В чем состоит процесс компиляции? — Студопедия
Компиляция — трансляция программы, составленной на исходном языке высокого уровня, в эквивалентную программу на низкоуровневом языке, близком машинному коду (абсолютный код, объектный модуль, иногда на язык ассемблера). Входной информацией для компилятора (исходный код) является описание алгоритма или программа на проблемно-ориентированном языке, а на выходе компилятора — эквивалентное описание алгоритма на машинно-ориентированном языке (объектный код).
Процесс компиляции состоит из двух основных частей — собственно компиляции и компоновки (генерации исполняемого файла).
1. Компиляция. Программа, как правило, состоит из нескольких модулей. В результате компиляции для каждого модуля генерируется объектный файл, который содержит инструкции на целевом языке и информацию о содержащихся в модуле функциях и о внешних функциях, используемых в модуле. Процесс компиляции зависит, как правило, только от типа процессора.
2. Компоновка (англ. linking, linkage). Все необходимые объектные файлы собираются вместе. Далее происходит процесс разрешения ссылок — все внешние по отношению к каждому отдельному модулю ссылки должны быть разрешены, то есть для каждой из них должна быть поставлена в соответствие конкретная функция из другого модуля программы, либо из внешней библиотеки. Например, если в модуле вызывается функция операционной системы, которая рисует на экране линию, то компилятор <верит на слово>, что такая функция существует. В процессе сборки этой ссылке должна быть сопоставлена конкретная функция из конкретной библиотеки (для Windows — это как правило dll, для Linux — so) операционной системы. Кроме того при генерации исполняемого файла (для Windows — exe-файл) должны быть соблюдены требования операционной системы к формату исполняемых файлов. Поэтому процесс сборки зависит от операционной системы, а зачастую — и от версии операционной системы.
Примеры компиляторов: GCC, Free Pascal Compiler.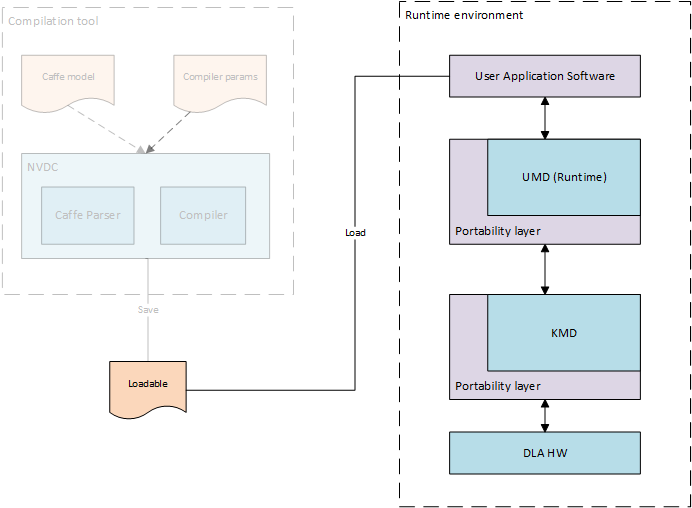
Процесс выполнения управляемого кода | Microsoft Docs
- Чтение занимает 7 мин
В этой статье
Процесс управляемого исполнения включает следующие шаги, которые подробно разбираются позднее в этом разделе:The managed execution process includes the following steps, which are discussed in detail later in this topic:
Выбор компилятора.Choosing a compiler.
Чтобы воспользоваться преимуществами среды CLR, необходимо использовать один или несколько языковых компиляторов, обращающихся к среде выполнения.To obtain the benefits provided by the common language runtime, you must use one or more language compilers that target the runtime.

Компиляция кода в MSIL.Compiling your code to MSIL.
При компиляции исходный код преобразуется в MSIL и создаются необходимые метаданные.Compiling translates your source code into Microsoft intermediate language (MSIL) and generates the required metadata.
Компиляция инструкций MSIL в машинный код.Compiling MSIL to native code.
Во время выполнения JIT-компилятор преобразует инструкции MSIL в машинный код.At execution time, a just-in-time (JIT) compiler translates the MSIL into native code. Во время этой компиляции выполняется проверка кода и метаданных MSIL с целью установить, можно ли для них определить, является ли код типобезопасным.During this compilation, code must pass a verification process that examines the MSIL and metadata to find out whether the code can be determined to be type safe.
Выполнение кода.Running code.
Среда CLR предоставляет инфраструктуру, обеспечивающую выполнение кода, и ряд служб, которые можно использовать при выполнении.
The common language runtime provides the infrastructure that enables execution to take place and services that can be used during execution.

 The common language runtime provides the infrastructure that enables execution to take place and services that can be used during execution.
The common language runtime provides the infrastructure that enables execution to take place and services that can be used during execution.Выбор компилятораChoosing a Compiler
Чтобы воспользоваться преимуществами, предоставляемыми средой CLR, необходимо применить один или несколько языковых компиляторов, ориентированных на среду выполнения, например компилятор Visual Basic, C#, Visual C++, F# или один из многочисленных компиляторов от независимых разработчиков, например компилятор Eiffel, Perl или COBOL.To obtain the benefits provided by the common language runtime (CLR), you must use one or more language compilers that target the runtime, such as Visual Basic, C#, Visual C++, F#, or one of many third-party compilers such as an Eiffel, Perl, or COBOL compiler.
Поскольку среда выполнения является многоязычной, она поддерживает широкий набор разнообразных типов данных и языковых средств.Because it is a multilanguage execution environment, the runtime supports a wide variety of data types and language features.
ВверхBack to top
Компиляция в MSILCompiling to MSIL
При компиляции в управляемый код компилятор преобразует исходный код в промежуточный язык Microsoft (MSIL), представляющий собой независимый от процессора набор инструкций, который можно эффективно преобразовать в машинный код.When compiling to managed code, the compiler translates your source code into Microsoft intermediate language (MSIL), which is a CPU-independent set of instructions that can be efficiently converted to native code. Язык MSIL включает инструкции для загрузки, сохранения, инициализации и вызова методов для объектов, а также инструкции для арифметических и логических операций, потоков управления, прямого доступа к памяти, обработки исключений и других операций.
Когда компилятор создает код MSIL, одновременно создаются метаданные.When a compiler produces MSIL, it also produces metadata. Метаданные содержат описание типов в коде, включая определение каждого типа, сигнатуры каждого члена типа, члены, на которые есть ссылки в коде, а также другие сведения, используемые средой выполнения во время выполнения.Metadata describes the types in your code, including the definition of each type, the signatures of each type’s members, the members that your code references, and other data that the runtime uses at execution time. MSIL и метаданные содержатся в переносимом исполняемом (PE) файле, который основывается на форматах Microsoft PE и COFF, ранее использовавшихся для исполняемого контента, но при этом расширяет их возможности.The MSIL and metadata are contained in a portable executable (PE) file that is based on and that extends the published Microsoft PE and common object file format (COFF) used historically for executable content. Этот формат файлов, позволяющий размещать код MSIL или машинный код, а также метаданные, позволяет операционной системе распознавать образы среды CLR.
Метаданные содержат описание типов в коде, включая определение каждого типа, сигнатуры каждого члена типа, члены, на которые есть ссылки в коде, а также другие сведения, используемые средой выполнения во время выполнения.Metadata describes the types in your code, including the definition of each type, the signatures of each type’s members, the members that your code references, and other data that the runtime uses at execution time. MSIL и метаданные содержатся в переносимом исполняемом (PE) файле, который основывается на форматах Microsoft PE и COFF, ранее использовавшихся для исполняемого контента, но при этом расширяет их возможности.The MSIL and metadata are contained in a portable executable (PE) file that is based on and that extends the published Microsoft PE and common object file format (COFF) used historically for executable content. Этот формат файлов, позволяющий размещать код MSIL или машинный код, а также метаданные, позволяет операционной системе распознавать образы среды CLR.
ВверхBack to top
Компиляция инструкций MSIL в машинный кодCompiling MSIL to Native Code
Перед запуском MSIL его необходимо скомпилировать в машинный код в среде CLR для архитектуры конечного компьютера.Before you can run Microsoft intermediate language (MSIL), it must be compiled against the common language runtime to native code for the target machine architecture. Платформа .NET предоставляет два способа такого преобразования:.NET provides two ways to perform this conversion:
Платформа .NET предоставляет два способа такого преобразования:.NET provides two ways to perform this conversion:
Компиляция с помощью JIT-компилятораCompilation by the JIT Compiler
При JIT-компиляции язык MSIL преобразуется в машинный код во время выполнения приложения по требованию, когда загружается и выполняется содержимое сборки.JIT compilation converts MSIL to native code on demand at application run time, when the contents of an assembly are loaded and executed. Поскольку среда CLR предоставляет JIT-компилятор для каждой поддерживаемой архитектуры процессора, разработчики могут создавать набор сборок MSIL, которые могут компилироваться с помощью JIT-компилятора и выполняться на разных компьютерах с разной архитектурой.Because the common language runtime supplies a JIT compiler for each supported CPU architecture, developers can build a set of MSIL assemblies that can be JIT-compiled and run on different computers with different machine architectures. Если управляемый код вызывает специфический для платформы машинный API или библиотеку классов, то он будет выполняться только в соответствующей операционной системе.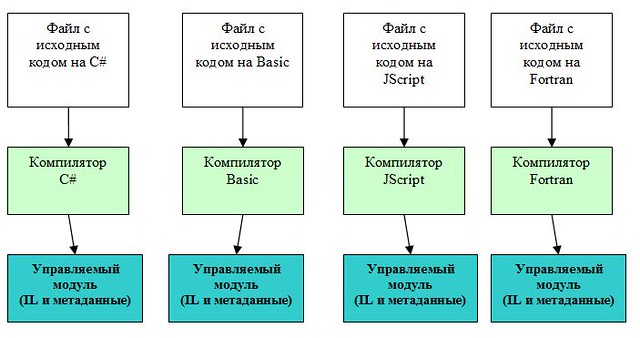 However, if your managed code calls platform-specific native APIs or a platform-specific class library, it will run only on that operating system.
However, if your managed code calls platform-specific native APIs or a platform-specific class library, it will run only on that operating system.
При JIT-компиляции учитывается возможность того, что определенный код может никогда не вызываться во время выполнения.JIT compilation takes into account the possibility that some code might never be called during execution. Чтобы не тратить время и память на преобразование всего содержащегося в PE-файле MSIL в машинный код, при компиляции MSIL преобразуется в машинный код по мере необходимости во время выполнения. Полученный таким образом машинный код сохраняется в памяти, что позволяет использовать его при дальнейших вызовах в контексте этого процесса.Instead of using time and memory to convert all the MSIL in a PE file to native code, it converts the MSIL as needed during execution and stores the resulting native code in memory so that it is accessible for subsequent calls in the context of that process. Загрузчик создает и присоединяет заглушки к каждому методу в типе, когда тип загружается и инициализируется. The loader creates and attaches a stub to each method in a type when the type is loaded and initialized. При первом вызове метода заглушка передает управление JIT-компилятору, который преобразует MSIL для этого метода в машинный код и заменяет заглушку на созданный машинный код.When a method is called for the first time, the stub passes control to the JIT compiler, which converts the MSIL for that method into native code and modifies the stub to point directly to the generated native code. Поэтому последующие вызовы метода, скомпилированного с помощью JIT-компилятора, ведут непосредственно к машинному коду.Therefore, subsequent calls to the JIT-compiled method go directly to the native code.
The loader creates and attaches a stub to each method in a type when the type is loaded and initialized. При первом вызове метода заглушка передает управление JIT-компилятору, который преобразует MSIL для этого метода в машинный код и заменяет заглушку на созданный машинный код.When a method is called for the first time, the stub passes control to the JIT compiler, which converts the MSIL for that method into native code and modifies the stub to point directly to the generated native code. Поэтому последующие вызовы метода, скомпилированного с помощью JIT-компилятора, ведут непосредственно к машинному коду.Therefore, subsequent calls to the JIT-compiled method go directly to the native code.
Создание кода во время установки с помощью NGen.exeInstall-Time Code Generation Using NGen.exe
Тот факт, что JIT-компилятор преобразует MSIL-код сборки в машинный код при вызове отдельных методов, определенных в этой сборке, отрицательно сказывается на производительности во время выполнения. Because the JIT compiler converts an assembly’s MSIL to native code when individual methods defined in that assembly are called, it affects performance adversely at run time. В большинстве случаев снижение производительности приемлемо.In most cases, that diminished performance is acceptable. Что более важно, код, созданный JIT-компилятором, будет привязан к процессу, вызвавшему компиляцию.More importantly, the code generated by the JIT compiler is bound to the process that triggered the compilation. Его нельзя сделать общим для нескольких процессов.It cannot be shared across multiple processes. Чтобы созданный код можно было использовать в нескольких вызовах приложения или в нескольких процессах, которые совместно используют набор сборок, среда CLR предоставляет режим предварительной компиляции.To allow the generated code to be shared across multiple invocations of an application or across multiple processes that share a set of assemblies, the common language runtime supports an ahead-of-time compilation mode.
