Парсинг XML на python — Stack Overflow на русском
Вопрос следующий нужен парсинг XML файла, необходимо вытащить поочередно определенные теги, например тег name
Код следующий, не работающий
import xml.etree.ElementTree as ET
root = ET.parse('файл.xml').getroot()
for type_tag in root.findall('shop/offers/offer'):
value = type_tag.get('name')
print(value)
Файл тут https://sotiknadom.ru/snprice.xml
Очень прошу о помощи!
- python
- xml
Вариант с BeautifulSoup
# pip install bs4 lxml (если не установлены)
from bs4 import BeautifulSoup as Soup
if __name__ == '__main__':
with open('snprice.xml', 'r', encoding='utf-8') as xml:
soup = Soup(xml.read(), 'lxml')
names = [offer.find('name').text for offer in soup.find_all('offer')]
print(names, sep='\n')
А это рабочий вариант Вашей реализации:
import xml.etree.ElementTree as ET
xml_file = ET.parse('snprice.xml')
for type_tag in xml_file. findall('shop/offers/offer'):
value = type_tag.find('name').text
print(value)
findall('shop/offers/offer'):
value = type_tag.find('name').text
print(value)
 findall('shop/offers/offer'):
value = type_tag.find('name').text
print(value)
findall('shop/offers/offer'):
value = type_tag.find('name').text
print(value)
Ну или можно немного сократить код:
from xml.etree.ElementTree import parse
print(
*(
type_tag.text for type_tag in parse('snprice.xml').findall('shop/offers/offer/name')
),
sep='\n'
)
Не рекомендуется, если не уверены в исходных данных и нужны какие либо проверки в ходе выполнения
1
Всем, кто столкнется с такой структурой XML:
<?xml version="1.0"?> <feed xmlns="http://www.w3.org/2005/Atom" xmlns:g="http://base.google.com/ns/1.0"> <title>SotikNadom</title> <link rel="alternate" type="text/html">https://sotiknadom.ru/</link> <updated>2020-08-01T06:03:43Z</updated> <entry > **<g:**title>Монитор Acer K242HLbd (черный)</g:title> **<g:**link>https://sotiknadom.ru/monitory/monitor-acer-k242hlbd-chernyj</g:link> **<g:**price>8800.00 RUB</g:price> **<g:**id>51</g:id> **<g:**availability>in stock</g:availability> **<g:**condition>new</g:condition>

Делать так:
import xml.etree.ElementTree as ET
xml_file = ET.parse('sngoogle2.xml')
for type_tag in xml_file.findall**('{http://www.w3.org/2005/Atom}entry')**:
value = type_tag.find**('{http://base.google.com/ns/1.0}price')**.text
print(value)
Документация: https://docs.python.org/3/library/xml.etree.elementtree.html#parsing-xml-with-namespaces
Зарегистрируйтесь или войдите
Регистрация через Google
Регистрация через Facebook
Регистрация через почту
Отправить без регистрации
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
Нажимая на кнопку «Отправить ответ», вы соглашаетесь с нашими пользовательским соглашением, политикой конфиденциальности и политикой о куки
python — Парсинг XML файла таблицы с передачей в DataFrame
Воспользуйтесь данным решением (с) Austin Taylor:
import xml.etree.ElementTree as ET import pandas as pd class XML2DataFrame: def __init__(self, xml_data): self.root = ET.XML(xml_data) def parse_root(self, root): return [self.parse_element(child) for child in iter(root)] def parse_element(self, element, parsed=None): if parsed is None: parsed = dict() for key in element.keys(): parsed[key] = element.attrib.get(key) if element.text: parsed[element.tag] = element.text for child in list(element): self.parse_element(child, parsed) return parsed def process_data(self): structure_data = self.parse_root(self.root) return pd.DataFrame(structure_data) xml2df = XML2DataFrame(xml_data) df = xml2df.process_data()
Пример:
with open(r"D:\download\20200915_ED807_full.xml") as f:
xml_data = f.read()
xml2df = XML2DataFrame(xml_data)
df = xml2df.process_data()
результат:
In [32]: df
Out[32]:
BIC NameP CntrCd Rgn Ind . .. SWBIC DefaultSWBIC \
0 041280103 УФК по Астраханской области RU 12 414056 ... NaN NaN
1 044525597 КУ "МИЛЛЕНИУМ БАНК" (ЗАО) - ГК "АСВ" RU 45 109240 ... NaN NaN
2 044525603 КУ ЗАО "ИПОТЕК БАНК" - ГК "АСВ" RU 45 109240 ... NaN NaN
3 044525608 КУ ООО КБ "ДОРИС БАНК" - ГК "АСВ" RU 45 109240 ... NaN NaN
4 044525652 КУ КБ "ПРИСКО КАПИТАЛ БАНК", АО - ГК... RU 45 109240 ... NaN NaN
... ... ... ... .. ... ... ... ...
