Представление нечисловой информации в компьютере
Представление текстовой информации в компьютере
Изучив эту тему, вы узнаете и повторите:
— как в компьютере представляется текстовая информация;
— что такое ASCII и Unicode;
— как в компьютере представляется графическая информация;
— какие форматы используются при хранении графических файлов;
— как в компьютере представляется звуковая информация;
— какие форматы используются при хранении звуковых файлов.
Компьютеры не с самого рождения могли обрабатывать символьную информацию. Лишь с конца 60-х годов они стали использоваться для обработки текстов и в настоящее время большинство пользователей ПК занимаются вводом, редактированием и форматированием текстовой информации.
1. Таблица кодирования ASCII.
А теперь «заглянем» в память компьютера и разберемся, как же представлена в нем текстовая информация.
Текстовая информация состоит из символов: букв, цифр, знаков препинания, скобок и других. Мы уже говорили, что множество всех символов, с помощью которых записывается текст, называется алфавитом, а число символов в алфавите — его мощностью.
Для представления текстовой информации в компьютере используется алфавит мощностью 256 символов. Мы знаем, что один символ такого алфавита несет 8 битов информации: 2 в 8 степени равно 256. 8 битов = 1 байт, следовательно:
Один символ в компьютерном тексте занимает 1 байт памяти.
Как мы выяснили, традиционно для кодирования одного символа используется 8 бит. И, когда люди определились с количеством бит, им осталось договориться о том, каким кодом кодировать тот или иной символ, чтобы не получилось путаницы, т.е. необходимо было выработать стандарт – все коды символов сохранить в специальной таблице кодов. В первые годы развития вычислительной техники таких стандартов не существовало, а сейчас наоборот, их стало очень много, но они противоречивы.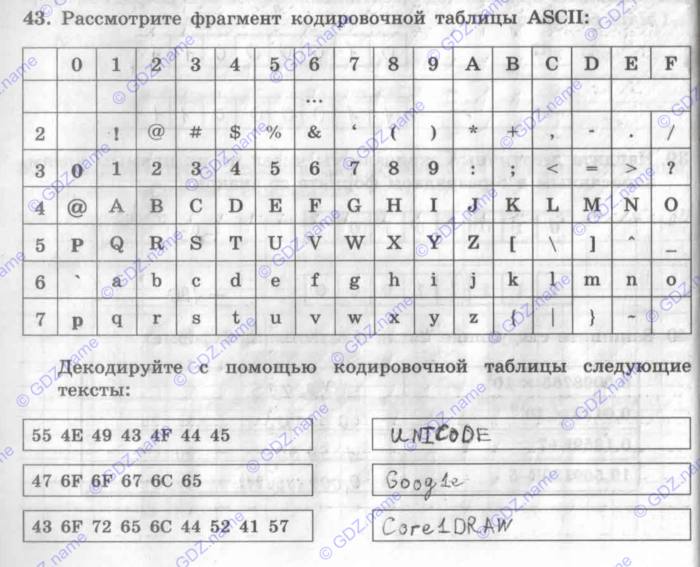
Рассмотрим таблицу кодов ASCII.
Пояснение: раздать учащимся распечатанную таблицу кодов ASCII.
Таблица ASCII разделена на две части. Первая – стандартная – содержит коды от 0 до 127. Вторая – расширенная – содержит символы с кодами от 128 до 255.
Первые 32 кода отданы производителям аппаратных средств и называются они управляющие, т.к. эти коды управляют выводом данных. Им не соответствуют никакие символы.
Коды с 32 по 127 соответствуют символам английского алфавита, знакам препинания, цифрам, арифметическим действиям и некоторым вспомогательным символам.
Коды расширенной части таблицы ASCII отданы под символы национальных алфавитов, символы псевдографики и научные символы.
Стандартная часть таблицы кодов ASCII
Если вы внимательно посмотрите на обе части таблицы, то увидите, что все буквы расположены в них по алфавиту, а цифры – по возрастанию. Этот принцип последовательного кодирования позволяет определить код символа, не заглядывая в таблицу.
Этот принцип последовательного кодирования позволяет определить код символа, не заглядывая в таблицу.
Коды цифр берутся из этой таблицы только при вводе и выводе и если они используются в тексте. Если же они участвуют в вычислениях, то переводятся в двоичную систему счисления.
Коды национального (русского) алфавита расширенной частитаблицы ASCII
Альтернативные системы кодирования кириллицы.
Для разных типов ЭВМ используются различные кодировки:
В настоящее время существует 5 кодовых таблиц для русских букв: Windows (СР(кодовая страница)1251), MS – DOS (СР(кодовая страница)866), KOИ – 8 (Код обмена информацией, 8-битный) (используется в OS UNIX), Mac (Macintosh), ISO (OS UNIX).
Одним из первых стандартов кодирования кириллицы на компьютерах был стан-дарт КОИ-8.
Национальная часть кодовой таблицы стандарта КОИ8-Р
В настоящее время применяется и кодовая таблица, размещенная на странице СР866 стандарта кодирования текстовой информации, которая используется в операционной системе MS DOS или сеансе работы MS DOS для кодирования кириллицы.
Национальная часть кодовой таблицы СР866
В настоящее время для кодирования кириллицы наибольшее распространение получила кодовая таблица, размещенная на странице СР1251 соответствующего стандарта, которая используется в операционных системах семейства Windows фирмы Microsoft.
Национальная часть кодовой таблицы СР1251
Во всех представленных кодовых таблицах, кроме таблицы стандарта Unicode, для кодирования одного символа отводится 8 двоичных разрядов (8 бит).
В мире существует примерно 6800 различных языков. Если прочитать текст, напечатанный в Японии на компьютере в России или США, то понять его будет нельзя. Чтобы буквы любой страны можно было читать на любом компьютере, для их кодировки стали использовать 2 байта (16 бит).
N = 2i 2i = 216 = 65536 N = 65536 N – мощность алфавита символов в кодовой таблице Unicode. i – информационный вес символа
Основополагающая таблица использования кодового пространства Unicode
Использование Unicode значительно упрощает создание многоязычных документов, публикаций и программных приложений.
Рассмотрим примеры.
1) Представьте в форме шестнадцатеричного кода слово «ЭВМ» во всех пяти кодировках. Воспользуемся компьютерным калькулятором для перевода чисел из десятичной в шестнадцатеричную систему счисления.
Последовательности десятичных кодов слова «ЭВМ» в различных кодировках составляем на основе кодировочных таблиц:
КОИ8-Р: 252 247 237 СР1251: 221 194 204 СР866: 157 130 140 Мас: 157 130 140 ISO: 205 178 188
Переводим с помощью калькулятора последовательности кодов из десятичной системы в шестнадцатеричную:
КОИ8-Р: FCF7 ED СР1251: DDC2 CC СР866: 9D 82 8C Мас: 9D 82 8C ISO: CDB2 BC
2) Определить числовой код символа в кодировке Unicode с помощью тексто-вого редактора MicrosoftWord.
1. В операционной системе Windows запустить текстовый редактор MicrosoftWord.
2. В текстовом редакторе MicrosoftWord ввести команду [Вставка-Символ…]. На экране появится диалоговое окно Символ. Центральную часть диалогового окна занимает фрагмент таблицы символов.
3. Для определения числового кола знака кириллицы с помощью раскрывающегося списка Набор: выбрать пункт кириллица.
4. Для определения шестнадцатеричного числового кода символа в кодировке Unicode с помощью раскрывающегося списка из: выбрать тип кодировки Юникод (шестн.).
5. В таблице символов выбрать символ Э. В текстовом поле кодзнака : появится его шестнадцатеричный числовой код (в данном случае 042D).
Решите задачи:
№1. Закодируйте с помощью таблицы ASCII слова: А) Excel; Б) Access; В) Windows; Г) ИНФОРМАЦИЯ.
№2. Буква «i» в таблице кодов имеет код 105. Не пользуясь таблицей, расшифруйте следующую последовательность кодов: 102, 105, 108, 101.
Не пользуясь таблицей, расшифруйте следующую последовательность кодов: 102, 105, 108, 101.
№3. Десятичный код буквы «е» в таблице ASCII равен 101. Не пользуясь таблицей, составьте последовательность кодов, соответствующих слову help.
№4. Десятичный код буквы «i» в таблице ASCII равен 105. Не пользуясь таблицей, составьте последовательность кодов, соответствующих слову link.
№5. Декодируйте следующие тексты, заданные десятичным кодом:
А) 192 235 227 238 240 232 242 236; Б) 193 235 238 234 45 241 245 229 236 224; В) 115 111 102 116 119 97 114 101.
№6. Во сколько раз увеличится информационный объем страницы текста при его преобразовании из кодировки Windows 1251 (таблица кодировки содержит 256 символов) в кодировку Unicode (таблица кодировки содержит 65536 символов)?
№7.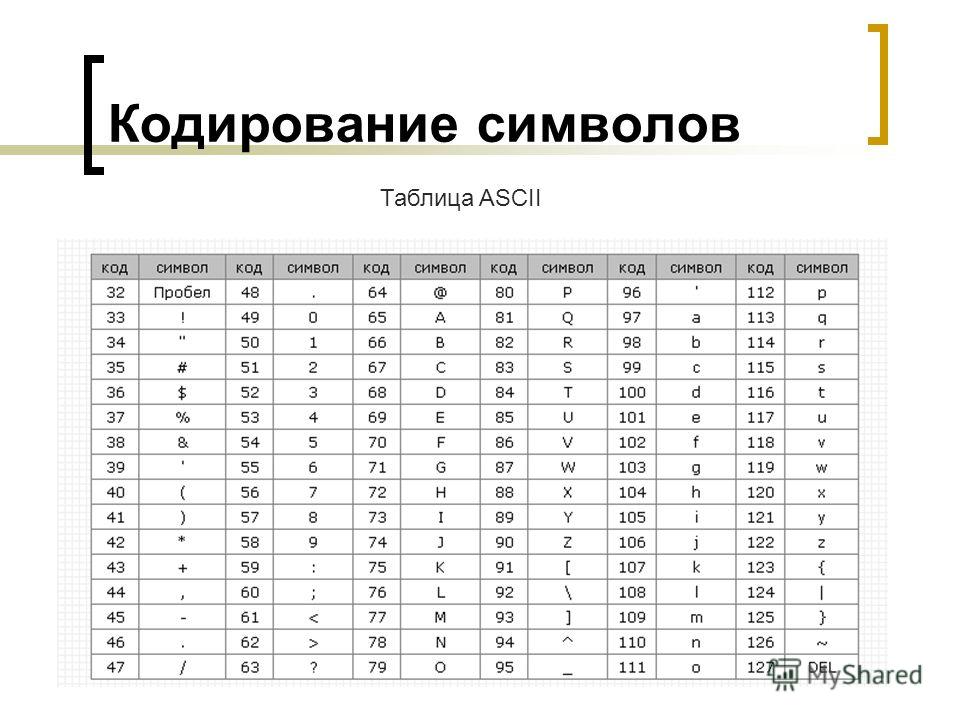
А) в 16-битной кодировке; Б) в 8-битной кодировке.
№8. Текст занимает ¼ Кбайта. Какое количество символов он содержит?
№9. Текст занимает полных 6 страниц. На каждой странице размещается 30 строк по 80 символов. Определить объем оперативной памяти, который займет этот текст.
№10. Свободный объем оперативной памяти компьютера 320 Кбайт. Сколько страниц книги поместится в ней, если на странице:
А) 32 строки по 32 символа; Б) 64 строки по 64 символа; В) 16 строк по 32 символа.
№11. Текст занимает 20 секторов на двусторонней дискете объемом 360 Кбайт. Дискета разбита на 40 дорожек по 9 секторов. Сколько символов содержит текст?
Урок 13. Практическая работа № 4. Представление текстов. Сжатие текстов
Практическая работа № 4. Представление текстов. Сжатие текстов
 Практическая работа № 4. Представление текстов. Сжатие текстов
Практическая работа № 4. Представление текстов. Сжатие текстовУрок 13. Представление текстовой информации в компьютере. Кодовые таблицы.
Практическая работа № 4. Представление текстов. Сжатие текстов
Кодирование текстовой информации
В этом параграфе обсудим способы компьютерного кодирования текстовой, графической и звуковой информации. С текстовой и графической информацией конструкторы «научили» работать ЭВМ, начиная с третьего поколения (1970-е годы). А работу со звуком «освоили» лишь машины четвертого поколения, современные персональные компьютеры. С этого момента началось распространение технологии мультимедиа.
Что принципиально нового появлялось в устройстве компьютеров с освоением ими новых видов информации? Главным образом, это периферийные устройства для ввода и вывода текстов, графики, видео, звука. Процессор же и оперативная память по своим функциям изменились мало. Существенно возросло их быстродействие, объем памяти. Но как это было на первых поколениях ЭВМ, так и осталось на современных ПК — основным навыком процессора в обработке данных является умение выполнять вычисления с двоичными числами. Обработка текста, графики и звука представляет собой тоже обработку числовых данных. Если сказать еще точнее, то это обработка целых чисел. По этой причине компьютерные технологии называют цифровыми технологиями.
Но как это было на первых поколениях ЭВМ, так и осталось на современных ПК — основным навыком процессора в обработке данных является умение выполнять вычисления с двоичными числами. Обработка текста, графики и звука представляет собой тоже обработку числовых данных. Если сказать еще точнее, то это обработка целых чисел. По этой причине компьютерные технологии называют цифровыми технологиями.
О том, как текст, графика и звук сводятся к целым числам, будет рассказано дальше. Предварительно отметим, что здесь мы снова встретимся с главной формулой информатики:
2i = N.
Смысл входящих в нее величин здесь следующий: i — разрядность ячейки памяти (в битах), N — количество различных целых положительных чисел, которые можно записать в эту ячейку.
Текстовая информация
Принципиально важно, что текстовая информация уже дискретна — состоит из отдельных знаков.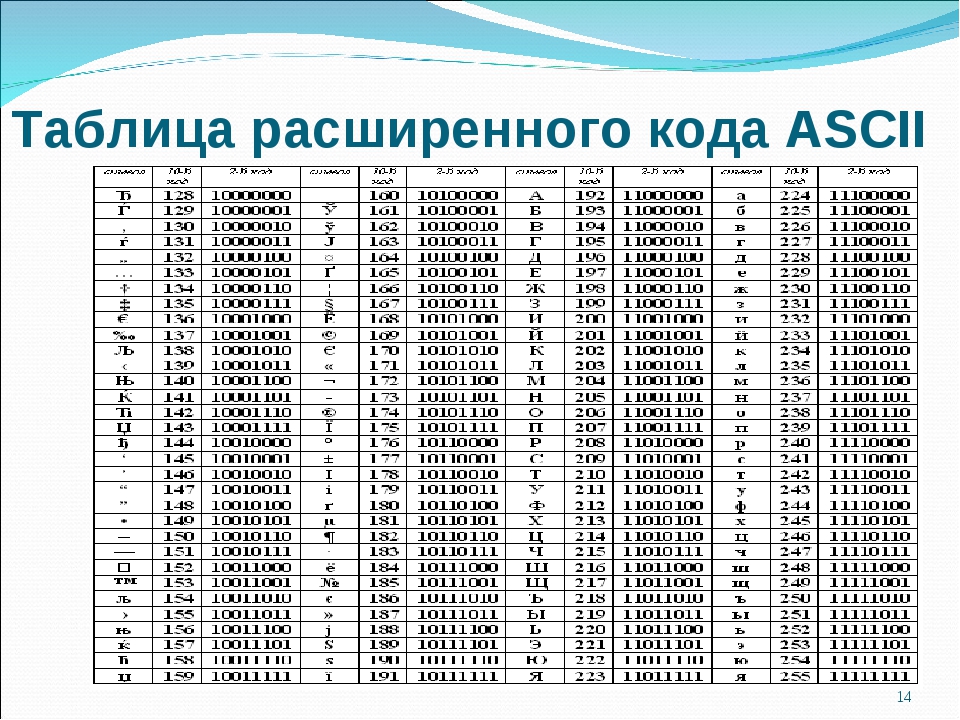 Поэтому возникает лишь технический вопрос — как разместить ее в памяти компьютера.
Поэтому возникает лишь технический вопрос — как разместить ее в памяти компьютера.