Because the JIT compiler converts an assembly’s MSIL to native code when individual methods defined in that assembly are called, it affects performance adversely at run time. В большинстве случаев снижение производительности приемлемо.In most cases, that diminished performance is acceptable. Что более важно, код, созданный JIT-компилятором, будет привязан к процессу, вызвавшему компиляцию.More importantly, the code generated by the JIT compiler is bound to the process that triggered the compilation. Его нельзя сделать общим для нескольких процессов.It cannot be shared across multiple processes. Чтобы созданный код можно было использовать в нескольких вызовах приложения или в нескольких процессах, которые совместно используют набор сборок, среда CLR предоставляет режим предварительной компиляции.To allow the generated code to be shared across multiple invocations of an application or across multiple processes that share a set of assemblies, the common language runtime supports an ahead-of-time compilation mode. В таком режиме компиляции для преобразования сборок MSIL в машинный код в стиле JIT-компилятора используется генератор образов в машинном коде (Ngen.exe).This ahead-of-time compilation mode uses the Ngen.exe (Native Image Generator) to convert MSIL assemblies to native code much like the JIT compiler does. Однако, работа Ngen.exe отличается от JIT-компилятора в трех аспектах.However, the operation of Ngen.exe differs from that of the JIT compiler in three ways:
В таком режиме компиляции для преобразования сборок MSIL в машинный код в стиле JIT-компилятора используется генератор образов в машинном коде (Ngen.exe).This ahead-of-time compilation mode uses the Ngen.exe (Native Image Generator) to convert MSIL assemblies to native code much like the JIT compiler does. Однако, работа Ngen.exe отличается от JIT-компилятора в трех аспектах.However, the operation of Ngen.exe differs from that of the JIT compiler in three ways:
Ngen.exe выполняет преобразование из MSIL-кода в машинный код перед выполнением приложения, а не во время его выполнения.It performs the conversion from MSIL to native code before running the application instead of while the application is running.
При этом сборка компилируется целиком, а не по одному методу за раз.It compiles an entire assembly at a time, instead of one method at a time.
Она сохраняет созданный код в кэше образа машинного кода в виде файла на диске.It persists the generated code in the Native Image Cache as a file on disk.
Проверка кодаCode Verification
В процессе компиляции в машинный код MSIL-код должен пройти проверку, если только администратор не установил политику безопасности, разрешающую пропустить проверку кода.As part of its compilation to native code, the MSIL code must pass a verification process unless an administrator has established a security policy that allows the code to bypass verification. MSIL-код и метаданные проверяются на типобезопасность. Это подразумевает, что код должен обращаться только к тем адресам памяти, к которым ему разрешен доступ.Verification examines MSIL and metadata to find out whether the code is type safe, which means that it accesses only the memory locations it is authorized to access. Типобезопасность помогает изолировать объекты друг от друга и способствует их защите от непредумышленного или злонамеренного повреждения.Type safety helps isolate objects from each other and helps protect them from inadvertent or malicious corruption. Она также гарантирует надежное применение условий безопасности для кода. It also provides assurance that security restrictions on code can be reliably enforced.
It also provides assurance that security restrictions on code can be reliably enforced.
Среда выполнения основывается на истинности следующих утверждений для поддающегося проверке типобезопасного кода:The runtime relies on the fact that the following statements are true for code that is verifiably type safe:
ссылка на тип строго совместима с адресуемым типом;A reference to a type is strictly compatible with the type being referenced.
для объекта вызываются только правильно определенные операции;Only appropriately defined operations are invoked on an object.
удостоверения являются подлинными.Identities are what they claim to be.
В процессе проверки кода MSIL делается попытка подтвердить, что код может получать доступ к расположениям в памяти и вызывать методы только через правильно определенные типы.During the verification process, MSIL code is examined in an attempt to confirm that the code can access memory locations and call methods only through properly defined types. Например, код не должен разрешать доступ к полям объекта так, чтобы можно было выходить за границы расположения в памяти.For example, code cannot allow an object’s fields to be accessed in a manner that allows memory locations to be overrun. Кроме того, проверка определяет, правильно ли был создан код MSIL, поскольку неверный код MSIL может приводить к нарушению правил строгой типизации.Additionally, verification inspects code to determine whether the MSIL has been correctly generated, because incorrect MSIL can lead to a violation of the type safety rules. В процессе проверки передается правильно определенный типобезопасный код.The verification process passes a well-defined set of type-safe code, and it passes only code that is type safe. Однако иногда типобезопасный код может не пройти проверку из-за ограничений процесса проверки, а некоторые языки по своей структуре не позволяют создавать поддающийся проверке типобезопасный код.However, some type-safe code might not pass verification because of some limitations of the verification process, and some languages, by design, do not produce verifiably type-safe code.
Например, код не должен разрешать доступ к полям объекта так, чтобы можно было выходить за границы расположения в памяти.For example, code cannot allow an object’s fields to be accessed in a manner that allows memory locations to be overrun. Кроме того, проверка определяет, правильно ли был создан код MSIL, поскольку неверный код MSIL может приводить к нарушению правил строгой типизации.Additionally, verification inspects code to determine whether the MSIL has been correctly generated, because incorrect MSIL can lead to a violation of the type safety rules. В процессе проверки передается правильно определенный типобезопасный код.The verification process passes a well-defined set of type-safe code, and it passes only code that is type safe. Однако иногда типобезопасный код может не пройти проверку из-за ограничений процесса проверки, а некоторые языки по своей структуре не позволяют создавать поддающийся проверке типобезопасный код.However, some type-safe code might not pass verification because of some limitations of the verification process, and some languages, by design, do not produce verifiably type-safe code. Если в соответствии с политикой безопасности использование типобезопасного кода является обязательным и код не проходит проверку, то при выполнении кода создается исключение.If type-safe code is required by the security policy but the code does not pass verification, an exception is thrown when the code is run.
Если в соответствии с политикой безопасности использование типобезопасного кода является обязательным и код не проходит проверку, то при выполнении кода создается исключение.If type-safe code is required by the security policy but the code does not pass verification, an exception is thrown when the code is run.
ВверхBack to top
Выполнение кодаRunning Code
Среда CLR предоставляет инфраструктуру, обеспечивающую управляемое выполнение кода, и ряд служб, которые можно использовать при выполнении.The common language runtime provides the infrastructure that enables managed execution to take place and services that can be used during execution. Перед выполнением метода его необходимо скомпилировать в код для конкретного процессора.Before a method can be run, it must be compiled to processor-specific code. Каждый метод, для которого создан MSIL-код, компилируется с помощью JIT-компилятора при первом вызове и затем запускается.Each method for which MSIL has been generated is JIT-compiled when it is called for the first time, and then run. При следующем вызове метода будет выполняться существующий JIT-скомпилированный код.The next time the method is run, the existing JIT-compiled native code is run. Процесс JIT-компиляции и последующего выполнения кода повторяется до завершения выполнения.The process of JIT-compiling and then running the code is repeated until execution is complete.
При следующем вызове метода будет выполняться существующий JIT-скомпилированный код.The next time the method is run, the existing JIT-compiled native code is run. Процесс JIT-компиляции и последующего выполнения кода повторяется до завершения выполнения.The process of JIT-compiling and then running the code is repeated until execution is complete.
Во время выполнения для управляемого кода доступны такие службы, как сборка мусора, обеспечение безопасности, взаимодействие с неуправляемым кодом, поддержка отладки на нескольких языках, а также поддержка расширенного развертывания и управления версиями.During execution, managed code receives services such as garbage collection, security, interoperability with unmanaged code, cross-language debugging support, and enhanced deployment and versioning support.
В Microsoft Windows Vista загрузчик операционной системы выполняет поиск управляемых модулей, анализируя бит в заголовке COFF.In Microsoft Windows Vista, the operating system loader checks for managed modules by examining a bit in the COFF header. Установленный бит обозначает управляемый модуль.The bit being set denotes a managed module. При обнаружении управляемых модулей загружается библиотека Mscoree.dll, а подпрограммы
Установленный бит обозначает управляемый модуль.The bit being set denotes a managed module. При обнаружении управляемых модулей загружается библиотека Mscoree.dll, а подпрограммы _CorValidateImage и _CorImageUnloading уведомляют загрузчик о загрузке и выгрузке образов управляемых модулей.If the loader detects managed modules, it loads mscoree.dll, and _CorValidateImage and _CorImageUnloading notify the loader when the managed module images are loaded and unloaded. Подпрограмма_CorValidateImage выполняет следующие действия:_CorValidateImage performs the following actions:
Проверяет, является ли код допустимым управляемым кодом.Ensures that the code is valid managed code.
Заменяет точку входа в образе на точку входа в среде выполнения.Changes the entry point in the image to an entry point in the runtime.
В 64-разрядных системах Windows _CorValidateImage изменяет образ, находящийся в памяти, путем преобразования его из формата PE32 в формат PE32+. On 64-bit Windows,
On 64-bit Windows, _CorValidateImage modifies the image that is in memory by transforming it from PE32 to PE32+ format.
ВверхBack to top
См. также разделSee also
Этапы компиляции и компоновки программ на языке C++
Вы когда-нибудь задумывались над тем, как именно создаются исполняемые файлы с расширением .exe из исходных кодов? Какова роль компилятора и компоновщика? В этой очень короткой заметке, я опишу этот процесс очень просто, не вдаваясь в подробности его реализации.
Объединенная единым алгоритмом совокупность описаний и операторов образует программу на алгоритмическом языке. Для того чтобы выполнить программу, требуется перевести ее на язык, понятный процессору — в машинные коды. Этот процесс состоит из нескольких этапов. Рисунок ниже иллюстрирует эти этапы для языка С++.
Этапы создания исполняемой программы на C++
Сначала программа передается препроцессору, который выполняет директивы, содержащиеся в ее тексте (например, включение в текст так называемых заголовочных файлов — текстовых файлов, в которых содержатся описания используемых в программе элементов).
Получившийся полный текст программы поступает на вход компилятора, который выделяет лексемы, а затем на основе грамматики языка распознает выражения и операторы, построенные из этих лексем. При этом компилятор выявляет синтаксические ошибки и в случае их отсутствия строит объектный модуль.
Компоновщик, или редактор связей, формирует исполняемый модуль программы, подключая к объектному модулю другие объектные модули, в том числе содержащие функции библиотек, обращение к которым содержится в любой программе (например, для осуществления вывода на экран). Если программа состоит из нескольких исходных файлов, они компилируются по отдельности и объединяются на этапе компоновки. Исполняемый модуль имеет расширение .ехе и запускается на выполнение обычным образом.
Таким образом создаются исполняемые программы на C++. Конечно это очень общее описание этого сложного процесса, но четко передает смысл всех этапов работы компилятора и компоновщика.
По материалам книги «Программирование на языке высокого уровня CC++», Павловская Т. А.
А.
Понятие компиляции в информатике
Определение 1
Компиляция в информатике — это формирование программы, которое включает транслирование всех программных модулей.
Введение
Под компиляцией понимаются процессы, которые облегчают диалог специалиста по написанию программ и компьютера. Формируя на этапе завершения свою программу, каждый программист вынужден использовать программу компиляции. В техническом описании эта программа занимает очень скромное место и определяется как утилита, которая осуществляет компиляцию. Компиляцией является операция преобразования программного приложения, которое выполнено на известном людям языке (определяется как язык высокого уровня), в команды языка низкого уровня, которые понимает компьютер. В итоге получается программа, приближённая к машинным кодам. Программа имеет вид объектного модуля или абсолютного кода. В отдельных случаях эта программа может походить на команды ассемблера. То есть, компиляцией является преобразование входных данных (исходного кода), описывающих некий алгоритм, выполненный на проблемном языке, в выбранный набор команд объектного кода (машинный язык).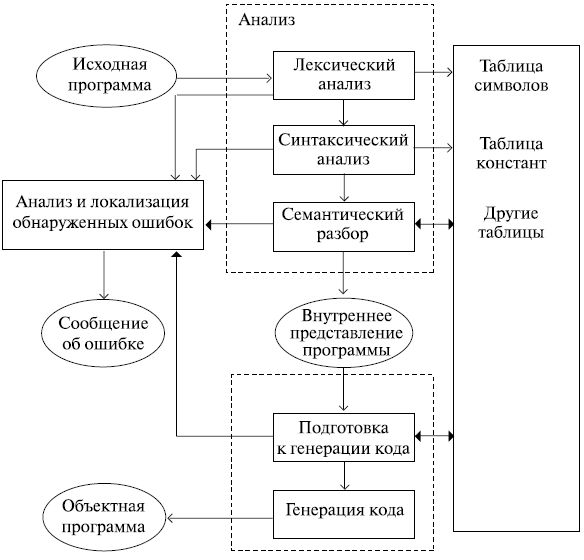
Если сформулировать более коротко, то процесс компиляции — это трансляция программы из проблемно-ориентированного языка в машинно-ориентированный. Это простая и прозрачная формулировка, но на самом деле процесс компиляции представляется очень многоплановым.
