запрос в запросе. MySQL: примеры запросов. Вложенные запросы MySQL
В настоящее время каждый человек может наблюдать стремительный рост объема цифровой информации. А так как большая часть этой информации является важной, возникает необходимость ее сохранения на цифровых носителях для последующего использования. В данной ситуации могут применяться такие современные технологии, как базы данных. Они обеспечивают надежное хранение любой цифровой информации, а доступ к данным может быть осуществлен в любой точке земного шара. Одной из рассматриваемых технологий является система управления базами данных MySQL.
СУБД MySQL – что это?
Реляционная система управления базами данных MySQL является одной из самых востребованных и часто используемых технологий хранения информации. Ее функциональные возможности превосходят по многим показателям существующие СУБД. В частности, одной из главных особенностей является возможность использовать вложенные запросы MySQL.

Поэтому многие проекты, где важно время быстродействия и необходимо обеспечить хранение информации, а также осуществлять сложные выборки данных, разрабатываются на базе СУБД MySQL. Большую часть таких разработок составляют интернет-сайты. При этом MySQL активно внедряется при реализации как небольших (блоги, сайт-визитки и т. п.), так и достаточно крупных задач (интернет-магазины, хранилище данных и т. д.). В обоих случаях для отображения информации на странице сайта применяется MySQL-запрос. В запросе разработчики стараются максимально использовать имеющиеся возможности, которые предоставляет система управления базами данных.
Как должно быть организовано хранение данных
Для удобного хранения и последующей обработки данные обязательно упорядочиваются. Структура данных позволяет определить, каким образом будут выглядеть таблицы, использующиеся для хранения информации. Таблицы базы данных представляют собой набор полей (столбцов), отвечающих за каждое определенное свойство объекта данных.
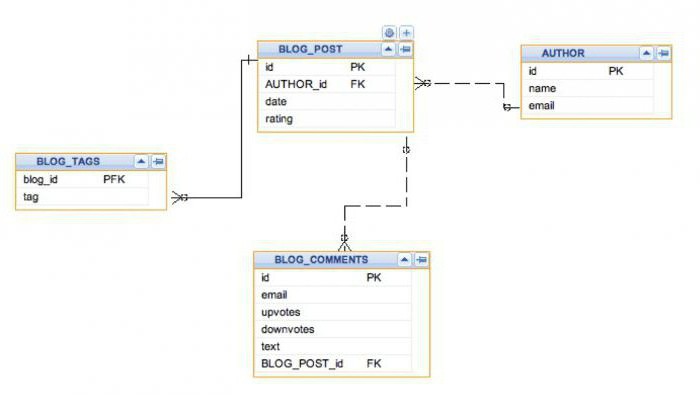
Например, если составляется таблица сотрудников определенной компании, то ее самая простая структура будет иметь следующий вид. За каждым сотрудником закреплен уникальный номер, который, как правило, используется в качестве первичного ключа к таблице. Затем в таблицу заносятся персональные данные сотрудника. Это может быть что угодно: Ф. И. О., номер отдела, за которым он закреплен, телефон, адрес и прочее. Согласно требованиям нормализации (6 нормальных форм баз данных), а также для того, чтобы MySQL-запросы выстраивались структурированно, поля таблицы должны быть атомарными, то есть не иметь перечислений или списков. Поэтому, как правило, в таблице существуют отдельные поля для фамилии, имени и т. д.
Employee_id | Surname | Name | Patronymic | Department_id | Position | Phone | Employer_id |
1 | Иванов | Иван | Иванович | Администрац. | Директор | 495**** | null |
2 | Петров | Петр | Петрович | Администрац. | Зам. директора | 495*** | 1 |
3 | Гришин | Григорий | Григорьевич | Продажи | Начальник | 1 | |
… | … | … | … | … | … | … | … |
59 | Сергеев | Сергей | Сергеевич | Продажи | Продавец-консульт. | 495*** | 32 |
Выше представлен тривиальный пример структуры таблицы базы данных. Однако она ещё не до конца отвечает основным требованиям нормализации. В реальных системах создается дополнительная таблица отделов. Поэтому приведенная таблица вместо слов в колонке «Отдел» должна содержать номера отделов.
Каким образом происходит выборка данных
Для получения данных из таблиц в СУБД используется специальная команда MySQL – запрос Select. Для того чтобы сервер базы данных правильно отреагировал на обращение, запрос должен быть корректно сформирован. Структура запроса формируется следующим образом. Любое обращение к серверу БД начинается с ключевого слова select. Именно с него строятся все в MySQL запросы. Примеры могут иметь различную сложность, но принцип построения очень похож.
