Сетевые базы данных.
Главная / Базы данных / Сетевые базы данных.
в Базы данных 14.01.2018 0 11,441 Просмотров
Сетевая база данных – это модель данных, где несколько записей или файлов могут быть связаны с несколькими владельцами файлов и наоборот. Модель может рассматриваться как перевернутое дерево, где каждый член – это отрасли, связанные с владельцем, который находится в нижней части дерева. По сути, это отношения в чистой форме, где один элемент может указывать на множество элементов данных, и само по себе может быть указано несколько элементов данных.
Модель сетевой базы данных позволяет каждой записи иметь несколько родителей и несколько дочерних записей, которые, когда они визуализируются, принимают форму сетевой структуры сетевых записей. В отличие от иерархической модели данных она может иметь только одну родительскую запись, но может иметь много дочерних записей.
Это свойство иметь несколько ссылок применяется двумя способами: схема и сама база данных может рассматриваться как обобщенный график типов записей, которые связаны типами отношений.
Сетевая модель базы данных
Улучшенная форма иерархической модели данных, сетевая модель представляет данные в виде дерева записей. Связи между таблицами (отчеты) выражаются в виде наборов. В наборе есть одна родительская запись (владелец) и одна или более дочерних записей (члены). Связанные записи в наборе напрямую связаны с указателями, а не путём сопоставления повторяющихся столбцов, как и в случае с реляционной моделью данных.
Записи, связанные с одним владельцем
Модель сетевой базы данных позволяет записям из более чем одной таблицы быть связанными с одним владельцем с записями из другой таблицы. Это обеспечивает определенное преимущество над реляционной базой при запросе результатов из нескольких внешних ключей таблиц, связанных с одним первичным ключом таблицы. В базе данных медиа-коллекции, таких как альбом песен и видео записи, все они могут быть членами собственника в одном комплекте, как показано на рисунке 2. Это означает, что оба альбома и фильмы для данного собственника могут быть получены за одну операцию. При этом отпадает необходимость хранить и потенциально изменять порядок временных результатов в середине операции, что приводит к повышению производительности запросов. Без необходимости хранить и сохранять дубликаты столбцы базы данных также помогают уменьшить дисковое пространство и память.
Это обеспечивает определенное преимущество над реляционной базой при запросе результатов из нескольких внешних ключей таблиц, связанных с одним первичным ключом таблицы. В базе данных медиа-коллекции, таких как альбом песен и видео записи, все они могут быть членами собственника в одном комплекте, как показано на рисунке 2. Это означает, что оба альбома и фильмы для данного собственника могут быть получены за одну операцию. При этом отпадает необходимость хранить и потенциально изменять порядок временных результатов в середине операции, что приводит к повышению производительности запросов. Без необходимости хранить и сохранять дубликаты столбцы базы данных также помогают уменьшить дисковое пространство и память.
Исследование эффективности
Реальные данные показывают, что прирост производительности и экономия ресурсов с использованием сетевых баз данных может быть довольно значительной. В структуре данных, используются трехсторонние отношения между художником, альбомом и таблицами песни, наши разработчики сравнили изменения данных и выполнение запросов в реляционной модели и сетевой базе данных с помощью настольных систем и небольших, потребительских устройств.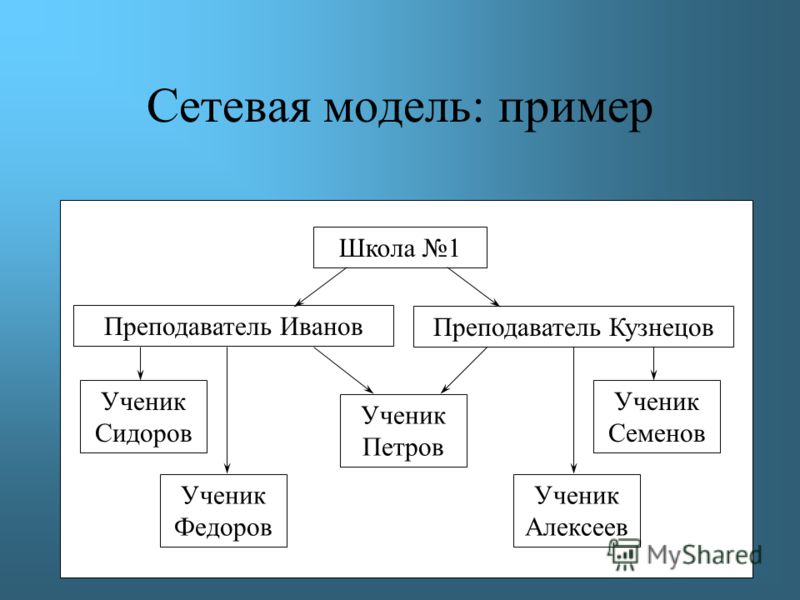 Они обнаружили, что сетевая модель использует на 29% меньше дискового пространства для хранения одинакового количества записей и связей, чем реляционная модель данных. Все сбережения при хранении можно отнести к замене ключевых показателей артист-альбом и альбом-песни зарубежные на установленные указатели.
Они обнаружили, что сетевая модель использует на 29% меньше дискового пространства для хранения одинакового количества записей и связей, чем реляционная модель данных. Все сбережения при хранении можно отнести к замене ключевых показателей артист-альбом и альбом-песни зарубежные на установленные указатели.
Удаление этих структур данных, оказало огромное влияние на требования к хранению, поскольку типичный индекс B-дерева требует примерно в 1,3 раза больше пространства, чем индексы. Они также обнаружили, что сетевая модель базы данных увеличила до 23 раз лучше производительность вставки и выросла в 123 раза быстрее производительность запросов, как показано в таблице 1.
Сетевая база данных против реляционной базы данных
Различные требования управления означают разные структуры данных и различные методы хранения и доступа к данным. В результате система может состоять из нескольких таблиц без связей или сотни таблиц, связанных со сложными взаимосвязями. В то время как реляционная модель данных является стандартом де-факто, теперь мы знаем, что она не всегда обеспечивает оптимальные решения для более сложных задач управления данными. Выбор подходящей модели данных, или даже объединение нескольких моделей, может дать гораздо более эффективный результат, чем реляционная модель данных работающая в одиночку. В результате достигается значительная экономия затрат, повышение качества и увеличение пользовательского опыта.
Выбор подходящей модели данных, или даже объединение нескольких моделей, может дать гораздо более эффективный результат, чем реляционная модель данных работающая в одиночку. В результате достигается значительная экономия затрат, повышение качества и увеличение пользовательского опыта.
Вывод
В то время как реляционная модель данных является очень популярной из-за её простоты использования, она не требует ключа и индексов таблицы, что существенно замедляет работу приложения. Сетевая модель базы данных обеспечивает более быстрый доступ к данным и является оптимальным методом для быстрого применения. Так что если Вы нажмете на любимого артиста, а также если хотите посмотреть список для поиска лишних альбомов и просмотреть названия фильмов на вашем медиа-плеере, это может быть создано сетевыми моделями СУБД.
2018-01-14
Предыдущий: Иерархическая база данных.