2368 298003187 Департамент финансов г. Якутска RU 98 677000 ... NaN NaN
2369 015354008 УФК по Оренбургской области RU 53 460014 ... NaN NaN
2370 200000099 Территориальная избирательная комисс... RU 36 443110 ... NaN NaN
2371 200001413 Территориальная избирательная комисс. 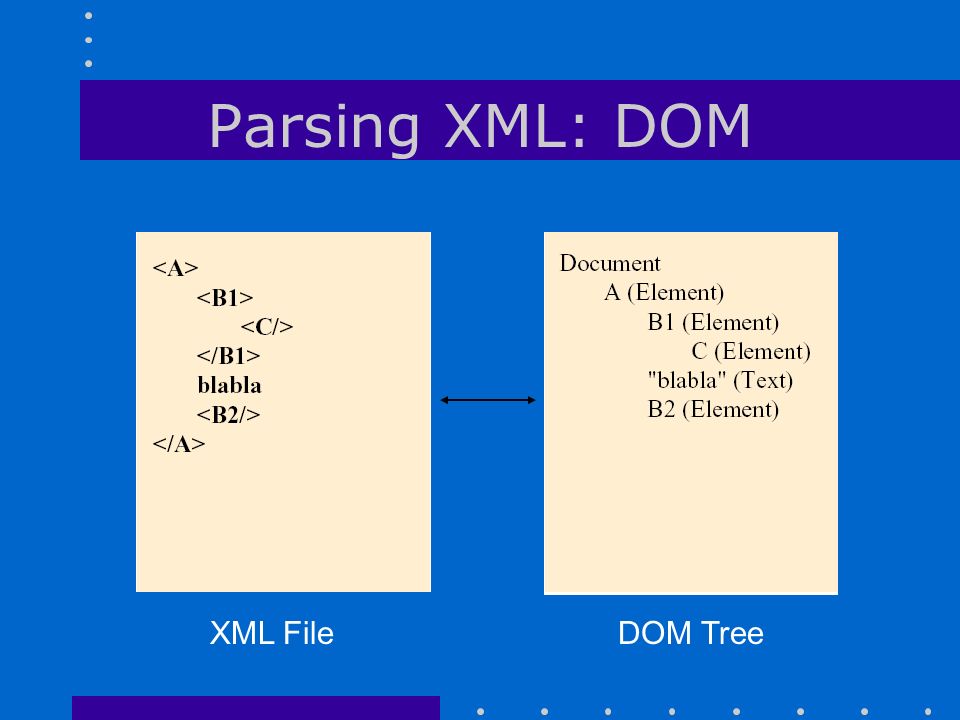 .. SWBIC DefaultSWBIC \
0 041280103 УФК по Астраханской области RU 12 414056 ... NaN NaN
1 044525597 КУ "МИЛЛЕНИУМ БАНК" (ЗАО) - ГК "АСВ" RU 45 109240 ... NaN NaN
2 044525603 КУ ЗАО "ИПОТЕК БАНК" - ГК "АСВ" RU 45 109240 ... NaN NaN
3 044525608 КУ ООО КБ "ДОРИС БАНК" - ГК "АСВ" RU 45 109240 ... NaN NaN
4 044525652 КУ КБ "ПРИСКО КАПИТАЛ БАНК", АО - ГК... RU 45 109240 ... NaN NaN
... ... ... ... .. ... ... ... ...
2368 298003187 Департамент финансов г. Якутска RU 98 677000 ... NaN NaN
2369 015354008 УФК по Оренбургской области RU 53 460014 ... NaN NaN
2370 200000099 Территориальная избирательная комисс... RU 36 443110 ... NaN NaN
2371 200001413 Территориальная избирательная комисс.
