MongoDB | Введение
Последнее обновление: 27.07.2022
MongoDB представляет наиболее популярную на данный момент документо-ориентированную систему управления базами данных. По разным оценкам входит в десяток самых используемых баз данных в мире.
На момент написания данного материала последней версией платформы была версия 6.0, которая увидела свет в июле 2022 года и которая будет использоваться далее в данном руководстве. Использование конкретной версии может несколько отличаться от применения иных версий платформы MongoDB. Но в целом отличия в построении запросов в mondogb между версиями минимальны, имеет место довольно большая совместимость предудщеих версий с последующими
Документы вместо строк
Если реляционные базы данных хранят строки, то MongoDB хранит документы. В отличие от строк документы могут хранить сложную по структуре информацию. Документ можно представить как хранилище ключей и значений.
Ключ представляет простую метку, с которым ассоциировано определенный кусок данных.
Однако при всех различиях есть одна особенность, которая сближает MongoDB и реляционные базы данных. В реляционных СУБД встречается такое понятие как первичный ключ. Это понятие описывает некий столбец, который имеет
уникальные значения. В MongoDB для каждого документа имеется уникальный идентификатор, который называется _id. И если явным образом не указать
его значение, то MongoDB автоматически сгенерирует для него значение.
Каждому ключу сопоставляется определенное значение. Но здесь также надо учитывать одну особенность: если в реляционных базах есть четко очерченная структура, где есть поля,
и если какое-то поле не имеет значение, ему (в зависимости от настроек конкретной бд) можно присвоить значение
Коллекции
Если в традиционном мире SQL есть таблицы, то в мире MongoDB есть коллекции. И если в реляционных БД таблицы хранят однотипные жестко структурированные
объекты, то в коллекции могут содержать самые разные объекты, имеющие различную структуру и различный набор свойств.
И если в реляционных БД таблицы хранят однотипные жестко структурированные
объекты, то в коллекции могут содержать самые разные объекты, имеющие различную структуру и различный набор свойств.
Репликация
Вся система MongoDB может представлять не только одну базу данных, которая располагается на одном физическом сервере. Функциональность MongoDB позволяет расположить несколько баз данных на нескольких физических серверах, и эти базы данных смогут легко обмениваться данными и сохранять целостность.
Система хранения данных в MongoDB представляет набор реплик. В этом наборе есть основной узел, а также может быть набор вторичных узлов. Все вторичные узлы сохраняют целостность и автоматически обновляются вместе с обновлением главного узла. И если основной узел по каким-то причинам выходит из строя, то один из вторичных узлов становится главным.
Формат данных в MongoDB
Одним из популярных стандартов обмена данными и их хранения является JSON (JavaScript Object Notation).
BSON позволяет работать с данными быстрее: быстрее выполняется поиск и обработка. Хотя надо отметить, что BSON в отличие от хранения данных в формате JSON имеет небольшой недостаток: в целом данные в JSON-формате занимают меньше места, чем в формате BSON, с другой стороны, данный недостаток с лихвой окупается скоростью.
Кроссплатформенность
MongoDB написана на C++, поэтому ее легко портировать на самые разные платформы. MongoDB может быть развернута на платформах Windows, Linux, MacOS, Solaris. Можно также загрузить исходный код и самому скомпилировать MongoDB, но рекомендуется использовать библиотеки с офсайта.
Простота в использовании
Отсутствие жесткой схемы базы данных и в связи с этим потребности при малейшем изменении концепции хранения данных пересоздавать эту схему
значительно облегчают работу с базами данных MongoDB и дальнейшим их масштабированием.
Но, даже учитывая все недостатки традиционных баз данных и достоинства MongoDB, важно понимать, что задачи бывают разные и методы их решения бывают разные. В какой-то ситуации MongoDB действительно улучшит производительность вашего приложения, например, если надо хранить сложные по структуре данные. В другой же ситуации лучше будет использовать традиционные реляционные базы данных. Кроме того, можно использовать смешенный подход: хранить один тип данных в MongoDB, а другой тип данных — в традиционных БД.
GridFS
В отличие от реляционных СУБД MongoDB позволяет сохранять различные документы с различным набором данных, однако при этом размер документа ограничивается 16 мб. Но MongoDB предлагает решение — специальную технологию GridFS, которая позволяет хранить данные по размеру больше, чем 16 мб.
Система GridFS состоит из двух коллекций. В первой коллекции, которая называется files, хранятся имена файлов, а также их метаданные, например, размер.
А в другой коллекции, которая называется chunks, в виде небольших сегментов хранятся данные файлов, обычно сегментами по 256 кб.
Для тестирования GridFS можно использовать специальную утилиту mongofiles, которая идет в пакете mongodb.
НазадСодержаниеВперед
Что такое MongoDB
Что такое MongoDB
MongoDB реализует новый подход к построению баз данных, где нет таблиц, схем, запросов SQL, внешних ключей и многих других вещей, которые присущи объектно-реляционным базам данных.
Со времен динозавров было обычным делом хранить все данные в реляционных базах данных (MS SQL, MySQL, Oracle, PostgresSQL). При этом было не столь важно, а подходят ли реляционные базы данных для хранения данного типа данных или нет.
В отличие от реляционных баз данных MongoDB предлагает документо-ориентированную модель данных, благодаря чему MongoDB работает быстрее, обладает лучшей масштабируемостью, ее легче использовать.
Но, даже учитывая все недостатки традиционных баз данных и достоинства MongoDB, важно понимать, что задачи бывают разные и методы их решения бывают разные. В какой-то ситуации MongoDB действительно улучшит производительность вашего приложения, например, если надо хранить сложные по структуре данные. В другой же ситуации лучше будет использовать традиционные реляционные базы данных. Кроме того, можно использовать смешенный подход: хранить один тип данных в MongoDB, а другой тип данных — в традиционных БД.
Вся система MongoDB может представлять не только одну базу данных, находящуюся на одном физическом сервере. Функциональность MongoDB позволяет расположить несколько баз данных на нескольких физических серверах, и эти базы данных смогут легко обмениваться данными и сохранять целостность.
Функциональность MongoDB позволяет расположить несколько баз данных на нескольких физических серверах, и эти базы данных смогут легко обмениваться данными и сохранять целостность.
Формат данных в MongoDB
Одним из популярных стандартов обмена данными и их хранения является JSON (JavaScript Object Notation). JSON эффективно описывает сложные по структуре данные. Способ хранения данных в MongoDB в этом плане похож на JSON, хотя формально JSON не используется. Для хранения в MongoDB применяется формат, который называется BSON (БиСон) или сокращение от binary JSON.
BSON позволяет работать с данными быстрее: быстрее выполняется поиск и обработка. Хотя надо отметить, что BSON в отличие от хранения данных в формате JSON имеет небольшой недостаток: в целом данные в JSON-формате занимают меньше места, чем в формате BSON, с другой стороны, данный недостаток с лихвой окупается скоростью.
Кроссплатформенность
MongoDB написана на C++, поэтому ее легко портировать на самые разные платформы. MongoDB может быть развернута на платформах Windows, Linux, MacOS, Solaris. Можно также загрузить исходный код и самому скомпилировать MongoDB, но рекомендуется использовать библиотеки с офсайта.
MongoDB может быть развернута на платформах Windows, Linux, MacOS, Solaris. Можно также загрузить исходный код и самому скомпилировать MongoDB, но рекомендуется использовать библиотеки с офсайта.
Документы вместо строк
Если реляционные базы данных хранят строки, то MongoDB хранит документы. В отличие от строк документы могут хранить сложную по структуре информацию. Документ можно представить как хранилище ключей и значений.
Ключ представляет простую метку, с которым ассоциировано определенный кусок данных.
Однако при всех различиях есть одна особенность, которая сближает MongoDB и реляционные базы данных. В реляционных СУБД встречается такое понятие как первичный ключ. Это понятие описывает некий столбец, который имеет уникальные значения. В MongoDB для каждого документа имеется уникальный идентификатор, который называется _id. И если явным образом не указать его значение, то MongoDB автоматически сгенерирует для него значение.
Каждому ключу сопоставляется определенное значение. Но здесь также надо учитывать одну особенность: если в реляционных базах есть четко очерченная структура, где есть поля, и если какое-то поле не имеет значение, ему (в зависимости от настроек конкретной бд) можно присвоить значение NULL. В MongoDB все иначе. Если какому-то ключу не сопоставлено значение, то этот ключ просто опускается в документе и не употребляется.
Коллекции
Если в традиционном мире SQL есть таблицы, то в мире MongoDB есть коллекции. И если в реляционных БД таблицы хранят однотипные жестко структурированные объекты, то в коллекции могут содержать самые разные объекты, имеющие различную структуру и различный набор свойств.
Репликация
Система хранения данных в MongoDB представляет набор реплик. В этом наборе есть основной узел, а также может быть набор вторичных узлов. Все вторичные узлы сохраняют целостность и автоматически обновляются вместе с обновлением главного узла. И если основной узел по каким-то причинам выходит из строя, то один из вторичных узлов становится главным.
И если основной узел по каким-то причинам выходит из строя, то один из вторичных узлов становится главным.
Простота в использовании
Отсутствие жесткой схемы базы данных и в связи с этим потребности при малейшем изменении концепции хранения данных пересоздавать эту схему значительно облегчают работу с базами данных MongoDB и дальнейшим их масштабированием. Кроме того, экономится время разработчиков. Им больше не надо думать о пересоздании базы данных и тратить время на построение сложных запросов.
GridFS
Одной из проблем при работе с любыми системами баз данных является сохранение данных большого размера. Можно сохранять данные в файлах, используя различные языки программирования. Некоторые СУБД предлагают специальные типы данных для хранения бинарных данных в БД (например, BLOB в MySQL).
В отличие от реляционных СУБД MongoDB позволяет сохранять различные документы с различным набором данных, однако при этом размер документа ограничивается 16 мб. Но MongoDB предлагает решение — специальную технологию GridFS, которая позволяет хранить данные по размеру больше, чем 16 мб.
Но MongoDB предлагает решение — специальную технологию GridFS, которая позволяет хранить данные по размеру больше, чем 16 мб.
Система GridFS состоит из двух коллекций. В первой коллекции, которая называется files, хранятся имена файлов, а также их метаданные, например, размер. А в другой коллекции, которая называется chunks, в виде небольших сегментов хранятся данные файлов, обычно сегментами по 256 кб.
Для тестирования GridFS можно использовать специальную утилиту mongofiles, которая идет в пакете mongodb.
У вас нет прав для комментирования.
MySQL и MongoDB — когда и что лучше использовать / Хабр
Петр Зайцев показывает разницу между MySQL и MongoDB. Это — расшифровка доклада с Highload++ 2016.
Если посмотреть такой известный DB-Engines Ranking, то можно увидеть, что в течении многих лет популярность open source баз данных растет, а коммерческих — постепенно снижается.
Что еще более интересно: если посмотреть на вот это отношение для разных типов баз данных, то видно, что для многих типов — таких, как колунарные базы данных, time series, document stories — open source базы данных наиболее популярны. Только для более старых технологий, таких как реляционные базы данных, или еще более древних, как multivalue база данных, коммерческие лицензии значительно популярнее.
Мы видим, что для многих приложений используют несколько баз данных для того, чтобы задействовать их сильные стороны. Ни одна база данных не оптимизирована для всех всевозможных юзкейсов. Даже если это PostgreSQL [смех на сцене и в зале].
С одной стороны, это хороший выбор, с другой — нужно пытаться найти баланс, так как чем у нас больше разных технологий, тем сложнее их поддерживать, особенно, если компания не очень большая.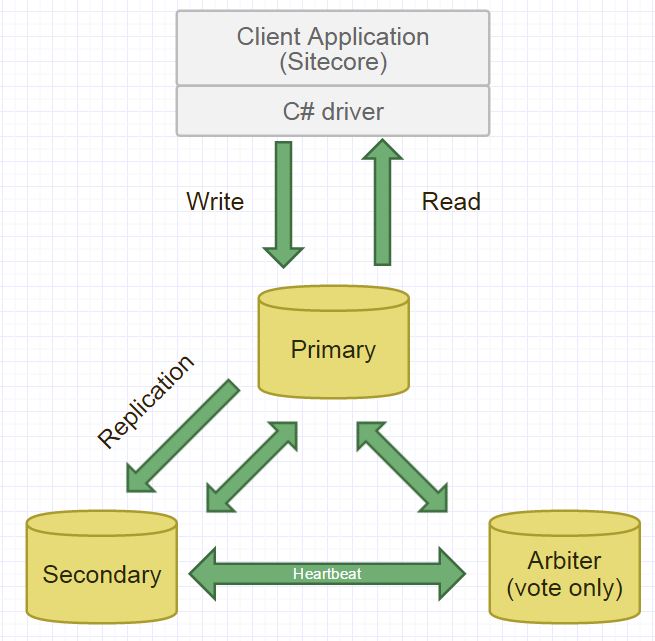
Часто что видим, что люди приходят на такие конференции, слушают Facebook или «Яндекс» и говорят: «Ух ты! Сколько вот люди делают интересного. У них технологий разных используется штук 20, и еще штук 10 они написали сами». А потом они тот же самый подход пытаются использовать в своем стартапе из 10 человек, что работает, разумеется, не очень хорошо. Это как раз тот случай, где размер имеет значение.
Очень часто мы видим, что используется основное операционное хранилище и какие-то дополнительные сервисы. Например, для кэширования или полнотекстового поиска.
Другой подход к архитектуре с использованием разных баз данных — это микросервисы, у каждого из которых может быть своя база данных, которая лучше оптимизирована для задач именно этого сервиса. Как пример: основное хранилище может быть на MySQL, Redis и Memcache — для кэширования, Elastic Search или родной Sphinx — для поиска. И что-то вроде Kafka — чтобы передавать данные в систему аналитики, которая часто делалась на чём-то вроде Hadoop.
