Регулярные выражения — PHP с нуля
Регулярные выражения — это специальные шаблоны для поиска подстроки в тексте. С их помощью можно решить одной строчкой такие задачи: «проверить, содержит ли строка цифры», «найти в тексте все адреса email», «заменить несколько идущих подряд знаков вопроса на один».
Начнем с одной народной программистской мудрости:
Некоторые люди, сталкиваясь с проблемой, думают: «Ага, я умный, я решу её с помощью регулярных выражений». Теперь у них две проблемы.
Это довольно-таки объемный и сложный урок. Но, если ты дошел до сюда, то ты способен осилить и это. Просто почти теорию, не надо запоминать, а когда дойдешь до задачек, вернись и проясни непонятные моменты. Ну или открой мануал — там эта тема подробно разъясняется. Ссылка: http://www.php.net/manual/ru/reference.pcre.pattern.syntax.php
Примеры шаблонов
Начнем с пары простых примеров.
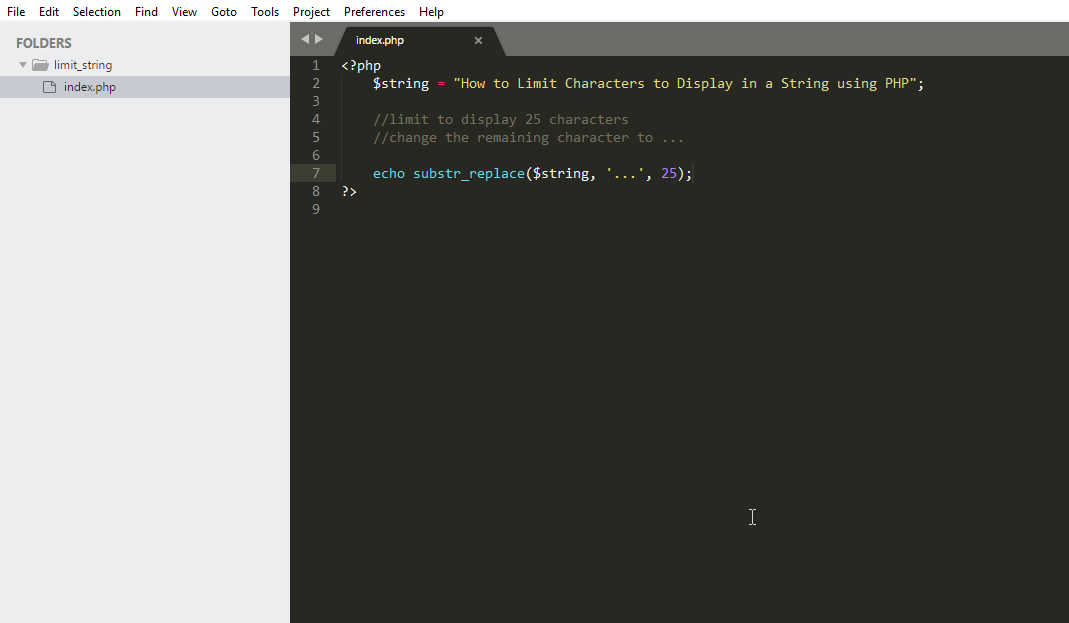
12:34.
Любое выражение начинается с символа-ограничителя (delimiter по англ.). В качестве
него обычно используют символ /, но можно использовать и другие
символы, не имеющие специального назначения в регулярках, например, ~,
# или @. Альтернативные разделители используют, если в
выражении может встречаться символ
i— говорит, что поиск должен вестись без учета регистра букв (по умолчанию регистр учитывается)u— говорит, что выражение и текст, по которому идет поиск, исплоьзуют кодировку utf-8, а не только латинские буквы. Без него поиск
русских (и любых других нелатинских) символов может работать некорректно,
потому стоит ставить его всегда.
Без него поиск
русских (и любых других нелатинских) символов может работать некорректно,
потому стоит ставить его всегда.
 Без него поиск
русских (и любых других нелатинских) символов может работать некорректно,
потому стоит ставить его всегда.
Без него поиск
русских (и любых других нелатинских) символов может работать некорректно,
потому стоит ставить его всегда.Сам шаблон состоит из обычных символов и специальных конструкций. Ну
например, буква «к» в регулярках обозначает саму себя, а вот символы [0-5]
значат «в этом месте может быть любая цифра от 0 до 5». Вот полный список
специальных символов (в мануале php их называют метасимволы),
а все остальные символы в регулярке — обычные:
Ниже мы разберем значение каждого из этих символов (а также объясним почему буква
«ё» вынесена отдельно в первом выражении), а пока попробуем
применить наши регулярки к тексту и посмотреть, что выйдет. В php есть
специальная функция 0, если нет,
или 1, если она есть. А в переданный массив в элемент с индексом
0 кладется первое найденное совпадение с регуляркой. Напишем простую
программу, применяющую регулярные выражения к разным строкам:
А в переданный массив в элемент с индексом
0 кладется первое найденное совпадение с регуляркой. Напишем простую
программу, применяющую регулярные выражения к разным строкам:
| Код | Результат |
|---|---|
$regexp = "/к[а-яё]т/ui";
// строки, к которым мы будем по очереди применять регулярку
$lines = [
'рыжий кот',
'рыжий крот',
'кит и кот'
];
foreach ($lines as $line) {
echo "Строка: $line\n";
// сюда будет помещено первое
// совпадение с шаблоном
$match = [];
if (preg_match($regexp, $line, $match)) {
echo "+ Найдено слово '{$match[0]}'\n";
} else {
echo "- Ничего не найдено\n";
}
} | Строка: рыжий кот + Найдено слово 'кот' Строка: рыжий крот - Ничего не найдено Строка: кит и кот + Найдено слово 'кит' |
Познакомившись с примером, изучим регулярные выражения более подробно.
abc+ знак «плюс» относится только
к букве c и это выражение ищет слова вроде abc, abcc, abccc. А если
поставить скобки a(bc)+ то квантифиактор плюс относится
уже к последовательности bc и выражение ищет слова
abc, abcbc, abcbcbcПримечание: в квадратных скобках можно указывать диапазоны
символов, но помни, что русская буква ё идет отдельно от
алфавита и чтобы написать «любая русская буква»,
надо писать
Бекслеши
Если ты смотрел другие учебники по регулярным выражениям, то наверно заметил,
что бекслеш везде пишут по-разному. Где-то пишут один бекслеш:
\d, а здесь в примерах он повторен 2 раза: \\d.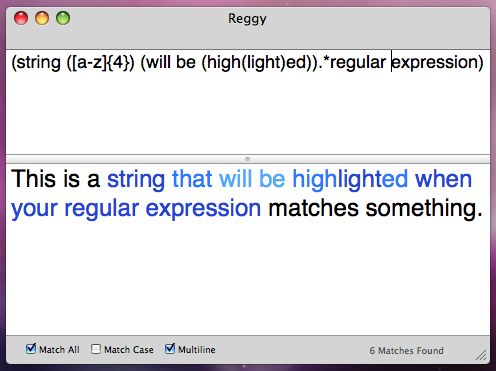 Почему?
Почему?
Язык регулярных выражений требует писать бекслеш один раз. Однако в
строках в одиночных и двойных кавычках в PHP бекслеш тоже имеет особое
значение: мануал про строки.
Ну например, если написать $
(и движок регулярных выражений не узнает о бекслеше перед ним). Чтобы
вставить в строку последовательность \$, мы должны удвоить бекслеш
и записать код в виде $x = "\\$";.
По этой причине в некоторых случаях (там, где последовательность символов имеет специальный смысл в PHP) мы обязаны удваивать бекслеш:
- Чтобы написать в регулярке
\$, мы пишем в коде"\\$" - Чтобы написать в регулярке
\\"\\\\" - Чтобы написать в регулярке бекслеш и цифру (
\1), бекслеш надо удвоить:"\\1"
В остальных случаях один или два бекслеша дадут один и тот же
результат: "\\d" и "\d" вставят в строку пару
символов \d — в первом случае 2 бекслеша это последовательность
для вставки бекслеша, во втором случае специальной последовательности
нет и символы вставятся как есть.
echo "\$";. Да, сложно, а что поделать?Специальные конструкции в регулярках
\dищет одну любую цифру,\D— один любой символ, кроме цифры\wсоответствует одной любой букве (любого алфавита), цифре или знаку подчеркивания_.\Wсоответствует любому символу, кроме буквы, цифры, знака подчеркивания.
Также, есть удобное условие для указания на границу слова: \b.
Эта конструкция обозначает, что с одной стороны от нее должен стоять символ,
являющийся буквой/цифрой/знаком подчеркивания (/кот/ui, то она
найдет последовательность этих букв в любом месте — например, внутри слова
«скотина». Это явно не то, что мы хотели. Если же мы добавим
условие границы слова в регулярку:
Это явно не то, что мы хотели. Если же мы добавим
условие границы слова в регулярку: /\bкот\b/ui, то теперь
искаться будет только отдельно стоящее слово «кот».
Мануал
- Синтаксис регулярных выражений в PHP, подробное описание
- Функции для работы с регулярными выражениями
Также, есть полезный сайт Regex101, где можно протестировать свою регулярку и проверить, что она найдет в тексте. Помни, что на том сайте бекслеши надо писать ровно один раз, и ставить флаг u не требуется.
Задачка
Напиши программу, получающую на вход автомобильный номер, и проверяющую, правильно ли он введен. Автомобильный номер имеет вид «а123вг», то есть начинается с буквы, за которой идет 3 цифры, и еще 2 буквы. Никаких посторонних символов быть в нем не должно.
Эту программу надо решить с помощью preg_match() и регулярного
выражения.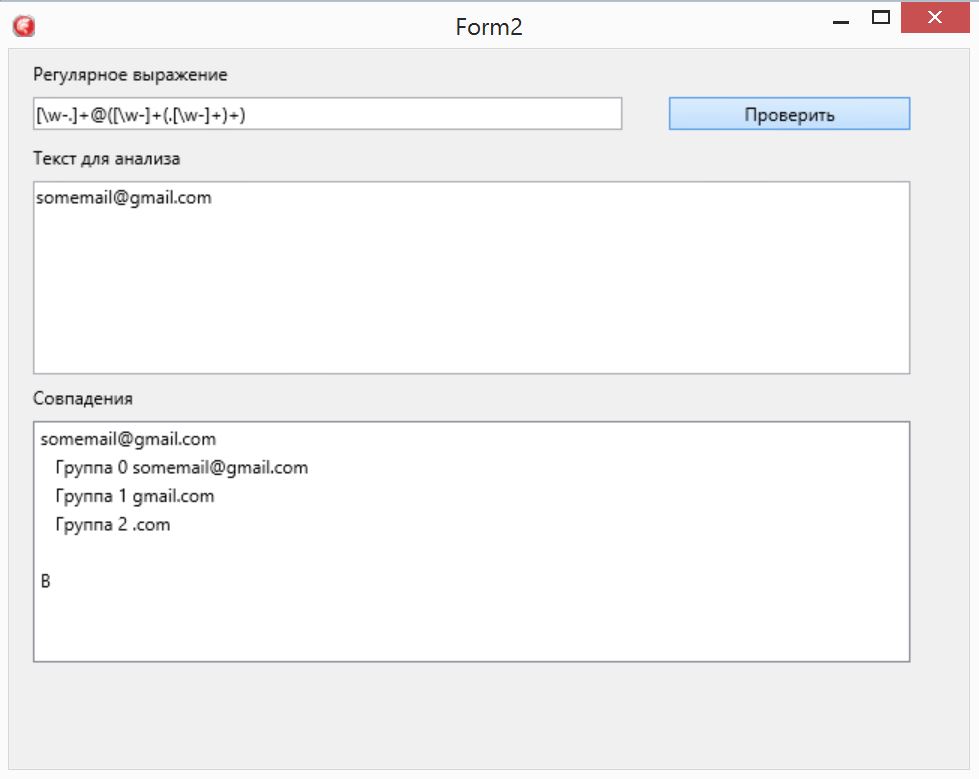 Протестировать его ты можешь например на сайте Regex101.
Протестировать его ты можешь например на сайте Regex101.
Задачка на проверку телефонов
Дан текст, который по идее должен быть номером телефона в виде 8-(911)-506 56 56 (т.е. человек может ввести не только цифры, но и скобки, минусы, может что-то еще). Но в реальности, пользователь может вместо номера написать что угодно. Напиши скрипт для проверки правильности введенного номера («8(911)-506 56 56» — правильный номер, «8-911-50-656-56» — правильный, «89115065656» — правильный, «02» — неправильный, «89115065656 позвать Люду» — неправильный).
Задачу надо проверить на большом числе телефонов,
чтобы убедиться что твой код правильный. Для этого давай добавим в программу
тесты, чтобы сразу было видно, верно все работает или нет.
Сделай 2 списка номеров (правильные и нет), добавь их в программу и напиши цикл,
который их по очереди прогоняет через регулярку и проверяет,
что они определяются как надо (если нет — надо вывести, какой именно номер
не распознается правильно).
Вот список номеров:
// Правильные: $correctNumbers = [ '84951234567', '+74951234567', '8-495-1-234-567', ' 8 (8122) 56-56-56', '8-911-1234567', '8 (911) 12 345 67', '8-911 12 345 67', '8 (911) - 123 - 45 - 67', '+ 7 999 123 4567', '8 ( 999 ) 1234567', '8 999 123 4567' ]; // Неправильные: $incorrectNumbers = [ '02', '84951234567 позвать люсю', '849512345', '849512345678', '8 (409) 123-123-123', '7900123467', '5005005001', '8888-8888-88', '84951a234567', '8495123456a', '+1 234 5678901', /* неверный код страны */ '+8 234 5678901', /* либо 8 либо +7 */ '7 234 5678901' /* нет + */ ];
Также, на regex101
https://regex101.com/r/qF7vT8/3 уже введены номера и можно простестировать
свою регулярку. Помни что на этом сайте надо писать бекслеш один раз,
например \s, а не \\s. Флаг m там стоит чтобы
^ и $ в регулярке обозначали «начало и конец
любой строки», а не «начало и конец всего текста». Флаг g (его нет в PHP,
он только на этом сайте) значит что надо искать все совпадения с
регуляркой, а не только первое.
Флаг g (его нет в PHP,
он только на этом сайте) значит что надо искать все совпадения с
регуляркой, а не только первое.
Подсказка: не надо строить сложных выражений и предусматривать все возможные комбинации символов. Достаточно написать: сначала идет +7 или 8, за ними ровно 10 цифр, между которыми может быть любое число скобок, минусов, пробелов
Повторим
- preg_match находит первое совпадение с регулярными выражением и проверяет, соответствует ли текст или часть выражению
- preg_match_all находит все фрагменты текста, соответствующие регулярке
- preg_split разбивает текст на массив частей по регулярному выражению
- preg_replace заменяет в тексте части, соответствующие регулярке, на данную строку
Задачки (пока без картинок)
Опечаточники
Как тебе наверно известно, многие люди, занимающие государственные посты, тратят свои силы
отнюдь не на улучшение ситуации в своем городе или регионе, а на придумывание разнообразных
схем по перемещению вверенных им бюджетных средств в свои карманы.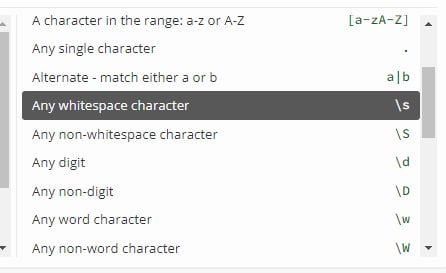
Например, государственные органы, которые хотят провести закупки, обязаны организовать публичные торги и разместить объявление о них на сайте госзакупок. Чтобы помешать всем желающим участвовать в тендере (и чтобы отдать заказ «своим людям» и получить потом от них в свой карман часть денег), они заменяют в описании заказа некоторые русские буквы на похожие на них латинские. Таким образом, не предупрежденные заранее организации не смогут найти объявление через поиск и принять участие в конкурсе.
Давай попробуем применить наши знания языка PHP для того, чтобы вывести жуликов на чистую воду.
Задача: дан текст, содержащий слова на русском и английском языках. В некоторых словах часть русских букв заменена на похожие на них латинские, и наоборот. Напиши программу, которая находит все такие слова, выводит их и выделяет квадратными скобками первую замененную букву.
Для проверки работоспособности, попробуй применить программу к тексту из поля «Наименование заказа» на
странице (осторожно, спойлер!)
http://zakupki. gov.ru/pgz/public/action/orders/info/common_info/show?notificationId=5193640
или http://zakupki.gov.ru/pgz/public/action/orders/info/common_info/show?notificationId=5138013
ололо кто бы поверил!
gov.ru/pgz/public/action/orders/info/common_info/show?notificationId=5193640
или http://zakupki.gov.ru/pgz/public/action/orders/info/common_info/show?notificationId=5138013
ололо кто бы поверил!
Дополнительная задача: добавь в программу автоматическое исправление найденных «опечаток».
Подсказки для глупеньких: слова с опечатками найти легко: это слово, которое начинается с одной или нескольких русских букв, за которыми идет латинская. Ну или начинается с латинской, за которой идет русская. Достаточно минимальных знаний регулярных выражений, чтобы написать решение.
P.S. На сайте программистских комиксов xkcd есть комикс про регулярные выражения: перевод, оригинал (англ.).
дальше: Повторим? →
——
Куда вводить код? Что надо скачать? Читай первый урок.
Есть вопросы? Задай гуглу или автору.
Нравится урок? Лайкай, репости, приглашай друзей, пости котов и Канако,
шли добра, решай задачи, помогай новичкам! Кнопок для лайка нет, кто хочет зарепостить, всегда может сделать это ручками.
Как связаться с автором? Я хочу переодеть его в платье школьницы и жениться на нем. Ящик codedokode (кот) gmail.com ждет ваших писем. А вконтактик и фейсбучек ждут ваших лайков. Но ответ на банальные вопросы лучше искать в Гугле или на stackoverflow.
Я решил задачку!!! Молодец, делай следующий урок
Ideone не работает!11 Ну так открой Гугл и найди сайты вроде https://repl.it/languages/php , http://phptester.net/ , http://sandbox.onlinephpfunctions.com/ , http://codepad.org/ или http://www.runphponline.com/ . Не ленись.
Почему так много рекламы? Всю рекламу на сайте ставит юкоз (бесплатный хостинг же), а не я.
На сайте установлена система Google Analytics (и еще несколько аналогичных систем от юкоза). Данные о твоем IP-адресе, посещаемых страницах,
времени посещения отправляются в Google Corporation, США. Хочу знать, кто и зачем сюда заходит. Поверь,
другие сайты делают точно так же. Все сайты пишут логи.
Хочу знать, кто и зачем сюда заходит. Поверь,
другие сайты делают точно так же. Все сайты пишут логи.
Php обрезать строку до символа с конца – ПК портал
Содержание
- mb_strimwidth()
- mb_substr()
- mb_substr(), substr() и mb_strcut()
- preg_match()
- Описание функции
- Строка 7
- Строка 9
- Строки 10, 11, и 12
- strrpos()
- wordwrap()
- str-split()
- Усечение по заданному количеству слов
- strtok()
- Обрезка слов в WordPress
- Заключение
- Скачать примеры
- Обрезаем текст с помощью функции substr PHP
- Обрезаем Русский текст с помощью функции mb_substr PHP
- Обрезаем текст с конца
- После обрезки ещё и дописываем текст
- Решение
В этой статье мы рассмотрим несколько различных способов в PHP обрезать строку на определенное количество слов и символов. Большая часть функций, описанных в этой статье, используется, чтобы продемонстрировать возможности PHP для работы со строками.
Во всех наших примерах мы будем использовать следующую строку, и будем исходить из того, что нам нужно уменьшить количество символов в строке со 187 до 120 символов ( для Twitter) .
В нашем примере мы также используем вторую строку из 55 символов, чтобы вы могли проверить возвращаемый результат на более короткой строке.
mb_strimwidth()
mb_strimwidth() возвращает в PHP обрезанную строку по длине и добавляет конечные символы, указанные в функции. Так как это одна из основных функций PHP , ее мы рассмотрим в первую очередь. Применяется она очень просто:
Функция рассматривает свободное пространство как символ. Но это значит, что между последним усеченным символом и конечным символом многоточием будет размещаться пробел. Вы можете обрезать строку без конечного символа, а затем добавить его отдельно. Посмотрите на следующий пример:
Приведенный выше код добавляет многоточие не зависимо от того, была ли PHP обрезана строка до символа или нет. Чтобы исправить это, мы будем рассчитывать длину строки, и только после этого добавлять многоточие, если исходная строка действительно должна обрезаться. Например:
Например:
При отправке сообщений в Twitter и на другие ресурсы, где символы чувствительны к регистру, каждый символ имеет значение… и эта функция в ряде случаев сэкономит вам один пробел!
mb_substr()
Функция PHP mb_substr() « получает часть строки «. Она возвращает подстроку на основе количества символов. Позиция обрезки отсчитывается от начала строки. Позиция первого символа равна 0 . Позиция второго символа равна 1 . И так далее.
Чтобы добавить многоточие ( или любой другой конечный символ ), мы можем изменить первую функцию, которую рассматривали. Мы обрезаем строку перед добавлением $trimmarker , чтобы гарантировать, что у нас не будет добавляться в PHP обрезанной строке с конца лишний пробел.
mb_substr(), substr() и mb_strcut()
mb_substr() , substr() и mb_strcut() — еще несколько функций, похожих на те, которые я описал выше. Они отличаются только тем, как обрабатываются многобайтовые наборы символов ( китайский язык и т.д. ).
Если вы выводите PHP обрезанную часть строки до ближайшего слова на основе количества символов ( но без конечного многоточия ), используйте следующий код:
preg_match()
Вы редко найдете тех, кто предпочитает использовать регулярные выражения, когда есть так много отличных функций PHP .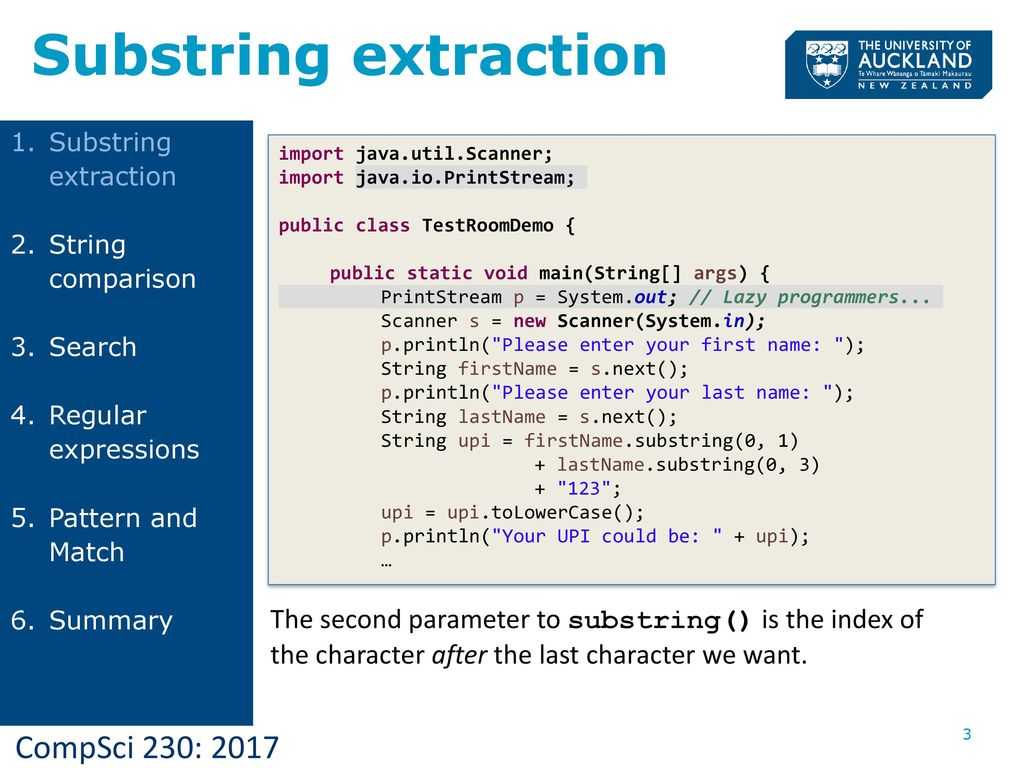 Тем не менее, вот функция, которая обрезает строку до определенного символа в PHP , исходя из заданного количества знаков от начала. В отличие от других функций, описанных выше, эта функция обрезает строку до целого слова.
