Сложные SQL-запросы
Сложные SQL-запросы Пожалуйста, включите JavaScript в браузере!Сложные SQL-запросы
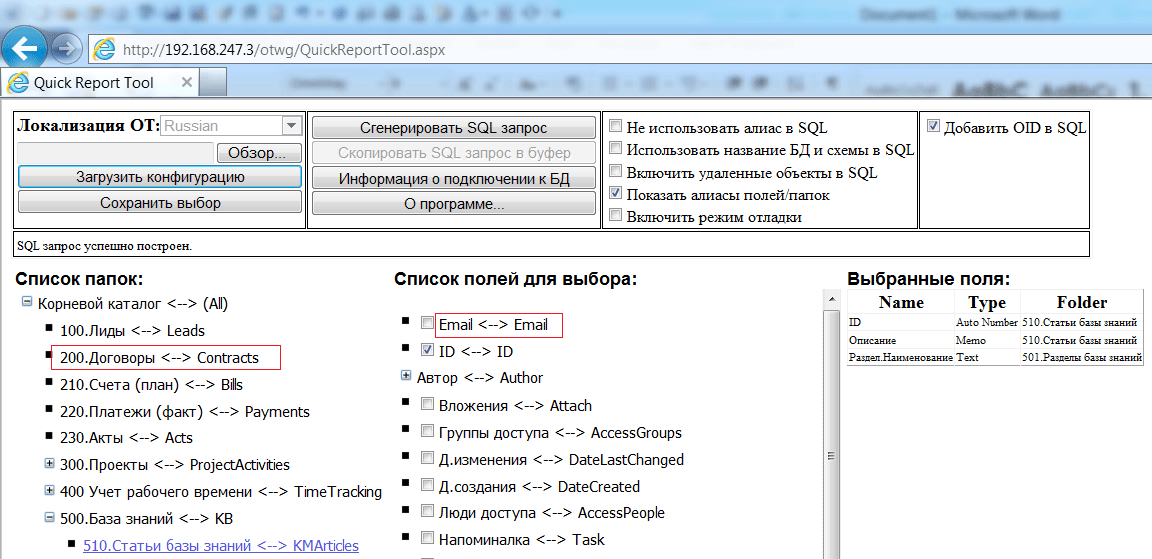
С помощью строки поиска вы можете вручную создавать SQL-запросы любой сложности для фильтрации событий.
Чтобы сформировать SQL-запрос вручную:
- Перейдите в раздел События веб-интерфейса KUMA.
Откроется форма с полем ввода.
- Введите SQL-запрос в поле ввода.
- Нажмите на кнопку .
Отобразится таблица событий, соответствующих условиям вашего запроса. При необходимости вы можете отфильтровать события по периоду.
Поддерживаемые функции и операторы
SELECT– поля событий, которые следует возвращать.Для
SELECTв программе поддержаны следующие функции и операторы:- Функции агрегации:
count, avg, max, min, sum. - Арифметические операторы:
+, -, *, /, <, >, =, !=, >=, <=.Вы можете комбинировать эти функции и операторы.

Если вы используете в запросе функции агрегации, настройка отображения таблицы событий, сортировка событий по возрастанию и убыванию, получение статистики, а также ретроспективная проверка недоступны.
- Функции агрегации:
FROM– источник данных.При создании запроса в качестве источника данных вам нужно указать значение events.
WHERE– условия фильтрации событий.AND, OR, NOT, =, !=, >, >=, <, <=INBETWEENLIKEILIKEinSubnetmatch(в запросах используется синтаксис регулярных выражений re2)
GROUP BY– поля событий или псевдонимы, по которым следует группировать возвращаемые данные.Если вы используете в запросе группировку данных, настройка отображения таблицы событий, сортировка событий по возрастанию и убыванию, получение статистики, а также ретроспективная проверка недоступны.
ORDER BY– столбцы, по которым следует сортировать возвращаемые данные.Возможные значения:
DESC– по убыванию.ASC– по возрастанию.
OFFSET– пропуск указанного количества строк перед выводом результатов запроса.LIMIT– количество отображаемых в таблице строк.Значение по умолчанию – 250.
Если при фильтрации событий по пользовательскому периоду количество строк в результатах поиска превышает заданное значение, вы можете отобразить в таблице дополнительные строки, нажав на кнопку Показать больше записей. Кнопка не отображается при фильтрации событий по стандартному периоду.
Примеры запросов:
SELECT * FROM `events` WHERE Type IN ('Base', 'Audit') ORDER BY Timestamp DESC LIMIT 250Все события таблицы events с типом Base и Audit, отсортированные по столбцу Timestamp в порядке убывания.
Количество отображаемых в таблице строк – 250.SELECT * FROM `events` WHERE BytesIn BETWEEN 1000 AND 2000 ORDER BY Timestamp ASC LIMIT 250Все события таблицы events, для которых в поле BytesIn значение полученного трафика находится в диапазоне от 1000 до 2000 байт, отсортированные по столбцу Timestamp в порядке возрастания. Количество отображаемых в таблице строк – 250.
SELECT * FROM `events` WHERE Message LIKE '%ssh:%' ORDER BY Timestamp DESC LIMIT 250Все события таблицы events, которые в поле Message содержат данные, соответствующие заданному шаблону
%ssh:%в нижнем регистре, и отсортированы по столбцу Timestamp в порядке убывания. Количество отображаемых в таблице строк – 250.SELECT * FROM `events` WHERE inSubnet(DeviceAddress, '10.0.0.1/24') ORDER BY Timestamp DESC LIMIT 250Все события таблицы events для хостов, которые входят в подсеть 10.0.0.1/24, отсортированные по столбцу Timestamp в порядке убывания.
Количество отображаемых в таблице строк – 250.SELECT * FROM `events` WHERE match(Message, 'ssh.*') ORDER BY Timestamp DESC LIMIT 250Все события таблицы events, которые в поле Message содержат текст, соответствующий шаблону
ssh.*, и отсортированы по столбцу Timestamp в порядке убывания. Количество отображаемых в таблице строк – 250.SELECT max(BytesOut) / 1024 FROM `events`Максимальный размер исходящего трафика (КБ) за выбранный период времени.
SELECT count(ID) AS "Count", SourcePort AS "Port" FROM `events` GROUP BY SourcePort ORDER BY Port ASC LIMIT 250Количество событий и номер порта. События сгруппированы по номеру порта и отсортированы по столбцу Port в порядке возрастания. Количество отображаемых в таблице строк – 250.
Столбцу ID в таблице событий присвоено имя Count, столбцу SourcePort присвоено имя Port.

 Количество отображаемых в таблице строк – 250.
Количество отображаемых в таблице строк – 250. Количество отображаемых в таблице строк – 250.
Количество отображаемых в таблице строк – 250.Если вы хотите указать в запросе специальный символ, вам требуется экранировать его, поместив перед ним обратную косую черту (\).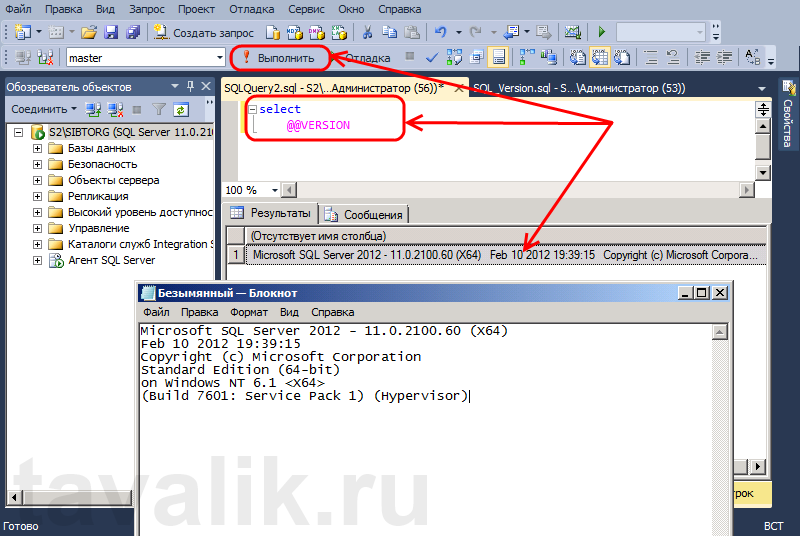
Пример:
Все события таблицы events, которые в поле Message содержат текст, соответствующий шаблону |
При переключении на конструктор параметры запроса, введенного вручную в строке поиска, не переносятся в конструктор: вам требуется создать запрос заново. При этом запрос, созданный в конструкторе, не перезаписывает запрос, введенный в строке поиска, пока вы не нажмете на кнопку Применить в окне конструктора.
После обновления KUMA до версии 1.6 при фильтрации событий с помощью SQL-запроса, содержащего условие inSubnet, может возвращаться ошибка Code: 441. DB::Exception: Invalid IPv4 value.
<cast_ipv4_ipv6_default_on_conversion_error>true</cast_ipv4_ipv6_default_on_conversion_error>.Подробнее об SQL см. в справке ClickHouse.
В начало
Запуск запросов: режим «только для чтения», планировщик, SQL-журнал
Консоль запросов
По опыту знаем, что консоль запросов — лучшее место для повседневной работы с SQL. Для каждого источника данных предусмотрена собственная консоль по умолчанию. Чтобы ее открыть, выберите Open Console в контекстном меню или нажмите F4.
Здесь вы можете написать SQL-запрос, запустить его и получить результат. Все просто.
Если вы вдруг захотите создать другую консоль для источника данных, сделайте это в меню: Context menu → New → Console.
Переключатель схем
Создавайте столько консолей запросов, сколько вам нужно, и запускайте запросы одновременно. У каждой консоли есть переключатель схем и баз данных. Если вы работаете с PostgreSQL , составьте здесь search_path.
Запуск выделенного фрагмента
Выделите фрагмент кода и запустите только его. Выбранный запрос посылается в базу «как есть», без дополнительной обработки jdbc-драйвером. Это может быть полезно, когда по той или иной причине IDE думает, что в запросе есть ошибка.
Настройки выполнения
Выполнять запрос можно несколькими способами. Поведение запуска запросов под кареткой можно настраивать. Возможные варианты того, что можно запустить: подзапрос, весь запрос, все после каретки, весь скрипт или предложить выбор.
Можно настроить три варианта поведения для запуска (Execute). По умолчанию, сочетание клавиш есть только у первого, но вы можете выбрать их и для остальных. Например, настроим два поведения: «показать выбор» и «запустить весь скрипт».
На видео пример, как сначала выполнено одно действие, затем второе.
Режим «только для чтения»
Режим «только для чтения» включайте в настройках источника данных: флажок Read-Only
На уровне jdbc-драйвера в режиме «для чтения» запросы, которые вносят изменения, нельзя запускать в базах: MySQL, PostgreSQL, AWS Redshift, h3 и Derby. В других СУБД этот режим не работает.
Поэтому мы сделали свой режим «только для чтения». Он включается одновременно с режимом на уровне драйвера. IDE понимает, какие запросы приведут к изменениям, и подчеркивает их. При запуске запроса DataGrip покажет предупреждение. Такой запрос можно запустить, нажав Execute на всплывающей панели, если вы точно уверены в том, что делаете.
DataGrip также индексирует все исходники функций и процедур и строит внутри дерево вызовов.
Контроль транзакций
Выберите контроль транзакций, который больше подходит вашей работе. Эта настройка есть в свойствах источника данных. В автоматическим режиме (флажок Auto) вам не надо каждый раз фиксировать транзакцию, а вот в ручном режиме (Manual), очевидно, надо.
Быстрый просмотр результата
Результаты запроса или выражения можно посмотреть во всплывающем окне. В других IDE на платформе IntelliJ Ctrl+Alt+F8 показывает результат вычисления выражения. В DataGrip то же самое работает для отображения результатов запуска. Если нажать эту комбинацию когда курсор на столбце, вы увидите ожидаемые значения этого столбца в результатах запроса. Та же самая операция на любом ключевом слове запроса покажет всплывающее окно с результатом. Клик мышкой при зажатом Alt работает так же.
История запущенных запросов
На панели инструментов каждой консоли есть такая кнопка: . Нажмите ее, чтобы увидеть историю всех запросов, выполненных в этом источнике данных из DataGrip. Еще здесь работает быстрый поиск!
Не забудьте и о локальной истории каждого файла.
Полный SQL-журнал
Буквально все запросы, которые запускает DataGrip, записываются в текстовый файл. Чтобы открыть его, используйте меню Help | Show SQL log.
Запуск хранимых процедур
DataGrip умеет генерировать код для запуска процедур. Укажите значения для параметров и нажмите OK.
Когда процедура открыта в редакторе, вы можете ее запустить, нажав Run на панели инструментов. Или используйте контекстное меню и выберите пункт Execute…
Небезопасные запросы
DataGrip предупредит, если вы собираетесь запустить запросы DELETE и UPDATE без предложения WHERE.
Планировщик запросов
План запросов покажет, как база данных собирается выполнить ваш запрос. Это помогает в оптимизации.
Это помогает в оптимизации.
План запросов может быть представлен в виде дерева или диаграммы.
Запросы с параметрами
В запросе могут быть параметры. DataGrip умеет запускать такие запросы.
Описать синтаксис параметров можно в Settings/Preferences → Database → User Parameters. Регулярные выражения для их описания подсвечиваются, а еще для каждого вида параметров можно указать SQL-диалект.
Структурный вид
Каждую консоль или файл можно открыть в структурном виде: в окне появится список запросов. Чтобы открыть структурный вид, используйте сочетание клавиш Ctrl+F12.
Результат запроса
Результат запроса
В DataGrip данные в результате простого запроса можно изменять. Используйте все возможности редактора данных: добавляйте, удаляйте строки, выбирайте режим контроля транзакций.
Сравнение результатов
Два результата можно сравнить, используя инструмент поиска различий. DataGrip подсветит те строчки, которые не являются общими для двух результатов. Параметр Tolerance используется для того, чтобы указать, сколько колонок могут иметь разные значения, чтобы строчки все равно считались одинаковыми. Из сравнения можно исключить любой столбец.
DataGrip подсветит те строчки, которые не являются общими для двух результатов. Параметр Tolerance используется для того, чтобы указать, сколько колонок могут иметь разные значения, чтобы строчки все равно считались одинаковыми. Из сравнения можно исключить любой столбец.
Нажмите кнопку сравнения на панели инструментов и выберите результат запроса, с которым нужно сравнить текущий результат.
Имена вкладок
Вы сами можете называть вкладки результатов: напишите имя в комментарии перед запросом.
Если вам не нравится, что любой предшествующий комментарий становится именем, укажите слово, после которого будет идти строка для заголовка. Это делается в соответствующих настройках: поле Prefix.
Быстрое изменение размера страницы
Меняйте размер страницы в редакторе данных, не заходя в настройки.
SQL-запросы к данным без серверов и СУБД с помощью Amazon S3 Select
by AWS Central EurAsia & Russia Team | on | in Amazon API Gateway, Amazon Simple Storage Service (S3), AWS CloudFormation, AWS Lambda, S3 Select, Storage | Permalink | ShareОригинал статьи: ссылка (David Green, Principal Serverless Solutions Architect и Mustafa Rahimi, Enterprise Solutions Architect)
Как AWS Solution Architect, мы ежедневно сталкиваемся с разными заказчиками и сценариями использования облачных технологий. Однако у многих из них похожие запросы: клиенты хотят уменьшить издержки на управление серверами, а также снизить сложность развертывания и поддержки инфраструктуры. И это понятно, они сфокусированы на эффективности своего бизнеса.
Однако у многих из них похожие запросы: клиенты хотят уменьшить издержки на управление серверами, а также снизить сложность развертывания и поддержки инфраструктуры. И это понятно, они сфокусированы на эффективности своего бизнеса.
У большинства заказчиков рано или поздно встает задача поиска среди большого объема данных, и это требуется сделать простым решением, без систем влекущих за собой высокие издержки. В этой статье мы рассмотрим использование SQL-запросов для работы с данными в CSV, JSON или Apache Parquet форматах, загруженными на Amazon Simple Storage Service (Amazon S3). Раньше, для того чтобы делать запросы к данным, необходимо было сначала загрузить их в какую-либо базу данных (СУБД). Мы же обойдемся без этого и, вместо развертывания баз данных и сопутствующих приложений, воспользуемся возможностью S3 под названием S3 Select. Мы продемонстрируем такой подход на примере поиска по телефонной книге, хранящийся в CSV файле. Полный код примера доступен на GitHub.
Amazon S3 используется для хранения любого объема данных без необходимости резервирования серверов и управления инфраструктурой. Amazon S3 Select и Amazon S3 Glacier Select позволяют напрямую выполнять SQL-запросы к CSV, JSON и Apache Parquet файлам, лежащим на S3 и Amazon S3 Glacier. При использовании S3 Select вы просто загружаете данные на S3, и выполняете SQL-запросы для фильтрации содержимого S3 объектов, получая на выходе нужные вам результаты. Запрашивая только необходимое подмножество хранящейся информации, вы уменьшаете объем передаваемых от Amazon S3 данных, что также уменьшает время и стоимость передачи. А уменьшение сложности, достигаемое благодаря такому решению, положительно влияет на скорость разработки.
S3 Select поддерживает сжатие CSV и JSON объектов с помощью GZIP и BZIP2, а также шифрование на стороне сервера. Вы можете выполнять SQL-запросы с помощью AWS SDK для поддерживаемых языков программирования, SELECT Object Content REST API, инструментов командной строки AWS Command Line Interface (AWS CLI), а также с помощью web консоли AWS Management Console.
Используемые AWS сервисы
Пример приложения для поиска в телефонной книге использует следующие сервисы:
- Amazon S3 – объектное хранилище, обеспечивающее высокую доступность и производительность, фактически неограниченное масштабирование и, конечно, высокий уровень безопасности.
- S3 Select – сервис, позволяющий получать подмножество данных из S3-объектов (файлов), выполняя простые SQL-запросы.
Кроме S3 и S3 Select наш пример приложения поиска в телефонной книге использует и другие сервисы:
- Amazon API Gateway – полностью управляемый (managed) сервис, позволяющий легко создавать, управлять, поддерживать и производить мониторинг защищенных API. Amazon API Gateway часто используют в serverless приложениях, и в нашем примере он используется для взаимодействия с AWS Lambda.
- AWS Lambda позволяет запускать код без развертывания и управления серверами. В нашем примере S3 Select запросы выполняются в AWS Lambda.
- AWS CloudFormation предоставляет язык для декларативного моделирования и развертывания AWS (а также сторонних) ресурсов, в облаке. CloudFormation используется в нашем примере для организации развертывания ресурсов, необходимых для примера.
Код проекта
Полный код примера приложения для поиска в телефонной книге доступен в GitHub репозитории AWS-Samples. Работа Amazon S3 Select, используемого в примере, описывается далее.
Начало работы, загрузка данных
Так как S3 Select работает напрямую с данными, хранящимися на S3, все, что вам нужно для начала работы — это AWS аккаунт и S3 бакет.
Войдите в существующий аккаунт или создайте новый. После того, как вы вошли в аккаунт, создайте S3 бакет, который будет использоваться для тестирования работы S3 Select.
Данные, которые мы будем использовать, представляют собой простой CSV файл, содержащий Имя, Номер Телефона, Город и Должность тестовых пользователей. Файл доступен в GitHub репозитории. Содержимое файла представлено далее, вы можете его дополнять и редактировать.
Файл доступен в GitHub репозитории. Содержимое файла представлено далее, вы можете его дополнять и редактировать.
Name,PhoneNumber,City,Occupation
Sam,(949) 555-6701,Irvine,Solutions Architect
Vinod,(949) 555-6702,Los Angeles,Solutions Architect
Jeff,(949) 555-6703,Seattle,AWS Evangelist
Jane,(949) 555-6704,Chicago,Developer
Sean,(949) 555-6705,Chicago,Developer
Mary,(949) 555-6706,Chicago,Developer
Kate,(949) 555-6707,Chicago,Developer
Загрузите файл sample_data.csv в ваш новый S3 бакет, созданный на предыдущем шаге.
Протестируем выполнение S3 Select запросов к файлу sample_data.csv с помощью Python скрипта. В примере используется имя бакета “s3select-demo”, вам необходимо заменить его на имя созданного вами бакета, куда был загружен файл.
Для быстрого тестирования скрипта мы развернем t3.micro EC2 инстанс с Amazon Linux 2 и установим на него boto3 – AWS SDK для Python. Проверьте, что IAM роль, назначенная EC2 инстансу, имеет доступ к созданному вами S3 бакету.
Выполняем S3 Select запросы из EC2 инстанса
После того, как вы создали и запустили EC2 инстанс, войдите на него по SSH как пользователь ec2-user, и запустите следующие команды для установки зависимостей и загрузки скриптов.
sudo yum update -y sudo yum install python3 -y python3 -m venv ~/s3select_example/env source ~/s3select_example/env/bin/activate pip install pip --upgrade pip install boto3 wget https://raw.githubusercontent.com/aws-samples/s3-select-phonebook-search/master/src/samples/jane.py wget https://raw.githubusercontent.com/aws-samples/s3-select-phonebook-search/master/src/samples/jane-gzip.py
Команды создают Python 3 environment и скачивают скрипт jane.py, содержимое которого представлено далее. Скрипт позволяет искать пользователей с именем Jane. Замените имя S3 бакета из скрипта, на имя созданного вами S3 бакета.
import boto3
s3 = boto3.client('s3')
resp = s3. select_object_content(
Bucket='s3select-demo',
Key='sample_data.csv',
ExpressionType='SQL',
Expression="SELECT * FROM s3object s where s.\"Name\" = 'Jane'",
InputSerialization = {'CSV': {"FileHeaderInfo": "Use"}, 'CompressionType': 'NONE'},
OutputSerialization = {'CSV': {}},
)
for event in resp['Payload']:
if 'Records' in event:
records = event['Records']['Payload'].decode('utf-8')
print(records)
elif 'Stats' in event:
statsDetails = event['Stats']['Details']
print("Stats details bytesScanned: ")
print(statsDetails['BytesScanned'])
print("Stats details bytesProcessed: ")
print(statsDetails['BytesProcessed'])
print("Stats details bytesReturned: ")
print(statsDetails['BytesReturned'])
 select_object_content(
Bucket='s3select-demo',
Key='sample_data.csv',
ExpressionType='SQL',
Expression="SELECT * FROM s3object s where s.\"Name\" = 'Jane'",
InputSerialization = {'CSV': {"FileHeaderInfo": "Use"}, 'CompressionType': 'NONE'},
OutputSerialization = {'CSV': {}},
)
for event in resp['Payload']:
if 'Records' in event:
records = event['Records']['Payload'].decode('utf-8')
print(records)
elif 'Stats' in event:
statsDetails = event['Stats']['Details']
print("Stats details bytesScanned: ")
print(statsDetails['BytesScanned'])
print("Stats details bytesProcessed: ")
print(statsDetails['BytesProcessed'])
print("Stats details bytesReturned: ")
print(statsDetails['BytesReturned'])
select_object_content(
Bucket='s3select-demo',
Key='sample_data.csv',
ExpressionType='SQL',
Expression="SELECT * FROM s3object s where s.\"Name\" = 'Jane'",
InputSerialization = {'CSV': {"FileHeaderInfo": "Use"}, 'CompressionType': 'NONE'},
OutputSerialization = {'CSV': {}},
)
for event in resp['Payload']:
if 'Records' in event:
records = event['Records']['Payload'].decode('utf-8')
print(records)
elif 'Stats' in event:
statsDetails = event['Stats']['Details']
print("Stats details bytesScanned: ")
print(statsDetails['BytesScanned'])
print("Stats details bytesProcessed: ")
print(statsDetails['BytesProcessed'])
print("Stats details bytesReturned: ")
print(statsDetails['BytesReturned'])
Параметр OutputSerialization имеет значение CSV, поэтому результат будет возвращен в CSV формате. Также можно получать результат в формате JSON.
Также можно получать результат в формате JSON.
После изменения имени S3 бакета в файле jane.py, запустите скрипт, используя следующую команду
python jane.py
Результат выполнения скрипта показан далее:
Jane,(949) 555-6704,Chicago,Developer
Stats details bytesScanned:326Stats details bytesProcessed:326Stats details BytesReturned:38
Найдена одна запись для пользователя с именем Jane. Также скрипт выводит объем просканированных, обработанных и возвращенных S3 Select данных. В нашем случае размер фала sample_data.csv – 326 байт, S3 Select сканирует весь файл и возвращает одну строку размером 38 байт.
