26.2. Описание таблиц SQL базы данных телеметрии
Структура создаваемой базы данных и наименования таблиц показаны на Рис. Ж.5. Имя базы данных, создаваемой по умолчанию – «TagsDb». Далее в документе приведено краткое описаниетаблиц БД.
Рис. Ж.5 Структура базы данных экспорта телеметрии
Aggr001, Aggr002, …,AggrNNN– таблицы агрегированных данных. Номер в названии таблицы соответствует идентификатору настроенного ранее интервала агрегации. Описание столбцов приведено в Табл. Ж.1.
Табл. Ж.1 Описание столбцов таблиц AggrNNN
Имя столбца | Описание |
Border1 | Дата и время границы интервала |
Ch | Канал параметра на сервере |
RTU | КП параметра на сервере |
Point | Объект параметра на сервере |
ValueMin | Минимальное значение параметра в заданном интервале |
ValueMax | Максимальное значение параметра в заданном интервале |
ValueAvg | Среднее значение параметра в заданном интервале |
AggrDef – таблица с определениями интервалов агрегации.
Табл. Ж.2 Описание столбцов таблиц AggrDef
Имя столбца | Описание |
Id | Уникальный идентификатор интервала, который ставится в соответствие с названием таблицы интервала AggrNNN |
SpanUnit | Единица измерения интервала (sec, min, hour и т.п.) |
SpanValue | Значение интервала |
LoadedBorder1 | Служебное поле, хранящее начальную метку времени интервала (заполняется автоматически) |
LoadedBorder2 | Служебное поле, хранящее конечную метку времени интервала (заполняется автоматически) |
Settings – служебная таблица дополнительных настроек комплекса, не рекомендуется к модификации.
TagCatalor – таблица с каталогом ретранслируемых параметров, заполняется автоматически при «Портировании номенклатуры параметров в БД» в приложении администрирования комплекса (см. раздел 28.1). Описание столбцов приведено в Табл. Ж.3.
Табл. Ж.3 Описание столбцов таблиц TagCatalogИмя столбца | Описание |
TagType | Номер типа параметра. Номера типов перечисляются в таблице TagType, описанной ниже |
Ch | Канал параметра на сервере |
RTU | КП параметра на сервере |
Point | Объект параметра на сервере |
TagName | Наименование параметра на сервере |
TagsTi – таблица, хранящая данные всех принимаемых измерений.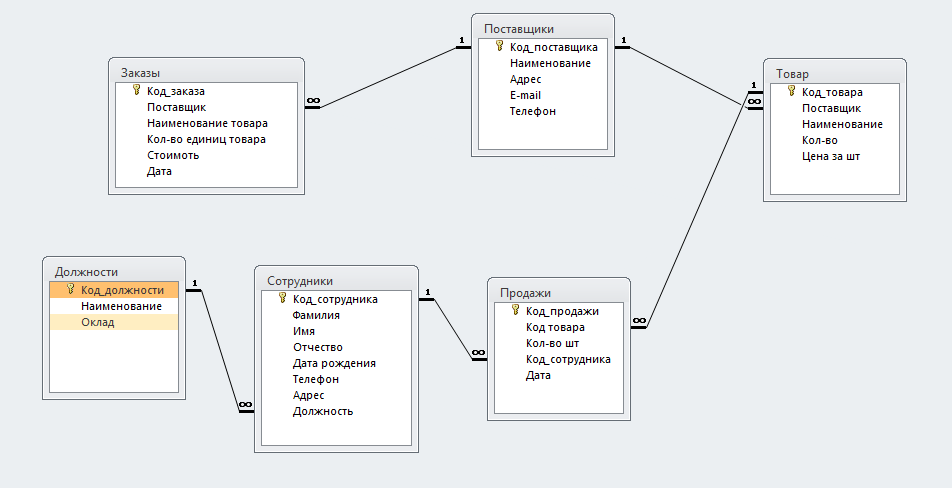
Табл. Ж.4 Описание столбцов таблиц TagsTi
Имя столбца | Описание |
Dt | Дата и время измерения, принятые от оборудования. По умолчанию тип столбца – datetime, обеспечивающий точность времени до 3,33 мс. В случае, когда требуется более высокая точность, следует вручную изменить тип на datetime2. |
FixDt | Дата и время фиксации измерения на сервере. По умолчанию тип столбца – datetime, обеспечивающий точность времени до 3,33 мс. В случае, когда требуется более высокая точность, следует вручную изменить тип на datetime2. Если информация данного столбца не является полезной, для экономии места на диске его можно удалить. |
Ch | Канал измерения на сервере |
RTU | КП измерения на сервере |
Point | Объект измерения на сервере |
Value | Значение измерения |
Flags | Первые 16 бит флагов измерения на сервере. |
FlagsHi | Последние 16 бит флагов измерения на сервере. Если информация данного столбца не является полезной, для экономии места на диске его можно удалить. |
trid | Служебный идентификатор |
 Если информация данного столбца не является полезной, для экономии места на диске его можно удалить.
Если информация данного столбца не является полезной, для экономии места на диске его можно удалить.TagsTs – таблица, хранящая данные всех принимаемых сигналов. Описание столбцов приведено в Табл. Ж.5.
