Подзапросы SQL
Подзапрос представляет собой оператор SELECT, вложенный в тело другого оператора.
Кодирование подзапроса подчиняется тем же правилам, что и кодирование простого оператора SELECT. Внешний оператор использует результат выполнения внутреннего оператора для определения окончательного результата.
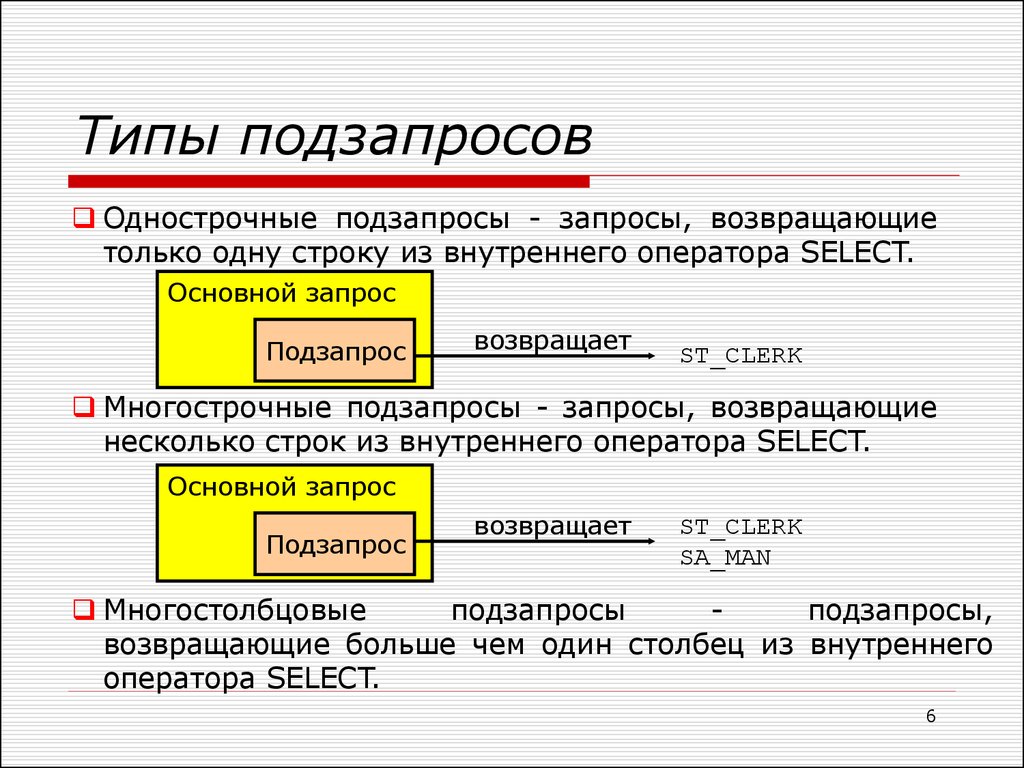
По количеству возвращаемых значений подзапросы разделяются на два типа:
- скалярные подзапросы, которые возвращают единственное значение;
- табличные подзапросы, которые возвращают множество значений.
По способу выполнения выделяют два типа подзапросов:
- простые подзапросы;
- сложные подзапросы.
Подзапрос называется простым, если он может рассматриваться независимо от внешнего запроса. СУБД выполняет такой подзапрос один раз и затем помещает его результат во внешний запрос.
Сложный подзапрос не может рассматриваться независимо от внешнего запроса. В этом случае выполнение оператора начинается с внешнего запроса, который отбирает каждую отдельную строку таблицы. Для каждой выбранной строки СУБД выполняет подзапрос один раз.
Для каждой выбранной строки СУБД выполняет подзапрос один раз.
Спонсор поста
Простые скалярные подзапросы
Приведем примеры простых скалярных подзапросов.
База данных, используемая в примерах, находится в этом посте.
Пример 1.
Определить наименования деталей, цена которых больше цены детали ‘болт’.
SELECT dname
FROM D
WHERE dprice > (SELECT dprice
FROM D
WHERE dname = ’болт’)Данный подзапрос относится к скалярным, так как возвращает единственное значение — цену детали болт.
Подзапрос является простым, потому что он может рассматриваться независимо от внешнего запроса. СУБД сначала выполняет подзапрос, в результате чего получает цену детали болт — значение 10, а затем помещает это значение во внешний запрос и выполняет его.
Пример 2.
Определить номера деталей, цена которых меньше средней цены деталей.
SELECT dname
FROM D
WHERE dprice < (SELECT AVG(dprice)
FROM D)Пример 3.
Определить номер поставщика, выполнившего поставку с минимальным объемом.
SELECT pnum
FROM PD
WHERE volume = (SELECT min(volume)
FROM PD)Пример 4.
Определить номера деталей, которых поставляется больше, чем деталей с номером 2.
SELECT pnum
FROM PD
GROUP BY dnum
HAVING sum(volume) > (SELECT sum(volume)
FROM PD
WHERE dnum = 2)Подзапросы можно использовать не только в предложении WHERE, но и в других предложениях оператора SELECT, например, в самом предложении
Пример 5.
Вывести следующую информацию о деталях: наименование, цена, отклонение от средней цены.
SELECT dname, dprice, dprice - (SELECT AVG(dprice) FROM PD) AS dif FROM PD
В результате получим таблицу:
| dname | dprice | dif |
|---|---|---|
| болт | 10 | -10 |
| гайка | 20 | 0 |
| винт | 30 | 10 |
Рандомный блок
Простые табличные подзапросы
Если подзапрос возвращает множество значений, то его результат следует обрабатывать специальным образом. Для этого предназначены операции
Для этого предназначены операции IN, ANY, SOME и ALL.
Такие операции могут использоваться с подзапросами, возвращающими таблицу, состоящую из одного столбца значений.