Компиляция в информатике
Есть различные виды компиляции:
- Компиляция пакетного типа. Она преобразует сразу несколько исходных модулей в едином комплекте.
- Компиляция построчного типа. Аналог интерпретации, то есть пошаговой независимой компиляции всех следующих операторов.
- Условная компиляция, при которой преобразование исходного текста зависит от заданных исходных условий с помощью директив компилятора. То есть путём изменения величины некоторых констант, возможно отключать или наоборот включать преобразование участков исходной программы.
Чтобы программистам было удобно решать разнообразные задачи, можно выбрать наиболее подходящий для данного случая компилятор. Если же выполнить подробную классификацию компиляторов, то возможно определить некоторое количество аналогичных утилит:
- Векторный компилятор. Выполняет перевод входных данных в машинный код, при этом выполняя подстройку под векторные процессоры.
- Гибкий компилятор. Базируется на модульном принципе и управляется при помощи таблиц. Его программа выполнена на языке высокого уровня и имеется возможность реализовать его посредством компилятора компиляторов.
- Инкрементальный компилятор. Выполняет вторичное преобразование компонентов исходной программы и приложений к ней, не делая перекомпиляцию всей программы.
- Компилятор пошаговый или выполняющий интерпретацию. Применяет методику поочерёдного проведения самостоятельной компиляции любого выбранного процесса исходного модуля.
- Компилятор компиляторов. Программа трансляции, воспринимающая формализованное представление языка программирования. У него имеется возможность самому сформировать необходимый компилятор для выбранного программного языка.
- Компилятор отладки. Способен выявить и устранить различные типы синтаксических ошибок.
- Резидентный компилятор. Имеет своё фиксированное расположение в оперативной памяти и может повторно применяться обширным диапазоном задач.
- Компилятор самокомпилируемый. Он формируется на том же языке, что и транслируемая программа. Это универсальный компилятор, в котором заложены семантика и синтаксис исходного языка. В его состав входят ядро, семантический и синтаксический загрузчики.
Наиболее часто встречаются задачи компиляции ядра для операционной системы Linux. Эта процедура способна разрешить обширный круг задач, которые связаны с привязкой аппаратного обеспечения и адаптации оптимальной версии операционной системы. При компиляции Java возможно применение компиляторов, которые работают под самыми разными платформами. Это даёт возможность перекомпиляции исходных кодов под нужды различных операционных систем разных брендов.
Структурное построение компилятора
В процессе выполнения компиляции, реализуются следующие этапы:
- Анализ лексики. Выполняется преобразование символики исходной программы в набор лексем (абстрактных единиц).
- Анализ синтаксиса (грамматики). Выполняется преобразование набора лексем в дерево разбора.
- Анализ семантики. Выполняется обработка дерева разбора для определения его смысловых значений (семантики). Это может быть процесс привязки идентификаторов к их видам, определение совместимости т так далее. В итоге формируется промежуточное представление (код), и возможно формирование дополненного дерева разбора или даже нового дерева. Возможно так же формирование абстрактного набора команд, удобного для последующего применения.
- Повышение оптимальности. Удаляются лишние образования и формируется упрощённый код без смысловых потерь. Процесс оптимизации возможно осуществлять на различных этапах. К примеру, можно оптимизировать промежуточный или окончательный машинный код.
- Процесс генерации кода. Выполняется трансформация промежуточных представлений в коды конечного языка.
Замечание 1
Для разных типов компиляторов возможно подразделение или совмещение данных этапов в различных вариациях.
Трансляция и компоновка
Следует отметить один важный исторический момент. На ранних стадиях своего развития, компилятор имел возможность выполнять не только трансляцию, но также и компоновку программы. Он состоял из двух составляющих, собственно транслятора и компоновщика. Это можно объяснить тем обстоятельством, что отделение компиляции от компоновки, как отдельного этапа, произошло гораздо позднее разработки компиляции. Но и сегодня во многих известных компиляторах есть физическое объединение с компоновщиками. По этой причине, терминология «компилятор» иногда заменяется словом «транслятор», которое является фактически синонимом.
Как происходит компиляция приложений на Android?
Ваш код написан к примеру на Java (Это более частый случай). Каждое Android-приложение состоит из компонентов. Компоненты реализованы в виде Java-классов.
Например, Activity в Android представляет экран или часть экрана устройства пользователя. Это экземпляр класса Java с именем Android.app.Activity.
Другим примером является элемент пользовательского интерфейса Button. Кнопка в приложении Android — это экземпляр класса Java с именем Android.widget.Button.
1. Компиляторы Android (DALVIK vs ART)
Ваш исходный код компилируется стандартным компилятором Java, который использует модель компиляции JIT-Just-In-Time. Как только код скомпилирован, он становится байт-кодом (с расширением «.class»). Этот код идет на второй раунд компиляции (опять-таки к байт-коду — но на этот раз он свернут). Байт-код исполняется с помощью JVM для конкретных целей (виртуальная машина Java), которая является средой выполнения для Java. Но для Android у нас есть две разные виртуальные машины:
DALVIK
До ART (который был представлен с выпуском Android 4.4, то есть Kitkat), средой выполнения для приложений Android была DALVIK. У DALVIK был один существенный недостаток — это было МЕДЛЕННО!
Пользователям было неприятно использовать свои приложения на своих устройствах, поскольку приложения зависали во время работы.
Dalvik использует модель компиляции JIT. JIT-компилятор компилирует приложение, когда они открываются пользователями (процедура запуска приложения). Таким образом, это замедляло открытие приложений и, в свою очередь, затрудняло работу пользователя.
ART
ART использует опережающую модель компиляции, которая компилирует приложения в машинный код после установки
Приложения работают немного быстрее! в рамках ART время запуска приложений сокращается.
Он также улучшил сборку мусора, так что пользователь видит меньше пауз и заиканий в среде с низким объемом памяти. АРТ имеет свои ограничения:
- Проблема со временем установки: Процесс установки медленный с ART, поскольку преобразование приложений в машинный код занимает много времени.
- Проблема размера: компиляция кода после установки означает, что приложение должно «жить» на вашем устройстве. Таким образом, для относительно меньшего Java-кода машина или байт-код будут сравнительно большими.
Вот тут обсуждают что лучше Dalvik или ART.
2. Процесс компиляции Android
2.1. Из исходного кода в байт-код
Вам понадобится JDK (Java Developer Kit) для компиляции кода Java вашего приложения.
Ваш код и предварительно скомпилированные классы из среды выполнения и пользовательских библиотек сначала компилируются Javac (JIT Compiler / Standard Java Compiler).
Javac выводит набор файлов байт-кода Java. Пока это выглядит как любой процесс компиляции Java, но следующий шаг компиляции делает процесс компиляции уникальным для Android.
2.2. Обфускатор (ProGuard инструмент)
Этот шаг не является обязательным, вы можете пропустить этот шаг, если хотите.
Инструмент ProGuard берет файлы байт-кода Java (выводится как шаг № 1) и отправляет их через инструмент с именем ProGuard. Это сведет к минимуму и запутает (то есть — сделает неясным, неясным или неразборчивым) ваш код.
По умолчанию он отключен в новых проектах Android, но когда ProGuard включен, он анализирует ваш код и удаляет реализации методов, например, которые не вызываются.
Это может значительно сократить ваш пакет распространяемого приложений. Он также запутывает ваш код, изменяя имена методов и так усложняя декомпиляцию упакованного Java-кода третьим лицом или организацией.
Независимо от использования ProGuard вы снова получите файлы .class (минимизированный байт-код).
2.3. От минимизированного байт-кода до кода dex
Следующим шагом является получение выходных файлов из шага № 2 и преобразование этих файлов в байт-код dex — Dalvik EXecutable (.DEX).
Байт-код DEX — это формат, оптимизированный для Android, который может быть выполнен в более старой среде выполнения DALVIK или более новой среде выполнения ART.
2.4. Исполнение машинного кода
Во время выполнения устройства считывают эти файлы dex (вывод шага № 3) и перекомпилируют некоторые файлы в машинный код для максимально быстрого выполнения.
В DALVIK этот шаг происходит, когда приложение работает с использованием архитектуры Just-In-Time или JIT.
В более новой версии ART перекомпиляция (или перевод в машинный код) происходит при первой установке приложения, что означает, что приложение может работать быстрее, когда пользователь запускает его на своем устройстве.
И вот как ваш код Java превращается во что-то, что работает на Android. Он начинается с Java и через пару шагов превращается в то, что может прочитать и выполнить среда выполнения Android.
Вот еще есть иллюстрация:
Вот ссылки после исследования вопроса. Некоторые были использованы для построения этого вопроса: ссылка_1 и ссылка_2. А вот и первоисточник этого ответа. Данная информация находится в полностью свободном доступе 🙂 Надеюсь вам стало немного понятнее как именно компилируются приложения.
Компиляция — Разработка программ — Справка по MetaEditor
Компиляция — это процесс перевода исходного кода MQL4/MQL5-программы на машинный язык. Ее результатом является создание исполняемого файла программы (*EX4 или *.EX5), который может быть запущен в торговой платформе.
Компиляция состоит из нескольких этапов:
- Лексический анализ
- Синтаксический анализ
- Семантический анализ
- Генерация кода
- Оптимизация кода
|
Чтобы получить исполняемый файл программы, откройте основной исходный файл или проект через «Навигатор», а затем нажмите » Компилировать» в меню «Файл» или «F7». Протокол процесса компиляции будет отображен на вкладке «Ошибки» в окне «Инструменты». Если компиляция прошла без ошибок, вы можете запустить полученную программу в торговой платформе.
Если в процессе компиляции возникли ошибки или предупреждения, их описание будет показано на вкладке «Ошибки».
Ошибки компиляции обозначаются иконками как на вкладке «Ошибки», так и в самом коде при переходе к ним. При их возникновении исполняемый файл программы (*EX4 или *.EX5) не создастся. Чтобы перейти к строке, где возникла ошибка, дважды щелкните мышью на ошибке или нажмите » Перейти к строке» в контекстном меню. Номер строки и столбца, где была найдена ошибка, показываются в соответствующих колонках.
Предупреждения, обозначаемые иконкой , указывают на места возможного появления ошибок. То есть компилятор обращает внимание на те места исходного кода, которые могли быть неверно интерпретированы (например, неявная смена типа значения). Перейти к такой строке в коде можно точно так же, как и в случае с ошибками.
Иконками помечаются различные информационные сообщения. Например, сообщения о включаемых файлах, к которым обращалась программа при компиляции.
|
Методы коррекции профильной информации в процессе компиляции | Четверина
1. Chang P. P., Mahlke S. A., Hwu W. W. Using profile information to assist classic compiler code optimizations. Software Practice and Experience, V. 21, No12. -1991.-P. 1301-1321
2. W. Chen, R. Bringmann, S. Mahlke, S. Anik, T. Kiyohara, N. Warter, D. Lavery, W. -M. Hwu, R. Hank and J. Gyllenhaal., Using profile information to assist advanced compiler optimization and scheduling, 1993
3. Jan Hunicka, Profile driven optimisations in GCC, Proceedings of the GCC Developers’ Summit June 22nd-24th, 2005, Ottawa, Ontario Canada
4. Волконский В. Ю., Ермолицкий А. В., Ровинский Е. В. Развитие метода векторизации циклов при помощи оптимизирующего компилятора. Высокопроизводительные вычислительные системы и микропроцессоры: сборник трудов ИМВС РАН, Выпуск N8, 2005.
