ASCII таблица / Программирование / stD
ASCII — AmericanStandardCode forInformationInterchange.
ASCII была разработана (1963 год) для кодирования символов, коды которых помещались в 7 бит (128 символов). Со временем кодировка была расширена до 8-ми бит (256 символов), коды первых 128-и символов не изменились.
Управляющие символы ASCII (код символа 0-31)
Первые 32 символа в ASCII-таблице не имеют печатных кодов и используются для управления периферийными устройствами, телетайпами, принтерами и т.д.
| DEC | OCT | HEX | BIN | Symbol | HTML Number | HTML Name | Description |
|---|---|---|---|---|---|---|---|
| 0 | 000 | 0x00 | 00000000 | NUL \0 | & #000; | Null char | |
| 1 | 001 | 0x01 | 00000001 | SOH | & #001; | Start of Heading | |
| 2 | 002 | 0x02 | 00000010 | STX | & #002; | Start of Text | |
| 3 | 003 | 0x03 | 00000011 | ETX | & #003; | End of Text | |
| 4 | 004 | 0x04 | 00000100 | EOT | & #004; | End of Transmission | |
| 5 | 005 | 0x05 | 00000101 | ENQ | & #005; | Enquiry | |
| 6 | 006 | 0x06 | 00000110 | ACK | & #006; | Acknowledgment | |
| 7 | 007 | 0x07 | 00000111 | BEL | & #007; | Bell | |
| 8 | 010 | 0x08 | 00001000 | BS | & #008; | Back Space | |
| 9 | 011 | 0x09 | 00001001 | HT \t | & #009; | Tab | |
| 10 | 012 | 0x0A | 00001010 | LF \n | & #010; | Новая строка | |
| 11 | 013 | 0x0B | 00001011 | VT | & #011; | Vertical Tab | |
| 12 | 014 | 0x0C | 00001100 | FF | & #012; | Form Feed | |
| 13 | 015 | 0x0D | 00001101 | CR \r | & #013; | Возврат каретки | |
| 14 | 016 | 0x0E | 00001110 | SO | & #014; | Shift Out / X-On | |
| 15 | 017 | 0x0F | 00001111 | SI | & #015; | Shift In / X-Off | |
| 16 | 020 | 0x10 | 00010000 | DLE | & #016; | Data Line Escape | |
| 17 | 021 | 0x11 | 00010001 | DC1 | & #017; | Device Control 1 (oft. XON) | |
| 18 | 022 | 0x12 | 00010010 | DC2 | & #018; | Device Control 2 | |
| 19 | 023 | 0x13 | 00010011 | DC3 | & #019; | Device Control 3 (oft. XOFF) | |
| 20 | 024 | 0x14 | 00010100 | DC4 | & #020; | Device Control 4 | |
| 21 | 025 | 0x15 | 00010101 | NAK | & #021; | Negative Acknowledgement | |
| 22 | 026 | 0x16 | 00010110 | SYN | & #022; | Synchronous Idle | |
| 23 | 027 | 0x17 | 00010111 | ETB | & #023; | End of Transmit Block | |
| 24 | 030 | 0x18 | 00011000 | CAN | & #024; | Cancel | |
| 25 | 031 | 0x19 | 00011001 | EM | & #025; | End of Medium | |
| 26 | 032 | 0x1A | 00011010 | SUB | & #026; | Substitute | |
| 27 | 033 | 0x1B | 00011011 | ESC | & #027; | Escape | |
| 28 | 034 | 0x1C | 00011100 | FS | & #028; | File Separator | |
| 29 | 035 | 0x1D | 00011101 | GS | & #029; | Group Separator | |
| 30 | 036 | 0x1E | 00011110 | RS | & #030; | Record Separator | |
| 31 | 037 | 0x1F | 00011111 | US | & #031; | Unit Separator | |
| DEC | OCT | HEX | BIN | Symbol | HTML Number | HTML Name | Description |
Печатные символы ASCII (код символа 32-127)
Буквы, цифры, знаки препинания и другие символы расположенные на клавиатуре (англ.).
| DEC | OCT | HEX | BIN | Symbol | HTML Number | HTML Name | Description |
|---|---|---|---|---|---|---|---|
| 32 | 040 | 0x20 | 00100000 | & #32; | Space | ||
| 33 | 041 | 0x21 | 00100001 | ! | & #33; | Exclamation mark | |
| 34 | 042 | 0x22 | 00100010 | « | & #34; | & quot; | Double quotes (or speech marks) |
| 35 | 043 | 0x23 | 00100011 | # | & #35; | Number | |
| 36 | 044 | 0x24 | 00100100 | $ | & #36; | Dollar | |
| 37 | 045 | 0x25 | 00100101 | % | & #37; | Procenttecken | |
| 38 | 046 | 0x26 | 00100110 | & | & #38; | & amp; | Ampersand |
| 39 | 047 | 0x27 | 00100111 | ‘ | & #39; | Single quote | |
| 40 | 050 | 0x28 | 00101000 | ( | & #40; | Open parenthesis (or open bracket) | |
| 41 | 051 | 0x29 | 00101001 | ) | & #41; | Close parenthesis (or close bracket) | |
| 42 | 052 | 0x2A | 00101010 | * | & #42; | Asterisk | |
| 43 | 053 | 0x2B | 00101011 | + | & #43; | Plus | |
| 44 | 054 | 0x2C | 00101100 | , | & #44; | Comma | |
| 45 | 055 | 0x2D | 00101101 | — | & #45; | Hyphen | |
| 46 | 056 | 0x2E | 00101110 | . | & #46; | Period, dot or full stop | |
| 47 | 057 | 0x2F | 00101111 | / | & #47; | Slash or divide | |
| 48 | 060 | 0x30 | 00110000 | 0 | & #48; | Zero | |
| 49 | 061 | 0x31 | 00110001 | 1 | & #49; | One | |
| 50 | 062 | 0x32 | 00110010 | 2 | & #50; | Two | |
| 51 | 063 | 0x33 | 00110011 | 3 | & #51; | Three | |
| 52 | 064 | 0x34 | 00110100 | 4 | & #52; | Four | |
| 53 | 065 | 0x35 | 00110101 | 5 | & #53; | Five | |
| 54 | 066 | 0x36 | 00110110 | 6 | & #54; | Six | |
| 55 | 067 | 0x37 | 00110111 | 7 | & #55; | Seven | |
| 56 | 070 | 0x38 | 00111000 | 8 | & #56; | Eight | |
| 57 | 071 | 0x39 | 00111001 | 9 | & #57; | Nine | |
| 58 | 072 | 0x3A | 00111010 | : | & #58; | Colon | |
| 59 | 073 | 0x3B | 00111011 | ; | & #59; | Semicolon | |
| 60 | 074 | 0x3C | 00111100 | < | & #60; | & lt; | Less than (or open angled bracket) |
| 61 | 075 | 0x3D | 00111101 | = | & #61; | Equals | |
| 62 | 076 | 0x3E | 00111110 | > | & #62; | & gt; | Greater than (or close angled bracket) |
| 63 | 077 | 0x3F | 00111111 | ? | & #63; | Question mark | |
| 64 | 100 | 0x40 | 01000000 | @ | & #64; | At symbol | |
| 65 | 101 | 0x41 | 01000001 | A | & #65; | A | |
| 66 | 102 | 0x42 | 01000010 | B | & #66; | B | |
| 67 | 103 | 0x43 | 01000011 | C | & #67; | C | |
| 68 | 104 | 0x44 | 01000100 | D | & #68; | D | |
| 69 | 105 | 0x45 | 01000101 | E | & #69; | E | |
| 70 | 106 | 0x46 | 01000110 | F | & #70; | F | |
| 71 | 107 | 0x47 | 01000111 | G | & #71; | G | |
| 72 | 110 | 0x48 | 01001000 | H | & #72; | H | |
| 73 | 111 | 0x49 | 01001001 | I | & #73; | I | |
| 74 | 112 | 0x4A | 01001010 | J | & #74; | J | |
| 75 | 113 | 0x4B | 01001011 | K | & #75; | K | |
| 76 | 114 | 0x4C | 01001100 | L | & #76; | L | |
| 77 | 115 | 0x4D | 01001101 | M | & #77; | M | |
| 78 | 116 | 0x4E | 01001110 | N | & #78; | N | |
| 79 | 117 | 0x4F | 01001111 | O | & #79; | O | |
| 80 | 120 | 0x50 | 01010000 | P | & #80; | P | |
| 81 | 121 | 0x51 | 01010001 | Q | & #81; | Q | |
| 82 | 122 | 0x52 | 01010010 | R | & #82; | R | |
| 83 | 123 | 0x53 | 01010011 | S | & #83; | S | |
| 84 | 124 | 0x54 | 01010100 | T | & #84; | T | |
| 85 | 125 | 0x55 | 01010101 | U | & #85; | U | |
| 86 | 126 | 0x56 | 01010110 | V | & #86; | V | |
| 87 | 127 | 0x57 | 01010111 | W | & #87; | W | |
| 88 | 130 | 0x58 | 01011000 | X | & #88; | X | |
| 89 | 131 | 0x59 | 01011001 | Y | & #89; | Y | |
| 90 | 132 | 0x5A | 01011010 | Z | & #90; | Z | |
| 91 | 133 | 0x5B | 01011011 | [ | & #91; | Opening bracket | |
