Полезные заметки php, jquery, mysql, ubuntu, android
admin
Очень часто бывает такая задача: просклонять слово в зависимости от числа и вывести не 21 комментариев а 21 комментарий и […]
Read more
irusik
В это статье мы рассмотрим как вставить в таблицу Excel одну или несколько строк.
Read more
irusik
В большинстве случаев информация воспринимается гораздо лучше, если она представлено наглядно — в виде графика или диаграммы. В Эксель есть […]
Read more
irusik
Excel предлагает очень много возможностей для работы с данными.
 В нем можно проводить безумное количество вычислений без особого труда. В […]
В нем можно проводить безумное количество вычислений без особого труда. В […]Read more
irusik
При создании документа в Microsoft Excel по умолчанию применяется шрифт Calibri с размером 11 px. Иногда необходимо его изменить, увеличить […]
Read more
Иногда возникает такая задача, которая может казаться довольно глупой
Read more
irusik
Часто возникает необходимость посмотреть сохраненные пароли в браузере, например, для того, чтобы передать его кому-то или набрать на другом устройстве.
[…]Read more
irusik
Случалось ли вам работать в большим количеством вкладок в браузере? Если да, то наверняка вы закрывали нужные вкладки. В этой […]
Read more
admin
Как то раз задался вопросом: как можно отслеживать исходящий трафик с сервера на centos, debian или ubuntu?
Read more
irusik
На сегодняшний день Яндекс является самой популярной поисковой системой в России и СНГ. В этой статье мы рассмотрим как сделать […]
Read more
irusik
Иногда необходимо сфотографировать экран монитора.
Существует несколько способов сделать снимок экрана на компьютере или ноутбуке с системой Windows. Рассмотрим самый […]Read more
Всем известно, что интернет-браузеры сохраняют историю посещений и поиска. Иногда требуется полностью стереть историю просмотров.
Read more
 В нем можно проводить безумное количество вычислений без особого труда. В […]
В нем можно проводить безумное количество вычислений без особого труда. В […] […]
[…] Существует несколько способов сделать снимок экрана на компьютере или ноутбуке с системой Windows. Рассмотрим самый […]
Существует несколько способов сделать снимок экрана на компьютере или ноутбуке с системой Windows. Рассмотрим самый […]- Популярное
- Новое
Фильтры Twig — Документация Grav CMS на русском
Фильтры Twig применяются к переменным Twig с помощью символа |, за которым следует имя фильтра. Параметры можно передавать так же, как функции Twig, используя круглые скобки.
absolute_urlПринимает фрагмент HTML, содержащий атрибут src или href, который использует относительный путь. Преобразует строку пути в абсолютный формат URL, включая имя хоста.
Преобразует строку пути в абсолютный формат URL, включая имя хоста.
{{ <img src="/some/path/to/image.jpg" />'|absolute_url }}
array_uniqueОболочка для PHP ‘array_unique()’, которая удаляет дубликаты из массива.
{{ ['foo', 'bar', 'foo', 'baz']|array_unique }}
base32_encodeВыполняет кодировку base32 для переменной
{{ 'some variable here'|base32_encode` }}
base32_decodeВыполняет декодирование base32 на переменной
{{ 'ONXW2ZJAOZQXE2LBMJWGKIDIMVZGK'|base32_decode }}
base64_encodeВыполняет кодировку base64 для переменной
{{ 'some variable here'|base64_encode }}
base64_decodeВыполняет декодирование base64 на переменной
{{ 'c29tZSB2YXJpYWJsZSBoZXJl'|base64_decode }}
basenameВозвращает базовое имя пути.
{{ '/etc/sudoers.d'|basename }}
camelizeПреобразует строку в формат «CamelCase»
{{ 'send_email'|camelize }}
chunk_splitРазбивает строку на более мелкие куски определенного размера.
{{ 'ONXW2ZJAOZQXE2LBMJWGKIDIMVZGKA'|chunk_split(6, '-') }}
ONXW2Z-JAOZQX-E2LBMJ-WGKIDI-MVZGKA-
containsОпределите, содержит ли конкретная строка другую строку
{{ 'some string with things in it'|contains('things') }}
Преобразование значений
PHP 7 получает более строгие проверки типов, а это означает, что передача значения неправильного типа теперь может вызвать исключение. Чтобы избежать этого, вы должны использовать фильтры, которые гарантируют, что значение, переданное методу, является допустимым:
stringИспользуйте |string для приведения значения к строке.
intИспользуйте |int для приведения значения к целому числу.
boolИспользуйте |bool для приведения значения к логическому.
floatИспользуйте |float для приведения значения к числу с плавающей запятой.
arrayИспользуйте |array для приведения значения к массиву.
definedИногда вы хотите проверить, определена ли какая-либо переменная, а если нет, укажите значение по умолчанию. Например:
{% set header_image_width = page.header.header_image_width|defined(900) %}
При этом переменная header_image_width будет установлена в значение 900, если она не определена в заголовке страницы.
dirnameВернуть имя каталога пути.
