Объединение таблиц при запросе (JOIN) в SQL
С помощью команды SELECT можно выбрать данные не только из одной таблицы, но и нескольких. Такая задача появляется довольно часто, потому что принято разносить данные по разным таблицам в зависимости от хранимой в них информации. К примеру, в одной таблице хранится информация о пользователях, во второй таблице о должностях компании, а в третьей и четвёртой о поставщиках и клиентах. Данные разбивают на таблицы так, чтобы с одной стороны получить самую высокую скорость выполнения запроса, а с другой стороны избежать ненужных объединений, которые снижают производительность.
Чем больше столбцов в таблице — тем сильнее падает скорость выборки из неё. Поэтому стараются делать в каждой таблице не больше 5-10 столбцов. Но чем сильнее данные разбиваются на разные таблицы, тем больше придётся делать объединений внутри запросов, что тоже снизит скорость получения выборки и увеличит нагрузку на базу.
Приведём пример запроса с объединением данных из двух таблиц. Для этого предположим, что существует две таблицы. Первая таблица будет иметь название USERS и будет иметь два столбца: ID и именами пользователей:
+-----------+ | USERS | +-----------+ | ID | NAME | +----+------+ | 1 | Мышь | +----+------+ | 2 | Кот | +----+------+
Вторая таблица будет называться FOOD и будет содержать два столбца: USER_ID и NAME. В этой таблице будет содержаться список любимых блюд пользователей из первой таблицы. В столбце USER_ID содержится ID пользователя, а в столбце PRODUCT находится название любимого блюда.
+-------------------+ | FOOD | +-------------------+ | USER_ID | PRODUCT | +---------+---------+ | 1 | Сыр | +---------+---------+ | 2 | Молоко | +---------+---------+
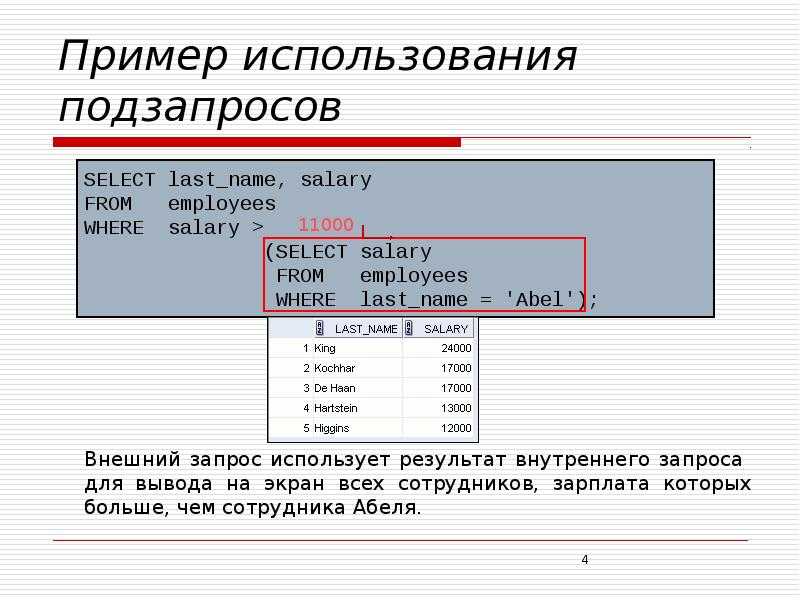
Условимся что поле ID в таблице USERS и поле USER_ID в таблице FOOD являются первичными ключами (то есть имеют уникальные значения, которые не повторяются).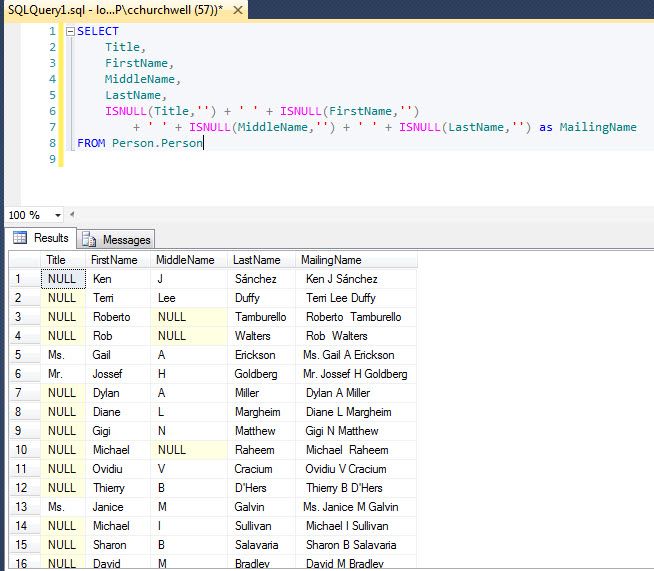 Теперь попробуем использовать логику и найти любимое блюдо пользователя «Мышь», используя обе таблицы. Для этого мы сначала посмотрим в первую таблицу и найдём ID пользователя под именем «Мышь», а затем найдём название продукта под таким же ID во второй таблице. Объединяющие SQL запросы работают по такой же логике: нужен столбец, в по которому таблицы могут быть объединены.
Теперь попробуем использовать логику и найти любимое блюдо пользователя «Мышь», используя обе таблицы. Для этого мы сначала посмотрим в первую таблицу и найдём ID пользователя под именем «Мышь», а затем найдём название продукта под таким же ID во второй таблице. Объединяющие SQL запросы работают по такой же логике: нужен столбец, в по которому таблицы могут быть объединены.
Продемонстрируем запрос, объединяющий таблицы по столбцам ID и USER_ID:
SELECT * FROM `USERS` INNER JOIN `FOOD` ON `USERS`.`ID`=`FOOD`.`USER_ID`;
Разберём команду по словам. Начинается она как обычная выборка из одной таблицы со слов «SELECT * FROM USERS». Но затем идёт слово INNER, которое означает тип объединения. Существует три типа объединения таблиц: INNER, LEFT, RIGHT. Все они связаны с тем, что некоторым строкам в одной таблице может не найтись соответствующей строки во второй таблице. В таком случае при использовании «INNER» из результатов запроса будет удалены все строки, которым не нашлась соответствующая пара в другой таблице.
После слова «INNER» стоит слово «JOIN» (которое переводится с английского как «ПРИСОЕДИНИТЬ»). После слова «JOIN» стоит название таблицы, которая будет присоединена. В нашем случае это таблица FOOD. После названия таблицы стоит слово «ON» и равенство USERS.ID=FOOD.USER_ID, которое задаёт правило присоединения. При выполнении выборки будут объединены две таблицы так, чтобы значения в столбце ID таблицы USERS равнялось значению USER_ID таблицы FOOD.
В результате выполнения этого SQL запроса мы получим таблицу с четырьмя столбцами:
+----+------+---------+---------+ | ID | NAME | USER_ID | PRODUCT | +----+------+---------+---------+ | 1 | Мышь | 1 | Сыр | +----+------+---------+---------+ | 2 | Кот | 2 | Молоко | +----+------+---------+---------+
Предлагаем модифицировать запрос, потому что нам не нужны все четыре столбца.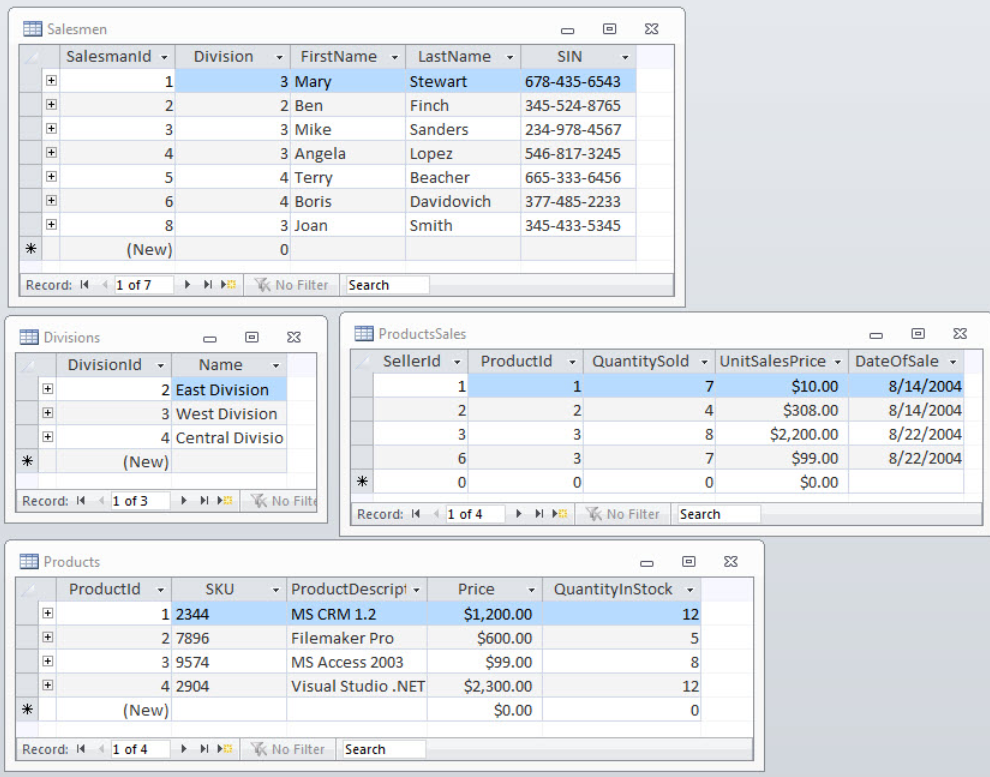 Уберём столбцы ID и USER_ID. Для этого вместо * в команде SELECT поставим название столбцов. Но необходимо сделать это, ставя сначала название таблицы и через точку название столбца. Чтобы получилось так:
Уберём столбцы ID и USER_ID. Для этого вместо * в команде SELECT поставим название столбцов. Но необходимо сделать это, ставя сначала название таблицы и через точку название столбца. Чтобы получилось так:
SELECT `USERS`.`NAME`, `FOOD`.`PRODUCT` FROM `USERS` INNER JOIN `FOOD` ON `USERS`.`ID`=`FOOD`.`USER_ID`;
Теперь результат будет компактнее. И благодаря уменьшенному количеству запрашиваемых данных, результат будет получаться из базы быстрее:
+------+---------+ | NAME | PRODUCT | +------+---------+ | Мышь | Сыр | +------+---------+ | Кот | Молоко | +------+---------+
Если в двух таблицах имеются столбцы с одинаковыми названиями, то будет показан только последний столбце с таким названием. Чтобы этого не происходило, выбирайте определённый столбцы и используйте команду «AS» с помощью которой можно переименовать столбец в результатах выборки.