Затем необходимо указать, с каких полей требуется выбрать интересующую информацию. Перечисление полей происходит через запятую после предложения select. После того как все необходимые поля были перечислены, в запросе указывается объект таблицы, из которого будет происходить выборка, при помощи предложения from и указания имени таблицы.
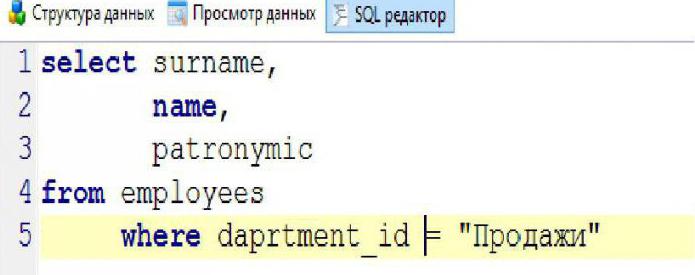
Для ограничения выборки в MySQL-запросы добавляются специальные операторы, предусмотренные СУБД. Для выборки неповторяющихся (уникальных) данных используется предложение distinct, а для задания условий – оператор where. В качестве примера, применимого к вышеуказанной таблице, можно рассмотреть запрос, требующий информацию о Ф.И.О. сотрудников, работающих в отделе «Продажи». Структура запроса примет вид, как в таблице ниже.
Понятие вложенного запроса
Но главная особенность СУБД, как было указано выше, возможность обрабатывать вложенные запросы MySQL. Как он должен выглядеть? Из названия логически понятно, что это запрос, сформированный в определенной иерархии из двух или более запросов. В теории по изучению особенностей СУБД сказано, что MySQL не накладывает ограничений на количество MySQL-запросов, которые могут быть вложены в главный запрос. Однако можно поэкспериментировать на практике и убедиться, что уже после второго десятка вложенных запросов время отклика серьезно увеличится. В любом случае на практике не встречаются задачи, требующие использовать чрезвычайно сложный MySQL-запрос. В запросе может потребоваться максимально до 3-5 вложенных иерархий.
Построение вложенных запросов
При анализе прочитанной информации возникает ряд вопросов о том, где могут быть использованы вложенные запросы и нельзя ли решить задачу разбиением их на простые без усложнения структуры. На практике вложенные запросы используются для решения сложных задач. К такому типу задач относятся ситуации, когда заранее неизвестно условие, по которому будет происходить ограничение дальнейшей выборки значений. Решить такие задачи невозможно, если просто использовать обычный MySQL-запрос. В запросе, состоящем из иерархий, будет происходить поиск ограничений, которые могут меняться с течением времени или заранее не могут быть известны.
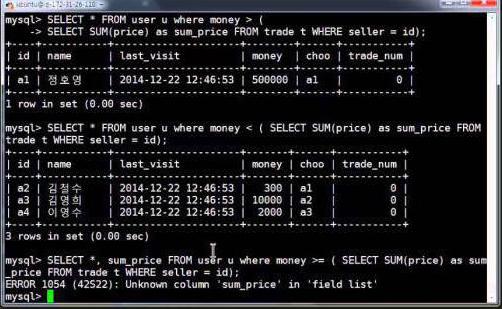
Если рассматривать таблицу, приведенную выше, то в качестве сложной задачи можно привести следующий пример. Допустим, нам необходимо узнать основную информацию о сотрудниках, находящихся в подчинении Гришина Григория Григорьевича, который является начальником отдела продаж. При формировании запроса нам неизвестен его идентификационный номер. Поэтому изначально нам необходимо его узнать. Для этого используется простой запрос, который позволит найти решение главного условия и дополнит основной MySQL-запрос. В запросе наглядно представлено, что подзапрос получает идентификационный номер сотрудника, который в дальнейшем определяет ограничение главного запроса:

В данном случае предложение any используется для того, чтобы исключить возникновение ошибок, если сотрудников с такими инициалами окажется несколько.
