Python: Set/Frozenset (Множество)
Статья проплачена кошками — всемирно известными производителями котят.
Если статья вам понравилась, то можете поддержать проект.
В статье использовались текст и картинки из Python и теория множеств
Множество (класс set) — это контейнер, который содержит уникальные не повторяющиеся элементы в случайном порядке (неупорядоченная коллекция).
Что значит неупорядоченная? Это значит, что два множества эквивалентны, если содержат одинаковые элементы.
Элементы множества должны быть уникальными, множество не может содержать одинаковых элементов. Добавление элементов, которые уже есть в множестве, не изменяет это множество.
Для множеств используются фигурные скобки, как у словарей. Достаточно перечислить элементы в скобках.
mySet = {'c', 'a', 't'}
# выводится в любом случайном порядке
print(mySet) # {'t', 'c', 'a'}
Но таким способом нельзя создать пустое множество, вместо него будет создан пустой словарь.
wrong_empty_set = {}
print(type(wrong_empty_set))
# <class "dict">
Для создания пустого множества нужно непосредственно использовать set():
correct_empty_set = set() print(type(correct_empty_set)) # <class "set">
Также в set() можно передать какой-либо объект, по которому можно пройтись (Iterable):
color_list = ["red", "green", "green", "blue", "purple", "purple"]
color_set = set(color_list)
print(color_set)
# порядок может быть другим
# {"red", "purple", "blue", "green"}
Число элементов вычисляется через len().
Существует ограничение, что элементами множества (как и ключами словарей) в Python могут быть только так называемые хешируемые (Hashable) объекты. Это обусловлено тем фактом, что внутренняя реализация set основана на хеш-таблицах. Например, списки и словари – это изменяемые объекты, которые не могут быть элементами множеств.
Проверить принадлежит ли какой-либо объект множеству можно с помощью оператора in.
tremendously_huge_set = {"red", "green", "blue"}
if "green" in tremendously_huge_set:
print("Green is there!")
else:
print("Unfortunately, there is no green...")
Множество удобно использовать для удаления повторяющихся элементов. Создадим список с элементами, которые повторяются по несколько раз и сконвертируем его во множество. На этот раз множество создадим через метод set().
words = ['a', 'a', 'b', 'b', 'c', 'd', 'e'] mySet = set(words) print(str(mySet))
Перебор элементов.
colors = {"red", "green", "blue"}
for color in colors:
print(color)
Два множества называются равными, если они состоят из одних и тех же элементов, порядок этих элементов не важен.
my_cats = {"bear", "pig", "cat", "cat"}
your_cats = {"pig", "pig", "bear", "cat", "cat"}
print(my_cats == your_cats)
# True
Если два множества не имеют общих элементов, то говорят, что эти множества не пересекаются и пересечение этих множеств является пустым множеством.
even_numbers = {i for i in range(10) if i % 2 == 0}
odd_numbers = {i for i in range(10) if i % 2 == 1}
# Очевидно, что множества чётных и нечётных чисел не пересекаются
if even_numbers.isdisjoint(odd_numbers):
print("Множества не пересекаются!")
# Множества не пересекаются!
Подмножество множества S – это такое множество, каждый элемент которого является также и элементом множества S. Множество S в свою очередь является надмножеством исходного множества.
# Множество чисел Фибоначчи меньших 100
fibonacci_numbers = {0, 1, 2, 3, 34, 5, 8, 13, 21, 55, 89}
# Множество натуральных чисел меньших 100
natural_numbers = set(range(100))
# Множество чисел Фибоначчи является подмножеством множества
# натуральных чисел
if fibonacci_numbers.
issubset(natural_numbers):
print("Подмножество!")
# Вывод:
Подмножество!
# В свою очередь множество натуральных чисел является
# надмножеством множества чисел Фибоначчи
if natural_numbers.issuperset(fibonacci_numbers):
print("Надмножество!")
# Вывод:
Надмножество!

Пустое множество является подмножеством абсолютно любого множества. Само множество является подмножеством самого себя.
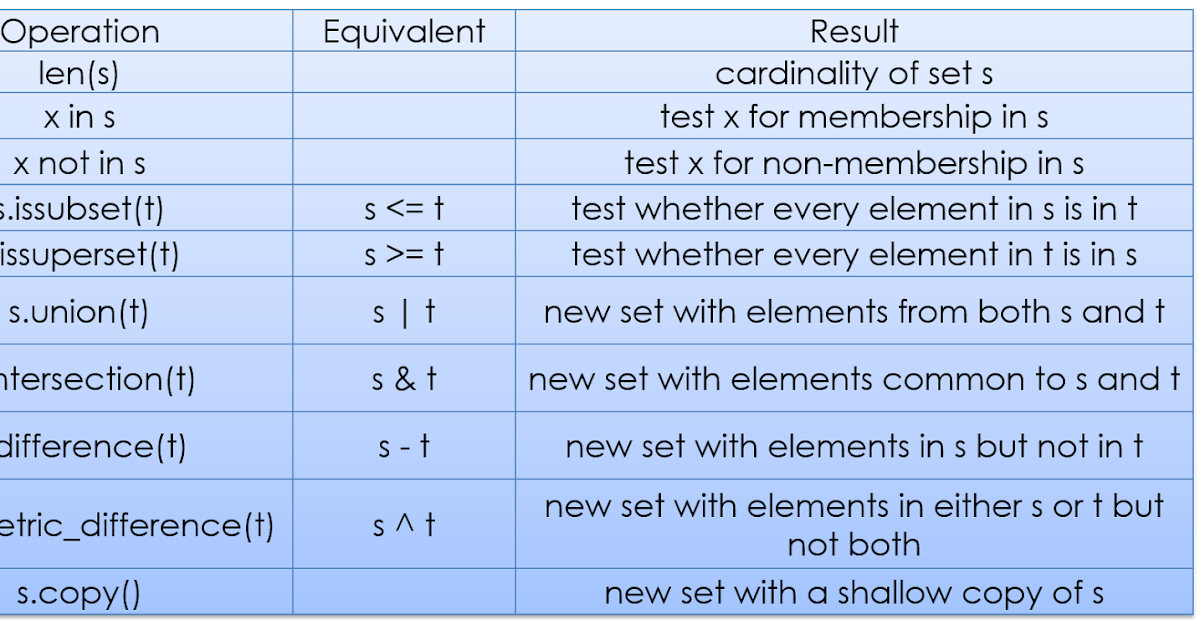
Другие методы: ‘clear’ (очистка множества), ‘copy’, ‘pop’ (удаляет первый элемент из множества. Так как множества не упорядочены, нельзя точно сказать, какой элемент будет первым), ‘remove’, ‘update’, ‘__bases__’, ‘__contains__’, ‘add’, ‘difference’, ‘difference_update’, ‘discard’, ‘intersection’ (пересечение), ‘intersection_update’, ‘isdisjoint’ (истина, если set и other не имеют общих элементов), ‘issubset’, ‘issuperset’, ‘symmetric_difference’, ‘symmetric_difference_update’, ‘union’ (объединение нескольких множеств).
У множеств можно находить объединение или пересечение элементов.
