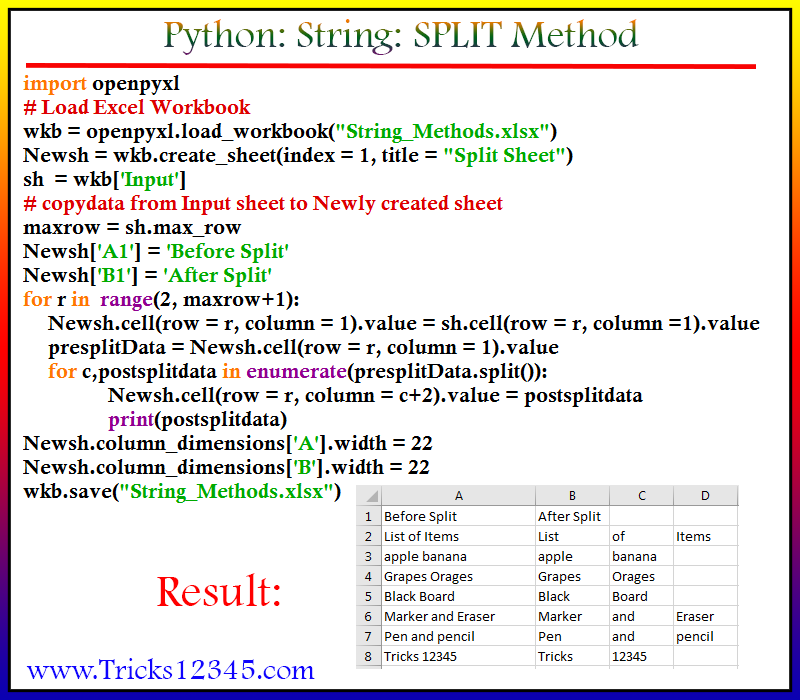
Разделение строки на списки в Python
В этой статье мы расскажем, как можно разбивать строки на списки. Вы узнаете, как при этом использовать разделители (в частности — как отделять часть строки только по первому разделителю и как быть с последовательно идущими разделителями) и регулярные выражения. Безусловно, эта информация будет особенно полезна начинающим питонистам, но, возможно, и более опытные найдут для себя кое-что интересное.
Мини-задача на разогрев: являются ли две строки анаграммами?
Простое разделение строки и получение списка ее составляющих
Если вы хотите разбить любую строку на подстроки и составить из них список, вы можете просто воспользоваться методом split(sep=None, maxsplit=-1). Этот метод принимает два параметра (опционально). Остановимся пока на первом из них — разделителе (sep).
Разделитель можно задать явно в качестве параметра, но можно и не задавать: в этом случае в его роли выступает пробел.
Пример использования метода
print("Python2 Python3 Python Numpy". split())
print("Python2, Python3, Python, Numpy".split())
split())
print("Python2, Python3, Python, Numpy".split()) split())
print("Python2, Python3, Python, Numpy".split())
split())
print("Python2, Python3, Python, Numpy".split())Результат:
['Python2', 'Python3', 'Python', 'Numpy'] ['Python2,', 'Python3,', 'Python,', 'Numpy']
Разделение строки с использованием разделителя
Python может разбивать строки по любому разделителю, указанному в качестве параметра метода split(). Таким разделителем может быть, например, запятая, точка или любой другой символ (или даже несколько символов).
Давайте рассмотрим пример, где в качестве разделителя выступает запятая и точка с запятой (это можно использовать для работы с CSV-файлами).
print("Python2, Python3, Python, Numpy".split(','))
print("Python2; Python3; Python; Numpy".split(';'))Результат:
['Python2', ' Python3', ' Python', ' Numpy'] ['Python2', ' Python3', ' Python', ' Numpy']
Как видите, в результирующих списках
отсутствуют сами разделители.