Итоги
Подводя итог, необходимо отметить, что существует ещё много других дополнительных возможностей, которые значительно облегчают построение запросов, так как СУБД MySQL – мощное средство с богатым арсеналом инструментов для хранения и обработки данных.
fb.ru
запрос в запросе. MySQL: примеры запросов. Вложенные запросы MySQL
В настоящее время каждый человек может наблюдать стремительный рост объема цифровой информации. А так как большая часть этой информации является важной, возникает необходимость ее сохранения на цифровых носителях для последующего использования. В данной ситуации могут применяться такие современные технологии, как базы данных. Они обеспечивают надежное хранение любой цифровой информации, а доступ к данным может быть осуществлен в любой точке земного шара. Одной из рассматриваемых технологий является система управления базами данных MySQL.
Реляционная система управления базами данных MySQL является одной из самых востребованных и часто используемых технологий хранения информации. Ее функциональные возможности превосходят по многим показателям существующие СУБД. В частности, одной из главных особенностей является возможность использовать вложенные запросы MySQL.
Поэтому многие проекты, где важно время быстродействия и необходимо обеспечить хранение информации, а также осуществлять сложные выборки данных, разрабатываются на базе СУБД MySQL. Большую часть таких разработок составляют интернет-сайты. При этом MySQL активно внедряется при реализации как небольших (блоги, сайт-визитки и т. п.), так и достаточно крупных задач (интернет-магазины, хранилище данных и т. д.). В обоих случаях для отображения информации на странице сайта применяется MySQL-запрос. В запросе разработчики стараются максимально использовать имеющиеся возможности, которые предоставляет система управления базами данных.
Как должно быть организовано хранение данных
Для удобного хранения и последующей обработки данные обязательно упорядочиваются. Структура данных позволяет определить, каким образом будут выглядеть таблицы, использующиеся для хранения информации. Таблицы базы данных представляют собой набор полей (столбцов), отвечающих за каждое определенное свойство объекта данных.

Например, если составляется таблица сотрудников определенной компании, то ее самая простая структура будет иметь следующий вид. За каждым сотрудником закреплен уникальный номер, который, как правило, используется в качестве первичного ключа к таблице. Затем в таблицу заносятся персональные данные сотрудника. Это может быть что угодно: Ф. И. О., номер отдела, за которым он закреплен, телефон, адрес и прочее. Согласно требованиям нормализации (6 нормальных форм баз данных), а также для того, чтобы MySQL-запросы выстраивались структурированно, поля таблицы должны быть атомарными, то есть не иметь перечислений или списков. Поэтому, как правило, в таблице существуют отдельные поля для фамилии, имени и т. д.
Employee_id | Surname | Name | Patronymic | Department_id | Position | Phone | Employer_id |
1 | Иванов | Иван | Иванович | Администрац. | Директор | 49 *** | null |
2 | Петров | Петр | Петрович | Администрац. | Зам. директора | 49 ** | 1 |
3 | Гришин | Григорий | Григорьевич | Продажи | Начальник | 1 | |
… | … | … | … | … | … | … | … |
59 | Сергеев | Сергей | Сергеевич | Продажи | Продавец-консульт. | 49 ** | 32 |
Выше представлен тривиальный пример структуры таблицы базы данных. Однако она ещё не до конца отвечает основным требованиям нормализации. В реальных системах создается дополнительная таблица отделов. Поэтому приведенная таблица вместо слов в колонке «Отдел» должна содержать номера отделов.
Каким образом происходит выборка данных
Для получения данных из таблиц в СУБД используется специальная команда MySQL – запрос Select. Для того чтобы сервер базы данных правильно отреагировал на обращение, запрос должен быть корректно сформирован. Структура запроса формируется следующим образом. Любое обращение к серверу БД начинается с ключевого слова select. Именно с него строятся все в MySQL запросы. Примеры могут иметь различную сложность, но принцип построения очень похож.
Затем необходимо указать, с каких полей требуется выбрать интересующую информацию. Перечисление полей происходит через запятую после предложения select. После того как все необходимые поля были перечислены, в запросе указывается объект таблицы, из которого будет происходить выборка, при помощи предложения from и указания имени таблицы.
Для ограничения выборки в MySQL-запросы добавляются специальные операторы, предусмотренные СУБД. Для выборки неповторяющихся (уникальных) данных используется предложение distinct, а для задания условий – оператор where. В качестве примера, применимого к вышеуказанной таблице, можно рассмотреть запрос, требующий информацию о Ф.И.О. сотрудников, работающих в отделе «Продажи». Структура запроса примет вид, как в таблице ниже.
