несколько физических БД (ФБД), но каждая из них описывается отдельно своим DBD и ей присваивается уникальное имя. Каждая ФБД содержит только один корневой сегмент. Совокупность ФБД образует концептуальную модель данных.
Внешние модели
При работе с иерархической моделью каждая программа, пользователь или приложение определяет свою внешнюю модель. Внешняя модель представляет собой совокупность поддеревьев для физических баз данных, с которыми работает данный пользователь. Каждый подграф внешней модели в обязательном порядке должен содержать корневой тип сегмента соответствующей физической базы данных концептуальной модели.
Представление внешней модели называется логической базой данных и определяется совокупностью блоков связи данного приложения с физическими БД, входящими в концептуальную схему БД. Блок связи — PCB, program communication block — описывает связь с одной физической БД по следующим правилам:
DBD NAME = < имя логической БД (подсхемы)> , ACCESS = LOGICAL DATA SET = LOGICAL. SEGM NAME = <имя сегмента в подсхеме>, PARENT =<имя родительского сегмента в подсхеме>, SOURCE =(Имя соответствующего сегмента ФБД, имя ФБД) ... DBDGEN FINISH END
Совокупность блоков PCB образует полное внешнее представление данного приложения, называемое «блоком спецификации программ» ( PSB, program specification block ).
Рассмотрим пример иерархической БД.
Наша организация занимается производством и продажей компьютеров, в рамках производства мы комплектуем компьютеры из готовых деталей по индивидуальным заказам. У нас существует несколько базовых моделей, которые мы продаем без предварительных заказов по наличию на складе. В организации существуют несколько филиалов (рис. 3.4) и несколько складов, на которых хранятся комплектующие. Нам необходимо вести учет продаваемой продукции.
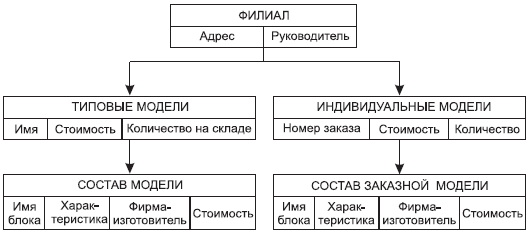
Рис. 3.4. Физическая БД «Филиалы»
Какие задачи нам надо решать в ходе разработки приложения?
- При приеме заказа мы должны выяснить, какую модель заказывает заказчик: типичную или индивидуальную комплектацию.
- Если заказывается типичная модель, то выясняется, какая модель и есть ли она в наличии, если модель есть, то надо уменьшить количество компьютеров данной модели в данном филиале на покупаемое количество. На этом будем считать заказ выполненным, однако при оформлении заказа может потребоваться задание полной спецификации покупаемого изделия.
- Если заказывается индивидуальная модель, то требуется описать весь состав новой модели.
Для того чтобы можно было бы принимать заказы на индивидуальные модели, нам понадобится информация о наличии конкретных деталей на складе, в этом случае нам необходимо второе дерево — Склады (см. рис. 3.5).
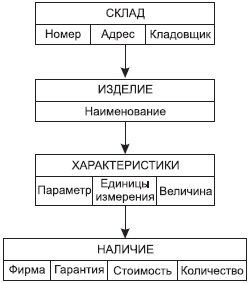
Рис. 3.5. Физическая модель «Склады»
Введение
«Нужно бежать со всех ног, чтобы только оставаться на месте,
а чтобы куда-то попасть, надо бежать как минимум вдвое быстрее!»
(с) Алиса в стране чудес
Некоторое время назад меня попросили прочитать лекцию аналитикам нашей компании на тему проектирования моделей данных, ведь сидя долгое время на проектах (порою по нескольку лет) мы упускаем из виду происходящее вокруг в мире ИТ-технологий. В нашей компании (уж так получилось) на многих проектах не используются NoSQL-базы данных (по крайней мере пока), поэтому в своей лекции я отдельно уделил им некоторое внимание на примере HBase и постарался ориентировать изложение материала на тех, кто с ними никогда не работал. В частности, я иллюстрировал некоторые особенности проектирования модели данных на примере, который несколько лет назад прочитал в статье «Introduction to HB ase Schema Design» by Amandeep Khurana. Разбирая примеры, я сравнивал между собой несколько вариантов решения одной и той же задачи, чтобы лучше донести до слушателей основные идеи.
Недавно, «от нечего делать», я задался вопросом (длинные майские выходные в режиме карантина к этому особенно располагают), насколько теоретические выкладки будут соответствовать практике? Собственно, так и родилась идея этой статьи. Разработчик, который не первый день работает с NoSQL, возможно и не почерпнет из нее что-то новое (и поэтому может сразу промотать полстатьи). Но для аналитиков, которые еще не работали плотно с NoSQL, полагаю, она будет полезна для получения базовых представлений об особенностях проектирования моделей данных для HBase.
Разбор примера
На мой взгляд, прежде чем начать использовать NoSQL базы данных, необходимо хорошо подумать и взвесить «за» и «против». Часто задачу скорее всего можно решить и на традиционных реляционных СУБД. Поэтому лучше не использовать NoSQL без существенных на то оснований. Если все же было принято решение использовать NoSQL базу данных, то следует учесть, что подходы к проектированию здесь несколько отличаются. Особенно некоторые из них могут быть непривычны тем, кто до этого имел дело только с реляционными СУБД (по моим наблюдениям). Так, в «реляционном» мире мы обычно идем от моделирования предметной области, и уже потом при необходимости проводим денормализацию модели. В NoSQL же мы сразу должны учитывать предполагаемые сценарии работы с данными и изначально денормализовывать данные. Кроме того, есть ряд других отличий, о которых будет написано ниже.
