Регулярные выражения в Python | Pythonist .ru
Перевод статьи «Python Regular Expression».
Сегодня мы хотим поговорить о регулярных выражениях в Python. Пожалуй, стоит начать с определения. Регулярные выражения, иногда называемые re, regex или regexp, представляют собой последовательности символов, составляющие шаблоны, соответствия которым ищутся в строке или тексте. Для работы с regexp в Python есть встроенный модуль re.
Обычное использование регулярного выражения:
- Поиск подстроки в строке (
searchandfind) - Поиск всех подходящих строк (
findall) - Разделение строки на подстроки (
split) - Замена части строки (
sub)
Основы
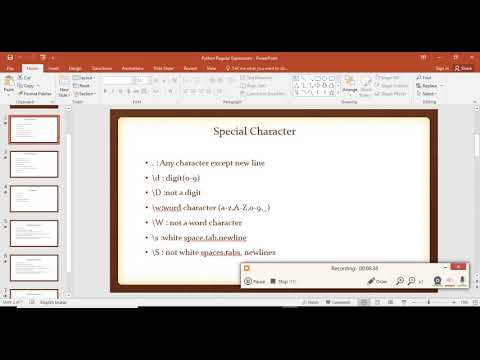
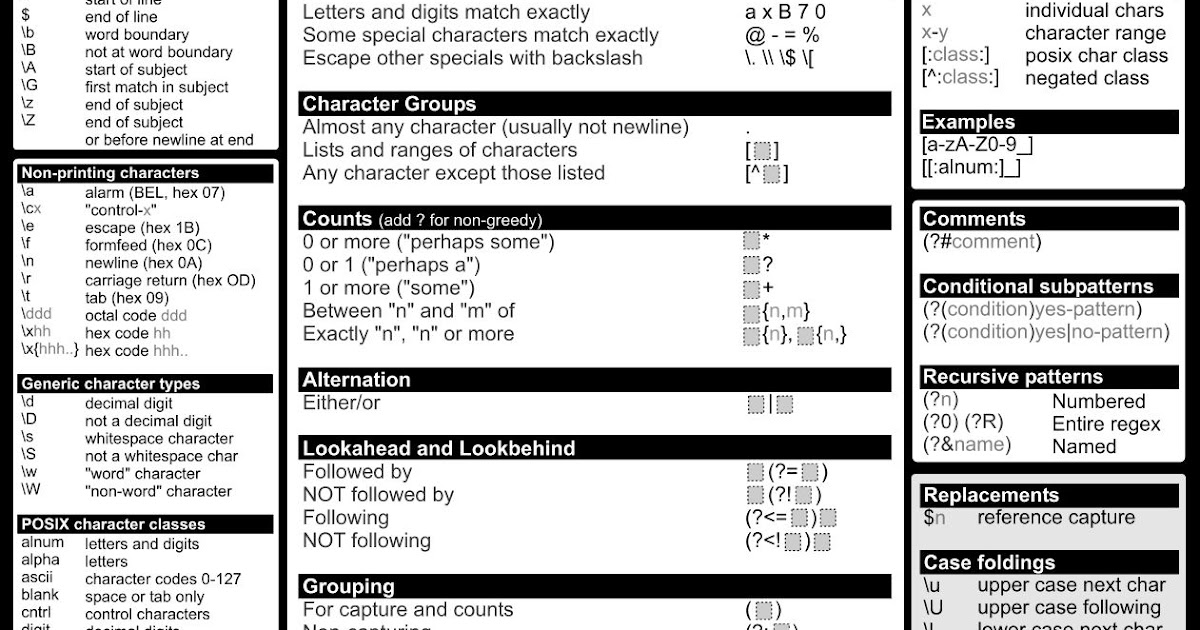
Регулярное выражение – это комбинация символов и метасимволов. Из метасимволов доступны следующие:
\используется для игнорирования специального значения символа[]указывает на класс символов. соответствует началу текста
соответствует началу текста$обозначает конец текста.соответствует любому символу, кроме символа новой строки?обозначает одно или ноль вхождений|означает ИЛИ (совпадение с любым из символов, разделенных им)*любое количество вхождений (включая 0 вхождений)+одно и более вхождений{}указывает на несколько совпадений предыдущего RE.()отделяет группу в регулярном выражении
Обратная косая черта (backslash) \ используется в сочетании с другими символами и тогда приобретает особые значения. Если же необходимо использовать backslash просто как символ, без учета специального значения, его нужно «экранировать» еще одной обратной косой чертой – \\. Что касается специальных значений:
\dсоответствует любой десятичной цифре, это то же самое, что и [0-9]\Dсоответствует любому нечисловому символу\sсоответствует любому пробельному символу\Sсоответствует любому не пробельному символу\wсоответствует любому буквенно-числовому символу; это то же самое, что и [a-zA-Z0-9_].\Wсоответствует любому не буквенно-числовому символу.
Мы разобрали основы регулярных выражений (подробнее про них вы можете почитать тут). Теперь давайте посмотрим, какие методы доступны в модуле re.
re.search()
Этот метод возвращает совпадающую часть строки и останавливается сразу же, как находит первое совпадение. Таким образом, его можно использовать для проверки выражения, а не для извлечения данных.
Синтаксис: re.search(шаблон, строка)
Возвращаемое значение может быть либо подстрокой, соответствующей шаблону, либо None, если такой подстроки не окажется.
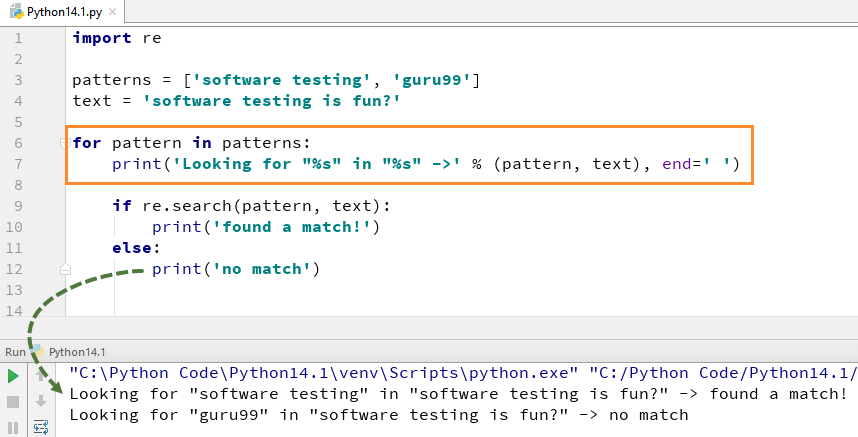
Давайте разберем пример: поищем в строке месяц и число.
import re
regexp = r"([a-zA-Z]+) (\d+)"
match = re.search(regexp, "My son birthday is on July 20")
if match != None:
print("Match at index %s, %s" % (match. start(), match.end())) #This provides index of matched string
print("Full match: %s" % (match.group(0)))
print("Month: %s" % (match.group(1)))
print("Day: %s" % (match.group(2)))
else:
print("The given regex pattern does not match") start(), match.end())) #This provides index of matched string
print("Full match: %s" % (match.group(0)))
print("Month: %s" % (match.group(1)))
print("Day: %s" % (match.group(2)))
else:
print("The given regex pattern does not match")
start(), match.end())) #This provides index of matched string
print("Full match: %s" % (match.group(0)))
print("Month: %s" % (match.group(1)))
print("Day: %s" % (match.group(2)))
else:
print("The given regex pattern does not match")re.match()
Этот метод ищет и возвращает первое совпадение. Но надо учесть, что он проверяет соответствие только в начале строки.
Синтаксис: re.match(шаблон, строка)
Возвращаемое значение, как и в search(), может быть либо подстрокой, соответствующей шаблону, либо None, если желаемый результат не найден.
Теперь давайте посмотрим на пример. Проверим, совпадает ли строка с шаблоном.
import re regexp = r"([a-zA-Z]+) (\d+)" match = re.match(regexp, "July 20") if match == None: print("Not a valid date") else: print("Given string: %s" % (match.
 group()))
print("Month: %s" % (match.group(1)))
print("Day: %s" % (match.group(2)))
group()))
print("Month: %s" % (match.group(1)))
print("Day: %s" % (match.group(2)))Рассмотрим другой пример. Здесь «July 20» находится не в начале строки, поэтому результатом кода будет «Not a valid date»
import re regexp = r"([a-zA-Z]+) (\d+)" match = re.match(regexp, "My son birthday is on July 20") if match == None: print("Not a valid date") else: print("Given string: %s" % (match.group())) print("Month: %s" % (match.group(1))) print("Day: %s" % (match.group(2)))
re.findall()
Этот метод возвращает все совпадения с шаблоном, которые встречаются в строке. При этом строка проверяется от начала до конца. Совпадения возвращаются в том порядке, в котором они идут в исходной строке.
Синтаксис: re.findall(шаблон, строка)
Возвращаемое значение может быть либо списком строк, совпавших с шаблоном, либо пустым списком, если совпадений не нашлось.
Рассмотрим пример. Используем регулярное выражение для поиска чисел в исходной строке.
import re string = "Bangalore pincode is 560066 and gulbarga pincode is 585101" regexp = '\d+' match = re.findall(regexp, string) print(match)
Или другой пример. Теперь нам нужно найти в заданном тексте номер мобильного телефона. То есть, в данном случае, нам нужно десятизначное число.
import re
string = "Bangalore office number 1234567891, My number is 8884278690, emergency contact 3456789123 invalid number 898883456"
regexp = '\d{10}' # Регулярное выражение, соответствующее числу из ровно 10 цифр
match = re. findall(regexp, string)
print(match) findall(regexp, string)
print(match)
findall(regexp, string)
print(match)re.compile()
С помощью этого метода регулярные выражения компилируются в объекты шаблона и могут использоваться в других методах. Рассмотрим это на примере поиска совпадений с шаблоном.
import re
e = re.compile('[a-e]')
print(e.findall("I born at 11 A.M. on 20th July 1989"))
e = re.compile('\d') # \d - эквивалент [0-9].
print(e.findall("I born at 11 A.M. on 20th July 1989"))
p = re.compile('\d+') # группа из одной или более цифр
print(p.findall("I born at 11 A.M. on 20th July 1989"))
# Результат:
# ['b', 'a']
# ['1', '1', '2', '0', '1', '9', '8', '9']
# ['11', '20', '1989']re.split()
Данный метод разделяет строку по заданному шаблону. Если шаблон найден, оставшиеся символы из строки возвращаются в виде результирующего списка.