5. Dmitry M Maslennikov, Vladimir Y Volkonsky: Compiler method and apparatus for elimination of redundant speculative computations from innermost loops. Elbrus International October 9, 2001: US06301706
6. Pengfei Yuan, Yao Guo , Xiangqun Chen, Experiences in profile-guided operating system kernel optimization, Proceedings of 5th Asia-Pacific Workshop on Systems, June 25-26, 2014, Beijing, China
7. Bo Wu, Mingzhou Zhou, Xipeng Shen, Yaoqing Gao, Raul Silvera, Graham Yiu, Simple profile rectifications go a long way, Proceedings of the 27th European conference on Object-Oriented Programming, July 01-05, 2013, Montpellier, France
8. Дроздов А.Ю., Степаненков А.М. Технология оптимизации цикловых участков процедур в компиляторах для архитектур с аппаратной поддержкой конвейризации циклов. Информационные технологии и вычислительные системы №3, М. 2004
9. Иванов Д.С. Распределение регистров при планировании инструкций для VLIW-архитектур. Программирование, № 6, 2010, С.74-80
10. Bo Wu, Zhijia Zhao, Xipeng Shen, Yunlian Jiang, Yaoqing Gao, Raul Silvera, Exploiting inter-sequence correlations for program behavior prediction, Proceedings of the ACM international conference on Object oriented programming systems languages and applications, October 19-26, 2012, Tucson, Arizona, USA [doi>10.1145/2384616.2384678]
11. Calin Cascaval , Luiz De Rose , David A. Padua , Daniel A. Reed, Compile-Time Based Performance Prediction, Proceedings of the 12th International Workshop on Languages and Compilers for Parallel Computing, p.365-379, August 04-06, 1999
12. Jeremy Lau , Matthew Arnold , Michael Hind , Brad Calder, Online performance auditing: using hot optimizations without getting burned, Proceedings of the 2006 ACM SIGPLAN conference on Programming language design and implementation, June 11-14, 2006, Ottawa, Ontario, Canada
13. Ананий В. Левитин. Алгоритмы: введение в разработку и анализ — М.: «Вильямс», 2006.- С. 220-224. — ISBN 5-8459-0987-2
14. Steven S. Muchnick, Advanced Compiler Design & Implementation, 2003
15. Introduction to algorithms, Third Edition, Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, Clifford Stein, 2009
16. Alfred V. Aho, Monica S. Lam, Ravi Sethi, and Jeffrey D. Ullman «Compilers: Principles, Techniques, and Tools» Book, Pearson Education, ISBN 0-321-48681-1, 2006
Процесс компиляции. Многие из нас пишут коды и выполняют… | Сибасиш Гош | Coding Den
Многие из нас пишут коды и исполняют их. Но все ли мы (ну, в основном новички, я думаю: P) знаем основной процесс, который преобразует исходный код в исполняемую программу? Думаю, не много. Что ж, эта статья для всех тех Not-Many , которые ищут секрет;)
Image Source — worldcomputerar article«Программисты пишут программы в форме, называемой исходным кодом.Исходный код должен пройти несколько этапов, прежде чем он станет исполняемой программой. Первым шагом является передача исходного кода через компилятор , который переводит инструкции языка высокого уровня в объектный код. Компоновщик объединяет модули и дает реальные значения всем символьным адресам, тем самым создавая машинный код ».
Вышеупомянутые строки объясняют весь процесс компиляции. Итак, в основном у вас есть программа, называемая исходным кодом , , которая должна пройти процесс компиляции для получения вывода с помощью исполняемой программы .
Итак, если есть процесс «компиляции», должен быть инструмент для выполнения этой работы. Да, есть одна такая вещь, известная под названием компилятор . Теперь давайте посмотрим, что такое компилятор.
Источник изображения — CraftingInterpretersКомпилятор — это специальная программа, которая обрабатывает операторы, написанные на определенном языке программирования, и превращает их в машинный язык или «код», который использует процессор компьютера. Обычно программист пишет операторы языка на языке, таком как Паскаль или Си, по одной строке за раз, используя редактор .Созданный файл содержит так называемые исходные операторы . Затем программист запускает компилятор соответствующего языка, указывая имя файла, содержащего исходные операторы.
При выполнении (запуске) компилятор сначала анализирует (или анализирует) все операторы языка синтаксически один за другим, а затем, на одном или нескольких последовательных этапах или «проходах», строит выходной код, проверяя, что операторы, которые ссылаться на другие операторы правильно упоминаются в окончательном коде.Традиционно выходные данные компиляции назывались объектным кодом или иногда объектным модулем . Объектный код — это машинный код, который процессор может выполнять по одной инструкции за раз.
Традиционно в некоторых операционных системах после компиляции требовался дополнительный этап — определение относительного расположения инструкций и данных, когда одновременно должно было выполняться более одного объектного модуля, и они перекрестно ссылались на последовательности инструкций друг друга. или данные.Этот процесс иногда назывался редактирования связей , а результат — как модуль загрузки .
Компилятор работает с так называемыми 3GL и языками более высокого уровня. Ассемблер работает с программами, написанными на языке ассемблера процессора.
(Источник — WhatIs )
Существуют определенные языки программирования, которые не компилируют исходный код. Так можно ли их казнить? К счастью или к сожалению, это вполне возможно.Ответ — с помощью переводчиков.
В информатике интерпретатор — это компьютерная программа, которая непосредственно выполняет, т. Е. выполняет инструкций, написанных на языке программирования или сценариях, не требуя их предварительной компиляции в программу на машинном языке. Интерпретатор обычно использует одну из следующих стратегий для выполнения программы:
1. Анализировать исходный код и напрямую выполнять его поведение;
2.Преобразуйте исходный код в какое-нибудь эффективное промежуточное представление и немедленно выполните его;
3. Явно выполнить сохраненный предварительно скомпилированный код, созданный компилятором, который является частью системы интерпретатора.
Ранние версии языка программирования Lisp и Dartmouth BASIC будут примерами первого типа. Perl, Python, MATLAB и Ruby являются примерами второго типа, а UCSD Pascal — примером третьего типа.
(Источник — Википедия )
Хорошо, я закончил большую часть теоретической части.Чтобы понять, как это работает на самом деле, давайте воспользуемся помощью известного языка программирования — C ++.
Компиляция программы на C ++ включает три этапа:
1. Предварительная обработка: препроцессор берет файл исходного кода C ++ и обрабатывает #include ’ s, #define’ s и другие директивы препроцессора. Результатом этого шага является «чистый» файл C ++ без директив препроцессора.
2. Компиляция: компилятор берет выходные данные препроцессора и создает из них объектный файл.
3. Связывание: компоновщик берет объектные файлы, созданные компилятором, и создает либо библиотеку, либо исполняемый файл.
1. Предварительная обработка Препроцессор обрабатывает директив препроцессора , например #include и #define . Он не зависит от синтаксиса C ++, поэтому его следует использовать с осторожностью.
Он работает с одним исходным файлом C ++ за раз, заменяя директивы #include содержимым соответствующих файлов (обычно это просто объявления), выполняя замену макросов ( #define ) и выбирая разные части текст в зависимости от директив #if , #ifdef и #ifndef .
Препроцессор работает с потоком токенов предварительной обработки. Макрозамена определяется как замена токенов другими токенами (оператор ## позволяет объединить два токена, когда это имеет смысл).
После всего этого препроцессор производит единственный вывод, который представляет собой поток токенов, полученных в результате преобразований, описанных выше. Он также добавляет некоторые специальные маркеры, которые сообщают компилятору, откуда взялась каждая строка, чтобы он мог использовать их для создания разумных сообщений об ошибках.
Некоторые ошибки могут возникнуть на этом этапе при грамотном использовании директив #if и #error .
2. Компиляция
Этап компиляции выполняется на каждом выходе препроцессора. Компилятор анализирует чистый исходный код C ++ (теперь без каких-либо директив препроцессора) и преобразует его в код сборки. Затем вызывает базовый сервер (ассемблер в инструментальной цепочке), который собирает этот код в машинный код, создавая фактический двоичный файл в некотором формате (ELF, COFF, a.из и т. д.). Этот объектный файл содержит скомпилированный код (в двоичной форме) символов, определенных во входных данных. Символы в объектных файлах называются по имени.
Объектные файлы могут ссылаться на символы, которые не определены. Это тот случай, когда вы используете декларацию и не даете ей определения. Компилятор не возражает против этого и с радостью создаст объектный файл, если исходный код правильно сформирован.
Обычно компиляторы позволяют остановить компиляцию на этом этапе. Это очень полезно, потому что с его помощью вы можете компилировать каждый файл исходного кода отдельно.Преимущество этого заключается в том, что вам не нужно перекомпилировать все , если вы изменяете только один файл.
Созданные объектные файлы могут быть помещены в специальные архивы, называемые статическими библиотеками, для облегчения повторного использования в дальнейшем.
Именно на этом этапе выявляются «обычные» ошибки компилятора, такие как синтаксические ошибки или ошибки с ошибками разрешения перегрузки.
3. Связывание
Компоновщик — это то, что производит окончательный вывод компиляции из объектных файлов, созданных компилятором.Этот вывод может быть либо разделяемой (или динамической) библиотекой (и, хотя название похоже, у них нет много общего со статическими библиотеками, упомянутыми ранее), либо исполняемым файлом.
Он связывает все объектные файлы, заменяя ссылки на неопределенные символы правильными адресами. Каждый из этих символов может быть определен в других объектных файлах или в библиотеках. Если они определены в библиотеках, отличных от стандартной, вам необходимо сообщить о них компоновщику.
На этом этапе наиболее распространенными ошибками являются отсутствие определений или дублирование определений.Первое означает, что либо определения не существуют (т.е. они не записаны), либо объектные файлы или библиотеки, в которых они находятся, не были переданы компоновщику. Последнее очевидно: один и тот же символ был определен в двух разных объектных файлах или библиотеках.
(Источник — stackoverflow )
Итак, в следующий раз, когда вы запустите код, помните, что это чертовски много основного процесса! Хорошего дня, amigos 🙂
Компиляция программы на C: — За кулисами
C — это язык среднего уровня, и ему нужен компилятор, чтобы преобразовать его в исполняемый код, чтобы программу можно было запускать на нашей машине.
Как скомпилировать и запустить программу C?
Ниже приведены шаги, которые мы используем на машине Ubuntu с компилятором gcc.
- Сначала мы создаем программу на языке C с помощью редактора и сохраняем файл как filename.c
$ vi filename.c
- На схеме справа показана простая программа для сложения двух чисел.
- Затем скомпилируйте его, используя команду ниже.
$ gcc –Настенное имя файла.c –o filename
- Параметр -Wall включает все предупреждающие сообщения компилятора. Этот вариант рекомендуется для создания лучшего кода.
Параметр -o используется для указания имени выходного файла. Если мы не используем эту опцию, то создается выходной файл с именем a.out.
- После создания исполняемого файла компиляции мы запускаем сгенерированный исполняемый файл, используя команду ниже.
$ ./filename
Что происходит внутри процесса компиляции?
Компилятор преобразует программу C в исполняемый файл.Чтобы программа C стала исполняемым файлом, существует четыре этапа:
- Предварительная обработка
- Компиляция
- Сборка
- Связывание
Выполнив команду ниже, мы получаем все промежуточные файлы в текущем каталоге вместе с исполняемым файлом. .
$ gcc –Wall –save-temps filename.c –o filename
На следующем снимке экрана показаны все сгенерированные промежуточные файлы.
Давайте по очереди посмотрим, что содержат эти промежуточные файлы.
Предварительная обработка
Это первая фаза, через которую проходит исходный код. Этот этап включает:
- Удаление комментариев
- Расширение макросов
- Расширение включенных файлов.
- Условная компиляция
Предварительно обработанный вывод сохраняется в имени файла .i . Давайте посмотрим, что находится внутри filename.i: using $ vi filename.i
В приведенном выше выводе исходный файл заполнен большим количеством информации, но в конце концов наш код сохраняется.
Анализ:
- printf теперь содержит a + b, а не добавляет (a, b), потому что макросы расширились.
- Комментарии удалены.
- #include
Компиляция
Следующим шагом является компиляция filename.i и создание файла; промежуточный скомпилированный выходной файл filename.с . Этот файл находится в инструкциях уровня сборки. Давайте посмотрим на этот файл, используя $ vi filename.s
Снимок показывает, что он написан на языке ассемблера, который ассемблер может понять.
