Книга «Обработка естественного языка. Python и spaCy на практике» / Хабр
Привет, Хаброжители! Python и spaCy помогут вам быстро и легко создавать NLP-приложения: чат-боты, сценарии для сокращения текста или инструменты принятия заказов. Вы научитесь использовать spaCy для интеллектуального анализа текста, определять синтаксические связи между словами, идентифицировать части речи, а также определять категории для имен собственных. Ваши приложения даже смогут поддерживать беседу, создавая собственные вопросы на основе разговора.
Вы научитесь:
- Работать с векторами слов, чтобы находить синонимы (глава 5).
- Выявлять закономерности в данных с помощью displaCy — встроенного средства визуализации библиотеки spaCy (глава 7).
- Автоматически извлекать ключевые слова из пользовательского ввода и сохранять их в реляционной базе данных (глава 9).
- Развертывать приложения на примере чат-бота для взаимодействия с пользователями (глава 11).


Прочитав эту книгу, вы можете сами расширить приведенные в ней сценарии, чтобы обрабатывать разнообразные варианты ввода и создавать приложения профессионального уровня.
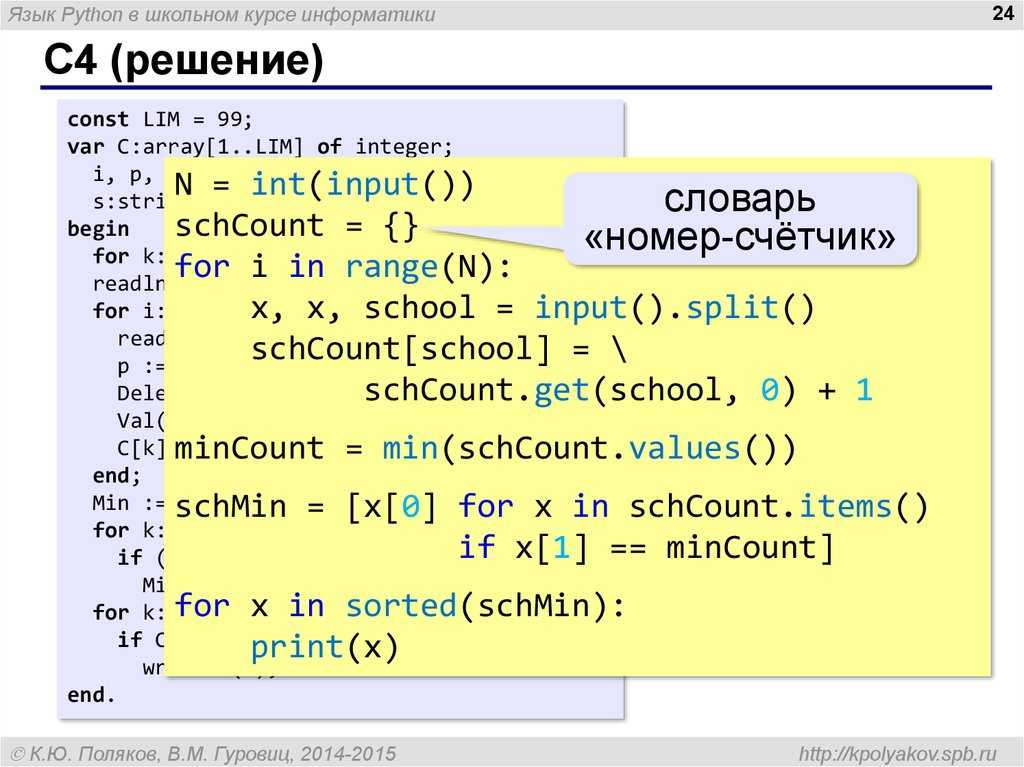
Как вы узнали из раздела «Выделение и генерация текста с помощью тегов частей речи» на с. 81, теги частей речи — весьма мощный инструмент для интеллектуальной обработки текста. Но на практике для этого может понадобиться больше информации о токенах предложения.
Например, часто необходимо знать, чем является личное местоимение в предложении: подлежащим или дополнением. Иногда это несложно определить. Личные местоимения I, he, she, they и we практически всегда выступают в роли подлежащего. При использовании в качестве дополнения I превращается в
Но с некоторыми другими личными местоимениями, например you или it, которые выглядят одинаково и в роли подлежащего и в роли дополнения, не всегда все очевидно. Рассмотрим два предложения: I know you. You know me. В первом предложении you является прямым дополнением глагола know. Во втором же you является подлежащим.
Рассмотрим два предложения: I know you. You know me. В первом предложении you является прямым дополнением глагола know. Во втором же you является подлежащим.
Попробуем решить эту задачу с помощью меток синтаксических зависимостей и тегов частей речи, после чего, опять же с помощью меток синтаксических зависимостей, создадим усовершенствованную версию нашего чат-бота, отвечающего на вопросы.
Различаем подлежащие и дополнения
Чтобы определить программным образом, чем в заданном предложении являются такие местоимения, как you или it, необходимо посмотреть на присвоенную им метку зависимости. Теги частей речи в сочетании с метками зависимостей позволяют получить гораздо больше информации о роли токена в предложении.
Вернемся к предложению из предыдущего примера и взглянем на результаты разбора зависимостей в нем:
>>> doc = nlp(u"I can promise it is worth your time.") >>> for token in doc: ... print(token.text, token.pos_, token.tag_, token.dep_, spacy.explain(token.dep_))

Для токенов предложения были извлечены теги частей речи, метки зависимостей и их описание:
I PRON PRP nsubj nominal subject can VERB MD aux auxiliary promise VERB VB ROOT None it PRON PRP nsubj nominal subject is VERB VBZ ccomp clausal complement worth ADJ JJ acomp adjectival complement your ADJ PRP$ poss possession modifier time NOUN NN npadvmod noun phrase as adverbial modifier . PUNCT . punct punctuation
Второй и третий столбцы содержат теги общих и уточненных частей речи соответственно. Четвертый столбец содержит метки зависимостей, а пятый — описания этих меток.
Сочетание тегов частей речи с метками зависимостей демонстрирует более ясную, чем теги частей речи или метки зависимости по отдельности, картину грамматической роли каждого из токенов в предложении. В данном примере тег части речи VBZ, присвоенный токену is, означает глагол третьего лица единственного числа настоящего времени, в то время как присвоенная тому же токену метка зависимости ccomp указывает, что
В данном примере тег части речи VBZ, присвоенный токену is, означает глагол третьего лица единственного числа настоящего времени, в то время как присвоенная тому же токену метка зависимости ccomp указывает, что
Чтобы определить роль you в I know you. You know me, взглянем на следующий список тегов частей речи и меток зависимостей, присвоенных токенам:
I PRON PRP nsubj nominal subject know VERB VBP ROOT None you PRON PRP dobj direct object . PUNCT . punct punctuation You PRON PRP nsubj nominal subject know VERB VBP ROOT None me PRON PRP dobj direct object . PUNCT . Punct punctuation
В обоих случаях токену you присвоены одни и те же теги частей речи: PRON и PRP (общий и уточненный соответственно). Но метки зависимости в этих двух случаях различны: dobj в первом предложении и nsubj — во втором.
Но метки зависимости в этих двух случаях различны: dobj в первом предложении и nsubj — во втором.
Выясняем, какой вопрос должен задать чат-бот
Иногда для извлечения необходимой информации приходится обходить дерево зависимостей предложения. Рассмотрим следующий диалог между чат-ботом и пользователем:
User: I want an apple. Bot: Do you want a red apple? User: I want a green apple. Bot: Why do you want a green one?
Чат-бот способен продолжать разговор, просто задавая вопросы. Но обратите внимание, что в выяснении того, какой вопрос ему следует задать, ключевую роль играет наличие/отсутствие прилагательного-модификатора.
В английском языке существует два основных типа вопросов: вопросы типа «да/нет» и информационные вопросы. Возможных ответов на вопросы типа «да/нет» (наподобие сгенерированного в примере из подраздела «Преобразование утвердительных высказываний в вопросительные» на с. 85) может быть только два: да или нет. Чтобы сформулировать подобный вопрос, необходимо поставить вспомогательный модальный глагол перед подлежащим, а смысловой глагол — после подлежащего.
Информационные вопросы предполагают развернутый ответ, а не только да/нет. Они начинаются с вопросительного слова, например с what, where, when, why или how. Далее процесс формирования информационного вопроса не отличается от процесса с вопросом типа «да/нет». Например: What do you think about it?
В первом случае в предыдущем примере с apple чат-бот задает вопрос типа «да/нет». Во втором случае, когда пользователь добавляет к слову
Краткая сводка этого подхода приведена на рис. 4.1.
Следующий сценарий анализирует введенное предложение, выбирая, какой вид вопроса задать, после чего формирует соответствующий вопрос. Код этого сценария мы рассмотрим по частям в различных разделах, но программу целиком я рекомендую сохранить в одном файле с названием question.py.
Начнем с импорта модуля sys, который позволяет получить предложение в виде аргумента для дальнейшей обработки:
import spacy import sys
Это шаг вперед по сравнению с предыдущими сценариями, в которых мы жестко «зашивали» анализируемое предложение.
Далее опишем функцию для распознавания и извлечения произвольного именного фрагмента — прямого дополнения из входного документа. Например, если вы ввели документ, содержащий предложение I want a green apple., то будет возвращен фрагмент a green apple:
Проходим в цикле по токенам введенного предложения 1 и, проверяя теги зависимостей на равенство dobj 2, ищем такой токен, который выступал бы в роли прямого дополнения. В предложении
Для выделения нужного фрагмента производим срез объекта Doc, вычисляя начальный и конечный индексы. Начальный индекс равен индексу найденного прямого дополнения минус число его синтаксических дочерних элементов: как вы, возможно, догадались, он представляет собой индекс крайнего слева дочернего элемента. Конечный индекс равен индексу прямого дополнения плюс один, так что последним включаемым в искомый фрагмент токеном и является это прямое дополнение 5.
Начальный индекс равен индексу найденного прямого дополнения минус число его синтаксических дочерних элементов: как вы, возможно, догадались, он представляет собой индекс крайнего слева дочернего элемента. Конечный индекс равен индексу прямого дополнения плюс один, так что последним включаемым в искомый фрагмент токеном и является это прямое дополнение 5.