Синтаксис: re.split(шаблон, строка, maxsplit = 0)
Возвращаемое значение может быть либо списком строк, на которые была разделена исходная строка, либо пустым списком, если совпадений с шаблоном не нашлось.
Рассмотрим, как работает данный метод, на примере.
import re # '\W+' совпадает с символами или группой символов, не являющихся буквами или цифрами # разделение по запятой ',' или пробелу ' ' print(re.split('\W+', 'Good, better , Best')) print(re.split('\W+', "Book's books Books")) # Здесь ':', ' ' ,',' - не буквенно-цифровые символы, по которым происходит разделение print(re.split('\W+', 'Born On 20th July 1989, at 11:00 AM')) # '\d+' означает цифры или группы цифр # Разделение происходит по '20', '1989', '11', '00' print(re.
 split('\d+', 'Born On 20th July 1989, at 11:00 AM'))
# Указано максимальное количество разделений - 1
print(re.split('\d+', 'Born On 20th July 1989, at 11:00 AM', maxsplit=1))
# Результат:
# ['Good', 'better', 'Best']
# ['Book', 's', 'books', 'Books']
# ['Born', 'On', '20th', 'July', '1989', 'at', '11', '00', 'AM']
# ['Born On ', 'th July ', ', at ', ':', ' AM']
# ['Born On ', 'th July 1989, at 11:00 AM']
split('\d+', 'Born On 20th July 1989, at 11:00 AM'))
# Указано максимальное количество разделений - 1
print(re.split('\d+', 'Born On 20th July 1989, at 11:00 AM', maxsplit=1))
# Результат:
# ['Good', 'better', 'Best']
# ['Book', 's', 'books', 'Books']
# ['Born', 'On', '20th', 'July', '1989', 'at', '11', '00', 'AM']
# ['Born On ', 'th July ', ', at ', ':', ' AM']
# ['Born On ', 'th July 1989, at 11:00 AM']re.sub()
Здесь значение «sub» — это сокращение от substring, т.е. подстрока. В данном методе исходный шаблон сопоставляется с заданной строкой и, если подстрока найдена, она заменяется параметром repl.
Кроме того, у метода есть дополнительные аргументы. Это count, счетчик, в нем указывается, сколько раз заменяется регулярное выражение. А также flag, в котором мы можем указать флаг регулярного выражения (например,
Синтаксис: re.sub(шаблон, repl, строка, count = 0, flags = 0)
В результате работы кода возвращается либо измененная строка, либо исходная.
Посмотрим на работу метода на следующем примере.
import re
# Шаблон 'lly' встречается в строке в "successfully" и "DELLY"
print(re.sub('lly', '#$', 'doctor appointment booked successfully in DELLY'))
# Благодаря использованию флага регистр игнорируется, и 'lly' находит два совпадения
# Когда совпадения найдены, 'lly' заменяется на '~*' в "successfully" и "DELLY".
print(re.sub('lly', '#$', 'doctor appointment booked successfully in DELLY', flags=re.IGNORECASE))
# Чувствительность к регистру: 'lLY' не находит совпадений, и ничего в строке не будет заменено
print(re.sub('lLY', '#$', 'doctor appointment booked successfully in DELLY'))
# С count = 1 заменяется только одно совпадение с шаблоном
print(re.sub('lly', '#$', 'doctor appointment booked successfully in DELLY', count=1, flags=re.IGNORECASE))re.
 subn()
subn()Функциональность subn() во всех отношениях такая же, как и sub(). Единственная разница – это формат вывода.
Синтаксис: re.subn(шаблон, repl, строка, count = 0, flags = 0)
Рассмотрим такой пример.
import re
print(re.subn('lly', '#$', 'doctor appointment booked successfully in DELLY'))
t = re.subn('lly', '#$', 'doctor appointment booked successfully in DELLY', flags=re.IGNORECASE)
print(t)
print(len(t))
# Это даст такой же вывод, как и sub()
print(t[0])re.escape()
Этот метод возвращает строку с обратной косой чертой \ перед каждым не буквенно-числовым символом. Это полезно, если мы хотим сопоставить произвольную буквенную строку, которая может содержать метасимволы регулярного выражения. ) Regex.
) Regex.
Оператор CARET по умолчанию относится только к началу строки. Поэтому, если у вас есть многострочная строка, например, при чтении текстового файла – он все равно будет соответствовать только один раз: в начале строки.
Однако вы можете подобрать в начале каждой строки. Например, вы можете найти все строки, которые начинаются с «Python» в данной строке.
Вы можете указать, что оператор Caret соответствует началу каждой строки через RE. Многослойный флаг. Вот пример, показывающий оба использования – без и с настройкой RE. Многоловый флаг:
>>> import re >>> text = ''' Python is great. Python is the fastest growing major programming language in the world.
 Python', text, re.MULTILINE)
['Python', 'Python', 'Python']
>>>
Python', text, re.MULTILINE)
['Python', 'Python', 'Python']
>>> Первый выход – это пустой список, потому что строка «Python» не отображается в начале строки.
Второй выход – это список трех соответствующих подстрок, потому что строка «Python» появляется три раза в начале строки.
Python re.sub ()
RE.SUB (Pattern, repl, string ,,) Метод возвращает новую строку, в которой все вхождения рисунка в старой строке заменены на REPL. Читайте больше в Учебник блогов Finxter Отказ
Вы можете использовать оператор CARET для замены, где какой-то шаблон появляется в начале строки:
>>> import re >>> re.
 Python', 'Code', 'Python is \nPython', flags=re.MULTILINE)
'Code is \nCode'
Python', 'Code', 'Python is \nPython', flags=re.MULTILINE)
'Code is \nCode'Теперь вы заменяете оба внешности строки «Python».
Python re.match (), re.search (), re.findall () и Re.fulllmatch ()
Давайте быстро переправимся самым важным методам Regex в Python:
- Re.findall (шаблон, строка) Метод возвращает список строковых совпадений. Читайте больше в Наше руководство в блоге Отказ
- Re.Search (шаблон, строка , ) Метод возвращает объект совпадения первого матча. Читайте больше в Наше руководство в блоге Отказ
- Re.match (шаблон, строка , ) Метод Возвращает объект совпадения, если установки Regeex в начале строки. Читайте больше в Наше руководство в блоге Отказ
- Re.fullmatch (шаблон, строка , ) Метод возвращает объект совпадения, если Regeex соответствует всей строке. Python’, text, flags=re.MULTILINE)
>>>
Опять же, это сомнительно, имеет ли это смысл для методов Re.match () и Re.fullmatch (), поскольку они ищут только матч в начале строки.
Python Re конец строки ($) Regex
Точно так же вы можете использовать оператор долларовой знак $, чтобы соответствовать концу строки. Вот пример:
>>> import re >>> re.findall('fun$', 'PYTHON is fun') ['fun']Метод findall () находит все вхождения рисунка в строке – хотя приводной долларовой знак $ гарантирует, что регулярные выражения соответствуют только в конце строки.
Это может значительно изменить значение вашего регулярного выражения, как вы можете увидеть в следующем примере:
>>> re.
findall('fun$', 'fun fun fun')
['fun']Хотя, есть три вхождения подстроки «Веселье», есть только одна подходящая подстрока – в конце строки.
Но что, если вы хотите подобрать не только в конце строки, но в конце каждой строки в многострочной строке?
Python Re конец строки ($)
Оператор долларовой подписи по умолчанию относится только к концу строки. Таким образом, если у вас есть многострочная строка, например, при чтении текстового файла – все равно будет только один раз: в конце строки.
Однако вы можете подобрать в конце каждой строки. Например, вы можете найти все строки, которые заканчиваются «.py».
Чтобы добиться этого, вы можете указать, что оператор долларового знака соответствует концу каждой строки через RE. Многослойный флаг. Вот пример, показывающий оба использования – без и с настройкой RE. Многоловый флаг:
>>> import re >>> text = ''' Coding is fun Python is fun Games are fun Agreed?''' >>> re.
findall('fun$', text)
[]
>>> re.findall('fun$', text, flags=re.MULTILINE)
['fun', 'fun', 'fun']
>>> Первый выход – это пустой список, потому что строка «Веселье» не отображается в конце строки.
Второй выход – это список трех подходящих подстроек, потому что строка «Веселье» появляется три раза в конце строки.
Python re.sub ()
RE.SUB (Pattern, repl, string ,,) Метод возвращает новую строку, в которой все вхождения рисунка в старой строке заменены на REPL. Читайте больше в Учебник блогов Finxter Отказ
Вы можете использовать оператор Dollar-Sign для замены, где какой-то шаблон появляется в конце строки:
>>> import re >>> re.
sub('Python$', 'Code', 'Is Python\nPython')
'Is Python\nCode'Только конец строки соответствует шаблону Regex, поэтому есть только одна замена.
Опять же, вы можете использовать RE. Многолитный флаг для соответствия концу каждой строки с оператором долларового знака:
>>> re.sub('Python$', 'Code', 'Is Python\nPython', flags=re.MULTILINE) 'Is Code\nCode'Теперь вы заменяете оба внешности строки «Python».
Python re.match (), re.search (), re.findall () и Re.fulllmatch ()
Все четыре метода – Re.findall (), Re.Search (), Re.match () и Re.fulllmatch () – поиск шаблона в данной строке. Вы можете использовать оператор долларовой знак $ в каждом шаблоне, чтобы соответствовать концу строки.
Вот один пример на один метод:>>> import re >>> text = 'Python is Python' >>> re.findall('Python$', text) ['Python'] >>> re.search('Python$', text) >>> re.match('Python$', text) >>> re.fullmatch('Python$', text) >>>Таким образом, вы можете использовать оператор долларового знака, чтобы соответствовать в конце строки. Однако следует отметить, что не имеет большого смысла использовать его для методов fullmatch (), как это, по определению, уже требует, чтобы последний символ строки является частью соответствующей подстроки.
Вы также можете использовать RE. Многолитный флаг, чтобы соответствовать концу каждой строки (а не только конец всей строки):
>> text = '''Is Python Python''' >>> re.
