Не четкий поиск по массиву значений — Вопросы на русском языке
Dima_Sid (Dima Sid) 1
Подскажите как оформить запрос что бы можно было сделать поиск по текстовому полю с использованием массива значений К примеру запросом
curl -XPOST 'elk:9200/shopcategory/shopcategory/_search?pretty' -d '{
"query": {
"bool": {
"must": [{
"match_all": {}
}],
"filter": {
"match": {
"name": "девочкам"
}
}
}
}
}}'
мы можем отфильтровать все записи по фразе "девочкам" Массив можно передавать только в тип term
"term": {
"name": ["девочкам","мальчикам" ]
}
Но term подразумевает только четкие вхождения, а нам нужно осуществить "не четкий поиск", т.е. что бы нашлись девочки, девочка, мальчик, и т.д На данный момент я просто делю массив по пробелам и заключаю фразы в кавычки по длинному предложений и делаю поиск. Вопрос в том как правильно отправить эластику массив значений для не четкого поиска по всем записям? mapping

'properties' => [
'id' => ['type' => 'long', 'index' => 'not_analyzed'],
'parent_id' => ['type' => 'long', 'index' => 'not_analyzed'],
'name' => ['type' => 'string', "index"=>"analyzed", "analyzer"=>"en_rus","fielddata"=> true],
]`Igor_Motov (Igor Motov) 2
Для нечеткого поиска надо индексировать со стемером (например kstem), а для поиска надо применять какой-нибудь запрос поддерживающий анализ, например match. Чтобы искать по нескольким словам, можно эти слова добавить в один
Чтобы искать по нескольким словам, можно эти слова добавить в один match или объединить несколько запросов match в один запрос bool.
Dima_Sid (Dima Sid) 3
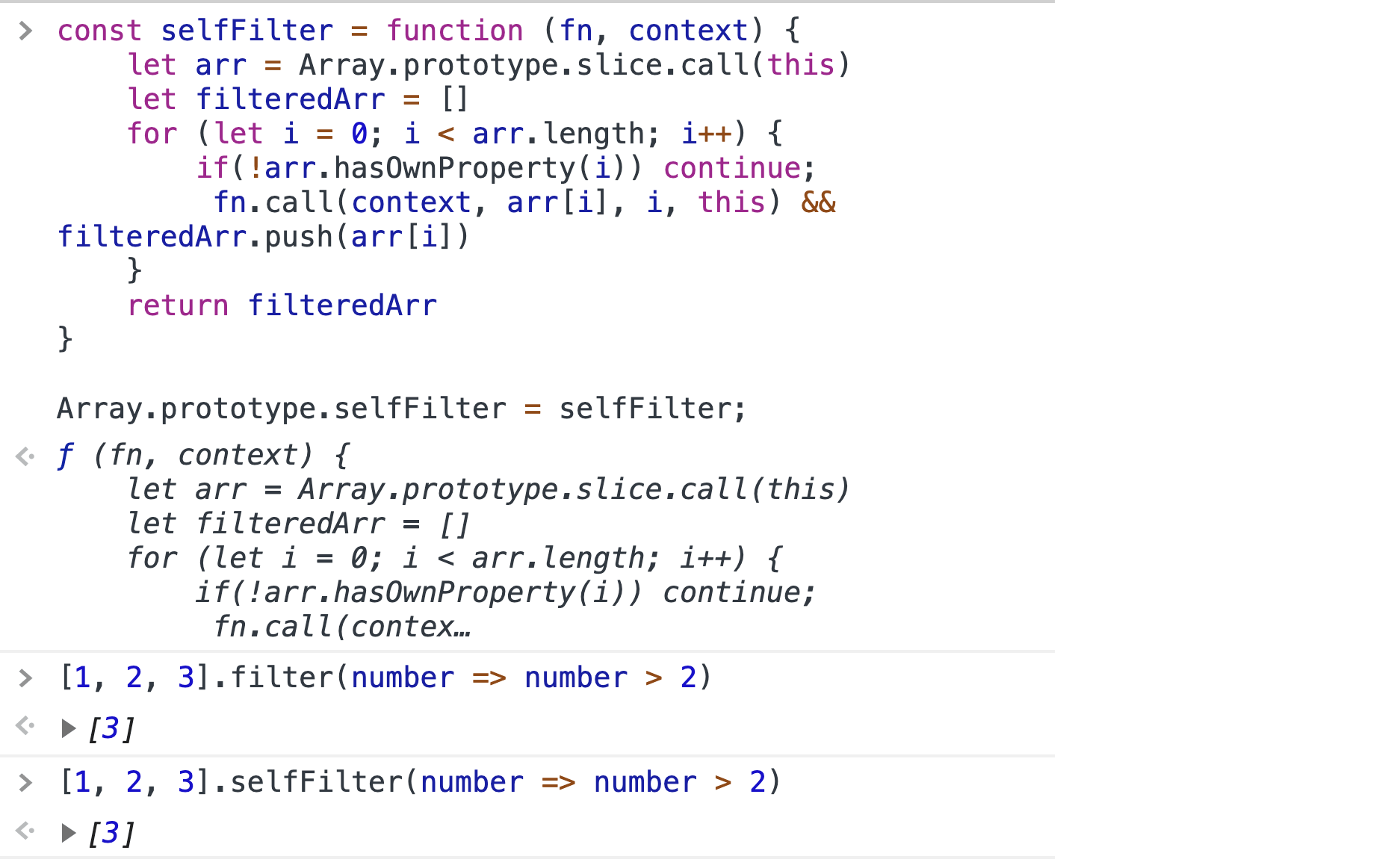
Для не четкого поиска я использую match
‘fuzziness’ => ‘auto’,
‘prefix_length’ => 3,
Все отлично ищется.
Но для того что бы отправить все запросы из массива, я объединяю кейворды в строку. Хотелось бы отправить все запросы массивом без лишних манипуляций.
Igor_Motov (Igor Motov) 4
без лишних манипуляций не получиться
Dima_Sid (Dima Sid) 5
Другой вопрос.
