Сетевые базы данных
Сетевая модель данных
Определение 1
Базы данных являются моделью реального мира, потому в них находят свое представление объекты реального мира и связи между ними. Основой для сетевой модели данных является понятие ориентированного графа. В математике графом называется модель, состоящая из узлов и ребер.
Узлами являются объекты сетевой базы данных, а ребрами – связи между объектами. В реальном мире связи между объектами делятся на три типа:
- один-к-одному;
- один-ко-многим;
- много-ко-многим.
Сетевая модель поддерживает только два из этих типов: «один-к-одному» и «один-ко-многим». Ребра направленного графа показывают не только саму связь, то и тип связи.

Сетевая модель данных состоит из следующих структурных элементов:
- Атрибут – минимальная информационная единица данных, к которой пользователь может обратиться по имени. Аналогом атрибута является поле в реляционной модели данных.
- Агрегат данных – именованная совокупность данных, объединенная логикой содержимого и относящаяся к одному объекту. Например, если имеется атрибут «серия паспорта» и «номер паспорта», то их можно объединить в агрегат данных «паспортные данные». Это будет выглядеть как таблица с иерархическим заголовком.

В реляционной модели данных аналогичное понятие отсутствует.
- Запись – совокупность атрибутов и/или агрегатов, соответствующая какому-либо объекту реального мира. Можно сказать, что запись – это агрегат, который не входит в другие агрегаты. В реляционной модели данных этому понятию соответствует таблица.
- Тип записи – совокупность записей с одинаковыми атрибутами.
Набор записей – структура, моделирующая связь между двумя типами записей. Если набор реализует отношение «один-ко-многим», то один тип записей в наборе называется «владельцем», другой – «подчиненным». Отношение «один-ко-многим» реализуется от владельца к подчиненным.
Например, между типами «Специальность» и «Студент» нужно установить связь типа «один-ко-многим», потому что на одной специальности учится много студентов. Тогда набор будет выглядеть, как показано на рисунке.

Тип записей «Специальность» является владельцем, тип записей «Студент» — подчиненным. Одной записи типа «Специальность» может соответствовать ноль или несколько записей типа «Студент». Связи устанавливаются за счет добавления в запись указателей на другие записи.
Сетевая база данных — это совокупность всех записей и наборов, которые достаточны для полного описания какой-либо предметной области.

Замечание 1
Сетевая база данных может состоять из любого количества записей и наборов разных типов. Две записи могут быть связаны любым количеством наборов, но в каждом наборе может быть только одна запись-владелец. Один и тот же тип записей может быть владельцем в одном наборе и подчиненным в другом наборе. Типа записи может вообще не входить ни в один набор.
Управление данными в сетевой базе данных
Все операции в сетевых базах производятся с записью, которая является текущей. Текущая запись выбирается путем навигационных операций. Навигационными являются следующие операции:
- Выбрать конкретную запись из совокупности однотипных записей.
- Перейти от записи-владельца к подчиненной записи в определенном наборе.
- Перейти к следующей записи.
- Перейти от подчиненной записи к записи-владельцу.
После выбора текущей записи становятся возможными следующие операции:
- Добавление новой записи с автоматическим включением ее в набор.
- Включение записи в набор, то есть связывание уже существующей записи с записью – владельцем.
- Переключение — связывание подчиненной записи с другим владельцем в том же наборе.
- Обновление – изменение атрибутов существующей записи.
- Исключение из набора позволяет разорвать связь между записью- владельцем и подчиненными записями.
- Удаление позволяет исключить запись из базы данных. Удаление требует предварительного анализа целостности данных. Если удаляется запись-владелец, то все подчиненные записи должны быть исключены из набора.
Достоинства и недостатки модели
Сетевая модель данных достаточно хорошо стандартизирована. В 1969 году консорциум CODASYL предложил спецификацию формального языка для описания сетевой модели. Модель обладает высокой выразительной способностью, так как позволяет устанавливать сложные отношения между данными. Сетевые базы данных отличаются высоким быстродействием и универсальностью.
Замечание 2
С другой стороны пользователи сетевых баз данных ограничены использованием той структуры данных, которую определил для них разработчик. Поэтому сетевые базы данных лишены гибкости – любое изменение структуры базы данных влечет перестройку всех записей путем введения новых указателей. Сетевые базы данных требуют сложной структуры памяти. В сетевых базах данных довольно трудно контролировать целостность данных.
