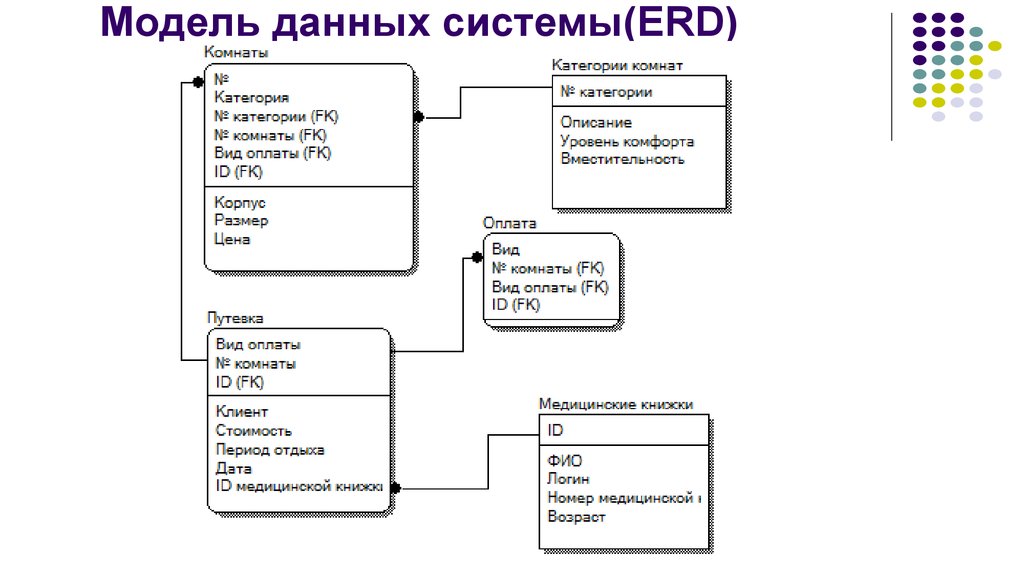
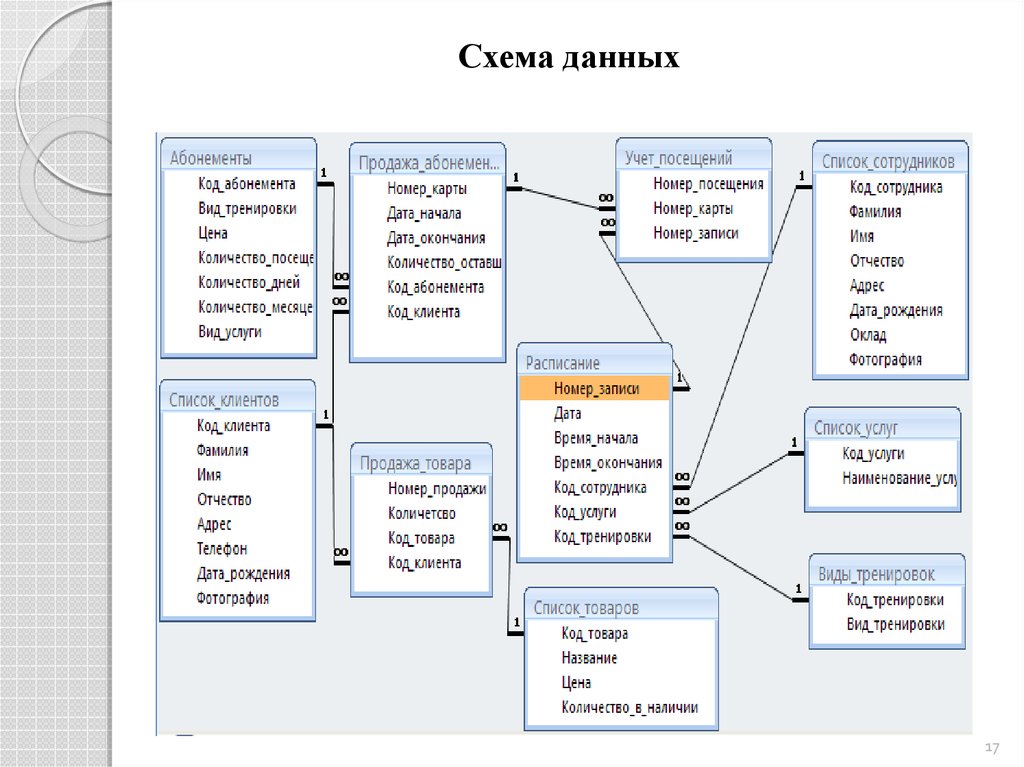
Изучение структуры базы данных Access
Знакомство с таблицами, формами, запросами и другими объектами в базе данных Access поможет вам с легкостью выполнять различные задачи, такие как ввод данных в форму, добавление или удаление таблиц, поиск и замена данных и выполнение запросов.
Данная статья содержит общие сведения о структуре базы данных Access. Access предоставляет несколько инструментов, которые можно использовать для ознакомления со структурой конкретной базы данных. Кроме того, в статье описано, как, для чего и когда следует использовать каждый из этих инструментов.
Примечание: Эта статья посвящена классическим базам данных Access, которые включают в себя один или несколько файлов, где хранятся все данные и определены все возможности приложения, такие как формы для ввода данных. Некоторые сведения из статьи неприменимы к веб-базам данных и веб-приложениям Access.
В этой статье
-
Общие сведения
-
Просмотр подробных сведений об объектах в базе данных
-
Просмотр таблицы в режиме конструктора
-
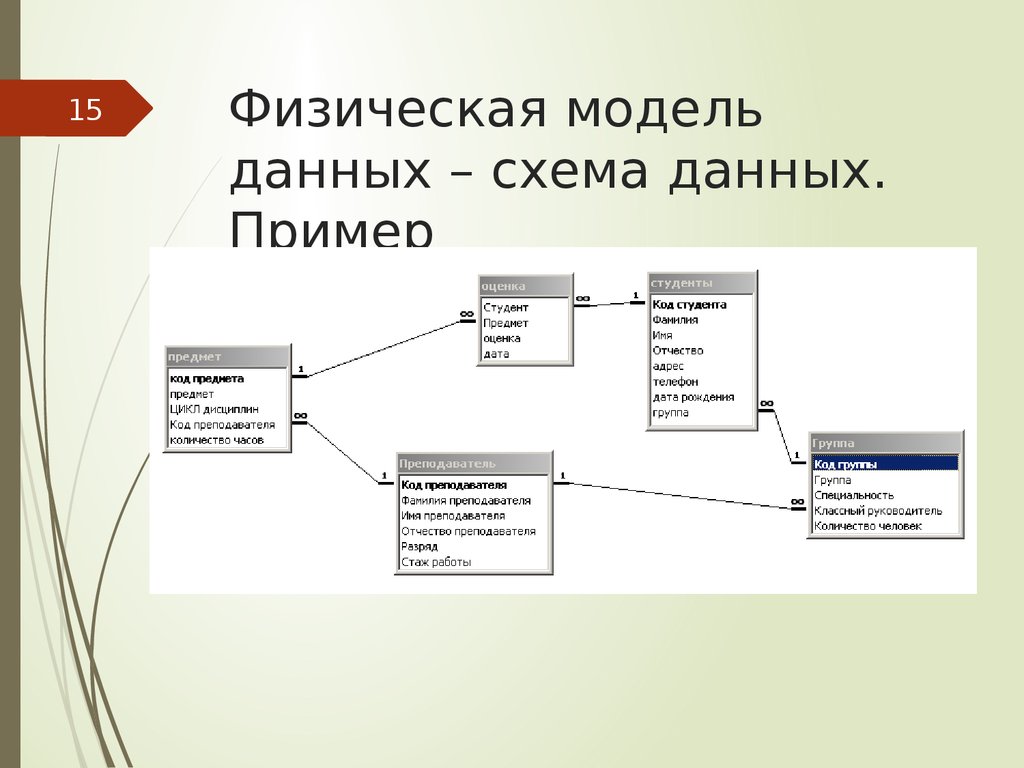
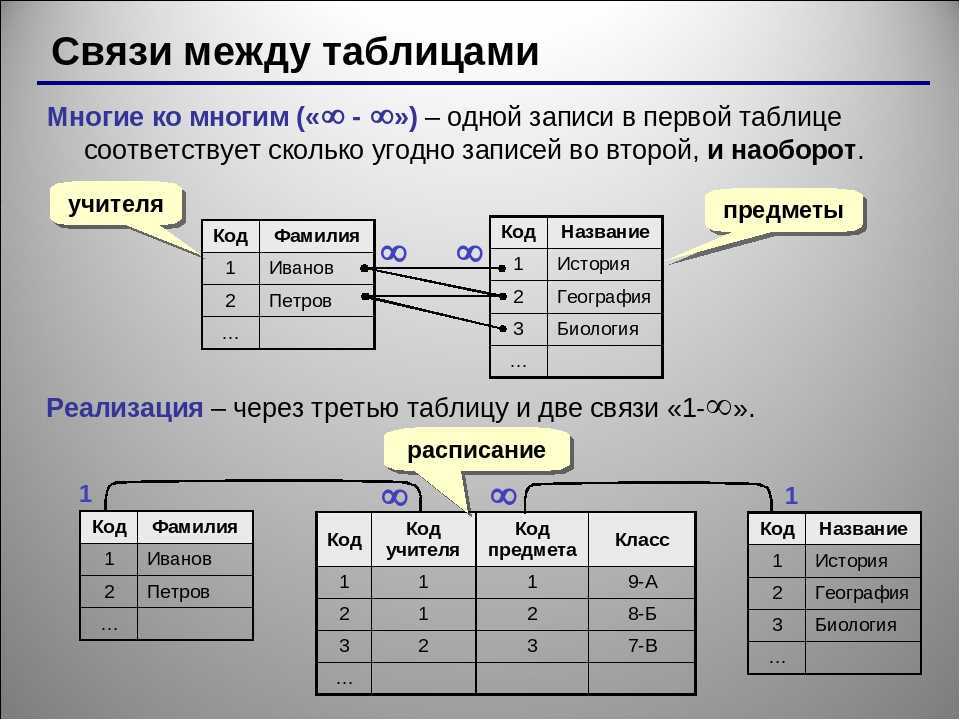
Просмотр связей между таблицами
Общие сведения
База данных представляет собой набор сведений, связанных с определенной темой или функцией, например отслеживанием заказов покупателей или обработкой музыкальной коллекции.
Предположим, что номера телефонов поставщиков хранятся в различных местах: в файле виртуальной визитной карточки, файлах со сведениями о продукте в картотеке и в электронной таблице со сведениями о заказах. В случае изменения телефона поставщика необходимо обновить соответствующие данные во всех трех местах. В грамотно спроектированной базе данных Access номер телефона сохраняется всего один раз, поэтому обновить данные придется лишь однажды. При обновлении номера телефона он автоматически будет обновлен в любом месте базы данных, где он используется.
Файлы баз данных Access
Приложение Access можно использовать для управления всеми данными в одном файле. В файле базы данных Access можно использовать:
-
запросы для поиска и извлечения только необходимых данных;
-
формы для просмотра, добавления и изменения данных в таблицах;
-
отчеты для анализа и печати данных в определенном формате.
 org/ListItem»>
org/ListItem»>
таблицы для сохранения данных;
1. Данные сохраняются один раз в одной таблице, но просматриваются из различных расположений. При изменении данных они автоматически обновляются везде, где появляются.
2. Извлечение данных с помощью запроса.
3. Просмотр или ввод данных с помощью формы.
4. Отображение или печать данных с помощью отчета.
Все эти элементы: таблицы, запросы, формы и отчеты — представляют собой объекты базы данных.
Примечание: Некоторые базы данных Access содержат ссылки на таблицы, хранящиеся в других базах. Например, одна база данных Access может содержать только таблицы, а другая — ссылки на них, а также запросы, формы и отчеты, основанные на связанных таблицах. В большинстве случаев неважно, содержится ли в базе данных сама таблица или ссылка на нее.
Таблицы и связи
Для хранения данных необходимо создать таблицу для каждого типа отслеживаемых сведений. Типы сведений могут включать данные о покупателях, продуктах или подробные сведения о заказах. Чтобы объединить данные из нескольких таблиц в запросе, форме или отчете, нужно определить связи между таблицами.
Примечание: В веб-базах данных и веб-приложениях создать связи на вкладке объекта «Схема данных» невозможно. Используйте для этого поля подстановки.
1. Сведения о клиентах, которые когда-то хранились в списке рассылки, теперь находятся в таблице «Покупатели».
2. Сведения о заказах, которые когда-то хранились в электронной таблице, теперь находятся в таблице «Заказы».
3. Уникальный код, например код покупателя, позволяет отличать записи в таблице друг от друга. Добавляя уникальное поле кода из одной таблицы в другую и определяя связи между полями, Access может сопоставить связанные записи в обеих таблицах, чтобы их можно было вместе добавить в форму, отчет или запрос.
Запросы
С помощью запроса можно найти и извлечь данные (в том числе и данные из нескольких таблиц), соответствующие указанным условиям. Запросы также используются для обновления или удаления нескольких записей одновременно и выполнения предопределенных или пользовательских вычислений на основе данных.
Запросы также используются для обновления или удаления нескольких записей одновременно и выполнения предопределенных или пользовательских вычислений на основе данных.
Примечание: В веб-базах данных и веб-приложениях использовать запросы для обновления или удаления записей невозможно.
1. Таблица «Покупатели» содержит сведения о покупателях.
2. Таблица «Заказы» содержит сведения о заказах.
3. Этот запрос извлекает из таблицы заказов код заказа и дату назначения, а из таблицы покупателей — название компании и город. Запрос возвращает только те заказы, которые были оформлены в апреле и только покупателями из Лондона.
Формы
Формы можно использовать для просмотра, ввода и изменения данных в одной строке за раз. Кроме того, с их помощью можно выполнять такие действия, как отправка данных другим приложениям.
Примечание: Для создания форм и отчетов в веб-базах данных и веб-приложениях используется режим макета, а не конструктора.
1. В таблице одновременно отображается множество записей, однако для просмотра всех данных в одной записи иногда необходимо прокрутить ее горизонтально. Кроме того, при просмотре таблицы невозможно обновить данные из нескольких таблиц одновременно.
2. В форме внимание сосредоточено на одной записи и могут отображаться поля из нескольких таблиц. Кроме того, форма позволяет отображать рисунки и другие объекты.
3. Форма может содержать кнопку, используемую для печати отчета, открытия других объектов или автоматического выполнения других задач.
Отчеты
1. Создание почтовых наклеек с помощью отчета.
2. Отображение итоговых значений на диаграмме с помощью отчета.
3. Использование отчета для отображения рассчитанных итоговых данных.
После того как вы ознакомились с базовой структурой баз данных Access, ознакомьтесь со сведениями об использовании встроенных инструментов для изучения конкретной базы данных Access.
Просмотр подробных сведений об объектах в базе данных
Лучше всего ознакомиться с определенной базой данных с помощью архивариуса базы данных. Он используется для создания отчетов с подробными сведениями об объектах в базе данных. Сначала необходимо выбрать объекты, которые должны быть описаны в отчете. Отчет архивариуса будет содержать все данные о выбранных объектах.
-
Откройте нужную базу данных.
-
На вкладке Работа с базами данных в группе Анализ нажмите кнопку Архивариус.
-
Выберите один или несколько указанных на вкладке объектов. Для выбора всех объектов нажмите кнопку Выбрать все.
-
Нажмите кнопку ОК.
Архивариус создаст отчет с подробными сведениями о каждом выбранном объекте, а затем откроет отчет в режиме просмотра перед печатью. Например, если архивариус был запущен для формы ввода данных, созданный им отчет будет содержать свойства всей формы, каждого раздела формы, всех кнопок, значков, текстовых полей и других элементов управления, а также модулей кода и пользовательских разрешений, связанных с формой.

-
Для печати отчета откройте вкладку Просмотр перед печатью и в группеПечать нажмите кнопкуПечать.
 org/ListItem»>
org/ListItem»>
В диалоговом окне Архивариус откройте вкладку, представляющую тип объекта базы данных, который необходимо задокументировать. Чтобы создать отчет обо всех объектах в базе данных, откройте вкладку Все типы объектов.
Просмотр таблицы в режиме конструктора
Примечание: Режим конструктора недоступен для таблиц в веб-базах данных.
Открытие таблицы в Конструкторе позволяет подробно изучить ее структуру. Например, можно найти параметры типа данных для каждого поля и любые маски ввода или узнать, используются ли в таблице поля подстановок — поля, которые с помощью запросов извлекают данные из других таблиц. Эти сведения полезны потому, что типы данных или маски ввода могут влиять на возможность искать данные и выполнять запросы на обновление. Предположим, что необходимо использовать запрос на обновление для обновления некоторых полей в таблице путем копирования данных из таких же полей другой таблицы. Запрос не удастся выполнить, если типы данных каждого поля в исходной и целевой таблицах не совпадают.
Запрос не удастся выполнить, если типы данных каждого поля в исходной и целевой таблицах не совпадают.
-
Откройте базу данных, которую необходимо проанализировать.
-
В области навигации щелкните правой кнопкой мыши таблицу, которую нужно изучить, и выберите в контекстном меню пункт Режим конструктора.
-
При необходимости запишите имя каждого поля таблицы и его тип данных.
Тип данных поля может ограничивать размер и тип данных, которые можно ввести в поле. Например, размер текстового поля может быть ограничен 20 знаками, а поле с типом данных «Числовой» не поддерживает ввод текста.
-
Чтобы определить, является ли поле полем подстановок, откройте вкладку Поле подстановки в нижней части бланка запроса в разделе Свойства поля.
Поле подстановок отображает один набор значений (одно или несколько полей, например имя и фамилию), но обычно хранит другой набор значений (одно поле, такое как числовой код). Например, поле подстановок может содержать код сотрудника (хранимое значение), но отображать имя сотрудника (отображаемое значение). При использовании поля подстановок в выражениях или при поиске и замене необходимо использовать хранимое значение, а не отображаемое. Знакомство с хранимыми и отображаемыми значениями полей подстановок — лучший способ убедиться в том, что выражение или операция поиска и замены с использованием поля подстановки работает надлежащим образом.
На приведенном ниже рисунке показано типичное поле подстановок.
Параметры, отображаемые в свойстве Источник строк поля, можно изменить.Показанное здесь поле подстановок использует запрос для извлечения данных из другой таблицы. Существует также другой тип поля подстановок — список значений, который использует определенный в программе список вариантов. На приведенном ниже рисунке показан типичный список значений.
По умолчанию списки значений используют текстовый тип данных.
Лучший способ найти списки подстановок и значений — открыть вкладку Подстановка , а затем щелкнуть записи в столбце Тип данных для каждого поля таблицы. Дополнительные сведения о создании полей подстановки и списков значений см. по ссылкам в разделе См. также .
 Параметры, отображаемые в свойстве Источник строк поля, можно изменить.
Параметры, отображаемые в свойстве Источник строк поля, можно изменить.К началу страницы
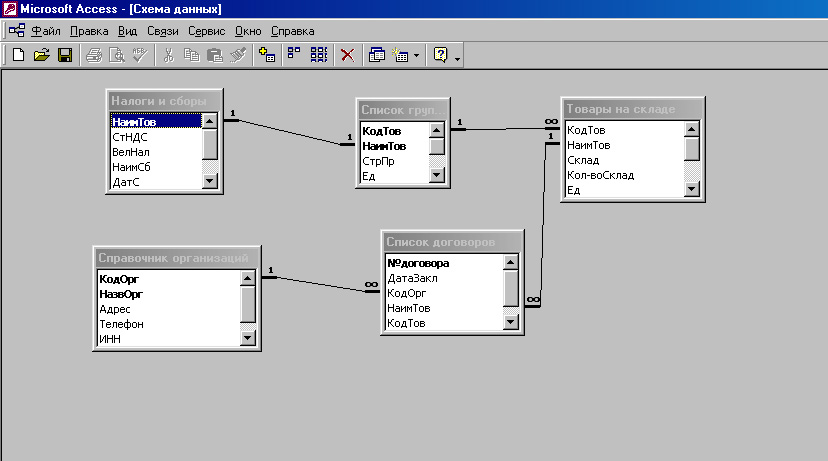
Просмотр связей между таблицами
Чтобы получить графическое представление таблиц в базе данных, полей в каждой таблице и связей между таблицами, используйте вкладку объектаСвязи.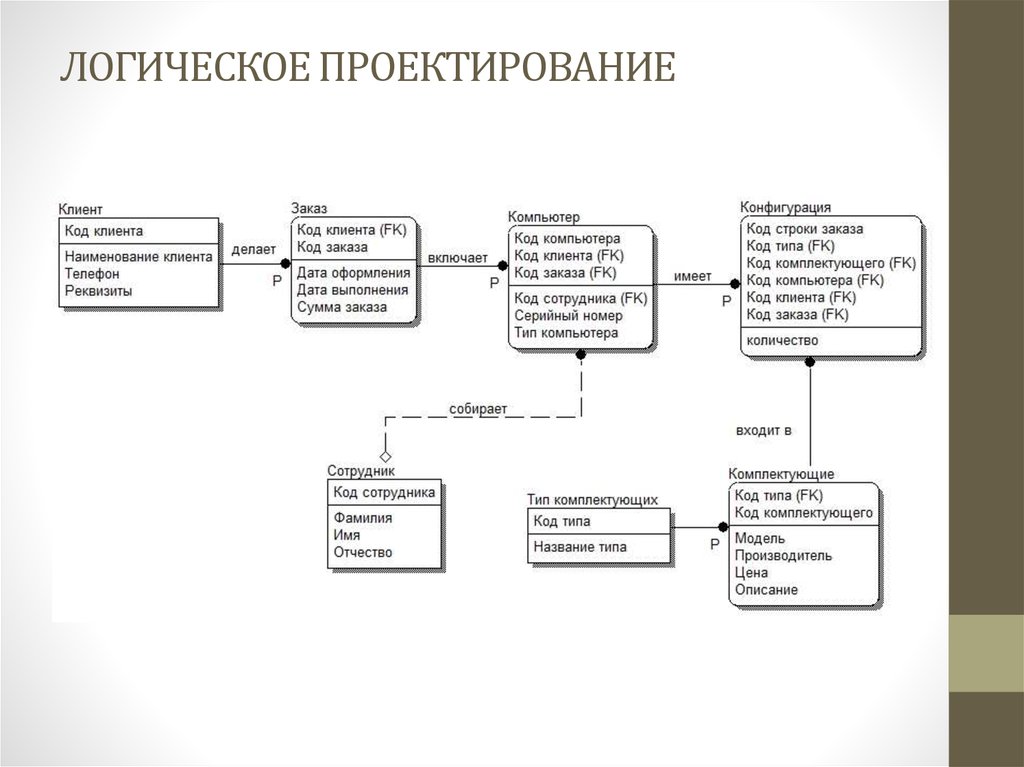 Вкладка объекта Связи позволяет получить общее представление о таблице и структуре связей базы данных; эти сведения необходимы при создании или изменении связей между таблицами.