Объединение множеств – это множество, которое содержит все элементы исходных множеств. В Python есть несколько способов объединить множества.
my_fruits = {"apple", "orange"}
your_fruits = {"orange", "banana", "pear"}
# Для объединения множеств можно использовать оператор `|`,
# оба операнда должны быть объектами типа set
our_fruits = my_fruits | your_fruits
print(our_fruits)
# Вывод (порядок может быть другим):
{"apple", "banana", "orange", "pear"}
# Также можно использовать метод union.
# Отличие состоит в том, что метод union принимает не только
# объект типа set, а любой iterable-объект
you_fruit_list: list = list(your_fruits)
our_fruits: set = my_fruits.union(you_fruit_list)
print(our_fruits)
# Вывод (порядок может быть другим):
{"apple", "banana", "orange", "pear"}
Добавление элементов в множество можно рассматривать как частный случай объединения множеств за тем исключением, что добавление элементов изменяет исходное множество, а не создаёт новый объект.
colors = {"red", "green", "blue"}
# Метод add добавляет новый элемент в множество
colors.add("purple")
# Добавление элемента, который уже есть в множестве, не изменяет
# это множество
colors.add("red")
print(colors)
# Вывод (порядок может быть другим):
{"red", "green", "blue", "purple"}
# Метод update принимает iterable-объект (список, словарь, генератор и т.п.)
# и добавляет все элементы в множество
numbers = {1, 2, 3}
numbers.update(i**2 for i in [1, 2, 3])
print(numbers)
# Вывод (порядок может быть другим):
{1, 2, 3, 4, 9}
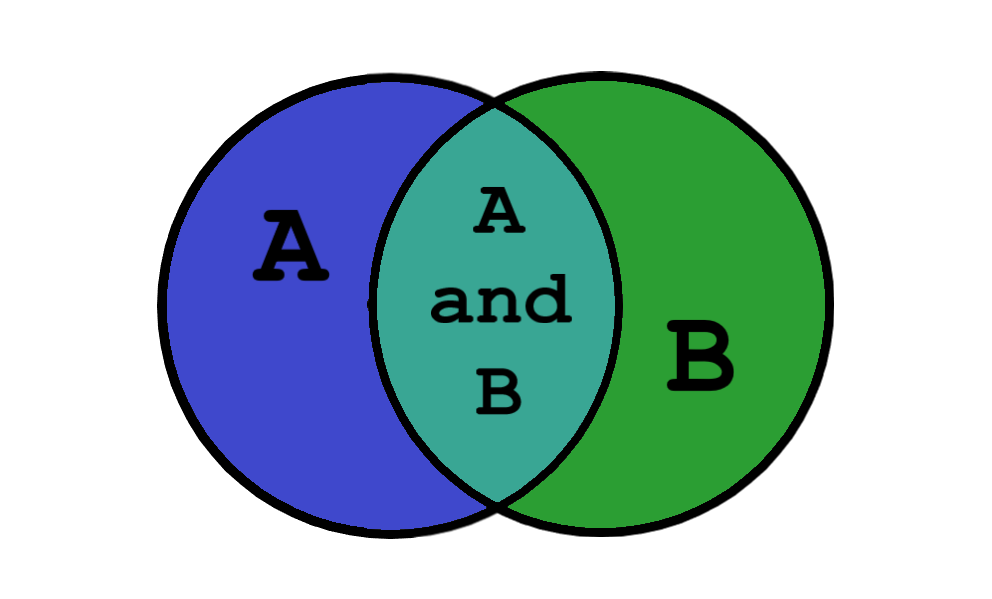
Пересечение множеств – это множество, в котором находятся только те элементы, которые принадлежат исходным множествам одновременно.
def is_prime(number: int) -> bool:
""" Возвращает True, если number - это простое число
"""
assert number > 1
return all(number % i for i in range(2, int(number**0. 5) + 1))
def is_fibonacci(number: int) -> bool:
""" Возвращает True, если number - это число Фибоначчи
"""
assert number > 1
a, b = 0, 1
while a + b 
Разность двух множеств – это множество, в которое входят все элементы первого множества, не входящие во второе множество.
i_know: set = {"Python", "Go", "Java"}
you_know: dict = {
"Go": 0.4,
"C++": 0.6,
"Rust": 0.2,
"Java": 0.9
}
# Обратите внимание, что оператор `-` работает только
# для объектов типа set
you_know_but_i_dont = set(you_know) - i_know
print(you_know_but_i_dont)
# Вывод (порядок может быть другим):
{"Rust", "C++"}
# Метод difference может работать с любым iterable-объектом,
# каким является dict, например
i_know_but_you_dont = i_know.difference(you_know)
print(i_know_but_you_dont)
# Вывод:
{"Python"}
Удаление элемента из множества можно рассматривать как частный случай разности, где удаляемый элемент – это одноэлементное множество. Следует отметить, что удаление элемента, как и в аналогичном случае с добавлением элементов, изменяет исходное множество.
Следует отметить, что удаление элемента, как и в аналогичном случае с добавлением элементов, изменяет исходное множество.
fruits = {"apple", "orange", "banana"}
# Удаление элемента из множества. Если удаляемого элемента
# нет в множестве, то ничего не происходит
fruits.discard("orange")
fruits.discard("pineapple")
print(fruits)
# Вывод (порядок может быть другим):
{"apple", "banana"}
# Метод remove работает аналогично discard, но генерирует исключение,
# если удаляемого элемента нет в множестве
fruits.remove("pineapple") # KeyError: "pineapple"
Симметрическая разность множеств – это множество, включающее все элементы исходных множеств, не принадлежащие одновременно обоим исходным множествам. Также симметрическую разность можно рассматривать как разность между объединением и пересечением исходных множеств.
non_positive = {-3, -2, -1, 0}
non_negative = {0, 1, 2, 3}
# Обратите внимание, что оператор `^` может применяться
# только для объектов типа set
non_zero = non_positive ^ non_negative
print(non_zero)
# Вывод (порядок может быть другим):
{-1, -2, -3, 1, 2, 3}
Как видно из примера выше, число 0 принадлежит обоим исходным множествам, и поэтому оно не входит в результирующее множество.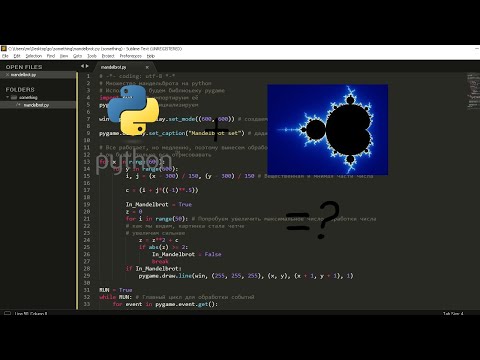 , также существует два специальных метода – symmetric_difference и symmetric_difference_update. Оба этих метода принимают iterable-объект в качестве аргумента, отличие же состоит в том, что symmetric_difference возвращает новый объект-множество, в то время как symmetric_difference_update изменяет исходное множество.
