Что такое SQL и как он работает | GeekBrains
https://d2xzmw6cctk25h.cloudfront.net/post/2491/og_image/9d0f392ec052f922f41e5792374d7fcd.png
Википедия гласит, что SQL — это декларативный язык программирования, применяемый для создания, модификации и управления данными в реляционной базе данных, управляемой соответствующей системой управления базами данных. Не самое удобоваримое определение. Чтобы понять, о чём вообще речь, разберём его.
Декларативный язык программирования говорит, что должно быть сделано, а не как это необходимо сделать. Ещё один пример декларативного языка — HTML. Рассмотрим такой код:
<div class=”className”>
<input type=”button” value=”Ясно. Понятно.”></input>
</div>С его помощью мы заявляем (declaration — заявление) браузеру, что хотим увидеть блок с классом className и кнопкой с текстом «Ясно. Понятно.» внутри. Для этого мы не создаём каких-либо переменных, циклов, условий.
Здесь смысл довольно прост: мы даём команду и получаем результат. Мы не описываем, как эту команду выполнять. Чтобы понять, что такое реляционная база данных, разберём, что такое база данных в принципе. Декомпозируем это понятие на «база» и «данные».
Данные
В контексте баз данных под данными понимают набор значений, который собирается в строки и столбцы, тем самым представляя таблицу. Представим, что у нас есть каталог мебельного магазина. Нам нужно сохранить все данные из раздела «Шкафы» этого каталога в таблицу. Мы решили, что все шкафы отличаются друг от друга характеристиками:
- название производителя;
- название модели;
- высота;
- длина;
- цвет;
- количество дверей.
Составим таблицу и вобьём в неё выдуманные данные.
У нас есть таблица с данными. Столбцами мы показываем, как они будут храниться.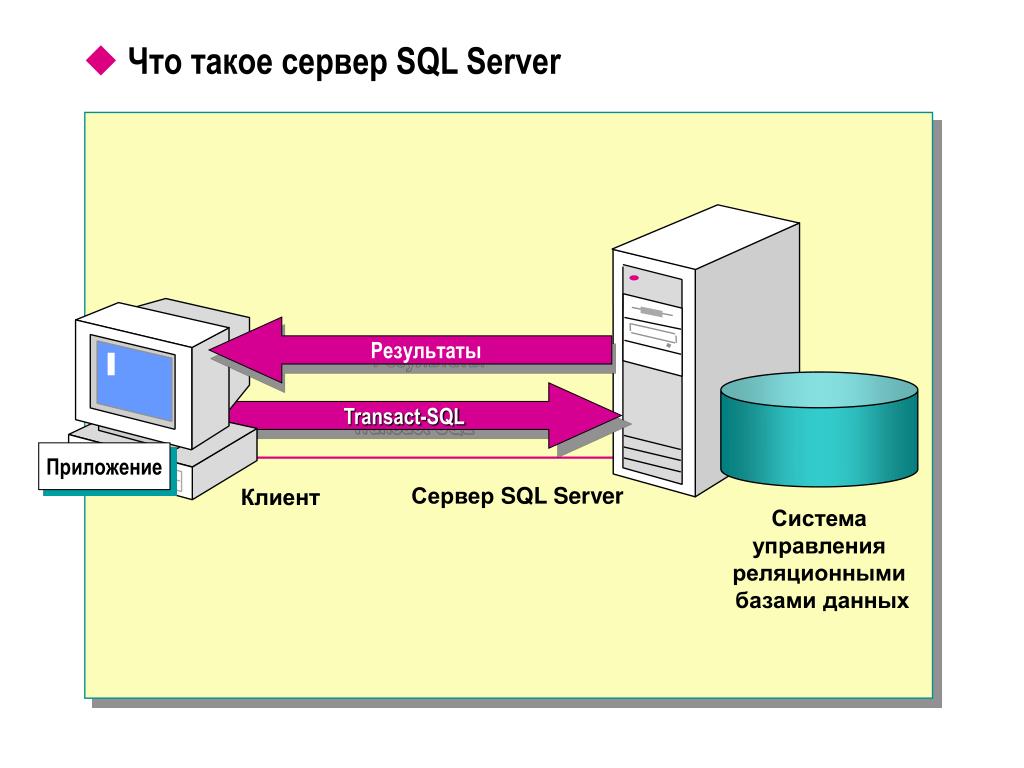 В примере я указал, что мы будем хранить информацию в структуре: производитель, модель, высота, длина, цвет, количество дверей. Иными словами, я создал структуру таблицы.
В примере я указал, что мы будем хранить информацию в структуре: производитель, модель, высота, длина, цвет, количество дверей. Иными словами, я создал структуру таблицы.
Добавляя в таблицу строки, я вводил в неё данные, ориентируясь на структуру, заданную в столбцах. Чем больше строк, тем больше данных. Чем больше столбцов, тем подробнее будут эти данные.
Ещё есть такое понятие, как «значение» — это пересечение столбца и строки. Например, у последней строки в столбце «Цвет» написано «хаки». Здесь «хаки» — значение. Если мы начнём группировать таблицы и добавим возможность манипулирования ими, то получим базу данных.
Теперь про базы
Получается, что БД — это совокупность данных, представленных определённым образом (в нашем случае — таблицей), и набор инструментов для манипулирования ими.
Данные могут быть сгруппированы не только в таблицы, но и в коллекции. У каждой базы есть свой инструмент для создания таблиц/коллекций, добавления, удаления или изменения данных, а также для составления выборки.
Таблицы между собой могут объединяться в схемы — в одной базе данных их может быть несколько, а может и не быть деления на схемы вообще. Это зависит от БД.
Вернёмся к определению из Википедии и вспомним про слово «реляционные». Реляционные (от англ. relation — отношения) — это базы данных, таблицы которых могут выстраиваться в различных отношениях. Возьмём предыдущий пример и добавим в него тех самых «отношений». Создадим таблицу «Производитель», а ту, что в примере, обозначим как «Каталог».
Таблица «Производитель»:
Теперь таблицу «Каталог» можно оформить в другом виде:
Получилось так, что у таблиц «Каталог» и «Прозводитель» появились отношения. Значения из столбца «Каталог» ссылаются на строки из таблицы «Производитель». Добавлением отношения мы решили нескольких проблем:
- Избавились от избыточных данных. Каталог стал занимать меньше места.
 Вместо хранения целой строки мы используем только номер строки из таблицы «Производитель».
Вместо хранения целой строки мы используем только номер строки из таблицы «Производитель». - Снизили вероятность ошибиться. При смене названия производителя нам достаточно отредактировать строку в таблице «Производитель», «Каталог» останется без изменений.
 Вместо хранения целой строки мы используем только номер строки из таблицы «Производитель».
Вместо хранения целой строки мы используем только номер строки из таблицы «Производитель». Это не все проблемы, которые мы решили добавлением отношений. Для понимания других проблем необходимо углубиться в тему баз данных. Разделение данных на таблицы с отношениями — это процесс нормализации. Так можно достигать различных нормализованных форм данных. При достижении каждой из нормализованных форм мы избавляем данные от дополнительных проблем.
Вернёмся к SQL
Если читателю показалось, что мы ушли в сторону от SQL, так оно и есть. Но очень трудно понять, что такое SQL, не зная, с чем он работает.
Выходит, что SQL — это язык программирования, необходимый для написания команд к БД, после выполнения которых она вернёт результат. Результат будет зависеть от команды, написанной на SQL.
- DDL — Data Definition Language;
- DML — Data Manipulation Language;
- DCL — Data Control Language;
- TCL — Transaction Control Language.
DDL
DDL (Data Definition Language, язык описания данных) — язык, включающий операторы для работы со структурой данных. Операторы DDL нужны для реализации этих возможностей:
- Создание объектов базы данных (таблиц, схем). Оператор: CREATE.
- Удаление объектов базы данных. Оператор: DROP.
- Изменение объектов базы данных. Оператор: ALTER.
DDL используется, когда нужно создать структуру для хранения данных. Он не отвечает за сами данные — только за то, как они будут разделены по таблицам и схемам.
DML
DML (Data Manipulation Language, язык манипуляции данными) — язык, который нужен для добавления, удаления, изменения данных и для выборки их из базы. Иными словами, для манипулирования данными. Пройдёмся по операторам:
Иными словами, для манипулирования данными. Пройдёмся по операторам:
- Оператор SELECT позволяет выбрать данные.
- Оператор INSERT — добавить новые.
- Оператор UPDATE — изменить существующие.
- Оператор DELETE — удалить.
DCL
DCL (Data Control Language, язык управления доступом к данным) — набор операторов, необходимых для предоставления доступа к данным. Кроме данных, в БД есть такие сущности, как пользователи. Нужно обязательно иметь возможность ограничить пользователям доступ к данным. Например, мы не хотим, чтобы менеджер проекта мог редактировать данные или их структуру. Для этого есть три группы операторов.
- GRANT — оператор предоставления пользователю или группе набор каких-либо разрешений;
- REVOKE — оператор отзыва разрешений;
- DENY — задаёт запрет. Приоритет оператора DENY выше, чем у разрешения, выданного оператором GRANT.
TCL
Есть такое понятие, как транзакции. Это набор команд (там может быть и всего одна), который завершается успешно тогда, когда правильно выполнены все команды из него. В случае неудачного завершения одной команды из транзакции, она вся откатывается (отменяются результаты выполнения предыдущих команд), реализуя принцип атомарности. Обычно в транзакцию включаются DML-команды.
Это набор команд (там может быть и всего одна), который завершается успешно тогда, когда правильно выполнены все команды из него. В случае неудачного завершения одной команды из транзакции, она вся откатывается (отменяются результаты выполнения предыдущих команд), реализуя принцип атомарности. Обычно в транзакцию включаются DML-команды.
Для управления транзакциями существует TCL (Transaction Control Language — язык управления транзакциями). Операторы здесь следующие:
- BEGIN TRANSACTION — необходим для обозначения начала транзакции;
- COMMIT TRANSACTION — применяет изменения команд внутри транзакции;
- ROLLBACK TRANSACTION — откатывает транзакцию;
- SAVE TRANSACTION — указывает промежуточную точку сохранения внутри транзакции.
TCL есть только в тех БД, которые поддерживают транзакции. Самое время поговорить о видах БД.
Виды СУБД
Познакомимся с новым понятием — СУБД, системой управления базой данных.
Сергей Кузнецов в книге «Основы баз данных» описал СУБД как комплекс программ, позволяющих создать базу данных (БД) и манипулировать данными (вставлять, обновлять, удалять и выбирать). Система обеспечивает безопасность, надёжность хранения и целостность данных, а также предоставляет средства для администрирования БД.
Получается что, СУБД — это SQL плюс комплекс программного обеспечения. Очень часто базы данных путают с системой управления базой данных. Это нормально: понятия неразрывны, сама по себе БД без системы управления мало чем отличается от текстового файла со строчками. Важно не только хранить данные, но и управлять ими. СУБД применяются везде, где нужно структурировано хранить данные — от простого блога до проектов Data Science.
Есть много популярных СУБД, рассмотрим несколько из них.
MySQL
MySQL — свободная реляционная СУБД. Разрабатывалась как легковесная замена тяжёлым СУБД, которую можно было установить на маломощный сервер, без сильных потерь в возможностях. MySQL трудится под капотом таких гигантов, как YouTube, Facebook, Twitter, GitHub.
MySQL трудится под капотом таких гигантов, как YouTube, Facebook, Twitter, GitHub.
СУБД написана на C и C++. MySQL породил множество ответвлений, которые сейчас стали самостоятельными СУБД, например Percona и MariaDB.
Oracle Database
История Oracle Database начинается с 1977 года. Это объектно-реляционная система управления данными. Это довольно тяжёлая СУБД, поддерживает системы любой сложности, например, в банковской или финансовой сферах. У неё нет бесплатной лицензии. Процедурный SQL — PL/SQL. Языки написания СУБД — Java/C/С++
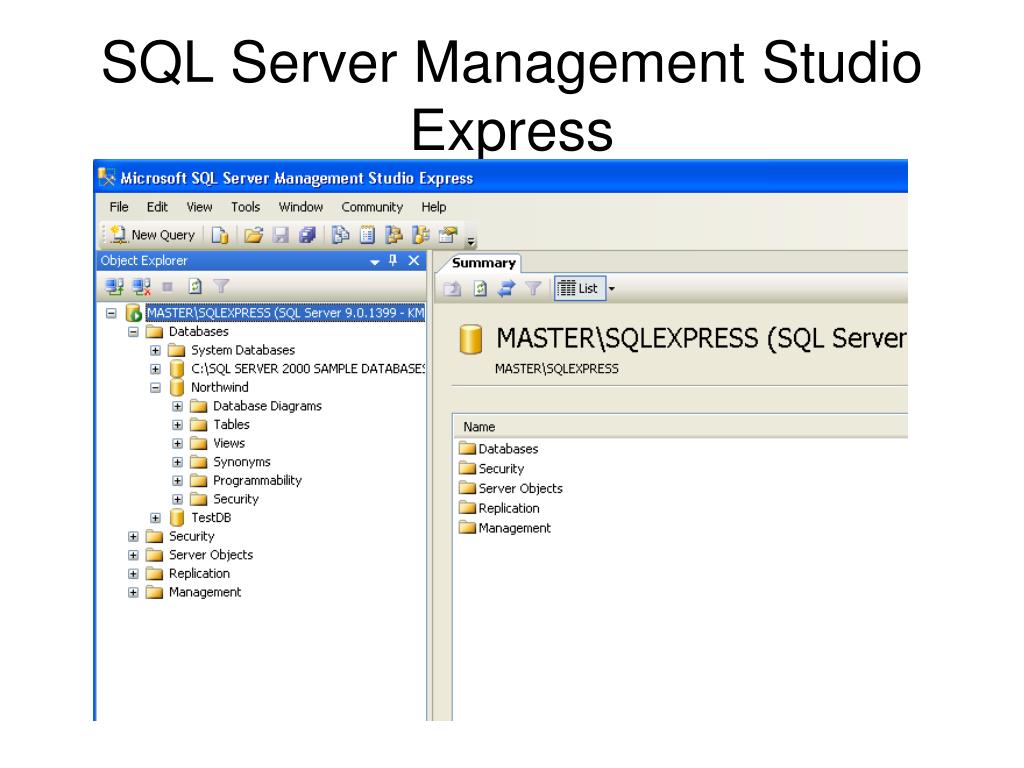
Microsoft SQL Server
Microsoft SQL Server — система управления реляционными базами данных, разработанная Microsoft. Первая версия SQL Server появилась 29 апреля 1989 года. Это конкурент Oracle Database. Есть бесплатная лицензия для разработчиков, но не для коммерческого использования. Процедурный SQL — Transact-SQL. СУБД написана на C/C++/C#.
PostgreSQL
PostgreSQL — свободная объектно-реляционная система управления базами данных. Эта СУБД увидела свет 8 июля 1996 года. Конкурент MySQL в веб-разработке проектов любой сложности, также соперничает с базами от Oracle и Microsoft в промышленной разработке. У неё прекрасная русскоязычная документация. Как и MySQL, имеет бесплатную лицензию для коммерческой разработки, за что так же, как и MySQL, горячо любима. Процедурный SQL — PL/pgSQL. Разработана на языке С.
Эта СУБД увидела свет 8 июля 1996 года. Конкурент MySQL в веб-разработке проектов любой сложности, также соперничает с базами от Oracle и Microsoft в промышленной разработке. У неё прекрасная русскоязычная документация. Как и MySQL, имеет бесплатную лицензию для коммерческой разработки, за что так же, как и MySQL, горячо любима. Процедурный SQL — PL/pgSQL. Разработана на языке С.
Каждая из приведённых СУБД работает на своём расширении SQL. У каждой — своя ниша применения, плюсы и минусы.
Что после знакомства?
Если вы не знаете, какая конкретно СУБД вам нужна, выбирайте MySQL. Она лишена изысканных возможностей, которые будут только сбивать начинающего разработчика. Большое комьюнити не оставит в беде и уже решило 95% проблем. Разнообразие графических клиентов для всех операционных систем хорошо помогает на ранних этапах. MySQL позволит набраться опыта и понять, чем она хуже или лучше других СУБД. Когда вы поймёте принципы работы MySQL, для вас не составит труда переключиться на работу с PostgreSQL или другой СУБД. Цель работы у всех СУБД одна — рациональное и надёжное хранение данных и быстрое их извлечение или изменение.
Цель работы у всех СУБД одна — рациональное и надёжное хранение данных и быстрое их извлечение или изменение.
После того как вы определитесь с выбором, хорошо будет посмотреть практики других разработчиков на YouTube-каналах «Технострим Mail.ru Group» или HighLoad Channel, почитать замечательный портал ruhighload.com, где, кроме статей про базы данных, рассматриваются проблемы больших нагрузок. А для тех, кто любит почитать больше, подойдёт книга «MySQL по максимуму. 3-е издание» Бэрона Шварца, Петра Зайцева и Вадима Ткаченко. Узнать больше вы, конечно, можете и в GeekBrains — приходите ко мне или моим коллегам на курс «Основы баз данных».