Если вам нужно получить список, в который войдут и разделители (в качестве отдельных элементов), можно разбить строку по шаблону, с использованием регулярных выражений (см. документацию re.split). Когда вы берете шаблон в захватывающие круглые скобки, группа в шаблоне также возвращается как часть результирующего списка.
import re
sep = re.split(',', 'Python2, Python3, Python, Numpy')
print(sep)
sep = re.split('(,)', 'Python2, Python3, Python, Numpy')
print(sep)Результат:
['Python2', ' Python3', ' Python', ' Numpy'] ['Python2', ',', ' Python3', ',', ' Python', ',', ' Numpy']
Если вы хотите, чтобы разделитель был частью каждой подстроки в списке, можно обойтись без регулярных выражений и использовать list comprehensions:
text = 'Python2, Python3, Python, Numpy' sep = ',' result = [x+sep for x in text.split(sep)] print(result)

Результат:
['Python2,', ' Python3,', ' Python,', ' Numpy,']
Разделение многострочной строки (построчно)
Создать список из отдельных строчек многострочной строки можно при помощи того же метода split(), указав в качестве разделителя символ новой строки \n. Если текст содержит лишние пробелы, их можно удалить при помощи методов strip() или lstrip():
str = """
Python is cool
Python is easy
Python is mighty
"""
list = []
for line in str.split("\n"):
if not line.strip():
continue
list.append(line.lstrip())
print(list)Результат:
['Python is cool', 'Python is easy', 'Python is mighty']
Разделение строки-словаря и преобразование ее в списки или словарь
Допустим, у нас есть строка, по сути являющаяся словарем и содержащая пары ключ-значение в виде key => value. Мы хотим получить эти пары в виде списков или настоящего словаря. Вот простой пример, как получить словарь и два списка:
Мы хотим получить эти пары в виде списков или настоящего словаря. Вот простой пример, как получить словарь и два списка:
dictionary = """\ key1 => value1 key2 => value2 key3 => value3 """ mydict = {} listKey = [] listValue = [] for line in dictionary.split("\n"): if not line.strip(): continue k, v = [word.strip() for word in line.split("=>")] mydict[k] = v listKey.append(k) listValue.append(v) print(mydict) print(listKey) print(listValue)
Результат:
{'key3': 'value3', 'key2': 'value2', 'key1': 'value1'}
['key1', 'key2', 'key3']
['value1', 'value2', 'value3']Отделение указанного количества элементов
Метод split() имеет еще один опциональный параметр — maxsplit. С его помощью можно указать, какое максимальное число «разрезов» нужно сделать. По умолчанию
По умолчанию maxsplit=-1, это означает, что число разбиений не ограничено.
Если вам нужно отделить от строки несколько первых подстрок, это можно сделать, указав нужное значение maxsplit. В этом примере мы «отрежем» от строки первые три элемента, отделенные запятыми:
str = "Python2, Python3, Python, Numpy, Python2, Python3, Python, Numpy" data = str.split(", ",3) for temp in data: print(temp)
Результат:
Python2 Python3 Python Numpy, Python2, Python3, Python, Numpy
Разделение строки при помощи последовательно идущих разделителей
Если вы для разделения строки используете метод split() и не указываете разделитель, то разделителем считается пробел. При этом последовательно идущие пробелы трактуются как один разделитель.
Но если вы указываете определенный разделитель, ситуация меняется. При работе метода будет считаться, что последовательно идущие разделители разделяют пустые строки. Например, '1,,2'.split(',') вернет ['1', '', '2'].
Если вам нужно, чтобы последовательно идущие разделители все-таки трактовались как один разделитель, нужно воспользоваться регулярными выражениями. Разницу можно видеть в примере:
import re
print('Hello1111World'.split('1'))
print(re.split('1+', 'Hello1111World' ))Результат:
['Hello', '', '', '', 'World'] ['Hello', 'World']
Разделить строку на список Python
В этом посте мы обсудим, как разделить строку с разделителями и без разделителей на список в Python.
Связанный пост:
Преобразование строки в список символов в Python
1.
 Использование
Использование list() конструкторThe list() конструктор строит список непосредственно из итерируемого объекта, а поскольку строка является итерируемой, вы можете создать из нее список, передав строку конструктору списка:
1 2 3 4 5 6 7 | if __name__ == ‘__main__’:
input = ‘ABC’
chars = list(input) print(chars) # [‘A’, ‘B’, ‘C’]
|
Скачать Выполнить код
2. Использование
str.split() функцияВы можете использовать str.split(sep=None) функция, которая возвращает список слов в строке, используя sep в качестве строки-разделителя.