Табл. Ж.5 Описание столбцов таблиц TagsTsИмя столбца | Описание |
Dt | Дата и время сигнала, принятые от оборудования. По умолчанию тип столбца – datetime, обеспечивающий точность времени до 3,33 мс. |
FixDt | Дата и время фиксации сигнала на сервере. По умолчанию тип столбца – datetime, обеспечивающий точность времени до 3,33 мс. В случае, когда требуется более высокая точность, следует вручную изменить тип на datetime2.Если информация данного столбца не является полезной, для экономии места на диске его можно удалить. |
Ch | Канал сигнала на сервере |
RTU | КП сигнала на сервере |
Point | Объект сигнала на сервере |
Value | Состояние сигнала |
Flags | Первые 16 бит флагов сигнала на сервере. |
FlagsHi | Последние 16 бит флагов сигнала на сервере. Если информация данного столбца не является полезной, для экономии места на диске его можно удалить. |
S2 | Флаги состояния двухпозиционного сигнала на сервере. Если информация данного столбца не является полезной, для экономии места на диске его можно удалить. |
trid | Служебный идентификатор |
 В случае, когда требуется более высокая точность, следует вручную изменить тип на datetime2.
В случае, когда требуется более высокая точность, следует вручную изменить тип на datetime2. Если информация данного столбца не является полезной, для экономии места на диске его можно удалить.
Если информация данного столбца не является полезной, для экономии места на диске его можно удалить.TagType – служебная таблица типов параметров. Заполняется автоматически при создании и не рекомендуется к модификации.
Структура базы данных WooCommerce
WooCommerce / 1 комментарий
В этом уроке покажу вам, что и где находится в базе данных WooCommerce, расскажу про назначение каждой из таблиц.
Также рекомендую вам свой видеокурс по WooCommerce, в котором мы создаём тему для интернет-магазина с нуля на основе готовой HTML вёрстки, вот ссылка.
Все названия таблиц базы данных указаны без префикса, по умолчанию это префикс wp_, то есть таблица например будет называться не actionscheduler_actions, а wp_actionscheduler_actions. Но префикс на вашем сайте может быть и другой (о том, как изменить его).
| Название таблицы | Описание |
|---|---|
actionscheduler_actions | Хранит информацию об экшенах, которые будут выполнены планировщиком Action Scheduler (что-то типо WP_Cron, но не совсем) |
actionscheduler_claims | |
actionscheduler_groups | |
actionscheduler_logs | Логи выполнения событий планировщика Action Scheduler |
woocommerce_sessions | Хранит сессии пользователей, например корзины |
woocommerce_api_keys | Ключи подключения по REST API |
woocommerce_attribute_taxonomies | Атрибуты товаров |
woocommerce_downloadable_product_permissions | Доступы загрузки скачиваемых товаров. |
woocommerce_order_items | Хранит позиции заказов. |
woocommerce_order_itemmeta | Метаданные позиций заказов. |
woocommerce_tax_rates | Налоговые ставки, указанные в админке. |
woocommerce_tax_rate_locations | Почтовые индексы и города, ассоциированные с вышеупомянутыми налоговыми ставками. |
woocommerce_shipping_zones | Зоны доставки, созданные в админке. |
woocommerce_shipping_zone_locations | Локации, ассоциированные с зонами доставки. |
woocommerce_shipping_zone_methods | Способы доставки, ассоциированные с зонами доставки. |
woocommerce_payment_tokens | Платёжные токены пользователей (используются методами оплаты, например при сохранении данных карт) |
woocommerce_payment_tokenmeta | Метаданные платёжных токенов. |
woocommerce_log | Логи. |
wc_webhooks | Вебхуки «Ловушки», которые создаются в Настройки > Дополнительно. |
wc_download_log | Логи загрузок скачиваемых товаров. |
wc_product_meta_lookup | Индекс для ускорения запросов. |
wc_tax_rate_classes | Данные о классах налогов. |
wc_reserved_stock | Хранит зарезервированное количество товара в наличии, чтобы предотвратить «состояние гонки» при оформлении заказа (предположим, что у нас всего одна единица товара в наличии и этот товар одновременно покупают два пользоваетеля). |
Как хранятся заказы в базе данных?
woocommerce_order_items– позиции заказов,woocommerce_order_itemmeta– метаданные позиций заказов,comments– заметки к заказам (да, это комментарии),posts– заказы же это тип записиshop_order,postmeta– метаданные типа записиshop_order.

Как товары хранятся в базе данных?
posts– товары это тип записиproduct,postmeta– метаданные товаров, например цены, количество в запасе и т д.comments– отзывы к товарам.
Миша
Впервые познакомился с WordPress в 2009 году. Организатор и спикер на конференциях WordCamp. Преподаватель в школе Нетология.
Пишите, если нужна помощь с сайтом или разработка с нуля.
Что такое структуры данных? — Определение из WhatIs.com
Управление данными- Давид Лошин, Целостность знаний Inc.