S3 Select и сжатые данные
Давайте запустим тот же самый тест ещё раз, но теперь со сжатыми данными. Сожмите CSV файл адресной книги с помощью gzip, назовите файл sample_data. csv.gz, и загрузите его на S3. Предварительно сжатый файл можно скачать с GitHub.
csv.gz, и загрузите его на S3. Предварительно сжатый файл можно скачать с GitHub.
Для работы с новым файлом нам потребуется модифицировать Python скрипт. В качестве значения параметра Key мы укажем имя сжатого файла, а также изменим InputSerialization CompressionType c None на GZIP. Новая версия скрипта, jane-gzip.py, доступна в репозитории, а также была скачена нами при настройке EC2 инстанса.
Мы поменяли имя S3 ключа (имя файла) на имя сжатого файла sample_data.csv.gz:
Key='sample_data.csv.gz',
Кроме того, мы поменяли строку с параметром InputSerialization чтобы указать значение GZIP для CompressionType.
InputSerialization = {'CSV': {"FileHeaderInfo": "Use"}, 'CompressionType': 'GZIP'},
Полный код файла jane-gzip.py представлен далее. Обратите внимание, что вам требуется заменить имя S3 бакета в скрипте на имя созданного вами бакета.
import boto3 s3 = boto3.
 client('s3')
resp = s3.select_object_content(
Bucket='s3select-demo',
Key='sample_data.csv.gz',
ExpressionType='SQL',
Expression="SELECT * FROM s3object s where s.\"Name\" = 'Jane'",
InputSerialization = {'CSV': {"FileHeaderInfo": "Use"}, 'CompressionType': 'GZIP'},
OutputSerialization = {'CSV': {}},
)
for event in resp['Payload']:
if 'Records' in event:
records = event['Records']['Payload'].decode('utf-8')
print(records)
elif 'Stats' in event:
statsDetails = event['Stats']['Details']
print("Stats details bytesScanned: ")
print(statsDetails['BytesScanned'])
print("Stats details bytesProcessed: ")
print(statsDetails['BytesProcessed'])
print("Stats details bytesReturned: ")
print(statsDetails['BytesReturned'])
client('s3')
resp = s3.select_object_content(
Bucket='s3select-demo',
Key='sample_data.csv.gz',
ExpressionType='SQL',
Expression="SELECT * FROM s3object s where s.\"Name\" = 'Jane'",
InputSerialization = {'CSV': {"FileHeaderInfo": "Use"}, 'CompressionType': 'GZIP'},
OutputSerialization = {'CSV': {}},
)
for event in resp['Payload']:
if 'Records' in event:
records = event['Records']['Payload'].decode('utf-8')
print(records)
elif 'Stats' in event:
statsDetails = event['Stats']['Details']
print("Stats details bytesScanned: ")
print(statsDetails['BytesScanned'])
print("Stats details bytesProcessed: ")
print(statsDetails['BytesProcessed'])
print("Stats details bytesReturned: ")
print(statsDetails['BytesReturned'])
Выполните скрипт следующей командой. Будет осуществлен S3 Select SQL-запрос к сжатым данным.
python jane-gzip.py
Результат выполнения скрипта представлен ниже.
Jane,(949) 555-6704,Chicago,Developer
Stats details bytesScanned:199Stats details bytesProcessed:326Stats details bytesReturned:38
Сравнение результатов запроса к сжатым и не сжатым данным
Использование сжатия позволяет сократить объем данных, хранящихся на S3. В случае нашего маленького CSV файла для теста, сжатие позволило сократить размер файла на 39%.
Таблица далее показывает разницу между запросами к не сжатому файлу sample_data.csv и сжатому sample_data.csv.gz.
| Размер файла (байт) | Просканировано байт | Обработано байт | Возвращено байт | Разница | |
| Не сжатые данные | 326 | 326 | 326 | 38 | N/A |
| Сжатые данные | 199 | 199 | 326 | 38 | ~39% меньше |
Преимущества сжатия данных становятся более существенны в случае больших файлов. Например, CSV файл размером 133,975,755 байт (~128 MB), состоящий из примерно миллиона строк, может быть уменьшен на ~ 60% до 50,308,104 байт (~50.3 MB) при использовании GZIP сжатия.
Например, CSV файл размером 133,975,755 байт (~128 MB), состоящий из примерно миллиона строк, может быть уменьшен на ~ 60% до 50,308,104 байт (~50.3 MB) при использовании GZIP сжатия.
| Размер файла (байт) | Просканировано байт | Обработано байт | Возвращено байт | Разница | |
| Не сжатые данные | 133,975,755 | 133,975,755 | 133,975,755 | 6 | N/A |
| Сжатые данные | 50,308,104 | 50,308,104 | 133,975,755 | 6 | ~60% меньше |
Запросы к архивам с S3 Glacier Select
Когда вы создаете SQL-запросы к архивным объектам, хранящимся в S3 Glacier, S3 Glacier Select выполняет запрос прямо в архиве, и возвращает результат в Amazon S3. С S3 Glacier Select вы можете запускать запросы к данным, находящимся в S3 Glacier, без необходимости восстанавливать эти данные на более “горячий” уровень, такой как S3 Standard.
С S3 Glacier Select вы можете запускать запросы к данным, находящимся в S3 Glacier, без необходимости восстанавливать эти данные на более “горячий” уровень, такой как S3 Standard.
Для выполнения SELECT запросов, S3 Glacier предлагает на выбор три уровня доступа к данным: expedited, standard, и bulk. Каждый из этих уровней имеет разное время доступа и цену, и вы можете выбрать один из них, в зависимости от того, как быстро вам нужно получить данные. Для архивов менее 250 мегабайт при использовании expedited уровня доступа, данные из S3 Glacier обычно доступны в течение 1-5 минут. В случае стандартного уровня это время увеличивается до 3-5 часов, для bulk оно составляет 5-12 часов.
Заключение
Мы показали, как S3 Select позволяет простым образом выполнять SQL-запросы напрямую к данным, хранящимся в Amazon S3 и Amazon S3 Glacier. S3 Select часто используется когда нужно обработать данные, которые были загружены на S3 програмно, или с помощью таких сервисов как AWS Transfer for SFTP (AWS SFTP). Например, вы можете загрузить данные на S3 c помощью AWS SFTP, а потом сделать выборку данных с помощью S3 Select. S3 Select запрос может быть выполнен из AWS Lambda функции, которая будет автоматически вызываться по событию загрузки нового файла на S3. Фильтрация данных с помощью S3 Select потенциально позволяет вам сэкономить вам время и деньги, по сравнению с другими способами фильтрации, когда данные сначала загружаются в базу.
Например, вы можете загрузить данные на S3 c помощью AWS SFTP, а потом сделать выборку данных с помощью S3 Select. S3 Select запрос может быть выполнен из AWS Lambda функции, которая будет автоматически вызываться по событию загрузки нового файла на S3. Фильтрация данных с помощью S3 Select потенциально позволяет вам сэкономить вам время и деньги, по сравнению с другими способами фильтрации, когда данные сначала загружаются в базу.
Для того чтобы лучше освоить работу с S3 Select и другими сервисами рекомендуем вам изучить GitHub репозиторий AWS Samples. Там вы можете найти полный пример приложения поиска в телефонной книге. Этот пример выполняет S3 Select запросы из AWS Lambda функции, выставленной наружу с помощью Amazon API Gateway.
Очистка аккаунта
В нашем примере мы создали S3 бакет и загрузили туда файлы sample_data.csv и sample_data.csv.gz. Мы осуществляли запросы из t3.micro EC2 инстанса. Для того чтобы избежать лишних трат, выключите EC2 инстанс и удалите его, выбрав terminate. А также удалите файлы из S3 бакета. Вы можете удалить и сам S3 бакет.
А также удалите файлы из S3 бакета. Вы можете удалить и сам S3 бакет.
Дополнительные ресурсы
- GitHub репозиторий, в котором находится пример приложения телефонной книги, а также CSV файл с примером данных
- AWS Samples GitHub, включающий в себя множество примеров использования самых разных AWS сервисов
- Документация по Amazon S3 Select
- Документация по поддерживаемым SQL командам в Amazon S3 Select
- AWS Transfer for SFTP
- Использование AWS Lambda с событиями Amazon S3
TAGS: Amazon API Gateway, Amazon S3 Select, Amazon Simple Storage Service (Amazon S3), AWS Cloud Storage, AWS CloudFormation, AWS Lambda
AWS Central EurAsia & Russia Team
SQL Server. Оптимизация запросов SQL. MS SQL Медленно работают запросы SELECT
Введение
В данном руководстве мы изложили некоторые рекомендации по оптимизации запросов SQL.
Оптимизация структуры таблиц SQL Server
Разбивайте сложные таблицы на несколько, помните, чем больше в вашей таблице столбцов и тяжелых типов (nvarchar(max)), тем тяжелее по ней проход. Если некоторые данные не всегда используются в select с ней, выносите большие столбцы в отдельные таблицы и связывайте через FK
Выберите правильные типы данных. Всегда выбирайте самый маленький тип для данных, которые Вы должны хранить в столбце.
Если текстовые данные в столбце имеют разную длину, используйте тип данных NVARCHAR вместо NCHAR.
Не используйте NVARCHAR или NCHAR типы данных, если Вы не должны сохранить 16-разрядные символьные данные (UNICODE). Они требуют в два раза больше места, чем CHAR и VARCHAR, что повышает расходы времени на ввод-вывод (но если у вас кириллица, то без NVARCHAR не обойтись).
Если Вы должны хранить большие строки данных и их длина меньше чем 8,000 символов, используют тип данных NVARCHAR вместо TEXT. Текстовые поля требуют больше ресурсов для обработки и снижают производительность.
Текстовые поля требуют больше ресурсов для обработки и снижают производительность.
Любое поле, в котором должны быть только отличные от нуля значения, нужно объявлять как NOT NULL
Для любого поля, которое должно содержать уникальные значения, стоит указать модификатор UNIQUE
Хранение изображений в БД нежелательно. Храните в таблице путь к файлу (локальный путь или URL), а сам файл помещайте в файловую систему сервера.
Оптимизация запросов SELECT
Не читайте больше данных, чем надо. Не используйте *
Если ваше приложение позволяет пользователям выполнять запросы, но вы не можете отсечь лишние тысячи возвращаемых строк, используйте оператор TOP внутри инструкции SELECT.
Не возвращайте клиенту большее количество столбцов или строк, чем действительно необходимо (Не используй * в Select).
Как можно раньше отфильтруйте данные. Не нужно выполнять большой тяжелый подзапрос для всех строк таблицы. Сначала отфильтруйте нужные строки.
Корректно используйте JOIN
Если Вы имеете две или более таблиц, которые часто объединяются вместе, тогда столбцы, используемые для объединений должны иметь соответствующий индекс.
Для лучшей производительности, столбцы, используемые в объединениях должны иметь одинаковые типы данных. И если возможно, это должны быть числовые типы данных, вместо символьных типов.
Избегайте объединять таблицы по столбцам с малым числом уникальных значений. Если столбцы, используемые при объединениях, имеют мало уникальных значений, то SQL сервер будет просматривать всю таблицу, даже если по данному столбцу существует индекс. Для наилучшей производительности объединение таблиц должно производится по столбцам с уникальными индексами.
Если Вы должны регулярно объединять четыре или более таблиц, для получения recordset’а, попробуйте денормализовать таблицы так, чтобы число таблиц, участвующих в объединении уменьшилось. Часто, при добавлении одного или двух столбцов из одной таблицы в другую, объединения могут быть уменьшены.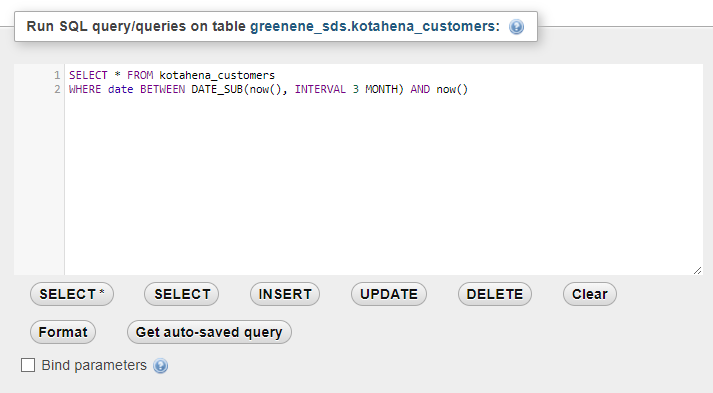
Если вам нужно постоянно получать некоторые данные на лету (например, расчет бонусов клиента), попробуйте это поле хранить в отдельной колонке и обновлять по необходимости. В этом случае не нужно будет делать лишние join и подзапросы.
Тип JOIN используйте только тот, который вернет вам НЕОБХОДИМЫЕ данные без каких-либо дублей или лишней информации (или совсем отказаться от join). Т.е. не нужно получать всех пользователей таким образом:
select users.username from users inner join roles on users.roleID=roles.id
В этом случае вы получите много повторов пользователей
Сортировка в SELECT
Самой ресурсоемкой сортировкой является сортировка строк.
При объявлении полей всегда следует использовать размер, который нужен, и не выделять лишние байты про запас.
Если сортируете по дате создания, то попробуйте сортировать просто по id (первичный ключ с identity(1,1)).
Группирование в SELECT
Используйте как можно меньше колонок для группировки.
По возможности лучше использовать Where вместо Having, т.к. это уменьшает количество строк для группировки на ранней стадии.
Если требуется группирование, но без использования агрегатных функций (COUNT(), MIN(), MAX и т.д.), разумно использовать DISTINCT.
Не используйте множественные вложенные группировки через подзапросы.
Ограничить использование DISTINCT
Эта команда исключает повторяющиеся строки в результате. Команда требует повышенного времени обработки. Лучше всего комбинировать с LIMIT.
Ограничить использование SELECT для постоянно изменяющихся таблиц.
Возможно имеет смысл сохранять промежуточные агрегированные данные в какой-то другой таблице, которая обновляется менее часто чем таблица изменений (например, таблица логов).
Оптимизация WHERE в запросе SELECT
Если where состоит из условий, объединенных AND, они должны располагаться в порядке возрастания вероятности истинности данного условия. Чем быстрее мы получим false в одном из условий — тем меньше условий будет обработано и тем быстрее выполняется запрос.
Если where состоит из условий, объединенных OR, они должны располагаться в порядке уменьшения вероятности истинности данного условия. Чем быстрее мы получим true в одном из условий — тем меньше условий будет обработано и тем быстрее выполняется запрос.
Исопльзуйте IN вместо OR. Операция IN работает гораздо быстрее, чем серия OR. Запрос «… WHERE column1 = 5 OR column1 = 6» медленнее чем «…WHERE column1 IN (5, 6)».
Используйте Exists вместо Count >0 в подзапросах. Используйте where exists (select id from t1 where id = t.id) вместо where count(select id from t1 where id=t.id) > 0
LIKE. Эту операцию следует использовать только при крайней необходимости, потому что лучше и быстрее использовать поиск, основанный на full-text индексах.
Советы по оптимизации хранимых процедур и SQL пакетов
Инкапсулируйте ваш код в хранимых процедурах
Для обработки данных используйте хранимые SQL процедуры.
Когда хранимая процедура выполняется в первый раз (и у нее не определена опция WITH RECOMPILE), она оптимизируется, для нее создается план выполнения запроса, который кешируется SQL сервером. Если та же самая хранимая процедура вызывается снова, она будет использовать кешированный план выполнения запроса, что экономит время и увеличивает производительность.
Если та же самая хранимая процедура вызывается снова, она будет использовать кешированный план выполнения запроса, что экономит время и увеличивает производительность.
Всегда включайте в ваши хранимые процедуры инструкцию «SET NOCOUNT ON». Если Вы не включите эту инструкцию, тогда каждый раз при выполнении запроса SQL сервер отправит ответ клиенту, указывающему число строк, на которые воздействует запрос.
Избегайте использования курсоров
По возможности выбирайте быстрый forward-only курсор
При использовании серверного курсора, старайтесь использовать как можно меньший рекордсет. Для этого выбирайте только те столбцы и строки, которые необходимы клиенту для решения его текущей задачи.
Когда Вы закончили использовать курсор, как можно раньше не только ЗАКРОЙТЕ (CLOSE) его, но и ОСВОБОДИТЕ (DEALLOCATE).
Используйте триггеры c осторожностью
Триггеры — это усложнение логики работы приложения, неявное неожиданное выполнение дополнительных действий.
Триггеры усложняют интерфейс хранимых процедур. Поместите все необходимые проверки и действия в рамки хранимых процедур.
Временные таблицы для больших таблиц, табличные переменные — для малых (меньше 1000)
Если вам требуется хранить промежуточные данные в таблицах, то используйте табличные переменные (@t1) для малых таблиц, а временные таблицы (#t1) — для больших.
Подробнее:
http://sqlcom.ru/helpful-and-interesting/compare-temp-table-vs-table-variable-vs-cte/
https://coderoad.ru/27894/%D0%92-%D1%87%D0%B5%D0%BC-%D1%80%D0%B0%D0%B7%D0%BD%D0%B8%D1%86%D0%B0-%D0%BC%D0%B5%D0%B6%D0%B4%D1%83-%D0%B2%D1%80%D0%B5%D0%BC%D0%B5%D0%BD%D0%BD%D0%BE%D0%B9-%D1%82%D0%B0%D0%B1%D0%BB%D0%B8%D1%86%D0%B5%D0%B9-%D0%B8-%D1%82%D0%B0%D0%B1%D0%BB%D0%B8%D1%87%D0%BD%D0%BE%D0%B9-%D0%BF%D0%B5%D1%80%D0%B5%D0%BC%D0%B5%D0%BD%D0%BD%D0%BE%D0%B9-%D0%B2-SQL-Server
При определении временной таблицы имеет смысл проверить ее на существование:
IF OBJECT_ID('tempdb..#eventIDs') IS NOT NULL begin
DROP TABLE #eventIDs
end
CREATE TABLE #eventIDs ( id int primary key,instanceID int )
Также для улучшения быстродействия используйте для временной таблицы первичный ключ и индексы.
Как уменьшить вероятность дедлоков на базе
Дедлок — это взаимная блокировка 2 выполняющихся пакетов sql. Это самым негативным образом сказывается на быстродействии запросов.
Чтобы избежать deadlocks, пытайтесь разрабатывать ваше приложение с учетом следующих рекомендаций:
- Всегда получайте доступ к объектам в одном и том же порядке.
- Старайтесь делать транзакции короткими и заключайте их в один пакет (batch)
- Старайтесь использовать максимально низкий уровень изоляции для пользовательского соединения, которое работает с транзакцией.
Работа с индексами SQL Server
Советы по созданию кластерных индексов
- Первичный ключ не всегда должен быть кластерным индексом. Если Вы создаете первичный ключ, тогда SQL сервер автоматически делает первичный ключ кластерным индексом.
- Кластерные индексы идеальны для запросов, где есть выбор по диапазону или вы нуждаетесь в сортированных результатах. Так происходит потому, что данные в кластерном индексе физически отсортированы по какому-то столбцу. Запросы, получающие выгоду от кластерных индексов, обычно включают в себя операторы BETWEEN, <, >, GROUP BY, ORDER BY, и агрегативные операторы типа MAX, MIN, и COUNT.
- Кластерные индексы хороши для запросов, которые ищут запись с уникальным значением (типа номера служащего) и когда Вы должны вернуть большую часть данных из записи или всю запись. Так происходит потому, что запрос покрывается индексом.
- Кластерные индексы хороши для запросов, которые обращаются к столбцам с ограниченным числом значений, например столбцы, содержащие данные о странах или штатах. Но если данные столбца мало отличаются, например, значения типа «да/нет», «мужчина/женщина», то такие столбцы вообще не должны индексироваться.
- Кластерные индексы хороши для запросов, которые используют операторы GROUP BY или JOIN.
- Кластерные индексы хороши для запросов, которые возвращают много записей, потому что данные находятся в индексе, и нет необходимости искать их где-то еще.
- Избегайте помещать кластерный индекс в столбцы, в которых содержатся постоянно возрастающие величины, например, даты, подверженные частым вставкам в таблицу (INSERT). Так как данные в кластерном индексе должны быть отсортированы, кластерный индекс на инкрементирующемся столбце вынуждает новые данные быть вставленным в ту же самую страницу в таблице, что создает «горячую зону в таблице» и приводит к большому объему дискового ввода-вывода. Постарайтесь найти другой столбец, который мог бы стать кластерным индексом.
 Запросы, получающие выгоду от кластерных индексов, обычно включают в себя операторы BETWEEN, <, >, GROUP BY, ORDER BY, и агрегативные операторы типа MAX, MIN, и COUNT.
Запросы, получающие выгоду от кластерных индексов, обычно включают в себя операторы BETWEEN, <, >, GROUP BY, ORDER BY, и агрегативные операторы типа MAX, MIN, и COUNT. Так как данные в кластерном индексе должны быть отсортированы, кластерный индекс на инкрементирующемся столбце вынуждает новые данные быть вставленным в ту же самую страницу в таблице, что создает «горячую зону в таблице» и приводит к большому объему дискового ввода-вывода. Постарайтесь найти другой столбец, который мог бы стать кластерным индексом.
Так как данные в кластерном индексе должны быть отсортированы, кластерный индекс на инкрементирующемся столбце вынуждает новые данные быть вставленным в ту же самую страницу в таблице, что создает «горячую зону в таблице» и приводит к большому объему дискового ввода-вывода. Постарайтесь найти другой столбец, который мог бы стать кластерным индексом.Советы по выбору некластерных индексов
- Некластерные индексы лучше подходят для запросов, которые возвращают немного записей (включая только одну запись) и где индекс имеет хорошую селективность (более чем 95 %).
- Если столбец в таблице не содержит по крайней мере 95% уникальных значений, тогда очень вероятно, что Оптимизатор Запроса SQL сервера не будет использовать некластерный индекс, основанный на этом столбце. Поэтому добавляйте некластерные индексы к столбцам, которые имеют хотя бы 95% уникальных записей. Например, столбец с «Да» или «Нет» не имеет 95% уникальных записей.
- Постарайтесь сделать ваши индексы как можно меньшего размера (особенно для многостолбцовых индексов). Это уменьшает размер индекса и уменьшает число чтений, необходимых, чтобы прочитать индекс, что увеличивает производительность.
- Если возможно, создавайте индексы на столбцах, которые имеют целочисленные значения вместо символов. Целочисленные значения имеют меньше потерь производительности, чем символьные значения.
- Если ваше приложение будет выполнять один и тот же запрос много раз на той же самой таблице, рассмотрите создание покрывающего индекса на таблице. Покрывающий индекс включает все столбцы, упомянутые в запросе. Из-за этого индекс содержит все данные, которые Вы ищете, и SQL сервер не должен искать фактические данные в таблице, что сокращает логический и/или физический ввод — вывод. С другой стороны, если индекс становится слишком большим (слишком много столбцов), это может увеличить объем ввода — вывода и ухудшить производительность.
- Индекс полезен для запроса только в том случае, если оператор WHERE запроса соответствует столбцу (столбцам), которые являются крайними левыми в индексе. Так, если Вы создаете составной индекс, типа «City, State», тогда запрос » WHERE City = ‘Хьюстон’ » будет использовать индекс, но запрос » WHERE State = ‘TX’ » не будет использовать индекс.
- Любая операция над полем в предикате поиска, которое лежит под индексом, сводит на нет его использование. where isnull(field,’’) = ‘’ здесь индекс не используется, where field = ‘’ and field is not null — здесь используется.
 Это уменьшает размер индекса и уменьшает число чтений, необходимых, чтобы прочитать индекс, что увеличивает производительность.
Это уменьшает размер индекса и уменьшает число чтений, необходимых, чтобы прочитать индекс, что увеличивает производительность.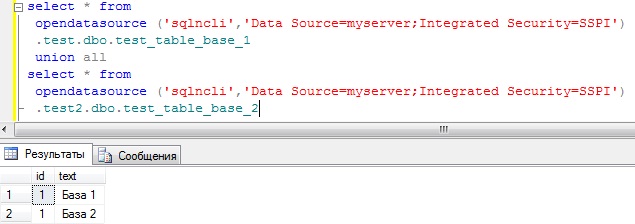 Так, если Вы создаете составной индекс, типа «City, State», тогда запрос » WHERE City = ‘Хьюстон’ » будет использовать индекс, но запрос » WHERE State = ‘TX’ » не будет использовать индекс.