что это такое, история языка SQL
SQL — что это, история появления SQL
Язык SQL был создан в 1974 году. Первым названием было «SEQUEL». Его изменили из-за совпадения названий торговых марок. Официальный стандарт языка приняли:
- в 1986 году – ANSI;
- в 1987 году – ISO.

Изначально язык создавался для пользователя БД. В ходе развития язык стал сложнее. Сейчас он является полноценным инструментом разработчика.
Описание
По форме использования SQL подразделяется на интерактивный и вложенный. Интерактивный SQL подходит для использования в самой БД. После ввода команды она сразу выполняется, а затем выводится её результат. Вложенный SQL используется внутри программ, написанных на другом языке. К примеру, в программах на PHP часто используются вставки SQL, чтобы оперативно вносить изменения в БД.
Все версии языка SQL поддерживают группу ключевых слов, которые являются основой команд при обращении к данным из базы. Например, с помощью слова «SELECT» во всех версиях можно получить все или конкретные строки из таблицы.
В SQL определены типы данных. С их помощью контролируется правильность заполнения таблиц БД.
Преимущества SQL:
Декларативность языка
Программист указывает, какие операции нужно выполнить, в способ их реализации выбирается автоматически.
Наличие стандартов
Существование единых стандартов и тестов совместимости способствует стабилизации языка.
Простота адаптации к конкретной СУБД
Обычно не возникает необходимости в сложных конструкциях для управления БД. Простые формулировки команд легко корректируются при необходимости переноса программы.
Недостатки SQL:
Язык SQL не поддерживает:
- рекурсии;
- циклы;
- пользовательские функции.
Постепенно были разработаны обходные пути для преодоления этих ограничений. Их применение требует наличия опыта у программиста.
Стандарт языка сложен и имеет большой объем. Сейчас существует множество отличающихся между собой реализаций SQL. Из-за этого программы обычно нельзя перенести между системами управления БД без изменения кода.
Из чего состоит SQL?
Язык SQL подразделяется на 4 части.
DDL – язык определения данных
Состоит из команд создания объектов в БД. С помощью команд DDL создаются новые таблицы, индексы и другие элементы.
DML – язык манипуляции данными
Включает команды управления данными. Они строятся на основе команд:
- select – для выбора элементов;
- delete – для удаления;
- update – для обновления;
- insert – для вставки данных.
DLC – язык определения контроля доступа к данным
Включает в себя средства, позволяющие запретить или разрешить пользователю конкретные действия.
TLC – язык управления транзакциями
Используется для контроля обработки транзакций.
iPipe – надёжный хостинг-провайдер с опытом работы более 15 лет.
Мы предлагаем:
Что такое SQL и как он работает?
Рано или поздно, каждый веб-мастер добирается до вопроса «Что такое SQL и как с ней работать». В этой статье мы познакомим вас с языком программирования SQL, который определяет запросы к базе данных.
SQL — это аббревиатура для термина Structured Query Language — так называется язык программирования, предназначенный для управления базами данных.
SQL был создан для управления данными, которые находятся в реляционных базах данных, хранящие данные в нескольких таблицах, состоящих из столбцов и строк.
Его появление восходит к 1970-м годам, задолго до того, как Oracle популяризировал SQL и помог сделать его одним из наиболее широко используемых языков управления базами данных. В настоящее время существует множество вариантов SQL с открытым исходным кодом, и стандарт этого языка настолько обширен, что только некоторые из его вариантов действительно совместимы, поскольку каждый использует разные аспекты целого стандарта.
Тем не менее, удивительная простота сделала SQL самым востребованным языком: с го помощью, используя всего одну команду, можно получить доступ сразу к нескольким записям данных, не требуя индекса для доступа к этим данным. Несмотря на то, что для запросов к базам данных язык использует простые декларативные инструкции, он, благодаря составляющим язык различным элементам, позволяет формулировать выполнять сложные и подробные запросы.
Из каких элементов состоит SQL?
Язык SQL состоит из нескольких отдельных элементов, каждый из которых содержит «оператор». Выражения или запросы начинаются с указания типа SELECT или CREATE и заканчиваются точкой с запятой, которая символизирует конец запроса.
Давайте рассмотрим элементы, которые, как правило, имеются в языке SQL:
Операторы — отдельные компоненты запроса; например, ‘UPDATE’ или ‘WHERE’ — они определяют характер запроса.
Предикаты — они определяют условия, которые могут изменить область запроса: например, запрос с условиями ‘BETWEEN’ или ‘ALL’ возвратят разные наборы данных; первый из диапазона между x и y, а последний — все данные, которые соответствуют вашему запросу.
Выражения — выражения могут представлять собой скалярные значения (указание на место хранения в паре с идентификатором) или таблицы, содержащие столбцы и строки.
Запросы — они позволяют получить данные, соответствующие критериям, которые вы определяете.
Инструкции — определяют способ, с помощью которого программное обеспечение SQL отправляет запросы на сервер базы данных. Они начинаются с оператора типа SELECT или CREATE и заканчиваются точкой с запятой, которая символизирует конец запроса.
Популярные QSL запросы
Приведем только несколько полезных SQL-запросов, на основе которых продемонстрируем, как используется SQL для запроса и управления данными.
ALTER TABLE — указание добавлять новые столбцы в базу данных, увеличивая количество данных, которые она может записывать.
CREATE TABLE — добавление новой таблицы позволяет вашей базе данных хранить совершено новый тип данных.
ORDER BY — полезная команда для того, чтобы данные, которые вы запрашиваете, были представлены каким-то полезным для вас способом — например, в алфавитном порядке.
UPDATE — обновление базы данных позволяет вам изменять содержимое строк, например, если данные были изменены, или вы обнаружили, что они некорректны.
Обработка данных SQL
Возможность SQL изменять и редактировать сохраненные в базе данные, как пишет сайт itvdn. com, делает этот язык программирования невероятно полезным. Вместо того, чтобы просто хранить данные, вы можете при необходимости создавать команды для их изменения. Устаревшие данные редко бывают полезными, поэтому важно обновлять базы, чтобы всегда иметь под рукой максимально точную и актуальную информацию.
com, делает этот язык программирования невероятно полезным. Вместо того, чтобы просто хранить данные, вы можете при необходимости создавать команды для их изменения. Устаревшие данные редко бывают полезными, поэтому важно обновлять базы, чтобы всегда иметь под рукой максимально точную и актуальную информацию.
Читатели этой статьи также смотрели на сайте rfcmd.ru
Преимущества облачных вычислений
Системный интегратор для СКС
Для чего нужен юрист по недвижимости
Современный интернет для рынка недвижимости
Google-сервисы для Мeizu
Умный дом и автономный генератор
Правильная CRM для вашего бизнеса
Кратко:
Рано или поздно, каждый веб-мастер добирается до вопроса «Что такое SQL и как с ней работать». В этой статье мы познакомим вас с языком программирования SQL, который определяет запросы к базе данных. Удивительная простота сделала SQL самым востребованным языком: с го помощью, используя всего одну команду, можно получить доступ сразу к нескольким записям данных, не требуя индекса для доступа к этим данным. Несмотря на то, что для запросов к базам данных язык использует простые декларативные инструкции, он, благодаря составляющим язык различным элементам, позволяет формулировать выполнять сложные и подробные запросы.
Несмотря на то, что для запросов к базам данных язык использует простые декларативные инструкции, он, благодаря составляющим язык различным элементам, позволяет формулировать выполнять сложные и подробные запросы.
Access SQL. Основные понятия, лексика и синтаксис
Для извлечения данных из базы данных используется язык SQL. SQL — это язык программирования, который очень напоминает английский, но предназначен для программ управления базами данных. SQL используется в каждом запросе в Access.
Понимание принципов работы SQL помогает создавать более точные запросы и упрощает исправление запросов, которые возвращают неправильные результаты.
Это статья из цикла статей о языке SQL для Access. В ней описаны основы использования SQL для выборки данных и приведены примеры синтаксиса SQL.
В ней описаны основы использования SQL для выборки данных и приведены примеры синтаксиса SQL.
В этой статье
Что такое SQL?
SQL — это язык программирования, предназначенный для работы с наборами фактов и отношениями между ними. В программах управления реляционными базами данных, таких как Microsoft Office Access, язык SQL используется для работы с данными. В отличие от многих языков программирования, SQL удобочитаем и понятен даже новичкам. Как и многие языки программирования, SQL является международным стандартом, признанным такими комитетами по стандартизации, как ISO и ANSI.
На языке SQL описываются наборы данных, помогающие получать ответы на вопросы. При использовании SQL необходимо применять правильный синтаксис. Синтаксис — это набор правил, позволяющих правильно сочетать элементы языка. Синтаксис SQL основан на синтаксисе английского языка и имеет много общих элементов с синтаксисом языка Visual Basic для приложений (VBA).
При использовании SQL необходимо применять правильный синтаксис. Синтаксис — это набор правил, позволяющих правильно сочетать элементы языка. Синтаксис SQL основан на синтаксисе английского языка и имеет много общих элементов с синтаксисом языка Visual Basic для приложений (VBA).
Например, простая инструкция SQL, извлекающая список фамилий контактов с именем Mary, может выглядеть следующим образом:
SELECT Last_Name
FROM Contacts
WHERE First_Name = 'Mary';
Примечание: Язык SQL используется не только для выполнения операций над данными, но еще и для создания и изменения структуры объектов базы данных, например таблиц. Та часть SQL, которая используется для создания и изменения объектов базы данных, называется языком описания данных DDL. Язык DDL не рассматривается в этой статье. Дополнительные сведения см. в статье Создание и изменение таблиц или индексов с помощью запроса определения данных.
Та часть SQL, которая используется для создания и изменения объектов базы данных, называется языком описания данных DDL. Язык DDL не рассматривается в этой статье. Дополнительные сведения см. в статье Создание и изменение таблиц или индексов с помощью запроса определения данных.
Инструкции SELECT
Чтобы описать набор данных с помощью SQL, нужно написать заявление SELECT. Инструкция SELECT содержит полное описание набора данных, которые вы хотите получить из базы данных. К ним относятся файлы со следующими элементами:
-
таблицы, в которых содержатся данные;
-
связи между данными из разных источников;
-
поля или вычисления, на основе которых отбираются данные;
-
условия отбора, которым должны соответствовать данные, включаемые в результат запроса;
-
необходимость и способ сортировки.
Предложения SQL
Инструкция SQL состоит из нескольких частей, называемых предложениями. Каждое предложение в инструкции SQL имеет свое назначение. Некоторые предложения являются обязательными. В приведенной ниже таблице указаны предложения SQL, используемые чаще всего.
Предложение SQL | Описание | Обязательное |
|---|---|---|
|
SELECT |
Определяет поля, которые содержат нужные данные. |
Да |
|
FROM |
Определяет таблицы, которые содержат поля, указанные в предложении SELECT. |
Да |
|
WHERE |
Определяет условия отбора полей, которым должны соответствовать все записи, включаемые в результаты. |
Нет |
|
ORDER BY |
Определяет порядок сортировки результатов. |
Нет |
|
GROUP BY |
В инструкции SQL, которая содержит статистические функции, определяет поля, для которых в предложении SELECT не вычисляется сводное значение. |
Только при наличии таких полей |
|
HAVING |
В инструкции SQL, которая содержит статистические функции, определяет условия, применяемые к полям, для которых в предложении SELECT вычисляется сводное значение. |
Нет |
Термины SQL
Каждое предложение SQL состоит из терминов, которые можно сравнить с частями речи. В приведенной ниже таблице указаны типы терминов SQL.
Термин SQL | Сопоставимая часть речи | Определение | Пример |
|---|---|---|---|
|
идентификатор |
существительное |
Имя, используемое для идентификации объекта базы данных, например имя поля. |
Клиенты.[НомерТелефона] |
|
оператор |
глагол или наречие |
Ключевое слово, которое представляет действие или изменяет его. |
AS |
|
константа |
существительное |
Значение, которое не изменяется, например число или NULL. |
42 |
|
выражение |
прилагательное |
Сочетание идентификаторов, операторов, констант и функций, предназначенное для вычисления одного значения. |
>= Товары.[Цена] |

К началу страницы
Основные предложения SQL: SELECT, FROM и WHERE
Общий формат инструкций SQL:
SELECT field_1
FROM table_1
WHERE criterion_1
;
Примечания:
-
Access не учитывает разрывы строк в инструкции SQL. Несмотря на это, каждое предложение рекомендуется начинать с новой строки, чтобы инструкцию SQL было удобно читать как тому, кто ее написал, так и всем остальным.
-
Каждая инструкция SELECT заканчивается точкой с запятой (;). Точка с запятой может стоять как в конце последнего предложения, так и на отдельной строке в конце инструкции SQL.
Пример в Access
В приведенном ниже примере показано, как в Access может выглядеть инструкция SQL для простого запроса на выборку.
1. Предложение SELECT
2. Предложение FROM
Предложение FROM
3. Предложение WHERE
Эту инструкцию SQL следует читать так: «Выбрать данные из полей «Адрес электронной почты» и «Компания» таблицы «Контакты», а именно те записи, в которых поле «Город» имеет значение «Ростов».
Разберем пример по предложениям, чтобы понять, как работает синтаксис SQL.
Предложение SELECT
SELECT [E-mail Address], Company
Это предложение SELECT. Оно содержит оператор (SELECT), за которым следуют два идентификатора («[Адрес электронной почты]» и «Компания»).
Оно содержит оператор (SELECT), за которым следуют два идентификатора («[Адрес электронной почты]» и «Компания»).
Если идентификатор содержит пробелы или специальные знаки (например, «Адрес электронной почты»), он должен быть заключен в прямоугольные скобки.
В предложении SELECT не нужно указывать таблицы, в которых содержатся поля, и нельзя задать условия отбора, которым должны соответствовать данные, включаемые в результаты.
В инструкции SELECT предложение SELECT всегда стоит перед предложением FROM.
Предложение FROM
FROM Contacts
Это предложение FROM. Оно содержит оператор (FROM), за которым следует идентификатор (Контакты).
Оно содержит оператор (FROM), за которым следует идентификатор (Контакты).
В предложении FROM не указываются поля для выборки.
Предложение WHERE
WHERE City=»Seattle»
Это предложение WHERE. Оно содержит оператор (WHERE), за которым следует выражение (Город=»Ростов»).
Примечание: В отличие от предложений SELECT и FROM, предложение WHERE является необязательным элементом инструкции SELECT.
С помощью предложений SELECT, FROM и WHERE можно выполнять множество действий.![]() Дополнительные сведения об использовании этих предложений см. в следующих статьях:
Дополнительные сведения об использовании этих предложений см. в следующих статьях:
К началу страницы
Сортировка результатов: ORDER BY
Как и в Microsoft Excel, в Access можно сортировать результаты запроса в таблице. Используя предложение ORDER BY, вы также можете указать способ сортировки результатов при выполнении запроса. Если используется предложение ORDER BY, оно должно находиться в конце инструкции SQL.
Предложение ORDER BY содержит список полей, для которых нужно выполнить сортировку, в том же порядке, в котором будут применена сортировка.
Предположим, например, что результаты сначала нужно отсортировать по полю «Компания» в порядке убывания, а затем, если присутствуют записи с одинаковым значением поля «Компания», — отсортировать их по полю «Адрес электронной почты» в порядке возрастания. Предложение ORDER BY будет выглядеть следующим образом:
ORDER BY Company DESC, [E-mail Address]
Примечание: По умолчанию Access сортирует значения по возрастанию (от А до Я, от наименьшего к наибольшему). Чтобы вместо этого выполнить сортировку значений по убыванию, необходимо указать ключевое слово DESC.
Дополнительные сведения о предложении ORDER BY см. в статье Предложение ORDER BY.
в статье Предложение ORDER BY.
К началу страницы
Работа со сводными данными: предложения GROUP BY и HAVING
Иногда возникает необходимость работы со сводными данными, такими как итоговые продажи за месяц или самые дорогие товары на складе. Для этого в предложении SELECT к полю применяется агрегатная функция. Например, если в результате выполнения запроса нужно получить количество адресов электронной почты каждой компании, предложение SELECT может выглядеть следующим образом:
SELECT COUNT([E-mail Address]), Company
Возможность использования той или иной агрегатной функции зависит от типа данных в поле и нужного выражения. Дополнительные сведения о доступных агрегатных функциях см. в статье Статистические функции SQL.
Дополнительные сведения о доступных агрегатных функциях см. в статье Статистические функции SQL.
Задание полей, которые не используются в агрегатной функции: предложение GROUP BY
При использовании агрегатных функций обычно необходимо создать предложение GROUP BY. В предложении GROUP BY указываются все поля, к которым не применяется агрегатная функция. Если агрегатные функции применяются ко всем полям в запросе, предложение GROUP BY создавать не нужно.
Предложение GROUP BY должно следовать сразу же за предложением WHERE или FROM, если предложение WHERE отсутствует. В предложении GROUP BY поля указываются в том же порядке, что и в предложении SELECT.
