Поисковые системы Интернета: Яндекс, Google, Rambler, Yahoo — информация, принципы работы
1. Введение
2. Понятие и функции поисковой системы
3. Основные характеристики поисковой системы
4. Краткая история развития поисковых систем
5. Состав и принципы работы поисковой системы
6. Заключение
1. Введение
Поисковые системы уже давно стали неотъемлемой частью российского Интернета. Поисковые системы сейчас – это огромные и сложные механизмы, представляющие собой не только инструмент поиска информации, но и заманчивые сферы для бизнеса.
Большинство пользователей поисковых систем никогда не задумывались (либо задумывались, но не нашли ответа) о принципе работы поисковых систем, о схеме обработки запросов пользователей, о том, из чего эти системы состоят и как функционируют…
Данный материал призван дать ответ на вопрос о том, как работают поисковые системы. Однако вы не найдете здесь факторов, влияющих на ранжирование документов.
2. Понятие и функции поисковой системы
Поисковая система – это программно-аппаратный комплекс, предназначенный для осуществления поиска в сети Интернет и реагирующий на запрос пользователя, задаваемый в виде текстовой фразы (поискового запроса), выдачей списка ссылок на источники информации, в порядке релевантности (в соответствии запросу). Наиболее крупные международные поисковые системы: «Google», «Yahoo», «MSN». В русском Интернете это – «Яндекс», «Рамблер», «Апорт».
Рассмотрим подробнее понятие поискового запроса на примере поисковой системы «Яндекс». Поисковый запрос должен быть сформулирован пользователем в соответствии с тем, что он хочет найти, максимально кратко и просто.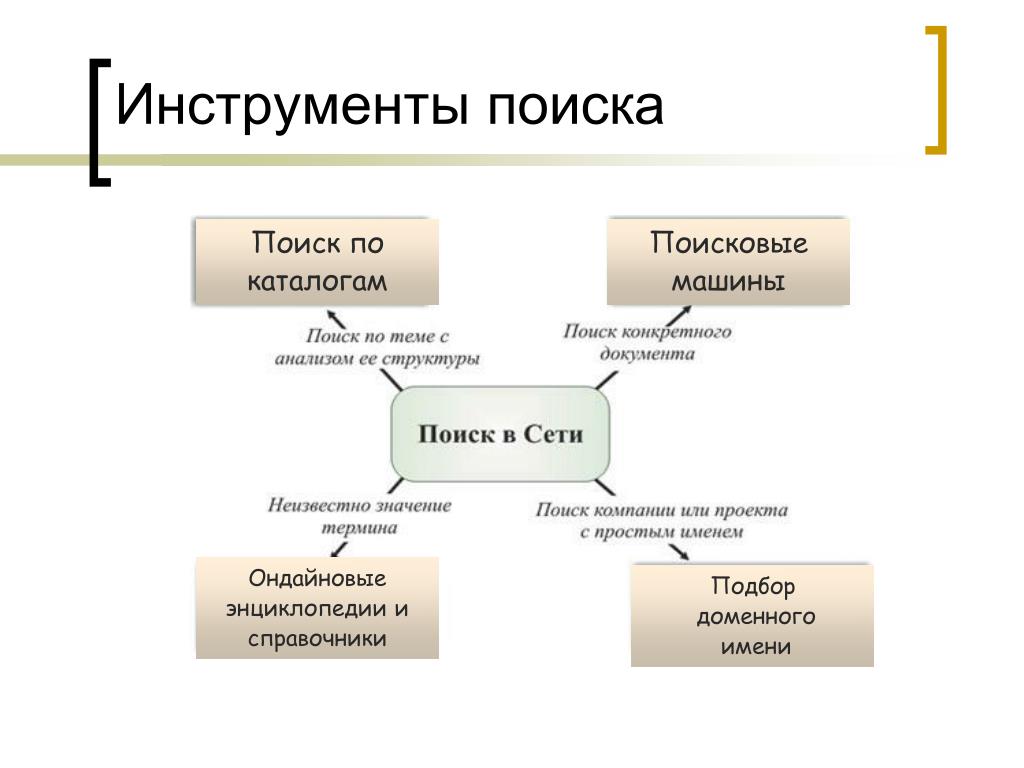 Допустим, мы хотим найти информацию в «Яндексе» о том, как выбрать автомобиль. Для этого, открываем главную страницу «Яндекса», и вводим текст поискового запроса «как выбрать автомобиль». Далее, наша задача сводится к тому, чтобы открыть предоставленные по нашему запросу ссылки на источники информации в Интернет. Однако, вполне можно и не найти нужную нам информацию. Если таковое произошло, то либо нужно перефразировать свой запрос, либо в базе поисковой системе действительно нет никакой актуальной информации по нашему запросу (такое может быть при задании очень «узких» запросов, как, например «как выбрать автомобиль в Архангельске»).
Допустим, мы хотим найти информацию в «Яндексе» о том, как выбрать автомобиль. Для этого, открываем главную страницу «Яндекса», и вводим текст поискового запроса «как выбрать автомобиль». Далее, наша задача сводится к тому, чтобы открыть предоставленные по нашему запросу ссылки на источники информации в Интернет. Однако, вполне можно и не найти нужную нам информацию. Если таковое произошло, то либо нужно перефразировать свой запрос, либо в базе поисковой системе действительно нет никакой актуальной информации по нашему запросу (такое может быть при задании очень «узких» запросов, как, например «как выбрать автомобиль в Архангельске»).
Первоочередная задача любой поисковой системы – доставлять людям именно ту информацию, которую они ищут. А научить пользователей делать «правильные» запросы к системе, т.е. запросы, соответствующие принципам работы поисковых систем, невозможно. Поэтому разработчики создают такие алгоритмы и принципы работы поисковых систем, которые бы позволяли находить пользователям искомую ими информацию.
Это означает, поисковая система должна «думать» так же, как думает пользователь при поиске информации. Когда пользователь обращается с запросом к поисковой машине, он хочет найти то, что ему нужно, максимально быстро и просто. Получая результат, он оценивает работу системы, руководствуясь несколькими основными параметрами. Нашел ли он то, что искал? Если не нашел, то сколько раз ему пришлось перефразировать запрос, чтобы найти искомое? Насколько актуальную информацию он смог найти? Насколько быстро обрабатывала запрос поисковая машина? Насколько удобно были представлены результаты поиска? Был ли искомый результат первым или же сотым? Как много ненужного мусора было найдено наравне с полезной информацией? Найдется ли нужная информация, при обращении к поисковой системе, скажем, через неделю, или через месяц?
Для того, чтобы удовлетворить ответами все эти вопросы, разработчики поисковых машин постоянно совершенствуют алгоритмы и принципы поиска, добавляют новые функции и возможности, всячески пытаются ускорить работу системы.
3. Основные характеристики поисковой системы
- Полнота
Полнота – одна из основных характеристик поисковой системы, представляющая собой отношение количества найденных по запросу документов к общему числу документов в сети Интернет, удовлетворяющих данному запросу. К примеру, если в Интернете имеется 100 страниц, содержащих словосочетание «как выбрать автомобиль», а по соответствующему запросу было найдено всего 60 из них, то полнота поиска будет 0,6. Очевидно, что чем полнее поиск, тем меньше вероятность того, что пользователь не найдет нужный ему документ, при условии, что он вообще существует в Интернете.
- Точность
Точность – еще одна основная характеристика поисковой машины, которая определяется степенью соответствия найденных документов запросу пользователя. Например, если по запросу «как выбрать автомобиль» находится 100 документов, в 50 из них содержится словосочетание «как выбрать автомобиль», а в остальных просто наличествуют эти слова («как правильно выбрать магнитолу и установить в автомобиль»), то точность поиска считается равной 50/100 (=0,5).