Сборка
На этом этапе filename.s берется в качестве входных данных и преобразуется ассемблером в filename.o . Этот файл содержит инструкции машинного уровня. На этом этапе только существующий код преобразуется в машинный язык, вызовы функций, такие как printf (), не разрешаются.Давайте рассмотрим этот файл, используя $ vi filename.o
Связывание
Это заключительный этап, на котором выполняется связывание всех вызовов функций с их определениями. Компоновщик знает, где реализованы все эти функции. Компоновщик также выполняет некоторую дополнительную работу, он добавляет некоторый дополнительный код в нашу программу, который требуется при запуске и завершении программы. Например, есть код, который требуется для настройки среды, например, для передачи аргументов командной строки.Эту задачу можно легко проверить, используя $ size filename.o и $ size filename . С помощью этих команд мы знаем, как выходной файл увеличивается от объектного файла до исполняемого файла. Это из-за дополнительного кода, который компоновщик добавляет в нашу программу.
Обратите внимание, что GCC по умолчанию выполняет динамическое связывание, поэтому printf () динамически связан в вышеуказанной программе. Обратитесь к this, this и this для получения более подробной информации о статических и динамических связях.
Эта статья предоставлена Vikash Kumar .Пожалуйста, напишите комментарии, если вы обнаружите что-то неправильное, или вы хотите поделиться дополнительной информацией по теме, обсужденной выше.
шагов компиляции
Этапы компиляцииЭтапы компиляции
Исполняемый файл получается путем перевода и связывания как показано на рисунке 7.1.Для начала предварительная обработка заменяет определенные фрагменты текста другим текстом в соответствии с система макросы. Затем компиляция переводит исходную программу в сборку. инструкции, которые затем преобразованы в машинные инструкции. Наконец, процесс связывания устанавливает подключение к операционной системе для примитивов. Это включает добавление среды выполнения библиотека, которая в основном состоит из процедур управления памятью.
Исходная программа предварительная обработка Исходная программа составление Программа сборки сборка Машинные инструкции соединение Исполняемый код Рисунок 7.1: Этапы создания исполняемого файла.
Объективные компиляторы CAML
Этапы генерации кода компилятора Objective CAML подробно представлены на рисунке 7.2. Внутреннее представление сгенерированного кода. компилятором называется промежуточным языком (Иллинойс).Этап лексического анализа преобразует последовательность символов в последовательность лексический элементы. Эти лексические объекты соответствуют в основном целым числам, с плавающей запятой. числа символы, строки символов и идентификаторы. Сообщение Незаконное характер мог быть произведенным этим анализом.
Последовательность символов лексический анализ Последовательность лексических элементов парсинг Синтаксическое дерево семантический анализ Аннотированное синтаксическое дерево генерация промежуточного кода Последовательность IL оптимизация промежуточного кода Последовательность IL генерация псевдокода Программа сборки Рисунок 7.2: Этапы компиляции.
На этапе синтаксического анализа создается синтаксическое дерево и проверяется, что
последовательность лексических
elements является правильным с точки зрения грамматики языка. Сообщение Синтаксическая ошибка указывает на то, что анализируемая фраза не соответствует грамматике
язык.
Этап семантического анализа проходит по синтаксическому дереву, проверяя другое аспект корректности программы. Анализ состоит в основном из типа вывод, который в случае успеха дает наиболее общий тип выражения или объявления. Сообщения об ошибках типа могут появляться во время этот этап. На этом этапе также определяется, есть ли какие-либо члены последовательности не относятся к типу , элемент . Могут возникнуть другие предупреждения, в том числе анализ сопоставления с образцом (например, сопоставление с образцом не является исчерпывающим, часть сопоставления с образцом не будет использоваться).
Генерация и оптимизация промежуточного кода не производят сообщения об ошибках или предупреждения.
Последний шаг в процессе компиляции — создание программы. двоичный. Детали различаются от компилятора к компилятору.
Описание компилятора байт-кода
Виртуальная машина Objective CAML называется Zinc ( « Zinc Is Not Caml » ). Первоначально созданный Ксавье Леруа, Zinc описан в ([ Ler90 ]). Zinc было выбрано для указать его отличие от первой реализации Caml на виртуальной машине CAM (Категориальная абстрактная машина, см. [ CCM87 ]).На рисунке 7.3 изображен компилятор байт-кода. Первая часть этого рисунка показывает Машинный интерпретатор цинка, связанный с библиотекой времени выполнения. Вторая часть соответствует Объективный компилятор байт-кода CAML который производит инструкции для цинковой машины. Третья часть содержит набор библиотеки, поставляемые с компилятором.Они будут описаны в главе 8.
Стандартные графические обозначения компилятора используются для описания компонентов на рисунке 7.3. Простая рамка представляет собой файл записан на языке, указанном в поле. Двойная рамка представляет интерпретация язык программой, написанной на другом языке. Тройной прямоугольник указывает что источник язык компилируется на машинный язык с помощью компилятора, написанного в третьем язык.На рис. 7.4 показаны условные обозначения каждого блока.Рисунок 7.3: Виртуальная машина.
Легенда к рисунку 7.3 выглядит следующим образом:Рисунок 7.4: Графическая нотация для интерпретаторов и компиляторов.
- BC: байт-код цинка;
- C: код C;
- .o: код объекта
- : микропроцессор;
- OC (v1 или v2): Объективный код CAML.
Примечание
Большая часть компилятора Objective CAML написана на языке Objective CAML. В вторая часть рисунок 7.3 показано, как перейти от версии v1 компилятора к версия v2.
Процесс компиляции — обзор
6.4 Процесс компиляции CUDA
В этом разделе мы исследуем процесс компиляции программы CUDA в форму, которая может быть развернута на графическом процессоре. Инструмент драйвера компилятора nvcc, безусловно, делает процесс прозрачным для программиста, но во многих случаях глубокое знание этого процесса может быть полезным и / или важным.
Мы начинаем с изучения различных форматов файлов, которые обрабатываются или генерируются в процессе компиляции.Особенностью nvcc является то, что он не сможет обработать файл, не имеющий одного из распознанных файловых префиксов:
- •
.cu: исходные файлы для функций устройства и хоста. Начиная с CUDA 5.0, несколько файлов .cu могут быть частью проекта. Раньше весь код устройства нужно было помещать в один файл.
- •
.cc, .cpp, .cxx: исходный код C ++.
- •
.c: исходный код C.
- •
.h, .cuh: файлы заголовков.
- •
.o (Linux) ,. obj (Windows): объектные файлы. Это продукты процесса компиляции, и они служат входными данными на этапе компоновки.
- •
.a (Linux) .lib (Windows): файлы статических библиотек. На этапе компоновки статические библиотеки становятся искусством финального двоичного исполняемого файла.
- •
.so: файлы общих объектов или динамических библиотек. Они не встроены в исполняемые файлы.
- •
.gpu: промежуточный файл компиляции, содержащий только исходный код устройства.
- •
.cubin: двоичный файл CUDA, предназначенный для определенного графического процессора. Следует подчеркнуть, что Nvidia не сохраняет двоичную совместимость между семействами графических процессоров, поскольку это серьезно ограничит ее способность вводить новшества и создавать радикально новые разработки.
- •
.ptx: формат сборки портативного устройства. Перед выполнением код PTX должен быть скомпилирован с помощью JIT-компилятора JIT.Файлы PTX — это текстовые файлы.
Как можно заключить из предыдущего списка, исполняемый файл CUDA может существовать в двух формах: двоичной, которая может нацеливаться только на определенные устройства, и промежуточной сборки, которая может нацеливаться на любое устройство с помощью JIT-компиляции. В последнем случае ассемблер PTX (ptxas) выполняет компиляцию во время выполнения, добавляя издержки запуска, по крайней мере, во время первого вызова ядра.
Программа CUDA все еще может нацеливаться на разные устройства, встраивая несколько кубинов в один файл (называемый толстым двоичным файлом ).Соответствующий кубин выбирается во время выполнения.
На рис. 6.5 показан обобщенный обзор процесса компиляции с удаленными некоторыми шагами. Фактические шаги описаны (возможно, слишком подробно) в Справочном руководстве Nvidia nvcc (файл CUDA_Compiler_Driver_NVCC.pdf в $ {CUDA} / doc / pdf 11 ). На рисунке 6.5 представлена суть процесса, и это не однозначный учет всех задействованных этапов (Nvidia также заявляет, что процесс может изменяться между выпусками SDK).Заинтересованный читатель может подробно наблюдать за этой последовательностью, вызвав драйвер компилятора nvcc с переключателем -dryrun, заставляя только отображение, но не выполнение задействованных программ или инструментов и используемых параметров среды, как показано в следующем примере:
Рисунок 6.5. Общее представление о процессе компиляции CUDA. Два разных пути работают с кодом устройства и хоста, соответственно, перед финальной фазой связывания, на которой создается единственный исполняемый файл. Этапы помечены некоторыми наиболее важными действиями, выполняемыми ими.
$ nvcc — dryrun hello.cu
# $ _SPACE_ =
# $ _CUDART_ = cudart
# $ _HERE_ = / opt / cuda / bin
# $ _THERE_ = / opt / cuda / bin
_TARGET_SIZE_ = 64
# $ TOP = / opt / cuda / bin / ..
# $ LD_LIBRARY_PATH = / opt / cuda / bin /../ lib: / opt / ati — stream — sdk / lib / x86_64↩
: / opt / mpich3 / lib: / usr / lib / fglrx: / opt / ati — поток — sdk / lib / x86_64: / ↩
opt / intel /Compiler/11.0/083/ lib / intel64: / opt / cuda / lib64: / opt / cuda / ↩
lib: / opt / omnetpp / lib: / usr / l / checkout / gpuocelot / ocelot / build_local / ↩
lib
# $ PATH = / opt / cuda / bin /../ open64 / bin: / opt / cuda / bin /../nvvm:/ opt / cuda / ↩
bin: / usr / local / sbin: / usr / local / bin: / usr / sbin: / usr / bin: / sbin: / bin: /
usr / games: / opt / mpich3 / bin: / opt / cuda / bin: / opt / ibm / systemsim — cell /
bin: / opt / ibm / systemsim — cell / include / callthru / spu /: / opt / intel / ↩
Compiler / 11.0 / 083 / bin / intel64: / opt / omnetpp / bin: / usr / l / checkout / ↩
gpuocelot / ocelot / build_local / bin
# $ INCLUDES = «- I / opt / cuda / bin /../ include»
# $ LIBRARIES = «- L / opt / cuda / bin /../ lib64» — lcudart
# $ CUDAFE_FLAGS =
# $ OPENCC_FLAGS =
# $ PTXAS_FLAGS =
# $ НКУ — D__CUDA_ARCH__ = 100 — E — х с ++ — DCUDA_FLOAT_MATH_FUNCTIONS — ↩
DCUDA_NO_SM_11_ATOMIC_INTRINSICS — DCUDA_NO_SM_12_ATOMIC_INTRINSICS↩
— DCUDA_NO_SM_13_DOUBLE_INTRINSICS — D__CUDACC__ — D__NVCC__ «- I / ↩
opt / cuda / bin /../ include» — include «cuda_runtime.h» — m64 — o «/ tmp↩
ough00055_h53_h0000.cpp1. ii «» hough.cu «
# $ cudafe …
Процесс компиляции следует двумя разными путями: один для компиляции устройства, а другой для компиляции кода хоста. Они связаны в большем количестве мест, чем показано , как, например, в случае генерации функций хоста-заглушки. Эти функции вызываются при вызове ядра хостом для установки и запуска соответствующего кода устройства.
Как видно на рисунке 6.5 , CUDA может фактически встраивать в создаваемый исполняемый файл как кубинскую, так и PTX-версию кода устройства.На самом деле это поведение по умолчанию. Сложность заключается в том, что nvcc по умолчанию генерирует код, который соответствует спецификации вычислительных возможностей 1.0. Это может быть значительно неоптимальным, учитывая, что ряд важных операций, таких как поддержка арифметики с плавающей запятой двойной точности или множество атомарных операций, которые поддерживаются аппаратно более поздними версиями графического процессора (с более высокими вычислительными возможностями), принудительно выполняются. с помощью программного обеспечения в автоматически генерируемом коде.
nvcc принимает ряд параметров, управляющих генерацией кода. Мы уже видели, как один из них используется в примере «Hello World» в Разделе 6.2, чтобы разрешить использование printf из кода устройства. Наиболее важные из них:
- •
-arch: Управляет «виртуальной» архитектурой, которая будет использоваться для генерации кода PTX, т.е. управляет выводом команды nvopencc. Возможные значения этого параметра показаны в первом столбце Таблицы 6.4.
