Меняем параметры запроса GET с помощью mod rewrite
Модуль rewrite сервера Apache предоставляет мощные возможности по перенаправленнию запросов. Это позволяет ещё до обработки запроса, к примеру, в коде программы на PHP вашего сайта, выполнить рутинные операции по изменению адреса страницы, параметров запроса и т.п.
В данной статье мы рассмотрим случаи, когда необходимо убрать параметры GET, или наоборот добавить/изменить.
Общие принципы
Если вы уже знаете, что такое mod_rewrite, как им пользоваться под apache, то пропускайте эту часть статьи.
Apache управляется конфигурационными файлами с именем .htaccess в директориях сервера и выполняет соответствующие инструкции. Главным из них является файл находящийся в корне сайта. В подкаталогах вашего сайта также могут находится .htaccess файлы, дополняющие/изменяющие директивы заданные в файлах ближе к корню.
Вот пример типичной переадресации в CMS средствами «мод рерайт»:
# Типичное перенаправлние всех запросов на скрипт /index.php # данные инструкции размещаются в корне сайта в файле .htaccess <IfModule mod_rewrite.c> #включаем использование модуля RewriteEngine On #устанавливаем базовый путь переадресации RewriteBase / #правила пишутся друг за другом и выполняются по порядку #1. Правило № 1 #если запрашивают файл index.php, то ничего не меняем (прочерк) #это позволяет избежать зацикливания RewriteRule ^index\.php$ — [L] #2. Правило № 2 #Эта переадресация сложнее, она предваряется условиями #если запрашивают не файл RewriteCond %{REQUEST_FILENAME} !-f #если запрашивают не каталог RewriteCond %{REQUEST_FILENAME} !-d #тогда выполняется перенаправление на скрипт index.php RewriteRule . /index.php [L] </IfModule>
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# Типичное перенаправлние всех запросов на скрипт /index.php # данные инструкции размещаются в корне сайта в файле .htaccess <IfModule mod_rewrite.c> #включаем использование модуля RewriteEngine On #устанавливаем базовый путь переадресации RewriteBase /
#правила пишутся друг за другом и выполняются по порядку #1. Правило № 1 #если запрашивают файл index.php, то ничего не меняем (прочерк) #это позволяет избежать зацикливания RewriteRule ^index\.php$ — [L] #2. Правило № 2 #Эта переадресация сложнее, она предваряется условиями #если запрашивают не файл RewriteCond %{REQUEST_FILENAME} !-f #если запрашивают не каталог RewriteCond %{REQUEST_FILENAME} !-d #тогда выполняется перенаправление на скрипт index.php RewriteRule . /index.php [L] </IfModule> |
Этот базовый пример не сможет показать все разнообразие возможностей, посмотрите обязательно полное описание команд модуля Rewrite.
Есть отличие перенаправления от переадресации.
Перенаправление
Отличие заключается в том, что в первом случае происходит обработка запроса, так как будто он был выполнен к указанному в перенаправлении скрипту/файлу/адресу. В нашем случае мы направляем все запросы к index.php
Переадресация
При переадресации, а в этом случае я бы добавил специальный флаг [R]:
RewriteRule . /index.php [R=301,L]
RewriteRule . /index.php [R=301,L] |
Сервер ответит клиенту, что нужно перейти по указанному адресу. Тогда клиент вновь запросит сервер, но уже по новому адресу. В адресной строке браузера, к примеру, отобразится этот новый адрес.
Теперь, когда вы имеете общие представления о работе модуля, то я покажу вам несколько примеров как с его помощью работать с параметрами GET .
Добавляем параметры GET к запросу в mod rewrite
Пример запроса:
http://mysite.ru/vazniy-razdel.html
нужно переадресовать на
http://mysite.ru/drugoy-razdel?param1=value
RewriteRule ^vazniy-razdel.html$ /drugoy-razdel?param1=value [R=301,L]
RewriteRule ^vazniy-razdel.html$ /drugoy-razdel?param1=value [R=301,L] |
Так мы добавили при переадресации нужный нам параметр GET param1.
Убрать любые GET параметры в запросе в mod rewrite
Пример запроса:
http://mysite.ru/vazniy-razdel.php?param1=value
нужно переадресовать на
http://mysite.ru/new-address.php
# обратите внимание, что условие — это регулярное выражение, # т.е. нужно экранировать спец символы в нем, если такие используются # а флаг [NC] — no case, означает, # что выражение не чувствительно к регистру RewriteCond %{QUERY_STRING} ^param1=value$ [NC] # тот факт, что GET параметры передавать не надо # указывается знаком ? без задания параметров RewriteRule ^vazniy-razdel\.php$ /new-address.php? [R=301,L]
# обратите внимание, что условие — это регулярное выражение, # т.е. нужно экранировать спец символы в нем, если такие используются # а флаг [NC] — no case, означает, # что выражение не чувствительно к регистру RewriteCond %{QUERY_STRING} ^param1=value$ [NC] # тот факт, что GET параметры передавать не надо # указывается знаком ? без задания параметров RewriteRule ^vazniy-razdel\.php$ /new-address.php? [R=301,L] |
Так мы переадресуем только запрос, где есть param1=value. Если надо убрать параметры GET и выполнить редирект для любых вариантов запроса скрипта vazniy-razdel.php, то правило будет выглядеть вот так:
RewriteRule ^vazniy-razdel\.php$ /new-address.php? [R=301,L]
RewriteRule ^vazniy-razdel\.php$ /new-address.php? [R=301,L] |
Теперь любые запросы на /vazniy-razdel.php переадресуются в новый раздел, при этом параметры GET будут убраны.
