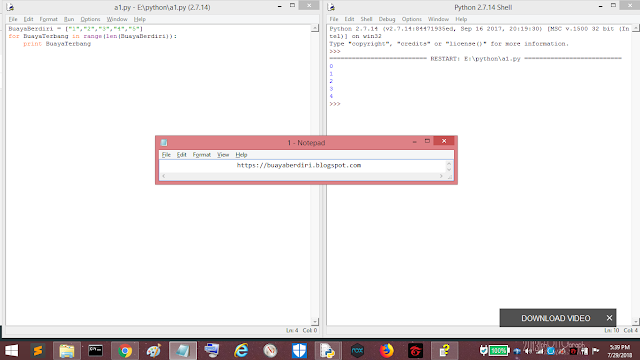
Открывать, работать и закрывать файлы в Python
Шаги по открытию файла: open ==> operation ==> close
1. Открытие файла
f = open ('/ tmp / pass', 'r +') ## Первый параметр в скобках - это файл, который нужно открыть, а второй параметр указывает, какие права доступа требуются для работы с файлом
## Следующее - разрешение второго параметра
"""
r: (по умолчанию)
-Можно только читать, но не писать
-Если прочитанный файл не существует, будет сообщено об ошибке
r+:
-Чтение и запись
-Если прочитанный файл не существует, будет сообщено об ошибке
w:
-write only
-Очистит предыдущее содержимое файла
-Файл не существует, ошибка не будет сообщаться, будет создан и записан новый файл
w+:
-rw
-Очистит содержимое файла
-Файл не существует, об ошибках не будет, будет создан новый файл
a:
-write only
-Не очищает содержимое файла
-Файл не существует, ошибка не будет сообщаться, будет создан и записан новый файл
a+:
-rw
-Ошибка не отображается, если файл не существует
-Не очищает содержимое файла
b:
Двоичный
"""Как узнать, все ли открываемые вами файлы доступны для чтения и записи
print (f.readable ()) ## Оценка читаемости print (f.writable ()) ## Оцените, доступен ли он для записи
 readable ()) ## Оценка читаемости
print (f.writable ()) ## Оцените, доступен ли он для записи
readable ()) ## Оценка читаемости
print (f.writable ()) ## Оцените, доступен ли он для записи2. Работа с файлами
1) Прочтите содержимое файла
content = f.read () ## прочитает все содержимое файла, выведет в одну строку content = f.read (3) ## прочитает первые 3 файла print (f.readline ()) ## Прочитать и вывести первую строку файла print (f.readlines ()) ## Прочитать содержимое файла, вернуть список, элементы списка являются содержимым строки файла
2) Записать в файл
f.write ('hello') ## Добавить привет в последнюю строку файла3) Положение указателя
print(f.tell())
метод поиска для перемещения указателя
Первый параметр поиска — смещение:> 0, что означает движение вправо, <0, что означает движение влево.
Второй параметр поиска:
0: переместить указатель в начало файла.
1: не перемещать указатель
2: переместите указатель в конец
f.seek (-1,2) ## означает переместить два юнита влево
4) Работа с непростым текстом
Следующая операция предназначена для копирования изображения
f1 = open('1111. jpg',mode='rb')
content = f1.read()
f1.close()
f2 = open('westos.jpg',mode='wb')
f2.write(content)
f2.close()
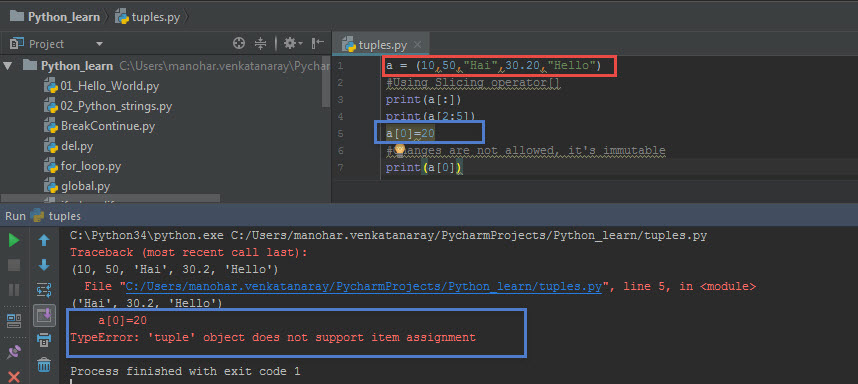
3. Закрытие файла
f.close () ## Открытый файл должен быть закрыт, иначе он всегда будет занимать системные ресурсы
4.with
Диспетчер контекста: откройте файл и автоматически закройте объект файла после выполнения содержимого инструкции with
Как следующая структура
# Открыть два файловых объекта одновременно
with open('/tmp/passwd') as f1,\
open('/tmp/passwdbackup','w+') as f2:
# Записываем содержимое первого файла во второй файл
f2.write(f1.read())
# Переместить указатель в начало файла
f2.seek(0)
# Читать содержимое файла
print(f2.read())5. Практика
Создайте файл data.txt, в файле всего 100000 строк, в каждой строке хранится целое число от 1 до 100, и прочтите содержимое файла после записи.
import random
f = open('date. txt','a+')
for i in range(100000):
f.write(str(random.randint(1,100)) + '\n')
f.seek(0,0)
print(f.read())
f.close() txt','a+')
for i in range(100000):
f.write(str(random.randint(1,100)) + '\n')
f.seek(0,0)
print(f.read())
f.close()
txt','a+')
for i in range(100000):
f.write(str(random.randint(1,100)) + '\n')
f.seek(0,0)
print(f.read())
f.close()ok~
Интеллектуальная рекомендация
Развитие iOS — один случай
Что такое один пример, цель пения? Когда класс — это только один экземпляр, вам необходимо использовать один пример, то есть этот класс имеет только один объект, который не может быть выпущен во время…
Разница между typeof, instanceof и конструктором в js
Оператор typeof возвращает строку. Например: число, логическое значение, строка, объект, неопределенное значение, функция, Но это недостаточно точно. Следующие примеры представляют собой различные рез…
Установка и использование Cocoapods, обработка ошибок
Использование какао-стручков Общие команды CocoaPods: $pod setup Обновите все сторонние индексные файлы Podspec в локальном каталоге ~ / .CocoaPods / repos / и обновите локальное хранилище. $pod repo …
Коллекция инструментов с неограниченной скоростью для облачного диска Baidu
Примечание: Недавно я обнаружил, что скорость загрузки файлов на Baidu Cloud Disk очень низкая. Лао-цзы не может выкупить участников. Невозможно выкупить участников в этой жизни. Если у вас нет денег,…
Лао-цзы не может выкупить участников. Невозможно выкупить участников в этой жизни. Если у вас нет денег,…
Шаблон проектирования — Подробное объяснение шаблона заводского метода
Предисловие В предыдущей статье «Шаблон проектирования — Подробное объяснение простого шаблона Factory», мы можем знать, что у простой фабричной модели есть некоторые недостатки: Класс фабри…
Вам также может понравиться
29 сентября, весенняя облачная суббота
Ложь, правда и ложь, как в шахматы, но кто пешка? «Тень»…
Logstash Delete Field.
Проблема После того, как FileBeat приобретает информацию журнала, Logstash Prints Information. В этом процессе FileBeat передает свою собственную информацию о клиентах в логисту, если лог-журнал отфил…
Глава 2 2.1-2.16 Предварительный просмотр
2.1 Системный каталог Структура Команда: ls = список Используется для перечисления системных каталогов или файлов Корневой каталог является каталогом пользователя, сохраняет файл конфигурации или друг. ..
..
Java фактическое боевое боевое издание 103 страниц Ответ
…
Алгоритм лунного календаря, включая праздники, солнечные термины, сезонные и т. Д.
Эпоха (день 0): пятница, 22 декабря 1899 года, григорианский календарь против китайского Нового года (двадцать пять лет в Гуансу), 20 ноября, зимнее солнцестояние Цзяцзы Диапазон лунного календаря: с …
Чтение данных из файла и запись в файл. Программирование на Python
Создание файла
В Python, чтобы создать файл, надо его открыть в режиме записи (‘w’, ‘wb’) или дозаписи (‘a’, ‘ab’).
f2 = open("text2.txt", 'w')Функция open() возвращает файловый объект.
Без ‘b’ создается текстовый файл, представляющий собой поток символов. С ‘b’ — файл, содержащий поток байтов.
В Python также существует режим ‘x’ или ‘xb’. В этом режиме проверяется, есть ли файл. Если файл с определенным именем уже существует, он не будет создан. В режиме ‘w’ файл создается заново, старый при этом теряется.
>>> f1 = open('text1.txt', 'w')
>>> f2 = open('text1.txt', 'x')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
FileExistsError: [Errno 17] File exists: 'text1.txt'
>>> f3 = open('text1.txt', 'w')Чтение данных из файла
Если в функцию open() не передается второй аргумент, файл расценивается как текстовый и открывается на чтение.
Попытка открыть на чтение несуществующий файл вызывает ошибку.
>>> f = open("text10.txt")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IOError: [Errno 2] No such file or directory: 'text10.txt'Перехватить возникшее исключение можно с помощью конструкции try-except.
>>> try:
... f = open("text10.txt")
... except IOError:
... print ("No file")
...
No fileПолучить все данные из файла можно с помощью метода read() файлового объекта, предварительно открыв файл на чтение. При этом файловый объект изменяется и получить из него данные еще раз не получится.
При этом файловый объект изменяется и получить из него данные еще раз не получится.
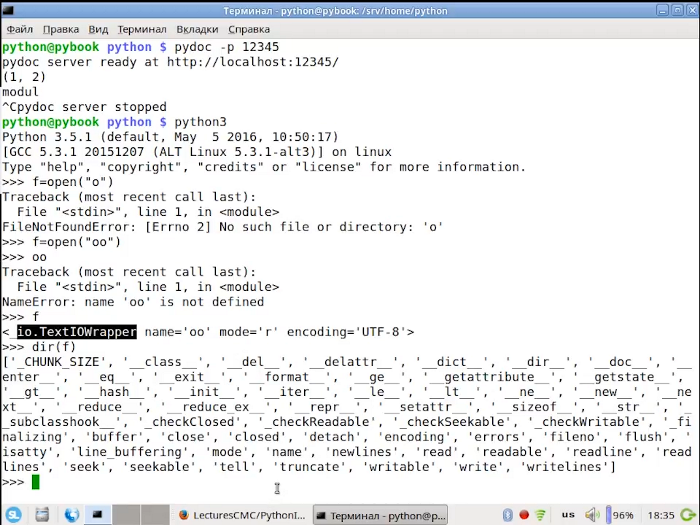
>>> f = open("text.txt")
>>> f
<_io.TextIOWrapper name='text.txt' mode='r' encoding='UTF-8'>
>>> fd = f.read()
>>> fd1 = f.read()
>>> fd
'Hello\n\tOne\n Two\nThree Four\nШесть!\n'
>>> fd1
''Методу read() может быть передан один аргумент, обозначающий количество байт для чтения.
>>> f = open("text.txt")
>>> fd = f.read(10)
>>> fd1 = f.read(5)
>>> fd
'Hello\n\tOne'
>>> fd1
'\n T'Метод readline() позволяет получать данные построчно.
>>> f = open("text.txt")
>>> f.readline()
'Hello\n'
>>> f.readline()
'\tOne\n'
>>> f.readline()
' Two\n'Принимает аргумент — число байт.
>>> f.readline(3) 'Thr' >>> f.readline(3) 'ee ' >>> f.readline(3) 'Fou' >>> f.readline(3) 'r\n' >>> f.
 readline(5)
'Шесть'
>>> f.readline(5)
'!\n'
readline(5)
'Шесть'
>>> f.readline(5)
'!\n'Метод readlines() считывает все строки и помещает их в список.
>>> f = open("text.txt")
>>> fd = f.readlines()
>>> fd
['Hello\n', '\tOne\n', ' Two\n', 'Three Four\n', 'Шесть!\n']Может принимать количество байт, но дочитывает строку до конца.
>>> f = open("text.txt")
>>> fd = f.readlines(3)
>>> fd
['Hello\n']
>>> fd1 = f.readlines(6)
>>> fd1
['\tOne\n', ' Two\n']Запись данных в файл
Записать данные в файл можно с помощью метода write(), который возвращает число записанных символов.
>>> f1 = open("text1.txt", 'w')
>>> f1.write("Table, cup.\nBig, small.")
23
>>> a = f1.write("Table, cup.\nBig, small.")
>>> type(a)
<class 'int'>Файл, открытый на запись, нельзя прочитать. Для этого требуется его закрыть, а потом открыть на чтение.
>>> f1.
 read()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
io.UnsupportedOperation: not readable
>>> f1.close()
>>> f1 = open("text1.txt", 'r')
>>> f1.read()
'Table, cup.\nBig, small.Table, cup.\nBig, small.'
read()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
io.UnsupportedOperation: not readable
>>> f1.close()
>>> f1 = open("text1.txt", 'r')
>>> f1.read()
'Table, cup.\nBig, small.Table, cup.\nBig, small.'С помощью метода writelines() можно записать в файл итерируемую последовательность.
>>> a = [1,2,3,4,5,6,7,8,9,0]
>>> f = open("text2.txt",'w')
>>> f.writelines("%s\n" % i for i in a)
>>> f.close()
>>> open("text2.txt").read()
'1\n2\n3\n4\n5\n6\n7\n8\n9\n0\n'
>>> print(open("text2.txt").read())
1
2
3
4
5
6
7
8
9
0Смена позиции в файле
>>> f = open('text.txt')
>>> f.read()
'Hello\n\tOne\n Two\nThree Four\nШесть!\n'
>>> f.close()
>>> f = open('text.txt')
>>> f.seek(10)
10
>>> f.read()
'\n Two\nThree Four\nШесть!\n'Двоичные файлы
Пример копирования изображения:
>>> f1 = open('flag. png', 'rb')
>>> f2 = open('flag2.png', 'wb')
>>> f2.write(f1.read())
446
>>> f1.close()
>>> f2.close() png', 'rb')
>>> f2 = open('flag2.png', 'wb')
>>> f2.write(f1.read())
446
>>> f1.close()
>>> f2.close()
png', 'rb')
>>> f2 = open('flag2.png', 'wb')
>>> f2.write(f1.read())
446
>>> f1.close()
>>> f2.close()Модуль struct позволяет преобразовывать данные к бинарному виду и обратно.
>>> f = open('text3.txt', 'wb')
>>> f.write('3')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'str' does not support the buffer interface
>>> d = struct.pack('>i',3)
>>> d
b'\x00\x00\x00\x03'
>>> f.write(d)
4
>>> f.close()
>>> f = open('text3.txt')
>>> d = f.read()
>>> d
'\x00\x00\x00\x03'
>>> struct.unpack('>i',d)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'str' does not support the buffer interface
>>> f = open('text3.txt', 'rb')
>>> d = f.read()
>>> d
b'\x00\x00\x00\x03'
>>> struct.unpack('>i',d)
(3,)Как прочитать файлы в Python и решить проблему с кодировками
На практике в реальных проектах Data Science часто приходится сталкиваться с чтением датасетов, а также записывать добытую в ходе вычислений информацию в файлы. Сегодня мы расскажем о работе с файлами в Python: чтение и запись, проблема с кодировками, добавление значений в конец файла, временные папки и файлы.
Сегодня мы расскажем о работе с файлами в Python: чтение и запись, проблема с кодировками, добавление значений в конец файла, временные папки и файлы.
Открываем, а затем читаем или записываем
Предположим, у нас имеется файл, который нужно прочитать в Python. Для этого можно воспользоваться функцией open внутри контекстного менеджера:
with open('file.txt') as f:
data = f.read() # содержимое файла
Таким же образом можно записать информацию в файл, указав w в качестве аргумента:
text = 'Hello'
with open('file.txt', 'w') as f:
f.write(text)
Отметим некоторые особенности данной функции. Во-первых, для чтения файла мы не указывали никаких аргументов кроме имени файла, поскольку по умолчанию уже стоит режим чтения. Мы также не указывали явно, что это именно текстовый файл, а не бинарный, так как это тоже стоит по умолчанию. Для чтения и записи бинарных файлов добавляется b, например, rb или wb.
Во-вторых, мы использовали функцию open в контекстном менеджере. Можно обойтись и без него, но тогда после чтения или записи следует закрыть файл.
f = open('file.txt')
f.read()
f.close()
На открытие файла Python выделяет память, поэтому, чтобы избежать ее утечки, рекомендуется закрывать файлы.
Чтение файла с разной кодировкой
На многих операционных системах Python в качестве стандарта кодирования использует UTF-8, который также поддерживает кириллицу. Тем не менее, часто можно столкнуться с проблемами неправильной кодировки и получить распространенную ошибку вроде этой:
>>> f = open('somefile.txt', encoding='ascii')
>>> f.read()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/Python3.8/encodings/ascii.py", line 26, in decode
return codecs.ascii_decode(input, self. errors)[0]
UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position
12: ordinal not in range(128))
 errors)[0]
UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position
12: ordinal not in range(128))
errors)[0]
UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position
12: ordinal not in range(128))
В примере указана кодировка ASCII, но файл закодирован в другом формате, поэтому и возникает такая ошибка. Решить ее можно тремя способами:
- Указать
erorr=replace, который заменит нераспознанные символы знаком?:>>> f = open('somefile.txt', encoding='ascii', errors='replace') >>> f.read() 'H?llo py?ho?-school!' - Указать
erorr=ignore, который проигнорирует нераспознанные символы:>>> f = open('somefile.txt', encoding='ascii', errors='replace') >>> f.read() 'Hllo pyho-school!' - Указать правильную кодировку. Если текст на русском языке, то можно посмотреть кодировки с поддержкой кириллицы, которые есть в документации Python. Например, явно указать UTF-8 или cp1251:
f = open('somefile. txt', encoding='utf-8')
# или cp1251
f = open('somefile.txt', encoding='cp1251')
 txt', encoding='utf-8')
# или cp1251
f = open('somefile.txt', encoding='cp1251')
txt', encoding='utf-8')
# или cp1251
f = open('somefile.txt', encoding='cp1251')
Добавление в конец и запрет открытия файлов
Как мы уже отметили ранее, для записи текстового файла добавляется аргумент w. Но если вызвать метод write, он перепишет весь файл. Во многих случаях требуется добавить данные в конец файла. Тогда используется a вместо w:
text2 = 'world'
with open('file.txt', 'a') as f:
f.write(text)
# Helloworld
Если файла не существует, то при a и при w он будет создан. Но чтобы не трогать существующие файлы, а создать новый, передается параметр x:
# 'x' не даст возможности открыть файл, так как он существует
>>> with open('file.txt', 'x') as f:
... f.write(text2)
FileExistsError Traceback (most recent call last)
FileExistsError: [Errno 17] File exists: 'file. txt'
# Поскольку file2.txt не существует, все OK
>>> with open('file2.txt', 'x') as f:
... f.write(text2)
 txt'
# Поскольку file2.txt не существует, все OK
>>> with open('file2.txt', 'x') as f:
... f.write(text2)
txt'
# Поскольку file2.txt не существует, все OK
>>> with open('file2.txt', 'x') as f:
... f.write(text2)
Временные файлы
Иногда бывает, что требуется создать файл или папку внутри Python-программы, а после ее закрытия их нужно удалить. Тогда пригодится стандартный модуль tempfile. Например, класс TemporaryFile создаст временный файл, который удалится после закрытия. Ниже пример в Python.