{{ '/etc/sudoers.d'|dirname }}
ends_withБерет иголку и стог сена и определяет, заканчивается ли стог иглой. Также теперь работает с массивом игл и будет возвращать true, если любой стог сена заканчивается иглой.
{{ 'the quick brown fox'|ends_with('fox') }}
fieldNameФильтрация имени поля путем замены записи через точку на запись массива
{{ 'field. name|fieldName }}
 name|fieldName }}
name|fieldName }}
get_typeПолучает тип переменной:
{{ page|get_type }}
humanizeПреобразует строку в более удобный для чтения формат.
{{ 'something_text_to_read'|humanize }}
hyphenizeПреобразует строку в версию с дефисом.
{{ 'Something Text to Read'|hyphenize }}
json_decodeВы можете декодировать JSON, просто применив этот фильтр:
{% set array = '{"first_name": "Guido", "last_name":"Rossum"}'|json_decode %}
{{ print_r(array) }}
stdClass Object
(
[first_name] => Guido
[last_name] => Rossum
)
ksortСортировать карту массива по каждому ключу
array|ksort
{% set ritems = {'orange':1, 'apple':2, 'peach':3}|ksort %}
{% for key, value in ritems %}{{ key }}:{{ value }}, {% endfor %}
Array
(
[apple] => 2
[orange] => 1
[peach] => 3
)
ltrimУдаляет пробелы в начале строки. Он также может удалить другие символы, с помощью маски (см. https://php.net/manual/ru/function.ltrim.php).
Он также может удалить другие символы, с помощью маски (см. https://php.net/manual/ru/function.ltrim.php).
{{ '/strip/leading/slash/'|ltrim('/') }}
markdownВозьмите произвольную строку, содержащую разметку, и конвертируйте её в HTML, используя парсер Markdown Grav. Необязательный
true(по умолчанию): обрабатывать как блок (текстовый режим, содержимое будет заключено в теги<p>)false: обрабатывать как строку (содержимое не будет обернуто никакими тегами)
{{ string|markdown($is_block) }}
<div>
{{ 'A paragraph with **markdown** and [a link](http://www.cnn.com)'|markdown }}
</div>
<p>{{'A line with **markdown** and [a link](http://www.cnn.com)'|markdown(false) }}</p>
md5Создает md5 хэш для строки
{{ 'anything'|md5 }}
modulusВыполняет ту же функциональность, что и символ Modulus % в PHP.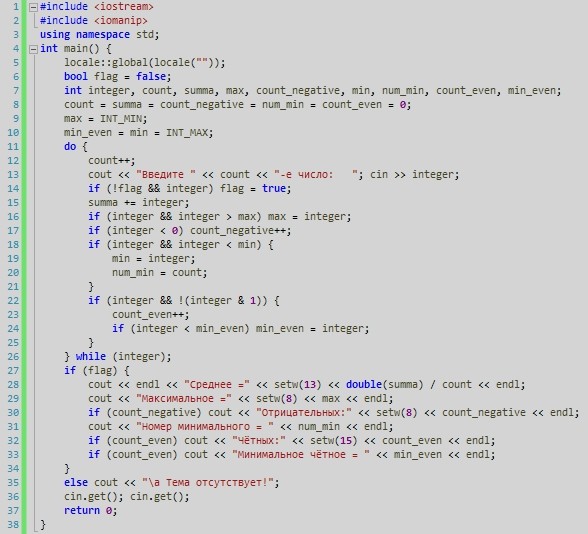 Он работает с числом, передавая в числовом делителе и необязательный массив элементов для выбора.
Он работает с числом, передавая в числовом делителе и необязательный массив элементов для выбора.
{{ 7|modulus(3, ['red', 'blue', 'green']) }}
monthizeПреобразовывает целое число дней в число месяцев
{{ '181'|monthize }}
nicecronПолучает читаемый человеком выходной сигнал для синтаксиса cron
{{ "2 * * * *"|nicecron }}
nicefilesizeВыводит размер файла в удобочитаемом для человека формате:
{{ 612394|nicefilesize }}
nicenumberВывод числа в удобочитаемом для человека формате красивых чисел:
{{ 12430|nicenumber }}
nicetimeВывод даты в удобочитаемом для человека формате времени:
{{ page.date|nicetime(false) }}
Первый аргумент указывает, следует ли использовать описание даты в полном формате. По умолчанию это true.
Вы можете указать второй аргумент false, если хотите удалить относительный дескриптор времени (например, «назад» или «с этого момента» на вашем языке) из результата.
of_typeПроверяет тип переменной на параметр:
{{ page|of_type('string') }}
ordinalizeДобавляет порядковый номер к целому числу (например, 1-е, 2-е, 3-е, 4-е):
{{ '10'|ordinalize }}
padЗаполняет строку до определенной длины другим символом. Это обёртка для PHP-функции str_pad().
