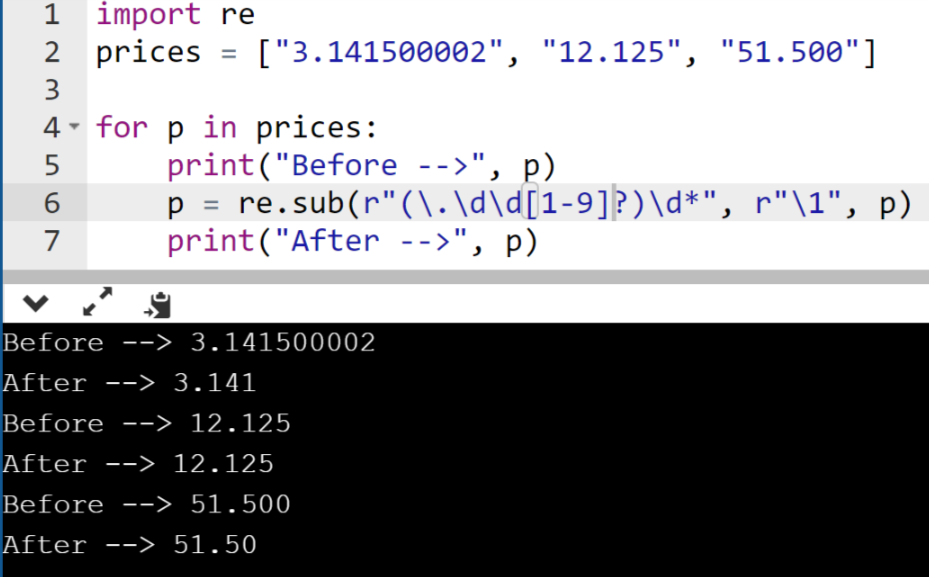
Python: поиск подстроки, операции со строками. Как выполнять поиск в строке Python?
В этой статье поговорим про строки в Python, особенности поиска, а также о том, как искать подстроку или символ в строке. Но сначала давайте вспомним основные методы для обработки строк в Python:
• isalpha(str): если строка в Python включает в себя лишь алфавитные символы, возвращается True;
• islower(str): True возвращается, если строка включает лишь символы в нижнем регистре;
• isupper(str): True, если символы строки в Python находятся в верхнем регистре;
• startswith(str): True, когда строка начинается с подстроки str;
• isdigit(str): True, когда каждый символ строки — цифра;
• endswith(str): True, когда строка в Python заканчивается на подстроку str;
• upper(): строка переводится в верхний регистр;
• lower(): строка переводится в нижний регистр;
• title(): для перевода начальных символов всех слов в строке в верхний регистр;
• capitalize(): для перевода первой буквы самого первого слова строки в верхний регистр;
• lstrip(): из строки в Python удаляются начальные пробелы;
• rstrip(): из строки в Python удаляются конечные пробелы;
• strip(): из строки в Python удаляются и начальные, и конечные пробелы;
• rjust(width): когда длина строки меньше, чем параметр width, слева добавляются пробелы, строка выравнивается по правому краю;
• ljust(width): когда длина строки в Python меньше, чем параметр width, справа от неё добавляются пробелы для дополнения значения  В том случае, если подстрока не найдена, выполняется возвращение числа -1;
• center(width): когда длина строки в Python меньше, чем параметр width, слева и справа добавляются пробелы (равномерно) для дополнения значения width, причём происходит выравнивание строки по центру;
• split([delimeter[, num]]): строку в Python разбиваем на подстроки в зависимости от разделителя;
• replace(old, new[, num]): в строке одна подстрока меняется на другую;
• join(strs): строки объединяются в одну строку, между ними вставляется определённый разделитель.
В том случае, если подстрока не найдена, выполняется возвращение числа -1;
• center(width): когда длина строки в Python меньше, чем параметр width, слева и справа добавляются пробелы (равномерно) для дополнения значения width, причём происходит выравнивание строки по центру;
• split([delimeter[, num]]): строку в Python разбиваем на подстроки в зависимости от разделителя;
• replace(old, new[, num]): в строке одна подстрока меняется на другую;
• join(strs): строки объединяются в одну строку, между ними вставляется определённый разделитель.
Обрабатываем строку в Python
Представим, что ожидается ввод числа с клавиатуры. Перед преобразованием введенной нами строки в число можно легко проверить, введено ли действительно число. Если это так, выполнится операция преобразования. Для обработки строки используем такой метод в Python, как isnumeric():
string = input("Введите какое-нибудь число: ")
if string.isnumeric():
number = int(string)
print(number)
Следующий пример позволяет удалять пробелы в конце и начале строки:
string = " привет мир! " string = string.strip() print(string) # привет мир!
 strip()
print(string) # привет мир!
strip()
print(string) # привет мир!
Так можно дополнить строку пробелами и выполнить выравнивание:
print("iPhone 7:", "52000".rjust(10))
print("Huawei P10:", "36000".rjust(10))
В консоли Python будет выведено следующее:
iPhone 7: 52000 Huawei P10: 36000
Поиск подстроки в строке
Чтобы в Python выполнить поиск в строке, используют метод find(). Он имеет три формы и возвращает индекс 1-го вхождения подстроки в строку: • find(str): поиск подстроки str производится с начала строки и до её конца; • find(str, start): с помощью параметра start задаётся начальный индекс, и именно с него и выполняется поиск; • find(str, start, end): посредством параметра end задаётся конечный индекс, поиск выполняется до него.
Когда подстрока не найдена, метод возвращает -1:
welcome = "Hello world! Goodbye world!"
index = welcome.find("wor")
print(index) # 6
# ищем с десятого индекса
index = welcome. find("wor",10)
print(index) # 21
# ищем с 10-го по 15-й индекс
index = welcome.find("wor",10,15)
print(index) # -1

Замена в строке
Чтобы в Python заменить в строке одну подстроку на другую, применяют метод replace(): • replace(old, new): подстрока old заменяется на new; • replace(old, new, num): параметр num показывает, сколько вхождений подстроки old требуется заменить на new.
Пример замены в строке в Python:
phone = "+1-234-567-89-10" # дефисы меняются на пробелы edited_phone = phone.replace("-", " ") print(edited_phone) # +1 234 567 89 10 # дефисы удаляются edited_phone = phone.replace("-", "") print(edited_phone) # +12345678910 # меняется только первый дефис edited_phone = phone.replace("-", "", 1) print(edited_phone) # +1234-567-89-10
Разделение на подстроки в Python
Для разделения в Python используется метод split(). В зависимости от разделителя он разбивает строку на перечень подстрок. В роли разделителя в данном случае может быть любой символ либо последовательность символов. Этот метод имеет следующие формы:
• split(): в роли разделителя применяется такой символ, как пробел;
• split(delimeter): в роли разделителя применяется delimeter
Этот метод имеет следующие формы:
• split(): в роли разделителя применяется такой символ, как пробел;
• split(delimeter): в роли разделителя применяется delimeter
Соединение строк в Python
Рассматривая простейшие операции со строками, мы увидели, как объединяются строки через операцию сложения. Однако есть и другая возможность для соединения строк — метод join():, объединяющий списки строк. В качестве разделителя используется текущая строка, у которой вызывается этот метод:
words = ["Let", "me", "speak", "from", "my", "heart", "in", "English"] # символ разделителя - пробел sentence = " ".join(words) print(sentence) # Let me speak from my heart in English # символ разделителя - вертикальная черта sentence = " | ".join(words) print(sentence) # Let | me | speak | from | my | heart | in | English
А если вместо списка в метод join передать простую строку, разделитель будет вставляться уже между символами:
word = "hello" joined_word = "|".
 join(word)
print(joined_word) # h|e|l|l|o
join(word)
print(joined_word) # h|e|l|l|o
Как найти символ в строке python методом find() c примерами
Часто нам нужно найти символ в строке python. Для решения этой задачи разработчики используют метод find(). Он помогает найти индекс первого совпадения подстроки в строке. Если символ или подстрока не найдены, find возвращает -1.
Синтаксис
string.find(substring,start,end)
Метод find принимает три параметра:
substring(символ/подстрока) — подстрока, которую нужно найти в данной строке.start(необязательный) — первый индекс, с которого нужно начинать поиск. По умолчанию значение равно 0.end(необязательный) — индекс, на котором нужно закончить поиск. По умолчанию равно длине строки.
Поиск символов методом find() со значениями по умолчанию
Параметры, которые передаются в метод, — это подстрока, которую требуются найти, индекс начала и конца поиска. Значение по умолчанию для начала поиска — 0, а для конца — длина строки.
Значение по умолчанию для начала поиска — 0, а для конца — длина строки.
В этом примере используем метод со значениями по умолчанию.
Метод find() будет искать символ и вернет положение первого совпадения. Даже если символ встречается несколько раз, то метод вернет только положение первого совпадения.
Копировать Скопировано Use a different Browser
>>> string = "Добро пожаловать!"
>>> print("Индекс первой буквы 'о':", string.find("о"))
Индекс первой буквы 'о': 1
Поиск не с начала строки с аргументом start
Можно искать подстроку, указав также начальное положение поиска.
В этом примере обозначим стартовое положение значением 8 и метод начнет искать с символа с индексом 8. Последним положением будет длина строки — таким образом метод выполнит поиска с индекса 8 до окончания строки.
Копировать Скопировано Use a different Browser
>>> string = "Специалисты назвали плюсы и минусы Python"
>>> print("Индекс подстроки 'али' без учета первых 8 символов:", string.
Индекс подстроки 'али' без учета первых 8 символов: 16
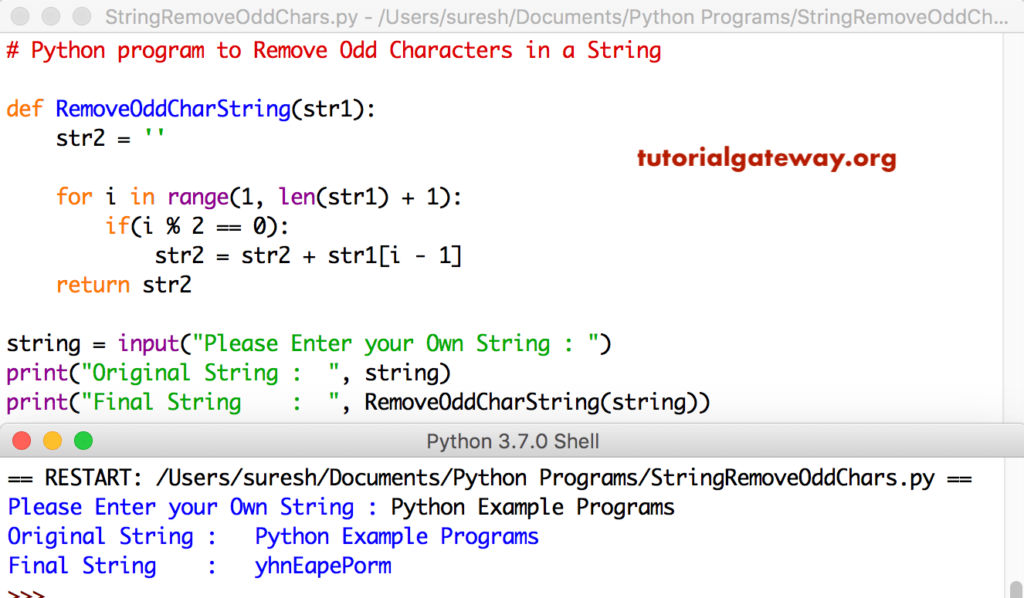 find("али", 8))
find("али", 8))Поиск символа в подстроке со start и end
С помощью обоих аргументов (start и end) можно ограничить поиск и не проводить его по всей строке. Найдем индексы слова «пожаловать» и повторим поиск по букве «о».
Копировать Скопировано Use a different Browser
>>> string = "Добро пожаловать!"
>>> start = string.find("п")
>>> end = string.find("ь") + 1
>>> print("Индекс первой буквы 'о' в подстроке:", string.find("о", start, end))
Индекс первой буквы 'о' в подстроке: 7
Проверка есть ли символ в строке
Мы знаем, что метод find() позволяет найти индекс первого совпадения подстроки. Он возвращает -1 в том случае, если подстрока не была найдена.
Копировать Скопировано Use a different Browser
>>> string = "Добро пожаловать!"
>>> print("Есть буква 'г'?", string.
Есть буква 'г'? False
>>> print("Есть буква 'т'?", string.find("т") != -1)
Есть буква 'т'? True
 find("г") != -1)
find("г") != -1)Поиск последнего вхождения символа в строку
Функция rfind() напоминает find(), а единое отличие в том, что она возвращает максимальный индекс. В обоих случаях же вернется -1, если подстрока не была найдена.
В следующем примере есть строка «Добро пожаловать!». Попробуем найти в ней символ «о» с помощью методов find() и rfind().
Копировать Скопировано Use a different Browser
>>> string = "Добро пожаловать"
>>> print("Поиск 'о' методом find:", string.find("о"))
Поиск 'о' методом find: 1
>>> print("Поиск 'о' методом rfind:", string.rfind("о"))
Поиск 'о' методом rfind: 11
Вывод показывает, что find() возвращает индекс первого совпадения подстроки, а rfind() — последнего совпадения.
Второй способ поиска — index()
Метод index() помогает найти положение данной подстроки по аналогии с find(). Единственное отличие в том, что index() бросит исключение в том случае, если подстрока не будет найдена, а find() просто вернет -1.
Вот рабочий пример, показывающий разницу в поведении index() и find():
Копировать Скопировано Use a different Browser
>>> string = "Добро пожаловать"
>>> print("Поиск 'о' методом find:", string.find("о"))
Поиск 'о' методом find: 1
>>> print("Поиск 'о' методом index:", string.index("о"))
Поиск 'о' методом index: 1
В обоих случаях возвращается одна и та же позиция. А теперь попробуем с подстрокой, которой нет в строке:
Копировать Скопировано Use a different Browser
>>> string = "Добро пожаловать"
>>> print("Поиск 'г' методом find:", string.