| 92 | 134 | 0x5C | 01011100 | \ | & #92; | Backslash | |
| 93 | 135 | 0x5D | 01011101 | ] | & #93; | Closing bracket | |
| 94 | 136 | 0x5E | 01011110 | ^ | & #94; | Caret — circumflex | |
| 95 | 137 | 0x5F | 01011111 | _ | & #95; | Underscore | |
| 96 | 140 | 0x60 | 01100000 | ` | & #96; | Grave accent | |
| 97 | 141 | 0x61 | 01100001 | a | & #97; | a | |
| 98 | 142 | 0x62 | 01100010 | b | & #98; | b | |
| 99 | 143 | 0x63 | 01100011 | c | & #99; | c | |
| 100 | 144 | 0x64 | 01100100 | d | & #100; | d | |
| 101 | 145 | 0x65 | 01100101 | e | & #101; | e | |
| 102 | 146 | 0x66 | 01100110 | f | & #102; | f | |
| 103 | 147 | 0x67 | 01100111 | g | & #103; | g | |
| 104 | 150 | 0x68 | 01101000 | h | & #104; | h | |
| 105 | 151 | 0x69 | 01101001 | i | & #105; | i | |
| 106 | 152 | 0x6A | 01101010 | j | & #106; | j | |
| 107 | 153 | 0x6B | 01101011 | k | & #107; | k | |
| 108 | 154 | 0x6C | 01101100 | l | & #108; | l | |
| 109 | 155 | 0x6D | 01101101 | m | & #109; | m | |
| 110 | 156 | 0x6E | 01101110 | n | & #110; | n | |
| 111 | 157 | 0x6F | 01101111 | o | & #111; | o | |
| 112 | 160 | 0x70 | 01110000 | p | & #112; | p | |
| 113 | 161 | 0x71 | 01110001 | q | & #113; | q | |
| 114 | 162 | 0x72 | 01110010 | r | & #114; | r | |
| 115 | 163 | 0x73 | 01110011 | s | & #115; | s | |
| 116 | 164 | 0x74 | 01110100 | t | & #116; | t | |
| 117 | 165 | 0x75 | 01110101 | u | & #117; | u | |
| 118 | 166 | 0x76 | 01110110 | v | & #118; | v | |
| 119 | 167 | 0x77 | 01110111 | w | & #119; | w | |
| 120 | 170 | 0x78 | 01111000 | x | & #120; | x | |
| 121 | 171 | 0x79 | 01111001 | y | & #121; | y | |
| 122 | 172 | 0x7A | 01111010 | z | & #122; | z | |
| 123 | 173 | 0x7B | 01111011 | { | & #123; | Opening brace | |
| 124 | 174 | 0x7C | 01111100 | | | & #124; | Vertical bar | |
| 125 | 175 | 0x7D | 01111101 | } | & #125; | Closing brace | |
| 126 | 176 | 0x7E | 01111110 | ~ | & #126; | Equivalency sign — tilde | |
| 127 | 177 | 0x7F | 01111111 | & #127; | Delete | ||
| DEC | OCT | HEX | BIN | Symbol | HTML Number | HTML Name | Description |
Расширенные символы ASCII Win-1251 кириллица (код символа 128-255)
| DEC | OCT | HEX | BIN | Symbol |
|---|---|---|---|---|
| 128 | 200 | 0x80 | 10000000 | Ђ |
| 129 | 201 | 0x81 | 10000001 | Ѓ |
| 130 | 202 | 0x82 | 10000010 | ‚ |
| 131 | 203 | 0x83 | 10000011 | ѓ |
| 132 | 204 | 0x84 | 10000100 | „ |
| 133 | 205 | 0x85 | 10000101 | … |
| 134 | 206 | 0x86 | 10000110 | † |
| 135 | 207 | 0x87 | 10000111 | ‡ |
| 136 | 210 | 0x88 | 10001000 | € |
| 137 | 211 | 0x89 | 10001001 | ‰ |
| 138 | 212 | 0x8A | 10001010 | Љ |
| 139 | 213 | 0x8B | 10001011 | ‹ |
| 140 | 214 | 0x8C | 10001100 | Њ |
| 141 | 215 | 0x8D | 10001101 | Ќ |
| 142 | 216 | 0x8E | 10001110 | Ћ |
| 143 | 217 | 0x8F | 10001111 | Џ |
| 144 | 220 | 0x90 | 10010000 | Ђ |
| 145 | 221 | 0x91 | 10010001 | ‘ |
| 146 | 222 | 0x92 | 10010010 | ’ |
| 147 | 223 | 0x93 | 10010011 | “ |
| 148 | 224 | 0x94 | 10010100 | ” |
| 149 | 225 | 0x95 | 10010101 | • |
| 150 | 226 | 0x96 | 10010110 | – |
| 151 | 227 | 0x97 | 10010111 | — |
| 152 | 230 | 0x98 | 10011000 | |
| 153 | 231 | 0x99 | 10011001 | ™ |
| 154 | 232 | 0x9A | 10011010 | љ |
| 155 | 233 | 0x9B | 10011011 | › |
| 156 | 234 | 0x9C | 10011100 | њ |
| 157 | 235 | 0x9D | 10011101 | ќ |
| 158 | 236 | 0x9E | 10011110 | ћ |
| 159 | 237 | 0x9F | 10011111 | џ |
| 160 | 240 | 0xA0 | 10100000 | |
| 161 | 241 | 0xA1 | 10100001 | Ў |
| 162 | 242 | 0xA2 | 10100010 | ў |
| 163 | 243 | 0xA3 | 10100011 | Ј |
| 164 | 244 | 0xA4 | 10100100 | ¤ |
| 165 | 245 | 0xA5 | 10100101 | Ґ |
| 166 | 246 | 0xA6 | 10100110 | ¦ |
| 167 | 247 | 0xA7 | 10100111 | § |
| 168 | 250 | 0xA8 | 10101000 | Ё |
| 169 | 251 | 0xA9 | 10101001 | © |
| 170 | 252 | 0xAA | 10101010 | Є |
| 171 | 253 | 0xAB | 10101011 | « |
| 172 | 254 | 0xAC | 10101100 | ¬ |
| 173 | 255 | 0xAD | 10101101 | |
| 174 | 256 | 0xAE | 10101110 | ® |
| 175 | 257 | 0xAF | 10101111 | Ї |
| 176 | 260 | 0xB0 | 10110000 | ° |
| 177 | 261 | 0xB1 | 10110001 | ± |
| 178 | 262 | 0xB2 | 10110010 | І |
| 179 | 263 | 0xB3 | 10110011 | і |
| 180 | 264 | 0xB4 | 10110100 | ґ |
| 181 | 265 | 0xB5 | 10110101 | µ |
| 182 | 266 | 0xB6 | 10110110 | ¶ |
| 183 | 267 | 0xB7 | 10110111 | · |
| 184 | 270 | 0xB8 | 10111000 | ё |
| 185 | 271 | 0xB9 | 10111001 | № |
| 186 | 272 | 0xBA | 10111010 | є |
| 187 | 273 | 0xBB | 10111011 | » |
| 188 | 274 | 0xBC | 10111100 | ј |
| 189 | 275 | 0xBD | 10111101 | Ѕ |
| 190 | 276 | 0xBE | 10111110 | ѕ |
| 191 | 277 | 0xBF | 10111111 | ї |
| 192 | 300 | 0xC0 | 11000000 | А |
| 193 | 301 | 0xC1 | 11000001 | Б |
| 194 | 302 | 0xC2 | 11000010 | В |
| 195 | 303 | 0xC3 | 11000011 | Г |
| 196 | 304 | 0xC4 | 11000100 | Д |
| 197 | 305 | 0xC5 | 11000101 | Е |
| 198 | 306 | 0xC6 | 11000110 | Ж |
| 199 | 307 | 0xC7 | 11000111 | З |
| 200 | 310 | 0xC8 | 11001000 | И |
| 201 | 311 | 0xC9 | 11001001 | Й |
| 202 | 312 | 0xCA | 11001010 | К |
| 203 | 313 | 0xCB | 11001011 | Л |
| 204 | 314 | 0xCC | 11001100 | М |
| 205 | 315 | 0xCD | 11001101 | Н |
| 206 | 316 | 0xCE | 11001110 | О |
| 207 | 317 | 0xCF | 11001111 | П |
| 208 | 320 | 0xD0 | 11010000 | Р |
| 209 | 321 | 0xD1 | 11010001 | С |
| 210 | 322 | 0xD2 | 11010010 | Т |
| 211 | 323 | 0xD3 | 11010011 | У |
| 212 | 324 | 0xD4 | 11010100 | Ф |
| 213 | 325 | 0xD5 | 11010101 | Х |
| 214 | 326 | 0xD6 | 11010110 | Ц |
| 215 | 327 | 0xD7 | 11010111 | Ч |
| 216 | 330 | 0xD8 | 11011000 | Ш |
| 217 | 331 | 0xD9 | 11011001 | Щ |
| 218 | 332 | 0xDA | 11011010 | Ъ |
| 219 | 333 | 0xDB | 11011011 | Ы |
| 220 | 334 | 0xDC | 11011100 | Ь |
| 221 | 335 | 0xDD | 11011101 | Э |
| 222 | 336 | 0xDE | 11011110 | Ю |
| 223 | 337 | 0xDF | 11011111 | Я |
| 224 | 340 | 0xE0 | 11100000 | а |
| 225 | 341 | 0xE1 | 11100001 | б |
| 226 | 342 | 0xE2 | 11100010 | в |
| 227 | 343 | 0xE3 | 11100011 | г |
| 228 | 344 | 0xE4 | 11100100 | д |
| 229 | 345 | 0xE5 | 11100101 | е |
| 230 | 346 | 0xE6 | 11100110 | ж |
| 231 | 347 | 0xE7 | 11100111 | з |
| 232 | 350 | 0xE8 | 11101000 | и |
| 233 | 351 | 0xE9 | 11101001 | й |
| 234 | 352 | 0xEA | 11101010 | к |
| 235 | 353 | 0xEB | 11101011 | л |
| 236 | 354 | 0xEC | 11101100 | м |
| 237 | 355 | 0xED | 11101101 | н |
| 238 | 356 | 0xEE | 11101110 | о |
| 239 | 357 | 0xEF | 11101111 | п |
| 240 | 360 | 0xF0 | 11110000 | р |
| 241 | 361 | 0xF1 | 11110001 | с |
| 242 | 362 | 0xF2 | 11110010 | т |
| 243 | 363 | 0xF3 | 11110011 | у |
