Что такое реляционная база данных
Реляционные базы данных представляют собой базы данных, которые используются для хранения и предоставления доступа к взаимосвязанным элементам информации. Реляционные базы данных основаны на реляционной модели — интуитивно понятном, наглядном табличном способе представления данных. Каждая строка, содержащая в таблице такой базы данных, представляет собой запись с уникальным идентификатором, который называют ключом. Столбцы таблицы имеют атрибуты данных, а каждая запись обычно содержит значение для каждого атрибута, что дает возможность легко устанавливать взаимосвязь между элементами данных.
Структура реляционных баз данных
Реляционная модель подразумевает логическую структуру данных: таблицы, представления и индексы. Логическая структура отличается от физической структуры хранения. Такое разделение дает возможность администраторам управлять физической системой хранения, не меняя данных, содержащихся в логической структуре.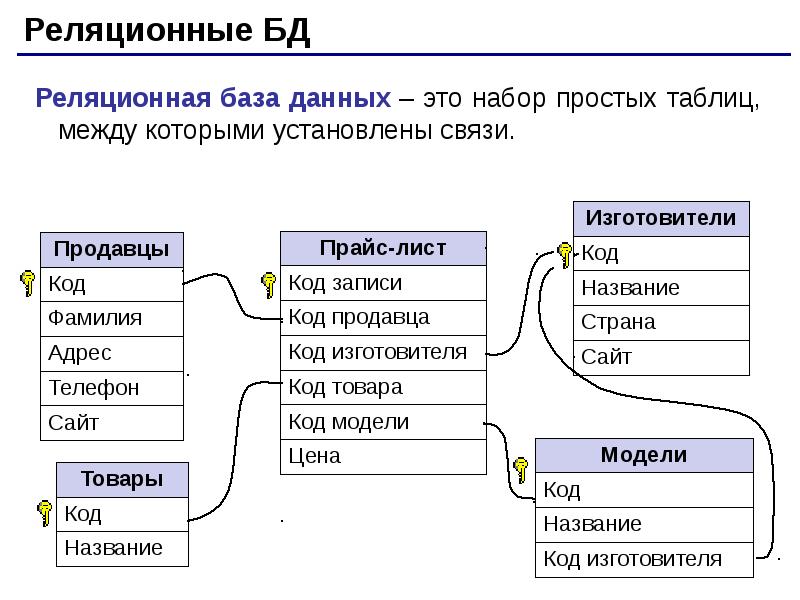
Разделение между физическим и логическим уровнем распространяется в том числе на операции, которые представляют собой четко определенные действия с данными и структурами базы данных. Логические операции дают возможность приложениям определять требования к необходимому содержанию, в то время как физические операции определяют способ доступа к данным и выполнения задачи.
Чтобы обеспечить точность и доступность данных, в реляционных базах должны соблюдаться определенные правила целостности. Например, в правилах целостности можно запретить использование дубликатов строк в таблицах, чтобы устранить вероятность попадания неправильной информации в базу данных.
Реляционная модель
В первых базах данных данные каждого приложения хранились в отдельной уникальной структуре. Если разработчик хотел создать приложение для использования таких данных, он должен был хорошо знать конкретную структуру, чтобы найти необходимые данные. Такой метод организации был неэффективен, сложен в обслуживании и затруднял оптимизацию эффективности приложений. Реляционная модель была разработана, чтобы устранить потребность в использовании разнообразных структур данных.
Такой метод организации был неэффективен, сложен в обслуживании и затруднял оптимизацию эффективности приложений. Реляционная модель была разработана, чтобы устранить потребность в использовании разнообразных структур данных.
Она обеспечила стандартный способ представления данных и отправки запросов, которые могли быть использованы в любых приложениях. Разработчики уяснили, что таблицы являются ключевым преимуществом реляционных баз данных, так как обеспечивают интуитивно понятный, эффективный и гибкий способ хранения структурированной информации и получения к ней доступа.
Со временем, когда разработчики стали использовать язык структурированных запросов (SQL) для записи данных в базу и отправки запросов, стало очевидным и другое преимущество реляционной модели. Вот уже на протяжении многих лет SQL широко используется в качестве языка запросов в базах данных. Он основан на алгоритмах реляционной алгебры и четкой математической структуре, что обеспечивает простоту и эффективность при оптимизации любых запросов к базе данных.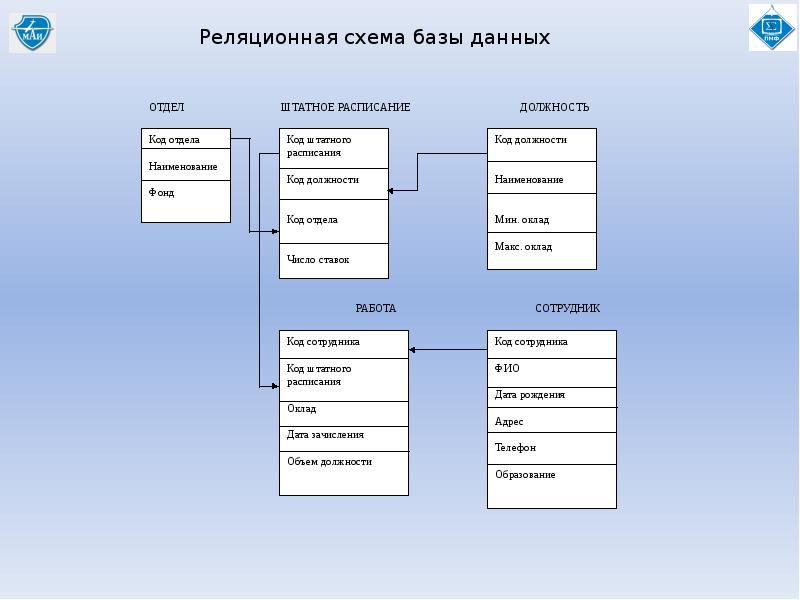
Преимущества реляционных баз данных
Компании всех типов и размеров используют простую, но функциональную реляционную модель для обслуживания разнообразных информационных потребностей. Реляционные базы данных применяются для отслеживания товарных запасов, обработки торговых транзакций через Интернет, управления большими объемами критически важных данных заказчиков и т. д. Реляционные базы данных можно рекомендовать для обслуживания любых информационных потребностей, где элементы данных связаны между собой и необходимо обеспечивать безопасное и надежное управление ими на основе правил целостности.
Реляционные базы данных появились в 1970-х годах. На сегодняшний день преимущества реляционного подхода сделали его самой распространенной моделью для баз данных в мире.
Целостность данных
Реляционная модель наиболее эффективно поддерживает целостность данных во всех приложениях и копиях (экземплярах) базы данных.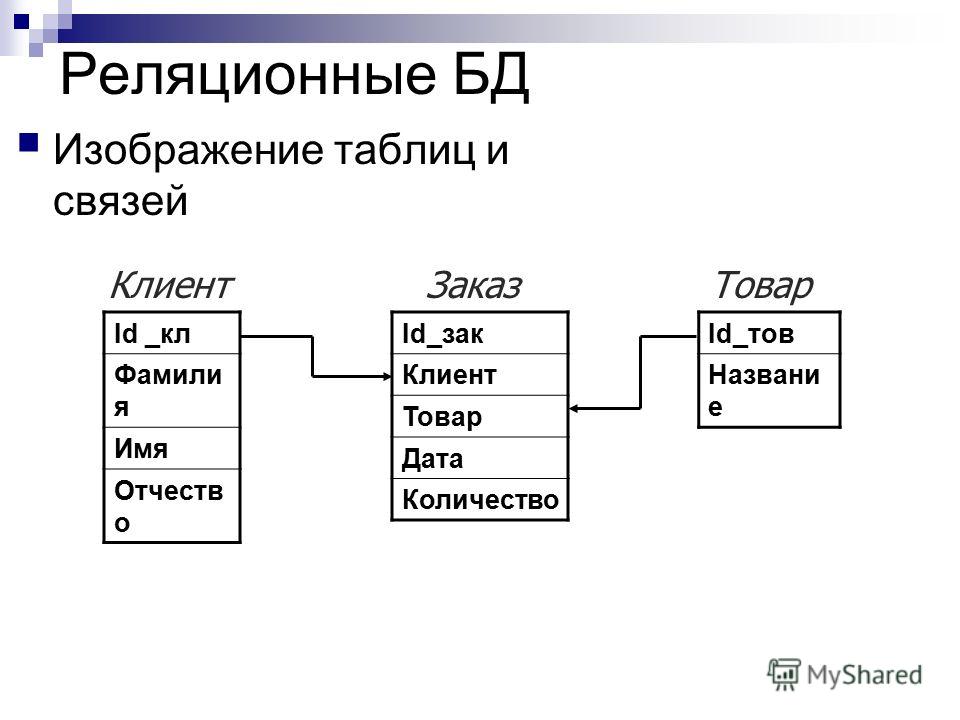 Например, когда заказчик кладет деньги на счет с помощью банкомата, а затем проверяет баланс на мобильном телефоне, он ожидает, что поступившие средства сразу же отобразятся на счете. Реляционные базы данных отлично подходят для обеспечения целостности данных в различных экземплярах базы в одно и то же время.
Например, когда заказчик кладет деньги на счет с помощью банкомата, а затем проверяет баланс на мобильном телефоне, он ожидает, что поступившие средства сразу же отобразятся на счете. Реляционные базы данных отлично подходят для обеспечения целостности данных в различных экземплярах базы в одно и то же время.
Другие типы баз данных не могут одновременно поддерживать целостность больших объемов данных. Некоторые современные типы баз данных, такие как NoSQL, обеспечивают только так называемую “окончательную целостность.” Это значит, что, когда выполняется масштабирование данных или несколько пользователей одновременно используют одни и те же данные, необходимо некоторое время на “внесение изменений”. В некоторых случаях окончательная целостность вполне приемлема (например, для обновления позиций в товарном каталоге), однако для критически важной операционной деятельности бизнеса (например, транзакций с использованием корзины) реляционные базы представляют собой фундаментальный стандарт.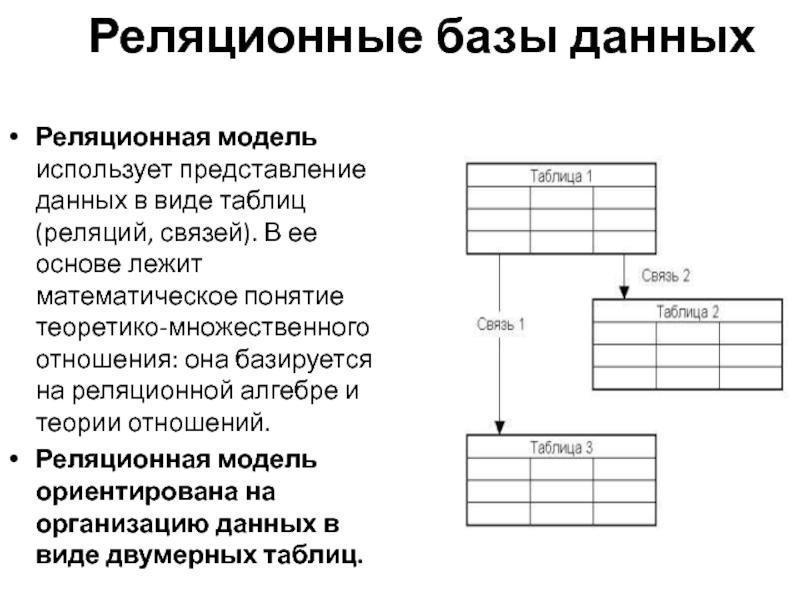
Фиксация изменений и атомарность
В реляционных базах данных используются очень детальные и строгие бизнес-правила и политики в отношении фиксации изменений в базе данных (то есть сохранения изменений в данных на постоянной основе). Рассмотрим для примера складскую базу данных, в которой отслеживаются три запчасти, всегда использующиеся в комплекте. Когда одну из них извлекают из товарных запасов, две другие также должны извлекаться. Если одна из трех запчастей недоступна, две другие также не могут быть проданы отдельно, то есть, чтобы в базу данных можно было внести изменения, должны быть доступны все три запчасти. Реляционная база данных не разрешит сохранять изменения, если они не касаются всех трех запчастей. Эту особенность реляционных баз данных называют
Хранимые процедуры и реляционные базы данных
Доступ к данным включает в себя множество повторяющихся действий.
Блокировки базы данных и параллельный доступ
Когда несколько пользователей или приложений пытаются одновременно изменить одни и те же данные, это может вести к возникновению конфликта в базе. Блокировки и параллельный доступ снижают вероятность конфликтов и способствуют сохранению целостности данных.
Блокировки и параллельный доступ снижают вероятность конфликтов и способствуют сохранению целостности данных.
Блокировка не разрешает другим пользователям и приложениям получать доступ к данным во время их обновления. В некоторых базах данных блокировка может применяться к целой таблице, что негативно отражается на эффективности приложения. В других типах баз данных, например реляционных базах Oracle, блокировка выполняется на уровне одной записи, оставляя другие записи в таблице доступными. Такой подход помогает сохранить эффективность приложения.
Инструмент параллельного доступа используется, когда несколько пользователей или приложений пытаются одновременно выполнить запросы к одной базе данных. Он обеспечивает доступ пользователей и приложений к базе данных в соответствии с политиками контроля.
Характеристики, на которые следует обратить внимание при выборе реляционной базы данных
Программное обеспечение, которое используется для сохранения, контроля и извлечения данных в базе, а также выполнения к ней запросов, называют системой управления реляционной базой данных (СУРБД)
 СУРБД обеспечивает интерфейс между пользователями и приложениями и базой данных, а также административные функции для управления хранением данных, их эффективностью и доступом к ним.
СУРБД обеспечивает интерфейс между пользователями и приложениями и базой данных, а также административные функции для управления хранением данных, их эффективностью и доступом к ним.При выборе типа базы данных и продуктов на основе реляционных баз данных необходимо учитывать несколько факторов. Выбор СУРБД зависит от потребностей Вашей организации. Задайте себе следующие вопросы.
- Каковы наши требования к точности данных? Будем ли мы использовать бизнес-логику для хранения и обеспечения точности данных? Предъявляются ли к нашим данным более строгие требования в отношении точности (например, если Вы работаете с финансовыми данными и отчетностью)?
- Нужна ли нам масштабируемость? Какими объемами данных требуется управлять и каков прогнозируемый рост этих объемов? Должна ли модель базы данных поддерживать зеркальные копии (как отдельные экземпляры) в целях масштабирования? Если да, сможем ли мы обеспечивать целостность данных в этих экземплярах?
- Насколько важно наличие параллельного доступа? Потребуется ли пользователям и приложениям одновременный доступ к данным? Поддерживает ли ПО базы данных параллельный доступ без ущерба для безопасности?
- Каковы наши потребности в эффективности и надежности баз данных? Требуется ли нам высокоэффективная и надежная система? Каковы требования к скорости выполнения запросов? Какие гарантии дает вендор услуг в соответствии с соглашением об обслуживании (SLA) или на случай незапланированного простоя?
Реляционная база данных будущего: автономная база данных
Реляционная модель баз данных
Реляционная база данных — это такая база данных, которая воспринимается ее пользователем как совокупность таблиц [8]. Если детализировать записи приведенного на рис. 5.5 примера, то получим структуру БД, изображенную на рис. 5.6. Эта база данных состоит из трех таблиц: R\ R2, R3.
Если детализировать записи приведенного на рис. 5.5 примера, то получим структуру БД, изображенную на рис. 5.6. Эта база данных состоит из трех таблиц: R\ R2, R3.
Таблица R\ представляет поставщиков. Каждый поставщик имеет номер, уникальный для этого поставщика, фамилию (естественно, неуникальную), значение рейтинга и местонахождение (город).
Таблица R2, описывает виды товаров. Каждый товар имеет уникальный номер, название, вес и цвет.
В таблице Rj отражена поставка товаров. Она служит для того, чтобы связать между собой две другие таблицы. Например, первая строка этой таблицы связывает определенного поставщика из таблицы R\ (поставщика Пі) с определенным товаром из таблицы /Ъ (с товаром Ті). Иными словами, она представляет поставку товаров вида Ті поставщиком по фамилии П; и объем поставки, равный 300 шт. Таким образом, для каждой поставки имеются номер поставщика, номер товара и количество товара.
Из приведенных на рис. 5.6 таблиц следует:
• все значения данных являются атомарными, т. е. в каждой таблице на пересечении строки и столбца всегда имеется в точности одно значение данных и никогда не бывает множества значений;
е. в каждой таблице на пересечении строки и столбца всегда имеется в точности одно значение данных и никогда не бывает множества значений;
• полное информационное содержание базы данных представляется в виде явных значений данных. Такой метод представления — единственный, имеющийся в распоряжении реляционной базы данных. В частности, не существует связей и указателей, соединяющих одну таблицу с другой. Для этой цели служат тоже таблицы. Так, таблица Rt, отражает связь таблиц R\ и Как указывалось ранее, математическим термином для обозначения таблицы является отношение (relation), и реляционные системы берут свое начало в математической теории отношений. Основы реляционной модели данных впервые были сформулированы и опубликованы в 1970 г. доктором Э.Ф. Коддом. Предло-
Рис. 5.6. Реляционная БД поставщиков и товаров женные им идеи оказали большое влияние на технологию баз данных во всех ее аспектах, а также на другие области информационных технологий, например на искусственный интеллект и обработку текстов на естественных языках.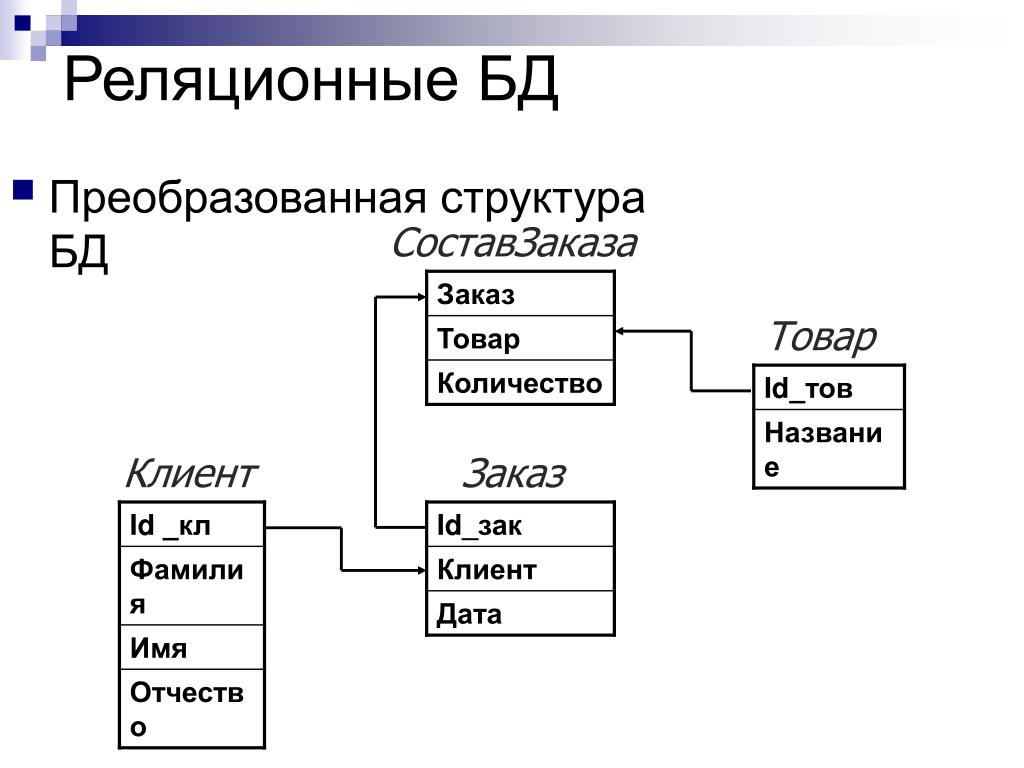
При работе с реляционными моделями используется как математическая терминология, так и терминология, исторически принятая в сфере обработки данных. Для того чтобы не возникало разночтений, ниже приведены основные формальные реляционные термины и соответствующие им неформальные эквиваленты:
Формальный реляционный термин |
Неформальный эквивалент |
Отношение |
Таблица |
Кортеж |
Запись, строка |
Атрибут |
Поле, столбец |
⇐Базы данных | Информационные системы и технологии в зкономике | Реляционная структура данных⇒
Знакомство с реляционными базами данных
Введение
Системы управления базами данных (СУБД) — это компьютерные программы, которые позволяют пользователям взаимодействовать с базой данных. СУБД позволяет пользователям контролировать доступ к базе данных, записывать данные, запускать запросы и выполнять любые другие задачи, связанные с управлением базами данных.
СУБД позволяет пользователям контролировать доступ к базе данных, записывать данные, запускать запросы и выполнять любые другие задачи, связанные с управлением базами данных.
Однако для выполнения любой из этих задач СУБД должна иметь в основе модель, определяющую организацию данных. Реляционная модель — это один из подходов к организации данных, который широко используется в программном обеспечении баз данных с момента своего появления в конце 60-х годов. Этот подход настолько распространен, что на момент написания данной статьи четыре из пяти самых популярных систем управления базами данных являются реляционными.
В этой концептуальной статье представлена история реляционной модели, порядок организации данных реляционными системами и примеры использования в настоящее время.
История реляционной модели
Базы данных — это логически сформированные кластеры информации, или данных. Любая коллекция данных является базой данных, независимо от того, как и где она хранится. Шкаф с платежными ведомостями, полка в регистратуре с карточками пациентов или хранящаяся в разных офисах клиентская картотека компании — все это базы данных. Прежде чем хранение данных и управление ими с помощью компьютеров стало общей практикой, правительственным организациям и коммерческим компаниям для хранения информации были доступны только физические базы данных такого рода.
Шкаф с платежными ведомостями, полка в регистратуре с карточками пациентов или хранящаяся в разных офисах клиентская картотека компании — все это базы данных. Прежде чем хранение данных и управление ими с помощью компьютеров стало общей практикой, правительственным организациям и коммерческим компаниям для хранения информации были доступны только физические базы данных такого рода.
Примерно в середине XX века развитие компьютерной науки привело к созданию машин с большей вычислительной мощностью, а также с увеличенными возможностями встроенной и внешней памяти. Эти достижения позволили специалистам в области вычислительной техники осознать потенциал таких устройств в области хранения и управления большими массивами данных.
Однако не существовало никаких теорий о том, как компьютеры могут организовывать данные осмысленным, логическим образом. Одно дело хранить несортированные данные на компьютере, но гораздо сложнее создать системы, которые позволяют последовательно добавлять, извлекать, сортировать и иным образом управлять этими данными на практике. Необходимость в логической конструкции для хранения и организации данных привела к появлению ряда предложений по использованию компьютеров для управления данными.
Необходимость в логической конструкции для хранения и организации данных привела к появлению ряда предложений по использованию компьютеров для управления данными.
Одной из ранних моделей базы данных была иерархическая модель, в которой данные были организованы в виде древовидной структуры, подобной современным файловым системам. Следующий пример показывает, как может выглядеть часть иерархической базы данных, используемой для классификации животных:
Иерархическая модель была широко внедрена в ранние системы управления базами данных, но она отличалась отсутствием гибкости. В этой модели каждая запись может иметь только одного «предка», даже если отдельные записи могут иметь несколько «потомков». Из-за этого эти ранние иерархические базы данных могли представлять только отношения «один к одному» или «один ко многим». Отсутствие отношений «много ко многим» могло привести к возникновению проблем при работе с точками данных, которые требуют привязки к нескольким предкам.
В конце 60-х годов Эдгар Ф. Кодд (Edgar F. Codd), программист из IBM, разработал реляционную модель управления базами данных. Реляционная модель Кодда позволила связать отдельные записи с несколькими таблицами, что дало возможность устанавливать между точками данных отношения «много ко многим» в дополнение к «один ко многим». Это обеспечило большую гибкость по сравнению с другими существующими моделями, если говорить о разработке структур баз данных, а значит реляционные системы управления базами данных (РСУБД) могли удовлетворить гораздо более широкий спектр бизнес-задач.
Кодд предложил язык для управления реляционными данными, известный как Alpha , оказавший влияние на разработку более поздних языков баз данных. Коллеги Кодда из IBM, Дональд Чемберлен (Donald Chamberlin) и Рэймонд Бойс (Raymond Boyce), создали один из языков под влиянием языка Alpha. Они назвали свой язык SEQUEL, сокращенное название от Structured English Query Language (структурированный английский язык запросов), но из-за существующего товарного знака сократили название до SQL (более формальное название — структурированный язык запросов).
Из-за ограниченных возможностей аппаратного обеспечения ранние реляционные базы данных были все еще непозволительно медленными, и потребовалось некоторое время, прежде чем технология получила широкое распространение. Но к середине 80-х годов реляционная модель Кодда была внедрена в ряд коммерческих продуктов по управлению базами данных от компании IBM и ее конкурентов. Вслед за IBM, эти поставщики также стали разрабатывать и применять свои собственные диалекты SQL. К 1987 году Американский национальный институт стандартов и Международная организация по стандартизации ратифицировали и опубликовали стандарты SQL, укрепив его статус признанного языка для управления РСУБД.