Понятие вложенного запроса
Но главная особенность СУБД, как было указано выше, возможность обрабатывать вложенные запросы MySQL. Как он должен выглядеть? Из названия логически понятно, что это запрос, сформированный в определенной иерархии из двух или более запросов. В теории по изучению особенностей СУБД сказано, что MySQL не накладывает ограничений на количество MySQL-запросов, которые могут быть вложены в главный запрос. Однако можно поэкспериментировать на практике и убедиться, что уже после второго десятка вложенных запросов время отклика серьезно увеличится. В любом случае на практике не встречаются задачи, требующие использовать чрезвычайно сложный MySQL-запрос. В запросе может потребоваться максимально до 3-5 вложенных иерархий.

Построение вложенных запросов
При анализе прочитанной информации возникает ряд вопросов о том, где могут быть использованы вложенные запросы и нельзя ли решить задачу разбиением их на простые без усложнения структуры. На практике вложенные запросы используются для решения сложных задач. К такому типу задач относятся ситуации, когда заранее неизвестно условие, по которому будет происходить ограничение дальнейшей выборки значений. Решить такие задачи невозможно, если просто использовать обычный MySQL-запрос. В запросе, состоящем из иерархий, будет происходить поиск ограничений, которые могут меняться с течением времени или заранее не могут быть известны.
Если рассматривать таблицу, приведенную выше, то в качестве сложной задачи можно привести следующий пример. Допустим, нам необходимо узнать основную информацию о сотрудниках, находящихся в подчинении Гришина Григория Григорьевича, который является начальником отдела продаж. При формировании запроса нам неизвестен его идентификационный номер. Поэтому изначально нам необходимо его узнать. Для этого используется простой запрос, который позволит найти решение главного условия и дополнит основной MySQL-запрос. В запросе наглядно представлено, что подзапрос получает идентификационный номер сотрудника, который в дальнейшем определяет ограничение главного запроса:

В данном случае предложение any используется для того, чтобы исключить возникновение ошибок, если сотрудников с такими инициалами окажется несколько.
Итоги
Подводя итог, необходимо отметить, что существует ещё много других дополнительных возможностей, которые значительно облегчают построение запросов, так как СУБД MySQL – мощное средство с богатым арсеналом инструментов для хранения и обработки данных.
autogear.ru
Примеры сложных запросов для выборки данных в СУБД MySQL
Окт 23 2014
Всего лишь пару лет назад, в проектах, которые предусматривали работу с базами данных и построением статистики, основным изобилием используемых SQL-запросов, преобладало в основном множество запросов, ориентированных на стандартную выборку данных и нечасто можно было увидеть другие, которые безо всяких сомнений можно было бы отнести к “эксклюзиву”. Хотя сложность запроса и зависит от количества используемых таблиц, но если мы всего лишь возьмем и выведем данные полей трех или более таблиц имеющих стандартное объединение, то явная сложность такого запроса не выйдет за пределы стандартной.
В данной статье по мере возможности будут рассматриваться те запросы, примеры которых мне найти не удалось и которые, по моему мнению, не относятся к классу простых.
Сравнение данных за две даты
Хотя данная статистика из рода задач довольно редко встречаемых, но все-таки необходимость в ее получении иногда существует. И получить такую статистику ничуть не сложнее других.