Вкладка объекта Связи позволяет получить общее представление о таблице и структуре связей базы данных; эти сведения необходимы при создании или изменении связей между таблицами.
Примечание: Вкладку объекта Связи можно также использовать для добавления, изменения или удаления связей.
Откроется вкладка объекта Связи, на которой будут показаны связи между всеми таблицами в открытой базе данных.
Примечание: В веб-базах данных и веб-приложениях использовать вкладку объекта «Схема данных» невозможно.
К началу страницы
Основы правил проектирования базы данных / Хабр
Введение
Как это часто бывает, архитектору БД нужно разработать базу данных под конкретное решение.
Однажды в пятницу вечером, возвращаясь на электричке домой с работы, я подумал о том, как бы я создал сервис по найму сотрудников в разные компании. Ведь ни один из существующих сервисов не позволяет быстро понять насколько подходит тебе кандидат. Нет возможности создать сложные фильтры, включающие или исключающие совокупность определенных навыков, проектов или позиций. Максимум, что обычно предлагают сервисы — фильтры по компаниям и частично по навыкам.
Ведь ни один из существующих сервисов не позволяет быстро понять насколько подходит тебе кандидат. Нет возможности создать сложные фильтры, включающие или исключающие совокупность определенных навыков, проектов или позиций. Максимум, что обычно предлагают сервисы — фильтры по компаниям и частично по навыкам.
В данной статье я позволю себе немного разбавить строгое изложение материала, смешав техническую информацию с не техническими примерами из жизни.
Для начала, разберем создание базы данных в MS SQL Server для сервиса поиска соискателей на работу.
Этот материал можно перенести и на другую СУБД такую как MySQL или PostgreSQL.
Основы правил проектирования
Для проектирования схемы базы данных, нужно вспомнить 7 формальных правил и саму концепцию нормализации и денормализации. Они и лежат в основе всех правил проектирования.
Опишем более детально 7 формальных правил:
- отношение один к одному:
1.
1) с обязательной связью:примером может выступать гражданин и его паспорт: у любого гражданина должен быть паспорт; паспорт один для каждого гражданина
Реализовать данную связь можно двумя способами:
1.1.1) в одной сущности (таблице):
Рис.1. Сущность CitizenЗдесь таблица Citizen представляет собой сущность гражданина, а атрибут (поле) PassportData содержит все паспортные данные гражданина и не может быть пустым (NOT NULL).
1.1.2) в двух разных сущностях (таблицах):
Рис.2. Отношение сущностей Citizen и PassportDataЗдесь таблица Citizen представляет собой сущность гражданина, а таблица PassportData — сущность паспортных данных гражданина (самого паспорта). Сущность гражданина содержит атрибут (поле) PassportID, который ссылается на первичный ключ таблицы PassportData. В свою очередь сущность паспортных данных содержит атрибут (поле) CitizenID, которое ссылается на первичный ключ CitizenID таблицы Citizen. Поле PassportID таблицы Citizen не может быть пустым (NOT NULL).
Также здесь важно поддерживать целостность поля CitizenID таблицы PassportData, чтобы обеспечить связь один к одному. Иными словами, поле PassportID таблицы Citizen и поле CitizenID таблицы PassportData должны ссылаться на одни и те же записи как если бы это была одна сущность (таблица), представленная в пункте 1.1.1.1.2) с необязательной связью:
примером может выступать человек, имеющий или не имеющий паспорт конкретной страны. В первом случае он будет являться гражданином рассматриваемой страны, а во втором — нет.
Реализовать данную связь можно двумя способами:
1.2.1) в одной сущности (таблице):
Рис.3. Сущность PersonТаблица Person представляет собой сущность человека, а атрибут (поле) PassportData содержит все его паспортные данные и может быть пустым (NULL).
1.2.2) в двух сущностях (таблицах):
Рис.4. Отношение сущностей Person и PassportData
Таблица Person представляет собой сущность человека, а таблица PassportData — сущность паспортных данных человека (самого паспорта). Сущность человека содержит атрибут (поле) PassportID, который ссылается на первичный ключ таблицы PassportData. В свою очередь сущность паспортных данных содержит атрибут (поле) PersonID, которое ссылается на первичный ключ PersonID таблицы Person. Поле PassportID таблицы Person может быть пустым (NULL). Здесь также важно поддерживать целостность поля PersonID таблицы PassportData. Это нужно, чтобы обеспечить связь один к одному. Поле PassportID таблицы Person и поле PersonID таблицы PassportData должны ссылаться на одни и те же записи как если бы это была одна сущность (таблица), показанная в пункте 1.2.1. Или же данные поля должны быть неопределенными, то есть, содержать NULL. - отношение один ко многим:
2.1) с обязательной связью:
примером могут выступать родитель и его дети. У каждого родителя есть как минимум один ребенок.
Реализовать данную связь можно двумя способами:
2.1.1) в одной сущности (таблице):
Рис.5. Сущность ParentТаблица Parent представляет сущность родителя, а атрибут (поле) ChildList содержит информацию о детях.
Данное поле не может быть пустым (NOT NULL). Обычно типом поля ChildList выступают неполно структурированные данные (NoSQL) такие как XML, JSON и т д.2.1.2) в двух сущностях (таблицах):
Рис.6. Отношение сущностей Parent и ChildТаблица Parent представляет сущность родителя, а таблица Child — сущность ребенка. У таблицы Child есть поле ParentID, ссылающееся на первичный ключ ParentID таблицы Parent. Поле ParentID таблицы Child не может быть пустым (NOT NULL).
2.2) с необязательной связью:
примером может выступать человек, у которого могут быть дети или их может не быть.
Реализовать данную связь можно двумя способами:
2.2.1) в одной сущности (таблице):
Рис.7. Сущность Person
Таблица Parent представляет сущность родителя, а атрибут (поле) ChildList содержит информацию о детях. Данное поле может быть пустым (NULL). Обычно типом поля ChildList выступают неполно структурированные данные (NoSQL) такие как XML, JSON и т д.2.2.2) в двух сущностях (таблицах):
Рис.8. Отношение сущностей Person и ChildТаблица Parent представляет сущность родителя, а таблица Child — сущность ребенка. У таблицы Child есть поле ParentID, ссылающееся на первичный ключ ParentID таблицы Parent. Поле ParentID таблицы Child может быть пустым (NULL).
2.2.3) в одной сущности со ссылкой на саму себя при условии, что у сущностей (таблиц) родителя и ребенка будут одинаковые наборы атрибутов (полей) без учета ссылки на родителя:
Рис.9. Сущность Person со связью на саму себя
Сущность (таблица) Person содержит атрибут (поле) ParentID, который ссылается на первичный ключ PersonID этой же таблицы Person и может содержать пустое значение (NULL).Также данная реализация является примером реализации отношения «многие к одному» с необязательной связью.
- отношение многие к одному:
Эту связь можно рассмотреть зеркально к приведенной выше связи один ко многим.
Иными словами, отношение сущности «дети» к сущности «родители», где обязательная связь будет при условии, что у ребенка есть хотя бы один родитель. Если же участвуют все дети, в том числе и находящиеся в детских домах, отношение будет с необязательной связью. - отношение многие ко многим:
Примером может выступить недвижимость: она может быть в собственности как одного человека, так и нескольких. С другой стороны, один человек может владеть несколькими домами или долями нескольких домов.
Реализовать данное отношение, с привлечением NoSQL, можно так же, как в описанных выше отношениях. Однако, в рамках реляционной модели обычно такое отношение реализуют через 3 сущности (таблицы):
Рис.10. Отношение сущностей Person и RealEstateТаблицы Person и RealEstate представляют соответственно сущности человека и недвижимости. Связываются данные сущности (таблицы) через сущность (таблицы) PersonRealEstate. Атрибуты (поля) PersonID и RealEstateID ссылаются на первичные ключи PersonID таблицы Person и RealEstateID таблицы RealEstate соответственно.
Обратите внимание, что для таблицы PersonRealEstate пара (PersonID; RealEstateID) всегда является уникальной и потому может выступать первичный ключем для самой связующей сущности PersonRealEstate.Также данное отношение можно реализовать через более чем три сущности. Для этого добавляются нужные атрибуты, которые ссылаются на первичные ключи необходимых соответствующих сущностей. Такая реализация схожа с примерами, описанными выше в пунктах 1.1.2 и 1.2.2.
 1) с обязательной связью:
1) с обязательной связью: Также здесь важно поддерживать целостность поля CitizenID таблицы PassportData, чтобы обеспечить связь один к одному. Иными словами, поле PassportID таблицы Citizen и поле CitizenID таблицы PassportData должны ссылаться на одни и те же записи как если бы это была одна сущность (таблица), представленная в пункте 1.1.1.
Также здесь важно поддерживать целостность поля CitizenID таблицы PassportData, чтобы обеспечить связь один к одному. Иными словами, поле PassportID таблицы Citizen и поле CitizenID таблицы PassportData должны ссылаться на одни и те же записи как если бы это была одна сущность (таблица), представленная в пункте 1.1.1. Сущность человека содержит атрибут (поле) PassportID, который ссылается на первичный ключ таблицы PassportData. В свою очередь сущность паспортных данных содержит атрибут (поле) PersonID, которое ссылается на первичный ключ PersonID таблицы Person. Поле PassportID таблицы Person может быть пустым (NULL). Здесь также важно поддерживать целостность поля PersonID таблицы PassportData. Это нужно, чтобы обеспечить связь один к одному. Поле PassportID таблицы Person и поле PersonID таблицы PassportData должны ссылаться на одни и те же записи как если бы это была одна сущность (таблица), показанная в пункте 1.2.1. Или же данные поля должны быть неопределенными, то есть, содержать NULL.
Сущность человека содержит атрибут (поле) PassportID, который ссылается на первичный ключ таблицы PassportData. В свою очередь сущность паспортных данных содержит атрибут (поле) PersonID, которое ссылается на первичный ключ PersonID таблицы Person. Поле PassportID таблицы Person может быть пустым (NULL). Здесь также важно поддерживать целостность поля PersonID таблицы PassportData. Это нужно, чтобы обеспечить связь один к одному. Поле PassportID таблицы Person и поле PersonID таблицы PassportData должны ссылаться на одни и те же записи как если бы это была одна сущность (таблица), показанная в пункте 1.2.1. Или же данные поля должны быть неопределенными, то есть, содержать NULL. Данное поле не может быть пустым (NOT NULL). Обычно типом поля ChildList выступают неполно структурированные данные (NoSQL) такие как XML, JSON и т д.
Данное поле не может быть пустым (NOT NULL). Обычно типом поля ChildList выступают неполно структурированные данные (NoSQL) такие как XML, JSON и т д.
 Иными словами, отношение сущности «дети» к сущности «родители», где обязательная связь будет при условии, что у ребенка есть хотя бы один родитель. Если же участвуют все дети, в том числе и находящиеся в детских домах, отношение будет с необязательной связью.
Иными словами, отношение сущности «дети» к сущности «родители», где обязательная связь будет при условии, что у ребенка есть хотя бы один родитель. Если же участвуют все дети, в том числе и находящиеся в детских домах, отношение будет с необязательной связью. Обратите внимание, что для таблицы PersonRealEstate пара (PersonID; RealEstateID) всегда является уникальной и потому может выступать первичный ключем для самой связующей сущности PersonRealEstate.
Обратите внимание, что для таблицы PersonRealEstate пара (PersonID; RealEstateID) всегда является уникальной и потому может выступать первичный ключем для самой связующей сущности PersonRealEstate.Отношения один ко многим и многие к одному можно реализовать через более чем две сущности. Для этого добавляются нужные атрибуты, которые ссылаются на первичные ключи необходимых соответствующих сущностей. Такая реализация схожа с примерами, описанными выше в пунктах 1.1.2 и 1.2.2.
А где же семь формальных правил?
Вот они:
- п.1 (п.1.1 и п.1.2) — первое и второе формальные правила
- п.2 (п.2.1 и п.2.2) — третье и четвертое формальные правила
- п. 3 (аналогично п.2) — пятое и шестое формальные правила
- п.4 — седьмое формальное правило
 3 (аналогично п.2) — пятое и шестое формальные правила
3 (аналогично п.2) — пятое и шестое формальные правилаВ тексте выше эти семь формальных правил объединены в четыре блока по функционалу.
Говоря о нормализации, нужно понимать ее суть. Нормализация ведет к уменьшению повторяемости хранения информации, а следовательно и к уменьшению возможности появления аномалий в данных. Однако, нормализация при дроблении сущностей приводит к более сложным построениям запросов для манипуляций с данными (вставки, модификации, выборки и удаления).
Обратным процессом нормализации называется денормализация. Это упрощение построения запросов доступа к данным за счет укрупнения и вложенности сущностей (например, как было показано выше в пунктах 2.1.1 и 2.2.1 с помощью неполно-структурированных данных (NoSQL)).
Вот и вся суть правил проектирования баз данных.
А вы уверены, что поняли отношения в семи формальных правилах? Именно поняли, а не узнали? Ведь знать и понимать — две совершенно разных концепции.
Объясню более детально. Спросите себя, можете ли вы за пару часов набросать пусть и укрупненную по сущностям, но модель базы данных для любой предметной области и для любой информационной системы? (тонкости и детали можно достроить, поспрашивав аналитиков и представителей заказчиков). Если вопрос вас удивил, и вы думаете, что это невозможно, значит вы знаете семь формальных правил, но не понимаете их.
Почему-то многие источники игнорируют тот факт, что эти отношения были не придуманы, а выявлены. Они изначально существуют в реальном мире как между субъектами, так и между субъектами и объектами.
Также, эти отношения могут меняться, переходя из один к одному к одному ко многим, многие к одному или многие ко многим. Обязательность связи может меняться или остаться неизменной.
Позволю себе рассказать об одном случае, когда от знания семи формальных правил я пришел именно к пониманию этих отношений.
В свое время меня смущало то, что в ВУЗе я знал эти семь формальных правил, но на производственной практике (ВУЗ отправляет студентов в различные компании для приобретения профессионального опыта) очень долго строил модели баз для разных предметных областей. Я задумался и понял, что не понимаю этих отношений.
Я задумался и понял, что не понимаю этих отношений.
Мне помогло наблюдение за людьми, а суть отношений раскрылась в сновидении. Этот сон я перескажу в упрощенной форме: только то, что позволяет лучше понять именно эти семь формальных правил — без детализации всего остального.
Сон был про семью, в которой есть отец, мать и дети. Отец погибает в автомобильной катастрофе, а мать начинает пить, и детей в итоге забирают в детский дом. Эти дети надолго остаются без родителей. Затем у некоторых детей появляются попечители, их тоже несколько.
Вы проследили, какие отношения были между субъектами, и как менялись эти отношения?
Давайте присмотримся внимательнее.
- Когда семья была полной, с несколькими детьми, отношение между родителями и детьми имело вид многие ко многим.
- Когда остались мать и дети, отношение между родителем и детьми стало один ко многим с обязательной связью. Однако, в любой семье, где может и не быть детей, это отношение будет таким же, но уже с необязательной связью.
- А вот со стороны детей отношение к родителю было как многие к одному с обязательной связью пока родителя не лишили родительских прав.
- Когда дети оказались в детском доме — отношение изменилось на многие к одному с необязательной связью.
- Когда у детей появились попечители, связь между ними стала многие ко многим: у каждого попечителя могут быть другие подопечные дети, а у каждого ребенка могут быть другие попечители (родители).
Отношение между мужем и женой один к одному с обязательной связью при официальной брака или один к одному с необязательной связью до регистрации. Жена может быть только одна, как и муж может быть только один. По крайней мере, в России. Но в другой стране возможно многоженство, и тогда связь между мужем и женами будет один ко многим, а между женами и мужем — многие к одному.
Надеюсь, теперь вы значительно приблизились к пониманию этих семи формальных правил.
Стоит постоянно практиковаться: наблюдать за людьми и выявлять существующие отношения как между субъектами, так и между субъектами и объектами. Выше описывался гражданин и его паспорт как отношение один к одному с обязательной связью. В тоже время, пример человека и его паспорта — это отношение один к одному с необязательной связью.
Поняв семь формальных правил, вы сможете без труда спроектировать модель базы данных любой сложности для любой информационной системы.
Также вы увидите, что реализовать отношение можно разными способами, а сами отношения могут меняться. Модель (схема) базы данных — это «снимок» отношений между сущностями в определенный момент времени. Именно поэтому важно определить как сами сущности — образы объектов из реального мира или предметной области, так и их отношения между собой с учетом изменений в будущем.
Хорошо спроектированную модель базы данных с учетом изменения отношений в реальности или в предметной области не понадобится менять годами или даже десятилетия. Это особенно важно для хранилищ данных, где изменения влекут пересохранение больших объемов данных (от нескольких гигабайт до многих терабайт).
Это особенно важно для хранилищ данных, где изменения влекут пересохранение больших объемов данных (от нескольких гигабайт до многих терабайт).
Важно запомнить, что таблицы в реляционной модели — это отношения сущностей, а строки (кортежи) — это экземпляры этих отношений. Но чтобы было проще, под таблицами часто понимаются сущности, а под строками таблицы — экземпляры сущностей. Их отношения выражаются через связи в форме внешних ключей.
Проектирование схемы базы данных для поиска соискателей на работу
После того, как мы описали основы правил проектирования БД в первой части, давайте создадим схему базы данных для поиска соискателей на работу.
Для начала, определим, что важно для сотрудников из компании, которые ищут кандидатов:
- для HR:
1.1) компании, где работал соискатель
1.2) позиции, которые ранее занимал соискатель в данных компаниях
1.3) навыки и умения, которыми соискатель пользовался в работе;
а также продолжительность работы соискателя в каждой компании на каждой позиции и длительность использования каждого навыка и умения - для технического специалиста:
2.
1) позиции, которые занимал соискатель в данных компаниях
2.2) навыки и умения, которыми соискатель пользовался в работе
2.3) проекты, в которых участвовал соискатель;
а также продолжительность работы соискателя на каждой позиции и в каждом проекте, длительность использования каждого навыка и умения
 1) позиции, которые занимал соискатель в данных компаниях
1) позиции, которые занимал соискатель в данных компанияхДля начала выявим нужные сущности:
- Сотрудник (Employee)
- Компания (Company)
- Позиция (должность) (Position)
- Проект (Project)
- Навык (Skill)
- Компании и сотрудники относятся как многие ко многим, так как сотрудник мог работать в нескольких компаниях, а в компании работают многие люди.
- Аналогично относятся позиции и сотрудники: несколько сотрудников могут занимать одну позицию как в рамках как одной, так и нескольких компаний.
- С другой стороны, сотрудник мог работать на разных позициях как в рамках одной, так разных компаний. Таким образом, отношение между позициями и компаниями — многие ко многим.
- Аналогично и по проектам: проекты относятся ко всем выше рассмотренным сущностям как многие ко многим.
- Для простоты будем считать, что в проекте сотрудник использует один набор навыков.
- Тогда проекты и навык относятся как многие ко многим.
 Таким образом, отношение между позициями и компаниями — многие ко многим.
Таким образом, отношение между позициями и компаниями — многие ко многим.Поскольку очень важно зафиксировать, как долго сотрудник работал на той или иной позиции в той или иной компании, а также на каждом проекте, схема нашей базы данных может быть следующей:
Рис.11. Схема базы данных для поиска соискателей на работу
Здесь таблица JobHistory выступает как сущность истории работы каждого соискателя. То есть, это резюме, которое педставляет отношения многие ко многим между сущностями сотрудник, компания, позиция и проект.
Проекты и навыки относятся друг другу как многие ко многим и потому связываются между собой через сущность (таблицу) ProjectSkill.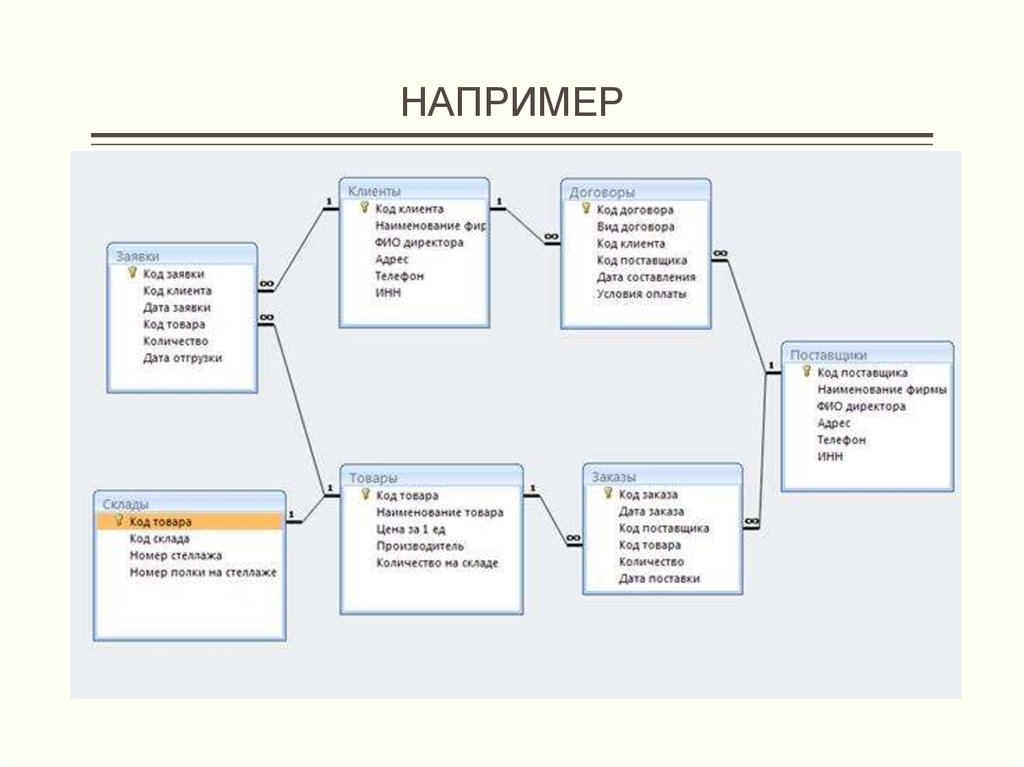
Когда вы понимаете отношения между субъектами и между субъектами и объектами — уже упомянутые семь формальных правил — эту или схожую схему можно реализовать «на коленке»: на листке бумаги, мене чем за час. И это еще с учетом усталости после плодотворного рабочего дня.