Проще говоря, реализованный в сценарии алгоритм предполагает, что у прямого дополнения есть только левосторонние дочерние элементы. В действительности это не всегда так. Например, в предложении I want to touch a wall painted green. необходимо проверять и левосторонние, и правосторонние дочерние элементы прямого дополнения wall. Кроме того, поскольку green не является прямым дочерним элементом wall, необходимо обойти дерево зависимостей, чтобы определить, является ли green модификатором wall.
Следующая функция просматривает фрагмент и определяет, какой тип вопроса должен задать чат-бот:
Сначала задаем начальное значение переменной question_type равным ‘yesno’, что соответствует вопросу типа «да/нет» 1. Далее в переданном в функцию chunk ищем токен с тегом amod, который означает прилагательное-модификатор 2. Если таковое находится, меняем значение переменной question_type на ‘info’, соответствующее информационному типу вопроса 3.
Далее в переданном в функцию chunk ищем токен с тегом amod, который означает прилагательное-модификатор 2. Если таковое находится, меняем значение переменной question_type на ‘info’, соответствующее информационному типу вопроса 3.
Определив, какой тип вопроса нам нужен, генерируем в следующей функции вопрос на основе входного предложения:
В серии циклов for превращаем входное утверждение в вопрос, производя инверсию и замену личных местоимений. Для формирования вопроса перед личным местоимением добавляем глагол do, поскольку в утверждении отсутствует вспомогательный модальный глагол. (Напомню, что такой алгоритм годится лишь для определенных предложений; в более полной реализации необходимо программным образом определять, какой подход к обработке использовать.)
Если значение переменной question_type равно ‘info’, добавляем слово why в начало вопроса 1. Если значение переменной question_type равно ‘yesno’ 2, вставляем прилагательное для модификации прямого дополнения в вопросе. В данном примере ради простоты мы жестко «зашили» прилагательное в код, выбрав для этого прилагательное red 3, которое в некоторых предложениях будет выглядеть странно. Например, можно сказать Do you want a red orange?, но никак не Do you want a red idea?. В более совершенной реализации такого чат-бота необходимо определить программным образом подходящее прилагательное для модификации прямого дополнения. Этот вопрос будет рассмотрен в главе 6.
В данном примере ради простоты мы жестко «зашили» прилагательное в код, выбрав для этого прилагательное red 3, которое в некоторых предложениях будет выглядеть странно. Например, можно сказать Do you want a red orange?, но никак не Do you want a red idea?. В более совершенной реализации такого чат-бота необходимо определить программным образом подходящее прилагательное для модификации прямого дополнения. Этот вопрос будет рассмотрен в главе 6.
Обратите внимание: используемый алгоритм предполагает, что входное предложение оканчивается знаком препинания, например. или!..
После описания всех функций посмотрим на основной блок сценария:
Прежде всего проверяем, передал ли пользователь предложение в виде аргумента командной строки 1. Если да, то применяем к аргументу конвейер spaCy, создавая экземпляр объекта Doc 2.
Далее передаем этот doc в функцию find_chunk, которая должна вернуть содержащий прямое дополнение именной фрагмент, например a green apple, для дальнейшей обработки 3. Если же во входном предложении такого именного фрагмента нет 4, мы получим сообщение The sentence does not contain a direct object.
Если же во входном предложении такого именного фрагмента нет 4, мы получим сообщение The sentence does not contain a direct object.
Затем передаем только что выделенный фрагмент в функцию determine_question_type, которая, проанализировав его структуру, определяет, какой вопрос задать 5.
Наконец, передаем входное предложение и определенный нами тип вопроса в функцию generate_question, генерирующую соответствующий вопрос и возвращающую его в виде строки 6.
Выводимый сценарием результат зависит от введенного предложения. Вот несколько возможных вариантов:
Если в качестве аргумента командной строки передать предложение, содержащее прилагательное-модификатор (например, green для прямого дополнения наподобие apple), сценарий должен сгенерировать информационный вопрос 1.
Если предложение содержит прямое дополнение без прилагательного-модификатора, сценарий должен ответить вопросом типа «да/нет» 2.
Если же ввести предложение без прямого дополнения, сценарий должен сразу это заметить и предложить повторный ввод 3.
Наконец, если вы забыли передать предложение, сценарий также должен вернуть соответствующее сообщение 4.
Попробуйте самиКак отмечалось ранее, сценарий, о котором шла речь в предыдущем разделе, годится не для всех предложений. Для формирования вопроса он добавляет глагол do, что подходит только для предложений без вспомогательного модального глагола.
Попробуйте расширить функциональность этого сценария для работы с утверждениями, содержащими вспомогательные модальные глаголы. Например, получив на входе утверждение I might want a green apple., сценарий должен вернуть Why might you want a green one?. Подробнее о том, как преобразовать в вопрос утвердительное высказывание, содержащее вспомогательный модальный глагол, вы прочитали в разделе «Преобразование утвердительных высказываний в вопросительные» на с. 85.
Более подробно с книгой можно ознакомиться на сайте издательства
» Оглавление
» Отрывок
Для Хаброжителей скидка 25% по купону — spaCy
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.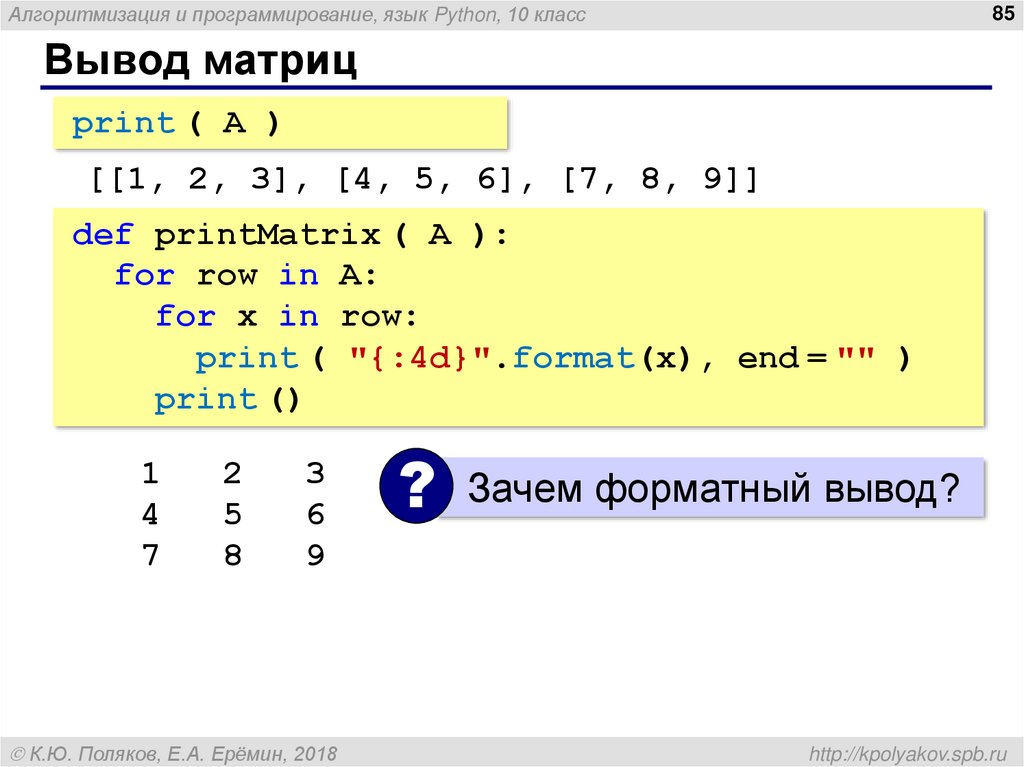
8 лучших библиотек обработки естественного языка для Python (NLP)
Natural language processing (NLP) – обработка естественного языка. Эта область знаний находится на стыке науки о данных и сферы искусственного интеллекта (ИИ). Она всецело посвящена обучению машин понимать человеческие языки и извлекать смысл из текста. Именно поэтому машинное обучение часто является частью проектов NLP.
Почему же в наши дни так много организаций интересуются NLP? Прежде всего потому, что эти технологии могут предоставить им широкий спектр ценных идей и решений. Они способны решить языковые проблемы, с которыми могут столкнуться потребители при взаимодействии с продуктом.
Технологические гиганты, такие как Google, Amazon или Facebook, вкладывают миллионы долларов в эту линию исследований. За этими вложениями стоит желание обеспечить питание своих чат-ботов, виртуальных помощников, рекомендательных систем и других решений, основанных на машинном обучении.
Поскольку NLP опирается на продвинутые вычислительные навыки, разработчикам нужны наилучшие доступные инструменты. Эти инструменты должны помочь извлечь максимальную пользу из подходов и алгоритмов NLP для создания сервисов, способных работать с естественными языками.
Что такое библиотека NLP?
В прошлом только эксперты могли участвовать в проектах по обработке естественного языка. Такая работа требовала превосходных знаний математики, машинного обучения и лингвистики. Теперь разработчики могут использовать готовые инструменты, упрощающие предварительную обработку текста. Это позволяет им сосредоточиться на построении моделей машинного обучения.
Для решения проблем NLP создано множество библиотек. Далее мы расскажем о 8 удивительных библиотеках обработки естественного языка Python, которые на протяжении многих лет помогали нам поставлять качественные проекты нашим клиентам.
Зачем использовать Python для обработки естественного языка (NLP)?
Многие свойства Python делают его очень привлекательным вариантом при выборе языка программирования для проекта NLP, особенно если речь идет об обработке естественного языка. К таким примечательным свойствам Python можно отнести, в первую очередь, простой синтаксис и прозрачную семантику языка. Кроме того, разработчики могут пользоваться отличной поддержкой интеграции с другими языками и инструментами — это пригодится для таких методов, как машинное обучение.
К таким примечательным свойствам Python можно отнести, в первую очередь, простой синтаксис и прозрачную семантику языка. Кроме того, разработчики могут пользоваться отличной поддержкой интеграции с другими языками и инструментами — это пригодится для таких методов, как машинное обучение.
Но есть еще кое-что в этом универсальном языке, что делает его такой замечательной технологией для обработки естественных языков. Python предоставляет разработчикам обширную коллекцию инструментов и библиотек для решения задач, связанных с NLP. Речь идет о классификации документов, моделировании тем, маркировке части речи (POS), векторах слов и анализе настроений.
1. Инструментарий естественного языка (NLTK)
NLTK — это важная библиотека, поддерживающая такие задачи, как классификация, стемминг, маркировка, синтаксический анализ и семантическое рассуждение в Python. Это ваш основной инструмент для обработки естественного языка и машинного обучения. Сегодня он служит образовательной основой для разработчиков Python, которые только приступают к изучению NLP и машинного обучения.