Работать мы будем с двумя таблицами, структура которых представлена ниже:
Структура таблицы products
CREATE TABLE IF NOT EXISTS `products` ( `id` int(11) NOT NULL AUTO_INCREMENT, `ShopID` int(11) NOT NULL, `Name` varchar(150) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=10 ;
Структура таблицы statistics
CREATE TABLE IF NOT EXISTS `statistics` ( `id` int(11) NOT NULL AUTO_INCREMENT, `ProductID` bigint(20) NOT NULL, `Orders` int(11) NOT NULL, `Date` date NOT NULL DEFAULT '0000-00-00', PRIMARY KEY (`id`), KEY `ProductID` (`ProductID`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=20 ;
Дело в том, что стандарт языка SQL допускает использование вложенных запросов везде, где разрешается использование ссылок на таблицы. Здесь вместо явно указанных таблиц, благодаря использованию псевдонимов, будут применяться результирующие таблицы вложенных запросов с имеющейся связью один – к – одному. Результатом каждой результирующей таблицы будут данные о количестве произведенных заказов некоего товара за определенную дату, полученные путем выполнения запроса на выборку данных из таблицы statistics по требуемым критериям. Иными словами мы свяжем таблицу statistics саму с собой. Пример запроса:
SELECT stat1.Name, stat1.Orders, stat1.Date, stat2.Orders, stat2.Date FROM (SELECT statistics.ProductID, products.Name, statistics.Orders, statistics.Date FROM products JOIN statistics ON products.id = statistics.ProductID WHERE DATE(statistics.date) = '2014-09-04') AS stat1 JOIN (SELECT statistics.ProductID, statistics.Orders, statistics.Date FROM statistics WHERE DATE(statistics.date) = '2014-09-12') AS stat2 ON stat1.ProductID = stat2.ProductID
В итоге имеем такой результат:
+------------------------+----------+------------+----------+------------+ | Name | Orders1 | Date1 | Orders2 | Date2 | +------------------------+----------+------------+----------+------------+ | Процессоры Pentium II | 1 | 2014-09-04 | 1 | 2014-09-12 | | Процессоры Pentium III | 1 | 2014-09-04 | 10 | 2014-09-12 | | Оптическая мышь Atech | 10 | 2014-09-04 | 3 | 2014-09-12 | | DVD-R | 2 | 2014-09-04 | 5 | 2014-09-12 | | DVD-RW | 22 | 2014-09-04 | 18 | 2014-09-12 | | Клавиатура MS 101 | 5 | 2014-09-04 | 1 | 2014-09-12 | | SDRAM II | 26 | 2014-09-04 | 12 | 2014-09-12 | | Flash RAM 8Gb | 8 | 2014-09-04 | 7 | 2014-09-12 | | Flash RAM 4Gb | 18 | 2014-09-04 | 30 | 2014-09-12 | +------------------------+----------+------------+----------+------------+
Подстановка нескольких значений из другой таблицы
Необходимость в данном запросе не является повседневной, но возникает не совсем уж и редко. Самый распространенный пример, это обычная сетевая игра. Где создается сессия на два игрока. Соответственно в таблице с данными об играх имеются два поля с идентификаторами зарегистрированных игроков. Для того чтобы вывести информацию об имеющихся играх, мы не можем обойтись стандартным объединением таблицы с данными об игроках и таблицы об имеющихся играх. Так как мы имеем два поля с идентификаторами неких игроков. Но мы можем обратиться опять за помощью к псевдонимам таблиц.
Демонстрация данного запроса будет происходить на другом примере, а не на примере сетевой игры. Это чтобы не создавать заново все необходимые таблицы. В качестве данных возьмем таблицу products из примера “сравнение данных за две даты” и создадим еще одну недостающую таблицу replace_com, структура которой представлена ниже:
CREATE TABLE IF NOT EXISTS `replace_com` ( `id` int(11) NOT NULL AUTO_INCREMENT, `sProductID` int(11) NOT NULL, `rProductID` int(11) NOT NULL, `Date` date NOT NULL DEFAULT '0000-00-00', PRIMARY KEY (`id`), KEY `sProductID` (`sProductID`,`rProductID`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=4 ;
Предположим, что у нас есть некий компьютерный салон и мы проводим модификации некоторых компьютерных составляющих, а все операции по замене комплектующих заносим в базу данных. В таблице replace_com интересующими нас полями являются: sProductID и rProductID. Где sProductID – идентификатор заменяемого модуля, а rProductID – идентификатор заменяющего модуля. Запрос, реализующий вывод данных о совершенных операциях выглядит следующим образом:
SELECT sProducts.Name AS sProduct, rProducts.Name AS rProduct, replace_com.Date FROM replace_com JOIN products AS sProducts ON sProducts.id = replace_com.sProductID JOIN products AS rProducts ON rProducts.id = replace_com.rProductID
Результирующая таблица данных:
+-----------------------+------------------------+------------+ | sProduct | rProduct | Date | +-----------------------+------------------------+------------+ | Процессоры Pentium II | Процессоры Pentium III | 2014-09-15 | | Flash RAM 4Gb | Flash RAM 8Gb | 2014-09-17 | | DVD-R | DVD-RW | 2014-09-18 | +-----------------------+------------------------+------------+
Вывод статистики с накоплением по дате
Предположим, что у нас имеется склад с некими товарами. Товары периодически поступают, и нам бы хотелось видеть в отчете остатки товаров по дням. Поскольку данные о наличии товаров необходимо накапливать, то мы введем пользовательскую переменную. Но есть одно небольшое “но”. Мы не можем использовать в запросе переменные пользователя и группировку данных одновременно (вернее можем, но в итоге получим, не то, что ожидаем), но мы можем использовать вложенный запрос, вместо явно указанной таблицы. Данные в таблице будут предварительно сгруппированы по дате. И уже затем на основе этих данных мы произведем расчет статистики с накоплением.