>>> from tempfile import TemporaryFile
>>> f = TemporaryFile("w+t")
>>> f.write("hello")
>>> f.seek(0)
>>> f.read()
'hello'
>>> f.close() # файл уничтожается
# либо в контекстном менеджере
f.write(text2)
Обратите внимание на 3 вещи. Первое, мы явно передаем "w+t", чтобы записать как текстовый файл, поскольку по умолчанию стоит "w+b" для бинарных файлов.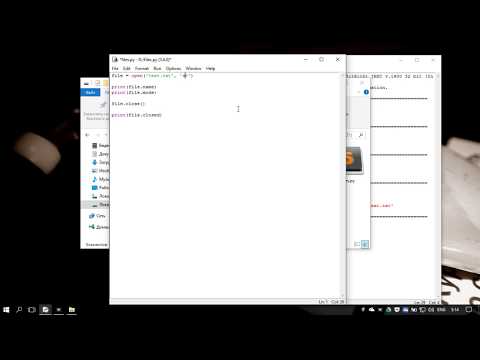 Второе, метод
Второе, метод seek(0) используется для перехода на самый первый символ, поскольку чтение происходит с текущего указателя, а он стоит в конце (после буквы ‘o’ в слове ‘hello’). Поэтому не стоит переживать, что мы можем стереть предыдущую запись:
>>> f.seek(5) # переходим в конец
>>> f.read()
''
>>> f.write("world")
5
>>> f.seek(0) # переходим в начало
>>> f.read()
'helloworld'
Третье, файл TemporaryFile невидим для файловой системы, он используется только внутри Python, поэтому извне будет трудно его найти.
Именованные временные файлы
А вот объекты класса NamedTemporaryFile будут видны файловой системе, и найти месторасположение можно с помощью атрибута name:
>>> from tempfile import NamedTemporaryFile
>>> f = NamedTemporaryFile("w+t")
>>> f. name
'/tmp/tmp60djsgli'
>>> f.close()
 name
'/tmp/tmp60djsgli'
>>> f.close()
name
'/tmp/tmp60djsgli'
>>> f.close()
Как можно заметить, файл называется tmp60djsgli. Для удобства можно явно указать его название и формат:
>>> f = NamedTemporaryFile("w+t", prefix="myfile", suffix=".txt")
>>> f.name
'/tmp/myfile7mxae0fi.txt'
Временные папки
Кроме временных файлов можно создавать временные папки. Для этого используется класс TemporaryDirectory:
>>> from tempfile import TemporaryDirectory >>> d = TemporaryDirectory() >>> d.name '/tmp/tmp5eadqzz5'
Он также принимает в качестве аргументов prefix и suffix, а также может использоваться внутри контекстного менеджера Python.
В следующей статье поговорим о взаимодействии файловой системы и Python. А получить практические навыки работы с файлами на реальных проектах Data Science вы сможете на наших курсах по Python в лицензированном учебном центре обучения и повышения квалификации IT-специалистов в Москве.
Смотреть расписание
Записаться на курс
Источники
- https://docs.python.org/3/library/functions.html#open
- https://docs.python.org/3/library/tempfile.html
Python 3: файлы — чтение и запись: open, read, write, seek, readline, dump, load, pickle
Смотреть материал на видео
На этом занятии мы поговорим, как в Python можно считывать информацию из файлов и записывать ее в файлы. Что такое файлы и зачем они нужны, думаю объяснять не надо, т.к. если вы дошли до этого занятия, значит, проблем с пониманием таких базовых вещей у вас нет. Поэтому сразу перейдем к функции
open(file [, mode=’r’, encoding=None, …])
через которую и осуществляется работа с файлами. Здесь
- file – это путь к файлу вместе с его именем;
- mode – режим доступа к файлу;
-
encoding
– кодировка
файла.

Для начала определимся с понятием «путь к файлу». Представим, что наш файл ex1.py находится в каталоге app:
Тогда, чтобы обратиться к файлу my_file.txt путь можно записать так:
«my_file.txt»
или
«d:\\app\\my_file.txt»
или так:
«d:/app/my_file.txt»
Последние два варианта представляют собой абсолютный путь к файлу, то есть, полный путь, начиная с указания диска. Причем, обычно используют обратный слеш в качестве разделителя: так короче писать и такой путь будет корректно восприниматься как под ОС Windows, так и Linux. Первый же вариант – это относительный путь, относительно рабочего каталога.
Теперь, предположим, мы хотим обратиться к файлу img.txt. Это можно сделать так:
«images/img.txt»
или так:
«d:/app/images/img. txt»
txt»
Для доступа к out.txt пути будут записаны так:
«../out.txt»
«d:/out.txt»
Обратите внимание, здесь две точки означают переход к родительскому каталогу, то есть, выход из каталога app на один уровень вверх.
И, наконец, для доступа к файлу prt.dat пути запишутся так:
«../parent/prt.dat»
«d:/ parent/prt.dat»
Вот так следует прописывать пути к файлам. В нашем случае мы имеем текстовый файл «myfile.txt», который находится в том же каталоге, что и программа ex1.py, поэтому путь можно записать просто указав имя файла:
file = open("myfile.txt")В результате переменная file будет ссылаться на файловый объект, через который и происходит работа с файлами. Если указать неверный путь, например, так:
file = open("myfile2.txt")то возникнет
ошибка FileNotFoundError. Это
стандартное исключение и как их обрабатывать мы с вами говорили на предыдущем
занятии. Поэтому, запишем этот критический код в блоке try:
Это
стандартное исключение и как их обрабатывать мы с вами говорили на предыдущем
занятии. Поэтому, запишем этот критический код в блоке try:
try:
file = open("myfile2.txt")
except FileNotFoundError:
print("Невозможно открыть файл")Изменим имя файла на верное и посмотрим, как далее можно с ним работать. По умолчанию функция open открывает файл в текстовом режиме на чтение. Это режим
mode = «r»
Если нам нужно поменять режим доступа к файлу, например, открыть его на запись, то это явно указывается вторым параметром функции open:
file = open("out.txt", "w")В Python имеются следующие режимы доступа:
|
Название |
Описание |
|
‘r’ |
открытие на чтение (значение по умолчанию) |
|
‘w’ |
открытие на запись (содержимое файла удаляется, а если его нет, то создается новый) |
|
‘x’ |
открытие файла на запись, если его нет генерирует исключение |
|
‘a’ |
открытие на дозапись (информация добавляется в конец файла) |
|
Дополнения |
|
|
‘b’ |
открытие в бинарном режиме доступа к информации файла |
|
‘t’ |
открытие в текстовом режиме доступа (если явно не указывается, то используется по умолчанию) |
|
‘+’ |
открытие на чтение и запись одновременно |
Здесь мы имеем
три основных режима доступа: на чтение, запись и добавление. И еще три
возможных расширения этих режимов, например,
И еще три
возможных расширения этих режимов, например,
- ‘rt’ – чтение в текстовом режиме;
- ‘wb’ – запись в бинарном режиме;
- ‘a+’ – дозапись или чтение данных из файла.
Чтение информации из файла
В чем отличие текстового режима от бинарного мы поговорим позже, а сейчас откроем файл на чтение в текстовом режиме:
file = open("myfile.txt")и прочитаем его содержимое с помощью метода read:
print( file.read() )
В результате, получим
строку, в которой будет находиться прочитанное содержимое. Действительно, в
этом файле находятся эти строчки из поэмы Пушкина А.С. «Медный всадник». И
здесь есть один тонкий момент. Наш текстовый файл имеет кодировку Windows-1251 и эта
кодировка используется по умолчанию в функции read. Но, если
изменить кодировку файла, например, на популярную UTF-8, то после
запуска программы увидим в консоли вот такую белиберду. Как это можно
исправить, не меняя кодировки самого файла? Для этого следует воспользоваться
именованным параметром encoding и записать метод open вот так:
Как это можно
исправить, не меняя кодировки самого файла? Для этого следует воспользоваться
именованным параметром encoding и записать метод open вот так:
file = open("myfile.txt", encoding="utf-8" )Теперь все будет работать корректно. Далее, в методе read мы можем указать некий числовой аргумент, например,
print( file.read(2) )
Тогда из файла будут считаны первые два символа. И смотрите, если мы запишем два таких вызова подряд:
print( file.read(2) ) print( file.read(2) )
то увидим, что при следующем вызове метод read продолжил читать следующие два символа. Почему так произошло? Дело в том, что у файлового объекта, на который ссылается переменная file, имеется внутренний указатель позиции (file position), который показывает с какого места производить считывание информации.
Когда мы
вызываем метод read(2) эта позиция автоматически сдвигается от начала
файла на два символа, т. к. мы именно столько считываем. И при повторном вызове read(2) считывание
продолжается, т.е. берутся следующие два символа. Соответственно, позиция файла
сдвигается дальше. И так, пока не дойдем до конца.
к. мы именно столько считываем. И при повторном вызове read(2) считывание
продолжается, т.е. берутся следующие два символа. Соответственно, позиция файла
сдвигается дальше. И так, пока не дойдем до конца.
Но мы в Python можем управлять этой файловой позицией с помощью метода
seek(offset[, from_what])
Например, вот такая запись:
file.seek(0)
будет означать, что мы устанавливаем позицию в начало и тогда такие строчки:
print( file.read(2) ) file.seek(0) print( file.read(2) )
будут считывать одни и те же первые символы. Если же мы хотим узнать текущую позицию в файле, то следует вызвать метод tell:
pos = file.tell() print( pos )
Следующий полезный метод – это readline позволяет построчно считывать информацию из текстового файла:
s = file.readline() print( s )
Здесь концом
строки считается символ переноса ‘\n’, либо конец файла. Причем, этот
символ переноса строки будет также присутствовать в строке. Мы в этом можем
убедиться, вызвав дважды эту функцию:
Причем, этот
символ переноса строки будет также присутствовать в строке. Мы в этом можем
убедиться, вызвав дважды эту функцию:
print( file.readline() ) print( file.readline() )
Здесь в консоли строчки будут разделены пустой строкой. Это как раз из-за того, что один перенос идет из прочитанной строки, а второй добавляется самой функцией print. Поэтому, если их записать вот так:
print( file.readline(), end="" ) print( file.readline(), end="" )
то вывод будет построчным с одним переносом.
Если нам нужно последовательно прочитать все строчки из файла, то для этого обычно используют цикл for следующим образом:
for line in file: print( line, end="" )
Этот пример показывает, что объект файл является итерируемым и на каждой итерации возвращает очередную строку.
Или же, все строчки можно прочитать методом
s = file.
 readlines()
readlines()и тогда переменная s будет ссылаться на упорядоченный список с этими строками:
print( s )
Однако этот метод следует использовать с осторожностью, т.к. для больших файлов может возникнуть ошибка нехватки памяти для хранения полученного списка.
По сути это все методы для считывания информации из файла. И, смотрите, как только мы завершили работу с файлом, его следует закрыть. Для этого используется метод close:
file.close()
Конечно, прописывая эту строчку, мы не увидим никакой разницы в работе программы. Но, во-первых, закрывая файл, мы освобождаем память, связанную с этим файлом и, во-вторых, у нас не будет проблем в потере данных при их записи в файл. А, вообще, лучше просто запомнить: после завершения работы с файлом, его нужно закрыть. Причем, организовать программу лучше так:
try:
file = open("myfile.txt")
try:
s = file. readlines()
print( s )
finally:
file.close()
except FileNotFoundError:
print("Невозможно открыть файл") readlines()
print( s )
finally:
file.close()
except FileNotFoundError:
print("Невозможно открыть файл")
readlines()
print( s )
finally:
file.close()
except FileNotFoundError:
print("Невозможно открыть файл")Мы здесь создаем вложенный блок try, в который помещаем критический текст программы при работе с файлом и далее блок finally, который будет выполнен при любом стечении обстоятельств, а значит, файл гарантированно будет закрыт.
Или же, забегая немного вперед, отмечу, что часто для открытия файла пользуются так называемым менеджером контекста, когда файл открывают при помощи оператора with:
try:
with open("myfile.txt", "r") as file: # file = open("myfile.txt")
s = file.readlines()
print( s )
except FileNotFoundError:
print("Невозможно открыть файл")При таком подходе файл закрывается автоматически после выполнения всех инструкций внутри этого менеджера. В этом можно убедиться, выведем в консоль флаг, сигнализирующий закрытие файла:
finally: print(file.
 closed)
closed)Запустим программу, видите, все работает также и при этом файл автоматически закрывается. Даже если произойдет критическая ошибка, например, пропишем такую конструкцию:
print( int(s) )
то, как видим, файл все равно закрывается. Вот в этом удобство такого подхода при работе с файлами.
Запись информации в файл
Теперь давайте посмотрим, как происходит запись информации в файл. Во-первых, нам нужно открыть файл на запись, например, так:
file = open("out.txt", "w")и далее вызвать метод write:
file.write("Hello World!")В результате у нас будет создан файл out.txt со строкой «Hello World!». Причем, этот файл будет располагаться в том же каталоге, что и файл с текстом программы на Python.
Далее сделаем такую операцию: запишем метод write следующим образом:
file.write("Hello")И снова выполним
эту программу. Смотрите, в нашем файле out.txt прежнее
содержимое исчезло и появилось новое – строка «Hello». То есть,
когда мы открываем файл на запись в режимах
Смотрите, в нашем файле out.txt прежнее
содержимое исчезло и появилось новое – строка «Hello». То есть,
когда мы открываем файл на запись в режимах
w, wt, wb,
то прежнее содержимое файла удаляется. Вот этот момент следует всегда помнить.
Теперь посмотрим, что будет, если вызвать метод write несколько раз подряд:
file.write("Hello1")
file.write("Hello2")
file.write("Hello3")Смотрите, у нас в файле появились эти строчки друг за другом. То есть, здесь как и со считыванием: объект file записывает информацию, начиная с текущей файловой позиции, и автоматически перемещает ее при выполнении метода write.
Если мы хотим записать эти строчки в файл каждую с новой строки, то в конце каждой пропишем символ переноса строки:
file.write("Hello1\n")
file.write("Hello2\n")
file.write("Hello3\n")Далее, для дозаписи информации в файл, то есть, записи с сохранением предыдущего содержимого, файл следует открыть в режиме ‘a’:
file = open("out. txt", "a") txt", "a")
txt", "a")Тогда, выполняя эту программу, мы в файле увидим уже шесть строчек. И смотрите, в зависимости от режима доступа к файлу, мы должны использовать или методы для записи, или методы для чтения. Например, если вот здесь попытаться прочитать информацию с помощью метода read:
file.read()
то возникнет ошибка доступа. Если же мы хотим и записывать и считывать информацию, то можно воспользоваться режимом a+:
file = open("out.txt", "a+")Так как здесь файловый указатель стоит на последней позиции, то для считывания информации, поставим его в самое начало:
file.seek(0) print( file.read() )
А вот запись данных всегда осуществляется в конец файла.
Следующий полезный метод для записи информации – это writelines:
file.writelines(["Hello1\n", "Hello2\n"])
Он записывает
несколько строк, указанных в коллекции. Иногда это бывает удобно, если в
процессе обработки текста мы имеем список и его требуется целиком поместить в
файл.
Иногда это бывает удобно, если в
процессе обработки текста мы имеем список и его требуется целиком поместить в
файл.
Чтение и запись в бинарном режиме доступа
Что такое бинарный режим доступа? Это когда данные из файла считываются один в один без какой-либо обработки. Обычно это используется для сохранения и считывания объектов. Давайте предположим, что нужно сохранить в файл вот такой список:
books = [
("Евгений Онегин", "Пушкин А.С.", 200),
("Муму", "Тургенев И.С.", 250),
("Мастер и Маргарита", "Булгаков М.А.", 500),
("Мертвые души", "Гоголь Н.В.", 190)
]Откроем файл на запись в бинарном режиме:
file = open("out.bin", "wb")Далее, для работы с бинарными данными подключим специальный встроенный модуль pickle:
import pickle
И вызовем него метод dump:
pickle.dump(books, file)
Все, мы
сохранили этот объект в файл. Теперь прочитаем эти данные. Откроем файл на
чтение в бинарном режиме:
Теперь прочитаем эти данные. Откроем файл на
чтение в бинарном режиме:
file = open("out.bin", "rb")и далее вызовем метод load модуля pickle:
bs = pickle.load(file)
Все, теперь переменная bs ссылается на эквивалентный список:
print( bs )
Аналогичным образом можно записывать и считывать сразу несколько объектов. Например, так:
import pickle
book1 = ["Евгений Онегин", "Пушкин А.С.", 200]
book2 = ["Муму", "Тургенев И.С.", 250]
book3 = ["Мастер и Маргарита", "Булгаков М.А.", 500]
book4 = ["Мертвые души", "Гоголь Н.В.", 190]
try:
file = open("out.bin", "wb")
try:
pickle.dump(book1, file)
pickle.dump(book2, file)
pickle.dump(book3, file)
pickle.dump(book4, file)
finally:
file.close()
except FileNotFoundError:
print("Невозможно открыть файл")А, затем, считывание в том же порядке:
file = open("out. bin", "rb")
b1 = pickle.load(file)
b2 = pickle.load(file)
b3 = pickle.load(file)
b4 = pickle.load(file)
print( b1, b2, b3, b4, sep="\n" ) bin", "rb")
b1 = pickle.load(file)
b2 = pickle.load(file)
b3 = pickle.load(file)
b4 = pickle.load(file)
print( b1, b2, b3, b4, sep="\n" )
bin", "rb")
b1 = pickle.load(file)
b2 = pickle.load(file)
b3 = pickle.load(file)
b4 = pickle.load(file)
print( b1, b2, b3, b4, sep="\n" )Вот так в Python выполняется запись и считывание данных из файла.