Библиотека была разработана Стивеном Бердом и Эдвардом Лопером в Пенсильванском университете. Она сыграла ключевую роль в прорывных исследованиях NLP. NLTK, наряду с другими библиотеками и инструментами Python, теперь используют в своих учебных программах университеты по всему миру.
Библиотека довольно универсальна, однако (и это следует признать!) ее трудно использовать для обработки естественного языка. NLTK может быть довольно медленным и не соответствовать требованиям быстро развивающегося производственного использования. Кривая обучения очень крутая, но разработчики могут воспользоваться такими ресурсами, как эта полезная книга. Из нее вы узнаете больше о концепциях, лежащих в основе задач обработки языка, которые поддерживает этот инструментарий.
2. TextBlo
TextBlob является обязательным для разработчиков, которые начинают свое путешествие в NLP в Python. Идеально подходит для первого знакомства с NLP. TextBlob предоставляет новичкам простой интерфейс для помощи в освоении большинства основных задач NLP, таких как анализ настроений, POS-маркировка или извлечение именных фраз.
Мы считаем, что любой, кто хочет сделать свои первые шаги в направлении NLP с помощью Python, должен использовать эту библиотеку. Она очень полезна при проектировании прототипов. Однако она также унаследовала основные недостатки NLTK. Для эффективной помощи разработчикам, сталкивающимся с требованиями использования NLP Python в производстве, эта библиотека слишком медленная.
3. CoreNLP
Эта библиотека была разработана в Стэнфордском университете и написана на языке Java. Тем не менее, она оснащена оболочками для многих языков, включая Python, что делает ее полезной разработчикам, желающим попробовать свои силы в обработке естественного языка на Python. В чем заключается самое большое преимущество CoreNLP? Библиотека действительно быстра и хорошо работает в средах разработки продуктов. Кроме того, некоторые компоненты CoreNLP могут быть интегрированы с NLTK, что неизбежно повысит эффективность последнего.
4. Gensim
Gensim — это библиотека Python, которая специализируется на выявлении семантического сходства между двумя документами посредством векторного пространственного моделирования и инструментария тематического моделирования. Она может обрабатывать большие текстовые массивы с помощью эффективной потоковой передачи данных и инкрементных алгоритмов. Это больше, чем мы можем сказать о других пакетах, которые нацелены только на пакетную обработку и обработку в памяти. Что нам нравится в этой библиотеке, так это ее невероятная оптимизация использования памяти и скорость обработки. Все это достигается при помощи другой библиотеки Python, NumPy. Возможности векторного моделирования пространства этого инструмента также являются первоклассными.
Она может обрабатывать большие текстовые массивы с помощью эффективной потоковой передачи данных и инкрементных алгоритмов. Это больше, чем мы можем сказать о других пакетах, которые нацелены только на пакетную обработку и обработку в памяти. Что нам нравится в этой библиотеке, так это ее невероятная оптимизация использования памяти и скорость обработки. Все это достигается при помощи другой библиотеки Python, NumPy. Возможности векторного моделирования пространства этого инструмента также являются первоклассными.
5. spaCy
spaCy относительно молодая библиотека, предназначенная для производственного использования. Вот почему она гораздо доступнее других NLP-библиотек Python, таких как NLTK. spaCy предлагает самый быстрый синтаксический парсер, имеющийся сегодня на рынке. Кроме того, поскольку инструментарий написан на языке Cython, он также очень быстр и эффективен.
Но ни один инструмент не является совершенным. По сравнению с библиотеками, которые мы рассматривали до сих пор, spaCy поддерживает наименьшее количество языков (семь). Однако растущая популярность машинного обучения, NLP и spaCy как ключевой библиотеки означает, что этот инструмент может вскоре начать поддерживать больше языков программирования.
Однако растущая популярность машинного обучения, NLP и spaCy как ключевой библиотеки означает, что этот инструмент может вскоре начать поддерживать больше языков программирования.
6. Polyglot
Следующая библиотека менее известна, но она относится к числу наших любимых библиотек, поскольку предлагает широкий спектр анализа и впечатляющий охват языка. Благодаря NumPy, она также работает очень быстро. Использование polyglot похоже на spaCy. Это очень эффективный, простой и в принципе отличный вариант для проектов, связанных с языками, не поддерживаемыми spaCy. Библиотека выделяется на фоне остальных еще и потому, что запрашивает использование выделенной команды в командной строке через конвейерные механизмы. Определенно стоит попробовать.
7. Scikit–learn
Эта NLP-библиотека удобна в использовании. Она предоставляет разработчикам широкий спектр алгоритмов для построения моделей машинного обучения. Ее функционал позволяет использовать метод «мешок слов» (bag-of-words model) для создания объектов, призванных решать задачи классификации текста. Сильной стороной этой библиотеки являются интуитивные методы классов. Кроме того, scikit-learn имеет отличную документацию, которая помогает разработчикам максимально использовать свои возможности.
Сильной стороной этой библиотеки являются интуитивные методы классов. Кроме того, scikit-learn имеет отличную документацию, которая помогает разработчикам максимально использовать свои возможности.
Однако библиотека не использует нейронные сети для предварительной обработки текста. Поэтому, если вы хотите выполнять более сложные задачи предварительной обработки, такие как POS-маркировка для ваших текстовых корпусов, лучше использовать другие библиотеки NLP, а затем вернуться к scikit-learn для построения ваших моделей.
8. Pattern
Еще одна жемчужина среди библиотек NLP, используемых разработчиками Python для работы с естественными языками. Pattern предоставляет инструменты для частеречной разметки (part-of-speech tagging), анализа настроений, векторных пространств, моделирования (SVM), классификации, кластеризации, n-граммы поиска и WordNet. Вы можете воспользоваться преимуществами парсера DOM, веб-искателя, а также некоторыми полезными API, такими как API Twitter или Facebook. Тем не менее, этот инструмент по сути является веб-майнером и может оказаться недостаточным для выполнения других задач обработки естественного языка.
Тем не менее, этот инструмент по сути является веб-майнером и может оказаться недостаточным для выполнения других задач обработки естественного языка.
Воспользуйтесь преимуществами Python для NLP
Когда дело доходит до обработки естественного языка, Python это лучшая технология. Разработка программного обеспечения, способного работать с естественными языками в контексте искусственного интеллекта, может быть сложной задачей. Однако, благодаря обширному инструментарию и NLP-библиотекам Python разработчики получают всю необходимую поддержку при создании удивительных инструментов.
Эти 8 библиотек и свойства, присущие этому удивительному языку программирования, делают его лучшим выбором для любого проекта, который опирается на понимание человеческих языков машинами.
Знаете ли вы какие-нибудь другие полезные NLP-библиотеки Python? Или, может быть, вы хотели бы узнать что-то еще об одной из библиотек, описанных в этом посте?
Мы приглашаем вас поделиться своим опытом и задать вопросы в комментариях, чтобы помочь всем узнать больше о лучших практиках разработки программного обеспечения на базе NLP.
Читайте больше статей по Python у нас на сайте.
Что такое NLP: история, терминология, библиотеки
Обработка естественного языка Natural language processing (NLP) – это сфера искусственного интеллекта, которая занимается применением алгоритмов машинного обучения и лингвистики для анализа текстовых данных. Цель NLP – понимание и воспроизведение естественного человеческого языка.
История
В 1954 году IBM проводит исследование в области машинного перевода с русского на английский (Джорджтаунский эксперимент) [1]. Система, которая состояла из 6 правил, перевела 60 предложений с транслитерированного (записанным латинским алфавитом) русского на английский. Авторы эксперимента заявили, что проблема машинного перевода будет решена через 3-4 года. Несмотря на последующие инвестиции правительства США прогресс был низкий. В 1966 году после отчета ALPAC о кризисе в машинного перевода и вычислительной лингвистики поток инвестиций уменьшается.
В 60-xх появилась интерактивная система с пользователем — SHRDLU [2]. Это был парсер с небольшим словарем, который определяет главные сущности в предложении (подлежащее, сказуемое, дополнение).
Это был парсер с небольшим словарем, который определяет главные сущности в предложении (подлежащее, сказуемое, дополнение).
В 70-х годах В. Вудс предлагает расширенную систему переходов (Augmented transition network) — графовая структура, использующая идею конечных автоматов для парсинга предложений [3].
После 80-хх для решения NLP-задач начинают активно применяться алгоритмы машинного обучения (Machine Learning). Например, одна из ранних работ опиралась на деревья решений (Decison Tree) для получения создания системы с правилами if-else. Кроме того, начали применяться статистические модели.
В 90-х годах стали популярны n-граммы [3]. В 1997 году была предложена модель LSTM (Long-short memory), которая была реализована на практике только в 2007 [4]. В 2011 году появляется персональный помощник от Apple — Siri. Вслед за Apple остальные крупные IT-компании стали выпускать своих голосовых ассистентов (Alexa от Amazon, Cortana от Microsoft, Google Assistant). В этом же году вопросно-ответная система Watson от IBM победила в игре Jeopardy!, аналог «Своей игры», в реальном времени [5].
На данный момент благодаря развитию Deep Learning, появлению большого количества данных и технологий Big Data методы NLP применяются во многих задачах, начиная от распознавания речи и машинного перевода, заканчивая написанием романов [6].
Терминология NLP
- Токен— текстовая единица, например, слово, словосочетание, предложение и т.д. Разбиение текста на токены называется токенизацией.
- Документ– это совокупность токенов, которые принадлежат одной смысловой единице, например, предложение, абзац, пост или комментарий.
- Корпус– это генеральная совокупность всех документов.
- Нормализация— приведение слов одинакового смысла к одной морфологической форме. Например, слово хотеть в тексте может встречаться в виде хотел, хотела, хочешь. К нормализации относится стемминг и лемматизация.
- Стемминг— процесс приведения слова к основе. Например, хочу может стать хоч. Для русского языка предпочтительней лемматизация.
- Лемматизация— процесс приведения слова к начальной форме. Слово глотаю может стать глотать, бутылкой — бутылка и т.д. Лемматизация затратный процесс, так как требуется работать со словарем.
- Стоп-слова— те слова, которые не несут информативный смысл. К ним чаще всего относятся служебные слова (предлоги, частицы и союзы).
ML-библиотеки для обработки естественного языка
- pymorphy2— морфологической анализатор для российского и украинского текстов. В нем присутствует лемматизатор.
