Ошибка — Vampyr`s House!
|
|
|
 Ссылка, по которой вы следовали, вероятно, устарела.
Ссылка, по которой вы следовали, вероятно, устарела.
 Все авторские права принадлежат их владельцам ( в случае указания) или владельцу сайта, если автор не указан. Все авторские права принадлежат их владельцам ( в случае указания) или владельцу сайта, если автор не указан.Копирование материалов с сайта возможно только в случае размещения ссылки на первоисточник. |
Массивы bash / Хабр
Предлагаю вашему вниманию перевод статьи Митча Фрейзера (Mitch Frazier) «Bash Arrays» с сайта linuxjournal.com.
Если вы используете «стандартную» оболочку *NIX-системы, возможно, вы не знакомы с такой полезной особенностью bash как массивы. Хотя массивы в bash не так круты, как в P-языках (Perl, Python и PHP) и других языках программирования, они часто бывают полезны.
Bash-массивы имеют только численные индексы, но они не обязательны к использованию, то есть вы не должны определять значения всех индексов в явном виде. Массив целиком может быть определен путем заключения записей в круглые скобки:
arr=(Hello World)
Отдельные записи могут быть определены с помощью знакомого всем синтаксиса (от Бейсика (да простит меня Дейкстра — прим. переводчика) до Фортрана):
переводчика) до Фортрана):
arr[0]=Hello arr[1]=World
Правда, обратное выглядит сравнительно более уродливо. Если нужно обратиться к определенной записи, тогда:
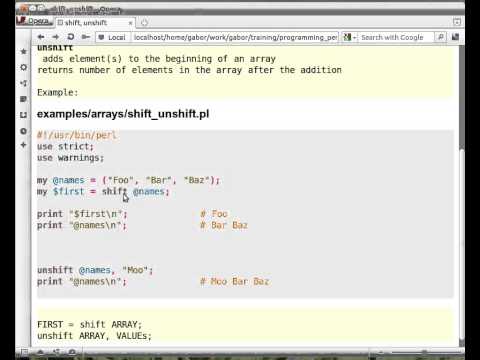
echo ${arr[0]} ${arr[1]}
Из страницы man:
«
Кроме того, доступны следующие странноватые конструкции:
${arr[*]} # Все записи в массиве
${!arr[*]}# Все индексы в массиве
${#arr[*]}# Количество записей в массиве
${#arr[0]}# Длина первой записи (нумерация с нуля)
${!arr[*]} — сравнительно новое дополнение в bash и не является частью оригинальной реализации. Следующая конструкция демонстрирует пример простого использования массива. Обратите внимание на «[index]=value», это позволяет назначить конкретное значение конкретному номеру записи.
#!/bin/bash
array=(one two three four [5]=five)
echo "Array size: ${#array[*]}" # Выводим размер массива
echo "Array items:" # Выводим записи массива
for item in ${array[*]}
do
printf " %s\n" $item
done
echo "Array indexes:" # Выводим индексы массива
for index in ${!array[*]}
do
printf " %d\n" $index
done
echo "Array items and indexes:" # Выводим записи массива с их индексами
for index in ${!array[*]}
do
printf "%4d: %s\n" $index ${array[$index]}
done
Запуск скрипта породит следующий вывод:
Array size: 5
Array items:
one
two
three
four
five
Array indexes:
0
1
2
3
5
Array items and indexes:
0: one
1: two
2: three
3: four
5: five
Обратите внимание, что символ «@» может быть использован вместо «*» в конструкциях типа {arr[*]}, результат будет одинаковым за исключением разворачивания записи в кавычках.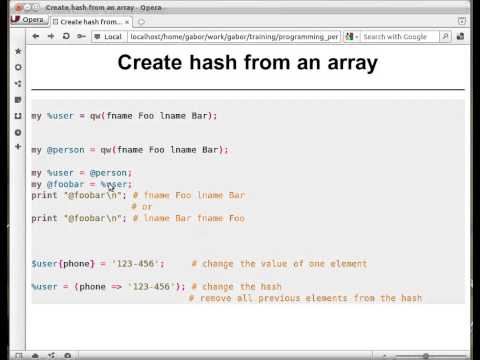 «$*» и «$@» выведут записи в кавычках, «${arr[*]}» вернет каждую запись как одно слово, «${arr[@]}» вернет каждую запись в виде отдельных слов.