Задания для самоподготовки
1. Выполните считывание данных из текстового файла через символ и записи прочитанных данных в другой текстовый файл. Прочитывайте так не более 100 символов.
2. Пользователь вводит предложение с клавиатуры. Разбейте это предложение по словам (считать, что слова разделены пробелом) и сохраните их в столбец в файл.
3. Пусть имеется словарь:
d = {«house»:
«дом», «car»: «машина»,
«tree»:
«дерево», «road»: «дорога»,
«river»:
«река»}
Необходимо
каждый элемент этого словаря сохранить в бинарном файле как объект. Затем,
прочитать этот файл и вывести считанные объекты в консоль.
Видео по теме
#1. Первое знакомство с Python Установка на компьютер
#2. Варианты исполнения команд. Переходим в PyCharm
#3. Переменные, оператор присваивания, функции type и id
#4. Числовые типы, арифметические операции
#5. Математические функции и работа с модулем math
#6. Функции print() и input(). Преобразование строк в числа int() и float()
#7. Логический тип bool. Операторы сравнения и операторы and, or, not
#8. Введение в строки. Базовые операции над строками
#9. Знакомство с индексами и срезами строк
#10. Основные методы строк
#11. Спецсимволы, экранирование символов, row-строки
#12. Форматирование строк: метод format и F-строки
#13. Списки — операторы и функции работы с ними
Списки — операторы и функции работы с ними
#14. Срезы списков и сравнение списков
#15. Основные методы списков
#16. Вложенные списки, многомерные списки
#17. Условный оператор if. Конструкция if-else
#18. Вложенные условия и множественный выбор. Конструкция if-elif-else
#19. Тернарный условный оператор. Вложенное тернарное условие
#20. Оператор цикла while
#21. Операторы циклов break, continue и else
#22. Оператор цикла for. Функция range()
#23. Примеры работы оператора цикла for. Функция enumerate()
#24. Итератор и итерируемые объекты. Функции iter() и next()
#25. Вложенные циклы. Примеры задач с вложенными циклами
#26. Треугольник Паскаля как пример работы вложенных циклов
#27..files/image030.png) Генераторы списков (List comprehensions)
Генераторы списков (List comprehensions)
#28. Вложенные генераторы списков
#29. Введение в словари (dict). Базовые операции над словарями
#30. Методы словаря, перебор элементов словаря в цикле
#31. Кортежи (tuple) и их методы
#32. Множества (set) и их методы
#33. Операции над множествами, сравнение множеств
#34. Генераторы множеств и генераторы словарей
#35. Функции: первое знакомство, определение def и их вызов
#36. Оператор return в функциях. Функциональное программирование
#37. Алгоритм Евклида для нахождения НОД
#38. Именованные аргументы. Фактические и формальные параметры
#39. Функции с произвольным числом параметров *args и **kwargs
#40.![]() Операторы * и ** для упаковки и распаковки коллекций
Операторы * и ** для упаковки и распаковки коллекций
#41. Рекурсивные функции
#42. Анонимные (lambda) функции
#43. Области видимости переменных. Ключевые слова global и nonlocal
#44. Замыкания в Python
#45. Введение в декораторы функций
#46. Декораторы с параметрами. Сохранение свойств декорируемых функций
#47. Импорт стандартных модулей. Команды import и from
#48. Импорт собственных модулей
#49. Установка сторонних модулей (pip install). Пакетная установка
#50. Пакеты (package) в Python. Вложенные пакеты
#51. Функция open. Чтение данных из файла
#52. Исключение FileNotFoundError и менеджер контекста (with) для файлов
#53. Запись данных в файл в текстовом и бинарном режимах
#54. Выражения генераторы
Выражения генераторы
#55. Функция-генератор. Оператор yield
#56. Функция map. Примеры ее использования
#57. Функция filter для отбора значений итерируемых объектов
#58. Функция zip. Примеры использования
#59. Сортировка с помощью метода sort и функции sorted
#60. Аргумент key для сортировки коллекций по ключу
#61. Функции isinstance и type для проверки типов данных
#62. Функции all и any. Примеры их использования
#63. Расширенное представление чисел. Системы счисления
#64. Битовые операции И, ИЛИ, НЕ, XOR. Сдвиговые операторы
#65. Модуль random стандартной библиотеки
Как прочитать текстовый файл в Python
В Python есть несколько способов прочитать текстовый файл. В этой статье мы рассмотрим функцию open(), методы read(), readline(), readlines(), close() и ключевое слово with.
Как открыть текстовый файл в Python с помощью open()
Если вы хотите прочитать текстовый файл с помощью Python, вам сначала нужно его открыть.
Вот так выглядит основной синтаксис функции open():
open("name of file you want opened", "optional mode")Имена файлов и правильные пути
Если текстовый файл, который нужно открыть, и ваш текущий файл находятся в одной директории (папке), можно просто указать имя файла внутри функции open(). Например:
open ("demo.txt")На скрине видно, как выглядят файлы, находящиеся в одном каталоге:
Но если ваш текстовый файл находится в другом каталоге, вам необходимо указать путь к нему.
В этом примере файл со случайным текстом находится в папке, отличной от той, где находится файл с кодом main.py:
В таком случае, чтобы получить доступ к этому файлу в main.py, вы должны включить имя папки с именем файла.
open("text-files/random-text.txt")
Если путь к файлу будет указан неправильно, вы получите сообщение об ошибке FileNotFoundError.
Таким образом, чтобы указать путь к файлу правильно, важно отслеживать, в каком каталоге вы находитесь.
Необязательный параметр режима в open()
При работе с файлами существуют разные режимы. Режим по умолчанию – это режим чтения.
Он обозначается буквой r.
open("demo.txt", mode="r")Вы также можете опустить mode= и просто написать «r».
open("demo.txt", "r")Существуют и другие типы режимов, такие как «w» для записи или «a» для добавления. Мы не будем вдаваться в подробности о других режимах, потому что в этой статье сосредоточимся исключительно на чтении файлов.
Полный список других режимов можно найти в документации.
Дополнительные параметры для функции open() в Python
Функция open() может также принимать следующие необязательные параметры:
- buffering
- encoding
- errors
- newline
- closefd
- opener
Если вы хотите узнать больше об этих опциональных параметрах, можно заглянуть в документацию.
Английский для программистов
Наш телеграм канал с тестами по английскому языку для программистов. Английский это часть карьеры программиста. Поэтому полезно заняться им уже сейчас
Английский это часть карьеры программиста. Поэтому полезно заняться им уже сейчас
Подробнее
×
Метод readable(): проверка доступности файла для чтения
Если вы хотите проверить, можно ли прочитать файл, используйте метод readable(). Он возвращает True или False.
Следующий пример вернет True, потому что мы находимся в режиме чтения:
file = open("demo.txt")
print(file.readable())Если бы мы изменили этот пример на режим «w» (для записи), тогда метод readable() вернул бы False:
file = open("demo. txt", "w")
print(file.readable()) txt", "w")
print(file.readable())
txt", "w")
print(file.readable())Что такое метод read() в Python?
Метод read() будет считывать все содержимое файла как одну строку. Это хороший метод, если в вашем текстовом файле мало содержимого .
В этом примере давайте используем метод read() для вывода на экран списка имен из файла demo.txt:
file = open("demo.txt")
print(file.read())Запустим этот код и получим следующий вывод:
# Output: # This is a list of names: # Jessica # James # Nick # Sara
Этот метод может принимать необязательный параметр, называемый размером. Вместо чтения всего файла будет прочитана только его часть.
Если мы изменим предыдущий пример, мы сможем вывести только первое слово, добавив число 4 в качестве аргумента для read().
file = open("demo.txt")
print(file.read(4))
# Output:
# ThisЕсли аргумент размера опущен или число отрицательное, то будет прочитан весь файл.
Что такое метод close() в Python?
Когда вы закончили читать файл, необходимо его закрыть. Если вы забудете это сделать, это может вызвать проблемы и дальнейшие ошибки.
Вот пример того, как закрыть файл demo.txt:
file = open("demo.txt")
print(file.read())
file.close()Как использовать ключевое слово with в Python
Один из способов убедиться, что ваш файл закрыт, – использовать ключевое слово with. Это считается хорошей практикой, потому что файл закрывается не вручную, а автоматически. Более того, это просто крайне удобно и защищает вас от ошибок, которые могут возникнуть, если вы случайно забудете закрыть файл.
Это считается хорошей практикой, потому что файл закрывается не вручную, а автоматически. Более того, это просто крайне удобно и защищает вас от ошибок, которые могут возникнуть, если вы случайно забудете закрыть файл.
Давайте попробуем переписать наш пример, используя ключевое слово with:
with open("demo.txt") as file:
print(file.read())Что такое метод readline() в Python?
Этот метод читает одну строку из файла и возвращает ее.
В следующем примере у нас есть текстовый файл с двумя предложениями:
This is the first line This is the second line
Если мы воспользуемся методом readline(), он выведет нам только первое предложение нашего файла.
with open("demo.txt") as file:
print(file.readline())
# Output:
# This is the first lineЭтот метод также принимает необязательный параметр размера. Мы можем изменить наш пример, добавив число 7. В таком случае программа считает и выведет нам только фразу This is:
with open("demo.txt") as file:
print(file.readline(7))Что такое метод readlines() в Python?
Этот метод читает и возвращает список всех строк в файле.
Предположим, у нас есть текстовый файл demo.txt со списком покупок:
Grosery Store List: Chicken Mango Rice Chocolate Cake
В следующем примере давайте выведем наши продукты в виде списка с помощью метода readlines().
with open("demo.txt") as file:
print(file.readlines())
# Output:
# ['Grocery Store List:\n', 'Chicken\n', 'Mangos\n', 'Rice\n', 'Chocolate Cake\n']Как прочитать текстовый файл при помощи цикла for
В качестве альтернативы методам чтения можно использовать цикл for.
Давайте распечатаем все элементы файла demo.txt, перебирая объект в цикле for.
with open("demo.txt") as file:
for item in file:
print(item)Запустим наш код и получим следующий результат:
# Output: # Grocery Store List: # Chicken # Mango # Rice # Chocolate Cake
Заключение
Итак, если вы хотите прочитать текстовый файл в Python, вам сначала нужно его открыть.
open("name of file you want opened", "optional mode")Если текстовый файл и ваш текущий файл, где вы пишете код, находятся в одной директории, можно просто указать имя файла в функции open().
Если ваш текстовый файл находится в другом каталоге, вам необходимо указать правильный путь к нему.
Функция open() принимает необязательный параметр режима. Режим по умолчанию – чтение («r»).
Чтобы проверить, можно ли прочитать текстовый файл, вы можете использовать метод readable(). Он возвращает True, если файл можно прочитать, или False в противном случае.
Метод read() будет читать все содержимое файла как одну строку.
Также, когда вы закончите читать файл, не забудьте закрыть его. Один из способов убедиться, что ваш файл закрыт, – использовать ключевое слово
Один из способов убедиться, что ваш файл закрыт, – использовать ключевое слово with. Оно закрывает файл автоматически и вам не нужно беспокоиться об этом.
Метод readline() будет считывать только одну строку из файла и возвращать ее.
Метод readlines() прочитает и вернет все строки в файле в виде списка.
Также для чтения содержимого файлов можно использовать цикл for.
Надеемся, вам понравилась эта статья. Желаем удачи в вашем путешествии по миру Python!
Перевод статьи «Python Open File – How to Read a Text File Line by Line».
Как проверить, открыт или закрыт файл в Python
Файл используется для постоянного хранения данных. Работа с файлом — очень распространенная задача любого языка программирования. В Python существует множество встроенных функций для создания, открытия, чтения, записи и закрытия файла. Для хранения данных можно создать два типа файлов. Это текстовые файлы и двоичные файлы. Любой файл необходимо открыть перед чтением или записью. Функция open() используется в Python для открытия файла. Использование функции open() — это один из способов проверить, открыт или закрыт конкретный файл. Если функция open() открывает ранее открытый файл, генерируется ошибка IOError. Другой способ проверить, открыт или закрыт файл — это проверить значения свойства closed объекта обработчика файлов. С использованием функции rename() — еще один способ проверить, открыт или закрыт файл. В этой статье показаны различные способы проверки открытия или закрытия любого файла в Python.
Любой файл необходимо открыть перед чтением или записью. Функция open() используется в Python для открытия файла. Использование функции open() — это один из способов проверить, открыт или закрыт конкретный файл. Если функция open() открывает ранее открытый файл, генерируется ошибка IOError. Другой способ проверить, открыт или закрыт файл — это проверить значения свойства closed объекта обработчика файлов. С использованием функции rename() — еще один способ проверить, открыт или закрыт файл. В этой статье показаны различные способы проверки открытия или закрытия любого файла в Python.
Создайте файл для проверки:
Вы можете использовать любой существующий файл или создать новый файл, чтобы протестировать пример кода, показанный в этой статьи. Был создан новый текстовый файл с именем clients.txt со следующим содержимым для использования в следующей части статьи.
ID Name Email 01 Andrey Ex Andrey***@gmail.
 com
02 Max Terminator Max***@gmail.com
03 Alex Murphy Alex***@gmail.com
com
02 Max Terminator Max***@gmail.com
03 Alex Murphy Alex***@gmail.com
Пример-1: проверьте, открыт файл или нет, с помощью IOError
IOError генерируется при вызове функции open() для открытия файла, который был открыт ранее. Создайте файл python со следующим сценарием, чтобы проверить, открыт ли файл или нет, с помощью блока try-except. Здесь любое существующее имя файла будет принято в качестве входных и открыто для чтения. Затем снова вызывается функция open(), чтобы открыть тот же файл, который вызовет ошибку IOError и распечатает сообщение об ошибке.
# Введите имя файла для проверки
filename = input("Введите любое существующее имя файла:\n")
# Откройте файл в первый раз с помощью функции open()
fileHandler = open(filename, "r")
# Попробуйте открыть файл с таким же именем снова
try:
with open("filename", "r") as file:
# Распечатать сообщение об успешном завершении
print("Файл открыт для чтения. ")
# Вызовите ошибку, если файл был открыт раньше
except IOError:
print("Файл уже открыт") ")
# Вызовите ошибку, если файл был открыт раньше
except IOError:
print("Файл уже открыт")
")
# Вызовите ошибку, если файл был открыт раньше
except IOError:
print("Файл уже открыт")Вывод:
Здесь в текущем расположении существует файл clients.txt, а сообщение об ошибке «Файл уже открыт» было напечатано для исключения IOError.
Пример-2: проверьте, закрыт ли файл, используя свойство closed.
Значение свойства closed будет истинным, если какой-либо файл закрыт. Создайте файл python с помощью следующего сценария, чтобы проверить, закрыт ли файл в текущем местоположении. Предыдущий пример сценария выдаст ошибку, если имя файла, полученное от пользователя, не существует в текущем местоположении. В этом примере эта проблема решена. Модуль os используется здесь для проверки существования имени файла, которое будет взято у пользователя. Функция check_closed() определена для проверки того, закрыт ли файл или нет, которая будет вызываться, если файл существует.
# Импортировать модуль os для проверки существования файла import os # Функция Drfine проверяет, закрыт ли файл или нет def check_closed(): if fileHandler.
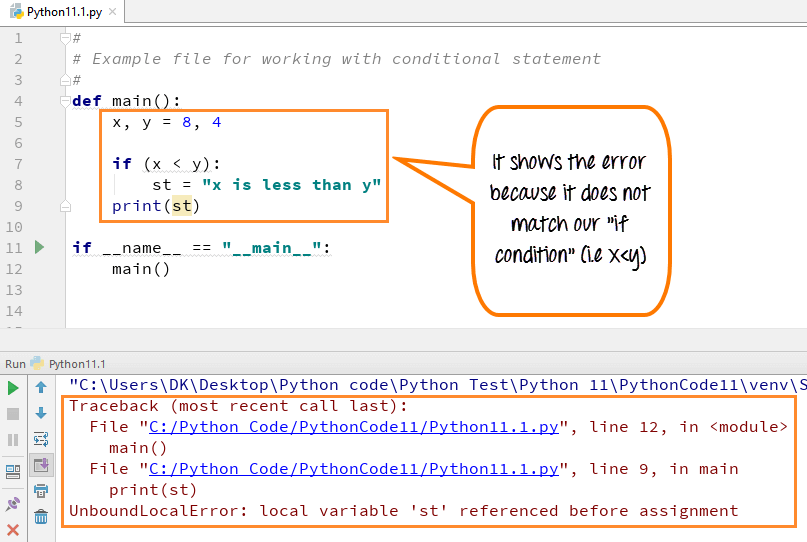 closed == False:
# Распечатать сообщение об успешном завершении
print("Файл открыт для чтения.")
else:
# Распечатать сообщение об ошибке
print(" Файл закрыт.")
# Взять имя файла для проверки
filename = input(" Введите любое существующее имя файла: \ n ")
# Проверить, существует
if os.path.exists(filename):
# Открыть файл для чтения
fileHandler = open(filename, "r")
# Вызвать функцию
check_closed()
else:
# Вывести сообщение, если файл не существует
print("Файл не существует.")
closed == False:
# Распечатать сообщение об успешном завершении
print("Файл открыт для чтения.")
else:
# Распечатать сообщение об ошибке
print(" Файл закрыт.")
# Взять имя файла для проверки
filename = input(" Введите любое существующее имя файла: \ n ")
# Проверить, существует
if os.path.exists(filename):
# Открыть файл для чтения
fileHandler = open(filename, "r")
# Вызвать функцию
check_closed()
else:
# Вывести сообщение, если файл не существует
print("Файл не существует.")Вывод:
Здесь client.txt существует в текущем месте, и сообщение об успешном завершении «Файл открыт для чтения» напечатано, поскольку значение свойства closed вернуло False.
Пример-3: проверьте, открыт файл или нет, с помощью OSError
OSError генерирует , когда функция переименования() вызывается более чем один раз для файла , который открыт уже. Создайте файл Python со следующим сценарием, чтобы проверить, открыт или закрыт файл с помощью OSError. Модуль os использовался в сценарии для проверки существования файла и его переименования. Когда функция rename() вызывается во второй раз, будет сгенерирована ошибка OSError, и будет напечатано настраиваемое сообщение об ошибке.