- Сара Льюис
Структура данных — это специальный формат для организации, обработки, извлечения и хранения данных. Существует несколько основных и расширенных типов структур данных, все из которых предназначены для организации данных в соответствии с определенной целью. Структуры данных упрощают пользователям доступ к нужным им данным и работу с ними надлежащим образом. Самое главное, структуры данных определяют организацию информации, чтобы машины и люди могли лучше ее понимать.
Структуры данных упрощают пользователям доступ к нужным им данным и работу с ними надлежащим образом. Самое главное, структуры данных определяют организацию информации, чтобы машины и люди могли лучше ее понимать.
В информатике и компьютерном программировании структура данных может быть выбрана или предназначена для хранения данных с целью их использования с различными алгоритмами. В некоторых случаях основные операции алгоритма тесно связаны с дизайном структуры данных. Каждая структура данных содержит информацию о значениях данных, взаимосвязях между данными и, в некоторых случаях, о функциях, которые можно применять к данным.
Например, в объектно-ориентированном языке программирования структура данных и связанные с ней методы связаны вместе как часть определения класса. В необъектно-ориентированных языках могут быть определены функции для работы со структурой данных, но технически они не являются частью структуры данных.
Почему важны структуры данных? Типичных базовых типов данных, таких как целые числа или значения с плавающей запятой, которые доступны в большинстве языков компьютерного программирования, как правило, недостаточно для того, чтобы уловить логическое назначение обработки и использования данных. Тем не менее, приложения, которые принимают, обрабатывают и производят информацию, должны понимать, как данные должны быть организованы, чтобы упростить обработку. Структуры данных логически объединяют элементы данных и облегчают эффективное использование, сохранение и совместное использование данных. Они обеспечивают формальную модель, описывающую способ организации элементов данных.
Тем не менее, приложения, которые принимают, обрабатывают и производят информацию, должны понимать, как данные должны быть организованы, чтобы упростить обработку. Структуры данных логически объединяют элементы данных и облегчают эффективное использование, сохранение и совместное использование данных. Они обеспечивают формальную модель, описывающую способ организации элементов данных.
Структуры данных являются строительными блоками для более сложных приложений. Они разрабатываются путем объединения элементов данных в логическую единицу, представляющую абстрактный тип данных, который имеет отношение к алгоритму или приложению. Примером абстрактного типа данных является «имя клиента», состоящее из строк символов «имя», «отчество» и «фамилия».
Важно не только использовать структуры данных, но также важно выбирать правильную структуру данных для каждой задачи. Выбор неподходящей структуры данных может привести к замедлению времени выполнения или зависанию кода. Пять факторов, которые следует учитывать при выборе структуры данных, включают следующее:
- Какая информация будет сохранена?
- Как эта информация будет использоваться?
- Где должны сохраняться или храниться данные после их создания?
- Как лучше организовать данные?
- Какие аспекты управления резервированием памяти и хранилища следует учитывать?
 youtube.com/embed/18V8Avz2OH8?autoplay=0&modestbranding=1&rel=0&widget_referrer=https://www.techtarget.com/searchdatamanagement/definition/data-structure&enablejsapi=1&origin=https://www.techtarget.com» type=»text/html» frameborder=»0″> Как используются структуры данных?
youtube.com/embed/18V8Avz2OH8?autoplay=0&modestbranding=1&rel=0&widget_referrer=https://www.techtarget.com/searchdatamanagement/definition/data-structure&enablejsapi=1&origin=https://www.techtarget.com» type=»text/html» frameborder=»0″> Как используются структуры данных?Как правило, структуры данных используются для реализации физических форм абстрактных типов данных. Структуры данных являются важной частью разработки эффективного программного обеспечения. Они также играют решающую роль в разработке алгоритмов и в том, как эти алгоритмы используются в компьютерных программах.
Ранние языки программирования, такие как Fortran, C и C++, позволяли программистам определять свои собственные структуры данных. Сегодня многие языки программирования включают обширный набор встроенных структур данных для организации кода и информации. Например, списки и словари Python, а также массивы и объекты JavaScript являются распространенными структурами кодирования, используемыми для хранения и извлечения информации.
Инженеры-программисты используют алгоритмы, которые тесно связаны со структурами данных, такими как списки, очереди и сопоставления одного набора значений с другим. Этот подход можно использовать в различных приложениях, включая управление коллекциями записей в реляционной базе данных и создание индекса этих записей с использованием структуры данных, называемой двоичным деревом.
Некоторые примеры использования структур данных включают следующее:
- Хранение данных. Структуры данных используются для эффективного сохранения данных, например для определения набора атрибутов и соответствующих структур, используемых для хранения записей в системе управления базами данных.
- Управление ресурсами и услугами. Ресурсы и службы основной операционной системы (ОС) активируются за счет использования структур данных, таких как связанные списки для выделения памяти, управления файловыми каталогами и деревьями структуры файлов, а также очередей планирования процессов.
- Обмен данными. Структуры данных определяют организацию информации, совместно используемой приложениями, например пакетов TCP/IP.
- Заказ и сортировка. Структуры данных, такие как двоичные деревья поиска, также известные как упорядоченное или отсортированное двоичное дерево, предоставляют эффективные методы сортировки объектов, таких как строки символов, используемые в качестве тегов. С помощью таких структур данных, как очереди с приоритетом, программисты могут управлять элементами, организованными в соответствии с определенным приоритетом.