| 244 | 364 | 0xF4 | 11110100 | ф |
| 245 | 365 | 0xF5 | 11110101 | х |
| 246 | 366 | 0xF6 | 11110110 | ц |
| 247 | 367 | 0xF7 | 11110111 | ч |
| 248 | 370 | 0xF8 | 11111000 | ш |
| 249 | 371 | 0xF9 | 11111001 | щ |
| 250 | 372 | 0xFA | 11111010 | ъ |
| 251 | 373 | 0xFB | 11111011 | ы |
| 252 | 374 | 0xFC | 11111100 | ь |
| 253 | 375 | 0xFD | 11111101 | э |
| 254 | 376 | 0xFE | 11111110 | ю |
| 255 | 377 | 0xFF | 11111111 | я |
| DEC | OCT | HEX | BIN | Symbol |
Расширенные символы ASCII Win-1252 (код символа 128-255)
| DEC | OCT | HEX | BIN | Symbol |
|---|---|---|---|---|
| 128 | 200 | 0x80 | 10000000 | € |
| 129 | 201 | 0x81 | 10000001 | |
| 130 | 202 | 0x82 | 10000010 | ‚ |
| 131 | 203 | 0x83 | 10000011 | ƒ |
| 132 | 204 | 0x84 | 10000100 | „ |
| 133 | 205 | 0x85 | 10000101 | … |
| 134 | 206 | 0x86 | 10000110 | † |
| 135 | 207 | 0x87 | 10000111 | ‡ |
| 136 | 210 | 0x88 | 10001000 | ˆ |
| 137 | 211 | 0x89 | 10001001 | ‰ |
| 138 | 212 | 0x8A | 10001010 | Š |
| 139 | 213 | 0x8B | 10001011 | ‹ |
| 140 | 214 | 0x8C | 10001100 | Π|
| 141 | 215 | 0x8D | 10001101 | |
| 142 | 216 | 0x8E | 10001110 | Ž |
| 143 | 217 | 0x8F | 10001111 | |
| 144 | 220 | 0x90 | 10010000 | |
| 145 | 221 | 0x91 | 10010001 | ‘ |
| 146 | 222 | 0x92 | 10010010 | ’ |
| 147 | 223 | 0x93 | 10010011 | “ |
| 148 | 224 | 0x94 | 10010100 | ” |
| 149 | 225 | 0x95 | 10010101 | • |
| 150 | 226 | 0x96 | 10010110 | – |
| 151 | 227 | 0x97 | 10010111 | — |
| 152 | 230 | 0x98 | 10011000 | ˜ |
| 153 | 231 | 0x99 | 10011001 | ™ |
| 154 | 232 | 0x9A | 10011010 | š |
| 155 | 233 | 0x9B | 10011011 | › |
| 156 | 234 | 0x9C | 10011100 | œ |
| 157 | 235 | 0x9D | 10011101 | |
| 158 | 236 | 0x9E | 10011110 | ž |
| 159 | 237 | 0x9F | 10011111 | Ÿ |
| 160 | 240 | 0xA0 | 10100000 | |
| 161 | 241 | 0xA1 | 10100001 | ¡ |
| 162 | 242 | 0xA2 | 10100010 | ¢ |
| 163 | 243 | 0xA3 | 10100011 | £ |
| 164 | 244 | 0xA4 | 10100100 | ¤ |
| 165 | 245 | 0xA5 | 10100101 | ¥ |
| 166 | 246 | 0xA6 | 10100110 | ¦ |
| 167 | 247 | 0xA7 | 10100111 | § |
| 168 | 250 | 0xA8 | 10101000 | ¨ |
| 169 | 251 | 0xA9 | 10101001 | © |
| 170 | 252 | 0xAA | 10101010 | ª |
| 171 | 253 | 0xAB | 10101011 | « |
| 172 | 254 | 0xAC | 10101100 | ¬ |
| 173 | 255 | 0xAD | 10101101 | � |
| 174 | 256 | 0xAE | 10101110 | ® |
| 175 | 257 | 0xAF | 10101111 | ¯ |
| 176 | 260 | 0xB0 | 10110000 | ° |
| 177 | 261 | 0xB1 | 10110001 | ± |
| 178 | 262 | 0xB2 | 10110010 | ² |
| 179 | 263 | 0xB3 | 10110011 | ³ |
| 180 | 264 | 0xB4 | 10110100 | ´ |
| 181 | 265 | 0xB5 | 10110101 | µ |
| 182 | 266 | 0xB6 | 10110110 | ¶ |
| 183 | 267 | 0xB7 | 10110111 | · |
| 184 | 270 | 0xB8 | 10111000 | ¸ |
| 185 | 271 | 0xB9 | 10111001 | ¹ |
| 186 | 272 | 0xBA | 10111010 | º |
| 187 | 273 | 0xBB | 10111011 | » |
| 188 | 274 | 0xBC | 10111100 | ¼ |
| 189 | 275 | 0xBD | 10111101 | ½ |
| 190 | 276 | 0xBE | 10111110 | ¾ |
| 191 | 277 | 0xBF | 10111111 | ¿ |
| 192 | 300 | 0xC0 | 11000000 | À |
| 193 | 301 | 0xC1 | 11000001 | Á |
| 194 | 302 | 0xC2 | 11000010 | Â |
| 195 | 303 | 0xC3 | 11000011 | Ã |
| 196 | 304 | 0xC4 | 11000100 | Ä |
| 197 | 305 | 0xC5 | 11000101 | Å |
| 198 | 306 | 0xC6 | 11000110 | Æ |
| 199 | 307 | 0xC7 | 11000111 | Ç |
| 200 | 310 | 0xC8 | 11001000 | È |
| 201 | 311 | 0xC9 | 11001001 | É |
| 202 | 312 | 0xCA | 11001010 | Ê |
| 203 | 313 | 0xCB | 11001011 | Ë |
| 204 | 314 | 0xCC | 11001100 | Ì |
| 205 | 315 | 0xCD | 11001101 | Í |
| 206 | 316 | 0xCE | 11001110 | Î |
| 207 | 317 | 0xCF | 11001111 | Ï |
| 208 | 320 | 0xD0 | 11010000 | Ð |
| 209 | 321 | 0xD1 | 11010001 | Ñ |
| 210 | 322 | 0xD2 | 11010010 | Ò |
| 211 | 323 | 0xD3 | 11010011 | Ó |
| 212 | 324 | 0xD4 | 11010100 | Ô |
| 213 | 325 | 0xD5 | 11010101 | Õ |
| 214 | 326 | 0xD6 | 11010110 | Ö |
| 215 | 327 | 0xD7 | 11010111 | × |
| 216 | 330 | 0xD8 | 11011000 | Ø |
| 217 | 331 | 0xD9 | 11011001 | Ù |
| 218 | 332 | 0xDA | 11011010 | Ú |
| 219 | 333 | 0xDB | 11011011 | Û |
| 220 | 334 | 0xDC | 11011100 | Ü |
| 221 | 335 | 0xDD | 11011101 | Ý |
| 222 | 336 | 0xDE | 11011110 | Þ |
| 223 | 337 | 0xDF | 11011111 | ß |
| 224 | 340 | 0xE0 | 11100000 | à |
| 225 | 341 | 0xE1 | 11100001 | á |
| 226 | 342 | 0xE2 | 11100010 | â |
| 227 | 343 | 0xE3 | 11100011 | ã |
| 228 | 344 | 0xE4 | 11100100 | ä |
| 229 | 345 | 0xE5 | 11100101 | å |
| 230 | 346 | 0xE6 | 11100110 | æ |
| 231 | 347 | 0xE7 | 11100111 | ç |
| 232 | 350 | 0xE8 | 11101000 | è |
| 233 | 351 | 0xE9 | 11101001 | é |
| 234 | 352 | 0xEA | 11101010 | ê |
| 235 | 353 | 0xEB | 11101011 | ë |
| 236 | 354 | 0xEC | 11101100 | ì |
| 237 | 355 | 0xED | 11101101 | í |
| 238 | 356 | 0xEE | 11101110 | î |
| 239 | 357 | 0xEF | 11101111 | ï |
| 240 | 360 | 0xF0 | 11110000 | ð |
| 241 | 361 | 0xF1 | 11110001 | ñ |
| 242 | 362 | 0xF2 | 11110010 | ò |
| 243 | 363 | 0xF3 | 11110011 | ó |
| 244 | 364 | 0xF4 | 11110100 | ô |
| 245 | 365 | 0xF5 | 11110101 | õ |
| 246 | 366 | 0xF6 | 11110110 | ö |
| 247 | 367 | 0xF7 | 11110111 | ÷ |
| 248 | 370 | 0xF8 | 11111000 | ø |
| 249 | 371 | 0xF9 | 11111001 | ù |
| 250 | 372 | 0xFA | 11111010 | ú |
| 251 | 373 | 0xFB | 11111011 | û |
| 252 | 374 | 0xFC | 11111100 | ü |
| 253 | 375 | 0xFD | 11111101 | ý |
| 254 | 376 | 0xFE | 11111110 | þ |
| 255 | 377 | 0xFF | 11111111 | ÿ |
| DEC | OCT | HEX | BIN | Symbol |
istarik.ru
§14. Кодирование текстовой информации
Главная | Информатика и информационно-коммуникационные технологии | Планирование уроков и материалы к урокам | 10 классы | Планирование уроков на учебный год (ФГОС) | Кодирование текстовой информации
| 14.1. Кодировка ASCII и её расширения | ||||
| Кодирование текстовой информации |
14.2. Стандарт Unicode |
14.1. Кодировка ASCII и её расширения
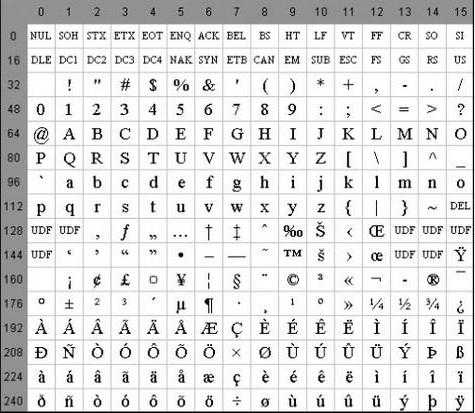
Основой для компьютерных стандартов кодирования символов послужил код ASCII (American Standard Code for Information Interchange) — американский стандартный код для обмена информацией, разработанный в 1960-х годах в США и применявшийся для любых, в том числе и некомпьютерных, способов передачи информации (телеграф, факсимильная связь и т. д.). Этот код 7-битовый: общее количество символов составляет 27 = 128, из них первые 32 символа — управляющие, а остальные — изображаемые, т. е. имеющие графическое изображение. К изображаемым символам в ASCII относятся буквы латинского алфавита (прописные и строчные), цифры, знаки препинания и арифметических операций, скобки и некоторые специальные символы. Кодировка ASCII приведена в табл. 3.8.