- Актуальность
Актуальность – не менее важная составляющая поиска, которая характеризуется временем, проходящим с момента публикации документов в сети Интернет, до занесения их в индексную базу поисковой системы. Например, на следующий день после появления интересной новости, большое количество пользователей обратились к поисковым системам с соответствующими запросами. Объективно с момента публикации новостной информации на эту тему прошло меньше суток, однако основные документы уже были проиндексированы и доступны для поиска, благодаря существованию у крупных поисковых систем так называемой «быстрой базы», которая обновляется несколько раз в день.
- Скорость поиска
Скорость поиска тесно связана с его устойчивостью к нагрузкам.
Например, по данным ООО «Рамблер Интернет Холдинг», на сегодняшний день в рабочие часы к поисковой машине Рамблер приходит около 60 запросов в секунду. Такая загруженность требует сокращения времени обработки отдельного запроса. Здесь интересы пользователя и поисковой системы совпадают: посетитель желает получить результаты как можно быстрее, а поисковая машина должна отрабатывать запрос максимально оперативно, чтобы не тормозить вычисление следующих запросов. - Наглядность
Наглядность представления результатов является важным компонентом удобного поиска. По большинству запросов поисковая машина находит сотни, а то и тысячи документов. Вследствие нечеткости составления запросов или неточности поиска, даже первые страницы выдачи не всегда содержат только нужную информацию. Это означает, что пользователю зачастую приходится производить свой собственный поиск внутри найденного списка. Различные элементы страницы выдачи поисковой системы помогают ориентироваться в результатах поиска.
 Например, по данным ООО «Рамблер Интернет Холдинг», на сегодняшний день в рабочие часы к поисковой машине Рамблер приходит около 60 запросов в секунду. Такая загруженность требует сокращения времени обработки отдельного запроса. Здесь интересы пользователя и поисковой системы совпадают: посетитель желает получить результаты как можно быстрее, а поисковая машина должна отрабатывать запрос максимально оперативно, чтобы не тормозить вычисление следующих запросов.
Например, по данным ООО «Рамблер Интернет Холдинг», на сегодняшний день в рабочие часы к поисковой машине Рамблер приходит около 60 запросов в секунду. Такая загруженность требует сокращения времени обработки отдельного запроса. Здесь интересы пользователя и поисковой системы совпадают: посетитель желает получить результаты как можно быстрее, а поисковая машина должна отрабатывать запрос максимально оперативно, чтобы не тормозить вычисление следующих запросов.
4. Краткая история развития поисковых систем
В начальный период развития Интернет, число его пользователей было невелико, а объем доступной информации сравнительно небольшим. В большинстве своем, доступ к сети Интернет имели лишь сотрудники научно-исследовательской сферы. В это время задача поиска информации в Интернете не была столь актуальной, как в настоящее время.
Одним из первых способов организации доступа к информационным ресурсам сети стало создание открытых каталогов сайтов, ссылки на ресурсы в которых группировались согласно тематике. Первым таким проектом стал сайт Yahoo.com, открывшийся весной 1994 года. После того, как количество сайтов в каталоге Yahoo значительно увеличилось, была добавлена возможность поиска нужной информации по каталогу.
Каталоги ссылок широко использовались ранее, однако практически полностью утратили свою популярность в настоящее время. Так как даже современные, огромные по своему объему каталоги, содержат информацию лишь о ничтожно малой части сети Интернет. Самый большой каталог сети DMOZ (его еще называют Open Directory Project) содержит информацию о 5 миллионах ресурсов, тогда как база поисковой системы Google состоит из более чем 8 миллиардов документов.
Первой полноценной поисковой системой стал проект WebCrawler, вышедший в свет в 1994 году.
В 1995 году появились поисковые системы Lycos и AltaVista. Последняя долгие годы была лидером в области поиска информации в сети Интернет.
В 1997 году Сергей Брин и Ларри Пейдж создали поисковую машину Google в рамках исследовательского проекта в Стэндфордском университете. В настоящий момент Google –самая популярная поисковая система в мире!
В настоящий момент Google –самая популярная поисковая система в мире!
В сентябре 1997 года была официально анонсирована поисковая система Yandex, являющаяся самой популярной в русскоязычном Интернете.
В настоящее время существуют три основные поисковые системы (международные) – Google, Yahoo и MSN, имеющие собственные базы и алгоритмы поиска. Большинство остальных поисковых систем (коих насчитывается большое количество) использует в том или ином виде результаты трех перечисленных. Например, поиск AOL (search.aol.com) использует базу Google, а AltaVista, Lycos и AllTheWeb – базу Yahoo.
5. Состав и принципы работы поисковой системы
В России основной поисковой системой является «Яндекс», далее – Rambler.ru, Google.ru, Aport.ru, Mail.ru. Причем, на данный момент, Mail.ru использует механизм и базу поиска «Яндекса».
Практически все крупные поисковые системы имеют свою собственную структуру, отличную от других. Однако можно выделить общие для всех поисковых машин основные компоненты. Различия в структуре могут быть лишь в виде реализации механизмов взаимодействия этих компонентов.
Однако можно выделить общие для всех поисковых машин основные компоненты. Различия в структуре могут быть лишь в виде реализации механизмов взаимодействия этих компонентов.
Модуль индексирования
Модуль индексирования состоит из трех вспомогательных программ (роботов):
Spider (паук) – программа, предназначенная для скачивания веб-страниц. «Паук» обеспечивает скачивание страницы и извлекает все внутренние ссылки с этой страницы. Скачивается html-код каждой страницы. Для скачивания страниц роботы используют протоколы HTTP. Работает «паук» следующим образом. Робот на сервер передает запрос “get/path/document” и некоторые другие команды HTTP-запроса. В ответ робот получает текстовый поток, содержащий служебную информацию и непосредственно сам документ.
Ссылки извлекаются из тэгов a, area, base, frame, frameset, и др. Наряду со ссылками, многими роботами обрабатываются редиректы (перенаправления). Каждая скачанная страница сохраняется в следующем формате:
- URL страницы
- дата, когда страница была скачана
- http-заголовок ответа сервера
- тело страницы (html-код)
Crawler («путешествующий» паук) – программа, которая автоматически проходит по всем ссылкам, найденным на странице. Выделяет все ссылки, присутствующие на странице. Его задача — определить, куда дальше должен идти паук, основываясь на ссылках или исходя из заранее заданного списка адресов. Crawler, следуя по найденным ссылкам, осуществляет поиск новых документов, еще неизвестных поисковой системе.
Выделяет все ссылки, присутствующие на странице. Его задача — определить, куда дальше должен идти паук, основываясь на ссылках или исходя из заранее заданного списка адресов. Crawler, следуя по найденным ссылкам, осуществляет поиск новых документов, еще неизвестных поисковой системе.
Indexer (робот- индексатор) – программа, которая анализирует веб-страницы, скаченные пауками. Индексатор разбирает страницу на составные части и анализирует их, применяя собственные лексические и морфологические алгоритмы. Анализу подвергаются различные элементы страницы, такие как текст, заголовки, ссылки структурные и стилевые особенности, специальные служебные html-теги и т.д.
Таким образом, модуль индексирования позволяет обходить по ссылкам заданное множество ресурсов, скачивать встречающиеся страницы, извлекать ссылки на новые страницы из получаемых документов и производить полный анализ этих документов.
База данных
База данных, или индекс поисковой системы — это система хранения данных, информационный массив, в котором хранятся специальным образом преобразованные параметры всех скачанных и обработанных модулем индексирования документов.
