Скрипт поиска слов в базе данных + замена (PHP, MySQL) • фриланс-работа для специалиста • категория PHP ≡ Заказчик Roman Lipatov
Здравствуйте!
Нужен следующий скрипт с web интерфейсом (Bootstrap пойдет).
1. Коннектимся к базе.
2. Выбираем таблицу.
3. Выбираем режим поиск по указаной фразе или поиск по содержанию поля таблицы.
a) Поиск по указанной фразе
В первом поле вводим руками текст;
Во втором dropdown выбираем столбец, в котором будет происходить поиск и замена;
В третьем поле — на что заменяем.
b) Поиск по содержанию поля таблицы.
В первом поле выбираем столбец значение которого будем искать;
Во втором dropdown выбираем столбец в котором будет происходить поиск и замена;
В третьем поле на что заменяем.
В обоих режимах нужно проверить, что заменяемый текст не находится внутри ссылки.
На экран вывести статус выполнения задачи.
Искомое слово, где найдено, результат замены.
Цель — в первом случае вводим фразу, скрипт проходит по всем записям таблицы, указанного столбца и заменяет фразу на новое значение.
Во втором случае скрипт берет из значение поля первой записи указанного столбца и ищет его во всех записях другого столбца. В этом режиме нужно, чтобы можно брать данные для поиска из одной таблицы, а искать в другой (или в той же). То есть грубо говоря, у нас есть таблица с карточками чего-либо. Скрипт забирает оттуда названия карточек, потом в другой таблице, например в блогах, ищет в их тексте совпадения и заменяет на нужные нам фразы.
Предоплату не делаю. Сделку защищаем. Комиссию оплачиваю я.
Делаете на своем сервере или если надо на моем. Но мне нужно будет все проверить предварительно.
- Ставки 6
- Обсуждение 4
дата онлайн рейтинг стоимость время выполнения
- фрилансер больше не работает на сервисе
- Победившая ставка2 дня1000 UAH Победившая ставка2 дня1000 UAH
Здравсвуйте, задачу понял — готов зделать.

Что по скорости?
Много вариантов перебора бд — скрипт будет использ. для большого объема Информации? 14226
358 19
2 дня750 UAHВасиль Заболотний 2 дня750 UAHЗдравствуйте, готов выполнить. Сделаю за 2 дня. Качественно и надежно
- фрилансер больше не работает на сервисе
- фрилансер больше не работает на сервисе

MySQL vs файлы.
 Скорость поиска строки по подстроке.
Скорость поиска строки по подстроке.На днях задался вопросом целесообразности хранение строковых данных в БД вместо файлов с точки зрения скорости поиска.
Хотя, конечно, вопрос правильней поставить так — чем быстрее осуществлять поиск в массиве строк, средствами языка программирования (в данном случае php) или средствами РСУБД (MySQL)? А сравнение «MySQL vs файлы» только для наглядности, ведь данные в базах тоже хранятся в файлах (а в чем же еще?) и используется все та же файловая система.
Решил провести небольшой тест. Сгенерировал 100к строк вида
MP0bWDXN1AxhI9yCZiGpKUZObSBOSrFv6vxTYkxPLUXjUmLJui
Z53PK4xcJgteCqAZ9p9w5LhTU15wBqFrlz6VtuX3Bg83xzSwOS
Tjt0seSoBkE6BPvyBPSoJjvHcS6VfLDYlXPD1ySsImp91Lxsrg
Каждая строка при генерации писалась одновременно в файл (*.txt) и в четыре таблицы — таблицу типа MyISAM, тип данных «text», таблицу MyISAM, тип данных «varchar(100)», таблицу InnoDB, тип данных «text» и таблицу InnoDB, тип данных «varchar(100)».
При генерации 100к строк из каждой тысячной строки из середины копировалось 10 символов, которые писались в отдельный файл. Таким образом получилось 100 подстрок, по которым и осуществляется поиск полной строки в файле и базе данных.
Суть теста заключается в следующем — берем первую подстроку, ищем ее вхождение в строках, сохраненных в файле и БД, потом берем вторую подстроку и так далее сто раз. При каждом поиске засекаем время, необходимое для нахождения строки по ее подстроке, потом вычисляем среднее и сравниваем.