На первом этапе требуется установить переменную и присвоить ей нулевое значение:
SET @cvalue = 0
В следующем запросе, мы созданную ранее переменную и применим:
SELECT products.Name AS Name, (@cvalue := @cvalue + Orders) as Orders, Date FROM (SELECT ProductID AS ProductID, SUM(Orders) AS Orders, DATE(date) AS Date FROM statistics WHERE ProductID = '1' GROUP BY date) AS statistics JOIN products ON statistics.ProductID = products.id
Итоговый отчет:
+-----------------------+--------+------------+ | Name | Orders | Date | +-----------------------+--------+------------+ | Процессоры Pentium II | 1 | 2014-09-04 | | Процессоры Pentium II | 2 | 2014-09-12 | | Процессоры Pentium II | 4 | 2014-09-14 | | Процессоры Pentium II | 6 | 2014-09-15 | +-----------------------+--------+------------+
Получить используемую в примерах базу данных можно здесь.
Рубрики: MySQL / Метки: MySQL, базы данных, статистика
swblog.ru
Как оптимизировать вложенные запрос mysql? — Хабр Q&A
Всем привет.Я пытаюсь разгрузить один запрос или думаю вообще переделать архитектуру хранения записей. Надеюсь вы мне поможете определиться 😉
На проекте есть 3 таблицы: Объект, к которым принадлежат Детали и Материалы
Поле status = 1 , item доступен или нет.
SELECT `Ob`.`id` AS `id`, `Ob`.`title` AS `title`, `Ob`.`poster` AS `poster` , @count_details := (SELECT count(*) FROM game.Details D WHERE D.objectId = Ob.id AND D.status = 1 ), @count_materials := (SELECT count(*) FROM game.Materials Ma WHERE Ma.objectId = Ob.id AND Ma.status = 1 ), @count_details + @count_materials as items_count, @max_update_details := (SELECT MAX(D.last_update) FROM game.Details D WHERE D.objectId = Ob.id AND D.status = 1 ), @max_update_materials := (SELECT MAX(Ma.last_update) FROM game.Materials Ma WHERE Ma.objectId = Ob.id AND Ma.status = 1 ), GREATEST( `Ob`.`last_update`, @max_update_details, ifnull(@max_update_materials, 0 ) ) as last_update FROM game.`Object` Ob WHERE status=1 ORDER BY last_update DESC;
В принципе все это работает, но проблема в том, что это чудо долго будет обрабатываться с нарастанием записей. 🙁
Реально ли как-то оптимизировать этот запрос?
Я думаю, что при сохранении формы добавления/изменения Details или Materials пересчитывать их кол-во к принадлежащему объекту. И заносить в Object таблицу, в какую нибудь новую колонку, а не делать каждый раз столько вложенных запросов. Тоже самое и касается время изменения last_update.
Еще наткнулся на один вопрос, где во вложенном запросе добавлена переменная @i в качестве инкремента. Можно ли сделать, чтобы на момент вычисления максимального значения, можно было подсчитать кол-во найденных записей, (псевдокод):
SELECT MAX(D.last_update), @i := @i +1
FROM game.Details D
WHERE D.objectId = Ob.id;Забыл кстати скинуть результаты Explain:
id |select_type |table |type |possible_keys |key |key_len |ref |rows |Extra |
---|-------------------|------|-----|------------------------------------------|------------------------------|--------|------|-------|---------------------------------------------|
1 |PRIMARY |Ob |ALL | | | | |139 |Using where; Using temporary; Using filesort |
5 |DEPENDENT SUBQUERY |D |ref |IX_Details_status_last_update |IX_Details_status_last_update |2 |const |25909 |Using where |
4 |DEPENDENT SUBQUERY |Ma |ref |IX_Materials_status,IX_Materials_objectId |IX_Materials_status |2 |const |125431 |Using where |
3 |DEPENDENT SUBQUERY |D |ref |IX_Details_status_last_update |IX_Details_status_last_update |2 |const |25909 |Using where |
2 |DEPENDENT SUBQUERY |Ma |ref |IX_Materials_status,IX_Materials_objectId |IX_Materials_status |2 |const |125431 |Using where |Вот схема Таблиц:
Спасибо за внимание!
toster.ru
Оптимизация сложных запросов MySQL / Habr
Введение
MySQL — весьма противоречивый продукт. С одной стороны, он имеет несравненное преимущество в скорости перед другими базами данных на простейших операциях/запросах. С другой стороны, он имеет настолько неразвитый (если не сказать недоразвитый) оптимизатор, что на сложных запросах проигрывает вчистую.