{{ 'foobar'|pad(10, '-') }}
pluralizeПреобразовывает строку в английскую множественную версию
{{ 'person'|pluralize }}
pluralize также принимает необязательный числовой параметр, который можно ввести, если заранее неизвестно, на сколько элементов будет ссылаться существительное. Значение по умолчанию равно 2, поэтому при опущении будет указана форма множественного числа. Например:
<p>We have {{ num_vacancies }} {{ 'vacancy'|pluralize(num_vacancies) }} right now.</p>
print_rПечатает читабельную информацию о переменной
{{ page. header|print_r }}
 header|print_r }}
header|print_r }}
randomizeРандомизирует предоставленный список. Если значение задано в качестве параметра, оно пропустит эти значения и сохранит их в порядке.
{{ array|randomize }}
{% set ritems = ['one', 'two', 'three', 'four', 'five', 'six', 'seven', 'eight', 'nine', 'ten']|randomize(2) %}
{% for ritem in ritems %}{{ ritem }}, {% endfor %}
Array
(
[0] => one
[1] => two
[2] => three
[3] => eight
[4] => seven
[5] => four
[6] => five
[7] => six
[8] => ten
[9] => nine
)
regex_replaceПолезная оболочка для PHP preg_replace() метод, вы можете выполнять сложные замены регулярных выражений в тексте с помощью этого фильтра:
{{ 'The quick brown fox jumps over the lazy dog.'|regex_replace(['/quick/','/brown/','/fox/','/dog/'], ['slow','black','bear','turtle']) }}
По возможности используйте разделитель ~ вместо /. В противном случае вам, скорее всего, придется удвоить определённые символы. Например,
В противном случае вам, скорее всего, придется удвоить определённые символы. Например, ~\/\#.*~~, а не‘/\/\#.*/’`, что более соответствует PCRE-синтаксису, используемому PHP.
rtrim{{ '/strip/trailing/slash/'|rtrim('/') }}
Удаляет пробелы в конце строки. Он также может удалить другие символы, с использованием маски (см. https://php.net/manual/ru/function.rtrim.php).
singularizeПреобразует строку в английскую единственную версию
{{ 'shoes'|singularize }}
safe_emailФильтр безопасной почты преобразует адрес электронной почты в символы ASCII, что затрудняет распознавание и захват спам-ботов.
{{ "[email protected]"|safe_email }}
Пример использования со ссылкой mailto:
<a href="mailto:{{'[email protected]'|safe_email}}">
Email me
</a>
Сначала вы можете и не заметить разницы, но изучение исходного текста страницы (не используя Инструменты разработчика браузера, фактического исходного текста страницы) выявит кодировку, лежащую в основе символов.
sort_by_keyМожно сортировать массив по определенному ключу
{{ array|sort_by_key }}
{% set people = [{'email':'[email protected]', 'id':34}, {'email':'[email protected]', 'id':21}, {'email':'[email protected]', 'id':2}]|sort_by_key('id') %}
{% for person in people %}{{ person.email }}:{{ person.id }}, {% endfor %}
starts_withБерет иглу и стог сена и определяет, начинается ли стог сена с иглы. Также теперь работает с массивом игл и вернет true, если ни стог сена начинается с иглы.
{{ 'the quick brown fox'|starts_with('the') }}
titleizeПреобразует строку в формат «Заголовок»
{{ 'welcome page'|titleize }}
tПереводит строку на текущий язык
{{ 'MY_LANGUAGE_KEY_STRING'|t }}
Предполагается, что на вашем сайте переведены эти языковые строки и включена поддержка нескольких языков. Пожалуйста, обратитесь к документации для получения более подробной информации.
tuПереводит строку на текущий язык, установленный в пользовательских настройках интерфейса администратора.
{{ 'MY_LANGUAGE_KEY_STRING'|tu }}
При этом используется языковое поле, установленное в пользовательском yaml.
taПереводит массив на язык с помощью фильтра |ta. См. Подробный пример в документации.
{{ 'MONTHS_OF_THE_YEAR'|ta(post.date|date('n') - 1) }}
tlПереводит строку на определённый язык. Для получения более подробной информации ознакомьтесь с документацией.
{{ 'SIMPLE_TEXT'|tl(['fr']) }}
truncateВы можете легко создать сокращенную, усеченную версию строки, используя этот фильтр. Единственное обязательное поле — это количество символов, но есть и другие параметры:
{{ 'одно предложение. два предложения'|truncate(5)|raw }}
Просто обрезается до 5 символов.
{{ 'одно предложение. два предложения'|truncate(5, true)|raw }}
Фильтр |raw следует использовать с элементом заполнения по умолчанию … (многоточие), чтобы он отображался с автоматическим экранированием Twig
Обрезается до ближайшего конца предложения после 5 символов.
