Обработка естественного языка (NLP) методами машинного обучения в Python / Хабр
Автор статьи — Виктория Ляликова.
В данной статье хотелось бы рассказать о том, как можно применить различные методы машинного обучения (ML) для обработки текста, чтобы можно было произвести его бинарную классифицию.
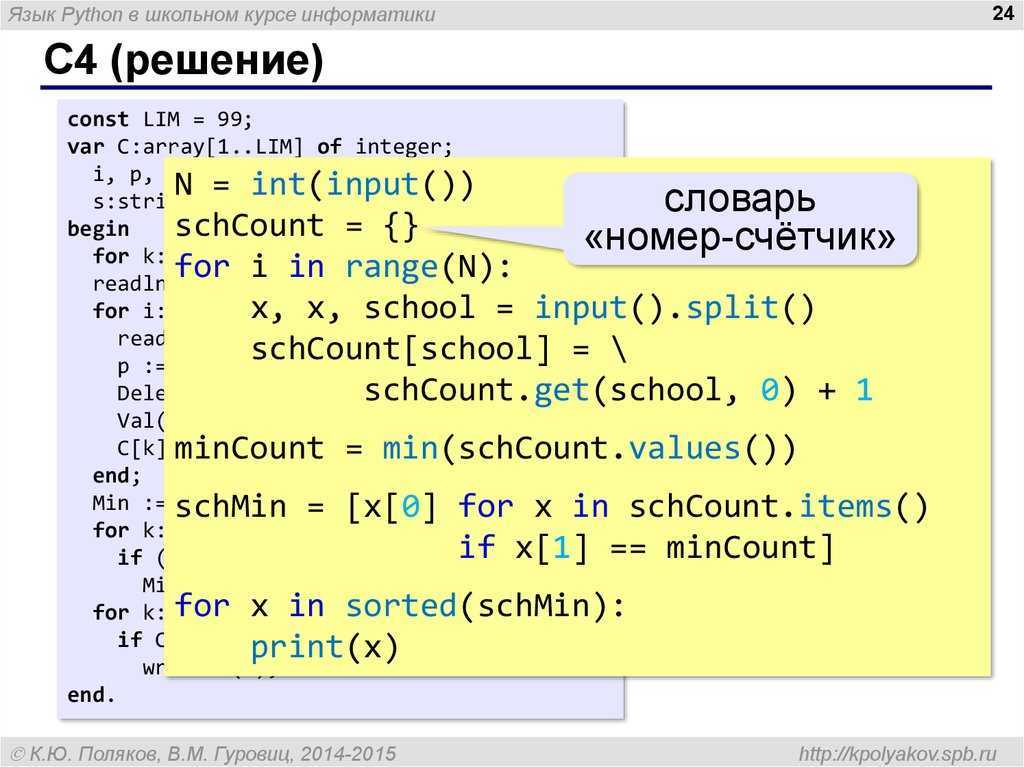
Рассмотрим задачу обработки естественного языка (NLP — Natural Lanuage Processing) на примере классификации психического здоровья для определения депрессии по комментариям в Reddit. Посмотрим на наш датасет:
import pandas as pd
data_depression = pd.read_csv('D:/vika/datasets/depression_dataset_reddit_cleaned.csv')
data_depressionПосмотрим, например, на какую-нибудь одну запись:
‘sleep is my greatest and most comforting escape whenever i wake up these day the literal very first emotion i feel is just misery and reminding myself of all my problem i can t even have a single second to myself it s like waking up everyday is just welcoming yourself back to hell’.
Данный комментарий классифицируется как наличие депрессии у человека.
Далее посмотрим на гистограмму распределения.
import seaborn as sns sns.countplot(data=data_depression, x="is_depression")
То есть можно увидеть, что в датасете количество комментариев соответствующих депрессии и ее отсутствию распределено приблизительно одинаково.Теперь приступим к обработке текста, чтобы его можно было применять в алгоритмах машинного обучения.
Сначала необходимо импортировать библиотеку NLTK, которая является ведущей для создания программ по обработке естественного языка на Python. И рассмотрим основные методы данного инструмента.
Также нам понадобится загрузить модуль RE, который является модулем по работе с регулярными выражениями и также помогает работать с текстом. Данный модуль позволяет производить поиск, замену, анализ и другие операции по работе с текстом.
import nltk
import re
nltk.download("stopwords") # поддерживает удаление стоп-слов
nltk. a-zA-Z]"," ",text)
a-zA-Z]"," ",text) a-zA-Z]"," ",text)
a-zA-Z]"," ",text)Токенизация. Данный метод позволяет разделить текст на так называемые токены, то есть на слова или предложения.
nltk.word_tokenize(text,language = "english")
Лемматизация. Позволяет привести словоформу к лемме — ее нормальной (словарной) форме. Другими словами, лемматизация схожа с выделением основы каждого слова в предложении. Она обычно выполняется простым поиском форм в таблице. Кроме того, можно добавить некоторые пользовательские правила для анализа слов.
lemmatize = nltk.WordNetLemmatizer() lemmatize.lemmatize(word) for word in text
Удаление стоп-слов. Под стоп-словами обычно понимаются артикли, междометия, союзы и т.д., которые не несут смысловой нагрузки. При применении алгоритмов машинного обучения такие слова могут добавить много шума, поэтому лучше избавляться от них. В NLTK есть предустановленный список стоп-слов.

lemmatize.lemmatize(word) for word in text if not word in set(stopwords.words("stopwords"))Векторизация текста или преобразование текста в численную форму. Алгоритмы машинного обучения не умеют работать с текстом, поэтому необходимо превратить текст в цифры. Данная стратегия называется представлением «Мешок слов». Документы описываются вхождениями слов, при этом полностью игнорируется информация об относительном положении слов в документе. По мешку слов находят количество появлений каждого слова во всем тексте.