Рассмотрим следующую «синтетическую» задачу, с которой и будем далее работать:
Необходимо спроектировать структуру хранения списка друзей пользователей некой абстрактной социальной сети. Для упрощения будем полагать, что все связи у нас направленные (как в Инстаграмме, а не в Linkedin). Структура должна позволять эффективно:
- Отвечать на вопрос, читает ли пользователь А пользователя Б (шаблон чтения)
- Позволять добавлять/удалять связи в случае подписки/отписки пользователя А от пользователя Б (шаблон изменения данных)
Конечно же, вариантов решения задачи множество. В обычной реляционной БД мы бы скорее всего просто сделали бы таблицу связей (возможно, типизированную, если, например, требуется хранить пользовательскую группу: семья, работа и т.п., в которую входит данный «друг»), а для оптимизации скорости доступа добавили бы индексы/партиционирование. Скорее всего итоговая таблица выглядела бы примерно вот так:
здесь и далее для наглядности и лучшего понимания вместо ID буду указывать имена
В случае же с HBase мы знаем, что:
- эффективный поиск, не приводящий к full table scan, возможен исключительно по ключу
- собственно, поэтому писать привычные многим SQL-запросы к подобным базам – плохая идея; технически, конечно, вы можете из той же Impala отправить SQL-запрос с Join’ами и прочей логикой в HBase, но вот насколько это будет эффективно…
Поэтому ID пользователя мы вынуждены использовать как ключ. А первой мыслью на тему «где и как хранить ID друзей?» может быть идея хранения их в колонках. Этот самый очевидный и «наивный» вариант будет выглядеть примерно так (назовем его Вариант 1 (default), чтобы ссылаться в дальнейшем):
Здесь каждая строка соответствует одному пользователю сети. Колонки имеют имена: 1, 2, … — по количеству друзей, и в колонках хранятся ID друзей. Важно заметить, что у каждой строки будет разное число колонок. В примере на рисунке выше одна строка имеет три колонки (1, 2 и 3), а вторая – только две (1 и 2) – здесь мы сами воспользовались двумя свойствами HBase, которых нет у реляционных БД:
- возможностью динамически менять состав колонок (добавляем друга -> добавляем колонку, удаляем друга -> удаляем колонку)
- у разных строк может быть различный состав колонок
Проверим нашу структуру на соответствие требованиям задачи:
- Чтение данных: для того, чтобы понять, подписан ли Вася на Олю, нам надо будет вычитать всю строку по ключу RowKey = «Вася» и перебирать значения колонок, пока не «встретим» в них Олю. Или перебрать значения всех колонок, «не встретить» Олю и вернуть ответ False;
- Изменение данных: добавление друга: для подобной задачи нам так же потребуется вычитать всю строку по ключу RowKey = «Вася», чтобы посчитать общее количество его друзей. Это общее кол-во друзей нам необходимо, чтобы определить номер колонки, в которую надо записать ID нового друга.
- Изменение данных: удаление друга:
- Необходимо вычитать всю строку по ключу RowKey = «Вася» и перебирать колонки для того, чтобы найти ту самую, в которой записан удаляемый друг;
- Далее нам, после удаления друга, надо «сдвинуть» все данные на одну колонку, чтобы не получить «разрывов» в их нумерации.
Давайте теперь оценим, насколько данные алгоритмы, которые нам необходимо будет реализовывать на стороне «условного приложения», будут производительны, используя О-символику. Обозначим размер нашей гипотетической социальной сети как n. Тогда максимальное число друзей у одного пользователя может быть (n-1). Этой (-1) мы можем в дальнейшем пренебречь для наших целей, так как в рамках использования О-символики она несущественна.
- Чтение данных: необходимо вычитать всю строку и перебрать в пределе все ее колонки. Значит верхняя оценка затрат будет примерно О(n)
- Изменение данных: добавление друга: для определения количества друзей требуется перебрать все колонки строки, после чего вставить новую колонку => О(n)
- Изменение данных: удаление друга:
- Аналогично добавлению – требуется в пределе перебрать все колонки => О(n)
- После удаления колонок нам надо «сдвинуть» их. Если реализовывать это «в лоб», то в пределе потребуется еще до (n-1) операций. Но мы здесь и далее в практической части применим иной подход, который будет реализовывать «псевдо-сдвиг» за фиксированное кол-во операций – то есть на него будет тратиться константное время вне зависимости от n. Этим константным временем (если быть точным, то О(2)) по сравнению с О(n) можно пренебречь. Подход проиллюстрирован на рисунке ниже: мы просто копируем данные из «последней» колонки в ту, из которой надо удалить данные, после чего удаляем последнюю колонку:
Итого, во всех сценариях мы получили асимптотическую вычислительную сложность O(n).
Наверное, вы уже заметили, что нам приходится почти всегда вычитывать из базы всю строку целиком, причем в двух случаях из трех только для того, чтобы перебрать все колонки и посчитать общее кол-во друзей. Поэтому в качестве попытки оптимизации можно добавить колонку «count», в которой хранить общее число друзей каждого пользователя сети. В этом случае мы можем не вычитывать всю строку целиком для подсчета общего кол-ва друзей, а прочитать только одну колонку «count». Главное, не забывать обновлять «count» при манипуляции с данными. Т.о. получаем улучшенный Вариант 2 (count):
По сравнению с первым вариантом:
- Чтение данных: для получения ответа на вопрос «Читает ли Вася Олю?» ничего не изменилось => О(n)
- Изменение данных: добавление друга: Мы упростили вставку нового друга, так как теперь нам не надо вычитывать всю строку и перебирать ее колонки, а можно получить только значение колонки «count» и т.о. сразу определить номер колонки для вставки нового друга. Это приводит к снижению вычислительной сложности до О(1)
- Изменение данных: удаление друга: При удалении друга мы можем так же воспользоваться данной колонкой, чтобы снизить количество операций ввода-вывода при «сдвиге» данных на одну ячейку влево. Но необходимость перебора колонок для поиска той, которую необходимо удалить, все равно остается, поэтому => O(n)
- С другой стороны, теперь нам при обновлении данных необходимо каждый раз обновлять и колонку «count», но на это уходит константное время, которым в рамках О-символики можно пренебречь
В целом вариант 2 видится чуть более оптимальным, но это скорее «эволюция вместо революции». Для совершения «революции» нам понадобится Вариант 3 (col).
Перевернем все «с ног на голову»: назначим именем колонки идентификатор пользователя! Что будет записано в самой колонке – для нас уже не суть важно, пусть будет цифра 1 (вообще, из полезного там можно хранить, например, группу «семья/друзья/и т.п.»). Данный подход может удивить неподготовленного «обывателя», который до этого не имел опыта работы с NoSQL-базами, но именно он позволяет использовать потенциал HBase в данной задаче намного эффективнее:
Здесь мы получаем сразу несколько преимуществ. Чтобы их понять, проанализируем новую структуру и оценим вычислительную сложность:
- Чтение данных: для того, чтобы ответить на вопрос, подписан ли Вася на Олю, достаточно прочитать одну колонку «Оля»: если она есть, то ответ True, если нет – False => O(1)
- Изменение данных: добавление друга: Добавление друга: достаточно просто добавить новую колонку «ID друга» => O(1)
- Изменение данных: удаление друга: достаточно просто удалить колонку «ID друга» => O(1)
Как видим, существенным преимуществом такой модели хранения является то, что мы во всех необходимых нам сценариях оперируем только одной колонкой, избегая вычитывания из базы всей строки и тем более, перебора всех колонок этой строки. На этом можно было бы остановиться, но…
Можно озадачиться и пойти еще немного дальше по пути оптимизации производительности и уменьшения операций ввода-вывода при обращении к базе. Что если хранить полную информацию о связи непосредственно в самом ключе строки? То есть сделать ключ составным вида userID.friendID? В этом случае нам вообще можно даже не вычитывать колонки строки (Вариант 4(row)):
Очевидно, что оценка всех сценариев манипуляции с данными в такой структуре также, как и в предыдущем варианте будет О(1). Разница с вариантом 3 будет уже исключительно в эффективности операций ввода-вывода в БД.