Поиск при хранении строк в текстовом файле осуществлялся четырьмя способами:
1. При каждом поиске (которых всего, как говорилось выше, сто) происходит чтение файла в массив функцией file(), потом осуществляется проход по получившемуся массиву конструкцией foreach(), где ищется вхождение подстроки в строку строковой функцией strpos().
2. Аналогично, только для поиска подстроки вместо строковой функции используются регулярные выражения, функция preg_match().
Третий и четвертый способы повторяют первые два, за исключением того, что при подсчете времени, затраченного на каждый поиск, не учитывается время формирования массива из файла. т.е. считается только время, необходимое на поиск по уже находящемуся в оперативке массиву.
Поиск по каждой из четырех созданных таблиц осуществлялся восемью способами:
1. Открытие соединения с БД. Поиск подстроки с использованием в SQL запросе операции сравнения LIKE. Закрытие соединения.
2. Открытие соединения с БД. Поиск подстроки с использованием в SQL запросе операции сравнения REGEXP. Закрытие соединения.
Третий и четвертый способы аналогичны предыдущим двум, но в них не учитывается время, необходимое на открытие и закрытие соединения с БД. Точнее, соединение с БД не закрывается до тех пор, пока не будут выполнены все сто запросов.
И 5-8 способы повторяют 1-4, но только в настройках MySQL отключается кэширование запросов (по умолчанию кэширование осуществляется). При использовании кэширования, поиск фактически происходит не по базе данных, а по кэшу (запрос хэшируется и ищется в кэше, если совпадения найдены — результат запроса возвращается из кэша, а сам запрос не делается).
Ниже представлена таблица с полученными в ходе теста данными.
| Хранение данных | Способ поиска | Учет времени на чтение файла или открытие/закрытие соединения с БД | Среднее время поиска, с |
| Файл, *.txt | Строковые функции, strpos() | Да | 0.252027 |
| Файл, *.txt | Регулярные выражения, preg_match() | Да | 0.334894 |
| Файл, *.txt | Строковые функции, strpos() | Нет | 0.129508 |
| Файл, *.txt | Регулярные выражения, preg_match() | Нет | 0.303539 |
| БД, MyISAM, text, без кэширования запросов | Операция сравнения like «%pattern%» | Да | 0.202112 |
| БД, InnoDB, text, без кэширования запросов | Операция сравнения like «%pattern%» | Да | 0. 335769 335769 |
| БД, MyISAM, varchar(100) , без кэширования запросов | Операция сравнения like «%pattern%» | Да | 0.194496 |
| БД, InnoDB, varchar(100), без кэширования запросов | Операция сравнения like «%pattern%» | Да | 0.261031 |
| БД, MyISAM, text, без кэширования запросов | Операция сравнения regexp «.*pattern.*» | Да | 1.074974 |
| БД, InnoDB, text, без кэширования запросов | Операция сравнения regexp «.*pattern.*» | Да | 1.225922 |
| БД, MyISAM, varchar(100), без кэширования запросов | Операция сравнения regexp «.*pattern.*» | 1.070542 | |
| БД, InnoDB, varchar(100), без кэширования запросов | Операция сравнения regexp «.*pattern.*» | Да | 1. 143679 143679 |
| БД, MyISAM, text, без кэширования запросов | Операция сравнения like «%pattern%» | Нет | 0.190953 |
| БД, InnoDB, text, без кэширования запросов | Операция сравнения like «%pattern%» | Нет | 0.333155 |
| БД, MyISAM, varchar(100), без кэширования запросов | Операция сравнения like «%pattern%» | Нет | 0.189853 |
| БД, InnoDB, varchar(100), без кэширования запросов | Операция сравнения like «%pattern%» | Нет | 0.262696 |
| БД, MyISAM, text, без кэширования запросов | Операция сравнения regexp «.*pattern.*» | Нет | 1.070554 |
| БД, InnoDB, text, без кэширования запросов | Операция сравнения regexp «.*pattern.*» | Нет | 1. 231657 231657 |
| БД, MyISAM, varchar(100), без кэширования запросов | Операция сравнения regexp «.*pattern.*» | Нет | 1.063102 |
| БД, InnoDB, varchar(100), без кэширования запросов | Операция сравнения regexp «.*pattern.*» | Нет | 1.139206 |
| БД, MyISAM, text, кэширование запросов | Операция сравнения like «%pattern%» | Да | 0.000332 |