Можно ли получить в ответе, статистику по совпадениям слова? Документы и сколько раз встретилось совпадение?
Т.е если мы искали слово «женщинам мужчинам детям»
то получаем ответ
женщинам 1
мужчинам 2
детям 1
?
Igor_Motov (Igor Motov) 6
Что вы потом будете с этими ответами делать?
Dima_Sid (Dima Sid) 7
Мне нужно посчитать вхождения и определить релевантность длинного фразы. А точнее ветки каталога категорий
Igor_Motov (Igor Motov)
Проблема в следующем — информация по частоте совпадений во время поиска имеется. Однако, после того, как релевантность записи во время поиска рассчитана, эта информация больше не доступна. Все что мы можем сохранить это
Однако, после того, как релевантность записи во время поиска рассчитана, эта информация больше не доступна. Все что мы можем сохранить это _score. Поэтому единственный способ вытащить эту информацию наружу — это путем рассчета _score на ее основе. Для этого в elasticsearch много средств.
Dima_Sid (Dima Sid) 9
В анализируемом контенте часто встречаются слова «уход» и все производные к этому слову, а также «ухо» в разных формах
«Лекарства для глаз и ушей» и т.д, я использую не четкий поиск
‘fuzziness’ => ‘auto’,
‘prefix_length’ => 3,
При поиске слова «уход», в результат попадают документы содержащие «ухо», «уши» , «ушить», «уход.»
Тоже самое и в обратном направлении когда ищем слово «ухо».
Как можно задать исключение, для того что бы эластик считал что слово ухо, уход, ушить это разные слова ?
Dima_Sid (Dima Sid)
Погряз я в эластике, чем глубже тем запутанней. В начале казалось все просто.
В начале казалось все просто.
Подскажите как заставить эластик считать «Женщинам» «Женская»
совпадением без использования словаря синонимов?
с разными настройками запроса
«fuzziness»: «auto»,
«prefix_length» : 2
не получается.
Dima_Sid (Dima Sid) 11
Имеет запись
id = 2029
Отправляю запрос
"query": {
"bool": {
"must": [
{ "match": {
"name": {
"query": "женщинам",
"fuzziness": "auto",
"prefix_length" : 2
}
}
},
{ "terms": { "id" : ["2029"]}}
]
}
}
Ответ ПУСТО!
