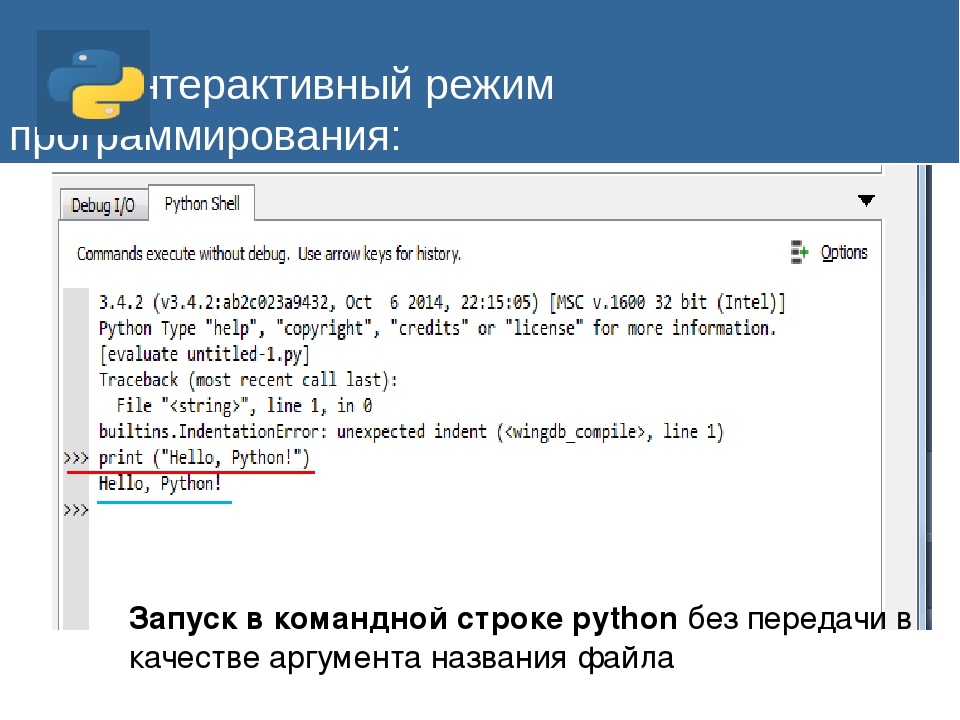
Работа с файлами в Python
Работа с файлами в Python
Для того, чтобы начать работать с файлом, его нужно открыть. Для этого есть специальна встроенная функция
open(file, mode=’r’, buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
Открывает файл и возвращает представляющий его объект.
Режимы открытия файла
| r | открытие файла на чтение |
| w | открытие файла на запись, содержимое файла удаляется, если файла не существует, создается новый |
| x | открытие файла на запись, если файла не существует. Если файл существует, возникает исключение |
| a | открытие файла на запись, информация добавляется в конец файла |
| b | открытие файла в двоичном режиме |
| t | открытие файла в текстовом режиме |
| + | открытие файла на чтение и запись |
Методы объекта файла
file. read([size])
read([size])
 read([size])
read([size])Считывает и возвращает информацию из файла. Если необязательный параметр size указан, возвращает только нужное количество символов/байт.
file.write(content)
Записывает информацию в файл
file.tell()
Возвращает текущий указатель внутри файла
file.seek(position, [from_what=0])
Перемещает указатель в заданную позицию. Первый аргумент — это количество позиций, на которое нужно переместить указатель. Если этот аргумент положительный, указатель будет перемещен вправо, если отрицательный — влево.
Второй, необязательный аргумент — это from_what. С помощью него можно указать, откуда следует переместить указатель: 0 — от начала файла, 1 — от текущей позиции и 2 — от конца файла. По‑умолчанию этот аргумент принимает значение 0
file.close()
Закрывает файл. Обязательно вызывайте этот метод после окончания работы с файлом.
Работа с текстовыми файлами Python 3
Независимо от того, какое приложение вы используете, гарантировано, что в процессе его работы будет задействован ввод или вывод данных.
Для этого руководства нужно установить Python 3. Также на вашем компьютере должна быть установлена локальная среда программирования.
Python может с относительной легкостью обрабатывать различные форматы файлов:
| Тип файла | Описание |
| Txt | Обычный текстовый файл хранит данные, которые представляют собой только символы (или строки) и не включает в себя структурированные метаданные. |
| CSV | Файл со значениями,для разделения которых используются запятые (или другие разделители). Что позволяет сохранять данные в формате таблицы. |
| HTML | HTML-файл хранит структурированные данные и используется большинством сайтов |
| JSON | JavaScript Object Notation — простой и эффективный формат, что делает его одним из часто используемых для хранения и передачи данных. |
В этой статье основное внимание будет уделено формату txt.
Сначала нужно подготовить файл для работы. Для этого мы откроем любой текстовый редактор для python и создадим новый txt-файл, назовем его days.txt.
В этом файле необходимо ввести несколько строк. В приведенном ниже примере мы перечислим дни недели:
days.txt
Monday Tuesday Wednesday Thursday Friday Saturday Sunday
Затем сохраните файл. В нашем примере пользователь sammy сохранил файл здесь: /users/sammy/days.txt. Это будет важно на последующих этапах, когда откроем файл в Python.
Прежде чем написать программу, нужно создать файл для кода Python. С помощью текстового редактора создадим файл files.py. Чтобы упростить задачу, сохраните его в том же каталоге, что и файл days.txt:
/users/sammy/.
Чтобы открыть файл, сначала нужно каким-то образом связать его с переменной в Python. Этот процесс называется открытием файла. Сначала мы укажем Python, где находится файл.
Чтобы Python мог открыть файл, ему требуется путь к нему: days.txt -/users/sammy/days.txt. Затем создаем строковую переменную для хранения этой информации. В нашем скрипте files.py мы создадим переменную path и установим для нее значение days.txt.
files.py
path = '/users/sammy/days.txt'
Затем используем функцию Python open(), чтобы открыть файл days.txt. В качестве первого аргумента она принимает путь к файлу.
Эта функция также позволяет использовать многие другие параметры. Но наиболее важным является параметр, определяющий режим открытия файла. Он зависит от того, что вы хотите сделать с файлом.
Вот некоторые из существующих режимов:
- ‘r’: использовать для чтения;
- ‘w’: использовать для записи;
- ‘x’: использование для создания и записи в новый файл;
- ‘a’: использование для добавления к файлу;
- ‘r +’: использовать для чтения и записи в тот же файл.
В текущем примере нужно только считать данные из файла, поэтому будем использовать режим «r».
files.py
days_file = open(path,'r')
После открытия файла мы сможем прочитать его, что сделаем на следующем шаге.
Файл был открыт, и мы можем работать с ним через переменную, которую мы ему присвоили. Python предоставляет три связанные операции для чтения информации из файла. Покажем, как использовать каждую из них.
Первая операция <file>.read() возвращает все содержимое файла как одну строку.
days_file.read() Вывод 'MondaynTuesdaynWednesdaynThursdaynFridaynSaturdaynSundayn'
Вторая операция <file>.readline() возвращает следующую строку файла (текст до следующего символа новой строки, включая сам символ). Проще говоря, эта операция считывает файл по частям.
days_file.readline() Вывод 'Mondayn'
Поэтому, когда вы прочтете строку с помощью readline, она перейдет к следующей строке. Если вы снова вызовете эту операцию, она вернет следующую строку, прочитанную в файле.
days_file.readline() Вывод 'Tuesdayn'
Последняя операция, <file>.readlines(), возвращает список строк в файле. При этом каждый элемент списка представляет собой одну строку.
days_file.readlines() Вывод ['Mondayn', 'Tuesdayn', 'Wednesdayn', 'Thursdayn', 'Fridayn', 'Saturdayn', 'Sundayn']
Как только файл был прочитан с использованием одной из операций, его нельзя прочитать снова. Например, если вы запустите days_file.read(), за которой следует days_file.readlines(), вторая операция вернет пустую строку. Поэтому, когда вы захотите прочитать содержимое файла, вам нужно будет сначала открыть новую файловую переменную.
На этом этапе мы запишем новый файл, который включает в себя название «Days of the Week», и дни недели. Сначала создадим переменную title.
files.py
title = 'Days of the Weekn'
Также нужно сохранить дни недели в строковой переменной days. Открываем файл в режиме чтения, считываем файл и сохраняем вывод в новую переменную days.
files.py
path = '/users/sammy/days.txt' days_file = open(path,'r') days = days_file.read()
Теперь, когда у нас есть переменные для названия и дней недели, запишем их в новый файл. Сначала нужно указать расположение файла. Мы будем использовать каталог /users/sammy/. Также нужно указать новый файл, который мы хотим создать. Фактический путь будет /users/sammy/new_days.txt. Мы записываем его в переменную new_path. Затем открываем новый файл в режиме записи, используя функцию open() с режимом w.
files.py
new_path = '/users/sammy/new_days.txt' new_days = open(new_path,'w')
Если файл new_days.txt уже существовал до открытия, его содержимое будет удалено, поэтому будьте осторожны при использовании режима «w».
Когда новый файл будет открыт, поместим в него данные, используя <file>.write(). Операция write принимает один параметр, который должен быть строкой, и записывает эту строку в файл.
Если хотите записать новую строку в файл, нужно указать символ новой строки. Мы записываем в файл заголовок, за которым следуют дни недели.
Мы записываем в файл заголовок, за которым следуют дни недели.
new_days.write(title) print(title) new_days.write(days) print(days)
Всякий раз, когда мы заканчиваем работу с файлом, нужно его закрыть. Мы покажем это в заключительном шаге.
Закрытие файла деактивирует соединение между файлом, сохраненным на жестком диске, и файловой переменной. Закрытие файлов также гарантирует, что другие программы смогут получить к ним доступ и безопасно сохранить данные. Закроем все наши файлы, используя функцию <file>.close().
files.py
days_file.close() new_days.close()
Мы закончили обработку файлов в Python и можем перейти к просмотру кода.
Конечный результат должен выглядеть примерно так:
files.py
path = '/users/sammy/days.txt' days_file = open(path,'r') days = days_file.read() new_path = '/users/sammy/new_days.txt' new_days = open(new_path,'w') title = 'Days of the Weekn' new_days.write(title) print(title) new_days.write(days) print(days) days_file.close() new_days.close()

После сохранения кода откройте терминал и запустите свой Python- скрипт, например:
python files.py
Результат должен выглядеть так:
Вывод Days of the Week Monday Tuesday Wednesday Thursday Friday Saturday Sunday
Теперь проверим код полностью, открыв файл new_days.txt. Если все пройдет хорошо, когда мы откроем этот файл, его содержимое должно выглядеть следующим образом:
new_days.txt
Days of the Week Monday Tuesday Wednesday Thursday Friday Saturday Sunday
В этой статье мы рассказали, как работать с простыми текстовыми файлами в Python 3. Теперь вы сможете открывать, считывать, записывать и закрывать файлы в Python.
Данная публикация является переводом статьи «How To Handle Plain Text Files in Python 3» , подготовленная редакцией проекта.
Программирование на Python: Часть 8. Файловая система
Программирование на Python
Сергей Яковлев
Опубликовано 02. 09.2010
09.2010
Серия контента:
Этот контент является частью # из серии # статей: Программирование на Python
https://www.ibm.com/developerworks/ru/library/?series_title_by=**auto**
Следите за выходом новых статей этой серии.
Этот контент является частью серии:Программирование на Python
Следите за выходом новых статей этой серии.
После изучения классов в Python мы перейдем к работе с файлами и файловой системой. Функции и объекты, описанные в этой главе, позволят вам сохранять данные между вызовами программы, а также обмениваться данными между программами.
Сегодня мы рассмотрим следующие темы.
- Как открыть файл.
- Базовые файловые методы.
- Стандартный ввод/вывод.
- Произвольный доступ.
- Построчная работа с файлами.
- Закрытие файла.
- Итерация.
- Pickling.
- Бинарные файлы – модуль struct.
- Работа с файловой системой.

1. Как открыть файл
Открыть файл можно с помощью функции open:
open(name[, mode[, buffering]])
Функция возвращает файловый объект. Обязателен только первый аргумент. Если остальные параметры отсутствуют, файл будет доступен на чтение. Таблица режимов (mode) функции open:
‘r’ – чтение.
‘w’ – запись.
‘a’ – добавление.
‘b’ – бинарный режим.
‘+’ – чтение/запись.
Режим ‘+’ может быть добавлен к остальным режимам. По умолчанию питон открывает файлы в текстовом режиме. Для открытия файла в бинарном режиме на чтение можно добавить ‘rb’. Третий параметр устанавливает размер буферизации при работе с файлом. По умолчанию он выключен, и чтение/запись идет напрямую с диска на диск. Для включения буфера третий параметр должен быть отличным от нуля.
Для включения буфера третий параметр должен быть отличным от нуля.
2. Базовые файловые методы
В питоне многие объекты являются файлами: стандартный ввод sys.stdin, стандартный вывод sys.stdout, объекты, открываемые функцией urllib.urlopen и т.д.
Запись в файл:
>>> f = open('my_file', 'w')
>>> f.write('Hello, ')
>>> f.write('World!')
>>> f.close()Чтение:
>>> f = open('my_file', 'r')
>>> f.read(5)
'Hello'
>>> f.read()
', World!'3. Стандартный ввод/вывод
В командной строке можно записать подряд несколько команд, передавая результат работы от одной команды к другой по конвейеру – или по каналу (pipe):
cat my_file | python test.py
Первая команда – cat – пишет содержимое текстового файла my_file на стандартный вывод sys.stdout . Вторая команда запускает питоновский файл, который читает стандартный ввод sys. stdin , подсчитывает в нем количество слов и выводит результат:
stdin , подсчитывает в нем количество слов и выводит результат:
test.py: import sys text = sys.stdin.read() words = text.split() wordcount = len(words) print 'Wordcount:', wordcount
Канал – или пайп (pipe) – это конструкция, объединяющая стандартный вывод со стандартным вводом и позволяющая обмениваться данными между двумя командами.
4. Произвольный доступ
По умолчанию метод read() читает данные последовательно по порядку, от начала и до конца файла. Для произвольного доступа к файлу есть функция seek:
seek(offset[, whence])
offset – смещение в байтах относительно начала файла;
whence – по умолчанию равен нулю, указывает на то, что смещение берется относительно начала файла.
Пример:
>>> f = open(r'my_file', 'w')
>>> f.write('01234567890123456789')
>>> f.seek(5)
>>> f.write('Hello, World!')
>>> f. close()
>>> f = open(r'my_file')
>>> f.read()
'01234Hello, World!89' close()
>>> f = open(r'my_file')
>>> f.read()
'01234Hello, World!89'
close()
>>> f = open(r'my_file')
>>> f.read()
'01234Hello, World!89'Функция tell() возвращает текущую позицию файла.
5. Построчная работа с файлами
Обычно мы имеем дело с текстовыми файлами. Прочитать одну строку:
file.readline()
Функция readline() без параметра читает всю строку, наличие параметра указывает функции максимальное число символов строки, которое будет прочитано. Прочитать все строки и вернуть список строк:
file.readlines()
Записать строки в файл:
file.writelines()
Пример. Прочитать файл и записать его содержимое в другой файл:
f = open(r'my_file') lines = f.readlines() f.close() lines[0] = "This is a my_file2 \n" # изменяем 1-ю строку f = open(r'my_file2','w') f.writelines(lines) f.close()
6. Закрытие файла
Для закрытия файла есть метод close(). Обычно файл закрывается сам после того, как вы выходите из программы, но файлы нужно закрывать вручную по нескольким причинам.
Обычно файл закрывается сам после того, как вы выходите из программы, но файлы нужно закрывать вручную по нескольким причинам.
- Питон может буферизировать запись в файл ваших данных, что может привести к неожиданным эффектам и возникновению ошибок.
- У операционной системы есть ограничение на число одновременно открытых файлов.
- При доступе к файлу из разных мест одновременно и на чтение, и на запись необходимо синхронизировать файловые операции. Буферизация записи может привести к тому, что запись уже произошла, а данных в файле еще нет.
Для полной уверенности в закрытии файла можно использовать блок try/finally:
try:
# Тут идет запись в файл
finally:
file.close()Можно также использовать менеджер контекста, который в любом случае закроет файл:
with open("my_file") as somefile:
do_something(somefile)Если вы все же не хотите закрывать файл, то синхронизировать многопользовательский доступ к файлу на чтение/запись можно с помощью функции flush(), которая актуализирует все операции записи на диск. При этом возможна блокировка файла на чтение.
При этом возможна блокировка файла на чтение.
7. Итерация
Итерация по файлу является базовой операцией и имеет множество вариантов. Использование функции read() для байтового чтения:
f = open(filename) while True: char = f.read(1) if not char: break process(char) f.close()
Построчное чтение текстовых файлов и функция readline():
f = open(filename) while True: line = f.readline() if not line: break process(line) f.close()
Файл сам может выступать в роли итератора:
for line in open(filename): process(line)
8. Pickling
Практически любой тип объекта может быть сохранен на диске в любой момент его жизни, а позже прочитан с диска. Для этого есть модуль pickle:
import pickle t1 = [1, 2, 3] s = pickle.dumps(t1) t2 = pickle.loads(s) print t2 [1, 2, 3]
Здесь есть небольшой нюанс: t1 и t2 будут двумя разными объектами, хотя и идентичными.
9. Бинарные файлы
Стандартный модуль struct позволяет преобразовывать объекты в структуры C в виде строк в бинарном формате и обратно. Данные в строке располагаются в соответствии со строкой формата. Эти возможности могут быть использованы для чтения и сохранения в двоичном формате.
Функции этого модуля:
pack(format, value1, value2 ...)
Возвращает строку, содержащую значения value1 …, упакованные в соответствии с форматом. Количество и тип аргументов должны соответствовать значениям, которые требует строка формата format.
unpack(format, string)
Распаковывает строку string в соответствии с форматом format и возвращает кортеж объектов.
calcsize(format)
Возвращает размер структуры (т.е. длину строки), соответствующей формату format.
Таблица основных форматов
=========================== Format C Type Python =========================== c char string of length 1 ? Bool bool i int integer l long integer f float float d double float s char[] string
Перед символом формата может идти число, обозначающее количество повторений. Например, строка формата ‘4h’ полностью эквивалентна строке ‘hhhh’. Символы пропуска между символами формата игнорируются, однако символы пропуска между числом и символом формата не допускаются.
Например, строка формата ‘4h’ полностью эквивалентна строке ‘hhhh’. Символы пропуска между символами формата игнорируются, однако символы пропуска между числом и символом формата не допускаются.
Число перед символом формата ‘s’ интерпретируется как длина строки, а не число повторений. То есть ’10s’ обозначает строку из 10 символов, в то время как ’10c’ – 10 раз по одному символу.
Можно изменить порядок следования байтов вручную:
< - little-endian > - big-endian
В следующем примере мы упаковываем в структуру два числа – целое и float, строку из пяти символов, сохраняем в бинарный файл, а потом извлекаем из файла:
from struct import *
out = open("123.bin", "wb")
format = "if5s"
data = pack(format, 24,12.48,'12345')
out.write(data)
out.close()
input = open("123.bin", "rb")
data = input.read()
input.close()
format = "if5s" # one integer
value,value2,value3 = unpack(format, data) # note the ',' in 'value,':
unpack apparently returns a n-uple
print value
print value2
print value3
print calcsize(format)
>>> 24
>>> 12. 4799995422
>>> 12345
>>> 13 4799995422
>>> 12345
>>> 13
4799995422
>>> 12345
>>> 1310. Работа с файловой системой
Стандартный модуль os имеет интерфейс работы с файловой системой. Каждая программа имеет текущий каталог. Функция os.getcwd возвращает текущий каталог:
import os cwd = os.getcwd() print cwd
Проверить наличие файла в текущем каталоге:
os.path.exists('my_file')Вывести список файлов и подкаталогов для данного каталога:
os.listdir(path)
Следующий пример рекурсивно выводит список всех файлов и подкаталогов для данного каталога:
import os
def walk(dir):
for name in os.listdir(dir):
path = os.path.join(dir, name)
if os.path.isfile(path):
print path
else:
walk(path)
walk(path)В следующем примере мы получим статистическую информацию о текущем каталоге: общий размер каталога в байтах, число файлов, число подкаталогов. Стандартная функция os.path.walk имеет три параметра: каталог, пользовательская функция, список для подсчета:
Стандартная функция os.path.walk имеет три параметра: каталог, пользовательская функция, список для подсчета:
import os, sys
def getlocaldata(sms,dr,flst):
for f in flst:
fullf = os.path.join(dr,f)
if os.path.islink(fullf): continue # don't count linked files
if os.path.isfile(fullf):
sms[0] += os.path.getsize(fullf)
sms[1] += 1
else:
sms[2] += 1
def dtstat(dtroot):
sums = [0,0,1] # 0 bytes, 0 files, 1 directory so far
os.path.walk(dtroot,getlocaldata,sums)
return sums
report = dtstat('.')
print reportВ следующем примере сделана интерпретация системной утилиты grep. В текущем каталоге будут найдены файлы с питоновским расширением, в которых будет найдена поисковая строка ‘import os’:
import os, sys, fnmatch
mask = '*.py'
pattern = 'import os'
def walk(arg,dir,files):
for file in files:
if fnmatch.fnmatch(file,mask):
name = os. path.join(dir,file)
try:
data = open(name,'rb').read()
if data.find(pattern) != -1:
print name
except:
pass
os.path.walk('.',walk,[]) path.join(dir,file)
try:
data = open(name,'rb').read()
if data.find(pattern) != -1:
print name
except:
pass
os.path.walk('.',walk,[])
path.join(dir,file)
try:
data = open(name,'rb').read()
if data.find(pattern) != -1:
print name
except:
pass
os.path.walk('.',walk,[])Заключение
Сегодня мы узнали, что файловые объекты поддерживают чтение/запись. Для корректной работы с данными файл нужно программно закрывать. Файлы можно открывать в различных режимах. Стандартный ввод/вывод – это тоже файлы. Можно построчно читать и писать в файл. К файлам можно применять байтовую и построчную итерацию. Любые объекты могут быть сохранены на диске в произвольный момент времени в произвольном состоянии и позже восстановлены путем считывания с диска. Чтение/запись можно выполнять в бинарном режиме, соблюдая совместимость со структурами на языке си. Интерфейс с операционной системой позволяет писать компактные программы, дополняющие стандартные утилиты операционной системы.
Приведенные примеры проверены на версии питона 2.6.
< Предыдущая статья. Следующая статья >
Ресурсы для скачивания
Python.
 Примеры работы с текстовыми файлами
Примеры работы с текстовыми файламиВ данной теме представлены примеры записи и чтения информации для текстовых файлов.
Содержание
Поиск на других ресурсах:
1. Чтение/запись списка, содержащего n целых чисел
В примере демонстрируются следующие операции:
- создание списка из 10 случайных чисел;
- сохранение списка в текстовом файле;
- чтение из файла в новый список с целью контроля.
Текст программы следующий:
# Запись/чтение списка случайных чисел
# 1. Подключить модуль random
import random
# 2. Создать список из 10 случайных чисел
i = 0
lst = []
while i<10:
number = random.randint(0, 101) # число от 0 до 100
lst = lst + [number]
i = i+1
print("lst = ", lst)
# 3. Сохранить список в текстовом файле
# 3.1. Открыть файл для записи
f = open('file.txt', 'wt')
# 3.2. Записать количество элементов в списке
s = str(len(lst)) # Конвертировать целое число в строку
f. write(s + '\n') # Записать строку
# 3.3. Записать каждый элемент
for i in lst:
s = str(i) # конвертировать элемент списка в строку
f.write(s + ' ') # записать число в строку
# 4. Закрыть файл
f.close()
# -------------------------------------------
# 5. Чтение из файла 'file.txt'
f = open('file.txt', 'r')
# 6. Прочитать из файла числа и сформировать список
# 6.1. Прочитать количество элементов в списке,
# сначала читается строка, затем эта строка
# конвертируется в целое число методом int()
s = f.readline()
n = int(s)
# 6.2. Создать пустой список
lst2 = []
# 6.3. Реализовать обход файла по строкам и считать числа.
# Для чтения строк используется итератор файла.
for line in f:
# метод split - разбивает на слова на основании символа пробел
strs = line.split(' ') # получить массив строк strs
# Вывести strs с целью контроля
print("strs = ", strs)
# прочитать все слова и записать их в список как целые числа
for s in strs:
if s!='':
lst2 = lst2 + [int(s)] # добавить число к списку
# 6. 4. Вывести результат для контроля
print("n = ", len(lst2))
print("lst2 = ", lst2)
# 6.5. Закрыть файл - необязательно
f.close() write(s + '\n') # Записать строку
# 3.3. Записать каждый элемент
for i in lst:
s = str(i) # конвертировать элемент списка в строку
f.write(s + ' ') # записать число в строку
# 4. Закрыть файл
f.close()
# -------------------------------------------
# 5. Чтение из файла 'file.txt'
f = open('file.txt', 'r')
# 6. Прочитать из файла числа и сформировать список
# 6.1. Прочитать количество элементов в списке,
# сначала читается строка, затем эта строка
# конвертируется в целое число методом int()
s = f.readline()
n = int(s)
# 6.2. Создать пустой список
lst2 = []
# 6.3. Реализовать обход файла по строкам и считать числа.
# Для чтения строк используется итератор файла.
for line in f:
# метод split - разбивает на слова на основании символа пробел
strs = line.split(' ') # получить массив строк strs
# Вывести strs с целью контроля
print("strs = ", strs)
# прочитать все слова и записать их в список как целые числа
for s in strs:
if s!='':
lst2 = lst2 + [int(s)] # добавить число к списку
# 6.
write(s + '\n') # Записать строку
# 3.3. Записать каждый элемент
for i in lst:
s = str(i) # конвертировать элемент списка в строку
f.write(s + ' ') # записать число в строку
# 4. Закрыть файл
f.close()
# -------------------------------------------
# 5. Чтение из файла 'file.txt'
f = open('file.txt', 'r')
# 6. Прочитать из файла числа и сформировать список
# 6.1. Прочитать количество элементов в списке,
# сначала читается строка, затем эта строка
# конвертируется в целое число методом int()
s = f.readline()
n = int(s)
# 6.2. Создать пустой список
lst2 = []
# 6.3. Реализовать обход файла по строкам и считать числа.
# Для чтения строк используется итератор файла.
for line in f:
# метод split - разбивает на слова на основании символа пробел
strs = line.split(' ') # получить массив строк strs
# Вывести strs с целью контроля
print("strs = ", strs)
# прочитать все слова и записать их в список как целые числа
for s in strs:
if s!='':
lst2 = lst2 + [int(s)] # добавить число к списку
# 6. 4. Вывести результат для контроля
print("n = ", len(lst2))
print("lst2 = ", lst2)
# 6.5. Закрыть файл - необязательно
f.close()
4. Вывести результат для контроля
print("n = ", len(lst2))
print("lst2 = ", lst2)
# 6.5. Закрыть файл - необязательно
f.close()Результат работы программы
lst = [48, 89, 1, 36, 68, 26, 61, 38, 1, 6] strs = ['48', '89', '1', '36', '68', '26', '61', '38', '1', '6', ''] n = 10 lst2 = [48, 89, 1, 36, 68, 26, 61, 38, 1, 6]
⇑
2. Чтение/запись списка, содержащего строки
При чтении/записи строк не нужно реализовывать дополнительные преобразования из одного типа в другой, так как данные из файла читаются в виде строк.