матчи в начале строки. Оператор долларовой подписи $ соответствует в конце строки. Если вы хотите подобрать в начале или в конце каждой строки в многострочной строке, вы можете установить RE. Многолитный флаг во всех соответствующих методах Re.Хотите заработать деньги, пока вы изучаете Python? Средние программисты Python зарабатывают более 50 долларов в час. Вы можете стать средним, не так ли?
Присоединяйтесь к свободному вебинару, которое показывает, как стать процветающим владельцем бизнеса в Интернете!
[Вебинар] Вы являетесь личным разработчиком Freelance Six
Присоединяйтесь к нам. Это весело! 🙂
Курс Python Regex
Инженеры Google являются регулярными мастерами. Система поисковой системы Google – это массивная Текстово-обработка двигателя Это извлекает значение из триллионов веб-страниц.
Инженеры Facebook являются регулярными мастерами экспрессии. Социальные сети, такие как Facebook, WhatsApp, и Instagram Подключите людей через Текстовые сообщения Отказ
Инженеры Amazon являются регулярными мастерами экспрессии.
Ecommerce Giants корабля продуктов на основе Описания текстовых продуктов Отказ Регулярные выражения правит игре, когда текстовая обработка соответствует информатике.Если вы хотите стать регулярным мастером выражения, проверьте Самый полный курс Python Regex на планете:
Работая в качестве исследователя в распределенных системах, доктор Кристиан Майер нашел свою любовь к учению студентов компьютерных наук.
Чтобы помочь студентам достичь более высоких уровней успеха Python, он основал сайт программирования образования Finxter.com Отказ Он автор популярной книги программирования Python одноклассники (Nostarch 2020), Coauthor of Кофе-брейк Python Серия самооставленных книг, энтузиаста компьютерных наук, Фрилансера и владелец одного из лучших 10 крупнейших Питон блоги по всему миру.
Его страсти пишут, чтение и кодирование. Но его величайшая страсть состоит в том, чтобы служить стремлению кодер через Finxter и помогать им повысить свои навыки. Вы можете присоединиться к его бесплатной академии электронной почты здесь.
Оригинал: “https://blog.finxter.com/python-regex-start-of-line-and-end-of-line/”
Модуль Python Re на примерах + задания и шаблоны ~ PythonRu
Регулярные выражения, также называемые regex, синтаксис или, скорее, язык для поиска, извлечения и работы с определенными текстовыми шаблонами большего текста. Он широко используется в проектах, которые включают проверку текста, NLP (Обработка естественного языка) и интеллектуальную обработку текста.
Введение в регулярные выражения
Регулярные выражения, также называемые regex, используются практически во всех языках программирования. В python они реализованы в стандартном модуле
re.
Он широко используется в естественной обработке языка, веб-приложениях, требующих проверки ввода текста (например, адреса электронной почты) и почти во всех проектах в области анализа данных, которые включают в себя интеллектуальную обработку текста.Эта статья разделена на 2 части.
Прежде чем перейти к синтаксису регулярных выражений, для начала вам лучше понять, как работает модуль
re. Итак, сначала вы познакомитесь с 5 основными функциями модуля
re, а затем посмотрите, как создавать регулярные выражения в python.
Узнаете, как построить практически любой текстовый шаблон, который вам, скорее всего, понадобится при работе над проектами, связанными с поиском текста.Что такое шаблон регулярного выражения и как его скомпилировать?
Шаблон регулярного выражения представляет собой специальный язык, используемый для представления общего текста, цифр или символов, извлечения текстов, соответствующих этому шаблону.
Основным примером является
\s+.
Здесь\ sсоответствует любому символу пробела. Добавив в конце оператор+, шаблон будет иметь не менее 1 или более пробелов. Этот шаблон будет соответствовать даже символам tab\t.В конце этой статьи вы найдете больший список шаблонов регулярных выражений. Но прежде чем дойти до этого, давайте посмотрим, как компилировать и работать с регулярными выражениями.
>>> import re >>> regex = re.compile('\s+')Вышеупомянутый код импортирует модуль
reи компилирует шаблон регулярного выражения, который соответствует хотя бы одному или нескольким символам пробела.Как разбить строку, разделенную регулярным выражением?
Рассмотрим следующий фрагмент текста.
>>> text = """100 ИНФ Информатика 213 МАТ Математика 156 АНГ Английский"""
У меня есть три курса в формате “[Номер курса] [Код курса] [Название курса]”. Интервал между словами разный.
Передо мной стоит задача разбить эти три предмета курса на отдельные единицы чисел и слов. Как это сделать?
Их можно разбить двумя способами:- Используя метод
re.split. - Вызвав метод
splitдля объектаregex.
# Разделит текст по 1 или более пробелами >>> re.split('\s+', text) # или >>> regex.split(text) ['100', 'ИНФ', 'Информатика', '213', 'МАТ', 'Математика', '156', 'АНГ', 'Английский']Оба эти метода работают.
Но какой же следует использовать на практике?
Если вы намерены использовать определенный шаблон несколько раз, вам лучше скомпилировать регулярное выражение, а не использоватьre.splitмножество раз.Поиск совпадений с использованием findall, search и match
Предположим, вы хотите извлечь все номера курсов, то есть 100, 213 и 156 из приведенного выше текста. Как это сделать?
Что делает re.findall()?
#найти все номера в тексте >>> print(text) 100 ИНФ Информатика 213 МАТ Математика 156 АНГ Английский >>> regex_num = re.compile('\d+') >>> regex_num.findall(text) ['100', '213', '156']В приведенном выше коде специальный символ
\ dявляется регулярным выражением, которое соответствует любой цифре. В этой статье вы узнаете больше о таких шаблонах.
Добавление к нему символа+означает наличие по крайней мере 1 числа.Подобно
+, есть символ*, для которого требуется 0 или более чисел. Это делает наличие цифры не обязательным, чтобы получилось совпадение. Подробнее об этом позже.В итоге, метод
findallизвлекает все вхождения 1 или более номеров из текста и возвращает их в список.re.search() против re.match()
Как понятно из названия,
regex.search()ищет шаблоны в заданном тексте.
Но, в отличие отfindall, который возвращает согласованные части текста в виде списка,regex.search()возвращает конкретный объект соответствия. Он содержит первый и последний индекс первого соответствия шаблону.Аналогично,
regex.match()также возвращает объект соответствия. Но разница в том, что он требует, чтобы шаблон находился в начале самого текста.>>> # создайте переменную с текстом >>> text2 = """ИНФ Информатика 213 МАТ Математика 156""" >>> # скомпилируйте regex и найдите шаблоны >>> regex_num = re.compile('\d+') >>> s = regex_num. search(text2)
>>> print('Первый индекс: ', s.start())
>>> print('Последний индекс: ', s.end())
>>> print(text2[s.start():s.end()])
Первый индекс: 17
Последний индекс: 20
213
В качестве альтернативы вы можете получить тот же результат, используя метод
group()для объекта соответствия.>>> print(s.group()) 205 >>> m = regex_num.match(text2) >>> print(m) None
Как заменить один текст на другой, используя регулярные выражения?
Для изменения текста, используйте
regex.sub().
Рассмотрим следующую измененную версию текста курсов. Здесь добавлена табуляция после каждого кода курса.# создайте переменную с текстом >>> text = """100 ИНФ \t Информатика 213 МАТ \t Математика 156 АНГ \t Английский""" >>> print(text) 100 ИНФ Информатика 213 МАТ Математика 156 АНГ Английский
Из вышеприведенного текста я хочу удалить все лишние пробелы и записать все слова в одну строку.
Для этого нужно просто использовать
regex.subдля замены шаблона\s+на один пробел.# заменить один или больше пробелов на 1 >>> regex = re.compile('\s+') >>> print(regex.sub(' ', text))или
>>> print(re.sub('\s+', ' ', text)) 101 COM Computers 205 MAT Mathematics 189 ENG EnglishПредположим, вы хотите избавиться от лишних пробелов и выводить записи курса с новой строки. Чтобы это сделать, используйте регулярное выражение, которое пропускает символ новой строки, но учитывает все другие пробелы.
Это можно сделать, используя отрицательное соответствие
(?!\n). Шаблон проверяет наличие символа новой строки, в python это\n, и пропускает его.# убрать все пробелы кроме символа новой строки >>> regex = re.compile('((?!\n)\s+)') >>> print(regex.sub(' ', text)) 100 ИНФ Информатика 213 МАТ Математика 156 АНГ АнглийскийГруппы регулярных выражений
Группы регулярных выражений — функция, позволяющая извлекать нужные объекты соответствия как отдельные элементы.
Предположим, что я хочу извлечь номер курса, код и имя как отдельные элементы. Не имея групп мне придется написать что-то вроде этого.
>>> text = """100 ИНФ Информатика 213 МАТ Математика 156 АНГ Английский""" # извлечь все номера курсов >>> re.findall('[0-9]+', text) # извлечь все коды курсов (для латиницы [A-Z]) >>> re.findall('[А-ЯЁ]{3}', text) # извлечь все названия курсов >>> re.findall('[а-яА-ЯёЁ]{4,}', text) ['100', '213', '156'] ['ИНФ', 'МАТ', 'АНГ'] ['Информатика', 'Математика', 'Английский']Давайте посмотрим, что получилось.
Я скомпилировал 3 отдельных регулярных выражения по одному для соответствия номерам курса, коду и названию.
Для номера курса, шаблон[0-9]+указывает на соответствие всем числам от 0 до 9. Добавление символа+в конце заставляет найти по крайней мере 1 соответствие цифрам 0-9. Если вы уверены, что номер курса, будет иметь ровно 3 цифры, шаблон мог бы быть[0-9] {3}.Для кода курса, как вы могли догадаться,
[А-ЯЁ]{3}будет совпадать с 3 большими буквами алфавита А-Я подряд (буква “ё” не включена в общий диапазон букв).Для названий курса,
[а-яА-ЯёЁ]{4,}будем искать а-я верхнего и нижнего регистра, предполагая, что имена всех курсов будут иметь как минимум 4 символа.Можете ли вы догадаться, каков будет шаблон, если максимальный предел символов в названии курса, скажем, 20?
Теперь мне нужно написать 3 отдельные строки, чтобы разделить предметы. Но есть лучший способ. Группы регулярных выражений.