Модуль os использовался в сценарии для проверки существования файла и его переименования. Когда функция rename() вызывается во второй раз, будет сгенерирована ошибка OSError, и будет напечатано настраиваемое сообщение об ошибке.
# Импортировать модуль os для проверки существования файла
import os
# Установить существующее имя файла
filename = 'clients.txt'
# Установить новое имя файла
newname = 'customers.txt'
# Проверить, существует ли файл или нет,
if os.path.exists(filename):
try:
# Вызов функции переименования в первый раз
os.rename(filename, newname)
# Вызов функции переименования во второй раз
os.rename(filename, newname)
# Вызов исключения при ошибки, если если файл открыт
except OSError:
print («Файл все еще открыт».)
else:
# Вывести сообщение, если файл не существует
print("Файл не существует.")Вывод:
Здесь clients.txt существует в текущем местоположении, и сообщение об ошибке, “File is still opened,” напечатал , потому что OSError исключение генерируется , когда вторая функция rename() выполнена.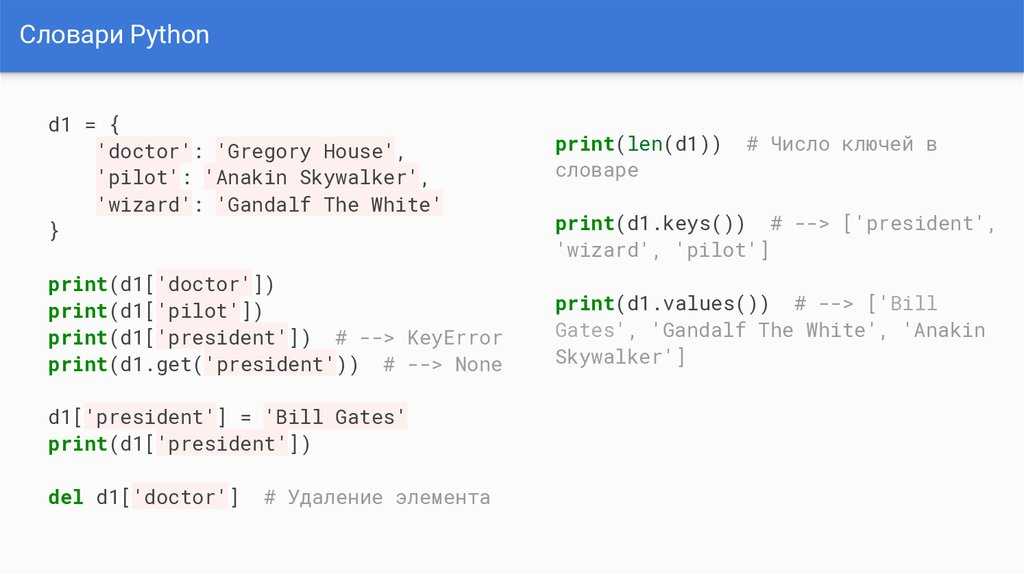
Вывод:
Когда нам нужно работать с одним и тем же файлом в сценарии несколько раз, важно знать, открыт ли файл или закрыт. Лучше вызвать функцию close(), чтобы закрыть файл после завершения операции с файлом. Ошибка возникает, когда файл открывается во второй раз в том же скрипте, не закрывая его. В этой статье на простых примерах показаны различные решения этой проблемы, которые помогут пользователям Python.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Как открыть и закрыть файл в Python
Может возникнуть ситуация, когда нужно взаимодействовать с внешними файлами с помощью Python. Python предоставляет встроенные функции для создания, записи и чтения файлов. В этой статье мы обсудим, как открыть внешний файл и закрыть его с помощью Python.
Открытие файла в Python Существует два типа файлов, которые можно обрабатывать в Python: обычные текстовые файлы и двоичные файлы (написанные на двоичном языке, 0 и 1).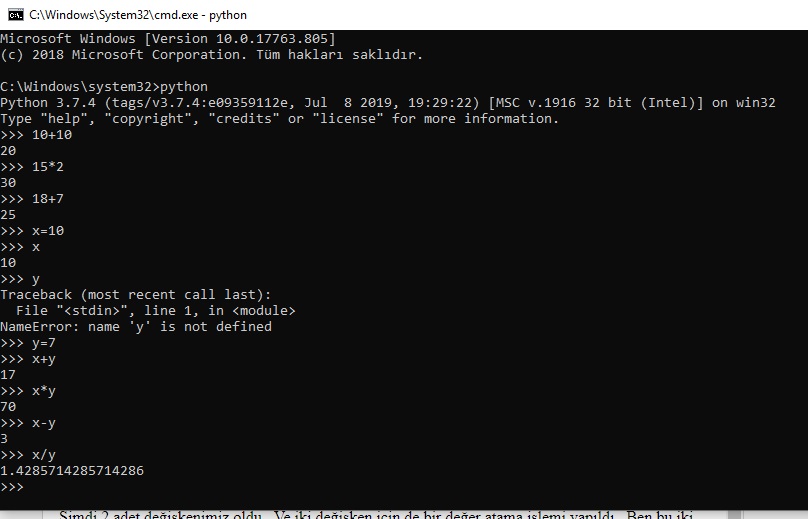 Открытие файла относится к подготовке файла либо к чтению, либо к записи. Это можно сделать с помощью функция open() . Эта функция возвращает файловый объект и принимает два аргумента, один из которых принимает имя файла, а другой принимает режим (режим доступа).
Открытие файла относится к подготовке файла либо к чтению, либо к записи. Это можно сделать с помощью функция open() . Эта функция возвращает файловый объект и принимает два аргумента, один из которых принимает имя файла, а другой принимает режим (режим доступа).
Примечание: Файл должен находиться в том же каталоге, что и скрипт Python, в противном случае необходимо записать полный адрес файла.
Синтаксис: File_object = open(«File_Name», «Access_Mode»)
Параметры:
- File_Name: Это имя файла, который необходимо открыть.
- Access_Mode: Режимы доступа определяют тип операций, возможных в открытом файле. В таблице ниже приведены список всего режима доступа, доступного в Python
| Операция | Синтаксис | Описание |
|---|---|---|
| только чтение | R | |
| Чтение и запись | r+ | Открыть файл для чтения и записи. |
| Только запись | w | Открыть файл для записи. |
| Запись и чтение | w+ | Открыть файл для чтения и записи. В отличие от «r+», это не вызывает ошибку ввода-вывода, если файл не существует. |
| Добавить только | a | Открыть файл для записи и создать новый файл, если он не существует. Все дополнения делаются в конце файла, и никакие существующие данные не могут быть изменены. |
| Добавить и прочитать | a+ | Открыть файл для чтения и записи и создать новый файл, если он не существует. Все дополнения делаются в конце файла, и никакие существующие данные не могут быть изменены. |

В этом примере мы будем открывать файл только для чтения. Исходный файл выглядит следующим образом:
Код:
Python3
|
 txt"
txt" Здесь мы открыли файл и распечатали его содержимое.
Вывод:
Привет, Компьютерщик! Это образец текстового файла для примера.Пример 2: Открытие и запись в файл с помощью Python
В этом примере мы будем добавлять новое содержимое к существующему файлу. So the initial file looks like the below:
Code:
Python3
|
 write(
write( Теперь, если вы откроете файл, вы увидите приведенный ниже результат,
Выход:
Пример 3: Открыть и перевернуть файл Pythonв этом примере 3: . , мы перезапишем содержимое файла примера следующим кодом:
Код:
Python3
|
Приведенный выше код приводит к следующему результату:
Вывод:
Пример 4.
 Создание файла, если он не существует в Python
Создание файла, если он не существует в PythonМетод path.touch() модуля pathlib создает файл в путь, указанный в пути path.touch().
Python3
| 1
 Хотя Python автоматически закрывает файл, если ссылочный объект файла выделяется для другого файла, стандартная практика — закрытие открытого файла, поскольку закрытый файл снижает риск необоснованного изменения или чтения.
Хотя Python автоматически закрывает файл, если ссылочный объект файла выделяется для другого файла, стандартная практика — закрытие открытого файла, поскольку закрытый файл снижает риск необоснованного изменения или чтения. |
 close ()
close () Теперь, когда мы пробуем все, что вы найдете в Amport Wis Pile On Pilece We Al Amport Wis Pile On Pail On Pilece We At Arame Pile On Pail. возникает ошибка ValueError:
Python3
|
Вывод:
ValueError: Операция ввода/вывода в закрытом файле.
Почему важно закрывать файлы в Python? – Real Python
В какой-то момент вашего пути к программированию на Python вы узнаете, что для открытия файлов следует использовать контекстный менеджер . Контекстные менеджеры Python упрощают закрытие ваших файлов после того, как вы закончите с ними:
Контекстные менеджеры Python упрощают закрытие ваших файлов после того, как вы закончите с ними:
с помощью open("hello.txt", mode="w") в качестве файла:
file.write("Привет, мир!")
Оператор с оператором инициирует диспетчер контекста. В этом примере диспетчер контекста открывает файл hello.txt и управляет файловым ресурсом, пока контекст активен. В общем, весь код в блоке с отступом зависит от того, какой файловый объект открыт. Как только блок с отступом заканчивается или вызывает исключение, файл закрывается.
Если вы не используете диспетчер контекста или работаете на другом языке, вы можете явно закрыть файлы с помощью попытка … наконец подход:
попытка:
файл = открыть ("hello.txt", режим = "w")
file.write("Привет, мир!")
в конце концов:
файл.закрыть()
Блок finally , который закрывает файл, выполняется безоговорочно, независимо от того, успешен или нет блок try .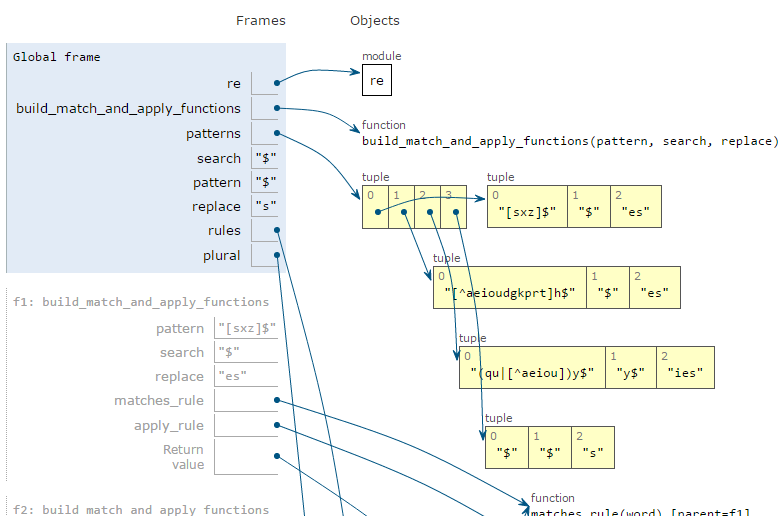 Хотя этот синтаксис эффективно закрывает файл, менеджер контекста Python предлагает менее подробный и более интуитивно понятный синтаксис. Кроме того, это немного более гибко, чем просто обертывание вашего кода
Хотя этот синтаксис эффективно закрывает файл, менеджер контекста Python предлагает менее подробный и более интуитивно понятный синтаксис. Кроме того, это немного более гибко, чем просто обертывание вашего кода попробовать … наконец .
Вероятно, вы уже используете контекстные менеджеры для управления файлами, но задумывались ли вы когда-нибудь, почему большинство учебных пособий и четыре из пяти стоматологов рекомендуют это делать? Короче говоря, почему важно закрывать файлы в Python?
В этом уроке вы погрузитесь в этот вопрос. Во-первых, вы узнаете, что дескрипторы файлов являются ограниченным ресурсом . Затем вы поэкспериментируете с последствиями незакрытия ваших файлов.
Вкратце: файлы — это ресурсы, ограниченные операционной системой
Python делегирует файловые операции операционной системе . Операционная система является посредником между процессами , такими как Python, и всеми системными ресурсами , такими как жесткий диск, оперативная память и процессорное время.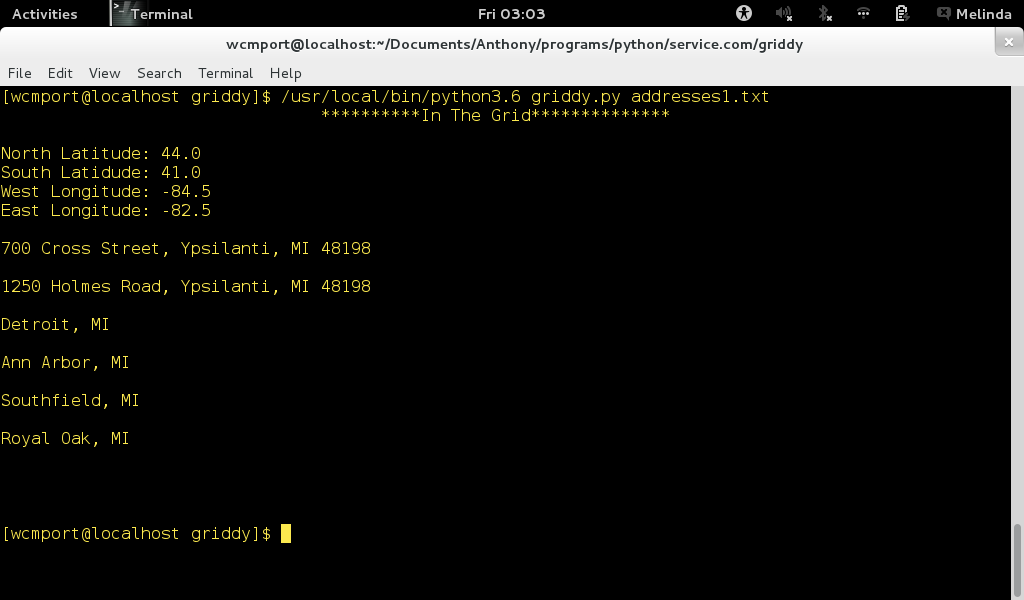
Когда вы открываете файл с помощью open() , вы выполняете системный вызов в операционную систему, чтобы найти этот файл на жестком диске и подготовить его для чтения или записи. Затем операционная система вернет целое число без знака, называемое 9.дескриптор файла 0005 в Windows и дескриптор файла в UNIX-подобных системах, включая Linux и macOS:
. Когда у вас есть число, связанное с файлом, вы готовы выполнять операции чтения или записи. Всякий раз, когда Python хочет прочитать, записать или закрыть файл, он сделает еще один системный вызов, предоставив номер дескриптора файла. Файловый объект Python имеет метод .fileno() , который можно использовать для поиска дескриптора файла:
>>>
>>> с open("test_file.txt", mode="w") в качестве файла:
... файл. fileno()
...
4
 fileno()
...
4
fileno()
...
4
Метод .fileno() для открытого файлового объекта вернет целое число, используемое операционной системой в качестве файлового дескриптора. Точно так же, как вы можете использовать поле идентификатора для получения записи из базы данных, Python предоставляет этот номер операционной системе каждый раз, когда она читает или записывает файл.
Операционные системы ограничивают количество открытых файлов, которые может иметь один процесс . Обычно это число исчисляется тысячами. Операционные системы устанавливают это ограничение, потому что, если процесс пытается открыть тысячи файловых дескрипторов, вероятно, что-то не так с процессом. Несмотря на то, что тысячи файлов могут показаться большим количеством, все же можно достичь предела.
Помимо риска превышения лимита, сохранение файлов открытыми делает вас уязвимыми к потере данных . В общем, Python и операционная система прилагают все усилия, чтобы защитить вас от потери данных. Но если ваша программа или компьютер выйдет из строя, обычные процедуры могут не выполняться, а открытые файлы могут быть повреждены.
Но если ваша программа или компьютер выйдет из строя, обычные процедуры могут не выполняться, а открытые файлы могут быть повреждены.
Примечание : Некоторые библиотеки имеют специальные методы и функции, которые, кажется, открывают файлы без менеджера контекста. Например, в библиотеке pathlib есть .write_text() , а в pandas — read_csv() .
Однако они правильно управляют ресурсами внутри, поэтому в таких случаях вам не нужно использовать контекстный менеджер. Лучше всего обратиться к документации по библиотеке, которую вы используете, чтобы узнать, нужен вам контекстный менеджер или нет.
Короче говоря, разрешение контекстным менеджерам управлять вашими файлами — это защитная техника, которую легко практиковать, и она делает ваш код лучше, так что вы тоже можете это сделать. Это как пристегиваться ремнем безопасности. Вероятно, вам это не понадобится, но затраты на то, чтобы обойтись без него, могут быть высокими.
В оставшейся части этого руководства вы более глубоко познакомитесь с ограничениями, последствиями и опасностями незакрытия файлов. В следующем разделе вы изучите ошибку Слишком много открытых файлов .
Удалить рекламу
Что происходит, когда вы открываете слишком много файлов?
В этом разделе вы узнаете, что происходит, когда вы достигаете предела файлов. Вы сделаете это, попробовав фрагмент кода, который создаст множество открытых файлов и спровоцирует Ошибка ОС .
Примечание : как предполагает OS в OSError , ограничение применяется операционной системой, а не Python. Однако теоретически операционная система может работать с гораздо большим количеством файловых дескрипторов. Позже вы узнаете больше о том, почему операционная система ограничивает дескрипторы файлов.
Вы можете проверить лимит файлов на процесс в вашей операционной системе, попытавшись одновременно открыть тысячи файлов. Вы сохраните файловые объекты в списке, чтобы они не очищались автоматически. Но сначала вам нужно сделать некоторую уборку, чтобы убедиться, что вы не создаете много файлов там, где они вам не нужны:
Вы сохраните файловые объекты в списке, чтобы они не очищались автоматически. Но сначала вам нужно сделать некоторую уборку, чтобы убедиться, что вы не создаете много файлов там, где они вам не нужны:
$ mkdir file_experiment $ cd file_experiment
Достаточно создать папку, в которую можно сбросить файлы, а затем перейти в эту папку. Затем вы можете открыть Python REPL и попытаться создать тысячи файлов:
>>>
>>> files = [open(f"file-{n}.txt", mode="w") для n в диапазоне (10_000)]
Traceback (последний последний вызов):
...