Например, чтобы разделить строку с разделителем -, ты можешь сделать:
1 2 3 4 5 6 | if __name__ == ‘__main__’:
s = ‘1-2-3’ l = s. print(l) # prints [‘1’, ‘2’, ‘3’]
|

Скачать Выполнить код
Если sep не указано или указано None, последовательные запуски пробелов считаются одним разделителем.
1 2 3 4 5 6 | if __name__ == ‘__main__’:
s = ‘1 2 3’ l = s.split() print(l) # prints [‘1’, ‘2’, ‘3’]
|
Скачать Выполнить код
3. Использование
shlex.split() функцияThe шлекс модуль определяет shlex.split(s) функция, которая разбивает строку s с использованием командного синтаксиса.
1 2 3 4 5 6 7 8 | import shlex
if __name__ == ‘__main__’:
s = ‘1 2 3’ l = shlex. print(l) # prints [‘1’, ‘2’, ‘3’]
|
 split(s)
split(s)Скачать Выполнить код
Это все о разбиении строки на список в Python.
Оценить этот пост
Средний рейтинг 4.1/5. Подсчет голосов: 63
Голосов пока нет! Будьте первым, кто оценит этот пост.
Сожалеем, что этот пост не оказался для вас полезным!
Расскажите, как мы можем улучшить этот пост?
Спасибо за чтение.
Пожалуйста, используйте наш онлайн-компилятор размещать код в комментариях, используя C, C++, Java, Python, JavaScript, C#, PHP и многие другие популярные языки программирования.
Как мы? Порекомендуйте нас своим друзьям и помогите нам расти. Удачного кодирования 🙂
python — Разделить строку на каждый n-й символ?
спросил
Изменено 27 дней назад
Просмотрено 595 тысяч раз
Можно ли разделить строку через каждый n-й символ?
Например, предположим, что у меня есть строка, содержащая следующее:
'1234567890'
Как сделать, чтобы это выглядело так:
['12','34','56','78','90']
Тот же вопрос со списком см. в разделе Как разделить список на части одинакового размера?. Обычно применяются одни и те же методы, хотя есть некоторые вариации.
в разделе Как разделить список на части одинакового размера?. Обычно применяются одни и те же методы, хотя есть некоторые вариации.
- питон
- строка
- сплит
0
>>> строка = '1234567890' >>> n = 2 >>> [строка[i:i+n] для i в диапазоне (0, len(line), n)] ['12', '34', '56', '78', '90']
4
Просто для полноты вы можете сделать это с помощью регулярного выражения:
>>> import re
>>> re.findall('..','1234567890')
['12', '34', '56', '78', '90']
Для нечетного количества символов вы можете сделать это:
>>> import re
>>> re.findall('..?', '123456789')
['12', '34', '56', '78', '9']
Вы также можете сделать следующее, чтобы упростить регулярное выражение для более длинных фрагментов:
>>> импортировать повторно
>>> re.findall('.{1,2}', '123456789')
['12', '34', '56', '78', '9']
И вы можете использовать re., если строка длинная, чтобы генерировать фрагмент за фрагментом. finditer
finditer
5
Для этого в Python уже есть встроенная функция.
>>> из переноса импорта textwrap >>> с = '1234567890' >>> упаковка(и, 2) ['12', '34', '56', '78', '90']
Это строка документации для обернуть говорит:
>>> help(обернуть)
'''
Справка по переносу функций в модуль textwrap:
обертка (текст, ширина = 70, ** kwargs)
Обернуть один абзац текста, возвращая список перенесенных строк.
Переформатируйте один абзац в «тексте», чтобы он помещался в строки без
больше, чем столбцы «ширина», и возвращает список строк с переносом. К
по умолчанию вкладки в «тексте» расширяются с помощью string.expandtabs() и
все остальные пробельные символы (включая новую строку) преобразуются в
космос. См. класс TextWrapper для доступных аргументов ключевого слова для настройки.
поведение упаковки.
'''
 '''
'''
10
Другой распространенный способ группировки элементов в группы длины n:
>>> s = '1234567890'
>>> map(''.join, zip(*[iter(s)]*2))
['12', '34', '56', '78', '90']
Этот метод взят прямо из документации для zip() .