Продолжим предыдущий пример.![]() Пусть в предложении SELECT агрегатная функция применяется только к полю [Адрес электронной почты], тогда предложение GROUP BY будет выглядеть следующим образом:
Пусть в предложении SELECT агрегатная функция применяется только к полю [Адрес электронной почты], тогда предложение GROUP BY будет выглядеть следующим образом:
GROUP BY Company
Дополнительные сведения о предложении GROUP BY см. в статье Предложение GROUP BY.
Ограничение агрегированных значений с помощью условий группировки: предложение HAVING
Если необходимо указать условия для ограничения результатов, но поле, к которому их требуется применить, используется в агрегированной функции, предложение WHERE использовать нельзя.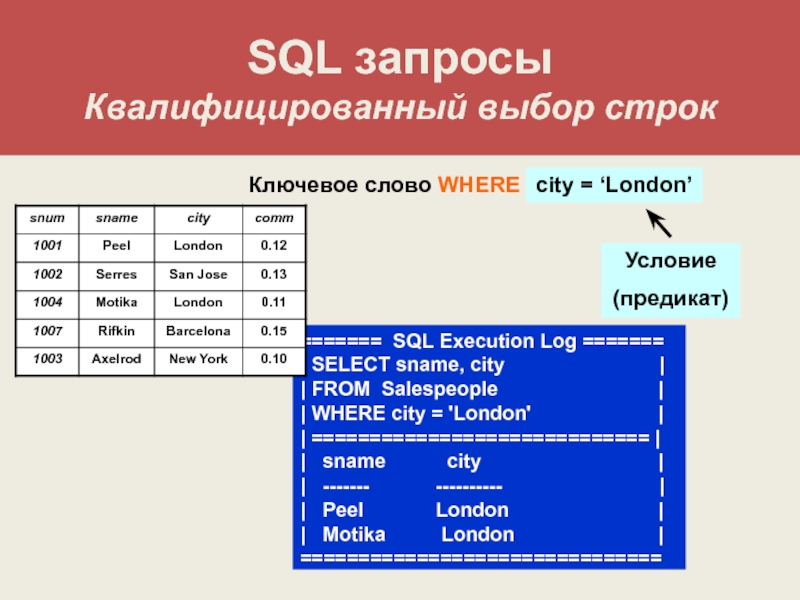 Вместо него следует использовать предложение HAVING. Предложение HAVING работает так же, как и WHERE, но используется для агрегированных данных.
Вместо него следует использовать предложение HAVING. Предложение HAVING работает так же, как и WHERE, но используется для агрегированных данных.
Предположим, например, что к первому полю в предложении SELECT применяется функция AVG (которая вычисляет среднее значение):
SELECT COUNT([E-mail Address]), Company
Если вы хотите ограничить результаты запроса на основе значения функции COUNT, к этому полю нельзя применить условие отбора в предложении WHERE. Вместо него условие следует поместить в предложение HAVING. Например, если нужно, чтобы запрос возвращал строки только в том случае, если у компании есть несколько адресов электронной почты, можно использовать следующее предложение HAVING:
HAVING COUNT([E-mail Address])>1
Примечание: Запрос может включать и предложение WHERE, и предложение HAVING, при этом условия отбора для полей, которые не используются в статистических функциях, указываются в предложении WHERE, а условия для полей, которые используются в статистических функциях, — в предложении HAVING.
Дополнительные сведения о предложении HAVING см. в статье Предложение HAVING.
К началу страницы
Объединение результатов запроса: оператор UNION
Оператор UNION используется для одновременного просмотра всех данных, возвращаемых несколькими сходными запросами на выборку, в виде объединенного набора.
Оператор UNION позволяет объединить две инструкции SELECT в одну. Объединяемые инструкции SELECT должны иметь одинаковое число и порядок выходных полей с такими же или совместимыми типами данных. При выполнении запроса данные из каждого набора соответствующих полей объединяются в одно выходное поле, поэтому выходные данные запроса имеют столько же полей, сколько и каждая инструкция SELECT по отдельности.
Объединяемые инструкции SELECT должны иметь одинаковое число и порядок выходных полей с такими же или совместимыми типами данных. При выполнении запроса данные из каждого набора соответствующих полей объединяются в одно выходное поле, поэтому выходные данные запроса имеют столько же полей, сколько и каждая инструкция SELECT по отдельности.
Примечание: В запросах на объединение числовой и текстовый типы данных являются совместимыми.
Используя оператор UNION, можно указать, должны ли в результаты запроса включаться повторяющиеся строки, если таковые имеются. Для этого следует использовать ключевое слово ALL.
Запрос на объединение двух инструкций SELECT имеет следующий базовый синтаксис:
SELECT field_1
FROM table_1
UNION [ALL]
SELECT field_a
FROM table_a
;
Предположим, например, что имеется две таблицы, которые называются «Товары» и «Услуги». Обе таблицы содержат поля с названием товара или услуги, ценой и сведениями о гарантии, а также поле, в котором указывается эксклюзивность предлагаемого товара или услуги. Несмотря на то, что в таблицах «Продукты» и «Услуги» предусмотрены разные типы гарантий, основная информация одна и та же (предоставляется ли на отдельные продукты или услуги гарантия качества). Для объединения четырех полей из двух таблиц можно использовать следующий запрос на объединение:
Обе таблицы содержат поля с названием товара или услуги, ценой и сведениями о гарантии, а также поле, в котором указывается эксклюзивность предлагаемого товара или услуги. Несмотря на то, что в таблицах «Продукты» и «Услуги» предусмотрены разные типы гарантий, основная информация одна и та же (предоставляется ли на отдельные продукты или услуги гарантия качества). Для объединения четырех полей из двух таблиц можно использовать следующий запрос на объединение:
SELECT name, price, warranty_available, exclusive_offer
FROM Products
UNION ALL
SELECT name, price, guarantee_available, exclusive_offer
FROM Services
;
Дополнительные сведения об объединении инструкций SELECT с помощью оператора UNION см. в статье Просмотр объединенных результатов нескольких запросов с помощью запроса на объединение.
в статье Просмотр объединенных результатов нескольких запросов с помощью запроса на объединение.
К началу страницы
Что Такое MySQL: Объяснение MySQL Для Начинающих
MySQL Глоссарий
access_time9 декабря, 2020
hourglass_empty4мин. чтения
Если вы хотите быстро разобраться в технической терминологии — вы попали по адресу. Мы делаем наш веб-хостинг простым и доступным, то же самое касается наших учебных материалов. Итак, что такое MySQL? Давайте разберёмся прямо сейчас.
Нужен недорогой, но надёжный хостинг для вашего проекта? Выберите подходящий тариф и получите скидку до 90%.
К предложению
Что такое MySQL?
Прежде всего, вы должны знать, как это произносится: MY-ES-KYOO-EL ’[май-эс-кью-эл]. Вы можете услышать и другие варианты произношения, но, по крайней мере теперь, вы знаете официальное произношение. Шведская компания MySQL AB первоначально разработала MySQL в 1994 году. Тогда американская технологическая компания Sun Microsystems полностью приобрела право собственности, купив MySQL AB в 2008 году. Американский технологический гигант Oracle в 2010 году приобрёл Sun Microsystems, а с тех пор MySQL практически принадлежала Oracle.
Шведская компания MySQL AB первоначально разработала MySQL в 1994 году. Тогда американская технологическая компания Sun Microsystems полностью приобрела право собственности, купив MySQL AB в 2008 году. Американский технологический гигант Oracle в 2010 году приобрёл Sun Microsystems, а с тех пор MySQL практически принадлежала Oracle.
Что касается общего определения, MySQL это система управления реляционными базами данных с открытым исходным кодом (СУРБД) с моделью клиент-сервер. СУРБД — это программное обеспечение или служба, используемая для создания и управления базами данных на основе реляционной модели. Теперь давайте подробнее рассмотрим каждый термин:
База данных
База данных — это просто набор структурированных данных. Например, когда вы делаете селфи: вы нажимаете кнопку и фотографируете себя. Ваша фотография — это данные, а галерея вашего телефона — это база данных. База данных — это место, в котором хранятся данные. Слово «реляционный» означает, что данные, хранящиеся в наборе данных, организованы в виде таблиц. Каждая таблица связана в некотором роде. Если программное обеспечение не поддерживает реляционную модель данных, просто назовите её СУБД.
Каждая таблица связана в некотором роде. Если программное обеспечение не поддерживает реляционную модель данных, просто назовите её СУБД.
Открытый исходный код
Открытый исходный код означает, что вы можете свободно использовать и изменять его. Любой может установить программное обеспечение. Вы также можете изучить и настроить исходный код, чтобы он лучше соответствовал вашим потребностям. Однако GPL (GPU Public License) определяет, что именно вы можете сделать в зависимости от условий. Коммерческая лицензированная версия доступна, если вам нужно более гибкое владение и расширенная поддержка.
Модель клиент-сервер
Компьютеры, которые устанавливают и запускают программное обеспечение СУРБД, называются клиентами. Когда им нужно получить доступ к данным, они подключаются к серверу СУРБД. Это система «клиент-сервер».
MySQL является одним из многих вариантов программного обеспечения СУРБД. Считается, что СУРБД и MySQL одинаковы из-за популярности MySQL. Назовите несколько крупных веб-приложений, таких как Facebook, Twitter, YouTube, Google и Yahoo! все используют MySQL для хранения данных. Хотя изначально он создавался для ограниченного использования, теперь он совместим со многими важными вычислительными платформами, такими как Linux, macOS, Microsoft Windows и Ubuntu.
Хотя изначально он создавался для ограниченного использования, теперь он совместим со многими важными вычислительными платформами, такими как Linux, macOS, Microsoft Windows и Ubuntu.
SQL
MySQL и SQL не совпадают. Помните, что MySQL является одной из самых популярных торговых марок программного обеспечения СУРБД, которая реализует модель клиент-сервер. Итак, как клиент и сервер взаимодействуют в среде СУРБД? Они используют специфичный для домена язык — язык структурированных запросов (SQL). Если вы когда-либо сталкивались с другими именами, в которых есть SQL, такими как PostgreSQL и сервер Microsoft SQL, они, скорее всего, являются брендами, которые также используют синтаксис SQL. Программное обеспечение СУРБД часто пишется на других языках программирования, но всегда использует SQL в качестве основного языка для взаимодействия с базой данных. Сам MySQL написан на C и C ++. Подумайте о странах Южной Америки, все они географически различны и имеют разную историю, но все они в основном говорят по-испански.
Инженер-компьютерщик Тед Кодд разработал SQL в начале 1970-х годов на основе реляционной модели IBM. Он стал более широко использоваться в 1974 году и быстро заменил аналогичные, тогда устаревшие языки, ISAM и VISAM. Помимо истории, SQL сообщает серверу, что делать с данными. Это похоже на ваш пароль или код WordPress. Вы вводите его в систему, чтобы получить доступ к области панели управления. В этом случае операторы SQL могут указать серверу выполнить определённые операции:
- Запрос данных: запрос конкретной информации из существующей базы данных.
- Обработка данных: добавление, удаление, изменение, сортировка и другие операции для изменения данных, значений или визуальных элементов.
- Идентификация данных: определение типов данных, например, изменение числовых данных в целые числа. Это также включает определение схемы или взаимосвязи каждой таблицы в базе данных.
- Контроль доступа к данным: обеспечение методов безопасности для защиты данных, в том числе принятие решения о том, кто может просматривать или использовать любую информацию, хранящуюся в базе данных.

Вы искали отличное решение для хостинга? Мы рекомендуем вам следить за страницей купонов Hostinger и быть первым, чтобы получить качественный хостинг по самой низкой цене на рынке!
Все ограниченные предложения
Как работает MySQL?
Изображение объясняет базовую структуру клиент-сервер. Одно или несколько устройств (клиентов) подключаются к серверу через определённую сеть. Каждый клиент может сделать запрос из графического интерфейса пользователя (GUI) на своих экранах, и сервер выдаст желаемый результат, если оба конца понимают инструкцию. Не вдаваясь в технические аспекты, основные процессы, происходящие в среде MySQL, одинаковы:
- MySQL создаёт базу данных для хранения и управления данными, определяющими отношения каждой таблицы.
- Клиенты могут делать запросы, вводя определённые команды SQL на MySQL.
- Приложение сервера ответит запрошенной информацией и появится на стороне клиента.
Вот и всё. Клиенты обычно указывают, какой MySQL GUI использовать. Чем легче и удобнее графический пользовательский интерфейс, тем быстрее и проще будут выполняться операции по управлению данными. Некоторыми из самых популярных графических интерфейсов MySQL (англ) являются MySQL WorkBench, SequelPro, DBVisualizer и Navicat DB Admin Tool. Некоторые из них бесплатны, некоторые коммерческие, некоторые работают исключительно для macOS, а некоторые совместимы с основными операционными системами. Клиенты должны выбирать графический интерфейс в зависимости от своих потребностей. Для управления базами данных, в том числе на сайте WordPress, наиболее очевидным подходом является phpMyAdmin.
Чем легче и удобнее графический пользовательский интерфейс, тем быстрее и проще будут выполняться операции по управлению данными. Некоторыми из самых популярных графических интерфейсов MySQL (англ) являются MySQL WorkBench, SequelPro, DBVisualizer и Navicat DB Admin Tool. Некоторые из них бесплатны, некоторые коммерческие, некоторые работают исключительно для macOS, а некоторые совместимы с основными операционными системами. Клиенты должны выбирать графический интерфейс в зависимости от своих потребностей. Для управления базами данных, в том числе на сайте WordPress, наиболее очевидным подходом является phpMyAdmin.
Почему MySQL так популярен?
MySQL действительно не единственная СУРБД на рынке, но она является одной из самых популярных и уступает только Oracle Database, когда оценивается с использованием таких важных параметров, как количество упоминаний в результатах поиска, профессиональных профилей в LinkedIn и частоты технических дискуссий на интернет-форумах. Тот факт, что многие крупные технологические гиганты полагаются на него, ещё больше укрепляет заслуженную позицию. Почему так? Вот причины:
Почему так? Вот причины:
Гибкость и простота в использовании
Вы можете изменить исходный код, чтобы он соответствовал вашим собственным ожиданиям, и вам не нужно ничего платить за этот уровень свободы, включая варианты обновления до расширенной коммерческой версии. Процесс установки относительно прост и не должен занимать более 30 минут.
Высокая производительность
Широкий спектр кластерных серверов поддерживает MySQL. Независимо от того, храните ли вы большие объёмы данных электронной коммерции или выполняете тяжелую бизнес-аналитику, MySQL может помочь вам с оптимальной скоростью.
Промышленный стандарт
Отрасли используют MySQL в течение многих лет, а это означает, что для опытных разработчиков имеются обильные ресурсы. Пользователи MySQL могут рассчитывать на быструю разработку программного обеспечения, а эксперты-фрилансеры, желающие работать в меньшей степени, будут нуждаться в них.
Безопасность
Безопасность ваших данных должна быть вашей главной задачей при выборе правильного программного обеспечения СУРБД. С помощью системы доступа и управления учётными записями MySQL устанавливает высокий уровень безопасности. Доступна проверка на основе хоста и шифрование пароля.
С помощью системы доступа и управления учётными записями MySQL устанавливает высокий уровень безопасности. Доступна проверка на основе хоста и шифрование пароля.
Теперь вы знаете, что такое MySQL. У вас уже есть опыт использования MySQL? Пожалуйста, дайте мне знать, оставив комментарий ниже или узнайте больше о настройке MySQL здесь, на Hostinger.
Что такое MS SQL Server
Давайте для начала разберемся что же такое SQL Server. SQL Server это обычная программа, которая работает на компьютере, сервере, на ноутбуке, на виртуальной машине, или даже в облаке. Она позволяет подключиться к ней локально или по сети, отправить команду по специальному протоколу TDS и соответственно получить ответ. Это мощная и современная платформа, позволяющая хранить и обрабатывать данные. Все что она делает это открывает сетевой порт и готовиться принимать команды от пользователя, а после этого в ответ отдает ему результат. Самое главное при работе с SQL Server это возможность при необходимости подключиться к нему и выполнить команду потому, что разумеется если он не работает смысла в остальном никакого нет.
При работе в локальной сети нужно установить программу на место работы каждого пользователя. Режим работы зависит от выбранной СУБД. В самом простейшем случае работа происходит с базой данных Microsoft Access, такой режим используется по умолчанию сразу после установки программы и подходит для большинства применений, если количество работающих з базой пользователей не превышает 10 12 человек. В сетевой среде файл базы данных выкладывается на общедоступном ресурсе к которому подключаются пользователи из других компьютеров, на которых установлено нужное ПО. Когда количество юзеров которые используют одновременно одну и ту же базу данных превышает 12 человек, или заметна плохая скорость работы сервера, имеет смысл перевести базу данных в формат Microsoft SQL. Это полноценная клиент-серверная архитектура в которой по сете не перекачиваются сами таблицы представления базы данных, а возвращается результат определенного запроса. Все вычисления производятся на сервере баз данных, а не на клиентских компьютерах. Быстродействие возрастёт значительно и это особенно важно при большом количестве рабочих мест.
Быстродействие возрастёт значительно и это особенно важно при большом количестве рабочих мест.
Для управления базами данных Microsoft SQL Server используется программа Microsoft SQL Management Studio. С ее помощью можно производить манипуляции с базами данных, в том числе такие как резервное копирование и восстановление баз данных.