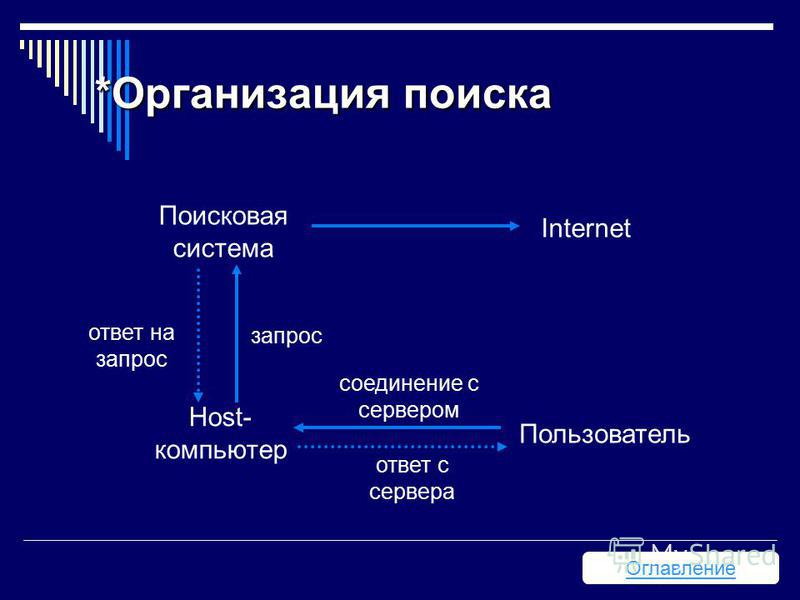
Поисковый сервер
Поисковый сервер является важнейшим элементом всей системы, так как от алгоритмов, которые лежат в основе ее функционирования, напрямую зависит качество и скорость поиска.
Поисковый сервер работает следующим образом:
- Полученный от пользователя запрос подвергается морфологическому анализу. Генерируется информационное окружение каждого документа, содержащегося в базе (которое и будет впоследствии отображено в виде сниппета, то есть соответствующей запросу текстовой информации на странице выдачи результатов поиска).
- Полученные данные передаются в качестве входных параметров специальному модулю ранжирования. Происходит обработка данных по всем документам, в результате чего, для каждого документа рассчитывается собственный рейтинг, характеризующий релевантность запроса, введенного пользователем, и различных составляющих этого документа, хранящихся в индексе поисковой системы.
- В зависимости от выбора пользователя этот рейтинг может быть скорректирован дополнительными условиями (например, так называемый «расширенный поиск»).
- Далее генерируется сниппет, то есть, для каждого найденного документа из таблицы документов извлекаются заголовок, краткая аннотация, наиболее соответствующая запросу и ссылка на сам документ, причем найденные слова подсвечиваются.
- Полученные результаты поиска передаются пользователю в виде SERP (Search Engine Result Page) – страницы выдачи поисковых результатов.

Как видно, все эти компоненты тесно связаны друг с другом и работают во взаимодействии, образовывая четкий, достаточно сложный механизм работы поисковой системы, требующий огромных затрат ресурсов.
По информации ООО «Рамблер Интернет Холдинг» обработка поискового запроса в системе «Рамблер» происходит, так, как это изображено на рисунке.
Запрос поступает в поисковую систему через маршрутизатор Cisco 6000 series. Cisco передает его наименее загруженной машине первого уровня — frontend (1.1 — 1.3, на рис. машине 1.3). Frontend, в свою очередь, отправляет запрос дальше, на один из восьми proxy-серверов, также выбирая наиболее свободный сервер (2. 1 — 2.8, на рис. машине 2.2). Одновременно frontend отправляет запрос на машины, осуществляющие поиск по товарам (3.1 — 3.2, на рис. машине 3.1) и по базе Тор 100 (4.1 — 4.2, на рис. машине 4.1). На proxy проводится поиск по ссылочному индексу, и его результаты вместе с поисковым запросом передаются на машины, которые содержат основную индексную базу, — backends (5.1.х — 5.7.х, на рис. машинам 5.1.2, 5.2.11, 5.3.1 и т.д.) Та же информация отправляется на машины с «быстрой базой» (6.1 — 6.2).
1 — 2.8, на рис. машине 2.2). Одновременно frontend отправляет запрос на машины, осуществляющие поиск по товарам (3.1 — 3.2, на рис. машине 3.1) и по базе Тор 100 (4.1 — 4.2, на рис. машине 4.1). На proxy проводится поиск по ссылочному индексу, и его результаты вместе с поисковым запросом передаются на машины, которые содержат основную индексную базу, — backends (5.1.х — 5.7.х, на рис. машинам 5.1.2, 5.2.11, 5.3.1 и т.д.) Та же информация отправляется на машины с «быстрой базой» (6.1 — 6.2).
На текущий момент в поиск включено 77 backend’ов. Они сгруппированы по 11 машин, и каждая группа содержит копию одной из частей поискового индекса. Таким образом, информация о сайтах, условно входящих в красный сектор Интернета, находится на backend’ах первой группы (5.1.1 — 5.1.11 на рис), оранжевый сектор — на backend’ах второй группы (5.2.1 — 5.2.11) и т.д. Proxy-сервер выбирает наименее загруженный backend в каждой группе машин и отправляет на него поисковый запрос с результатами ссылочного поиска.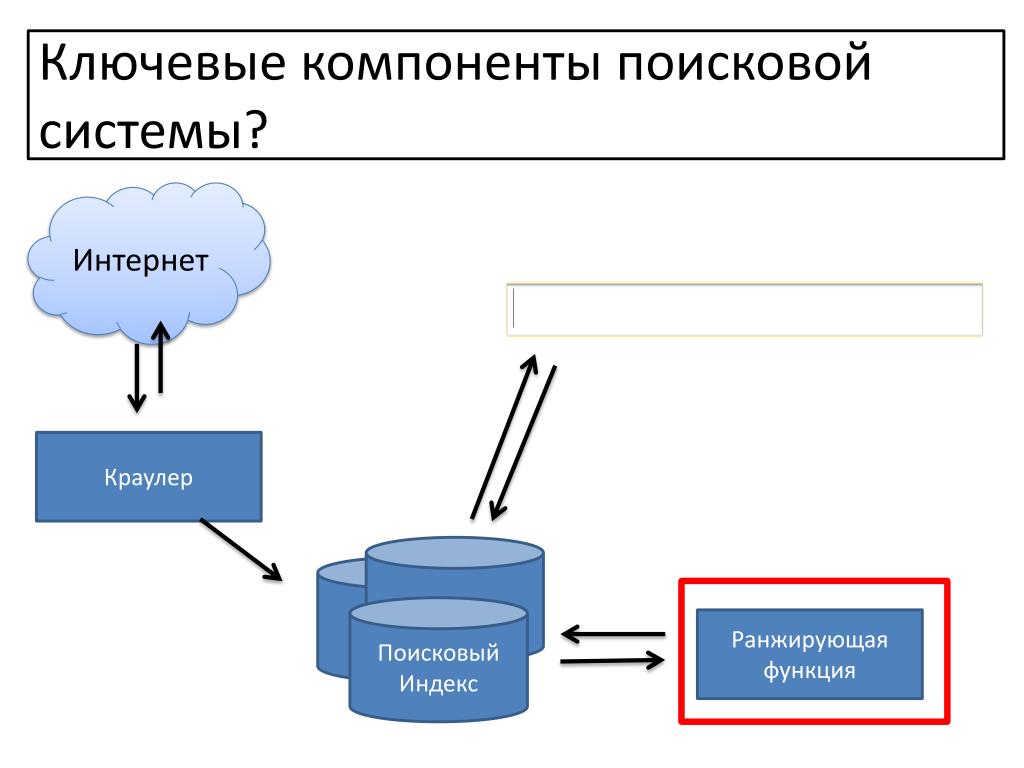 На backend’ах осуществляется поиск по частям индексной базы и ранжирование с учетом результатов поиска по ссылочному индексу. При ранжировании для всех найденных документов высчитываются веса по конкретному запросу.