# Запись/чтение списка строк
# 1. Заданный список строк
L = [ 'abc', 'bcd', 'cba', 'abd']
# 2. Открыть файл для записи
f = open('filestrs.txt', 'wt')
# 3. Цикл записи строк
for s in L:
# записать каждую строку в отдельную строку файла
f.write(s + '\n')
# 4. Закрыть файл
f.close()
# -------------------------------------------
# 5. Чтение из файла 'filestrs.txt'
f = open('filestrs.txt', 'rt')
# 6. Сформировать новый список
lst2 = [] # сначала пустой список
# 7. Реализовать обход файла по строкам и считать числа.
# Для чтения строк используется итератор файла.
for s in f:
# Убрать последний символ '\n' из s
s = s.rstrip()
# Вывести s для контроля
print("s = ", s)
# Добавить строку s в список lst2
lst2 = lst2 + [s]
# 8. Вывести список lst2 для контроля
print("lst2 = ", lst2)
# 9. Закрыть файл - необязательно
f.close() Чтение из файла 'filestrs.txt'
f = open('filestrs.txt', 'rt')
# 6. Сформировать новый список
lst2 = [] # сначала пустой список
# 7. Реализовать обход файла по строкам и считать числа.
# Для чтения строк используется итератор файла.
for s in f:
# Убрать последний символ '\n' из s
s = s.rstrip()
# Вывести s для контроля
print("s = ", s)
# Добавить строку s в список lst2
lst2 = lst2 + [s]
# 8. Вывести список lst2 для контроля
print("lst2 = ", lst2)
# 9. Закрыть файл - необязательно
f.close()
Чтение из файла 'filestrs.txt'
f = open('filestrs.txt', 'rt')
# 6. Сформировать новый список
lst2 = [] # сначала пустой список
# 7. Реализовать обход файла по строкам и считать числа.
# Для чтения строк используется итератор файла.
for s in f:
# Убрать последний символ '\n' из s
s = s.rstrip()
# Вывести s для контроля
print("s = ", s)
# Добавить строку s в список lst2
lst2 = lst2 + [s]
# 8. Вывести список lst2 для контроля
print("lst2 = ", lst2)
# 9. Закрыть файл - необязательно
f.close()Результат работы программы
s = abc s = bcd s = cba s = abd lst2 = ['abc', 'bcd', 'cba', 'abd']
⇑
3. Чтение/запись кортежа, содержащего объекты чисел с плавающей запятой
Пример демонстрирует запись и чтение кортежа, который содержит объекты чисел с плавающей запятой.
# Запись/чтение кортежа, содержащего объекты типа float.
 # 1. Исходный кортеж
T1 = ( 3.8, 2.77, -11.23, 14.75)
# 2. Запись кортежа в файл
# 2.2. Открыть файл для записи в текстовом режиме
f = open('myfile5.txt', 'wt')
# 2.3. Цикл записи объектов в файл
for item in T1:
# 2.3.1. Конвертировать item в строку
s = str(item)
# 2.3.2. Записать строку + символ ' ' пробел
f.write(s + ' ')
# 2.4. Закрыть файл
f.close()
# 3. Чтение из файла, который содержит вещественные числа
# и создание нового кортежа T2
f = open('myfile5.txt', 'rt')
# 3.1. Создать пустой кортеж T2
T2 = ()
# 3.2. Чтение данных из файла и образование кортежа
for lines in f: # Использовать итератор файла
# 3.2.1. Разбить строку lines на подстроки strings.
# Любая подстрока strings[i] - это вещественное число,
# представленное в строчном формате
strings = lines.split(' ')
# 3.
# 1. Исходный кортеж
T1 = ( 3.8, 2.77, -11.23, 14.75)
# 2. Запись кортежа в файл
# 2.2. Открыть файл для записи в текстовом режиме
f = open('myfile5.txt', 'wt')
# 2.3. Цикл записи объектов в файл
for item in T1:
# 2.3.1. Конвертировать item в строку
s = str(item)
# 2.3.2. Записать строку + символ ' ' пробел
f.write(s + ' ')
# 2.4. Закрыть файл
f.close()
# 3. Чтение из файла, который содержит вещественные числа
# и создание нового кортежа T2
f = open('myfile5.txt', 'rt')
# 3.1. Создать пустой кортеж T2
T2 = ()
# 3.2. Чтение данных из файла и образование кортежа
for lines in f: # Использовать итератор файла
# 3.2.1. Разбить строку lines на подстроки strings.
# Любая подстрока strings[i] - это вещественное число,
# представленное в строчном формате
strings = lines.split(' ')
# 3. 2.2. Обойти все подстроки в файле,
# конвертировать и добавить их к кортежу T2
for s in strings:
if s != '': # если непустая строка
# Конвертировать в вещественное число
num = float(s)
# Добавить к кортежу
T2 += (num,)
# 3.3. Вывести кортеж для контроля
print("T2 = ", T2) # T2 = (3.8, 2.77, -11.23, 14.75)
# 3.4. Закрыть файл
f.close()
2.2. Обойти все подстроки в файле,
# конвертировать и добавить их к кортежу T2
for s in strings:
if s != '': # если непустая строка
# Конвертировать в вещественное число
num = float(s)
# Добавить к кортежу
T2 += (num,)
# 3.3. Вывести кортеж для контроля
print("T2 = ", T2) # T2 = (3.8, 2.77, -11.23, 14.75)
# 3.4. Закрыть файл
f.close()Результат работы программы
T2 = (3.8, 2.77, -11.23, 14.75)
Вид файла myfile5.txt
3.8 2.77 -11.23 14.75
⇑
4. Чтение/запись кортежа содержащего разнотипные объекты
В случае, если кортеж содержит объекты разных типов при записи/чтении важно придерживаться последовательности этапов конвертирования объектов в нужный тип. Ниже приведен пример записи и чтения кортежа, который содержит объекты целого, логического и строчного типов.
# Запись/чтение кортежа, содержащего разнотипные объекты # 1.
 Запись кортежа в файл
# 1.1. Исходный кортеж
T1 = ( 5, True, "abcde fghi")
# 1.2. Открыть файл для записи в текстовом режиме
f = open('myfile4.txt', 'wt')
# 1.3. Поэлементная запись кортежа в файл,
# поскольку в кортеже есть строки, то записываем
# каждый элемент в отдельную строку
for item in T1:
s = str(item) + '\n' # добавить символ новой строки
f.write(s)
# Закрыть файл
f.close()
# 2. Чтение кортежа
f = open('myfile4.txt', 'rt')
# 2.1. Создать пустой кортеж
T3 = ()
# 2.2. Чтение данных из файла и создание кортежа
# Первым читается число типа int
s = f.readline()
T3 = T3 + (int(s),) # конкатенация кортежей
# Вторым читается логическое значение типа bool
s = f.readline()
T3 = T3 + (bool(s),)
# Третьим читается строка типа str
s = f.readline()
s = s.rstrip() # убрать символ '\n' из строки
T3 = T3 + (s,)
# 2.
Запись кортежа в файл
# 1.1. Исходный кортеж
T1 = ( 5, True, "abcde fghi")
# 1.2. Открыть файл для записи в текстовом режиме
f = open('myfile4.txt', 'wt')
# 1.3. Поэлементная запись кортежа в файл,
# поскольку в кортеже есть строки, то записываем
# каждый элемент в отдельную строку
for item in T1:
s = str(item) + '\n' # добавить символ новой строки
f.write(s)
# Закрыть файл
f.close()
# 2. Чтение кортежа
f = open('myfile4.txt', 'rt')
# 2.1. Создать пустой кортеж
T3 = ()
# 2.2. Чтение данных из файла и создание кортежа
# Первым читается число типа int
s = f.readline()
T3 = T3 + (int(s),) # конкатенация кортежей
# Вторым читается логическое значение типа bool
s = f.readline()
T3 = T3 + (bool(s),)
# Третьим читается строка типа str
s = f.readline()
s = s.rstrip() # убрать символ '\n' из строки
T3 = T3 + (s,)
# 2. 3. Вывести кортеж для контроля
print("T3 = ", T3) # T3 = (5, True, 'abcde fghi')
# 2.4. Закрыть файл
f.close()
3. Вывести кортеж для контроля
print("T3 = ", T3) # T3 = (5, True, 'abcde fghi')
# 2.4. Закрыть файл
f.close()Результат выполнения программы
T3 = (5, True, 'abcde fghi')
⇑
5. Чтение/запись словаря
Словарь также можно записывать в файл. В данном примере записывается и читается словарь, который содержит перечень номеров дней недели и их названий. Для облегчения чтения данных каждый элемент словаря размещается в отдельной строке.
# Запись/чтение словаря в текстовый файл.
# Словарь содержит объекты типа {int:str}
# 1. Исходный словарь - перечень дней недели и их номеров
D = { 1:'Sun', 2:'Mon', 3:'Tue', 4:'Wed', 5:'Thu', 6:'Fri', 7:'Sat' }
# 2. Запись словаря в файл
# 2.1. Открыть текстовый файл для записи
f = open('myfile6.txt', 'w')
# 2.2. Цикл записи элементов словаря в файл
for item in D:
# 2.2.1. Сформировать строку вида key:value
s = str(item) # взять ключ как строку
s += ':' # добавить символ ':'
s += D. get(item) # добавить значение value по его ключу
s += '\n' # добавить символ новой строки
# 2.2.2. Записать строку в файл
f.write(s)
# 2.3. Закрыть файл
f.close()
# 3. Чтение из файла, который содержит данные словаря D
# 3.1. Открыть файл для чтения
f = open('myfile6.txt', 'rt')
# 3.2. Создать пустой словарь D2
D2 = {}
# 3.3. Чтение данных из файла и образование нового словаря
for lines in f: # Использовать итератор файла
# 3.3.1. Любая подстрока lines - это элемент вида key:value
# представленный в строчном формате.
# Разбить lines на 2 подстроки
strings = lines.split(':')
# 3.3.2. Получить ключ и значение
key = int(strings[0]) # получить ключ
value = strings[1].rstrip() # получить значение без '\n'
# 3.3.3. Добавить пару key:value к словарю D2
D2[key] = value
# 3.4. Вывести словарь для контроля
print("D2 = ", D2)
# 3. 5. Закрыть файл
f.close() get(item) # добавить значение value по его ключу
s += '\n' # добавить символ новой строки
# 2.2.2. Записать строку в файл
f.write(s)
# 2.3. Закрыть файл
f.close()
# 3. Чтение из файла, который содержит данные словаря D
# 3.1. Открыть файл для чтения
f = open('myfile6.txt', 'rt')
# 3.2. Создать пустой словарь D2
D2 = {}
# 3.3. Чтение данных из файла и образование нового словаря
for lines in f: # Использовать итератор файла
# 3.3.1. Любая подстрока lines - это элемент вида key:value
# представленный в строчном формате.
# Разбить lines на 2 подстроки
strings = lines.split(':')
# 3.3.2. Получить ключ и значение
key = int(strings[0]) # получить ключ
value = strings[1].rstrip() # получить значение без '\n'
# 3.3.3. Добавить пару key:value к словарю D2
D2[key] = value
# 3.4. Вывести словарь для контроля
print("D2 = ", D2)
# 3.
get(item) # добавить значение value по его ключу
s += '\n' # добавить символ новой строки
# 2.2.2. Записать строку в файл
f.write(s)
# 2.3. Закрыть файл
f.close()
# 3. Чтение из файла, который содержит данные словаря D
# 3.1. Открыть файл для чтения
f = open('myfile6.txt', 'rt')
# 3.2. Создать пустой словарь D2
D2 = {}
# 3.3. Чтение данных из файла и образование нового словаря
for lines in f: # Использовать итератор файла
# 3.3.1. Любая подстрока lines - это элемент вида key:value
# представленный в строчном формате.
# Разбить lines на 2 подстроки
strings = lines.split(':')
# 3.3.2. Получить ключ и значение
key = int(strings[0]) # получить ключ
value = strings[1].rstrip() # получить значение без '\n'
# 3.3.3. Добавить пару key:value к словарю D2
D2[key] = value
# 3.4. Вывести словарь для контроля
print("D2 = ", D2)
# 3. 5. Закрыть файл
f.close()
5. Закрыть файл
f.close()Результат работы программы
D2 = {1: 'Sun', 2: 'Mon', 3: 'Tue', 4: 'Wed', 5: 'Thu', 6: 'Fri', 7: 'Sat'}Вид файла myfile6.txt
1:Sun 2:Mon 3:Tue 4:Wed 5:Thu 6:Fri 7:Sat
⇑
6. Чтение/запись двумерной матрицы целых чисел, представленной в виде списка
В примере демонстрируется запись и чтение двумерной матрицы целых чисел размерностью 3*4.
# Запись/чтение двумерной матрицы чисел
# 1. Исходная матрица целых чисел размером 3*4
M = [ [ 2, 1, -3],
[ 4, 8, -2],
[ 1, 2, 3],
[ 7, -3, 8] ]
# 2. Запись матрицы в текстовый файл
# 2.1. Открыть текстовый файл для записи
f = open('myfile8.txt', 'w')
# 2.2. Цикл записи элементов матрицы в файл
# в удобном для отображения виде
i = 0
while i < 4: # цикл по строкам
j = 0
while j < 3: # цикл по столбцам
s = str(M[i][j])
f. write(s + ' ') # между числами символ ' ' пробел
j = j+1
f.write('\n')
i = i + 1
# 2.3. Закрыть файл
f.close()
# 3. Чтение матрицы из файла
# 3.1. Открыть файл для чтения
f = open('myfile8.txt', 'rt')
# 3.2. Создать пустой список
M2 = []
# 3.3. Чтение данных из файла и образование новой матрицы
i = 0
for line in f: # Использовать итератор файла
# Конвертировать строку line в список строк
lines = line.split(' ') # разбить строку line на подстроки lines
# временный список
lst = []
# обход элементов в строке
for ln in lines:
# забрать символ '\n'
ln = ln.rstrip()
if ln != '':
num = int(ln) # взять отдельное число
lst = lst + [num] # добавить число к списку
M2 = M2 + [lst] # добавить строку к результирующей матрице
# 3. 4. Вывести матрицу M2 для контроля
print("M2 = ", M2) #
# 3.5. Закрыть файл
f.close() write(s + ' ') # между числами символ ' ' пробел
j = j+1
f.write('\n')
i = i + 1
# 2.3. Закрыть файл
f.close()
# 3. Чтение матрицы из файла
# 3.1. Открыть файл для чтения
f = open('myfile8.txt', 'rt')
# 3.2. Создать пустой список
M2 = []
# 3.3. Чтение данных из файла и образование новой матрицы
i = 0
for line in f: # Использовать итератор файла
# Конвертировать строку line в список строк
lines = line.split(' ') # разбить строку line на подстроки lines
# временный список
lst = []
# обход элементов в строке
for ln in lines:
# забрать символ '\n'
ln = ln.rstrip()
if ln != '':
num = int(ln) # взять отдельное число
lst = lst + [num] # добавить число к списку
M2 = M2 + [lst] # добавить строку к результирующей матрице
# 3.
write(s + ' ') # между числами символ ' ' пробел
j = j+1
f.write('\n')
i = i + 1
# 2.3. Закрыть файл
f.close()
# 3. Чтение матрицы из файла
# 3.1. Открыть файл для чтения
f = open('myfile8.txt', 'rt')
# 3.2. Создать пустой список
M2 = []
# 3.3. Чтение данных из файла и образование новой матрицы
i = 0
for line in f: # Использовать итератор файла
# Конвертировать строку line в список строк
lines = line.split(' ') # разбить строку line на подстроки lines
# временный список
lst = []
# обход элементов в строке
for ln in lines:
# забрать символ '\n'
ln = ln.rstrip()
if ln != '':
num = int(ln) # взять отдельное число
lst = lst + [num] # добавить число к списку
M2 = M2 + [lst] # добавить строку к результирующей матрице
# 3. 4. Вывести матрицу M2 для контроля
print("M2 = ", M2) #
# 3.5. Закрыть файл
f.close()
4. Вывести матрицу M2 для контроля
print("M2 = ", M2) #
# 3.5. Закрыть файл
f.close()Результат работы программы
M2 = [[2, 1, -3], [4, 8, -2], [1, 2, 3], [7, -3, 8]]
Вид файла myfile8.txt
2 1 -3 4 8 -2 1 2 3 7 -3 8
⇑
7. Чтение/запись множества, которое содержит целые числа
В примере демонстрируется возможный вариант сохранения множества в текстовом файле
# Запись/чтение множества в текстовом файле.
# 1. Задано множество целочисленных объектов
M = { 2, 3, -12, 22, 38 }
# 2. Запись множества в файл
# 2.1. Открыть текстовый файл для записи
f = open('myfile7.txt', 'w')
# 2.2. Цикл записи элементов множества в файл
for item in M:
# 2.2.1. Конвертировать элемент множества в строку + '\n'
s = str(item) + '\n'
# 2.2.2. Записать строку в файл
f.write(s)
# 2.3. Закрыть файл
f. close()
# 3. Чтение множества из файла
# 3.1. Открыть файл для чтения
f = open('myfile7.txt', 'rt')
# 3.2. Создать пустое множество
M2 = set()
# 3.3. Чтение данных из файла и образование нового множества
for line in f: # Использовать итератор файла
# Конвертировать строку line в целое число
num = int(line)
M2 = M2.union({num})
# 3.4. Вывести множество для контроля
print("M2 = ", M2) # M2 = {2, 3, -12, 38, 22}
# 3.5. Закрыть файл
f.close() close()
# 3. Чтение множества из файла
# 3.1. Открыть файл для чтения
f = open('myfile7.txt', 'rt')
# 3.2. Создать пустое множество
M2 = set()
# 3.3. Чтение данных из файла и образование нового множества
for line in f: # Использовать итератор файла
# Конвертировать строку line в целое число
num = int(line)
M2 = M2.union({num})
# 3.4. Вывести множество для контроля
print("M2 = ", M2) # M2 = {2, 3, -12, 38, 22}
# 3.5. Закрыть файл
f.close()
close()
# 3. Чтение множества из файла
# 3.1. Открыть файл для чтения
f = open('myfile7.txt', 'rt')
# 3.2. Создать пустое множество
M2 = set()
# 3.3. Чтение данных из файла и образование нового множества
for line in f: # Использовать итератор файла
# Конвертировать строку line в целое число
num = int(line)
M2 = M2.union({num})
# 3.4. Вывести множество для контроля
print("M2 = ", M2) # M2 = {2, 3, -12, 38, 22}
# 3.5. Закрыть файл
f.close()Результат работы программы
M2 = {2, 3, -12, 38, 22}Вид файла myfile7.txt
2 3 38 -12 22
⇑
8. Чтение/запись данных разных типов: список и кортеж
Чтобы записать в текстовый файл данные разных базовых типов нужно последовательно записать данные одного типа, затем другого типа. При считывании таких данных нужно придерживаться такого самого порядка чтобы не нарушить полученную структуру данных.
В примере демонстрируется последовательная запись в файл списка и кортежа. При чтении придерживается такая же последовательность: сначала читается список, затем кортеж. Список включает строки. Кортеж содержит вещественные числа. Чтобы облегчить работу по распознаванию формата файла, каждый записываемый (читаемый) элемент размещается в отдельной строке файла.
Поскольку список и кортеж могут содержать разное количество элементов, то в файл записываются их размерности.
# Запись/чтение данных разных типов.
# Обработка списка и кортежа.
# 1. Задан некоторый список строк и кортеж чисел
L = [ 'John Johnson', 'Peter Petrov', 'O Neill', 'J. Dunkan' ]
T = ( 2, 3.85, 7.77, -1.8, 5.25 )
# 2. Запись данных в файл: сначала записывается список, затем кортеж
# 2.1. Открыть текстовый файл для записи
f = open('myfile9.txt', 'w')
# 2.2. Записать количество элементов списка + '\n'
f.write(str(len(L)) + '\n')
# 2.3. Цикл записи элементов списка в файл
# Каждый из элементов списка размещается в новой строке.
for item in L: # обход списка
f.write(item + '\n') # записать строку в файл
# 2.4. После списка записывается кортеж,
# каждый элемент кортежа размещается в отдельной строке.
# Сначала записать количество элементов кортежа
f.write(str(len(T)) + '\n')
# обход кортежа в цикле
for item in T:
f.write(str(item) + '\n') # запись каждого элемента кортежа
# 2.3. Закрыть файл
f.close()
# 3. Чтение списка и кортежа из файла
# 3.1. Открыть файл для чтения
f = open('myfile9.txt', 'rt')
# 3.2. Создать результирующий пустой список
# и результирующий кортеж
L2 = []
T2 = ()
# 3.3. Чтение данных из файла и формирование списка L2
n = int(f.readline()) # прочитать количество элементов в списке
i = 0
while i < n: # цикл чтения строк из файла и образования списка
s = f.readline().rstrip() # прочитать строку без символа '\n'
if (s != ''):
L2 += [s]
i = i + 1
# 3. 4. Прочитать количество элементов кортежа
n = int(f.readline())
i = 0
while i < n: # цикл чтения строк и образование кортежа
s = f.readline()
if (s != ''):
T2 = T2 + (float(s),) # добавить вещественное число к кортежу
i = i+1
# 3.5. Закрыть файл
f.close()
# Вывести список и кортеж для контроля
print("L2 = ", L2)
print("T2 = ", T2)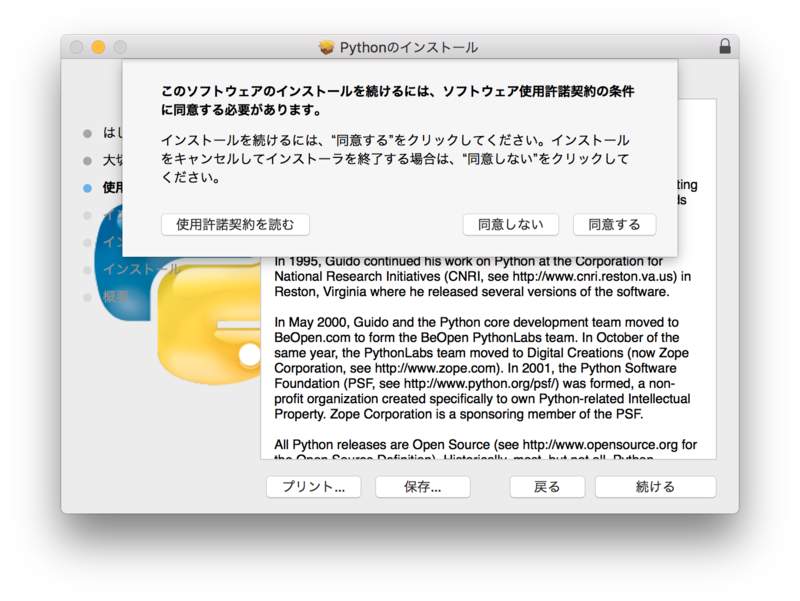 for item in L: # обход списка
f.write(item + '\n') # записать строку в файл
# 2.4. После списка записывается кортеж,
# каждый элемент кортежа размещается в отдельной строке.
# Сначала записать количество элементов кортежа
f.write(str(len(T)) + '\n')
# обход кортежа в цикле
for item in T:
f.write(str(item) + '\n') # запись каждого элемента кортежа
# 2.3. Закрыть файл
f.close()
# 3. Чтение списка и кортежа из файла
# 3.1. Открыть файл для чтения
f = open('myfile9.txt', 'rt')
# 3.2. Создать результирующий пустой список
# и результирующий кортеж
L2 = []
T2 = ()
# 3.3. Чтение данных из файла и формирование списка L2
n = int(f.readline()) # прочитать количество элементов в списке
i = 0
while i < n: # цикл чтения строк из файла и образования списка
s = f.readline().rstrip() # прочитать строку без символа '\n'
if (s != ''):
L2 += [s]
i = i + 1
# 3.
for item in L: # обход списка
f.write(item + '\n') # записать строку в файл
# 2.4. После списка записывается кортеж,
# каждый элемент кортежа размещается в отдельной строке.
# Сначала записать количество элементов кортежа
f.write(str(len(T)) + '\n')
# обход кортежа в цикле
for item in T:
f.write(str(item) + '\n') # запись каждого элемента кортежа
# 2.3. Закрыть файл
f.close()
# 3. Чтение списка и кортежа из файла
# 3.1. Открыть файл для чтения
f = open('myfile9.txt', 'rt')
# 3.2. Создать результирующий пустой список
# и результирующий кортеж
L2 = []
T2 = ()
# 3.3. Чтение данных из файла и формирование списка L2
n = int(f.readline()) # прочитать количество элементов в списке
i = 0
while i < n: # цикл чтения строк из файла и образования списка
s = f.readline().rstrip() # прочитать строку без символа '\n'
if (s != ''):
L2 += [s]
i = i + 1
# 3. 4. Прочитать количество элементов кортежа
n = int(f.readline())
i = 0
while i < n: # цикл чтения строк и образование кортежа
s = f.readline()
if (s != ''):
T2 = T2 + (float(s),) # добавить вещественное число к кортежу
i = i+1
# 3.5. Закрыть файл
f.close()
# Вывести список и кортеж для контроля
print("L2 = ", L2)
print("T2 = ", T2)
4. Прочитать количество элементов кортежа
n = int(f.readline())
i = 0
while i < n: # цикл чтения строк и образование кортежа
s = f.readline()
if (s != ''):
T2 = T2 + (float(s),) # добавить вещественное число к кортежу
i = i+1
# 3.5. Закрыть файл
f.close()
# Вывести список и кортеж для контроля
print("L2 = ", L2)
print("T2 = ", T2)Результат работы программы
L2 = ['John Johnson', 'Peter Petrov', 'O Neill', 'J. Dunkan'] T2 = (2.0, 3.85, 7.77, -1.8, 5.25)
Вид файла myfile9.txt
4 John Johnson Peter Petrov O Neill J. Dunkan 5 2 3.85 7.77 -1.8 5.25
⇑
Связанные темы
⇑
Python. Работа с файлами
Для того, чтобы открыть файл, в Python предусмотрена команда «open». Она может открывать как бинарные, так и текстовые файлы. У нее два параметра: имя файла и режим открытия. Например:
Например:
f = open(‘text.txt’, ‘r’)
f = open(‘text.txt’, ‘r’) |
откроет файл с именем “text.txt” для чтения.