Так, если Вы создаете составной индекс, типа «City, State», тогда запрос » WHERE City = ‘Хьюстон’ » будет использовать индекс, но запрос » WHERE State = ‘TX’ » не будет использовать индекс.Бывает ли слишком много индексов?
Да. Проблема с лишними индексами состоит в том, что SQL сервер должен изменять их при любых изменениях таблицы (INSERT, UPDATE, DELETE).
Лучшим решением ставить сомнительный индекс или нет, будет подождать и собрать статистику по работе индексов.
Лучшие кандидаты на установку индекса
- Это поля, по которым идет Join
- Поля связи, участвующие в подзапросах
- Поля, по которым идет фильтрация в where
- Поля, по которым выполняется сортировка.
Советы по использованию временных таблиц и табличных переменных
Если вы замечаете, что обращаетесь к одной и той же таблице несколько раз, то это явный знак необходимости использовать временную таблицу.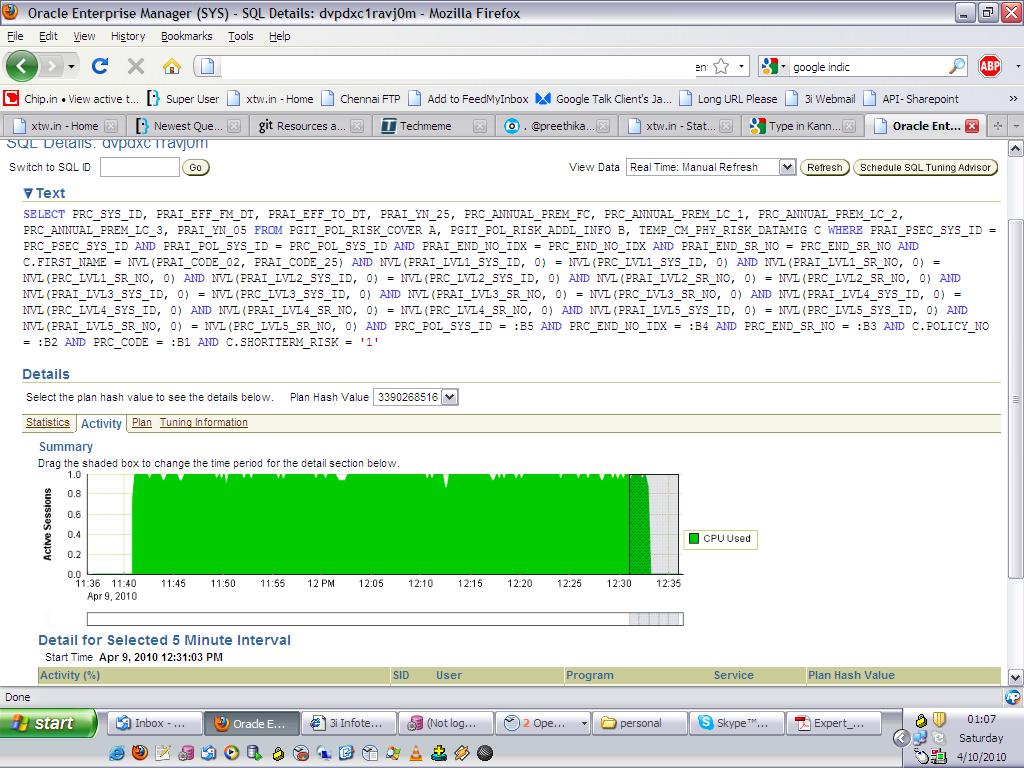
- Временная таблица храниться физически в tempdb, табличная переменная хранится в памяти SQL
- SQL может сам решить сохранить табличную переменную физически, если там будет много данных, это потеря ресурсов
- Временная таблица подходит для большого объема данных (полноценная выборка), табличная переменная — для малого объема данных (справочники или набор ID для чего-то)
- Временная таблица доступна из любой процедуры SQL, табличная переменная только в рамках запроса. Не забывайте очищать временные таблицы после их использования
Если вы SQL-разработчик или администратор MS SQL Server, и вы хотели бы разрабатывать веб-решения на SQL, то веб-платформа Falcon Space — это то, что вам нужно.
В ней SQL — это основной язык разработки, который позволяет реализовать систему личных кабинетов с формами, таблицами, дашбордами и другими компонентами. Все настраивается на SQL. Для поддержки решения надо иметь знания только по SQL и HTML.
Вводная статья по Falcon Space для SQL специалиста
SQL-запрос — Документация Bpium
Используется для выполнения SQL-запросов к внешним базам данных.
Секция «Подключение»
Тип базы данных Выбор протокола подключения к базе данных. Подключиться можно к одной из следующих баз данных: PostgreSQL, MySQL, Oracle, SQLite, MsSQL.
Способ подключения Позволяет указать формат для подключения, передав отдельно параметры или целиком строку подключения.
Способ подключения: Параметры
Адрес сервера Адрес (домен или IP-адрес) сервера базы данных. Доступен, если способ подключения «Параметры». Допустимо указывать адрес хоста вместе с портом, разделенные через двоеточие. Формат: «значение в кавычках» или выражение.
Доступен, если способ подключения «Параметры». Допустимо указывать адрес хоста вместе с портом, разделенные через двоеточие. Формат: «значение в кавычках» или выражение.
База данных Имя базы данных. Доступен, если способ подключения «Параметры». Формат: «значение в кавычках» или выражение.
Логин Доступен, если способ подключения «Параметры». Формат: «значение в кавычках» или выражение.
Пароль Доступен, если способ подключения «Параметры». Формат: «значение в кавычках» или выражение.
Формат: «значение в кавычках» или выражение.
Способ подключения: Строка подключения
Строка подключения Строка подключения к базе данных со всеми параметрами подключения. Для разных типов баз данных используется свой синтаксис. Подробнее в документации соответствующей базы данных. Свойство доступно, если способ подключения «Строка подключения». Формат: «значение в кавычках» или выражение.
Пример для PostgreSQL:
«postgres://user:[email protected]:port/dbname»
Секция «Запрос»
SQL-запрос SQL-запрос или SQL-код в синтаксисе выбранного типа базы данных.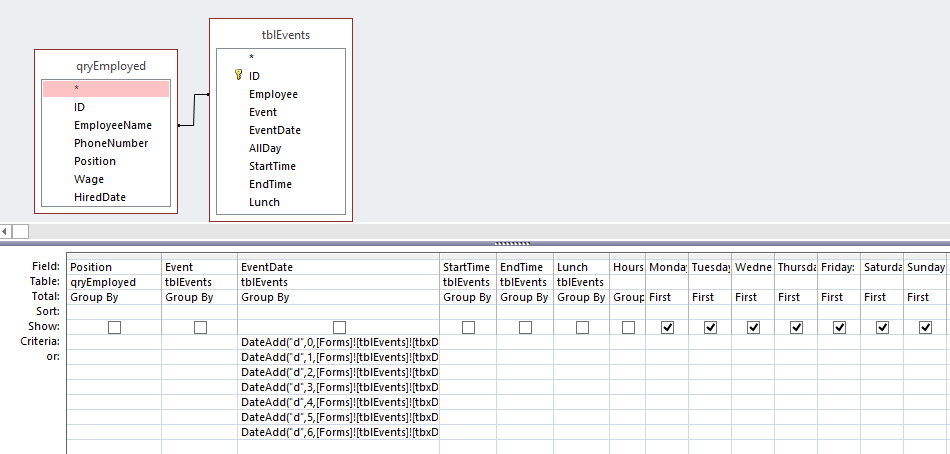 Позволяет использовать именные параметры. Формат: «значение в кавычках» или выражение. Пример:
Позволяет использовать именные параметры. Формат: «значение в кавычках» или выражение. Пример:
«Select * from tablename where id > :paramname1»
При формировании SQL-запроса будет подставлен параметр paramname1, указанный в свойстве «Параметры запроса».
Параметры запроса Позволяет передать именные параметры для SQL-запроса. Формат: список «параметр = значение/выражение».
Помимо использования переменных из поля Параметры запроса можно так же использовать глобальные сценарные переменные, посредством синтаксиса ${value}. Например, описанный выше запрос с переменной можно описать следующим образом, при условии, что в сценарии существует переменная paramname1:
Например, описанный выше запрос с переменной можно описать следующим образом, при условии, что в сценарии существует переменная paramname1:
`Select * from tablename where id > ${paramname1}`
Секция «Ответ»
Ожидать ответа Указывает дожидаться ли компоненту возврата результата запроса.
Сохранить в Выходной параметр. Сохраняет ответ в указанную переменную. В качестве ответа компонент возвращает массив из строк. Каждая строка представлена в виде обьекта, ключами которого являются имена колонок. Формат: имя переменной. Пример:
«fieldname1»: value,
«fieldname2»: value,
В «Сохранить в» можно указать ключ объекта и массив из строк сохранится как значения этого ключа.
Пример
Если указать в поле «Сохранить в» переменнуюdata.temp, то результат будет выглядеть следующим образом:
data: {
«temp»: [
«fieldname1»: value,
«fieldname2»: value,
Компонент поддерживает 2 типа пограничных событий:
Ошибка — выход из компонента, если произошла какая-либо ошибка
Таймаут — выход из компонента, спустя заданное ограничение по времени
Если компонент завершился с ошибкой, но на нем не было пограничного события, то процесс завершается. Сообщение ошибки возвращается в результатах процесса.
вложенные запросы и временные таблицы
Добро пожаловать в следующую статью из цикла про SQL! В предыдущей статье мы считали Transactions и Gross для приложения на двух платформах и получили отдельный результат для каждого приложения.
Transactions и Gross для приложения «3 in a row». Скриншот из демо devtodevНо что если мы хотим обобщить его и для каждой метрики иметь только одно значение? Для этого мы будем использовать результат, получившийся с помощью операции union, как таблицу в операторе from. И затем в select вычислять сумму по полю transactions и gross из объединенной таблицы (скриншот выше).
Залогиньтесь на сайте, зайдите в демо и найдите SQL отчёт во вкладке Reports.
Результат запроса. Скриншот из демо devtodevselect ‘Metrics for all projects’ as «App»
, sum(transactions) as «Transactions»
, sum(gross) as «Gross»
from (
select count() as transactions
, sum(priceusd) as gross
from p102968.
where eventtime > current_date — interval ‘7 day’ and eventtime < current_dateunion all
select count() as «Transactions»
, sum(priceusd) as «Gross»
from p104704.payments
where eventtime > current_date — interval ‘7 day’ and eventtime < current_date
) as metrics_by_platform
 payments
paymentsОператор from теперь содержит целый запрос внутри себя, который обращается сразу к двум таблицам. Тоже самое можно провернуть и с внутренним запросом, добавив в каждый из from еще запрос select, если это необходимо. Важно, чтобы такие запросы были заключены в скобки и им было дано имя – имя результирующей таблицы.
) as metrics_by_platform
Такую конструкцию можно использовать во всех операторах, обращающихся к таблицам. Например, в join.
Inner join (select … from … where …) as join_table
on join_table.param = t.param
Метрики по отдельным приложениям и суммарно по всем
Давайте в одном запросе посчитаем суммарные метрики по всем приложениям, а также выведем расшифровку (метрики по каждому из приложений) ниже.
Результат запроса. Скриншот из демо devtodevselect ‘Metrics for all projects’ as «App»
, sum(transactions) as «Transactions»
, sum(gross) as «Gross»
from (
select ‘3 in a row. iOS’ as «App»
, count() as transactions
, sum(priceusd) as gross
from p102968.payments
where eventtime > current_date — interval ‘7 day’ and eventtime < current_dateunion all
select ‘3 in a row. Android’ as «App»
, count() as transactions
, sum(priceusd) as gross
from p104704.payments
where eventtime > current_date — interval ‘7 day’ and eventtime < current_date
) metrics_by_platformunion all
select ‘3 in a row.
, count() as transactions
, sum(priceusd) as gross
from p102968.payments
where eventtime > current_date — interval ‘7 day’ and eventtime < current_dateunion
select ‘3 in a row. Android’ as «App»
, count() as «Transactions»
, sum(priceusd) as «Gross»
from p104704.payments
where eventtime > current_date — interval ‘7 day’ and eventtime < current_date
order by 3 desc
 iOS’ as «App»
iOS’ as «App»Получается довольно громоздкий запрос, в котором мы по два раза обращаемся к каждой из таблиц payments, и к тому же мы два раза написали один и тот же код (при изменении запроса нам придётся вносить изменения в двух местах).
Чтобы избежать этого, мы можем создать представление (Common Table Expression – CTE), и затем в ходе запроса обращаться к нему несколько раз. Конструкция может содержать в себе сколь угодно сложные запросы и обращаться к другим представлениям. Она выглядит следующим образом:
Она выглядит следующим образом:
with temp_table_name as
(select … from …)
Можно сказать, что мы создаем временную таблицу, которая рассчитывается один раз в ходе выполнения запроса даже если вы обращаетесь к ней из разных мест. Использование представлений CTE также сильно упрощает чтение запроса и его последующее редактирование.
Вот как вышеуказанный запрос будет выглядеть с использованием представлений CTE:
with metrics_by_platform as (
select ‘3 in a row. iOS’ as app
, count() as transactions
, sum(priceusd) as gross
from p102968.payments
where eventtime > current_date — interval ‘9 day’ and eventtime < current_dateunion all
select ‘3 in a row. Android’ as app
, count() as transactions
, sum(priceusd) as gross
from p104704.payments
where eventtime > current_date — interval ‘9 day’ and eventtime < current_date
)
select ‘Metrics for all projects’ as «App»
, sum(transactions) as «Transactions»
, sum(gross) as «Gross»
from metrics_by_platformunion all
select app
, transactions
, gross
from metrics_by_platform
order by 3 desc
Выглядит проще, не правда ли? Если мы добавим новое приложение и захотим анализировать и его метрики, мы просто добавим его в представление metrics_by_platform, а расчет самих метрик и итоговый вывод результатов никак не зависит от количества приложений.
Доля пользователей, совершивших максимальное количество платежей (вложенные запросы)
Рассмотрим более сложный пример. Давайте узнаем, какое максимальное число платежей совершено одним пользователем за 7 дней и сколько таких пользователей.
Сложные запросы всегда лучше писать частями, и начнем мы с максимального количества платежей.
У нас есть таблица со всеми платежами пользователей from p102968.payment. Из нее мы посчитаем количество совершенных платежей для каждого из пользователей, сгруппировав их по devtodevid, а потом найдем максимальное число таких платежей с помощью max().
Результат запроса.select max(user_payments) as «max_payments»
from (
select devtodevid
, count() user_payments
from p102968.payments
where eventtime > current_date — interval ‘9 day’ and eventtime < current_date
group by devtodevid
) as payments_count
 Скриншот из демо devtodev
Скриншот из демо devtodevОсталось узнать, сколько пользователей совершили 12 платежей за это же время. Для этого только что выполненный запрос мы помещаем в фильтр where user_payments = (запрос), который оставит нам только пользователей с соответствующим максимальному количеством платежей. Сам запрос будет возвращать число таких пользователей select count() as «Users» и максимальное количество платежей max(user_payments) as «Max payments count» из таблицы from (…) as payments_count.
Результат запроса. Скриншот из демо devtodevselect count(devtodevid) as «Users»
, max(user_payments) as «Max payments count»
from (
select devtodevid
, count() user_payments
from p102968.payments
where eventtime > current_date — interval ‘7 day’ and eventtime < current_date
group by devtodevid
) as payments_countwhere user_payments = (select max(user_payments)
from
(select devtodevid
, count() user_payments
from p102968.
where eventtime > current_date — interval ‘7 day’ and eventtime < current_date
group by devtodevid) as payments_count
)
 payments
paymentsПри выполнении для каждой строчки из внешнего запроса будет производиться сравнение максимального количества платежей пользователей where user_payments = (…) . В коде мы два раза использовали один и тот же запрос, поэтому давайте оптимизируем его с помощью представления CTE.
with payments_count as (
select devtodevid
, count() user_payments
from p102968.payments
where eventtime > current_date — interval ‘7 day’ and eventtime < current_date
group by devtodevid
)select count() as «Users»
, max(user_payments) as «Payments count»
from payments_count
where user_payments = (select max(user_payments)
from payments_count
А какова доля пользователей с таким количеством платежей среди всех платящих пользователей? Может быть он всего один и платил?
Чтобы узнать это, мы должны добавить вложенный запрос прямо в select, который посчитает всех платящих пользователей. На это число мы затем и поделим количество пользователей с максимальным платежом.
На это число мы затем и поделим количество пользователей с максимальным платежом.
Результат запроса. Скриншот из демо devtodevwith payments_count as (
select devtodevid
, count() user_payments
from p102968.payments
where eventtime > current_date — interval ‘7 day’ and eventtime < current_date
group by devtodevid
)select count() as «Users with max payments count»
, max(user_payments) as «Payments count»
, round(count()*100::numeric / (select count(distinct devtodevid)
from p102968.payments
where eventtime > current_date — interval ‘7 day’ and eventtime < current_date
, 2) ||’%’ as «% of all payers»
from payments_count
where user_payments = (select max(user_payments)
from payments_count)
Вложенные запросы внутри select – довольно распространенная практика.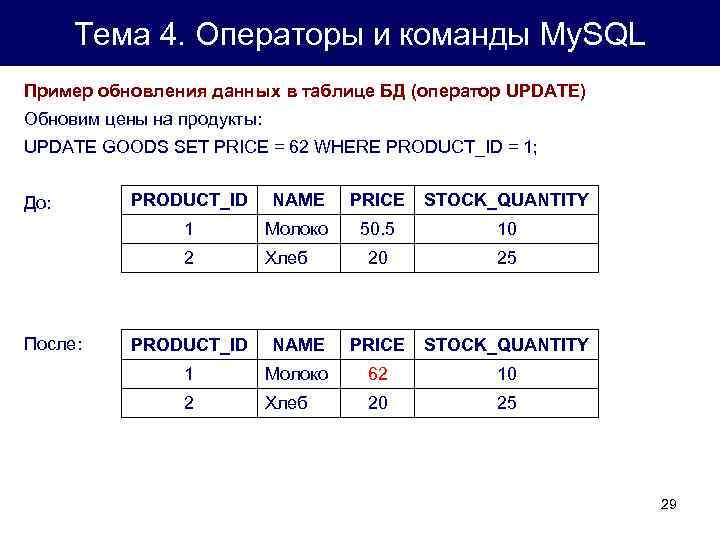 Они часто используются для расчета доли от чего-либо, либо отображения информации из другой таблицы без использования join.
Они часто используются для расчета доли от чего-либо, либо отображения информации из другой таблицы без использования join.
P.S.
В этой статье мы рассмотрели несколько примеров использования временных таблиц и вложенных запросов. В следующий раз вы научитесь заполнять пустые даты на графиках и формировать гистограмму распределения.
Введение в интерфейс SQLite C/C++
Введение в интерфейс SQLite C/C++
► Оглавление
1. Резюме
2. Введение
3. Основные объекты и интерфейсы
4. Типичное использование основных подпрограмм и объектов
5. Удобные обертки вокруг основных подпрограмм
30 Операторы 900 2 Preparedи привязка 7. Настройка SQLite
8. Расширение SQLite
9. Другие интерфейсы
Следующие два объекта и восемь методов составляют основные элементы интерфейса SQLite:
sqlite3 → Объект подключения к базе данных.
Сделано
sqlite3_open() и уничтожается sqlite3_close().sqlite3_stmt → Подготовленный объект оператора. Сделано sqlite3_prepare() и уничтожается sqlite3_finalize().
sqlite3_open() → Откройте соединение с новой или существующей базой данных SQLite. Конструктор для sqlite3.
sqlite3_prepare() → Скомпилируйте текст SQL в байт-код, который будет выполнять работу по запросу или обновлению базы данных. Конструктор для sqlite3_stmt.
sqlite3_bind() → Храните данные приложения в параметры исходного SQL.
sqlite3_step() → Переместите sqlite3_stmt к следующей строке результата или к завершению.
sqlite3_column() → Значения столбцов в текущей строке результатов для sqlite3_stmt.
sqlite3_finalize() → Деструктор для sqlite3_stmt.
sqlite3_close() → Деструктор для sqlite3.
sqlite3_exec() → Функция-оболочка, которая выполняет функции sqlite3_prepare(), sqlite3_step(), sqlite3_column() и sqlite3_finalize() для строка из одного или нескольких операторов SQL.
 Сделано
sqlite3_open() и уничтожается sqlite3_close().
Сделано
sqlite3_open() и уничтожается sqlite3_close().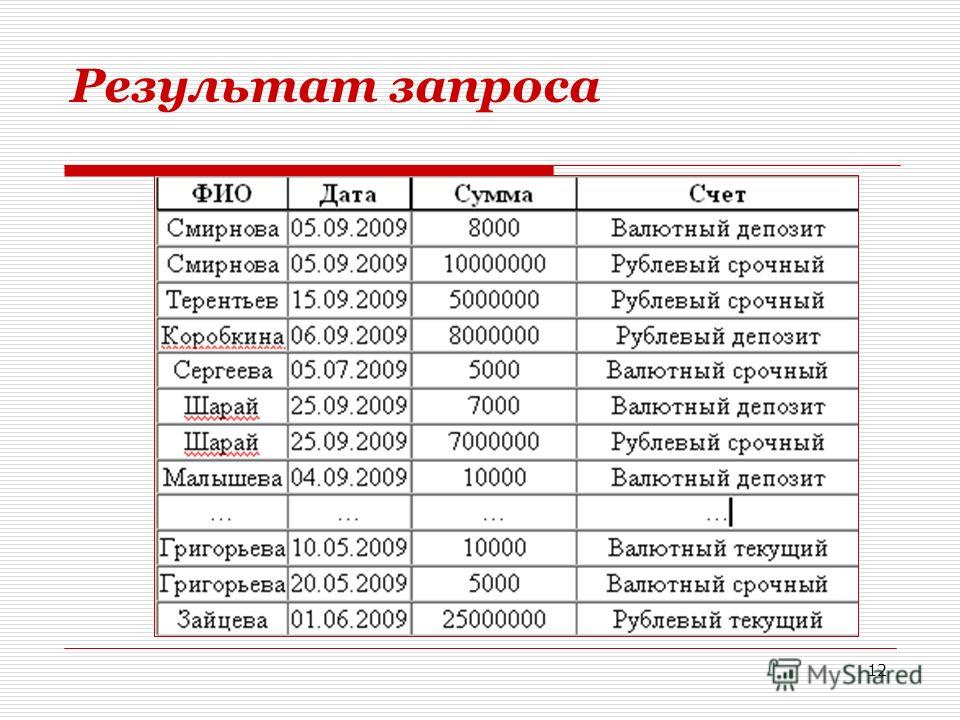
SQLite имеет более 225 API. Однако большинство API являются необязательными и очень специализированными. и могут быть проигнорированы новичками. Основной API небольшой, простой и легкий в освоении. В этой статье кратко изложен основной API.
Отдельный документ, The SQLite C/C++ Interface, предоставляет подробные спецификации для всех API-интерфейсов C/C++ для SQLite. Один раз читатель понимает основные принципы работы SQLite, этот документ следует использовать в качестве справочного руководство. Эта статья предназначена только для ознакомления и не является полный и авторитетный справочник по SQLite API.
Основная задача ядра базы данных SQL состоит в том, чтобы оценивать операторы SQL. SQL. Для этого разработчику нужны два объекта:
- Объект подключения к базе данных: sqlite3
- Подготовленный объект оператора: sqlite3_stmt
Строго говоря, подготовленный объект оператора не требуется, поскольку
удобные интерфейсы-оболочки, sqlite3_exec или
sqlite3_get_table, можно использовать и эти удобные обертки
инкапсулировать и скрыть подготовленный объект оператора.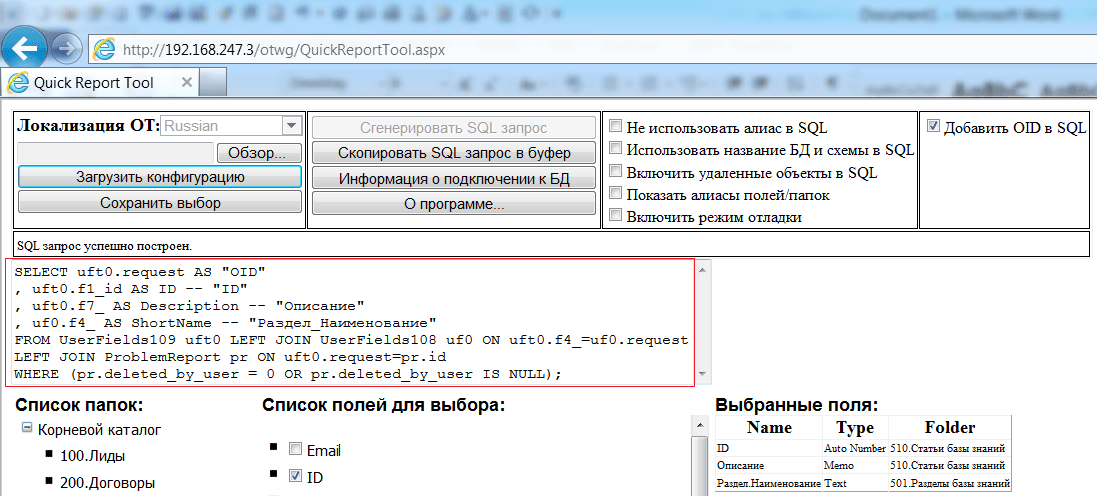 Тем не менее, понимание
подготовленные операторы необходимы для полного использования SQLite.