На backend’ах осуществляется поиск по частям индексной базы и ранжирование с учетом результатов поиска по ссылочному индексу. При ранжировании для всех найденных документов высчитываются веса по конкретному запросу.
После того, как запрос обработан на backend’ах, информация о результатах и ранжировании отдается обратно на proxy-сервер. Туда же поступают отсортированные результаты с машин «быстрой базы». Proxy интегрирует данные, полученные с восьми машин: клеит дубли, объединяет зеркала сайтов, переранжирует документы в общий список по весам, рассчитанным на backend’ах. Так, первым в списке найденного может быть документ с машины 5.3.1, вторым и третьим – с 6.1, четвертым — с 5.5.2 и т.д. На proxy-сервере также реализуется построение цитат к документам и подсветка слов запроса в тексте. Полученные результаты отдаются на frontend.
Помимо информации с proxy-сервера, frontend получает результаты из поиска по товарам и из базы Тор 100, отсортированные, с цитатами и подсветкой слов запроса. Frontend осуществляет окончательное объединение результатов, генерирует html со списком найденного, вставляет баннеры и перевязки (ссылки на различные разделы Рамблера) и отдает html Cisco, который маршрутизирует информацию пользователю.
Frontend осуществляет окончательное объединение результатов, генерирует html со списком найденного, вставляет баннеры и перевязки (ссылки на различные разделы Рамблера) и отдает html Cisco, который маршрутизирует информацию пользователю.
При написании мастер-класса были использованы материалы и данные ООО «Рамблер Интернет Холдинг», RuSeo.info
6. Заключение
Теперь подытожим все вышесказанное.
- Первоочередная задача любой поисковой системы – доставлять людям именно ту информацию, которую они ищут.
- Основные характеристики поисковых систем:
- Полнота
- Точность
- Актуальность
- Скорость поиска
- Наглядность
- Первой полноценной поисковой системой стал проект WebCrawler, вышедший в свет в 1994 году.
- В состав поисковой системы входят компоненты:
- Модуль индексирования
- База данных
- Поисковый сервер
Надеемся, наш материал позволит вам поближе познакомиться с понятием ПС, лучше узнать основные функции, характеристики и принцип работы поисковых систем.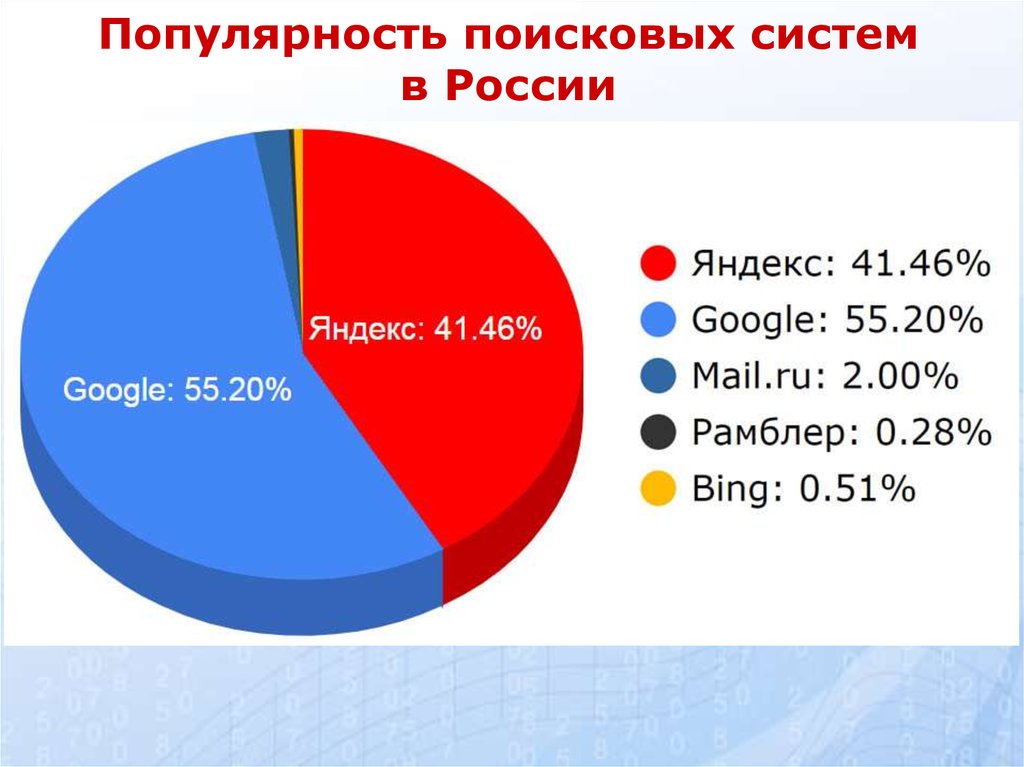
структуры, функция, характеристики. Что нужно знать о поисковиках для успешного продвижения сайтов?
Поисковые системы (ПС) уже давно являются обязательной частью интернета и нашей повседневной жизни. Сегодня они громадные и сложнейшие механизмы, которые представляют собой не только инструмент для нахождения любой необходимой информации, но и довольно увлекательные сферы для бизнеса.
Многие пользователи поиска никогда не думали о принципах их работы, о способах обработки пользовательских запросов, о том, как построены и функционируют данные системы. Данный материал поможет людям, которые занимаются оптимизацией и продвижение своих сайтов, понять устройство и основные функции поисковых машин.
Функции и понятие ПС
Поисковая система – это аппаратно-программный комплекс, который предназначен для осуществления функции поиска в интернете, и реагирующий на пользовательский запрос который обычно задают в виде какой-либо текстовой фразы (или точнее поискового запроса), выдачей ссылочного списка на информационные источники, осуществляющейся по релевантности. Самые распространенные и крупные системы поиска: Google, Bing, Yahoo, Baidu. В Рунете – Яндекс, Mail.Ru, Рамблер.
Самые распространенные и крупные системы поиска: Google, Bing, Yahoo, Baidu. В Рунете – Яндекс, Mail.Ru, Рамблер.
Рассмотрим поподробнее само значение запроса для поиска, взяв для примера систему Яндекс.
Запрос обязан быть сформулирован пользователем в полном соответствии с предметом его поиска, максимально просто и кратко. К примеру, мы желаем найти информацию в данном поисковике: «как выбрать автомобиль для себя». Чтобы сделать это, открываем главную страницу и вводим запрос для поиска «как выбрать авто». Потом наши функции сводятся к тому, чтобы зайти по предоставленным ссылкам на информационные источники в сети.
Но даже действуя таким образом, можно и не получить необходимую нам информацию. Если мы получили подобный отрицательный результат, нужно просто переформировать свой запрос, или же в базе поиска действительно нет никакой полезной информации по данному виду запроса (такое вполне возможно при заданных «узких» параметров запроса, как, к примеру, «как выбрать автомобиль в Туле»).
Самая основная задача каждой поисковой системы – доставить людям именно тот вид информации, который им нужен. Приучить же пользователей создавать «правильный» вид запросов к поисковым системам, то есть фразы, которые будут соответствовать их принципам работы, практически, невозможно.
Именно поэтому специалисты-разработчики поисковиков делают такие принципы и алгоритмы их работы, которые бы давали пользователям находить интересующие их сведения. Это означает, что система, должна «думать» так же, как мыслит человек при поиске необходимой информации в интернете.
Когда он вводит свой запрос в поисковую машину, он желает найти то, что ему надо, как можно проще и быстрее. Получив результат, пользователь составляет свою оценку работе системы, руководствуясь несколькими критериями. Получилось ли у него найти нужную информацию? Если нет, то сколько раз ему пришлось переформатировать текст запроса, чтобы найти ее? Насколько актуальная информация была им получена? Как быстро поисковая система обработала его запрос? Насколько удобно были предоставлены поисковые результаты? Был ли нужный результат первым, или находился на 30-ом месте? Сколько «мусора» (ненужной информации) было найдено вместе с полезными сведениями? Найдется ли актуальная для него информация, при использовании ПС, через неделю, либо через месяц?