| БД, InnoDB, text, кэширование запросов | Операция сравнения like «%pattern%» | Да | 0.000357 |
| БД, MyISAM, varchar(100) , кэширование запросов | Операция сравнения like «%pattern%» | Да | 0.000294 |
| БД, InnoDB, varchar(100), кэширование запросов | Операция сравнения like «%pattern%» | Да | 0.000377 |
| БД, MyISAM, text, кэширование запросов | Операция сравнения regexp «. *pattern.*» *pattern.*» | Да | 0.000332 |
| БД, InnoDB, text, кэширование запросов | Операция сравнения regexp «.*pattern.*» | Да | 0.000349 |
| БД, MyISAM, varchar(100), кэширование запросов | Операция сравнения regexp «.*pattern.*» | Да | 0.000335 |
| БД, InnoDB, varchar(100), кэширование запросов | Операция сравнения regexp «.*pattern.*» | Да | 0.000365 |
| БД, MyISAM, text, кэширование запросов | Операция сравнения like «%pattern%» | Нет | 0.000071 |
| БД, InnoDB, text, кэширование запросов | Операция сравнения like «%pattern%» | Нет | 0.000126 |
| БД, MyISAM, varchar(100), кэширование запросов | Операция сравнения like «%pattern%» | Нет | 0. 000071 000071 |
| БД, InnoDB, varchar(100), кэширование запросов | Операция сравнения like «%pattern%» | Нет | 0.000108 |
| БД, MyISAM, text, кэширование запросов | Операция сравнения regexp «.*pattern.*» | Нет | 0.000072 |
| БД, InnoDB, text, кэширование запросов | Операция сравнения regexp «.*pattern.*» | Нет | 0.000070 |
| БД, MyISAM, varchar(100), кэширование запросов | Операция сравнения regexp «.*pattern.*» | Нет | 0.000071 |
| БД, InnoDB, varchar(100), кэширование запросов | Операция сравнения regexp «.*pattern.*» | Нет | 0.000109 |
Исходя из полученных данных, можно сделать несколько выводов, банальных и не очень.
Открытие или закрытие какого-то ресурса (будь то файл или соединение с БД) — очень времязатратная процедура. Оформлять кусок кода в функцию, где что-то открывается, пишется, закрывается, и потом эту функцию вызывать несколько раз в разных местах программы или даже в цикле — неправильное решение с точки зрения производительности.
Оформлять кусок кода в функцию, где что-то открывается, пишется, закрывается, и потом эту функцию вызывать несколько раз в разных местах программы или даже в цикле — неправильное решение с точки зрения производительности.
Строковые функции работают быстрее, чем регулярные выражения. Поэтому то, что можно сделать строковыми функциями, надо делать именно строковыми функциями, а не регулярками.
Скорость поиска строковых данных в таблицах типа MyISAM быстрее, чем в таблицах типа InnoDB. Поэтому если при выборе таблицы того или иного типа основным критерием является скорость чтения и не требуется каких-то специфичных свойств (механизм транзакций, работа с внешними ключами), то использовать следует MyISAM.
Скорость поиска по данным типа text и varchar при использовании таблиц типа MyISAM примерно сопоставима. При использовании же таблиц типа InnoDB, скорость поиска по данным text осуществляется медленнее, чем по данным типа varchar.
Поиск с использованием в SQL запросах операции сравнения «REGEXP» работает в разы медленнее, чем с использованием операции сравнения «LIKE». Что еще раз подтверждает тот факт, что регулярными выражениями надо пользоваться только при отсутствии альтернатив.
Что еще раз подтверждает тот факт, что регулярными выражениями надо пользоваться только при отсутствии альтернатив.
В MySQL очень мощная система кэширования (которая по умолчанию включена). Если вы делаете какой-то запрос более одного раза, то повторный поиск не происходит, а вам отдаются данные из кэша со скорость в десяти-стотысячные доли секунды.
Вывод из сравнения можно сделать такой: без учета времени на открытие файла/соединение с БД, поиск средствами php по данным, находящимся в оперативной памяти, осуществляется в среднем в два раза быстрее, чем средствами MySQL по данным, находящимся в БД. Однако MySQL имеет систему кэширования запросов, поэтому если требуется регулярно обращаться к одним и тем же данным и делать одинаковые выборки, то выигрыш в скорости при использовании баз данных становится весьма значительным.
