Regular expressions — регулярные выражения (Java)
Похожие презентации:
Программирование на Python
Моя будущая профессия. Программист
Программирование станков с ЧПУ
Язык программирования «Java»
Базы данных и язык SQL
Основы web-технологий. Технологии создания web-сайтов
Методы обработки экспериментальных данных
Программирование на языке Python (§ 62 — § 68)
Микроконтроллеры. Введение в Arduino
Программирование на языке Python (§ 54 — § 61)
1. Regular expressions
REGULAREXPRESSIONS
2. Определение
Формальный язык поиска и осуществленияманипуляций с подстроками в тексте.
Основан на использовании метасимволов.
Kolesnikov D.O. SED KNURE
3. Символы
x==> символ x
\\
==> обратный слеш
\xhh
==> символ с кодом U+00hh
\xhhhh ==> символ с кодом U+hhhh
\n
==> перевод строки
\r
==> возврат каретки
\t
==> табуляция
Kolesnikov D.
 ab
abВходная строка: ababab
$ ==> конец строки
Регулярное выражение: ab$
Входная строка: ababab
Kolesnikov D.O. SED KNURE
16. Границы
\b\B
==> граница слова
==> отрицание \b
Регулярное выражение: abc\b
Входная строка: abc abcd
Kolesnikov D.O. SED KNURE
17. Границы
\A==> начало вводаРегулярное выражение: \Aabc
Входная строка:
abc abc
abc abc
Kolesnikov D.O. SED KNURE
18. Границы
\z==> конец ввода
Регулярное выражение: abc\z
Входная строка:
abc abc
abc abc
Kolesnikov D.O. SED KNURE
19. Границы
\Z==> конец ввода, как и \z, но
может включать ограничитель
строки
Регулярное выражение: abc\Z
Входная строка:
abc abc
abc abc<ограничитель строки>
Kolesnikov D.O. SED KNURE
20. Ограничители строк
‘\n’==> LF (новая строка)
‘\r’
==> CR (возврат каретки)
«\r\n» ==> CR+LF
‘\u0085’ ==> следующая строка
‘\u2028’ ==> разделитель строки
‘\u2029’ ==> разделитель параграфа
Kolesnikov D.
 O. SED KNURE
O. SED KNURE21. Квантификаторы
Квантификатор определяетповторяемость.
Жадный квантификатор определяет
максимально возможную подстроку.
Ленивый квантификатор определяет
минимально возможную подстроку.
Kolesnikov D.O. SED KNURE
22. Квантификаторы
X? ==> один или ноль раз (жадный)Регулярное выражение: ab?
Входная строка: aabcabbb
X?? ==> один или ноль раз (ленивый)
Регулярное выражение: ab??
Входная строка: aabcabbb
Kolesnikov D.O. SED KNURE
23. Квантификаторы
X* ==> ноль или более раз (жадный)Регулярное выражение: ab*
Входная строка: aabcabbb
X*? ==> ноль или более раз (ленивый)
Регулярное выражение: ab*?
Входная строка: aabcabbb
Kolesnikov D.O. SED KNURE
24. Квантификаторы
X+ ==> один или более раз (жадный)Регулярное выражение: ab+
Входная строка: aabcabbb
X+? ==> один или более раз (ленивый)
Регулярное выражение: ab+?
Входная строка: aabcabbb
Kolesnikov D.
 O. SED KNURE
O. SED KNURE25. Квантификаторы
X{n}==> ровно n раз (жадный)
или (совпадает по результату применения)
X{n}? ==> ровно n раз (ленивый)
Регулярное выражение: ab{2} или ab{2}?
Входная строка: aabcabbb
Kolesnikov D.O. SED KNURE
26. Квантификаторы
X{n,} ==> не менее n раз (жадный)Регулярное выражение: ab{2,}
Входная строка: aabcabbb
X{n,}? ==> не менее n раз (ленивый)
Регулярное выражение: ab{2,}?
