Работа с файлами в Python
python-scripts.com
Работа с файлами в Python
автор
9-12 минут
В данном материале мы рассмотрим, как читать и вписывать данные в файлы на вашем жестком диске. В течение всего обучения, вы поймете, что выполнять данные задачи в Python – это очень просто. Начнем же.
Как читать файлы
Python содержит в себе функцию, под названием «open», которую можно использовать для открытия файлов для чтения. Создайте текстовый файл под названием test.txt и впишите:
This is test file line 2 line 3 this line intentionally left lank |
Вот несколько примеров того, как использовать функцию «открыть» для чтения:
handle = open(«test.txt») handle = open(r»C:\Users\mike\py101book\data\test.txt», «r») |
В первом примере мы открываем файл под названием test.txt в режиме «только чтение». Это стандартный режим функции открытия файлов. Обратите внимание на то, что мы не пропускаем весь путь к файлу, который мы собираемся открыть в первом примере. Python автоматически просмотрит папку, в которой запущен скрипт для text.txt. Если его не удается найти, вы получите уведомление об ошибке IOError. Во втором примере показан полный путь к файлу, но обратите внимание на то, что он начинается с «r». Это значит, что мы указываем Python, чтобы строка обрабатывалась как исходная. Давайте посмотрим на разницу между исходной строкой и обычной:
>>> print(«C:\Users\mike\py101book\data\test.txt») C:\Users\mike\py101book\data est.txt >>> print(r»C:\Users\mike\py101book\data\test.txt») C:\Users\mike\py101book\data\test.txt |
Как видно из примера, когда мы не определяем строку как исходную, мы получаем неправильный путь.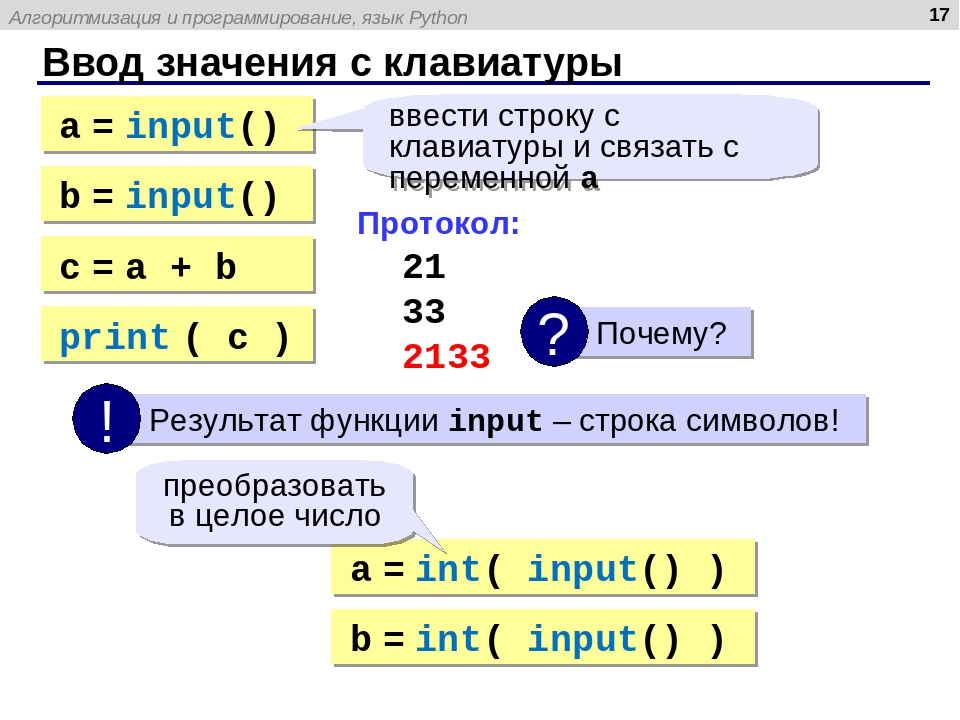 Почему это происходит? Существуют определенные специальные символы, которые должны быть отображены, такие как “n” или “t”. В нашем случае присутствует “t” (иными словами, вкладка), так что строка послушно добавляет вкладку в наш путь и портит её для нас. Второй аргумент во втором примере это буква “r”. Данное значение указывает на то, что мы хотим открыть файл в режиме «только чтение». Иными словами, происходит то же самое, что и в первом примере, но более явно. Теперь давайте, наконец, прочтем файл!
Почему это происходит? Существуют определенные специальные символы, которые должны быть отображены, такие как “n” или “t”. В нашем случае присутствует “t” (иными словами, вкладка), так что строка послушно добавляет вкладку в наш путь и портит её для нас. Второй аргумент во втором примере это буква “r”. Данное значение указывает на то, что мы хотим открыть файл в режиме «только чтение». Иными словами, происходит то же самое, что и в первом примере, но более явно. Теперь давайте, наконец, прочтем файл!
Введите нижеизложенные строки в скрипт, и сохраните его там же, где и файл test.txt.
handle = open(«test.txt», «r») data = handle.read() print(data) handle.close() |
После запуска, файл откроется и будет прочитан как строка в переменную data. После этого мы печатаем данные и закрываем дескриптор файла. Следует всегда закрывать дескриптор файла, так как неизвестно когда и какая именно программа захочет получить к нему доступ. Закрытие файла также поможет сохранить память и избежать появления странных багов в программе. Вы можете указать Python читать строку только раз, чтобы прочитать все строки в списке Python, или прочесть файл по частям. Последняя опция очень полезная, если вы работаете с большими фалами и вам не нужно читать все его содержимое, на что может потребоваться вся память компьютера.
Давайте обратим внимание на различные способы чтения файлов.
handle = open(«test.txt», «r») data = handle.readline() # read just one line print(data) handle.close() |
handle = open(«test. data = handle.readlines() # read ALL the lines! print(data) handle.close() |
 txt», «r»)
txt», «r»)После запуска данного кода, вы увидите напечатанный на экране список, так как это именно то, что метод readlines() и выполняет. Далее мы научимся читать файлы по мелким частям.
Как читать файл по частям
Самый простой способ для выполнения этой задачи – использовать цикл. Сначала мы научимся читать файл строку за строкой, после этого мы будем читать по килобайту за раз. В нашем первом примере мы применим цикл:
handle = open(«test.txt», «r») for line in handle: print(line) handle.close() |
Таким образом мы открываем файл в дескрипторе в режиме «только чтение», после чего используем цикл для его повторения. Стоит обратить внимание на то, что цикл можно применять к любым объектам Python (строки, списки, запятые, ключи в словаре, и другие). Весьма просто, не так ли? Попробуем прочесть файл по частям:
handle = open(«test.txt», «r») while True: data = handle.read(1024) print(data) if not data: break |
В данном примере мы использовали Python в цикле, пока читали файл по килобайту за раз. Как известно, килобайт содержит в себе 1024 байта или символов. Теперь давайте представим, что мы хотим прочесть двоичный файл, такой как PDF.
Как читать бинарные (двоичные) файлы
Это очень просто. Все что вам нужно, это изменить способ доступа к файлу:
handle = open(«test.pdf», «rb») |
Мы изменили способ доступа к файлу на rb, что значит read-binaryy. Стоит отметить то, что вам может понадобиться читать бинарные файлы, когда вы качаете PDF файлы из интернете, или обмениваетесь ими между компьютерами.
Пишем в файлах в Python
Как вы могли догадаться, следуя логике написанного выше, режимы написания файлов в Python это “w” и “wb” для write-mode и write-binary-mode соответственно. Теперь давайте взглянем на простой пример того, как они применяются.
ВНИМАНИЕ: использование режимов “w” или “wb” в уже существующем файле изменит его без предупреждения. Вы можете посмотреть, существует ли файл, открыв его при помощи модуля ОС Python.
handle = open(«output.txt», «w») handle.write(«This is a test!») handle.close() |
Вот так вот просто. Все, что мы здесь сделали – это изменили режим файла на “w” и указали метод написания в файловом дескрипторе, чтобы написать какой-либо текст в теле файла. Файловый дескриптор также имеет метод writelines (написание строк), который будет принимать список строк, который дескриптор, в свою очередь, будет записывать по порядку на диск.
Использование оператора «with»
В Python имеется аккуратно встроенный инструмент, применяя который вы можете заметно упростить чтение и редактирование файлов. Оператор with создает диспетчер контекста в Пайтоне, который автоматически закрывает файл для вас, по окончанию работы в нем. Посмотрим, как это работает:
with open(«test.txt») as file_handler: for line in file_handler: print(line) |
Синтаксис для оператора with, на первый взгляд, кажется слегка необычным, однако это вопрос недолгой практики. Фактически, все, что мы делаем в данном примере, это:
handle = open(«test.txt») |
Меняем на это:
with open(«test.txt») as file_handler: |
Вы можете выполнять все стандартные операции ввода\вывода, в привычном порядке, пока находитесь в пределах блока кода. После того, как вы покинете блок кода, файловый дескриптор закроет его, и его уже нельзя будет использовать. И да, вы все прочли правильно. Вам не нужно лично закрывать дескриптор файла, так как оператор делает это автоматически. Попробуйте внести изменения в примеры, указанные выше, используя оператор with.
После того, как вы покинете блок кода, файловый дескриптор закроет его, и его уже нельзя будет использовать. И да, вы все прочли правильно. Вам не нужно лично закрывать дескриптор файла, так как оператор делает это автоматически. Попробуйте внести изменения в примеры, указанные выше, используя оператор with.
Выявление ошибок
Иногда, в ходе работы, ошибки случаются. Файл может быть закрыт, потому что какой-то другой процесс пользуется им в данный момент или из-за наличия той или иной ошибки разрешения. Когда это происходит, может появиться IOError. В данном разделе мы попробуем выявить эти ошибки обычным способом, и с применением оператора with. Подсказка: данная идея применима к обоим способам.
try: file_handler = open(«test.txt») for line in file_handler: print(line) except IOError: print(«An IOError has occurred!») finally: file_handler.close() |
В описанном выше примере, мы помещаем обычный код в конструкции try/except. Если ошибка возникнет, следует открыть сообщение на экране. Обратите внимание на то, что следует удостовериться в том, что файл закрыт при помощи оператора finally. Теперь мы готовы взглянуть на то, как мы можем сделать то же самое, пользуясь следующим методом:
try: with open(«test.txt») as file_handler: for line in file_handler: print(line) except IOError: print(«An IOError has occurred!») |
Как вы можете догадаться, мы только что переместили блок with туда же, где и в предыдущем примере. Разница в том, что оператор finally не требуется, так как контекстный диспетчер выполняет его функцию для нас.
Подведем итоги
С данного момента вы уже должны легко работать с файлами в Python. Теперь вы знаете, как читать и вносить записи в файлы двумя способами. Теперь вы сможете с легкостью ориентироваться в данном вопросе.
Теперь вы сможете с легкостью ориентироваться в данном вопросе.
Как прочитать файлы в Python и решить проблему с кодировками
На практике в реальных проектах Data Science часто приходится сталкиваться с чтением датасетов, а также записывать добытую в ходе вычислений информацию в файлы. Сегодня мы расскажем о работе с файлами в Python: чтение и запись, проблема с кодировками, добавление значений в конец файла, временные папки и файлы.
Открываем, а затем читаем или записываем
Предположим, у нас имеется файл, который нужно прочитать в Python. Для этого можно воспользоваться функцией open внутри контекстного менеджера:
with open('file.txt') as f:
data = f.read() # содержимое файла
Таким же образом можно записать информацию в файл, указав w в качестве аргумента:
text = 'Hello'
with open('file.txt', 'w') as f:
f.write(text)
Отметим некоторые особенности данной функции. Во-первых, для чтения файла мы не указывали никаких аргументов кроме имени файла, поскольку по умолчанию уже стоит режим чтения. Мы также не указывали явно, что это именно текстовый файл, а не бинарный, так как это тоже стоит по умолчанию. Для чтения и записи бинарных файлов добавляется b, например, rb или wb.
Во-вторых, мы использовали функцию open в контекстном менеджере. Можно обойтись и без него, но тогда после чтения или записи следует закрыть файл.
f = open('file.txt')
f.read()
f.close()
На открытие файла Python выделяет память, поэтому, чтобы избежать ее утечки, рекомендуется закрывать файлы.
Чтение файла с разной кодировкой
На многих операционных системах Python в качестве стандарта кодирования использует UTF-8, который также поддерживает кириллицу. Тем не менее, часто можно столкнуться с проблемами неправильной кодировки и получить распространенную ошибку вроде этой:
>>> f = open('somefile. txt', encoding='ascii')
>>> f.read()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/Python3.8/encodings/ascii.py", line 26, in decode
return codecs.ascii_decode(input, self.errors)[0]
UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position
12: ordinal not in range(128))
txt', encoding='ascii')
>>> f.read()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/Python3.8/encodings/ascii.py", line 26, in decode
return codecs.ascii_decode(input, self.errors)[0]
UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position
12: ordinal not in range(128))
 txt', encoding='ascii')
>>> f.read()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/Python3.8/encodings/ascii.py", line 26, in decode
return codecs.ascii_decode(input, self.errors)[0]
UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position
12: ordinal not in range(128))
txt', encoding='ascii')
>>> f.read()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/Python3.8/encodings/ascii.py", line 26, in decode
return codecs.ascii_decode(input, self.errors)[0]
UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position
12: ordinal not in range(128))
В примере указана кодировка ASCII, но файл закодирован в другом формате, поэтому и возникает такая ошибка. Решить ее можно тремя способами:
- Указать
erorr=replace, который заменит нераспознанные символы знаком?:>>> f = open('somefile.txt', encoding='ascii', errors='replace') >>> f.read() 'H?llo py?ho?-school!' - Указать
erorr=ignore, который проигнорирует нераспознанные символы:>>> f = open('somefile.txt', encoding='ascii', errors='replace') >>> f.read() 'Hllo pyho-school!' - Указать правильную кодировку. Если текст на русском языке, то можно посмотреть кодировки с поддержкой кириллицы, которые есть в документации Python. Например, явно указать UTF-8 или cp1251:
f = open('somefile.txt', encoding='utf-8') # или cp1251 f = open('somefile.txt', encoding='cp1251')
Добавление в конец и запрет открытия файлов
Как мы уже отметили ранее, для записи текстового файла добавляется аргумент w. Но если вызвать метод write, он перепишет весь файл. Во многих случаях требуется добавить данные в конец файла. Тогда используется a вместо w:
text2 = 'world'
with open('file.txt', 'a') as f:
f.write(text)
# Helloworld
Если файла не существует, то при a и при w он будет создан. Но чтобы не трогать существующие файлы, а создать новый, передается параметр
Но чтобы не трогать существующие файлы, а создать новый, передается параметр x:
# 'x' не даст возможности открыть файл, так как он существует
>>> with open('file.txt', 'x') as f:
... f.write(text2)
FileExistsError Traceback (most recent call last)
FileExistsError: [Errno 17] File exists: 'file.txt'
# Поскольку file2.txt не существует, все OK
>>> with open('file2.txt', 'x') as f:
... f.write(text2)
Временные файлы
Иногда бывает, что требуется создать файл или папку внутри Python-программы, а после ее закрытия их нужно удалить. Тогда пригодится стандартный модуль tempfile. Например, класс TemporaryFile создаст временный файл, который удалится после закрытия. Ниже пример в Python.