Что такое база данных и SQL. Как работают с базами и что в них хранят
Если сказать упрощённо, то база данных — это среда, в которой существуют таблицы с данными. Если вы когда-нибудь работали в офисной программе «Excel», в которой можно делать таблицы, то считайте что работали с базой данных.В базах данных сайтов могут содержаться таблицы, в которых может быть записано всё что угодно:
- данные новостей, которые опубликованы на сайте
- данные пользователей, которые зарегистрированы на сайте
+--------------------+ | Пользователи | +--------------------+ | Имя | Любимая еда | +------+-------------+ | Мышь | Сыр | +------+-------------+ | Кот | Молоко | +------+-------------+Как можно заметить, это обычная таблица. Но в таком виде на сайте её увидеть нельзя. Сайт делает запрос к ней с помощью специального языка, который называется SQL (Structured Query Language — «язык структурированных запросов»). Эти запросы возвращают массив строк, которые подходят под параметр запроса. Разберём далее логику запросов.
Представьте, что необходимо получить из примера выше все данные таблицы и вывести их на экран. Тогда нужно сделать запрос к базе данных на языке SQL:
SELECT 'Имя пользователя', 'Любимая еда' FROM 'Пользователи';Последняя часть запроса содержит слово FROM, которое дословно переводится как «из». После этого слова стоит таблица ИЗ которой надо получить данные. Если не указать из какой таблицы нужны данные, то база данных выдаст ошибку.
Пример SQL запроса, который приведён выше, сильно утрирован для большей наглядности и простоты. Потому что в базах данных крайне нежелательно создавать таблицы с кириллическими названиями таблиц и столбцов. А ещё названия столбцов и самой таблицы нужно заключать не в одинарную кавычку ‘ , а в наколнную `
Перейдём к обработке результатов выполнения запроса. Если утрировать, то после выполнения запроса из примера выше база данных вернёт такой массив:Array
(
[0] => Array
(
[Имя] => Мышь
[Любимая еда] => Сыр
)
[1] => Array
(
[Имя] => Кот
[Любимая еда] => Молоко
)
)После получения этого массива необходимо сделать цикл аналогичный foreach( ) по всем элементам полученного массива. Внутри цикла можно обернуть полученные значения в различные HTML теги, чтобы вывод был красивым, чтобы у страницы сайта был дизайн. Так и происходит взаимодействие сайтов с базами данных. Базы данных — это не лучшее хранилище информации. Конёк баз данных — это быстрый поиск информации и вывод с сортировкой. Поэтому базы данных целесообразно использовать далеко не везде. Если же нужно обрабатывать терабайты статичной информации без необходимости поиска и сортировки, то выгоднее использовать использовать простые файлы для хранения информации.Базы данных используются для сайтов в основном потому, что с их помощью можно организовать уровни доступа к информации. И базы данных большинства сайтов в интернете очень редко когда превышают 10 Гигабайт (считая размеры всех таблиц в базе).
В следующих статьях мы разберём более сложные примеры обращения с базой данных: научимся создавать и удалять таблицы, объединять результаты выборки из нескольких разных таблиц и обновлять данные в таблицах. Если вам не терпится приступить к программированию, то рекомендуем ознакомиться со статьёй «Как сделать запрос из PHP к базе данных».SQL: что это такое?
Язык структурированных запросов, широко известный как SQL, является стандартным языком программирования для реляционных баз данных. Несмотря на то, что он старше многих других типов кода, это наиболее широко используемый язык баз данных.
Поскольку SQL настолько распространен, знание его важно для всех, кто занимается компьютерным программированием или использует базы данных для сбора и организации информации. Узнайте больше о том, что такое SQL, и о возможностях карьерного роста в этой области.
Что такое SQL?
SQL можно использовать для совместного использования и управления данными, особенно данными, которые находятся в системах управления реляционными базами данных, которые включают данные, организованные в таблицы.Несколько файлов, каждый из которых содержит таблицы данных, также могут быть связаны общим полем. Используя SQL, вы можете запрашивать, обновлять и реорганизовывать данные, а также создавать и изменять схему (структуру) системы баз данных и контролировать доступ к ее данным.
В электронную таблицу, такую как Microsoft Excel, можно скомпилировать много информации, но SQL предназначен для компиляции и управления данными в гораздо больших объемах. В то время как электронные таблицы могут стать громоздкими из-за слишком большого количества информации, базы данных SQL могут обрабатывать миллионы или даже миллиарды ячеек данных.
Используя SQL, вы можете хранить данные о каждом клиенте, с которым когда-либо работал ваш бизнес, от основных контактов до сведений о продажах. Так, например, если вы хотите найти каждого клиента, который потратил не менее 5000 долларов на ваш бизнес за последнее десятилетие, база данных SQL могла бы получить эту информацию для вас мгновенно.
Как работает изучение SQL
Язык структурированных запросов более простой, чем другие более сложные языки программирования. Как правило, новичкам легче изучить SQL, чем им освоить такие языки, как Java, C ++, PHP или C #.
Некоторые онлайн-ресурсы, включая бесплатные учебные пособия и платные курсы дистанционного обучения, доступны для тех, у кого мало опыта программирования, но которые хотят изучить SQL. Официальные курсы университета или колледжа также обеспечат более глубокое понимание языка.
История SQL
История SQL насчитывает более полувека. В 1969 году исследователь IBM Эдгар Ф. Кодд определил модель реляционной базы данных, которая стала основой для разработки языка SQL.Эта модель построена на общих порциях информации (или «ключах»), связанных с различными данными. Например, имя пользователя может быть связано с фактическим именем и номером телефона.
Несколько лет спустя IBM начала работу над новым языком для систем управления реляционными базами данных, основанным на выводах Кодда. Первоначально этот язык назывался SEQUEL, или язык структурированных английских запросов. Названный System R, проект претерпел несколько реализаций и изменений, и название языка менялось несколько раз, прежде чем окончательно перейти на SQL.
После начала тестирования в 1978 году IBM приступила к разработке коммерческих продуктов, включая SQL / DS (1981) и DB2 (1983). Другие производители последовали их примеру, объявив о своих коммерческих предложениях на основе SQL. К ним относятся Oracle, выпустившая свой первый продукт в 1979 году, а также Sybase и Ingres.
SQL в действии: MySQL
Обычное программное обеспечение, используемое для серверов SQL, включает MySQL Oracle, возможно, самую популярную программу для управления базами данных SQL. MySQL — это программное обеспечение с открытым исходным кодом, что означает, что его можно использовать бесплатно, и он важен для веб-разработчиков, потому что большая часть Интернета и очень много приложений построены на базах данных.
Рассмотрим музыкальную программу, такую как iTunes, которая хранит музыку по исполнителям, песням, альбомам, спискам воспроизведения и т. Д. Как пользователь, вы можете искать музыку по любому из этих и других параметров, чтобы найти то, что ищете. Чтобы создать подобное приложение, вам понадобится программное обеспечение для управления вашей базой данных SQL, и это то, что делает MySQL.
Требуемые навыки SQL
Большинству организаций нужен кто-то со знанием SQL. Заработная плата на должностях, основанных на SQL, варьируется в зависимости от типа работы и опыта, но обычно выше среднего.
Некоторые должности, требующие навыков SQL, включают:
- Администратор базы данных (DBA ): это тот, кто специализируется на обеспечении правильного и эффективного хранения и управления данными. Базы данных наиболее ценны, когда они позволяют пользователям быстро и легко извлекать желаемые комбинации данных.
- Инженер по миграции баз данных : Этот человек специализируется на перемещении данных из различных баз данных на сервер SQL.
- Специалист по анализу данных : Эта должность очень похожа на должность аналитика данных, но специалистам по обработке данных обычно поручено обрабатывать данные в гораздо больших объемах и накапливать их с гораздо большей скоростью.
- Архитектор больших данных : Кто-то в этой роли создает продукты для обработки больших объемов данных.
Ключевые выводы
- Язык структурированных запросов (SQL) — стандартный и наиболее широко используемый язык программирования для реляционных баз данных.
- Он используется для управления и организации данных во всех видах систем, в которых существуют различные отношения данных.
- SQL — ценный язык программирования с хорошими карьерными перспективами.
SQL Basics — практическое руководство по SQL для начинающих Анализируя совместное использование велосипедов
В этом руководстве мы будем работать с набором данных из службы проката велосипедов Hubway, который включает данные о более чем 1,5 миллионах поездок, совершенных с помощью этой службы.
Прежде чем приступить к написанию некоторых собственных запросов на SQL, мы начнем с небольшого изучения баз данных, того, что они такое и почему мы их используем.
Если вы хотите продолжить, вы можете скачать hubway .db здесь (130 МБ).
Основы SQL: реляционные базы данных
Реляционная база данных — это база данных, которая хранит связанную информацию в нескольких таблицах и позволяет запрашивать информацию в нескольких таблицах одновременно.
Проще понять, как это работает, на примере. Представьте, что вы работаете в бизнесе и хотите отслеживать информацию о продажах. Вы можете настроить электронную таблицу в Excel со всей информацией, которую вы хотите отслеживать, в виде отдельных столбцов: номер заказа, дата, сумма к оплате, номер для отслеживания отгрузки, имя клиента, адрес клиента и номер телефона клиента.
Эта установка отлично подойдет для отслеживания информации, которая вам нужна для начала, но когда вы начнете получать повторные заказы от одного и того же клиента, вы обнаружите, что их имя, адрес и номер телефона хранятся в нескольких строках вашей электронной таблицы.
По мере роста вашего бизнеса и увеличения количества отслеживаемых заказов эти избыточные данные будут занимать ненужное место и в целом снизят эффективность вашей системы отслеживания продаж. Вы также можете столкнуться с проблемами с целостностью данных.Например, нет гарантии, что каждое поле будет заполнено правильным типом данных или что имя и адрес будут вводиться каждый раз точно так же.
С реляционной базой данных, подобной той, что показана на диаграмме выше, вы избегаете всех этих проблем. Вы можете настроить две таблицы, одну для заказов и одну для клиентов. Таблица «клиенты» будет включать уникальный идентификационный номер для каждого клиента, а также имя, адрес и номер телефона, которые мы уже отслеживаем.Таблица «заказы» будет включать номер вашего заказа, дату, сумму к оплате, номер отслеживания и вместо отдельного поля для каждого элемента данных о клиенте будет иметь столбец для идентификатора клиента.
Это позволяет нам запрашивать всю информацию о клиенте для любого конкретного заказа, но нам нужно сохранить ее в нашей базе данных только один раз, а не выводить ее повторно для каждого отдельного заказа.
Наш набор данных
Начнем с рассмотрения нашей базы данных. В базе есть две таблицы, поездок и станций .Для начала просто посмотрим на таблицу поездок и . Он содержит следующие столбцы:
-
id— Уникальное целое число, которое служит ссылкой для каждой поездки -
duration— Продолжительность поездки в секундах -
start_date— Дата и время начала поездки -
start_station— Целое число, соответствующее столбцуidв таблицеstationдля станции, с которой началось путешествие с . -
end_date— Дата и время окончания поездки -
end_station— ‘id’ станции, на которой завершилась поездка -
bike_number— Уникальный идентификатор Hubway для велосипеда, использованного в поездке -
sub_type— Тип подписки пользователя.«Зарегистрированный»для пользователей с членством,«Обычный»для пользователей без членства -
zip_code— Почтовый индекс пользователя (доступен только для зарегистрированных пользователей) -
Birth_date— Год рождения пользователя (доступно только для зарегистрированных участников) -
пол— Пол пользователя (доступно только для зарегистрированных пользователей)
Наш анализ
С этой информацией и командами SQL, которые мы вскоре узнаем, вот несколько вопросов, на которые мы попытаемся ответить в ходе этого поста:
- Какова была самая длинная поездка?
- Сколько поездок совершили «зарегистрированные» пользователи?
- Какая была средняя продолжительность поездки?
- Бывают ли более длительные поездки зарегистрированные или случайные пользователи?
- Какой велосипед использовался для большинства поездок?
- Какова средняя продолжительность поездок пользователей старше 30 лет?
Для ответа на эти вопросы мы будем использовать следующие команды SQL:
-
ВЫБРАТЬ -
ГДЕ -
ПРЕДЕЛ -
ЗАКАЗАТЬ В -
ГРУППА ПО -
И -
ИЛИ -
МИН -
МАКС -
СРЕДНЕЕ -
СУММ -
СЧЕТ
Установка и настройка
Для целей этого руководства мы будем использовать систему баз данных под названием SQLite3.SQLite входит в состав Python начиная с версии 2.5, поэтому, если у вас установлен Python, у вас почти наверняка будет SQLite. Python и библиотеку SQLite3 можно легко установить и настроить с помощью Anaconda, если у вас их еще нет.
Использование Python для запуска нашего кода SQL позволяет нам импортировать результаты в фреймворк Pandas, чтобы упростить отображение наших результатов в удобном для чтения формате. Это также означает, что мы можем выполнять дальнейший анализ и визуализацию данных, которые мы извлекаем из базы данных, хотя это выходит за рамки данного руководства.
В качестве альтернативы, если мы не хотим использовать или устанавливать Python, мы можем запустить SQLite3 из командной строки. Просто загрузите «предварительно скомпилированные двоичные файлы» с веб-страницы SQLite3 и используйте следующий код для открытия базы данных:
~ $ sqlite hubway.db Версия SQLite 3.14.0 2016-07-26 15: 17: 14 Введите ".help" для использования hints.sqlite> Отсюда мы можем просто ввести запрос, который хотим запустить, и мы увидим данные, возвращенные в окне нашего терминала.
Альтернативой использованию терминала является подключение к базе данных SQLite через Python.Это позволит нам использовать записную книжку Jupyter, чтобы мы могли видеть результаты наших запросов в аккуратно отформатированной таблице.
Для этого мы определим функцию, которая принимает наш запрос (сохраненный в виде строки) в качестве входных данных и отображает результат в виде отформатированного фрейма данных:
импорт sqlite3
импортировать панд как pd
db = sqlite3.connect ('hubway.db')
def run_query (запрос):
вернуть pd.read_sql_query (запрос, БД) Конечно, нам не обязательно использовать Python с SQL. Если вы уже являетесь программистом R, наш курс «Основы SQL для пользователей R» будет отличным местом для начала.ВЫБРАТЬ
Первая команда, с которой мы будем работать, — это SELECT . SELECT будет основой почти каждого написанного нами запроса — он сообщает базе данных, какие столбцы мы хотим видеть. Мы можем указать столбцы по имени (через запятую) или использовать подстановочный знак * для возврата каждого столбца в таблице.
Помимо столбцов, которые мы хотим получить, мы также должны указать базе данных, из какой таблицы их получить. Для этого мы используем ключевое слово FROM , за которым следует имя таблицы.Например, если мы хотим видеть start_date и bike_number для каждой поездки в таблице trips , мы могли бы использовать следующий запрос:
ВЫБРАТЬ start_date, bike_number ИЗ поездок; В этом примере мы начали с команды SELECT , чтобы база данных знала, что мы хотим, чтобы она нашла нам некоторые данные. Затем мы сообщили базе данных, что нас интересуют столбцы start_date и bike_number .Наконец, мы использовали FROM , чтобы сообщить базе данных, что столбцы, которые мы хотим видеть, являются частью таблицы trips .
Одна важная вещь, о которой следует помнить при написании SQL-запросов, заключается в том, что мы хотим заканчивать каждый запрос точкой с запятой (; ). Не каждая база данных SQL на самом деле требует этого, но некоторые требуют, поэтому лучше сформировать эту привычку.
ПРЕДЕЛ
Следующая команда, которую нам нужно знать, прежде чем мы начнем выполнять запросы в нашей базе данных Hubway, — это LIMIT . LIMIT просто сообщает базе данных, сколько строк вы хотите вернуть.
Запрос SELECT , который мы рассмотрели в предыдущем разделе, будет возвращать запрошенную информацию для каждой строки в таблице поездок , но иногда это может означать большой объем данных. Мы можем не захотеть всего этого. Если бы вместо этого мы хотели видеть start_date и bike_number для первых пяти поездок в базе данных, мы могли бы добавить LIMIT к нашему запросу следующим образом:
ВЫБРАТЬ start_date, bike_number ИЗ поездок LIMIT 5; Мы просто добавили команду LIMIT , а затем число, представляющее количество строк, которые мы хотим вернуть.В этом случае мы использовали 5, но вы можете заменить его любым числом, чтобы получить соответствующий объем данных для проекта, над которым вы работаете.
Мы будем часто использовать LIMIT в наших запросах к базе данных Hubway в этом руководстве — таблица поездок содержит более 1,5 миллионов строк данных, и нам, конечно, не нужно отображать их все!
