python — Как можно засечь время выполнения каждой из функций и суммарное время выполнения программы
Чтобы измерить время выполнения программы, можно time команду использовать (часто встроена в shell):
$ time python -c 'import time; time.sleep(1)' python -c 'import time; time.sleep(1)' 0.01s user 0.00s system 1% cpu 1.021 total
Если команда недоступна, её можно реализовать в Питоне.
Чтобы посмотреть сколько времени индивидуальные функции занимают, можно cProfile модуль использовать:
$ python -m cProfile -s time your_module.py
В графическом виде результаты удобно в KCachegrind просматривать. Пример команд. Больше вариантов: How can you profile a script?
line_profiler позволяет построчно сравнение производить.
Содержание:
- timeit
- reporttime.py
- make-figures.py
- reporttime + pandas
Чтобы измерить производительность отдельной функции, можно timeit модуль использовать:
$ python -m timeit -s 'from insertion_sort import sorted; L = list(range(10**5))' 'sorted(L)'
Тот же интерфейс предоставляет pyperf модуль (помимо прочего):
$ python -m pyperf timeit -s '...' 'sorted(L)'
 ..' 'sorted(L)'
..' 'sorted(L)'
Документация утверждает, что pyperf более надёжные результаты выдаёт.
Для интерактивной работы можно %timeit magic в ipython/jupyter notebook использовать.
Оптимизируя выполнение функции, стоит убедиться что она работает корректно (тесты), что изменения действительно ускорили её работу (сравнение производительности). Для этого можно pytest-benchmarkиспользовать.
Для удобства сравнения производительности нескольких алгоритмов, можно автоматически соответствующие функции собрать по общему префиксу в имени (sorted_selection, sorted_insertion, sorted_bubble и поместить в daedra.py файл:
#!/usr/bin/env python
import random
from reporttime import get_functions_with_prefix, measure
import daedra
funcs = get_functions_with_prefix('sorted_', module=daedra)
for comment, L in [
("all same", [1] * 10**3),
("range", list(range(10**3))),
("random", list(range(10**3)))]:
if comment == "random":
random. shuffle(L)
measure(funcs, args=[L], comment=comment)
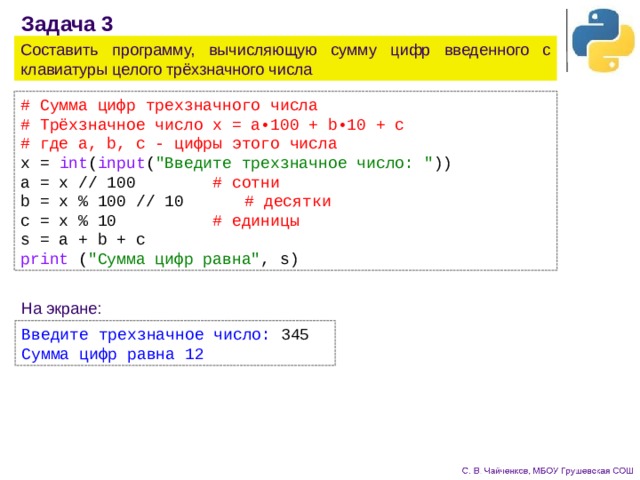
где reporttime.py. measure() функция измеряет производительность функций похожим на python -mtimeit команду способом.
Результаты
name time ratio comment sorted_insertion 184 usec 1.00 all same sorted_selection 55.9 msec 303.86 all same sorted_bubble 59.4 msec 322.92 all same name time ratio comment sorted_insertion 186 usec 1.00 range sorted_selection 57.7 msec 309.44 range sorted_bubble 60.8 msec 326.40 range name time ratio comment sorted_selection 58 msec 1.00 random sorted_insertion 66.2 msec 1.14 random sorted_bubble 119 msec 2.05 random
Таблица показывает, что на уже отсортированном вводе sorted_insertion() функция заметно выигрывает (в этом случае линейное время для этой функции требуется по сравнению с квадратичным для sorted_selection() и sorted_bubble()). Для случайного ввода, производительность примерно одинаковая.
Для случайного ввода, производительность примерно одинаковая. sorted_bubble() хуже во всех вариантах.
В качестве альтернативы можно декоратор использовать такой как @to_compare, чтобы собрать функции для сравнения и адаптировать их для
Чтобы нарисовать время выполнения функций для разных вводов:
#!/usr/bin/env python
#file: plot_daedra.py
import random
def seq_range(n):
return list(range(n))
def seq_random(n):
L = seq_range(n)
random.shuffle(L)
return L
if __name__ == '__main__':
import sys
from subprocess import check_call
import daedra
from reporttime import get_functions_with_prefix
# measure performance and plot it
check_call(["make-figures.py"] + [
"--sort-function=daedra." + f.__name__
for f in get_functions_with_prefix('sorted_', module=daedra)
] + [
"--sequence-creator=plot_daedra. " + f.__name__
for f in get_functions_with_prefix('seq_')
] + sys.argv[1:])
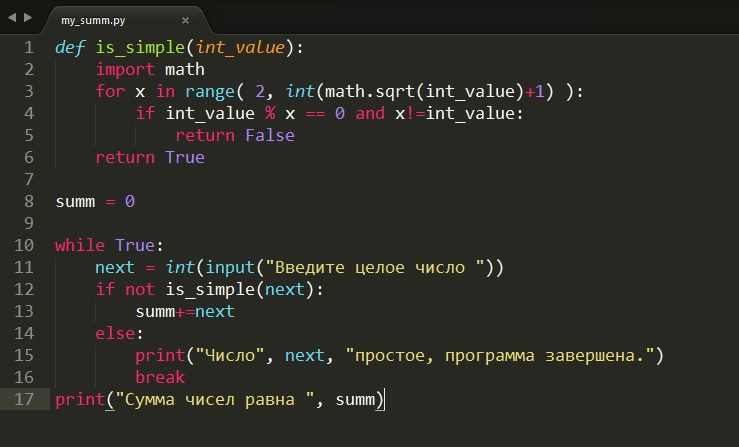
seq_range(), seq_random() задают два типа ввода (уже отсортированный и случайный соответственно). Можно определить дополнительные типы, определив seq_*(n) функцию. Пример запуска:
$ PYTHONPATH=. python plot_daedra.py --maxn 1024
PYTHONPATH=. используется, чтобы make-figures.py смог найти plot_daedra модуль (с seq_range, seq_random функциями) в текущей директории. n, которое в seq_(n) функции передаётся.
Результаты
Рисунки подтверждают, что sorted_insertion() показывает линейное поведение на отсортированном вводе (seq_range=0,1,2,3,4,…,n-1). И квадратичное на случайном вводе (seq_random). Коэффициент перед log2(N) показывает приближённо соответствующую степень в функции роста алгоритма в зависимости от размера ввода:
|------------------------------+-------------------| | Fitting polynom | Function | |------------------------------+-------------------| | 1.00 log2(N) + 1.25e-015 | N | | 2.00 log2(N) + 5.31e-018 | N*N | | 1.19 log2(N) + 1.116 | N*log2(N) | | 1.37 log2(N) + 2.232 | N*log2(N)*log2(N) |

Собрав результаты измерений времени выполнения функций сортировки из daedra.py (sorted_*()) для разных типов (уже отсортированный/случайный) и размеров ввода (длины от 1 до 100000):
import random
import daedra
from reporttime import get_functions_with_prefix, measure_func
times = {} # (function name, input type, exp size) -> time it takes
for f in get_functions_with_prefix('sorted_', module=daedra):
for N in range(6):
for case, L in [
("range", list(range(10**N))),
("random", list(range(10**N)))]:
if case == "random":
random.shuffle(L)
times[(f.__name__, case, N)] = measure_func(f, [L])
Удобно исследовать результаты интерактивно, используя pandas.DataFrame:
import pandas as pd df = pd.