Тем не менее, вот функция, которая обрезает строку до определенного символа в PHP , исходя из заданного количества знаков от начала. В отличие от других функций, описанных выше, эта функция обрезает строку до целого слова.
Описание функции
Функция принимает три параметра: $string , $length и $trimmarker ( многоточие или другие символы, которые добавляются в конце строки ).
Строка 7
Первое, что мы делаем, это проверяем длину PHP обрезанной строки после символа. Если строка короче, чем $length , то мы возвращаем эту строку.
Строка 9
Функция mb_substr() прерывает строку в $length , если это количество символов не содержит окончания слова ( пробела ). Если мы передали строку длиною 500 символов и эта строка не содержит пробелов, то будет возвращена вся строка ( так как функция preg_match не нашла окончания слова ). На данный момент мы обрезаем строку таким образом, и возвращаем ее полностью.
Строки 10, 11, и 12
Если длина нашей строки превышает максимальную длину, определенную в качестве параметра функции, мы выполняем регулярное выражение функции preg_match() , чтобы вернуть часть строки до символа с номером $length , который определяется как конец слова ( ‘/^. <1,$length>b/s’ ). Знак периода означает любой символ, кроме символа новой строки ( n ). Фигурная скобка определяет диапазон, который задает, сколько символов должен PHP обрезать в строке. Таким образом <1,$length>означает от 1 до символа $length . Наконец, b означает, что шаблон будет соответствовать окончанию слова. Мы можем производить поиск только слов целиком по шаблону, который мы предоставили. И в конце s задает поиск всех пробелов.
<1,$length>b/s’ ). Знак периода означает любой символ, кроме символа новой строки ( n ). Фигурная скобка определяет диапазон, который задает, сколько символов должен PHP обрезать в строке. Таким образом <1,$length>означает от 1 до символа $length . Наконец, b означает, что шаблон будет соответствовать окончанию слова. Мы можем производить поиск только слов целиком по шаблону, который мы предоставили. И в конце s задает поиск всех пробелов.
Так как мы не хотим, чтобы возвращаемая строка превышала длину $length , максимальное количество символов в функции preg_match должно быть равно максимальной длине минус длина $trimmarke.r . Мы должны учитывать это.
Затем мы возвращаем либо усеченную строку, либо исходную строку, если она меньше заданной длины усечения.
strrpos()
Функция strrpos() находит позицию последнего вхождения подстроки в строке. Она возвращает позицию, на которой располагается искомая подстрока относительно начала строки. Отметим также, что первая позиция в строке имеет номер 0 — а не 1 , поэтому мы учитываем это в функции, добавляя 1 к длине строки при применении функции strrpos() .
wordwrap()
Использование wordwrap() — это еще один способ, с помощью которого можно в PHP обрезать строку до пробела, хотя он не очень эффективен и не является лучшим выбором (если только обстоятельства не требуют этого). Wordwrap оборачивает строку в заданное число символов с использованием символа разрыва строки. Применив функцию PHP explode() , мы можем построить массив из каждой строки текста. Мы определяем, нужен ли $trimmarker ( конечное многоточие ), запросив, пусто ли второе значение массива. Если пусто, то строка не оборачивается.
Определение для параметра cut значения true означает, что строка всегда оборачивается до или на указанном символе.
str-split()
Функция str-split() может быть использована в приведенной выше функции для преобразования строки в массив. str-split () не разбивает строку до целого слова. С ее помощью PHP обрезает последний символ в строке ровно до 120 знаков.
Усечение по заданному количеству слов
Ниже приведен пример PHP обрезки строки по количеству символов, пробелов или слов. Это не слишком отличается от того, что мы уже делали. Затем мы сводим скорректированный массив в строку символов, максимальное количество которых задается $limit . Мы добавляем $trimmarker (…) , если наш $limit меньше, чем количество слов в массиве.
Это не слишком отличается от того, что мы уже делали. Затем мы сводим скорректированный массив в строку символов, максимальное количество которых задается $limit . Мы добавляем $trimmarker (…) , если наш $limit меньше, чем количество слов в массиве.
strtok()
Совместно применив strtok() и wordwrap() мы можем создать короткую, но эффективную функцию, которая будет в PHP обрезать строку до нужной длины. Как показано ниже, она не будет учитывать при усечении $length +$trimmarker . Но это удобно, если вы не слишком заботитесь о длине возвращаемой строки.
Обрезка слов в WordPress
Для возврата обрезанного слова в WordPress используется wp_trim_words . Данная функция часто применяется в сочетании с wp_strip_all_tags для очистки текста до его обработки. Конечно, есть и другие функции, которые служат для той же цели.
Заключение
Мы могли бы написать еще сотни примеров PHP обрезки строк, но когда-то нужно остановиться. Функции, приведенные в этой статье, являются частью ядра PHP , и вы можете использовать их для усечения строк. Хотя чаще всего программисты стараются избегать регулярных выражений, если другого выхода нет, вы можете прибегнуть и к их помощи.
Хотя чаще всего программисты стараются избегать регулярных выражений, если другого выхода нет, вы можете прибегнуть и к их помощи.
В ряде примеров мы вернули $trimmarker, представляющий собой многоточие. При необходимости вы можете вернуть HTML-объект Ellipsis , для этого используется код …. Но лично я предпочитаю многоточие.
Скачать примеры
Скачать примеры из этой статьи вы можете здесь .
Данная публикация представляет собой перевод статьи « Truncate (Shorten) Strings to the Nearest Whole Word or Character Count with Trailing Dots using PHP Functions » , подготовленной дружной командой проекта Интернет-технологии.ру
Обрезаем текст с помощью функции substr PHP
Функция substr ( $string, $start, $length ) , где $string – это переменная с текстом, $start – это символ, с которого начинается отсчёт (за первый символ берётся 0), а $length – это количество символов выделенного текста.
Если не указать параметр Количество символов (2 цифра), то функция выведет все оставшиеся символы
Обрезаем Русский текст с помощью функции mb_substr PHP
Функция mb_substr выполняет те же самые задачи, что и substr, но также способна обрабатывать многобайтные кодировки. Поэтому в случае с русским текстом Вам пригодится именно mb_substr. Работает так же
Поэтому в случае с русским текстом Вам пригодится именно mb_substr. Работает так же
Обратите внимание на то, что в случае с кириллицей (русский текст) лучше указывать кодировку в конце функции. В примере использован самый популярный вариант – UTF-8
Обрезаем текст с конца
Если Вы хотите обрезать текст с конца, то для этого укажем отрицательное число для переменной, обозначающей с какого символа начинается вычленение текста
После обрезки ещё и дописываем текст
После обрезки переменной с текстом дописываем в конец дополнительный текст
Можно наоборот, запись сделать в начале, а потом уже обрезанный текст
Я хотел бы знать, как я могу сократить string в PHP начиная с последнего символа -> до конкретного символа. Допустим, у меня есть следующая ссылка:
и я хочу получить 2535834
Важное примечание: номер может иметь различную длину, поэтому я хочу вырезать в / неважно, сколько там чисел.
Решение
В этом особом случае, URL, используйте basename() :
Более общее решение будет preg_replace() , как это:
Шаблон ‘#. * / #’ Использует жадность по умолчанию механизма регулярных выражений PCRE — это означает, что он будет соответствовать как можно большему числу символов и, следовательно, будет потреблять /abc/123/xyz/ вместо просто /abc/ при сопоставлении с шаблоном.
* / #’ Использует жадность по умолчанию механизма регулярных выражений PCRE — это означает, что он будет соответствовать как можно большему числу символов и, следовательно, будет потреблять /abc/123/xyz/ вместо просто /abc/ при сопоставлении с шаблоном.
6 пунктов, которые помогут легко разобраться с regexp
Давно хотели изучить regexp? Это небольшое руководство поможет разобраться с ними в 6 этапов, а обилие примеров позволит закрепить материал.
Regexp представляет собой группу символов или знаков, которая используется для поиска определенного текстового шаблона.
Регулярное выражение – это шаблон, который сравнивается с предметной строкой слева направо. Словосочетание “regular expression” применяется не так широко, вместо него обычно употребляют “regex” и “regexp”. Регулярное выражение используется для замены текста внутри строки, проверки формы, извлечения подстроки из строки на основе соответствия шаблона и т. д.
Предположим, вы создаете приложение и хотите определить правила, согласно которым пользователи будут выбирать себе имя. Например, мы хотим, чтобы оно содержало буквы, цифры, нижнее подчеркивание и дефисы. Также нам бы хотелось ограничить количество символов в имени пользователя, чтобы оно не выглядело уродливым. Поэтому для проверки будем использовать следующее регулярное выражение:
Например, мы хотим, чтобы оно содержало буквы, цифры, нижнее подчеркивание и дефисы. Также нам бы хотелось ограничить количество символов в имени пользователя, чтобы оно не выглядело уродливым. Поэтому для проверки будем использовать следующее регулярное выражение:
Это выражение принимает строки john_doe, jo-hn_doe и john12_as. Однако имя пользователя Jo не будет соответствовать этому выражению, потому что оно содержит прописную букву, а также является слишком коротким.
Регулярное выражение — это всего лишь шаблон из символов, который мы используем для выполнения поиска в тексте. Например, регулярное выражение the означает букву t, за которой следует буква h, за которой следует буква e.
"the" => The fat cat sat on the mat.
Регулярное выражение 123 соответствует строке 123. Регулярное выражение сопоставляется входной строке путем сравнения каждого символа в regexp с каждым символом входной строки.
2.1 Точка
. — это простейший пример метасимвола. Метасимвол . соответствует любому единичному символу. Например, регулярное выражение .ar означает: любой символ, за которым следует буква a, за которой следует буква r.
«.ar» => The car parked in the garage.
Тестировать выражение
2.2 Интервал символов
Интервал или набор символов также называют символьным классом. Для его обозначения используются квадратные скобки. Чтобы указать диапазон символов внутри класса, необходимо поставить знак тире. Порядок ряда символов в наборе неважен. Так, например, регулярное выражение [Tt]he означает: T или t, за которым следует буква h, за которой следует буква e. c]ar» => The car parked in the garage.
c]ar» => The car parked in the garage.
Тестировать выражение
2.3 Повторения
Следующие мета-символы + ,* или ? используются для того, чтобы обозначить допустимое количество повторения подшаблона. Их роль зависит от конкретного случая.
2.3.1 Звездочка
Этот символ поможет найти одно или более копий какого-либо символа. Регулярное выражение a* означает 0 или более повторений символа a. Но если этот символ появится после набора или класса символов, тогда будут найдены повторения всего сета. Например, выражение [a-z]* означает любое количество этих символов в строке.
"[a-z]*" => The car parked in the garage #21.
Тестировать выражение
Также символ может быть использован вместе с метасимволом . для подбора строки из любых символов .*.
Еще звездочку можно использовать со знаком пробела \s, чтобы подобрать строку из пробелов.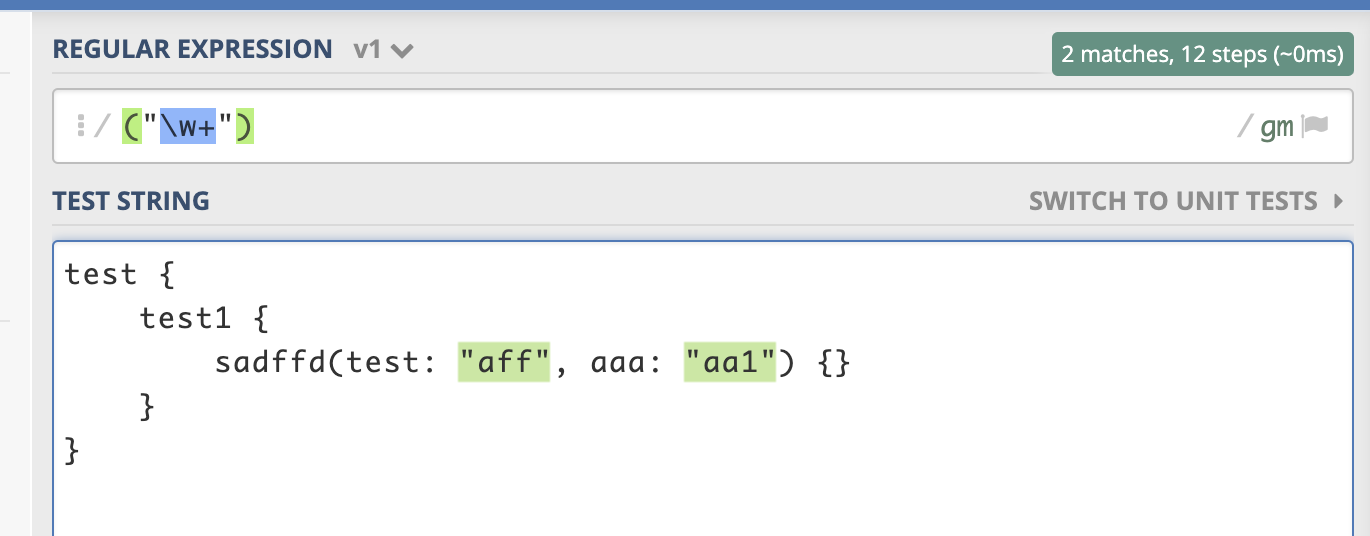 Например, выражение
Например, выражение \s*cat\s будет означать 0 или более пробелов, за которыми следует символ с, за ним а и t, а за ними снова 0 либо больше пробелов.
"\s*cat\s*" => The fat cat sat on the concatenation.
Тестировать выражение
2.3.2 Плюс
+ соответствует одному или нескольким повторениям предыдущего символа. Например, регулярное выражение c.+t означает: строчная буква c, за которой следует хотя бы один символ, за которым следует строчный символ t. Необходимо уточнить, что буква t должна быть последней t в предложении.
"c.+t" => The fat cat sat on the mat.
Тестировать выражение
2.3.3. Вопросительный знак
В regexp метасимвол ? делает предшествующий символ необязательным. Этот символ соответствует полному отсутствию или же одному экземпляру предыдущего символа. Например, регулярное выражение
Например, регулярное выражение [T]?he означает: необязательно заглавную букву T, за которой следует строчный символ h, за которым следует строчный символ e."[T]he" => The car is parked in the garage.
Тестировать выражение
"[T]?he" => The car is parked in the garage.
Тестировать выражение
2.4 Скобки
Скобки в regexp, которые также называются квантификаторами, используются для указания допустимого количества повторов символа или группы символов. Например, регулярное выражение [0-9]{2,3} означает, что допустимое количество цифр должно быть не менее двух цифр, но не более 3 (символы в диапазоне от 0 до 9).
"[0-9]{2,3}" => The number was 9.9997 but we rounded it off to 10.0.
Тестировать выражение
Мы можем убрать второе число. Например, выражение [0-9]{2,} означает 2 или более цифр.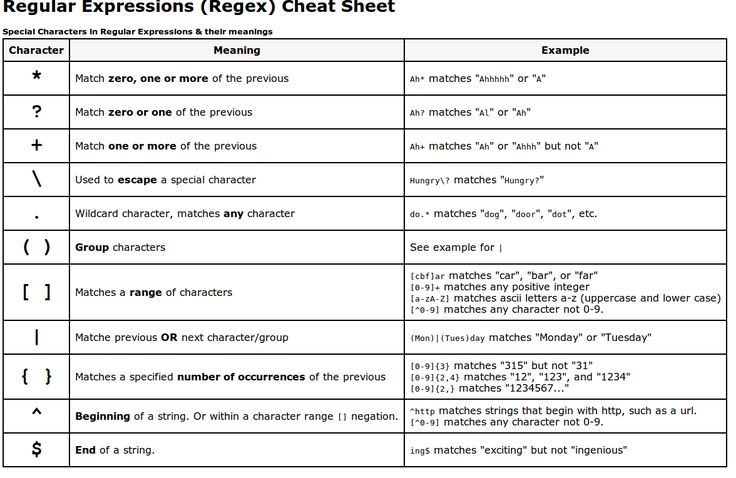 Если мы также уберем запятую, то тогда выражение
Если мы также уберем запятую, то тогда выражение [0-9]{3} будет находить только лишь 3 цифры, ни меньше и ни больше.
"[0-9]{2,}" => The number was 9.9997 but we rounded it off to 10.0.
Тестировать выражение
"[0-9]{3}" => The number was 9.9997 but rounded it off to 10.0.
Тестировать выражение
2.5 Символьная группа
Группа символов — это группа подшаблонов, которая записывается внутри скобок (...). Как было упомянуто раньше, если в регулярном выражении поместить квантификатор после символа, он повторит предыдущий символ. Но если мы поставим квантификатор после группы символов, он просто повторит всю группу. Например, регулярное выражение (ab)* соответствует нулю или более повторениям символа «ab». Мы также можем использовать | — метасимвол чередования внутри группы символов. Например, регулярное выражение (c|g|p)ar означает: символ нижнего регистра c, g или p, за которым следует символ a, за которым следует символ r.
"(c|g|p)ar" => The car is parked in the garage.
Тестировать выражение
2.6 Перечисление
В regexp вертикальная полоса | используется для определения перечисления. Перечисление — это что-то вроде условия между несколькими выражениями. Можно подумать, что набор символов и перечисление работают одинаково, но это совсем не так, между ними существует огромная разница. Перечисление работает на уровне выражений, а набор символов на уровне знаков. Например, регулярное выражение (T|t)he|car означает: T или t, сопровождаемая строчным символом h, сопровождаемый строчным символом e или строчным символом c, а затем a и r.
"(T|t)he|car" => The car is parked in the garage.
Тестировать выражение
2.7 Исключение специального символа
Обратная косая черта \ используется в regexp, чтобы избежать символа, который следует за ней. (T|t)he» => The car is parked in the garage.
(T|t)he» => The car is parked in the garage.
Тестировать выражение
2.8.2 Доллар
Знак доллара используется для проверки, является ли символ в выражении последним в введенной строке. Например (at\.)$ означает строчную а, за которой следует t, за которой следует a ., которые должны заканчивать строку.
"(at\.)" => The fat cat. sat. on the mat.
Тестировать выражение
"(at\.)$" => The fat cat. sat. on the mat.
Тестировать выражение
Regexp позволяет использовать сокращения для некоторых наборов символов, что делает работу с ними более комфортной. Таким образом, здесь используются следующие сокращения:
| Сокращение | Описание |
|---|---|
| . | Любой символ, кроме новой строки |
| \w | Соответствует буквенно-цифровым символам:[a-zA-Z0-9_] |
| \W | Соответствует не буквенно-цифровым символам:[^\w] |
| \d | Соответствует цифрам: [0-9] |
| \D | Соответствует нецифровым знакам: [^\d] |
| \s | Соответствует знаку пробела: [\t\n\f\r\p{Z}] |
| \S | Соответствует символам без пробела: [^\s] |
Lookbehind и lookahead (также называемые lookaround) — это определенные типы non-capturing групп (Они используются для поиска, но сами в него не входят). Lookaheads используются, когда у нас есть условие, что этому шаблону предшествует или следует другой шаблон. Например, мы хотим получить все числа, которым предшествует символ
Lookaheads используются, когда у нас есть условие, что этому шаблону предшествует или следует другой шаблон. Например, мы хотим получить все числа, которым предшествует символ $ из входной строки $4.44 and $10.88. Мы будем использовать регулярное выражение (?<=\$)[0-9\.]*, которое означает: получить все числа, содержащие . и которым предшествует символ $. Ниже приведены lookarounds, что используются в регулярных выражениях:
| Символ | Описание |
|---|---|
| ?= | Положительный Lookahead |
| ?! | Отрицательный Lookahead |
| ?<= | Положительный Lookbehind |
| ?<! | Отрицательный Lookbehind |
4.1 Положительный Lookahead
Положительный lookahead означает, что эта часть выражения должна следовать за впереди идущим выражением.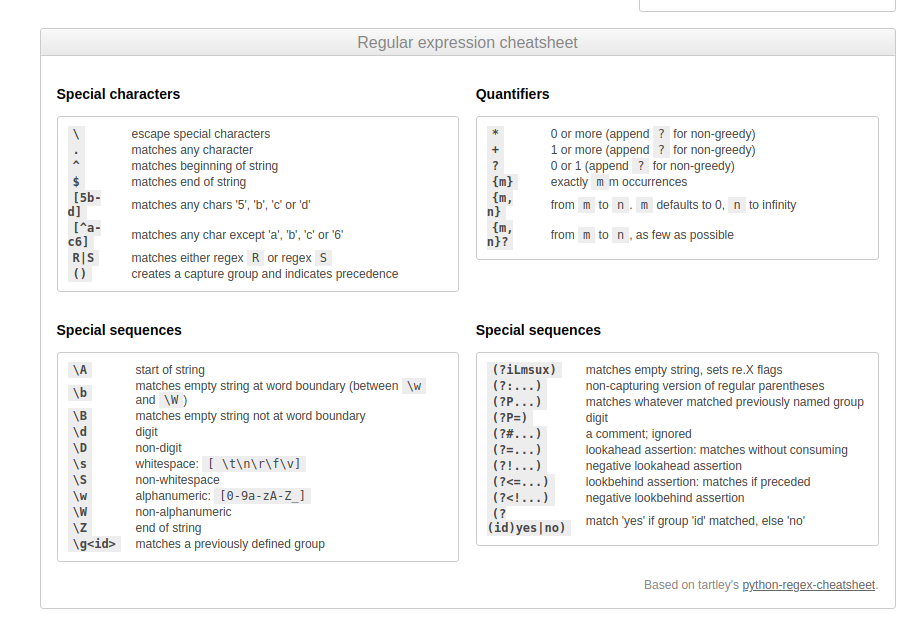 Возвращаемое значение содержит текст, который совпадает с первой частью выражения. Чтобы определить позитивный lookahead, используют скобки. Внутри них размещают знак вопроса и знак равенства:
Возвращаемое значение содержит текст, который совпадает с первой частью выражения. Чтобы определить позитивный lookahead, используют скобки. Внутри них размещают знак вопроса и знак равенства: (?=...). Само же выражение пишется после =. Например, выражение (T|t)he(?=\sfat) — это T в верхнем или нижнем регистре, за которым следует h и e. В скобках мы определяем позитивный lookahead, который говорит движку регулярного выражения искать The или the, за которыми следует fat.