OSError: [Errno 24] Слишком много открытых файлов: «file-1021.txt»
Этот фрагмент пытается открыть десять тысяч файлов и сохранить их в списке. Операционная система начинает создавать файлы, но отбрасывает их, как только достигает своего предела. Если вы перечислите файлы во вновь созданном каталоге, вы заметите, что даже несмотря на то, что понимание списка в конечном итоге дало сбой, операционная система создала многие из файлов — но не те десять тысяч, которые вы просили.
Ограничение, с которым вы столкнетесь, зависит от операционной системы и кажется больше по умолчанию в Windows. В зависимости от операционной системы существуют способы увеличить это ограничение файлов на процесс. Тем не менее, вы должны спросить себя, действительно ли вам это нужно. Есть только несколько законных вариантов использования для выбора этого решения.
Один допустимый сценарий для серверов. Серверы работают с сокетами, которые во многом похожи на файлы. Операционная система отслеживает сокеты в таблице файлов, используя дескрипторы файлов. Серверу может потребоваться открыть много сокетов для каждого клиента, к которому они подключаются. Кроме того, сервер может обмениваться данными с несколькими клиентами. Эта ситуация может привести к тому, что потребуются многие тысячи файловых дескрипторов.
Как ни странно, несмотря на то, что некоторые приложения могут требовать увеличения лимита операционной системы для открытых файлов, обычно именно эти приложения должны быть особенно внимательны при закрытии файлов!
Возможно, вы думаете, что вам не грозит непосредственная опасность достижения предела.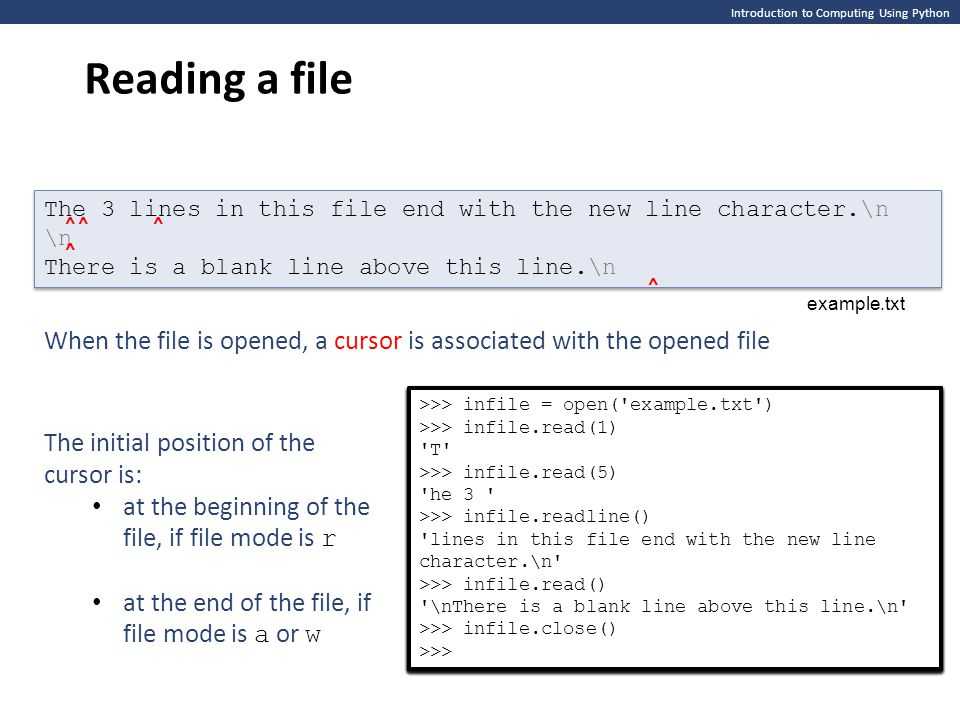 Тем не менее, читайте дальше, потому что в следующем разделе вы более подробно рассмотрите некоторые последствия случайного превышения этого предела.
Тем не менее, читайте дальше, потому что в следующем разделе вы более подробно рассмотрите некоторые последствия случайного превышения этого предела.
Каковы реальные последствия превышения лимита файлов?
Если вы открываете файлы и никогда не закрываете их в Python, вы можете не заметить никакой разницы, особенно если вы работаете над однофайловыми сценариями или небольшими проектами. Однако по мере того, как проекты, над которыми вы работаете, усложняются, вы будете все чаще сталкиваться с проблемными ситуациями.
Представьте, что вы работаете в большой команде над огромной кодовой базой. Затем в один прекрасный день вы достигнете предела для открытых файлов. Фишка в том, что сообщение об ошибке для лимита не скажет вам , где проблема. Это будет универсальный OSError , которую вы видели ранее, которая сообщает вам только Слишком много открытых файлов .
В вашей кодовой базе могут быть тысячи мест, где вы открываете файлы. Представьте себе поиск мест, где код неправильно обрабатывает файлы. Представьте, что код передает файловые объекты между функциями, и вы не можете сразу сказать, закрыт какой-либо данный файловый объект в конечном итоге или нет. Это не веселое время.
Представьте себе поиск мест, где код неправильно обрабатывает файлы. Представьте, что код передает файловые объекты между функциями, и вы не можете сразу сказать, закрыт какой-либо данный файловый объект в конечном итоге или нет. Это не веселое время.
Если вам интересно, есть способы изучить дескрипторы открытых файлов вашей системы. Разверните следующий блок для изучения:
- Окна
- Linux + macOS
Установка процесса хакера:
PS> выборочная установка процесса хакера
Откройте приложение и нажмите кнопку Найти дескрипторы или библиотеки DLL . Установите флажок regex и введите .* , чтобы увидеть все дескрипторы файлов с сопутствующей информацией.
Официальная версия Microsoft process hacker является частью утилит Sysinternals, а именно Process Monitor и Process Explorer.
Возможно, вам потребуется установить lsof , утилиту Linux для l i s t o pen f файлов. С помощью этой утилиты можно получить информацию и подсчитать количество открытых файлов:
$ lsof | глава $ лсоф | туалет -л
Команда lsof печатает новую строку для каждого открытого файла с основной информацией об этом файле. Введя его в команду head , вы увидите начало вывода, включая имена столбцов.
Вывод lsof может быть передан в команду wc или подсчет слов. Переключатель -l означает, что будут учитываться только новые строки. Вероятно, это число будет исчисляться сотнями тысяч.
Вы можете направить вывод lsof в grep , чтобы найти строки, содержащие строку типа python . Вы также можете передать идентификатор процесса, который может быть полезен, если вы хотите найти файловые дескрипторы:
$ lsof | питон
Эта команда отфильтрует все строки, которые не содержат термин после grep , в данном случае python .
Если вас интересует теоретический предел для файлов в вашей системе, вы можете изучить его в системах на базе UNIX, изучив содержимое специального файла:
$ cat /proc/sys/fs/file-max
Число сильно зависит от платформы, но, скорее всего, оно велико. Система почти наверняка исчерпает другие ресурсы, прежде чем достигнет этого предела.
Вы можете задаться вопросом почему операционная система ограничивает файлы. Предположительно, он может обрабатывать гораздо больше файловых дескрипторов, чем показывает, верно? В следующем разделе вы узнаете, почему операционная система заботится об этом.
Почему операционная система ограничивает число дескрипторов файлов?
Фактические пределы количества файлов, которые операционная система может держать открытыми одновременно, огромны. Вы говорите о миллионах файлов. Но на самом деле достижение этого предела и присвоение ему фиксированного числа не является четким. Как правило, система исчерпает другие ресурсы раньше, чем закончатся дескрипторы файлов.
Ограничение является консервативным с точки зрения операционной системы, но достаточным с точки зрения большинства программ. С точки зрения операционной системы, любой процесс, который достигает предела, вероятно, приводит к утечке файловых дескрипторов вместе с другими ресурсами.
Утечка ресурсов может быть вызвана плохой практикой программирования или попыткой вредоносной программы атаковать систему. Вот почему операционная система накладывает ограничения — чтобы уберечь вас от других и от самого себя!
Плюс, для большинства приложений нет смысла открывать столько файлов. На одном жестком диске одновременно может выполняться не более одной операции чтения или записи, поэтому если вы работаете только с файлами, процесс не ускорится.
Итак, вы знаете, что открывать много файлов проблематично, но есть и другие недостатки, связанные с тем, что вы не закрываете файлы в Python, даже если вы открываете только несколько.
Удалить рекламу
Что произойдет, если вы не закроете файл и произойдет сбой Python?
В этом разделе вы поэкспериментируете с моделированием сбоя и увидите, как это влияет на открытые файлы. Вы можете использовать специальную функцию в модуле
Вы можете использовать специальную функцию в модуле os , которая завершится без выполнения какой-либо очистки, которую обычно делает Python, но сначала вы увидите, как обычно происходит очистка.
Выполнение операций записи для каждой команды может быть дорогостоящим. По этой причине по умолчанию Python использует буфер, который собирает операции записи. Когда буфер заполняется или когда файл явно закрывается, буфер сбрасывается, и операция записи завершается.
Python усердно работает, чтобы убрать за собой. В большинстве случаев он сам проактивно очищает и закрывает файлы:
# write_hello.py
файл = открыть ("hello.txt", режим = "w")
file.write("Привет, мир!")
При выполнении этого кода операционная система создает файл. Операционная система также записывает содержимое, даже если вы никогда не очищаете и не закрываете файл в коде. Об этой очистке и закрытии заботится подпрограмма очистки, которую Python выполнит в конце выполнения.
Однако иногда выходы не так контролируются, и сбой может привести к обходу этой очистки:
# сбой_hello.
 py
импорт ОС
файл = открыть ("crash.txt", режим = "w")
file.write("Привет, мир!")
os._exit(1)
py
импорт ОС
файл = открыть ("crash.txt", режим = "w")
file.write("Привет, мир!")
os._exit(1)
После запуска фрагмента выше вы можете использовать cat для проверки содержимого только что созданного файла:
$ кошка краш.txt $ # Нет вывода!
Вы увидите, что несмотря на то, что операционная система создала файл, в нем нет содержимого. Отсутствие выхода, потому что os._exit() обходит обычную процедуру выхода Python, имитируя сбой. Тем не менее, даже этот тип симуляции относительно контролируем, поскольку предполагает, что произошел сбой Python, а не вашей операционной системы.
За кулисами, как только Python завершится, операционная система также выполнит собственную очистку, закрыв все файловые дескрипторы, открытые процессом. Сбои могут возникать на многих уровнях и мешать очистке операционной системы, оставляя дескрипторы файлов «висящими».
В Windows, например, висячие дескрипторы файлов могут быть проблематичными, поскольку любой процесс, который открывает файл, также блокирует его. Другой процесс не может открыть этот файл, пока он не будет закрыт. Пользователи Windows могут быть знакомы с мошенническими процессами, которые не позволяют вам открывать или удалять файлы.
Другой процесс не может открыть этот файл, пока он не будет закрыт. Пользователи Windows могут быть знакомы с мошенническими процессами, которые не позволяют вам открывать или удалять файлы.
Что может быть хуже блокировки файлов? Утечка файловых дескрипторов может представлять угрозу безопасности, поскольку разрешения, связанные с файлами, иногда смешиваются.
Примечание : Наиболее распространенная реализация Python, CPython, идет дальше в очистке дескрипторов оборванных файлов, чем вы думаете. Он использует подсчет ссылок для сборки мусора, поэтому файлы закрываются, когда на них больше не ссылаются. Тем не менее, другие реализации, такие как PyPy, используют другие стратегии, которые могут быть не такими агрессивными при очистке неиспользуемых файловых дескрипторов.
Тот факт, что некоторые реализации могут выполнять очистку не так эффективно, как CPython, является еще одним аргументом в пользу постоянного использования менеджера контекста!
Утечка файловых дескрипторов и потеря содержимого в буфере — это уже достаточно плохо, но сбой, прерывающий операцию с файлом, также может привести к повреждению файла.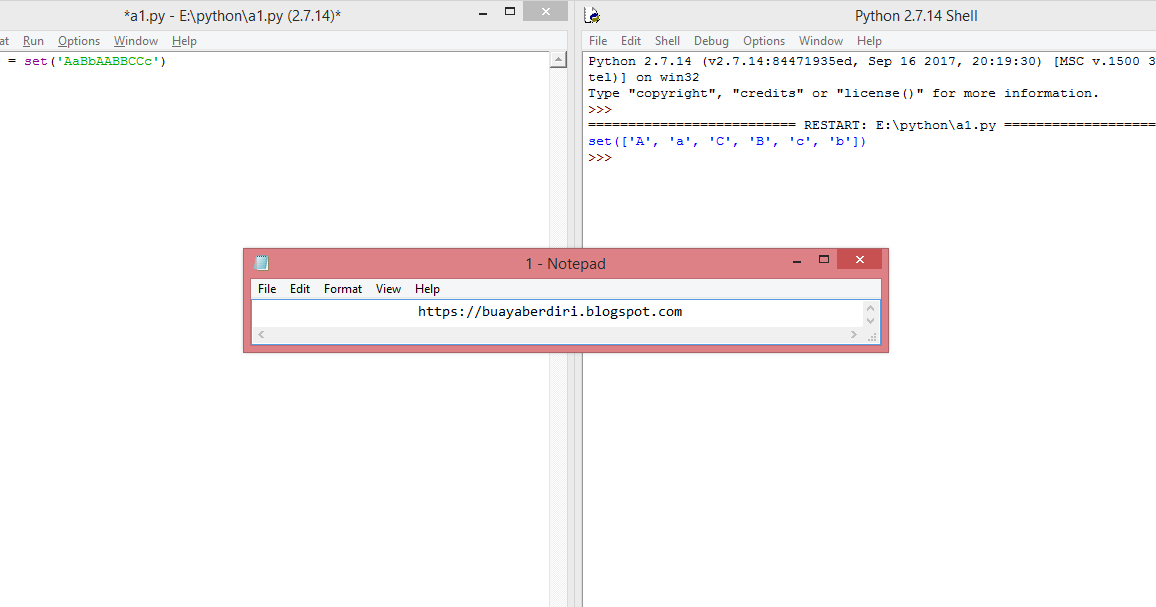 Это значительно увеличивает вероятность потери данных. Опять же, это маловероятные сценарии, но они могут быть дорогостоящими.
Это значительно увеличивает вероятность потери данных. Опять же, это маловероятные сценарии, но они могут быть дорогостоящими.
Вы никогда не сможете полностью оградить себя от сбоя, но вы можете уменьшить воздействие, используя контекстный менеджер. Синтаксис менеджера контекста, естественно, приведет вас к коду, который будет держать файл открытым только до тех пор, пока он необходим.
Заключение
Вы узнали почему важно закрывать файлы в Python . Поскольку файлы — это ограниченные ресурсы, которыми управляет операционная система, убедитесь, что файлы закрыты после использования, чтобы защитить от трудно отлаживаемых проблем, таких как исчерпание файловых дескрипторов или повреждение данных. Лучшая защита — всегда открывать файлы с помощью контекстного менеджера.
Копаясь глубже, вы видели, что происходит, когда вы открываете слишком много файлов, и вы спровоцировали сбой, который приводит к пропаже содержимого файла. Дополнительные сведения об открытии файлов см. в разделе Чтение и запись файлов в Python. Подробное руководство по контекстным менеджерам см. в разделе Context Managers и Python’s 9.0120 с заявлением
в разделе Чтение и запись файлов в Python. Подробное руководство по контекстным менеджерам см. в разделе Context Managers и Python’s 9.0120 с заявлением
Python close() File — Правильное открытие и закрытие файлов — LearnDataSci
Автор: Alfie Grace
Data Scientist
Руководство
Для любого, кто работает с Python, взаимодействие с файлами будет неизбежным. Самый простой способ открытия и закрытия файлов описан ниже.
file = open('example_file.txt') # открыть файл примера
file.close() # закрыть его Одна из самых распространенных ошибок, которую люди допускают при использовании файлов в Python, заключается в том, что они не закрывают их после этого. В этом уроке мы рассмотрим некоторые проблемы, вызванные тем, что файлы остаются открытыми, и способы их предотвращения, используя общепринятые рекомендации.
Незакрытие файла после взаимодействия — это не только пустая трата ресурсов программы, но также может предотвратить другие взаимодействия с файлами и привести к несоответствиям при выполнении сценариев в разных версиях Python. Оставлять файлы открытыми также считается плохой практикой, и всегда лучше завести хорошие привычки как можно раньше.
Оставлять файлы открытыми также считается плохой практикой, и всегда лучше завести хорошие привычки как можно раньше.
Представьте, что у вас есть файл с именем file_1.txt , который хранится в том же каталоге, что и ваш скрипт Python. Этот файл содержит текст «Это текст файла 1».
Вы хотите прочитать файл в Python, отобразить текст и добавить новую строку, чтобы отметить, что вы прочитали текстовый файл. Этот процесс показан (неверно) ниже:
file = open('file_1.txt','r') # файл открыт в режиме чтения (r)
печать (файл.чтение())
file = open('file_1.txt', 'a') # файл открывается в режиме добавления (a)
file.write(' и мы его прочитали.')
file = open('file_1.txt','r') # файл открывается в режиме чтения (r)
печать (файл.чтение())
file.close() Выход:
Это текст файла 1 Это текст файла 1, и мы его прочитали.
Файл был правильно закрыт, верно? Неправильно.
В этом примере мы закрыли файл только после последнего открытия. Для некоторых версий Python используемый код может неправильно записывать добавленный текст, поскольку файл не был закрыт после завершения операции. Чтобы продемонстрировать это, посмотрите, что произойдет, если мы попытаемся закрыть каждый файл отдельно в конце в качестве решения:
f1 = open('file_1.txt','r')
печать (f1.read())
f2 = открыть('файл_1.txt', 'а')
f2.write(' и мы это прочитали.')
f3 = открыть('file_1.txt','r')
печать (f3.read())
f1.закрыть()
f2.закрыть()
f3.close() Исходящий:
Это файл 1 текст Это текст файла 1
Мы видим, что добавление к файлу f2 не отражается в f3 .
Подобное кодирование также может потенциально повредить файл, препятствуя его чтению или повторному использованию в будущем. Этот пример прост, но если бы вы писали сценарий, который добавлял дополнительную информацию к длинному файлу, заполненному ценными данными о клиентах, или данными, на изучение которых ушли месяцы, повреждение файла стало бы дорогостоящей проблемой.