Заменить имя GET параметра в запросе на другое в mod rewrite
Пример запроса:
http://mysite.ru/vazniy-razdel.php?param1=value
нужно переадресовать на
http://mysite.ru/new-address.php?prm=value
# нам нужно извлечь значение старого параметра, # чтобы потом его передать в RewriteRule RewriteCond %{QUERY_STRING} ^param1=(.*)$ [NC] # теперь значение value находится у нас в щаблоне %1 RewriteRule ^vazniy-razdel\.php$ /new-address.php?prm=%1 [R=301,L]
# нам нужно извлечь значение старого параметра, # чтобы потом его передать в RewriteRule RewriteCond %{QUERY_STRING} ^param1=(.*)$ [NC] # теперь значение value находится у нас в щаблоне %1 RewriteRule ^vazniy-razdel\.php$ /new-address.php?prm=%1 [R=301,L] |
Так мы заменили параметр param1 на prm.
shra.ru
Схема функционирования HTTP-сообщений и возможные риски
Схема функционирования HTTP-сообщений и возможные риски
В этой статье мы рассмотрим структуру HTTP-сообщений и проанализируем, что происходит за кадром при просмотре веб-страниц.
Автор: Ryan Brown
Протокол HTTP используется в мировой паутине для обеспечения информационных транзакций между клиентом и сервером. На данный момент широко распространена версия HTTP/1.1, однако мировая индустрия вскоре начнет переходить на версию 2.0. Веб-сайты и веб-приложения являются тем, на чем построена всемирная паутина, однако между этими двумя сущностями есть ключевое различие, которое заключается в том, что веб-приложения принимают данные от пользователей. Веб-сайт может быть статическим, а веб-приложение обязательно должно быть динамическим. Веб-сайт хранит содержимое на веб-сервере, и ресурсы веб-сервера могут быть получены клиентами, однако сами ресурсы остаются неизменными. С другой стороны, веб приложение принимает данные от пользователя и динамически генерирует выходные сведения на базе того, что введено. В самом начале мировая паутина состояла только из веб-сайтов. Постепенно сайтов становилось все меньше, веб-приложения стали занимать более доминантную позицию.
Коммуникационная транзакция между клиентом и сервером через протокол HTTP состоит из того, что мы называем HTTP-сообщениями. HTTP-сообщение состоит из HTTP-запроса, посылаемого клиентом серверу, и HTTP-ответа, возвращаемого сервером клиенту на основе полученного запроса. Ключевой момент при тестировании безопасности веб-приложения связан с пониманием логики этих коммуникаций. В этой статье мы рассмотрим структуру HTTP-сообщений и проанализируем, что происходит за кадром при просмотре веб-страниц.
HTTP-запросы
Простой HTTP-запрос:
Рисунок 1: Элементарный HTTP-запрос
GET – HTTP-метод
/ — Путь к ресурсу
HTTP/1.1 – Версия протокола HTTP
HTTP-методы:
Протокол HTTP поддерживает несколько методов. В самой первой версии HTTP/1.0 было три метода: GET, POST и HEAD. В HTTP/1.1 появилось несколько новых методов (см. RFC 2616): OPTIONS, CONNECT, TRACE, PUT и DELETE. В RFC 5789, появившегося в 2010 году, добавился метод PATCH.

Рисунок 2: Перечень методов, поддерживаемых протоколом HTTP/1.1
GET используется для простого запроса ресурсов с веб-сервера. Параметры для этого метода передаются через URL.
POST используется для отсылки данных на веб-сервер через тело HTTP-запроса.
HEAD схож с методом GET, но выводит только заголовки HTTP-ответа, который возвращает сервер.
OPTIONS используется для получения списка методов, принимаемых веб-сервером, которые хранятся в заголовке ‘Allow’ в HTTP-ответе.
PUT предназначен для замены существующего или создания нового ресурса на веб-сервере.
TRACE используется при тестировании и отсылает полное сообщение, полученное веб-сервером, обратно клиенту, что позволяет увидеть конкретное содержимое, полученное веб-сервером.
PATCH схож с методом PUT. Отличие заключается в этом, что PATCH поддерживает частичную модификацию, в то время как метод PUT поддерживает только полную замену ресурса.
Примечание:
В большинстве приложений используются в основном GET и POST, поскольку HTML поддерживает только эти два метода. Если предполагается использование методов OPTIONS, PUT, DELETE, PATCH, TRACE или CONNECT, необходимо все тщательно продумать и оценить риски в отношении приложения или веб-сервера.
URL:
URL или Uniform Resource Locator (унифицированный указатель ресурсов) является подмножеством унифицированных идентификаторов ресурсов (Uniform Resource Identifiers; URI). Типичная структура URL выглядит так:
[Protocol]://[host]/[resource path]?[parameter1]&[parameter2]
По сути, это способ обозначения местонахождения сетевого ресурса и метод передачи данных целевому ресурсу.
Рисунок 3: Переменная HOST представляет собой сетевой адрес веб-сервера, куда клиент отсылает HTTP-запрос
Рисунок 4: Наиболее распространенные заголовки HTTP-запроса
User-Agent содержит информацию о браузере.
Accept определяет тип содержимого, который может принять клиент.
Accept-Encoding определяет тип кодировки, которую может принять клиент.
Content-Length определяет длину тела запроса в октетах. Это значение не имеет особой важности, но некоторые HTTP-методы (например, PUT) требуют этот заголовок. Если необходимо, в значение этого заголовка можно установить 0.
Referer содержит URL-источник запроса.
Cookie предназначен для отправки cookies на сервер для управления сессией.
Connection используется для того, чтобы сообщить серверу о том, что нужно закрыть соединение или оставить открытым для последующих запросов.
Authorization содержит информацию, имеющую отношение к аутентификации на конкретной платформе.
HTTP-ответы
Пример простого HTTP-ответа:
Рисунок 5: Элементарный HTTP-ответ
В примере выше обратим особое внимание на первую строчку, где указана используемая HTTP-версия и код статуса, возвращенный сервером. Код статуса – важная часть HTTP-сообщения, поскольку свидетельствует о том, как приложение обработало запрос.