Входная строка: aabcabbb
Kolesnikov D.O. SED KNURE
27. Квантификаторы
X{n,m} ==> от n до m раз (жадный)Регулярное выражение: ab{1,2}
Входная строка: aabcabbb
X{n,m}? ==> от n до m раз (ленивый)
Регулярное выражение: ab{1,2}?
Входная строка: aabcabbb
Kolesnikov D.O. SED KNURE
28. Сверхжадные квантификаторы
При поиске в строке aab с помощью рег.выражения a+b шаги анализатора:
a+ ==> a (соответствует)
a+ ==> aa(соответствует)
a+ ==> aab (не соответствует)
откат назад (возврат b) к последнему
соответствию (aa) и проверка a+b:
a+b ==> aab (соответствует)
Kolesnikov D.
 O. SED KNURE
O. SED KNURE29. Сверхжадные квантификаторы
Сверхжадный квантификатор действует какжадный, но никогда не откатывается назад.
a++ ==> a (соответствует)
a++ ==> aa(соответствует)
a++ ==> aab (не соответствует)
Последний символ ввода (b) прочтен,
соответствие не найдено.
Kolesnikov D.O. SED KNURE
30. Сверхжадные квантификаторы
Чтобы сделать жадный квантификаторсверхжадным достаточно добавить + справа
от квантификатора:
X? ==> X?+ X{n} ==> X{n}+
X* ==> X*+ X{n,} ==> X{n,}+
X+ ==> X++ X{n,m} ==> X{n,m}+
Сверхжадные квантификаторы работают как
правило быстрее, чем жадные.
Kolesnikov D.O. SED KNURE
31. Логические операции
XY ==> X за которым следует Y (AND)X|Y ==> X илиY (OR)
Приоритет AND выше чем OR.
Регулярное выражение: aa|b
Входная строка: aabcabbb
Kolesnikov D.O. SED KNURE
32. Группы
Выражение в круглых скобка — группа.Каждая группа имеет номер.
 \$
\$Kolesnikov D.O. SED KNURE
36. Экранирование символов
Для указания диапазона экранированияможно использовать \Q и/или \E
\Q
\E
==> начало диапазона
==> окончание диапазона
Регулярное выражение: \Q\(*\E(a)\1
Входная строка: ab\(*aa
Kolesnikov D.O. SED KNURE
37. Упреждающий просмотр вперед
Позитивный: (?=X)Регулярное выражение: a(?=b)
Входная строка: abacab
Негативный: (?!X)
Регулярное выражение: a(?!b)
Входная строка: abacab
Kolesnikov D.O. SED KNURE
38. Просмотр назад
Позитивный: (?<=X)Регулярное выражение: (?<=b)a
Входная строка: abacab
Негативный: (?<!X)
Регулярное выражение: (?<!b) a
Входная строка: abacab
Kolesnikov D.O. SED KNURE
39. Режимы
Влияют на работу регулярных выражений.Каждый режим имеет буквенный код.
COMMENTS
==>
x
CASE_INSENSITIVE
==>
i
UNIX_LINES
==>
d
DOTALL
==>
s
UNICODE_CASE
==>
u
MULTILINE
==>
m
Kolesnikov D.
 O. SED KNURE
O. SED KNURE40. Режимы
Чтобы включить режим, достаточнопредварить регулярное выражение
комбинацией: (?КОД_РЕЖИМА).
(?m)
(?s)
Если нужно включить сразу несколько
режимов, можно писать несколько
кодов:
(?iu)
Kolesnikov D.O. SED KNURE
41. Режимы
COMMENTS==>
x
Режим комментариев. Пробельные символы
игнорируются, после символа # можно
писать комментарий к рег. выражению.
Регулярное выражение: (?x)a bc #comment
Входная строка: abcab
Kolesnikov D.O. SED KNURE
42. Режимы
CASE_INSENSITIVE ==>i
Игнорирует регистр символов.
UNIX_LINES
==>
d
Разделитель строк только CR (\r)
DOTALL
==>
s
Точка (.) может включать \n
Kolesnikov D.O. SED KNURE
43. Режимы
UNICODE_CASE==>
u
Игнорирует регистр символов.
MULTILINE
==>
m
Многострочный режим (по умолчанию $ конец ввода).