Здесь можно было упростить схему добавления данных, если «навыки» вложить в сущность «проекты» через неполно структурированные данные (NoSQL) в виде XML, JSON или просто перечислять названия навыков через точку с запятой. Но это бы усложнило выборку с группировкой по навыкам и фильтрацию по отдельным навыкам.
Подобная модель лежит в основе базы данных проекта Geecko.
Как видите, ничего сложного в проектировании информационных систем в части проектирования базы данных нет. Это всего лишь отражение объектов и субъектов из реальности, перенесенное в «сущности» схемы базы данных. Отношения между этими сущностями фиксируются на определенный момент времени, с учетом будущих изменений.
Что именно мы возьмем из реальности и вложим в сущность схемы, и какие отношения построим в модели, будет зависеть от того, что мы хотим от информационной системы в общем, здесь и в будущем. Иными словами — какие данные мы хотим получить в текущий момент времени и через определенное время в будущем.
Иными словами — какие данные мы хотим получить в текущий момент времени и через определенное время в будущем.
Немного лирики
После того, как вы внедрите модель в работу, остановитесь на миг и подумайте: только что был создан новый маленький мир. В нем есть свои сущности из реального мира и свои отношения. Да, это цифровой мир, но он теперь будет развиваться своей дорогой. Он будет общаться (интегрироваться) с другими системами (мирами), тоже созданными по своим правилам. Данные будут течь в этих системах, как кровь в живом организме.
А перед сном подумайте о том, что семь формальных правил были всегда, и что они окружают нас всюду. Не больше и не меньше, всегда семь. Все отношения реальной жизни можно разложить на эти семь формальных правил. А когда вы думаете или видите сны, как там сущности относятся друг к другу — не по тем же семи формальным правилам?
Вообще, я уверен, что эти отношения (семь формальных правил) выявил очень хороший психотерапевт, возможно — женщина. Это было очень давно, задолго до появления самого понятия информационных технологий. И самое интересное, что эти отношения живут вне базы данных и ИТ — последние лишь используют их для моделирования информационных систем.
Это было очень давно, задолго до появления самого понятия информационных технологий. И самое интересное, что эти отношения живут вне базы данных и ИТ — последние лишь используют их для моделирования информационных систем.
Но мы немного отошли от темы. Я лишь призываю в момент создания новой системы подойти к этому процессу с душой. И тогда поверьте, случится момент творения. Спроектированная таким образом система будет живее всех живых в цифровом мире.
Послесловие
Диаграммы для примеров были реализованы с помощью инструмента Database Diagram Tool for SQL Server. Однако, подобный функционал есть и в DBeaver.
Источники
- SQL Database Design Basics with Example
- Geecko
- Microsoft SQL documentation
- SSMS
- Database Diagram Tool for SQL Server
Создание базы данных для мониторинга пользователей информационных контентов
Введение
В настоящее время базы данных имеют огромную популярность. Их используют для управления и анализа данных. Они помогают сохранять большое количество информации, а также систематизировать ее для быстрого доступа к ней. Базы данных облегчают такие задачи, как извлечение, добавление и обновление новых данных, а также удаление старых данных. Цель данной статьи – показать, как и где собирается информация для мониторинга, какие направления мониторинга бывают и к какому результату может привести создание структуры базы данных.
Их используют для управления и анализа данных. Они помогают сохранять большое количество информации, а также систематизировать ее для быстрого доступа к ней. Базы данных облегчают такие задачи, как извлечение, добавление и обновление новых данных, а также удаление старых данных. Цель данной статьи – показать, как и где собирается информация для мониторинга, какие направления мониторинга бывают и к какому результату может привести создание структуры базы данных.
Понятие контента
Контентом сайта называется все содержимое сайта: статьи, изображения, видеозаписи, аудиозаписи и многое другое. Для заинтересованности пользователей сайт должен быть: полезный, правдивый, грамотный, с красивой подачей, разнообразный, актуальный, а таже соответствовал требованиям поисковых систем.
Контент бывает продающим, развлекательным и образовательным.
Продающий контент. Цель: продажа товаров или услуг [1].
Развлекательный контент. Цель: повышение настроения и реклама своего бренда.
Образовательный контент. Цель: укрепить статус эксперта, предоставить полезную информацию и привлечь целевую аудиторию. Целевая аудитория – это люди с выраженным или потенциальным интересом к продукту. В первом случае пользователи приобретали или собираются приобрести продукт, а во втором случае спрос еще не сформирован, но пользователю интересны смежные тематики, и он может являться уже потенциальным клиентом [2].
Для опубликования более качественного контента необходимо учитывать интересы пользователей, а для этого необходимо просматривать (мониторить) их активность.
Мониторинг пользователей
Система контроля действий пользователя – это программный или программно-аппаратный комплекс, который позволяет отслеживать действия пользователя. Данная система осуществляет мониторинг (просмотр, отслеживание) рабочих операций пользователя.
В настоящее время мониторят почти все: веб-сайты, социальные сети, IM, электронную почту и другое. Для того, чтобы собрать информацию, многие используют различные метрики, которые показывают охват пользователей, их активность, географическое положение, возраст и многое другое.
Благодаря мониторингу пользователей компания может узнать лучше своих клиентов, узнать их интересы, а также привлечь новых клиентов, делать правильную рекламу для каждого из них и определять какого типа информацию необходимо размещать, какие разделы можно добавить в структуру сайта и как правильно выстраивать диалог с потенциальным клиентом. Основные вопросы, на которые должны быть получены ответы:
- What? – В чем заинтересован покупатель?
- Who? – Кем является пользователь?
- Why? – Какая мотивация при использовании данной информации?
- When? – Когда и при каких условиях повышается спрос?
- Where? – Где можно найти аудиторию и привлечь ее? [2]
Для сбора информации, большинство компаний используют методы: анкетирование, онлайн-сервисы для проведения опросов, сервисы аналитики поисковых систем (Например, Яндекс.Метрика), социальные сети и т.п. [2]
Виды мониторинга:
- Информационный. Цель: сбор данных при условии, что анализ носит констатирующий характер.
- Диагностический. Цель: определить, как справляются с различными задачами большинство пользователей/сотрудников.
- Сравнительный. Цель: сопоставить количественные оценки по совокупности показателей.
- Прогностический. Цель: выявить и предсказать позитивные и негативные тенденции в развитии систем.
Структура базы данных для мониторинга пользователей
Главная задача для создания средств мониторинга пользователей – это создание структуры базы данных, а также сбор информации о пользователях и составления отчетов о собранной информации. Для решения поставленной задачи использовался MySQL и материалы образовательного контента: электронной библиотеки цифрового сотрудничества (ЭБЦС) [3].
Структуру базы данных можно увидеть на рис. 1. В каждую таблицу информация передавалась автоматически с сайта электронной библиотеки.
Рис. 1. Структура базы данных для образовательного контента
По созданной структуре была создана база данных.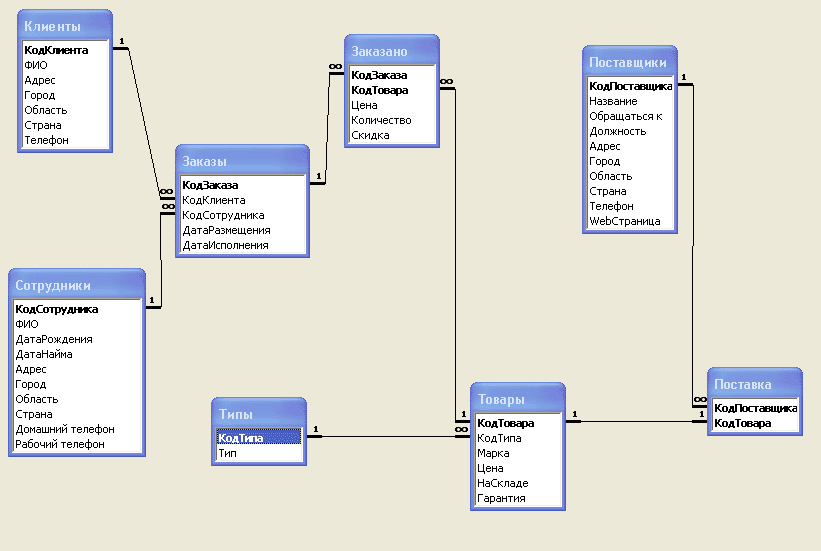
Чтобы получить интересующую информацию, были созданы математические модели. Например: для определения самого популярного действия на сайте, использовалась модель: P1=max(T2 (T1 (ⅇ))), где e – интересующая характеристика, T1 (х) – количество данных с интересующей характеристикой х, Т2 (у) – список с необходимыми данными у, max – поиск данных, которые чаще используются в списке.
Формирование отчетов по мониторингу
Создав базу данных и заполнив ее, можно ввести запрос и получить необходимую информацию. Сначала определен тип занятости, встречающийся чаще среди людей (рис. 2). Он может помочь определить, что добавить на сайт.
Рис. 2. Наиболее частый тип занятости у пользователей
Мы видим, что большинство пользователей проходят обучение, следовательно, могут быть востребованы учебные файлы.
Далее было определено, что чаще делают пользователи на сайте и какие материалы больше интересуют их (рис. 3). В БД есть пять типов действий, которые описаны в таблице.
3). В БД есть пять типов действий, которые описаны в таблице.
Таблица
Типы действий пользователей
|
Типы действий |
Значения |
|
1 |
Посмотреть описание книги |
|
2 |
Прочитать книгу |
|
3 |
Скачать книгу |
|
4 |
Посмотреть медиафайл |
|
5 |
Скачать медиафайл |
Рис. 3. Популярные действия пользователей
На рис. 3 видим: чаще всего смотрят медиафайлы (41 просмотр), при этом популярнее видео файлы (33 просмотр из 41), среди видео популярны фильмы (16 из 33 просмотров), но в целом уделяли внимание смешанному жанру.
Можно проверить активность определенного пользователя (рис. 4).
Рис. 4. Активность случайного пользователя
По рис. 4 видим: Мурада интересуют смешанный, веселый и комедийный жанр, но больше интересны медиафайлы со смешанным жанром. Следовательно, ему можно делать рекомендации с медиафайлами смешанного жанра.
Чтобы решить где лучше размещать рекламу, можно посмотреть откуда чаще заходят на сайт (рис. 5.).
Рис. 5. Места, откуда заходят на сайт
На рис.5. видим, что на сайт чаще переходят из социальных сетей.
Мозжо узнать, сколько человек заходит в 1-ой и 2-ой половине дня (рис. 6). В менее популярный промежуток можно проводить технические работы.
Рис. 6. Количество людей, зашедших на сайт за 1 месяц
Благодаря этим данным и аналогичным данным, которые можно получить с помощью созданной базы данных, можно правильно поддерживать сайт, дополняя его нужным материалом, а также повышать его популярность.
Заключение
В данной статье были рассмотрены основные понятия контента, целевой аудитории, базы данных, мониторинга пользователей, а также для электронной библиотеки была создана структура базы данных, сама БД и сделаны небольшие отчеты об активности пользователей. Данные отчеты помогают вести свой сайт и дополнять его различным полезным материалом, тем самым привлекая большую аудиторию.
Данные отчеты помогают вести свой сайт и дополнять его различным полезным материалом, тем самым привлекая большую аудиторию.
Как спроектировать базу данных, чтобы в будущем не пришлось её переписывать — базовые советы
Прим. перев. Предполагается, что вы уже имеете начальные знания по SQL. Если вы плохо понимаете, что такое таблицы, строки, индексы, первичные ключи и ссылочная целостность, то лучше сначала изучить их, например по этим видео:
А если вы знакомы с SQL и вас не остановили предыдущие термины, на всякий случай напомним, что:
- атомарность предполагает, что значение нельзя разделить на несколько атрибутов;
- под кортежем понимается запись (строка) в таблице базы данных;
- атрибут — это колонка таблицы;
- неключевой атрибут — это атрибут, не входящий в состав никакого потенциального ключа.
***
Есть минимум два требования, которые должны быть соблюдены при проектировании структуры БД:
- Сохранить всю информацию после разделения её на таблицы.
- Минимизировать избыточность того, как эта информация хранится.
Примечание Второй пункт важен не только из-за того, что избыточность влияет на размер БД. Чаще всего при обновлении данных нужно обработать много строк. В таком случае вы рискуете просто забыть обновить некоторые из них, что приведёт к коллизиям внутри БД.
Ниже перечислены некоторые рекомендации, которые помогут добиться эффективной структуры:
- используйте хотя бы третью нормальную форму;
- создавайте ограничения для входных данных;
- не храните ФИО в одном поле, также как и полный адрес;
- установите для себя правила именования таблиц и полей.
Используйте хотя бы третью нормальную форму
Нормальные формы — это требования, которые должны соблюдаться при правильной проектировке базы данных.
Нормальных форм существует целых 6 штук, однако обычно соблюдают всего лишь 3 и для начала этого более чем достаточно.
Первая нормальная форма
Для примера будем использовать отношение сотрудники_отделы_проекты. В нём есть информация о номере сотрудника, его фамилии, номере отдела, в котором он работает, номере телефона отдела и так далее.
В нём есть информация о номере сотрудника, его фамилии, номере отдела, в котором он работает, номере телефона отдела и так далее.
Это отношение, как и любое другое, автоматически находится в первой нормальной форме:
- в отношении нет одинаковых кортежей;
- кортежи не упорядочены;
- атрибуты не упорядочены и различаются по наименованию;
- все значения атрибутов атомарны.
Вторая нормальная форма
В нашем случае у таблицы выше имеется сложный (составной) ключ {Н_СОТР, Н_ПРО}. От части ключа Н_СОТР зависят неключевые атрибуты ФАМ, Н_ОТД, ТЕЛ. От части ключа Н_ПРО зависит неключевой атрибут ПРОЕКТ. А вот атрибут Н_ЗАДАН зависит от всего составного ключа, так как сотрудник может выполнять одно задание в одном проекте.
Поэтому для приведения отношения ко второй нормальной форме из отношения сотрудники_отделы_проекты нужно выделить два отношения сотрудники_отделы и проекты, а исходное отношение оставим отношением задания.
Наконец, третья нормальная форма
Отношение находится в третьей нормальной форме, когда отношение находится во второй нормальной форме и все неключевые атрибуты взаимно независимы.
Для того, чтобы устранить зависимость неключевых атрибутов, нужно произвести декомпозицию отношения ещё на несколько отношений. При этом те неключевые атрибуты, которые являются зависимыми, выносятся в отдельное отношение.
Отношение сотрудники_отделы не находится в третьей нормальной форме, так как имеется зависимость неключевых атрибутов, таких как зависимость номера телефона от номера отдела. Поэтому декомпозируем отношение сотрудники_отделы на два отношения — сотрудники и отделы:
Используйте проверочные ограничения
База данных — это не просто набор таблиц. В неё встроено много инструментов, которые помогут с сохранностью и качеством данных.
В первую очередь БД поможет с ограничением значений, которые принимают поля.
Внешние ключи регламентируют отношения между таблицами. Благодаря им сильно упрощается контроль за структурой базы, уменьшается и упрощается код приложения. Правильно настроенные внешние ключи — это гарант того, что увеличится целостность данных за счёт уменьшения избыточности. Поэтому обязательно применяйте ограничение внешнего ключа при определении связей между таблицами.
Благодаря им сильно упрощается контроль за структурой базы, уменьшается и упрощается код приложения. Правильно настроенные внешние ключи — это гарант того, что увеличится целостность данных за счёт уменьшения избыточности. Поэтому обязательно применяйте ограничение внешнего ключа при определении связей между таблицами.
Выражения ON DELETE и ON UPDATE внешних ключей используются для указания действий, которые будут выполняться при удалении строк родительской таблицы (ON DELETE) или изменении родительского ключа (ON UPDATE). Не пренебрегайте ими.
Стоит убедиться, что обязательность заполнения (NOT NULL) проверяется для полей, которые строго не должны оставаться пустыми.
Используйте CHECK, чтобы убедиться, что значения входят в диапазон (например чтобы цена не была отрицательной).
Не храните ФИО в одном поле, также как и полный адрес
Представим ситуацию, когда вам понадобится узнать, в каком городе продукт более популярен. В таком случае, если полный адрес хранится в виде цельной строки, сделать это будет очень тяжело, ведь вам нужно будет каким-то образом выделить из этой строки город. Учитывая все возможные форматы и варианты адресов, эта задача становится практически невыполнимой. Похожая ситуация и с ФИО. Даже если кажется, что это ни к чему, храните эти данные в разных полях, и в будущем вы поблагодарите себя.
В таком случае, если полный адрес хранится в виде цельной строки, сделать это будет очень тяжело, ведь вам нужно будет каким-то образом выделить из этой строки город. Учитывая все возможные форматы и варианты адресов, эта задача становится практически невыполнимой. Похожая ситуация и с ФИО. Даже если кажется, что это ни к чему, храните эти данные в разных полях, и в будущем вы поблагодарите себя.
Установите для себя правила именования таблиц и полей
Сложно работать с данными, которые выглядят как-то так: user.firstName, user.last_name, user.birthDate. Конечно, каждый программист в праве сам выбирать для себя стиль наименования, но для SQL рекомендуется выбрать наименование с подчёркиванием. Потому что не все SQL-движки одинаково работают с заглавными буквами, а помещать всё в кавычки бывает утомительно.
Ещё нужно определиться как будут называться таблицы — во множественном числе (users) или в единственном (user). Каждая базовая структура в БД обычно настроена на множественное число, поэтому и именовать таблицы стоит соответственно.
Каждая базовая структура в БД обычно настроена на множественное число, поэтому и именовать таблицы стоит соответственно.
Не упускайте возможность сложить побольше обязанностей на базу данных, чтобы облегчить себе работу над приложением и думать о его структуре, а не о контроле табличных связей.
Всё приходит с опытом. Спроектируйте две-три схемы, и картинка сама сложится у вас в голове. Отталкивайтесь от задачи —некоторыми рекомендациями иногда можно пренебречь.
Перевод статьи «A humble guide to database schema design»
Проектирование структуры БД. Методические указания к курсовой работе «Разработка и эксплуатация АИС» Часть 1
Похожие презентации:
Базы данных и язык SQL
Базы данных. Access
Базы данных. Системы управления базами данных
Базы данных. Access 2007
Язык SQL
Системы управления базами данных (СУБД)
SQL. Базовый курс
Управление данными
Базы данных. Введение
Системы управления базами данных (СУБД)
1.
 Проектирование структуры базы данныхМетодические указания к курсовой
Проектирование структуры базы данныхМетодические указания к курсовойработе по дисциплине «Разработка и
эксплуатация АИС»
Часть 1
2. Основные этапы
1. Уточнение задачи и формированиетребований к работе системы
2. Анализ предметной области и
определение сущностей и взаимосвязей
3. Нормализация
4. Проектирование таблиц
5. Создание основы базы данных
Теория по данному разделу
3. 1. Уточнение задачи и формирование требований к работе системы
• На этом этапе вам необходимо получитьответы на следующие вопросы:
1.1 Назначение БД
1.2 Требования к информации в БД
1.3 Требования к функциям БД
1.4 Специальные требования по
безопасности, быстродействию,
возможности многопоточной работы
4. 1.1 Назначение БД
• На данном этапе необходимо определитькак, кем и для каких целей будет
использоваться БД. Прописать функции
всех
предполагаемых
пользователей
(работников и руководителей)
В отчете необходимо указать все категории
пользователей и цели их работы с базой.
Пример
5. 1.2 Требования к информации в БД
• Нужно определить какая информациядолжна храниться в БД
Отчет
должен
содержать
перечень
информации, хранимой в базе.
Пример
6. 1.3 Требования к функциям БД
• Необходимо указать все функции, которыенеобходимо реализовать в явном виде
Отчет должен содержать перечень функций
базы.
Пример
7. 1.4 Специальные требования по безопасности, быстродействию, возможности многопоточной работы
• На данном этапе необходимо определить правадоступа к базе каждой категории пользователей,
определенной в пп 1.1, характер обращений
пользователей к базе (как много пользователей
могут обратиться к базе одновременно, каков будет
характер основной работы с базой)
Отчет должен содержать описание характера работы с
базой
различных
групп
пользователей
и
ограничения на их права доступа.
Пример
8. 2. Анализ предметной области и определение сущностей и взаимосвязей
• На данном этапе необходимо в явном видевыделить основные сущности, представить их в
виде схемы и описать в текстовом виде
взаимосвязи между сущностями.

• Цель данного этапа – представить всю информацию
базы в виде относительно независимого набора
атрибутов, которые и называются сущностями, и
которые соответствуют объектам или явлениям
предметной области.
• Результат этого пункта сильно зависит от
субъективных факторов (опыта, привычек и
индивидуального мнения разработчика)
• По выполнении данного этапа вы получите
первичную структуру базы данных, где
каждой сущности соответствует своя
таблица, а полями таблицы являются
атрибуты сущности. Кроме того, в структуре
необходимо
указать
связи
между
образовавшимися таблицами
Отчет по данному пункту должен содержать
перечень всех сущностей базы и основных
атрибутов, схему получившейся базы с
указанием взаимосвязи между таблицами
Пример
10. 3. Нормализация
• Данный этап заключается в последовательномприближении базы к нормальным формам.
Отчет по данному этапу должен содержать структуру
базы, приведенной к первой, второй и третьей
нормальной форме, а также обоснование всех
действий по нормализации.

Только после этого этапа можно переходить к
созданию программной части работы.