Этот пример прост, но если бы вы писали сценарий, который добавлял дополнительную информацию к длинному файлу, заполненному ценными данными о клиентах, или данными, на изучение которых ушли месяцы, повреждение файла стало бы дорогостоящей проблемой.
Чтобы исправить этот пример, нам нужно убедиться, что файл закрыт после записи, прежде чем пытаться прочитать его снова:
f1 = open('file_1.txt','r')
печать (f1.read())
f1.закрыть()
f2 = открыть('файл_1.txt', 'а')
f2.write(' и мы это прочитали.')
f2.закрыть()
f3 = открыть('file_1.txt','r')
печать (f3.read())
f3.close() Out:
Это текст файла 1 Это текст файла 1, и мы его прочитали.
Более простой альтернативой ручной обработке .close() для каждого файла является использование менеджера контекста.
Чтобы закрыть свойство файлов, самое простое решение, соответствующее рекомендациям, — это использовать то, что называется оператором с оператором при каждом открытии файла. Этот шаблон также известен как использование менеджера контекста, фундаментальной концепции Python.
Этот шаблон также известен как использование менеджера контекста, фундаментальной концепции Python.
Ниже приведен пример использования оператора с оператором , чтобы убедиться, что файлы закрыты:
с open('file_1.txt','r') as f:
печать (f.read())
с open('file_1.txt', 'a') как f:
f.write(' и мы это прочитали.')
с open('file_1.txt','r') как f:
печать(f.read()) Исходящий:
Это текст файла 1, и мы его прочитали. Это текст файла 1, и мы его прочитали. и мы прочитали это.
Обновленный код обеспечивает ту же функциональность при меньшем объеме кода. Использование с оператором open() автоматически закроет файл после завершения блока.
Использование менеджера контекста не только избавит вас от необходимости помнить о закрытии файлов вручную, но также значительно облегчит другим людям, читающим ваш код, возможность точно увидеть, как программа использует файл.
Использование с open() часто является правильным выбором, но могут быть ситуации, когда ваш проект может потребовать закрытия файлов вручную.
При использовании менеджера контекста может возникнуть несколько ошибок. Одним из примеров этого является ValueError: операция ввода-вывода в закрытом файле . Рассмотрим код ниже:
с open('file_2.txt', 'a') как f:
message = 'Это текст файла 2'
f.write(сообщение) Исходящий:
----------------------------------------------------- ------------------------------------- ValueError Traceback (последний последний вызов)в <модуле> 1 с open('file_2.txt', 'w') как f: 2 сообщение = 'Это текст файла 2' ----> 3 f.write(сообщение) ValueError: операция ввода-вывода в закрытом файле.
Эта ошибка возникает из-за того, что мы использовали файловую операцию write() за пределами с областью действия open() . Поскольку диспетчер контекста автоматически закрывает файл после выполнения кода с отступом, Python не может выполнять какие-либо последующие операции с файлами. Мы можем легко решить эту проблему, сохранив все под
Поскольку диспетчер контекста автоматически закрывает файл после выполнения кода с отступом, Python не может выполнять какие-либо последующие операции с файлами. Мы можем легко решить эту проблему, сохранив все под с областью действия open() , например так:
с open('file_2.txt', 'a') как f:
message = 'Это текст файла 2'
f.write(сообщение) Новый сценарий выполняется успешно, записывая сообщение в файл перед его закрытием.
Любому, кто работает с Python, скорее всего, придется много работать с файлами. Неотъемлемой частью взаимодействия с файлами является обязательное закрытие их после завершения работы!
Если оставить файлы открытыми, это может вызвать множество проблем, особенно в больших проектах, использующих большое количество файлов.
Как мы уже говорили, простой способ избежать осложнений, которые потенциально может вызвать оставление файлов открытыми, — это открывать файлы с помощью менеджера контекста, который автоматически закрывает файлы для вас. Следование этому шаблону сэкономит вам работу, предотвратив напрасную трату ресурсов и несоответствие версий. Самое главное, используя
Следование этому шаблону сэкономит вам работу, предотвратив напрасную трату ресурсов и несоответствие версий. Самое главное, используя с операторами поможет сделать ваш код чистым и профессиональным.
Начните учиться бесплатно
Познакомьтесь с авторами
Алфи Грейс Специалист по обработке и анализу данных
Алфи получила степень магистра машиностроения в Университетском колледже Лондона. В настоящее время он работает специалистом по данным в Square Enix. Найдите его в LinkedIn.
Редактор: Брендан Мартин
Основатель LearnDataSci
Назад к оглавлению блога
Открытие и закрытие файлов в Python
Обзор
Могут быть случаи, когда при использовании языка программирования Python требуется взаимодействие с внешними файлами. В Python встроены функции создания, записи и чтения файлов, а также методы открытия и закрытия этих файлов в Python.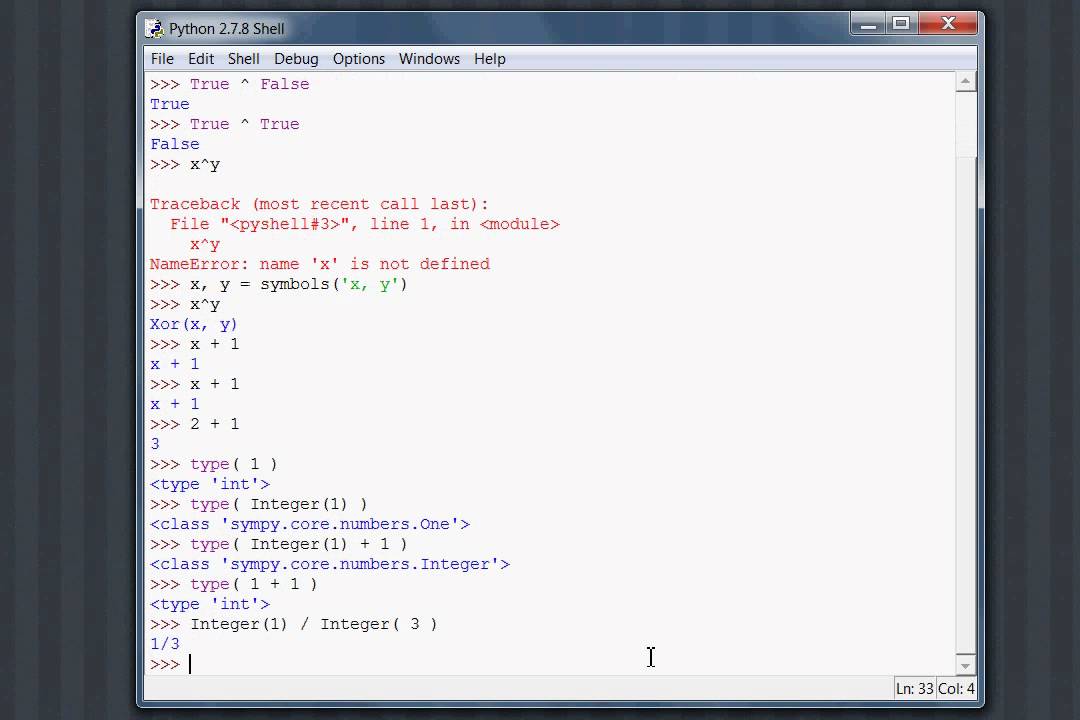
Scope
- В этой статье мы узнаем, как открывать и закрывать файлы с помощью Python.
Что такое обработка файлов в Python?
Предположим, вы работаете с файлом, сохраненным на вашем персональном компьютере. Если вы хотите выполнить какую-либо операцию с этим файлом, например, открыть его, обновить или любую другую операцию с ним, все это относится к Обработке файлов. Итак, обработка файлов в информатике означает работу с файлами, хранящимися на диске. Сюда входит создание, удаление, открытие или закрытие файлов, а также запись, чтение или изменение данных, хранящихся в этих файлах.
Что нужно для
Обработка файлов ? В информатике у нас есть программы для выполнения самых разных задач. Программе может потребоваться прочитать данные с диска и сохранить результаты на диске для будущего использования. Вот почему нам нужна обработка файлов.
Например, если вам нужно анализировать, обрабатывать и хранить данные с веб-сайта, вам сначала нужно удалить (это означает получение всех данных, отображаемых на веб-странице, таких как текст и изображения) данные и сохранить их на вашем диске, а затем загрузить эти данные и провести анализ, а затем сохранить обработанные данные на диске в файле. Делается это потому, что вычищать данные с сайта каждый раз, когда вам это нужно, нежелательно, так как это займет много времени.
Делается это потому, что вычищать данные с сайта каждый раз, когда вам это нужно, нежелательно, так как это займет много времени.
Открытие и закрытие файла в Python
При обработке файлов у нас есть два типа файлов: текстовые файлы и двоичные файлы. Мы можем открывать файлы в Python с помощью функции open
open() Function:
Эта функция принимает два аргумента. Первый — это имя файла вместе с его полным путем , а второй — режим доступа. Эта функция возвращает файловый объект.
Синтаксис:
open(имя файла, режим)
Важные моменты:
- Файл и скрипт Python должны находиться в одном каталоге. В противном случае вам необходимо указать полный путь к файлу.
- По умолчанию режим доступа — режим чтения, если вы не укажете какой-либо режим. Все режимы доступа к файлам описаны ниже.
Режим доступа указывает тип операций, возможных в открытом файле. Существуют различные режимы, в которых мы можем открыть файл. Давайте посмотрим их:
Существуют различные режимы, в которых мы можем открыть файл. Давайте посмотрим их:
| Серийный № | Режимы | Описание |
|---|---|---|
| 1. | r | 66Указатель файла находится в начале файла. Это также режим по умолчанию. |
| 2. | rb | То же, что и режим r , за исключением того, что файл открывается в двоичном режиме. |
| 3. | r+ | Открывает файл для чтения и записи. Указатель находится в начале файла. |
| 4. | rb+ | То же, что и режим r+ , за исключением того, что файл открывается в двоичном режиме. |
| 5. | w | Открывает файл для записи. Перезаписывает существующий файл, а если файла нет, то создает новый. |
| 6. | wb | То же, что и w , за исключением того, что файл открывается в двоичном формате. |
| 7. | w+ | Открывает файл как для чтения, так и для записи, остальное аналогично режиму w . |
| 8. | wb+ | То же, что и w+ , за исключением того, что файл открывается в двоичном формате. |
| 9. | a | Открывает файл для добавления. Если файл присутствует, то указатель находится в конце файла, иначе он создает новый файл для записи. |
| 10. | ab | То же, что и режим a , за исключением того, что файл открывается в двоичном формате. |
| 11. | a+ | Открывает файл для добавления и чтения. Указатель файла находится в конце файла, если файл существует, иначе он создает новый файл для чтения и записи. |
| 12. | ab+ | То же, что и режим a+ , за исключением того, что файл открывается в двоичном формате. |
Пример открытия и закрытия файлов в Python
Код:
# Когда файл находится в той же папке, где находится скрипт Python. Также режим доступа — «r», который является режимом чтения.
файл = открыть ('test.txt', режим = 'r')
# Когда файл находится не в той же папке, где находится скрипт python. В этом случае должен быть прописан весь путь к файлу.
файл = открыть('D:/data/test.txt',режим='r')
Общей практикой является закрытие открытого файла, так как закрытый файл снижает риск несанкционированного обновления или чтения. Мы можем закрыть файлы в python, используя функцию закрытия. Давайте обсудим это.
Функция close():
Эта функция не принимает никаких аргументов, и вы можете напрямую вызвать функцию close(), используя файловый объект. Его можно вызывать несколько раз, но если какая-либо операция выполняется с закрытым файлом, возникает исключение «ValueError».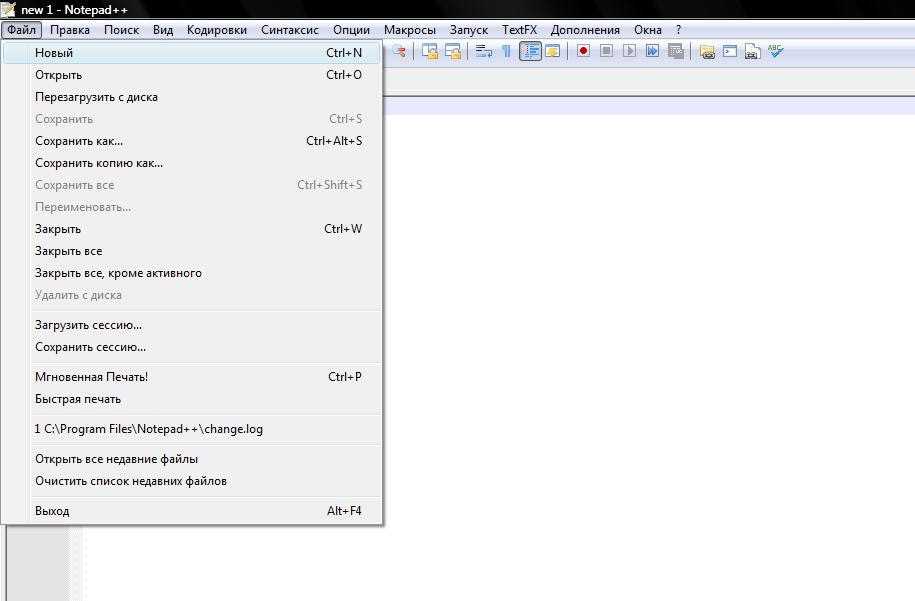
Синтаксис:
файл.**close()**
Вы также можете использовать оператор with с open, так как он обеспечивает лучшую обработку исключений и упрощает ее, предоставляя некоторые задачи очистки. Кроме того, он автоматически закроет файл, и вам не придется делать это вручную.
Пример использования с оператором
Код:
с open("test.txt", mode='r') as f:
# выполняем файловые операции
Метод, показанный в предыдущем разделе, не совсем безопасен. Если при открытии файла возникает какое-то исключение, то код завершится без закрытия файла. Более безопасный способ — использовать блок try-finally при открытии файлов.
Код:
попробуйте:
файл = открыть ('test.txt', режим = 'r')
# Выполняем операции по обработке файлов
в конце концов:
файл.закрыть()
Теперь это гарантирует, что файл будет закрыт, даже если при открытии файла возникнет исключение. Таким образом, вместо этого вы можете использовать метод оператора with. Любой из двух методов хорош.
Таким образом, вместо этого вы можете использовать метод оператора with. Любой из двух методов хорош.
Сейчас мы посмотрим примеры как открывать и закрывать файлы в питоне в различных режимах. Ниже приведен пример нескольких важных режимов для отдыха, которые вы можете попробовать сами.
Теперь мы выполним некоторые операции с файлом и распечатаем содержимое файла после каждой операции, чтобы лучше понять, как это работает. Пример приведен ниже. И файл, и скрипт Python должны находиться в одной папке.
Код:
# Открытие файла в режиме чтения и печать содержимого файла.
с open("test.txt", mode='r') как f:
data = f.readlines() # Это читает все строки из файла в списке.
print(data) # Будет напечатано содержимое файла Hello World!
# Открытие файла в режиме записи.
с open("test.txt", mode='w') как f:
f.write("Данные после операции записи")
# Открытие файла в режиме чтения для проверки содержимого.
с open("test.txt", mode='r') как f:
data = f. readlines() # это читает все строки из файла в списке.
print(data) # это напечатает перезаписанное содержимое файла "Данные после операции записи"
# Открытие файла в режиме добавления и добавление данных в файл.
с open("test.txt", "a") как f:
f.write(" Добавление новых данных в файл")
# Открытие файла в режиме чтения для проверки содержимого.
с open("test.txt", mode='r') как f:
data = f.readlines() # Это читает все строки из файла в списке.
print(data) # это напечатает существующее содержимое файла плюс добавленное содержимое
 readlines() # это читает все строки из файла в списке.
print(data) # это напечатает перезаписанное содержимое файла "Данные после операции записи"
# Открытие файла в режиме добавления и добавление данных в файл.
с open("test.txt", "a") как f:
f.write(" Добавление новых данных в файл")
# Открытие файла в режиме чтения для проверки содержимого.
с open("test.txt", mode='r') как f:
data = f.readlines() # Это читает все строки из файла в списке.
print(data) # это напечатает существующее содержимое файла плюс добавленное содержимое
readlines() # это читает все строки из файла в списке.
print(data) # это напечатает перезаписанное содержимое файла "Данные после операции записи"
# Открытие файла в режиме добавления и добавление данных в файл.
с open("test.txt", "a") как f:
f.write(" Добавление новых данных в файл")
# Открытие файла в режиме чтения для проверки содержимого.
с open("test.txt", mode='r') как f:
data = f.readlines() # Это читает все строки из файла в списке.
print(data) # это напечатает существующее содержимое файла плюс добавленное содержимое
Объяснение:
В приведенном выше примере сначала был открыт файл test.txt в режиме чтения (r) для чтения его содержимого, и данные этого файла будут распечатаны, а после этого файл был открыт с помощью write(w), чтобы он перезаписал все содержимое этого файла, и новые данные были записаны в этот файл. После того, как этот файл был открыт в режиме append(a), новые данные будут добавлены к существующим данным файла и не будут перезаписаны.
Заключение
- Создание, чтение, открытие, запись и закрытие файлов с использованием Python входит в раздел Обработка файлов
- Существуют различные методы работы с файлами, которые подробно обсуждались выше.
- При попытке записи в уже закрытый файл возникает исключение ValueError.
Это зависит. — Реувен Лернер
15
Одна из первых вещей, которую узнают программисты Python, это то, что вы можете легко прочитать содержимое открытого файла, перебирая его:
f = открыть('/etc/passwd')
для строки в f:
print(line) Обратите внимание, что приведенный выше код возможен, потому что наш файловый объект «f» является итератором. Другими словами, f знает, как вести себя внутри цикла — или любого другого контекста итерации, такого как понимание списка.
Большинство студентов на моих курсах Python приходят из других языков программирования, в которых они должны закрыть файл, когда они закончат его использовать. Поэтому меня не удивляет, когда вскоре после того, как я знакомлю их с файлами на Python, они спрашивают, как мы должны их закрывать.
Поэтому меня не удивляет, когда вскоре после того, как я знакомлю их с файлами на Python, они спрашивают, как мы должны их закрывать.
