Руководство по проектированию реляционных баз данных (1-3 часть из 15) [перевод] / Хабр
Перевод цикла из 15 статей о проектировании баз данных.
Информация предназначена для новичков.
Помогло мне. Возможно, что поможет еще кому-то восполнить пробелы.
Другие части: 4-6, 7-9, 10-13, 14-15.
Руководство по проектированию баз данных.
1. Вступление.
Если вы собираетесь создавать собственные базы данных, то неплохо было бы придерживаться правил проектирования баз данных, так как это обеспечит долговременную целостность и простоту обслуживания ваших данных. Данное руководство расскажет вам что представляют из себя базы данных и как спроектировать базу данных, которая подчиняется правилам проектирования реляционных баз данных.
Базы данных – это программы, которые позволяют сохранять и получать большие объемы связанной информации. Базы данных состоят из таблиц, которые содержат информацию. Когда вы создаете базу данных необходимо подумать о том, какие таблицы
Когда вы создаете базу данных необходимо подумать о том, какие таблицы
Структурированный язык запросов (SQL).
База данных создается для хранения в ней информации и получения этой информации при необходимости. Это значит, что мы должны иметь возможность помещать, вставлять (INSERT) информацию в базу данных и мы хотим иметь возможность делать выборку информации из базы данных (SELECT).
Язык запросов к базам данных был придуман для этих целей и был назван Структурированный язык запросов или SQL. Операции вставки данных (INSERT) и их выборки (SELECT) – части этого самого языка. Ниже приведен пример запроса на выборку данных и его результат.
SQL – большая тема для повествования и его рассмотрение выходит за рамки данного руководства. Данная статья строго сфокусирована на изложении процесса проектирования баз данных. Позднее, в отдельном руководстве, я расскажу об основах SQL.
Реляционная модель.
В этом руководстве я покажу вам как создавать реляционную модель данных. Реляционная модель – это модель, которая описывает как организовать данные в таблицах и как определить связи между этими таблицами.
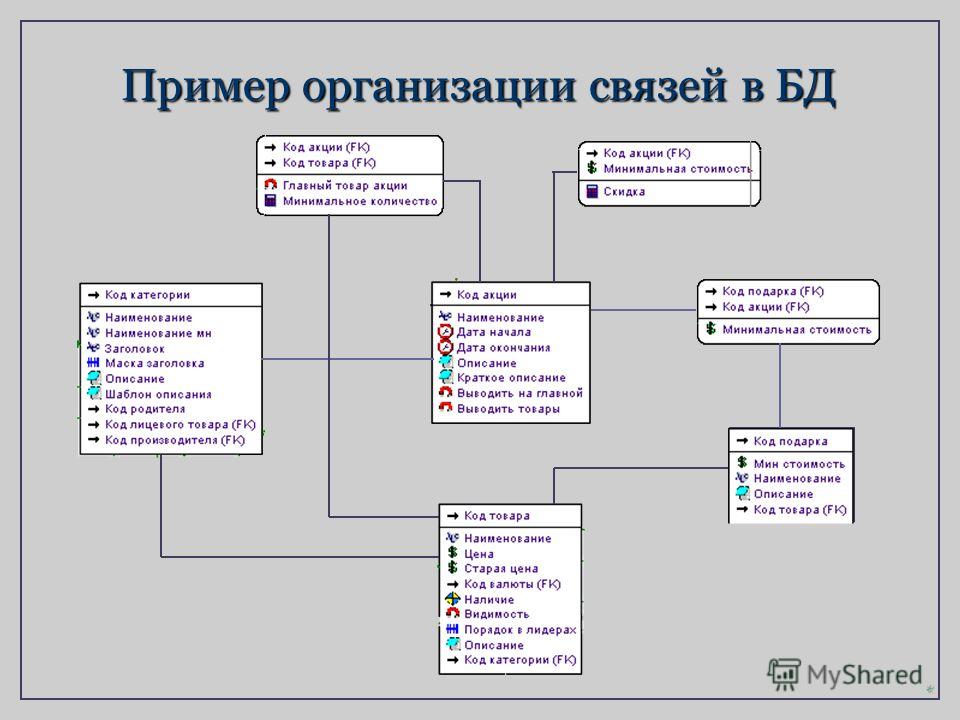
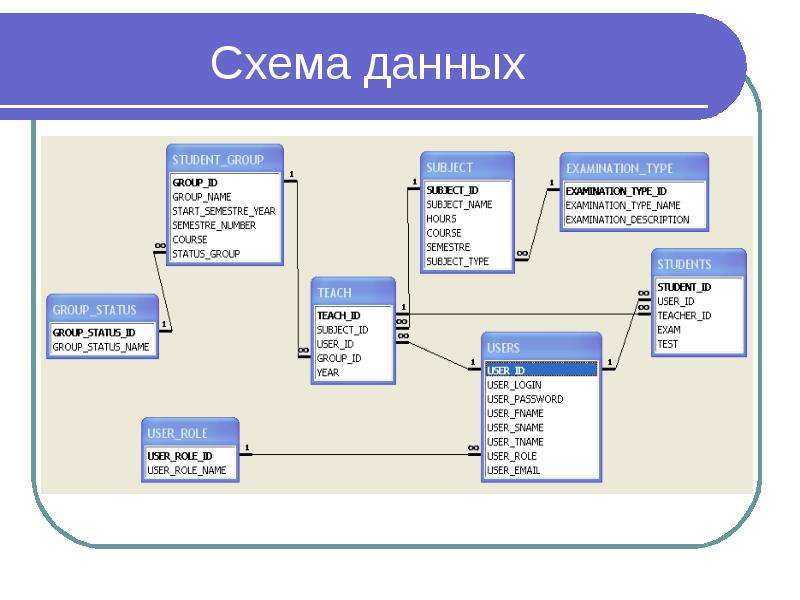
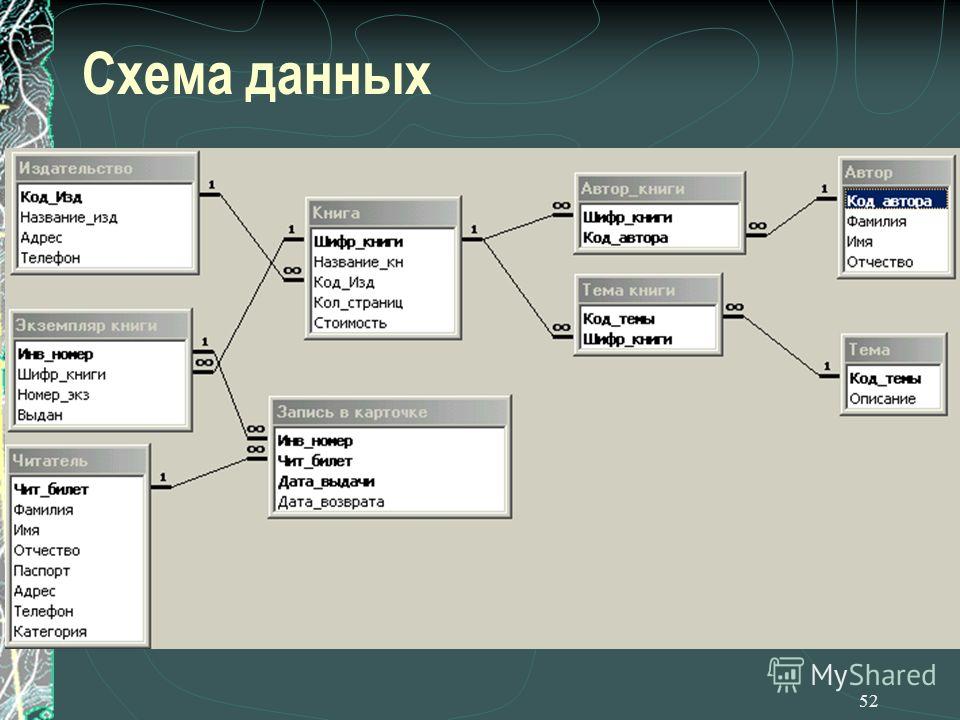
Правила реляционной модели диктуют, как информация должна быть организована в таблицах и как таблицы связаны друг с другом. В конечном счете результат можно предоставить в виде диаграммы базы данных или, если точнее, диаграммы «сущность-связь», как на рисунке (Пример взят из MySQL Workbench).
Примеры.
В качестве примеров в руководстве я использовал ряд приложений.
РСУБД.
РСУБД, которую я использовал для создания таблиц примеров – MySQL.
Утилита для администрирования БД.
После установки MySQL вы получаете только интерфейс командной строки для взаимодействия с MySQL. Лично я предпочитаю графический интерфейс для управления моими базами данных. Я часто использую SQLyog. Это бесплатная утилита с графическим интерфейсом. Изображения таблиц в данном руководстве взяты оттуда.
Визуальное моделирование.
Существует отличное бесплатное приложение MySQL Workbench. Оно позволяет спроектировать вашу базу данных графически. Изображения диаграмм в руководстве сделаны в этой программе.
Проектирование независимо от РСУБД.
В следующей части я коротко расскажу об эволюции баз данных. Вы узнаете откуда взялись базы данных и реляционная модель данных.
2. История.
В 70-х – 80-х годах, когда компьютерные ученые все еще носили коричневые смокинги и очки с большими, квадратными оправами, данные хранились бесструктурно в файлах, которые представляли собой текстовый документ с данными, разделенными (обычно) запятыми или табуляциями.
Так выглядели профессионалы в сфере информационных технологий в 70-е. (Слева внизу находится Билл Гейтс).
Текстовые файлы и сегодня все еще используются для хранения малых объемов простой информации. Comma-Separated Values (CSV) — значения, разделённые запятыми, очень популярны и широко поддерживаются сегодня различным программным обеспечением и операционными системами. Microsoft Excel – один из примеров программ, которые могут работать с CSV–файлами. Данные, сохраненные в таком файле могут быть считаны компьютерной программой.
Выше приведен пример того, как такой файл мог бы выглядеть. Программа, производящая чтение данного файла, должна быть уведомлена о том, что данные разделены запятыми. Если программа хочет выбрать и вывести категорию, в которой находится урок ‘Database Design Tutorial’, то она должна строчка за строчкой производить чтение до тех пор, пока не будут найдены слова ‘Database Design Tutorial’ и затем ей нужно будет прочитать следующее за запятой слово для того, чтобы вывести категорию Software.
Таблицы баз данных.
Компьютерная программа могла бы осуществить поиск в столбце tutorial_id данной таблицы по специфическому идентификатору tutorial_id для того, чтобы быстро найти соответствующие ему заголовок и категорию.
Современные реляционные базы данных созданы так, чтобы позволять делать выборку данных из специфических строк, столбцов и множественных таблиц, за раз, очень быстро.
История реляционной модели.
Реляционная модель баз данных была изобретена в 70-х Эдгаром Коддом (Ted Codd), британским ученым. Он хотел преодолеть недостатки сетевой модели баз данных и иерархической модели. И он очень в этом преуспел. Реляционная модель баз данных сегодня всеобще принята и считается мощной моделью для эффективной организации данных.
Сегодня доступен широкий выбор систем управления базами данных: от небольших десктопных приложений до многофункциональных серверных систем с высокооптимизированными методами поиска. Вот некоторые из наиболее известных систем управления реляционными базами данных (РСУБД):
— Oracle – используется преимущественно для профессиональных, больших приложений.
— Microsoft SQL server – РСУБД компании Microsoft. Доступна только для операционной системы Windows.