Теория по данному разделу
Алгоритм
Пример
11. 4. Проектирование таблиц
• Для каждой полученной на предыдущемэтапе таблицы необходимо привести
следующую информацию:
1. Имя таблицы;
2. Список полей таблицы;
3. Для каждого поля привести имя поля,
обоснованно выбрать тип и привести все
правила целостности, как для полей, так и
для таблицы в целом.
• Главными требованиями в отношении целостности
является такая организация базы, чтобы вся работа по
поддержанию целостности возлагалась на СУБД. Любые
действия
пользователя
не
должны
нарушать
целостность БД.
Отчет по данному этапу должен содержать описание всех
таблиц. Описание представляют в виде таблицы со
следующими полями:
Имя поля
Тип данных
поля
Ограничения на
данные
Кроме того отчет должен содержать описание всех мер по
обеспечению целостности, принятых при создании БД.
Пример
Только после данного этапа можно переходить к созданию
программной части работы.
13. 1.5. Создание основы базы данных
• Этот этап посвящен созданию программной частикурсовой работы.
• При выполнении данного этапа необходимо в
Microsoft Office Acсess 2007 создать все таблицы,
спроектированные
на
предыдущем
этапе,
назначить тип полей, ограничения, создать связи
между таблицами.
Результат выполнения данного этапа отражается в
пояснительной записке схемой данных базы
(screenshot из Acсess)
Пример
Возврат к содержанию проекта
English Русский Правила
Базы Данных. Проектирование. Модель. Нормализация. Техническое задание
Проектирование реляционных баз данных
Базы Данных. Проектирование. Модель. Нормализация. Техническое задание.
Инфологическое проектирование БД
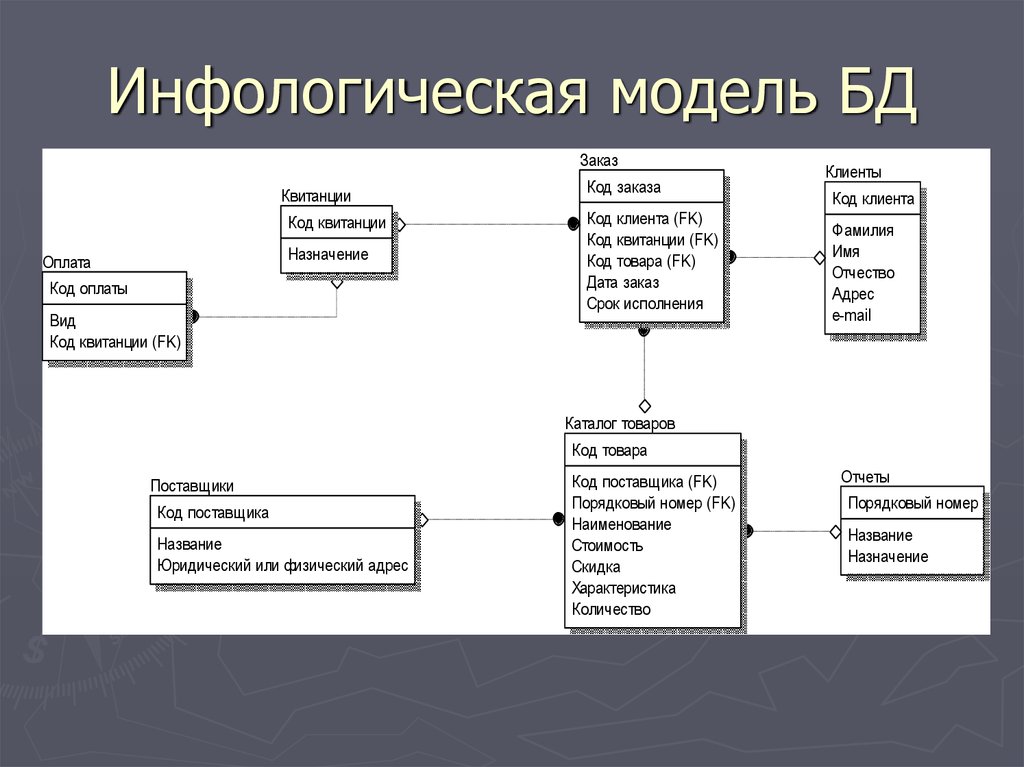
Инфологическое проектирование БД – фундамент информационной системы
Проектирование базы данных – самый трудный и ответственный этап во всем процессе разработки БД.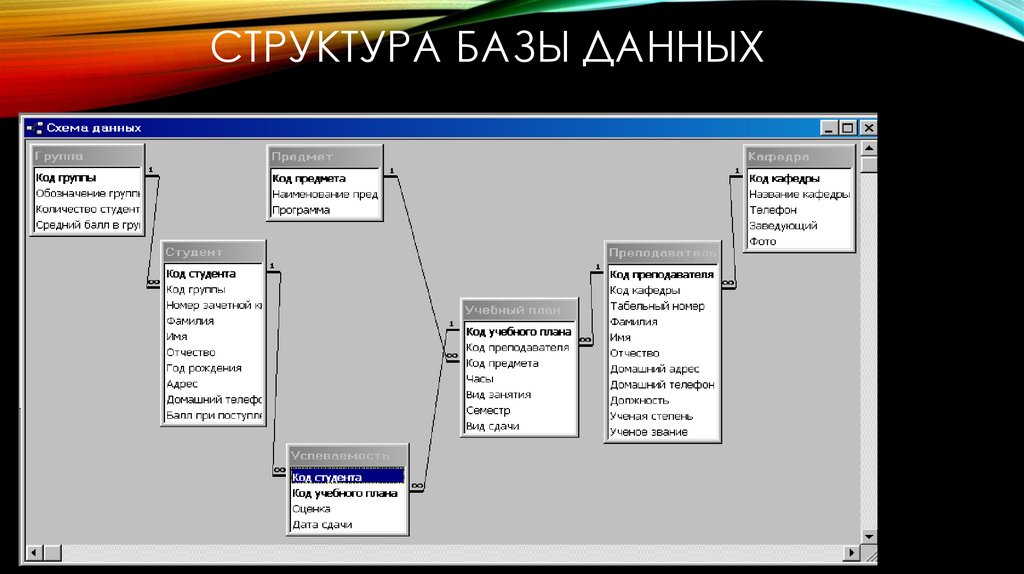 Проект базы данных – это фундамент будущего программного комплекса. Если проект точен и выверен, работа с БД будет удобной и без конфликтов, необходимость внесение дополнений в БД не потребует кардинальных изменений в остальной программе.
Проект базы данных – это фундамент будущего программного комплекса. Если проект точен и выверен, работа с БД будет удобной и без конфликтов, необходимость внесение дополнений в БД не потребует кардинальных изменений в остальной программе.
Проектирование информационных систем, включающих в себя базы данных, осуществляется на физическом и логическом уровнях. Решение проблем проектирования на физическом уровне зависит от используемой СУБД. Это проектирование часто автоматизировано и скрыто от пользователя.
Решение задач информационно-логического (инфологического) проектирования БД определяется спецификой задач предметной области и наиболее важной здесь является проблема структуризации данных.
При проектировании информационной системы необходимо провести анализ целей этой системы и выявить требования к ней отдельных пользователей (сотрудников организации) и заинтересованных лиц. Сбор данных начинается с изучения сущностей организации и процессов, использующих эти сущности.
Структурный анализ предметной области – это начало проектирования БД. В результате него определяется вся совокупность данных разрабатываемой базы данных. Одни и те же данные могут группироваться в таблицы (отношения) различными способами.
Аномалии ненормализованной базы данных
Группировка атрибутов в отношениях должна быть рациональной, такой чтобы в таблицах были сведены к минимуму или отсутствовали:
Достигается это нормализацией отношений. Использование ненормализованных таблиц может привести к нарушению целостности данных (противоречивости информации) в базе данных.
Избыточность данных (дублирование) проявляется в том, что в нескольких записях таблицы базы данных повторяется одна и та же информация.
Например, имеем отношение Сотрудник = (Табельный_№, ФИО, ГодРождения, Пол, Отдел, Должность, Номер_рабочей_комнаты, ФИО_ребенка). Для сотрудников, у которых есть дети, их личные данные будут повторяться столько раз, сколько у сотрудника детей.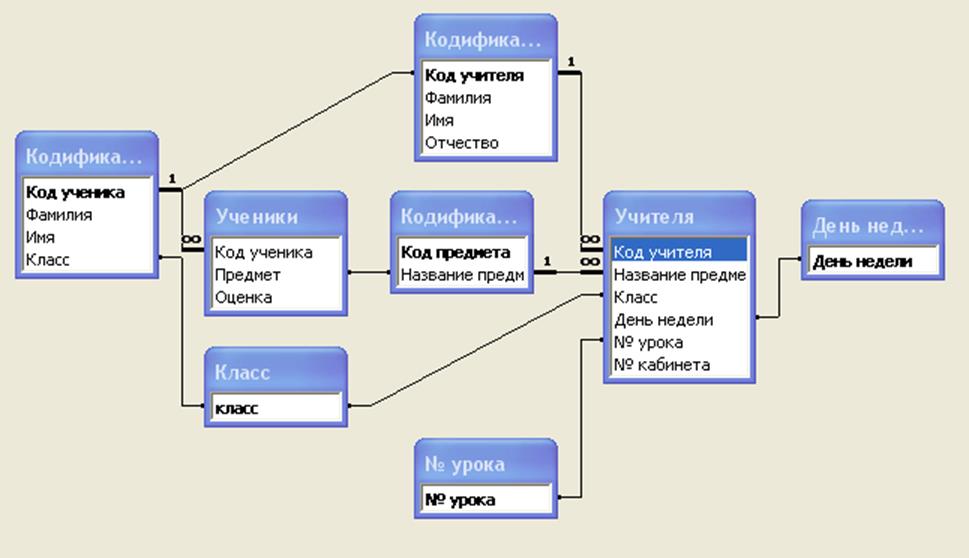
Аномалиями называются противоречия в БД либо существенные сложности в обработке данных, вызванные состоянием структуры таблиц базы данных.
Аномалии обновления проявляются в том, что изменение значения одного данного может повлечь за собой просмотр всей таблицы и соответствующее изменение некоторых других записей таблицы. Аномалии обновления тесно связаны с избыточностью данных.
Предположим, что в предыдущем отношении «Сотрудник» кроме «Номера рабочей комнаты» требуется вводить «Номер рабочего телефона» (он один). Если в одной рабочей комнате изменился номер телефона, то необходимо внести изменения во все записи сотрудников, работающих в этой комнате. Если же исправление будет внесено не во все записи, то возникнет несоответствие информации, которое и называется аномалией обновления.
Аномалии удаления состоят в том, что при удалении каких-либо данных из таблицы может пропасть и другая информация, которая не связана напрямую с удаляемыми данными.
Аномалии удаления возникают при удалении записей из ненормализованной таблицы. Например, в фирме на одной из должностей работали только один или два сотрудника, которые увольняются. Тогда удаление записей об этих сотрудниках приведет к потере информации о должности, которую они занимали.
Например, в фирме на одной из должностей работали только один или два сотрудника, которые увольняются. Тогда удаление записей об этих сотрудниках приведет к потере информации о должности, которую они занимали.
Аномалии добавления возникают в случаях, когда информацию в таблицу нельзя поместить до тех пор, пока она неполная, либо вставка новой записи требует дополнительного просмотра таблицы. Аномалии ввода возникают при добавлении в таблицу новых записей.
Например, в вышеприведенном примере невозможно добавить в БД информацию о структуре организации (отделах, должностях) до ввода данных о сотруднике в соответствующем отделе на соответствующей должности, либо необходимо добавлять записи с «пустыми» значениями (NULL) данных о сотруднике, которые потом необходимо будет удалять, просматривая таблицу при наступлении соответствующих событий.
Нормализация БД – аппарат исключения избыточности и аномалий базы данных
Чтобы свести к минимуму возможность появления аномалий БД используется нормализация.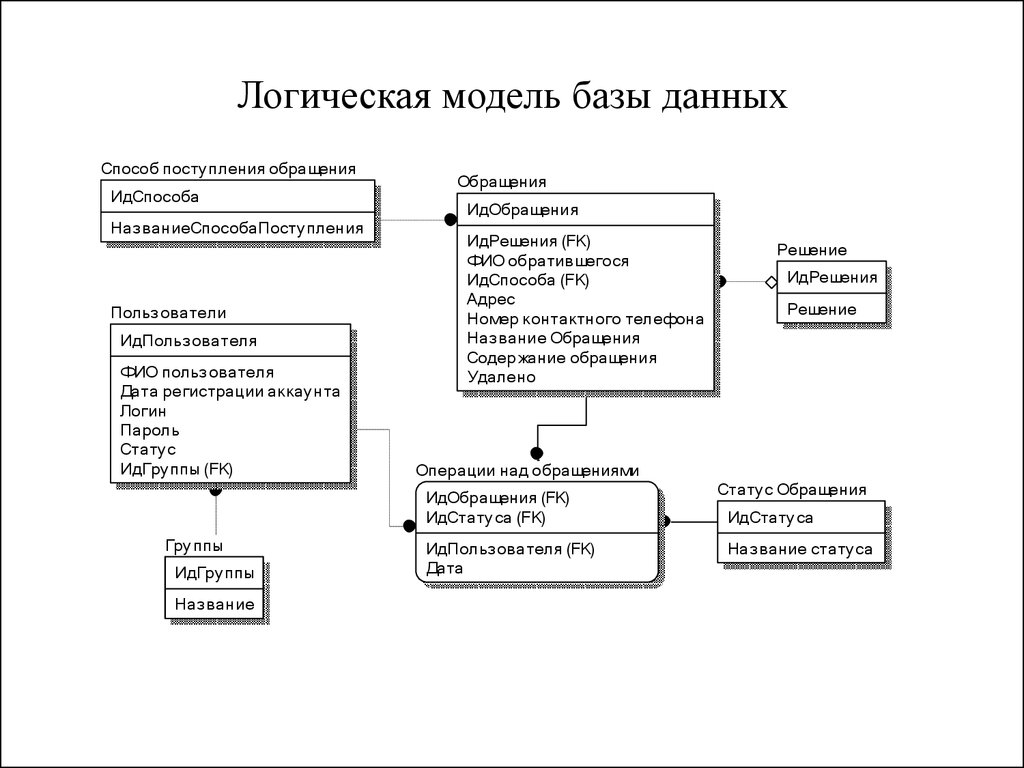
Начинающий проектировщик зачастую использует ненормализованную базу данных в качестве завершенной БД. Однако, при этом возникают проблемы, неминуемо приводящие к многочисленным сложностям при разработке архитектуры системы, написании кода и, как следствие, ошибкам в работе системы и проблемам пользователей при взаимодействии с ней, устранять которые путем изменения и усложнения кода все сложнее с каждой выявленной проблемой и, в конечном итоге, становится в принципе невозможным.
Проблемы, проистекающие из плохо спроектированной схемы данных, можно исправить только путем правильного проектирования БД.
Основная цель проектирования БД – это сокращение избыточности хранимых данных, а следовательно, экономия объема используемой памяти, уменьшение затрат на многократные операции обновления избыточных копий и, самое главное, — устранение возможности возникновения противоречий из-за хранения в разных местах сведений об одном и том же объекте. Так называемый, «чистый» проект БД («Каждый факт в одном месте») можно создать, используя методологию нормализации отношений.
Нормализация отношений — формальный аппарат ограничений на формирование отношений (таблиц), который позволяет устранить дублирование, обеспечивает непротиворечивость хранимых в базе данных, уменьшает трудозатраты на ведение (ввод, корректировку) базы данных.
Нормализация – это разбиение таблицы на две или более, обладающих лучшими свойствами при включении, изменении и удалении данных. Окончательная цель нормализации сводится к получению такого проекта базы данных, в котором каждый факт появляется лишь в одном месте, т.е. исключена избыточность информации. Это делается не столько с целью экономии памяти, сколько для исключения возможной противоречивости хранимых данных.
Нормализация отношений информационной модели предметной области является механизмом создания логической модели реляционной базы данных.
Задача построения как информационной модели предметной области, так и логической модели реляционной базы данных является результатом решения следующих комбинаторных задач:
Такие задачи имеют решения, допускающие большое число вариантов, и приводят к проблеме выбора рационального варианта из множества альтернативных вариантов схем отношений. Выбор наиболее рационального варианта обусловлен соблюдением различного рода соглашений и требований.
Выбор наиболее рационального варианта обусловлен соблюдением различного рода соглашений и требований.
Перечень наиболее важных требований:
Первичные ключи отношений должны быть минимальными (требование минимальности первичных ключей).
Число отношений базы данных должно по возможности давать наименьшую избыточность данных (требование надежности данных).
Число отношений базы данных не должно приводить к потере производительности системы (требование производительности системы).
Данные не должны быть противоречивыми, т.е. при выполнении операций включения, удаления и обновления данных их потенциальная противоречивость должна быть сведена к минимуму (требования непротиворечивости данных).
Схема отношений базы данных должна быть устойчивой, способной адаптироваться к изменениям при ее расширении дополнительными атрибутами (требование гибкости структуры базы данных).
Разброс времени реакции на различные запросы к базе данных не должен быть большим (требование производительности системы).
Данные должны правильно отражать состояние предметной области базы данных в каждый конкретный момент времени (требование актуальности данных).

Создание системы, одновременно удовлетворяющей всем вышеназванным требованиям, представляет собой сложную оптимизационную задачу, которая подчас не имеет однозначного решения. Многие из требований находятся в противоречии друг к другу. Так, например, требование производительности находится в противоречии к требованию гибкости. Требование минимизировать число отношений в базе данных находится в противоречии к требованию надежности данных.
Функциональная и многозначная зависимости
Теория нормализации основывается на наличии той или иной зависимости между полями таблицы. Определены два вида таких зависимостей: функциональные и многозначные.
Функциональная зависимость (ФЗ). Поле В таблицы функционально зависит от поля А той же таблицы в том и только в том случае, когда в любой заданный момент времени для каждого из различных значений поля А обязательно существует только одно из различных значений поля В. Отметим, что здесь допускается, что поля А и В могут быть составными.
Отметим, что здесь допускается, что поля А и В могут быть составными.
Полная функциональная зависимость. Поле В находится в полной функциональной зависимости от составного поля А, если оно функционально зависит от А и не зависит функционально от любого подмножества поля А.
Многозначная зависимость. Поле А многозначно определяет поле В той же таблицы, если для каждого значения поля А существует хорошо определенное множество соответствующих значений В.
Нормальные формы
Первая нормальная форма (1НФ)
Таблица находится в первой нормальной форме (1НФ) тогда и только тогда, когда ни одна из ее строк не содержит в любом своем поле более одного значения и ни одно из ее ключевых полей не пусто.
Вторая нормальная форма (2НФ)
Таблица находится во второй нормальной форме (2НФ), если она удовлетворяет определению 1НФ и все ее поля, не входящие в первичный ключ, связаны полной функциональной зависимостью с первичным ключом.
Третья нормальная форма (3НФ)
Таблица находится в третьей нормальной форме (3НФ), если она удовлетворяет определению 2НФ и не одно из ее неключевых полей не зависит функционально от любого другого неключевого поля.
Нормальная форма Бойса-Кодда (НФБК) (усиленная 3НФ)
Таблица находится в нормальной форме Бойса-Кодда (НФБК), если и только если любая функциональная зависимость между его полями сводится к полной функциональной зависимости от возможного ключа.
Четвертая нормальная форма (4НФ)
Полной декомпозицией таблицы называют такую совокупность произвольного числа ее проекций, соединение которых полностью совпадает с содержимым таблицы.
Отношение находится в четвертой нормальной форме (4НФ), если оно находится в 3НФ или НФБК и все независимые многозначные ФЗ разнесены в отдельные отношения с одним и тем же ключом. Иными словами, 4НФ применяется при наличии в отношении более чем одной многозначной ФЗ и требует, чтобы отношение не содержало независимых многозначных ФЗ.
Таким образом, процедура приведения отношения к 4НФ сводится к выполнению нескольких проекций.
Пятая нормальная форма (5НФ)
Отношение находится в пятой нормальной форме (5НФ), если оно находится в 4НФ и удовлетворяет зависимости по соединению относительно своих проекций. 5НФ называют также нормальной формой с проецированием соединений. Она используется для разрешения трех и более отношений, которые связаны более чем тремя ФЗ по типу «многие-ко-многим».
Таким образом, процедура приведения отношения, содержащего многозначные ФЗ, к 5НФ состоит в построении связывающего отношения, позволяющего исключить появление в соединениях ложных кортежей.
Нормализация как процесс декомпозиции таблиц
Теперь можно дать и другое определение: нормализация – это процесс последовательной замены таблицы ее полными декомпозициями до тех пор, пока все они не будут находиться в целевой нормальной форме.
Следовательно, каждая нормальная форма ограничивает определенный тип ФЗ и устраняет аномалии обработки данных.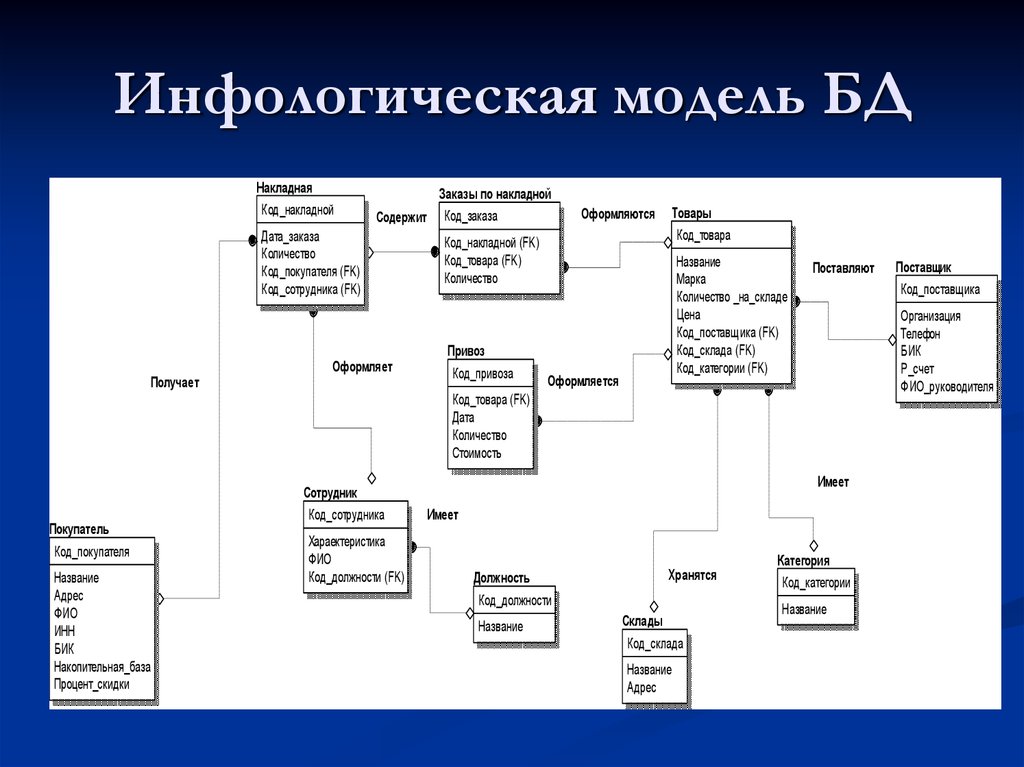 Нормальные формы характеризуются следующими свойствами:
Нормальные формы характеризуются следующими свойствами:
1НФ — все атрибуты отношения простые;
2НФ — отношение находится в 1НФ и не содержит частичных ФЗ;
3НФ — отношение находится во 2НФ и не содержит транзитивных ФЗ от ключа;
НФБК — отношение находится в 3НФ и не содержит ФЗ ключей от неключевых атрибутов;
4НФ, применяется при наличии более чем одной многозначной ФЗ — отношение находится в НФБК или 3НФ и не содержит независимых многозначных ФЗ;
5НФ — отношение находится в 4НФ и не содержит ФЗ по соединению.