>>> from tempfile import TemporaryFile
>>> f = TemporaryFile("w+t")
>>> f.write("hello")
>>> f.seek(0)
>>> f.read()
'hello'
>>> f.close() # файл уничтожается
# либо в контекстном менеджере
f.write(text2)
Обратите внимание на 3 вещи. Первое, мы явно передаем "w+t", чтобы записать как текстовый файл, поскольку по умолчанию стоит "w+b" для бинарных файлов. Второе, метод seek(0) используется для перехода на самый первый символ, поскольку чтение происходит с текущего указателя, а он стоит в конце (после буквы ‘o’ в слове ‘hello’). Поэтому не стоит переживать, что мы можем стереть предыдущую запись:
>>> f.seek(5) # переходим в конец
>>> f.read()
''
>>> f.write("world")
5
>>> f.seek(0) # переходим в начало
>>> f.read()
'helloworld'
Третье, файл TemporaryFile невидим для файловой системы, он используется только внутри Python, поэтому извне будет трудно его найти.
Именованные временные файлы
А вот объекты класса NamedTemporaryFile будут видны файловой системе, и найти месторасположение можно с помощью атрибута name:
>>> from tempfile import NamedTemporaryFile
>>> f = NamedTemporaryFile("w+t")
>>> f.name
'/tmp/tmp60djsgli'
>>> f.close()
Как можно заметить, файл называется tmp60djsgli. Для удобства можно явно указать его название и формат:
>>> f = NamedTemporaryFile("w+t", prefix="myfile", suffix=".txt")
>>> f.name
'/tmp/myfile7mxae0fi.txt'
Временные папки
Кроме временных файлов можно создавать временные папки. Для этого используется класс TemporaryDirectory:
>>> from tempfile import TemporaryDirectory >>> d = TemporaryDirectory() >>> d.name '/tmp/tmp5eadqzz5'
Он также принимает в качестве аргументов prefix и suffix, а также может использоваться внутри контекстного менеджера Python.
В следующей статье поговорим о взаимодействии файловой системы и Python. А получить практические навыки работы с файлами на реальных проектах Data Science вы сможете на наших курсах по Python в лицензированном учебном центре обучения и повышения квалификации IT-специалистов в Москве.
Источники
- https://docs.python.org/3/library/functions.html#open
- https://docs.python.org/3/library/tempfile.html
21 — Работа с файлами и папками
- Содержание папки
- Работа с путями к файлам и папкам
- Манипуляции с файлами и папками
Модуль стандартной библиотеки os (от «operation system») предоставляет множество полезных функций для произведения системных вызовов. Одна из базовых функций этого модуля —
Одна из базовых функций этого модуля — os.listdir.
>>> import os
>>> file_list = os.listdir() # список файлов и папок в директории, где запущена программа
>>> file_list = os.listdir('.') # синоним
>>> file_list = os.listdir('C:/Users') # список имен файлов и папок в данной папке
С точки зрения операционной системы нет разницы между файлом, папкой или другим подобным объектом, типа ссылки. Поэтому os.listdir() возвращает список как файлов, так и папок. Обратите внимание, что порядок элементов возвращаемого списка не регламентируется, если вам нужно их отсортировать не забудьте сделать это:
>>> import os
>>> unsorted_file_list = os.listdir()
>>> sortetd_file_list = sorted(unsorted_file_list)
Модуль os содержит подмодуль os.path, который позволяет работать с путями файлов и папок. Импортировать этот модуль отдельно не нужно, достаточно выполнить import os.
Присоединение одной части пути к другой
Работа с путями к файлам и папкам как с простыми строками чревата множеством ошибок и может создать проблемы при переносе программы между различными операционными системами. Правильный путь объединить две части пути — это использование os.path.join:
>>> import os
>>> dirpath = '../books'
>>> # Здесь filename - имя файла, а не путь от места запуска программы до него:
>>> for filename in os.listdir(dirpath):
... # filepath = dirname + filename - сработает неправильно, так как будет не хватать "/"
... filepath = os.path.join(dirname, filename) # поставит "/" или "\" за нас
... with open(filepath, encoding='utf-8') as fd:
... if 'нагваль' in fd.read():
... print('Книга ' + filename + ' об индейцах')
Извлечение имени файла из пути
Функция os. совершает обратное действие — отрезает имя файла или ниже лежащей папки от пути: path.split
path.split
>>> import os
>>> path = './work/project/version8/final.txt'
>>> dirpath, filename = os.path.split(path)
>>> print(dirpath)
./work/project/version8
>>> print(filename)
final.txt
>>> project_dir, version_dir = os.path.split(dirpath)
>>> print(project_dir)
./work/project
>>> print(version_dir)
version8
Извлечение расширения
Кроме того, может пригодиться функция os.path.splitext, котоая отрезает расширение файла:
>>> import os
>>> path = './work/project/version12/final.txt'
>>> base, ext = os.path.splitext(path)
>>> print(base, ext, sep='\n')
./work/project/version12/final
.txt
Проверка типа файла
Кроме прочего, модуль os.path содержит функции для проверки существования файла и для определения его типа:
>>> import os
>>> path = './kursach/text'
>>> if os.path.exists(path):
... print(path, 'существует')
... if os.path.isfile(path):
... print(path, '— это файл')
... elif os.path.isdir(path):
... print(path, '— это папка')
... else:
... print(path, '— это ни файл и ни папка')
... else:
... print(path, 'не существует')
Производите все манипуляции с файлами с осторожностью, придерживайтесь правила «семь раз отмерь — один раз отрежь». Не забывайте программно производить все возможные проверки перед выполнением операций.
Создание файла
Нет ничего проще, чем создать пустой файл, достаточно открыть несуществующий файл с флагом 'x':
>>> with open('empty.txt', 'x'):
... pass
Конечно, можно было бы использовать флаг 'w', но тогда уже существующий файл был бы стёрт. С флагом 'x' open либо создаст новый файл, либо выбросит ошибку.
Создание папки
Для создания новой папки используйте os.mkdir(name). Эта функция выбросит ошибку, если по указанному пути уже существует файл или папка. Если вам нужно создать сразу несколько вложенных папок, то смотрите функцию os.makedirs(name, exist_ok=False).
Перемещение и переименование
Для удобной манипуляции с файлами и папками в стандартной библиотеки Python существует специальный модуль shutil. Функция shutil.move(source, destination) позволяет вам переместить любой файл или папку (даже непустую). Обратите внимание, что если destination — это уже существующая папка, то файл/папка будет перемещена внутрь неё, в остальных случаях файл/папка будут скопированы точно по нужному адресу. В случае успеха, функция вернёт новое местоположение файла. Если destination существует и не является папкой, то будет выброшена ошибка.
>>> import shutil
>>> source = 'my_poem.txt'
>>> destination = 'trash'
>>> # Создаем папку назначения
>>> os.mkdir(destination)
>>> # Перенесем файл внутрь папки
>>> path = shutil.move(source, destination)
>>> print(path)
trash/my_poem.txt
>>> # Перенесем файл обратно
>>> new_name = 'poem.txt'
>>> final_path = shutil.move(path, new_name)
>>> print(final_path)
poem.txt
Как же переименовать файл? Несмотря на то, что os содержит специальную функцию для переименования, нужно понимать, что в рамках одной файловой системы перемещение и переименование — это одно и то же. Когда вы переименовываете файл, его содержимое не переписывается на носителе в другое место, просто файловая система теперь обозначает его положение другим путём.
Копирование
Скопировать файл можно с помощью функции shutil.copy(source, destination). Правила расположения копии будут те же, что и при использовании shutil., за тем исключением, что если  move
movedestination существует и не является файлом, то он будет заменён и ошибки это не вызовет.
Скопировать папку для операционной системы сложнее, ведь мы всегда хотим скопировать не только папку, но и её содержимое. Для копирования папок используйте shutil.copytree(source, destination). Обратите внимание, что для этой функции destination всегда должно быть путём конечного расположения файлов и не может быть уже существующей папкой.
Удаление
Удалить файл можно с помощью функции os.remove, а пустую папку с помощью функции os.rmdir.
А вот для удаления папки с содержимым вновь понадобится shutil. Для удаления такой папки используйте shutil.rmtree.
Будьте осторожны, команды удаления стирают файл, а не перемещают его в корзину, вне зависимости от операционной системы! После такого удаления восстановить файл может быть сложно или вовсе невозможно.
- В текущей папке лежат файлы с расширениями
.mp3,.flacи.oga. Создайте папкиmp3,flac,ogaи положите туда все файлы с соответствующими расширениями. - В текущей папке лежит две других папки:
vasyaиmila, причём в этих папках могут лежать файлы с одинаковыми именами, напримерvasya/kursovaya.docиmila/kursovaya.doc. Скопируйте все файлы из этих папок в текущую папку назвав их следующим образом:vasya_kursovaya.doc,mila_test.pdfи т.п. - В текущей папке лежат файлы следующего вида:
S01E01.mkv,S01E02.mkv,S02E01.mkvи т.п., то есть все файлы начинаются сS01илиS02. Создайте папкиS01иS02и переложите туда соответствующие файлы. - В текущей папке лежат файлы вида
2019-03-08., jpg2019-04-01.jpgи т.п. Отсортируйте файлы по имени и переименуйте их в1.jpg,2.jpg, …,10.jpg, и т.д. - В текущей папке лежат две другие папки:
videoиsub. Создайте новую папкуwatch_meи переложите туда содержимое указанных папок (сами папки класть не надо). - В текущей папке лежат файлы типа
Nina_Stoletova.jpg,Misha_Perelman.jpgи т.п. Переименуйте их переставив имя и фамилию местами. - В текущей папке лежит файл
list.tsv, в котором с новой строки написаны имена некоторых других файлов этой папки. Создайте папкуlistи переложите в неё данные файлы.
 jpg
jpgДля тестирования вашей программы положите в репозиторий файлы и папки с соответствующими именами. Файлы должны быть пустыми, если не указано обратного.
Как работать с простыми текстовыми файлами в Python 3
Python очень удобен и может с относительной легкостью обрабатывать различные форматы файлов, включая, помимо прочего, следующие:
| Тип файла | Описание |
|---|---|
txt | В текстовом файле хранятся данные, представляющие только символы (илиstrings), и исключаются любые структурированные метаданные. |
CSV | В файле значений, разделенных запятыми, используются запятые (или другие разделители) для структурирования хранимых данных, что позволяет сохранять данные в формате таблицы. |
HTML | Файл языка разметки гипертекста хранит структурированные данные и обычно используется на большинстве веб-сайтов. |
JSON | Нотация объектов JavaScript — это простой и эффективный формат, что делает его одним из наиболее часто используемых форматов для хранения и передачи данных. |
В этом руководстве основное внимание уделяется формату файловtxt.
[[step-1 -—- create-a-text-file]] == Шаг 1. Создание текстового файла
Прежде чем мы начнем работать в Python, мы должны убедиться, что у нас есть файл для работы. Для этого мы откроем текстовый редактор и создадим новый текстовый файл, назовем егоdays.txt.
В новом файле введите несколько строк текста. В этом примере давайте перечислим дни недели:
Monday
Tuesday
Wednesday
Thursday
Friday
Saturday
SundayЗатем сохраните ваш файл и убедитесь, что вы знаете, куда его поместить. В нашем примере наш пользовательsammy сохранил файл здесь:/users/sammy/days.txt. Это будет очень важно на следующих этапах, когда мы открываем файл в Python.
Теперь, когда у нас есть текстовый файл для обработки, мы можем начать наш код!
[[step-2 -—- open-a-file]] == Шаг 2 — Открытие файла
Прежде чем мы сможем написать нашу программу, мы должны создать программный файл Python, поэтому создайте файлfiles.py в текстовом редакторе. Чтобы упростить задачу, сохраните его в том же каталоге, что и наш файлdays.txt:/users/sammy/.
Чтобы открыть файл в Python, нам сначала нужен способ связать файл на диске сvariable в Python. Этот процесс называетсяopening файлом. Мы начнем с сообщения Python, где находится файл. Расположение вашего файла часто обозначается как файлpath. Чтобы Python открыл ваш файл, ему нужен путь. Путь к нашему файлуdays.txt:/users/sammy/days.txt. В Python мы создадим строковую переменную для хранения этой информации. В нашем сценарииfiles.py мы создадим переменнуюpath и установим для нее путь days.txt.
path = '/users/sammy/days.txt'Затем мы воспользуемся функцией Pythonopen(), чтобы открыть наш файлdays.. Функция txt
txtopen() требует в качестве первого аргумента путь к файлу. Функция также учитывает многие другие параметры. Однако наиболее важным является необязательный параметрmode. Mode — это необязательная строка, которая указывает режим, в котором открывается файл. Выбранный вами режим будет зависеть от того, что вы хотите сделать с файлом. Вот некоторые из наших опций режима:
'r': использовать для чтения'w': использовать для записи'x': использовать для создания и записи в новый файл'a': использовать для добавления в файл'r+': использовать для чтения и записи в один и тот же файл
В этом примере мы хотим только читать из файла, поэтому мы будем использовать режим'r'. Мы будем использовать функциюopen(), чтобы открыть файлdays.txt и назначить его переменнойdays_file.
days_file = open(path,'r')После того, как мы открыли файл, мы можем прочитать его, что мы и сделаем на следующем шаге.
[[шаг-3 -—- чтение-файл]] == Шаг 3 — Чтение файла
Так как наш файл был открыт, теперь мы можем манипулировать им (т.е. читать из него) через переменную, которую мы ему присвоили. Python предоставляет три связанные операции для чтения информации из файла. Мы покажем, как использовать все три операции в качестве примеров, которые вы можете попробовать, чтобы понять, как они работают.
Первая операция<file>.read() возвращает все содержимое файла в виде одной строки.