Использование сетевой модели в современных информационных технология
Сетевая модель данных предшествовала реляционной и потому долгое время считалась устаревшей. Однако, практика показала, что для структурирования больших объемов трудноформализуемых данных сетевая модель подходит лучше реляционной. Например, сетевая организация данных лежит в основе глобальной сети Интернет, а реляционную модель с этой целью использовать невозможно.
В последние годы на рынке ИТ стали появляться новые программные продукты, основанные на сетевой модели данных. Среди них инструментальная система управления базами данных CronosPRO, сетевая объектно-ориентированная база знаний Cerebrum. Cистема управления базами данных GT.M поддерживает несколько моделей данных одновременно, в том числе и сетевую.
spravochnick.ru
Сетевая СУБД Википедия
Сетевая модель данных — логическая модель данных, являющаяся расширением иерархического подхода, строгая математическая теория, описывающая структурный аспект, аспект целостности и аспект обработки данных в сетевых базах данных.
 Сетевая СУБД, графическое представление связей
Сетевая СУБД, графическое представление связейОписание[ | ]
Сетевая БД состоит из набора экземпляров определенного типа записи и набора экземпляров определенного типа связей между этими записями.
Тип связи определяется для двух типов записи: предка и потомка. Экземпляр типа связи состоит из одного экземпляра типа записи предка и упорядоченного набора экземпляров типа записи потомка. Для данного типа связи L с типом записи предка P и типом записи потомка C должны выполняться следующие два условия:
- каждый экземпляр типа записи P является предком только в одном экземпляре типа связи L;
- каждый экземпляр типа записи C является потомком не более чем в одном экземпляре типа связи L.
Аспект манипуляции[ | ]
Примерный набор операций манипулирования данными:
- найти конкретную запись в наборе однотипных записей;
- перейти от предка к первому потомку по некоторой связи;
- перейти к следующему потомку в некоторой связи;
- перейти от потомка к предку по некоторой связи;
- создать новую запись;
- уничтожить запись;
- модифицировать запись;
- включить в связь;
- исключить из связи;
- переставить в другую связь и т. д.
Аспект целостности[ | ]
Достоинства[
ru-wiki.ru
Сетевая база данных. Сетевая модель данных. Концептуальная модель и структура сетевой БД.
Здравствуйте, уважаемые посетители моего скромного блога для начинающих вебразработчиков и web мастеров ZametkiNaPolyah.ru. Продолжаем рубрику Заметки о MySQL, в которой уже были публикации: Нормальные формы и транзитивная зависимость, избыточность данных в базе данных, типы и виды баз данных, настройка MySQL сервера и файл my.ini, MySQL сервер, установка и настройка, Архитектура СУБД и архитектура баз данных. Сегодня я бы хотел более подробно остановиться на сетевых базах данных, в общем-то, в одной из прошлых публикация я практически вскользь упоминал о них, но особой ясности не вносил. Следует сказать, что сетевая база данных относится к теоретико-графовым моделям, про то, что такое графы я постараюсь объяснить в другой публикации, сейчас этот момент не столь важен, но если хотите, то почитайте учебник математики. В этой публикации я постараюсь доступным и понятным языком рассказать о сетевых базах данных и принципе их работы, как обычно всю математику я сведу к минимуму и все умные термины оставлю за пределами данной публикации. Там, где я не смогу что-то объяснить без специфической терминологии, а такие моменты могут появиться, я все обязательно поясню.
Так вот, сетевые базы данных относятся к теоретико-графовым моделям баз данных, помимо сетевых баз данных сюда еще входят иерархические базы данных. Кстати, на основе математики сетевых баз данных существуют различные СУБД, это в основном коммерческие версии. У сетевых баз данных существуют характерные операции навигации, манипуляции и управления данными, с которыми мы и постараемся разобраться в данной публикации. Стоит сказать, что помимо теоретико-графовой модели баз данных существует еще и теоретико-множественная модель, к которой относятся реляционные базы данных, математика которых заложена в MySQL сервере, но до них мы еще обязательно дойдем. А теперь приступим к рассмотрению
Не забываем подписываться на RSS-ленту и на публичную страницу Вконтакте.