Рисунок 6: Перечень кодов статуса
Код ответа «100 Continue» редко когда-либо используется. Наиболее распространенный код «200 OK», который сигнализирует о том, что запрос корректен, ресурс существует, сервер обработал запрос и вернул ресурс в теле ответа. Код 201 означает, что ресурс, запрашиваемый в запросе, был успешно создан. Этот код обычно является результатом запроса с использованием метода PUT. Коды статуса 3xx возвращается приложениями со ссылкой на ресурс, куда нужно перенаправить клиента. Ссылка находится либо в тебе ответа, либо в заголовке «location». Коды статуса 4xx отсылаются в случае, если запрашиваемого ресурса на сервере не существует или пользователь не авторизован для получения содержимого или при возникновении ошибки в запросе, отправленном серверу. Коды статуса 5xx возвращаются в случае, когда сервере возникает ошибка, и нет возможности обработать запрос.
Рисунок 7: Наиболее распространенные HTTP-заголовки ответов
Date содержит дату, когда получен запрос.
Server содержит информацию о веб-сервере (например, IIS/Apache).
X-Powered-By содержит информацию, касающуюся технологии, используемой в скриптах, и текущую версию (например, PHP или Asp.net).
Content-Length схож с аналогичным заголовком в запросе. Содержит длину тела ответа в октетах.
Set-Cookie содержит cookie, используемые клиентом при формировании запроса с целью управления сессией.
Expires содержит, время по истечению которого сервер не будет рассматривать ответ как корректный.
Cache-Control указывает клиенту, нужно ли кэшировать возвращаемые запросы.
Пример HTTP-запроса с использованием метода GET:
Рисунок 8: Пример использования метода GET
Как видно на рисунке выше, в первой строчке указан метод, путь к ресурсу с параметрами и используемая версия HTTP. Во второй строчке указан хост, которому посылается запрос. В третьей строке содержится информация о браузере клиента. В четвертной строчке указан тип данных, который может принимать клиент. В пятой строчке указан язык, используемый клиентом. В шестой – cookie, полученные с сервера для поддержания сессии. Седьмая строчка указывает, нужно ли закрывать сессию или оставить открытой. Последняя строчка нужна при использовании метода GET и является пустой.
Пример ответа на запрос с использованием метода GET:
Рисунок 9: Ответ на запрос с использованием метода GET
В ответе на запрос содержится несколько HTTP-заголовков, которые уже обсуждались ранее.
Пример использования метода POST:
Рисунок 10: Пример отправки информации методом POST
HTTP-запрос с использованием метода POST во многом схож с запросом с методом GET, который мы только что рассматривали. Основное отличие заключается в том, что параметры передаются не через URL, а через тело запроса. Этот метод более безопасен и пригоден для передачи конфиденциальной информации, поскольку передаваемые сведения нельзя получить из кэша на стороне клиента. Если планируется передавать параметры, имеющие отношение к аутентификации, следует использовать протокол HTTPS вместе с TLS с целью включения функции шифрования передаваемой информации. Заголовок Content-Length содержит длину тела запроса в октетах. И, наконец, заголовок Referer указывает серверу место возникновения запроса.
Пример HTTP-запроса с методом TRACE:
Рисунок 11: Запрос с использованием метода TRACE
Пример ответа на запрос с методом TRACE:
Рисунок 12: Ответ на запрос с методом TRACE
Как видно из рисунка выше, при использовании метода TRACE сервер возвращает в теле ответа все, что было отправлено в запросе. Эта функция может быть полезна в том случае, если клиенту нужно точно знать, что получено сервером. Метод TRACK выполняет ту же самую функцию, но используется при работе с сервером Microsoft IIS. Уязвимости, которые могут возникать при использовании метода TRACE, связаны с межсайтовой трассировкой (Cross-Site Tracing; XST). Этот класс брешей злоумышленник может использовать для кражи cookie или другой конфиденциальной информации (например, учетных записей), хранимых в заголовке Authorization при помощи межсайтового скриптинга (XSS).
Пример HTTP-запроса с методом PUT:
Рисунок 13: Создание простейшей страницы при помощи метода PUT
Метод PUT требует использования в запросе заголовка Content-Length. Значение этого заголовка особого значение не имеет и может быть установлено нулевым без каких-либо непредсказуемых последствий. Если директория, указанная в URL, уже существует на сервере, соответствующий ресурс будет полностью заменен. Если ресурса, указанного в URL, не существует, то будет создан новый ресурс (предполагается, что соответствующий метод реализован на сервере). Содержимое ресурса, который нужно создать, указывается в теле запроса. В примере выше создается простая html-страница.
Пример ответа на запрос с методом PUT:
Рисунок 14: Ответ с кодом об успешном создании страницы
В идеале от сервера должен прийти ответ с кодом статуса «201 Created», свидетельствующий о том, что ресурс создан. Кроме того, в HTTP-запрос можно было бы вставить заголовок «Expect: 100-continue», чтобы удостовериться, что сервер готов к обработке и не закроет сокет до того, как получит содержимое, которое вы указали в теле запроса. При использовании в запросе заголовка «Expect» в ответ может прийти один из двух кодов статуса: «100 Continue» или «417 Expectation Failed».
После ознакомления с вышеуказанной информации становится понятно, почему этот метод может стать причиной потенциальных проблем и привести к тому, что злоумышленник завладеет вашим сервером. В реальных условиях использование метода PUT разрешено нечасто, и для того, чтобы сервер принял содержимое тело запроса, необходимо наличие заголовка «Authorization».
Пример атаки показан на рисунке ниже. В этом примере в тело HTTP-запроса вставляется код шелла, который, в случае принятия запроса сервером, позволяет злоумышленнику выполнять команды.
Пример HTTP-запроса с методом PUT и вставкой кода шелла:
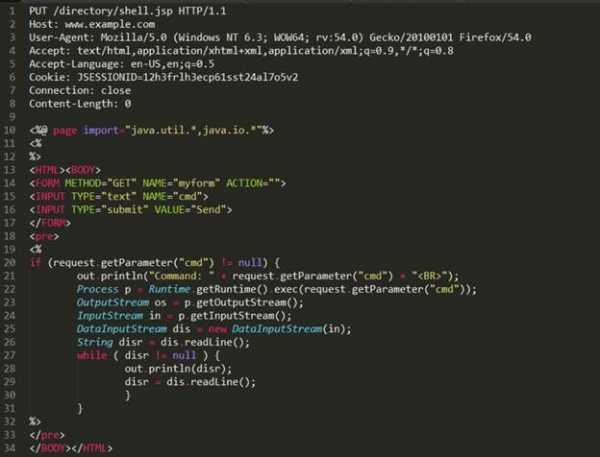
Рисунок 15: Пример использования кода шелла в теле запроса
Пример HTTP-запроса с методом DELETE:
Рисунок 15: Запрос на удаление ресурса при помощи метода DELETE
Пример ответа на запрос с методом DELETE:
Рисунок 16: Ответ на запрос об успешном удалении ресурса
После успешного удаления ресурса, указанного в URL, сервер должен вернуть код статуса 200 OK.