Операция
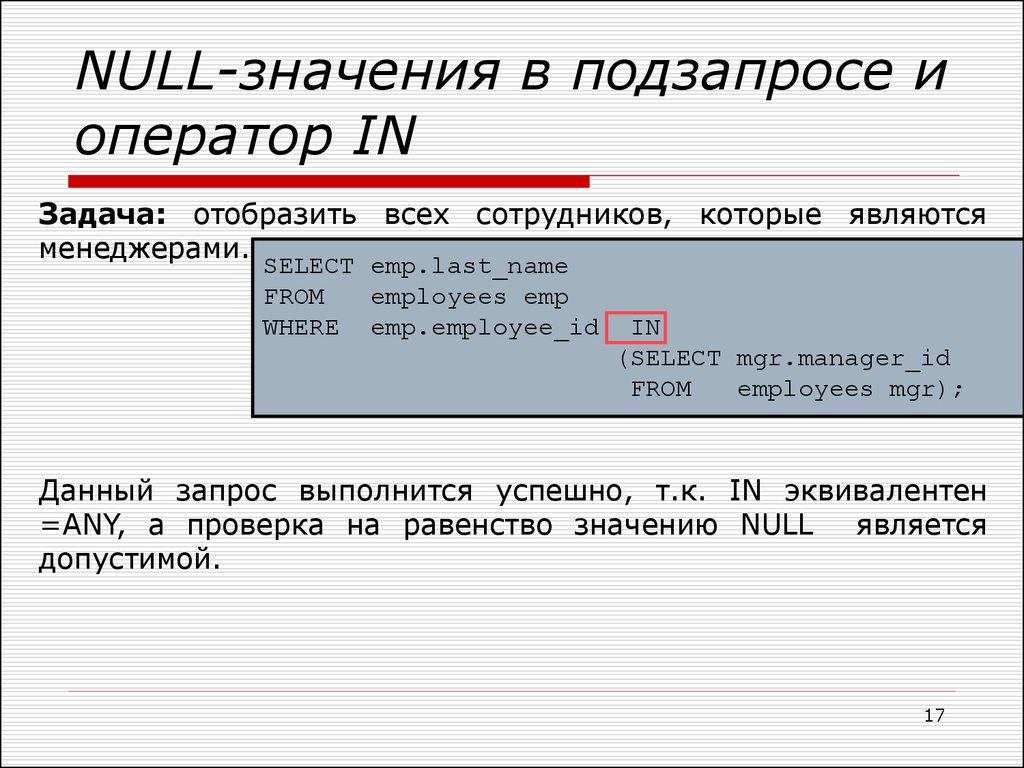
INОперация IN осуществляет проверку на принадлежность значения множеству, которое получается после выполнения подзапроса.
Пример 6.
Определить наименования поставщиков, которые поставляют детали.
SELECT pname
FROM P
WHERE pnum in (SELECT pnum
FROM PD)Такой подзапрос относится к табличным, так как возвращает множество значений. Подзапрос является простым, потому что он может рассматриваться независимо от внешнего запроса.
СУБД сначала выполняет подзапрос, в результате чего получает множество номеров поставщиков, которые поставляют детали. Затем СУБД проверяет номер каждого поставщика из таблицы P на принадлежность полученному множеству.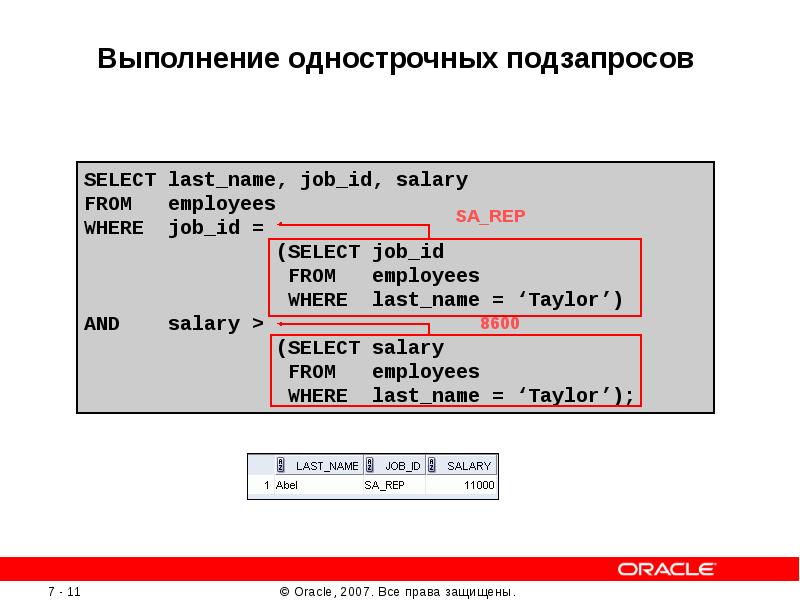
Пример 7.
Определить наименования поставщиков, которые не поставляют деталь с номером 2.
SELECT pname
FROM P
WHERE pnum not in (SELECT pnum
FROM PD
WHERE dnum = 2)Пример 8.
Определить наименования поставщиков, которые поставляют только деталь с номером 1.
SELECT pname
FROM PD
WHERE pnum in (SELECT pnum
FROM PD
WHERE dnum = 1) AND pnum not in (SELECT pnum
FROM PD
WHERE dnum <> 1)Операции
ANY, SOME, ALLЕсли подзапросу предшествует ключевое слово ANY, то условие сравнения считается выполненным, когда оно выполняется хотя бы для одного из значений, которые получаются после выполнения подзапроса.
Если подзапросу предшествует ключевое слово ALL, то условие сравнения считается выполненным, только если оно выполняется для всех значений, которые получаются после выполнения подзапроса.
Если в результате выполнения подзапроса получено пустое множество, то для операции ALL условие сравнения будет считаться ANY — не выполненным.
Ключевое слово SOME является синонимом ANY и используется для повышения наглядности текстов запросов.
Пример 9.
Определить наименования поставщиков, которые поставляют детали.
SELECT pname
FROM P
WHERE pnum = ANY(SELECT pnum
FROM PD)Такой подзапрос относится к табличным, так как возвращает множество значений. Подзапрос является простым, потому что он может рассматриваться независимо от внешнего запроса.
СУБД сначала выполняет подзапрос, в результате чего получает множество номеров поставщиков, которые поставляют детали. Затем СУБД проверяет номер каждого поставщика из таблицы P на равенство хотя бы одному из номеров из полученного множества.
Пример 10.
Определить наименование детали с максимальной ценой.
SELECT dname
FROM D
WHERE dprice >= ALL(SELECT dprice
FROM PD)Последний пример можно решить следующим способом:
SELECT dname
FROM D
WHERE dprice = (SELECT max(dprice)
FROM PD)Сложные табличные подзапросы
Операция EXISTS
TRUE или FALSE.Для операции EXISTS результат равен TRUE, если в возвращаемой подзапросом таблице присутствует хотя бы одна строка. Если в результирующей таблице подзапроса пуста, то операция EXISTS возвращает значение FALSE. Для операции NOT EXISTS используются обратные правила обработки.
Поскольку обе операции проверяют лишь наличие строк в результирующей таблице подзапроса, то эта таблица может содержать произвольное количество столбцов.
Пример 11.
Определить наименования поставщиков, которые поставляют детали.