Давайте запустим наш первый запрос к базе данных Hubway. Сначала мы сохраним наш запрос в виде строки, а затем воспользуемся функцией, которую мы определили ранее, чтобы запустить его в базе данных.Взгляните на следующий пример:
query = 'ВЫБРАТЬ * ИЗ ОТКЛЮЧЕНИЯ ОГРАНИЧЕНИЯ 5;'
run_query (запрос) | id | продолжительность | start_date | start_station | end_date | конечная станция | номер велосипеда | подтип | почтовый индекс | дата рождения | пол | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 9 | 28.07.2011 10:12:00 | 23 | 28.07.2011 10:12:00 | 23 | B00468 | Зарегистрировано | ‘97217 | 1976 г.0 | Мужской |
| 1 | 2 | 220 | 28.07.2011 10:21:00 | 23 | 28.07.2011 10:25:00 | 23 | B00554 | Зарегистрировано | ‘02215 | 1966,0 | Мужской |
| 2 | 3 | 56 | 28.07.2011 10:33:00 | 23 | 28.07.2011 10:34:00 | 23 | B00456 | Зарегистрировано | ‘02108 | 1943 г.0 | Мужской |
| 3 | 4 | 64 | 28.07.2011 10:35:00 | 23 | 28.07.2011 10:36:00 | 23 | B00554 | Зарегистрировано | ‘02116 | 1981,0 | Женский |
| 4 | 5 | 12 | 28.07.2011 10:37:00 | 23 | 28.07.2011 10:37:00 | 23 | B00554 | Зарегистрировано | ‘97214 | 1983.0 | Женский |
В этом запросе * используется как подстановочный знак вместо указания возвращаемых столбцов. Это означает, что команда SELECT дала нам каждый столбец в таблице trip . Мы также использовали функцию LIMIT , чтобы ограничить вывод первыми пятью строками таблицы.
Вы часто будете видеть, что люди используют ключевые слова команды в своих запросах (соглашение, которому мы будем следовать в этом руководстве), но это в основном вопрос предпочтений.Использование заглавных букв упрощает чтение кода, но на самом деле никоим образом не влияет на работу кода. Если вы предпочитаете писать запросы с командами в нижнем регистре, запросы по-прежнему будут выполняться правильно.
В нашем предыдущем примере возвращены все столбцы в таблице поездок . Если бы нас интересовали только столбцы продолжительности и start_date , мы могли бы заменить подстановочный знак именами столбцов следующим образом:
query = 'ВЫБЕРИТЕ длительность, начальную_дату ИЗ ПРЕДЕЛ 5 отключений'
run_query (запрос) | продолжительность | start_date | |
|---|---|---|
| 0 | 9 | 28.07.2011 10:12:00 |
| 1 | 220 | 28.07.2011 10:21:00 |
| 2 | 56 | 28.07.2011 10:33:00 |
| 3 | 64 | 28.07.2011 10:35:00 |
| 4 | 12 | 28.07.2011 10:37:00 |
ЗАКАЗАТЬ В
Последняя команда, которую нам нужно знать, прежде чем мы сможем ответить на первый из наших вопросов, — это ORDER BY .Эта команда позволяет нам отсортировать базу данных по заданному столбцу.
Чтобы использовать его, мы просто указываем имя столбца, по которому хотим выполнить сортировку. По умолчанию ORDER BY сортируется по возрастанию. Если мы хотим указать, в каком порядке база данных должна быть отсортирована, мы можем добавить ключевое слово ASC для возрастания или DESC для убывания.
Например, если мы хотим отсортировать таблицу поездок от самой короткой продолжительности до самой длинной, мы могли бы добавить в наш запрос следующую строку:
ЗАКАЗАТЬ ПО продолжительности ASC С помощью команд SELECT , LIMIT, и ORDER BY в нашем репертуаре мы можем теперь попытаться ответить на наш первый вопрос: Какова была продолжительность самой продолжительной поездки?
Чтобы ответить на этот вопрос, полезно разбить его на разделы и определить, какие команды нам понадобятся для решения каждой части.
Сначала нам нужно извлечь информацию из столбца длительности таблицы поездок . Затем, чтобы определить, какая поездка самая длинная, мы можем отсортировать столбец продолжительность в порядке убывания. Вот как мы можем проработать это, чтобы придумать запрос, который получит информацию, которую мы ищем:
- Используйте
SELECTдля получения продолжительностиИЗотключает - Используйте
ORDER BYдля сортировки столбцапродолжительностии используйте ключевое словоDESC, чтобы указать, что вы хотите отсортировать в порядке убывания - Используйте
LIMIT, чтобы ограничить вывод одной строкой
Использование этих команд таким образом вернет единственную строку с самой длинной продолжительностью, которая даст нам ответ на наш вопрос.
Еще одно замечание — по мере того, как ваши запросы добавляют больше команд и усложняются, вам может быть легче читать, если вы разделите их на несколько строк. Это, как и использование заглавных букв, зависит от личных предпочтений. Это не влияет на выполнение кода (система просто считывает код от начала до точки с запятой), но может сделать ваши запросы более понятными и понятными. В Python мы можем разделить строку на несколько строк, используя тройные кавычки.
Давайте продолжим и запустим этот запрос и выясним, как долго длилась самая длинная поездка.
запрос = '' '
ВЫБРАТЬ ДЛИТЕЛЬНОСТЬ ИЗ поездок
ЗАКАЗАТЬ ПО длительности DESC
LIMIT 1;
'' '
run_query (запрос) Теперь мы знаем, что самая длинная поездка длилась 9999 секунд, или чуть более 166 минут. Однако при максимальном значении 9999 мы не знаем, действительно ли это длина самой длинной поездки или база данных была настроена только для четырехзначного числа.
Если это правда, что база данных сокращает особенно длинные поездки, то мы можем ожидать увидеть много поездок на 9999 секундах, где они достигают предела.Давайте попробуем выполнить тот же запрос, что и раньше, но скорректируем LIMIT , чтобы вернуть 10 самых высоких значений длительности, чтобы проверить, так ли это:
запрос = '' '
ВЫБЕРИТЕ ДЛИТЕЛЬНОСТЬ ОТ поездок
ЗАКАЗАТЬ ПО длительности DESC
ПРЕДЕЛ 10
'' '
run_query (запрос) | продолжительность | |
|---|---|
| 0 | 9999 |
| 1 | 9998 |
| 2 | 9998 |
| 3 | 9997 |
| 4 | 9996 |
| 5 | 9996 |
| 6 | 9995 |
| 7 | 9995 |
| 8 | 9994 |
| 9 | 9994 |
Что мы видим здесь, так это то, что на 9999 не так много поездок, поэтому не похоже, что мы сокращаем верхний предел нашей продолжительности, но все же трудно сказать, является ли это реальная длина поездка или просто максимально допустимое значение.
Hubway взимает дополнительную плату за поездки продолжительностью более 30 минут (кто-то, кто держит велосипед в течение 9999 секунд, должен будет заплатить дополнительные 25 долларов США), поэтому вполне вероятно, что они решили, что 4 цифры будет достаточно для отслеживания большинства поездок.
ГДЕ
Предыдущие команды отлично подходят для извлечения отсортированной информации для определенных столбцов, но что, если есть определенное подмножество данных, которые мы хотим просмотреть? Вот где приходит WHERE . Команда WHERE позволяет нам использовать логический оператор, чтобы указать, какие строки должны быть возвращены.Например, вы можете использовать следующую команду, чтобы отображать информацию о каждой поездке на велосипеде B00400 :
ГДЕ bike_number = "B00400" Вы также заметите, что в этом запросе используются кавычки. Это потому, что bike_number хранится в виде строки. Если столбец содержит числовые типы данных, в кавычках нет необходимости.
Давайте напишем запрос, который использует WHERE для возврата каждого столбца в таблице поездок для каждой строки с продолжительностью дольше 9990 секунд:
запрос = '' '
ВЫБРАТЬ * ИЗ поездок
ГДЕ длительность> 9990;
'' '
run_query (запрос) | id | продолжительность | start_date | start_station | end_date | конечная станция | номер велосипеда | подтип | почтовый индекс | дата рождения | пол | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 4768 | 9994 | 2011-08-03 17:16:00 | 22 | 2011-08-03 20:03:00 | 24 | B00002 | Повседневный | |||
| 1 | 8448 | 9991 | 2011-08-06 13:02:00 | 52 | 2011-08-06 15:48:00 | 24 | B00174 | Повседневный | |||
| 2 | 11341 | 9998 | 2011-08-09 10:42:00 | 40 | 2011-08-09 13:29:00 | 42 | B00513 | Повседневный | |||
| 3 | 24455 | 9995 | 2011-08-20 12:20:00 | 52 | 2011-08-20 15:07:00 | 17 | B00552 | Повседневный | |||
| 4 | 55771 | 9994 | 14.09.2011 15:44:00 | 40 | 14.09.2011 18:30:00 | 40 | B00139 | Повседневный | |||
| 5 | 81191 | 9993 | 2011-10-03 11:30:00 | 22 | 2011-10-03 14:16:00 | 36 | B00474 | Повседневный | |||
| 6 | 89335 | 9997 | 2011-10-09 02:30:00 | 60 | 2011-10-09 05:17:00 | 45 | B00047 | Повседневный | |||
| 7 | 124500 | 9992 | 2011-11-09 09:08:00 | 22 | 2011-11-09 11:55:00 | 40 | B00387 | Повседневный | |||
| 8 | 133967 | 9996 | 2011-11-19 13:48:00 | 4 | 2011-11-19 16:35:00 | 58 | B00238 | Повседневный | |||
| 9 | 147451 | 9996 | 23.03.2012 14:48:00 | 35 | 23.03.2012 17:35:00 | 33 | B00550 | Повседневный | |||
| 10 | 315737 | 9995 | 2012-07-03 18:28:00 | 12 | 2012-07-03 21:15:00 | 12 | B00250 | Зарегистрировано | ‘02120 | 1964 | Мужской |
| 11 | 319597 | 9994 | 05.07.2012 11:49:00 | 52 | 2012-07-05 14:35:00 | 55 | B00237 | Повседневный | |||
| 12 | 416523 | 9998 | 2012-08-15 12:11:00 | 54 | 2012-08-15 14:58:00 | 80 | B00188 | Повседневный | |||
| 13 | 541247 | 9999 | 26.09.2012 18:34:00 | 54 | 26.09.2012 21:21:00 | 54 | T01078 | Повседневный |
Как мы видим, этот запрос вернул 14 различных поездок, каждая длительностью 9990 секунд или более.Что выделяется в этом запросе, так это то, что все результаты, кроме одного, имеют sub_type из "Casual" . Возможно, это показатель того, что «зарегистрированных» пользователей больше осведомлены о дополнительных сборах за дальние поездки. Возможно, Hubway сможет лучше донести свою структуру ценообразования до обычных пользователей, чтобы помочь им избежать дополнительных расходов.
Мы уже видим, как команда SQL даже для начинающих может помочь нам ответить на бизнес-вопросы и найти понимание в наших данных.
Возвращаясь к WHERE , мы также можем объединить несколько логических тестов в нашем предложении WHERE , используя AND или OR . Если, например, в нашем предыдущем запросе мы хотели вернуть только поездки с длительностью за 9990 секунд, которые также имели подтип Зарегистрировано, мы могли бы использовать И , чтобы указать оба условия.
Вот еще одна личная рекомендация по выбору: используйте круглые скобки для разделения каждого логического теста, как показано в блоке кода ниже.Это не является строго обязательным для работы кода, но круглые скобки упрощают понимание ваших запросов по мере увеличения сложности.
Теперь давайте запустим этот запрос. Мы уже знаем, что он должен возвращать только один результат, поэтому будет легко убедиться, что мы все правильно поняли:
запрос = '' '
ВЫБРАТЬ * ИЗ поездок
ГДЕ (продолжительность> = 9990) И (sub_type = "Зарегистрировано")
ЗАКАЗАТЬ ПО длительности DESC;
'' '
run_query (запрос) | id | продолжительность | start_date | start_station | end_date | конечная станция | номер велосипеда | подтип | почтовый индекс | дата рождения | пол | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 315737 | 9995 | 2012-07-03 18:28:00 | 12 | 2012-07-03 21:15:00 | 12 | B00250 | Зарегистрировано | ‘02120 | 1964 г.0 | Мужской |
Следующий вопрос, который мы задали в начале поста, — «Сколько поездок совершили« зарегистрированные »пользователи?» Чтобы ответить на него, мы могли бы выполнить тот же запрос, что и выше, и изменить выражение WHERE , чтобы вернуть все строки, в которых подтип равен «Зарегистрировано» , а затем подсчитать их.
Однако на самом деле в SQL есть встроенная команда для этого подсчета: COUNT .
COUNT позволяет перенести вычисления в базу данных и избавить нас от необходимости писать дополнительные скрипты для подсчета результатов. Чтобы использовать его, мы просто включаем COUNT (column_name) вместо (или в дополнение к) столбцов, которые вы хотите SELECT , например:
ВЫБРАТЬ СЧЕТЧИК (id)
ИЗ поездок В этом случае не имеет значения, какой столбец мы выбираем для подсчета, потому что каждый столбец должен содержать данные для каждой строки в нашем запросе.Но иногда в запросе могут отсутствовать (или быть «нулевые») значения для некоторых строк. Если мы не уверены, содержит ли столбец нулевые значения, мы можем запустить наш COUNT для столбца id — столбец id никогда не будет нулевым, поэтому мы можем быть уверены, что наш счетчик ничего не пропустил.
Мы также можем использовать COUNT (1) или COUNT (*) для подсчета каждой строки в нашем запросе. Стоит отметить, что иногда нам может потребоваться запустить COUNT для столбца с нулевыми значениями.Например, нам может потребоваться узнать, сколько строк в нашей базе данных имеют отсутствующие значения для столбца.
Давайте взглянем на запрос, чтобы ответить на наш вопрос. Мы можем использовать SELECT COUNT (*) для подсчета общего количества возвращенных строк и WHERE sub_type = "Registered" , чтобы убедиться, что мы подсчитываем только поездки, совершенные зарегистрированными пользователями.
запрос = '' '
ВЫБРАТЬ КОЛИЧЕСТВО (*) ИЗ поездок
ГДЕ sub_type = "Зарегистрировано";
'' '
run_query (запрос) Этот запрос сработал и вернул ответ на наш вопрос.Но заголовок столбца не особо описательный. Если бы кто-то еще взглянул на эту таблицу, он не смог бы понять, что это значит. Если мы хотим сделать наши результаты более читабельными, мы можем использовать AS , чтобы дать нашему выводу псевдоним (или псевдоним). Давайте повторно запустим предыдущий запрос, но дадим заголовку нашего столбца псевдоним Всего поездок по зарегистрированным пользователям :
запрос = '' '
ВЫБЕРИТЕ СЧЕТЧИК (*) КАК "Общее количество поездок зарегистрированных пользователей"
ИЗ поездок
ГДЕ sub_type = "Зарегистрировано";
'' '
run_query (запрос) | Всего поездок по зарегистрированным пользователям | |
|---|---|
| 0 | 1105192 |
Агрегатные функции
COUNT — не единственный математический трюк, который есть у SQL.Мы также можем использовать SUM , AVG , MIN и MAX для возврата суммы, среднего, минимума и максимума столбца соответственно. Они, наряду с COUNT , известны как агрегатные функции.
Итак, чтобы ответить на наш третий вопрос, «Какова была средняя продолжительность поездки?» , мы можем использовать функцию AVG в столбце duration (и, опять же, использовать AS , чтобы дать нашему выходному столбцу более информативное имя):
запрос = '' '
ВЫБЕРИТЕ СРЕДНЮЮ (продолжительность) КАК "Средняя продолжительность"
ОТ поездок;
'' '
run_query (запрос) | Средняя продолжительность | |
|---|---|
| 0 | 912.409682 |
Получается, что средняя продолжительность поездки составляет 912 секунд, то есть примерно 15 минут. В этом есть смысл, поскольку мы знаем, что Hubway взимает дополнительную плату за поездки продолжительностью более 30 минут. Услуга предназначена для любителей коротких поездок в одну сторону.
Что насчет нашего следующего вопроса: зарегистрированные или случайные пользователи совершают более длительные поездки? Мы уже знаем один способ ответить на этот вопрос — мы могли бы запустить два запроса SELECT AVG (duration) FROM trip с предложениями WHERE , которые ограничивают один до «зарегистрированных» и один до «случайных» пользователей.
Но давайте сделаем по-другому. SQL также включает способ ответить на этот вопрос в одном запросе с помощью команды GROUP BY .
ГРУППА ПО
GROUP BY разделяет строки на группы в зависимости от содержимого определенного столбца и позволяет нам выполнять агрегированные функции для каждой группы.
Чтобы лучше понять, как это работает, давайте взглянем на столбец , пол . Каждая строка может иметь одно из трех возможных значений в столбце пол , «Мужской» , «Женский» или Нулевой (отсутствует; у нас нет данных , пол для случайных пользователей).
Когда мы используем GROUP BY , база данных будет разделять каждую из строк в другую группу на основе значения в столбце , пол , почти так же, как мы могли бы разделить колоду карт на разные масти. . Мы можем представить себе две стопки, одну из самцов, одну из самок.
Когда у нас есть две отдельные стопки, база данных будет выполнять любые агрегатные функции в нашем запросе для каждой из них по очереди. Если бы мы использовали, например, COUNT , запрос подсчитал бы количество строк в каждой стопке и вернул бы значение для каждой отдельно.