Ну и последний «бантик». Легко заметить, что в варианте 4 у нас ключ строки будет иметь переменную длину, что, возможно, может повлиять на производительность (тут вспоминаем, что HBase хранит данные как набор байтов и строки в таблицах отсортированы по ключу). Плюс у нас есть разделитель, который в некоторых сценариях может потребоваться обрабатывать. Чтобы исключить это влияние, можно использовать хэши от userID и friendID, и так как оба хэша будут иметь постоянную длину, то можно просто конкатенировать их, без разделителя. Тогда данные в таблице будут выглядеть так (Вариант 5(hash)):
Очевидно, что алгоритмическая сложность работы с такой структурой по рассматриваемом нами сценариями, будет такая же, как у варианта 4 – то есть О(1).
Итого, сведем все наши оценки вычислительной сложности в одну таблицу:
Как видно, варианты 3-5 выглядят наиболее предпочтительным и теоретически обеспечивает выполнение всех необходимых сценариев манипуляции с данными за константное время. В условии нашей задачи нет явного требования по получению списка всех друзей пользователя, но в реальной проектной деятельности нам, как хорошим аналитикам, хорошо бы «предвидеть», что подобная задача может возникнуть и «подстелить соломку». Поэтому мои симпатии на стороне варианта 3. Но вполне вероятно, что в реальном проекте данный запрос могл быть уже решен иными средствами, поэтому без общего видения всей задачи лучше не делать окончательных выводов.
Подготовка эксперимента
Вышеизложенные теоретические рассуждения хотелось бы проверить на практике – это и было целью возникшей на долгих выходных задумки. Для этого необходимо оценить скорость работы нашего «условного приложения» во всех описанных сценариях использования базы, а также рост этого времени с ростом размера социальной сети (n). Целевым параметром, который нас интересует и который мы будем замерять в ходе эксперимента, является время, затраченное «условным приложением», на выполнение одной «бизнес-операции». Под «бизнес-операцией» мы понимаем одну из следующих:
- Добавление одного нового друга
- Проверка, является ли пользователь А другом пользователя Б
- Удаление одного друга
Таким образом, с учетом обозначенных в изначальной постановке требований, сценарий проверки вырисовывается следующий:
- Запись данных. Сгенерировать случайным образом исходную сеть размером n. Для большего приближения к «реальному миру» количество друзей у каждого пользователя – так же случайная величина. Замерить время, за которое наше «условное приложение» запишет в HBase все сгенерированные данные. Потом полученное время разделить на общее количество добавленных друзей – так мы получим среднее время на одну «бизнес-операцию»
- Чтение данных. Для каждого пользователя составить список «личностей», для которых надо получить ответ, подписан ли на них пользователь или нет. Длина списка = примерно кол-ву друзей пользователя, причем для половины проверяемых друзей ответ должен быть «Да», а для другой половины – «Нет». Проверка производится в таком порядке, чтобы ответы «Да» и «Нет» чередовались (то есть в каждом втором случае нам придется перебирать все колонки строки для вариантов 1 и 2). Общее время проверки затем разделить на количество проверяемых друзей для получения среднего времени на проверку одного субъекта.
- Удаление данных. Удалить у пользователя всех друзей. Причем порядок удаления – случайный (то есть «перемешиваем» изначальный список, использовавшийся для записи данных). Общее время проверки затем разделить на количество удаляемых друзей для получения среднего времени на одну проверку.
Сценарии необходимо прогнать для каждого из 5 вариантов моделей данных и для разных размеров социальной сети, чтобы посмотреть, как меняется время с ее ростом. В рамках одного n связи в сети и список пользователей для проверки должны быть, естественно, одинаковыми для всех 5 вариантов.
Для лучшего понимания ниже привожу пример сгенерированных данных для n= 5. Написанный «генератор» дает на выходе три словаря ID-шников:
- первый – для вставки
- второй – для проверки
- третий – для удаления
{0: [1], 1: [4, 5, 3, 2, 1], 2: [1, 2], 3: [2, 4, 1, 5, 3], 4: [2, 1]} # всего 15 друзей
{0: [1, 10800], 1: [5, 10800, 2, 10801, 4, 10802], 2: [1, 10800], 3: [3, 10800, 1, 10801, 5, 10802], 4: [2, 10800]} # всего 18 проверяемых субъектов
{0: [1], 1: [1, 3, 2, 5, 4], 2: [1, 2], 3: [4, 1, 2, 3, 5], 4: [1, 2]} # всего 15 друзей
Как можно заметить, все ID, большие 10 000 в словаре для проверки – это как раз те, которые заведомо дадут ответ False. Вставка, проверка и удаление «друзей» производятся именно в указанной в словаре последовательности.
Эксперимент проводился на ноутбуке под управлением Windows 10, где в одном докер-контейнере была запущена база HBase, а в другом – Python с Jupyter Notebook. Докеру было выделено 2 ядра CPU и 2 Гб оперативной памяти. Вся логика, как и эмуляции работы «условного приложения», так и «обвязка» для генерации тестовых данных и замера времени были написаны на Python. Для работы с HBase использовалась библиотека happybase, для вычисления хэшей (MD5) для варианта 5 — hashlib
С учетом вычислительной мощности конкретного ноутбука экспериментально был выбран запуск для n = 10, 30, …. 170 – когда общее время работы полного цикла тестирования (все сценарии для всех вариантов для всех n) было еще более-менее разумным и умещалось во время одного чаепития (в среднем 15 минут).
Тут необходимо сделать ремарку, что в данном эксперименте мы в первую очередь оцениваем не абсолютные цифры производительности. Даже относительное сравнение разных двух вариантов может быть не совсем корректным. Сейчас нас интересует именно характер изменения времени в зависимости от n, так как с учетом указанной выше конфигурации «тестового стенда» получить временные оценки, «очищенные» от влияния случайных и прочих факторов, очень сложно (да и такой задачи не ставилось).
Результат эксперимента
Первый тест – как меняется время, затрачиваемое на заполнение списка друзей. Результат – на графике ниже.