Для того чтобы получить правильные ответы на подобные вопросы, разработчики поиска постоянно улучшают принципы ранжирования и его алгоритмы, добавляют им новые возможности и функции и любыми средствами пытаются сделать быстрее работу системы.
Основные характеристики поисковых систем
Обозначим главные характеристики поиска:
Полнота.
Полнота является одной из главнейших характеристик поиска, она представляет собой отношение цифры найденных по запросу информационных документов к их общему числу в интернете, относящихся к данному запросу. Например, в сети есть 100 страниц имеющих словосочетание «как выбрать авто», а по такому же запросу было отобрано всего 60 из общего количества, то в данном случае полнота поиска составит 0,6. Понятно, что чем полнее сам поиск, тем больше вероятность, что пользователь найдет именно тот документ, который ему необходим, конечно, если он вообще существует.
Точность.
Еще одна основная функция поисковой системы – точность. Она определяет степень соответствия запросу пользователя найденных страниц в Сети. К примеру, если по ключевой фразе «как выбрать автомобиль» найдется сотня документов, в половине из них содержится данное словосочетание, а в остальных просто есть в наличии такие слова (как грамотно выбрать автомагнитолу, и установить ее в автомобиль»), то поисковая точность равна 50/100 = 0,5.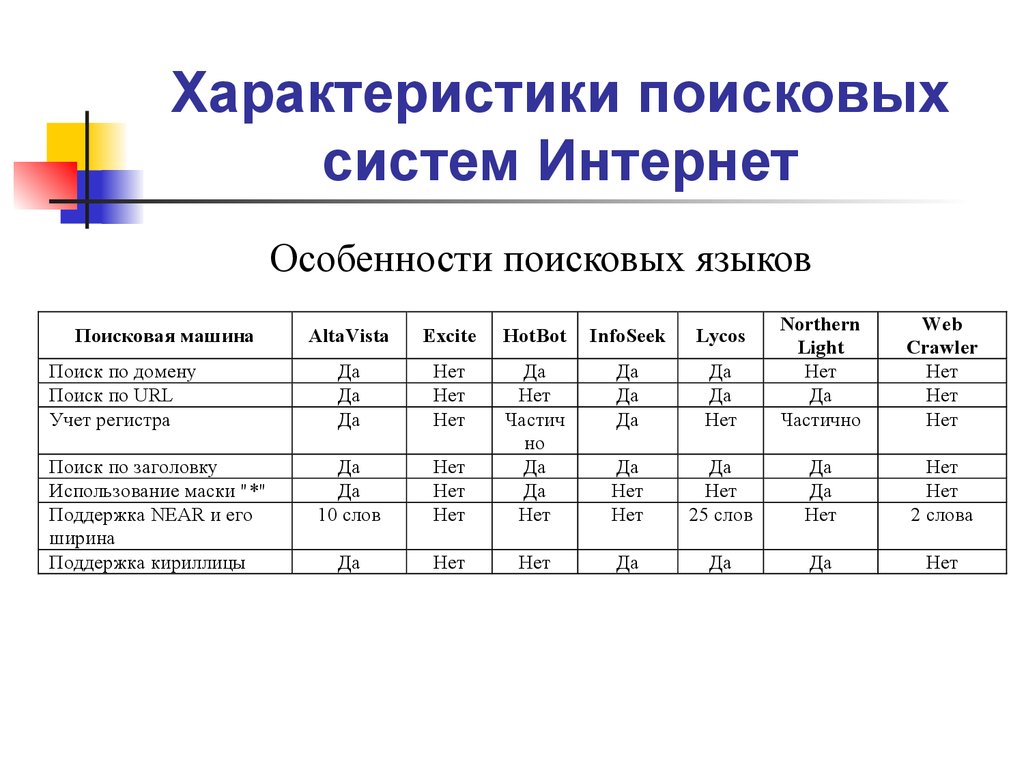
Чем поиск точнее, тем скорее пользователь найдет необходимую ему информацию, тем меньше разнообразного «мусора» будет встречаться среди результатов, тем меньше найденных документов будут не соответствовать смыслу запроса.
Актуальность.
Это значимая составляющая поиска, которую характеризует время, проходящее с момента опубликования информации в интернете до занесения ее в индексную базу поисковика.
К примеру, на следующий день после возникновения информации о выходе нового iPad, множество пользователей обратилась к поиску с соответствующими видами запросов. В большинстве случаев информация об этой новости уже доступна в поиске, хотя времени с момента ее появления прошло очень мало. Это происходит благодаря наличию у крупных поисковых систем «быстрой базы», которая обновляется несколько раз за день.
Скорость поиска.
Такая функция как скорость поиска теснейшим образом связана с так называемой «устойчивостью к нагрузкам». Ежесекундно к поиску обращается огромное количество людей, подобная загруженность требует значительного сокращения времени для обработки одного запроса. Тут интересы, как поисковой системы, так и пользователя целиком совпадают: посетитель хочет получить результаты как можно быстрее, а поисковая система должна отработать его запрос тоже максимально быстро, чтобы не притормозить обработку последующих запросов.
Ежесекундно к поиску обращается огромное количество людей, подобная загруженность требует значительного сокращения времени для обработки одного запроса. Тут интересы, как поисковой системы, так и пользователя целиком совпадают: посетитель хочет получить результаты как можно быстрее, а поисковая система должна отработать его запрос тоже максимально быстро, чтобы не притормозить обработку последующих запросов.
Наглядность.
Наглядное представление результатов является важнейшим элементом удобства поиска. По множеству запросов поисковая система находит тысячи, а в некоторых случаях и миллионы разных документов. Вследствие нечеткости составления ключевых фраз для поиска или его не точности, даже самые первые результаты запроса не всегда имеют только нужные сведения.
Это значит, что человеку часто приходится осуществлять собственный поиск среди предоставленных результатов. Разнообразные компоненты страниц выдачи ПС помогают ориентироваться в поисковых результатах.
История развития поисковых систем
Когда интернет только начал развиваться, число его постоянных пользователей было небольшим, и объем информации для доступа был сравнительно невеликим. В основном доступ к этой сети имели лишь специалисты научно-исследовательских сфер. В то время, задача нахождения информации не была столь актуальна как сейчас.