Давайте теперь решим логическую задачу, которую поставили в начале статьи. Попробуем выбрать в этой объединённой таблице только одну строку, которая соответствует пользователю «Мышь». Для этого используем условие WHERE в SQL запросе:
SELECT `USERS`.`NAME`, `FOOD`.`PRODUCT` FROM `USERS` INNER JOIN `FOOD` ON `USERS`.`ID`=`FOOD`.`USER_ID` WHERE `USERS`.`NAME` LIKE 'Мышь';
Обратите внимание, что в условии WHERE название полей так же необходимо ставить вместе с названием таблицы через точку: USERS.NAME. В результате выполнения этого запроса появится такой результат:
+------+---------+ | NAME | PRODUCT | +------+---------+ | Мышь | Сыр | +------+---------+
Отлично! Теперь мы знаем, как делать объединение таблиц.
Была ли эта статья полезна? Есть вопрос?
Закажите недорогой хостинг Заказать
всего от 290 руб
Многотабличные запросы, оператор JOIN
Многотабличные запросы
В предыдущих статьях описывалась работа только с одной таблицей базы данных. В реальности же очень часто приходится делать выборку из нескольких таблиц, каким-то образом объединяя их. В данной статье вы узнаете основные способы соединения таблиц.
В реальности же очень часто приходится делать выборку из нескольких таблиц, каким-то образом объединяя их. В данной статье вы узнаете основные способы соединения таблиц.
Общая структура многотабличного запроса
SELECT поля_таблиц
FROM таблица_1
[INNER] | [[LEFT | RIGHT | FULL][OUTER]] JOIN таблица_2
ON условие_соединения
[[INNER] | [[LEFT | RIGHT | FULL][OUTER]] JOIN таблица_n
ON условие_соединения]Эту же структуру можно переписать следующим образом:
SELECT поля_таблиц
FROM таблица_1
[INNER] | [[LEFT | RIGHT | FULL][OUTER]] JOIN таблица_2[ JOIN таблица_n]
ON условие_соединения [AND условие_соединения]В большинстве случаев условием соединения является равенство столбцов таблиц (таблица_1.поле = таблица_2.поле), однако точно так же можно использовать и другие операторы сравнения.
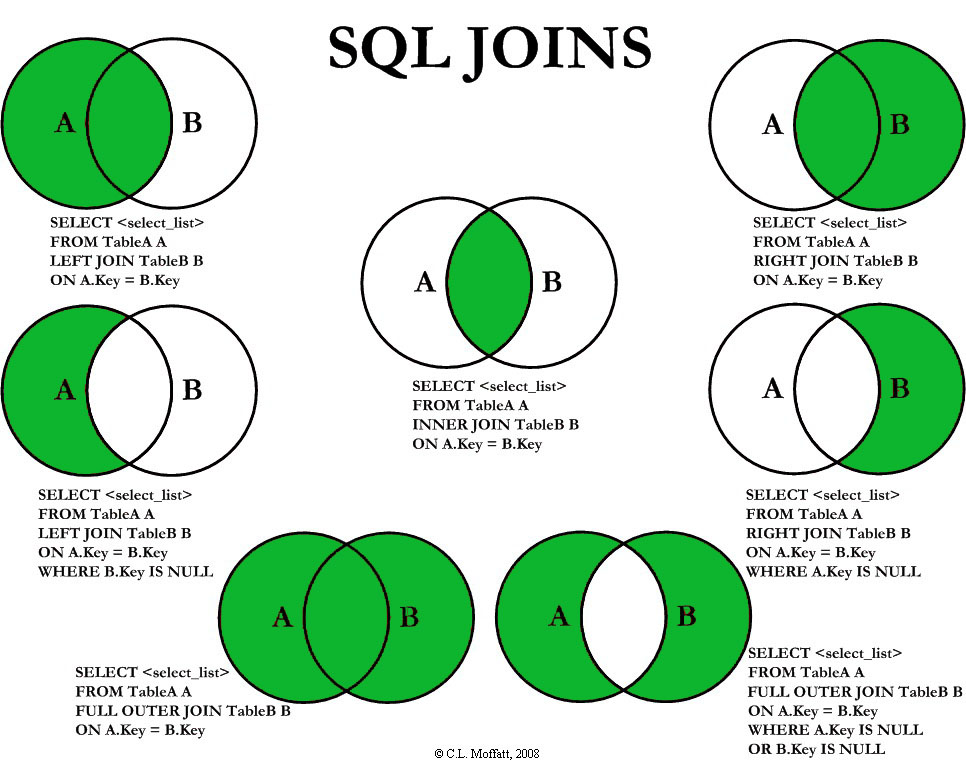
Соединение бывает внутренним (INNER) или внешним (OUTER), при этом внешнее соединение делится на левое (LEFT), правое (RIGHT) и полное (FULL).
INNER JOIN
По умолчанию, если не указаны какие-либо параметры, JOIN выполняется как INNER JOIN, то есть как внутреннее (перекрёстное) соединение таблиц.
Внутреннее соединение — соединение двух таблиц, при котором каждая запись из первой таблицы соединяется с каждой записью второй таблицы, создавая тем самым все возможные комбинации записей обеих таблиц (декартово произведение).
Например, объединим таблицы покупок (Payments) и членов семьи (FamilyMembers) таким образом, чтобы дополнить каждую покупку данными о том, кто её совершил.
Данные в таблице Payments:
Данные в таблице FamilyMembers:
Для того, чтобы решить поставленную задачу выполним запрос, который объединяет поля строки из одной таблицы с полями другой, если выполняется условие, что покупатель товара (family_member) совпадает с идентификатором члена семьи (member_id):
SELECT *
FROM Payments
JOIN FamilyMembers ON family_member = member_id;В результате вы можете видеть, что каждая строка из таблицы Payments дополнилась данными о члене семьи, который совершил покупку. Обратите внимание на поля family_member и member_id — они одинаковы, что и было отражено в запросе.
Использование WHERE для соединения таблиц
Для внутреннего соединения таблиц также можно использовать оператор WHERE. Например, вышеприведённый запрос, написанный с помощью INNER JOIN, будет выглядеть так:
SELECT * FROM Payments, FamilyMembers WHERE family_member = member_id;
OUTER JOIN
Внешнее соединение может быть трёх типов: левое (LEFT), правое (RIGHT) и полное (FULL). По умолчанию оно является полным.
Главным отличием внешнего соединения от внутреннего является то, что оно обязательно возвращает все строки одной (LEFT, RIGHT) или двух таблиц (FULL).
Внешнее левое соединение (LEFT OUTER JOIN)
Соединение, которое возвращает все значения из левой таблицы, соединённые с соответствующими значениями из правой таблицы если они удовлетворяют условию соединения, или заменяет их на NULL в обратном случае.