Kolesnikov D.O. SED KNURE
English Русский Правила
6.
 5. Основы Kotlin. Регулярные выражения RegExp
5. Основы Kotlin. Регулярные выражения RegExpПредыдущий раздел
Регулярные выражения (RegExp) — специальный язык для описания множества строк. Они помогают решать задачу поиска какого-либо текста (из описанного множества) в другом тексте, описывают интересующий нас текст и работают достаточно эффективно для быстрого решения задачи поиска.
В некоторых случаях количество вариантов искомого текста настолько велико, что перечислять все варианты становится неудобно. Иногда все эти варианты могут быть представлены одной строкой — регулярным выражением.
Примеры регулярных выражений (см. слайды):
KotlinAsFirst[A-Z0-9._%-]@[A-Z0-9.-]+\.[A-Z]{2,}ˆ4[0-9]{12}(?:[0-9]{3})?$[-]?[0-9]*\.?[0-9]<()([ˆ<])(?:>(.)<\/\1>|\s+\/>)
Поиск регулярного выражения осуществляется с помощью автомата с состояниями, или конечного автомата.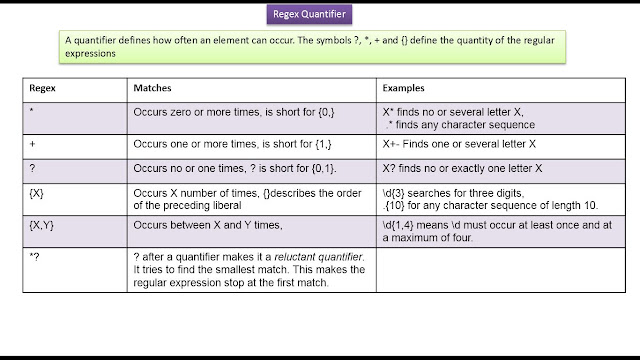 обозначает символ-шапку,
обозначает символ-шапку, \$ — символ доллара, \[ — открывающую квадратную скобку,\] — закрывающую квадратную скобку.
Особые символы ищут символы по специальным правилам:
` …..` — любая последовательность из пяти символов, начинающаяся и заканчивающаяся пробелов\t— табуляция,\n— новая строка,\r— возврат каретки (два последних символа унаследованы компьютерами от эпохи пишущих машинок, когда для начала печати с новой строки необходимо было выполнить два действия — возврат каретки в начало строки и перевод каретки на новую строку)\s— произвольный вид пробела (пробел, табуляция, новая строка, возврат каретки)\d— произвольная цифра, аналог[0-9]\w— произвольная “символ в слове”, обычно аналог[a-zA-z0-9], то есть, латинская буква или цифра\S— НЕ пробел,\D— НЕ цифра,\W— НЕ “символ в слове”
Шаблон выбора | ищет одну строку из нескольких, например:
Марат|Михаил— Марат или Михаил^\[|\]$— открывающая квадратная скобка в начале строки или закрывающая в концеfor.— цикл (val|var).
(val|var).forс последующимvalилиvar
 (val|var).
(val|var).Шаблоны количества ищут определённое число совпадений:
.*— любое количество (в том числе ноль) любых символов(Марат)+— строка Марат один или более раз (но не ноль)(Михаил)?— строка Михаил ноль или один раз([0-9]{4})— последовательность из ровно четырёх любых цифр\w{8,16}— последовательность из 8-16 “символов в слове”
Круглые скобки () задают так называемые группы поиска, объединяя несколько символов вместе.