- Индексация . Еще более сложные структуры данных, такие как B-деревья, используются для индексации объектов, например, хранящихся в базе данных.
- Поиск. Индексы, созданные с использованием бинарных деревьев поиска, B-деревьев или хэш-таблиц, ускоряют поиск определенного искомого элемента.
- Масштабируемость. Приложения для работы с большими данными используют структуры данных для распределения и управления хранилищем данных в распределенных хранилищах, обеспечивая масштабируемость и производительность. Некоторые среды программирования больших данных, такие как Apache Spark, предоставляют структуры данных, которые отражают базовую структуру записей базы данных для упрощения запросов.

 Приложения для работы с большими данными используют структуры данных для распределения и управления хранилищем данных в распределенных хранилищах, обеспечивая масштабируемость и производительность. Некоторые среды программирования больших данных, такие как Apache Spark, предоставляют структуры данных, которые отражают базовую структуру записей базы данных для упрощения запросов.
Приложения для работы с большими данными используют структуры данных для распределения и управления хранилищем данных в распределенных хранилищах, обеспечивая масштабируемость и производительность. Некоторые среды программирования больших данных, такие как Apache Spark, предоставляют структуры данных, которые отражают базовую структуру записей базы данных для упрощения запросов.Структуры данных часто классифицируют по их характеристикам. Следующие три характеристики являются примерами:
- Линейная или нелинейная. Эта характеристика описывает, расположены ли элементы данных в последовательном порядке, например в виде массива, или в неупорядоченной последовательности, например в виде графика.
- Гомогенные или гетерогенные. Эта характеристика описывает, относятся ли все элементы данных в данном репозитории к одному типу. Одним из примеров является набор элементов в массиве или различных типов, таких как абстрактный тип данных, определенный как структура в C или спецификация класса в Java.
- Статическая или динамическая. Эта характеристика описывает, как компилируются структуры данных. Статические структуры данных имеют фиксированные размеры, структуры и места в памяти во время компиляции. Динамические структуры данных имеют размеры, структуры и области памяти, которые могут уменьшаться или расширяться в зависимости от использования.
Если структуры данных являются строительными блоками алгоритмов и компьютерных программ, то примитивные или базовые типы данных являются строительными блоками структур данных. К типичным базовым типам данных относятся следующие:
- Логическое значение , в котором хранятся логические значения, которые либо истинны, либо ложны.
- целое число , в котором хранится диапазон математических целых чисел или счетных чисел. Целые числа разного размера содержат разный диапазон значений — например, 8-битное целое со знаком содержит значения от -128 до 127, а длинное 32-битное целое без знака содержит значения от 0 до 4 294 967 295.
- Числа с плавающей запятой , хранящие формульное представление действительных чисел.
- Числа с фиксированной точкой , которые используются в некоторых языках программирования и содержат действительные значения, но обрабатываются как цифры слева и справа от десятичной точки.
- Символ , который использует символы из определенного отображения целочисленных значений в символы.
- Указатели, которые являются опорными значениями, указывающими на другие значения.
- Строка , представляющая собой массив символов, за которым следует код остановки — обычно значение «0» — или управляется с помощью поля длины, которое представляет собой целочисленное значение.
Тип структуры данных, используемый в конкретной ситуации, определяется типом операций, которые потребуются, или видами алгоритмов, которые будут применяться.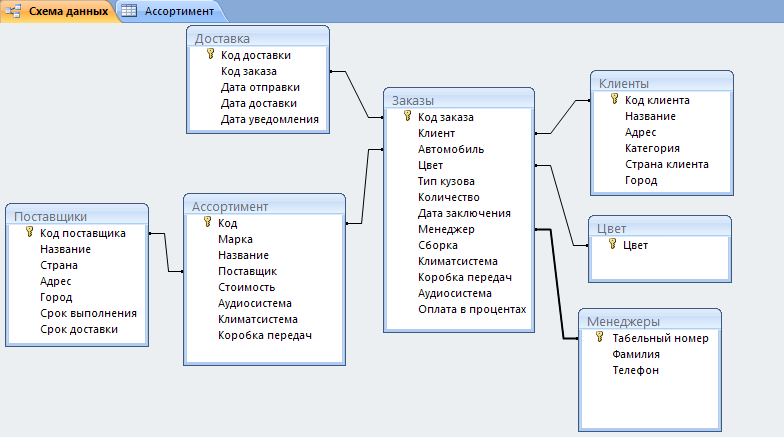 Различные типы структур данных включают следующие:
Различные типы структур данных включают следующие:
- Массив. Массив хранит набор элементов в смежных ячейках памяти. Элементы одного типа хранятся вместе, поэтому положение каждого элемента можно легко вычислить или получить с помощью индекса. Массивы могут быть фиксированными или гибкими по длине.
- Стек . В стеке хранится набор элементов в линейном порядке применения операций. Этот порядок может быть последним пришел, первым ушел (LIFO) или первым пришел, первым ушел (FIFO).
- Очередь . Очередь хранит набор элементов подобно стеку; однако порядок операций может быть только «первым пришел, первым вышел».