- PyMystem3— аналог pymorhy2 от Яндекса.
- nltk— большой инструмент для работы с текстами. Предоставляет токенизатор, лемматизатор, стемминг, стоп-слова (в том числе и для русского языка).
- spacy— аналог nltk, но многие функции работают быстрее. Также как и nltk, плохо работает с русским языком. Однако, могут использоваться специальные модели ru2 или spacy russian—tokenizer.
- scikit—learn— самая популярна библиотека машинного обучения, которая также пересоставляет способы обработки текстов, например, TF—IDF.
- gensim— библиотека предоставляет методы векторизации слов.
- deeppavlov— фреймфворк для разработки чатботов и персональных помошников.
- yargy— парсер для извлечения сущностей в текстах на русском языке.

Подробнее про обработку текста читайте в нашей отдельной статье «4 метода векторизации текстов».
Источники
- https://ru.wikipedia.org/wiki/Джорджтаунский_эксперимент
- https://ru.wikipedia.org/wiki/Расширенная_сеть_переходов
- https://ru.wikipedia. org/wiki/N-грамма
- https://ru.wikipedia.org/wiki/LSTM
- https://ru.wikipedia.org/wiki/IBM_Watson
- https://openai.com/blog/better-language-models/#sample1
 org/wiki/N-грамма
org/wiki/N-граммаNLTK :: Индекс модуля Python
и | б | с | д | ф | г | ч | и | и | л | м | п | р | с | т | и | с
| а | ||
nltk.app | ||
nltk.app.chartparser_app | ||
nltk. | ||
nltk.app.collocations_app | ||
nltk.app.concordance_app | ||
nltk.app.nemo_app | ||
nltk.app.rdparser_app | ||
nltk.app.srparser_app | ||
nltk.app.wordfreq_app | ||
nltk.app.wordnet_app | ||
| б | ||
нлтк.бук | ||
| с | ||
nltk. | ||
нлтк.ccg.api | ||
nltk.ccg.chart | ||
nltk.ccg.combinator | ||
nltk.ccg.lexicon | ||
nltk.ccg.logic | ||
nltk.chat | ||
нлтк.чат.элиза | ||
nltk.chat.iesha | ||
nltk.chat.rude | ||
нлтк. | ||
nltk.chat.util | ||
nltk.chat.zen | ||
нлтк.чанк | ||
нлтк.чанк.апи | ||
nltk.chunk.named_entity | ||
nltk.chunk.regexp | ||
нлтк.чанк.утилит | ||
нлтк.классифицировать | ||
nltk.classify.api | ||
nltk. | ||
nltk.classify.maxent | ||
нлтк.классифицировать.мегам | ||
nltk.classify.naivebayes | ||
nltk.classify.positivenaivebayes | ||
nltk.classify.rte_classify | ||
nltk.classify.scikitlearn | ||
нлтк.классифицировать.сенна | ||
nltk.classify.svm | ||
nltk. | ||
nltk.classify.textcat | ||
nltk.classify.util | ||
nltk.classify.weka | ||
nltk.cli | ||
нлтк.кластер | ||
нлтк.кластер.апи | ||
nltk.cluster.em | ||
нлтк.кластер.гаак | ||
nltk.cluster.kmeans | ||
нлтк. | ||
нлтк.коллекции | ||
nltk.collocations | ||
nltk.compat | ||
нлтк.корпус | ||
nltk.corpus.europarl_raw | ||
nltk.corpus.reader | ||
nltk.corpus.reader.aligned | ||
nltk.corpus.reader.api | ||
nltk.corpus.reader.bnc | ||
nltk. | ||
nltk.corpus.reader.categorized_sents | ||
nltk.corpus.reader.chasen | ||
nltk.corpus.reader.childes | ||
nltk.corpus.reader.chunked | ||
nltk.corpus.reader.cmudict | ||
nltk.corpus.reader.comparative_sents | ||
nltk.corpus.reader.conll | ||
nltk.corpus.reader.crubadan | ||
nltk. | ||
нлтк.корпус.ридер.фреймнет | ||
nltk.corpus.reader.ieer | ||
нлтк.корпус.ридер.индийский | ||
nltk.corpus.reader.ipipan | ||
nltk.corpus.reader.knbc | ||
nltk.corpus.reader.lin | ||
nltk.corpus.reader.mte | ||
nltk.corpus.reader.nkjp | ||
нлтк. | ||
nltk.corpus.reader.nps_chat | ||
nltk.corpus.reader.opinion_lexicon | ||
nltk.corpus.reader.panlex_lite | ||
nltk.corpus.reader.panlex_swadesh | ||
nltk.corpus.reader.pl196x | ||
nltk.corpus.reader.plaintext | ||
nltk.corpus.reader.ppattach | ||
нлтк.корпус.ридер.пропбанк | ||
nltk. | ||
nltk.corpus.reader.reviews | ||
nltk.corpus.reader.rte | ||
нлтк.корпус.ридер.семкор | ||
nltk.corpus.reader.senseval | ||
nltk.corpus.reader.sentiwordnet | ||
nltk.corpus.reader.sinica_treebank | ||
nltk.corpus.reader.string_category | ||
nltk.corpus.reader.коммутатор | ||
nltk. | ||
nltk.corpus.reader.timit | ||
nltk.corpus.reader.toolbox | ||
nltk.corpus.reader.twitter | ||
nltk.corpus.reader.udhr | ||
nltk.corpus.reader.util | ||
nltk.corpus.reader.verbnet | ||
nltk.corpus.reader.словарь | ||
nltk.corpus.reader.wordnet | ||
nltk. | ||
nltk.corpus.reader.ycoe | ||
нлтк.корпус.утил | ||
| д | ||
нлтк.данные | ||
нлтк.декораторы | ||
nltk.downloader | ||
nltk.draw | ||
nltk.draw.cfg | ||
nltk.draw.дисперсия | ||
nltk. | ||
nltk.draw.tree | ||
nltk.draw.util | ||
| ф | ||
nltk.featstruct | ||
| г | ||
nltk.grammar | ||
| ч | ||
nltk.help | ||
| и | ||
nltk. | ||
nltk.inference.api | ||
nltk.inference.discourse | ||
nltk.inference.mace | ||
nltk.inference.nonmonotonic | ||
nltk.inference.prover9 | ||
nltk.inference.разрешение | ||
nltk.inference.tableau | ||
нлтк.внутренние | ||
| к | ||
nltk. | ||
| л | ||
nltk.lazyimport | ||
нлтк.лм | ||
нлтк.лм.апи | ||
nltk.lm.счетчик | ||
nltk.lm.models | ||
nltk.lm.предварительная обработка | ||
nltk.lm.сглаживание | ||
nltk.lm.util | ||
nltk. | ||
| м | ||
nltk.metrics | ||
nltk.metrics.agreement | ||
nltk.metrics.aline | ||
nltk.metrics.association | ||
nltk.metrics.confusionmatrix | ||
nltk.metrics.distance | ||
nltk.metrics.paice | ||
nltk.metrics.scores | ||
nltk. | ||
nltk.metrics.spearman | ||
нлтк.разное | ||
nltk.misc.babelfish | ||
нлтк.разное.хомский | ||
nltk.misc.минимальный набор | ||
nltk.misc.sort | ||
nltk.misc.wordfinder | ||
| п | ||
нлтк | ||
| р | ||
nltk. | ||
нлтк.парсе.апи | ||
nltk.parse.bllip | ||
nltk.parse.chart | ||
нлтк.парсе.коренлп | ||
nltk.parse.dependencygraph | ||
nltk.parse.earleychart | ||
нлтк.парсе.оценить | ||
nltk.parse.featurechart | ||
нлтк.парсе.генерировать | ||
нлтк. | ||
nltk.parse.nonprojectivedependencyparser | ||
nltk.parse.pchart | ||
nltk.parse.projectivedependencyparser | ||
nltk.parse.recursivedescent | ||
nltk.parse.shiftreduce | ||
нлтк.парсе.станфорд | ||
nltk.parse.transitionparser | ||
nltk.parse.util | ||
нлтк. | ||
nltk.вероятность | ||
| с | ||
нлтк.сем | ||
нлтк.сем.боксер | ||
нлтк.сем.чат80 | ||
nltk.sem.cooper_storage | ||
нлтк.сем.дрт | ||
nltk.sem.drt_glue_demo | ||
нлтк.сем.оценить | ||
нлтк. | ||
нлтк.сем.отверстие | ||
нлтк.сем.лфг | ||
nltk.sem.linearlogic | ||
nltk.sem.logic | ||
nltk.sem.relextract | ||
нлтк.сем.сколемизе | ||
nltk.sem.util | ||
нлтк.настроение | ||
nltk.sentiment.sentiment_analyzer | ||
nltk. | ||
нлтк.сентимент.вейдер | ||
нлтк.шток | ||
нлтк.стем.апи | ||
nltk.stem.arlstem | ||
nltk.stem.arlstem2 | ||
нлтк.шток.система | ||
нлтк.стем.исри | ||
нлтк.шток.ланкастер | ||
нлтк.стем.портер | ||