Широкое использование реляционной модели во многих отраслях привело к тому, что она была признана стандартной моделью для управления данными. Даже с появлением в последнее время все большего числа различных баз данных NoSQL реляционные базы данных остаются доминирующим инструментом хранения и организации данных.
Как реляционные базы данных структурируют данные
Теперь, когда у вас есть общее понимание истории реляционной модели, давайте более подробно рассмотрим, как данная модель структурирует данные.
Наиболее значимыми элементами реляционной модели являются отношения, которые известны пользователям и современным РСУБД как таблицы. Отношения — это набор кортежей, или строк в таблице, где каждый кортеж имеет набор атрибутов, или столбцов:
Столбец — это наименьшая организационная структура реляционной базы данных, представляющая различные ячейки, которые определяют записи в таблице. Отсюда происходит более формальное название — атрибуты. Вы можете рассматривать каждый кортеж в качестве уникального экземпляра чего-либо, что может находиться в таблице: категории людей, предметов, событий или ассоциаций. Такими экземплярами могут быть сотрудники компаний, продажи в онлайн-бизнесе или результаты лабораторных тестов. Например, в таблице с трудовыми записями учителей в школе кортежи могут иметь такие атрибуты, как name, subjects, start_date и т. д.
д.
При создании столбцов вы указываете тип данных, определяющий, какие записи могут вноситься в данный столбец. РСУБД часто используют свои собственные уникальные типы данных, которые могут не быть напрямую взаимозаменяемы с аналогичными типами данных из других систем. Некоторые распространенные типы данных включают даты, строки, целые числа и логические значения.
В реляционной модели каждая таблица содержит по крайней мере один столбец, который можно использовать для уникальной идентификации каждой строки. Он называется первичным ключом. Это важно, поскольку это означает, что пользователям не нужно знать, где физически хранятся данные на компьютере. Их СУБД может отслеживать каждую запись и возвращать ее в зависимости от конкретной цели. В свою очередь, это означает, что записи не имеют определенного логического порядка, и пользователи могут возвращать данные в любом порядке или с помощью любого фильтра по своему усмотрению.
Если у вас есть две таблицы, которые вы хотите связать друг с другом, можно сделать это с помощью внешнего ключа.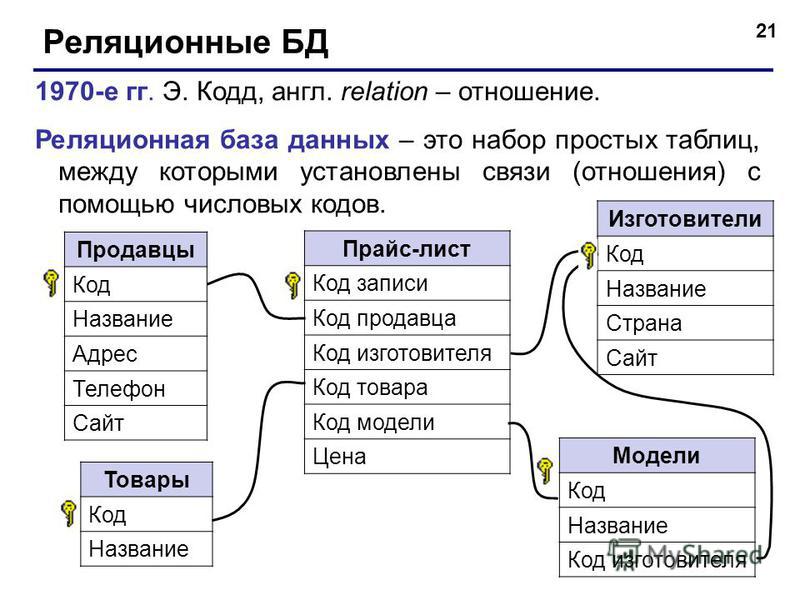 Внешний ключ — это, по сути, копия основного ключа одной таблицы (таблицы «предка»), вставленная в столбец другой таблицы («потомка»). Следующий пример показывает отношения между двумя таблицами: одна используется для записи информации о сотрудниках компании, а другая — для отслеживания продаж компании. В этом примере первичный ключ таблицы
Внешний ключ — это, по сути, копия основного ключа одной таблицы (таблицы «предка»), вставленная в столбец другой таблицы («потомка»). Следующий пример показывает отношения между двумя таблицами: одна используется для записи информации о сотрудниках компании, а другая — для отслеживания продаж компании. В этом примере первичный ключ таблицы EMPLOYEES используется в качестве внешнего ключа таблицы SALES:
Если вы попытаетесь добавить запись в таблицу «потомок», и при этом значение, вводимое в столбец внешнего ключа, не существует в первичном ключе таблицы «предок», вставка будет недействительной. Это помогает поддерживать целостность уровня отношений, поскольку ряды в обеих таблицах всегда будут связаны корректно.
Структурные элементы реляционной модели помогают хранить данные в структурированном виде, но хранение имеет значение только в том случае, если вы можете извлечь эти данные. Для извлечения информации из РСУБД вы можете создать запрос, т. е. структурированный запрос на набор информации. Как уже упоминалось ранее, большинство реляционных баз данных используют язык SQL для управления данными и отправки запросов. SQL позволяет фильтровать результаты и обрабатывать их с помощью различных пунктов, предикатов и выражений, позволяя вам контролировать, какие данные появятся в результате.
е. структурированный запрос на набор информации. Как уже упоминалось ранее, большинство реляционных баз данных используют язык SQL для управления данными и отправки запросов. SQL позволяет фильтровать результаты и обрабатывать их с помощью различных пунктов, предикатов и выражений, позволяя вам контролировать, какие данные появятся в результате.
Преимущества и ограничения реляционных баз данных
Учитывая организационную структуру, положенную в основу реляционных баз данных, давайте рассмотрим их некоторые преимущества и недостатки.
Сегодня как SQL, так и базы данных, которые ее используют, несколько отклоняются от реляционной модели Кодда. Например, модель Кодда предписывает, что каждая строка в таблице должна быть уникальной, а по соображениям практической целесообразности большинство современных реляционных баз данных допускают дублирование строк. Есть и те, кто не считает базы данных на основе SQL истинными реляционными базами данных, если они не соответствуют каждому критерию реляционной модели по версии Кодда. Но на практике любая СУБД, которая использует SQL и в какой-то мере соответствует реляционной модели, может быть отнесена к реляционным системам управления базами данных.
Но на практике любая СУБД, которая использует SQL и в какой-то мере соответствует реляционной модели, может быть отнесена к реляционным системам управления базами данных.
Хотя популярность реляционных баз данных стремительно росла, некоторое недостатки реляционной модели стали проявляться по мере того, как увеличивались ценность и объемы хранящихся данных. К примеру, трудно масштабировать реляционную базу данных горизонтально. Горизонтальное масштабирование или масштабирование по горизонтали — это практика добавления большего количества машин к существующему стеку, что позволяет распределить нагрузку, увеличить трафик и ускорить обработку. Часто это контрастирует с вертикальным масштабированием, которое предполагает модернизацию аппаратного обеспечения существующего сервера, как правило, с помощью добавления оперативной памяти или центрального процессора.
Реляционную базу данных сложно масштабировать горизонтально из-за того, что она разработана для обеспечения целостности, т. е. клиенты, отправляющие запросы в одну и ту же базу данных, всегда будут получать одинаковые данные. Если вы масштабируете реляционную базу данных горизонтально по всем машинам, будет трудно обеспечить целостность, т.к. клиенты могут вносить данные только в один узел, а не во все. Вероятно, между начальной записью и моментом обновления других узлов для отображения изменений возникнет задержка, что приведет к отсутствию целостности данных между узлами.
е. клиенты, отправляющие запросы в одну и ту же базу данных, всегда будут получать одинаковые данные. Если вы масштабируете реляционную базу данных горизонтально по всем машинам, будет трудно обеспечить целостность, т.к. клиенты могут вносить данные только в один узел, а не во все. Вероятно, между начальной записью и моментом обновления других узлов для отображения изменений возникнет задержка, что приведет к отсутствию целостности данных между узлами.
Еще одно ограничение, существующее в РСУБД, заключается в том, что реляционная модель была разработана для управления структурированными данными, или данными, которые соответствуют заранее определенному типу данных, или, по крайней мере, каким-либо образом предварительно организованы. Однако с распространением персональных компьютеров и развитием сети Интернет в начале 90-х годов появились неструктурированные данные, такие как электронные сообщения, фотографии, видео и пр.
Но все это не означает, что реляционные базы данных бесполезны. Напротив, спустя более 40 лет, реляционная модель все еще является доминирующей основой для управления данными. Распространенность и долголетие реляционных баз данных свидетельствуют о том, что это зрелая технология, которая сама по себе является главным преимуществом. Существует много приложений, предназначенных для работы с реляционной моделью, а также много карьерных администраторов баз данных, которые являются экспертами, когда дело доходит до реляционных баз данных. Также существует широкий спектр доступных печатных и онлайн-ресурсов для тех, кто хочет начать работу с реляционными базами данных.
Напротив, спустя более 40 лет, реляционная модель все еще является доминирующей основой для управления данными. Распространенность и долголетие реляционных баз данных свидетельствуют о том, что это зрелая технология, которая сама по себе является главным преимуществом. Существует много приложений, предназначенных для работы с реляционной моделью, а также много карьерных администраторов баз данных, которые являются экспертами, когда дело доходит до реляционных баз данных. Также существует широкий спектр доступных печатных и онлайн-ресурсов для тех, кто хочет начать работу с реляционными базами данных.
Еще одно преимущество реляционных баз данных заключается в том, что почти все РСУБД поддерживают транзакции. Транзакция состоит из одного или более индивидуального выражения SQL, выполняемого последовательно, как один блок работы. Транзакции представляют подход «все или ничего», означающий, что все операторы SQL в транзакции должны быть действительными. В противном случае вся транзакция не будет выполнена. Это очень полезно для обеспечения целостности данных при внесении изменений в несколько строк или в таблицы.
Это очень полезно для обеспечения целостности данных при внесении изменений в несколько строк или в таблицы.
Наконец, реляционные базы данных демонстрируют чрезвычайную гибкость. Они используются для построения широкого спектра различных приложений и продолжают эффективно работать даже с большими объемами данных. Язык SQL также обладает огромным потенциалом и позволяет вам добавлять или менять данные на лету, а также вносить изменения в структуру схем баз данных и таблиц, не влияя на существующие данные.
Заключение
Благодаря гибкости и проектному решению, направленному на сохранение целостности данных, спустя пятьдесят лет после появления такого замысла, реляционные базы данных все еще являются основным способом управления данными и их хранения. Даже с увеличением в последние годы числа разнообразных баз данных NoSQL понимание реляционной модели и принципов ее работы с РСУБД является ключевым моментом для всех, кто хочет создавать приложения, использующие возможности данных.
Чтобы узнать больше о нескольких популярных РСУБД с открытым исходным кодом, мы рекомендуем вам ознакомиться с нашим сравнением различных реляционных баз данных с открытым исходным кодом. Если вам интересно узнать больше о базах данных в целом, мы рекомендуем вам ознакомиться с нашей полной библиотекой материалов о базах данных.
Реляционная модель данных — Основы реляционных баз данных
Основы реляционных баз данныхОсновой логики работы в реляционных СУБД является реляционная алгебра, именно поэтому в подобных системах добавляют приставку «реляционная». Если посмотреть книги, посвященные базам данных (особенно университетские), то они в обязательном порядке дают её, и иногда в больших количествах. Несмотря на то, что прикладному программисту не обязательно разбираться в её тонкостях, знать основы реляционной алгебры всё же полезно. Ниже я попробую дать некоторое общее представление без привлечения соответствующего математического аппарата. Если вы захотите копнуть глубже, то смотрите ссылки в дополнительных материалах.
Иерархическая модель
Существует множество разных способов представить одни и те же данные. Один из первых широко используемых способов — иерархическая модель. В такой модели данные представлены в виде дерева, где дочерние элементы находятся в зависимости от родительских. Самый яркий пример древовидной структуры — файловая система (ФС). Вероятно, будет сюрпризом для вас, что файловая система — это база данных, а операционная система ведёт себя, как СУБД по отношению к ФС. Однако то, как мы видим данные и как они хранятся в реальности (на диске) — две большие разницы. Физическое размещение данных на носителях — прерогатива конкретных СУБД, и здесь они соревнуются, кто быстрее и эффективнее. А вот их внешнее представление — это то, что видит пользователь, и оно очень сильно влияет на способ взаимодействия с данными. Именно поэтому разные способы представления данных называются моделями. Эти модели не отражают то, что происходит на самом деле (на физическом уровне), они лишь описывают то, как данные структурированы и как с ними можно взаимодействовать.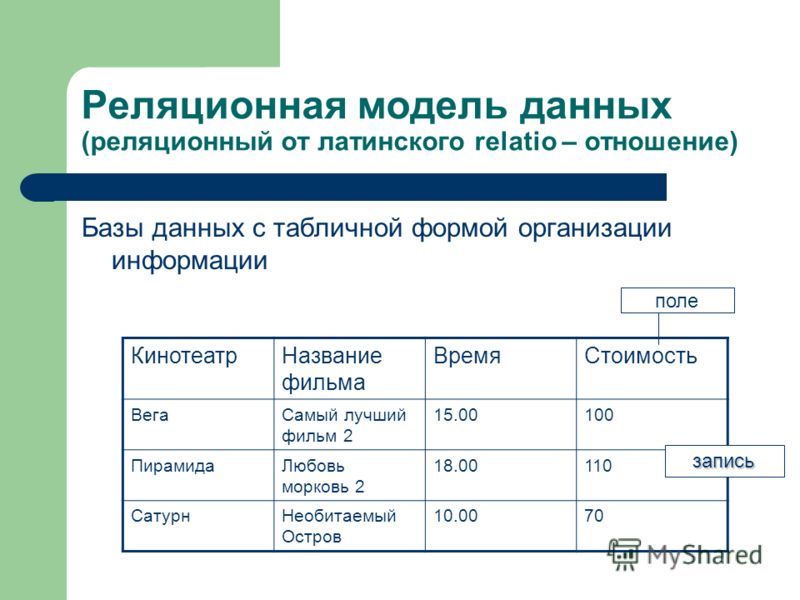 Модели данных очень похожи на абстрактные типы данных, которые определяют интерфейс взаимодействия с типом и не определяют его внутреннюю реализацию.
Модели данных очень похожи на абстрактные типы данных, которые определяют интерфейс взаимодействия с типом и не определяют его внутреннюю реализацию.
С помощью иерархической модели можно представить и бизнес области. К примеру, в предметной области интернет-магазина есть такие понятия, как пользователь и заказ. Причём, у одного пользователя может быть множество заказов, что сразу определяет структуру дерева, где вершиной становится пользователь, а его детьми — заказы. Подобным образом структурируются и все остальные части.
Проблемы начинаются, когда у одного ребёнка может быть несколько родителей. В современных сервисах такси есть возможность оплачивать счёт за такси совместно — это значит, что у одного заказа сразу несколько клиентов. Как быть в такой ситуации? К сожалению, иерархическая модель не может предложить хорошего решения данной задачи. Придётся создавать параллельные деревья, в которых появится дублирование данных.
Сетевая модель
Эта проблема решается в сетевой модели данных, которая расширяет иерархическую и даёт возможность иметь множество предков. По сути, сетевая модель представляет собой граф. В сетевой структуре каждый элемент может быть связан с любым другим элементом.
По сути, сетевая модель представляет собой граф. В сетевой структуре каждый элемент может быть связан с любым другим элементом.
Недостатком сетевой модели данных являются высокая сложность и жесткость схемы БД, построенной на её основе. Поскольку логика процедуры выборки данных зависит от физической организации этих данных, то эта модель не является полностью независимой от приложения. Другими словами, если необходимо изменить структуру данных, то нужно изменить и приложение.
Реляционная модель
Зарегистрироваться
или войти в аккаунт
Курсы программирования для новичков и опытных разработчиков. Начните обучение бесплатно.
- 115 курсов, 2000+ часов теории
- 800 практических заданий в браузере
- 250 000 студентов
Наши выпускники работают в компаниях:
Реляционная модель данных — ПИЭ.Wiki
Материал из ПИЭ.Wiki
Реляционная модель данных – логическая модель данных. Впервые была предложена британским учёным сотрудником компании IBM Эдгаром Франком Коддом (E. F. Codd) в 1970 году в статье «A Relational Model of Data for Large Shared Data Banks» (русский перевод статьи, в которой она впервые описана, опубликован в журнале «СУБД» N 1 за 1995 г.). В настоящее время эта модель является фактическим стандартом, на который ориентируются практически все современные коммерческие СУБД.
Впервые была предложена британским учёным сотрудником компании IBM Эдгаром Франком Коддом (E. F. Codd) в 1970 году в статье «A Relational Model of Data for Large Shared Data Banks» (русский перевод статьи, в которой она впервые описана, опубликован в журнале «СУБД» N 1 за 1995 г.). В настоящее время эта модель является фактическим стандартом, на который ориентируются практически все современные коммерческие СУБД.
В реляционной модели достигается гораздо более высокий уровень абстракции данных, чем в иерархической или сетевой. В упомянутой статье Е.Ф. Кодда утверждается, что «реляционная модель предоставляет средства описания данных на основе только их естественной структуры, т.е. без потребности введения какой-либо дополнительной структуры для целей машинного представления». Другими словами, представление данных не зависит от способа их физической организации. Это обеспечивается за счет использования математической теории отношений (само название «реляционная» происходит от английского relation – «отношение»).
В состав реляционной модели данных обычно включают теорию нормализации.
Состав реляционной модели данных
Кристофер Дейт определил три составные части реляционной модели данных:
- структурная
- манипуляционная
- целостная
Структурная часть модели определяет, что единственной структурой данных является нормализованное n-арное отношение. Отношения удобно представлять в форме таблиц, где каждая строка есть кортеж, а каждый столбец – атрибут, определенный на некотором домене. Данный неформальный подход к понятию отношения дает более привычную для разработчиков и пользователей форму представления, где реляционная база данных представляет собой конечный набор таблиц.
Манипуляционная часть модели определяет два фундаментальных механизма манипулирования данными – реляционная алгебра и реляционное исчисление.
Основной функцией манипуляционной части реляционной модели является обеспечение меры реляционности любого конкретного языка реляционных БД: язык называется реляционным, если он обладает не меньшей выразительностью и мощностью, чем реляционная алгебра или реляционное исчисление.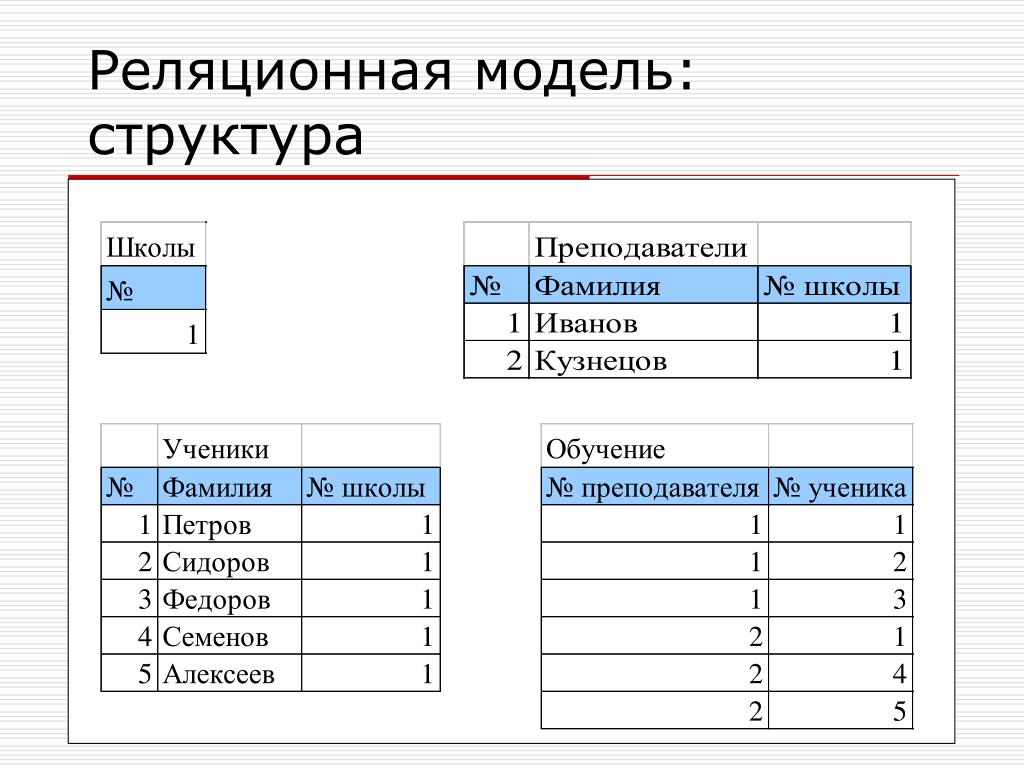
Целостная часть модели определяет требования целостности сущностей и целостности ссылок. Первое требование состоит в том, что любой кортеж любого отношения отличим от любого другого кортежа этого отношения, т.е. другими словами, любое отношение должно обладать первичным ключом. Требование целостности по ссылкам, или требование внешнего ключа состоит в том, что для каждого значения внешнего ключа, появляющегося в ссылающемся отношении, в отношении, на которое ведет ссылка, должен найтись кортеж с таким же значением первичного ключа, либо значение внешнего ключа должно быть неопределенным (т.е. ни на что не указывать).
Структура реляционной модели данных
Можно провести аналогию между элементами реляционной модели данных и элементами модели «сущность-связь». Реляционные отношения соответствуют наборам сущностей, а кортежи – сущностям. Поэтому, также как и в модели «сущность-связь» столбцы в таблице, представляющей реляционное отношение, называют атрибутами.
Основные компоненты реляционного отношения
Каждый атрибут определен на домене, поэтому домен можно рассматривать как множество допустимых значений данного атрибута. Несколько атрибутов одного отношения и даже атрибуты разных отношений могут быть определены на одном и том же домене.
В примере, показанном на рисунке, атрибуты «Оклад» и «Премия» определены на домене «Деньги». Поэтому, понятие домена имеет семантическую нагрузку: данные можно считать сравнимыми только тогда, когда они относятся к одному домену. Таким образом, в рассматриваемом нами примере сравнение атрибутов «Табельный номер» и «Оклад» является семантически некорректным, хотя они и содержат данные одного типа.
Именованное множество пар «имя атрибута – имя домена» называется схемой отношения. Мощность этого множества — называют степенью или «арностью» отношения. Набор именованных схем отношений представляет из себя схему базы данных.
Атрибут, значение которого однозначно идентифицирует кортежи, называется ключевым (или просто ключом). В нашем случае ключом является атрибут «Табельный номер», поскольку его значение уникально для каждого работника предприятия. Если кортежи идентифицируются только сцеплением значений нескольких атрибутов, то говорят, что отношение имеет составной ключ. Отношение может содержать несколько ключей. Всегда один из ключей объявляется первичным, его значения не могут обновляться. Все остальные ключи отношения называются возможными ключами.
В нашем случае ключом является атрибут «Табельный номер», поскольку его значение уникально для каждого работника предприятия. Если кортежи идентифицируются только сцеплением значений нескольких атрибутов, то говорят, что отношение имеет составной ключ. Отношение может содержать несколько ключей. Всегда один из ключей объявляется первичным, его значения не могут обновляться. Все остальные ключи отношения называются возможными ключами.
В отличие от иерархической и сетевой моделей данных в реляционной отсутствует понятие группового отношения. Для отражения ассоциаций между кортежами разных отношений используется дублирование их ключей.
Применение реляционной модели данных
Пример базы данных, содержащей сведения о подразделениях предприятия и работающих в них сотрудниках, применительно к реляционной модели будет иметь вид:
База данных о подразделениях и сотрудниках предприятия
Например, связь между отношениями ОТДЕЛ и СОТРУДНИК создается путем копирования первичного ключа «Номер_отдела» из первого отношения во второе.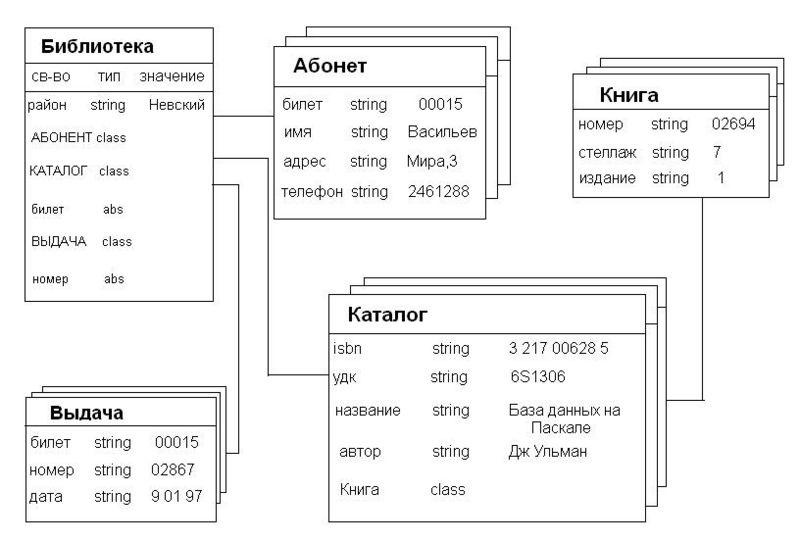 Таким образом:
Таким образом:
- для того, чтобы получить список работников данного подразделения, необходимо:
- из таблицы ОТДЕЛ установить значение атрибута «Номер_отдела», соответствующее данному «Наименованию_отдела»
- выбрать из таблицы СОТРУДНИК все записи, значение атрибута «Номер_отдела» которых равно полученному на предыдущем шаге
- для того, чтобы узнать в каком отделе работает сотрудник, нужно выполнить обратную операцию:
- определяем «Номер_отдела» из таблицы СОТРУДНИК
- по полученному значению находим запись в таблице ОТДЕЛ
Атрибуты, представляющие собой копии ключей других отношений, называются внешними ключами.