Существуют следующие режимы открытия файла:
· На чтение “r”
· На запись “w”. Если файл существует, он будет перезаписан.
· На запись нового файла “x”. Если файл уже есть, выскочит исключение.
· На дозапись “a”. Информация будет добавлена в конец файла.
· В двоичном режиме “b”.
· В текстовом режиме “t”.
· На чтение и запись “+”.
Режимы можно комбинировать, например, если вы хотите открыть бинарник на чтение, то нужно использовать “rb”. Если вы хотите открыть текстовый файл, то “t” можно опустить, это является режимом по умолчанию.
Примеры работы с текстовым файлом вы можете посмотреть в цикле уроков «Взлом шифров»:
· http://wiki. programstore.ru/python-vzlom-shifrov/
programstore.ru/python-vzlom-shifrov/
· http://wiki.programstore.ru/python-vzlom-shifrov-prodolzhenie/
· http://wiki.programstore.ru/python-vzlom-shifrov-prodolzhenie-2/
Теперь разберем еще примеры.
Чтение списка файлов из каталога с заданными расширениями и поиск в них заданной строки:
#Подключаем модуль import os #Каталог из которого будем брать файлы directory = ‘d:\\1’ #Получаем список файлов в переменную files files = os.listdir(directory) #Задаем строку поиска search_str=»body» for file in files: filename, file_extension = os.path.splitext(file) s=file_extension.lower() if s==».txt» or s==».html» or s==».htm»: f = open(directory+»\\»+file) for line in f: if line.find(search_str)>-1: print(«В файле «+file+» найдена строка «+search_str) break
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
#Подключаем модуль import os
#Каталог из которого будем брать файлы directory = ‘d:\\1’
#Получаем список файлов в переменную files files = os.
#Задаем строку поиска search_str=»body»
for file in files: filename, file_extension = os.path.splitext(file) s=file_extension.lower() if s==».txt» or s==».html» or s==».htm»: f = open(directory+»\\»+file) for line in f: if line.find(search_str)>-1: print(«В файле «+file+» найдена строка «+search_str) break |
 listdir(directory)
listdir(directory)Здесь для чтения списка файлов в каталоге используем модуль «os», его же и для распарсивания имени файла на расширение и собственно имя. Результат работ что-то вроде того:
В файле 1.html найдена строка body
Теперь попробуем сохранить в файле данные в json-формате:
import json numbers = [2, 3, 5, 7, 11, 13] filename = ‘numbers1.json’ with open(filename, ‘w’) as f_obj: json.dump(numbers, f_obj)
import json numbers = [2, 3, 5, 7, 11, 13] filename = ‘numbers1. with open(filename, ‘w’) as f_obj: json.dump(numbers, f_obj) |
 json’
json’Как прочитать? Вот так:
import json filename = ‘numbers.json’ with open(filename) as f_obj: numbers=json.load(f_obj) print(numbers)
import json filename = ‘numbers.json’ with open(filename) as f_obj: numbers=json.load(f_obj)
print(numbers) |
Если открыть этот файл, то мы увидим нечто вот такое:
[2, 3, 5, 7, 11, 13]
А если попробовать записать более сложную структуру:
import json
numbers = [2, 3, 5, 7, 11, 13]
dic1={«proba1″:1,»probs2″:2,»proba3»:{«proba4″:(1,2),»proba5″:5},»proba6»:4}
dic={«numbers»:numbers,»proba»:1,»dictionary»:dic1}
filename = ‘numbers2.json’
with open(filename, ‘w’) as f_obj:
json. dump(dic, f_obj)
dump(dic, f_obj)
import json numbers = [2, 3, 5, 7, 11, 13] dic1={«proba1″:1,»probs2″:2,»proba3»:{«proba4″:(1,2),»proba5″:5},»proba6»:4} dic={«numbers»:numbers,»proba»:1,»dictionary»:dic1} filename = ‘numbers2.json’ with open(filename, ‘w’) as f_obj: json.dump(dic, f_obj) |
То и сам получены файл будет больше похож на истинный JSON:
{«numbers»: [2, 3, 5, 7, 11, 13], «proba»: 1, «dictionary»: {«proba1»: 1, «probs2»: 2, «proba3»: {«proba4»: [1, 2], «proba5»: 5}, «proba6»: 4}}
Ну и напоследок, сериализация в бинарные файлы:
import pickle
numbers = [2, 3, 5, 7, 11, 13]
dic1={«proba1″:1,»probs2″:2,»proba3»:{«proba4″:(1,2),»proba5″:5},»proba6»:4}
dic={«numbers»:numbers,»proba»:1,»dictionary»:dic1}
filename = ‘pickle.dat’
with open(filename, ‘wb’) as f_obj:
pickle. dump(dic, f_obj)
dump(dic, f_obj)
import pickle numbers = [2, 3, 5, 7, 11, 13] dic1={«proba1″:1,»probs2″:2,»proba3»:{«proba4″:(1,2),»proba5″:5},»proba6»:4} dic={«numbers»:numbers,»proba»:1,»dictionary»:dic1} filename = ‘pickle.dat’ with open(filename, ‘wb’) as f_obj: pickle.dump(dic, f_obj) |
А прочитать можно вот так:
import pickle filename = ‘pickle.dat’ with open(filename, ‘rb’) as f_obj: dic=pickle.load(f_obj) print(dic)
import pickle filename = ‘pickle.dat’ with open(filename, ‘rb’) as f_obj: dic=pickle.load(f_obj) print(dic) |
Чтение данных из файла и запись в файл
Создание файла
В Python, чтобы создать файл, надо его открыть в режиме записи (‘w’, ‘wb’) или дозаписи (‘a’, ‘ab’).
f2 = open("text2.txt", 'w')Функция open() возвращает файловый объект.
Без ‘b’ создается текстовый файл, представляющий собой поток символов. С ‘b’ — файл, содержащий поток байтов.
В Python также существует режим ‘x’ или ‘xb’. В этом режиме проверяется, есть ли файл. Если файл с определенным именем уже существует, он не будет создан. В режиме ‘w’ файл создается заново, старый при этом теряется.
>>> f1 = open('text1.txt', 'w')
>>> f2 = open('text1.txt', 'x')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
FileExistsError: [Errno 17] File exists: 'text1.txt'
>>> f3 = open('text1.txt', 'w')Чтение данных из файла
Если в функцию open() не передается второй аргумент, файл расценивается как текстовый и открывается на чтение.
Попытка открыть на чтение несуществующий файл вызывает ошибку.
>>> f = open("text10.txt")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IOError: [Errno 2] No such file or directory: 'text10. txt' txt'
txt'Перехватить возникшее исключение можно с помощью конструкции try-except.
>>> try:
... f = open("text10.txt")
... except IOError:
... print ("No file")
...
No fileПолучить все данные из файла можно с помощью метода read() файлового объекта, предварительно открыв файл на чтение. При этом файловый объект изменяется и получить из него данные еще раз не получится.
>>> f = open("text.txt")
>>> f
<_io.TextIOWrapper name='text.txt' mode='r' encoding='UTF-8'>
>>> fd = f.read()
>>> fd1 = f.read()
>>> fd
'Hello\n\tOne\n Two\nThree Four\nШесть!\n'
>>> fd1
''Методу read() может быть передан один аргумент, обозначающий количество байт для чтения.
>>> f = open("text.txt")
>>> fd = f.read(10)
>>> fd1 = f.read(5)
>>> fd
'Hello\n\tOne'
>>> fd1
'\n T'Метод readline() позволяет получать данные построчно.
>>> f = open("text. txt")
>>> f.readline()
'Hello\n'
>>> f.readline()
'\tOne\n'
>>> f.readline()
' Two\n' txt")
>>> f.readline()
'Hello\n'
>>> f.readline()
'\tOne\n'
>>> f.readline()
' Two\n'
txt")
>>> f.readline()
'Hello\n'
>>> f.readline()
'\tOne\n'
>>> f.readline()
' Two\n'Принимает аргумент — число байт.
>>> f.readline(3) 'Thr' >>> f.readline(3) 'ee ' >>> f.readline(3) 'Fou' >>> f.readline(3) 'r\n' >>> f.readline(5) 'Шесть' >>> f.readline(5) '!\n'
Метод readlines() считывает все строки и помещает их в список.
>>> f = open("text.txt")
>>> fd = f.readlines()
>>> fd
['Hello\n', '\tOne\n', ' Two\n', 'Three Four\n', 'Шесть!\n']Может принимать количество байт, но дочитывает строку до конца.
>>> f = open("text.txt")
>>> fd = f.readlines(3)
>>> fd
['Hello\n']
>>> fd1 = f.readlines(6)
>>> fd1
['\tOne\n', ' Two\n']Запись данных в файл
Записать данные в файл можно с помощью метода write(), который возвращает число записанных символов.
>>> f1 = open("text1. txt", 'w')
>>> f1.write("Table, cup.\nBig, small.")
23
>>> a = f1.write("Table, cup.\nBig, small.")
>>> type(a)
<class 'int'> txt", 'w')
>>> f1.write("Table, cup.\nBig, small.")
23
>>> a = f1.write("Table, cup.\nBig, small.")
>>> type(a)
<class 'int'>
txt", 'w')
>>> f1.write("Table, cup.\nBig, small.")
23
>>> a = f1.write("Table, cup.\nBig, small.")
>>> type(a)
<class 'int'>Файл, открытый на запись, нельзя прочитать. Для этого требуется его закрыть, а потом открыть на чтение.
>>> f1.read()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
io.UnsupportedOperation: not readable
>>> f1.close()
>>> f1 = open("text1.txt", 'r')
>>> f1.read()
'Table, cup.\nBig, small.Table, cup.\nBig, small.'С помощью метода writelines() можно записать в файл итерируемую последовательность.
>>> a = [1,2,3,4,5,6,7,8,9,0]
>>> f = open("text2.txt",'w')
>>> f.writelines("%s\n" % i for i in a)
>>> f.close()
>>> open("text2.txt").read()
'1\n2\n3\n4\n5\n6\n7\n8\n9\n0\n'
>>> print(open("text2.txt").read())
1
2
3
4
5
6
7
8
9
0Смена позиции в файле
>>> f = open('text. txt')
>>> f.read()
'Hello\n\tOne\n Two\nThree Four\nШесть!\n'
>>> f.close()
>>> f = open('text.txt')
>>> f.seek(10)
10
>>> f.read()
'\n Two\nThree Four\nШесть!\n' txt')
>>> f.read()
'Hello\n\tOne\n Two\nThree Four\nШесть!\n'
>>> f.close()
>>> f = open('text.txt')
>>> f.seek(10)
10
>>> f.read()
'\n Two\nThree Four\nШесть!\n'
txt')
>>> f.read()
'Hello\n\tOne\n Two\nThree Four\nШесть!\n'
>>> f.close()
>>> f = open('text.txt')
>>> f.seek(10)
10
>>> f.read()
'\n Two\nThree Four\nШесть!\n'Двоичные файлы
Пример копирования изображения:
>>> f1 = open('flag.png', 'rb')
>>> f2 = open('flag2.png', 'wb')
>>> f2.write(f1.read())
446
>>> f1.close()
>>> f2.close()Модуль struct позволяет преобразовывать данные к бинарному виду и обратно.
>>> f = open('text3.txt', 'wb')
>>> f.write('3')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'str' does not support the buffer interface
>>> d = struct.pack('>i',3)
>>> d
b'\x00\x00\x00\x03'
>>> f.write(d)
4
>>> f.close()
>>> f = open('text3.txt')
>>> d = f.read()
>>> d
'\x00\x00\x00\x03'
>>> struct.unpack('>i',d)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'str' does not support the buffer interface
>>> f = open('text3. txt', 'rb')
>>> d = f.read()
>>> d
b'\x00\x00\x00\x03'
>>> struct.unpack('>i',d)
(3,) txt', 'rb')
>>> d = f.read()
>>> d
b'\x00\x00\x00\x03'
>>> struct.unpack('>i',d)
(3,)
txt', 'rb')
>>> d = f.read()
>>> d
b'\x00\x00\x00\x03'
>>> struct.unpack('>i',d)
(3,)Файлы. Работа с файлами. — Питошка
В данной статье мы рассмотрим встроенные средства python для работы с файлами: открытие / закрытие, чтение и запись.
Итак, начнем. Прежде, чем работать с файлом, его надо открыть. С этим замечательно справится встроенная функция open:
f = open('text.txt', 'r')
У функции open много параметров, они указаны в статье «Встроенные функции«, нам пока важны 3 аргумента: первый, это имя файла. Путь к файлу может быть относительным или абсолютным. Второй аргумент, это режим, в котором мы будем открывать файл.
| Режим | Обозначение |
| ‘r’ | открытие на чтение (является значением по умолчанию). |
| ‘w’ | открытие на запись, содержимое файла удаляется, если файла не существует, создается новый. |
| ‘x’ | открытие на запись, если файла не существует, иначе исключение. |
| ‘a’ | открытие на дозапись, информация добавляется в конец файла. |
| ‘b’ | открытие в двоичном режиме. |
| ‘t’ | открытие в текстовом режиме (является значением по умолчанию). |
| ‘+’ | открытие на чтение и запись |
Режимы могут быть объединены, то есть, к примеру, ‘rb’ — чтение в двоичном режиме. По умолчанию режим равен ‘rt’.
И последний аргумент, encoding, нужен только в текстовом режиме чтения файла. Этот аргумент задает кодировку.
Чтение из файлаОткрыли мы файл, а теперь мы хотим прочитать из него информацию. Для этого есть несколько способов, но большого интереса заслуживают лишь два из них.
Первый — метод read, читающий весь файл целиком, если был вызван без аргументов, и n символов, если был вызван с аргументом (целым числом n).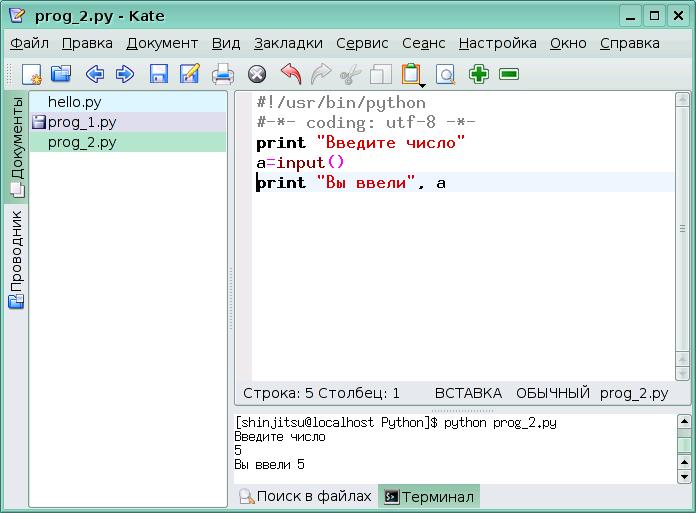
>>> f = open('text.txt')
>>> f.read(1)
'H'
>>> f.read()
'ello world!\nThe end.\n\n'
Ещё один способ сделать это — прочитать файл построчно, воспользовавшись циклом for:
>>> f = open('text.txt')
>>> for line in f:
... line
...
'Hello world!\n'
'\n'
'The end.\n'
'\n'
Запись в файлТеперь рассмотрим запись в файл. Попробуем записать в файл вот такой вот список:
>>> l = [str(i)+str(i-1) for i in range(20)] >>> l ['0-1', '10', '21', '32', '43', '54', '65', '76', '87', '98', '109', '1110', '1211', '1312', '1413', '1514', '1615', '1716', '1817', '1918']
Откроем файл на запись:
>>> f = open('text.txt', 'w')
Запись в файл осуществляется с помощью метода write:
>>> for index in l: ... f.write(index + '\n') ... 4 3 3 3 3
Для тех, кто не понял, что это за цифры, поясню: метод write возвращает число записанных символов.
После окончания работы с файлом его обязательно нужно закрыть с помощью метода close:
>>> f.close()
Теперь попробуем воссоздать этот список из получившегося файла. Откроем файл на чтение (надеюсь, вы поняли, как это сделать?), и прочитаем строки.
>>> f = open('text.txt', 'r')
>>> l = [line.strip() for line in f]
>>> l
['0-1', '10', '21', '32', '43', '54', '65', '76', '87', '98', '109', '1110', '1211', '1312', '1413', '1514', '1615', '1716', '1817', '1918']
>>> f.close()
Мы получили тот же список, что и был. В более сложных случаях (словарях, вложенных кортежей и т. д.) алгоритм записи придумать сложнее. Но это и не нужно. В python уже давно придумали средства, такие как pickle или json, позволяющие сохранять в файле сложные структуры.
Работа с файлами в Python — Настоящий Python
Python имеет несколько встроенных модулей и функций для работы с файлами. Эти функции распределены по нескольким модулям, таким как
Эти функции распределены по нескольким модулям, таким как os , os.path , shutil и pathlib , и это лишь некоторые из них. В этой статье собраны в одном месте многие функции, которые вам необходимо знать для выполнения наиболее распространенных операций с файлами в Python.
Из этого руководства вы узнаете, как:
- Получить свойства файла
- Создать каталог
- Шаблоны соответствия в именах файлов
- Переход по деревьям каталогов
- Создавать временные файлы и каталоги
- Удалить файлы и каталоги
- Копирование, перемещение или переименование файлов и каталогов
- Создание и распаковка архивов ZIP и TAR
- Открыть несколько файлов с помощью модуля
fileinput
Бесплатный бонус: 5 мыслей о Python Mastery, бесплатный курс для разработчиков Python, который показывает вам план развития и образ мышления, который вам понадобится, чтобы вывести свои навыки Python на новый уровень.
Шаблон Python «с открытым (…) как…»
Чтение и запись данных в файлы с помощью Python довольно просты. Для этого сначала необходимо открыть файлы в соответствующем режиме. Вот пример того, как использовать шаблон Python «with open (…) as…» для открытия текстового файла и чтения его содержимого:
с open ('data.txt', 'r') как f:
data = f.read ()
open () принимает в качестве аргументов имя файла и режим. r открывает файл в режиме только для чтения.Чтобы записать данные в файл, вместо этого передайте w в качестве аргумента:
с open ('data.txt', 'w') как f:
data = 'некоторые данные для записи в файл'
f.write (данные)
В приведенных выше примерах open () открывает файлы для чтения или записи и возвращает дескриптор файла (в данном случае f ), который предоставляет методы, которые можно использовать для чтения или записи данных в файл. Прочтите Работа с файловым вводом-выводом в Python для получения дополнительной информации о том, как читать и писать в файлы.
Прочтите Работа с файловым вводом-выводом в Python для получения дополнительной информации о том, как читать и писать в файлы.
Получение листинга каталога
Предположим, в вашем текущем рабочем каталоге есть подкаталог с именем my_directory со следующим содержимым:
my_directory /
|
├── sub_dir /
| ├── bar.py
| └── foo.py
|
├── sub_dir_b /
| └── file4.txt
|
├── sub_dir_c /
| ├── config.py
| └── file5.txt
|
├── file1.py
├── file2.csv
└── file3.txt
Встроенный модуль os имеет ряд полезных функций, которые можно использовать для отображения содержимого каталогов и фильтрации результатов.Чтобы получить список всех файлов и папок в конкретном каталоге файловой системы, используйте os.listdir () в устаревших версиях Python или os.scandir () в Python 3.x. os.scandir () — предпочтительный метод для использования, если вы также хотите получить свойства файла и каталога, такие как размер файла и дата модификации.
в устаревших версиях Python
В версиях Python до Python 3 os.listdir () — это метод, используемый для получения списка каталогов:
>>> импорт ОС
>>> entry = os.listdir ('мой_директория /')
os.listdir () возвращает список Python, содержащий имена файлов и подкаталогов в каталоге, заданном аргументом пути:
>>> os.listdir ('my_directory /')
['sub_dir_c', 'file1.py', 'sub_dir_b', 'file3.txt', 'file2.csv', 'sub_dir']
Такой список каталогов нелегко прочитать. Распечатка вывода вызова на os.listdir () с использованием цикла помогает навести порядок:
>>> entry = os.listdir ('мой_директория /')
>>> для записи в записи:
... печать (запись)
...
...
sub_dir_c
file1.py
sub_dir_b
file3.txt
file2.csv
sub_dir
Список каталоговв современных версиях Python
В современных версиях Python альтернативой os. является использование  listdir ()
listdir () os.scandir () и pathlib.Path () .
os.scandir () был представлен в Python 3.5 и задокументирован в PEP 471. os.scandir () при вызове возвращает итератор, а не список:
>>> импорт ОС
>>> entry = os.scandir ('мой_каталог /')
>>> записи
<объект posix.ScandirIterator по адресу 0x7f5b047f3690>
ScandirIterator указывает на все записи в текущем каталоге. Вы можете перебрать содержимое итератора и распечатать имена файлов:
импорт ОС
с os.scandir ('my_directory /') в качестве записей:
для записи в записи:
печать (entry.name)
Здесь os.scandir () используется вместе с оператором с , поскольку он поддерживает протокол диспетчера контекста.Использование диспетчера контекста закрывает итератор и автоматически освобождает полученные ресурсы после того, как итератор исчерпан. Результатом является распечатка имен файлов в
Результатом является распечатка имен файлов в my_directory / , как вы видели в примере os.listdir () :
sub_dir_c
file1.py
sub_dir_b
file3.txt
file2.csv
sub_dir
Другой способ получить список каталогов — использовать модуль pathlib :
из пути импорта pathlib
записи = Путь ('my_directory /')
для записи в записи.iterdir ():
печать (entry.name)
Объекты, возвращаемые Path , являются объектами PosixPath или WindowsPath в зависимости от ОС.
pathlib.Path () Объекты имеют метод .iterdir () для создания итератора всех файлов и папок в каталоге. Каждая запись, выдаваемая .iterdir () , содержит информацию о файле или каталоге, такую как его имя и атрибуты файла. pathlib впервые был представлен в Python 3.4 и является отличным дополнением к Python, предоставляющим объектно-ориентированный интерфейс для файловой системы.
В приведенном выше примере вы вызываете pathlib.Path () и передаете ему аргумент пути. Далее следует вызов .iterdir () для получения списка всех файлов и каталогов в my_directory .
pathlib предлагает набор классов, отображающих большинство общих операций над путями простым и объектно-ориентированным способом. Использование pathlib более, если не столь же эффективно, как использование функций в os .Еще одно преимущество использования pathlib по сравнению с os заключается в том, что это уменьшает количество операций импорта, которые необходимо выполнить для управления путями файловой системы. Для получения дополнительной информации прочтите модуль pathlib Python 3: Укрощение файловой системы.
Выполнение приведенного выше кода дает следующее:
sub_dir_c
file1.py
sub_dir_b
file3.txt
file2.csv
sub_dir
Использование pathlib. или  Path ()
Path () os.scandir () вместо os.listdir () является предпочтительным способом получения списка каталогов, особенно когда вы работаете с кодом, которому требуется тип файла и информация об атрибутах файла. pathlib.Path () предлагает большую часть функций обработки файлов и путей, которые есть в os и shutil , и его методы более эффективны, чем некоторые из этих модулей. Вскоре мы обсудим, как получить свойства файла.
Вот еще раз функции списка каталогов:
| Функция | Описание |
|---|---|
os.listdir () | Возвращает список всех файлов и папок в каталоге |
ос.скандир () | Возвращает итератор всех объектов в каталоге, включая информацию об атрибутах файла. |
pathlib.Path.iterdir () | Возвращает итератор всех объектов в каталоге, включая информацию об атрибутах файла. |
Эти функции возвращают список из всего в каталоге, включая подкаталоги. Это не всегда может быть тем поведением, которое вам нужно. В следующем разделе будет показано, как фильтровать результаты из списка каталогов.