SELECT pname
FROM P
WHERE EXISTS(SELECT *
FROM PD
WHERE PD.pnum = P.pnum)Такой подзапрос относится к табличным, так как возвращает множество значений. Подзапрос является сложным, потому что он не может выполняться независимо от внешнего запроса.
В этом случае выполнение оператора начинается с внешнего запроса, который поочередно отбирает каждую отдельную строку таблицы P. Для каждой выбранной строки СУБД выполняет подзапрос один раз. В результирующую таблицу помещаются только те наименования поставщиков, для которых подзапрос возвращает хотя бы одну строку.
Первой выбирается строка с информацией о поставщике Иванов. В подзапрос вместо P.pnum подставляется значение 1 (номер поставщика Иванова), после чего подзапрос выполняется.
Подзапрос возвращает три первых строки из таблицы PD, соответствующие поставкам Иванова, поэтому результат операции EXISTS равен TRUE, и наименование Иванов помещается в результирующую таблицу.
Аналогично результат получается для поставщиков Петров и Сидоров. При выборе строки с информацией о поставщике Кузнецов, подзапрос возвращает пустое множество, поэтому результат операции FALSE, и наименование Кузнецов не помещается в результирующую таблицу.
Создание самосоединений
Самосоединение это обычное соединение языка SQL, которое соединяет таблицу саму с собой. Такое соединение позволяет сравнивать значения, хранящиеся в одном столбце таблицы.
При самосоединении используются псевдонимы таблиц, которые позволяют различать соединяемые копии таблиц. Псевдонимы вводятся в предложении FROM и используются как обычные имена таблиц.
Пример 12.
Определить наименования поставщиков, которые поставляют и деталь с номером 1, и деталь с номером 2.
Один из вариантов решения задачи можно записать с помощью подзапроса следующим образом.
SELECT pnum
FROM PD
WHERE dnum = 1 AND pnum in (SELECT pnum
FROM PD
WHERE dnum = 2)Тот же самый результат можно получить используя соединение таблицы PD с ее копией, назовем ее PD1, следующим образом:
SELECT PD.pnum FROM PD INNER JOIN PD AS PD1 ON PD.pnum = PD1.pnum WHERE PD.dnum = 1 AND PD1.dnum = 2
 pnum
FROM PD INNER JOIN PD AS PD1 ON PD.pnum = PD1.pnum
WHERE PD.dnum = 1 AND PD1.dnum = 2
pnum
FROM PD INNER JOIN PD AS PD1 ON PD.pnum = PD1.pnum
WHERE PD.dnum = 1 AND PD1.dnum = 2Пример 13.
Определить наименования поставщиков, которые поставляют и деталь с номером 1, и деталь с номером 2, и деталь с номером 3.
SELECT PD.pnum FROM (PD INNER JOIN PD AS PD1 ON PD.pnum=PD1.pnum) INNER JOIN PD AS PD2 ON PD1.pnum=PD2.pnum WHERE PD.dnum=1 AND PD1.dnum=2 AND PD2.dnum=3
Резюмирую
Из этой статьи вы узнали что такое подзапрос в SQL. Теперь вы легко отличите скалярный запрос от табличного, и простой запрос от сложного.
Также мы рассмотрели на примерах такие операции, как IN, ANY, SOME и ALL.
ПОДЗАПРОСЫ
Автор: Роман Буданов, тренер курса “Первый Онлайн ИНститут Тестировщиков” (компания “Лаборатория Качества”)
Всем доброго времени суток, мои маленькие (и не очень) любители (и не очень) SQL! На курсе ПОИНТ мы с нуля разбираем построение запросов, обучаемся основным операторам, работе с разными типами данных, но сейчас я хочу с вами поговорить про один из полезных инструментов, увы, оставшихся за рамками ПОИНТ — сегодня я хочу рассказать вам про такую полезную штуку, как подзапросы и показать несколько вариантов их приготовления.
1. Что такое подзапросы?
А начать свой рассказ я хочу с объяснения того, что же такое этот ваш (наш) подзапрос — по сути своей, это запрос внутри запроса, с результирующей выборкой которого вы можете творить очень много разных вещей — от вытаскивания из неё всех данных (блок FROM) до задания условий на её основе(блок WHERE). То есть сначала у вас выполняется подзапрос, возвращает свою результирующую выборку, а уже потом, основываясь на результатах работы подзапроса, формируется результирующая выборка основного, “внешнего”, запроса. Впрочем, на словах не особо понятно, давайте покажу на примерах.
Примеры я буду приводить, основываясь на учебной базе данных ПОИНТ. Её схема выглядит вот так:
2. Места для использования подзапроса
a. Блок From
Самый банальный и бесполезный, на первый взгляд, метод применения подзапросов — когда результирующая выборка копирует собой результирующую выборку подзапроса. Пример:
Пример:
Запрос SELECT * FROM company вернёт нам вот такую результирующую выборку:
А запрос SELECT * FROM (select * from company) c … вернёт нам абсолютно такую же результирующую выборку!
Чудеса, да и только. Как это работает:
- Сначала мы в подзапросе выводим все поля из таблицы company.
- Потом во внешнем запросе выводим все поля из результирующей выборки подзапроса (обратите внимание, что для подзапроса в блоке FROM обязательно нужно указать алиас, иначе в MySQL это работать не будет).
Казалось бы — абсолютно бесполезная штука, лишняя трата времени, нервов и ресурсов. Так оно, в принципе, и есть… До тех пор, пока не придёт осознание того, что в блоке FROM есть еще и такая полезная штука, как, например, JOIN — да, джоинить с подзапросом тоже можно! И вот тут-то мы начинаем понимаааааааать. Но еще не до конца. Поэтому давайте разберём пример: допустим, мы ищем покупки всех пользователей, у которых логин заканчивается на букву “а”.
Можно написать так:
select t.*, a.id, a.login from transactions t
join account a on t.account_id=a.id
where a.login like ‘%a’
и этот запрос нам вернёт такую результирующую выборку (выполнялся 3мс).
А можно написать так:
select * from transactions t
join (select id, login from account where login like ‘%a’) a on t.account_id=a.id
и этот запрос вернёт нам абсолютно такую же результирующую выборку,
но сделает это втрое быстрее — за 1 мс! Да, понятно, что выигрыш в 2 мс очень не солидно смотрится — но вы учтите, что у нас учебная база в 5 таблиц и, суммарно, 200 записей. А если представить, что записей не 200, а, допустим, 20000, а то и все 200000 (а такое часто бывает на “боевых” проектах — там просто ОГРОМНЫЕ базы), то выигрыш в 3 раза смотрится уже не так плохо, а? Давайте теперь подумаем, почему второй вариант работает быстрее.