Тем не менее, понимание
подготовленные операторы необходимы для полного использования SQLite.
Соединение с базой данных и подготовленные объекты операторов контролируются с помощью небольшого набора подпрограмм интерфейса C/C++, перечисленных ниже.
- sqlite3_open()
- sqlite3_prepare()
- sqlite3_step()
- sqlite3_column()
- sqlite3_finalize()
- sqlite3_close()
Обратите внимание, что приведенный выше список подпрограмм является концептуальным, а не фактическим.
Многие из этих подпрограмм имеют несколько версий.
Например, в приведенном выше списке показана одна подпрограмма
с именем sqlite3_open(), хотя на самом деле это три отдельные процедуры
которые выполняют одно и то же немного разными способами:
sqlite3_open(), sqlite3_open16() и sqlite3_open_v2().
В списке упоминается sqlite3_column()
когда на самом деле такой процедуры не существует.
«sqlite3_column()», показанный в списке, является заполнителем для
целое семейство подпрограмм, что дополнительный столбец
данные в различных типах данных.
Вот краткое изложение того, что делают основные интерфейсы:
sqlite3_open()
Эта рутина открывает соединение с файлом базы данных SQLite и возвращает объект подключения к базе данных. Часто это первый SQLite API. вызов, который делает приложение, и является необходимым условием для большинства других SQLite API. Для многих интерфейсов SQLite требуется указатель на объект подключения к базе данных в качестве их первого параметра и может следует рассматривать как методы объекта подключения к базе данных. Эта подпрограмма является конструктором объекта соединения с базой данных.
sqlite3_prepare()
Эта рутина преобразует текст SQL в подготовленный объект оператора и возвращает указатель к этому объекту. Для этого интерфейса требуется указатель подключения к базе данных. созданный предыдущим вызовом sqlite3_open() и текстовой строкой, содержащей оператор SQL, который необходимо подготовить.
Этот API на самом деле не оценивает
оператор SQL. Он просто подготавливает оператор SQL для оценки.Думайте о каждом операторе SQL как о небольшой компьютерной программе. Цель sqlite3_prepare() состоит в том, чтобы скомпилировать эту программу в объектный код. Подготовленный оператор является объектным кодом. Интерфейс sqlite3_step() затем запускает объектный код, чтобы получить результат.
Новые приложения всегда должны вместо этого вызывать sqlite3_prepare_v2() из sqlite3_prepare(). Старый sqlite3_prepare() сохраняется для обратная совместимость. Но sqlite3_prepare_v2() предоставляет много возможностей. лучший интерфейс.
sqlite3_step()
Эта процедура используется для оценки подготовленного оператора, который был ранее созданный интерфейсом sqlite3_prepare(). Заявление оценивается до момента, когда доступна первая строка результатов. Чтобы перейти ко второй строке результатов, снова вызовите sqlite3_step().
Продолжайте вызывать sqlite3_step(), пока инструкция не будет завершена.
Операторы, не возвращающие результатов (например, INSERT, UPDATE или DELETE).
операторы) выполняются до завершения одним вызовом sqlite3_step().sqlite3_column()
Эта процедура возвращает один столбец из текущей строки результата. установлен для подготовленного оператора, который оценивается sqlite3_step(). Каждый раз, когда sqlite3_step() останавливается с новой строкой набора результатов, эта процедура можно вызывать несколько раз, чтобы найти значения всех столбцов в этой строке.
Как отмечалось выше, на самом деле не существует такой вещи, как sqlite3_column(). функция в SQLite API. Вместо этого то, что мы здесь называем sqlite3_column(), является заполнителем для целого семейства функций, которые возвращают значение из набора результатов в различных типах данных. Есть и рутины в этом семействе, которые возвращают размер результата (если это строка или BLOB) и количество столбцов в результирующем наборе.
- sqlite3_column_blob()
- sqlite3_column_bytes()
- sqlite3_column_bytes16()
- sqlite3_column_count()
- sqlite3_column_double()
- sqlite3_column_int()
- sqlite3_column_int64()
- sqlite3_column_text()
- sqlite3_column_text16()
- sqlite3_column_type()
- sqlite3_column_value()
sqlite3_finalize()
Эта процедура уничтожает подготовленный оператор, созданный предыдущим вызовом в sqlite3_prepare(). Каждый подготовленный оператор должен быть уничтожен с помощью вызов этой подпрограммы, чтобы избежать утечек памяти.
sqlite3_close()
Эта процедура закрывает соединение с базой данных, ранее открытое вызовом в sqlite3_open(). Все подготовленные заявления, связанные с соединение должно быть завершено до закрытия связь.
 Этот API на самом деле не оценивает
оператор SQL. Он просто подготавливает оператор SQL для оценки.
Этот API на самом деле не оценивает
оператор SQL. Он просто подготавливает оператор SQL для оценки. Продолжайте вызывать sqlite3_step(), пока инструкция не будет завершена.
Операторы, не возвращающие результатов (например, INSERT, UPDATE или DELETE).
операторы) выполняются до завершения одним вызовом sqlite3_step().
Продолжайте вызывать sqlite3_step(), пока инструкция не будет завершена.
Операторы, не возвращающие результатов (например, INSERT, UPDATE или DELETE).
операторы) выполняются до завершения одним вызовом sqlite3_step().
Приложение обычно использует
sqlite3_open() для создания одного соединения с базой данных
во время инициализации. Обратите внимание, что sqlite3_open() можно использовать либо для открытия существующей базы данных,
файлов или для создания и открытия новых файлов базы данных.
Хотя многие приложения используют только одно соединение с базой данных,
нет причин, по которым приложение не может вызывать sqlite3_open() несколько раз
чтобы открыть несколько подключений к базе данных — либо к одному и тому же
базу данных или к другим базам данных. Иногда многопоточное приложение
создаст отдельные подключения к базе данных для каждого потока.
Обратите внимание, что одно соединение с базой данных может иметь доступ к двум или более
базы данных с помощью SQL-команды ATTACH, поэтому нет необходимости
иметь отдельное соединение с базой данных для каждого файла базы данных.
Обратите внимание, что sqlite3_open() можно использовать либо для открытия существующей базы данных,
файлов или для создания и открытия новых файлов базы данных.
Хотя многие приложения используют только одно соединение с базой данных,
нет причин, по которым приложение не может вызывать sqlite3_open() несколько раз
чтобы открыть несколько подключений к базе данных — либо к одному и тому же
базу данных или к другим базам данных. Иногда многопоточное приложение
создаст отдельные подключения к базе данных для каждого потока.
Обратите внимание, что одно соединение с базой данных может иметь доступ к двум или более
базы данных с помощью SQL-команды ATTACH, поэтому нет необходимости
иметь отдельное соединение с базой данных для каждого файла базы данных.
Многие приложения разрушают свои соединения с базой данных, используя вызовы
sqlite3_close() при завершении работы. Или, например, приложение, которое
использует SQLite, так как его формат файла приложения может
открывать соединения с базой данных в ответ на действие меню File/Open
а затем уничтожить соответствующее соединение с базой данных в ответ
в меню Файл/Закрыть.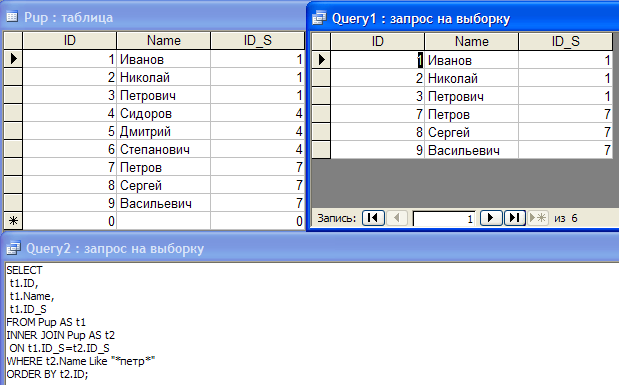
Чтобы запустить инструкцию SQL, приложение выполняет следующие шаги:
- Создайте подготовленный оператор, используя sqlite3_prepare().
- Оцените подготовленный оператор, вызвав sqlite3_step() один или более раз.
- Для запросов извлекайте результаты, вызывая sqlite3_column() между ними два вызова sqlite3_step().
- Уничтожить подготовленный оператор с помощью sqlite3_finalize().
Вышеизложенное — это все, что действительно нужно знать, чтобы использовать SQLite. эффективно. Все остальное оптимизация и детализация.
Интерфейс sqlite3_exec() — это удобная оболочка, которая выполняет
все четыре вышеуказанных шага с помощью одного вызова функции. Обратный звонок
функция, переданная в sqlite3_exec(), используется для обработки каждой строки
набор результатов. sqlite3_get_table() — еще одна удобная оболочка.
который выполняет все четыре вышеуказанных шага. Интерфейс sqlite3_get_table()
отличается от sqlite3_exec() тем, что сохраняет результаты запросов
в куче памяти, а не вызывать обратный вызов.
Важно понимать, что ни sqlite3_exec(), ни sqlite3_get_table() делает все, что не может быть выполнено с помощью основные процедуры. На самом деле эти обертки реализованы исключительно в с точки зрения основных процедур.
В предыдущем обсуждении предполагалось, что каждый оператор SQL подготавливается один раз, оценивается, затем уничтожается. Однако SQLite позволяет то же самое. подготовленный оператор для многократной оценки. Это выполнено используя следующие подпрограммы:
- sqlite3_reset()
- sqlite3_bind()
После того, как подготовленный оператор был оценен одним или несколькими вызовами
sqlite3_step(), его можно сбросить для повторной оценки с помощью
вызов sqlite3_reset().
Думайте о sqlite3_reset() как о перемотке подготовленной программы операторов.
вернуться к началу.
Использование sqlite3_reset() для существующего подготовленного оператора, а не
создание нового подготовленного оператора позволяет избежать ненужных вызовов
sqlite3_prepare(). Для многих операторов SQL время, необходимое
для запуска sqlite3_prepare() равно или превышает время, необходимое
sqlite3_step(). Поэтому избегание вызовов sqlite3_prepare() может дать
значительное улучшение производительности.
Для многих операторов SQL время, необходимое
для запуска sqlite3_prepare() равно или превышает время, необходимое
sqlite3_step(). Поэтому избегание вызовов sqlite3_prepare() может дать
значительное улучшение производительности.
Обычно нецелесообразно оценивать точных одинаковых SQL-запросов. утверждение более одного раза. Чаще хочется оценить похожие заявления. Например, вы можете захотеть оценить оператор INSERT. несколько раз с разными значениями. Или вы хотите оценить один и тот же запрос несколько раз, используя другой ключ в предложении WHERE. Разместить это, SQLite позволяет операторам SQL содержать параметры которые «привязаны» к значениям до их оценки. Эти значения могут позже может быть изменен, и тот же подготовленный оператор может быть оценен второй раз, используя новые значения.
SQLite позволяет параметр везде
допускается строковый литерал, числовая константа или NULL.
(Параметры нельзя использовать для имен столбцов или таблиц. )
Параметр принимает одну из следующих форм:
)
Параметр принимает одну из следующих форм:
- ?
- ? ННН
- : ААА
- $ ААА
- @ ААА
В приведенных выше примерах NNN является целым числом и AAA — это идентификатор. Изначально параметр имеет значение NULL. Перед вызовом sqlite3_step() в первый раз или сразу после sqlite3_reset() приложение может вызывать Интерфейсы sqlite3_bind() для прикрепления значений к параметрам. Каждый вызов sqlite3_bind() переопределяет предыдущие привязки того же параметра.
Приложение может заранее подготовить несколько операторов SQL.
и оценивать их по мере необходимости.
Нет произвольного ограничения на количество непогашенных
подготовленные заявления.
Некоторые приложения вызывают sqlite3_prepare() несколько раз при запуске, чтобы
создать все подготовленные операторы, которые им когда-либо понадобятся. Другой
приложения сохраняют кеш самых последних использованных подготовленных операторов
а затем повторно использовать подготовленные операторы из кеша, когда они доступны.
Другой подход заключается в повторном использовании подготовленных операторов только тогда, когда они
внутри петли.
Другой
приложения сохраняют кеш самых последних использованных подготовленных операторов
а затем повторно использовать подготовленные операторы из кеша, когда они доступны.
Другой подход заключается в повторном использовании подготовленных операторов только тогда, когда они
внутри петли.
Конфигурация по умолчанию для SQLite отлично подходит для большинства приложений. Но иногда разработчики хотят настроить установку, чтобы попытаться выжать немного больше производительности, или воспользоваться какой-то малоизвестной функцией.
Интерфейс sqlite3_config() используется для создания глобальных, общепроцессных изменения конфигурации для SQLite. Интерфейс sqlite3_config() должен вызываться до того, как будут созданы какие-либо соединения с базой данных. Интерфейс sqlite3_config() позволяет программисту делать такие вещи, как:
- Настройка способа выделения памяти SQLite, включая настройку
альтернативные распределители памяти, подходящие для критически важных с точки зрения безопасности
встроенные системы реального времени и определяемые приложениями распределители памяти.
- Настройте журнал ошибок для всего процесса.
- Укажите определяемый приложением кэш страниц.
- Отрегулируйте использование мьютексов, чтобы они подходили для различных резьбовые модели или заменить определяемая приложением система мьютексов.

После завершения настройки всего процесса и подключения к базе данных были созданы, отдельные подключения к базе данных могут быть настроены с помощью вызовы sqlite3_limit() и sqlite3_db_config().
SQLite включает в себя интерфейсы, которые можно использовать для расширения его функциональности. К таким процедурам относятся:
- sqlite3_create_collation()
- sqlite3_create_function()
- sqlite3_create_module()
- sqlite3_vfs_register()
Интерфейс sqlite3_create_collation() используется для создания новых
сопоставление последовательностей для сортировки текста.
Интерфейс sqlite3_create_module() используется для регистрации новых
реализации виртуальных таблиц. Интерфейс sqlite3_vfs_register() создает новые VFS.
Интерфейс sqlite3_vfs_register() создает новые VFS.
Интерфейс sqlite3_create_function() создает новые функции SQL — либо скалярные, либо агрегатные. Реализация новой функции обычно использует следующие дополнительные интерфейсы:
- sqlite3_aggregate_context()
- sqlite3_result()
- sqlite3_user_data()
- sqlite3_value()
Все встроенные SQL-функции SQLite созданы именно с использованием эти самые интерфейсы. Обратитесь к исходному коду SQLite и, в частности, в дата.с и Исходные файлы func.c Например.
Общие библиотеки или библиотеки DLL можно использовать в качестве загружаемых расширений для SQLite.
В этой статье упоминаются только самые важные и наиболее часто
используемые интерфейсы SQLite.
Библиотека SQLite включает множество других API, реализующих полезные
особенности, которые здесь не описаны.
Полный список функций, образующих SQLite
Интерфейс прикладного программирования находится на
Спецификация интерфейса C/C++. Обратитесь к этому документу за полной и достоверной информацией о
все интерфейсы SQLite.
Обратитесь к этому документу за полной и достоверной информацией о
все интерфейсы SQLite.
Использование SQL с онлайн-классом C++
- Все темы
- Технологии
- Разработка программного обеспечения
- Языки программирования
С Биллом Вайнманом Нравится 418 пользователям
Продолжительность: 1ч 27м Уровень мастерства: средний Дата выпуска: 12.08.2021
Начать бесплатную пробную версию на 1 месяц
Детали курса
C++ — это мощный язык для приложений баз данных, который может быть отличным инструментом для использования с SQL. В этом курсе инструктор Билл Вейнман расскажет вам, как использовать возможности C++ в SQL, начиная с основ, таких как подключение к базе данных, выполнение простых запросов и чтение строк из таблицы. Он также объясняет, как использовать подготовленные операторы и переменные связывания, а также как создать класс-оболочку для оптимизации интерфейса SQL. Наконец, он показывает вам, как построить специализированный класс приложения, чтобы вы могли создать приложение, используя то, что вы узнали. Если вы опытный разработчик C++ и хотите научиться использовать C++ с SQL, этот курс для вас.
В этом курсе инструктор Билл Вейнман расскажет вам, как использовать возможности C++ в SQL, начиная с основ, таких как подключение к базе данных, выполнение простых запросов и чтение строк из таблицы. Он также объясняет, как использовать подготовленные операторы и переменные связывания, а также как создать класс-оболочку для оптимизации интерфейса SQL. Наконец, он показывает вам, как построить специализированный класс приложения, чтобы вы могли создать приложение, используя то, что вы узнали. Если вы опытный разработчик C++ и хотите научиться использовать C++ с SQL, этот курс для вас.
Навыки, которые вы приобретете
- SQL
- С++
Получите общий сертификат
Поделитесь тем, что вы узнали, и станьте выдающимся профессионалом в желаемой отрасли с сертификатом, демонстрирующим ваши знания, полученные на курсе.
Обучение LinkedIn Обучение
Сертификат об окончанииДемонстрация в вашем профиле LinkedIn в разделе «Лицензии и сертификаты»
Загрузите или распечатайте в формате PDF, чтобы поделиться с другими
Поделитесь изображением в Интернете, чтобы продемонстрировать свое мастерство
Познакомьтесь с инструктором
Билл Вайнман
Отзывы учащихся
29рейтинги
Общий рейтинг рассчитывается на основе среднего значения представленных оценок. Оценки и обзоры могут быть отправлены только тогда, когда неанонимные учащиеся завершат не менее 40% курса. Это помогает нам избежать поддельных отзывов и спама.
Оценки и обзоры могут быть отправлены только тогда, когда неанонимные учащиеся завершат не менее 40% курса. Это помогает нам избежать поддельных отзывов и спама.
- 5 звезд Текущее значение: 19 65%
- 4 звезды Текущее значение: 9 31%
- 3 звезды Текущее значение: 1 3%
Георгий Петросян
Георгий Петросян
Старший инженер-программист
5/5
14 мая 2022 г.
Этот курс хорош для начинающих. Но я думаю, что готовые примеры бесполезны. Полезнее будет написать код с объяснением каждой функции и ее параметров.
Полезный · Отчет
Марк Финли
Марк Финли
Студент Университета Вэлли Вью
Содержание
Что включено
- Практикуйтесь, пока учитесь 1 файл с упражнениями
- Проверьте свои знания 4 викторины
- Учитесь на ходу Доступ на планшете и телефоне
Похожие курсы
Скачать курсы
Используйте приложение LinkedIn Learning для iOS или Android и смотрите курсы на своем мобильном устройстве без подключения к Интернету.
запрос.скала
query.scala // Перейти к …
- СУО
- Учебники
- запрос.скала
¶
Коммерческие и открытые системы баз данных состоят из миллионов строк оптимизированный код C. Тем не менее, их производительность по отдельным запросам падает в 10 или 100 раз. за исключением того, что может написать написанная от руки специализированная реализация того же запроса. достигать.
В этом руководстве мы создадим небольшой механизм обработки SQL, состоящий из всего около 500 строк высокоуровневого кода Scala. В то время как другие системы интерпретируют запрос планы, оператор за оператором, мы будем использовать LMS для генерации и компиляции низкоуровневого C код для целых запросов.
Мы намеренно сделали запрос простым. Более совершенный двигатель
который обрабатывает полный набор тестов TPCH и состоит примерно из 3000 строк
код был разработан в проекте LegoBase, который недавно получил
приз за лучшую статью на VLDB’14.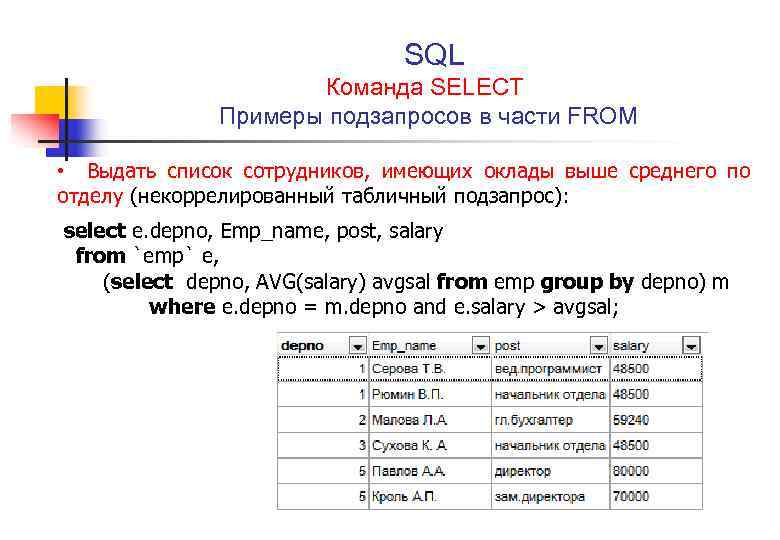
См. также:
- Создание эффективных механизмов запросов на языке высокого уровня (PDF)
Яннис Клонатос, Кристоф Кох, Тиарк Ромпф, Хассан Чафи. ВЛДБ’14 - Функциональная жемчужина: компилятор SQL в C в 500 строках кода (PDF)
Тиарк Ромпф, Нада Амин. ICFP’15
Схема:
Подготовка к сцене
Давайте проведем несколько быстрых тестов, чтобы получить представление об относительной производительности различных системы обработки данных. Мы берем образец данных из проекта Google Books NGram Viewer. Файл размером 2 ГБ, содержащий статистику по словам, начинающимся с буквы «А», является хорошим кандидатом для запуска. несколько простых запросов. Нас могут заинтересовать все вхождения слова «Auswanderung»:
выберите * из 1gram_a, где n_gram = «Auswanderung»
Вот некоторые тайминги:
Загрузка файла CSV в базу данных MySQL занимает > 5 минут, выполнение запроса около 50 секунд.
Загрузка PostgreSQL занимает 3 минуты, первый запуск запроса занимает 46 секунд, но последующие запуски со временем выполняются быстрее (до 7 секунд).
Сценарий AWK, обрабатывающий файл CSV напрямую, занимает 45 секунд.
Интерпретатор запросов, написанный на Scala, занимает 39 секунд.
Написанная от руки специализированная программа на языке Scala выполняется за 13 сек.
Аналогичная написанная от руки программа на C работает немного быстрее, но с большей оптимизацией мы можем получить целых 3,2 секунды.

Процессор запросов, который мы разработаем в этом руководстве, соответствует производительности рукописных запросов Scala и C (13 с и 3 с соответственно).
Дополнительные сведения о выполнении тестов доступны здесь. Теперь перейдем к нашей фактической реализации.
пакет scala.lms.tutorial импортировать scala.lms.common._
¶
Реляционная алгебра AST
Ядром любого механизма обработки запросов является представление AST операторы реляционной алгебры.