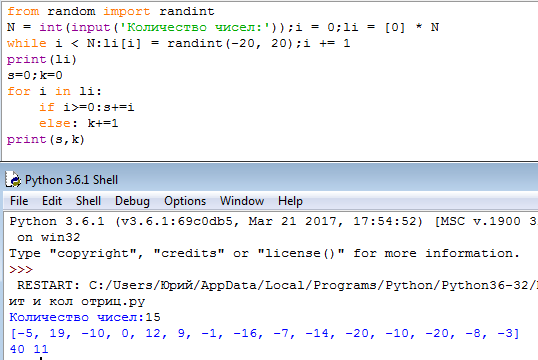 DataFrame([dict(function=f, input=i, size=10**n, time=t)
for (f,i,n), t in times.items()])
DataFrame([dict(function=f, input=i, size=10**n, time=t)
for (f,i,n), t in times.items()])
К примеру, чтобы сравнить поведение функций на уже отсортированном вводе:
def plot_input(input):
p = df[df.input==input].pivot(index='function', columns='size', values='time')
p.T.plot(loglog=True,, title=input) # same style as in @MaxU's answer
return p
plot_input('range')
Поведение на случайном вводе:
plot_input('random')
Или сравнить поведение одной функции для разных типов ввода на одном графике:
p = df[df.function=='sorted_insertion'].pivot(index='input', columns='size', values='time') p.T.plot(loglog=True,, title='sorted_insertion')
соответствующий jupyter notebook.
Измерьте прошедшее время в Python
В этом посте мы обсудим, как измерить прошедшее время в Python.
1. Использование
timeit модульPython timeit Модуль широко используется для измерения времени выполнения небольших фрагментов кода.
timeit() функция, которая выполняет анонимную функцию с number исполнений, которое по умолчанию равно 1 миллиону. Он временно отключает сборку мусора на время.1 2 3 4 5 6 7 8 | import timeit import time
if __name__ == ‘__main__’:
t = timeit.timeit(lambda: time.sleep(1), number=5) print(t)
|
The timeit модуль предлагает еще одну удобную функцию, repeat(), которая выполняет анонимную функцию с заданным repeat считать и number казни.
1 2 3 4 5 6 7 8 | import timeit import time
if __name__ == ‘__main__’:
t = timeit. print(t) |
 repeat(lambda: time.sleep(1), repeat=10, number=5)
repeat(lambda: time.sleep(1), repeat=10, number=5)
Наконец, вы можете использовать таймер по умолчанию timeit.default_timer().
1 2 3 4 5 6 7 8 9 10 11 | import timeit import time
if __name__ == ‘__main__’:
start = timeit.default_timer() time.sleep(1) end = timeit.default_timer()
print(f»Time taken is {end — start}s»)
|
Скачать Выполнить код
2. Использование
time модульНачиная с Python 3.3, вы можете использовать time.perf_counter() функция для получения значения счетчика производительности. Вы можете использовать его для измерения короткой продолжительности и использовать часы с самым высоким доступным разрешением. Таймер по умолчанию модуля timeit
Таймер по умолчанию модуля timeit default_timer() всегда используйте time.perf_counter().
1 2 3 4 5 6 7 8 9 10 | import time
if __name__ == ‘__main__’:
start = time.perf_counter() time.sleep(1) end = time.perf_counter()
print(f»Time taken is {end — start}»)
|
Скачать Выполнить код
Чтобы измерить время, прошедшее между двумя экземплярами кода в наносекундах, вы можете использовать time.time_ns() функция, которая возвращает время в наносекундах с начала эпохи в виде числа с плавающей запятой.
1 2 3 4 5 6 7 8 9 10 | import time
if __name__ == ‘__main__’:
start = time. time.sleep(1) end = time.time_ns()
print(f»Time taken is {end — start}ns»)
|
 time_ns()
time_ns()Скачать Выполнить код
3. Использование
datetime модульЕсли вам не нужна высокая точность, вы можете рассчитать время, прошедшее между двумя экземплярами кода, с помощью datetime.now() функцию, как показано ниже:
1 2 3 4 5 6 7 8 9 10 11 | from datetime import datetime import time
if __name__ == ‘__main__’:
start = datetime.now() time.sleep(1) end = datetime.now()
print(f»Time taken in (hh:mm:ss.ms) is {end — start}»)
|
Скачать Выполнить код
Это все, что касается измерения прошедшего времени в Python.
Оценить этот пост
Средний рейтинг 5/5. Подсчет голосов: 21
Подсчет голосов: 21
Голосов пока нет! Будьте первым, кто оценит этот пост.
Сожалеем, что этот пост не оказался для вас полезным!
Расскажите, как мы можем улучшить этот пост?
Спасибо за чтение.
Пожалуйста, используйте наш онлайн-компилятор размещать код в комментариях, используя C, C++, Java, Python, JavaScript, C#, PHP и многие другие популярные языки программирования.
Как мы? Порекомендуйте нас своим друзьям и помогите нам расти. Удачного кодирования 🙂
Python Получить время выполнения программы [5 способов] — PYnative
Прочитав эту статью, вы узнаете: —
- Как рассчитать время выполнения программы в Python
- Измерить общее время, затраченное на выполнение кода блок в секундах, миллисекундах, минутах и часах
- Также получите время выполнения функций и циклов.
В этой статье Мы будем использовать следующие четыре способа для измерения времени выполнения в Python: –
-
time.функция: измерить общее время, затраченное на выполнение сценария в секундах. time() -
time.process_time(): измерение времени выполнения ЦП кода - модуль timeit : измерение времени выполнения небольшого фрагмента кода, включая одну строку кода, а также code
- Модуль DateTime : измерение времени выполнения в формате часы-минуты-секунды.
 time()
time() Чтобы измерить производительность кода, нам нужно рассчитать время, необходимое скрипту/программе для выполнения. Измерение времени выполнения программы или ее частей будет зависеть от вашей операционной системы, версии Python и того, что вы подразумеваете под словом «время».
Прежде чем двигаться дальше, сначала поймите, что такое время.
Содержание
- Время стены в сравнении с временем процессора
- Как измерить время выполнения в Python
- Пример: получение времени выполнения программы в секундах
- Получение времени выполнения в миллисекундах
- Получение времени выполнения в минутах
- Получение времени выполнения ЦП программы с помощью process_time()
- Модуль timeit для измерения времени выполнения кода
- Пример. Измерение времени выполнения функции
- Измерение времени выполнения одной строки кода
- Измерение времени выполнения нескольких строк кода
- Пример.