.. SWBIC DefaultSWBIC \
0 041280103 УФК по Астраханской области RU 12 414056 ... NaN NaN
1 044525597 КУ "МИЛЛЕНИУМ БАНК" (ЗАО) - ГК "АСВ" RU 45 109240 ... NaN NaN
2 044525603 КУ ЗАО "ИПОТЕК БАНК" - ГК "АСВ" RU 45 109240 ... NaN NaN
3 044525608 КУ ООО КБ "ДОРИС БАНК" - ГК "АСВ" RU 45 109240 ... NaN NaN
4 044525652 КУ КБ "ПРИСКО КАПИТАЛ БАНК", АО - ГК... RU 45 109240 ... NaN NaN
... ... ... ... .. ... ... ... ...
2368 298003187 Департамент финансов г. Якутска RU 98 677000 ... NaN NaN
2369 015354008 УФК по Оренбургской области RU 53 460014 ... NaN NaN
2370 200000099 Территориальная избирательная комисс... RU 36 443110 ... NaN NaN
2371 200001413 Территориальная избирательная комисс.
столбцы DataFrame:
In [33]: df.columns Out[33]: Index(['BIC', 'NameP', 'CntrCd', 'Rgn', 'Ind', 'Tnp', 'Nnp', 'Adr', 'DateIn', 'PtType', 'Srvcs', 'XchType', 'UID', 'ParticipantStatus', 'Account', 'RegulationAccountType', 'CK', 'AccountCBRBIC', 'AccountStatus', 'RegN', 'Rstr', 'RstrDate', 'PrntBIC', 'SWBIC', 'DefaultSWBIC', 'EnglName', 'AccRstr', 'AccRstrDate'], dtype='object')
все значения первой строки фрейма:
In [34]: pd.set_option("display.max_rows", 30)
In [35]: df.iloc[0]
Out[35]:
BIC 041280103
NameP УФК по Астраханской области
CntrCd RU
Rgn 12
Ind 414056
Tnp г
Nnp Астрахань
Adr ул Латышева, 6 Г
DateIn 2013-01-09
PtType 52
Srvcs 3
XchType 1
UID 1280002005
ParticipantStatus PSAC
Account 40116810600000010015
RegulationAccountType TRSA
CK 99
AccountCBRBIC 041280002
AccountStatus ACAC
RegN NaN
Rstr NaN
RstrDate NaN
PrntBIC NaN
SWBIC NaN
DefaultSWBIC NaN
EnglName NaN
AccRstr NaN
AccRstrDate NaN
Python XML Parsing — полные примеры
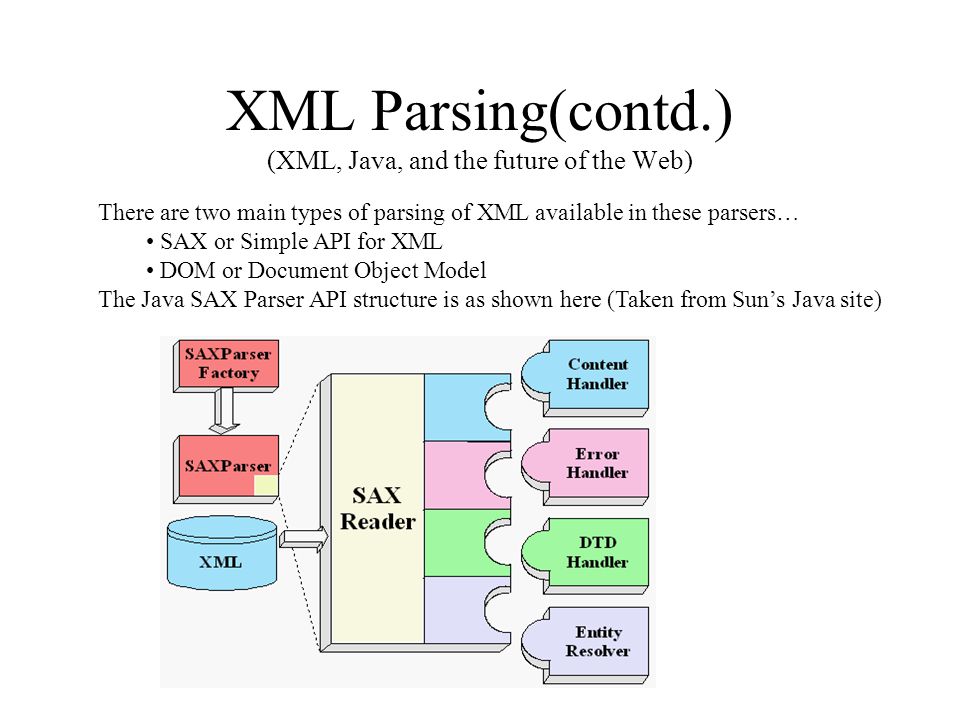
Python XML Parsing
Python XML Parsing — Мы научимся анализировать XML-документы на языке программирования Python.