— Mysql – очень популярная РСУБД с открытым исходным кодом. Широко используется как профессионалами, так и новичками. Что еще нужно?! Она бесплатна.
— Microsoft Access – РСУБД, которая используется в офисе и дома. На самом деле – это больше, чем просто база данных. MS Access позволяет создавать базы данных с пользовательским интерфейсом.
В следующей части я расскажу кое-что о характеристиках реляционных баз данных.
3. Характеристики реляционных баз данных.
Реляционные базы данных разработаны для быстрого сохранения и получения больших объемов информации. Ниже приведены некоторые характеристики реляционных баз данных и реляционной модели данных.
Использование ключей.
Каждая строка данных в таблице идентифицируется уникальным “ключом”, который называется первичным ключом.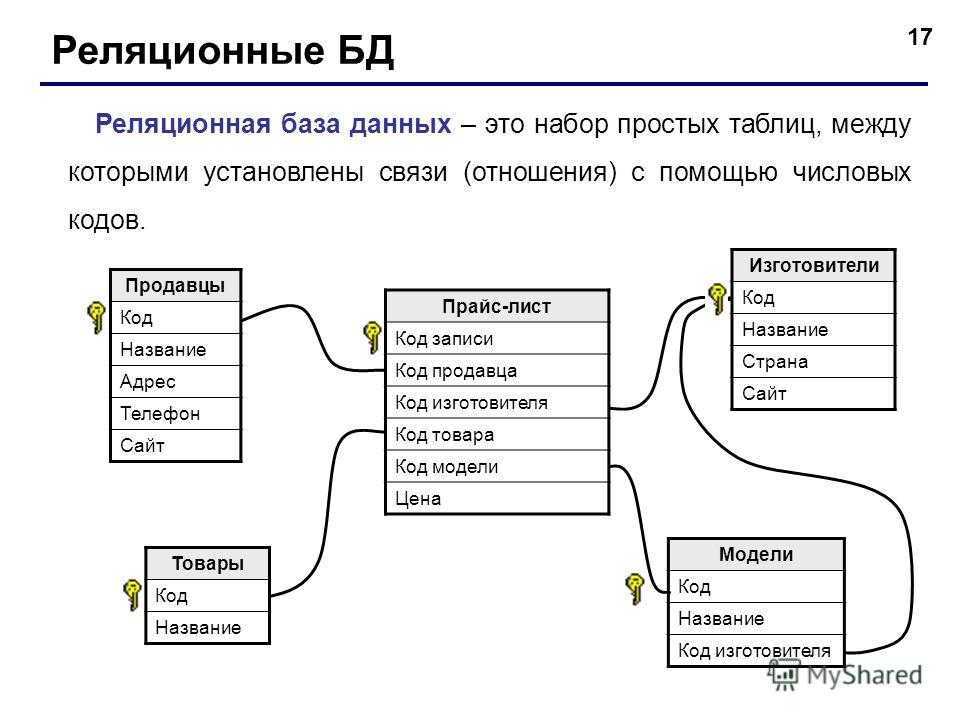
Используя структурированный язык запросов (SQL), данные из разных таблиц, которые связаны ключом, могут быть выбраны за один раз. Для примера вы можете создать запрос, который выберет все заказы из таблицы заказов (orders), которые принадлежат пользователю с идентификатором (id) 3 (Mike) из таблицы пользователей (users). О ключах мы поговорим далее, в следующих частях.
Столбец id в данной таблице является первичным ключом. Каждая запись имеет уникальный первичный ключ, часто число. Столбец usergroup (группы пользователей) является внешним ключом. Судя по ее названию, она видимо ссылается на таблицу, которая содержит группы пользователей.
Отсутствие избыточности данных.
В проекте базы данных, которая создана с учетом правил реляционной модели данных, каждый кусочек информации, например, имя пользователя, хранится только в одном месте. Это позволяет устранить необходимость работы с данными в нескольких местах. Дублирование данных называется избыточностью данных и этого следует избегать в хорошем проекте базы данных.
Ограничение ввода.
Используя реляционную базу данных вы можете определить какой вид данных позволено сохранять в столбце. Вы можете создать поле, которое содержит целые числа, десятичные числа, небольшие фрагменты текста, большие фрагменты текста, даты и т.д.
Когда вы создаете таблицу базы данных вы предоставляете тип данных для каждого столбца. К примеру, varchar – это тип данных для небольших фрагментов текста с максимальным количеством знаков, равным 255, а int – это числа.
Помимо типов данных РСУБД позволяет вам еще больше ограничить возможные для ввода данные. Например, ограничить длину или принудительно указать на уникальность значения записей в данном столбце. Последнее ограничение часто используется для полей, которые содержат регистрационные имена пользователей (логины), или адреса электронной почты.
Например, ограничить длину или принудительно указать на уникальность значения записей в данном столбце. Последнее ограничение часто используется для полей, которые содержат регистрационные имена пользователей (логины), или адреса электронной почты.
Эти ограничения дают вам контроль над целостностью ваших данных и предотвращают ситуации, подобные следующим:
— ввод адреса (текста) в поле, в котором вы ожидаете увидеть число
— ввод индекса региона с длинной этого самого индекса в сотню символов
— создание пользователей с одним и тем же именем
— создание пользователей с одним и тем же адресом электронной почты
— ввод веса (числа) в поле дня рождения (дата)
Поддержание целостности данных.
Настраивая свойства полей, связывая таблицы между собой и настраивая ограничения, вы можете увеличить надежность ваших данных.
Назначение прав.
Большинство РСУБД предлагают настройку прав доступа, которая позволяет назначать определенные права определенным пользователям. Некоторые действия, которые могут быть позволены или запрещены пользователю: SELECT (выборка), INSERT (вставка), DELETE (удаление), ALTER (изменение), CREATE (создание) и т.д. Это операции, которые могут быть выполнены с помощью структурированного языка запросов (SQL).
Некоторые действия, которые могут быть позволены или запрещены пользователю: SELECT (выборка), INSERT (вставка), DELETE (удаление), ALTER (изменение), CREATE (создание) и т.д. Это операции, которые могут быть выполнены с помощью структурированного языка запросов (SQL).
Структурированный язык запросов (SQL).
Для того, чтобы выполнять определенные операции над базой данных, такие, как сохранение данных, их выборка, изменение, используется структурированный язык запросов (SQL). SQL относительно легок для понимания и позволяет в т.ч. и уложненные выборки, например, выборка связанных данных из нескольких таблиц с помощью оператора SQL JOIN. Как и упоминалось ранее, SQL в данном руководстве обсуждаться не будет. Я сосредоточусь на проектировании баз данных.
То, как вы спроектируете базу данных будет оказывать непосредственное влияние на запросы, которые вам будет необходимо выполнить, чтобы получить данные из базы данных. Это еще одна причина, почему вам необходимо задуматься о том, какой должна быть ваша база. С хорошо спроектированной базой данных ваши запросы могут быть чище и проще.
С хорошо спроектированной базой данных ваши запросы могут быть чище и проще.
Переносимость.
Реляционная модель данных стандартна. Следуя правилам реляционной модели данных вы можете быть уверены, что ваши данные могут быть перенесены в другую РСУБД относительно просто.
Как говорилось ранее, проектирование базы данных – это вопрос идентификации данных, их связи и помещение результатов решения данного вопроса на бумагу (или в компьютерную программу). Проектирование базы данных независимо от РСУБД, которую вы собираетесь использовать для ее создания.
В следующей части подробнее рассмотрим первичные ключи.
Основы правил проектирования базы данных / Хабр
Введение
Как это часто бывает, архитектору БД нужно разработать базу данных под конкретное решение.
Однажды в пятницу вечером, возвращаясь на электричке домой с работы, я подумал о том, как бы я создал сервис по найму сотрудников в разные компании. Ведь ни один из существующих сервисов не позволяет быстро понять насколько подходит тебе кандидат. Нет возможности создать сложные фильтры, включающие или исключающие совокупность определенных навыков, проектов или позиций. Максимум, что обычно предлагают сервисы — фильтры по компаниям и частично по навыкам.
Ведь ни один из существующих сервисов не позволяет быстро понять насколько подходит тебе кандидат. Нет возможности создать сложные фильтры, включающие или исключающие совокупность определенных навыков, проектов или позиций. Максимум, что обычно предлагают сервисы — фильтры по компаниям и частично по навыкам.
В данной статье я позволю себе немного разбавить строгое изложение материала, смешав техническую информацию с не техническими примерами из жизни.
Для начала, разберем создание базы данных в MS SQL Server для сервиса поиска соискателей на работу.
Этот материал можно перенести и на другую СУБД такую как MySQL или PostgreSQL.
Основы правил проектирования
Для проектирования схемы базы данных, нужно вспомнить 7 формальных правил и саму концепцию нормализации и денормализации. Они и лежат в основе всех правил проектирования.
Опишем более детально 7 формальных правил:
- отношение один к одному:
1.
 1) с обязательной связью:
1) с обязательной связью:примером может выступать гражданин и его паспорт: у любого гражданина должен быть паспорт; паспорт один для каждого гражданина
Реализовать данную связь можно двумя способами:
1.1.1) в одной сущности (таблице):
Рис.1. Сущность CitizenЗдесь таблица Citizen представляет собой сущность гражданина, а атрибут (поле) PassportData содержит все паспортные данные гражданина и не может быть пустым (NOT NULL).
1.1.2) в двух разных сущностях (таблицах):
Рис.2. Отношение сущностей Citizen и PassportDataЗдесь таблица Citizen представляет собой сущность гражданина, а таблица PassportData — сущность паспортных данных гражданина (самого паспорта). Сущность гражданина содержит атрибут (поле) PassportID, который ссылается на первичный ключ таблицы PassportData. В свою очередь сущность паспортных данных содержит атрибут (поле) CitizenID, которое ссылается на первичный ключ CitizenID таблицы Citizen. Поле PassportID таблицы Citizen не может быть пустым (NOT NULL).
Также здесь важно поддерживать целостность поля CitizenID таблицы PassportData, чтобы обеспечить связь один к одному. Иными словами, поле PassportID таблицы Citizen и поле CitizenID таблицы PassportData должны ссылаться на одни и те же записи как если бы это была одна сущность (таблица), представленная в пункте 1.1.1.1.2) с необязательной связью:
примером может выступать человек, имеющий или не имеющий паспорт конкретной страны. В первом случае он будет являться гражданином рассматриваемой страны, а во втором — нет.
Реализовать данную связь можно двумя способами:
1.2.1) в одной сущности (таблице):
Рис.3. Сущность PersonТаблица Person представляет собой сущность человека, а атрибут (поле) PassportData содержит все его паспортные данные и может быть пустым (NULL).
1.2.2) в двух сущностях (таблицах):
Рис.4. Отношение сущностей Person и PassportData
Таблица Person представляет собой сущность человека, а таблица PassportData — сущность паспортных данных человека (самого паспорта). Сущность человека содержит атрибут (поле) PassportID, который ссылается на первичный ключ таблицы PassportData. В свою очередь сущность паспортных данных содержит атрибут (поле) PersonID, которое ссылается на первичный ключ PersonID таблицы Person. Поле PassportID таблицы Person может быть пустым (NULL). Здесь также важно поддерживать целостность поля PersonID таблицы PassportData. Это нужно, чтобы обеспечить связь один к одному. Поле PassportID таблицы Person и поле PersonID таблицы PassportData должны ссылаться на одни и те же записи как если бы это была одна сущность (таблица), показанная в пункте 1.2.1. Или же данные поля должны быть неопределенными, то есть, содержать NULL. - отношение один ко многим:
2.1) с обязательной связью:
примером могут выступать родитель и его дети. У каждого родителя есть как минимум один ребенок.