Одним из самых первых методов организации широкого доступа к ресурсам информации стало создание каталогов сайтов, причем ссылки на них начали группировать по тематике. Таким первым проектом стал ресурс Yahoo.com, который открылся весной 1994-ого года. Впоследствии когда количество сайтов в Yahoo-каталоге существенно увеличилось, была добавлена опция поиска необходимых сведений по каталогу. Это еще не было в полной мере поисковой системой, так как область такого поиска была ограничена только сайтами, входящими в данный каталог, а не абсолютно всеми ресурсами в интернете. Каталоги ссылок весьма широко использовались раньше, однако в настоящее время, практически в полной мере утратили свою популярность.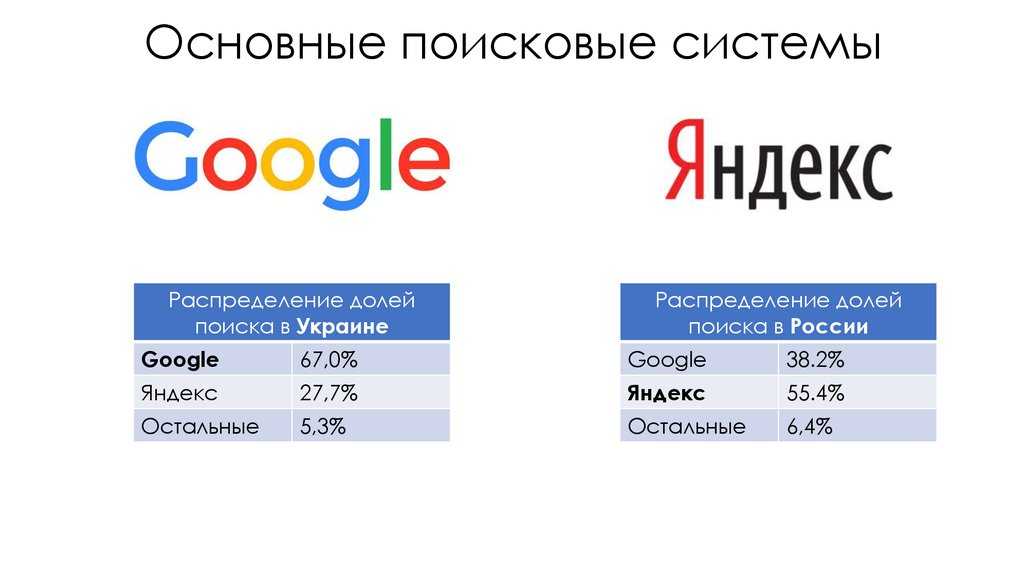
Ведь даже сегодняшние, громадные по своим объемам каталоги имеют информацию о незначительно части сайтов в интернете. Самым известным и большим каталогом в мире был DMOZ (прекратил работу 14 марта 2017 года) имеет информацию о пяти миллионах сайтов, когда база Google содержит информацию о более чем 25 миллиардов страниц.
Самой первой настоящей поисковой системой стала WebCrawler, возникшая еще в 1994-ом году.
В следующем году появились AltaVista и Lycos. Причем первая была лидером по поиску информации очень длительное время.
В 1997-ом году Сергей Брин вместе с Ларри Пейджем создал машину поисковую Google как исследовательский проект в Стэндфордском университете. Сегодня именно Google, самая востребованная и популярная поисковая система в мире.
В сентябре 1997-ом году была анонсирована (официально) ПС Yandex, которая в настоящий момент является самой популярной системой поиска в Рунете.
Доля поисковых систем
По данным на апрель 2020 года, доли поисковых систем в мире распределены следующим образом:
- Google — 70,83 %;
- Bing — 12,61 %;
- Baidu — 11,83 %;
- Yahoo! — 2,30 %;
- Яндекс — 1,41 %;
- DuckDuckGo — 0,42 %;
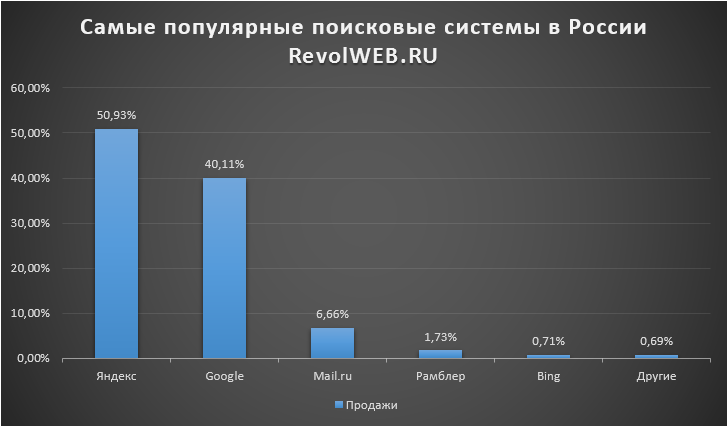
По данным на апрель 2020 года, доли поисковых систем в Рунете (данные сервиса Яндекс.Радар):
- Яндекс — 59,10%
- Google — 38,85%
- Поиск.Mail.ru — 1,18%
- Rambler — 0,07%
- Остальные — 0,80%
Принципы работы поисковой системы
В России главной системой поиска является Яндекс, затем Google, а потом Поиск@Mail.ru. Все большие системы поиска имеют свою структуру, которая весьма отличается от других. Но все-таки можно выделить общие для всех поисковиков основные элементы.
Модуль индексирования.
Данный компонент состоит из трех программ-роботов:
Spider (по англ. паук) – программа которая предназначена для того чтобы скачивать веб-страницы. «Паук» скачивает определенную страницу, одновременно извлекая из нее все ссылки. Скачивается код html практически с каждой страницы. Для этого роботы используют HTTP-протоколы.
«Паук» функционирует следующим образом. Робот передает запрос на сервер “get/path/document” и иные команды запроса HTTP. В ответ программа-робот получает поток текста, который содержит информацию служебного вида и, естественно, сам документ.
Извлекаются все ссылки из тэгов. Вместе с ними обрабатывают редиректы. Любая скачанная страница сохраняется в таком формате:
- URL скаченной страницы;
- дата, когда осуществлялось скачивание страницы;
- заголовок http-ответа сервера;
- html-код, «тела» страницы.

Crawler («путешествующий» паук). Данная программа автоматически заходит на все ссылки, которые найдены на странице, а также выделяет их. Его задача – определиться, куда в дальнейшем должен заходить паук, основываясь на этих ссылках или исходя из заданного списка адресов.
Crawler, исследуя найденные ссылки, ищет новые документы, еще не ставшие известными поисковой системе.
Indexer (робот-индексатор) – это программа, анализирующая страницы, которые скачали пауки.
Индексатор полностью разбирает страницу на составные элементы и проводит их анализ, применяя свои морфологические и лексические виды алгоритмов.
Анализ проводится над разнообразными частями страницы, такими как заголовки, текст, ссылки, стилевые и структурные особенности, теги html и др.
Таким образом, модуль индексирования дает возможность проходить по ссылкам заданного количества ресурсов, скачивать страницы, извлекать ссылочную массу на новые страницы из полученных документов и делать подробный их анализ.
База данных
База данных (или индекс поисковика) — комплекс хранения данных, массив информации в котором сохраняются определенным образом переделанные параметры каждого обработанного модулем индексации и скачанного документа.
Поисковый сервер
Это самый важный элемент всей системы, потому что от алгоритмов, лежащих в основе ее функциональности, прямо зависит скорость и, конечно же, качество поиска.
Поисковый сервер работает следующим образом:
- Запрос, который идет от пользователя подвергается морфологическому анализу. Информационное окружение любого документа, имеющегося в базе, генерируется (оно и будет в дальнейшем отображаться как сниппет, т.е. информационное поле текста соответствующего данному запросу).
- Полученные данные передают как входные параметры специализированному модулю ранжирования. Они обрабатываются по всем документам, и в итоге для каждого такого документа рассчитывается свой рейтинг, который характеризует релевантность такого документа запросу пользователя, и иных составляющих.
- В зависимости от условий заданных пользователем этот рейтинг вполне может быть подкорректирован дополнительными.
- Затем генерируется сам сниппет, т.е. для любого найденного документа из соответствующей таблицы извлекают заголовок, аннотацию, наиболее отвечающую запросу, и ссылка на этот документ, при этом найденные словоформы и слова подсвечивают.
- Результаты полученного поиска передаются осуществившему его человеку в виде страницы, на которую выдают поисковые результаты (SERP).
Все эти элементы тесно связаны между собой и функционируют, взаимодействуя, образовывая отчетливый, но достаточно непростой механизм функционирования ПС, требующий громадных затрат ресурсов.
Топ-8 лучших поисковых систем (2022 г.)