- Связанный список. Связанный список хранит набор элементов в линейном порядке. Каждый элемент или узел в связанном списке содержит элемент данных, а также ссылку или ссылку на следующий элемент в списке.
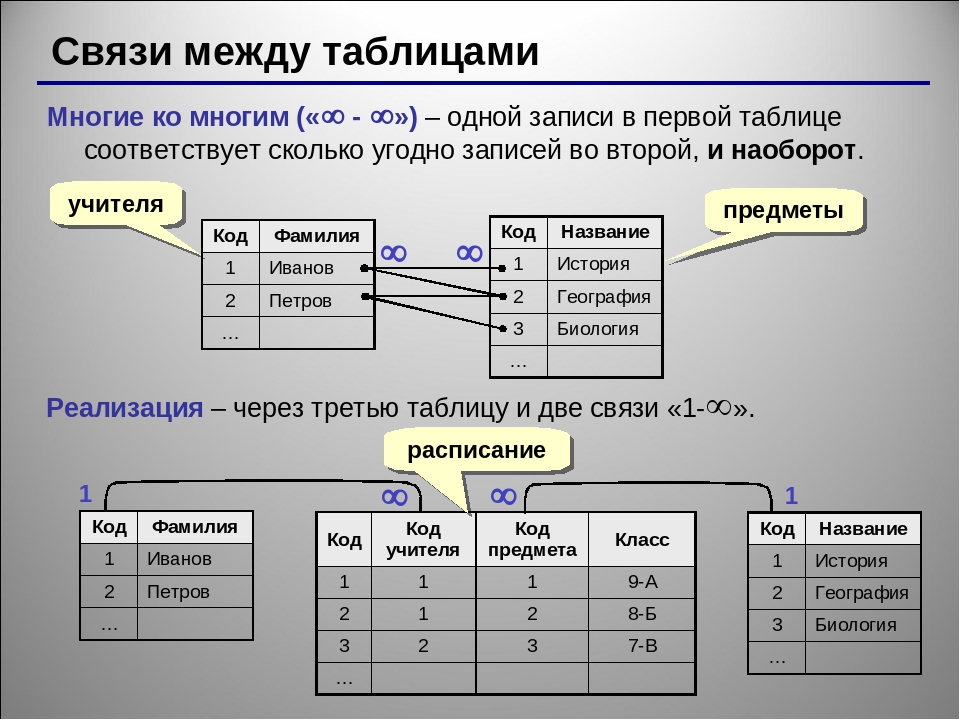 Каждый элемент или узел в связанном списке содержит элемент данных, а также ссылку или ссылку на следующий элемент в списке.
Каждый элемент или узел в связанном списке содержит элемент данных, а также ссылку или ссылку на следующий элемент в списке.- Дерево. Дерево хранит набор элементов в абстрактной иерархической форме. Каждый узел связан со значением ключа, а родительские узлы связаны с дочерними узлами или подузлами. Существует один корневой узел, который является предком всех узлов в дереве.
- Куча. Куча — это древовидная структура, в которой значение ключа, связанное с каждым родительским узлом, больше или равно значению ключа любого из его дочерних значений ключа.
- График. График хранит набор элементов нелинейным образом. Графы состоят из конечного набора узлов, также известных как вершины, и соединяющих их линий, также известных как ребра. Они полезны для представления реальных систем, таких как компьютерные сети.
- Трие. Дерево, также известное как дерево ключевых слов, представляет собой структуру данных, в которой строки хранятся как элементы данных, которые можно организовать в виде визуального графа.
- Хэш-таблица. Хеш-таблица, также известная как хэш-карта, хранит набор элементов в ассоциативном массиве, который отображает ключи в значения. Хеш-таблица использует хеш-функцию для преобразования индекса в массив сегментов, содержащих нужный элемент данных.
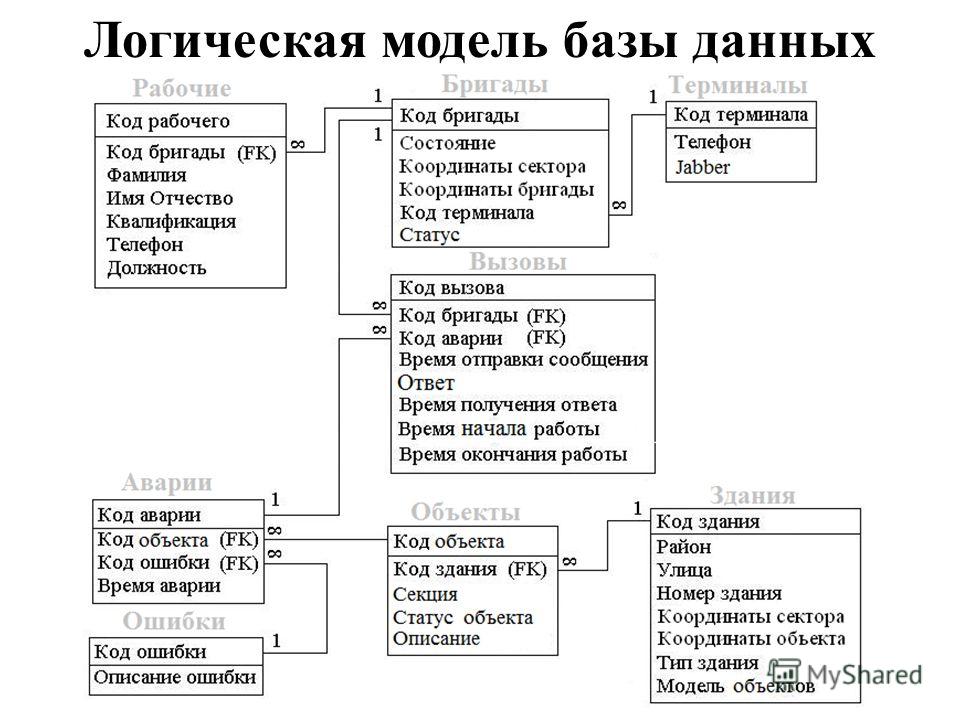 Графы состоят из конечного набора узлов, также известных как вершины, и соединяющих их линий, также известных как ребра. Они полезны для представления реальных систем, таких как компьютерные сети.