Список всех файлов в каталоге
В этом разделе показано, как распечатать имена файлов в каталоге с помощью os.listdir () , os.scandir () и pathlib.Path () . Чтобы отфильтровать каталоги и перечислить только файлы из списка каталогов, созданного os.listdir () , используйте os.path :
импорт ОС
# Вывести список всех файлов в каталоге с помощью os.listdir
basepath = 'my_directory /'
для записи в os.listdir (базовый путь):
если os.path.isfile (os.path.join (базовый путь, запись)):
печать (запись)
Здесь вызов os.listdir () возвращает список всего по указанному пути, а затем этот список фильтруется os., чтобы распечатать только файлы, а не каталоги. Это дает следующий результат: path.isfile ()
path.isfile ()
file1.py
file3.txt
file2.csv
Более простой способ вывести список файлов в каталоге — использовать os.scandir () или pathlib.Path () :
импорт ОС
# Вывести список всех файлов в каталоге с помощью scandir ()
basepath = 'my_directory /'
с os.scandir (basepath) как записи:
для записи в записи:
если entry.is_file ():
печать (entry.name)
Использование os.scandir () имеет то преимущество, что выглядит чище и легче для понимания, чем использование os.listdir () , хотя это на одну строку кода длиннее. Вызов entry.is_file () для каждого элемента в ScandirIterator возвращает True , если объект является файлом. Распечатав имена всех файлов в каталоге, вы получите следующий результат:
файл1. ру
file3.txt
file2.csv
 ру
file3.txt
file2.csv
ру
file3.txt
file2.csv
Вот как вывести список файлов в каталоге с помощью pathlib.Path () :
из пути импорта pathlib
basepath = Путь ('my_directory /')
files_in_basepath = basepath.iterdir ()
для элемента в files_in_basepath:
если item.is_file ():
печать (название предмета)
Здесь вы вызываете .is_file () для каждой записи, полученной с помощью .iterdir () . На выходе такая же:
file1.py
файл3.текст
file2.csv
Приведенный выше код можно сделать более кратким, если объединить цикл for и оператор if в одно выражение генератора. У Дэна Бадера есть отличная статья о выражениях генератора и понимании списков.
Модифицированная версия выглядит так:
из пути импорта pathlib
# Список всех файлов в каталоге, используя pathlib
basepath = Путь ('my_directory /')
files_in_basepath = (запись для входа в basepath. iterdir (), если запись.is_file ())
для элемента в files_in_basepath:
печать (название предмета)
 iterdir (), если запись.is_file ())
для элемента в files_in_basepath:
печать (название предмета)
iterdir (), если запись.is_file ())
для элемента в files_in_basepath:
печать (название предмета)
Результат точно такой же, как в предыдущем примере. В этом разделе показано, что фильтрация файлов или каталогов с использованием os.scandir () и pathlib.Path () более интуитивно понятна и выглядит чище, чем использование os.listdir () в сочетании с os.path .
Список подкаталогов
Чтобы вывести список подкаталогов вместо файлов, используйте один из следующих способов.Вот как использовать os.listdir () и os.path () :
импорт ОС
# Список всех подкаталогов с помощью os.listdir
basepath = 'my_directory /'
для записи в os.listdir (базовый путь):
если os.path.isdir (os.path.join (basepath, entry)):
печать (запись)
Управление путями файловой системы таким образом может быстро стать обременительным, если у вас есть несколько вызовов os.. Запуск этого на моем компьютере дает следующий результат: path.join ()
path.join ()
sub_dir_c
sub_dir_b
sub_dir
Вот как использовать os.scandir () :
импорт ОС
# Вывести список всех подкаталогов с помощью scandir ()
basepath = 'my_directory /'
с os.scandir (basepath) в качестве записей:
для записи в записи:
если entry.is_dir ():
печать (entry.name)
Как и в примере со списком файлов, здесь вы вызываете .is_dir () для каждой записи, возвращаемой os.scandir () . Если запись является каталогом, .is_dir () возвращает True , и имя каталога распечатывается.Вывод такой же, как и выше:
sub_dir_c
sub_dir_b
sub_dir
Вот как использовать pathlib.Path () :
из пути импорта pathlib
# Список всех подкаталогов с помощью pathlib
basepath = Путь ('my_directory /')
для входа в basepath. iterdir ():
если entry.is_dir ():
печать (entry.name)
 iterdir ():
если entry.is_dir ():
печать (entry.name)
iterdir ():
если entry.is_dir ():
печать (entry.name)
Вызов .is_dir () для каждой записи базового пути Итератор проверяет, является ли запись файлом или каталогом.Если запись является каталогом, ее имя выводится на экран, а результат такой же, как и в предыдущем примере:
sub_dir_c
sub_dir_b
sub_dir
Получение атрибутов файла
Python упрощает получение атрибутов файла, таких как размер файла и время изменения. Это делается через os.stat () , os.scandir () или pathlib.Path () .
os.scandir () и pathlib.Path () получить список каталогов с объединенными атрибутами файлов. Это может быть потенциально более эффективным, чем использование os.listdir () для вывода списка файлов и последующего получения информации об атрибутах для каждого файла.
Примеры ниже показывают, как получить время последнего изменения файлов в my_directory / . Вывод в секундах:
Вывод в секундах:
>>> импорт ОС
>>> с os.scandir ('my_directory /') в качестве dir_contents:
... для записи в dir_contents:
... info = entry.stat ()
... печать (info.st_mtime)
...
15399,0052035
15369,6324475
1538998552.2402923
1540233322.4009316
15371.0497339
1540266380.3434134
os.scandir () возвращает объект ScandirIterator . Каждая запись в объекте ScandirIterator имеет метод .stat () , который извлекает информацию о файле или каталоге, на который он указывает. .stat () предоставляет такую информацию, как размер файла и время последней модификации.В приведенном выше примере код распечатывает атрибут st_mtime , который указывает время последнего изменения содержимого файла.
Модуль pathlib имеет соответствующие методы для получения информации о файлах, которые дают те же результаты:
>>> from pathlib import Path
>>> current_dir = Путь ('my_directory')
>>> для пути в current_dir. iterdir ():
... информация = путь.stat ()
... печать (info.st_mtime)
...15399,0052035
15369,6324475
1538998552.2402923
1540233322.4009316
15371.0497339
1540266380.3434134
 iterdir ():
... информация = путь.stat ()
... печать (info.st_mtime)
...15399,0052035
153
iterdir ():
... информация = путь.stat ()
... печать (info.st_mtime)
...15399,0052035
153 В приведенном выше примере код просматривает объект, возвращаемый функцией .iterdir () , и извлекает атрибуты файла с помощью вызова .stat () для каждого файла в списке каталогов. Атрибут st_mtime возвращает значение с плавающей запятой, которое представляет секунды с начала эпохи. Чтобы преобразовать значения, возвращаемые st_mtime для отображения, вы можете написать вспомогательную функцию для преобразования секунд в объект datetime :
из datetime import datetime
из os import scandir
def convert_date (отметка времени):
d = дата и время.utcfromtimestamp (отметка времени)
formated_date = d.strftime ('% d% b% Y')
вернуть formated_date
def get_files ():
dir_entries = scandir ('мой_каталог /')
для записи в dir_entries:
если entry. is_file ():
info = entry.stat ()
print (f '{entry.name} \ t Последнее изменение: {convert_date (info.st_mtime)}')
 is_file ():
info = entry.stat ()
print (f '{entry.name} \ t Последнее изменение: {convert_date (info.st_mtime)}')
is_file ():
info = entry.stat ()
print (f '{entry.name} \ t Последнее изменение: {convert_date (info.st_mtime)}')
Это сначала получит список файлов в my_directory и их атрибуты, а затем вызовет convert_date () для преобразования времени последнего изменения каждого файла в удобочитаемую форму. convert_date () использует .strftime () для преобразования времени в секундах в строку.
В .strftime () передаются следующие аргументы:
-
% d: день месяца -
% b: месяц, сокращенно -
% Y: год
Вместе эти директивы производят вывод, который выглядит следующим образом:
>>> >>> get_files ()
файл1.py Последнее изменение: 4 октября 2018 г.
file3.txt Последнее изменение: 17 сен 2018
file2.txt Последнее изменение: 17 сен 2018
Синтаксис преобразования даты и времени в строки может сбивать с толку.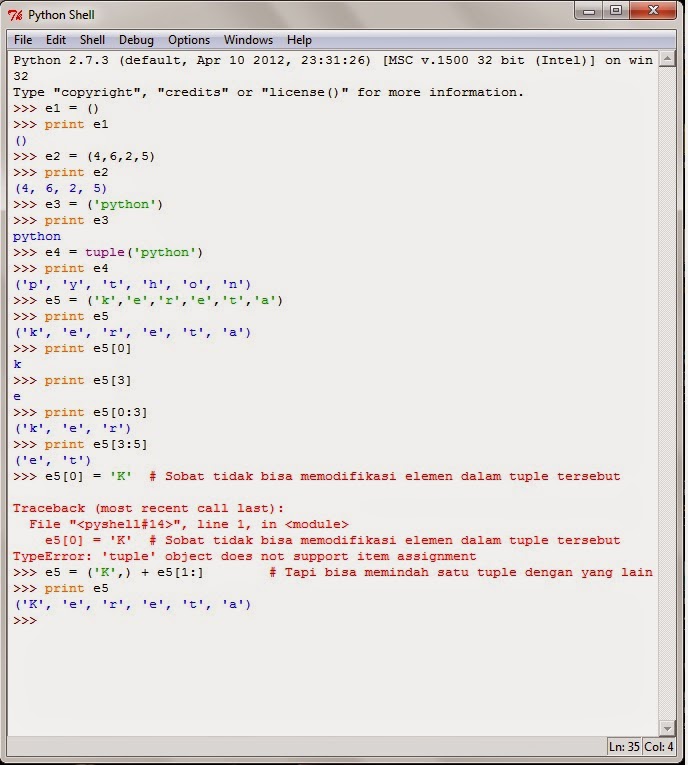 Чтобы узнать больше об этом, ознакомьтесь с официальной документацией по нему. Еще одна удобная ссылка, которую легко запомнить, — это http://strftime.org/.
Чтобы узнать больше об этом, ознакомьтесь с официальной документацией по нему. Еще одна удобная ссылка, которую легко запомнить, — это http://strftime.org/.
Создание каталогов
Рано или поздно программы, которые вы пишете, должны будут создавать каталоги для хранения в них данных. os и pathlib включают функции для создания каталогов. Мы рассмотрим это:
| Функция | Описание |
|---|---|
os.mkdir () | Создает единственный подкаталог |
pathlib.Path.mkdir () | Создает один или несколько каталогов |
os.makedirs () | Создает несколько каталогов, включая промежуточные каталоги |
Создание единого каталога
Чтобы создать отдельный каталог, передайте путь к каталогу в качестве параметра os.mkdir () :
импорт ОС
os. mkdir ('каталог_пример /')
 mkdir ('каталог_пример /')
mkdir ('каталог_пример /')
Если каталог уже существует, os.mkdir () вызывает FileExistsError . В качестве альтернативы вы можете создать каталог, используя pathlib :
из пути импорта pathlib
p = Путь ('example_directory /')
p.mkdir ()
Если путь уже существует, mkdir () вызывает FileExistsError :
>>> п.mkdir ()
Отслеживание (последний вызов последний):
Файл '', строка 1, в
Файл '/usr/lib/python3.5/pathlib.py', строка 1214, в mkdir
self._accessor.mkdir (сам, режим)
Файл '/usr/lib/python3.5/pathlib.py', строка 371, в оболочке
вернуть strfunc (str (pathobj), * args)
FileExistsError: [Errno 17] Файл существует: '.'
[Errno 17] Файл существует: '.'
Чтобы избежать подобных ошибок, перехватите ошибку, когда она возникает, и сообщите своему пользователю:
из пути импорта pathlib
p = Путь ('example_directory')
пытаться:
п. mkdir ()
кроме FileExistsError как exc:
печать (искл)
 mkdir ()
кроме FileExistsError как exc:
печать (искл)
mkdir ()
кроме FileExistsError как exc:
печать (искл)
Кроме того, вы можете игнорировать FileExistsError , передав аргумент exist_ok = True в .mkdir () :
из пути импорта pathlib
p = Путь ('example_directory')
p.mkdir (exist_ok = True)
Это не вызовет ошибки, если каталог уже существует.
Создание нескольких каталогов
os.makedirs () похож на os.mkdir () . Разница между ними состоит в том, что os.makedirs () может не только создавать отдельные каталоги, но также может использоваться для создания деревьев каталогов. Другими словами, он может создавать любые необходимые промежуточные папки, чтобы гарантировать существование полного пути.
os.makedirs () аналогичен запуску mkdir -p в Bash. Например, чтобы создать группу каталогов типа 2018/10/05 , все, что вам нужно сделать, это следующее:
импорт ОС
Операционные системы. makedirs ('2018/10/05')
 makedirs ('2018/10/05')
makedirs ('2018/10/05')
Будет создана вложенная структура каталогов, содержащая папки 2018, 10 и 05:
.
|
└── 2018 /
└── 10 /
└── 05 /
.makedirs () создает каталоги с разрешениями по умолчанию. Если вам нужно создать каталоги с разными разрешениями, вызовите .makedirs () и перейдите в режим, в котором вы хотите, чтобы каталоги были созданы:
импорт ОС
os.makedirs ('2018/10/05', mode = 0o770)
Это создает структуру каталогов 2018/10/05 и дает владельцу и группе пользователей права на чтение, запись и выполнение.Режим по умолчанию — 0o777 , и биты прав доступа к файлам существующих родительских каталогов не меняются. Дополнительные сведения о разрешениях для файлов и о том, как применяется режим, см. В документации.
Запустите tree , чтобы убедиться, что были применены правильные разрешения:
$ дерево -p -i.
.
[drwxrwx ---] 2018 г.
[drwxrwx ---] 10
[drwxrwx ---] 05
 .
[drwxrwx ---] 2018 г.
[drwxrwx ---] 10
[drwxrwx ---] 05
.
[drwxrwx ---] 2018 г.
[drwxrwx ---] 10
[drwxrwx ---] 05
Распечатывает дерево каталогов текущего каталога. дерево обычно используется для отображения содержимого каталогов в древовидном формате.Передача ему аргументов -p и -i выводит имена каталогов и информацию о правах доступа к файлам в вертикальном списке. -p распечатывает права доступа к файлам, а -i заставляет tree создавать вертикальный список без строк отступов.
Как видите, все каталоги имеют 770 разрешений. Альтернативный способ создания каталогов — использовать .mkdir () из pathlib.Path :
импорт pathlib
p = pathlib.Путь ('2018/10/05')
p.mkdir (родители = Истина)
Передача parent = True в Path.mkdir () заставляет его создать каталог 05 и все родительские каталоги, необходимые для обеспечения правильности пути.
По умолчанию os.makedirs () и Path.mkdir () вызывают OSError , если целевой каталог уже существует. Это поведение можно переопределить (начиная с Python 3.2), передав exist_ok = True в качестве аргумента ключевого слова при вызове каждой функции.
Выполнение приведенного выше кода за один раз создает структуру каталогов, подобную приведенной ниже:
.
|
└── 2018 /
└── 10 /
└── 05 /
Я предпочитаю использовать pathlib при создании каталогов, потому что я могу использовать ту же функцию для создания одиночных или вложенных каталогов.
Сопоставление с шаблоном имени файла
После получения списка файлов в каталоге одним из описанных выше методов вы, скорее всего, захотите найти файлы, соответствующие определенному шаблону.
Это доступные вам методы и функции:
-
заканчивается с ()иначинается с ()строковых методов -
fnmatch. fnmatch () -
glob.glob () -
pathlib.Path.glob ()
 fnmatch ()
fnmatch () Каждый из них обсуждается ниже. Примеры в этом разделе будут выполняться в каталоге с именем some_directory , который имеет следующую структуру:
.|
├── sub_dir /
| ├── file1.py
| └── file2.py
|
├── admin.py
├── data_01_backup.txt
├── data_01.txt
├── data_02_backup.txt
├── data_02.txt
├── data_03_backup.txt
├── data_03.txt
└── tests.py
Если вы используете оболочку Bash, вы можете создать указанную выше структуру каталогов с помощью следующих команд:
$ mkdir some_directory
$ cd some_directory /
$ mkdir sub_dir
$ touch sub_dir / file1.py sub_dir / file2.py
$ touch data_ {01..03} .txt data_ {01..03} _backup.txt admin.py tests.py
Это создаст каталог some_directory / , перейдет в него, а затем создаст sub_dir . Следующая строка создает file1.py и file2. в  py
py sub_dir , а последняя строка создает все остальные файлы с использованием расширения. Чтобы узнать больше о расширении оболочки, посетите этот сайт.
Использование строковых методов
Python имеет несколько встроенных методов для изменения и управления строками. Два из этих методов, .Startwith () и .endswith () полезны при поиске шаблонов в именах файлов. Для этого сначала получите список каталогов, а затем переберите его:
>>> импорт ОС
>>> # Получить файлы .txt
>>> для f_name в os.listdir ('some_directory'):
... если f_name.endswith ('. txt'):
... печать (f_name)
Приведенный выше код находит все файлы в some_directory / , перебирает их и использует .endwith () , чтобы распечатать имена файлов с расширением .txt . Запуск этого на моем компьютере дает следующий результат:
data_01.txt
data_03.txt
data_03_backup.txt
data_02_backup. txt
data_02.txt
data_01_backup.txt
 txt
data_02.txt
data_01_backup.txt
txt
data_02.txt
data_01_backup.txt
Сопоставление простого имени файла с шаблоном с использованием
fnmatch Строковые методы ограничены в возможностях сопоставления. fnmatch имеет более продвинутые функции и методы для сопоставления с образцом.Мы рассмотрим fnmatch.fnmatch () , функцию, которая поддерживает использование подстановочных знаков, таких как * и ? для соответствия имен файлов. Например, чтобы найти все файлов .txt в каталоге с помощью fnmatch , вы должны сделать следующее:
>>> импорт ОС
>>> импортировать fnmatch
>>> для имени_файла в os.listdir ('some_directory /'):
... если fnmatch.fnmatch (имя_файла, '* .txt'):
... печать (имя_файла)
Перебирает список файлов в some_directory и использует .fnmatch () для выполнения поиска по шаблону для файлов с расширением .txt .
Более расширенное сопоставление с образцом
Предположим, вы хотите найти файлов .txt , которые соответствуют определенным критериям. Например, вам может быть интересно найти только файлов .txt , которые содержат слово data , число между набором символов подчеркивания и слово backup в своем имени файла. Что-то похожее на data_01_backup , data_02_backup или data_03_backup .
Используя fnmatch.fnmatch () , вы можете сделать это так:
>>> для имени файла в os.listdir ('.'):
... если fnmatch.fnmatch (имя файла, 'data _ * _ backup.txt'):
... печать (имя файла)
Здесь вы печатаете только имена файлов, которые соответствуют шаблону data _ * _ backup.txt . Звездочка в шаблоне будет соответствовать любому символу, поэтому при его запуске будут найдены все текстовые файлы, имена файлов которых начинаются со слова data и заканчиваются резервной копией ., как видно из вывода ниже: txt
txt
data_03_backup.txt
data_02_backup.txt
data_01_backup.txt
Сопоставление с шаблоном имени файла с использованием
glob Еще один полезный модуль для сопоставления с образцом — glob .
.glob () в модуле glob работает так же, как fnmatch.fnmatch () , но в отличие от fnmatch.fnmatch () , он обрабатывает файлы, начинающиеся с точки (. ), как особые.
UNIX и родственные системы переводят шаблоны имен с использованием подстановочных знаков, например ? и * в список файлов. Это называется глобусом.
Например, при вводе mv * .py python_files / в оболочке UNIX ( mv ) все файлы с расширением .py из текущего каталога в каталог python_files . Символ * — это подстановочный знак, который означает «любое количество символов», а * . — шаблон глобуса.Эта возможность оболочки недоступна в операционной системе Windows. Модуль  py
py glob добавляет эту возможность в Python, что позволяет программам Windows использовать эту функцию.
Вот пример того, как использовать glob для поиска всех исходных файлов Python ( .py ) в текущем каталоге:
>>> импорт глоб
>>> glob.glob ('*. py')
['admin.py', 'tests.py']
glob.glob ('*. Py') выполняет поиск всех файлов с .py в текущем каталоге и возвращает их в виде списка. glob также поддерживает подстановочные знаки в стиле оболочки для соответствия шаблонам:
>>> импорт глоб
>>> для имени в glob.glob ('* [0-9] *. txt'):
... печать (имя)
Это находит все текстовые файлы ( .txt ), которые содержат цифры в имени файла:
data_01.txt
data_03.txt
data_03_backup.txt
data_02_backup.txt
data_02. txt
data_01_backup.txt
 txt
data_01_backup.txt
txt
data_01_backup.txt
glob упрощает рекурсивный поиск файлов в подкаталогах:
>>> импорт глоб
>>> для файла в glob.iglob ('** / *. py', рекурсивный = True):
... распечатать файл)
В этом примере используется glob.iglob () для поиска файлов .py в текущем каталоге и подкаталогах. Передача recursive = True в качестве аргумента функции .iglob () приводит к поиску файлов .py в текущем каталоге и любых подкаталогах. Разница между glob.iglob () и glob.glob () заключается в том, что .iglob () возвращает итератор вместо списка.
Выполнение указанной выше программы дает следующее:
admin.py
tests.py
под_каталог / file1.py
под_каталог / file2.py
pathlib содержит аналогичные методы для создания гибких списков файлов. В приведенном ниже примере показано, как можно использовать . для перечисления типов файлов, начинающихся с буквы  Path.glob ()
Path.glob () p :
>>> from pathlib import Path
>>> p = Путь ('.')
>>> для имени в p.glob ('*.п*'):
... печать (имя)
admin.py
scraper.py
docs.pdf
Вызов p.glob ('*. P *') возвращает объект-генератор, который указывает на все файлы в текущем каталоге, которые начинаются с буквы p в их расширении.
Path.glob () аналогичен os.glob () , описанному выше. Как видите, pathlib сочетает в себе многие из лучших функций модулей os , os.path и glob в одном модуле, что делает его использование приятным.
Напомним, вот таблица функций, которые мы рассмотрели в этом разделе:
| Функция | Описание |
|---|---|
начинается с () | Проверяет, начинается ли строка с указанного шаблона и возвращает Истина или Ложь |
заканчивается с () | Проверяет, заканчивается ли строка указанным шаблоном и возвращает True или False |
fnmatch. | Проверяет соответствие имени файла шаблону и возвращает True или False |
glob.glob () | Возвращает список имен файлов, соответствующих шаблону |
pathlib.Path.glob () | Находит шаблоны в именах путей и возвращает объект-генератор |
 fnmatch (имя файла, шаблон)
fnmatch (имя файла, шаблон) Обход каталогов и обработка файлов
Обычная задача программирования — это обход дерева каталогов и обработка файлов в дереве.Давайте посмотрим, как для этого можно использовать встроенную функцию Python os.walk () . os.walk () используется для генерации имени файла в дереве каталогов путем обхода дерева сверху вниз или снизу вверх. В этом разделе мы будем работать со следующим деревом каталогов:
.
|
├── folder_1 /
| ├── file1.py
| ├── file2.py
| └── file3.py
|
├── folder_2 /
| ├── file4.py
| ├── file5.py
| └── file6. py
|
├── test1.txt
└── test2.txt
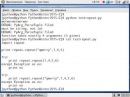 py
|
├── test1.txt
└── test2.txt
py
|
├── test1.txt
└── test2.txt
Ниже приведен пример, показывающий, как вывести список всех файлов и каталогов в дереве каталогов с помощью os.прогулка () .
os.walk () по умолчанию для обхода каталогов сверху вниз:
# Обход дерева каталогов и печать имен каталогов и файлов
для dirpath, dirnames, файлов в os.walk ('.'):
print (f'Найденный каталог: {dirpath} ')
для file_name в файлах:
печать (имя_файла)
os.walk () возвращает три значения на каждой итерации цикла:
Имя текущей папки
Список папок в текущей папке
Список файлов в текущей папке
На каждой итерации он распечатывает имена подкаталогов и файлов, которые он находит:
Найденный каталог:.test1.txt
test2.txt
Найден каталог: ./folder_1
file1.py
file3.py
file2.py
Найден каталог: ./folder_2
file4.py
file5. py
file6.py
 py
file6.py
py
file6.py
Чтобы пройти по дереву каталогов снизу вверх, передайте аргумент ключевого слова topdown = False в os.walk () :
для dirpath, dirnames, файлов в os.walk ('.', Topdown = False):
print (f'Найденный каталог: {dirpath} ')
для file_name в файлах:
печать (имя_файла)
Передача аргумента topdown = False даст os.walk () распечатывает файлы, которые он находит в подкаталогах , сначала :
Найденный каталог: ./folder_1
file1.py
file3.py
file2.py
Найден каталог: ./folder_2
file4.py
file5.py
file6.py
Найден каталог:.
test1.txt
test2.txt
Как видите, программа запускается с перечисления содержимого подкаталогов перед выводом содержимого корневого каталога. Это очень полезно в ситуациях, когда вы хотите рекурсивно удалить файлы и каталоги.Вы узнаете, как это сделать, в следующих разделах. По умолчанию os.walk не переходит к символическим ссылкам, которые разрешаются в каталоги. Это поведение можно изменить, вызвав его с аргументом
Это поведение можно изменить, вызвав его с аргументом followlinks = True .
Создание временных файлов и каталогов
Python предоставляет удобный модуль для создания временных файлов и каталогов под названием tempfile .
tempfile можно использовать для временного открытия и хранения данных в файле или каталоге во время работы вашей программы. tempfile обрабатывает удаление временных файлов, когда ваша программа завершает работу с ними.
Вот как создать временный файл:
из временного файла импорт временного файла
# Создать временный файл и записать в него данные
fp = временный файл ('w + t')
fp.write ('Привет, вселенная!')