Отправляю запрос
"query": {
"bool": {
"must": [
{ "match": {
"name": {
"query": "женская",
"fuzziness": "auto",
"prefix_length" : 2
}
}
},
{ "terms": { "id" : ["2029"]}}
]
}
}
Ответ
"hits" : [
{
"_index" : "shopcategory",
"_type" : "shopcategory",
"_id" : "2029",
"_score" : 6. 8748565,
"_source" : {
"id" : 2029,
"parent_id" : 1986,
"name" : "Женская обувь"
}
}
8748565,
"_source" : {
"id" : 2029,
"parent_id" : 1986,
"name" : "Женская обувь"
}
}
 8748565,
"_source" : {
"id" : 2029,
"parent_id" : 1986,
"name" : "Женская обувь"
}
}
8748565,
"_source" : {
"id" : 2029,
"parent_id" : 1986,
"name" : "Женская обувь"
}
}
Настройки индекса такие
'settings' => [
'index' => ['refresh_interval' => '1s'],
'analysis' => [
'filter' => [
'stopwords_ru' => [
'type' => 'stop',
'stopwords' => ['для','Для','от','из','со','на','по','за','до','них','все','под','другое','другие','другой','другая','товары','группа',],
'ignore_case' => 'true',
],
'my_synonym_filter' => [
'type' => 'synonym',
'synonyms' => [
'женщинам, женская',
],
'ignore_case' => 'true',
],
'russian_stop' => [
'type' => 'stop',
'stopwords' => '_russian_',
],
'russian_keywords' => [
'type' => 'keyword_marker',
'keywords' => ["пример"],
],
'russian_stemmer' => [
'type' => 'stemmer',
'language' => 'russian',
//'language' => 'russian_morphology',
],
'english_stemmer' => [
'type' => 'stemmer',
'language' => 'english',
],
],
'analyzer' => [
'en_rus' => [
'type' => 'custom',
'tokenizer' => 'standard',
'filter' => [
'lowercase',
'russian_morphology',
'my_synonym_filter',
'russian_stemmer',
'english_stemmer',
'russian_stop',
'my_synonym_filter',
'stopwords_ru',
]
]
]
],
],
Dima_Sid (Dima Sid) 12
Почему эластик не показывает совпадение при запросе Женщинам и id 2029?
Igor_Motov (Igor Motov) 13
Без mapping- а для поля name сказать сложно. А зачем вы два русских стеммера добавили?
А зачем вы два русских стеммера добавили?
Dima_Sid (Dima Sid) 14
Проблема решилась, модуль russian_morphology не корректно работает, отключили его.
Igor_Motov (Igor Motov) 15
Два стеммера для одного и того же языка работать одновременно не могут.
Dima_Sid (Dima Sid) 16
да все верно но при одном russian_morphology результаты теже. Вырубили и все заработало
system (system) Closed 17
This topic was automatically closed 28 days after the last reply. New replies are no longer allowed.
New replies are no longer allowed.
Могу ли я использовать… Таблицы поддержки для HTML5, CSS3 и т. д.
Могу ли я использовать Поиск ?Массив.прототип.найти
— ПРОЧЕЕГлобальное использование
96,32% + 0% «=» 96,32%
Метод find() возвращает значение первого элемента в массиве на основе результата предоставленной функции тестирования.