Output'Monday\nTuesday\nWednesday\nThursday\nFriday\nSaturday\nSunday\n'Вторая операция<file>.readline() возвращает следующую строку файла, возвращая текст до следующего символа новой строки включительно.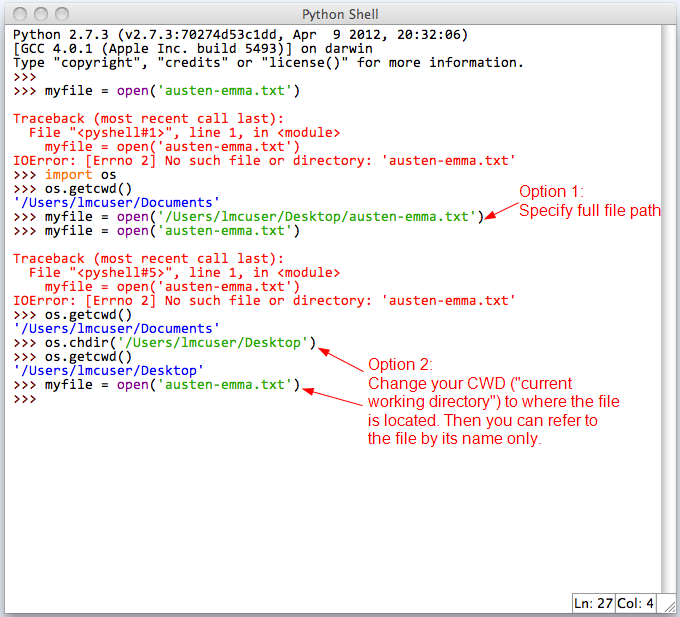 Проще говоря, эта операция будет читать файл построчно.
Проще говоря, эта операция будет читать файл построчно.
Поэтому, как только вы прочитаете строку с операцией readline, она перейдет к следующей строке. Таким образом, если вы вызовете эту операцию снова, она вернет следующую строку в файле, как показано.
Последняя операция<file>.readlines() возвращает список строк в файле, где каждый элемент списка представляет одну строку.
Output['Monday\n', 'Tuesday\n', 'Wednesday\n', 'Thursday\n', 'Friday\n', 'Saturday\n', 'Sunday\n']Что следует иметь в виду, когда вы читаете из файлов, после того, как файл был прочитан с помощью одной из операций чтения, он не может быть прочитан снова. Например, если вы сначала запуститеdays_file.read(), а затемdays_file.readlines(), вторая операция вернет пустую строку. Поэтому в любое время, когда вы хотите прочитать файл, вам сначала нужно открыть новую файловую переменную. Теперь, когда мы прочитали из файла, давайте узнаем, как записать в новый файл.
[[step-4 -—- writing-a-file]] == Шаг 4 — Запись файла
На этом этапе мы собираемся написать новый файл, который будет включать заголовокDays of the Week, за которым следуют дни недели. Во-первых, давайте создадим нашу переменнуюtitle.
title = 'Days of the Week\n'Нам также необходимо сохранить дни недели в строковой переменной, которую мы назовемdays. Чтобы было легче следовать, мы включили код из вышеперечисленных шагов. Мы открываем файл в режиме чтения, читаем файл и сохраняем возвращенный результат операции чтения в нашей новой переменнойdays.
path = '/users/sammy/days.txt'
days_file = open(path,'r')
days = days_file.read()Теперь, когда у нас есть переменные для заголовка и дней недели, мы можем начать запись в наш новый файл. Для начала нам нужно указать местоположение файла. И снова мы будем использовать каталог
И снова мы будем использовать каталог/users/sammy/. Нам нужно будет указать новый файл, который мы хотим создать. Итак, наш путь на самом деле будет/users/sammy/new_days.txt. Мы предоставляем информацию о нашем местоположении в переменнойnew_path. Затем мы открываем наш новый файл в режиме записи, используя функциюopen() с указанным режимом'w'.
new_path = '/users/sammy/new_days.txt'
new_days = open(new_path,'w')Важно отметить, что если new_days.txt уже существовал до открытия файла, его старое содержимое было бы уничтожено, поэтому будьте осторожны при использовании режима'w'.
Как только наш новый файл открыт, мы можем поместить данные в файл, используя операцию записи<file>.write(). Операция записи принимает один параметр, который должен быть строкой, и записывает эту строку в файл. Если вы хотите начать новую строку в файле, вы должны явно указать символ новой строки. Сначала мы записываем заголовок в файл, а затем дни недели. Давайте также добавим в некоторые инструкции для печати то, что мы пишем, что часто является хорошей практикой для отслеживания прогресса ваших сценариев.
new_days.write(title)
print(title)
new_days.write(days)
print(days)Наконец, всякий раз, когда мы заканчиваем работу с файлом, мы должны обязательно закрыть его. Мы покажем это на нашем последнем этапе.
[[шаг-5 -—- закрытие-файла]] == Шаг 5. Закрытие файла
Закрытие файла гарантирует, что соединение между файлом на диске и файловой переменной завершено. Закрытие файлов также гарантирует, что другие программы могут получить к ним доступ и сохраняет ваши данные в безопасности. Поэтому всегда закрывайте свои файлы. Теперь закроем все наши файлы с помощью функции<file>.close().
days_file.close()
new_days. close()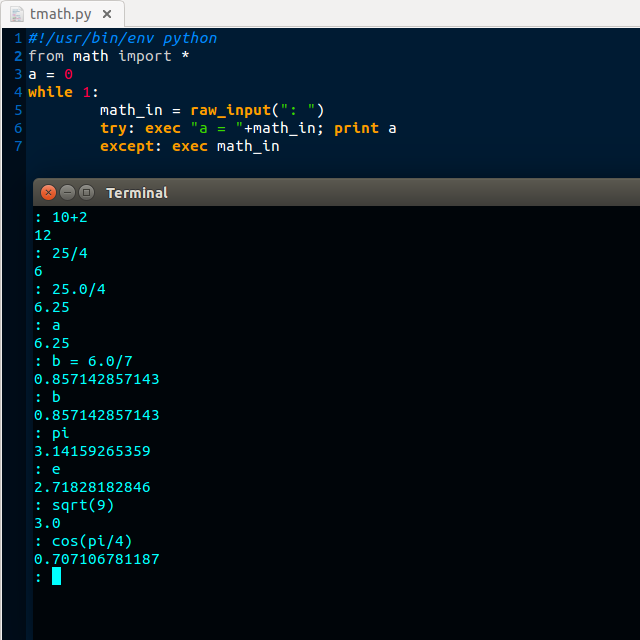 close()
close()Теперь мы закончили обработку файлов в Python и можем перейти к просмотру нашего кода.
[[step-6 -—- verify-our-code]] == Шаг 6. Проверка нашего кода
Прежде чем запускать наш код, давайте удостоверимся, что все выглядит хорошо. Конечный продукт должен выглядеть примерно так:
path = '/users/sammy/days.txt'
days_file = open(path,'r')
days = days_file.read()
new_path = '/users/sammy/new_days.txt'
new_days = open(new_path,'w')
title = 'Days of the Week\n'
new_days.write(title)
print(title)
new_days.write(days)
print(days)
days_file.close()
new_days.close()После сохранения кода откройте терминал и запустите скрипт Python, например:
Наш вывод должен выглядеть так:
OutputDays of the Week
Monday
Tuesday
Wednesday
Thursday
Friday
Saturday
SundayТеперь давайте дважды проверим, что наш код полностью работает, открыв новый файл (new_days.txt). Если все прошло хорошо, когда мы открываем наш новый файл, он должен выглядеть так:
Days of the Week
Monday
Tuesday
Wednesday
Thursday
Friday
Saturday
SundayВаш файл будет выглядеть одинаково или аналогично — вы успешно прошли этот урок!
Работа с файлами в Python
Файл — области постоянной памяти в вашем компьютере, которыми управляет операционная система. Объект файла создает функция open или file.
При работе с файлами используется буферизация и она включена по умолчанию. При буферизации данные не записываются в файл непосредственно при вызове метода записи. Они записываются, когда все действия с файлом прекращены или вызвана функция close().
f1 = open("test") # по умолчанию файл открывается в режиме r(чтение)
f2 = open("test", "w") # файл открывается для записи
f2 = open("test", "w", 0) # отключает буферизацию, данные сразу записываются в файл (например при вызове метода write())
f3 = open("test", "a") # файл открывается для записи в конец
f4 = open("test", "a+") # файл открывается как для чтения так и для записи в конец
f5 = open("test", "ab") # добавляя к режиму символ "b" мы можем работать с файлам как с двоичными данными(интерпритация символа новой строки отключена)
xfile = open("test. txt")
xString = xfile.read() # прочитать весь файл в строку
xString = xfile.read(N) # прочитать N-байтов в строку
xString = xfile.readline() # прочитать текстовую строку включая символ конца строки
xList = xfile.readlines() # прочитать весь файл целиком в список строк
xfile.write(xString) # записать строку в файл
xfile.writelines(xList) # записать строки из списка в файл
xfile.close() # закрытие файла в ручную (выполняется по окончанию работы с файлом)
xfile.flush() # выталкивает выходные буферы на диск, файл остается открытым
xfile.seek(N) # изменяет текущую позицию в файле для следующей операции, смещая ее на N-байтов от начала файлаПример скрипта который сам создает файлы Python c баш-строкой. txt")
xString = xfile.read() # прочитать весь файл в строку
xString = xfile.read(N) # прочитать N-байтов в строку
xString = xfile.readline() # прочитать текстовую строку включая символ конца строки
xList = xfile.readlines() # прочитать весь файл целиком в список строк
xfile.write(xString) # записать строку в файл
xfile.writelines(xList) # записать строки из списка в файл
xfile.close() # закрытие файла в ручную (выполняется по окончанию работы с файлом)
xfile.flush() # выталкивает выходные буферы на диск, файл остается открытым
xfile.seek(N) # изменяет текущую позицию в файле для следующей операции, смещая ее на N-байтов от начала файла
txt")
xString = xfile.read() # прочитать весь файл в строку
xString = xfile.read(N) # прочитать N-байтов в строку
xString = xfile.readline() # прочитать текстовую строку включая символ конца строки
xList = xfile.readlines() # прочитать весь файл целиком в список строк
xfile.write(xString) # записать строку в файл
xfile.writelines(xList) # записать строки из списка в файл
xfile.close() # закрытие файла в ручную (выполняется по окончанию работы с файлом)
xfile.flush() # выталкивает выходные буферы на диск, файл остается открытым
xfile.seek(N) # изменяет текущую позицию в файле для следующей операции, смещая ее на N-байтов от начала файла#!/usr/bin/env python
# -*- coding: utf-8 -*-
myfile = open("newfile.py", "w")
myfile.write("#!/usr/bin/env python\n# -*- coding: utf-8 -*-")
myfile.close()Скачать и сохранить файл, используя Python#!/usr/bin/env python
# -*- coding: utf-8 -*-
url = "http://www.google.ru/index.html"
import urllib
webFile = urllib.urlopen(url)
localFile = open(url.split('/')[-1], 'wb')
localFile.write(webFile.read())
webFile.close()
localFile.close()Сегодня может быть Ваш день. Попробуйте свою удачу в наших играх на http://oligarhcasino.com/ которые обеспечат Вам незабываемое удовольствие от игры и выигрыша. Честные результаты игры повысит Ваше доверие к нам.
Python: работа с файлами
Для работы с файлами в Python используется встроенная функция open():
Help on built-in function open in module __builtin__:
open(...)
open(name[, mode[, buffering]]) -> file object
Open a file using the file() type, returns a file object. This is the
preferred way to open a file.
С помощью open() создаётся новый объект, над которым потом можно выполнять другие действия.
Полный список методов можно получить с помощью функции dir():
In [25]: dir(file) Out[25]: ['__class__', '__delattr__', '__doc__', '__enter__', '__exit__', '__format__', '__getattribute__', '__hash__', '__init__', '__iter__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'close', 'closed', 'encoding', 'errors', 'fileno', 'flush', 'isatty', 'mode', 'name', 'newlines', 'next', 'read', 'readinto', 'readline', 'readlines', 'seek', 'softspace', 'tell', 'truncate', 'write', 'writelines', 'xreadlines']
Для завершения работы — используется метод close(), применяемый к созданном объекту.
In [15]: text = 'This is text fro new file.n'
In [16]: file = open('newfile', 'w')
In [17]: file.close()Функция open() принимает первым аргументом имя файла, и вторым — режим доступа:
w (write) — для записи;r (read) — чтение файла;a (append) — добавление строк в файл;r+ (read+) — чтение и/или запись.
Полный список методов можно найти тут>>>.
Второй аргумент не обязателен — если вызвать open() без него — то по-умолчанию будет использоваться режим read.
Добавление текста в файл выполняется методом write() (для записи одной строки) или writelines() (для записи нескоких строк, переданных в виде списка).
In [28]: file = open('onelinefile', 'w')
In [29]: file.write('This is text line in new file.')
In [33]: file.close()
In [52]: file = open('multilinefile', 'w')
In [54]: longtext = ('nThis is first string;n', 'This is second string;n', 'This is third string.')
In [55]: file.writelines(longtext)
In [57]: file.close()После чего у нас в файловой системе появятся два новых файла:
$ ls -l | grep file -rw-rw-r-- 1 setevoy setevoy 67 Aug 24 13:45 multilinefile -rw-rw-r-- 1 setevoy setevoy 30 Aug 24 13:43 onelinefile
Для чтения из файла — методы read() (читает указанное аргументом количество байт, если не указано — читает весь файл), readline() (читает одну строку) и readlines() (читает все строки в объекте-файле):
In [59]: file.read(10)
Out[59]: 'This is te'
In [84]: file.read()
Out[84]: 'nThis is first string;nThis is second string;nThis is third string.'
In [66]: file.readline()
Out[66]: 'This is text line in new file.'
In [70]: file.close()
In [71]: file = open('multilinefile', 'r+')
In [72]: file. readlines()
Out[72]:
['n',
'This is first string;n',
'This is second string;n',
'This is third string.']
In [76]: print file.readlines()
['n', 'This is first string;n', 'This is second string;n', 'This is third string.'] readlines()
Out[72]:
['n',
'This is first string;n',
'This is second string;n',
'This is third string.']
In [76]: print file.readlines()
['n', 'This is first string;n', 'This is second string;n', 'This is third string.']
readlines()
Out[72]:
['n',
'This is first string;n',
'This is second string;n',
'This is third string.']
In [76]: print file.readlines()
['n', 'This is first string;n', 'This is second string;n', 'This is third string.']Другой способ чтения строк из файла — с помощью цикла for:
In [80]: file = open('multilinefile', 'r+')
In [81]: for string in file:
print string,
....:
This is first string;
This is second string;
This is third string.
