Что такое DOM?
Основы PHP 8
Пройдя курс, Вы узнаете:
— Как установить и настроить OpenServer
— Всю необходимую базу по PHP 8
— Как писать самые различные скрипты на PHP
Общая продолжительность курса 7 часов, плюс более 100 упражнений и поддержка!
Чтобы получить Видеокурс,
заполните форму
| E-mail: | |
| Имя: | |
Другие курсы
Как создать профессиональный Интернет-магазин
После семинара:
— Вы будете знать, как создать Интернет-магазин.
— Вы получите бесплатный подарок с подробным описанием каждого шага.
— Вы сможете уже приступить к созданию Интернет-магазина.
Записаться
Другие курсы
Бессмысленно продолжать делать то же самое и ждать других результатов.
Альберт Эйнштейн
DOM (Document Object Model) — это стандарт (интерфейс или библиотека) для работы с разметкой документов. DOM позволяет работать с HTML и XML документами, изменяя их структуру. О том, что такое DOM, более подробно читайте ниже.
Основное преимущество DOM состоит в том, что он не зависит от языка. То есть если Вы его выучили, изучая, например, JavaScript, то изучать его в PHP Вам не придётся. Аналогично, и с другими языками.
Есть несколько уровней DOM:
- 2-й уровень — всё тоже самое, но добавились пространства имён (xmlns).
- 3-й уровень — имеет язык запросов XPath (похож на SQL, но только для документов, а не для базы данных), а также другие технологии.


Применений у DOM очень много. В первую очередь, он применяется для генерации XML-документов (например, карты сайта в формате XML
В последующих статьях мы с Вами будем разбирать возможности DOM по работе с XML-документами с использованием PHP. Ещё раз повторяю, что всё, что будет там разбираться подходит и для JavaScript, а также для работы не только с XML, но и с HTML-документами.
- Создано 20.04.2012 14:08:41
- Михаил Русаков
Предыдущая статьяСледующая статья
Копирование материалов разрешается только с указанием автора (Михаил Русаков) и индексируемой прямой ссылкой на сайт (http://myrusakov.ru)!
Добавляйтесь ко мне в друзья ВКонтакте: http://vk. com/myrusakov.
com/myrusakov.
Если Вы хотите дать оценку мне и моей работе, то напишите её в моей группе: http://vk.com/rusakovmy.
Если Вы не хотите пропустить новые материалы на сайте,
то Вы можете подписаться на обновления: Подписаться на обновления
Если у Вас остались какие-либо вопросы, либо у Вас есть желание высказаться по поводу этой статьи, то Вы можете оставить свой комментарий внизу страницы.
Если Вам понравился сайт, то разместите ссылку на него (у себя на сайте, на форуме, в контакте):
- Кнопка:
<a href=»https://myrusakov.ru» target=»_blank»><img src=»https://myrusakov.ru/images/button.gif» alt=»Как создать свой сайт» /></a>Она выглядит вот так:
- Текстовая ссылка:
<a href=»https://myrusakov.ru» target=»_blank»>Как создать свой сайт</a>Она выглядит вот так: Как создать свой сайт
- BB-код ссылки для форумов (например, можете поставить её в подписи):
[URL=»https://myrusakov. ru»]Как создать свой сайт[/URL]
 ru»]Как создать свой сайт[/URL]
ru»]Как создать свой сайт[/URL]PHP: DOMElement — Руководство
класс DOMElement расширяет DOMNode реализует DOMParentNode, DOMCChildNode {
общедоступный только для чтения нить $ имя тега ;
общественный только для чтения смешанный $ schemaTypeInfo = ноль;
общественный только для чтения ?DOMEэлемент $ firstElementChild ;