Если мы говорим про основное операционное хранилище, наверное, у нас есть два выбора. С одной стороны, мы можем выбрать реляционные базы данных, с языком SQL. С другой стороны — что-то нереляционное, а дальше уже смотреть на подвиды, которые доступы в данном случае.
Если говорить про NoSQL-модели данных, то их тоже достаточно много. Наиболее типичные — это либо key value, либо document, либо wide column базы данных. Примеры: Memcache, MongoDB, Cassandra, соответственно.
Почему в данном случае мы сравниваем именно MySQL и MongoDB? На самом деле причин несколько. Если посмотреть на Ranking баз данных, то мы видим, что MySQL, согласно этому рейтингу, — наиболее популярная реляционная база данных, а MongoDB — наиболее популярная нереляционная база данных. Поэтому их разумно сравнивать.
А ещё у меня есть наибольший опыт в использовании этих двух баз данных. Мы в Percona занимаемся плотно именно с ними, работаем с многими клиентами, помогаем им сделать такой выбор. Еще одна причина: обе технологии изначально ориентированы на разработчиков простых приложений. Для тех людей, для которых PostgreSQL — это слишком сложно.
Для тех людей, для которых PostgreSQL — это слишком сложно.
Компания MongoDB изначально очень активно фокусировалась на пользователях MySQL. Поэтому очень часто у людей есть опыт использования и выбор между этими двумя технологиями.
В Percona кроме того, что мы занимаемся поддержкой, консалтингом для этих технологий, у нас есть достаточно много написанного open source софта для обеих технологий. На слайде можно посмотреть. Подробно я рассказывать об этом не буду.
Что следует обо мне лично: я занимаюсь MySQL значительно больше, чем MongoDB. Несмотря на то, что я постараюсь предоставить сбалансированный обзор с моей стороны, у меня могут быть какие-то предрасположенности к MySQL, так как его тараканы я знаю лучше.
Вот список разных вопросов, которые на мой взгляд имеет смысл рассматривать. Сейчас из них рассмотрим каждый более детально.
Что наиболее важно на мой взгляд — это учитывать, какие есть опыт и предпочтения команды. Для многих задач подходят оба решения. Их можно сделать и так, и так, может быть несколько сложнее, может быть несколько проще. Но если у вас команда, которая долго работала с SQL-базами данных и понимает реляционную алгебру и прочее, может быть сложно перетягивать и заставлять их использовать нереляционные базы данных, такие как MongoDB, где нет даже полноценной транзакции.
Их можно сделать и так, и так, может быть несколько сложнее, может быть несколько проще. Но если у вас команда, которая долго работала с SQL-базами данных и понимает реляционную алгебру и прочее, может быть сложно перетягивать и заставлять их использовать нереляционные базы данных, такие как MongoDB, где нет даже полноценной транзакции.
И наоборот: если есть какая-то команда, которая использует и хорошо знает MongoDB, SQL-язык может быть для неё сложен. Также имеет смысл рассматривать как оригинальную разработку, так и дальнейшее сопровождение и администрирование, поскольку всё это в итоге важно в цикле приложения.
Какие есть преимущества у данных систем?
Если говорить про MySQL — это проверенная технология. Понятно, что MySQL используется крупными компаниями более 15 лет. Так как он использует стандарт SQL, есть возможность достаточно простой миграции на другие SQL-базы данных, если захочется. Есть возможность транзакций. Поддерживаются сложные запросы, включая аналитику. И так далее.
И так далее.
С точки зрения MongoDB, здесь преимущество то, что у нас гибкий JSON-формат документов. Для некоторых задач и каким-то разработчикам это удобнее, чем мучиться с добавлением колонок в SQL-базах данных. Не нужно учить SQL — для некоторых это сложно. Простые запросы реже создают проблемы. Если посмотреть на проблемы производительности, в основном они возникают, когда люди пишут сложные запросы с JOIN в кучу таблиц и GROUP BY. Если такой функциональности в системе нет, то создать сложный запрос получается сложнее.
В MongoDB встроена достаточно простая масштабируемость с использованием технологии шардинга. Сложные запросы если возникают, мы их обычно решаем на стороне приложения. То есть, если нам нужно сделать что-то вроде JOIN, мы можем сходить выбрать данные, потом сходить выбрать данные по ссылкам и затем их обработать на стороне приложения. Для людей, которые знают язык SQL, это выглядит как-то убого и ненатурально. Но на самом деле для многих разработка application-серверов такое куда проще, чем разбираться с JOIN.
Если говорить про приложения, где используется MongoDB, и на чём они фокусируются — это очень быстрая разработка. Потому что всё можно постоянно менять, не нужно постоянно заботиться о строгом формате документа.
Второй момент — это схема данных. Здесь нужно понимать, что у данных всегда есть схема, вопрос лишь в том, где она реализуется. Вы можете реализовывать схему данных у себя в приложении, потому что каким-то же образом вы эти данные используете. Либо эта схема реализуется на уровне базы данных.
Очень часто если у вас есть какое-то приложение, с данными в базе данных работает только это приложение. Например, мы сохраняем данные из этого приложения в эту базу данных. Схема на уровне приложения работает хорошо. Если у нас одни и те же данные используются многими приложениями, то это очень неудобно, сложно контролировать.
Здесь возникает также вопрос времени жизни приложения. С MongoDB хорошо делать приложения, у которых очень ограниченный цикл жизни. То есть если мы делаем приложение, которое живёт недолго, например, сайт для запуска фильма или олимпиады. Мы пожили несколько месяцев после этого, и это приложение практически не используется. Если приложение живёт дольше, то тут уже другой вопрос.
То есть если мы делаем приложение, которое живёт недолго, например, сайт для запуска фильма или олимпиады. Мы пожили несколько месяцев после этого, и это приложение практически не используется. Если приложение живёт дольше, то тут уже другой вопрос.
Если говорить про распределение преимуществ и недостатков MySQL и MongoDB с точки зрения цикла разработки приложения, то их можно представить так:
Модель данных очень сильно зависит от приложения и опыта команды. Было бы странным сказать, что у нас реляционный или нереляционный подход к базам данных лучше и лучше всегда.
Если сравнивать их между собой, то понятно, что у нас есть. В MySQL — реляционная база данных. Мы можем с помощью реляционной базы данных легко отображать связи между таблицами. Нормализуя данные, мы можем заставлять изменения данных происходить атомарно в одном месте. Когда данные у нас денормализованы, нам не нужно при каких-то изменениях бежать и модифицировать кучу документов.
Хорошо это или плохо? Результат — всегда таблица.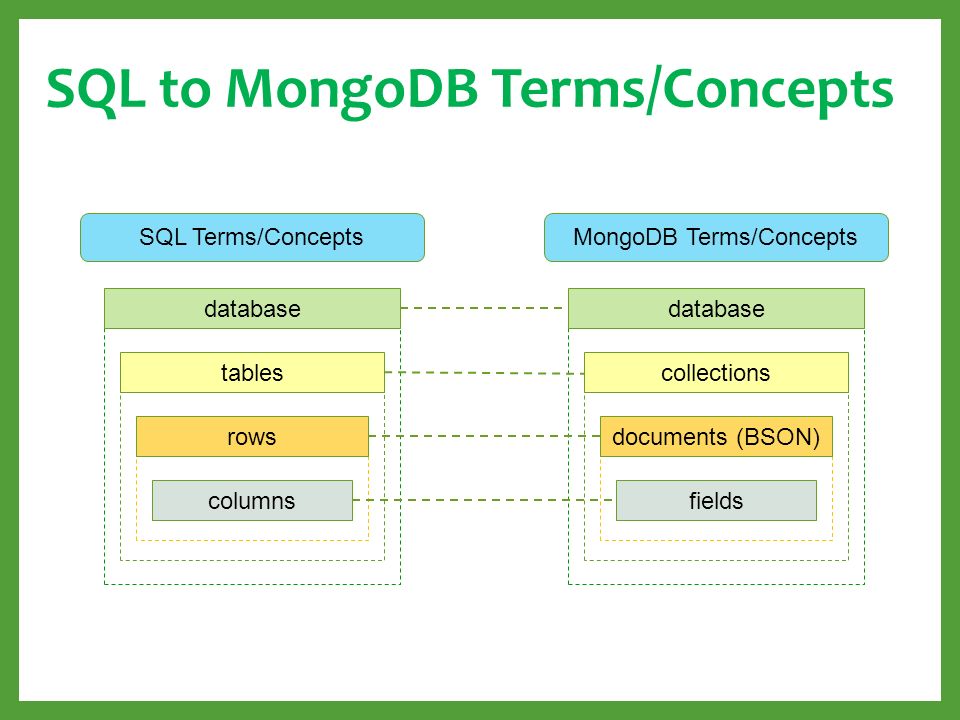 С одной стороны, это просто, с другой — некоторые структуры данных не всегда хорошо ложатся на таблицу, нам может быть неудобно с этим работать.
С одной стороны, это просто, с другой — некоторые структуры данных не всегда хорошо ложатся на таблицу, нам может быть неудобно с этим работать.
Это всё в теории. Если говорить о практическом использовании MySQL, мы знаем, что часто денормализуем данные, иногда для некоторых приложений мы используем что-то подобное: храним JSON, XML или другую структуру в колонках приложения.
У MongoDB структура данных основана на документах. Данные многих веб-приложений отображать очень просто. Потому что если храним структуру — что-то вроде ассоциированного массива приложения, то это очень просто и понятно для разработчика сериализуется в JSON-документ. Раскладывать такое в реляционной базе данных по разным табличкам — задача более нетривиальная.
Результаты как список документов, у которых может быть совершенно разная структура — более гибкое решение.
Пример. Мы хотим сохранить контакт-лист с телефона. Понятно, что есть данные, которые хорошо кладутся в одну реляционную табличку: Фамилия, Имя и т. д. Но если посмотреть на телефоны или email-адреса, то у одного человека их может быть несколько. Если подобное хранить в хорошем реляционном виде, то нам неплохо бы это хранить в отдельных таблицах, потом это всё собирать
д. Но если посмотреть на телефоны или email-адреса, то у одного человека их может быть несколько. Если подобное хранить в хорошем реляционном виде, то нам неплохо бы это хранить в отдельных таблицах, потом это всё собирать JOIN, что менее удобно, чем хранить это всё в одной коллекции, где находятся иерархические документы.
Следует сказать, что это всё в строго реляционной теории — некоторые базы данных поддерживают массивы. В MySQL поддерживается формат JSON, в который можно засунуть такие вещи, как несколько email-адресов. Или многие годы люди серилизовали это ручками: надо нам сохранить несколько email-адресов, то давайте запишем их через запятую, и дальше приложение разберётся. Но как-то это не очень кошерно.
Интересно, что между MySQL и MongoDB — вообще, между реляционными и нереляционными СУБД — что-то совпадает, что-то различается. Например, в обоих случаях мы говорим о базах данных, но то, что мы называем таблицей в реляционной базе данных, часто в нереляционной называется коллекцией.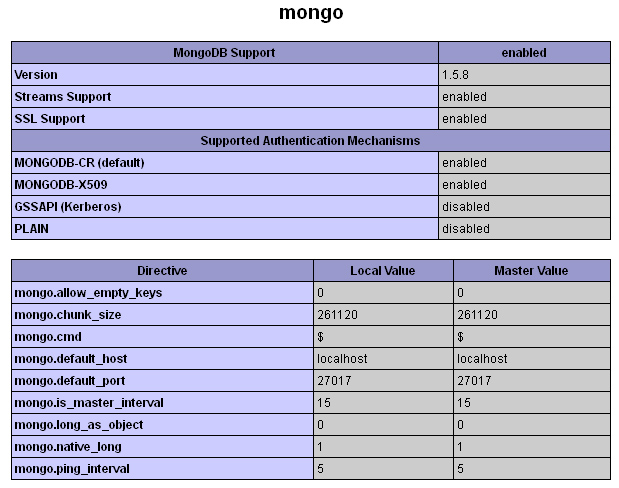 То, что в MySQL — колонка, в MongoDB — поле. И так далее.
То, что в MySQL — колонка, в MongoDB — поле. И так далее.
С точки зрения использования JOIN, в MongoDB нет такого понятия — это вообще понятие из реляционной структуры. Там мы либо делаем встроенный документ, что близко к концепту денормализации, либо мы просто сохраняем идентификатор документа в каком-то поле, называем это ссылкой и дальше ручками выбираем данные, которые нам нужны.
Что касается доступа: там, где мы к реляционным данным используем язык SQL, в MongoDB и многих других NoSQL-базах данных используется такой стандарт, как CRUD. Этот стандарт говорит, что есть операции для создания, чтения, удаления и обновления документов.
Несколько примеров.
Как у нас могут выглядеть наиболее типичные задачи по работе с документами в MySQL и MongoDB:
Вот пример вставки.
Пример обновления.
Пример удаления.