Как работает первый запрос, с обычным джоином?
- Берётся первая таблица.
- Объединяется со второй таблицей.
- Из получившейся результирующей выборки отбираются подходящие под условие записи.
Как работает второй запрос, с “подзапросным” джоином?
- Берётся подзапрос, в нём находятся все записи, удовлетворяющие условию.
- С этими записями уже происходит джоин первой таблицы.
То есть если в первом случае мы джоиним таблицу в 256 записей с таблицей в 20 записей, то во втором случае мы джоиним таблицу в 256 записей с таблицей в 3 записи. А ведь внутри подзапроса можно точно так же использовать джоины… Так что прирост быстродействия — налицо!
b. Блок WHERE
А сейчас начнётся самое зрелищное — условия формирования результирующей выборки внешнего запроса, основывающиеся на результате работы подзапроса!
Как это может быть? Да очень просто, на самом деле: давайте представим, что нам нужно вывести логины пользователей, купивших самую дорогую игру. Для этого нам сначала нужно сделать что? Правильно, эту самую игру надо определить.
Для этого нам сначала нужно сделать что? Правильно, эту самую игру надо определить.
Делаем так:
select max(price) from game
находим цену самой дорогой игры. Нашли, отлично. Получилось 8000. Дальше что? Можно, конечно, ручками вбить эти самые 8000 в другой запрос и получить искомое, да. Но это будет справедливо для текущего “наполнения” базы данных. А БД штука такая непостоянная… Я сейчас серьёзно — база, как правило, постоянно обновляется, получая “свежие” записи.
Поэтому нам нужно сделать так, чтобы в одном запросе и самая дорогая игра находилась, и люди, её купившие. Здесь-то нам на помощь и приходит наш верный друг — подзапрос. Заручившись его помощью, мы идём писать. Пишем, пишем и получаем вот, что:
select a.login from account a
join transactions t on a.id=t.account_id
join game g on t.game_id=g.id
where
g.price=(select max(g1.price) from game g1)
получаем
То есть для начала мы находим цену самой дорогой игры, а потом, через список транзакций, находим людей, которые купили игры, чья цена равна максимальной.
Если вы принципиально хотите цепляться к айдишнику, а не к цене, то можно поизвращаться и сделать несколько по-другому:
select a.login from account a
join transactions t on a.id=t.account_id
join game g on t.game_id=g.id
where
g.id=
(
select id from game g1
where g1.price=(select max(price) from game g2)
)
На выходе получаем абсолютно то же самое:
Да, глаза вас не обманывают — вы увидели именно то, что увидели — это подзапрос внутри подзапроса. Да, так тоже можно было.
Почти уверен, что вы сейчас задались — вопросом: “А насколько глубока кроличья нора?”, поэтому сразу отвечу: “Имя им легион”. Вложенным подзапросам, я имею в виду. Т. е. вы можете плодить столько вложенных друг в друга подзапросов, сколько вашей душе (и здравому смыслу) угодно. И это действительно бывает полезно!
Как это работает: как я и говорил, разворачивать “матрёшку” из подзапросов мы начинаем с самого “дна” — с последнего вложенного подзапроса, то бишь:
- Сначала мы находим во вложенном подзапросе самую дорогую игру.
- Потом находим её айдишник в подзапросе “верхнего уровня”.
- После чего во внешнем запросе отбираем все транзакции, в которых участвовала игра с этим айдишником.

Думаю, вы уже задались вопросом: “А почему нельзя было в одном подзапросе вывести и цену самой дорогой игры, и её айдишник, а не городить один подзапрос в другом?”. А всё потому, дамы и господа, что оператор max(), как и любая уважающая себя агрегатная функция, нормально работает только по одному полю — т. е. если написать так:
select id, game_name, max(price) from game
то в результате мы увидим вот такую красоту:
Казалось бы — всё ок, да? Вывелся айдишник игры, вывелось её название и цена, как заказывали. Но, вот незадача — это неправильные данные. Проверяем:
select id, game_name, price from game
where id=1 or price=8000
Если бы подвоха не было, то этот запрос вернул бы нам одну-единственную запись — ту же, что и предыдущий запрос.
А мы получаем вот это:
то есть мы видим, что поля id и game_name у нас запрос вывел от первой (по порядку) записи в таблице, а в поле price — самую большую цену, как и заказывали. Вот такой вот обман. MySQL просто вежливый и не стал нам говорить: “Что за ты бред несёшь, я это выполнять не буду” (как сделала бы почти любая другая СУБД), а взял и выполнил тот бред, что мы написали.
Это первый пункт ответа на вопрос “А почему нельзя было в одном подзапросе вывести и цену самой дорогой игры, и её айдишник, а не городить один подзапрос в другом?”. Второй пункт заключается в том, мы используем оператор математического сравнения — а в этом случае подзапрос должен возвращать только одно значение (одно поле, одна запись), чтобы MySQL не растерялся и не спросил: “А с чем именно в подзапросе мне сравнивать значение g.id?”. Вы же не пишете в реальной жизни a=b,c,d,e,f ? Нет, вы пишете a=b — одно значение слева от знака равенства, одно — справа, чтобы не возникло путаницы. Так и здесь — запрос должен возвращать одно-единственное значение, и тогда всё у вас будет работать верно.
Так и здесь — запрос должен возвращать одно-единственное значение, и тогда всё у вас будет работать верно.
3. Основные операторы взаимодействия с подзапросами в блоке WHERE
a. Операторы сравнения
Раз уж я начал рассказывать про операторы сравнения, давайте ими и продолжу — особенно если учесть то, что, по сути, всё основное я уже рассказал. К вышесказанному добавить хочу только то, что сравнивать можно не только знаком “равно” = , но и всеми остальными логическими операторами:
больше > (находим всех пользователей, которые купили игры, стоящие дороже самой дорогой игры):
select a.login from account a
join transactions t on a.id=t.account_id
join game g on t.game_id=g.id
where
g.price>(select max(g1.price) from game g1)
меньше < (находим всех пользователей, которые купили игры, стоящие дешевле самой дорогой игры):
select a. login from account a
login from account a
join transactions t on a.id=t.account_id
join game g on t.game_id=g.id
where
g.price<(select max(g1.price) from game g1)
и не равно != (находим всех пользователей, которые купили игры, стоящие дороже или дешевле самой дорогой игры):
select a.login from account a
join transactions t on a.id=t.account_id
join game g on t.game_id=g.id
where
g.price!=(select max(g1.price) from game g1)
b. Операторы вхождения во множество
Помните, выше мы с вами писали прекрасный запрос на поиск людей, купивших самую дорогую игру? Тот, который напоминал капусту — с двумя вложенными подзапросами?