- ElementTree
- cElementTree
- minidom
- objectify
Мы рассмотрим примеры для анализа XML-файла, извлечения атрибутов, извлечения элементов и т. д. для всего вышеперечисленного. библиотеки.
Мы рассмотрим следующий XML-файл в качестве примеров в этом руководстве.
<праздничный год="2017">
<тип праздника="другое">
1 января
Новый год
<тип праздника="общественный">
2 октября
Ганди Джаянти
Попробуйте онлайн
ElementTree — Python XML Parser
ElementTree поставляется вместе с python.
Получить имя корневого тега
example.py — Программа Python
# Python XML Parsing импортировать xml.
 etree.ElementTree как ET
корень = ET.parse('sample.xml').getroot()
тег = корень.тег
print(tag)
etree.ElementTree как ET
корень = ET.parse('sample.xml').getroot()
тег = корень.тег
print(tag) Попробуйте онлайн
Вывод
tutorialkart@arjun-VPCEh36EN:~/PycharmProjects/PythonTutorial/parsing$ python python_xml_parse_ElementTree.py праздники
Получить атрибуты корня
example.py — Программа Python
# Python XML Parsing
импортировать xml.etree.ElementTree как ET
корень = ET.parse('sample.xml').getroot()
# получить все атрибуты
атрибуты = root.attrib
печать (атрибуты)
# извлечь определенный атрибут
год = атрибуты.get('год')
print('year : ',year) Try Online
Output
tutorialkart@arjun-VPCEh36EN:~/PycharmProjects/PythonTutorial/parsing$ python python_xml_parse_ElementTree.py
{'год': '2017'}
год : 2017 Перебор дочерних узлов корня
example. py — Программа Python
py — Программа Python
# Python XML Parsing
импортировать xml.etree.ElementTree как ET
корень = ET.parse('sample.xml').getroot()
# перебираем все узлы с именем тега - праздник
на праздник в root.findall('праздник'):
print(праздник) Попробуйте онлайн
Вывод
tutorialkart@arjun-VPCEh36EN:~/PycharmProjects/PythonTutorial/parsing$ python python_xml_parse_ElementTree.py <Элемент «праздник» по адресу 0x7fb5a107d3b8> <Элемент «праздник» по адресу 0x7fb59fc2f868>
Перебрать дочерние узлы корня и получить их атрибуты
example.py — Программа Python
# Python XML Parsing
импортировать xml.etree.ElementTree как ET
корень = ET.parse('sample.xml').getroot()
# перебираем дочерние узлы
на праздник в root.findall('праздник'):
# получить все атрибуты узла
атрибуты = праздник.атриб
печать (атрибуты)
# получить определенный атрибут
тип = атрибуты. получить('тип')
print(type)  получить('тип')
print(type)
получить('тип')
print(type) Попробуйте онлайн
Вывод
tutorialkart@arjun-VPCEh36EN:~/PycharmProjects/PythonTutorial/parsing$ python python_xml_parse_ElementTree.py
{'тип': 'другое'}
Другой
{'тип': 'общедоступный'}
public Доступ к элементам узла
example.py — Программа Python
# Python XML Parsing
импортировать xml.etree.ElementTree как ET
корень = ET.parse('sample.xml').getroot()
# перебираем все узлы
на праздник в root.findall('праздник'):
# элемент доступа - имя
имя = праздник.найти('имя').текст
печать('имя:', имя)
# элемент доступа - дата
дата = праздник.найти('дата').текст
печать('дата:', дата) Попробуйте онлайн
Вывод
tutorialkart@arjun-VPCEh36EN:~/PycharmProjects/PythonTutorial/parsing$ python python_xml_parse_ElementTree.