"(T|t)he(?=\sfat)" => The fat cat sat on the mat.
Тестировать выражение
4.2 Отрицательный Lookahead
Негативный lookahead используется, когда нам нужно получить все совпадения в строке, за которой не следует определенный шаблон. Негативный lookahead определяется так же, как и позитивный, с той лишь разницей, что вместо знака равенства мы используем знак отрицания !. Таким образом, наше выражение приобретает следующий вид:
Таким образом, наше выражение приобретает следующий вид: (?!...). Теперь рассмотрим (T|t)he(?!\sfat), что означает: получить все The или the в введенной строке, за которыми не следует слово fat, предшествующее знаку пробела.
"(T|t)he(?!\sfat)" => The fat cat sat on the mat.
Тестировать выражение
4.3 Положительный Lookbehind
Положительный lookbehind используется для получения всех совпадений, которым предшествует определенный шаблон. Положительный lookbehind обозначается так: (?<=...). Например, регулярное выражение (?<=(T|t)he\s)(fat|mat) означает получить все fat или mat из строки ввода, которые идут после слова The или the.
"(? The fat cat sat on the mat.
Тестировать выражение
4.4 Отрицательный Lookbehind
Отрицательный lookbehind используется для получения всех совпадений, которым не предшествует определенный шаблон. Отрицательный lookbehind обозначается выражением
Отрицательный lookbehind обозначается выражением (?<!...). Например, регулярное выражение (?<!(T|t)he\s)(cat) означает: получить все cat слова из строки ввода, которые не идут после The или the.
"(? The cat sat on cat.
Тестировать выражение
Флаги также часто называют модификаторами, так как они могут изменять вывод regexp. Флаги, приведенные ниже являются неотъемлемой частью и могут быть использованы в любом порядке или сочетании regexp.
| Флаг | Описание |
|---|---|
| i | Нечувствительность к регистру: делает выражение нечувствительным к регистру. |
| g | Глобальный поиск: поиск шаблона во всей строке ввода. |
| m | Многострочность: анкер метасимвола работает в каждой строке. |
5.1 Нечувствительные к регистру
Модификатор i используется для поиска совпадений, нечувствительных к регистру.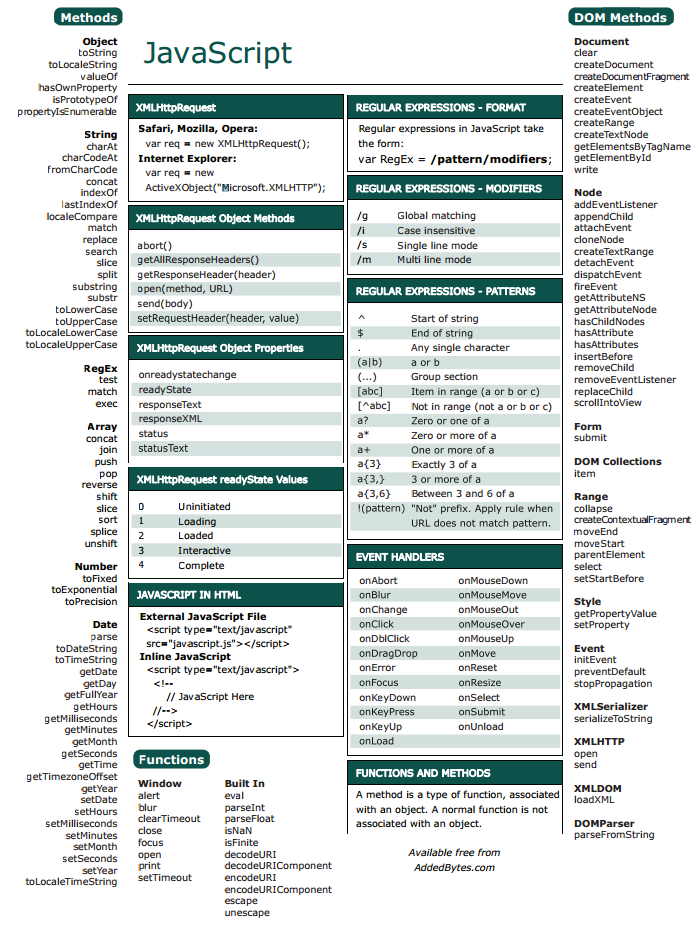 Например, выражение
Например, выражение /The/gi означает прописную букву T, за которой следуют h и e. И в самом конце выражения стоит i, благодаря которому можно проигнорировать регистр. g применяется для того, чтобы найти шаблон во всей введенной строке."The" => The fat cat sat on the mat.
Тестировать выражение
"/The/gi" => The fat cat sat on the mat.
Тестировать выражение
5.2 Глобальный поиск
Модификатор используется для выполнения глобального поиска шаблона(поиск будет продолжен после первого совпадения). Например, регулярное выражение /.(at)/g означает любой символ, кроме новой строки, за которым следует строчный символ a, а затем t. Поскольку мы использовали флаг g в конце регулярного выражения, теперь он найдет все совпадения в вводимой строке, а не только в первой (что является стандартом). , $) используются для проверки, является ли шаблон началом или концом строки. Но если мы хотим, чтобы привязки работали в каждой строке, нужно использовать флаг
, $) используются для проверки, является ли шаблон началом или концом строки. Но если мы хотим, чтобы привязки работали в каждой строке, нужно использовать флаг m. Например, регулярное выражение /at(.)?$/gm означает: строчный символ a, за которым следует t и что угодно, только не новая строка. А благодаря флагу m этот механизм регулярных выражений соответствует шаблону в конце каждой строки строки.
"/.at(.)?$/" => The fat
cat sat
on the mat.
Тестировать выражение
"/.at(.)?$/gm" => The fat
cat sat
on the mat.
Тестировать выражение
По умолчанию регулярные выражения выполняются благодаря «жадным» квантификаторам, им соответсвует максимально длинная строка из всех возможных.
"/(.*at)/" => The fat cat sat on the mat.
Тестировать выражение
Чтобы получить «ленивое» выражение, нужно использовать ?.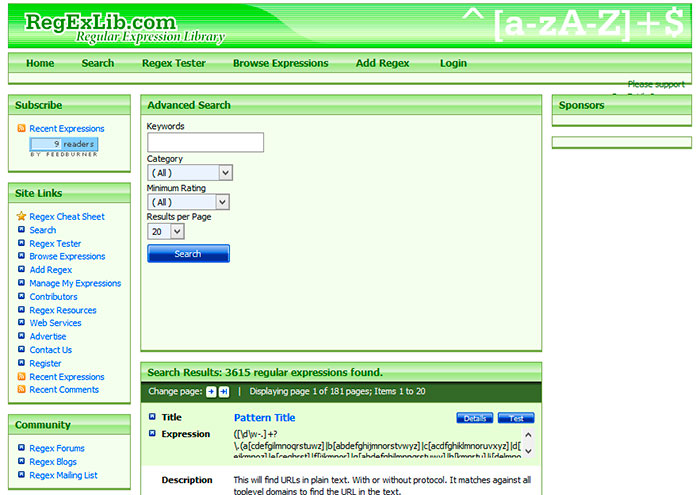 Так будет получена максимально короткая строка.
Так будет получена максимально короткая строка.
"/(.*?at)/" => The fat cat sat on the mat.
Тестировать выражение
- Практическое введение в регулярные выражения для новичков
- 5 практических примеров использования регулярных выражений на JavaScript
- 11 материалов по регулярным выражениям
Источник
Анализ текста регулярными выражениями (RegExp) в Excel
741 11.02.2018 Скачать пример
Одной из самых трудоемких и неприятных задач при работе с текстом в Excel является парсинг — разбор буквенно-цифровой «каши» на составляющие и извлечение из нее нужных нам фрагментов. Например:
- извлечение почтового индекса из адреса (хорошо, если индекс всегда в начале, а если нет?)
- нахождение номера и даты счета из описания платежа в банковской выписке
- извлечение ИНН из разношерстных описаний компаний в списке контрагентов
- поиск номера автомобиля или артикула товара в описании и т. д.
 д.
д. Обычно во подобных случаях, после получасового муторного ковыряния в тексте вручную, в голову начинают приходить мысли как-то автоматизировать этот процесс (особенно если данных много). Решений тут несколько и с разной степенью сложности-эффективности:
- Использовать встроенные текстовые функции Excel для поиска-нарезки-склейки текста: ЛЕВСИМВ (LEFT), ПРАВСИМВ (RIGHT), ПСТР (MID), СЦЕПИТЬ (CONCATENATE) и ее аналоги, ОБЪЕДИНИТЬ (JOINTEXT), СОВПАД (EXACT) и т.д. Этот способ хорош, если в тексте есть четкая логика (например, индекс всегда в начале адреса). В противном случае формулы существенно усложняются и, порой, дело доходит даже до формул массива, что сильно тормозит на больших таблицах.
- Использование оператора проверки текстового подобия Like из Visual Basic, обернутого в пользовательскую макро-функцию. Это позволяет реализовать более гибкий поиск с использованием символов подстановки (*,#,? и т. д.) К сожалению, этот инструмент не умеет извлекать нужную подстроку из текста — только проверять, содержится ли она в нем.
 д.) К сожалению, этот инструмент не умеет извлекать нужную подстроку из текста — только проверять, содержится ли она в нем.
д.) К сожалению, этот инструмент не умеет извлекать нужную подстроку из текста — только проверять, содержится ли она в нем.Кроме вышеперечисленного, есть еще один подход, очень известный в узких кругах профессиональных программистов, веб-разработчиков и прочих технарей — это регулярные выражения (Regular Expressions = RegExp = «регэкспы» = «регулярки»). Упрощенно говоря, RegExp — это язык, где с помощью специальных символов и правил производится поиск нужных подстрок в тексте, их извлечение или замена на другой текст. Регулярные выражения — это очень мощный и красивый инструмент, на порядок превосходящий по возможностям все остальные способы работы с текстом. Многие языки программирования (C#, PHP, Perl, JavaScript…) и текстовые редакторы (Word, Notepad++…) поддерживают регулярные выражения.
Microsoft Excel, к сожалению, не имеет поддержки RegExp по-умолчанию «из коробки», но это легко исправить с помощью VBA. Откройте редактор Visual Basic с вкладки Разработчик (Developer) или сочетанием клавиш Alt+F11. Затем вставьте новый модуль через меню Insert — Module и скопируйте туда текст вот такой макрофункции:
Затем вставьте новый модуль через меню Insert — Module и скопируйте туда текст вот такой макрофункции:
Public Function RegExpExtract(Text As String, Pattern As String, Optional Item As Integer = 1) As String
On Error GoTo ErrHandl
Set regex = CreateObject("VBScript.RegExp")
regex.Pattern = Pattern
regex.Global = True
If regex.Test(Text) Then
Set matches = regex.Execute(Text)
RegExpExtract = matches.Item(Item - 1)
Exit Function
End If
ErrHandl:
RegExpExtract = CVErr(xlErrValue)
End Function
Теперь можно закрыть редактор Visual Basic и, вернувшись в Excel, опробовать нашу новую функцию. Синтаксис у нее следующий:
=RegExpExtract( Txt ; Pattern ; Item )
где
- Txt — ячейка с текстом, который мы проверяем и из которого хотим извлечь нужную нам подстроку
- Pattern — маска (шаблон) для поиска подстроки
- Item — порядковый номер подстроки, которую надо извлечь, если их несколько (если не указан, то выводится первое вхождение)
Самое интересное тут, конечно, это Pattern — строка-шаблон из спецсимволов «на языке» RegExp, которая и задает, что именно и где мы хотим найти. Вот самые основные из них — для начала:
Вот самые основные из них — для начала:
| Паттерн | Описание | |
| . |
Самое простое — это точка. Она обозначает любой символ в шаблоне на указанной позиции. |
|
| \s |
Любой символ, выглядящий как пробел (пробел, табуляция или перенос строки). |
|
|
\S |
Анти-вариант предыдущего шаблона, т.е. любой НЕпробельный символ. |
|
|
\d |
Любая цифра |
|
|
\D |
Анти-вариант предыдущего, т.е. любая НЕ цифра |
|
| \w |
Любой символ латиницы (A-Z), цифра или знак подчеркивания |
|
| \W |
Анти-вариант предыдущего, т.
|
Начало строки |
| $ |
Конец строки |
|
| \b |
Край слова |
Если мы ищем определенное количество символов, например, шестизначный почтовый индекс или все трехбуквенные коды товаров, то на помощь нам приходят квантификаторы или кванторы — специальные выражения, задающие количество искомых знаков. Квантификаторы применяются к тому символу, что стоит перед ним:
| Квантор | Описание |
| ? |
Ноль или одно вхождение. Например .? будет означать один любой символ или его отсутствие. |
| + |
Одно или более вхождений. Например \d+ означает любое количество цифр (т.е. любое число от 0 до бесконечности). Например \d+ означает любое количество цифр (т.е. любое число от 0 до бесконечности). |
| * |
Ноль или более вхождений, т.е. любое количество. Так \s* означает любое количество пробелов или их отсутствие. |
|
{число} или {число1,число2} |
Если нужно задать строго определенное количество вхождений, то оно задается в фигурных скобках. Например \d{6} означает строго шесть цифр, а шаблон \s{2,5} — от двух до пяти пробелов |
Теперь давайте перейдем к самому интересному — разбору применения созданной функции и того, что узнали о паттернах на практических примерах из жизни.
Извлекаем числа из текста
Для начала разберем простой случай — нужно извлечь из буквенно-цифровой каши первое число, например мощность источников бесперебойного питания из прайс-листа:
Логика работы регулярного выражения тут простая: \d — означает любую цифру, а квантор + говорит о том, что их количество должно быть одна или больше. Двойной минус перед функцией нужен, чтобы «на лету» преобразовать извлеченные символы в полноценное число из числа-как-текст.
Двойной минус перед функцией нужен, чтобы «на лету» преобразовать извлеченные символы в полноценное число из числа-как-текст.
Почтовый индекс
На первый взгляд, тут все просто — ищем ровно шесть цифр подряд. Используем спецсимвол \d для цифры и квантор {6} для количества знаков:
Однако, возможна ситуация, когда левее индекса в строке стоит еще один большой набор цифр подряд (номер телефона, ИНН, банковский счет и т.д.) Тогда наша регулярка выдернет из нее первых 6 цифр, т.е. сработает некорректно:
Чтобы этого не происходило, необходимо добавить в наше регулярное выражение по краям модификатор \b означающий конец слова. Это даст понять Excel, что нужный нам фрагмент (индекс) должен быть отдельным словом, а не частью другого фрагмента (номера телефона):
Телефон
Проблема с нахождением телефонного номера среди текста состоит в том, что существует очень много вариантов записи номеров — с дефисами и без, через пробелы, с кодом региона в скобках или без и т. д. Поэтому, на мой взгляд, проще сначала вычистить из исходного текста все эти символы с помощью нескольких вложенных друг в друга функций ПОДСТАВИТЬ (SUBSTITUTE), чтобы он склеился в единое целое, а потом уже примитивной регуляркой \d{11} вытаскивать 11 цифр подряд:
д. Поэтому, на мой взгляд, проще сначала вычистить из исходного текста все эти символы с помощью нескольких вложенных друг в друга функций ПОДСТАВИТЬ (SUBSTITUTE), чтобы он склеился в единое целое, а потом уже примитивной регуляркой \d{11} вытаскивать 11 цифр подряд:
ИНН
Тут чуть сложнее, т.к. ИНН (в России) бывает 10-значный (у юрлиц) или 12-значный (у физлиц). Если не придираться особо, то вполне можно удовлетвориться регуляркой \d{10,12}, но она, строго говоря, будет вытаскивать все числа от 10 до 12 знаков, т.е. и ошибочно введенные 11-значные. Правильнее будет использовать два шаблона, связанных логическим ИЛИ оператором | (вертикальная черта):
Обратите внимание, что в запросе мы сначала ищем 12-разрядные, и только потом 10-разрядные числа. Если же записать нашу регулярку наоборот, то она будет вытаскивать для всех, даже длинных 12-разрядных ИНН, только первые 10 символов. То есть после срабатывания первого условия дальнейшая проверка уже не производится:
То есть после срабатывания первого условия дальнейшая проверка уже не производится:
Это принципиальное отличие оператора | от стандартной экселевской логической функции ИЛИ (OR), где от перестановки аргументов результат не меняется.
Артикулы товаров
Во многих компаниях товарам и услугам присваиваются уникальные идентификаторы — артикулы, SAP-коды, SKU и т.д. Если в их обозначениях есть логика, то их можно легко вытаскивать из любого текста с помощью регулярных выражений. Например, если мы знаем, что наши артикулы всегда состоят из трех заглавных английских букв, дефиса и последующего трехразрядного числа, то:
Логика работы шаблона тут проста. [A-Z] — означает любые заглавные буквы латиницы. Следующий за ним квантор {3} говорит о том, что нам важно, чтобы таких букв было именно три. После дефиса мы ждем три цифровых разряда, поэтому добавляем на конце \d{3}
Денежные суммы
Похожим на предыдущий пункт образом, можно вытаскивать и цены (стоимости, НДС. ..) из описания товаров. Если денежные суммы, например, указываются через дефис, то:
..) из описания товаров. Если денежные суммы, например, указываются через дефис, то:
Паттерн \d с квантором + ищет любое число до дефиса, а \d{2} будет искать копейки (два разряда) после.
Если нужно вытащить не цены, а НДС, то можно воспользоваться третьим необязательным аргументом нашей функции RegExpExtract, задающим порядковый номер извлекаемого элемента. И, само-собой, можно заменить функцией ПОДСТАВИТЬ (SUBSTITUTE) в результатах дефис на стандартный десятичный разделитель и добавить двойной минус в начале, чтобы Excel интерпретировал найденный НДС как нормальное число:
Автомобильные номера
Если не брать спецтранспорт, прицепы и прочие мотоциклы, то стандартный российский автомобильный номер разбирается по принципу «буква — три цифры — две буквы — код региона». Причем код региона может быть 2- или 3-значным, а в качестве букв применяются только те, что похожи внешне на латиницу. Таким образом, для извлечения номеров из текста нам поможет следующая регулярка:
Таким образом, для извлечения номеров из текста нам поможет следующая регулярка:
Время
Для извлечения времени в формате ЧЧ:ММ подойдет такое регулярное выражение:
После двоеточия фрагмент [0-5]\d, как легко сообразить, задает любое число в интервале 00-59. Перед двоеточием в скобках работают два шаблона, разделенных логическим ИЛИ (вертикальной чертой):
- [0-1]\d — любое число в интервале 00-19
- 2[0-3] — любое число в интервале 20-23
К полученному результату можно применить дополнительно еще и стандартную Excel’евскую функцию ВРЕМЯ (TIME), чтобы преобразовать его в понятный программе и пригодный для дальнейших расчетов формат времени.
Проверка пароля
Предположим, что нам надо проверить список придуманных пользователями паролей на корректность. По нашим правилам, в паролях могут быть только английские буквы (строчные или прописные) и цифры. ) и концом ($) в нашем тексте находились только символы из заданного в квадратных скобках набора. Если нужно проверить еще и длину пароля (например, не меньше 6 символов), то квантор + можно заменить на интервал «шесть и более» в виде {6,}:
) и концом ($) в нашем тексте находились только символы из заданного в квадратных скобках набора. Если нужно проверить еще и длину пароля (например, не меньше 6 символов), то квантор + можно заменить на интервал «шесть и более» в виде {6,}:
Город из адреса
Допустим, нам нужно вытащить город из строки адреса. Поможет регулярка, извлекающая текст от «г.» до следующей запятой:
Давайте разберем этот шаблон поподробнее.
Если вы прочитали текст выше, то уже поняли, что некоторые символы в регулярных выражениях (точки, звездочки, знаки доллара и т.д.) несут особый смысл. Если же нужно искать сами эти символы, то перед ними ставится обратная косая черта (иногда это называют экранированием). Поэтому при поиске фрагмента «г.» мы должны написать в регулярке г\. если ищем плюсик, то \+ и т.д.
Следующих два символа в нашем шаблоне — точка и звездочка-квантор — обозначают любое количество любых символов, т.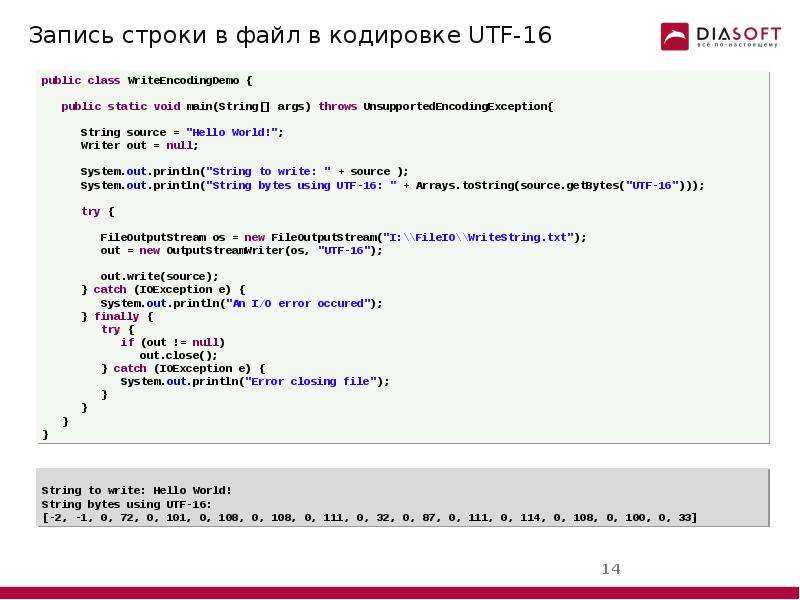 е. любое название города.
е. любое название города.
На конце шаблона стоит запятая, т.к. мы ищем текст от «г.» до запятой. Но ведь в тексте может быть несколько запятых, правда? Не только после города, но и после улицы, дома и т.д. На какой из них будет останавливаться наш запрос? Вот за это отвечает вопросительный знак. Без него наша регулярка вытаскивала бы максимально длинную строку из всех возможных:
В терминах регулярных выражений, такой шаблон является «жадным». Чтобы исправить ситуацию и нужен вопросительный знак — он делает квантор, после которого стоит, «скупым» — и наш запрос берет текст только до первой встречной запятой после «г.»:
Имя файла из полного пути
Еще одна весьма распространенная ситуация — вытащить имя файла из полного пути. Тут поможет простая регулярка вида:
Тут фишка в том, что поиск, по сути, происходит в обратном направлении — от конца к началу, т. к. в конце нашего шаблона стоит $, и мы ищем все, что перед ним до первого справа обратного слэша. Бэкслэш заэкранирован, как и точка в предыдущем примере.