Варианты 3-5 ожидаемо показывают практически константное время «бизнес-операции», которое не зависит от роста размера сети и неотличимую разницу в производительности.
Вариант 2 показывает тоже константную, но чуть худшую производительность, причем практически ровно в 2 раза относительно вариантов 3-5. И это не может не радовать, так как соотноситься с теорией – в этом варианте количество операций ввода-вывода в/из HBase как раз в 2 раза больше. Это может служить косвенным свидетельством, что наш тестовый стенд в принципе дает неплохую точность.
Вариант 1 так же ожидаемо оказывается самым медленным и демонстрирует линейный от размера сети рост времени, затрачиваемого на добавление одно друга.
Посмотрим теперь результаты второго теста.
Варианты 3-5 опять же ведет себя ожидаемо – константное время, не зависящее от размера сети. Варианты 1 и 2 демонстрируют линейный рост времени при росте размера сети и схожую производительность. Причем вариант 2 оказывается чуть медленнее – по всей видимости из-за необходимости вычитки и обработки дополнительной колонки «count», что при росте n становится более заметным. Но я все же воздержусь от каких-либо выводов, так как точность данного сравнения относительно невысока. Кроме того, данные соотношения (какой вариант, 1 или 2, быстрее) менялись от запуска к запуску (при этом сохраняя характер зависимости и «идя ноздря в ноздрю»).
Ну и последний график – результат тестирования удаления.
Здесь опять же без сюрпризов. Варианты 3-5 осуществляют удаление за константное время.
Причем, что интересно, варианты 4 и 5, в отличии от предыдущих сценариев, показывают заметную чуть худшую производительность, чем вариант 3. По всей видимости, операция удаления строки – более затратная, нежели операция удаления колонки, что в целом логично.
Варианты 1 и 2, ожидаемо, демонстрируют линейный рост времени. При этом вариант 2 стабильно медленнее варианта 1 – из-за дополнительной операции ввода-вывода по «обслуживанию» колонки count.
Общие выводы эксперимента:
- Варианты 3-5 демонстрируют бОльшую эффективность, так как они использует преимущества HBase; при этом их производительность отличается друг относительно друга на константу и не зависит от размера сети.
- Разница между вариантами 4 и 5 не была зафиксирована. Но это не значит, что вариант 5 не следует использовать. Вполне вероятно, что используемый сценарий эксперимента с учетом ТТХ тестового стенда не позволил ее выявить.
- Характер роста времени, необходимого на выполнение «бизнес-операций» с данными, в целом подтвердил полученные ранее теоретические выкладки для всех вариантов.
Эпилог
Проведенные грубые эксперименты не следует воспринимать как абсолютную истину. Есть множество факторов, которые не были учтены и вносили искажения в результаты (особенно хорошо эти флуктуации видны на графиках при небольшом размере сети). Например, скорость работы thrift, который используется happybase, объем и способ реализации логики, которая у меня была написана на Python (не берусь утверждать, что код был написан оптимально и эффективно использовал возможности всех компонент), возможно особенности кэширования HBase, фоновая активность Windows 10 на моем ноутбуке и т.п. В целом можно считать, что все теоретические выкладки экспериментально показали свою состоятельность. Ну или как минимум опровергнуть их таким вот «наскоком в лоб» не получилось.
В заключении — рекомендации всем, кто только начинает проектировать модели данных в HBase: абстрагируйтесь от предыдущего опыта работы с реляционными базами и помните «заповеди»:
- Проектируя, идем от задачи и шаблонов манипуляции с данными, а не от модели предметной области
- Эффективный доступ (без full table scan) – только по ключу
- Денормализация
- Разные строки могу содержать разные колонки
- Динамический состав колонок
Виды моделей данных — Студопедия
Ядром любой базы данных является модель данных. С помощью модели данных могут быть представлены объекты предметной области и взаимосвязи между ними.
Модель данных – совокупность структур данных и операций их обработки.
Рассмотрим 3 основных типа моделей данных: иерархическую, сетевую и реляционную.
а) иерархическая модель данных
Иерархическая модель базы данных представляет собой совокупность элементов, расположенных в порядке их подчинения от общего к частному и образующих перевернутое дерево (граф).
К основным понятиям иерархической структуры относятся: уровень, элемент (узел), связь.
Узел – это информационная модель элемента, находящегося на данном уровне иерархии. На схеме иерархического дерева узлы представляются вершинами графа.
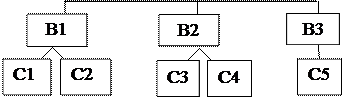 | |||
Рис. 3 Графическое изображение иерархической структуры БД
Пример. Иерархическая модель «ВУЗ».

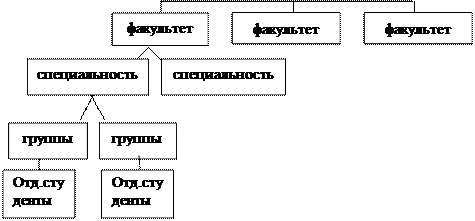 | |||||
Свойства иерархической модели:
— несколько узлов низшего уровня связано только с одним узлом высшего уровня;
— иерархическое дерево имеет только одну вершину (корень дерева), не подчиненный никакой другой вершине и находящуюся на самом верхнем (первом) уровне. Зависимые (подчиненные) узлы находятся на втором, третьем и т.д. уровнях.
— каждый узел имеет свое имя (идентификатор).
— количество деревьев в базе данных определяется числом корневых записей;
б) сетевая модель данных:
Сетевая модель имеет те же основные составляющие (узел, уровень, связь). Однако в ней принята свободная связь между элементами разных уровней, т.е. каждый элемент может быть связан с любым другим элементом.
 |
Рис. 4 Графическое изображение сетевой структуры БД
Пример. Сетевая модель «Профессорско-преподавательский состав»
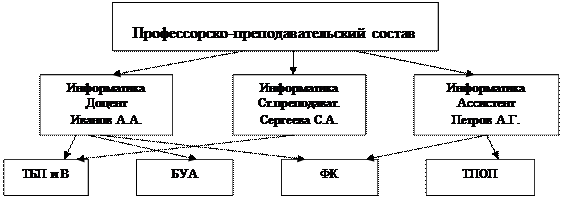 |
в) реляционная модель данных (табличная)
Термин «реляционный» произошел от англ. слова relation – отношение.
Отношение – математическое понятие, но в терминологии моделей данных отношения удобно изображать в виде таблицы.
Теоретической основой этой модели стала теория отношений американца Чарльза Пирса и немца Эрнеста Шредера. Ими было показано, что множество отношений замкнуто относительно некоторых специальных операций и образует вместе с ними абстрактную алгебру. Американский математик Э.Ф. Кодд в 1970 г. впервые сформулировал основные понятия и ограничения реляционной модели, ограничив набор операций в ней семью основными и одной дополнительной.