Напомним о байтовом принципе организации памяти компьютеров, обсуждавшемся в курсе информатики основной школы. Вернемся к рис. 1.5. Каждая клеточка на нем обозначает бит памяти. Восемь подряд расположенных битов образуют байт памяти. Байты пронумерованы. Порядковый номер байта определяет его адрес в памяти компьютера. Именно по адресам процессор обращается к данным, читая или записывая их в память (рис. 1.10).
Модель представления текста в памяти весьма проста. За каждой буквой алфавита, цифрой, знаком препинания и иным общепринятым при записи текста символом закрепляется определенный двоичный код, длина которого фиксирована. В популярных системах кодировки (Windows-1251, KOI8 и др.) каждый символ заменяется на 8-разрядное целое положительное двоичное число; оно хранится в одном байте памяти. Это число является порядковым номером символа в кодовой таблице. Согласно главной формуле информатики, определяем, что размер алфавита, который можно закодировать, равен: 28 = 256. Этого количества вполне достаточно для размещения двух алфавитов естественных языков (английского и русского) и всех необходимых дополнительных символов.
Этого количества вполне достаточно для размещения двух алфавитов естественных языков (английского и русского) и всех необходимых дополнительных символов.
Поскольку в мире много языков и много алфавитов, постепенно совершается переход на международную систему кодировки Unicode, в которой используются многобайтовые коды. Например, если код символа занимает 2 байта, то с его помощью можно закодировать 216 = 65 536 различных символов.
При работе с электронной почтой почтовая программа иногда нас спрашивает, не хотим ли мы прибегнуть к кодировке Unicode для пересылаемых сообщений. Таким способом можно избежать проблемы несоответствия кодировок, из-за которой иногда не удается прочитать русский текст.
Текстовый документ, хранящийся в памяти компьютера, состоит не только из кодов символьного алфавита. В нем также содержатся коды, управляющие форматами текста при его отображении на мониторе или на печати: тип и размер шрифта, положение строк, поля и отступы и пр. Кроме того, текстовые процессоры (например, Microsoft Word) позволяют включать в документ и редактировать такие «нелинейные» объекты, как таблицы, оглавления, ссылки и гиперссылки, историю вносимых изменений и т. д. Всё это также представляется в виде последовательности байтовых кодов.
Кроме того, текстовые процессоры (например, Microsoft Word) позволяют включать в документ и редактировать такие «нелинейные» объекты, как таблицы, оглавления, ссылки и гиперссылки, историю вносимых изменений и т. д. Всё это также представляется в виде последовательности байтовых кодов.
Практикум
Практическая работа № 1.4 «Представление текстов. Сжатие текстов»
Цель работы: практическое закрепление знаний о представлении в компьютере текстовых данных.
Задание 1
Определить, какие символы кодируются таблицей ASCII (DOS) соответствуют всем прописным буквам русского алфавита в кодировочной таблице ANSI (Windows). Для выполнения задания создать текст с русским алфавитом в Блокноте, а затем открыть его в режиме просмотра (клавиша F3) в любом файловом менеджере (Windows Commander, Far, Total Commander, Norton Commander) и преобразовать в другую кодировку. После выполнения задания заполнить таблицу.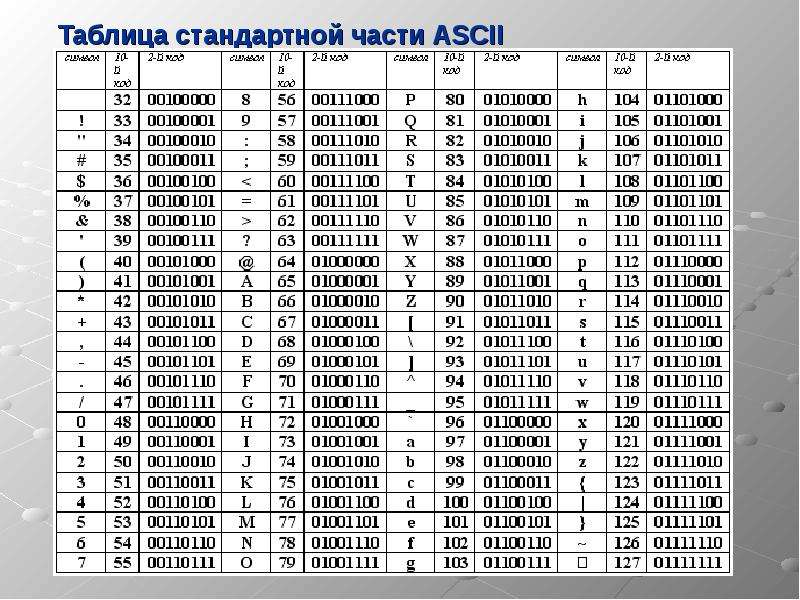
Задание 2
Закодировать текст Happy Birthday to you!! с помощью кодировочной таблицы ASCII
Записать двоичное и шестнадцатеричное представление кода (для записи шестнадцатеричного кода использовать средство для просмотра файлов любого файлового менеджера).
Задание 3
Декодировать текст, записанный в международной кодировочной таблице ASCII (дано десятичное представление).
72 101 108 108 111 44 32 109 121 32 102 114 105 101 110 100 33
Задание 4
Пользуясь таблицей кодировки ASCII, расшифровать текст, представленный в виде двоичных кодов символов.
01010000 01100101 01110010 01101101 00100000 01010101
01101110 01101001 01110110 01100101 01110010 01110011
01101001 01110100 01111001
Задание 5
Пользуясь кодовой страницей Windows-1251 таблицы кодировки ASCII, получить шестнадцатеричный код слова ИНФОРМАТИЗАЦИЯ.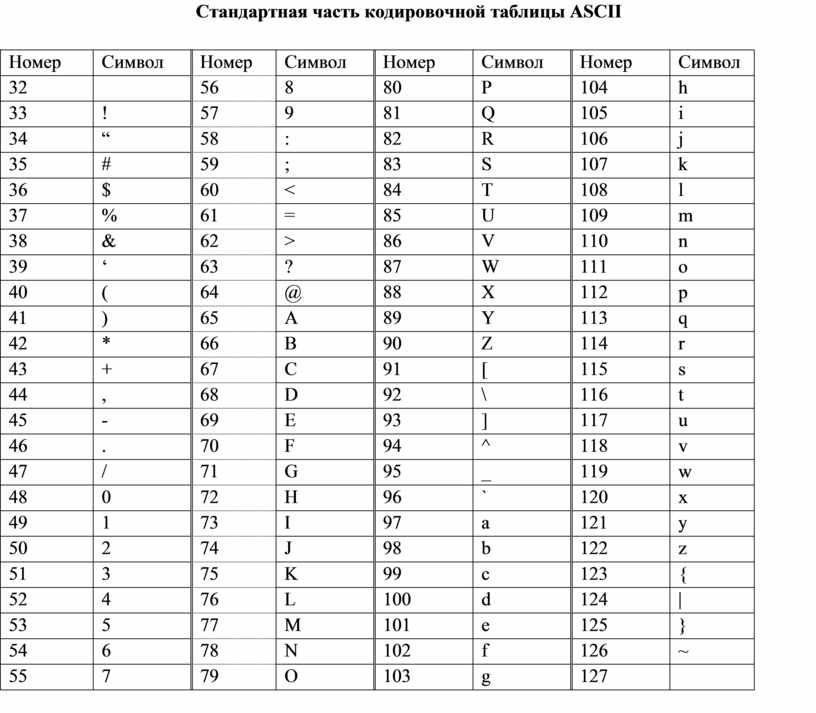
Задание 6
Во сколько раз увеличится объём памяти, необходимый для хранения текста, если его преобразовать из кодировки KOI8-R в кодировку Unicode?
Задание 7
С помощью табличного процессора Excel построить кодировочную таблицу ASCII, в которой символы буду автоматически отображаться на экране в соответствии с их заданным десятичным номером (использовать соответствующую текстовую функцию).
Справочная информация
Алгоритм Хаффмена. Сжатием информации в памяти компьютера называют такое её преобразование, которое ведёт к сокращению объёма ханимаемой памяти при сохранении закодированного содержания. Рассмотрим один из способов сжатия текстовой информации — алгоритм Хаффмена. С помощью этого алгоритма строится двоичное дерево, которое позволяет однозначно декодировать двоичный код, состоящий из символьный кодов различной длины. Двоичным называется дерево, из каждой вершины которого выходят две ветви.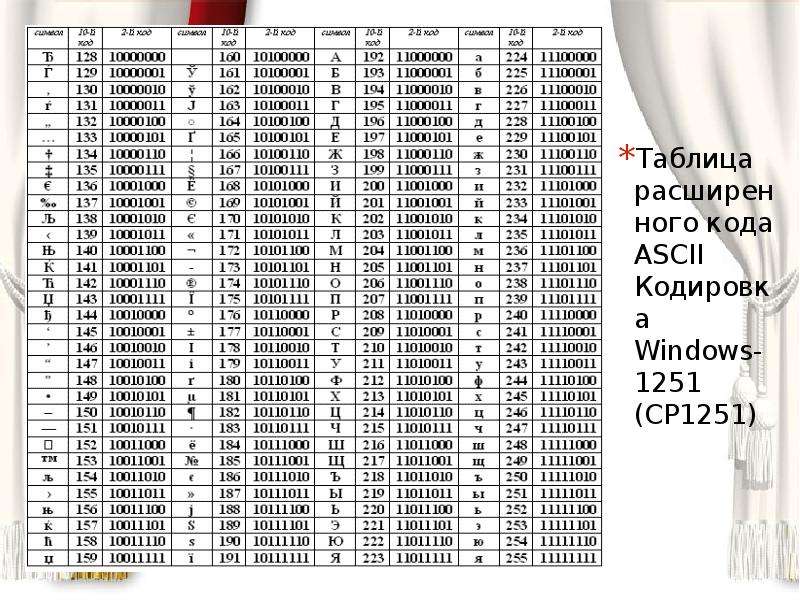 На рисунке приведён пример такого дерева, построенный для алфавита английского языка с учётом частоты встречаемости его букв.
На рисунке приведён пример такого дерева, построенный для алфавита английского языка с учётом частоты встречаемости его букв.
Закодируем с помощью данного дерева слово «hello»:
0101 100 01111 01111 1110
При размещении этого кода в памяти побитово он примет вид:
010110001111011111110
Таким образом, текст, занимающий в кодировки ASCII 5 байтов, в кодировке Хаффмена займет 3 байта.
Задание 8
Используя метод сжатия Хаффмена, закодируйте следующие слова:
а) administrator
б) revolution
в) economy
г) department
Задание 9
Используя дерево Хаффмена, декодируйте следующие слова:
а) 01110011 11001001 10010110 10010111 100000
б) 00010110 01010110 10011001 01101101 01000100 000
Кодировка текста ASCII (Windows 1251, CP866, KOI8-R) и Юникод (UTF 8, 16, 32) — как исправить проблему с кракозябрами
Сегодня мы поговорим с вами про то, откуда берутся кракозябры на сайте и в программах, какие кодировки текста существуют и какие из них следует использовать.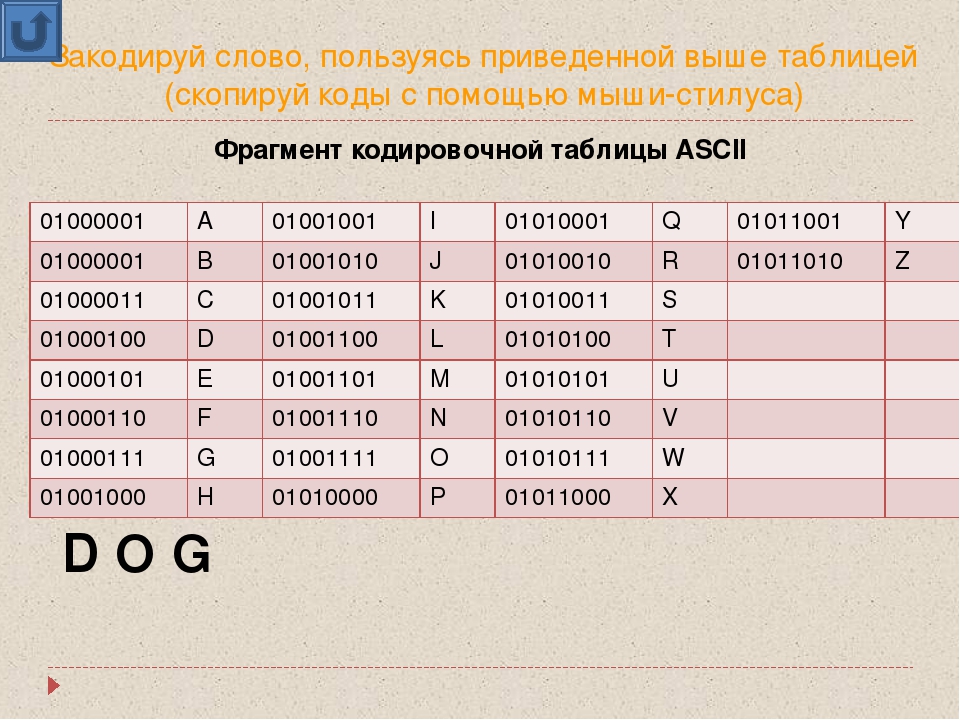 Подробно рассмотрим историю их развития, начиная от базовой ASCII, а также ее расширенных версий CP866, KOI8-R, Windows 1251 и заканчивая современными кодировками консорциума Юникод UTF 16 и 8. Оглавление:
Кому-то эти сведения могут показаться излишними, но знали бы вы, сколько мне приходит вопросов именно касаемо вылезших кракозябров (не читаемого набора символов). Теперь у меня будет возможность отсылать всех к тексту этой статьи и самостоятельно отыскивать свои косяки. Ну что же, приготовьтесь впитывать информацию и постарайтесь следить за ходом повествования.
Подробно рассмотрим историю их развития, начиная от базовой ASCII, а также ее расширенных версий CP866, KOI8-R, Windows 1251 и заканчивая современными кодировками консорциума Юникод UTF 16 и 8. Оглавление:
Кому-то эти сведения могут показаться излишними, но знали бы вы, сколько мне приходит вопросов именно касаемо вылезших кракозябров (не читаемого набора символов). Теперь у меня будет возможность отсылать всех к тексту этой статьи и самостоятельно отыскивать свои косяки. Ну что же, приготовьтесь впитывать информацию и постарайтесь следить за ходом повествования.ASCII — базовая кодировка текста для латиницы
Развитие кодировок текстов происходило одновременно с формированием отрасли IT, и они за это время успели претерпеть достаточно много изменений. Исторически все начиналось с довольно-таки не благозвучной в русском произношении EBCDIC, которая позволяла кодировать буквы латинского алфавита, арабские цифры и знаки пунктуации с управляющими символами. Но все же отправной точкой для развития современных кодировок текстов стоит считать знаменитую ASCII (American Standard Code for Information Interchange, которая по-русски обычно произносится как «аски»). Она описывает первые 128 символов из наиболее часто используемых англоязычными пользователями — латинские буквы, арабские цифры и знаки препинания. Еще в эти 128 знаков, описанных в ASCII, попадали некоторые служебные символы навроде скобок, решеток, звездочек и т.п. Собственно, вы сами можете увидеть их:
Именно эти 128 символов из первоначального вариант ASCII стали стандартом, и в любой другой кодировке вы их обязательно встретите и стоять они будут именно в таком порядке. Но дело в том, что с помощью одного байта информации можно закодировать не 128, а целых 256 различных значений (двойка в степени восемь равняется 256), поэтому вслед за базовой версией Аски появился целый ряд расширенных кодировок ASCII, в которых можно было кроме 128 основных знаков закодировать еще и символы национальной кодировки (например, русской). Тут, наверное, стоит еще немного сказать про системы счисления, которые используются при описании. Во-первых, как вы все знаете, компьютер работает только с числами в двоичной системе, а именно с нулями и единицами («булева алгебра», если кто проходил в институте или в школе).