Сетевая модель данных
Содержание статьи:
Прежде чем перейти к описанию процессов, которые происходят внутри сетевой модели данных, давайте ознакомимся со структурой сетевой базы данных, чтобы иметь представление о том, с чем предстоит иметь нам дело. Прежде всего, следует разобраться со словом сети, которое присутствует в название: «сетевая модель». Сети – это естественный способ представления отношений между объектами базы данных и связей между этими объектами. Под словом объекты следует понимать таблицы баз данных или сущности. В общем, как вам удобно, так и называйте, вас везде поймут правильно.
Сетевые базы данных опираются на математику графов, конкретнее, сетевую модель данных можно представить в виде ориентированного графа. Направленный граф состоит из узлов и ребер. Узлы направленного графа – это ни что иное, как объекты сетевой базы данных, а ребра такого графа показывают связи между объектами сетевой модели данных, причем ребра показывают не только саму связь, но и тип связи (связь один к одному или связь один ко многим). Взгляните на рисунок, чтобы лучше осознать суть написанного выше:

Структура сетевой базы данных, пример
Стоит заметить, что иерархическая модель баз данных является частным и упрощенным случаем сетевых баз данных.
Структура сетевых баз данных
Сетевые базы данных имеют достаточно простую структуру, во всяком случае, сетевая модель имеет более простую структуру, нежели реляционная модель. Структура сетевых баз данных состоит из четырех компонентов, то есть в сетевой модели используют четыре типа структур данных. Два из которых являются главными и два, если можно так сказать, не главными. Главные типы структур сетевых данных – это запись и набор. Вспомогательные типы структур сетевой модели данных, которые используются для построения главных структур – это элемент данных и агрегат данных. Сама структура сетевой базы данных выглядит так:

Сетевая модель данных, пример
Пять элементов структуры сетевой модели данных образуют саму базу данных. Теперь пройдемся по каждому из типов структуры сетевых баз данных.
Элемент данных – это наименьшая информационная именованная единица данных, доступная пользователю, если провести аналогию с файловой системой, то это поле в файловой системе, если проводит аналогию с реляционной базой данных, то элемент данных – один столбец таблицы реляционной БД. Если говорить точнее, то это подстолбец. Не знаю, как правильно выразиться, вообще, я косноязычен.
Агрегат данных – это следующий уровень обобщения данных сетевой модели. Агрегат данных – это именованная совокупность данных внутри одной записи. Аналогию с реляционными БД тут не проведешь, поскольку агрегат данных – это столбец над столбцами, который объединяет элементы данных по логике их содержимого, следующий рисунок внесет ясность во все выше написанное:

Агрегат данных сетевой модели данных
На данном рисунке видно, что дата – это агрегат данных структуры сетевой модели, а день, месяц и год – это элемент данных сетевой БД.
Запись в сетевой модели данных – это конечный уровень обобщения данных, что-то наподобие таблицы в реляционной базе данных. Каждая запись в сетевой базе данных должна обладать или содержать в себе, как минимум один именованный элемент данных, если элементов внутри записи более одного, то каждый элемент данных должен обладать уникальным форматом.
Давайте разбираться со структурой сетевых баз данных на примере, поскольку так будет более понятно и доступно. Представим, что мы хотим создать запись в сетевую базу данных, назовем ее скажем «Сотрудник», в которую обязательно должен входить агрегат данных, который представлен на рисунке выше, его мы назовем «Дата». В эту запись нам необходимо будет добавить: табельный номер, ФИО и адрес сотрудника. Выглядеть такая запись в сетеовой модели данных будет следующим образом:

Записей сетевой базы данных
Прежде, чем переходить к набору записей, нужно разобраться с тем, что такое тип записи и для чего нужен тип записи в сетевой базе данных. И так, тип записей – это совокупность логически связанных экземпляров записей. Проще сказать – это все записи, которые связаны между собой по смыслу и, которые дополняют друг друга. Если переложить термин тип записей на реальный мир, то это информационная модель (иначе, полное описание) какого-либо объекта из реального мира, например сотрудника фирмы.