Графы состоят из конечного набора узлов, также известных как вершины, и соединяющих их линий, также известных как ребра. Они полезны для представления реальных систем, таких как компьютерные сети.Они считаются сложными структурами данных, поскольку могут хранить большие объемы взаимосвязанных данных.
Как выбрать структуру данныхПри выборе структуры данных для программы или приложения разработчики должны учитывать ответы на следующие три вопроса:
- Поддерживаемые операции. 2).
- Элегантность программирования. Удобны ли организация структуры данных и ее функциональный интерфейс?
 2).
2).Некоторые реальные примеры:
- Связанные списки лучше всего подходят, если программа управляет коллекцией элементов, которые не нужно заказывать, требуется постоянное время для добавления или удаления элемента из коллекции, а увеличенное время поиска допустимо.
- Стеки лучше всего подходят, если программа управляет коллекцией, которая должна поддерживать порядок LIFO.
- Очереди следует использовать, если программа управляет коллекцией, которая должна поддерживать порядок FIFO.
- Двоичные деревья хороши для управления коллекцией элементов с отношениями родитель-потомок, например семейным древом.
- Двоичные деревья поиска подходят для управления отсортированной коллекцией, когда целью является оптимизация времени, необходимого для поиска определенных элементов в коллекции.
- Графики работают лучше всего, если приложение будет анализировать возможности подключения и отношения между группой людей в сети социальных сетей.

Последнее обновление: март 2021 г.
Продолжить чтение О структурах данных- Redis стремится к бесконечному разнообразию структур данных
- Развитие мультимодельных баз данных для поддержки разнообразия данных
- Руководство для архитекторов предприятий по процессу моделирования данных
- Как конкурс SHA-3 объявил выигрыш имеет функцию
- 7 лучших курсов для изучения структуры данных и алгоритмов
Домен Active Directory (домен AD)
Автор: Стивен Бигелоуинкапсуляция (объектно-ориентированное программирование)
Автор: Роберт Шелдонбаза данных (БД)
Автор: Бен ЛуткевичКак создавать и использовать карты в Голанге
Автор: Мэтью Грасбергер
- 5 преимуществ облачной бизнес-аналитики по сравнению с локальными решениями
BI, перемещающийся из локальной среды в облако, использует операционные усовершенствования и преимущества.
Оптимизация этих инструментов создает более … - Collins Aero сокращает задержки рейсов с помощью платформы Databricks
Инструменты поставщика хранилища данных составляют основу аналитических продуктов, призванных помочь авиакомпаниям прогнозировать и предотвращать …
- Teradata делает VantageCloud Lake доступным в Azure
Делая свою облачную платформу изначально доступной в Azure, поставщик средств управления данными и аналитики стремится более …
 Оптимизация этих инструментов создает более …
Оптимизация этих инструментов создает более …- AWS Control Tower стремится упростить управление несколькими учетными записями
Многие организации изо всех сил пытаются управлять своей огромной коллекцией учетных записей AWS, но Control Tower может помочь. Услуга автоматизирует…
- Разбираем модель ценообразования Amazon EKS
В модели ценообразования Amazon EKS есть несколько важных переменных. Покопайтесь в цифрах, чтобы убедиться, что вы развернули службу.
.. - Сравните EKS и самоуправляемый Kubernetes на AWS
Пользователи AWS сталкиваются с выбором при развертывании Kubernetes: запускать его самостоятельно на EC2 или позволить Amazon выполнять тяжелую работу с помощью EKS. См…
 ..
..- 5 шагов для интеграции механизма персонализации контента в CMS
Качество обслуживания клиентов является главным приоритетом в современном деловом мире, и персонализированный контент может иметь большое значение для обеспечения …
- 7 советов по созданию базы знаний
База знаний предлагает самообслуживание для клиентов и сотрудников. Организации могут собирать отзывы и формировать культуру …
- 4 шаблона статей базы знаний
Базы знаний могут улучшить клиентский опыт и производительность сотрудников, но организации могут не знать, с чего начать. Откройте для себя четыре шаблона.
..
 ..