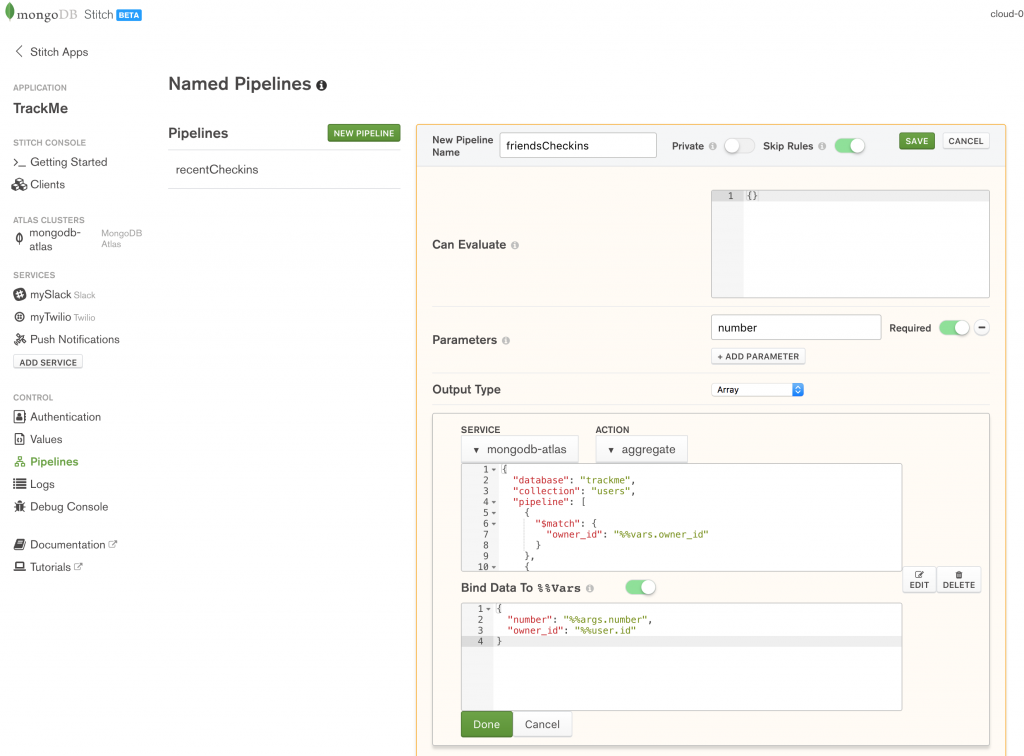
Если вы разработчик, который знаком с языком JavaScript, то такой синтаксис, который предоставляет CRUD (MongoDB), для вас будет более естественным, чем синтаксис SQL.![]()
На мой взгляд, когда у нас есть простейшие операции: поиск, вставка, они все работают достаточно хорошо. Когда речь идёт о более интересных операциях выборки, на мой взгляд, язык SQL куда более читаемый.
> вместо простого знака «>». Не очень читаемо, на мой взгляд.
Достаточно легко с помощью интерфейса делать такие вещи, как подсчёт числа строк в таблице или коллекции.
Но если мы делаем более сложные вещи, например, GROUP BY, в MongoDB для этого требуется использовать Aggregation Framework. Это несколько более сложный интерфейс, который показывает, как мы хотим отфильтровать, как мы хотим группировать и т.д. Aggregation Framework уже поддерживает что-то вроде операций JOIN.
Следующий момент — это транзакции и консистентность (ACID). Если пойти и почитать документацию MongoDB, там будет: «Мы поддерживаем ACID-транзакции, но с ограничением». На мой взгляд, стоит сказать: «ACID мы не поддерживаем, но поддерживаем другие минимальные нетранзакционные гарантии».
Какая у нас между ними разница?
Если говорить про MySQL, он поддерживает ACID-транзакции произвольного размера. У нас есть атомарность этих транзакций, у нас есть мультиверсионность, можно выбирать уровень изоляции транзакций, который может начинаться с READ UNCOMMITED и заканчиваться SERIALIZABLE. На уровне узла и репликаций мы можем конфигурировать, как данные хранятся.
Мы можем сконфигурировать у InnoDB, как работать с лог-файлом: сохранять его на диск при коммите транзакции или же делать это периодически. Мы можем сконфигурировать репликацию, включить, например, Semisynchronous Replication, когда у нас данные будут считаться сохранёнными только тогда, когда их копия будет принята на одном из slave’ов.
MongoDB не поддерживает транзакции, но он поддерживает атомарные операции над документом. Это значит, что с точки зрения одного документа операция у нас будет атомарна. Если у нас операция изменяет несколько документов, и во время этой операции произойдет какой-то сбой внутри, то какие-то из этих документов могут быть изменены, а какие-то — не изменены.
Консистентность тоже делается на уровне документов. В кластере мы можем выбирать гибкую консистентность. Мы можем указать, какие мы хотим гарантии — гарантии, что у нас данные были записаны только на один узел, или они были реплицированы на все узлы кластеров. Чтение консистентности тоже происходит на уровне документа.
Есть такой вариант обновления isolated, который позволяет выполнить обновление изолированно от других транзакций, но он очень неэффективен — он переключает базы данных в монопольный режим доступа, поэтому он используется достаточно редко. На мой взгляд, если говорить про транзакции и консистентность, то MongoDB достаточна убогая.
Производительность очень сложно сравнивать напрямую, потому что мы часто делаем разные схемы баз данных, дизайн приложения. Но если говорить в целом, MongoDB изначально была сделана, чтобы хорошо масштабироваться на много узлов через шардинг, поэтому эффективности было уделено меньше внимания.
Это результаты бенчмарка, который делал Марк Каллаган. Здесь видно, что с точки зрения использования процессора, ввода/вывода MySQL — как InnoDB, так и MyRocks — использует значительно меньше процессора и дискового ввода/вывода на операции бенчмарка Linkbench от Facebook.
Масштабируемость.
Что такое масштабируемость в данном контексте? То, насколько легко нам взять наше маленькое приложение и масштабировать его на многие миллионы, может быть, даже на миллиарды пользователей.
Масштабируемость бывает разная. Она бывает средняя, в рамках одной машины, когда мы хотим поддерживать приложения среднего размера, либо масштабируемость на кластере, когда у нас приложения уже очень большие, когда понятно, что даже одна самая мощная машина не справится.
Также имеет смысл говорить о том, масштабируем ли мы чтение, запись или объем данных. В разных приложениях их приоритеты могут различаться, но в целом, если приложение очень большое, обычно им приходится работать со всеми из этих вещей.
В MySQL в новых версиях весьма хорошая масштабируемость в рамках одного узла для LTP-нагрузок. Если у нас маленькие транзакции, есть какое-нибудь железо, в котором 64 процессора, то масштабируется достаточно хорошо. Аналитика или сложные запросы масштабируются плохо, потому что MySQL может использовать для одного запроса только один поток, что плохо.
Традиционно чтение в MySQL масштабируется с репликацией, запись и размер данных — через шардинг. Если смотреть на все большие компании — Facebook, Twitter — они все используют шардинг. Традиционно шардинг в MySQL используется вручную. Есть некоторые фреймворки для этого. Например, Vitess — это фреймворк, который Google использует для scaling сервиса YouTube, они его выпустили в open source. До этого был framework Jetpants. Стандартного решения для шардинга MySQL не предлагает, часто переход на шардинг требует внимания от разработчиков.
В MongoDB фокус изначально был в масштабируемости на многих узлах. Даже в случаях с маленьким приложением многим рекомендуется использовать шардинг с самого начала. Может, всего пару replica set, потом вы будете расти вместе со своим приложением.
Может, всего пару replica set, потом вы будете расти вместе со своим приложением.
В шардинге MongoDB есть некоторые ограничения: не все операторы с ним работают, например, есть isolated-вариант для обеспечения консистентности. Она не работает если использовать шардинг. Но при этом многие основные операции хорошо работают в шардингом, поэтому людям позволяется scale’ить приложения значительно лучше. На мой взгляд, шардинг и вообще репликация в MongoDB сделаны куда лучше, чем MySQL, значительно проще в использовании для пользователя.
Администрирование – это все те вещи, о которых не думают разработчики. По крайней мере в первую очередь. Администрирование — это то, что нам приложение придётся бэкапить, обновлять версии, мониторить, восстановливать при сбоях и так далее.
MySQL достаточно гибок, у него есть много разных подходов. Есть хорошие open source реализации всего, но это множество вариантов порождает сложность. Я часто общаюсь с пользователями, которые только начинают изучать MySQL.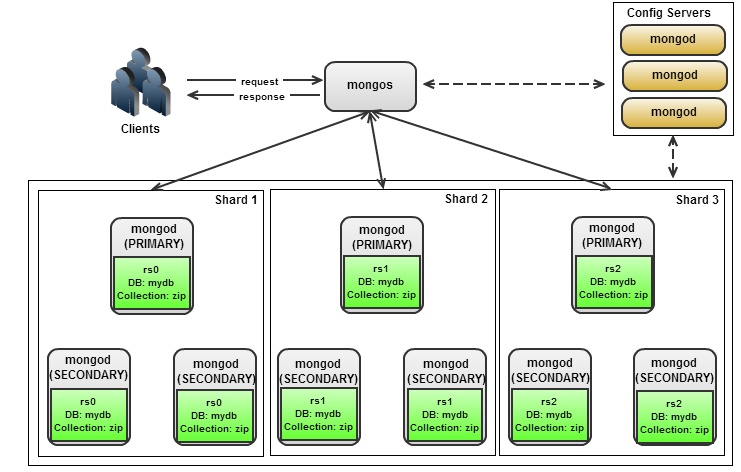 Они говорят: «Ёлки-палки, сколько же у вас всего вариантов. Вот только репликация — какую мне использовать: statement-репликацию, raw-репликацию, или mix? А еще есть gtid и стандартная репликация. Почему нельзя сказать „просто работай“?»
Они говорят: «Ёлки-палки, сколько же у вас всего вариантов. Вот только репликация — какую мне использовать: statement-репликацию, raw-репликацию, или mix? А еще есть gtid и стандартная репликация. Почему нельзя сказать „просто работай“?»
В MongoDB всё больше ориентированно на то, что оно работает каким-то одним стандартным образом — есть минимизация администрирования. Но понятно, что это происходит при потере гибкости. Коммьюнити open source решений для MongoDB значительно меньше. Многие вещи в MongoDB с точки зрения рекомендаций достаточно жестко привязаны к Ops Manager — коммерческой разработке MongoDB.
Как в MongoDB, так и в MySQL есть мифы, которые были в прошлом, которые были исправлены, но у людей хорошая память, особенно если что-то не работает. Помню, в MySQL после того как появились транзакции с InnoDB, люди мне лет десять говорили: «А в MySQL нет же транзакций?»
В MongoDB было много разных проблем с производительностью MMAP storage engine: гигантские блокировки, неэффективное использование дискового пространства. Сейчас в стандартном движке WiredTiger уже нет многих из этих проблем. Есть другие проблемы, но не эти.
Сейчас в стандартном движке WiredTiger уже нет многих из этих проблем. Есть другие проблемы, но не эти.
«Нет контроля схемы» — ещё такой миф. В новых версиях MongoDB можно для каждой коллекции определить на JSON структуру, где данные будут валидироваться. Данные, которые мы пытаемся вставить, и они не соответствуют какому-то формату, можно выкидывать.
«Нет аналога JOIN» — то же самое. В MongoDB это появилось, но нескольких ограниченных вещах. Только на уровне одного шарда и только если мы используем Aggregation Framework, а не в стандартных запросах.
Какие у нас есть мифы в MySQL? Здесь я буду говорить больше о поддержке NoMySQL решений в MySQL, об этом я буду говорить завтра. Следует сказать, что MySQL сейчас тоже можно использовать через интерфейс CRUD’a, использовать в NoSQL режиме примерно как MongoDB.
Типичный пример, где используется MySQL-решение — это сайт электронной коммерции. Когда у нас идёт вопрос о деньгах, часто мы хотим полноценные транзакции и консистентность. Для таких вещей хорошо подходит реляционная структура, которая была проработана, и commerce на реляционных базах данных уже делается многие десятилетия. Так что можно взять один из готовых подходов к структуре данных и использовать его.
Для таких вещей хорошо подходит реляционная структура, которая была проработана, и commerce на реляционных базах данных уже делается многие десятилетия. Так что можно взять один из готовых подходов к структуре данных и использовать его.
Обычно с точки зрения e-commerce объем данных у нас не такой большой, так что даже достаточно большие магазины могут долго работать без шардинга. Приложения у нас постоянно разрабатываются и усовершенствуется на протяжении многих лет. И у этого приложения много компонент, которые работают с одними и теми же данными: кто-то рассчитывает, где цены поменять, кто-то ещё что-то делает.
MongoDB часто задействуется как бэкенд больших онлайн-игр. Electronic Arts для очень многих игр использует MongoDB. Почему? Потому что масштабируемость важна. Если какая-то игра хорошо выстрелит, её приходится масштабировать значительно больше, чем предполагалось.
С другой стороны, если не выстрелит, нам хотелось бы, чтобы инфраструктуру можно было бы уменьшить. Во многих играх это идет так: мы запустили игру, у нее есть какой-то пик, приходится делать большой кластер. Потом игра уже выходит из популярности, для неё бэкенд нужно сжимать, сохранять и использовать. В данном случае есть одно приложение (игра), база данных, с одной стороны, несложная, с другой — сильно привязанная к приложению, в котором хранятся все важные для игры параметры.
Во многих играх это идет так: мы запустили игру, у нее есть какой-то пик, приходится делать большой кластер. Потом игра уже выходит из популярности, для неё бэкенд нужно сжимать, сохранять и использовать. В данном случае есть одно приложение (игра), база данных, с одной стороны, несложная, с другой — сильно привязанная к приложению, в котором хранятся все важные для игры параметры.
Часто консистентность базы данных на уровне объектов здесь достаточна, потому что многие вопросы консистентости решаются на уровне приложения. Например, данные одного игрока сохраняет только один application service.
Всем рекомендую это старое, древнее, но очень смешное видео http://www.mongodb-is-web-scale.com/ [YouTube]. На этом мы закончим.
MySQL и MongoDB — когда что лучше использовать?
Обзор СУБД MongoDB и сфер ее применения – Market.CNews
|
Поделиться
Безопасность Бизнес Телеком Интернет Цифровизация ИТ в банках ИТ в госсекторе Ритейл Техника Маркет
MongoDB — яркий пример грамотной реализации NoSQL-системы управления базами данных. Программное обеспечение распространяется в соответствии с лицензией SSPL — это несвободная «Source Available» лицензия со значительными ограничениями.
Программное обеспечение распространяется в соответствии с лицензией SSPL — это несвободная «Source Available» лицензия со значительными ограничениями.
В частности, в ее требованиях содержится ограничение на использование MongoDB в качестве DBaaS, если остальная инфраструктура не соответствует SSPL. В этом случае необходимо использовать коммерческую версию, которая отличается дополнительными возможностями: расширенными штатными интеграциями и набором инструментов, бэкапами, а также технической поддержкой.