Как видно из рисунка выше: в качестве элементов данных сетевой модели могут быть использованы только простые типы, если хотите данных, но это не совсем так. Потому что в качестве агрегатов данных можно использовать сложные типы. Сложные типы в структуре сетевых баз данных бывают двух видов: вектор и повторяющаяся группа. Агрегат типа вектор соответствует линейному набору элементов данных, такой агрегат вы уже видели, он называется у нас «Дата», ну это чтобы вы представляли себе, что такое линейный набор элементов данных.
Агрегат типа повторяющаяся группа – это совокупность векторов данных (то есть несколько векторов). Для большей ясности давайте представим новый агрегат данных, который назовем, ну скажем «Товар»:

Агрегат типа повторяющаяся группа
Товары обычно хранятся на складе или их продают, зачастую по нескольку штук. Я хочу подвести к тому, что агрегат типа повторяющаяся группа – это несколько агрегатов типа вектор, объединенных вместе, допустим, у нас покупают 5 товаров, значит, если наш агрегат «Товар» будет иметь тип повторяющаяся группа, то он будет состоять из 5 агрегатов типа вектор, примерно так.
Перейдем к дальнейшему рассмотрению структуры сетевой модели данных. Набор записей – это именованная двухуровневая иерархическая структура, которая содержит управляемую и управляющую записи. При помощи наборов указывается тип связи между записями. Что это означает? Проще говоря, набор это две записи, между которыми есть связь: один ко многим или один к одному. Представим, что у нас имеется две записи в сетевой базе данных: запись «Сотрудник», структуру которой я привел выше и запись «Отдел», структура которой в данном контексте нам не важна.
Перед нами стоит задача: осуществить логическую связь между двумя этими записями, то есть определить какая запись будет управляемой, а какая управляющей. Логично предположить, что запись «Отдел» должна быть управляющей, поскольку сотрудник работает в отделе, а не отдел в сотруднике. И понятно, что связь между этими записями должна быть один ко многим, потому что отдел один, а сотрудников много, назовем эту связь «Работает». И так, мы приходим к выводу, что набор записей сетевой модели данных определяет: управляющую запись, в нашем случае это «Отдел», подчиненную запись, которую мы назвали «Сотрудник», а так же тип связи между этими записями, которую мы обозвали «Работает». «Работает» — это не только имя связи, но еще и метка, которая именует сам набор данных сетевой модели. Впрочем, рисунок должны внести ясность в мои несколько путаные пояснения:

Набор записей сетевой модели данных
В данном случае связь один ко многим говорит нам о том, что с одним экземпляром записи «Отдел» может быть связано ноль, один или несколько экземпляров записи «Сотрудник». Экземпляр записи – это что-то наподобие кортежа (строки таблицы) из реляционной БД. Использую понятия сетевой модели данных, приведенные выше, можно нарисовать набор записей по-другому. На рисунке можно отобразить логические типы данных для обеих записей, структуру записей сетевой модели данных и указать связь между записями, которую мы обозвали «Работает»:
Теперь обобщим все то, что было написано выше про структуру сетевой базы данных, собственно обобщает все база данных. База данных сетевой модели данных – это именованная совокупность экземпляров записей различного типа и экземпляров наборов, хранящих в себе типы связей между записями. Проще говоря, это все записи и все связи между записями. Что же, мы познакомились со структурой сетевой модели данных, рассмотрели несколько примеров и заодно ознакомились с самыми простыми основами проектирования сетевых баз данных. Жаль, что я ничего не писал про концептуальное проектирование баз данных и концептуальную модель данных. В дальнейшем постараюсь исправить этот недостаток, потому что следующий раздел будет связан с концептуальной моделью.
Преобразование концептуальной модели в сетевую модель данных
На детальное рассмотрение концептуальное модели данных и концептуального проектирования баз данных может потребоваться пара публикаций, а ограничиваться общими словами я не хочу, поэтому сейчас, уважаемые посетители, я буду считать, что вы имеете представление о том, что такое концептуальная модель, если не знаете, то тут два выхода: либо вы ждете соответствующую публикацию на моем блоге, либо пользуетесь поисковыми системами. Думаю, на других сайтах люди пишут не хуже меня, а может быть и лучше. Если вы ничего не знаете про концептуальную модель данных, то смело пропускайте данный раздел.