Давайте подробно рассмотрим, как написать запрос, чтобы ответить на наш вопрос о том, совершают ли более длительные поездки зарегистрированные или случайные пользователи.
- Как и каждый из наших запросов до сих пор, мы начнем с
SELECT, чтобы сообщить базе данных, какую информацию мы хотим видеть. В этом случае нам нужныsub_typeиAVG (продолжительность). - Мы также включим
GROUP BY sub_type, чтобы разделить наши данные по типу подписки и отдельно рассчитать средние значения зарегистрированных и случайных пользователей.
Вот как выглядит код, если собрать все вместе:
запрос = '' '
ВЫБЕРИТЕ sub_type, AVG (продолжительность) AS "Средняя продолжительность"
ИЗ поездок
GROUP BY sub_type;
'' '
run_query (запрос) | подтип | Средняя продолжительность | |
|---|---|---|
| 0 | Повседневный | 1519.643897 |
| 1 | Зарегистрировано | 657.026067 |
Вот это большая разница! В среднем зарегистрированные пользователи совершают поездки продолжительностью около 11 минут, тогда как обычные пользователи тратят почти 25 минут на поездку.Зарегистрированные пользователи, вероятно, будут совершать более короткие и частые поездки, возможно, по дороге на работу. С другой стороны, обычные пользователи тратят примерно вдвое больше времени на поездку.
Возможно, что случайные пользователи, как правило, происходят из демографических групп (например, туристов), которые более склонны совершать длительные поездки, убедитесь, что они передвигаются и видят все достопримечательности. Как только мы обнаружим эту разницу в данных, компания сможет исследовать ее разными способами, чтобы лучше понять, что ее вызывает.
Однако для целей этого урока давайте продолжим. Наш следующий вопрос был , какой велосипед использовался для большинства поездок? . Мы можем ответить на этот вопрос, используя очень похожий запрос. Взгляните на следующий пример и посмотрите, сможете ли вы выяснить, что делает каждая строка — позже мы рассмотрим это шаг за шагом, чтобы вы могли убедиться, что все правильно:
запрос = '' '
ВЫБЕРИТЕ bike_number как "Номер велосипеда", COUNT (*) как "Количество поездок"
ИЗ поездок
ГРУППА ПО номеру велосипеда
ЗАКАЗАТЬ ПО КОЛИЧЕСТВУ (*) УДАЛ.
LIMIT 1;
'' '
run_query (запрос) | Номер велосипеда | Количество поездок | |
|---|---|---|
| 0 | B00490 | 2120 |
Как видно из выходных данных, наибольшее количество поездок ездил на велосипеде B00490 .Давайте разберемся, как мы туда попали:
- Первая строка — это предложение
SELECT, чтобы сообщить базе данных, что мы хотим видеть столбецbike_numberи количество каждой строки. Он также используетAS, чтобы указать базе данных отображать каждый столбец с более удобным именем. - Во второй строке используется
ИЗ, чтобы указать, что данные, которые мы ищем, находятся в таблицепоездок. - В третьей строке начинаются сложности.Мы используем
GROUP BY, чтобы указать функцииCOUNTв строке 1 для отдельного подсчета каждого значения дляbike_number. - В четвертой строке у нас есть предложение
ORDER BY, чтобы отсортировать таблицу в порядке убывания и убедиться, что наш наиболее часто используемый велосипед находится наверху. - Наконец, мы используем
LIMIT, чтобы ограничить вывод первой строкой, которая, как мы знаем, будет велосипедом, который использовался в наибольшем количестве поездок, из-за того, как мы отсортировали данные в четвертой строке.
Арифметические операторы
Наш последний вопрос немного сложнее остальных. Мы хотим знать, что средняя продолжительность поездок зарегистрированных пользователей в возрасте от 30 до .
Мы могли бы просто вычислить год, в котором 30-летние родились в наших головах, а затем подключить его, но более элегантное решение — использовать арифметические операции непосредственно в нашем запросе. SQL позволяет нам использовать + , - , * и / для выполнения арифметической операции сразу над всем столбцом.
запрос = '' '
ВЫБРАТЬ СРЕДНЕЕ (длительность) ИЗ поездок
ГДЕ (2017 - дата рождения)> 30;
'' '
run_query (запрос) | AVG (продолжительность) | |
|---|---|
| 0 | 923.014685 |
ПРИСОЕДИНЯЙТЕСЬ
До сих пор мы рассматривали запросы, которые извлекают данные только из таблицы , отключающей . Однако одна из причин, по которой SQL является настолько мощным, заключается в том, что он позволяет нам извлекать данные из нескольких таблиц в одном запросе.
Наша база данных по прокату велосипедов содержит вторую таблицу, станций . Таблица станций содержит информацию о каждой станции в сети Hubway и включает столбец id , на который ссылается таблица поездок .
Прежде чем мы начнем работать с некоторыми реальными примерами из этой базы данных, давайте вернемся к гипотетической базе данных отслеживания заказов, представленной ранее. В этой базе данных у нас было две таблицы: заказов и клиентов , и они были связаны столбцом customer_id .
Допустим, мы хотели написать запрос, который возвращал бы номер заказа и имя для каждого заказа в базе данных. Если бы они оба хранились в одной таблице, мы могли бы использовать следующий запрос:
ВЫБРАТЬ номер_заказа, имя
ОТ заказов; К сожалению, столбец order_number и столбец name хранятся в двух разных таблицах, поэтому нам нужно добавить несколько дополнительных шагов. Давайте поразмышляем над дополнительными вещами, которые должна знать база данных, прежде чем она сможет вернуть нужную нам информацию:
- В какой таблице находится столбец
order_number? - В какой таблице находится столбец
name? - Как информация в таблице
ordersсвязана с информацией в таблицеcustomers?
Чтобы ответить на первые два из этих вопросов, мы можем включить имена таблиц для каждого столбца в нашу команду SELECT .Мы делаем это просто, записывая имя таблицы и имя столбца, разделенные . . Например, вместо SELECT order_number, name мы должны написать SELECT orders.order_number, customers.name . Добавление сюда имен таблиц помогает базе данных находить нужные столбцы, сообщая ей, в какой таблице искать каждый.
Чтобы сообщить базе данных, как связаны таблицы заказов и клиентов , мы используем JOIN и ON . JOIN указывает, какие таблицы должны быть связаны, а ON указывает, какие столбцы в каждой таблице связаны.
Мы собираемся использовать внутреннее соединение, что означает, что строки будут возвращаться только тогда, когда есть совпадения в столбцах, указанных в ON . В этом примере мы захотим использовать JOIN для той таблицы, которую мы не включили в команду FROM . Таким образом, мы можем использовать FROM заказов INNER JOIN клиентов или FROM клиентов INNER JOIN orders .
Как мы обсуждали ранее, эти таблицы связаны по столбцу customer_id в каждой таблице. Следовательно, мы захотим использовать ON , чтобы сообщить базе данных, что эти два столбца относятся к одному и тому же, например:
ON orders.customer_ID = customers.customer_id Мы снова используем . , чтобы убедиться, что база данных знает, в какой таблице находится каждый из этих столбцов. Итак, когда мы сложим все это вместе, мы получим запрос, который выглядит следующим образом:
ВЫБРАТЬ заказы.order_number, customers.name
ИЗ заказов
INNER JOIN клиенты
ON orders.customer_id = customers.customer_id Этот запрос вернет порядковый номер каждого заказа в базе данных вместе с именем клиента, который связан с каждым заказом.
Возвращаясь к нашей базе данных Hubway, теперь мы можем написать несколько запросов, чтобы увидеть JOIN в действии.
Прежде чем мы начнем, мы должны взглянуть на остальные столбцы в таблице станций . Вот запрос, показывающий нам первые 5 строк, чтобы мы могли увидеть, как выглядит таблица станций :
запрос = '' '
ВЫБРАТЬ * ИЗ станций
LIMIT 5;
'' '
run_query (запрос) | id | станция | муниципалитет | шир. | lng | |
|---|---|---|---|---|---|
| 0 | 3 | Колледжи Фенуэй | Бостон | 42.340021 | -71.100812 |
| 1 | 4 | Тремонт-стрит, Беркли-стрит, | Бостон | 42.345392 | -71.069616 |
| 2 | 5 | Северо-Восточный U / Северная парковка | Бостон | 42,34 1814 | -71.0 |
| 3 | 6 | Кембридж-стрит, Джой-стрит, | Бостон | 42,361284999999995 | -71.06514 |
| 4 | 7 | Пирс вентилятора | Бостон | 42,35 3412 | -71.044624 |
-
id— Уникальный идентификатор для каждой станции (соответствует столбцамstart_stationиend_stationв таблицепоездок) -
станция— Название станции -
муниципалитет— муниципалитет, в котором находится станция (Бостон, Бруклин, Кембридж или Сомервилль) -
lat— Широта станции -
lng— Долгота станции - Какие станции чаще всего используются для поездок туда и обратно?
- Сколько поездок начинается и заканчивается в разных муниципалитетах?
Как и раньше, мы попытаемся ответить на некоторые вопросы в данных, начиная с , какая станция является наиболее частой отправной точкой? Давайте поработаем пошагово:
- Сначала мы хотим использовать
SELECTдля возврата столбцаstationиз таблицыstationиCOUNTколичества строк. - Затем мы указываем таблицы, которые хотим
JOIN, и говорим базе данных подключить ихON, столбецstart_stationв таблицепоездоки столбецidв таблицестанций. - Затем мы переходим к сути нашего запроса — мы
GROUP BYстолбецstationв таблицеstation, чтобы нашCOUNTподсчитывал количество поездок для каждой станции отдельно - Наконец, мы можем
ЗАКАЗАТЬ ПОнашимCOUNTиLIMITвывод на управляемое количество результатов
запрос = '' '
ВЫБЕРИТЕ станции.станция AS "Станция", COUNT (*) AS "Count"
ИЗ поездок INNER JOIN станции
ВКЛ. Trips.start_station = station.idGROUP BY station.station ORDER BY COUNT (*) DESC
LIMIT 5;
'' '
run_query (запрос) | Станция | Счетчик | |
|---|---|---|
| 0 | Южный вокзал — 700 Атлантик авеню, | 56123 |
| 1 | Публичная библиотека Бостона — 700 Boylston St. | 41994 |
| 2 | Charles Circle — Charles St.на Кембридж-стрит | 35984 |
| 3 | Beacon St / Mass Ave | 35275 |
| 4 | MIT на Mass Ave / Amherst St | 33644 |
Если вы знакомы с Бостоном, вы поймете, почему это самые популярные станции. Южный вокзал — одна из главных станций пригородной железной дороги в городе, Чарльз-стрит проходит вдоль реки рядом с красивыми живописными маршрутами, а улицы Бойлстон и Бикон находятся в самом центре города, рядом с несколькими офисными зданиями.
Следующий вопрос, который мы рассмотрим, — это , какие станции наиболее часто используются для поездок туда и обратно? Мы можем использовать тот же запрос, что и раньше. Мы будем SELECT тех же выходных столбцов и JOIN таблицы таким же образом, но на этот раз мы добавим предложение WHERE , чтобы ограничить наш COUNT поездками, где start_station совпадает с конечная станция .
query = '' 'ВЫБРАТЬ станции. Станция КАК "Станция", СЧЁТ (*) КАК "Счетчик"
ИЗ поездок INNER JOIN станции
ПО поездкам.start_station = station.id
ГДЕ trips.start_station = trips.end_station
ГРУППА ПО станциям. Станции
ЗАКАЗАТЬ ПО КОЛИЧЕСТВУ (*) УДАЛ.
LIMIT 5;
'' '
run_query (запрос) | Станция | Счетчик | |
|---|---|---|
| 0 | Эспланада — Бикон-стрит на Арлингтон-стрит | 3064 |
| 1 | Чарльз Серкл — Чарльз-стрит, Кембридж-стрит, | 2739 |
| 2 | Публичная библиотека Бостона — 700 Boylston St. | 2548 |
| 3 | Бойлстон-стрит на Арлингтон-стрит | 2163 |
| 4 | Beacon St / Mass Ave | 2144 |
Как мы видим, количество этих станций такое же, как и в предыдущем вопросе, но их количество намного меньше. Самые загруженные станции по-прежнему остаются самыми загруженными, но в целом более низкие цифры говорят о том, что люди обычно используют велосипеды Hubway, чтобы добраться из точки A в точку B, а не какое-то время кататься на велосипеде, прежде чем вернуться туда, откуда они начали.
Здесь есть одно существенное отличие — Esplande, которая не была одной из самых загруженных станций по нашему первому запросу, кажется, самая загруженная для поездок туда и обратно. Почему? Что ж, картинка стоит тысячи слов. Это определенно похоже на хорошее место для велосипедной прогулки:
Переходим к следующему вопросу: сколько поездок начинается и заканчивается в разных муниципалитетах? Этот вопрос продвигает дальше. Мы хотим знать, сколько поездок начинается и заканчивается в другом муниципалитете .Чтобы достичь этого, нам нужно JOIN , чтобы дважды переходил от таблицы к таблице станций . После ON столбец start_station , а затем ON столбец end_station .
Для этого мы должны создать псевдоним для таблицы station , чтобы мы могли различать данные, относящиеся к start_station , и данные, относящиеся к end_station . Мы можем сделать это точно так же, как мы создавали псевдонимы для отдельных столбцов, чтобы они отображались с более интуитивно понятным именем, используя AS .
Например, мы можем использовать следующий код для JOIN с таблицей станций и с таблицей trips , используя псевдоним «start». Затем мы можем объединить «начало» с именами наших столбцов, используя . для ссылки на данные, которые поступают из этого конкретного JOIN (вместо второго JOIN мы сделаем ON в столбце end_station ):
INNER JOIN станции AS start ON trips.start_station = start.id Вот как будет выглядеть окончательный запрос, когда мы его запустим. Обратите внимание, что мы использовали <> для обозначения «не равно», но ! = также подойдет.
запрос =
'' '
ВЫБЕРИТЕ СЧЕТЧИК (trips.id) КАК "Счетчик"
ИЗ поездок ВНУТРЕННИЕ СОЕДИНЯЙТЕ станции КАК начало
ВКЛ. Trips.start_station = start.id
INNER JOIN станции как конец
ВКЛ. Trips.end_station = end.id
ГДЕ start.municipality <> end.municipality;
'' '
run_query (запрос) Это показывает, что около 300000 из 1.5 миллионов поездок (или 20%) закончились в другом муниципалитете, чем начали, — еще одно свидетельство того, что люди в основном используют велосипеды Hubway для относительно коротких поездок, а не для длительных поездок между городами.
Если вы зашли так далеко, поздравляем! Вы начали осваивать основы SQL. Мы рассмотрели ряд важных команд, SELECT , LIMIT , WHERE , ORDER BY , GROUP BY и JOIN , а также агрегатные и арифметические функции.Это даст вам прочную основу для дальнейшего развития SQL.
Вы освоили основы SQL. Что теперь?
После завершения этого учебника по SQL для начинающих вы сможете выбрать базу данных, которая вам интересна, и написать запросы для получения информации. Хорошим первым шагом может быть продолжение работы с базой данных Hubway, чтобы посмотреть, что еще вы можете узнать. Вот еще несколько вопросов, на которые вы, возможно, захотите ответить:
- За сколько поездок взимается дополнительная плата (продолжительностью более 30 минут)?
- Какой велосипед использовался дольше всего?
- Были ли у зарегистрированных или случайных пользователей больше поездок туда и обратно?
- У какого муниципалитета была самая длинная средняя продолжительность?
Если вы хотите сделать еще один шаг вперед, ознакомьтесь с нашими интерактивными курсами по SQL, которые охватывают все, что вам нужно знать, от начального уровня до SQL продвинутого уровня для работы аналитиком и специалистом по данным.
Вы также можете прочитать нашу публикацию об экспорте данных из ваших SQL-запросов в Pandas или ознакомьтесь с нашей шпаргалкой по SQL и нашей статьей о сертификации SQL.
Шпаргалка поSQL и синтаксис запросов | Sisense
Блог
SQL — один из самых мощных инструментов аналитика. В SQL Superstar мы даем вам действенные советы, которые помогут вам максимально эффективно использовать этот универсальный язык и создавать красивые и эффективные запросы.
Когда вы новичок в программировании на SQL, вы встретите множество сложных для поиска символьных операторов.Если вы склонны забывать ~ называется тильда , вам интересно, почему в ваших строках так много% s, или вам трудно найти в Google, что означает символ (+) , где users.group_id (+) = group .id, это руководство для вас.
Операторы сравненияВы хорошо знакомы с операторами равенства и неравенства для равно, меньше и больше, чем быть =, <и>, но, возможно, вы не видели все варианты для указания не равно, не меньше и не больше.