Реализовать данную связь можно двумя способами:
2.1.1) в одной сущности (таблице):
Рис.5. Сущность ParentТаблица Parent представляет сущность родителя, а атрибут (поле) ChildList содержит информацию о детях.
Данное поле не может быть пустым (NOT NULL). Обычно типом поля ChildList выступают неполно структурированные данные (NoSQL) такие как XML, JSON и т д.2.1.2) в двух сущностях (таблицах):
Рис.6. Отношение сущностей Parent и ChildТаблица Parent представляет сущность родителя, а таблица Child — сущность ребенка. У таблицы Child есть поле ParentID, ссылающееся на первичный ключ ParentID таблицы Parent. Поле ParentID таблицы Child не может быть пустым (NOT NULL).
2.2) с необязательной связью:
примером может выступать человек, у которого могут быть дети или их может не быть.
Реализовать данную связь можно двумя способами:
2.2.1) в одной сущности (таблице):
Рис.7. Сущность Person
Таблица Parent представляет сущность родителя, а атрибут (поле) ChildList содержит информацию о детях. Данное поле может быть пустым (NULL). Обычно типом поля ChildList выступают неполно структурированные данные (NoSQL) такие как XML, JSON и т д.2.2.2) в двух сущностях (таблицах):
Рис.8. Отношение сущностей Person и ChildТаблица Parent представляет сущность родителя, а таблица Child — сущность ребенка. У таблицы Child есть поле ParentID, ссылающееся на первичный ключ ParentID таблицы Parent. Поле ParentID таблицы Child может быть пустым (NULL).
2.2.3) в одной сущности со ссылкой на саму себя при условии, что у сущностей (таблиц) родителя и ребенка будут одинаковые наборы атрибутов (полей) без учета ссылки на родителя:
Рис.9. Сущность Person со связью на саму себя
Сущность (таблица) Person содержит атрибут (поле) ParentID, который ссылается на первичный ключ PersonID этой же таблицы Person и может содержать пустое значение (NULL).Также данная реализация является примером реализации отношения «многие к одному» с необязательной связью.
- отношение многие к одному:
Эту связь можно рассмотреть зеркально к приведенной выше связи один ко многим.
Иными словами, отношение сущности «дети» к сущности «родители», где обязательная связь будет при условии, что у ребенка есть хотя бы один родитель. Если же участвуют все дети, в том числе и находящиеся в детских домах, отношение будет с необязательной связью. - отношение многие ко многим:
Примером может выступить недвижимость: она может быть в собственности как одного человека, так и нескольких. С другой стороны, один человек может владеть несколькими домами или долями нескольких домов.
Реализовать данное отношение, с привлечением NoSQL, можно так же, как в описанных выше отношениях. Однако, в рамках реляционной модели обычно такое отношение реализуют через 3 сущности (таблицы):
Рис.10. Отношение сущностей Person и RealEstateТаблицы Person и RealEstate представляют соответственно сущности человека и недвижимости. Связываются данные сущности (таблицы) через сущность (таблицы) PersonRealEstate. Атрибуты (поля) PersonID и RealEstateID ссылаются на первичные ключи PersonID таблицы Person и RealEstateID таблицы RealEstate соответственно.
Обратите внимание, что для таблицы PersonRealEstate пара (PersonID; RealEstateID) всегда является уникальной и потому может выступать первичный ключем для самой связующей сущности PersonRealEstate.Также данное отношение можно реализовать через более чем три сущности. Для этого добавляются нужные атрибуты, которые ссылаются на первичные ключи необходимых соответствующих сущностей. Такая реализация схожа с примерами, описанными выше в пунктах 1.1.2 и 1.2.2.
 1) с обязательной связью:
1) с обязательной связью: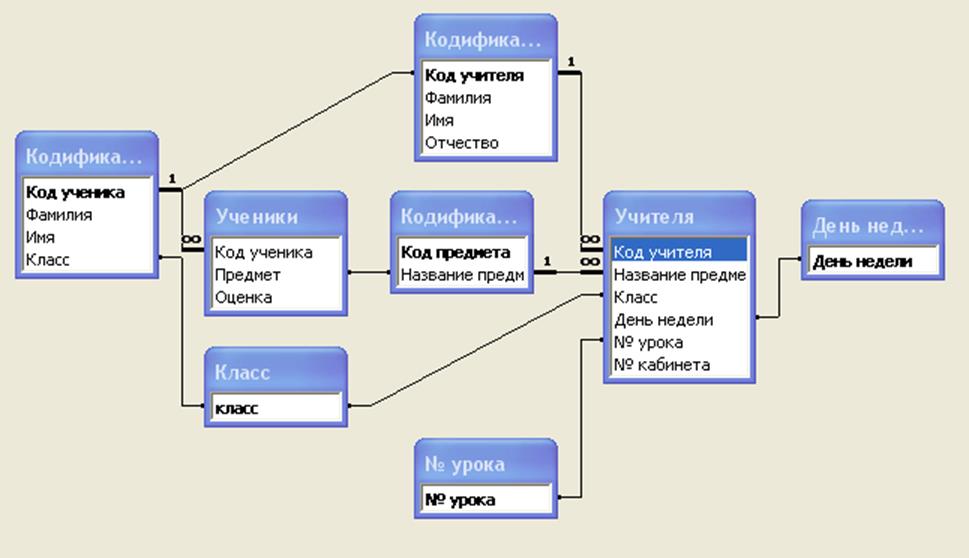 Также здесь важно поддерживать целостность поля CitizenID таблицы PassportData, чтобы обеспечить связь один к одному. Иными словами, поле PassportID таблицы Citizen и поле CitizenID таблицы PassportData должны ссылаться на одни и те же записи как если бы это была одна сущность (таблица), представленная в пункте 1.1.1.
Также здесь важно поддерживать целостность поля CitizenID таблицы PassportData, чтобы обеспечить связь один к одному. Иными словами, поле PassportID таблицы Citizen и поле CitizenID таблицы PassportData должны ссылаться на одни и те же записи как если бы это была одна сущность (таблица), представленная в пункте 1.1.1. Сущность человека содержит атрибут (поле) PassportID, который ссылается на первичный ключ таблицы PassportData. В свою очередь сущность паспортных данных содержит атрибут (поле) PersonID, которое ссылается на первичный ключ PersonID таблицы Person. Поле PassportID таблицы Person может быть пустым (NULL). Здесь также важно поддерживать целостность поля PersonID таблицы PassportData. Это нужно, чтобы обеспечить связь один к одному. Поле PassportID таблицы Person и поле PersonID таблицы PassportData должны ссылаться на одни и те же записи как если бы это была одна сущность (таблица), показанная в пункте 1.2.1. Или же данные поля должны быть неопределенными, то есть, содержать NULL.
Сущность человека содержит атрибут (поле) PassportID, который ссылается на первичный ключ таблицы PassportData. В свою очередь сущность паспортных данных содержит атрибут (поле) PersonID, которое ссылается на первичный ключ PersonID таблицы Person. Поле PassportID таблицы Person может быть пустым (NULL). Здесь также важно поддерживать целостность поля PersonID таблицы PassportData. Это нужно, чтобы обеспечить связь один к одному. Поле PassportID таблицы Person и поле PersonID таблицы PassportData должны ссылаться на одни и те же записи как если бы это была одна сущность (таблица), показанная в пункте 1.2.1. Или же данные поля должны быть неопределенными, то есть, содержать NULL. Данное поле не может быть пустым (NOT NULL). Обычно типом поля ChildList выступают неполно структурированные данные (NoSQL) такие как XML, JSON и т д.
Данное поле не может быть пустым (NOT NULL). Обычно типом поля ChildList выступают неполно структурированные данные (NoSQL) такие как XML, JSON и т д.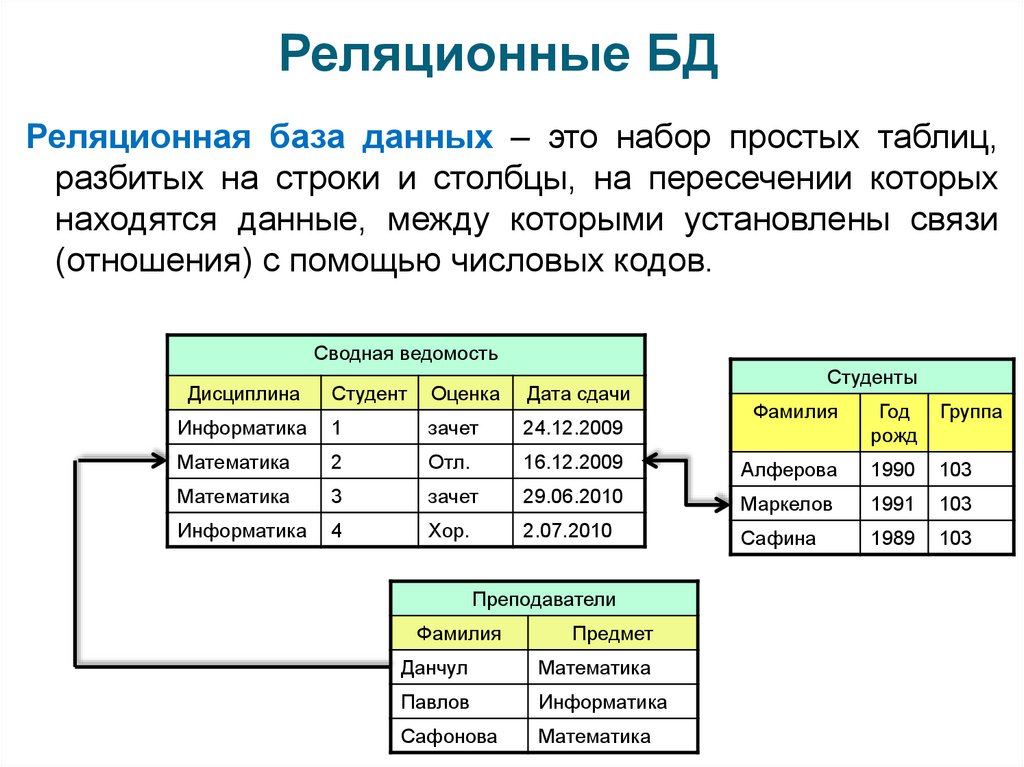
 Иными словами, отношение сущности «дети» к сущности «родители», где обязательная связь будет при условии, что у ребенка есть хотя бы один родитель. Если же участвуют все дети, в том числе и находящиеся в детских домах, отношение будет с необязательной связью.
Иными словами, отношение сущности «дети» к сущности «родители», где обязательная связь будет при условии, что у ребенка есть хотя бы один родитель. Если же участвуют все дети, в том числе и находящиеся в детских домах, отношение будет с необязательной связью. Обратите внимание, что для таблицы PersonRealEstate пара (PersonID; RealEstateID) всегда является уникальной и потому может выступать первичный ключем для самой связующей сущности PersonRealEstate.
Обратите внимание, что для таблицы PersonRealEstate пара (PersonID; RealEstateID) всегда является уникальной и потому может выступать первичный ключем для самой связующей сущности PersonRealEstate.Отношения один ко многим и многие к одному можно реализовать через более чем две сущности. Для этого добавляются нужные атрибуты, которые ссылаются на первичные ключи необходимых соответствующих сущностей. Такая реализация схожа с примерами, описанными выше в пунктах 1.1.2 и 1.2.2.