Поскольку все записи имеют один и тот же шаблон, вы можете создать единый шаблон для всех записей курса и внести данные, которые хотите извлечь из пары скобок ().# создайте группы шаблонов текста курса и извлеките их >>> course_pattern = '([0-9]+)\s*([А-ЯЁ]{3})\s*([а-яА-ЯёЁ]{4,})' >>> re.findall(course_pattern, text) [('100', 'ИНФ', 'Информатика'), ('213', 'МАТ', 'Математика'), ('156', 'АНГ', 'Английский')]Обратите внимание на шаблон номера курса:
[0-9]+, код:[А-ЯЁ]{3}и название:[а-яА-ЯёЁ]{4,}они все помещены в круглую скобку (), для формирования группы.Что такое “жадное” соответствие в регулярных выражениях?
По умолчанию, регулярные выражения должны быть жадными. Это означает, что они пытаются извлечь как можно больше, пока соответствуют шаблону, даже если требуется меньше.
Давайте рассмотрим пример фрагмента HTML, где нам необходимо получить тэг HTML.
>>> text = "<body>Пример жадного соответствия регулярных выражений</body>" >>> re.findall('<.*>', text) ['<body>Пример жадного соответствия регулярных выражений</body>']Вместо совпадения до первого появления ‘>’, которое, должно было произойти в конце первого тэга тела, он извлек всю строку. Это по умолчанию “жадное” соответствие, присущее регулярным выражениям.
С другой стороны, ленивое соответствие “берет как можно меньше”. Это можно задать добавлением
?в конец шаблона.>>> re.findall('<.*?>', text) ['<body>', '</body>']Если вы хотите получить только первое совпадение, используйте вместо этого метод поиска
search.re.search('<.*?>', text).group() '<body>'Наиболее распространенный синтаксис и шаблоны регулярных выражений
Теперь, когда вы знаете как пользоваться модулем re, давайте рассмотрим некоторые обычно используемые шаблоны подстановок.
Основной синтаксис
. Один символ кроме новой строки \. Просто точка ., обратный слеш\убирает магию всех специальных символов.\d Одна цифра \D Один символ кроме цифры \w Один буквенный символ, включая цифры \W Один символ кроме буквы и цифры \s Один пробельный (включая таб и перенос строки) \S Один не пробельный символ \b Границы слова \n Новая строка \t Табуляция Модификаторы
$ Конец строки ^ Начало строки ab|cd Соответствует ab или de. ab-d]Любой символ, кроме: a, b, c, d () Извлечение элементов в скобках (a(bc)) Извлечение элементов в скобках второго уровня Повторы
[ab]{2} 2 непрерывных появления a или b [ab]{2,5} от 2 до 5 непрерывных появления a или b [ab]{2,} 2 и больше непрерывных появления a или b + одно или больше * 0 или больше ? 0 или 1 Примеры регулярных выражений
Любой символ кроме новой строки
>>> text = 'python.org' >>> print(re.findall('.', text)) # Любой символ кроме новой строки ['p', 'y', 't', 'h', 'o', 'n', '.', 'o', 'r', 'g'] >>> print(re.findall('...', text)) ['pyt', 'hon', '.or']Точки в строке
>>>text = 'python.
\.]', text)) # соответствует всему кроме точки
['p', 'y', 't', 'h', 'o', 'n', 'o', 'r', 'g']
Любая цифра
>>> text = '01, Янв 2018' >>> print(re.findall('\d+', text)) # Любое число (1 и более цифр подряд) ['01', '2018']Все, кроме цифры
>>> text = '01, Янв 2018' >>> print(re.findall('\D+', text)) # Любая последовательность, кроме цифр [', Янв ']Любая буква или цифра
>>> text = '01, Янв 2018' >>> print(re.findall('\w+', text)) # Любой символ(1 или несколько подряд) ['01', 'Янв', '2018']Все, кроме букв и цифр
>>> text = '01, Янв 2018' >>> print(re.findall('\W+', text)) # Все кроме букв и цифр [', ', ' ']Только буквы
>>> text = '01, Янв 2018' >>> print(re.findall('[а-яА-ЯёЁ]+', text)) # Последовательность букв русского алфавита ['Янв']Соответствие заданное количество раз
>>> text = '01, Янв 2018' >>> print(re.
findall('\d{4}', text)) # Любые 4 цифры подряд
['2018']
>>> print(re.findall('\d{2,4}', text))
['01', '2018']
1 и более вхождений
>>> print(re.findall(r'Co+l', 'So Cooool')) # 1 и более буква 'o' в строке ['Cooool']
Любое количество вхождений (0 или более раз)
>>> print(re.findall(r'Pi*lani', 'Pilani')) ['Pilani']
0 или 1 вхождение
>>> print(re.findall(r'colou?r', 'color')) ['color']
Граница слова
Границы слов\bобычно используются для обнаружения и сопоставления началу или концу слова. То есть, одна сторона является символом слова, а другая сторона является пробелом и наоборот.Например, регулярное выражение
\btoyсовпадает с ‘toy’ в ‘toy cat’, но не в ‘tolstoy’. Для того, чтобы ‘toy’ соответствовало ‘tolstoy’, используйтеtoy\b.
Можете ли вы придумать регулярное выражение, которое будет соответствовать только первой ‘toy’в ‘play toy broke toys’? (подсказка:\ bс обеих сторон)
Аналогично,\ Bбудет соответствовать любому non-boundary( без границ).
Например,\ Btoy \ Bбудет соответствовать ‘toy’, окруженной словами с обеих сторон, как в ‘antoynet’.>>> re.findall(r'\btoy\b', 'play toy broke toys') # соедини toy с ограничениями с обеих сторон ['toy']
Практические упражнения
Давайте немного попрактикуемся. Пришло время открыть вашу консоль. (Варианты ответов здесь)
1. Извлеките никнейм пользователя, имя домена и суффикс из данных email адресов.
emails = """[email protected] [email protected] [email protected]""" # требуеый вывод [('zuck26', 'facebook', 'com'), ('page33', 'google', 'com'), ('jeff42', 'amazon', 'com')]
2. Извлеките все слова, начинающиеся с ‘b’ или ‘B’ из данного текста.
text = """Betty bought a bit of butter, But the butter was so bitter, So she bought some better butter, To make the bitter butter better.""" # требуеый вывод ['Betty', 'bought', 'bit', 'butter', 'But', 'butter', 'bitter', 'bought', 'better', 'butter', 'bitter', 'butter', 'better']
3.
Уберите все символы пунктуации из предложенияsentence = """A, very very; irregular_sentence""" # требуеый вывод A very very irregular sentence
4. Очистите следующий твит, чтобы он содержал только одно сообщение пользователя. То есть, удалите все URL, хэштеги, упоминания, пунктуацию, RT и CC.
tweet = '''Good advice! RT @TheNextWeb: What I would do differently if I was learning to code today https://t.co/lbwej0pxOd cc: @garybernhardt #rstats''' # требуеый вывод 'Good advice What I would do differently if I was learning to code today'
- Извлеките все текстовые фрагменты между тегами с HTML страницы: https://raw.githubusercontent.com/selva86/datasets/master/sample.html
Код для извлечения HTML страницы:
import requests r = requests.get("https://raw.githubusercontent.com/selva86/datasets/master/sample.html") r.text # здесь хранится html # требуеый вывод ['Your Title Here', 'Link Name', 'This is a Header', 'This is a Medium Header', 'This is a new paragraph! ', 'This is a another paragraph!', 'This is a new sentence without a paragraph break, in bold italics. ']
Ответы
# 1 задание >>> pattern = r'(\w+)@([A-Z0-9]+)\.([A-Z]{2,4})' >>> re.findall(pattern, emails, flags=re.IGNORECASE) [('zuck26', 'facebook', 'com'), ('page33', 'google', 'com'), ('jeff42', 'amazon', 'com')]Есть больше шаблонов для извлечения домена и суфикса. Это лишь один из них.
# 2 задание >>> import re >>> re.findall(r'\bB\w+', text, flags=re.IGNORECASE) ['Betty', 'bought', 'bit', 'butter', 'But', 'butter', 'bitter', 'bought', 'better', 'butter', 'bitter', 'butter', 'better']
\bнаходится слева от ‘B’, значит слово должно начинаться на ‘B’.
Добавьтеflags=re.IGNORECASE, что бы шаблон был не чувствительным к регистру.# 3 задание >>> import re >>> " ".join(re.split('[;,\s_]+', sentence)) 'A very very irregular sentence'# 4 задание >>> import re >>> def clean_tweet(tweet): tweet = re.
_`{|}~"""), '', tweet) # удалит символы пунктуации
tweet = re.sub('\s+', ' ', tweet) # заменит пробельные символы на 1 пробел
return tweet
>>> print(clean_tweet(tweet))
'Good advice What I would do differently if I was learning to code today'
# 5 задание >>> re.findall('<.*?>(.*)</.*?>', r.text) ['Your Title Here', 'Link Name', 'This is a Header', 'This is a Medium Header', 'This is a new paragraph! ', 'This is a another paragraph!', 'This is a new sentence without a paragraph break, in bold italics.']Надеемся, информация была вам полезна. Стояла цель — познакомить вас с примерами регулярных выражений легким и доступным для запоминания способом.
Python RegEx
❮ Предыдущий Далее ❯
Регулярное выражение или регулярное выражение представляет собой последовательность символов, образующую шаблон поиска.
RegEx можно использовать для проверки наличия в строке указанного шаблона поиска.