Реляционная модель хранения данных построена на взаимоотношении составляющих ее частей. В простейшем случае она представляет собой двухмерный массив или двухмерную таблицу, а при создании сложных информационных моделей составляет совокупность взаимосвязанных таблиц.
Пример реляционной таблицы:
| № личного дела | Фамилия | Имя | Отчество | Дата рождения | Группа |
| Костин | Владимир | Владимирович | 01.03.78 | БУА | |
| Антонов | Юрий | Петрович | 18.09.80 | ФК |
Реляционная модель базы данных имеет следующие свойства:
1) каждый элемент таблицы – один элемент данных;
2) все столбцы в таблице являются однородными, т.е. имеют один тип (числа, текст, дата и т.д.)
3) каждый столбец (поле) имеет уникальное имя;
4) одинаковые строки в столбце отсутствуют;
5) порядок следования строк и столбцов может быть произвольным.
Отношения представлены в виде таблиц, строки которых соответствуют кортежам или записям, а столбцы – атрибутам отношений, доменам, полям.
Если реляционная модель данных состоит из нескольких таблиц, то они связываются между собой ключами.
Ключ – поле, которое однозначно определяет соответствующую запись (ключевое поле).
В данном примере в качестве ключа может служить номер личного дела студента.
Что такое модели данных? Тип данных моделей.
Модель — это представление реальности, объектов и событий «реального мира», ассоциаций. Это абстракция, которая концентрируется на основных, неотъемлемых аспектах организации и игнорирует случайные свойства. Модель данных представляет саму организацию. В нем должны быть представлены основные понятия и обозначения, которые позволят разработчикам баз данных и конечным пользователям однозначно и точно передавать свое понимание организационных данных.
Модель данныхможет быть определена как интегрированный набор понятий для описания и управления данными, отношений между данными и ограничений на данные в организации.
Модель данных состоит из трех компонентов:
• Структурная часть, состоящая из набора правил, в соответствии с которыми могут создаваться базы данных.
• Манипулятивная часть, определяющая типы операций, которые разрешены для данных (это включает операции, которые используются для обновления или извлечения данных из базы данных и для изменения структуры базы данных).
• Возможно, набор правил целостности, который гарантирует точность данных.
Цель модели данных — представить данные и сделать данные понятными. В литературе было предложено много моделей данных. Они делятся на три широкие категории:
• Объектные модели данных
• Физические модели данных
• Модели данных на основе записей
Модели данных на основе объектов и записей используются для описания данных на концептуальном и внешнем уровнях, а физическая модель данных — для описания данных на внутреннем уровне.
Объектно-ориентированные модели данных
В объектных моделях данных используются такие понятия, как сущности, атрибуты и отношения. Сущность — это отдельный объект (человек, место, концепция и событие) в организации, который должен быть представлен в базе данных. Атрибут — это свойство, которое описывает некоторый аспект объекта, который мы хотим записать, а отношение — это связь между сущностями.
Некоторые из наиболее распространенных типов объектной модели данных:
• Сущность-Отношения
• Объектно-ориентированный
• Семантическая
• Функциональный
Модель Entity-Relationship возникла как один из основных методов моделирования проектирования базы данных и служит основой для методологии проектирования базы данных.Объектно-ориентированная модель данных расширяет определение объекта и включает в себя не только атрибуты, которые описывают состояние объекта, но также и действия, связанные с объектом, то есть его поведение. Говорят, что объект инкапсулирует как состояние, так и поведение. Сущности в семантических системах представляют собой эквивалент записи в реляционной системе или объекта в ОО-системе, но они не включают поведение (методы). Это абстракции, используемые для представления реального мира (например,клиент) или концептуальные (например, банковский счет) объекты. Функциональной модели данных сейчас почти двадцать лет. Первоначальная идея заключалась в том, чтобы «рассматривать базу данных как набор расширенных функций и использовать функциональный язык для запросов к базе данных.
Физические модели данных
Физические модели данных описывают, как данные хранятся в компьютере, представляя такую информацию, как структуры записей, порядок записей и пути доступа. Физических моделей данных не так много, как логических моделей данных, наиболее распространенной из которых является Объединяющая модель.
Записанные логические модели
Логические модели на основе записей используются при описании данных на логическом уровне и на уровне просмотра. В отличие от моделей данных на основе объектов, они используются для определения общей логической структуры базы данных и для предоставления описания реализации более высокого уровня. Модели, основанные на записях, названы так, потому что база данных структурирована в виде записей фиксированного формата нескольких типов. Каждый тип записи определяет фиксированное количество полей или атрибутов, и каждое поле обычно имеет фиксированную длину.
Три наиболее распространенных модели данных на основе записей:
• Иерархическая модель
• Сетевая модель
• реляционная модель
Реляционная модель получила преимущество над двумя другими в последние годы. Сетевые и иерархические модели все еще используются в большом количестве старых баз данных.
- Главная
Испытание
- Назад
- Agile тестирование
- BugZilla
- Огурцы
- База данных Тестирование
- ETL Тестирование
- Jmeter
- JIRA
- Назад
- JUnit
- LoadRunner
- Ручное тестирование
- Мобильное тестирование
- Mantis
- Почтальон
- QTP
- Назад
SAP000 SAP000- Управление тестированием
- TestLink
SAP
- Назад 9 0004 ABAP
- APO
- Новичок
- Основа
- Bods
- BI
- BPC
- CO
- Назад
- CRM
- Crystal Reports
- КУКИШ
- HANA
- HR
- MM
- QM
- Заработная плата
- Назад
- 9000 9000 9000
- 000
- 000 000
- подписываются с отделениями
- и получают
- Apache
- Android
- AngularJS
- ASP.Чистая
- C
- C #
- C ++
- CodeIgniter
- СУБД
- Назад
- Java
- JavaScript
- JSP
- Kotlin
- Back
- Perl
- PHP
- PL / SQL
- PostgreSQL
- Python
- ReactJS
- Ruby & Rails
- Scala
- SQL5000
- SQL000
- UML
- VB.Net
- VBScript
- Веб-сервисы
- WPF
Необходимо учиться!