Вы также можете обрезать текст HTML, но сначала следует использовать фильтр |striptags, чтобы удалить любое форматирование HTML, которое может быть нарушено, если вы остановитесь между тегами:
{{ '<span>одно <strong>предложение</strong>. два предложения</span>'|raw|striptags|truncate(25) }}
safe_truncateИспользуйте |safe_truncate для обрезки текста по количеству символов, с сохранением полных слов.
truncate_htmlИспользуйте |truncate_html для обрезки HTML по количеству символов, без сохранения полных слов.
safe_truncate_htmlИспользуйте |safe_truncate_html для обрезки HTML по количеству символов, с сохранением полных слов.
underscorizeПреобразует строку в формат «under_scored»
{{ 'CamelCased'|underscorize }}
yaml_encodeДамп/кодирование переменной в синтаксис YAML
{% set array = {foo: [0, 1, 2, 3], baz: 'qux' } %}
{{ array|yaml_encode }}
foo: - 0 - 1 - 2 - 3 baz: qux
yaml_decodeДекодирование/парсинг переменной из синтаксиса YAML
{% set yaml = "foo: [0, 1, 2, 3]\nbaz: qux" %}
{{ yaml|yaml_decode|var_dump }}
array(2) {
["foo"]=>
array(4) {
[0]=>
int(0)
[1]=>
int(1)
[2]=>
int(2)
[3]=>
int(3)
}
["baz"]=>
string(3) "qux"
}
Советы по строковым функциям PHP: Объяснение обрезки строк PHP
Из всех восьми типов данных строки PHP считаются одними из самых простых, наряду с целыми числами, числами с плавающей запятой и логическими значениями.
Существуют встроенные строковые функции PHP для работы со строками. Одним из распространенных применений является использование одной из функций PHP для разделения строки на более мелкие части, если длина строки. Вы также можете использовать их для замены, изменения определенной строки PHP или выполнения других действий.
Давайте посмотрим полный список строковых функций PHP и их описания. Таблица организована в алфавитном порядке, поэтому вы всегда можете быстро найти нужную, когда вам нужно, например, заменить определенную строку PHP:
| Функция | Описание |
|---|---|
| addcslashes() | Создает новую строку, добавляя обратную косую черту перед каждым указанным символом |
| добавляет слеши() | Создает новую строку, добавляя обратную косую черту перед предопределенными символами |
| bin2hex() | Создает новую строку путем преобразования каждого символа строки в шестнадцатеричные значения |
| отбивная() | Создает новую строку, удаляя пробелы и другие ненужные символы с правой стороны строки |
| хр() | Отображает символ, определенный указанным значением ASCII |
| chunk_split() | Разбивает строку на более мелкие части |
| convert_cyr_string() | Преобразует строку из одного кириллического набора символов в другой |
| convert_uudecode() | Декодирует незакодированную строку |
| convert_uuencode() | Создает новую строку путем преобразования с использованием алгоритма uuencode |
| count_chars() | Предоставляет информацию о символах, содержащихся в строке |
| crc32() | Вычисляет 32-битный CRC для строки |
| крипт() | Выполняет одностороннее хеширование строки |
| эхо() | Отображает указанные строки |
| взорвать() | Разбивает строку на элементы массива |
| fprintf() | Записывает строку в указанный выходной поток |
| get_html_translation_table() | Возвращает таблицу перевода, используемую htmlspecialchars() и htmlentities() |
| иврит() | Текст на иврите преобразуется в обычный текст |
| hebrevc() | Преобразует текст на иврите в визуальный текст и новые строки (\n) в |
| hex2bin() | Создает новую строку путем преобразования указанной строки шестнадцатеричных символов в символы ASCII |
| html_entity_decode() | Создает новую строку путем преобразования элементов HTML в символы |
| htmlentities() | Создает новую строку путем преобразования обычного текста в объекты HTML |
| htmlspecialchars_decode() | Создает новую строку путем преобразования предопределенных элементов HTML в символы |
| htmlspecialchars() | Создает новую строку путем преобразования предопределенных символов в элементы HTML |
| взорваться() | Присоединяет массив PHP к строке |
| присоединиться() | Альтернатива implode() |
| lcfirst() | Создает новую строку путем преобразования первой буквы указанной строки в нижний регистр |
| Левенштейн() | Возвращает расстояние Левенштейна между двумя строками PHP |
| локальная конв() | Возвращает информацию о языковом стандарте числового и денежного форматирования |
| ltrim() | Создает новую строку, удаляя пробелы и другие ненужные символы с левой стороны строки |
| md5() | Создает хеш MD5 строки |
| md5_file() | Создает хэш MD5 указанного файла |
| метафон() | Создает метафонный ключ строки |
| money_format() | Создает новую строку, форматируя ее как строку валюты |
| nl_langinfo() | Возвращает информацию об определенном местоположении |
| nl2br() | Помещает новые разрывы строк HTML перед каждой новой строкой в строке |
| число_формат() | Создает новую строку путем форматирования числа. Группы тысяч Группы тысяч |
| порядок() | Берет первый символ строки и возвращает его значение ASCII |
| parse_str() | Помещает строку запроса в указанные переменные |
| печать() | Отображает указанную строку или несколько строк |
| printf() | Отображает указанную отформатированную строку или несколько строк |
| quoted_printable_decode() | Создает новую строку путем преобразования строки в кавычках в 8-битную строку |