Пример HTTP-запроса с методом OPTIONS:
Рисунок 17: Запрос методов, доступных на сервере, при помощи метода OPTIONS
Пример ответа на запрос с методом OPTIONS:
Рисунок 18: Ответ с перечнем методов, доступных на сервере
Цель метода OPTIONS – узнать, какие методы разрешены на сервере. При помощи этого метода нельзя нанести какой-либо ущерб, а только собрать нужную информацию. Важно отметить, что содержимое заголовка «Allow» в заголовке ответа часто содержит методы, разрешенные не на сервере, а на прокси-сервере в случае, если трафик проходит через туннель.
В данной статье была представлена информация относительно использования HTTP-сообщений и методов, реализованных в протоколе HTTP/1.1. Кроме того, затрагивалась информация о возможных сценариях атак против веб-приложений при помощи этих методов. Эти сведения могут помочь вам в разработке сценариев пентестов. Надеемся, что после ознакомления с этой заметкой, вы стали лучше понимать механизмы функционирования и потоков данных протокола HTTP.
www.securitylab.ru
Быстрый запрос GET с параметрами — ios
При создании запроса GET для запроса нет тела, но все идет по URL-адресу. Чтобы создать URL-адрес (и, соответственно, процент его ускорения), вы также можете использовать URLComponents.
var url = URLComponents(string: "https://www.google.com/search/")!
url.queryItems = [
URLQueryItem(name: "q", value: "War & Peace")
]
Единственный трюк заключается в том, что для большинства веб-служб требуется + процент символа, который был экранирован (потому что они будут интерпретировать это как пробельный символ, продиктованный application/x-www-form-urlencoded спецификация). Но URLComponents не сможет избежать этого. Apple утверждает, что + является допустимым символом в запросе и поэтому не должен быть экранирован. Технически они верны, что это разрешено в запросе URI, но оно имеет особое значение в запросах application/x-www-form-urlencoded и действительно не должно передаваться без сохранения.
Apple признает, что нам приходится отказываться от символов +, но советуем сделать это вручную:
var url = URLComponents(string: "https://www.wolframalpha.com/input/")!
url.queryItems = [
URLQueryItem(name: "i", value: "1+2")
]
url.percentEncodedQuery = url.percentEncodedQuery?.replacingOccurrences(of: "+", with: "%2B")
Это неэлегантная работа, но она работает, и Apple советует, если ваши запросы могут включать символ +, и у вас есть сервер, который интерпретирует их как пробелы.
Итак, комбинируя это с вашей подпрограммой sendRequest, вы получите что-то вроде:
func sendRequest(_ url: String, parameters: [String: String], completion: @escaping ([String: Any]?, Error?) -> Void) {
var components = URLComponents(string: url)!
components.queryItems = parameters.map { (key, value) in
URLQueryItem(name: key, value: value)
}
components.percentEncodedQuery = components.percentEncodedQuery?.replacingOccurrences(of: "+", with: "%2B")
let request = URLRequest(url: components.url!)
let task = URLSession.shared.dataTask(with: request) { data, response, error in
guard let data = data, // is there data
let response = response as? HTTPURLResponse, // is there HTTP response
(200 ..< 300) ~= response.statusCode, // is statusCode 2XX
error == nil else { // was there no error, otherwise ...
completion(nil, error)
return
}
let responseObject = (try? JSONSerialization.jsonObject(with: data)) as? [String: Any]
completion(responseObject, nil)
}
task.resume()
}
И вы бы назвали это так:
sendRequest("someurl", parameters: ["foo": "bar"]) { responseObject, error in
guard let responseObject = responseObject, error == nil else {
print(error ?? "Unknown error")
return
}
// use `responseObject` here
}
Лично я бы использовал JSONDecoder в настоящее время и вернул пользовательский struct, а не словарь, но это действительно не актуально. Надеюсь, это иллюстрирует основную идею о том, как проценты кодируют параметры в URL запроса GET.
Мой первоначальный ответ, минус-минус вручную, ниже.
Параметры запроса GET включены в URL-адрес после ?:
http://www.example.com?key1=value1&key2=value2
Примечание. HTTPBody запроса не используется в запросах GET.
Строки key и value также должны быть процентными. Таким образом, в Swift 3 функция sendRequest может выглядеть так:
func sendRequest(url: String, parameters: [String: AnyObject], completionHandler: @escaping (Data?, URLResponse?, Error?) -> Void) -> URLSessionTask {
let parameterString = parameters.stringFromHttpParameters()
let requestURL = URL(string: url + "?" + parameterString)!
var request = URLRequest(url: requestURL)
request.httpMethod = "GET"
let task = URLSession.shared.dataTask(with: request, completionHandler: completionHandler)
task.resume()
return task
}
(Заметьте, я заметил, что вы использовали закрытие loadedData, которое вы определили в другом месте. Это хорошо, хотя я бы предпочел сделать его параметром метода, как и выше. Но, надеюсь, это иллюстрирует идею.)
Мы используем следующие категории String и Dictionary в Swift 3:
extension String {
/// Percent escapes values to be added to a URL query as specified in RFC 3986
///
/// This percent-escapes all characters besides the alphanumeric character set and "-", ".", "_", and "~".