А где же семь формальных правил?
Вот они:
- п.1 (п.1.1 и п.1.2) — первое и второе формальные правила
- п.2 (п.2.1 и п.2.2) — третье и четвертое формальные правила
- п. 3 (аналогично п.2) — пятое и шестое формальные правила
- п.4 — седьмое формальное правило
 3 (аналогично п.2) — пятое и шестое формальные правила
3 (аналогично п.2) — пятое и шестое формальные правилаВ тексте выше эти семь формальных правил объединены в четыре блока по функционалу.
Говоря о нормализации, нужно понимать ее суть. Нормализация ведет к уменьшению повторяемости хранения информации, а следовательно и к уменьшению возможности появления аномалий в данных. Однако, нормализация при дроблении сущностей приводит к более сложным построениям запросов для манипуляций с данными (вставки, модификации, выборки и удаления).
Обратным процессом нормализации называется денормализация. Это упрощение построения запросов доступа к данным за счет укрупнения и вложенности сущностей (например, как было показано выше в пунктах 2.1.1 и 2.2.1 с помощью неполно-структурированных данных (NoSQL)).
Вот и вся суть правил проектирования баз данных.
А вы уверены, что поняли отношения в семи формальных правилах? Именно поняли, а не узнали? Ведь знать и понимать — две совершенно разных концепции.
Объясню более детально. Спросите себя, можете ли вы за пару часов набросать пусть и укрупненную по сущностям, но модель базы данных для любой предметной области и для любой информационной системы? (тонкости и детали можно достроить, поспрашивав аналитиков и представителей заказчиков). Если вопрос вас удивил, и вы думаете, что это невозможно, значит вы знаете семь формальных правил, но не понимаете их.
Почему-то многие источники игнорируют тот факт, что эти отношения были не придуманы, а выявлены. Они изначально существуют в реальном мире как между субъектами, так и между субъектами и объектами.
Также, эти отношения могут меняться, переходя из один к одному к одному ко многим, многие к одному или многие ко многим. Обязательность связи может меняться или остаться неизменной.
Позволю себе рассказать об одном случае, когда от знания семи формальных правил я пришел именно к пониманию этих отношений.
В свое время меня смущало то, что в ВУЗе я знал эти семь формальных правил, но на производственной практике (ВУЗ отправляет студентов в различные компании для приобретения профессионального опыта) очень долго строил модели баз для разных предметных областей.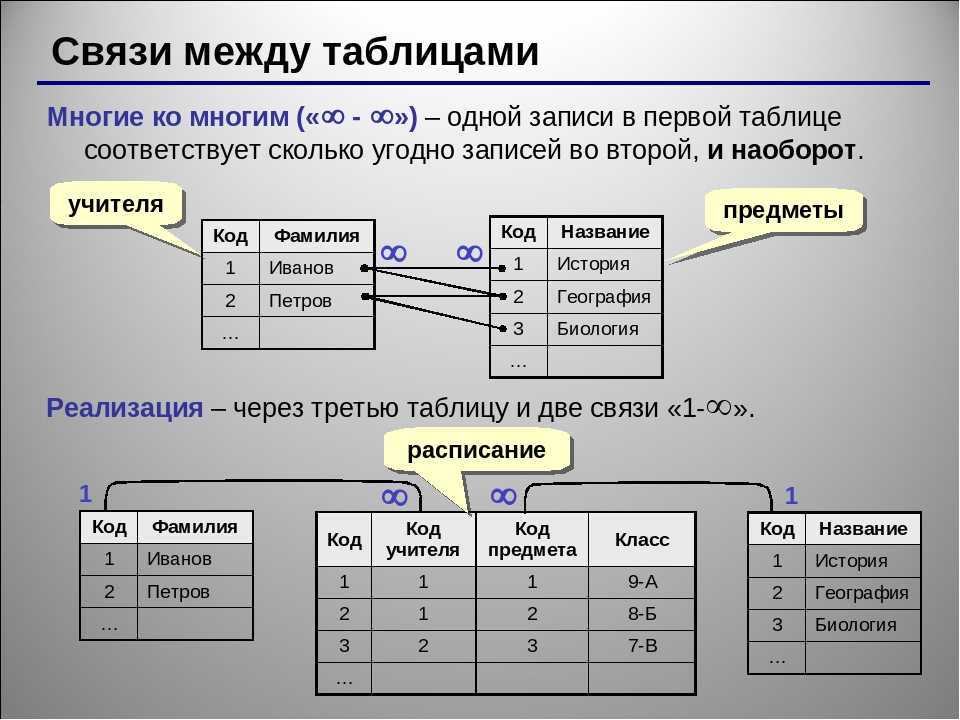 Я задумался и понял, что не понимаю этих отношений.
Я задумался и понял, что не понимаю этих отношений.
Мне помогло наблюдение за людьми, а суть отношений раскрылась в сновидении. Этот сон я перескажу в упрощенной форме: только то, что позволяет лучше понять именно эти семь формальных правил — без детализации всего остального.
Сон был про семью, в которой есть отец, мать и дети. Отец погибает в автомобильной катастрофе, а мать начинает пить, и детей в итоге забирают в детский дом. Эти дети надолго остаются без родителей. Затем у некоторых детей появляются попечители, их тоже несколько.
Вы проследили, какие отношения были между субъектами, и как менялись эти отношения?
Давайте присмотримся внимательнее.
- Когда семья была полной, с несколькими детьми, отношение между родителями и детьми имело вид многие ко многим.
- Когда остались мать и дети, отношение между родителем и детьми стало один ко многим с обязательной связью. Однако, в любой семье, где может и не быть детей, это отношение будет таким же, но уже с необязательной связью.
- А вот со стороны детей отношение к родителю было как многие к одному с обязательной связью пока родителя не лишили родительских прав.
- Когда дети оказались в детском доме — отношение изменилось на многие к одному с необязательной связью.
- Когда у детей появились попечители, связь между ними стала многие ко многим: у каждого попечителя могут быть другие подопечные дети, а у каждого ребенка могут быть другие попечители (родители).

Отношение между мужем и женой один к одному с обязательной связью при официальной брака или один к одному с необязательной связью до регистрации. Жена может быть только одна, как и муж может быть только один. По крайней мере, в России. Но в другой стране возможно многоженство, и тогда связь между мужем и женами будет один ко многим, а между женами и мужем — многие к одному.
Надеюсь, теперь вы значительно приблизились к пониманию этих семи формальных правил.
Стоит постоянно практиковаться: наблюдать за людьми и выявлять существующие отношения как между субъектами, так и между субъектами и объектами. Выше описывался гражданин и его паспорт как отношение один к одному с обязательной связью. В тоже время, пример человека и его паспорта — это отношение один к одному с необязательной связью.
Поняв семь формальных правил, вы сможете без труда спроектировать модель базы данных любой сложности для любой информационной системы.
Также вы увидите, что реализовать отношение можно разными способами, а сами отношения могут меняться. Модель (схема) базы данных — это «снимок» отношений между сущностями в определенный момент времени. Именно поэтому важно определить как сами сущности — образы объектов из реального мира или предметной области, так и их отношения между собой с учетом изменений в будущем.
Хорошо спроектированную модель базы данных с учетом изменения отношений в реальности или в предметной области не понадобится менять годами или даже десятилетия. Это особенно важно для хранилищ данных, где изменения влекут пересохранение больших объемов данных (от нескольких гигабайт до многих терабайт).
Это особенно важно для хранилищ данных, где изменения влекут пересохранение больших объемов данных (от нескольких гигабайт до многих терабайт).
Важно запомнить, что таблицы в реляционной модели — это отношения сущностей, а строки (кортежи) — это экземпляры этих отношений. Но чтобы было проще, под таблицами часто понимаются сущности, а под строками таблицы — экземпляры сущностей. Их отношения выражаются через связи в форме внешних ключей.
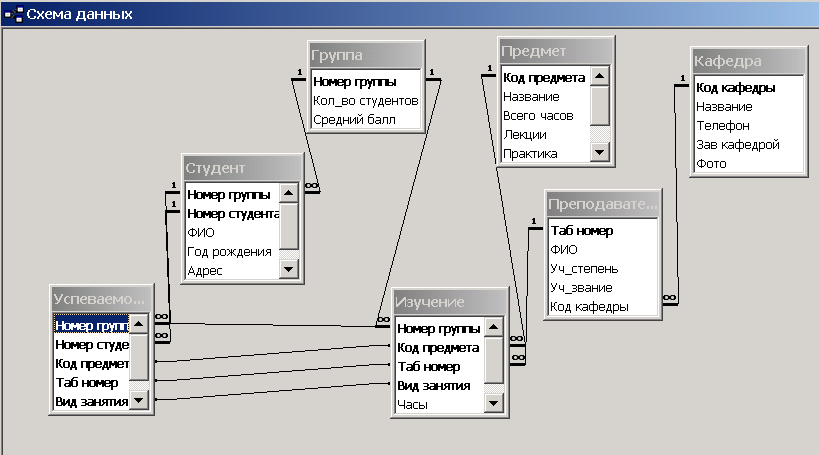
Проектирование схемы базы данных для поиска соискателей на работу
После того, как мы описали основы правил проектирования БД в первой части, давайте создадим схему базы данных для поиска соискателей на работу.
Для начала, определим, что важно для сотрудников из компании, которые ищут кандидатов:
- для HR:
1.1) компании, где работал соискатель
1.2) позиции, которые ранее занимал соискатель в данных компаниях
1.3) навыки и умения, которыми соискатель пользовался в работе;
а также продолжительность работы соискателя в каждой компании на каждой позиции и длительность использования каждого навыка и умения - для технического специалиста:
2.
1) позиции, которые занимал соискатель в данных компаниях
2.2) навыки и умения, которыми соискатель пользовался в работе
2.3) проекты, в которых участвовал соискатель;
а также продолжительность работы соискателя на каждой позиции и в каждом проекте, длительность использования каждого навыка и умения
 1) позиции, которые занимал соискатель в данных компаниях
1) позиции, которые занимал соискатель в данных компанияхДля начала выявим нужные сущности:
- Сотрудник (Employee)
- Компания (Company)
- Позиция (должность) (Position)
- Проект (Project)
- Навык (Skill)
- Компании и сотрудники относятся как многие ко многим, так как сотрудник мог работать в нескольких компаниях, а в компании работают многие люди.
- Аналогично относятся позиции и сотрудники: несколько сотрудников могут занимать одну позицию как в рамках как одной, так и нескольких компаний.
- С другой стороны, сотрудник мог работать на разных позициях как в рамках одной, так разных компаний. Таким образом, отношение между позициями и компаниями — многие ко многим.
- Аналогично и по проектам: проекты относятся ко всем выше рассмотренным сущностям как многие ко многим.
- Для простоты будем считать, что в проекте сотрудник использует один набор навыков.
- Тогда проекты и навык относятся как многие ко многим.