Таблица 3.8
Кодировка ASCII
Хотя для кодирования символов в ASCII достаточно 7 битов, в памяти компьютера под каждый символ отводится ровно 1 байт (8 битов), при этом код символа помещается в младшие биты, а в старший бит заносится 0.
Например, 01000001 — код прописной латинской буквы «А»; с помощью шестнадцатеричных цифр его можно записать как 41.
Стандарт ASCII рассчитан на передачу только английского текста. Со временем возникла необходимость кодирования и неанглийских букв. Во многих странах для этого стали разрабатывать расширения ASCII -кодировки, в которых применялись однобайтовые коды символов. При этом первые 128 символов кодовой таблицы совпадали с кодировкой ASCII, а остальные (со 128-го по 255-й) использовались для кодирования букв национального алфавита, символов национальной валюты и т. п. Из-за несогласованности этих разработок для многих языков было создано несколько вариантов кодовых таблиц (например, для русского языка их было создано около десятка!).
Впоследствии использование кодовых таблиц было несколько упорядочено: каждой кодовой таблице было присвоено особое название и номер. Для русского языка наиболее распространёнными стали однобайтовые кодовые таблицы CP-866, Windows-1251 (табл. 3.9) и КОИ-8 (табл. 3.10). В них первые 128 символов совпадают с ASCII-кодировкой, а русские буквы размещены во второй части таблицы. Обратите внимание на то, что коды русских букв в этих кодировках различны.
Таблица 3.9
Кодировка Windows-1251
Таблица 3.10
Кодировка КОИ-8
Мы выяснили, что при нажатии на алфавитно-цифровую клавишу в компьютер посылается некоторая цепочка нулей и единиц. В текстовых файлах хранятся не изображения символов, а их коды.
При выводе текста на экран монитора или принтера необходимо восстановить изображения всех символов, составляющих данный текст, причём изображения эти могут быть разнообразны и достаточно причудливы. Внешний вид выводимых на экран символов кодируется и хранится в специальных шрифтовых файлах. Современные текстовые процессоры умеют внедрять шрифты в файл. В этом случае файл содержит не только коды символов, но и описание используемых в этом документе шрифтов. Кроме того, файлы, создаваемые с помощью текстовых процессоров, включают в себя и такие данные о форматировании текста, как его размер, начертание, размеры полей, отступов, межстрочных интервалов и другую дополнительную информацию.
Cкачать материалы урока
xn—-7sbbfb7a7aej.xn--p1ai
Кодирование символов
Кодировка символов (часто называемая также кодовой страницей) – это набор числовых значений, которые ставятся в соответствие группе алфавитно-цифровых символов, знаков пунктуации и специальных символов.
Для кодировки символов в Windows используется таблица ASCII (American Standard Code for Interchange of Information).
В ASCII первые 128 символов всех кодовых страниц состоят из базовой таблицы символов. Первые 32 кода базовой таблицы, начиная с нулевого, размещают управляющие коды.
| Символ | Код | Клавиши | Значение |
| nul | 0 | Ctrl + @ | Нуль |
| soh | 1 | Ctrl + A | Начало заголовка |
| stx | 2 | Ctrl + B | Начало текста |
| etx | 3 | Ctrl + C | Конец текста |
| eot | 4 | Ctrl + D | Конец передачи |
| enq | 5 | Ctrl + E | Запрос |
| ack | 6 | Ctrl + F | Подтверждение |
| bel | 7 | Ctrl + G | Сигнал (звонок) |
| bs | 8 | Ctrl + H | Забой (шаг назад) |
| ht | 9 | Ctrl + I | Горизонтальная табуляция |
| lf | 10 | Ctrl + J | Перевод строки |
| vt | 11 | Ctrl + K | Вертикальная табуляция |
| ff | 12 | Ctrl + L | Новая страница |
| cr | 13 | Ctrl + M | Возврат каретки |
| so | 14 | Ctrl + N | Выключить сдвиг |
| si | 15 | Ctrl + O | Включить сдвиг |
| dle | 16 | Ctrl + P | Ключ связи данных |
| dc1 | 17 | Ctrl + Q | Управление устройством 1 |
| dc2 | 18 | Ctrl + R | Управление устройством 2 |
| dc3 | 19 | Ctrl + S | Управление устройством 3 |
| dc4 | 20 | Ctrl + T | Управление устройством 4 |
| nak | 21 | Ctrl + U | Отрицательное подтверждение |
| syn | 22 | Ctrl + V | Синхронизация |
| etb | 23 | Ctrl + W | Конец передаваемого блока |
| can | 24 | Ctrl + X | Отказ |
| em | 25 | Ctrl + Y | |
| sub | 26 | Ctrl + Z | Замена |
| esc | 27 | Ctrl + [ | Ключ |
| fs | 28 | Ctrl + \ | Разделитель файлов |
| gs | 29 | Ctrl + ] | Разделитель группы |
| rs | 30 | Ctrl + ^ | Разделитель записей |
| us | 31 | Ctrl + _ | Разделитель модулей |
Базовая таблица кодировки ASCII
| 32 пробел | 48 0 | 64 @ | 80 P | 96 ` | 112 p |
| 33 ! | 49 1 | 65 A | 81 Q | 97 a | 113 q |
| 34 “ | 50 2 | 66 B | 82 R | 98 b | 114 r |
| 35 # | 51 3 | 67 C | 83 S | 99 c | 115 s |
| 36 $ | 52 4 | 68 D | 84 T | 100 d | 116 t |
| 37 % | 53 5 | 69 E | 85 U | 101 e | 117 u |
| 38 & | 54 6 | 70 F | 86 V | 102 f | 118 v |
| 39 ‘ | 55 7 | 71 G | 87 W | 103 g | 119 w |
| 40 ( | 56 8 | 72 H | 88 X | 104 h | 120 x |
| 41 ) | 57 9 | 73 I | 89 Y | 105 i | 121 y |
| 42 * | 58 : | 74 J | 90 Z | 106 j | 122 z |
| 43 + | 59 ; | 75 K | 91 [ | 107 k | 123 { |
| 44 , | 60 < | 76 L | 92 \ | 108 l | 124 | |
| 45 — | 61 = | 77 M | 93 ] | 109 m | 125 } |
| 46 . | 62 > | 78 N | 94 ^ | 110 n | 126 ~ |
| 47 / | 63 ? | 79 O | 95 _ | 111 o | 127 |
Символы с номерами от 128 до 255 представляют собой таблицу расширения и варьируются в зависимости от набора скриптов, представленных кодировкой символов. Набор символов таблицы расширения различается в зависимости от выбранной кодовой страницы:
1251 – кодовая страница Windows
| 128 Ђ | 144 Ђ | 160 | 176 ° | 192 А | 208 Р | 224 а | 240 р |
| 129 Ѓ | 145 ‘ | 161 Ў | 177 ± | 193 Б | 209 С | 225 б | 241 с |
| 130 ‚ | 146 ’ | 162 ў | 178 I | 194 В | 210 Т | 226 в | 242 т |
| 131 ѓ | 147 “ | 163 J | 179 i | 195 Г | 211 У | 227 г | 243 у |
| 132 „ | 148 ” | 164 ¤ | 180 ґ | 196 Д | 212 Ф | 228 д | 244 ф |
| 133 … | 149 • | 165 Ґ | 181 μ | 197 Е | 213 Х | 229 е | 245 х |
| 134 † | 150 – | 166 ¦ | 182 ¶ | 198 Ж | 214 Ц | 230 ж | 246 ц |
| 135 ‡ | 151 — | 167 § | 183 · | 199 З | 215 Ч | 231 з | 247 ч |
| 136 € | 152 □ | 168 Ё | 184 ё | 200 И | 216 Ш | 232 и | 248 ш |
| 137 ‰ | 153 ™ | 169 © | 185 № | 201 Й | 217 Щ | 233 й | 249 щ |
| 138 Љ | 154 љ | 170 Є | 186 є | 202 К | 218 Ъ | 234 к | 250 ъ |
| 139 < | 155 > | 171 « | 187 » | 203 Л | 219 Ы | 235 л | 251 ы |