# Вернуться к началу и прочитать данные из файла
fp.seek (0)
данные = fp.read ()
# Закройте файл, после чего он будет удален
fp.close ()
Первым шагом является импорт TemporaryFile из модуля tempfile .Затем создайте объект, подобный файлу, используя метод TemporaryFile () , вызвав его и передав режим, в котором вы хотите открыть файл. Это создаст и откроет файл, который можно использовать в качестве области временного хранения.
Это создаст и откроет файл, который можно использовать в качестве области временного хранения.
В приведенном выше примере используется режим 'w + t' , что заставляет tempfile создавать временный текстовый файл в режиме записи. Нет необходимости давать временному файлу имя файла, так как он будет уничтожен после завершения выполнения сценария.
После записи в файл вы можете прочитать его и закрыть, когда закончите обработку.После закрытия файла он будет удален из файловой системы. Если вам нужно назвать временные файлы, созданные с использованием tempfile , используйте tempfile.NamedTemporaryFile () .
Временные файлы и каталоги, созданные с помощью tempfile , хранятся в специальном системном каталоге для хранения временных файлов. Python ищет в стандартном списке каталогов тот, в котором пользователь может создавать файлы.
В Windows это каталоги C: \ TEMP , C: \ TMP , \ TEMP и \ TMP в указанном порядке. На всех других платформах каталоги
На всех других платформах каталоги / tmp , / var / tmp и / usr / tmp в указанном порядке. В крайнем случае tempfile сохранит временные файлы и каталоги в текущем каталоге.
.TemporaryFile () также является диспетчером контекста, поэтому его можно использовать вместе с оператором with . Использование диспетчера контекста автоматически закрывает и удаляет файл после его чтения:
с TemporaryFile ('w + t') как fp:
fp.write ('Привет, вселенная!')
fp.seek (0)
fp.read ()
# Файл закрыт и удален
Создает временный файл и считывает из него данные. Как только содержимое файла считывается, временный файл закрывается и удаляется из файловой системы.
tempfile также можно использовать для создания временных каталогов. Давайте посмотрим, как это можно сделать с помощью tempfile.TemporaryDirectory () :
>>> импортировать временный файл
>>> с временным файлом.TemporaryDirectory () как tmpdir:
... print ('Создан временный каталог', tmpdir)
... os.path.exists (tmpdir)
...
Создан временный каталог / tmp / tmpoxbkrm6c
Истинный
>>> # Содержимое каталога удалено
...
>>> tmpdir
'/ tmp / tmpoxbkrm6c'
>>> os.path.exists (tmpdir)
Ложь
Вызов tempfile.TemporaryDirectory () создает временный каталог в файловой системе и возвращает объект, представляющий этот каталог. В приведенном выше примере каталог создается с помощью диспетчера контекста, а имя каталога хранится в tmpdir .Третья строка выводит имя временного каталога, а os.path.exists (tmpdir) подтверждает, действительно ли каталог был создан в файловой системе.
После того, как диспетчер контекста выходит из контекста, временный каталог удаляется, а вызов os.path.exists (tmpdir) возвращает False , что означает, что каталог был успешно удален.
Удаление файлов и каталогов
Вы можете удалять отдельные файлы, каталоги и целые деревья каталогов, используя методы, найденные в модулях os , shutil и pathlib .В следующих разделах описывается, как удалить файлы и каталоги, которые вам больше не нужны.
Удаление файлов в Python
Чтобы удалить один файл, используйте pathlib.Path.unlink () , os.remove () . или os.unlink () .
os.remove () и os.unlink () семантически идентичны. Чтобы удалить файл с помощью os.remove () , выполните следующие действия:
импорт ОС
data_file = 'C: \ Users \ vuyisile \ Desktop \ Test \ data.текст'
os.remove (файл_данных)
Удаление файла с помощью os.unlink () аналогично тому, как это делается с помощью os.remove () :
импорт ОС
data_file = 'C: \ Users \ vuyisile \ Desktop \ Test \ data.txt'
os.unlink (файл_данных)
Вызов .unlink () или .remove () для файла удаляет файл из файловой системы. Эти две функции вызовут OSError , если переданный им путь указывает на каталог, а не на файл.Чтобы избежать этого, вы можете либо проверить, что то, что вы пытаетесь удалить, на самом деле является файлом и удалить его только в том случае, если это так, либо вы можете использовать обработку исключений для обработки ошибки OSError :
импорт ОС
data_file = 'главная / data.txt'
# Если файл существует, удалите его
если os.path.isfile (файл_данных):
os.remove (файл_данных)
еще:
print (f'Error: {data_file} недопустимое имя файла ')
os.path.isfile () проверяет, действительно ли data_file является файлом.Если это так, он удаляется вызовом os.remove () . Если data_file указывает на папку, на консоль выводится сообщение об ошибке.
В следующем примере показано, как использовать обработку исключений для обработки ошибок при удалении файлов:
импорт ОС
data_file = 'главная / data.txt'
# Использовать обработку исключений
пытаться:
os.remove (файл_данных)
кроме OSError как e:
print (f'Error: {data_file}: {e.strerror} ')
Код выше пытается удалить файл перед проверкой его типа.Если data_file на самом деле не является файлом, то генерируемая OSError обрабатывается в , за исключением предложения , и на консоль выводится сообщение об ошибке. Распечатываемое сообщение об ошибке форматируется с использованием f-строк Python.
Наконец, вы также можете использовать pathlib.Path.unlink () для удаления файлов:
из пути импорта pathlib
data_file = Путь ('home / data.txt')
пытаться:
data_file.unlink ()
кроме IsADirectoryError как e:
print (f'Error: {data_file}: {e.strerror} ')
Это создает объект Path с именем data_file , который указывает на файл. Вызов .remove () для data_file удалит home / data.txt . Если data_file указывает на каталог, возникает IsADirectoryError . Стоит отметить, что указанная выше программа Python имеет те же разрешения, что и пользователь, запускающий ее. Если у пользователя нет разрешения на удаление файла, возникает ошибка PermissionError .
Удаление каталогов
Стандартная библиотека предлагает следующие функции для удаления каталогов:
-
os.rmdir () -
pathlib.Path.rmdir () -
shutil.rmtree ()
Чтобы удалить отдельный каталог или папку, используйте os.rmdir () или pathlib.rmdir () . Эти две функции работают, только если каталог, который вы пытаетесь удалить, пуст. Если каталог не пустой, возникает ошибка OSError .Вот как удалить папку:
импорт ОС
trash_dir = 'мои_документы / bad_dir'
пытаться:
os.rmdir (trash_dir)
кроме OSError как e:
print (f'Error: {trash_dir}: {e.strerror} ')
Здесь каталог trash_dir удаляется путем передачи его пути в os.rmdir () . Если каталог не пустой, на экран выводится сообщение об ошибке:
Traceback (последний звонок последний):
Файл '', строка 1, в
OSError: [Errno 39] Каталог не пуст: 'my_documents / bad_dir'
В качестве альтернативы вы можете использовать pathlib для удаления каталогов:
из пути импорта pathlib
trash_dir = Путь ('my_documents / bad_dir')
пытаться:
trash_dir.rmdir ()
кроме OSError как e:
print (f'Error: {trash_dir}: {e.strerror} ')
Здесь вы создаете объект Path , который указывает на каталог, который нужно удалить. Вызов .rmdir () для объекта Path удалит его, если он пуст.
Удаление всех деревьев каталогов
Для удаления непустых каталогов и целых деревьев каталогов Python предлагает shutil.rmtree () :
импортный шутил
trash_dir = 'мои_документы / bad_dir'
пытаться:
шутил.rmtree (trash_dir)
кроме OSError как e:
print (f'Error: {trash_dir}: {e.strerror} ')
Все в trash_dir удаляется при вызове shutil.rmtree () . Могут быть случаи, когда вы хотите рекурсивно удалить пустые папки. Вы можете сделать это, используя один из методов, описанных выше в сочетании с os.walk () :
импорт ОС
для dirpath, dirnames, файлов в os.walk ('.', topdown = False):
пытаться:
os.rmdir (dirpath)
кроме OSError как ex:
проходить
Это перемещается по дереву каталогов и пытается удалить каждый найденный каталог.Если каталог не пустой, возникает ошибка OSError и этот каталог пропускается. В таблице ниже перечислены функции, рассматриваемые в этом разделе:
| Функция | Описание |
|---|---|
os.remove () | Удаляет файл и не удаляет каталоги |
os.unlink () | Идентичен os.remove () и удаляет один файл |
pathlib.Path.unlink () | Удаляет файл без возможности удаления каталогов |
os.rmdir () | Удаляет пустой каталог |
pathlib.Path.rmdir () | Удаляет пустой каталог |
shutil.rmtree () | Удаляет все дерево каталогов и может использоваться для удаления непустых каталогов |
Копирование, перемещение и переименование файлов и каталогов
Python поставляется с модулем shutil . shutil — это сокращение от служебных программ оболочки. Он обеспечивает ряд высокоуровневых операций с файлами для поддержки копирования, архивирования и удаления файлов и каталогов. В этом разделе вы узнаете, как перемещать и копировать файлы и каталоги.
Копирование файлов в Python
shutil предлагает несколько функций для копирования файлов. Чаще всего используются функции shutil.copy () и shutil.copy2 () . Чтобы скопировать файл из одного места в другое, используйте shutil.copy () , выполните следующие действия:
импортный шутил
src = 'путь / к / file.txt'
dst = 'путь / к / каталог-назначения'
shutil.copy (src, dst)
shutil.copy () сравнимо с командой cp в системах на основе UNIX. shutil.copy (src, dst) скопирует файл src в место, указанное в dst . Если dst является файлом, содержимое этого файла заменяется содержимым src . Если dst — это каталог, то src будет скопирован в этот каталог. shutil.copy () копирует только содержимое файла и разрешения файла. Другие метаданные, такие как время создания и изменения файла, не сохраняются.
Чтобы сохранить все метаданные файла при копировании, используйте shutil.copy2 () :
импортный шутил
src = 'путь / к / file.txt'
dst = 'путь / к / каталог-назначения'
shutil.copy2 (src, dst)
Использование .copy2 () сохраняет сведения о файле, такие как время последнего доступа, биты прав доступа, время последнего изменения и флаги.
Каталоги копирования
В то время как shutil.copy () копирует только один файл, shutil.copytree () копирует весь каталог и все, что в нем содержится. shutil.copytree (src, dest) принимает два аргумента: исходный каталог и целевой каталог, в который будут скопированы файлы и папки.
Вот пример того, как скопировать содержимое одной папки в другое место:
>>> >>> импортный шутил
>>> шутил.copytree ('данные_1', 'данные1_backup')
'data1_backup'
В этом примере .copytree () копирует содержимое data_1 в новое место data1_backup и возвращает целевой каталог. Целевой каталог еще не должен существовать. Он будет создан вместе с отсутствующими родительскими каталогами. shutil.copytree () — хороший способ сделать резервную копию ваших файлов.
Перемещение файлов и каталогов
Чтобы переместить файл или каталог в другое место, используйте shutil.переместить (src, dst) .
src — это файл или каталог, который нужно переместить, а dst — это место назначения:
>>> импортный шутил
>>> shutil.move ('каталог_1 /', 'резервная копия /')
'резервный'
shutil.move ('dir_1 /', 'backup /') перемещает dir_1 / в backup / , если существует backup / . Если backup / не существует, dir_1 / будет переименован в backup .
Переименование файлов и каталогов
Python включает os.rename (src, dst) для переименования файлов и каталогов:
>>> os.rename ('first.zip', 'first_01.zip')
Строка выше переименует first.zip в first_01.zip . Если целевой путь указывает на каталог, это вызовет OSError .
Другой способ переименовать файлы или каталоги — использовать rename () из модуля pathlib :
>>> from pathlib import Path
>>> data_file = Путь ('data_01.текст')
>>> файл_данных.rename ('data.txt')
Чтобы переименовать файлы с использованием pathlib , вы сначала создаете объект pathlib.Path () , который содержит путь к файлу, который вы хотите заменить. Следующим шагом является вызов rename () для объекта пути и передача нового имени файла или каталога, который вы переименовываете.
Архивирование
Архивы — это удобный способ упаковать несколько файлов в один. Двумя наиболее распространенными типами архивов являются ZIP и TAR.Написанные вами программы Python могут создавать, читать и извлекать данные из архивов. В этом разделе вы узнаете, как читать и писать в оба формата архивов.
Чтение файлов ZIP
Модуль zipfile — это модуль низкого уровня, который является частью стандартной библиотеки Python. zipfile имеет функции, упрощающие открытие и извлечение файлов ZIP. Чтобы прочитать содержимое ZIP-файла, первое, что нужно сделать, это создать объект ZipFile . Объекты ZipFile аналогичны файловым объектам, созданным с помощью open () . ZipFile также является диспетчером контекста и поэтому поддерживает с оператором :
импорт zip-файла
с zipfile.ZipFile ('data.zip', 'r') как zipobj:
Здесь вы создаете объект ZipFile , передавая имя ZIP-файла для открытия в режиме чтения. После открытия ZIP-файла информация об архиве может быть доступна с помощью функций, предоставляемых модулем zipfile . Архив data.zip в приведенном выше примере был создан из каталога с именем data , который содержит всего 5 файлов и 1 подкаталог:
.|
├── sub_dir /
| ├── bar.py
| └── foo.py
|
├── file1.py
├── file2.py
└── file3.py
Чтобы получить список файлов в архиве, вызовите namelist () на объекте ZipFile :
импорт zip-файла
с zipfile.ZipFile ('data.zip', 'r') как zipobj:
zipobj.namelist ()
Это дает список:
['file1.py', 'file2.py', 'file3.py', 'sub_dir /', 'sub_dir / bar.py', 'sub_dir / foo.py']
.namelist () возвращает список имен файлов и каталогов в архиве. Чтобы получить информацию о файлах в архиве, используйте .getinfo () :
импорт zip-файла
с zipfile.ZipFile ('data.zip', 'r') как zipobj:
bar_info = zipobj.getinfo ('подкаталог / bar.py')
bar_info.file_size
Вот результат:
.getinfo () возвращает объект ZipInfo , в котором хранится информация об одном элементе архива.Чтобы получить информацию о файле в архиве, вы передаете его путь в качестве аргумента .getinfo () . Используя getinfo () , вы можете получить информацию об элементах архива, такую как дату последнего изменения файлов, их сжатые размеры и их полные имена файлов. При доступе к .file_size получает исходный размер файла в байтах.
В следующем примере показано, как получить более подробную информацию об архивных файлах в Python REPL. Предположим, что модуль zipfile был импортирован, а bar_info — это тот же объект, который вы создали в предыдущих примерах:
>>> bar_info.date_time
(2018, 10, 7, 23, 30, 10)
>>> bar_info.compress_size
2856
>>> bar_info.filename
'sub_dir / bar.py'
bar_info содержит подробную информацию о bar.py , такую как его размер в сжатом виде и полный путь.
В первой строке показано, как получить дату последнего изменения файла. В следующей строке показано, как получить размер файла после сжатия. Последняя строка показывает полный путь к bar.py в архиве.
ZipFile поддерживает протокол диспетчера контекста, поэтому вы можете использовать его с с оператором .Это автоматически закроет объект ZipFile после того, как вы закончите с ним. Попытка открыть или извлечь файлы из закрытого объекта ZipFile приведет к ошибке.
Создание новых ZIP-архивов
Чтобы создать новый ZIP-архив, откройте объект ZipFile в режиме записи ( w ) и добавьте файлы, которые хотите заархивировать:
>>> импортировать zip-файл
>>> file_list = ['file1.py', 'sub_dir /', 'sub_dir / bar.py ',' sub_dir / foo.py ']
>>> с zipfile.ZipFile ('new.zip', 'w') как new_zip:
... для имени в file_list:
... new_zip.write (имя)
В примере new_zip открывается в режиме записи, и каждый файл в file_list добавляется в архив. Когда с набором операторов завершается, new_zip закрывается. Открытие ZIP-файла в режиме записи стирает содержимое архива и создает новый архив.
Чтобы добавить файлы в существующий архив, откройте объект ZipFile в режиме добавления и затем добавьте файлы:
>>> # Открываем объект ZipFile в режиме добавления
>>> с zip-файлом.ZipFile ('new.zip', 'a') как new_zip:
... new_zip.write ('data.txt')
... new_zip.write ('latin.txt')
Здесь вы открываете архив new.zip , созданный в предыдущем примере, в режиме добавления. Открытие объекта ZipFile в режиме добавления позволяет вам добавлять новые файлы в ZIP-файл без удаления его текущего содержимого. После добавления файлов в ZIP-файл оператор с выходит из контекста и закрывает ZIP-файл.
Открытие архива TAR
Файлы TAR представляют собой несжатые файловые архивы, такие как ZIP.Их можно сжать с помощью методов сжатия gzip, bzip2 и lzma. TarFile Класс позволяет читать и записывать архивы TAR.
Сделайте это, чтобы прочитать из архива:
импортный tarfile
с tarfile.open ('example.tar', 'r') как tar_file:
печать (tar_file.getnames ())
tarfile объекта открываются, как и большинство файловых объектов. У них есть функция open () , которая принимает режим, определяющий способ открытия файла.
Используйте режимы 'r' , 'w' или 'a' , чтобы открыть несжатый файл TAR для чтения, записи и добавления соответственно. Чтобы открыть сжатые файлы TAR, передайте в tarfile.open () аргумент режима, который имеет форму filemode [: сжатие] . В таблице ниже перечислены возможные режимы открытия файлов TAR:
| Режим | Действие |
|---|---|
r | Открывает для чтения архив с прозрачным сжатием |
r: gz | Открывает архив для чтения со сжатием gzip |
r: bz2 | Открывает для чтения архив со сжатием bzip2 |
r: xz | Открывает для чтения архив со сжатием lzma |
w | Открывает архив для записи без сжатия |
w: gz | Открывает архив для записи в сжатом формате gzip |
ширина: xz | Открывает архив для сжатой записи lzma |
а | Открывает архив для добавления без сжатия |
.open () по умолчанию 'r' режим. Чтобы прочитать несжатый файл TAR и получить имена файлов в нем, используйте .getnames () :
>>> импортный tarfile
>>> tar = tarfile.open ('example.tar', mode = 'r')
>>> tar.getnames ()
['CONTRIBUTING.rst', 'README.md', 'app.py']
Возвращает список с именами содержимого архива.
Примечание: Чтобы показать вам, как использовать различные методы объекта tarfile , файл TAR в примерах открывается и закрывается вручную в интерактивном сеансе REPL.
Такое взаимодействие с файлом TAR позволяет увидеть результат выполнения каждой команды. Обычно вам нужно использовать диспетчер контекста для открытия файловых объектов.
К метаданным каждой записи в архиве можно получить доступ с помощью специальных атрибутов:
>>> >>> для ввода в tar.getmembers ():
... печать (entry.name)
... print ('Изменено:', time.ctime (entry.mtime))
... print ('Размер:', размер записи, 'байты')
... Распечатать()
СОДЕЙСТВИЕ.первый
Обновлено: Сб, 1 ноября, 09:09:51 2018
Размер: 402 байта
README.md
Обновлено: 3 ноября, сб, 07:29:40 2018
Размер: 5426 байтов
app.py
Обновлено: 3 ноября, сб, 07:29:13 2018
Размер: 6218 байтов
В этом примере вы просматриваете список файлов, возвращаемых функцией .getmembers () , и распечатываете атрибуты каждого файла. Объекты, возвращаемые функцией .getmembers () , имеют атрибуты, к которым можно получить доступ программно, например имя, размер и время последнего изменения каждого из файлов в архиве.После чтения или записи в архив его необходимо закрыть, чтобы освободить ресурсы системы.
Создание новых архивов TAR
Вот как это сделать:
>>> >>> импортный tarfile
>>> file_list = ['app.py', 'config.py', 'CONTRIBUTORS.md', 'tests.py']
>>> с tarfile.open ('packages.tar', mode = 'w') как tar:
... для файла в file_list:
... tar.add (файл)
>>> # Прочитать содержимое вновь созданного архива
>>> с tarfile.open ('package.tar', mode = 'r') как t:
... для члена t.getmembers ():
... печать (имя члена)
app.py
config.py
CONTRIBUTORS.md
tests.py
Сначала вы составляете список файлов, которые нужно добавить в архив, чтобы вам не приходилось добавлять каждый файл вручную.
Следующая строка использует с менеджером контекста для открытия нового архива с именем packages.tar в режиме записи. Открытие архива в режиме записи ( 'w' ) позволяет записывать в архив новые файлы.Все существующие файлы в архиве удаляются, и создается новый архив.
После создания и заполнения архива с диспетчером контекста автоматически закрывает его и сохраняет в файловой системе. Последние три строки открывают только что созданный архив и распечатывают имена содержащихся в нем файлов.
Чтобы добавить новые файлы в существующий архив, откройте архив в режиме добавления ( 'a' ):
>>> с tarfile.open ('package.tar', mode = 'a') как tar:
... tar.add ('foo.bar')
>>> с tarfile.open ('package.tar', mode = 'r') как tar:
... для члена tar.getmembers ():
... печать (имя члена)
app.py
config.py
CONTRIBUTORS.md
tests.py
foo.bar
Открытие архива в режиме добавления позволяет добавлять в него новые файлы, не удаляя уже существующие.
Работа со сжатыми архивами
tarfile также может читать и записывать архивы TAR, сжатые с использованием сжатия gzip, bzip2 и lzma.Для чтения или записи в сжатый архив используйте tarfile.open () , передав режим, соответствующий типу сжатия.
Например, для чтения или записи данных в архив TAR, сжатый с помощью gzip, используйте режимы 'r: gz' или 'w: gz' соответственно:
>>> files = ['app.py', 'config.py', 'tests.py']
>>> с tarfile.open ('packages.tar.gz', mode = 'w: gz') как tar:
... tar.add ('app.py')
... tar.add ('config.ру ')
... tar.add ('tests.py')
>>> с tarfile.open ('packages.tar.gz', mode = 'r: gz') как t:
... для члена t.getmembers ():
... печать (имя члена)
app.py
config.py
tests.py
Режим 'w: gz' открывает архив для записи со сжатием gzip, а 'r: gz' открывает архив для чтения со сжатием gzip.
Открытие сжатых архивов в режиме добавления невозможно. Чтобы добавить файлы в сжатый архив, вам необходимо создать новый архив.
Более простой способ создания архивов
Стандартная библиотека Python также поддерживает создание архивов TAR и ZIP с использованием высокоуровневых методов модуля shutil .Утилиты архивирования в shutil позволяют создавать, читать и извлекать архивы ZIP и TAR. Эти утилиты используют модули нижнего уровня tarfile и zipfile .
Работа с архивами с использованием shutil.make_archive ()
shutil.make_archive () принимает как минимум два аргумента: имя архива и формат архива.
По умолчанию он сжимает все файлы в текущем каталоге в формат архива, указанный в аргументе формат .Вы можете передать необязательный аргумент root_dir для сжатия файлов в другом каталоге. .make_archive () поддерживает форматы архивов zip , tar , bztar и gztar .
Вот как создать архив TAR с помощью shutil :
импортный шутил
# shutil.make_archive (базовое_имя, формат, корневой_каталог)
shutil.make_archive ('данные / резервная копия', 'tar', 'данные /')
Это копирует все в data / и создает архив под названием backup.tar в файловой системе и возвращает его имя. Чтобы распаковать архив, вызовите .unpack_archive () :
shutil.unpack_archive ('backup.tar', 'extract_dir /')
Вызов .unpack_archive () и передача имени архива и целевого каталога извлекает содержимое backup.tar в extract_dir / . ZIP-архивы можно создавать и извлекать аналогичным образом.
Чтение нескольких файлов
Python поддерживает чтение данных из нескольких входных потоков или из списка файлов с помощью модуля fileinput .Этот модуль позволяет быстро и легко перебирать содержимое одного или нескольких текстовых файлов.
Вот типичный способ использования fileinput :
импорт файла ввода
для строки в fileinput.input ()
процесс (линия)
fileinput получает входные данные из аргументов командной строки, переданных по умолчанию в sys.argv .
Использование fileinput для перебора нескольких файлов
Давайте воспользуемся fileinput для создания грубой версии общей утилиты UNIX cat .Утилита cat последовательно читает файлы, записывая их на стандартный вывод. Если в аргументах командной строки указано более одного файла, cat объединит текстовые файлы и отобразит результат в терминале:
# Файл: fileinput-example.py
импортировать файл
import sys
файлы = fileinput.input ()
для строки в файлах:
если fileinput.isfirstline ():
print (f '\ n --- чтение {fileinput.filename ()} ---')
print ('->' + строка, конец = '')
Распечатать()
Выполнение этого для двух текстовых файлов в моем текущем каталоге дает следующий результат:
$ python3 fileinput-example.py bacon.txt cupcake.txt
--- Чтение bacon.txt ---
-> Пряный халапеньо бекон ipsum dolor amet in aute est qui enim aliquip,
-> irure cillum голень elit.
-> Doner jowl shank ea упражнение landjaeger incididunt ut porchetta.
-> Вырезка бекон аликвип купидатат курица цыпленок quis anim et свинья.
-> Донер с тремя наконечниками, кевин силлум, ветчина, вениам, коровий гамбургер.
-> Индейка свиная корейка купидатат филе миньон капикола грудинка купим объявление в.
-> Ball tip dolor do magna labouris nisi pancetta nostrud doner.--- Чтение cupcake.txt ---
-> Кекс ipsum dolor sit amet candy Я люблю чизкейк кекс.
-> Посыпать маффин сахарной ватой.
-> Жевательные конфеты макаруны марципановые марципановые марципановые марципаны марципановые мармелад
fileinput позволяет получить дополнительную информацию о каждой строке, например, является ли она первой строкой ( .isfirstline () ), номером строки ( .lineno () ) и именем файла (. имя файла () ). Вы можете прочитать больше об этом здесь.
Заключение
Теперь вы знаете, как использовать Python для выполнения наиболее распространенных операций с файлами и группами файлов.Вы узнали о различных встроенных модулях, которые используются для их чтения, поиска и управления ими.