Для примера получим из базы данных расписание звонков объединённых с соответствующими занятиями в расписании занятий:
SELECT *
FROM Timepair
LEFT JOIN Schedule ON Schedule. number_pair = Timepair.id;
number_pair = Timepair.id;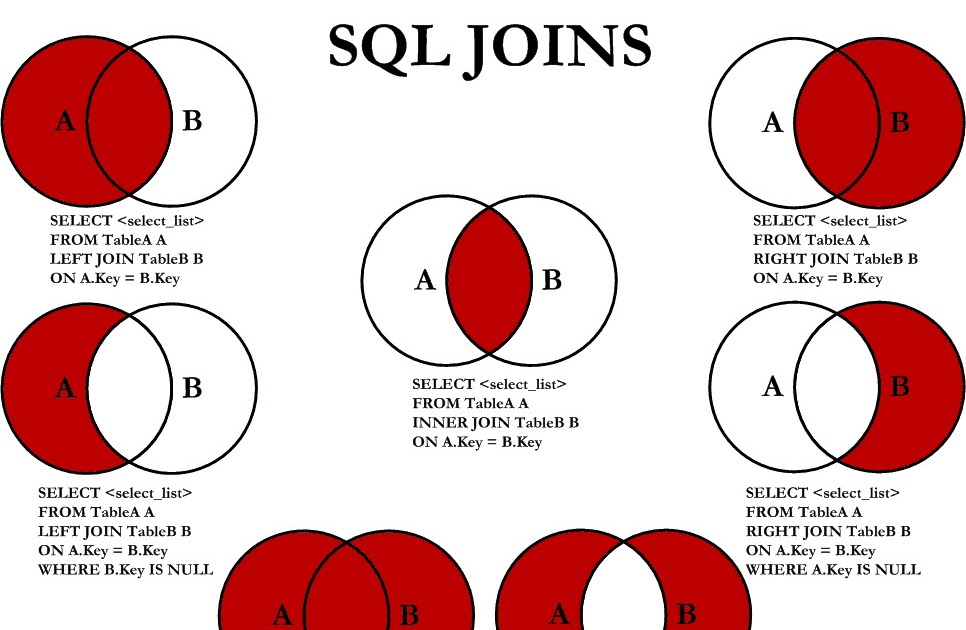 number_pair = Timepair.id;
number_pair = Timepair.id;Данные в таблице Timepair (расписание звонков):
Данные в таблице Schedule (расписание занятий):
В выборку попали все строки из левой таблицы, дополненные данными о занятиях. Примечательно, что в конце таблицы есть строки с полями, заполненными NULL. Это те строки, для которых не нашлось соответствующих занятий, однако они присутствуют в левой таблице, поэтому тоже были выведены.
Внешнее правое соединение (RIGHT OUTER JOIN)
Соединение, которое возвращает все значения из правой таблицы, соединённые с соответствующими значениями из левой таблицы если они удовлетворяют условию соединения, или заменяет их на NULL в обратном случае.
Внешнее полное соединение (FULL OUTER JOIN)
Соединение, которое выполняет внутреннее соединение записей и дополняет их левым внешним соединением и правым внешним соединением.
Алгоритм работы полного соединения:
- Формируется таблица на основе внутреннего соединения (INNER JOIN).
- В таблицу добавляются значения не вошедшие в результат формирования из левой таблицы (LEFT OUTER JOIN).
- В таблицу добавляются значения не вошедшие в результат формирования из правой таблицы (RIGHT OUTER JOIN).
Соединение FULL JOIN реализовано не во всех СУБД. Например, в MySQL оно отсутствует, однако его можно очень просто эмулировать:
SELECT *
FROM левая_таблица
LEFT JOIN правая_таблица
ON правая_таблица.ключ = левая_таблица.ключ
UNION ALL
SELECT *
FROM левая_таблица
RIGHT JOIN правая_таблица
ON правая_таблица.ключ = левая_таблица.ключ
WHERE левая_таблица.key IS NULLБазовые запросы для разных вариантов объединения таблиц
| Схема | Запрос с JOIN |
|---|---|
Получение всех данных из левой таблицы, соединённых с соответствующими данными из правой:SELECT поля_таблиц
FROM левая_таблица LEFT JOIN правая_таблица
ON правая_таблица.ключ = левая_таблица. | |
Получение всех данных из правой таблицы, соединённых с соответствующими данными из левой:SELECT поля_таблиц
FROM левая_таблица RIGHT JOIN правая_таблица
ON правая_таблица.ключ = левая_таблица.ключ | |
Получение данных, относящихся только к левой таблице:SELECT поля_таблиц
FROM левая_таблица LEFT JOIN правая_таблица
ON правая_таблица.ключ = левая_таблица.ключ
WHERE правая_таблица.ключ IS NULL | |
Получение данных, относящихся только к правой таблице:SELECT поля_таблиц
FROM левая_таблица RIGHT JOIN правая_таблица
ON правая_таблица.ключ = левая_таблица.ключ
WHERE левая_таблица.ключ IS NULL | |
Получение данных, относящихся как к левой, так и к правой таблице:SELECT поля_таблиц
FROM левая_таблица INNER JOIN правая_таблица
ON правая_таблица.ключ = левая_таблица.ключ | |
Получение всех данных, относящихся к левой и правой таблицам, а также их внутреннему соединению:SELECT поля_таблиц
FROM левая_таблица
FULL OUTER JOIN правая_таблица
ON правая_таблица. | |
Получение данных, не относящихся к левой и правой таблицам одновременно (обратное INNER JOIN):SELECT поля_таблиц
FROM левая_таблица
FULL OUTER JOIN правая_таблица
ON правая_таблица.ключ = левая_таблица.ключ
WHERE левая_таблица.ключ IS NULL
OR правая_таблица.ключ IS NULL |
 ключ
ключ ключ = левая_таблица.ключ
ключ = левая_таблица.ключРуководство по SQL. Объединения. – PROSELYTE
Для комбинирования результатов двух и более SQL запросов без возвращения повторяющихся данных используется оператор UNION.
Для того, чтобы мы могли использовать данный оператор, каждый из запросов SELECT должен содержать одинаковое количество выбранных колонок, одинаковое количество выражений, одинаковые типы данных и иметь одинаковый порядок.
Запрос с использованием оператора UNION имеет следующий вид:
SELECT колонка1 [, колонка2 ] FROM таблица1 [, таблица2 ] [WHERE условие] UNION SELECT колонка1 [, колонка2 ] FROM таблица1 [, таблица2 ] [WHERE условие]
Пример:
Предположим, что у нас есть две таблицы:
developers:
+----+-------------------+------------+------------+--------+ | ID | NAME | SPECIALTY | EXPERIENCE | SALARY | +----+-------------------+------------+------------+--------+ | 1 | Eugene Suleimanov | Java | 2 | 2500 | | 2 | Peter Romanenko | Java | 3 | 3500 | | 3 | Andrei Komarov | JavaScript | 3 | 2500 | | 4 | Konstantin Geiko | C# | 2 | 2000 | | 5 | Asya Suleimanova | UI/UX | 2 | 1800 | | 6 | Kolya Nikolaev | Javascript | 5 | 3400 | | 7 | Ivan Ivanov | C# | 1 | 900 | | 8 | Ludmila Geiko | UI/UX | 2 | 1800 | +----+-------------------+------------+------------+--------+
tasks:
+---------+-------------+------------------+------------+--------------+ | TASK_ID | TASK_NAME | DESCRIPTION | DEADLINE | DEVELOPER_ID | +---------+-------------+------------------+------------+--------------+ | 1 | Bug#123 | Fix company list | 2016-06-03 | 1 | | 2 | Bug#321 | Fix registration | 2016-06-06 | 2 | | 3 | Feature#777 | Latest actions | 2016-06-25 | 3 | +---------+-------------+------------------+------------+--------------+
Попробуем выполнить следующий запрос:
mysql> SELECT ID, NAME, TASK_NAME, DEADLINE FROM developers LEFT JOIN tasks ON developers.
 ID = tasks.DEVELOPER_ID
UNION
SELECT ID, NAME, TASK_NAME, DEADLINE
FROM developers
RIGHT JOIN tasks
ON developers.ID = tasks.DEVELOPER_ID;
ID = tasks.DEVELOPER_ID
UNION
SELECT ID, NAME, TASK_NAME, DEADLINE
FROM developers
RIGHT JOIN tasks
ON developers.ID = tasks.DEVELOPER_ID;
В результате мы получим следующий результат:
+------+-------------------+-------------+------------+ | ID | NAME | TASK_NAME | DEADLINE | +------+-------------------+-------------+------------+ | 1 | Eugene Suleimanov | Bug#123 | 2016-06-03 | | 2 | Peter Romanenko | Bug#321 | 2016-06-06 | | 3 | Andrei Komarov | Feature#777 | 2016-06-25 | | 4 | Konstantin Geiko | NULL | NULL | | 5 | Asya Suleimanova | NULL | NULL | | 6 | Kolya Nikolaev | NULL | NULL | | 7 | Ivan Ivanov | NULL | NULL | | 8 | Ludmila Geiko | NULL | NULL | +------+-------------------+-------------+------------+
Элемент UNION ALL
Элемент UNION ALL комбинирует результаты двух запросов SELECT, исключая повторяющиеся записи.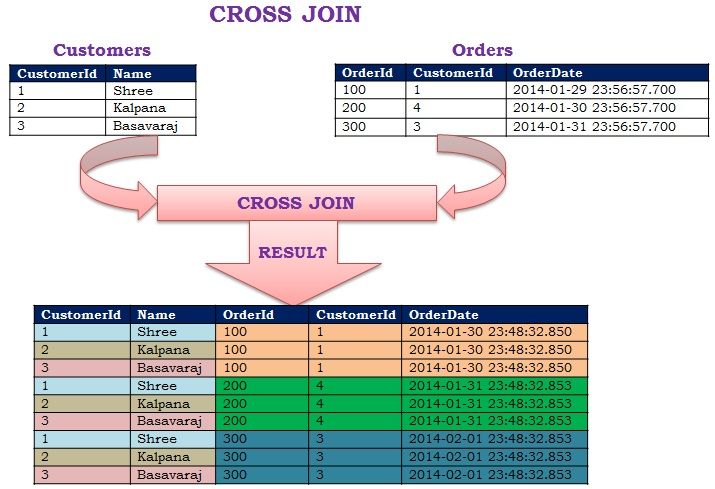
Данный запрос имеет следующий вид:
SELECT колонка1 [, колонка2 ] FROM таблица1 [, таблица2 ] [WHERE условие] UNION ALL SELECT колонка1 [, колонка2 ] FROM таблица1 [, таблица2 ] [WHERE условие]
Пример:
Предположим, что у нас есть две таблицы:
developers:
+----+-------------------+------------+------------+--------+ | ID | NAME | SPECIALTY | EXPERIENCE | SALARY | +----+-------------------+------------+------------+--------+ | 1 | Eugene Suleimanov | Java | 2 | 2500 | | 2 | Peter Romanenko | Java | 3 | 3500 | | 3 | Andrei Komarov | JavaScript | 3 | 2500 | | 4 | Konstantin Geiko | C# | 2 | 2000 | | 5 | Asya Suleimanova | UI/UX | 2 | 1800 | | 6 | Kolya Nikolaev | Javascript | 5 | 3400 | | 7 | Ivan Ivanov | C# | 1 | 900 | | 8 | Ludmila Geiko | UI/UX | 2 | 1800 | +----+-------------------+------------+------------+--------+
tasks:
+---------+-------------+------------------+------------+--------------+ | TASK_ID | TASK_NAME | DESCRIPTION | DEADLINE | DEVELOPER_ID | +---------+-------------+------------------+------------+--------------+ | 1 | Bug#123 | Fix company list | 2016-06-03 | 1 | | 2 | Bug#321 | Fix registration | 2016-06-06 | 2 | | 3 | Feature#777 | Latest actions | 2016-06-25 | 3 | +---------+-------------+------------------+------------+--------------+
Попробуем выполнить следующий запрос:
mysql> SELECT ID, NAME, TASK_NAME, DEADLINE FROM developers LEFT JOIN tasks ON developers.