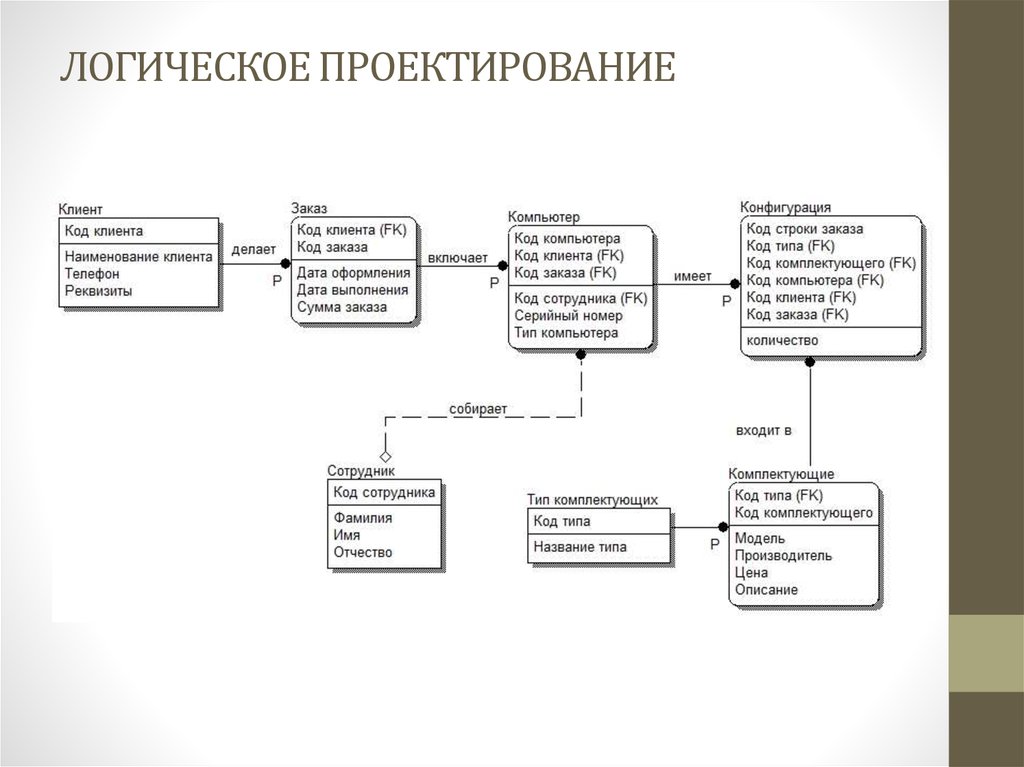 Таким образом, отношение между позициями и компаниями — многие ко многим.
Таким образом, отношение между позициями и компаниями — многие ко многим.Поскольку очень важно зафиксировать, как долго сотрудник работал на той или иной позиции в той или иной компании, а также на каждом проекте, схема нашей базы данных может быть следующей:
Рис.11. Схема базы данных для поиска соискателей на работу
Здесь таблица JobHistory выступает как сущность истории работы каждого соискателя. То есть, это резюме, которое педставляет отношения многие ко многим между сущностями сотрудник, компания, позиция и проект.
Проекты и навыки относятся друг другу как многие ко многим и потому связываются между собой через сущность (таблицу) ProjectSkill.
Когда вы понимаете отношения между субъектами и между субъектами и объектами — уже упомянутые семь формальных правил — эту или схожую схему можно реализовать «на коленке»: на листке бумаги, мене чем за час. И это еще с учетом усталости после плодотворного рабочего дня.
Здесь можно было упростить схему добавления данных, если «навыки» вложить в сущность «проекты» через неполно структурированные данные (NoSQL) в виде XML, JSON или просто перечислять названия навыков через точку с запятой. Но это бы усложнило выборку с группировкой по навыкам и фильтрацию по отдельным навыкам.
Подобная модель лежит в основе базы данных проекта Geecko.
Как видите, ничего сложного в проектировании информационных систем в части проектирования базы данных нет. Это всего лишь отражение объектов и субъектов из реальности, перенесенное в «сущности» схемы базы данных. Отношения между этими сущностями фиксируются на определенный момент времени, с учетом будущих изменений.
Что именно мы возьмем из реальности и вложим в сущность схемы, и какие отношения построим в модели, будет зависеть от того, что мы хотим от информационной системы в общем, здесь и в будущем. Иными словами — какие данные мы хотим получить в текущий момент времени и через определенное время в будущем.
Иными словами — какие данные мы хотим получить в текущий момент времени и через определенное время в будущем.
Немного лирики
После того, как вы внедрите модель в работу, остановитесь на миг и подумайте: только что был создан новый маленький мир. В нем есть свои сущности из реального мира и свои отношения. Да, это цифровой мир, но он теперь будет развиваться своей дорогой. Он будет общаться (интегрироваться) с другими системами (мирами), тоже созданными по своим правилам. Данные будут течь в этих системах, как кровь в живом организме.
А перед сном подумайте о том, что семь формальных правил были всегда, и что они окружают нас всюду. Не больше и не меньше, всегда семь. Все отношения реальной жизни можно разложить на эти семь формальных правил. А когда вы думаете или видите сны, как там сущности относятся друг к другу — не по тем же семи формальным правилам?
Вообще, я уверен, что эти отношения (семь формальных правил) выявил очень хороший психотерапевт, возможно — женщина. Это было очень давно, задолго до появления самого понятия информационных технологий. И самое интересное, что эти отношения живут вне базы данных и ИТ — последние лишь используют их для моделирования информационных систем.
Это было очень давно, задолго до появления самого понятия информационных технологий. И самое интересное, что эти отношения живут вне базы данных и ИТ — последние лишь используют их для моделирования информационных систем.
Но мы немного отошли от темы. Я лишь призываю в момент создания новой системы подойти к этому процессу с душой. И тогда поверьте, случится момент творения. Спроектированная таким образом система будет живее всех живых в цифровом мире.
Послесловие
Диаграммы для примеров были реализованы с помощью инструмента Database Diagram Tool for SQL Server. Однако, подобный функционал есть и в DBeaver.
Источники
- SQL Database Design Basics with Example
- Geecko
- Microsoft SQL documentation
- SSMS
- Database Diagram Tool for SQL Server
Учебное пособие по проектированию баз данных в СУБД: изучение моделирования данных
Ричард Петерсон
ЧасыОбновлено
Что такое проектирование базы данных?
Проектирование базы данных представляет собой набор процессов, облегчающих проектирование, разработку, внедрение и обслуживание корпоративных систем управления данными. Правильно разработанная база данных проста в обслуживании, повышает согласованность данных и экономична с точки зрения дискового пространства. Разработчик базы данных решает, как соотносятся элементы данных и какие данные должны храниться.
Основными целями проектирования базы данных в СУБД являются создание логических и физических моделей предлагаемой системы баз данных.
Логическая модель концентрируется на требованиях к данным и данных, которые должны храниться независимо от физических соображений. Он не заботится о том, как данные будут храниться или где они будут храниться физически.
Модель проектирования физических данных включает в себя перенос логической структуры БД базы данных на физический носитель с использованием аппаратных ресурсов и программных систем, таких как системы управления базами данных (СУБД).
В этом руководстве по проектированию баз данных вы узнаете:
- Почему важно проектирование баз данных?
- Жизненный цикл разработки базы данных
- Анализ требований
- Проектирование базы данных
- Реализация
- Типы методов баз данных
Почему важно проектирование базы данных?
Помогает создавать системы баз данных
- Отвечающие требованиям пользователей
- Иметь высокую производительность.
Процесс проектирования базы данных в СУБД имеет решающее значение для высокопроизводительной системы баз данных .
Обратите внимание, гениальность базы данных заключается в ее дизайне. Операции с данными с использованием SQL относительно просты.
Жизненный цикл разработки базы данных
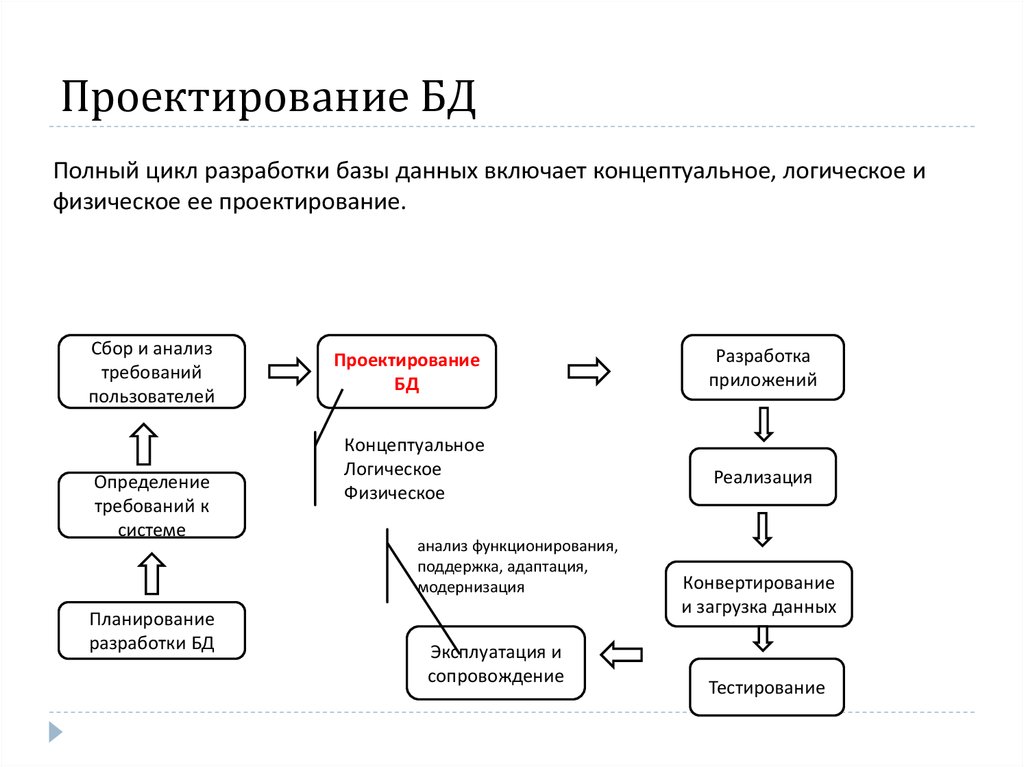
Жизненный цикл разработки базы данных состоит из нескольких этапов, которым следуют при разработке систем баз данных.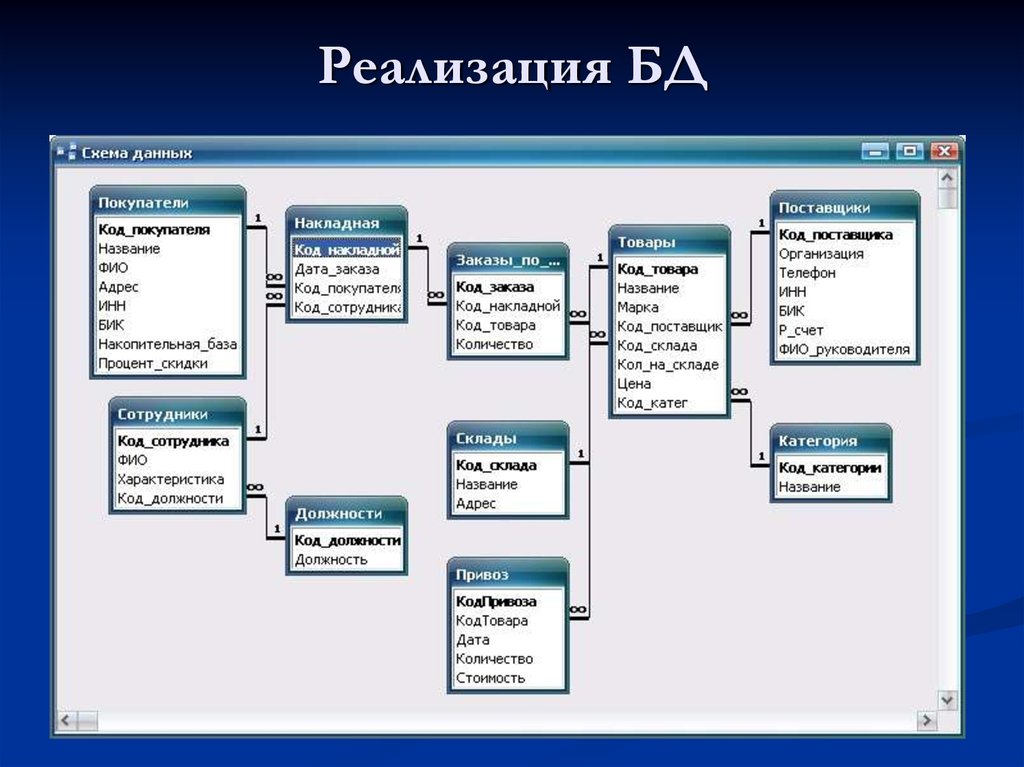
Шаги в жизненном цикле разработки не обязательно должны выполняться неукоснительно последовательно.