| quoted_printable_encode() | Создает новую строку путем преобразования 8-битной строки в строку для печати в кавычках |
| цитата () | Метасимволы кавычек |
| rtrim() | Создает новую строку, удаляя пробелы и другие ненужные символы с правой стороны строки |
| setlocale() | Устанавливает информацию о локали |
| ша1() | Создает хэш SHA-1 для строки |
| sha1_file() | Создает хэш SHA-1 для файла |
| подобный_текст() | Сравнивает две строки PHP |
| звук () | Создает ключ soundex для строки |
| спринтф() | Берет отформатированную строку и записывает ее в переменную |
| sscanf() | Принимает ввод из строки в зависимости от формата |
| str_getcsv() | Берет строку CSV и помещает ее в массив |
| str_ireplace() | Создает новую строку, заменяя символы строки. Метод не чувствителен к регистру Метод не чувствителен к регистру |
| str_pad() | Создает новую строку, дополняя ее до новой длины строки PHP |
| str_repeat() | Создает новую строку, повторяя указанную строку заданное количество раз |
| str_replace() | Заставляет строку PHP заменить часть своего содержимого. Метод чувствителен к регистру |
| spstr_rot13() | Выполняет кодирование ROT13 для строки |
| str_shuffle() | Создает новую строку путем случайного перемешивания всех символов |
| str_split() | Разбивает строку PHP на массив |
| str_word_count() | Возвращает количество слов в строке |
| strcasecmp() | Сравнивает две указанные строки PHP. Метод не чувствителен к регистру |
| стрхр() | Ищет первое вхождение указанной строки в другой строке |
| strcmp() | Сравнивает две указанные строки PHP. Метод чувствителен к регистру Метод чувствителен к регистру |
| стрколл() | Сравнивает две указанные строки PHP. Сравнение основано на строке локали | .
| стркспн() | Возвращает количество символов, пока не будет найден указанный символ |
| strip_tags() | Удаляет теги PHP и HTML из строки |
| полосы косой черты () | Создает новую строку, удаляя кавычки, которые были добавлены с помощью метода addcslashes() |
| полоски () | Создает новую строку, удаляя кавычки, которые были добавлены с помощью метода addlashes() |
| полосы() | Ищет первое вхождение указанной строки в другую строку. Возвращает позицию. Метод не чувствителен к регистру |
| строка() | Ищет первое вхождение указанной строки в другую строку. Метод не чувствителен к регистру |
| строка() | Вычисляет длину строки PHP и возвращает ее |
| strnatcasecmp() | Сравнивает две указанные строки PHP. Использует алгоритм естественного порядка. Метод не чувствителен к регистру Использует алгоритм естественного порядка. Метод не чувствителен к регистру |
| стрнаткмп() | Сравнивает две указанные строки PHP. Использует алгоритм естественного порядка. Метод чувствителен к регистру |
| strncasecmp() | Сравнивает две указанные строки PHP. Сравнивает только указанное количество первых символов. Метод не чувствителен к регистру |
| стрнкмп() | Сравнивает две указанные строки PHP. Сравнивает только указанное количество первых символов. Метод чувствителен к регистру |
| стрпбрк() | Ищет любой из указанных символов в заданной строке |
| строка() | Ищет первое вхождение указанной строки в другую строку. Метод чувствителен к регистру |
| стррхр() | Ищет последнее вхождение указанной строки в другую строку |
| стррев() | Создает новую строку путем перестановки данной строки |
| стрипос() | Ищет последнюю позицию указанной строки в другой строке. Метод не чувствителен к регистру Метод не чувствителен к регистру |
| стррпос() | Ищет последнюю позицию указанной строки в другой строке. Метод чувствителен к регистру |
| стрспн() | Подсчитывает количество символов, найденных в строке, которые находятся в указанном списке символов |
| стрстр() | Ищет первое вхождение указанной строки в другую строку. Метод чувствителен к регистру |
| стрток() | Разбивает указанную строку на более мелкие строки |
| strtolower() | Заменяет все символы строки строчными буквами |
| строкавверх() | Заменяет все символы строки на заглавные буквы PHP |
| стртр() | Переводит определенные символы в строке |
| подстрока() | Вырезает часть строки и возвращает ее |
| substr_compare() | Сравнивает части двух строк PHP. Начальная позиция и чувствительность к регистру могут быть указаны |
| substr_count() | Возвращает, сколько раз подстрока встречается в строке |
| substr_replace() | Заменяет часть строки другой строкой |
| отделка() | Создает новую строку, удаляя пробелы и другие ненужные символы с обеих сторон строки |
| ucfirst() | Изменяет первый символ строки на верхний регистр PHP |
| ucword() | Изменяет первую букву каждого слова на верхний регистр PHP |
| vfprintf() | Помещает отформатированную строку в выходной поток |
| vprintf() | Отображает отформатированную строку в выводе |
| vsprintf() | Помещает отформатированную строку в переменную |
| перенос слов() | Оборачивает заданную строку в указанное количество символов |
Функция ОБРЕЗКИ в Excel — быстрый способ удаления лишних пробелов
В этом учебном пособии показано несколько быстрых и простых способов обрезки пробелов в Excel. Узнайте, как удалить начальные, конечные и лишние пробелы между словами, почему не работает функция ТРИМ в Excel и как это исправить.