«$*» и «$@» выведут записи в кавычках, «${arr[*]}» вернет каждую запись как одно слово, «${arr[@]}» вернет каждую запись в виде отдельных слов.
Следующий пример покажет, как кавычки и конструкции без кавычек возвращают строки (особенно важно, когда в этих строках есть пробелы):
#!/bin/bash
array=("first item" "second item" "third" "item")
echo "Number of items in original array: ${#array[*]}"
for ix in ${!array[*]}
do
printf " %s\n" "${array[$ix]}"
done
echo
arr=(${array[*]})
echo "After unquoted expansion: ${#arr[*]}"
for ix in ${!arr[*]}
do
printf " %s\n" "${arr[$ix]}"
done
echo
arr=("${array[*]}")
echo "After * quoted expansion: ${#arr[*]}"
for ix in ${!arr[*]}
do
printf " %s\n" "${arr[$ix]}"
done
echo
arr=("${array[@]}")
echo "After @ quoted expansion: ${#arr[*]}"
for ix in ${!arr[*]}
do
printf " %s\n" "${arr[$ix]}"
done
Вывод при запуске:
Number of items in original array: 4
first item
second item
third
item
After unquoted expansion: 6
first
second
item
third
item
After * quoted expansion: 1
first item second item third item
After @ quoted expansion: 4
first item
second item
third
item
Perl ищет строку, содержащуюся в массиве
У меня есть массив со следующими значениями:
push @fruitArray, "apple|0"; push @fruitArray, "яблоко | 1"; push @fruitArray, "груша | 0"; push @fruitArray, "груша | 0";
Я хочу узнать, существует ли в этом массиве строка «яблоко» (игнорируя «|0» «|1»)
Я использую:
$fruit = 'apple';
if( $fruit ~~ @fruitArray ){ print "Я нашел яблоко"; }
Что не работает.
1
Не использовать интеллектуальное сопоставление. Он никогда не работал должным образом по ряду причин, и теперь он помечен как Experimental
. В этом случае вы можете использовать вместо него grep вместе с соответствующим шаблоном регулярного выражения
Эта программа проверяет каждый элемент @fruitArray на посмотрите, начинается ли он с букв $fruit , за которыми следует вертикальная черта | . grep возвращает количество элементов, соответствующих шаблону, то есть 9\Q$fruit\E\|/, @fruitArray)) { print «Я нашел яблоко»; }
что выводит:
Я нашел яблоко
-
\Q...\Eпреобразует вашу строку в шаблон регулярного выражения. - В поисках
|не позволяет найти фрукт, название которого начинается с названия фрукта, который вы ищете.
Просто и эффективно. \Q$fruit\E|/, @fruitArray;
\Q$fruit\E|/, @fruitArray;
4
Если ваш Perl не является устаревшим, вы можете использовать подпрограмму first из модуля List::Util (который стал основным модулем в Perl 5.8) для эффективной проверки:
use List::Util qw { первый };
мой $first_fruit = first { /\Q$fruit\E/ } @fruitArray;
if (defined $first_fruit) { print "Я нашел $fruit\n"; }
Вы можете приблизиться к солнцу smartmatch, не растопив крылья, используя match::simple :
use match::simple; my @fruits = qw/яблоко|0 яблоко|1 груша|0 груша|0/; $fruit = qr/яблоко/ ; сказать "найден $фрукт", если $фрукт |M| \@фрукты ;
Существует также функция match() , если инфикс [M] плохо читается.
Мне нравится, как match::simple делает почти все, что я ожидал от ~~ без какой-либо неожиданной сложности. Если вы свободно владеете Perl, это, вероятно, не то, что вам нужно, но особенно с match() — код можно сделать приятно читаемым. .. за счет использования ссылок, и т.д. .
.. за счет использования ссылок, и т.д. .
Не используйте grep , это зациклит весь массив, даже если он найдет то, что вы ищете в первом индексе, поэтому это неэффективно.