В пакете scikit-learn есть модуль CountVectorizer, который преобразовывает входной текст в матрицу, значениями которой являются количества вхождения данного ключа(слова) в текст. Таким образом, мы получим матрицу, размерность которой будет равна количеству всех слов, умноженных на количество документов. И элементами матрицы будут числа, которые означают, сколько раз всего слово встретилось в тексте.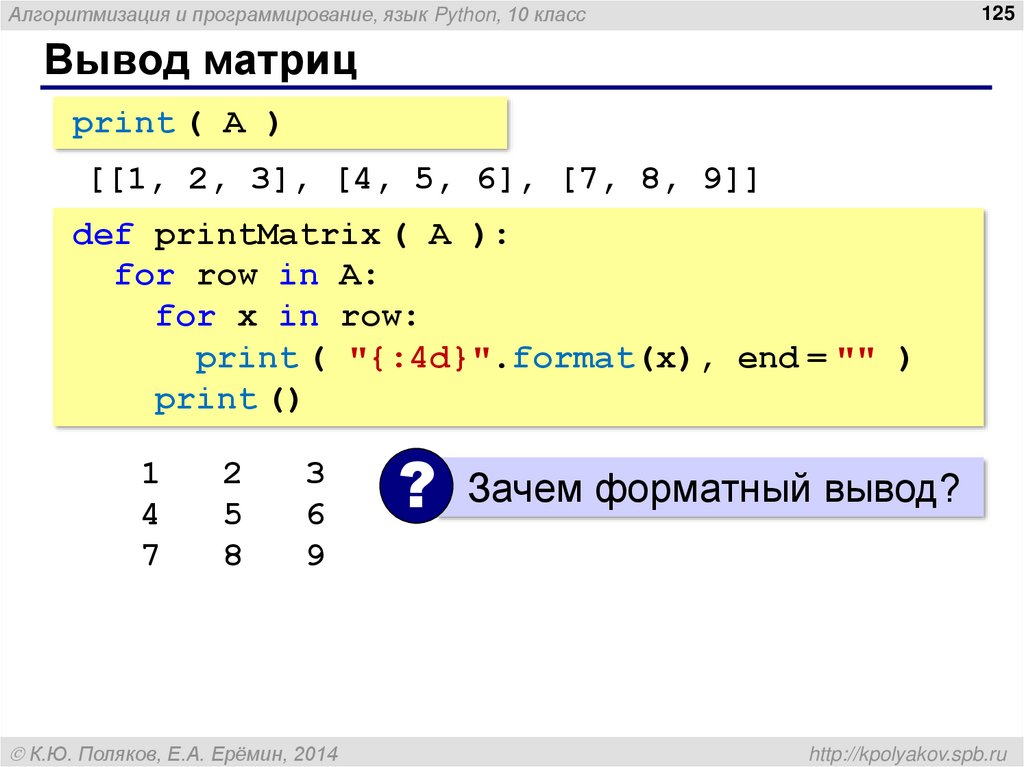
Также популярным методом для векторизации текста является метод TF-IDF, который является статистической мерой для оценки важности слова в документе.
В тексте большого объема некоторые слова могут присутствовать очень часто, но при этом не нести никакой значимой информации о фактическом содержании текста (документа). Если такие данные передавать непосредственно классификатору, то такие частые термины могут затенять частоты более редких, но при этом более интересных терминов. Для того, чтобы этого избежать, достаточно разделить количество употреблений каждого слова в документе на общее количество слов в документе, это есть TF — частота термина. Термин IDF (inverse document frequency) обозначает обратную частоту термина (инверсия частоты) с которой некоторое слово встречается в документах. IDF позволяет измерить непосредственную важность термина.
Тогда TF-IDF вычисляется следующим образом:
TF-IDF(term)=TF(term)*IDF(term)
В итоге код по работе с текстом выглядит следующим образом,
new_text = [] for i in data_depression.
 a-zA-Z]"," ",i)
# токенизируем слова
text = nltk.word_tokenize(text,language = "english")
# лемматирзируем слова
text = [lemmatize.lemmatize(word) for word in i]
# соединяем слова
text = "".join(text)
new_text.append(text)
a-zA-Z]"," ",i)
# токенизируем слова
text = nltk.word_tokenize(text,language = "english")
# лемматирзируем слова
text = [lemmatize.lemmatize(word) for word in i]
# соединяем слова
text = "".join(text)
new_text.append(text)В данной задаче текст будем преобразовывать в набор цифр с помощью модуля CountVectorizer для получения матрицы, содержащей 0 и 1.
# импортируем модуль from sklearn.feature_extraction.text import CountVectorizer count = CountVectorizer(stop_words="english") # проводим преобразование текста matrix = count.fit_transform(new_text).toarray()
Если мы ходим преобразовать текст, используя метод TF-IDF, тогда можно поступить следующим образом:
# импортируем модуль TfidfVectorizer from sklearn.feature_extraction.text import TfidfVectorizer tfidf_vectorizer = TfidfVectorizer(stop_words="english") #преобразуем текст values = tfidf_vectorizer.fit_transform(new_text)
После того, как обработка текста закончена, можно переходить непосредственно к применению алгоритмов машинного обучения.
Определим вектор с данными для обучения и вектор правильных ответов.
X=matrix y = data_depression["is_depression"].values Далее разделим выборку на тестовую и обучающую from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(X, y, test_size = 0.33, random_state = 42)
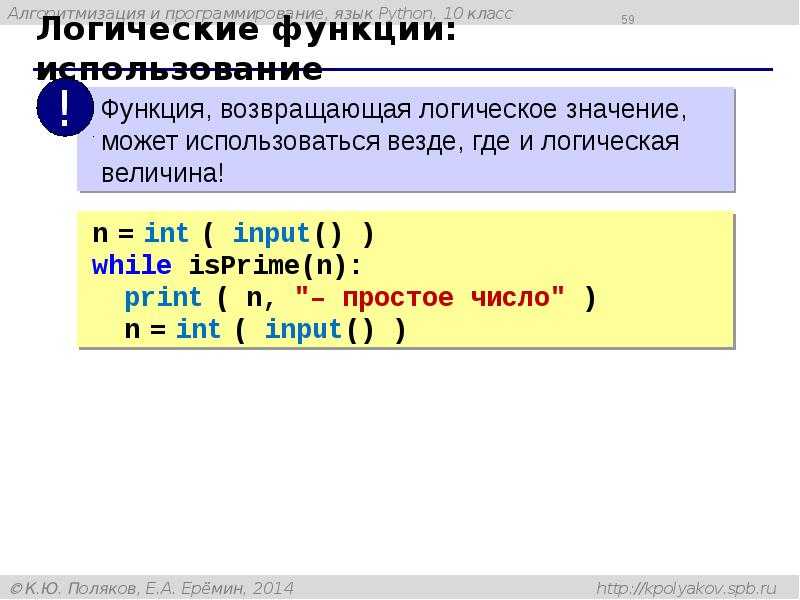
Рассмотрим самый известный алгоритм — наивный классификатор Байеса. Данный алгоритм является одним из самых простых алгоритмов классификации, но при этом часто может работать не хуже более сложных алгоритмов. Метрики качества работы алгоритмов будут приведено ниже. Пока буду приводить только точность алгоритмов.
from sklearn.naive_bayes import GaussianNB nb = GaussianNB() result_bayes = nb.fit(x_train, y_train) nb.score(x_test,y_test) 0.8436520376175548
Логистическая регрессия. Также является простейшим алгоритмом классификации. С помощью данного алгоритма можно разделить несложные объекты на 2 класса. Модель логистической регрессии быстро обучается и подходит для задач бинарной классификации.