- Модуль DateTime для определения времени выполнения сценария
- Заключение
 Измерение времени выполнения функции
Измерение времени выполнения функцииВремя стены и время процессора
Мы часто сталкиваемся с двумя терминами для измерения времени выполнения: время настенных часов и время процессора.
Таким образом, важно определить и различать эти два термина.
- Время на стене (также известное как время по часам или время настенных часов) — это просто общее время, прошедшее во время измерения. Это время можно измерить секундомером. Это разница между временем окончания выполнения программы и временем ее запуска. Сюда также входит время ожидания ресурсов .
- Время ЦП, с другой стороны, относится к времени, в течение которого ЦП был занят обработкой инструкций программы. Время, потраченное на ожидание завершения другой задачи (например, операций ввода-вывода), не включается во время ЦП. Не включает время ожидания ресурсов.
 Не включает время ожидания ресурсов.
Не включает время ожидания ресурсов. Разница между временем стены и временем ЦП может быть связана с архитектурой и зависимостью времени выполнения, например, запрограммированными задержками или ожиданием доступности системных ресурсов.
Например, программа сообщает, что она использовала «время ЦП 0 м 0,2 с, время стены 2 м 4 с». Это означает, что программа была активна в течение 2 минут и четырех секунд. Тем не менее, процессор компьютера потратил всего 0,2 секунды на выполнение вычислений для программы. Возможно, программа ждала освобождения некоторых ресурсов.
В начале каждого решения я явно указал, какое время измеряет каждый метод .
Таким образом, в зависимости от того, почему вы измеряете время выполнения вашей программы, вы можете рассчитать время стены или процессорное время.
Как измерить время выполнения в Python
Модуль времени Python предоставляет различные функции, связанные со временем, такие как получение текущего времени и приостановка выполнения вызывающего потока на заданное количество секунд. Следующие шаги показывают, как использовать модуль времени для расчета времени выполнения программы.
Следующие шаги показывают, как использовать модуль времени для расчета времени выполнения программы.
- Импорт модуля времени
Модуль времени поставляется со стандартной библиотекой Python. Во-первых, импортируйте его, используя оператор импорта.
- Сохранить время начала
Теперь нам нужно получить время начала перед выполнением первой строки программы. Для этого мы будем использовать функцию
time(), чтобы получить текущее время и сохранить его в переменной « start_time » перед первой строкой программы.
Функцияtime()модуля времени используется для получения времени в секундах с начала эпохи. Обработка високосных секунд зависит от платформы. - Сохранить время окончания
Далее нам нужно получить время окончания перед выполнением последней строки.
Опять же, мы будем использовать функциюtime(), чтобы получить текущее время и сохранить его в переменной « end_time » перед последней строкой программы. - Расчет времени выполнения
Разница между временем окончания и временем начала является временем выполнения. Получите время выполнения, вычтя время начала из времени окончания.

Пример: получение времени выполнения программы в секундах
Используйте это решение в следующих случаях: –
- Определение времени выполнения сценария
- Измерение времени между строками кода.
Примечание : Это решение измеряет время стены, т. е. общее прошедшее время, а не время процессора.
время импорта
# получить время начала
ст = время.время()
# основная программа
# найти сумму до первого миллиона чисел
сумма_х = 0
для я в диапазоне (1000000):
сумма_х += я
# ждем 3 секунды
время сна(3)
print('Сумма первых 1 миллиона чисел равна:', sum_x)
# получить время окончания
et = время.время()
# получаем время выполнения
прошедшее_время = et - st
print('Время выполнения:', elapsed_time, 'секунды') Выход :
Сумма первого миллиона чисел: 499999500000 Время выполнения: 3,125561475753784 секунды
Примечание : Если ваш компьютер занят другими задачами, будет указано больше времени. Если бы ваш скрипт ожидал некоторых ресурсов, время выполнения увеличилось бы, потому что время ожидания будет добавлено к конечному результату.
Если бы ваш скрипт ожидал некоторых ресурсов, время выполнения увеличилось бы, потому что время ожидания будет добавлено к конечному результату.
Получение времени выполнения в миллисекундах
Используйте приведенный выше пример, чтобы получить время выполнения в секундах, затем умножьте его на 1000, чтобы получить окончательный результат в миллисекундах.
Пример :
# получить время выполнения в миллисекундах рез = эт - ст final_res = разрешение * 1000 Печать («Время выполнения:», Final_res, 'Milliseconds')
Выход :
Сумма первых 1 миллионов номеров: 499999500000414143333.5015. чтобы получить время выполнения в секундах, затем разделите его на 60, чтобы получить окончательный результат в минутах.
Время исполнения: 3125.988006591797 Milliseconds
Пример :
# получить время выполнения в минутах
рез = эт - ст
final_res = разрешение / 60
print('Время выполнения:', final_res, 'минуты') Вывод :
Сумма первого миллиона чисел: 499999500000 Время выполнения: 0.
 052008008956 минут
052008008956 минут Вы хотите более качественное форматирование ?
Используйте функцию strftime() для преобразования времени в более удобочитаемый формат, например (чч-мм-сс) часы-минуты-секунды.
время импорта
ст = время.время()
# ваш код
сумма_х = 0
для я в диапазоне (1000000):
сумма_х += я
время сна(3)
print('Сумма:', sum_x)
прошедшее_время = время.время() - ст
print('Время выполнения:', time.strftime("%H:%M:%S", time.gmtime(elapsed_time)))
Вывод :
Сумма: 499999500000
Время выполнения: 00:00:03
Получите время выполнения программы с помощью
process_time() 8 time 90.1 2time будет измерять время настенных часов 90.1119. Если вы хотите измерить время выполнения программы процессором, используйте time.process_time() вместо time.time() . Используйте это решение, если вы не хотите включать время ожидания ресурсов в окончательный результат. Давайте посмотрим, как получить время выполнения программы процессором.
Давайте посмотрим, как получить время выполнения программы процессором.
время импорта
# получить время начала
ст = время.процесс_время()
# основная программа
# найти сумму до первого миллиона чисел
сумма_х = 0
для я в диапазоне (1000000):
сумма_х += я
# ждем 3 секунды
время сна(3)
print('Сумма первых 1 миллиона чисел равна:', sum_x)
# получить время окончания
et = время.процесс_время()
# получить время выполнения
рез = эт - ст
print('Время выполнения ЦП:', res, 'секунды') Вывод :
Сумма первого миллиона чисел: 499999500000 Время выполнения процессора: 0,234375 секунд
Примечание :
Поскольку мы рассчитываем время выполнения программы процессором, как вы видите, программа была активна более 3 секунд. Тем не менее, эти 3 секунды не были добавлены к процессорному времени, потому что процессор был идеальным, а процессор компьютера потратил всего 0,23 секунды на выполнение вычислений для программы.
Модуль timeit для измерения времени выполнения кода
Модуль Python timeit обеспечивает простой способ измерения времени небольшого фрагмента кода Python. Он имеет как интерфейс командной строки, так и вызываемый. Это позволяет избежать многих распространенных ловушек для измерения времени выполнения.
Он имеет как интерфейс командной строки, так и вызываемый. Это позволяет избежать многих распространенных ловушек для измерения времени выполнения.