Она описывает первые 128 символов из наиболее часто используемых англоязычными пользователями — латинские буквы, арабские цифры и знаки препинания. Еще в эти 128 знаков, описанных в ASCII, попадали некоторые служебные символы навроде скобок, решеток, звездочек и т.п. Собственно, вы сами можете увидеть их:
Именно эти 128 символов из первоначального вариант ASCII стали стандартом, и в любой другой кодировке вы их обязательно встретите и стоять они будут именно в таком порядке. Но дело в том, что с помощью одного байта информации можно закодировать не 128, а целых 256 различных значений (двойка в степени восемь равняется 256), поэтому вслед за базовой версией Аски появился целый ряд расширенных кодировок ASCII, в которых можно было кроме 128 основных знаков закодировать еще и символы национальной кодировки (например, русской). Тут, наверное, стоит еще немного сказать про системы счисления, которые используются при описании. Во-первых, как вы все знаете, компьютер работает только с числами в двоичной системе, а именно с нулями и единицами («булева алгебра», если кто проходил в институте или в школе). Один байт состоит из восьми бит, каждый из которых представляет из себя двойку в степени, начиная с нулевой, и до двойки в седьмой: Не трудно понять, что всех возможных комбинаций нулей и единиц в такой конструкции может быть только 256. Переводить число из двоичной системы в десятичную довольно просто. Нужно просто сложить все степени двойки, над которыми стоят единички. В нашем примере это получается 1 (2 в степени ноль) плюс 8 (два в степени 3), плюс 32 (двойка в пятой степени), плюс 64 (в шестой), плюс 128 (в седьмой). Итого получает 233 в десятичной системе счисления. Как видите, все очень просто. Но если вы присмотритесь к таблице с символами ASCII, то увидите, что они представлены в шестнадцатеричной кодировке. Например, «звездочка» соответствует в Аски шестнадцатеричному числу 2A. Наверное, вам известно, что в шестнадцатеричной системе счисления используются кроме арабских цифр еще и латинские буквы от A (означает десять) до F (означает пятнадцать). Ну так вот, для перевода двоичного числа в шестнадцатеричное прибегают к следующему простому и наглядному способу.
Один байт состоит из восьми бит, каждый из которых представляет из себя двойку в степени, начиная с нулевой, и до двойки в седьмой: Не трудно понять, что всех возможных комбинаций нулей и единиц в такой конструкции может быть только 256. Переводить число из двоичной системы в десятичную довольно просто. Нужно просто сложить все степени двойки, над которыми стоят единички. В нашем примере это получается 1 (2 в степени ноль) плюс 8 (два в степени 3), плюс 32 (двойка в пятой степени), плюс 64 (в шестой), плюс 128 (в седьмой). Итого получает 233 в десятичной системе счисления. Как видите, все очень просто. Но если вы присмотритесь к таблице с символами ASCII, то увидите, что они представлены в шестнадцатеричной кодировке. Например, «звездочка» соответствует в Аски шестнадцатеричному числу 2A. Наверное, вам известно, что в шестнадцатеричной системе счисления используются кроме арабских цифр еще и латинские буквы от A (означает десять) до F (означает пятнадцать). Ну так вот, для перевода двоичного числа в шестнадцатеричное прибегают к следующему простому и наглядному способу. Каждый байт информации разбивают на две части по четыре бита, как показано на приведенном выше скриншоте. Т.о. в каждой половинке байта двоичным кодом можно закодировать только шестнадцать значений (два в четвертой степени), что можно легко представить шестнадцатеричным числом. Причем, в левой половине байта считать степени нужно будет опять начиная с нулевой, а не так, как показано на скриншоте. В результате, путем нехитрых вычислений, мы получим, что на скриншоте закодировано число E9. Надеюсь, что ход моих рассуждений и разгадка данного ребуса вам оказались понятны. Ну, а теперь продолжим, собственно, говорить про кодировки текста.
Каждый байт информации разбивают на две части по четыре бита, как показано на приведенном выше скриншоте. Т.о. в каждой половинке байта двоичным кодом можно закодировать только шестнадцать значений (два в четвертой степени), что можно легко представить шестнадцатеричным числом. Причем, в левой половине байта считать степени нужно будет опять начиная с нулевой, а не так, как показано на скриншоте. В результате, путем нехитрых вычислений, мы получим, что на скриншоте закодировано число E9. Надеюсь, что ход моих рассуждений и разгадка данного ребуса вам оказались понятны. Ну, а теперь продолжим, собственно, говорить про кодировки текста.Расширенные версии Аски — кодировки CP866 и KOI8-R с псевдографикой
Итак, мы с вами начали говорить про ASCII, которая являлась как бы отправной точкой для развития всех современных кодировок (Windows 1251, юникод, UTF 8). Изначально в нее было заложено только 128 знаков латинского алфавита, арабских цифр и еще чего-то там, но в расширенной версии появилась возможность использовать все 256 значений, которые можно закодировать в одном байте информации.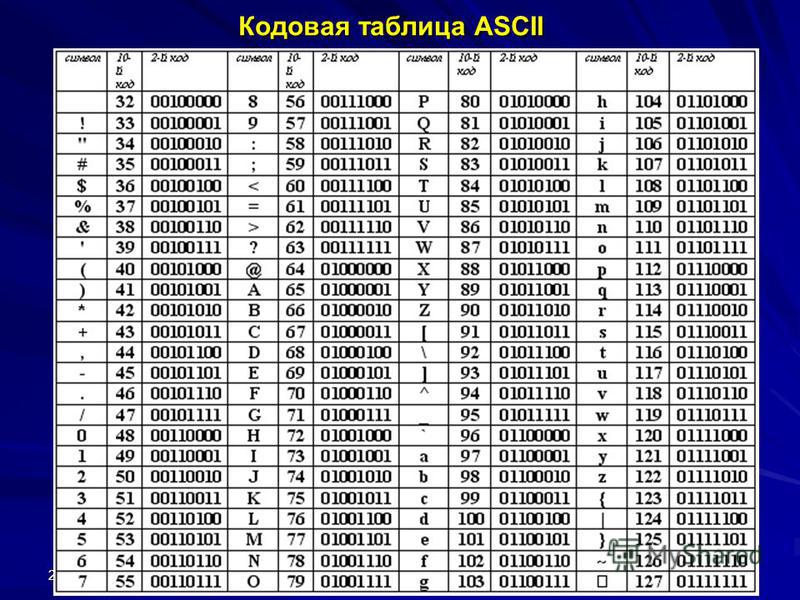 Т.е. появилась возможность добавить в Аски символы букв своего языка. Тут нужно будет еще раз отвлечься, чтобы пояснить — зачем вообще нужны кодировки текстов и почему это так важно. Символы на экране вашего компьютера формируются на основе двух вещей — наборов векторных форм (представлений) всевозможных знаков (они находятся в файлах со шрифтами, которые установлены на вашем компьютере) и кода, который позволяет выдернуть из этого набора векторных форм (файла шрифта) именно тот символ, который нужно будет вставить в нужное место. Понятно, что за сами векторные формы отвечают шрифты, а вот за кодирование отвечает операционная система и используемые в ней программы. Т.е. любой текст на вашем компьютере будет представлять собой набор байтов, в каждом из которых закодирован один единственный символ этого самого текста. Программа, отображающая этот текст на экране (текстовый редактор, браузер и т.п.), при разборе кода считывает кодировку очередного знака и ищет соответствующую ему векторную форму в нужном файле шрифта, который подключен для отображения данного текстового документа.
Т.е. появилась возможность добавить в Аски символы букв своего языка. Тут нужно будет еще раз отвлечься, чтобы пояснить — зачем вообще нужны кодировки текстов и почему это так важно. Символы на экране вашего компьютера формируются на основе двух вещей — наборов векторных форм (представлений) всевозможных знаков (они находятся в файлах со шрифтами, которые установлены на вашем компьютере) и кода, который позволяет выдернуть из этого набора векторных форм (файла шрифта) именно тот символ, который нужно будет вставить в нужное место. Понятно, что за сами векторные формы отвечают шрифты, а вот за кодирование отвечает операционная система и используемые в ней программы. Т.е. любой текст на вашем компьютере будет представлять собой набор байтов, в каждом из которых закодирован один единственный символ этого самого текста. Программа, отображающая этот текст на экране (текстовый редактор, браузер и т.п.), при разборе кода считывает кодировку очередного знака и ищет соответствующую ему векторную форму в нужном файле шрифта, который подключен для отображения данного текстового документа. Все просто и банально. Значит, чтобы закодировать любой нужный нам символ (например, из национального алфавита), должно быть выполнено два условия — векторная форма этого знака должна быть в используемом шрифте и этот символ можно было бы закодировать в расширенных кодировках ASCII в один байт. Поэтому таких вариантов существует целая куча. Только лишь для кодирования символов русского языка существует несколько разновидностей расширенной Аски. Например, изначально появилась CP866, в которой была возможность использовать символы русского алфавита и она являлась расширенной версией ASCII. Т.е. ее верхняя часть полностью совпадала с базовой версией Аски (128 символов латиницы, цифр и еще всякой лабуды), которая представлена на приведенном чуть выше скриншоте, а вот уже нижняя часть таблицы с кодировкой CP866 имела указанный на скриншоте чуть ниже вид и позволяла закодировать еще 128 знаков (русские буквы и всякая там псевдографика): Видите, в правом столбце цифры начинаются с 8, т.
Все просто и банально. Значит, чтобы закодировать любой нужный нам символ (например, из национального алфавита), должно быть выполнено два условия — векторная форма этого знака должна быть в используемом шрифте и этот символ можно было бы закодировать в расширенных кодировках ASCII в один байт. Поэтому таких вариантов существует целая куча. Только лишь для кодирования символов русского языка существует несколько разновидностей расширенной Аски. Например, изначально появилась CP866, в которой была возможность использовать символы русского алфавита и она являлась расширенной версией ASCII. Т.е. ее верхняя часть полностью совпадала с базовой версией Аски (128 символов латиницы, цифр и еще всякой лабуды), которая представлена на приведенном чуть выше скриншоте, а вот уже нижняя часть таблицы с кодировкой CP866 имела указанный на скриншоте чуть ниже вид и позволяла закодировать еще 128 знаков (русские буквы и всякая там псевдографика): Видите, в правом столбце цифры начинаются с 8, т. к. числа с 0 до 7 относятся к базовой части ASCII (см. первый скриншот). Т.о. русская буква «М» в CP866 будет иметь код 9С (она находится на пересечении соответствующих строки с 9 и столбца с цифрой С в шестнадцатеричной системе счисления), который можно записать в одном байте информации, и при наличии подходящего шрифта с русскими символами эта буква без проблем отобразится в тексте. Откуда взялось такое количество псевдографики в CP866? Тут все дело в том, что эта кодировка для русского текста разрабатывалась еще в те мохнатые года, когда не было такого распространения графических операционных систем как сейчас. А в Досе, и подобных ей текстовых операционках, псевдографика позволяла хоть как-то разнообразить оформление текстов и поэтому ею изобилует CP866 и все другие ее ровесницы из разряда расширенных версий Аски. CP866 распространяла компания IBM, но кроме этого для символов русского языка были разработаны еще ряд кодировок, например, к этому же типу (расширенных ASCII) можно отнести KOI8-R:
Принцип ее работы остался тот же самый, что и у описанной чуть ранее CP866 — каждый символ текста кодируется одним единственным байтом.
к. числа с 0 до 7 относятся к базовой части ASCII (см. первый скриншот). Т.о. русская буква «М» в CP866 будет иметь код 9С (она находится на пересечении соответствующих строки с 9 и столбца с цифрой С в шестнадцатеричной системе счисления), который можно записать в одном байте информации, и при наличии подходящего шрифта с русскими символами эта буква без проблем отобразится в тексте. Откуда взялось такое количество псевдографики в CP866? Тут все дело в том, что эта кодировка для русского текста разрабатывалась еще в те мохнатые года, когда не было такого распространения графических операционных систем как сейчас. А в Досе, и подобных ей текстовых операционках, псевдографика позволяла хоть как-то разнообразить оформление текстов и поэтому ею изобилует CP866 и все другие ее ровесницы из разряда расширенных версий Аски. CP866 распространяла компания IBM, но кроме этого для символов русского языка были разработаны еще ряд кодировок, например, к этому же типу (расширенных ASCII) можно отнести KOI8-R:
Принцип ее работы остался тот же самый, что и у описанной чуть ранее CP866 — каждый символ текста кодируется одним единственным байтом.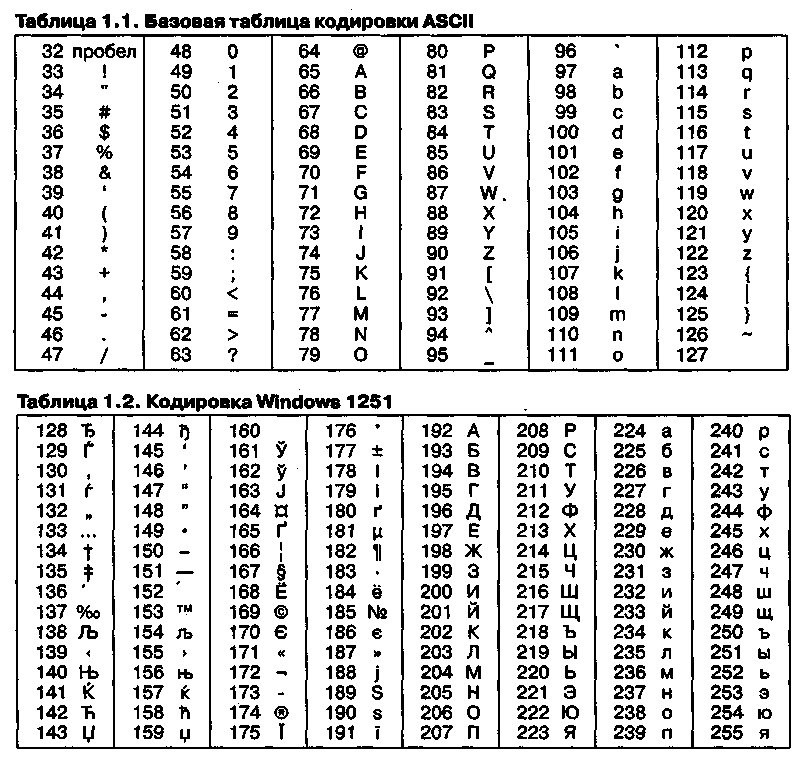 На скриншоте показана вторая половина таблицы KOI8-R, т.к. первая половина полностью соответствует базовой Аски, которая показана на первом скриншоте в этой статье. Среди особенностей кодировки KOI8-R можно отметить то, что русские буквы в ее таблице идут не в алфавитном порядке, как это, например, сделали в CP866. Если посмотрите на самый первый скриншот (базовой части, которая входит во все расширенные кодировки), то заметите, что в KOI8-R русские буквы расположены в тех же ячейках таблицы, что и созвучные им буквы латинского алфавита из первой части таблицы. Это было сделано для удобства перехода с русских символов на латинские путем отбрасывания всего одного бита (два в седьмой степени или 128).
На скриншоте показана вторая половина таблицы KOI8-R, т.к. первая половина полностью соответствует базовой Аски, которая показана на первом скриншоте в этой статье. Среди особенностей кодировки KOI8-R можно отметить то, что русские буквы в ее таблице идут не в алфавитном порядке, как это, например, сделали в CP866. Если посмотрите на самый первый скриншот (базовой части, которая входит во все расширенные кодировки), то заметите, что в KOI8-R русские буквы расположены в тех же ячейках таблицы, что и созвучные им буквы латинского алфавита из первой части таблицы. Это было сделано для удобства перехода с русских символов на латинские путем отбрасывания всего одного бита (два в седьмой степени или 128).Windows 1251 — современная версия ASCII и почему вылезают кракозябры
Дальнейшее развитие кодировок текста было связано с тем, что набирали популярность графические операционные системы и необходимость использования псевдографики в них со временем пропала. В результате возникла целая группа, которая по своей сути по-прежнему являлись расширенными версиями Аски (один символ текста кодируется всего одним байтом информации), но уже без использования символов псевдографики. Они относились к так называемым ANSI кодировкам, которые были разработаны американским институтом стандартизации. В просторечии еще использовалось название кириллица для варианта с поддержкой русского языка. Примером такой может служить Windows 1251. Она выгодно отличалась от используемых ранее CP866 и KOI8-R тем, что место символов псевдографики в ней заняли недостающие символы русской типографики (окромя знака ударения), а также символы, используемые в близких к русскому славянских языках (украинскому, белорусскому и т.д.):
Из-за такого обилия кодировок русского языка, у производителей шрифтов и производителей программного обеспечения постоянно возникала головная боль, а у нас с вам, уважаемые читатели, зачастую вылезали те самые пресловутые кракозябры, когда происходила путаница с используемой в тексте версией. Очень часто они вылезали при отправке и получении сообщений по электронной почте, что повлекло за собой создание очень сложных перекодировочных таблиц, которые, собственно, решить эту проблему в корне не смогли, и зачастую пользователи для переписки использовали транслит латинских букв, чтобы избежать пресловутых кракозябров при использовании русских кодировок подобных CP866, KOI8-R или Windows 1251.