| 140 Њ | 156 њ | 172 ¬ | 188 j | 204 М | 220 Ь | 236 м | 252 ь |
| 141 Ќ | 157 ќ | 173 | 189 S | 205 Н | 221 Э | 237 н | 253 э |
| 142 Ћ | 158 ћ | 174 ® | 190 s | 206 О | 222 Ю | 238 о | 254 ю |
| 143 Џ | 159 џ | 175 Ï | 191 ї | 207 П | 223 Я | 239 п | 255 я |
866 – кодовая страница DOS
| 128 А | 144 Р | 160 а | 176 ░ | 192 └ | 208 ╨ | 224 р | 240 ≡Ё |
| 129 Б | 145 С | 161 б | 177 ▒ | 193 ┴ | 209 ╤ | 225 с | 241 ±ё |
| 130 В | 146 Т | 162 в | 178 ▓ | 194 ┬ | 210 ╥ | 226 т | 242 ≥ |
| 131 Г | 147 У | 163 г | 179 │ | 195 ├ | 211 ╙ | 227 у | 243 ≤ |
| 132 Д | 148 Ф | 164 д | 180 ┤ | 196 ─ | 212 ╘ | 228 ф | 244 ⌠ |
| 133 Е | 149 Х | 165 е | 181 ╡ | 197 ┼ | 213 ╒ | 229 х | 245 ⌡ |
| 134 Ж | 150 Ц | 166 ж | 182 ╢ | 198 ╞ | 214 ╓ | 230 ц | 246 ¸ |
| 135 З | 151 Ч | 167 з | 183 ╖ | 199 ╟ | 215 ╫ | 231 ч | 247 » |
| 136 И | 152 Ш | 168 и | 184 ╕ | 200 ╚ | 216 ╪ | 232 ш | 248 ° |
| 137 Й | 153 Щ | 169 й | 185 ╣ | 201 ╔ | 217 ┘ | 233 щ | 249 · |
| 138 К | 154 Ъ | 170 к | 186 ║ | 202 ╩ | 218 ┌ | 234 ъ | 250 ∙ |
| 139 Л | 155 Ы | 171 л | 187 ╗ | 203 ╦ | 219 █ | 235 ы | 251 √ |
| 140 М | 156 Ь | 172 м | 188 ╝ | 204 ╠ | 220 ▄ | 236 ь | 252 ⁿ |
| 141 Н | 157 Э | 173 н | 189 ╜ | 205 ═ | 221 ▌ | 237 э | 253 ² |
| 142 О | 158 Ю | 174 о | 190 ╛ | 206 ╬ | 222 ▐ | 238 ю | 254 ■ |
| 143 П | 159 Я | 175 п | 191 ┐ | 207 ╧ | 223 ▀ | 239 я | 255 |
Русские названия основных спецсимволов:
| Символ | Название |
| ` | гравис, кавычка, обратный машинописный апостроф |
| ` | гравис, кавычка, обратный машинописный апостроф |
| ~ | тильда |
| ! | восклицательный знак |
| @ | эт, коммерческое эт, «собака» |
| # | октоторп, решетка, диез |
| $ | знак доллара |
| % | процент |
| ^ | циркумфлекс, знак вставки |
| & | амперсанд |
| * | астериск, звездочка, знак умножения |
| ( | левая открывающая круглая скобка |
| ) | правая закрывающая круглая скобка |
| — | минус, дефис |
| _ | знак подчеркивания |
| = | знак равенства |
| + | плюс |
| [ | левая открывающая квадратная скобка |
| ] | правая закрывающая квадратная скобка |
| { | левая открывающая фигурная скобка |
| } | правая закрывающая фигурная скобка |
| ; | точка с запятой |
| : | двоеточие |
| ‘ | машинописный апостроф, одинарная кавычка |
| « | двойная кавычка |
| , | запятая |
| . | точка |
| / | слэш, косая черта, знак дроби |
| < | левая открытая угловая скобка, знак меньше |
| > | правая закрытая угловая скобка, знак больше |
| \ | обратный слэш, обратная косая черта |
| | | вертикальная черта |
Кодировка UNICODE
Юникод (Unicode) — стандарт кодирования символов, позволяющий представить знаки практически всех письменных языков. Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода».
В Unicode используются 16-битовые (2-байтовые) коды, что позволяет представить 65536 символов.
Применение стандарта Unicode позволяет закодировать очень большое число символов из разных письменностей: в документах Unicode могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, при этом становится ненужным переключение кодовых страниц.
Для представления символьных данных в кодировке Unicode используется символьный тип wchar_t.
| ASCII | UNICODE |
| char | wchar_t |
| 1 байт | 2 байта |
Тип кодировки задается в свойствах проекта Microsoft Visual Studio:

Многобайтовая кодировка предполагает использование кодировки ASCII.
При этом при построении проекта используется директива условной компиляции, переопределяющая тип TCHAR:
#ifdef _UNICODE
typedef wchar_t TCHAR;
#else
typedef char TCHAR;
#endif
Для перекодирования строки в формат Unicode без изменения кодировки файла используется макроопределение
_T(«строка»)
Прототип макроса содержится в файле tchar.h.
Назад: Представление данных и архитектура ЭВМ
prog-cpp.ru
Что нужно знать каждому разработчику о кодировках и наборах символов для работы с текстом
Это первая часть перевода статьи What Every Programmer Absolutely, Positively Needs To Know About Encodings And Character Sets To Work With TextЕсли вы работаете с текстом в компьютере, вам обязательно нужно знать про кодировки. Даже если вы посылаете электронные письма. Даже если вы их только получаете. Необязательно понимать каждую деталь, но надо хотя бы знать, что из себя представляют кодировки. И вот первая хорошая новость: статья может быть немного запутанной, но основная идея очень и очень простая.
Эта статья о кодировках и наборах символов.
Статья Джоеэля Спольски под названием «Абсолютный минимум о Unicode и наборе символов для каждого разработчика(без исключений!)» будет хорошей вводной и мне доставляет большое удовольствие перечитывать ее время от времени. Я стесняюсь отсылать к ней тех людей, которые испытывают трудности с пониманием проблем с кодировкам, хотя она довольно легкая в плане технических деталей. Я надеюсь, эта статья прольет немного света на то, чем именно являются кодировки, и почему все ваши тексты оказываются испорченными в самый ненужный момент. Статья предназначена для разработчиков(главным образом, на PHP), но пользу от нее может получить любой пользователь компьютера.
Основы
Все более или менее слышали об этом, но каким-то образом знание испаряется, когда дело доходит до обсуждения, так что вот вам: компьютер не может хранить буквы, числа, картинки или что-либо еще. Он может запомнить только биты. Бит имеет только два значения: ДА или НЕТ, ПРАВДА или ЛОЖЬ, 1 или 0 или любую другую пару, которую вы можете вообразить. Раз уж компьютер работает с электричеством, бит представлен электрическим зарядом: он либо есть, либо его нет. Людям проще представлять это в виде 1 и 0, так что я буду придерживаться этих обозначений.
Чтобы с помощью битов представлять нечно полезное, нам нужны правила. Надо сконвертировать последовательность бит в что-то похожее на буквы, числа и изображения, используя схему кодирования, или, коротко, кодировку. Вот так, например:
01100010 01101001 01110100 01110011
b i t s
В этой кодировке, 01100010 представляет из себя ‘b’, 01101001 — ‘i’, 01110100 — ‘t’, 01110011 — ‘s’. Конкретная последовательность бит соответствует букве, а буква – конкретной последовательности битов. Если вы можете запомнить последовательности для 26 букв или умеете действительно быстро находить нужное соответствие, то вы сможете читать биты, как книги.