к. в конце нашего шаблона стоит $, и мы ищем все, что перед ним до первого справа обратного слэша. Бэкслэш заэкранирован, как и точка в предыдущем примере.
P.S.
«Под занавес» хочу уточнить, что все вышеописанное — это малая часть из всех возможностей, которые предоставляют регулярные выражения. Спецсимволов и правил их использования очень много и на эту тему написаны целые книги (рекомендую для начала хотя бы эту). В некотором смысле, написание регулярных выражений — это почти искусство. Почти всегда придуманную регулярку можно улучшить или дополнить, сделав ее более изящной или способным работать с более широким диапазоном вариантов входных данных.
Для анализа и разбора чужих регулярок или отладки своих собственных есть несколько удобных онлайн-сервисов: RegEx101, RegExr и др.
К сожалению, не все возможности классических регулярных выражений поддерживаются в VBA (например, обратный поиск или POSIX-классы) и умеют работать с кириллицей, но и того, что есть, думаю, хватит на первое время, чтобы вас порадовать.
Если же вы не новичок в теме, и вам есть чем поделиться — оставляйте полезные при работе в Excel регулярки в комментариях ниже. Один ум хорошо, а два сапога — пара!
Ссылки по теме
- Замена и зачистка текста функцией ПОДСТАВИТЬ (SUBSTITUTE)
- Поиск и подсветка символов латиницы в русском тексте
- Поиск ближайшего похожего текста (Иванов = Ивонов = Иваноф и т.д.)
Регулярные выражения в Python: теория и практика
Рассмотрим регулярные выражения в Python, начиная синтаксисом и заканчивая примерами использования.
Примечание Вы читаете улучшенную версию некогда выпущенной нами статьи.
- Основы регулярных выражений
- Регулярные выражения в Python
- Задачи
Основы регулярных выражений
Регулярками называются шаблоны, которые используются для поиска соответствующего фрагмента текста и сопоставления символов.
Грубо говоря, у нас есть input-поле, в которое должен вводиться email-адрес. 0-9];
0-9];
Для чего используются регулярные выражения
- для определения нужного формата, например телефонного номера или email-адреса;
- для разбивки строк на подстроки;
- для поиска, замены и извлечения символов;
- для быстрого выполнения нетривиальных операций.
Синтаксис таких выражений в основном стандартизирован, так что вам следует понять их лишь раз, чтобы использовать в любом языке программирования.
Примечание Не стоит забывать, что регулярные выражения не всегда оптимальны, и для простых операций часто достаточно встроенных в Python функций.
Хотите узнать больше? Обратите внимание на статью о регулярках для новичков.
Регулярные выражения в Python
В Python для работы с регулярками есть модуль re. Его нужно просто импортировать:
import re
А вот наиболее популярные методы, которые предоставляет модуль:
re.match()re.search()re.findall()re.split()re.sub()re.compile()
Рассмотрим каждый из них подробнее.
re.match(pattern, string)
Этот метод ищет по заданному шаблону в начале строки. Например, если мы вызовем метод match() на строке «AV Analytics AV» с шаблоном «AV», то он завершится успешно. Но если мы будем искать «Analytics», то результат будет отрицательный:
import re result = re.match(r'AV', 'AV Analytics Vidhya AV') print result Результат: <_sre.SRE_Match object at 0x0000000009BE4370>
Искомая подстрока найдена. Чтобы вывести её содержимое, применим метод group() (мы используем «r» перед строкой шаблона, чтобы показать, что это «сырая» строка в Python):
result = re.
 match(r'AV', 'AV Analytics Vidhya AV')
print result.group(0)
Результат:
AV
match(r'AV', 'AV Analytics Vidhya AV')
print result.group(0)
Результат:
AVТеперь попробуем найти «Analytics» в данной строке. Поскольку строка начинается на «AV», метод вернет None:
result = re.match(r'Analytics', 'AV Analytics Vidhya AV') print result Результат: None
Также есть методы start() и end() для того, чтобы узнать начальную и конечную позицию найденной строки.
result = re.match(r'AV', 'AV Analytics Vidhya AV') print result.start() print result.end() Результат: 0 2
Эти методы иногда очень полезны для работы со строками.
re.search(pattern, string)
Метод похож на match(), но ищет не только в начале строки. В отличие от предыдущего, search() вернёт объект, если мы попытаемся найти «Analytics»:
result = re.search(r'Analytics', 'AV Analytics Vidhya AV') print result.group(0) Результат: Analytics
Метод search() ищет по всей строке, но возвращает только первое найденное совпадение.
re.findall(pattern, string)
Возвращает список всех найденных совпадений. У метода findall() нет ограничений на поиск в начале или конце строки. Если мы будем искать «AV» в нашей строке, он вернет все вхождения «AV». Для поиска рекомендуется использовать именно findall(), так как он может работать и как re.search(), и как re.match().
result = re.findall(r'AV', 'AV Analytics Vidhya AV') print result Результат: ['AV', 'AV']
re.split(pattern, string, [maxsplit=0])
Этот метод разделяет строку по заданному шаблону.
result = re.split(r'y', 'Analytics') print result Результат: ['Anal', 'tics']
В примере мы разделили слово «Analytics» по букве «y». Метод split() принимает также аргумент maxsplit со значением по умолчанию, равным 0. В данном случае он разделит строку столько раз, сколько возможно, но если указать этот аргумент, то разделение будет произведено не более указанного количества раз. Давайте посмотрим на примеры Python RegEx:
Давайте посмотрим на примеры Python RegEx:
result = re.split(r'i', 'Analytics Vidhya') print result Результат: ['Analyt', 'cs V', 'dhya'] # все возможные участки.
result = re.split(r'i', 'Analytics Vidhya',maxsplit=1) print result Результат: ['Analyt', 'cs Vidhya']
Мы установили параметр maxsplit равным 1, и в результате строка была разделена на две части вместо трех.
re.sub(pattern, repl, string)
Ищет шаблон в строке и заменяет его на указанную подстроку. Если шаблон не найден, строка остается неизменной.
result = re.sub(r'India', 'the World', 'AV is largest Analytics community of India') print result Результат: 'AV is largest Analytics community of the World'
re.compile(pattern, repl, string)
Мы можем собрать регулярное выражение в отдельный объект, который может быть использован для поиска. Это также избавляет от переписывания одного и того же выражения.
pattern = re.compile('AV')
result = pattern.findall('AV Analytics Vidhya AV')
print result
result2 = pattern.findall('AV is largest analytics community of India')
print result2
Результат:
['AV', 'AV']
['AV']До сих пор мы рассматривали поиск определенной последовательности символов. Но что, если у нас нет определенного шаблона, и нам надо вернуть набор символов из строки, отвечающий определенным правилам? Такая задача часто стоит при извлечении информации из строк. Это можно сделать, написав выражение с использованием специальных символов. Вот наиболее часто используемые из них:
| Оператор | Описание |
|---|---|
| . | Один любой символ, кроме новой строки \n. |
| ? | 0 или 1 вхождение шаблона слева |
| + | 1 и более вхождений шаблона слева |
| * | 0 и более вхождений шаблона слева |
| \w | Любая цифра или буква (\W — все, кроме буквы или цифры) |
| \d | Любая цифра [0-9] (\D — все, кроме цифры) |
| \s | Любой пробельный символ (\S — любой непробельный символ) |
| \b | Граница слова |
[. и $ и $ | Начало и конец строки соответственно |
| {n,m} | От n до m вхождений ({,m} — от 0 до m) |
| a|b | Соответствует a или b |
| () | Группирует выражение и возвращает найденный текст |
| \t, \n, \r | Символ табуляции, новой строки и возврата каретки соответственно |
Больше информации по специальным символам можно найти в документации для регулярных выражений в Python 3.
Перейдём к практическому применению Python регулярных выражений и рассмотрим примеры.
Задачи
Вернуть первое слово из строки
Сначала попробуем вытащить каждый символ (используя .)
result = re.findall(r'.', 'AV is largest Analytics community of India') print result Результат: ['A', 'V', ' ', 'i', 's', ' ', 'l', 'a', 'r', 'g', 'e', 's', 't', ' ', 'A', 'n', 'a', 'l', 'y', 't', 'i', 'c', 's', ' ', 'c', 'o', 'm', 'm', 'u', 'n', 'i', 't', 'y', ' ', 'o', 'f', ' ', 'I', 'n', 'd', 'i', 'a']
Для того, чтобы в конечный результат не попал пробел, используем вместо . 
\w.
result = re.findall(r'\w', 'AV is largest Analytics community of India') print result Результат: ['A', 'V', 'i', 's', 'l', 'a', 'r', 'g', 'e', 's', 't', 'A', 'n', 'a', 'l', 'y', 't', 'i', 'c', 's', 'c', 'o', 'm', 'm', 'u', 'n', 'i', 't', 'y', 'o', 'f', 'I', 'n', 'd', 'i', 'a']
Теперь попробуем достать каждое слово (используя * или +)
result = re.findall(r'\w*', 'AV is largest Analytics community of India') print result Результат: ['AV', '', 'is', '', 'largest', '', 'Analytics', '', 'community', '', 'of', '', 'India', '']
И снова в результат попали пробелы, так как * означает «ноль или более символов». Для того, чтобы их убрать, используем +:
result = re.findall(r'\w+', 'AV is largest Analytics community of India') print result Результат: ['AV', 'is', 'largest', 'Analytics', 'community', 'of', 'India']
Теперь вытащим первое слово, используя ^:
result = re.Квантификаторы — * + ? и {}result = re.findall(r'\w+$', 'AV is largest Analytics community of India') print result Результат: [‘India’]Вернуть первые два символа каждого слова
Вариант 1: используя
\w, вытащить два последовательных символа, кроме пробельных, из каждого слова:result = re.findall(r'\w\w', 'AV is largest Analytics community of India') print result Результат: ['AV', 'is', 'la', 'rg', 'es', 'An', 'al', 'yt', 'ic', 'co', 'mm', 'un', 'it', 'of', 'In', 'di']Вариант 2: вытащить два последовательных символа, используя символ границы слова (
\b):result = re.findall(r'\b\w.', 'AV is largest Analytics community of India') print result Результат: ['AV', 'is', 'la', 'An', 'co', 'of', 'In']Вернуть домены из списка email-адресов
Сначала вернём все символы после «@»:
result = re.findall(r'@\w+', 'abc.Как видим, части «.com», «.in» и т. д. не попали в результат. Изменим наш код:
result = re.findall(r'@\w+.\w+', '[email protected], [email protected], [email protected], [email protected]') print result Результат: ['@gmail.com', '@test.in', '@analyticsvidhya.com', '@rest.biz']Второй вариант — вытащить только домен верхнего уровня, используя группировку —
( ):result = re.findall(r'@\w+.(\w+)', '[email protected], [email protected], [email protected], [email protected]') print result Результат: ['com', 'in', 'com', 'biz']Извлечь дату из строки
Используем
\dдля извлечения цифр.result = re.findall(r'\d{2}-\d{2}-\d{4}', 'Amit 34-3456 12-05-2007, XYZ 56-4532 11-11-2011, ABC 67-8945 12-01-2009') print result Результат: ['12-05-2007', '11-11-2011', '12-01-2009']Для извлечения только года нам опять помогут скобки:
result = re.Извлечь слова, начинающиеся на гласную
Для начала вернем все слова:
result = re.findall(r'\w+', 'AV is largest Analytics community of India') print result Результат: ['AV', 'is', 'largest', 'Analytics', 'community', 'of', 'India']А теперь — только те, которые начинаются на определенные буквы (используя
[]):result = re.findall(r'[aeiouAEIOU]\w+', 'AV is largest Analytics community of India') print result Результат: ['AV', 'is', 'argest', 'Analytics', 'ommunity', 'of', 'India']Выше мы видим обрезанные слова «argest» и «ommunity». Для того, чтобы убрать их, используем
\bдля обозначения границы слова:result = re.findall(r'\b[aeiouAEIOU]\w+', 'AV is largest Analytics community of India') print result Результат: ['AV', 'is', 'Analytics', 'of', 'India']Также мы можем использовать
^внутри квадратных скобок для инвертирования группы:result = re.Проверить формат телефонного номера
Номер должен быть длиной 10 знаков и начинаться с 8 или 9. Есть список телефонных номеров, и нужно проверить их, используя регулярки в Python:
li = ['9999999999', '999999-999', '99999x9999'] for val in li: if re.match(r'[8-9]{1}[0-9]{9}', val) and len(val) == 10: print 'yes' else: print 'no' Результат: yes no noРазбить строку по нескольким разделителям
Возможное решение:
line = 'asdf fjdk;afed,fjek,asdf,foo' # String has multiple delimiters (";",","," "). result = re.split(r'[;,\s]', line) print result Результат: ['asdf', 'fjdk', 'afed', 'fjek', 'asdf', 'foo']Также мы можем использовать метод
re.sub()для замены всех разделителей пробелами:line = 'asdf fjdk;afed,fjek,asdf,foo' result = re.Извлечь информацию из html-файла
Допустим, нужно извлечь информацию из html-файла, заключенную между
<td>и</td>, кроме первого столбца с номером. Также будем считать, что html-код содержится в строке.Пример содержимого html-файла:
1NoahEmma2LiamOlivia3MasonSophia4JacobIsabella5WilliamAva6EthanMia7MichaelEmilyС помощью регулярных выражений в Python это можно решить так (если поместить содержимое файла в переменную
test_str):result = re.findall(r'\d([A-Z][A-Za-z]+)([A-Z][A-Za-z]+)', test_str) print result Результат: [('Noah', 'Emma'), ('Liam', 'Olivia'), ('Mason', 'Sophia'), ('Jacob', 'Isabella'), ('William', 'Ava'), ('Ethan', 'Mia'), ('Michael', 'Emily')]Адаптированный перевод «Beginners Tutorial for Regular Expressions in Python»
Шпаргалка по регулярным выражениям.
 , то мы получим последнее слово, а не первое:
, то мы получим последнее слово, а не первое:
 findall(r'\d{2}-\d{2}-(\d{4})', 'Amit 34-3456 12-05-2007, XYZ 56-4532 11-11-2011, ABC 67-8945 12-01-2009')
print result
Результат:
['2007', '2011', '2009']
findall(r'\d{2}-\d{2}-(\d{4})', 'Amit 34-3456 12-05-2007, XYZ 56-4532 11-11-2011, ABC 67-8945 12-01-2009')
print result
Результат:
['2007', '2011', '2009'] aeiouAEIOU ]\w+', 'AV is largest Analytics community of India')
print result
Результат:
['largest', 'community']
aeiouAEIOU ]\w+', 'AV is largest Analytics community of India')
print result
Результат:
['largest', 'community'] sub(r'[;,\s]',' ', line)
print result
Результат:
asdf fjdk afed fjek asdf foo
sub(r'[;,\s]',' ', line)
print result
Результат:
asdf fjdk afed fjek asdf foo Привет пока$ точное совпадение (начинается и заканчивается как Привет пока)воробушки соответствует любой строке, в которой есть текст воробушки
Привет пока$ точное совпадение (начинается и заканчивается как Привет пока)воробушки соответствует любой строке, в которой есть текст воробушкиabc* соответствует строке, в которой после ab следует 0 или более символов c -> тестabc+ соответствует строке, в которой после ab следует один или более символов cabc? соответствует строке, в которой после ab следует 0 или один символ cabc{2} соответствует строке, в которой после ab следует 2 символа cabc{2,} соответствует строке, в которой после ab следует 2 или более символов cabc{2,5} соответствует строке, в которой после ab следует от 2 до 5 символов ca(bc)* соответствует строке, в которой после ab следует 0 или более последовательностей символов bca(bc){2,5} соответствует строке, в которой после ab следует от 2 до 5 последовательностей символов bcОператор ИЛИ — | или []a(b|c) соответствует строке, в которой после a следует b или c -> тестa[bc] как и в предыдущем примереСимвольные классы — \d \w \s и .

\d соответствует одному символу, который является цифрой -> тест\w соответствует слову (может состоять из букв, цифр и подчёркивания) -> тест\s соответствует символу пробела (включая табуляцию и прерывание строки). соответствует любому символу -> тест
Используйте оператор . с осторожностью, так как зачастую класс или отрицаемый класс символов (который мы рассмотрим далее) быстрее и точнее.
У операторов \d, \w и \s также есть отрицания ― \D, \W и \S соответственно.
Например, оператор \D будет искать соответствия противоположенные \d.
\D соответствует одному символу, который не является цифрой -> тест
Некоторые символы, например ^. и 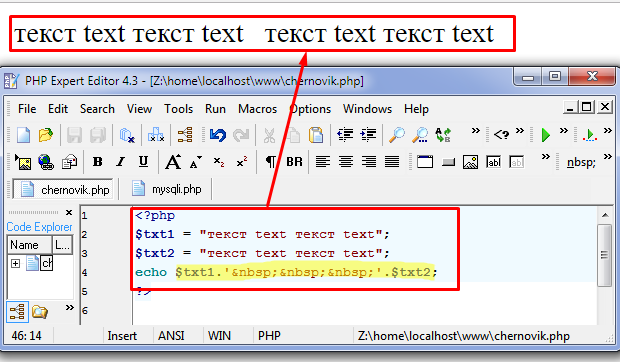
$ вызовут совпадение в начале и конце строки ввода (line), вместо строки целиком (string).
a(bc) создаём группу со значением bc -> тестa(?:bc)* оперетор ?: отключает группу -> тестa(?<foo>bc) так, мы можем присвоить имя группе -> тест
Этот оператор очень полезен, когда нужно извлечь информацию из строк или данных, используя ваш любимый язык программирования. Любые множественные совпадения, по нескольким группам, будут представлены в виде классического массива: доступ к их значениям можно получить с помощью индекса из результатов сопоставления.
Если присвоить группам имена (используя Помните, что внутри скобочных выражений все специальные символы (включая обратную косую черту Квантификаторы ( Например, выражение Обратите внимание, что хорошей практикой считается не использовать оператор Вы можете использовать оператор отрицания ! Как вы могли убедиться, области применения регулярных выражений разнообразны. Перевод статьи Jonny Fox: Regex tutorial — A quick cheatsheet by examples(?<foo>. используется как отрицание в выражении -> тест
используется как отрицание в выражении -> тест\) теряют своё служебное значение, поэтому нам ненужно их экранировать.* + {}) ― это «жадные» операторы, потому что они продолжают поиск соответствий, как можно глубже ― через весь текст.<.+> соответствует <div>simple div</div> в This is a <div> simple div</div> test. Чтобы найти только тэг div ― можно использовать оператор ?, сделав выражение «ленивым»:<.+?> соответствует любому символу, один или несколько раз найденному между < и >, расширяется по мере необходимости -> тест
.), где предыдущий символ ― словесный (например, 
\w), а следующий ― нет, либо наоборот, (например, это может быть начало строки или пробел).\B ― соответствует несловообразующей границе. Соответствие не должно обнаруживаться на границе \b .\Babc\B соответствует, только если шаблон полностью окружён словами -> тест
Обратные ссылки — \1([abc])\1 \1 соответствует тексту из первой захватываемой группы -> тест([abc])([de])\2\1 можно использовать \2 (\3, \4, и т.д.) для определения порядкового номера захватываемой группы -> тест(?<foo>[abc])\k<foo> мы присвоили имя foo группе, и теперь ссылаемся на неё используя ― (\k<foo>).
 Результат, как и в первом выражении -> тест
Результат, как и в первом выражении -> тестОпережающие и ретроспективные проверки — (?=) and (?<=)
d(?=r) соответствует d, только если после этого следует r, но r не будет входить в соответствие выражения -> тест(?<=r)d соответствует d, только если перед этим есть r, но r не будет входить в соответствие выражения -> тест
d(?!r) соответствует d, только если после этого нет r, но r не будет входить в соответствие выражения -> тест(?<!r)d соответствует d, только если перед этим нет r, но r не будет входить в соответствие выражения -> тест
 Я уверен, что вы сталкивались с похожими задачами в своей работе (хотя бы с одной из них), например такими:
Я уверен, что вы сталкивались с похожими задачами в своей работе (хотя бы с одной из них), например такими: 4.9. Ограничение длины текста
Проблема
Вы хотите проверить, состоит ли строка из 1
и 10 букв от А до Я.
Решение
Все языки программирования, описанные в этой книге, обеспечивают
простой и эффективный способ проверить длину текста. Например,
Строки JavaScript имеют свойство длины , которое
содержит целое число, указывающее длину строки. Однако при использовании обычных
выражения для проверки длины текста могут быть полезны в некоторых ситуациях,
особенно когда длина является лишь одним из нескольких правил, определяющих
соответствует ли текст темы желаемому шаблону. Следующие регулярные
выражение гарантирует, что длина текста составляет от 1 до 10 символов, а
дополнительно ограничивает текст заглавными буквами A–Z. Вы можете
изменить регулярное выражение, чтобы разрешить любой минимальный или максимальный текст
длину или разрешить использование символов, отличных от A–Z. 9 › и
‹ $ ›анкеры
убедитесь, что регулярное выражение соответствует всей строке темы; в противном случае это
может соответствовать 10 символам в более длинном тексте. Класс символов ‹
Класс символов ‹ [A-Z] › соответствует любому
один символ верхнего регистра от A до Z и квантификатор интервала
‹ {1,10} › повторяет
класс персонажа от 1 до 10 раз. Комбинируя квантификатор интервала
с окружающими якорями начала и конца строки, регулярное выражение будет
не совпадать, если длина текста темы выходит за пределы желаемого
диапазон.
Обратите внимание, что класс символов ‹ [A-Z] › явно допускает использование только прописных букв.
Если вы хотите также разрешить строчные буквы от a до z, вы можете либо
измените класс символов на ‹ [A-Za-z] › или примените параметр без учета регистра.
В рецепте 3.4 показано, как это сделать.
Подсказка
Ошибка, обычно совершаемая новыми пользователями регулярных выражений, состоит в том, что они
попытайтесь сэкономить несколько символов, используя диапазон классов символов
‹ [А-Я] 9_`a-z] ›.
Варианты
Ограничение длины произвольного шаблона
Поскольку кванторы, такие как ‹ {1,10} ›, применяются только к непосредственно предшествующему
элемент, ограничивающий количество символов, которые могут быть сопоставлены
шаблоны, включающие более одного токена, требуют другого
подход.
Как описано в рецепте 2.16,
просмотр вперед (и их аналог, просмотр назад) представляют собой особый вид
утверждение, что, как и ‹ 9 › и
‹ $ ›, сопоставьте позицию
внутри строки темы и не использовать никаких символов.
Упреждения могут быть как положительными, так и отрицательными, что означает, что они могут
проверить, следует ли шаблон за текущей позицией в
матч. Положительный просмотр вперед, записанный как ‹ (?=⋯) ›, может использоваться в начале
шаблон, чтобы убедиться, что строка находится в пределах целевого диапазона длины. Затем оставшаяся часть регулярного выражения может проверить желаемый шаблон.
не беспокоясь о длине текста. Вот простой пример: 9(?=[\S\s]{1,10}$)[\S\s]*
Затем оставшаяся часть регулярного выражения может проверить желаемый шаблон.