///
/// http://www.ietf.org/rfc/rfc3986.txt
///
/// - returns: Returns percent-escaped string.
func addingPercentEncodingForURLQueryValue() -> String? {
let generalDelimitersToEncode = ":#[]@" // does not include "?" or "/" due to RFC 3986 - Section 3.4
let subDelimitersToEncode = "!$&'()*+,;="
var allowed = CharacterSet.urlQueryAllowed
allowed.remove(charactersIn: generalDelimitersToEncode + subDelimitersToEncode)
return addingPercentEncoding(withAllowedCharacters: allowed)
}
}
extension Dictionary {
/// Build string representation of HTTP parameter dictionary of keys and objects
///
/// This percent escapes in compliance with RFC 3986
///
/// http://www.ietf.org/rfc/rfc3986.txt
///
/// - returns: String representation in the form of key1=value1&key2=value2 where the keys and values are percent escaped
func stringFromHttpParameters() -> String {
let parameterArray = map { key, value -> String in
let percentEscapedKey = (key as! String).addingPercentEncodingForURLQueryValue()!
let percentEscapedValue = (value as! String).addingPercentEncodingForURLQueryValue()!
return "\(percentEscapedKey)=\(percentEscapedValue)"
}
return parameterArray.joined(separator: "&")
}
}
Смотрите предыдущую версию этого ответа для версий Swift 2.
qaru.site
PHP: POST и GET запросы для начинающих
Да да, все когда-то учились чему либо. Единственное что в этом плане отличает людей — кому-то учения даются легко, а кто-то не может разобраться в сути вопроса долгие месяцы. Сегодня мы поговорим о POST и GET запросах в HTML\PHP.
Сами запросы POST и GET (далее просто запросы) давно проросли корнями во все Интернет ресурсы. Если вдруг когда нибудь и появится альтернатива данным технологиям, то наверное это будет не скоро, да и, наверное, не нужно. Потому что наши запросы вполне полно выполняют задачу обмена данными между Интернет страницами.
Давайте рассмотри сначала запрос типа GET. Создадим файл index.php со стандартным html кодом, а так же разместим на нем форму, пусть это будет форма заказа товара.
<html>
<head></head>
<body>
<form action="index.php" method="GET">
<input type="text" name="orderName" />
<input type="text" name="count" />
<input type="submit" value="Заказать" />
</form>
</body>
</html>
Здесь обратим внимание на тег form. Он имеет два параметра action и method. Первый отвечает за адрес страницы, на которую мы будем передавать наши данные, второй — за метод, которым эти данные будут передаваться. Внутри данного тега описываются набор наших данных, которые мы хотим передавать. Обязательно данным присваиваются имена (параметр name). Так же обязателен input типа submit, который является кнопкой, по нажатию на которую происходит отправка данных.
Давайте сохраним наш файл и откроем его в браузере.
Путь нашей страницы в браузере «…/index.php». На самой странице мы видим два поля для ввода и кнопку. Давайте вобъем в наши поля что-нибудь и нажмем на кнопку «Заказать». Наша страница обновилась. Давайте посмотрим на ее адрес: «…/index.php?orderName=Test&count=12». (я вбил в первое поле слово ‘Test’ во второе ’12’). Как мы видим адрес страницы немного поменялся. Дело в том что передача параметров GET запросом осуществляется путем их приписывания в строку адреса страницы. Параметры отделяются от основного адреса символом ‘?’, а разные параметры символом ‘&’. Структура параметров следующая: название_параметра=значение. Название параметра будет совпадать со значением атрибута name в поле input.
Давайте немного подредактируем код страницы:
<html>
<head></head>
<body>
<form action="index.php" method="GET">
<input type="text" name="orderName" value=<?=$_GET["orderName"]?> >
<input type="text" name="count" value=<?=$_GET["count"]?> >
<input type="submit" value="Заказать" />
</form>
</body>
</html>
Теперь нажмем на кнопку «Заказать» еще раз. Как мы видим страница обновилась, однако наши поля остались заполнены. Это произошло благодаря тому, что мы указали значение по умолчанию для наших полей. Причем эти значения — полученный параметр GET. Как мы видим в PHP коде GET параметры являются массивом со строковым индексом равным имени параметра. Если сейчас поиграться с адресом сайта и в нем поменять значения параметров и нажать кнопку «Enter», то мы опять заметим картину с обновлением страницы и заполнением нашей формы.
Очевидно что пересылать секретные или служебные данные в GET запросе неправильно (и не безопасно). Его лучше использовать для передачи, например, id новости, которую стоит взять из базы или имени страницы, которую стоит отобразить.
Другое дело POST запрос. Работает он аналогично, однако не сохраняет параметры в строке адреса. Изменим нашу форму:
<html>
<head></head>
<body>
<form action="index.php" method="POST">
<input type="text" name="orderName" value=<?=$_POST["orderName"]?> >
<input type="text" name="count" value=<?=$_POST["count"]?> >
<input type="submit" value="Заказать" />
</form>
</body>
</html>
Как видно изменилось не многое, Однако! Откроем нашу страницу, вобъем что-нибудь в поля и нажмем кнопку «Заказать». Все сработало аналогично, однако (однако), как мы видим в строке запросов красуется адрес «…/index.php» без всякого рода параметров. Таким образом мы как бы «скрыли» наши данные от посторонних глаз. Конечно понятие скрыли, достаточно условное, так как эти данные все равно можно перехватить, но это уже другая история. Давайте допишем в наш адрес параметры «…/index.php?orderName=Trololo&count=100» и нажмем «Enter». Как мы видим страница загрузилась, однако даже не смотря на передачу параметров, поля оказались пустые. Это говорит о том что несмотря на большую схожесть, данные виды запросов никак не пересекаются между собой и если есть необходимость стоит писать обработчик для каждого типа запроса отдельно.
Думаю на этом хватит. Азы вопроса, я думаю, описаны с головой.
И еще немного… Не стоит забывать о проверке передаваемых параметров. Если Вы точно знаете, что параметр должен являться числом, то присекайте все попытки передачи не числового значения и т.п…
blog.foolsoft.ru
Методы и структура протокола HTTP [АйТи бубен]
HTTP (HyperText Transfer Protocol — «протокол передачи гипертекста») — протокол прикладного уровня передачи данных (изначально — в виде гипертекстовых документов). Основой HTTP является технология «клиент-сервер», то есть предполагается существование потребителей (клиентов), которые инициируют соединение и посылают запрос, и поставщиков (серверов), которые ожидают соединения для получения запроса, производят необходимые действия и возвращают обратно сообщение с результатом.