Теперь вы можете использовать Python для:
- Получить содержимое каталога и свойства файла
- Создание каталогов и деревьев каталогов
- Найти шаблоны в именах файлов
- Создание временных файлов и каталогов
- Перемещение, переименование, копирование и удаление файлов или каталогов
- Чтение и извлечение данных из разных типов архивов
- Чтение нескольких файлов одновременно с использованием файлового входа
Чтение и запись файлов на Python (Руководство) — Real Python
Смотреть сейчас Это руководство содержит соответствующий видеокурс, созданный командой Real Python.Посмотрите его вместе с письменным руководством, чтобы углубить свое понимание: Чтение и запись файлов на Python
Одна из наиболее распространенных задач, которые вы можете выполнять с помощью Python, — это чтение и запись файлов. Будь то запись в простой текстовый файл, чтение сложного журнала сервера или даже анализ необработанных байтовых данных, все эти ситуации требуют чтения или записи файла.
Из этого руководства вы узнаете:
- Из чего состоит файл и почему это важно в Python
- Основы чтения и записи файлов в Python
- Некоторые базовые сценарии чтения и записи файлов
Это руководство в основном предназначено для питонистов от начинающего до среднего уровня, но здесь есть несколько советов, которые могут быть оценены и более продвинутыми программистами.
Пройдите тест: Проверьте свои знания с помощью нашей интерактивной викторины «Чтение и запись файлов на Python». По завершении вы получите балл, чтобы вы могли отслеживать свой прогресс в обучении с течением времени:
Пройти тест »
Что такое файл?
Прежде чем мы перейдем к тому, как работать с файлами в Python, важно понять, что именно представляет собой файл и как современные операционные системы обрабатывают некоторые из их аспектов.
По своей сути файл — это непрерывный набор байтов, используемых для хранения данных.Эти данные организованы в определенном формате и могут быть как простыми, как текстовый файл, так и сложными, как исполняемый файл программы. В конце эти байтовые файлы затем преобразуются в двоичные 1 и 0 для облегчения обработки компьютером.
Файлы в большинстве современных файловых систем состоят из трех основных частей:
- Заголовок: метаданные о содержимом файла (имя файла, размер, тип и т. Д.)
- Данные: содержимое файла, написанное создателем или редактором
- Конец файла (EOF): специальный символ, обозначающий конец файла
То, что представляют эти данные, зависит от используемой спецификации формата, которая обычно представлена расширением.Например, файл с расширением .gif , скорее всего, соответствует спецификации формата обмена графическими данными. Существуют сотни, если не тысячи, расширений файлов. В этом руководстве вы будете иметь дело только с расширениями файлов .txt или .csv .
Пути к файлам
При доступе к файлу в операционной системе требуется указать путь к файлу. Путь к файлу — это строка, представляющая расположение файла. Он разбит на три основные части:
- Путь к папке: расположение папки с файлами в файловой системе, где последующие папки разделены косой чертой
/(Unix) или обратной косой чертой\(Windows) - Имя файла: фактическое имя файла
- Расширение: конец пути к файлу с точкой (
.) используется для обозначения типа файла
Вот небольшой пример. Допустим, у вас есть файл, расположенный в такой файловой структуре:
/
│
├── путь /
| │
│ ├── к /
│ │ └── cats.gif
│ │
│ └── dog_breeds.txt
|
└── animals.csv
Допустим, вы хотите получить доступ к файлу cats.gif , и ваше текущее местоположение было в той же папке, что и path . Чтобы получить доступ к файлу, вам нужно пройти через папку , путь , а затем папку с по , наконец, дойдя до кошек.gif файл. Путь к папке — путь / к / . Имя файла — cats . Расширение файла — .gif . Таким образом, полный путь — path / to / cats.gif .
Теперь предположим, что ваше текущее местоположение или текущий рабочий каталог (cwd) находится в папке – структуры папок нашего примера. Вместо того, чтобы ссылаться на cats.gif по полному пути path / to / cats.gif , на файл можно просто ссылаться по имени файла и расширению cats.gif .
/
│
├── путь /
| │
| ├── to / ← Ваш текущий рабочий каталог (cwd) здесь
| │ └── cats.gif ← Доступ к этому файлу
| │
| └── dog_breeds.txt
|
└── animals.csv
А как насчет dog_breeds.txt ? Как бы вы могли получить к нему доступ, не используя полный путь? Вы можете использовать специальные символы с двумя точками ( .. ) для перемещения на один каталог вверх. Это означает, что ../dog_breeds.txt будет ссылаться на dog_breeds.txt из каталога с по :
/
│
├── путь / ← Ссылка на эту родительскую папку
| │
| ├── to / ← Текущий рабочий каталог (cwd)
| │ └── cats.gif
| │
| └── dog_breeds.txt ← Доступ к этому файлу
|
└── animals.csv
Двойная точка ( .. ) может быть объединена в цепочку для перемещения по нескольким каталогам над текущим каталогом. Например, чтобы получить доступ к animals.csv из папок с по , вы должны использовать ../../animals.csv .
Окончание строк
Одна из проблем, часто возникающих при работе с данными файла, — это представление новой строки или окончания строки. Окончание строки уходит корнями в эпоху азбуки Морзе, когда определенный про-знак использовался для обозначения конца передачи или конца строки.
Позже это было стандартизовано для телетайпов Международной организацией по стандартизации (ISO) и Американской ассоциацией стандартов (ASA).Стандарт ASA гласит, что в конце строки должна использоваться последовательность символов возврата каретки ( CR или \ r ) и перевода строки ( LF или \ n ) ( CR + LF или \ г \ п ). Однако стандарт ISO допускает символы CR + LF или только символы LF .
Windows использует символы CR + LF для обозначения новой строки, тогда как Unix и более новые версии Mac используют только символ LF .Это может вызвать некоторые сложности при обработке файлов в операционной системе, отличной от исходной. Вот небольшой пример. Допустим, мы исследуем файл dog_breeds.txt , созданный в системе Windows:
Мопс \ r \ n
Джек Рассел терьер \ r \ n
Английский спрингер-спаниель \ r \ n
Немецкая овчарка \ r \ n
Стаффордширский бультерьер \ r \ n
Кавалер кинг чарльз спаниель \ r \ n
Золотистый ретривер \ r \ n
Вест-хайленд-уайт-терьер \ r \ n
Боксёр \ r \ n
Бордер терьер \ r \ n
Этот же вывод будет по-разному интерпретирован на устройстве Unix:
Мопс \ г
\ п
Джек Рассел терьер \ r
\ п
Английский спрингер-спаниель \ r
\ п
Немецкая овчарка \ r
\ п
Стаффордширский бультерьер \ r
\ п
Кавалер кинг чарльз спаниель \ r
\ п
Золотистый ретривер \ r
\ п
Вест-хайленд-уайт-терьер \ r
\ п
Боксёр \ r
\ п
Бордер терьер \ r
\ п
Это может сделать перебор каждой строки проблематичным, и вам, возможно, придется учитывать подобные ситуации.
Кодировки символов
Другая распространенная проблема, с которой вы можете столкнуться, — это кодирование байтовых данных. Кодировка — это перевод байтовых данных в символы, читаемые человеком. Обычно это делается путем присвоения числового значения, представляющего символ. Двумя наиболее распространенными кодировками являются форматы ASCII и UNICODE. ASCII может хранить только 128 символов, а Unicode может содержать до 1114 112 символов.
ASCII на самом деле является подмножеством Unicode (UTF-8), что означает, что ASCII и Unicode имеют одинаковые числовые и символьные значения.Важно отметить, что синтаксический анализ файла с неправильной кодировкой символов может привести к сбоям или искажению символа. Например, если файл был создан с использованием кодировки UTF-8, и вы пытаетесь проанализировать его с использованием кодировки ASCII, если есть символ, который находится за пределами этих 128 значений, то будет выдана ошибка.
Открытие и закрытие файла в Python
Если вы хотите работать с файлом, первое, что нужно сделать, — это открыть его. Это делается путем вызова встроенной функции open () . open () имеет единственный обязательный аргумент — путь к файлу. open () имеет единственный возврат, файловый объект:
файл = открытый ('dog_breeds.txt')
После того, как вы открыли файл, нужно научиться его закрывать.
Предупреждение: Вы должны всегда убедиться, что открытый файл правильно закрыт.
Важно помнить, что вы несете ответственность за закрытие файла. В большинстве случаев после завершения работы приложения или скрипта файл в конечном итоге закрывается.Однако нет никакой гарантии, когда именно это произойдет. Это может привести к нежелательному поведению, включая утечку ресурсов. Также рекомендуется использовать Python (Pythonic), чтобы убедиться, что ваш код ведет себя хорошо определенным образом и снижает любое нежелательное поведение.
Когда вы манипулируете файлом, вы можете использовать два способа, чтобы убедиться, что файл закрыт правильно, даже при возникновении ошибки. Первый способ закрыть файл — использовать блок try-finally :
reader = open ('dog_breeds.текст')
пытаться:
# Здесь идет дальнейшая обработка файла
наконец-то:
reader.close ()
Если вы не знакомы с блоком try-finally , ознакомьтесь с исключениями Python: введение.
Второй способ закрыть файл — использовать с оператором :
с открытым ('dog_breeds.txt') в качестве читателя:
# Здесь идет дальнейшая обработка файла
Оператор с автоматически закрывает файл, когда он выходит из блока с , даже в случае ошибки.Я настоятельно рекомендую вам как можно чаще использовать с оператором , поскольку он позволяет сделать код более чистым и упрощает обработку любых неожиданных ошибок.
Скорее всего, вы также захотите использовать второй позиционный аргумент, mode . Этот аргумент представляет собой строку, содержащую несколько символов, обозначающих способ открытия файла. По умолчанию и наиболее часто используется 'r' , что означает открытие файла в режиме только для чтения в виде текстового файла:
с открытым ('dog_breeds.txt ',' r ') в качестве читателя:
# Здесь идет дальнейшая обработка файла
Другие варианты режимов полностью задокументированы в Интернете, но наиболее часто используются следующие:
| Персонаж | Значение |
|---|---|
'r' | Открыто для чтения (по умолчанию) |
'ширина' | Открыть для записи, обрезать (перезаписать) первый файл |
'rb' или 'wb' | Открыть в двоичном режиме (чтение / запись с использованием байтовых данных) |
Давайте вернемся и поговорим немного о файловых объектах.Файловый объект:
«объект, предоставляющий файловый API (с такими методами, как
read ()илиwrite ()) для базового ресурса». (Источник)
Существует три различных категории файловых объектов:
- Текстовые файлы
- Буферизованные двоичные файлы
- Необработанные двоичные файлы
Каждый из этих типов файлов определен в модуле io . Вот краткое изложение того, как все выстраивается.
Типы текстовых файлов
Текстовый файл — это самый распространенный файл, с которым вы можете столкнуться. Вот несколько примеров того, как открываются эти файлы:
открыто ('abc.txt')
open ('abc.txt', 'r')
open ('abc.txt', 'ш')
Для файлов этих типов open () вернет объект файла TextIOWrapper :
>>> file = open ('dog_breeds.txt')
>>> тип (файл)
<класс '_io.TextIOWrapper'>
Это объект файла по умолчанию, возвращаемый функцией open () .
Типы буферизованных двоичных файлов
Буферизованный двоичный тип файла используется для чтения и записи двоичных файлов. Вот несколько примеров того, как открываются эти файлы:
открыто ('abc.txt', 'rb')
открыть ('abc.txt', 'wb')
С этими типами файлов open () вернет объект файла BufferedReader или BufferedWriter :
>>> file = open ('dog_breeds.txt', 'rb')
>>> тип (файл)
<класс '_io.BufferedReader '>
>>> file = open ('dog_breeds.txt', 'wb')
>>> тип (файл)
<класс '_io.BufferedWriter'>
Типы файлов Raw
Необработанный тип файла:
«обычно используется в качестве низкоуровневого строительного блока для двоичных и текстовых потоков». (Источник)
Поэтому обычно не используется.
Вот пример того, как открываются эти файлы:
открыть ('abc.txt', 'rb', буферизация = 0)
Для файлов этих типов open () вернет объект файла FileIO :
>>> file = open ('dog_breeds.txt ',' rb ', буферизация = 0)
>>> тип (файл)
<класс '_io.FileIO'>
Чтение и запись открытых файлов
После того, как вы открыли файл, вы захотите прочитать или записать в файл. Во-первых, давайте рассмотрим чтение файла. Есть несколько методов, которые могут быть вызваны для файлового объекта, чтобы помочь вам:
| Метод | Что он делает |
|---|---|
.read (размер = -1) | Читает из файла на основе числа размером байта.Если аргумент не передан или Нет или -1 , то читается весь файл. |
.readline (size = -1) | Считывает не более размера символов из строки. Это продолжается до конца строки, а затем возвращается обратно. Если аргумент не передан или Нет или -1 , то читается вся строка (или остальная часть строки). |
.readlines () | Это считывает оставшиеся строки из файлового объекта и возвращает их в виде списка. |
Используя тот же файл dog_breeds.txt , который вы использовали выше, давайте рассмотрим несколько примеров использования этих методов. Вот пример того, как открыть и прочитать весь файл с помощью .read () :
>>> с open ('dog_breeds.txt', 'r') в качестве читателя:
>>> # Прочитать и распечатать весь файл
>>> print (reader.read ())
Мопс
Джек Рассел терьер
Английский спрингер-спаниель
Немецкая овчарка
Стаффордширский бультерьер
Кавалер кинг чарльз спаниель
Золотистый ретривер
Вест-хайленд-уайт-терьер
Боксер
Бордер терьер
Вот пример того, как каждый раз читать 5 байтов строки с помощью Python .readline () метод:
>>> с open ('dog_breeds.txt', 'r') в качестве читателя:
>>> # Прочтите и распечатайте первые 5 символов строки 5 раз
>>> print (reader.readline (5))
>>> # Обратите внимание, что строка больше пяти символов и продолжается
>>> # вниз по строке, читая каждый раз по 5 символов до конца
>>> # строка, а затем "оборачивается" вокруг
>>> print (reader.readline (5))
>>> напечатайте (читатель.readline (5))
>>> print (reader.readline (5))
>>> print (reader.readline (5))
Мопс
Джек
Russe
ll Te
Rrier
Вот пример того, как прочитать весь файл в виде списка с помощью метода Python .readlines () :
>>> f = open ('dog_breeds.txt')
>>> f.readlines () # Возвращает объект списка
['Мопс \ n', 'Джек-рассел-терьер \ n', 'Английский спрингер-спаниель \ n', 'Немецкая овчарка \ n', 'Стаффордширский бультерьер \ n', 'Кавалер-кинг Чарльз-спаниель \ n', 'Золотистый ретривер \ n ',' Вест-хайленд-уайт-терьер \ n ',' Боксер \ n ',' Бордер-терьер \ n ']
Приведенный выше пример также можно выполнить, используя list () для создания списка из файлового объекта:
>>> f = open ('dog_breeds.текст')
>>> список (f)
['Мопс \ n', 'Джек-рассел-терьер \ n', 'Английский спрингер-спаниель \ n', 'Немецкая овчарка \ n', 'Стаффордширский бультерьер \ n', 'Кавалер-кинг Чарльз-спаниель \ n', 'Золотистый ретривер \ n ',' Вест-хайленд-уайт-терьер \ n ',' Боксер \ n ',' Бордер-терьер \ n ']
Итерация по каждой строке в файле
Обычное дело при чтении файла — перебирать каждую строку. Вот пример того, как использовать метод Python .readline () для выполнения этой итерации:
>>> с открытым ('dog_breeds.txt ',' r ') в качестве читателя:
>>> # Прочитать и распечатать весь файл построчно
>>> line = reader.readline ()
>>> while line! = '': # Символ EOF - пустая строка
>>> печать (строка, конец = '')
>>> line = reader.readline ()
Мопс
Джек Рассел терьер
Английский спрингер-спаниель
Немецкая овчарка
Стаффордширский бультерьер
Кавалер кинг чарльз спаниель
Золотистый ретривер
Вест-хайленд-уайт-терьер
Боксер
Бордер терьер
Другой способ перебора каждой строки файла — использовать Python .readlines () метод файлового объекта. Помните, .readlines () возвращает список, где каждый элемент в списке представляет строку в файле:
>>> с open ('dog_breeds.txt', 'r') в качестве читателя:
>>> для строки в reader.readlines ():
>>> печать (строка, конец = '')
Мопс
Джек Рассел терьер
Английский спрингер-спаниель
Немецкая овчарка
Стаффордширский бультерьер
Кавалер кинг чарльз спаниель
Золотистый ретривер
Вест-хайленд-уайт-терьер
Боксер
Бордер терьер
Однако приведенные выше примеры можно еще больше упростить, перебирая сам файловый объект:
>>> >>> с открытым ('dog_breeds.txt ',' r ') в качестве читателя:
>>> # Прочитать и распечатать весь файл построчно
>>> для строки в ридере:
>>> печать (строка, конец = '')
Мопс
Джек Рассел терьер
Английский спрингер-спаниель
Немецкая овчарка
Стаффордширский бультерьер
Кавалер кинг чарльз спаниель
Золотистый ретривер
Вест-хайленд-уайт-терьер
Боксер
Бордер терьер
Этот последний подход более питонический и может быть более быстрым и более эффективным с точки зрения памяти. Поэтому рекомендуется использовать это вместо этого.
Примечание: Некоторые из приведенных выше примеров содержат print ('some text', end = '') . end = '' предотвращает добавление Python дополнительной строки в печатаемый текст и выводит только то, что читается из файла.
Теперь перейдем к написанию файлов. Как и при чтении файлов, файловые объекты имеют несколько методов, которые полезны для записи в файл:
| Метод | Что он делает |
|---|---|
.запись (строка) | Это записывает строку в файл. |
.writelines (seq) | Это записывает последовательность в файл. К каждому элементу последовательности не добавляются окончания строк. Вам решать, как добавить соответствующие окончания строки. |
Вот быстрый пример использования .write () и .writelines () :
с open ('dog_breeds.txt', 'r') в качестве читателя:
# Примечание: строки чтения не обрезают окончания строк
dog_breeds = читатель.readlines ()
с open ('dog_breeds_reversed.txt', 'w') в качестве писателя:
# В качестве альтернативы вы можете использовать
# writer.writelines (обратный (dog_breeds))
# Запишите породы собак в файл в обратном порядке
для породы реверс (dog_breeds):
писатель. пишите (порода)
Работа с байтами
Иногда может потребоваться работа с файлами, использующими байтовые строки. Это делается путем добавления символа 'b' к аргументу mode . Применяются все те же методы для файлового объекта.Однако каждый из методов ожидает и вместо этого возвращает объект байта :
>>> с open ('dog_breeds.txt', 'rb') в качестве читателя:
>>> print (reader.readline ())
б'Мопс \ п '
Открытие текстового файла с помощью флага b не так уж и интересно. Допустим, у нас есть симпатичная фотография джек-рассел-терьера ( jack_russell.png ):
. Вы действительно можете открыть этот файл в Python и изучить его содержимое! Начиная с версии .Формат файла png четко определен, заголовок файла состоит из 8 байт, разбитых следующим образом:
| Значение | Интерпретация |
|---|---|
0x89 | «Магическое» число, указывающее, что это начало PNG |
0x50 0x4E 0x47 | PNG в ASCII |
0x0D 0x0A | Строка в стиле DOS, заканчивающаяся \ r \ n |
0x1A | Символ EOF в стиле DOS |
0x0A | Строка в стиле Unix, заканчивающаяся \ n |
Конечно, когда вы открываете файл и читаете эти байты по отдельности, вы можете видеть, что это действительно .png заголовочный файл:
>>> с open ('jack_russell.png', 'rb') как byte_reader:
>>> печать (byte_reader.read (1))
>>> печать (byte_reader.read (3))
>>> печать (byte_reader.read (2))
>>> печать (byte_reader.read (1))
>>> печать (byte_reader.read (1))
б '\ x89'
b'PNG '
б '\ г \ п'
б '\ x1a'
б '\ п'
Полный пример:
dos2unix.py Давайте принесем все это домой и рассмотрим полный пример того, как читать и записывать в файл.Ниже приведен инструмент, подобный dos2unix , который преобразует файл, содержащий окончания строк \ r \ n , в \ n .
Этот инструмент разбит на три основных раздела. Первый - str2unix () , который преобразует строку из \ r \ n окончаний строки в \ n . Второй - dos2unix () , который преобразует строку, содержащую \ r \ n символа, в \ n . dos2unix () вызывает внутри себя str2unix () .Наконец, есть блок __main__ , который вызывается только тогда, когда файл выполняется как сценарий. Думайте об этом как об основной функции , которую можно найти в других языках программирования.
"" "
Простой скрипт и библиотека для преобразования файлов или строк из dos, например
окончания строк в Unix, как окончания строк.
"" "
import argparse
импорт ОС
def str2unix (input_str: str) -> str:
р"""
Преобразует строку из концов строки \ r \ n в \ n
Параметры
----------
input_str
Строка, окончание строки которой будет преобразовано
Возврат
-------
Преобразованная строка
"" "
r_str = input_str.replace ('\ r \ n', '\ n')
вернуть r_str
def dos2unix (исходный_файл: стр., целевой_файл: стр.):
"" "
Преобразует файл, содержащий окончания строк типа Dos, в Unix, например
Параметры
----------
исходный файл
Путь к исходному файлу для преобразования
dest_file
Путь к преобразованному файлу для вывода
"" "
# ПРИМЕЧАНИЕ: можно добавить проверку существования файла и перезапись файла
# защита
с open (source_file, 'r') в качестве читателя:
dos_content = reader.read ()
unix_content = str2unix (dos_content)
с open (dest_file, 'w') как писатель:
писатель.написать (unix_content)
если __name__ == "__main__":
# Создадим наш парсер аргументов и зададим его описание
parser = argparse.ArgumentParser (
description = "Скрипт, преобразующий файл, подобный DOS, в файл, подобный Unix",
)
# Добавьте аргументы:
# - source_file: исходный файл, который мы хотим преобразовать
# - dest_file: место назначения, куда должен идти вывод
# Примечание: использование типа аргумента argparse.FileType может
# оптимизировать некоторые вещи
parser.add_argument (
'исходный файл',
help = 'Местоположение источника'
)
парсер.add_argument (
'--dest_file',
help = 'Расположение файла назначения (по умолчанию: исходный_файл с добавлением `_unix`',
по умолчанию = Нет
)
# Разбираем аргументы (argparse автоматически берет значения из
# sys.argv)
args = parser.parse_args ()
s_file = args.source_file
d_file = args.dest_file
# Если целевой файл не был передан, предположим, что мы хотим
# создаем новый файл на основе старого
если d_file - None:
file_path, file_extension = os.path.splitext (s_file)
d_file = f '{file_path} _unix {file_extension}'
dos2unix (s_file, d_file)
Советы и хитрости
Теперь, когда вы освоили основы чтения и записи файлов, вот несколько советов и приемов, которые помогут вам развить свои навыки.
__файл__ Атрибут __file__ - это специальный атрибут модулей, аналогичный __name__ . Это:
«путь к файлу, из которого был загружен модуль, если он был загружен из файла.»(Источник
Примечание: Чтобы повторить итерацию, __file__ возвращает путь , относительный к тому месту, где был вызван исходный скрипт Python. Если вам нужен полный системный путь, вы можете использовать os.getcwd () , чтобы получить текущий рабочий каталог вашего исполняемого кода.
Вот пример из реальной жизни. На одной из моих прошлых работ я провел несколько тестов для аппаратного устройства. Каждый тест был написан с использованием скрипта Python с именем файла тестового скрипта, используемым в качестве заголовка.Затем эти сценарии будут выполнены и смогут распечатать свой статус с помощью специального атрибута __file__ . Вот пример структуры папок:
проект /
|
├── тесты /
| ├── test_commanding.py
| ├── test_power.py
| ├── test_wireHousing.py
| └── test_leds.py
|
└── main.py
Запуск main.py дает следующее:
>>> python main.py
tests / test_commanding.py Начато:
tests / test_commanding.py Пройдено!
тесты / test_power.py Начато:
tests / test_power.py Пройдено!
tests / test_wireHousing.py Начато:
tests / test_wireHousing.py Ошибка!
tests / test_leds.py Начато:
tests / test_leds.py Пройдено!
Мне удалось запустить и получить статус всех моих тестов динамически с помощью специального атрибута __file__ .
Добавление к файлу
Иногда может потребоваться добавить в файл или начать запись в конце уже заполненного файла. Это легко сделать, используя символ 'a' для аргумента режима :
с открытым ('dog_breeds.txt ',' a ') как a_writer:
a_writer.write ('\ nБигл')
Когда вы снова изучите dog_breeds.txt , вы увидите, что начало файла не изменилось, а Beagle теперь добавлен в конец файла:
>>> с open ('dog_breeds.txt', 'r') в качестве читателя:
>>> print (reader.read ())
Мопс
Джек Рассел терьер
Английский спрингер-спаниель
Немецкая овчарка
Стаффордширский бультерьер
Кавалер кинг чарльз спаниель
Золотистый ретривер
Вест-хайленд-уайт-терьер
Боксер
Бордер терьер
Бигль
Работа с двумя файлами одновременно
Бывают случаи, когда вам может понадобиться прочитать файл и записать в другой файл одновременно.Если вы воспользуетесь примером, который был показан, когда вы учились писать в файл, его можно объединить в следующее:
d_path = 'dog_breeds.txt'
d_r_path = 'dog_breeds_reversed.txt'
с open (d_path, 'r') как читатель, open (d_r_path, 'w') как писатель:
dog_breeds = reader.readlines ()
писатель.writelines (перевернутый (dog_breeds))
Создание собственного диспетчера контекста
Может наступить время, когда вам понадобится более тонкий контроль над файловым объектом, поместив его в специальный класс.Когда вы это сделаете, использование с оператором больше нельзя будет использовать, если вы не добавите несколько магических методов: __enter__ и __exit__ . Добавив их, вы создадите так называемый диспетчер контекста.