Достоинства и недостатки реляционной модели данных
Достоинства реляционной модели:
- простота и доступность для понимания пользователем. Единственной используемой информационной конструкцией является «таблица»;
- строгие правила проектирования, базирующиеся на математическом аппарате;
- полная независимость данных.
 Изменения в прикладной программе при изменении реляционной БД минимальны;
Изменения в прикладной программе при изменении реляционной БД минимальны; - для организации запросов и написания прикладного ПО нет необходимости знать конкретную организацию БД во внешней памяти.
 Изменения в прикладной программе при изменении реляционной БД минимальны;
Изменения в прикладной программе при изменении реляционной БД минимальны;Недостатки реляционной модели:
- далеко не всегда предметная область может быть представлена в виде «таблиц»;
- в результате логического проектирования появляется множество «таблиц». Это приводит к трудности понимания структуры данных;
- БД занимает относительно много внешней памяти;
- относительно низкая скорость доступа к данным.
Ссылки
Иллюстрированный самоучитель по SQL для начинающих › Основы реляционных баз данных [страница — 6] | Самоучители по программированию
Основы реляционных баз данных
Модели баз данных
Независимо от размеров баз данных все они относятся к одной из трех нижеприведенных моделей.
- Реляционная. Если сейчас где-нибудь развертывают новую систему, предназначенную для управления базами данных, то почти всегда такая система является реляционной. Конечно, в организациях, где уже вложено много ресурсов в иерархическую и сетевую технологии, могут наращивать и имеющуюся модель. Однако в группах, где нет необходимости поддерживать совместимость с унаследованными от прошлого системами, для своих баз данных почти всегда выбирают реляционную модель.
- Иерархическая. Иерархические базы данных получили такое название потому, что имеют простую иерархическую структуру, позволяющую иметь быстрый доступ к данным. Их недостатками являются избыточность данных, т.е. их дублирование, и негибкость структуры, что усложняет модификацию таких баз данных.
- Сетевая. В сетевых базах данных дублирование минимально, но за это приходится платить сложностью структуры.
 Конечно, в организациях, где уже вложено много ресурсов в иерархическую и сетевую технологии, могут наращивать и имеющуюся модель. Однако в группах, где нет необходимости поддерживать совместимость с унаследованными от прошлого системами, для своих баз данных почти всегда выбирают реляционную модель.
Конечно, в организациях, где уже вложено много ресурсов в иерархическую и сетевую технологии, могут наращивать и имеющуюся модель. Однако в группах, где нет необходимости поддерживать совместимость с унаследованными от прошлого системами, для своих баз данных почти всегда выбирают реляционную модель.Первыми базами данных, получившими широкое распространение, были большие базы данных организаций, созданные в соответствии с иерархической или сетевой моделью. Через несколько лет появились системы, созданные в соответствии с реляционной моделью. Язык SQL является по-настоящему современным; он применяется только к реляционной модели и ее производной – объектно-реляционной модели. Так что в этом месте книги остается сказать иерархической и сетевой моделям: «Приятно было познакомиться, а теперь – до свидания».
Язык SQL является по-настоящему современным; он применяется только к реляционной модели и ее производной – объектно-реляционной модели. Так что в этом месте книги остается сказать иерархической и сетевой моделям: «Приятно было познакомиться, а теперь – до свидания».
Новые системы управления базами данных, которые не являются реляционными, соответствуют, скорее всего, более новой, чем реляционная, объектной модели или гибридной объектно-реляционной модели.
Реляционная модель
Впервые реляционную модель баз данных сформулировал в 1970 году работавший в компании IBM доктор И.Ф. Кодд (E. F. Codd), а примерно десятилетие спустя эта модель начала появляться в готовых продуктах. По иронии судьбы первую реляционную СУБД разработала не IBM. Такая честь выпала на долю маленькой компании-новичка, назвавшей свой продукт Oracle.
Базы данных, созданные на основе предыдущих моделей, были заменены реляционными, потому что не имели тex ценных свойств, которые и отличают реляционные базы от баз других типов.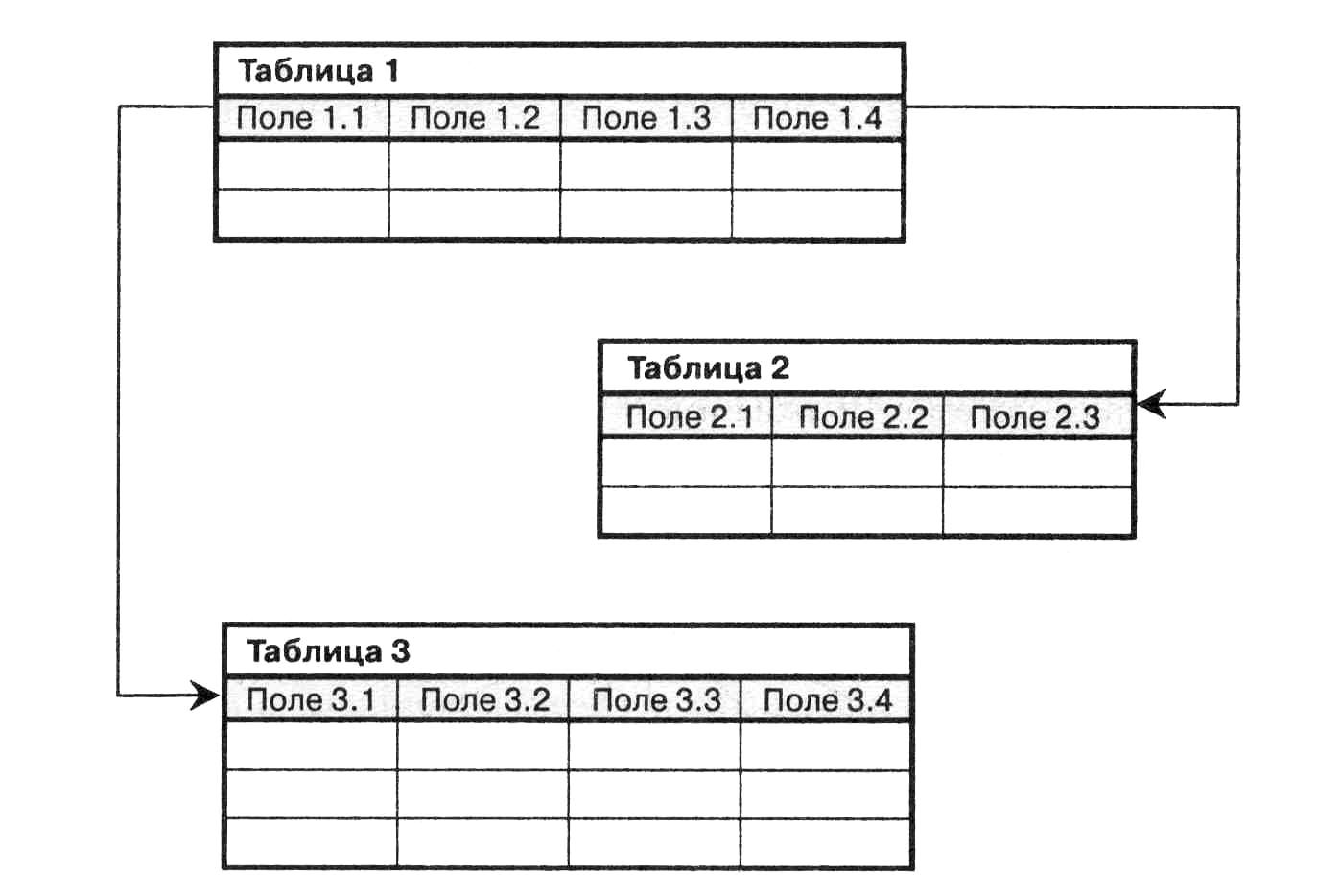 Вероятно, самым важным из этих свойств является то, что в реляционной базе данных можно менять структуру, не внося изменений в приложения. Такого не скажешь о приложениях, созданных на основе старых структур. Предположим, например, что в таблицу базы данных вы добавили один или несколько новых столбцов. В этом случае нет необходимости менять никакое из уже написанных приложений, которые будут продолжать обрабатывать эту таблицу, – только если вы не изменили столбцы, с которыми работают эти приложения.
Вероятно, самым важным из этих свойств является то, что в реляционной базе данных можно менять структуру, не внося изменений в приложения. Такого не скажешь о приложениях, созданных на основе старых структур. Предположим, например, что в таблицу базы данных вы добавили один или несколько новых столбцов. В этом случае нет необходимости менять никакое из уже написанных приложений, которые будут продолжать обрабатывать эту таблицу, – только если вы не изменили столбцы, с которыми работают эти приложения.
Внимание:
Конечно, если вы удалили столбец, к которому обращается имеющееся приложение, то какая бы модель базы данных ни применялась, вы столкнетесь с трудностями. Один из лучших способов устроить аварийное завершение работы приложения базы данных – запросить у него такую информацию, которой нет в вашей базе данных.
Почему реляционная модель лучше
В приложениях, работающих с СУБД, которые следуют иерархической или сетевой модели, структура базы данных «зашита» в само приложение.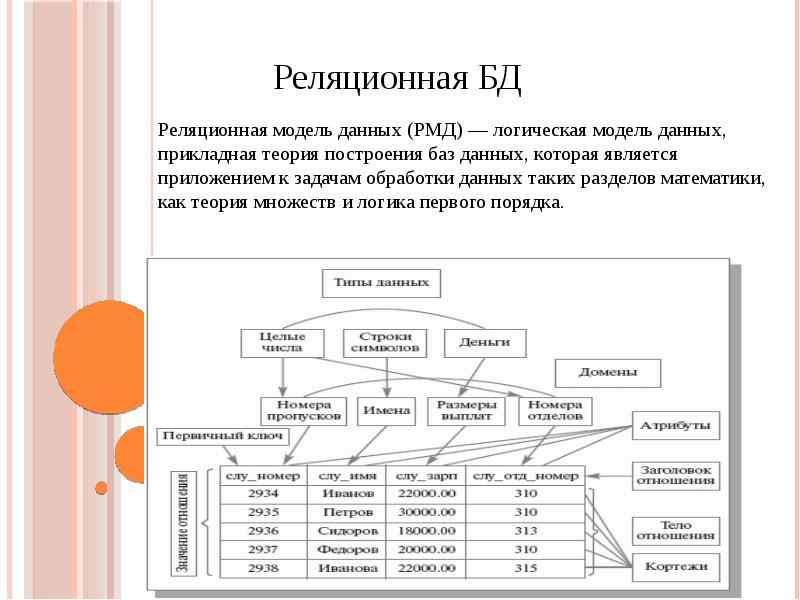 Это означает, что приложение зависит от определенной физической реализации базы данных. При добавлении в базу данных нового атрибута вам, чтобы привести свое приложение в соответствие с изменением базы, придется это приложение изменить, причем неважно, будет ли оно использовать новый атрибут.
Это означает, что приложение зависит от определенной физической реализации базы данных. При добавлении в базу данных нового атрибута вам, чтобы привести свое приложение в соответствие с изменением базы, придется это приложение изменить, причем неважно, будет ли оно использовать новый атрибут.
У реляционных баз данных более гибкая структура. Приложения для таких баз поддерживать легче, чем те, что написаны для иерархических или сетевых баз данных. Эта гибкость структуры дает возможность получать такие комбинации данных, которые, возможно, еще не были нужны при проектировании базы данных.
Компоненты реляционной базы данных
Гибкость реляционных баз данных объясняется тем, что их данные находятся в таблицах, которые в значительной степени независимы друг от друга. В таблицу данные можно добавлять, удалять их из нее, вносить в них изменения и при этом не затрагивать данные из других таблиц – если только таблица не является родительской по отношению к этим другим таблицам.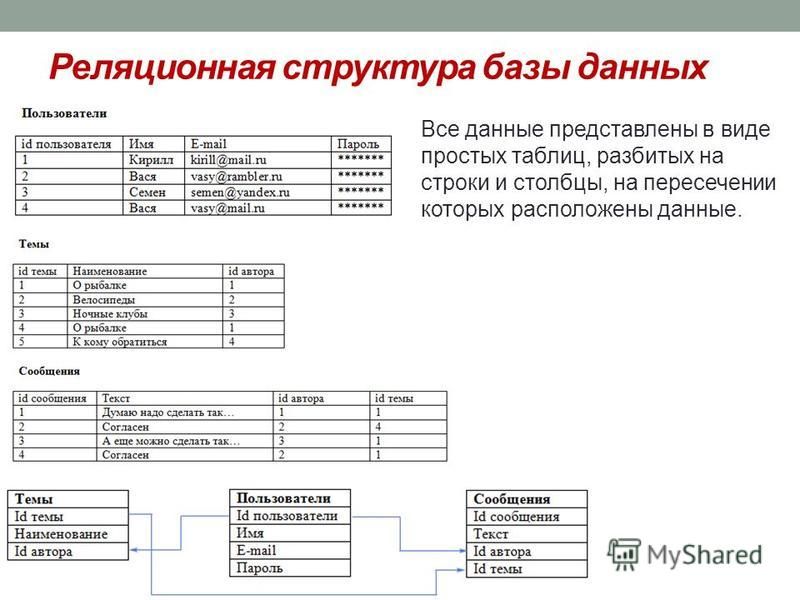 (Об отношениях родительских и дочерних таблиц рассказывается в главе 5, но там речь пойдет не о конфликте поколений.) В этом разделе будет показано из чего состоят таблицы и как они связаны с другими частями реляционной базы данных.
(Об отношениях родительских и дочерних таблиц рассказывается в главе 5, но там речь пойдет не о конфликте поколений.) В этом разделе будет показано из чего состоят таблицы и как они связаны с другими частями реляционной базы данных.
4. Реляционная модель данных » СтудИзба
Лекция 4. Реляционная модель данных. Основные понятия
Теоретической основой модели стала теория отношений, основу которой заложили два логика – американец Чарльз Содерс Пирс и немец Эрнст Шредер. Позднее, в 1970-1971 годах американский математик Э. Ф. Кодд, основываясь на трудах предшественников, сформулировал основные понятия и ограничения реляционной модели, ограничив набор операций семью основными и одной дополнительной. Предложения Кодда были настолько эффективны для систем баз данных, что он был удостоен премии Тьюринга в области теоретических основ вычислительной техники.
Реляционная модель данных (РМД) наиболее проста и имеет в основе развитый математический аппарат (реляционная алгебра или реляционное исчисление), поэтому она фактически стала стандартной моделью представления данных в СУБД.
Основными понятиями реляционных баз данных являются тип данных, домен, атрибут, кортеж, первичный ключ и отношение.
Базы данных, между отдельными таблицами которой существуют связи, называются реляционными (от relation – отношение). Таким образом, реляционная модель данных представляет информацию в виде совокупности взаимосвязанных таблиц, которые принято называть отношениями или реляциями.
Связанные отношения взаимодействуют по принципу главная (master) – подчиненная (detail). Главную таблицу часто называют родительской, а подчиненную – дочерней. Одна и та же таблица может быть главной по отношению к одной таблице БД и дочерней по отношению к другой.
Отношение – реляционная таблица.
Тип данных. Понятие тип данных в реляционной модели полностью эквивалентно соответствующему понятию в алгоритмических языках. Тип данных определяет возможные способы обработки данных и место, необходимое для их хранения. Набор поддерживаемых типов данных определяется СУБД и может сильно различаться в разных системах. Однако существуют типы данных общие для всех СУБД:
Набор поддерживаемых типов данных определяется СУБД и может сильно различаться в разных системах. Однако существуют типы данных общие для всех СУБД:
· целочисленный тип;
· вещественный;
· строковый;
· специализированный тип данных для денежных величин;
· специальные типы данных для хранения даты или даты и времени;
· типы двоичных объектов (данный тип не имеет аналога в языка программирования; обычно для его обозначения используется аббревиатура BLOB – Binary Large Object).
Домен – это множество атомарных значений одного и того же типа. Домены представляют собой пользовательский тип.
Атрибут – это характеристика объекта (сущности). Атрибуты имеют имена, через которые к ним производится обращение. Имя атрибута должно быть уникальным внутри отношения.
Схема отношения — это именованное множество пар {имя атрибута, имя домена (или типа, если понятие домена не поддерживается)}.
Степень отношения – это число атрибутов отношения. Отношение степени один называют унарным, степени два – бинарным, степени три – тернарным, степени n – n-арным.
Схема базы данных (в структурном смысле) — это набор именованных схем отношений с указанием взаимосвязей между ними.
Кортеж (схемы отношения) представляет собой множество пар (имя атрибута, значение), которое содержит одно значение каждого имени атрибута, принадлежащего схеме отношения. «Значение» является допустимым значением домена данного атрибута (или типа, если домены не поддерживается). Степень кортежа отношения (число элементов в нем) совпадает со степенью соответствующей схемы отношения.
Ключи отношения. Отношение с математической точки зрения является множеством и не может содержать совпадающих элементов, т.е. в любой момент времени никакие два кортежа отношения не могут быть дубликатами друг друга. Таким образом, в отношении должен присутствовать некоторый атрибут (или набор атрибутов), однозначно определяющий каждый кортеж отношения и обеспечивающий уникальность строк таблицы.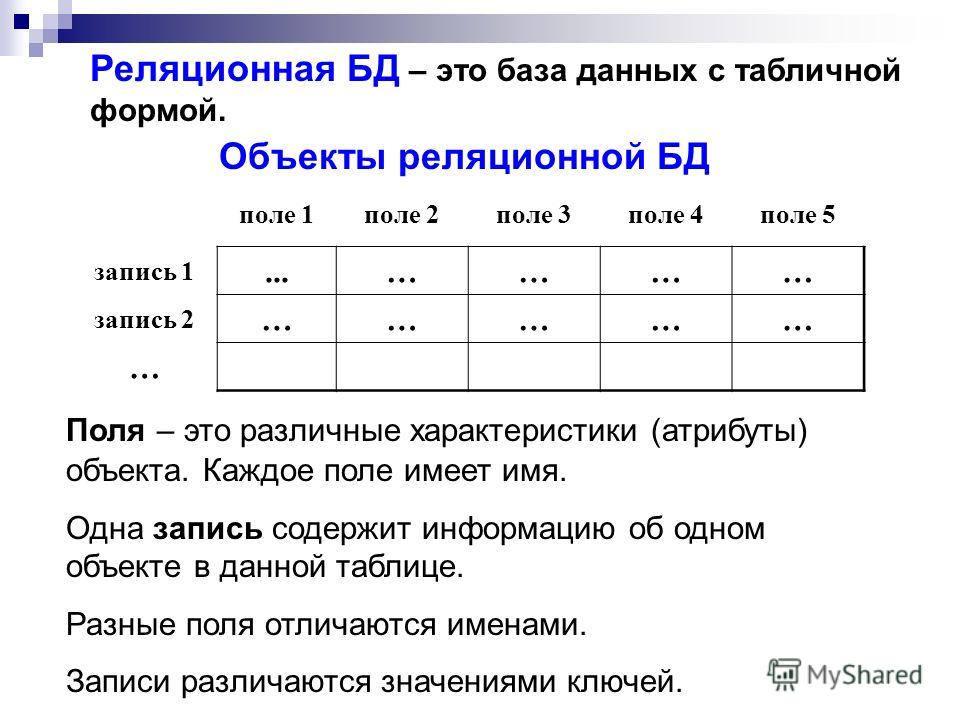 Такой атрибут (или набор атрибутов) называют первичным ключом отношения.
Такой атрибут (или набор атрибутов) называют первичным ключом отношения.
Свойства первичного ключа:
· уникальность: в любой момент времени никакие два кортежа отношения не должны иметь одного и того же значения;
· минимальность: ни один из атрибутов не может быть исключен из набора атрибутов первичного ключа, без нарушения свойств уникальности.
Рисунок 4.1 – Основные понятия РМД, на примере фрагмента отношения «Студент» для медпункта.
В зависимости от количества атрибутов, ходящих в ключ, различают простые и сложные (составные) ключи.
Простой ключ – ключ, одержащий только один атрибут. Как правило, в качестве него используют самый короткий и простой из возможных типов данных (целочисленный тип), при этом операции использующие ключ (операции объединения) выполняются значительно быстрее.
Сложный (составной) ключ – ключ, состоящий из нескольких атрибутов.
Суперключ – сложный ключ, с большим числом столбцов, не удовлетворяющий свойству минимальности. Используется крайне редко, когда избыточность может оказаться полезной пользователю.
С точки зрения информативности атрибута (или нескольких атрибутов) составляющего первичный ключ, различают искусственные и естественные ключи.
Искусственный или суррогатный ключ – ключ создаваемый самой СУБД или пользователем с помощью некоторой процедуры, который сам по себе не одержит информации. Используется для создания уникальности идентификаторов строк. Им так же заменяют слишком сложные ключи. Как правило, пользователю они не показываются.
Естественный ключ – ключ, содержащий только значимые атрибуты, т.е. содержащий информацию.
К достоинствам естественных ключей можно отнести следующие: они несут вполне определенную информацию, и их использование не приводит к необходимости добавлять к таблице атрибуты, значения которых для пользователя не несут никакого смысла и используются только для связи между отношениями, что позволяет получить более компактную форму таблиц.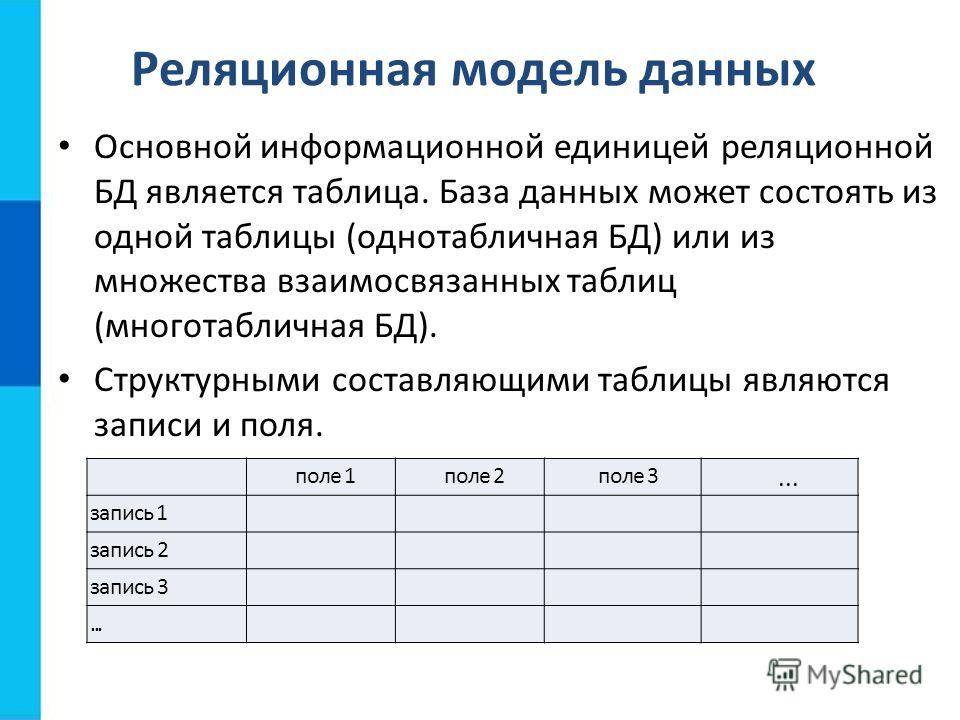
Основным же недостатком естественных ключей является то, что их использование весьма затруднительно в случае изменения предметной области. Значения атрибутов первичного ключа не должны изменяться, т.е. однажды заданное значение первичного ключа для кортежа не может быть изменено. Это требование необходимо для поддержания ссылочной целостности базы данных, т.к. связь между отношениями обычно устанавливается по первичному ключу. Как правило, для избежания подобных проблем в отношения водятся искусственные ключи.
Другим недостатком естественных ключей является то, что, как правило, они являются составными и содержат строковые атрибуты, что сказывается на скорости выполнения операций над данными и в этом случае так же удобнее бывает вводить суррогатные ключи.
В любой из таблиц может оказаться несколько наборов атрибутов, которые можно выбрать в качестве ключа, такие наборы называются потенциальными и альтернативными ключами.