, также существует два специальных метода – symmetric_difference и symmetric_difference_update. Оба этих метода принимают iterable-объект в качестве аргумента, отличие же состоит в том, что symmetric_difference возвращает новый объект-множество, в то время как symmetric_difference_update изменяет исходное множество.
non_positive = {-3, -2, -1, 0}
non_negative = range(4)
non_zero = non_positive.symmetric_difference(non_negative)
print(non_zero)
# Вывод (порядок может быть другим):
{-1, -2, -3, 1, 2, 3}
# Метод symmetric_difference_update изменяет исходное множество
colors = {"red", "green", "blue"}
colors.symmetric_difference_update(["green", "blue", "yellow"])
print(colors)
# Вывод (порядок может быть другим):
{"red", "yellow"}
frozenset — это неизменяемое множество.
Методы: ‘__name__’, ‘copy’, ‘__bases__’, ‘__contains__’, ‘difference’, ‘intersection’, ‘isdisjoint’, ‘issubset’, ‘issuperset’, ‘symmetric_difference’, ‘union’.
Создадим два разных типа множества, сравним их и попытаемся добавить новые элементы.
setCat = set('кот')
frozenCat = frozenset('кот')
print(setCat == frozenCat)
print(type(setCat)) # set
print(type(frozenCat)) #frozenset
setCat.add('э') # можем добавить
print(setCat)
frozenCat.add('e') # эта строка вызовет ошибку при компиляции
Реклама
Python и теория множеств / Хабр
В Python есть очень полезный тип данных для работы с множествами – это set. Об этом типе данных, примерах использования, и небольшой выдержке из теории множеств пойдёт речь далее.
Следует сразу сделать оговорку, что эта статья ни в коем случае не претендует на какую-либо математическую строгость и полноту, скорее это попытка доступно продемонстрировать примеры использования множеств в языке программирования Python.
- Множество
- Множества в Python
- Хешируемые объекты
- Свойства множеств
- Принадлежность множеству
- Мощность множества
- Перебор элементов множества
- Отношения между множествами
- Равные множества
- Непересекающиеся множества
- Подмножество и надмножество
- Операции над множествами
- Объединение множеств
- Добавление элементов в множество
- Пересечение множеств
- Разность множеств
- Удаление элементов из множества
- Симметрическая разность множеств
- Заключение
- Полезные ссылки
Множество
Множество – это математический объект, являющийся набором, совокупностью, собранием каких-либо объектов, которые называются элементами этого множества.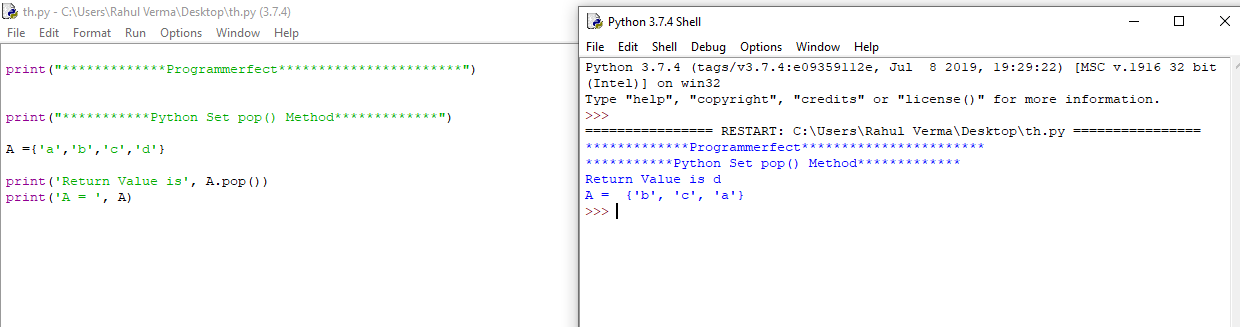 Или другими словами:
Или другими словами:
Множество – это не более чем неупорядоченная коллекция уникальных элементов.
Что значит неупорядоченная? Это значит, что два множества эквивалентны, если содержат одинаковые элементы.
Элементы множества должны быть уникальными, множество не может содержать одинаковых элементов. Добавление элементов, которые уже есть в множестве, не изменяет это множество.
Множества, состоящие из конечного числа элементов, называются конечными, а остальные множества – бесконечными. Конечное множество, как следует из названия, можно задать перечислением его элементов. Так как темой этой статьи является практическое использование множеств в Python, то я предлагаю сосредоточиться на конечных множествах.
Множества в Python
Множество в Python можно создать несколькими способами. Самый простой – это задать множество перечислением его элементов в фигурных скобках:
fruits = {"banana", "apple", "orange"}Единственное ограничение, что таким образом нельзя создать пустое множество. Вместо этого будет создан пустой словарь:
Вместо этого будет создан пустой словарь:
wrong_empty_set = {}
print(type(wrong_empty_set))
# Вывод
<class "dict">Для создания пустого множества нужно непосредственно использовать set():
correct_empty_set = set() print(type(correct_empty_set)) # Вывод <class "set">
Также в set() можно передать какой-либо объект, по которому можно проитерироваться (Iterable):
color_list = ["red", "green", "green", "blue", "purple", "purple"]
color_set = set(color_list)
print(color_set)
# Вывод (порядок может быть другим):
{"red", "purple", "blue", "green"}Ещё одна возможность создания множества – это использование set comprehension. Это специальная синтаксическая конструкция языка, которую иногда называют абстракцией множества по аналогии с list comprehension (Списковое включение).
numbers = [1, 2, 2, 2, 3, 3, 4, 4, 5, 6]
# Единственное отличие со списковыми включениями - это
# использование фигурных скобок вместо квадратных
even_numbers = {
number for number in numbers
if number % 2 == 0
}
print(even_numbers)
# Вывод (порядок может быть другим):
{2, 4, 6}Хешируемые объекты
Существует ограничение, что элементами множества (как и ключами словарей) в Python могут быть только так называемые хешируемые (Hashable) объекты. Это обусловлено тем фактом, что внутренняя реализация set основана на хеш-таблицах. Например, списки и словари – это изменяемые объекты, которые не могут быть элементами множеств. Большинство неизменяемых типов в Python (int, float, str, bool, и т.д.) – хешируемые. Неизменяемые коллекции, например tuple, являются хешируемыми, если хешируемы все их элементы.
Это обусловлено тем фактом, что внутренняя реализация set основана на хеш-таблицах. Например, списки и словари – это изменяемые объекты, которые не могут быть элементами множеств. Большинство неизменяемых типов в Python (int, float, str, bool, и т.д.) – хешируемые. Неизменяемые коллекции, например tuple, являются хешируемыми, если хешируемы все их элементы.