__enter __ () вызывается при вызове с оператором . __exit __ () вызывается при выходе из с блоком операторов .
Вот шаблон, который можно использовать для создания собственного класса:
класс my_file_reader ():
def __init __ (self, file_path):
себя.__path = путь к файлу
self .__ file_object = Нет
def __enter __ (сам):
self .__ file_object = open (собственный .__ путь)
вернуть себя
def __exit __ (self, type, val, tb):
self .__ file_object.close ()
# Дополнительные методы, реализованные ниже
Теперь, когда у вас есть собственный класс, который теперь является диспетчером контекста, вы можете использовать его аналогично встроенному open () :
с my_file_reader ('dog_breeds.txt') в качестве читателя:
# Выполнение пользовательских операций класса
проходить
Вот хороший пример.Помните милый образ Джека Рассела, который у нас был? Возможно, вы хотите открыть другие файлы .png , но не хотите каждый раз анализировать файл заголовка. Вот пример того, как это сделать. В этом примере также используются настраиваемые итераторы. Если вы не знакомы с ними, ознакомьтесь с Python Iterators:
класс PngReader ():
# Каждый файл .png содержит это в заголовке. Используйте это для проверки
# файл действительно имеет формат .png.
_expected_magic = b '\ x89PNG \ r \ n \ x1a \ n'
def __init __ (self, file_path):
# Убедитесь, что файл имеет правильное расширение
если не file_path.заканчивается с ('. png'):
поднять NameError ("Файл должен иметь расширение .png")
self .__ path = file_path
self .__ file_object = Нет
def __enter __ (сам):
self .__ file_object = open (self .__ путь, 'rb')
magic = self .__ file_object.read (8)
если магия! = self._expected_magic:
Raise TypeError ("Файл не является правильно отформатированным .png файлом!")
вернуть себя
def __exit __ (self, type, val, tb):
self .__ file_object.close ()
def __iter __ (сам):
# This и __next __ () используются для создания собственного итератора
# См. Https: // dbader.org / blog / python-итераторы
вернуть себя
def __next __ (сам):
# Прочитать файл в "Chunks"
# См. Https://en.wikipedia.org/wiki/Portable_Network_Graphics#%22Chunks%22_within_the_file
исходные_данные = self .__ file_object.read (4)
# Файл не был открыт или достиг EOF. Это означает, что мы
# дальше идти нельзя, поэтому остановите итерацию, подняв
# StopIteration.
если self .__ file_object равно None или initial_data == b '':
поднять StopIteration
еще:
# У каждого чанка есть len, тип, данные (на основе len) и crc
# Возьмите эти значения и верните их как кортеж
chunk_len = int.from_bytes (начальные_данные, byteorder = 'большой')
chunk_type = self .__ file_object.read (4)
chunk_data = self .__ file_object.read (chunk_len)
chunk_crc = self .__ file_object.read (4)
вернуть chunk_len, chunk_type, chunk_data, chunk_crc
Теперь вы можете открыть файлов .png и правильно проанализировать их, используя свой собственный диспетчер контекста:
>>> с PngReader ('jack_russell.png') в качестве читателя:
>>> для l, t, d, c в читателе:
>>> print (f "{l: 05}, {t}, {c}")
00013, b'IHDR ', b'v \ x121k'
00001, b'sRGB ', b' \ xae \ xce \ x1c \ xe9 '
00009, b'pHYs ', b' (<] \ x19 '
00345, b'iTXt ', b "L \ xc2'Y"
16384, b'IDAT ', b'i \ x99 \ x0c ('
16384, b'IDAT ', b' \ xb3 \ xfa \ x9a $ '
16384, b'IDAT ', b' \ xff \ xbf \ xd1 \ n '
16384, b'IDAT ', b' \ xc3 \ x9c \ xb1} '
16384, b'IDAT ', b' \ xe3 \ x02 \ xba \ x91 '
16384, b'IDAT ', b' \ xa0 \ xa99 = '
16384, b'IDAT ', b' \ xf4 \ x8b.\ x92 '
16384, b'IDAT ', b' \ x17i \ xfc \ xde '
16384, b'IDAT ', b' \ x8fb \ x0e \ xe4 '
16384, b'IDAT ', b') 3 = {'
01040, b'IDAT ', b' \ xd6 \ xb8 \ xc1 \ x9f '
00000, b'IEND ', b' \ xaeB` \ x82 '
Не изобретайте змею заново
Существуют распространенные ситуации, с которыми вы можете столкнуться при работе с файлами. Большинство этих случаев можно обрабатывать с помощью других модулей. Вам могут понадобиться два распространенных типа файлов: .csv и .json . Real Python уже собрал несколько отличных статей о том, как с этим справиться:
Кроме того, существуют встроенные библиотеки, которые вы можете использовать, чтобы помочь вам:
-
wave: чтение и запись файлов WAV (аудио) -
aifc: чтение и запись файлов AIFF и AIFC (аудио) -
sunau: чтение и запись файлов Sun AU -
tarfile: чтение и запись файлов архива tar -
zipfile: работа с ZIP-архивами -
configparser: легко создавать и анализировать файлы конфигурации -
xml.etree.ElementTree: создание или чтение файлов на основе XML -
msilib: чтение и запись файлов установщика Microsoft -
plistlib: создание и анализ Mac OS X.plistфайлов
Есть еще много всего. Кроме того, на PyPI доступно еще больше сторонних инструментов. Вот некоторые популярные:
Ты - файловый мастер, Гарри!
Вы сделали это! Теперь вы знаете, как работать с файлами с помощью Python, включая некоторые продвинутые методы.Работа с файлами в Python теперь должна быть проще, чем когда-либо, и это приятное чувство, когда вы начинаете это делать.
Из этого руководства вы узнали:
- Что это за файл
- Как правильно открывать и закрывать файлы
- Как читать и писать файлы
- Некоторые продвинутые приемы работы с файлами
- Некоторые библиотеки для работы с общими типами файлов
Если у вас есть вопросы, пишите в комментариях.
Пройдите тест: Проверьте свои знания с помощью нашей интерактивной викторины «Чтение и запись файлов на Python».По завершении вы получите балл, чтобы вы могли отслеживать свой прогресс в обучении с течением времени:
Пройти тест »
Смотреть сейчас Это руководство содержит соответствующий видеокурс, созданный командой Real Python. Посмотрите его вместе с письменным руководством, чтобы углубить свое понимание: Чтение и запись файлов на Python
Обработка файловв Python - GeeksforGeeks
Python также поддерживает обработку файлов и позволяет пользователям обрабатывать файлы i.е., для чтения и записи файлов, а также для многих других опций обработки файлов для работы с файлами. Концепция обработки файлов распространилась на различные другие языки, но реализация либо сложна, либо длинна, но, как и другие концепции Python, эта концепция здесь также проста и коротка. Python по-разному обрабатывает файл как текстовый или двоичный, и это важно. Каждая строка кода включает последовательность символов, и они образуют текстовый файл. Каждая строка файла заканчивается специальным символом, который называется EOL или символом конца строки, например запятой {,} или символом новой строки.Он завершает текущую строку и сообщает интерпретатору, что началась новая. Начнем с чтения и записи файлов.
Работа функции open ()
Мы используем функцию open () в Python, чтобы открыть файл в режиме чтения или записи. Как объяснялось выше, open () вернет файловый объект. Чтобы вернуть объект файла, мы используем функцию open () вместе с двумя аргументами, которые принимают имя файла и режим, читать или писать. Итак, синтаксис: open (имя файла, режим) .Python предоставляет три режима и способы открытия файлов:
- « r », для чтения.
- « w », для письма.
- « a », для добавления.
- « r + », для чтения и записи
Следует иметь в виду, что аргумент режима не является обязательным. Если не передан, Python по умолчанию примет значение « r ». Давайте посмотрим на эту программу и попробуем проанализировать, как работает режим чтения:
|
Команда open откроет файл в режиме чтения, а цикл for напечатает каждую строку, присутствующую в файле.
Работа в режиме чтения ()
Существует несколько способов чтения файла в Python.Если вам нужно извлечь строку, содержащую все символы в файле, мы можем использовать file.read () . Полный код будет работать так:
|
Другой способ прочитать файл - вызвать определенное количество символов, как в следующем коде, интерпретатор прочитает первые пять символов сохраненных данных и вернет их в виде строки:
|
Создание файла в режиме записи ()
Давайте посмотрим, как создать файл и как работает режим записи:
Чтобы управлять файлом, напишите в среде Python следующее:
|
Команда close () завершает работу всех используемых ресурсов и освобождает систему от этой конкретной программы.
Работа режима добавления ()
Давайте посмотрим, как работает режим добавления:
|
Существуют также различные другие команды обработки файлов, которые используются для обработки различных задач, например:
rstrip (): Эта функция удаляет пробелы из каждой строки файла с правой стороны.lstrip (): эта функция удаляет каждую строку файла из пробелов с левой стороны.
Он разработан для обеспечения более чистого синтаксиса и обработки исключений при работе с кодом. Это объясняет, почему рекомендуется использовать их с утверждениями, где это применимо. Это полезно, потому что при использовании этого метода все открытые файлы будут автоматически закрыты после того, как один будет выполнен, поэтому автоматическая очистка.
Пример:
|
Использование записи вместе с функцией ()
Мы также можем использовать функцию записи вместе с функцией ():
|
split () с использованием обработки файлов
Мы также можем разделить строки, используя обработку файлов в Python. Это разбивает переменную, когда встречается пробел. Вы также можете разделить, используя любые символы, как захотим. Вот код:
|
Существуют также различные другие функции, которые помогают управлять файлами и их содержимым. Можно изучить различные другие функции в Документах Python.
Автор статьи: Чинмой Ленка .Если вам нравится GeeksforGeeks, и вы хотели бы внести свой вклад, вы также можете написать статью с помощью provide.geeksforgeeks.org или отправить ее по электронной почте на [email protected]. Смотрите, как ваша статья появляется на главной странице GeeksforGeeks, и помогайте другим гикам.
Пожалуйста, напишите комментарии, если вы обнаружите что-то неправильное, или если вы хотите поделиться дополнительной информацией по теме, обсужденной выше.
Внимание компьютерщик! Укрепите свои основы с помощью курса Python Programming Foundation и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS .
Работа с файлами и каталогами в Python
Все примеры предполагают Python 3, если не указано иное
Записать строку в файл
запись - это всего лишь один из методов класса File . Все здесь
# будет перезаписан, если он уже существует!
с открытым ("имя файла.txt "," w ") как f:
f.write ("foo bar")
Прочитать файл в строку
Heads-up : это сломается, если файл не помещается в памяти
с open ("filename.txt", "r") как f:
content = f.read ()
# использовать переменную `contents`
Буферизованное чтение
Обрабатывать большой текстовый файл, не загружая его в память одновременно (чтение с буфером)
Это просто с python:
с открытым ("путь / к / файлу") как f:
для строки в f:
# обработать строку
Вы также можете использовать f.readline () для чтения всей строки (опасно, если файл не имеет разрывов строк) или f.read (size) , который принимает аргумент, указывающий максимальное количество байтов, которые должны быть прочитаны в память.
Обработать файл построчно
См. Выше: Буферизованное чтение
Проверить наличие файла
Этот метод возвращает True , если заданный путь существует и это файл.
Если вы просто хотите проверить, существует ли путь (будь то файл, каталог или даже ссылка), используйте os.path.exists () вместо этого.
импорт os.path
path_to_file = "/ путь / к / файлу"
если os.path.isfile (путь_к_файлу):
# он существует, и это обычный
# (т.е. не каталог) файл
Список файлов в каталоге
Чтобы показать все файлы, существующие в каталоге, используйте os.listdir (path_to_directory) :
импорт ОС
os.listdir (путь_к_каталогу)
>>> ['file1.txt', 'file2.json', 'myfile.png']
Перебирать файлы в каталоге
И.е. для файла в каталоге , сделайте что-нибудь.
импорт ОС
root_path = "/ путь / к / каталогу"
для имени_файла в os.listdir (корень):
# /path/to/directory/myfile.txt
full_path_to_file = os.path.join (корень, имя_файла)
Перебирать файлы в каталоге, рекурсивно
Чтобы перебрать все файлы рекурсивно по некоторому пути (т.е. включая подкаталоги):
импорт ОС
# вы можете опустить завершающие слэши
# т.е. '/ tmp' тоже работает
путь = '/ tmp /'
для корня, каталогов, имен файлов в os.прогулка (путь):
для каталога в каталогах:
directory_path = os.path.join (корень, каталог)
# сделать что-нибудь с directory_path
для имени файла в именах файлов:
file_path = os.path.join (корень, имя файла)
# сделать что-нибудь с directory_path
Удалить файл
Используйте os.remove (<путь-к-файлу>) .
импорт ОС
# вызывает FileNotFoundError, если файл не существует
os.remove ("/ путь / к / файлу")
Переместить / переименовать файл
Использование: os.replace (
импорт ОС
# вызывает FileNotFoundError, если исходный файл не существует
os.replace ('/ путь / к / источнику / файлу', '/ путь / к / новому / местоположению / файлу')
Копировать файл
Используйте: shutil.copy (<от>, и shutil.copy2 (. Оба метода используются одинаково. Смотрите различия ниже.
Shutil является частью стандартной библиотеки Python; ничего устанавливать не нужно.
| Метод | Копирует данные файла | Копирует права доступа к файлам | Копирует дату создания файла и изменения |
|---|---|---|---|
| shutil.copy | ДА | ДА | НЕТ |
| shutil.copy2 | ДА | ДА | ДА |
Добавить каталог в систему PATH
То есть переменная среды PATH .
импорт ОС
os.environ ["ПУТЬ"] + = os.pathsep + "/ путь / к / каталогу"
Чтение и запись файлов на Python
Обзор
Когда вы работаете с Python, вам не нужно импортировать библиотеку для чтения и записи файлов. Он реализован на родном языке, хотя и уникальным образом.
Первое, что вам нужно сделать, это использовать встроенную функцию файла python open , чтобы получить объект файла .
Функция open открывает файл. Это просто. Это первый шаг в чтении и записи файлов на Python.
Когда вы используете функцию open , она возвращает нечто, называемое файловым объектом . Объекты файла содержат методы и атрибуты, которые можно использовать для сбора информации об открытом вами файле. Их также можно использовать для управления указанным файлом.
Например, атрибут mode файлового объекта сообщает вам, в каком режиме был открыт файл.А атрибут name сообщает вам имя файла, который открыл объект файла .
Вы должны понимать, что файл и объект файла - это две полностью отдельные, но взаимосвязанные вещи.
Типы файлов
То, что вы можете знать как файл, в Python немного отличается.
В Windows, например, файл может быть любым элементом, которым манипулируют, редактируют или создают пользователь / ОС.Это означает, что файлы могут быть изображениями, текстовыми документами, исполняемыми файлами, файлами Excel и многим другим. Большинство файлов организовано путем хранения их в отдельных папках.
В Python файл подразделяется на текстовый или двоичный, и разница между этими двумя типами файлов важна.
Текстовые файлы структурированы как последовательность строк, где каждая строка включает последовательность символов. Это то, что вы знаете как код или синтаксис.
Каждая строка заканчивается специальным символом, который называется EOL или Конец строки символ.Есть несколько типов, но наиболее распространенными являются запятая {,} или символ новой строки. Он завершает текущую строку и сообщает интерпретатору, что началась новая.
Также можно использовать символ обратной косой черты, который сообщает интерпретатору, что следующий за косой чертой символ следует рассматривать как новую строку. Этот символ полезен, когда вы хотите начинать новую строку не в самом тексте, а в коде.
Двоичный файл - это файл любого типа, кроме текстового. Из-за своей природы двоичные файлы могут обрабатываться только приложением, которое знает или понимает структуру файла.Другими словами, это должны быть приложения, которые могут читать и интерпретировать двоичные файлы.
Функция открытия ()
Чтобы начать чтение и запись файлов в python, вы должны полагаться на встроенную функцию python open file. Используйте open (), чтобы открыть файл в python.
Как объяснено выше, open () вернет файловый объект, поэтому он чаще всего используется с двумя аргументами.
Рекомендуемое обучение Python
Для обучения Python наша главная рекомендация - DataCamp.
Аргумент - это не что иное, как значение, предоставленное функции, которое передается при ее вызове. Так, например, если мы объявим имя файла как «Тестовый файл», это имя будет считаться аргументом.
Синтаксис для открытия файлового объекта в Python:
файл_ объект = открытый ( « имя файла » , « режим » ) файл, где файл для добавления файлового объекта. Второй аргумент, который вы видите - режим - сообщает интерпретатору и разработчику, каким образом будет использоваться файл.
Режим
Включение аргумента режима является необязательным, поскольку в случае его отсутствия будет принято значение по умолчанию « r ». Значение « r » обозначает режим чтения, который является лишь одним из многих.
Режимы:
- ‘ r ’ - файл чтения Python.Режим чтения, который используется, когда файл только читается
- ‘ w ’ - файл записи Python. Режим записи, который используется для редактирования и записи новой информации в файл (все существующие файлы с тем же именем будут удалены при активации этого режима)
- ‘ a ’ - файл добавления Python. Режим добавления, который используется для добавления новых данных в конец файла; то есть новая информация автоматически дополняется до конца
- ‘ r + ’ - специальный режим чтения и записи, который используется для обработки обоих действий при работе с файлом
Итак, давайте взглянем на быстрый пример, в котором мы пишем файл с именем «рабочий файл», используя метод open python.
F = open («рабочий файл», «w»)
Печать f Этот фрагмент кода открывает файл с именем «рабочий файл» в режиме записи, чтобы мы могли вносить в него изменения. Убедитесь, что у вас правильный путь к файлу. Текущая информация, хранящаяся в файле, также отображается или распечатывается для нашего просмотра.
Как только это будет сделано, вы можете переходить к вызову функций объектов. Две наиболее распространенные функции - это чтение и запись.
Python записать в файл
Чтобы лучше познакомиться с текстовыми файлами в Python, давайте создадим наши собственные и выполним несколько дополнительных упражнений.
Давайте создадим файл с помощью простого текстового редактора. Вы можете называть его как угодно, и лучше использовать то, с чем вы будете себя идентифицировать. В этом примере мы будем использовать тип файла txt, но вы также можете создать файл csv.
Однако для целей этого руководства мы будем называть новый файл «testfile.txt».
После создания нового файла он будет пустым.Следующим шагом является добавление содержимого с помощью метода записи python.
Чтобы управлять файлом, напишите в среде Python следующее (при желании вы можете скопировать и вставить):
file = open («testfile.txt», «w»)
file.write («Привет, мир»)
file.write («Это наш новый текстовый файл»)
file.write («а это еще одна строка.»)
файл.напишите («Почему? Потому что мы можем»)
file.close () Естественно, если вы откроете текстовый файл - или посмотрите на него - с помощью Python, вы увидите только текст, который мы сказали интерпретатору добавить. Мы не добавляли символы новой строки выше, но вы, безусловно, можете использовать «\ n» для форматирования файла при просмотре.
$ cat testfile.txt
Привет, мир
Это наш новый текстовый файл
а это еще одна строка.
Почему? Потому что мы можем.
Чтение файла в Python
На самом деле существует несколько способов чтения текстового файла в Python, а не только один.
Если вам нужно извлечь строку, содержащую все символы в файле, вы можете использовать следующую операцию файла python:
file.read () Полный код для работы с этим методом будет выглядеть примерно так:
файл = открыть ( « тестовый файл.txt ” , “ r ”)
распечатать файл. Прочитать () Убедитесь, что у вас правильный путь к файлу, будь то относительный путь или абсолютный путь, иначе ваша программа python не сможет открыть файл. Результат этой команды будет отображать весь текст внутри файла, тот же текст, который мы сказали интерпретатору добавить ранее. Нет необходимости переписывать все это заново, но если вам нужно знать, будет показано все, кроме «$ cat testfile.txt ».
Другой способ прочитать файл - вызвать определенное количество символов.
Например, с помощью следующего кода интерпретатор прочитает первые пять символов сохраненных данных и вернет их в виде строки:
файл = открытый ( «testfile.txt», «r»)
распечатать файл. Прочитать (5) Обратите внимание, что мы используем тот же метод file.read () , только на этот раз мы указываем количество символов для обработки из входного файла.
Результат будет выглядеть так:
Привет Если вы хотите читать файл построчно, а не извлекать содержимое всего файла сразу, вы используете функцию readline ( ) .
Зачем вам использовать что-то подобное?
Допустим, вы хотите видеть только первую строку файла или третью. Вы должны выполнить функцию readline ( ) столько раз, сколько возможно, чтобы получить данные, которые вы ищете.
Каждый раз, когда вы запускаете метод, он возвращает строку символов, содержащую одну строку информации из файла.
файл = открыть ( « testfile.txt » , « r » )
печать file.readline (): Это вернет первую строку файла, например:
Привет, мир Если бы мы хотели вернуть только третью строку в файле, мы бы использовали это:
файл = открыть ( « тестовый файл.txt ” , “ r ” )
печать file.readline (3): Но что, если бы мы хотели вернуть каждую строку в файле, разделенную должным образом? Вы бы использовали ту же функцию, только в новой форме. Это называется функцией file.readlines () .
f ile = open ( « testfile.txt ” , “ r ” )
p rint file.readlines () В результате вы получите:
[«Hello World», «Это наш новый текстовый файл», «и это еще одна строка». «Почему? Потому что мы можем. »] Обратите внимание, как каждая строка разделена соответствующим образом? Обратите внимание, что это не лучший способ показать пользователям содержимое файла.Но это здорово, если вы хотите быстро собрать информацию для личного использования во время разработки или отзыва.
Цикл по файловому объекту
Если вы хотите прочитать - или вернуть - все строки из файла с более эффективным использованием памяти и быстрым способом, вы можете использовать метод цикла. Преимущество использования этого метода заключается в том, что связанный код прост и удобен для чтения.
f ile = open ( « testfile.txt ” , “ r ” )
f или строка в файле:
p линия обтекания, Это вернет:
Привет, мир
Это наш новый текстовый файл
а это еще одна строка.
Почему? Потому что мы можем. Видите, насколько это проще предыдущих методов?
Использование метода записи файла
Одна вещь, которую вы заметите в методе записи в файл, заключается в том, что для него требуется только один параметр, который представляет собой строку, которую вы хотите записать.
Этот метод используется для добавления информации или содержимого в существующий файл. Чтобы начать новую строку после записи данных в файл, вы можете добавить символ EOL.
f ile = open ( «testfile.txt», «w»)
f ile.write («Это тест»)
f ile.write («Чтобы добавить больше строк.»)
f ile.close () Очевидно, это изменит наш текущий файл, включив в него две новые строки текста.Нет необходимости показывать результат.
Закрытие файла
Когда вы закончите работу, вы можете использовать команду f h .close () , чтобы завершить работу. Это означает полное закрытие файла, прекращение использования используемых ресурсов и их освобождение для системы для развертывания в другом месте.
Важно понимать, что при использовании метода f h .close () любые дальнейшие попытки использования файлового объекта не удастся.
Обратите внимание, как мы использовали это в нескольких наших примерах для завершения взаимодействия с файлом? Это хорошая практика.
Обработка файлов в Python
Чтобы помочь вам лучше понять некоторые из обсуждаемых здесь методов обработки файлов, мы собираемся предложить скрипт Python с реальными примерами каждого использования. Не стесняйтесь копировать код и опробовать его на себе в интерпретаторе Python (сначала убедитесь, что у вас есть все именованные файлы, созданные и доступные).
Открытие текстового файла:
fh = open ( «привет.txt »,« r ») Чтение текстового файла:
Fh = открытый ( «hello.txt», «r»)
печать fh.read () Чтобы читать текстовый файл по одной строке за раз:
fh = open ( « hello.text », «r»)
печать fh.readline () Чтобы прочитать список строк в текстовом файле:
fh = открытый ( «hello.txt», «r»)
печать fh.readlines () Чтобы записать новый контент или текст в файл:
fh = открытый ( «hello.txt», «w»)
fh.напишите (« Поместите сюда текст , который вы хотите добавить»)
fh.write («и больше строк, если необходимо»)
fh.close () Вы также можете использовать это для одновременной записи нескольких строк в файл (пример новой строки python):
f h = open (« hello.txt» , «w »)
l ines_of_text = [«Одна строка текста здесь \ n», «и еще одна строка здесь \ n», «и еще одна здесь \ n», «и так далее и тому подобное»]
f h.Writelines ( lines_of_text )
f h. Закрыть () Чтобы добавить файл:
fh = открытый ( «hello.txt», «a»)
fh.write («Мы снова встретимся, мир»)
fh.close Чтобы полностью закрыть файл, когда вы закончите:
f h = open ( «привет.txt »,« r »)
p rint fh.read ()
f h. Закрыть () с заявлением
Вы также можете работать с файловыми объектами, используя оператор with. Он разработан для обеспечения более чистого синтаксиса и обработки исключений при работе с кодом. Это объясняет, почему рекомендуется использовать оператор with там, где это возможно.
Одним из преимуществ этого метода является то, что все открытые файлы будут автоматически закрыты после того, как вы закончите.Это оставляет меньше забот во время очистки.
Чтобы использовать оператор with для открытия файла:
с открытым («имя файла») как файл: Теперь, когда вы понимаете, как называть это утверждение, давайте рассмотрим несколько примеров.
w с открытым («testfile.txt») как файл:
d ata = файл. Читать ()
d или что-то с данными При использовании этого оператора вы также можете вызывать другие методы.Например, вы можете сделать что-то вроде цикла над файловым объектом:
w с открытым («testfile.txt») как f:
f или строка в f:
p линия обтекания, Вы также заметите, что в приведенном выше примере мы не использовали метод « file.close () », потому что оператор with автоматически вызывает его при выполнении. Это действительно упрощает жизнь, не так ли?