(Kotlin)+AsFirst— KotlinAsFirst, KotlinKotlinAsFirst, KotlinKotlinKotlinAsFirst, …(?:\$\$)+—`, ``, `, …(\w+)\s\1— слово, за которым следует пробел и то же самое слово.fun\s+(/w+)\s*\{.\1.\}—funс последующими пробелами, произвольным словом в круглых скобках, пробелами и тем же словом в фигурных скобках
Здесь \1 (\2, \3, …) ищет уже описанную группу поиска по её номеру внутри регулярного выражения (в данном случае — первую группу). Комбинация
Комбинация (?:…) задаёт группу поиска без номера. В целом, (?…) задаёт группы особого поиска:
Марат(?=\sАхин)— Марат, за которым следует пробел и Ахин(?⇐Михаил\s)Глухих— Глухих, перед которым стоит Михаил с пробелом\d+(?![$\d])— число, после которого НЕ стоит знак доллара(?<!root\s)beer— beer, перед которым НЕ стоит root с пробелом
Сторінки: 1 2
Документация JDK 20 — Главная
- Главная
- Ява
- 20
Обзор
- Прочтите меня
- Примечания к выпуску
- Что нового
- Руководство по миграции
- Загрузить JDK
- Руководство по установке
- Формат строки версии
Инструменты
- Технические характеристики инструментов JDK
- Руководство пользователя JShell
- Руководство по JavaDoc
- Руководство пользователя средства упаковки
Язык и библиотеки
- Обновления языка
- Основные библиотеки
- HTTP-клиент JDK
- Учебники по Java
- Модульный JDK
- Руководство программиста API бортового регистратора
- Руководство по интернационализации
Технические характеристики
- Документация API
- Язык и ВМ
- Имена стандартных алгоритмов безопасности Java
- банок
- Собственный интерфейс Java (JNI)
- Инструментальный интерфейс JVM (JVM TI)
- Сериализация
- Проводной протокол отладки Java (JDWP)
- Спецификация комментариев к документации для стандартного доклета
- Прочие характеристики
Безопасность
- Руководство по безопасному кодированию
- Руководство по безопасности
Виртуальная машина HotSpot
- Руководство по виртуальной машине Java
- Настройка сборки мусора
Управление и устранение неполадок
- Руководство по устранению неполадок
- Руководство по мониторингу и управлению
Client Technologies
- Руководство по специальным возможностям Java
Java Regex — синтаксис регулярного выражения
Чтобы эффективно использовать регулярные выражения в Java, вам необходимо знать их синтаксис. Синтаксис расширен, что позволяет вам писать очень сложные регулярные выражения.
Чтобы полностью освоить синтаксис, может потребоваться много упражнений.
Синтаксис расширен, что позволяет вам писать очень сложные регулярные выражения.
Чтобы полностью освоить синтаксис, может потребоваться много упражнений.
В этом тексте я рассмотрю основы синтаксиса с примерами. Я не буду
охватить каждую маленькую деталь синтаксиса, но сосредоточьтесь на основных понятиях, которые вам нужны
понимать, чтобы работать с регулярными выражениями. Полное объяснение см. Pattern страница класса JavaDoc.
Основной синтаксис
Прежде чем показать все дополнительные параметры, которые вы можете использовать в регулярных выражениях Java, я дам вам краткое изложение основ синтаксиса регулярных выражений Java.
символов
Самая простая форма регулярных выражений — это выражение, которое просто соответствует определенным символам. Вот пример:
Джон
Это простое регулярное выражение будет соответствовать вхождению текста «Джон» в заданный входной текст.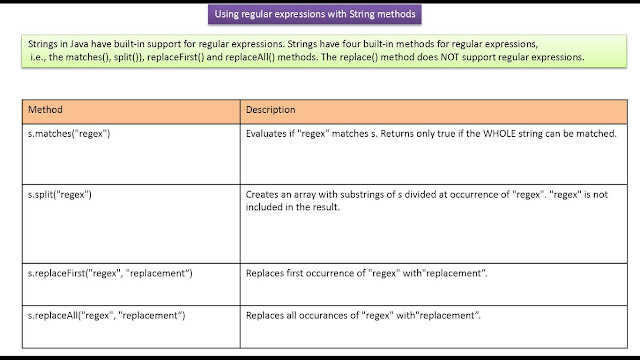
В регулярном выражении можно использовать любые символы алфавита.
Вы также можете обращаться к символам через их восьмеричный, шестнадцатеричный код или код Unicode. Вот два примера:
\0101 \x41 \u0041
Все эти три выражения относятся к символу 101 ) для A , второй использует шестнадцатеричный код ( 41 )
а третий использует код юникода ( 0041 ).