# Множество кортежей (tuple)
records = {
("Москва", 17_200_000),
("Санкт-Петербург", 5_400_000),
("Новосибирск", 1_600_000),
("Москва", 17_200_000),
}
for city, population in records:
print(city)
# Вывод (порядок может быть другим):
Москва
Новосибирск
Санкт-ПетербургОбъекты пользовательских классов являются хешируемыми по умолчанию. Но практического смысла чаще всего в этом мало из-за того, что сравнение таких объектов выполняется по их адресу в памяти, т.е. невозможно создать два «равных» объекта.
class City:
def __init__(self, name: str):
self. name = name
def __repr__(self) -> str:
""" Определим метод __repr__ для наглядности следующих примеров
"""
return f'City("{self.name}")'
print(City("Moscow") == City("Moscow"))
# Вывод:
False
cities = {City("Moscow"), City("Moscow")}
print(cities)
# Вывод
{City("Moscow"), City("Moscow")} name = name
def __repr__(self) -> str:
""" Определим метод __repr__ для наглядности следующих примеров
"""
return f'City("{self.name}")'
print(City("Moscow") == City("Moscow"))
# Вывод:
False
cities = {City("Moscow"), City("Moscow")}
print(cities)
# Вывод
{City("Moscow"), City("Moscow")}
name = name
def __repr__(self) -> str:
""" Определим метод __repr__ для наглядности следующих примеров
"""
return f'City("{self.name}")'
print(City("Moscow") == City("Moscow"))
# Вывод:
False
cities = {City("Moscow"), City("Moscow")}
print(cities)
# Вывод
{City("Moscow"), City("Moscow")}Скорее всего мы предполагаем, что объекты City("Moscow") должны быть равными, и следовательно в множестве cities должен находиться один объект.
Этого можно добиться, если определить семантику равенства для объектов класса City:
class City:
def __init__(self, name: str):
# Атрибут name не должен изменяться, пока объект существует
# Для простоты пометим этот атрибут как внутренний
self._name = name
def __hash__(self) -> int:
""" Хеш от объекта
"""
return hash((self._name, self.__class__))
def __eq__(self, other) -> bool:
""" Определяем семантику равентсва (оператор ==)
"""
if not isinstance(other, self. __class__):
return False
return self._name == other._name
def __repr__(self) -> str:
""" Определим метод __repr__ для наглядности следующих примеров
"""
return f'City("{self._name}")'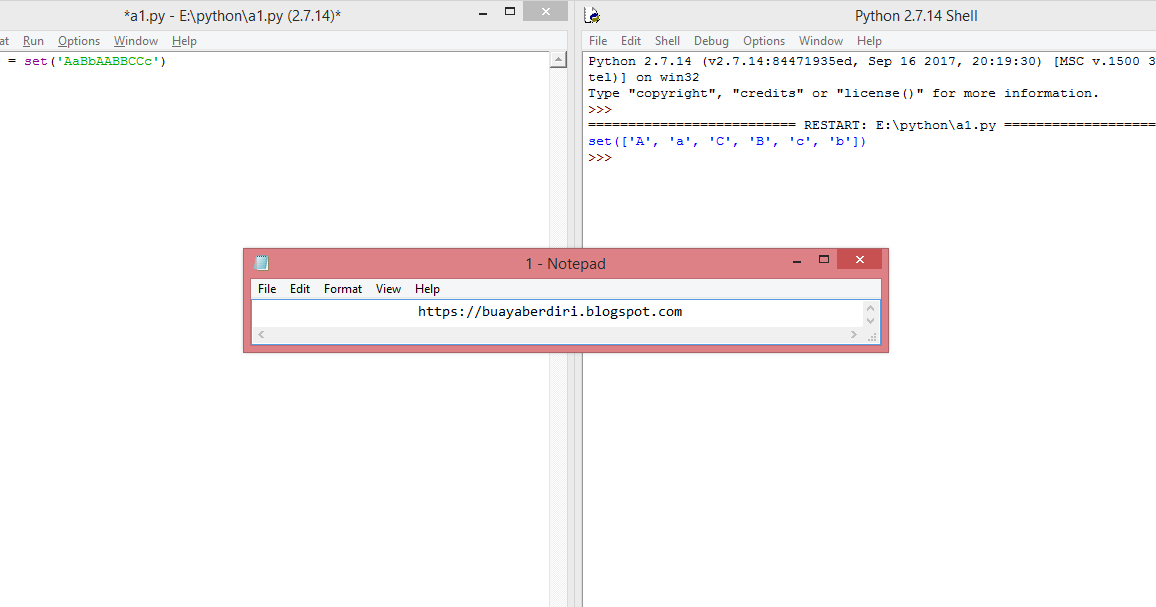 __class__):
return False
return self._name == other._name
def __repr__(self) -> str:
""" Определим метод __repr__ для наглядности следующих примеров
"""
return f'City("{self._name}")'
__class__):
return False
return self._name == other._name
def __repr__(self) -> str:
""" Определим метод __repr__ для наглядности следующих примеров
"""
return f'City("{self._name}")'Чтобы протокол хеширования работал без явных и неявных логических ошибок, должны выполняться следующие условия:
- Хеш объекта не должен изменяться, пока этот объект существует
- Равные объекты должны возвращать одинаковый хеш
moscow = City("Moscow")
moscow_again = City("Moscow")
print(moscow == moscow_again and hash(moscow) == hash(moscow_again))
# Вывод:
True
# Теперь множество городов работает более логично и интуитивно
cities = {City("Moscow"), City("Kazan"), City("Moscow")}
print(cities)
# Вывод (порядок может быть другим):
{City("Kazan"), City("Moscow")}Свойства множеств
Тип set в Python является подтипом Collection (про коллекции), из данного факта есть три важных следствия:
- Определена операция проверки принадлежности элемента множеству
- Можно получить количество элементов в множестве
- Множества являются iterable-объектами
Принадлежность множеству
Проверить принадлежит ли какой-либо объект множеству можно с помощью оператора in. Это один из самых распространённых вариантов использования множеств. Такая операция выполняется в среднем за
Это один из самых распространённых вариантов использования множеств. Такая операция выполняется в среднем за O(1) с теми же оговорками, которые существуют для хеш-таблиц.
tremendously_huge_set = {"red", "green", "blue"}
if "green" in tremendously_huge_set:
print("Green is there!")
else:
print("Unfortunately, there is no green...")
# Вывод:
Green is there!
if "purple" in tremendously_huge_set:
print("Purple is there!")
else:
print("Unfortunately, there is no purple...")
# Вывод:
Unfortunately, there is no purple...Мощность множества
Мощность множества – это характеристика множества, которая для конечных множеств просто означает количество элементов в данном множестве. Для бесконечных множеств всё несколько сложнее.
even_numbers = {i for i in range(100) if i % 2 == 0}
# Мощность множества
cardinality = len(even_numbers)
print(cardinality)
# Вывод:
50Перебор элементов множества
Как уже было отмечено выше, множества поддерживают протокол итераторов, таким образом любое множество можно использовать там, где ожидается iterable-объект.
colors = {"red", "green", "blue"}
# Элементы множества можно перебрать с помощью цикла for
for color in colors:
print(color)
# Вывод (порядок может быть другим):
red
green
blue
# Множества можно использовать там, где ожидается iterable-объект
color_counter = dict.fromkeys(colors, 1)
print(color_counter)
# Вывод (порядок может быть другим):
{"green": 1, "red": 1, "blue": 1}Отношения между множествами
Между множествами существуют несколько видов отношений, или другими словами взаимосвязей. Давайте рассмотрим возможные отношения между множествами в этом разделе.