Лицензия SSPL — предмет серьезных споров. Open Source Initiative не признает ее в качестве свободной лицензии из-за значительных несоответствий набору правил, определяющих программное обеспечение с открытым исходным кодом. Если вы собираетесь бесплатно использовать MongoDB, то в первую очередь необходимо изучить все тонкости условий, на которых вы сможете это сделать.
Программное обеспечение распространяется в соответствии с лицензией SSPL — это несвободная «Source Available» лицензия со значительными ограничениямиНа данный момент существует несколько изданий:
- MongoDB Community Edition — бесплатное издание, доступное для основных операционных систем: macOS, Windows и Linux.

- MongoDB Enterprise Server — коммерческое издание, требующее оплаченную подписку MongoDB Enterprise Advanced.
- MongoDB Atlas — облачный сервис, оказывающий услуги по управлению базами данных: для хранения задействуются сервера таких гигантов, как AWS, Azure, Google Cloud.
В случае с MongoDB Atlas можно выбрать как платные, так и бесплатные варианты использования. Они неравнозначные: бесплатные возможности урезаны как по объему хранилища, так и по доступным инструментам.
Краткая история
Компания-разработчик зарегистрировалась еще в далеком 2007 г., но первый выпуск СУБД появился только в 2009 г. — в этом же году компания стала использовать модель разработки с открытым исходным кодом, оказывая дополнительные коммерческие услуги: техподдержку, резервное копирование и прикладные инструменты для работы с данными.
Изначально компания называлась 10gen, но в 2013 г. выбрала в качестве названия MongoDB Inc — это было сделано с целью подчеркнуть основное направление развития. Штаб-квартиры компании расположены в Нью-Йорке (США) и Дублине. В 2019 г. MongoDB заключила договор с Alibaba Cloud (Aliyun) и теперь она предлагает СУБД своим клиентам в качестве услуги.
Штаб-квартиры компании расположены в Нью-Йорке (США) и Дублине. В 2019 г. MongoDB заключила договор с Alibaba Cloud (Aliyun) и теперь она предлагает СУБД своим клиентам в качестве услуги.
В начале марта этого года разработчикам из России и Беларуси пришло уведомление от компании. В нем содержалось предупреждение о том, что все их данные, хранимые на MongoDB Atlas, будут удалены без возможности восстановления.
Техническая сторона
Система написана на языке C++, что подразумевает кроссплатформенность, а в качестве драйверов для программирования доступны Java, PHP, Python, Perl, C# и другие. Помимо этого, существует и неофициальная поддержка различных языков и фреймворков.
Это документоориентированная система управления базами данных, обеспечивающая высокую производительность и простоту масштабирования. В отличие от традиционных способов построения баз, тут не применяются таблицы, внешние ключи, запросы SQL. Вместо этого для хранения данных используются документы JavaScript Object Notation (JSON) и Binary JavaScript Object Notation (BSON).
Документы позволяют хранить бинарные данные — музыку, изображения, но для файлов размером свыше 1 Mb лучше использовать GridFS. Это спецификация MongoDB, которая предназначена для работы с большими файлами — видео, аудио, картинками — позволяющая хранить файлы, размером свыше 16 Mb. Достигается это за счет разделения файла на части по 255 Kb, информация о которых записывается в fs.files и fs.chunks. Такой метод позволяет обеспечить высокую скорость работы и широкие возможности.
К особенностям этой системы можно отнести:
- поддержка ad-hoc-запросов — функционал, позволяющий возвращать определенные поля документа, а также пользовательские функции;
- поиск по регулярным выражениям;
- поддержка индексов по вложенным документам и массивам, включая геопространственные;
- в запросах и функциях агрегации поддерживается JavaScript;
- поддержка атомарных операций, записи без подтверждения, compare-and-swap и других.
Отказ от привычных для реляционных баз практик позволил разработчикам добиться высокой скорости работы и хорошей производительности, сохранив при этом отказоустойчивость и надежность хранения данных.
Безопасность и производительность
Если рассматривать использование системы с точки зрения безопасности, то MongoDB может обеспечить транзакции, соответствующие требованиям ACID — эти требования определяют наиболее надежное и предсказуемое поведение работы СУБД в неопределенных условиях и при возникновении ошибок.
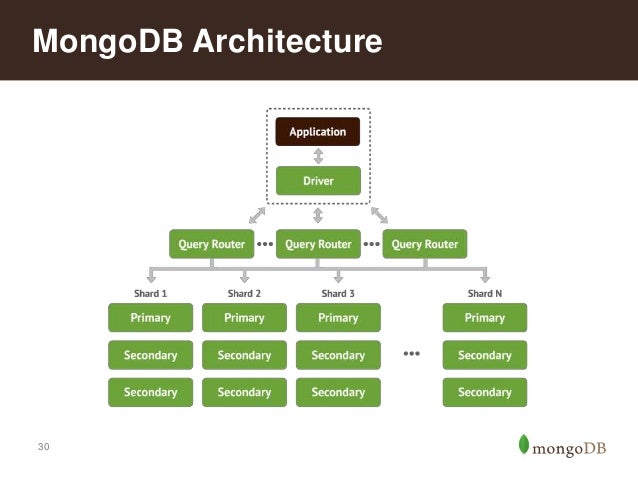
Отказоустойчивость обеспечивают журналирование и репликация: поддерживается два вида репликации — наборы реплик и технология «master/slave» — сами разработчики советуют использовать именно наборы реплик, если у проекта нет жесткой привязки к выбору. С точки зрения выстраивания работы эти технологии практически идентичны: главное отличие набора реплик заключается в автоматическом выборе нового «master», если с существующим произойдут неполадки, и возвращением его в строй в качестве реплики, после восстановления работоспособности.
В системе реализована возможность автоматической сегментации по нескольким наборам реплик. В основе сегментирования находится диапазон — для определения документа к определенному диапазону используется shard key (сегментный ключ). Распределение нагрузки происходит равномерно между всеми участниками набора реплик. Поэтому для того, чтобы разгрузить кластер, который перестает справляться с работой, достаточно просто добавить в него дополнительный набор реплик, и данные автоматически перераспределятся.
Распределение нагрузки происходит равномерно между всеми участниками набора реплик. Поэтому для того, чтобы разгрузить кластер, который перестает справляться с работой, достаточно просто добавить в него дополнительный набор реплик, и данные автоматически перераспределятся.
Варианты использования
На самом деле примеров использования в самых разных областях можно привести сколько угодно, главное, что вы должны понимать — это нереляционная БД, а следовательно, сама логика работы у нее другая. Востребованность таких СУБД подтверждает использование MongoDB в своих проектах крупными корпорациями, среди которых находятся Facebook, Google, Twitter и другие.
Система подходит для реализации схем, где требуется аналитика в реальном времени, быстрое журналирование. Кроме этого, ее традиционно используют для кэширования данных и проектов, в которых важное значение имеет масштабируемость. Вот несколько примеров, где можно задействовать MongoDB:
- Социальные сети, чаты, генераторы новостей и схожие сценарии использования.
- Большие данные — нереляционная структура системы хорошо подходит для работы с big data.
- Каталоги для магазинов электронной торговли, содержащие большое количество разных наименований товаров.
- Работа с данными, основанными на местоположении — геопространственными данными.
- Сбор и обработка информации с различных датчиков и считывающих устройств;
- Сервисы блогосферы — особенно те, которые подразумевают большое количество изображений, аудио и видеоматериалов.
Система плохо подходит для хранения сильно связанных данных и проектов, основной упор в которых сделан на транзакции на уровне базы данных. К минусам MongoDB традиционно относят:
- неполное соответствие требованиям ACID — реляционные БД в этом плане выигрывают;
- невозможно реализовать бизнес-логику на уровне БД, так как в базе нет положений о хранимых функциях и процедурах;
- сложная реализация транзакций.
Собственно, как и любой инструмент, MongoDB в чем-то лучше других СУБД, а в чем-то проигрывает.
Подведение итогов
MongoDB — это популярная СУБД, способная хранить и обрабатывать любые данные, если они будут в JSON/BSON-формате. На выбор доступны несколько различных редакций, в том числе и бесплатная, если она удовлетворяет требованиям лицензии SSPL. В свою очередь, коммерческая редакция предоставляет расширенный набор инструментов, включая резервное копирование и техническую поддержку. Есть возможность использовать вариант в облаке: платный или бесплатный, с ограничениями.
Система хорошо подходит для обработки больших данных и может использоваться в таких отраслях, как машинное обучение, аналитика в реальном времени, web-ресурсы с большим количеством фото и видеоматериалов, чаты, новостные ленты, блоги. Плохо подходит для проектов, в которых важны соответствие требованиям ACID и множественные транзакции.
Поделиться
Короткая ссылка
Когда выбрать базу данных MongoDB: гайд для новичков
Подготовили небольшой гайд по СУБД MongoDB: вы узнаете, в чем ее особенности, плюсы и недостатки, для каких проектов она подходит, а когда лучше выбрать реляционную базу данных.
Что такое база данных MongoDB и в чем ее особенности
MongoDB — документоориентированная система управления базами данных с открытым исходным кодом. Для хранения данных используется JSON-подобный формат. Эта СУБД отличается высокой доступностью, масштабируемостью и безопасностью.
Главные особенности MongoDB:
- Это кроссплатформенная документоориентированная база данных NoSQL с открытым исходным кодом.
- Она не требует описания схемы таблиц, как в реляционных БД. Данные хранятся в виде коллекций и документов.
- Между коллекциями нет сложных соединений типа JOIN, как между таблицами реляционных БД. Обычно соединение производится при сохранении данных путем объединения документов.
- Данные хранятся в формате BSON (бинарные JSON-подобные документы).
- У коллекций не обязательно должна быть схожая структура. У одного документа может быть один набор полей, в то время как у другого документа — совершенно другой (как тип, так и количество полей).

В одном документе могут быть поля разных типов данных, данные не нужно приводить к одному типу. Основное преимущество MongoDB заключается в том, что она может хранить любые данные, но эти данные должны быть в формате JSON.
Пример документа в MongoDB
На схеме показано, как выглядит документ в MongoDB:
ИсточникMongoDB добавляет поле _id с уникальным значением для идентификации документа в коллекции. Это поле обязательно для заполнения в каждом документе. Оно похоже на первичный ключ документа. Если вы создаете новый документ без поля _id, то MongoDB автоматически создаст его и добавит 24-значный уникальный идентификатор к каждому документу в коллекции.
Обратите внимание: сами данные заказа (OrderID, Product и Quantity) в MongoDB фактически хранятся как встроенный документ в самой коллекции, а в реляционных СУБД они обычно хранятся в отдельной таблице. Это одно из ключевых особенностей модели данных MongoDB.
Структура хранилища MongoDB
СУБД MongoDB полагается на концепции базы данных, коллекций и документов. Рассмотрим основные термины, а для лучшего понимания сравним их с терминами из языка структурированных запросов (SQL):
Рассмотрим основные термины, а для лучшего понимания сравним их с терминами из языка структурированных запросов (SQL):
- База данных — это физический контейнер для коллекций.
- Коллекция — группа документов MongoDB. В терминологии SQL это соответствует таблице.
- Документ — запись в коллекции MongoDB, набор пар ключ-значение. В терминологии SQL это похоже на строку в таблице базы данных.
- Поле — ключ в документе. В терминологии SQL похоже на столбец в таблице.
- Встроенный документ — в терминологии SQL похоже на создание связей между несколькими таблицами, по которым разбросаны данные, что делается операциями JOIN.
Зачем использовать MongoDB: преимущества этой СУБД
Ниже приведены несколько причин, по которым стоит использовать MongoDB:
- Документоориентированная база — сохранение данных в формате документов вместо формата реляционного типа, это делает MongoDB очень гибкой и адаптируемой к бизнес-требованиям. Возможность хранения разных типов данных особенно важна при работе с большими данными, которые собираются из разных источников и не ложатся в одну структуру.
- Специальные запросы — MongoDB поддерживает поиск по полям, диапазонные запросы и поиск по регулярным выражениям. Могут быть сделаны запросы для возврата определенных полей в документах.
- Индексация — можно создать индексы для улучшения производительности поиска в MongoDB. Любое поле в документе может быть проиндексировано. Это обеспечивает высокую скорость работы СУБД.
- Репликация — эта СУБД может обеспечить высокую доступность с помощью наборов реплик. Набор реплик состоит из двух или более экземпляров MongoDB. Каждая реплика набора может выступать в роли первичной или вторичной. Первичная реплика — главный сервер, который взаимодействует с клиентом и выполняет все операции чтения/записи. Вторичные реплики сохраняют копию данных первичной реплики с помощью встроенной репликации. Если с первичной репликой что-то случилось, происходит автоматическое переключение на вторичную реплику, затем она становится основным сервером.
- Балансировка нагрузки — MongoDB использует концепцию шардинга для горизонтального масштабирования с помощью разделения данных между несколькими экземплярами БД. Она может работать на нескольких серверах, балансируя нагрузку и/или дублируя данные, чтобы поддерживать работоспособность системы в случае аппаратного сбоя.
- Возможность развернуть в облаке — вы получаете готовую к работе, оптимально сконфигурированную, масштабируемую и управляемую базу данных по запросу за две минуты.
- Доступность — MongoDB поддерживает все популярные языки программирования, ее можно использовать бесплатно как open source решение.
 Возможность хранения разных типов данных особенно важна при работе с большими данными, которые собираются из разных источников и не ложатся в одну структуру.
Возможность хранения разных типов данных особенно важна при работе с большими данными, которые собираются из разных источников и не ложатся в одну структуру. Если с первичной репликой что-то случилось, происходит автоматическое переключение на вторичную реплику, затем она становится основным сервером.
Если с первичной репликой что-то случилось, происходит автоматическое переключение на вторичную реплику, затем она становится основным сервером.В облаке VK Cloud (бывш. MCS) реализована техническая поддержка, хостинг и обновление СУБД MongoDB до актуальных версий. Доступна помощь экспертов VK в миграции данных и настройке баз данных.