признак QueryAST {
тип Таблица
тип Схема = Вектор[Строка]
// операции реляционной алгебры
запечатанный абстрактный класс Оператор
класс case Scan (имя: таблица, схема: схема, разделитель: Char, extSchema: Boolean) расширяет оператор
класс case PrintCSV (родитель: оператор) расширяет оператор
case class Project (outSchema: Schema, inSchema: Schema, parent: Operator) расширяет оператор
класс case Filter (предыдущий: предикат, родитель: оператор) расширяет оператор
класс case Join (родительский1: оператор, родительский2: оператор) расширяет оператор
Группа классов case (ключи: Схема, agg: Схема, родитель: Оператор) расширяет Оператор
класс case HashJoin (parent1: оператор, parent2: оператор) расширяет оператор
// фильтровать предикаты
запечатанный абстрактный класс Predicate
case class Eq(a: Ref, b: Ref) расширяет предикат
запечатанный абстрактный класс Ref
поле класса случая (имя: строка) расширяет ссылку
case class Value(x: Any) extends Ref
// некоторые умные конструкторы
Схема защиты (схема: строка *): Схема = схема. toVector
def Scan(tableName: String): Scan = Scan(tableName, None, None)
def Scan(tableName: String, schema: Option[Schema], delim: Option[Char]): Scan
}
9(s => Значение (s.toInt))
def parseAll (ввод: строка): Оператор = parseAll (stm, input) match {
case Success(res,_) => res
case res => генерировать новое исключение (res.toString)
}
}
}
 toVector
def Scan(tableName: String): Scan = Scan(tableName, None, None)
def Scan(tableName: String, schema: Option[Schema], delim: Option[Char]): Scan
}
9(s => Значение (s.toInt))
def parseAll (ввод: строка): Оператор = parseAll (stm, input) match {
case Success(res,_) => res
case res => генерировать новое исключение (res.toString)
}
}
}
toVector
def Scan(tableName: String): Scan = Scan(tableName, None, None)
def Scan(tableName: String, schema: Option[Schema], delim: Option[Char]): Scan
}
9(s => Значение (s.toInt))
def parseAll (ввод: строка): Оператор = parseAll (stm, input) match {
case Success(res,_) => res
case res => генерировать новое исключение (res.toString)
}
}
}
¶
Итеративная разработка обработчика запросов
Мы разрабатываем наш механизм SQL в несколько этапов. Каждый шаг ведет к работающий процессор, и каждый последующий шаг либо добавляет функцию, либо оптимизация.
Шаг 1: (простой) интерпретатор запросов
Начнем с простого процессора запросов: интерпретатора.
- query_unstaged.scala
Шаг 2: Поэтапный интерпретатор запросов (= компилятор)
Постановка нашего интерпретатора запросов дает компилятор запросов. В первой итерации мы генерируем код Scala, но не учитываем операторы, требующие внутренних структур данных:
- query_staged0
Шаг 3.
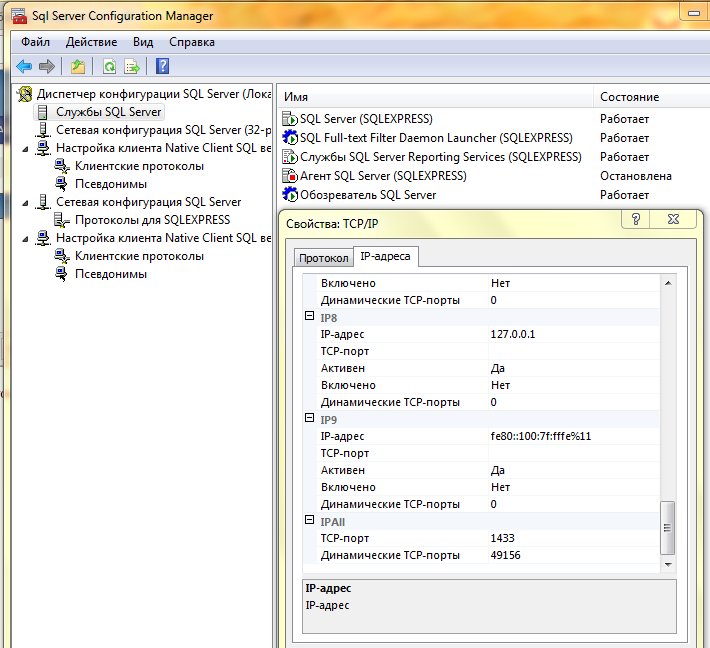 Специализация структур данных
Специализация структур данныхСледующая итерация добавляет оптимизированные реализации структур данных которые следуют макету хранилища столбцов. Это включает в себя специализированный хэш таблицы для операторов groupBy и join:
- query_staged
Шаг 4: переход на C и оптимизация ввода-вывода
Для дополнительной низкоуровневой оптимизации мы переключаемся на генерацию C код:
- query_optc
На уровне C мы оптимизируем уровень ввода-вывода путем прямого сопоставления файлов в память, и мы дополнительно специализируемся на внутренних структурах данных чтобы свести к минимуму преобразования данных и включить представление строковых объектов непосредственно как указатели на отображаемый в памяти входной файл.
Сантехника
Для фактического выполнения запросов и тестирования различных реализаций.
сбоку, немного сантехники необходимо. Мы определяем общий
интерфейс для всех обработчиков запросов (обычных или поэтапных, Scala или C).
признак QueryProcessor расширяет QueryAST {
версия по умолчанию: строка
val defaultFieldDelimiter = ','
def filePath (таблица: строка): строка = таблица
def dynamicFilePath (таблица: строка): таблица
def Scan(tableName: String, schema: Option[Schema], delim: Option[Char]): Scan = {
val dfile = dynamicFilePath (tableName)
val (schema1, externalSchema) = schema.map(s=>(s,true)).getOrElse((loadSchema(filePath(tableName)),false))
Scan(dfile, schema1, delim.getOrElse(defaultFieldDelimiter), externalSchema)
}
def loadSchema (имя файла: строка): Схема = {
val s = новый сканер (имя файла)
схема val = Схема (s.next ('\ n'). Split (defaultFieldDelimiter): _ *)
с.закрыть
схема
}
def execQuery(q: Оператор): Единица измерения
}
черта PlainQueryProcessor расширяет QueryProcessor {
тип Таблица = Строка
}
черта StagedQueryProcessor расширяет QueryProcessor с помощью Dsl {
type Table = Rep[String] // динамическое имя файла
переопределить def filePath(table: String) = if (table == "?") throw new Exception("путь к файлу для таблицы? недоступен") else super. filePath(table)
}
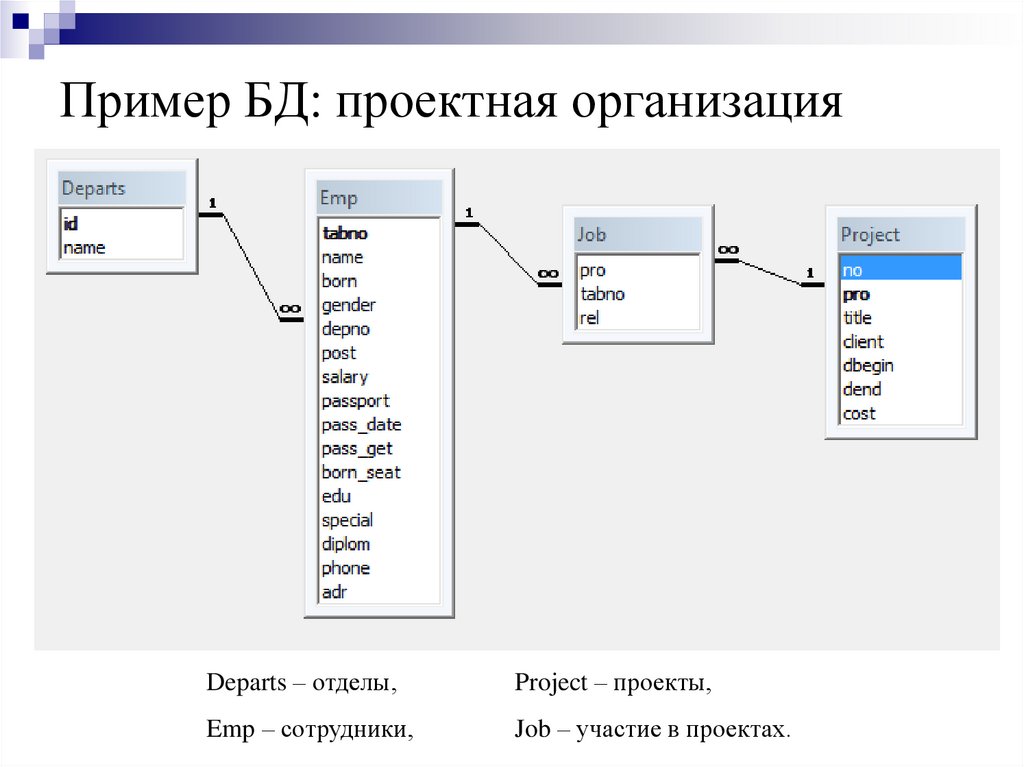 filePath(table)
}
filePath(table)
}
¶
Интерактивный режим
Примеры:
test:run unstaged "select * from ? schema Phrase, Year, MatchCount, VolumeCount delim \\t where Phrase='Auswanderung'" src/data/t1gram.csv test:run c "select * from ? schema Phrase, Year, MatchCount, VolumeCount delim \\t where Phrase='Auswanderung'" src/data/t1gram.csv
Черта Engine расширяет QueryProcessor с помощью SQLParser {
деф-запрос: строка
def имя файла: Строка
def liftTable(n: String): Таблица
Оценка по умолчанию: Единица измерения
подготовка по определению: единица = {}
def run: Unit = execQuery (PrintCSV (parseSql (запрос)))
переопределить определение dynamicFilePath (таблица: строка): Таблица =
liftTable(if (table == "?") имя файла еще путь к файлу(таблица))
защита evalString = {
val источник = новый java.io.ByteArrayOutputStream()
utils.withOutputFull (новый java.io.PrintStream (источник)) {
оценка
}
источник.toString
}
}
черта StagedEngine расширяет Engine с помощью StagedQueryProcessor {
переопределить def liftTable(n: String) = unit(n)
}
объект Выполнить {
переменная qu: строка = _
переменная fn: строка = _
черта MainEngine расширяет Engine {
переопределить запрос def = qu
переопределить имя файла по умолчанию = fn
}
def unstaged_engine: Двигатель =
новый движок с MainEngine с query_unstaged. QueryInterpreter {
переопределить def liftTable(n: Table) = n
переопределить def eval = запустить
}
защита scala_engine =
новый DslDriver[String,Unit] со ScannerExp
с StagedEngine с MainEngine с query_staged.QueryCompiler { q =>
переопределить val codegen = новый DslGen со ScalaGenScanner {
val IR: q.type = q
}
override def snippet(fn: Table): Rep[Unit] = run
переопределить def prepare: Unit = precompile
переопределить def eval: Unit = eval(имя файла)
}
защита c_engine =
новый DslDriverC[String,Unit] со ScannerLowerExp
с StagedEngine с MainEngine с query_optc.QueryCompiler { q =>
переопределить val codegen = новый DslGenC с CGenScannerLower {
val IR: q.type = q
}
override def snippet(fn: Table): Rep[Unit] = run
переопределить определение подготовки: Unit = {}
переопределить def eval: Unit = eval(имя файла)
}
def main(аргументы: Массив[Строка]) {
если (args.length < 2) {
println("Синтаксис:")
println(" test:run (unstaged|scala|c) sql [файл]")
println()
println("пример использования:")
println(" test:run c \"select * from ? schema Phrase, Year, MatchCount, VolumeCount delim \\t where Phrase='Auswanderung'\" src/data/t1gram. csv")
возвращаться
}
val версия = аргументы (0)
val engine = соответствие версии {
случай "с" => c_engine
case "скала" => scala_engine
case "unstaged" => unstaged_engine
case _ => println("предупреждение: неожиданный движок, по умолчанию используется 'unstaged'")
unstaged_engine
}
ц = аргументы (1)
если (args.length > 2)
fn = аргументы (2)
пытаться {
двигатель.подготовить
utils.time(engine.eval)
} ловить {
случай пример: Исключение =>
println("ОШИБКА: " + пример)
}
}
}
 QueryInterpreter {
переопределить def liftTable(n: Table) = n
переопределить def eval = запустить
}
защита scala_engine =
новый DslDriver[String,Unit] со ScannerExp
с StagedEngine с MainEngine с query_staged.QueryCompiler { q =>
переопределить val codegen = новый DslGen со ScalaGenScanner {
val IR: q.type = q
}
override def snippet(fn: Table): Rep[Unit] = run
переопределить def prepare: Unit = precompile
переопределить def eval: Unit = eval(имя файла)
}
защита c_engine =
новый DslDriverC[String,Unit] со ScannerLowerExp
с StagedEngine с MainEngine с query_optc.QueryCompiler { q =>
переопределить val codegen = новый DslGenC с CGenScannerLower {
val IR: q.type = q
}
override def snippet(fn: Table): Rep[Unit] = run
переопределить определение подготовки: Unit = {}
переопределить def eval: Unit = eval(имя файла)
}
def main(аргументы: Массив[Строка]) {
если (args.length < 2) {
println("Синтаксис:")
println(" test:run (unstaged|scala|c) sql [файл]")
println()
println("пример использования:")
println(" test:run c \"select * from ? schema Phrase, Year, MatchCount, VolumeCount delim \\t where Phrase='Auswanderung'\" src/data/t1gram.
QueryInterpreter {
переопределить def liftTable(n: Table) = n
переопределить def eval = запустить
}
защита scala_engine =
новый DslDriver[String,Unit] со ScannerExp
с StagedEngine с MainEngine с query_staged.QueryCompiler { q =>
переопределить val codegen = новый DslGen со ScalaGenScanner {
val IR: q.type = q
}
override def snippet(fn: Table): Rep[Unit] = run
переопределить def prepare: Unit = precompile
переопределить def eval: Unit = eval(имя файла)
}
защита c_engine =
новый DslDriverC[String,Unit] со ScannerLowerExp
с StagedEngine с MainEngine с query_optc.QueryCompiler { q =>
переопределить val codegen = новый DslGenC с CGenScannerLower {
val IR: q.type = q
}
override def snippet(fn: Table): Rep[Unit] = run
переопределить определение подготовки: Unit = {}
переопределить def eval: Unit = eval(имя файла)
}
def main(аргументы: Массив[Строка]) {
если (args.length < 2) {
println("Синтаксис:")
println(" test:run (unstaged|scala|c) sql [файл]")
println()
println("пример использования:")
println(" test:run c \"select * from ? schema Phrase, Year, MatchCount, VolumeCount delim \\t where Phrase='Auswanderung'\" src/data/t1gram. csv")
возвращаться
}
val версия = аргументы (0)
val engine = соответствие версии {
случай "с" => c_engine
case "скала" => scala_engine
case "unstaged" => unstaged_engine
case _ => println("предупреждение: неожиданный движок, по умолчанию используется 'unstaged'")
unstaged_engine
}
ц = аргументы (1)
если (args.length > 2)
fn = аргументы (2)
пытаться {
двигатель.подготовить
utils.time(engine.eval)
} ловить {
случай пример: Исключение =>
println("ОШИБКА: " + пример)
}
}
}
csv")
возвращаться
}
val версия = аргументы (0)
val engine = соответствие версии {
случай "с" => c_engine
case "скала" => scala_engine
case "unstaged" => unstaged_engine
case _ => println("предупреждение: неожиданный движок, по умолчанию используется 'unstaged'")
unstaged_engine
}
ц = аргументы (1)
если (args.length > 2)
fn = аргументы (2)
пытаться {
двигатель.подготовить
utils.time(engine.eval)
} ловить {
случай пример: Исключение =>
println("ОШИБКА: " + пример)
}
}
}
¶
Модульные тесты
class QueryTest extends TutorialFunSuite {
значение под = "запрос_"
trait TestDriver расширяет SQLParser с помощью QueryProcessor с ExpectedASTs {
Def runtest: Единица измерения
переопределить def filePath (таблица: строка) = dataFilePath (таблица)
имя защиты: строка
деф-запрос: строка
def parsedQuery: Оператор = если (query.isEmpty) ожидаемыйAstForTest(имя) else parseSql(запрос)
}
trait PlainTestDriver расширяет TestDriver с помощью PlainQueryProcessor {
переопределить def dynamicFilePath(table: String): Table = if (table == "?") defaultEvalTable else filePath(table)
def eval(fn: Table): Unit = {
execQuery (PrintCSV (parsedQuery))
}
}
trait StagedTestDriver расширяет TestDriver с помощью StagedQueryProcessor {
переменная dynamicFileName: Таблица = _
переопределить определение dynamicFilePath(table: String): Table = if (table == "?") dynamicFileName else unit(filePath(table))
def snippet(fn: Table): Rep[Unit] = {
динамическое имя_файла = fn
execQuery (PrintCSV (parsedQuery))
}
}
абстрактный класс ScalaPlainQueryDriver (val name: String, val query: String) расширяет PlainTestDriver с помощью QueryProcessor { q =>
переопределить определение runtest: Unit = {
тест(версия+" "+имя) {
for (expectedParsedQuery <- expectAstForTest. get(name)) {
утверждать (ожидаемыйParsedQuery == parsedQuery)
}
checkOut(имя, "csv", eval(defaultEvalTable))
}
}
}
абстрактный класс ScalaStagedQueryDriver(val name: String, val query: String) расширяет DslDriver[String,Unit] с помощью StagedTestDriver с StagedQueryProcessor со ScannerExp { q =>
переопределить val codegen = новый DslGen со ScalaGenScanner {
val IR: q.type = q
}
переопределить определение runtest: Unit = {
if (версия == "query_staged0" && List("Group","HashJoin").exists(parsedQuery.toString содержит _)) return ()
тест(версия+" "+имя) {
for (expectedParsedQuery <- expectAstForTest.get(name)) {
утверждать (ожидаемыйParsedQuery == parsedQuery)
}
проверить (имя, код)
предварительная компиляция
checkOut(имя, "csv", eval(defaultEvalTable))
}
}
}
абстрактный класс CStagedQueryDriver(val name: String, val query: String) расширяет DslDriverC[String,Unit] с помощью StagedTestDriver с StagedQueryProcessor с помощью ScannerLowerExp { q =>
переопределить val codegen = новый DslGenC с CGenScannerLower {
val IR: q. type = q
}
переопределить определение runtest: Unit = {
тест(версия+" "+имя) {
for (expectedParsedQuery <- expectAstForTest.get(name)) {
утверждать (ожидаемыйParsedQuery == parsedQuery)
}
проверить(имя, код, "с")
//прекомпилировать
checkOut(имя, "csv", eval(defaultEvalTable))
}
}
}
def testquery (имя: строка, запрос: строка = "") {
val драйверы: Список[TestDriver] =
Список(
новый ScalaPlainQueryDriver(имя, запрос) с query_unstaged.QueryInterpreter,
новый ScalaStagedQueryDriver(имя, запрос) с query_staged0.QueryCompiler,
новый ScalaStagedQueryDriver(имя, запрос) с query_staged.QueryCompiler,
новый CStagedQueryDriver (имя, запрос) с query_optc.QueryCompiler {
// FIXME: взломать, чтобы мне не нужно было заменять Value -> #Value во всех файлах прямо сейчас
переопределить def isNumericCol(s: String) = s == "Value" || super.isNumericCol(s)
}
)
driver. foreach(_.runtest)
}
// ПРИМЕЧАНИЕ: мы можем использовать "выбрать * из?" использовать динамические имена файлов (сейчас здесь не используется)
трейт ExpectedASTs расширяет QueryAST {
val scan_t = сканирование ("t.csv")
val scan_t1gram = Scan("?", Some(Schema("Phrase", "Year", "MatchCount", "VolumeCount")), Some('\t'))
val ожидаемоеAstForTest = Карта(
"t1" -> scan_t,
"t2" -> Проект(Схема("Имя"), Схема("Имя"), scan_t),
"t3" -> Проект(Схема("Имя"), Схема("Имя"),
Фильтр(Уравнение(Поле("Флаг"), Значение("да")),
скан_т)),
"t4" -> Присоединиться (scan_t,
Проект(Схема("Имя1"), Схема("Имя"), scan_t)),
"t5" -> Присоединиться (scan_t,
Проект(Схема("Имя"), Схема("Имя"), scan_t)),
"t4h" -> HashJoin(scan_t,
Проект(Схема("Имя1"), Схема("Имя"), scan_t)),
"t5h" -> HashJoin(scan_t,
Проект(Схема("Имя"), Схема("Имя"), scan_t)),
«t6» -> Группа (Схема («Имя»), Схема («Значение»), scan_t),
"t1gram1" -> scan_t1gram,
"t1gram2" -> Filter(Eq(Field("Phrase"), Value("Auswanderung")), scan_t1gram)
)
}
testquery("t1", "выбрать * из t. csv")
testquery("t2", "выберите имя из t.csv")
testquery ("t3", "выберите имя из t.csv, где флаг = 'да'")
testquery("t4", "выберите * из вложенных циклов t.csv join (выберите имя как Name1 из t.csv)")
testquery("t5", "выбрать * из вложенных циклов t.csv join (выбрать имя из t.csv)")
testquery("t4h","выберите * из соединения t.csv (выберите Имя как Имя1 из t.csv)")
testquery("t5h","выберите * из соединения t.csv (выберите имя из t.csv)")
testquery("t6", "выберите * из группы t.csv по значению суммы имени") // не на 100% правильный синтаксис, но эй...
val defaultEvalTable = dataFilePath("t1gram.csv")
val t1gram = "? schema Phrase, Year, MatchCount, VolumeCount delim \\t"
testquery("t1gram1", s"выбрать * из $t1gram")
testquery("t1gram2", s"выберите * из $t1gram, где Phrase='Auswanderung'")
testquery("t1gram2n", s"выберите * из вложенных циклов words.csv join (выберите Phrase as Word, Year, MatchCount, VolumeCount из $t1gram)")
testquery("t1gram2h", s"select * from words. csv join (выберите Phrase as Word, Year, MatchCount, VolumeCount из $t1gram)")
testquery("t1gram3", s"выбрать * из вложенных циклов words.csv join (выбрать * из $t1gram)")
testquery("t1gram3h", s"выбрать * из words.csv присоединиться (выбрать * из $t1gram)")
testquery("t1gram4", s"выберите * из вложенных циклов words.csv join (выберите Phrase as Word, Year, MatchCount, VolumeCount из $t1gram)")
testquery("t1gram4h", s"select * from words.csv join (выберите Phrase as Word, Year, MatchCount, VolumeCount из $t1gram)")
}
 get(name)) {
утверждать (ожидаемыйParsedQuery == parsedQuery)
}
checkOut(имя, "csv", eval(defaultEvalTable))
}
}
}
абстрактный класс ScalaStagedQueryDriver(val name: String, val query: String) расширяет DslDriver[String,Unit] с помощью StagedTestDriver с StagedQueryProcessor со ScannerExp { q =>
переопределить val codegen = новый DslGen со ScalaGenScanner {
val IR: q.type = q
}
переопределить определение runtest: Unit = {
if (версия == "query_staged0" && List("Group","HashJoin").exists(parsedQuery.toString содержит _)) return ()
тест(версия+" "+имя) {
for (expectedParsedQuery <- expectAstForTest.get(name)) {
утверждать (ожидаемыйParsedQuery == parsedQuery)
}
проверить (имя, код)
предварительная компиляция
checkOut(имя, "csv", eval(defaultEvalTable))
}
}
}
абстрактный класс CStagedQueryDriver(val name: String, val query: String) расширяет DslDriverC[String,Unit] с помощью StagedTestDriver с StagedQueryProcessor с помощью ScannerLowerExp { q =>
переопределить val codegen = новый DslGenC с CGenScannerLower {
val IR: q.