Модель логистической регрессии быстро обучается и подходит для задач бинарной классификации.
from sklearn.linear_model import LogisticRegression logreg = LogisticRegression() result_logreg = logreg.fit(x_train, y_train) logreg.score(x_test,y_test) 0.9564655172413793
Метод опорных векторов. Данный метод также можно использовать для задач классификации, поскольку он категоризирует данные с помощью гиперплоскости.
from sklearn import svm metodsvm = svm.SVC() result_svm = metodsvm.fit(x_train, y_train) metodsvm.score(x_test, y_test) 0.9543103448275863
Теперь можно попробовать рассмотреть некоторые ансамблевые методы машинного обучения, такие как адаптивный бустинг и градиентный бустинг. Что мы знаем про ансамблевые методы? В ансамблевых методах несколько моделей обучаются для решения одной и той же проблемы и объединяются для получения более эффективных результатов. Основная идея заключается в том, что при правильном сочетании моделей можно получить более точную и надежную модель.
Считается, что алгоритм адаптивного бустинга лучше всего работает со слабыми обучающими алгоритмами и может достичь достаточно высокой точности при решении задач классификации. В AdaBoost базовые алгоритмы обучаются последовательно, учитывая опыт предыдущего. Так, каждый последующий алгоритм начинает придавать большее значение тем наблюдениям из тренировочного набора данных, на которых ошиблись предыдущие.
#адаптивный бустинг from sklearn.tree import DecisionTreeClassifier from sklearn.model_selection import train_test_split from sklearn.ensemble import AdaBoostClassifier modelClf = AdaBoostClassifier(base_estimator=DecisionTreeClassifier(max_depth=2), n_estimators=100, random_state=42) X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size = 0.33, random_state = 42) modelclf_fit = modelClf.fit(X_train, y_train) modelClf.score(X_valid, y_valid) 0.9361285266457681
Градиентный бустинг, также как и адаптивный, обучает слабые алгоритмы последовательно, исправляя ошибки предыдущих.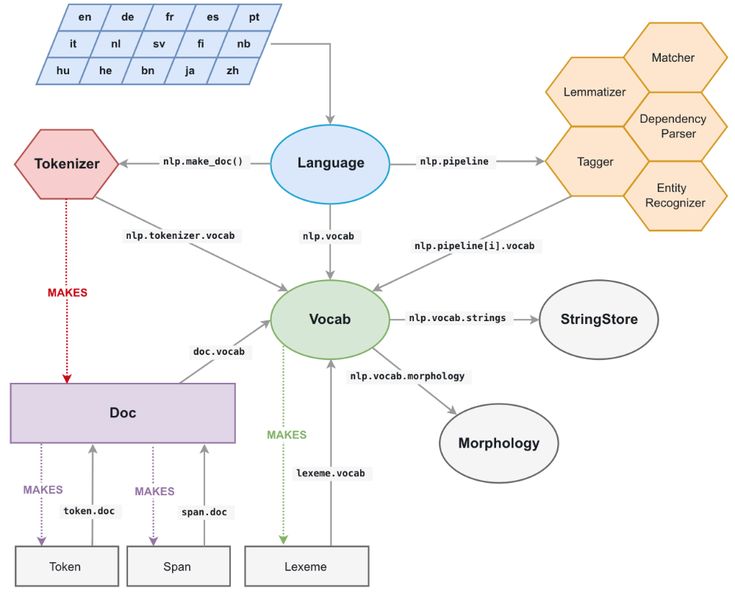 Принципиальное отличие этих алгоритмов заключается в способах изменения весов. Адаптивный бустинг использует итеративный метод оптимизации, в то время как градиентный оптимизирует веса с помощью градиентного спуска.
Принципиальное отличие этих алгоритмов заключается в способах изменения весов. Адаптивный бустинг использует итеративный метод оптимизации, в то время как градиентный оптимизирует веса с помощью градиентного спуска.
# градиентный бустинг from sklearn.model_selection import train_test_split # импортируем библиотеку from sklearn.ensemble import GradientBoostingClassifier modelClf = GradientBoostingClassifier(max_depth=2, n_estimators=150,random_state=12, learning_rate=1) X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.3, random_state=12) modelClf.fit(X_train, y_train) modelClf.score(X_valid, y_valid) 0.928448275862069
И напоследок хочется рассмотреть алгоритм работы простой нейронной сети (многослойный персептрон), в которой будет 2 полносвязнных слоя и 1 выходной с 1 выходом. Чтобы смоделировать нейронную сеть в python, нам понадобится фреймворк Keras, который является оболочкой над Tensorflow.
В Keras для построения моделей нейронных сетей (models) мы собираем слои (layers). Для описания стандартных архитектур нейронных сетей в Keras уже существуют предопределенные классы для слоев:
Dense() – полносвязный слой;
Conv1D, Conv2D, Conv3D – сверточные слои;
Conv2DTranspose, Conv3DTranspose – транспонированные (обратные) сверточные слои;
SimpleRNN, LSTM, GRU – рекуррентные слои;
MaxPooling2D, Dropout, BatchNormalization – вспомогательные слои
Обратим внимание, что в Keras слои автоматически конструируются таким образом, чтобы соответствовать форме входного слоя, поэтому нет необходимости беспокоиться о совместимости слоев, что очень удобно.
Типичный процесс использования Keras для построения нейронной сети можно описать так:
Определение обучающих данных: входные и целевые векторы
Определение слоев сети (модель), отображающих входные данные в целевые
Настройка процесса обучения выбором функции потерь, оптимизатора и некоторых параметров для мониторинга
Выполнение итераций по обучающим данным вызовом метода
fit()и модели.
Если мы хотим создать нейронную сеть с последовательными слоями, нам также понадобится класс Sequential.
Загружаем необходимые библиотеки:
from keras import models from keras import layers from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense
1. Получаем обучающую и тестовую выборку:
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size = 0.33, random_state = 42)
2. Сначала создаем пустую модель Sequential:
model = models.Sequential()
Теперь в пустую модель нейронной сети можно добавлять слои. Добавим 2 полносвязных слоя с 64 выходными нейронами и активационной функцией Relu (фактор нелинейности). Функция relu является самой популярной функцией в глубоком обучении, но, конечно, можно использовать и другие. Первому слою надо обязательно передать ожидаемую форму входных данных, т.е. размер входного вектора, это указывается в параметре input_shape.
model.add(layers.Dense(64,activation='relu',input_shape=(voc_len,))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(1, activation = 'sigmoid'))
Последний слой сети имеет сигмоидальную активационную функцию, так как наша задача является задачей бинарной классификации и на выходе сети мы хотим получить оценку вероятности между 0 и 1 того, что наш образец относится к классу “1”.