Недостатки MongoDB
Вот основные минусы MongoDB:
- Эта база данных не настолько соответствует требованиям ACID (атомарность, согласованность, изолированность и устойчивость), как реляционные базы данных.
- Транзакции с использованием MongoDB являются сложными
- В MongoDB нет положений о хранимых процедурах или функциях, поэтому не получится реализовать какую-либо бизнес-логику на уровне базы данных, что можно сделать в реляционных БД.
Когда стоит и не стоит использовать MongoDB
MongoDB часто выбирают, когда нужна масштабируемая база данных, в настоящее время ее используют в качестве хранилища внутренних данных многие организации, такие как IBM, Twitter, Zendesk, Forbes, Facebook, Google и другие.
Примеры, когда MongoDB подходит для проекта:
- Каталог товаров в электронной коммерции.
- Блоги и системы управления контентом, особенно те, где много контента, в том числе видео и изображений.
- Аналитика в реальном времени и высокоскоростное журналирование, кэширование данных и кейсов, когда важна высокая масштабируемость системы.
- Хранение данных датчиков и устройств.
- Работа с большими данными для машинного обучения и исследований в ритейле и других отраслях.
- Ведение данных на основе местоположения, то есть геопространственных данных.
- Социальные сети, новостные форумы и другие похожие сценарии.
- Слабосвязанные данные без четкой схемы хранения.
- Стартапы и развертывание новых проектов, где структура данных пока неизвестна.

Примеры, когда MongoDB лучше не использовать:
- Транзакционные системы, приложения, требующие транзакций на уровне базы данных, например банковские приложения.
- Проекты, где модель данных определена заранее.
- Хранение сильносвязанных данных.
В этой статье мы познакомились с MongoDB, одной из самых популярных баз данных NoSQL. Для более глубокого погружения можно продолжить изучение MongoDB по документации.
Большой туториал по MongoDB. Обзор | by Merrick
Обзор
MongoDB — это мощная, гибкая и масштабируемая база данных общего назначения. Mongo сочетает в себе вторичные индексы, запросы с диапазонами и сортировкой, агрегацией и геопозиционные запросы.
Mongo сочетает в себе вторичные индексы, запросы с диапазонами и сортировкой, агрегацией и геопозиционные запросы.
Установка
Начнем с установки. Мы рассмотрим установку на macos, но установка для другой системы мало чем отличается. Есть два способа установить mongoDB, через установщик и через пакетный менеджер.
В первом варианте мы просто скачиваем установщик с сайта и устанавливаем.
Второй вариант такой же простой как первый, у вас должен быть установлен пакетный менеджер brew и просто вводим несколько следующих команд.
brew update
brew install mongodb
# или с флагом --devel, чтобы установить development версию
brew install mongodb --devel
После установки последней стабильной версии mongoDB, нам нужно создать папку, где mongo будет хранить свои файлы. По стандарту это папка /data/db. Создадим эту папку.
mkdir -p /data/db
На этом установка закончена. Рассмотрим основные понятия базы данных.
Документ
MongoDB — это JSON подобная база данных, но основана на спецификации BSON. В основе базы лежит документ в контексте javascript это обычный объект, он же является основным строительным блоком.
В основе базы лежит документ в контексте javascript это обычный объект, он же является основным строительным блоком.
{
name: 'Merrick',
article: 'MongoDB - part 1'
}И как становится очевидно из примера, то документ это простой набор key/value.
MongoDB case-sensitive и type-sensitive база данных, что означает, что регистр имеет значение и тип передаваемых данных тоже имеет значение. В примере выше мы используем только строки, но ниже это будут 4 совершенно разных документа.
{ count: 5 }
{ count: '5' }
{ Count: 5 }
{ Count: '5' }Ключи в документе это строки, для задания имени доступны все UTF-8 символы, но есть пару исключений:
- Ключи не могут использовать символ
\0этот символ используется для обозначения окончания ключа. - Символы
.и$имеют особое назначение и должны использоваться только в определенных случаях, которые мы рассмотрим в следующих статьях.

Документы отсортированы в том порядке в котором были добавлены в базу, { x: 1, y: 2 } не тоже самое, что { y: 2, x: 1 }. Обычно в языках программирования не обязателен порядок в структурах данных key/value.
И последняя важная вещь, документ не может содержать поля с одинаковыми ключами или другими словами, документ ниже не может существовать.
{ greeting: "Hello, world!", greeting: "Hello, MongoDB!" }Коллекции
Коллекция это группа документов. Идентифицируются коллекцию по name. На картинке ниже name коллекции это users.
users:
{ name: 'Merrick', views: 5 }
{ name: 'John', views: 15 }
Несколько правил для именования коллекций:
- Пустая строка
""это невалидное имя. - Имя коллекции не может содержать знак
\0, потому что он обозначается для окончания наименования коллекции. - Не следует создавать коллекции начинающиеся с
system., mongo использует некоторые имена таких коллекций для собственных нужд. Например в коллекции system.usersхранится информация о юзерах данной базы. - Не следует использовать
$в именах коллекций. Mongo не запрещает использование в имени $, потому что некоторые автогенерируемые коллекции используют его для собственных нужд.
 Например в коллекции
Например в коллекции На самом деле у коллекций нет определенного паттерна и мы можем добавлять любые документы в коллекцию, например это будет рабочая структура.
users:
{ name: 'Merrick', views: 5 }
{ name: 'John', views: 15 }
{ weather: 'rain', walk: false }
Так что мы абстрактно назвали коллекцию users, на самом деле мы можем добавить в нее, документ с любыми полями, потому что коллекции имеют динамическую схему(dynamic schema).
У данного подхода конечно есть ряд недостатков:
- Во первых коллекция содержащая документы разных паттернов, заставить плакать разработчиков и администраторов, потому что при разработке необходимо убедиться, что ваш код умеет работать с разными паттернами из коллекции.
- Гораздо быстрее получить список коллекций, чем извлечь список из коллекции и только после отфильтровать. Например если бы в каждом документе было поле
typeс возможными вариантами: ‘skim’, ‘whole’ или ‘chunky monkey’, то было бы медленнее найти определенные документы в одной коллекции, чем иметь 3 разные коллекции. - Объединение документов одного и того же типа в коллекцию позволяет оптимизировать работу с данными. Получение нескольких сообщений в блоге из коллекции, содержащей только сообщения, скорее всего потребует меньше обращений к диску, чем получение таких же сообщений, но хранящихся в коллекции с данными автора.
- Мы накладываем некоторую структуру на наши документы при создании индексов(создание уникальных полей). Эти индексные элементы определены для каждой коллекции. Помещая совпадающие по определенному паттерну документы, мы можем более эффективно проиндексировать нашу коллекцию.

Подколлекции
Один из способов организовать структуру коллекций это использовать символ . в имени коллекции.
Например у нас есть приложение блога и там существует 2 коллекции это blog.posts и отдельную blog.authors . Здесь нет никакой связи с коллекцией blog(ее вообще может не существовать) и это не дочерние коллекции. То есть как таковых подколлекций не существует, но многие инструменты дают дополнительные возможности при подобном наименовании.
Например в mongo shell мы можем иметь 2 коллекции db.blog иdb.blog.posts хотя это две разные коллекции, но визуально blog.posts выглядит дочерней коллекцией blog, что помогает очень просто ориентироваться в структуре коллекций.
Базы данных
И в свою очередь коллекции объединяются в одну базу данных, которых в свою очередь в mongo может быть сколько угодно.
У баз данных тоже есть свои правила именования:
- Пустая строка
""является невалидным именем. - База данных не может содержать в имени
| / \ $ # . " * < > : ? \s \0 - Имя базы данных case-sensetive даже на os, где такое понятие отсутсвует, чтобы не усложнять себе жизнь используйте везде имена баз данных lowercase.
- Лимит имени 64 байта.
- Есть уже зарезервированные базы, с именами которых вы не можете создать свои
adminlocalconfig
 " * < > : ? \s \0
" * < > : ? \s \0Получается следующая иерархия.
Сервер MongoDB -> Базы данных -> Коллекции -> Документы
Таким образом получается древовидная структура, где дочерних элементов может быть сколько угодно.
Благодаря этому мы можем объединять имя базы и коллекции и получать namespace. Например если у нас есть коллекция blog.posts и база данных cms, то namespace будет следующий cms.blog.posts. Namespace может быть длинной до 121 байта, на практике он почти всегда меньше 100 байтов. Про внутреннее устройство коллекций более подробно мы напишем позже.
Что же давайте посмотрим все своими глазами. Чтобы запустить базу нужно написать команду в терминале.
Чтобы запустить базу нужно написать команду в терминале.
mongod
Если вы не дали доступ папке /data/db, то вы получите ошибку запуска, для этого нужно запустить команду с правами суперпользователя sudo mongod.
Команда mongod запускает локально сервер mongoDB.
После того, как сервер запущен, можно обращаться к нему. Откроем вторую вкладку терминала и запустим командную оболочку mongo с помощью команды
mongo
Mongo shell это инструмент для управления базой с помощью консоли, который имеет доступ к API базы + это полноценный интерпретатор JS.
При старте оболочки, mongo shell использует по умолчанию базу данных с именем test. В mongoDB можно обращаться к базе даже которая не существует, просто при первом подключении к базе, mongo создаст данную базу. Чтобы переключиться на другую базу(P.S. даже не существующую) мы можем использовать команду use.
use tutorialDB
switched to db tutorialDB
Теперь вся работа с базой будет происходить через базу tutorialDB.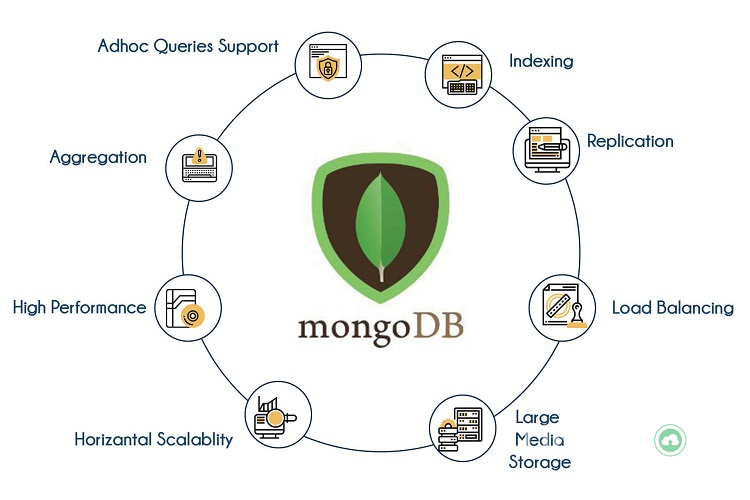
Также для администрирования mongoDB есть такой инструмент как mongoDB compass. Можете сами установить и попробовать использовать данный инструмент.
Что такое MongoDB? Введение, архитектура, функции и пример
ByDavid Taylor
HoursОбновлено
Что такое MongoDB?
MongoDB — документно-ориентированная база данных NoSQL, используемая для хранения больших объемов данных. Вместо использования таблиц и строк, как в традиционных реляционных базах данных, MongoDB использует коллекции и документы. Документы состоят из пар ключ-значение, которые являются основной единицей данных в MongoDB. Коллекции содержат наборы документов и функций, которые эквивалентны таблицам реляционных баз данных. MongoDB — это база данных, появившаяся примерно в середине 2000-х годов.
В этом руководстве вы узнаете:
- Возможности MongoDB
- Пример MongoDB
- Ключевые компоненты архитектуры MongoDB
- Зачем использовать MongoDB
- Моделирование данных в MongoDB
- Разница между MongoDB и РСУБД
Функции MongoDB
- Каждая база данных содержит коллекции, которые, в свою очередь, содержат документы. Каждый документ может быть разным с разным количеством полей. Размер и содержание каждого документа могут отличаться друг от друга.
- Структура документа больше соответствует тому, как разработчики создают свои классы и объекты в соответствующих языках программирования. Разработчики часто говорят, что их классы — это не строки и столбцы, а четкая структура с парами ключ-значение.
- Строки (или документы, как они называются в MongoDB) не должны иметь заранее определенную схему. Вместо этого поля можно создавать на лету.
- Модель данных, доступная в MongoDB, упрощает представление иерархических отношений, хранение массивов и других более сложных структур.
- Масштабируемость. Среды MongoDB очень масштабируемы. Компании по всему миру создали кластеры, в некоторых из которых работает более 100 узлов с примерно миллионами документов в базе данных .
 Каждый документ может быть разным с разным количеством полей. Размер и содержание каждого документа могут отличаться друг от друга.
Каждый документ может быть разным с разным количеством полей. Размер и содержание каждого документа могут отличаться друг от друга.Пример MongoDB
В приведенном ниже примере показано, как можно смоделировать документ в MongoDB.
- Поле _id добавляется MongoDB для уникальной идентификации документа в коллекции.
- Что вы можете заметить, так это то, что данные заказа (OrderID, Product и Quantity), которые в СУБД обычно хранятся в отдельной таблице, в то время как в MongoDB они фактически хранятся как встроенный документ в самой коллекции. Это одно из ключевых отличий в моделировании данных в MongoDB.
Ключевые компоненты архитектуры MongoDB
Ниже приведены некоторые общие термины, используемые в MongoDB
- _id — это поле обязательно для каждого документа MongoDB. Поле _id представляет собой уникальное значение в документе MongoDB. Поле _id похоже на первичный ключ документа. Если вы создадите новый документ без поля _id, MongoDB автоматически создаст это поле. Так, например, если мы увидим пример приведенной выше таблицы клиентов, Mongo DB добавит 24-значный уникальный идентификатор к каждому документу в коллекции.
| _Идентификатор | идентификатор клиента | ИмяКлиента | ID заказа |
|---|---|---|---|
| 563479cc8a8a4246bd27d784 | 11 | Гуру99 | 111 |
| 563479cc7a8a4246bd47d784 | 22 | Тревор Смит | 222 |
| 563479cc9a8a4246bd57d784 | 33 | Николь | 333 |
- Коллекция — это группа документов MongoDB. Коллекция является эквивалентом таблицы, созданной в любой другой RDMS, такой как Oracle или MS SQL. Коллекция существует в одной базе данных. Как видно из введения, коллекции не навязывают никакой структуры.