общественный только для чтения ?DOMEэлемент $ lastElementChild ;
общественный
только для чтения
инт $ childElementCount
общественный только для чтения ?DOMEэлемент $ предыдущий элементSibling ;
общественный только для чтения ?DOMEэлемент $ nextElementSibling ;
общественный только для чтения нить $ имя_узла ;
общественный ?нить $ nodeValue ;
общественный только для чтения инт $ nodeType ;
общественный только для чтения ?DOMNode $ parentNode ;
общественный
только для чтения
DOMNodeList
общественный только для чтения ?DOMNode $ firstChild ;
общественный только для чтения ?DOMNode $ lastChild ;
общественный только для чтения ?DOMNode $ предыдущий брат ;
общественный только для чтения ?DOMNode $ следующий брат ;
общественный только для чтения ?DOMNamedNodeMap $ атрибуты ;
общественный
только для чтения
?DOMДокумент $ владелецДокумент
общественный только для чтения ?нить $ namespaceURI ;
общественный нить $ префикс ;
общественный только для чтения ?нить $ localName ;
общественный только для чтения ?нить $ baseURI ;
общественный нить $ textContent ;
public __construct(string $qualifiedName , ?string $value = null , string $namespace = «»)
$qualifiedName ): String Public getAttributeNode (String $ CalfiedName ): Domattr | Domnamespacenode | False
Public getAttributeNodens (? String $ namespace , String $ localname ) $ namespace , String $ localname ) $ namespace , String $ localname ): domaTrems.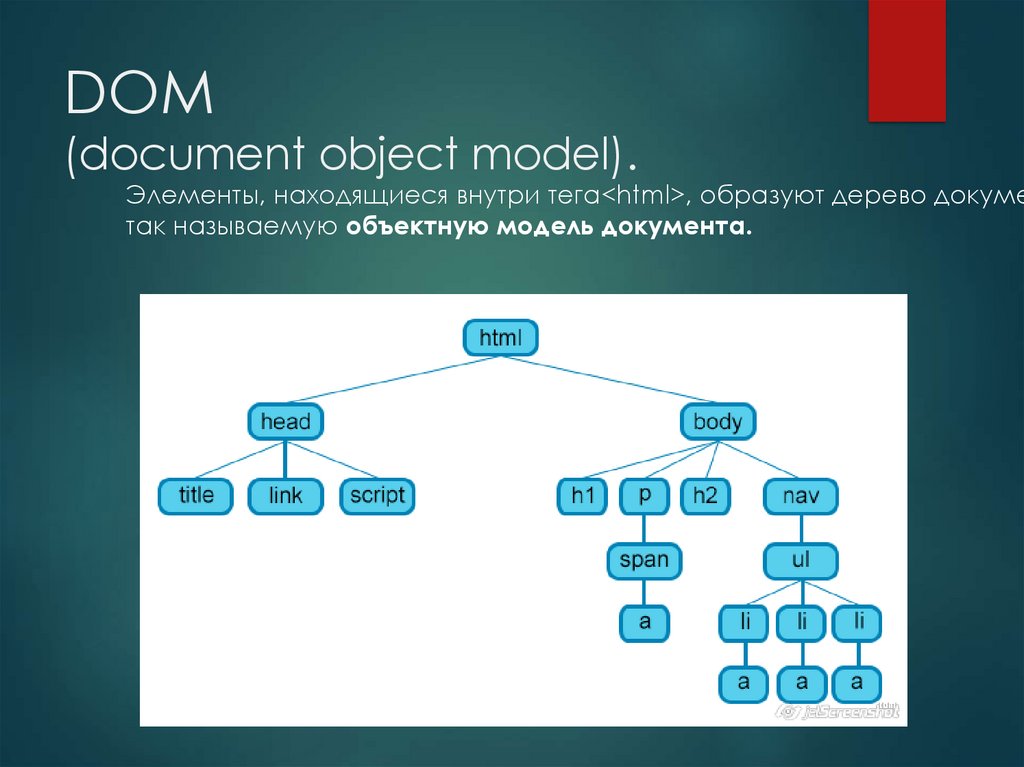 ?string
?string $namespace , string $localName ): string
public getElementsByTagName(string
public getElementsByTagNameNS(?string $ пространство имен , строка $ localname ): Domnodelist
Public Hasattribute (String $ CalfiedName ): Bool
Public hasattributens (? String $ lognal , String . (строка $qualifiedName ): bool
public removeAttributeNode(DOMAttr $attr ): DOMAttr|false
public removeAttributeNS(?string $namespace , string $localName
Public SetAttribute (String $ CalfiedName , String $ Value ): Domattr | Bool
Public SetAttributedode (Domattr $ attra attr ): DOMAttr|null|false
public setAttributeNS(?string $namespace , string $qualifiedName , string $value ): void
public setIdAttribute(5 $qualifiedName 146, bool $ isid ): void
Public setIdattributeNode (Domattr $ attr , bool $ isid ): void
Public SetIdattribuens (String $ namesspace 4646461464646461464646146146464614645646464646461464564614564646464646146456464564646464646146464646464646464646464646464646464646464646. ): void
): void
Public Domnode :: AppendChild (Domnode $ Узел ): Domnode | False
Public Domnode :: C14N ( 5. . . . . . . , , 9014, 9014, 9014, , 9014, , $
Bool $ Exclusive = False 4.com...95. .0146 = , FALSE ,
? Array $ xpath = NULL ,
? Строка $ uri ,
Bool $ Exclusive = False ,
Bool $ с помощью = False ,
? Array
??0146
?array $nsPrefixes = null
): int|false
public DOMNode::cloneNode(bool $deep = false ): DOMNode|false
public DOMNode ::getLineNo(): int
public DOMNode::getNodePath(): ?string
public DOMNode::hasAttributes(): bool
public DOMNode::hasChildNodes(): bool
public DOMNode::insertBefore(DOMNode $узел , ?DOMУзел $ Child = NULL ): DOMNODE | FALSE
Public Domnode :: ISdefaultNamespace (String $ Lopace ): Bool
Public Domnode ::: Issamenode (Domnode