3. После того, как модель создана, необходимо настроить процесс ее обучения с помощью вызова метода compile
from keras import optimizers model.compile(optimizer='rmsprop',loss='binary_crossentropy',metrics=['accuracy'])
Объект optimizer определяет процедуру обучения, а именно оптимизатор алгоритма градиентного спуска. Доступны оптимизаторы SGD, RMSprop, Adam, Adadelta, Adagrad, Adamax, Nadam, Ftrl.
Объект loss — это функция, которая минимизируется в процессе обучения. Среди распространенных вариантов: среднеквадратичная ошибка (mse), categorical_crossentropy, binary_crossentropy.
Объект metrics используется для мониторинга обучения.
4. Для обучения модели необходимо вызвать метод fit(). Задаем тренировочные данные, количество эпох для обучения, валидационные данные для отслеживания производительности модели, что позволит отобразить значения функции потерь и метрики в режиме вывода для передаваемых данных в конце каждой эпохи. Зададим 20 эпох, чтобы потом можно было найти оптимальное количество эпох, которое необходимо для обучения.
history=model.fit(x_train, y_train, epochs=20,batch_size=512,validation_data=(x_test,y_test))
Вызов метода fit вернет нам объект history, с помощью которого можно получить данные обо всем происходящем в процессе обучения.
history_dict = history.history history_dict.keys() dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])
Теперь можно вывести графики потерь и точности на этапах обучения и проверки
# построение графика потери на этапах проверки и обучения loss_values = history_dict['loss'] val_loss_values = history_dict['val_loss'] epochs = range(1, len(history_dict['accuracy'])+1) # построение графика потери на этапах проверки и обучения loss_values = history_dict['loss'] val_loss_values = history_dict['val_loss'] epochs = range(1, len(history_dict['accuracy'])+1) plt.
 plot(epochs, loss_values, 'bo', label = 'Потери на этапе обучения')
plt.plot(epochs, val_loss_values, 'b', label = 'Потери на этапе проверки')
plt.title('Потери на этапах обучения и проверки')
plt.xlabel('Эпохи')
plt.ylabel('Потери')
plt.legend()
plt.show()
# построение графика точности на этапах обучения и проверки
acc_values = history_dict['accuracy']
val_acc_values = history_dict['val_accuracy']
plt.plot(epochs, acc_values, 'bo', label = 'Точность на этапе обучения')
plt.plot(epochs, val_acc_values, 'b', label = 'Точность на этапе проверки')
plt.title('Точность на этапах обучения и проверки')
plt.xlabel('Эпохи')
plt.ylabel('Точность')
plt.legend()
plt.show()
plot(epochs, loss_values, 'bo', label = 'Потери на этапе обучения')
plt.plot(epochs, val_loss_values, 'b', label = 'Потери на этапе проверки')
plt.title('Потери на этапах обучения и проверки')
plt.xlabel('Эпохи')
plt.ylabel('Потери')
plt.legend()
plt.show()
# построение графика точности на этапах обучения и проверки
acc_values = history_dict['accuracy']
val_acc_values = history_dict['val_accuracy']
plt.plot(epochs, acc_values, 'bo', label = 'Точность на этапе обучения')
plt.plot(epochs, val_acc_values, 'b', label = 'Точность на этапе проверки')
plt.title('Точность на этапах обучения и проверки')
plt.xlabel('Эпохи')
plt.ylabel('Точность')
plt.legend()
plt.show()Посмотрев на графики, можно увидеть, что на этапе обучения потери снижаются с каждой эпохой, а точность растет. Как раз такого поведения и можно ожидать от оптимизации градиентным спуском, та величина, которую мы минимизируем, должна становиться все меньше с каждой итерацией. Но это не относится к потерям и точности на этапе проверки, можно заметить, что здесь пик был достигнут где-то на 4-5 эпохе.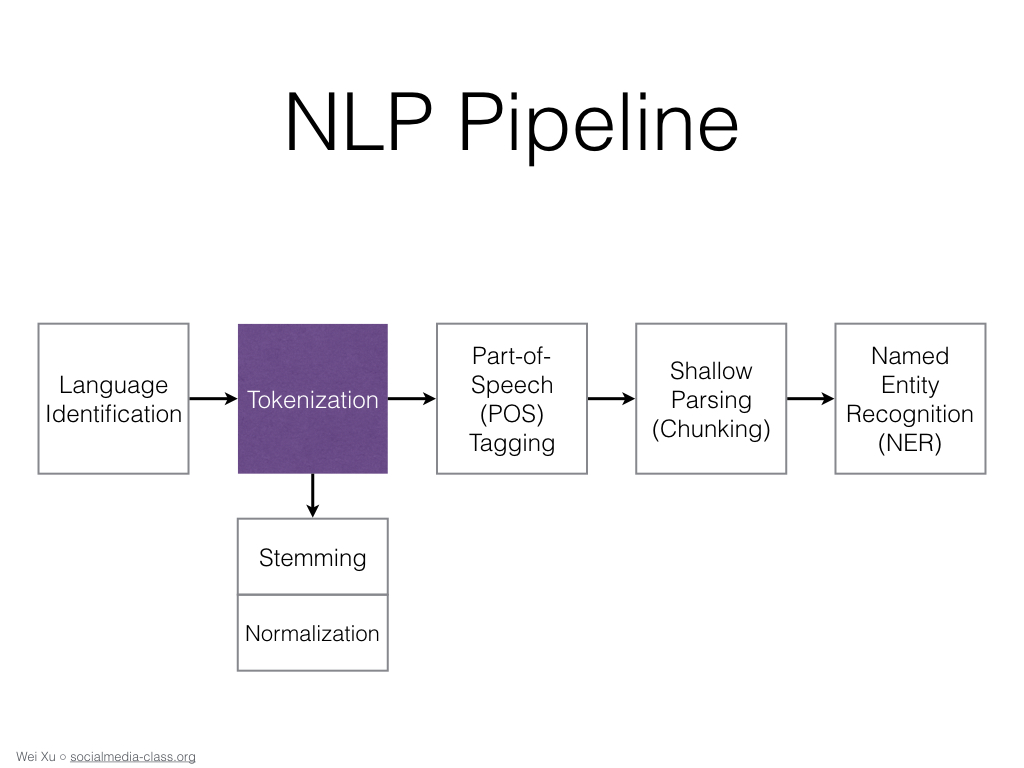 И, начиная с пятой эпохи, наблюдается переобучение, которое выражается в том, что функция потерь начинает расти. Такой картины стоило ожидать, так как модель, которая показывает хорошие результаты на обучающих данных, не обязательно будет показывать такие же хорошие результаты на данных, которых никогда не видела.