это вернет true, если найдет подстроку «яблоко», а затем вернет и не закончит итерацию по остальной части массива
# принимает ссылку на массив в качестве первого параметра
суб найти_яблоко {
@array_input = @{$_[0]};
foreach $плод (@array_input){
если (индекс ($ фрукт, 'яблоко')! = -1) {
вернуть 1;
}
}
}
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Текстовые шаблоны Perl для поиска и замены
Изначально Perl был разработан Ларри Уоллом как гибкий язык обработки текста. За прошедшие годы он превратился в полноценный язык программирования, уделяя особое внимание обработке текста. Когда всемирная паутина стала популярной, Perl стал стандартом де-факто для создания сценариев CGI. Сценарий CGI — это небольшая часть программного обеспечения, которое создает динамическую веб-страницу на основе базы данных и/или информации, полученной от человека, посещающего веб-сайт. Поскольку сценарий CGI в основном представляет собой сценарий обработки текста, Perl был и остается естественным выбором.
За прошедшие годы он превратился в полноценный язык программирования, уделяя особое внимание обработке текста. Когда всемирная паутина стала популярной, Perl стал стандартом де-факто для создания сценариев CGI. Сценарий CGI — это небольшая часть программного обеспечения, которое создает динамическую веб-страницу на основе базы данных и/или информации, полученной от человека, посещающего веб-сайт. Поскольку сценарий CGI в основном представляет собой сценарий обработки текста, Perl был и остается естественным выбором.
Из-за того, что Perl ориентирован на управление текстом и его изменение, текстовые шаблоны регулярных выражений являются неотъемлемой частью языка Perl. Это отличается от большинства других языков, где регулярные выражения доступны в виде дополнительных библиотек. В Perl вы можете использовать оператор m//, чтобы проверить, может ли регулярное выражение соответствовать строке, например:
if ($string =~ m/regex/) {
напечатать «совпадение»;
} еще {
вывести «нет совпадения»;
} Выполнить поиск и замену регулярных выражений так же просто:
$string =~ s/regex/replacement/g;
Я добавил «g» после последней косой черты. «g» означает «глобальный», что указывает Perl заменить все совпадения, а не только первое. Параметры обычно указываются вместе с косой чертой, например «/g», даже если вы не добавляете дополнительную косую черту и даже если вместо косой черты можно использовать любой символ, не являющийся словом. Если ваше регулярное выражение содержит косые черты, используйте другой символ, например s!regex!replacement!g.
«g» означает «глобальный», что указывает Perl заменить все совпадения, а не только первое. Параметры обычно указываются вместе с косой чертой, например «/g», даже если вы не добавляете дополнительную косую черту и даже если вместо косой черты можно использовать любой символ, не являющийся словом. Если ваше регулярное выражение содержит косые черты, используйте другой символ, например s!regex!replacement!g.
Вы можете добавить «i», чтобы сделать регулярное выражение нечувствительным к регистру. Вы можете добавить «s», чтобы точка соответствовала новой строке. Вы можете добавить «m», чтобы доллар и каретка совпадали в новых строках, встроенных в строку, а также в начале и конце строки.
Вместе вы получите что-то вроде m/regex/sim;
Специальные переменные, связанные с регулярными выражениями
Perl имеет множество специальных переменных, которые заполняются после каждого m// или s/// соответствия регулярному выражению. $1, $2, $3 и т. д. содержат обратные ссылки. $+ содержит последнюю обратную ссылку (с наибольшим номером). $& (долларовый амперсанд) содержит полное совпадение с регулярным выражением.
$+ содержит последнюю обратную ссылку (с наибольшим номером). $& (долларовый амперсанд) содержит полное совпадение с регулярным выражением.
@- массив индексов начала совпадения в строке. $-[0] содержит начало всего совпадения регулярного выражения, $-[1] начало первой обратной ссылки и т. д. Аналогично, @+ содержит позиции конца совпадения. Чтобы получить длину совпадения, вычтите $+[0] из $-[0].
В Perl 5.10 и более поздних версиях вы можете использовать ассоциативный массив %+ для сопоставления текста с именованными группами захвата. Например, $+{name} содержит текст, соответствующий группе «name». Perl не предоставляет способа получить совпадающие позиции захваченных групп, ссылаясь на их имена. Так как именованные группы также нумеруются, вы можете использовать @- и @+ для именованных групп, но вам придется вычислить номер группы самостоятельно.