не беспокоясь о длине текста. Вот простой пример: 9(?=[\S\s]{1,10}$)[\S\s]*
| Параметры регулярного выражения: Нет |
| Варианты регулярных выражений: .NET, Java, JavaScript, PCRE, Perl, Python, Ruby |
тест максимальной длины работает только в том случае, если мы гарантируем, что больше нет
символов после того, как мы достигли предела. Поскольку взгляд вперед на
начало регулярного выражения обеспечивает диапазон длин, следующие
Затем шаблон может применять любые дополнительные правила проверки. В таком случае,
выкройка № .* › (или
‹ [\S\s]* › в версии
который добавляет встроенную поддержку JavaScript) используется для простого сопоставления
весь текст темы без дополнительных ограничений.
В первом регулярном выражении используется параметр «точка соответствует разрыву строки», поэтому что он будет работать правильно, когда ваша строка темы содержит строку перерывы. Подробную информацию о как применить этот модификатор к вашему языку программирования. Стандарт JavaScript без XRegExp не имеет «точка соответствует разрыву строки» вариант, поэтому второе регулярное выражение использует класс символов, который соответствует любому персонаж. Подробнее см. Любой символ, включая разрывы строк. Информация. 9\s*(?:\S\s*){10,100}$
| Параметры регулярного выражения: Нет |
| Варианты регулярных выражений: .NET, Java, JavaScript, PCRE, Perl, Python, Ruby |
По умолчанию ‹ \s › in
.NET, JavaScript, Perl и Python 3.x соответствуют всем пробелам Unicode,
и ‹ \S › соответствует
все остальное. В Java, PCRE, Python 2.x и Ruby ‹
В Java, PCRE, Python 2.x и Ruby ‹ \s › соответствует пробелу ASCII.
только и ‹ \S › спички
все остальное. В Python 2.x вы можете заставить ‹ \s › соответствовать всем пробелам Unicode, передав ЮНИКОД или U флаг
при создании регулярного выражения. В Java 7 вы можете сделать ‹ \s › соответствовать всем пробелам Unicode
путем передачи флага UNICODE_CHARACTER_CLASS . Разработчики, использующие
Java 4–6, PCRE и Ruby 1.9, которые хотят избежать использования Unicode
счетчик пробелов против их ограничения символов может переключиться на
следующая версия регулярного выражения, которая использует Unicode
категории (описаны в рецепте 2.7): 9\p{Z}\s][\p{Z}\s]*){10,100}$
| Опции регулярного выражения: Нет |
Варианты регулярных выражений: . NET,
Java, XRegExp, PCRE, Perl, Ruby 1.9 NET,
Java, XRegExp, PCRE, Perl, Ruby 1.9 |
PCRE должен быть скомпилирован с поддержкой UTF-8.
Работа. В PHP включите поддержку UTF-8 с модификатором шаблона /u .
Это последнее регулярное выражение объединяет Unicode ‹ \p{Z} ›
Свойство-разделитель с сокращением ‹ \s › для пробела. Это потому, что
символы, соответствующие ‹ \p{Z} ›
и ‹ \s › не
полностью перекрываются. ‹ \с ›
включает символы в позициях от 0x09 до 0x0D (табуляция, строка
подача, вертикальная табуляция, подача страницы и возврат каретки), которые не
присвоено свойство Separator по стандарту Unicode. Комбинируя
‹ \p{Z} ›
и ‹ \s › в символе
class вы гарантируете, что все символы пробела совпадают.
В обоих регулярных выражениях квантификатор интервала ‹ {10,100} › применяется к
не захватывающая группа, которая предшествует ей, а не одиночный токен. group соответствует любому одиночному символу, отличному от пробела, за которым следует ноль или
больше пробельных символов. Квантификатор интервала может надежно отслеживать
сколько непробельных символов совпало, потому что ровно один
непробельный символ сопоставляется во время каждой итерации.
group соответствует любому одиночному символу, отличному от пробела, за которым следует ноль или
больше пробельных символов. Квантификатор интервала может надежно отслеживать
сколько непробельных символов совпало, потому что ровно один
непробельный символ сопоставляется во время каждой итерации.
Ограничить количество слов
Следующее регулярное выражение очень похоже на предыдущее пример ограничения количества непробельных символов, кроме что каждое повторение соответствует целому слову, а не одному непробельный символ. Соответствует от 10 до 100 слов, пропуская за любыми несловесными символами, включая знаки препинания и пробел: 9\W*(?:\w+\b\W*){10,100}$
| Параметры регулярного выражения: Нет |
| Варианты регулярных выражений: .NET, Java, JavaScript, PCRE, Perl, Python, Ruby |
В Java 4–6, JavaScript, PCRE, Python 2. x и Ruby слово
токен символа ‹
x и Ruby слово
токен символа ‹ \w › в
это регулярное выражение будет соответствовать только символам ASCII A–Z, a–z, 0–9 и _,
и поэтому это не может правильно подсчитывать слова, содержащие не-ASCII
буквы и цифры. В .NET и Perl, ‹ \w › основан на таблице Unicode (как и его
обратный, ‹ \W ›, и
граница слова ‹ \b ›) и
будет соответствовать буквам и цифрам из всех сценариев Unicode. В Python 2.x,
вы можете сделать эти токены основанными на Unicode, передав ЮНИКОД или U флаг при создании
регулярное выражение. В Python 3.x они по умолчанию основаны на Unicode. В Яве
7, вы можете сделать сокращения для слова и не слова
символов на основе Unicode, передав 9\p{L}\p{M}\p{Nd}\p{Pc}]+|$)){10,100}$
| Параметры регулярного выражения: Нет |
Варианты регулярных выражений: . NET,
Java, XRegExp, PCRE, Perl, Ruby 1.9 NET,
Java, XRegExp, PCRE, Perl, Ruby 1.9 |
Чтобы это работало, PCRE должен быть скомпилирован с поддержкой UTF-8. В
PHP, включите поддержку UTF-8 с модификатором шаблона /u .
Как уже отмечалось, причина этих разных (но эквивалентных) регулярные выражения — это различная обработка символа слова и слова маркеры границ, более подробно объясненные в разделе «Символы Word».
Последние два регулярных выражения используют классы символов, которые включают
отдельные категории Unicode для букв, меток (необходимы для сопоставления
слова многих языков), десятичные числа и пунктуация соединителей
(подчеркивание и подобные символы), что делает их эквивалентными
к более раннему регулярному выражению, которое использовало ‹ \w › и ‹ \W ›.
Каждое повторение группы без захвата в первых двух
эти три регулярных выражения соответствуют целому слову, за которым следует ноль или более
несловесные символы. ‹ 9\p{L}\p{M}\p{Nd}\p{Pc}] ›), чтобы гарантировать, что каждый
повторение группы действительно соответствует всему слову. Без
граница слова, однократное повторение будет разрешено для соответствия любой части
слова, с последующими повторениями, соответствующими дополнительным
частей.
‹ 9\p{L}\p{M}\p{Nd}\p{Pc}] ›), чтобы гарантировать, что каждый
повторение группы действительно соответствует всему слову. Без
граница слова, однократное повторение будет разрешено для соответствия любой части
слова, с последующими повторениями, соответствующими дополнительным
частей.
Третья версия регулярного выражения (в которой добавлена поддержка XRegExp,
PCRE и Ruby 1.9) работают немного по-другому. Он использует плюс (один или
больше) вместо квантификатора звездочки (ноль или больше) и явно
позволяет сопоставлять нулевые символы только в том случае, если процесс сопоставления
дошел до конца строки. Это позволяет нам избежать слова
граничный токен, необходимый для обеспечения точности с ‹ \b › не поддерживает Unicode в
XRegExp, PCRE или Ruby. ‹ \b › — это с поддержкой Unicode в
Java, даже несмотря на то, что Java ‹ \w › не является (если вы не используете флаг UNICODE_CHARACTER_CLASS в Java 7).
К сожалению, ни один из этих вариантов не поддерживает стандартный JavaScript или Ruby 1.8 для правильной обработки слов, в которых используются символы, отличные от ASCII. А возможный обходной путь — переформулировать регулярное выражение для подсчета пробелов, а не чем последовательности символов слова, как показано здесь: 9\s*(?:\S+(?:\s+|$)){10,100}$
| Параметры регулярного выражения: Нет |
| Варианты регулярных выражений: .NET, Java, JavaScript, Perl, PCRE, Python, Ruby |
Во многих случаях это будет работать так же, как и предыдущее.
решения, хотя это не совсем эквивалентно. Например, один
разница в том, что составные части, соединенные дефисом, такие как
«далеко идущие» теперь будут считаться одним словом вместо двух.
то же самое относится и к словам с апострофами, например, «не».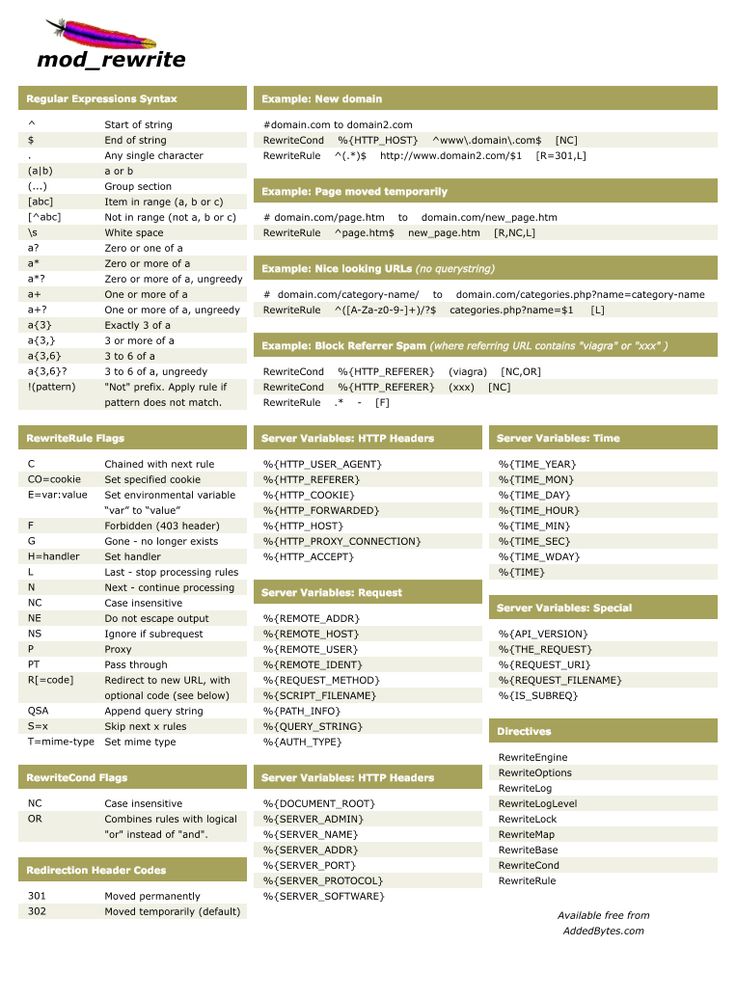
См. также
В рецепте 4.8 показано, как ограничить ввод набор символов (буквенно-цифровой, только ASCII и т. д.) вместо длины.
Рецепт 4.10 объясняет тонкости которые входят в точное ограничение количества строк в вашем тексте.
Методы, используемые в регулярных выражениях в этом рецепте, обсуждается в главе 2. В рецепте 2.3 объясняются классы символов. Рецепт 2.4 объясняет, что точка соответствует любому символу. Рецепт 2.5 объясняет якоря. В рецепте 2.7 объясняется, как сопоставлять символы Юникода. Рецепт 2.12 объясняет повторение. Рецепт 2.16 объясняет обход.
Получите Поваренную книгу по регулярным выражениям, 2-е издание прямо сейчас с обучающей платформой O’Reilly.
участника O’Reilly проходят онлайн-обучение в режиме реального времени, а также получают книги, видео и цифровой контент почти от 200 издателей.
Начать бесплатную пробную версию
Все, что вам нужно знать о регулярных выражениях | by Slawomir Chodnicki
Photo by NESA by Makers on Unsplash После прочтения этой статьи у вас будет четкое представление о том, что такое регулярные выражения, что они могут делать и чего они не могут.
Вы сможете решить, когда их использовать, а когда — что не следует.
Начнем с самого начала.
На абстрактном уровне регулярное выражение, сокращенно регулярное выражение, является сокращенным представлением множества. Набор струн.
Допустим, у нас есть список всех действительных почтовых индексов. Вместо того, чтобы хранить этот длинный и громоздкий список, зачастую более практично иметь краткий и точный шаблон, полностью описывающий этот набор. Всякий раз, когда вы хотите проверить, является ли строка допустимым почтовым индексом, вы можете сопоставить ее с шаблоном. Вы получите истинный или ложный результат, указывающий, принадлежит ли строка набору почтовых индексов, которые представляет шаблон регулярного выражения.
Давайте расширим набор почтовых индексов. Список почтовых индексов конечен, состоит из довольно коротких строк и не требует больших вычислительных усилий.
Как насчет набора строк, заканчивающихся на .csv ? Может быть весьма полезным при поиске файлов данных. Это множество бесконечно. Вы не можете составить список заранее. И единственный способ проверить принадлежность — перейти к концу строки и сравнить последние четыре символа. Регулярные выражения — это способ стандартизированного кодирования таких шаблонов. 9.*\.csv$
Это множество бесконечно. Вы не можете составить список заранее. И единственный способ проверить принадлежность — перейти к концу строки и сравнить последние четыре символа. Регулярные выражения — это способ стандартизированного кодирования таких шаблонов. 9.*\.csv$
Давайте оставим в стороне механику этого конкретного шаблона и посмотрим на практичность: механизм регулярных выражений может проверить шаблон на соответствие входной строке, чтобы увидеть, совпадает ли он. Приведенный выше шаблон соответствует foo.csv , но не соответствует bar.txt или my_csv_file .
Прежде чем использовать регулярные выражения в своем коде, вы можете протестировать их с помощью онлайн-оценщика регулярных выражений и поэкспериментировать с удобным пользовательским интерфейсом.
Мне нравится regex101.com: вы можете выбрать вариант движка регулярных выражений, и шаблоны хорошо разложены для вас, так что вы получите хорошее представление о том, что на самом деле делает ваш шаблон. Шаблоны регулярных выражений могут быть загадочными.
Шаблоны регулярных выражений могут быть загадочными.
Я рекомендую вам открыть regex101.com в другом окне или вкладке и поэкспериментировать с примерами, представленными в этой статье, в интерактивном режиме. Я обещаю, что таким образом вы получите гораздо лучшее представление о шаблонах регулярных выражений.
отладка регулярных выраженийРегулярные выражения полезны в любом сценарии, который выигрывает от полного или частичного совпадения строк с шаблонами. Вот некоторые распространенные варианты использования:
- проверка структуры строк
- извлечение подстрок из структурированных строк
- поиск/замена/перестановка частей строки
- разделение строки на токены
Все это регулярно возникает при подготовке данных.
Шаблон регулярного выражения состоит из отдельных стандартных блоков. Он может содержать литералы, классы символов, сопоставители границ, квантификаторы, группы и оператор ИЛИ.
Давайте рассмотрим несколько примеров.
Литералы
Самым основным строительным блоком в регулярном выражении является символ, также известный как литерал. Большинство символов в шаблоне регулярного выражения не имеют специального значения, они просто соответствуют самим себе. Рассмотрим следующий шаблон:
Я безобидный шаблон регулярного выражения
Ни один из символов в этом шаблоне не имеет специального значения. Таким образом, каждый символ шаблона соответствует самому себе. Следовательно, этому шаблону соответствует только одна строка, и она идентична самой строке шаблона.
соответствие простому шаблонуЭкранирование буквенных символов
Какие символы имеют особое значение? В следующем списке показаны символы, имеющие особое значение в регулярном выражении. Они должны быть экранированы обратной косой чертой, если они предназначены для представления самих себя.
символов со специальным значением в регулярных выраженияхРассмотрим следующий шаблон:
\+21\. 5
5
Шаблон состоит только из литералов — + имеет особое значение и был экранирован, как и . — и, таким образом, шаблон соответствует только одной строке: +21,5
Соответствие непечатаемым символам
Иногда необходимо сослаться на какой-нибудь непечатаемый символ, например, символ табуляции ⇥ или символ новой строки ↩
Лучше всего использовать для них соответствующие escape-последовательности:
Если вам нужно сопоставить разрыв строки, они обычно бывают одного из двух видов:
-
\n, часто называемые символом новой строки в стиле unix -
\r\nчасто называют новой строкой в стиле Windows
Чтобы поймать обе возможности, вы можете сопоставить \r?\n , что означает: необязательный \r , за которым следует \n
Соответствует любому символу Unicode
Иногда вам нужно сопоставить символы, которые лучше всего выражены с помощью их индекса Unicode. Иногда символ просто невозможно напечатать — например, управляющие символы, такие как ASCII
Иногда символ просто невозможно напечатать — например, управляющие символы, такие как ASCII NUL , ESC , VT и т. д.
Иногда ваш язык программирования просто не поддерживает включение определенных символов в шаблоны. Символы вне BMP, такие как 𝄞 или эмодзи, часто не поддерживаются дословно.
Во многих механизмах регулярных выражений, таких как Java, JavaScript, Python и Ruby, вы можете использовать \uHexIndex escape-синтаксис для соответствия любому символу по его индексу Unicode. Скажем, мы хотим сопоставить символ натуральных чисел: ℕ — U+2115
Шаблон для сопоставления этого символа: \u2115
Другие движки часто предоставляют эквивалентный синтаксис escape. В Go вы должны использовать \x{2115} для соответствия ℕ
. Поддержка Unicode и синтаксис escape различаются в зависимости от движка. Если вы планируете сопоставлять технические символы, музыкальные символы или смайлики — особенно за пределами BMP — проверьте документацию механизма регулярных выражений, который вы используете, чтобы убедиться в адекватной поддержке вашего варианта использования.
Экранирование частей шаблона
Иногда шаблон требует, чтобы последовательные символы экранировались как литералы. Скажем, он должен соответствовать следующей строке: +???+
Шаблон будет выглядеть так:
\+\?\?\?\+
Необходимость экранировать каждый символ как литерал делает его сложнее читать и понимать.
В зависимости от вашего движка регулярных выражений может быть способ начать и закончить литеральный раздел в вашем шаблоне. Проверьте свои документы. В Java и Perl последовательности символов, которые следует интерпретировать буквально, могут быть заключены в 9 символов.0013\Q и \E . Следующий шаблон эквивалентен приведенному выше:
\Q+???+\E
Экранирование частей шаблона также может быть полезно, если он состоит из частей, некоторые из которых должны интерпретироваться буквально, как пользователь -Предоставленные поисковые слова.
Если ваш механизм регулярных выражений не имеет этой функции, экосистема часто предоставляет функцию для экранирования всех символов со специальным значением из строки шаблона, например, lodash escapeRegExp.
Символ трубы | — оператор выбора. Он соответствует альтернативам. Предположим, что шаблон должен соответствовать строкам 1 и 2
Следующий шаблон делает свое дело:
1|2
Допустимыми альтернативами являются шаблоны слева и справа от оператора.
Следующий шаблон соответствует William Turner и Bill Turner
William Turner|Bill Turner
Вторая часть альтернатив последовательно Turner . Было бы удобно поставить альтернативы William и Bill впереди и упомянуть Turner только один раз. Для этого используется следующий шаблон:
(William|Bill) Turner
Это выглядит более читабельно. Он также вводит новую концепцию: группы.
Вы можете группировать подшаблоны в секции, заключенные в круглые скобки. Они группируют содержащиеся выражения в единое целое. Группировка частей шаблона имеет несколько применений:
Группировка частей шаблона имеет несколько применений:
- упростить запись регулярных выражений, сделав намерение более понятным
- применить квантификаторы к подвыражениям
- извлечь подстроки, соответствующие группе
- заменить подстроки, соответствующие группе
Давайте посмотрим на регулярное выражение с группой: William|Bill) Turner
Группы иногда называют «группами захвата», потому что в случае совпадения совпадающая подстрока каждой группы захватывается и становится доступной для извлечения.
Доступность захваченных групп зависит от используемого вами API. В JavaScript вызов "моя строка".match(/pattern/) возвращает массив совпадений. Первый элемент — это вся совпадающая строка, а последующие элементы — это подстроки, соответствующие группам шаблонов в порядке появления в шаблоне.
Пример: Шахматная нотация
Рассмотрим строку, идентифицирующую поле шахматной доски. Поля на шахматной доске могут быть обозначены как A1-A8 для первого столбца, B1-B8 для второго столбца и так далее до h2-H8 для последнего столбца. Предположим, что строка, содержащая это обозначение, должна быть проверена, а компоненты (буква и цифра) извлечены с использованием групп захвата. Следующее регулярное выражение сделает это.
Поля на шахматной доске могут быть обозначены как A1-A8 для первого столбца, B1-B8 для второго столбца и так далее до h2-H8 для последнего столбца. Предположим, что строка, содержащая это обозначение, должна быть проверена, а компоненты (буква и цифра) извлечены с использованием групп захвата. Следующее регулярное выражение сделает это.
(A|B|C|D|E|F|G|H)(1|2|3|4|5|6|7|8)
Приведенное выше регулярное выражение допустимо и выполняет работа, это несколько неуклюже. Это работает так же хорошо, но немного более лаконично:
([A-H])([1-8])
Это выглядит более лаконично. Но он вводит новую концепцию: классы символов.
Классы символов используются для определения набора допустимых символов. Набор разрешенных символов заключен в квадратные скобки, и каждый разрешенный символ указан в списке. Класс персонажа [abcdef] эквивалентно (a|b|c|d|e|f) . Поскольку класс содержит альтернативы, он соответствует ровно одному символу.
Шаблон [ab][cd] соответствует ровно 4 строкам ac , ad , bc и bd . , а не соответствует ab , первый символ соответствует, но второй символ должен быть либо c , либо d .
Предположим, шаблон должен соответствовать двузначному коду. Шаблон, соответствующий этому, может выглядеть так:
[0123456789][0123456789]
Этот шаблон соответствует всем 100 двузначным строкам в диапазоне от 00 до 99 .