Узнайте, как удалить начальные, конечные и лишние пробелы между словами, почему не работает функция ТРИМ в Excel и как это исправить.
Вы сравниваете два столбца на наличие дубликатов, о которых вы знаете, но ваши формулы не могут найти ни одной повторяющейся записи? Или вы складываете два столбца чисел, но получаете только нули? И с какой стати ваша очевидно правильная формула Vlookup возвращает только кучу ошибок N/A? Это лишь несколько примеров проблем, ответы на которые вы, возможно, ищете. И все они вызваны дополнительными пробелами , скрывающимися до, после или между числовыми и текстовыми значениями в ваших ячейках.
Microsoft Excel предлагает несколько различных способов удаления пробелов и очистки данных. В этом руководстве мы рассмотрим возможности функции TRIM как самого быстрого и простого способа удаления пробелов в Excel.
Функция TRIM — удаление лишних пробелов в Excel
Вы используете функцию TRIM в Excel, чтобы удалить лишние пробелы из текста. Он удаляет все начальные, конечные и промежуточные пробелы 90 615, кроме одного символа пробела 90 616 между словами.
Он удаляет все начальные, конечные и промежуточные пробелы 90 615, кроме одного символа пробела 90 616 между словами.
Синтаксис функции TRIM самый простой, какой только можно себе представить:
ОТДЕЛКА(текст)
Где текст — это ячейка, из которой вы хотите удалить лишние пробелы.
Например, чтобы удалить пробелы в ячейке A1, используйте следующую формулу:
= ОТДЕЛКА (A1)
На следующем снимке экрана показан результат:
Да, это так просто!
Обратите внимание, что функция TRIM предназначена для удаления только символа пробела, который имеет значение 32 в 7-битной кодовой системе ASCII. Если в дополнение к дополнительным пробелам ваши данные содержат разрывы строк и непечатаемые символы, используйте функцию TRIM в сочетании с CLEAN, чтобы удалить первые 32 непечатаемых символа в системе ASCII.
Например, чтобы удалить пробелы, разрывы строк и другие нежелательные символы из ячейки A1, используйте следующую формулу:
= ОТДЕЛКА (ЧИСТКА (A1))
Дополнительные сведения см. в разделе Как удалить непечатаемые символы в Excel
в разделе Как удалить непечатаемые символы в Excel
Чтобы избавиться от неразрывных пробелов (html-символ ), который имеет значение 160, используйте TRIM вместе с функциями SUBSTITUTE и CHAR:
=ОТРЕЗАТЬ(ЗАМЕНИТЬ(A1, СИМВОЛ(160), " "))
Подробную информацию см. в разделе Как удалить неразрывные пробелы в Excel 9.0663
Как использовать функцию TRIM в Excel — примеры формул
Теперь, когда вы знакомы с основами, давайте обсудим несколько конкретных вариантов использования TRIM в Excel, подводные камни, с которыми вы можете столкнуться, и рабочие решения.
Как обрезать пробелы во всем столбце данных
Предположим, у вас есть столбец с именами, в котором есть пробелы до и после текста, а также более одного пробела между словами. Итак, как удалить все начальные, конечные и лишние пробелы во всех ячейках одновременно? Скопировав формулу TRIM из Excel в столбце, а затем заменив формулы их значениями. Подробные шаги следуют ниже.
Подробные шаги следуют ниже.
- Напишите формулу TRIM для самой верхней ячейки, A2 в нашем примере:
= ОТДЕЛКА (A2) - Поместите курсор в правый нижний угол ячейки формулы (в данном примере B2), и, как только курсор примет форму знака «плюс», дважды щелкните его, чтобы скопировать формулу вниз по столбцу до последней ячейки с данные. В результате у вас будет 2 столбца — исходные имена с пробелами и усеченные имена по формуле.
- Наконец, замените значения в исходном столбце усеченными данными. Но будь осторожен! Простое копирование обрезанного столбца поверх исходного столбца уничтожит ваши формулы. Чтобы этого не произошло, нужно копировать только значения, а не формулы. Вот как:
- Выделите все ячейки с формулами обрезки (в данном примере B2:B8) и нажмите Ctrl+C, чтобы скопировать их.
- Выберите все ячейки с исходными данными (A2:A8) и нажмите Ctrl+Alt+V, а затем V. Это ярлык вставки значений, который применяет Специальная вставка > Значения
- Нажмите клавишу Enter. Сделанный!
 Сделанный!
Сделанный!Как удалить начальные пробелы в числовом столбце
Как вы только что видели, функция TRIM в Excel без проблем удалила все лишние пробелы из столбца текстовых данных. Но что, если ваши данные — это числа, а не текст?