6
Я думаю, что это короче и читабельнее, чем версия itertools:
по определению split_by_n(seq, n):
'''Генератор для разделения последовательности на куски по n единиц.'''
в то время как последовательность:
выход последовательности [: n]
последовательность = последовательность [n:]
печать (список (split_by_n ('1234567890', 2)))
2
Использование more-itertools из PyPI:
>>> from more_itertools import sliced
>>> список(нарезанный('1234567890', 2))
['12', '34', '56', '78', '90']
Мне нравится это решение:
s = '1234567890'
о = []
пока с:
о. добавлять(ы[:2])
с = с[2:]
 добавлять(ы[:2])
с = с[2:]
добавлять(ы[:2])
с = с[2:]
1
Вы можете использовать рецепт grouper() из itertools :
Python 2.x:
из itertools import izip_longest
def grouper (итерируемый, n, fillvalue = None):
«Собирать данные в куски или блоки фиксированной длины»
# grouper('ABCDEFG', 3, 'x') --> ABC DEF Gxx
args = [iter(итерируемый)] * n
вернуть izip_longest(fillvalue=fillvalue, *аргументы)
Python 3.x:
из itertools import zip_longest
def grouper (итерируемый, n, *, неполный = 'fill', fillvalue = None):
«Собирать данные в неперекрывающиеся фрагменты или блоки фиксированной длины»
# grouper('ABCDEFG', 3, fillvalue='x') --> ABC DEF Gxx
# grouper('ABCDEFG', 3,plete='strict') --> ABC DEF ValueError
# grouper('ABCDEFG', 3, complete='ignore') --> ABC DEF
args = [iter(итерируемый)] * n
если неполный == 'заполнить':
вернуть zip_longest(*args, fillvalue=fillvalue)
если неполный == 'строгий':
вернуть zip(*args, strict=True)
если неполный == 'игнорировать':
вернуть почтовый индекс (*аргументы)
еще:
поднять ValueError('Ожидаемое заполнение, строгое или игнорирование')
Эти функции эффективно используют память и работают с любыми итерируемыми объектами.
2
Этого можно добиться с помощью простого цикла for.
а = '1234567890а'
результат = []
для i в диапазоне (0, len (a), 2):
результат.append (а [я: я + 2])
печать (результат)
Вывод выглядит так [’12’, ’34’, ’56’, ’78’, ’90’, ‘а’]
3
Я застрял в том же сценарии.
У меня сработало:
x = "1234567890"
п = 2
мой_список = []
для i в диапазоне (0, len (x), n):
my_list.append(x[i:i+n])
распечатать (мой_список)
Вывод:
['12', '34', '56', '78', '90']
1
Попробуйте это:
с = '1234567890' print([s[idx:idx+2] для idx в диапазоне(len(s)) if idx % 2 == 0])
Вывод:
['12', '34', '56', '78', '90']
1
Попробуйте следующий код:
из itertools import islice
def split_every(n, итерируемый):
я = итер (повторяемый)
кусок = список (islice (i, n))
в то время как часть:
уступка
кусок = список (islice (i, n))
с = '1234567890'
распечатать список (split_every (2, список (с))))
1
>>> из functools импортировать уменьшить
>>> из оператора импорта добавить
>>> из itertools импортировать izip
>>> x = iter('1234567890')
>>> [уменьшить (добавить, tup) для tup в izip (x, x)]
['12', '34', '56', '78', '90']
>>> х = итер('1234567890')
>>> [уменьшить (добавить, tup) для tup в izip (x, x, x)]
['123', '456', '789']
0
Как всегда, для любителей одного вкладыша:
n=2 line = "это строка, разделенная на n символов" строка = [строка[i * n:i * n+n] для i, бла в enumerate(line[::n])]
4
more_itertools. уже упоминалось ранее. Вот еще четыре варианта из библиотеки  sliced
sliced more_itertools :
s="1234567890" ["".join(c) для c в mit.grouper(2, s)] ["".join(c) для c в mit.chunked(s, 2)] ["".join(c) для c в mit.windowed(s, 2, step=2)] ["".join(c) для c в mit.split_after(s, lambda x: int(x) % 2 == 0)]
Каждый из последних вариантов дает следующий результат:
['12', '34', '56', '78', '90']
Документация по обсуждаемым опциям: grouper , chunked , windowed , split_after
0
Простое рекурсивное решение для короткой строки:
def split(s, n):
если len(s) < n:
возвращаться []
еще:
вернуть [s[:n]] + разделить(s[n:], n)
печать (разделить ('1234567890', 2))
Или в такой форме:
def split(s, n):
если len(s) < n:
возвращаться []
Элиф лен(ы) == n:
возврат [с]
еще:
вернуть split(s[:n], n) + split(s[n:], n)
, который более подробно иллюстрирует типичный шаблон «разделяй и властвуй» в рекурсивном подходе (хотя практически нет необходимости делать это таким образом)
Решение с groupby :
text = "wwworldgggggreattecchemggpwwwzaz" п = 3 c = цикл (цепочка (повторить (0, n), повторить (1, n))) res = ["".