Таблица 6.4. Возможные значения для параметров -arch и -code команды nvcc
Виртуальная архитектура (-arch) Код многопроцессорной потоковой передачи (-code) Функция включена compute_10 sm_10 Базовые функции compute_11 sm_11 Атомарные операции глобальной памяти compute_12 sm_12 Атомарные операции с общей памятью и инструкции голосования 75 поддержка плавающей точки compute_20 sm_20 Поддержка Fermi sm_21 Изменения в структуре SM (например,g., больше ядер) compute_30 sm_30 Поддержка Kepler compute_35 sm_35 Динамический параллелизм (включает рекурсию) 90_331 поддержка вычислений - •
-code: Определяет фактическое устройство, на которое будет нацелен двоичный файл cubin, т. Е. Он управляет выводом команды ptxas. Возможные значения этого параметра показаны во втором столбце таблицы 6.4.
Как показано в таблице 6.4, нет точного однозначного соответствия между параметрами -arch и -code. Хотя первый позволяет использовать определенные возможности компилятором nvopencc, последний позволяет процессу компиляции адаптироваться (оптимизировать) к особенностям конкретного устройства и учитывать это во время генерации кубина.
Параметр -arch может принимать одно значение, но параметр -code может иметь список значений, и в этом случае кубин создается для каждой из указанных машин и внедряется в двоичный файл fat.Список значений параметра -code может включать одну виртуальную архитектуру, и в этом случае соответствующий код PTX также добавляется в двоичный файл fat. Очевидно, что архитектура, на которую нацелен -код, никогда не должна быть ниже вычислительных возможностей указанной виртуальной архитектуры. В противном случае компиляция не удастся.
Примеры:
- •
nvcc hello.cu -arch = compute_20 -code = sm_20, sm_30: этап генерации PTX включает в себя код вычислительных возможностей 2.0.Бинарный файл fat включает два кубина, один для sm_20 и один для sm_30 (но без PTX).
- •
nvcc hello.cu -arch = compute_20 -code = compute_20, sm_20, sm_30: То же, что и в предыдущем примере, с добавлением кода PTX в толстый двоичный файл.
- •
nvcc hello.cu -arch = compute_20 -code = sm_10, sm_20: не удается скомпилировать.
- •
nvcc hello.cu: Сокращение для nvcc hello.cu -arch = compute_10-code = compute_10, sm_10.
- •
nvcc hello.cu -arch = sm_20: Сокращение для nvcc hello.cu-arch = compute_20 -code = compute_20, sm_20.
- •
nvcc hello.cu -arch = compute_20 -code = compute_20: кубин не будет создан, так как ptxas не вызывается. Жирный двоичный файл будет содержать только версию кода PTX.
На платформах Linux nvcc по умолчанию использует компилятор GNU C / C ++ (gcc или g ++). В Windows по умолчанию используется версия компилятора Visual Studio C / C ++ (cl) для командной строки.Программа компилятора должна находиться в пути к исполняемому файлу. Альтернативные компиляторы можно протестировать с помощью параметра -compiler-bindir.
Модель компиляцииC и процессы
Как вы, , компилируете код C ? Как сделать исполняемые программы из файлов исходного кода C? В этом руководстве описывается базовая модель компиляции C и процессы, которые решают эти вопросы. Вы лучше поймете, как сделать исполняемый файл из файлов исходного кода C.
На следующем рисунке показана модель компиляции C.
Рассмотрим каждый компонент более подробно.
- Ввод процесса компиляции C — это файл исходного кода C, а его результат — исполняемый файл. Выход предыдущего компонента является входом следующего компонента.
- Препроцессор использует исходный код в качестве входных данных. Препроцессор отвечает за удаление всех комментариев и интерпретацию директив препроцессора, обозначенных знаком хеша
#. Например, в программе hello world директива#includeиспользуется для включения кода соответствующего файла e.g., стандартный файл ввода-вывода,stdio.h. Препроцессор включит исходный код в файлstdio.hв основную программу перед передачей его компилятору. - После обработки исходного кода препроцессором он передает результат компилятору C. . Компилятор C отвечает за перевод из простого исходного кода в код сборки. Мы используем компилятор gcc для перевода кода C в код ассемблера.
- Ассемблер отвечает за создание объектного кода.В системах Windows файлы объектного кода имеют расширение
.obj, а в системах UNIX файл объектного кода имеет расширение.o. - Если в файле исходного кода вы используете функции из библиотеки, редактор ссылок объединит эти функции с функцией
main (), чтобы создать исполняемый файл программы. Редактор ссылок иногда также известен как компоновщик .
Процесс компиляции кажется долгим. Если вы сами скомпилируете программу, потребуется время и больше усилий.Однако с хорошей IDE, такой как CodeBlocks, вы можете настроить все компоненты один раз, и IDE будет обрабатывать задачи автоматически одним нажатием кнопки.
Если вы хотите использовать другой компилятор C, чтобы программа C работала на определенной платформе, вы можете проверить его на странице со списком компиляторов C. Википедия.
- Было ли это руководство полезным?
- Да Нет
Процесс компиляции и выполнения программ C
Заметки по истории компьютеров — Учебные заметки Херонга
–1972 — Язык C, разработанный Деннисом Ричи
∟Процесс компиляции и выполнения программ на языке C
В этом разделе описаны этапы процесса компиляции и выполнения программ C: предварительная обработка, компиляция, сборка, компоновка и загрузка.
Процесс компиляции и выполнения C можно разделить на несколько этапов:
- Предварительная обработка — Использование программы препроцессора для преобразования исходного кода C в расширенный исходный код. Операторы «#includes» и «#defines» будут обработаны и заменены фактически исходными кодами на этом этапе.
- Компиляция — Использование программы компилятора для преобразования расширенного исходного кода C в исходный код сборки.
- Assembly — Использование программы на ассемблере для преобразования исходного кода сборки в объектный код.
- Связывание — Использование программы компоновщика для преобразования объектного кода в исполняемый код. На этом этапе несколько единиц объектных кодов связываются вместе.
- Загрузка — Использование программы загрузчика для загрузки исполняемого кода в ЦП для выполнения.
Вот простая таблица, показывающая ввод и вывод каждого шага в процессе компиляции и выполнения:
Входная программа Выход исходный код> препроцессор> расширенный исходный код расширенный исходный код> Компилятор> исходный код сборки ассемблерный код> Ассемблер> объектный код объектный код> компоновщик> исполняемый код исполняемый код> Загрузчик> выполнение
Вот примеры часто используемых программ для различных этапов компиляции и выполнения в системе Linux:
- «cpp привет.c -o hello.i «- препроцессор выполняет предварительную обработку hello.c и сохраняет вывод в hello.i.
- «cc1 hello.i -o hello.s» — Компилятор, компилирующий hello.i и сохраняющий вывод в hello.s.
- «as hello.s -o hello.o» — Ассемблер собирает hello.s и сохраняет вывод в hello.o.
- «ld hello.o -o hello» — компоновщик, связывающий hello.o и сохраняющий вывод в hello.
- «load hello» — Загрузчик загружает привет и запускает привет.
Содержание
Об этой книге
2002 -.NET Framework, разработанная Microsoft
1995 — PHP: препроцессор гипертекста, созданный Расмусом Лердорфом
1995 — Язык Java, разработанный Sun Microsystems
1991 — WWW (Всемирная паутина) Разработано Тимом Бернерсом-Ли
1991 — Протокол Gopher, созданный командой Университета Миннесоты
1984 — X Window System, разработанная командой MIT
1984 — Macintosh, разработанный Apple Inc.
1983 — Агент пересылки почты «Sendmail», разработанный Эриком Аллманом
1979 — Tcsh (оболочка TENEX C), разработанная Кеном Гриром
1978 — Bash (Bourne-Again Shell), разработанный Брайаном Фоксом
1978 — C Shell, разработанный Биллом Джоем
1977 — Оболочка Борна, разработанная Стивеном Борном
1977 — Apple II, разработанный Стивом Джобсом и Стивом Возняком
1976 — vi Текстовый редактор, разработанный Биллом Джоем
1974 — Интернет, Винтон Серф
►1972 — Язык C, разработанный Деннисом Ричи
Что такое язык C
TCC — Компилятор Tiny C
►Процесс компиляции и выполнения программ на языке C
Компилятор GNU C
Пример программы на языке C для массивов и указателей
Пример программы C для динамического распределения памяти — malloc ()
1971 — Протокол FTP, созданный Абхаем Бхушаном
1970 — Операционная система UNIX, разработанная AT&T Bell Labs
1957 — язык FORTRAN, разработанный IBM
Список литературы
Полная версия в PDF / EPUB
Лаборатория 2: Компиляция программ на языке C
«Вернуться к основному веб-сайту CS 131
Срок сдачи: 19 февраля 2020 г., 20:00.
До сих пор вам действительно не приходилось думать о том, как компилируются программы .В этой лабораторной работе мы подробно рассмотрим, как вы компилируете программы на C и как автоматизировать компиляцию в более крупных проектах, состоящих из нескольких исходных файлов.
Сегодня используются два основных компилятора C:
gcc(компилятор GNU C) иclang(новый компилятор из среды компилятора LLVM, который по большей части поддерживает более информативные сообщения об ошибках). На протяжении этой лабораторной работы вы будете использоватьgcc, чтобы почувствовать процесс компиляции, но не стесняйтесь использовать компиляторclangна протяжении всего курса.После перехода на C ++ вы будете работать сg ++иclang ++, которые являются эквивалентами этих компиляторов на C ++.Что такое компиляция?
Прежде чем мы перейдем к лабораторной работе, давайте обсудим, что значит компилировать программу в исполняемый файл. Прежде всего, что такое исполняемый файл ? Исполняемый файл — это особый тип файла, который содержит машинные инструкции (единицы и нули), и запуск этого файла заставляет компьютер выполнять эти инструкции. Компиляция — это процесс превращения наших программных файлов C в исполняемый файл.
Вот конкретный пример (в значительной степени взятый из этой статьи, в которой гораздо более подробно рассказывается о карте памяти в C). Предположим, мы хотим скомпилировать программу на C, содержащуюся в
hello.c. Процесс компиляции включает четыре этапа и использует различные «инструменты», такие как препроцессор, компилятор, ассемблер и компоновщик, чтобы создать окончательный исполняемый файл.- Предварительная обработка — это первый проход любой компиляции C. Он удаляет комментарии, расширяет включаемые файлы и макросы и обрабатывает инструкции условной компиляции.Его можно вывести как файл
.i. - Компиляция — это второй проход. Он принимает выходные данные препроцессора и исходный код и генерирует исходный код ассемблера (
hello.s). Ассемблер — это язык программирования низкого уровня (даже ниже C), который по-прежнему удобочитаем, но состоит из мнемонических инструкций, которые строго соответствуют машинным инструкциям. - Сборка — третий этап компиляции. Он берет исходный код сборки и создает объектный файл
hello.o, который содержит фактические машинные инструкции и символы (например, имена функций), которые больше не читаются человеком, поскольку они представлены в битах. - Связывание — заключительный этап компиляции. Он принимает один или несколько объектных файлов или библиотек в качестве входных данных и объединяет их для создания одного (обычно исполняемого) файла. При этом он разрешает ссылки на внешние символы, назначает конечные адреса процедурам / функциям и переменным и изменяет код и данные, чтобы отразить новые адреса (процесс, называемый перемещением).
Обычно программисты больше всего заботятся о конечном исполняемом файле, поэтому наиболее распространенное использование
gccкомпилирует c-файл непосредственно в исполняемый файл — внутриgccгенерирует эти промежуточные выходные данные и передает их от одного этапа к другому, пока он не производит исполняемый файл. Вспомните запускgcc simple_repl.c -o simple_replв лабораторной работе 1 — именно так мы скомпилировали программуsimple_repl.cнепосредственно в исполняемый файл. В этой лабораторной работе мы в основном будем работать с объектными и исполняемыми файлами.Однако позже в ходе курса вы узнаете больше о промежуточном этапе сборки.О чем лаборатория? Помимо возможности превращать код в исполняемый файл, компиляторы C также имеют множество флагов, которые мы можем использовать для настройки компиляции. В части 1 этой лабораторной работы вы будете использовать эти флаги для отладки программы на языке C. Надеюсь, вы также заметите, что по мере того, как программы на C становятся больше, компилирование большого количества файлов вручную может стать очень утомительным. Во второй части вы напишете Makefile , который поможет автоматизировать процесс компиляции всех этих файлов и объединения результатов в исполняемый файл
Во-первых, убедитесь, что в вашем репозитории есть раздаточный файл
$ git remote show раздаточный материалЕсли это сообщает об ошибке, запустите:
$ git remote add раздаточный материал https://github.com/csci1310/cs131-s20-labs.gitЗатем запустите:
$ git pull $ git pull мастер раздаточного материалаЭто объединит наш код трафарета Лаборатории 2 с вашей предыдущей работой. Если у вас есть какие-либо «конфликты» из лабораторной работы 1, разрешите их, прежде чем продолжить. Запустите
git push, чтобы сохранить вашу работу обратно в личный репозиторий.Примечание. Все команды в этой лабораторной работе должны выполняться на виртуальной машине вашего курса.