На первый взгляд может показаться, что функция TRIM сделала свое дело. Однако при ближайшем рассмотрении вы заметите, что усеченные значения не ведут себя как числа. Вот лишь несколько признаков аномалии:
- И исходный столбец с начальными пробелами, и обрезанные числа выравниваются по левому краю, даже если к ячейкам применяется числовой формат, в то время как обычные числа по умолчанию выравниваются по правому краю.
- Если выбраны две или более ячеек с обрезанными номерами, Excel отображает в строке состояния только COUNT. Для чисел он также должен отображать СУММУ и СРЗНАЧ.
- Формула СУММ, примененная к обрезанным ячейкам, возвращает ноль.
Судя по всему, обрезанные значения — это текстовых строк , а нам нужны числа.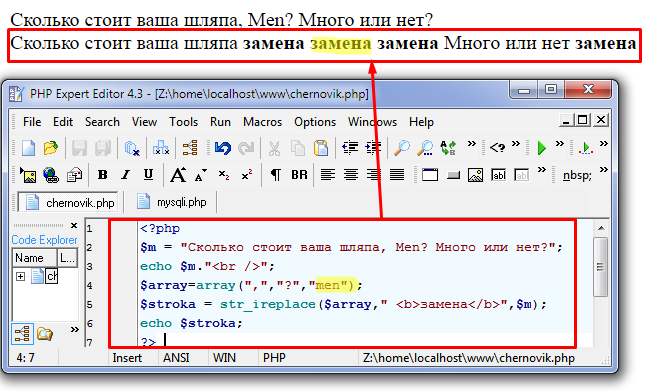 Чтобы исправить это, вы можете умножить обрезанные значения на 1 (чтобы умножить все значения одним махом, используйте параметр «Специальная вставка» > «Умножение»).
Чтобы исправить это, вы можете умножить обрезанные значения на 1 (чтобы умножить все значения одним махом, используйте параметр «Специальная вставка» > «Умножение»).
Более элегантное решение заключается в заключении функции TRIM в VALUE, например:
= ЗНАЧЕНИЕ (ОТРЕЗКА (A2))
Приведенная выше формула удаляет все начальные и конечные пробелы, если они есть, и превращает полученное значение в число, как показано на снимке экрана ниже:
Как удалить только начальные пробелы в Excel (Обрезка слева)
В некоторых ситуациях вы можете вводить повторяющиеся и даже тройные пробелы между словами, чтобы сделать ваши данные более читабельными. Однако вы хотите избавиться от начальных пробелов, например:
Как вы уже знаете, функция TRIM удаляет лишние пробелы в середине текстовых строк, а это нам не нужно. Чтобы сохранить все промежуточные пробелы нетронутыми, мы будем использовать более сложную формулу:
. =СРЕДН(A2,НАЙТИ(СРЕДНЯЯ(ОТРЕЗАТЬ(A2),1,1),A2),ДЛСТР(A2))
В приведенной выше формуле комбинация FIND, MID и TRIM вычисляет позицию первого символа текста в строке.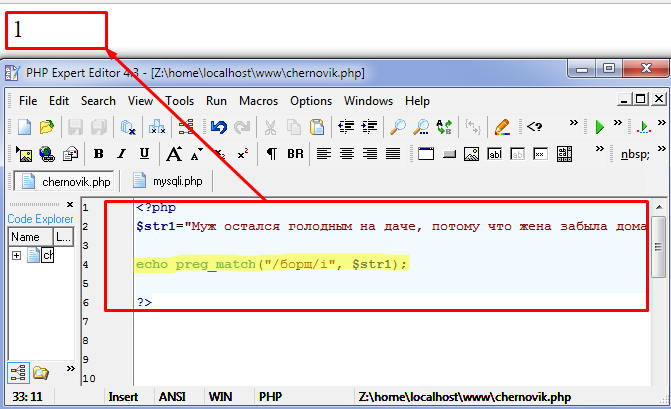 Затем вы передаете это число другой функции MID, чтобы она возвращала всю текстовую строку (длина строки вычисляется по LEN), начиная с позиции первого текстового символа.
Затем вы передаете это число другой функции MID, чтобы она возвращала всю текстовую строку (длина строки вычисляется по LEN), начиная с позиции первого текстового символа.
На следующем снимке экрана видно, что все начальные пробелы исчезли, но несколько пробелов между словами остались:
В качестве последнего штриха замените исходный текст усеченными значениями, как показано в шаге 3 примера формулы обрезки, и все готово!
Совет. Если вы также хотите удалить пробелы в конце ячеек, используйте инструмент «Обрезать пробелы». Не существует очевидной формулы Excel для удаления начальных и конечных пробелов, сохраняя несколько пробелов между словами.
Иногда перед удалением пробелов на листе Excel может потребоваться узнать, сколько на самом деле лишних пробелов.
Чтобы получить количество лишних пробелов в ячейке, узнайте общую длину текста с помощью функции ДЛСТР, затем рассчитайте длину строки без лишних пробелов и вычтите последнее из первого:
=ДЛСТР(A2)-ДЛСТР(ОТДЕЛКА(A2))
На следующем снимке экрана показана приведенная выше формула в действии:
Примечание. Формула возвращает количество 90 615 дополнительных пробелов 90 616 в ячейке, т. е. начальных, конечных и более одного последовательного пробела между словами, но она не считает одиночные пробелы в середине текста. Если вы хотите получить общее количество пробелов в ячейке, используйте эту формулу замены.