Вторичные ключи – ключи, имеющие комбинации атрибутов отличные от комбинации атрибутов первичного ключа.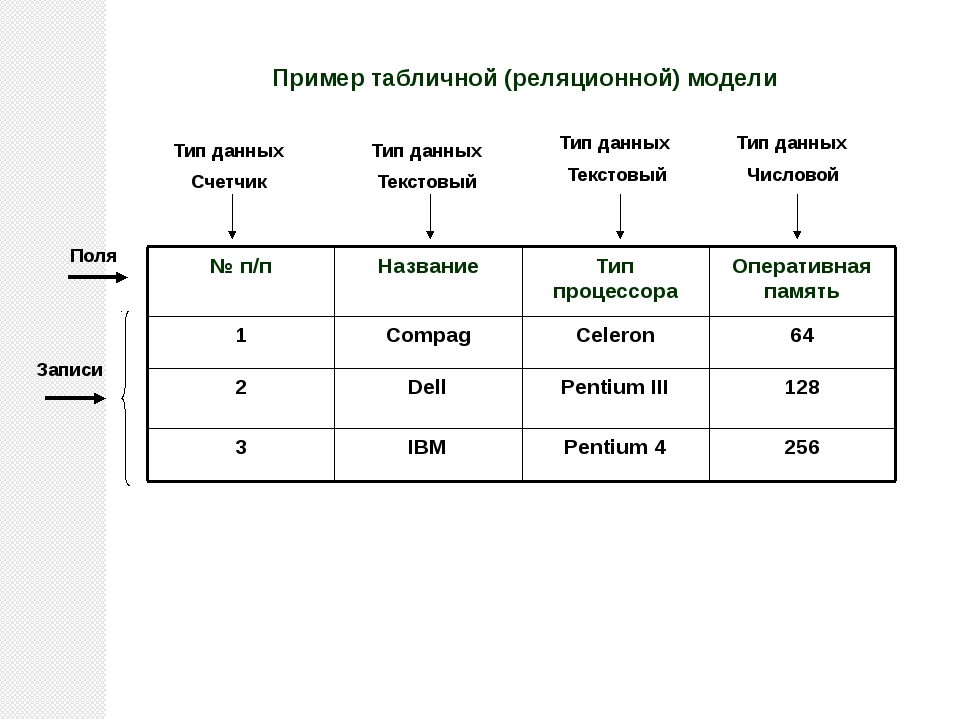 Они могут не обладать свойством уникальности.
Они могут не обладать свойством уникальности.
Перекрывающиеся ключи – сложные ключи, которые имеют один или несколько общих столбцов.
Контрольные вопросы
1. Для чего необходим тип данных?
2. Чем отличается домен от типа данных?
3. Что такое атрибут?
4. Как можно представить схему отношения?
5. Что такое схема базы данных?
6. Что такое картеж?
7. В чем заключается назначение первичного ключа?
8. Какие основные свойства первичного ключа вы знаете и в чем их смысл?
9. Назовите классификацию ключей по количеству входящих в него атрибутов.
10. Назовите классификацию ключей с точки зрения информативности входящих в них атрибутов.
11. В чем причины использования искусственных ключей?
12. Что такое потенциальный ключ?
13. В чем различие вторичных и первичных ключей?
Задания для самостоятельной работы
Задание 1.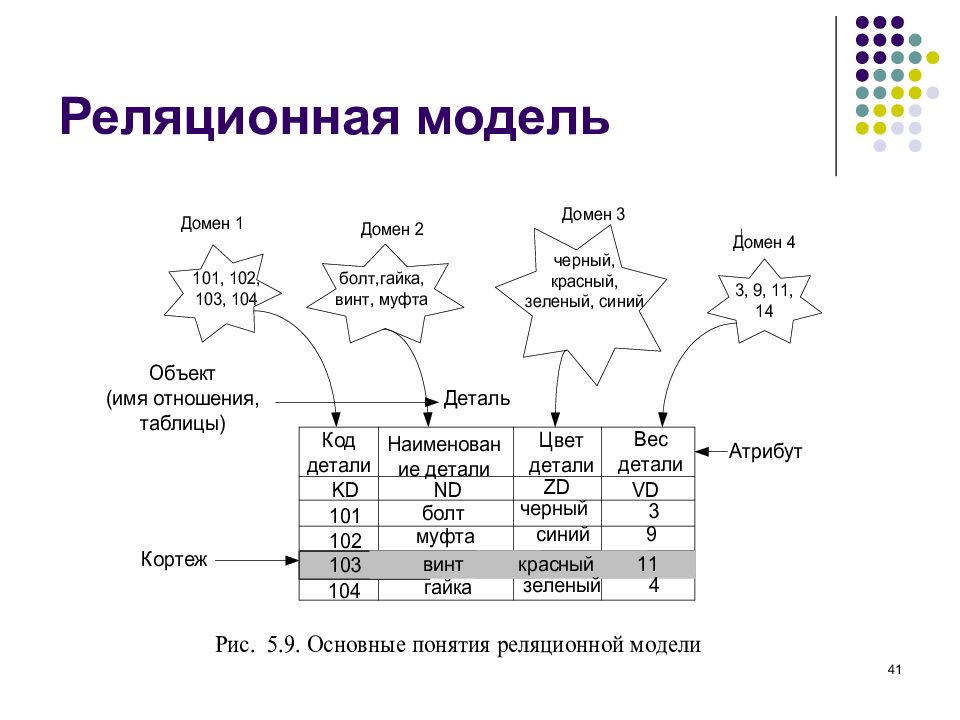 Рассмотрите таблицу изображенную на рисунке 1.1 и определите атрибуты, кортежи, типы данных (домены) и ключи отношений.
Рассмотрите таблицу изображенную на рисунке 1.1 и определите атрибуты, кортежи, типы данных (домены) и ключи отношений.
Задание 2. Определите первичный ключ для таблицы изображенной на рисунке 1.1 и выполните его классификацию.
Знакомство с реляционными базами данных
Введение
Системы управления базами данных (СУБД) — это компьютерные программы, которые позволяют использовать с базой данных. СУБД позволяет управлять доступом к базе данных, записывать данные, запускать запросы и выполнять любые другие задачи, связанные с управлением базами данных.
для выполнения любой из этих задач СУБД должна иметь в основе модель, определяющую организацию данных. Реляционная модель — это один из подходов к организации данных, который широко используется в программном секторе баз данных с момента своего появления в конце 60-х годов. Этот подход настолько распространен, что на момент написания данной статьи четыре самых популярных систем управления базами данных являются реляционными.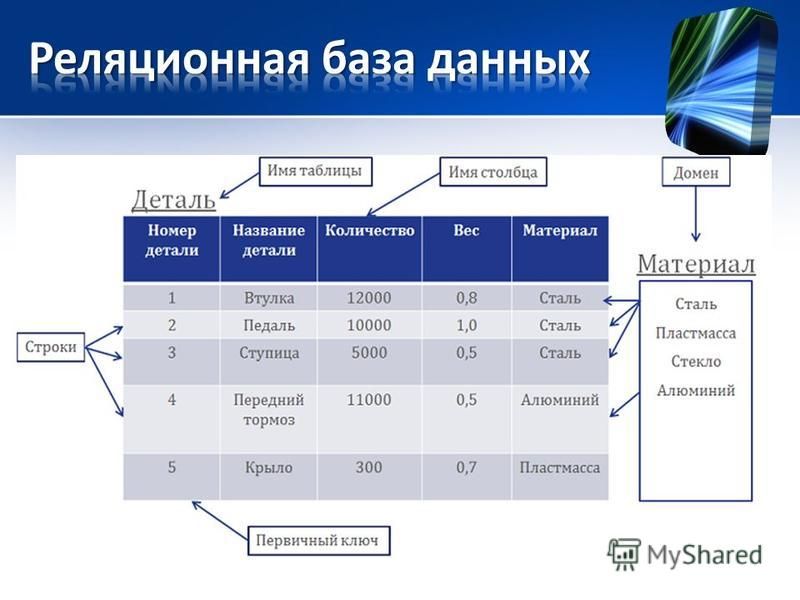
В этой концептуальной статье используется история реляционной модели, использования реляционных систем и примеров использования в настоящее время.
История реляционной модели
Базы данных — это логически сформированные кластеры информации, или данных . Любая коллекция данных является базой данных независимо от того, как и где она хранится. Шкаф с платежными данными, полка в регистратуре с карточками пациентов или хранящаяся в разных офисах клиентская картотека компании — все это базы данных. Прежде чем хранение данных и управление ими с помощью компьютеров стало общей практикой, правительственным организациям и коммерческим компаниям для хранения информации доступны только физические базы данных такого рода.
Примерно в середине XX века развитие компьютерной науки к созданию машин с большей вычислительной мощностью. Эти достижения позволили специалистам в области вычислительной техники осознать потенциал таких устройств в области хранения и управления большими массивами данных.
Однако не существовало никаких теорий о том, как компьютеры организовывать данные осмысленным, логическим образом. Одно дело хранить несортированные данные на компьютере, но намного сложнее создать систему, которая включает в себя, сортировать и управлять данным методом.Необходимость в логической конструкции для хранения и организации данных привела к появлению ряда предложений по использованию компьютеров для управления данными.
Одной из ранних моделей базы данных была иерархическая модель , в которой данные были организованы в виде древовидной структуры, подобной современной файловым системам. Следующий пример показывает, как может выглядеть часть иерархической базы данных, используемой для классификации животных:
широко используется в ранние системы управления базами данных, но она отличается отсутствием гибкости.В этой модели каждая запись может иметь только отдельные «предка», даже если записи могут иметь несколько «потомков». Из-за этого ранние иерархические базы данных могли только отношения «один к одному» или «один ко многим». Отсутствие отношений «много ко многим» должно привести к возникновению проблем при работе с точками данных, которые требуют привязки к нескольким предкам.
Отсутствие отношений «много ко многим» должно привести к возникновению проблем при работе с точками данных, которые требуют привязки к нескольким предкам.
В конце 60-х годов Эдгар Ф. Кодд (Эдгар Ф. Кодд), программист из IBM, разработал реляционную модель управления базами данных.Реляционная модель Кодда позволяла связать отдельные записи с использованием таблиц, что дало возможность установить между точками данных отношений «много ко многим» в дополнение к «один ко многим». Это обеспечило большую гибкость по сравнению с другими существующими моделями, если говорить о разработке структурных баз данных, а значит реляционные системы управления базами данных (РСУБД), можно использовать более широкий спектр бизнес-задач.
Кодд язык для управления реляционными данными, известный как Alpha, оказавший влияние на более поздних языков баз данных.Коллеги Кодда из IBM, Дональд Чемберлен (Дональд Чемберлен) и Рэймонд Бойс (Раймонд Бойс), создают один из языков под языковой Alpha.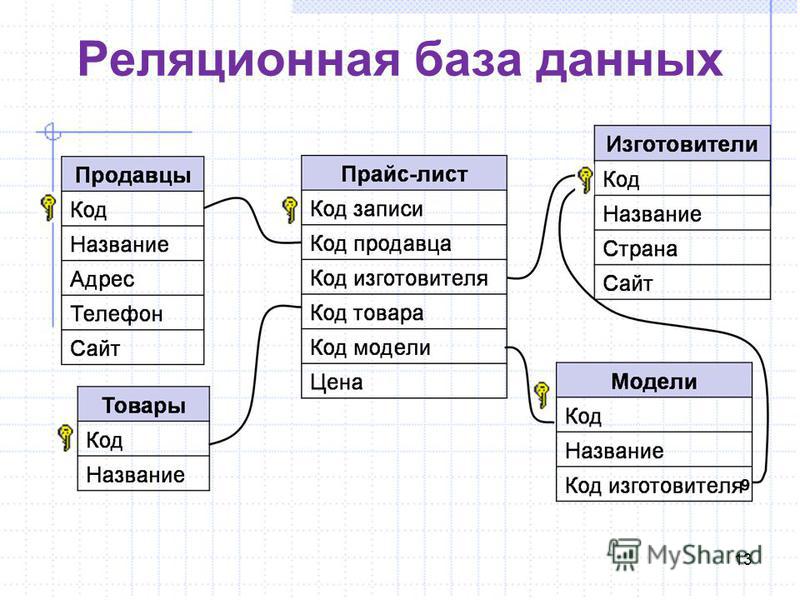 Они назвали свой язык SEQUEL , сокращенное название от S Tructured E nglish Que ry L anguage (структурированный английский язык запроса), но из-за существующего товарного знака сократили название до SQL (более формальное название — структурированный язык запросов ).
Они назвали свой язык SEQUEL , сокращенное название от S Tructured E nglish Que ry L anguage (структурированный английский язык запроса), но из-за существующего товарного знака сократили название до SQL (более формальное название — структурированный язык запросов ).
Из-за ограниченных возможностей аппаратного обеспечения ранние реляционные базы данных были все еще потребовалось некоторое время, прежде чем технология получила широкое распространение. Но к середине 80-х годов реляционная модель Кодда была внедрена в ряд коммерческих продуктов по управлению базами данных от компании IBM и ее конкурентов. Вслед за IBM, эти поставщики также стали разрабатывать и использовать свои собственные диалекты SQL. К 1987 году Американский национальный институт стандартов и Международная организация по стандартизации ратификации и опубликовали стандарты SQL, укрепив его статус признанного языка для управления РСУБД.
Широкое использование реляционной модели во многих отраслях привело к тому, что она была признана стандартной моделью управления данными. Даже с появлением в последнее время все большего числа различных баз данных NoSQL реляционные базы данных доминирующим инструментом хранения и организации данных.
Как реляционные базы данных структурируют данные
Теперь, когда у вас есть общее понимание истории реляционной модели, давайте более подробно рассмотрим, как модель структурирует данные.
Наиболее значимыми элементами реляционной модели являются отношения , которые известны пользователям и современным РСУБД как таблицы . Отношения — это набор кортежей , или строк в таблице, где каждый кортеж имеет набор атрибутов , или столбцов:
Столбец — это наименьшая организационная структура реляционной базы данных, представляющая различные ячейки, которые определяют записи в таблице. Отсюда происходит более формальное название — атрибуты. Вы можете рассматривать каждый кортеж в качестве уникального экземпляра-либо, что может находиться в таблице: категории людей, предметов, событий или ассоциаций. Такими экземплярами могут быть сотрудники компаний, продажи в онлайн-бизнесе или результаты лабораторных тестов. Например, в таблице с трудовыми трудовымими учителями в школе кортежи могут иметь такие атрибуты, как
Вы можете рассматривать каждый кортеж в качестве уникального экземпляра-либо, что может находиться в таблице: категории людей, предметов, событий или ассоциаций. Такими экземплярами могут быть сотрудники компаний, продажи в онлайн-бизнесе или результаты лабораторных тестов. Например, в таблице с трудовыми трудовымими учителями в школе кортежи могут иметь такие атрибуты, как имя , предметы , начальная дата и т. д.
При создании столбцов вы указываете тип данных , определяющий, какие записи могут вноситься в данный столбец.РСУБД часто используют свои собственные уникальные типы данных, которые не могут быть напрямую взаимозаменяемы с аналогичными типами данных из других систем. Некоторые распространенные значения даты даты, строки, целые числа и логические.
В реляционной модели каждая таблица содержит по крайней мере один столбец, который можно использовать для уникальной каждой строки. Он называется первичным ключом . Это важно, поскольку это означает, что пользователям не нужно знать, где физически хранятся данные на компьютере.Их СУБД может отслеживать каждую запись и возвращать ее в зависимости от конкретной цели. В свою очередь, это означает, что пользователи могут возвращать данные в любом порядке или с помощью любого фильтра по своему усмотрению.
Это важно, поскольку это означает, что пользователям не нужно знать, где физически хранятся данные на компьютере.Их СУБД может отслеживать каждую запись и возвращать ее в зависимости от конкретной цели. В свою очередь, это означает, что пользователи могут возвращать данные в любом порядке или с помощью любого фильтра по своему усмотрению.
Если у вас есть две таблицы, которые вы хотите связать друг с другом, это можно сделать с помощью внешнего ключа . Внешний ключ — это, по сути, копия основного ключа одной таблицы (таблица «предка»), вставленная в столбец другая таблица («потомка»).Следующий пример показывает отношения между двумя таблицами: одна используется для записи информации о сотрудниках компании, а другая — для службы продаж компании. В этом примере первичный ключ таблицы СОТРУДНИКИ используются в качестве внешнего ключа таблицы ПРОДАЖИ :
Если вы попытаетесь добавить запись в таблицу «потомок», и при этом значение вводимое в столбец внешнего ключа не существует в первичном ключе таблицы «предок», вставка будет недействительной.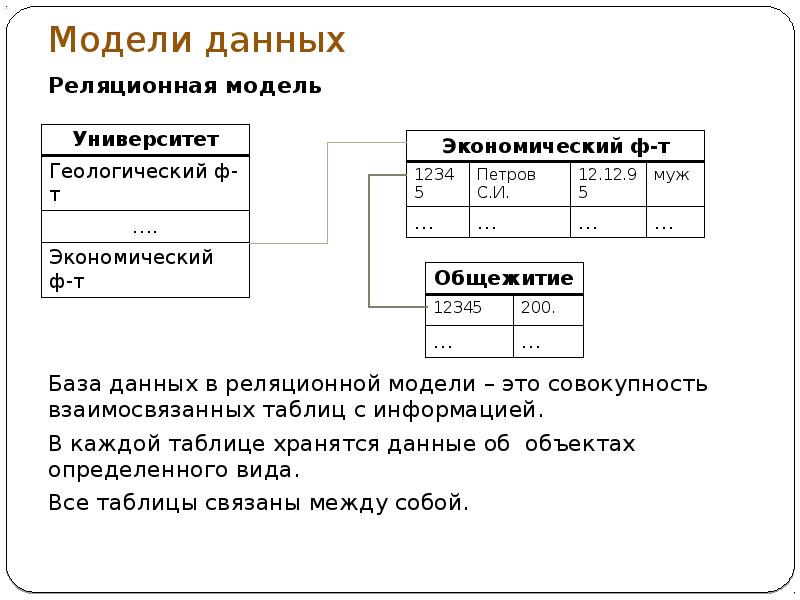 Это помогает обеспечить целостность отношений, поскольку ряды в уровне показателей всегда связаны правильно.
Это помогает обеспечить целостность отношений, поскольку ряды в уровне показателей всегда связаны правильно.
Структурные элементы реляционной модели содержат данные в структурированном виде, но хранение имеет значение только в том случае, если вы можете извлечь эти данные. Для извлечения информации из РСУБД вы можете создать запрос , т. е. структурированный запрос на набор информации. Как уже установлено большинство реляционных баз данных использует язык SQL для управления данными и отправки запросов.SQL позволяет фильтровать результаты и обрабатывать их с помощью различных пунктов, предикатов и выражений, позволяя вам контролировать, какие данные появятся в результате.
Преимущества и ограничения реляционных баз данных
, учитывая организационные структуры, положительные в основе реляционных данных, давайте рассмотрим их преимущества и недостатки.
Сегодня как SQL, так и базы данных, которые используют, несколько отклоняются от реляционной модели Кодда.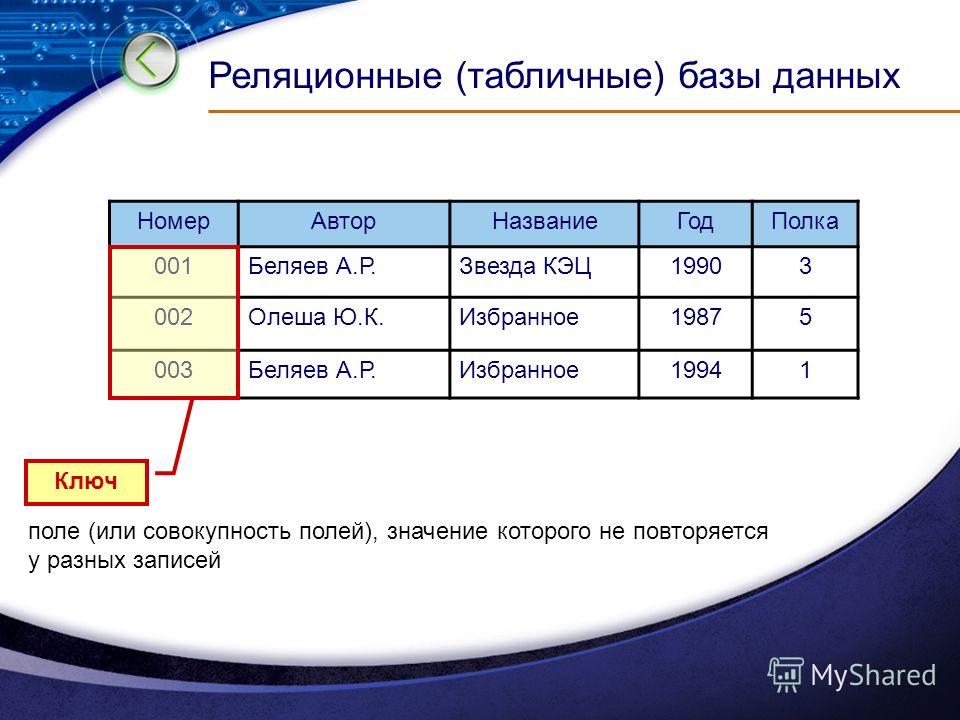 Например, модель Кодда предписывает, что каждая строка в таблице должна быть уникальной, а по соображениям практической целесообразности других современных реляционных баз допускают дублирование строк. Есть и те, кто не считает базы данных на основе истинными реляционными базами данных, если они не соответствуют стандартам реляционной модели по версии Кодда. Но на практике любая СУБД, которая использует SQL и в какой-то мере соответствует реляционной модели, может быть отнесена к реляционным системам управления базами данных.
Например, модель Кодда предписывает, что каждая строка в таблице должна быть уникальной, а по соображениям практической целесообразности других современных реляционных баз допускают дублирование строк. Есть и те, кто не считает базы данных на основе истинными реляционными базами данных, если они не соответствуют стандартам реляционной модели по версии Кодда. Но на практике любая СУБД, которая использует SQL и в какой-то мере соответствует реляционной модели, может быть отнесена к реляционным системам управления базами данных.
Несмотря на то, что реляционные базовые данные стремительно росла, немного реляционные модели проявляются по мере, как увеличивающиеся показатели и объемы хранящихся данных. К примеру, трудно масштабировать реляционную базу данных горизонтально. Горизонтальное масштабирование или масштабирование по горизонтали — это добавление большего количества машин к существующему стеку, что позволяет распределить нагрузку, увеличить трафик и ускорить обработку. Часто это использует вертикальным масштабированием , которое предполагает модернизацию существующего сервера, как правило, с помощью добавления оперативной памяти или центрального процессора.
Часто это использует вертикальным масштабированием , которое предполагает модернизацию существующего сервера, как правило, с помощью добавления оперативной памяти или центрального процессора.
Реляционную базу данных сложно масштабировать горизонтально из-за того, что она предусматривает обеспечение целостности , т.е. клиенты, отправляющие запросы в одну и ту же базу данных, всегда будут получать одинаковые данные. Если вы масштабируете реляционную базу данных горизонтально по всем машинам, будет трудно обеспечить целостность, т.к. клиенты могут вносить данные только в один узел, а не во все. Вероятно, между предварительной записью и моментом обновления других узлов.
Еще одно ограничение, существующее в РСУБД, заключается в том, что реляционная модель была ограничена для управления структурированными данными , или данными, которые соответствуют заранее определенному типу данных, или, по крайней мере, каким-либо образом организованы.Однако с распространением сетевых компьютеров и развития сети в начале 90-х годов появились неструктурированные данные , такие как электронные сообщения, фотографии, видео и пр.
Но все это не означает, что реляционные базы данных бесполезны. Напротив, спустя более 40 лет, реляционная модель все еще доминирующей для управления данными. Распространенность и долголетние реляционные базовые данные свидетельствуют о том, что это зрелая технология, которая сама по себе является преимуществом.Существует много приложений, предназначенных для работы с реляционной моделью, а также много карьерных администраторов данных, которые являются экспертами, когда дело доходит до реляционных баз данных. Также существует широкий спектр доступных печатных и онлайн-ресурсов для тех, кто хочет начать работу с реляционными базами данных.
Еще одно преимущество реляционных баз данных заключается в том, что почти все РСУБД базу транзакции . Транзакция состоит из одного или более индивидуального выражения SQL, выполняемого последовательно, как один блок работы.Транзакции представляют подход «все или ничего», означающий, что все операторы SQL в транзакции должны быть действительными. В случае всякая транзакция не будет выполнена. Это очень полезно для целостности данных при внесении изменений в несколько строк или в таблицы.
В случае всякая транзакция не будет выполнена. Это очень полезно для целостности данных при внесении изменений в несколько строк или в таблицы.
, реляционные базы данных демонстрируют чрезвычайную гибкость. Они используются для широкого спектра приложений и эффективно работать даже с большими объемами данных.Язык SQL также обладает огромным потенциалом и позволяет вам изменять или изменять данные на лету, а также вносить изменения в структуру баз данных и таблиц, не влияя на соответствующие данные.