Сетевую модель данных можно легко получить из концептуальной модели, причем нужно соблюсти всего лишь одно условие: в концептуальной модели данных должны использоваться только бинарные связи, которые принадлежат к типам: «один к одному» или «один ко многим». При этом вместо сущностей концептуальной модели данных следует использовать типы записей сетевой базы данных, собственно, имена сущностей из одной будут являться именами типов записей другой модели данных. Атрибуты, которые есть у сущностей (иначе столбцы таблицы) превращаются в поля записей сетевой модели данных, а связи между сущностями становятся связями между типами записей.
Бинарные связи концептуальной модели данных без затруднений переносятся на сетевую модель данных. Связь один ко многим переносится следующим образом: тип записи со стороны один становится управляющей записью, а тип записи со стороны многим становится подчиненной записью. Для связи один к одному запись владелец и подчиненная запись определяется произвольно.
Управление сетевыми данными
И последнее, о чем я бы хотел поговорить в этой публикации – управление сетевыми данными. Стоит сказать, что для манипулирования и управления данными в сетевой модели данных используется ряд типичных операций (о специфических операциях, присущих различным сетевым СУБД, мы говорить не будем), которые присущи для всех систем управления сетевыми базами данных. Все операции с сетевыми данными можно разделить на две группы: навигационные операции с данными и операции модификации данных.
Навигационные операции сетевых баз данных осуществляют переход по связям, определенных в схеме баз данных, в результате таких переходов определяется запись, которую называют текущей (запись сетевой модели, с которой мы будем работать). К навигационным операциям можно отнести:
- найти конкретную запись в наборе однотипных записей и сделать ее текущей;
- перейти от записи-владельца к записи-члену в некотором наборе;
- перейти к следующей записи в некоторой связи;
- перейти от записи-члена к владельцу по некоторой связи.
При помощи операций модификации сетевых баз данных осуществляется добавление новых записей данных, добавление новых наборов данных, удаление записей данных и наборов записей, модификация агрегатов и элементов данных. Для реализации этих операций в системе текущее состояние детализируется путем запоминания трех его составляющих: текущего набора, текущего типа записи, текущего экземпляра типа записи. В такой ситуации возможны следующие операции:
- извлечь текущую запись в буфер прикладной программы для обработки;
- заменить в извлеченной записи значения указанных элементов данных на заданные новые их значения;
- запомнить запись из буфера в БД;
- создать новую запись;
- уничтожить запись;
- включить текущую запись в текущий экземпляр набора;
- исключить текущую запись из текущего экземпляра набора.
Поддержание ограничений целостности в сетевых моделях в принципе не требуется. На этом всё, спасибо за внимание, надеюсь, что был хоть чем-то полезен и до скорых встреч на страницах блога для начинающих вебразработчиков и вебмастеров ZametkiNaPolyah.ru. Не забываем комментировать и делиться с друзьями;)
zametkinapolyah.ru
Сетевая СУБД Википедия
Сетевая модель данных — логическая модель данных, являющаяся расширением иерархического подхода, строгая математическая теория, описывающая структурный аспект, аспект целостности и аспект обработки данных в сетевых базах данных.
Сетевая СУБД, графическое представление связейОписание
Разница между иерархической моделью данных и сетевой состоит в том, что в иерархических структурах запись-потомок должна иметь в точности одного предка, а в сетевой структуре данных у потомка может иметься любое число предков.
Сетевая БД состоит из набора экземпляров определенного типа записи и набора экземпляров определенного типа связей между этими записями.
Тип связи определяется для двух типов записи: предка и потомка. Экземпляр типа связи состоит из одного экземпляра типа записи предка и упорядоченного набора экземпляров типа записи потомка. Для данного типа связи L с типом записи предка P и типом записи потомка C должны выполняться следующие два условия:
- каждый экземпляр типа записи P является предком только в одном экземпляре типа связи L;
- каждый экземпляр типа записи C является потомком не более чем в одном экземпляре типа связи L.
Аспект манипуляции
Примерный набор операций манипулирования данными:
- найти конкретную запись в наборе однотипных записей;
- перейти от предка к первому потомку по некоторой связи;
- перейти к следующему потомку в некоторой связи;
- перейти от потомка к предку по некоторой связи;
- создать новую запись;
- уничтожить запись;
- модифицировать запись;
- включить в связь;
- исключить из связи;
- переставить в другую связь и т. д.
Аспект целостности
Имеется (необязательная) возможность потребовать для конкретного типа связи отсутствие потомков, не участвующих ни в одном экземпляре этого типа связи (как в иерархической модели).