Следующий: Объектно-ориентированная база данных (ООСУБД).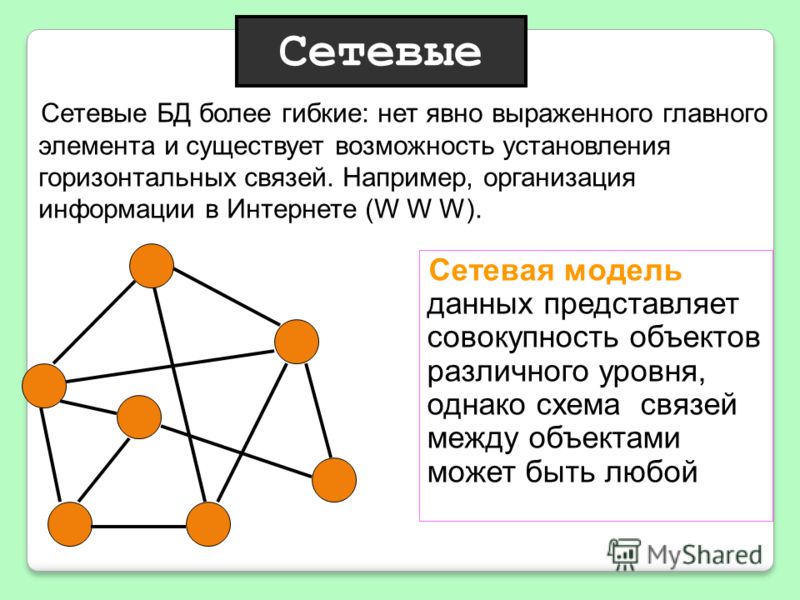
Сетевые БД
На прошлом уроке мы с вами рассмотрели иерархические базы данных. В частности, узнали, что иерархическая структура
Также познакомились с такими элементами иерархической базы данных, как корень, предок, потомок и близнецы.
На этом уроке мы с вами рассмотрим сетевые базы данных, узнаем, чем сетевая структура отличается от иерархической, а также создадим сетевую базу данных на примере.
Сетевая структура – это логическая модель данных, которая является расширением иерархической структуры.
Давайте рассмотрим, чем отличается иерархическая структура от сетевой. Нам показаны два рисунка, на которых изображены иерархическая и сетевая структуры соответственно.
Как мы можем видеть, в
иерархической структуре у потомка может быть только один предок. А вот в
сетевой структуре у потомка может быть несколько предков.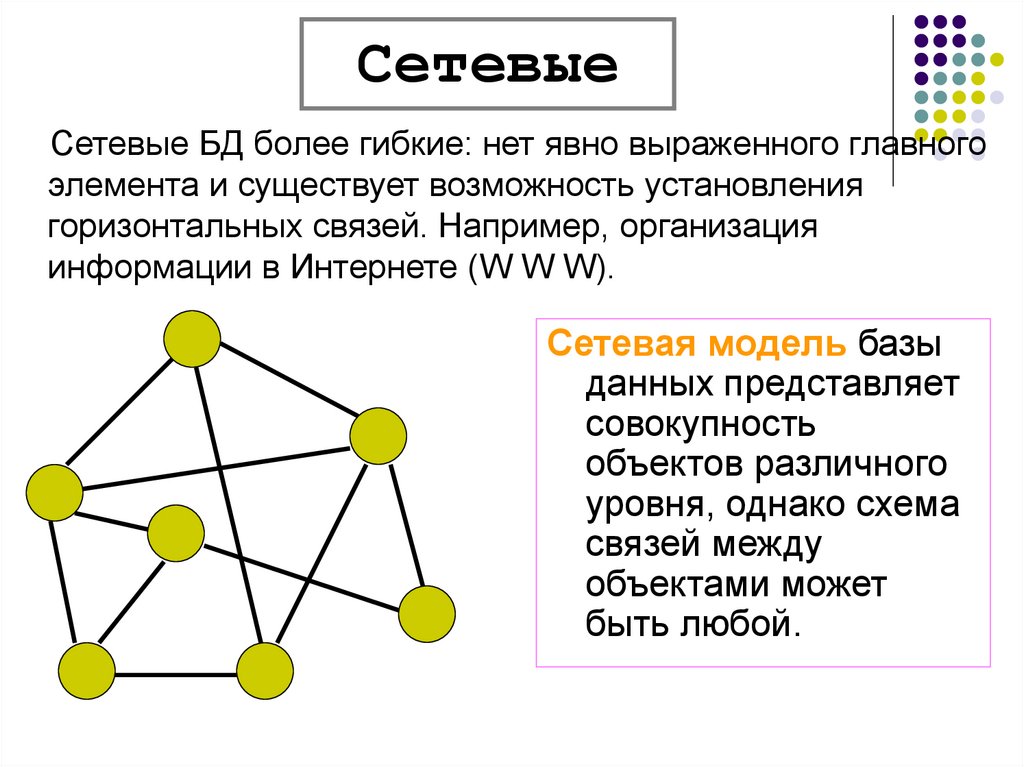
Т. е. в сетевой структуре нет ограничений на связи между объектами. Это говорит о том, что в ней могут находиться объекты, которые имеют более одного предка. Таким образом они организуют структуру, похожую на сеть. Примером сетевой базы данных является организация информации во Всемирной паутине глобальной компьютерной сети Интернет. Гиперссылки связывают между собой сотни миллионов документов в единую распределённую сетевую базу данных.
Также к примерам сетевой базы данных относится генеалогическое древо, т. к. в данной структуре у потомков имеется по 2 предка. То есть потомки (объекты нижележащего уровня) имеют всегда более одно предка (объекта вышестоящего уровня).
К примерам сетевой базы данных можно отнести и организацию работы на факультете.
Давайте составим схему. На любом факультете есть преподаватели и декан. Изобразим при помощи прямоугольников сам факультет, преподавателей и декана.