В системах с небольшими базами данных процесс проектирования базы данных обычно очень прост и не требует большого количества шагов.
Чтобы в полной мере оценить приведенную выше диаграмму, давайте рассмотрим отдельные компоненты, перечисленные на каждом этапе, для обзора процесса проектирования в СУБД.
Анализ требований
- Планирование . Эти этапы концепции проектирования базы данных связаны с планированием всего жизненного цикла разработки базы данных. Он принимает во внимание стратегию информационных систем организации.
- Определение системы — На этом этапе определяются объем и границы предлагаемой системы баз данных.
Проектирование баз данных
- Логическая модель . Этот этап связан с разработкой модели базы данных на основе требований. Весь проект находится на бумаге без каких-либо физических реализаций или конкретных соображений СУБД.
- Физическая модель — На этом этапе реализуется логическая модель базы данных с учетом факторов СУБД и физической реализации.
Внедрение
- Преобразование данных и загрузка — этот этап проектирования реляционных баз данных связан с импортом и преобразованием данных из старой системы в новую базу данных.
- Тестирование – этот этап связан с выявлением ошибок во вновь внедряемой системе. Он проверяет базу данных на соответствие спецификациям требований.
Два типа методов баз данных
- Нормализация
- ER Моделирование
Давайте изучим их один за другим
Введение в проектирование баз данных | Учебник
Эта статья/учебник расскажет об основах проектирования реляционных баз данных и объяснит, как сделать хороший дизайн базы данных. Это довольно длинный текст, но мы советуем прочитать его полностью.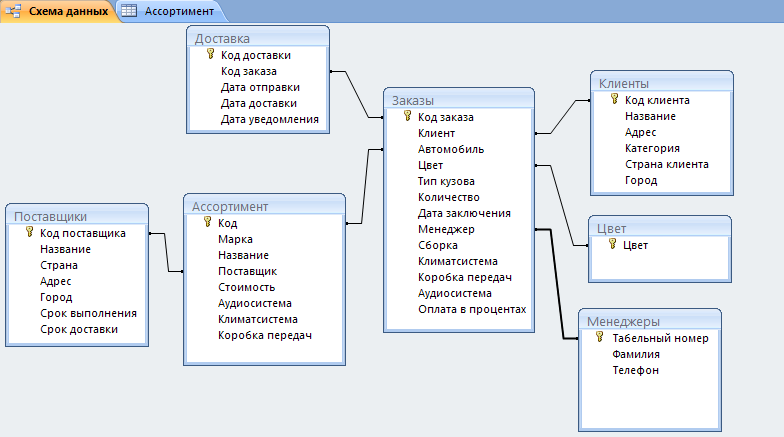 На самом деле разработать базу данных довольно просто, но есть несколько правил, которых следует придерживаться. Важно знать, что это за правила, но еще важнее знать, почему эти правила существуют, иначе вы будете склонны совершать ошибки!
На самом деле разработать базу данных довольно просто, но есть несколько правил, которых следует придерживаться. Важно знать, что это за правила, но еще важнее знать, почему эти правила существуют, иначе вы будете склонны совершать ошибки!
Стандартизация делает вашу модель данных гибкой, что значительно упрощает работу с вашими данными. Пожалуйста, найдите время, чтобы изучить эти правила и применять их! База данных, используемая в этой статье, разработана с помощью нашего инструмента проектирования и моделирования баз данных DeZign for Databases.
Хороший дизайн базы данных начинается со списка данных, которые вы хотите включить в свою базу данных, и того, что вы хотите делать с базой данных позже. Все это можно написать на вашем родном языке, без всякого SQL. На этом этапе вы должны стараться не думать таблицами или колонками, а просто думать: «Что мне нужно знать?» Не относитесь к этому слишком легкомысленно, потому что, если вы позже обнаружите, что что-то забыли, обычно вам нужно начинать все сначала. Добавление вещей в вашу базу данных в основном требует много работы.
Добавление вещей в вашу базу данных в основном требует много работы.
Идентификация объектов
Типы информации, которые сохраняются в базе данных, называются «сущностями». Эти сущности существуют четырех видов: люди, вещи, события и местоположения. Все, что вы хотели бы поместить в базу данных, относится к одной из этих категорий. Если информация, которую вы хотите включить, не вписывается в эти категории, то, вероятно, это не сущность, а свойство сущности, атрибут.
Чтобы пояснить информацию, приведенную в этой статье, мы будем использовать пример. Представьте, что вы создаете сайт для магазина, с какой информацией вам приходится иметь дело? В магазине вы продаете товары покупателям. «Магазин» — это локация; «Распродажа» — это событие; «Продукты» — это вещи; а «Клиенты» — люди. Все эти объекты должны быть включены в вашу базу данных.
Но что еще происходит при продаже продукта? Покупатель приходит в магазин, подходит к продавцу, задает вопрос и получает ответ. «Продавцы» также участвуют, и поскольку поставщики — это люди, нам нужна сущность поставщиков.
«Продавцы» также участвуют, и поскольку поставщики — это люди, нам нужна сущность поставщиков.
| Рисунок 1: Сущности: типы информации. |
Выявление отношений
Следующим шагом является определение отношений между сущностями и определение кардинальности каждого отношения. Отношения — это связь между сущностями, как и в реальном мире: что одна сущность делает с другой, как они связаны друг с другом? Например, клиенты покупают товары, товары продаются покупателям, распродажа включает товары, распродажа происходит в магазине.
Кардинальность показывает, какая часть одной стороны отношения принадлежит другой стороне отношения. Во-первых, вам нужно указать для каждого отношения, какая часть одной стороны принадлежит ровно 1 другой стороне. Например: Сколько клиентов принадлежит 1 продаже?; Сколько продаж принадлежит 1 покупателю?; Сколько продаж происходит в 1 магазине?
Вы получите такой список: (обратите внимание, что «продукт» представляет собой тип продукта, а не его появление)
- Клиенты —> Продажи; 1 клиент может купить что-то несколько раз
- Продажи —> Клиенты; 1 продажа всегда совершается 1 покупателем за раз
- Клиенты —> Продукты; 1 покупатель может купить несколько товаров
- Продукты —> Клиенты; 1 продукт могут приобрести несколько клиентов
- Клиенты —> Магазины; 1 покупатель может совершать покупки в нескольких магазинах
- Магазины —> Покупатели, 1 магазин может принимать несколько покупателей
- Магазины —> Товары; в 1 магазине есть несколько товаров
- Продукты —> Магазины; 1 товар (тип) может продаваться в нескольких магазинах
- Магазины —> Продажи; в 1 магазине можно совершить несколько продаж
- Продажи —> Магазины; 1 продажа может быть совершена только в 1 магазине одновременно
- Продукты —> Продажи; 1 продукт (тип) можно приобрести в нескольких распродажах
- Продажи —> Продукты; 1 продажа может существовать из нескольких продуктов
Мы упомянули все отношения? Существует четыре объекта, и каждый объект связан со всеми другими объектами, поэтому каждый объект должен иметь три отношения, а также трижды появляться в левом конце отношения. Выше было упомянуто 12 отношений, что составляет 4*3, поэтому мы можем сделать вывод, что были упомянуты все отношения.
Выше было упомянуто 12 отношений, что составляет 4*3, поэтому мы можем сделать вывод, что были упомянуты все отношения.
Теперь мы объединим данные, чтобы найти кардинальность всей связи. Чтобы сделать это, мы набросаем количество элементов для каждого отношения. Чтобы это было легко сделать, мы немного изменим нотацию, отметив «обратную» связь наоборот:
- Клиенты —> Продажи; 1 клиент может купить что-то несколько раз
- Продажи —> Клиенты; 1 продажа всегда совершается 1 покупателем за раз
Второе отношение мы изменим, чтобы оно имело тот же порядок сущностей, что и первое. Обратите внимание на стрелку, которая теперь обращена в другую сторону!
- Клиенты
Существует четыре типа кардинальности: один-к-одному, один-ко-многим, многие-к-одному и многие-ко-многим. В проекте базы данных это обозначается как: 1:1, 1:N, M:1 и M:N. Чтобы найти правильное указание, просто оставьте «1». Если слева стоит «много», это будет обозначено «М», если «много» справа, то это будет обозначено «N».
- Клиенты —> Продажи; 1 клиент может покупать что-то несколько раз; 1:Н.
- Клиенты
Истинную кардинальность можно рассчитать, присвоив наибольшие значения для левого и правого, для которых «N» или «M» больше «1». В этом примере в обоих случаях слева стоит «1». С правой стороны есть «N» и «1», «N» — самое большое значение. Таким образом, общая кардинальность равна «1: N». Клиент может совершить несколько «продаж», но у каждой «продажи» есть только один покупатель.
Если мы сделаем это и для других отношений, мы получим:
- Клиенты —> Продажи; —> 1:Н
- Клиенты —> Продукты; —> М:Н
- Клиенты —> Магазины; —> М:Н
- Продажи —> Продукты; —> М:Н
- Магазины —> Продажи; —> 1:Н
- Магазины —> Товары; —> М:Н
Итак, у нас есть два отношения «1 ко многим» и четыре отношения «многие ко многим».
Рисунок 2: Отношения между сущностями. Между сущностями может существовать взаимная зависимость. Это означает, что один элемент не может существовать, если другой элемент не существует. Например, не может быть продажи, если нет покупателей, и не может быть продажи, если нет товаров.
Отношения Продажи —> Клиенты и Продажи —> Продукты являются обязательными, но не наоборот. Покупатель может существовать без продажи, а продукт может существовать без продажи. Это важно для следующего шага.
Рекурсивные отношения
Иногда сущность ссылается на себя. Например, подумайте о рабочей иерархии: у сотрудника есть начальник; и шеф-повар тоже наемный работник. Атрибут «босс» объекта «сотрудники» относится к объекту «сотрудники».
В ERD (см. следующую главу) этот тип отношений представляет собой линию, которая выходит из объекта и возвращается с помощью красивого цикла к тому же объекту.
Избыточные связи
Иногда в вашей модели вы получите «избыточные отношения».