Формула возвращает количество 90 615 дополнительных пробелов 90 616 в ячейке, т. е. начальных, конечных и более одного последовательного пробела между словами, но она не считает одиночные пробелы в середине текста. Если вы хотите получить общее количество пробелов в ячейке, используйте эту формулу замены.
Как выделить ячейки с лишними пробелами
При работе с конфиденциальной или важной информацией вы можете не решиться удалить что-либо, не видя, что именно вы удаляете. В этом случае вы можете сначала выделить ячейки, содержащие лишние пробелы, а затем безопасно удалить эти пробелы.
Для этого создайте правило условного форматирования со следующей формулой:
=ДЛСТР($A2)>ДЛСТР(ОТРЕЗКА($A2))
Где A2 — самая верхняя ячейка с данными, которые вы хотите выделить.
Формула предписывает Excel выделить ячейки, в которых общая длина строки превышает длину обрезанного текста.
Чтобы создать правило условного форматирования, выберите все ячейки (строки), которые вы хотите выделить, без заголовков столбцов, перейдите на вкладку Главная > группу Стили и нажмите Условное форматирование > Новое правило > Используйте формулу, чтобы определить, какие ячейки форматировать .
Если вы еще не знакомы с условным форматированием Excel, вы найдете подробные инструкции здесь: Как создать правило условного форматирования на основе формулы.
Как показано на снимке экрана ниже, результат полностью соответствует подсчету дополнительных пробелов, который мы получили в предыдущем примере:
Как видите, пользоваться функцией TRIM в Excel легко и просто. Тем не менее, если кто-то хочет поближе познакомиться с формулами, обсуждаемыми в этом руководстве, вы можете загрузить рабочую книгу Trim Excel Spaces.
ТРИМ Excel не работает
Функция TRIM удаляет только символ пробела представлен кодовым значением 32 в 7-битном наборе символов ASCII. В наборе символов Unicode есть еще один символ пробела, называемый неразрывным пробелом , , который обычно используется на веб-страницах как html-символ . Неразрывный пробел имеет десятичное значение 160, и функция TRIM не может удалить его сама по себе.
Таким образом, если ваш набор данных содержит один или несколько пробелов, которые функция ОБРЕЗАТЬ не удаляет, используйте функцию ПОДСТАВИТЬ, чтобы преобразовать неразрывные пробелы в обычные пробелы, а затем обрезать их. Предполагая, что текст находится в формате A1, формула выглядит следующим образом:
Предполагая, что текст находится в формате A1, формула выглядит следующим образом:
=ОТРЕЗАТЬ(ЗАМЕНИТЬ(A1, СИМВОЛ(160), " "))
В качестве дополнительной меры предосторожности вы можете внедрить функцию CLEAN для очистки ячейки от любых непечатаемых символов:
=ОТРЕЗАТЬ(ОЧИСТИТЬ(ЗАМЕНИТЬ(A1, СИМВОЛ(160), " ")))
На следующем снимке экрана показана разница:
Если приведенные выше формулы также не работают для вас, есть вероятность, что ваши данные содержат определенные непечатаемые символы с кодовыми значениями, отличными от 32 и 160. В этом случае используйте одну из следующих формул, чтобы узнать код символа, где A1 — проблемная ячейка:
Начальный пробел: =КОД(СЛЕВА(A1,1))
Конечный пробел: =КОД(ПРАВО(A1,1))
Промежуточный пробел (где n — позиция проблемного символа в текстовой строке):
=КОД(СРЕДНИЙ(A1, n , 1)))
Затем введите возвращенный код символа в формулу TRIM(SUBSTITUTE()), описанную выше.
Например, если функция КОД возвращает 9, что является символом горизонтальной табуляции, вы можете использовать следующую формулу для его удаления:
=TRIM(SUBSTITUTE(A1, CHAR(9), " "))
Обрезать пробелы для Excel — удалить лишние пробелы одним щелчком мыши
Не кажется ли смехотворной идея выучить несколько разных формул для решения тривиальной задачи? Тогда вам может понравиться этот метод одним щелчком мыши, чтобы избавиться от пробелов в Excel. Позвольте представить вам Text Toolkit, включенный в наш Ultimate Suite. Среди прочего, такие как изменение регистра, разделение текста и очистка форматирования, он предлагает Trim Spaces 9.вариант 0616.
Если в Excel установлен Ultimate Suite, удалить пробелы в Excel очень просто:
- Выберите ячейки, из которых вы хотите удалить пробелы.
- Нажмите кнопку Trim Spaces на ленте.
- Выберите один или все из следующих вариантов:
- Обрезка начальные и конечные пробелы
- Обрезка дополнительные пробелы между словами, кроме одного пробела
- Trim неразрывные пробелов ( )
- Щелкнуть Обрезать .