Преподаватели и декан
работают на факультете. Давайте изобразим это при помощи стрелок.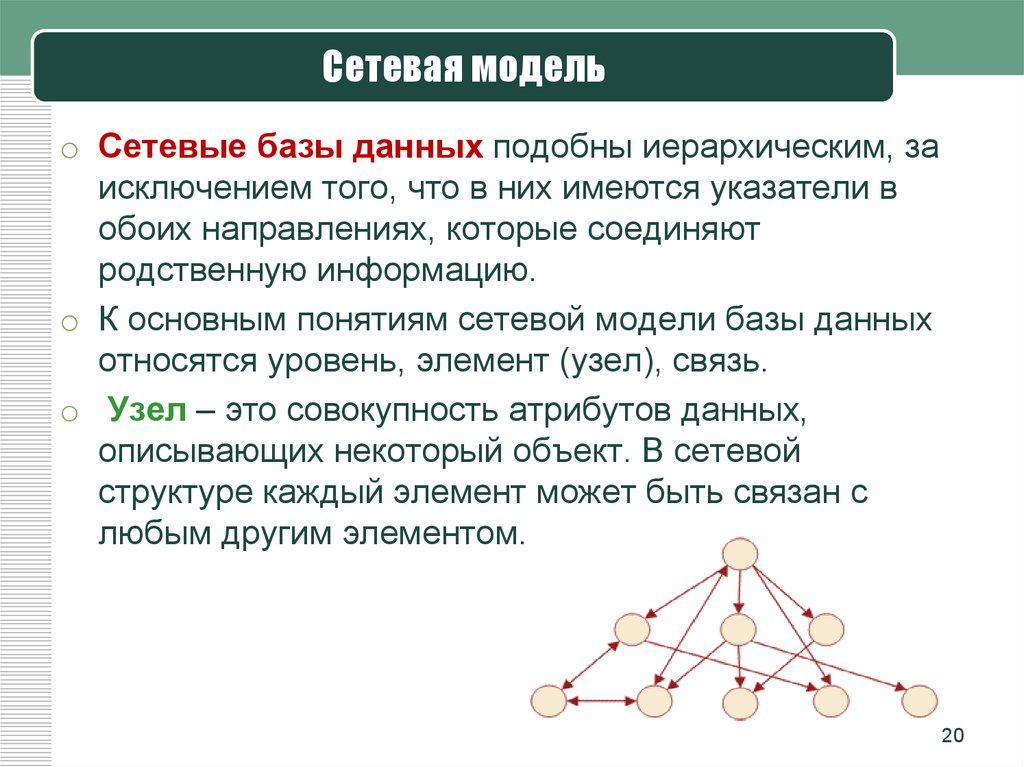
В свою очередь, любой факультет состоит из преподавателей. Также отобразим это отношение на схеме.
Ну и любой факультет имеет начальника, то есть декана. Снова изобразим это отношение.
Таким образом мы составили с вами сетевую структуру факультета.
Любая сетевая база данных состоит из наборов записей, которые связаны между собой так, что записи могут содержать явные ссылки на другие наборы записей. То есть все объекты сетевой базы данных так или иначе связаны между собой. Так они образуют сеть. Все же связи между записями хранятся непосредственно в самой базе данных.
А сейчас рассмотрим операции, которые могут выполняться над данными в сетевой базе данных.
· Добавить. Внесение (добавление) записи в базу данных. Например, добавление нового преподавателя на факультет при его приёме на работу.
· Извлечь. Извлечение нужной нам записи из базы данных. Например, сведения о каком-либо преподавателе.
· Обновить. Это действие включает в себя изменение значения элементов записи, которая была
предварительно извлечена. То есть, например, внесение дополнительных данных о
преподавателе.
Это действие включает в себя изменение значения элементов записи, которая была
предварительно извлечена. То есть, например, внесение дополнительных данных о
преподавателе.
· Включить в групповое отношение. При выполнении этого действия мы связываем существующую подчинённую запись с записью-владельцем, то есть создаём своеобразную группу. Например, при приёме на работу нового преподавателя после внесения о нём записи в базу данных, мы будем связывать его с факультетом, на котором он работает.
· Исключить из группового отношения. Это действие разрывает связь между записью-владельцем и записью-членом. Такое действие выполняется, например, при увольнении преподавателя.
· Переключить. При помощи этого действия можно связать существующую подчинённую запись с другой записью-владельцем в том же групповом отношении. Например, при переводе преподавателя с одного факультета на другой в этом же университете.
Первоначально сетевая
модель данных создавалась как инструмент для программистов. Базовым же языком
программирования был выбран COBOL. Первая сетевая модель была предложена в 1969
году и развивалась до 1980-х годов.
Базовым же языком
программирования был выбран COBOL. Первая сетевая модель была предложена в 1969
году и развивалась до 1980-х годов.
К основному достоинству сетевой модели относятся высокая эффективность затрат памяти и оперативность (быстродействие). К основным недостаткам относятся сложность и жёсткость схемы базы, а также сложное понимание. Помимо этого, из-за возможности установки произвольных связей между записями, в этой модели ослаблен контроль целостности.
Возвращаясь же к сравнению иерархической базы данных и сетевой, можно сказать, что они обе обеспечивают достаточно быстрый доступ к данным. Но, в то же время, если нам необходимо получить какие-либо данные из иерархической базы данных, мы должны начинать запрос с корневой вершины. А вот в сетевой базе данных, так как каждая вершина может иметь связь с любой другой, соответственно данные являются более равноправными, то запрос можно отправлять на любой узел этой структуры.
А сейчас давайте составим генеалогическое древо, исходя из следующих данных:
·
Иванов
Андрей Геннадьевич, 28.
· Иванова (Кулибина) Виктория Сергеевна, 05.08.1947 г. р.
· Кулаго Сергей Евгеньевич, 01.01.1947 г. р.
· Кулаго (Каменева) Елена Анатольевна, 19.04.1948 г. р.
· Сергеев Константин Алексеевич, 26.06.1955 г. р.
· Сергеева (Мирская) Анна Александровна, 06.09.1956 г. р.
· Иванов Юрий Андреевич, 04.05.1967 г. р.
· Иванова (Кулаго) Татьяна Сергеевна, 17.03.1968 г. р.
· Сергеев Виталий Валерьевич, 13.11.1977 г. р.
· Сергеева (Кулаго) Наталья Сергеевна, 06.12.1977 г. р.
· Иванова Ольга Юрьевна, 03.08.1991 г. р.
· Иванова Мария Юрьевна, 31.09.1998 г. р.
· Сергеева Екатерина Витальевна, 19.04.1995 г. р.
· Сергеева Дарья Витальевна, 17.03.2000 г. р.
Андрей и Виктория являются родителями Юрия. Сергей и Елена являются родителями Татьяны и Натальи. Константин и Анна – родители Виталия.
Юрий
и Татьяна являются родителями Ольги и Марии.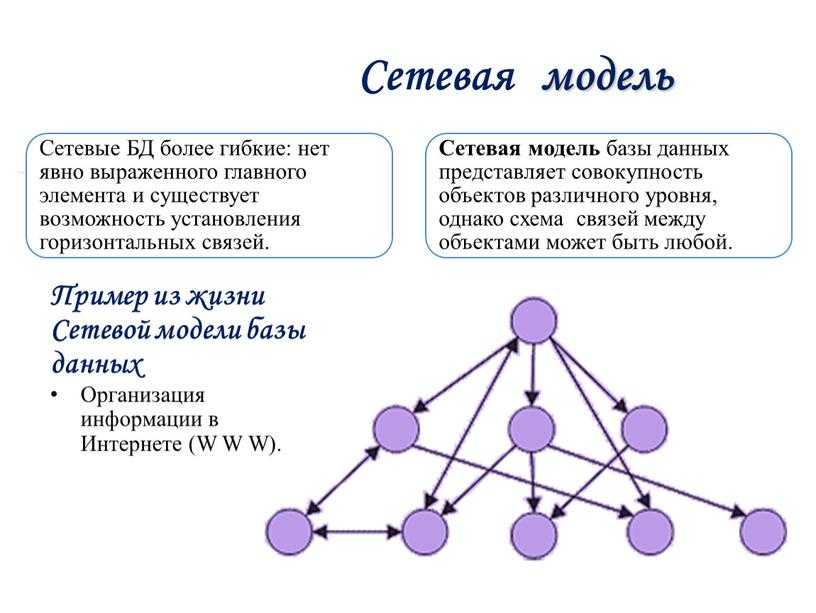 Наталья и Виталий – родители
Екатерины и Дарьи.