- Курсор — это указатель на набор результатов запроса. Клиенты могут перебирать курсор для получения результатов.
- База данных — это контейнер для коллекций, как в RDMS, где он является контейнером для таблиц. Каждая база данных получает свой собственный набор файлов в файловой системе. Сервер MongoDB может хранить несколько баз данных.
- Документ . Запись в коллекции MongoDB в основном называется документом. Документ, в свою очередь, будет состоять из имени поля и значений.
- Поле — Пара имя-значение в документе. Документ имеет ноль или более полей. Поля аналогичны столбцам в реляционных базах данных. На следующей диаграмме показан пример полей с парами значений ключа. Таким образом, в приведенном ниже примере CustomerID и 11 являются одной из пар ключ-значение, определенных в документе.
 Коллекция является эквивалентом таблицы, созданной в любой другой RDMS, такой как Oracle или MS SQL. Коллекция существует в одной базе данных. Как видно из введения, коллекции не навязывают никакой структуры.
Коллекция является эквивалентом таблицы, созданной в любой другой RDMS, такой как Oracle или MS SQL. Коллекция существует в одной базе данных. Как видно из введения, коллекции не навязывают никакой структуры.- JSON — это известно как нотация объектов JavaScript. Это удобочитаемый текстовый формат для представления структурированных данных. В настоящее время JSON поддерживается многими языками программирования.
Небольшое замечание о ключевой разнице между полем _id и обычным полем коллекции. Поле _id используется для уникальной идентификации документов в коллекции и автоматически добавляется MongoDB при создании коллекции.
Зачем использовать MongoDB?
Ниже приведены несколько причин, по которым следует начать использовать MongoDB
- Ориентированность на документы. Поскольку MongoDB является базой данных типа NoSQL, вместо того, чтобы иметь данные в формате реляционного типа, она хранит данные в документах. Это делает MongoDB очень гибкой и адаптируемой к реальной ситуации и требованиям делового мира.
- Специальные запросы — MongoDB поддерживает поиск по полям, запросам диапазона и поиску по регулярным выражениям. Запросы могут быть сделаны для возврата определенных полей в документах.
- Индексирование. Можно создавать индексы для повышения производительности поиска в MongoDB. Любое поле в документе MongoDB может быть проиндексировано.
- Репликация — MongoDB может обеспечить высокую доступность с помощью наборов реплик. Набор реплик состоит из двух или более экземпляров mongo DB. Каждый член набора реплик может выступать в роли первичной или вторичной реплики в любое время. Первичная реплика — это основной сервер, который взаимодействует с клиентом и выполняет все операции чтения/записи. Вторичные реплики поддерживают копию данных первичной реплики с помощью встроенной репликации. При сбое первичной реплики набор реплик автоматически переключается на вторичный, а затем становится первичным сервером.
- Балансировка нагрузки — MongoDB использует концепцию сегментирования для горизонтального масштабирования путем разделения данных между несколькими экземплярами MongoDB. MongoDB может работать на нескольких серверах, балансируя нагрузку и/или дублируя данные, чтобы поддерживать работоспособность системы в случае сбоя оборудования.
Моделирование данных в MongoDB
Как мы видели из раздела «Введение», данные в MongoDB имеют гибкую схему. В отличие от баз данных SQL, где вы должны объявить схему таблицы перед вставкой данных, коллекции MongoDB не применяют структуру документа. Такая гибкость делает MongoDB такой мощной.
При моделировании данных в Mongo помните о следующем.
- Каковы потребности приложения. Посмотрите на бизнес-потребности приложения и посмотрите, какие данные и тип данных необходимы для приложения. Исходя из этого, убедитесь, что структура документа определена соответствующим образом.
- Что такое шаблоны извлечения данных. Если вы предвидите интенсивное использование запросов, рассмотрите возможность использования индексов в вашей модели данных для повышения эффективности запросов.
- Частые вставки, обновления и удаления в базе данных? Пересмотрите использование индексов или включите сегментирование, если это необходимо, в структуру моделирования данных, чтобы повысить эффективность всей среды MongoDB.
Разница между MongoDB и РСУБД
Ниже приведены некоторые ключевые различия терминов между MongoDB и РСУБД
| РСУБД | МонгоДБ | Разница |
|---|---|---|
| Стол | Коллекция | В СУБД таблица содержит столбцы и строки, которые используются для хранения данных, тогда как в MongoDB эта же структура называется коллекцией. Коллекция содержит документы, которые, в свою очередь, содержат поля, которые, в свою очередь, представляют собой пары ключ-значение. |
| Ряд | Документ | В СУБД строка представляет один неявно структурированный элемент данных в таблице. В MongoDB данные хранятся в документах. |
| Столбец | Поле | В СУБД столбец обозначает набор значений данных. В MongoDB они известны как поля. |
| Соединения | Встроенные документы | В РСУБД данные иногда распределяются по разным таблицам, и для того, чтобы показать полное представление всех данных, иногда создается соединение между таблицами для получения данных. В MongoDB данные обычно хранятся в одной коллекции, но разделены с помощью встроенных документов. Таким образом, в MongoDB нет концепции соединений. |
Помимо различий в терминах, несколько других различий показаны ниже.
- Известно, что реляционные базы данных обеспечивают целостность данных. Это не является явным требованием в MongoDB.
- РСУБД требует, чтобы данные были сначала нормализованы, чтобы предотвратить появление потерянных записей и дубликатов. Для нормализации данных требуется больше таблиц, что приводит к большему количеству объединений таблиц, что требует большего количества ключей и индексов. По мере роста баз данных производительность может начать становиться проблемой. Опять же, это не является явным требованием в MongoDB. MongoDB является гибким и не требует предварительной нормализации данных.
404: Страница не найдена
Страница, которую вы пытались открыть по этому адресу, похоже, не существует. Обычно это результат плохой или устаревшей ссылки. Мы приносим свои извинения за доставленные неудобства.
Что я могу сделать сейчас?
Если вы впервые посещаете TechTarget, добро пожаловать! Извините за обстоятельства, при которых мы встречаемся. Вот куда вы можете пойти отсюда:
Поиск- Ознакомьтесь с последними новостями.
- Наша домашняя страница содержит самую свежую информацию об управлении данными/хранении данных.
- Наша страница «О нас» содержит дополнительную информацию о сайте, на котором вы находитесь, SearchDataManagement.
- Если вам нужно, пожалуйста, свяжитесь с нами, мы будем рады услышать от вас.
Поиск по категории
ПоискБизнесАналитика
- Ricoh модернизирует свою аналитику с помощью Qlik
Компания по управлению информацией и цифровыми услугами начинает развивать культуру данных, и платформа поставщика BI имеет …
- Данные потребителей нуждаются в лучшей защите со стороны правительства
Несмотря на то, что в Конгрессе находится законодательство, касающееся конфиденциальности данных, оно может не устанавливать достаточно четких руководящих принципов или не давать отдельным лицам.
.. - Опасения по поводу конфиденциальности данных растут по мере отставания законодательства
Несмотря на то, что медицинские и финансовые данные защищены федеральным законодательством, частные лица практически не контролируют, как данные о потребителях …
ПоискAWS
- AWS Control Tower стремится упростить управление несколькими учетными записями
Многие организации изо всех сил пытаются управлять своей огромной коллекцией учетных записей AWS, но Control Tower может помочь. Услуга автоматизирует…
- Разбираем модель ценообразования Amazon EKS
В модели ценообразования Amazon EKS есть несколько важных переменных. Покопайтесь в цифрах, чтобы убедиться, что вы развернули службу…
- Сравните EKS и самоуправляемый Kubernetes на AWS
Пользователи
AWS сталкиваются с выбором при развертывании Kubernetes: запустить его самостоятельно на EC2 или позволить Amazon выполнить тяжелую работу с помощью EKS.
См…
SearchContentManagement
- Как создать контент-стратегию электронной коммерции для увеличения продаж
Контент-стратегия, включающая автоматизированную CMS, полезную информацию о продукте и визуальные эффекты, может привлечь внимание клиентов к вашему …
- 5 безбумажных офисных программных инструментов, на которые следует обратить внимание
Выбор подходящего безбумажного программного обеспечения для офиса, казалось бы, бесконечный, начинается с понимания того, что …
- Викторина: проверьте свои знания в области управления цифровыми активами
Системы
DAM помогают отделам маркетинга управлять мультимедийным контентом, с которым они работают каждый день. С помощью этого теста проверьте свои знания о …
ПоискOracle
- Oracle ставит перед собой высокие национальные цели в области ЭУЗ с приобретением Cerner
С приобретением Cerner Oracle нацелилась на создание национальной анонимной базы данных пациентов — дорога, заполненная .
.. - Благодаря Cerner Oracle Cloud Infrastructure получает импульс
Oracle планирует приобрести Cerner в рамках сделки на сумму около 30 миллиардов долларов. Второй по величине поставщик электронных медицинских карт в США может вдохнуть новую жизнь …
- Верховный суд встал на сторону Google в иске о нарушении авторских прав на Oracle API
Верховный суд постановил 6-2, что API-интерфейсы Java, используемые в телефонах Android, не подпадают под действие американского закона об авторском праве.
ПоискSAP
- Сантандер присоединяется к SAP MBC, чтобы внедрить финансы в процессы
SAP Multi-Bank Connectivity добавил Santander Bank в свой список партнеров, чтобы помочь компаниям упростить внедрение …
- В 50 лет SAP оказалась на очередном распутье
За свою 50-летнюю историю компания SAP вывела бизнес и технологические тренды на вершину индустрии ERP, но сейчас она находится на перепутье .
.. - Сторонняя поддержка SAP обеспечивает гибкость миграции
Сторонние поставщики услуг поддержки заявляют, что они могут обеспечить большую гибкость при меньших затратах, но клиенты должны подумать …
Что такое MongoDB? – Нереляционная база данных
Нереляционная база данных для документов в формате JSON
Начало работы с Amazon DocumentDB (с совместимостью с MongoDB)
MongoDB — это нереляционная база данных документов, обеспечивающая поддержку хранилища, подобного JSON. База данных MongoDB имеет гибкую модель данных, которая позволяет хранить неструктурированные данные, а также обеспечивает полную поддержку индексации и репликацию с помощью многофункциональных и интуитивно понятных API.
Ниже приведен пример документа в формате JSON в базе данных MongoDB:
{
company_name: "ACME Limited Foodstuffs",
адрес: {улица: "1212 Main Street", город: "Спрингфилд"},
номер_телефона: "1-800-0000",
промышленность: ["пищевая промышленность", "бытовая техника"]
тип: "частный",
число_оф_сотрудников: 987
} AWS позволяет настроить инфраструктуру для поддержки развертывания баз данных MongoDB гибким, масштабируемым и экономичным способом в облаке AWS. AWS также позволяет выполнять рабочие нагрузки, совместимые с MongoDB, с помощью Amazon DocumentDB (с совместимостью с MongoDB) — быстрой, масштабируемой и полностью управляемой службы нереляционных баз данных. С Amazon DocumentDB вам не нужно беспокоиться об операционных проблемах, включая подготовку оборудования, резервное копирование, обновления, надежность, установку исправлений, высокую доступность и многое другое. Будучи облачной базой данных, Amazon DocumentDB позволяет создавать приложения, которые можно быстро и легко масштабировать в соответствии с вашей рабочей нагрузкой.
Возможности базы данных MongoDB
MongoDB стала популярной среди разработчиков отчасти благодаря своему интуитивно понятному API, гибкой модели данных и функциям, которые включают:
Специальные запросы
может возвращать целые документы, определенные поля документов или случайные выборки результатов.
Индексирование
Поля в документе MongoDB можно индексировать с помощью первичных и вторичных индексов. MongoDB поддерживает ряд различных типов индексов, включая одно поле, составной (несколько полей), многоключевой (массив), геопространственный, текстовый и хешированный.
Репликация
MongoDB обеспечивает высокую доступность с помощью наборов реплик, включающих две или более копий данных. Записи обрабатываются первичной репликой, а любая реплика способна обслуживать запросы на чтение. Если первичная реплика выходит из строя, вторичная реплика становится первичной репликой.
Узнайте больше об API MongoDB, операциях и типах данных, поддерживаемых в Amazon DocumentDB, в документации.
Запуск рабочих нагрузок MongoDB в Amazon DocumentDB (с совместимостью с MongoDB)
В то время как модель документов MongoDB предлагает гибкость и интуитивно понятный API, любимый разработчиками, самоуправляемые базы данных MongoDB сложны, трудоемки и дороги, особенно при масштабировании приложений. AWS создала Amazon DocumentDB (с совместимостью с MongoDB) как полностью управляемую и совместимую с MongoDB службу базы данных документов, позволяющую использовать существующие драйверы MongoDB, клиенты MongoDB и инструменты с Amazon DocumentDB.
Будучи полностью управляемым сервисом баз данных AWS, Amazon DocumentDB позволяет настраивать, защищать и масштабировать базы данных, совместимые с MongoDB, в облаке, не беспокоясь об обслуживании и исправлении программного обеспечения баз данных, ручной настройке и защите кластеров баз данных, запуске программного обеспечения для управления кластерами. , настройка резервного копирования и мониторинг рабочих нагрузок.
Вы можете перенести рабочие нагрузки MongoDB в Amazon DocumentDB с помощью службы миграции баз данных AWS (AWS DMS) и утилит командной строки, таких как mongodump и mongorestore.
Узнайте больше о миграции баз данных MongoDB в Amazon DocumentDB (с совместимостью с MongoDB).