Достоинства
Достоинством сетевой модели данных является возможность эффективной реализации по показателям затрат памяти и оперативности.
Недостатки
Недостатком сетевой модели данных являются высокая сложность и жесткость схемы БД, построенной на её основе. Поскольку логика процедуры выборки данных зависит от физической организации этих данных, то эта модель не является полностью независимой от приложения. Другими словами, если необходимо изменить структуру данных, то нужно изменить и приложение.
История
Сетевая модель была одним из первых подходов, использовавшимся при создании баз данных в конце 50-х — начале 60-х годов. Активным пропагандистом этой модели был Чарльз Бахман. Идеи Бахмана послужили основой для разработки стандартной сетевой модели под эгидой организации CODASYL. После публикации отчетов рабочей группы этой организации в 1969, 1971 и 1973 годах многие компании привели свои сетевые базы данных более-менее в соответствие со стандартами CODASYL. До середины 70-х годов главным конкурентом сетевых баз данных была иерархическая модель данных, представленная ведущим продуктом компании IBM в области баз данных — IBM IMS[1].
В конце 60-х годов Эдгаром Коддом была предложена реляционная модель данных и после долгих и упорных споров с Бахманом[2] реляционная модель приобрела большую популярность и теперь является доминирующей на рынке СУБД.
Сетевые СУБД
Сетевая СУБД — СУБД, построенная на основе сетевой модели данных.
К основным понятиям сетевой модели базы данных относятся: уровень, элемент (узел), связь.
Узел — это совокупность атрибутов данных, описывающих некоторый объект. На схеме иерархического дерева узлы представляются вершинами графа. В сетевой структуре каждый элемент может быть связан с любым другим элементом.
Сетевые базы данных подобны иерархическим, за исключением того, что в них имеются указатели в обоих направлениях, которые соединяют родственную информацию.
Несмотря на то, что эта модель решает некоторые проблемы, связанные с иерархической моделью, выполнение простых запросов остается достаточно сложным процессом.
Также, поскольку логика процедуры выборки данных зависит от физической организации этих данных, то эта модель не является полностью независимой от приложения. Другими словами, если необходимо изменить структуру данных, то нужно изменить и приложение.
Список самых значимых сетевых СУБД на 1978 год[3]:
- IDS (Integrated Data Store) компании General Electric — самая первая сетевая СУБД, разработаная Чарльзом Бахманом в 1960 г.
- IDS/2 или IDS/II) компании Honeywell, купившей IDS у General Electric, позднее — компании Bull[4][5]
- Integrated Database Management System (IDMS) компании Cullinet, развитие IDS на основе её исходных кодов
- DMS-1100 (для мейнфреймов UNIVAC 1100) и DMS-90 (для мини-компьютеров, первый релиз — ноябрь 1974) компании UNIVAC
- DBMS-10 компании DEC для Decsystem-10 и Decsystem-20
- CDC DMS-170
- Burroughs Data Management System (DMS-2[6]). Продукт представлен на рынке в октябре 1974 года.
Другие подобные СУБД:[источник не указан 1895 дней]
Примечания
- ↑ Liu and Ozsu, 2009, p. 1900.
- ↑ Знаменитый спор под названием «The Great Debate произошел в 1974 году на конференции ACM SIGMOD Workshop on Data Description, Access, and Control, где Бахман и Кодд решали одну и ту же бизнес-задачу, используя каждый свой подход. Кодд решил её правильно, хоть и не с первого раза, а Бахман предложил громоздкое решение, которое оказалось неверным. [источник?]
- ↑ Computerworld 5 июн 1978, стр.160 — обзор главных СУБД на то время
- ↑ Celko, 2012, p. 6.
- ↑ Computerworld 5 Jun 1978// Data Base Systems: Design, Implementation and Management, Part III
- ↑ или DMS-II см. Computerworld 5 июн 1978
- ↑ Cerebrum : Сетевая объектно-ориентированная система управления базой знаний
Литература
Ссылки
wikiredia.ru
8.2 Сетевая модель базы данных
2. Сетевая модель данных является более общей структурой по сравнению с иерархической. Основные принципы сетевой модели данных были разработаны в середине 60-х годов, эталонный вариант сетевой модели данных описан в отчетах рабочей группы по языкам баз данных (COnference on DAta SYstem Languages) CODASYL (1971 г.).