Public Domnode ::: Issamenode (domnode . public DOMNode::lookupNamespaceUri(string public DOMNode::lookupPrefix(string ) ?строка public DOMNode::normalize(): void public DOMNode::removeChild(DOMNode DOMNode|ложь } Компонент DomCrawler упрощает навигацию по DOM для документов HTML и XML. Примечание Хотя это и возможно, компонент DomCrawler не предназначен для манипулирования
DOM или повторный дамп HTML/XML. Примечание Если вы устанавливаете этот компонент вне приложения Symfony, вы должны
требуется файл Смотрите также В этой статье объясняется, как использовать функции DomCrawler в качестве независимого
компонент в любом PHP-приложении. Прочтите функциональные тесты Symfony
статью, чтобы узнать, как использовать его при создании тестов Symfony. Класс Crawler предоставляет методы
для запроса и обработки документов HTML и XML. Экземпляр Crawler представляет набор объектов DOMElement,
которые являются узлами, которые можно пройти следующим образом: Специализированная ссылка,
Изображение и
Классы форм полезны для
взаимодействие с html-ссылками, изображениями и формами при переходе через HTML
дерево. Примечание DomCrawler попытается автоматически исправить ваш HTML, чтобы он соответствовал
официальная спецификация. Например, если вы вложите тег Используя выражения XPath, вы можете выбрать определенные узлы в документе: Кончик Если вы предпочитаете селекторы CSS вместо XPath, установите компонент CssSelector.
Он позволяет использовать селекторы, подобные jQuery: Анонимная функция может использоваться для фильтрации по более сложным критериям: Чтобы удалить узел, анонимная функция должна возвращать Примечание Все методы фильтрации возвращают новый Crawler
экземпляр с отфильтрованным содержимым. Чтобы проверить, действительно ли фильтр
что-то нашел, используйте Как filterXPath(), так и
методы filter() работают с
Пространства имен XML, которые могут быть либо автоматически обнаружены, либо зарегистрированы
явно. Рассмотрим XML ниже: Это можно отфильтровать с помощью , так и с filter(): Примечание Пространство имен по умолчанию зарегистрировано с префиксом "по умолчанию". Может быть
изменилось с
setDefaultNamespacePrefix()
метод. Пространство имен по умолчанию удаляется при загрузке содержимого, если оно единственное
пространство имен в документе. Пространства имен могут быть явно зарегистрированы с
Метод registerNamespace(): Проверить, соответствует ли текущий узел селектору: Доступ к узлу по его положению в списке: Получить первый или последний узел текущего выбора: Получить узлы того же уровня, что и текущий выбор: Получить узлы того же уровня после или перед текущим выбором: Получить все дочерние узлы или узлы-предки: Получить все прямые дочерние узлы, соответствующие селектору CSS: Получить первого родителя (направляясь к корню документа) элемента, который соответствует предоставленному селектору: Примечание Все методы обхода возвращают новый Crawler
пример. Доступ к имени узла (имя тега HTML) первого узла текущего выбора (например, "p" или "div"): Доступ к значению первого узла текущего выбора: 6. Удаление пробельных символов по умолчанию в Доступ к значению атрибута первого узла текущего выбора: Извлечение значений атрибута и/или узла из списка узлов: Примечание Специальный атрибут Вызов анонимной функции на каждом узле списка: Анонимная функция получает узел (как Crawler) и позицию в качестве аргументов.