Модуль timeit полезен в следующих случаях: –
- Определение времени выполнения небольшого фрагмента кода, такого как функции и циклы
- Измерение времени между строками кода.
Функция timeit() : –
Функция timeit.timeit() возвращает время (в секундах), которое потребовалось для выполнения кода число раз.
timeit.timeit(stmt='pass', setup='pass', timer=<таймер по умолчанию>, number=1000000, globals=None)
Примечание : это решение измеряет время стены, т. е. общее прошедшее время, а не процессорное время.
Следующие шаги показывают, как измерить время выполнения кода с помощью модуля timeit.
- Сначала создайте экземпляр Timer с помощью функции
timeit() - Затем передайте код вместо аргумента
stmt. stmt — это код, для которого мы хотим измерить время. - Далее, если вы хотите выполнить несколько операторов перед вашим фактическим кодом, передайте их в аргумент настройки, например операторы импорта.
- Чтобы установить значение таймера, мы будем использовать таймер по умолчанию, предоставленный Python.
- Затем решите, сколько раз вы хотите выполнить код, и передайте его числовому аргументу. Значение числа по умолчанию — 1 000 000.
- В конце мы выполним функцию
timeit()с вышеуказанными значениями для измерения времени выполнения кода
 stmt — это код, для которого мы хотим измерить время.
stmt — это код, для которого мы хотим измерить время.Пример: Измерение времени выполнения функции
Здесь мы рассчитаем время выполнения функция «дополнение()». Мы будем работать add() функцию пять раз, чтобы получить среднее время выполнения.
время импорта
# напечатать сложение первых 1 миллиона чисел
добавление защиты():
print('Дополнение:', сумма(диапазон(1000000)))
# запустить один и тот же код 5 раз, чтобы получить измеримые данные
п = 5
# рассчитать общее время выполнения
результат = timeit. timeit(stmt='дополнение()', globals=globals(), число=n)
# рассчитать время выполнения
# получить среднее время выполнения
print(f"Время выполнения {result / n} секунд")  timeit(stmt='дополнение()', globals=globals(), число=n)
# рассчитать время выполнения
# получить среднее время выполнения
print(f"Время выполнения {result / n} секунд")
timeit(stmt='дополнение()', globals=globals(), число=n)
# рассчитать время выполнения
# получить среднее время выполнения
print(f"Время выполнения {result / n} секунд") Вывод :
Дополнение: 499999500000 Дополнение: 499999500000 Дополнение: 499999500000 Дополнение: 499999500000 Дополнение: 499999500000 Время выполнения составляет 0,03770382 секунды
Примечание :
Если вы запускаете трудоемкий код со значением по умолчанию номер , это займет много времени. Поэтому присвойте меньшее значение аргументу число или решите, сколько выборок вы хотите измерить, чтобы получить точное время выполнения кода.
-
функции timeit()отключают сборщик мусора, что приводит к точному захвату времени. - Также с помощью функции
timeit()мы можем повторять выполнение одного и того же кода столько раз, сколько захотим, что минимизирует влияние других задач, запущенных в вашей операционной системе. Благодаря этому мы можем получить более точное среднее время выполнения.
 Благодаря этому мы можем получить более точное среднее время выполнения.
Благодаря этому мы можем получить более точное среднее время выполнения.Измерение времени выполнения одной строки кода
Запустите команду %timeit в командной строке или на ноутбуке Jupyter, чтобы получить время выполнения одной строки кода.
Пример : Используйте %timeit непосредственно перед строкой кода
%timeit [x вместо x в диапазоне (1000)] # Выход 2,08 мкс ± 223 нс на цикл (среднее значение ± стандартное отклонение для 7 запусков, 1000000 циклов в каждом)
Кроме того, мы можем настроить команду, используя различные параметры для улучшения профилирования и получения более точного времени выполнения.
- Определите количество прогонов с помощью параметра
-r. Например,%timeit -r10 your_codeозначает запуск строки кода 10 раз. - Определите циклы в каждом цикле с помощью параметров
-rи-n. - Если вы опустите параметры по умолчанию, это будет 7 прогонов с 1 миллионом циклов в каждом прогоне

Пример: Настройте операцию временного профиля на 10 прогонов и 20 циклов в каждом прогоне.
# Настройка количества прогонов и циклов в %timeit %timeit -r10 -n20 [x для x в диапазоне (1000)] # выход 1,4 мкс ± 12,34 нс на петлю (среднее значение ± стандартное отклонение для 10 циклов, по 20 циклов в каждом)
Измерение времени выполнения нескольких строк кода
Используя команду %%timeit , мы можем измерить время выполнения нескольких строк кода. Параметры команды останутся прежними.
Примечание : вам нужно заменить один процент ( % ) на двойной процент ( %% ) в команде timeit, чтобы получить время выполнения нескольких строк кода
Пример :
# Профилирование времени с помощью %%timeit
%%timeit -r5 -n10
# найти сумму до первого миллиона чисел
сумма_х = 0
для я в диапазоне (1000000):
сумма_х += я
# Выход
10,5 мкс ± 226 нс на петлю (среднее значение ± стандартное отклонение для 5 циклов, по 10 циклов в каждом) Модуль DateTime для определения времени выполнения скрипта
Кроме того, вы можете использовать модуль Datetime для измерения времени выполнения программы. Используйте следующие шаги.
Используйте следующие шаги.
Импорт модуля DateTime
- Затем сохраните время начала с помощью функции
datetime.now()перед первой строкой сценария - Затем сохраните время окончания перед использованием той же функции перед последней строкой сценария
- В конце рассчитайте время выполнения, вычитая время начала из времени окончания
Примечание : это решение измеряет время стены, т. е. общее прошедшее время, а не процессорное время.
Пример :
импорт даты и времени
время импорта
# получить начальную дату и время
ул = datetime.datetime.now ()
# основная программа
# найти сумму до первого миллиона чисел
сумма_х = 0
для я в диапазоне (1000000):
сумма_х += я
# ждем 3 секунды
время сна(3)
print('Сумма первых 1 миллиона чисел равна:', sum_x)
# получить конечную дату и время
et = datetime.datetime.now()
# получить время выполнения
прошедшее_время = et - st
print('Время выполнения:', elapsed_time, 'секунды') Выход :
Сумма первого миллиона чисел: 499999500000 Время выполнения: 0:00:03.
 115498 секунд
115498 секунд Заключение
Python предоставляет несколько функций для получения времени выполнения кода. Кроме того, мы узнали разницу между временем настенных часов и временем процессора, чтобы понять, какое время выполнения нам нужно измерить.
Используйте следующие функции для измерения времени выполнения программы в Python:
-
time.time(): измерьте общее время, затраченное на выполнение кода в секундах. -
timeit.timeit(): Простой способ замерить время небольшого фрагмента кода Python -
%timeitи%%timeit: команда для получения времени выполнения одной строки кода и нескольких строк кода . -
datetime.datetime.now(): Получить время выполнения в формате часы-минуты-секунды
Также используйте функцию time.process_time() , чтобы получить время выполнения программы процессором.
производительность. Как измерить прошедшее время в Python?