 ID = tasks.DEVELOPER_ID
UNION ALL
SELECT ID, NAME, TASK_NAME, DEADLINE
FROM developers
RIGHT JOIN tasks
ON developers.ID = tasks.DEVELOPER_ID;
ID = tasks.DEVELOPER_ID
UNION ALL
SELECT ID, NAME, TASK_NAME, DEADLINE
FROM developers
RIGHT JOIN tasks
ON developers.ID = tasks.DEVELOPER_ID;
В результате мы получим следующую таблицу:
+------+-------------------+-------------+------------+ | ID | NAME | TASK_NAME | DEADLINE | +------+-------------------+-------------+------------+ | 1 | Eugene Suleimanov | Bug#123 | 2016-06-03 | | 2 | Peter Romanenko | Bug#321 | 2016-06-06 | | 3 | Andrei Komarov | Feature#777 | 2016-06-25 | | 4 | Konstantin Geiko | NULL | NULL | | 5 | Asya Suleimanova | NULL | NULL | | 6 | Kolya Nikolaev | NULL | NULL | | 7 | Ivan Ivanov | NULL | NULL | | 8 | Ludmila Geiko | NULL | NULL | | 1 | Eugene Suleimanov | Bug#123 | 2016-06-03 | | 2 | Peter Romanenko | Bug#321 | 2016-06-06 | | 3 | Andrei Komarov | Feature#777 | 2016-06-25 | +------+-------------------+-------------+------------+
Как мы видим, таблица содержит результаты обоих запросов SELECT и данные повторяются.
Существует два других оператора, чьё поведение крайне схоже с UNION:
- INTERSECT
Комбинирует два запроса SELECT, но возвращает записи только первого SELECT, которые имеют совпадения во втором элементе SELECT. - EXCEPT
Комбинирует два запроса SELECT, но возвращает записи только первого SELECT, которые не имеют совпадения во втором элементе SELECT.
На этом мы заканчиваем изучение способов объединения данных.
В следующей статье мы рассмотрим индексы.
Как соединить три таблицы в SQL-запросе – Пример MySQL
Три таблицы JOIN Пример SQL Соединение трех таблиц в одном SQL-запросе может быть очень сложным, если вы плохо разбираетесь в концепции SQL Join. Соединения SQL всегда были сложными не только для новых программистов, но и для многих других, кто занимается программированием и SQL более 2-3 лет. Их достаточно, чтобы запутать кого-то в SQL JOIN, начиная от различных типов SQL JOIN, таких как соединение INNER и OUTER, внешнее соединение LEFT и RIGHT, соединение CROSS и т.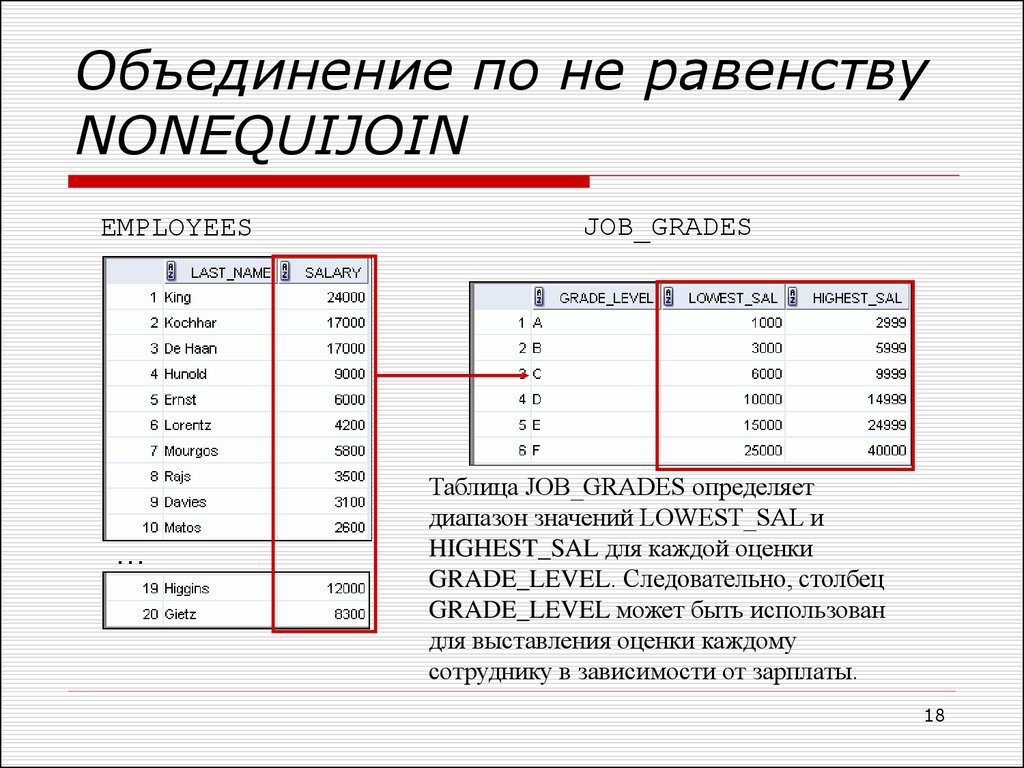 д. Среди всех этих основ самое важное в соединении — это объединение нескольких таблиц. . Если вам нужны данные из нескольких таблиц в одном запросе SELECT, вам нужно использовать либо подзапрос, либо JOIN.
д. Среди всех этих основ самое важное в соединении — это объединение нескольких таблиц. . Если вам нужны данные из нескольких таблиц в одном запросе SELECT, вам нужно использовать либо подзапрос, либо JOIN.
В большинстве случаев мы объединяем только две таблицы, такие как Employee и Department, но иногда может потребоваться объединение более двух таблиц, и популярным случаем является объединение трех таблиц в SQL.
В случае объединения трех таблиц таблица 1 относится к таблице 2, а затем таблица 2 относится к таблице 3. Если вы внимательно посмотрите, вы обнаружите, что таблица 2 – это объединяющая таблица, которая содержит первичный ключ как из таблицы 1, так и из таблицы. 2. Как я уже сказал, может быть очень сложно понять объединение трех или более таблиц.
Я обнаружил, что понимание отношений между таблицами как первичного ключа и внешнего ключа помогает избежать путаницы, чем классическая парадигма сопоставления строк.
Объединение SQL также является очень популярной темой на собеседованиях по SQL, и всегда были некоторые вопросы от объединений, например, о разнице между ВНУТРЕННИМ и ВНЕШНИМ СОЕДИНЕНИЕМ, SQL-запросе с СОЕДИНЕНИЕМ, таких как отношения отдела сотрудников и разница между ЛЕВЫМ и ПРАВЫМ ВНЕШНИМ СОЕДИНЕНИЕМ и т. д. Короче говоря, это одна из самых важных тем в SQL как с точки зрения опыта, так и с точки зрения интервью.
д. Короче говоря, это одна из самых важных тем в SQL как с точки зрения опыта, так и с точки зрения интервью.