Классы символов
Классы символов представляют собой конструкторы, которые позволяют указать соответствие нескольким символам, а не только одному.
Другими словами, класс символов сопоставляет один символ во входном тексте с несколькими разрешенными символами.
в классе персонажей.
Например, вы можете сопоставить любой из символов и , b или c .
так:
[абв]
Классы символов заключены в пару квадратных скобок [] . Сами скобки
не являются частью того, что сопоставляется.
Сами скобки
не являются частью того, что сопоставляется.
Вы можете использовать классы символов для многих вещей. Например, этот пример находит все вхождения слова John со строчными или прописными буквами J :
[Jj] охн
Класс символов [Jj] будет соответствовать либо J , либо j , а остальные
выражения будет соответствовать символам или именно в этой последовательности.
Есть несколько других классов персонажей, которые вы можете использовать. См. таблицу классов персонажей далее в этом тексте.
Предопределенные классы символов
Синтаксис регулярных выражений Java имеет несколько предопределенных классов символов, которые вы можете использовать. Например,
класс символов \d соответствует любой цифре, класс символов \s соответствует
любой символ пробела, а символ \w соответствует любому символу слова.
Предопределенные классы символов не обязательно заключать в квадратные скобки, но вы можете, если хотите их объединить. Вот несколько примеров:
\ д [\д\с]
Первый пример соответствует любому цифровому символу. Второй пример соответствует любой цифре или любому символ пробела.
Предопределенные классы символов перечислены в таблице далее в этом тексте.
Сопоставители границ
Синтаксис также включает сопоставители для сопоставления границ, таких как границы между словами, начало
и конец введенного текста и т. д. Например, \w соответствует границам между словами,
9Это одна строка$
Это выражение соответствует строке текста, содержащей только текст . Это одна строка .
Обратите внимание на сопоставители начала и конца строки в выражении. Эти утверждают, что есть
не может быть ничем до или после текста, кроме начала и конца строки.
Полный список сопоставителей границ приведен далее в этом тексте.
Квантификаторы
Квантификаторы позволяют вам сопоставлять заданное выражение или подвыражение несколько раз.
Например, следующее выражение соответствует букве A ноль или
больше раз:
А*
Символ * — это квантификатор, означающий «ноль или более раз».
Существует также квантификатор + , означающий «один или несколько раз», ? Квантификатор , означающий «ноль или один раз», и некоторые другие.
которые вы можете увидеть в таблице квантификаторов далее в этом тексте.
Квантификаторы могут быть «неохотными», «жадными» или «притяжательными». неохотно
квантификатор будет соответствовать как можно меньшему количеству входного текста. жадный
квантификатор будет максимально соответствовать входному тексту. Притяжательный
квантификатор будет совпадать в максимально возможной степени, даже если он делает остальную часть
выражение ничему не соответствует, и выражение не может найти совпадение.
Я проиллюстрирую разницу между неохотными, жадными и притяжательными кванторами. с примером. Вот вводимый текст:
Джон пошел гулять, и Джон упал, и Джон повредил колено.
Затем посмотрите на следующее выражение с неохотным квантором:
Джон.*?
Это выражение будет соответствовать слову John , за которым следует ноль или более символов. . означает «любой символ», а * означает «ноль или более раз». ? после * делает * неохотным квантором.
Будучи неохотным квантификатором, квантификатор будет совпадать как можно меньше, то есть ноль.
персонажи. Таким образом, выражение найдет слово John с нулевыми символами.
после, 3 раза в приведенном выше вводном тексте.
Если мы изменим квантификатор на жадный квантификатор, выражение будет выглядеть так:
Джон.*
Жадный квантификатор будет соответствовать как можно большему числу символов. Теперь выражение будет
соответствует только первому вхождению
Теперь выражение будет
соответствует только первому вхождению John , и жадный квантификатор будет
соответствуют остальным символам вводимого текста. Таким образом, найдено только одно совпадение.
Наконец, давайте немного изменим выражение, чтобы оно содержало притяжательный квантор:
Джон.*+больно
+ после * делает его квантором притяжения.