Диапазоны
Часто бывает утомительно и подвержено ошибкам перечисление всех возможных символов в классе символов. Последовательные символы могут быть включены в класс символов как диапазоны с помощью оператора тире: [0–9][0–9]
Символы упорядочены по числовому индексу — в 2019 г.это почти всегда индекс Unicode. Если вы работаете с числами, латинскими символами и базовой пунктуацией, вы можете вместо этого взглянуть на гораздо меньшее историческое подмножество Unicode: ASCII.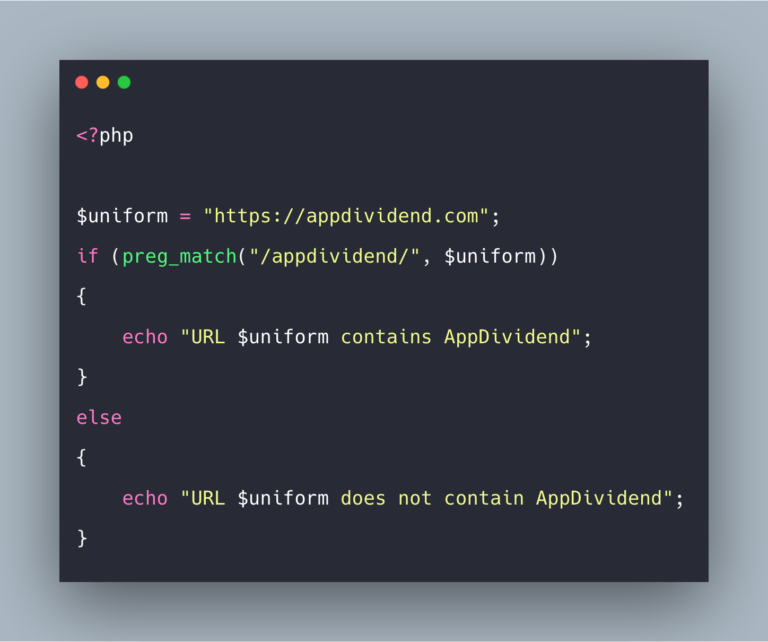
Цифры от нуля до девяти кодируются последовательно с помощью кодовых точек: U+0030 для 0 до кодовой точки U+0039 для 9 , поэтому набор символов [0–9] допустимый диапазон.
Строчные и прописные буквы латинского алфавита также кодируются последовательно, поэтому часто встречаются также классы символов для буквенных символов. Следующий набор символов соответствует любому латинскому символу нижнего регистра:
[a-z]
В одном классе символов можно определить несколько диапазонов. Следующий класс символов соответствует всем строчным и прописным латинским символам:
[A-Za-z]
У вас может сложиться впечатление, что приведенный выше шаблон можно сократить до:
[A-z]
Это допустимый класс символов, но он соответствует не только A-Z и az, он также соответствует всем символам, определенным между Z и a, например, 9 .
Если вы рвете на себе волосы, проклиная глупость людей, которые определили ASCII и ввели эту ошеломляющую прерывистость, придержите лошадей на некоторое время. ASCII был определен в то время, когда вычислительная мощность была гораздо более ценной, чем сегодня.
Посмотрите на
A hex: 0x41 bin: 0100 0001иa hex: 0x61 bin: 0110 0001Как вы конвертируете между верхним и нижним регистром? Вы переворачиваете один бит . Это справедливо для всего алфавита. ASCII оптимизирован для упрощения преобразования регистра. Люди, определяющие ASCII, были очень вдумчивыми. Некоторыми желательными качествами приходилось жертвовать ради других. Пожалуйста.
Вы можете задаться вопросом, как поместить символ - в класс символов. В конце концов, он используется для определения диапазонов. Большинство движков интерпретируют символы - буквально, если они помещены в качестве первого или последнего символа в классе: [-+0–9o] , и что это средство сопоставления границ, если оно используется вне классов символов.
Предопределенные классы символов
Некоторые классы символов используются настолько часто, что для них определены сокращенные обозначения. Рассмотрим класс символов [0–9] . Он соответствует любому цифровому символу и используется так часто, что для него существует мнемоническое обозначение: \d .
В следующем списке показаны классы символов с наиболее распространенными сокращенными обозначениями, которые, вероятно, будут поддерживаться любым используемым вами механизмом регулярных выражений.
Большинство движков поставляются с исчерпывающим списком предопределенных классов символов, соответствующих определенным блокам или категориям стандарта Unicode, знакам препинания, определенным алфавитам и т. д. Эти дополнительные классы символов часто зависят от используемого движка и не очень переносимы.
Класс символов «точка»
Самый распространенный предопределенный класс символов — точка, и он заслуживает отдельного небольшого раздела. Он соответствует любому символу, кроме разделителей строк, таких как 9.0013\r и
Он соответствует любому символу, кроме разделителей строк, таких как 9.0013\r и \n .
Следующий шаблон соответствует любой строке из трех символов, оканчивающейся строчной буквой x:
..x
.* используется для соответствия разделам «все что угодно» или «все равно». соответствует любому числу от 1 до 2 Обратите внимание, что . Символ теряет свое особое значение при использовании внутри класса символов. Класс символов [.,] просто соответствует двум символам, точке и запятой.
В зависимости от используемого механизма регулярных выражений вы можете установить флаг выполнения dotAll , в этом случае . будет соответствовать чему угодно, включая терминаторы строк.
Сопоставители границ — также известные как «якоря» — не сопоставляются с символом как таковым, они сопоставляются с границей. Если хотите, они соответствуют позициям между символами. Наиболее распространены якоря 9[0–9] находит каждую цифру, которая является первым символом в строке.
Если хотите, они соответствуют позициям между символами. Наиболее распространены якоря 9[0–9] находит каждую цифру, которая является первым символом в строке.
Та же идея применима к окончаниям строки с $ .
Якоря \A и \Z или \z полезны для сопоставления многострочных строк. Они привязываются к началу и концу всего ввода. Вариант \Z в верхнем регистре допускает завершающие символы новой строки и совпадения непосредственно перед этим, эффективно отбрасывая любой завершающий символ новой строки в совпадении.
Якоря \A и \Z поддерживаются большинством основных движков регулярных выражений, за заметным исключением JavaScript.
Предположим, требуется проверить, является ли текст двухстрочной записью, определяющей шахматную позицию. Вот как выглядят входные строки:
Столбец: F
Строка: 7
Следующий шаблон соответствует приведенной выше структуре:
\AColumn: [A-H]\r?\nRow: [1-8]\Z
Совпадения целых слов
Якорь \b соответствует краю любой буквенно-цифровой последовательности.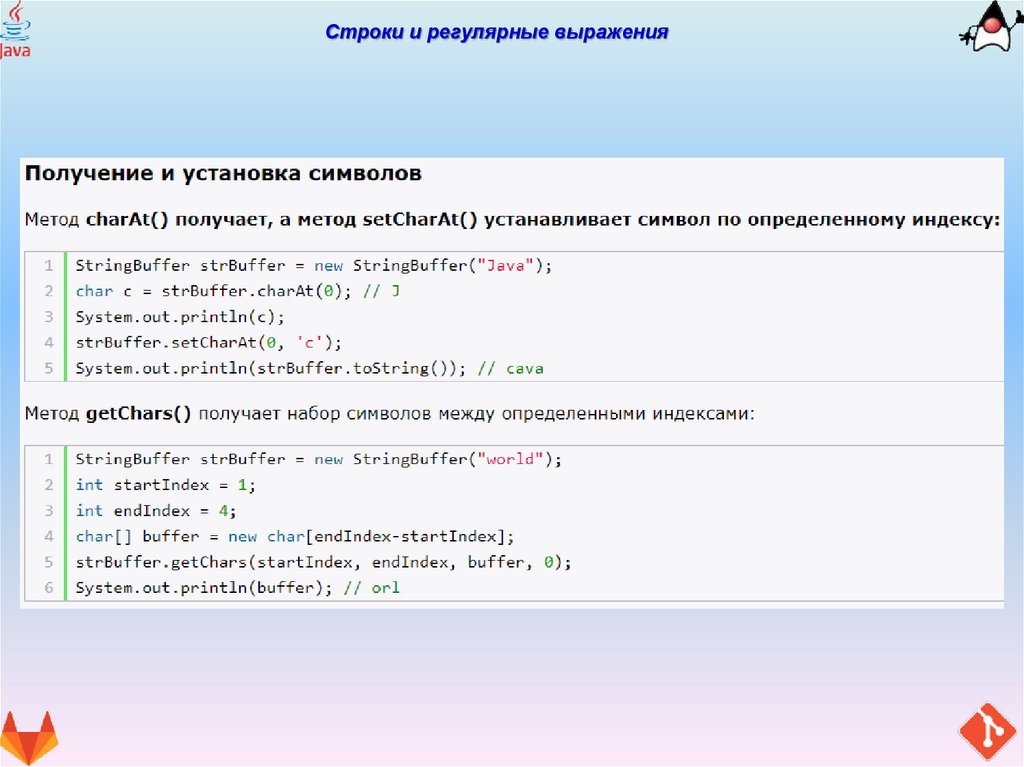 Это полезно, если вы хотите найти совпадения «целого слова». Следующий шаблон ищет отдельный верхний регистр
Это полезно, если вы хотите найти совпадения «целого слова». Следующий шаблон ищет отдельный верхний регистр I .
\bI\b
Шаблон не соответствует первой букве Иллинойс , потому что справа нет границы слова. Следующая буква — буква слова, определяемая классом символов 9.0013 \w as [a-zA-Z0–9_] — а не несловесная буква, которая составляла бы границу.
Давайте заменим Illinois на I!linois . Восклицательный знак не является символом слова и, таким образом, образует границу.
Разные Якоря
Несколько эзотерическая граница без слов \B является отрицанием \b . Он соответствует любой позиции, которая не соответствует \b . Соответствует каждой позиции между символами в пределах пробелов и буквенно-цифровых последовательностей.
Некоторые механизмы регулярных выражений поддерживают сопоставление границ \G . Это полезно при программном использовании регулярных выражений, когда шаблон многократно применяется к строке, пытаясь найти все совпадения с шаблоном в цикле. Он привязывается к позиции последнего найденного совпадения.
Это полезно при программном использовании регулярных выражений, когда шаблон многократно применяется к строке, пытаясь найти все совпадения с шаблоном в цикле. Он привязывается к позиции последнего найденного совпадения.
Любой литерал или группа символов соответствует вхождению ровно одного символа. Шаблон [0–9][0–9] соответствует ровно двум цифрам. Квантификаторы помогают указать ожидаемое количество совпадений шаблона. Они обозначаются с помощью фигурных скобок. Следующее эквивалентно [0–9][0–9]
[0-9]{2}
Основные обозначения могут быть расширены для получения верхней и нижней границ. Скажем, необходимо сопоставить от двух до шести цифр. Точное количество варьируется, но оно должно быть от двух до шести. Следующая запись делает это:
[0-9]{2,6}
Верхняя граница необязательна, если опущено любое количество вхождений, равное или превышающее нижнюю границу является приемлемым. Следующий пример соответствует двум или более последовательным цифрам.
[0-9]{2,}
Существует несколько предопределенных сокращений для общих квантификаторов, которые очень часто используются на практике.
? квантификатор
? Квантификатор эквивалентен {0, 1} , что означает: необязательное единичное вхождение. Предыдущий шаблон может не совпадать или совпадать один раз.
Найдем целые числа, необязательно со знаком плюс или минус: [-+]?\d{1,}
Квантификатор +
Квантификатор + эквивалентен {1,} , что означает: хотя бы одно вхождение.
Мы можем изменить наш шаблон сопоставления целых чисел, приведенный выше, чтобы сделать его более идиоматичным, заменив {1,} на + , и мы получим: [-+]?\d+
* квантификатор
Квантификатор * эквивалентен {0,} , что означает: ноль или более вхождений. Вы будете видеть его очень часто в сочетании с точкой 9.0013 .* , что означает: любому символу все равно, как часто.
Давайте сопоставим список целых чисел, разделенных запятыми. Пробелы между записями не допускаются, и должно присутствовать хотя бы одно целое число: \d+(,\d+)*
Мы сопоставляем целое число, за которым следует любое количество групп, содержащих запятую, за которой следует целое число.
Жадный по умолчанию
Предположим, требуется соответствие доменной части URL-адреса http в группе захвата. Следующее кажется хорошей идеей: сопоставить протокол, затем захватить домен, затем необязательный путь. Идея переводится примерно так:
http://(.*)/?
Если вы используете движок, который использует нотацию
/regex/, такую как JavaScript, вы должны экранировать прямую косую черту:http:\/\/(.*)\/?.*
Он соответствует протоколу, фиксирует то, что идет после протокола, как домен, и допускает необязательную косую черту и некоторый произвольный текст после этого, который будет путем к ресурсу.
Как ни странно, группа захватывает следующее:
непредвиденная часть URL-адреса, захваченная группойРезультаты несколько удивительны, поскольку шаблон был разработан для захвата только части домена, но, похоже, захватывает все до конца URL-адреса.
Это происходит из-за того, что каждый квантификатор, встречающийся в шаблоне, пытается соответствовать как можно большей части строки. По этой причине квантификаторы называются жадными .
Давайте проверим поведение сопоставления: http://(.*)/?.*
Жадный * в группе захвата является первым обнаруженным квантификатором. . класс символов, к которому он применяется, соответствует любому символу, поэтому квантификатор распространяется до конца строки. Таким образом, группа захвата захватывает все. Но подождите, скажете вы, в конце есть часть /?.* . Ну да, и он идеально соответствует тому, что осталось от строки — ничего, то есть пустой строке. Косая черта необязательна, за ней следует ноль или более символов. Пустая строка подходит. Весь узор прекрасно сочетается.
Альтернативы жадному сопоставлению
Жадное сопоставление используется по умолчанию, но не является единственной разновидностью квантификаторов. Каждый квантификатор имеет неохотно версий, которые соответствуют наименьшему возможному количеству символов. Жадные версии квантификаторов преобразуются в неохотные версии путем добавления ? им.
В следующей таблице приведены обозначения для всех квантификаторов.
quanfier {n} эквивалентен как в жадной, так и в неохотной версиях. Для других количество совпадающих символов может отличаться. Давайте вернемся к приведенному выше примеру и изменим группу захвата, чтобы она соответствовала как можно меньшему количеству, в надежде правильно захватить доменное имя.
http://(.*?)/?.*
При использовании этого шаблона ничего — точнее, пустая строка — не захватывается группой. Почему это? Группа захвата теперь захватывает как можно меньше: ничего. (.*?) ничего не фиксирует, /? ничего не соответствует, а .* полностью соответствует тому, что осталось от строки. Итак, опять же, этот шаблон не работает должным образом.
Пока что группа захвата соответствует слишком мало или слишком много. Давайте вернемся к жадному квантификатору, но запретим использование косой черты в имени домена, а также потребуем, чтобы имя домена имело длину не менее одного символа. 9/]+)/?.*
Этот шаблон жадно захватывает один или несколько символов без косой черты после протокола в качестве домена, и если, наконец, появляется какая-либо необязательная косая черта, за ней может следовать любое количество символов в пути.
Производительность квантификатора
Как жадные, так и неохотные квантификаторы влекут за собой некоторые накладные расходы во время выполнения. Если присутствует только несколько таких квантификаторов, проблем не возникает. Но если каждая из нескольких вложенных групп квантифицируется как жадная или сопротивляющаяся, определение самого длинного или самого короткого возможного совпадения является нетривиальной операцией, которая подразумевает бег вперед и назад по входной строке, корректируя длину совпадения каждого квантификатора, чтобы определить, соответствует ли выражение в целом. .
Возможны патологические случаи катастрофического возврата. Если вас беспокоит производительность или злонамеренный ввод, лучше отдать предпочтение неохотным квантификаторам, а также обратить внимание на третий вид квантификаторов: притяжательные квантификаторы.
Квантификаторы притяжения: никогда не отдавать назад
Квантификаторы притяжения, если они поддерживаются вашим движком, действуют во многом как жадные квантификаторы, с тем отличием, что они не поддерживают возврат. Они пытаются сопоставить как можно больше символов, и как только они это сделают, они никогда не выдадут ни одного совпадающего символа для размещения возможных совпадений для любых других частей шаблона.
Они обозначаются добавлением + к базовому жадному квантификатору.
Это быстродействующая версия «жадных» квантификаторов, что делает их хорошим выбором для операций, чувствительных к производительности.
Давайте посмотрим на них в движке PHP. Во-первых, давайте рассмотрим простые жадные совпадения. Давайте сопоставим несколько цифр, за которыми следует девятка: ([0–9]+)9
Соответствует входной строке: 123456789 жадный квантификатор сначала сопоставит весь ввод, а затем вернет 9 , так что остальная часть шаблона может совпасть.
Теперь, когда мы заменим greedy притяжательным квантором, он будет соответствовать всему входу, а затем откажется возвращать 9 , чтобы избежать возврата, и это приведет к тому, что весь шаблон вообще не будет соответствовать.
Когда вам нужно собственническое поведение? Когда ты знаешь, что всегда хочешь самого длинного мыслимого матча.
Допустим, вы хотите извлечь часть имени файла из путей файловой системы. Допустим 9\/]+\/)++(.*)
Примечание: здесь используется нотация PHP
/regex/, поэтому косая черта экранируется.
Мы хотим разрешить абсолютные пути, поэтому разрешаем ввод начинаться с необязательной косой черты. Затем мы собственнически используем имена папок, состоящие из ряда символов без косой черты, за которыми следует косая черта. Я использовал для этого группу без захвата, поэтому она обозначена как (?:pattern) вместо просто (pattern) . Все, что осталось после последней косой черты, мы собираем в группу для извлечения.
Группы без захвата сопоставляются точно так же, как и обычные группы. Однако они не делают совпадающий контент доступным. Если нет необходимости захватывать контент, их можно использовать для повышения производительности сопоставления. Группы без захвата записываются следующим образом: (?:шаблон)
Предположим, мы хотим проверить правильность шестнадцатеричной строки. Он должен состоять из четного числа шестнадцатеричных цифр от 0 до 9 или от a до f . Следующее выражение делает работу, используя группу:
([0-9a-f][0-9a-f])+
Поскольку цель группы в шаблоне состоит в том, чтобы убедиться, что цифры идут парами, а цифры, которые действительно совпадают, не совпадают. при любом значении группа может быть заменена более быстрой группой без захвата:
(?:[0-9a-f][0-9a-f])+
Atomic Groups
Существует также быстродействующая версия группы без захвата, которая не поддерживает поиск с возвратом. Ее называют «независимой незахватывающей группой» или «атомарной группой».
Записывается как (?>шаблон)
Атомарная группа — это незахватывающая группа, которую можно использовать для оптимизации сопоставления с образцом для повышения скорости. Обычно он поддерживается механизмами регулярных выражений, которые также поддерживают притяжательные квантификаторы.
Его поведение также похоже на притяжательные квантификаторы: как только атомарная группа совпала с частью строки, это первое совпадение является постоянным. Группа никогда не будет пытаться пересопоставить по-другому, чтобы приспособить другие части схемы.
a(?>bc|b)c соответствует abcc , но не соответствует abc .
Первое успешное совпадение атомной группы приходится на г. до н.э. г. и остается таким. Обычная группа будет повторно сопоставляться во время поиска с возвратом, чтобы разместить c в конце шаблона для успешного сопоставления. Но первое совпадение атомарной группы постоянно, оно не изменится.
Это полезно, если вы хотите найти совпадение как можно быстрее и не хотите, чтобы в любом случае происходил возврат.
Допустим, мы сопоставляем часть имени файла пути. Мы можем сопоставить атомарную группу любых символов, за которыми следует косая черта. Затем захватите остальные:
(?>. *\/)(.*)
атомарная группа, соответствующаяПримечание: здесь используется нотация PHP
/regex/, поэтому косая черта экранируется.
Обычная группа также справилась бы с этой задачей, но устранение возможности возврата повышает производительность. Если вы сопоставляете миллионы входных данных с нетривиальными шаблонами регулярных выражений, вы начнете замечать разницу.
Он также повышает устойчивость к вредоносным данным, предназначенным для DoS-атак на службу, инициируя катастрофические сценарии возврата.
Иногда бывает полезно сослаться на что-то, что совпало ранее в строке. Предположим, строковое значение допустимо только в том случае, если оно начинается и заканчивается одной и той же буквой. Слова «альфа», «радар», «удар», «уровень» и «звезды» являются примерами. Можно захватить часть строки в группе и обратиться к этой группе позже в шаблоне шаблона: обратной ссылке.
Обратные ссылки в шаблоне регулярного выражения обозначаются с использованием синтаксиса \n , где n — номер группы захвата. Нумерация ведется слева направо, начиная с 1. Если группы являются вложенными, они нумеруются в порядке появления открывающей скобки. Группа 0 всегда означает все выражение.
Следующий шаблон соответствует вводу, который содержит не менее 3 символов и начинается и заканчивается одной и той же буквой:
([a-zA-Z]).+\1
В словах: буква нижнего или верхнего регистра — эта буква захватывается в группу — за которой следует любая непустая строка, за которой следует буква, которую мы захватили в начале совпадения.
письменные обратные ссылкиДавайте немного расширимся. Входная строка сопоставляется, если она содержит любую буквенно-цифровую последовательность — например, слово — более одного раза. Границы слов используются для обеспечения совпадения целых слов.
\b(\w+)\b.*\b\1\b
Поиск и замена с обратными ссылками
Регулярные выражения полезны в операциях поиска и замены. Типичный вариант использования — найти подстроку, соответствующую шаблону, и заменить ее чем-то другим. Большинство API, использующих регулярные выражения, позволяют ссылаться на группы захвата из шаблона поиска в строке замены.
Эти обратные ссылки эффективно позволяют переупорядочивать части входной строки.
Рассмотрим следующий сценарий: входная строка содержит префикс символов от A до Z, за которым следует необязательный пробел, за которым следует число из 3–6 цифр. Строки вроде A321 , B86562 , F 8753 и L 287 .
Задача состоит в том, чтобы преобразовать его в другую строку, состоящую из числа, за которым следует тире, за которым следует префикс символа.
Ввод Вывод
A321 321-A
B86562 86562-B
F 8753 8753-F
L 287 287-L
Первый шаг для преобразования одной части строки в другую для захвата одной части строки в другую. в группе захвата. Шаблон поиска выглядит следующим образом:
([A-Z])\s?([0-9]{3,6})
Он захватывает префикс в группу, допускает необязательный пробел, а затем захватывает цифры во вторую группу. Обратные ссылки в строке замены обозначаются с использованием синтаксиса $n , где n — это номер группы захвата. Строка замены для этой операции должна сначала ссылаться на группу, содержащую числа, затем буквенное тире, затем на первую группу, содержащую буквенный префикс. Это дает следующую строку замены:
$2-$1
Таким образом, A321 соответствует шаблону поиска, помещая A в $1 и 312 в $2 . Строка замены устроена так, чтобы давать желаемый результат: сначала идет число, затем тире, затем буквенный префикс.
Обратите внимание, что поскольку символ $ имеет особое значение в строке замены, его необходимо экранировать как $$ , если он должен быть вставлен как символ.
Этот тип поиска и замены с поддержкой регулярных выражений часто предлагается текстовыми редакторами. Предположим, у вас есть список путей в вашем редакторе, и задача состоит в том, чтобы поставить перед именем каждого файла префикс подчеркивания. Путь /foo/bar/file.txt должен стать /foo/bar/_file.txt
Со всем, что мы узнали до сих пор, мы можем сделать это следующим образом:
пример поиска и замены с поддержкой регулярных выражений в VS КодИногда полезно утверждать, что строка имеет определенную структуру, не сопоставляя ее на самом деле. Чем это полезно?
Давайте напишем шаблон, который соответствует всем словам, за которыми следует слово, начинающееся с a
Давайте попробуем \b(\w+)\s+a он привязывается к границе слова и сопоставляет символы слова до тех пор, пока он видит пробел, за которым следует a.