Заключение
. Благодаря гибкости и проектному решению, направленному на сохранение целостности данных, спустя пятьдесят лет после такого появления замысла, реляционные базы данных являются основным способом управления данными и их хранением. Понимание NoSQL реляционной модели и принципов ее работы с РСУБД является ключевым моментом для всех, кто хочет создать приложения, используя возможности данных.
Чтобы узнать больше о нескольких популярных РСУБД с открытым исходным кодом, мы рекомендуем вам ознакомиться с нашим сравнением различных реляционных баз данных с открытым исходным кодом. Если вам интересно узнать больше о базах данных в целом, мы рекомендуем вам ознакомиться с нашей полной библиотекой материалов о базах данных.
Если вам интересно узнать больше о базах данных в целом, мы рекомендуем вам ознакомиться с нашей полной библиотекой материалов о базах данных.
Реляционная модель баз данных — Основы реляционных баз данных
Основы реляционных баз данныхОсновой логики работы в реляционных СУБД является реляционная алгебра, именно поэтому в подобных системах приставку «реляционная».Если посмотреть книги, посвященные базам данных (особенно университетских), то они в обязательном порядке дают её, и иногда в количествах. Несмотря на то, что прикладному программисту не обязательно разбираться в ее тонкостях, знать основы реляционной алгебры всё же полезно. Ниже я попробую некоторое общее представление без соответствующего математического аппарата. Если вы захотите копнуть глубже, то смотрите ссылки в дополнительных материалов.
Иерархическая модель
Существует множество разных способов представить одни и те же данные.Один из первых широко используемых способов — иерархическая модель. В такой модели дерева данные представлены в виде , где дочерние элементы находятся в зависимости от родительских. Самый яркий пример древовидной структуры — файловая система (ФС). Вероятно, будет сюрпризом для вас, что файловая система — это база данных, операционная система ведёт себя, как СУБД по отношению к ФС. Однако то, как мы видимые данные и как они хранятся в реальности (на диске) — две большие разницы. Физическое размещение данных на носителях — прерогативы СУБД, и здесь они соревнуются, кто быстрее и эффективнее.А вот их внешнее представление — это то, что видит пользователя, и оно очень сильно влияет на способ взаимодействия с данными. Именно поэтому разные способы представления данных называются моделями. Эти модели не отражают то, что происходит на физическом уровне, они лишь описывают то, как данные структурированы и как с ними можно взаимодействовать. Модели данных очень похожи на абстрактные типы данных , которые определяют интерфейс взаимодействия с типом и не определяют его внутреннюю работу.
В такой модели дерева данные представлены в виде , где дочерние элементы находятся в зависимости от родительских. Самый яркий пример древовидной структуры — файловая система (ФС). Вероятно, будет сюрпризом для вас, что файловая система — это база данных, операционная система ведёт себя, как СУБД по отношению к ФС. Однако то, как мы видимые данные и как они хранятся в реальности (на диске) — две большие разницы. Физическое размещение данных на носителях — прерогативы СУБД, и здесь они соревнуются, кто быстрее и эффективнее.А вот их внешнее представление — это то, что видит пользователя, и оно очень сильно влияет на способ взаимодействия с данными. Именно поэтому разные способы представления данных называются моделями. Эти модели не отражают то, что происходит на физическом уровне, они лишь описывают то, как данные структурированы и как с ними можно взаимодействовать. Модели данных очень похожи на абстрактные типы данных , которые определяют интерфейс взаимодействия с типом и не определяют его внутреннюю работу.
С помощью иерархической модели можно представить и бизнес области. К примеру, в предметной области интернет-магазина есть такие понятия, как пользователь и заказ. Причём, у одного пользователя может быть множество заказов, что сразу определяет дерево, где вершина становится пользователем, а его детьми — заказы. Подобным образом структурируются и все остальные части.
Проблемы начинаются, когда у одного ребёнка может быть несколько родителей.В современных сервисах такси есть возможность оплачивать счёт за такси совместно — это значит, что у одного заказа сразу несколько клиентов. Как быть в такой ситуации? К сожалению, иерархическая модель не может предложить решения хорошей задачи данной. Придётся создавать параллельные деревья, которые появляются дублирование данных.
Сетевая модель
Эта проблема решается в сетевой модели данных, которая расширяет иерархическую и даёт возможность установить предков.По сути, сетевая модель представляет собой граф .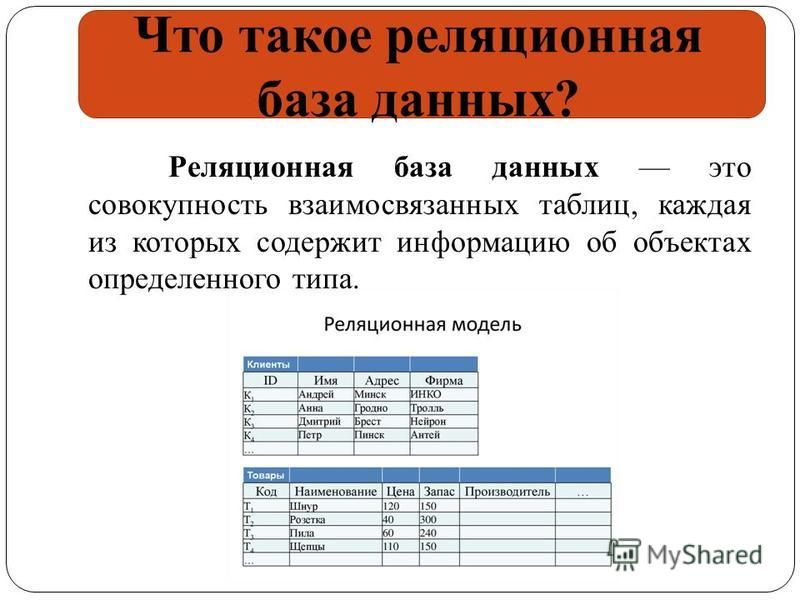 В сетевой структуре каждый элемент может быть связан с любым другим элементом.
В сетевой структуре каждый элемент может быть связан с любым другим элементом.
Недостатком сетевых моделей высокая сложность и жесткость схемы БД, построенной на ее основе. Оперативная система независимой финансовой системы независимой независимой от приложения. Другими словами, если необходимо изменить измененные данные, то нужно изменить и приложение.
Реляционная модель
Зарегистрироваться
или войти в аккаунт
Курсы программирования для новичков и опытных разработчиков. Начните обучение бесплатно.
- 115 курсов, 2000+ часов теории
- 800 практических заданий в браузере
- 250 000 студентов
Наши выпускники работают в компаниях:
4. Реляционная модель данных »СтудИзба
Лекция 4.Реляционная модель данных. Основные понятия
Теоретической модели стала теория отношений, которая основана на заложили два логика — американец Чарльз Содерс Пирс и немец Эрнст Шредер. Позднее, в 1970-1971 годах американский математик Э. Ф. Кодд, на основе трудах предшественников, сформулировал основные и понятия ограничения реляционной модели, ограничивает набор операций семью и одной внешней. Предложения были эффективны для систем баз данных, что он был удостоен премии Тьюринга в области теоретических основ вычислительной техники.
Позднее, в 1970-1971 годах американский математик Э. Ф. Кодд, на основе трудах предшественников, сформулировал основные и понятия ограничения реляционной модели, ограничивает набор операций семью и одной внешней. Предложения были эффективны для систем баз данных, что он был удостоен премии Тьюринга в области теоретических основ вычислительной техники.
Реляционная модель данных (РМД) наиболее проста и имеет развитый математический аппарат (реляционная алгебра или реляционное исчисление), поэтому она стала стандартной моделью представления данных в СУБД.
Основными понятиями реляционных баз данных являются тип данных, домен, атрибут, кортеж, первичный ключ и отношение.
Базы данных, между отдельными таблицами которой существуют реляционными элементами (от отношение — отношение).Таким образом, реляционная модель данных представляет информацию в виде совокупности связанных таблиц, которые приняты называть отношениями или реляциями .
Связанные отношения используют принцип по главная (мастер) — подчиненная (деталь). Главную таблицу часто родительской, а подчиненную — дочернюю. Одна и та же таблица может быть главным по отношению к одной таблице БД и дочерней по отношению к другой таблице.
Отношение — реляционная таблица.
Тип данных . Понятие тип данных в реляционной модели полностью эквивалентно соответствующему понятию в алгоритмических языках. Тип данных определяет возможные способы обработки данных и место, необходимое для их хранения. Набор поддерживаемых типов данных определяется СУБД и может сильно различаться в разных системах. Существуют типы общих для всех СУБД:
· целочисленный тип;
· вещественный;
· строковый;
· специализированный тип данных для денежных величин;
· специальные данные для хранения даты или даты и времени;
· тип двоичных объектов (данный тип не имеет аналога в языке программирования; обычно для его обозначения используется аббревиатура BLOB — большой двоичный объект).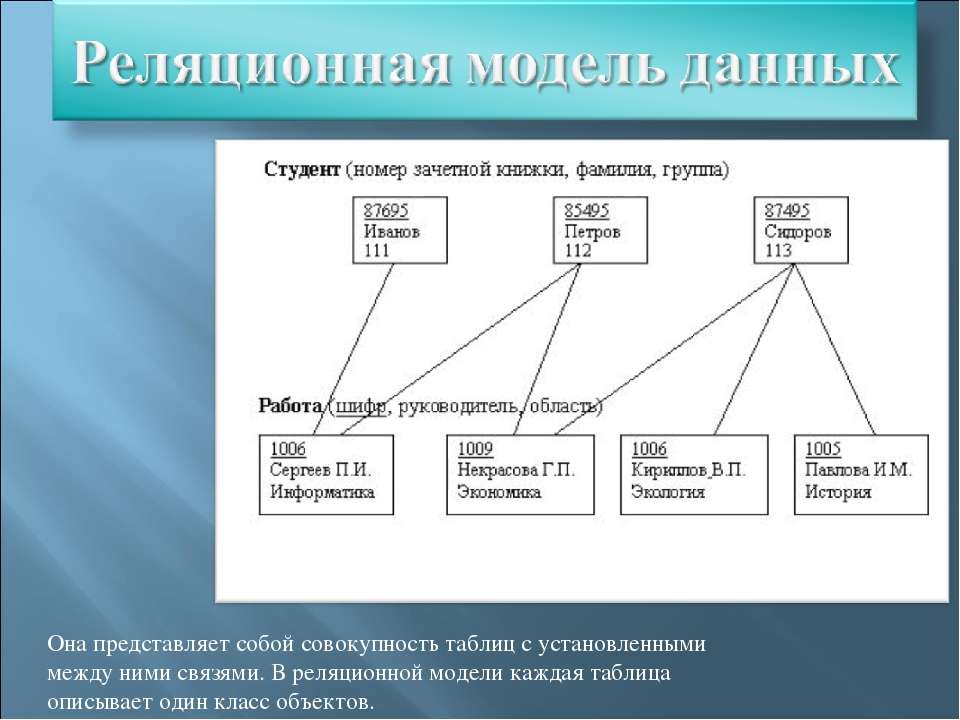
Домен — это множество атомарных значений одного и того же типа. Домены предоставьте собой пользовательский тип.
Атрибут — это характеристика объекта (сущности). Атрибуты имеют имена, через которые к ним производится обращение. Имя атрибута должно быть уникальным внутри отношений.
Схема отношений — это именованное множество пар {имя атрибута, домена домена (или типа, если понятие домена не поддерживается)}.
Степень отношений — это число атрибутов отношений. Отношение степени один называют унарным, степени два — бинарным, степени три — тернарным, степени n — n -арным.
Схема базы данных (в структурном смысле) — это набор именованных отношений с указанием взаимосвязей между ними.
Кортеж (схемы) представляет собой множество пар (имя атрибута, значение), которое содержит одно значение каждого имени атрибута, принадлежащее схеме отношения. «Значение» является допустимым типом атрибута данного домена (или, если домены не поддерживается). Степень кортежа отношения (число элементов в нем) совпадает со степенью сложности схемы отношений.
«Значение» является допустимым типом атрибута данного домена (или, если домены не поддерживается). Степень кортежа отношения (число элементов в нем) совпадает со степенью сложности схемы отношений.
Ключи отношения . Отношение с математической точки зрения является множеством и не может содержать совпадающих элементов, т.е. в любой момент времени никакие два кортежа отношения не могут быть дубликатами друг друга. Таким образом, в отношении присутствовать некоторый атрибут (или набор атрибутов), однозначно определяющий каждый кортеж отношения и обеспечивающий уникальность таблиц таблицы.Такой атрибут (или набор атрибутов) называют первичным ключом отношения .
Свойства первичного ключа:
· уникальность : в любой момент времени никакие два кортежа отношения не должны иметь одного и того же значения;
· минимальность : ни один из атрибутов не может быть исключен из атрибутов первичного ключа, без нарушения свойств уникальности.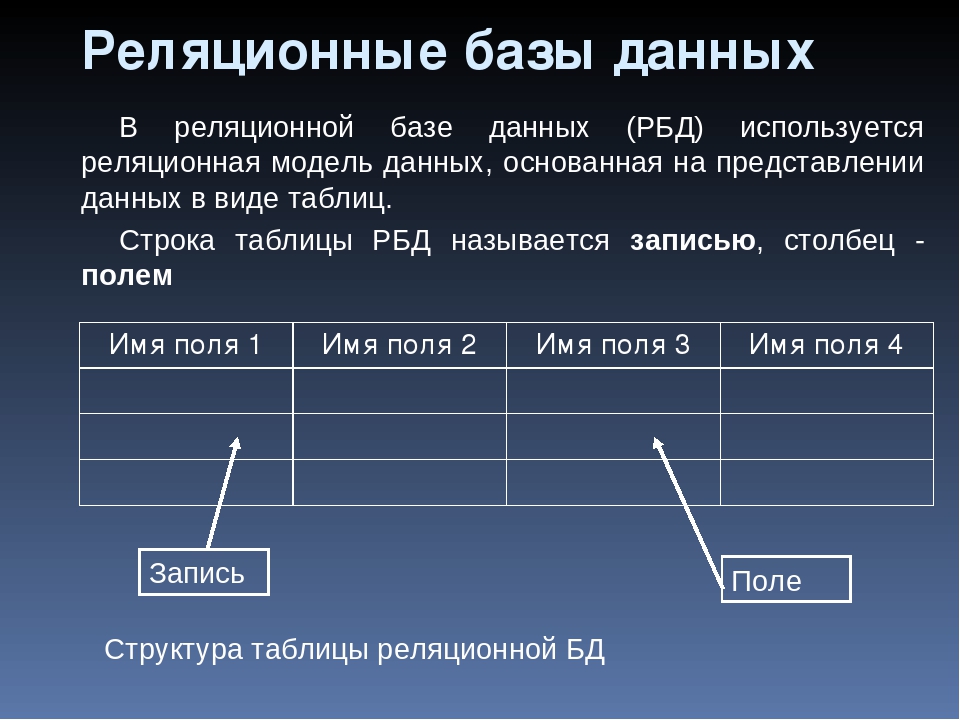
Рисунок 4.1 — Основные понятия РМД, на примере фрагмента отношения «Студент» для медпункта.
В зависимости от характеристик атрибутов , ходящих в ключ, различают простые и сложные (сложные) ключи.
Простой ключ — ключ, одержащий только один атрибут. Как правило, используется самый короткий и простой из типов данных (целочисленный тип), при этом операции используются ключ (операции объединения) используются быстрее.
Сложный (составной) ключ — ключ, состоящий из нескольких атрибутов.
Суперключ — сложный ключ, с большим числом столбцов, не удовлетворяющий свойству минимальности. Используется крайне редко, когда избыточность может оказаться полезной пользователю.
С точки зрения информативности атрибута (или нескольких атрибутов) составляющего первичный ключ, различают искусственные и естественные ключи.
Искусственный или суррогатный ключ — ключ создаваемый самой СУБД или посредством некоторой процедуры, который сам по себе не одержит информацию. Используется для создания уникальности цифровых строк. Им так же заменяют слишком сложные ключи. Как правило, пользователю они не показываются.
Используется для создания уникальности цифровых строк. Им так же заменяют слишком сложные ключи. Как правило, пользователю они не показываются.
Естественный ключ — ключ, предоставленный только значимыми атрибутами, т.е.нарушить информацию.
К достоинствам данных ключей можно отнести следующие: они несут вполне определенную информацию, и их использование не приводит к необходимости в таблице атрибутов, значения для пользователя несут смысла и используются только для связи между отношениями, что позволяет получить более компактную форму. таблиц.
Основным же недостатком естественных ключей является то, что их использование весьма затруднительно в случае изменения предметной области.Значения атрибутов первичного ключа не должны изменяться, т.е. однажды заданное значение первичного ключа для кортежа не может быть изменено. Это требование необходимо для поддержания ссылочной целостности базы данных, т.к. связь между отношениями обычно устанавливается по первичному ключу.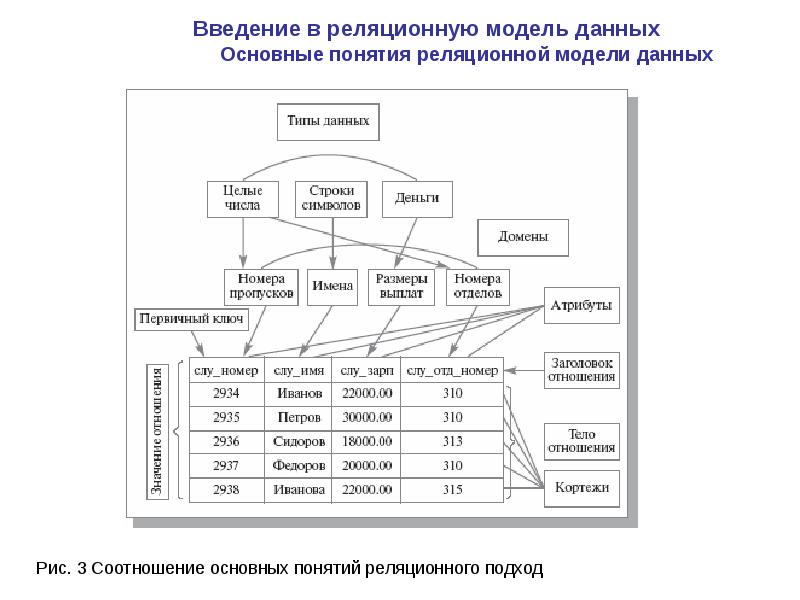 Как правило, для избегания подобных проблем в отношениях водятся искусственные ключи.
Как правило, для избегания подобных проблем в отношениях водятся искусственные ключи.
Другим недостатком естественных ключей является то, что, как правило, они являются составными и содержат строковые атрибуты, которые сказываются на скорости выполнения операций над данными, в этом случае так же удобнее вводить суррогатные ключи.
В любой из таблиц может оказаться несколько наборов атрибутов, которые можно выбрать в качестве ключа, такие наборы называются потенциальными и альтернативными ключами.
Вторичные ключи — ключи, связанные с атрибутами отличные от ключей атрибутов первичного ключа. Они могут не обладать своим уникальности.
Перекрывающиеся ключи — сложные ключи, которые имеют один или несколько общих столбцов.
Контрольные вопросы
1. Для чего необходим тип данных?
2. Чем отличается домен от типа данных?
3. Что такое атрибут?
Что такое атрибут?
4. Как можно представить схему отношений?
5. Что такое схема базы данных?
6. Что такое картаж?
7. В чем заключается назначение первичного ключа?
8.Какие основные свойства первичного ключа вы знаете и в чем их смысл?
9. Назовите классификацию ключей по количеству входящих в него атрибутов.
10. Назовите классификацию ключей с точки зрения информативности входящих в них атрибутов.
11. В чем причины использования искусственных ключей?
12. Что такое потенциальный ключ?
13. В чем различие вторичных и первичных ключей?
Задания для самостоятельной работы
Задание 1. Рассмотрите таблицу представленную на рисунке 1.1 и определите атрибуты, кортежи, типы данных (домены) и ключи отношений.
Задание 2. Определите первичный ключ для таблицы изображенной на рисунке 1.1 и выполните его классификацию.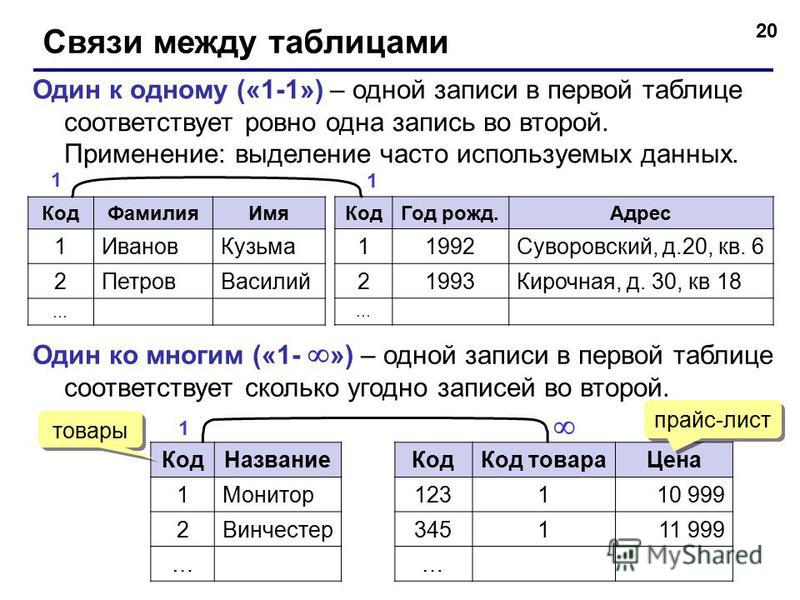
Руководство по проектированию реляционных баз данных
Вступление.
. Это обеспечит долговременную целостность и простоту обслуживания ваших данных.Руководство расскажет вам что следует из себя базы данных и как спроектировать базу данных, которая подчиняется правилам проектирования реляционных баз данных.
Базы данных — это программы. Базы данных состоят из таблиц, которые содержат информацию. Когда вы создаете базу данных, необходимо подумать о том, какие таблицы вам нужно создать и какие связи существуют между информацией в таблицах. Иначе говоря, вам нужно подумать о вашей базе данных.Хороший проект базы данных, как было сказано ранее, обеспечивает целостность данных и простоту их обслуживания.
Структурированный язык запросов ( SQL ).
База данных создается для хранения информации в ней и получения этой информации при необходимости. Это значит, что мы должны иметь возможность помещать, вставлять ( INSERT ) информацию в базу данных и хотим иметь возможность делать выборку информации из базы данных ( SELECT ).
Язык запросов к базам данных был придуман для этих целей и был назван «Структурированный язык запросов» или SQL. Операции вставки данных ( INSERT ) и их выборки ( SELECT ) — части этого самого языка.
Реляционная модель.
В этой игре я покажу вам как создать реляционную модель данных. Реляционная модель — это модель, которая определяет данные в таблицах.
Правила реляционной модели диктуют, как информация должна быть организована в таблицах и как связаны друг с другом. В конечном счете результат можно предоставить в виде диаграммы базы данных или, если точнее, диаграммы «сущность-связь».
РСУБД.
РСУБД, которую я использовал для создания таблиц примеров — MySQL. MySQL — наиболее популярная РСУБД и она бесплатна.
История.
В 70-х — 80-х годах, когда компьютерные ученые все еще носили коричневые смокинги и очки с большими квадратными оправами, данные хранились бесструктурно в файлах, которые представляют собой текстовый документ с данными, разделенными ( обычно ) запятыми или табуляциями .
Так выглядели профессионалы в сфере информационных технологий в 70-е. ( Слева внизу находится Билл Гейтс ).
Текстовые файлы и сегодня все еще используются для хранения малых размеров простой. Значения, разделенные запятыми ( CSV ) — значения, разделённые запятыми, очень популярны и широко поддерживаются сегодня различными программными и операционными системами. Microsoft Excel — один из примеров программ, которые могут работать с CSV – файлами.Данные, сохраненные в таком файле могут быть считаны компьютерной программой.
Программа, производящая чтение данного файла, должна быть уведомлена о том, что данные разделены запятыми. В этом уроке находится ‘Учебное пособие по проектированию баз данных’, которое она должна строчка за строчкой повторять до тех пор, пока не будут найдены слова ‘Учебное пособие по проектированию баз данных’ и ей нужно прочитать следующее за запятой слово для того, чтобы вывести категорию Программное обеспечение.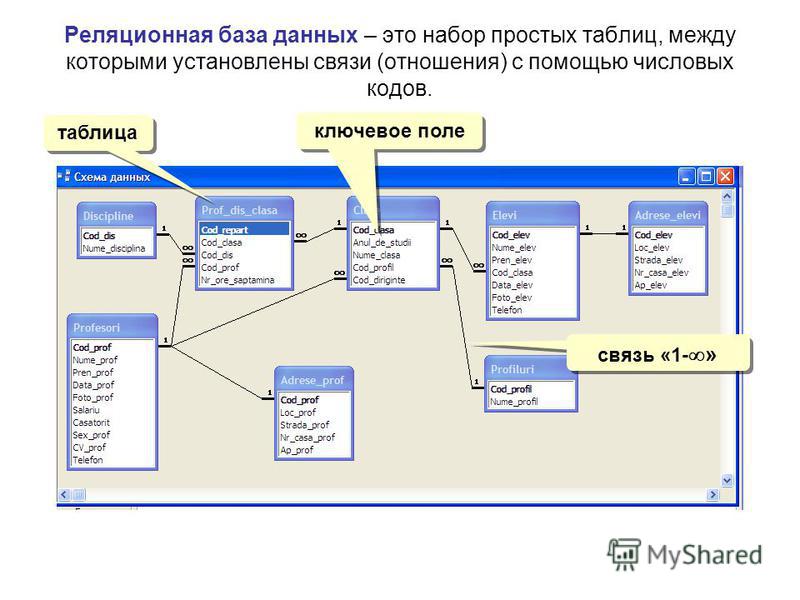
Таблицы баз данных.