Они относились к так называемым ANSI кодировкам, которые были разработаны американским институтом стандартизации. В просторечии еще использовалось название кириллица для варианта с поддержкой русского языка. Примером такой может служить Windows 1251. Она выгодно отличалась от используемых ранее CP866 и KOI8-R тем, что место символов псевдографики в ней заняли недостающие символы русской типографики (окромя знака ударения), а также символы, используемые в близких к русскому славянских языках (украинскому, белорусскому и т.д.):
Из-за такого обилия кодировок русского языка, у производителей шрифтов и производителей программного обеспечения постоянно возникала головная боль, а у нас с вам, уважаемые читатели, зачастую вылезали те самые пресловутые кракозябры, когда происходила путаница с используемой в тексте версией. Очень часто они вылезали при отправке и получении сообщений по электронной почте, что повлекло за собой создание очень сложных перекодировочных таблиц, которые, собственно, решить эту проблему в корне не смогли, и зачастую пользователи для переписки использовали транслит латинских букв, чтобы избежать пресловутых кракозябров при использовании русских кодировок подобных CP866, KOI8-R или Windows 1251.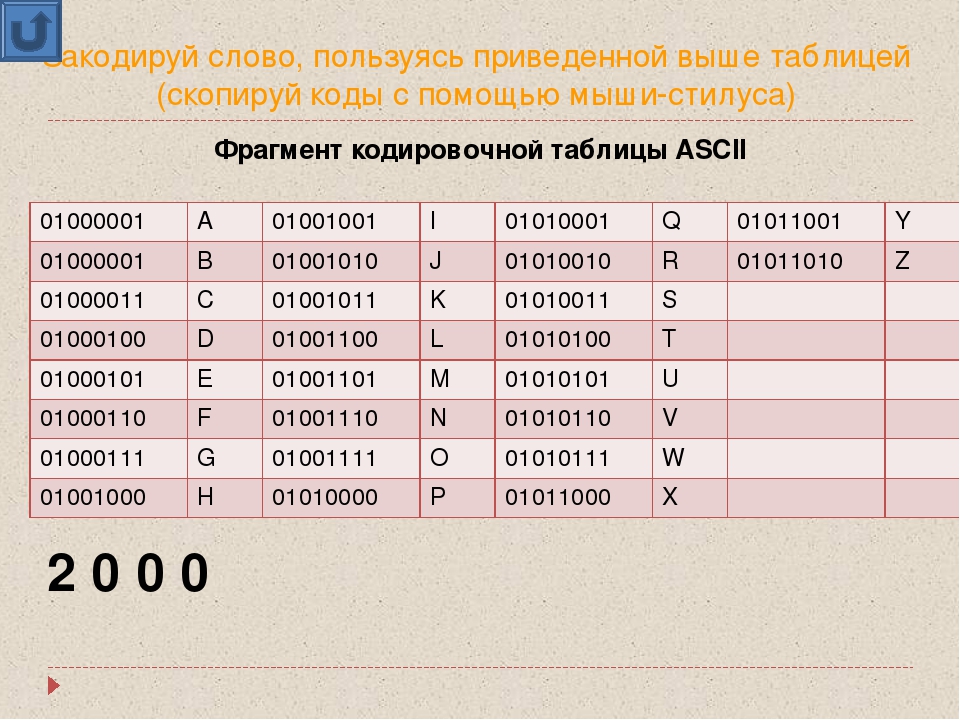 По сути, кракозябры, вылазящие вместо русского текста, были результатом некорректного использования кодировки данного языка, которая не соответствовала той, в которой было закодировано текстовое сообщение изначально. Допустим, если символы, закодированные с помощью CP866, попробовать отобразить, используя кодовую таблицу Windows 1251, то эти самые кракозябры (бессмысленный набор знаков) и вылезут, полностью заменив собой текст сообщения.
Аналогичная ситуация очень часто возникает при создании и настройке сайтов, форумов или блогов, когда текст с русскими символами по ошибке сохраняется не в той кодировке, которая используется на сайте по умолчанию, или же не в том текстовом редакторе, который добавляет в код отсебятину не видимую невооруженным глазом. В конце концов такая ситуация с множеством кодировок и постоянно вылезающими кракозябрами многим надоела, появились предпосылки к созданию новой универсальной вариации, которая бы заменила собой все существующие и решила бы, наконец, на корню проблему с появлением не читаемых текстов.
По сути, кракозябры, вылазящие вместо русского текста, были результатом некорректного использования кодировки данного языка, которая не соответствовала той, в которой было закодировано текстовое сообщение изначально. Допустим, если символы, закодированные с помощью CP866, попробовать отобразить, используя кодовую таблицу Windows 1251, то эти самые кракозябры (бессмысленный набор знаков) и вылезут, полностью заменив собой текст сообщения.
Аналогичная ситуация очень часто возникает при создании и настройке сайтов, форумов или блогов, когда текст с русскими символами по ошибке сохраняется не в той кодировке, которая используется на сайте по умолчанию, или же не в том текстовом редакторе, который добавляет в код отсебятину не видимую невооруженным глазом. В конце концов такая ситуация с множеством кодировок и постоянно вылезающими кракозябрами многим надоела, появились предпосылки к созданию новой универсальной вариации, которая бы заменила собой все существующие и решила бы, наконец, на корню проблему с появлением не читаемых текстов. Кроме этого существовала проблема языков подобных китайскому, где символов языка было гораздо больше, чем 256.
Кроме этого существовала проблема языков подобных китайскому, где символов языка было гораздо больше, чем 256.Юникод (Unicode) — универсальные кодировки UTF 8, 16 и 32
Эти тысячи знаков языковой группы юго-восточной Азии никак невозможно было описать в одном байте информации, который выделялся для кодирования символов в расширенных версиях ASCII. В результате был создан консорциум под названием Юникод (Unicode — Unicode Consortium) при сотрудничестве многих лидеров IT индустрии (те, кто производит софт, кто кодирует железо, кто создает шрифты), которые были заинтересованы в появлении универсальной кодировки текста. Первой вариацией, вышедшей под эгидой консорциума Юникод, была UTF 32. Цифра в названии кодировки означает количество бит, которое используется для кодирования одного символа. 32 бита составляют 4 байта информации, которые понадобятся для кодирования одного единственного знака в новой универсальной кодировке UTF. В результате чего, один и тот же файл с текстом, закодированный в расширенной версии ASCII и в UTF-32, в последнем случае будет иметь размер (весить) в четыре раза больше. Это плохо, но зато теперь у нас появилась возможность закодировать с помощью ЮТФ число знаков, равное двум в тридцать второй степени (миллиарды символов, которые покроют любое реально необходимое значение с колоссальным запасом). Но многим странам с языками европейской группы такое огромное количество знаков использовать в кодировке вовсе и не было необходимости, однако при задействовании UTF-32 они ни за что ни про что получали четырехкратное увеличение веса текстовых документов, а в результате и увеличение объема интернет трафика и объема хранимых данных. Это много, и такое расточительство себе никто не мог позволить. В результате развития Юникода появилась UTF-16, которая получилась настолько удачной, что была принята по умолчанию как базовое пространство для всех символов, которые у нас используются. Она использует два байта для кодирования одного знака. Давайте посмотрим, как это дело выглядит. В операционной системе Windows вы можете пройти по пути «Пуск» — «Программы» — «Стандартные» — «Служебные» — «Таблица символов».
Это плохо, но зато теперь у нас появилась возможность закодировать с помощью ЮТФ число знаков, равное двум в тридцать второй степени (миллиарды символов, которые покроют любое реально необходимое значение с колоссальным запасом). Но многим странам с языками европейской группы такое огромное количество знаков использовать в кодировке вовсе и не было необходимости, однако при задействовании UTF-32 они ни за что ни про что получали четырехкратное увеличение веса текстовых документов, а в результате и увеличение объема интернет трафика и объема хранимых данных. Это много, и такое расточительство себе никто не мог позволить. В результате развития Юникода появилась UTF-16, которая получилась настолько удачной, что была принята по умолчанию как базовое пространство для всех символов, которые у нас используются. Она использует два байта для кодирования одного знака. Давайте посмотрим, как это дело выглядит. В операционной системе Windows вы можете пройти по пути «Пуск» — «Программы» — «Стандартные» — «Служебные» — «Таблица символов». В результате откроется таблица с векторными формами всех установленных у вас в системе шрифтов. Если вы выберете в «Дополнительных параметрах» набор знаков Юникод, то сможете увидеть для каждого шрифта в отдельности весь ассортимент входящих в него символов. Кстати, щелкнув по любому из них, вы сможете увидеть его двухбайтовый код в формате UTF-16, состоящий из четырех шестнадцатеричных цифр:
Сколько символов можно закодировать в UTF-16 с помощью 16 бит? 65 536 (два в степени шестнадцать), и именно это число было принято за базовое пространство в Юникоде. Помимо этого существуют способы закодировать с помощью нее и около двух миллионов знаков, но ограничились расширенным пространством в миллион символов текста. Но даже эта удачная версия кодировки Юникода не принесла особого удовлетворения тем, кто писал, допустим, программы только на английском языке, ибо у них, после перехода от расширенной версии ASCII к UTF-16, вес документов увеличивался в два раза (один байт на один символ в Аски и два байта на тот же самый символ в ЮТФ-16).
В результате откроется таблица с векторными формами всех установленных у вас в системе шрифтов. Если вы выберете в «Дополнительных параметрах» набор знаков Юникод, то сможете увидеть для каждого шрифта в отдельности весь ассортимент входящих в него символов. Кстати, щелкнув по любому из них, вы сможете увидеть его двухбайтовый код в формате UTF-16, состоящий из четырех шестнадцатеричных цифр:
Сколько символов можно закодировать в UTF-16 с помощью 16 бит? 65 536 (два в степени шестнадцать), и именно это число было принято за базовое пространство в Юникоде. Помимо этого существуют способы закодировать с помощью нее и около двух миллионов знаков, но ограничились расширенным пространством в миллион символов текста. Но даже эта удачная версия кодировки Юникода не принесла особого удовлетворения тем, кто писал, допустим, программы только на английском языке, ибо у них, после перехода от расширенной версии ASCII к UTF-16, вес документов увеличивался в два раза (один байт на один символ в Аски и два байта на тот же самый символ в ЮТФ-16).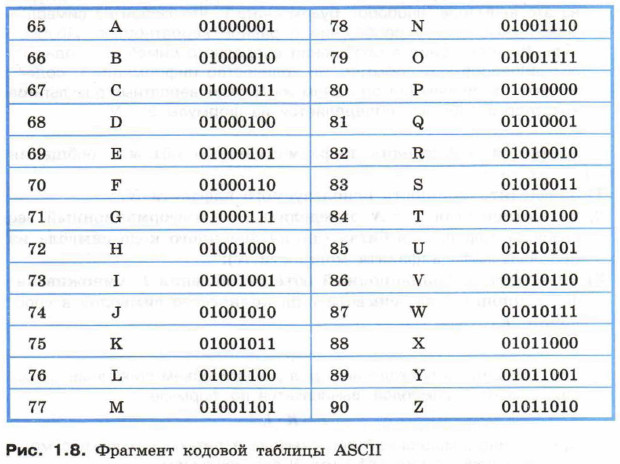 Вот именно для удовлетворения всех и вся в консорциуме Unicode было решено придумать кодировку переменной длины. Ее назвали UTF-8. Несмотря на восьмерку в названии, она действительно имеет переменную длину, т.е. каждый символ текста может быть закодирован в последовательность длиной от одного до шести байт. На практике же в UTF-8 используется только диапазон от одного до четырех байт, потому что за четырьмя байтами кода ничего уже даже теоретически не возможно представить. Все латинские знаки в ней кодируются в один байт, так же как и в старой доброй ASCII. Что примечательно, в случае кодирования только латиницы, даже те программы, которые не понимают Юникод, все равно прочитают то, что закодировано в ЮТФ-8. Т.е. базовая часть Аски просто перешла в это детище консорциума Unicode. Кириллические же знаки в UTF-8 кодируются в два байта, а, например, грузинские — в три байта. Консорциум Юникод после создания UTF 16 и 8 решил основную проблему — теперь у нас в шрифтах существует единое кодовое пространство.
Вот именно для удовлетворения всех и вся в консорциуме Unicode было решено придумать кодировку переменной длины. Ее назвали UTF-8. Несмотря на восьмерку в названии, она действительно имеет переменную длину, т.е. каждый символ текста может быть закодирован в последовательность длиной от одного до шести байт. На практике же в UTF-8 используется только диапазон от одного до четырех байт, потому что за четырьмя байтами кода ничего уже даже теоретически не возможно представить. Все латинские знаки в ней кодируются в один байт, так же как и в старой доброй ASCII. Что примечательно, в случае кодирования только латиницы, даже те программы, которые не понимают Юникод, все равно прочитают то, что закодировано в ЮТФ-8. Т.е. базовая часть Аски просто перешла в это детище консорциума Unicode. Кириллические же знаки в UTF-8 кодируются в два байта, а, например, грузинские — в три байта. Консорциум Юникод после создания UTF 16 и 8 решил основную проблему — теперь у нас в шрифтах существует единое кодовое пространство. И теперь их производителям остается только исходя из своих сил и возможностей заполнять его векторными формами символов текста. В приведенной чуть выше «Таблице символов» видно, что разные шрифты поддерживают разное количество знаков. Некоторые насыщенные символами Юникода шрифты могут весить очень прилично. Но зато теперь они отличаются не тем, что они созданы для разных кодировок, а тем, что производитель шрифта заполнил или не заполнил единое кодовое пространство теми или иными векторными формами до конца.