Обычно применяется нормализация базы данных до НФБК, в случаях достаточно сложных зависимостей между сущностями может быть проведена нормализация до 4НФ и 5НФ.
Нормализация гарантирует целостность данных
Почему нормализация схем отношений важна для проектирования реляционных баз данных? Многочисленные испытания показали, что нормализация схем отношений дает наилучший результат при моделировании предметной области с использованием реляционной модели данных; при этом не вводится большого числа ограничений, не искажаются данные.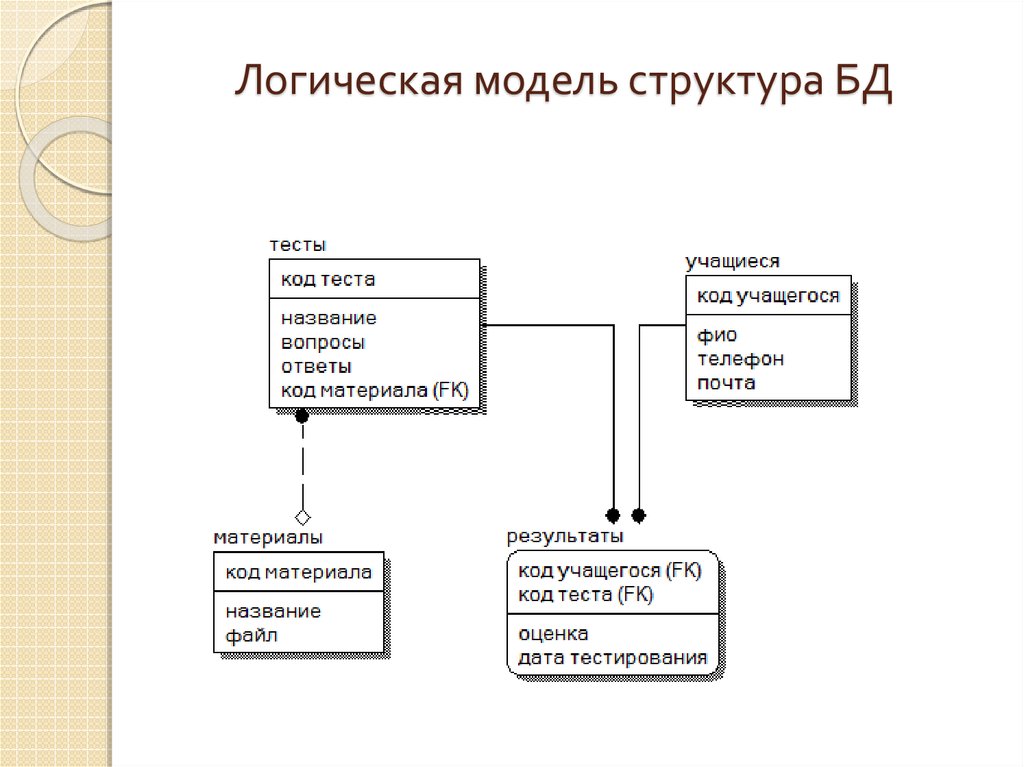 Таким образом, нормализация отношений является методом удаления из отношения ФЗ, которые приводят к аномалиям модификации данных. Иными словами, нормализация отношений помогает проектировать реляционную базу данных, которая не содержит избыточных данных и гарантирует их целостность.
Таким образом, нормализация отношений является методом удаления из отношения ФЗ, которые приводят к аномалиям модификации данных. Иными словами, нормализация отношений помогает проектировать реляционную базу данных, которая не содержит избыточных данных и гарантирует их целостность.
Процедура проектирования базы данных
Процесс проектирования информационных систем является достаточно сложной задачей. Он начинается с построения инфологической модели данных, т.е. идентификации сущностей. Затем необходимо выполнить следующие шаги процедуры проектирования даталогической модели:
Представить каждый стержень (независимую сущность) таблицей базы данных (базовой таблицей) и специфицировать первичный ключ этой базовой таблицы.
Представить каждую ассоциацию (связь вида «многие-ко-многим» или «многие-ко-многим-ко-многим» и т.д. между сущностями) как базовую таблицу. Использовать в этой таблице внешние ключи для идентификации участников ассоциации и специфицировать ограничения, связанные с каждым из этих внешних ключей.
Представить каждую характеристику как базовую таблицу с внешним ключом, идентифицирующим сущность, описываемую этой характеристикой. Специфицировать ограничения на внешний ключ этой таблицы и ее первичный ключ – по всей вероятности, комбинации этого внешнего ключа и свойства, которое гарантирует «уникальность в рамках описываемой сущности».
Представить каждое обозначение, которое не рассматривалось в предыдущем пункте, как базовую таблицу с внешним ключом, идентифицирующим обозначаемую сущность. Специфицировать связанные с каждым таким внешним ключом ограничения.
Представить каждое свойство как поле в базовой таблице, представляющей сущность, которая непосредственно описывается этим свойством.
Для того чтобы исключить в проекте непреднамеренные нарушения каких-либо принципов нормализации, выполнить процедуру нормализации.
Если в процессе нормализации было произведено разделение каких-либо таблиц, то следует модифицировать инфологическую модель базы данных и повторить перечисленные шаги.
Указать ограничения целостности проектируемой базы данных и дать (если это необходимо) краткое описание полученных таблиц и их полей.


ER-диаграмма (диаграмма «сущность-связь»)
Процесс проектирования баз данных — определение того, какого рода информация должна быть в ней представлена и каковы взаимосвязи между элементами информации. Структура или схема (schema) определяется средствами языков или систем обозначений для модели. По завершению моделирования схема преобразовывается в форму, которая может быть воспринята СУБД.
Чаще всего модель представляется в виде диаграммы «сущность – связь» (entity – relationship) или ER-диаграммы. Процесс построения ER-диаграммы называется ER-моделированием.
Модель «сущность-связь» предложена американским исследователем в области баз данных Питером Ченом в 1976 году. С тех пор она расширялась и модифицировалась как самим Ченом, так и многими другими исследователями. В различных вариантах она вошла в состав многих автоматизированных средств поддержки проектирования информационных систем.
В различных вариантах она вошла в состав многих автоматизированных средств поддержки проектирования информационных систем.
ER-диаграмма позволяет графически представить все элементы логической модели согласно простым, интуитивно понятным, но строго определенным правилам.
Схема базы данных в виде ER-модели включается в проектную документацию (спецификация, техническое задание и т.п.).
Сущности и атрибуты
Сущность — это класс однотипных объектов, информация о которых должна быть учтена в модели.
Атрибут сущности — это именованная характеристика, являющаяся некоторым свойством сущности.
Сущность на ER-диаграмме представляется прямоугольником с именем в верхней части. В прямоугольнике перечисляются атрибуты сущности, при этом атрибуты, составляющие уникальный идентификатор сущности, выделяются.
Поскольку сущность определяется набором своих атрибутов, для каждой сущности выделяется такое подмножество атрибутов, которое однозначно идентифицирует экземпляр данной сущности.
Ключ сущности — это неизбыточный набор атрибутов, значения которых в совокупности являются уникальными для каждого экземпляра сущности.
Идентификатор сущности называют первичным ключом (primary key). Первичный ключ (primary key) – это атрибут или группа атрибутов, однозначно идентифицирующая экземпляр сущности. Выбор первичного ключа может оказаться непростой задачей, решение которой в состоянии повлиять на эффективность будущей ИС. В одной сущности могут оказаться несколько атрибутов или наборов атрибутов, претендующих на роль первичного ключа. Такие претенденты называются потенциальными ключами (candidate key). Ключи могут быть сложными, т.е. содержащими несколько атрибутов.
Каждая сущность должна иметь, по крайней мере, один потенциальный ключ. Многие сущности имеют только один потенциальный ключ. Такой ключ становится первичным. Некоторые сущности могут иметь более одного возможного ключа. Тогда один из них становится первичным, а остальные – альтернативными ключами. Альтернативный ключ (Alternate Key) – это потенциальный ключ, не ставший первичным.
Альтернативный ключ (Alternate Key) – это потенциальный ключ, не ставший первичным.
Во многих случаях проектировщик может создать суррогатный ключ (Surrogate Key) – атрибут, значение которого создается искусственно и не имеет отношения к предметной области. При моделировании структур данных суррогатные ключи во многих ситуациях являются более предпочтительными.
Домены
Каждый атрибут имеет домен. Домен можно определить как абстрактный атрибут, на основе которого можно создавать обычные атрибуты, при этом создаваемые атрибуты будут иметь все свойства домена-прародителя. Каждый атрибут может быть определен только на одном домене, но на каждом домене может быть определено множество атрибутов. В понятие домена входит не только тип данных, но и область значений данных. Например, можно определить домен «Возраст» как положительное целое число и определить атрибут «Возраст сотрудника» как принадлежащий этому домену. На последующих стадиях тип домена конкретизируется, смысл понятия домена в физической модели уже, чем в логической.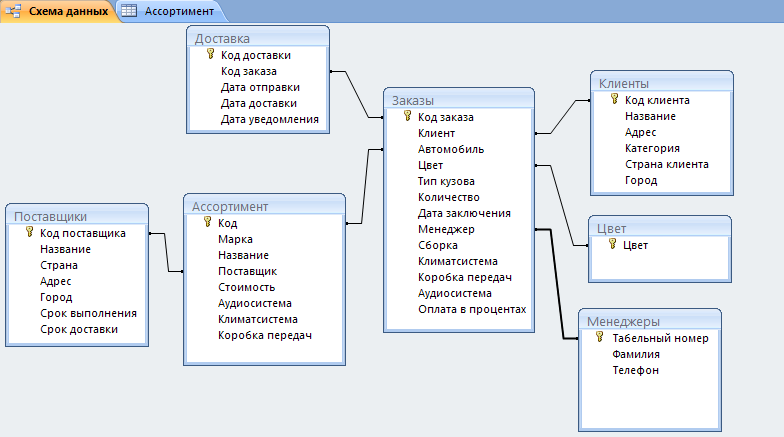
Отношения (связи)
Отношение (связь) сущностей на ER-диаграмме изображается линией, соединяющей эти сущности. Связь представляет собой взаимоотношение между двумя или более сущностями. Каждая связь реализуется через значения атрибутов сущностей. При создании связи в одной из сущностей, называемой дочерней сущностью, создается новый атрибут, называемый внешним ключом (Foreign Key, FK).
Существуют различные типы связей: идентифицирующая связь (identifying relationship) и неидентифицирующая связь (non-identifying relationship), связи «один ко многим» и «многие ко многим». С типами связей связывают и различные типы сущностей.
Различают два типа сущностей: зависимые (Dependent entity) и независимые (Independent entity). Тип сущности определяется ее связью с другими сущностями. Идентифицирующая связь устанавливается между независимой (родительский конец связи) и зависимой (дочерний конец связи) сущностями.
При установлении идентифицирующей связи (на рисунке обозначается непрерывной линией) атрибуты первичного ключа родительской сущности автоматически переносятся в состав первичного ключа дочерней сущности.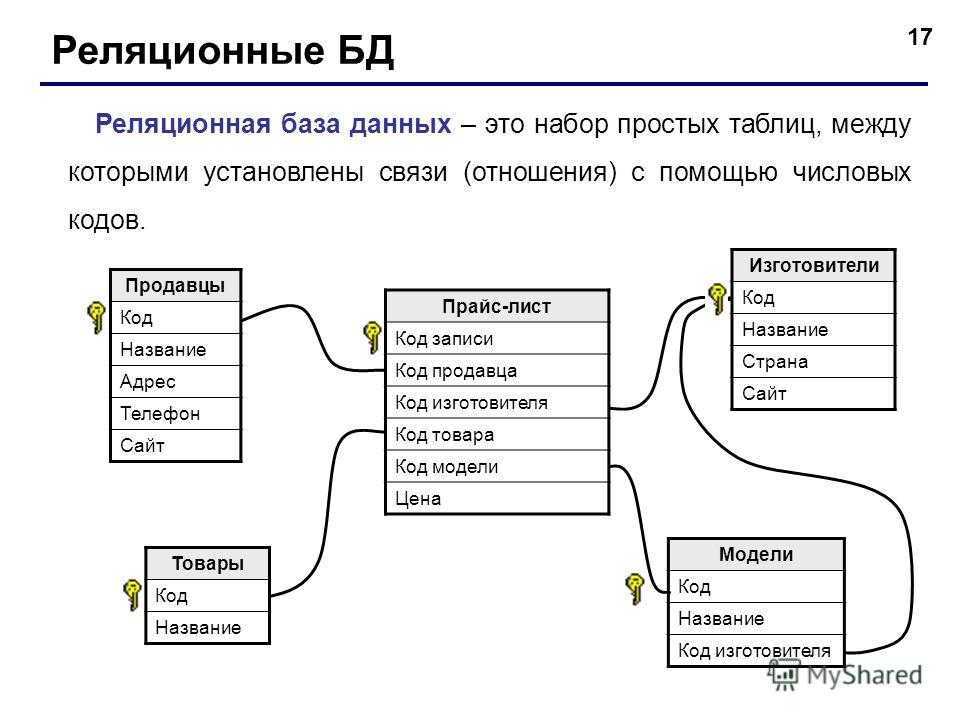 При установлении неидентифицирующей связи (обозначается пунктирной линией) атрибуты первичного ключа одной сущности мигрируют в состав неключевых компонентов другой сущности. Операция дополнения атрибутов одной сущности при создании связи называется миграцией атрибутов. Для сущности, в которую произошла миграция, такой атрибут является внешним ключом.
При установлении неидентифицирующей связи (обозначается пунктирной линией) атрибуты первичного ключа одной сущности мигрируют в состав неключевых компонентов другой сущности. Операция дополнения атрибутов одной сущности при создании связи называется миграцией атрибутов. Для сущности, в которую произошла миграция, такой атрибут является внешним ключом.
Связь «многие ко многим» (many-to-many relationship) может быть создана только на уровне концептуальной или логической модели. На уровне физической (или уже на уровне логической) модели она должна быть разрешена путем введения промежуточной (ассоциативной) сущности.
Please reload
Аномалии ненормализованной БД
Нормализация БД исключает избыточность
Функциональная и многозначная зависимости
Нормальные формы БД
Нормализация как процесс декомпозии таблиц
Нормализация гарантирует целостность данных
Процедура проектирования БД
ER-диаграмма
Сущности и атрибуты
Ключи
Домены
Отношения (связи)
Разработка базы данных: что вам нужно знать
Разработка базы данных — это проектирование, создание базы данных или модели данных и анализ требований и их намерений в виде необработанных данных. Разработка базы данных направлена на создание структуры, которая позволит эффективно хранить и извлекать данные.
Разработка базы данных направлена на создание структуры, которая позволит эффективно хранить и извлекать данные.
Являясь прототипом базы данных, она должна соответствовать потребностям бизнеса. Разработка базы данных включает проектирование структуры таблицы, создание индексов и разработку процедур и триггеров.
Это неотъемлемая часть любого проекта. Программное обеспечение, которое предприятия и правительства используют для хранения данных, должно поддерживать все необходимые вам функции. Для хранения и обработки больших объемов данных обычно лучше всего подходят реляционные базы данных.
Итак, давайте продолжим изучение процесса разработки базы данных и ее использования. Продолжать идти!
Процесс разработки базы данныхРазработка базы данных включает проектирование базы данных, создание базы данных и заполнение базы данных данными.
Этот процесс обычно начинается с определения бизнес-требований и формулировки проекта базы данных. Анализ проекта включает в себя создание основных форматов, включающих аппаратное и программное обеспечение.
Анализ проекта включает в себя создание основных форматов, включающих аппаратное и программное обеспечение.
Структура базы данных имеет решающее значение, поскольку она определяет, как пользователи получают доступ к данным при использовании базы данных. Затем организация внедряет систему управления базами данных для аутентификации и проверки перед развертыванием в производственной среде. Тогда это постоянный мониторинг и обслуживание базы данных, отвечающие требованиям бизнеса.
А с помощью последних версий администраторы эффективно разделяют и хранят данные. Он предоставляет выдающиеся возможности для сложных потребностей бизнеса, создавая соответствующие ответы на эксклюзивные запросы к базам данных различных отделов и функциональных подразделений независимо друг от друга и в совокупности.
Как разработка и поддержка базы данных способствуют успеху в бизнесе Обслуживание базы данных имеет решающее значение для любого бизнеса. Хорошо поддерживаемая база данных обеспечит бесперебойную работу вашего бизнеса, а также организованность и легкий доступ к вашим данным.
База данных похожа на картотеку вашего бизнеса. Он хранит все ваши данные в удобном для доступа формате. Это важно для любого бизнеса, но важно для стартапов. Успех стартапа зависит от его способности эффективно собирать и хранить данные.
База данных полной емкости:
- Имеет надлежащую целостность данных . Когда ваши сотрудники постоянно загружают данные в ваши различные базы данных, они производят хорошо интегрированные данные. Обновление одной системы должно отражаться на всей базе данных.
- Устранение простоев в вашем бизнесе . Многие организации полагаются на устаревшие системы, которые медлительны, неуклюжи и постоянно обновляются, что приводит к большему количеству проблем.
- Улучшает отношения с клиентами . Когда вы используете новейшие технологии в своей базе данных, вы завоевываете доверие клиентов. Новая универсальная база данных обеспечивает оптимизированное обслуживание благодаря идеальной серверной системе, работающей как хорошо смазанная машина.

Около 92,5 млрд долларов США поступило от аутсорсинговых услуг в 2019 году. Почти 54% предприятий используют механизмы аутсорсинга для привлечения клиентов. Аутсорсинговые услуги по разработке баз данных могут быть очень выгодными для компаний любого размера.
Когда предприятия отдают разработку своей базы данных на аутсорсинг, они могут воспользоваться знаниями и опытом команды разработчиков. Это может привести к более быстрой, точной и надежной разработке базы данных.
Аутсорсинговые услуги по разработке баз данных могут предоставить вашей компании несколько преимуществ, включая экономию затрат, повышение эффективности и доступ к команде квалифицированных специалистов.
Когда вы работаете с подходящим поставщиком услуг аутсорсинга, вы можете рассчитывать на следующие преимущества:
- Экономия средств. Передавая разработку базы данных на аутсорсинг, вы можете сэкономить до 60 % затрат. Это связано с тем, что провайдер имеет доступ к глобальному пулу ресурсов и может предоставить вам наилучшие возможные тарифы.
- Повышенная эффективность. Работая с опытной командой разработчиков, вы можете сократить время завершения своего проекта. Эта повышенная эффективность может привести к экономии средств и более быстрому выходу на рынок.
- Защита инвестиций. Развитие инфраструктуры не требует дополнительных затрат. Ваши внешние сотрудники будут корректировать любые инфраструктурные изменения в соответствии с потребностями.
- Устраняет колебания в работе. Рабочих мало, рабочий процесс беспокойный, часто в праздники. Однако аутсорсинг обеспечивает круглосуточную работу.
 Это связано с тем, что провайдер имеет доступ к глобальному пулу ресурсов и может предоставить вам наилучшие возможные тарифы.
Это связано с тем, что провайдер имеет доступ к глобальному пулу ресурсов и может предоставить вам наилучшие возможные тарифы. Разработчики баз данных создают, разрабатывают и поддерживают надежные пространства для хранения данных. Webhead гарантирует, что пользовательские данные легко доступны и организованы. Чтобы узнать больше об услугах Webhead по разработке баз данных, обратитесь к нашим экспертам.
Чтобы узнать больше об услугах Webhead по разработке баз данных, обратитесь к нашим экспертам.
Программные инструменты для проектирования и разработки баз данных
01:12
Разрабатывайте и развертывайте высококачественный и высокопроизводительный код почти в два раза быстрее, чем аналогичные наборы инструментов, не срезая углов. Получите возможность внедрить согласованные, воспроизводимые процессы разработки баз данных, чтобы соответствовать бизнес-требованиям и сделать свою организацию более гибкой. Широкие возможности автоматизации и совместной работы упрощают выполнение циклов разработки и минимизируют риски.
Наши средства разработки баз данных работают на различных платформах баз данных, обеспечивая готовое к будущему решение для всех типов баз данных и сокращая время на изучение, внедрение и управление новыми платформами.
из списка Fortune 500 Trust Quest Software
Клиенты в 100 странах
Онлайн Члены сообщества
Возможности
Идите в ногу с требованиями бизнеса, не жертвуя качеством, производительностью или масштабируемостью производства. Наши решения для разработки баз данных помогут вашему персоналу масштабироваться по мере необходимости — без компромиссов.
Рекомендуемые продукты
Toad для IBM DB2
Улучшение и ускорение повседневных задач разработки и администрирования в Linux, Unix и Windows
Скачать бесплатную пробную версиюКупить онлайн
Toad для Oracle
Разработка и управление базами данных Oracle с меньшими затратами времени и усилий.