Это отношения, на которые уже указывают другие отношения, хотя и не прямо.В случае нашего примера существует прямая связь между клиентами и продуктами. Но есть также отношения от клиентов к продажам и от продаж к продуктам, так что косвенно отношения между клиентами и продуктами через продажи уже существуют. Отношение «Продукты клиентов» создается дважды, поэтому одно из них является избыточным. В этом случае продукты покупаются только через продажу, поэтому отношения «Продукты клиентов» можно удалить. Тогда модель будет выглядеть так:
Рисунок 3: Отношения между сущностями. Решение отношений «многие ко многим»
Отношения «многие ко многим» (M:N) в базе данных невозможны напрямую. Отношение M:N говорит о том, что количество записей из одной таблицы принадлежит количеству записей из другой таблицы. Где-то вам нужно сохранить, какие это записи, и решение состоит в том, чтобы разделить отношение на два отношения «один ко многим».
Это можно сделать, создав новый объект, который находится между связанными объектами. В нашем примере существует связь «многие ко многим» между продажами и продуктами. Это можно решить, создав новую сущность: продажи-продукты. Эта сущность имеет связь «многие к одному» с «Продажи» и связь «многие к одному» с «Продукты». В логических моделях это называется ассоциативной сущностью, а в терминах физической базы данных это называется таблицей ссылок, таблицей пересечений или таблицей соединений.
Рис. 4. Реализация отношения «многие ко многим» с помощью ассоциативного объекта. В примере есть два отношения «многие ко многим», которые необходимо решить: «Продажи продуктов» и «Магазины продуктов». Для обеих ситуаций необходимо создать новую сущность, но что это за сущность?
Для отношения «Продажи продуктов» каждая продажа включает в себя больше продуктов. Отношения показывают содержание продажи.
Другими словами, он дает подробную информацию о продаже. Таким образом, объект называется «Сведения о продажах». Вы также можете назвать это «проданные продукты».Отношение «Магазины продуктов» показывает, какие продукты доступны в каких магазинах, также называемых «запасами». Теперь наша модель будет выглядеть так:
Рисунок 5: Модель со связанными таблицами Stock и Sales_details.
 Это отношения, на которые уже указывают другие отношения, хотя и не прямо.
Это отношения, на которые уже указывают другие отношения, хотя и не прямо.
 Другими словами, он дает подробную информацию о продаже. Таким образом, объект называется «Сведения о продажах». Вы также можете назвать это «проданные продукты».
Другими словами, он дает подробную информацию о продаже. Таким образом, объект называется «Сведения о продажах». Вы также можете назвать это «проданные продукты».Начните проектирование базы данных сегодня
Загрузите 14-дневную пробную версию DeZign для баз данных
Идентификация атрибутов
Элементы данных, которые вы хотите сохранить для каждой сущности, называются «атрибутами».
О продуктах, которые вы продаете, вы хотите знать, например, какова цена, как называется производитель и какой номер типа. О клиентах вы знаете их номер клиента, их имя и адрес. О магазинах вы знаете код расположения, название, адрес. О продажах вы знаете, когда они произошли, в каком магазине, какие продукты были проданы и общая сумма продажи. О продавце вы знаете его штатный номер, имя и адрес. Что именно будет включено, пока не важно; это все еще только о том, что вы хотите сохранить.
О продажах вы знаете, когда они произошли, в каком магазине, какие продукты были проданы и общая сумма продажи. О продавце вы знаете его штатный номер, имя и адрес. Что именно будет включено, пока не важно; это все еще только о том, что вы хотите сохранить.
| Рисунок 6: Сущности с атрибутами. |
Производные данные
Производные данные — это данные, полученные из других данных, которые вы уже сохранили. В этом случае «сумма» является классическим случаем производных данных. Вы точно знаете, что было продано и сколько стоит каждый продукт, поэтому вы всегда можете рассчитать общую сумму продаж. Так что действительно не надо экономить общую сумму.
Так почему же он сохраняется здесь? Ну, потому что это распродажа, и цена товара со временем может меняться. Продукт может быть оценен в 10 евро сегодня и в 8 евро в следующем месяце, и для вашей администрации вам нужно знать, сколько он стоил на момент продажи, и самый простой способ сделать это — сохранить его здесь.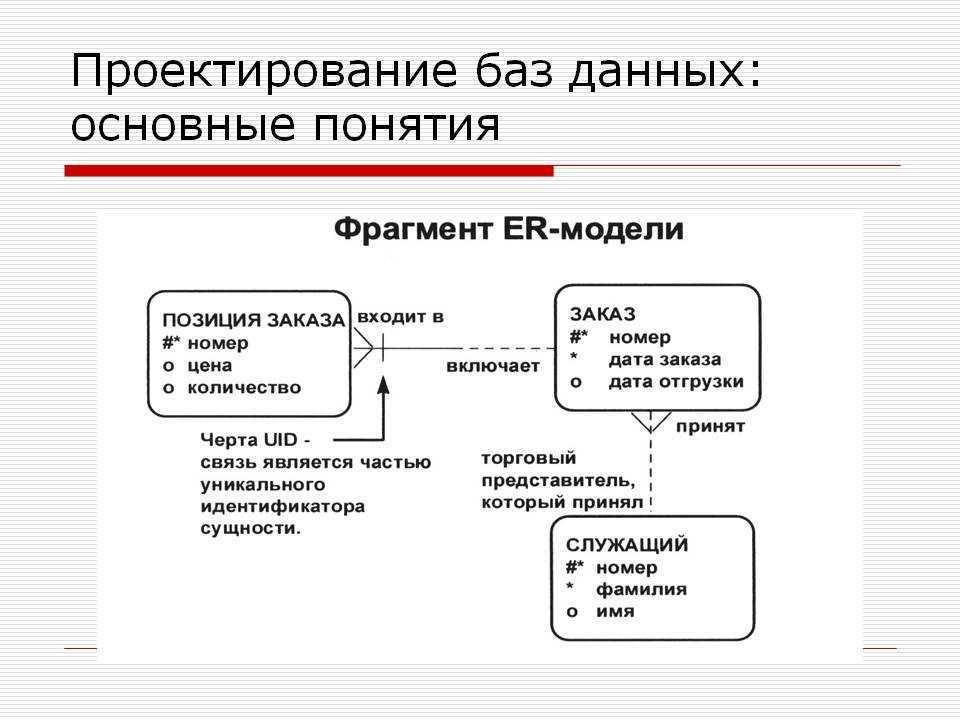 Есть масса более элегантных способов, но они слишком глубоки для этой статьи.
Есть масса более элегантных способов, но они слишком глубоки для этой статьи.
Представление сущностей и отношений: диаграмма отношений сущностей (ERD)
Диаграмма отношений сущностей (ERD) дает графический обзор базы данных. Существует несколько стилей и типов ER-диаграмм. Часто используемая нотация — это нотация «гусиные лапки», где объекты представлены в виде прямоугольников, а отношения между объектами представлены в виде линий между объектами. Знаки в конце строк указывают на тип отношений. Сторона отношений, которая является обязательной для существования другого, будет обозначена через тире на линии. Необязательные сущности обозначены кружком. «Много» обозначается через «гусиные лапки»; линия отношений разделяется на три линии.
В этой статье мы используем DeZign для баз данных для разработки и представления нашей базы данных.
Обязательная связь 1:1 представлена следующим образом:
Рисунок 7: Обязательные отношения один к одному.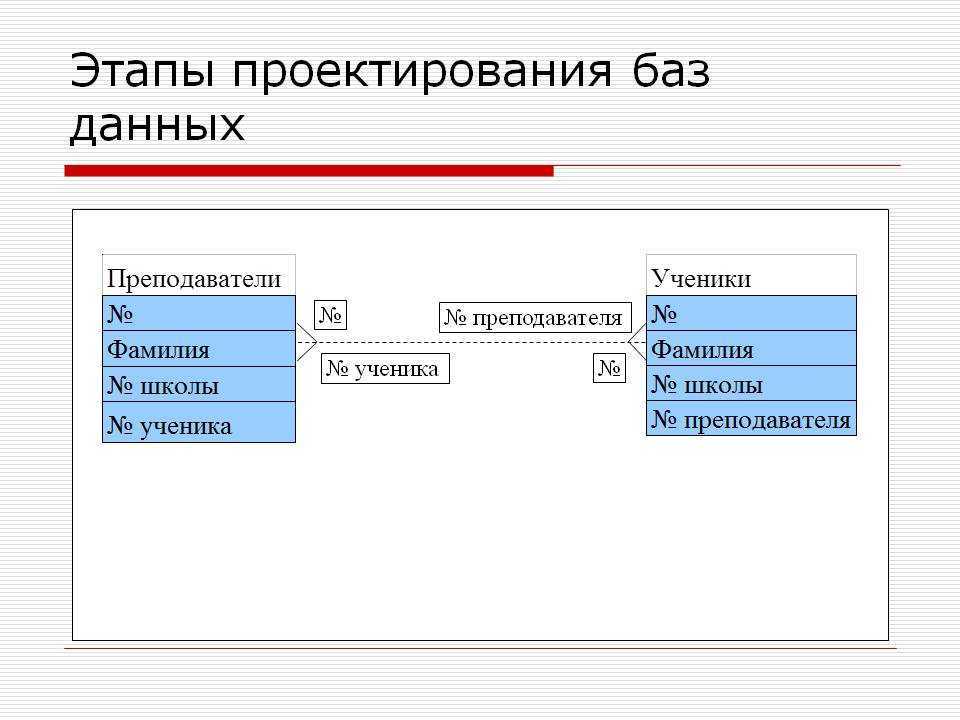 |
Обязательная связь 1:N:
| Рис. 8. Обязательная связь один ко многим. |
Отношения M:N:
| Рис. 9. Обязательная связь «многие ко многим». |
Модель нашего примера будет выглядеть так:
| Рисунок 10: Модель со связями. |
Назначение ключей
Первичные ключи
Первичный ключ (PK) — это один или несколько атрибутов данных, которые однозначно идентифицируют объект. Ключ, состоящий из двух или более атрибутов, называется составным ключом. Все атрибуты, входящие в состав первичного ключа, должны иметь значение в каждой записи (которая не может быть оставлена пустой), а комбинация значений этих атрибутов должна быть уникальной в таблице.
В примере есть несколько очевидных кандидатов на роль первичного ключа. У всех клиентов есть номер клиента, у всех продуктов есть уникальный номер продукта, а у продаж есть номер продажи. Каждая из этих данных уникальна, и каждая запись будет содержать значение, поэтому эти атрибуты могут быть первичным ключом. Часто для первичного ключа используется целочисленный столбец, поэтому запись можно легко найти по его номеру.
У всех клиентов есть номер клиента, у всех продуктов есть уникальный номер продукта, а у продаж есть номер продажи. Каждая из этих данных уникальна, и каждая запись будет содержать значение, поэтому эти атрибуты могут быть первичным ключом. Часто для первичного ключа используется целочисленный столбец, поэтому запись можно легко найти по его номеру.
Объекты-ссылки обычно относятся к атрибутам первичного ключа объектов, которые они связывают. Первичный ключ объекта-ссылки обычно представляет собой набор этих атрибутов-ссылок. Например, в сущности Sales_details мы могли бы использовать комбинацию PK сущностей продаж и продуктов в качестве PK Sales_details. Таким образом мы добиваемся того, чтобы один и тот же продукт (тип) мог использоваться только один раз в одной и той же продаже. Несколько товаров одного и того же типа в продаже должны быть указаны количеством.
В ERD атрибуты первичного ключа обозначаются текстом «PK» после имени атрибута. В примере только объект «магазин» не имеет очевидного кандидата на PK, поэтому мы введем для этого объекта новый атрибут: shopnr.