И, начиная с пятой эпохи, наблюдается переобучение, которое выражается в том, что функция потерь начинает расти. Такой картины стоило ожидать, так как модель, которая показывает хорошие результаты на обучающих данных, не обязательно будет показывать такие же хорошие результаты на данных, которых никогда не видела.
Благодаря такому графику можно оценить оптимальное количество эпох, которое необходимо для обучения сети. В данном случае для предотвращения переобучения нейронную сеть будем обучать на 5 эпохах. Таким образом, обучим сеть с нуля и рассчитаем метрики качества разработанной модели нейронной сети.
Y_pred=model.predict(x_test)
# задаем порог 0,5 для классификации текста
Y_pred=(Y_pred>=0.5).astype("int")
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
print(classification_report(y_test,Y_pred))
print(confusion_matrix(y_test,Y_pred))Результаты работы всех алгоритмов можно увидеть в таблице
Алгоритм | Accuracy | Precision | Recall | F1 |
Классификатор Байеса | 0. | 0.785 | 0.939 | 0.855 |
Логистическая регрессия | 0.956 | 0.987 | 0.924 | 0.954 |
Метод опорных векторов | 0.954 | 0.998 | 0.909 | 0.951 |
AdaBoost | 0.936 | 0.935 | 0.935 | 0.935 |
GradientBoost | 0.928 | 0.953 | 0.896 | 0.924 |
Многослойный персептрон | 0. | 0.968 | 0.937 | 0.951 |
 844
844 953
953Посмотрев на данную сравнительную таблицу, можно сказать, что классификатор Байеса, к сожалению, показал самые плохие результаты с точностью 0,84. У алгоритма адаптивного бустинга одинаковые показатели по всем метрикам, равные 0.94. Это связано с тем, что целью данного алгоритма является улучшение производительности алгоритмов. На мой взгляд, можно выделить 3 алгоритма, которые хорошо справились с задачей — это логистическая регрессия, метод опорных векторов и многослойный персептрон с точностью 0,95.
Приглашаем на открытое занятие «Пишем первую нейронную сеть». На нем рассмотрим основные этапы создания и обучения своей первой нейронной сети и попробуем решить известную задачу классификации MNIST полносвязной и сверточной нейронными сетями на примере фреймворка PyTorch. Регистрация — по ссылке.
Книга «Обработка естественного языка.
/thumb.jpg) Python и spaCy на практике» / Хабр
Python и spaCy на практике» / ХабрПривет, Хаброжители! Python и spaCy помогут вам быстро и легко создавать NLP-приложения: чат-боты, сценарии для сокращения текста или инструменты принятия заказов. Вы научитесь использовать spaCy для интеллектуального анализа текста, определять синтаксические связи между словами, идентифицировать части речи, а также определять категории для имен собственных. Ваши приложения даже смогут поддерживать беседу, создавая собственные вопросы на основе разговора.
Вы научитесь:
- Работать с векторами слов, чтобы находить синонимы (глава 5).
- Выявлять закономерности в данных с помощью displaCy — встроенного средства визуализации библиотеки spaCy (глава 7).
- Автоматически извлекать ключевые слова из пользовательского ввода и сохранять их в реляционной базе данных (глава 9).
- Развертывать приложения на примере чат-бота для взаимодействия с пользователями (глава 11).
Прочитав эту книгу, вы можете сами расширить приведенные в ней сценарии, чтобы обрабатывать разнообразные варианты ввода и создавать приложения профессионального уровня.
Как вы узнали из раздела «Выделение и генерация текста с помощью тегов частей речи» на с. 81, теги частей речи — весьма мощный инструмент для интеллектуальной обработки текста. Но на практике для этого может понадобиться больше информации о токенах предложения.
Например, часто необходимо знать, чем является личное местоимение в предложении: подлежащим или дополнением. Иногда это несложно определить. Личные местоимения I, he, she, they и we практически всегда выступают в роли подлежащего. При использовании в качестве дополнения I превращается в me, как в предложении A postman brought me a letter.
Но с некоторыми другими личными местоимениями, например you или it, которые выглядят одинаково и в роли подлежащего и в роли дополнения, не всегда все очевидно. Рассмотрим два предложения: I know you. You know me. В первом предложении you является прямым дополнением глагола know. Во втором же you является подлежащим.
Попробуем решить эту задачу с помощью меток синтаксических зависимостей и тегов частей речи, после чего, опять же с помощью меток синтаксических зависимостей, создадим усовершенствованную версию нашего чат-бота, отвечающего на вопросы.
Различаем подлежащие и дополнения
Чтобы определить программным образом, чем в заданном предложении являются такие местоимения, как you или it, необходимо посмотреть на присвоенную им метку зависимости. Теги частей речи в сочетании с метками зависимостей позволяют получить гораздо больше информации о роли токена в предложении.
Вернемся к предложению из предыдущего примера и взглянем на результаты разбора зависимостей в нем:
>>> doc = nlp(u"I can promise it is worth your time.") >>> for token in doc: ... print(token.text, token.pos_, token.tag_, token.dep_, spacy.explain(token.dep_))
Для токенов предложения были извлечены теги частей речи, метки зависимостей и их описание:
I PRON PRP nsubj nominal subject can VERB MD aux auxiliary promise VERB VB ROOT None it PRON PRP nsubj nominal subject is VERB VBZ ccomp clausal complement worth ADJ JJ acomp adjectival complement your ADJ PRP$ poss possession modifier time NOUN NN npadvmod noun phrase as adverbial modifier .
 PUNCT . punct punctuation
PUNCT . punct punctuationВторой и третий столбцы содержат теги общих и уточненных частей речи соответственно. Четвертый столбец содержит метки зависимостей, а пятый — описания этих меток.
Сочетание тегов частей речи с метками зависимостей демонстрирует более ясную, чем теги частей речи или метки зависимости по отдельности, картину грамматической роли каждого из токенов в предложении. В данном примере тег части речи VBZ, присвоенный токену is, означает глагол третьего лица единственного числа настоящего времени, в то время как присвоенная тому же токену метка зависимости ccomp указывает, что is — это клаузальное дополнение (зависимое придаточное предложение с внутренним подлежащим). Здесь is представляет собой клаузальное дополнение глагола promise с внутренним подлежащим it.
Чтобы определить роль you в I know you. You know me, взглянем на следующий список тегов частей речи и меток зависимостей, присвоенных токенам:
I PRON PRP nsubj nominal subject know VERB VBP ROOT None you PRON PRP dobj direct object .