- Назад
- Учет
- Алгоритмы
- Blockchain
- Бизнес-аналитик
- Сложение Сайт
- CCNA
- Cloud Computing
- COBOL
- Compiler Design
- Embedded Systems
- Назад
- Ethical Hacking
- Excel Учебники
- Go Программирование
- IoT
- ITIL
- Дженкинс
- MIS
- Networking
- Операционная система
- Prep
- Назад
- PMP
- Photoshop Управление
- Проект
- Отзывы
- Salesforce
- SEO
- Разработка программного обеспечения
- VBA
Big Data
- Назад
- AWS
- BigData
- Cassandra
- Cognos
- Складирование данных 000000000 HBB
- Назад
— Общая модель данных — Общая модель данных
- 9 минут, чтобы прочитать
В этой статье
Файл метаданных (или model.json) в папке Common Data Model описывает данные в папке, метаданные и местоположение, а также то, как файл был сгенерирован и каким производителем данных.
Файл модели позволяет:
- Обнаруживаемость на основе метаданных производителя данных
- Получение семантической информации о записях / атрибутах сущностей и ссылок на базовые файлы данных
- Указывает на соответствие стандартным объектам общей модели данных
- Информация о том, когда сущности были недавно обновлены
Загрузите схему файла model.json.
Содержимое файла модели
Содержимое папки Common Data Model описывается стандартными метаданными.JSON-файл, который содержит следующие ключевые категории метаданных:
Корневые элементы
Метаданные, которые применяются ко всем объектам в папке, например описание, время последнего изменения и культура данных
Информация об объекте
Общие метаданные, такие как тип, описание и т. Д.
Атрибуты, включая метаданные, такие как типы данных
[опционально] Соответствие стандартным формам данных формы стандартной сущности
Например, данный объект в папке соответствует всем атрибутам, необходимым для «основного» объекта счета
Расположение файлов данных (разделов) и метаданные о кодировании данных файлов данных
Эталонные модели
Существующие сущности и файлы данных, к которым относится данная модель.JSON файл ссылается на
Отношения
Описывает отношения между сущностями
В дополнение к стандартным элементам дополнительные специфичные для производителя элементы или расширения могут быть добавлены с префиксом, таким как «pbi: mashup», где «pbi:» является префиксом. Потребители могут игнорировать эти поля, но библиотеки будут обходить поля в обратном направлении, чтобы не допустить потери точности.
В следующих разделах каждая стандартная категория описывается более подробно.
Свойства корня
Эти свойства перечислены в корне файла model.json и описывают свойства, относящиеся ко всем сущностям, отношениям и т. Д.
| Недвижимость | Тип | Описание | Требуется? |
|---|---|---|---|
| заявка | строка | Название производящей заявки. Потребитель использует это свойство, чтобы определить, какое приложение создало модель.JSON файл. | № |
| имя | строка | Название модели | Да |
| описание | строка | Описание модели | № |
| версия | строка (enum) | Версия схемы модели (в настоящее время должна быть 1.0) | Да |
| культура | строка | Тег языка IETF (например, «en-US»), который представляет язык и страну / регион, поддерживаемые Windows и.СЕТЬ. Это значение следует использовать для анализа типов данных, которые могут быть чувствительны к культуре, например, даты и числа. Если этот параметр не задан, форматы типов данных должны соответствовать не заданным форматам культуры, определенным далее в этом разделе. | № |
| доработано время | datetimeoffset | Самое последнее время, когда определение модели обновлялось в смещении даты и времени согласно ISO 8601. | № |
| скрыто | логическое | Является ли эта модель скрытой.Если установлено значение «истина», эта модель не предназначена для использования другими приложениями. | № |
| аннотации | Аннотация [] | Массив необязательных аннотаций модели — несущественные пары ключ / значение, которые содержат контекстную информацию, которая может использоваться для хранения дополнительного контекста | № |
| юридических лиц | Entity [] | Модель предприятия | Да |
| СсылкаМодели | ReferenceModel [] | Ссылки на другие подержанные / расширенные модели | № |
| отношения | Отношения [] | Отношения между сущностями в модели.Отношения могут быть от / к местным или ссылочным объектам. Когда отношение включает в себя эталонный объект, атрибуты должны быть разрешены из локального объекта в ссылочной модели | № |
Образец:
{
"Приложение": "MyApplication",
"Название": "OrdersProducts",
"description": "Модель, содержащая данные для заказа и продуктов.",
«Версия»: «1,0»,
"ModifiedTime": "2018-01-02T12: 00: 00 + 08: 00",
"Аннотация": [
],
"сущность": [
],
"referenceModels": [
]
}
Аннотации
Наименование: аннотации
Дополнительная необязательная контекстная информация (пары ключ / значение), которую можно использовать для хранения дополнительного контекста о свойстве в файле модели.Аннотации могут применяться на нескольких уровнях, включая объекты и атрибуты. Производители могут добавить префикс, такой как «pbi: MappingDisplayHint», где «pbi:» — это префикс, когда аннотации не обязательно относятся к другим потребителям.
| Недвижимость | Тип | Описание | Требуется? |
|---|---|---|---|
| имя | строка | Название аннотации | Да |
| значение | строка | Значение аннотации | № |
Образец:
{
"Аннотация": [
{
"Название": "MyApp: VersionNum",
"Значение": "3.0,1"
}
]
}
Эталонные модели
Название недвижимости: СсылкаМодели
Эталонные модели — это существующие файлы model.json с сущностями и файлами данных, на которые ссылается этот файл model.json. Это позволяет повторно использовать существующие метаданные и данные, не копируя их в эту папку Common Data Model.
| Недвижимость | Тип | Описание | Требуется? |
|---|---|---|---|
| id | строка | Идентификатор ссылочной модели, которая будет использоваться в этой модели.JSON файл. Это значение должно быть уникальным в этом файле модели и может использоваться как сокращение для свойства location. Конкретное значение зависит от исполнителя. | Да |
| место | URI | Местоположение модели, на которую ссылаются. URI должен включать версию / снимок модели, которой соответствует эта модель. (Когда эта модель обновляется, она должна соответственно обновить версию / снимок.) | Да |
Образец:
{
"referenceModels": [
{
"id": "f19bbb97-c031-441a-8bd1-61b9181c0b83",
"Место": "https: // contosostorageaccount.dfs.core.windows.net/contosoFilesystem/cdmFolder/model.json»
}
]
}
Сущности
Наименование объекта: объекта
Сущность — это совокупность атрибутов и метаданных, которые определяют концепцию (например, Учетная запись или Контакт) и могут быть определены любым производителем данных. Объект может соответствовать схеме стандартного объекта, определенного как часть общей модели данных и указанного в репозитории GitHub. Объекты, которые не соответствуют ни одной из стандартных форм, называются пользовательскими объектами.
В файле model.json вы можете указать локальные или ссылочные объекты. Локальный объект содержит сведения об объекте (например, атрибуты, схемы и разделы), определенные в файле model.json, и файлы данных должны находиться в той же папке Common Data Model. Ссылочная сущность — это указатель на сущность, определенную ссылочной моделью, в которой определены все метаданные и файлы данных.