Наталья и Виталий – родители
Екатерины и Дарьи.
Исходя из этих данных, давайте построим генеалогическое древо.
У нас будет шесть вершин: Андрей, Виктория, Сергей, Елена, Константин и Анна. А также изобразим при помощи стрелок, что Андрей и Виктория, Сергей и Елена, Константин и Анна являются семьями.
Далее у нас сказано, что Андрей и Виктория являются родителями Юрия. Изобразим на втором уровне Юрия и проведём к нему стрелки от Андрея и Виктории.
Сергей и Елена являются родителями Татьяны и Натальи. Проведём стрелки от родителей к дочерям.
Также у нас сказано, что Юрий и Татьяна являются родителями Ольги и Марии. Исходя из этого следует, что Юрий и Татьяна являются мужем и женой.
В условии также сказано, что Константин и Анна являются родителя Виталия. Проведём стрелки от родителей к сыну.
Также
у нас сказано, что Наталья и Виталий являются родителями Екатерины и Дарьи,
соответственно они являются мужем и женой.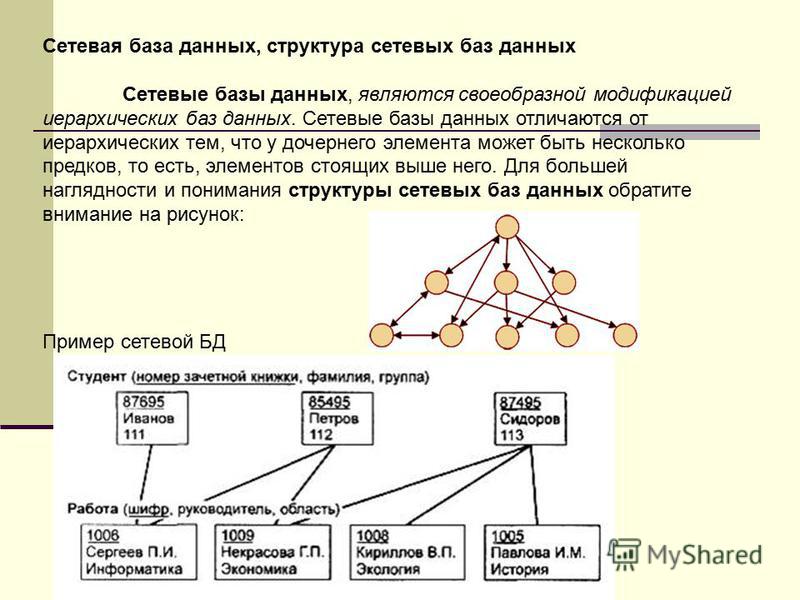 Изобразим это отношение на схеме.
Изобразим это отношение на схеме.
У нас осталось четыре человека: Ольга, Мария, Екатерина и Дарья.
Ольга и Мария являются дочерями Юрия и Татьяны. Изобразим это на схеме при помощи стрелок.
Екатерина и Дарья являются дочерями Натальи и Виталия. Также проведём стрелки от родителей к дочерям.
Подпишем каждого из членов семьи, а также даты их рождения.
Мы с вами составили генеалогическое древо семьи. Данное древо является примером сетевой структуры, так как у нас потомки имеют по два предка. Например, Юрий является потомком Андрея и Виктории. Или же Екатерина является потомком Натальи и Виталия.
Если же более подробно рассматривать нашу схему, то мы можем видеть, что Андрей, Виктория, Сергей, Елена, Константин и Анна находятся на первом уровне. Юрий, Татьяна, Наталья и Виталий находятся на втором уровне. А Ольга, Мария, Екатерина и Дарья находятся на третьем уровне.
Также, исходя из этой
схемы можно сказать, что те, кто находятся на первом уровне, являются дедушками
и бабушками по отношению к Ольге, Марии, Екатерине и Дарье. Те, кто находятся
на втором уровне, являются родителями.
Те, кто находятся
на втором уровне, являются родителями.
Если же обратить внимание на данные, которые нам были предоставлены изначально, то мы можем заметить, что у некоторых членов семьи женского рода две фамилии, одна из которых написана в скобках. Обычно так пишется девичья фамилия тех, кто замужем.
Каждый из вас может построить генеалогическое древо своей семьи, причём количество предков и потомков может быть намного больше, чем в представленном примере.
А сейчас пришла пора подвести итоги урока.
На этом уроке мы с вами познакомились с сетевой структурой. Узнали, чем отличается иерархическая структура от сетевой. Помимо этого, мы построили генеалогическое древо семьи.
Сравнение сетевых баз данных, реляционных баз данных и графических баз данных
Что такое сетевые базы данных?
Система управления сетевыми базами данных (сетевая СУБД) основана на сетевой модели данных, которая позволяет каждой записи быть связанной с несколькими первичными записями и несколькими вторичными записями. Сетевые базы данных позволяют создавать гибкие модели отношений между сущностями. Сетевая модель была предложена в 1969 году Чарльзом Бахманом как расширение модели иерархической базы данных.
Сетевые базы данных позволяют создавать гибкие модели отношений между сущностями. Сетевая модель была предложена в 1969 году Чарльзом Бахманом как расширение модели иерархической базы данных.
Слово «сеть» в сетевых базах данных относится не к соединениям между различными компьютерами и программным обеспечением (известным как сеть), а скорее к отношениям между различными объектами данных.
- Как работает сетевая база данных?
- Плюсы и минусы сетевой модели данных
- Плюсы
- Минусы
- Иерархическая модель, сетевая модель и модель реляционной базы данных
- Сетевая база данных и графическая база данных
- Системы баз данных, использующие сетевую модель
- Интегрированное хранилище данных
- ИДМС
- Диспетчер баз данных Raima
Как работает сетевая база данных?