nltk. | ||
nltk.stem.rslp | ||
nltk.шток.снежок | ||
nltk.stem.util | ||
nltk.stem.wordnet | ||
| т | ||
nltk.tag | ||
нлтк.таг.апи | ||
нлтк.таг.брилл | ||
nltk.tag.brill_trainer | ||
nltk. | ||
нлтк.таг.хмм | ||
нлтк.таг.хунпос | ||
nltk.tag.mapping | ||
нлтк.таг.перцептрон | ||
нлтк.таг.сенна | ||
nltk.tag.sequential | ||
nltk.tag.stanford | ||
нлтк.таг.тнт | ||
nltk.tag.util | ||
нлтк. | ||
nltk.tbl.demo | ||
nltk.tbl.erroranalysis | ||
nltk.tbl.feature | ||
nltk.tbl.rule | ||
нлтк.табл.шаблон | ||
нлтк.тест | ||
нлтк.тест.все | ||
nltk.test.childes_fixt | ||
nltk.test.classify_fixt | ||
nltk. | ||
нлтк.тест.дискурс_фикст | ||
nltk.test.gensim_fixt | ||
nltk.test.gluesemantics_malt_fixt | ||
nltk.test.inference_fixt | ||
nltk.test.nonmonotonic_fixt | ||
nltk.test.portuguese_en_fixt | ||
nltk.test.probability_fixt | ||
nltk.test.unit | ||
nltk. | ||
nltk.test.unit.lm.test_counter | ||
nltk.test.unit.lm.test_models | ||
nltk.test.unit.lm.test_preprocessing | ||
nltk.test.unit.lm.test_vocabulary | ||
nltk.test.unit.test_aline | ||
nltk.test.unit.test_bllip | ||
nltk.test.unit.test_brill | ||
nltk.test.unit.test_cfd_mutation | ||
nltk. | ||
nltk.test.unit.test_chunk | ||
nltk.test.unit.test_classify | ||
nltk.test.unit.test_collocations | ||
nltk.test.unit.test_concordance | ||
нлтк.тест.юнит.тест_коренлп | ||
nltk.test.unit.test_corpora | ||
nltk.test.unit.test_corpus_views | ||
nltk.test.unit.test_data | ||
nltk. | ||
nltk.test.unit.test_distance | ||
nltk.test.unit.test_downloader | ||
nltk.test.unit.test_freqdist | ||
nltk.test.unit.test_hmm | ||
nltk.test.unit.test_json2csv_corpus | ||
nltk.test.unit.test_json_serialization | ||
nltk.test.unit.test_metrics | ||
nltk.test.unit.test_naivebayes | ||
nltk. | ||
nltk.test.unit.test_pl196x | ||
nltk.test.unit.test_pos_tag | ||
nltk.test.unit.test_ribes | ||
nltk.test.unit.test_rte_classify | ||
nltk.test.unit.test_seekable_unicode_stream_reader | ||
nltk.test.unit.test_senna | ||
nltk.test.unit.test_stem | ||
nltk.test.unit.test_tag | ||
нлтк. | ||
nltk.test.unit.test_tokenize | ||
nltk.test.unit.test_twitter_auth | ||
nltk.test.unit.test_util | ||
nltk.test.unit.test_wordnet | ||
nltk.test.unit.translate | ||
nltk.test.unit.translate.test_bleu | ||
nltk.test.unit.translate.test_gdfa | ||
nltk.test.unit.translate.test_ibm1 | ||
nltk. | ||
nltk.test.unit.translate.test_ibm3 | ||
nltk.test.unit.translate.test_ibm4 | ||
nltk.test.unit.translate.test_ibm5 | ||
nltk.test.unit.translate.test_ibm_model | ||
nltk.test.unit.translate.test_meteor | ||
nltk.test.unit.translate.test_nist | ||
nltk.test.unit.translate.test_stack_decoder | ||
нлтк.текст | ||
нлтк. | ||
nltk.tokenize | ||
nltk.tokenize.api | ||
nltk.tokenize.casual | ||
nltk.tokenize.destructive | ||
nltk.tokenize.legality_principle | ||
nltk.tokenize.mwe | ||
nltk.tokenize.nist | ||
nltk.tokenize.point | ||
nltk.tokenize.regexp | ||
nltk. | ||
nltk.tokenize.sexpr | ||
nltk.tokenize.simple | ||
nltk.tokenize.sonority_sequencing | ||
nltk.tokenize.stanford | ||
nltk.tokenize.stanford_segmenter | ||
nltk.tokenize.texttiling | ||
nltk.tokenize.toktok | ||
nltk.tokenize.treebank | ||
nltk. | ||
нлтк.тулбокс | ||
nltk.translate | ||
nltk.translate.api | ||
nltk.translate.bleu_score | ||
nltk.translate.chrf_score | ||
nltk.translate.gale_church | ||
nltk.translate.gdfa | ||
nltk.translate.gleu_score | ||
nltk.translate.ibm1 | ||
nltk. | ||
nltk.translate.ibm3 | ||
nltk.translate.ibm4 | ||
nltk.translate.ibm5 | ||
nltk.translate.ibm_model | ||
nltk.translate.meteor_score | ||
nltk.translate.metrics | ||
nltk.translate.nist_score | ||
nltk.translate.phrase_based | ||
nltk.translate. | ||
nltk.translate.stack_decoder | ||
нлтк.дерево | ||
нлтк.дерево.иммутабле | ||
nltk.tree.parented | ||
нлтк.дерево.разбор | ||
nltk.tree.prettyprinter | ||
nltk.tree.вероятностный | ||
нлтк.дерево.трансформирует | ||
нлтк.дерево.дерево | ||
nltk. | ||
nltk.treetransforms | ||
nltk.twitter | ||
nltk.twitter.api | ||
nltk.twitter.common | ||
nltk.twitter.twitter_demo | ||
nltk.twitter.twitterclient | ||
nltk.twitter.util | ||
| у | ||
nltk.util | ||
| с | ||
nltk. |
 app.chunkparser_app
app.chunkparser_app  ccg
ccg  чат.сунцу
чат.сунцу  classify.decisiontree
classify.decisiontree  classify.tadm
classify.tadm  кластер.утили
кластер.утили 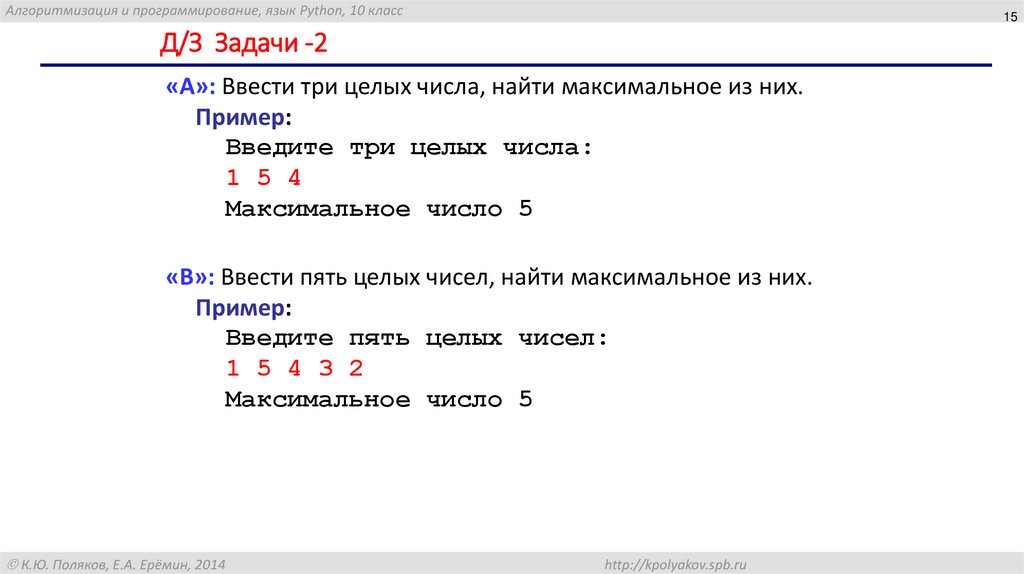 corpus.reader.bracket_parse
corpus.reader.bracket_parse  corpus.reader.зависимость
corpus.reader.зависимость  корпус.ридер.номбанк
корпус.ридер.номбанк  corpus.reader.pros_cons
corpus.reader.pros_cons  corpus.reader.tagged
corpus.reader.tagged  corpus.reader.xmldocs
corpus.reader.xmldocs  draw.table
draw.table  inference
inference  jsontags
jsontags  lm.словарь
lm.словарь  metrics.segmentation
metrics.segmentation  parse
parse  парсе.солод
парсе.солод  парсе.витерби
парсе.витерби  сем.клей
сем.клей  sentiment.util
sentiment.util 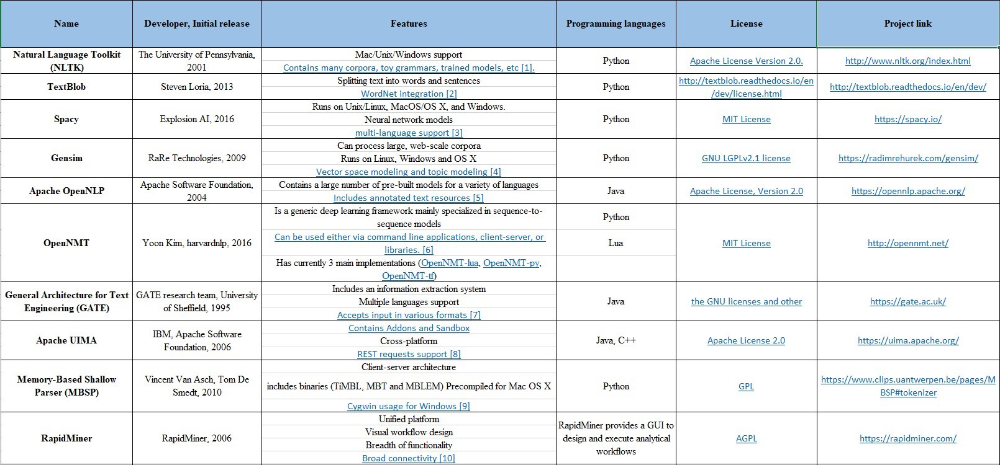 stem.regexp
stem.regexp  tag.crf
tag.crf  табл
табл 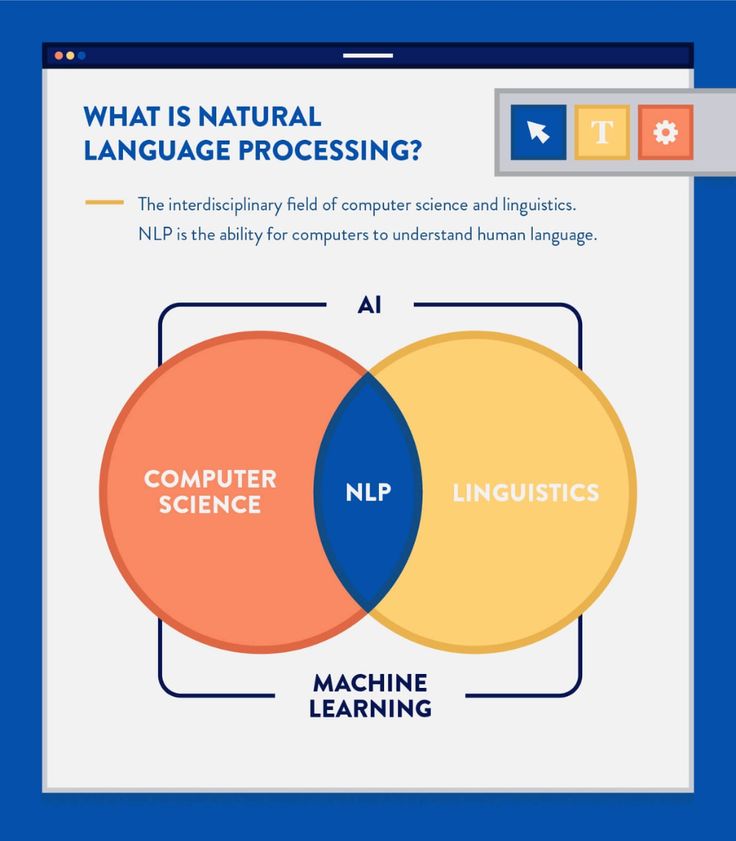 test.conftest
test.conftest  test.unit.lm
test.unit.lm  test.unit.test_cfg2chomsky
test.unit.test_cfg2chomsky  test.unit.test_disagreement
test.unit.test_disagreement  test.unit.test_nombank
test.unit.test_nombank  тест.юнит.тест_тгреп
тест.юнит.тест_тгреп  test.unit.translate.test_ibm2
test.unit.translate.test_ibm2  тгреп
тгреп  tokenize.repp
tokenize.repp  tokenize.util
tokenize.util  translate.ibm2
translate.ibm2  ribes_score
ribes_score 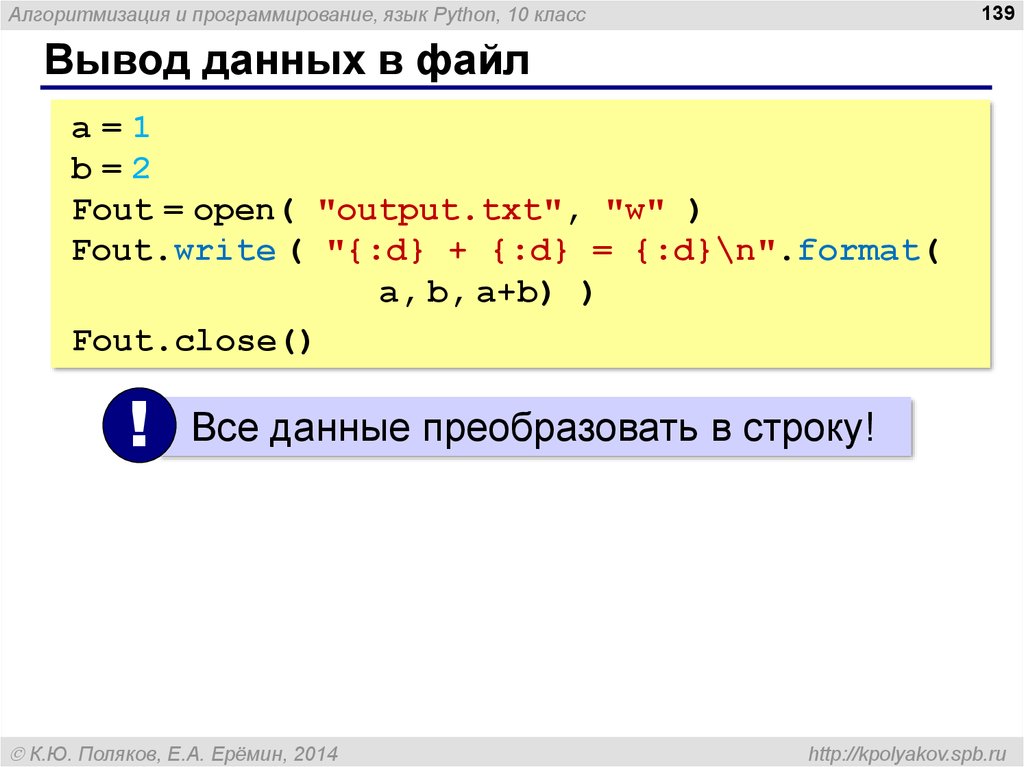 treeprettyprinter
treeprettyprinter  wsd
wsd 7 техник НЛП, которые можно легко реализовать с помощью Python | Фрэнк Андраде
Вам просто нужно несколько строк кода для реализации методов НЛП с помощью Python.
Фото Сафара Сафарова на UnsplashОбработка естественного языка (NLP) направлена на то, чтобы компьютеры могли понимать и обрабатывать человеческие языки. Компьютеры отлично справляются со структурированными данными, такими как электронные таблицы; однако большая часть информации, которую мы пишем или говорим, неструктурирована.
Цель НЛП — научить компьютеры понимать неструктурированные тексты и извлекать из них осмысленные фрагменты информации. Мы можем реализовать многие методы NLP всего несколькими строками кода Python благодаря библиотекам с открытым исходным кодом, таким как spaCy и NLTK.
В этой статье мы изучим основные понятия семи техник НЛП и узнаем, как их легко реализовать в Python.