Результатом является массив значений, возвращаемых вызовами анонимных функций. При использовании вложенного искателя помните, что Искатель поддерживает несколько способов добавления контента, но они взаимно
эксклюзивный, поэтому вы можете использовать только один из них для добавления контента (например, если вы передадите
содержимое в конструктор Примечание addHtmlContent() и
методы addXmlContent()
по умолчанию используется кодировка UTF-8, но вы можете изменить это поведение с помощью второго
необязательный аргумент. Метод addContent()
угадывает лучший набор символов в соответствии с заданным содержимым и по умолчанию Поскольку реализация Crawler основана на расширении DOM, он также может
для взаимодействия с родным DOMDocument, DOMNodeList
и объекты DOMNode: Метод Это поведение лучше всего иллюстрируется примерами: Используйте метод Оба метода возвращают экземпляр Объект Link имеет несколько полезных
способы получения дополнительной информации о самой выбранной ссылке: Примечание Функция Чтобы найти изображение по атрибуту Объект изображения имеет то же самое Формам также уделяется особое внимание. А Этот метод особенно полезен, потому что вы можете использовать его для возврата
объект Form, представляющий
форма, в которой находится кнопка: Объект Form имеет множество очень
полезные методы для работы с формами: Метод getUri() делает больше
чем просто вернуть атрибут Примечание Необязательные атрибуты кнопки Вы можете виртуально задавать и получать значения на форме: Для работы с многомерными полями: Передать массив значений: Это здорово, но становится еще лучше! Объект Какой смысл все это делать? Если вы проводите внутреннее тестирование, вы
может получить информацию из вашей формы, как если бы она была только что отправлена
используя значения PHP: Если вы используете внешний HTTP-клиент, вы можете использовать форму для получения всех
информации, необходимой для создания POST-запроса для формы: Одним из замечательных примеров интегрированной системы, которая использует все это, является
HttpBrowser, предоставленный
Компонент BrowserKit. По умолчанию для полей выбора (выбор, радио) активирована внутренняя проверка
чтобы вы не установили недопустимые значения. Если вы хотите иметь возможность установить
недопустимые значения, вы можете использовать метод Класс UriResolver принимает URI
(относительный, абсолютный, фрагмент и т. д.) и превращает его в абсолютный URI против
другой указанный базовый URI: Если вам нужно, чтобы Crawler использовал HTML5
парсер, установите его При этом сканер будет использовать анализатор HTML5, предоставленный masterminds/html5
библиотека для разбора документов. 6.3 Аргумент  DOMNode::isSupported(string
DOMNode::isSupported(string $feature , string $version ): bool $prefix ): string $child ): DOMNode|false Компонент DomCrawler (документы Symfony)
Изменить эту страницу
vendor/autoload.php в вашем коде, чтобы включить класс
механизм автозагрузки, предоставляемый Composer. Читать
эту статью для более подробной информации.
DOMXPath::query используется внутри для фактического выполнения запроса XPath. ложно .
$crawler->count() > 0 на этом новом сканере. Искатель без необходимости регистрации пространства имен
псевдонимы как с filterXPath(): Это сделано для упрощения запросов XPath.
Это сделано для упрощения запросов XPath. 3
3 innerText() было
представлен в Symfony 6.3. _text представляет значение узла, а _name представляет имя элемента (имя тега HTML). filterXPath() оценивается в
контекст сканера: Crawler , вы не можете вызвать addContent() позже):
ISO-8859-1 на случай, если невозможно угадать кодировку. Assessment() оценивает заданное выражение XPath. Возврат
значение зависит от выражения XPath. Если выражение оценивается как скаляр
значение (например, атрибуты HTML), будет возвращен массив результатов. Если
выражение оценивается как документ DOM, новый Crawler экземпляр будет
вернулся. filter() для поиска ссылок по их идентификатору или классу атрибуты и используйте метод selectLink() для поиска ссылок по их содержимому
(он также находит интерактивные изображения с этим содержимым в атрибуте alt ).
Crawler только с выбранной ссылкой. Использовать link() метод для получения объекта Link
который представляет ссылку: getUri() особенно полезна, поскольку очищает значение href и
преобразует его в то, как он должен действительно обрабатываться. Например, для
ссылка с href="#foo" , это вернет полный URI текущего
страница с суффиксом #foo . Возврат из getUri() всегда полный
URI, с которым вы можете действовать. alt , используйте метод selectImage на
существующий поисковый робот. Это возвращает экземпляр
Это возвращает экземпляр Crawler только с выбранным
изображений). Вызов image() дает вам специальный
Объект изображения: метод getUri() как ссылка. метод selectButton() доступен на краулере, который возвращает другой краулер, соответствующий или или элементов (или элемент внутри них). Строка, указанная в качестве аргумента, ищется в
атрибуты
id , alt , name и value , а также текстовое содержимое
эти элементы. action формы. Если метод формы
является GET, то он имитирует поведение браузера и возвращает действие
Если метод формы
является GET, то он имитирует поведение браузера и возвращает действие атрибут, за которым следует строка запроса всех значений формы. formaction и formmethod поддерживается. методы getUri() и getMethod() учитывают
эти атрибуты всегда возвращают правильное действие и метод в зависимости от
кнопка, используемая для получения формы. Form позволяет взаимодействовать
с вашей формой, как в браузере, выбирая значения радио, отмечая флажки,
и загрузка файлов: Он понимает объект Symfony Crawler и может использовать его для отправки форм.
напрямую:
Он понимает объект Symfony Crawler и может использовать его для отправки форм.
напрямую: disableValidation() либо для
вся форма или определенные поля: useHtml5Parser аргумент конструктора для true : useHtml5Parser был введен в Symfony 6.