Блог » Сообщество » Топ-8 лучших поисковых систем (2022 г.) Google Поисковые системы позволяют нам фильтровать тонны информации, доступной в Интернете, и получать самые точные результаты. И хотя большинство людей не уделяют слишком много внимания поисковым системам, они в огромной степени способствуют точности результатов и опыту, которым вы наслаждаетесь при поиске в Интернете. Хотя вы можете подумать, что Google — единственная поисковая система из-за ее доминирующего положения, вы будете удивлены, узнав, что существуют и другие выдающиеся поисковые системы. Эта статья направлена на то, чтобы обеспечить ранг некоторых из лучших поисковых систем. Узнайте, как создать систему пользовательского поиска, здесь Помимо того, что Google является самой популярной поисковой системой, охватывающей более 90% мирового рынка, Google может похвастаться выдающимися функциями, которые делают ее лучшей поисковой системой на рынке. Он может похвастаться передовыми алгоритмами, простым в использовании интерфейсом и персонализированным пользовательским интерфейсом. Платформа известна тем, что постоянно обновляет результаты и функции своей поисковой системы, чтобы предоставить пользователям лучший опыт. Связано с: Google Translate API Tutorial Microsoft Bing — вторая по известности поисковая система в мире. Несмотря на то, что когда-то он был популярнее Google и даже шел ноздря в ноздрю с Google в первые дни своего существования, Yahoo опустился на третье место по доле рынка. Его веб-портал по-прежнему популярен, и, согласно Alexa, он является одиннадцатым по посещаемости сайтом. Baidu, основанная в 2000 году, является первоклассной поисковой системой, доминирующей в Китае. На протяжении многих лет платформа демонстрирует устойчивый рост числа пользователей. И хотя он в основном используется в Китае, он по-прежнему может похвастаться интуитивно понятным интерфейсом, множеством параметров поиска и результатами поиска премиум-класса. Яндекс был создан в 1997 году и может похвастаться тем, что является наиболее используемой поисковой системой в России. Еще одна выдающаяся поисковая система — Duckduckgo. В отличие от других поисковых систем, Duckduckgo ценит конфиденциальность пользователей, поскольку они не отслеживают и не хранят личную информацию о поиске. Контекстный веб-поиск — это надежный API, который предоставляет пользователям доступ к миллиардам веб-страниц, новостей и изображений с помощью одного вызова API. API связывает вас с поисковой системой, которая имитирует то, как человеческий мозг индексирует воспоминания для получения более информативных результатов поиска. Yippy Search — это современная система глубокого Интернета, которая помогает пользователям исследовать то, что не могут найти другие поисковые системы. Поскольку глубокие веб-страницы труднее найти при обычном поиске, Yippy Search поможет вам найти эти веб-страницы. Это позволяет вам искать труднодоступную информацию, такую как каналы, связанные с правительством, блоги по интересам, научные исследования или необычные новости. Рубрики: Сообщество С тегами: baidu, bing, duckduckgo, Google, поиск, поисковая система, веб-поиск, yahoo, yandex Персонал RapidAPI состоит из различных авторов организации RapidAPI. Для поддержки, пожалуйста, напишите нам по адресу [email protected]. Поиск на этом веб-сайте У вас есть вопрос, который беспокоит вас, и вам нужно знать ответ? Погугли это! Хотите узнать, чем закончилось ваше любимое телешоу? Погугли это! Нужна информация для вашего эссе? Погугли это! Сколько раз вы слышали фразу «Погуглите » ? Весь мир у нас под рукой, поиск информации стал проще и эффективнее, чем когда-либо. Итак, что на самом деле представляет собой поисковую систему в Интернете, и как ее можно использовать, чтобы помочь вам в изучении английского языка? Начнем с определения: Интернет-поисковик — это программа, используемая для поиска в Интернете. Пользователи могут вводить запрос, а поисковая система эффективно и методологически ищет информацию в Интернете. Это генерирует ряд результатов, которые могут варьироваться от веб-страниц, статей, исследовательских работ, изображений, видео и т. д. Рис. 1. Строка результатов поиска называется страницей результатов. Взгляните на график ниже, чтобы узнать больше об истории поисковых систем в Интернете: 2 сентября 1993 г. в списках существующих веб-сайтов. Бот (сокращение от «робот») — это компьютерная программа, используемая для выполнения задач в Интернете. ↓ 12 декабря 1993 г. — Выпущен JumpStation. В отличие от W3Catalog, он впервые сочетает в себе три важнейших элемента поисковой системы в Интернете: сканирование, индексирование и поиск. Сканирование — это процесс, в котором боты используются поисковыми системами для обнаружения нового и/или обновленного контента в Интернете. Индексация — это процесс, в ходе которого поисковые системы находят, систематизируют и сохраняют данные, позволяющие быстро реагировать на запросы. Поиск относится к процессу поиска информации. ↓ 20 апреля 1994 — Выпущен WebCrawler. Он устанавливает стандарт для будущих поисковых систем, позволяя пользователям искать любое слово на любой веб-странице. ↓ 2 марта 1995 — Yahoo! Запускается поиск. Это первая популярная поисковая система в Интернете, используемая широкой публикой. ↓ 15 сентября 1997 г. — Запущен поиск Google. В настоящее время это самая популярная поисковая система в Интернете с миллиардами поисковых запросов каждый день! Ниже приведены три самых популярных поисковых системы в Интернете в мире: 1. Google Самая известная и часто используемая поисковая система — Google, впервые запущенная в 1997 году. его основателями Ларри Пейджем и Сергеем Брином. Он имеет более 92% акций на мировом рынке поисковых систем. Чем выше процент акций компании, тем крупнее и влиятельнее она. Это показывает, что Google более успешен, чем другие поисковые системы! Под рыночной долей понимается доля рынка, контролируемая определенной компанией. Рис. 2. Знаете ли вы, что Google является самым посещаемым веб-сайтом в мире? Вам может быть интересно, что делает Google таким популярным. Одна из причин заключается в том, что Google выполнил намного больше поисковых запросов, чем другие поисковые системы. Это затем предоставляет Google больше данных, что дает пользователю более точные и качественные результаты. 2. Bing Второй по популярности поисковой системой в Интернете является Bing. Он был запущен в 2009 году генеральным директором Microsoft Стивом Балмером. Его доля на мировом рынке составляет около 8%. Доля рынка относится к проценту рынка или отрасли, который зарабатывает определенная компания. 3. Baidu Третьей по популярности поисковой системой в Интернете является Baidu. Он был основан предпринимателями Робином Ли и Эриком Сюй в 2000 году. Ему принадлежит более 7% акций мирового рынка. Хотя он доступен во всем мире, он доступен только на китайском языке. Вот список других поисковых систем в Интернете. Сколько из них вы слышали?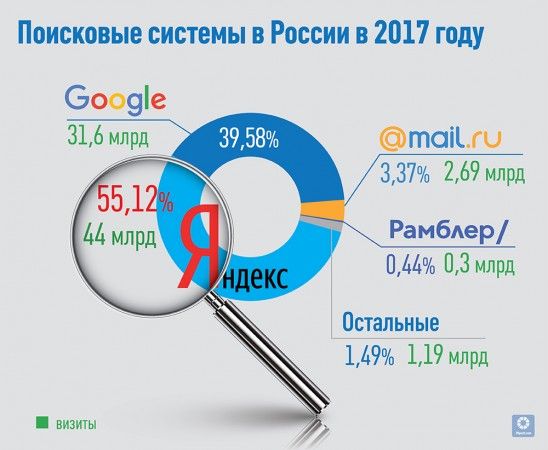 Yahoo
Yahoo
Pros
 И хотя он значительно уступает Google с точки зрения доли рынка, он может похвастаться некоторыми уникальными функциями, которые могут заинтересовать пользователей. Во-первых, фильтры поисковой системы приводят к различным вкладкам, таким как реклама, изображения, карты, видео и новости. Это также дает пользователям возможность накапливать баллы, которые они позже могут использовать в магазинах Microsoft и Windows. Он также безупречно работает во всех браузерах.