Это выражение не будет соответствовать входному тексту, указанному выше, даже если оба слова Джон и больно найдены во входном тексте. Почему это?
Потому что .*+ является притяжательным. Вместо того, чтобы максимально соответствовать
чтобы выражение соответствовало, как это сделал бы жадный квантификатор, притяжательное
квантор соответствует как можно большему количеству, независимо от того, будет ли выражение
совпадают или нет.
.*+ будет соответствовать всем символам после первого появления John во вводном тексте, включая слово больно . Таким образом, нет
Таким образом, нет больно слово, оставшееся для сопоставления, когда квантор притяжения заявил о своем совпадении.
Если вы измените квантификатор на жадный квантификатор, выражение будет соответствовать введите текст один раз. Вот как выражение выглядит с жадным квантором:
Джон. * больно
Вам придется поиграть с различными квантификаторами и типами, чтобы понять, как они работа. Полный список квантификаторов см. в таблице далее в этом тексте.
Логические операторы
Синтаксис регулярных выражений Java также поддерживает несколько логических операторов (и, или, не).
Оператор и является неявным. Когда вы пишете выражение John ,
тогда это означает « J и o и h и n «.
Оператор или является явным и записывается с помощью | . Например,
выражение John|больно будет соответствовать слову John ,
или слово больно .
Символы
| Конструкция | совпадений |
х | Символ x. Вместо х можно использовать любой символ алфавита. |
\ | Символ обратной косой черты. Одинарная обратная косая черта используется в качестве escape-символа в сочетании с другими символами для сигнализировать о специальном совпадении, поэтому, чтобы соответствовать только самому символу обратной косой черты, вам нужно экранировать символом обратной косой черты. Следовательно, двойная обратная косая черта соответствует одному символу обратной косой черты. |
\0n | Символ с восьмеричным значением 0n . n должен быть между 0 и 7. |
\0nn | Символ с восьмеричным значением 0nn . n должен быть между 0 и 7. n должен быть между 0 и 7. |
\0мнн | Символ с восьмеричным значением 0mnn . m должно быть между 0 и 3, n должно быть между 0 и 7. |
\xhh | Символ с шестнадцатеричным значением 0xhh . |
\ухххх | Символ с шестнадцатеричным значением 0xhhhh . Эта конструкция используется для сопоставления символов Юникода. |
\т | Символ табуляции. |
\n | Символ новой строки (перевода строки) (unicode: '\ u000A' ). |
\r | Символ возврата каретки (юникод: '\u000D' ). |
\ф | Символ перевода страницы (юникод: '\u000C' ). |
\а | Символ предупреждения (звонка) (Unicode: '\u0007' ). |
\е | Экранирующий символ (unicode: '\u001B' ). |
\сх | Управляющий символ, соответствующий x |
|
Классы символов
| Конструкция | совпадений | |
[абв] | Совпадает с и , или с , или с . Это называется простым классом, и он соответствует любому символу в классе. 9абв] | Соответствует любому символу, кроме a , b и c . Это отрицание. |
[a-zA-Z] | Соответствует любому символу от a до z или от A до Z , включая , , z и Z . bc]] 9м-п]] bc]] 9м-п]] | Соответствует всем символам от a до z , кроме символов от m до p .
Это также называется вычитанием. |
Предопределенные классы символов
| Конструкция | совпадений |
. | Соответствует любому одиночному символу. Может совпадать или не совпадать с разделителями строк, в зависимости от того, какие флаги использовались для компиляции 90-9] |
| Соответствует любому символу пробела (пробел, табуляция, разрыв строки, возврат каретки) |
\С | Соответствует любому символу, отличному от пробела. |
\ш | Соответствует любому символу слова. |
\ Вт | Соответствует любому символу, не являющемуся словом. |
Сопоставители границ 9
$ \б \Б \А \Г \Z \з Квантификаторы
| Жадные | Неохотно | Притяжательный | совпадений |
Х? | Х?? | Х?+ | Совпадает с X один раз или вообще не совпадает (0 или 1 раз). |