Сетевая база данных основана на традиционной иерархической базе данных, за исключением того, что она позволяет каждому объекту иметь несколько родителей вместо одного родителя.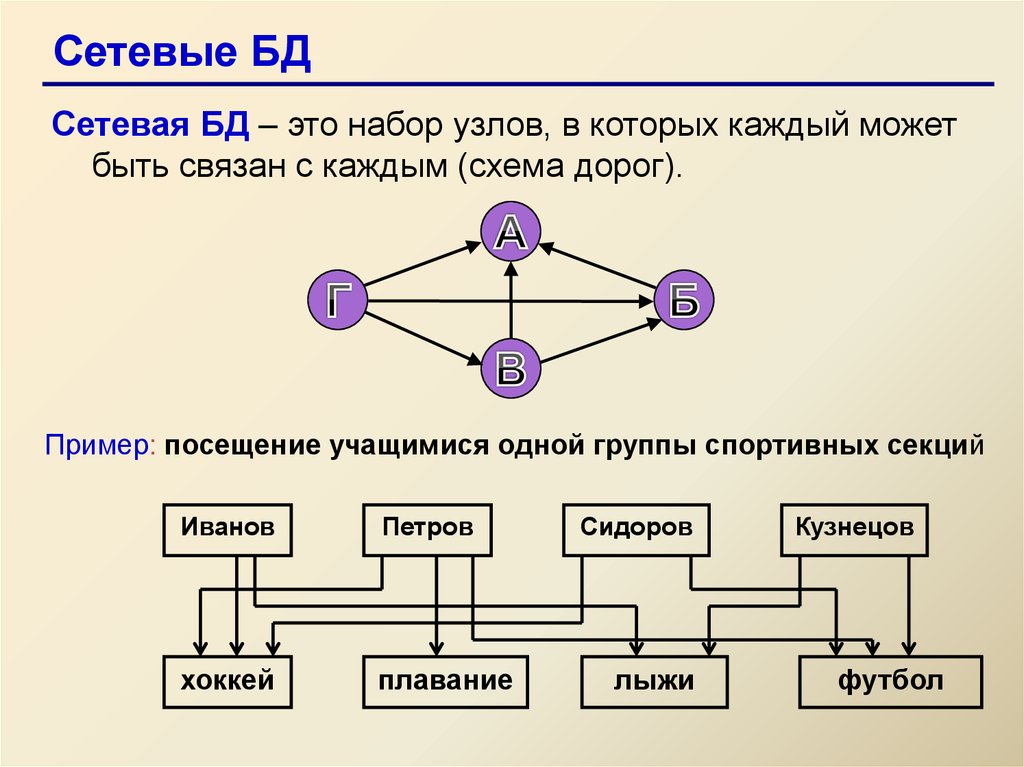 Это позволяет моделировать более сложные отношения.
Это позволяет моделировать более сложные отношения.
Сетевые базы данных могут быть представлены в виде графа вместо древовидной структуры. Граф определяется схемой, которая представляет собой список узлов данных и отношений между ними. Это обеспечивает структуру данных, к которой в обычной реляционной базе данных можно получить доступ только путем логического вывода.
Сетевые базы данных обеспечивают большую гибкость, но по-прежнему ограничены схемами доступа и конструктивными ограничениями иерархических баз данных. Позднее эти ограничения были преодолены системами управления реляционными базами данных.
Плюсы и минусы сетевой модели данных
Плюсы
- Простая концепция — подобно иерархической базе данных, сетевые базы данных концептуально просты и легко проектируются.
- Несколько типов отношений — сетевые модели могут поддерживать отношения «один ко многим» и «многие ко многим», что полезно для фиксации реальных отношений между объектами.

- Целостность данных — модель сети не позволяет членам существовать без владельца.
- Независимость от данных — сетевая модель превосходит иерархическую модель в отделении обработки данных от деталей физического хранения.
- Доступ к данным — доступ к данным быстрее и проще, чем в иерархической базе данных.

Минусы
- Сложная реализация — все записи должны храниться с использованием указателей, что делает структуру базы данных намного более сложной, чем в иерархической базе данных.
- Неэффективная обработка операций — операции вставки, удаления и обновления требуют множества настроек указателя, что может снизить производительность.
- Негибкая структура — трудно изменить структуру базы данных, если она уже заполнена.
Иерархическая модель, сетевая модель и модель реляционной базы данных
Ниже приводится сводка различий между традиционной иерархической моделью данных, сетевой моделью данных и современной реляционной моделью данных.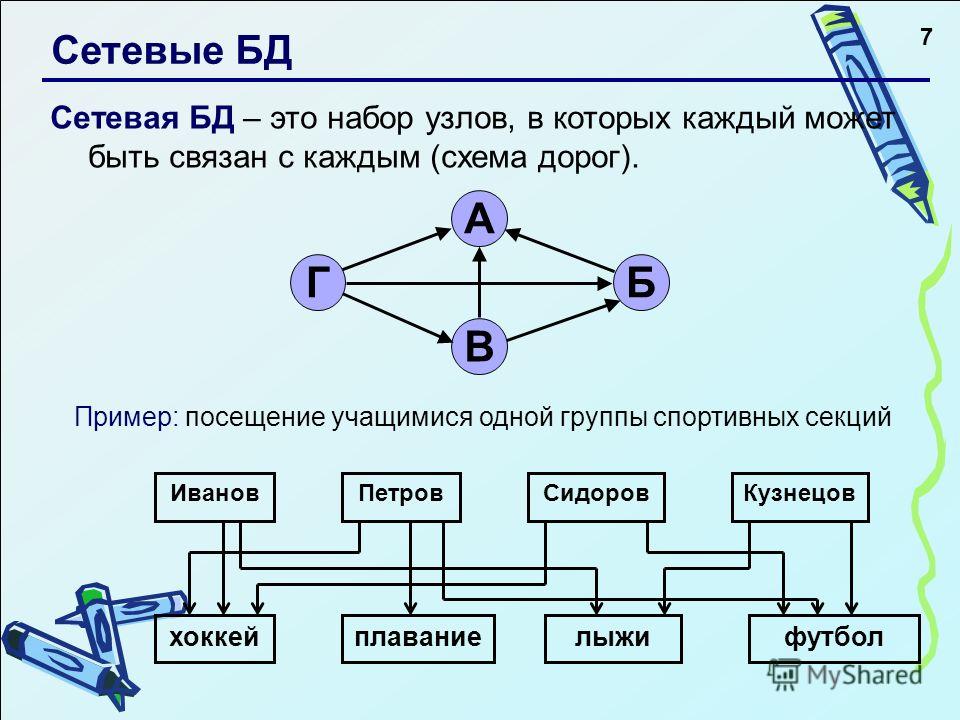
| Иерархическая модель | Сетевая модель | Реляционная модель |
| Организует данные в виде древовидной структуры | Организация данных в графическую структуру | Сохраняет данные в таблицах |
| Представляет отношения «один ко многим» | Представляет отношения «многие ко многим» | Поддерживает отношения «один ко многим» и «многие ко многим» |
| Неэффективный доступ к данным | Эффективный доступ к данным | Эффективный доступ к данным |
| Негибкий | Гибкость при проектировании базы данных, менее гибкая после заполнения данными | Гибкость как во время проектирования, так и после загрузки данных |
Сетевая база данных и графовая база данных
Сетевые базы данных похожи на новый тип нереляционной базы данных — графовую базу данных.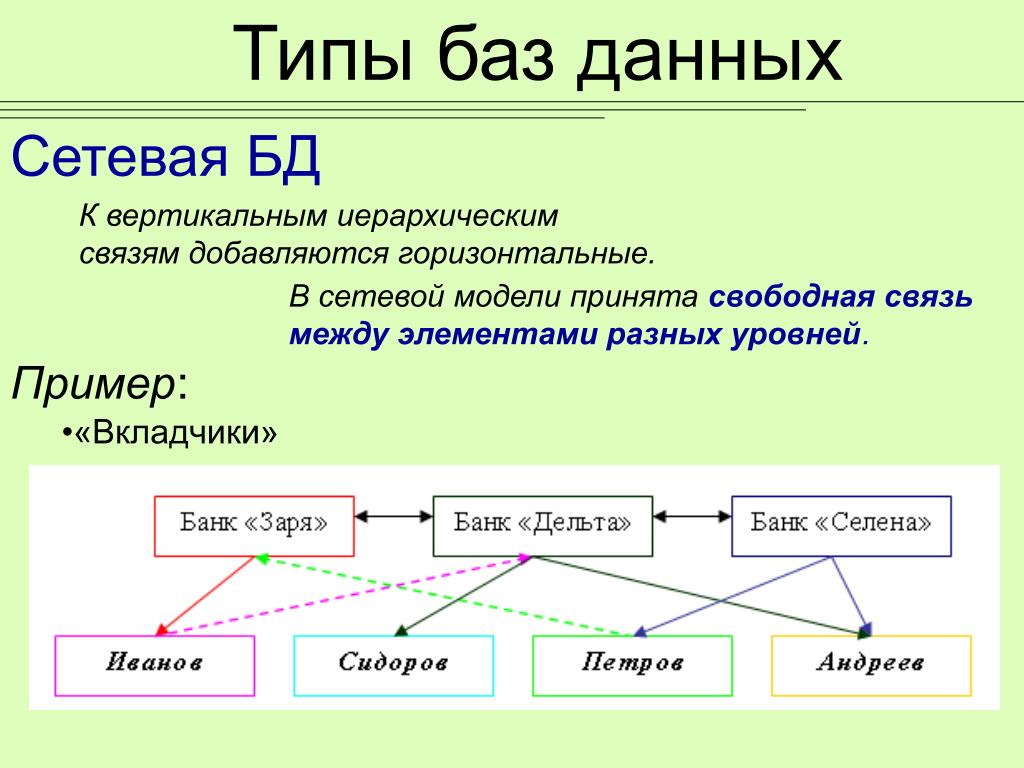 Вот некоторые различия между сетевыми базами данных и графовыми базами данных.