Поиск 'г' методом find: 1
>>> print("Поиск 'г' методом index:", string.index("г"))
Traceback (most recent call last):
File "pyshell#21", line 1, in module
print("Поиск 'г' методом index:", string.index("г"))
ValueError: substring not found
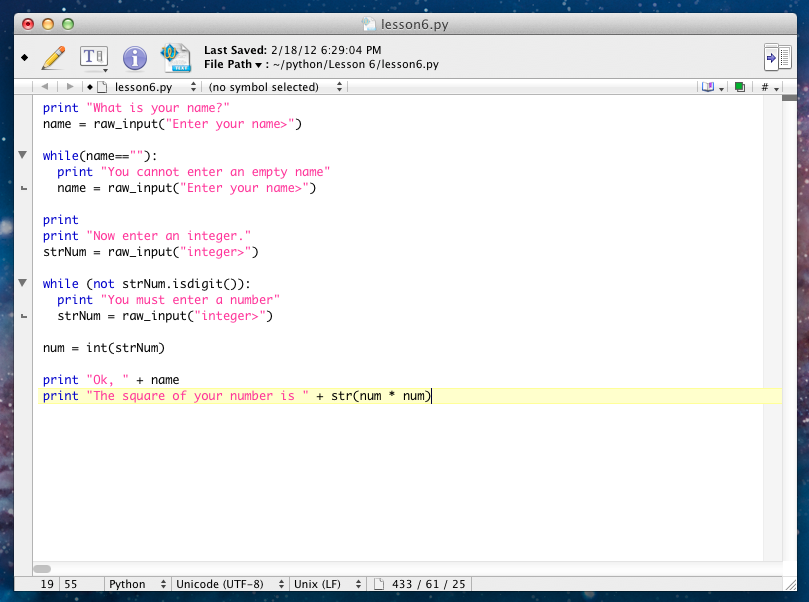 find("г"))
find("г"))В этом примере мы пытались найти подстроку «г». Ее там нет, поэтому find() возвращает -1, а index() бросает исключение.
Поиск всех вхождений символа в строку
Чтобы найти общее количество совпадений подстроки в строке можно использовать ту же функцию find(). Пройдемся циклом while по строке и будем задействовать параметр start из метода find().
Изначально переменная start будет равна -1, что бы прибавлять 1 у каждому новому поиску и начать с 0. Внутри цикла проверяем, присутствует ли подстрока в строке с помощью метода find.
Если вернувшееся значение не равно -1, то обновляем значением count.
Вот рабочий пример:
Копировать Скопировано Use a different Browser
my_string = "Добро пожаловать"
start = -1
count = 0while True:
start = my_string.find("о", start+1)
if start == -1:
break
count += 1print("Количество вхождений символа в строку: ", count )
Количество вхождений символа в строку: 4
Выводы
- Метод
find()помогает найти индекс первого совпадения подстроки в данной строке. Возвращает -1, если подстрока не была найдена. - В метод передаются три параметра: подстрока, которую нужно найти,
startсо значением по умолчанию равным 0 иendсо значением по умолчанию равным длине строки. - Можно искать подстроку в данной строке, задав начальное положение, с которого следует начинать поиск.
- С помощью параметров
startиendможно ограничить зону поиска, чтобы не выполнять его по всей строке. - Функция
rfind()повторяет возможностиfind(), но возвращает максимальный индекс (то есть, место последнего совпадения). В обоих случаях возвращается -1, если подстрока не была найдена. index()— еще одна функция, которая возвращает положение подстроки. Отличие лишь в том, чтоindex()бросает исключение, если подстрока не была найдена, аfind()возвращает -1.find()можно использовать в том числе и для поиска общего числа совпадений подстроки.
 В обоих случаях возвращается -1, если подстрока не была найдена.
В обоих случаях возвращается -1, если подстрока не была найдена.Найти все вхождения подстроки в строке в Python
Автор оригинала: Team Python Pool.
Привет, кодеры!! В этой статье мы рассмотрим методы в Python, чтобы найти все вхождения в строку. Чтобы сделать концепцию ясной, мы рассмотрим подробную иллюстрацию кода для достижения требуемого результата.
Что такое подстрока?
Подстрока в Python – это последовательность символов, представленных в другой строке. Например, рассмотрим сильный abaabaabbaab. Здесь arab – это подстрока, встречающаяся дважды в строке. Кроме того, abs – это еще одна подстрока, встречающаяся трижды в строке.
Часто при обработке строк у нас могут возникнуть проблемы с обработкой подстрок. Это включает в себя неудобство нахождения всех позиций определенной подстроки в строке. В этой статье мы обсудим, как мы можем справиться с этим.
Код Python для поиска всех вхождений в строку
1)Использование понимания списка + начинается с() в Python для поиска всех вхождений в строку
Эта функция помогает найти заданную подстроку во всей строке или в заданной части строки.
Синтаксис:
string.startswith(значение, начало, конец)
Список параметров:
- значение: Это обязательное поле. Он содержит значение, с помощью которого мы проверяем, начинается ли строка с этого значения.
- start: Это необязательное поле. Это целочисленное значение, которое определяет позицию, с которой следует начать поиск.
- конец: Это необязательное поле. Это целочисленное значение, которое указывает позицию, с которой следует завершить поиск.
Возвращаемое значение:
Возвращает индекс, по которому найдена данная подстрока.![]()
Вывод и объяснение:
Выход
В этом коде входная строка была “python pool for python coding”. Мы выбрали подстроку “python”. Используя функцию starts with() , мы нашли вхождения подстроки в строку. В результате мы нашли подстроку в индексах 0 и 15.
2) Использование re.finditer() в Python для поиска всех вхождений в строку
Это функция href=”https://docs.python.org/3/library/re.html”>библиотека регулярных выражений, предоставляемая python, которая помогает найти вхождение определенного шаблона в строку. href=”https://docs.python.org/3/library/re.html”>библиотека регулярных выражений, предоставляемая python, которая помогает найти вхождение определенного шаблона в строку.
Синтаксис:
re.finditer(шаблон, строка,)
Список параметров:
- pattern: шаблон, который должен быть согласован
Возвращаемое значение:
Эта функция возвращает итератор неперекрывающихся совпадений для шаблона в строке.
import re print("The original string is: " + string) print("The substring to find: " + substring) result = [i.
 start() for i in re.finditer(substring, string)]
print("The start indices of the substrings are : " + str(result))
start() for i in re.finditer(substring, string)]
print("The start indices of the substrings are : " + str(result))Вывод и объяснение:
Выход
В этом коде входная строка была “python pool for python coding”. Мы выбрали подстроку “python”. Используя функцию re.finditer (), мы нашли неперекрывающиеся вхождения подстроки в строке. В результате мы нашли подстроку в индексах 0 и 15.
3) Использование re.findall() в Python для поиска всех вхождений в строку
Эта функция используется для поиска всех неперекрывающихся подстрок в данной строке. Строка тщательно сканируется слева направо, возвращая совпадения в том же порядке.
Синтаксис:
re.finditer(шаблон, строка,)
Список параметров:
- pattern: шаблон, который должен быть согласован
Возвращаемое значение:
Он возвращает все совпадения шаблона в виде списка строк.
import re print("The original string is: " + string) print("The substring to find: " + substring) .
 findall(substring, string)
print(result)
findall(substring, string)
print(result)Вывод и объяснение:
Выход
В этом коде входная строка была “python pool 123 for python 456 coding”. Мы выбрали подстроку “\d+”. Используя функцию re.findall (), мы нашли вхождения подстроки. В этом случае мы ищем целые числа в строке. В результате на выходе получается список, содержащий все целочисленные значения.
Вывод: Python находит все вхождения в строку
В этой статье мы изучили различные способы поиска всех вхождений данной подстроки в строку с помощью различных функций в Python.
Python Substring |Операции с подстроками в Python
Автор оригинала: Team Python Pool.
Python substring – это строка, которая является частью другой (или большей) Python String. В программировании на Python этот метод также известен как нарезка строки.
Как создать подстроку Python
В языке программирования Python обычно существует два метода создания подстрок.
- Ломтик
- Расщеплять
Создание Подстроки Python С Помощью Метода Slice
- Во-первых, вы должны хранить строку в переменной Python. Наш пример:
- С помощью команды “str [4:]” теперь вы выведете строку без первых четырех символов: ‘o world this is Karan from Python Pool’
- С помощью команды “str [: 4]” в свою очередь выводятся только первые четыре символа: “Hello”
- Команда “str [: – 2]”, которая выводит строку без последних двух символов, также очень практична: “Hello world this is Karan from Python Po”
- Это также работает наоборот, “str[-2:]” так что выводятся только последние два символа:”ol”
- Наконец, вы также можете комбинировать команды. Например, команда “x [4: -4]” выводит строку без первых и последних четырех символов:’o world this is Karan from Python ‘
 Наш пример:
Наш пример:Вы можете выполнить все вышеперечисленные команды в терминале Python, как показано на рисунке ниже.
Создание Подстроки Python С Помощью Метода Split
Split strings-это еще одна функция, которая может быть применена в Python, давайте посмотрим на строку “Python Pool Best Place to Learn Python”. Сначала здесь мы разделим строку с помощью командного слова. разделитесь и получите результат.
разделитесь и получите результат.
Выход
['Python', 'Pool', 'Best', 'Place', 'to', 'Learn', 'Python']
Чтобы лучше понять это, мы увидим еще один пример разделения, вместо пробела (‘ ‘) мы заменим его на (‘r’), и он разделит строку везде, где в строке упоминается ‘r’
Выход
['Python Pool Best Place to Lea', 'n Python ']
Примечание: В Python строки неизменяемы.
Строковые методы Python
Метод в Python похож на функцию, но он работает “на” объекте. Если переменная s рассматривается как строка, то код s.lower() запускает метод lower() на этом строковом объекте и затем возвращает результат (эта концепция метода, работающего на объекте, является одной из основных идей, составляющих Объектно-ориентированное программирование, ООП)
Python substring имеет довольно много методов, которые строковые объекты могут вызывать для выполнения часто встречающихся задач (связанных со строкой). Например, если требуется, чтобы первая буква строки была заглавной, можно использовать метод capitalize (). Ниже приведены все методы строковых объектов. Кроме того, включены все встроенные функции, которые могут принимать строку в качестве параметра и выполнять некоторую задачу.
Ниже приведены все методы строковых объектов. Кроме того, включены все встроенные функции, которые могут принимать строку в качестве параметра и выполнять некоторую задачу.
Таблица, содержащая все Строковые методы Python
| Метод | Описание |
| Python String capitalize() | Преобразует первый символ в заглавную букву |
| Центр строк Python() | Колодки строка с указанным символом |
| Python String casefold() | преобразуется в строки сложенные в регистр |
| Количество строк Python() | возвращает вхождения подстроки |
| Python String endswith() | Проверяет, заканчивается ли строка указанным суффиксом |
| Python String expandtabs() | Заменяет Табуляцию Пробелами |
| Кодирование строк Python() | возвращает кодированную строку |
| Python String find() | Возвращает индекс первого вхождения подстроки |
| Формат строки Python() | форматирует строку |
| Индекс строки Python() | Возвращает индекс подстроки Python |
| Python String isalnum() | Проверки Буквенно-Цифровые |
| Python String isalpha() | Проверяет, все ли это алфавиты |
| Строка Python является десятичной() | Проверяет Десятичные дроби |
| Python String isdigit() | Проверяет Цифры |
| Python String isidentifier() | Проверяет наличие действительного идентификатора |
| Строка Python ниже() | Проверяет, все ли они строчные |
| Python String isnumeric() | Чеки Числовые |
| Строка Python доступна для печати() | Чеки для печати |
| Python String isspace() | Проверяет пробелы |
| Строка Python-это заголовок() | Чеки для титульного дела |
| Строка Python является верхней() | возвращает, если все они прописные |
| Python String join() | Возвращает Конкатенированную строку |
| Python String просто() | возвращает строку с выравниванием по левому краю |
| Python String rjust() | возвращает строку с выравниванием по правому краю |
| Строка Python ниже() | возвращает строку в нижнем регистре |
| Верхняя строка Python() | возвращает строку в верхнем регистре |
| Python String swapcase() | поменять прописные буквы на строчные |
| Python String strip() | Удаляет Ведущие |
| Python String strip() | Удаляет Трейлинг |
| Python String strip() | Удаляет как Ведущий, Так и Трейлинг |
| Раздел строк Python() | Возвращает кортеж |
| Python String maketrans() | возвращает таблицу перевода |
| Раздел строк Python() | Возвращает кортеж |
| Python String translate() | возвращает сопоставленную строку |
| Python String replace() | Заменяет Подстроку Внутри |
| Python String find() | Возвращает самый высокий индекс подстроки |
| Разделение строк Python() | Расщепляет строку слева |
| Разделение строк Python() | Расщепляет Строку Справа |
| Python String startswith() | Проверяет, начинается ли строка с указанной строки |
| Заголовок строки Python() | Возвращает строку в оболочке Заголовка |
| Python String zfill() | Возвращает копию строки, заполненную Нулями |
Извлечение подстроки в Python
Мы можем извлекать подстроки в Python с помощью квадратных скобок, которые могут содержать один или два индекса и двоеточие. Вот так,
Вот так,
- myString[0] извлекает первый символ ;
- myString[1:] the second through last characters;
- myString[:4] извлекает символы с первого по четвертый ;
- myString[1:3] символы со второго по третий ;
- myString[-1] извлекает последний символ .
Must Read: Python Book | Лучшая книга для изучения Python в 2020 году
Как проверить, содержит ли строка подстроку в Python
Независимо от того, является ли это просто слово, буква или фраза, которую вы хотите проверить в строке, с помощью Python вы можете легко использовать встроенные методы и тест членства в операторе.
Стоит отметить, что вы получите логическое значение (True или False) или целое число , чтобы указать, содержит ли строка то, что вы искали. Вы узнаете об этом больше, когда я покажу код ниже.
Давайте рассмотрим потенциальные решения, с помощью которых вы можете узнать, содержит ли строка или подстрока в Python определенное слово/букву.
- С помощью метода find()
- Использование в операторе
- С помощью метода count()
- Использование метода operator. contains()
- С помощью Регулярных выражений (REGEX)
 contains()
contains()1. Подстрока Python с использованием метода find
Другой метод, который вы можете использовать, – это метод поиска строки.
В отличие от оператора in, который вычисляется до логического значения, метод find возвращает целое число.
Это целое число по существу является индексом начала подстроки, если подстрока существует, в противном случае возвращается -1.
Давайте посмотрим на метод find в действии.
>>>
>>> str.find("soccer")
18
>>> str.find("Ronaldo")
-1
>>> str.find("Messi")
0Одна интересная вещь в этом методе заключается в том, что вы можете дополнительно указать начальный индекс и конечный индекс, чтобы ограничить свой поиск внутри.