HTTP используется также в качестве «транспорта» для других протоколов прикладного уровня, таких как SOAP, XML-RPC, WebDAV.
Основным объектом манипуляции в HTTP является ресурс, на который указывает URI (Uniform Resource Identifier) в запросе клиента. Обычно такими ресурсами являются хранящиеся на сервере файлы, но ими могут быть логические объекты или что-то абстрактное. Особенностью протокола HTTP является возможность указать в запросе и ответе способ представления одного и того же ресурса по различным параметрам: формату, кодировке, языку и т. д. Именно благодаря возможности указания способа кодирования сообщения клиент и сервер могут обмениваться двоичными данными, хотя данный протокол является текстовым.
HTTP — протокол прикладного уровня, аналогичными ему являются Протокол FTP протокол передачи файлов и SMTP — простой протокол передачи почты. Обмен сообщениями идёт по обыкновенной схеме «запрос-ответ». Для идентификации ресурсов HTTP использует глобальные URI. В отличие от многих других протоколов, HTTP не сохраняет своего состояния. Это означает отсутствие сохранения промежуточного состояния между парами «запрос-ответ». Компоненты, использующие HTTP, могут самостоятельно осуществлять сохранение информации о состоянии, связанной с последними запросами и ответами. Браузер, посылающий запросы, может отслеживать задержки ответов. Сервер может хранить IP-адреса и заголовки запросов последних клиентов. Однако сам протокол не осведомлён о предыдущих запросах и ответах, в нём не предусмотрена внутренняя поддержка состояния, к нему не предъявляются такие требования.
Возможности протокола легко расширяются благодаря внедрению своих собственных заголовков, сохраняя совместимость с другими клиентами и серверами. Они будут игнорировать неизвестные им заголовки, но при этом можно получить необходимую функциональность при решении специфической задач.
HTTP/1.1 — текущая версия протокола. Новым в этой версии был режим «постоянного соединения»: TCP-соединение может оставаться открытым после отправки ответа на запрос, что позволяет посылать несколько запросов за одно соединение. Клиент теперь обязан посылать информацию об имени хоста, к которому он обращается, что сделало возможным более простую организацию виртуального хостинга.
HTTP не сохраняет информацию по транзакциям, поэтому в следующей транзакции приходится начинать все заново. Преимущество состоит в том, что HTTP сервер может обслужить в заданный промежуток времени гораздо больше клиентов, ибо устраняются дополнительные расходы на отслеживание сеансов от одного соединения к другому. Есть и недостаток: для сохранения информации по транзакциям более сложные CGI- программы должны пользоваться скрытыми полями ввода или внешними средствами, например Cookie.
Метод HTTP — последовательность из любых символов, кроме управляющих и разделителей, указывающая на основную операцию над ресурсом. Обычно метод представляет собой короткое английское слово, записанное заглавными буквами. Обратите внимание, что название метода чувствительно к регистру.
Каждый сервер обязан поддерживать как минимум методы GET и HEAD. Если сервер не распознал указанный клиентом метод, то он должен вернуть статус 501 (Not Implemented). Если серверу метод известен, но он не применим к конкретному ресурсу, то возвращается сообщение с кодом 405 (Method Not Allowed). В обоих случаях серверу следует включить в сообщение ответа заголовок Allow со списком поддерживаемых методов.
Кроме методов GET и HEAD, часто применяется метод POST.
- GET — запрос содержимого указанного ресурса. Может кешироваться.
- HEAD HTTP запрос — аналогичен методу GET, за исключением того, что в ответе сервера отсутствует тело. Проверка наличия ресурса. Может кэшироваться.
- POST — применяется для передачи пользовательских данных заданному ресурсу. Не кэшируется.
- OPTIONS — запрашивает информацию о коммуникационных параметрах сервера. Чтобы запросить данные обо всем сервере в целом, вместо URI запроса следует использовать символ *.
- PUT — помещает тело содержимого запроса по указанному URI.
PATCH — аналогично PUT, но применяется только к фрагменту ресурса.
DELETE — удаляет данные, находящиеся на сервере.
TRACE — требует, чтобы тело содержимого запроса было возвращено без изменений. Используется для отладки.
LINK — связывает информацию заголовка с документом на сервере.
UNLINK — о связь информации заголовка с документом на сервере.
Заголовки (параметры) HTTP запроса, ответа, сущности
Все заголовки в протоколе HTTP разделяются на четыре основных группы (в нижеприведенном порядке рекомендуется посылать заголовки получателю):
General Headers (Основные заголовки) — должны включаться в любое сообщение клиента и сервера.
Request Headers (Заголовки запроса) — используются только в запросах клиента.
Response Headers (Заголовки ответа) — только для ответов от сервера.
- Entity Headers (Заголовки сущности) — сопровождают каждую сущность сообщения. В отдельный класс заголовки сущности выделены для того, чтобы не путать их с заголовками запроса или заголовками ответа при передаче множественного содержимого (MIME).
Все необходимые для функционирования HTTP заголовки описаны в основных RFC. При необходимости можно создавать свои заголовки. Традиционно к именам таких дополнительных заголовков добавляют префикс «X-» для избежания конфликта имён с возможно существующими.
Строки после главной строки запроса (GET /index.html HTTP/1.1) имеют следующий формат: Параметр: значение. Таким образом задаются параметры запроса. Это является необязательным, все строки после главной строки запроса могут отсутствовать; в этом случае сервер принимает их значение по умолчанию или по результатам предыдущего запроса (при работе в режиме Connection: Keep-Alive).
Параметр Connection(соединение) — может принимать значения Keep-Alive и close. В HTTP 1.0 за передачей сервером затребованных данных следует разъединение с клиентом, и транзакция считается завершённой, если не передан заголовок Connection: Keep Alive. В HTTP 1.1 сервер по умолчанию не разрывает соединение и клиент может посылать другие запросы. Поскольку во многие документы встроены другие документы — изображения, кадры, апплеты и т.д., это позволяет сэкономить время и затраты клиента, которому в противном случае пришлось бы для получения всего одной страницы многократно соединяться с одним и тем же сервером. Таким образом, в HTTP 1.1 транзакция может циклически повторяться, пока клиент или сервер не закроет соединение явно.