Среди унарных операторов + и — есть дополнительный побитовый оператор для определения положительного или отрицательного числа.Побитовое not, ~, инвертирует каждый бит в вашем числе.
| Символ | Эксплуатация |
| + | Положительный |
| — | Отрицательный |
| ~ | Побитовый60 не |
| Символ | Эксплуатация |
| + | Сложение |
| — | Вычитание |
| * | 3 | по модулю |
Некоторые языки SL, например SQL Server, используют = для присваивания, в то время как другие, такие как MySQL и Postgres, используют: =. =
Другой способ манипулировать битами в SQL — использовать арифметический сдвиг бит.Эта операция «перемещает» биты в вашем числе влево или вправо и заполняет новые значения нулями. Битовый сдвиг влево — это простой способ умножения на степени 2, а битовый сдвиг вправо делит на степени 2. Например, 5 << 2 равно 20. Вы перемещаете биты с 101 на 10100, что является тем же результатом, что и умножение на четыре.
| Символ | Эксплуатация |
| << | Битовый сдвиг влево |
| >> | Битовый сдвиг вправо |
Числа в SQL ограничены фиксированным числом бит.Например, целочисленный тип будет иметь только 32 бита, и если вы немного сдвинете его с 32-го значения, он будет исключен из числа. Как правило, если вы выполняете битовый сдвиг на число больше 32, он использует модуль по модулю: 7 << 34 ведет себя как 7 << 2.
Логическая логикаMySQL позволяет вам заменять символьные эквиваленты на и, или, а не на условные выражения. Можно заменить
, где user_id <10, а не group_id = 3 с
, где user_id <10 &&! group_id = 3 | Символ | Операция |
| && | Логический и |
| || | Логический или |
| ! | Логическое не |
Работа со строками может быть незнакомой, если вы новичок в программировании или только что освоили SQL.Некоторые варианты SQL используют знакомый + для объединения строк, в то время как другие, такие как MySQL, используют ||. При сравнении строк с использованием оператора like% и _ действуют как символы совпадения с подстановочными знаками. Например, «Data» соответствует D_t_ и% at%, в то время как только последний будет соответствовать группам данных. Вы можете прочитать более подробное введение в струнные здесь.
| Символ | Операция |
| + | Конкатенация |
| || | Конкатенация |
| + = | Конкатенация и назначение |
| % | Соответствие 0 или более подстановочных знаков |
| _ | Соответствие точно 1 подстановочный знак |
Существует дополнительная разница между строками, заключенными в одинарные кавычки (‘) и двойные кавычки (“).Строковые литералы заключаются в «одинарные кавычки», а «двойные кавычки» обозначают идентификаторы, такие как имена таблиц и столбцов.
Регулярные выраженияРегулярные выражения заполнены эзотерическими символами со специальным использованием широкого диапазона символов, включая? для необязательного соответствия, {2} для повторения и заключения диапазонов символов в скобки: [A-Za-z0-9].
Чтобы узнать, как расшифровать регулярное выражение «. * ([0-9] +) [_-]? Ye? A? Rs (old)?» В SQL, ознакомьтесь с этим сообщением в блоге.
СчетчикВ запросах могут отображаться как count (1), так и count (*). Они взаимозаменяемы и оба подсчитывают количество выбранных строк.
| Символ | Работа |
| (*) | Подсчет строк на группу |
| (1) | Подсчет строк на группу |
Вы можете столкнуться со случайным случаем, когда подсчет применяется к определенной таблице - в этих случаях он подсчитывает поля, а не строки в таблице.Мы рекомендуем вам выбрать один и придерживаться его - между этими двумя форматами нет семантической разницы или разницы в производительности. Обратите внимание, что два счетчика здесь будут возвращать разные количества.
выбрать
считать(*)
, количество (группы. *)
из
пользователи
покинул группу
на users.group_id = groups.id Преобразование типа
Помимо использования приведения, вы можете использовать :: для приведения значения к определенному типу.
выберите состав (дата '2016-12-25') как Рождество становится
выберите '2016-12-25' :: дата Рождества | Символ | Эксплуатация |
| :: | Преобразование типа |
Postgres Json
Postgres отлично поддерживает типы json, включая множество символьных операторов для извлечения данных из большого двоичного объекта json.
| Символ | Операция | |
| -> | Получить элемент json | |
| - >> | Получить элемент json в виде текста | |
| #> | Получить элемент | Получить элемент по пути в виде текста |
| @> | Содержит | |
| <@ | Содержит | |
| ? | Строка существует | |
| ? | | Любая строка существует | |
| ? & | Все строки существуют |
При определении переменных в MySQL они могут иметь префикс @ или @@.Одиночный @ позволяет определяемой пользователем переменной сохраняться за пределами запроса, который определяет переменные, а @@ является ссылкой на глобальное состояние, например @@ global.port.
| Символ | Операция |
| @ | Переменная сеанса пользователя |
| @@ | Системная переменная |
Oracle использует @ для запуска скриптов. Вы можете узнать больше здесь.
КомментарииВы можете использовать комментарии для включения текста, который не будет оцениваться как часть вашего sql-запроса.Стандартный набор токенов комментариев -, / *, * /, и MySQL дополнительно использует # для встроенных комментариев.
| Символ | Операция | ||||||||||||||||||||||||||
| - | Встроенный комментарий | ||||||||||||||||||||||||||
| # | Встроенный комментарий | ||||||||||||||||||||||||||
| / * | Блок-комментарий | 3 * | |||||||||||||||||||||||||
| Символ | Эксплуатация |
| (+) | Наружное соединение |
Он в основном ведет себя так же, как внешнее соединение, но есть некоторые исключения, которые вы можете проверить в справочнике по языку Oracle.
Получите советы и рекомендации по SQL от наших экспертов :
Читать далееКрис Майер - менеджер по аналитическим разработкам в Sisense. Он имеет 8-летний опыт работы в области данных и аналитики в Ernst & Young и Soldsie. Он увлечен созданием современных стеков данных, которые открывают трансформационные идеи для бизнеса.
Что такое база данных SQL?
Базы данных SQL использовались десятилетиями - и используются до сих пор.В этом блоге мы даем базовый обзор того, что такое база данных SQL, и приводим примеры.
Что такое база данных SQL?
SQL означает язык структурированных запросов. Используется для реляционных баз данных . База данных SQL - это набор таблиц, в которых хранится определенный набор структурированных данных.
База данных SQL долгое время была проверенной и верной рабочей лошадкой серверного предприятия и лежала в основе всего, что мы делаем в этот электронный век.SQL был создан в начале 1970-х в IBM как метод доступа к системе баз данных IBM System R.
История баз данных SQL
Полезность возможности доступа к нескольким записям с помощью одной команды, которая не требует указания способа достижения данной записи, была немедленно признана компьютерным миром. Он был быстро принят в качестве основного языка запросов для других систем управления базами данных или СУБД, таких как IBM DB2, а в 1979 году - сервера базы данных Oracle V2 от Relational Software Inc. (теперь известного как Oracle Software) для систем Vax.В конце концов, в 1986 году SQL был принят организациями по стандартизации ANSI и ISO, проложив путь для Microsoft SQL Server и различных баз данных с открытым исходным кодом, имеющихся сегодня на рынке.
СУБД, которую мы использовали сегодня, полагается на SQL как на механизм, который позволяет нам выполнять все операции, необходимые для создания, извлечения, обновления и удаления данных по мере необходимости. С точки зрения открытого исходного кода, эти СУБД включают MySQL, MariaDB и PostgreSQL как наиболее часто используемые СУБД с открытым исходным кодом в настоящее время.Многие компании из списка Fortune 100 из нескольких различных секторов бизнеса, включая финансовую, розничную торговлю, здравоохранение и другие, обратились к этим альтернативам с открытым исходным кодом, чтобы значительно снизить общую стоимость владения по сравнению с предложениями с оплатой за игру, такими как сервер Oracle Database и Microsoft. SQL Server.
[Узнайте о плюсах и минусах баз данных с открытым исходным кодом здесь]
Примеры баз данных SQL
MariaDB и MySQL
MariaDB и MySQL - это бинарно-совместимые серверы баз данных SQL с открытым исходным кодом, которые изначально начинались как просто MySQL.Однако из-за опасений по поводу будущего MySQL после того, как она была приобретена Oracle Software, MariaDB была выделена из проекта как отдельная сущность, но сохраняет свою совместимость с клиентскими API и протоколами MySQL в дополнение к файлам данных и определений таблиц.
Это означает, что в большинстве случаев сторонние инструменты будут работать с обеими версиями и, как правило, их можно рассматривать как замену любой версии. С приобретением MySQL Oracle стала довольно доброжелательно относиться к проекту с открытым исходным кодом, и большинство опасений, которые сообщество испытывало в первые дни приобретения, не сбылось, однако некоторые пуристы с открытым исходным кодом все еще могут предпочесть MariaDB MySQL. .
PostgreSQL
PostgreSQL - это объектно-реляционная система управления базами данных (ORDBMS), а не чисто СУБД, такая как MySQL и MariaDB. Это означает, что модели данных PostgreSQL могут быть основаны на моделях реляционных баз данных, но также могут быть объектно-ориентированными. На практике это означает, что мы видим, что PostgreSQL используется в более сложных и разнообразных моделях данных, а MariaDB и MySQL используются для более легких моделей данных.
Развиваясь из проекта Ingres в Калифорнийском университете в Беркли в 1982 году, PostgreSQL был создан с целью добавления минимального количества функций, необходимых для поддержки всех основных типов данных.Этот менталитет «большой отдачи» продолжает стимулировать развитие PostgreSQL и по сей день. Для сторонников открытого исходного кода это, как правило, предпочтительная база данных, так как это настоящий проект с открытым исходным кодом, который видят в PostgreSQL Global Development Group, некоммерческой организации, которую нелегко продать из-за ее образования.
Какое будущее у баз данных SQL?
В последние годы появились новые технологии для удовлетворения потребностей серверов баз данных, которые могут обрабатывать чрезвычайно большие наборы данных с чрезвычайно высокой общей скоростью без ущерба для стабильности или доступности.Базы данных NoSQL (не только SQL или не-SQL) становятся все более популярными для удовлетворения этих требований. Базы данных NoSQL хранят свои данные иначе, чем реляционные базы данных, используя базы данных на основе JSON или базы данных «ключ-значение», чтобы назвать несколько общих типов хранилищ. PostgreSQL с JSON и его методология, основанная на OORDMS, является свидетельством долговечности этих баз данных NoSQL.
Тем не менее, до традиционной базы данных SQL еще долго не зайдет солнце. Степень того, что базы данных SQL вошли в нашу повседневную жизнь, означает, что эти высокофункциональные и надежные СУБД будут опорой предприятия на десятилетия вперед.
Дальнейшие действия
Если вам нужна дополнительная информация о переходе с дорогостоящего предложения РСУБД с оплатой за игру на более экономически целесообразную альтернативу, свяжитесь с командой OpenLogic от Perforce. OpenLogic помог многим организациям во многих масштабах отказаться от дорогостоящего мира серверов баз данных с закрытым исходным кодом и добиться значительной экономии, переключившись на мир с открытым исходным кодом.
СВЯЗАТЬСЯ С ЭКСПЕРТОМ
Что такое SQL? Изучите основы SQL, полную форму SQL и способы использования
Что такое SQL?
SQL - стандартный язык для работы с реляционными базами данных.SQL можно использовать для вставки, поиска, обновления и удаления записей базы данных. SQL может выполнять множество других операций, включая оптимизацию и обслуживание баз данных.
Полная форма SQL
SQL означает язык структурированных запросов, произносится как «S-Q-L» или иногда как «See-Quel» ... Реляционные базы данных, такие как MySQL Database, Oracle, MS SQL Server, Sybase и т. Д., Используют ANSI SQL.
Что такое SQL?Как использовать SQL
Пример кода SQL:
SELECT * FROM Members WHERE Age> 30
Синтаксисы SQL, используемые в разных базах данных, почти одинаковы, хотя некоторые СУБД используют несколько разных команд и даже собственные синтаксисы SQL.
Щелкните здесь, если видео недоступно
Для чего используется SQL?
Вот важные причины для использования SQL
- Он помогает пользователям получать доступ к данным в системе СУБД.
- Помогает описать данные.
- Это позволяет вам определять данные в базе данных и управлять этими конкретными данными.
- С помощью SQL вы можете создавать и удалять базы данных и таблицы.
- SQL предлагает вам использовать функцию в базе данных, создать представление и хранимую процедуру.
- Вы можете установить разрешения для таблиц, процедур и представлений.
Краткая история SQL
Вот важные вехи из истории SQL:
- 1970 - Доктор Эдгар Ф. «Тед» Кодд описал реляционную модель для баз данных.
- 1974 - Появился язык структурированных запросов.
- 1978 - IBM выпустила продукт под названием System / R.
- 1986 - IBM разработала прототип реляционной базы данных, стандартизированной ANSI.
- 1989 - Выпущена первая версия SQL
- 1999 - Запущен SQL 3 с такими функциями, как триггеры, объектная ориентация и т. Д.
- SQL 2003 - оконные функции, функции, связанные с XML и т. Д.
- SQL 2006 - Поддержка для Язык запросов XML
- SQL 2011 - улучшенная поддержка временных баз данных
Типы операторов SQL
Вот пять типов широко используемых SQL-запросов.
- Язык определения данных (DDL)
- Язык управления данными (DML)
- Язык управления данными (DCL)
- Язык управления транзакциями (TCL)
- Язык запросов данных (DQL)
Список команд SQL
Вот список некоторых из наиболее часто используемых команд SQL :
- CREATE - определяет схему структуры базы данных
- INSERT - вставляет данные в строку таблицы
- UPDATE - обновляет данные в база данных
- DELETE - удаляет одну или несколько строк из таблицы
- SELECT - выбирает атрибут на основе условия, описанного в предложении WHERE
- DROP - удаляет таблицы и базы данных
SQL Process
Если вы хотите выполнить команду SQL для любой системы СУБД, вам нужно найти лучший метод выполнения вашего запроса, d Механизм SQL определяет, как интерпретировать эту конкретную задачу.
Важные компоненты, включенные в этот процесс SQL:
- Механизм запросов SQL
- Механизмы оптимизации
- Диспетчер запросов
- Классический механизм запросов
Классический механизм запросов позволяет управлять всеми не-SQL запросами.
Процесс SQLСтандарты SQL
SQL - это язык для работы с базами данных. Он включает создание базы данных, удаление, выборку строк, изменение строк и т. Д. SQL - это стандартный язык ANSI (Американский национальный институт стандартов).Стандарты SQL разделены на несколько частей.
Вот некоторые важные части стандартов SQL:
| Часть | Описание |
|---|---|
| Часть 1 - SQL / Framework | Предлагает логические концепции. |
| Часть 2 - SQL / Foundation | Включает центральные элементы SQL. |
| Часть 3 - SQL / CLI | Этот стандарт включает центральные элементы SQL. |
| Часть 4 - Постоянно хранимые модули | Сохраненные подпрограммы, внешние подпрограммы и расширения процедурного языка для SQL. |
| Часть 9 - Управление внешними данными | Добавляет синтаксис и определения в SQL / Foundation, которые обеспечивают доступ SQL к источникам данных (файлам), отличным от SQL. |
| Часть 10 - Привязки объектного языка | Привязки объектного языка: Эта часть определяет синтаксис и семантику встраивания SQL в Java ™. |
| Часть 11 - SQL / Schema | Информация и схемы определений |
| Часть 12 - SQL / Replication | Этот проект начался в 2000 году.Эта часть помогает определить синтаксис и семантику, позволяющие определять схемы и правила репликации. |
| Часть 13 - Подпрограммы и типы Java | Подпрограммы и типы Java: Эта часть подпрограмм, использующих язык программирования Java. |
| Часть 14 - SQL / XML | SQL и XML |
| Часть 15 - SQL / MDA | Обеспечение поддержки SQL для многомерных массивов |
Элементы языка SQL
Вот важные элементы Язык SQL:
- Ключевые слова: Каждый оператор SQL содержит одно или несколько ключевых слов.
- Идентификаторы: Идентификаторы - это имена объектов в базе данных, например идентификаторы пользователей, таблицы и столбцы.
- Строки: Строки могут быть как буквальными строками, так и выражениями с типами данных VARCHAR или CHAR.
- Выражения: Выражения состоят из нескольких элементов, таких как константы, операторы SQL, имена столбцов и подзапросы.
- Условия поиска: Условия используются для выбора подмножества строк из таблицы или используются для управления операторами, такими как оператор IF, для определения управления потоком.
- Специальные значения: Специальные значения следует использовать в выражениях и в качестве значений столбцов по умолчанию при построении таблиц.
- Переменные: Sybase IQ поддерживает локальные переменные, глобальные переменные и переменные уровня соединения.
- Комментарии: Комментарий - это еще один элемент SQL, который используется для присоединения пояснительного текста к операторам SQL или блокам операторов. Сервер базы данных не выполняет никаких комментариев.
- NULL Значение: Используйте NULL, что помогает указать значение, которое неизвестно, отсутствует или неприменимо.
Что такое база данных в SQL?
База данных в SQL Server, состоящая из набора таблиц, в которых хранится подробный набор структурированных данных. Это таблица, содержащая набор строк, называемых записями или кортежами, и столбцов, которые также называются атрибутами.
Каждый столбец в таблице предназначен для хранения информации определенного типа, например имен, дат, долларовых сумм и чисел.
Что такое NoSQL?