Прежде всего хотелось бы ограничить круг рассматриваемых проблем оптимизации «широкими» и большими таблицами. Скажем до 10m записей и размером до 20Gb, с большим количеством изменяемых запросов к ним. Если в вашей в таблице много миллионов записей, каждая размером по 100 байт, и пять несложных возможных запросов к ней — это статья не для Вас. NB: Рассматривается движок MySQL innodb/percona — в дальнейшем просто MySQL.
Большинство запросов не являются очень сложными. Поэтому очень важно знать как построить индекс для использования нужным запросом и/или модифицировать запрос таким образом, чтобы он использовал уже имеющиеся индексы. Мы рассмотрим работу оптимизатора для выбора индекса обычных запросов (select_type=simple), без джойнов, подзапросов и объединений.
Отбросим простейшие случаи для очень небольших таблиц, для которых оптимизатор зачастую использует type=all (полный просмотр) вне зависимости от наличия индексов — к примеру, классификатор с 40-ка записями. MySQL имеет алгоритм использования нескольких индексов (index merge), но работает этот алгоритм не очень часто, и только без order by. Единственный разумный способ пытаться использовать index merge — случаи выборки по разным столбцам с OR.
Еще одно отступление: подразумевается что читатель уже знаком с explain. Часто сам запрос немного модифицируется оптимизатором, поэтому для того, чтобы понять, почему использовался или нет тот или иной индекс, следует вызвать
explain extended select xxx;
show warnings;
Покрывающий индекс — от толстых таблиц к индексам
Итак задача: пусть у нас есть довольно простой запрос, который выполняется довольно часто, но для такого частого вызова относительно медленно. Рассмотрим стратегию приведения нашего запроса к using index, как к наиболее быстрому выбору.
Почему using index? Да, MySQL используют только B-tree индексы, но тем не менее MySQL старается по возможности держать индексы целиком в памяти (и при этом может даже добавить поверх них адаптивные хеш-индексы) — собственно все это и дает сказочный прирост производительности MySQL по отношению к другим базам данных. К тому же оптимизатор зачастую предпочтет использовать хоть и не лучший, но уже загруженный в память индекс, нежели более лучший, но на диске (для type=index/range). Отсюда несколько выводов:
- слишком тяжелые индексы — зло. Либо они не будут использоваться потому что они еще не в памяти, либо их не будут грузить в память потому что при этом вытеснятся другие индексы.
- если размер индекса сопоставим с размером таблицы, либо совокупность используемых индексов для разных частых запросов существенно превышает размер памяти сервера — существенной оптимизации не добиться.
- Нюанс — индексировать/сортировать по TEXT — обрекать себя на постоянный using filesort.
Один тонкий момент, про который иногда забываешь — MySQL создает только кластерные индексы. Кластерный — по сути указывающий не на абсолютное положение записи в таблице, а (условно) на запись первичного ключа, который в свою очередь позволяет извлечь саму искомую запись. Но MySQL, не мудрствуя лукаво, для того чтобы обойтись без второго лукапа, поступает просто — расширяя любой ключ на ширину первичного ключа. Таким образом если у вас в таблице primary key (ID), key (A,B,C), то в реальности у вас второй ключ не (A,B,C), а (A,B,C,ID). Отсюда мораль — толстый первичный ключ суть зло.
Следует указать на разницу в кешировании запросов в разных базах. Если PostgreSQL/Oracle кешируют планы запросов (как бы prepare for some timeout), то MySQL просто кеширует СТРОКУ запроса (включая значение параметров) и сохраняет результат запроса. То есть если последовательно селектировать
select AAA from BBB where CCC=DDD
Таким образом, считаем, что мы не просто вызываем один и тот же запрос несколько раз. Параметры запроса меняются, данные таблицы меняются. Наилучший вариант — использование покрывающего индекса. Какой же индекс будет покрывающим?
- Во-первых, смотрим на клоз order by. Используемый индекс должен начинаться с тех же столбцов что упомянуты в order by, в той же или в полностью обратной сортировке. Если сортировка не прямая и не обратная — индекс не может быть использован. Здесь есть одно но… MySQL до сих пор не поддерживает индексов со смешанными сортировками. Индекс всегда asc. Так что если у вас есть order by A asc, B desc — распрощайтесь с using index.