Задавать вопрос
спросил
Изменено 2 дня назад
Просмотрено 2,5 млн раз
Я хочу измерить время, необходимое для выполнения функции. Я не мог заставить
Я не мог заставить timeit работать:
время импорта
начало = время.время()
распечатать("привет")
конец = время.время()
печать (конец - начало)
- питон
- производительность
- мера
- времяит
3
Используйте time.time() для измерения прошедшего времени настенных часов между двумя точками:
время импорта
начало = время.время()
распечатать("привет")
конец = время.время()
печать (конец - начало)
Время выполнения в секундах.
Другим вариантом, начиная с Python 3.3, может быть использование perf_counter или process_time , в зависимости от ваших требований. До версии 3.3 рекомендовалось использовать time.clock (спасибо Amber). Однако в настоящее время он устарел:
В Unix вернуть текущее время процессора в виде числа с плавающей запятой выражается в секундах.
В Windows эта функция возвращает количество секунд настенных часов, прошедших с момента первый вызов этой функции в виде числа с плавающей запятой на основе Функция Win32
QueryPerformanceCounter(). Разрешение, как правило, лучше одной микросекунды.Устарело, начиная с версии 3.3 : поведение этой функции зависит на платформе: используйте
perf_counter()илиprocess_time()вместо , в зависимости от ваших требований, чтобы иметь четко определенное поведение.
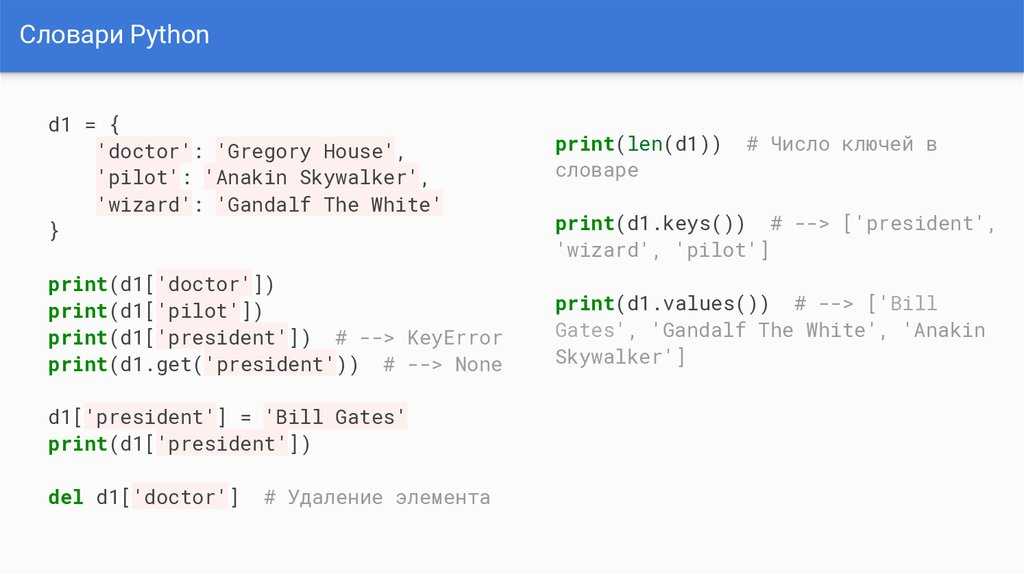 Точность, а на самом деле само определение
значения «процессорного времени», зависит от значения функции C
того же имени.
Точность, а на самом деле само определение
значения «процессорного времени», зависит от значения функции C
того же имени. Используйте timeit.default_timer вместо timeit.timeit . Первый автоматически предоставляет лучшие часы, доступные на вашей платформе и версии Python:
from timeit import default_timer as timer старт = таймер() # ... конец = таймер() print(end - start) # Время в секундах, например 5.
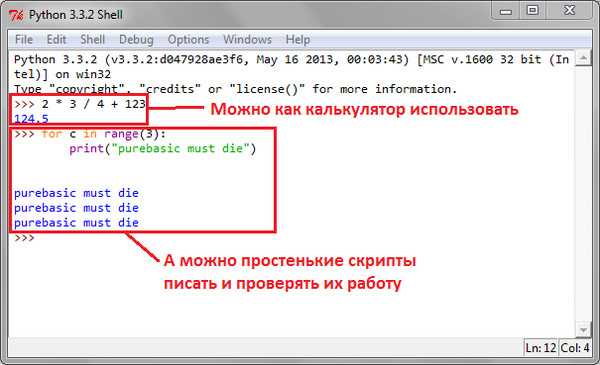 38091952400282
38091952400282
timeit.default_timer назначается для time.time() или time.clock() в зависимости от ОС. В Python 3.3+ default_timer — это time.perf_counter() на всех платформах. См. Python — time.clock () против time.time () — точность?
См. также:
- Код оптимизации
- Как оптимизировать скорость
1
Поскольку time.clock() устарел, начиная с Python 3.3, вы можете использовать time.perf_counter() для общесистемной синхронизации или time.process_time() для общепроцессной синхронизации, просто как вы использовали time.clock() :
время импорта т = время.процесс_время() #сделай что-нибудь прошедшее_время = время.время_процесса() - t
Новая функция process_time не будет включать время, прошедшее во время сна.
1
Время измерения в секундах:
из timeit импортировать default_timer как таймер из datetime импортировать timedelta старт = таймер() # .
 ...
# (здесь работает ваш код)
# ...
конец = таймер()
печать (timedelta (секунды = конец-начало))
...
# (здесь работает ваш код)
# ...
конец = таймер()
печать (timedelta (секунды = конец-начало))
Выход :
0:00:01.946339
0
Учитывая функцию, которую вы хотите вычислить по времени,
test.py:
def foo():
# напечатать "привет"
верни "привет"
Самый простой способ использовать timeit — вызвать его из командной строки:
% python -mtimeit -s'import test' 'test.foo()' 1000000 циклов, лучшее из 3: 0,254 мкс на цикл
Не пытайтесь использовать time.time или time.clock (наивно) для сравнения скорости функций. Они могут дать вводящие в заблуждение результаты.
PS. Не помещайте операторы печати в функцию, которую вы хотите задать по времени; в противном случае измеренное время будет зависеть от скорости терминала.
0
Забавно делать это с помощью менеджера контекста, который автоматически запоминает время начала при входе в блок с , а затем фиксирует время окончания при выходе из блока. С небольшими хитростями вы даже можете получить подсчет прошедшего времени внутри блока из той же функции менеджера контекста.
С небольшими хитростями вы даже можете получить подсчет прошедшего времени внутри блока из той же функции менеджера контекста.
В основной библиотеке этого нет (но, вероятно, должно быть). Оказавшись на месте, вы можете делать такие вещи, как:
с elapsed_timer() как истекшее:
# какой-то длинный код
print("midpoint at %.2f секунды" % elapsed() ) # время на данный момент
# другой длинный код
print("все сделано за %.2f секунд" % истекло() )
Вот достаточный код contextmanager:
from contextlib import contextmanager
из timeit импортировать default_timer
@contextmanager
прошедший_таймер защиты ():
запуск = таймер_по умолчанию()
elapser = lambda: default_timer() — запуск
выход лямбда: eplapser()
конец = таймер_по умолчанию()
elapser = лямбда: конец-начало
И некоторый исполняемый демонстрационный код:
время импорта
с elapsed_timer() как истекшим:
время сна(1)
печать (истекшее())
время сна(2)
печать (истекшее())
время сна(3)
Обратите внимание, что по замыслу этой функции возвращаемое значение elapsed() замораживается при выходе из блока, и дальнейшие вызовы возвращают ту же продолжительность (около 6 секунд в этом игрушечном примере).