В приведенном выше примере мы сопоставляем love , swat , fly и с , но не можем захватить и до и . Это связано с тем, что и , начиная с и , были использованы как часть сопоставления и . Мы просканировали эти и , и слово и не имеет шансов совпасть.
Было бы здорово, если бы был способ установить свойства первого символа следующего слова без фактического его использования.
Конструкции, утверждающие существование, но не использующие входные данные, называются «упреждающими» и «обратными».
Упреждающий просмотр
Упреждающий просмотр используется для утверждения, что шаблон соответствует заранее. Они записываются как (?=шаблон)
Давайте воспользуемся этим, чтобы исправить наш шаблон:
\b(\w+)(?=\s+a)
Мы поставили пробел и инициал следующего слова в просмотр вперед, поэтому при сканировании строки на совпадения они проверяются, но не используются.
Отрицательный просмотр вперед утверждает, что его шаблон не совпадает с опережением. Обозначается как (?!шаблон)
Давайте найдем все слова, за которыми не следует слово, начинающееся с a .
\b(\w+)\b(?!\s+a)
Мы сопоставляем целые слова, за которыми не следует пробел, и .
Просмотр назад
Просмотр назад служит той же цели, что и просмотр вперед, но он применяется слева от текущей позиции, а не справа. Многие движки регулярных выражений ограничивают тип шаблона, который вы можете использовать в просмотре назад, потому что применение шаблона в обратном направлении — это то, для чего они не оптимизированы. Проверьте свои документы!
Просмотр назад записывается как (?<=шаблон)
Он утверждает существование чего-то перед текущей позицией. Давайте найдем все слова, которые идут после слова, оканчивающегося на r или t .
(?<=[rt]\s)(\w+)
Мы утверждаем, что существует r или t , за которым следует пробел, затем мы фиксируем следующую последовательность словесных символов.
Существует также отрицательный просмотр назад, подтверждающий отсутствие шаблона слева. Пишется как (?
Давайте инвертируем найденные слова: Мы хотим сопоставить все слова, которые идут после слов, не заканчивающихся на r или t .
(?
Мы сопоставляем все слова по \b(\w+) и добавляем (? мы гарантируем, что ни одному слову, с которым мы совпадаем, не предшествует слово, оканчивающееся на r или t .
Шаблоны разделения
Если вы работаете с API, позволяющим разбивать строку по шаблону, часто бывает полезно помнить о просмотрах вперед и назад.
Разделение регулярного выражения обычно использует шаблон в качестве разделителя и удаляет разделитель из частей. Помещение секций просмотра вперед или назад в разделитель обеспечивает совпадение без удаления частей, на которые просто смотрели.
Предположим, у вас есть строка, разделенная : , в которой часть частей представляет собой метки, состоящие из буквенных символов, а часть — метки времени в формате ЧЧ:мм .
Давайте посмотрим на входную строку time_a:9:23:time_b:10:11
Если мы просто разделим : , мы получим части: [time_a, 9, 32, time_b, 10, 11]
Допустим, мы хотим улучшить путем разделения, только если : имеет букву с обеих сторон. Разделитель теперь [a-z]:|:[a-z]
Мы получаем части: [time_, 9:32, ime_, 10:11] Мы потеряли соседние символы, так как они были частью разделителя.
Если мы уточним разделитель, чтобы использовать просмотр вперед и назад для соседних символов, их существование будет проверено, но они не будут совпадать как часть разделителя: (?<[a-z]):|:(?=[ a-z])
Наконец мы получаем нужные части: [время_a, 9:32, время_b, 10:11]
Большинство движков регулярных выражений позволяют устанавливать флаги или модификаторы для настройки аспектов процесса сопоставления с образцом. Обязательно ознакомьтесь с тем, как выбранный вами движок обрабатывает такие модификаторы.
Они часто определяют разницу между непрактично сложным рисунком и тривиальным.
Можно ожидать, что вы найдете модификаторы чувствительности к регистру (не-), параметры привязки, режим полного совпадения и частичного совпадения, а также режим dotAll, который позволяет . Класс символов соответствует чему угодно, включая разделители строк.
JavaScript, Python, Java, Ruby, .NET
Давайте рассмотрим, например, JavaScript. Если вам нужен режим без учета регистра и только первое найденное совпадение, вы можете использовать модификатор i и не забудьте пропустить модификатор g .
Дойдя до конца этой статьи, вы можете почувствовать, что все возможные проблемы синтаксического анализа строк могут быть решены, как только вы освоите регулярные выражения.
Нет.
В этой статье регулярные выражения представляют собой сокращенную запись для наборов строк. Если у вас есть точное регулярное выражение для почтовых индексов, у вас есть сокращенная запись для набора всех строк, представляющих допустимые почтовые индексы. Вы можете легко проверить входную строку, чтобы проверить, является ли она элементом этого набора. Однако есть проблема.
Существует много значимых наборов строк, для которых нет регулярного выражения!
Набор действительных программ JavaScript, например, не имеет регулярного выражения. Никогда не будет шаблона регулярного выражения, который мог бы проверить, является ли источник JavaScript синтаксически правильным.
В основном это происходит из-за присущей регулярному выражению неспособности работать с вложенными структурами произвольной глубины. Регулярные выражения по своей сути не рекурсивны. XML и JSON являются вложенными структурами, как и исходный код многих языков программирования. Другим примером являются палиндромы — слова, которые читаются одинаково вперед и назад, как гоночный автомобиль — — это очень простая форма вложенной структуры. Каждый символ открывает или закрывает уровень вложенности.
Вы можете создавать шаблоны, которые будут соответствовать вложенным структурам до определенной глубины, но вы не можете написать шаблон, который соответствует произвольной глубине вложенности.
Вложенные структуры часто оказываются неправильными. Если вас интересует теория вычислений и классификации языков — то есть наборов строк — взгляните на иерархию Хомского, формальные грамматики и формальные языки.
Позвольте мне в заключение предостеречь. Иногда я вижу попытки использовать регулярные выражения не только для лексического анализа — идентификации и извлечения токенов из строки — но также и для семантического анализа, пытающегося интерпретировать и проверить значение каждого токена.
В то время как лексический анализ является вполне допустимым вариантом использования регулярных выражений, попытка семантической проверки чаще всего приводит к возникновению другой проблемы.
Множественное число от «regex» — «сожаления»
Позвольте мне проиллюстрировать это примером.
Предположим, что строка представляет собой IPv4-адрес в десятичной системе счисления с точками, разделяющими числа. Регулярное выражение должно проверять, действительно ли входная строка является IPv4-адресом. Первая попытка может выглядеть примерно так:
([0-9]{1,3})\.([0-9]{1,3})\.([0-9]{1,3})\.([0-9 ]{1,3})
Соответствует четырем группам от одной до трех цифр, разделенных точкой. Некоторым читателям может показаться, что эта схема не соответствует действительности. Например, он соответствует 111.222.333.444 , что не является допустимым IP-адресом.
Если вы сейчас чувствуете желание изменить шаблон, чтобы он проверял для каждой группы цифр, что закодированное число находится в диапазоне от 0 до 255 — с возможными ведущими нулями — тогда вы на пути к созданию второй проблемы и сожалеете .
Попытка сделать это ведет от лексического анализа — идентификации четырех групп цифр — к семантическому анализу, проверяющему, что группы цифр переводятся в допустимые числа.
Это дает значительно более сложное регулярное выражение, примеры которого можно найти здесь. Я бы рекомендовал решить подобную проблему, захватив каждую группу цифр с помощью шаблона регулярного выражения, затем преобразовав захваченные элементы в целые числа и проверив их диапазон на отдельном логическом шаге.
Используйте регулярные выражения — как и все ваши инструменты — с умом. Фото Тодда Квакенбуша на Unsplash При работе с регулярными выражениями компромисс между сложностью, ремонтопригодностью, производительностью и правильностью всегда должен быть осознанным решением. В конце концов, шаблон регулярного выражения предназначен только для записи, насколько это возможно синтаксис вычислений. Трудно правильно читать шаблоны регулярных выражений, не говоря уже об их отладке и расширении.
Мой совет: используйте их как мощный инструмент обработки строк, но не переоценивайте ни их возможности, ни способность людей обращаться с ними.
Если вы сомневаетесь, подумайте о том, чтобы достать из коробки еще один молоток.
Извлечь строку между двумя STRINGS
Регулярное выражение
- JavascriptPCRE
- флаги
Тестовая струна
[youtube] reuJ8yVCgSM: Загрузка веб-страницы [youtube] reuJ8yVCgSM: веб-страница с информацией о загрузке видео [youtube] reuJ8yVCgSM: Извлечение информации о видео
[youtube] reuJ8yVCgSM: Загрузка манифеста MPD [скачать] Место назначения: C:\Users\Google\Downloads\Testpy\Switzerland Second (официальный) _ DEVILLE LATE-NIGHT.f137.mp4 [скачать] 0,0% от 57,90 МБ при 24,96 КБ/с ETA 39:35 [загрузить] 0,0% от 57,90 МиБ при скорости 73,05 КиБ/с, расчетное время прибытия 13:31. [скачать] 0,0% от 57,90 МБ при 170,45 КБ/с ETA 05:47
[скачать] 0,0% от 57,90 МБ при 365,26 КБ/с ETA 02:42
[скачать] 0,1% от 57,90 МБ при 526,02 КБ/с ETA 01:52 [скачать] 0,1% от 57,90 МБ при 396,39 КБ/с ETA 02:29 [скачать] 0,2% от 57,90 МБ при 469,45 КБ/с ETA 02:06 [скачать] 0,4% от 57,90 МБ при 554,37 КБ/с ETA 01:46 [скачать] 0,9% от 57,90МиБ при 773,70КиБ/с ETA 01:15 [скачать] 1,7% от 57,90 МБ при 1,09 МБ/с ETA 00:52 [скачать] 3,5% от 57,90 МБ при 1,32 МБ/с ETA 00:42 [скачать] 6,4% от 57,90 МБ при 1,45 МБ/с ETA 00:37 [скачать] 9,2% от 57,90 МБ при 1,49 МБ/с ETA 00:35 [скачать] 11,9% от 57,90 МБ при 1,48 МБ/с ETA 00:34 [скачать] 14,4% от 57,90 МБ при 1,47 МБ/с ETA 00:33 [скачать] 16,9% от 57,90 МБ при 1,50 МБ/с ETA 00:32 [скачать] 190,9% от 57,90 МБ при 1,51 МБ/с ETA 00:30 [скачать] 22,6% от 57,90 МБ при 1,52 МБ/с ETA 00:29 [скачать] 25,3% от 57,90 МБ при 1,54 МБ/с ETA 00:28 [скачать] 28,2% от 57,90 МБ при 1,54 МБ/с ETA 00:26 [скачать] 30,9% от 57,90 МБ при 1,55 МБ/с ETA 00:25 [скачать] 33,9% от 57,90 МБ при 1,56 МБ/с ETA 00:24 [скачать] 36,7% от 57,90 МБ при 1,56 МБ/с ETA 00:23 [скачать] 39,5% от 57,90 МБ при 1,57 МБ/с ETA 00:22 [скачать] 42,3% из 57,90МиБ при 1,57МиБ/с ETA 00:21 [скачать] 45,0% от 57,90 МБ при 1,57 МБ/с ETA 00:20 [скачать] 47,9% от 57,90 МБ при 1,58 МБ/с ETA 00:19 [скачать] 50,7% от 57,90 МБ при 1,58 МБ/с ETA 00:18 [скачать] 53,5% от 57,90 МБ при 1,58 МБ/с ETA 00:17 [скачать] 56,3% от 57,90 МБ при 1,58 МБ/с ETA 00:15 [скачать] 59,1% от 57,90 МБ при 1,58 МБ/с ETA 00:14 [скачать] 61,9% от 57,90 МБ при 1,59 МБ/с ETA 00:13 [скачать] 64,7% из 57,90МиБ при 1,59МиБ/с ETA 00:12 [скачать] 67,5% от 57,90 МБ при 1,59 МБ/с ETA 00:11 [скачать] 70,3% от 57,90 МБ при 1,59 МБ/с ETA 00:10 [скачать] 73,1% от 57,90 МБ при 1,59 МБ/с ETA 00:09 [скачать] 75,9% от 57,90 МБ при 1,59 МБ/с ETA 00:08 [скачать] 78,7% от 57,90 МБ при 1,59 МБ/с ETA 00:07 [скачать] 81,5% от 57,90 МБ при 1,59 МБ/с ETA 00:06 [скачать] 84,3% от 57,90 МБ при 1,59 МБ/с ETA 00:05 [скачать] 87,1% из 57,90МиБ при 1. 60МиБ/с ETA 00:04 [скачать] 89,9% от 57,90 МБ при 1,60 МБ/с ETA 00:03 [скачать] 92,7% от 57,90 МБ при 1,60 МБ/с ETA 00:02 [скачать] 95,5% от 57,90 МБ при 1,60 МБ/с ETA 00:01 [скачать] 98,2% от 57,90 МБ при 1,60 МБ/с ETA 00:00 [скачать] 100,0% от 57,90 МБ при 1,59 МБ/с ETA 00:00
[скачать] 100% 57,90 МБ в 00:36 [скачать] Место назначения: C:\Users\Google\Downloads\Testpy\Switzerland Второй (официальный) _ DEVILLE LATE-NIGHT.f140.m4a [скачать] 0,0% от 3,43 МБ при 57,64 КБ/с ETA 01:00
[скачать] 0,1% от 3,43 МБ на 163,49КиБ/с ETA 00:21
[скачать] 0,2% от 3,43 МБ при 381,47 КБ/с ETA 00:09
[скачать] 0,4% от 3,43 МБ при 817,43 КБ/с ETA 00:04
[скачать] 0,9% от 3,43 МБ при 1,24 МБ/с ETA 00:02 [скачать] 1,8% от 3,43 МБ при 1,25 МБ/с ETA 00:02
[скачать] 3,6% от 3,43 МБ при 1,39 МБ/с ETA 00:02 [скачать] 7,3% от 3,43 МБ при 1,27 МБ/с ETA 00:02 [скачать] 14,6% от 3,43 МБ при 1,23 МБ/с ETA 00:02 [скачать] 29,2% от 3,43 МБ при 1,46 МБ/с ETA 00:01 [скачать] 58,4% от 3,43 МБ при 1,60 МБ/с ETA 00:00 [скачать] 100,0% от 3,43 МБ при 1,60 МБ/с ETA 00:00
[скачать] 100% 3,43 МБ за 00:02
[ffmpeg] Объединение форматов в "C:\Users\Google\Downloads\Testpy\Switzerland Second (официальный) _ DEVILLE LATE-NIGHT. mp4" Удаление исходного файла C:\Users\Google\Downloads\Testpy\Switzerland Second (официальный) _ DEVILLE LATE-NIGHT.f137.mp4 (пропустить -k, чтобы сохранить)
Удаление оригинального файла C:\Users\Google\Downloads\Testpy\Switzerland Второй (официальный) _ DEVILLE LATE-NIGHT.f140.m4a (пропустить -k, чтобы сохранить)
[ffmpeg] Добавление метаданных в «C:\Users\Google\Downloads\Testpy\Switzerland Second (официальный) _ DEVILLE LATE-NIGHT.mp4» [уникальный идентификатор: 1 / текущий идентификатор потока: 8828] Завершено ---------------
Замена
Комментарии
Руководство по публикацииФорматирование
Верхние регулярные выражения строка содержит только цифры
Только буквы и цифры
Соответствие элементам URL
Регулярное выражение проверки URL | Регулярное выражение — Таха
Совпадение с адресом электронной почты
Формат даты (гггг-мм-дд)
Подтверждение IP-адреса
Совпадение целого слова
Тест nginx
Совпадение или проверка номера телефона
Совпадение тега html
Поиск подстроки в строке, которая начинается и заканчивается скобками
Блокировка сайта с незаблокированными играми
Даты совпадения (М/Д/ГГ, М/Д/ГГГ, ММ/ДД/ГГ, ММ/ДД/ГГГГ)
Пустая строка
Проверяет длину числа и не начинается с 0
Соответствует, если не начинается со строки
RegEx для Json
Памятка
| Классы символов | ||
|---|---|---|
| . | любой символ кроме новой строки | |
| \ш\д\с | слово, цифра, пробел | |
| \Ш \Д \С | не слово, цифра, пробел | |
| [абв] | любой из a, b или c 9абв$ | начало/конец строки |
| \б | граница слова | |
| Экранированные символы | ||
| \. \*\ | экранированные специальные символы | |
| \т \н \р | вкладка, перевод строки, возврат каретки | |
| \u00A9 | Юникод сбежал © | |
| Группы и поиск | ||
| (абв) | группа захвата | |
| \1 | обратная ссылка на группу #1 | |
| (?:abc) | группа без захвата | |
| (?=abc) | положительный прогноз | |
| (?!abc) | отрицательный просмотр вперед | |
| Квантификаторы и чередование | ||
| а* а+ а? | 0 или более, 1 или более, 0 или 1 | |
| а{5} а{2,} | ровно пять, два или больше | |
| а{1,3} | между одним и тремя | |
| а+? а{2,}? | соответствует как можно меньшему числу | |
| аб|кд | соответствует ab или cd | |
Regex Tester еще не оптимизирован для мобильных устройств. Вы все еще можете взглянуть, но это может быть немного причудливо.
> Хорошо!
Для проверки регулярных выражений требуется современный браузер. Пожалуйста, обновите браузер до последней версии и повторите попытку.
Если у вас еще нет учетной записи, зарегистрируйтесь сейчас
Присоединяйтесь, чтобы получить доступ к дискуссионным форумам и расширенным функциям сайта.
Спасибо за использование моего инструмента. Если бы вы могли поделиться этим инструментом со своими друзьями, это было бы огромной помощью:
Твитнуть
Или подпишитесь на нас, чтобы узнать о наших последних инструментах:
Подписывайтесь на @danstools00
Ссылки из текста
У вас есть электронное письмо или письмо с номерами телефонов, адресами электронной почты или ссылками на веб-сайты по всему тексту, и вы хотели бы получить список каждого из этих элементов по отдельности. Копирование и вставка утомительны и отнимают много времени — и, в конце концов, разве компьютеры не предназначены для выполнения таких задач за нас?
Так и есть. Все, что вам нужно, это немного Regex — или регулярное выражение — кода и текстовый редактор, и вы можете извлечь нужные данные из своего текста, чтобы вставить их в другое приложение. Или, если вы хотите автоматически извлекать текст из нескольких сотен приложений для отправки в другое приложение, вы также можете сделать это с помощью Formatter от Zapier. Вот как можно использовать Regex в популярных текстовых редакторах или Formatter в популярных веб-приложениях.
Извлечение текста с помощью регулярных выражений
Извлечение текста онлайн
Автоматическое извлечение текста с помощью Zapier
Как извлечь текст с помощью регулярных выражений
Скрипты регулярных выражений выглядят как длинные строки случайного текста, но они могут быть самым мощным способом найти любой текст хочу Вы, вероятно, знакомы с инструментом поиска, встроенным в большинство приложений на вашем компьютере. Нажмите Control + F или Command + F , введите слово, которое вы хотите найти, и приложение будет выделять его каждый раз, когда это слово появляется в вашем тексте. Например, если вы ищете число «47» в предложении «Я купил 47 яблок», ваша программаИнструмент 1714 Find выделит число 47 в этом предложении.
Что, если вместо этого вы хотите найти любое число в тексте? Возможно, теперь ваше предложение гласит: «Я купил 47 яблок и 23 яйца», и вам нужен список чисел. Вы будете использовать Regex или REGular EXpressions . Regex позволяет вам сообщить компьютеру, какой тип текста вы ищете, используя его собственный синтаксис. Скажем, мы хотим найти любое число. Мы бы выполнили поиск по регулярному выражению для [0-9] — будет искать все, что содержит хотя бы одну цифру (цифры от 0 до 9). Хотите найти любое число или букву "а"? [0-9]|подойдет , так как регулярное выражение использует канал | Символ означает или .
Итак, если вы ищете адреса электронной почты, вы можете просто найти @ с помощью обычного инструмента Найти , чтобы выделить каждый адрес электронной почты — вместе со всем, что включает символ @, хотя мало что, кроме адресов электронной почты делать. Однако подробный сценарий регулярных выражений мог бы работать лучше. Он мог найти все символы вокруг символа «@» и выбрать полный адрес электронной почты. А затем, с помощью инструментов популярных текстовых редакторов, вы можете скопировать каждый адрес электронной почты из своего текста.
Хотите узнать больше о Regex? Статья Википедии о регулярных выражениях хорошо объясняет основной синтаксис, а Regex Tester (на фото выше) и RegExr — отличные способы научиться использовать регулярные выражения с всплывающими окнами, которые объясняют, что делают сценарии, когда вы их пишете.
Регулярные выражения сложны, но на самом деле ими можно легко пользоваться благодаря инструментам регулярных выражений в популярных приложениях и готовым сценариям регулярных выражений. Во-первых, давайте проверим несколько быстрых сценариев регулярных выражений для извлечения ссылок, адресов электронной почты и телефонных номеров, а затем узнаем, как использовать регулярные выражения в популярных программах редактирования текста Sublime Text, Notepad++ и BBEdit:
Сценарии регулярных выражений для извлечения данных
Прежде чем вы сможете извлекать текст в своих приложениях, вам потребуются некоторые сценарии регулярных выражений. Вот три скрипта, которые мы тщательно протестировали для извлечения ссылок на веб-сайты, электронных писем и телефонных номеров из больших блоков текста. Каждый из них работает с максимально возможным диапазоном результатов — и все они работают в каждом из упомянутых здесь текстовых редакторов. Хотя они могут показаться устрашающей абракадаброй, все, что вам нужно сделать, чтобы использовать их, — это скопировать и вставить в команды поиска текстового редактора. 9\s`!()\[\]{};:'".,<>?«»""'']))
Работает со всеми стандартными ссылками, включая неанглийские символы, если ссылка включает начальный http , https и/или www или конечный / , за которым следует текст. Например, google.com/about будет работать, как и https://google .com , но google.com не будет._`{|}~-]+)*|"(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21\x23-\x5b\x5d-\x7f]|\\[\x01 -\x09\x0b\x0c\x0e-\x7f])*")@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9] )?\.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|\[(?:(?:25[0-5]| 2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4] [0-9]|[01]?[0-9][0-9]?|[a-z0-9-]*[a-z0-9]:(?:[\x01-\x08\x0b \x0c\x0e-\x1f\x21-\x5a\x53-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])+)\])
Работает со всеми стандартные адреса электронной почты, поддомены и TLD — при условии, что в адресе электронной почты и домене используются стандартные английские символы.
Извлечение телефонных номеров ( изменено на основе скрипта из Переполнение стека )
(?:[?:+]?([0-9]| 0-9][0-9])\s (?: [.-] \s )?)?(?:(\s ( [2-9] 1 [02-9] ] | [02-8] 1| [02-8][02-9] )\s )|([1-9]|[0-9]1[02-9]|[ 02-8]1|[02-8][02-9]))\s (?: [.
-] \s )?)?([2-9]1[02-9]| [02-9]1|[02-9]{2})\s (?: [.-] \s )?([0-9]{4})(?:\s (?:#|x.?|доб.?|расширение)\s (\d+))?