In [82]: file.close()
При использовании метода readline() необходимо учитывать, что при каждой итерации (вызова read() к объекту) — он будет считывать следующую строку, а не начинать сначала:
In [86]: file = open('multilinefile', 'r+')
In [87]: file.readline()
Out[87]: 'n'
In [88]: file.readline()
Out[88]: 'This is first string;n'
In [89]: file.readline()
Out[89]: 'This is second string;n'
In [90]: file.readline()
Out[90]: 'This is third string.'
In [91]: file.readline()
Out[91]: ''
In [92]: file.close()
Хорошим способом работы с файлами является использование оператора With, т.к. он всегда выполняет close(), и не оставляет «мусора»:
In [94]: with open('multilinefile', 'r+') as file:
....: strings = file.readlines()
....: print strings
....:
['n', 'This is first string;n', 'This is second string;n', 'This is third string.']
Т.к. методы read* возвращают обычный строковый объект- над ним можно выполнять обычные строковые методы:
In [115]: file = open('newfile', 'r+')
In [116]: file.write('string')
In [117]: result = file.readline()
In [118]: print type(result)
<type 'str'>
In [100]: with open('multilinefile', 'r+') as file:
strings = file. readlines()
for lines in strings:
result = lines.split()
print result
.....:
[]
['This', 'is', 'first', 'string;']
['This', 'is', 'second', 'string;']
['This', 'is', 'third', 'string.']
 readlines()
for lines in strings:
result = lines.split()
print result
.....:
[]
['This', 'is', 'first', 'string;']
['This', 'is', 'second', 'string;']
['This', 'is', 'third', 'string.']
readlines()
for lines in strings:
result = lines.split()
print result
.....:
[]
['This', 'is', 'first', 'string;']
['This', 'is', 'second', 'string;']
['This', 'is', 'third', 'string.']
Ссылки по теме
https://thenewcircle.com
https://docs.python.org
http://www.tutorialspoint.com
Статьи Python. Работа с файлами для Python.
Для работы с файлами в основном применяется модуль os. Далее, для перемещения и копирования файлов мы будем использовать модуль shutil, для сравнения файлов — filecmp, для поиска по образцу — glob . А пока импортируем os.import os
Обработка пути к файлу
os.path.join(r'c:\home', 'index.html') # соединение пути # возвращает r'c:\home\index.html' os.path.split(r'c:\home\index.html') # разделение пути # возвращает (r'c:\home', 'index.html')
Как узнать, существует ли данный путь?
path = 'index.html'
if os.path.exists(path):
print path, ' exists'
Как определить, данный путь — это файл или директория?
if os.path.isfile(path):
print path, ' is file'
elif os.path.isdir(path):
print path, ' is directory'
Получаем свойства файла.
from datetime import datetime # для преобразования даты в приемлемый формат size = os.path.getsize(path) # размер файла в байтах ksize = size//1024 # размер в килобайтах atime = os.path.getatime(path) # дата последнего доступа в секундах с начала эпохи mtime = os.path.getmtime(path) # дата последней модификации в секундах с начала эпохи print 'Size: ', ksize, ' KB' print 'Last access date: ', datetime.fromtimestamp(atime) print 'Last modification date: ', datetime.fromtimestamp(mtime)
Стандартные операции с файлами
import shutil
os.rename('index. html','index2.html') # переименовать
shutil.copy('index2.html','index.html') # копировать
shutil.move('index2.html', 'index3.html') # переместить
os.remove('index3.html') # удалить
 html','index2.html') # переименовать
shutil.copy('index2.html','index.html') # копировать
shutil.move('index2.html', 'index3.html') # переместить
os.remove('index3.html') # удалить
html','index2.html') # переименовать
shutil.copy('index2.html','index.html') # копировать
shutil.move('index2.html', 'index3.html') # переместить
os.remove('index3.html') # удалить
Сравнение двух файлов
import filecmp
eq = filecmp.cmp('index.html', 'index3.html') # сравнить файлы
if eq:
print 'equal'
else:
print 'not equal'
Обработка всех файлов в директории
dir = 'c:\home'
names = os.listdir(dir) # список файлов и поддиректорий в данной директории
for name in names:
fullname = os.path.join(dir, name) # получаем полное имя
if os.path.isfile(fullname): # если это файл...
print fullname # делаем что-нибудь с ним
Обработка всех файлов в директории рекурсивно (включая все поддиректории)
dir = 'c:\home'
for root, dirs, files in os.walk(dir): # пройти по директории рекурсивно
for name in files:
fullname = os.path.join(root, name) # получаем полное имя файла
print fullname # делаем что-нибудь с ним
Здесь os.walk — это итератор, который проходит по директориям
рекурсивно, и возвращает для каждой директории кортеж из трёх
значений:root — имя текущей директории
dirs — имена поддиректорий в текущей директории
files — имена файлов в текущей директории
Получение списка файлов, совпадающих с образцом
import glob
names = glob.glob('c:\home\*') # все файлы и поддиректории в "с:\home"
names = glob.glob('c:\home\*.txt') # только с расширением "txt"
for name in names:
if os.path.isfile(name): # если это файл (а не директория)
print name # делаем что-нибудь с ним
Вот наверно и все основные операции с файлами. А если Вам понадобится произвести какие-то другие действия над файлами, обратитесь к стандартной документации Python.
 Учебное пособие по
Учебное пособие поPython: Управление файлами
Предыдущая глава: Глобальные и локальные переменныеСледующая глава: Модульное программирование и модули
Файловый ввод / вывод
Работа с файлами
Хотя все понимают термин файл, мы все равно хотим дать формальное определение: Файл или компьютерный файл — это фрагмент логически связанных данных или информации, которые могут использоваться компьютерные программы. Обычно файл хранится на надежном хранилище. Можно использовать уникальное имя и путь пользователями-людьми или в программах или сценариях для доступа к файлу с целью чтения и модификации.
Термин «файл» в описанном выше значении появился в истории компьютеров очень рано. Это использовался еще в 1952 году, когда использовались перфокарты.
Язык программирования без возможности сохранения и извлечения ранее сохраненных
информация вряд ли будет полезной.
Самыми основными задачами, связанными с манипуляциями с файлами, являются чтение данных из файлов и
запись или добавление данных в файлы.
Синтаксис для чтения и записи файлов в Python аналогичен языкам программирования, таким как C и C ++ или Perl, но с ними проще работать.
В нашем первом примере мы хотим показать, как читать данные из файла. Как сказать Python что мы хотим читать из файла, — это использовать функцию открытия. Первый параметр — это имя файла, который мы хотим прочитать, и со вторым параметром, присвоенным «r», мы определяем что мы хотим прочитать.
fobj = open ("ad_lesbiam.txt", "r")
Буква «r» не обязательна. По умолчанию для чтения открывается команда open (), содержащая только имя файла.
Функция open () возвращает файловый объект, который предлагает атрибуты и методы.
fobj = open ("ad_lesbiam.txt")
После того, как мы закончили работу с файлом, мы должны снова закрыть его, используя
метод файлового объекта close ():fobj.close ()Теперь мы хотим наконец открыть и прочитать файл. Вы можете скачать текстовый файл ad_lesbiam.txt, если вы хотите проверить это сами:
fobj = open ("ad_lesbiam.txt")
для строки в fobj:
печать line.rstrip ()
fobj.close ()
Если мы сохраним этот скрипт и назовем его «file_read.py», мы получим следующий вывод:
при условии, что текстовый файл доступен:$ python file_read.ру В. ад Лесбиам VIVAMUS mea Lesbia, atque amemus, Rumoresque senum severiorum omnes unius aestimemus assis! soles occidere et redire Possunt: nobis cum semel occidit breuis lux, nox est perpetua una dormienda. да ми basia mille, deinde centum, dein mille altera, dein secunda centum, deinde usque altera mille, deinde centum. деин, сперма милиа мульта фецеримус, conturbabimus illa, ne sciamus, aut ne quis malus inuidere Possit, cum tantum sciat esse basiorum. (ГАЙУС ВАЛЕРИУС КАТУЛЛ)Кстати, стихотворение выше — это любовное стихотворение Катулла к своей возлюбленной Лесбии.
Запись в файл
Запись в файл так же проста, как и чтение из файла. Чтобы открыть файл для записи
мы используем в качестве второго параметра «w» вместо «r». Чтобы действительно записать данные
в этот файл мы используем метод write () файлового объекта.
Пример:
fobj_in = open ("ad_lesbiam.txt")
fobj_out = open ("ad_lesbiam2.txt", "w")
я = 1
для строки в fobj_in:
печать line.rstrip ()
fobj_out.write (str (i) + ":" + строка)
я = я + 1
fobj_in.close ()
fobj_out.Закрыть()
Каждая строка входного текстового файла имеет префикс ее номера. Так выглядит результат
так:$ more ad_lesbiam2.txt 1: В. ад Лесбиам 2: 3: VIVAMUS mea Lesbia, atque amemus, 4.Rumoresque senum seueriorum. 5: omnes unius aestimemus assis! 6: подошвы на западе и возможность перенаправления: 7: nobis cum semel occidit breuis lux, 8: nox est perpetua una dormienda. 9: da mi basia mille, deinde centum, 10: dein mille altera, dein secunda centum, 11: deinde usque altera mille, deinde centum.12: деин, cum milia multa fecerimus, 13: conturbabimus illa, ne sciamus, 14: aut ne quis malus inuidere Possit, 15: cum tantum sciat esse basiorum. 16: (ГАЙУС ВАЛЕРИУС КАТУЛЛ)Мы должны указать на одну возможную проблему: что произойдет, если вы откроете файл для записи, и этот файл уже существует. Будьте счастливы, если у вас была резервная копия этого файла, если она вам нужна, потому что как только open () с «w» файл будет удален. Часто это именно то, что вам нужно, но иногда вы просто хотите добавить в файл, как в случае с файлами журнала.
Если вы хотите что-то добавить к существующему файлу, вы должны использовать «a» вместо «w».
Чтение за один раз
До сих пор мы работали с файлами построчно, используя цикл for. Очень часто, особенно если файл не слишком большой, удобнее читать файл в полную структуру данных, например строка или список. Файл можно закрыть после чтение и работа над этой структурой данных:
>>> poem = open ("ad_lesbiam.txt"). readlines ()
>>> напечатать стихотворение
['В.ad Lesbiam \ n ',' \ n ',' VIVAMUS mea Lesbia, atque amemus, \ n ',' rumoresque senum seueriorum \ n ',' omnes unius aestimemus assis! \ n ',' soles occidere et redire Possunt: \ n ',' nobis cum semel occidit breuis lux, \ n ',' nox est perpetua una dormienda. \ n ',' da mi basia mille, deinde centum, \ n ',' dein mille altera, dein secunda centum, \ n ' , 'deinde usque altera mille, deinde centum. \ n', 'dein, cum milia multa fecerimus, \ n', 'conturbabimus illa, ne sciamus, \ n', 'aut ne quis malus inuidere Possit, \ n', ' cum tantum sciat esse basiorum.\ n ',' (ГАЙУС ВАЛЕРИУС КАТУЛЛУС) ']
>>> печатное стихотворение [2]
VIVAMUS mea Lesbia, atque amemus,
В приведенном выше примере полное стихотворение читается в стихотворении-списке. Мы можем получить доступ, например, 3-я линия с
Поэма [2] .Еще один удобный способ чтения файла — это метод read () of open. С помощью этого метода мы можем прочитать Полный файл в строку, как мы видим в следующем примере:
>>> poem = open ("ad_lesbiam.txt"). read ()
>>> печатное стихотворение [16:34]
VIVAMUS mea Lesbia
>>> тип (стихотворение)
<тип 'str'>
>>>
Эта строка содержит полный файл, включая символы возврата каретки и перевода строки.«Как попасть в рассол»
Мы не имеем в виду то, что написано в заголовке. Мы просто хотим показать вам, как можно легко сохранить свои данные, так что вы или лучше ваша программа можете перечитать их позже снова. Мы «травим» данные, чтобы это не теряется.
Python предлагает для этой цели модуль, который называется «pickle». С помощью алгоритмов модуля pickle мы можем сериализовать и десериализовать структуры объектов Python. «Обработка» обозначает процесс, который преобразует иерархию объектов Python в поток байтов, а «распаковка», с другой стороны, является обратной операцией, т.е.е. байтовый поток конвертируется обратно в иерархию объектов. То, что мы называем травлением (и распаковкой), также известно как «сериализация». или «сглаживание» структуры данных.
Объект может быть сброшен с помощью метода дампа модуля pickle:
pickle.dump (объект, файл [, протокол])Сериализованная версия объекта «obj» будет записана в файл «file». Протокол определяет способ записи объекта:
- 0 = ascii
- 1 = компактный (не читаемый человеком)
- 2 = оптимизированные классы
Объекты, которые были выгружены в файл с рассолом .дамп можно перечитать в программу с помощью метода pickle.load (file). pickle.load автоматически распознает, какой формат был использован для записи данных.
Простой пример:
импортный рассол
данные = (1,4,42)
output = open ('data.pkl', 'ш')
pickle.dump (данные, вывод)
output.close ()
После выполнения этого кода содержимое файла data.pkl будет выглядеть так:(F1.3999999999999999 I42 tp0 .Этот файл можно легко прочитать снова:
>>> импортный рассол
>>> f = open ("data.пкл ")
>>> data = pickle.load (f)
>>> распечатать данные
(1,3999999999999999, 42)
>>>
Сохраняются только объекты, а не их названия. Вот почему мы используем присвоение данных в
предыдущий пример, т.е. data = pickle.load (f). Предыдущая глава: Глобальные и локальные переменные Следующая глава: Модульное программирование и модули
Учебное пособие по Python: Управление файлами
«Как попасть в рассол»
Мы действительно не имеем в виду то, что написано в заголовке.Напротив, мы хотим предотвратить любую неприятную ситуацию, например потерю данных, рассчитанных вашей программой Python. Итак, мы покажем вам, как вы можете легко сохранить свои данные, чтобы вы или, лучше, ваша программа могла повторно прочитать их позже. Мы «травим» данные, чтобы ничего не потерялось.
Python предлагает модуль для этой цели, который называется «pickle». С помощью алгоритмов модуля pickle мы можем сериализовать и десериализовать структуры объектов Python. «Обработка» обозначает процесс, который преобразует иерархию объектов Python в поток байтов, а «выделение», с другой стороны, является обратной операцией, т.е.е. поток байтов преобразуется обратно в иерархию объектов. То, что мы называем травлением (и распаковкой), также известно как «сериализация» или «выравнивание» структуры данных.