2. Использование оператора in для поиска подстроки Python
Оператор in возвращает true, если подстрока существует в строке, и false, если нет.
Синтаксис
Общий синтаксис таков:
substring in string
Пример
Выход
Check if Python Programming contains Programming: True Check if Python Programming contains Language: False
3.
 С помощью метода count()
С помощью метода count()Метод count() для поиска или поиска подстроки Python проверяет наличие подстроки в строке. Если подстрока не найдена в строке, она возвращает 0.
Синтаксис: string.count(подстрока)
Пример: Проверка наличия подстроки в строке с помощью метода count()
Выход:
4. Использование Метода Contains
__contains__() – это еще одна функция, которая поможет вам проверить, содержит ли строка определенную букву/слово.
Вот как вы можете его использовать:
Вы получите вывод как True/False. Для приведенного выше фрагмента кода вы получите вывод в виде:
Обратите внимание, что при написании метода используются 4 символа подчеркивания (2 перед словом и 2 после).
Вот программа, чтобы объяснить то же самое:
В этом случае выход:
Yeyy, found the substring!
5. Использование регулярных выражений (REGEX) для поиска подстроки Python
Регулярные выражения предоставляют более гибкий (хотя и более сложный) способ проверки подстрок python на соответствие шаблону. Python поставляется со встроенным модулем для регулярных выражений, называемым re. Модуль re содержит функцию search, которую мы можем использовать для сопоставления шаблона подстроки следующим образом:
Python поставляется со встроенным модулем для регулярных выражений, называемым re. Модуль re содержит функцию search, которую мы можем использовать для сопоставления шаблона подстроки следующим образом:
from re import search
if search(substring, fullstring):
print "Found!"
else:
print "Not found!"Этот метод лучше всего подходит, если вам нужна более сложная функция сопоставления, например сопоставление без учета регистра. В противном случае следует избегать усложнения и более низкой скорости регулярных выражений для простых вариантов использования сопоставления подстрок.
Пример подстрок альтернативных символов в Python
Вы также можете использовать ту же концепцию нарезки в python для генерации подстрок, формируя гораздо больше логик. Следующие строки кода помогут вам сформировать строку, выбрав альтернативные символы строки.
Выход
AtraeCaatr
Подстрока Python с использованием цикла For
Вы также можете использовать for loop с функцией range для возврата подстроки. Для этого мы должны использовать функцию print вместе с аргументом end. Этот пример строки Python возвращает подстроку, начинающуюся с 3 и заканчивающуюся на 24.
Для этого мы должны использовать функцию print вместе с аргументом end. Этот пример строки Python возвращает подстроку, начинающуюся с 3 и заканчивающуюся на 24.
Совпадение подстрок Python
В этом примере мы проверяем, присутствует ли подстрока в данной строке или нет, используя Python If Else и not In operator.
Выход
[0, 8, 17]
Резюме:
Поскольку Python является объектно-ориентированным языком программирования, многие функции могут быть применены к объектам Python и Python Substring. Примечательной особенностью Python является его отступы исходных операторов, чтобы сделать код более легким для чтения.
- Доступ к значениям через нарезку – квадратные скобки используются для нарезки вместе с индексом или индексами для получения подстроки.При нарезке, если диапазон объявлен [1:5], он фактически может извлечь значение из диапазона [1:4]
- При нарезке, если диапазон объявлен [1:5], он фактически может извлечь значение из диапазона [1:4]
- Вы можете обновить строку Python, переназначив переменную другой строке
- Метод replace() возвращает копию строки, в которой вхождение old заменяется новым. Синтаксис метода заменяет oldstring.replace(“value to change”,”value to be replaced”)
- Синтаксис метода заменяет старую строку.replace(“value to change”,”value to be replaced”)
- Строковые операторы, такие как [], [:], in, Not in и т. Д., могут быть применены для объединения строки, извлечения или вставки определенных символов в строку или для проверки наличия определенного символа в строке
 Синтаксис метода заменяет oldstring.replace(“value to change”,”value to be replaced”)
Синтаксис метода заменяет oldstring.replace(“value to change”,”value to be replaced”)С помощью срезов или Python Substring мы извлекаем части строк. Мы можем указать необязательный начальный индекс и необязательный последний индекс (не длину). Смещения полезны.
Если у вас все еще есть какие-либо сомнения или путаница, сообщите нам об этом в разделе комментариев ниже.
У Python есть метод подстроки «содержит»? Ru Python
- Ru Python
- Подстрока содержит строки python
- У Python есть метод подстроки «содержит»?
Я ищу метод string.contains или string.indexof в Python.
Я хочу делать:
if not somestring.contains("blah"): continue Вы можете использовать оператор in :
if "blah" not in somestring: continue
Если это просто поиск подстроки, вы можете использовать string.find("substring") .
Вы должны быть немного осторожны с find , index и, хотя, как и подстроками. Другими словами, это:
s = "This be a string" if s.find("is") == -1: print "No 'is' here!" else: print "Found 'is' in the string." Он напечатает Found 'is' in the string. Аналогично, if "is" in s: будет оцениваться True . Это может быть или не быть тем, что вы хотите.
if needle in haystack: это обычное использование, как говорит Майкл, – он полагается на оператора in , более читаемый и быстрее, чем вызов метода.
Если вам действительно нужен метод вместо оператора (например, чтобы сделать какой-то странный key= для очень своеобразного вида …?), Это будет 'haystack'. . Но так как ваш пример предназначен для использования в  __contains__
__contains__if , я думаю, вы действительно не имеете в виду то, что вы говорите ;-). Это не хорошая форма (и не читаемая, и не эффективная) напрямую использовать специальные методы – они предназначены для использования вместо операторов и встроенных функций, которые им делегируют.
В принципе, вы хотите найти подстроку в строке в python. Существует два способа поиска подстроки в строке в Python.
Способ 1: in операторе
Вы можете использовать оператор Python для проверки подстроки. Это довольно просто и интуитивно понятно. Он вернет True если подстрока была найдена в строке else False .
>>> "King" in "King's landing" True >>> "Jon Snow" in "King's landing" False
Метод 2: метод str.find()
Второй метод – использовать метод str.find() . Здесь мы вызываем метод . в строке, в которой должна быть найдена подстрока. Мы передаем подстроку методу find () и проверяем его возвращаемое значение. Если его значение отличается от -1, подстрока была найдена в строке, в противном случае – нет. Возвращаемое значение – это индекс, в котором была найдена подстрока.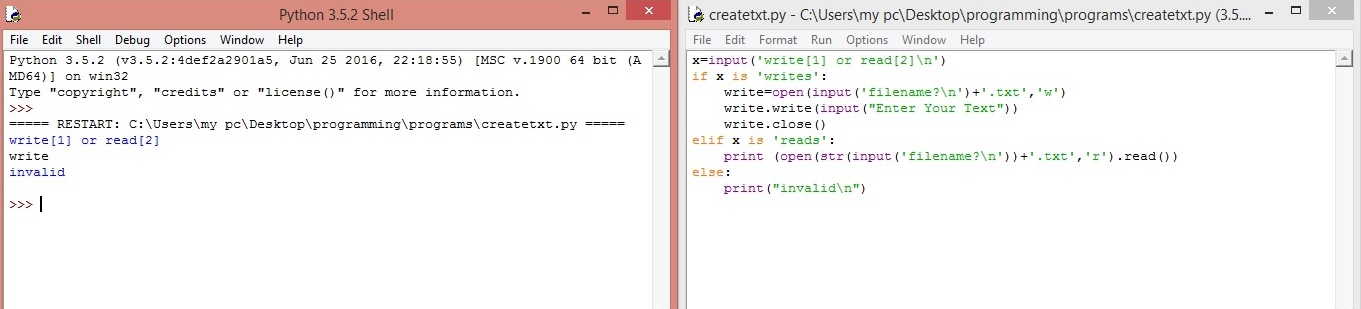 find()
find()
>>> some_string = "valar morghulis" >>> some_string.find("morghulis") 6 >>> some_string.find("dohaeris") -1 Я бы рекомендовал вам использовать первый метод, поскольку он более Pythonic и интуитивно понятен.
Нет, никакого string.contains(str) , но есть оператор in :
if substring in someString: print "It's there!!!"
Вот более сложный рабочий пример:
# Print all files with dot in home directory import commands (st, output) = commands.getstatusoutput('ls -a ~') print [f for f in output.split('\n') if '.' in f ] Да, но у Python есть оператор сравнения, который вы должны использовать вместо этого, потому что язык намеревается использовать его, а другие программисты ожидают, что вы его используете. Это ключевое слово присутствует, которое используется в качестве оператора сравнения:
Это ключевое слово присутствует, которое используется в качестве оператора сравнения:
'foo' in '**foo**' # returns True
Противоположность (дополнение), которую задает первоначальный вопрос, отсутствует:
'foo' not in '**foo**' # returns False
Это семантически то же самое, что not 'foo' in '**foo**' но это гораздо более читаемо и явно предусмотрено в языке как улучшение удобочитаемости.
Как и было обещано, вот метод contains :
str.__contains__('**foo**', 'foo') возвращает значение True . Вы также можете вызвать эту функцию из экземпляра суперструны:
'**foo**'.__contains__('foo') Но не надо. Методы, начинающиеся с подчеркивания, считаются семантически частными. Единственная причина, по которой это нужно использовать, – это расширение функции, а not in функциональности (например, при подклассификации str ):
class NoisyString(str): def __contains__(self, other): print('testing if "{0}" in "{1}"'. format(other, self)) return super(NoisyString, self).__contains__(other) ns = NoisyString('a string with a substring inside')  format(other, self)) return super(NoisyString, self).__contains__(other) ns = NoisyString('a string with a substring inside')
format(other, self)) return super(NoisyString, self).__contains__(other) ns = NoisyString('a string with a substring inside') и сейчас:
>>> 'substring' in ns testing if "substring" in "a string with a substring inside" True
Кроме того, избегайте следующих строковых методов:
>>> '**foo**'.index('foo') 2 >>> '**foo**'.find('foo') 2 >>> '**oo**'.find('foo') -1 >>> '**oo**'.index('foo') Traceback (most recent call last): File "<pyshell#40>", line 1, in <module> '**oo**'.index('foo') ValueError: substring not found У других языков нет методов прямого тестирования подстрок, поэтому вам придется использовать эти типы методов, но с Python более эффективно использовать оператор сравнения:
def in_(s, other): return other in s def contains(s, other): return s.__contains__(other) def find(s, other): return s.find(other) != -1 def index(s, other): try: s.index(other) except ValueError: return False else: return True import timeit
И теперь мы видим, что использование in –
>>> min(timeit.
 repeat(lambda: in_('superstring', 'str'))) 0.18740022799465805 >>> min(timeit.repeat(lambda: in_('superstring', 'not'))) 0.18568819388747215
repeat(lambda: in_('superstring', 'str'))) 0.18740022799465805 >>> min(timeit.repeat(lambda: in_('superstring', 'not'))) 0.18568819388747215 намного быстрее, чем ниже:
>>> min(timeit.repeat(lambda: contains('superstring', 'str'))) 0.28179835493210703 >>> min(timeit.repeat(lambda: contains('superstring', 'not'))) 0.2830145370680839 >>> min(timeit.repeat(lambda: find('superstring', 'str'))) 0.3496236199280247 >>> min(timeit.repeat(lambda: find('superstring', 'not'))) 0.35399469605181366 >>> min(timeit.repeat(lambda: index('superstring', 'str'))) 0.3490336430259049 >>> min(timeit.repeat(lambda: index('superstring', 'not'))) 0.6793600760865957 Вот несколько полезных примеров, которые говорят сами за себя по методу:
"foo" in "foobar" True "foo" in "Foobar" False "foo" in "Foobar".lower() True "foo".capitalize() in "Foobar" True "foo" in ["bar", "foo", "foobar"] True "foo" in ["fo", "o", "foobar"] False
Предостережение. Списки являются итерабельными, а метод
Списки являются итерабельными, а метод in действует на iterables, а не только на строки.
По-видимому, нет ничего подобного для векторного сравнения. Очевидным способом Python для этого было бы:
names = ['bob', 'john', 'mike'] any(st in 'bob and john' for st in names) >> True any(st in 'mary and jane' for st in names) >> False
Другой способ определить, содержит ли строка несколько символов или нет с возвращаемым значением Boolean (т.е. True или `False):
str1 = "This be a string" find_this = "tr" if find_this in str1: print find_this, " is been found in ", str1 else: print find_this, " is not found in ", str1
В Python есть два простых способа достижения этого:
Путь Pythonic: использование Python’s in in Keyword-
in принимает два «аргумента», один слева ( подстрока ) и один справа, и возвращает « True если левый аргумент содержится внутри аргумента прав, а если нет, он возвращает False .
example_string = "This is an example string" substring = "example" print(substring in example_string)
Вывод:
True
Непитонический путь: использование str.find на Python:
Метод find возвращает позицию строки в строке или -1, если она не найдена. Но просто проверьте, нет ли позиции -1.
if example_string.find(substring) != -1: print('Substring found!') else: print('Substring not found!') Вывод:
Substring found!
Вот ваш ответ:
if "insert_char_or_string_here" in "insert_string_to_search_here": //DOSTUFF
Для проверки, является ли он ложным:
if not "insert_char_or_string_here" in "insert_string_to_search_here": //DOSTUFF
ИЛИ:
if "insert_char_or_string_here" not in "insert_string_to_search_here": //DOSTUFF
- Как получить имя переменной в виде строки в Python?
- Как получить имя функции в виде строки в Python?
Строки
Содержание
- Строки
- Тип
str - Доступ к символам и срезы строк
- Конкатенация и неизменяемость строк
- Тип
- Некоторые методы строк
- Поиск
- Подсчёт
- Замена
- Разбиение и объединение
- Префикс-функция, алгоритм Кнута-Морриса-Пратта, Z-функция
- Контест №11
Строки предоставляют возможность хранить и оперировать с данными, представленными в виде последовательности символов. Язык Python из «коробки» имеет широкую поддержку строк и позволяет обращаться с символами из самых разных алфавитов.
Язык Python из «коробки» имеет широкую поддержку строк и позволяет обращаться с символами из самых разных алфавитов.
Тип
strДля взаимодействия со строками в языке есть встроенный тип str.
Его литералом являются одиночные ' или двойные кавычки ".