Равные множества
Тут всё довольно просто – два множества называются равными, если они состоят из одних и тех же элементов. Как следует из определения множества, порядок этих элементов не важен.
my_fruits = {"banana", "apple", "orange", "orange"}
your_fruits = {"apple", "apple", "banana", "orange", "orange"}
print(my_fruits == your_fruits)
# Вывод:
TrueНепересекающиеся множества
Если два множества не имеют общих элементов, то говорят, что эти множества не пересекаются. Или другими словами, пересечение этих множеств является пустым множеством.
Или другими словами, пересечение этих множеств является пустым множеством.
even_numbers = {i for i in range(10) if i % 2 == 0}
odd_numbers = {i for i in range(10) if i % 2 == 1}
# Очевидно, что множества чётных и нечётных чисел не пересекаются
if even_numbers.isdisjoint(odd_numbers):
print("Множества не пересекаются!")
# Вывод:
Множества не пересекаются!Подмножество и надмножество
Подмножество множества S – это такое множество, каждый элемент которого является также и элементом множества S. Множество S в свою очередь является надмножеством исходного множества.
# Множество чисел Фибоначчи меньших 100
fibonacci_numbers = {0, 1, 2, 3, 34, 5, 8, 13, 21, 55, 89}
# Множество натуральных чисел меньших 100
natural_numbers = set(range(100))
# Множество чисел Фибоначчи является подмножеством множества
# натуральных чисел
if fibonacci_numbers.issubset(natural_numbers):
print("Подмножество!")
# Вывод:
Подмножество!
# В свою очередь множество натуральных чисел является
# надмножеством множества чисел Фибоначчи
if natural_numbers. issuperset(fibonacci_numbers):
print("Надмножество!")
# Вывод:
Надмножество! issuperset(fibonacci_numbers):
print("Надмножество!")
# Вывод:
Надмножество!
issuperset(fibonacci_numbers):
print("Надмножество!")
# Вывод:
Надмножество!Пустое множество является подмножеством абсолютно любого множества.
empty = set()
# Методы issubset и issuperset могут принимать любой iterable-объект
print(
empty.issubset(range(100))
and empty.issubset(["red", "green", "blue"])
and empty.issubset(set())
)
# Вывод:
TrueСамо множество является подмножеством самого себя.
natural_numbers = set(range(100))
if natural_numbers.issubset(natural_numbers):
print("Подмножество!")
# Вывод:
Подмножество!Операции над множествами
Рассмотрим основные операции, опредяляемые над множествами.
Объединение множеств
Объединение множеств – это множество, которое содержит все элементы исходных множеств. В Python есть несколько способов объединить множества, давайте рассмотрим их на примерах.
my_fruits = {"apple", "orange"}
your_fruits = {"orange", "banana", "pear"}
# Для объединения множеств можно использовать оператор `|`,
# оба операнда должны быть объектами типа set
our_fruits = my_fruits | your_fruits
print(our_fruits)
# Вывод (порядок может быть другим):
{"apple", "banana", "orange", "pear"}
# Также можно использовать ментод union.
# Отличие состоит в том, что метод union принимает не только
# объект типа set, а любой iterable-объект
you_fruit_list: list = list(your_fruits)
our_fruits: set = my_fruits.union(you_fruit_list)
print(our_fruits)
# Вывод (порядок может быть другим):
{"apple", "banana", "orange", "pear"} # Отличие состоит в том, что метод union принимает не только
# объект типа set, а любой iterable-объект
you_fruit_list: list = list(your_fruits)
our_fruits: set = my_fruits.union(you_fruit_list)
print(our_fruits)
# Вывод (порядок может быть другим):
{"apple", "banana", "orange", "pear"}
# Отличие состоит в том, что метод union принимает не только
# объект типа set, а любой iterable-объект
you_fruit_list: list = list(your_fruits)
our_fruits: set = my_fruits.union(you_fruit_list)
print(our_fruits)
# Вывод (порядок может быть другим):
{"apple", "banana", "orange", "pear"}Добавление элементов в множество
Добавление элементов в множество можно рассматривать как частный случай объединения множеств за тем исключением, что добавление элементов изменяет исходное множество, а не создает новый объект. Добавление одного элемента в множество работает за O(1).
colors = {"red", "green", "blue"}
# Метод add добаляет новый элемент в множество
colors.add("purple")
# Добавление элемента, который уже есть в множестве, не изменяет
# это множество
colors.add("red")
print(colors)
# Вывод (порядок может быть другим):
{"red", "green", "blue", "purple"}
# Метод update принимает iterable-объект (список, словарь, генератор и т.п.)
# и добавляет все элементы в множество
numbers = {1, 2, 3}
numbers. update(i**2 for i in [1, 2, 3])
print(numbers)
# Вывод (порядок может быть другим):
{1, 2, 3, 4, 9} update(i**2 for i in [1, 2, 3])
print(numbers)
# Вывод (порядок может быть другим):
{1, 2, 3, 4, 9}
update(i**2 for i in [1, 2, 3])
print(numbers)
# Вывод (порядок может быть другим):
{1, 2, 3, 4, 9}Пересечение множеств
Пересечение множеств – это множество, в котором находятся только те элементы, которые принадлежат исходным множествам одновременно.
def is_prime(number: int) -> bool:
""" Возвращает True, если number - это простое число
"""
assert number > 1
return all(number % i for i in range(2, int(number**0.5) + 1))
def is_fibonacci(number: int) -> bool:
""" Возвращает True, если number - это число Фибоначчи
"""
assert number > 1
a, b = 0, 1
while a + b < number:
a, b = b, a + b
return a + b == number
# Множество простых чисел до 100
primes = set(filter(is_prime, range(2, 101)))
# Множество чисел Фибоначчи до 100
fibonacci = set(filter(is_fibonacci, range(2, 101)))
# Множество простых чисел до 100, которые одновременно являются
# числами Фибоначчи
prime_fibonacci = primes.intersection(fibonacci)
# Или используя оператор `&`, который определён для множеств
prime_fibonacci = fibonacci & primes
print(prime_fibonacci)
# Вывод (порядок может быть другим):
{2, 3, 5, 13, 89}При использовании оператора & необходимо, чтобы оба операнда были объектами типа set.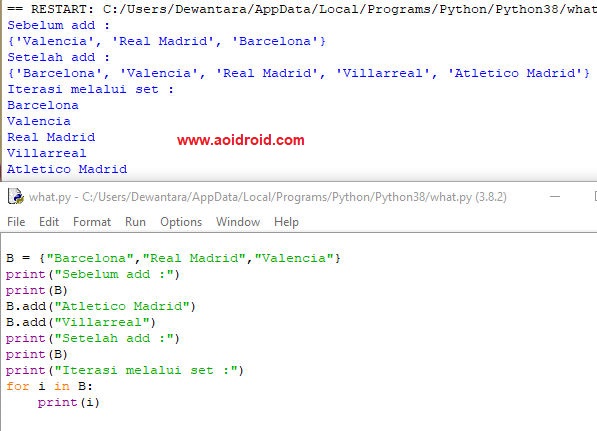 Метод
Метод intersection, в свою очередь, принимает любой iterable-объект. Если необходимо изменить исходное множество, а не возращать новое, то можно использовать метод intersection_update, который работает подобно методу intersection, но изменяет исходный объект-множество.