Упомянутая схема носит название ASCII. Строка с нолями и единицами разбивается на части по 8 бит(по байтам). Кодировка ASCII определяет таблицу перевода байтов в человеческие буквы. Вот небольшой кусочек этой таблицы:
bits character01000001 A
01000010 B
01000011 C
01000100 D
01000101 E
01000110 F
В ней 95 символов, включая буквы от A до Z, в нижнем и верхнем регистре, цифры от 0 до 9, с десяток знаков препинания, амперсанд, знак доллара и прочие. В нее также включены 33 значения, такие как пробел, табуляция, перевод строки, возврат символа и прочие. Это непечатаемые символы, хотя они видимы человеку и используются им. Некоторые значения полезны только компьютеру, такие как коды начала и конца текста. Всего в кодировку ASCII включены 128 символов — прекрасное ровное число для тех, кто смыслит в компьютерах, так как оно использует все комбинации 7ми битов (от 0000000 до 1111111).
Вот вам способ представить человеческую строку, используя только единицы и нули:
01001000 01100101 01101100 01101100 01101111 00100000
01010111 01101111 01110010 01101100 01100100«Hello World»
Важные термины
Для кодирования чего-либо в ASCII двигайтесь справа налево, подменяя буквы на биты. Для декодирования битов в символы, следуйте по таблице слева направо, подменяя биты на буквы.
encode |enˈkōd|
verb [ with obj. ]
convert into a coded form
code |kōd|
noun
a system of words, letters, figures, or other symbols substituted for other words, letters, etc.
Кодирование – это представление чего-либо чем-нибудь другим. Кодировка – это набор правил, описывающий способ перевода одного представления в другое.
Прочие термины, заслуживающие прояснения:
Набор символов, чарсет, charset – Набор символов, который может быть закодирован. «Кодировка ASCII включает набор из 128 символов». Синоним к кодировке.
Кодовая страница – страница кодов, закрепляюшая за символом набор битов. Таблица. Синоним к кодировке.
Строка – пачка чего-нибудь, объединенных вместе. Битовая строка – это пачка бит, такая как 00011011. Символьная строка – это пачка символов, например «Вот эта». Синоним к последовательности.
Двоичный, восьмеричный, десятичный, шестнадцатеричный
Существует множество способов записывать числа. 10011111 – это бинарная запись для 237 в восьмеричной, 159 в десятичной и 9F в шестнадцатиричной системах. Значения у всех этих чисел одинаково, но шестнадцатиричная система короче и проще для понимания, чем двоичная. Я буду придерживаться двоичной системы в этой статье, чтобы улучшить понимание и убрать лишний уровень абстракции. Не пугайтесь, встречая коды символов в других нотациях, все значения эквиваленты.
Excusez-Moi?
Раз уж мы теперь знаем, о чем говорим, заметим: 95 символов – это совсем немного, когда речь идет о языках. Этот набор покрывает базовый английский, но как насчет французских символов? А вот это Straßen¬übergangs¬änderungs¬gesetz из немецкого языка? А приглашение на smörgåsbord в шведском? В-общем, не получится. Не в ASCII. Спецификация на представление é, ß, ü, ä, ö просто отсутствует.
“Постойте-ка”, скажут европейцы, “в обычных компьютерах с 8 битами в байте, ASCII никак не использует бит, который всегда равен 0! Мы можем использовать его, чтобы расширить таблицу еще на 128 значений”. И было так. Но способов обозначить звучание гласных еще слишком много. Не все сочетания букв и значений, используемые в европейских языках, влезают в таблицу из 256 записей. Так мир пришел к изобилию кодировок, стандартов, стандартов де-факто и недостандартов, которые покрывают все субнаборы символов. Кому-то понадобилось написать документ на шведском или чешском, и, не найдя нужной кодировки, просто изобрел еще одну. Или я думаю, что все так и произошло.
Не забывайте о русском, хинди, арабском, корейском и множестве других живых языков планеты. Про мертвые уж молчим. Как только вы найдете способ писать документ, использующий несколько языков, попробуйте добавить китайский. Или японский. Оба содержат тысячи символов. И у вас всего 256 значений. Вперед!
Многобайтные кодировки
Для создания таблиц, которые содержат более 256 символов, одного байта просто недостаточно. Двух байтов (16 бит) хватит для кодировки 65536 различных значений. Big-5 например, кодировка двухбайтная. Вместо разбиения последовательности битов в блоки по 8, она использует блоки по 16 битов и содержит большую(я имею ввиду БОЛЬШУЮ) таблицу с соответствием. Big-5 в своем основном виде покрывает большинство символов традиционного китайского. GB18030 – это похожая кодировка, но она включает как традиционный, так и упрощенный китайский. И, прежде чем вы спросите, да, есть кодировки только для упрощенного китайского. А разве одной недостаточно?
Вот кусок таблицы GB18030:
bits character
10000001 01000000 丂
10000001 01000001 丄
10000001 01000010 丅
10000001 01000011 丆
10000001 01000100 丏
GB18030 покрывает довольно большой диапазон символов, включая большую часть латинских символов, но в конце концов, это всего лишь еще одна кодировка среди многих других.
Путаница с Unicode
В итоге тем, кому больше всех надоела эта каша, пришла в голову идея разработать единый стандарт, объединяющий все кодировки. Этим стандартом стал Unicode. Он определяет невероятную таблицу из 1 114 112 пунктов, используемую для всех вариантов букв и символов. Этого хватит для кодирования всех европейских, средне-азиатских, дальневосточных, южных, северных, западных, доисторических и будущих символов, о которых человечеству известно. Unicode позволяет создать документ на любом языке любыми символами, которые можно ввести в компьютер. Это было невозможно, или очень затруднительно до эры Unicode. В стандарте есть даже неофициальная секция под клингонский. Вы поняли, Unicode настолько большой, чтобы допускает неофициальные секции.
Итак, и сколько же байт использует Unicode для кодирования? Нисколько. Потому что Unicode – это не кодировка.
Смущены? Не вы одни. Unicode в первую и главную очередь определяет таблицу пунктов для символов. Это такой способ сказать «65 – A, 66 – B, 9731 – »(я не шучу, так и есть). Как эти пункты кодируются в байты является предметом другого разговора. Для представления 1 114 112 значений двух байт недостаточно. Трех достаточно, но 3 – странное число, так что 4 является комфортным минимумом. Но, пока вы не используете китайский, или другой язык со множеством символов, которые требуют большого количества битов для кодирования, вам никогда не придет в голову использовать толстую колбасу из 4х байт. Если “A” всегда кодируется в 00000000 00000000 00000000 01000001, а “B” – в 00000000 00000000 00000000 01000010, то документ, использующий такую кодировку, распухнет в 4 раза.
Существует несколько способов решения этой проблемы. UTF-32 – это кодировка, которая переводит все символы в наборы из 32 бит. Это простой алгоритм, но изводящий много места впустую. UTF-16 и UTF-8 являются кодировками с переменной длиной кодирования. Если символ может быть закодирован одним байтом(потому что номер пункта символа очень маленький), UTF-8 закодирует его одним байтом. Если нужно 2 байта, то используется 2 байта. Кодировка сообщает старшими битами, сколькими битами кодируется текущий символ. Такой способ экономит место, но так же и тратит его в случае, если эти сигнальные биты часто используются. UTF-16 является компромиссом: все символы как минимум двухбайтные, но их размер может увеличиваться до 4 байт, если нужно.
character encoding bits
A UTF-8 01000001
A UTF-16 00000000 01000001
A UTF-32 00000000 00000000 00000000 01000001
あ UTF-8 11100011 10000001 10000010
あ UTF-16 00110000 01000010
あ UTF-32 00000000 00000000 00110000 01000010
И все. Unicode – это огромная таблица соответствия символов и чисел, а различные UTF кодировки определяют, как эти числа переводятся в биты. В-общем, Unicode – это просто еще одна схема. Ничего особенного, она просто пытается покрыть все, что можно, оставаясь эффективной. И это хорошо.
Пункты
Символы определяются по их Unicode-пунктам. Эти пункты записаны в шестнадцатеричной системе и предварены “ U+” (просто для удобство, не значит ничего, кроме “Это пункт Unicode”). Символ Ḁ имеет пункт U+1E00. Иными(десятичными) словами, это 7680й символ таблицы Unicode. Он официально называется “ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА А С КОЛЬЦОМ СНИЗУ”.
Ниасилил
Суть вышесказанного: любой символ может быть закодирован множеством разных последовательностей бит, и любая последовательность бит может представлять разные символы, в зависимости от используемой кодировки. Причина в том, что разные кодировки используют разное число бит на символ и разные значения для кодирования разных символов.
bits encoding characters11000100 01000010 Windows Latin 1 ÄB
11000100 01000010 Mac Roman ƒB
11000100 01000010 GB18030 腂characters encoding bits
Føö Windows Latin 1 01000110 11111000 11110110
Føö Mac Roman 01000110 10111111 10011010
Føö UTF-8 01000110 11000011 10111000 11000011 10110110
Заблуждения, смущения и проблемы
Имея все вышесказанное, мы приходим к насущным проблемам, которые испытывают множество пользователей и разработчиков каждый день, как они соотносятся с указанным выше, и каковы пути решения. Сама большая проблема – это
Какого черта мой текст нечитаем?