В зависимости от типа объекта, вы можете найти различные поля:
| Недвижимость | местное юридическое лицо | Ссылочный объект |
|---|---|---|
| $ тип | R | R |
| имя | R | R |
| описание | O | O |
| аннотации | O | O |
| схемы | O | |
| атрибутов | R | |
| перегородки | O | |
| источник | R | |
| ModelId | R |
R — требуется, O — необязательно, (пусто) — не указано
Свойства уровня объекта
В обязательных столбцах «н / д» означает, что поле не должно существовать для этого типа объекта.
| Недвижимость | Тип | Описание | Требуется LocalEntity? | ReferencedEntity Требуется? |
|---|---|---|---|---|
| $ тип | Константа | Тип объекта, определяемого в этой модели. Этот атрибут должен быть установлен в «LocalEntity». | Да | Да |
| имя | Строка | Наименование объекта | Да | Да |
| описание | строка | Описание сущности | № | № |
| аннотации | Аннотация [] | Массив необязательных аннотаций модели — несущественные пары ключ / значение, которые содержат контекстную информацию, которая может использоваться для хранения дополнительного контекста | № | № |
| схемы | SchemaURI [] | Набор URI для определений схемы, которым соответствует объект. Разрешенный шаблон: https://raw.githubusercontent.com/Microsoft/CDM/master/schemaDocuments//..cdm.json Пример: https://raw.githubusercontent.com/Microsoft/CDM/master/schemaDocuments/ core / applicationCommon / Account.0.8.cdm.json | № | не указано |
| атрибутов | Атрибут [] | Атрибуты внутри объекта. У каждой сущности должен быть хотя бы один. | Да | не указано |
| перегородки | Раздел [] | Физические разделы объекта (файлы данных) | № | не указано |
| источник | Строка | Исходное (указанное) имя объекта | не указано | Да |
| ModelId | Строка | Исходный (ссылочный) идентификатор модели должен совпадать с идентификатором одной из эталонных моделей модели | не указано | Да |
Пример LocalEntity:
{
"сущность": [
{
"$ Типа": "LocalEntity",
«Название»: «Продукты»,
"description": "Информация о товарах и их ценовая информация.»,
"Аннотация": [
],
"Атрибуты": [
],
"перегородка": [
],
"схемы": [
"Https://raw.githubusercontent.com/Microsoft/CDM/master/schemaDocuments/core/applicationCommon/foundationCommon/Product.0.7.cdm.json"
]
}
]
}
ReferencedEntity sample:
{
"сущность": [
{
"$ Типа": "ReferenceEntity",
«Название»: «Продукты»,
"description": "Информация о товарах и их ценовая информация.»,
«Источник»: «Продукты»,
"ModelID": "f19bbb97-c031-441a-8bd1-61b9181c0b83",
"Аннотация": [
]
}
]
}
Атрибуты
Наименование объекта: атрибутов
Атрибуты — это поля внутри объекта, которые соответствуют значениям данных в файле данных. Например, объект «Контакт» может иметь такие атрибуты, как Имя и Фамилия.
| Недвижимость | Тип | Описание | Требуется? |
|---|---|---|---|
| имя | строка | имя атрибута | Да |
| описание | строка | описание атрибута | № |
| dataType | enum | Для этого атрибута должно быть установлено одно из следующих значений: строка, int64, double, dateTime, dateTimeOffset, десятичное, логическое, GUID или JSON.Если указана культура, ее следует использовать для анализа типа данных. Дополнительная информация | Да |
| аннотации | Аннотация [] | Массив необязательных аннотаций модели — несущественные пары ключ / значение, которые содержат контекстную информацию, которая может использоваться для хранения дополнительного контекста | № |
Образец:
{
"Атрибуты": [
{
"Название": "ProductID",
"description": "Уникальный идентификатор продукта.»,
"DATATYPE": "строка",
"Аннотация": [
]
}
]
}
Перегородки
Название недвижимости: перегородки
Массив разделов указывает имя и расположение фактических файлов данных, которые соответствуют определению объекта. Сегодня раздел содержит полный URI для местоположения файла данных, поэтому новые файлы данных необходимо вручную добавить в список разделов. В будущем мы ищем поддержку шаблонов файлов данных (например, групповых символов)
| Недвижимость | Тип | Описание | Требуется? |
|---|---|---|---|
| имя | строка | Название раздела | Да |
| описание | строка | Описание раздела | № |
| refreshTime | datetimeoffset | Самая последняя дата, когда данные раздела были обновлены в смещении даты по ISO 8601 | № |
| место | URI | Расположение физического файла раздела, включая сам файл.Если ноль, это определение сущности только для целей схемы. | № |
| fileFormatSettings | FileFormatSettings | Дополнительные параметры формата файла. | № |
Настройки формата файла
Наименование объекта: fileFormatSettings
Настройки формата файла предоставляют метаданные, относящиеся к файлам данных в разделе. В зависимости от типа, вы можете найти разные поля, но сегодня поддерживается только один тип.Кодировка файлов данных — UTF-8, но вы можете запросить другие кодировки, создав проблему в репозитории GitHub.
| Недвижимость | Тип | Описание | CsvFormatSetting Требуется? |
|---|---|---|---|
| $ тип | строка (enum) | Определяет тип настройки формата файла. На момент написания статьи поддерживается только «CsvFormatSettings». | Да |
| columnHeaders | логическое | Указывает, является ли.CSV-файл имеет заголовки. Этот атрибут должен быть установлен в «истина» или «ложь». Если не указано, это может быть интерпретировано как ложное. | № |
| разделитель | строка | Тип разделителя в файле .csv. Если не указано, это можно интерпретировать как «,» | № |
| кодировка | строка | Кодировка строки в файле .csv. Если не указано, это можно интерпретировать как «UTF-8» | № |
| quoteStyle | строка (enum) | CSV стиль цитаты.Этот атрибут должен быть установлен в «QuoteStyle.Csv» или «QuoteStyle.None». Если не указано, это можно интерпретировать как «QuoteStyle.Csv». | № |
| csvStyle | строка (enum) | Стиль CSV, значения: для этого атрибута должно быть указано «CsvStyle.QuoteAlways» или «CsvStyle.QuoteAfterDelimiter». По умолчанию установлено значение «CsvStyle.QuoteAlways» | .№ |
Отношения
Название недвижимости: отношения
Отношения описывают, как связаны сущности, такие как Учетная запись, у которой есть Контакт.На момент написания статьи поддерживаются только отношения, основанные на одном атрибуте в исходном и целевом объектах, но в будущем может поддерживаться больше типов.