Разность множеств
Разность двух множеств – это множество, в которое входят все элементы первого множества, не входящие во второе множество.
i_know: set = {"Python", "Go", "Java"}
you_know: dict = {
"Go": 0.4,
"C++": 0.6,
"Rust": 0.2,
"Java": 0.9
}
# Обратите внимание, что оператор `-` работает только
# для объектов типа set
you_know_but_i_dont = set(you_know) - i_know
print(you_know_but_i_dont)
# Вывод (порядок может быть другим):
{"Rust", "C++"}
# Метод difference может работать с любым iterable-объектом,
# каким является dict, например
i_know_but_you_dont = i_know.difference(you_know)
print(i_know_but_you_dont)
# Вывод:
{"Python"}Удаление элементов из множества
Удаление элемента из множества можно рассматривать как частный случай разности, где удаляемый элемент – это одноэлементное множество. Следует отметить, что удаление элемента, как и в аналогичном случае с добавлением элементов, изменяет исходное множество. Удаление одного элемента из множества имеет вычислительную сложность
Следует отметить, что удаление элемента, как и в аналогичном случае с добавлением элементов, изменяет исходное множество. Удаление одного элемента из множества имеет вычислительную сложность O(1).
fruits = {"apple", "orange", "banana"}
# Удаление элемента из множества. Если удаляемого элемента
# нет в множестве, то ничего не происходит
fruits.discard("orange")
fruits.discard("pineapple")
print(fruits)
# Вывод (порядок может быть другим):
{"apple", "banana"}
# Метод remove работает аналогично discard, но генерирует исключение,
# если удаляемого элемента нет в множестве
fruits.remove("pineapple") # KeyError: "pineapple"Также у множеств есть метод differenсe_update, который принимает iterable-объект и удаляет из исходного множества все элементы iterable-объекта. Этот метод работает аналогично методу difference, но изменяет исходное множество, а не возвращает новое.
numbers = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
even_numbers_under_100 = (i for i in range(1, 101) if i % 2 == 0)
numbers. , также существует два специальных метода – symmetric_difference и symmetric_difference_update. Оба этих метода принимают iterable-объект в качестве аргумента, отличие же состоит в том, что symmetric_difference возвращает новый объект-множество, в то время как symmetric_difference_update изменяет исходное множество.non_positive = {-3, -2, -1, 0}
non_negative = range(4)
non_zero = non_positive.symmetric_difference(non_negative)
print(non_zero)
# Вывод (порядок может быть другим):
{-1, -2, -3, 1, 2, 3}
# Метод symmetric_difference_update изменяет исходное множество
colors = {"red", "green", "blue"}
colors.symmetric_difference_update(["green", "blue", "yellow"])
print(colors)
# Вывод (порядок может быть другим):
{"red", "yellow"}
Заключение
Я надеюсь, мне удалось показать, что Python имеет очень удобные встроенные средства для работы с множествами. На практике это часто позволяет сократить количество кода, сделать его выразительнее и легче для восприятия, а следовательно и более поддерживаемым. Я буду рад, если у вас есть какие-либо конструктивные замечания и дополнения.
Полезные ссылки
Множества (Статья на Википедии)
Документация по типу set
Iterable-объекты (Глоссарий Python)
Hashable-объекты (Глоссарий Python)
Sets in Python
Set Theory: the Method To Database Madness
Наборы в Python — GeeksforGeeks
Набор в программировании на Python — это неупорядоченный тип данных коллекции, который является повторяемым, изменяемым и не имеет повторяющихся элементов.
Набор представлен { } (значения заключены в фигурные скобки). набор. Это основано на структуре данных, известной как хеш-таблица. Поскольку множества неупорядочены, мы не можем обращаться к элементам с помощью индексов, как в списках.
Example of Python Sets
Python3
var = { "Geeks" , "for" , "Geeks" }
type (var)
Вывод:
set
Приведение типов с помощью метода Python Set
Метод Python set() используется для приведения типов Python.
Python3
myset = set ([ "a" , "b" , "c" ])
print (myset)
myset.add( "d" )
print (myset)
Output:
Python set is an неупорядоченный тип данных, что означает, что мы не можем знать, в каком порядке хранятся элементы набора.
{'в', 'б', 'а'}
{'d', 'c', 'b', 'a'} Проверка уникальности и неизменяемости с помощью Python Set
Наборы Python не могут иметь повторяющееся значение, и после создания мы не можем изменить его значение.
Python3
myset = { "Geeks" , "for" , "Geeks" }
print (мой набор)
myset[ 1 ] = "Hello"
print (myset)
Output:
The first code explains that the set не может иметь повторяющееся значение. Каждый элемент в нем является уникальным значением.
Второй код генерирует ошибку, поскольку мы не можем присвоить или изменить значение после создания набора. Мы можем только добавлять или удалять элементы в наборе.
{'Гики', 'для'}
TypeError: объект 'set' не поддерживает назначение элементов Гетерогенный элемент с набором Python
Наборы Python могут хранить в нем гетерогенные элементы, т. е. набор может хранить смесь строковых, целых, логических и т. д. типов данных.
Python3
myset = { "Geeks" , "for" , 10 , 52.7 , True }
Печать (MYSE)
Выход:
{True, 10, 'Geeks, 52.7, 52.7, 52.7, 52.7, 52.7, 52.7, 52.7, 52.7, 52.7, 52.7, 52.7, 52.7, 9003 {True, 10,' Geeks 52.7, 9003 (True, 10, 'Geeks'. Наборы Замороженные наборы в Python — это неизменяемые объекты, которые поддерживают только методы и операторы, которые производят результат, не затрагивая замороженный набор или наборы, к которым они применяются. Это можно сделать с помощью метода Frozenset() в Python.
Хотя элементы набора можно изменить в любое время, элементы фиксированного набора остаются неизменными после создания.
Если параметры не переданы, возвращается пустой замороженный набор.
Python
normal_set = set ([ "a" , "b" , "c" ])
печать ( "Normal Set" )
print (normal_set)
frozen_set = frozenset ([ "e" , "f" , "g" ])
print ( "\nFrozen Set" )
print (frozen_set)
Выход:
Нормальный набор
{'а', 'в', 'б'}
Замороженный набор
{'e', 'g', 'f'} Внутренняя работа Set
Это основано на структуре данных, известной как хеш-таблица. Если несколько значений присутствуют в одной и той же позиции индекса, то значение добавляется к этой позиции индекса для формирования связанного списка.
В Python Sets реализованы с использованием словаря с фиктивными переменными, где ключевыми являются члены, установленные с большей оптимизацией временной сложности.