Содержание
1.
2. Распознавание именованных объектов (NER)
3. Стемминг
4. Лемматизация
5. Сумка слов (BoW)
6. Частота терминов – обратная частота документа (TF-IDF)
7. Wordcloud
 Анализ тональности
Анализ тональности фрагмент текста (например, комментарий, обзор или документ) и определяет, являются ли данные положительными, отрицательными или нейтральными. Он имеет множество приложений в здравоохранении, обслуживании клиентов, банковском деле и т. д.
Реализация Python
Для простых случаев в Python мы можем использовать VADER (Valence Aware Dictionary for Sentiment Reasoning), который доступен в пакете NLTK и может применяться непосредственно к немаркированным текстовым данным. В качестве примера, давайте получим все оценки тональности реплик, произнесенных персонажами телешоу.
Сначала мы обрабатываем набор данных, доступный на Kaggle или моем Github, под названием «avatar.csv», затем с помощью VADER мы вычисляем оценку каждой произнесенной строки. Все это хранится в кадре данных
Все это хранится в кадре данных df_character_sentiment .
В df_character_sentiment ниже мы видим, что каждое предложение получает отрицательную, нейтральную и положительную оценку.
Мы могли бы даже сгруппировать оценки по персонажам и вычислить среднее значение, чтобы получить оценку настроений для персонажа, а затем представить ее в виде горизонтальных полос с помощью библиотеки matplotlib (результат этого показан в этой статье)
Примечание: VADER оптимизирован для текста в социальных сетях, поэтому мы должны воспринимать результаты с долей скептицизма. Вы можете использовать более полный алгоритм или разработать собственный с помощью библиотек машинного обучения. По ссылке ниже есть полное руководство о том, как создать его с нуля с помощью Python, используя библиотеку sklearn.
Простое руководство по Scikit-Learn — создание модели машинного обучения на Python
Ваша первая модель машинного обучения на Python.

по направлению datascience.com
Распознавание именованных объектов — это метод, используемый для обнаружения и классификации именованных объектов в тексте по категориям, таким как лица, организации, местоположения, выражения времени, количества, денежные значения, проценты и т. д. Он используется для оптимизации алгоритмов поисковых систем, системы рекомендаций, поддержка клиентов, классификация контента и т. д.
Реализация Python
В Python мы можем использовать распознавание именованных сущностей SpaCy, которое поддерживает следующие типы сущностей.
Источник (документация Spacy) Чтобы увидеть это в действии, мы сначала импортируем spacy , а затем создаем переменную nlp , в которой будет храниться конвейер en_core_web_sm . Это небольшой англоязычный пайплайн, обученный письменному веб-тексту (блоги, новости, комментарии), который включает словарный запас, векторы, синтаксис и сущности. Чтобы найти сущности, мы применяем nlp к предложению.
import spacynlp = spacy.load("en_core_web_sm")
doc = nlp("Байден приглашает президента Украины в Белый дом этим летом")print([(X.text, X.label_) for X in doc.ents]) Это напечатает следующие значения
[('Байден', 'ЧЕЛОВЕК'), ('Украинец', 'ГПО'), ('Белый дом', 'ОРГ'), ('этим летом', 'ДАТА ')] Спейси нашел, что «Байден» — это человек, «украинец» — это ГПЭ (страны, города, штаты, «Белый дом» — это организация, а «этим летом» — дата.
Стемминг и лемматизация — это 2 популярных метода в НЛП. Оба нормализуют слово, но по-разному.
- Stemming: Обрезает слово до его основного слова. Например, слова «друзья», «дружба», «дружба» будут сокращены до «друг». Стемминг не может дать нам словарь, грамматическое слово для определенного набора слов.
- Лемматизация : В отличие от метода стемминга, лемматизация находит словарное слово вместо усечения исходного слова. Алгоритмы лемматизации извлекают правильную лемму из каждого слова, поэтому им часто требуется словарь языка, чтобы правильно классифицировать каждое слово.

Оба метода широко используются, и вам следует выбирать их с умом, исходя из целей вашего проекта. Лемматизация имеет более низкую скорость обработки по сравнению со стеммингом, поэтому, если целью проекта является не точность, а скорость, то стемминг является подходящим подходом; Однако. если точность имеет решающее значение, рассмотрите возможность использования лемматизации.
Библиотека Python NLTK упрощает работу с обоими методами. Давайте посмотрим на это в действии.
Реализация Python (Stemming)
Для английского языка в nltk доступны две популярные библиотеки — Porter Stemmer и LancasterStemmer.
из nltk.stem import PorterStemmer
из nltk.stem import LancasterStemmer# PorterStemmer
porter = PorterStemmer()
# LancasterStemmer
lancaster = LancasterStemmer()print(porter.stem("дружба"))
print(lancaster.stem("дружба"))
Алгоритм PorterStemmer не следует лингвистике, а представляет собой набор из 5 правил для разных случаев, которые применяются поэтапно для создания стеблей. Код
Код print(porter.stem("Friendship")) напечатает слово Friendly
LancasterStemmer прост, но может возникнуть тяжелое выделение корней из-за итераций и чрезмерного стемминга. Это приводит к тому, что основы не являются лингвистическими, или они могут не иметь значения. Отпечаток (lancaster.stem("дружба")) 9Код 0058 напечатает слово друг .
Вы можете попробовать любое другое слово, чтобы увидеть, чем отличаются оба алгоритма. В случае других языков вы можете импортировать SnowballStemme из nltk.stem
Реализация Python (лемматизация)
Мы снова будем использовать NLTK, но на этот раз мы импортируем WordNetLemmatizer , как показано в коде ниже.
from nltk import WordNetLemmatizerlemmatizer = WordNetLemmatizer()
words = ['статьи', 'дружба', 'учеба', 'телефоны'] на слово прописью:
print(lemmatizer.lemmatize(word))
Лемматизация создает разные выходные данные для разных значений части речи (POS). Некоторые из наиболее распространенных значений POS — это глагол (v), существительное (n), прилагательное (a) и наречие (r). Значением POS по умолчанию в лемматизации является существительное, поэтому напечатанные значения для предыдущего примера будут
Некоторые из наиболее распространенных значений POS — это глагол (v), существительное (n), прилагательное (a) и наречие (r). Значением POS по умолчанию в лемматизации является существительное, поэтому напечатанные значения для предыдущего примера будут article , Friendship , Study и phone .