В первой части этой лабораторной работы вы очистите плохо написанную программу на C в
lab2.c.lab2.c: Эта программа должна делать две вещи. Сначала он принимает в качестве аргументов два целых числа, а затем вычисляет сумму последовательных чисел от первого до второго целого числа. Во-вторых, он используетmallocдля выделения некоторых данных и пытается записать в них.Это очень простая программа, предназначенная для демонстрации различных методов, которые мы можем использовать для компиляции, отладки и оптимизации нашей программы.Компиляция: Чтобы скомпилировать программу непосредственно из файла c в исполняемый файл, запустите:
$ gcc lab2.cЕсли компилятор не обнаружит ошибок, будет создан исполняемый файл с именем
a.out. В нашем случае вы можете запустить исполняемый файл, набрав:./a.out [integer1] [integer2].Однако в большинстве случаев вы захотите дать своему исполняемому файлу определенное имя (а не
a.из). В проектах, которые содержат много разных исполняемых файлов, имена — хороший способ отслеживать, какой исполняемый файл имеет какие функции.Компиляция с именем: Флаг
-oпозволяет вам помещать вывод любой программы gcc в файл, указанный аргументом, следующим сразу за флагом. Чтобы скомпилировать файл c с именем, которое вы хотите, введите:$ gcc lab2.c -o <имя-исполняемого файла>Задача: Скомпилировать
lab2.cи назовите исполняемый файлlab2. Если вы запустите программу следующим образом, вы должны увидеть следующий результат:$ ./лаб2 10 100 Арифметическая сумма от 10 до 100: 100. Данные запрошены для arg1 (0) и arg2 (0).На следующих нескольких этапах лабораторной работы мы увидим, как флаги могут помочь нам быстро выявлять ошибки с помощью
lab2.c.Flags
Компилятор gcc поддерживает использование сотен различных флагов, которые мы можем использовать для настройки процесса компиляции.Флаги, обычно начинающиеся с одного или двух тире (
-или-), могут помочь нам во многих отношениях: от предупреждения об ошибках программирования до оптимизации нашего кода, чтобы он работал быстрее.В этом разделе вы будете использовать флаги для поиска ошибок в
lab2.cи повышения производительности исполняемого файлаlab2. Общая структура для компиляции программы с флагами:$ gcc-o Предупреждающие флаги:
1.
-СтенаОдним из наиболее распространенных флагов является флаг
-Wall. Это заставит компилятор предупредить вас о технически законном, но потенциально проблемном синтаксисе, включая:- неинициализированные и неиспользуемые переменные
- неправильные типы возврата
- недопустимые сравнения типов
Задача: Скомпилировать
lab2.cс флагом-Wall. Для этого введите:
gcc -Wall lab2.c -o lab2- Здесь вы увидите предупреждение. Предупреждения отличаются от ошибок тем, что предупреждения фактически не препятствуют компиляции кода, в то время как ошибки мешают.
2.
-ОшибкаФлаг
-Werrorзаставляет компилятор обрабатывать все предупреждения компилятора как ошибки, что означает, что ваш код не будет компилироваться, пока вы не исправите ошибки. Поначалу это может показаться раздражающим, но в конечном итоге может сэкономить вам много времени, заставив взглянуть на потенциально проблемный код.Задача: Добавьте флаг
-Werrorпри компиляцииlab2.c. Для этого введите:
gcc -Wall -Werror lab2.c -o lab2Этот флаг добавляет еще несколько предупреждений (которые будут отображаться как ошибки из-за
-Werror), не охваченных-Wall. Некоторые проблемы, о которых предупреждает-Wextra, включают:- утверждения утверждения, которые всегда оцениваются как истина из-за типа данных аргумента
- неиспользуемых функциональных параметра (только при использовании вместе с
-Wall) - пустые операторы if / else
Задача: Добавить флаг
-Wextraпри компиляцииlab2.cи исправьте возникающие ошибки в соответствии со спецификациями в комментариях. Если вы исправили ошибки, ваш результат должен выглядеть примерно так:
Что должен делать `argc`?$ ./lab2 Неверное количество аргументов. $ ./lab2 5 100 Арифметическая сумма от 5 до 100: 4940. Данные запрошены для arg1 (0) и arg2 (0).argcуказывает количество аргументов, переданных программе.- Используйте эту переменную, чтобы убедиться, что пользователи передают ожидаемое количество аргументов и в противном случае выводят ошибку.Посмотрите лекцию 2, чтобы увидеть больше примеров.
- Не забудьте вернуть
1из main в случае ошибки, чтобы ОС могла определить, что ваша программа завершилась с ошибками.
Отладка с помощью дезинфицирующих средств
Кажется, что ваша программа не содержит ошибок, но все же есть некоторые скрытые ошибки. Например, попробуйте выполнить следующую команду. Результат должен выглядеть несколько подозрительно
./lab2 100 10000000Какими бы полезными ни были флаги предупреждений, есть некоторые ошибки, которые они не могут обнаружить.К ним относятся такие ошибки, как утечки памяти, повреждение стека или кучи, а также случаи неопределенного поведения — проблемы, которые не сразу очевидны, но могут вызвать серьезные ошибки в вашем коде. Вот тут и пригодятся дезинфицирующие средства! Дезинфицирующие средства решения проблем жертвуют эффективностью, чтобы добавить дополнительные проверки в ваш код. Они работают вместе с вашей программой для выполнения анализа, поэтому добавление дезинфицирующих средств замедляет вашу программу.
Вот несколько полезных флагов отладки и дезинфекции:
Помните об использовании этого флага в Лаборатории 1? Этот флаг просит компилятор сгенерировать и встроить отладочную информацию в исполняемый файл, особенно в исходный код.Это предоставляет более конкретную информацию об отладке, когда вы запускаете свой исполняемый файл с помощью gdb или средств очистки адресов!
Этот флаг включает программу AddressSanitizer, которая является детектором ошибок памяти, разработанным Google. Это может обнаруживать ошибки, такие как доступ за пределы к куче / стеку / глобальным переменным и висячие указатели (с использованием указателя после освобождения объекта, на который указывает указатель). На практике этот флаг также добавляет еще одно средство очистки, LeakSanitizer, которое обнаруживает утечки памяти (также доступно через
-fsanitize = leak).Этот флаг включает программу UndefinedBehaviorSanitizer. Он может обнаруживать и перехватывать различные типы неопределенного поведения во время выполнения программы, такие как использование нулевых указателей или целочисленное переполнение со знаком.
Задача: Добавьте три вышеуказанных флага к вашей компиляции, а затем запустите исполняемый файл
lab2, чтобы найти и исправить любые возникающие ошибки. Если вы исправили ошибки, вы должны увидеть следующий результат.$ ./lab2 0 2147483647 Арифметическая сумма от 0 до 2147483647: 2305843005992468481.Данные с ошибкой для arg1 (0) и arg2 (2147483647).Примечание: ошибки появятся при запуске программы
ПодсказкаВы можете изменить тип данных, который возвращает
arithmeticSum, чтобы было достаточно места для максимально возможного арифметического суммирования двух целых чисел.Интерпретация выходных данных средства очистки адресов
Средства очистки адресов часто распечатывают ошибки, подобные изображению ниже, с некоторыми вариациями:
Примечание: Вы можете щелкнуть изображение, чтобы рассмотреть его поближе.
Есть много информации, которая выбрасывается, но не паникуйте. Вот что происходит!
Верхний блок: Указывает, какая ошибка произошла, чем она вызвана и когда она возникла.
- Красное сообщение (какая ошибка?): Это говорит о том, что мы вызвали переполнение буфера кучи.
- Синее сообщение (Что вызвало ошибку?): Это означает, что наша ошибка была вызвана именно записью 4 байтов в кучу.
- Stack Trace (Когда произошла ошибка?): Это сообщает нам точный номер строки, которая выполняет эту запись (строка 43 в
lab2.c). Это относится к строке, в которой мы пытались записать целое число (4 байта) в наш массив malloc’d.
Нижний блок: Это сообщение дает нам дополнительную информацию о выделенном блоке, ближайшем к данным, к которым мы пытаемся получить доступ.
- Ярко-зеленое сообщение (Где был выделен ближайший блок?): Он сообщает нам, что область, к которой мы пытались получить доступ, находится на 0 байтов справа от 8-байтовой области, которую мы выделили (это целочисленный массив, который мы выделили для 2 целых числа).
- Stack Trace (Когда произошла ошибка?): Это означает, что область памяти была выделена в строке 41 в
lab2.c.
Примечание: имейте в виду, что в зависимости от того, как вы исправляли предыдущие проблемы компиляции, эти номера строк могут отличаться.
Флаги оптимизации
Помимо флагов, которые сообщают вам о проблемах в вашем коде, есть также флаги оптимизации, которые ускоряют время выполнения вашего кода за счет более длительного времени компиляции.Более высокие уровни оптимизации будут оптимизировать, запустив анализ вашей программы, чтобы определить, может ли компилятор внести определенные изменения, которые улучшат его скорость. Чем выше уровень оптимизации, тем больше времени потребуется компилятору для компиляции программы, поскольку он выполняет более сложный анализ вашей программы. Это столичные флаги
O, в том числе-O,-O2,-O3и-Os.При этом ваш код будет скомпилирован без оптимизации — это эквивалентно тому, что параметр
-Oвообще не указан.Поскольку более высокие уровни оптимизации часто удаляют и изменяют части исходного кода, лучше всего использовать этот флаг при отладке с помощью gdb или средств очистки адресов.Это позволит выполнить наиболее агрессивную оптимизацию, благодаря чему ваш код будет работать быстрее всего.
- Прочитать о других флагах оптимизации можно здесь.
Задача: Измерьте время своей программы перед добавлением флага
-O3, а затем после того, как вы добавили флаг-O3в вашу компиляцию, и обратите внимание на разницу в скорости.- Вам следует удалить
-gи флаги очистки адреса, так как они замедляют работу вашей программы из-за добавления дополнительной отладочной информации. - В этом случае флаг
-O3попросит компилятор проверить, что пытается сделать функцияarithmeticSum, и вместо того, чтобы дословно следовать предоставленному коду, он заменит его инструкциями сборки, которые функционально делают то же самое, но более эффективным способом. - Вы можете рассчитать время своей программы, выполнив команду
timeв своем бродячем экземпляре. В этом упражнении обратите внимание на реальное время , но если вам интересно узнать о различных типах времени, указанных ниже, посмотрите этот пост.
$ раз. / Лаб2 100 1000000000 Арифметическая сумма от 100 до 1000000000: 499999999499995050. Данные Malloc'd для arg1 (100) и arg2 (1000000000). реальный 0m0.210s пользователь 0m0.199s sys 0m0.010sЧасть 2: Makefiles
Теперь вы знаете, как компилировать программы на языке C! Это здорово, но, к сожалению, реальные проекты не так просты.В реальном мире вы можете столкнуться с ситуациями, когда вам придется скомпилировать множество исходных файлов и использовать определенные наборы флагов. Очень легко забыть флаг или исходный файл, а выполнение всего этого вручную из командной строки занимает много времени. Кроме того, когда у вас много исходных файлов, может раздражать индивидуальная перекомпиляция / повторная компоновка каждого исходного файла при внесении в него изменений.
Вот почему был создан инструмент
make! При запуске инструментаmakeбудет прочитан файл с именемMakefile, содержащий спецификации того, как скомпилировать и связать программу.Хорошо написанный Makefile автоматизирует все сложные части компиляции, поэтому вам не нужно запоминать каждый шаг. Кроме того, они могут выполнять другие задачи, помимо компиляции программы — они могут выполнять любую предоставленную нами команду оболочки .Makefile состоит из одного или нескольких правил . Основная структура правила Makefile:
<цель>: <зависимости> [tab]- Цель — это имя выходного файла, сгенерированного этим правилом, или метка правила, которую вы выбираете в определенных особых случаях.
- Зависимости — это файлы или другие цели, от которых зависит эта цель.
- Команда оболочки — это команда, которую нужно запустить, когда цель или зависимости устарели.