Ниже приведен общий синтаксис запроса SQL для объединения трех или более таблиц. Этот SQL-запрос должен работать во всех основных реляционных базах данных, таких как MySQL, Oracle, Microsoft SQLServer, Sybase и PostgreSQL:
SELECT t1.col, t3.col
FROM table1
JOIN table2 ON 1. table первичный ключ = таблица2.внешний ключ
ПРИСОЕДИНЯЙТЕСЬ таблица3 ON table2.primarykey = table3.foreignkey
Сначала мы объединяем таблицы 1 и 2, которые создают временную таблицу с объединенными данными из таблиц 1 и 2, которая затем соединяется с таблицей 3. Эта формула может быть расширена до более чем 3 таблиц до N таблиц. Вам просто нужно убедиться, что SQL-запрос должен иметь оператор соединения N-1, чтобы присоединиться к N таблицам. для соединения двух таблиц нам требуется 1 оператор соединения, а для соединения 3 таблиц нам нужны 2 оператора соединения.
для соединения двух таблиц нам требуется 1 оператор соединения, а для соединения 3 таблиц нам нужны 2 оператора соединения.
Вот хорошая диаграмма, которая также показывает, как различные типы JOIN, например. внутренние, левые внешние, правые внешние и перекрестные соединения работают в SQL:
SQL-запрос для соединения трех таблиц в MySQL
Чтобы лучше понять объединение трех таблиц в SQL-запросе , давайте рассмотрим пример. Рассмотрим популярный пример схемы Сотрудник и Отдел. В нашем случае мы использовали таблицу ссылок под названием «Реестр», которая связывает или связывает как сотрудника с отделом.
Первичный ключ таблицы «Сотрудник» (emp_id) является внешним ключом в таблице «Реестр», и аналогичным образом первичный ключ таблицы «Отдел» (dept_id) является внешним ключом в таблице «Реестр».
Кстати, единственный способ освоить SQL-соединение — делать как можно больше упражнений.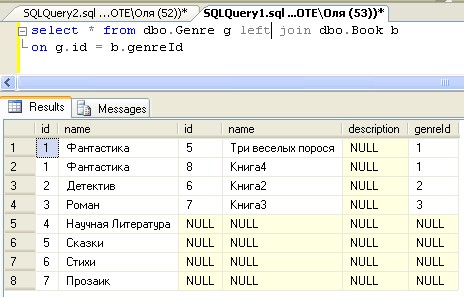 Если бы вы могли решить большинство головоломок SQL из классической книги Джо Селко «Загадки SQL и ответы», 2-е издание, вы бы более уверенно справлялись с соединениями SQL, будь то две, три или четыре таблицы.
Если бы вы могли решить большинство головоломок SQL из классической книги Джо Селко «Загадки SQL и ответы», 2-е издание, вы бы более уверенно справлялись с соединениями SQL, будь то две, три или четыре таблицы.
Чтобы написать SQL-запрос для печати имени сотрудника и названия отдела , нам нужно объединить 3 таблицы . Первый оператор JOIN соединит Employee и Register и создаст временную таблицу, которая будет иметь dept_id в качестве другого столбца. Теперь второй оператор JOIN соединит эту временную таблицу с таблицей отдела по dept_id, чтобы получить желаемый результат.
Вот полный пример SQL-запроса SELECT для объединения 3 таблиц, который можно расширить для объединения более 3 или N таблиц.
mysql> ВЫБРАТЬ * ИЗ Сотрудник;
+ ———+———-+———+
| emp_id | emp_name | зарплата |
+ ———+———-+———+
| 1 | Джеймс | 2000 |
| 2 | Джек | 4000 |
| 3 | Генри | 6000 |
| 4 | Том | 8000 |
+ ———+———-+———+
4 строки IN SET (0,00 сек)
mysql> ВЫБЕРИТЕ * ИЗ Отдел;
+ ———+————+
| dept_id | имя_отдела |
+ ———+————+
| 101 | Продажи |
| 102 | Маркетинг |
| 103 | Финансы |
+ ———+————+
3 ряда IN НАБОР (0,00 сек)
mysql> ВЫБРАТЬ * ИЗ Зарегистрировать;
+ ———+———+
| emp_id | dept_id |
+ ———+———+
| 1 | 101 |
| 2 | 102 |
| 3 | 103 |
| 4 | 102 |
+ ———+———+
4 строки IN SET (0,00 сек)
mysql> SELECT emp_name, dept_name 9 0 0 900 Сотрудник е
JOIN Регистрация r ON e.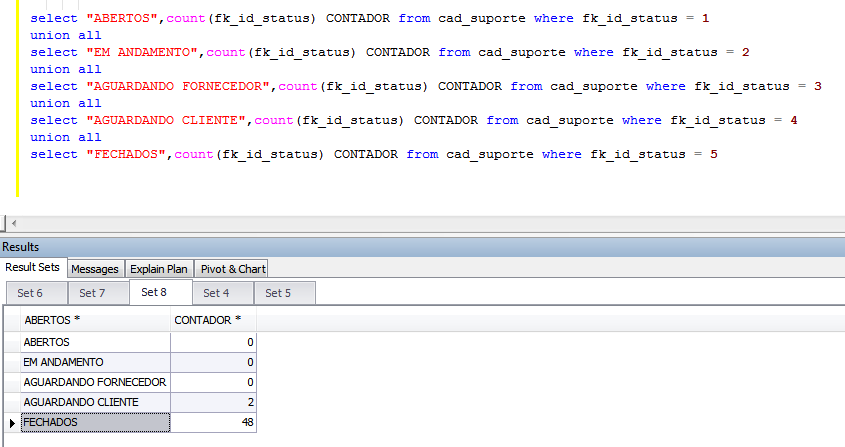 emp_id=r.emp_id
emp_id=r.emp_id
JOIN Отдел d ON r.dept_id=d.dept_id;
+ ———-+————+
| emp_name | имя_отдела |
+ ———-+————+
| Джеймс | Продажи |
| Джек | Маркетинг |
| Генри | Финансы |
| Том | Маркетинг |
+ ———-+————+
4 ряда IN НАБОР (0,01 сек)
Если вы хотите понять это еще лучше, попробуйте объединить столы шаг за шагом. Таким образом, вместо объединения 3 таблиц за один раз, сначала соедините 2 таблицы и посмотрите, как будет выглядеть таблица результатов. Это все о том, как соединить три таблицы одним SQL-запросом в реляционной базе данных.
Кстати, в этом примере SQL JOIN мы использовали ANSI SQL, и он будет работать в другой реляционной базе данных, а также в Oracle, SQL Server, Sybase, PostgreSQL и т. д. Сообщите нам, если у вас возникнут какие-либо проблемы при запуске этого 3 таблица JOIN запроса в любой другой базе данных.
Другое Вопросы к интервью по SQL статьи для подготовки
- В чем разница между коррелированными и некоррелированными подзапросами в SQL
- Разница между кластеризованным и некластеризованным индексом в SQL
- Что такое ACID-свойства транзакции в базе данных
- Когда использовать усечение вместо удаления в SQL-запросе
- Список часто используемых команд MySQL Server
- 10 популярных SQL-запросов из интервью
Спасибо, что прочитали эту статью до сих пор , если вам понравилась эта статья, поделитесь ею с друзьями и коллегами. Если у вас есть какие-либо вопросы, предложения или сомнения, пожалуйста, оставьте комментарий, и я постараюсь ответить на ваш вопрос.
SQL объединяется с использованием WHERE или ON | Промежуточный SQL
Начиная здесь? Этот урок является частью полного учебника по использованию SQL для анализа данных. Проверьте начало.
В этом уроке мы рассмотрим:
- Фильтрация в разделе ON
- Фильтрация в предложении WHERE
- Практические задачи
Фильтрация в предложении ON
Обычно фильтрация выполняется в предложении WHERE после того, как две таблицы уже объединены.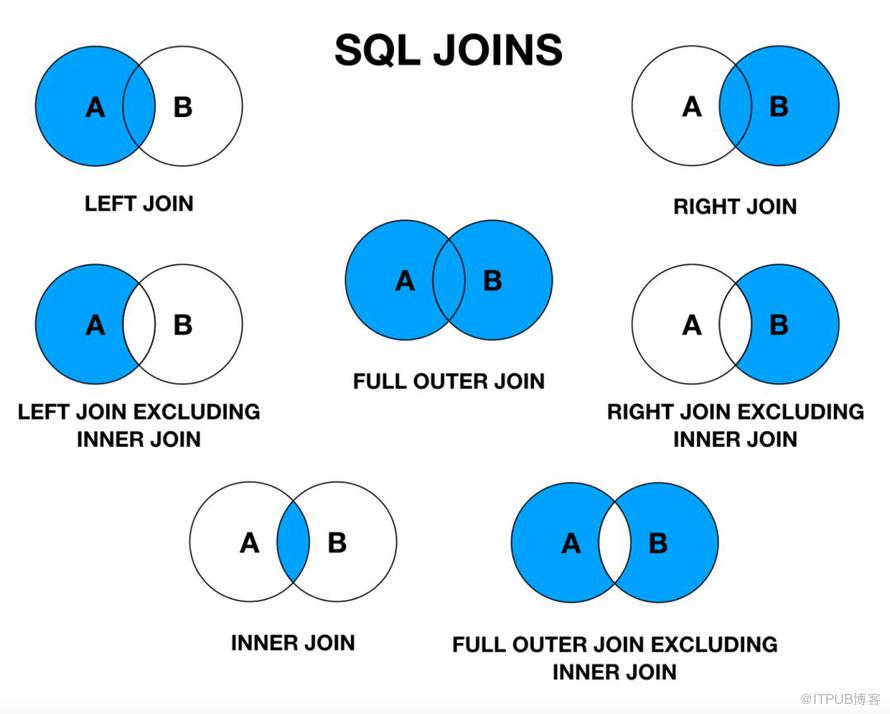 Однако возможно, что вы захотите отфильтровать одну или обе таблицы до того, как к ним присоединился . Например, вы хотите создавать совпадения между таблицами только при определенных обстоятельствах.