Символы (код), заключенный между кавычками будет восприниматься Python, как строка:
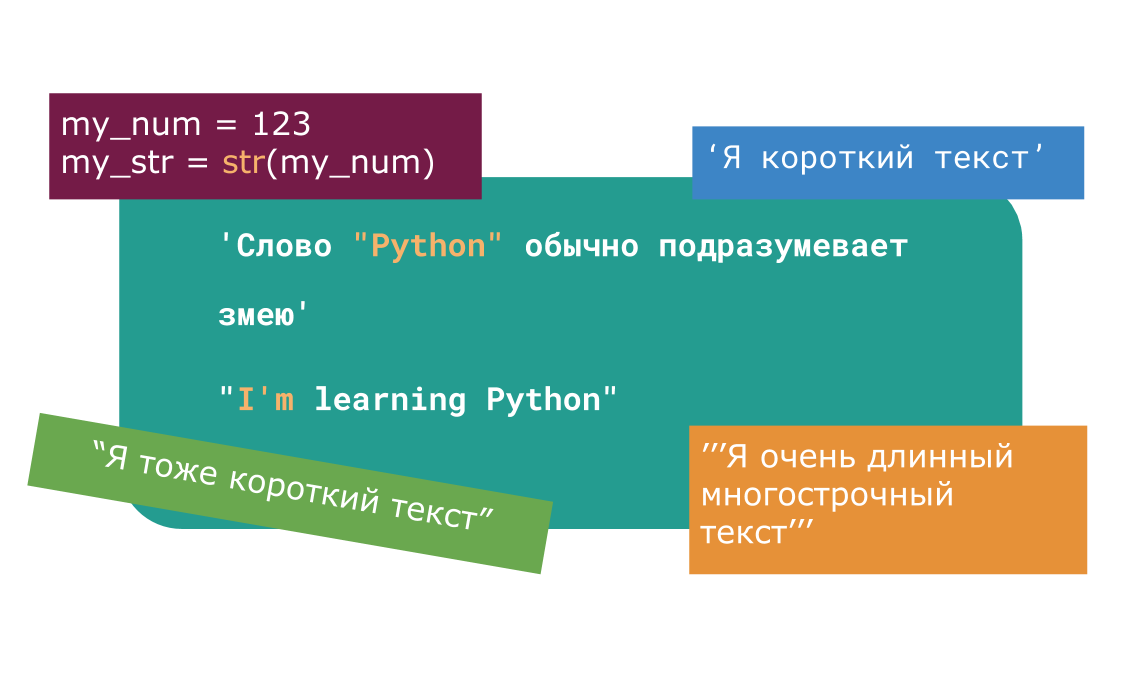
>>> s1 = 'Привет! Я строка!' >>> s2 = "Привет! Я тоже строка!" >>> type(s1) <class 'str'> >>> type(s2) <class 'str'>
Строка может быть пустой: '' или "".
Чтобы воспользоваться кавычками внутри строки, есть два пути:
- Воспользоваться в качестве литерала одним видом кавычек, а внутри строки пользоваться вторым видом кавычек;
- Экранировать кавычки внутри строки с помощью символа экранирования (escape character) \, он же называется обратной косой чертой.
Например:
>>> s4 = '\'Я внутри одинарных кавычек\', а "я внутри двойных"' >>> s4 '\'Я внутри одинарных кавычек\', а "я внутри двойных"' >>> print(s4) 'Я внутри одинарных кавычек', а "я внутри двойных"
Здесь в качестве литерала взяты одинарные кавычки, для первой части фразы используется экранирование, а для второй двойные.
Более того, для удобного написания многострочной строки (простите), можно воспользоваться тройными одинарными или тройными двойными кавычками, причём внутри такой строки экранирование не понадобится:
>>> multiline_str = '''Я первая строка ... I'm the second line ... А я третья!''' >>> multiline_str "Я первая строка\nI'm the second line\nА я третья!" >>> print(multiline_str) Я первая строка I'm the second line А я третья!
Заметьте, что во второй строке экранирование кавычки не понадобилось (I'm).
Также, вы могли заметить, что при вызове в интерактивном режиме строка отображается в виде, в котором представлена в программе, и только при печати print() отображается ожидаемо.
В случае печати чисел это было не заметно.
Напоследок, небольшой список часто используемых экранированных последовательностей (escape sequence):
- символ новой строки
\n - табуляция
\t, с помощью табуляции можно получать удобные для чтения таблицы - кавычки
\',\" - обратная косая
\\
Доступ к символам и срезы строк
Так же, как и список, строка это упорядоченная последовательность.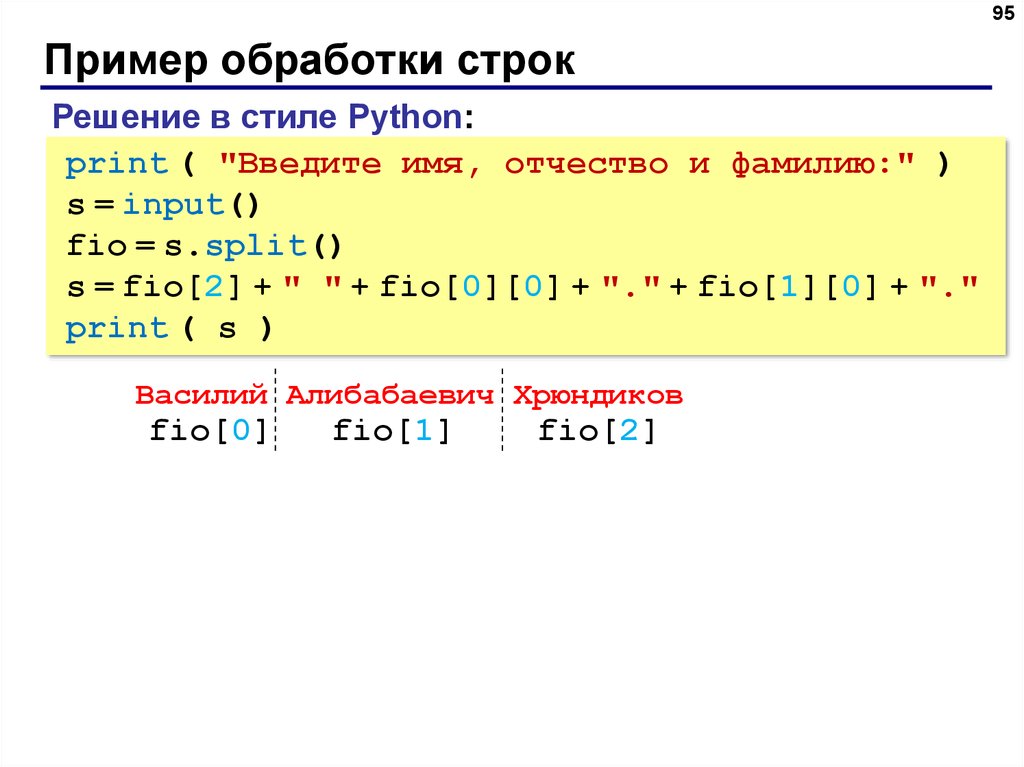 Если список это последовательность объектов произвольного типа, то строка это последовательность символов.
Если список это последовательность объектов произвольного типа, то строка это последовательность символов.
Можно узнать длину строки, получить символ на определённой позиции и даже получить срез строки:
>>> s = "Hello, World!" >>> len(s) 13 >>> s[0] 'H' >>> s[7:] 'World!' >>> s[::2] 'Hlo ol!'
Конкатенация и неизменяемость строк
Простейшая операция над двумя строками это конкатенация — приписывание второй строки в конец первой:
>>> str_1 = "ABC" >>> str_2 = "def" >>> str_1 + str_2 'ABCdef' >>> str_2 + str_1 'defABC'
Более того, с помощью символа умножения * можно конкатенировать строку с самой собой несколько раз:
>>> str_1 'ABC' >>> str_1 * 10 'ABCABCABCABCABCABCABCABCABCABC' >>> 5 * str_1 'ABCABCABCABCABC' >>> str_1 'ABC' >>> str_2 'def' >>> (str_1 + str_2) * 5 'ABCdefABCdefABCdefABCdefABCdef'
Строки являются неизменяемым типом в Python. При попытке изменения символа на какой-то позиции произойдёт ошибка:
При попытке изменения символа на какой-то позиции произойдёт ошибка:
>>> s = 'ваза' >>> s[0] = 'б' Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'str' object does not support item assignment
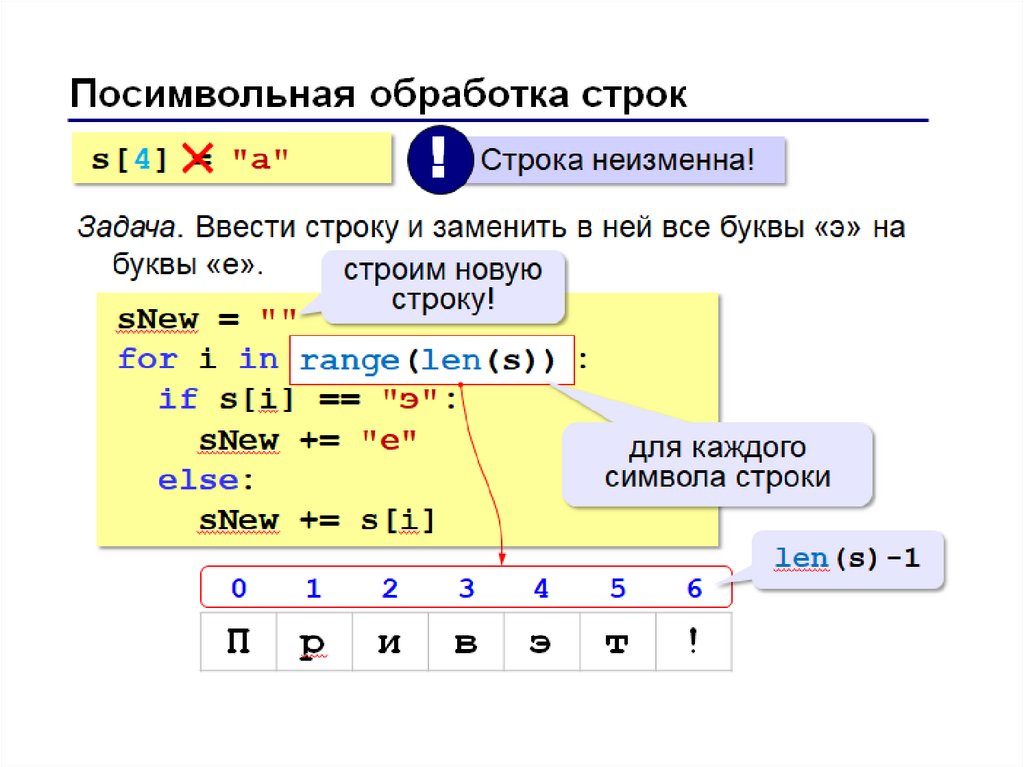
На самом деле, в примерах по конкатенации Python создавал новые объекты строк. Даже операция инкрементирования создаёт новую строку, в чём можно убедиться, узнав их идентификатор (в данном случае это равносильно адресу в памяти):
>>> s = 'a' >>> id(s) 4465232176 >>> s += 'b' >>> s 'ab' >>> id(s) 4466564720
У строк в Python огромное количество методов. Не верите? Вот они:
str.capitalize() str.casefold() str.center(width[, fillchar]) str.count(sub[, start[, end]]) str.encode(encoding="utf-8", errors="strict") str.endswith(suffix[, start[, end]]) str.expandtabs(tabsize=8) str.find(sub[, start[, end]]) str.format(*args, **kwargs) str.format_map(mapping) str.
 index(sub[, start[, end]])
str.isalnum()
str.isalpha()
str.isascii()
str.isdecimal()
str.isdigit()
str.isidentifier()
str.islower()
str.isnumeric()
str.isprintable()
str.isspace()
str.istitle()
str.isupper()
str.join(iterable)
str.ljust(width[, fillchar])
str.lower()
str.lstrip([chars])
static str.maketrans(x[, y[, z]])
str.partition(sep)
str.replace(old, new[, count])
str.rfind(sub[, start[, end]])
str.rindex(sub[, start[, end]])
str.rjust(width[, fillchar])
str.rpartition(sep)
str.rsplit(sep=None, maxsplit=-1)
str.rstrip([chars])
str.split(sep=None, maxsplit=-1)
str.splitlines([keepends])
str.startswith(prefix[, start[, end]])
str.strip([chars])
str.swapcase()
str.title()
str.translate(table)
str.upper()
str.zfill(width)
index(sub[, start[, end]])
str.isalnum()
str.isalpha()
str.isascii()
str.isdecimal()
str.isdigit()
str.isidentifier()
str.islower()
str.isnumeric()
str.isprintable()
str.isspace()
str.istitle()
str.isupper()
str.join(iterable)
str.ljust(width[, fillchar])
str.lower()
str.lstrip([chars])
static str.maketrans(x[, y[, z]])
str.partition(sep)
str.replace(old, new[, count])
str.rfind(sub[, start[, end]])
str.rindex(sub[, start[, end]])
str.rjust(width[, fillchar])
str.rpartition(sep)
str.rsplit(sep=None, maxsplit=-1)
str.rstrip([chars])
str.split(sep=None, maxsplit=-1)
str.splitlines([keepends])
str.startswith(prefix[, start[, end]])
str.strip([chars])
str.swapcase()
str.title()
str.translate(table)
str.upper()
str.zfill(width)
Мы разберём только некоторые из них (для остальных есть help(str.method_name) 🙂
Поиск
Метод str.find ищет подстроку в строке и возвращает индекс начала найденной подстроки.
Если вхождение не найдено, вернётся -1:
>>> s = 'Hello, World!' >>> s.
 find('World')
7
>>> s[7]
'W'
>>> s.find('Universe')
-1
find('World')
7
>>> s[7]
'W'
>>> s.find('Universe')
-1
Этот метод имеет два необязательных аргумента start и end.
Если их указать, то поиск будет осуществляться в срезе строки s[start:end]:
>>> s
'Hello, World!'
>>> s.find('o')
4
>>> s[3:6]
'lo,'
>>> s.find('o', 7)
8
>>> s[7:10]
'Wor'
И, как видно, str.find осуществляет поиск первого вхождения подстроки, начиная слева.
Чтобы осуществить поиск подстроки, начиная справа (т.е. с конца) строки, можно воспользоваться методом str.rfind.
Сравните:
>>> s
'Hello, World!'
>>> s.rfind('o')
8
>>> s.find('o')
4
Метод str.rfind имеет тот же интерфейс, что и str.find: он имеет два необязательных аргумента, чтобы задать диапазон поиска и возвращает -1, если подстрока не найдена.