Скачать бесплатную пробную версиюКупить онлайн
Toad для решений SAP
Оптимизация разработки и администрирования SAP.
Скачать бесплатную пробную версиюКупить онлайн
Toad для SQL Server
Сокращение времени, затрачиваемого на разработку приложений SQL Server и администрирование баз данных.
Скачать бесплатную пробную версиюКупить онлайн
Toad Data Modeler
Создавайте высококачественные модели данных и легко внедряйте точные изменения в структуры данных
Скачать бесплатную пробную версиюКупить онлайн
Benchmark Factory для баз данных
Экономьте время на устранении неполадок в работе и быстро внедряйте новые приложения.
Загрузить бесплатную пробную версию Купить через Интернет
Рекомендуемые продукты
Жаба для IBM DB2
Улучшить и ускорить выполнение повседневных задач разработки и администрирования в Linux, Unix и Windows
Загрузить бесплатную пробную версию Купить онлайн
Жаба для Oracle
Разработка и управление базами данных Oracle с меньшими затратами времени и усилий.
Скачать бесплатную пробную версиюКупить онлайн
Toad для решений SAP
Оптимизация разработки и администрирования SAP.
Скачать бесплатную пробную версиюКупить онлайн
Toad для SQL Server
Сокращение времени, затрачиваемого на разработку приложений SQL Server и администрирование баз данных.
Скачать бесплатную пробную версиюКупить онлайн
Рекомендуемые продукты
Toad для Oracle
Разрабатывайте и управляйте базами данных Oracle с меньшими затратами времени и усилий.
Скачать бесплатную пробную версиюКупить онлайн
Toad Edge
Упрощение разработки и управления средами MySQL и Postgres.
Загрузить бесплатную пробную версию MySQLКупить онлайн
Benchmark Factory для баз данных
Экономьте время на устранении неполадок в работе и быстро внедряйте новые приложения.
Скачать бесплатную пробную версиюКупить онлайн
Toad для SQL Server
Сокращение времени, затрачиваемого на разработку приложений SQL Server и администрирование баз данных.
Скачать бесплатную пробную версиюКупить онлайн
Жаба для решений SAP
Оптимизация разработки и администрирования SAP.
Скачать бесплатную пробную версию Online
Toad для IBM DB2
Улучшить и ускорить выполнение повседневных задач разработки и администрирования в Linux, Unix и Windows
Скачать бесплатную пробную версию Online
Рекомендуемые продукты
Toad для Oracle
Разработка и управление базами данных Oracleс меньшими затратами времени и усилий.
Скачать бесплатную пробную версиюКупить онлайн
Toad для решений SAP
Оптимизация разработки и администрирования SAP.
Скачать бесплатную пробную версиюКупить онлайн
Toad для SQL Server
Сокращение времени, затрачиваемого на разработку приложений SQL Server и администрирование баз данных.
Скачать бесплатную пробную версиюКупить онлайн
Toad DevOps Toolkit
Toad DevOps Toolkit повышает скорость DevOps за счет интеграции управления изменениями базы данных Oracle.
Скачать бесплатную пробную версию
Benchmark Factory для баз данных
Экономьте время на устранении производственных проблем и быстро внедряйте новые приложения.
Скачать бесплатную пробную версиюКупить онлайн
Рекомендуемые продукты
Toad для Oracle
Разрабатывайте и управляйте базами данных Oracle с меньшими затратами времени и усилий.
Скачать бесплатную пробную версиюКупить онлайн
Toad Intelligence Central
Легко обменивайтесь данными, файлами и проектами между командами Toad. Пришло время подключиться.
Скачать бесплатную пробную версиюКупить онлайн
Жаба для SQL Server
Сокращение времени, затрачиваемого на разработку приложений SQL Server и администрирование баз данных.
Скачать бесплатную пробную версиюКупить онлайн
Toad для решений SAP
Оптимизация разработки и администрирования SAP.
Скачать бесплатную пробную версию Online
Toad для IBM DB2
Улучшение и ускорение повседневных задач разработки и администрирования в Linux, Unix и Windows
Скачать бесплатную пробную версию Online
Отмеченные наградами решения для разработки баз данных
Ресурсы
DevOps для баз данных Oracle
Узнайте, как Toad для Oracle может помочь вам эффективно внедрить DevOps
Читать электронную книгуAgile при разработке баз данных
Как только ваша организация убедится в преимуществах гибкой разработки, пути назад уже не будет.
Более короткое время окупаемости, меньший риск и большая гибкость являются одними из наиболее часто упоминаемых преимуществ гибкого менталитета. Читать электронную книгуПять главных причин выбрать Toad вместо SQL Developer
В этом техническом обзоре эксперт Toad® Джон Покнелл рассказывает, что не только возможно, но и весьма вероятно, что с помощью Toad вы сэкономите больше денег, чем с помощью SQL Developer, несмотря на то, что последний является бесплатным.
Читать техническое описаниеПомогите защитить данные вашей компании с помощью Toad для Oracle — защита конфиденциальных данных
Вы знаете, что вам необходимо защищать личные и конфиденциальные данные, чтобы соблюдать правила конфиденциальности.
Но уверены ли вы, что знаете все места, где ваша организация хранит эти данные? В этом техническом обзоре рассматриваются проблемы, с которыми сталкиваются администраторы баз данных, пытаясь защитить данные своей компании и смягчить последствия.
Читать техническое описаниеГотовность ваших баз данных к будущему
В этом техническом документе вы узнаете, как улучшить совместную работу, оптимизировать рабочие процессы и использовать автоматизацию для интеграции управления изменениями базы данных в конвейер DevOps. Под руководством ведущего эксперта по базам данных вы сможете достичь своих целей Agile DevOps.
Читать технический документToad® для IBM Советы и рекомендации по DB2
Узнайте, как Toad для DB2 может упростить разработку SQL.
Узнайте, как создавать и оптимизировать операторы SQL, просматривать и анализировать наборы результатов, создавать профессиональные отчеты и многое другое. Читать электронную книгуРешение проблемы настройки SQL: секреты Quest SQL Optimizer
В этом техническом обзоре представлен подробный технический взгляд на оптимизатор SQL и на то, как он обеспечивает решение для повышения производительности операторов SQL, которое не может обеспечить оптимизатор SQL внутренней системы управления базами данных. Мы также видим, как SQL Optim
Читать техническое описаниеУскорьте и защитите конвейеры SQL Server DevOps CI/CD
Если вы хотите, чтобы разработка вашей базы данных стала гибкой, вам придется автоматизировать управление изменениями без ущерба для конфиденциальности данных.
Прочтите этот технический обзор и узнайте, как организовывать и защищать конвейеры CI/CD с помощью набора инструментов ApexSQL DevOps Plus Toolkit. Читать техническое описаниеПросмотреть все ресурсы
Блоги
Quest Software получает награду «Выбор читателей» DBTA
Quest Software занимает первые места в каждой отдельной категории на конкурсе DBTA Readers’ Choice Awards 2019, заняв первое место в четырех категориях. Тенденции и приложения баз данных (DBTA) предоставляют информацию о данных, управлении информацией, больших данных и науке о данных в печатном и цифровом виде для ИТ-специалистов и заинтересованных сторон бизнеса.
Квест Программное обеспечение
15 августа 2019 г.
Модернизация вашей инфраструктуры базы данных
Если Agile существует с 1990-х годов, а инструменты DevOps — с конца 2000-х, то почему наша разработка баз данных не может догнать разработку наших приложений?
Джон Покнелл 15 июля 2019 г.
Как интегрировать систему контроля версий в Toad для Oracle
Посмотрите это краткое видео о том, как интегрировать систему управления версиями в Toad для Oracle.
Роберт Паунд 16 мая 2019 г.
Как лицензировать продукты Toad
Посмотрите краткое видеоруководство о том, как добавлять лицензии Toad, управлять рабочими местами и т. д.
Роберт Паунд 03 мая 2019 г.
Перенос существующих настроек Toad for Oracle на новый компьютер
Одной из программ является Toad for Oracle. Вы использовали его некоторое время и настроили внешний вид, и вся информация о вашем подключении доступна в диалоговом окне «Сеансы».
Марк Курц 02 мая 2019 г.
Часто задаваемые вопросы о модуле защиты конфиденциальных данных Toad for Oracle
Модуль защиты конфиденциальных данных Toad для Oracle — это новый модуль, доступный для пользователей Toad для Oracle. Этот новый модуль содержит две функциональные области — Осведомленность о защите конфиденциальных данных и Поиск защиты конфиденциальных данных, которые позволяют разработчикам и администраторам баз данных эффективно работать с конфиденциальными данными в своей среде.
Джули Хайман 13 мая 2019 г.
Посмотреть все блоги
Процессы разработки баз данных
Хорошо спланированные процессы разработки баз данных могут значительно повысить эффективность организации. Приложениям обычно требуется база данных, которая, как следует из названия, представляет собой централизованную базу, в которой хранятся все данные, необходимые приложению. Приложение и другие связанные системы могут получать доступ к этим данным различными способами. Система управления базой данных обычно управляет базой данных.
Для повышения эффективности обработки и запроса данных данные в большинстве распространенных типов баз данных обычно моделируются в виде строк и столбцов. Язык структурированных запросов или SQL обычно используется большинством баз данных для записи и запроса данных. Это обеспечивает легкий доступ, модификацию и организацию данных.
Приложение без стабильной и оптимизированной базы данных не сможет работать в полную силу. Таким образом, это важная часть процесса разработки приложения, требующая не меньше внимания, чем дизайн и функциональность.
Что такое процессы разработки базы данных?
Как вы теперь знаете, сбор данных организации составляет базу данных. Однако она не материализуется из воздуха. На самом деле процесс начинается с проектирования базы данных, что требует создания подробной модели данных создаваемой базы данных.
Эта модель включает все логические и физические шаблоны проектирования, которые будут использоваться для создания базы данных. Модель данных должна быть очень подробной, особенно с учетом требований к приложению и будущей масштабируемости.
После этого процесс переходит к фактической разработке базы данных. К тому времени остается только воплотить в жизнь дизайн базы данных и разработать ее в соответствии со спецификациями схемы. Необходимо точно соблюдать стандарты проектирования, чтобы ограничить вероятность аномалий данных.
Другим важным фактором при проектировании базы данных является время доступа. Например, если требуется частый доступ к сложному запросу, база данных должна быть спроектирована определенным образом, чтобы это могло происходить, чтобы оптимизировать общую производительность.
Какое место занимает разработка базы данных в жизненном цикле разработки программного обеспечения?
По своей сути программная инженерия делит процессы разработки баз данных на ряд этапов. Каждый этап фокусируется на одном конкретном аспекте разработки, вся эта серия называется жизненным циклом разработки программного обеспечения.
Приложение проходит весь жизненный цикл, когда оно воплощается в жизнь из простой концепции, и может проходить жизненный цикл несколько раз, в зависимости от того, как часто оно перерабатывается и дорабатывается с добавлением дополнительных функций.
Разработка базы данных является неотъемлемой частью этапа разработки жизненного цикла. Как правило, модель жизненного цикла включает планирование, требования, проектирование, разработку, тестирование, развертывание и обслуживание. Эти этапы определяются очень широко и могут различаться для определенных видов приложений, но в целом работа протекает таким образом.
Процессы разработки базы данных должны выполняться поэтапно.
Подобно жизненному циклу разработки программного обеспечения, разработка базы данных во многом является системой, основанной на процессах. Этот «водопадный» процесс состоит из пяти основных шагов, которым следуют разработчики при выполнении проекта.
Первое, что они делают, — это садятся с клиентом, чтобы понять, каковы его требования и какую функциональность они хотят получить от своего приложения. Это помогает им составить более четкое представление о том, что от них требуется, сколько времени потребуется для завершения проекта и во что это может в конечном итоге стоить клиенту.
После достижения взаимопонимания между клиентом и разработчиком, расставления точек над «И» и пересечения «Т» начинается работа, которая следует описанному ниже процессу. В основном он остается неизменным независимо от типа разрабатываемого приложения, поскольку разработка баз данных лежит в основе всего этого.
Что необходимо на всех этапах процесса разработки системы баз данных?
- Тщательное планирование
Одним из первых этапов разработки базы данных является планирование. Без надлежащего планирования нельзя гарантировать, что работа принесет оптимальные результаты. Поэтому крайне важно, чтобы в первую очередь были определены структура и требования к разрабатываемой базе данных.
Это также важно, поскольку только на этапе планирования вы узнаете, позволит ли объем этого проекта базы данных завершить его в установленные сроки без превышения бюджета.
Какие ресурсы потребуются для работы, а также распределение людей и бюджетов осуществляется на этом этапе. Все люди, которые должны работать над проектом, уведомляются об их обязанностях и целях.
- Анализ требований
Это можно рассматривать как продолжение этапа планирования, поскольку оно влечет за собой более подробное изучение того, как должна выполняться разработка базы данных.
Идея здесь состоит в том, чтобы посмотреть на требования и ожидания клиента и выяснить, насколько это может быть достигнуто.На этом шаге проектировщики баз данных опросят клиентов и получат от них функциональные требования. Чтобы процесс разработки базы данных был успешным, необходимо согласие между всеми вовлеченными сторонами, потому что было бы слишком много ненужного туда и обратно, если бы они не были на одной странице.
Функциональные требования на самом деле не предназначены для объяснения того, как будут обрабатываться данные. По сути, это руководство для разработчиков, чтобы они знали, что представляют собой элементы данных и какими атрибутами они обладают. Это также помогает им понять отношения между различными элементами данных.
- Дизайн
Это один из наиболее важных этапов в жизненном цикле разработки базы данных. Здесь на первый план выходит вся работа, проделанная на предыдущих этапах. Все, что делается на этапе планирования и анализа, реализуется на этапе проектирования.
Это та часть, где разработчики фактически проектируют базу данных. На этом этапе обычно проходит этап проб и ошибок, поэтому разработчики нередко предоставляют клиентам доступ к новой базе данных на ограниченной основе. Это делается для формирования оценки функции и выяснения необходимости внесения каких-либо изменений в план для достижения поставленных целей.
Результатом этапа проектирования является логическая схема всех таблиц данных и ограничений, основанная на концептуальной модели данных. На этом этапе также решается, какие таблицы будут использоваться для представления данных в базе данных.
- Внедрение и развертывание
После того, как на предыдущем этапе была определена спецификация логической схемы, следует реализация, которая включает в себя создание фактической базы данных. Реализация в значительной степени зависит от выбора доступных инструментов базы данных, операционной среды и систем, управляемых базой данных.
При необходимости систему управления базами данных можно установить на новый сервер или на существующие серверы.
Виртуализация — это новая тенденция, которая все чаще используется для систем управления. Он включает в себя создание логических представлений вычислительных ресурсов, которые могут быть развернуты независимо от базовых физических вычислительных ресурсов.После внедрения база данных проходит серию тестов для оценки ее производительности, безопасности и целостности. Затем выполняется любая дальнейшая тонкая настройка, которая может потребоваться. Наконец, база данных развернута.
- Обслуживание
Процесс не заканчивается после развертывания базы данных. Чтобы убедиться, что она продолжает функционировать в соответствии с потребностями, необходимо проводить регулярное обслуживание базы данных, особенно если возникают проблемы с масштабируемостью.
Администратору базы данных поручено выполнение регламентных работ по обслуживанию. Они могут включать профилактическое обслуживание, требующее резервного копирования данных, или корректирующее обслуживание, связанное с восстановлением данных.
Также может быть выполнена дополнительная работа по улучшению производительности базы данных, а также по управлению правами доступа для пользователей. Если где-то в будущем возникнет серьезная проблема с платформой базы данных, администратору также потребуется перестроить базу данных и еще раз провести ее через этапы реализации и тестирования.
Получите разработчиков приложений, которые понимают процесс разработки базы данных.
Само собой разумеется, что ваш проект приложения не может быть успешным, пока у вас нет разработчиков, которые разбираются в разработке баз данных и знают, насколько это важно для обеспечения оптимальной функциональности вашего приложения.
Вот почему так важно работать с разработчиками, которые не только хорошо разбираются в концептуализации, дизайне и разработке приложений, но и могут выполнять эту важную задачу. Ваш разработчик должен быть в состоянии предоставить универсальное решение вместо того, чтобы искать отдельный ресурс для разработки базы данных.
Неудивительно, что Zibtek предпочитают компании, входящие в список Fortune 500, и стартапы для разработки приложений. Компания имеет более чем десятилетний опыт разработки приложений, начиная от пользовательских мобильных приложений, интегрированных с ERM, и заканчивая образовательными приложениями.
Компания Zibtek базируется в США и имеет офисы в Солт-Лейк-Сити, штат Юта. Он также имеет глобальный кадровый резерв разработчиков, все из которых управляются из Соединенных Штатов, которые являются экспертами в области разработки для iOS и Android со знанием нативной разработки React, Phonegap и гибридной разработки. Их команда понимает важность разработки баз данных и обладает необходимыми навыками для воплощения в жизнь приложений любой сложности. Свяжитесь с командой Zibtek сегодня, чтобы узнать, как они могут позаботиться о разработке базы данных для вас.
Какие существуют распространенные средства разработки баз данных?
Некоторые общие инструменты, используемые при разработке баз данных, включают системы управления базами данных (СУБД), такие как MySQL, Oracle RDBMS, PostgreSQL и Microsoft SQL Server.
Хорошо спроектированная база данных может принести пользу организации, предоставляя структурированный и эффективный способ хранения и извлечения данных. Это может привести к повышению производительности, поскольку сотрудникам больше не нужно тратить время на ручное отслеживание и организацию данных. Хорошо спроектированная база данных также может повысить точность данных, поскольку она может быть разработана для обеспечения соблюдения правил и ограничений, чтобы гарантировать, что в систему вводятся только достоверные данные.
Как индексирование базы данных может улучшить производительность базы данных?
Индексирование базы данных может повысить производительность базы данных, позволяя ускорить поиск и извлечение данных. Это связано с тем, что индекс создает отдельную структуру данных, в которой хранятся значения для определенного столбца или набора столбцов, и программное обеспечение базы данных может использовать эту структуру данных для быстрого поиска нужных данных.
9 лучших программ для проектирования баз данных на 2023 год (платные и бесплатные)
Мы финансируемся нашими читателями и можем получать комиссию, когда вы покупаете по ссылкам на нашем сайте.
Несмотря на то, что существует множество поставщиков программного обеспечения для проектирования баз данных, бывает трудно провести различие между ними. Мы рассмотрим девять лучших программ для проектирования баз данных на рынке.
Тим Кири Эксперт по сетевому администрированию
ОБНОВЛЕНО: 25 февраля 2023 г.
Если вам нужна высокопроизводительная база данных с быстрым поиском, проектирование базы данных необходимо. Потратив время на разработку базы данных, вы сможете избежать таких проблем, как неэффективность и высокая избыточность.
Использование программного обеспечения для проектирования баз данных делает ваши данные доступными для ваших пользователей, упрощая создание и оптимизацию проектов баз данных.
- Lucidchart — наш лучший выбор среди программ для проектирования баз данных. Инструмент для создания баз данных с более чем 500 шаблонами изображений, импортом и экспортом базы данных, интеграцией, совместным использованием и многим другим.
- DeZign для баз данных — инструмент моделирования баз данных с редактором перетаскивания, прямым и обратным проектированием, синхронизацией, настраиваемыми отчетами и т. д.
- SqlDBM — бесплатный инструмент для проектирования баз данных с прямым и обратным проектированием, управлением командой, экспортом документации и многим другим.
- dbForge Studio для SQL Server — интегрированная среда разработки для проектирования баз данных с визуальным конструктором запросов, сравнением схем, синхронизацией и т. д.
- DbDesigner — Бесплатный веб-инструмент для моделирования баз данных с поддержкой MySQL, MS SQL, PostgreSQL, Oracle, SQLite, с прямым и обратным проектированием.
- DbSchema — инструмент проектирования схем баз данных с обратным проектированием, синхронизацией схем, редактором SQL, экспертами по проектированию, формами базы данных/построителем отчетов и т. д.
- Navicat Data Modeler — программное обеспечение для проектирования баз данных с функциями прямого проектирования, обратного проектирования, преобразования моделей, сравнения и синхронизации баз данных и т. д.
- SmartDraw — веб-инструмент создания диаграмм баз данных с автоматизированными диаграммами отношений между объектами, более 34 000 символов, совместное использование и многое другое.
- Vertabelo — средство моделирования базы данных на основе браузера с реверс-инжинирингом, совместным использованием, созданием сценариев ASQL, динамической проверкой и т. д.
Список включает ряд инструментов проектирования баз данных для Windows, macOS и Linux, которые можно использовать для создания, импорта и оптимизации баз данных. Мы включили набор инструментов прямого и обратного проектирования с такими функциями, как редакторы перетаскивания, сравнение и синхронизация схем и многое другое.
Мы изучили рынок программного обеспечения для проектирования баз данных и проанализировали инструменты на основе следующих критериев:
- Режим редактора, специфичный для проектирования баз данных
- Форматирование отображения отношений
- Идентификаторы потенциальных ключей и первичных ключей
- Поля дескриптора атрибута
- Генератор объектов
- Бесплатная пробная версия или демонстрационная система, позволяющая изучить инструмент перед покупкой
- Соотношение цены и качества благодаря надежному инструменту, включающему проверку и автоматизацию, который продается по справедливой цене
Помня об этих критериях выбора, мы искали системы проектирования баз данных, которые имеют высокие рейтинги одобрения пользователей и имеют солидную и стабильную историю.
Lucidchart — это инструмент визуального проектирования, который можно использовать для создания проектов баз данных. Инструмент поставляется с более чем 500 шаблонами , которые вы можете перетаскивать из библиотеки для создания пользовательских диаграмм. Вы также можете импортировать структуры базы данных из MySQL, Oracle, PostgreSQL, и SQL Server .
Основные характеристики:
- Более 500 шаблонов
- Импорт структуры базы данных
- Экспорт дизайнов баз данных
- Общий доступ к проектам с помощью Confluence, Jira, G Suite и Microsoft Office
- Единый вход
- Автоматическая подготовка лицензии
Lucidchart позволяет создавать структуру базы данных с нуля или импортировать структуру из существующего экземпляра и отображать ее. Инструмент может подключаться к стандартным инструментам управления проектами и системам совместной работы, чтобы сообщать о проектах или сохранять их как часть библиотеки проектов.