И теперь их производителям остается только исходя из своих сил и возможностей заполнять его векторными формами символов текста. В приведенной чуть выше «Таблице символов» видно, что разные шрифты поддерживают разное количество знаков. Некоторые насыщенные символами Юникода шрифты могут весить очень прилично. Но зато теперь они отличаются не тем, что они созданы для разных кодировок, а тем, что производитель шрифта заполнил или не заполнил единое кодовое пространство теми или иными векторными формами до конца.Кракозябры вместо русских букв — как исправить
Давайте теперь посмотрим, как появляются вместо текста кракозябры или, другими словами, как выбирается правильная кодировка для русского текста. Собственно, она задается в той программе, в которой вы создаете или редактируете этот самый текст, или же код с использованием текстовых фрагментов. Для редактирования и создания текстовых файлов лично я использую очень хороший, на мой взгляд, Html и PHP редактор Notepad++. Впрочем, он может подсвечивать синтаксис еще доброй сотни языков программирования и разметки, а также имеет возможность расширения с помощью плагинов.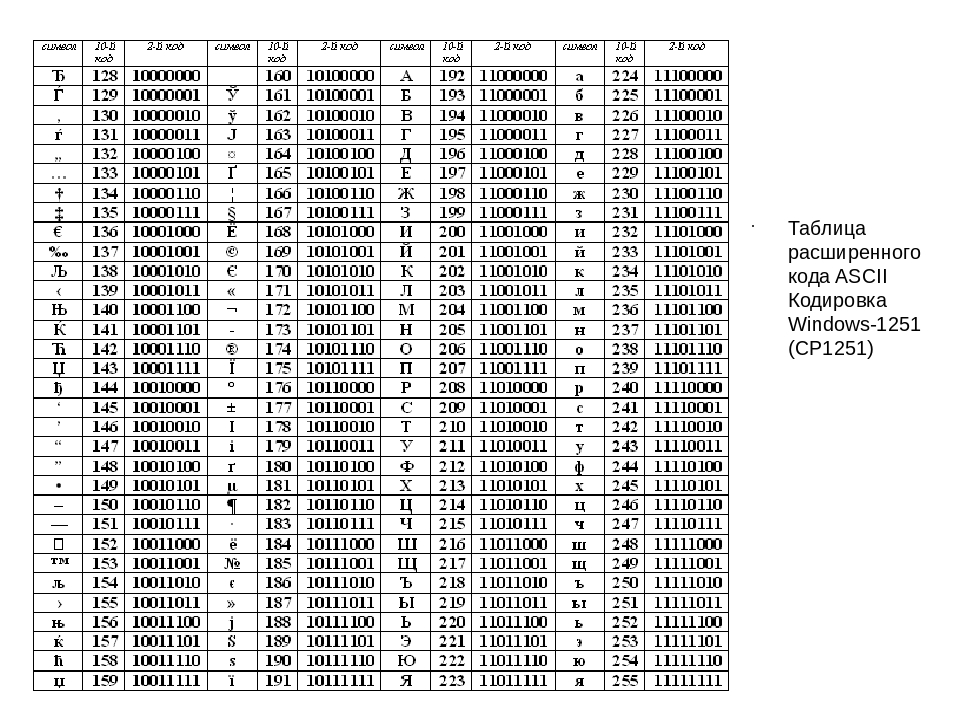 Читайте подробный обзор этой замечательной программы по приведенной ссылке. В верхнем меню Notepad++ есть пункт «Кодировки», где у вас будет возможность преобразовать уже имеющийся вариант в тот, который используется на вашем сайте по умолчанию:
В случае сайта на Joomla 1.5 и выше, а также в случае блога на WordPress следует во избежании появления кракозябров выбирать вариант UTF 8 без BOM. А что такое приставка BOM? Дело в том, что когда разрабатывали кодировку ЮТФ-16, зачем-то решили прикрутить к ней такую вещь, как возможность записывать код символа, как в прямой последовательности (например, 0A15), так и в обратной (150A). А для того, чтобы программы понимали, в какой именно последовательности читать коды, и был придуман BOM (Byte Order Mark или, другими словами, сигнатура), которая выражалась в добавлении трех дополнительных байтов в самое начало документов. В кодировке UTF-8 никаких BOM предусмотрено в консорциуме Юникод не было и поэтому добавление сигнатуры (этих самых пресловутых дополнительных трех байтов в начало документа) некоторым программам просто-напросто мешает читать код.
Читайте подробный обзор этой замечательной программы по приведенной ссылке. В верхнем меню Notepad++ есть пункт «Кодировки», где у вас будет возможность преобразовать уже имеющийся вариант в тот, который используется на вашем сайте по умолчанию:
В случае сайта на Joomla 1.5 и выше, а также в случае блога на WordPress следует во избежании появления кракозябров выбирать вариант UTF 8 без BOM. А что такое приставка BOM? Дело в том, что когда разрабатывали кодировку ЮТФ-16, зачем-то решили прикрутить к ней такую вещь, как возможность записывать код символа, как в прямой последовательности (например, 0A15), так и в обратной (150A). А для того, чтобы программы понимали, в какой именно последовательности читать коды, и был придуман BOM (Byte Order Mark или, другими словами, сигнатура), которая выражалась в добавлении трех дополнительных байтов в самое начало документов. В кодировке UTF-8 никаких BOM предусмотрено в консорциуме Юникод не было и поэтому добавление сигнатуры (этих самых пресловутых дополнительных трех байтов в начало документа) некоторым программам просто-напросто мешает читать код.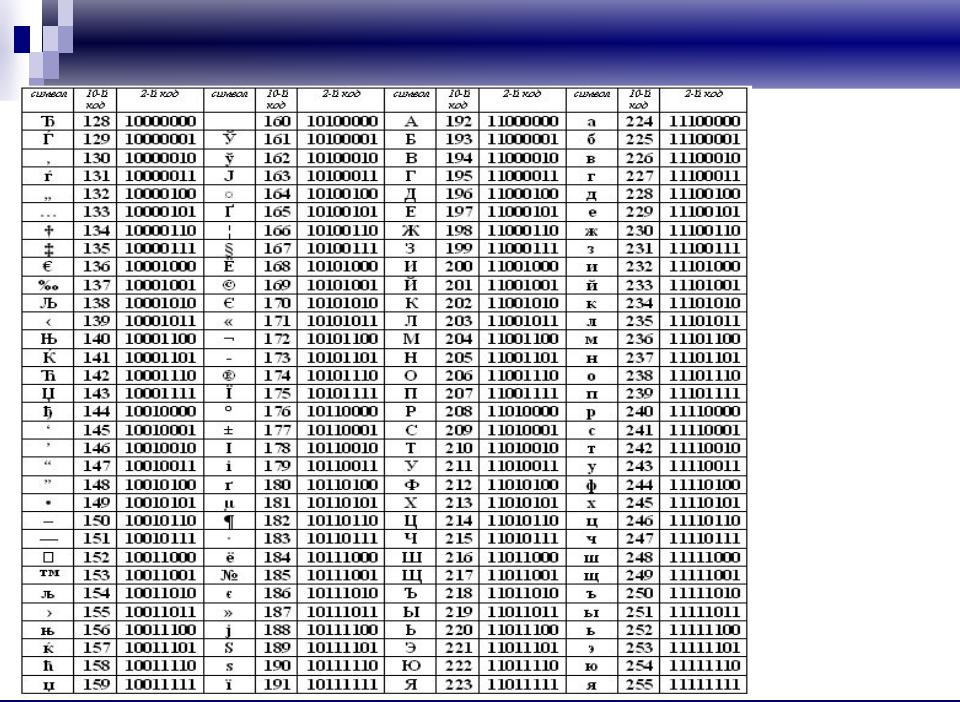 Поэтому мы всегда при сохранении файлов в ЮТФ должны выбирать вариант без BOM (без сигнатуры). Таким образом, вы заранее обезопасите себя от вылезания кракозябров. Что примечательно, некоторые программы в Windows не умеют этого делать (не умеют сохранять текст в ЮТФ-8 без BOM), например, все тот же пресловутый Блокнот Windows. Он сохраняет документ в UTF-8, но все равно добавляет в его начало сигнатуру (три дополнительных байта). Причем эти байты будут всегда одни и те же — читать код в прямой последовательности. Но на серверах из-за этой мелочи может возникнуть проблема — вылезут кракозябры. Поэтому ни в коем случае не пользуйтесь обычным блокнотом Windows для редактирования документов вашего сайта, если не хотите появления кракозябров. Лучшим и наиболее простым вариантом я считаю уже упомянутый редактор Notepad++, который практически не имеет недостатков и состоит из одних лишь достоинств. В Notepad ++ при выборе кодировки у вас будет возможность преобразовать текст в кодировку UCS-2, которая по своей сути очень близка к стандарту Юникод.
Поэтому мы всегда при сохранении файлов в ЮТФ должны выбирать вариант без BOM (без сигнатуры). Таким образом, вы заранее обезопасите себя от вылезания кракозябров. Что примечательно, некоторые программы в Windows не умеют этого делать (не умеют сохранять текст в ЮТФ-8 без BOM), например, все тот же пресловутый Блокнот Windows. Он сохраняет документ в UTF-8, но все равно добавляет в его начало сигнатуру (три дополнительных байта). Причем эти байты будут всегда одни и те же — читать код в прямой последовательности. Но на серверах из-за этой мелочи может возникнуть проблема — вылезут кракозябры. Поэтому ни в коем случае не пользуйтесь обычным блокнотом Windows для редактирования документов вашего сайта, если не хотите появления кракозябров. Лучшим и наиболее простым вариантом я считаю уже упомянутый редактор Notepad++, который практически не имеет недостатков и состоит из одних лишь достоинств. В Notepad ++ при выборе кодировки у вас будет возможность преобразовать текст в кодировку UCS-2, которая по своей сути очень близка к стандарту Юникод.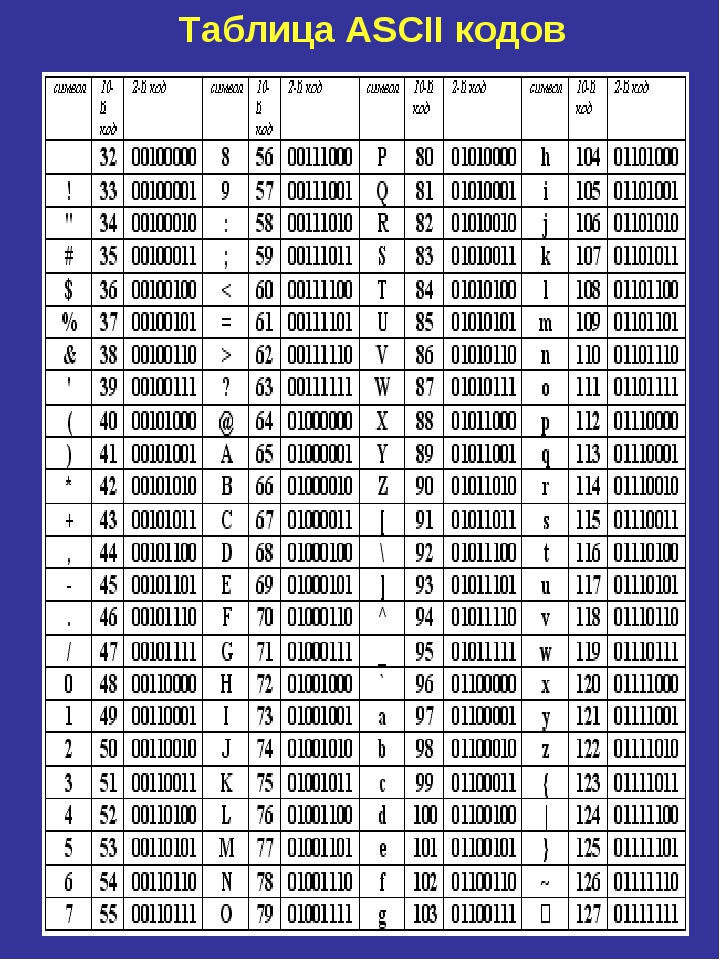 Также в Нотепаде можно будет закодировать текст в ANSI, т.е. применительно к русскому языку это будет уже описанная нами чуть выше Windows 1251. Откуда берется эта информация? Она прописана в реестре вашей операционной системы Windows — какую кодировку выбирать в случае ANSI, какую выбирать в случае OEM (для русского языка это будет CP866). Если вы установите на своем компьютере другой язык по умолчанию, то и эти кодировки будут заменены на аналогичные из разряда ANSI или OEM для того самого языка. После того, как вы в Notepad++ сохраните документ в нужной вам кодировке или же откроете документ с сайта для редактирования, то в правом нижнем углу редактора сможете увидеть ее название: Чтобы избежать кракозябров, кроме описанных выше действий, будет полезным прописать в его шапке исходного кода всех страниц сайта информацию об этой самой кодировке, чтобы на сервере или локальном хосте не возникло путаницы. Вообще, во всех языках гипертекстовой разметки кроме Html используется специальное объявление xml, в котором указывается кодировка текста.
Также в Нотепаде можно будет закодировать текст в ANSI, т.е. применительно к русскому языку это будет уже описанная нами чуть выше Windows 1251. Откуда берется эта информация? Она прописана в реестре вашей операционной системы Windows — какую кодировку выбирать в случае ANSI, какую выбирать в случае OEM (для русского языка это будет CP866). Если вы установите на своем компьютере другой язык по умолчанию, то и эти кодировки будут заменены на аналогичные из разряда ANSI или OEM для того самого языка. После того, как вы в Notepad++ сохраните документ в нужной вам кодировке или же откроете документ с сайта для редактирования, то в правом нижнем углу редактора сможете увидеть ее название: Чтобы избежать кракозябров, кроме описанных выше действий, будет полезным прописать в его шапке исходного кода всех страниц сайта информацию об этой самой кодировке, чтобы на сервере или локальном хосте не возникло путаницы. Вообще, во всех языках гипертекстовой разметки кроме Html используется специальное объявление xml, в котором указывается кодировка текста.
<?xml version="1.0" encoding="windows-1251"?>
<head>
...
<meta charset="utf-8">
...