Параметр User-Agent — значением является «кодовое обозначение» браузера.
Параметр Accept — список поддерживаемых браузером типов содержимого в порядке их предпочтения данным браузером.
- Параметр Referer — URL, с которого перешли на этот ресурс.
Параметр Host — имя домена, с которого запрашивается ресурс. Полезно, если на сервере имеется несколько виртуальных серверов под одним IP- адресом. В этом случае имя виртуального домена определяется по этому полю.
- Параметр Cache-Control — используется для проверки того, не изменился ли документ; может использоваться как в запросе, так и в ответе, т.е. и клиент, и сервер могут решать, сколько времени будут действительны передаваемые ими документы.
- Set-Cookie: name=value — указание браузеру сохранить Cookie. В этом случае, если куки поддерживаются браузером и их приём включён, браузер запоминает строку name=value (имя = значение) и отправляет её обратно серверу с каждым последующим запросом. Браузер при запросе следующей страницы вышлет заголовок Cookie: name=value. Этот запрос отличается от первого запроса тем, что содержит строку, которую сервер отправил браузеру ранее. Таким образом, сервер узнает, что этот запрос связан с предыдущим. Сервер отвечает, отправляя запрашиваемую страницу и, возможно, добавив новые куки. Для избежания межсайтового скриптинга(XSS) нужно устанавливать флаг HttpOnly, который делает cookies недоступными для скриптов со стороны клиента.
Формат ответа также имеет заголовок и тело, разделенное пустой строкой.
- Параметр Content-Type (тип содержимого) — содержит обозначение типа (MIME) содержимого ответа.
- Параметр Content-Length (длина содержимого) — длина содержимого ответа в байтах, а не символов. Начало работы с node.js — если тело сообщения содержит многобайтные символы, то необходимо использовать Buffer.byteLength() для определения количества использованных для кодирования байтов, вместо length.
- Параметр Transfer-Encoding используется, когда заранее не известен размер данных (Content-Length) в ответе сервера, например для динамически формируемых объектов. В этом случае используется механизм Chunked transfer encoding.
- Параметр Last-Modified (модифицирован в последний раз) (W3C Last-Modified) — дата и время последнего изменения документа. Используя его, клиент, подобно случаю с ETag, может обращаться к серверу с запросом ‘If-Modified-Since’ — в этом случае сервер должен сравнить дату последней модификации копии, сохраненной на клиенте, с актуальной датой последней модификации. Если они совпадут, это значит, что копия в кэше клиента не устарела, и повторное скачивание не нужно (код ответа ‘304 Not Modified’). Last-Modified также необходим для корректной обработки сайта роботами, которые используют информацию о дате модификации страниц в целях сортировки результатов поиска по дате, а также для определения частоты обновляемости Вашего сайта.
- Параметр ETag (объектная метка) — появился в HTTP 1.1(W3C ETag). ETag служит для присвоения каждой странице уникального идентификатора, значение которого меняется при изменении страницы (документа). ETag представляет собой хеш («отпечаток») байтов документа, если в документе изменится хоть один байт, то изменится и ETag. ETag используется при кэшировании документа. Этот заголовок сохраняется на клиенте, и в случае повторного обращения к документу позволяет браузеру обратиться к серверу с запросом ‘If-None-Match’, а сервер должен по значению ETag- метки определить, не изменился ли документ(страница), и если нет, ответить кодом ‘304 Not Modified’.
- Параметр Expires (истечение)(W3C Expires) — он сообщает браузеру, какой временной промежуток можно считать, что копия страницы в кэше свежа, и вообще не обращаться к серверу с запросами. Это удобно для таких файлов, о которых вы точно знаете, что они не изменятся ближайший час/день/месяц: фоновая картинка страницы, например.
Другие заголовки HTTP:
HTTP запрос состоит из трех частей: строки запроса (ответа), раздела заголовка, за которым следует необязательное тело. Заголовки представляют собой простой текст, при этом каждый заголовок отделен от следующего символом новой строки(\r\n), в то время как тело может быть как текстом, так и бинарными данными. Тело отделяется от заголовков двумя символами новой строки.
Заголовок запроса состоит из главной (первой) строки запроса и последующих строк, уточняющих запрос в главной строке. Последующие строки также могут отсутствовать.
Клиент инициирует транзакцию следующим образом:
- Клиент устанавливает связь с сервером по назначенному номеру порта, официальный номер порта по умолчанию — 80. Затем клиент посылает запрос документа, указав метод, адрес документа и номер версии HTTP. Например, в главной строке запроса
GET /index.html HTTP/1.1
используется метод GET, которым с помощью версии 1.1 HTTP запрашивается документ index.html.
- Клиент посылает информацию заголовка (необязательную, заголовок host обязателен), чтобы сообщить серверу информацию о своей конфигурации и данные о форматах документов, которые он может принимать. Вся информация заголовка указывается построчно, при этом в каждой строке приводится имя и значение. Например, приведённый ниже заголовок, посланный клиентом, содержит его имя и номер версии, а также информацию о некоторых предпочтительных для клиента типах документов:
Host: list.mail.ru User-Agent: Mozilla/5.0 (Ubuntu; X11; Linux x86_64; rv:8.0) Gecko/20100101 Firefox/8.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Завершается заголовок пустой строкой.
Послав запрос и заголовки, клиент может отправить и дополнительные данные, например, для CGI скриптов.
Сервер отвечает на запрос клиента следующим образом:
- Первая часть ответа сервера — строка состояния, содержащая три поля: версию HTTP, код состояния и описание. Поле версии содержит номер версии HTTP, которой данный сервер пользуется для передачи ответа. Код состояния — это трехразрядное число, обозначающее результат обработки сервером запроса клиента. Описание, следующее за кодом состояния, представляет собой просто понятный для человека текст, поясняющий код состояния. Например, строка состояния
HTTP/1.1 304 Not Modified
говорит о том, что сервер для ответа использует версию HTTP 1.1. Код состояния 304 означает, что клиент запросил документ методом GET, использовал заголовок If-Modified-Since или If-None-Match и документ не изменился с указанного момента.