Общий доступ к базе данных позволяет вам делиться своими проектами с другими и собирать отзывы. Вы можете обмениваться живыми версиями проектов через такие среды, как Confluence, Jira, G Suite, и Microsoft Office . Lucidchart также можно интегрировать с рядом платформ, включая G Suite, Atlassian, Slack, Salesforce и Microsoft Office.
Чтобы обеспечить безопасность ваших проектов, Lucidchart выполняет единый вход с SAML 2.0 , где графики хранятся в вашей учетной записи. У вас также есть возможность автоматически предоставлять членам команды одобрение запросов на получение лицензии.
Для кого рекомендуется? Это облачный пакет, который полезен не только для создания проектной документации базы данных. Его также можно использовать для создания диаграмм бизнес-процессов, таких как блок-схемы, или системных планов, таких как карты топологии сети. Это гибкий инструмент с масштабируемой ценой, что делает его подходящим для предприятий любого размера.
Плюсы:
- Поддерживает множество типов баз данных
- Хорошо визуализируется и хорошо масштабируется даже в корпоративных средах
- Упрощает совместную работу благодаря интеграции с такими инструментами, как Google Диск, Dropbox и Jira
- Предлагает четыре плана, что делает Lucidchart доступным для команды любого размера
Минусы:
- Имеет множество различных опций, для полного изучения которых может потребоваться время
Lucidchart идеально подходит для предприятий, которым требуется простой и недорогой инструмент для проектирования баз данных. Существует бесплатный план, который позволяет редактировать три документа и выбирать из 100 шаблонов. Платные версии начинаются с $7,9.5 (£8,00) для индивидуального плана. Lucidchart — это облачная система. Вы можете зарегистрироваться бесплатно.
DeZign для баз данных — это инструмент моделирования баз данных, который можно использовать для создания баз данных. DeZign для баз данных предоставляет диаграммы отношений объектов , которые можно использовать для проектирования баз данных. Вы можете перетаскивать объекты на холст для создания пользовательских дизайнов.
Основные характеристики:
- Редактор перетаскивания
- Форвард инжиниринг
- Реверс-инжиниринг
- Автоматически создавать проекты баз данных Oracle, MySQL, MS SQL и PostgreSQL
- Синхронизация базы данных и модели
- Отчеты
DeZign для баз данных — это специальный инструмент для проектирования баз данных, поэтому, если вас не интересует система рисования диаграмм общего назначения, такая как Lucidchart, вам следует рассмотреть этот вариант. Вы создаете ERD в редакторе, а затем он генерирует сценарии создания для SQL Server, MySQL, Oracle или Postgres.
Платформа предоставляет пользователям сочетание прямого и обратного проектирования. Это означает, что он может создавать базы данных из предоставленных вами моделей данных или разрабатывать графическую модель данных из существующей базы данных. Существует поддержка более 15 баз данных, включая Oracle, MySQL, MS SQL, и PostgreSQL .
База данных и Синхронизация моделей позволяет конкурировать и синхронизировать изменения, внесенные в модель или базу данных, что позволяет более эффективно обновлять изменения. Настраиваемые отчеты HTML, Word, и в формате PDF позволяют создавать документацию по всем вашим базам данных. У вас также есть возможность экспортировать диаграммы базы данных в виде изображения через png, jpeg, gif, растровое изображение, или метафайл Windows .
Эта система полезна для разработчиков баз данных и руководителей проектов. Инструмент также может импортировать дизайн из существующего экземпляра, поэтому его может использовать администратор баз данных, начиная с компании с недокументированными базами данных. Другой вариант использования — извлечь дизайн, изменить его, а затем сгенерировать измененные сценарии создания.
Плюсы:
- Автоматически создает диаграммы на основе базы данных, на которую указывает
- Поддерживает моделирование отношений
- Упрощает настройку благодаря простым функциям перетаскивания
Минусы:
- Визуализация лучше подходит для небольших сред
- Хотелось бы более продолжительный пробный период
DeZign for Databases — это надежный выбор для предприятий, которым нужен экономичный инструмент для создания баз данных. Цены начинаются от 19 долларов. (14,21 фунта стерлингов) в месяц за DeZign для баз данных Standard. Он доступен для Windows. Вы можете начать 14-дневную бесплатную пробную версию.
SqlDBM — это бесплатный инструмент проектирования баз данных, который можно использовать для создания моделей баз данных. Платформа позволяет использовать обратный инжиниринг для импорта сценария SQL для автоматического создания модели базы данных или использовать прямой инжиниринг для создания модели с нуля.
Основные характеристики:
- Форвард инжиниринг
- Реверс-инжиниринг
- Управление командой
- Создать документацию
- Сравнить ревизии
SqlDBM — это высокоавтоматизированная онлайн-система, совместимая с большим списком СУБД, включая SQL Server, MySQL и Oracle. Система может извлекать словарь данных из существующей базы данных и генерировать ERD. вы можете адаптировать импортированный дизайн или создать новый.
Чтобы помочь вам редактировать базы данных, SqlDBM поддерживает Alter скрипты . Любые изменения, которые вы вносите в модель базы данных, можно отслеживать путем сравнения версий. Вы можете сотрудничать с другими членами команды, выбрав Project Collaborators . Выбор параметра Разрешить редактирование предоставляет пользователям разрешения уровня доступа.
Программное обеспечение также предоставляет ряд функций, позволяющих создавать документацию по базе данных. Например, вы можете создавать спецификации с изображениями и экспортировать их в PNG .
Для кого рекомендуется? Простота использования этого инструмента означает, что можно создать структуру базы данных, не зная, как писать SQL. Однако вам нужно знать правила нормализации, так что это не инструмент для полных новичков. Администраторы баз данных и системные аналитики выиграют от этой системы.
Плюсы:
- Предназначен для предприятий и больших баз данных
- Поддерживает несколько типов баз данных, включая PostgreSQL, Redshift и MySQL
- Обладает элегантным интерфейсом, который использует цвет, чтобы все было организовано
Минусы:
- Лучше подходит для развертывания больших баз данных
SqlDBM — отличный выбор для предприятий, стремящихся разрабатывать и поддерживать базы данных SQL по низкой цене. Бесплатная версия поддерживает одновременно один проект и одну таблицу прямого проектирования. Платные версии начинаются с 240 долларов США (179,47 фунтов стерлингов) в год с неограниченным количеством проектов, таблиц и редакций. Вы можете подписаться на программное обеспечение здесь.
4. dBForge Studio для SQL Server dbForge Studio для SQL Server — это интегрированная среда разработки, которую можно использовать для проектирования баз данных. dbForge Studio для SQL Server позволяет создавать объекты базы данных с помощью визуального редактора. Точно так же построитель запросов позволяет вам создавать и визуализировать запросы дизайна.
Основные характеристики:
- Визуальный редактор
- Отслеживание изменений в базе данных
- Форвард инжиниринг
- Реверс-инжиниринг
- Сравнение и синхронизация баз данных
dbForge Studio для SQL Server — первая локальная система в этом списке. Это система управления базами данных, а также конструктор баз данных. Система может импортировать дизайн, просматривать базу данных в реальном времени и генерировать сценарии создания. Вы также можете проанализировать существующие базы данных на наличие медленных запросов и неэффективного индексирования.
У вас также есть возможность реконструировать базы данных путем перетаскивания. Например, вы можете перетащить базу данных на холст и просматривать объекты базы данных на экране.
Сравнение схемы базы данных и синхронизация позволяют более эффективно управлять проектами. Например, вы можете создать сценарий синхронизации схемы для выполнения обновлений и автоматически синхронизировать базы данных через командную строку.
Для кого рекомендуется?Это программное обеспечение работает в Windows. Он подходит для использования администраторами баз данных и разработчиками существующих баз данных. Хотя инструменты проектирования можно использовать для создания новых баз данных, функции администрирования баз данных будут ненужными для чисто проектных групп, которым будет лучше использовать один из других инструментов в этом списке.
Плюсы:
- Пользователи могут создавать диаграммы с помощью простого рабочего процесса перетаскивания
- Автоматически извлекает свойства базы данных и зависимости
- Панель предварительного просмотра упрощает поиск по различным столбцам и индексам
Минусы:
- Разработан специально для SQL Server
dbForge Studio для SQL Server — это решение, разработанное для предприятий, которым требуется инструмент для создания проектов баз данных для SQL Server. Цены начинаются с 249,95 долларов США (186,88 фунтов стерлингов) за версию с основными функциями. Он доступен для Windows. Вы можете скачать бесплатную пробную версию.
DbDesigner — это бесплатный веб-инструмент для моделирования баз данных, который можно использовать для проектирования баз данных и схем. Для разработки диаграммы вы можете создать UML-диаграмму или импортировать данные из внешней базы данных . Платформа совместима с рядом поставщиков баз данных, включая MySQL, MS SQL, PostgreSQL, Oracle, и SQLite, , хотя обратное проектирование поддерживается только для MySQL, PostgreSQL и Oracle.
Основные характеристики:
- Передовой инжиниринг
- Реверс-инжиниринг
- Совместимость с MySQL, MS SQL, PostgreSQL, Oracle, SQLite
- Управление командой
- Общий доступ к базам данных с живыми комментариями
- Экспорт проекта базы данных
- Полная история версий
DbDesigner — это сложный онлайн-инструмент для проектирования баз данных, который предлагает бесплатную версию. Он может взаимодействовать с SQL Server, SQLite, MySQL, PostgreSQL и Oracle для извлечения определений базы данных, а также для создания сценариев создания. Хранящиеся в облаке проекты могут быть переданы другим пользователям для редактирования или просто для просмотра.
Вы можете поделиться доступом с другими пользователями, введя их адреса электронной почты. Добавление адресов электронной почты других членов команды позволит им оставлять живые комментарии, что упростит совместную работу и внесение изменений в проекты. После того, как вы закончите редактирование, вы можете экспортировать дизайн вашей базы данных в PNG или PDF и создать ссылку для публичного просмотра.
Вы можете управлять всеми проектами через панель инструментов, где вы можете открывать, удалять, архивировать или копировать существующие проекты и просматривать полную историю версий проектов. Вы также можете добавлять или удалять членов команды в проекты.
Бесплатная версия этого инструмента должна заинтересовать малый бизнес. Однако ограничение в 10 таблиц на проект распространяется на очень маленькие базы данных, которые превышают большинство проектов. Ограничение в 25 столов на нижнем из платных планов также очень ограничивает. Таким образом, безлимитный план будет иметь наибольшую привлекательность.
Плюсы:
- Поддерживает различные типы баз данных SQL
- Можно экспортировать в формат изображения или документа
- Поддерживает внутренний контроль доступа и аудит
Минусы:
- Визуализация проста и лучше подходит для небольших проектов
DbDesigner отлично подходит для групп, которым нужен инструмент для проектирования баз данных на основе браузера. Бесплатный план поддерживает до двух моделей баз данных и до 10 таблиц на модель. Платные версии начинаются с 7 долларов (5,82 доллара) в месяц с поддержкой пяти моделей баз данных и 25 таблиц на модель. Вы можете начать бесплатную пробную версию.
DbSchema — это инструмент проектирования диаграмм баз данных, который можно использовать для проектирования баз данных и управления ими. С помощью DbSchema вы можете реконструировать схемы из существующих баз данных. Поддерживается ряд СУБД, включая SQL Server, MySQL, PostgreSQL, Oracle, Redshift, Cassandra и MongoDB.
Основные характеристики:
- Обратный инжиниринг
- Синхронизация схемы
- Редактор SQL
- Импортер данных
- Конструктор форм баз данных и отчетов
DbSchema — это локальная система, такая как dbForge Studio для SQL Server. Однако между этими двумя системами есть много различий. DbSchema предлагается по бессрочной лицензии вместо подписки и доступна для macOS и Linux, а также для Windows. Этот пакет может считывать структуры данных из всех основных СУБД и записывать сценарии создания.
Синхронизация схемы позволяет изменять схемы баз данных и автоматически синхронизировать их при подключении к базе данных. Редактор SQL обеспечивает подсветку синтаксиса, чтобы упростить редактирование баз данных.
Вы также можете выполнять SQL-запросы и сценарии для просмотра результатов в виде таблиц и текстовых файлов. Выполнив запрос, вы можете экспортировать результат в виде файла CSV или XLSX. Существует также графический план, который можно использовать для просмотра планов выполнения запросов.
Вы можете импортировать данные в базу данных из нескольких типов файлов, включая g CSV, XML, XLS, и XLSX . Для дополнительных вариантов дизайна вы можете использовать движок Forms & Reports для разработки форм и отчетов базы данных. Формы запускаются как веб-приложения с помощью Bootstrap.
Бесплатная версия DbSchema не имеет ограничений по емкости и может импортировать структуры баз данных, а также создавать сценарии создания. Это делает инструмент очень удобным для любого малого бизнеса. Платная версия подходит для проектных групп, которым не нужны функции администрирования баз данных dbForge.
Плюсы:
- Работает как с локальными, так и с облачными базами данных
- Предлагает встроенные функции совместной работы для команд
- Поддерживает схемы обратного проектирования
Минусы:
- Можно использовать более длительное пробное время
DbSchema стоит изучить предприятиям, которые ищут многофункциональный инструмент для проектирования баз данных. Персональная лицензия стоит 127 долларов США (94,99 фунтов стерлингов) и поддерживает одного пользователя. Он доступен для Windows, macOS и Linux. Вы можете начать 15-дневную бесплатную пробную версию.
Navicat Data Modeler — это инструмент проектирования баз данных, который позволяет создавать модели баз данных с объектами базы данных, включая таблицы, заметки, изображения, фигуры, слои, внешние ключи и многое другое. Платформа поддерживает прямой и обратный инжиниринг и совместима с MySQL, SQL Server, Oracle, PostgreSQL, SQLite, и Maria DB .
Основные характеристики:
- Передовой инжиниринг
- Реверс-инжиниринг
- Преобразование модели
- Сравнение баз данных и синхронизация
- Доступ к проектам через Navicat Cloud
Navicat Data Modeler — еще одна локальная система, работающая в Windows, macOS и Linux. Эта система может подключаться к облачным базам данных, а также к локальным системам. Маркетинговое преимущество этой системы заключается в том, что за нее можно платить ежемесячно или за годовую подписку, или вы можете купить бессрочную лицензию.
При разработке моделей можно использовать Преобразование модели для изменения типов моделей с Концептуальная (Бизнес-модель) на Логическую (Техническая модель) или Физическая (Техническая модель). Переключение типов моделей позволяет вам более внимательно изучить отношения связанных объектов, чтобы вы могли вносить более обоснованные изменения в проект.
Сравнение баз данных и Синхронизация позволяют отслеживать различия между базами данных и создавать скрипт синхронизации для их обновления. Вы также можете использовать генерацию кода SQL для создания кода SQL для вашей базы данных. Доступ ко всем проектам возможен в любом месте в режиме реального времени через Navicat Cloud.
Для кого рекомендуется? Бесплатная версия этого инструмента под названием Essentials будет конкурировать с бесплатной версией DbSchema. Однако этот вариант не обеспечивает возможности импорта базы данных или создания сценариев. Эта система предназначена для разработки баз данных и не имеет функций администрирования. Командное сотрудничество возможно с помощью Navicat Data Modeler.
Плюсы:
- Элегантный и простой в использовании интерфейс
- Включает визуальный конструктор SQL
- Поддерживает Linux, Windows и macOS
Минусы:
- Хотелось бы более продолжительный пробный период
Navicat Data Modeler стоит изучить, если вам нужен инструмент, обеспечивающий доступ к проектам баз данных в облаке. Цены начинаются с 229,99 долларов США (172,07 фунтов стерлингов) в год. Он доступен для Windows, macOS и Linux. Вы можете скачать 14-дневную бесплатную пробную версию.
8. SmartDraw SmartDraw — онлайн-инструмент для создания диаграмм базы данных. С SmartDraw, вы можете автоматически генерировать диаграммы путем экспорта данных из существующей базы данных с помощью Automatic ERD Extension . После создания диаграммы вы можете редактировать диаграмму отношений сущностей, перетаскивая объекты туда, куда вы хотите.
Основные характеристики:
- Более 34 000 символов
- Форвард инжиниринг
- Реверс-инжиниринг
- Поделитесь своими дизайнами
- Совместимость с Confluence, Jira и Trello
SmartDraw похожа на Lucidchart, потому что это онлайн-система для создания корзин, которая может генерировать широкий список типов диаграмм, а не только ERD. Система предоставляет расширение для импорта словаря данных из существующих баз данных. Инструмент может хранить ERD как изображение для создания отчетов.
Что касается вариантов дизайна, SmartDraw имеет обширную библиотеку из более чем 34 000 символов , с 70 типами диаграмм и более 4500 шаблонов . Хотя не все эти параметры предназначены для проектирования базы данных, их более чем достаточно для сопоставления отношений сущностей.
Когда вы закончите работу над дизайном, вы можете поделиться им с такими приложениями, как Dropbox , Google Drive, Box, и OneDrive . Диаграммы также можно экспортировать в формате PDF или как часть приложения Microsoft Office или G Suite . SmartDraw также совместим с такими инструментами, как Confluence, Jira и Trello, поэтому он интегрируется с более широкими операциями.
Для кого рекомендуется? SmartDraw — хороший инструмент для создания диаграмм, и он не ограничивается ERD, поэтому его могут использовать многие бизнес-подразделения. Процесс импорта структуры базы данных немного сложен, поскольку он включает в себя просмотр файла CSV. Инструмент не создает сценарии, поэтому он подходит для использования дизайнером высокого уровня, а не администратором баз данных.
Плюсы:
- Простой инструмент для работы с диаграммами, который работает с базами данных и другими проектами
- Доступен из любого браузера
- Позволяет легко создавать элегантные диаграммы
Минусы:
- Не предлагает никаких функций, специфичных для базы данных
SmartDraw подходит для предприятий, которым нужен простой онлайн-инструмент для создания баз данных. Инструмент стоит 9,95 долларов США (7,44 фунтов стерлингов) для одного пользователя или 5,95 долларов США (4,45 фунтов стерлингов) для пяти с лишним пользователей. Вы можете подписаться на программное обеспечение.
9. Vertabelo Vertabelo — это инструмент моделирования базы данных на основе браузера, который позволяет автоматически реконструировать диаграммы базы данных с помощью инструмента командной строки. Платформа совместима с широко используемыми базами данных, включая Oracle , MySQL, SQLite, IBM DB2, SQL Server, Amazon Redshift и PostgreSQL .
Основные характеристики:
- Форвард инжиниринг
- Реверс-инжиниринг
- Совместное использование моделей базы данных
- Создать скрипт SQL
- Текущая проверка
Vertabelo — это облачная система проектирования баз данных, которая конкурирует с другими онлайн-системами в этом списке. Эта система включает в себя функции совместной работы, позволяющие вам обмениваться ERD для редактирования или просмотра. Vertabelo может моделировать как облачные базы данных, так и локальные экземпляры. Он может импортировать структуру базы данных и создавать скрипты.
Вы можете поделиться моделями баз данных, добавив адрес электронной почты других членов команды, чтобы пригласить их для работы над документом. Назначьте членов команды владельцем, редактором, или наблюдателем , чтобы определить, могут ли они редактировать или просматривать. Вы также можете поделиться моделями по общедоступной ссылке, которую вы можете отправить другим по электронной почте.
Генерация сценариев SQL позволяет создавать сценарии SQL для создания и удаления элементов из базы данных. При проектировании базы данных проверка в реальном времени проверяет модель и дает советы по ее улучшению. Проверка в реальном времени полезна для оптимизации структуры базы данных.
Для кого рекомендуется?Эта система является хорошим инструментом для использования разработчиками новых баз данных, а также может быть полезна администраторам баз данных, которым необходимо документировать существующие экземпляры. Система обеспечивает хорошую помощь в проектной документации и может использоваться разработчиками и администраторами баз данных для корректировки существующих баз данных.
Плюсы:
- Гибкий инструмент на основе браузера – доступный практически из любого места
- Поддерживает групповой доступ
- Поддерживает проверку в реальном времени — отлично подходит для мониторинга
Минусы:
- Подходит больше для технических пользователей
- Хотелось бы более продолжительный пробный период
Vertabelo — хороший выбор для предприятий, которые ищут инструмент моделирования баз данных на основе браузера по конкурентоспособной цене. Цены начинаются с 7 долларов США (5,24 фунта стерлингов) в месяц для пяти моделей баз данных и 25 таблиц на модель. Вы можете начать 7-дневную бесплатную пробную версию.
Средства проектирования баз данных — это полезные инструменты для быстрого и безболезненного создания баз данных. Из инструментов, которые мы рассмотрели в этом списке, Lucidchart , DeZign for Databases и SqlDBM выделяются как инструменты, которые предоставляют вам все функции, необходимые для эффективного создания диаграмм, сохраняя при этом конкурентоспособную цену.
Однако, чтобы найти наиболее подходящий для вашего предприятия, мы рекомендуем попробовать хотя бы одну бесплатную пробную версию, прежде чем совершать покупку, чтобы вы могли выбрать, какой инструмент лучше всего соответствует вашим потребностям.
Часто задаваемые вопросы о программном обеспечении для проектирования баз данных
Какое программное обеспечение для проектирования баз данных является лучшим?
Пять лучших программ для проектирования баз данных, доступных сегодня на рынке:
- Lucidchart
- DeZign для баз данных
- SqlDBM
- Студия dbForge для SQL Server
- Дбдизайнер
Что такое программное обеспечение для проектирования баз данных?
Проектирование базы данных проходит через ряд этапов, начиная с идентификации атрибутов, нормализации и, наконец, создания диаграммы отношений сущностей (ERD). Программное обеспечение для проектирования баз данных может поддерживать все эти задачи. Однако прежде всего система проектирования баз данных будет охватывать создание ERD. Многие системы проектирования баз данных также могут генерировать словарь данных из ERD для создания базы данных.
Какие четыре этапа проектирования базы данных?