- Столбцы, которые извлекаются, должны присутствовать в покрывающем индексе. Очень часто это невыполнимое условие в связи с бесконечным ростом индекса, что, как известно, зло. Поэтому существует способ обойти этот момент — использование self join‘а. То есть разделение запроса на выбор строк и извлечение данных. Во-первых, выбираем по заданному условию только столбцы первичного ключа (который всегда присутствует в кластером индексе), и во-вторых, полученный результат джойним к селекту всех требуемых столбцов, используя этот самый первичный ключ. Таким образом у нас будет чистый using index в первом селекте, и eq_ref (суть множественный const) для второго селекта. Итак, мы получаем что-то похожее на:
select AAA,BBB,CCC,DDD from tableName as a join tableName as b using (PK) «where over table b» - Далее клоз where. Здесь в худшем случае мы можем перебрать весь индекс (type=index), но по возможности стоит стремиться использовать функции, не выводящие за рамки type=range (>, >=, <, <=, like «xxx%» и так далее). Используемый индекс должен включать все поля из where, для того чтобы сохранить using index. Как уже было отмечено выше — можно пытаться использовать index_merge — но зачастую это просто не возможно со сложными условиями.
Собственно, это все, что можно сделать для случая, когда мы имеем только один вид запроса. К сожалению, оптимизатор MySQL не всегда при наличии покрывающего индекса может выбрать именно его для выполнения запроса. Что ж, в таком случае приходится помогать оптимизатору с помощью стандартных хинтов use/force index.
Вычленение толстых полей из покрывающего индекса — от толстых индексов к тонким
Но что делать, если у нас запросы бывают нескольких видов, или требуются разные сортировки и при этом используются толстые поля (varchar)? Просто посчитайте размер индекса поля varchar(100) в миллионе записей. А если это поле используется в разных видах запросов — для которых у нас разные покрывающие индексы? Возможно ли иметь в памяти только ОДИН индекс по этому толстому полю, сохранив при этом ту же (или почти ту же) производительность в разных запросах? Итак — последний пункт.
- Толстые и тонкие поля. Очевидно, что иметь несколько РАЗНЫХ вариантов ключей с использованием толстых полей — непозволительная роскошь. Поэтому по возможности мы должны пытаться иметь только один ключ начинающийся на толстое поле. И здесь уместно использовать некоторый искусственный алгоритм замены условий. То есть заменить условие по толстому полю на джойн по результатам этого условия. К примеру:
вместо создания ключа key(fatB, A) мы создадим тонкий ключ key(A) и толстый key(fatB). И перепишем условие след образом.select A from tableName where A=1 or fatB='test'create temporary table tmp as select PK from tableName where fatB='test'; select A from tableName left join tmp using (PK) where A=1 or tmp.PK is not null;
Следовательно, мы можем иметь много тонких ключей, для разных запросов и только один толстый по полю fatB. Реальная экономия памяти, при почти полном сохранении производительности.
Задание для самостоятельного разбора
Требуется создать минимальное количество ключей (с точки зрения памяти) и оптимизировать запросы вида:
select A,B,C,D from tableName where A=1 and B=2 or C=3 and D like 'test%';
select A,C,D from tableName where B=3 or C=3 and D ='test' order by B;
Список используемой литературы
- High Performance MySQL, 2nd Edition
Optimization, Backups, Replication, and More
By Baron Schwartz, Peter Zaitsev, Vadim Tkachenko, Jeremy D. Zawodny, Arjen Lentz, Derek J. Balling
Publisher: O’Reilly Media
Released: June 2008
Pages: 712 - www.mysqlperformanceblog.com
habr.com
Запрос в запросе или получение данных из двух таблиц mysql php
Stack Overflow на русскомLoading…
- 0
- +0
- Тур Начните с этой страницы, чтобы быстро ознакомиться с сайтом
- Справка Подробные ответы на любые возможные вопросы
- Мета Обсудить принципы работы и политику сайта
- О нас Узнать больше о компании Stack Overflow
- Бизнес Узнать больше о поиске разработчиков или рекламе на сайте
- Войти Регистрация
-
текущее сообщество
- Stack Overflow на русском справка чат
- Stack Overflow на русском Meta
ru.stackoverflow.com