И хотя он значительно уступает Google с точки зрения доли рынка, он может похвастаться некоторыми уникальными функциями, которые могут заинтересовать пользователей. Во-первых, фильтры поисковой системы приводят к различным вкладкам, таким как реклама, изображения, карты, видео и новости. Это также дает пользователям возможность накапливать баллы, которые они позже могут использовать в магазинах Microsoft и Windows. Он также безупречно работает во всех браузерах. Плюсы
 Yahoo предлагает впечатляющий интерфейс, чистые результаты и впечатляющий каталог веб-сайтов.
Yahoo предлагает впечатляющий интерфейс, чистые результаты и впечатляющий каталог веб-сайтов. Pros
Минусы
Pros
Минусы
 Материнская компания Яндекса позиционирует себя как технологическая компания, специализирующаяся на создании интеллектуальных продуктов и услуг на основе машинного обучения. Тем не менее, он поддерживает одну из самых обширных поисковых систем в России, на долю которой приходится более 65% рынка. С помощью Яндекса вы можете искать что угодно, включая изображения, карты и даже видео.
Материнская компания Яндекса позиционирует себя как технологическая компания, специализирующаяся на создании интеллектуальных продуктов и услуг на основе машинного обучения. Тем не менее, он поддерживает одну из самых обширных поисковых систем в России, на долю которой приходится более 65% рынка. С помощью Яндекса вы можете искать что угодно, включая изображения, карты и даже видео. Pros
Минусы
 Поисковая система позволяет вам искать все, начиная от изображений, карт и видео. Он может похвастаться выдающимися функциями, такими как информация без щелчка, когда все ответы появляются на первой странице. Подсказки по устранению неоднозначности поясняют, что вы ищете, для получения более точных результатов.
Поисковая система позволяет вам искать все, начиная от изображений, карт и видео. Он может похвастаться выдающимися функциями, такими как информация без щелчка, когда все ответы появляются на первой странице. Подсказки по устранению неоднозначности поясняют, что вы ищете, для получения более точных результатов. Плюсы
Минусы
 Этот API использует комбинацию информации о пользователях и их поведении для создания контекста для персонализированного поиска. Это поможет вам настроить свой опыт и получить точные и релевантные результаты поиска.
Этот API использует комбинацию информации о пользователях и их поведении для создания контекста для персонализированного поиска. Это поможет вам настроить свой опыт и получить точные и релевантные результаты поиска. Pros
Минусы

Плюсы
Персонал RapidAPI
Взаимодействие с читателями
Интернет-поисковые системы: примеры и список
 Благодаря поисковым системам в Интернете, таким как Google, у нас есть мгновенный доступ к большому количеству бесплатного и полезного контента.
Благодаря поисковым системам в Интернете, таким как Google, у нас есть мгновенный доступ к большому количеству бесплатного и полезного контента. Интернет-поисковики Определение
История поисковых систем в Интернете
 Его основная проблема — снижение производительности, вызванное ботом, который заходит на каждую веб-страницу сотни раз в день.
Его основная проблема — снижение производительности, вызванное ботом, который заходит на каждую веб-страницу сотни раз в день.
Примеры поисковых систем в Интернете
 ..
.. Список поисковых систем в Интернете
A 204s 9 com
com другие поисковые системы в Интернете включают:
YouTube — YouTube — это не просто социальная сеть; он также считается поисковой системой, поскольку позволяет пользователям искать видео. Несмотря на то, что это платформа только для видео, это второй по посещаемости веб-сайт в мире (после Google) и имеет более 2 миллиардов пользователей в месяц.
Ecosia (известная как поисковая система по посадке деревьев) — это более экологичная поисковая система! Он использует деньги от рекламы для посадки деревьев по всему миру, что приносит пользу людям, окружающей среде и местной экономике.
StartPage — основана в 2006 году в Нидерландах. Он считается одной из самых закрытых поисковых систем в мире, поскольку не ведет учет поисковых запросов пользователей и не хранит личную информацию.
Как использовать поисковые системы в Интернете
Поисковые системы можно использовать, если вам нужно провести исследование для изучения английского языка. Вы можете перепроверить свои знания или поискать новую информацию. Например, если вы пишете аргументированное эссе на какую-либо тему, вы можете использовать поисковую систему, чтобы найти дополнительную информацию, подтверждающую ваши утверждения и мнения. Или вы могли бы найти новые взгляды, чтобы аргументировать или против!
Вот несколько советов, которые могут помочь вам при поиске:
1. Используйте кавычки для поиска определенного термина/фразы.
Ввод убедительного эссе в Google без кавычек дает почти 50 миллионов результатов. Тем не менее, ввод «убедительного эссе» сужает его примерно до 3,7 миллиона результатов, поскольку все эти результаты содержат именно эту фразу.
2. Если вы хотите найти похожие термины/фразы, например альтернативные варианты написания или разные формы слова/фразы, используйте звездочки (*).
Ввод *semantics* в Google со звездочками расширяет результаты поиска и выводит похожие термины, такие как лексическая семантика, семантическое поле, семантические теории, динамическая семантика и т. д.
3. Хотите найти что-то из определенной даты или времени ? Отфильтруйте результаты поиска или используйте расширенные инструменты. Это может показаться очевидным, но в большинстве поисковых систем вы можете выбрать определенную дату и/или время, чтобы получить более конкретные результаты поиска.
Если вы хотите найти информацию за 2015 год, вы можете установить дату с 1 января 2015 года по 31 декабря 2015 года. Таким образом, будут отображаться результаты только за 2015 год.
4. Пытаетесь найти академические источники? Попробуйте выполнить поиск в Google Scholar вместо основного браузера. Google Scholar часто более полезен для студентов, поскольку основное внимание уделяется академическим ресурсам, таким как рецензируемые журналы и статьи.
Несколько альтернатив Google Scholar включают Microsoft Academic, ResearchGate и Scinapse.
5. Хотя Google является самой популярной поисковой системой, почему бы не попробовать другие? Различные поисковые системы дают разные результаты, поэтому вам может быть полезно использовать несколько поисковых систем, чтобы найти то, что вы ищете!
Не верьте всему, что вы читаете в Интернете
Вы также должны знать, что хотя поисковые системы в Интернете могут быть полезными, у них есть недостатки. Одним из основных вопросов является достоверность информации. Распространять ложную информацию в Интернете становится все проще, поэтому не стоит верить всему, что читаешь!
При проверке веб-сайтов во время исследования имейте в виду следующее:
- Предвзятость — некоторые веб-сайты могут быть предвзяты в отношении определенного взгляда/концепции, поскольку они хотят, чтобы читатель согласился с ними. Например, многие политические веб-сайты предвзято относятся к той или иной политической партии. Это может привести к менее надежным исследованиям, поскольку может дать искаженное представление об информации. Попробуйте найти несколько авторитетных источников, подтверждающих теорию.
 Попробуйте найти несколько авторитетных источников, подтверждающих теорию.
Попробуйте найти несколько авторитетных источников, подтверждающих теорию.- Орфография и грамматика . Если на сайте не всегда хорошее правописание и грамматика, он может быть менее надежным, чем другие сайты. Надежные сайты, как правило, более профессиональные.
- Дата — если веб-сайт слишком старый, на нем может быть нет точной информации. Это означает, что информация, вероятно, будет недостоверной или просто больше не соответствует действительности! Вещи постоянно меняются, поэтому важно быть в курсе последних событий.
Поисковые системы в Интернете – основные выводы
- Интернет-поисковик — это программа, используемая для поиска в Интернете.
- Первая в мире поисковая система в Интернете, W3Catalog, была запущена в 1993 году.
- Тремя ключевыми элементами поисковой системы в Интернете являются сканирование, индексирование и поиск.
- Самая популярная поисковая система в Интернете — Google.