 join(g) for _, g in groupby(text, lambda x: next(c))]
печать (разрешение)
join(g) for _, g in groupby(text, lambda x: next(c))]
печать (разрешение)
Вывод:
['www', 'orl', 'dgg', 'ggr', 'eat', 'tec', 'che', 'mgg', 'pww', 'wza', 'z' ]
Все эти ответы хороши и работают, но синтаксис такой загадочный... Почему бы не написать простую функцию?
def SplitEvery(строка, длина):
если len(строка) <= длина: возврат [строка]
разделы = длина (строка) / длина
строки = []
старт = 0;
для i в диапазоне (разделах):
строка = строка[начало:начало+длина]
lines.append(строка)
начало += длина
линии возврата
И назовите это просто:
text = '1234567890' строки = РазделитьКаждый(текст, 2) печать (строки) # вывод: ['12', '34', '56', '78', '90']
1
Другое решение с использованием groupby и index//n в качестве ключа для группировки букв:
из itertools import groupby текст = "abcdefghij" п = 3 результат = [] для idx, чанк в groupby(text, key=lambda x: x.
 index//n):
результат.append("".join(кусок))
# результат = ['abc', 'def', 'ghi', 'j']
index//n):
результат.append("".join(кусок))
# результат = ['abc', 'def', 'ghi', 'j']
массивов — Python разделяет строку на несколько частей
спросил
Изменено 2 года, 5 месяцев назад
Просмотрено 456 раз
У меня есть эта строка:
"[22.190894440000001, -100.99684750999999] 6 2011-08-28 19:48:11 @Karymitaville, ты можешь танцевать, ты можешь подарить лучшее время в моей жизни(8) ABBA :D"
Где
- два числа внутри [] - это широта и язык
- 6 это значение
- 2011-08-28 - это дата
- 19:48:11 время
- остальное текст
Я хочу разделить эту строку на список длиной 5 в следующем формате: [широта, язык, значение, дата, время, текст]
Как это сделать наиболее эффективно?
- python
- массивы
- строка
- список
- разделить
3
Вы можете использовать str. с аргументом  split
split maxsplit , управляющим количеством разделений. Тогда вы можете Стрип Компания и кронштейны от LAT и LANG :
>>> Текст = »[22.190894440000001, -100,9968475099999] 6 2011-08-28 могу дать лучшее время в моей жизни(8) ABBA :D"
>>> широта, язык, значение, дата, время, текст = text.split(maxsplit=5)
>>> lat, lang, value, date, time, text
('[22.190894440000001,', '-100.99684750999999]', '6', '2011-08-28', '19:48:11', '@Karymitaville, ты можешь танцевать, ты можешь подарить лучшее время в моей жизни(8) ABBA : Д')
>>> широта = широта.strip('[').rstrip(',')
>>> lang = lang.rstrip(']')
>>> lat, lang, value, date, time, text
('22.190894440000001', '-100.99684750999999', '6', '2011-08-28', '19:48:11', '@Karymitaville, ты можешь танцевать, ты можешь подарить лучшее время в моей жизни(8) ABBA : Д')
Вот решение с использованием регулярного выражения.
импорт текст = "[22.190894440000001, -100.