Вот некоторые различия между сетевыми базами данных и графовыми базами данных.
| Сетевая база данных | Графическая база данных |
| Использует схему, указывающую, какой тип записи может быть вложен в какой другой тип записи | Нет ограничений, любая вершина может иметь ребро в любую другую вершину |
| Доступ к записи возможен только через один из путей доступа к этой записи | Можно напрямую обращаться ко всем вершинам с уникальными идентификаторами или использовать индекс для поиска вершин с определенным значением |
| Дочерние элементы каждой записи имеют предустановленный порядок, и база данных должна поддерживать этот порядок. | Вершины и ребра не сортируются, сортируются только результаты при выполнении запроса. |
| Использует язык запросов SQL | Поддерживает декларативные языки запросов, такие как Cypher и SparQL |
Системы баз данных, использующие сетевую модель
К хорошо известным системам баз данных, использующим сетевую модель, относятся;
Интегрированное хранилище данных
Интегрированное хранилище данных (IDS) — ранняя система управления сетевыми базами данных, известная своей высокой производительностью.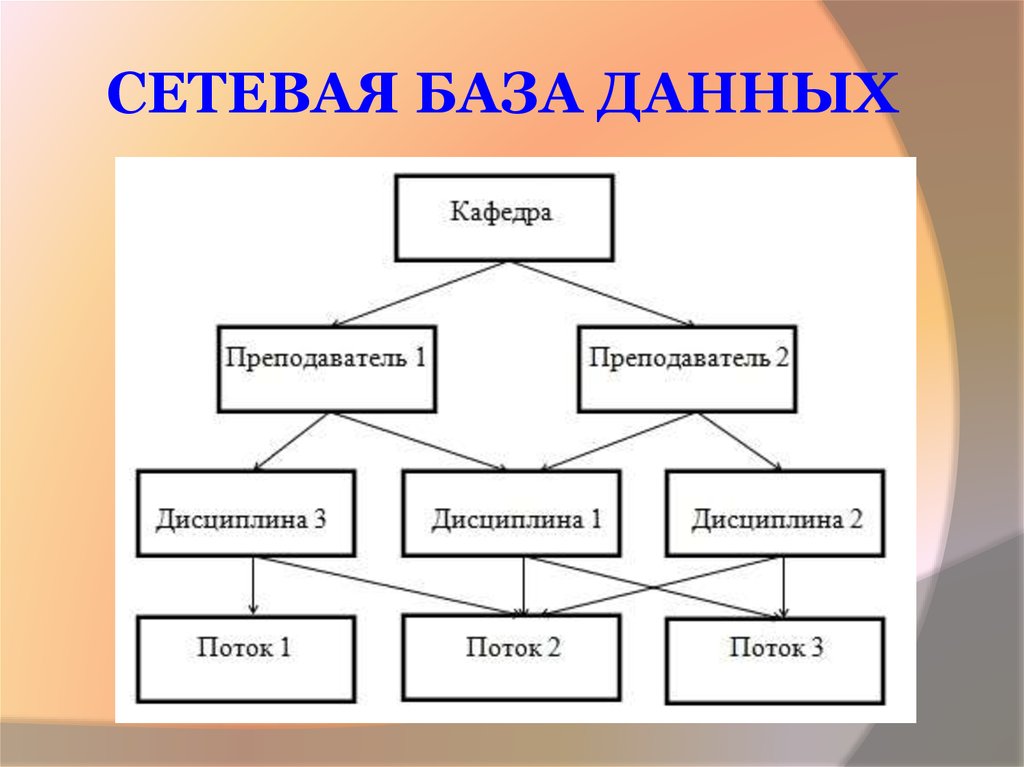
IDS был разработан Чарльзом Бахманом из General Electric и получил премию Тьюринга Компьютерного общества в 1919 году.73.
IDS стремится максимизировать производительность с использованием доступного оборудования, которое в то время было крайне ограниченным, поэтому было непросто использовать или внедрять приложения с использованием IDS. Однако разумная реализация баз данных типа IDS (например, крупный проект CSS компании British Telecom) продемонстрировала уровень производительности при работе с терабайтными данными, не имеющий себе равных в любой современной реализации реляционной базы данных.
IDMS
Интегрированная система управления базами данных (IDMS) использовала сетевую модель CODASYL. Первоначально разработан Б. Ф. Гудричем, с 1989 он принадлежал Computer Associates, которая переименовала его в CA IDMS.
Сегодня CA IDMS используется как часть IBM z Systems в качестве высокопроизводительной системы управления базами данных и используется сотнями крупных предприятий и государственных учреждений по всему миру. CAI IDMS/DB — это мощное ядро базы данных, которое обеспечивает как сетевой, так и реляционный доступ и использует новейшее оборудование для достижения высокой производительности, включая интегрированный информационный процессор IBM z Systems (zIIP).
CAI IDMS/DB — это мощное ядро базы данных, которое обеспечивает как сетевой, так и реляционный доступ и использует новейшее оборудование для достижения высокой производительности, включая интегрированный информационный процессор IBM z Systems (zIIP).