get(name)) {
утверждать (ожидаемыйParsedQuery == parsedQuery)
}
checkOut(имя, "csv", eval(defaultEvalTable))
}
}
}
абстрактный класс ScalaStagedQueryDriver(val name: String, val query: String) расширяет DslDriver[String,Unit] с помощью StagedTestDriver с StagedQueryProcessor со ScannerExp { q =>
переопределить val codegen = новый DslGen со ScalaGenScanner {
val IR: q.type = q
}
переопределить определение runtest: Unit = {
if (версия == "query_staged0" && List("Group","HashJoin").exists(parsedQuery.toString содержит _)) return ()
тест(версия+" "+имя) {
for (expectedParsedQuery <- expectAstForTest.get(name)) {
утверждать (ожидаемыйParsedQuery == parsedQuery)
}
проверить (имя, код)
предварительная компиляция
checkOut(имя, "csv", eval(defaultEvalTable))
}
}
}
абстрактный класс CStagedQueryDriver(val name: String, val query: String) расширяет DslDriverC[String,Unit] с помощью StagedTestDriver с StagedQueryProcessor с помощью ScannerLowerExp { q =>
переопределить val codegen = новый DslGenC с CGenScannerLower {
val IR: q.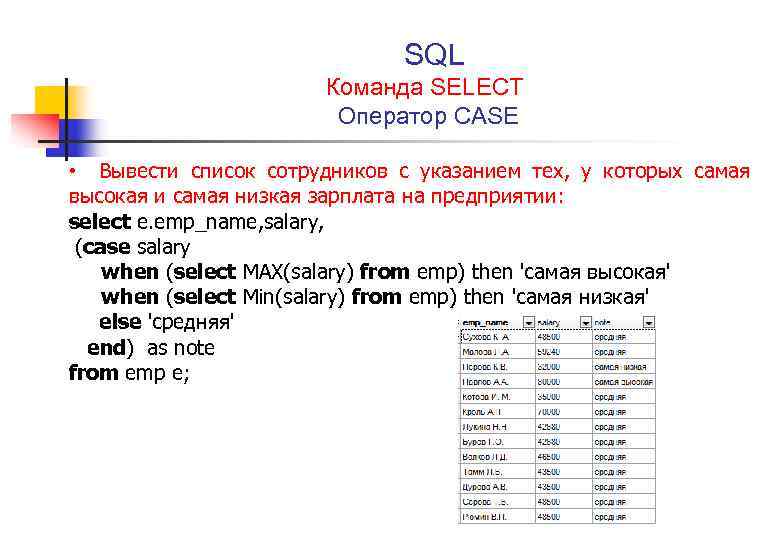 type = q
}
переопределить определение runtest: Unit = {
тест(версия+" "+имя) {
for (expectedParsedQuery <- expectAstForTest.get(name)) {
утверждать (ожидаемыйParsedQuery == parsedQuery)
}
проверить(имя, код, "с")
//прекомпилировать
checkOut(имя, "csv", eval(defaultEvalTable))
}
}
}
def testquery (имя: строка, запрос: строка = "") {
val драйверы: Список[TestDriver] =
Список(
новый ScalaPlainQueryDriver(имя, запрос) с query_unstaged.QueryInterpreter,
новый ScalaStagedQueryDriver(имя, запрос) с query_staged0.QueryCompiler,
новый ScalaStagedQueryDriver(имя, запрос) с query_staged.QueryCompiler,
новый CStagedQueryDriver (имя, запрос) с query_optc.QueryCompiler {
// FIXME: взломать, чтобы мне не нужно было заменять Value -> #Value во всех файлах прямо сейчас
переопределить def isNumericCol(s: String) = s == "Value" || super.isNumericCol(s)
}
)
driver.
type = q
}
переопределить определение runtest: Unit = {
тест(версия+" "+имя) {
for (expectedParsedQuery <- expectAstForTest.get(name)) {
утверждать (ожидаемыйParsedQuery == parsedQuery)
}
проверить(имя, код, "с")
//прекомпилировать
checkOut(имя, "csv", eval(defaultEvalTable))
}
}
}
def testquery (имя: строка, запрос: строка = "") {
val драйверы: Список[TestDriver] =
Список(
новый ScalaPlainQueryDriver(имя, запрос) с query_unstaged.QueryInterpreter,
новый ScalaStagedQueryDriver(имя, запрос) с query_staged0.QueryCompiler,
новый ScalaStagedQueryDriver(имя, запрос) с query_staged.QueryCompiler,
новый CStagedQueryDriver (имя, запрос) с query_optc.QueryCompiler {
// FIXME: взломать, чтобы мне не нужно было заменять Value -> #Value во всех файлах прямо сейчас
переопределить def isNumericCol(s: String) = s == "Value" || super.isNumericCol(s)
}
)
driver. foreach(_.runtest)
}
// ПРИМЕЧАНИЕ: мы можем использовать "выбрать * из?" использовать динамические имена файлов (сейчас здесь не используется)
трейт ExpectedASTs расширяет QueryAST {
val scan_t = сканирование ("t.csv")
val scan_t1gram = Scan("?", Some(Schema("Phrase", "Year", "MatchCount", "VolumeCount")), Some('\t'))
val ожидаемоеAstForTest = Карта(
"t1" -> scan_t,
"t2" -> Проект(Схема("Имя"), Схема("Имя"), scan_t),
"t3" -> Проект(Схема("Имя"), Схема("Имя"),
Фильтр(Уравнение(Поле("Флаг"), Значение("да")),
скан_т)),
"t4" -> Присоединиться (scan_t,
Проект(Схема("Имя1"), Схема("Имя"), scan_t)),
"t5" -> Присоединиться (scan_t,
Проект(Схема("Имя"), Схема("Имя"), scan_t)),
"t4h" -> HashJoin(scan_t,
Проект(Схема("Имя1"), Схема("Имя"), scan_t)),
"t5h" -> HashJoin(scan_t,
Проект(Схема("Имя"), Схема("Имя"), scan_t)),
«t6» -> Группа (Схема («Имя»), Схема («Значение»), scan_t),
"t1gram1" -> scan_t1gram,
"t1gram2" -> Filter(Eq(Field("Phrase"), Value("Auswanderung")), scan_t1gram)
)
}
testquery("t1", "выбрать * из t.
foreach(_.runtest)
}
// ПРИМЕЧАНИЕ: мы можем использовать "выбрать * из?" использовать динамические имена файлов (сейчас здесь не используется)
трейт ExpectedASTs расширяет QueryAST {
val scan_t = сканирование ("t.csv")
val scan_t1gram = Scan("?", Some(Schema("Phrase", "Year", "MatchCount", "VolumeCount")), Some('\t'))
val ожидаемоеAstForTest = Карта(
"t1" -> scan_t,
"t2" -> Проект(Схема("Имя"), Схема("Имя"), scan_t),
"t3" -> Проект(Схема("Имя"), Схема("Имя"),
Фильтр(Уравнение(Поле("Флаг"), Значение("да")),
скан_т)),
"t4" -> Присоединиться (scan_t,
Проект(Схема("Имя1"), Схема("Имя"), scan_t)),
"t5" -> Присоединиться (scan_t,
Проект(Схема("Имя"), Схема("Имя"), scan_t)),
"t4h" -> HashJoin(scan_t,
Проект(Схема("Имя1"), Схема("Имя"), scan_t)),
"t5h" -> HashJoin(scan_t,
Проект(Схема("Имя"), Схема("Имя"), scan_t)),
«t6» -> Группа (Схема («Имя»), Схема («Значение»), scan_t),
"t1gram1" -> scan_t1gram,
"t1gram2" -> Filter(Eq(Field("Phrase"), Value("Auswanderung")), scan_t1gram)
)
}
testquery("t1", "выбрать * из t. csv")
testquery("t2", "выберите имя из t.csv")
testquery ("t3", "выберите имя из t.csv, где флаг = 'да'")
testquery("t4", "выберите * из вложенных циклов t.csv join (выберите имя как Name1 из t.csv)")
testquery("t5", "выбрать * из вложенных циклов t.csv join (выбрать имя из t.csv)")
testquery("t4h","выберите * из соединения t.csv (выберите Имя как Имя1 из t.csv)")
testquery("t5h","выберите * из соединения t.csv (выберите имя из t.csv)")
testquery("t6", "выберите * из группы t.csv по значению суммы имени") // не на 100% правильный синтаксис, но эй...
val defaultEvalTable = dataFilePath("t1gram.csv")
val t1gram = "? schema Phrase, Year, MatchCount, VolumeCount delim \\t"
testquery("t1gram1", s"выбрать * из $t1gram")
testquery("t1gram2", s"выберите * из $t1gram, где Phrase='Auswanderung'")
testquery("t1gram2n", s"выберите * из вложенных циклов words.csv join (выберите Phrase as Word, Year, MatchCount, VolumeCount из $t1gram)")
testquery("t1gram2h", s"select * from words.
csv")
testquery("t2", "выберите имя из t.csv")
testquery ("t3", "выберите имя из t.csv, где флаг = 'да'")
testquery("t4", "выберите * из вложенных циклов t.csv join (выберите имя как Name1 из t.csv)")
testquery("t5", "выбрать * из вложенных циклов t.csv join (выбрать имя из t.csv)")
testquery("t4h","выберите * из соединения t.csv (выберите Имя как Имя1 из t.csv)")
testquery("t5h","выберите * из соединения t.csv (выберите имя из t.csv)")
testquery("t6", "выберите * из группы t.csv по значению суммы имени") // не на 100% правильный синтаксис, но эй...
val defaultEvalTable = dataFilePath("t1gram.csv")
val t1gram = "? schema Phrase, Year, MatchCount, VolumeCount delim \\t"
testquery("t1gram1", s"выбрать * из $t1gram")
testquery("t1gram2", s"выберите * из $t1gram, где Phrase='Auswanderung'")
testquery("t1gram2n", s"выберите * из вложенных циклов words.csv join (выберите Phrase as Word, Year, MatchCount, VolumeCount из $t1gram)")
testquery("t1gram2h", s"select * from words. csv join (выберите Phrase as Word, Year, MatchCount, VolumeCount из $t1gram)")
testquery("t1gram3", s"выбрать * из вложенных циклов words.csv join (выбрать * из $t1gram)")
testquery("t1gram3h", s"выбрать * из words.csv присоединиться (выбрать * из $t1gram)")
testquery("t1gram4", s"выберите * из вложенных циклов words.csv join (выберите Phrase as Word, Year, MatchCount, VolumeCount из $t1gram)")
testquery("t1gram4h", s"select * from words.csv join (выберите Phrase as Word, Year, MatchCount, VolumeCount из $t1gram)")
}
csv join (выберите Phrase as Word, Year, MatchCount, VolumeCount из $t1gram)")
testquery("t1gram3", s"выбрать * из вложенных циклов words.csv join (выбрать * из $t1gram)")
testquery("t1gram3h", s"выбрать * из words.csv присоединиться (выбрать * из $t1gram)")
testquery("t1gram4", s"выберите * из вложенных циклов words.csv join (выберите Phrase as Word, Year, MatchCount, VolumeCount из $t1gram)")
testquery("t1gram4h", s"select * from words.csv join (выберите Phrase as Word, Year, MatchCount, VolumeCount из $t1gram)")
}
¶
Предложения для упражнений
Механизм запросов, который мы представили, определенно прост, чтобы представить сквозная система, которую можно понять в целом. Ниже приведены несколько предложения по интересным расширениям.
Реализовать сканер, который считывает URL-адрес по запросу.
(Прикольно: новый оператор, который печатает только первые N результатов.)
(просто) Реализовать типизированную схему в версии Scala, чтобы типы столбцов известны статически, а значения — нет.
(Подсказка: версия C уже делает это, но также требует больше усилий из-за представлений пользовательского типа.)
(просто) Реализовать больше предикатов (например,
LessThan) и предикат комбинаторы (например,И,Или) для того, чтобы запускать интереснее запросы.(средний) Реализовать настоящую базу данных, ориентированную на столбцы, где каждый столбец имеет свою собственный файл, чтобы его можно было прочитать независимо.
(жесткий) Реализовать оптимизатор реляционной алгебры перед генерацией кода. (Подсказка: умные конструкторы могут помочь.)
Оптимизатор запросов должен переупорядочить деревья операторов запросов для лучшего порядка соединений, т. е. решить, выполнять ли соединения для отношений S0 x S1 x S2 как (S0 x (S1 x S2)) или ((S0 x S1) x S2).
Используйте алгоритм динамического программирования, который для n объединений в таблицах S0 x S1 x …x Sn сначала пытается найти оптимальное решение для S1 x .
. x Sn, а затем оптимальную комбинацию с S0.Чтобы найти оптимальное сочетание, попробуйте все варианты и оцените стоимость каждого. Стоимость может быть приблизительно измерена как количество обработанных записей. В качестве простого приближения можно использовать размер каждой входной таблицы и предположить, что все предикаты фильтра совпадают с вероятностью 0,5.

 . x Sn, а затем оптимальную комбинацию с S0.
. x Sn, а затем оптимальную комбинацию с S0.Комментарии? Предложения по улучшению? Посмотреть этот файл на GitHub.
- СУО
- Учебники
- запрос.скала
sql-запросов для практики | расширенные SQL-запросы
Автор: Иша Малхотра
- SQL-вопрос на собеседовании
- Технический Альтум
Запросы SQL с ответом
В этом уроке я представляю некоторые запросов sql с ответом . Это поможет всем улучшить свои навыки sql. Эти SQL-запросы делятся на две части. В первой части я обсудил основных запросов sql с ответами. во второй части я обсудил вложенных запросов .
В первой части я обсудил основных запросов sql с ответами. во второй части я обсудил вложенных запросов .
Для этого урока я использую следующие таблицы: —
Имя таблицы: — Сотрудник
| Empid | EmpName | Отдел | ContactNo | EmailId | EmpHeadId |
|---|---|---|---|---|---|
| 101 | Иша | E-101 | 1234567890 | [email protected] | 105 |
| 102 | Прия | E-104 | 1234567890 | [email protected] | 103 |
| 103 | Неха | E-101 | 1234567890 | [email protected] | 101 |
| 104 | Рахул | E-102 | 1234567890 | [email protected] | 105 |
| 105 | Абхишек | E-101 | 1234567890 | abhishek@gmail.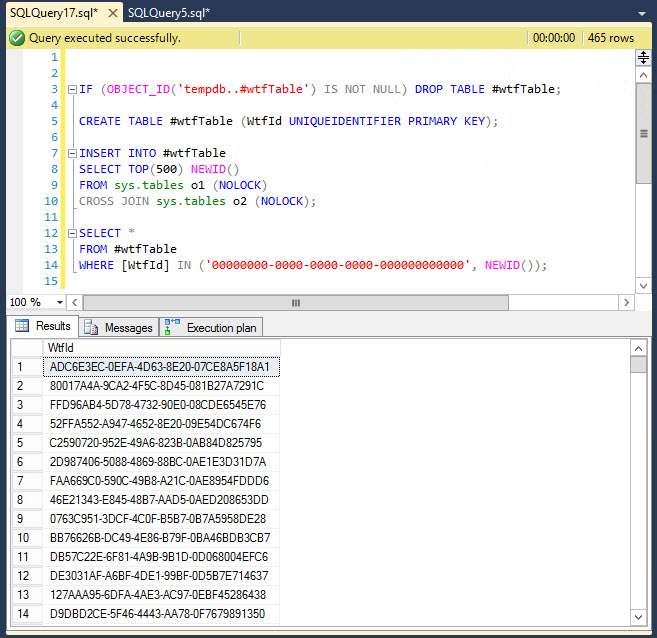 com com | 102 |
Таблица :- EmpDept
| DeptId | DeptName | Dept_off | DeptHead |
|---|---|---|---|
| E-101 | ЧАС | Понедельник | 105 |
| E-102 | Развитие | Вторник | 101 |
| E-103 | Жилищное хозяйство | Суббота | 103 |
| E-104 | Отдел продаж | Воскресенье | 104 |
| E-105 | Закупки | Вторник | 104 |
Таблица: — Оклад
| EmpId | Заработная плата | Постоянный |
|---|---|---|
| 101 | 2000 | Да |
| 102 | 10000 | Да |
| 103 | 5000 | Нет |
| 104 | 1900 | Да |
| 105 | 2300 | Да |
:- Проект
| Идентификатор проекта | Продолжительность |
|---|---|
| стр-1 | 23 |
| стр-2 | 15 |
| стр-3 | 45 |
| стр-4 | 2 |
| р-5 | 30 |
Таблица :- Страна
| идентификатор | псевдоним |
|---|---|
| c-1 | Индия |
| c-2 | США |
| c-3 | Китай |
| c-4 | Пакистан |
| с-5 | Россия |
Таблица: — ClientTable
| ClientId | ClientName | cid |
|---|---|---|
| кл-1 | ABC Group | кл-1 |
| кл-2 | PQR | ц-1 |
| кл-3 | XYZ | с-2 |
| cl-4 | tech altum | c-3 |
| ц-5 | ц-5 | ц-5 |
Таблица: — EmpProject
| EmpId | ProjectId | ClientID | StartYear | Конец Года |
|---|---|---|---|---|
| 101 | р-1 | Кл-1 | 2010 | 2010 |
| 102 | р-2 | Кл-2 | 2010 | 2012 |
| 103 | р-1 | Кл-3 | 2013 | |
| 104 | р-4 | Кл-1 | 2014 | 2015 |
| 105 | п-4 | Кл-5 | 2015 |
Запросы:-
Простые запросы1.
 Выберите сведения о сотруднике, имя которого начинается с P.
Выберите сведения о сотруднике, имя которого начинается с P.выберите * из сотрудника, где empname как «p%» выход:-
2. Сколько постоянных кандидатов берут зарплату более 5000.
выберите количество (зарплата) как количество из empsalary, где ispermanent = 'да' и зарплата> 5000 выход:-
3. Выберите сведения о сотруднике, чей адрес электронной почты указан в gmail.
выберите * у сотрудника, где электронная почта похожа на «%@gmail.com» выход:-
4. Выберите сведения о сотруднике, который работает в отделе E-104 или E-102.
выберите * из сотрудника, где отдел = «E-102» или отдел = «E-104»
или же
выберите * у сотрудника, где находится отдел ('E-102','E-104')
выход:-
5. Как называется отдел для DeptID E-102?
выберите имя отдела из empdept, где deptid = 'E-102' выход:-
6. Какая общая заработная плата выплачивается постоянным сотрудникам?
выберите сумму (зарплату) в качестве зарплаты из empsalary, где ispermanent = 'да' выход:-
7.
 Перечислите имена всех сотрудников, чьи имена заканчиваются на a.
Перечислите имена всех сотрудников, чьи имена заканчиваются на a.выберите * из сотрудника, где empname как «%a» выход:-
8. Укажите количество сотрудников отдела в каждом проекте.
выберите количество (empid) в качестве сотрудника, идентификатор проекта из группы empproject по идентификатору проекта выход:-
9. Сколько проектов было запущено в 2010 году.
выберите count(projectid) в качестве проекта из empproject, где startyear=2010 выход:-
10. Сколько проектов было начато и завершено в одном и том же году.
выберите count (projectid) в качестве проекта из empproject, где startyear = endyear выход:-
11. выберите имя сотрудника, в имени которого третий символ — «h».
выберите * из сотрудника, где empname как «__h%» выход:-
Вложенные запросы
1. Выберите название отдела компании, которое назначено сотруднику, чей идентификатор больше 103.
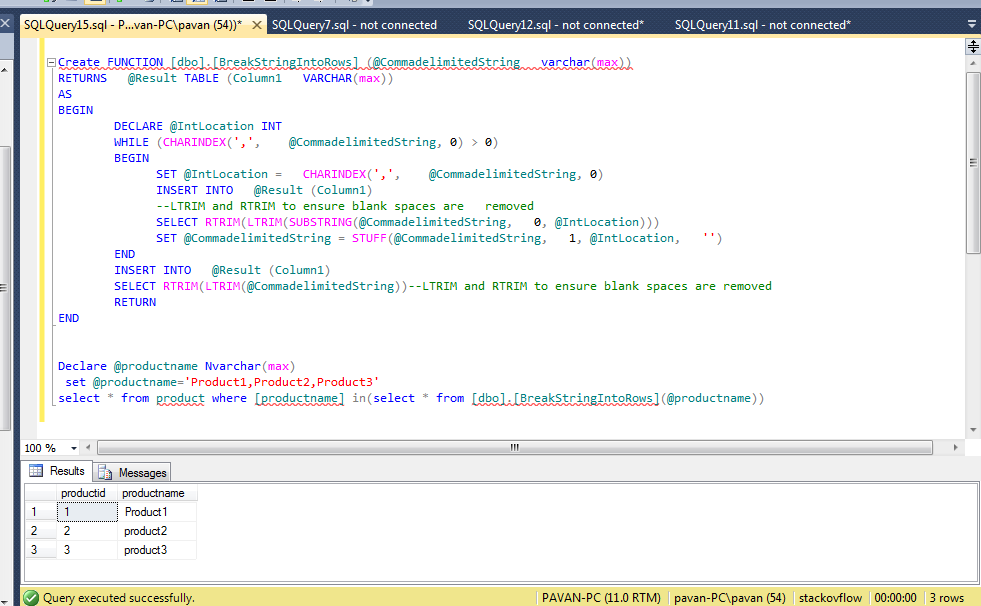
выберите имя отдела из empdept, где находится deptid (выберите отдел из сотрудника, где empid > 103) выход:-
2. Выберите имя сотрудника, который работает под началом Абхишека.
выберите empname от сотрудника, где empheadid = (выберите empid от сотрудника, где empname = 'abhishek') выход:-
3. Выберите имя сотрудника, который является начальником отдела кадров.
выберите empname из сотрудника, где empid = (выберите deepead из empdept, где deptname = 'hr') выход:-
4. Выберите имя руководителя сотрудника, который является постоянным.
выберите empname из сотрудника, где empid in (выберите empheadid из сотрудника) и empid in (выберите empid из empsalary, где ispermanent = 'да') выход:-
5. Выберите имя и адрес электронной почты руководителя отдела, который не является постоянным.
выберите empname, emaildid от сотрудника, где empid (выберите depthead из empdept) и empid (выберите empid из empsalary, где ispermanent = 'нет') выход:-
6.
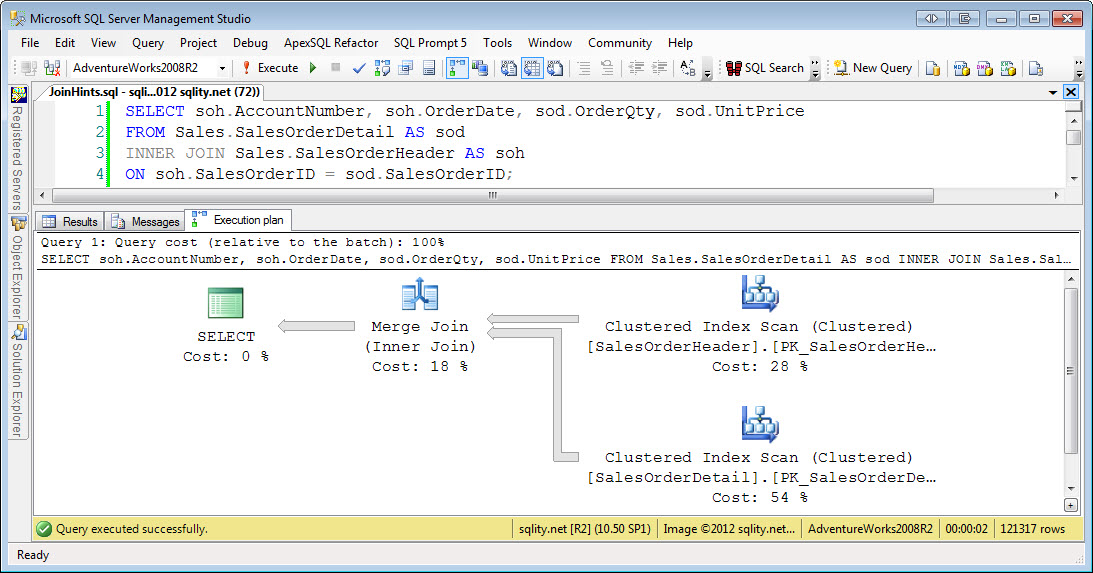 Выберите сотрудника, чей отдел не работает в понедельник .
Выберите сотрудника, чей отдел не работает в понедельник .выберите * из сотрудника, в котором находится отдел (выберите deptid из empdept, где dept_off = 'понедельник') выход:-
7. выберите сведения об индийских клинетах.
выберите * из клиентской таблицы, где находится cid (выберите cid из страны, где cname='india') выход:-
8. выберите сведения обо всех сотрудниках, работающих в отделе разработки.
выберите * из сотрудника, в котором находится отдел (выберите deptid из empdept, где deptname='development') выход:-
Видеоруководство по базовым SQL-запросам
Запросы SQL на основе агрегатной функции
Логика предметной области и SQL
Посмотрите любую недавнюю книгу по созданию корпоративных приложений (например,
как мой недавний P из EAA), и вы найдете
разбивка логики на несколько слоев, которые отделяют разные
части корпоративного приложения. Разные авторы используют разные
слоев, но общей темой является разделение между доменной логикой
(бизнес-правила) и логика источника данных (откуда поступают данные). С
большая часть данных корпоративных приложений хранится в реляционных
баз данных, эта схема уровней направлена на то, чтобы отделить бизнес-логику от
реляционная база данных
Разные авторы используют разные
слоев, но общей темой является разделение между доменной логикой
(бизнес-правила) и логика источника данных (откуда поступают данные). С
большая часть данных корпоративных приложений хранится в реляционных
баз данных, эта схема уровней направлена на то, чтобы отделить бизнес-логику от
реляционная база данных
Многие разработчики приложений, особенно опытные разработчики объектно-ориентированного программирования как и я, склонен относиться к реляционным базам данных как к механизму хранения то, что лучше всего спрятать. Существуют фреймворки, рекламирующие преимущества защита разработчиков приложений от сложностей SQL.