Однако возможно, что вы захотите отфильтровать одну или обе таблицы до того, как к ним присоединился . Например, вы хотите создавать совпадения между таблицами только при определенных обстоятельствах.
Используя данные Crunchbase, давайте еще раз взглянем на пример LEFT JOIN из предыдущего урока (на этот раз мы добавим предложение ORDER BY ):
компании.название КАК компании_название,
Acquisitions.company_permalink AS Acquisitions_permalink,
Acquires.acquired_at КАК приобрел_дата
ОТ компании tutorial.crunchbase_companies
LEFT JOIN tutorial.crunchbase_acquisitions приобретения
ВКЛ.company.permalink = Acquisitions.company_permalink
ЗАКАЗАТЬ ПО 1
Сравните следующий запрос с предыдущим, и вы увидите, что все в таблице tutorial.crunchbase_acquisitions было объединено по , кроме для строки, для которой company_permalink равно '/company/1000memories' :77 ВЫБЕРИТЕ компании.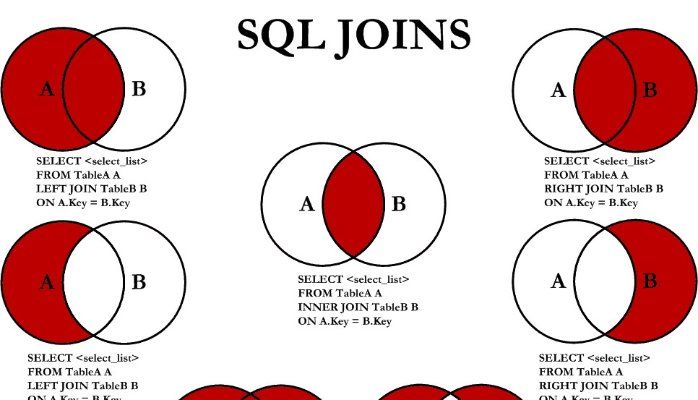 постоянная ссылка КАК компании_постоянная ссылка,
компании.название КАК компании_название,
Acquisitions.company_permalink AS Acquisitions_permalink,
Acquires.acquired_at КАК приобрел_дата
ОТ компании tutorial.crunchbase_companies
LEFT JOIN tutorial.crunchbase_acquisitions приобретения
ВКЛ.company.permalink = Acquisitions.company_permalink
И Acquisitions.company_permalink != ‘/company/1000memories’
ЗАКАЗАТЬ ПО 1
постоянная ссылка КАК компании_постоянная ссылка,
компании.название КАК компании_название,
Acquisitions.company_permalink AS Acquisitions_permalink,
Acquires.acquired_at КАК приобрел_дата
ОТ компании tutorial.crunchbase_companies
LEFT JOIN tutorial.crunchbase_acquisitions приобретения
ВКЛ.company.permalink = Acquisitions.company_permalink
И Acquisitions.company_permalink != ‘/company/1000memories’
ЗАКАЗАТЬ ПО 1
То, что происходит выше, заключается в том, что условный оператор И... оценивается до того, как произойдет соединение. Вы можете думать об этом как о предложении WHERE , которое применяется только к одной из таблиц. Вы можете сказать, что это происходит только в одной из таблиц, потому что постоянная ссылка 1000memories все еще отображается в столбце, который извлекается из другой таблицы:
Фильтрация в предложении WHERE
Если вы переместите тот же фильтр в предложение WHERE , вы заметите, что фильтрация происходит после объединения таблиц. В результате строка 1000memories соединяется с исходной таблицей, но затем полностью отфильтровывается (в обеих таблицах) в
В результате строка 1000memories соединяется с исходной таблицей, но затем полностью отфильтровывается (в обеих таблицах) в Предложение WHERE перед отображением результатов.
ВЫБЕРИТЕ компании.постоянная ссылка КАК компании_постоянная ссылка,
компании.название КАК компании_название,
Acquisitions.company_permalink AS Acquisitions_permalink,
Acquires.acquired_at КАК приобрел_дата
ОТ компании tutorial.crunchbase_companies
LEFT JOIN tutorial.crunchbase_acquisitions приобретения
ВКЛ.company.permalink = Acquisitions.company_permalink
ГДЕ Acquisitions.company_permalink != '/company/1000memories'
ИЛИ Acquisitions.company_permalink IS NULL
ЗАКАЗАТЬ ПО 1
Вы можете видеть, что строка 1000memories не возвращается (она должна быть между двумя выделенными строками ниже). Также обратите внимание, что фильтрация в предложении WHERE также может фильтровать нулевые значения, поэтому мы добавили дополнительную строку, чтобы убедиться, что они включены.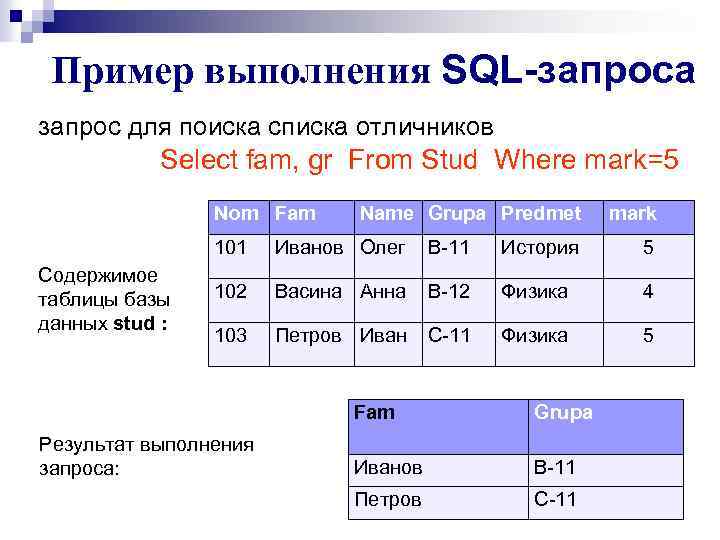
Отточите свои навыки SQL
Для этого набора практических задач мы собираемся представить новый набор данных: tutorial.crunchbase_investments . Эта таблица также взята из Crunchbase и содержит большую часть той же информации, что и таблица 9.0226 tutorial.crunchbase_companies данных. Однако он структурирован по-другому: он содержит одну строку на инвестиций . В одну компанию может вкладываться несколько человек — возможно даже, что один инвестор может инвестировать в одну и ту же компанию несколько раз. Имена столбцов говорят сами за себя. Важно то, что company_permalink в таблице tutorial.crunchbase_investments соответствует permalink в tutorial.crunchbase_companies 9.0227 стол. Имейте в виду, что некоторые случайные данные были удалены из этой таблицы ради этого урока.
Весьма вероятно, что вам потребуется провести некоторый исследовательский анализ этой таблицы, чтобы понять, как вы могли бы решить следующие проблемы.
Практическая задача
Напишите запрос, который показывает название компании, «статус» (из таблицы «Компании») и количество уникальных инвесторов в этой компании. Отсортируйте по количеству инвесторов от большинства к наименьшему. Ограничьтесь только компаниями в штате Нью-Йорк.
ПопробуйтеСмотреть ответ
Практическая задача
Напишите запрос, который перечисляет инвесторов в зависимости от количества компаний, в которые они инвестируют. Включите строку для компаний без инвестора и упорядочите от большинства компаний к наименьшим.
ПопробуйтеСмотреть ответ
Объяснение соединений SQL — внутренние, левые, правые и полные соединения . Он предоставляет нам различные функции, такие как триггеры, инъекции, хостинг и объединение — это лишь одна из наиболее важных концепций, которые необходимо освоить в SQL. В этой статье о соединениях SQL я расскажу о различных типах соединений, используемых в SQL.

В этой статье будут рассмотрены следующие темы:
- Что такое соединения?
- Сколько типов соединений существует в SQL?
- How do I know which join to use in SQL
- INNER JOIN
- FULL JOIN
- LEFT JOIN
- RIGHT JOIN
- Most Common Questions asked about Joins
СОЕДИНЕНИЯ в SQL — это команды, которые используются для объединения строк из двух или более таблиц на основе связанного столбца между этими таблицами. В основном они используются, когда пользователь пытается извлечь данные из таблиц, между которыми установлены отношения «один ко многим» или «многие ко многим».
Теперь, когда вы знаете, что означают соединения, давайте теперь изучим различные типы соединений.
Сколько типов соединений существует в SQL? В основном существует четыре типа соединений, которые необходимо понимать. Это:
Это:
- ВНУТРЕННЕЕ СОЕДИНЕНИЕ
- ПОЛНОЕ СОЕДИНЕНИЕ
- ЛЕВОЕ СОЕДИНЕНИЕ
- ПРАВОЕ СОЕДИНЕНИЕ
Вы можете обратиться к изображению ниже.