Чтение файла строчка за строчкой не является очень эффективным. В реляционной базе данных данные хранятся в таблицах. Таблица ниже содержит те же самые данные, что и файл. Каждая строка или «запись» содержит один урок. Каждый столбец содержит какое-то свойство урока. В данном случае это заголовок ( название ) и его категория ( категория ).
Компьютерная программа могла бы осуществить поиск в столбце tutorial_id данной таблицы по специфическому указатору tutorial_id для того, чтобы быстро найти соответствующие заголовок и категорию.Это намного быстрее, чем поиск по той же самой программе в текстовом файле.
Современные реляционные базы данных созданного так, чтобы позволять делать выборку данных из специфических строк, столбцов и множественных таблиц, за раз, очень быстро.
История реляционной модели.
Реляционная модель баз данных была изобретена в 70-х Эдгаром Коддом ( Ted Codd ), британским ученым. Он хотел преодолеть недостатки сетевой модели базовых данных и иерархической модели.И он очень в этом преуспел. Реляционная модель базовых данных сегодня всеобще принята мощной моделью для эффективной организации данных.
Он хотел преодолеть недостатки сетевой модели базовых данных и иерархической модели.И он очень в этом преуспел. Реляционная модель базовых данных сегодня всеобще принята мощной моделью для эффективной организации данных.
Сегодня доступен широкий выбор управления базами данных: от небольших десктопных приложений до многофункциональных серверных систем с высокооптимизированными методами поиска. Вот некоторые из наиболее известных систем управления реляционными данными ( РСУБД ):
- Oracle — используется преимущественно для профессиональных, больших приложений.
- Сервер Microsoft SQL — РСУБД компании Microsoft. Доступна только для операционной системы Windows.
- MySQL — очень популярная РСУБД с открытым исходным кодом. Широко используется как профессионалами, так и новичками. Что еще нужно ?! Она бесплатна.
- IBM — имеет ряд РСУБД, наиболее известна DB2.
- Microsoft Access — РСУБД, которая используется в офисе и дома. На самом деле — это больше, чем просто база данных. MS Access позволяет создавать базы данных с пользовательским интерфейсом.
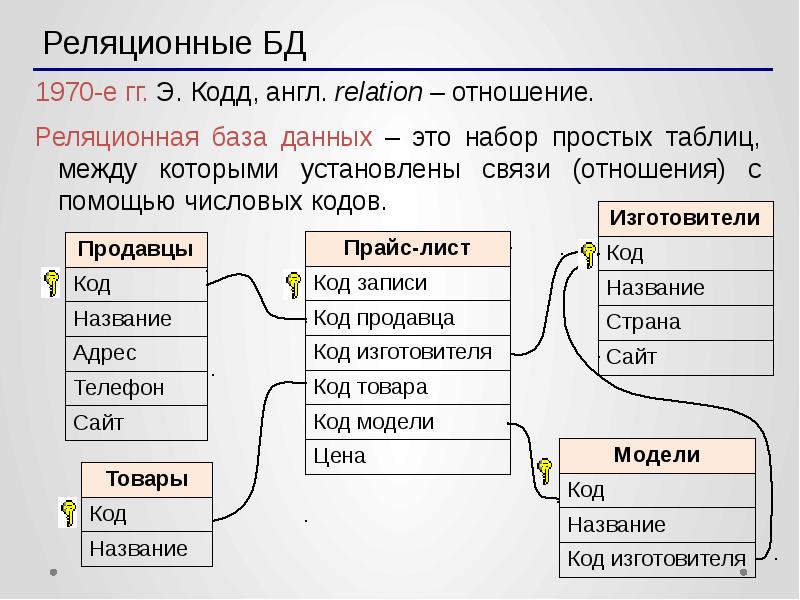 На самом деле — это больше, чем просто база данных. MS Access позволяет создавать базы данных с пользовательским интерфейсом.
На самом деле — это больше, чем просто база данных. MS Access позволяет создавать базы данных с пользовательским интерфейсом.Характеристики реляционных баз данных.
Реляционные базы данных разработаны для быстрого сохранения и измерения больших объемов. Ниже приведены некоторые характеристики реляционных баз данных и реляционной модели данных.
Использование ключей.
Каждая строка данных в таблице используется уникальным «ключом», который называется первичным ключом. За начальный ключ это автоматически увеличиваемое ( автоинкрементное ) число ( 1,2,3,4 и т.д ). Данные в различных таблицах могут быть связаны вместе при использовании ключей. Значения первичного ключа одной таблицы могут быть добавлены в строки ( записи ) другая таблица, тем самым, связывая эти записи вместе.
Отсутствие избыточности данных.
В проекте базы данных, которая создана с учетом правил реляционной модели данных, каждый кусочек информации, например, имя пользователя, хранится только в одном месте.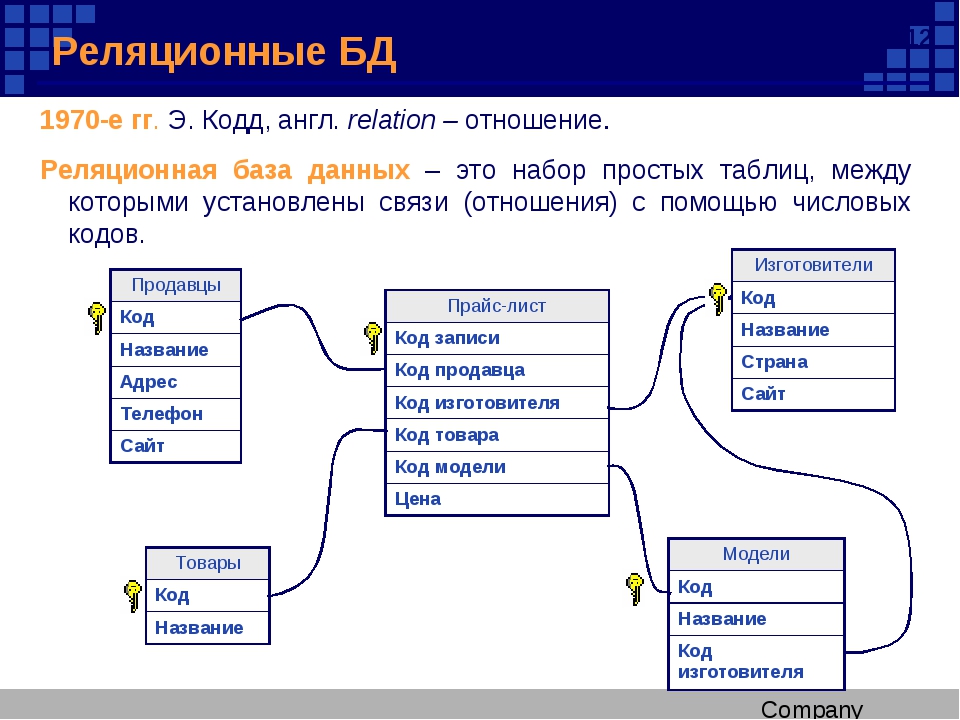 Это позволяет устранить необходимость работы с данными в нескольких местах.Дублирование данных называется избыточностью данных.
Это позволяет устранить необходимость работы с данными в нескольких местах.Дублирование данных называется избыточностью данных.
Ограничение ввода.
Используя реляционную базу данных вы определить какой вид данных позволено в столбце. Вы можете создать поле, которое содержит целые числа, десятичные числа, небольшие фрагменты текста, большие фрагменты текста, дату и т.д.
Когда вы создадите таблицу базы данных, вы предоставите тип данных для каждого столбца.К примеру, varchar — это тип данных для небольших фрагментов текста с максимальным количеством знаков, равным 255, а int — это числа.
Помимо типов данных РБД позволяет вам еще больше ограничить возможные для ввода данные. Например, ограничить длину или принудительно указать на уникальность значения записей в данном столбце. Последнее ограничение часто используется для полей, которые содержат регистрационные имена пользователей (, ), или адреса электронной почты.
Эти ограничения дают вам контроль над целостностью ваших данных и предотвращают ситуацию, следующим следующим образом:
- ввод адреса ( текста ) в поле, в котором вы ожидаете увидеть число
- ввод интерфейса с длиной самого индекса в сотню символов
- создание пользователей с одним и тем же именем
- создание пользователей с одним и тем же адресом электронной почты
- ввод веса ( числа ) в поле дня рождения ( дата )
Поддержание целостности данных.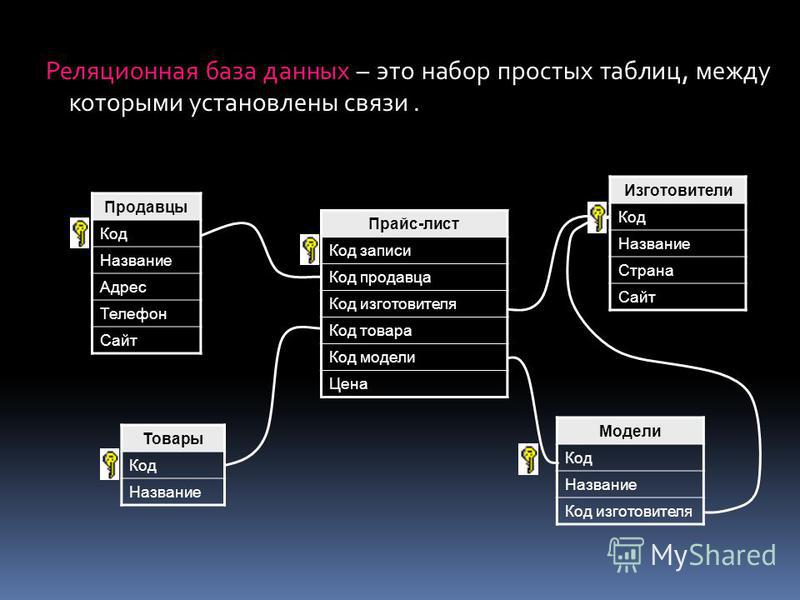
Настраивая свойства полей, связывая таблицы между собой и настраивая ограничения, вы можете увеличить надежность ваших данных.
Назначение прав.
Большинство РСУБД настройку прав доступа, которая позволяет назначать верх права определенным пользователям. Некоторые действия, которые могут быть позволены или запрещены пользователю: SELECT ( выборка ), INSERT ( вставка ), DELETE ( удаление ), ALTER ( изменение ), CREATE (, создание ) и т.д. Это операции, которые могут быть выполнены с помощью структурированного языка запросов ( SQL ).
Структурированный язык запросов ( SQL ).
Для того, чтобы выполнить операции над базой данных, такие, сохранение данных, их выборка, изменение, используется структурированный язык запросов ( SQL ). SQL относительно легок для понимания и позволяет в т.ч. и уложненные выборки, например, выборка связанных данных из нескольких таблиц с помощью оператора SQL JOIN.
То, как вы спроектируете базу данных, чтобы создать непосредственное влияние на запросы, которые вам будет необходимо выполнить, получить данные из базы данных. Это еще одна причина, почему вам необходимо задуматься о том, какой должна быть ваша база. С хорошо спроектированной базой данных ваши запросы могут быть чище и проще.
Переносимость.
Реляционная модель данных стандартна. Следуя правила реляционной модели данных вы уверены, что ваши данные могут быть перенесены в другую РСУБД относительно просто.
Таблицы и первичные ключи.
Как вы уже знаете из прошлых частей, данные хранятся в таблицах, которые используются или по-другому записи. Ранее я приводил пример таблицы. Давайте снова на нее взглянем.
В таблице имеются 6 уроков. Все 6 — разные, но для каждого урока значения одинаковых полей хранятся в таблице, а именно: tutorial_id ( идентификатор урока ), title ( заголовок ) и category ( категория ).
Tutorial_id — первичный ключ таблицы уроков. Первичный ключ — это значение, уникально для каждой записи в таблице.
Первичные ключи в повседневной жизни.
В базе данных первичные ключи используются для идентификации. В жизни первичные ключи вокруг нас везде. Каждый раз, когда вы сталкиваетесь с индивидуальным числом это число может быть первичным ключом в базе данных ( может, но не обязательно автоматически генерировать уникальное число как таковое. вместе с каждой новой записью ).
Несколько примеров:
- Номер, который вы получаете при покупке в интернет-магазине может быть первичным ключом какой-нибудь таблицы заказов в базе данных этого магазина, т.к. он является уникальным значением.
- Номер социального страхования может быть первичным ключом в какой-нибудь таблице в базе данных государственного учреждения, т.к. она также как и в предыдущем примере уникален.
- Номер счета-фактуры может быть использован в качестве первичного ключа в таблице данных, в которой хранятся выданные клиенты-фактуры.
- Числовой номер клиента часто используется как первичный ключ в таблице клиентов.
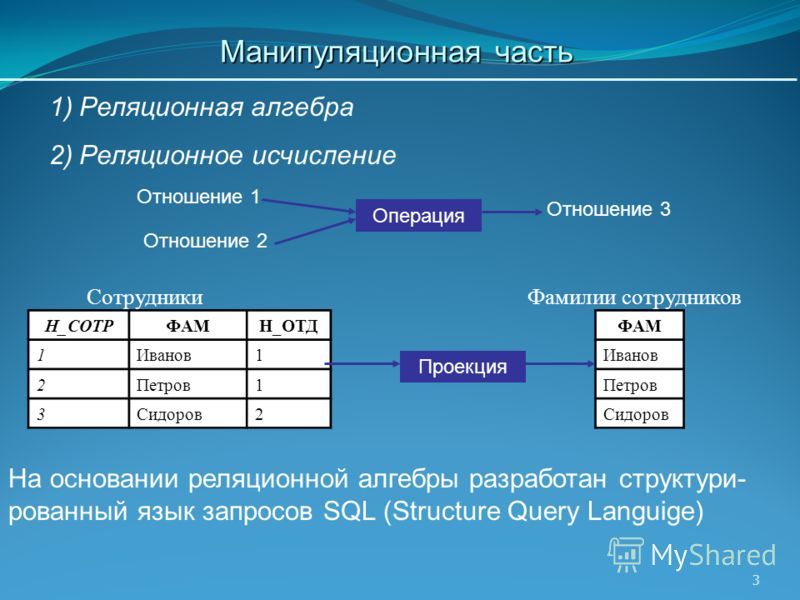
Что объединяет эти примеры? То, что во всех из них в качестве первичного ключа выбирается уникальное, не повторяющееся значение для каждой записи. Еще раз. Значения поля таблицы базы данных, выбранного в качестве первичного ключа, всегда уникально.
Что описывает первичный ключ? Характеристики первичного ключа.
— Первичный ключ для идентификации записей.
Первичный ключ используется для идентификации в таблице, для того, чтобы каждая запись стала уникальной. Еще один аналогия … Когда вы звоните в службу технической поддержки, оператор просит вас назвать какой-либо номер ( договора, телефон и пр. ), по которому вас можно идентифицировать в системе.
. Оператор службы технической поддержки предоставит вам какую-либо информацию, которая поможет уникальным идентифицировать вас.Например, комбинация вашего дня рождения и фамилия. Они тоже могут являться первичным ключом, точнее их комбинация.
Они тоже могут являться первичным ключом, точнее их комбинация.
— Первичный ключ уникален.
Первичный ключ всегда имеет уникальное значение. Представьте, что его значение не уникально. Тогда его бы нельзя было использовать для того, чтобы идентифицировать данные в таблице. Это значит, что какое-либо значение первичного ключа может встретиться в столбце, который выбран в качестве первичного ключа, только один раз. РСУБД устроены так, что не позволят вам вставить дубликаты в поле первичного ключа, получите ошибку.
Еще один пример. Представьте, что у вас есть таблица с полями first_name и last_name и есть две записи:
| first_name | last_name | | вася | пупкин | | вася | пупкин |
Т.е. есть два Васи. Вы хотите выбрать из таблицы какого-то конкретного Васю. Как это сделать? Записи ничем друг от друга не отличаются. Вот здесь и помогает первичный ключ. Добавляем столбец id ( классический вариант синтетического первичного ключа ) и . ..
..
id | first_name | last_name | 1 | вася | пупкин | 2 | вася | пупкин |
Теперь каждый Вася уникален.
— Типы первичных ключей.
Обычно первичный ключ — числовое значение. Но он также может быть и другим типом данных. Не является обычной практикой использования строки в качестве первичного ключа ( строка — фрагмент текста ), но теоретически и практически это возможно.
Часто первичный ключ состоит из одного поля, но он может быть и комбинацией нескольких столбцов, например, двух ( трех, четырех … ). Но вы помните, что первичный ключ всегда уникален, а значит, чтобы комбинация n-го количества полей, в данном случае 2-х, была уникальна.
— Автонумерация.
Поле первичного ключа часто, но не всегда, обрабатывается самой базой данных. Вы можете, условно говоря, сказать базу данных, чтобы она сама автоматически присваивала уникальное числовое значение каждой записи при ее создании.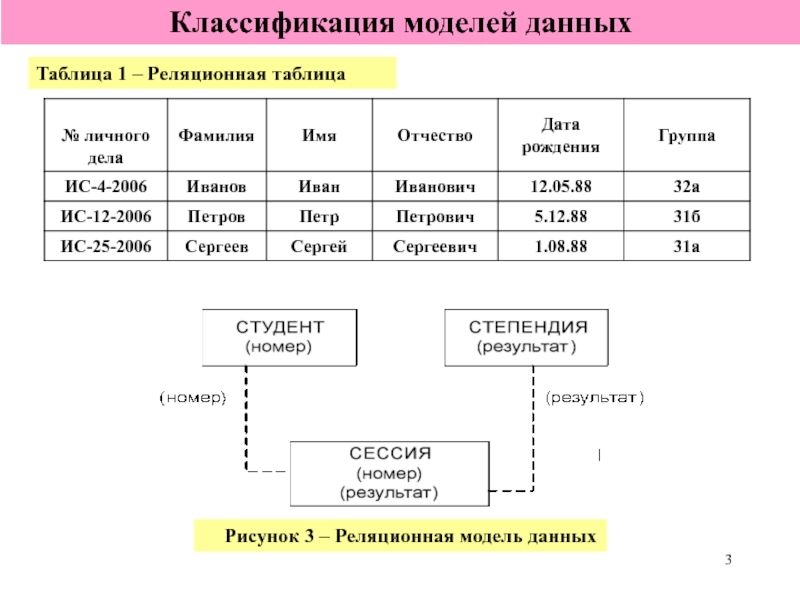 База данных, обычно, начинает нумерацию с 1 и увеличивает это число для каждой записи на одну единицу. Такой первичный ключ называется автоинкрементным или автонумерованным. Использование автоинкрементных ключей — хороший способ для задания уникальных первичных ключей.Классическое название такого ключа — суррогатный первичный ключ. Такой ключ не содержит полезной информации, относящейся к сущности ( объекту ), информация о которой хранится в таблице, поэтому он и называется суррогатным.
База данных, обычно, начинает нумерацию с 1 и увеличивает это число для каждой записи на одну единицу. Такой первичный ключ называется автоинкрементным или автонумерованным. Использование автоинкрементных ключей — хороший способ для задания уникальных первичных ключей.Классическое название такого ключа — суррогатный первичный ключ. Такой ключ не содержит полезной информации, относящейся к сущности ( объекту ), информация о которой хранится в таблице, поэтому он и называется суррогатным.
Связывание таблиц с помощью внешних ключей.
. Когда я начинал разрабатывать базу данных, которая должна быть судебной, в одной таблице. Я мог, например, хранить информацию о заказах в таблице.Ведь заказы оригинальные клиенты, верно? Нет. Клиенты и заказы представляют собой отдельные сущности в базе данных. И тому и другому нужна своя собственная таблица. Между ними есть записи в этих двух отношениях. Проектирование базы данных — это решение двух вопросов:
- определение того, какие сущности вы хотите хранить в ней
- какие связи между этими сущностями существуют
Один-ко-многим.
Клиенты и заказы имеют связь ( состоят в отношениях ) один-ко-многим, потому что один клиент может иметь много заказов, но каждый конкретный заказ ( их множество ) оформлен только одним клиентом, т.е. может иметь только одного клиента.
Какую информацию мы будем хранить? Решаем первый вопрос.
Для начала мы определимся какую информацию о заказах и о клиенте мы будем хранить. Чтобы это сделать, мы должны задать себе вопрос: «Какие единичные блоки информации к клиентам, а какие единичные блоки информации к заказам?»
Проектируем таблицу клиентов.
Заказ действительно принадлежит клиентам, но заказ — это не минимальный блок информации, который относится к клиентам ( т.е. этот блок можно разбить на более мелкие: дата заказа, адрес доставки заказа и пр., К примеру ).
Поля ниже — это минимальные блоки информации, которые относятся к клиентам:
- customer_id ( первичный ключ ) — идентификатор клиента
- имя — имя
- last_name — отчество Адрес
- — адрес
- zip_code — почтовый индекс
- страна — страна
- Дата рождения — дата рождения
- логин — регистрационное имя пользователя ( логин )
- пароль — пароль
Давайте перейдем к непосредственному созданию этой таблицы.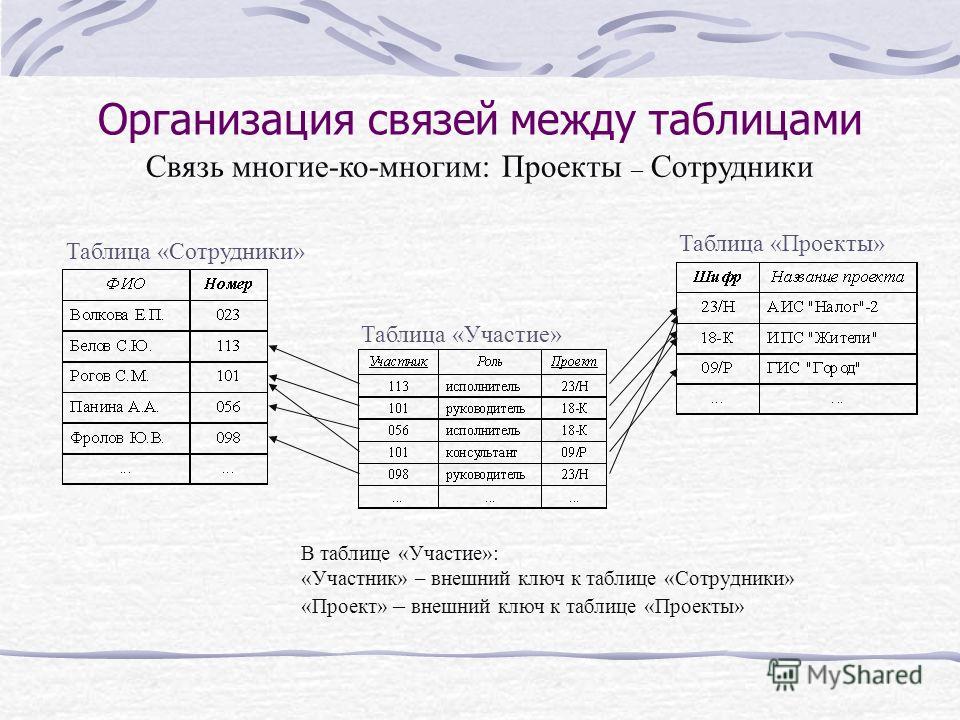
Обратите внимание, что выбран параметр первичного ключа ( PK ) для поля customer_id. Поле customer_id является первичным ключом. Также выбран флажок Auto Incr, что означает, что база данных будет автоматически подставлять уникальное числовое значение, которое, начиная с нуля, будет каждый раз увеличиваться на одну единицу.
Проектируем таблицу заказов.
Какие минимальные блоки информации, необходимые нам, нападение к заказу?
- order_id ( первичный ключ ) — идентификатор заказа
- order_date — дата и время заказа
- клиент — клиент, который сделал заказ
Проект таблицы.Поле customer является ссылкой ( внешний ключ ) для поля customer_id в таблице клиентов.
Эти две таблицы ( клиентов и заказов ) связаны, потому что поле клиента в таблице заказов указано на первичный ключ ( customer_id ) таблицы клиентов. Такая связь называется связью по внешнему ключу. Вы должны представлять себе внешний ключ как простую копию ( копия ) первичного ключа другой таблицы. В нашем случае значение поля customer_id из таблицы клиентов копируется в таблицу заказов при вставке каждой записи.Таким образом, у нас каждый заказ привязан к клиенту. И заказов у каждого клиента может быть много, как и говорилось выше.
Вы должны представлять себе внешний ключ как простую копию ( копия ) первичного ключа другой таблицы. В нашем случае значение поля customer_id из таблицы клиентов копируется в таблицу заказов при вставке каждой записи.Таким образом, у нас каждый заказ привязан к клиенту. И заказов у каждого клиента может быть много, как и говорилось выше.