Тем не менее, SQL — это гораздо больше, чем простое обновление и поиск данных. механизм. Обработка запросов SQL может выполнять множество задач. Скрывая SQL разработчики приложений исключают мощный инструмент.
В этой статье я хочу изучить плюсы и минусы использования расширенных
SQL-запросы, которые могут содержать доменную логику. Я должен заявить, что я
привнести в дискуссию ОО-предвзятость, но я жил по другую сторону
слишком. (Экспертная группа одного бывшего клиента выгнала меня из компании.
потому что я был «разработчиком моделей данных».)
Я должен заявить, что я
привнести в дискуссию ОО-предвзятость, но я жил по другую сторону
слишком. (Экспертная группа одного бывшего клиента выгнала меня из компании.
потому что я был «разработчиком моделей данных».)
Сложные запросы
Все реляционные базы данных поддерживают стандартный язык запросов — SQL. По сути, я считаю, что SQL является основной причиной, по которой реляционные базы данных преуспели в той мере, в какой они это сделали. А стандартный способ взаимодействия с базами данных обеспечивает прочную степень независимости от поставщиков, что способствовало росту реляционных баз данных и помог решить проблему объектно-ориентированного программирования.
SQL имеет много сильных сторон, но одна из них чрезвычайно
мощные возможности для запросов к базе данных, позволяющие клиентам
фильтровать и суммировать большие объемы данных с очень небольшим количеством строк SQL
код. Тем не менее, использование мощных SQL-запросов часто включает логику предметной области, которая
противоречит основным принципам многоуровневого корпоративного приложения
архитектура.
Чтобы глубже изучить эту тему, давайте поиграем с простым пример. Мы начнем с модели данных, аналогичной рисунку 1. Представьте, что у нашей компании есть специальная скидка, которую мы позвони Куиллену. Клиенты имеют право на скидку Cuillen, если они сделать хотя бы один заказ в месяц на сумму более $5000 Стоит Талискер. Обратите внимание, что два заказа в одном месяце на сумму 3000 долларов США каждый не считается, должен быть один заказ на более чем 5000 долларов. Давайте представим, что вы хотите посмотреть на конкретного клиента и определить, в какие месяцы в прошлом году они имели право на Cuillen скидка. Я проигнорирую пользовательский интерфейс и просто предположу, что мы хотим представляет собой список чисел, соответствующих их квалификационным месяцам.
Рисунок 1: Схема базы данных для примера (нотация UML)
Есть много способов ответить на этот вопрос. я начну
с тремя грубыми альтернативами: сценарий транзакции, модель предметной области,
и сложный SQL.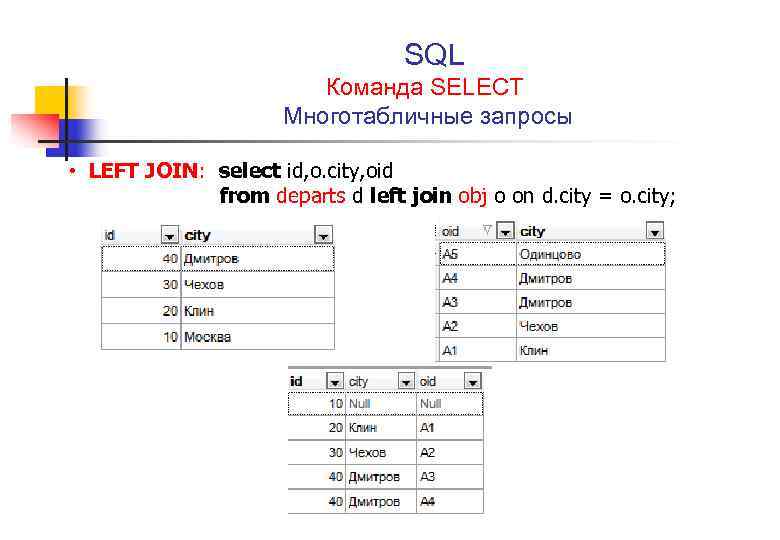
Все эти примеры я проиллюстрирую с помощью Язык программирования Руби. Здесь я немного выхожу из себя: обычно я использую Java и/или C#, чтобы проиллюстрировать эти вещи. разработчики приложений могут читать языки на основе C. я выбираю Руби немного в качестве эксперимента. Мне нравится язык, потому что он поощряет компактный, но хорошо структурированный код, который упрощает написание в объектно-ориентированном подходе. стиль. Это мой предпочтительный язык для написания сценариев. я добавил быстро руководство по синтаксису ruby, основанное на ruby, который я использую здесь.
Сценарий транзакции
Сценарий транзакции — это имя шаблона, которое я придумал для процедурный стиль обработки запроса в P of ЕАА. В этом случае процедура считывает все данные это может понадобиться, а затем делает выбор и манипулирует в памяти, чтобы выяснить, какие месяцы необходимы.
def cuillen_months имя customerID = find_customerID_named(имя) результат = [] find_orders(customerID).
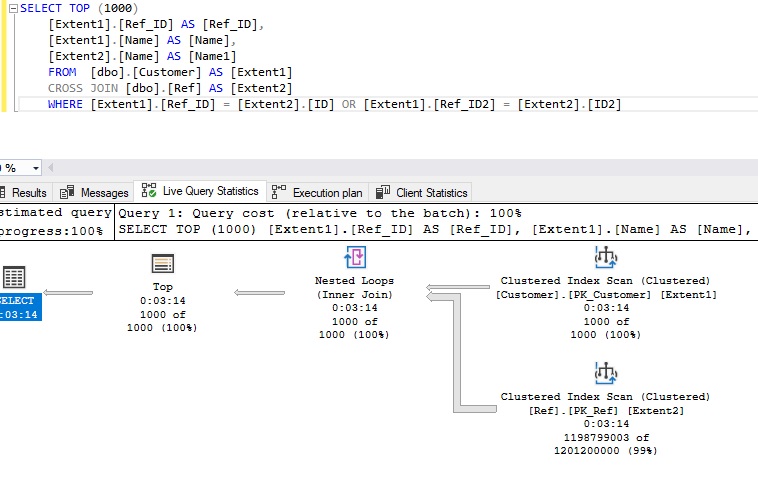 каждый сделать |строка|
результат << строка ['дата']. месяц, если cuillen? (строка ['orderID'])
конец
вернуть результат.uniq
конец
Деф Куиллен? номер заказа
talisker_total = 0.долларов
find_line_items_for_orderID(orderID).каждое действие |строка|
talisker_total += row['cost'].доллары if 'Talisker' == row['product']
конец
возврат (talisker_total > 5000 долларов)
конец
каждый сделать |строка|
результат << строка ['дата']. месяц, если cuillen? (строка ['orderID'])
конец
вернуть результат.uniq
конец
Деф Куиллен? номер заказа
talisker_total = 0.долларов
find_line_items_for_orderID(orderID).каждое действие |строка|
talisker_total += row['cost'].доллары if 'Talisker' == row['product']
конец
возврат (talisker_total > 5000 долларов)
конец
Два метода, cuillen_months и cuillen?, содержат Логика домена. Они используют ряд методов поиска, которые выдают запросы. в базу данных.
def find_customerID_названное имя
sql = 'ВЫБРАТЬ * из клиентов, где имя = ?'
вернуть $dbh.select_one(sql, имя)['идентификатор_заказчика']
конец
def find_orders идентификатор клиента
результат = []
sql = 'ВЫБЕРИТЕ * ИЗ заказов, ГДЕ customerID = ?'
$dbh.execute(sql, customerID) сделать |sth|
результат = sth.collect{|строка| row.dup}
конец
вернуть результат
конец
def find_line_items_for_orderID ID заказа
результат = []
sql = 'SELECT * FROM lineItems l WHERE orderID = ?'
$dbh. execute(sql, orderID) сделать |sth|
результат = sth.collect{|строка| row.dup}
конец
вернуть результат
конец
 execute(sql, orderID) сделать |sth|
результат = sth.collect{|строка| row.dup}
конец
вернуть результат
конец
execute(sql, orderID) сделать |sth|
результат = sth.collect{|строка| row.dup}
конец
вернуть результат
конец
Во многом это очень простодушный подход, в в частности, он очень неэффективен в использовании SQL — требуется несколько запросов для извлечения данных (2 + N, где N — количество заказы). Не беспокойтесь об этом слишком сильно в данный момент, я поговорю о том, как улучшить это позже. Вместо этого сконцентрируйтесь на сущности подход: прочитайте все данные, которые вы должны рассмотреть, затем выполните цикл и выберите то, что вам нужно.
(Кроме того, приведенная выше логика домена реализована таким образом, чтобы его легко читать, но это не то, что я считаю идиоматическим Ruby. Идентификатор предпочитайте метод ниже, который больше использует мощные блоки Ruby а также методы сбора. Этот код многим покажется странным, но Мелкоговорящим должно понравится.)
def cuillen_months2 имя customerID = find_customerID_named(имя) квалификационные_заказы = найти_заказы(идентификатор_заказчика).
 выберите {|строка| куиллен?(строка['orderID'])}
return (qualifying_orders.collect {|row| row['date'].month}).uniq
конец
выберите {|строка| куиллен?(строка['orderID'])}
return (qualifying_orders.collect {|row| row['date'].month}).uniq
конец
Модель домена
В качестве второй отправной точки рассмотрим классический объектно-ориентированная модель предметной области. В этом случае мы создаем в памяти объекты, которые в данном случае отражают таблицы базы данных (на самом деле системах они обычно не являются точными зеркалами.) Набор объектов поиска загружает эти объекты из базы данных, когда у нас есть объекты в памяти, мы затем запускаем логику на них.
Начнем с искателей. Они захлопывают запросы против базу данных и создавать объекты.
класс CustomerMapper
деф найти имя
результат = ноль
sql = 'ВЫБЕРИТЕ * ОТ клиентов, ГДЕ имя =?'
возврат нагрузки ($ dbh.select_one (sql, имя))
конец
деф загрузка строки
результат = Customer.new (строка ['customerID'], строка ['ИМЯ'])
result.orders = Результат OrderMapper.new.find_for_customer
вернуть результат
конец
конец
класс OrderMapper
def find_for_customer Клиент
результат = []
sql = "ВЫБЕРИТЕ * ИЗ заказов, ГДЕ customerID =?"
$dbh. select_all(sql, aCustomer.db_id) {|строка| результат << загрузить (строка)}
результат load_line_items
вернуть результат
конец
деф загрузка строки
результат = Order.new (строка ['orderID'], строка ['дата'])
вернуть результат
конец
заказы def load_line_items
# Невозможно выполнить загрузку с помощью load(row), так как соединение занято
заказы.каждый делать
|заказ| anOrder.line_items = LineItemMapper.new.find_for_order
конец
конец
конец
класс LineItemMapper
заказ def find_for_order
результат = []
sql = "выбрать * из элементов строки, где orderID =?"
$dbh.select_all(sql, order.db_id) {|строка| результат << загрузить (строка)}
вернуть результат
конец
деф загрузка строки
return LineItem.new(строка['lineNumber'], строка['product'], строка['cost'].to_i.dollars)
конец
конец
 select_all(sql, aCustomer.db_id) {|строка| результат << загрузить (строка)}
результат load_line_items
вернуть результат
конец
деф загрузка строки
результат = Order.new (строка ['orderID'], строка ['дата'])
вернуть результат
конец
заказы def load_line_items
# Невозможно выполнить загрузку с помощью load(row), так как соединение занято
заказы.каждый делать
|заказ| anOrder.line_items = LineItemMapper.new.find_for_order
конец
конец
конец
класс LineItemMapper
заказ def find_for_order
результат = []
sql = "выбрать * из элементов строки, где orderID =?"
$dbh.select_all(sql, order.db_id) {|строка| результат << загрузить (строка)}
вернуть результат
конец
деф загрузка строки
return LineItem.new(строка['lineNumber'], строка['product'], строка['cost'].to_i.dollars)
конец
конец
select_all(sql, aCustomer.db_id) {|строка| результат << загрузить (строка)}
результат load_line_items
вернуть результат
конец
деф загрузка строки
результат = Order.new (строка ['orderID'], строка ['дата'])
вернуть результат
конец
заказы def load_line_items
# Невозможно выполнить загрузку с помощью load(row), так как соединение занято
заказы.каждый делать
|заказ| anOrder.line_items = LineItemMapper.new.find_for_order
конец
конец
конец
класс LineItemMapper
заказ def find_for_order
результат = []
sql = "выбрать * из элементов строки, где orderID =?"
$dbh.select_all(sql, order.db_id) {|строка| результат << загрузить (строка)}
вернуть результат
конец
деф загрузка строки
return LineItem.new(строка['lineNumber'], строка['product'], строка['cost'].to_i.dollars)
конец
конец
Эти методы загрузки загружают следующие классы
класс Заказчик...
attr_accessor : имя, : db_id, : заказы
def инициализировать db_id, имя
@db_id, @name = db_id, имя
конец
порядок класса. ..
attr_accessor :дата, :db_id, :line_items
def инициализировать (идентификатор, дата)
@db_id, @date, @line_items = идентификатор, дата, []
конец
класс LineItem...
attr_reader :line_number, :product, :cost
def инициализировать номер строки, продукт, стоимость
@line_number, @product, @cost = line_number, продукт, стоимость
конец
 ..
attr_accessor :дата, :db_id, :line_items
def инициализировать (идентификатор, дата)
@db_id, @date, @line_items = идентификатор, дата, []
конец
класс LineItem...
attr_reader :line_number, :product, :cost
def инициализировать номер строки, продукт, стоимость
@line_number, @product, @cost = line_number, продукт, стоимость
конец
..
attr_accessor :дата, :db_id, :line_items
def инициализировать (идентификатор, дата)
@db_id, @date, @line_items = идентификатор, дата, []
конец
класс LineItem...
attr_reader :line_number, :product, :cost
def инициализировать номер строки, продукт, стоимость
@line_number, @product, @cost = line_number, продукт, стоимость
конец
Логика определения cuillen месяцев может быть описана в пару методов.
класс Заказчик...
def cuillenМесяцы
результат = []
заказы.каждый делать |o|
результат << o.date.month, если o.cuillen?
конец
вернуть результат.uniq
конец
порядок класса...
Деф Куиллен?
DiscountableAmount = 0.долларов
line_items.each сделать |строка|
DiscountableAmount += line.cost, если 'Talisker' == line.product
конец
вернуть дисконтируемую сумму > 5000.долларов
конец
Это решение длиннее, чем версия скрипта транзакции.
Однако стоит отметить, что логика загрузки объектов и
фактическая логика домена более разделена. Любая другая обработка на
этот набор объектов домена будет использовать ту же логику загрузки. Итак, если мы
выполняли множество различных частей логики предметной области усилиями
логика загрузки будет амортизироваться по всей логике предметной области, что
сделать это менее проблемой. Эта стоимость может быть дополнительно снижена за счет
методы, такие как метаданные
Отображение.
Любая другая обработка на
этот набор объектов домена будет использовать ту же логику загрузки. Итак, если мы
выполняли множество различных частей логики предметной области усилиями
логика загрузки будет амортизироваться по всей логике предметной области, что
сделать это менее проблемой. Эта стоимость может быть дополнительно снижена за счет
методы, такие как метаданные
Отображение.
Опять много SQL-запросов (2 + количество ордеров).
Логика в SQL
При обоих первых двух база данных используется в значительной степени как накопительный механизм. Все, что мы сделали, попросили все записи из конкретной таблицы с очень простой фильтрацией. SQL очень мощный язык запросов и может делать гораздо больше, чем простая фильтрация которые используют эти примеры.
Используя SQL в полной мере, мы можем выполнять всю работу в SQL
ID клиента в скидках_месяцев
sql = <<-END_SQL
ВЫБЕРИТЕ РАЗЛИЧНЫЙ МЕСЯЦ (o.date) КАК месяц
ИЗ позиций л
Заказы INNER JOIN o ON l. orderID = o.orderID
ВНУТРЕННЕЕ СОЕДИНЕНИЕ клиентов c ON o.customerID = c.customerID
ГДЕ (c.name = ?) И (l.product = 'Талискер')
СГРУППИРОВАТЬ ПО o.orderID, o.date, c.NAME
ИМЕЮЩИЙ (СУММА(l.cost) > 5000)
END_SQL
результат = []
$dbh.select_all(sql, идентификатор клиента) {|строка| результат << строка ['месяц']}
вернуть результат
конец
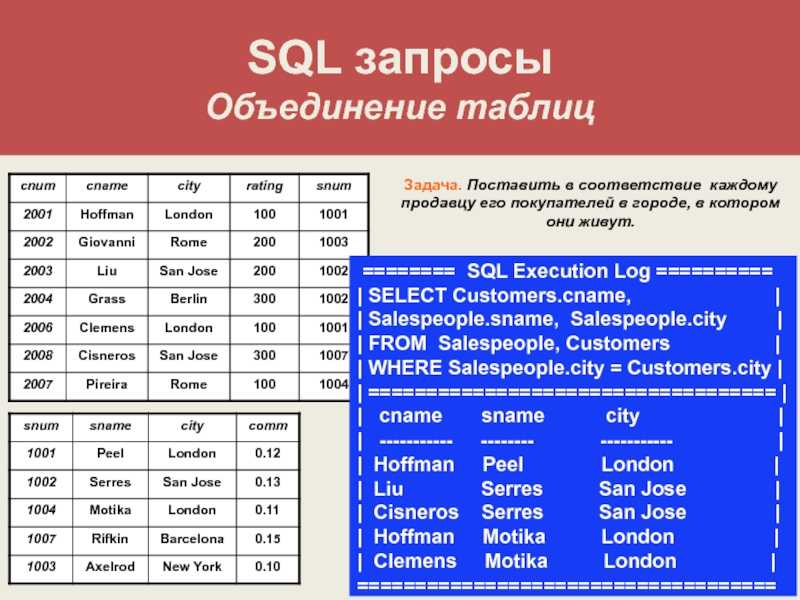 orderID = o.orderID
ВНУТРЕННЕЕ СОЕДИНЕНИЕ клиентов c ON o.customerID = c.customerID
ГДЕ (c.name = ?) И (l.product = 'Талискер')
СГРУППИРОВАТЬ ПО o.orderID, o.date, c.NAME
ИМЕЮЩИЙ (СУММА(l.cost) > 5000)
END_SQL
результат = []
$dbh.select_all(sql, идентификатор клиента) {|строка| результат << строка ['месяц']}
вернуть результат
конец
orderID = o.orderID
ВНУТРЕННЕЕ СОЕДИНЕНИЕ клиентов c ON o.customerID = c.customerID
ГДЕ (c.name = ?) И (l.product = 'Талискер')
СГРУППИРОВАТЬ ПО o.orderID, o.date, c.NAME
ИМЕЮЩИЙ (СУММА(l.cost) > 5000)
END_SQL
результат = []
$dbh.select_all(sql, идентификатор клиента) {|строка| результат << строка ['месяц']}
вернуть результат
конец
Хотя я назвал это сложным запросом, только сложный по сравнению с простым выбором и запросами предложения where из более ранних примеров. SQL-запросы могут быть намного сложнее, чем этот, хотя многие разработчики приложений будут избегать даже такой минимально сложный запрос, как этот.
Анализ производительности
Один из первых вопросов, которые люди задают при таком
дело в производительности. Лично я не думаю, что производительность должна быть
первый вопрос. Моя философия заключается в том, что большую часть времени вы должны
сконцентрируйся
написание поддерживаемого кода. Затем используйте профайлер для выявления горячих точек. а затем замените только эти горячие точки более быстрыми, но менее четкими
код. Основная причина, по которой я это делаю, заключается в том, что в большинстве систем только очень
небольшая часть кода на самом деле критична для производительности, и
Гораздо проще улучшить производительность хорошо факторизованных
поддерживаемый код.
а затем замените только эти горячие точки более быстрыми, но менее четкими
код. Основная причина, по которой я это делаю, заключается в том, что в большинстве систем только очень
небольшая часть кода на самом деле критична для производительности, и
Гораздо проще улучшить производительность хорошо факторизованных
поддерживаемый код.
Но в любом случае давайте рассмотрим компромиссы производительности первый. На моем маленьком ноутбуке сложный SQL-запрос выполняется двадцать раз быстрее, чем два других подхода. Теперь вы не можете формировать выводы о производительности сервера центра обработки данных из стройный, но пожилой ноутбук, но я бы удивился, если бы комплекс запрос будет менее чем на порядок быстрее, чем в приближается память.
Частично это связано с тем, что оперативная память приближается
написаны таким образом, что это очень неэффективно с точки зрения SQL
запросы. Как я указал в их описаниях, каждый выдает
SQL-запрос для каждого заказа, который есть у клиента, и моя тестовая база данных
имеет тысячу заказов для каждого клиента.
Мы можем значительно уменьшить эту нагрузку, перезаписав in-memory программы для использования одного SQL-запроса. начну с сделки сценарий.
SQL = <<-END_SQL
ВЫБЕРИТЕ * из заказов o
INNER JOIN lineItems li ON li.orderID = o.orderID
ВНУТРЕННЕЕ СОЕДИНЕНИЕ клиентов c ON c.customerID = o.customerID
ГДЕ c.name = ?
END_SQL
def cuillen_months имя_клиента
заказы = {}
$dbh.select_all(SQL, имя_клиента) сделать |строка|
process_row (строка, заказы)
конец
результат = []
заказы.каждое_значение сделать |o|
результат << o.date.month если o.talisker_cost > 5000.долларов
конец
вернуть результат.uniq
конец
строка def process_row, заказы
ID заказа = строка['ID заказа']
заказы[идентификатор_заказа] = Order.new(строка['дата']), если только заказы[идентификатор_заказа]
если 'Талискер' == строка['продукт']
заказы[идентификатор_заказа].talisker_cost += строка['стоимость'].доллары
конец
конец
класс Порядок
attr_accessor :дата, :talisker_cost
определить дату инициализации
@date, @talisker_cost = дата, 0 долларов
конец
конец
Это довольно большое изменение в сценарии транзакции, но оно
ускоряет работу в три раза.
Я могу проделать аналогичный трюк с моделью предметной области. Здесь мы видим преимущество более сложной структуры модели предметной области. мне нужно только изменить метод загрузки, бизнес-логику в объектах предметной области себя менять не надо.
класс CustomerMapper
SQL = <<-END_SQL
ВЫБЕРИТЕ c.customerID,
c.ИМЯ как ИМЯ,
о.orderID,
o.date как дата,
li.lineNumber как номер строки,
li.product как продукт,
li.cost как себестоимость
ОТ клиентов c
INNER JOIN заказы o ON o.customerID = c.customerID
INNER JOIN lineItems li ON o.orderID = li.orderID
ГДЕ c.name = ?
END_SQL
деф найти имя
результат = ноль
om = OrderMapper.new
lm = LineItemMapper.new
$dbh.execute (SQL, имя) сделать |sth|
sth.each сделать |строка|
результат = загрузка (строка), если результат == ноль
если результат. заказ (строка ['orderID'])
result.add_order (om. load (строка))
конец
результат.порядок(строка['orderID']).add_line_item(lm.load(строка))
конец
конец
вернуть результат
конец
(Я немного солгу, когда скажу, что мне не нужно изменять объекты домена. Для того, чтобы получить достойную производительность, мне нужно изменить структуру данных клиента, чтобы заказы сохранялись в хеше, а не в массиве. Но опять же, это было очень самостоятельное изменение и не повлияло на код для определения скидки.)
Здесь есть несколько точек. Во-первых, стоит помнить
что код в памяти часто может быть усилен более интеллектуальными
запросы. Всегда стоит посмотреть, звоните ли вы
базу данных несколько раз, и если есть способ сделать это с помощью одного
позвоните вместо этого. Это особенно легко упустить из виду, когда у вас есть
модель домена, потому что люди обычно думают о классе за раз
доступ. (Я даже видел случаи, когда люди загружали по одной строке за раз, но
что патологическое поведение встречается относительно редко. )
Одно из самых больших различий между сценарием транзакции а модель предметной области — это влияние изменения запроса структура. Для сценария транзакции это в значительной степени означает изменение весь сценарий. Кроме того, если было много сценариев доменной логики, использующих аналогичные данные, каждый из них должен быть изменен. С доменной моделью вы изменяете красиво разделенный участок кода и логику предметной области сам не должен меняться. Это очень важно, если у вас много Логика домена. Это общий компромисс между транзакцией скрипты и доменная логика - есть первоначальная стоимость в сложности доступ к базе данных для логики домена, который окупается, если у вас много Логика домена.