- Общие правила:
- Из gnu.org: цель устарела, если она не существует или если она старше любой из зависимостей (при сравнении времени последней модификации). Идея состоит в том, что содержимое целевого файла вычисляется на основе информации в зависимостях, поэтому, если какая-либо из зависимостей изменяется, содержимое существующего целевого файла больше не обязательно является действительным.
- Если цель устарела, запуск
makeсначала переделает любую из своих целевых зависимостей, а затем выполнит - В общем, имя цели Makefile должно быть таким же, как имя выходного файла, потому что при выполнении
makeбудет перестроена цель, когда выходной файл старше, чем его зависимости.
Простой Makefile, компилирующий
lab2.cбудет выглядеть так:lab2: lab2.c gcc lab2.c -o lab2
Чтобы скомпилировать
lab2.cс использованием этого Makefile, введите:$ make lab2Это заставит Makefile запустить цель
lab2, которая выполнит командуgcc lab2.c -o lab2, если исполняемый файлlab2не существует или если исполняемый файлlab2старшеlab2 .c.Обратите внимание, как это работает правильно, только если имя выходного исполняемого файла совпадает с именем цели.Задача:
- Создайте пустой файл Makefile, набрав
и коснитесь Makefileв своем каталоге. - Измените свой Makefile так, чтобы у него была одна цель,
lab2, которая будет компилироватьlab2.cсо всеми флагами предупреждений, обсуждаемыми в Части 1 этой лабораторной работы. - Запустите
make lab2, чтобы убедиться, что он компилируется успешно.(Вам может потребоваться удалить двоичный файлlab2черезrm lab2, чтобы это работало.)
Примечание. Не беспокойтесь об ошибках с «временем модификации» или «часами». Это происходит из-за того, что часы во внутренних часах вашей виртуальной машины отличаются от реальных часов вашего компьютера, но не должны вызывать каких-либо серьезных проблем с нашим процессом компиляции.
А что, если мы хотим создать несколько целей? Мы можем использовать переменные, чтобы еще больше упростить наш Makefile!
Переменные
Makefile поддерживает определение переменных, так что вы можете повторно использовать флаги и имена, которые вы обычно используете.
MY_VAR = "something"определит переменную, которая может использоваться как$ (MY_VAR)или$ {MY_VAR}в ваших правилах. Распространенный способ определения флагов для компиляции программы C — иметь переменнуюCFLAGS, которую вы включаете всякий раз, когда запускаетеgcc. Например, вы можете затем переписать свою цель следующим образом:CFLAGS = -Wall -Werror lab2: lab2.c gcc $ (CFLAGS) lab2.c -o lab2
Автоматические переменные: Кроме того, существуют специальные переменные, называемые автоматические переменные , которые могут иметь разные значения для каждого правила в Makefile и предназначены для упрощения записи правил. представляет имена всех зависимостей текущего правила с пробелами между ними.
$ <представляет имя первой зависимости текущего правила.Если бы мы хотели прекратить использование
lab2.cиlab2, чтобы избежать повторяемости, мы могли бы переписать нашу цель следующим образом:CFLAGS = -Wall -Werror lab2: lab2.c gcc $ (CFLAGS) $ <-o $ @
Задача: Используя обычные и автоматические переменные для упрощения вашего Makefile, замените цель lab2 двумя новыми целями:
-
fast_lab2, который компилируетlab2.cс флагом-O3и тремя флагами предупреждений, описанными выше. -
debug_lab2, который компилируетlab2.cс флагом-g(используется для генерации информации, которую может использовать отладчик, такой как gdb), флагами средства очистки адреса и тремя флагами предупреждений.
Фальшивые цели
Существуют также цели, известные как «фальшивые» цели. Это цели, которые сами по себе не создают файлов, а существуют, скорее, для предоставления ярлыков для выполнения других общих операций, таких как создание всех целей в нашем Makefile или избавление от всех исполняемых файлов, которые мы создали.
Чтобы пометить цели как фальшивые, вам необходимо включить эту строку перед любыми целями в вашем Makefile:
.PHONY: [target1] [target2] [и т. Д.]Почему нам нужно объявлять цель фальшивой?
- Чтобы избежать конфликта с файлом с тем же именем: ранее мы узнали, что цели будут выполнять свои
makeвосстановить цель, даже если она не «устарела». - Для повышения производительности: есть также более продвинутое преимущество в производительности, о котором вы можете узнать больше здесь.
Вот несколько распространенных ложных целей , которые мы будем использовать в этом курсе:
всецель
Мы используем цель
allдля одновременного создания всех исполняемых файлов (целей) в нашем проекте.Обычно это выглядит так:all: target1 target2 target3Как видите, нет команд оболочки, связанных с целью
all. Фактически, нам не нужно включать команды оболочки длявсех, потому что, включая каждую цель (target1, target2, target3) в качестве зависимостей длявсех целей, Makefile автоматически построит эти цели для выполнения требованиявсе.Другими словами, поскольку цель
allзависит от всех исполняемых файлов в проекте, сборка целиallзаставляетmakeсначала построить каждую другую цель в нашем Makefile.чистаяцель
У нас также есть цель избавиться от всех исполняемых файлов (и других файлов, которые мы создали с помощью
make) в нашем проекте. Это чистая цельЧистая цель
чистая: rm -f exec1 exec2 obj1.o obj2.o
Как видите, цель
cleanпо сути является просто командой оболочки для удаления всех исполняемых и объектных файлов, которые мы создали ранее.По соглашению, цельcleanдолжна удалить весь контент, автоматически созданныйmake. У него нет зависимостей, потому что нас не волнует, создавали ли мы ранее различные исполняемые файлы в нашем проекте. Все, что мы хотим сделать сmake clean, - это очистить те, которые мы сделали.Примечание: Будьте осторожны, какие файлы вы помещаете после команды
rm -f, так как они будут удалены при запускеmake clean.форматцель
В этом классе вы заметите, что все файлы Makefile также будут содержать цель формата
, которая использует командуclang-formatдля стилизации вашего.cифайлы .hв соответствии с указанным стандартом. Типичная команда формата будет выглядеть так:формат: clang-format -style = Google -i <файл1> .h <файл2> .c ...
Приведенная выше команда отформатирует все перечисленные файлы в соответствии со спецификацией Google.
Примечание: При использовании помните порядок файлов
#include. Форматирование может изменить порядок включения операторов.Это следует учитывать, если, например, вы импортируете файл заголовка, который использует стандартные библиотеки из файла, в который вы его импортируете. Чтобы избежать этого, убедитесь, что файлы заголовков являются самодостаточными.checktargetВы также заметите цель
checkв предоставляемых Make-файлах. Вам не нужно создавать эту цель в этой лабораторной работе, но в проектах эта цель будет ярлыком для запуска набора тестов.Задача: Добавьте
все цели,cleanиформатав ваш Makefile.- Запуск
makeбез каких-либо целей запустит первую цель в вашем файле Makefile. Следовательно, вы должны поместить цельallв качестве первой цели, чтобы при вводеmakeавтоматически генерировались все исполняемые файлы. - Не забудьте пометить эти цели как фальшивые!
Упрощение связывания
Напомним из начала этой лабораторной работы, что связывание - это процесс объединения множества объектных файлов и библиотек в один (обычно исполняемый) файл.Чтобы лучше понять это, давайте вызовем функцию из
lab2_helper.cвlab2.c.Задача: Вызов функции
helperFunctionизlab2_helper.cвlab2.c. Вот что нам нужно сделать:- Добавьте оператор
#include "lab2_helper.h"в началоlab2.c, чтобы использовать функциюhelperFunction. - Вызов функции
helperFunctionизlab2_helper.cв основной функцииlab2.c, используяarg1иarg2в качестве аргументов. Вызовите эту функцию после оператора печати «Данные Malloc’d для…»
Один из способов скомпилировать эти два файла
.cв один исполняемый файл:$ gcc lab2.c lab2_helper.c -o lab2В процессе
gccсоздает два отдельных файла.o- один дляlab2.cи один дляlab2_helper.c, а затем связывает их вместе.Сравнение больших и малых проектов: Для небольших проектов это хорошо работает. Однако для больших проектов может быть быстрее сгенерировать промежуточные файлы
.o, а затем отдельно связать файлы.oвместе в исполняемый файл.Почему? Представьте себе проект, который генерирует две общие библиотеки и четыре исполняемых файла, каждый из которых по отдельности связывает файл с именем
data.c. Допустим, данные.o Файлкомпилируется за 1 секунду. Если вы скомпилируете и скомпилируете каждый исполняемый файл в одной команде (без создания промежуточных файлов.o),gccперестроит файлdata.oпять раз, в результате чего время сборки составит 5 секунд. Если вы создадите отдельно файлdata.o, вы создадите файлdata.cтолько один раз (за 1 секунду), а затем свяжете его (что намного быстрее, чем компиляция с нуля, особенно с большими исходными файлами) .Хотя этот метод не продемонстрирует значительного повышения производительности в случае нашей небольшой лаборатории, давайте попробуем использовать его, чтобы реализовать концепцию домашнего соединения.Затем мы можем использовать наш Makefile, чтобы автоматизировать этот процесс для нас, чтобы нам не приходилось повторно создавать все объектные и исходные файлы каждый раз, когда мы редактируем один из них.
Для этого нам нужно сначала сгенерировать объектные файлы для каждого файла, содержащие машинные инструкции. Затем нам нужно связать эти программы вместе в один исполняемый файл.
Чтобы создать объектные файлы без связывания их , мы используем флаг
-cпри запускеgcc. Например, чтобы создать объектные файлы дляlab2.cиlab2_helper.c, мы должны запустить:$ gcc-c lab2.c -o lab2.o $ gcc <флаги> -c lab2_helper.c -o lab2_helper.o Это сгенерирует файлы
lab2.oиlab2_helper.o.Затем, чтобы связать объектные файлы с исполняемым файлом , мы должны запустить:
$ gcc lab2.o lab2_helper.o -o <имя исполняемого файла>Преимущество независимого создания объектных файлов состоит в том, что при изменении исходного файла нам нужно только создать объектный файл для этого исходного файла.Например, если мы изменим
lab2_helper.c, нам просто нужно будет запуститьgcc -c lab2_helper.c -o lab2_helper.c, чтобы получить объектный файл, а затемgcc lab2_helper.o lab2.o, чтобы получить последний исполняемый файл.Задача: В Makefile создайте цели для
fast_lab2.o,debug_lab2.o,fast_lab2_helper.oиdebug_lab2_helper.o, каждая из которых включает соответствующий исходный файл в качестве зависимости.- Каждая из этих целей должна скомпилировать свой исходный файл в объектный файл (а не в исполняемый файл). Им также нужны правильные флаги для оптимизации или отладки.
- Обновите целевые объекты
fast_lab2иdebug_lab2, чтобы использовать флаги.o. Сохраните соответствующие флаги для оптимизации и отладки - Обновите ваши
чистые целииформата.
Благодаря этому,
makeбудет перекомпилировать каждый отдельный объектный файл только в том случае, если его источник был изменен.Это может не иметь большого значения для этой лабораторной работы, но в более крупном проекте это сэкономит вам много времени.Шаблонные правила
Последний метод Makefile, который мы обсудим, - это шаблонных правил . Они очень часто используются в файлах Makefile. Шаблонное правило использует символ
%в целевом объекте для создания общего правила. Например:-
%будет соответствовать любой непустой подстроке в целевом объекте, а%, используемое в зависимостях, заменит согласованную строку целевого объекта. - В этом случае это будет указывать, как сделать любой
file_исполняемым файлом с другим файлом с именем.c .c - Например, если бы мы удалили код
helperFunctionи операторlab2_helper.hinclude изlab2.c, мы могли бы использовать это правило, запустивmake file_lab2для созданияfile_lab2исполняемый файл изlab2.c.
Задача: Используйте шаблонные правила для упрощения целевых файлов Makefile, чтобы вы могли генерировать
fast_lab2.o,debug_lab2.o,fast_lab2_helper.oиdebug_lab2_helper.o, используя только 2 правила, а не 4 отдельных правила.Если вам нужна помощь, эта документация может помочь.
Теперь вы познакомились с некоторыми из самых популярных флагов
gccи техниками Makefile.Для большинства заданий в этом курсе вам не нужно писать собственный Makefile, но если вы когда-нибудь столкнетесь с ошибками компиляции, надеюсь, теперь вам будет легче понять, что происходит. Попробуйте взглянуть на часть назначения строк в Makefile проекта 1. Возможно, появятся некоторые новые флаги, которые вы, возможно, захотите найти в Интернете, но по большей части вы должны быть в состоянии понять, как он компилирует ваши исходные файлы на C!Теперь вы готовы приступить к этой лабораторной работе.