Модуль регулярных выражений
Python имеет встроенный пакет
re, который можно использовать для работы с Обычные выражения.Импорт модуля
re:import re
RegEx в Python 9The.*Spain$", txt)
Попробуйте сами »
Функции регулярных выражений
Модуль
reпредлагает набор функций, который позволяет нам искать строку для совпадения:Функция Описание находка Возвращает список, содержащий все совпадения поиск Возвращает объект Match, если в строке есть совпадение. сплит Возвращает список, в котором строка была разделена при каждом совпадении суб Заменяет одно или несколько совпадений строкой Метасимволы
Метасимволы — это символы со специальным значением:
Символ Описание Пример Попробуйте [] Набор символов "[днём]" Попробуй » 9привет" Попробуй » $ Заканчивается на "планета$" Попробуй » * Ноль или более вхождений "хе. *о"Попробуй » + Одно или несколько вхождений "хе.+о" Попробуй » ? Ноль или одно вхождение "хе.?о" Попробуй » {} Ровно указанное количество вхождений "он.{2}о" Попробуй » | Либо, либо "падает|остается" Попробуй » () Захват и группировка Специальные последовательности
Специальная последовательность представляет собой
\, за которой следует один из символов из списка ниже, и имеет особое значение:Символ Описание Пример Попробуйте \А Возвращает совпадение, если указанные символы находятся в начале строка "\А" Попробуй » \б Возвращает совпадение, в котором указанные символы находятся в начале или в конце конец слова
("r" в начале означает, что строка обрабатывается как «необработанная строка»)r"\bain"
r"ain\b"Попробуй »
Попробуй »\В Возвращает совпадение, в котором присутствуют указанные символы, но НЕ в начале (или на конец) слова
("r" в начале означает, что строка обрабатывается как "необработанная строка")r"\Bain"
r"ain\B"Попробуй »
Попробуй »\д Возвращает совпадение, в котором строка содержит цифры (числа от 0 до 9). )"\ д" Попробуй » \Д Возвращает совпадение, в котором строка НЕ содержит цифр "\Д" Попробуй » \с Возвращает совпадение, в котором строка содержит символ пробела "\с" Попробуй » \С Возвращает совпадение, в котором строка НЕ содержит символ пробела "\С" Попробуй » \ш Возвращает совпадение, в котором строка содержит любые символы слова (символы из от a до Z, цифры от 0 до 9 и символ подчеркивания _) "\ш" Попробуй » \Вт Возвращает совпадение, в котором строка НЕ содержит символов слова "\W" Попробуй » \З Возвращает совпадение, если указанные символы находятся в конце строки "Испания\Z" Попробуй » Наборы
Набор — это набор символов, заключенных в пару квадратных скобок
[]со специальным значением:Набор Описание Попробуйте [арен] Возвращает совпадение, в котором один из указанных символов ( a,rилиn) есть подарокПопробуй » [а-н] 9арн] Возвращает совпадение для любого символа, КРОМЕ a,ринПопробуй » [0123] Возвращает совпадение, в котором любая из указанных цифр ( 0,1,2или3) являются подарокПопробуй » [0-9] Возвращает совпадение любой цифры между 0и9Попробуй » [0-5][0-9] Возвращает совпадение любых двузначных чисел из 00и. 59 Попробуй » [a-zA-Z] Возвращает совпадение любого символа в алфавитном порядке между aиz, нижний регистр ИЛИ верхний регистрПопробуй » [+] В наборах, +,*,.,|,(),$,{}не имеет особого значения, поэтому[+]означает: вернуть совпадение для любого+символов в строкеПопробуй » Функция findall()
Функция
findall()возвращает список, содержащий все совпадения.Пример
Распечатать список всех совпадений:
import re
txt = "Дождь в Испании"
x = re.findall("ai", txt)
печать(x)Попробуйте сами »
Список содержит совпадения в порядке их обнаружения.
Если совпадений не найдено, возвращается пустой список:
Пример
Возврат пустого списка, если совпадений не найдено:
import re
txt = "Дождь в Испании"
x = re.findall("Португалия", txt)
print(x)Попробуйте сами »
Функция search()
Функция
search()выполняет поиск строки для совпадения и возвращает объект Match, если есть соответствие.Если имеется более одного совпадения, будет возвращено только первое совпадение:
Пример
Поиск первого символа пробела в строке:
import re
txt = "Дождь в Испании"
x = re.search("\s", txt)print("Первый пробел находится в position:", x.start())
Попробуйте сами »
Если совпадений не найдено, возвращается значение
Нет:Пример
Сделать поиск, который не дает совпадений:
import re
txt = "Дождь в Испании"
x = re. search("Португалия",
txt)
print(x)Попробуйте сами »
Функция split()
Функция
split()возвращает список, в котором строка была разделена при каждом совпадении:Пример
Разделена при каждом пробеле:
import re
txt = "Дождь в Испании"
х = re.split("\s", txt)
print(x)Попробуйте сами »
Вы можете управлять количеством вхождений, указав
макссплитпараметр:Пример
Разделить строку только при первом вхождении:
import re
txt = "Дождь в Испании"
x = re.split("\s", текст, 1)
print(x)Попробуйте сами »
Функция sub()
Функция
sub() 9Функция 0014 заменяет совпадения на текст на ваш выбор:Пример
Замените каждый пробел цифрой 9:
import re
txt = "Дождь в Испании"
x = re. sub("\s",
"9", txt)
print(x)Попробуйте сами »
Вы можете контролировать количество замен, указав
количествопараметр:Пример
Замените первые 2 вхождения:
импорт повторно
txt = "Дождь в Испании"
x = re.sub("\s", "9", txt, 2)
print(x)Попробуйте сами »
Match Object
Match Object — это объект, содержащий информацию о поиске и результате.
Примечание: Если совпадений нет, значение
Noneбудет возвращается вместо Match Object.Пример
Выполните поиск, который вернет объект соответствия:
импорт повторно
txt = "Дождь в Испании"
x = re.search("ai", txt)
print(x) #this напечатает объектПопробуйте сами »
Объект Match имеет свойства и методы, используемые для получения информации о поиске и результате:
.возвращает кортеж, содержащий начальную и конечную позиции совпадения. span()
.stringвозвращает строку, переданную в функцию
.group()возвращает часть строки, где было совпадениеПример
Вывести положение (начальное и конечное положение) первого совпадения.
Регулярное выражение ищет любые слова, начинающиеся с прописной буквы "С":
import re
txt = "Дождь в Испании"
x = re.search(r"\bS\w+", txt)
print( x.span() )Попробуйте сами »
Пример
Вывести строку, переданную в функцию:
import re
txt = "Дождь в Испании"
x = re.search(r"\bS\w+", txt)
print( x.string )Попробуйте сами »
Пример
Вывести часть строки, в которой было совпадение.
Регулярное выражение ищет любые слова, начинающиеся с прописной буквы "С":
import re
txt = "Дождь в Испании"
x = re.search(r"\bS\w+", txt)
print( x.group() )Попробуйте сами »
Примечание : Если совпадений нет, значение 9а...с$
абсНет соответствия псевдонимМатч безднаМатч ПсевдонимНет соответствия СчетыНет соответствия Python имеет модуль с именем
reдля работы с RegEx. Вот пример: 9а...с$' test_string = 'бездна' результат = re.match (шаблон, тестовая_строка) если результат: print("Поиск успешен.") еще: print("Поиск не удался.")Здесь мы использовали функцию
re.для поиска шаблона в пределах test_string . Метод возвращает объект соответствия, если поиск успешен. Если нет, возвращается match() None.В модуле re определены несколько других функций для работы с RegEx. Прежде чем мы исследуем это, давайте узнаем о самих регулярных выражениях. 9 $ * + ? {} () \ |
[]— Квадратные скобкиКвадратные скобки определяют набор символов, которые вы хотите сопоставить.
Выражение Строка Совпало? [абв]и1 совпадение ак2 спички Эй, ДжудНет соответствия абв де ка5 спичек Здесь
[abc]будет соответствовать, если строка, которую вы пытаетесь сопоставить, содержит любой изa,bилиc.Вы также можете указать диапазон символов, используя
-в квадратных скобках. 90-9] означает любой нецифровой символ. - Используя метод
 Python’, text, flags=re.MULTILINE)
>>>
Python’, text, flags=re.MULTILINE)
>>>  findall('fun$', 'fun fun fun')
['fun']
findall('fun$', 'fun fun fun')
['fun'] findall('fun$', text)
[]
>>> re.findall('fun$', text, flags=re.MULTILINE)
['fun', 'fun', 'fun']
>>>
findall('fun$', text)
[]
>>> re.findall('fun$', text, flags=re.MULTILINE)
['fun', 'fun', 'fun']
>>>  sub('Python$', 'Code', 'Is Python\nPython')
'Is Python\nCode'
sub('Python$', 'Code', 'Is Python\nPython')
'Is Python\nCode' Вот один пример на один метод:
Вот один пример на один метод: матчи в начале строки. Оператор долларовой подписи $ соответствует в конце строки. Если вы хотите подобрать в начале или в конце каждой строки в многострочной строке, вы можете установить RE. Многолитный флаг во всех соответствующих методах Re.
матчи в начале строки. Оператор долларовой подписи $ соответствует в конце строки. Если вы хотите подобрать в начале или в конце каждой строки в многострочной строке, вы можете установить RE. Многолитный флаг во всех соответствующих методах Re. Ecommerce Giants корабля продуктов на основе Описания текстовых продуктов Отказ Регулярные выражения правит игре, когда текстовая обработка соответствует информатике.
Ecommerce Giants корабля продуктов на основе Описания текстовых продуктов Отказ Регулярные выражения правит игре, когда текстовая обработка соответствует информатике.

 Но какой же следует использовать на практике?
Но какой же следует использовать на практике? Это делает наличие цифры не обязательным, чтобы получилось совпадение. Подробнее об этом позже.