Работает со всеми стандартными телефонными номерами, включая коды страны и города для большинства международных номеров. Все номера от +65 800 123 4567 доб.405 до 02-201-1222 до 865.101.1000 и более должны работать.
Просто используйте эти сценарии Regex в инструменте Find вашего текстового редактора, и они должны найти все ссылки, электронные письма и номера телефонов в вашем тексте. Затем используйте описанные выше шаги, чтобы скопировать каждый из них в свой собственный список.
Хотите больше скриптов регулярных выражений? RegExLib включает в себя широкий спектр готовых сценариев регулярных выражений, по которым вы можете выполнять поиск, и если вы не найдете то, что вам нужно, часто результаты поиска Google будут содержать нужные вам сценарии регулярных выражений.
Теперь давайте узнаем, как использовать регулярное выражение в Sublime Text, Notepad++, BBEdit и Google Sheets:
Как использовать регулярное выражение в Sublime Text (Windows, Mac, Linux)
Функция поиска регулярного выражения в Sublime TextCross -платформенный текстовый редактор Sublime Text — один из самых простых способов извлечь текст с помощью регулярных выражений через встроенный : Найти все инструменты .
В текстовом документе, из которого вы хотите извлечь определенный текст, нажмите Control + F или Command + F , чтобы открыть панель поиска. Щелкните значок * справа, чтобы включить режим регулярных выражений, затем введите или вставьте свой скрипт регулярных выражений. Теперь нажмите Find All , и Sublime Text выделит и выберет каждый экземпляр вашего текста, который он найдет.
Хотите извлечь этот текст и добавить его в собственный список? Просто снова нажмите Control + F или Command + F , затем создайте новый документ и вставьте свои результаты в список всех извлеченных вами вещей.
Sublime Text Цена: Бесплатная оценка; 70 долл. США за пользовательскую лицензию
Как регулярное выражение в Notepad++ (Windows)
В Notepad++ вы будете использовать функцию замены, чтобы поместить каждый результат в отдельную строкуВ бесплатном текстовом редакторе Windows Notepad++ есть параметр регулярного выражения в егоИнструмент 1714 Find тоже, но он не позволяет копировать текст так же, как это делает Sublime Text. Вместо этого мы будем использовать его, чтобы поместить каждый результат в отдельную строку, добавить эти строки в закладки, а затем скопировать эти строки с закладками сами по себе.
Вот как это работает. Просто введите или вставьте текст в Notepad++ и нажмите Control + F , чтобы открыть инструмент поиска. Перейдите на вкладку Заменить , затем введите или вставьте скрипт регулярного выражения в поле Найти что: . Под этим введите следующее в Заменить на: , чтобы поместить каждый результат в отдельную строку:
\n\1\n
Теперь щелкните маркер Регулярное выражение в левом нижнем углу, затем щелкните Заменить все кнопка. Это должно получить каждый из ваших результатов поиска регулярных выражений в отдельной строке.
Чтобы скопировать только результатов вашего регулярного выражения, вам нужно сделать еще две вещи. Сначала щелкните поле Mark в окне Find, выберите Bookmark line в параметрах и нажмите Отметить все . Это поставит красную пулю рядом с каждой строкой с вашими результатами регулярного выражения.
Наконец, щелкните меню поиска и выберите Закладка -> Копировать отмеченные строки . Откройте новый документ и вставьте текст, и у вас будет список только текста, который вы хотели найти с помощью регулярного выражения.
Notepad++ Цена: Бесплатная загрузка с открытым исходным кодом
Как использовать регулярное выражение в BBEdit (Mac)
Используйте параметр «Извлечь» в BBEdit, чтобы скопировать результаты регулярного выражения в новый документ Возможно, самый простой способ извлечь текст с помощью регулярных выражений — использовать текстовый редактор Mac BBEdit. Просто введите свой текст в Regex, нажмите Command + F , чтобы открыть окно Find , и введите скрипт регулярного выражения в поле Find . Отметьте опцию Grep в нижней части страницы, чтобы запустить скрипт регулярного выражения (который в BBEdit работает от терминального приложения Grep , еще один способ извлечения текста с помощью регулярного выражения).
Теперь нажмите Извлечь справа, и BBEdit создаст новый текстовый файл и добавит каждый из извлеченных элементов в документ. Это самый быстрый способ извлечь текст с помощью регулярных выражений.
BBEdit Цена: Бесплатная пробная версия; Лицензия на 49,99 долл. США на пользователя
Как использовать регулярное выражение в Google Sheets (Web)
Если вам нужен только один результат регулярного выражения, функция Google Sheet' =regextract позволяет использовать регулярное выражение внутри вашей электронной таблицы для поиска первого совпадающего результата. Просто введите =regextract( , затем введите текст, который вы хотите найти, или выберите правильную ячейку, добавьте запятую, затем введите скрипт регулярного выражения в кавычках и добавьте закрывающую скобку в конце. Затем Google Таблицы извлекут первый соответствует вашему тексту, и если ваш скрипт регулярного выражения включает в себя разделы, такие как изображенный на рисунке скрипт, который проверяет каждую часть номера телефона, Google Sheets разделит результат на одну ячейку для каждого раздела.
То же самое работает в Google Docs, хотя нет простого способа скопировать все результаты. Нажмите Control + F или Command + F , чтобы открыть диалоговое окно поиска, коснитесь значка с тремя точками, чтобы открыть диалоговое окно полного поиска, добавьте скрипт регулярного выражения в диалоговое окно Find и проверьте совпадение , используя поле регулярных выражений . Это позволит вам найти каждый элемент, соответствующий вашему регулярному выражению, хотя вам придется копировать каждый результат вручную, чтобы извлечь его из документа.
Google Sheets and Docs Цена: Бесплатно для личного использования; от 5 долларов США в месяц План G Suite Basic для бизнеса
Извлечение адресов электронной почты, номеров телефонов и ссылок в Интернете
ConvertCSV может извлекать ваш текст в ИнтернетеХотите что-нибудь попроще? Существует ряд простых веб-приложений, которые могут извлечь нужный текст несколькими щелчками мыши. Самым универсальным из протестированных нами приложений является ConvertCSV.com. Он может извлекать адреса электронной почты, ссылки и номера телефонов, хотя и не распознает столько вариантов, сколько приведенные выше сценарии регулярных выражений. И, если вам нужно, он также может конвертировать ваши файлы электронных таблиц в разные форматы.
Вот некоторые из лучших бесплатных простых инструментов для извлечения текста онлайн:
Извлечение телефонных номеров: ConvertCSV Phone Number Extractor
Извлечение адресов электронной почты: ConvertCSV Email Extractor или Procato Email Extractor ConvertCSV URL Extractor or Note Parse
Автоматическое извлечение адресов электронной почты, номеров телефонов и ссылок с помощью Zapier
Zapier Formatter может автоматически извлекать электронные письма, ссылки и номера всякий раз, когда в ваши приложения добавляется что-то новое. Regex отлично работает, когда у вас есть длинный документ с адресами электронной почты, ссылками и номерами, и вам нужно извлечь их все. Но гораздо чаще вам нужно будет извлечь текст из одной вещи и использовать его непосредственно в другом приложении.
Например, кто-то прислал вам ссылку по электронной почте, и вы хотите автоматически добавить эту ссылку в Pocket, чтобы вы могли прочитать ее позже. Или, возможно, вы сохранили свою контактную информацию в заметках Evernote и хотите извлечь адрес электронной почты и автоматически отправить электронное письмо своим новым контактам.
Средство форматирования Zapier может помочь. Zapier — это инструмент автоматизации приложений, который объединяет более 750 приложений, поэтому всякий раз, когда что-то происходит в одном приложении, Zapier может запускать цепную реакцию, копируя ваш текст в другие приложения, чтобы добавлять контакты, запускать проекты, отправлять электронные письма и т. д. А Zapier's Formatter может, среди прочего, извлекать текст, чтобы вы получали именно то, что хотите от своих приложений.
Вот как это работает. Во-первых, вы создадите новый Zap и выберите приложение, которое хотите инициировать — или запустить — рабочий процесс. Здесь мы выберем Gmail, чтобы следить за ссылками в новых электронных письмах.
Затем добавьте шаг Formatter и выберите действие Text . Выберите преобразование Извлечь URL , чтобы найти ссылку в электронном письме, и нажмите кнопку + рядом с полем Ввод и выберите поле Body Plain , чтобы программа Zapier нашла ссылку в тексте электронного письма. Протестируйте этот шаг, и Zapier найдет первую ссылку в тексте письма.
Хотите вместо этого найти адрес электронной почты, номер телефона или индивидуальный номер, например цену? Просто выберите Извлечь адрес электронной почты , Извлечь номер телефона или Извлечь номер преобразует, чтобы найти эти элементы в вашем тексте.
Наконец, добавьте приложение действия в свой Zap. Мы выберем Pocket здесь. Выберите Сохранить на потом , затем нажмите кнопку + рядом с полем URL-адрес и выберите ссылку на этапе форматирования.
Вуаля ! Теперь каждый раз, когда вы получаете электронное письмо со ссылкой, Zapier автоматически добавит его в ваш список для чтения Pocket.
Вот готовый Zap, чтобы попробовать его с Gmail и Ontraport. Zapier's Formatter может разделить имя отправителя на два поля и отправить адрес электронной почты для создания нового контакта в Ontraport:
Добавить новые входящие электронные письма Gmail в качестве контактов в Ontraport
Добавить новые входящие электронные письма Gmail в качестве контактов в Ontraport
Попробовать it
Formatter от Zapier, Gmail, Ontraport
Formatter от Zapier + Gmail + Ontraport
Хотите использовать свои собственные запросы Regex в Zapier? Вы также можете сделать это с помощью шагов кода Zapier. Вот как..
Теперь займитесь своими собственными автоматами. Инструменты извлечения Zapier Formatter — это мощный способ найти то, что вам нужно, из вашего текста, а затем использовать его в других приложениях. Если вам нужно скопировать контактную информацию, финансовые данные, ссылки на веб-сайты и многое другое, Formatter может помочь — автоматически и мгновенно.
Или, если вы хотите извлекать текст одновременно, регулярное выражение — ваш лучший новый друг.
У вас есть любимый скрипт регулярного выражения для извлечения текста? Мы будем рады услышать об этом в комментариях ниже!
Делайте больше с Zapier Formatter
Хотите автоматизировать работу с текстом? Ознакомьтесь с другими руководствами из этой серии, чтобы узнать больше о способах использования Formatter, а также получить полезные советы для других приложений, которые вы, возможно, уже используете:
Как разделить текст в Excel, Google Таблицах и других ваших любимых приложениях
Как автоматически использовать заглавные буквы в тексте так, как вы хотите
Как найти и заменить любой текст в ваших документах
Как автоматически изменить формат даты и времени в вашем тексте
Как автоматически преобразовать Markdown в HTML
следующий → ← предыдущая
Регулярные выражения широко известны как regex .
Это не что иное, как шаблон или последовательность символов, которые описывают специальный шаблон поиска в виде текстовой строки. 9) для создания сложных выражений.По умолчанию регулярные выражения чувствительны к регистру .
Преимущество и использование регулярных выражений
Регулярные выражения используются почти везде в современном программировании приложений. Ниже приведены некоторые преимущества и способы использования регулярных выражений:
- Регулярное выражение помогает программистам проверять текстовую строку.
- Он предлагает мощный инструмент для анализа и поиска шаблона, а также для изменения текстовой строки.
- С помощью функций регулярных выражений предоставляются простые и легкие решения для выявления шаблонов.
- Регулярные выражения полезны для создания системы шаблонов HTML, распознающей теги.
- Регулярные выражения широко используются для обнаружения браузеров, проверки форм, фильтрации спама и проверки надежности паролей.
- Это полезно при проверке ввода данных пользователем, таких как адрес электронной почты, номер мобильного телефона и IP-адрес.
- Помогает выделять специальные ключевые слова в файле на основе результатов поиска или ввода. 9xyz] означает НЕ x, y или z.
- Находит диапазон между элементами, например. , [a-z] означает от a до z. | Это логический оператор ИЛИ, который используется между элементами. напр. , a|b, что означает либо a ИЛИ b. ? Указывает ноль или один из предшествующих символов или диапазонов элементов. * Указывает ноль или более предшествующих символов или диапазонов элементов. + Указывает ноль или более предшествующих символов или диапазонов элементов. {н} Обозначает как минимум n раз предшествующий диапазон символов. Например - п{3}{н,} Обозначает как минимум n, но не более m раз, например, n{2,5} означает от 2 до 5 из n. {н, м} Указывает не менее n, но не более m раз. Например - n{3,6} означает от 3 до 6 из n. \ Обозначает escape-символ. Класс специальных символов в регулярном выражении
Специальный символ Описание \н Указывает на новую строку. \r Указывает на возврат каретки. \т Представляет вкладку. \v Представляет собой вертикальную вкладку. \ф Представляет собой подачу страницы. \xxx Представляет восьмеричный символ. \ххч Обозначает шестнадцатеричный символ hh. PHP предлагает два набора функций регулярных выражений:
- Регулярное выражение POSIX
- Регулярное выражение в стиле PERL
Регулярное выражение POSIX
Структура регулярного выражения POSIX аналогична типичному арифметическому выражению: несколько операторов/элементов объединяются для формирования более сложных выражений.
Простейшее регулярное выражение — это выражение, которое соответствует одному символу внутри строки. Например - "g" внутри тумблера или струны клетки. Давайте представим некоторые концепции, используемые в регулярных выражениях POSIX:
Кронштейны
Скобки [] имеют особое значение, когда они используются в регулярных выражениях. Они используются для поиска диапазона символов внутри него.
Выражение Описание [0-9] Соответствует любой десятичной цифре от 0 до 9. [а-я] Соответствует любому символу нижнего регистра от a до z. [А-Я] Соответствует любому символу верхнего регистра от A до Z. [от А до Я] Соответствует любому символу от строчной a до прописной Z. Приведенные выше диапазоны обычно используются. Вы можете использовать значения диапазона в соответствии с вашими потребностями, например [0-6], чтобы соответствовать любой десятичной цифре от 0 до 6.
Квантификаторы
Специальный символ может представлять позицию последовательности символов в квадратных скобках и одиночных символов. Каждый специальный символ имеет определенное значение. Указанные символы +, *, ?, $ и флаги {int range} следуют за последовательностью символов.
Выражение Описание р+ Соответствует любой строке, содержащей хотя бы один p. р* Соответствует любой строке, содержащей один или несколько символов p. р? Соответствует любой строке, содержащей ноль или одну букву p. р{N} Соответствует любой строке, содержащей последовательность N p. стр{2,3} Соответствует любой строке, содержащей последовательность из двух или трех символов p. стр{2,} Соответствует любой строке, содержащей не менее двух символов p. 9р Соответствует любой строке, в начале которой есть p. Функция PHP Regexp POSIX
PHP предоставляет семь функций для поиска строк с использованием регулярных выражений в стиле POSIX —
Функция Описание эрег() Ищет шаблон строки внутри другой строки и возвращает true, если шаблон совпадает, в противном случае возвращает false. ereg_replace() Ищет шаблон строки внутри другой строки и заменяет соответствующий текст замещающей строкой. эреги() Ищет шаблон внутри другой строки и возвращает длину совпадающей строки, если найдено, в противном случае возвращает false. Это функция , нечувствительная к регистру. eregi_replace() Эта функция работает так же, как ereg_replace() функция. Единственное отличие состоит в том, что поиск шаблона этой функции нечувствителен к регистру.разделить() Функция split() делит строку на массив. разделить() Похожа на функцию split(), так как также делит строку на массив с помощью регулярного выражения. Sql_regcase() Создает регулярное выражение для совпадения без учета регистра и возвращает допустимое регулярное выражение, которое будет соответствовать строке. Примечание. Обратите внимание, что вышеуказанные функции устарели в PHP 5.3.0 и удалены в PHP 7.0.0.
Регулярное выражение в стиле PERL
Регулярные выражения в стиле Perl очень похожи на POSIX. Синтаксис POSIX можно взаимозаменяемо использовать с функцией регулярного выражения в стиле Perl. Квантификаторы, представленные в разделе POSIX, также можно использовать в регулярных выражениях в стиле PERL.
Метасимволы
Метасимвол — это буквенный символ, за которым следует обратная косая черта, придающая особое значение комбинации.
Например, - метасимвол '\d' можно использовать для поиска крупных денежных сумм: /([\d]+)000/. Здесь /d будет искать строку числового символа.
Ниже приведен список метасимволов, которые можно использовать в регулярных выражениях в стиле PERL —
Символ Описание . Соответствует одному символу \с Соответствует пробельным символам, таким как пробел, новая строка, табуляция. \С Непробельный символ \д Соответствует любой цифре от 0 до 9. \D Соответствует нецифровому символу. \ш Соответствует словесному символу, такому как -az, A-Z, 0-9, _ \Вт Соответствует символу, не являющемуся словом. [аиоу] 9aeiou] Соответствует любому одиночному символу, кроме данного набора. (фу|баз|бар) Соответствует любой из указанных альтернатив. Модификаторы
Доступно несколько модификаторов, которые значительно облегчают работу с регулярным выражением. Например, - с учетом регистра или поиск по нескольким строкам и т. д.
Ниже приведен список модификаторов, используемых в регулярных выражениях в стиле PERL - 9будет соответствовать границе новой строки, а не границе строки.
или Вычисляет выражение только один раз с Позволяет использовать .(точку) для соответствия символу новой строки х Этот модификатор позволяет нам использовать пробелы в выражении для ясности. г Глобальный поиск всех совпадений. кг Позволяет продолжить поиск даже после неудачного глобального поиска. Функция PHP Regexp POSIX
В настоящее время PHP предоставляет семь функций для поиска строк с использованием регулярных выражений в стиле POSIX —
Функция Описание preg_match() Эта функция ищет шаблон внутри строки и возвращает true , если шаблон существует, в противном случае возвращает ложь . preg_match_all() Эта функция соответствует всем вхождениям шаблона в строку. preg_replace() Функция preg_replace() аналогична функции ereg_replace(), за исключением того, что при поиске и замене можно использовать регулярные выражения. preg_split() Эта функция работает точно так же, как функция split(), за исключением того, что она принимает регулярное выражение в качестве входного параметра для шаблона. В основном он делит строку на регулярное выражение.preg_grep() Функция preg_grep() находит все элементы input_array и возвращает элементы массива, соответствующие шаблону regexp (реляционное выражение). preg_quote() Заключить символы регулярного выражения в кавычки. Следующая темаФункция PHP preg_match()
← предыдущая следующий →
Ограничение текстовых ответов с помощью регулярных выражений — Документация KoboToolbox
Выполните поиск в базе знаний, просмотрите наши ресурсы и посетите наш форум для получения более подробной информации.
Последнее обновление: 15 февраль 2022
Регулярное выражение или регулярное выражение — это шаблон поиска, используемый для сопоставления определенных символы и диапазоны символов в строке.
Он широко используется для
проверять, искать, извлекать и ограничивать текст на большинстве языков программирования.
KoboToolbox поддерживает регулярное выражение для управления длиной и символами во время передачи данных.
вход в конкретный вопрос (например, контроль ввода номера мобильного телефона в
ровно 10 цифр, контроль ввода действительного идентификатора электронной почты и т. д.) .Чтобы использовать регулярное выражение в KoboToolbox, выполните следующие действия
Подготовьте вопрос типа Text .
Перейти к вопросу Настройки .
Перейдите к Критерии проверки и выберите Вручную введите свою проверку логика в опции кода XLSForm .
В поле Validation Code введите формулу регулярного выражения между цитатой отмечает
(' ')форматаregex(., ' '). Для справки период (.) относится к «этот вопрос» , в то время как регулярное выражение внутри кавычки (' ') должны соответствовать установленным правилам регулярных выражений.(необязательно) Добавьте пользовательское сообщение об ошибке , которое будет видеть лицо, вводящее данные. когда они не соответствуют критериям регулярного выражения.
Regex также можно закодировать в XLSForm, в столбце ограничения :
тип
наименование
этикетка
внешний вид
ограничение
ограничение_сообщение
текст
1 квартал
Мобильный номер респондента 9[0-9]{10}$’)
Это значение должно состоять только из 10 цифр
Кроме того, вы можете создать тип вопроса
вычислить, а затем определить код регулярного выражения в столбце вычисления . Затем вы можете использовать эту переменную как столько раз, сколько нужно в опросе:тип
наименование
этикетка
расчет
текст
1 квартал
Имя счетчика
регулярное выражение(.
, ${q0})Пожалуйста, используйте этот формат: Коби Брайант
текст
2 кв.
Имя респондента
регулярное выражение(., ${q0})
Пожалуйста, используйте этот формат: Коби Брайант
целое число
3 квартал
Возраст респондента
Как создать нужное регулярное выражение?
В дополнение к приведенным ниже примерам и советам посетите этот веб-сайт для получения дополнительной помощи и примеров.
Регулярное выражение в KoboToolbox всегда должно быть написано между апострофами
регулярное выражение (., ' ') 9Символ вставки соответствует началу строки, не занимая ни одного символа.
$Символ доллара соответствует концу строки, не занимая ни одного символа.
[абв]Соответствует
a,bилиcв квадратных скобках[ ].[а-я]Соответствует любому символу нижнего регистра от
aдоz.[А-Я]Соответствует любому символу верхнего регистра от
AдоZ.[0-9]Соответствует любым целым числам от
0до9.9А-Я] Соответствует любым символам , кроме , которые находятся в диапазоне от
AдоZ.(яблоко)Символ группировки
( )соответствует всему, что находится в скобках.|Вертикальная черта соответствует любому отделенному элементу.
\Обратная косая черта используется для соответствия буквальному значению любого метасимвола (например, попробуйте использовать
\.или\@или\$при построении регулярного выражения).\номерСоответствует тому же символу, который последний раз был сопоставлен группой захвата n th (используемый номер).
Соответствует любому пробелу или вкладка .
\бСоответствует, без использования каких-либо символов непосредственно между символом, совпадающим с
\w, и символом, не совпадающим с\w(в любом порядке). \bтакже известен как граница слова .\дСоответствует любым эквивалентным числам
[0-9]\ДСоответствует чему угодно, кроме чисел
(от 0 до 9).\шСоответствует любому символу слова (например,
aдоzилиAдоZили0до9или_).\ВтСоответствует чему угодно, кроме того, что
\wсоответствует (т. е. соответствует подстановочным знакам и пробелам).?Знак вопроса, используемый сразу после символа, соответствует или пропускает (если не требуется) совпадение символа.
*Символ звездочки, используемый сразу после символа, соответствует нулю или более последовательным символам.
+Символ плюса, используемый сразу после символа, соответствует одному или нескольким последовательным символам.
{х}Точно соответствует
xпоследовательных символов.{х}Соответствует как минимум
xпоследовательных символов (или более).{х, у}Совпадения между
xиyпоследовательных символов.Рекомендации по использованию регулярных выражений
Если вы хотите использовать ограничение регулярного выражения для числа в вопросе типа
text, убедитесь, что вы всегда имеете значениечислапод видом