Скрипт поиска и замены базы данных в PHP
Search Replace DB версии 4 — это мощный инструмент разработчика, который позволяет быстро выполнять поиск в базе данных из веб-интерфейса, когда невозможно использовать инструменты командной строки.
Прежде чем идти дальше. Мы знаем, что эта страница привлекает большое внимание со всего мира, так как это полезный инструмент для многих. Мы хотели бы сказать, что мы поддерживаем Украину. У нас много друзей из России и из Украины. Мы верим в прозрачность и свободу. Российское правительство зашло слишком далеко на опасный шаг, который вызывает трагедию по всей Украине и лишения простых россиян. Пожалуйста, работайте над тем, чтобы принести современную, прозрачную демократию в Россию и свободу в Украину. Чтобы помочь, рассмотрите возможность сделать пожертвование в одну из многих честных благотворительных организаций, поддерживающих детей и народ Украины.
Кредит Ольге Субач, изображение найдено на Unsplash.Чтобы узнать, как мы используем ваши данные, ознакомьтесь с нашей политикой конфиденциальности.
Загрузите сценарий по ссылке, полученной по электронной почте, и установите его в секретную папку с запутанным именем, если он используется на общедоступном сервере. Ваш сервер также не должен быть настроен на предоставление списков каталогов, если это общедоступный сервер.
Ваш сервер также не должен быть настроен на предоставление списков каталогов, если это общедоступный сервер.
Не устанавливайте Поиск Замените БД в корневую папку, иначе вы рискуете столкнуться с потенциальными проблемами. Просто не надо. Он должен работать в своей собственной папке и, в идеале, в той, которую нельзя легко угадать.
Чтобы узнать, как вы можете использовать этот инструмент для облегчения миграции, ознакомьтесь с нашей статьей о миграции WordPress или посетите статью WP Tuts+, в которой упоминается этот скрипт.
Если у вас есть какие-либо сомнения относительно того, как использовать этот автономный сценарий, рассмотрите возможность привлечения эксперта. Это действительно мощный фрагмент кода, который при неправильном использовании может повредить вашу базу данных без возможности восстановления. Если вам нужна помощь, обратитесь к кому-нибудь вроде нас, например, или к любому из других отличных парней, перечисленных на CodePoet.
Лицензия
Код предоставляется под лицензией GPL V3 и является полностью открытым исходным кодом. Имейте в виду, что это означает, что люди могут изменить этот код и предложить его, и что другие версии могут быть хуже… или лучше. Это код для разработчиков, созданный разработчиками, и вы должны использовать код только из источников, которым вы доверяете.
Имейте в виду, что это означает, что люди могут изменить этот код и предложить его, и что другие версии могут быть хуже… или лучше. Это код для разработчиков, созданный разработчиками, и вы должны использовать код только из источников, которым вы доверяете.
Часто задаваемые вопросы
Куда установить распакованные файлы?
В каталоге на вашем веб-сервере. Это может быть папка, защищенная httpauth, если это общедоступный веб-сервер.
Должен ли я платить?
Нет, это бесплатно с открытым исходным кодом, и вы можете найти его на GitHub. Вы также можете делать такие вещи, как отправлять копии своим друзьям или использовать код в других проектах. Полная лицензия включена в программное обеспечение. Мы делаем по умолчанию путь, позволяющий вам сделать пожертвование, но если вы ограничены и работаете в одной из тех корпораций, где получение одобрения на 5 долларов не стоит хлопот, вы можете воспользоваться. Просто помните нас, если сценарий сделает вас лучше и принесет вам повышение!
Я слышал, что этот сценарий небезопасен.
 Это действительно так?
Это действительно так?Уже не так опасно, как раньше! Для удобства мы подобрали переменные конфигурации WP для предварительного заполнения сведений о базе данных. Проблема в том, что оказывается, что люди небрежны и оставят скрипт лежать на своем рабочем сервере. Так что пришлось уйти. Удобен для установки разработчика, кошмар на рабочем сервере. Это по-прежнему мощный инструмент, и он дает хакеру доступ, чтобы попытаться взломать ваши учетные данные базы данных, поэтому очень важно, чтобы вы не просто оставляли скрипт лежать без дела, но если вы используете его на рабочих серверах, и вы немного рассеяны, тогда вас не будут наказывать за то, что вас так легко взломают.