Это делает наличие цифры не обязательным, чтобы получилось совпадение. Подробнее об этом позже. search(text2)
>>> print('Первый индекс: ', s.start())
>>> print('Последний индекс: ', s.end())
>>> print(text2[s.start():s.end()])
Первый индекс: 17
Последний индекс: 20
213
search(text2)
>>> print('Первый индекс: ', s.start())
>>> print('Последний индекс: ', s.end())
>>> print(text2[s.start():s.end()])
Первый индекс: 17
Последний индекс: 20
213



 ab-d]
ab-d] \.]', text)) # соответствует всему кроме точки
['p', 'y', 't', 'h', 'o', 'n', 'o', 'r', 'g']
\.]', text)) # соответствует всему кроме точки
['p', 'y', 't', 'h', 'o', 'n', 'o', 'r', 'g']
 findall('\d{4}', text)) # Любые 4 цифры подряд
['2018']
>>> print(re.findall('\d{2,4}', text))
['01', '2018']
findall('\d{4}', text)) # Любые 4 цифры подряд
['2018']
>>> print(re.findall('\d{2,4}', text))
['01', '2018']
 Уберите все символы пунктуации из предложения
Уберите все символы пунктуации из предложения ']
']
 _`{|}~"""), '', tweet) # удалит символы пунктуации
tweet = re.sub('\s+', ' ', tweet) # заменит пробельные символы на 1 пробел
return tweet
>>> print(clean_tweet(tweet))
'Good advice What I would do differently if I was learning to code today'
_`{|}~"""), '', tweet) # удалит символы пунктуации
tweet = re.sub('\s+', ' ', tweet) # заменит пробельные символы на 1 пробел
return tweet
>>> print(clean_tweet(tweet))
'Good advice What I would do differently if I was learning to code today'

 *о"
*о" )
) 59
59 
 search("Португалия",
txt)
search("Португалия",
txt)  sub("\s",
"9", txt)
sub("\s",
"9", txt)  span()
span() 
 match()
match() 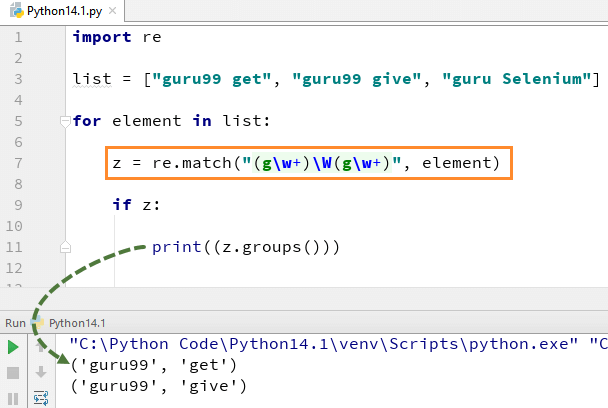
. — Точка
Точка соответствует любому одиночному символу (кроме новой строки '\n' ).
| Выражение | Строка | Совпало? |
|---|---|---|
.. | и | Нет соответствия |
ак | 1 совпадение | абв | 1 совпадение |
акб | Нет совпадений (начинается с a , но не сопровождается b ) |
$ — Доллар
Символ доллара $ используется для проверки того, заканчивается ли строка на определенным символом.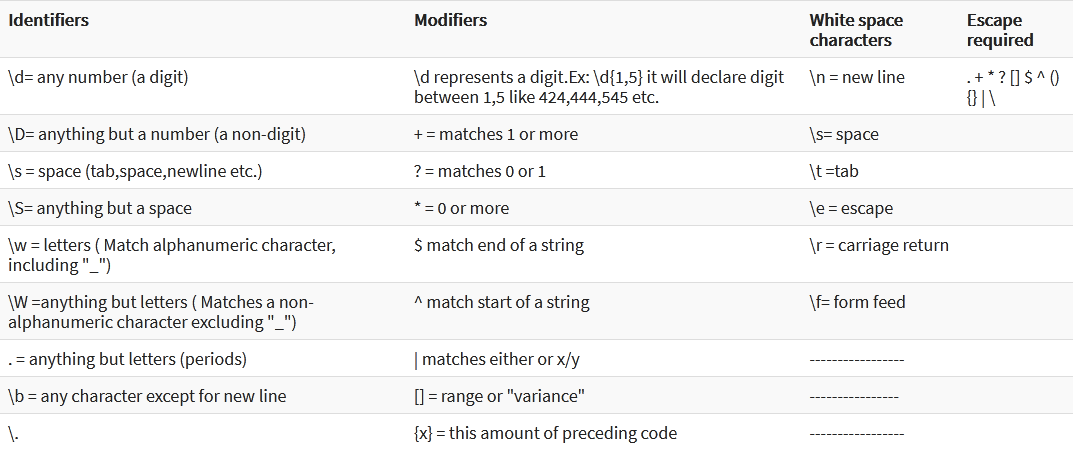
| Выражение | Строка | Совпало? |
|---|---|---|
$ | и | 1 совпадение |
формула | 1 совпадение | |
кабина | Нет соответствия |
* — Звезда
Символ звезды * соответствует нулю или более вхождений оставшегося шаблона.
| Выражение | Строка | Совпало? |
|---|---|---|
основной | мин | 1 совпадение |
мужчина | 1 совпадение | |
маан | 1 совпадение | |
основной | Нет соответствия (за и не следует n ) | |
женщина | 1 совпадение |
+ — Плюс
Символ плюс + соответствует одному или нескольким вхождениям оставшегося шаблона.
| Выражение | Строка | Совпало? |
|---|---|---|
м+н | мин | Нет соответствия (без символ ) |
мужчина | 1 совпадение | |
маан | 1 совпадение | |
основной | Нет совпадений (за a не следует n) | |
женщина | 1 совпадение |
? — Знак вопроса
Знак вопроса ? соответствует нулю или одному вхождению оставшегося шаблона.
| Выражение | Строка | Совпало? |
|---|---|---|
основной | мин | 1 совпадение |
мужчина | 1 совпадение | |
маан | Нет совпадения (более одного символа и ) | |
основной | Нет совпадения (за a не следует n) | |
женщина | 1 совпадение |
{} — Скобы
Рассмотрим этот код: {n,m} . Это означает, что ему осталось не менее 90 726 n 90 727 и не более 90 726 m 90 727 повторений паттерна.
Это означает, что ему осталось не менее 90 726 n 90 727 и не более 90 726 m 90 727 повторений паттерна.
| Выражение | Строка | Совпало? |
|---|---|---|
а{2,3} | абв дат | Нет соответствия |
абв даат | 1 спичка ( d aa t ) | |
аабв дааат | 2 спички (at aa bc и d aaa t ) | |
аабв даааат | 2 спички (at aa bc и d aaa at ) |
Давайте попробуем еще один пример. Это регулярное выражение [0-9]{2, 4} соответствует как минимум 2 цифрам, но не более 4 цифрам
| Выражение | Строка | Совпало? |
|---|---|---|
[0-9]{2,4} | ab123csde | 1 совпадение (совпадение по адресу ab 123 csde ) |
12 и 345673 | 3 совпадения ( 12 , 3456 , 73 ) | |
1 и 2 | Нет соответствия |
| — Чередование
Вертикальная перекладина | Для чередования используется (оператор или ).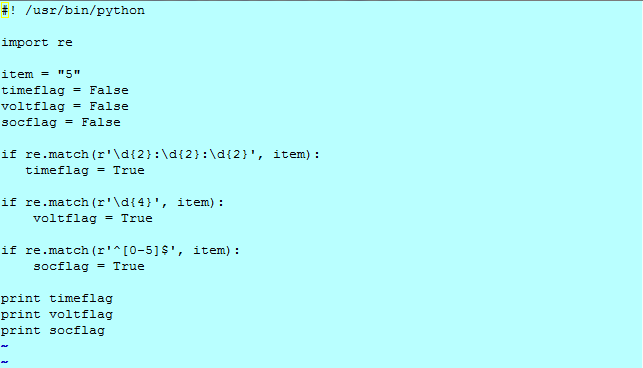
| Выражение | Строка | Совпало? |
|---|---|---|
а|б | Код | Нет соответствия |
аде | 1 совпадение (совпадение по и по ) | |
акдбеа | 3 спички ( a cd b e a ) |
Здесь a|b соответствует любой строке, содержащей либо a , либо b
() — Group
30014 используется для группировки подшаблонов. Например,
(a|b|c)xz соответствует любой строке, которая соответствует либо a , либо b , либо c , за которыми следует xz | Выражение | Строка | Совпало? |
|---|---|---|
(a|b|c)xz | аб хз | Нет соответствия |
абхз | 1 совпадение (совпадение на а бхз ) | |
аксз кабксз | 2 совпадения (at axz bc ca bxz ) |
\ — Обратная косая черта
Обратная косая черта \ используется для экранирования различных символов, включая все метасимволы.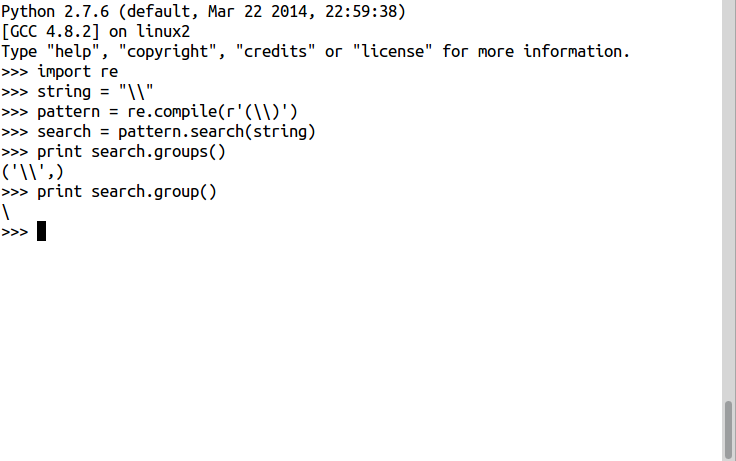 Например,
Например,
\$a соответствует, если строка содержит $ , за которыми следует a . Здесь $ не интерпретируется движком RegEx особым образом.
Если вы не уверены, имеет ли символ особое значение или нет, вы можете поставить перед ним \. Это гарантирует, что с персонажем не обращаются особым образом.