</head>
| Кодовая точка Unicode | символ | UTF-8 (шест.) | наименование |
|---|---|---|---|
| U + 0000 | 00 | <контроль> | |
| U + 0001 | 01 | <контроль> | |
| U + 0002 | 02 | <контроль> | |
| U + 0003 | 03 | <контроль> | |
| U + 0004 | 04 | <контроль> | |
| U + 0005 | 05 | <контроль> | |
| U + 0006 | 06 | <контроль> | |
| U + 0007 | 07 | <контроль> | |
| U + 0008 | 08 | <контроль> | |
| U + 0009 | 09 | <контроль> | |
| U + 000A | 0a | <контроль> | |
| U + 000B | 0b | <контроль> | |
| U + 000C | 0c | <контроль> | |
| U + 000D | 0d | <контроль> | |
| U + 000E | 0e | <контроль> | |
| U + 000F | 0f | <контроль> | |
| U + 0010 | 10 | <контроль> | |
| U + 0011 | 11 | <контроль> | |
| U + 0012 | 12 | <контроль> | |
| U + 0013 | 13 | <контроль> | |
| U + 0014 | 14 | <контроль> | |
| U + 0015 | 15 | <контроль> | |
| U + 0016 | 16 | <контроль> | |
| U + 0017 | 17 | <контроль> | |
| U + 0018 | 18 | <контроль> | |
| U + 0019 | 19 | <контроль> | |
| U + 001A | 1a | <контроль> | |
| U + 001B | 1b | <контроль> | |
| U + 001C | 1c | <контроль> | |
| U + 001D | 1d | <контроль> | |
| U + 001E | 1e | <контроль> | |
| U + 001F | 1f | <контроль> | |
| U + 0020 | 20 | ПРОСТРАНСТВО | |
| U + 0021 | ! | 21 | Восклицательный знак |
| U + 0022 | « | 22 | ЦЕННЫЙ ЗНАК |
| U + 0023 | # | 23 | НОМЕРНЫЙ ЗНАК |
| U + 0024 | $ | 24 | ЗНАК ДОЛЛАРА |
| U + 0025 | % | 25 | ЗНАК ПРОЦЕНТА |
| U + 0026 | и | 26 | AMPERSAND |
| U + 0027 | ‘ | 27 | АПОСТРОФ |
| U + 0028 | ( | 28 | ЛЕВЫЙ ПАРЕНТЕЗ |
| U + 0029 | ) | 29 | ПРАВЫЙ ПАРЕНТЕЗ |
| U + 002A | * | 2a | ASTERISK |
| U + 002B | + | 2b | PLUS SIGN |
| U + 002C | , | 2c | ЗАПЯТАЯ |
| U + 002D | — | 2d | ДЕФИНА-МИНУС |
| U + 002E | . | 2e | ПОЛНАЯ ОСТАНОВКА |
| U + 002F | / | 2f | SOLIDUS |
| U + 0030 | 0 | 30 | ЦИФРОВОЙ НУЛЬ |
| U + 0031 | 1 | 31 | DIGIT ONE |
| U + 0032 | 2 | 32 | ЦИФРА ДВА |
| U + 0033 | 3 | 33 | ТРИ ЦИФРА |
| U + 0034 | 4 | 34 | ЦИФРА ЧЕТЫРЕ |
| U + 0035 | 5 | 35 | ПЯТЬ ЦИФРОВ |
| U + 0036 | 6 | 36 | ШЕСТЬ ЦИФРОВ |
| U + 0037 | 7 | 37 | СЕМЬ ЦИФРОВ |
| U + 0038 | 8 | 38 | ЦИФРА ВОСЕМЬ |
| U + 0039 | 9 | 39 | ДЕВЯТЬ ЦИФРОВ |
| U + 003A | : | 3a | КОЛОНКА |
| U + 003B | ; | 3б | СЕМИКОЛОН |
| U + 003C | < | 3c | МЕНЬШЕ ЗНАКА |
| U + 003D | = | 3d | ЗНАК РАВНО |
| U + 003E | > | 3e | БОЛЬШЕ, ЧЕМ ЗНАК |
| U + 003F | ? | 3f | ВОПРОСНЫЙ ЗНАК |
| U + 0040 | @ | 40 | КОММЕРЧЕСКОЕ ПОМЕЩЕНИЕ |
| U + 0041 | A | 41 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА A |
| U + 0042 | B | 42 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА B |
| U + 0043 | C | 43 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА C |
| U + 0044 | D | 44 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА D |
| U + 0045 | E | 45 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА E |
| U + 0046 | F | 46 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА F |
| U + 0047 | G | 47 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА G |
| U + 0048 | H | 48 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА H |
| U + 0049 | I | 49 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА I |
| U + 004A | J | 4a | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА J |
| U + 004B | K | 4b | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА K |
| U + 004C | L | 4c | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА L |
| U + 004D | M | 4d | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА M |
| U + 004E | N | 4e | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА N |
| U + 004F | O | 4f | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА O |
| U + 0050 | P | 50 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА P |
| U + 0051 | Q | 51 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА Q |
| U + 0052 | R | 52 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА R |
| U + 0053 | S | 53 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА S |
| U + 0054 | T | 54 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА T |
| U + 0055 | U | 55 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА U |
| U + 0056 | V | 56 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА V |
| U + 0057 | W | 57 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА W |
| U + 0058 | X | 58 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА X |
| U + 0059 | Y | 59 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА Y |
| U + 005A | Z | 5a | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА Z |
| U + 005B | [ | 5b | КРОНШТЕЙН КВАДРАТНЫЙ ЛЕВЫЙ |
| U + 005C | \ | 5c | REVERSE SOLIDUS |
| U + 005D | ] | 5d | КРОНШТЕЙН ПРАВЫЙ КВАДРАТНЫЙ |
| U + 005E | ^ | 5e | CIRCUMFLEX ACCENT |
| U + 005F | _ | 5f | НИЗКАЯ ЛИНИЯ |
| U + 0060 | ` | 60 | МОЩНЫЙ АКЦЕНТ |
| U + 0061 | a | 61 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A |
| U + 0062 | b | 62 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА B |
| U + 0063 | c | 63 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА C |
| U + 0064 | d | 64 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА D |
| U + 0065 | e | 65 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА E |
| U + 0066 | f | 66 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА F |
| U + 0067 | г | 67 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА G |
| U + 0068 | h | 68 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА H |
| U + 0069 | i | 69 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА I |
| U + 006A | j | 6a | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА J |
| U + 006B | k | 6b | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА K |
| U + 006C | l | 6c | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА L |
| U + 006D | m | 6d | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА M |
| U + 006E | n | 6e | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА N |
| U + 006F | o | 6f | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O |
| U + 0070 | p | 70 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА P |
| U + 0071 | q | 71 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Q |
| U + 0072 | r | 72 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА R |
| U + 0073 | s | 73 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА S |
| U + 0074 | t | 74 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА T |
| U + 0075 | u | 75 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА U |
| U + 0076 | v | 76 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА V |
| U + 0077 | w | 77 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА W |
| U + 0078 | x | 78 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА X |
| U + 0079 | y | 79 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Y |
| U + 007A | z | 7a | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Z |
| U + 007B | { | 7b | КРОНШТЕЙН ЛЕВЫЙ ИЗОГНУТЫЙ |
| U + 007C | | | 7c | ВЕРТИКАЛЬНАЯ ЛИНИЯ |
| U + 007D | } | 7d | ПРАВЫЙ КРОНШТЕЙН |
| U + 007E | ~ | 7e | TILDE |
| U + 007F | 7f | <контроль> | |
| U + 0080 | c2 80 | <контроль> | |
| U + 0081 | c2 81 | <контроль> | |
| U + 0082 | c2 82 | <контроль> | |
| U + 0083 | c2 83 | <контроль> | |
| U + 0084 | c2 84 | <контроль> | |
| U + 0085 | c2 85 | <контроль> | |
| U + 0086 | c2 86 | <контроль> | |
| U + 0087 | c2 87 | <контроль> | |
| U + 0088 | c2 88 | <контроль> | |
| U + 0089 | c2 89 | <контроль> | |
| U + 008A | c2 8a | <контроль> | |
| U + 008B | c2 8b | <контроль> | |
| U + 008C | c2 8c | <контроль> | |
| U + 008D | c2 8d | <контроль> | |
| U + 008E | c2 8e | <контроль> | |
| U + 008F | c2 8f | <контроль> | |
| U + 0090 | c2 90 | <контроль> | |
| U + 0091 | c2 91 | <контроль> | |
| U + 0092 | c2 92 | <контроль> | |
| U + 0093 | c2 93 | <контроль> | |
| U + 0094 | c2 94 | <контроль> | |
| U + 0095 | c2 95 | <контроль> | |
| U + 0096 | c2 96 | <контроль> | |
| U + 0097 | c2 97 | <контроль> | |
| U + 0098 | c2 98 | <контроль> | |
| U + 0099 | c2 99 | <контроль> | |
| U + 009A | c2 9a | <контроль> | |
| U + 009B | c2 9b | <контроль> | |
| U + 009C | c2 9c | <контроль> | |
| U + 009D | c2 9d | <контроль> | |
| U + 009E | c2 9e | <контроль> | |
| U + 009F | c2 9f | <контроль> | |
| U + 00A0 | c2 a0 | БЛОКИРОВКА ПЕРЕРЫВА | |
| U + 00A1 | ¡ | c2 a1 | ПЕРЕВЕРНУТЫЙ восклицательный знак |
| U + 00A2 | ¢ | c2 a2 | ЦЕНТРАЛЬНЫЙ ЗНАК |
| U + 00A3 | £ | c2 a3 | ЗНАК ФУНДА |
| U + 00A4 | ¤ | c2 a4 | ЗНАК ВАЛЮТЫ |
| U + 00A5 | ¥ | c2 a5 | Знак йены |
| U + 00A6 | ¦ | c2 a6 | СЛОМАННАЯ ШИНА |
| U + 00A7 | § | c2 a7 | ЗНАК РАЗДЕЛА |
| U + 00A8 | ¨ | c2 a8 | DIAERESIS |
| U + 00A9 | © | c2 a9 | ЗНАК АВТОРСКОГО ПРАВА |
| U + 00AA | ª | c2 aa | ЖЕНСКИЙ ОБЫЧНЫЙ ИНДИКАТОР |
| U + 00AB | « | c2 ab | ЛЕВЫЙ ДВОЙНОЙ УГЛОВОЙ ЦИТАТНЫЙ ЗНАК |
| U + 00AC | ¬ | c2 ac | НЕ ЗНАК |
| U + 00AD | c2 ad | SOFT HYPHEN | |
| U + 00AE | ® | c2 ae | ЗАРЕГИСТРИРОВАННЫЙ ЗНАК |
| U + 00AF | ¯ | c2 af | МАКРОН |
| U + 00B0 | ° | c2 b0 | ЗНАК СТЕПЕНИ |
| U + 00B1 | ± | c2 b1 | ЗНАК ПЛЮС-МИНУС |
| U + 00B2 | ² | c2 b2 | SUPERSCRIPT TWO |
| U + 00B3 | ³ | c2 b3 | SUPERSCRIPT THREE |
| U + 00B4 | ´ | c2 b4 | ACUTE ACCENT |
| U + 00B5 | µ | c2 b5 | MICRO SIGN |
| U + 00B6 | ¶ | c2 b6 | ЗНАК ПИЛКРОУ |
| U + 00B7 | · | c2 b7 | СРЕДНЯЯ ТОЧКА |
| U + 00B8 | ¸ | c2 b8 | CEDILLA |
| U + 00B9 | ¹ | c2 b9 | SUPERSCRIPT ONE |
| U + 00BA | º | c2 ba | ИНДИКАТОР ОБОРУДОВАНИЯ МАССЫ |
| U + 00BB | » | c2 bb | ДВОЙНОЙ УГОЛ, УКАЗЫВАЮЩИЙ ВПРАВО, ЦИТАТНЫЙ ЗНАК |
| U + 00BC | ¼ | c2 bc | VULGAR FRACTION ONE QUARTER |
| U + 00BD | ½ | c2 bd | VULGAR FRACTION ONE HALF |
| U + 00BE | ¾ | c2 be | ВУЛГАРНАЯ ФРАКЦИЯ ТРИ ЧЕТВЕРТИ |
| U + 00BF | ¿ | c2 bf | ПЕРЕВЕРНУТЫЙ ВОПРОСНЫЙ ЗНАК |
| U + 00C0 | À | c3 80 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА А С ТЯЖЕЛЫМ |
| U + 00C1 | Á | c3 81 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА А С ОСТРЫМ |
| U + 00C2 | Â | c3 82 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА A С CIRCUMFLEX |
| U + 00C3 | Ã | c3 83 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА A С ТИЛЬДОЙ |
| U + 00C4 | Ä | c3 84 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА A С ДИАРЕЗОМ |
| U + 00C5 | Å | c3 85 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА А С КОЛЬЦОМ ВЫШЕ |
| U + 00C6 | Æ | c3 86 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА AE |
| U + 00C7 | Ç | c3 87 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА C С СЕДИЛЬЕЙ |
| U + 00C8 | È | c3 88 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА E С ТЯЖЕЛЫМ |
| U + 00C9 | É | c3 89 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА E С ОСТРЫМ |
| U + 00CA | Ê | c3 8a | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА E с CIRCUMFLEX |
| U + 00CB | Ë | c3 8b | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА E С ДИАРЕЗОМ |
| U + 00CC | Ì | c3 8c | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА I С ТЯЖЕЛЫМ |
| U + 00CD | Í | c3 8d | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА I С ОСТРЫМ |
| U + 00CE | Î | c3 8e | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА I С CIRCUMFLEX |
| U + 00CF | Ï | c3 8f | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА I С ДИАРЕЗОМ |
| U + 00D0 | Ð | c3 90 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА ETH |
| U + 00D1 | Ñ | c3 91 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА N С ТИЛЬДОЙ |
| U + 00D2 | Ò | c3 92 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА O С ТЯЖЕЛЫМ |
| U + 00D3 | Ó | c3 93 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА O С ОСТРЫМ |
| U + 00D4 | Ô | c3 94 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА O с CIRCUMFLEX |
| U + 00D5 | Õ | c3 95 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА O с тильдой |
| U + 00D6 | Ö | c3 96 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА O С ДИАРЕЗОМ |
| U + 00D7 | × | c3 97 | ЗНАК УМНОЖЕНИЯ |
| U + 00D8 | Ø | c3 98 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА O С ИНСУЛЬТОМ |
| U + 00D9 | Ù | c3 99 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА U С ТЯЖЕЛЫМ |
| U + 00DA | Ú | c3 9a | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА U С ОСТРЫМ |
| U + 00DB | Û | c3 9b | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА U С CIRCUMFLEX |
| U + 00DC | Ü | c3 9c | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА U С ДИАРЕЗОМ |
| U + 00DD | Ý | c3 9d | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА Y С ОСТРЫМ |
| U + 00DE | Þ | c3 9e | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА THORN |
| U + 00DF | ß | c3 9f | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА SHARP S |
| U + 00E0 | à | c3 a0 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A С ТЯЖЕЛЫМ |
| U + 00E1 | á | c3 a1 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A с ОСТРЫМ |
| U + 00E2 | â | c3 a2 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A с CIRCUMFLEX |
| U + 00E3 | ã | c3 a3 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A с тильдой |
| U + 00E4 | ä | c3 a4 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A С ДИАРЕЗОМ |
| U + 00E5 | å | c3 a5 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A С КОЛЬЦОМ ВЫШЕ |
| U + 00E6 | æ | c3 a6 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА AE |
| U + 00E7 | ç | c3 a7 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА C с CEDILLA |
| U + 00E8 | è | c3 a8 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА E С ТЯЖЕЛЫМ |
| U + 00E9 | é | c3 a9 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА E с ОСТРЫМ |
| U + 00EA | ê | c3 aa | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА E с CIRCUMFLEX |
| U + 00EB | ë | c3 ab | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА E с ДИАРЕЗОМ |
| U + 00EC | ì | c3 ac | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА I С ТЯЖЕЛЫМ |
| U + 00ED | í | c3 ad | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА I С ОСТРЫМ |
| U + 00EE | î | c3 ae | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА I с CIRCUMFLEX |
| U + 00EF | ï | c3 af | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА I С ДИАРЕЗОМ |
| U + 00F0 | ð | c3 b0 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА ETH |
| U + 00F1 | ñ | c3 b1 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА N С ТИЛЬДОЙ |
| U + 00F2 | ò | c3 b2 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O С ТЯЖЕЛЫМ |
| U + 00F3 | ó | c3 b3 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O С ОСТРЫМ |
| U + 00F4 | ô | c3 b4 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O с CIRCUMFLEX |
| U + 00F5 | х | c3 b5 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O с тильдой |
| U + 00F6 | ö | c3 b6 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O С ДИАРЕЗИСОМ |
| U + 00F7 | ÷ | c3 b7 | ЗНАК РАЗДЕЛЕНИЯ |
| U + 00F8 | ø | c3 b8 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O С ИНСУЛЬТОМ |
| U + 00F9 | ù | c3 b9 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА U С ТЯЖЕЛЫМ |
| U + 00FA | ú | c3 ba | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА U С ОСТРЫМ |
| U + 00FB | û | c3 bb | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА U с CIRCUMFLEX |
| U + 00FC | ü | c3 bc | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА U С ДИАРЕЗИСОМ |
| U + 00FD | ý | c3 bd | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Y с ОСТРЫМ |
| U + 00FE | þ | c3 be | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА THORN |
| U + 00FF | ÿ | c3 bf | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Y С ДИАРЕЗИСОМ |
Как преобразовать данные Unicode в ASCII и обратно на сервере SQL — статьи TechNet — США (английский)
Целевой продукт
MS SQL Server 2012
Резюме
В SQL-сервере несколько конкретных сценариев обработки данных требуют, чтобы исходные данные Unicode были перемещены в формат назначения, отличный от Unicode, например ASCII формат.Во время преобразования данных можно заметить, что символы Unicode преобразуются в «?» Вместо того, чтобы сохранять значение данных Unicode в месте назначения.
Данные Unicode в SQL Server или источнике плоских файлов, если они перенесены в таблицу SQL-сервера в столбце VARCHAR, с использованием SSIS, BCP или любого другого средства будут показать подобное поведение.
Описание проблемы
MS SQL Server по умолчанию поддерживает Кодовая страница 1252 (набор символов ISO — SQL_Latin1_General_CP1_CI_AS), но отличается тем, как реализует другие кодовые страницы, связанные с другими стандартами ISO.Ниже запрос предоставит подробную информацию о все поддерживаемые кодовые страницы в SQL Server …
ВЫБРАТЬ
[имя]
, COLLATIONPROPERTY ([имя], ‘CodePage’) AS [CodePage]
, COLLATIONPROPERTY ([имя], ‘LCID’) AS [LCID]
, COLLATIONPROPERTY ([имя], ‘ComparisonStyle’) AS [ComparisonStyle]
, COLLATIONPROPERTY ([имя], ‘Версия’) AS [Версия]
, [описание]
ОТ :: fn_helpcollations () СОРТИРОВАТЬ ПО КОДЕКС
Маленькая сложная часть — SQL Server после 2005 года для SQL Server 2008 R2 не поддерживает кодовую страницу 65001 (кодировка UTF-8) и усложняет для перемещения данных между кодировкой UTF16 — UTF8 без потери данных.Приведено выше с использованием версий SQL Server, упомянутых выше. Из-за этого ограничения невозможно перенести данные Unicode из столбца NVARCHAR в столбец VARCHAR без потери специальных символов.
Хорошие новости: SQL Server 2012 поддерживает перенос данных из кодировки UTF16 — UTF 8. т.е. можно экспортировать данные Unicode в файл с кодовой страницей 65001 (понижающее преобразование), а также импорт обратно в столбец с типом данных VARCHAR в таблице SQL (повышающее преобразование). Этого можно достичь, сначала экспортируя данные Unicode в файл с кодовой страницей 65001 (понижающее преобразование), а затем импортируя обратно в столбец VARXHAR. в таблице SQL-сервера (преобразование с повышением)
Подход к решению
В SQL Server 2012 есть поддержка кодовой страницы 65001, поэтому можно быстро использовать мастер импорта и экспорта для экспорта данных из таблицы SQL в формат не-Unicode (также можно сохранить полученный пакет SSIS для дальнейшего использования) и импортировать его обратно в таблицу SQL Server в таблице со столбцом VARCHAR.Единственная разница в том, что данные в столбце VARCHAR будут выглядеть как мусор из-за преобразования собственного набора символов данных, но сохранит исходное значение на основе настройки параметров сортировки для объекта.