Использование оператора With в Python
Чтобы лучше понять оператор with, давайте рассмотрим несколько реальных примеров, как мы это делали с файловыми функциями.
Чтобы записать в файл с помощью оператора with:
с открытым ( «hello.txt», «w») как f:
f.write («Hello World») Чтобы прочитать файл построчно, выведите в список:
w с открытым («hello.txt») как f:
d ata = f.readlines () Это займет весь текст или содержимое из «hello.txt »и сохраните его в строке с именем« data ».
Разделение строк в текстовом файле
В качестве последнего примера давайте рассмотрим уникальную функцию, которая позволяет разделять строки, взятые из текстового файла. Это сделано для того, чтобы разбить строку, содержащуюся в переменных данных, всякий раз, когда интерпретатор встречает пробел.
Но то, что мы собираемся использовать его для разделения строк после символа пробела, не означает, что это единственный способ. Фактически вы можете разделить свой текст, используя любой символ, который вы хотите - например, двоеточие.
Код для этого (также с использованием оператора with):
с открытым ( « hello.text », «r») как f:
data = f.readlines ()
для строки в данных:
слов = line.split ()
печатные слова Если вы хотите использовать двоеточие вместо пробела для разделения текста, вы просто измените строку.split () в line.split («:»).
Результатом будет:
[«привет», «мир», «как», «есть», «ты», «сегодня?»]
[«сегодня», «будет», «суббота»] Причина, по которой слова представлены таким образом, заключается в том, что они сохраняются - и возвращаются - в виде массива. Обязательно помните об этом при работе с функцией разделения.
Больше чтения
Официальная документация Python - чтение и запись файлов
Шпаргалка по работе с файлами Python
Рекомендуемое обучение Python
Для обучения Python наша главная рекомендация - DataCamp.
Управление каталогами и файлами Python
Каталог Python
Если в нашей программе Python нужно обрабатывать большое количество файлов, мы можем расположить наш код в разных каталогах, чтобы упростить управление.
Каталог или папка - это набор файлов и подкаталогов. Python имеет модуль os , который предоставляет нам множество полезных методов для работы с каталогами (а также с файлами).
Получить текущий каталог
Мы можем получить текущий рабочий каталог, используя метод getcwd () модуля os .
Этот метод возвращает текущий рабочий каталог в виде строки. Мы также можем использовать метод getcwdb () , чтобы получить его как байтовый объект.
>>> импорт ОС
>>> os.getcwd ()
'C: \ Program Files \ PyScripter'
>>> os.getcwdb ()
b'C: \ Program Files \ PyScripter ' Дополнительная обратная косая черта подразумевает escape-последовательность. Функция print () отрендерит это правильно.
>>> печать (os.getcwd ())
C: \ Program Files \ PyScripter Смена каталога
Мы можем изменить текущий рабочий каталог с помощью метода chdir () .
Новый путь, который мы хотим изменить, должен быть передан этому методу в виде строки. Мы можем использовать как прямую косую черту /, так и обратную косую черту \ для разделения элементов пути.
При использовании обратной косой черты безопаснее использовать escape-последовательность.
>>> os.chdir ('C: \\ Python33')
>>> печать (os.getcwd ())
C: \ Python33 Список каталогов и файлов
Все файлы и подкаталоги внутри каталога можно получить с помощью метода listdir () .
Этот метод принимает путь и возвращает список подкаталогов и файлов по этому пути. Если путь не указан, возвращается список подкаталогов и файлов из текущего рабочего каталога.
>>> печать (os.getcwd ())
C: \ Python33
>>> os.listdir ()
['DLL',
"Док",
'включают',
'Lib',
'библиотеки',
"LICENSE.txt",
"NEWS.txt",
'python.exe',
'pythonw.exe',
'README.txt',
'Скрипты',
'tcl',
'Инструменты']
>>> os.listdir ('G: \\')
['$ RECYCLE.BIN',
'Фильмы',
'Музыка',
'Фото',
'Серии',
«Информация о системном объеме»] Создание нового каталога
Мы можем создать новый каталог, используя метод mkdir () .
Этот метод принимает путь к новому каталогу.Если полный путь не указан, новый каталог создается в текущем рабочем каталоге.
>>> os.mkdir ('тест')
>>> os.listdir ()
['test'] Переименование каталога или файла
Метод rename () может переименовать каталог или файл.
Для переименования любого каталога или файла метод rename () принимает два основных аргумента: старое имя в качестве первого аргумента и новое имя в качестве второго аргумента.
>>> os.listdir ()
['тест']
>>> os.rename ('test', 'new_one')
>>> os.listdir ()
['new_one'] Удаление каталога или файла
Файл можно удалить (удалить) с помощью метода remove () .
Аналогичным образом, метод rmdir () удаляет пустой каталог.
>>> os.listdir ()
['new_one', 'old.txt']
>>> os.remove ('old.txt')
>>> os.listdir ()
['новый']
>>> os.rmdir ('новый_он')
>>> os.listdir ()
[] Примечание : Метод rmdir () может удалять только пустые каталоги.
Чтобы удалить непустой каталог, мы можем использовать метод rmtree () внутри модуля shutil .
>>> os.listdir ()
['тест']
>>> os.rmdir ('тест')
Отслеживание (последний вызов последний):
...
OSError: [WinError 145] Каталог не пуст: 'test'
>>> импорт шутил
>>> шутил.rmtree ('тест')
>>> os.listdir ()
[] Dead Simple Python: Работа с файлами
Для меня ни один проект не начинает ощущаться «реальным», пока программа не начнет чтение или запись во внешние файлы.
К сожалению, это одна из тех тем, которая больше всего страдает от чрезмерного упрощения руководств. Если бы только кто-то документировал все странности с файлами в одном месте ...
Начнем с самого простого примера чтения файлов.Предположим, у меня есть файл в том же каталоге, что и мой файл кода, под названием journal1.txt .
Стандартный способ открытия файлов - использование встроенной функции open () , которая по умолчанию импортируется из модуля io .
file = open ("journal1.txt", 'r')
для строки в файле:
печать (строка)
file.close ()
Войти в полноэкранный режимВыйти из полноэкранного режима Функция open () принимает ряд аргументов для расширенного взаимодействия с файлами, но в большинстве случаев вам понадобятся только первые два.
Первый аргумент, файл , принимает строку, содержащую абсолютный или относительный путь к открываемому файлу. Это единственный строго обязательный аргумент.
Второй аргумент, mode , принимает строку, указывающую файловый режим . Если это не указано, будет использоваться 'rt' , что означает, что он будет читать файл как текст. Режим 'r' фактически то же самое, поскольку текстовый режим ( t ) является частью поведения по умолчанию.
Я мог бы просто использовать эту строку и получить такое же поведение ...
file = open ("journal1.txt")
Войти в полноэкранный режимВыйти из полноэкранного режима ... но я лично предпочитаю явно указывать, читаю ли я ( r ), пишу ( w ) или что есть у вас.
Все "файловые" объекты, возвращаемые из open () , являются повторяемыми. В случае текстовых файлов возвращается объект TextIOWrapper .В моем примере выше я перебираю строки в файле объекта TextIOWrapper и распечатываю каждую строку.
Когда я закончу работу с файлом, мне нужно закрыть его с помощью file.close () . Важно, чтобы , а не , полагался на сборщик мусора, чтобы закрыть файлы за вас, поскольку такое поведение не гарантируется и не переносимо между реализациями. Кроме того, не гарантируется, что Python закончит запись в файл, пока не будет вызван .close () .
Запуск этого кода, по крайней мере, в моем случае, распечатывает содержимое journal1.txt :
Может быть, здесь все пропавшие вещи найдены?
Волшебные волосы только для чистых сердцем
Не встречается в природе?
Это может привести к незначительным аномалиям силы тяжести!
Войти в полноэкранный режимВыйти из полноэкранного режимаМенеджеры контекста
На практике всегда помнить о вызове close () может быть королевской болью, особенно если учесть возможные ошибки при открытии файла.К счастью, есть еще более чистый способ: контекстных менеджеров !
Контекстный менеджер определяется оператором с в Python. Я могу переписать свой предыдущий код, используя этот синтаксис:
с открытым ("journal1.txt", 'r') как файл:
для строки в файле:
печать (строка)
Войти в полноэкранный режимВыйти из полноэкранного режима Вызывается функция open () , и если она завершается успешно, полученный объект TextIOWrapper сохраняется в файле и может использоваться в теле с оператором . file.close () неявно вызывается, когда элемент управления покидает с оператором ; вам никогда не нужно помнить, как это назвать!
Мы рассмотрим это более подробно в следующей главе.
В документации упоминается несколько режимов, которые можно использовать с open () :
-
rоткрывает файл для чтения (по умолчанию). -
wоткрывает или создает файл для записи, сначала удаляя (усекая) его содержимое. -
-
xсоздает и открывает новый файл для записи; он не может открывать существующие файлы. -
+открывает файл как для чтения, так и для записи (см. Таблицу ниже). -
tработает с файлом в текстовом режиме (по умолчанию). -
bработает с файлом в двоичном режиме.
Эти флаги режима можно комбинировать.Например, a + b разрешает запись и чтение, где запись добавляется в конец файла в двоичном режиме.
Флаг + всегда комбинируется с другим флагом. В сочетании с r он добавляет функциональность и , за исключением того, что он запускается в начале файла (без усечения). В сочетании с w , a или x он также позволяет читать.
Поведение различных флагов лучше всего можно понять с помощью этой таблицы, адаптированной из этого ответа на переполнение стека, предоставленного industryworker 35:
| г г + ш ш + а а + х х +
-------------------------- | ----------------------- -----------
разрешить читать | ✓ ✓ ✓ ✓ ✓
разрешить писать | ✓ ✓ ✓ ✓ ✓ ✓ ✓
создать новый файл | ✓ ✓ ✓ ✓ ✓ ✓
открыть существующий файл | ✓ ✓ ✓ ✓ ✓ ✓
стереть содержимое файла | ✓ ✓
разрешить искать | ✓ ✓ ✓ ✓ ✓
позиция в начале | ✓ ✓ ✓ ✓ ✓ ✓
позиция в конце | ✓ ✓
Войти в полноэкранный режимВыйти из полноэкранного режима Мы можем читать из файла в текстовом режиме, используя функции read () , readline () или readlines () , или выполняя итерацию напрямую.
Конечно, для этого необходимо, чтобы файл был открыт для чтения с использованием соответствующих флагов файлового режима (см. Раздел «Режимы файлов»). Если вам когда-нибудь понадобится проверить, можно ли прочитать объект file , используйте функцию file.readable () .
Давайте сравним три способа чтения из файла:
читать()
Функция read () считывает все содержимое файла как одну длинную строку.
с открытым ("journal1.txt ", 'r') как файл:
содержимое = file.read ()
печать (содержание)
# Может ли здесь быть найдено все недостающее?
# Волшебные волосы только для чистых сердцем
# Не встречающиеся в природе?
# Может привести к незначительным аномалиям силы тяжести!
Войти в полноэкранный режимВыйти из полноэкранного режима В качестве альтернативы вы можете указать read () максимальное количество символов для чтения из файлового потока:
с открытым ("journal1.txt", 'r') как файл:
содержимое = файл.читать (20)
печать (содержание)
# Это могло быть где
Войти в полноэкранный режимВыйти из полноэкранного режимаreadline ()
Функция readline () ведет себя точно так же, как read () , за исключением того, что она останавливает чтение, когда обнаруживает разрыв строки. Разрыв строки включается в возвращаемую строку.
с открытым ("journal1.txt", 'r') как файл:
content = file.readline ()
печать (содержание)
# Может ли здесь быть найдено все недостающее?
Войти в полноэкранный режимВыйти из полноэкранного режима Как и read () , вы можете указать максимальное количество символов для чтения:
с открытым ("journal1.txt ", 'r') как файл:
content = file.readline (20)
печать (содержание)
# Это могло быть где
Войти в полноэкранный режимВыйти из полноэкранного режимаreadlines ()
Функция readlines () возвращает весь файл в виде списка строк, каждая из которых представляет собой одну строку.
с открытым ("journal1.txt", 'r') как файл:
content = file.readlines ()
для c в содержании:
печать (с)
# Может ли здесь быть найдено все недостающее?
#
# Волшебные волосы только для чистых сердцем
#
# Не встречающиеся в природе?
#
# Может привести к незначительным аномалиям силы тяжести!
#
Войти в полноэкранный режимВыйти из полноэкранного режима Вы заметите, что символ новой строки включен в каждую строку.Мы можем удалить это, вызвав функцию .strip () для каждой строки.
с открытым ("journal1.txt", 'r') как файл:
content = file.readlines ()
для c в содержании:
печать (c.strip ())
# Может ли здесь быть найдено все недостающее?
# Волшебные волосы только для чистых сердцем
# Не встречающиеся в природе?
# Может привести к незначительным аномалиям силы тяжести!
Войти в полноэкранный режимВыйти из полноэкранного режимаВы также можете ограничить объем чтения из файла, указав максимальное количество символов.Однако, в отличие от предыдущего, это , а не - жесткий предел. Вместо этого, как только указанный предел будет превышен на общее количество символов, прочитанных из всех строк на данный момент, будет прочитана только остальная часть текущей строки.
Это лучше всего понять, сравнив read () и readlines () . Во-первых, я буду читать до жесткого ограничения в 60 символов:
с открытым ("journal1.txt", 'r') как файл:
содержимое = file.read (60)
печать (содержание)
# Может ли здесь быть найдено все недостающее?
# Волшебные волосы
Войти в полноэкранный режимВыйти из полноэкранного режима Сравните это с вызовом readlines () с «подсказкой» из 60 символов:
с открытым ("journal1.txt ", 'r') как файл:
content = file.readlines (60)
для c в содержании:
печать (c.strip ())
# Может ли здесь быть найдено все недостающее?
# Волшебные волосы только для чистых сердцем
Войти в полноэкранный режимВыйти из полноэкранного режимаВо втором примере считываются первые две строки целиком, но не более.
В отличие от двух других функций, readlines () всегда читает только всю строку.
Итерация
Как вы видели ранее, мы можем перебирать файл напрямую:
с открытым ("journal1.txt ", 'r') как файл:
для строки в файле:
печать (строка)
# Может ли здесь быть найдено все недостающее?
# Волшебные волосы только для чистых сердцем
# Не встречающиеся в природе?
# Может привести к незначительным аномалиям силы тяжести!
Войти в полноэкранный режимВыйти из полноэкранного режима Функционально аналогичен:
с открытым ("journal1.txt", 'r') как файл:
для строки в file.readlines ():
печать (строка)
Войти в полноэкранный режимВыйти из полноэкранного режимаРазница между ними состоит в том, что первый подход, прямая итерация, ленивый , тогда как второй подход сначала считывает весь файл, а затем итерацию по содержимому.
Мы можем записывать в файл почти таким же образом, используя функции write () или writelines () .
Для этого необходимо, чтобы файл был открыт для записи (см. Раздел «Режимы файлов»). Функцию file.writable () можно использовать, чтобы проверить, доступен ли для записи объект file .
В примерах для этого раздела я покажу содержимое файла в комментарии внизу.
записывать()
Функция write () записывает заданные строки в файл.
Я могу записать целую многострочную строку в новый файл с именем journal3.txt с write () , например:
entry = "" "Если вы много ездите по дорогам
скорее всего, вы видели
определенная наклейка на бампер:
ЧТО ТАКОЕ ТАИНСТВЕННЫЙ ШЕК?
"" "
с open ("journal3.txt", 'x') как файл:
file.write (запись)
# Если вы совершите достаточно поездок
# скорее всего, вы видели
# определенная наклейка на бампер:
# ЧТО ТАКОЕ ТАЙНА SHACK?
#
Войти в полноэкранный режимВыйти из полноэкранного режима Пока journal3.txt , если еще не существует, будет создан с указанным содержимым.
Я могу переопределить все содержимое файла journal3.txt , используя файловый режим w :
с открытым ("journal3.txt", 'w') как файл:
file.write ("ГНОМЫ \ n СЛАБОСТЬ? \ n")
# ГНОМЫ
# СЛАБОЕ МЕСТО?
#
Войти в полноэкранный режимВыйти из полноэкранного режимаGOTCHA ALERT: Следите за своим файловым режимом!
wиw +удалит все содержимое файла.Используйтеaилиa +для записи в конец файла.
Я могу добавить в файл вместо этого, используя файловый режим и :
с открытым ("journal3.txt", 'a') как файл:
file.write ("воздуходувки \ n")
# ГНОМЫ
# СЛАБОЕ МЕСТО?
# воздуходувки
#
Войти в полноэкранный режимВыйти из полноэкранного режима Функция write () также возвращает целое число, представляющее количество записанных символов.
Writelines ()
Функция writelines () записывает список строк в файл.
строк = [
"Наконец-то вернулся в целости и сохранности \ n",
"в один из самых странных дней \ n",
"в Гравити Фолз. \ n"
]
с open ("journal3.txt", 'w') как файл:
file.writelines (строки)
# Наконец-то вернулся в целости и сохранности
# с одного из самых странных дней
# в Гравити Фолз.
#
Войти в полноэкранный режимВыйти из полноэкранного режима В отличие от write () , функция writelines () всегда возвращает только None .
Файл .Функция seek () позволяет перемещаться вперед и назад внутри файлового объекта файла , посимвольно. При работе с текстовыми потоками он принимает один аргумент: положительное целое число, представляющее новую позицию, в которую нужно перейти, представленное как количество символов от начала.
Помимо изменения позиции, функция file.seek () также возвращает целое число, представляющее новую абсолютную позицию в файле. Вы также можете получить текущую позицию, вызвав файл .Функция tell () .
Файловый режим r + лучше всего использовать вместе с функцией seek () , хотя его можно использовать с любым другим файловым режимом , кроме a и a + .
Сначала я воспользуюсь функцией seek () , чтобы читать только часть файла journal1.txt :
с открытым ("journal1.txt", 'r') как файл:
file.seek (50)
содержимое = file.read (5)
печать (содержание)
# МАГИЯ
Войти в полноэкранный режимВыйти из полноэкранного режима Напишу новую начальную версию журнала 3.txt файл:
с открытым ("journal3.txt", 'w') как файл:
file.write («ПЛАВАЮЩИЕ ГЛАЗЫ»)
# ПЛАВАЮЩИЕ ГЛАЗНЫЕ ЯБЛОКИ
Войти в полноэкранный режимВыйти из полноэкранного режима Я могу использовать режим r + , чтобы изменить часть этого файла.
GOTCHA ALERT: Команда
write ()всегда будет записывать поверх существующего содержимого файла, если вы не добавите его в конец. Чтобы вставить текст в файл неразрушающим образом, обычно лучше всего прочитать все содержимое в виде строки (или списка), отредактировать строку, а затем записать ее обратно.
Здесь я заменю слово "ГЛАЗНЫЕ ЯДЕРЫ" на "БЕЗ СМЫСЛА!":
с открытым ("journal3.txt", 'r +') как файл:
file.seek (9)
file.write ("БЕЗ СМЫСЛА!")
# ПЛАВАЮЩИЙ БЕЗУМНЫЙ!
Войти в полноэкранный режимВыйти из полноэкранного режима После открытия файла я перехожу к 9-му символу с начала, а затем write () новые данные.
Искать с двоичным
Когда вы открываете файл в двоичном режиме ( b ), вы можете перемещаться в файле более динамично, используя два аргумента вместо одного:
-
смещение: расстояние в символах для перемещения (может быть отрицательным) -
откуда: позиция, из которой следует вычислить смещение:0для начала файла (по умолчанию),1для текущей позиции или2для конца файла.
К сожалению, использование аргумента откуда не работает с файлами, открытыми в текстовом режиме.
Четыре наиболее распространенные ошибки, связанные с работой с файлами:
FileNotFoundError
Режимы r и r + требуют, чтобы файл существовал перед его открытием. В противном случае будет выдано FileNotFoundError :
попробовать:
с open ("notreal.txt", 'r') как файл:
распечатать файл.читать())
кроме FileNotFoundError как e:
печать (е)
Войти в полноэкранный режимВыйти из полноэкранного режимаFileExistsError
Режимы файлов x и x + предназначены специально для создания нового файла. Если файл уже существует, будет выдано FileExistsError :
попробовать:
с open ("journal3.txt", 'x +') как файл:
печать (file.read ())
кроме FileExistsError как e:
печать (е)
Войти в полноэкранный режимВыйти из полноэкранного режимаUnsupportedOperation
Модель io.Ошибка UnsupportedOperation возникает всякий раз, когда вы пытаетесь прочитать файл, открытый только для записи, или записать в файл, открытый только для чтения:
импорт io
пытаться:
с open ("journal3.txt", 'w') как файл:
печать (file.read ())
кроме io.UnsupportedOperation как e:
печать (е)
пытаться:
с open ("journal3.txt", 'r') как файл:
file.write ('')
кроме io.UnsupportedOperation как e:
печать (е)
Войти в полноэкранный режимВыйти из полноэкранного режима Некоторые опытные читатели помнят, что в то время как UNIX использует \ n в качестве разделителя строк, Windows использует \ r \ n .Конечно, это важно, когда мы читаем и записываем файлы, верно?
Фактически, Python абстрагируется для нас за кулисами. Всегда используйте \ n в качестве разделителя строк при записи файлов в текстовом режиме, независимо от операционной системы!
До этого момента я просто использовал файл в той же папке, что и код, но это очень редко то, что нам нужно! Нам нужно иметь возможность строить пути к файлам.
Проблема в том, что пути к файлам не совпадают во всех системах.Системы в стиле UNIX, такие как macOS и Linux, используют соглашения о путях к файлам UNIX, в то время как Windows использует совершенно другую схему. Наше решение должно работать как для , так и для , а это означает, что использование сложных путей недопустимо.
Для решения этой проблемы Python предлагает два модуля: os и pathlib .
Создание пути
Python фактически предлагает несколько классов для построения путей, в зависимости от ваших конкретных потребностей. Однако в большинстве случаев вам следует просто использовать pathlib.Путь .
Допустим, я хотел создать в домашней папке текущего пользователя специальный каталог с именем .dead_simple_python , а затем записать в это место файл. Вот как бы я это сделал:
Сначала я создаю объект Path () , указывающий только на последний желаемый каталог (еще не на файл).
В конструкторе Path () я передаю каждую часть пути как отдельную строку. Я могу использовать метод класса Path.home () , чтобы получить путь к каталогу пользователя.
из пути импорта pathlib
импорт ОС
file_path = Путь (Path.home (), ".dead_simple_python")
Войти в полноэкранный режимВыйти из полноэкранного режима Затем я проверю, существует ли уже путь, используя file_path.exists () , и если он не существует, я использую функцию os.makedirs для создания любого из отсутствующих каталогов в пути :
, если не file_path.exists ():
os.makedirs (путь к файлу)
Войти в полноэкранный режимВыйти из полноэкранного режима Наконец, я могу добавить имя файла к объекту пути, который у меня уже есть, а затем открыть этот файл для записи:
file_path = file_path.joinpath ("journal4.txt")
с file_path.open ('w') в качестве файла:
lines = [
"Если вы когда-нибудь путешествовали \ n",
"через Тихоокеанский северо-запад, вы \ n",
"наверное видел наклейку на бампер \ n",
"место под названием Гравити Фолз. \ n"
]
file.writelines (строки)
Войти в полноэкранный режимВыйти из полноэкранного режима Вы заметите, что я использовал file_path.open ('w') вместо open (file_path, 'w') . Технически оба делают одно и то же, хотя функция-член предпочтительнее.
Относительные пути
Причина того, что open ("journal1.txt") работает, заключается в том, что это относительный путь, начиная с каталога, из которого выполняется код.
Если у меня есть каталог journals / в том же каталоге, что и мой код, я могу использовать это:
из пути импорта pathlib
file_path = Путь ("журналы", "journal1.txt")
с file_path.open ('r') как файл:
печать (file.read ())
Войти в полноэкранный режимВыйти из полноэкранного режима Если я не начинаю с абсолютного пути, такого как путь, созданный Path.home () , пути относительны.
Но что, если я хочу переместить вверх по каталогу , а не вниз? У вас может возникнуть соблазн использовать .. , но, как вы можете догадаться, это не гарантирует переносимость во всех операционных системах. Вместо этого я могу использовать os.pardir для перехода в предыдущий каталог.
Представьте, что у нас есть структура каталогов, которая выглядит так:
пример
├── код
│ └── read_file.py
└── журналы
└── journal1.текст
Войти в полноэкранный режимВыйти из полноэкранного режима Если из path_relative2 / code я запускаю python read_file.py , я могу получить доступ к journal1.txt со следующим:
из пути импорта pathlib
импорт ОС
file_path = Путь (os.pardir, "журналы", "journal1.txt")
с file_path.open ('r') как файл:
печать (file.read ())
Войти в полноэкранный режимВыйти из полноэкранного режима Мы только что коснулись поверхности работы с файлами, но, надеюсь, это демистифицировало функцию open () и Path объекты.Вот краткое резюме:
Функция
open ()имеет несколько режимов:rдля чтения,wдля усечения и записи,xдля создания и записи иaдля добавления. Добавление+к любому из них добавляет недостающую функциональность, будь то чтение или запись.Вы должны не забыть закрыть любой открытый файл. Вы можете сделать это вручную с помощью
open ()или ...Если вы используете
с оператором(диспетчер контекста) для открытия файла, файл будет закрыт автоматически.myfile.seek ()позволяет изменять позицию в открытом файлеmyfile. Это не работает с режимамиr,aилиa +.Объект
pathlib.Pathпозволяет создать переносимый путь из строк, переданных в инициализаторPath ().Вы можете вызвать
open ()непосредственно на объектеPath.Использовать путь
.home (), чтобы получить абсолютный путь к домашней папке текущего пользователя.Используйте
os.pardirдля доступа к родительскому каталогу (эквивалент..в Unix.)
В следующем разделе я более подробно расскажу о менеджерах контекста.
Вот, как обычно, документация:
.