Существует три уровня проектирования: концептуальный, логический и физический. Интерпретируя эти уровни как этапы проектирования, многие теоретики утверждают, что процесс нормализации сам по себе является этапом. Это приводит к четырем этапам проектирования базы данных:
- Концептуальное проектирование
- Логический дизайн
- Нормализация
- Физическая конструкция
См. также: Инструменты построения диаграмм базы данных
Проектирование, разработка и управление базами данных
Проекты по разработке баз данных
Проекты разработки баз данных часто сосредоточены на следующих трех компонентах:
База данных
Любая база данных может хранить данные, но только хорошо спроектированные базы данных могут эффективно распространять информацию для улучшения операций и процессов принятия решений. Помещение корпоративных данных в базу данных позволяет использовать передовые технологии, такие как аналитика или искусственный интеллект. Он также устанавливает единый источник достоверной информации для надежных выводов.
Настольное/веб-приложение
Приложения — лучший способ доступа к данным. Они могут быть разработаны, чтобы помочь в управлении базой данных или предоставлять определенные результаты в настольное или веб-приложение. Создание безопасных приложений гарантирует, что только авторизованный персонал имеет доступ к критически важной информации, поскольку нет ничего более ценного, чем данные компании.
Мобильное приложение
Мобильные приложения могут передавать ту же информацию на смартфон. Или они могут быть построены для предоставления совершенно другого опыта. Сделать данные удобными для мобильных устройств означает получить доступ к информации везде, где есть телефон. Эта возможность упрощает работу для тех, кто работает удаленно.
Решения для баз данных
Предоставление решений для баз данных включает в себя ряд услуг, таких как интеллектуальный анализ данных, интеграция и миграция. В Ayoka наши команды используют свой опыт для предоставления следующих решений.
Дизайн пользовательской базы данных
Каждая организация и ее данные уникальны, и лучшие решения для баз данных должны быть настроены с учетом этой уникальности. Создание специального программного обеспечения базы данных гарантирует доступность важных данных для достижения бизнес-целей и содействия развитию бизнеса. Хорошо спроектированная архитектура базы данных обеспечивает надежность приложений, зависящих от данных.
Интеллектуальный анализ и преобразование данных
Недостатка в информации нет, но не все данные одинаковы. Вот почему так важно работать с экспертами по базам данных, которые знают, как найти высококачественные данные для поддержки роста бизнеса. Извлечение лучших данных из того объема данных, который проходит через предприятие, является сложной задачей. Очистка, анализ и преобразование данных могут занимать много времени, если не используются автоматизированные процессы. Мы работаем с клиентами, чтобы улучшить интеллектуальный анализ данных и трансформационные операции за счет автоматизации.
Разработка приложений для баз данных
Разработка приложений означает прислушиваться к бизнес-целям и потребностям. Если разработчики не понимают, какие данные нужны и почему, они изо всех сил пытаются найти высококачественные данные или предоставить необходимую информацию в удобных для использования форматах. Наши команды тесно сотрудничают с клиентами, чтобы обеспечить достижение бизнес-целей на каждом этапе пути, внося коррективы как можно раньше в процесс разработки, чтобы снизить затраты на разработку.
Интеграция и миграция данных
Интеграция и миграция данных позволяют получать нужную информацию нужным людям в нужное время. Интеграция данных обеспечивает согласованность между платформами сбора данных и консолидирует протоколы для эффективной передачи данных. Иногда устаревшие системы нуждаются в замене, но перемещение данных может занять много времени. С помощью автоматизированных процессов мы можем переносить данные из старых систем в новые базы данных, которые работают с более безопасными приложениями, обеспечивая целостность и безопасность данных.
Приложения баз данных
Наши клиенты и решения охватывают несколько отраслей и функциональных подразделений, таких как:
- Служба поддержки клиентов
- Маркетинг
- членства
- Инвентарь
- Производительность оборудования
- Недвижимость
- Сотрудники
- Вербовка
- Изображения
- Здравоохранение
Адаптация решений баз данных для удовлетворения конкретных потребностей делает результаты целенаправленными и эффективными. Потребляется меньше ресурсов, потому что лучшие данные легко доступны, что позволяет получить более четкое представление. Будь то обслуживание клиентов или опыт сотрудников, база данных должна соответствовать приложению, потому что один размер не подходит для всех.
популярных консультационных услуг по базам данных в Ayoka
Проектирование и разработка баз данных
Отладка и ремонт
Разработка форм и автоматизация отчетов
Модернизация, миграция данных и увеличение размера БД
Оптимизация производительности и восстановление БД
Интеграция устройств (телефоны, планшеты и встроенные технологии)
Решения для хранилищ данных
Большие данные, аналитика, интеллектуальный анализ данных, BI и OLAP
Интеграция нескольких источников для пакетной и потоковой обработки
6-этапная методология
- Посвящение
- Дизайн
- Строить
- Тест
- Доставка
- Развертывание
Инициация
У нас будет стартовое совещание, на котором мы обсудим объем, бизнес-цели и общую миссию проекта. Клиент предоставит первоначальный обзор своих пользователей, текущих операций и любой доступной документации с описанием текущих бизнес-процессов. Вместе мы разработаем план коммуникаций, определяющий формат, частоту и распространение отчетов о состоянии… а также формат, частоту, место и участников будущих встреч.
Дизайн
Мы соберем, разработаем и задокументируем бизнес-требования клиента, чтобы определить системную архитектуру, наиболее подходящую для каждого клиента. Во время дизайнерских совещаний мы будем работать вместе с клиентом над разработкой всех необходимых проектных заметок. При необходимости мы разработаем пользовательские интерфейсы, варианты использования, дизайн базы данных и методы интеграции в рамках технических ограничений архитектуры системы и ИТ-среды клиента.
Сборка
Мы разработаем приложение на основе результатов этапа проектирования. Этап сборки будет динамичным и совместным, с использованием гибкой разработки, чтобы обеспечить выполнение бизнес-требований. Приложения обычно поставляются в виде нескольких выпусков в предоставленную клиентом ИТ-среду.
Тест
Мы продемонстрируем базовую работу приложения, убедившись, что клиент уверен, что его требования были выполнены. После демонстрации мы развернем приложение в инфраструктуре клиента, где клиент сможет приступить к тестированию приложения. Этап тестирования завершится через две недели после доставки приложения.
Доставка
Мы интегрируем проверенный пользователем код, переведем его в исполняемый формат и доработаем приложение для доставки. Полный исходный код будет доставлен клиенту после завершения выпусков, приемочного тестирования пользователями и окончательной оплаты.
Развертывание
Мы развернем приложение в предоставленной клиентом производственной среде, которая будет включать в себя как промежуточные, так и производственные возможности. Текущее управление приложениями является необязательным и доступно по отдельному соглашению.
Службы баз данных
Ayoka предоставляет консультации и разработку программного обеспечения для баз данных, чтобы убедиться, что полученное решение соответствует потребностям клиента.
Консультации по программному обеспечению баз данных
Эффективные решения для баз данных имеют решающее значение для развития предприятия. Разработчики и дизайнеры получают доступ к существующей инфраструктуре, чтобы найти лучшее решение. Этот процесс может включать в себя чистую миграцию базы данных или может потребовать базы данных с новой архитектурой, которая интегрируется с рядом приложений. Будь то реляционная, сетевая или объектно-ориентированная база данных, наши консультанты обладают знаниями и опытом, чтобы предоставить правильное решение.
Разработка программного обеспечения для баз данных
Разработка программного обеспечения для баз данных означает проектирование и создание решения, отвечающего бизнес-целям. Программное обеспечение может быть веб-приложением, мобильным или настольным приложением. Проект может варьироваться от одного приложения до решения для всего предприятия. Независимо от приложения, необходима надежная и безопасная база данных. Без надежной структуры базы данных аналитика становится неэффективной, а машинное обучение менее эффективным.
Типы баз данных
Мы поддерживаем как реляционные, так и нереляционные базы данных, перечисленные ниже:
- MS Access и SQL Server (реляционные базы данных Microsoft)
- MySQL (реляционная база данных Java)
- IBM DB2
- PostgreSQL (объектно-ориентированная реляционная база данных)
- Oracle, MongoDB и другие решения для баз данных NoSQL
Наши специалисты по базам данных помогут определить наиболее экономичные варианты для ваших нужд.
Наше обязательство
Защита данных компании имеет ключевое значение для поддержания ее конкурентного преимущества. Вот почему мы стремимся предоставлять решения, которые обеспечивают:
- Непротиворечивость и безопасность данных
- Быстрое время отклика
- Изящный пользовательский опыт
- Надежная интеграция
- Текущая поддержка
Мы также стремимся предоставлять решения, которые можно масштабировать по мере роста бизнеса.
Чем мы можем помочь
Ayoka — компания по разработке баз данных, которая разрабатывает и внедряет надежные решения для баз данных, помогающие повысить прозрачность, прозрачность и согласованность данных. Мы полагаемся на зрелое управление качеством и гарантируем, что сотрудничество не представляет никаких рисков для безопасности данных. Наши решения улучшают существующие программные решения для баз данных и помогают организациям собирать, систематизировать и использовать критически важные данные.
Услуги по разработке баз данных
Консультации по программному обеспечению баз данных
- Определение функциональности базы данных и технического стека
- Разработка бизнес-кейса
- Оценка рентабельности инвестиций решения
- Разработка архитектуры базы данных для обеспечения высокой производительности, безопасности и масштабируемости
- Создание макетов UX/UI
- Предоставить сценарий управления проектом и его реализации, оценку стоимости и времени проекта
Запросить консультацию
Разработка программного обеспечения для баз данных полного цикла
- Консультации по решениям и планирование
- База данных, разработка веб-приложений и мобильных приложений
- Интеграция со сторонними системами
- Обучение пользователей
- Поддержка после запуска
- Непрерывное управление программным обеспечением
Запросить разработку
Часто задаваемые вопросы
Эта проблема распространена и требует много времени. Мы можем вместе с вами проверить процессы и улучшить их, создав специальное программное обеспечение, объединяющее и упрощающее этапы процесса.
Задачи, выполняемые вручную, обычно занимают больше времени и оставляют больше места для ошибок. Там, где это возможно, мы можем автоматизировать задачи, которые сокращают время обработки и минимизируют потери.
Большинство отраслей должны соблюдать один или несколько законов о конфиденциальности данных. Мы можем создать специальное программное обеспечение, которое гарантирует, что ваш бизнес соответствует всем действующим нормам в отношении данных. Это включает в себя будущие обновления по мере изменения правил.
Наша работа — понимать новые технологические тренды. Затем мы можем оценить, как можно обновить устаревшую систему для повышения эффективности. Там, где это возможно, мы можем изменить существующие системы или создать новое индивидуальное программное решение.
Системы и технологии постоянно меняются. Там, где это возможно, мы можем оценить текущую систему, чтобы понять, является ли она кандидатом на улучшение или интеграцию. Мы также создаем индивидуальные программные решения, которые могут изменяться по мере изменения и роста вашего бизнеса.
Обычно предприятия продолжают использовать программное обеспечение, которое хорошо зарекомендовало себя. Однако также важно быть открытым к тому, как другое программное решение может улучшить процессы, сократить время выполнения задач, затраты и потери. Наша работа в Ayoka — работать с вами, чтобы вы понимали программные решения, которые могут помочь улучшить ваш бизнес.
Восемь распространенных ошибок при проектировании баз данных
Всякий раз, когда вы, как разработчик, получаете задачу, основанную на существующем коде, вам приходится сталкиваться со многими проблемами. Одна из таких задач — чаще всего самая сложная — связана с пониманием модели данных приложения.
Обычно вы сталкиваетесь с запутанными таблицами, представлениями, столбцами, значениями, хранимыми процедурами, функциями, ограничениями и триггерами, для понимания которых требуется много времени. И как только они это сделают, вы начнете замечать множество способов улучшить и использовать сохраненную информацию.
Если вы опытный разработчик, скорее всего, вы также заметите вещи, которые можно было бы сделать лучше в начале, т. е. недостатки дизайна.
В этой статье вы узнаете о некоторых распространенных плохих методах проектирования баз данных, почему они плохие и как их избежать.
Плохая практика № 1: игнорирование назначения данных
Данные хранятся для последующего использования, и цель всегда состоит в том, чтобы хранить и извлекать их наиболее эффективным способом. Для этого разработчик базы данных должен заранее знать, что будут представлять данные, как и с какой скоростью они будут получены, каков будет их рабочий объем (т. е. сколько данных ожидается) и, наконец, , как он будет использоваться.
Например, промышленная информационная система, в которой данные собираются вручную каждый день, не будет иметь той же модели данных, что и промышленная система, в которой информация генерируется в режиме реального времени. Почему? Потому что обработка нескольких сотен или тысяч записей в месяц сильно отличается от управления миллионами записей за тот же период. Разработчики должны принять особые меры, чтобы сохранить эффективность и удобство использования базы данных, если объемы данных должны быть большими.
Но, конечно, объем данных — не единственный аспект, который следует учитывать, поскольку назначение данных также влияет на уровень нормализации, структуру данных, размер записи и общую реализацию всей системы.
Таким образом, доскональное знание цели системы данных, которую вы создаете, приводит к соображениям при выборе ядра базы данных, сущностей для разработки, размера и формата записи, а также политик управления ядром базы данных.
Игнорирование этих целей приведет к проектам, которые ошибочны в своих основах, хотя структурно и математически правильны.
Плохая практика № 2: плохая нормализация
Проектирование базы данных не является детерминированной задачей; два проектировщика баз данных могут следовать всем правилам и принципам нормализации для данной задачи, и в большинстве случаев они будут генерировать разные макеты данных. Это присуще творческой природе разработки программного обеспечения. Тем не менее, есть некоторые методы анализа, которые имеют смысл в каждом случае, и следование им — лучший способ получить базу данных, которая работает наилучшим образом.
Несмотря на это, мы часто сталкиваемся с базами данных, которые разрабатывались на лету без соблюдения самых основных правил нормализации. Мы должны четко понимать: каждая база данных должна быть, по крайней мере, нормализована до третьей нормальной формы, поскольку именно ее макет будет лучше всего представлять ваши сущности, а его производительность будет наилучшим образом сбалансирована между запросами и вставкой-обновлением-удалением записей. .
Если вы столкнулись с таблицами, которые не соответствуют 3NF, 2NF или даже 1NF, рассмотрите возможность изменения дизайна этих таблиц. Усилия, которые вы вкладываете в это, окупятся в очень краткосрочной перспективе.
Плохая практика № 3: Избыточность
Очень похоже на предыдущий пункт, поскольку одной из целей нормализации является ее уменьшение, избыточность — еще одна плохая практика, которая встречается довольно часто.
Избыточные поля и таблицы — кошмар для разработчиков, поскольку они требуют бизнес-логики для поддержания многих версий одной и той же информации в актуальном состоянии. Это накладные расходы, которых можно избежать, если строго следовать правилам нормализации. Хотя иногда резервирование может показаться необходимым, оно должно использоваться только в очень специфических случаях и должно быть четко задокументировано, чтобы его можно было учитывать в будущих разработках.
Типичными негативными последствиями избыточности являются ненужное увеличение размера базы данных, склонность данных к несогласованности и снижение эффективности базы данных, но, что более важно, это может привести к повреждению данных.
Неправильная практика № 4: Плохая ссылочная целостность (ограничения)
Ссылочная целостность — это один из самых ценных инструментов, которые механизмы базы данных предоставляют для поддержания качества данных на самом высоком уровне. Если на этапе проектирования не реализовано никаких ограничений или введено очень мало ограничений, целостность данных должна будет полностью зависеть от бизнес-логики, что делает ее подверженной человеческим ошибкам.
Плохая практика № 5: Неиспользование возможностей механизма БД
При использовании механизма базы данных (DBE) у вас есть мощное программное обеспечение для задач обработки данных, которое упрощает разработку программного обеспечения и гарантирует, что информация всегда правильный, безопасный и удобный. DBE предоставляет такие услуги, как:
- Представления, которые обеспечивают быстрый и эффективный способ просмотра ваших данных, обычно денормализуя их для целей запроса без потери правильности данных.
- Индексы, помогающие ускорить запросы к таблицам.
- Агрегирующие функции, помогающие анализировать информацию без программирования.
- Транзакции или блоки предложений, изменяющих данные, которые все выполняются и фиксируются или отменяются (откатываются), если происходит что-то непредвиденное, таким образом сохраняя информацию в постоянно правильном состоянии.
- Блокировки, обеспечивающие безопасность и правильность данных во время выполнения транзакций.
- Хранимые процедуры, предоставляющие функции программирования для решения сложных задач управления данными.
- Функции, позволяющие выполнять сложные вычисления и преобразования данных.
- Ограничения, помогающие гарантировать правильность данных и избегать ошибок.
- Триггеры, помогающие автоматизировать действия при возникновении событий с данными.
- Оптимизатор команд (планировщик выполнения), который работает под капотом, гарантируя, что каждое предложение выполняется наилучшим образом, и сохраняет планы выполнения для будущих случаев. Это одна из лучших причин для использования представлений, хранимых процедур и функций, поскольку их планы выполнения постоянно хранятся в DBE.
Незнание или игнорирование этих возможностей приведет разработку к крайне неопределенной траектории и, несомненно, к ошибкам и будущим проблемам.
Плохая практика № 6: составные первичные ключи
Это своего рода спорный момент, поскольку многие разработчики баз данных в настоящее время говорят об использовании автоматически сгенерированного целочисленного идентификатора в качестве первичного ключа вместо составного, определяемого комбинацией два и более полей. В настоящее время это определяется как «лучшая практика», и лично я склонен с этим согласиться.
Однако это всего лишь соглашение, и, конечно же, DBE позволяют определять составные первичные ключи, что, по мнению многих разработчиков, неизбежно. Поэтому, как и в случае с избыточностью, составные первичные ключи являются конструктивным решением.
Будьте осторожны: если ожидается, что таблица с составным первичным ключом будет содержать миллионы строк, индекс, управляющий составным ключом, может вырасти до такой степени, что производительность операции CRUD сильно снизится. В этом случае намного лучше использовать первичный ключ с простым целочисленным идентификатором, индекс которого будет достаточно компактным и установит необходимые ограничения DBE для обеспечения уникальности.
Плохая практика № 7: Плохая индексация
Иногда у вас будет таблица, которую нужно запросить по многим столбцам. По мере роста таблицы вы заметите, что операции SELECT для этих столбцов замедляются. Если таблица достаточно велика, вы логично подумаете о создании индекса для каждого столбца, который вы используете для доступа к этой таблице, но почти сразу обнаружите, что производительность операций SELECT улучшается, а операций INSERT, UPDATE и DELETE падает. Это, конечно, связано с тем, что индексы должны быть синхронизированы с таблицей, что означает огромные накладные расходы для DBE. Это типичный случай чрезмерного индексирования, который можно решить разными способами; например, имея только один индекс для всех столбцов, отличных от первичного ключа, который вы используете для запроса таблицы, упорядочивание этих столбцов от наиболее часто используемых к наименее может обеспечить лучшую производительность во всех операциях CRUD, чем один индекс для каждого столбца.
С другой стороны, наличие таблицы без индекса по столбцам, которые используются для запросов к ней, как мы все знаем, приведет к снижению производительности операций SELECT.
Кроме того, эффективность индекса иногда зависит от типа столбца; индексы по столбцам INT показывают наилучшую возможную производительность, но индексы по VARCHAR, DATE или DECIMAL (если это когда-либо имеет смысл) не так эффективны. Это соображение может даже привести к перепроектированию таблиц, доступ к которым должен осуществляться с максимально возможной эффективностью.
Таким образом, индексация всегда является деликатным решением, так как слишком много индексации может быть столь же плохо, как и слишком мало, и потому что тип данных столбцов для индексации оказывает большое влияние на окончательный результат.
Плохая практика № 8: Плохие соглашения об именах
Это то, с чем программисты всегда сталкиваются при работе с существующей базой данных: понимание того, какая информация хранится в ней, по именам таблиц и столбцов, потому что зачастую другого пути нет. .
Имя таблицы должно описывать, какую сущность она содержит, а имя каждого столбца должно описывать, какую информацию он представляет. Это легко, но становится сложно, когда таблицы должны быть связаны друг с другом. Имена начинают запутываться и, что еще хуже, если соглашения об именах путают с нелогичными нормами (например, «имя столбца должно быть 8 символов или меньше»). Конечным последствием является то, что база данных становится нечитаемой.
Таким образом, соглашение об именах всегда необходимо, если предполагается, что база данных будет существовать и развиваться вместе с поддерживаемым приложением, и вот несколько рекомендаций по созданию краткого, простого и удобочитаемого:
- Нет ограничений на таблицу или столбец. размер имени. Лучше иметь описательное имя, чем аббревиатуру, которую никто не помнит или не понимает.
- Равные имена имеют одинаковое значение. Избегайте полей с одинаковыми именами, но с разными типами или значениями; это рано или поздно приведет к путанице.
- Без необходимости, не быть избыточным. Например, в таблице «Товар» нет необходимости иметь такие столбцы, как «ИмяТовара», «ЦенаТовара» или подобные имена; «Имя» и «Цена» достаточно.
- Остерегайтесь зарезервированных слов DBE. Если столбец должен называться «Index», что является зарезервированным словом SQL, попробуйте использовать другое, например «IndexNumber».
- Если вы придерживаетесь простого правила первичного ключа (одиночное целое число генерируется автоматически), назовите его «Id» в каждой таблице.
- При присоединении к другой таблице определите необходимый внешний ключ как целое число с именем «Id», за которым следует имя присоединяемой таблицы (например, IdItem).
- При именовании ограничений используйте префикс, описывающий ограничение (например, «PK» или «FK»), за которым следует имя задействованной таблицы или таблиц. Конечно, экономное использование символов подчеркивания («_») помогает сделать текст более читабельным.
- Чтобы назвать индексы, используйте префикс «IDX», за которым следует имя таблицы и столбец или столбцы индекса. Кроме того, используйте «UNIQUE» в качестве префикса или суффикса, если индекс уникален, и подчеркивайте, где это необходимо.
В Интернете есть много руководств по именованию баз данных, которые проливают больше света на этот очень важный аспект проектирования баз данных, но с помощью этих основных вы можете, по крайней мере, получить удобочитаемую базу данных. Здесь важен не размер или сложность ваших рекомендаций по именованию, а ваша последовательность в их следовании!
Проектирование баз данных — это сочетание знаний и опыта; индустрия программного обеспечения претерпела значительные изменения с момента своего появления. К счастью, имеется достаточно знаний, чтобы помочь разработчикам баз данных достичь наилучших результатов.
В Интернете есть хорошие рекомендации по проектированию баз данных, а также плохие методы и вещи, которых следует избегать при проектировании баз данных.