 py
Название: Новый год
дата: 1 января
Имя: Ганди Джаянти
date : 2 октября
py
Название: Новый год
дата: 1 января
Имя: Ганди Джаянти
date : 2 октября Доступ к элементам узла без знания имен их тегов
example.py — Программа Python
# Python XML Parsing
импортировать xml.etree.ElementTree как ET
корень = ET.parse('sample.xml').getroot()
на праздник в root.findall('праздник'):
# доступ ко всем элементам в узле
для элемента в отпуске:
ele_name = элемент.тег
ele_value = holiday.find(element.tag).text
print(ele_name, ' : ', ele_value) Попробуйте онлайн
Вывод
tutorialkart@arjun-VPCEh36EN:~/PycharmProjects/PythonTutorial/parsing$ python python_xml_parse_ElementTree.py дата: 1 января Название: Новый год дата : 2 октября name : Gandhi Jayanti
❮ Предыдущая Следующая ❯
Анализ XML в сценариях данных
Начиная с Avi Vantage 21.1.1, появилась возможность анализа полезных данных XML в сценариях данных. Используя эту возможность, вы можете получить представление о полезной нагрузке XML или выполнить некоторые действия на основе параметров в теле XML.
Используя эту возможность, вы можете получить представление о полезной нагрузке XML или выполнить некоторые действия на основе параметров в теле XML.
Avi добавил анализатор XML, который используется для обработки XML.
Анализаторам XML требуется оболочка. Для этого в начале DataScript используется анализатор Avi XML:
локальный avixmlparser = требуется ("avixmlparser")
успех, документ = avixmlparser.parse(body)
успех, содержимое = avixmlparser.search(документ, xpath)
avixmlparser выполняет две функции:
- Анализ
- Поиск
| Функция | Параметр | Возвращает |
|---|---|---|
| Анализ | Тело запроса | Возвращает два значения: 1. Первое значение показывает, был ли синтаксический анализ успешным. 2. Второе значение представляет собой проанализированную информацию. Если синтаксический анализ завершается неудачей, то второе значение представляет собой информацию об ошибке.  |
| Поиск | 1. Объект документа 2. XPath: Вы можете использовать выражения XPath для извлечения соответствующих атрибутов, таких как пароль и имя пользователя, из полезных данных XML | Возвращает два значения: 1. Первое значение показывает, успешен ли синтаксический анализ. 2. Второе значение отображает результаты поиска |
Варианты использования
- Horizon — серверы UAG балансировки нагрузки:
XML — это протокол управления для Horizon. В полезных данных содержится много информации, которая может представлять интерес для выполнения любых настраиваемых действий, таких как имя пользователя, тип клиента (клиент Horizon: Windows/MAC и т. д.).
Примечание . Если вы используете сценарии использования, связанные с DataScript для Horizon, убедитесь, что буферизация тела запроса отключена для URL-адресов /ice. В противном случае туннельное соединение не будет установлено.
Чтобы выборочно отключить буферизацию тела в DataScript, добавьте следующее под событием запроса:
Событие HTTP_REQ:
локальная функция startup_with(str, start)
вернуть строку: sub (1, # start) == начало
конец
если start_with(avi.http.get_uri(), "/ice/tunnel"), то
avi.http.set_request_body_buffer_size(0)
конец
Событие HTTP_REQ_DATA:
локальный avixmlparser = требуется ("avixmlparser")
локальное тело = avi.http.get_req_body(2048)
local xpath = "/broker/do-submit-authentication/screen[name='windows-password']/params/param[name='username']/values/value"
локальный succ_parse, документ = avixmlparser.parse (тело)
если succ_parse то
локальный succ_search, содержимое = avixmlparser.search (документ, xpath)
если succ_search то
for i, v в ipairs(content) do
если v ~= ноль, то
avi.vs.log(v) конец
конец
иначе avi.vs.log(содержимое)
конец
иначе avi.vs.log(документ)
конец
Здесь мы сначала получаем тело запроса.
Затем анализируется тело запроса.
Если синтаксический анализ прошел успешно, для поиска в теле используется xpath.
При успешном поиске отображаются результаты поиска.
мы сначала получаем тело запроса. Затем мы разбираем тело запроса. Если синтаксический анализ прошел успешно, мы используем xpath для поиска тела, и если поиск успешен, мы получаем результаты поиска.
Если поиск завершился неудачей, информация об ошибке может быть зарегистрирована.
Журналы отображаются, как показано ниже:
- Наиболее распространенным примером является печать имени пользователя в журналах приложения Avi.
DataScript для извлечения имени пользователя из запроса XML API показан ниже:
локальный avixmlparser = требуется ("avixmlparser")
локальное тело = avi.http.get_req_body(2048)
local xpath = "/broker/do-submit-authentication/screen[name='windows-password']/params/param[name='username']/values/value"
локальный succ_parse, документ = avixmlparser.