Вот он, красавец:
select a.login from account a
join transactions t on a.id=t.account_id
join game g on t.game_id=g.id
where
g.id=(select id from game g1 where g1. price=(select max(price) from game g2))
price=(select max(price) from game g2))
Он, конечно, всем хорош, но, увы, как и все в этом мире, неидеален. В чём же заключается его неидеальность, вполне резонно спросите вы? А в том, что запрос этот будет работать только в том случае, когда у нас в базе всего одна “самая дорогая” игра. А может у нас быть в базе несколько игр с одинаковой самой высокой ценой? Да запросто, как два байта переслать! И в этом случае у нас запрос споткнётся. Угадаете, почему? Прааааавильно, потому что “внешний” подзапрос вернёт больше одного значения. Что с этим делать? Обратить внимание на операторы вхождения значения в множество, IN и NOT IN. Честно говоря, за проверку вхождения в множество отвечает только один из них, IN. NOT IN делает, как вы, наверное, догадались, диаметрально противоположную проверку.
Так вот, раз уж у нас “внешний” подзапрос будет выводить не одно значение, а несколько (читай — множество), то мы смело можем заменить в нашем запросе знак равенства оператором IN, вот так:
select a. login from account a
login from account a
join transactions t on a.id=t.account_id
join game g on t.game_id=g.id
where
g.id in (select id from game g1 where g1.price=(select max(price) from game g2))
и всё у нас прекрасно заработает. А как оно заработает? Да достаточно просто на самом деле:
- Сначала во “внутреннем” подзапросе находится цена самой дорогой игры.
- Потом во “внешнем” подзапросе находятся игры, имеющие самую высокую цену (несколько).
- И, под конец, у нас в основном запросе отбираются те транзакции, у которых game_id входит во множество айдишников игр, которое вернул нам “внешний” подзапрос.
Вот видите? Как я и говорил, всё достаточно просто. А если бы мы заменили в запросе IN на NOT IN, тогда бы запрос выдавал нам все транзакции, в которых НЕ участвовали самые дорогие игры.
c. Операторы существования записей
Не пугайтесь страшного названия, мои дорогие читатели — не так страшен чёрт, как его малюют. Сейчас я вам это докажу. Смотрите — этих операторов, как и со множествами, всего 2 — EXISTS и NOT EXISTS. И опять, как и раньше, за проверку существования записей отвечает только EXISTS. NOT EXISTS проверяет, что записей не существует.
Сейчас я вам это докажу. Смотрите — этих операторов, как и со множествами, всего 2 — EXISTS и NOT EXISTS. И опять, как и раньше, за проверку существования записей отвечает только EXISTS. NOT EXISTS проверяет, что записей не существует.
Если говорить чуть подробнее, то EXISTS проверяет, что подзапрос вернул непустую результирующую выборку. А NOT EXISTS, соответственно, пустую.
Давайте пример: допустим, нам надо найти всех пользователей, у которых нет ни одной игры, вышедшей в нечётный день месяца. Запрос будет выглядеть так:
select * from account a
where not exists
(
select t.account_id from transactions t
join game g on t.game_id=g.id
where day(g.Release_date)%2=1 and t.account_id=a.id
)
и вернёт он нам пустую результирующую выборку. Нет, это не потому, что запрос неверный. Это потому, что подходящих записей в базе просто нет — да, и такое бывает.
Теперь давайте с вами посмотрим, как это работает (для удобства объяснения давайте представим, что СУБД обрабатывает записи в таблице по очереди).
Как это работает:
- Берётся первая запись из таблицы account.
- Строится подзапрос, в котором для этой записи (условие t.account_id=a.id в подзапросе) ищутся транзакции, в которых участвовали игры, вышедшие в нечётный день месяца.
- Если подзапрос вернул пустоту, значит, первая запись из таблицы account удовлетворяет условию NOT EXISTS и она добавляется в результирующую выборку запроса.
- Берётся вторая запись из таблицы account.
- И для неё (как и для всех остальных записей таблицы account) повторяются шаги 2 и 3.
То есть, грубо говоря, для каждой записи таблицы account создаётся отдельный подзапрос, и СУБД проверяет, вернул этот подзапрос пустоту или нет.
Как вы, наверное, заметили, здесь используется такая интересная штука, как связь между данными из внешнего запроса и данными из внутреннего запроса (то самое условие t. account_id=a.id в подзапросе) — здесь оно просто необходимо, т. к. оператор NOT EXISTS не даёт нам доступа к данным подзапроса — он только говорит нам, вернул ли запрос пустоту, как мы того ожидали, или нет, и мы не можем проверить, для какой именно записи из таблицы account этот подзапрос был создан.
account_id=a.id в подзапросе) — здесь оно просто необходимо, т. к. оператор NOT EXISTS не даёт нам доступа к данным подзапроса — он только говорит нам, вернул ли запрос пустоту, как мы того ожидали, или нет, и мы не можем проверить, для какой именно записи из таблицы account этот подзапрос был создан.
Заключение
Вот, в принципе, и всё, что я хотел вам сегодня рассказать. Надеюсь, эта статья была для вас полезна и помогла вам разобраться в повадках этих грудоломов (личинок Чужих из одноименного фильма) от мира SQL.
Интересных вам задач и объёмных БД, дамы и господа!
Обсудить в форуме
подзапросов — База знаний MariaDB
Подзапрос — это запрос, вложенный в другой запрос.
Скалярные подзапросы
Подзапрос, возвращающий одно значение.Подзапросы строки
Подзапрос, возвращающий строку.Подзапросы и ВСЕ
Возвращает true, если сравнение возвращает true для каждой строки или подзапрос не возвращает ни одной строки.Подзапросы и ЛЮБОЙ
Возвращает true, если сравнение возвращает true хотя бы для одной строки, возвращенной подзапросом.Подзапросы и EXISTS
Возвращает true, если подзапрос возвращает какие-либо строки.Подзапросы в пункте FROM
Подзапросы чаще помещаются в предложение WHERE, но также могут быть частью предложения FROM.Оптимизация подзапросов
Статьи об оптимизации подзапросов в MariaDB.Подзапросы и соединения
Переписывание подзапросов как JOIN и использование подзапросов вместо JOIN.Ограничения подзапросов
Существует ряд ограничений в отношении подзапросов.