Самый простой ответ заключается в том, что мы можем явно закрыть наш файл, вызвав f.close(). Как только мы это сделали, объект продолжает существовать, но мы больше не можем читать из него, а вывод объекта на печать также будет указывать на то, что файл был закрыт:
>>> f = open('/etc/passwd ')
>>> ф
<открыть файл '/etc/passwd', режим 'r' по адресу 0x10f023270>
>>> f.read(5)
'##\n#'
е.закрыть()
>>> ф
<закрытый файл '/etc/passwd', режим 'r' по адресу 0x10f023270>
f.читать(5)
-------------------------------------------------- -------------------------
ValueError Traceback (последний последний вызов)
в ()
----> 1 f.read(5)
ValueError: операция ввода-вывода в закрытом файле Но вот в чем дело: когда я программирую на Python, я довольно редко явно вызываю метод «закрыть» для файла. Более того, велика вероятность, что вы, вероятно, не хотите или не должны этого делать.
Предпочтительный способ открытия файлов — с оператором with, как показано ниже:
с open('/etc/passwd') as f:
для строки в f:
print(line) Оператор with вызывает то, что Python называет «контекстным менеджером» для f. То есть он назначает f новым экземпляром файла, указывающим на содержимое /etc/passwd. В блоке кода, открытом с помощью «с», наш файл открыт и может быть свободно прочитан.
Однако, как только Python выходит из блока with, файл автоматически закрывается. Попытка чтения из f после того, как мы вышли из блока with, приведет к тому же исключению ValueError, которое мы видели выше. Таким образом, используя with, вы избегаете необходимости явно закрывать файлы. Python делает это за вас несколько непитоновским способом, волшебным образом, молча и за кулисами.
Но что, если вы явно не закроете файл? Что, если вы немного ленивы и не используете блок with и не вызываете f.close()? Когда файл закрывается? Когда следует ли файл закрыть?
Я спрашиваю об этом, потому что на протяжении многих лет я обучал Python многих людей и убежден, что попытки преподавать «с помощью» и/или менеджеров контекста, а также попытки преподавать многие другие темы — это больше, чем студенты могут усвоить. Хотя я затрагиваю слово «с» на своих вводных занятиях, я обычно говорю им, что на данном этапе их карьеры можно разрешить Python закрывать файлы, когда счетчик ссылок на файловый объект падает до нуля, или когда Python завершает работу.
Хотя я затрагиваю слово «с» на своих вводных занятиях, я обычно говорю им, что на данном этапе их карьеры можно разрешить Python закрывать файлы, когда счетчик ссылок на файловый объект падает до нуля, или когда Python завершает работу.
В своем бесплатном курсе по электронной почте по работе с файлами Python я придерживался аналогичного взгляда на вещи и не использовал его во всех своих предлагаемых решениях. Несколько человек бросили мне вызов, заявив, что отказ от использования «с» показывает людям, что это плохая практика, и есть риск, что данные не будут сохранены на диск.
Я получил достаточно писем на эту тему, чтобы спросить себя: когда Python закрывает файлы, если мы сами не делаем этого явно или не используем блок with? То есть, если я позволю файлу закрыться автоматически, то чего мне ожидать?
Я всегда предполагал, что Python закрывает файлы, когда счетчик ссылок на объект падает до нуля, и, таким образом, выполняется сборка мусора. Это трудно доказать или проверить, когда мы открыли файл для чтения, но это тривиально легко проверить, когда мы открываем файл для записи. Это связано с тем, что когда вы записываете в файл, содержимое не сразу сбрасывается на диск (если только вы не передадите «False» в качестве третьего, необязательного аргумента «открыть»), а сбрасывается только при закрытии файла.
Это связано с тем, что когда вы записываете в файл, содержимое не сразу сбрасывается на диск (если только вы не передадите «False» в качестве третьего, необязательного аргумента «открыть»), а сбрасывается только при закрытии файла.
Поэтому я решил провести несколько экспериментов, чтобы лучше понять, что я могу (и не могу) ожидать, что Python сделает для меня автоматически. Мой эксперимент состоял из открытия файла, записи в него данных, удаления ссылки и выхода из Python. Мне было любопытно узнать, когда данные будут записаны, если вообще будут.
Мой эксперимент выглядел так:
f = open('/tmp/output', 'w')
f.write('abc\n')
f.write('def\n')
# проверить содержимое /tmp/output (1)
дел (ф)
# проверить содержимое /tmp/output (2)
# выйти из Python
# проверить содержимое /tmp/output (3) В моем первом эксперименте, проведенном с Python 2.7.9 на моем Mac, я могу сообщить, что на этапе (1) файл существовал, но был пуст, а на этапах (2) и (3) файл содержал все его содержимое. Таким образом, казалось бы, в CPython 2.7 моя первоначальная интуиция была верна: когда файловый объект очищается сборщиком мусора, его __del__ (или его эквивалент) сбрасывается и закрывает файл. И действительно, вызов «lsof» в моем процессе IPython показал, что файл был закрыт после удаления ссылки.
Таким образом, казалось бы, в CPython 2.7 моя первоначальная интуиция была верна: когда файловый объект очищается сборщиком мусора, его __del__ (или его эквивалент) сбрасывается и закрывает файл. И действительно, вызов «lsof» в моем процессе IPython показал, что файл был закрыт после удаления ссылки.
Как насчет Python 3? Я провел описанный выше эксперимент под Python 3.4.2 на своем Mac и получил идентичные результаты. Удаление последней (ну, единственной) ссылки на файловый объект приводило к тому, что файл сбрасывался и закрывался.
Подходит для 2.7 и 3.4. А как насчет альтернативных реализаций, таких как PyPy и Jython? Возможно, они делают что-то по-другому.
Таким образом, я провел тот же эксперимент под PyPy 2.7.8. И на этот раз я получил другие результаты! Удаление ссылки на наш файловый объект, то есть этап (2), сделал вместо приводит к тому, что содержимое файла сбрасывается на диск. Я должен предположить, что это связано с различиями в сборщике мусора или чем-то еще, что в PyPy работает иначе, чем в CPython. Но если вы запускаете программы в PyPy, вам определенно не следует ожидать, что файлы будут очищены и закрыты только потому, что конечная ссылка, указывающая на них, вышла за рамки. lsof показал, что файл зависает до тех пор, пока процесс Python не завершится.
Но если вы запускаете программы в PyPy, вам определенно не следует ожидать, что файлы будут очищены и закрыты только потому, что конечная ссылка, указывающая на них, вышла за рамки. lsof показал, что файл зависает до тех пор, пока процесс Python не завершится.
Ради интереса решил попробовать Jython 2.7b3. И Jython продемонстрировал то же поведение, что и PyPy. То есть выход из Python всегда гарантирует, что данные будут сброшены из буферов и сохранены на диск.
Я повторил эти эксперименты, но вместо «abc\n» и «def\n» я написал «abc\n» * 1000 и «def\n» * 1000.
В случае Python 2.7, после «abc\n» * 1000 ничего не было написано. Но когда я написал «def\n» * 1000, файл содержал 4096 байт — что, вероятно, указывает на размер буфера. Вызов del(f) для удаления ссылки на файловый объект привел к тому, что он был сброшен и закрыт с общим размером 8000 байт. Таким образом, в случае с Python 2.7 поведение практически одинаково независимо от размера строки; разница только в том, что если вы превысите размер буфера, то некоторые данные будут записаны на диск до окончательного сброса + закрытия.
В случае с Python 3 поведение было другим: никакие данные не записывались после любого из 4000-байтовых выходных данных, записанных с помощью f.write. Но как только ссылка была удалена, файл сбрасывался и закрывался. Это может указывать на больший размер буфера. Но тем не менее это означает, что удаление последней ссылки на файл приводит к сбросу и закрытию файла.
В случае PyPy и Jython поведение с большим файлом было таким же, как и с маленьким: файл сбрасывался и закрывался при выходе из процесса PyPy или Jython, а не при удалении последней ссылки на файловый объект .
Просто для перепроверки я также пробовал использовать «с». Во всех этих случаях было легко предсказать, когда файл будет сброшен и закрыт: когда блок вышел, и менеджер контекста за кулисами запустил соответствующий метод.
Другими словами: если вы не используете «с», то вашим данным не обязательно грозит исчезновение — по крайней мере, в простых ситуациях. Однако вы не можете знать наверняка, когда данные будут сохранены — будь то удаление последней ссылки или выход из программы. Если вы предполагаете, что файлы будут закрыты, когда функции вернутся, потому что единственная ссылка на файл находится в локальной переменной, то вас может ждать сюрприз. И если у вас есть несколько процессов или потоков, записывающих в один и тот же файл, вам действительно нужно быть осторожным здесь.
Если вы предполагаете, что файлы будут закрыты, когда функции вернутся, потому что единственная ссылка на файл находится в локальной переменной, то вас может ждать сюрприз. И если у вас есть несколько процессов или потоков, записывающих в один и тот же файл, вам действительно нужно быть осторожным здесь.
Возможно, это поведение можно было бы определить лучше, чтобы оно работало одинаково или идентично на разных платформах? Возможно, мы могли бы даже увидеть начало спецификации Python, а не указывать на CPython и говорить: «Да, все, что делает эта версия, правильно».
Я все еще думаю, что менеджеры with и контекста — это здорово. И я все еще думаю, что новичкам в Python сложно понять, что делает with. Но я также думаю, что мне придется начать предупреждать новых разработчиков о том, что если они решат использовать альтернативные версии Python, возникнут всевозможные странные пограничные случаи, которые могут не работать идентично CPython, и это может сильно их укусить, если они не осторожен.
Понравилась эта статья? Присоединяйтесь к более чем 11 000 других разработчиков, которые получают мою бесплатную еженедельную рассылку «Лучшие разработчики». Каждый понедельник вы будете получать подобную статью о разработке программного обеспечения и Python:
. Адрес электронной почты
Имя
7. Ввод и вывод — документация по Python 3.10.7
Существует несколько способов представления вывода программы; данные можно распечатать в удобочитаемой форме или записаны в файл для будущего использования. Эта глава будет обсудить некоторые возможности.
7.1. Форматирование вывода Fancier
До сих пор мы сталкивались с двумя способами записи значений: операторы выражений и
функция print() . (Третий способ — использовать метод write() файловых объектов; на стандартный выходной файл можно ссылаться как sys.stdout .
Дополнительную информацию об этом см. в справочнике по библиотеке.)
в справочнике по библиотеке.)
Часто вам потребуется больший контроль над форматированием вывода, чем просто печать значений, разделенных пробелами. Существует несколько способов форматирования вывода.
Чтобы использовать форматированные строковые литералы, начните строку с
fилиFперед открывающей кавычкой или тройной кавычкой. Внутри этой строки вы можете написать выражение Python между{и}символы, которые могут относиться к переменным или литеральным значениям.>>> год = 2016 >>> событие = 'Референдум' >>> f'Результаты {года} {события}' «Итоги референдума 2016 года»Строковый метод
str.format()требует дополнительного ручного усилие. Вы по-прежнему будете использовать{и}, чтобы отметить, где находится переменная. будет заменен и может предоставить подробные директивы форматирования, но вам также нужно будет предоставить информацию для форматирования.>>> yes_votes = 42_572_654 >>> нет_голосов = 43_132_495 >>> процент = голоса_да / (голоса_да + голоса_нет) >>> '{:-9} ДА голосов {:2,2%}'.format(yes_votes, процент) ' 42572654 ДА голосов 490,67%'Наконец, вы можете выполнять всю обработку строк самостоятельно, используя нарезку строк и операции конкатенации для создания любого макета, который вы можете себе представить. Строковый тип имеет несколько методов, выполняющих полезные операции для заполнения. строки до заданной ширины столбца.

Когда вам не нужен красивый вывод, а просто нужно быстро отобразить некоторые
переменные в целях отладки, вы можете преобразовать любое значение в строку с помощью repr() или str() функции.
Функция str() предназначена для возврата представлений значений, которые
довольно удобочитаемый, в то время как repr() предназначен для создания представлений
который может быть прочитан интерпретатором (или вызовет SyntaxError , если
нет эквивалентного синтаксиса). Для объектов, не имеющих особого
представление для человеческого потребления,
Для объектов, не имеющих особого
представление для человеческого потребления, str() вернет то же значение, что и repr() . Многие значения, такие как числа или структуры, такие как списки и
словари имеют одинаковое представление с использованием любой функции. Струны, в
частности, имеют два различных представления.
Некоторые примеры:
>>> s = 'Привет, мир.'
>>> ул(ы)
'Привет, мир.'
>>> репр(ы)
"'Привет, мир.'"
>>> ул(1/7)
«0,14285714285714285»
>>> х = 10 * 3,25
>>> у = 200 * 200
>>> s = 'Значение x равно ' + repr(x) + ', а y равно ' + repr(y) + '...'
>>> печать(и)
Значение x равно 32,5, а y равно 40000...
>>> # Функция repr() строки добавляет строковые кавычки и обратную косую черту:
... привет = 'привет, мир\n'
>>> привет = repr(привет)
>>> распечатать (привет)
'привет, мир\n'
>>> # Аргументом repr() может быть любой объект Python:
... repr((x, y, ('спам', 'яйца')))
"(32,5, 40000, ('спам', 'яйца'))"
Модуль string содержит класс Template , который предлагает
еще один способ подставить значения в строки, используя заполнители, такие как $x и заменив их значениями из словаря, но предлагает гораздо меньше
контроль форматирования.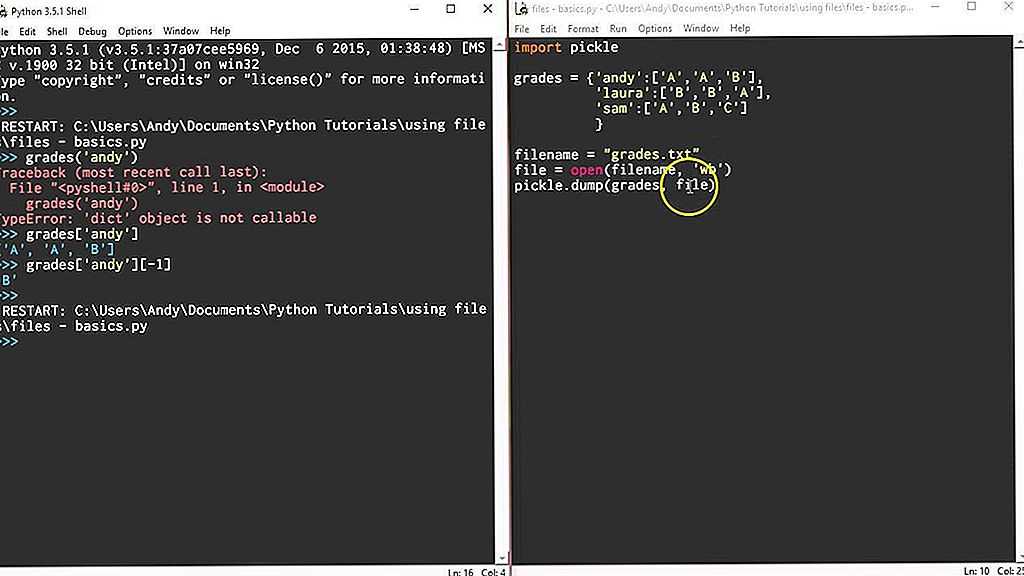
7.1.1. Форматированные строковые литералы
Отформатированные строковые литералы (также называемые f-строками для
короткая) позволяет включать значение выражений Python в строку с помощью
префикс строки с f или F и запись выражений в виде {выражение} .
За выражением может следовать необязательный описатель формата. Это позволяет больше контроль над форматированием значения. В следующем примере число пи округляется до три знака после запятой:
>>> импортировать математику
>>> print(f'Значение числа пи приблизительно равно {math.pi:.3f}.')
Значение числа пи приблизительно равно 3,142.
Передача целого числа после ':' приведет к тому, что это поле будет минимальным
количество символов в ширину. Это полезно для выравнивания столбцов.
>>> table = {'Шёрд': 4127, 'Джек': 4098, 'Дкаб': 7678}
>>> для имени, телефона в table.items():
... print(f'{имя:10} ==> {телефон:10d}')
. ..
Сьерд ==> 4127
Джек ==> 4098
Дкаб ==> 7678
 ..
Сьерд ==> 4127
Джек ==> 4098
Дкаб ==> 7678
..
Сьерд ==> 4127
Джек ==> 4098
Дкаб ==> 7678
Можно использовать другие модификаторы для преобразования значения перед его форматированием. '!a' применяется ascii() , '!s' применяется str() и '!r' применяется repr() :
>>> животные = 'угри'
>>> print(f'Мой корабль на воздушной подушке полон {животных}.')
Мое судно на воздушной подушке полно угрей.
>>> print(f'Мой корабль на воздушной подушке полон {животных!r}.')
Мое судно на воздушной подушке полно угрей'.
Спецификатор = можно использовать для расширения выражения до текста
выражение, знак равенства, затем представление оцениваемого выражения:
>>> жуки = 'тараканы'
>>> количество = 13
>>> площадь = 'гостиная'
>>> print(f'Отладка {ошибок=} {количество=} {область=}')
Отладка ошибок = количество тараканов = 13 площадь = 'гостиная'
Дополнительные сведения см. в самодокументирующихся выражениях.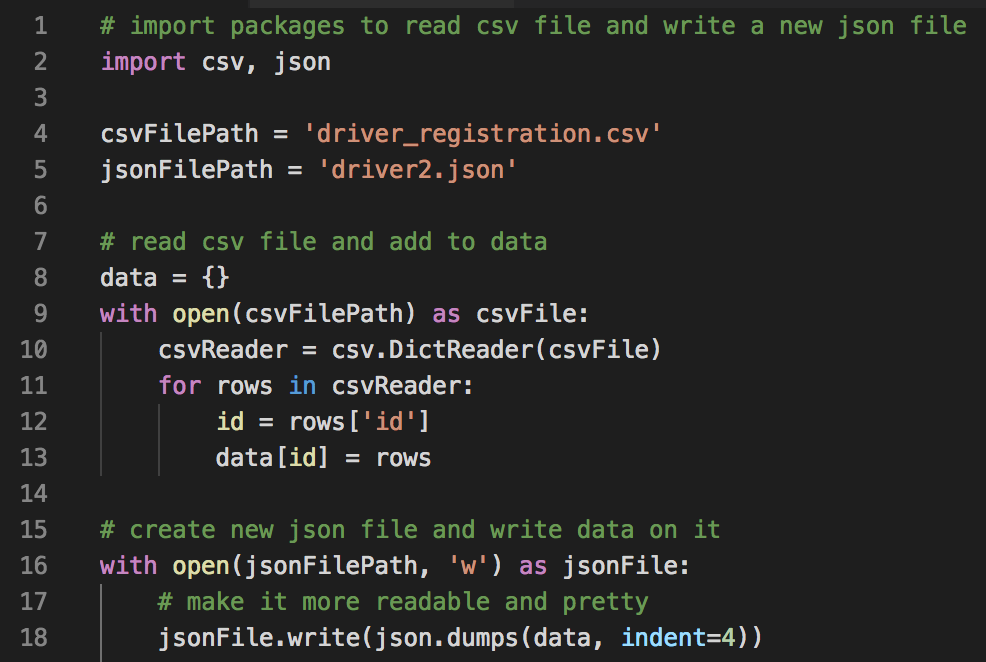 в спецификаторе
в спецификаторе = . Справку по этим спецификациям формата см.