Создание связи по внешнему ключу.
Вы можете задаться вопросом: «Каким образом я могу убедиться, что я могу увидеть, что поле клиента в таблице заказов указано на поле customer_id в таблице клиентов». Ответ прост — вы не можете сделать этого потому, что я еще не показал вам как создать связь.
Ниже — окно SQLyog, которое я использовал для создания связи между таблицами.
Создание связи по внешнему ключу между таблицами заказов и клиентов.
В окне выше вы видите, как поле клиента заказов слева связывается с первичным ключом ( customer_id ) таблицы клиентов справа.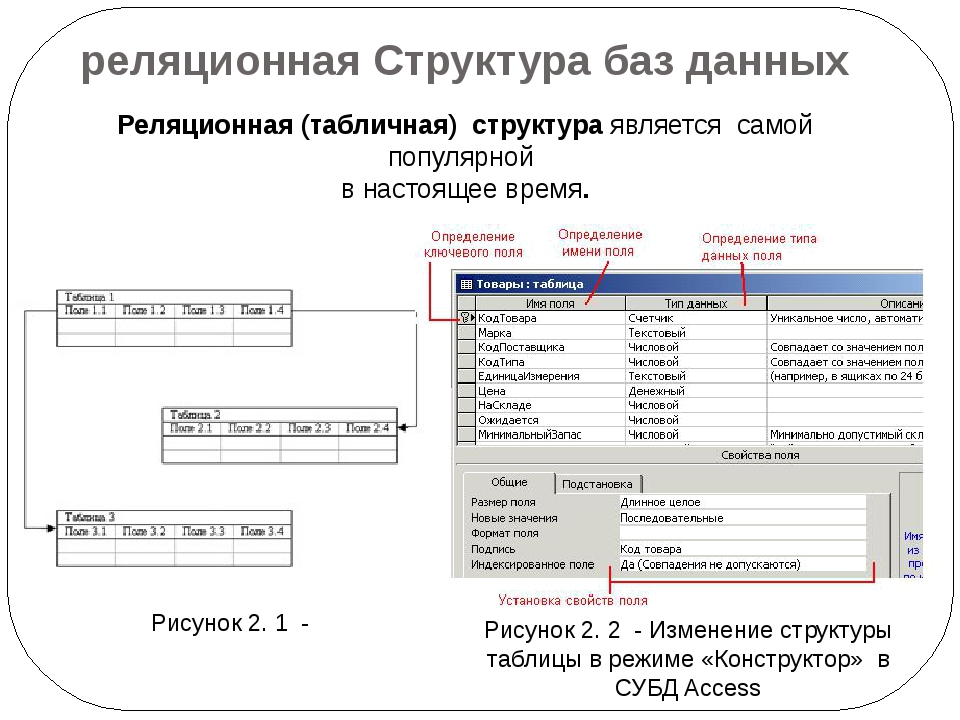
Теперь, когда вы посмотрите на данные, которые могли бы быть в таблицах, вы видите, что две таблицы связаны.
Заказы связаны с клиентами через поле клиента, которое связано с таблицей клиентов.
На изображении вы видите, что клиент поместила три заказа, поместил один клиент John — ни одного.
Вы можете спросить: «А что же именно заказали все эти люди?» Это хороший вопрос. Вы возможно ожидали увидеть заказанные товары в таблице заказов. Но это плохой пример проектирования. Как бы вы поместили множественные продукты в единственную запись? Товары — это отдельные сущности, которые должны храниться в отдельной таблице. И связь между таблицами заказов и товаров будет являться связью один-ко-многим.
Создание диаграммы сущность-связь.
Ранее вы узнали как записи из разных таблиц связаны друг с другом в реляционных базах данных. Передача данных и связываний таблиц важна, чтобы вы могли создать базу данных , чтобы вы смогли создать базу данных . В проектировании базовых данных сущности и их отношения обычно в диаграмме сущность-связь ( англ.диаграмма сущность-связь, ERD ). Данная диаграмма является результатом процесса проектирования базы данных.
В проектировании базовых данных сущности и их отношения обычно в диаграмме сущность-связь ( англ.диаграмма сущность-связь, ERD ). Данная диаграмма является результатом процесса проектирования базы данных.
Сущности.
В концепции проектирования базовых данных сущность — это нечто, что заслуживает своей таблицы в модели вашей базы данных. Когда вы создаете базу данных, вы должны определить сущность в системе.
Давайте возьмем интернет-магазин для примера. Интернет-магазин продает товары.Товар мог бы стать очевидной сущностью в системе интернет-магазина. Товары заказываются клиентами. Вот мы с вами и увидели еще две очевидных сущности: заказы и клиенты. Заказ оплачивается клиентом … это интересно. Мы собираемся создать отдельную таблицу для платежей в базе данных нашего интернет-магазина? Возможно. Но разве платежи — это минимальный блок информации, который относится к заказам? Это тоже возможно.
Если вы не уверены, то просто подумайте о том, какую информацию о платежах вы хотите хранить. Возможно, вы захотите хранить метод платежа или дату платежа. Но это все еще минимальные блоки информации, которые могли бы относиться к заказу. Можно изменить формулировки. Метод платежа — метод платежа заказа. Дата платежа — дата платежа заказа. Таким образом, я не вижу необходимости выносить платежи в отдельную таблицу, хотя концептуально вы бы могли иметь платежи как сущность, т.к. вы бы рассматривать платежи как контейнер информации ( платежа, дата платежа ).
Возможно, вы захотите хранить метод платежа или дату платежа. Но это все еще минимальные блоки информации, которые могли бы относиться к заказу. Можно изменить формулировки. Метод платежа — метод платежа заказа. Дата платежа — дата платежа заказа. Таким образом, я не вижу необходимости выносить платежи в отдельную таблицу, хотя концептуально вы бы могли иметь платежи как сущность, т.к. вы бы рассматривать платежи как контейнер информации ( платежа, дата платежа ).
Как вы видите определение того, какие сущности имеет ваша система — это немного интеллектуальный процесс, который требует некоторого опыта и часто — это предмет для внесения изменений, пересмотров, раздумий…
Связь один-ко-многим.
Когда одна запись в таблице А может быть связана с 0, 1 или множеством записей в таблице B, вы имеете дело со связью один-многим. В реляционной модели данных связь один-ко-многим использует две таблицы.
Схематическое представление связи один-ко-многим. Запись в таблице А имеет 0, 1 или множество ассоциированных ей записей в таблице B.
Запись в таблице А имеет 0, 1 или множество ассоциированных ей записей в таблице B.
Как опознать связь один-ко-многим?
Если у вас есть две сущности спросите себя:
- Сколько объектов из B может относится к объекту A?
- Сколько объектов из A могут относиться к объекту из B?
Если на первый вопрос ответ — множество, а на второй — один ( или возможно, что ни одного ), то вы имеете дело со связью один-ко-многим.
Некоторые примеры связи один-ко-многим:
- Машина и ее части. Каждая часть машины единовременно принадлежит только одной машине, но машина может иметь множество частей.
- Кинотеатры и экраны. В одном кинотеатре может быть множество экранов, но каждый экран принадлежит только одному кинотеатру.
- Диаграмма сущность-связь и ее таблицы. Диаграмма может иметь больше, чем одну таблицу, но каждая из этих таблиц принадлежит только одной диаграмме.
- Дома и улицы. На улице может быть несколько домов, но каждый дом принадлежит только одной улице.
 На улице может быть несколько домов, но каждый дом принадлежит только одной улице.
На улице может быть несколько домов, но каждый дом принадлежит только одной улице.Связь многие-ко-многим.
Связь многие-ко-многим — это связь, которая содержит набор сигналов из одной таблицы ( A ), соответствующие множественные записи из другого ( B ). Примером такой связи может служить школа, где учителя обучают учащихся. В большинстве школ каждый учитель обучает многих учащихся, каждый учащийся может обучаться учителями.
Обратите внимание, что при проектировании базы данных вы должны спросить себя не о том, существуют ли источники связи в данный момент, а о том, возможно ли наличие связей в целом, в перспективе. Если в настоящий момент все поставщики предоставят множество видов пива, но каждый вид пива предоставляется только одним поставщиком, но … Не торопитесь реализовывать связь один-ко-многим в этой ситуации . Существует высокая вероятность того, что в будущем два или более поставщиков будут поставлять один и тот же вид пива и когда это случится ваша база данных — со связью один-ко-многим между поставщиком и видами пива — не будет подготовлена к этому.
Создание связи многие-ко-многим.
Связь многие-ко-многим создается с помощью трех таблиц. Две таблицы — «источник» и одна соединительная таблица. Первичный ключ соединительной таблицы A_B — составной. Она состоит из двух полей, двух внешних ключей, которые являются первичными ключами таблиц A и B.
Все первичные ключи должны быть уникальными. Это подразумевает и то, что комбинация полей A и B должна быть уникальной в таблице A_B.
Пример проекта базы данных ниже демонстрирует вам таблицы, которые могли бы существовать в рамках многих-многим между бельгийскими брендами пива и их поставщиками в Нидерландах. Обратите внимание, что все комбинации beer_id и Distributor_id уникальны в соединительной таблице.
Таблицы выше связывают поставщиков и пиво многие-ко-многим, используя соединительную таблицу. Обратите внимание, что пиво ‘Gentse Tripel’ ( 157 ) поставляют Horeca Import NL ( 157, AC001 ) Jansen Horeca ( 157, AB899 ) и Petersen Drankenhandel ( 157, AC009 ).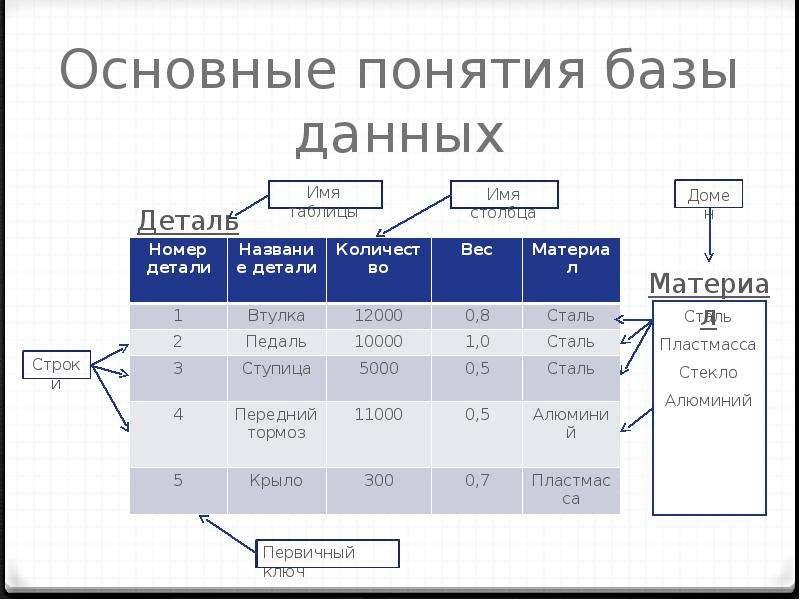 И наоборот, Petersen Drankenhandel предлагает 3 вида пива из таблицы, а именно: Gentse Tripel ( 157, AC009 ), Uilenspiegel ( 158, AC009 ) и Jupiler ( 163, AC009 ).
И наоборот, Petersen Drankenhandel предлагает 3 вида пива из таблицы, а именно: Gentse Tripel ( 157, AC009 ), Uilenspiegel ( 158, AC009 ) и Jupiler ( 163, AC009 ).
Еще обратите внимание, что в таблицах выше указаны поля первичных ключей. В модели проекта базы данных первичные ключи обычно подчеркнуты. И снова обратите внимание, что соединительная таблица beer_distributor имеет первичный ключ, составленный из двух внешних ключей.Соединительная таблица всегда имеет составной первичный ключ.
Есть еще одна важная вещь которую нужно знать. Связь многие-ко-многим состоит из двух связей один-ко-многим. Обе таблицы: поставщики пива и пиво — имеют связь один-ко-многим с соединительной таблицыей.
Связь один-к-одному.
В связи один-к-одному каждый блок сущности A может быть ассоциирован с 0, 1 блоком сущности B. Наемный работник, например, обычно связан с одним офисом. Или пивной бренд может иметь только одну страну происхождения.
Связь один-к-одному легко моделируется в одной таблице. Записи таблицы содержат данные, которые находятся в связи один-к-одному с первичным ключом или записью.
В редких случаях связь один-к-одному модели использует две таблицы. Такой вариант иногда необходим для ускорения поиска по ограничению РСУБД или с целью увеличения производительности ( например, иногда — это ограничение поля с типом данных blob в таблице для ускорения поиска по родительской таблице ).Или порой вы можете две решить, что вы разделите сущности в разные таблицы в то время, как они все еще имеют связь один-к-одному. Но обычно наличие двух таблиц в связи один-к-одному считается дурной практикой.
Примеры связи один-к-одному.
Люди и их паспорта. Каждый человек в стране имеет только один действующий паспорт и каждый паспорт принадлежит только одному человеку.
Проект реляционной базы данных — это коллекция таблиц, которые перелинковываются ( связываются ) первичными и внешними ключами. Реляционная модель данных включает в себя ряд правил, которые позволяют вам создать верные связи между таблицами. Эти правила называются «нормальными формами».
Реляционная модель данных включает в себя ряд правил, которые позволяют вам создать верные связи между таблицами. Эти правила называются «нормальными формами».
Нормализация баз данных.
Указания для правильного проектирования реляционных базовых данных изложены в реляционной модели данных. Они собраны в 5 групп, которые называются нормальными формами. Первая нормальная форма представляет самый низкий уровень нормализации базовых данных. Пятый уровень представляет высший уровень нормализации.
Нормальные формы — это рекомендации по проектированию баз данных. Вы не обязаны придерживаться всех пяти нормальных форм проектирования баз данных. Тем не менее, рекомендуется нормализовать базу данных в некоторой степени, потому что этот процесс имеет значительное преимущество с точки зрения эффективности и удобства с вашей точки зрения.
- В нормализованной структуре данных вы можете выполнять сложные операции относительно простыми SQL-запросами.
- Целостность данных. Нормализованная база данных позволяет надежно хранить данные.
- Нормализация предотвращает появление избыточности хранимых данных. Данные всегда хранятся только в одном месте, что делает легким процесс вставки, обновления и удаление данных. Есть исключение из этого правила. Ключи, сами по себе, хранятся в нескольких местах, потому что они копируются как внешние ключи в другие таблицы.
- Масштабируемость — это возможность системы справляться с будущим ростом.Для базы данных это значит, что она должна быть способна работать быстро, когда число пользователей и объемы данных возрастают. Масштабируемость — это очень важная характеристика любые модели базы данных и для РСУБД.

Вот некоторые основные из пунктов, которые связаны с базлизацией данных:
- Упорядочивание данных в логические группы или наборы.
- Нахождение связей между наборами данных. Вы уже видели примеры связей один-ко-многим и многие-ко-многим.
- Минимизация избыточности данных.
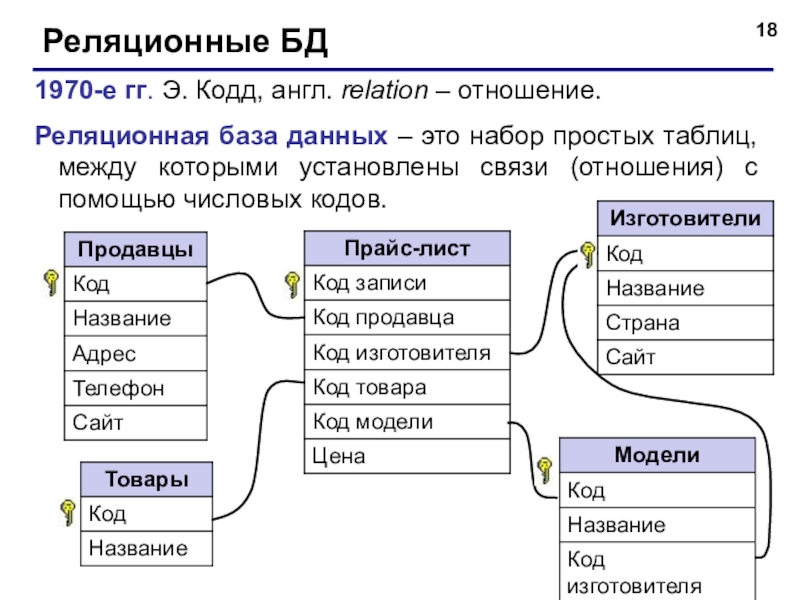
Очень малое количество баз данных следуют всем пяти нормальным формам, предоставленным в реляционной модели данных. Обычно базы данных нормализуются до второй или третьей нормальной формы. Четвертая и пятая формы используются редко.
Первая нормальная форма ( 1НФ ).
Первая нормальная форма гласит, что таблица базы данных — это представление сущности вашей системы, которую вы создаете.Примеры сущностей: заказы, клиенты, заказ билетов, отель, товар и т.д. Каждая запись в базе данных представляет один экземпляр сущности. Например, в таблице клиентов каждая запись представляет одного клиента.
— Первичный ключ.
Правило: каждая таблица имеет первичный ключ, состоящий из наименьшего возможного количества полей.
Как вы знаете, первичный ключ может состоять из нескольких полей. Вы, к примеру, можете выбрать имя и фамилию в качестве первичного ключа ( и надеяться, что эта комбинация будет уникальной всегда ).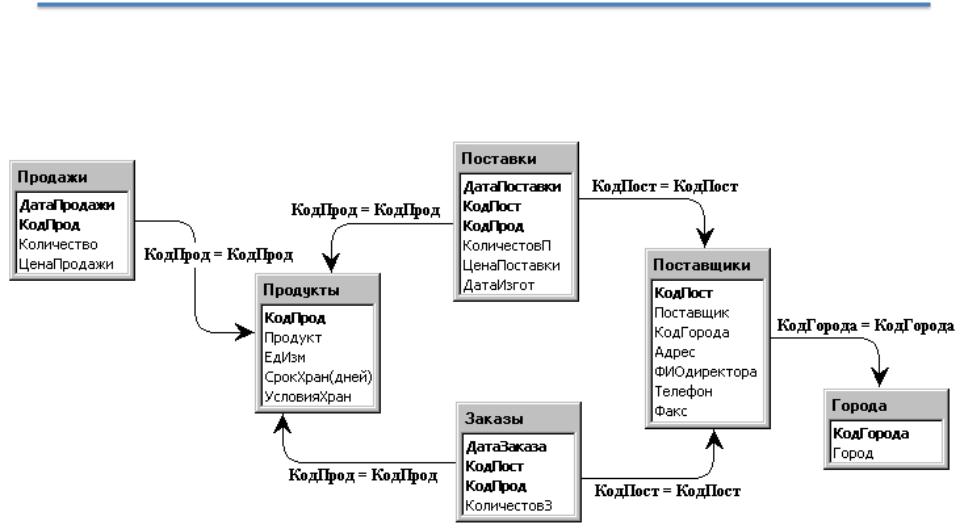 Будет намного более хорошим выбором номер соц. страхование в качестве первичного ключа, т.к. это единственное поле, которое уникальным образом идентифицирует человека. Еще лучше, когда нет очевидного кандидата на звание первичного ключа, создайте суррогатный первичный ключ в виде числового автоинкрементного поля.
Будет намного более хорошим выбором номер соц. страхование в качестве первичного ключа, т.к. это единственное поле, которое уникальным образом идентифицирует человека. Еще лучше, когда нет очевидного кандидата на звание первичного ключа, создайте суррогатный первичный ключ в виде числового автоинкрементного поля.
— Атомарность.
Правило: поля не имеют дубликатов в каждой записи и каждое поле содержит только одно значение.
— Порядок записей не должен иметь значение.
Правило: порядок записей таблицы не должен иметь значения.
. Какой из клиентов зарегистрировался первым в таблице клиентов для определения. Для этих целей вам лучше создать даты и времени регистрации клиентов. Порядок записей будет неизбежно меняться, когда клиенты будут удаляться, изменяться. Вот почему вам никогда не следует полагаться на порядок записей в таблице.
Вторая нормальная форма ( 2НФ ).
Для того, чтобы база данных была нормализована согласно второй нормальной форме, она должна быть нормализована согласно первой нормальной форме.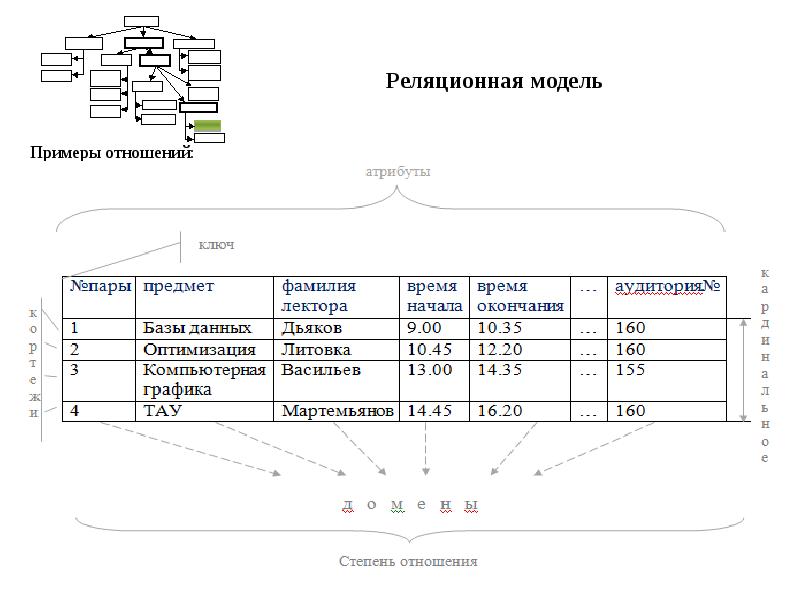 Вторая нормальная форма связ с избыточностью данных.
Вторая нормальная форма связ с избыточностью данных.
— Избыточность данных.
Правило: поля с не первичным ключом не должны быть зависимы от первичного ключа.
Может звучать немного заумно. А это означает, что вы должны хранить в таблице только данные, которые связаны с ней и не имеют отношения к другим сущностям.С помощью этой второй нормальной формы — это вопрос нахождения данных.
Насколько строго вы подходите к созданию ваших таблиц — решать вам и зависит от конкретной ситуации. Если вы планируете хранить огромное количество единиц продукции в системе и вы хотите иметь возможность производить поиск по цвету ( цвет ), то было бы мудрым решением цвета в отдельной таблице так, чтобы они не дублировались.
Может существует другой случай, когда вы захотеть цвета в отдельную таблицу. Если вы хотите, чтобы они имели возможность выбрать цвет машины из заранее заданного списка. В этом случае вы захотите хранить все возможные цвета в вашей базе данных. Даже если еще нет машин таким цветом, вы захотите, чтобы эти цвета присутствовали в базе данных, чтобы работники могли их выбирать. Это определенно тот случай, когда вам нужно выделить в отдельную таблицу.
Даже если еще нет машин таким цветом, вы захотите, чтобы эти цвета присутствовали в базе данных, чтобы работники могли их выбирать. Это определенно тот случай, когда вам нужно выделить в отдельную таблицу.
Третья нормальная форма ( 3НФ ).
Третья нормальная форма зависит с транзитивными зависимостями. Транзитивные зависимости между полями базы данных существуют тогда, когда значения не ключевые поля зависят от значений других не ключевых полей. Чтобы база данных была в третьей нормальной форме, она должна быть во второй нормальной форме.
— Транзитивные зависимости.
Правило: не может быть транзитивных зависимостей между полями в таблице.
Таблица клиентов ( мои клиенты — игроки немецкой и французской футбольной команды ) ниже содержит транзитивные зависимости.
В этой таблице не все поля зависят исключительно от первичного ключа. Существует отдельная связь между полем postal_code и полями города ( город ) и провинция ( провинция ). В Нидерландах оба значения: город и провинция — определение почтовым кодом, индексом. Таким образом, нет необходимости хранить и провинцию в клиентской таблице.Если вы знаете почтовый код, то вы уже знаете город и провинцию.
В Нидерландах оба значения: город и провинция — определение почтовым кодом, индексом. Таким образом, нет необходимости хранить и провинцию в клиентской таблице.Если вы знаете почтовый код, то вы уже знаете город и провинцию.
Такой транзитивной зависимости следует исключить, если вы хотите, чтобы ваша модель базы данных была в нормальной форме.
В данном случае устранение уязвимой зависимости из таблицы может быть достигнуто путем удаления полей города и провинции из таблицы и хранения их в таблице, исходный код ( первичный ключ ), имя провинции и имя города. Получение комбинации почтовый код-город-провинция для целой страны может быть весьма нетривиальным занятием.Вот почему такие таблицы часто продаются.
Третья нормальная форма гласит, что вы не должны хранить данные в таблице, которые могут быть получены из других ( не ключевые ) таблицы полей.
Третья нормальная форма не всегда используется при проектировании баз данных. Когда используется база данных, вы всегда можете использовать преимущества более высокой формы в сравнении с объемом работ, которые требуются для использования третьей формы и поддержания данных в таком состоянии.