Контент, воспроизведенный на этом сайте, является собственностью его соответствующих владельцев, и этот контент не проверяется заранее MariaDB. Взгляды, информация и мнения выраженные в этом контенте, не обязательно представляют собой материалы MariaDB или любой другой стороны.
CALL {} (подзапрос) — Руководство по шифрованию
Предложение
CALL {}оценивает подзапрос, который возвращает некоторые значения.
CALL позволяет выполнять подзапросы, т.е. запросы внутри других запросов.
Подзапросы позволяют составлять запросы, что особенно полезно при работе с UNION или агрегациями.
Предложение |

Подзапросы, которые заканчиваются оператором RETURN , называются возвращающими подзапросами , а подзапросы без такого оператора возврата называются модульными подзапросами .
Подзапрос оценивается для каждой входящей входной строки. Каждая выходная строка возвращаемого подзапроса объединяется с входной строкой для создания результата подзапроса. Это означает, что возвращаемый подзапрос повлияет на количество строк. Если подзапрос не возвращает ни одной строки, после подзапроса не будет доступных строк.
Подзапросы модуля , с другой стороны, вызываются из-за их побочных эффектов, а не из-за их результатов, и поэтому не влияют на результаты включающего запроса.
Существуют ограничения на взаимодействие подзапросов с объемлющим запросом:
Подзапрос может ссылаться на переменные из включающего запроса только в том случае, если они явно импортированы.
Подзапрос не может возвращать переменные с теми же именами, что и переменные в окружающем запросе.
Все переменные, возвращаемые из подзапроса, впоследствии становятся доступными во включающем запросе.

Следующий график используется для приведенных ниже примеров:
Чтобы воссоздать график, запустите следующий запрос в пустой базе данных Neo4j:
CREATE
(a: Person: Child {возраст: 20, имя: «Алиса»}),
(б: Человек {возраст: 27, имя: «Боб»}),
(c:Person:Parent {возраст: 65, имя: «Чарли»}),
(d:Person {возраст: 30, имя: 'Дора'})
СОЗДАТЬ (а)-[:FRIEND_OF]->(б)
СОЗДАТЬ (а)-[:CHILD_OF]->(с)
СОЗДАТЬ (:Счетчик {количество: 0}) Семантика
Предложение CALL выполняется один раз для каждой входящей строки.
Пример 1. Выполнять для каждой входящей строки
Предложение CALL выполняется три раза, по одному разу для каждой строки, которую выводит предложение UNWIND .
Запрос
РАЗМОТКА [0, 1, 2] AS x
ВЫЗОВ {
ВОЗВРАТ 'привет' КАК innerReturn
}
RETURN innerReturn | внутренний возврат |
|---|
|
|
|
Ряды:3 |
 Результат
Результат При каждом выполнении предложения CALL могут наблюдаться изменения по сравнению с предыдущими исполнениями.
Пример 2. Просмотр изменений по сравнению с предыдущим выполнением
Запрос
UNWIND [0, 1, 2] AS x
ВЫЗОВ {
ПОИСКПОЗ (n:счетчик)
НАБОР n.count = n.count + 1
ВОЗВРАТ n.count AS innerCount
}
С внутренним счетом
ПОИСКПОЗ (n:счетчик)
ВОЗВРАЩАТЬСЯ
внутренний граф,
n.count AS totalCount | внутренний возврат | общее количество |
|---|---|
1 | 3 |
2 | 3 |
3 | 3 |
Ряды:3 | |
Переменные импортируются в подзапрос с помощью импорта С пункт. Поскольку подзапрос оценивается для каждой входящей входной строки, импортированные переменные привязываются к соответствующим значениям из входной строки в каждой оценке.
Поскольку подзапрос оценивается для каждой входящей входной строки, импортированные переменные привязываются к соответствующим значениям из входной строки в каждой оценке.
Запрос
РАЗМОТКА [0, 1, 2] AS x
ВЫЗОВ {
С х
ВОЗВРАТ x * 10 КАК у
}
RETURN x, y | х | и |
|---|---|
| |
| |
| |
Ряды: 3 | |
Пункт импорта WITH должен:
Состоят только из простых ссылок на внешние переменные — т.е.
С х, у, з. Псевдонимы или выражения не поддерживаются при импортеС пунктами— напр. С a AS bилиС a+1 AS b.Быть первым предложением подзапроса (или вторым предложением, если оно следует непосредственно за предложением
USE).

Порядок выполнения подзапросов не определен.
Если результат запроса зависит от порядка выполнения подзапросов, предложение |
Пример 3. Порядок выполнения подзапросов
Этот запрос создает связанный список всех узлов :Person в порядке возрастания возраста.
Предложение CALL полагается на порядок входящих строк, чтобы гарантировать создание правильно связанного списка, поэтому входящие строки должны быть упорядочены с предшествующим предложением ORDER BY .
Запрос
ПОИСКПОЗ (человек:человек) С человеком ORDER BY person.
 age ASC LIMIT 1
УСТАНОВИТЕ человека:ListHead
С *
ПОИСКПОЗ (следующий: человек)
ГДЕ НЕ рядом:ListHead
ЗАКАЗАТЬ ПО next.age
ВЫЗОВ {
С рядом
ПОИСКПОЗ (текущий:ListHead)
УДАЛИТЬ текущий:ListHead
УСТАНОВИТЬ следующее:ListHead
CREATE(текущий)-[r:IS_YOUNGER_THAN]->(следующий)
ВОЗВРАТ текущей AS из следующей AS в
}
ВОЗВРАЩАТЬСЯ
from.name Имя AS,
от.возраст КАК возраст,
to.name КАК Ближайшее СтароеИмя,
to.age AS ближайшийOlderAge
age ASC LIMIT 1
УСТАНОВИТЕ человека:ListHead
С *
ПОИСКПОЗ (следующий: человек)
ГДЕ НЕ рядом:ListHead
ЗАКАЗАТЬ ПО next.age
ВЫЗОВ {
С рядом
ПОИСКПОЗ (текущий:ListHead)
УДАЛИТЬ текущий:ListHead
УСТАНОВИТЬ следующее:ListHead
CREATE(текущий)-[r:IS_YOUNGER_THAN]->(следующий)
ВОЗВРАТ текущей AS из следующей AS в
}
ВОЗВРАЩАТЬСЯ
from.name Имя AS,
от.возраст КАК возраст,
to.name КАК Ближайшее СтароеИмя,
to.age AS ближайшийOlderAge | имя | возраст | ближайшийOlderName | ближайшийOlderAge |
|---|---|---|---|
| | | |
| | | |
| | | |
Ряды: 3 | |||
Обработка после объединения
Подзапросы могут использоваться для обработки результатов UNION запросить дальше. Этот пример запроса находит самого молодого и самого старшего человека в базе данных и упорядочивает их по именам.