Подсчёт
Методом str. можно подсчитать количество вхождений подстроки в строку: count
count
>>> s = 'Пингвины не любят окна.'
>>> s.count('а')
1
>>> s.count('ин')
2
>>> s.count('яблоки')
0
Диапазон поиска можно указать так же, как в str.find.
Замена
Для замены подстроки в строке существует метод str.replace:
>>> src = 'Пингвины не любят окна.'
>>> replaced = src.replace('Пингвины', 'Даже окна')
>>> src
'Пингвины не любят окна.'
>>> replaced
'Даже окна не любят окна.'
Так как строки в Python неизменяемые, то str.replace на базе исходной строки создает и возвращает новую.
У этого метода есть дополнительный параметр — количество производимых замен. Если этот параметр выставлен в -1 (значение по умолчанию), то произойдёт замена всех вхождений.
>>> s = 'aaaaa'
>>> s.replace('a', 'b')
'bbbbb'
>>> s.replace('a', 'b', 3)
'bbbaa'
Разбиение и объединение
По существу, вы уже знакомы с этими операциями и применяли их.
Можно разбивать строку на основе подстроки с помощью str.split.
Результатом этой операции является список.
Например, может стоять задача по разбиению предложения на слова:
>>> sentence = 'Пингвины не любят окна.'
>>> sentence.split()
['Пингвины', 'не', 'любят', 'окна.']
>>> sentence2 = 'вставка, выбор, пузырёк, подсчёт, Хоар, слияние'
>>> sentence2.split(', ')
['вставка', 'выбор', 'пузырёк', 'подсчёт', 'Хоар', 'слияние']
В первом случае в качестве подстроки для разбиения используется значение по умолчанию: разбиение по символам, обозначающих пустое пространство (пробелы, табуляция, перенос строки).
Во втором случае разбиение задано явно — по подстроке ', '.
Больше примеров:
>>> sentence3 = 'вставка -- выбор -- пузырёк -- подсчёт -- Хоар -- слияние' >>> sentence3.split() ['вставка', '--', 'выбор', '--', 'пузырёк', '--', 'подсчёт', '--', 'Хоар', '--', 'слияние'] >>> sentence3.
 split('--')
['вставка ', ' выбор ', ' пузырёк ', ' подсчёт ', ' Хоар ', ' слияние']
>>> sentence3.split(' -- ')
['вставка', 'выбор', 'пузырёк', 'подсчёт', 'Хоар', 'слияние']
split('--')
['вставка ', ' выбор ', ' пузырёк ', ' подсчёт ', ' Хоар ', ' слияние']
>>> sentence3.split(' -- ')
['вставка', 'выбор', 'пузырёк', 'подсчёт', 'Хоар', 'слияние']
У str.split есть ещё один необязательный аргумент — количество разбиений.
Итак, str.split разбивает строку по подстроке и возвращает список строк.
Обратная операция это объединение массива строк в одну строку, она осуществляется с помощью str.join:
>>> sentence3 = 'вставка -- выбор -- пузырёк -- подсчёт -- Хоар -- слияние'
>>> sort_algs = sentence3.split(' -- ')
>>> sort_algs
['вставка', 'выбор', 'пузырёк', 'подсчёт', 'Хоар', 'слияние']
>>> ''.join(sort_algs)
'вставкавыборпузырёкподсчётХоарслияние'
>>> ' '.join(sort_algs)
'вставка выбор пузырёк подсчёт Хоар слияние'
>>> ' + '.join(sort_algs)
'вставка + выбор + пузырёк + подсчёт + Хоар + слияние'
Этот метод более гибкий для входных данных и позволяет объединять не только список строк, но и любой другой итерируемый объект.![]() Главное, чтобы этот объект содержал только строки:
Главное, чтобы этот объект содержал только строки:
>>> ' '.join(range(10)) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: sequence item 0: expected str instance, int found >>> ' '.join(map(str, range(10))) '0 1 2 3 4 5 6 7 8 9'
Описание алгоритмов вы можете найти по ссылке.
Участвовать в контесте.
МетодPython String find()
Улучшить статью
Сохранить статью
- Уровень сложности: Базовый
- Последнее обновление: 18 авг, 2022
Посмотреть обсуждение
Улучшить статью
Сохранить статью
Метод Python String find() возвращает наименьший индекс или первое вхождение подстроки, если она найдена в данной строке. Если он не найден, то возвращается -1.
Синтаксис: str_obj.find(sub, start, end)
Параметры:
- sub: Подстрока, которую необходимо найти в заданной строке.
- начало (необязательно): Начальная позиция, в которой необходимо проверить подстроку в строке.
- конец (необязательно): Конечная позиция — это индекс последнего значения для указанного диапазона. Исключается при проверке.
Возврат: Возвращает наименьший индекс подстроки, если она найдена в заданной строке. Если он не найден, он возвращает -1.

Python String find() method Example
Python3
|
Вывод:
6
Примечание:
- Если начальный и конечный индексы не указаны, то по умолчанию в качестве начального и конечного индексов используются 0 и длина-1, где конечные индексы не включены в наш поиск.
- Метод find() аналогичен index(). Единственное отличие заключается в том, что find() возвращает -1, если искомая строка не найдена, и index() в этом случае выдает исключение.
Пример 1: find() без начального и конечного аргумента
Python3
|
 find(
find( Вывод:
Подстрока 'geeks' найдена в индексе: 0 Подстрока for найдена по индексу: 6 Не содержит заданной подстроки
Пример 2: find() С начальным и конечным аргументами
В этом примере мы указали начальный и конечный аргументы метода Python String find(). Так что данная подстрока ищется в указанной части исходной строки.
Python3
|
 find(
find( Output:
10 -1 -1 6
Объяснение:
- В первом операторе выход равен 10, поскольку задано начальное значение, равное 2, поэтому подстрока проверяется по второму индексу, который называется «eks for geeks».
- Во втором операторе начальное значение задано как 2, а подстрока задана как «выродки», поэтому индексная позиция «выродки» равна 10, но из-за того, что последнее значение исключается, будет найдено только «выродок», который не совпадает с исходной строкой, поэтому вывод равен -1.
- В третьем операторе начальное значение = 4, конечное значение = 10 и задана подстрока = ‘g’, позиция индекса из 4 будет проверена для данной подстроки, которая находится в позиции 10, которая исключается, поскольку она является конечным индексом.
- В четвертом операторе задано начальное значение = 4, конечное значение = 11 и подстрока = ‘for’, позиция индекса с 4 по 11 будет проверена для данной подстроки, и указанная подстрока присутствует в индексе 6, так получается вывод.

Рекомендуемые статьи
Страница :
Python | Проверка наличия подстроки в заданной строке
В этой статье мы расскажем, как проверить, содержит ли строка Python другую строку или подстроку в Python. Учитывая две строки, проверьте, есть ли подстрока в данной строке или нет.
Учитывая две строки, проверьте, есть ли подстрока в данной строке или нет.
Пример 1: Ввод: Подстрока = "выродки"
String="гики для гиков"
Выход: да
Пример 2: Ввод: Подстрока = "выродок"
String="гики для гиков"
Вывод: да Есть ли в Python строка, содержащая метод подстроки
Да, проверка подстроки — одна из наиболее часто используемых задач в python. Python использует множество методов для проверки строки, содержащей подстроку, например, find(), index(), count() и т. д.0028», который используется как оператор сравнения. Здесь мы рассмотрим различные подходы, такие как:
- Использование if… in
- Проверка с использованием метода split()
- Использование метода find()
- Использование метода count()
- Использование метода index()
- Использование магического класса __contains__.
- Использование регулярных выражений

Python3
|
Выход
Да! она присутствует в строкеСпособ 2: Проверка подстроки с помощью метода split()
Проверка наличия или отсутствия подстроки в заданной строке без использования какой-либо встроенной функции. Сначала разбейте данную строку на слова и сохраните их в переменной s, затем, используя условие if, проверьте, присутствует ли подстрока в данной строке или нет.
Сначала разбейте данную строку на слова и сохраните их в переменной s, затем, используя условие if, проверьте, присутствует ли подстрока в данной строке или нет.
Питон3
69 667 67 67 7 |
Output
yesMethod 3: Check substring using the find() method
Мы можем итеративно проверять каждое слово, но Python предоставляет нам встроенную функцию find(), которая проверяет наличие подстроки в строке, что делается в одной строке. Функция find() возвращает -1, если она не найдена, иначе она возвращает первое вхождение, поэтому с помощью этой функции эта проблема может быть решена.
Функция find() возвращает -1, если она не найдена, иначе она возвращает первое вхождение, поэтому с помощью этой функции эта проблема может быть решена.
Python3
|
Вывод
YESМетод 4.
 Проверка подстроки с помощью метода count() 5 900 строку, то вы можете использовать метод count() Python. Если подстрока не найдена, то будет напечатано «да», иначе будет напечатано «нет».
Проверка подстроки с помощью метода count() 5 900 строку, то вы можете использовать метод count() Python. Если подстрока не найдена, то будет напечатано «да», иначе будет напечатано «нет».Python3
9. Вывод НЕТМетод 5: Проверка подстроки с помощью метода index() Метод .index() возвращает начальный индекс подстроки, переданной в качестве параметра. Здесь « подстрока ” is present at index 16. Python3
Выход: 2 1692 16 |
. Строка Python __contains__(). Этот метод используется для проверки наличия строки в другой строке или нет. Вывод RegEx можно использовать для проверки наличия в строке указанного шаблона поиска. В Python есть встроенный пакет re , который можно использовать для работы с регулярными выражениями. 68. Выход 9 Output Output Method: Using функция countof 99% вариантов использования будут покрыты с помощью ключевого слова В случае получения индекса используйте или Используйте оператор сравнения Противоположное (дополнение), которое задавал исходный вопрос, Это семантически то же самое, что и Метод «содержит» реализует поведение для возвращает Но не надо. Методы, начинающиеся с подчеркивания, считаются семантически закрытыми. Единственная причина использовать это — при реализации или расширении и теперь: Не используйте следующие строковые методы для проверки наличия "содержит": Другие языки могут не иметь методов для прямой проверки подстрок, поэтому вам придется использовать эти типы методов, но с Python гораздо эффективнее использовать оператор сравнения Кроме того, это не замена Если вы действительно имеете в виду Мы можем сравнить различные способы достижения одной и той же цели. И теперь мы видим, что использование Это прекрасный дополнительный вопрос. Разберем функции интересующими методами: , так что мы видим, что метод Спросил Изменено
2 года, 2 месяца назад Просмотрено
247k раз У меня есть: функция: и строка: По сути, я хочу ввести Код: Не знаю, что случилось! 1 Есть встроенный метод find для строковых объектов. Python - это "язык с включенными батареями", в нем написан код, который делает большую часть того, что вы хотите (все, что вы хотите).. если это не домашнее задание 🙂 3 В идеале вы должны использовать str. Ваша проблема в том, что ваш код ищет только первый символ вашей строки поиска, которая (первая) находится в индексе 2. Вы в основном говорите, если Результат: 4 В регулярном выражении есть еще одна опция, Кстати, если вы хотите найти все вхождения шаблона, а не только первое, вы можете использовать метод , который напечатает все начальные позиции матчей. Добавление ответа @demented hedgehog при использовании С точки зрения эффективности Возможно, стоит сначала проверить, находится ли s1 в s2, прежде чем вызывать Поскольку оператор Преобразование может быть более эффективным: до Это полезно, когда Я нашел это значительно быстрее, так как Вот простой подход: Вывод: 3 Если подстроки нет, вы получите -1 .
Например: Вывод: -1 Иногда вам может понадобиться создать исключение, если подстроки нет: Вывод: Трассировка (последний последний вызов): Файл "test. ValueError: подстрока не найдена опоздал на вечеринку, искал то же самое, поскольку "in" недействителен, я только что создал следующее. который производит удалить нижний() в случае, если поиск без учета регистра не требуется. Не отвечая напрямую на вопрос, но недавно я получил аналогичный вопрос, когда меня попросили подсчитать, сколько раз подстрока повторяется в данной строке. Вот функция, которую я написал: Функция find(), вероятно, возвращает индекс только первого вхождения. Сохранение индекса вместо простого подсчета может дать нам отдельный набор индексов, в которых подстрока повторяется в строке. Отказ от ответственности: я «чрезвычайно» новичок в программировании на Python. Зарегистрироваться через Google Зарегистрироваться через Facebook Зарегистрируйтесь, используя электронную почту и пароль Электронная почта Требуется, но не отображается Электронная почта Требуется, но не отображается Не существует простой встроенной строковой функции, которая делает то, что вам нужно, но вы можете использовать более мощные регулярные выражения: Если вы хотите найти перекрывающиеся совпадения, поиск вперед сделает это: Если вам нужен обратный поиск без перекрытий, вы можете объединить положительный и отрицательный просмотр вперед в выражение, подобное этому: 9 Таким образом, мы можем построить его сами: Временные строки или регулярные выражения не требуются. 6 Использовать Для 2 Вот (очень неэффективный) способ получить все (т.е. даже перекрывающиеся) совпадения: 3 Опять же, старая тема, но вот мое решение с использованием 9Генератор 0027 и обычный возвращает 3 Вы можете использовать , но не будет работать для: 2 Давай рекурсируем вместе. Таким образом, регулярные выражения не нужны. 2 Если вы ищете только один символ, это будет работать: Кроме того, Я подозреваю, что ни один из них (особенно #2) не обладает ужасной производительностью. 1 это старая тема, но я заинтересовался и хотел поделиться своим решением. Должен вернуть список позиций, в которых была найдена подстрока.