Реализация набора:
Наборы с многочисленными операциями над одной HashTable:
Методы для наборов
Добавление элементов в наборы Python с помощью функции set()
5 900 , где создается соответствующее значение записи для сохранения в хеш-таблице. То же, что и при проверке элемента, т. е. в среднем O(1). Однако в худшем случае это может стать O(n) . Python3
people = { "Jay" , "Idrish" , "Archi" }
print ( "Люди:" , конец = "" )
Печать (люди)
PEON. 0020
for i in range ( 1 , 6 ):
people.add(i)
Печать ( "\ nset после добавления элемента:" , конец = "" )
Печать (люди)
0002 Вывод: Люди: {'Идриш', 'Арчи', 'Джей'}
Установить после добавления элемента: {1, 2, 3, 4, 5, 'Идриш', 'Арчи', 'Джей', 'Даксит'} Операция объединения в наборах Python
Два набора можно объединить с помощью union() функция или | оператор. Доступ к обоим значениям хеш-таблицы и их обход осуществляется с помощью операции слияния, выполняемой над ними для объединения элементов, в то же время дубликаты удаляются. Временная сложность составляет O(len(s1) + len(s2)) , где s1 и s2 — два набора, объединение которых необходимо выполнить.
Python3
people = { "Jay" , "Idrish" , "Archil" }
vampires = { "Karan" , "Arjun" }
Dracula = { "Дипанш 1920192019201920120192019201019201920192019201920192019201920192019201920192019201920192019201920192019201001920192019201920100
{ " 1920120019 }
population = people. union(vampires)
print ( "Union using union() function" )
print (популяция)
Популяция = человек | Dracula
Печать ( »\ Nunion с использованием '|' | 'Operator" 0019 )
печать (население)
Вывод:
Объединение с использованием функции union()
{'Каран', 'Идриш', 'Джей', 'Арджун', 'Арчил'}
Союз с использованием '|' оператор
{'Deepanshu', 'Idrish', 'Jay', 'Raju', 'Archil'} Операция пересечения наборов Python
Это можно сделать с помощью оператора cross() или &. Выбраны общие элементы. Они аналогичны перебору списков хешей и объединению одних и тех же значений в обеих таблицах. Временная сложность этого O(min(len(s1), len(s2)) где s1 и s2 — два набора, объединение которых необходимо выполнить.
Python3
set1 = set ()
set2 = set ()
for i В Диапазон ( 5 ):
SET1.Add (I)
9003
для I I I I 0019 range ( 3 , 9 ):
set2. add(i)
set3 = set1.intersection(set2)
print ( "Intersection using intersection() function" )
print (set3)
set3 = set1 & set2
print ( "\nIntersection using '&' operator" )
print (set3)
Output:
Пересечение с использованием функции пересечения()
{3, 4}
Пересечение с использованием оператора '&'
{3, 4} Поиск различий наборов в Python
Для поиска различий между наборами. Аналогично поиску различий в связанном списке. Это делается через разницу() или – оператор. Временная сложность поиска разницы s1 – s2 равна O(len(s1))
Python3
set1 = set ()
set2 = set ()
for i В Диапазон ( 5 ):
SET1.Add (I)
9003
для I I I I 0019 Диапазон ( 3 , ):
SET2. Add (I)
SET3 .920201392013.92013 9003
) Печать ( "Разница в двух наборах с использованием различий () Функция" )
Печать (SET3)
SET3 9009 =
SET3 9009 =
=
=
. 0020 set1 - set2
print ( "\nDifference of two sets using '-' operator" )
print (set3)
Вывод:
Разница двух наборов с использованием функции разность()
{0, 1, 2}
Разница двух наборов с помощью оператора «-»
{0, 1, 2} Очистка наборов Python
Метод Set Clear() очищает весь набор на месте.
Python3
set1 = { 1 , 2 , 3 , 4 , 5 , 6 }
print ( "Initial set" )
print (set1)
set1. clear()
print ( "\nSet after using clear() function" )
print (set1)
Output:
Initial set
{1, 2, 3, 4, 5, 6}
Установить после использования функции clear()
set() Однако в наборах Python есть две основные ловушки:
- Набор не поддерживает элементы в каком-либо определенном порядке.
- : В набор Python можно добавлять только экземпляры неизменяемых типов.
Time complexity of Sets
Operation Average case Worst Case notes x in s O(1) O(n) Union s|t O(len(s)+len(t)) Пересечение s&t O(min(len(s), len(t)) O(len(s) * len(t)) заменить «min» на «max», если t не является множеством O(l), где l max(len(s1),. .,len(sn)) Разность s-t O(len(s)) Наборы и замороженные наборы поддерживают следующие операторы:
Операторы Notes key in s containment check key not in s non-containment check s1 == s2 s1 is equivalent to s2 s1 ! = S2 S1 не эквивалентен S2 S1 <= S2 S1 - подмножество S2 S1 S1 - это подразделение S2 S1.0044 s1 является надмножеством s2 s1 > s2 s1 является правильным надмножеством s2 s1 | S2 Союз S1 и S2 S1 & S2 Пересечение S1 и S2 S1 - S2 Набор элементов в S1, но не S2 4979716161616161616161616161616161616161616400161616 41416161616161616161616161616 40014161616161616164 614 414 4 4914. набор элементов ровно в одном из s1 или s2
Последние статьи о Python Set.
комплект — Справочник по Python (Правильный путь) 0.1 документация
комплект — Справочник по Python (Правильный путь) 0.1 документация Наборы — это изменяемые неупорядоченные наборы уникальных элементов. Обычное использование включает проверку принадлежности, удаление дубликатов из последовательности и вычисление стандартных математических операций над множествами, такими как пересечение, объединение, разность и симметричная разность.
Наборы не записывают позицию элемента или порядок вставки. Соответственно, наборы не поддерживают индексирование, нарезку или другое поведение, подобное последовательности.
Наборы реализованы с помощью словарей. Они не могут содержать изменяемые элементы, такие как списки или словари. Однако они могут содержать неизменяемые коллекции.
Конструкторы
- set()
- Возвращает тип набора, инициализированный из iterable.
- {} установить понимание
- Возвращает набор на основе существующих итераций.
- литеральный синтаксис
- Инициализирует новый экземпляр типа set .
Методы
Добавление элементов
- добавить
- Добавляет указанный элемент в набор.
- обновление
- Добавляет указанные элементы в набор.
Удаление
- удаление
- Удаляет элемент из набора.
- удалить
- Удаляет элемент из набора (выдает KeyError , если не найден).
- поп
- Удаляет и возвращает произвольный элемент из набора.
- прозрачный
- : Удаляет все элементы из набора.
Набор операций
- разница
- Возвращает новый набор с элементами набора, которых нет в указанных итерируемых объектах.
- перекресток
- Возвращает новый набор с элементами, общими для набора и указанных итераций.
- симметричная_разность
- Возвращает новый набор с элементами либо из набора, либо из указанного итерируемого объекта, но не из обоих.
- соединение
- Возвращает новый набор с элементами из набора и указанными итерируемыми объектами.
Копирование
- копирование
- Возвращает копию набора.
Набор операторов
Добавление элементов
- |= (обновление)
- Добавляет элементы из другого набора.
Реляционные операторы
- == (равно)
- Возвращает логическое значение, указывающее, содержит ли набор те же элементы, что и другой набор.
- != (не равно)
- Возвращает логическое значение, указывающее, содержит ли набор элементы, отличные от элементов другого набора.
- <= (подмножество)
- Возвращает логическое значение, указывающее, содержится ли набор в другом наборе.
- < (собственно подмножество)
- Возвращает логическое значение, указывающее, содержится ли набор в указанном наборе и что наборы не равны.