- После строки состояния сервер передает клиенту информацию заголовка, содержащую данные о самом сервере и затребованном документе. Ниже приведен пример заголовка:
Date: Thu, 15 Dec 2011 09:34:15 GMT Server: Apache/2.2.21 (Debian) X-Powered-By: PHP/5.3.8-1+b1 Expires: Thu, 19 Nov 1981 08:52:00 GMT Cache-Control: no-store, no-cache, must-revalidate, post-check=0, pre-check=0 Pragma: no-cache Vary: Accept-Encoding Content-Encoding: gzip Keep-Alive: timeout=5, max=100 Connection: Keep-Alive Content-Type: text/html; charset=utf-8
Завершает заголовок пустая строка.
Если запрос клиента успешен, то посылаются затребованные данные. Это может быть копия файла или результат выполнения CGI- программы. Если запрос клиента удовлетворить нельзя, передаются дополнительные данные в виде понятного для пользователя разъяснения причин, по которым сервер не смог выполнить данный запрос.
Код состояния HTTP (HTTP status code) является частью первой строки ответа сервера. Он представляет собой целое число из трех цифр. Первая цифра указывает на класс состояния. За кодом ответа обычно следует отделённая пробелом поясняющая фраза на английском языке, которая разъясняет человеку причину именно такого ответа.
Клиент может не знать все коды состояния, но он обязан отреагировать в соответствии с классом кода. В настоящее время выделено пять классов кодов состояния:
1xx: Informational (Информационные). Информационные коды состояния, сообщающие клиенту, что сервер пребывает в процессе обработки запроса. Реакция клиента на данные коды не требуется;
2xx: Success (Успешно).
200 OK (Хорошо). Появился в HTTP/1.0. Успешный запрос ресурса. Если клиентом были запрошены какие-либо данные, то они находятся в заголовке и/или теле сообщения.
- 3xx: Redirection (Перенаправление(переадресация)). Коды класса 3xx сообщают клиенту, что для успешного выполнения операции необходимо сделать другой запрос (как правило по другому URI). Из данного класса пять кодов 301, 302, 303, 305 и 307 относятся непосредственно к перенаправлениям (редирект). Адрес, по которому клиенту следует произвести запрос, сервер указывает в заголовке Location. Многие клиенты при перенаправлениях с кодами 301 и 302 ошибочно применяют метод GET ко второму ресурсу несмотря на то, что к первому запрос был с иным методом. Чтобы избежать недоразумений в версии HTTP/1.1 были введены коды 303 и 307 вместо 302. Изменять метод запроса нужно только если сервер ответил 303. В остальных случаях следующий запрос производить с исходным методом.
- 302 Found (Найдено). Введено в HTTP/1.0. Запрошенный документ временно доступен по другому URI, указанному в заголовке в поле Location.
- 4xx: Client Error (Ошибка клиента). Класс кодов 4xx предназначен для указания ошибок со стороны клиента. При использовании всех методов, кроме HEAD HTTP запрос, сервер должен вернуть в теле сообщения гипертекстовое пояснение для пользователя.
- 404 Not Found (Не найдено). Появился в HTTP/1.0. Сервер понял запрос, но не нашёл соответствующего ресурса по указанному URI.
5xx: Server Error (Ошибка сервера)
Ссылки по теме HTTP 1.1
HTTP/2 (изначально HTTP/2.0) — вторая крупная версия сетевого протокола HTTP. Протокол основан на SPDY (HTTP-совместимый протокол, разработанный Google).
19 декабря 2016 года Google объявил, что GoogleBot теперь поддерживает HTTP/2.
Протокол HTTP/2 является бинарным. По сравнению с предыдущим стандартом изменены способы разбития данных на фрагменты и транспортирования их между сервером и клиентом.
В HTTP/2 сервер имеет право послать то содержимое, которое ещё не было запрошено клиентом. Это позволит серверу сразу выслать дополнительные файлы, которые потребуются браузеру для отображения страниц, без необходимости анализа браузером основной страницы и запрашивания необходимых дополнений.
загрузка…
http.txt · Последние изменения: 2018/08/12 01:49 (внешнее изменение)
wiki.dieg.info
Получение данных из строки запроса в PHP
Получение данных из строки запроса
Последнее обновление: 1.11.2015
Другим распространенным способом отправки данных на сервер является метод GET. Его сущность состоит в том, что данные передаются в адресной строке браузера.
Итак, создадим простой скрипт get.php со следующим содержимым:
<?php
$login = "не определен";
$age = "не определен";
if(isset($_GET['login'])){
$login = $_GET['login'];
}
if(isset($_GET['age'])){
$age = $_GET['age'];
}
echo "Ваш логин: $login <br> Ваш возраст: $age";
?>
В PHP по умолчанию определен глобальный ассоциативный массив $_GET, который хранит все значения, передаваемые в строке запроса.
Его действие подобно массиву $_POST: также по ключу мы можем получить передаваемое значение.
Теперь обратимся к этому скрипту, например, так http://localhost:8080/get.php?login=mailcom&age=22:
Все параметры передаются на сервер в следующей форме: get.php?параметр1=значение1&параметр2=значение2&параметрN=значениеN.
Чтобы передать список параметров, после названия скрипта ставится знак вопроса, за которым идут наборы параметров и их значений. Название параметра и будет ключом
в массиве $_GET. Наборы параметр-значения отделяются друг от друга знаком амперсанда (&)
Данные формы мы также можем передать через запрос GET. Для этого достаточно у формы указать атрибут method="get", и тогда все значения
полей формы также будут передаваться через строку запроса:
<form method="GET"> Логин: <input type="text" name="login" /><br><br> Пароль: <input type="text" name="password" /><br><br> <input type="submit" value="Отправить"> </form>
metanit.com