| Недвижимость | Тип | Описание | SingleKeyRelationhip Требуется? |
|---|---|---|---|
| $ тип | строка (enum) | Определяет тип отношений. Поддерживается только «SingleKeyRelationship». | Да |
| из атрибута | ReferenceAttribute | Объект в исходном объекте (см. Ниже), который ссылается на атрибут в другом объекте, «toAttribute». | Да |
| к атрибуту | ReferenceAttribute | Объект в целевом объекте (см. Ниже), на который ссылается «fromAttribute». | Да |
ReferenceAttribute
| Недвижимость | Тип | Описание | Требуется? |
|---|---|---|---|
| имя_ сущности | строка | Имя объекта в локальной модели.Это имя должно существовать в списке объектов модели. | Да |
| attributeName | строка | Имя атрибута (для ссылочных объектов, которые должны быть разрешены из целевого объекта в ссылочной модели). | Да |
Образец:
{
"отношения": [
{
"$ Типа": "SingleKeyRelationship",
"FromAttribute": {
"EntityName": "Счет",
"ATTRIBUTENAME": "ContactId"
},
"ToAttribute": {
"EntityName": "Контакт",
"ATTRIBUTENAME": "Id"
}
}
]
}
форматы типов данных
Как правило, производители данных должны использовать форматы типов данных, не учитывающие культурные особенности, такие как ISO 8601 для смещений datetime / datetime.Однако, если производитель данных записывает данные в специфичных для культуры форматах, свойство «culture» должно быть задано в формате model.json, и потребители должны использовать это значение для правильного анализа данных в файлах разделов.
Не указано культура
Когда «культура» не указана в файле model.json, потребители могут принять следующие форматы данных:
| Тип данных | Формат | Описание |
|---|---|---|
| дата / время | 2018-01-02T12: 00: 00Z | UTC дата-время в ISO 8601 |
| datetimeoffset | 2018-01-02T12: 00: 00 + 08: 00 | Дата и время в ISO 8601 со смещением часового пояса. |
| десятичное | 1,0 | Десятичное число с «.» или точка в качестве десятичного разделителя. |
Атрибуты файла модели
Мы также предлагаем установить метаданные в качестве свойств файла непосредственно в model.json для эффективного обнаружения метаданных источника данных приложениями.
| Имя | Требуется | Описание |
|---|---|---|
| Имя приложения | № | Имя приложения, которое имеет значение для бизнес-пользователя и может отображаться в пользовательском интерфейсе. |
| Имя экземпляра приложения | № | Имя экземпляра для устранения неоднозначности, если необходимо; значение должно быть значимым для бизнес-пользователя. |
| Название модели | № | То же значение, что и у свойства «Name» внутри model.json. |
Обзор моделирования данных — LearnDataModeling.com
Стандартизация моделирования данных осуществляется на протяжении многих лет, и в следующем разделе освещаются потребности и внедрение стандартов моделирования данных.
Потребности в стандартизации | Данные моделирования:
Некоторые разработчики моделей данных могут работать в различных предметных областях модели данных, и все разработчики моделей данных должны использовать одно и то же соглашение об именах, определения написания и бизнес-правила.
В настоящее время бизнес-транзакции (B2B) довольно распространены, а стандартизация помогает лучше понять бизнес.Несоответствие между именами и определениями столбцов может привести к хаосу в бизнесе.
Например, когда проектируется хранилище данных, оно может получать данные из нескольких исходных систем, и каждый источник может иметь свои собственные имена, типы данных и т. Д. Эти аномалии могут быть устранены, если в организации поддерживается надлежащая стандартизация.
Столовые имена Стандартизация:
Если вы дадите полное имя таблицам, вы поймете, что это за данные. Как правило, не сокращайте имена таблиц; однако это может отличаться в зависимости от стандартов организации.Если длина имени таблицы превышает стандарты базы данных, попробуйте сократить имена таблиц. Ниже приведены некоторые общие рекомендации, которые могут использоваться в качестве префикса или суффикса для таблицы.
Примеры:
Lookup — LKP — Используется для кодов, таблиц типа, с помощью которых можно напрямую обращаться к таблице фактов. Например,
Поиск типа кредитной карты — CREDIT_CARD_TYPE_LKP
Факт — FCT — Используется для таблиц транзакций:
, например. Факт кредитной карты — CREDIT_CARD_FCT
Перекрестная ссылка — XREF — таблицы, которые разрешают множество отношений.Например,
Участник кредитной карты XREF — CREDIT_CARD_MEMBER_XREF
История — HIST — Таблицы истории магазинов. Например,
История удаления кредитной карты — CREDIT_CARD_RETIRED_HIST
Статистика — STAT — Таблицы, в которых хранится статистическая информация. Например,
Веб-статистика кредитных карт — CREDIT_CARD_WEB_STAT
Стандартизация имен столбцов:
Ниже перечислены некоторые общие рекомендации, которые могут использоваться в качестве префикса или суффикса для столбца.
Примеры:
Ключ — Ключ, сгенерированный системой суррогатного ключа. Например,
Ключ кредитной карты — CRDT_CARD_KEY
Идентификатор — ID — Символьный столбец, который используется в качестве идентификатора. Например,
Идентификатор кредитной карты — CRDT_CARD_ID
Код — CD — числовой или буквенно-цифровой столбец, который используется в качестве идентифицирующего атрибута. Например,
Государственный кодекс — ST_CD
Описание — DESC — Описание для кода, идентификатора или ключа.Например,
Описание состояния — ST_DESC
Индикатор — IND — для обозначения столбцов индикатора. Например,
Гендерный показатель — GNDR_IND
Стандартизация параметров базы данных:
Ниже перечислены некоторые общие рекомендации, которые могут использоваться для других физических параметров.
Примеры:
Index — Index — IDX — для имен индексов. Например,
Факт кредитной карты IDX01 — CRDT_CARD_FCT_IDX01
Первичный ключ — PK — для имен ограничений Первичного ключа.Например,
КРЕДИТ Факт карты PK01- CRDT-CARD_FCT_PK01
Альтернативные ключи — AK — для имен альтернативных ключей. Например,
Факт кредитной карты AK01 — CRDT_CARD_FCT_AK01
Внешние ключи — FK — для имен ограничений внешнего ключа. Например,
Факт кредитной карты FK01 — CRDT_CARD_FCT_FK01
Примечание:
Если вы присоединяетесь к компании в качестве разработчика моделей данных, сначала поговорите с администраторами баз данных или группой управления конфигурацией программного обеспечения, чтобы узнать стандарты.
,