В сетевых БД наряду с вертикальными реализованы и горизонтальные связи. Каждый отдельный сегмент (ячейка) может иметь произвольное число непосредственных исходных (старших) сегментов, а также и произвольное число порожденных (младших) ( рис. 8). Это обеспечиваетпредставление отношения «многие к многим».
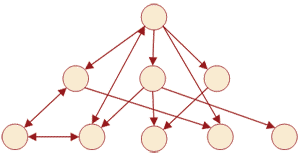
Рис. 8. Сетевая модель данных
Однако унаследованы многие недостатки иерархической и главный из них, необходимость четко определять на физическом уровне связи данных и столь же четко следовать этой структуре связей при запросах к базе. Поскольку логика процедуры выборки данных зависит от их физической организации, то сетевая модель не является полностью независимой от приложения. Другими словами, если необходимо изменить структуру данных, то нужно поменять и приложение.
Основное различие этих моделей состоит в том, что в сетевой модели запись может быть членом более чем одного группового отношения. Согласно этой модели каждое групповое отношение именуется и проводится различие между его типом и экземпляром. Тип группового отношения задается его именем и определяет свойства общие для всех экземпляров данного типа. Экземпляр группового отношения представляется записью-владельцем и множеством (возможно пустым) подчиненных записей. При этом имеется следующее ограничение: экземпляр записи не может быть членом двух экземпляров групповых отношений одного типа (т.е. сотрудник из примера в п..1, например, не может работать в двух отделах).
8.3. Достоинства и недостатки ранних субд
Достоинства ранних СУБД:
развитые средства управления данными во внешней памяти на низком уровне;
возможность построения вручную эффективных прикладных систем;
возможность экономии памяти за счет разделения подобъектов (в сетевых системах)
Недостатки ранних СУБД:
сложность использования;
высокий уровень требований к знаниям о физической организации БД;
зависимость прикладных систем от физической организации БД;
перегруженность логики прикладных систем деталями организации доступа к БД.
Как иерархическая, так и сетевая модель данных предполагает наличие высококвалифицированных программистов. И даже в таких случаях реализация пользовательских запросов часто затягивается на длительный срок.
8.4. Реляционная модель данных
Понятие реляционный (англ. relation — отношение) связано с разработками известного американского специалиста в области систем баз данных Е. Кодда. Эта модель характеризуется простотой структуры данных, удобным для пользователя табличным представлением и возможностью использования формального аппарата алгебры отношений и реляционного исчисления для обработки данных.
Все данные в модели представляются в виде таблиц и только таблиц. Реляционная модель — единственная из всех обеспечивает единообразие представления данных. И сущности, и связи этих самых сущностей представляются в модели совершенно одинаково — таблицами. Таблица является наиболее удобным инженерным представлением для пользователя ( рис. 9,а). Каждый столбец ее соответствует атрибуту объекта, и ему присваивается соответствующее имя. В столбцах таблицы (отношения) вводятся значения атрибутов. Используя отношения связи и язык реляционной алгебры, можно осуществлять выбор любого подмножества информации: по строкам, столбцам или другим признакам. Применяя операции «разрезания» и «склеивания» отношений, можно получить разнообразные файлы в нужной форме ( рис. 9,б).
При использовании реляционной модели атрибут объекта может сам выступать как объект другой предметной области, т.е. задействуется относительность (отсюда – отношение) понятий объекта и его атрибутов.