Специальные последовательности
Специальные последовательности упрощают запись часто используемых шаблонов. Вот список специальных последовательностей:
\A — Соответствует, если указанные символы находятся в начале строки.
| Выражение | Строка | Совпало? |
|---|---|---|
\Athe | солнце | Матч |
На солнце | Нет соответствия |
\b — Соответствует, если указанные символы находятся в начале или в конце слова.
| Выражение | Строка | Совпало? |
|---|---|---|
\bfoo | футбольный мяч | Матч |
футбольный мяч | Матч | |
футбол | Нет соответствия | |
foo\b | фу | Матч |
тест афу | Матч | |
самый нижний | Нет соответствия |
\B — Напротив \b . Соответствует, если указанные символы равны , а не в начале или конце слова.
| Выражение | Строка | Совпало? |
|---|---|---|
\Bfoo | футбольный мяч | Нет соответствия |
футбольный мяч | Нет совпадения | |
футбол | Матч | |
foo\B | фу | Нет соответствия |
тест афу | Нет соответствия | |
самый нижний | Матч |
\d — соответствует любой десятичной цифре. Эквивалент
Эквивалент [0-9]
| Выражение | Строка | Совпало? |
|---|---|---|
\Д | 1ab34"50 | 3 совпадения (в 1 аб 34 " 50 ) |
1345 | Нет соответствия |
\s — Соответствует строкам, содержащим любой пробельный символ. Эквивалент 9\t\n\r\f\v] .
| Выражение | Строка | Совпало? |
|---|---|---|
\С | а б | 2 спички (по a b ) |
| Нет соответствия |
\w — Соответствует любому буквенно-цифровому символу (цифры и буквы). Эквивалент
Эквивалент [a-zA-Z0-9_] . Кстати, подчеркивание _ тоже считается буквенно-цифровым символом.
| Выражение | Строка | Совпало? | ||||||
|---|---|---|---|---|---|---|---|---|
\ш | 12"": ;c | 3 совпадения (в 12 &": ; c ) | ||||||
%"> ! | Нет соответствия | |||||||
| Выражение | Строка | Совпало? |
|---|---|---|
\Вт | 1а2%с | 1 совпадение (в 1 a 2 % c ) |
Питон | Нет соответствия |
\Z — Соответствует, если указанные символы находятся в конце строки.
| Выражение | Строка | Совпало? |
|---|---|---|
Python\Z | Мне нравится Python | 1 совпадение |
Мне нравится программировать на Python | Нет соответствия | |
Python — это весело. | Нет соответствия |
Совет: Для создания и тестирования регулярных выражений можно использовать инструменты проверки регулярных выражений, такие как regex101. Этот инструмент не только поможет вам в создании регулярных выражений, но и поможет вам изучить их.
Теперь вы понимаете основы RegEx, давайте обсудим, как использовать RegEx в вашем коде Python.
Python RegEx
Python имеет модуль с именем re для работы с регулярными выражениями. Чтобы использовать его, нам нужно импортировать модуль.
Чтобы использовать его, нам нужно импортировать модуль.
import re
Модуль определяет несколько функций и констант для работы с RegEx.
re.findall()
Метод re.findall() возвращает список строк, содержащих все совпадения.
Пример 1: re.findall()
# Программа для извлечения чисел из строки импортировать повторно строка = 'привет 12 привет 89. Привет 34' шаблон = '\d+' результат = re.findall (шаблон, строка) печать (результат) # Вывод: ['12', '89', '34']
Если шаблон не найден, re.findall() возвращает пустой список.
re.split()
Метод re.split разбивает строку, в которой есть совпадение, и возвращает список строк, в которых произошло разбиение.
Пример 2: re.split()
импортировать повторно строка = 'Двенадцать:12 восемьдесят девять:89.' шаблон = '\d+' результат = re.split (шаблон, строка) печать (результат) # Вывод: ['Двенадцать:', ' Восемьдесят девять:', '.
 ']
']
Если шаблон не найден, re.split() возвращает список, содержащий исходную строку.
Вы можете передать аргумент maxsplit методу re.split() . Это максимальное количество расщеплений, которое может произойти.
импортировать повторно строка = 'Двенадцать:12 восемьдесят девять:89Девять: 9». шаблон = '\d+' # макссплит = 1 # разбить только при первом вхождении результат = re.split (шаблон, строка, 1) печать (результат) # Вывод: ['Двенадцать:', ' Восемьдесят девять:89 Девять:9.']
Кстати, значение по умолчанию maxsplit равно 0; что означает все возможные расщепления.
re.sub()
Синтаксис re.sub() :
re.sub(шаблон, замена, строка)
Метод возвращает строку, в которой совпадающие вхождения заменяются содержимым заменяет переменную .
Пример 3: re.sub()
# Программа для удаления всех пробелов импортировать повторно # многострочная строка строка = 'абв 12\ де 23 \н ф45 6' # соответствует всем пробельным символам шаблон = '\s+' # пустой строки заменить = '' new_string = re.
 sub (шаблон, замена, строка)
печать (новая_строка)
# Вывод: abc12de23f456
sub (шаблон, замена, строка)
печать (новая_строка)
# Вывод: abc12de23f456
Если шаблон не найден, re.sub() возвращает исходную строку.
Вы можете передать count в качестве четвертого параметра в метод re.sub() . Если его опустить, результатом будет 0. Это заменит все вхождения.
импортировать повторно # многострочная строка строка = 'абв 12\ де 23 \н ф45 6' # соответствует всем пробельным символам шаблон = '\s+' заменить = '' new_string = re.sub(r'\s+', заменить, строка, 1) печать (новая_строка) # Выход: # abc12de 23 # ф45 6
re.subn()
Функция re.subn() аналогична re.sub() , за исключением того, что она возвращает кортеж из двух элементов, содержащих новую строку и количество произведенных замен.
Пример 4: re.subn()
# Программа для удаления всех пробелов импортировать повторно # многострочная строка строка = 'абв 12\ де 23 \н ф45 6' # соответствует всем пробельным символам шаблон = '\s+' # пустой строки заменить = '' new_string = re.
 subn (шаблон, замена, строка)
печать (новая_строка)
# Вывод: ('abc12de23f456', 4)
subn (шаблон, замена, строка)
печать (новая_строка)
# Вывод: ('abc12de23f456', 4)
re.search()
Метод re.search() принимает два аргумента: шаблон и строку. Метод ищет первое место, где шаблон RegEx создает совпадение со строкой.
Если поиск успешен, re.search() возвращает объект соответствия; если нет, возвращается None .
match = re.search(pattern, str)
Пример 5: re.search()
импортировать повторно
string = "Питон - это весело"
# проверить, стоит ли 'Python' в начале
match = re.search('\APython', строка)
если совпадают:
print("Шаблон найден внутри строки")
еще:
print("шаблон не найден")
# Вывод: шаблон найден внутри строки
Здесь совпадение содержит объект соответствия.
Объект соответствия
Вы можете получить методы и атрибуты объекта совпадения, используя функцию dir().
Некоторые из часто используемых методов и атрибутов объектов соответствия:
match.
 group()
group() Метод group() возвращает часть строки, в которой есть совпадение.
Пример 6: Подбор объекта
импортировать повторно
строка = '39801 356, 2102 1111'
# Трехзначное число, за которым следует пробел, за которым следует двузначное число
шаблон = '(\d{3}) (\d{2})'
# переменная match содержит объект Match.
match = re.search(шаблон, строка)
если совпадают:
печать (совпадение.группа())
еще:
print("шаблон не найден")
# Вывод: 801 35
Здесь match переменная содержит объект match.
Наш шаблон (\d{3}) (\d{2}) имеет две подгруппы (\d{3}) и (\d{2}) . Вы можете получить часть строки этих подгрупп в скобках. Вот как:
>>> match.group(1) «801» >>> match.group(2) '35' >>> match.group(1, 2) («801», «35») >>> match.groups() («801», «35»)
match.start(), match.end() и match.span()
Функция start() возвращает индекс начала совпадающей подстроки.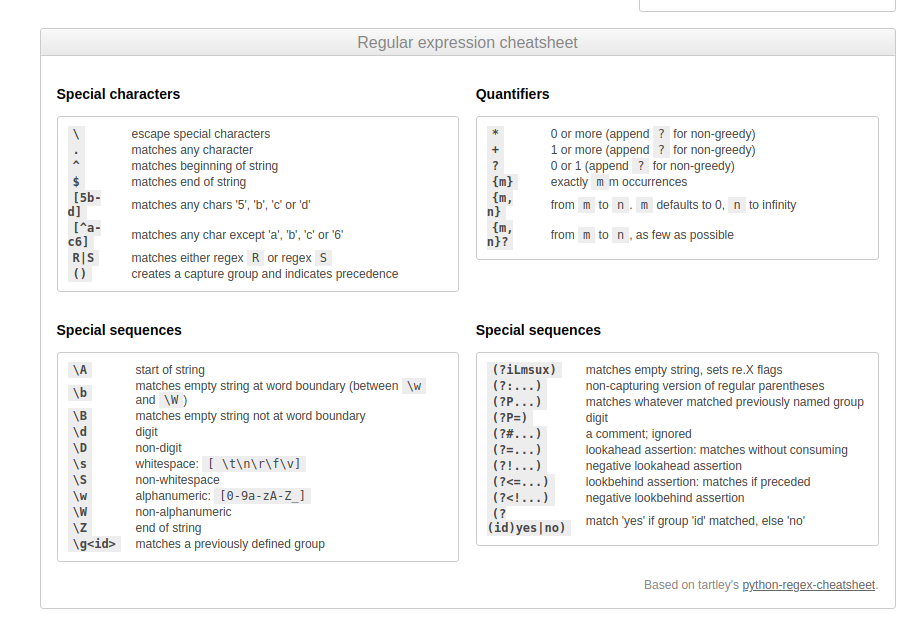 Аналогично,
Аналогично, end() возвращает конечный индекс совпадающей подстроки.
>>> match.start() 2 >>> match.end() 8
Функция span() возвращает кортеж, содержащий начальный и конечный индексы совпадающей части.
>>> match.span() (2, 8)
match.re и match.string
Атрибут re совпадающего объекта возвращает объект регулярного выражения. Точно так же string атрибут возвращает переданную строку.
>>> match.re
re.compile('(\\d{3}) (\\d{2})')
>>> match.string
'39801 356, 2102 1111'
Мы рассмотрели все часто используемые методы, определенные в модуле re . Если вы хотите узнать больше, посетите модуль Python 3 re.
Использование префикса r перед регулярным выражением
Когда префикс r или R используется перед регулярным выражением, это означает необработанную строку. Например, '\n' — это новая строка, тогда как r'\n' означает два символа: обратную косую черту \ , за которой следует n .
Backlash \ используется для экранирования различных символов, включая все метасимволы. Однако использование префикса r приводит к тому, что \ рассматривается как обычный символ.
Пример 7. Необработанная строка с префиксом r
импортировать повторно string = '\n и \r являются управляющими последовательностями.' результат = re.findall(r'[\n\r]', строка) печать (результат) # Вывод: ['\n', '\r']
Регулярное выражение в Python с примерами | Набор 1
A Регулярные выражения (RegEx) — это специальная последовательность символов, которая использует шаблон поиска для поиска строки или набора строк. Он может обнаруживать наличие или отсутствие текста, сопоставляя его с определенным шаблоном, а также может разбивать шаблон на один или несколько подшаблонов. Python предоставляет модуль re , который поддерживает использование регулярных выражений в Python. Его основная функция — предлагать поиск, где он принимает регулярное выражение и строку. Здесь он либо возвращает первое совпадение, либо ничего.