Чтобы получить исходное значение Unicode, можно преобразовать эти данные VARCHAR обратно в данные NVARCHAR, используя определенную кодовую страницу и импортировав экспортированный плоский файл обратно в столбец Unicode.
ступеней
1. Используйте мастер импорта и экспорта SQL (?) Для экспорта данных Unicode в UTF8 с использованием кодовой страницы 65001 в место назначения для плоского файла
2.Создайте новую таблицу с аналогичной схемой, но замените тип данных столбца Unicode столбцом данных, отличным от Unicode (т.е. отдельная таблица со столбцом VARCHAR для данных столбца NVARCHAR)
3. Импортируйте экспортированный плоский файл в новую таблицу, и он должен быть успешным, но исходные данные будут выглядеть иначе, как показано ниже, в зависимости от сортировки столбцов.
4. Если необходимо преобразовать данные из UTF-8 в UTF -16, то есть из VARCHAR в NVARCHAR, обратно к исходному значению, просто нужно снова экспортировать их обратно в плоский файл и импортировать снова в столбце NARCHAR, и он сохранит исходное значение
5.Если данные используются через веб-приложение, то повышающее преобразование может выполняться клиентским приложением с использованием соответствующей кодировки.
Определение кодировки символов — документация feedparser 5.2.0
RFC 3023 определяет взаимодействие между XML и HTTP что касается кодировки символов. XML и HTTP имеют разные способы указание кодировки символов и различных значений по умолчанию в случае, если кодировка не указано, и определение того, какое значение имеет приоритет, зависит от множества факторы.
Введение в кодировку символов
В XML кодировка символов не обязательна и может быть дан в декларации XML в первая строка документа, например:
Если кодировка не указана, XML поддерживает использование метки порядка байтов для идентификации документа как разновидности UTF-32, UTF-16 или UTF-8. Раздел F спецификации XML описывает процесс определения кодировки символов на основе уникальных свойства метки порядка байтов в первых двух-четырех байтах документ.
Если кодировка не указана и метка порядка байтов отсутствует, XML по умолчанию используется UTF-8.
HTTP использует MIME для определения метода указания кодировки символов как часть Content-Type HTTP заголовок, который выглядит так:
Content-Type: текст / html; charset = "utf-8"
Если кодировка не указана, по умолчанию HTTP в iso-8859-1, но только для типов мультимедиа text / *. Для других типов носителей кодировка по умолчанию не определена, поэтому здесь используется RFC 3023.
Согласно RFC 3023, если указан тип носителя в заголовке Content-Type HTTP приложение / xml, приложение / xml-dtd, приложение / xml-external-parsed-entity, или любой из подтипов application / xml, например application / atom + xml или application / rss + xml или даже application / rdf + xml, тогда кодировка будет
- кодировка, указанная в параметре
charsetзаголовка Content-Type HTTP , или - — кодировка, указанная в атрибуте кодирования объявления XML в документе, или
- утф-8.
С другой стороны, если тип носителя, указанный в Content-Type HTTP-заголовок — text / xml, text / xml-external-parsed-entity или подтип, например text / AnythingAtAll + xml, затем атрибут кодирования XML объявление в документе полностью игнорируется, а кодировка —
- кодировка, указанная в параметре charset заголовка Content-Type HTTP , или
- us-ascii.
Обработка неправильно объявленных кодировок
Универсальный синтаксический анализатор каналов изначально использует правила, указанные в RFC 3023 для определения кодировки символов
корм.Если синтаксический анализ прошел успешно, то все. Если синтаксический анализ не удается, Универсальный синтаксический анализатор каналов устанавливает бит bozo на 1 и устанавливает bozo_exception to feedparser.CharacterEncodingOverride . Затем он пытается
для повторной обработки фида со следующими кодировками символов:
- кодировка, указанная в декларации XML
- кодировка, полученная из первых четырех байтов документа (согласно Разделу F)
- кодировка, автоматически определяемая универсальным детектором кодирования, если он установлен
- утф-8
- окна-1252
Если кодировка символов не может быть определена, Универсальный синтаксический анализатор каналов устанавливает bozo бит на 1 и устанавливает bozo_exception на feedparser.CharacterEncodingUnknown . В этом случае проанализированные значения будут
строки, а не строки Unicode.
Таблица ASCII
ASCII (, что означает Американский стандартный код для обмена информацией ) — это стандарт кодировки символов для текстовых файлов в компьютерах и других устройствах. ASCII является подмножеством Unicode и состоит из 128 символов в наборе символов. Эти символы состоят из букв (как прописных, так и строчных), цифр, знаков препинания, специальных и управляющих символов.Каждый символ в наборе символов может быть представлен десятичным значением в диапазоне от 0 до 127, а также эквивалентными шестнадцатеричными и восьмеричными значениями.
Ниже приведен список значений ASCII, отображающих десятичные, шестнадцатеричные, восьмеричные и символьные значения для каждого символа ASCII.
Стандартные символы ASCII
| дек | шестнадцатеричный | Октябрь | Char | Описание |
|---|---|---|---|---|
| 0 | 00 | 000 | ^ @ | Нулевой (NUL) |
| 1 | 01 | 001 | ^ А | Начало заголовка (SOH) |
| 2 | 02 | 002 | ^ В | Начало текста (STX) |
| 3 | 03 | 003 | ^ С | Конец текста (ETX) |
| 4 | 04 | 004 | ^ Д | Конец передачи (EOT) |
| 5 | 05 | 005 | ^ E | Запрос (ENQ) |
| 6 | 06 | 006 | ^ F | Подтверждение (ACK) |
| 7 | 07 | 007 | ^ G | Звонок (BEL) |
| 8 | 08 | 010 | ^ H | Backspace (BS) |
| 9 | 09 | 011 | ^ I | Горизонтальная вкладка (HT) |
| 10 | 0A | 012 | ^ J | Перевод строки (LF) |
| 11 | 0Б | 013 | ^ К | Вертикальная табуляция (VT) |
| 12 | 0C | 014 | ^ L | Новая страница / подача формы (FF) |
| 13 | 0D | 015 | ^ М | Возврат каретки (CR) |
| 14 | 0E | 016 | ^ N | Выключить (SO) |
| 15 | 0F | 017 | ^ O | Сдвиг в (SI) |
| 16 | 10 | 020 | ^ P | Прерывание канала передачи данных (DLE) |
| 17 | 11 | 021 | ^ Q | Устройство управления 1 (DC1) |
| 18 | 12 | 022 | ^ R | Устройство управления 2 (DC2) |
| 19 | 13 | 023 | ^ S | Устройство управления 3 (DC3) |
| 20 | 14 | 024 | ^ Т | Устройство управления 4 (DC4) |
| 21 | 15 | 025 | ^ U | Отрицательное подтверждение (NAK) |
| 22 | 16 | 026 | ^ V | Синхронный холостой ход (SYN) |
| 23 | 17 | 027 | ^ W | Конец блока трансмиссии (ETB) |
| 24 | 18 | 030 | ^ Х | Отмена (CAN) |
| 25 | 19 | 031 | ^ Y | Конец среды (EM) |
| 26 | 1A | 032 | ^ Z | Запасной (SUB) |
| 27 | 1Б | 033 | ^ [ | Побег (ESC) |
| 28 | 1С | 034 | ^ \ | Разделитель файлов (ФС) |
| 29 | 1D | 035 | ^] | Групповой сепаратор (ГС) |
| 30 | 1E | 036 | ^^ | Разделитель записей (RS) |
| 31 | 1 этаж | 037 | ^ _ | Разделитель единиц (США) |
| 32 | 20 | 040 | Космос | |
| 33 | 21 | 041 | ! | Восклицательный знак |
| 34 | 22 | 042 | « | Кавычки / Двойные кавычки |
| 35 | 23 | 043 | # | Цифровой знак |
| 36 | 24 | 044 | $ | Знак доллара |
| 37 | 25 | 045 | % | Знак процента |
| 38 | 26 | 046 | и | Амперсанд |
| 39 | 27 | 047 | ‘ | Апостроф / одинарная цитата |
| 40 | 28 | 050 | ( | Левая скобка |
| 41 | 29 | 051 | ) | Правая скобка |
| 42 | 2A | 052 | * | Звездочка |
| 43 | 2Б | 053 | + | Знак плюс |
| 44 | 2C | 054 | , | запятая |
| 45 | 2Д | 055 | – | Дефис / Минус |
| 46 | 2E | 056 | . | Точка / Период |
| 47 | 2F | 057 | / | Солидус / Слэш |
| 48 | 30 | 060 | 0 | Нулевая цифра |
| 49 | 31 | 061 | 1 | Первая цифра |
| 50 | 32 | 062 | 2 | Цифра два |
| 51 | 33 | 063 | 3 | Третья цифра |
| 52 | 34 | 064 | 4 | Четвертая цифра |
| 53 | 35 | 065 | 5 | Цифра пять |
| 54 | 36 | 066 | 6 | Шесть цифр |
| 55 | 37 | 067 | 7 | Цифра семь |
| 56 | 38 | 070 | 8 | Цифра восемь |
| 57 | 39 | 071 | 9 | Цифра девять |
| 58 | 3A | 072 | : | Двоеточие |
| 59 | 3Б | 073 | ; | точка с запятой |
| 60 | 3C | 074 | < | Знак «меньше» |
| 61 | 3D | 075 | = | Знак равенства / равенства |
| 62 | 3E | 076 | > | Знак «больше» |
| 63 | 3F | 077 | ? | Вопросительный знак |
| дек | шестнадцатеричный | Октябрь | Char | Описание |
|---|---|---|---|---|
| 64 | 40 | 100 | @ | Коммерческая на / на знак |
| 65 | 41 | 101 | А | Заглавная латинская буква А |
| 66 | 42 | 102 | B | Заглавная латинская буква B |
| 67 | 43 | 103 | С | Заглавная латинская буква C |
| 68 | 44 | 104 | D | Заглавная латинская буква D |
| 69 | 45 | 105 | E | Заглавная латинская буква E |
| 70 | 46 | 106 | F | Заглавная латинская буква F |
| 71 | 47 | 107 | G | Заглавная латинская буква G |
| 72 | 48 | 110 | H | Заглавная латинская буква H |
| 73 | 49 | 111 | I | Заглавная латинская буква I |
| 74 | 4A | 112 | Дж | Заглавная латинская буква J |
| 75 | 4Б | 113 | К | Заглавная латинская буква K |
| 76 | 4C | 114 | л | Заглавная латинская буква L |
| 77 | 4D | 115 | M | Заглавная латинская буква M |
| 78 | 4E | 116 | N | Заглавная латинская буква N |
| 79 | 4F | 117 | O | Заглавная латинская буква O |
| 80 | 50 | 120 | -P | Заглавная латинская буква P |
| 81 | 51 | 121 | Q | Заглавная латинская буква Q |
| 82 | 52 | 122 | R | Заглавная латинская буква R |
| 83 | 53 | 123 | S | Заглавная латинская буква S |
| 84 | 54 | 124 | т | Заглавная латинская буква T |
| 85 | 55 | 125 | U | Заглавная латинская буква U |
| 86 | 56 | 126 | В | Заглавная латинская буква V |
| 87 | 57 | 127 | Вт | Заглавная латинская буква W |
| 88 | 58 | 130 | х | Заглавная латинская буква X |
| 89 | 59 | 131 | Y | Заглавная латинская буква Y |
| 90 | 5A | 132 | Z | Заглавная латинская буква Z |
| 91 | 5Б | 133 | [ | Левая квадратная скоба |
| 92 | 5C | 134 | \ | Обратный солидус / обратная косая черта |
| 93 | 5D | 135 | ] | Кронштейн квадратный правый |
| 94 | 5E | 136 | ^ | Circumflex accent / Caret |
| 95 | 5F | 137 | _ | Подчеркивание / Низкая линия |
| 96 | 60 | 140 | ` | Надгробие |
| 97 | 61 | 141 | a | Строчная латинская буква а |
| 98 | 62 | 142 | б | Строчная латинская буква b |
| 99 | 63 | 143 | c | Строчная латинская буква c |
| 100 | 64 | 144 | d | Строчная латинская буква d |
| 101 | 65 | 145 | e | Строчная латинская буква е |
| 102 | 66 | 146 | f | Строчная латинская буква f |
| 103 | 67 | 147 | г | Строчная латинская буква g |
| 104 | 68 | 150 | ч | Строчная латинская буква h |
| 105 | 69 | 151 | и | Строчная латинская буква i |
| 106 | 6A | 152 | j | Строчная латинская буква j |
| 107 | 6Б | 153 | к | Строчная латинская буква k |
| 108 | 6C | 154 | л | Строчная латинская буква l |
| 109 | 6D | 155 | м | Строчная латинская буква м |
| 110 | 6E | 156 | n | Строчная латинская буква n |
| 111 | 6F | 157 | или | Строчная латинская буква o |
| 112 | 70 | 160 | с. | Строчная латинская буква p |
| 113 | 71 | 161 | q | Строчная латинская буква q |
| 114 | 72 | 162 | r | Строчная латинская буква r |
| 115 | 73 | 163 | с | Строчная латинская буква s |
| 116 | 74 | 164 | т | Строчная латинская буква t |
| 117 | 75 | 165 | u | Строчная латинская буква u |
| 118 | 76 | 166 | v | Строчная латинская буква v |
| 119 | 77 | 167 | Вт | Строчная латинская буква w |
| 120 | 78 | 170 | х | Строчная латинская буква х |
| 121 | 79 | 171 | л | Строчная латинская буква y |
| 122 | 7A | 172 | z | Строчная латинская буква z |
| 123 | 7Б | 173 | { | Кронштейн фигурный левый |
| 124 | 7C | 174 | | | Вертикальная линия / Вертикальная полоса |
| 125 | 7D | 175 | } | Кронштейн фигурный правый |
| 126 | 7E | 176 | ~ | Тильда |
| 127 | 7F | 177 | DEL | Удалить (DEL) |
В наборе символов ASCII десятичные значения от 0 до 31, а также десятичные значения 127 представляют символы, которые нельзя распечатать.M ).
Все остальные символы в наборе символов могут быть напечатаны или представлены на экране. Эти печатаемые значения символов можно увидеть в поле Char в таблице выше.