2
Я предпочитаю это. время doc слишком запутанный.
из даты и времени импорта даты и времени
start_time = дата и время.сейчас()
# ВСТАВЬТЕ СВОЙ КОД
time_elapsed = datetime.now() - start_time
print('Время истекло (чч:мм:сс.мс) {}'.format(time_elapsed))
Обратите внимание, что здесь не происходит никакого форматирования, я просто написал чч:мм:сс в распечатке, чтобы можно было интерпретировать time_elapsed
3
Вот еще один способ сделать это:
>> из pytictoc импортировать TicToc >> t = TicToc() # создать экземпляр TicToc >> t.tic() # Запустить таймер >> # сделать что-нибудь >> t.toc() # Вывести прошедшее время Прошедшее время составляет 2,612231 секунды.
По сравнению с традиционным способом:
>> со времени импорта со времени
>> t1 = время()
>> # сделать что-нибудь
>> t2 = время()
>> прошло = t2 - t1
>> print('Прошедшее время: %f секунд. ' Прошло %)
Прошедшее время составляет 2,612231 секунды.
 ' Прошло %)
Прошедшее время составляет 2,612231 секунды.
' Прошло %)
Прошедшее время составляет 2,612231 секунды.
Установка:
pip install pytictoc
Дополнительные сведения см. на странице PyPi.
5
Самый простой способ рассчитать продолжительность операции:
время импорта
start_time = время.monotonic()
<операции, программы>
print('секунды:', time.monotonic() - start_time)
Официальная документация здесь.
2
Вот мои выводы после прочтения многих хороших ответов здесь, а также нескольких других статей.
Во-первых, если вы колеблетесь между timeit и time.time , timeit имеет два преимущества:
-
timeitвыбирает лучший таймер, доступный для вашей ОС и версии Python. -
timeitотключает сборку мусора, однако это не то, чего вы можете хотеть или не хотеть.
Теперь проблема в том, что timeit не так прост в использовании, потому что его нужно настроить, а когда у вас есть куча импорта, все становится ужасно. В идеале вам просто нужен декоратор или используйте с блоком и измерением времени. К сожалению, для этого нет ничего встроенного, поэтому у вас есть два варианта:
Вариант 1: использовать библиотеку timebudget
Timebudget — это универсальная и очень простая библиотека, которую вы можете использовать всего в одной строке кода после pip. установить.
@timebudget # Запишите, сколько времени занимает эта функция
определить мой_метод():
# мой код
Вариант 2: Используйте мой небольшой модуль
Ниже я создал небольшой служебный модуль синхронизации под названием Timing.py. Просто поместите этот файл в свой проект и начните его использовать. Единственная внешняя зависимость — это runstats, которая опять же невелика.
Теперь вы можете синхронизировать любую функцию, просто поставив перед ней декоратор:
время импорта
@timing.MeasureTime
определение MyBigFunc():
#сделай что-нибудь, отнимающее много времени
для я в диапазоне (10000):
печать (я)
время.print_all_timings()
Если вы хотите синхронизировать часть кода, просто поместите ее в с блоком :
время импорта
#где-то в моем коде
со временем.MeasureBlockTime("MyBlock"):
#сделай что-нибудь, отнимающее много времени
для я в диапазоне (10000):
печать (я)
# остальная часть моего кода
время.print_all_timings()
Преимущества:
Существует несколько недоработанных версий, поэтому я хочу отметить несколько основных моментов:
- Используйте таймер из timeit вместо time.time по причинам, описанным ранее.
- При желании вы можете отключить сборщик мусора во время синхронизации.
- Decorator принимает функции с именованными или безымянными параметрами.
- Возможность отключить печать в блоке времени (используйте
с time.MeasureBlockTime() как t, а затемt.elapsed). - Возможность оставить gc включенным для синхронизации блоков.

2
Использование time.time для измерения выполнения дает вам общее время выполнения ваших команд, включая время выполнения, затрачиваемое другими процессами на вашем компьютере. Это время, которое замечает пользователь, но не очень хорошо, если вы хотите сравнить разные фрагменты кода/алгоритмы/функции/…
Дополнительная информация о timeit :
- Использование модуля timeit
- timeit — Время выполнения небольших фрагментов кода Python
Если вы хотите глубже понять профилирование:
- http://wiki.python.org/moin/PythonSpeed/PerformanceTips#Profiling_Code
- Как вы можете профилировать скрипт Python?
Обновление : я много использовал http://pythonhosted. org/line_profiler/ в течение последнего года и считаю его очень полезным и рекомендую использовать его вместо модуля профиля Python.
org/line_profiler/ в течение последнего года и считаю его очень полезным и рекомендую использовать его вместо модуля профиля Python.
Использовать модуль профилировщика. Это дает очень подробный профиль.
профиль импорта
profile.run('основной()')
выводит что-то вроде:
5 вызовов функций за 0,047 секунды
Упорядочено: стандартное имя
ncalls tottime percall cumtime percall имя файла:lineno(функция)
1 0,000 0,000 0,000 0,000 :0(исполнение)
1 0,047 0,047 0,047 0,047 :0(установитьпрофиль)
1 0,000 0,000 0,000 0,000 <строка>:1(<модуль>)
0 0,000 0,000 профиль:0(профилировщик)
1 0,000 0,000 0,047 0,047 профиль:0(основной())
1 0,000 0,000 0,000 0,000 two_sum.py:2(twoSum)
Я нашел это очень информативным.
1
Модули Python cProfile и pstats предлагают отличную поддержку для измерения времени, прошедшего в определенных функциях, без необходимости добавлять какой-либо код вокруг существующих функций.
Например, если у вас есть скрипт python timeFunctions.py:
время импорта
привет ():
напечатать "Привет :)"
время сна (0,1)
спасибо ():
печатать "Спасибо!"
время сна (0,05)
для idx в диапазоне (10):
привет()
для idx в диапазоне (100):
Спасибо()
Чтобы запустить профилировщик и сгенерировать статистику для файла, вы можете просто запустить:
python -m cProfile -o timeStats.profile timeFunctions.py
При этом используется модуль cProfile для профилирования всех функций в timeFunctions.py и сбора статистики в файле timeStats.profile. Обратите внимание, что нам не нужно было добавлять какой-либо код в существующий модуль (timeFunctions.py), и это можно сделать с любым модулем.