справочное руководство для мини-языка спецификации формата.
7.1.2. Метод String format()
Основное использование метода str.format() выглядит следующим образом:
>>> print('Мы те {}, которые говорят "{}!"'.format('рыцари', 'Ни'))
Мы рыцари, которые говорят "Ни!"
Скобки и символы внутри них (называемые полями формата) заменены на
объекты перешли в метод str.format() . Номер в
скобки могут использоваться для обозначения положения объекта, переданного в метод str.format() .
>>> print('{0} и {1}'.format('спам', 'яйца'))
спам и яйца
>>> print('{1} и {0}'.format('спам', 'яйца'))
яйца и спам
Если в методе str.format() используются аргументы ключевого слова, их значения
ссылаются, используя имя аргумента.
>>> print('Эта {еда} является {прилагательным}.'.format(
... food='спам', adjective='абсолютно ужасный'))
Этот спам просто ужасен.

Аргументы позиции и ключевого слова можно произвольно комбинировать:
>>> print('История {0}, {1} и {другого}.'.format('Билл', 'Манфред',
...другое='Георг'))
История Билла, Манфреда и Георга.
Если у вас очень длинная строка формата, которую вы не хотите разбивать,
было бы неплохо, если бы вы могли ссылаться на переменные, которые должны быть отформатированы по имени
а не по должности. Это можно сделать, просто передав dict и используя
квадратные скобки '[]' для доступа к ключам.
>>> table = {'Шёрд': 4127, 'Джек': 4098, 'Дкаб': 8637678}
>>> print('Джек: {0[Джек]:d}; Сьерд: {0[Джек]:d}; '
... 'Dcab: {0[Dcab]:d}'.format(table))
Джек: 4098; Сьерд: 4127; Дкаб: 8637678
Это также можно сделать, передав словарь таблицы в качестве аргументов ключевого слова с помощью ** обозначение.
>>> table = {'Шёрд': 4127, 'Джек': 4098, 'Дкаб': 8637678}
>>> print('Джек: {Джек:d}; Сьорд: {Сджорд:d}; Dcab: {Dcab:d}'. format(**table))
Джек: 4098; Сьерд: 4127; Дкаб: 8637678
 format(**table))
Джек: 4098; Сьерд: 4127; Дкаб: 8637678
format(**table))
Джек: 4098; Сьерд: 4127; Дкаб: 8637678
Это особенно полезно в сочетании со встроенной функцией vars() , который возвращает словарь, содержащий все локальные переменные.
В качестве примера следующие строки создают аккуратно выровненный набор столбцов с целыми числами и их квадратами и кубами:
>>> для x в диапазоне (1, 11):
... print('{0:2d} {1:3d} {2:4d}'.format(x, x*x, x*x*x))
...
1 1 1
2 4 8
3 9 27
4 16 64
5 25 125
6 36 216
7 49343
8 64 512
9 81 729
10 100 1000
Полный обзор форматирования строк с помощью str.format() см.
Синтаксис строки формата.
7.1.3. Ручное форматирование строк
Вот та же таблица квадратов и кубов, отформатированная вручную:
>>> для x в диапазоне (1, 11): ... print(repr(x).rjust(2), repr(x*x).rjust(3), end=' ') ... # Обратите внимание на использование 'end' в предыдущей строке ... печать (репр (х * х * х). rjust (4)) ... 1 1 1 2 4 8 3 927 4 16 64 5 25 125 6 36 216 7 49 343 8 64 512 9 81 729 10 100 1000
(Обратите внимание, что один пробел между каждым столбцом был добавлен
способ print() работает: он всегда добавляет пробелы между своими аргументами.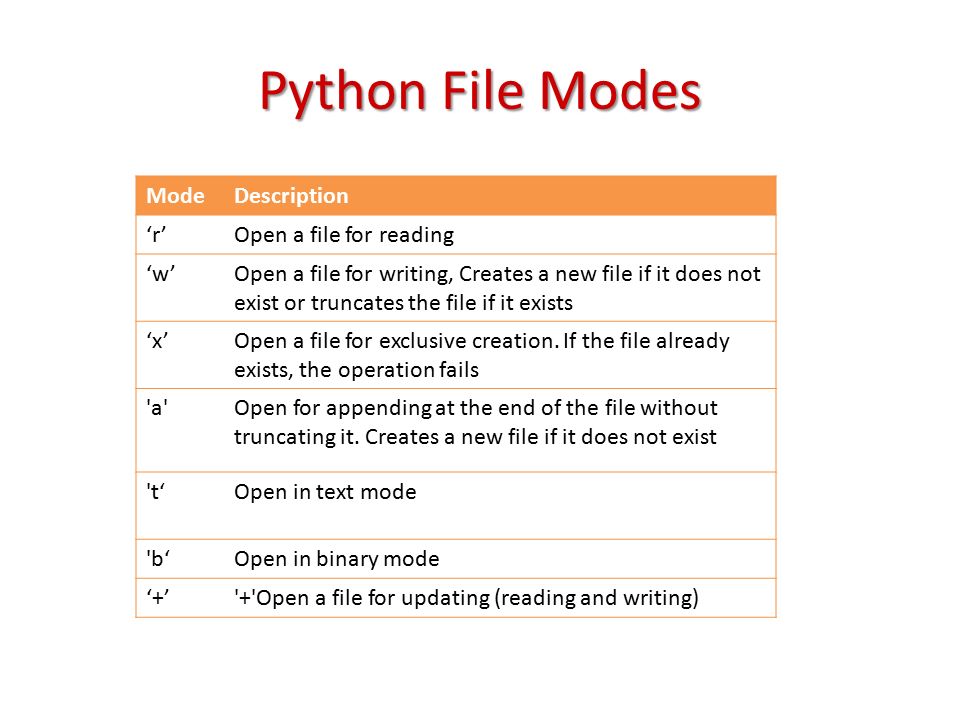 )
)
Метод str.rjust() строковых объектов выравнивает строку по правому краю в
поле заданной ширины, дополнив его пробелами слева. Есть
аналогичные методы str.ljust() и str.center() . Эти методы делают
ничего не пишут, они просто возвращают новую строку. Если входная строка слишком
long не усекают, а возвращают без изменений; это испортит твое
расположение столбцов, но это обычно лучше, чем альтернатива, которая была бы
ложь о стоимости. (Если вы действительно хотите усечение, вы всегда можете добавить
операция среза, как в x.ljust(n)[:n] .)
Существует еще один метод, str.zfill() , который дополняет числовую строку в
осталось с нулями. Он понимает про знаки плюс и минус:
>>> '12'.zfill(5) '00012' >>> '-3.14'.zfill(7) '-003.14' >>> '3.14159265359'.zfill(5) '3.14159265359'
7.1.4. Старое форматирование строки
Оператор % (по модулю) также можно использовать для форматирования строк. Дана
Дана "строка"
% значений , экземпляров % в строке заменяются нулем или более
элементы значений . Эта операция широко известна как строка
интерполяция. Например:
>>> импортировать математику
>>> print('Значение числа пи приблизительно равно %5.3f.' % math.pi)
Значение числа пи приблизительно равно 3,142.
Дополнительную информацию можно найти в разделе Форматирование строк в стиле printf.
7.2. Чтение и запись файлов
open() возвращает файловый объект и чаще всего используется с
два позиционных аргумента и один аргумент ключевого слова: открыть (имя файла, режим, кодировка = нет)
>>> f = открыть('рабочий файл', 'w', encoding="utf-8")
Первый аргумент — это строка, содержащая имя файла. Второй аргумент
другая строка, содержащая несколько символов, описывающих способ, которым файл
будет использован. режим может быть 'r' , когда файл будет только читаться, 'w' только для записи (существующий файл с таким же именем будет стерт) и 'a' открывает файл для добавления; любые данные, записанные в файл,
автоматически добавляется в конец.
'r+' открывает файл как для чтения, так и
пишу. Аргумент режима является необязательным; 'r' будет считаться, если это
опущено.
Обычно файлы открываются в текстовом режиме , то есть вы читаете и пишете
строки из и в файл, которые закодированы в определенной кодировке .
Если кодировка не указана, значение по умолчанию зависит от платформы.
(см. open() ).
Поскольку UTF-8 является современным стандартом де-факто, encoding="utf-8" это
рекомендуется, если вы не знаете, что вам нужно использовать другую кодировку.
Добавление 'b' к режиму открывает файл в двоичном режиме .
Данные двоичного режима читаются и записываются как байтов объекта.
Нельзя указывать кодировку при открытии файла в бинарном режиме.
В текстовом режиме по умолчанию при чтении преобразуется строка, зависящая от платформы
окончания ( \n в Unix, \r\n в Windows) до \n . При записи в
текстовый режим, по умолчанию используется преобразование вхождений
При записи в
текстовый режим, по умолчанию используется преобразование вхождений \n вернуться к
окончание строки для конкретной платформы. Эта закулисная модификация
в файл данных подходит для текстовых файлов, но искажает двоичные данные, как в JPEG или EXE файлы. Будьте очень осторожны, чтобы использовать двоичный режим, когда
чтение и запись таких файлов.
Хорошей практикой является использование ключевого слова с при работе с
с файловыми объектами. Преимущество в том, что файл правильно закрыт
после завершения его набора, даже если в какой-то момент возникнет исключение.
точка. Использование с также намного короче, чем запись
эквивалент попытка - окончательно блоков:
>>> с open('workfile', encoding="utf-8") как f:
... read_data = f.read()
>>> # Мы можем проверить, что файл был автоматически закрыт.
>>> f.закрыто
Истинный
Если вы не используете ключевое слово с , вам следует позвонить f., чтобы закрыть файл и немедленно освободить любую систему
используемых ею ресурсов. close()
close()
Предупреждение
Вызов f.write() без использования ключевого слова with или вызова f.close() может привести к аргументам
из f.write() не полностью записывается на диск, даже если
программа завершается успешно.
После закрытия файлового объекта оператором с оператором или вызвав f.close() , попытки использовать файловый объект будут
автоматически терпят неудачу.
>>> f.close() >>> f.read() Traceback (последний последний вызов): Файл "", строка 1, в ValueError: операция ввода-вывода в закрытом файле.
7.2.1. Методы файловых объектов
В остальных примерах этого раздела предполагается, что файловый объект с именем f уже создан.
Чтобы прочитать содержимое файла, вызовите f.read(size) , который считывает некоторое количество
данные и возвращает их в виде строки (в текстовом режиме) или байтового объекта (в двоичном режиме). размер — необязательный числовой аргумент. Когда размер опущен или отрицателен,
все содержимое файла будет прочитано и возвращено; это ваша проблема, если
файл в два раза больше памяти вашей машины. В противном случае не более размер символы (в текстовом режиме) или размером байт (в двоичном режиме) читаются и возвращаются.
Если достигнут конец файла,
размер — необязательный числовой аргумент. Когда размер опущен или отрицателен,
все содержимое файла будет прочитано и возвращено; это ваша проблема, если
файл в два раза больше памяти вашей машины. В противном случае не более размер символы (в текстовом режиме) или размером байт (в двоичном режиме) читаются и возвращаются.
Если достигнут конец файла, f.read() вернет пустой
строка ( '' ).
>>> f.read() 'Это весь файл.\n' >>> f.read() ''
f.readline() читает одну строку из файла; символ новой строки ( \n )
остается в конце строки и опускается только в последней строке
файл, если файл не заканчивается новой строкой. Это делает возвращаемое значение
однозначный; если f.readline() возвращает пустую строку, конец файла
была достигнута, а пустая строка представлена '\n' , строка
содержащий только одну новую строку.
>>> f.readline() 'Это первая строка файла.
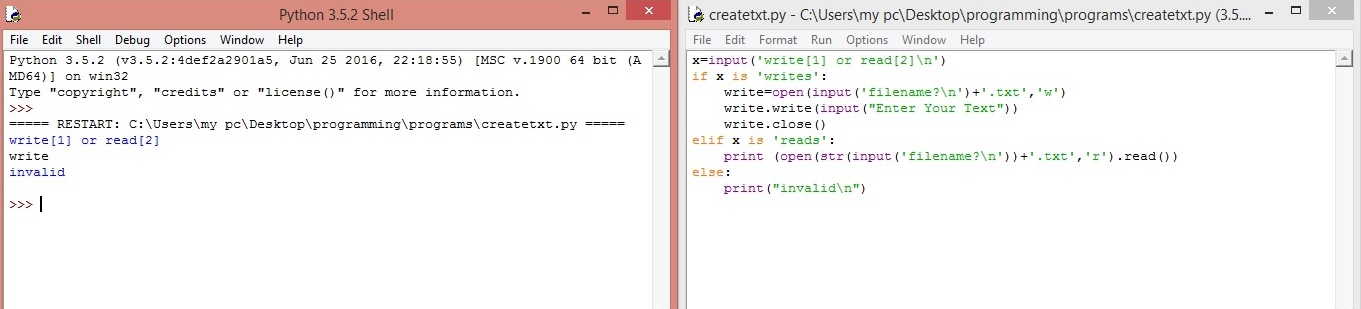 \n'
>>> f.readline()
'Вторая строка файла\n'
>>> f.readline()
''
\n'
>>> f.readline()
'Вторая строка файла\n'
>>> f.readline()
''
Для чтения строк из файла можно зациклиться на файловом объекте. это память эффективный, быстрый и приводит к простому коду:
>>> для строки в f: ... печать (строка, конец = '') ... Это первая строка файла. Вторая строка файла
Если вы хотите прочитать все строки файла в списке, вы также можете использовать list(f) или f.readlines() .
f.write(string) записывает содержимое строки в файл, возвращая
количество написанных символов.
>>> f.write('Это тест\n')
15
Другие типы объектов необходимо преобразовать – либо в строку (в текстовом режиме) или объект bytes (в бинарном режиме) — перед их записью:
>>> значение = ('ответ', 42)
>>> s = str(value) # преобразовать кортеж в строку
>>> f.пишите(и)
18
f.tell() возвращает целое число, указывающее текущую позицию файлового объекта в файле
представлен как количество байтов от начала файла в двоичном режиме и
непрозрачный номер в текстовом режиме.
Чтобы изменить позицию файлового объекта, используйте f.seek(offset, откуда) . Позиция вычисляется
от добавления смещения до контрольной точки; опорная точка выбирается
аргумент откуда . , откуда значение 0 измеряет с самого начала
файла, 1 использует текущую позицию файла, а 2 использует конец файла как
точка отсчета. , откуда может быть опущено и по умолчанию равно 0, используя
начало файла в качестве контрольной точки.
>>> f = открыть('рабочий файл', 'rb+')
>>> f.write(b'0123456789abcdef')
16
>>> f.seek(5) # Перейти к 6-му байту в файле
5
>>> f.read(1)
б'5'
>>> f.seek(-3, 2) # Перейти к 3-му байту перед концом
13
>>> f.read(1)
б'д'
В текстовых файлах (открытых без b в строке режима) ищет только
относительно начала файла разрешены (за исключением поиска
до самого конца файла с seek(0, 2) ) и единственными допустимыми значениями смещения являются
возвращенные из f. или нулевые. Любое другое значение смещения дает
неопределенное поведение. tell()
tell()
Файловые объекты имеют некоторые дополнительные методы, такие как isatty() и усекать() , которые используются реже; проконсультироваться в библиотеке
Ссылка на полное руководство по файловым объектам.
7.2.2. Сохранение структурированных данных с помощью
json Строки можно легко записывать и читать из файла. Числа занимают немного больше
усилия, так как метод read() возвращает только строки, которые должны быть
быть передана функции типа int() , которая принимает строку типа '123' и возвращает числовое значение 123. Если вы хотите сохранить более сложные данные
типы, такие как вложенные списки и словари, разбор и сериализация вручную
усложняется.
Вместо того, чтобы пользователи постоянно писали и отлаживали код для сохранения
сложные типы данных в файлы, Python позволяет использовать популярные данные
формат обмена, называемый JSON (нотация объектов JavaScript). Стандартный модуль под названием
Стандартный модуль под названием json может принимать Python
иерархии данных и преобразование их в строковые представления; этот процесс
называется , сериализующим . Восстановление данных из строкового представления
называется десериализацией . Между сериализацией и десериализацией
строка, представляющая объект, могла быть сохранена в файле или данных, или
отправлено по сетевому соединению на какую-то удаленную машину.
Примечание
Формат JSON обычно используется современными приложениями для передачи данных обмен. Многие программисты уже знакомы с ним, что делает это хороший выбор для взаимодействия.
Если у вас есть объект x , вы можете просмотреть его строковое представление JSON с помощью
простая строка кода:
>>> импорт json >>> x = [1, 'простой', 'список'] >>> json.dumps(x) '[1, "простой", "список"]'
Другой вариант dump() функция, называемая dump() ,
просто сериализует объект в текстовый файл. Итак, если
Итак, если f является
объект текстового файла открыт для записи, мы можем сделать это:
json.dump(x, f)
Для повторного декодирования объекта, если f является двоичным файлом или
объект текстового файла, который был открыт для чтения:
х = json.load(f)
Примечание
Файлы JSON должны иметь кодировку UTF-8. Используйте кодировку = "utf-8" при открытии
JSON в виде текстового файла для чтения и записи.
Этот простой метод сериализации может работать со списками и словарями, но
сериализация произвольных экземпляров класса в JSON требует дополнительных усилий.
Ссылка на модуль json содержит объяснение этого.
См. также
pickle — модуль pickle
В отличие от JSON, pickle — это протокол, который позволяет
сериализация произвольно сложных объектов Python. Таким образом, это
специфичен для Python и не может использоваться для связи с приложениями
написаны на других языках.