- >= (дополнительный набор)
- Возвращает логическое значение, указывающее, содержит ли набор другой набор.
- > (собственный набор)
- Возвращает логическое значение, указывающее, содержит ли набор другой набор и что наборы не равны. 9(симметричная_разница)
- Возвращает новый набор с элементами либо из набора, либо из другого набора, но не из обоих.
- | (союз)
- Возвращает новый набор с элементами из набора и другого набора.
Установить назначение операций
- -= (difference_update)
- Обновляет набор, удаляя элементы из другого набора.
- &= (intersection_update)
- Обновляет набор, сохраняя только элементы, найденные в нем и в другом наборе. 9= (симметричное_разница_обновление)
- Обновляет набор, сохраняя только элементы, найденные в одном из наборов или в другом наборе, но не в обоих одновременно.
Функции
- длинный
- Возвращает тип int, указывающий количество элементов в коллекции.
- мин
- Возвращает наименьший элемент из коллекции.
- макс.
- Возвращает самый большой элемент в итерируемом объекте или самый большой из двух или более аргументов.
- сумма
- Возвращает общее количество элементов, содержащихся в итерируемом объекте.
- отсортировано
- Возвращает отсортированный список из итерируемого объекта.
- наоборот
- Возвращает обратный итератор для последовательности.
- все
- Возвращает логическое значение, указывающее, содержит ли коллекция только те значения, которые оцениваются как True.
- любой
- Возвращает логическое значение, указывающее, содержит ли коллекция какие-либо значения, которые оцениваются как True.
- перечислить
- Возвращает перечисляемый объект.
- почтовый индекс
- Возвращает список кортежей, где i-й кортеж содержит i-й элемент из каждой из последовательностей аргументов или итераций.
 , также существует два специальных метода –
, также существует два специальных метода –  Я буду рад, если у вас есть какие-либо конструктивные замечания и дополнения.
Я буду рад, если у вас есть какие-либо конструктивные замечания и дополнения.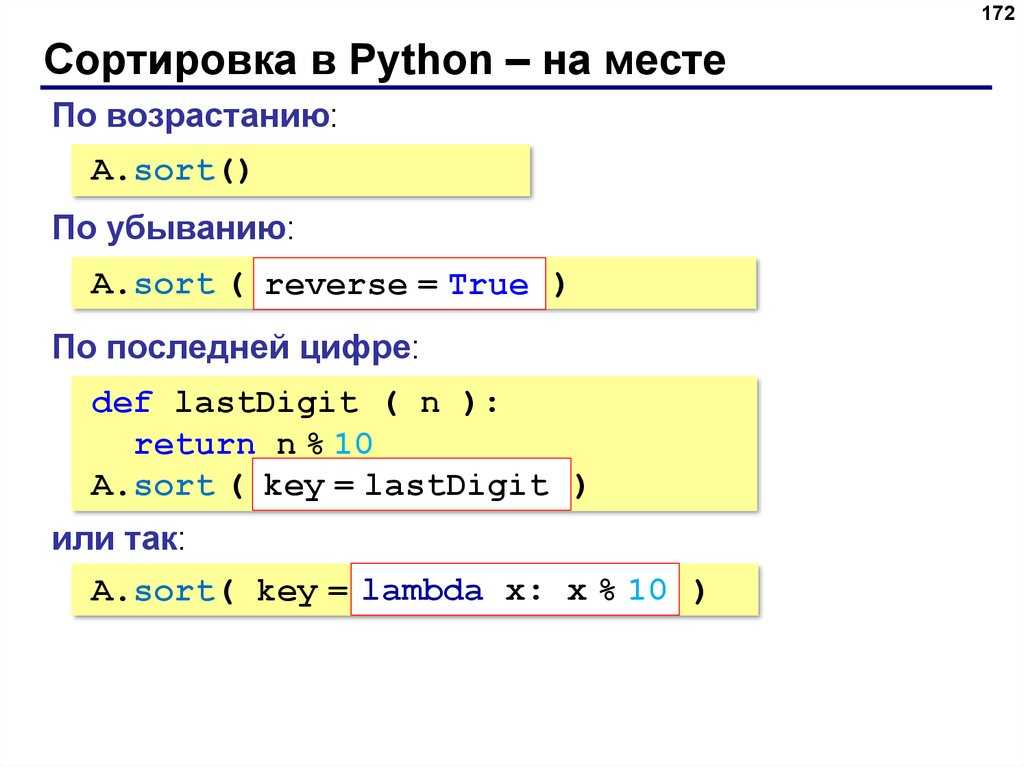
 Наборы
Наборы  Если несколько значений присутствуют в одной и той же позиции индекса, то значение добавляется к этой позиции индекса для формирования связанного списка.
Если несколько значений присутствуют в одной и той же позиции индекса, то значение добавляется к этой позиции индекса для формирования связанного списка. 0020
0020  Временная сложность составляет O(len(s1) + len(s2)) , где s1 и s2 — два набора, объединение которых необходимо выполнить.
Временная сложность составляет O(len(s1) + len(s2)) , где s1 и s2 — два набора, объединение которых необходимо выполнить. union(vampires)
union(vampires)  Выбраны общие элементы. Они аналогичны перебору списков хешей и объединению одних и тех же значений в обеих таблицах. Временная сложность этого O(min(len(s1), len(s2)) где s1 и s2 — два набора, объединение которых необходимо выполнить.
Выбраны общие элементы. Они аналогичны перебору списков хешей и объединению одних и тех же значений в обеих таблицах. Временная сложность этого O(min(len(s1), len(s2)) где s1 и s2 — два набора, объединение которых необходимо выполнить. add(i)
add(i) 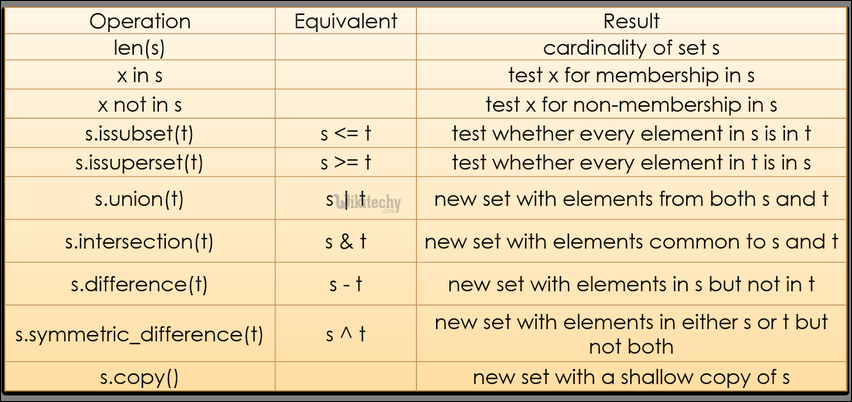 Аналогично поиску различий в связанном списке. Это делается через разницу() или – оператор. Временная сложность поиска разницы s1 – s2 равна O(len(s1))
Аналогично поиску различий в связанном списке. Это делается через разницу() или – оператор. Временная сложность поиска разницы s1 – s2 равна O(len(s1)) Add (I)
Add (I)  0020
0020  clear()
clear()  .,len(sn))
.,len(sn))