Объект можно выгрузить методом дампа модуля pickle:
pickle.dump (obj, file [, protocol, *, fix_imports = True])
dump () записывает консервированное представление obj в объектный файл открытого файла. Необязательный аргумент протокола указывает сборщику использовать указанный протокол:
- Протокол версии 0 является исходным (до Python3) удобочитаемым (ascii) протоколом и обратно совместим с предыдущими версиями Python. Протокол
- версии 1 — это старый двоичный формат, который также совместим с предыдущими версиями Python. Протокол
- версии 2 был представлен в Python 2.3. Он обеспечивает гораздо более эффективное «консервирование» классов нового стиля. Протокол
- версии 3 был представлен в Python 3.0. Он имеет явную поддержку байтов и не может быть извлечен модулями pickle Python 2.x. Это рекомендуемый протокол Python 3.x.
Протокол Python3 по умолчанию — 3.
Если fix_imports имеет значение True и протокол меньше 3, pickle попытается сопоставить новые имена Python3 со старыми именами модулей, используемыми в Python2, чтобы поток данных pickle был доступен для чтения с помощью Python 2.
Объекты, которые были выгружены в файл с помощью pickle.dump, можно перечитать в программе с помощью метода pickle.load (file). pickle.load автоматически распознает, какой формат был использован для записи данных. Простой пример:
импортный рассол
cities = ["Париж", "Дижон", "Лион", "Страсбург"]
fh = open ("data.pkl", "bw")
pickle.dump (города, fh)
fh.close () Файл data.pkl может быть снова прочитан Python в том же или другом сеансе или другой программой:
импортный рассол
f = open ("данные.пкл »,« рб »)
villes = pickle.load (е)
печать (виллес)
["Париж", "Дижон", "Лион", "Страсбург"]
Сохраняются только объекты, а не их имена. Вот почему мы используем присвоение villes в предыдущем примере, т.е. data = pickle.load (f).
В нашем предыдущем примере мы выбрали только один объект, то есть список французских городов. Но как насчет травления нескольких объектов? Решение простое: мы упаковываем объекты в другой объект, поэтому нам нужно будет снова засолить один объект.Мы упакуем два списка «programming_languages» и «python_dialects» в список pickle_objects в следующем примере:
импортный рассол
fh = open ("data.pkl", "bw")
программирование_languages = ["Python", "Perl", "C ++", "Java", "Lisp"]
python_dialects = ["Jython", "IronPython", "CPython"]
pickle_object = (программирование_языков, python_dialects)
pickle.dump (pickle_object, fh)
fh.close ()
Консервированные данные из предыдущего примера, то есть данные, которые мы записали в файл data.pkl, — снова можно разделить на два списка, когда мы перечитаем данные:
импортный рассол f = open («data.pkl», «rb») языки, диалекты) = pickle.load (f) печать (языки, диалекты) [Python, Perl, C ++, Java, Lisp] [Jython, IronPython, CPython]
Модуль полки
Один из недостатков модуля травления заключается в том, что он способен протравливать только один объект за раз, который нужно отобрать за один раз. Представим, что этот объект данных представляет собой словарь.Может быть желательно, чтобы нам не нужно было каждый раз сохранять и загружать весь словарь, а сохранять и загружать только одно значение, соответствующее только одному ключу. Модуль полки — решение этого запроса. «Полка», используемая в модуле полки, представляет собой постоянный объект, подобный словарю. Разница с базами данных dbm состоит в том, что значения (не ключи!) На полке могут быть по существу произвольными объектами Python — всем, что может обрабатывать модуль «pickle». Это включает в себя большинство экземпляров классов, рекурсивных типов данных и объектов, содержащих множество общих подобъектов.Ключи должны быть строками.
Модуль полки можно легко использовать. На самом деле это так же просто, как использовать словарь в Python. Прежде чем мы сможем использовать объект полки, мы должны импортировать модуль. После этого мы должны открыть объект полки с открытым методом полки. Открытый метод открывает специальный файл полки для чтения и записи:
импортная полка s = shelve.open («MyShelve»)
Если файл «MyShelve» уже существует, метод open попытается открыть его.Если это не файл полки, то есть файл, созданный с помощью модуля полки, мы получим сообщение об ошибке. Если файл не существует, он будет создан.
Мы можем использовать s как обычный словарь, если мы используем строки в качестве ключей:
s ["street"] = "Fleet Str"
s ["city"] = "Лондон"
для ввода s:
печать (ключ) Python Запись в файл — объяснение функций открытия, чтения, добавления и других функций обработки файлов
Добро пожаловать
Привет! Если вы хотите научиться работать с файлами в Python, эта статья для вас.Работа с файлами — важный навык, которому должен овладеть каждый разработчик Python, поэтому приступим.
Из этой статьи вы узнаете:
- Как открыть файл.
- Как читать файл.
- Как создать файл.
- Как изменить файл.
- Как закрыть файл.
- Как открывать файлы для нескольких операций.
- Как работать с методами файлового объекта.
- Как удалить файлы.
- Как работать с менеджерами контекста и чем они полезны.
- Как обрабатывать исключения, которые могут возникать при работе с файлами.
- и другие!
Начнем! ✨
🔹 Работа с файлами: базовый синтаксис
Одна из наиболее важных функций, которые вам нужно будет использовать при работе с файлами в Python, — это open () , встроенная функция, которая открывает файл и позволяет вашей программе использовать его и работать с ним.
Это основной синтаксис :
💡 Совет: Это два наиболее часто используемых аргумента для вызова этой функции.Есть шесть дополнительных необязательных аргументов. Чтобы узнать о них больше, прочтите эту статью в документации.
Первый параметр: файл
Первый параметр функции open () — это файл , абсолютный или относительный путь к файлу, с которым вы пытаетесь работать.
Обычно мы используем относительный путь, который указывает, где расположен файл относительно местоположения скрипта (файла Python), который вызывает функцию open () .
Например, путь в этом вызове функции:
open ("names.txt") # Относительный путь - "names.txt" Содержит только имя файла. Это можно использовать, когда файл, который вы пытаетесь открыть, находится в том же каталоге или папке, что и сценарий Python, например:
Но если файл находится во вложенной папке, например:
Файл names.txt — это в папке «data»Затем нам нужно использовать определенный путь, чтобы сообщить функции, что файл находится в другой папке.
В этом примере это будет путь:
open ("data / names.txt") Обратите внимание, что мы сначала пишем data / (имя папки, за которым следует / ), а затем names.txt (имя файла с расширением).
💡 Совет: Три буквы .txt , следующие за точкой в names.txt , являются «расширением» файла или его типом. В этом случае .txt означает, что это текстовый файл.
Второй параметр: Mode
Второй параметр функции open () — это mode , строка из одного символа. Этот единственный символ в основном сообщает Python, что вы планируете делать с файлом в своей программе.
Доступные режимы:
- Чтение (
"r"). - Добавить (
"a") - Запись (
"w") - Создать (
"x")
Вы также можете открыть файл в:
- Текстовый режим (
"t") - Двоичный режим (
"b")
Чтобы использовать текстовый или двоичный режим, вам нужно добавить эти символы в основной режим.Например: «wb» означает запись в двоичном режиме.
💡 Совет: Режимы по умолчанию — это чтение ( "r" ) и текст ( "t" ), что означает «открыт для чтения текста» ( "rt" ), поэтому вы не необходимо указать их в open () , если вы хотите их использовать, потому что они назначаются по умолчанию. Вы можете просто написать open (<файл>) .
Почему именно режимы?
Для Python действительно имеет смысл предоставлять только определенные разрешения в зависимости от того, что вы планируете делать с файлом, верно? Почему Python должен позволять вашей программе делать больше, чем необходимо? В основном поэтому существуют режимы.
Подумайте об этом — позволить программе делать больше, чем необходимо, может быть проблематичным. Например, если вам нужно только прочитать содержимое файла, может быть опасно позволить вашей программе неожиданно изменить его, что потенциально может привести к ошибкам.
🔸 Как читать файл
Теперь, когда вы знаете больше об аргументах, которые принимает функция open () , давайте посмотрим, как вы можете открыть файл и сохранить его в переменной для использования в своей программе. .
Это основной синтаксис:
Мы просто присваиваем значение, возвращаемое переменной.Например:
names_file = open ("data / names.txt", "r") Я знаю, что вы можете спросить: какой тип значения возвращает open () ?
Ну, файл объект .
Давайте немного о них поговорим.
Файловые объекты
Согласно документации Python, файловый объект — это:
Объект, предоставляющий файловый API (с такими методами, как read () или write ()) для базового ресурса.
По сути, это говорит нам, что файловый объект — это объект, который позволяет нам работать и взаимодействовать с существующими файлами в нашей программе Python.
Файловые объекты имеют такие атрибуты, как:
- имя : имя файла.
- закрыт :
Истинно, если файл закрыт.Неверноиначе. - режим : режим, используемый для открытия файла.
Например:
f = open ("данные / имена.txt "," а ")
print (f.mode) # Вывод: "a" Теперь давайте посмотрим, как вы можете получить доступ к содержимому файла через файловый объект.
Методы чтения файла
Чтобы мы могли работать с файловыми объектами, нам нужен способ «взаимодействовать» с ними в нашей программе, и это именно то, что делают методы. Посмотрим на некоторые из них.
Read () Первый метод, о котором вам нужно узнать, — это read () , , который возвращает все содержимое файла в виде строки.
Вот пример:
f = open ("data / names.txt")
print (f.read ()) Результат:
Нора
Джино
Тимми
William Вы можете использовать функцию type () , чтобы подтвердить, что значение, возвращаемое функцией f.read () , является строкой:
print (type (f.read ()))
# Выход
Да, это строка!
В этом случае был напечатан весь файл, потому что мы не указали максимальное количество байтов, но мы тоже можем это сделать.
Вот пример:
f = open ("data / names.txt")
print (f.read (3)) Возвращаемое значение ограничено этим количеством байтов:
Nor ❗️ Важно: Вам нужно закрыть файл после завершения задачи, чтобы освободить ресурсы, связанные с файлом. Для этого вам нужно вызвать метод close () , например:
Readline () vs. Readlines ()
С помощью этих двух методов вы можете читать файл построчно.Они немного отличаются, поэтому давайте рассмотрим их подробнее.
readline () считывает одну строку файла, пока не достигнет конца этой строки. Завершающий символ новой строки ( \ n ) сохраняется в строке.
💡 Совет: При желании вы можете передать размер, максимальное количество символов, которое вы хотите включить в результирующую строку.
Например:
f = open ("data / names.txt")
печать (f.readline ())
f.close () Результат:
Нора
Это первая строка файла.
Напротив, readlines () возвращает список со всеми строками файла как отдельными элементами (строками). Это синтаксис:
Например:
f = open ("data / names.txt")
печать (f.readlines ())
f.close () Результат:
['Нора \ n', 'Джино \ n', 'Тимми \ n', 'Уильям'] Обратите внимание, что есть \ n (символ новой строки) в конце каждой строки, кроме последней.
💡 Совет: Вы можете получить тот же список со списком (f) .
Вы можете работать с этим списком в своей программе, назначив его переменной или используя его в цикле:
f = open ("data / names.txt")
для строки в f.readlines ():
# Сделайте что-нибудь с каждой строкой
f.close () Мы также можем перебирать f напрямую (файловый объект) в цикле:
f = open ("data / names.txt", "r")
для строки в f:
# Сделайте что-нибудь с каждой строкой
f.close () Это основные методы, используемые для чтения файловых объектов. Теперь посмотрим, как можно создавать файлы.
🔹 Как создать файл
Если вам нужно создать файл «динамически» с помощью Python, вы можете сделать это в режиме "x" .
Посмотрим как. Это основной синтаксис:
Вот пример. Это мой текущий рабочий каталог:
Если я запустил эту строку кода:
f = open ("new_file.txt", "x") Будет создан новый файл с таким именем:
С этим В режиме вы можете создать файл, а затем динамически записать в него данные, используя методы, которым вы научитесь всего за несколько минут.
💡 Совет: Файл будет изначально пустым, пока вы его не измените.
Любопытно, что если вы попытаетесь запустить эту строку еще раз, а файл с таким именем уже существует, вы увидите следующую ошибку:
Traceback (последний вызов последним):
Файл «<путь>», строка 8, в <модуле>
f = open ("новый_файл.txt", "x")
FileExistsError: [Errno 17] Файл существует: 'new_file.txt' Согласно документации Python, это исключение (ошибка времени выполнения):
Возникает при попытке создать файл или каталог, который уже существует.
Теперь, когда вы знаете, как создать файл, давайте посмотрим, как вы можете его изменить.
🔸 Как изменить файл
Для изменения (записи) файла необходимо использовать метод write () . У вас есть два способа сделать это (добавить или записать) в зависимости от того, в каком режиме вы его открываете. Посмотрим на них подробнее.
Приложение
«Добавление» означает добавление чего-либо в конец другого предмета. Режим "a" позволяет открывать файл для добавления к нему некоторого содержимого.
Например, если у нас есть этот файл:
И мы хотим добавить к нему новую строку, мы можем открыть его, используя режим "a" (добавить), а затем вызвать команду записи ( ) , передавая содержимое, которое мы хотим добавить в качестве аргумента.
Это основной синтаксис для вызова метода write () :
Вот пример:
f = open ("data / names.txt", "a")
f.write ("\ nНовая строка")
f.close () 💡 Совет: Обратите внимание, что я добавляю \ n перед строкой, чтобы указать, что я хочу, чтобы новая строка отображалась как отдельная строка, а не как продолжение существующей строки.
Теперь это файл после запуска сценария:
💡 Совет: Новая строка может не отображаться в файле до тех пор, пока не запустится f.close () .
Запись
Иногда может потребоваться удалить содержимое файла и полностью заменить его новым содержимым.Вы можете сделать это с помощью метода write () , если вы откроете файл в режиме "w" .
Здесь у нас есть этот текстовый файл:
Если я запустил этот скрипт:
f = open ("data / names.txt", "w")
f.write («Новый контент»)
f.close ()
Это результат:
Как видите, открытие файла в режиме "w" с последующей записью в него заменяет существующее содержимое.
💡 Совет: Метод write () возвращает количество записанных символов.
Если вы хотите написать несколько строк одновременно, вы можете использовать метод writerelines () , который принимает список строк. Каждая строка представляет собой строку, которую нужно добавить в файл.