Chrome
- 4–44: не поддерживается
- 45–113: поддерживается
- 114: поддерживается
- 115–117: поддерживается
- 12–14: поддержка неизвестна
- 15–113: Поддерживается
 00% — Supported»> 114: Поддерживается
00% — Supported»> 114: ПоддерживаетсяSafari
- 3.1–7: Не поддерживается
- 7.1–16.4: Поддерживается
- 16.5: Поддерживается 90 040 16.6 — TP: поддерживается
Firefox
- 2 — 24: нет поддерживается
- 25–112: поддерживается
- 113: поддерживается
- 114–115: поддерживается
Opera
- 9–31: не поддерживается 9007 2 32–98: Поддерживается
- 99: Поддерживается
IE
- 5.5–10: не поддерживается
 37% — Not supported»> 11: не поддерживается
37% — Not supported»> 11: не поддерживаетсяChrome для Android
- 114: поддерживается
Safari на iOS
- 3 .2 — 7.1: не поддерживается
- 8 — 16.4: поддерживается
- 16.5: Поддерживается
- 17: Поддерживается
Samsung Internet
- 4: Не поддерживается
- 5–20: Поддерживается
- 21: Поддерживается 90 015
Opera Mini
- все: Не поддерживается
Opera Мобильный телефон
- 10–12.1: не поддерживается
 00% — Supported»> 73: поддерживается
00% — Supported»> 73: поддерживаетсяUC Browser для Android
- 13.4: поддерживается
Android Browser
- 2.1–4.4.4: не поддерживается
- 113: Поддерживается
Firefox для Android
- 113: Поддерживается
Браузер QQ
- 13.1: Поддерживается 90 032
- 13.18: Поддерживается
- 2.5: Поддерживается
- 3: Поддерживается
- Ресурсы:
- Статья MDN
- Полифил для этой функции доступен в библиотеке core-js
Браузер Baidu
Браузер KaiOS
Введение в метод find() массива JavaScript | Кевин Чисхолм
Метод JavaScript Array find() позволяет вам найти первый элемент, который соответствует предоставленной вами логике.

Если у вас есть массив значений, вполне вероятно, что вам может понадобиться найти элемент в этом массиве. В частности, вам может понадобиться узнать, какой элемент в этом массиве соответствует определенному критерию. Ну, критерии на ваше усмотрение. Например, если ваш массив содержит числа, вам может понадобиться узнать, сколько элементов в этом массиве имеют значение выше определенной суммы. Что ж, в этой статье я продемонстрирую JavaScript Метод Array find() , который обеспечивает простой способ решения этой проблемы.
Итерация массива обычно требует подсчета. Это имеет смысл, потому что для того, чтобы «что-то сделать» с каждым элементом в массиве, вы должны знать, сколько элементов в нем содержится (т. е. «длина массива »). Затем вам нужно отслеживать, как вы считаете до (или вниз) длины массива. Этот подход вполне действенен, но он сопряжен с проблемами.
Первая проблема заключается в том, что создание цикла любого типа создает шаблонный код, тогда вам нужен счетчик (например, « i » или « j »), и, наконец, вам нужна логика, которая использует значение вашего счетчика, чтобы определить, были ли найдены ваши целевые элементы. Просто обсуждать это в контексте «псевдокода» утомительно, а написание фактического кода еще более утомительно. Но метод JavaScript Array find() решает эту проблему, поскольку устраняет необходимость в утомительном шаблонном коде.
Просто обсуждать это в контексте «псевдокода» утомительно, а написание фактического кода еще более утомительно. Но метод JavaScript Array find() решает эту проблему, поскольку устраняет необходимость в утомительном шаблонном коде.
Использование цикла while — пример № 1
См. Pen Array.prototype.find() — вызов Кевина Чисхолма (@kevinchisholm) на CodePen.
Утомительный шаблонный код, который мы обсуждали выше, точно такой же, как и в примере № 1. Мы используем цикл while для перебора массива someNumbers. На каждой итерации цикла мы используем значение « i », чтобы проверить текущий итерируемый элемент массива и определить, соответствует ли он критериям нашего поиска. Этот код действителен и работает, но не оптимален.
Использование метода Array find() — Пример № 2
См. Pen Array.prototype.find() — Решение Кевина Чисхолма (@kevinchisholm) на CodePen.
В примере № 2 мы используем метод Array find() для устранения проблем, возникших в предыдущем примере. Мы передали анонимную функцию методу Array find() , и этот метод принимает текущий итерируемый элемент в качестве первого аргумента. Внутри этой анонимной функции мы предоставляем некоторую логику, которая определяет текущий итерируемый элемент массива, а затем мы решаем, соответствует ли он критериям нашего поиска. Первым большим преимуществом здесь является то, что мы удалили цикл «пока». Кроме того, у нас больше нет « и ”переменная. Это может показаться мелочью, но каждая переменная занимает память и имеет область видимости.