NoSQL - новая категория систем управления базами данных.Его основная характеристика - это не приверженность концепциям реляционных баз данных. NoSQL означает «Не только SQL». Концепция баз данных NoSQL выросла с появлением таких интернет-гигантов, как Google, Facebook, Amazon и т. Д., Которые имеют дело с гигантскими объемами данных.
Когда вы используете реляционную базу данных для больших объемов данных, система начинает замедляться с точки зрения времени отклика. Чтобы преодолеть это, мы могли «масштабировать» наши системы, модернизировав существующее оборудование. Альтернативой описанной выше проблеме было бы распределение нагрузки нашей базы данных на несколько хостов по мере увеличения нагрузки.Это известно как «горизонтальное масштабирование».
База данных NoSQL - это нереляционные базы данных , которые масштабируются лучше, чем реляционные базы данных, и разработаны с учетом веб-приложений. Они не используют SQL для запроса данных и не следуют строгим схемам, например реляционным моделям. В NoSQL функции ACID (атомарность, согласованность, изоляция, долговечность) не всегда гарантируются.
Почему имеет смысл изучать SQL после NoSQL?
Выявив преимущества баз данных NoSQL, которые масштабируются лучше, чем реляционные модели, вы, возможно, думаете, , почему все еще нужно изучать базу данных SQL? Ну, базы данных NoSQL - это узкоспециализированные системы со своими особенностями использования и ограничениями.NoSQL больше подходит для тех, кто обрабатывает огромные объемы данных. Подавляющее большинство используют реляционные базы данных и связанные с ними инструменты.
Реляционные базы данных имеют следующие преимущества перед базами данных NoSQL.
- SQL (реляционные) базы данных имеют зрелую модель хранения и управления данными. Это очень важно для корпоративных пользователей.
- База данных SQL поддерживает понятие представлений, которые позволяют пользователям видеть только те данные, которые им разрешено просматривать. Данные, которые им не разрешено просматривать, скрыты от них.
- Базы данных SQL поддерживают хранимую процедуру SQL, которая позволяет разработчикам баз данных внедрять часть бизнес-логики в базу данных.
- Базы данных SQL имеют лучшие модели безопасности по сравнению с базами данных NoSQL.
Мир не отказался от использования реляционных баз данных. Существует растущий спрос на специалистов, которые могут работать с реляционными базами данных. Таким образом, изучение баз данных и основ SQL все еще имеет смысл.
Лучшая книга для изучения SQL
Вот несколько лучших книг по SQL:
- Учебное пособие по SQL для начинающих
В этом учебном пособии по SQL для начинающих в формате PDF вы изучите основные концепции баз данных, команды MS-SQL и продвинутый уровень. такие темы, как соединения SQL, создание, добавление и удаление таблицы и т. д. КУПИТЬ
- SQL за 10 минут:
Эта книга SQL предлагает полноцветные примеры кода, которые помогут вам понять, как структурированы операторы SQL. Вы также узнаете о ярлыках и решениях. КУПИТЬ СЕЙЧАС
- Поваренная книга SQL:
В этой книге по SQL вы сможете изучить технику перемещения по строке, которая позволяет использовать SQL для анализа символов, слов или элементов строки с разделителями. КУПИТЬ
- SQL: полный справочник
Эта книга включает важные темы Microsoft SQL, такие как оконные функции, преобразование строк в столбцы, обратное преобразование столбцов в строки. КУПИТЬ
- Карманное руководство по SQL: Руководство по использованию SQL
В книге рассказывается, как системы используют функции SQL, синтаксис регулярных выражений и функции преобразования типов. КУПИТЬ СЕЙЧАС
Дополнительные книги по SQL - Щелкните здесь
Сводка / ключевые выводы
- Язык SQL используется для запросов к базе данных
- Что означает SQL или что означает SQL: язык структурированных запросов
- SQL Используется для:
- Система РСУБД
- Описание, определение и управление данными
- Создание и удаление баз данных и таблиц
- Типы операторов SQL: DDL, DML, DCL, TCL, DQL
- Список команд SQL : CREATE, INSERT, UPDATE, DELETE, SELECT, DROP
- Элементы языка SQL: ключевые слова, идентификаторы, строки, выражения, переменные и т. Д.
- NoSQL: означает «Не только SQL» - это новая категория систем управления базами данных.
- Подход базы данных имеет много преимуществ, когда дело доходит до хранения данных по сравнению с традиционными системами на основе плоских файлов.
Что такое SQL в SQL Server?
Что такое SQL в контексте SQL Server, часто задают новички. Эта статья призвана ответить на этот вопрос, в то же время предоставляя некоторую историю, контекст и обзор основ языка.Значение и определение
SQL означает язык структурированных запросов, язык для управления данными в базах данных и обмена ими.Впервые он был введен в употребление в 1970 году, а в 1986 году он стал стандартом IBM в связи с несколькими проектами для правительства США и в течение многих лет оставался проектом только для правительства. Это язык программирования, который используется для доступа к данным, хранящимся в базе данных.
Слово «SQL» - это аббревиатура, которая сегодня ассоциируется с «языком структурированных запросов». Первоначально он назывался SEQUEL с немного другим значением. Некоторые люди до сих пор произносят аббревиатуру SEQUEL, а некоторые произносят каждую отдельную букву S-Q-L.Они означают одно и то же.
SQL, как язык поиска данных, является отраслевым стандартом; Во всех продуктах реляционных баз данных SQL - это механизм, язык и синтаксис, используемые для извлечения данных из базы данных ar.
Согласно Википедии…
- «SQL разработан на основе реляционной алгебры и реляционного исчисления кортежей, SQL состоит из множества типов операторов, которые можно неофициально классифицировать как подъязыки, обычно: язык запросов данных (DQL), [a] язык определения данных ( DDL), [b] язык управления данными (DCL) и язык управления данными (DML).Сфера применения SQL включает запрос данных, манипулирование данными (вставка, обновление и удаление), определение данных (создание и изменение схемы) и управление доступом к данным. Хотя SQL часто называют декларативным языком (4GL), и в значительной степени таковым является, он также включает в себя процедурные элементы.
- SQL был одним из первых коммерческих языков для реляционной модели Эдгара Ф. Кодда, как описано в его влиятельной статье 1970 года «Реляционная модель данных для больших общих банков данных».[11] Несмотря на то, что он не полностью придерживается реляционной модели, описанной Коддом, он стал наиболее широко используемым языком баз данных «
Технический обзор
SQL - это язык программирования специального назначения. Это отличает его от других языков, таких как C, C ++, JavaScript или Java, которые являются языками программирования общего назначения. Это означает, что SQL имеет очень конкретную цель - манипулировать наборами данных. Мы манипулируем наборами данных с помощью реляционного исчисления.
Как правило, мы можем использовать SQL в любых базах данных или источниках данных, и даже если мы не можем использовать SQL напрямую с некоторыми источниками данных, большинство языков запросов сегодня имеют некоторое отношение к SQL. В общем, после того, как вы изучили SQL, довольно легко освоить другие языки запросов.
SQL имеет ряд стандартов. Он соответствует стандартам ANSI и ISO. Эти стандарты жизненно важны, потому что каждый поставщик реляционных баз данных должен реализовать стандарт, по крайней мере, в качестве наименьшего общего знаменателя, чтобы вы знали, что, изучив стандарт SQL, вы можете применить эти знания к другим продуктам баз данных.
Интересные факты:
- Первый общедоступный продукт, в котором использовался язык SQL, был выпущен в 1979 году с Oracle версии 2, и Oracle остается одной из ведущих систем баз данных на сегодняшний день.
- Большинство баз данных имеют некоторые дополнительные функции, не являющиеся частью стандарта. Если вы хотите изучить конкретный продукт для баз данных, вам придется их освоить. Но базовый стандарт SQL всегда будет одним и тем же.
- SQL обычно не зависит от пробелов, что означает, что если вы хотите добавить некоторый пробел между предложениями или выражениями, чтобы облегчить чтение вашего оператора, вы можете сделать это
- Большинство команд SQL сосредоточено на четырех основных глаголы, то есть ВЫБРАТЬ ВСТАВИТЬ, ОБНОВИТЬ и УДАЛИТЬ.
SQL стандартизирован таким образом, что задаются конкретные вопросы объекта базы данных в форме структурированного запроса, на который база данных знает, как отвечать.SQL использует интерпретатор команд для анализа SQL. Поскольку это такой мощный способ мышления о данных, SQL был принят во многие продукты для баз данных. Некоторые продукты поддерживают стандарт SQL и добавляют к нему другие функции, а некоторые поддерживают часть, но не все, стандарта SQL.
Выписки DML
Прежде чем мы начнем строить операторы SQL в SQL Server, нам нужно понять, каковы основные части оператора. В целом, «оператор» - это то, что вы пишете на языке SQL, чтобы получить ответ из базы данных или внести в него изменения.
DML расшифровывается как операторы языка манипулирования данными. Это операторы, которые читают, добавляют, редактируют или удаляют данные
- Первый оператор, который мы опишем, - это SELECT. Это используется для извлечения данных из базы данных.
Пример утверждения:
- Затем у нас есть ОБНОВЛЕНИЕ. UPDATE изменит одну или несколько существующих строк в базе данных.
Подробное описание SQL Update можно найти здесь: Обзор оператора обновления SQL
- INSERT создает одну или несколько новых строк в базе данных. Подробное описание SQL Insert можно найти здесь: Обзор оператора SQL Insert
- DELETE удалит одну или несколько существующих строк из базы данных. INSERT и DELETE всегда управляют всей строкой. Мы можем удалить только целую строку. Мы не можем удалить часть строки. Единственный оператор, который управляет частью строки, - это оператор UPDATE. Он может обновлять только один столбец или несколько столбцов или все столбцы. Подробное объяснение SQL Delete можно найти здесь: Обзор оператора SQL Delete
- Первый оператор, который мы опишем, - это SELECT. Это используется для извлечения данных из базы данных.
Операторы DDL
DDL расшифровывается как операторы языка определения данных.Это операторы, относящиеся к объектам, таким как таблицы, в SQL Server по сравнению с данными. Например, чтобы создать таблицу, вы должны использовать оператор CREATE TABLE, указав имя и другие атрибуты вашей таблицы. Позже вы можете использовать операторы DML для добавления к нему данных, обновления или удаления этих данных и чтения данных.
Примечание. Подробное объяснение SQL Create можно найти здесь: Обзор оператора SQL create
ОператорыCreate, Read (Выбрать), Update (Обновить) и Delete (Удалить) вместе называются аббревиатурой CRUD.Подробное объяснение операций SQL CRUD можно найти здесь: Создание и использование хранимых процедур CRUD
Статьи
Пункты - это основные компоненты операторов SQL, более мелкие строительные блоки, составляющие единое целое. Эти предложения состоят из ключевых слов, которые сообщают базе данных о необходимости выполнения определенного действия. Также есть имена полей, которые сообщают базе данных, где искать и что искать. Также существуют предикаты, которые позволяют нам указать, с какой информацией мы работаем.Предикаты включают значение или условие, называемое выражением. Предложение может быть утверждением, если вы пишете действительно базовое предложение. Как мы увидим позже, существуют также операторы, которые позволяют нам сравнивать равенство или диапазоны данных или обрабатывать информацию другими способами.
- Примечание. Ключевые слова и операторы обычно пишутся в верхнем регистре, хотя обычно это не обязательно. Но это помогает с первого взгляда отличить SQL от ваших выражений и имен полей
Сводка
Используя SQL, вы можете просматривать некоторые данные; выбирать данные только из определенных таблиц; добавить фильтрацию к данным; манипулировать данными.Все это можно сделать с помощью языка SQL. Итак, думайте о SQL как об API или интерфейсе прикладного программирования, основном языке, который вы используете для взаимодействия с вашей базой данных.
Во-вторых, вы можете изменять данные; вставить новые данные; обновить или удалить существующие данные.
В-третьих, язык SQL позволяет изменять объекты в базе данных. Это создает новые таблицы. Или измените структуру существующих таблиц, например добавив столбцы в таблицы или удалив столбцы из таблиц
Сильные стороны
Некоторые сильные стороны SQL включают фильтрацию, особенно при выполнении оператора SELECT.У нас есть простые и мощные инструменты для фильтрации возвращаемых нам результатов. Сортировка любых результатов, возвращаемых из запроса SQL, легко сортируется по возрастанию или убыванию по любому столбцу.
- Подробное описание оператора SQL Like можно найти здесь: Обзор оператора SQL LIKE
- Подробное объяснение SQL Coalesce Функция , часто используемую функцию манипулирования данными, можно найти здесь: Использование функции SQL Coalesce в SQL Server
- Подробное объяснение предложения SQL Order by можно найти здесь: Обзор заказа SQL по пункту
В SQL уровень сложности работы с двумя и более таблицами аналогичен уровню сложности работы с одной таблицей.
- Подробное описание объединения SQL можно найти здесь: Обзор и руководство по объединению SQL
Слабые стороны
Самый большой недостаток SQL - это структурированный поток управления. Базовый стандарт SQL на самом деле не имеет никаких структур принятия решений, таких как операторы IF-ELSE, и не имеет много циклических структур, таких как For, While и Do-While, где мы хотим выполнить итерацию по некоторому условному условию для выполнения некоторого SQL и над.
Таким образом, некоторые производители предлагают определенные решения. Эти языковые дополнения включают все стандартные команды SQL для управления данными. Microsoft реализует T-SQL. Буква T означает «транзакция». Аналогичным образом Oracle поддерживает расширение программирования PLSQL, также известное как процедурный язык SQL
.На этом пока все…
Надеюсь, вам понравится эта статья. Не стесняйтесь комментировать ниже.
Я технолог по базам данных с более чем 11-летним богатым практическим опытом работы с технологиями баз данных.Я сертифицированный специалист Microsoft и имею степень магистра компьютерных приложений.Моя специальность заключается в разработке и внедрении решений высокой доступности и кроссплатформенной миграции БД. В настоящее время работают над технологиями SQL Server, PowerShell, Oracle и MongoDB.
Посмотреть все сообщения от Prashanth Jayaram
Последние сообщения от Prashanth Jayaram (посмотреть все)SQL - простой язык. SQL - простыми словами, это… | by Akademily
SQL - простыми словами, это язык программирования для структурированных запросов (SQL, Structured Query Language), , который используется как эффективный способ сохранения данных, поиска их частей, обновления, извлечения из базы данных и Удалить.
Произносится как «Escuel», но чаще всего можно услышать сленг «Sequel».
Основной инструмент оптимизации и обслуживания базы данных - это то, для чего предназначен SQL, хотя он не ограничивается этими целями. Возможности обработки охватывают команды определения представления, права доступа, схемы отношений (включая их удаление и изменение), взаимодействие с другими языками программирования, проверки целостности, начало и конец транзакций.
Для непрофессионала, чтобы понять, что SQL означает для ИТ-индустрии, давайте приведем простой пример.
Представьте себе таблицу с информацией о студентах: имена, возраст, предмет обучения и так далее. В нем есть определенное количество строк и столбцов. Одна из строк содержит успеваемость студентов.
Как только все данные вводятся в таблицу, каждая запись попадает в отдельную категорию (столбцы или «атрибуты»). Это организованная база данных. Вся информация, организованная внутри нее, которой можно управлять, называется схемой базы данных.
Если вы хотите предоставить стипендии студентам, получившим оценку 90% или более, то запрос данных выполняется в SQL, что простыми словами означает «запросить базу данных для предоставления информации о студентах, получивших 90% или более. точки.
Команда будет иметь синтаксический вид:
SELECT * FROM Student WHERE Percentage> = 90;
Когда количество данных невелико (скажем, 10 студентов), вы можете легко все рассчитать и написать на листе бумаги. Но когда объем данных увеличивается до тысяч записей, становится необходим SQL - он помогает эффективно управлять огромными данными, то есть быстро производить вычисления на их основе.
С 1974 года, когда впервые появился язык структурированных запросов, он обеспечивает взаимодействие с системами управления базами данных (СУБД) по всему миру.
SQL, как простой и легкий в изучении язык бесплатного программного обеспечения, активно используется сегодня:
- разработчиками баз данных (обеспечивают функциональность приложений),
- тестировщиками (в ручном и автоматическом режиме),
администраторами (выполняют поддержание окружающей среды).
Язык универсален и имеет четко определенную структуру в соответствии с устоявшимися стандартами. Взаимодействие с базами данных происходит быстро даже в ситуациях, когда объемы данных большие (большие данные).Кроме того, эффективное управление возможно даже без глубокого знания кода.
Области применения и где используется SQL:
В качестве языка определения данных (DDL) он позволяет самостоятельно создавать базу данных, определять ее структуру, использовать ее, а затем сбрасывать ее после завершения манипуляций.
Как язык управления данными (DML) - для поддержки существующих баз данных на языке, эффективном с точки зрения трудозатрат и производительности, для ввода, модификации и извлечения данных по отношению к базе данных.
В качестве языка управления данными (DCL), когда вам нужно защитить вашу базу данных от повреждений и неправильного использования.
Открывает систему единого входа (SSO) с аутентификацией пользователя в нескольких веб-приложениях в рамках одного сеанса.
Гарантирует защиту информационных компонентов от несанкционированного использования и цифрового копирования.