Вот пример. Это исходный файл:
Если мы запустим этот скрипт:
f = open ("data / names.txt", "a")
f.writelines (["\ nline1", "\ nline2", "\ nline3"])
f.close () Строки добавляются в конец файла:
Открыть файл для нескольких операций
Теперь вы знаете, как создавать, читать и записывать в файл, но что, если вы хотите сделать более одного объекта в одной программе? Давайте посмотрим, что произойдет, если мы попытаемся сделать это с режимами, которые вы уже изучили:
Если вы откроете файл в режиме "r" (чтение), а затем попытаетесь записать в него:
f = open ("данные / имена.текст")
f.write ("New Content") # Пытаюсь написать
f.close () Вы получите следующую ошибку:
Traceback (последний вызов последний):
Файл «<путь>», строка 9, в <модуле>
f.write («Новый контент»)
io.UnsupportedOperation: не доступен для записи Аналогично, если вы откроете файл в режиме "w" (запись), а затем попытаетесь его прочитать:
f = open ("data / names.txt", " w ")
print (f.readlines ()) # Пытаюсь прочитать
f.write («Новый контент»)
f.close () Вы увидите эту ошибку:
Traceback (последний вызов последний):
Файл «<путь>», строка 14, в <модуле>
печать (f.readlines ())
io.UnsupportedOperation: не читается То же самое произойдет с режимом "a" (добавление).
Как решить эту проблему? Чтобы иметь возможность читать файл и выполнять другую операцию в той же программе, вам необходимо добавить в режим символ "+" , например:
f = open ("data / names.txt", " w + ") # Чтение + Запись f = open (" data / names.txt "," a + ") # Чтение + Добавление f = open (" data / names.txt "," r + ") # Чтение + запись Очень полезно, не так ли? Это, вероятно, то, что вы будете использовать в своих программах, но обязательно включайте только те режимы, которые вам нужны, чтобы избежать потенциальных ошибок.
Иногда файлы больше не нужны. Давайте посмотрим, как удалить файлы с помощью Python.
🔹 Как удалить файлы
Чтобы удалить файл с помощью Python, вам необходимо импортировать модуль под названием os , который содержит функции, которые взаимодействуют с вашим Операционная система.
💡 Совет: Модуль — это файл Python со связанными переменными, функциями и классами.
В частности, вам понадобится функция remove () . Эта функция принимает путь к файлу в качестве аргумента и автоматически удаляет файл.
Давайте посмотрим на пример. Мы хотим удалить файл с именем sample_file.txt .
Для этого напишем такой код:
import os
os.remove ("файл_выпуска.txt ") - Первая строка:
import osназывается« оператором импорта ». Этот оператор записывается в верхней части файла и дает вам доступ к функциям, определенным в модулеos. - Вторая строка:
os.remove ("sample_file.txt")удаляет указанный файл.
💡 Совет: вы можете использовать абсолютный или относительный путь.
Теперь, когда вы знаете, как удалять файлы , посмотрим интересный инструмент… Менеджеры контекста!
🔸 Познакомьтесь с менеджерами контекста
Контекстные менеджеры — это конструкции Python, которые сделают вашу жизнь намного проще. Используя их, вам не нужно помнить о закрытии файла в конце вашей программы, и у вас есть доступ к файлу в конкретной части программы, которую вы выбираете.
Синтаксис
Это пример диспетчера контекста, используемого для работы с файлами:
💡 Совет: Тело диспетчера контекста должно иметь отступ, точно так же, как мы делаем отступ для циклов, функций и классов.Если код без отступа, он не будет считаться частью диспетчера контекста.
Когда тело диспетчера контекста завершено, файл закрывается автоматически.
с open ("<путь>", "<режим>") как :
# Работа с файлом ...
# Здесь файл закрыт! Пример
Вот пример:
с open ("data / names.txt", "r +") как f:
print (f.readlines ()) Этот диспетчер контекста открывает имена .txt для операций чтения / записи и назначает этот файловый объект переменной f . Эта переменная используется в теле диспетчера контекста для ссылки на файловый объект.
Попытка прочитать его снова
После того, как тело было завершено, файл автоматически закрывается, поэтому его нельзя прочитать, не открывая его снова. Но ждать! У нас есть строка, которая пытается прочитать его снова, прямо здесь, ниже:
с open ("data / names.txt", "r +") как f:
печать (f.readlines ())
печать (f.readlines ()) # Попытка прочитать файл снова, вне контекстного менеджера Посмотрим, что произойдет:
Traceback (последний вызов последним):
Файл «<путь>», строка 21, в <модуле>
печать (f.readlines ())
ValueError: операция ввода-вывода для закрытого файла. Эта ошибка возникает из-за того, что мы пытаемся прочитать закрытый файл. Классно, правда? Менеджер контекста делает всю тяжелую работу за нас, он удобочитаем и лаконичен.
🔹 Как обрабатывать исключения при работе с файлами
При работе с файлами могут возникать ошибки.Иногда у вас может не быть необходимых разрешений для изменения файла или доступа к нему, или файл может даже не существовать.
Как программист, вы должны предвидеть эти обстоятельства и обрабатывать их в своей программе, чтобы избежать внезапных сбоев, которые определенно могут повлиять на работу пользователя.
Давайте посмотрим на некоторые из наиболее распространенных исключений (ошибок времени выполнения), которые вы можете обнаружить при работе с файлами:
FileNotFoundError
Согласно документации Python, это исключение:
Возникает, когда файл или каталог запрашивается, но не существует.
Например, если файл, который вы пытаетесь открыть, не существует в вашем текущем рабочем каталоге:
f = open ("names.txt") Вы увидите эту ошибку:
Отслеживание (последний вызов последний):
Файл «<путь>», строка 8, в <модуле>
f = open ("names.txt")
FileNotFoundError: [Errno 2] Нет такого файла или каталога: 'names.txt' Давайте разберем эту ошибку по строкам:
-
Файл «<путь>», строка 8, в <модуль>.Эта строка сообщает вам, что ошибка возникла, когда выполнялся код файла, расположенного в<путь>. В частности, когдастрока 8выполнялась в -
f = open ("names.txt"). Это строка, которая вызвала ошибку. -
FileNotFoundError: [Errno 2] Нет такого файла или каталога: 'names.txt'. В этой строке говорится, что возникло исключениеFileNotFoundErrorиз-за имени файла или каталога.txtне существует.
💡 Совет: Python очень информативен с сообщениями об ошибках, верно? Это огромное преимущество в процессе отладки.
PermissionError
Это еще одно распространенное исключение при работе с файлами. Согласно документации Python, это исключение:
Возникает при попытке запустить операцию без соответствующих прав доступа — например, разрешений файловой системы.
Это исключение возникает, когда вы пытаетесь прочитать или изменить файл, для которого нет разрешения на доступ.Если вы попытаетесь это сделать, вы увидите эту ошибку:
Traceback (последний вызов последний):
Файл «<путь>», строка 8, в <модуле>
f = open ("<путь-к-файлу>")
PermissionError: [Errno 13] Permission denied: 'data' IsADirectoryError
Согласно документации Python, это исключение:
Возникает, когда в каталоге запрашивается файловая операция.
Это конкретное исключение возникает, когда вы пытаетесь открыть каталог или работать с ним, а не с файлом, поэтому будьте очень осторожны с путем, который вы передаете в качестве аргумента.
Как обрабатывать исключения
Для обработки этих исключений можно использовать оператор try / except . С помощью этого оператора вы можете «сказать» своей программе, что делать в случае чего-то неожиданного.
Это основной синтаксис:
попробуйте:
# Попробуйте запустить этот код
кроме :
# Если возникает исключение этого типа, остановить процесс и перейти к этому блоку
Здесь вы можете увидеть пример с FileNotFoundError :
попробуйте:
f = open ("имена.текст")
кроме FileNotFoundError:
print («Файл не существует») В основном это говорит:
- Попробуйте открыть файл
names.txt. - Если выдается
FileNotFoundError, не сбой! Просто распечатайте описательное заявление для пользователя.
💡 Совет: Вы можете выбрать, как справиться с ситуацией, написав соответствующий код в блоке , кроме блока . Возможно, вы могли бы создать новый файл, если он еще не существует.
Чтобы автоматически закрыть файл после выполнения задачи (независимо от того, было ли исключение вызвано или нет в блоке try ), вы можете добавить блок finally .
попробуйте:
# Попробуйте запустить этот код
кроме <исключение>:
# Если возникает это исключение, немедленно остановить процесс и перейти к этому блоку
наконец-то:
# Сделайте это после запуска кода, даже если возникло исключение Это пример:
попробуйте:
f = open ("имена.текст")
кроме FileNotFoundError:
print («Файл не существует»)
наконец-то:
f.close () Есть много способов настроить оператор try / except / finally, и вы даже можете добавить блок else для запуска блока кода, только если в блоке try не возникло никаких исключений.
💡 Совет: Чтобы узнать больше об обработке исключений в Python, вы можете прочитать мою статью «Как обрабатывать исключения в Python: подробное визуальное введение».
🔸 Вкратце
- Вы можете создавать, читать, записывать и удалять файлы с помощью Python.
- Файловые объекты имеют собственный набор методов, которые вы можете использовать для работы с ними в своей программе.
- Контекстные менеджеры помогают работать с файлами и управлять ими, автоматически закрывая их после завершения задачи.
- Обработка исключений является ключевым моментом в Python. Общие исключения при работе с файлами включают
FileNotFoundError,PermissionErrorиIsADirectoryError.С ними можно справиться с помощью try / except / else / finally.
Я очень надеюсь, что вам понравилась моя статья и вы нашли ее полезной. Теперь вы можете работать с файлами в своих проектах Python. Ознакомьтесь с моими онлайн-курсами. Подпишись на меня в Твиттере. 000
Учебное пособие по основам Python: Работа с файлами
Получение данных в файлы и из файлов в Python во многом похоже на использование низкоуровневых методов языка C, но в нем есть вся легкость Python, наложенная сверху.
Например, чтобы открыть файл для записи, используйте встроенную (и очень похожую на C) функцию open () . Но затем запишите содержимое списка одним вызовом. Функция open () возвращает объект открытого файла, и закрытие файла выполняется путем вызова метода close () этого объекта.
| Примечание | |
|---|---|
методы |
>>> colors = ['красный \ n', 'желтый \ n', 'синий \ n']
>>> f = open ('colors.txt', 'w')
>>> f.writelines (цвета)
>>> f.close () По умолчанию функция open () возвращает файл, открытый для чтения. Отдельные строки можно прочитать с помощью метода readline () , который вернет пустую строку. Поскольку строка нулевой длины не соответствует действительности, она представляет собой простой маркер.
>>> f = open ('colors.txt')
>>> f.readline ()
'красный \ п'
>>> f.readline ()
'желтый \ n'
>>> f.readline ()
'синий \ п'
>>> f.readline ()
''
>>> f.close () В качестве альтернативы, все строки файла могут быть считаны в список одним вызовом метода, а затем повторены оттуда.
>>> f = open ('colors.txt')
>>> f.readlines ()
['красный \ n', 'желтый \ n', 'синий \ n']
>>> е.close () Однако для больших файлов чтение содержимого в память может быть непрактичным. Поэтому лучше всего использовать сам файловый объект в качестве итератора, который будет потреблять содержимое файла по мере необходимости без промежуточных требований к памяти.
>>> f = open ('colors.txt')
>>> для строки в f:
... строка печати,
...
красный
желтый
синий
>>> f.close () Чтобы гарантировать, что файлы в приведенных выше примерах были должным образом закрыты, они должны быть защищены от ненормального выхода (посредством исключения или другого неожиданного возврата) с помощью оператора finally .См. Следующий пример, где в последней строке seek () видно, что файл закрывается в случае правильного выполнения.
>>> f = open ('colors.txt')
>>> попробуйте:
... lines = f.readlines ()
... наконец-то:
... f.close ()
...
>>> линии
['красный \ n', 'желтый \ n', 'синий \ n']
>>> f.seek (0)
Отслеживание (последний вызов последний):
Файл "", строка 1, в
ValueError: операция ввода-вывода для закрытого файла В следующем примере путь кода не выполняет попытку записи в файл, открытый для чтения.Файл по-прежнему закрыт в пункте finally .
>>> f = open ('colors.txt')
>>> попробуйте:
... f.writelines ('пурпурный \ n')
... наконец-то:
... f.close ()
...
Отслеживание (последний вызов последний):
Файл "", строка 2, в
IOError: файл не открыт для записи
>>> f.seek (0)
Отслеживание (последний вызов последний):
Файл "", строка 1, в
ValueError: операция ввода-вывода в закрытом файле Начиная с Python 2.6, есть встроенный синтаксис для работы с этой парадигмой, использующий с ключевым словом . с создает контекст и независимо от того, как этот контекст завершается, вызывает метод __exit __ () управляемого объекта. В следующем примере этим объектом является файл f , но эта модель работает для любого файлового объекта (объектов с базовыми методами файлов).
Еще раз, выполнение операции с файлом вне этого контекста показывает, что он был закрыт.
>>> с открытым ('colors.txt') как f:
... для строки в f:
... строка печати,
...
красный
желтый
синий
>>> f.seek (0)
Отслеживание (последний вызов последний):
Файл "", строка 1, в
ValueError: операция ввода-вывода для закрытого файла Как упоминалось выше, файловые объекты — это объекты, которые выглядят и воспринимаются как файлы. В Python нет строгого требования наследования для использования объекта, как если бы он был другим. StringIO — это пример файлового объекта, который управляет своим содержимым в памяти, а не на диске.
Здесь важно помнить о файловом поведении. Обратите внимание, что после записи требуется поиск, чтобы вернуться к началу и прочитать. Попытка запустить один и тот же итератор дважды не приводит к получению значений во второй раз.
StringIO.getvalue () возвращает вновь созданный строковый объект с полным содержимым буфера StringIO .
>>> colors = ['красный \ n', 'желтый \ n', 'синий \ n'] >>> из StringIO импортировать StringIO >>> буфер = StringIO () >>> buffer.writelines (цвета) >>> buffer.seek (0) >>> для строки в буфере: ... строка печати, ... красный желтый синий >>> для строки в буфере: ... строка печати, ... >>> buffer.getvalue () 'red \ nyellow \ nblue \ n'
Обработка файлов в Python
Введение
Это неписаный консенсус в отношении того, что Python — один из лучших начальных языков программирования для изучения новичком.Он чрезвычайно универсален, легко читается / анализируется и довольно приятен для глаз. Язык программирования Python отличается высокой масштабируемостью и широко считается одним из лучших наборов инструментов для создания инструментов и утилит, которые вы можете использовать по разным причинам.
В этой статье кратко описывается, как Python обрабатывает один из самых важных компонентов любой операционной системы: ее файлы и каталоги. К счастью, Python имеет встроенные функции для создания файлов и управления ими, будь то плоские или текстовые файлы.Модуль io является модулем по умолчанию для доступа к файлам, поэтому нам не нужно импортировать какую-либо внешнюю библиотеку для общих операций ввода-вывода.
Ключевые функции, используемые для обработки файлов в Python: open () , close () , read () , write () и append () .