 PUNCT . punct punctuation
You PRON PRP nsubj nominal subject
know VERB VBP ROOT None
me PRON PRP dobj direct object
. PUNCT . Punct punctuation
PUNCT . punct punctuation
You PRON PRP nsubj nominal subject
know VERB VBP ROOT None
me PRON PRP dobj direct object
. PUNCT . Punct punctuationВ обоих случаях токену you присвоены одни и те же теги частей речи: PRON и PRP (общий и уточненный соответственно). Но метки зависимости в этих двух случаях различны: dobj в первом предложении и nsubj — во втором.
Выясняем, какой вопрос должен задать чат-бот
Иногда для извлечения необходимой информации приходится обходить дерево зависимостей предложения. Рассмотрим следующий диалог между чат-ботом и пользователем:
User: I want an apple. Bot: Do you want a red apple? User: I want a green apple. Bot: Why do you want a green one?
Чат-бот способен продолжать разговор, просто задавая вопросы. Но обратите внимание, что в выяснении того, какой вопрос ему следует задать, ключевую роль играет наличие/отсутствие прилагательного-модификатора.
В английском языке существует два основных типа вопросов: вопросы типа «да/нет» и информационные вопросы. Возможных ответов на вопросы типа «да/нет» (наподобие сгенерированного в примере из подраздела «Преобразование утвердительных высказываний в вопросительные» на с. 85) может быть только два: да или нет. Чтобы сформулировать подобный вопрос, необходимо поставить вспомогательный модальный глагол перед подлежащим, а смысловой глагол — после подлежащего. Например: Could you modify it?
Информационные вопросы предполагают развернутый ответ, а не только да/нет. Они начинаются с вопросительного слова, например с what, where, when, why или how. Далее процесс формирования информационного вопроса не отличается от процесса с вопросом типа «да/нет». Например: What do you think about it?
В первом случае в предыдущем примере с apple чат-бот задает вопрос типа «да/нет». Во втором случае, когда пользователь добавляет к слову apple модификатор green, чат-бот формулирует информационный вопрос.
Краткая сводка этого подхода приведена на рис. 4.1.
Следующий сценарий анализирует введенное предложение, выбирая, какой вид вопроса задать, после чего формирует соответствующий вопрос. Код этого сценария мы рассмотрим по частям в различных разделах, но программу целиком я рекомендую сохранить в одном файле с названием question.py.
Начнем с импорта модуля sys, который позволяет получить предложение в виде аргумента для дальнейшей обработки:
import spacy import sys
Это шаг вперед по сравнению с предыдущими сценариями, в которых мы жестко «зашивали» анализируемое предложение. Теперь пользователи могут подавать на вход собственные предложения.
Далее опишем функцию для распознавания и извлечения произвольного именного фрагмента — прямого дополнения из входного документа. Например, если вы ввели документ, содержащий предложение I want a green apple., то будет возвращен фрагмент a green apple:
Проходим в цикле по токенам введенного предложения 1 и, проверяя теги зависимостей на равенство dobj 2, ищем такой токен, который выступал бы в роли прямого дополнения. В предложении I want a green apple. прямым дополнением является существительное apple. После обнаружения прямого дополнения необходимо определить элементы, являющиеся для него синтаксически дочерними 3, поскольку именно из них состоит фрагмент, на основе которого будет определяться тип задаваемого вопроса. В целях отладки полезно вывести на экран дочерние элементы этого прямого дополнения 4.
В предложении I want a green apple. прямым дополнением является существительное apple. После обнаружения прямого дополнения необходимо определить элементы, являющиеся для него синтаксически дочерними 3, поскольку именно из них состоит фрагмент, на основе которого будет определяться тип задаваемого вопроса. В целях отладки полезно вывести на экран дочерние элементы этого прямого дополнения 4.
Для выделения нужного фрагмента производим срез объекта Doc, вычисляя начальный и конечный индексы. Начальный индекс равен индексу найденного прямого дополнения минус число его синтаксических дочерних элементов: как вы, возможно, догадались, он представляет собой индекс крайнего слева дочернего элемента. Конечный индекс равен индексу прямого дополнения плюс один, так что последним включаемым в искомый фрагмент токеном и является это прямое дополнение 5.
Проще говоря, реализованный в сценарии алгоритм предполагает, что у прямого дополнения есть только левосторонние дочерние элементы. В действительности это не всегда так. Например, в предложении I want to touch a wall painted green. необходимо проверять и левосторонние, и правосторонние дочерние элементы прямого дополнения wall. Кроме того, поскольку green не является прямым дочерним элементом wall, необходимо обойти дерево зависимостей, чтобы определить, является ли green модификатором wall.
В действительности это не всегда так. Например, в предложении I want to touch a wall painted green. необходимо проверять и левосторонние, и правосторонние дочерние элементы прямого дополнения wall. Кроме того, поскольку green не является прямым дочерним элементом wall, необходимо обойти дерево зависимостей, чтобы определить, является ли green модификатором wall.
Следующая функция просматривает фрагмент и определяет, какой тип вопроса должен задать чат-бот:
Сначала задаем начальное значение переменной question_type равным ‘yesno’, что соответствует вопросу типа «да/нет» 1. Далее в переданном в функцию chunk ищем токен с тегом amod, который означает прилагательное-модификатор 2. Если таковое находится, меняем значение переменной question_type на ‘info’, соответствующее информационному типу вопроса 3.
Определив, какой тип вопроса нам нужен, генерируем в следующей функции вопрос на основе входного предложения:
В серии циклов for превращаем входное утверждение в вопрос, производя инверсию и замену личных местоимений. Для формирования вопроса перед личным местоимением добавляем глагол do, поскольку в утверждении отсутствует вспомогательный модальный глагол. (Напомню, что такой алгоритм годится лишь для определенных предложений; в более полной реализации необходимо программным образом определять, какой подход к обработке использовать.)
Для формирования вопроса перед личным местоимением добавляем глагол do, поскольку в утверждении отсутствует вспомогательный модальный глагол. (Напомню, что такой алгоритм годится лишь для определенных предложений; в более полной реализации необходимо программным образом определять, какой подход к обработке использовать.)
Если значение переменной question_type равно ‘info’, добавляем слово why в начало вопроса 1. Если значение переменной question_type равно ‘yesno’ 2, вставляем прилагательное для модификации прямого дополнения в вопросе. В данном примере ради простоты мы жестко «зашили» прилагательное в код, выбрав для этого прилагательное red 3, которое в некоторых предложениях будет выглядеть странно. Например, можно сказать Do you want a red orange?, но никак не Do you want a red idea?. В более совершенной реализации такого чат-бота необходимо определить программным образом подходящее прилагательное для модификации прямого дополнения. Этот вопрос будет рассмотрен в главе 6.