Raima Database Manager
Raima Database Manager (RDM) — это встроенная реляционная база данных, оптимизированная для работы на периферийных устройствах IoT с ограниченными ресурсами, требующих ответов в реальном времени.
RDM поддерживает noSQL (доступ к базе данных на уровне записей и курсоров), структуру базы данных SQL и манипуляции с данными, подобные SQL. Функции, отличные от SQL, очень важны во встроенной системной среде с крайне ограниченными ресурсами. В такой среде на первое место выходят высокая производительность и очень малые габариты. SQL важен для предоставления стандартных методов доступа к базе данных.
Сетевая база данных с Raima
Диспетчер базы данных Raima, также называемый RDM, представляет собой СУБД (систему управления реляционными базами данных), разработанную для вариантов использования IoT Edge. Объединяя технологии сети и реляционной модели в одной системе, RDM позволяет эффективно организовывать информацию и получать к ней доступ, независимо от сложности данных. Система баз данных Raima оптимизирована для работы как в качестве СУБД в оперативной памяти с возможностью сохранения данных на диске, так и в качестве полностью дисковой системы баз данных. Он отличается высокой производительностью, низкой задержкой ввода-вывода и минимальными затратами на обработку.
Объединяя технологии сети и реляционной модели в одной системе, RDM позволяет эффективно организовывать информацию и получать к ней доступ, независимо от сложности данных. Система баз данных Raima оптимизирована для работы как в качестве СУБД в оперативной памяти с возможностью сохранения данных на диске, так и в качестве полностью дисковой системы баз данных. Он отличается высокой производительностью, низкой задержкой ввода-вывода и минимальными затратами на обработку.
Raima Database Manager предоставляет разработчикам богатый набор функций базы данных, включая несколько API и методов индексирования, требующих минимальных ресурсов. Отличная СУБД для встроенных устройств и приложений, работающих в операционных системах реального времени.
Откройте для себя возможности Raima Database Manager и получите бесплатную пробную версию.
Сетевая модель в СУБД — GeeksforGeeks
Сетевая модель:
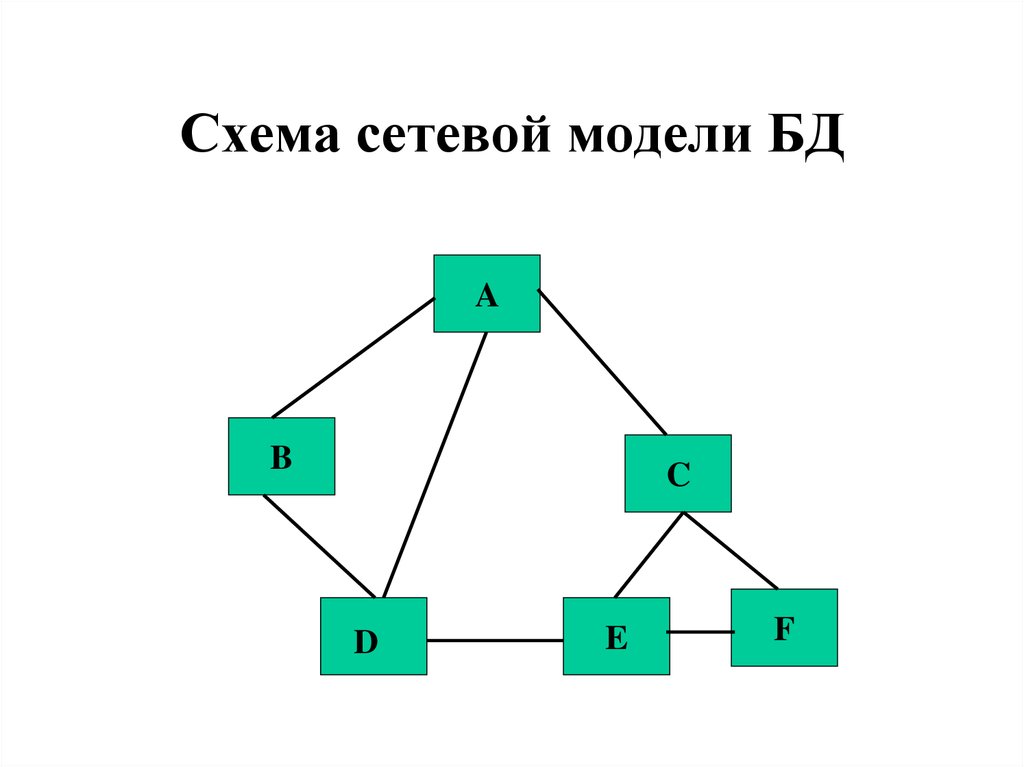
Эта модель была формализована рабочей группой по базе данных в 1960-е годы.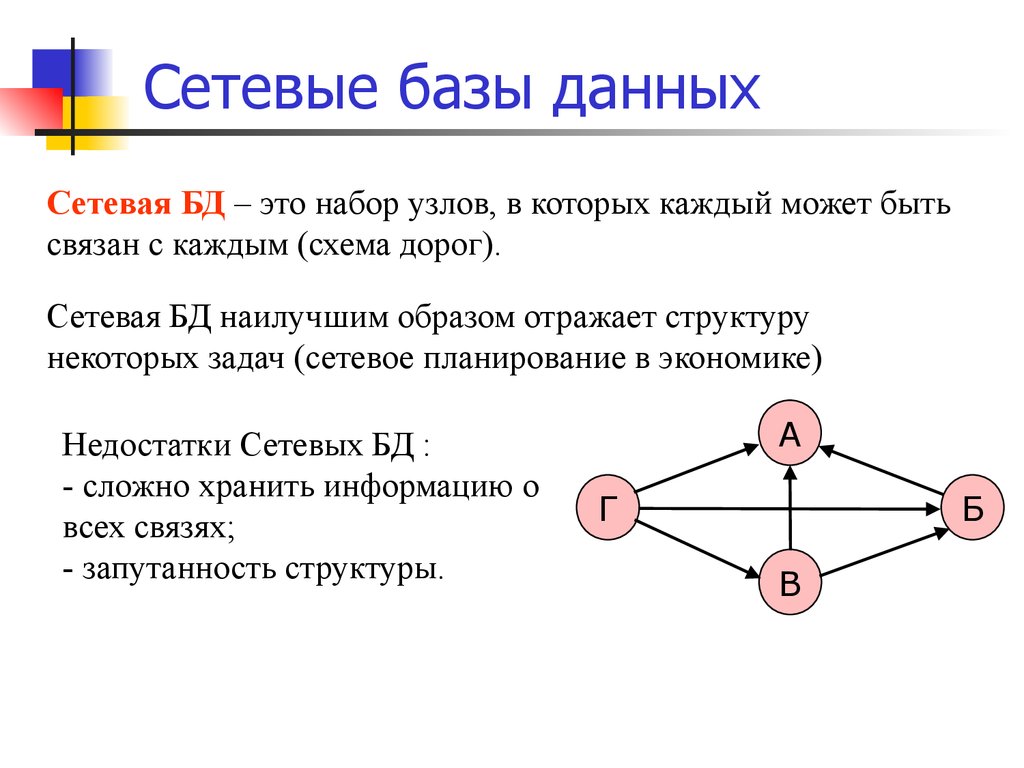 Эта модель является обобщением иерархической модели. Эта модель может состоять из нескольких родительских сегментов, и эти сегменты сгруппированы как уровни, но существует логическая связь между сегментами, принадлежащими любому уровню. В основном существует логическая связь «многие ко многим» между любым из двух сегментов. Мы назвали графов логическими связями между сегментами. Следовательно, эта модель заменяет иерархическое дерево структурой, подобной графу, и при этом могут быть более общие связи между различными узлами. Он может иметь отношения M:N, то есть многие ко многим, что позволяет записи иметь более одного родительского сегмента.