Пожалуйста, прокомментируйте, если вы видите ошибку или место для улучшения. Это помогает мне использовать re.finditer Этот поток немного устарел, но у меня сработало: Вы можете попробовать: При поиске большого количества ключевых слов в документе используйте flashtext Flashtext работает быстрее, чем регулярное выражение в большом списке поисковых слов. Эта функция не просматривает все позиции внутри строки, она не тратит вычислительные ресурсы. Моя попытка: , чтобы использовать его, назовите его так: 0 Какие бы решения не предоставлялись другими, они полностью основаны на доступном методе find() или любых других доступных методах. Каков базовый алгоритм поиска всех вхождений
подстрока в строке? Вы также можете наследовать класс str новому классу и можете использовать эту функцию
ниже. Вызов метода newstr.find_all('Считаете ли вы этот ответ полезным? Тогда проголосуйте за
это!','это') 1 Вы можете попробовать: 1 Пифонический способ: 2 Это решение похожего вопроса от hackerrank. Я надеюсь, что это может помочь вам. Вывод: , если вы хотите использовать только numpy, вот решение , если вы хотите использовать без re(regex), то: Вот решение, которое я придумал, используя выражение присваивания (новая функция начиная с Python 3.8): Вывод: посмотрите код ниже 1 например: возвращает: 1 Не совсем то, что спрашивал OP, но вы также можете использовать функцию разделения, чтобы получить список, где все подстроки не встречаются . Кратко просмотрел другие ответы, так что извините, если это уже там. 2 Я столкнулся с той же проблемой и сделал следующее: Я довольно новичок в программировании, поэтому вы, вероятно, можете упростить его (и, если вы планируете использовать его постоянно, конечно, сделайте его функцией). Все работает так, как и предполагалось для того, что я делал. Изменить: пожалуйста, учтите, что это только для отдельных символов, и это изменит вашу переменную, поэтому вам нужно создать копию строки в новой переменной, чтобы сохранить ее, я не помещал ее в код, потому что это легко и просто только чтобы показать, как я заставил это работать. Для поиска всех вхождений символа в заданной строке и возврата в виде словаря например: привет
результат : {'h':1, 'e':1, 'l':2, 'o':1} или еще вот так Попробуйте, у меня сработало! Разбивая, мы находим все возможные комбинации, добавляем их в список и находим, сколько раз они встречаются, используя 2 Спросил Изменено
6 месяцев назад Просмотрено
3,5 млн раз Я хочу получить новую строку от третьего символа до конца строки, например 1 Python называет эту концепцию «нарезкой», и она работает не только со строками. 0 Просто для полноты, поскольку никто другой не упомянул об этом. Третий параметр среза массива — это шаг. Таким образом, изменить строку так же просто, как: Или выбор альтернативных символов: Возможность шагать вперед и назад по строке поддерживает согласованность с возможностью среза массива с начала или с конца. 4 Substr() обычно (т.е. PHP и Perl) работает следующим образом: Итак, параметры Но поведение Python отличается; он ожидает начала и одного после END (!). Это трудно заметить новичкам. Таким образом, правильная замена Substr(s, begin, LENGTH): 6 Обычный способ добиться этого — нарезать строку. 0 Кажется, здесь отсутствует один пример: полная (поверхностная) копия. Это распространенная идиома для создания копии типов последовательностей (не интернированных строк), 5 Есть ли способ подстроки в Python, чтобы получить новую строку от 3-го символа до конца строки? Может быть, как Да, это действительно работает, если вы назначаете или связываете имя Нотация среза имеет 3 важных аргумента: Их значения по умолчанию, если они не указаны, равны Если выход из второй части означает «до конца», если вы покидаете первую часть, начинается ли она с самого начала? Да, например: Обратите внимание, что мы включаем начало в срезе, но идем только вверх, не включая остановку. Когда шаг равен Я очень подробно объясняю нотацию слайса в своем ответе на вопрос «Объяснение нотации слайса». 0 Я хотел бы добавить к обсуждению два момента: Вы можете использовать Это особенно полезно в функциях, где вы не можете указать пустое место в качестве аргумента: Python имеет объекты среза: Все верно, кроме "конец". Это называется записью среза. Ваш пример должен выглядеть так: Если вы опустите второй параметр, это неявно конец строки. Если myString содержит номер счета, который начинается со смещения 6 и имеет длину 9, то вы можете извлечь номер счета следующим образом: Если OP примет это, они могут попробовать в экспериментальном порядке Работает - ошибка не возникает, и не происходит "заполнение строки" по умолчанию. 3 У меня возникла ситуация, когда мне нужно было перевести PHP-скрипт на Python, и в нем было много использований 1 Возможно, я пропустил это, но я не смог найти на этой странице полный ответ на исходный вопрос (вопросы), потому что переменные здесь больше не обсуждаются. Поскольку мне еще не разрешено комментировать, позвольте мне добавить сюда свое заключение. Я уверен, что я был не единственным, кто интересовался этим при доступе к этой странице: Если оставить первую часть, получится И если вы оставите : в середине, вы получите самую простую подстроку, которая будет 5-м символом (начиная с 0, так что в данном случае это пробел): 0 Само по себе использование жестко заданных индексов может привести к беспорядку. Чтобы избежать этого, Python предлагает встроенный объект Если мы хотим знать, сколько денег у меня осталось. Обычное решение: Использование срезов: Используя слайс, вы получаете удобочитаемость. 1 В приведенном выше коде [:-1] объявляет печать от начального до максимального limit-1. ВЫВОД: Примечание. Здесь [:-1] также совпадает с [0:-1] и [0:len(a)-1] ВЫВОД: В приведенном выше коде a [2:] объявляет печать a от индекса 2 до последнего элемента. Помните, что если вы установите максимальное ограничение для печати строки как (x), тогда она будет печатать строку до (x-1), а также помните, что индекс списка или строки всегда будет начинаться с 0. 0093 Способ 6. Проверка подстроки с помощью магического класса «__contains__».
0093 Способ 6. Проверка подстроки с помощью магического класса «__contains__». Python3
a = [ 'Geeks-13' , 'for-56' , 'Geeks-78' , ' xyz-46' ] для I в A: IF I .__ Содержит __ ( "FANDES" ). } содержит." ) Да! Компьютерщики-13 содержат.
Способ 7. Проверка подстроки с помощью регулярных выражений  Да! Выродки-78 содержат.
Да! Выродки-78 содержат. Python3
import re MyString1 = "A geek in need is a geek indeed" MyString2 = "geeks" IF RE.Search (MyString2, MyString1): Печать ( "Да, строка '{0}' присутствует в строке '{1}' 
Формат ( MyString2, MyString1)) ELSE : (9006 9006. '{1}' " . Формат ( MYSTRING2, MYSTRING1)) NO.
Метод: Использование Понимания списка
Python3
S = "Geeks для Geeks" S2 = 9006 " 9006" 9006 "9006" 9006 "9006" 9006 "9006" 9006 "9006" 9006 "9006" 9006 "9006" 9006 "9006" 9006 "9006" 9006 "9006" 9006 "9006" 9006 "9006" 9006 "9006" ""0003 print ([ "yes" if s2 in s else "no" ]) [ 'yes']
Method: Using lambda function
Python3
s = "geeks for geeks" s2 = "geeks" x = Список ( Фильтр ( Lambda x: (S2 в S), с.  с. ([
с. ([ "yes" if x else "no" ]) ['yes']
Python3
import operator as op s = "geeks for geeks" s2 = "geeks" print ([ "Да" IF Op.Countof (S.Split (), S2)> 0 ELS ['да']
Есть ли в Python метод «содержит» подстроку?
Есть ли в Python метод строки, содержащей подстроку?
в , которое возвращает True или False : 'substring' в any_string
str. (который возвращает -1 в случае ошибки и имеет необязательные позиционные аргументы): find
find пуск = 0
стоп = длина (любая_строка)
any_string.find('подстрока', начало, остановка)
str.index (аналогично найти , но при сбое вызывает ValueError): start = 100
конец = 1000
any_string.index('подстрока', начало, конец)
Объяснение
в , потому что >>> 'foo' в '**foo**'
Истинный
не в : >>> 'foo' не в '**foo**' # возвращает False
ЛОЖЬ
, а не 'foo' в '**foo**' , но гораздо более удобочитаемо и явно предусмотрено в языке для улучшения удобочитаемости.
Избегайте использования
__contains__ в . Этот пример, стр.__contains__('**foo**', 'foo')
True . Вы также можете вызвать эту функцию из экземпляра суперстроки: '**foo**'.__contains__('foo')
в и не в функциях (например, если str является подклассом): class NoisyString(str):
def __contains__(я, другой):
print(f'проверка, если "{other}" в "{self}"')
вернуть super(NoisyString, self).__contains__(другое)
ns = NoisyString('строка с подстрокой внутри')
>>> 'подстрока' в нс
проверка "подстроки" в "строке с подстрокой внутри"
Истинный
Не используйте
find и индекс для проверки наличия "содержит" >>> '**foo**'.
 index («фу»)
2
>>> '**foo**'.find('foo')
2
>>> '**oo**'.find('foo')
-1
>>> '**oo**'.index('foo')
Traceback (последний последний вызов):
Файл "
index («фу»)
2
>>> '**foo**'.find('foo')
2
>>> '**oo**'.find('foo')
-1
>>> '**oo**'.index('foo')
Traceback (последний последний вызов):
Файл " в . в . Возможно, вам придется обрабатывать исключение или случаи -1 , и если они вернут 0 (потому что они нашли подстроку в начале), логическая интерпретация будет False вместо Правда ., а не any_string.startswith(substring) , то скажите это. Сравнение производительности
время импорта
def in_(s, другое):
вернуть другое в s
def содержит (ы, другое):
вернуть s. __contains__(другое)
найти(и, другое):
вернуть s.find(другое) != -1
индекс(ы) защиты, другое:
пытаться:
s.index(другое)
кроме ValueError:
вернуть ложь
еще:
вернуть Истина
perf_dict = {
'in: True': мин (timeit.repeat (лямбда: in_ ('суперстрока', 'str'))),
'in: False': мин (timeit.repeat (лямбда: in_ ('суперстрока', 'не'))),
'__contains__: True': мин (timeit.repeat (лямбда: содержит ('суперстрока', 'str'))),
'__contains__: False': мин (timeit.repeat (лямбда: содержит ('суперстрока', 'не'))),
'find: True': min (timeit.repeat (лямбда: find ('superstring', 'str'))),
'найти: Ложь': мин (timeit.repeat (лямбда: найти ('суперстрока', 'не'))),
'index: True': min (timeit.repeat (лямбда: index ('superstring', 'str'))),
'index: False': мин (timeit.repeat (лямбда: индекс ('суперстрока', 'не'))),
}
__contains__(другое)
найти(и, другое):
вернуть s.find(другое) != -1
индекс(ы) защиты, другое:
пытаться:
s.index(другое)
кроме ValueError:
вернуть ложь
еще:
вернуть Истина
perf_dict = {
'in: True': мин (timeit.repeat (лямбда: in_ ('суперстрока', 'str'))),
'in: False': мин (timeit.repeat (лямбда: in_ ('суперстрока', 'не'))),
'__contains__: True': мин (timeit.repeat (лямбда: содержит ('суперстрока', 'str'))),
'__contains__: False': мин (timeit.repeat (лямбда: содержит ('суперстрока', 'не'))),
'find: True': min (timeit.repeat (лямбда: find ('superstring', 'str'))),
'найти: Ложь': мин (timeit.repeat (лямбда: найти ('суперстрока', 'не'))),
'index: True': min (timeit.repeat (лямбда: index ('superstring', 'str'))),
'index: False': мин (timeit.repeat (лямбда: индекс ('суперстрока', 'не'))),
}
в намного быстрее, чем другие.
Чем меньше времени на эквивалентную операцию, тем лучше: >>> perf_dict
{'in:True': 0,16450627865128808,
«в: Ложь»: 0,1609668098178645,
'__contains__: True': 0,24355481654697542,
'__contains__:False': 0,24382793854783813,
«найти: правда»: 0,3067379407923454,
«найти: Ложь»: 0,29860888058124146,
'индекс: Истина': 0,29647137792585454,
'индекс: Ложь': 0,5502287584545229}
Как можно
в будет быстрее, чем __contains__ , если в использует __contains__ ?
>>> from dis import dis
>>> dis(лямбда: 'a' в 'b')
1 0 LOAD_CONST 1 ('а')
2 LOAD_CONST 2 ('b')
4 COMPARE_OP 6 (вход)
6 ВОЗВРАТ_ЗНАЧЕНИЕ
>>> dis(лямбда: 'b'.__contains__('a'))
1 0 LOAD_CONST 1 ('b')
2 LOAD_METHOD 0 (__содержит__)
4 LOAD_CONST 2 ('а')
6 CALL_METHOD 1
8 ВОЗВРАТ_ЗНАЧЕНИЕ
.__contains__ нужно искать отдельно, а затем вызывать из виртуальной машины Python — это должно адекватно объяснить разницу. Python: найти подстроку в строке и вернуть индекс подстроки
def find_str(s, char) "С Днем Рождения" , "py" и вернуть 3 , но вместо этого я продолжаю получать 2 .
def find_str(s, char):
индекс = 0
если символ в s:
символ = символ [0]
для вп с:
если ch в s:
индекс += 1
если ч == символ:
возвращаемый индекс
еще:
возврат -1
print(find_str("С днем рождения", "py"))
с = "С днем рождения"
с2 = "ру"
печать (s.find (s2))
find возвращает -1, если строка не может быть найдена. find или str.index , как сказал сумасшедший ёжик. Но вы сказали, что не можете...
find или str.index , как сказал сумасшедший ёжик. Но вы сказали, что не можете... char[0] находится в s , приращение index до ch == char[0] , который вернул 3, когда я тестировал его, но он все еще был неправильным. Вот как это сделать. по определению find_str(s, char):
индекс = 0
если символ в s:
с = символ [0]
для вп с:
если ч == с:
если s[index:index+len(char)] == char:
возвращаемый индекс
индекс += 1
возврат -1
print(find_str("С днем рождения", "py"))
print(find_str("С днем рождения", "rth"))
print(find_str("С днем рождения", "rh"))
3
8
-1
поиск метод импорт повторно
строка = 'С Днем Рождения'
шаблон = 'ру'
print(re.
 search(pattern, string).span()) ## печатает начальный и конечный индексы
print(re.search(pattern, string).span()[0]) ## это делает то, что вы хотели
search(pattern, string).span()) ## печатает начальный и конечный индексы
print(re.search(pattern, string).span()[0]) ## это делает то, что вы хотели
finditer import re
string = 'я думаю, что то, что там написал тот студент, не совсем так'
шаблон = 'это'
print([match.start() для совпадения в re.finditer(шаблон, строка)])
find() find() .