Обратите внимание: используемый алгоритм предполагает, что входное предложение оканчивается знаком препинания, например. или!..
После описания всех функций посмотрим на основной блок сценария:
Прежде всего проверяем, передал ли пользователь предложение в виде аргумента командной строки 1. Если да, то применяем к аргументу конвейер spaCy, создавая экземпляр объекта Doc 2.
Далее передаем этот doc в функцию find_chunk, которая должна вернуть содержащий прямое дополнение именной фрагмент, например a green apple, для дальнейшей обработки 3. Если же во входном предложении такого именного фрагмента нет 4, мы получим сообщение The sentence does not contain a direct object.
Затем передаем только что выделенный фрагмент в функцию determine_question_type, которая, проанализировав его структуру, определяет, какой вопрос задать 5.
Наконец, передаем входное предложение и определенный нами тип вопроса в функцию generate_question, генерирующую соответствующий вопрос и возвращающую его в виде строки 6.
Выводимый сценарием результат зависит от введенного предложения. Вот несколько возможных вариантов:
Если в качестве аргумента командной строки передать предложение, содержащее прилагательное-модификатор (например, green для прямого дополнения наподобие apple), сценарий должен сгенерировать информационный вопрос 1.
Если предложение содержит прямое дополнение без прилагательного-модификатора, сценарий должен ответить вопросом типа «да/нет» 2.
Если же ввести предложение без прямого дополнения, сценарий должен сразу это заметить и предложить повторный ввод 3.
Наконец, если вы забыли передать предложение, сценарий также должен вернуть соответствующее сообщение 4.
Попробуйте самиКак отмечалось ранее, сценарий, о котором шла речь в предыдущем разделе, годится не для всех предложений. Для формирования вопроса он добавляет глагол do, что подходит только для предложений без вспомогательного модального глагола.
Попробуйте расширить функциональность этого сценария для работы с утверждениями, содержащими вспомогательные модальные глаголы. Например, получив на входе утверждение I might want a green apple., сценарий должен вернуть Why might you want a green one?. Подробнее о том, как преобразовать в вопрос утвердительное высказывание, содержащее вспомогательный модальный глагол, вы прочитали в разделе «Преобразование утвердительных высказываний в вопросительные» на с. 85.
Более подробно с книгой можно ознакомиться на сайте издательства
» Оглавление
» Отрывок
Для Хаброжителей скидка 25% по купону — spaCy
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.
NLTK :: Инструментарий естественного языка
NLTK — это ведущая платформа для создания программ Python для работы с данными человеческого языка.
Он предоставляет простые в использовании интерфейсы для более чем 50 корпусов и лексических
ресурсы, такие как WordNet,
наряду с набором библиотек обработки текста для классификации, токенизации, выделения корней, тегов, синтаксического анализа и семантических рассуждений,
оболочки для промышленных библиотек NLP,
и активный дискуссионный форум.
Благодаря практическому руководству, знакомящему с основами программирования наряду с темами компьютерной лингвистики, а также исчерпывающей документации по API, NLTK одинаково подходит для лингвистов, инженеров, студентов, преподавателей, исследователей и отраслевых пользователей. NLTK доступен для Windows, Mac OS X и Linux. Лучше всего то, что NLTK — это бесплатный проект с открытым исходным кодом, управляемый сообществом.
NLTK был назван «прекрасным инструментом для обучения и работы в области компьютерной лингвистики с использованием Python». и «потрясающая библиотека для игры с естественным языком».
Обработка естественного языка с помощью Python обеспечивает практическое
введение в программирование для обработки языка.
Написанный создателями NLTK, он знакомит читателя с основами
написания программ на Python, работы с корпусами, категоризации текста, анализа лингвистической структуры,
и более.
Электронная версия книги была обновлена для Python 3 и NLTK 3. (Исходная версия Python 2 все еще доступна по адресу https://www.nltk.org/book_1ed.)
(Исходная версия Python 2 все еще доступна по адресу https://www.nltk.org/book_1ed.)
Несколько простых вещей, которые можно делать с помощью NLTK
Маркировать и пометить текст:
>>> импорт нлтк
>>> предложение = """В восемь часов утра в четверг
... Артур чувствовал себя не очень хорошо."""
>>> токены = nltk.word_tokenize(предложение)
>>> токены
['В', 'восемь', "часы", 'на', 'четверг', 'утро',
«Артур», «сделал», «нет», «чувствую», «очень», «хорошо», «.»]
>>> tagged = nltk.pos_tag(токены)
>>> помечено[0:6]
[('В', 'В'), ('восемь', 'CD'), ("часы", 'JJ'), ('вкл', 'В'),
(«Четверг», «NNP»), («Утро», «NN»)]
Идентифицировать именованные объекты:
>>> сущности = nltk.chunk.ne_chunk(с тегами)
>>> сущности
Дерево('S', [('В', 'В'), ('восемь', 'CD'), ("часы", 'JJ'),
(«в», «в»), («четверг», «NNP»), («утро», «NN»),
Дерево('ЧЕЛОВЕК', [('Артур', 'NNP')]),
(«делал», «ВБД»), («нет», «РБ»), («чувствовал», «ВБ»),
('очень', 'RB'), ('хорошо', 'JJ'), ('. ', '.')])
 ', '.')])
', '.')])
Показать дерево синтаксического анализа:
>>> из банка дерева импорта nltk.corpus
>>> t = treebank.parsed_sents('wsj_0001.mrg')[0]
>>> t.draw()
НБ. Если вы публикуете работу, в которой используется NLTK, цитируйте книгу NLTK как следует:
Берд, Стивен, Эдвард Лопер и Эван Кляйн (2009), Обработка естественного языка с помощью Python . О’Рейли Медиа Инк.
Следующие шаги
Подпишитесь на анонсы выпусков
Присоединяйтесь к обсуждению
spaCy · Промышленная обработка естественного языка в Python
Добивайтесь цели
spaCy разработан, чтобы помочь вам выполнять настоящую работу — создавать настоящие продукты или собирать реальные идеи. Библиотека уважает ваше время и старается не тратить его попусту. Его легко установить, а его API простой и продуктивный.
Начало работыНевероятная скорость
spaCy отлично справляется с крупномасштабными задачами извлечения информации. Он написан с нуля на Cython с тщательно управляемой памятью. Если вашему приложению необходимо обрабатывать целые веб-дампы, spaCy — это библиотека, которую вы хотите использовать.
Он написан с нуля на Cython с тщательно управляемой памятью. Если вашему приложению необходимо обрабатывать целые веб-дампы, spaCy — это библиотека, которую вы хотите использовать.