Открытие файлов с открытием
() Эта функция возвращает файловый объект с именем «handle», который используется для чтения и записи в файл.Аргументы, которые может получить функция, следующие:
открыть (имя файла, режим = 'r', буферизация = -1, кодировка = Нет, ошибки = Нет, новая строка = Нет, closefd = True, opener = Нет)
Обычно необходимы только параметры filename и mode , в то время как остальные используются неявно с их значениями по умолчанию.
В следующем фрагменте кода показано, как можно использовать эту функцию:
file_example = open ("TestingText.текст")
Это откроет текстовый файл под названием «TestingText» в режиме только для чтения. Обратите внимание, что был указан только параметр имени файла, это связано с тем, что режим «чтения» является режимом по умолчанию для функции открытия.
Для функции open () доступны следующие режимы доступа:
-
r: открывает файл в режиме только для чтения. Начинает чтение с начала файла и является режимом по умолчанию для функцииopen (). -
rb: открывает файл только для чтения в двоичном формате и начинает чтение с начала файла. Хотя двоичный формат может использоваться для разных целей, обычно он , используется при работе с такими вещами, как изображения, видео и т. Д. -
r +: открывает файл для чтения и записи, помещая указатель в начало файла. -
w: открывается в режиме только записи. Указатель помещается в начало файла, и это перезаписывает любой существующий файл с тем же именем.Он создаст новый файл, если файл с таким же именем не существует. -
wb: открывает файл только для записи в двоичном режиме. -
w +: открывает файл для записи и чтения. -
wb +: открывает файл для записи и чтения в двоичном режиме. -
a: открывает файл для добавления к нему новой информации. Указатель помещается в конец файла. Если файл с таким же именем не существует, создается новый файл. -
ab: открывает файл для добавления в двоичном режиме. -
a +: открывает файл как для добавления, так и для чтения. -
ab +: открывает файл для добавления и чтения в двоичном режиме.
Если и исполняемый файл Python, и целевой файл для чтения не существуют в одном каталоге, нам нужно передать полный путь к файлу для чтения в функцию open () , как показано ниже. фрагмент кода:
file_example = open ("F: \\ Directory \\ AnotherDirectory \\ tests \\ TestingText.текст")
Примечание : Следует всегда помнить о том, чтобы всегда проверять правильность имени файла и указанного пути. Если либо неверно, либо не существует, будет выдана ошибка FileNotFoundError , которую затем необходимо перехватить и обработать вашей программой, чтобы предотвратить ее сбой.
Чтобы избежать этой проблемы, рекомендуется перехватывать ошибки с помощью блока try-finally для обработки исключения, как показано ниже.
попробовать:
file_example = open ("F: \\ Directory \\ AnotherDirectory \\ tests \\ TestingText.текст")
кроме IOError:
print («Обнаружена ошибка. Либо путь неверен, либо файл не существует!»)
наконец-то:
print ("Прекращение процесса!")
Чтение из файлов с
чтением () Python содержит 3 функции для чтения файлов: read () , readline () и readlines () . Последние две функции являются просто вспомогательными функциями, которые упрощают чтение определенных типов файлов.
Для примеров, которые будут использоваться, «TestingText.txt «содержит следующий текст:
Привет, мир! Python - это способ создавать отличное кодирование.
Если вы мне не верите, попробуйте сами.
Приходите, вам понравится Темная сторона. У нас есть куки!
Метод чтения используется следующим образом:
file_example = open ("F: \\ Directory \\ AnotherDirectory \\ tests \\ TestingText.txt", "r")
печать (file_example.read ())
Результат будет следующим:
Привет, мир! Python - это способ создавать отличное кодирование.Если вы мне не верите, попробуйте сами.
Приходите, вам понравится Темная сторона. У нас есть куки!
Примечание : Специальные символы могут быть неправильно прочитаны при использовании функции чтения . Чтобы правильно читать специальные символы, вы можете передать параметр кодирования в функцию read () и установить для него значение utf8 , как показано ниже:
file_example = open ("F: \\ Directory \\ AnotherDirectory \\ tests \\ TestingText.txt", "r", encoding = "utf8")
Кроме того, функция read () , а также вспомогательная функция readline () , могут получать число в качестве параметра, который будет определять количество байтов для чтения из файла.В случае текстового файла это будет количество возвращенных символов.
file_example = open ("F: \\ Directory \\ AnotherDirectory \\ tests \\ TestingText.txt", "r")
печать (file_example.read (8))
Результат будет следующим:
Привет, ш
Вспомогательная функция readline () ведет себя аналогичным образом, но вместо возврата всего текста она вернет одну строку.
file_example = open ("F: \\ Directory \\ AnotherDirectory \\ tests \\ TestingText.txt "," r ")
печать (file_example.readline ())
печать (file_example.readline (5))
В приведенном выше сценарии первая инструкция print () возвращает первую строку и вставляет пустую строку в консоль вывода. Следующий оператор print () отделяется от предыдущей строки пустой строкой и начинается с новой строки, как показано в выходных данных:
Привет, мир! Python - это способ создавать отличное кодирование.
Если ты
Наконец, вспомогательная функция readlines () считывает весь текст и разбивает его на строки для удобства чтения.Взгляните на следующий пример:
печать (file_example.readlines ())
Результатом этого кода будет:
Привет, мир! Python - это способ создавать отличное кодирование. Если вы мне не верите, попробуйте сами. Приходите, вам понравится Темная сторона. У нас есть куки!
Имейте в виду, что функция readlines () считается намного более медленной и более неэффективной, чем функция read () , без особых преимуществ.Хорошей альтернативой этому является использование цикла, который будет работать намного плавнее и быстрее:
file_example = open ("F: \\ Directory \\ AnotherDirectory \\ tests \\ TestingText.txt", "r")
для строк в file_example:
печать (строки)
Обратите внимание, что если строка не печатается, она будет заменена в буфере следующим оператором
Запись в файлы с помощью
write () При использовании этой функции любая информация внутри файла с тем же именем будет перезаписана.Его поведение похоже на функцию read () , но вставляет информацию, а не читает ее.
file_example2 = open ("F: \\ Directory \\ AnotherDirectory \\ tests \\ TestingTextTwo.txt", "w")
file_example2.write («Это тест. Наслаждайтесь! \ n») # '\ n' - для строки изменения.
file_example2.write ("Еще нужно знать, что делать это медленно. \ n")
file_example2.write («Один за другим. Ура!»)
Если необходимо записать несколько строк, вместо этого можно использовать подфункцию writelines () :
listOfThingsToSay = ["Мне нравятся такие вещи, как: \ n", "Мороженое \ n", "Фрукты \ n", "Фильмы \ n", "Аниме \ n", "Дремота \ n", "Вяленое мясо \ n" "]
file_example2 = open ("F: \\ Directory \\ AnotherDirectory \\ tests \\ TestingTextTwo.txt "," w ")
file_example2.writelines (listOfThingsToSay)
Примечание : для использования функции print () необходимо установить режим w + , что позволяет читать и писать.
Добавление в файлы с добавлением
() Эта функция действует аналогично функции write () и , однако вместо перезаписи файла функция append () добавляет содержимое в существующий файл.
Если текстовый файл с именем «TestingTextThree» содержит следующую информацию:
Чего-то важного в жизни не хватает, и этого не следует избегать. Для добавления нового текста можно использовать следующий код:
listOfThingsDo = [«Вам нужно как минимум: \ n», «Съесть жареное мороженое \ n», «Сходить в Дисней \ n», «Путешествовать на Луну \ n», «Приготовить пиццу с ананасом \ n», "Танцевальная сальса \ n"]
file_example3 = open ("F: \\ Directory \\ AnotherDirectory \\ tests \\ TestingTextThree.txt", "a +")
file_example3.writelines (listOfThingsToDo)
для новой строки в file_example3
печать (новые строки)
Результат будет следующим:
Чего-то важного в жизни не хватает, и этого не следует избегать.Вам необходимо как минимум:
Ешьте жареное мороженое
Перейти в Дисней
Путешествие на Луну
Приготовить пиццу с ананасом
Танцевальная сальса
Закрытие открытых файлов с закрытием
() Функция close () очищает буфер памяти и закрывает файл. Это означает, что мы больше не сможем читать из файла, и нам придется повторно открыть его, если мы захотим прочитать из него снова. Кроме того, некоторые операционные системы, такие как Windows, рассматривают открытые файлы как заблокированные, поэтому важно убирать за собой в коде.
Используя ранее использованный пример кода, эта функция используется следующим образом:
file_example = open ("F: \\ Directory \\ AnotherDirectory \\ tests \\ TestingText.txt", "r")
печать (file_example.read ())
file_example.close ()
Заключение
Python — один из самых надежных языков программирования, а также один из наиболее часто используемых. Его легко реализовать, а также проанализировать, что делает его идеальным инструментом для новичков в программировании. Кроме того, его универсальность делает его идеальной отправной точкой для новичков в программировании.
Что касается обработки файлов, Python имеет простые в использовании функции с быстрым временем отклика и относительно устойчивыми методами обработки ошибок, поэтому процессы разработки и отладки намного проще, чем в других языках, когда дело доходит до работы с файлами.
Repl.it — Работа с файлами
В этом уроке вы получите опыт использования файлов и управления ими с помощью Repl.it. На предыдущем уроке вы видели, как добавлять новые файлы в проект, но вы можете сделать гораздо больше.
Файлы можно использовать для разных целей. В программировании вы в первую очередь будете использовать их для хранения данных или кода. Вместо того, чтобы вручную создавать файлы и вводить данные, вы также можете использовать свои программы для создания файлов и автоматической записи в них данных.
Repl.it также предлагает функции для массового импорта или экспорта файлов из или в IDE; это полезно в тех случаях, когда ваша программа записывает данные в несколько файлов, и вы хотите экспортировать их все для использования в другой программе.
Работа с файлами с использованием Python
Создайте новый ответ Python и назовите его работа с файлами .
Как и раньше, вы получите проект repl по умолчанию с файлом main.py . Нам нужен файл данных, чтобы практиковаться в чтении данных программным способом.
- Создайте новый файл с помощью кнопки
добавить файл. - Назовите файл
mydata.txt. Ранее мы создали файл Python (.py), но в этом случае мы создаем простой текстовый файл (.txt). - Введите строку текста в файл.
Теперь у вас должно быть что-то похожее на то, что вы видите ниже.
Вернитесь к файлу main.py и добавьте следующий код.
f = открытый ("mydata.txt")
content = f.read ()
f.close ()
печать (содержание) Это открывает файл программно, считывает данные из файла в переменную с именем content , закрывает файл и выводит содержимое файла на нашу панель вывода.
Нажмите кнопку Выполнить . Если все прошло хорошо, вы должны увидеть результат, как показано на изображении ниже.
Создание файлов с использованием Python
Вместо того, чтобы создавать файлы вручную, вы также можете использовать для этого Python. Добавьте следующий код в файл main.py .
f = open («createdfile.txt», «w»)
f.write ("Это некоторые данные, созданные нашим скриптом Python. \ n")
f.close () Обратите внимание на аргумент w , который мы сейчас передаем в функцию open . Это означает, что мы хотим открыть файл в режиме «записи». Будьте осторожны: если файл уже существует, Python удалит его и создаст новый.Существует множество различных «режимов» работы с файлами по-разному, о которых вы можете прочитать в документации Python.
Запустите код еще раз, и на панели файлов должен появиться новый файл. Если вы нажмете на файл, вы найдете данные, которые скрипт Python записал в него, как показано ниже.
Создание системы регистрации погоды с использованием Python и Repl.it
Теперь, когда вы можете читать из файлов и записывать в них, давайте создадим мини-проект, который записывает исторические погодные температуры.Наша программа будет
- Получить текущую температуру для указанного набора городов.
- Запишите эти данные в файл с сегодняшней датой.
- Вывести сводку этих данных на консоль.
Создание учетной записи WeatherStack и получение ключа API
Мы будем получать данные о погоде из WeatherStack API. Вам нужно будет зарегистрироваться на сайте weatherstack.com и, следуя инструкциям, получить собственный ключ доступа. Выберите вариант «бесплатный уровень», который ограничен 1000 звонками в месяц.
После регистрации вы должны увидеть страницу, похожую на следующую, содержащую ключ доступа к API.
Вы должны хранить этот ключ в секрете, чтобы другие люди не использовали все ваши ежемесячные звонки.
Создание проекта прогнозирования погоды
Вы можете продолжать использовать проект working-with-files , который вы создали ранее, если хотите, но для демонстрации мы создадим новый Python-ответ под названием weather report .
В файле main.py добавьте следующий код, но замените строку для API_KEY своей собственной.
запросов на импорт
API_KEY = "baaf201731c0cbc4af2c519cb578f907"
WS_URL = "http://api.weatherstack.com/current"
city = "Лондон"
параметры = {'access_key': API_KEY, 'query': city}
response = requests.get (WS_URL, параметры)
js = response.json ()
печать (js)
печать () Этот код запрашивает у WeatherStack текущую температуру в Лондоне, получает версию в формате JSON и распечатывает ее.Вы должны увидеть что-то похожее на то, что показано ниже.
WeatherStack возвращает много данных, но нас в основном интересует
- Местоположение: Чтобы узнать, правильно ли мы нашли Лондон, а не одно из 29 других мест под названием Лондон.
- Дата: Мы запишем это, когда сохраним эти данные в файл.
- Текущая температура: По умолчанию указывается в градусах Цельсия, но может быть изменена, если вы предпочитаете градусы Фаренгейта.
Добавьте следующий код под существующим кодом, чтобы извлечь эти значения в более удобный для чтения формат.
температура = js ['текущий'] ['температура']
date = js ['местоположение'] ['местное время']
city = js ['местоположение'] ['имя']
country = js ['location'] ['country']
print (f "Температура в {городе}, {стране} на {date} равна {temperature} градусам Цельсия") Если вы запустите код еще раз, вы увидите более понятный для человека результат, как показано ниже.
Это отлично подходит для получения текущей погоды, но теперь мы хотим немного расширить его, чтобы записывать погоду в историческом плане.
Мы создадим файл с именем cities.txt , содержащий список городов, для которых мы хотим получить данные о погоде. Наш скрипт запросит погоду для каждого города и сохранит новую строку с погодой и меткой времени.
Добавьте файл cities.txt , как показано на изображении ниже (конечно, вы можете изменить, для каких городов вы хотите получать информацию о погоде).
Теперь удалите код, который у нас есть в настоящее время в main.py , и замените его следующим.