Этот пример запроса находит самого молодого и самого старшего человека в базе данных и упорядочивает их по именам.
Запрос
ЗВОНОК {
ПОИСКПОЗ (p:лицо)
ВОЗВРАТ р
ЗАКАЗАТЬ ПО СТРАНИЦЕ ASC
ПРЕДЕЛ 1
СОЮЗ
ПОИСКПОЗ (p:лицо)
ВОЗВРАТ р
ЗАКАЗАТЬ ПО СТРАНИЦЕ DESC
ПРЕДЕЛ 1
}
ВОЗВРАТ p.name, p.age
ORDER BY p.name | ф.имя | стр. |
|---|---|
| |
| |
Ряды: 2 | |
Если разные части результата должны сопоставляться по-разному, с некоторой агрегацией по всем результатам, необходимо использовать подзапросы.
Этот пример запроса находит друзей и/или родителей для каждого человека. Впоследствии количество друзей и родителей подсчитывается вместе.
Впоследствии количество друзей и родителей подсчитывается вместе.
Запрос
ПОИСКПОЗ (p:Person)
ВЫЗОВ {
С р
ДОПОЛНИТЕЛЬНОЕ СОВПАДЕНИЕ (p)-[:FRIEND_OF]->(другое:Человек)
ВЕРНУТЬ другое
СОЮЗ
С р
ДОПОЛНИТЕЛЬНОЕ СОВПАДЕНИЕ (p)-[:CHILD_OF]->(другое:Родитель)
ВЕРНУТЬ другое
}
RETURN DISTINCT p.name, count(other) | ф.имя | количество(другое) |
|---|---|
| |
| |
| |
| |
Ряды: 4 | |
Агрегации
Возвращаемые подзапросы изменяют количество результатов запроса: Результат 9Предложение 0048 CALL — это объединенный результат оценки подзапроса для каждой входной строки.
В следующем примере выполняется поиск имени каждого человека и имен его друзей:
Запрос
ПОИСКПОЗ (p:Person)
ВЫЗОВ {
С р
ПОИСКПОЗ (p)-[:FRIEND_OF]-(c:человек)
ВЕРНУТЬ c.name КАК друга
}
RETURN p.name, friend | ф.имя | друг |
|---|---|
| |
| |
Ряды: 2 | |
Количество результатов подзапроса изменило количество результатов объемлющего запроса: Вместо 4 строк, по одной на каждый узел), теперь найдено 2 строки для Алисы и Боба соответственно. Для Чарли и Доры строки не возвращаются, так как у них нет друзей в нашем примере графа.
Мы также можем использовать подзапросы для выполнения изолированных агрегаций.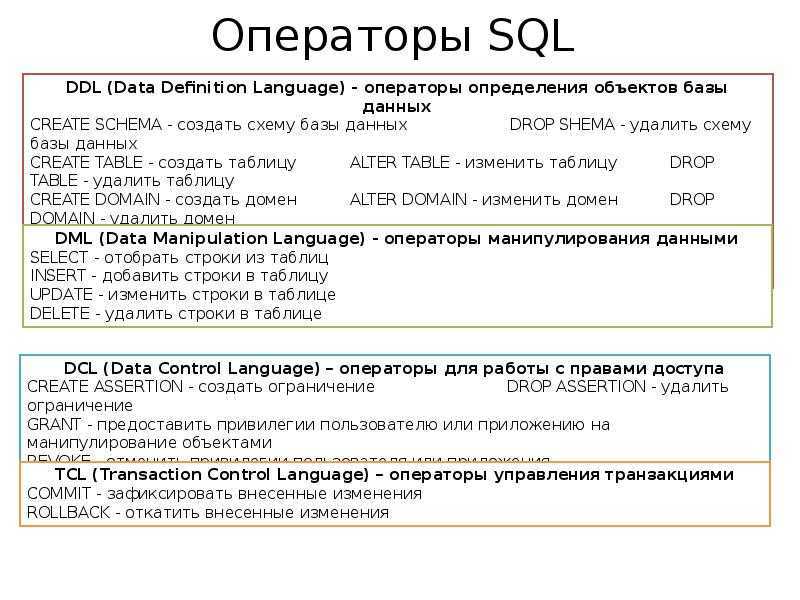 В этом примере мы подсчитываем количество отношений, которые есть у каждого человека.
Поскольку мы получаем одну строку из каждой оценки подзапроса, количество строк одинаково до и после предложения
В этом примере мы подсчитываем количество отношений, которые есть у каждого человека.
Поскольку мы получаем одну строку из каждой оценки подзапроса, количество строк одинаково до и после предложения CALL :
Query
MATCH (p:Person)
ВЫЗОВ {
С р
МАТЧ (p)--(c)
RETURN count(c) AS numberOfConnections
}
RETURN p.name, numberOfConnections | ф.имя | количество подключений |
|---|---|
| |
| |
| |
| |
Ряды: 4 | |
Подзапросы модуля и побочные эффекты
Подзапросы модуля не возвращают никаких строк и поэтому используются для их побочных эффектов.
Этот пример запроса создает пять клонов каждого существующего человека. Поскольку подзапрос является единичным подзапросом, он не меняет количество строк включающего его запроса.
Запрос
ПОИСКПОЗ (p:Person)
ВЫЗОВ {
С р
Диапазон UNWIND (1, 5) AS i
CREATE (:Person {имя: p.name})
}
Количество возвратов(*) | количество(*) |
|---|
|
Строки: 1 |
Агрегации в подзапросах ограничиваются оценкой подзапроса, в том числе и для импортированных переменных. В следующем примере подсчитывается количество молодых людей для каждого человека на графике:
Запрос
ПОИСКПОЗ (p:Person)
ВЫЗОВ {
С р
МАТЧ (другое:Человек)
ГДЕ др. возраст < стр.возраст
ВОЗВРАЩАТЬ количество (другое) КАК youngPersonsCount
}
RETURN p.name, youngPersonsCount  возраст < стр.возраст
ВОЗВРАЩАТЬ количество (другое) КАК youngPersonsCount
}
RETURN p.name, youngPersonsCount
возраст < стр.возраст
ВОЗВРАЩАТЬ количество (другое) КАК youngPersonsCount
}
RETURN p.name, youngPersonsCount | ф.имя | младшийPersonsCount |
|---|---|
| |
| |
| |
| |
Ряды: 4 | |
Подзапросы в транзакциях
Подзапросы могут выполняться в отдельных внутренних транзакциях, создавая промежуточные фиксации.