Хранение данных, воспроизводимых из использования, обычно плохая идея.
Иллюстрированный самоучитель по SQL для начинающих ›Основы реляционных баз данных [страница — 6] | Самоучители по программированию
Основы реляционных баз данных
Модели баз данных
Независимо от размеров базовых данных одной из трех нижеприведенных моделей.
- Реляционная . Если сейчас где-нибудь развертывают новую систему, предназначенную для управления базами данных, то почти всегда такая система является реляционной.Конечно, в организациих, где уже вложено много ресурсов в иерархическую и сетевую технологии, могут наращивать и имеющуюся модель. Однако в группах, где нет необходимости поддерживать совместимость с унаследованными от прошлого системами, для своих баз данных почти всегда выбирают реляционную модель.
- Иерархическая . Иерархические базы данных получили такое название, что имеют простую иерархическую структуру, позволяющую иметь быстрый доступ к данным. Их недостатками избыточность данных, т.е. их дублирование, и негибкость структуры, что усложняет модификацию баз данных.
- Сетевая . В сетевых базах данных дублирование минимально, но за это приходится платить сложностью структуры.
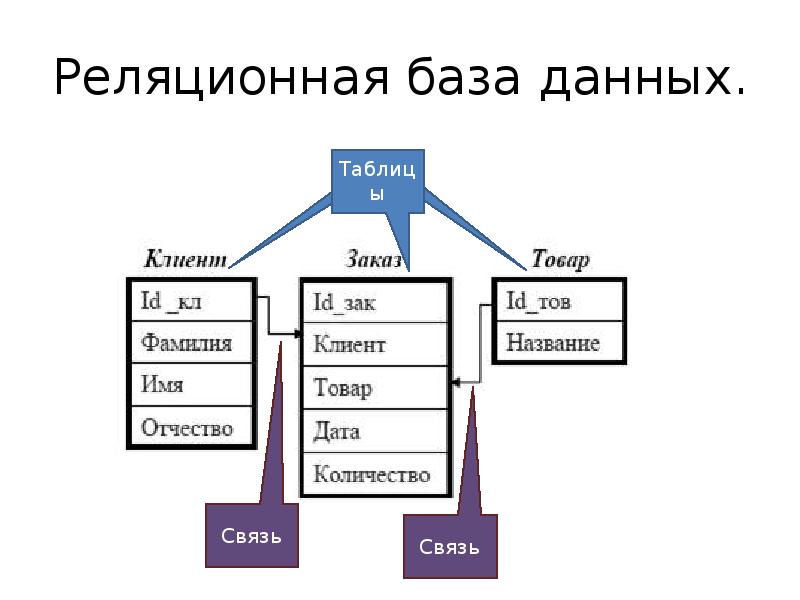 Их недостатками избыточность данных, т.е. их дублирование, и негибкость структуры, что усложняет модификацию баз данных.
Их недостатками избыточность данных, т.е. их дублирование, и негибкость структуры, что усложняет модификацию баз данных.Первыми базами данных, получившими широкое распространение, были большие базы данных организаций, созданные в соответствии с иерархической или сетевой моделью. Через несколько лет появились системы, созданные в соответствии с реляционной моделью. Язык SQL является по-настоящему современным; он применяется только к реляционной модели и ее производной — объектно-реляционной модели.Так что в этом месте книги остается сказать иерархической и сетевой моделям: «Приятно было познакомиться, а теперь — до свидания».
Новые системы управления базами данных, которые не являются реляционными, соответствуют, скорее всего, более новой, чем реляционная, объектной модели или гибридной объектно-реляционной модели.
Реляционная модель
Впервые реляционная модель базовых разработал в 1970 году работающий в компании IBM доктор И.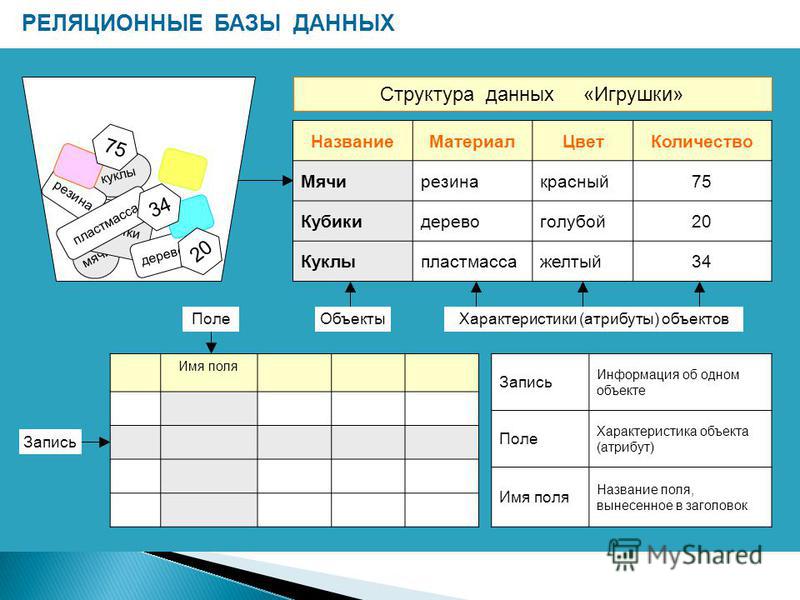 Ф. Кодд ( E.F. Codd ), а примерно десятилетие эта модель начала появляться в готовых продуктах. По иронии судьбы первую реляционную СУБД разработала не IBM. Такая честь выпала на долю маленькой компании-новичка, назвавшей свой продукт Oracle.
Ф. Кодд ( E.F. Codd ), а примерно десятилетие эта модель начала появляться в готовых продуктах. По иронии судьбы первую реляционную СУБД разработала не IBM. Такая честь выпала на долю маленькой компании-новичка, назвавшей свой продукт Oracle.
Базы данных, созданные на основе предыдущих моделей, были заменены реляционными, потому что не имели реляционных свойств, которые и отличают реляционные базы от других типов. Вероятно, самым важным из этих свойств является то, что в реляционной базе данных можно менять, не внося изменений в приложения.Такого не скажешь о приложениях, созданных на основе старых структур. Предположим, например, что в таблицу базы данных вы добавили один или несколько новых столбцов. В этом случае нет необходимости менять никакое из уже написанных приложений, которые продолжают обрабатывать эту таблицу, — только если вы не изменили эти таблицы.
Внимание:
, если вы удалили столбец, к которому применяется соответствующее приложение, то какая бы модель базы данных ни применялась, вы столкнетесь с трудностями.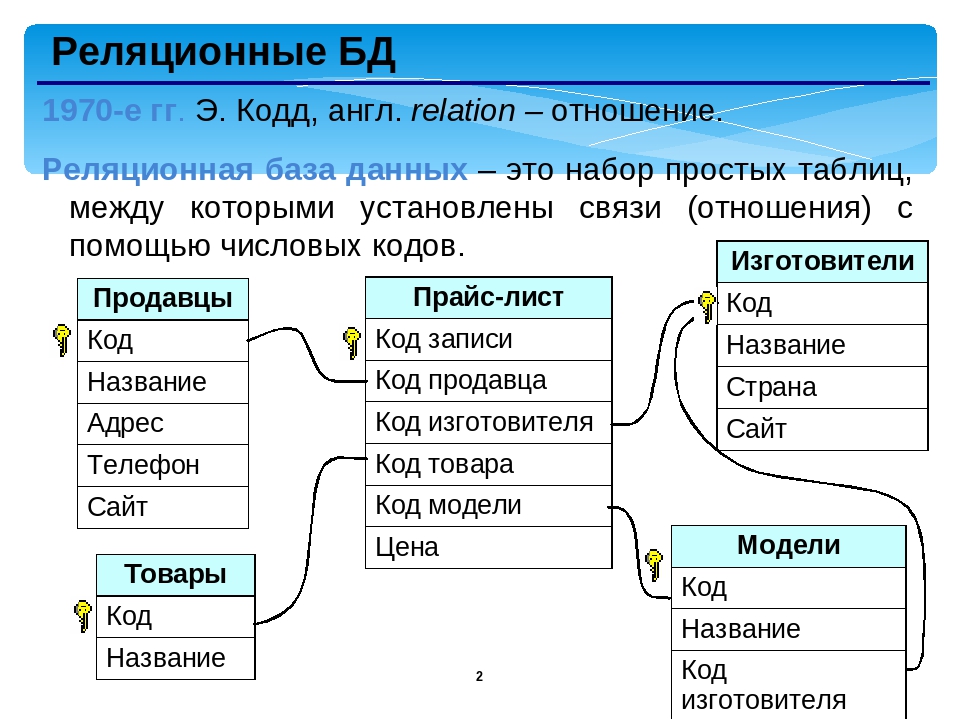 Один из лучших способов устроить аварийное завершение работы приложения базы данных — запросить у него такую информацию, которая нет в вашей базе данных .
Один из лучших способов устроить аварийное завершение работы приложения базы данных — запросить у него такую информацию, которая нет в вашей базе данных .
Почему реляционная модель лучше
В приложениях, работающих с СУБД, которые следуют иерархической или сетевой модели, структура базы данных «зашита» в само приложение. Это означает, что приложение зависит от физической реализации базы данных. При добавлении в базу данных нового атрибута вам, чтобы привести приложение в соответствие с новым атрибутом базы, придется это приложение изменить, причем неважно, будет ли оно использовать новый атрибут.
У реляционных баз данных более гибкая структура. Приложения для таких базовых баз легче, чем те, что написаны для иерархических или сетевых данных. Эта гибкость структуры дает возможность получать такие комбинации данных, которые, возможно, еще не были нужны при проектировании базы данных.
Компоненты реляционной базы данных
Гибкость реляционных баз данных объясняется тем, что их данные находятся в таблицах, которые в степени независимы друг от друга. В таблице данные можно добавить, удалить их из нее, внести в них изменения и при этом не использовать данные из других таблиц — если только таблица не используется родительской по отношению к этим другим таблицам. (Об отношениях родительских и дочерних таблиц рассказывается в главе 5, но там речь пойдет не о конфликте поколений.) В этом разделе показано чего состоят таблицы и как они связаны с другими частями реляционной базы данных.
В таблице данные можно добавить, удалить их из нее, внести в них изменения и при этом не использовать данные из других таблиц — если только таблица не используется родительской по отношению к этим другим таблицам. (Об отношениях родительских и дочерних таблиц рассказывается в главе 5, но там речь пойдет не о конфликте поколений.) В этом разделе показано чего состоят таблицы и как они связаны с другими частями реляционной базы данных.
разбираемся в основных моделях баз данных
Перевод статьи «Понимание баз данных SQL и NoSQL и различных моделей баз данных»
С незапамятных временная память была одной из самых важных и необходимых составляющих компьютера.Несмотря на разницу в способе реализации. В наше время невозможно представить работу какого-либо приложения, хоть игры, хоть сайта, без получения, обработки и записи определенного типа данных. Системы управления базами данных (СУБД) — это высокоуровневое программное обеспечение, работающее с низкоуровневыми API.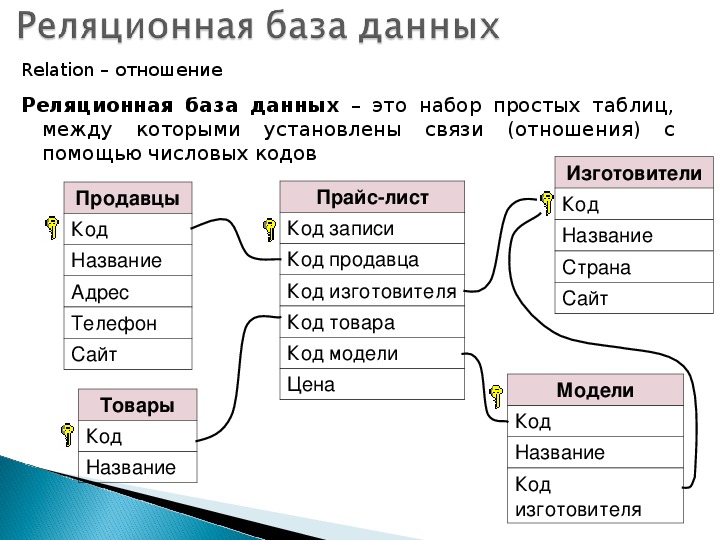 Для решения различных проблем создавались новые виды СУБД (реляционные, NoSQL и т.д.) и их новые реализации (MySQL, PostgreSQL, MongoDB, Redis и т.д.). В этой статье мы разберемся в основах баз данных и СУБД.
Для решения различных проблем создавались новые виды СУБД (реляционные, NoSQL и т.д.) и их новые реализации (MySQL, PostgreSQL, MongoDB, Redis и т.д.). В этой статье мы разберемся в основах баз данных и СУБД.
Системы управления базами данных
СУБД — это общий термин, относящийся ко всем видам абсолютно разных инструментов, от компьютерных программ до встроенных библиотек. Эти приложения управляют или позволяют управлять наборами данных. Так как эти данные могут быть разного формата и размера, были созданы разные виды СУБД.
СУБД основаны на моделях баз данных — установленные структурых для обработки данных.Каждая СУБД создана для работы с одной из них с учётом выполнения операций над информацией.
различных решений, реализующих модели базовых данных, периодически используются некоторые из них становятся очень популярными на протяжении многих лет. Сейчас самой популярной моделью является реляционная система управления базами данных (РСУБД).
Модели баз данных
Каждая СУБД реализует одну из моделей баз данных для логической структуры использования данных.Эти модели являются главным критерием того, как будет работать и управлять своим приложением. Существует несколько таких моделей, среди самой популярной реляционной.
Хотя она и является весьма мощной и гибкой, есть решения, которые она предлагает не может. Тут на помощь придёт сравнительно новая модель, называемая NoSQL. Она набирает популярность и предлагает весьма интересные решения и дополнительный функционал. Из-за того, что эти системы не используют строгую структуризацию данных, они обладают большой свободой действий при обработке информации.
Реляционная модель
Представленная в 70-х, реляционная модель предлагает математический способ структуризации, хранения и использования данных. Отношения (англ. Relations ) предоставляют возможность группировки данных как связанных наборов, представленных в виде таблиц, упорядоченную информацию (например, имя и адрес человека) и соотносящих значения и атрибуты (его номер паспорта).
десятилетиям исследований и разработки РСУБД работают производительно и надёжно.В сочетании с большим опытом использования администратора реляционные базы данных выбора, гарантирующим защиту информации от потерь.
Несмотря на строгие принципы формирования и обработки данных, РСУБД могут быть весьма гибкими, если приложить немного усилий.
Безмодельный (NoSQL) подход
NoSQL-способ структуризации данных — избавление от ограничений при хранении и использовании информации. Базы данных NoSQL, используя неструктуризированный подход, обеспечивает много эффективных способов обработки данных в отдельных случаях (например, при работе с хранилищем текстовых документов).
Популярные СУБД
В этой статье мы опишем вам парадигмы основных решений для работы с базами данных. Хотя точные цифры очень сложно, в большинстве случаев используется реляционная модель или NoSQL. Прежде чем мы сравним их, давайте узнаем, что находится «под капотом» у каждой из них.
РСУБД
Реляционные системы управления базами данных берут своё название реализуемой модели — реляционной. Сейчас они остаются, самым популярным выбором для надёжного, безопасного и производственного хранения данных.
РСУБД требует четких и ясных схем — не стоит путать со специфическим определением для PostgreSQL — для работы с данными. Эти рамки, устанавливаемые пользователем, задают способ их хранения и использования. Схемы очень похожи на таблицы, столбцы которых отражают порядковый номер и тип информации в каждой записи, а строке — содержимое этих записей.
Самыми популярными РСУБД сейчас являются:
- SQLite: очень мощная встраиваемая РСУБД.
- MySQL: самая популярная и часто используемая РСУБД.
- PostgreSQL: самая продвинутая и гибкая РСУБД.
NoSQL-СУБД
NoSQL-СУБД не используйте реляционную модель структуризации данных. Существует много реализаций, рещающих этот вопрос по-своему, часто весьма специфично. Эти бессхемные решения допускают неограниченное создание записей и хранение данных в виде ключ-значение.
В отличие от РСУБД, некоторые базы данных NoSQL, например, MongoDB позволяет группировать коллекции данных с другими базами данных.Такие СУБД хранят данные как одно целое. Эти данные могут представлять собой одиночный объект наподобие JSON и вместе с тем корректно отвечать на запросы к полям.
NoSQL базы данных не используют общий формат запроса (как SQL в реляционных базах данных). Каждое решение использует собственную систему запросов.
Сравнение SQL и NoSQL
Для того, чтобы прийти к простому и понятному выводу, давайте проанализируем разницу между SQL- и NoSQL-подходами:
- Структура и типовые данные: SQL / реляционные базы данных требуют наличия однозначно определенной структуры хранения данных, а NoSQL базы данных таких ограничений не ставят.
- Запросы: вне зависимости от лицензии, РСУБД реализуют стандарты SQL, поэтому из них можно получать данные при помощи языка SQL. Каждую NoSQL реализует свой способ работы с базой данных.
- Масштабируемость: оба решения легко растягиваются вертикально (например, путём увеличения системных ресурсов). Тем не менее, решения NoSQL обычно менее простые способы горизонтального масштабирования (например, создания кластера из нескольких машин).
- Надёжность: когда речь заходит о надёжности, SQL базы данных однозначно впереди.
- Поддержка: РСУБД имеют очень долгую историю. Они очень популярны, и поэтому получить поддержку, платную или нет, очень легко. Поэтому при необходимости решить проблемы с ними намного проще, чем с NoSQL, особенно если проблема сложна по своей природе (например, при работе с MongoDB).
- Хранение и доступ к сложным структурам данных: по своей природе реляционные базы данных предполагают работу со сложными ситуациями, поэтому и здесь они превосходят NoSQL-решения.
Модели данных ГИС
Модели данных ГИС
Как уже отмечалось, различаются три типа СУБД по общему структурам данных представления — т. н. моделей данных: иерархические, сетевые и реляционные. Среди них наибольшее распространение
Получили последние. В настоящее время иерархические и сетевые модели значительно уступают реляционным по количеству реализации в коммерческом СУБД, поэтому ограничиваются здесь их кратким описанием, стандартным читателем к специальной литературе
И.В иерархических моделях данные организованы в виде иерархической структуры (имеющей вид «дерева»), в которой исходные элементы порождают элементы, причем эти элементы в свою очередь порождают следующие элементы и т. д. Элементы (поля), связывающие верхние и нижние уровни иерархии, отражают принципиальную особенность иерархической организации: каждая запись приобретает смысл лишь тогда, когда она в определенном контексте. Иными словами, любой подчиненный элемент не может существовать без своего предшественника по иерархии.Как указывается в, иерархические модели, как обеспечивается естественный и адекватный метод информационного анализа реальных объектов, иерархически организованных географических объектов:
Экономических и природных ландшафтов, систем расселения и гидрографических сетей, систем обслуживания и административно-территориальных единиц. В то же время, несмотря на то, что иерархическая модель по самой сути ориентирована на организацию данных в территориальном разрезе, любые возможные выборки (отраслевые, классификационные), но связаны со значительными затратами времени на поиск необходимой информации.В этом состоит основной недостаток иерархической модели данных.
II. Сетевые модели допускают любые группировки и произвольные связи между ними, и в этом смысле являются универсальными. Однако структура сетевой модели обычно намного сложнее иерархической, и для переходов в такой БД необходимы дополнительные вычислительные ресурсы. В иерархической структуре можно легко удалить устаревшую информацию без риска потерять нужные сведения.»Узкое место» сетевого подхода включает в необходимость выбора стратегии поиска необходимой информации (эта проблема аналогична нахождению кратчайшего пути между двумя пунктами сложной и разветвленной сети), что сопряжено с трудностями программного и вычислительного характера.
Невзирая на то, что соответствующие ограничения, иерархическая и сетевая модели будут существовать.
III. Реляционная модель базы данных была предложена в 1970 году американским ученым Коддом. Она на основе представлении данных в виде отношений между ними. При этом представлении этих отношений подвергается нормализации — пошаговому процессу приведения к примерной табличной форме, причем информация об отношениях сохраняется полностью. Представление в виде двухмерных таблиц является естественным и хорошо воспринимается пользователями. Под элементами в данном случае понимают прямоугольные массивы, обладают свойствами: элементу данных соответствует вход в таблицу; в каждой из колонок таблицы располагаются: элементного вида; каждая колонке присваивается имя; Не допускаются совместные изменяющиеся значения всех колонок и строк.Отношения в реляционной модели базы данных представлений таблицами, каждая из которых содержит значения свойств (или атрибутов), имеющий некоторый объект данного типа;
Каждый из столбцов соответствует множеству значений, которому присущ некоторый атрибут этою типа. Совокупность значений одного атрибута (соответствующая столбцу таблицы) называется его Доменом. Для описания отношений и манипуляций над ними используется строгий математический язык, основанный на алгебре отношений и исчислении отношений.При этом возможны три уровня сопряжения пользователя с базой данных: на высшем уровне пользователь формулирует свои запросы в терминах реляционного исчисления, определяя, какие новые отношения он желает образовать из соотвествующих; на среднем уровне формулируется как последовательность операций реляционной алгебры, выполняемых над отношениями; на самом низком уровне пользователь определяет шаги получения некоторого Кортежами отношений (кортежами называются Строки таблицы отношений), т.е. полностью управляет поиском данных в базе данных. приведен условный экономико-географический пример реляционной базы данных, предложенный И. А.Портянским и частично адаптированный нами для целей наглядности (см. Рис. 2.14).
Как видно из Рис. 2.14 «в этой условной реляционной базе данных отношение» П «содержит сведения о промышленных предприятиях. Отношение «Труд» содержит данные о половом и образовательном составе трудовых ресурсов в городах региона. Отношение «ПТ» содержит сведения о том, какие трудовые ресурсы заняты на том или ином предприятии; так, первые кортежи этого отношения свидетельствуют, что на
Предприятии 1 в Городе 1 занято 500 мужчин с высшим образованием, со средним, проживающих в этом же городе.Отметим, что фигурирующие в базе данных значения атрибутов «Город» взят из основного диапазона всех вероятных названий городов, который в данном случае специально не задан. Заметим также, что все отношения имеют какой-либо общий домен.
Это обстоятельство наглядно демонстрирует основные свойства реляционных данных — связи между кортежами разных отношений прослеживаются только в одинаковых значениях атрибутов, извлеченных из общего домена. Тот факт, например, что предприятие П1 и трудовые ресурсы Т1 находятся в одном городе, отражается одинаковыми значениями (Город 1) в столбцах «Город» двух указанных кортежей.Таким образом, реляционный подход реализует оригинальную идею — рассматривать связи между объектами как типовые объекты. Следовательно, вся информация в базе данных, как «объекты», так и «связи», могут быть представлены в единой унифицированной форме. Этим преимуществом не иерархический и сетевой подходы.
Программные средства СУБД
. Большое распространение получили так называемые DBASE-подобные системы управления базами данных (СУБД), которые используют в качестве основных рабочих файлов с расширением.dbf. Известно по крайней мере три вида таких СУБД (dBASE, FoxBase и Clipper), однако версий систем и их адаптированных вариантов гораздо больше.
, которые используют одни и те же файлы, являются отличными между командными языками и форматом индексных файлов. dbf, формат по существу стал своеобразным стандартом данных.
Во всех dBASE-подобных базах данных используется реляционный подход к организации данных, т.е. каждый файл dbf представляет собой двухмерную таблицу, которая из фиксированного числа столбцов и состоит из числа строк (записей). В терминах, используемых в технической документации, каждому столбцу соответствует по одному из пяти типов (N — числовое, С — символьное, D — дата, L — лог или М — примечание), каждая строка — запись фиксированной данной, состоящая из фиксированного числа полей.
Следует отметить, что все большее распространение получают данные с другим форматом файлов — например, Paradox, Clarion, de_Vista.Эти системы представляются как универсальные средства для создания и размещения баз данных в любой предметной области. Как правило, необходимо иметь ввиду, что использовать эти инструменты для разработки и эксплуатации прикладных информационных систем необходимо, как правило, реализовать всю технологическую цепочку подготовки информации проекта: алгоритмизация — программирование — отладка — сопровождение. И хотя почти все эти содержат ряд технологических «программ без программиста» (типа «Ассистента», они часто не исчерпывают возможности системы и всегда удовлетворяют конечного пользователя.
Особое место занимает пакет Access различных версий (Open Access, DOS, Windows Access). Это мощная интегрированная система, в состав которой входят: реляционная СУБД, электронные таблицы, текстовый редактор, средства для организации коммуникаций и многое другое. Например, эта система может манипулировать не только числовой и текстовой информацией, но и графическими изображениями (рисунками, фотографиями), звуковыми фрагментами и видеоклипами. С помощью пакета Access можно создать таблицу, содержащую до 2 миллиардов записей и 255 полей.
Следует отметить, что большинство коммерческих пакетов ГИС имеют интерфейсы с перечисленными СУБД, включая импорт и экспорт данных в наиболее распространенных СУБД и даже организуют собственное хранение атрибутивных данных (например, в ASCII-таблицах)
Модели данных ГИС — 3.