запросов на импорт
API_KEY = "baaf201731c0cbc4af2c519cb578f907"
WS_URL = "http://api.weatherstack.com/current"
города = []
с open ("cities.txt") как f:
для строки в f:
city.append (line.strip ())
печать (города)
для города в городах:
параметры = {'access_key': API_KEY, 'query': city}
response = requests.get (WS_URL, параметры)
js = response.json ()
температура = js ['текущая'] ['температура']
date = js ['местоположение'] ['местное время']
с открытым (ф "{город}.txt "," w ") как f:
f.write (f "{date}, {temperature} \ n") Это похоже на код, который у нас был раньше, но теперь мы
- Прочтите названия городов из нашего файла
cities.txtи поместите каждый город в список Python. - Прокрутите города и получите данные о погоде для каждого из них.
- Создайте новый файл с тем же именем, что и каждый город, и запишите дату и температуру (через запятую) в каждый файл.
В наших предыдущих примерах мы явно закрывали файлы с помощью f.закрыть () . В этом примере мы вместо этого открываем наши файлы в блоке с . Это обычная идиома в Python, и обычно именно так вы открываете файлы. Вы можете узнать больше об этом в разделе файлов документации Python.
Если вы запустите этот код, вы увидите, что он создает по одному файлу для каждого города.
Если вы откроете один из файлов, вы увидите, что он содержит дату и температуру, полученные из WeatherStack.
Если вы запускаете сценарий несколько раз, каждый файл по-прежнему будет содержать только одну строку данных: строку самого последнего запуска.Это потому, что когда мы открываем файл в режиме «записи» ( «w» ), он перезаписывает его новыми данными. Поскольку мы хотим создать исторические журналы погоды, нам нужно изменить вторую последнюю строку, чтобы вместо этого использовать режим «добавления» ( «a» ).
Изменение
с открытым (f "{city} .txt", "w") как f: Спо
с открытым (f "{city} .txt", "a") как f: и снова запустите скрипт. Если вы снова откроете один из файлов города, вы увидите, что в нем новая строка вместо перезаписываемых старых данных.Новые данные добавляются в конец файла. WeatherStack обновляет свои данные только каждые 5 минут или около того, поэтому вы можете увидеть точные повторяющиеся строки, если запустите сценарий несколько раз в быстрой последовательности.
Экспорт файлов с данными о погоде
Если вы запускаете этот сценарий каждый день в течение нескольких месяцев, у вас будет хороший набор данных, который может быть полезен и в других контекстах. Если вы хотите загрузить все данные с Repl.it, вы можете использовать функцию Download as zip для экспорта всех файлов в реплике (включая файлы кода и данных).
После того, как вы загрузили файл .zip , вы можете извлечь его в свою локальную файловую систему и найти все файлы данных, которые теперь можно открывать другими программами по мере необходимости.
В том же меню вы также можете выбрать файл загрузки или папку загрузки , чтобы импортировать файлы в свой ответ. Например, если вы очистили файлы с помощью внешнего программного обеспечения, а затем хотите, чтобы ваш ответ начал добавлять новые данные к очищенным версиям, вы можете повторно импортировать их.
Repl.it предупредит вас о перезаписи существующих файлов, если вы не изменили имена.
Сделай сам
Если вы продолжили, у вас уже есть собственная версия ответа, которую нужно расширить. Если нет, начните с нашего. Разветвите его из вставки ниже.
Куда дальше?
Вот и все, что касается нашего проекта по прогнозированию погоды. Вы узнали, как работать с файлами в Python и Repl.it, включая различные режимы (чтение, запись или добавление), в которых файлы можно открывать.
Вы также работали с внешней библиотекой, запросов и , для получения данных через Интернет. Этот модуль на самом деле не является частью Python, и в следующей статье вы узнаете больше о том, как управлять внешними модулями или зависимостями.
Открытие файлов и чтение из файлов
Вот официальная документация Python по чтению и записи из файлов. Но прежде чем читать это, давайте погрузимся в самый минимум, который я хочу, чтобы вы знали.
Давайте сразу перейдем к примеру кода.Представьте, что у вас есть файл с именем example.txt в текущем каталоге. Если вы этого не сделаете, просто создайте его, а затем заполните его этими строками и сохраните:
привет мир
и сейчас
Я говорю
до свидания
Вот короткий фрагмент кода Python, чтобы открыть этот файл и распечатать его содержимое на экране — обратите внимание, что этот код Python должен запускаться в том же каталоге, в котором находится файл example.txt .
myfile = open ("example.txt")
txt = myfile.читать()
печать (txt)
myfile.close ()
Это показалось слишком сложным? Вот менее подробная версия:
myfile = open ("example.txt")
печать (myfile.read ())
myfile.close ()
Вот как прочитать этот файл построчно, используя цикл for:
myfile = open ("example.txt")
для строки в myfile:
печать (строка)
myfile.close ()
(Примечание: если вы получаете FileNotFoundError уже — этого почти следовало ожидать.Продолжайте читать!)
Все еще кажется слишком сложным? Что ж, нельзя обойти стороной тот факт, что на программном уровне , открывающий файл, отличается от , читающего его содержимое. Мало того, мы также должны вручную закрыть файл.
А теперь давайте рассмотрим это по шагам.
Чтобы открыть файл, мы просто используем метод open () и передаем в качестве первого аргумента имя файла :
myfile = open ("example.текст")
Это кажется достаточно простым, поэтому давайте перейдем к некоторым распространенным ошибкам.
Как напортачить при открытии файла
Вот, вероятно, самая частая ошибка, которую вы получите при попытке открыть файл .
FileNotFoundError: [Errno 2] Нет такого файла или каталога: 'SOME_FILENAME'
На самом деле, я видел, как студенты тратили десятки часов, пытаясь обойти это сообщение об ошибке, потому что они не останавливаются, чтобы прочитать его .Итак, прочитал это : Что означает FileNotFoundError ?
Попробуйте поставить пробелы там, где используются заглавные буквы:
Файл не найден Ошибка
Вы получите эту ошибку, потому что вы пытались открыть файл, которого просто не существует. Иногда это простая опечатка: open () пытается открыть файл с именем "example.txt" , но случайно неправильно написала его как "exmple.txt" .
Но чаще всего это происходит потому, что вы знаете, что файл существует под заданным именем, например, "например.txt " — но как ваш код Python узнает, где находится этот файл? Это " example.txt ", который существует в вашей папке Downloads ? Или тот, который может существовать в вашей папке Documents ? Или тысячи других папок в вашей компьютерной системе?
Это довольно сложный вопрос. Но первый шаг в , чтобы не тратить зря время , состоит в том, что если вы когда-нибудь увидите эту ошибку, прекратите все, что вы делаете. Не изменяйте запутанный цикл for.Не пытайтесь установить новую библиотеку Python. Не перезагружайте компьютер, а затем повторно запустите скрипт, чтобы увидеть, не исчезнет ли ошибка волшебным образом.
Ошибка FileNotFoundError возникает из-за того, что вы либо не знаете, где на самом деле находится файл на вашем компьютере. Или, даже если вы это сделаете, вы не знаете, как сообщить своей программе Python, где она находится. Не пытайтесь исправить другие части вашего кода, которые не связаны с указанием имен файлов или путей.
Как исправить ошибку FileNotFoundError
Вот верное решение: убедитесь, что файл действительно существует.
Давайте начнем с нуля, сделав ошибку. В вашей системной оболочке (т.е. Терминале) перейдите в папку Desktop :
$ cd ~ / Рабочий стол
Теперь запустите ipython :
$ ipython
И теперь, когда вы находитесь в интерактивном интерпретаторе Python, попробуйте открыть имя файла, которое, как вы знаете, не существует на вашем рабочем столе , и затем получите сообщение об ошибке:
>>> myfile = open ("whatdude.текст")
------------------------------------------------ ---------------------------
FileNotFoundError Traceback (последний вызов последним)
в ()
----> 1 myfile = open ("whatdude.txt")
FileNotFoundError: [Errno 2] Нет такого файла или каталога: 'anydude.txt'
Теперь вручную создайте файл на рабочем столе , используя Sublime Text 3 или что угодно.Добавьте к нему текст и сохраните его.
это
мой
файл
Посмотрите и убедитесь сами, что этот файл действительно существует в вашей папке Desktop :
Хорошо, теперь переключитесь обратно на интерактивную оболочку Python (например, ipython ), ту, которую вы открыли после перехода в папку Desktop (например, cd ~ / Desktop ). Повторите команду open () , которая привела к ошибке FileNotFoundError :
>>> myfile = open ("whatdude.текст")
Надеюсь, вы не получите ошибку.
Но что это за объект, на который указывает переменная myfile ? Используйте метод type () , чтобы выяснить это:
>>> тип (myfile)
_io.TextIOWrapper
А что такое , что ? Детали не важны, кроме как указать, что myfile определенно не просто строковый литерал, то есть str .
Используйте автозаполнение Tab (т.е.е. введите myfile. ), чтобы получить список существующих методов и атрибутов для объекта myfile :
myfile.buffer myfile.isatty myfile.readlines
myfile.close myfile.line_buffering myfile.seek
myfile.closed myfile.mode myfile.seekable
myfile.detach myfile.name myfile.tell
myfile.encoding myfile.newlines myfile.truncate
myfile.errors myfile.read myfile.writable
мой файл.fileno myfile.readable myfile.write
myfile.flush myfile.readline myfile.writelines
Что ж, с файлами мы можем делать гораздо больше, чем просто read () из них. Но давайте пока сосредоточимся на чтении.
Предполагая, что переменная myfile указывает на какой-то файловый объект, вы читаете из нее вот так:
>>> mystuff = myfile.read ()
Что находится в этой переменной mystuff ? Снова используйте функцию type () :
>>> тип (mystuff)
ул.
Это просто строка.Что, конечно, означает, что мы можем его распечатать:
>>> печать (mystuff)
это
мой
файл
Или посчитайте количество символов:
>>> len (mystuff)
15
Или распечатайте прописными буквами:
>>> печать (mystuff.upper ())
ЭТО
МОЙ
ФАЙЛ
И это все, что нужно для чтения из открытого файла.
Теперь об ошибках.
Как напортачить при чтении из файла
Вот очень-очень распространенная ошибка:
>>> filename = "пример.текст"
>>> filename.read ()
Вывод ошибки:
AttributeError Traceback (последний вызов последним)
в <модуль> ()
----> 1 имя_файла.read ()
AttributeError: объект 'str' не имеет атрибута 'read'
Обратите внимание, что это , а не a FileNotFoundError . Это AttributeError — что, по общему признанию, не очень понятно — но прочтите следующую часть:
объект 'str' не имеет атрибута 'read'
Сообщение об ошибке доходит до сути: объект str — i.е. строковый литерал, например что-то вроде "hello world" не имеет атрибута read .
Возвращаясь к ошибочному коду:
>>> filename = "example.txt"
>>> filename.read ()
Если filename указывает на «example.txt», тогда filename — это просто объект str .
Другими словами, имя файла — это , а не — файловый объект . Вот более наглядный пример ошибочного кода:
>>> "пример.txt ".read ()
И бить точку про голову:
>>> "привет мир, это всего лишь строка" .read ()
Почему это такая частая ошибка? Потому что в 99% наших типичных взаимодействий с файлами мы видим имя файла в графическом интерфейсе рабочего стола и дважды щелкаем по нему, чтобы открыть его. Графический интерфейс запутывает процесс — и не зря. Какая разница, что происходит, если мой файл открывается, когда я дважды щелкаю по нему!
К сожалению, мы должны проявлять осторожность, пытаясь прочитать файл программно. Открытие файла — это отдельная операция от чтения его.
- Вы открываете файл, передав его имя файла — например,
example.txt— в функциюopen (). Функцияopen ()возвращает файловый объект. - Чтобы на самом деле прочитать содержимое файла, вы вызываете метод read () этого файлового объекта.
Опять же, вот код, немного более подробный:
>>> myfilename = "пример.текст"
>>> myfile = open (myfilename)
>>> mystuff = myfile.read ()
>>> # сделать что-нибудь с mystuff, например, распечатать или что-то в этом роде
>>> myfile.close ()
Файловый объект также имеет метод close () , который формально очищает открытый файл и позволяет другим программам безопасно обращаться к нему. Опять же, это мелкие детали, о которых вы никогда не задумываетесь в повседневных вычислениях. Фактически, это то, что вы, вероятно, забудете в контексте программирования, поскольку закрытие файла , а не не приведет к автоматическому повреждению ничего (до тех пор, пока мы не начнем выполнять гораздо более сложные типы файловых операций, по крайней мере…).Обычно, как только сценарий завершается, все незакрытые файлы автоматически закрываются.
Однако мне нравится закрывать файл явно — не только на всякий случай — но это помогает укрепить концепцию этого файлового объекта.
Одно из преимуществ погружения в детали более низкого уровня открытия и чтения из файлов состоит в том, что теперь у нас есть возможность читать файлы построчно, а не одним гигантским фрагментом. Опять же, чтобы читать файлы как один гигантский кусок контента, используйте метод read () :
>>> myfile = open ("example.текст")
>>> mystuff = myfile.read ()
Сейчас это не кажется таким уж большим делом, но это потому, что example.txt , вероятно, содержит всего несколько строк. Но когда мы имеем дело с файлами, которые составляют огромных — как и все 3,3 миллиона записей всех, кто пожертвовал более 200 долларов одному комитету президентской кампании США в 2012 году или всех, кто когда-либо посещал Белый дом, — открытие и чтение файла все сразу заметно медленнее. И это может даже привести к сбою вашего компьютера.
Если вам интересно, почему программное обеспечение для работы с электронными таблицами, такое как Excel, имеет ограничение на количество строк (примерно 1 000 000), это потому, что большинство пользователей – хотят работать с файлом данных одновременно. Однако многие интересные файлы данных слишком велики для этого. Мы столкнемся с этими сценариями позже в этом квартале.
А пока вот как обычно выглядит построчное чтение:
myfile = open ("example.txt")
для строки в myfile:
печать (строка)
myfile.close ()
Поскольку каждая строка в текстовом файле имеет символ новой строки (который представлен как \ n , но обычно «невидимый»), вызов функции print () создаст вывод с двойным интервалом, потому что print () добавляет новую строку к тому, что он выводит (т.е. вспомните свою исходную программу печати ("привет, мир") ).
Чтобы избавиться от этого эффекта, вызовите метод strip () , который принадлежит объектам str и удаляет символы пробела с левой и правой стороны текстовой строки:
myfile = open ("example.txt")
для строки в myfile:
печать (line.strip ())
myfile.close ()
И, конечно, вы можете сделать вещи громкими с помощью старой доброй функции upper () :
myfile = open ("example.текст")
для строки в myfile:
печать (line.strip ())
myfile.close ()
На этом пока все. Мы не рассмотрели, как записать в файл (что является гораздо более опасной операцией) — я оставлю это для отдельного урока. Но достаточно знать, что, имея дело с файлами как программист, мы должны быть более точными и конкретными в шагах.
.