Когда у вас есть файл статистики, вы можете запустить модуль pstats следующим образом:
python -m pstats timeStats.profile
Запускает интерактивный браузер статистики, предоставляющий множество приятных функций. Для вашего конкретного случая использования вы можете просто проверить статистику для вашей функции. В нашем примере проверка статистики для обеих функций показывает нам следующее:
В нашем примере проверка статистики для обеих функций показывает нам следующее:
Добро пожаловать в браузер статистики профиля.
timeStats.profile% статистика привет
<отметка времени> timeStats.profile
224 вызова функций за 6,014 секунды
Был использован случайный порядок перечисления
Список сокращен с 6 до 1 из-за ограничения <'hello'>
ncalls tottime percall cumtime percall имя файла:lineno(функция)
10 0,000 0,000 1,001 0,100 timeFunctions.py:3(привет)
timeStats.profile% статистика спасибо
<отметка времени> timeStats.profile
224 вызова функций за 6,014 секунды
Был использован случайный порядок перечисления
Список сокращен с 6 до 1 из-за ограничения <'thankyou'>
ncalls tottime percall cumtime percall имя файла:lineno(функция)
100 0,002 0,000 5,012 0,050 timeFunctions.py:7(спасибо)
Этот фиктивный пример мало что дает, но дает представление о том, что можно сделать. Самое приятное в этом подходе то, что мне не нужно редактировать какой-либо из моего существующего кода, чтобы получить эти числа и, очевидно, помочь с профилированием.
3
Вот еще один диспетчер контекста для кода синхронизации —
Использование:
из эталонного теста импорта
с эталоном ("Тест 1+1"):
1+1
=>
Тест 1+1: 1.41e-06 секунд
или, если вам нужно значение времени
с эталоном («Тест 1+1») как b:
1+1
печать (б.время)
=>
Тест 1+1: 7.05e-07 секунд
7.05233786763э-07
Benchmark.py :
из timeit импортировать default_timer как таймер
эталон класса (объект):
def __init__(self, msg, fmt="%0.3g"):
self.msg = сообщение
селф.фмт = фмт
защита __enter__(сам):
self.start = таймер ()
вернуть себя
def __exit__(я, *аргументы):
t = таймер () - self.start
print(("%s : " + self.fmt + " секунды") % (self.msg, t))
собственное время = т
Взято с http://dabeaz.blogspot.fr/2010/02/context-manager-for-timing-benchmarks.html
Вот крошечный класс таймера, который возвращает строку «чч:мм:сс»:
класс Таймер:
защита __init__(сам):
self. start = время.время()
перезагрузка защиты (самостоятельно):
self.start = время.время()
защита get_time_hhmmss (я):
конец = время.время()
m, s = divmod(end - self.start, 60)
ч, м = divmod(m, 60)
time_str = "%02d:%02d:%02d" % (ч, м, с)
возврат time_str
 start = время.время()
перезагрузка защиты (самостоятельно):
self.start = время.время()
защита get_time_hhmmss (я):
конец = время.время()
m, s = divmod(end - self.start, 60)
ч, м = divmod(m, 60)
time_str = "%02d:%02d:%02d" % (ч, м, с)
возврат time_str
start = время.время()
перезагрузка защиты (самостоятельно):
self.start = время.время()
защита get_time_hhmmss (я):
конец = время.время()
m, s = divmod(end - self.start, 60)
ч, м = divmod(m, 60)
time_str = "%02d:%02d:%02d" % (ч, м, с)
возврат time_str
Использование:
# Запуск таймера
мой_таймер = Таймер()
# ... сделай что-нибудь
# Получить строку времени:
time_hhmmss = my_timer.get_time_hhmmss()
print("Прошло время: %s" % time_hhmmss )
# ... снова использовать таймер
мой_таймер.restart()
# ... сделай что-нибудь
# Получить время:
time_hhmmss = my_timer.get_time_hhmmss()
# ... и т. д
1
(только с Ipython) вы можете использовать %timeit для измерения среднего времени обработки:
def foo():
напечатать "привет"
, а затем:
%timeit foo()
результат примерно такой:
10000 циклов, лучшее из 3: 27 мкс на цикл
1
Мне нравится простой (python 3):
из timeit импортировать timeit
timeit(лямбда: печать("привет"))
Вывод микросекунд для одного выполнения:
2.
 430883963010274
430883963010274
Объяснение : timeit выполняет анонимную функцию 1 миллион раз по умолчанию, результат выдается за секунд . Следовательно, результат для 90 117 1 однократного выполнения 90 118 такой же, но в среднем 90 118 микросекунд за 90 117 микросекунд.
Для медленных операций добавьте меньшее число итераций, иначе вы можете ждать вечно:
время импорта timeit(лямбда: time.sleep(1.5), число=1)
Вывод всегда за секунд для общего числа итераций:
1.5015795179999714
2
на python3:
из времени импорта сна, perf_counter как ПК t0 = пк() спать(1) печать (пк () - t0)
элегантный и короткий.
2
Еще один способ использования timeit:
из timeit импортировать timeit
Функция определения():
вернуть 1 + 1
время = время (функция, число = 1)
печать (время)
%load_ext змеиная визуализация %%snakeviz
Он просто берет эти 2 строки кода в блокноте Jupyter и создает красивую интерактивную диаграмму. Например:
Например:
Вот код. Опять же, 2 строки, начинающиеся с % , являются единственными дополнительными строками кода, необходимыми для использования змеиной визуализации:
# !pip install snapviz
%load_ext змеиная визуализация
импортировать глобус
импортировать хеш-библиотеку
%%snakeviz
файлы = glob.glob('*.txt')
def print_files_hashed (файлы):
для файла в файлах:
с открытым (файл) как f:
print(hashlib.md5(f.read().encode('utf-8')).hexdigest())
print_files_hashed(файлы)
9123
t2 = время.время()
печать (t2-t1)
7.9870223994e-05
1
Вот довольно хорошо документированный и полностью типизированный декоратор, который я использую в качестве общей утилиты:
из functools import wraps
со времени импорта perf_counter
от ввода import Any, Callable, Optional, TypeVar, cast
F = TypeVar("F",bound=Callable[..., Any])
def timer (префикс: Необязательный [str] = Нет, точность: int = 6) -> Вызываемый [[F], F]:
"""Используйте в качестве декоратора для определения времени выполнения любой функции.
Аргументы:
префикс: строка для печати до истечения времени.
По умолчанию это имя функции.
точность: сколько десятичных знаков включать в значение секунд.
Примеры:
>>> @таймер()
... определение foo(x):
... вернуть х
>>> фоо(123)
фу: 0,000... с
123
>>> @timer("Затраченное время: ", 2)
... определение foo(x):
... вернуть х
>>> фоо(123)
Затраченное время: 0,00 с
123
"""
def decorator(func: F) -> F:
@обертывания (функция)
def wrapper(*args: Any, **kwargs: Any) -> Any:
нелокальный префикс
prefix = префикс, если префикс не None else f"{func.__name__}: "
старт = perf_counter()
результат = функция (* аргументы, ** kwargs)
конец = perf_counter()
print(f"{prefix}{конец - начало:.{точность}f}s")
вернуть результат
возвратное литье (F, обертка)
вернуться декоратор
 Аргументы:
префикс: строка для печати до истечения времени.
По умолчанию это имя функции.
точность: сколько десятичных знаков включать в значение секунд.