Как узнать, какое объединение использовать в SQL?
Давайте рассмотрим каждый из них. Чтобы вы лучше поняли эту концепцию, я рассмотрю следующие три таблицы, чтобы показать вам, как выполнять операции соединения с такими таблицами.
Employee Table:| EmpID | EmpFname | EmpLname | Age | EmailID | PhoneNo | Address |
| 1 | Vardhan | Kumar | 22 | [email protected] | 9876543210 | Delhi |
| 2 | Himani | Sharma | 32 | himani@abc.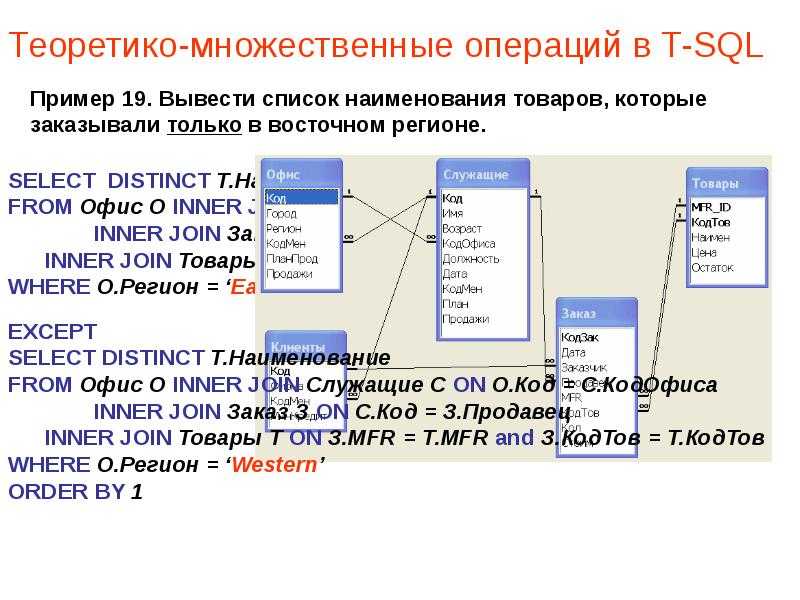 com com | 9977554422 | Mumbai |
| 3 | Aayushi | Shreshth | 24 | [email protected] | 9977555121 | Kolkata |
| 4 | Hemanth | Sharma | 25 | [email protected] | 9876545666 | Bengaluru |
| 5 | Swatee | Kapoor | 26 | [email protected] | 9544567777 | Хайдарабад |
| ProjectID | EMPID | 1 | 7 | 7 | 77787878778| 8 | 787878778 777787878 | .0208 ProjectName | ProjectStartDate | | |||
| 111 | 1 | 3 | Project1 | 2019-04-21 | ||||||||
| 222 | 2 | 1 | Project2 | 2019-02-12 | ||||||||
| 333 | 3 | 5 | Project3 | 2019-01-10 | ||||||||
| 444 | 3 | 2 | Project4 | 2019-04-16 | ||||||||
| 555 | 5 | 4 | Project5 | 2019-05-23 | ||||||||
| 666 | 9 | 1 | Project6 | 2019-01-12 | ||||||||
| 777 | 7 | 2 | Project7 | 2019-07-25 | ||||||||
| 888 | 8 | 3 | Project8 | 2019-08-20 |
Client Table:
| ClientID | ClientFname | ClientLname | Age | ClientEmailID | PhoneNo | Address | EmpID |
| 1 | Susan | Смит | 30 | susan@adn. com com | 9765411231 | Калькутта | 3 |
| 2 | |||||||
| Ali | 27 | [email protected] | 9876543561 | Kolkata | 3 | ||
| 3 | Soma | Paul | 22 | [email protected] | 9966332211 | Delhi | 1 |
| 4 | Zainab | Daginawala | 40 | [email protected] | 9955884422 | Hyderabad | 5 |
| 5 | Bhaskar | REDDY | 32 | [email protected] | 9636963269 | Mumbai | 2 | 2 | 2 | 2 | 2 |
 Синтаксис:
Синтаксис: SELECT Таблица1.Столбец1,Таблица1.Столбец2,Таблица2.Столбец1,.... ИЗ Таблицы1 ВНУТРЕННЕЕ СОЕДИНЕНИЕ Таблица 2 ON Table1.MatchingColumnName = Table2.MatchingColumnName;
ПРИМЕЧАНИЕ. Для выполнения этой операции можно использовать ключевое слово INNER JOIN или JOIN.
Пример:ВЫБЕРИТЕ Employee.EmpID, Employee.EmpFname, Employee.EmpLname, Projects.ProjectID, Projects.ProjectName ОТ Сотрудника INNER JOIN Projects ON Employee.EmpID=Projects.EmpID;Вывод:
| EmpID | EmpFname | EmpLname 19 1 ProjectID | ProjectName | ||
| 1 | Vardhan | Kumar | 111 | Project1 | |
| 2 | Himani | Sharma | 222 | Project2 | |
| 3 | Aayushi | Шрешт | 333 | Проект3 | |
| 3 | Ааюши | Шрешт | 9084 344 | 4 Проект | 10406 |
| 5 | Swatee | Kapoor | 555 | Project5 |
Full Join or the Full Outer Join returns all those records which either have a match in the left(Table1) or правая (Таблица 2) таблица.
SELECT Таблица1.Столбец1,Таблица1.Столбец2,Таблица2.Столбец1,.... ИЗ Таблицы1 ПОЛНОЕ СОЕДИНЕНИЕ Таблица2 ON Table1.MatchingColumnName = Table2.MatchingColumnName;Пример:
ВЫБЕРИТЕ Сотрудник.EmpFname, Сотрудник.EmpLname, Проекты.ProjectID ОТ Сотрудника ПОЛНОЕ СОЕДИНЕНИЕ Проекты ON Сотрудник.EmpID = Проекты.EmpID;Output:
| EmpFname | EmpLname | ProjectID |
| Vardhan | Kumar | 111 |
| Himani | Sharma | 222 |
| Aayushi | Shreshth | 333 |
| Aayushi | Shreshth | 444 |
| Hemanth | Sharma | NULL |
| Swatee | Kapoor | 555 |
| NULL | NULL | 666 |
| NULL | NULL | 777 |
| NULL | NULL | 888 |
LEFT JOIN или LEFT OUTER JOIN возвращает все записи из левой таблицы, а также те записи, которые удовлетворяют условию из правой таблицы.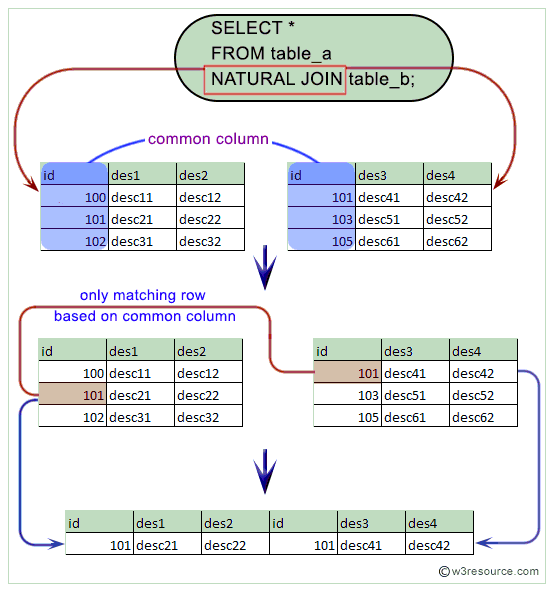 Кроме того, для записей, не имеющих совпадающих значений в правой таблице, выходные данные или набор результатов будут содержать значения NULL.
Кроме того, для записей, не имеющих совпадающих значений в правой таблице, выходные данные или набор результатов будут содержать значения NULL.
SELECT Таблица1.Столбец1,Таблица1.Столбец2,Таблица2.Столбец1,.... ИЗ Таблицы1 ЛЕВОЕ СОЕДИНЕНИЕ Таблица2 ON Table1.MatchingColumnName = Table2.MatchingColumnName;Пример:
ВЫБЕРИТЕ Employee.EmpFname, Employee.EmpLname, Projects.ProjectID, Projects.ProjectName ОТ Сотрудника ЛЕВОЕ СОЕДИНЕНИЕ ON Сотрудник.EmpID = Проекты.EmpID ;Output:
| EmpFname | EmpLname | ProjectID | ProjectName |
| Vardhan | Kumar | 111 | Project1 |
| Himani | Sharma | 222 | Project2 |
| Aayushi | Shreshth | 333 | Project3 |
| Aayushi | Shreshth | 444 | Project4 |
| Swatee | Kapoor | 555 | Проект5 |
| Хемант | Шарма | НУЛЬ | НУЛЬ |
ПРАВО
10209 ПРАВОЕ СОЕДИНЕНИЕ или ПРАВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ возвращает все записи из правой таблицы, а также те записи, которые удовлетворяют условию из левой таблицы.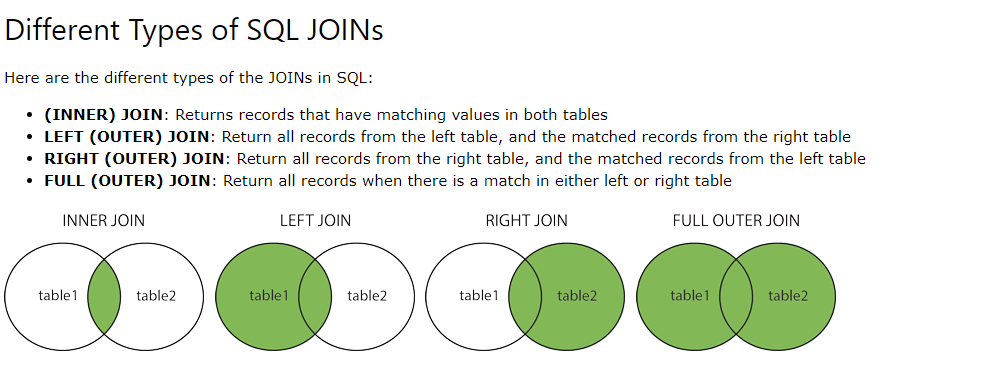 Кроме того, для записей, не имеющих совпадающих значений в левой таблице, выходные данные или набор результатов будут содержать значения NULL.