Расширенные символы ASCII
| дек | шестнадцатеричный | Октябрь | Char | Описание |
|---|---|---|---|---|
| 128 | 80 | 200 | ||
| 129 | 81 | 201 | ||
| 130 | 82 | 202 | ||
| 131 | 83 | 203 | ||
| 132 | 84 | 204 | ||
| 133 | 85 | 205 | ||
| 134 | 86 | 206 | ||
| 135 | 87 | 207 | ||
| 136 | 88 | 210 | ||
| 137 | 89 | 211 | ||
| 138 | 8A | 212 | ||
| 139 | 8Б | 213 | ||
| 140 | 8C | 214 | ||
| 141 | 8D | 215 | ||
| 142 | 8E | 216 | ||
| 143 | 8F | 217 | ||
| 144 | 90 | 220 | ||
| 145 | 91 | 221 | ||
| 146 | 92 | 222 | ||
| 147 | 93 | 223 | ||
| 148 | 94 | 224 | ||
| 149 | 95 | 225 | ||
| 150 | 96 | 226 | ||
| 151 | 97 | 227 | ||
| 152 | 98 | 230 | ||
| 153 | 99 | 231 | ||
| 154 | 9A | 232 | ||
| 155 | 9Б | 233 | ||
| 156 | 9C | 234 | ||
| 157 | 9D | 235 | ||
| 158 | 9E | 236 | ||
| 159 | 9F | 237 | ||
| 160 | A0 | 240 | Бесперебойное пространство | |
| 161 | A1 | 241 | ¡ | Перевернутый восклицательный знак |
| 162 | A2 | 242 | ¢ | Знак центов |
| 163 | A3 | 243 | £ | Знак фунта |
| 164 | A4 | 244 | ¤ | Знак валюты |
| 165 | A5 | 245 | ¥ | Знак йены / юаня |
| 166 | A6 | 246 | ¦ | Сломанный стержень |
| 167 | A7 | 247 | § | Знак раздела |
| 168 | A8 | 250 | ¨ | Диэрезис |
| 169 | A9 | 251 | © | Знак авторского права |
| 170 | AA | 252 | ª | Женский порядковый указатель |
| 171 | AB | 253 | « | Двойные угловые кавычки, указывающие влево |
| 172 | AC | 254 | ¬ | Не подписывать |
| 173 | н.э. | 255 | Мягкий перенос | |
| 174 | AE | 256 | ® | Зарегистрированный товарный знак |
| 175 | AF | 257 | ¯ | Макрон |
| 176 | B0 | 260 | ° | Знак градуса |
| 177 | B1 | 261 | ± | Знак плюс-минус |
| 178 | B2 | 262 | ² | Два надстрочных индекса |
| 179 | B3 | 263 | ³ | Тройной верхний индекс |
| 180 | B4 | 264 | ´ | Острый акцент |
| 181 | B5 | 265 | µ | Микро знак (мю) |
| 182 | B6 | 266 | ¶ | Знак Pilcrow |
| 183 | B7 |
Кодирование и отправка форматированного текста
Обзор
На этом уроке студенты сначала знакомятся со стандартной схемой кодирования числа в текст, используемой в компьютерах и в Интернете, известной как кодирование ASCII.Учащиеся изобретут протокол связи, который использует только символы обычного текста ASCII для кодирования более красивого форматирования текста, такого как шрифты, цвета, размеры и т. Д. Учащиеся продемонстрируют свой протокол, используя Интернет-симулятор для отправки закодированного сообщения партнеру, который должен правильно интерпретировать форматирование и нарисовать результат на листе бумаги.
Назначение
Этот урок дает представление о «языках программирования», предлагая учащимся изобрести способ использования простого текста ASCII для кодирования другого текста.На этом этапе мы действительно начинаем видеть, как слои за слоями кодировок — все восходящие к двоичным — работают вместе для кодирования сложной информации.
Мы также хотим подключиться к Интернету и протоколам. Информация, передаваемая через Интернет, часто должна содержать как содержание сообщения, так и информацию, которая помогает форматировать, направлять или интерпретировать эти данные.
Разработка средств различения этих двух типов информации привела к созданию ряда широко распространенных протоколов и языков.HTML (сокращение от HyperText Markup Language) — это язык, на котором написано содержимое и форматирование веб-страницы. И протокол HTTP, или протокол передачи гипертекста, — это еще один протокол на основе ASCII, который является основой коммуникации в Интернете — он был разработан для отправки и получения данных веб-страниц через Интернет. В обоих случаях простой текст ASCII наполняется более глубоким смыслом благодаря разработке четко определенных протоколов.
Повестка дня
Начало работы (15 минут)
Активность
Заключение
Оценка
Расширенное обучение
Посмотреть на Code Studio
Цели
Студенты смогут:
- Опишите схему кодирования ASCII.
- Разработайте / изобрести протокол для отправки форматированного текста с помощью Internet Simulator.
- Изобретите язык форматирования текста.
- Объясните связь между двоичным и более сложным кодированием форматированного текста
Препарат
- (дополнительно) Плакат
- Маркеры или мелки
- Раздел подготовлен для использования Internet Simulator в Code Studio.
Ссылки
Внимание! Сделайте копии любых документов, которыми вы планируете поделиться со студентами.
Учителям
Студентам
Словарь
- ASCII — Американский стандартный код для обмена информацией; общепризнанный формат исходного текста, понятный любому компьютеру
- код — (v) для написания кода или для написания инструкций для компьютера.
- Протокол — Набор правил, регулирующих обмен или передачу данных между устройствами.
Начало работы (15 минут)
Замечания
В предыдущих уроках мы изучили, как кодировать числа в двоичном формате, а вы также разработали протоколы для отправки списка чисел.Сегодня мы сделаем еще один шаг вперед в этом методе и посмотрим, как мы можем кодировать текст в двоичном представлении. Надеюсь, вы начинаете понимать, что если мы сможем найти способ представления информации в виде набора чисел, то мы сможем закодировать ее в битах и сохранить эту информацию на компьютере или отправить ее через Интернет.
Учебный совет
- Обычный способ сделать это — сделать простое отображение 26 букв алфавита в числа, как в примере справа.Однако это не единственное решение.
- Студенты должны иметь право изобретать схему кодирования текста, как им нравится. Некоторые студенты могут пожелать дать обычным фразам или словам их собственные последовательности битов, а не буквенно-числовые сопоставления.
- Если учащиеся быстро двигаются, предложите им добавить больше функций. Как их протоколы будут кодировать знаки препинания, заглавные буквы и специальные символы?
Подсказка:
«Одно из самых мощных способов использования Интернета — это отправка текста людям.Поскольку Интернет может передавать только биты, нам нужен способ кодирования текста битами … «
«Если бы это было на ваше усмотрение, как бы вы закодировали текст в двоичном формате? Быстро набросайте идею кодирования текста».
- Дайте студентам пару минут, чтобы они могли записать свои мысли.
- Подчеркните, что им не нужно фактически указывать каждую деталь схемы, а просто необходимо обрисовать ее структуру.
Цель обсуждения
На что следует обратить внимание при обсуждении:
- Скорее всего, изобрел схему, которая отображала буквы алфавита и другие текстовые символы на числа.
- Есть компромиссы при выборе необходимого количества бит на символ. Насколько различаются предложения студентов?
- Для того, чтобы передать текстовых данных, нам всем нужно согласовать схему кодирования (предвещает ASCII)
Обсудить
Попросите учащихся сначала сравнить и сопоставить схемы кодирования со своими соседями, а затем начать обсуждение в классе. Вот несколько подсказок:
- Вы и ваш сосед пришли в голову точно такую же идею? Что было по-другому?
- Сколько битов требуется для вашей схемы кодирования? Например, сколько бит вам нужно, чтобы сказать «привет»?
- Вы учли что-нибудь, кроме букв алфавита (или целых слов)?
- Какая из схем кодирования, упомянутых выше, является «лучшей»? Почему?
Представьте схему кодирования ASCII.
Замечания
Вы только что придумали свою схему кодирования текста числами. Оказывается, для большинства символов, которые можно набрать на американской клавиатуре, существует стандартная кодировка.
Эта кодировка называется Американский стандартный код для обмена информацией или ASCII (произносится: «Аск-и»).
Учебный совет
Если позволит время, вы можете отправить студентов провести собственное «быстрое исследование» ASCII и отчитаться.У вас должны получиться те же точки.
Быстрое действие: напишите свое имя в кодах ASCII
Используя таблицу ASCII, переведите свое имя из букв в числа с помощью таблицы ASCII.
- Напишите свое имя как: * Имя! »(Первая заглавная буква, восклицательный знак в конце)
- Дайте учащимся минуту на это
Переходное замечание
- Наличие стандартизированного протокола, такого как ASCII, для кодирования текста позволяет нам отправлять и получать текстовую информацию.
- Это очень полезно, но все же есть случаи, когда нам понадобится еще большая выразительность в наших цифровых коммуникациях.
Действия
Проблема форматирования текста: создайте протокол для кодирования форматированного текста
Введение:
«Что, если вы хотите отправить отформатированный текст , который включал такие вещи, как возможность подчеркивания, полужирного или курсивного начертания слов…. указать другой размер или цвет шрифта? «
Учебный совет
Вы можете опросить класс на предмет других видов форматирования текста. Некоторые вещи, которые могут появиться: таблицы или сетки текста различных начертания шрифта (например, Arial, Times, gill sans и т. Д.) * размещение текста на странице, как плавающие текстовые поля и т. д.
Вот такие вещи:
Замечания
Сегодня ваша задача:
- Изобретите протокол для отправки форматированного текста
- Используйте симулятор Интернета, чтобы проверить свой протокол.
Вы также заметите , что Internet Simulator был обновлен , так что теперь вы можете вводить текстовые символы ASCII для отправки.
Переход на Code Studio
Учебный совет
Перед тем, как начать упражнение, вы можете попросить студентов попрактиковаться в отправке текстовых сообщений ASCII друг другу, чтобы почувствовать новую среду.
При этом вы должны указать, что все по-прежнему двоичное под капотом.
Вы можете использовать вкладку My Device в Internet Simulator, чтобы включать или выключать различные схемы кодирования.
- Учащиеся должны заметить новую возможность отправки текста.
Цель деятельности
Студенты должны определить протокол, который позволяет кодировать форматирование текста, используя только печатаемый набор символов ASCII, то есть 32-126.
Обычный способ сделать это — указать набор «зарезервированных слов» или символов, которые следует интерпретировать как инструкции форматирования.Например, HTML использует угловые скобки <...> с открывающими и закрывающими тегами, например:
Учащиеся, знакомые с HTML до этого курса, могут легко придумать схемы для простых задач; дайте им несколько более сложных кодировок, таких как добавление форматирования столбцов к их тексту, размещение текста в произвольном месте на странице (например, текстовое поле), создание таблиц и т. д.
Изобретите протокол для отправки форматированного текста с помощью Internet Simulator
(из руководства)
Проезд
Совместно с партнером или небольшой командой разработайте протокол, который позволит вам отправлять форматированный текст.
Руководящие принципы
И текст, и инструкции форматирования должны быть производными от печатаемого набора символов ASCII (то есть кодов 32-126).
Ваш протокол должен кодировать как минимум:
Учебный совет
Дайте командам время разработать свои протоколы либо в своих руководствах по занятиям, либо на отдельном плакате, документе, слайд-шоу и т. Д.
Поощряйте студентов многократно тестировать свои протоколы, чтобы убедиться, что они не упустили ни одного пробела в своем протоколе.
Разработайте свой протокол
Используйте место ниже, чтобы обсудить идеи для вашего протокола. Итеративно улучшайте свой протокол, тестируя его с помощью простых примеров сообщений.
Продемонстрируйте:
- Протестируйте протоколы учащихся, предоставив отформатированное сообщение одному члену группы и попросив его отправить сообщение своему партнеру с помощью Интернет-симулятора.
- Учащиеся могут воссоздать сообщение вручную или в текстовом документе и сравнить результаты с предполагаемым сообщением.
- Для более убедительного доказательства попросите одного члена каждой группы перейти в другую сторону комнаты или коридора.
Заключение
Уголок содержимого
Скорее всего, ученики изобрели текстовый код. Независимо от того, являются ли они языками форматирования, такими как HTML или Markdown, или языками программирования, такими как Java, C или Python, все эти языки имеют одну общую черту: они используют текст ASCII для кодирования другого текста или информации.
Не стесняйтесь говорить студентам, что они только что изобрели язык программирования. На данный момент код и протокол очень похожи. Несмотря на то, что это, вероятно, то, что никто другой не будет использовать, процесс, который только что прошли студенты, дает возможность изобрести любой формальный язык или протокол, который в конечном итоге должен быть интерпретирован и обработан компьютером.
Обсудить результаты деятельности
Обсудить Используйте стратегию группового обсуждения, чтобы ответить на эти вопросы:
- Были ли успешными большинство групп?
- Если нет, то что вызвало больше всего проблем?
- Было ли легче решить некоторые компоненты проблемы, чем другие?
Сравнить / сопоставить схемы кодирования с HTML
Дополнительная демонстрация
- Большинство веб-браузеров позволяют просматривать исходный код веб-сайта (например,г. Chrome позволяет это в Инструментах разработчика).
- Укажите на систему тегов, используемую для структурирования текста веб-сайта. Попросите учащихся подумать, насколько этот протокол похож или отличается от их собственного.
- Вводный HTML-код W3Schools: http://www.w3schools.com/html/html_intro.asp
- Сегодняшняя деятельность мотивирована реальной задачей оживить веб-страницы.
- Студенты, более знакомые с HTML / CSS, могут распознать многие из этих идей, но все же может быть поучительно показать классу, что большая часть информации, необходимой для просмотра веб-страницы, — это не сам контент, а информация о том, как он должен быть отформатированным.
Цель обсуждения
Есть много способов ответить на этот вопрос. Любой ответ, подтверждающий:
- последовательности двоичных состояний могут использоваться для представления чисел
- цифр можно присвоить буквам алфавита для кодирования текста
- с обычным текстом, вы можете создать код , который вы можете использовать для применения других значений (или форматов) к тексту
- Вы можете изобрести «язык форматирования» (например, HTML) для представления различных способов отображения текстовых сообщений.
Обсудить слои кодировок
Сделайте быстрый Think Pair Поделитесь или, возможно, назначьте этот вопрос письменной работой.
Подсказка:
«Найдите минутку, чтобы подумать об уровнях кодирования, которые позволяли передавать форматированный текст через Интернет».
«Представьте, что кто-то указал на отформатированный текст и спросил:« Вы можете мне объяснить, как он кодируется в двоичном формате? » Как бы вы это объяснили? »
- Дайте учащимся время, чтобы записать идеи.
- Обсуди с соседом.
- Поделитесь объяснениями с классом.
Оценка
Оценка урока
Рубрика:
Вопросы (можно найти как в Рубрике, так и в Code Studio):
- Сколько битов требуется для хранения числа «150» в ASCII?
- 3 бита
- 8 бит
- 16 бит
- 24 бита
- 32 бита
- Слово «Apple», переведенное на его эквивалент в формате ASCII:
- 097 112 112 108 101
- 097 108 108 111 119
- 065 112 112 108 101
- 065 110 110 105 101
- 065 108 108 111 119
- Какие проблемы возникли при ваших попытках создать рабочий протокол? Как вы относились к проблемам, чтобы их решить?
- Опишите один случай, когда сотрудничество с партнером повлияло на окончательный протокол, созданный вашей командой.
Оценка главы
Учебный совет
Некоторые вопросы по этой оценке могут показаться «выходящими за рамки» или только косвенно связанными с материалом уроков. Это сделано намеренно, так как это хорошая имитация вопросов, которые студенты могут найти на реальном экзамене. Во многих случаях ученик, вероятно, может использовать свои суждения и интуицию, основываясь на том, что они узнали, чтобы сделать довольно хорошее предположение по вопросу.
Однако, как всегда, эти ресурсы являются лишь рекомендацией, и вы должны использовать их так, как лучше всего подходит вашему классу и их потребностям.Цель CSP — расширить участие в информатике, поэтому, если предложение этого теста в качестве теста с высокими ставками в начале года будет противоречить этой цели, возможно, попробуйте пройти оценку с меньшими ставками (разрешите учащимся работать с партнером, сделайте оценку меньше баллов и т. д.), чтобы попрактиковаться в будущем.
В Code Studio есть экзамен с несколькими вариантами ответов для этой главы. Его можно найти на сцене сразу после этого урока и использовать функцию Lockable Stages.Если вы новичок в блокируемых этапах, ознакомьтесь с разделом «Как управлять заблокированным тестом».
Расширенное обучение
- Дополнительные проблемы с кодировкой форматирования:
- Специальные символы, не найденные в кодировке ASCII (например, ñ)
- Несколько столбцов текста
- Текстовое поле в любом месте экрана
- Информационная таблица
- Продолжите изучение HTML, определив, как бы вы завершили сегодняшнюю деятельность в HTML.Далее сравните свой собственный протокол с HTML.
- Прочтите «Раздутый на биты» (www.bitsbook.com), Глава 3, Призраки в машине, стр. 73-80 (То, что вы видите, не то, что знает компьютер), затем ответьте на следующие вопросы:
- Приведите пример ваш собственный, когда простого знания того, что делает компьютер, было недостаточно — вам действительно нужно было знать, как и почему он делает то, что делает.
- Поговорите о метаданных файла и о том, как они «отпечатывают» файл. Включите обсуждение преимуществ и проблем метаданных файла.
- Прочтите «Раздутый на биты» (www.bitsbook.com), Глава 3, Призраки в машине, стр. 80-88 (Представление, реальность и иллюзия), затем ответьте на следующие вопросы:
- Как выделяется в PDF-документе Работа? Какие вычислительные идеи используются?
- Продолжите изучение HTML, определив, как бы вы завершили сегодняшнюю деятельность в HTML. Далее сравните свой собственный протокол с HTML.