Но даже при многотабличном запросе оперативная память приближается
все еще не так быстры, как сложный SQL - в 6 раз по моему
кейс. Это имеет смысл: сложный SQL выполняет выборку и суммирование
затрат в базе данных, и ему нужно всего лишь перетащить несколько значений
обратно клиенту, в то время как метод in-memory требует пяти
тысячи строк данных обратно клиенту.
Производительность — не единственный фактор, влияющий на выбор пути. но это часто заключительный. Если у вас есть горячая точка, которую вы абсолютно необходимо улучшить, тогда другие факторы на втором месте. Как В результате многие поклонники моделей предметной области следуют системе ведения дел в памяти по умолчанию и с использованием таких вещей, как сложные запросы для горячих пятна только тогда, когда они должны.
Также стоит отметить, что этот пример играет на сильных сторонах базы данных. Многие запросы не имеют сильного элементы выбора и агрегации, которые этот делает и не будет показать такое изменение производительности. Кроме того, многопользовательские сценарии часто вызвать неожиданные изменения в поведении запросов, поэтому реальное профилирование должно выполняться при реалистичной многопользовательской нагрузке. Вы можете обнаружить, что проблемы с блокировкой перевешивают все, что вы можете получить за счет более быстрых отдельных запросов.
Модифицируемость
Для любого долгоживущего корпоративного приложения вы можете быть уверены в
одно - это многое изменит. В результате вы должны обеспечить
что система организована таким образом, что ее легко
сдача. Изменяемость, вероятно, является основной причиной, по которой люди помещают
бизнес-логика в памяти.
SQL может делать многое, но его возможности ограничены. Некоторые вещи, которые он может делать, требуют довольно умного кодирования, например, просмотр алгоритмы для медианы отображения набора данных. Другие невозможны сделать, не прибегая к нестандартным расширениям, что проблема, если вы хотите портативности.
Часто вы хотите запустить бизнес-логику перед записью данных в базу данных, особенно если вы работаете на некоторую ожидающую информацию. Загрузка в базу данных может быть проблематично, потому что часто вы хотите, чтобы ожидающие данные сеанса были изолированы из полностью принятых данных. Эти данные сеанса часто не должны подвергаться тем же правилам проверки, что и полностью принятые данные.
Понятность
SQL часто считают особым языком, не
то, с чем должны иметь дело разработчики приложений. Верно
многие фреймворки баз данных любят говорить, как, используя их, вы избегаете
необходимо иметь дело с SQL. Я всегда находил это несколько странным
аргумент, так как я всегда был довольно комфортно с умеренно
сложный SQL. Однако многим разработчикам сложнее иметь дело с SQL, чем
традиционные языки, и ряд идиом SQL трудно понять
всем, кроме экспертов по SQL.
Хороший тест для вас - посмотреть на три решения и посмотреть, какие из них делают логику предметной области проще для понимания и таким образом изменить. Я нахожу версию модели домена, которая всего лишь пара методов, которым легче всего следовать; во многом потому, что данные доступ разделен. Далее я предпочитаю версию SQL над скрипт транзакции в памяти. Но я уверен, что другие читатели другие предпочтения.
Если большая часть команды менее комфортно работает с SQL, то это причина
чтобы логика предметной области была отделена от SQL. (Это также повод задуматься
обучение большего количества людей SQL - по крайней мере, до среднего уровня. ) Это
это одна из тех ситуаций, когда вы должны принять во внимание
состав вашей команды — люди влияют на архитектурные решения.
Избегание дублирования
Один из самых простых, но самых мощных принципов проектирования Я столкнулся с тем, что избегает дублирования - сформулировано Прагматичные программисты как принцип DRY (не повторяйтесь).
Чтобы подумать о принципе DRY для этого случая, давайте учтите еще одно требование к этому приложению - список заказов для клиента в определенный месяц с указанием идентификатора заказа, даты, общей стоимости и является ли этот заказ квалификационным заказом для плана Cuillen. Все это отсортировано по общей стоимости.
Используя подход объекта домена для обработки этого запроса, мы необходимо добавить в заказ метод расчета общей стоимости.
класс Заказать...
деф общая_стоимость
результат = 0.долларов
line_items.each {|строка| результат += строка.стоимость}
вернуть результат
конец
После этого легко распечатать список заказов
класс Заказчик
def order_list месяц
результат = ''
selected_orders = orders. select {|o| месяц == o.date.month}
selected_orders.sort! {|о1, о2| o2.total_cost <=> o1.total_cost}
selected_orders.each сделать |o|
результат << sprintf("%10d %20s %10s %3s\n",
o.db_id, o.date, o.total_cost, o.discount?)
конец
вернуть результат
конец
Для определения того же запроса с помощью одного оператора SQL требуется коррелированный подзапрос, который некоторые люди находят пугающим.
def order_list имя_клиента, месяц
sql = <<-END_SQL
ВЫБЕРИТЕ o.orderID, o.date, sum(li.cost) как totalCost,
СЛУЧАЙ, КОГДА
(ВЫБЕРИТЕ СУММУ(li.cost)
FROM позиций li
ГДЕ li.product = 'Талискер'
И o.orderID = li.orderID) > 5000
ТОГДА 'Й'
ИНАЧЕ 'Н'
КОНЕЦ КАК естьКуиллен
ОТ dbo.КЛИЕНТЫ c
ВНУТРЕННЕЕ СОЕДИНЕНИЕ dbo.orders o ON c.customerID = o.customerID
INNER JOIN lineItems li ON o.orderID = li.orderID
ГДЕ (c. name = ?)
И (МЕСЯЦ(o.date) = ?)
СГРУППИРОВАТЬ по o.orderID, o.date
ORDER BY totalCost desc
END_SQL
результат = ""
$dbh.select_all(sql, имя_клиента, месяц) сделать |строка|
результат << sprintf("%10d %20s %10s %3s\n",
строка['идентификатор заказа'],
строка['дата'],
строка['общая стоимость'],
строка['isCuillen'])
конец
вернуть результат
конец
Разные люди будут расходиться в том, кто из этих двоих главный.
проще всего понять. Но проблема, которую я здесь разжевываю, заключается в том, что
дублирование. Этот запрос дублирует логику исходного запроса, который
просто дает месяцы. Объектный подход предметной области не имеет этого
дублирование - если я хочу изменить определение для cuillen
план, все, что мне нужно сделать, это изменить определение куиллен? и все виды использования обновлены.
Несправедливо выбрасывать SQL из-за проблемы с дублированием.
потому что вы можете избежать дублирования в расширенном подходе SQL, поскольку
Что ж. Уловка, поскольку поклонники баз данных должны задыхаться, чтобы указать
out, это использовать представление.
Я могу определить представление, для простоты назвав его Orders2 на основе следующий запрос.
ВЫБЕРИТЕ ПЕРВЫЕ 100 ПРОЦЕНТОВ
o.orderID, c.name, c.customerID, o.date,
SUM(li.cost) AS totalCost,
СЛУЧАЙ, КОГДА
(ВЫБЕРИТЕ СУММУ(li2.cost)
ИЗ позиций li2
ГДЕ li2.product = 'Талискер'
И o.orderID = li2.orderID) > 5000
ТОГДА 'Й'
ИНАЧЕ 'Н'
КОНЕЦ КАК естьКуиллен
ОТ dbo.orders o
ВНУТРЕННЕЕ СОЕДИНЕНИЕ dbo.lineItems li ON o.orderID = li.orderID
ВНУТРЕННЕЕ СОЕДИНЕНИЕ dbo.CUSTOMERS c ON o.customerID = c.customerID
СГРУППИРОВАТЬ ПО o.orderID, c.name, c.customerID, o.date
ORDER BY totalCost DESC
Теперь я могу использовать это представление как для получения месяцев, так и для составление списка заказов
def cuillen_months_view идентификатор клиента sql = "ВЫБЕРИТЕ РАЗЛИЧНЫЙ месяц (дату) ИЗ заказов2, ГДЕ имя = ? И isCuillen = 'Y'" результат = [] $dbh.
Представление упрощает как запросы, так и помещает ключ бизнес-логику в одном месте.
Кажется, люди редко обсуждают использование подобных представлений для
избегать дублирования. Книги, которые я видел по SQL, кажется, не обсуждают выполнение
такого рода вещи. В некоторых средах это сложно из-за
организационные и культурные различия между базой данных и
разработчики приложений. Часто разработчикам приложений не разрешается
определяют представления, а разработчики баз данных образуют узкое место, которое
отговаривает разработчиков приложений от создания подобных представлений. Администраторы баз данных могут даже отказаться создавать представления, которые нужны только одному
заявление. Но я считаю, что SQL заслуживает не меньше внимания, чем
дизайн как и все остальное.
Инкапсуляция
Инкапсуляция — хорошо известный принцип объектно-ориентированного дизайн, и я думаю, что он хорошо подходит для общего программного обеспечения дизайн. По сути, это говорит о том, что программа должна быть разделена на модули, которые скрывают структуры данных за интерфейсом процедуры звонки. Цель этого состоит в том, чтобы позволить вам изменить базовый структуры данных, не вызывая большого волнового эффекта в системе.
В данном случае возникает вопрос, как мы можем инкапсулировать база данных? Хорошая схема инкапсуляции позволила бы нам изменить схему базы данных, не вызывая болезненного раунда редактирования через заявление.
Распространенная форма инкапсуляции для корпоративных приложений.
это многослойность, где мы стремимся отделить доменную логику от данных
исходная логика. Таким образом, код, работающий с бизнес-логикой, не
затрагивается, когда мы изменяем дизайн базы данных.
Версия модели предметной области является хорошим примером такого рода инкапсуляция. Бизнес-логика работает только с объектами в памяти. Как данные попадают туда полностью разделены. Скрипт транзакции подход имеет некоторую инкапсуляцию базы данных с помощью методов поиска, хотя структура базы данных более раскрывается через возврат наборы результатов.
В мире приложений вы достигаете инкапсуляции через API процедур и объектов. Эквивалентом SQL является использование представлений. Если вы меняете таблицу, вы можете создать представление, которое поддерживает старую стол. Самая большая проблема здесь связана с обновлениями, которые часто не могут быть сделано правильно с представлениями. Вот почему многие магазины оборачивают все DML хранимые процедуры.
Инкапсуляция — это больше, чем просто поддержка изменений в
Просмотры. Это также касается разницы между доступом к данным и
определение бизнес-логики. С SQL эти два понятия можно легко размыть, но
вы все еще можете сделать некоторую форму разделения.
В качестве примера рассмотрим представление, которое я определил выше, чтобы избежать дублирование запросов. Это представление представляет собой единое представление, которое может быть разделить по линиям источника данных и бизнес-логики разделение. Представление источника данных будет выглядеть примерно так:
ВЫБЕРИТЕ o.orderID, o.date, c.customerID, c.name,
СУММ(li.cost) КАК total_cost,
(ВЫБЕРИТЕ СУММУ(li2.cost)
ИЗ позиций li2
ГДЕ li2.product = 'Talisker' И o.orderID = li2.orderID
) AS taliskerCost
ОТ dbo.КЛИЕНТЫ c
ВНУТРЕННЕЕ СОЕДИНЕНИЕ dbo.orders o ON c.customerID = o.customerID
ВНУТРЕННЕЕ СОЕДИНЕНИЕ dbo.lineItems li ON li.orderID = o.orderID
СГРУППИРОВАТЬ ПО o.orderID, o.date, c.customerID, c.name
Затем мы можем использовать это представление в других представлениях, которые больше ориентированы на
Логика домена. Вот тот, который указывает на право Cuillen
ВЫБЕРИТЕ идентификатор заказа, дату, идентификатор клиента, имя, общую стоимость,
СЛУЧАЙ, КОГДА taliskerCost > 5000 THEN 'Y' ELSE 'N' END AS isCuillen
ОТ dbo.OrdersTal
Этот тип мышления также может быть применен к случаям, когда мы загружаем данные в модель предметной области. Ранее я говорил о том, как проблемы производительности с моделью предметной области можно решить, взяв весь запрос на количество месяцев cuillen и заменив его одним SQL-запрос. Другим подходом было бы использование вышеуказанного источника данных. Посмотреть. Это позволило бы нам сохранить более высокую производительность, оставаясь при этом сохранение логики предметной области в модели предметной области. Позиции будут только быть загружены при необходимости с помощью отложенной загрузки, но подходящая сводная информация может быть введена через представление.
Использование представлений или даже хранимых процедур обеспечивает
инкапсуляция только до определенного момента. Во многих корпоративных приложениях данные
поступает из нескольких источников, а не только из нескольких реляционных баз данных,
но также и устаревшие системы, другие приложения и файлы. Действительно
рост XML, вероятно, приведет к тому, что больше данных будет поступать из плоских файлов.
делятся по сетям. В этом случае полная инкапсуляция действительно может быть только
выполняется слоем в коде приложения, что также подразумевает
эта доменная логика также должна находиться в памяти.
Переносимость базы данных
Одной из причин, по которой многие разработчики избегают сложного SQL, является Проблема переносимости базы данных. Ведь обещания SQL что он позволяет вам использовать один и тот же стандартный SQL для множества баз данных платформы, позволяющие легко менять поставщиков баз данных
На самом деле это всегда было немного выдумкой. На практике
SQL в основном стандартный, но со множеством мелких мест, которые могут вас сбить с толку.
вверх. Однако с осторожностью вы можете создать SQL, который не будет слишком болезненным для понимания. переключение между серверами баз данных. Но для этого вы теряете много возможностей.
Решение о переносимости базы данных оказывается конкретно для вашего проекта. В наши дни это гораздо меньшая проблема, чем это было. Рынок баз данных потрясен, поэтому большинство мест падает в один из трех основных лагерей. Корпорации часто имеют сильные приверженность тому лагерю, в котором они находятся. Если вы считаете, что изменение баз данных маловероятно из-за такого рода инвестиций, вы также можете начать пользоваться особыми функциями вашего предоставляет база данных.
Некоторым людям по-прежнему нужна мобильность, например тем, кто предоставлять продукты, которые можно установить и взаимодействовать с несколькими базы данных. В этом случае есть более сильный аргумент против логику в SQL, так как вы должны быть очень осторожны с тем, какие части SQL вы можете безопасно использовать.
Тестируемость
Тестируемость — это не та тема, которая часто поднимается в
дискуссии о дизайне. Одним из преимуществ разработки через тестирование (TDD) является то, что она
возродил представление о том, что тестируемость является жизненно важной частью дизайна.
Обычная практика в SQL, по-видимому, не проверяется. На самом деле это не редко можно найти важные представления и хранимые процедуры, которые даже не проводятся в средствах управления конфигурацией. Тем не менее, безусловно, возможно иметь тестируемый SQL. В популярном семействе xunit есть количество инструментов, которые можно использовать для тестирования в базе данных Окружающая среда. Эволюционная база данных методы, такие как тестовые базы данных, могут быть использованы для обеспечения тестируемая среда, очень похожая на ту, что нравится TDD-программистам.
Основная область, которая может иметь значение, — это производительность. Хотя прямой SQL часто быстрее в производстве, он может быть намного быстрее запускать тесты бизнес-логики в памяти, если интерфейс базы данных разработан таким образом, что вы можете заменить фактическую базу данных связь с сервисом Заглушка
Подведение итогов
До сих пор я говорил о проблемах. Теперь пришло время
сделать выводы. Главное, что вам нужно сделать, это рассмотреть
различные вопросы, о которых я говорил здесь, судите о них по своим предубеждениям и
решить, какую политику использовать для использования расширенных запросов и размещения домена
логика там.
То, как я смотрю на картину, одна из самых критических элементами является то, поступают ли ваши данные из одного логического реляционного базы данных или разбросаны по множеству различных, часто не связанных с SQL, источники. Если он разбросан, вам следует создать слой источника данных. в памяти, чтобы инкапсулировать ваши источники данных и сохранить логику вашего домена в памяти. В этом случае сильные стороны SQL как языка не проблема, потому что не все ваши данные находятся в SQL.
Ситуация становится интересной, когда подавляющее большинство
ваши данные находятся в одной логической базе данных. В этом случае у вас есть два
основные вопросы для рассмотрения. Одним из них является выбор языка программирования:
SQL против языка вашего приложения. Другой, где код
работает, SQL в базе данных или в памяти.
SQL делает некоторые вещи простыми, но другие более сложными. сложно. Некоторым людям с SQL легко работать, другим — ужасно загадочно. Личный комфорт команды является большой проблемой здесь. я бы предложить, чтобы, если вы пойдете по пути добавления большого количества логики в SQL, не ожидайте, что он будет переносимым — используйте все расширения ваших поставщиков и весело привязать себя к их технологии. Если вам нужна портативность держите логику вне SQL.
До сих пор я говорил о модифицируемости. я думаю эти
проблемы должны быть на первом месте, но их важнее любые критические показатели
вопросы. Если вы используете подход в памяти и имеете горячие точки, которые могут
быть решена более мощными запросами, затем сделайте это. я бы предложил
посмотреть, насколько вы можете организовать запросы, повышающие производительность
как запросы к источнику данных, как я описал выше. Так вы сможете свести к минимуму
помещая доменную логику в SQL.
Язык структурированных запросов — важность изучения SQL
Написано Амарендрой Бабу• 30 июля 2018 г.• 16:56• Администрирование базы данных, разработка базы данных • Один комментарий
ГлавнаяАдминистрирование баз данных, Разработка баз данныхСтруктурированный язык запросов – Важность изучения SQL
Язык компьютерного программирования представляет собой набор подробных инструкций для компьютеров или машин для выполнения определенных действий. С помощью языка программирования мы можем управлять поведением и выводом компьютера с помощью точных алгоритмов. Язык программирования также называют компьютерным языком или системой программирования. Компьютер работает с различными языками программирования, такими как SQL, Java, C++, Python и т. д. Эти языки позволяют компьютерам и машинам более эффективно и быстро обрабатывать большие и сложные данные. Именно поэтому мы считаем их ценными для организаций, особенно при создании системных служб управления базами данных.
SQL означает «язык структурированных запросов». Рэймонд Бойс и Дональд Чемберлин разработали SQL в IBM в начале 1970-х годов. Он был создан для получения доступа и изменения данных, хранящихся в базах данных. Первоначально он назывался SEQUEL (язык структурированных запросов на английском языке), но позже ему пришлось изменить свое название, потому что другая компания заявила, что это имя является товарным знаком. Впоследствии SQL стал официальным стандартом для ANSI (Американский национальный институт стандартов) и ISO (Международная организация по стандартизации).
SQL — это особый язык программирования, который используется для взаимодействия с базами данных. Он работает, понимая и анализируя базы данных, которые включают поля данных в свои таблицы. Например, мы можем взять большую организацию, в которой необходимо хранить и управлять большим количеством данных. Организация должна собирать и хранить всю информацию от различных отделов. Вся собранная информация организована и хранится в базе данных, но она должна быть ценной и доступной — вот где на помощь приходит SQL. В такой ситуации SQL — это платформа, которая связывается с внешними и внутренними базами данных ( компьютеры и базы данных, хранящиеся на серверах).
По сути, база данных представляет собой организованный набор информации. База данных включает в себя множество таблиц, и в таблице хранятся строки данных в организованном формате, характеризуемом столбцами таблицы (также называемыми полями). Большая часть этого приводит к фундаментальному развитию базы данных. Таким образом, SQL-запросы управляют строками информации, которая хранится в таблицах, а таблицы, в свою очередь, содержатся в базе данных.
SQL включает множество важных команд, позволяющих взаимодействовать с этими данными.
Если эти команды используются эффективно, они могут быть очень мощными и помогать клиентам легко управлять и изменять огромные объемы данных. Вот несколько важных команд: SELECT, DELETE, CREATE DATABASE, INSERT INTO, ALTER DATABASE, CREATE TABLE и CREATE INDEX.
SQL является наиболее распространенным языком, используемым для доступа к базам данных, поскольку он может работать с любой базой данных. Базы данных, с которыми вы взаимодействуете, представляют собой программы, которые позволяют клиентам хранить информацию и управлять ею логическим образом. Обычно базы данных подразделяются на две категории, основанные на использовании стандартов SQL. Они известны как базы данных SQL и NoSQL. Существует множество разновидностей баз данных SQL с небольшими отличиями. Существует множество разновидностей баз данных SQL с небольшими вариациями. Чтобы сделать вещи более запутанными, многие из этих баз данных имеют имена, включающие термин SQL, например, MySQL и PostgreSQL.
Разнообразные базы данных SQL содержат одинаковое ядро команд SQL, которые могут различаться в разных регионах. Обычно один тип базы данных предпочтительнее для конкретной задачи, чем другие, и вы часто нанимаете разработчиков, специализирующихся на конкретной базе данных.
Преимущества изучения SQL расширяются и становятся значительными. За последние пару лет у SQL был колоссальный рост использования. Сейчас эта тенденция продолжается, потому что компании собирают все больше и больше информации, которую потом приходится хранить и осмысливать.
1. Универсальный язык
SQL — это одна из технологий, которая проникает в другие многочисленные дисциплины. Когда вы работаете с SQL, вы используете язык компьютера. Это стимулирует вас переходить к программированию на других языках, например C++, Javascript, Python и других. Все эти языки бесценны и до сих пор востребованы.
Все, что вам нужно для достижения успеха в языке программирования, — это мечта о сфере, в которой вы хотите работать. Во время изучения SQL вы можете улучшить свои способности, чтобы специализироваться в качестве программиста, разработчика, менеджера и т. д. Это звучит глупо; тем не менее, нет никаких ограничений в том, что вы можете делать с SQL.
2. Открытый исходный код — простота изучения и использования
SQL — это язык программирования с открытым исходным кодом, поэтому у него большое сообщество разработчиков. Многие темы, связанные с SQL и MySQL, постоянно публикуются на StackOverflow. SQL сравнительно легче изучить, чем другие языки программирования, например C++. Кроме того, значительное количество распространенных баз данных, использующих SQL (MySQL, MariaDB и Postgres), имеют открытый исходный код.
3. Управление миллионами строк данных
Традиционные электронные таблицы могут использоваться для управления небольшими и средними наборами информации, поэтому нам потребуется альтернативное решение для управления такими огромными записями. К счастью, это область, в которой SQL блистает: независимо от того, 1000 это записей или 100 миллионов, SQL полностью оборудован для обработки пулов данных практически любого размера.
Произошел ли сбой вашей электронной таблицы, так как у вас были тысячи столбцов информации? Реляционные базы данных предназначены для хранения миллионов строк данных. SQL позволяет вам выполнять действия с этим большим объемом данных, не беспокоясь о сбое. Microsoft Excel — невероятный инструмент, но он не был разработан для одновременного выполнения задач с миллионами строк. Реляционные базы данных предназначены для таких огромных задач, а SQL — это язык, который позволяет вам их выполнять.
4. Эволюция технологий
Технологии баз данных, такие как MySQL, Microsoft SQL и PostgreSQL Server, укрепляют огромные ассоциации, небольшие компании, банки, больницы, колледжи. На самом деле, каждый ПК или человек, имеющий доступ к какому-либо механическому устройству, рано или поздно касается SQL. Это даже на вашем смартфоне, так как Android и iOS используют SQL.
5. Высокий спрос
В настоящее время не так много людей, имеющих опыт работы с SQL. Многие предприятия осознают ценность такого навыка на текущем рынке. Тем не менее, это простая продажа.
В настоящее время компании ищут тех, кто хорошо разбирается в SQL. Одно дело иметь возможность получать высокую зарплату. Тем не менее, работодатели знают цену тому, что кто-то, кто хорошо разбирается в SQL, приводит их в ассоциацию и должен нанять этих людей. Кроме того, если вы захотите сменить работу, изучение SQL сделает вас привлекательным кандидатом.
У вас не будет проблем с поиском работы программистом SQL. Существует гораздо больше возможностей для программирования на SQL, чем в некоторых других языках программирования, включая C+, C++, Java, JavaScript, Python и PHP.
Заключение SQL является чрезвычайно важным и ценным навыком, который нужен бизнесу. Почти каждый бизнес стал цифровым. Цифровые данные означают данные — данные поступают в базы данных, и чтобы нести ответственность за эти базы данных, вам требуется SQL. Прочтите любой бизнес-журнал, и вы найдете что-нибудь об аналитике или бизнес-аналитике (BI). Поскольку компании стремятся достичь большего с помощью своей информации, им потребуется больше людей, обладающих навыками доступа к этим данным и их анализа.