Кроме того, для записей, не имеющих совпадающих значений в левой таблице, выходные данные или набор результатов будут содержать значения NULL.
SELECT Таблица1.Столбец1,Таблица1.Столбец2,Таблица2.Столбец1,.... ИЗ Таблицы1 ПРАВОЕ СОЕДИНЕНИЕ Таблица 2 ON Table1.MatchingColumnName = Table2.MatchingColumnName;Пример:
ВЫБЕРИТЕ Employee.EmpFname, Employee.EmpLname, Projects.ProjectID, Projects.ProjectName ОТ Сотрудника ПРАВОЕ ПРИСОЕДИНЕНИЕ ON Сотрудник.EmpID = Проекты.EmpID;Output:
| EmpFname | EmpLname | ProjectID | ProjectName |
| Vardhan | Kumar | 111 | Project1 |
| Himani | Sharma | 222 | Project2 |
| Aayushi | Shreshth | 333 | Project3 |
| Aayushi | Shreshth | 444 | Project4 |
| Swatee | Kapoor | 555 | Project5 |
| NULL | NULL | 666 | Project6 |
| NULL | |||
| 777 | Project7 | ||
| NULL | NULL | 888 | Project8 |
теперь.
Естественное соединение также является операцией соединения, которая используется для получения выходных данных на основе столбцов в обеих таблицах, между которыми должна быть реализована эта операция соединения. Чтобы понять ситуации, в которых используется естественное соединение, вам необходимо понять разницу между естественным соединением и внутренним соединением.
Основное различие между естественным соединением и внутренним соединением заключается в количестве возвращаемых столбцов. См. ниже, например.
Теперь, если вы примените INNER JOIN к этим 2 таблицам, вы увидите вывод, как показано ниже:
Если применить ЕСТЕСТВЕННОЕ СОЕДИНЕНИЕ к двум указанным выше таблицам, вывод будет следующим:
количество столбцов, возвращенных из Natural Join.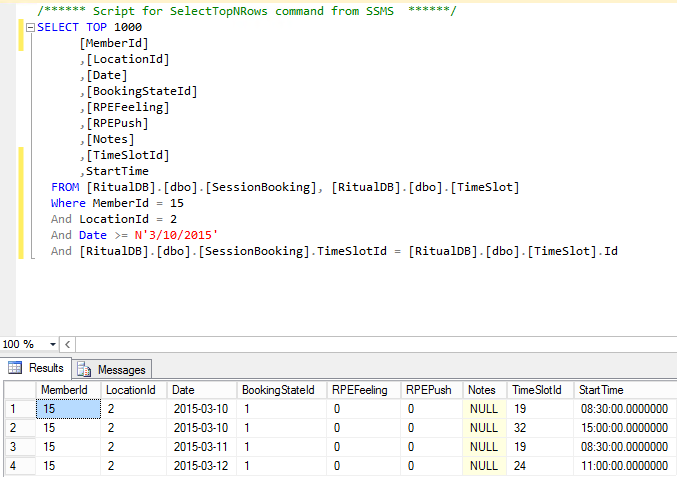 Итак, если вы хотите получить вывод с меньшим количеством столбцов, вы можете использовать Natural Join
Итак, если вы хотите получить вывод с меньшим количеством столбцов, вы можете использовать Natural Join
Чтобы отобразить отношения «многие ко многим» с помощью соединений, вам нужно использовать два оператора JOIN.
Например, если у нас есть три таблицы (Сотрудники, Проекты и Технологии), и предположим, что каждый сотрудник работает над одним проектом. Таким образом, один проект не может быть назначен более чем одному сотруднику. Таким образом, это в основном отношения один ко многим.
Аналогичным образом, если учесть, что проект может быть основан на нескольких технологиях, а любая технология может использоваться в нескольких проектах, то такой вид отношений является отношением «многие ко многим».
Чтобы использовать соединения для таких отношений, вам необходимо структурировать базу данных с двумя внешними ключами. Итак, чтобы сделать это, вы должны создать следующие 3 таблицы:
Итак, чтобы сделать это, вы должны создать следующие 3 таблицы:
- Проекты
- Технологии
- Projects_to_technologies
Таблица project_to_technologies содержит комбинации проектов и технологий в каждой строке. Эта таблица сопоставляет элементы в таблице проектов с элементами в таблице технологий, так что несколько проектов могут быть назначены одной или нескольким технологиям.
После создания таблиц используйте следующие два оператора JOIN, чтобы связать все вышеперечисленные таблицы вместе:
- проекты_в_технологии в проекты
- проекты_в-технологии в технологии
Соединения по хешу также являются типом соединений, которые используются для соединения больших таблиц или в случае, когда пользователь хочет большую часть строк соединяемой таблицы.
Алгоритм хэш-соединения — это двухэтапный алгоритм. См. шаги ниже:
См. шаги ниже:
- Фаза сборки: Создание хэш-индекса в памяти на левой стороне ввода
- Фаза проверки: Пройдите по правой стороне ввода, каждую строку за раз, чтобы найти совпадения, используя индекс, созданный в приведенном выше примере. шаг.
САМОСОЕДИНЕНИЕ, другими словами, это соединение таблицы с самой собой. Это означает, что каждая строка в таблице соединена сама с собой.
Cross JoinCROSS JOIN — это тип соединения, в котором предложение соединения применяется к каждой строке таблицы и к каждой строке другой таблицы. Кроме того, когда используется условие WHERE, этот тип СОЕДИНЕНИЯ ведет себя как ВНУТРЕННЕЕ СОЕДИНЕНИЕ, а когда условие WHERE отсутствует, он ведет себя как декартово произведение.
Вопрос 5: Можно ли СОЕДИНИТЬ 3 таблицы в SQL? Решение: Да.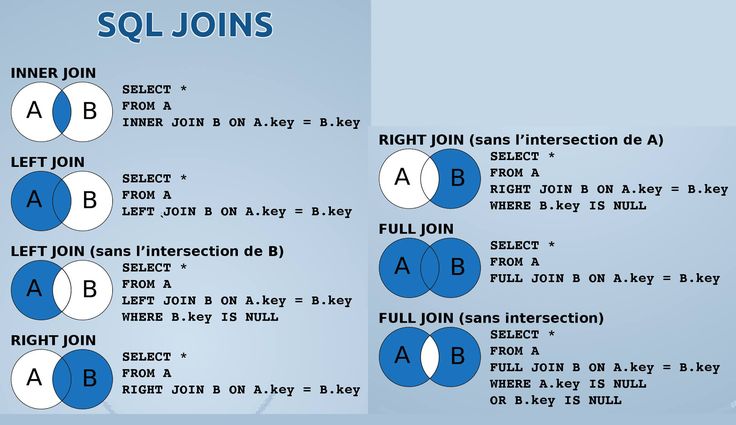 Чтобы выполнить операцию JOIN для 3 таблиц, вам нужно использовать 2 оператора JOIN. Вы можете обратиться ко второму вопросу, чтобы понять, как объединить 3 таблицы с примером.
Чтобы выполнить операцию JOIN для 3 таблиц, вам нужно использовать 2 оператора JOIN. Вы можете обратиться ко второму вопросу, чтобы понять, как объединить 3 таблицы с примером.
ПРИМЕЧАНИЕ. Чтобы применить операцию JOIN между «n» таблицами, вы должны использовать операторы JOIN «n-1».
Теперь, когда вы знакомы с SQL Joins, я уверен, что вам интересно узнать больше об SQL. Вот список статей, на которые вы можете сослаться:
- Команды SQL
- Типы данных SQL
- Spark SQL
- Вопросы интервью SQL
- Что такое MYSQL?
На этом я подхожу к концу этой статьи о соединениях SQL. Надеюсь, вам понравилось читать эту статью о соединениях SQL. Мы рассмотрели различные команды, которые помогут вам писать запросы и экспериментировать с базами данных. Если вы хотите узнать больше о MySQL и познакомиться с этой реляционной базой данных с открытым исходным кодом, ознакомьтесь с нашим курсом Сертификационный курс администраторов баз данных MySQL , который включает в себя интерактивное обучение под руководством инструктора и реальный опыт работы над проектами.