Это может быть более эффективно, если вы знаете, что в большинстве случаев s1 не будет подстрокой s2 в очень эффективен s1 в s2
index = s2.
 find(s1)
find(s1)
индекс = -1
если s1 в s2:
индекс = s2.find(s1)
find() будет часто возвращать -1. find() вызывалась много раз в моем алгоритме, поэтому я подумал, что стоит упомянуть my_string = 'abcdefg'
печать (текст. найти ('def'))
my_string = 'abcdefg'
печать (текст. найти ('xyz'))
my_string = 'abcdefg'
print(text.index('xyz')) # Возвращает индекс, только если он присутствует
 py", строка 6, в print(text.index('xyz'))
py", строка 6, в print(text.index('xyz')) по определению find_str(полный, дополнительный):
индекс = 0
суб_индекс = 0
позиция = -1
для ch_i, ch_f в перечислении (полное):
если ch_f.lower() != sub[sub_index].lower():
позиция = -1
суб_индекс = 0
если ch_f.lower() == sub[sub_index].lower():
если sub_index == 0 :
позиция = ch_i
если (len(sub) - 1) <= sub_index :
ломать
еще:
суб_индекс += 1
обратная позиция
print(find_str("С днем рождения", "py"))
print(find_str("С днем рождения", "rth"))
print(find_str("С днем рождения", "rh"))
3
8
-1
def count_substring(string, sub_string):
цент = 0
len_ss = len(sub_string)
для i в диапазоне (len (строка) - len_ss + 1):
если строка[i:i+len_ss] == sub_string:
цент += 1
возврат центов
Твой ответ
Зарегистрируйтесь или войдите
Опубликовать как гость
Опубликовать как гость
python – Как найти все вхождения подстроки?
import re
[m.
 start() для m в re.finditer('test', 'test test test test')]
#[0, 5, 10, 15]
start() для m в re.finditer('test', 'test test test test')]
#[0, 5, 10, 15]
[m.start() for m in re.finditer('(?=tt)', 'ttt')]
#[0, 1]
поиск = 'тт'
[m.start() для m в re.finditer('(?=%s)(?!.{1,%d}%s)' % (search, len(search)-1, search), 'ttt ')]
#[1]
re.finditer возвращает генератор, поэтому вы можете изменить [] выше на () , чтобы получить генератор вместо списка, который будет более эффективным, если вы только перебираете результаты однажды. >>> помощь(ул.найти)
Справка по method_descriptor:
найти(...)
S.find(sub [start [end]]) -> int
def find_all(a_str, sub):
начало = 0
пока верно:
start = a_str.![]() find(sub, start)
если start == -1: возврат
начало выхода
start += len(sub) # используйте start += 1 для поиска перекрывающихся совпадений
list(find_all('спам спам спам спам', 'спам')) # [0, 5, 10, 15]
find(sub, start)
если start == -1: возврат
начало выхода
start += len(sub) # используйте start += 1 для поиска перекрывающихся совпадений
list(find_all('спам спам спам спам', 'спам')) # [0, 5, 10, 15]
re.finditer : импортировать повторно
предложение = ввод ("Дайте мне предложение")
word = input("Какое слово вы хотите найти")
для совпадения в re.finditer(слово, предложение):
печать (match.start(), match.end())
слово = "это" и предложение = "это предложение это это" это даст результат: (0, 4)
(19, 23)
(24, 28)
>>> string = "test test test test"
>>> [i для i в диапазоне (len(string)) if string.
 startswith('test', i)]
[0, 5, 10, 15]
startswith('test', i)]
[0, 5, 10, 15]
ул. найти . def findall(p, s):
'''Выдает все позиции
образец p в строке s.'''
я = с. найти (р)
пока я != -1:
выход я
я = s.find(p, i+1)
Пример
x = 'banananassantana'
[(i, x[i:i+2]) для i в findall('na', x)]
[(2, 'нет'), (4, 'нет'), (6, 'нет'), (14, 'нет')]
re.finditer() для непересекающихся совпадений. >>> импорт повторно
>>> aString = 'это строка, в которой подстрока "is" повторяется несколько раз'
>>> print [(a.start(), a.end()) для списка (re.finditer('is', aString))]
[(2, 4), (5, 7), (38, 40), (42, 44)]
В [1]: aString="ababa"
В [2]: напечатайте [(a.
 start(), a.end()) для списка в (re.finditer('aba', aString))]
Вывод: [(0, 3)]
start(), a.end()) для списка в (re.finditer('aba', aString))]
Вывод: [(0, 3)]
определение location_of_substring (строка, подстрока):
"""Вернуть список местоположений подстроки."""
substring_length = длина (подстрока)
def recurse (locations_found, start):
location = string.find (подстрока, начало)
если местоположение != -1:
вернуть рекурсию (местоположения_найдено + [местоположение], местоположение+подстрока_длина)
еще:
вернуть location_found
вернуть рекурсию ([], 0)
print(locations_of_substring('это тест на нахождение этого и этого', 'это'))
# печатает [0, 27, 36]
string = "dooobiedoobiedoobie"
совпадение = 'о'
уменьшить (количество лямбда, char: количество + 1, если char == соответствует, иначе количество, строка, 0)
# производит 7
строка = "тест тест тест тест"
совпадение = "тест"
len(string.
 split(match)) - 1
# производит 4
split(match)) - 1
# производит 4
по определению find_all (a_string, sub):
результат = []
к = 0
пока k < len(a_string):
k = a_string.find(sub, k)
если к == -1:
вернуть результат
еще:
результат .append(k)
k += 1 # измените на k += len(sub), чтобы не искать перекрывающиеся результаты
вернуть результат
import re
text = 'Это образец текста для проверки, является ли этот pythonic'\
'может служить платформой для индексации '\
'нахождение слов в абзаце. Это может дать '\
'значения относительно того, где находится слово с '\
«различные примеры, как указано»
# найти все вхождения слова as в приведенном выше тексте
find_the_word = re.finditer('как', текст)
для совпадения в find_the_word:
print('начало {}, конец {}, строка поиска \'{}\''.
формат(match.start(), match.end(), match.group()))
Это может дать '\
'значения относительно того, где находится слово с '\
«различные примеры, как указано»
# найти все вхождения слова as в приведенном выше тексте
find_the_word = re.finditer('как', текст)
для совпадения в find_the_word:
print('начало {}, конец {}, строка поиска \'{}\''.
формат(match.start(), match.end(), match.group()))
numberString = "onetwothreefourfivesixseveneightninefiveten"
тестовая строка = "пять"
маркер = 0
в то время как маркер < len(numberString):
пытаться:
print(numberString.index("пять",маркер))
маркер = числовая строка.индекс ("пять", маркер) + 1
кроме ValueError:
print("Строка не найдена")
маркер = длина (строка числа)
>>> строка = "тест тест тест тест"
>>> для индекса, значение в перечислении (строка):
если строка[индекс:индекс+(len("тест"))] == "тест":
индекс печати
0
5
10
15
из flashtext import KeywordProcessor
слова = ['тест', 'экзамен', 'викторина']
txt = «это тест»
kwp = процессор ключевых слов ()
kwp.
 add_keywords_from_list(слова)
результат = kwp.extract_keywords (txt, span_info = True)
add_keywords_from_list(слова)
результат = kwp.extract_keywords (txt, span_info = True)
по определению найтиВсе(строка,слово):
all_positions=[]
следующая_позиция=-1
пока верно:
next_pos=string.find(слово,next_pos+1)
если (следующая_позиция<0):
ломать
all_positions.append(следующая_позиция)
вернуть все_позиции
result=findAll('это слово большое, чувак, сколько там слов?','слово')
определение find_all (строка, подстрока):
"""
Функция: Возврат всего индекса подстроки в строке
Аргументы: строка и строка поиска
Возврат: Возврат списка
"""
длина = длина (подстрока)
с=0
индексы = []
в то время как c < len (строка):
если строка[c:c+length] == подстрока:
indexes. append(c)
с=с+1
индексы возврата
append(c)
с=с+1
индексы возврата
класс newstr(str):
def find_all (строка, подстрока):
"""
Функция: Возврат всего индекса подстроки в строке
Аргументы: строка и строка поиска
Возврат: Возврат списка
"""
длина = длина (подстрока)
с=0
индексы = []
в то время как c < len (строка):
если строка[c:c+length] == подстрока:
indexes.append(c)
с=с+1
индексы возврата
src = input() # мы найдем подстроку в этой строке
sub = input() # подстрока
разрешение = []
pos = src.find(sub)
а поз != -1:
res.append(pos)
pos = src.find(sub, pos + 1)
импортировать повторно
str1 = "Это платье выглядит хорошо, у тебя хороший вкус в одежде.
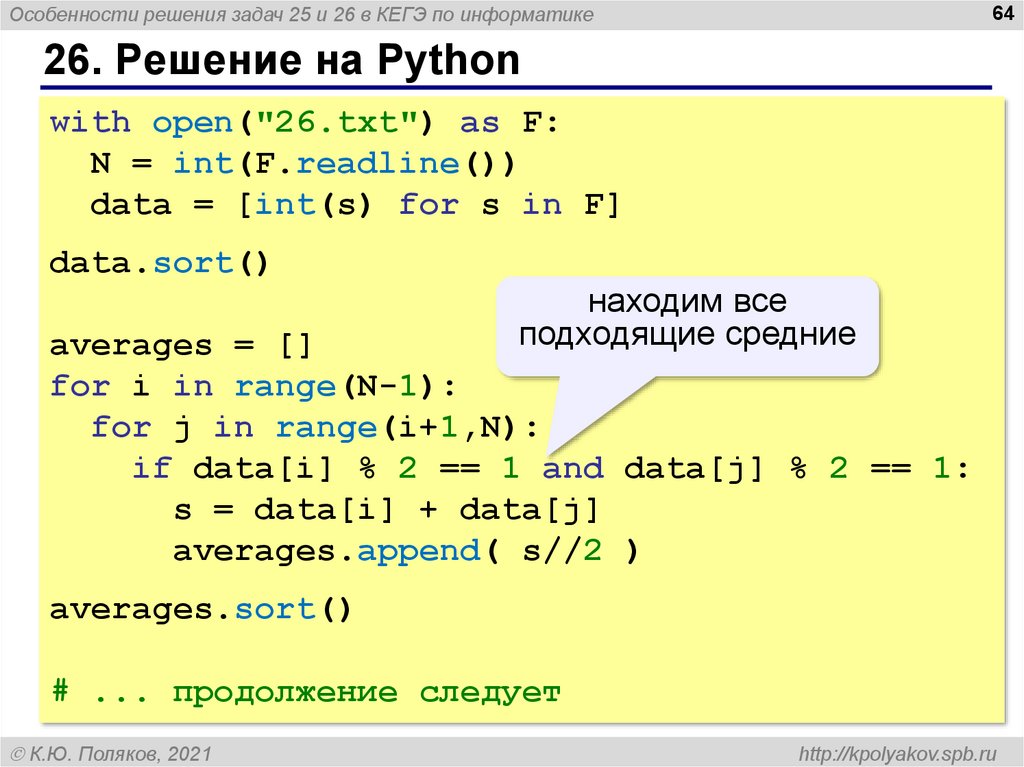 "
substr = "хорошо"
результат = [_.start() для _ в re.finditer(substr, str1)]
# результат = [17, 32]
"
substr = "хорошо"
результат = [_.start() для _ в re.finditer(substr, str1)]
# результат = [17, 32]
mystring = 'Привет, мир, это должно работать!'
find_all = lambda c,s: [x для x в диапазоне (c.find(s), len(c)) if c[x] == s]
# s представляет строку поиска
# c представляет строку символов
find_all(mystring,'o') # вернет все позиции 'o'
[4, 7, 20, 26]
>>>
импорт повторно
а = ввод ()
б = ввод ()
если б не в а:
напечатать((-1,-1))
еще:
#создать два списка как
start_indc = [m.start() для m в re.finditer('(?=' + b + ')', a)]
для i в диапазоне (len (start_indc)):
print((start_indc[i], start_indc[i]+len(b)-1))
ааадаа
аа
(0, 1)
(1, 2)
(4, 5)
импортировать numpy как np
S = "тест тест тест тест"
S2 = «тест»
inds = np.
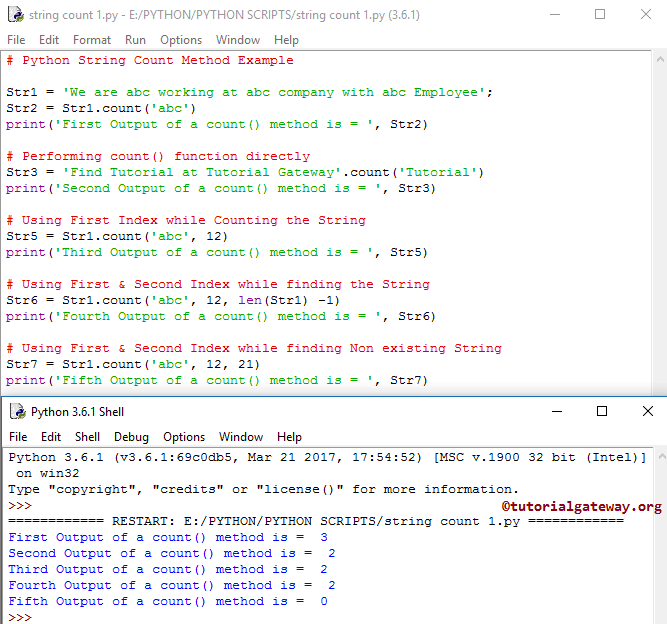 cumsum([len(k)+len(S2) для k в S.split(S2)[:-1]])- len(S2)
печать (инд.)
cumsum([len(k)+len(S2) для k в S.split(S2)[:-1]])- len(S2)
печать (инд.)
find_all = lambda _str,_w : [i for i in range(len(_str)) if _str.startswith(_w,i)]
строка = "тест тест тест тест тест"
print(find_all(string, 'test')) # >>> [0, 5, 10, 15]
string = "test test test test"
фраза = "тест"
начало = -1
результат = [(начало:= string.find(фраза, начало + 1)) для _ в диапазоне(string.count(фраза))]
[0, 5, 10, 15]
#!/usr/bin/env python
# кодировка: utf-8
'''黄哥Python'''
def get_substring_indices (текст, с):
результат = [i для i в диапазоне (длина (текст)) if text.startswith (s, i)]
вернуть результат
если __name__ == '__main__':
text = "Сколько древесины мог бы зажать дровосек, если бы дровосек мог забивать дрова?"