Это может пригодиться при выполнении больших операций записи, таких как пакетное обновление, импорт и удаление.
Чтобы выполнить подзапрос в отдельных транзакциях, вы добавляете модификатор В ТРАНЗАКЦИЯХ после подзапроса.
В следующем примере используется файл CSV и предложение LOAD CSV для импорта дополнительных данных в пример диаграммы.
Он создает узлы в отдельных транзакциях, используя CALL {...} IN TRANSACTIONS :
Query
LOAD CSV FROM 'file:///friends.csv' AS строка
ВЫЗОВ {
С линией
CREATE (:PERSON {имя: строка[1], возраст: toInteger(строка[2])})
} IN TRANSACTIONS |
Строки: 0 |
Поскольку размер CSV-файла в этом примере небольшой, запускается и фиксируется только одна отдельная транзакция.
|
Удаление большого количества узлов
Использование CALL { ... } IN TRANSACTIONS является рекомендуемым способом удаления большого количества узлов.
Пример 4. DETACH DELETE
Запрос
MATCH (n)
ВЫЗОВ {
С н
ОТСОЕДИНИТЬ УДАЛИТЬ n
} IN TRANSACTIONS |
Ряды: 0 |
Подзапрос |
Пример 5. DETACH DELETE
DETACH DELETE
CALL { ... } IN TRANSACTIONS подзапрос не должен быть изменен.
Перед подзапросом можно выполнить любую необходимую фильтрацию.
Запрос
ПОИСКПОЗ (n:Label) ГДЕ n.prop > 100
ВЫЗОВ {
С н
ОТСОЕДИНИТЬ УДАЛИТЬ n
} IN TRANSACTIONS |
Строки: 0 |
Пакетная обработка
Объем работы, выполняемой в каждой отдельной транзакции, может быть указан с точки зрения количества входных строк.
для обработки перед фиксацией текущей транзакции и запуском новой.
Количество входных строк задается модификатором ИЗ n РЯД (или РЯД ).
Если этот параметр не указан, размер пакета по умолчанию составляет 1000 строк.
Ниже приведен тот же пример, но с одной транзакцией через каждые 2 входных строк:
Запрос
ЗАГРУЗИТЬ CSV ИЗ 'file:///friends.
 csv' Строка AS
ВЫЗОВ {
С линией
CREATE (:Person {имя: строка[1], возраст: toInteger(строка[2])})
} В ТРАНЗАКЦИЯХ 2 СТРОКИ
csv' Строка AS
ВЫЗОВ {
С линией
CREATE (:Person {имя: строка[1], возраст: toInteger(строка[2])})
} В ТРАНЗАКЦИЯХ 2 СТРОКИ |
Строки: 0 |
Теперь запрос запускается и фиксирует три отдельные транзакции:
Первые два выполнения подзапроса (для первых двух входных строк из
LOAD CSV) происходят в первой транзакции.Затем перед продолжением фиксируется первая транзакция.
Следующие два выполнения подзапроса (для следующих двух входных строк) происходят во второй транзакции.
Вторая транзакция зафиксирована.
Последнее выполнение подзапроса (для последней входной строки) происходит в третьей транзакции.
Третья транзакция зафиксирована.

Вы также можете использовать CALL { ... } IN TRANSACTIONS OF n ROWS для удаления всех ваших данных в пакетах, чтобы избежать огромной сборки мусора или Исключение OutOfMemory .
Например:
Запрос
ПОИСКПОЗ (n)
ВЫЗОВ {
С н
ОТСОЕДИНИТЬ УДАЛИТЬ n
} В ТРАНЗАКЦИЯХ 2 СТРОКИ |
Строки: 0 |
До определенного момента использование большего размера пакета будет более производительным.
Размер пакета |

Ошибки
Если в CALL { ... } IN TRANSACTIONS возникает ошибка, весь запрос не выполняется и
как текущая внутренняя транзакция, так и внешняя транзакция откатываются.
В случае ошибки все ранее зафиксированные внутренние транзакции остаются зафиксированными и не откатываются. |
В следующем примере происходит сбой последнего выполнения подзапроса во второй внутренней транзакции. из-за деления на ноль.
Запрос
РАЗМОТКА [4, 2, 1, 0] AS i
ВЫЗОВ {
С я
СОЗДАТЬ (:Пример {число: 100/i})
} В ТРАНЗАКЦИЯХ 2 СТРОКИ
RETURN i Сообщение об ошибке
/ нулем (совершенных транзакций: 1)
Когда произошел сбой, первая транзакция уже была зафиксирована, поэтому база данных содержит два примерных узла.
Запрос
ПОИСКПОЗ (e:Пример) RETURN e.
 num
num | e.num |
|---|
|
|
Ряды: 2 |
Ограничения
Это ограничения на запросы, использующие CALL { ... } IN TRANSACTIONS :
Вложенное предложение
CALL { ... } IN TRANSACTIONSвнутри предложенияCALL { ... }не поддерживается.CALL {...} IN TRANSACTIONSвUNIONне поддерживается.A
CALL { ... } IN TRANSACTIONSпосле предложения записи не поддерживается, если только это предложение записи не находится внутриЗВОНИТЕ { ... } В ТРАНЗАКЦИЯХ.
Кроме того, существуют некоторые ограничения, которые применяются при использовании предложения импорта WITH в подзапросе CALL :
Можно использовать только переменные, импортированные с предложением importing
WITH.В предложении импорта
WITHне допускаются никакие выражения или псевдонимы.Невозможно отследить импорт
Предложение WITHс любым из следующих предложений:DISTINCT,ORDER BY,WHERE,SKIPиLIMIT.

Попытка выполнить любое из вышеперечисленных действий приведет к ошибке.
Например, следующий запрос с использованием предложения WHERE после импорта предложения WITH вызовет ошибку:
Query
UNWIND [[1,2],[1,2,3,4],[1, 2,3,4,5]] АС л
ВЫЗОВ {
С л
ГДЕ размер (л) > 2
ВОЗВРАТ l КАК большие списки
}
RETURN большие списки Сообщение об ошибке
Импорт WITH должен состоять только из простых ссылок на внешние переменные. ГДЕ нельзя.
Решение для этого ограничения, необходимого для любой фильтрации или упорядочения импортирующего предложения WITH , заключается в объявлении второго предложения WITH после импортирующего предложения WITH .