Эта модель является обобщением иерархической модели. Эта модель может состоять из нескольких родительских сегментов, и эти сегменты сгруппированы как уровни, но существует логическая связь между сегментами, принадлежащими любому уровню. В основном существует логическая связь «многие ко многим» между любым из двух сегментов. Мы назвали графов логическими связями между сегментами. Следовательно, эта модель заменяет иерархическое дерево структурой, подобной графу, и при этом могут быть более общие связи между различными узлами. Он может иметь отношения M:N, то есть многие ко многим, что позволяет записи иметь более одного родительского сегмента.
Здесь связь называется набором, и каждый набор состоит как минимум из двух типов записей, которые приведены ниже:
- Запись владельца, которая совпадает с родительской в иерархической модели.
- Запись участника, которая совпадает с дочерней в иерархической модели.
Структура сетевой модели:
Модель сетевых данных
На приведенном выше рисунке элемент ДВА имеет только одного владельца «ОДИН», тогда как элемент ПЯТЬ имеет двух владельцев, т.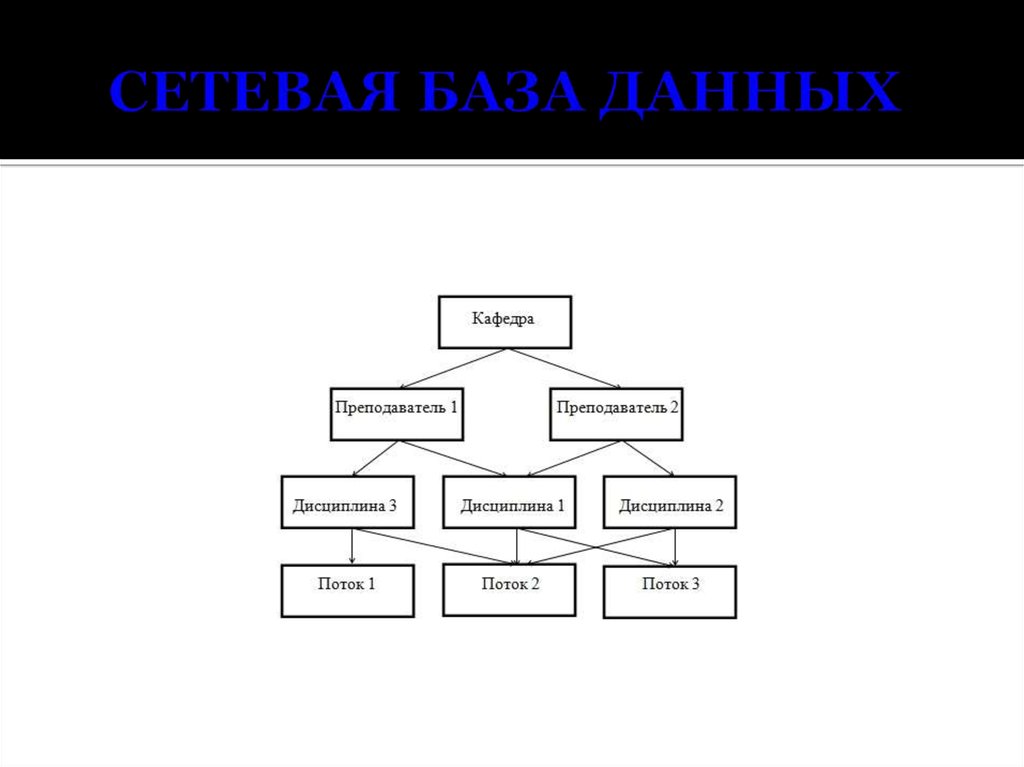 е. ДВА и ТРИ. Здесь каждая ссылка между двумя типами записей представляет отношение 1 : M между ними. Эта модель состоит как из боковых, так и из нисходящих связей между узлами. Таким образом, он допускает отношения 1:1, 1:M, M:N между заданными объектами, что помогает избежать проблем с избыточностью данных, поскольку поддерживает несколько путей к одной и той же записи. Существуют различные примеры, такие как TOTAL от Cincom Systems Inc., EDMS от Xerox Corp. и т. д.
е. ДВА и ТРИ. Здесь каждая ссылка между двумя типами записей представляет отношение 1 : M между ними. Эта модель состоит как из боковых, так и из нисходящих связей между узлами. Таким образом, он допускает отношения 1:1, 1:M, M:N между заданными объектами, что помогает избежать проблем с избыточностью данных, поскольку поддерживает несколько путей к одной и той же записи. Существуют различные примеры, такие как TOTAL от Cincom Systems Inc., EDMS от Xerox Corp. и т. д.
Пример: Модель сети для финансового отдела.
Ниже мы разработали сетевую модель для финансового отдела:
Сетевая модель финансового отдела.
Итак, в сетевой модели отношение «один ко многим» (1:N) имеет связь между двумя типами записей. Теперь на приведенном выше рисунке ПРОДАВЕЦ, КЛИЕНТ, ПРОДУКТ, СЧЕТ, ОПЛАТА, СЧЕТ-ЛИНИЯ — это типы записей о продажах компании. Теперь, как вы можете видеть на данном рисунке, INVOICE-LINE принадлежит PRODUCT & INVOICE. INVOICE также имеет двух владельцев: SALES-MAN & CUSTOMER.
Давайте посмотрим еще один пример , в котором у нас есть два сегмента: Факультет и Студент. Предположим, что студент Джон посещает курсы как на факультетах CS, так и на факультетах EE. Теперь найдите, сколько экземпляров будет там?
В приведенном выше примере экземпляр студентов может иметь как минимум 2 родительских экземпляра, поэтому между экземплярами студентов и сегментом преподавателей существуют отношения. Модель может быть очень сложной, как если бы мы использовали другие сегменты, например «Курсы», и логические ассоциации, такие как «Студент-зачисление» и «Факультет-курс». Таким образом, в этой модели студент может быть логически связан с различными экземплярами факультетов и курсов.
Преимущества сетевой модели:
- Эта модель очень проста и легка в разработке, как и иерархическая модель данных.
- Эта модель способна обрабатывать несколько типов отношений, которые могут помочь в моделировании реальных приложений, например, отношения 1:1, 1:M, M:N.