Здесь он либо возвращает первое совпадение, либо ничего.
Example:
Python3
|
Индекс 90:07 2 Выход End Index: 40 Приведенный выше код дает начальный индекс и конечный индекс строкового портала. Примечание: Здесь символ r (r’portal’) означает необработанное, а не регулярное выражение. Необработанная строка немного отличается от обычной строки, она не интерпретирует символ \ как escape-символ. Это связано с тем, что обработчик регулярных выражений использует символ \ для собственной цели экранирования. Прежде чем приступить к работе с модулем регулярных выражений Python, давайте посмотрим, как на самом деле писать регулярные выражения с использованием метасимволов или специальных последовательностей. Чтобы понять аналогию RE, метасимволы полезны, важны и будут использоваться в функциях модуля re. Ниже приведен список метасимволов. Давайте подробно обсудим каждый из этих метасимволов . Это можно рассматривать как способ экранирования метасимволов. Например, если вы хотите найти точку (.) в строке, вы обнаружите, что точка (.) будет рассматриваться как специальный символ, как и один из метасимволов (как показано в таблице выше). Поэтому в этом случае мы будем использовать обратную косую черту (\) непосредственно перед точкой (. Example: Вывод Квадратные скобки ([]) представляют собой класс символов, состоящий из набора символов, которые мы хотим сопоставить. Например, класс символов [abc] будет соответствовать любому отдельному символу a, b или c. Мы также можем указать диапазон символов, используя – внутри квадратных скобок. Например, 9ge проверит, начинается ли строка с ge, например geeks, geeksforgeeks и т. д. символ доллара ($) соответствует концу строки, т. е. проверяет, заканчивается ли строка заданным символом (символами) или нет. Например, Символ точки (.) соответствует только одному символу, за исключением символа новой строки (\n). Например – Символ Or работает как оператор or, то есть он проверяет, присутствует ли в строке шаблон до или после символа or. Например, Вопросительный знак(?) проверяет, встречается ли строка перед вопросительным знаком в регулярном выражении хотя бы один раз или не встречается вообще. Например, Символ звездочки (*) соответствует нулю или более вхождениям регулярного выражения, предшествующего символу *. Например – Символ плюс (+) соответствует одному или нескольким вхождениям регулярного выражения, предшествующего символу +. Например, Фигурные скобки соответствуют любым повторениям, предшествующим регулярному выражению от m до n включительно. Например, Символ группы используется для группировки подшаблонов. Например, Специальные последовательности не соответствуют фактическому символу в строке, вместо этого они сообщают конкретное место в строке поиска, где должно произойти совпадение. В Python есть модуль с именем re, который используется для регулярных выражений в Python. Пример: Импорт модуля RE в Python Let Let Let Let's Let Tot't Let Tot't Let Tot't Let Tot't Let Tot't Let Tot'T Let Tot'T Let Tot'T Let Tot At't Let Tot't Let Tot't Let's Let Tot't Let's Let Tot't Let Thet's See. Возвращает все непересекающиеся совпадения шаблона в строке в виде списка строк. Строка сканируется слева направо, и совпадения возвращаются в том порядке, в котором они были найдены. Example: Finding all occurrences of a pattern Выход Rathers Arpression для сопоставления шаблонов или выполнения подстановок строк. Пример 1: Вывод: Понимание вывода: Пример 2: Set class [\s,.] будет соответствовать любому символу пробела, ',', или, '.' . Вывод: 
Метасимволы
MetaCharacters Описание \ Используется для удаления специального значения символа, следующего за ним 9 Совпадает с началом $ Совпадает с концом . 
Соответствует любому символу, кроме новой строки | Means OR (Matches with any of the characters separated by it. ? Matches zero or one occurrence * Any number of occurrences (including 0 occurrences) + Одно или несколько событий {} Укажите количество вхождений предшествующего регулярного выражения для сопоставления. () Заключите группу регулярных выражений  ), чтобы она потеряла свою особенность. См. приведенный ниже пример для лучшего понимания.
), чтобы она потеряла свою особенность. См. приведенный ниже пример для лучшего понимания. Python3
import re s = 'geeks.forgeeks' match = re .search(r '.' , s) print (match) match = re.search(r '\.' , s) печать (совпадение) <_Srech объект; диапазон = (0, 1), совпадение = 'g'>
<_sre.
 SRE_Match объект; span=(5, 6), match='.'>
SRE_Match объект; span=(5, 6), match='.'> [] – Квадратные скобки
$ — символ доллара
. – Точка
 b проверит строку, содержащую любой символ на месте точки, такой как acb, acbd, abbb и т. д.
b проверит строку, содержащую любой символ на месте точки, такой как acb, acbd, abbb и т. д. | – Or
? – Вопросительный знак
* – Звездочка
 д., но не будет соответствовать строке abdc, поскольку за b не следует c.
д., но не будет соответствовать строке abdc, поскольку за b не следует c. + – Плюс
{m, n} – Скобы
(
Специальные последовательности
 Это упрощает написание часто используемых шаблонов.
Это упрощает написание часто используемых шаблонов. Список специальных последовательностей
Специальная последовательность Описание Примеры \ A Матчи, если струна начинается с данного символа \ A.0055 для гиков для всего мира \b Совпадает, если слово начинается или заканчивается данным символом. \b(string) проверит начало слова, а (string)\b проверит окончание слова. \bge гики get \B Это противоположно \b, т.е. строка не должна начинаться или заканчиваться данным регулярным выражением. \Bge вместе 90-9] \D geeks geek1 \s Соответствует любому символу пробела. 
\s gee ks a bc a \S Matches any non-whitespace character \S a bd abcd \w Соответствует любому буквенно-цифровому символу, это эквивалентно классу [a-zA-Z0-9_]. \ш 123 geeks4 \W Соответствует любому небуквенно-цифровому символу. \W >$ gee<> \Z Matches if the string ends with the given regex ab\Z abcdab abababab Модуль регулярных выражений в Python
 Мы можем импортировать этот модуль, используя оператор импорта.
Мы можем импортировать этот модуль, используя оператор импорта. Python3
Import RE re.findall()
Python3
import re string = regex = '\d+' совпадение = re. findall(регулярное выражение, строка)
findall(регулярное выражение, строка) печать (совпадение) 0003 ['123456789', '987654321']
re.compile () Python
импорт повторно р = ре. Compile ( '[A-E]' ) Печать (P.Findall ( "AYE, сказал г-н Гибенсон Стк. ['e', 'a', 'd', 'b', 'e', 'a']

Питон
импорт пере p = пере. compile ( '\d' ) print (p.findall( "I went to him at 11 A.M. on 4th July 1886" )) р = ре. компиляция ( '\d+' ) печать (p.findall( "Я пошел к нему в 11 часов утра 4 июля 1886 года" ))
['1','4'1 8', '8', '6'] ['11', '4', '1886']
Example 3:
Python
['H', 'e', 's', 'a', 'i', 'd', 'i', 'n', 's', 'o', 'm' , 'е', '_', 'л', 'а', 'н', 'г'] ['Я', 'пошел', 'к', 'его', 'в', '11', 'А', 'М', 'он', 'сказал', 'в', 'some_language'] [' ', ' ', '*', '*', '*', ' ', ' ', '.'] Пример 4: Python
Output: [ 'аб', 'абб', 'а', 'аббб'] Понимание вывода:
Разделить строку по количеству вхождений символа или шаблона, при обнаружении этого шаблона оставшиеся символы из строки возвращаются как часть результирующего списка. Синтаксис: re.split(шаблон, строка, maxsplit=0, flags=0) Первый параметр, шаблон обозначает регулярное выражение, строка — заданная строка, в которой будет выполняться поиск шаблона и в какое разбиение происходит, maxsplit, если оно не указано, считается равным нулю '0', а если указано любое ненулевое значение, то происходит не более того количества разбиений. Example 1: Python
Вывод: ['Слово', 's', 'слова', 'Слова'] ['На', '12th', 'Январь', '2016', 'в', '11', '02', 'AM'] ['On', 'th Jan', ', at ', ':', 'AM'] Example 2: Python
Вывод: ['Вкл.', 'январь 2016 г., 11:02'] ['', 'у,', 'ой о', 'ой,', 'ом', 'ч', 'р', ''] ['A', 'y, Boy oh', 'oy,', 'om', 'h', 'r', '']re. sub() 'sub' в функции означает SubString, определенный шаблон регулярного выражения ищется в заданной строке (3-й параметр), и при обнаружении шаблона подстроки заменяется repl (2-й параметр), count проверяет и поддерживает количество раз, когда это происходит. Syntax: re.sub(pattern, repl, string, count=0, flags=0) Example 1: Python
Output S~*ject has ~*er booked уже S~*ject уже забронирован Uber S~*ject уже забронирован Uber Запеченная фасоль и спамre. subn() subn() похож на sub() во всех отношениях, за исключением способа обеспечения вывода. Он возвращает кортеж с подсчетом общего количества замен и новую строку, а не только строку. Syntax: re.subn(pattern, repl, string, count=0, flags=0) Example: Python
Output («Экзамен ~* уже забронирован Uber», 1) («Экзакт ~* уже забронирован», 2) Длина кортежа: 2 S~*ject уже забронирован ~*erre.escape() Возвращает строку со всеми символами, не являющимися буквенно-цифровыми, с обратной косой чертой, это полезно, если вы хотите сопоставить произвольную литеральную строку, которая может содержать метасимволы регулярного выражения. re.search()Этот метод либо возвращает None (если шаблон не совпадает), либо re.MatchObject содержит информацию о совпадающей части строки. Этот метод останавливается после первого совпадения, поэтому он больше подходит для проверки регулярного выражения, чем для извлечения данных. Пример: Поиск экземпляра шаблона Python3
Вывод re.compile('\\bG')
Добро пожаловать в GeeksForGeeks Получение индекса совпадающего объекта
Example: Getting index of matched object Python3
Выход 11 14 (11, 14) Получение совпадающей подстрокиМетод group() возвращает часть строки, для которой совпадают шаблоны. См. приведенный ниже пример для лучшего понимания. Пример: Получение совпадающей подстроки Python3
Выход 9003 23 2 . наш шаблон указывает на строку, содержащую как минимум 2 символа, за которыми следует пробел, а за этим пробелом следует буква t. |