Я получаю сообщение об ошибке 2: Класс __PHP_Incomplete_Class не имеет десериализатора
Это распространенная ошибка, которая обычно возникает у пользователей плагинов Yoast, но также и у некоторых других. Это то, о чем мы знаем. В подавляющем большинстве случаев все нормально. Вы можете попробовать запустить скрипт из другой установки PHP — нет никаких причин, по которым вы не можете подключиться к рабочей базе данных и подключиться к ней, например, со своей рабочей станции. Мы сделали все возможное, чтобы сценарий немного подробнее был в нашем репозитории на github.
Мы сделали все возможное, чтобы сценарий немного подробнее был в нашем репозитории на github.
Список изменений:
Мы больше не публикуем журнал изменений на этой странице — вы можете просмотреть его на Github.
Вклады
Мы будем рады получать дополнения, отчеты об ошибках и многое другое в репозитории Search Replace DB github. Пожалуйста, приходите — мы будем более чем рады, но вам нужно будет запросить доступ по электронной почте [email protected]
Простой, но мощный алгоритм поиска на PHP, MySQL | Эжил Каннан B R
Опубликовано в·
5 мин чтения·
6 марта 2019 г.Всем привет, я некоторое время работал с PHP, и в одном из моих проектов мне нужно было реализовать алгоритм поиска. После некоторого обучения я нашел несколько лучших способов реализовать это.
Предположим, мы создаем веб-сайт агрегатора технологий и сохраняем URL-адреса статей, заголовок, содержание статьи в базе данных mysqli. Теперь наша задача — отобразить лучшие результаты URL-адресов статей на основе условий поиска, предоставленных пользователем.
Прежде всего, мы должны создать базу данных для хранения заданных значений и отдельный столбец под названием «индексирование» для хранения значений индексирования. Когда пользователь вводит строку поиска, мы будем искать в этом столбце. Используется для быстрого и эффективного поиска. База данных выглядит так.
Существует множество различных методов индексации. Но вы должны выбрать лучший и надежный метод. При получении поискового запроса мы смотрим только на таблицу индексации и возвращаем результаты вместо поиска во всей таблице. Теперь давайте создадим очень простой макет для формы поиска. Назовем его «sample_search.php».
Давайте проигнорируем пользовательский интерфейс и сосредоточимся на внутренних работах. Вывод формы выглядит так
Теперь приступим к индексации. В чем вообще проблема с индексацией? Мы можем просто сравнить и найти совпадающие строки запроса, верно?
Не совсем. Предположим, пользователь ищет слово «наука». Мы просто ищем строку «наука» и возвращаем содержимое, соответствующее слову «наука». Теперь, что если пользователь в результате опечатки ввел поисковый запрос как «synce» или «Science» или «SCience» или «SCIence» или «SCIENS» или «Science». Если мы будем следовать той же процедуре, что и выше, мы, скорее всего, вернем пустой результат.
Теперь, что если пользователь в результате опечатки ввел поисковый запрос как «synce» или «Science» или «SCience» или «SCIence» или «SCIENS» или «Science». Если мы будем следовать той же процедуре, что и выше, мы, скорее всего, вернем пустой результат.
TO ERR IS HYUMANN
И, конечно же, большинство людей знают правильное написание слова «наука». Но что делать, если произошла какая-то ошибка в правописании. Есть ключ к решению этой проблемы. Без каких-либо методов обработки текста мы видим, что все слова «синхронизация», «Наука», «Наука» и т. д. звучат одинаково.