ÉGÉìÉRÅ[ÉfÉBÉìÉOÇÕìÔǵÇ≠ǻǢ
Если вы откроете документ, и он выглядит так, как текст выше, то причина у этого одна: ваша программа ошиблась с кодировкой. И все. Документ не испорчен(по крайней мере, пока), и не нужно никакое волшебство. Вместо него надо просто выбрать правильную кодировку для отображения текста. Предполагаемый документ выше содержит биты:
10000011 01000111 10000011 10010011 10000011 01010010 10000001 01011011
10000011 01100110 10000011 01000010 10000011 10010011 10000011 01001111
10000010 11001101 10010011 11101111 10000010 10110101 10000010 10101101
10000010 11001000 10000010 10100010
Так, быстренько угадали кодировку? Если вы пожали плечами, то вы правы. Да кто знает?
Попробуем с ASCII. Большая часть этих байтов начинается с 1. Если вы правильно помните, ASCII вообще-то не использует этот бит. Так что ASCII не вариант. Как насчет UTF-8? Большая часть байт не является валидными значениями в этой кодировке. Как насчет Mac Roman(еще одна европейская кодировка)? Хм, для нее эти байты являются правильными значениями. 10000011 декодируетися в ”É”, в “G” и так далее. Так что в Mac Roman текст будет выглядеть так: ÉGÉìÉRÅ[ÉfÉBÉìÉOÇÕìÔǵÇ≠ǻǢ. Правильно? Нет? Может быть? А компьютер-то откуда знает? Может кто-то хотел написать именно это. Насколько я знаю, это может быть последовательностью ДНК! Так и порешим: это Mac Roman, и это ДНК.
Конечно, это полный бред. Правильный ответ таков: текст закодирован в Japanes Shift-JIS и должен выглядеть как エンコーディングは難しくない. Кто бы мог подумать?
Первая причина нечитаемости текста в том, что кто-то пытается прочитать последовательность байт в неверной кодировке. Компьютеру всегда нужно подсказывать. Сам он не догадается. Некоторые типы документов определяют кодировку своего содержимого, но последовательность байт всегда остается черным ящиком.
Большинство браузеров предоставляют возможность указать кодировку страницы с помощью специального пункта меню. Иные программы тоже имеют аналогичные пункты.
У автора нет разбиения на части, но статья и так длинна. Продолжение будет через пару дней.
habr.com
Кодировка ASCII. Таблица кодировки ASCII :: SYL.ru
Под кодированием информации в компьютере понимается процесс ее преобразования в форму, позволяющую организовать более удобную передачу, хранение или автоматическую переработку этих данных. С этой целью используются различные таблицы. Кодировка ASCII — это первая система, разработанная в Соединенных Штатах для работы с англоязычным текстом, которая получила впоследствии распространение во всем мире. Ее описанию, особенностям, свойствам и дальнейшему использованию посвящена статья, представленная ниже.

Отображение и хранение информации в ЭВМ
Символы на мониторе компьютера или того или иного мобильного цифрового гаджета формируются на основе наборов векторных форм всевозможных знаков и кода, позволяющего найти среди них тот символ, который необходимо вставить в нужное место. Он представляет собой последовательностей бит. Таким образом, каждому символу должен однозначно соответствовать набор нулей и единиц, которые стоят в определенном, уникальном порядке.
Как все начиналось
Исторически сложилось так, что первые ЭВМ были англоязычными. Для кодирования символьной информации в них было достаточно использовать всего лишь 7 бит памяти, тогда как для этой цели выделялся 1 байт, состоящий из 8 битов. Количество знаков, понимаемых компьютером в таком случае, было равно 128. В число таких символов входили английский алфавит с его знаками препинания, числа и некоторые специальные символы. Англоязычная семибитная кодировка с соответствующей таблицей (кодовой страницей), разработанная в 1963 году, была названа American Standard Code for Information Interchange. Обычно для ее обозначения использовалась и используется и по сей день аббревиатура «Кодировка ASCII».
Переход к мультиязычности
Со временем компьютеры стали широко использоваться и в неанглоговорящих странах. В связи с этим появилась нужда в кодировках, позволяющих использовать национальные языки. Было решено не изобретать велосипед, и взять за основу ASCII. Таблица кодировки в новой редакции значительно расширилась. Использование 8-го бита позволило переводить на компьютерный язык уже 256 символов.

Описание
Кодировка ASCII имеет таблицу, которая делится на 2 части. Общепринятым международным стандартом принято считать лишь ее первую половину. В нее входят:
- Символы с порядковыми номерами от 0 до 31, кодируемые последовательностями от 00000000 до 00011111. Они отведены для управляющих символов, которые руководят процессом вывода текста на экран или принтер, подачей звукового сигнала и т. п.
- Символы с NN в таблице от 32 до 127, кодируемые последовательностями от 00100000 до 01111111 составляют стандартную часть таблицы. В их число входят пробел (N 32), буквы латинского алфавита (строчные и прописные), десятизначные цифры от 0 до 9, знаки препинания, скобки разного начертания и другие символы.
- Символы с порядковыми номерами от 128 до 255, кодируемые последовательностями от 10000000 до 11111111. В их число включены буквы национальных алфавитов, отличные от латинского. Именно эта альтернативная часть таблицы кодировка ASCII используется для преобразования в компьютерную форму русских символов.
Некоторые свойства
К особенностям кодировки ASCII относится отличие букв «A» — «Z» нижнего и верхнего регистров только одним битом. Это обстоятельство значительно упрощает преобразование регистра, а также его проверку на принадлежность к заданному диапазону значений. Кроме того, все буквы в системае кодировки ASCII представляются собственными порядковыми номерами в алфавите, которые записаны 5 цифрами в двоичной системе счисления, перед которыми для букв нижнего регистра стоит 0112, а верхнего — 0102.
К числу особенностей кодировки ASCII можно причислить и представление 10 цифр — «0»-«9». Во второй системе счисления они начинаются с 00112, а заканчиваются 2-ми значениями чисел. Так, 01012 эквивалентно десятичному числу пять, поэтому символ «5» записывается как 0011 01012. Опираясь на сказанное, можно легко преобразовать двоично-десятичные числа в строку в кодировке ASCII посредством добавления слева битовой последовательности 00112 к каждому полубайту.

«Юникод»
Как известно, для отображения текстов на языках группы юго-восточной Азии требуются тысячи знаков. Такое их количество никак не описывается в одном байте информации, поэтому даже расширенные версии ASCII уже не могли удовлетворять возросшие потребности пользователей из разных стран.
Так, возникла необходимость создания универсальной кодировки текста, разработкой которой при сотрудничестве со многими лидерами мировой IT-индустрии занялся консорциум «Юникод». Его специалистами была создана система UTF 32. В ней для кодирования 1 символа выделялось 32 бита, составляющих 4 байта информации. Главным недостатком было резкое увеличение объема необходимой памяти в целых 4 раза, что влекло за собой множество проблем.
В то же время для большинства стран с официальными языками, относящимися к индоевропейской группе, количество знаков, равное 232, является более чем избыточным.
В результате дальнейшей работы специалистов из консорциума «Юникод» появилась кодировка UTF-16. Она стала тем вариантом преобразования символьной информации, которая устроила всех как по объему требуемой памяти, так и по числу кодируемых символов. Именно поэтому UTF-16 была принята по умолчанию и в ней для одного знака требуется зарезервировать 2 байта.
Даже эта достаточно продвинутая и удачная версия «Юникода» имела некоторые недостатки, и после перехода от расширенной версии ASCII к UTF-16 увеличивала вес документа в два раза.
В связи с этим было решено использовать кодировку переменной длины UTF-8. В таком случае каждый символ исходного текста кодируется последовательностью длиной от 1 до 6 байт.

Связь с American standard code for information interchange
Все знаки латинского алфавита в UTF-8 переменной длины кодируются в 1 байт, как в системе кодировки ASCII.
Особенностью ЮТФ-8 является то, что в случае текста на латинице без использования других символов, даже программы, не понимающие «Юникод», все равно позволят его прочитать. Иными словами, базовая часть кодировки текста ASCII просто переходит в состав новой UTF переменной длины. Кириллические знаки в ЮТФ-8 занимают 2 байта, а, например, грузинские — 3 байта. Созданием UTF-16 и 8 была решена основная проблема создания единого кодового пространства в шрифтах. С тех пор производителям шрифтов остается только заполнять таблицу векторными формами символов текста исходя из своих потребностей.
В различных операционных системах предпочтение отдается различным кодировкам. Чтобы иметь возможность читать и редактировать тексты, набранные в другой кодировке, применяются программы перекодировки русского текста. Некоторые текстовые редакторы содержат встроенные перекодировщики и позволяют читать текст вне зависимости от кодировки.

Теперь вы знаете, сколько символов в кодировке ASCII и, как и почему она была разработана. Конечно, сегодня наибольшее распространение в мире получил стандарт «Юникод». Однако нельзя забывать, что он создан на базе ASCII, поэтому следует по достоинству оценивать вклад его разработчиков в сферу IT.
www.syl.ru
Представление нечисловой информации в компьютере
Главная | Информатика и информационно-коммуникационные технологии | Планирование уроков и материалы к урокам | 10 классы | Планирование уроков на учебный год | Представление текстовой информации в компьютере
Представление текстовой информации в компьютере
Изучив эту тему, вы узнаете и повторите:
— как в компьютере представляется текстовая информация;
— что такое ASCII и Unicode;
— как в компьютере представляется графическая информация;
— какие форматы используются при хранении графических файлов;
— как в компьютере представляется звуковая информация;
— какие форматы используются при хранении звуковых файлов.