Примеры:
>>> @таймер()
... определение foo(x):
... вернуть х
>>> фоо(123)
фу: 0,000... с
123
>>> @timer("Затраченное время: ", 2)
... определение foo(x):
... вернуть х
>>> фоо(123)
Затраченное время: 0,00 с
123
"""
def decorator(func: F) -> F:
@обертывания (функция)
def wrapper(*args: Any, **kwargs: Any) -> Any:
нелокальный префикс
prefix = префикс, если префикс не None else f"{func.__name__}: "
старт = perf_counter()
результат = функция (* аргументы, ** kwargs)
конец = perf_counter()
print(f"{prefix}{конец - начало:.{точность}f}s")
вернуть результат
возвратное литье (F, обертка)
вернуться декоратор
Аргументы:
префикс: строка для печати до истечения времени.
По умолчанию это имя функции.
точность: сколько десятичных знаков включать в значение секунд.
Примеры:
>>> @таймер()
... определение foo(x):
... вернуть х
>>> фоо(123)
фу: 0,000... с
123
>>> @timer("Затраченное время: ", 2)
... определение foo(x):
... вернуть х
>>> фоо(123)
Затраченное время: 0,00 с
123
"""
def decorator(func: F) -> F:
@обертывания (функция)
def wrapper(*args: Any, **kwargs: Any) -> Any:
нелокальный префикс
prefix = префикс, если префикс не None else f"{func.__name__}: "
старт = perf_counter()
результат = функция (* аргументы, ** kwargs)
конец = perf_counter()
print(f"{prefix}{конец - начало:.{точность}f}s")
вернуть результат
возвратное литье (F, обертка)
вернуться декоратор
Пример использования:
из таймера импорта таймера
@таймер (точность = 9)
def take_long(x: int) -> bool:
вернуть x в (i для i в диапазоне (x + 1))
результат = принимает_долго(10**8)
печать (результат)
Выход:
занимает_долго: 4,942629056 с Истинный
doctests можно проверить с помощью:
$ python3 -m doctest --verbose -o=ELLIPSIS timer.
 py
py
И тип намекает на:
$ mypy timer.py
3
Если вы хотите иметь возможность удобного времени функций, вы можете использовать простой декоратор:
время импорта
определение time_decorator (функция):
обертка def (*args, **kwargs):
начало = время.perf_counter()
original_return_val = func(*args, **kwargs)
конец = время.perf_counter()
print("прошедшее время в", func.__name__, ": ", end-start, sep='')
вернуть original_return_val
возвратная упаковка
Вы можете использовать его для функции, которую вы хотите синхронизировать следующим образом:
@timing_decorator
определение function_to_time():
время сна(1)
function_to_time()
Каждый раз, когда вы вызываете function_to_time , он будет печатать, сколько времени это заняло, и имя функции, замеряемой по времени.
3
Очень поздний ответ, но, возможно, кому-то он пригодится. Это способ сделать это, который я считаю очень чистым.
Это способ сделать это, который я считаю очень чистым.
время импорта
def timed(fun, *args):
с = время.время()
г = весело (*аргументы)
print('{} выполнение заняло {} секунд.'.format(fun.__name__, time.time()-s))
возврат (г)
timed(печать, "Привет")
Имейте в виду, что «печать» — это функция в Python 3, а не в Python 2.7. Однако он работает с любой другой функцией. Ваше здоровье!
2
Вы можете использовать timeit.
Вот пример того, как протестировать naive_func, который принимает параметр, используя Python REPL:
>>> import timeit >>> определение наивной_функции (х): ... а = 0 ... для i в диапазоне (a): ... а += я ... вернуть >>> def wrapper(func, *args, **kwargs): ... деф обертка(): ... return func(*args, **kwargs) ... возвратная обертка >>> обернутый = обертка (naive_func, 1_000) >>> timeit.timeit(обернутый, число=1_000_000) 0,4458435332577161
Вам не нужна функция-оболочка, если у функции нет параметров.
1
Функция print_elapsed_time ниже
def print_elapsed_time (префикс = ''):
e_time = время.время()
если не hasattr(print_elapsed_time, 's_time'):
print_elapsed_time.s_time = e_time
еще:
print(f'{prefix} прошедшее время: {e_time - print_elapsed_time.s_time:.2f} sec')
print_elapsed_time.s_time = e_time
используйте его таким образом
print_elapsed_time()
....тяжелые работы...
print_elapsed_time('после тяжелой работы')
....тонны рабочих мест...
print_elapsed_time('после тонны заданий')
результат
после выполнения тяжелых заданий время: 0,39 сек. после тонны заданий прошло время: 0,60 сек.
плюсы и минусы этой функции в том, что вам не нужно передавать время начала
Мы также можем преобразовать время в удобочитаемое время.
время импорта, дата и время начало = время.часы() определение num_multi1 (макс.
 ):
результат = 0
для числа в диапазоне (0, 1000):
если (число % 3 == 0 или число % 5 == 0):
результат += число
напечатать "Сумма %d" % результат
num_multi1 (1000)
конец = время.часы()
значение = конец - начало
отметка времени = datetime.datetime.fromtimestamp (значение)
печать timestamp.strftime('%Y-%m-%d %H:%M:%S')
):
результат = 0
для числа в диапазоне (0, 1000):
если (число % 3 == 0 или число % 5 == 0):
результат += число
напечатать "Сумма %d" % результат
num_multi1 (1000)
конец = время.часы()
значение = конец - начало
отметка времени = datetime.datetime.fromtimestamp (значение)
печать timestamp.strftime('%Y-%m-%d %H:%M:%S')
Хотя в вопросе это строго не задано, довольно часто требуется простой и унифицированный способ постепенного измерения времени, прошедшего между несколькими строками кода.
Если вы используете Python 3.8 или более позднюю версию, вы можете использовать выражения присваивания (также известные как оператор walrus), чтобы добиться этого довольно элегантным способом:
время импорта
начало, раз = time.perf_counter(), {}
распечатать("привет")
times["print"] = -start + (start := time.perf_counter())
время сна(1.42)
times["sleep"] = -start + (start := time.perf_counter())
a = [n**2 для n в диапазоне (10000)]
раз["pow"] = -start + (start := time. perf_counter())
печать (раз)
 perf_counter())
печать (раз)
perf_counter())
печать (раз)
=>
{'печать': 2.193450927734375e-05, 'сон': 1.4210970401763916, 'мощность': 0.005671024322509766}
Я сделал для этого библиотеку, если вы хотите измерить функцию, вы можете просто сделать это так
из импорта pythonbenchmark сравнить, измерить
время импорта
а, б, в, г, д = 10,10,10,10,10
что-то = [а, б, в, г, д]
@мера
def myFunction (что-то):
время сна (0,4)
@мера
def myOptimizedFunction (что-то):
время сна (0,2)
моя функция (ввод)
мояОптимизированнаяФункция(ввод)
https://github.com/Karlheinzniebuhr/pythonbenchmark
Этот уникальный подход на основе классов предлагает печатное строковое представление, настраиваемое округление и удобный доступ к прошедшему времени в виде строки или числа с плавающей запятой. Он был разработан с помощью Python 3.7.
импорт даты и времени импортировать время класс Таймер: """Измерение использованного времени.""" # Ссылка: https://stackoverflow.