Удивительная экосистема
С момента своего выпуска в 2015 году spaCy стал отраслевым стандартом с огромной экосистемой. Выбирайте из множества подключаемых модулей, интегрируйте их со своим стеком машинного обучения и создавайте собственные компоненты и рабочие процессы.
ПодробнееОтредактируйте код и попробуйте spaCyspaCy v3.5 · Python 3 · через Binder
Особенности
- Поддержка 72+ языков0038
- Multi-task learning with pretrained transformers like BERT
- Pretrained word vectors
- State-of-the-art speed
- Production-ready training system
- Linguistically-motivated tokenization
- Components для именованных объектов распознавание, тегирование частей речи, анализ зависимостей, сегментация предложений, классификация текста , лемматизация, морфологический анализ, связывание объектов и многое другое
- Легко расширяется с пользовательскими компонентами и атрибутами
- Поддержка для пользовательских моделей в Pytorch , Tensorflow и других Frameworks
- встроенных в 6666666666666669 гг.
управление- Надежная, тщательно проверенная точность
 управление
управлениеВоспроизводимое обучение для пользовательских конвейеров
В spaCy v3.0 представлена всеобъемлющая и расширяемая система для настройка тренировочных прогонов . Ваш файл конфигурации будет описывать каждую деталь вашего тренировочного прогона без скрытых значений по умолчанию, что позволит легко повторно запускать эксперименты и отслеживать изменения. Вы можете использовать виджет быстрого запуска или команду init config , чтобы начать работу, или клонировать шаблон проекта для сквозного рабочего процесса.
Get started
Language
AfrikaansAlbanianAmharicAncient GreekArabicArmenianAzerbaijaniBasqueBengaliBulgarianCatalanChineseCroatianCzechDanishDutchEnglishEstonianFinnishFrenchGermanGreekGujaratiHebrewHindiHungarianIcelandicIndonesianIrishItalianJapaneseKannadaKoreanKyrgyzLatinLatvianLigurianLithuanianLower SorbianLugandaLuxembourgishMacedonianMalayalamMarathiMulti-languageNepaliNorwegian BokmålPersianPolishPortugueseRomanianRussianSanskritSerbianSetswanaSinhalaSlovakSlovenianSpanishSwedishTagalogTamilTatarTeluguThaiTigrinyaTurkishUkrainianUpper SorbianUrduVietnameseYoruba
Компоненты
taggermorphologizertrainable_lemmatizerparsernerspancattextcat
Аппаратное обеспечение
CPUGPU (преобразователь)
Оптимизация для
efficiencyaccuracy
# Это частичная конфигурация.
 Чтобы использовать его с «пространственным поездом»
# вы можете запустить spacy init fill-config для автоматического заполнения всех настроек по умолчанию:
# python -m spacy init fill-config ./base_config.cfg ./config.cfg
[пути]
поезд = ноль
Разработчик = ноль
векторы = ноль
[система]
gpu_allocator = ноль
[нлп]
язык = "en"
трубопровод = []
размер партии = 1000
[компоненты]
[корпуса]
[corpora.train]
@readers = "spacy.Corpus.v1"
путь = ${paths.train}
максимальная_длина = 0
[corpora.dev]
@readers = "spacy.Corpus.v1"
путь = ${paths.dev}
максимальная_длина = 0
[обучение]
dev_corpus = "corpora.dev"
train_corpus = "corpora.train"
[обучение.оптимизатор]
@optimizers = "Адам.v1"
[обучение.дозатор]
@batchers = "spacy.batch_by_words.v1"
discard_oversize = ложь
допуск = 0,2
[обучение.batcher.size]
@schedules = "состав.v1"
начало = 100
стоп = 1000
соединение = 1,001
[инициализировать]
векторы = ${paths.vectors}
Чтобы использовать его с «пространственным поездом»
# вы можете запустить spacy init fill-config для автоматического заполнения всех настроек по умолчанию:
# python -m spacy init fill-config ./base_config.cfg ./config.cfg
[пути]
поезд = ноль
Разработчик = ноль
векторы = ноль
[система]
gpu_allocator = ноль
[нлп]
язык = "en"
трубопровод = []
размер партии = 1000
[компоненты]
[корпуса]
[corpora.train]
@readers = "spacy.Corpus.v1"
путь = ${paths.train}
максимальная_длина = 0
[corpora.dev]
@readers = "spacy.Corpus.v1"
путь = ${paths.dev}
максимальная_длина = 0
[обучение]
dev_corpus = "corpora.dev"
train_corpus = "corpora.train"
[обучение.оптимизатор]
@optimizers = "Адам.v1"
[обучение.дозатор]
@batchers = "spacy.batch_by_words.v1"
discard_oversize = ложь
допуск = 0,2
[обучение.batcher.size]
@schedules = "состав.v1"
начало = 100
стоп = 1000
соединение = 1,001
[инициализировать]
векторы = ${paths.vectors} Сквозные рабочие процессы от прототипа до производства
Новая система проектов spaCy обеспечивает плавный путь от прототипа до производства. Он позволяет отслеживать все эти преобразований данных , предварительную обработку и этапов обучения , поэтому вы можете быть уверены, что ваш проект всегда готов к передаче для автоматизации. Он включает загрузку исходных ресурсов, выполнение команд, проверку контрольной суммы и кэширование с различными бэкэндами и интеграциями.
Он позволяет отслеживать все эти преобразований данных , предварительную обработку и этапов обучения , поэтому вы можете быть уверены, что ваш проект всегда готов к передаче для автоматизации. Он включает загрузку исходных ресурсов, выполнение команд, проверку контрольной суммы и кэширование с различными бэкэндами и интеграциями.
Попробуйте
Benchmarks
В spaCy v3.0 представлены конвейеры на основе трансформаторов, которые доводят точность spaCy до уровня современного современного . Вы также можете использовать конвейер, оптимизированный для ЦП, который менее точен, но гораздо дешевле в эксплуатации.
More results
| Pipeline | Parser | Tagger | NER |
|---|---|---|---|
en_core_web_trf (spaCy v3) | 95.1 | 97. 8 8 | 89.8 |
en_core_web_lg (spaCy v3) | 92.0 | 97.4 | 85.5 |
en_core_web_lg (spaCy v2) | 91.9 | 97.2 | 85.5 |
Полная конвейерная точность на Корпус OntoNotes 5.0 (сообщено набор для разработки).
| Система распознавания именованных объектов | OntoNotes | CoNLL ‘03 |
|---|---|---|
| spaCy RoBERTa (2020) | 89.8 | 91.6 |
| Stanza (StanfordNLP) 1 | 88.8 | 92.1 |
| Flair 2 | 89.7 | 93.1 |
Точность распознавания именованного объекта на
OntoNotes 5.