Компьютеры не с самого рождения могли обрабатывать символьную информацию. Лишь с конца 60-х годов они стали использоваться для обработки текстов и в настоящее время большинство пользователей ПК занимаются вводом, редактированием и форматированием текстовой информации.
1. Таблица кодирования ASCII.
А теперь «заглянем» в память компьютера и разберемся, как же представлена в нем текстовая информация.
Текстовая информация состоит из символов: букв, цифр, знаков препинания, скобок и других. Мы уже говорили, что множество всех символов, с помощью которых записывается текст, называется алфавитом, а число символов в алфавите — его мощностью.
Для представления текстовой информации в компьютере используется алфавит мощностью 256 символов. Мы знаем, что один символ такого алфавита несет 8 битов информации: 2 в 8 степени равно 256. 8 битов = 1 байт, следовательно:
Один символ в компьютерном тексте занимает 1 байт памяти.
Как мы выяснили, традиционно для кодирования одного символа используется 8 бит. И, когда люди определились с количеством бит, им осталось договориться о том, каким кодом кодировать тот или иной символ, чтобы не получилось путаницы, т.е. необходимо было выработать стандарт – все коды символов сохранить в специальной таблице кодов. В первые годы развития вычислительной техники таких стандартов не существовало, а сейчас наоборот, их стало очень много, но они противоречивы. Первыми решили эти проблемы в США, в институте стандартизации. Этот институт ввел в действие таблицу кодов ASCII (AmericanStandardCodeforInformationInterchange – стандартный код информационного обмена США).
Рассмотрим таблицу кодов ASCII.
Пояснение: раздать учащимся распечатанную таблицу кодов ASCII.
Таблица ASCII разделена на две части. Первая – стандартная – содержит коды от 0 до 127. Вторая – расширенная – содержит символы с кодами от 128 до 255.
Первые 32 кода отданы производителям аппаратных средств и называются они управляющие, т.к. эти коды управляют выводом данных. Им не соответствуют никакие символы.
Коды с 32 по 127 соответствуют символам английского алфавита, знакам препинания, цифрам, арифметическим действиям и некоторым вспомогательным символам.
Коды расширенной части таблицы ASCII отданы под символы национальных алфавитов, символы псевдографики и научные символы.
Стандартная часть таблицы кодов ASCII
Если вы внимательно посмотрите на обе части таблицы, то увидите, что все буквы расположены в них по алфавиту, а цифры – по возрастанию. Этот принцип последовательного кодирования позволяет определить код символа, не заглядывая в таблицу.
Коды цифр берутся из этой таблицы только при вводе и выводе и если они используются в тексте. Если же они участвуют в вычислениях, то переводятся в двоичную систему счисления.
Коды национального (русского) алфавита расширенной частитаблицы ASCII
Альтернативные системы кодирования кириллицы.
Тексты, созданные в одной кодировке, не будут правильно отображаться в другой.В настоящее время для поддержки букв русского алфавита (кириллицы) существует несколько кодовых таблиц (кодировок), которые используются различными операционными системами, что является существенным недостатком и в ряде случаев при-водит к проблемам, связанным с операциями декодирования числовых значений символов.
Для разных типов ЭВМ используются различные кодировки:
В настоящее время существует 5 кодовых таблиц для русских букв: Windows (СР(кодовая страница)1251), MS – DOS (СР(кодовая страница)866), KOИ – 8 (Код обмена информацией, 8-битный) (используется в OS UNIX), Mac (Macintosh), ISO (OS UNIX).
Одним из первых стандартов кодирования кириллицы на компьютерах был стан-дарт КОИ-8.
Национальная часть кодовой таблицы стандарта КОИ8-Р
В настоящее время применяется и кодовая таблица, размещенная на странице СР866 стандарта кодирования текстовой информации, которая используется в операционной системе MS DOS или сеансе работы MS DOS для кодирования кириллицы.
Национальная часть кодовой таблицы СР866
В настоящее время для кодирования кириллицы наибольшее распространение получила кодовая таблица, размещенная на странице СР1251 соответствующего стандарта, которая используется в операционных системах семейства Windows фирмы Microsoft.
Национальная часть кодовой таблицы СР1251
Во всех представленных кодовых таблицах, кроме таблицы стандарта Unicode, для кодирования одного символа отводится 8 двоичных разрядов (8 бит).
В мире существует примерно 6800 различных языков. Если прочитать текст, напечатанный в Японии на компьютере в России или США, то понять его будет нельзя. Чтобы буквы любой страны можно было читать на любом компьютере, для их кодировки стали использовать 2 байта (16 бит).
N = 2i 2i = 216 = 65536 N = 65536 N – мощность алфавита символов в кодовой таблице Unicode. i – информационный вес символа
Основополагающая таблица использования кодового пространства Unicode
Использование Unicode значительно упрощает создание многоязычных документов, публикаций и программных приложений.
Рассмотрим примеры.
1) Представьте в форме шестнадцатеричного кода слово «ЭВМ» во всех пяти кодировках. Воспользуемся компьютерным калькулятором для перевода чисел из десятичной в шестнадцатеричную систему счисления.
Последовательности десятичных кодов слова «ЭВМ» в различных кодировках составляем на основе кодировочных таблиц:
КОИ8-Р: 252 247 237 СР1251: 221 194 204 СР866: 157 130 140 Мас: 157 130 140 ISO: 205 178 188
Переводим с помощью калькулятора последовательности кодов из десятичной системы в шестнадцатеричную:
КОИ8-Р: FCF7 ED СР1251: DDC2 CC СР866: 9D 82 8C Мас: 9D 82 8C ISO: CDB2 BC
2) Определить числовой код символа в кодировке Unicode с помощью тексто-вого редактора MicrosoftWord.
1. В операционной системе Windows запустить текстовый редактор MicrosoftWord.
2. В текстовом редакторе MicrosoftWord ввести команду [Вставка-Символ…]. На экране появится диалоговое окно Символ. Центральную часть диалогового окна занимает фрагмент таблицы символов.
3. Для определения числового кола знака кириллицы с помощью раскрывающегося списка Набор: выбрать пункт кириллица.
4. Для определения шестнадцатеричного числового кода символа в кодировке Unicode с помощью раскрывающегося списка из: выбрать тип кодировки Юникод (шестн.).
5. В таблице символов выбрать символ Э. В текстовом поле кодзнака : появится его шестнадцатеричный числовой код (в данном случае 042D).
Решите задачи:
№1. Закодируйте с помощью таблицы ASCII слова: А) Excel; Б) Access; В) Windows; Г) ИНФОРМАЦИЯ.
№2. Буква «i» в таблице кодов имеет код 105. Не пользуясь таблицей, расшифруйте следующую последовательность кодов: 102, 105, 108, 101.
№3. Десятичный код буквы «е» в таблице ASCII равен 101. Не пользуясь таблицей, составьте последовательность кодов, соответствующих слову help.
№4. Десятичный код буквы «i» в таблице ASCII равен 105. Не пользуясь таблицей, составьте последовательность кодов, соответствующих слову link.
№5. Декодируйте следующие тексты, заданные десятичным кодом:
А) 192 235 227 238 240 232 242 236; Б) 193 235 238 234 45 241 245 229 236 224; В) 115 111 102 116 119 97 114 101.
№6. Во сколько раз увеличится информационный объем страницы текста при его преобразовании из кодировки Windows 1251 (таблица кодировки содержит 256 символов) в кодировку Unicode (таблица кодировки содержит 65536 символов)?
№7. Каков информационный объем текста, содержащего слово ПРОГРАММИРОВАНИЕ:
А) в 16-битной кодировке; Б) в 8-битной кодировке.
№8. Текст занимает ¼ Кбайта. Какое количество символов он содержит?
№9. Текст занимает полных 6 страниц. На каждой странице размещается 30 строк по 80 символов. Определить объем оперативной памяти, который займет этот текст.
№10. Свободный объем оперативной памяти компьютера 320 Кбайт. Сколько страниц книги поместится в ней, если на странице:
А) 32 строки по 32 символа; Б) 64 строки по 64 символа; В) 16 строк по 32 символа.
№11. Текст занимает 20 секторов на двусторонней дискете объемом 360 Кбайт. Дискета разбита на 40 дорожек по 9 секторов. Сколько символов содержит текст?
xn—-7sbbfb7a7aej.xn--p1ai
кто знает, сколько один символ в кодировке ASCII?
двести пятьдесят шесть
это было в доссе напр. Alt 92 \ надо сделать нажми Alt дай номер напр. 66 пусти Alt увидишь B наверно ещо можно найти таблицу знаков или изпробовать
ASCII это 7 бит, 128 символов. Кодировка вошла в Юникод, поэтому её легко увидеть в Windows программе «Таблица символов» (%SystemRoot%\System32\charmap.exe) на любом человеческом шрифте. ASCII заканчивается непечатным символом DEL, код 7F. Так как он непечатный, в шрифтах его нет, последний печатный символ тильда (tilde, код 7E). Дальше идёт кодировка Latin1, она же ANSI в Windows (в Notepad’е, например) — это 8 бит, 256 символов. Непечатные символы в ASCII называются диапазоном C0, в Latin1 — С1. В доюникодовское время на месте символов Latin 1 жили русские буквы. Они и сечас там живут, если выбрать тоже самое ANSI в Notepad’е, и называется это безобразие кодировкой windows-1251.
touch.otvet.mail.ru