с = 'дерево'
распечатать get_substring_indices (текст, с)
определение find_index (строка, пусть):
enumerated = [место для места, буква в перечислении (строка), если буква == пусть]
вернуть перечисленные
find_index("привет, найди d", "d")
[4, 7, 13, 15]
 OP не указал конечную цель кода, но если ваша цель в любом случае состоит в том, чтобы удалить подстроки, то это может быть простой однострочный код. Вероятно, есть более эффективные способы сделать это с большими строками; регулярные выражения были бы предпочтительнее в этом случае
OP не указал конечную цель кода, но если ваша цель в любом случае состоит в том, чтобы удалить подстроки, то это может быть простой однострочный код. Вероятно, есть более эффективные способы сделать это с большими строками; регулярные выражения были бы предпочтительнее в этом случае # Извлечь все неподстроки
s = "пример строки"
s_no_dash = s.split('-')
# >>> s_no_dash
# ['an', 'пример', 'строка']
# Или извлеките и соедините их в предложение
s_no_dash3 = ' '.join(s.split('-'))
# >>> s_no_dash3
# 'пример строки'
по определению count_substring(строка, подстрока):
с=0
для я в диапазоне (0, len (строка)-2):
если строка[i:i+len(sub_string)] == sub_string:
с+=1
вернуться с
если __name__ == '__main__':
строка = ввод (). полоса ()
sub_string = ввод (). полоса ()
count = count_substring(строка, sub_string)
распечатать (количество)
hw = 'Hello oh World!'
list_hw = список (hw)
о_in_hw = []
пока верно:
о = hw. find('o')
если о != -1:
o_in_hw.append(o)
list_hw[o] = ' '
hw = ''.join(list_hw)
еще:
печать (o_in_hw)
ломать
find('o')
если о != -1:
o_in_hw.append(o)
list_hw[o] = ' '
hw = ''.join(list_hw)
еще:
печать (o_in_hw)
ломать
def count(string):
результат = {}
если (строка):
для я в строке:
результат[я] = string.count(я)
вернуть результат
возвращаться {}
из коллекций импортировать счетчик
количество деф (строка):
вернуть счетчик (строка)
x=ввод('введите строку')
y=input('введите подстроку')
z,r=x. find(y),x.rfind(y)
а z!=r:
печать (г, г, конец = ' ')
г = г + лен (у)
г = г-лен (у)
z,r=x.find(y,z,r),x.rfind(y,z,r)
find(y),x.rfind(y)
а z!=r:
печать (г, г, конец = ' ')
г = г + лен (у)
г = г-лен (у)
z,r=x.find(y,z,r),x.rfind(y,z,r)
счет функция s=ввод()
n=длина(ы)
л=[]
е = ввод ()
печать (с [0])
для я в диапазоне (0, n):
для j в диапазоне (1, n + 1):
l.append(s[i:j])
если f в l:
печать (л.счет (е))
Как получить подстроку строки в Python?
мояСтрока[2:конец] . Если опустить вторую часть означает «до конца», и если вы опустите первую часть, начнется ли она с самого начала? >>> x = "Привет, мир!"
>>> х[2:]
«Привет, мир!»
>>> х[:2]
'Он'
>>> х[:-2]
«Привет, мир»
>>> х[-2:]
'д!'
>>> х[2:-2]
'привет мир'
 Взгляните здесь для всестороннего введения.
Взгляните здесь для всестороннего введения. some_string[::-1]
"H-e-l-l-o- -W-o-r-l-d"[::2] # выводит "Hello World"
s = Substr(s, начало, ДЛИНА)
начало и ДЛИНА . s = s[ начало : начало + ДЛИНА]

MyString[a:b] дает вам подстроку от индекса a до (b - 1). >>> x = "Привет, мир!"
>>> х
'Привет, мир!'
>>> х[:]
'Привет, мир!'
>>> х==х[:]
Истинный
>>>
[:] . Shallow копирует список, см. Синтаксис фрагмента списка Python используется без видимой причины . myString[2:end] ? end с константой singleton, None : >>> end = None
>>> myString = '1234567890'
>>> мояСтрока[2:конец]
'34567890'
Нет - но мы можем передать их явно: >>> stop = step = None
>>> начало = 2
>>> myString[начало:стоп:шаг]
'34567890'
>>> start = None
>>> стоп = 2
>>> myString[начало:стоп:шаг]
'12'

None , по умолчанию слайс использует для шага 1 . Если вы делаете шаг с отрицательным целым числом, Python достаточно умен, чтобы перейти от конца к началу. >>> мояСтрока[::-1]
'0987654321'
None вместо пустого места, чтобы указать "с начала" или "до конца": 'abcde'[2: Нет] == 'abcde'[2:] == 'cde'
def подстрока(и, начало, конец):
"""Удалить `начальные` символы с начала и `конца`
символы с конца строки `s`.
Примеры
--------
>>> подстрока('abcde', 0, 3)
'абв'
>>> подстрока('abcde', 1, нет)
'до н.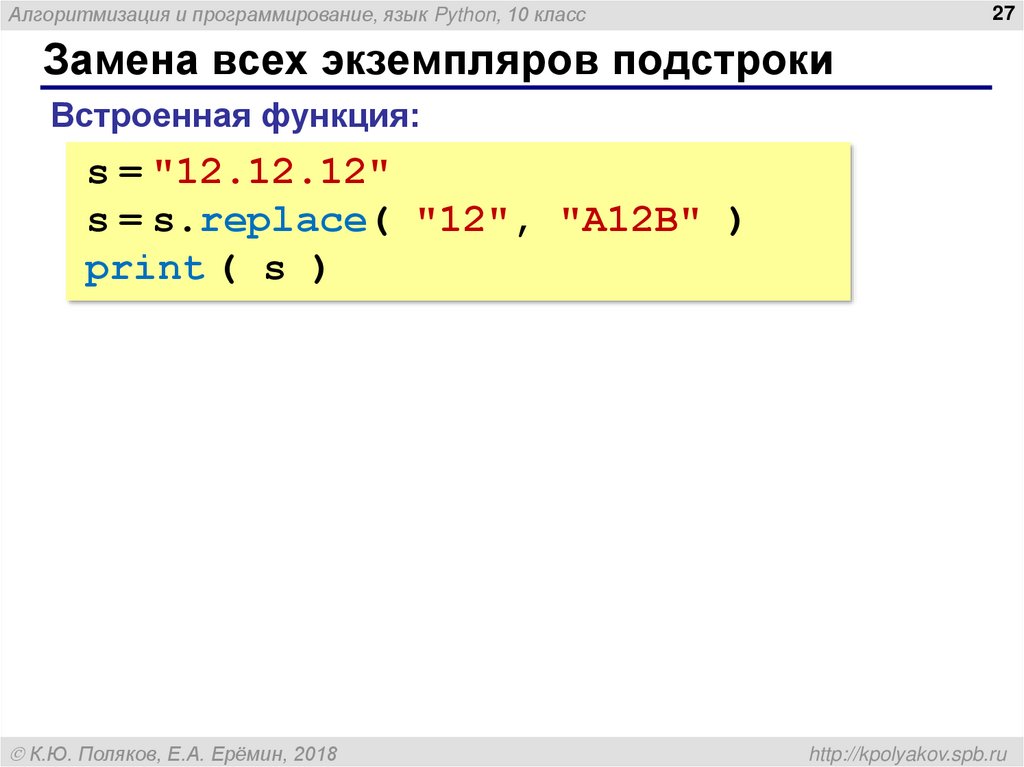 э.'
"""
вернуть s[начало:конец]
э.'
"""
вернуть s[начало:конец]
idx = срез (2, нет)
'abcde'[idx] == 'abcde'[2:] == 'cde'
новая_подстрока = моя строка[2:]
acct = myString[6:][:9] . myString[2:][:999999]
substr(string, begin, LENGTH) .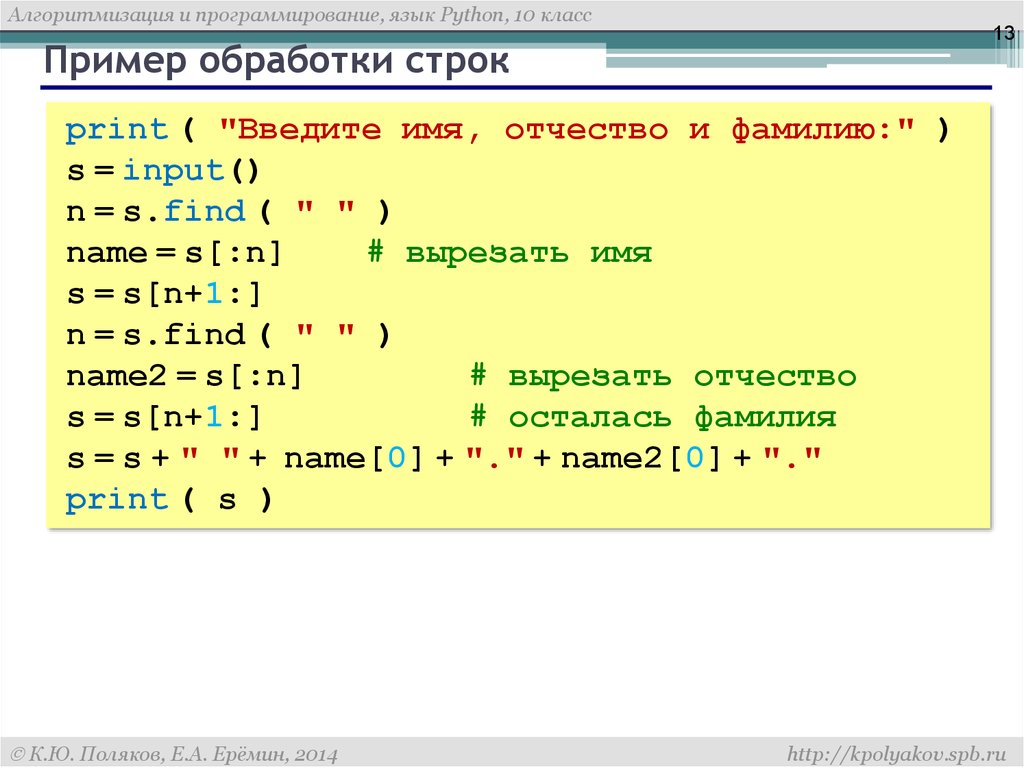
Если бы я выбрал Python string[beginning:end] , мне пришлось бы вычислять много конечных индексов, поэтому проще было использовать string[beginning:][:length] , это сэкономило мне много неприятностей. str1='Вот ты где'
>>> строка1[:]
'Вот ты где'
>>> строка1[1:]
'вот, пожалуйста'
#Чтобы напечатать альтернативные символы, пропуская один элемент между ними
>>> строка1[::2]
'Тэюэ'
#Чтобы напечатать последний элемент из последних двух элементов
>>> строка1[:-2:-1]
'е'
#Сходным образом
>>> строка1[:-2:-1]
'е'
#Использование типа данных slice
>>> str1='Вот ты где'
>>> s1=срез(2,6)
>>> ул1[s1]
'здесь'
текст = "Переполнение стека"
#используя нарезку python, вы можете получить разные подмножества приведенной выше строки
# обратная сторона строки
text[::-1] # 'wolfrevOkcatS'
#первые пять символов
text[:5] # Стек
#последние пять символов
текст[-5:] # 'rflow'
#3-й символ до пятого символа
текст[2:5] # 'rflow'
#символы на четных позициях
text[1::2] # 'tcOefo'
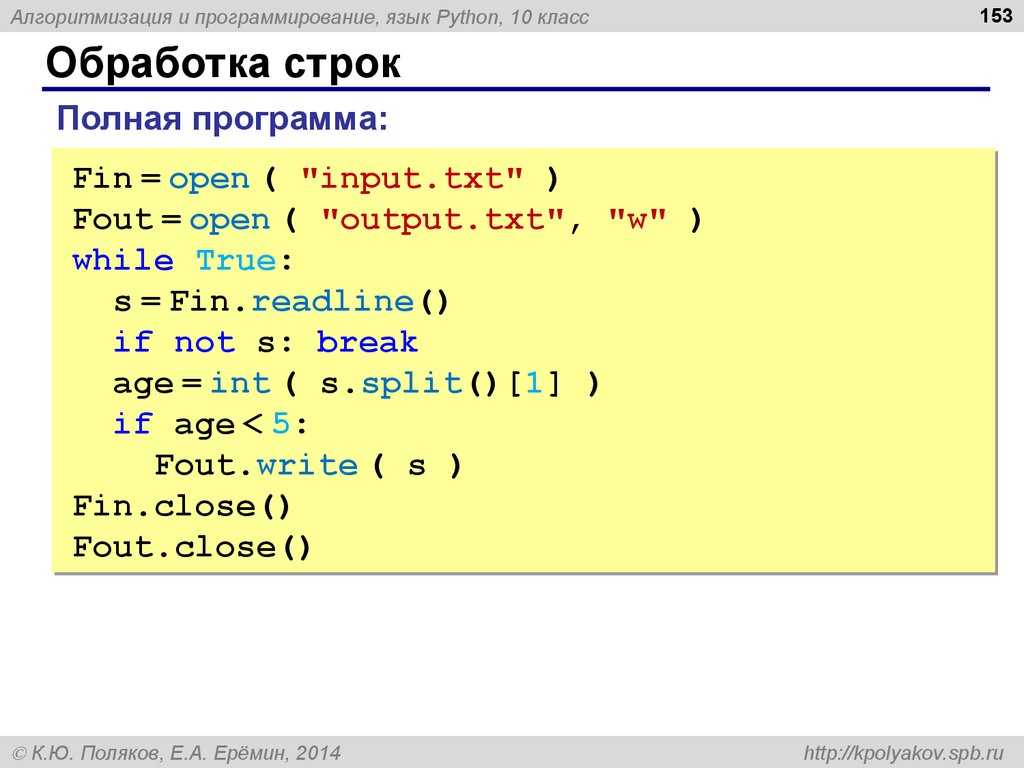 Поэтому мне пришлось продолжить поиски.
Поэтому мне пришлось продолжить поиски. >>>myString = 'Hello World'
>>>конец = 5
>>>моя строка[2:конец]
'привет'
>>>myString[:end]
'Привет'
>>>моя строка[конец]
' '
slice() . string = "моя компания имеет 1000$ прибыли, но я проиграл 500$ в азартных играх."

final = int(string[15:19]) - int(string[43:46])
печать (окончательная)
>>>500
ПРИБЫЛЬ = срез(15, 19)
ПОТЕРИ = срез (43, 46)
final = int(строка[ДОХОД]) - int(строка[УБЫТКИ])
печать (окончательная)
>>>500
а = "Привет"
распечатать (а [:-1])
>>> Привет
а = "Я Шива"
печать (а [2:])
>>> Ам Шива