..- Oracle ставит перед собой высокие национальные цели в области ЭУЗ с приобретением Cerner
Приобретя Cerner, Oracle нацелилась на создание национальной анонимной базы данных пациентов — дорога, заполненная …
- Благодаря Cerner Oracle Cloud Infrastructure получает импульс
Oracle планирует приобрести Cerner в рамках сделки на сумму около 30 миллиардов долларов. Второй по величине поставщик электронных медицинских карт в США может вдохнуть новую жизнь в …
- Верховный суд встал на сторону Google в иске о нарушении авторских прав на Oracle API
Верховный суд постановил 6-2, что API-интерфейсы Java, используемые в телефонах Android, не подпадают под действие американского закона об авторском праве, положив конец …
- Доходы SAP от облачных вычислений растут, но реакция Уолл-стрит снижается
Акции SAP упали после неутешительного отчета о прибылях и убытках, но аналитики говорят, что компания находится в хорошем состоянии благодаря высокому потребительскому спросу .
.. - Миграция SAP S/4HANA требует тщательного управления данными
Работа с данными — один из самых сложных аспектов миграции S/4HANA, поскольку клиенты должны решить, на какие данные перемещать …
- Arista отказывается от электронных таблиц и электронной почты в пользу SAP IBP
Поскольку быстрый рост опережает процессы цепочки поставок на основе электронных таблиц Arista Networks, компания внедрила цифровое снабжение …
 ..
..Что такое схема базы данных и почему она важна?
Если вы отвечаете за управление базой данных или предоставление ценности данных с помощью таких приложений, как бизнес-аналитика, важно понимать схему базы данных. Схема определяет структуру базы данных и описывает таблицы и поля, включая отношения между ними, и другие элементы данных, необходимые для точного доступа и обновления информации, хранящейся внутри.
Глубокое понимание схем баз данных не только позволяет эффективно разрабатывать платформы данных, включая облачную платформу данных, но также может помочь выявить потенциальные проблемы, такие как узкие места в производительности, которые могут повлиять на работу системы, привести к простоям и снизить рентабельность инвестиций в данные. В этом подробном руководстве мы расскажем все, что вам нужно знать о схемах баз данных: что это такое, как они работают, типы, взаимосвязь между схемами баз данных и системами управления базами данных, а также что следует учитывать при разработке схемы базы данных.
В этом подробном руководстве мы расскажем все, что вам нужно знать о схемах баз данных: что это такое, как они работают, типы, взаимосвязь между схемами баз данных и системами управления базами данных, а также что следует учитывать при разработке схемы базы данных.
Что такое схема базы данных?
Схема базы данных — это план логической структуры базы данных, описывающий, как организованы и структурированы данные. Он описывает различные объекты в базе данных, такие как таблицы, столбцы, представления, индексы и хранимые процедуры. Вы можете думать об этом как о скелете, обеспечивающем структуру и основу для того, как различные элементы данных связаны и работают вместе. Основная цель создания схемы базы данных — обеспечить целостность данных, хранящихся в базе данных, чтобы ее можно было уверенно использовать в более широком бизнесе для таких приложений, как бизнес-аналитика. Наличие правильной схемы является важным элементом моделирования данных, особенно для организаций, которые полагаются на данные для управления несколькими частями своего бизнеса.
Схема базы данных определяется в виде диаграммы таблицы или диаграммы сущность-связь (ERD). Диаграмма таблицы иллюстрирует структуру каждой таблицы в базе данных, тогда как ERD показывает, как различные таблицы или объекты связаны друг с другом. Эти диаграммы используются для определения структуры данных в базе данных, звездообразной схемы или схемы снежинки, а также для обеспечения согласованности способов их хранения.
Важность схемы базы данных заключается в ее способности определять логическую структуру базы данных и поддерживать организованность данных. Это помогает пользователям определить, какие таблицы, столбцы и отношения существуют между объектами, что позволяет им эффективно получать доступ, запрашивать или изменять данные. Четко определенная схема базы данных также повышает точность данных, поскольку снижает вероятность ввода неверной информации в базу данных. Кроме того, это помогает гарантировать, что пользователи не смогут получить доступ или изменить конфиденциальную информацию, к которой у них не должно быть доступа. Самые успешные организации используют инструменты в современном стеке данных, которые делают построение и использование этих схем невероятно простыми.
Самые успешные организации используют инструменты в современном стеке данных, которые делают построение и использование этих схем невероятно простыми.
3 наиболее распространенных типа схем базы данных
Источник изображения
1. Концептуальная схема
Концептуальная схема представляет собой высокоуровневое представление структуры и отношений в базе данных. Он описывает основные концепции данных, а также то, как они связаны друг с другом. Концептуальная схема не содержит подробностей о конкретных объектах, таких как таблицы, представления и столбцы; вместо этого он фокусируется на абстрактных понятиях и на том, как они соотносятся друг с другом.
Целью концептуальной схемы является предоставление общего представления о структуре и связях в базе данных. Это помогает пользователям понять базовую структуру, а также выявить любые потенциальные проблемы или несоответствия, прежде чем они попадут в приложения для работы с данными или повлияют на результаты, полученные в результате аналитики. Этот тип схемы также может использоваться разработчиками баз данных для разработки более подробных схем.