$’ (доллар, за которым следует апостроф или одинарная кавычка) содержит часть строки после (справа) совпадения с регулярным выражением.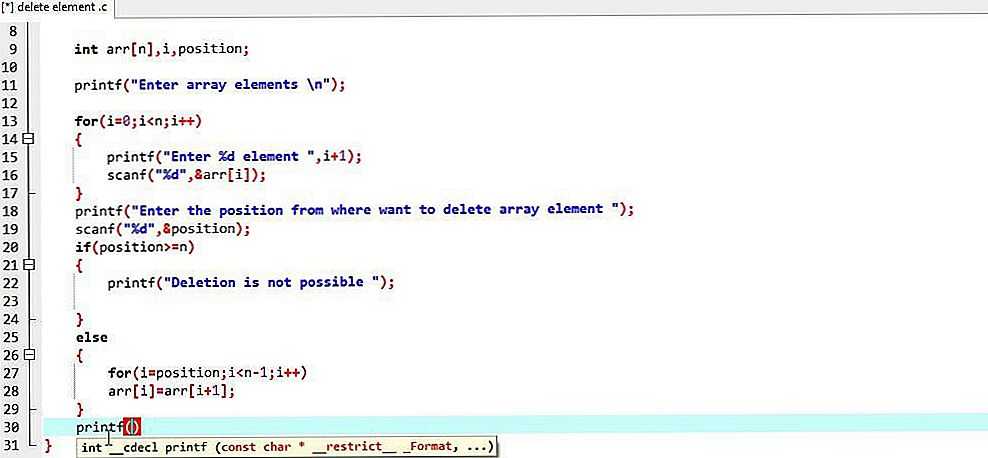 $` (обратная кавычка в долларах) содержит часть строки до (слева) от совпадения с регулярным выражением. Не рекомендуется использовать эти переменные в сценариях, когда важна производительность, так как это замедляет работу Perl все совпадений регулярных выражений во всем вашем скрипте.
$` (обратная кавычка в долларах) содержит часть строки до (слева) от совпадения с регулярным выражением. Не рекомендуется использовать эти переменные в сценариях, когда важна производительность, так как это замедляет работу Perl все совпадений регулярных выражений во всем вашем скрипте.
Все эти переменные доступны только для чтения и сохраняются до тех пор, пока не будет предпринята попытка следующего совпадения с регулярным выражением. Они имеют динамическую область действия, как если бы они имели неявное «местное» в начале объемлющей области. Таким образом, если вы выполняете сопоставление с регулярным выражением и вызываете подпрограмму, которая выполняет соответствие регулярному выражению, когда эта подпрограмма возвращается, ваши переменные по-прежнему устанавливаются так, как они были для первого совпадения.
Поиск всех совпадений в строке
Модификатор «/g» можно использовать для обработки всех совпадений регулярных выражений в строке. Первый m/regex/g найдет первое совпадение, второй m/regex/g — второе совпадение и т. д. Perl автоматически запоминает место в строке, с которого будет начинаться следующая попытка сопоставления, отдельно для каждой строки. Вот пример:
д. Perl автоматически запоминает место в строке, с которого будет начинаться следующая попытка сопоставления, отдельно для каждой строки. Вот пример:
в то время как ($string =~ m/regex/g) {
print "Найдено '$&'. Следующая попытка ввести символ " . поз($строка)+1 . "\п";
} Функция pos() получает позицию, с которой начинается следующая попытка. Первый символ в строке имеет нулевую позицию. Вы можете изменить эту позицию, используя функцию в качестве левой части присваивания, например pos($string) = 123;.
Дополнительная литература
Выше описано, как вы можете использовать регулярные выражения в Perl, и, вероятно, это все, что вам нужно знать. Но если вы хотите получить подробную информацию обо всех трюках, связанных с регулярными выражениями, которые может выполнять Perl, я рекомендую вам взять копию второго издания книги Джеффри Фридля «Освоение регулярных выражений». В нем есть интересная 80-страничная глава о странностях Perl, связанных с регулярными выражениями.