Преимущества выполнения рабочих нагрузок MongoDB в Amazon DocumentDB (с совместимостью с MongoDB)
Amazon DocumentDB поддерживает API MongoDB, и выполнение рабочих нагрузок MongoDB в Amazon DocumentDB имеет определенные преимущества и преимущества.
Масштабируемость
Amazon DocumentDB разделяет хранилище и вычислительные ресурсы, позволяя масштабировать каждую из них независимо друг от друга, чтобы вы могли легко масштабировать производительность чтения до миллионов запросов в секунду. Вы можете увеличить скорость чтения до миллионов запросов в секунду, добавив до 15 реплик чтения с малой задержкой за считанные минуты, независимо от размера ваших данных.
Высокая доступность и надежность
Amazon DocumentDB обеспечивает доступность на уровне 99,99 % и реплицирует шесть копий ваших данных в трех зонах доступности (AZ) AWS. В Amazon DocumentDB непрерывное резервное копирование включено по умолчанию, обеспечивая 1 день восстановления на момент времени (PITR).
Безопасность и соответствие требованиям
Amazon DocumentDB работает в Amazon VPC, что позволяет изолировать кластер в собственной виртуальной сети. Amazon DocumentDB поддерживает шифрование при хранении с помощью AWS KMS, шифрование при передаче, управление доступом на основе ролей и сертификаты соответствия, включая PCI DSS, ISO 9001, 27001, 27017 и 27018, SOC 1, 2 и 3, а также HITRUST. соответствие требованиям HIPAA.
Интеграция сервисов AWS
Amazon DocumentDB легко интегрируется с другими сервисами AWS для расширения функциональности, включая Amazon CloudWatch для мониторинга и оповещений, AWS CloudTrail для журналов аудита, AWS Glue для ETL и AWS Secrets Manager, и это лишь некоторые из них.
Amazon DocumentDB продолжает улучшать совместимость с рабочими нагрузками MongoDB, работая в обратном направлении от возможностей, которые наши клиенты просят нас создать. Чтобы узнать больше о преимуществах DocumentDB для рабочих нагрузок MongoDB, посмотрите презентацию AWS re:Invent, Amazon DocumentDB Deep Dive.
AWS re:Invent 2019: подробное изучение Amazon DocumentDB (DAT326)
Клиенты, выполняющие рабочие нагрузки, совместимые с MongoDB, в Amazon DocumentDB
«В Freshworks мы используем DocumentDB для нашей интеграционной платформы, чтобы синхронизировать различные продукты друг с другом — например, ваши лиды в CRM Freshworks с вашей маркетинговой аудиторией в Mailchimp.
Виджай Лакшминараянан, старший менеджер отдела инженерных разработок — Freshworks
«В Hudl мы используем значительное количество сервисов AWS, поскольку мы всегда ищем возможности отказаться от управления собственной инфраструктурой.
Брайан Кайзер, технический директор, Hudl
«Вот! заменили нашу устаревшую, самоуправляемую и операционную базу данных каталога продуктов кошмара, работающую на MongoDB 2.2, на Amazon DocumentDB. С минимальными изменениями мы смогли обновить наш драйвер и завершить полную миграцию рабочей среды за три недели. При этом мы сократили расходы на инфраструктуру базы данных на 82 %, включая расходы на лицензирование. Благодаря Amazon DocumentDB мы добились уменьшения задержки и масштабируемости, теперь у нас есть более безопасное решение для резервного копирования, которое позволяет выполнять восстановление на момент времени в любую секунду в течение 35-дневного окна.
Сэм Джагцоглу, инженер-разработчик программного обеспечения — Woot!
Начало работы
Подробнее
Узнайте больше об Amazon DocumentDB на странице обзора продукта.
Читать обзор
Ознакомьтесь с руководством по миграции
Ознакомьтесь с руководством по миграции в документации Amazon DocumentDB.
Ознакомьтесь с руководством
Попробуйте учебник
Начало работы с учебным пособием «Миграция с MongoDB на Amazon DocumentDB»
Начало работы
Войдите в консоль
Узнайте об AWS
- Что такое AWS?
- Что такое облачные вычисления?
- AWS Разнообразие, равенство и инклюзивность
- Что такое DevOps?
- Что такое контейнер?
- Что такое озеро данных?
- Облачная безопасность AWS
- Что нового
- Блоги
- Пресс-релизы
Ресурсы для AWS
- Начало работы
- Обучение и сертификация
- Портфолио решений AWS
- Архитектурный центр
- Часто задаваемые вопросы по продуктам и техническим вопросам
- Аналитические отчеты
- Партнеры AWS
Разработчики на AWS
- Центр разработчиков
- SDK и инструменты
- . NET на AWS
- Python на AWS
- Java на AWS
- PHP на AWS
- JavaScript на AWS
Помощь
- Свяжитесь с нами
- Подайте заявку в службу поддержки
- Центр знаний
- AWS re: Сообщение
- Обзор поддержки AWS
- Юридический
- Карьера в AWS
Amazon является работодателем с равными возможностями: Меньшинства / Женщины / Инвалидность / Ветеран / Гендерная идентичность / Сексуальная ориентация / Возраст.
- Конфиденциальность
- |
- Условия сайта
- |
- Настройки файлов cookie
- |
- © 2022, Amazon Web Services, Inc. или ее дочерние компании. Все права защищены.
Поддержка AWS для Internet Explorer заканчивается 31. 07.2022. Поддерживаемые браузеры: Chrome, Firefox, Edge и Safari.
Узнать больше »
Что такое MongoDB — работа и функции
MongoDB — это ориентированная на документы база данных с открытым исходным кодом, предназначенная для хранения больших объемов данных, а также позволяющая очень эффективно работать с этими данными. Он относится к базе данных NoSQL (не только SQL), поскольку хранение и извлечение данных в MongoDB осуществляется не в виде таблиц.
База данных MongoDB разработана и управляется MongoDB.Inc в соответствии с SSPL (публичная лицензия на стороне сервера) и первоначально выпущена в феврале 2009 года. Она также обеспечивает официальную поддержку драйверов для всех популярных языков, таких как C, C++, C# и .Net, Go, Java, Node.js, Perl, PHP, Python, Motor, Ruby, Scala, Swift, Mongoid. Таким образом, вы можете создать приложение, используя любой из этих языков. В настоящее время существует так много компаний, которые используют MongoDB, таких как Facebook, Nokia, eBay, Adobe, Google и т. д., для хранения большого объема данных.
Как это работает ?
Теперь посмотрим, как на самом деле все происходит за кулисами. Как мы знаем, MongoDB — это сервер базы данных, и данные хранятся в этих базах данных. Другими словами, среда MongoDB предоставляет вам сервер, который вы можете запустить, а затем создать на нем несколько баз данных с помощью MongoDB.
Из-за базы данных NoSQL данные хранятся в коллекциях и документах. Следовательно, база данных, коллекция и документы связаны друг с другом, как показано ниже:
- База данных MongoDB содержит коллекции так же, как база данных MYSQL содержит таблицы. Вам разрешено создавать несколько баз данных и несколько коллекций.
- Теперь внутри коллекции у нас есть документы. Эти документы содержат данные, которые мы хотим сохранить в базе данных MongoDB, и одна коллекция может содержать несколько документов, и вы не имеете схемы, что означает, что нет необходимости, чтобы один документ был похож на другой.
- Документы создаются с использованием полей. Поля представляют собой пары «ключ-значение» в документах, точно так же, как столбцы в реляционной базе данных. Значение полей может относиться к любым типам данных BSON, таким как double, string, boolean и т. д.
- Данные, хранящиеся в MongoDB, имеют формат документов BSON. Здесь BSON означает двоичное представление документов JSON. Или, другими словами, сервер MongoDB преобразует данные JSON в двоичную форму, известную как BSON, и этот BSON хранится и запрашивается более эффективно.
- В документах MongoDB разрешено хранить вложенные данные. Такое вложение данных позволяет создавать сложные отношения между данными и хранить их в одном документе, что делает работу и выборку данных чрезвычайно эффективной по сравнению с SQL. В SQL вам нужно написать сложные соединения, чтобы получить данные из таблицы 1 и таблицы 2. Максимальный размер документа BSON составляет 16 МБ.
ПРИМЕЧАНИЕ. На сервере MongoDB вам разрешено запускать несколько баз данных.
Например, у нас есть база данных GeeksforGeeks. Внутри этой базы данных у нас есть две коллекции и в этих коллекциях у нас есть два документа. И в этих документах мы храним наши данные в виде полей. Как показано на рисунке ниже:
Чем mongoDB отличается от СУБД?
Некоторые основные различия между MongoDB и РСУБД следующие:
| MongoDB | РСУБД |
|---|---|
| Это нереляционная и ориентированная на документы база данных. | Это реляционная база данных. |
| Подходит для иерархического хранения данных. | Не подходит для иерархического хранения данных. |
| Имеет динамическую схему. | Имеет предопределенную схему. |
| Он основан на теореме CAP (непротиворечивость, доступность и устойчивость к разделам). | Он основан на свойствах ACID (атомарность, согласованность, изоляция и долговечность). |
| С точки зрения производительности, это намного быстрее, чем РСУБД. | С точки зрения производительности он медленнее, чем MongoDB. |
Особенности MongoDB-
- Бата данных без схемы: Это отличная функция, предоставленная MongoDB. База данных без схемы означает, что одна коллекция может содержать документы разных типов. Или, другими словами, в базе данных MongoDB одна коллекция может содержать несколько документов, и эти документы могут состоять из разного количества полей, содержимого и размера. Нет необходимости, чтобы один документ был похож на другой документ, как в реляционных базах данных. Благодаря этой интересной функции MongoDB обеспечивает большую гибкость для баз данных.
- Документоориентированность: В MongoDB все данные хранятся в документах, а не в таблицах, как в СУБД. В этих документах данные хранятся в полях (паре ключ-значение), а не в строках и столбцах, что делает данные гораздо более гибкими по сравнению с СУБД. И каждый документ содержит свой уникальный идентификатор объекта.
- Индексирование: В базе данных MongoDB каждое поле в документах индексируется с помощью первичных и вторичных индексов, что упрощает и занимает меньше времени для получения или поиска данных из пула данных. Если данные не проиндексированы, то поиск по базе данных каждого документа по указанному запросу занимает много времени и не так эффективен.
- Масштабируемость: MongoDB обеспечивает горизонтальную масштабируемость с помощью сегментирования. Разделение означает распределение данных на нескольких серверах, здесь большой объем данных разбивается на блоки данных с использованием ключа сегмента, и эти блоки данных равномерно распределяются по сегментам, которые находятся на многих физических серверах. Он также добавит новые машины в работающую базу данных.
- Репликация: MongoDB обеспечивает высокую доступность и избыточность с помощью репликации, она создает несколько копий данных и отправляет эти копии на другой сервер, так что в случае сбоя одного сервера данные извлекаются с другого сервера.
- Агрегирование: Позволяет выполнять операции над сгруппированными данными и получать один результат или вычисленный результат. Это похоже на предложение SQL GROUPBY. Он обеспечивает три различных агрегации, то есть конвейер агрегации, функцию уменьшения карты и одноцелевые методы агрегации
- Высокая производительность: Производительность MongoDB очень высока, а постоянство данных по сравнению с другой базой данных благодаря ее функциям, таким как масштабируемость, индексирование, репликация и т. д.
Преимущества MongoDB:
- Это база данных NoSQL без схемы. Вам не нужно проектировать схему базы данных при работе с MongoDB.
- Не поддерживает операцию соединения.
- Обеспечивает большую гибкость полей в документах.
- Содержит разнородные данные.
- Обеспечивает высокую производительность, доступность, масштабируемость.
- Эффективно поддерживает геопространственные данные.
- Это база данных, ориентированная на документы, и данные хранятся в документах BSON.
- Он также поддерживает переход нескольких документов ACID (строка из MongoDB 4.0).
- Не требует внедрения SQL.
- Легко интегрируется с Big Data Hadoop
Недостатки MongoDB:
- Использует много памяти для хранения данных.
- Вам не разрешено хранить в документах более 16 МБ данных.
- Вложенность данных в BSON также ограничена. Вы не можете вкладывать данные более чем на 100 уровней.
Что такое MongoDB и зачем ее использовать для современных веб-приложений?
Обзор
Организации разного масштаба и формы хотят использовать силу данных для выявления новых возможностей для бизнеса и улучшения текущих бизнес-операций. Организации, эффективно использующие данные, могут иметь потенциальное преимущество — способность принимать более быстрые и обоснованные бизнес-решения. Однако работа с данными может быть давней проблемой для предприятий и функций, особенно в области управления данными и разработки программного обеспечения.
Один из важных вариантов использования, в котором организациям требуется быстрая фаза разработки и отличное управление данными, — это создание современных веб-приложений. Организациям требуется качественная работающая система, которую можно развернуть как можно быстрее. Кроме того, эти приложения должны иметь возможность масштабирования. Таким образом, каждое приложение должно быть разработано и построено на подходящей базе данных. Традиционно веб-приложения использовали реляционные базы данных в качестве основного хранилища данных с учетом хорошо нормализованной модели данных. Но по мере модернизации приложений все больше разработчиков склоняются к использованию альтернативных хранилищ данных, таких как NoSQL (не только язык структурированных запросов) из-за их преимуществ.
Одним из приложений, которое может помочь организациям в разработке современных веб-приложений, является MongoDB. Эта база данных позволяет организациям создавать масштабируемые приложения, управляемые данными. Модель данных и стратегии сохраняемости рассчитаны на высокую пропускную способность чтения и записи. Кроме того, он имеет возможность автоматического аварийного переключения. Если вам интересно, что такое MongoDB, ее преимущества и как MongoDB помогает запускать современные веб-приложения, этот блог для вас.
Что такое MongoDB?
MongoDB — это приложение для управления базами данных NoSQL. Системы баз данных NoSQL предлагают альтернативу традиционным реляционным базам данных с использованием SQL (язык структурированных запросов) . Данные хранятся в таблицах, строках и столбцах реляционной базы данных со связями между сущностями. В MongoDB данные хранятся в документах с использованием JSON-подобной структуры для представления данных и взаимодействия с ними.