Давайте изменим значение POS на глагол (v).
из nltk import WordNetLemmatizerlemmatizer = WordNetLemmatizer()
words = ['be', 'is', 'are', 'were', 'was'] для слова в словах:
print(lemmatizer.lemmatize(word, pos=' v'))
В этом случае Python напечатает слово вместо для всех значений в списке.
Модель Bag of Words (BoW) — это представление, которое превращает текст в векторы фиксированной длины. Это помогает нам представлять текст в числах, чтобы мы могли использовать его для моделей машинного обучения. Модель не заботится о порядке слов, а только о частоте слов в тексте. Он применяется в НЛП, поиске информации из документов и классификации документов.
Он применяется в НЛП, поиске информации из документов и классификации документов.
Типичный рабочий процесс BoW включает в себя очистку необработанного текста, токенизацию, создание словаря и создание векторов.
Реализация Python
Библиотека Python sklearn содержит инструмент под названием CountVectorizer, который выполняет большую часть рабочего процесса BoW.
Давайте используем следующие 2 предложения в качестве примера.
Предложение 1: «Я люблю писать код на Python. Я люблю код Python»
Предложение 2: «Я ненавижу писать код на Java. Я ненавижу Java-код»
Оба предложения будут сохранены в списке с именем text . Затем мы собираемся создать кадр данных df для хранения этого списка text . После этого мы инициируем экземпляр CountVectorizer (cv) , а затем подгоним и преобразуем текстовые данные, чтобы получить числовое представление. Это будет сохранено в матрице терминов документа df_dtm .
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizertext = ["Я люблю писать код на Python. Я люблю код на Python",
"Я ненавижу писать код на Java. Я ненавижу код Java"]df = pd.DataFrame({'review': ['review1', 'review2'], 'text':text})
cv = CountVectorizer(stop_words= 'английский')
cv_matrix = cv.fit_transform(df['text'])
df_dtm = pd.DataFrame(cv_matrix.toarray(),
index=df['review'].values,
columns=cv.get_feature_names( ))
df_dtm
Представление BoW, созданное с помощью CountVectorizer, сохраненного в df_dtm , выглядит так, как показано на рисунке ниже. Имейте в виду, что слова, состоящие из 2 букв или менее, не учитываются CountVectorizer.
Как вы можете видеть, числа внутри матрицы представляют собой количество упоминаний каждого слова в каждом обзоре. Такие слова, как «любовь», «ненависть» и «код», имеют одинаковую частоту (2) в этом примере.
В целом, мы можем сказать, что CountVectorizer хорошо справляется с токенизацией текста, построением словаря и генерацией векторов; однако он не будет очищать необработанные данные за вас. Я сделал руководство по очистке и подготовке данных в Python, ознакомьтесь с ним, если хотите изучить лучшие практики.
Я сделал руководство по очистке и подготовке данных в Python, ознакомьтесь с ним, если хотите изучить лучшие практики.
Простое руководство по очистке и подготовке данных в Python
Как определить и справиться с грязными данными.
в направлении datascience.com
В отличие от CountVectorizer, TF-IDF вычисляет «веса», которые представляют, насколько релевантно слово документу в наборе документов (он же корпус). Значение TF-IDF увеличивается пропорционально количеству раз, которое слово встречается в документе, и компенсируется количеством документов в корпусе, содержащих это слово. Проще говоря, чем выше оценка TF-IDF, тем реже, уникальнее или ценнее термин, и наоборот. У него есть приложения для поиска информации, такие как поисковые системы, которые стремятся предоставлять результаты, наиболее соответствующие тому, что вы ищете.
Прежде чем мы рассмотрим реализацию Python, давайте рассмотрим пример, чтобы у вас было представление о том, как рассчитываются TF и IDF. В следующем примере мы будем использовать те же предложения, что и в примере с CountVectorizer.
В следующем примере мы будем использовать те же предложения, что и в примере с CountVectorizer.
Предложение 1: «Мне нравится писать код на Python. Я люблю код Python»
Предложение 2: «Я ненавижу писать код на Java. Я ненавижу Java-код»
Частота терминов (TF)
Существуют разные способы определения частоты терминов. Один предлагает сам необработанный подсчет (то есть то, что делает векторизатор подсчета), но другие предполагают, что это частота слова в предложении, деленная на общее количество слов в предложении. В этом простом примере мы будем использовать первый критерий, поэтому частота термина показана в следующей таблице.
Изображение автораКак видите, значения такие же, как и ранее рассчитанные для CountVectorizer. Также не учитываются слова, состоящие из 2 букв и менее.
Обратная частота документа (IDF)
IDF также рассчитывается по-разному. Хотя стандартная нотация учебника определяет IDF как idf(t) = log [ n / (df(t) + 1), библиотека sklearn, которую мы будем использовать позже в Python, вычисляет формулу по умолчанию следующим образом.
Кроме того, sklearn принимает натуральный логарифм ln вместо log и сглаживание (smooth_idf=True) . Давайте посчитаем значения IDF для каждого слова, как это сделает sklearn.
TF-IDF
Получив значения TF и IDF, мы можем получить TF-IDF, умножив оба значения (TF-IDF = TF * IDF). Значения показаны в таблице ниже.
Изображение автораРеализация Python
Для вычисления TF-IDF, показанного в таблице выше, в Python требуется несколько строк кода благодаря библиотеке sklearn.
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
text = ["Я люблю писать код на Python. Я люблю код Python",
"Я ненавижу писать код на Java. Я ненавижу код Java"]df = pd.DataFrame({'review': ['review1', 'review2'], 'text':text})
tfidf = TfidfVectorizer(stop_words='english', norm=None)
tfidf_matrix = tfidf.fit_transform(df[ 'текст'])
df_dtm = pd.
index=df['review'].values,
columns=tfidf.get_feature_names())
df_dtm
 DataFrame(tfidf_matrix.toarray(),
DataFrame(tfidf_matrix.toarray(), Представление TF-IDF, сохраненное в df_dtm , выглядит так, как показано на рисунке ниже. Опять же, слова, состоящие из 2 букв или менее, не учитываются TF-IDF.
Примечание. По умолчанию TfidfVectorizer() использует нормализацию l2, но для использования тех же формул, показанных выше, мы устанавливаем norm=None в качестве параметра. Для получения более подробной информации о формулах, используемых по умолчанию в sklearn, и о том, как вы можете их настроить, ознакомьтесь с документацией 9.3882 .
Wordcloud — популярный метод, который помогает нам идентифицировать ключевые слова в тексте. В облаке слов более часто встречающиеся слова имеют более крупный и жирный шрифт, в то время как менее часто встречающиеся слова имеют меньший или более тонкий шрифт. В Python вы можете создавать простые облака слов с помощью библиотеки wordcloud и красиво выглядящие облака слов с библиотекой stylecloud .
Ниже вы можете найти код для создания облака слов в Python. Я использую текстовый файл речи Стива Джобса, который вы можете найти на моем Github.
import stylecloudstylecloud.gen_stylecloud(file_path='SJ-Speech.txt',
icon_name= "fas fa-apple-alt")
Это результат кода выше.
Изображение автораWordclouds так популярны, потому что они привлекательны, просты для понимания и просты в создании.
Вы можете расширить возможности настройки, изменив цвета, удалив стоп-слова, выбрав свое изображение или даже добавив собственное изображение, чтобы использовать его в качестве маски облака слов. Для получения более подробной информации ознакомьтесь с руководством ниже.
Как легко создавать красивые облака слов в Python
Используйте библиотеки stylecloud и wordcloud для настройки своего облака слов.
в сторону datascience.com
Готово! Вы только что изучили основную концепцию семи техник НЛП и способы их реализации в Python. Весь код, написанный в этой статье, можно найти на моем Github .
Весь код, написанный в этой статье, можно найти на моем Github .
Присоединяйтесь к моему списку рассылки с более чем 3 000 человек, чтобы получить мою памятку по Python для Data Science, которую я использую во всех своих руководствах (бесплатный PDF)
spaCy · Промышленная обработка естественного языка в Python
spaCy · Промышленная обработка естественного языка в Python Это приложение лучше всего работает с включенным JavaScript.на Python
Добивайтесь цели
spaCy разработан, чтобы помочь вам выполнять настоящую работу — создавать настоящие продукты или собирать реальные идеи. Библиотека уважает ваше время и старается не тратить его попусту. Его легко установить, а его API простой и продуктивный.
Начало работыНевероятная скорость
spaCy отлично справляется с крупномасштабными задачами извлечения информации. Он написан с нуля на Cython с тщательно управляемой памятью. Если вашему приложению необходимо обрабатывать целые веб-дампы, spaCy — это библиотека, которую вы хотите использовать.
Удивительная экосистема
За пять лет с момента выпуска spaCy стал отраслевым стандартом с огромной экосистемой. Выбирайте из множества подключаемых модулей, интегрируйте их со своим стеком машинного обучения и создавайте собственные компоненты и рабочие процессы.
ПодробнееОтредактируйте код и попробуйте spaCy
# pip install -U spacy # python -m spacy скачать en_core_web_sm импортировать просторный # Загружаем английский токенизатор, теггер, парсер и NER nlp = spacy.load ("en_core_web_sm") # Обрабатывать целые документы text = ("Когда Себастьян Трун начал работать над беспилотными автомобилями в " «Google в 2007 году мало кто за пределами компании брал его» "серьезно. "Я могу сказать вам, что очень высокопоставленные руководители крупных американских " "автомобильные компании пожимали мне руку и отворачивались, потому что я не был" «С ним стоит поговорить», — сказал Трун в интервью Recode ранее.
 "На этой неделе.")
документ = нлп (текст)
# Анализ синтаксиса
print("Существительные фразы:", [chunk.text для чанка в doc.noun_chunks])
print("Глаголы:", [token.lemma_ для токена в документе, если token.pos_ == "VERB"])
# Найти именованные сущности, фразы и понятия
для объекта в doc.ents:
печать (entity.text, entity.label_)
"На этой неделе.")