Здесь мы будем использовать мощную функцию PHP под названием metaphone(). Он возвращает значение, соответствующее звучанию данного слова
Теперь попробуйте запустить следующий PHP-код
Вывод приведенного выше кода выглядит следующим образом:
Абрака Табра! Мы получаем одни и те же звуки для разных написаний науки. Теперь если мы сделаем индексацию таким образом, что сохраним звуки каждого из слов в содержании и названии.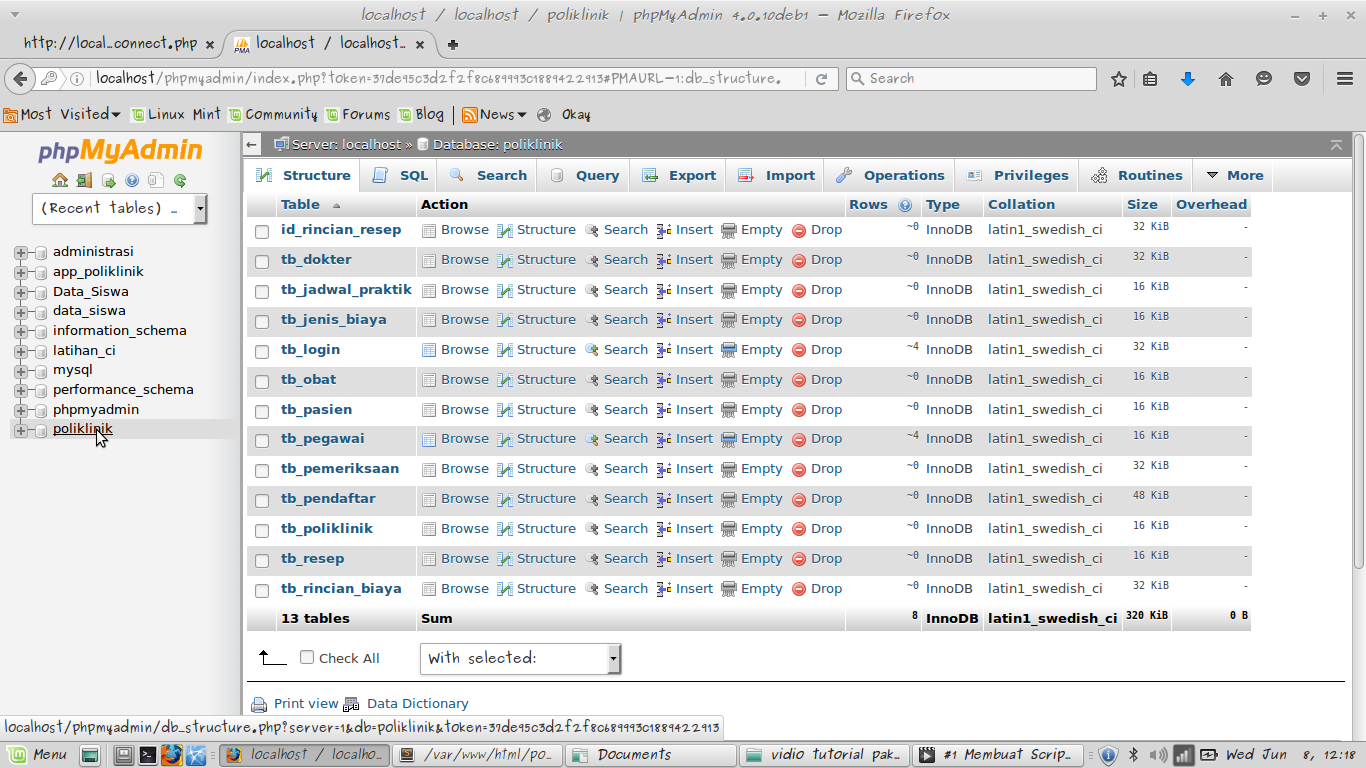 Мы можем легко вернуть самые надежные результаты теста с заданной строкой поиска. Вот шаги, выполняемые для индексации
Мы можем легко вернуть самые надежные результаты теста с заданной строкой поиска. Вот шаги, выполняемые для индексации
1. Сначала установите соединение
2. Получите article_title, article_content из базы данных
3. Для каждой строки article_title и article_content разделите содержимое на отдельные слова с помощью функции взрыва() и добавьте метафон($word) с пробелом к переменной $sound. Обновите соответствующий столбец «индексирование»
Теперь мы успешно проиндексировали наш заголовок и контент и сохранили их в столбце «индексирование». Теперь мы реализуем логику поиска в файле «sample_search.php»
1. После отправки запроса мы преобразуем поисковый запрос в строку метафона. Затем найдите эту строку в столбце индексации, используя запрос «LIKE» в SQL 9.0071
Но помните, что при индексировании мы добавили метафон слов в содержимое по отдельности. Поэтому, если в строке есть два или более слова, например «HELLO WORLD», мы не сможем найти соответствующий метафон в столбце «индексация».