Этот тип схемы также может использоваться разработчиками баз данных для разработки более подробных схем.
2. Логическая схема
Логическая схема представляет собой промежуточный уровень детализации между концептуальной и физической структурой базы данных. Он предоставляет более подробное описание данных, включая конкретные объекты, такие как таблицы и столбцы. Логическая схема описывает структуру и отношения между различными сущностями в базе данных, а также то, как данные хранятся в таблицах.
Назначение логической схемы — обеспечить логическую организацию и эффективное хранение данных. Он помогает пользователям определить отношения между объектами, предоставляя еще больше способов, чем концептуальная схема, для раннего выявления проблем в схеме. Логические схемы особенно полезны для разработчиков, поскольку они обеспечивают лучшее понимание того, как структурированы данные, и при необходимости могут использоваться для разработки еще более подробных схем.
3.
 Физическая схема
Физическая схемаФизическая схема является наиболее подробным уровнем проектирования базы данных. Он описывает, как данные физически хранятся в системе, и выделяет конкретные объекты, такие как таблицы, столбцы, индексы и представления. Физическая схема также включает информацию о носителях, используемых для каждой таблицы, таких как облачное хранилище данных или хранилище данных, а также любые ограничения или триггеры, связанные с данными или методологией хранения.
Назначение физической схемы — предоставить подробное описание того, как данные хранятся в системе. Это помогает разработчикам баз данных определить, какие носители следует использовать для каждой таблицы, и обеспечить логическую организацию данных. Кроме того, это может помочь выявить любые потенциальные проблемы или несоответствия до их возникновения. Имея установленную физическую схему, разработчики могут гарантировать, что данные хранятся эффективно и легко извлекаются при необходимости.
Взаимосвязь между схемой базы данных и системами управления базами данных
Структура и взаимосвязи схемы базы данных отражаются в конструкции системы управления базами данных (СУБД). Управление данными Системы действуют как интерфейс между пользователями и данными, хранящимися в базе данных, позволяя им получать доступ к информации и управлять ею. Чтобы пользователи могли эффективно использовать СУБД, она должна быть разработана с учетом схемы базы данных. Это требует глубокого понимания базовой структуры, взаимосвязей и типов данных, представленных в схеме.
Управление данными Системы действуют как интерфейс между пользователями и данными, хранящимися в базе данных, позволяя им получать доступ к информации и управлять ею. Чтобы пользователи могли эффективно использовать СУБД, она должна быть разработана с учетом схемы базы данных. Это требует глубокого понимания базовой структуры, взаимосвязей и типов данных, представленных в схеме.
Хорошо спроектированная схема базы данных также может предоставить пользователям много преимуществ. Правильно спроектированная схема помогает обеспечить точность и целостность данных, а также уменьшить избыточность и повысить производительность системы. Кроме того, разработчикам легче понять базовую структуру базы данных, что позволяет им быстрее вносить улучшения. Наконец, хорошо спроектированная схема облегчает пользователям доступ к данным и управление ими, так как им легче понять ее структуру. Это особенно важно для организаций, которые хотят предоставить аналитику широкому кругу пользователей через самообслуживание или визуализация данных . В конечном счете, хорошо спроектированная схема базы данных может повысить эффективность любой системы и является важным шагом к построению культуры и бизнеса, основанного на данных.
В конечном счете, хорошо спроектированная схема базы данных может повысить эффективность любой системы и является важным шагом к построению культуры и бизнеса, основанного на данных.
Что следует учитывать при разработке схемы базы данных
При разработке схемы базы данных необходимо учитывать несколько факторов. Во-первых, важно понять, какие данные будут храниться в системе, и соответственно определить структуру таблиц и столбцов. Кроме того, важно определить любые отношения между сущностями в системе и убедиться, что они должным образом представлены в проекте. Наконец, важно учитывать любые ограничения или триггеры, которые могут быть необходимы для поддержания целостности данных.
Помимо приведенных выше соображений, существуют рекомендации, которым следует следовать при разработке схемы базы данных. Важно убедиться, что таблицы и столбцы имеют правильные имена, так как это облегчит их понимание. Кроме того, важно поддерживать согласованность при разработке схемы и по возможности избегать избыточных данных.
Наконец, важно тщательно протестировать схему базы данных, чтобы убедиться, что она соответствует потребностям пользователей. Создание схем баз данных имеет смысл только в том случае, если бизнес может использовать их для повышения эффективности, извлечения выгоды из возможностей или снижения рисков. Таким образом, наиболее успешные организации не рассматривают схемы баз данных изолированно, а как часть своей более широкой аналитической стратегии, в которой ценность этих схем раскрывается лицам, принимающим решения, на всех уровнях посредством бизнес-аналитики с самообслуживанием.
Следуя этим передовым методам, разработчики могут гарантировать, что схемы их баз данных хорошо спроектированы и оптимизированы для повышения производительности.
Используйте возможности принятия решений на основе данных
Схема базы данных является важным элементом при следовании рекомендациям по эффективному управлению базами данных. Без него запуск запросов и получение точных результатов становятся практически невозможными.