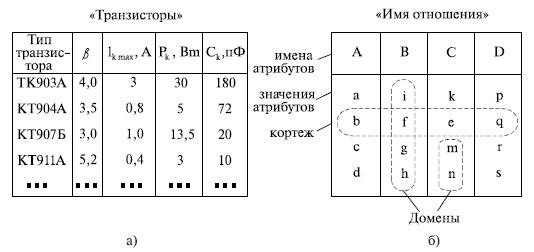
Рис. 9 Пример (а) и общий вид (б) реляционной модели данных
studfile.net
Википедия — свободная энциклопедия
Избранная статья
Первое сражение при реке Булл-Ран (англ. First Battle of Bull Run), также Первое сражение при Манассасе) — первое крупное сухопутное сражение Гражданской войны в США. Состоялось 21 июля 1861 года возле Манассаса (штат Виргиния). Федеральная армия под командованием генерала Ирвина Макдауэлла атаковала армию Конфедерации под командованием генералов Джонстона и Борегара, но была остановлена, а затем обращена в бегство. Федеральная армия ставила своей целью захват важного транспортного узла — Манассаса, а армия Борегара заняла оборону на рубеже небольшой реки Булл-Ран. 21 июля Макдауэлл отправил три дивизии в обход левого фланга противника; им удалось атаковать и отбросить несколько бригад конфедератов. Через несколько часов Макдауэлл отправил вперёд две артиллерийские батареи и несколько пехотных полков, но южане встретили их на холме Генри и отбили все атаки. Федеральная армия потеряла в этих боях 11 орудий, и, надеясь их отбить, командование посылало в бой полк за полком, пока не были израсходованы все резервы. Между тем на поле боя подошли свежие бригады армии Юга и заставили отступить последний резерв северян — бригаду Ховарда. Отступление Ховарда инициировало общий отход всей федеральной армии, который превратился в беспорядочное бегство. Южане смогли выделить для преследования всего несколько полков, поэтому им не удалось нанести противнику существенного урона.
Хорошая статья
«Хлеб» (укр. «Хліб») — одна из наиболее известных картин украинской советской художницы Татьяны Яблонской, созданная в 1949 году, за которую ей в 1950 году была присуждена Сталинская премия II степени. Картина также была награждена бронзовой медалью Всемирной выставки 1958 года в Брюсселе, она экспонировалась на многих крупных международных выставках.
В работе над полотном художница использовала наброски, сделанные летом 1948 года в одном из наиболее благополучных колхозов Советской Украины — колхозе имени В. И. Ленина Чемеровецкого района Каменец-Подольской области, в котором в то время было одиннадцать Героев Социалистического Труда. Яблонская была восхищена масштабами сельскохозяйственных работ и людьми, которые там трудились. Советские искусствоведы отмечали, что Яблонская изобразила на своей картине «новых людей», которые могут существовать только в социалистическом государстве. Это настоящие хозяева своей жизни, которые по-новому воспринимают свою жизнь и деятельность. Произведение было задумано и создано художницей как «обобщённый образ радостной, свободной творческой работы». По мнению французского искусствоведа Марка Дюпети, эта картина стала для своего времени программным произведением и образцом украинской реалистической живописи XX столетия.
Изображение дня
Рассвет в деревне Бёрнсте в окрестностях Дюльмена, Северный Рейн-Вестфалия
ru.wikipedia.green
Сетевая модель данных Википедия
Сетевая модель данных — логическая модель данных, являющаяся расширением иерархического подхода, строгая математическая теория, описывающая структурный аспект, аспект целостности и аспект обработки данных в сетевых базах данных.
Сетевая СУБД, графическое представление связейОписание[ | ]
Разница между иерархической моделью данных и сетевой состоит в том, что в иерархических структурах запись-потомок должна иметь в точности одного предка, а в сетевой структуре данных у потомка может иметься любое число предков.
Сетевая БД состоит из набора экземпляров определенного типа записи и набора экземпляров определенного типа связей между этими записями.
Тип связи определяется для двух типов записи: предка и потомка. Экземпляр типа связи состоит из одного экземпляра типа записи предка и упорядоченного набора экземпляров типа записи потомка. Для данного типа связи L с типом записи предка P и типом записи потомка C должны выполняться следующие два условия:
- каждый экземпляр типа записи P является предком только в одном экземпляре типа связи L;
- каждый экземпляр типа записи C является потомком не более чем в одном экземпляре типа связи L.
Аспект манипуляции[ | ]
Примерный набор операций манипулирования данными:
- найти конкретную запись в наборе однотипных записей;
- перейти от предка к первому потомку по некоторой связи;
- перейти к следующему потомку в некоторой связи;
- перейти от потомка к предку по некоторой связи;
- создать новую запись;
- уничтожить запись;
- модифицировать запись;
- включить в связь;
- исключить из связи;
- переставить в другую связь и т. д.
Аспект целостности[ | ]
Имеется (необязательная) возможность потребовать для конкретного типа связи отсутствие потомков, не участвующих ни в одном экземпляре этого типа связи (как в иерархической модели).
Достоинства[
ru-wiki.ru