Внешние ключи
Внешний ключ (FK) в объекте — это ссылка на первичный ключ другого объекта. В ERD этот атрибут будет указан с «FK» после его имени. Внешний ключ объекта также может быть частью первичного ключа, в этом случае атрибут будет указан с «PF» после его имени. Обычно это происходит с объектами-ссылками, потому что вы обычно связываете два экземпляра только один раз вместе (при 1 продаже только 1 тип продукта продается 1 раз).
Если мы поместим все связанные сущности, PK и FK в ERD, мы получим модель, как показано ниже. Обратите внимание, что атрибут «Продукты» больше не нужен в «Продажи», потому что «Проданные продукты» теперь включены в таблицу ссылок. В ссылку-таблицу было добавлено еще одно поле «количество», которое указывает, сколько товаров было продано. Поле количества также было добавлено в таблицу запасов, чтобы указать, сколько товаров еще есть в наличии.
Рисунок 11: Первичные и внешние ключи.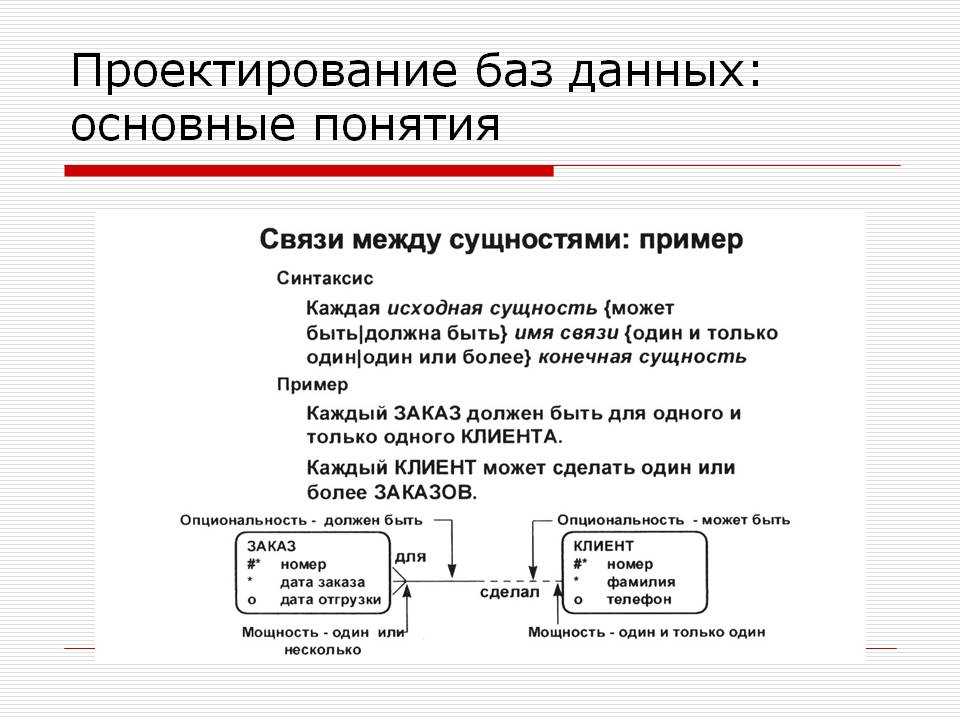 |
Определение типа данных атрибута
Теперь пришло время выяснить, какие типы данных нужно использовать для атрибутов. Существует множество различных типов данных. Некоторые из них стандартизированы, но многие базы данных имеют свои собственные типы данных, каждая из которых имеет свои преимущества. Некоторые базы данных предлагают возможность определять свои собственные типы данных на тот случай, если стандартные типы не могут делать то, что вам нужно.
Стандартные типы данных, которые известны каждой базе данных и которые наиболее часто используются: CHAR, VARCHAR, TEXT, FLOAT, DOUBLE и INT.
Текст:
- CHAR(длина) — включает текст (символы, цифры, знаки препинания…). Характерной чертой CHAR является то, что он всегда сохраняет фиксированное количество позиций. Если вы определяете CHAR(10), вы можете сохранить максимум десять позиций, но если вы используете только две позиции, база данных все равно сохранит 10 позиций. Остальные восемь позиций будут заполнены пробелами.
- VARCHAR(длина) — включает текст (символы, цифры, знаки препинания…). VARCHAR — это то же самое, что и CHAR, разница в том, что VARCHAR занимает ровно столько места, сколько необходимо.
- ТЕКСТ — может содержать большое количество текста. В зависимости от типа базы данных это может составлять до гигабайт.
 Остальные восемь позиций будут заполнены пробелами.
Остальные восемь позиций будут заполнены пробелами.Номера:
- INT — содержит положительное или отрицательное целое число. Многие базы данных имеют варианты INT, такие как TINYINT, SMALLINT, MEDIUMINT, BIGINT, INT2, INT4, INT8. Эти вариации отличаются от INT только размером фигуры, которая в них помещается. Обычный INT имеет размер 4 байта (INT4) и соответствует числам от -2147483647 до +2147483646, или, если вы определяете его как UNSIGNED, от 0 до 429.4967296. INT8, или BIGINT, может быть еще больше по размеру, от 0 до 18446744073709551616, но занимает до 8 байт дискового пространства, даже если в нем содержится небольшое число.
- FLOAT, DOUBLE — та же идея, что и у INT, но также может хранить числа с плавающей запятой. . Обратите внимание, что это не всегда работает идеально. Например, в MySQL вычисления с этими числами с плавающей запятой не идеальны, (1/3) * 3 приведет к тому, что числа с плавающей запятой MySQL будут равны 0,9999999, а не 1.

Другие типы:
- BLOB — для двоичных данных, таких как файлы.
- INET — для IP-адресов. Также можно использовать для сетевых масок.
Для нашего примера типы данных следующие:
| Рисунок 12: Модель данных, отображающая типы данных. |
Нормализация
Нормализация делает вашу модель данных гибкой и надежной. Это приводит к некоторым накладным расходам, поскольку обычно вы получаете больше таблиц, но позволяет выполнять многие действия с вашей моделью данных без необходимости ее настройки. Подробнее о нормализации базы данных вы можете прочитать в этой статье.
Нормализация, первая форма
Первая форма нормализации гласит, что в объекте не может быть повторяющихся групп столбцов. Мы могли бы создать объект «продажи» с атрибутами для каждого из купленных продуктов. Это будет выглядеть так:
| Рис. 13: Не в 1-й нормальной форме. |
Что не так, так это то, что теперь можно продать только 3 продукта. Если вам нужно продать 4 продукта, вам придется начать вторую продажу или настроить модель данных, добавив атрибуты «product4». Оба решения нежелательны. В этих случаях вы всегда должны создавать новую сущность, которую вы связываете со старой через отношение «один ко многим».
| Рисунок 14: В соответствии с 1-й нормальной формой. |
Нормализация, вторая форма
Вторая форма нормализации гласит, что все атрибуты объекта должны полностью зависеть от всего первичного ключа. Это означает, что каждый атрибут объекта может быть идентифицирован только через весь первичный ключ. Предположим, у нас есть дата в сущности Sales_details:
Это означает, что каждый атрибут объекта может быть идентифицирован только через весь первичный ключ. Предположим, у нас есть дата в сущности Sales_details:
| Рисунок 15: Не во второй нормальной форме. |
Этот объект не соответствует второй форме нормализации, потому что для того, чтобы найти дату продажи, мне не нужно знать, что продается (номер продукта), единственное, что мне нужно знать, это номер продажи. Это было решено путем разделения таблиц на продажи и таблицу Sales_details:
| Рисунок 16: В соответствии со 2-й нормальной формой. |
Теперь каждый атрибут объектов зависит от всего PK объекта. Дата зависит от номера продажи, а количество зависит от номера продажи и проданного продукта.
Нормализация, третья форма
Третья форма нормализации гласит, что все атрибуты должны напрямую зависеть от первичного ключа, а не от других атрибутов. Кажется, это то, что утверждает вторая форма нормализации, но во второй форме фактически утверждается обратное. Во второй форме нормализации вы указываете атрибуты через ПК, в третьей форме нормализации каждый атрибут должен зависеть от ПК и ничего больше.
Кажется, это то, что утверждает вторая форма нормализации, но во второй форме фактически утверждается обратное. Во второй форме нормализации вы указываете атрибуты через ПК, в третьей форме нормализации каждый атрибут должен зависеть от ПК и ничего больше.
| Рис. 17: Не в 3-й нормальной форме. |
В этом случае цена сыпучего продукта зависит от номера заказа, а номер заказа зависит от номера продукта и номера продажи. Это не соответствует третьей форме нормализации. Опять же, разделение таблиц решает эту проблему.
| Рисунок 18: В соответствии с 3-й нормальной формой. |
Нормализация, дополнительные формы
Форм нормализации больше, чем упомянутых выше трех форм, но они не представляют большого интереса для обычного пользователя. Эти другие формы являются узкоспециализированными для определенных приложений. Если вы будете придерживаться правил проектирования и нормализации, упомянутых в этой статье, вы создадите дизайн, который отлично работает для большинства приложений.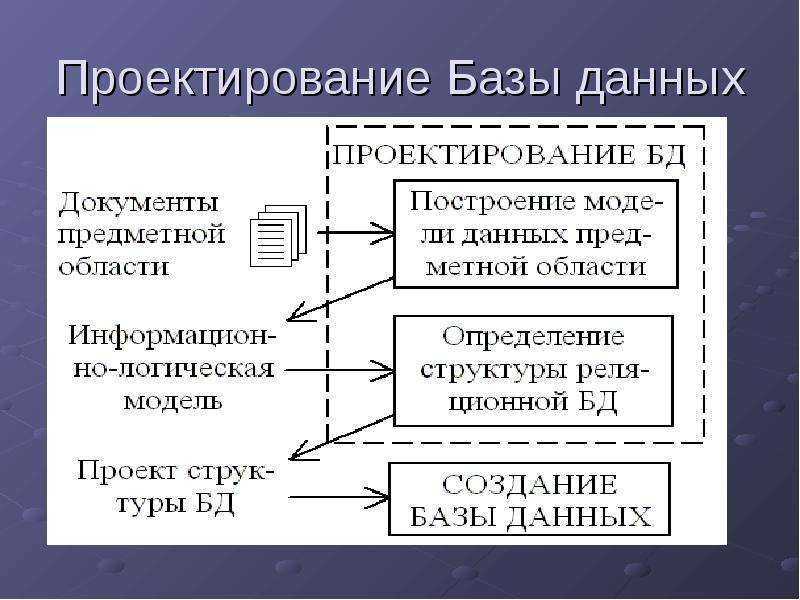
Модель нормализованных данных
Если вы примените правила нормализации, вы обнаружите, что «производитель» в таблице продуктов также должен быть отдельной таблицей:
| Рисунок 19: Модель данных в соответствии с 1-й, 2-й и 3-й нормальной формой. |
Глоссарий
Атрибуты — подробные данные о сущности, такие как цена, длина, имя
Кардинальность — отношение между двумя сущностями, в цифрах. Например, человек может разместить несколько заказов.
Сущности — абстрактные данные, которые вы сохраняете в базе данных. Например: клиенты, продукты.
Внешний ключ (FK) — ссылка на первичный ключ другой таблицы. Столбцы внешнего ключа могут содержать только те значения, которые существуют в столбце первичного ключа, на который они ссылаются.
Ключ — ключ используется для указания записей. Наиболее известным ключом является первичный ключ (см. Первичный ключ).
Нормализация.