документ = нлп (текст)
# Анализ синтаксиса
print("Существительные фразы:", [chunk.text для чанка в doc.noun_chunks])
print("Глаголы:", [token.lemma_ для токена в документе, если token.pos_ == "VERB"])
# Найти именованные сущности, фразы и понятия
для объекта в doc.ents:
печать (entity.text, entity.label_)
Особенности
- Поддержка для 66+ языков
- 80 ОБУЧЕНИЯ ТРУБОВЫЕ для 24 языков
- Многозадачное обучение с предварительно проведенными .
- .
- Готовая к производству система обучения
- Лингвистически мотивированная токенизация
- Компоненты для именованного объекта 9Распознавание 0004, тегирование частей речи, анализ зависимостей, сегментация предложений, классификация текста , лемматизация, морфологический анализ, связывание сущностей и многое другое
- Легко расширяется с помощью пользовательских компонентов и атрибутов
- Поддержка пользовательских моделей в PyTorch , TensorFlow и другие платформы
- Встроенные визуализаторы для синтаксиса и NER
- Простая упаковка модели , развертывание и управление рабочим процессом
- Надежная, тщательно проверенная точность
Получите собственный конвейер spaCy, созданный специально для вашей задачи NLP основными разработчиками spaCy.
- Обтекаемый. Никто не знает spaCy лучше нас. Отправьте нам свои требования к конвейеру, и мы будем готовы начать производство вашего решения в кратчайшие сроки.
- Производство готово. Конвейеры spaCy надежны и просты в развертывании. Вы получите полную папку проекта spaCy, готовую к
космический запуск проекта. - Предсказуемо. Вы будете точно знать, что вы получите и сколько это будет стоить. Мы заранее указываем комиссию, позволяем вам попробовать, прежде чем купить, и не взимаем плату за превышение лимита с нашей стороны — весь риск лежит на нас.
- Ремонтопригодный. spaCy — это отраслевой стандарт, и мы предоставим вам полный код, данные, тесты и документацию, чтобы ваша команда могла переобучить, обновить и расширить решение по мере изменения ваших требований.
Узнать больше
От создателей spaCy
Prodigy: радикально эффективное машинное обучение Prodigy — это инструмент для создания аннотаций, настолько эффективный, что специалисты по обработке и анализу данных могут делать аннотации самостоятельно, обеспечивая новый уровень быстрой итерации. Работаете ли вы над распознаванием сущностей, обнаружением намерений или классификацией изображений, Prodigy поможет вам обучать и оценивать ваши модели быстрее.
Работаете ли вы над распознаванием сущностей, обнаружением намерений или классификацией изображений, Prodigy поможет вам обучать и оценивать ваши модели быстрее.
Попробуйте
Воспроизводимое обучение для пользовательских конвейеров
spaCy v3.0 представляет комплексную и расширяемую систему для настройки тренировочных заездов . Ваш файл конфигурации будет описывать каждую деталь вашего тренировочного прогона без каких-либо скрытых значений по умолчанию, упрощая повторный запуск ваших экспериментов и отслеживание изменений. Вы можете использовать виджет быстрого запуска или команду init config , чтобы начать работу, или клонировать шаблон проекта для сквозного рабочего процесса.
Get started
Language
AfrikaansAlbanianArabicArmenianBasqueBengaliBulgarianCatalanChineseCroatianCzechDanishDutchEnglishEstonianFinnishFrenchGermanGreekGujaratiHebrewHindiHungarianIcelandicIndonesianIrishItalianJapaneseKannadaKoreanKyrgyzLatvianLigurianLithuanianLower SorbianLuxembourgishMacedonianMalayalamMarathiMulti-languageNepaliNorwegian BokmålPersianPolishPortugueseRomanianRussianSanskritSerbianSetswanaSinhalaSlovakSlovenianSpanishSwedishTagalogTamilTatarTeluguThaiTurkishUkrainianUpper SorbianUrduVietnameseYoruba
Компоненты
taggermorphologizertrainable_lemmatizerparsernerspancattextcat
Аппаратное обеспечение
CPUGPU (преобразователь)
Оптимизация для
efficiencyaccuracy
# Это частичная конфигурация.
 Чтобы использовать его с «пространственным поездом»
# вы можете запустить spacy init fill-config для автоматического заполнения всех настроек по умолчанию:
# python -m spacy init fill-config ./base_config.cfg ./config.cfg
[пути]
поезд = ноль
Разработчик = ноль
векторы = ноль
[система]
gpu_allocator = ноль
[нлп]
язык = "en"
трубопровод = []
размер партии = 1000
[составные части]
[корпуса]
[corpora.train]
@readers = "spacy.Corpus.v1"
путь = ${paths.train}
максимальная_длина = 0
[corpora.dev]
@readers = "spacy.Corpus.v1"
путь = ${paths.dev}
максимальная_длина = 0
[подготовка]
dev_corpus = "corpora.dev"
train_corpus = "corpora.train"
[обучение.оптимизатор]
@optimizers = "Адам.v1"
[обучение.дозатор]
@batchers = "spacy.batch_by_words.v1"
discard_oversize = ложь
допуск = 0,2
[обучение.batcher.size]
@schedules = "состав.v1"
начало = 100
стоп = 1000
соединение = 1,001
[инициализировать]
векторы = ${paths.vectors}
Чтобы использовать его с «пространственным поездом»
# вы можете запустить spacy init fill-config для автоматического заполнения всех настроек по умолчанию:
# python -m spacy init fill-config ./base_config.cfg ./config.cfg
[пути]
поезд = ноль
Разработчик = ноль
векторы = ноль
[система]
gpu_allocator = ноль
[нлп]
язык = "en"
трубопровод = []
размер партии = 1000
[составные части]
[корпуса]
[corpora.train]
@readers = "spacy.Corpus.v1"
путь = ${paths.train}
максимальная_длина = 0
[corpora.dev]
@readers = "spacy.Corpus.v1"
путь = ${paths.dev}
максимальная_длина = 0
[подготовка]
dev_corpus = "corpora.dev"
train_corpus = "corpora.train"
[обучение.оптимизатор]
@optimizers = "Адам.v1"
[обучение.дозатор]
@batchers = "spacy.batch_by_words.v1"
discard_oversize = ложь
допуск = 0,2
[обучение.batcher.size]
@schedules = "состав.v1"
начало = 100
стоп = 1000
соединение = 1,001
[инициализировать]
векторы = ${paths.vectors} Сквозные рабочие процессы от прототипа до производства
Новая система проектов spaCy обеспечивает плавный путь от прототипа до производства. Он позволяет вам отслеживать все эти преобразования данных , предварительную обработку и этапов обучения , поэтому вы можете быть уверены, что ваш проект всегда готов к передаче для автоматизации. Он включает загрузку исходных ресурсов, выполнение команд, проверку контрольной суммы и кэширование с различными бэкэндами и интеграциями.
Он позволяет вам отслеживать все эти преобразования данных , предварительную обработку и этапов обучения , поэтому вы можете быть уверены, что ваш проект всегда готов к передаче для автоматизации. Он включает загрузку исходных ресурсов, выполнение команд, проверку контрольной суммы и кэширование с различными бэкэндами и интеграциями.
Попробуйте
Новое в v3.0
Конвейеры на основе трансформаторов, новая система обучения, шаблоны проектов и многое другое spaCy v3.0 содержит все новые конвейеры на основе трансформаторов , которые доводят точность spaCy до текущего состояния . искусство . Вы можете использовать любой предварительно обученный преобразователь для обучения собственных конвейеров и даже использовать один преобразователь для нескольких компонентов с многозадачным обучением . Обучение теперь полностью настраивается и расширяется, и вы можете определять свои собственные пользовательские модели, используя PyTorch , TensorFlow и другие фреймворки.
Узнайте, что нового
В этом бесплатном и интерактивном онлайн-курсе вы узнаете, как использовать spaCy для создания передовых систем понимания естественного языка, используя подходы как на основе правил, так и на основе машинного обучения. Он включает в себя 55 упражнений с видеороликами, наборами слайдов, вопросами с несколькими вариантами ответов и интерактивными практиками кодирования в браузере.
Начать курс
Benchmarks
spaCy v3.0 представляет конвейеры на основе трансформаторов, которые доводят точность spaCy до уровня современного современного . Вы также можете использовать конвейер, оптимизированный для ЦП, который менее точен, но гораздо дешевле в эксплуатации.
More results
| Pipeline | Parser | Tagger | NER |
|---|---|---|---|
en_core_web_trf (spaCy v3) | 95.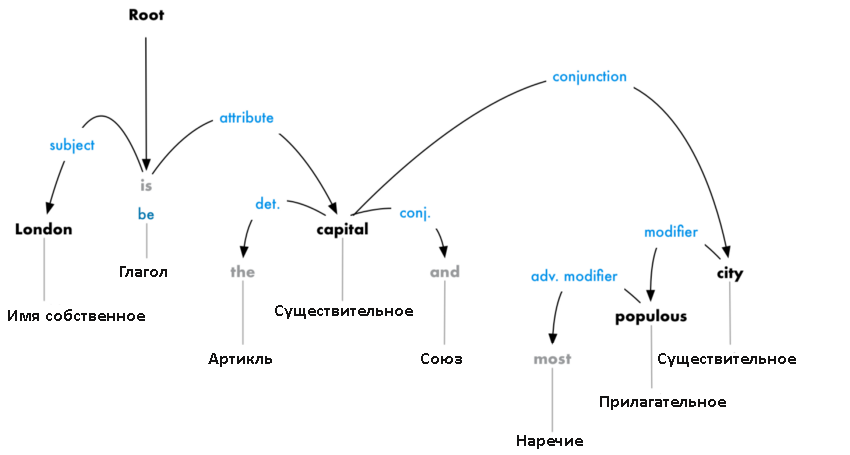 1 1 | 97.8 | 89.8 |
en_core_web_lg (spaCy v3) | 92.0 | 97.4 | 85.5 |
en_core_web_lg (spaCy v2) | 91.9 | 97.2 | 85.5 |
Full pipeline точность на Корпус OntoNotes 5.0 (сообщено набор для разработки).
| Система распознавания именованных объектов | OntoNotes | CoNLL ‘03 |
|---|---|---|
| spaCy RoBERTa (2020) | 89.8 | 91.6 |
| Stanza (StanfordNLP) 1 | 88.8 | 92.1 |
| Flair 2 | 89.7 | 93. |