Преимущества использования MongoDB
Транзакционность и скорость
Наиболее известной особенностью MongoDB является гибкое хранилище данных благодаря формату документов, подобному JSON. MongoDB хранит записи в виде документов (в частности, документов BSON), собранных вместе в коллекций . База данных содержит одну или несколько коллекций документов. См. представление базы данных, коллекции и документа ниже.
Учитывая, что модель данных на основе документов может представлять богатые иерархические структуры данных, часто можно моделировать данные без сложных многотабличных объединений, навязываемых реляционными базами данных. Например, предположим, что вы моделируете продукты для веб-приложения электронной коммерции. В полностью нормализованной реляционной модели данных информация о продуктах может состоять из нескольких таблиц. Если вы хотите получить представление продукта из оболочки базы данных, вам нужно будет написать сложный SQL-запрос, полный объединений. Следовательно, настройка базы данных может быть очень сложной и может замедлить время разработки и конечное приложение.
В отличие от базы данных документов информация о продукте может быть смоделирована в рамках одного документа. Кроме того, структура, подобная JSON, описывает понятное представление продуктов с иерархией. Кроме того, возможности запросов MongoDB разработаны специально для манипулирования как структурированными документами, так и неструктурированными данными, что упрощает их использование пользователями.
Еще одна особенность MongoDB заключается в том, что она предлагает эффективный способ поиска данных с текстовыми, геопространственными или временными измерениями. Кроме того, MongoDB включает в себя функции для анализа данных, включая поддержку нескольких одновременных запросов, индексирование и агрегирование. Последние версии MongoDB также включают поддержку распределенных транзакций, транзакций с несколькими документами, несколькими коллекциями, несколькими базами данных и несколькими сегментами с высокой гарантией целостности данных.
Масштабируемость и высокая доступность
По мере того, как веб-приложения, сайты и службы становятся популярными и получают все больше трафика, важно обеспечить масштабируемость поддерживающих их баз данных для адаптации к требованиям пользователей. Поэтому MongoDB построена на горизонтально масштабируемой архитектуре, как показано на рисунке ниже. Горизонтальное масштабирование означает добавление дополнительных серверов для распределения нагрузки между несколькими узлами.
Масштабирование базы данных по горизонтали может быть достигнуто в MongoDB через шардинг и набор реплик имеют . Эти функции масштабируемости также имеют преимущества для отказоустойчивости в развертывании базы данных MongoDB. На рисунке ниже показана модель шардинга.
Шардинг — это метод распределения данных между несколькими машинами. В сегментированном кластере есть различные компоненты:
- клиент — это сервер приложений, который использует такие драйверы, как python, javascript, C#, C++ и другие, для интеграции с маршрутизатором MongoDB. 9Маршрутизатор 0018
- (mongos) — это оператор mangos, выступающий в роли интерфейса между клиентскими приложениями и шардированным кластером.
- config-server (mongod) — хранить метаданные и настройки конфигурации для кластера.
- несколько сегментов (mongod) — содержат подмножество сегментированных данных, при этом каждый сегмент может быть развернут как набор реплик. Несколько сегментов представляют собой горизонтальную масштабируемую архитектуру, поскольку сегменты развернуты на нескольких серверах.
Набор реплик — это группа процессов mongod, которые поддерживают один и тот же набор данных в сегменте или на сервере конфигурации. Наборы реплик обеспечивают избыточность и высокую доступность и являются основой для всех производственных развертываний.
Масштабируемость и высокая доступность современных веб-приложений позволяют справляться с большой рабочей нагрузкой, обеспечивать постоянное время отклика, упростить обслуживание системы и снизить эксплуатационные расходы. Кроме того, приложения должны обрабатывать растущее число пользователей, использующих приложения одновременно. Эти требования с точки зрения масштабируемости — это функции, которые MongoDB может поддерживать благодаря своей горизонтально масштабируемой архитектуре. Внедрение их в веб-приложения может принести бизнесу множество преимуществ и, следовательно, становится жизненно важным.
Реляционные базы данных, с другой стороны, может быть сложно настроить таким образом, чтобы данные распределялись между несколькими системами и масштабировались горизонтально, отчасти из-за реляционной модели данных. Таким образом, большинство систем управления базами данных SQL используют масштабируемую архитектуру, основанную на покупке более быстрого и мощного оборудования для удовлетворения требований использования.
Резюме
MongoDB — одна из самых популярных баз данных NoSQL, которая широко используется в различных отраслях и вариантах использования. Будучи очень универсальным решением для управления данными, MongoDB предоставляет мощные возможности масштабирования, согласованности, отказоустойчивости, оперативности и гибкости, что способствует быстрой разработке и малому времени простоя.
Авторские права и товарный знак
Поддержка Canonical MongoDB, управляемые приложения и решения Charm созданы Canonical на основе исходного кода, опубликованного MongoDB Inc. Этот продукт не одобрен и не опубликован MongoDB, Inc.
MongoDB и логотип являются товарными знаками или зарегистрированными товарными знаками MongoDB Inc., и другие стороны также могут иметь права на товарные знаки в других терминах, используемых в настоящем документе.
Что такое MongoDB и зачем ее использовать?
В мире баз данных наиболее распространенными и популярными системами баз данных являются СУБД (системы управления реляционными базами данных). Теперь, если мы хотим разработать приложение, которое работает с большим объемом данных, нам нужно выбрать одну такую базу данных, которая всегда обеспечивает высокопроизводительные решения для хранения данных. Таким образом, мы можем добиться производительности решения с точки зрения хранения и извлечения данных с точностью, скоростью и надежностью. Теперь, если мы классифицировали решения для баз данных, то в основном доступны два типа категорий баз данных, т. е. RDBMS или реляционная база данных, такая как SQL Server, Oracle и т. д., а другой тип — это база данных NoSQL, такая как MongoDB, CosmosDB и т. д.
База данных NoSQL на самом деле является альтернативой обычной базе данных SQL, а также этот тип базы данных предоставляет в основном все типы функций, которые обычно доступны в системах СУБД. В настоящее время базы данных NoSQL становятся более популярными по сравнению с прошлым благодаря простому дизайну, возможности как горизонтального, так и вертикального масштабирования, а также легкому и простому контролю над хранимыми данными. Этот тип базы данных в основном нарушает обычную традицию структуры хранения данных реляционной базы данных. Это дает разработчикам возможность хранить данные в базе данных в соответствии с фактическими требованиями их программы. Мы не можем достичь такого типа возможностей, используя традиционную базу данных RDBMS.
Также прочтите – 20 основных вопросов и ответов на собеседованиях по MongoDB
Типы NoSQL
Базы данных NoSQL можно разделить на четыре различных типа, как указано ниже:
Из этих четырех типов базы данных документов являются наиболее популярными и широко используемыми. базы данных в современном мире. Этот тип баз данных всегда разрабатывался на основе документно-ориентированного подхода к хранению данных. Этот тип баз данных всегда играет важную роль в агрегировании данных из документов, а также представляет данные в очень простой и доступной для поиска или организованной форме. MongoDB — наиболее часто используемая база данных в индустрии разработки в качестве базы данных документов. В базах данных документов основная концепция таблицы и строки по сравнению с базой данных SQL была изменена. Здесь строка была заменена термином документ, который является гораздо более гибкой и основанной на модели структурой данных. Мы можем хранить иерархические данные в одном документе в базе данных документов. На самом деле база данных документов всегда поддерживает полуструктурированную модель данных. В базе документов. Таблица была заменена термином «Коллекция», который представляет собой контейнер из нескольких документов с одинаковой или разной структурой.
Что такое MongoDB?
MongoDB — одна из самых популярных баз данных NoSQL с открытым исходным кодом, написанная на C++. По состоянию на февраль 2015 года MongoDB является четвертой по популярности системой управления базами данных. Он был разработан компанией 10gen, которая теперь известна как MongoDB Inc.
MongoDB — это документно-ориентированная база данных, которая хранит данные в JSON-подобных документах с динамической схемой. Это означает, что вы можете хранить свои записи, не беспокоясь о структуре данных, например о количестве полей или типах полей для хранения значений. Документы MongoDB аналогичны объектам JSON.
История версий
MongoDB — это документная база данных, разработанная на языках программирования C++. Слово Mongo в основном происходит от Humongous. MongoDB была впервые разработана нью-йоркской организацией под названием 10gen в 2007 году. Позже 10gen сменила название и на сегодняшний день известна как MongoDB Inc. Вначале MongoDB в основном разрабатывалась как база данных PAAS (платформа как услуга). Но в 2009 году она была представлена как база данных с открытым исходным кодом под названием MongoDB 1. 0. На приведенной ниже диаграмме показана история выпусков MongoDB на сегодняшний день. MongoDB 4.0 — это текущая стабильная версия, выпущенная в феврале 2018 года.0003
Кто использует MongoDB?
В современной ИТ-индустрии существует большое количество компаний, которые используют MongoDB в качестве службы базы данных для приложений или систем хранения данных. Согласно опросу, проведенному Siftery в MongoDB, более 4000 компаний подтвердили, что они используют MongoDB в качестве базы данных. Вот некоторые из ключевых имен:
Castlight Health
IBM
Ситрикс
Твиттер
Т-Мобайл
Зендеск
Сони
БрайтРолл
Foursquare
ХТК
Инвижн
Домофон и т. д.
Как MongoDB хранит данные?
Как вы знаете, RDMS хранит данные в формате таблиц и использует язык структурированных запросов (SQL) для запросов к базе данных. РСУБД также имеет предопределенную схему базы данных, основанную на требованиях и наборе правил для определения отношений между полями в таблицах.
Но MongoDB хранит данные в документах, несмотря на таблицы. Вы можете изменить структуру записей (которая в MongoDB называется документами), просто добавив новые поля или удалив существующие. Эта способность MongoDB помогает вам легко представлять иерархические отношения, хранить массивы и другие более сложные структуры. MongoDB обеспечивает высокую производительность, высокую доступность, простую масштабируемость, готовую репликацию и автоматическое сегментирование.
Почему и где следует использовать Mongo DB?
Поскольку MongoDB является базой данных NoSQL, нам нужно понять, когда и почему нам нужно использовать этот тип базы данных в реальных приложениях. Так как в обычных обстоятельствах разработчики или менеджеры проектов всегда предпочитают MongoDB, когда нашей основной задачей является работа с большими объемами данных с высокой производительностью. Если мы хотим вставлять тысячи записей в секунду, MongoDB — лучший выбор для этого. Кроме того, горизонтальное масштабирование (добавление новых столбцов) не является таким простым процессом в любых системах СУБД. Но в случае MongoDB это очень просто, поскольку это база данных без схемы. Кроме того, этот тип работы может выполняться непосредственно приложением автоматически. Нет необходимости в какой-либо административной работе для выполнения любого типа горизонтального масштабирования в MongoDB. MongoDB хорош для следующих типов ситуаций:
Тип приложений для электронной коммерции
Системы управления блогами и контентом
Высокоскоростное ведение журнала, кэширование и т. д. в режиме реального времени
Необходимость хранения геопространственных данных с учетом местоположения
Для ведения данных, относящихся к типам Social и Networking
Если приложение представляет собой слабосвязанный механизм, значит конструкция может измениться в любой момент времени.
Преимущества MongoDB
Поскольку MongoDB — это не только база данных, которая может выполнять только операции CRUD (создание, чтение, обновление и удаление) с данными. Помимо этого, MongoDB также содержит так много важных функций, благодаря которым MongoDB стала самой популярной базой данных в категории NoSQL. Вот некоторые из важных особенностей:
MongoDB — это база данных без схемы документов.
Поле поддержки MongoDB, запрос на основе диапазона, регулярное выражение или регулярное выражение и т. д. для поиска данных из сохраненных данных.
MongoDB очень легко масштабировать.
MongoDB в основном использует внутреннюю память для хранения рабочих временных наборов данных, для которых это намного быстрее.
MongoDB поддерживает первичный и вторичный индекс для любых полей.
MongoDB поддерживает репликацию базы данных.
Мы можем выполнить балансировку нагрузки в MongoDB с помощью Sharding.
Он масштабирует базу данных по горизонтали с помощью Sharding.MongoDB можно использовать в качестве системы хранения файлов, известной как GridFS.
MongoDB предоставляет различные способы выполнения операций агрегации данных, таких как конвейер агрегации, уменьшение карты или команды агрегации с одной целью.
MongoDB может хранить файлы любого типа и любого размера, не влияя на наш стек
MongoDB в основном использует объекты JavaScript вместо процедур.
MongoDB поддерживает специальный тип сбора данных, такой как TTL (Time-To-Live), для хранения данных, срок действия которых истекает в определенное время
Динамическая схема базы данных, используемая в MongoDB, называется BSON
Поддержка платформ и языков
Как и другие системы СУБД, MongoDB также предоставляет официальную поддержку большого количества языков программирования и сред. Драйверы Mongo доступны для следующих популярных языков и платформ:
Сравнение между схемой SqlDB и схемой MongoDB
Поскольку, если мы не очень хорошо знакомы с системами баз данных MongoDB и в основном знаем о системах СУБД, то в приведенных ниже таблицах представлены простые терминологические переводы из SQL DB в схему MongoDB.
SQL Server
MongoDB
База данных
База данных
Таблица
Коллекция
Строка
Индекс
Индекс
30003
столбец
Поле
Присоединение
Связывание и встраивание
Раздел
Sharding
Репликация
Replset
MongoDB Ограничения
С тех пор, в вышеупомянутом разделе мы обсудим основные примерно по поводу MongoDB. Но, несмотря на эти преимущества, у MongoDB также есть некоторые ограничения, такие как:
Поскольку MongoDB не такой сильный ACID (атомарность, согласованность, изоляция и долговечность) по сравнению с большинством систем СУБД.